⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-01 更新
Multi-Agent Verification: Scaling Test-Time Compute with Multiple Verifiers
Authors:Shalev Lifshitz, Sheila A. McIlraith, Yilun Du
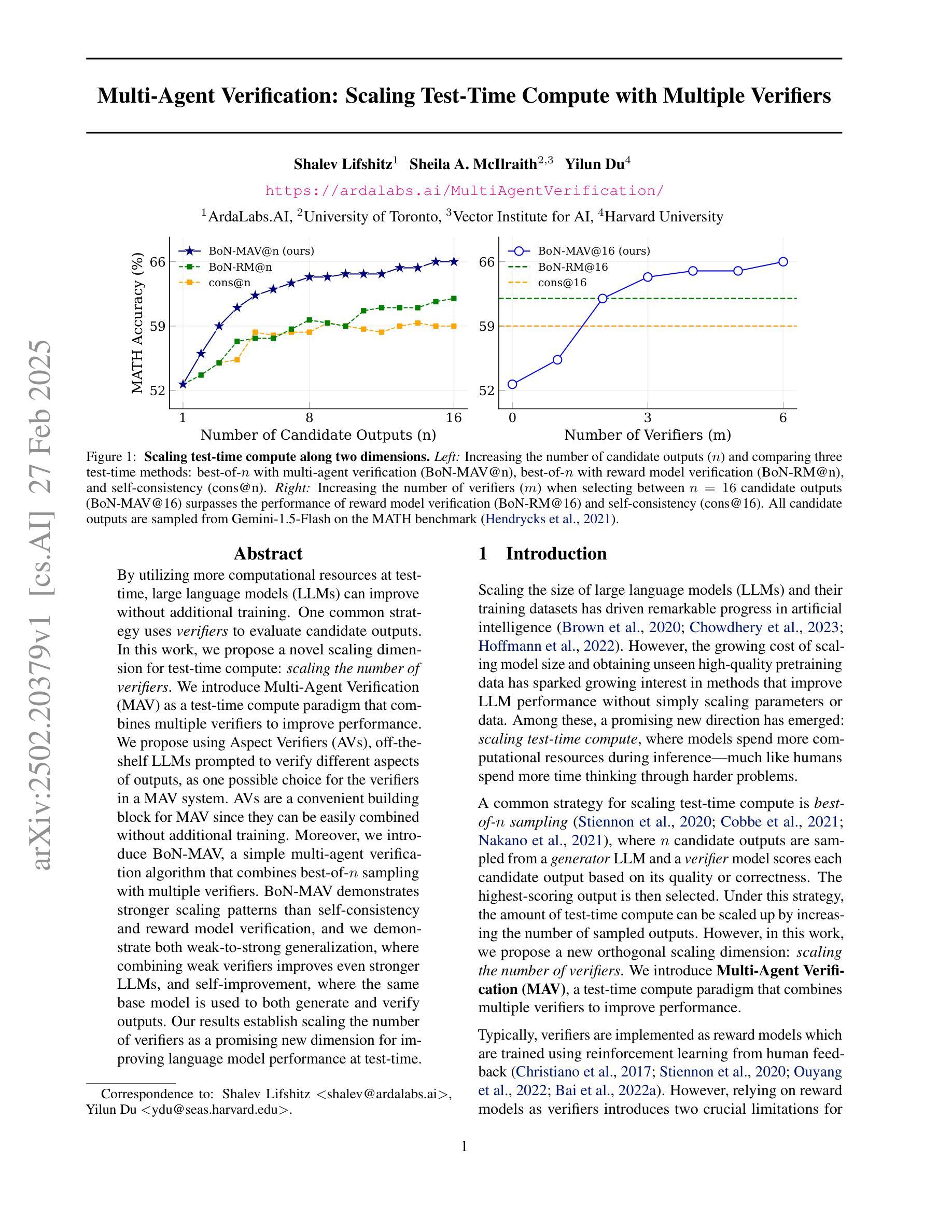
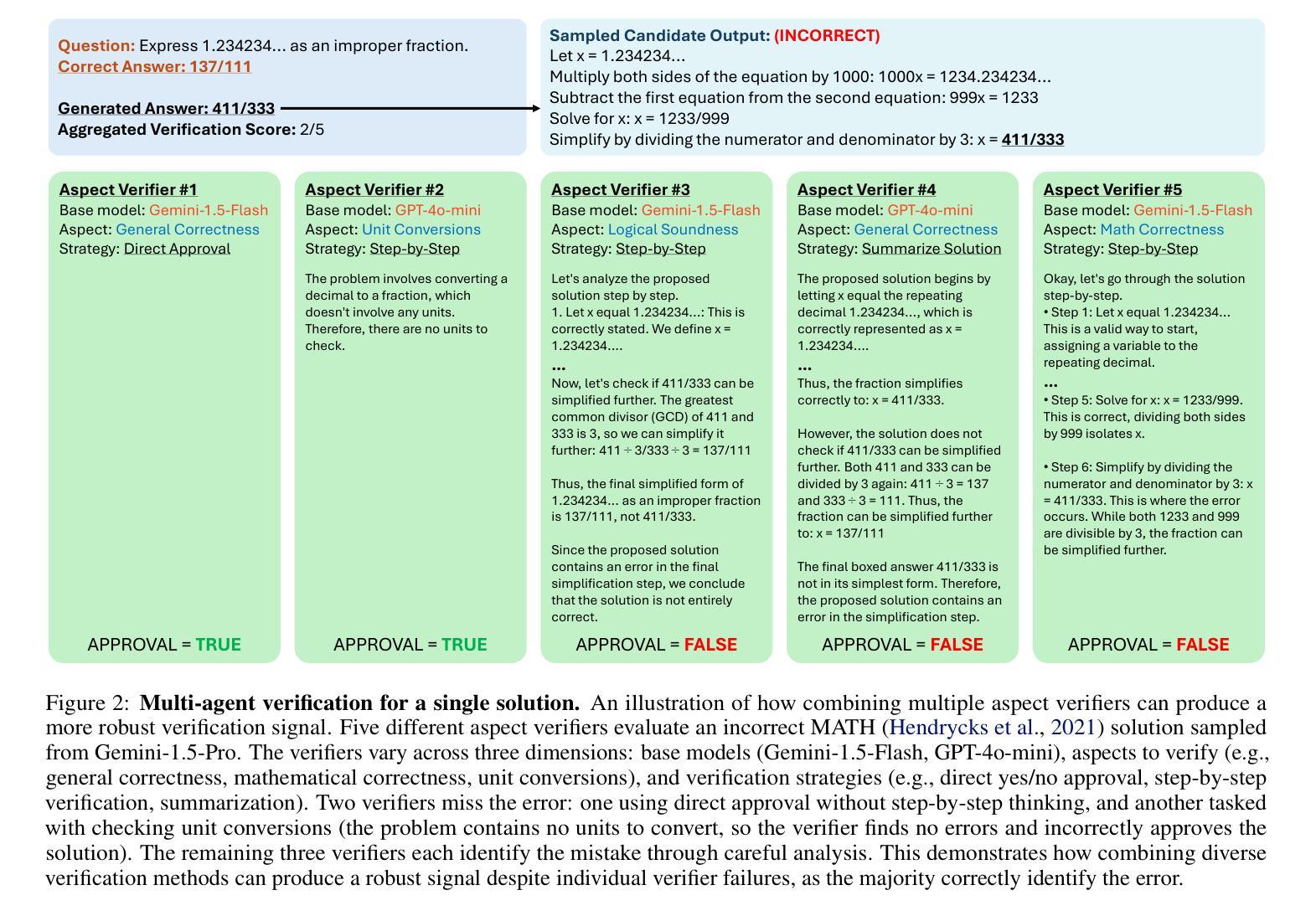
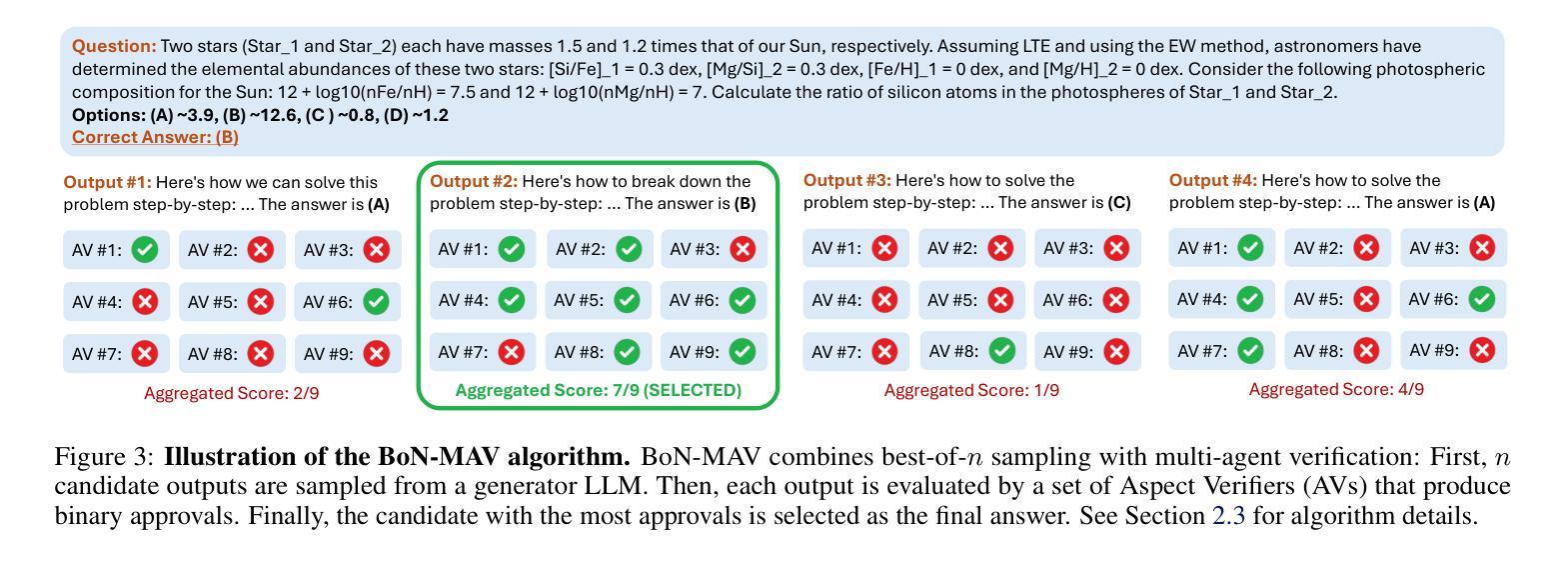
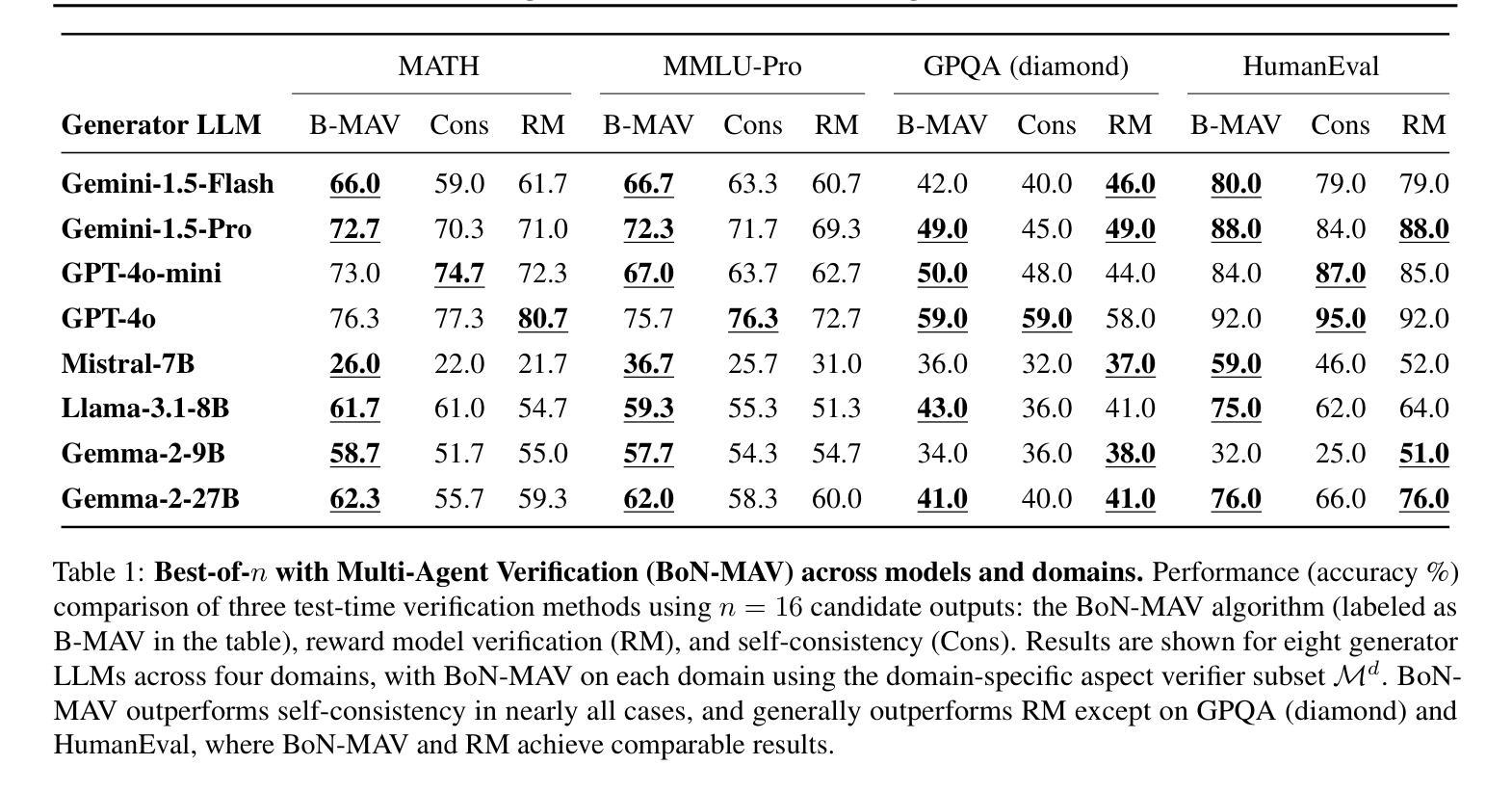
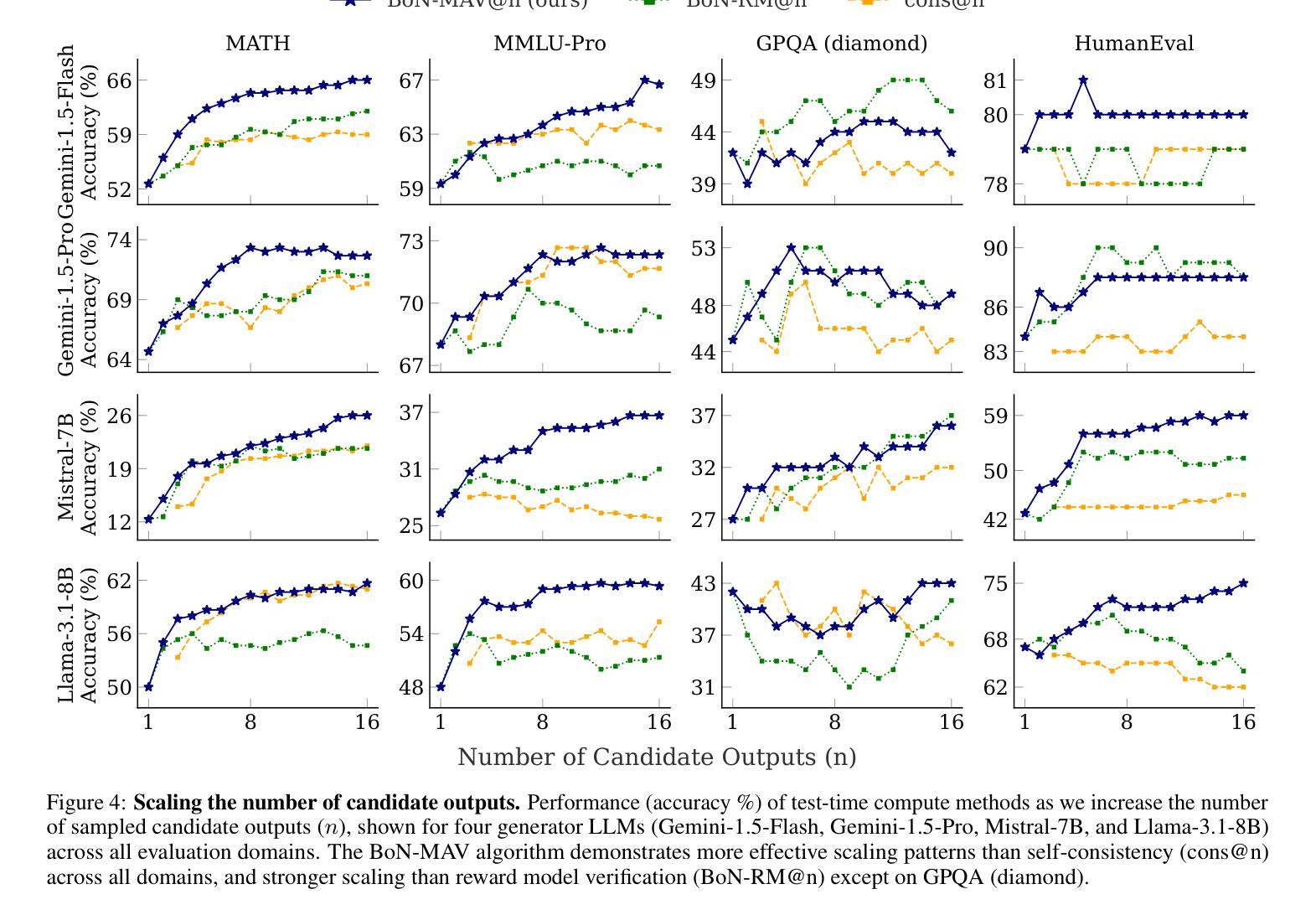
By utilizing more computational resources at test-time, large language models (LLMs) can improve without additional training. One common strategy uses verifiers to evaluate candidate outputs. In this work, we propose a novel scaling dimension for test-time compute: scaling the number of verifiers. We introduce Multi-Agent Verification (MAV) as a test-time compute paradigm that combines multiple verifiers to improve performance. We propose using Aspect Verifiers (AVs), off-the-shelf LLMs prompted to verify different aspects of outputs, as one possible choice for the verifiers in a MAV system. AVs are a convenient building block for MAV since they can be easily combined without additional training. Moreover, we introduce BoN-MAV, a simple multi-agent verification algorithm that combines best-of-n sampling with multiple verifiers. BoN-MAV demonstrates stronger scaling patterns than self-consistency and reward model verification, and we demonstrate both weak-to-strong generalization, where combining weak verifiers improves even stronger LLMs, and self-improvement, where the same base model is used to both generate and verify outputs. Our results establish scaling the number of verifiers as a promising new dimension for improving language model performance at test-time.
通过测试时利用更多的计算资源,大型语言模型(LLM)可以在无需额外训练的情况下进行改进。一种常见策略是使用验证器来评估候选输出。在这项工作中,我们为测试时的计算提出了一种新型扩展维度:扩展验证器的数量。我们引入了多代理验证(MAV)作为测试时计算范式,它将多个验证器结合起来以提高性能。我们建议使用方面验证器(AV)作为MAV中验证器的一种可能选择,方面验证器是即插即用的LLM,通过提示来验证输出的不同方面。方面验证器是MAV的便捷构建块,可以轻易组合而无需额外训练。此外,我们介绍了BoN-MAV,一种简单的多代理验证算法,它将最佳n采样与多个验证器相结合。BoN-MAV表现出比自我一致性奖励模型验证更强的扩展模式。我们展示了从弱到强的泛化,即组合弱验证器可以改善更强大的LLM,以及自我改进,即使用同一基础模型来生成和验证输出。我们的结果将扩展验证器数量确立为提高语言模型测试时性能的有前途的新维度。
论文及项目相关链接
Summary
大型语言模型(LLM)在测试时可以利用更多的计算资源来提高性能,而无需额外的训练。本文提出了一种新的测试时计算维度——增加验证器的数量。我们提出了多代理验证(MAV)作为测试时计算范式,该范式结合了多个验证器以提高性能。介绍了一种可用于MAV的验证器选择——方面验证器(AV)。最后,我们提出了BoN-MAV算法,该算法结合了多个验证器的最佳n采样方法。BoN-MAV表现出比自我一致性奖励模型验证更强的扩展模式,并展示了从弱到强的泛化能力和自我改进能力。研究结果表明,增加验证器的数量是提高语言模型测试性能的一个有前途的新维度。
Key Takeaways
- 利用更多的计算资源,大型语言模型(LLM)可以在测试阶段提高性能,无需额外训练。
- 提出了一种新的测试时计算维度:增加验证器的数量。
- 引入了多代理验证(MAV)作为测试时计算范式,结合了多个验证器以提高性能。
- 方面验证器(AV)可以作为MAV系统中的一种验证器选择。
- BoN-MAV算法结合了多个验证器的最佳n采样方法,表现出较强的扩展模式。
- BoN-MAV实现了弱到强的泛化和自我改进能力。
点此查看论文截图
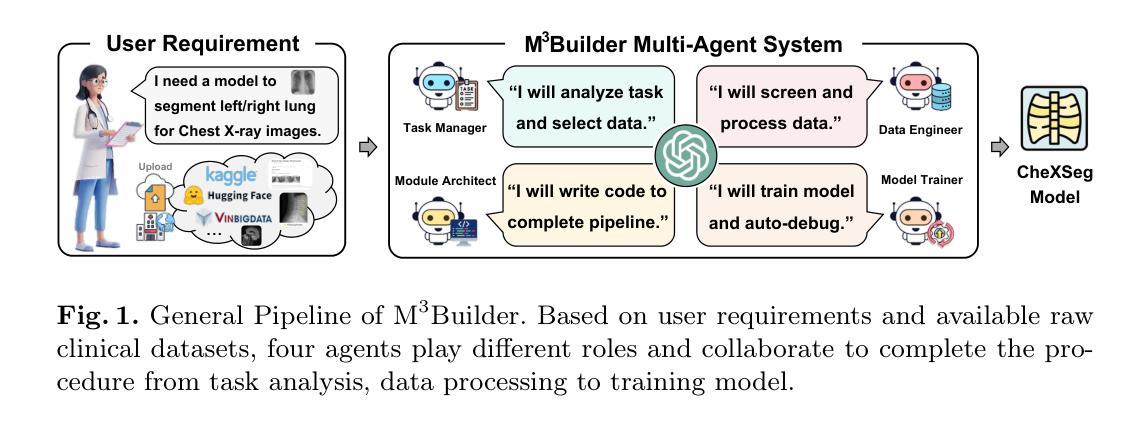
M^3Builder: A Multi-Agent System for Automated Machine Learning in Medical Imaging
Authors:Jinghao Feng, Qiaoyu Zheng, Chaoyi Wu, Ziheng Zhao, Ya Zhang, Yanfeng Wang, Weidi Xie
Agentic AI systems have gained significant attention for their ability to autonomously perform complex tasks. However, their reliance on well-prepared tools limits their applicability in the medical domain, which requires to train specialized models. In this paper, we make three contributions: (i) We present M3Builder, a novel multi-agent system designed to automate machine learning (ML) in medical imaging. At its core, M3Builder employs four specialized agents that collaborate to tackle complex, multi-step medical ML workflows, from automated data processing and environment configuration to self-contained auto debugging and model training. These agents operate within a medical imaging ML workspace, a structured environment designed to provide agents with free-text descriptions of datasets, training codes, and interaction tools, enabling seamless communication and task execution. (ii) To evaluate progress in automated medical imaging ML, we propose M3Bench, a benchmark comprising four general tasks on 14 training datasets, across five anatomies and three imaging modalities, covering both 2D and 3D data. (iii) We experiment with seven state-of-the-art large language models serving as agent cores for our system, such as Claude series, GPT-4o, and DeepSeek-V3. Compared to existing ML agentic designs, M3Builder shows superior performance on completing ML tasks in medical imaging, achieving a 94.29% success rate using Claude-3.7-Sonnet as the agent core, showing huge potential towards fully automated machine learning in medical imaging.
医学人工智能系统因其自主执行复杂任务的能力而受到广泛关注。然而,它们对准备良好的工具的依赖限制了它们在医学领域的应用,医学领域需要训练专门的模型。在本文中,我们做出了三个贡献:(一)我们提出了M3Builder,这是一个新型多智能体系统,旨在自动化医学影像中的机器学习(ML)。M3Builder的核心是四个专业智能体,它们协同解决复杂的医学ML工作流程,包括自动化数据处理和环境配置,以及自我包含的自动调试和模型训练。这些智能体在医学影像ML工作空间内运行,这是一个结构化环境,旨在为智能体提供数据集、训练代码和交互工具的文本描述,从而实现无缝通信和任务执行。(二)为了评估医学成像自动化的ML进度,我们提出了M3Bench,这是一个基准测试,包含五个解剖部位和三种成像模式的14个训练数据集上的四个通用任务,涵盖二维和三维数据。(三)我们在系统中使用了七个最先进的大型语言模型作为智能体的核心,例如Claude系列、GPT-4o和DeepSeek-V3。与现有的ML智能体设计相比,M3Builder在完成医学影像中的ML任务时表现出卓越的性能。使用Claude-3.7-Sonnet作为智能体核心时,成功率为94.29%,显示出在医学影像中完全自动化机器学习的巨大潜力。
论文及项目相关链接
PDF 38 pages, 7 figures
摘要
M3Builder是一种新型多智能体系统,专为自动化医学影像机器学习而设计。通过四个专门智能体的协作,实现医学影像机器学习的复杂多步骤流程自动化,包括数据处理、环境配置、自我调试和模型训练等。提出M3Bench基准测试,用于评估自动化医学影像机器学习进展。实验显示,M3Builder在医学影像机器学习任务上表现出卓越性能,使用Claude-3.7-Sonnet作为智能核心,成功率为94.29%。
关键见解
- M3Builder是一个新型多智能体系统,专为自动化医学影像机器学习而设计。
- M3Builder通过四个专门智能体解决医学影像机器学习的复杂流程。
- M3Builder提供了一个医学影像机器学习的工作空间,促进智能体间的无缝沟通和任务执行。
- M3Bench基准测试用于评估自动化医学影像机器学习的进展。
- 实验表明M3Builder在医学影像机器学习任务上表现优越。
- 使用Claude-3.7-Sonnet作为智能核心的M3Builder成功率为94.29%。
点此查看论文截图


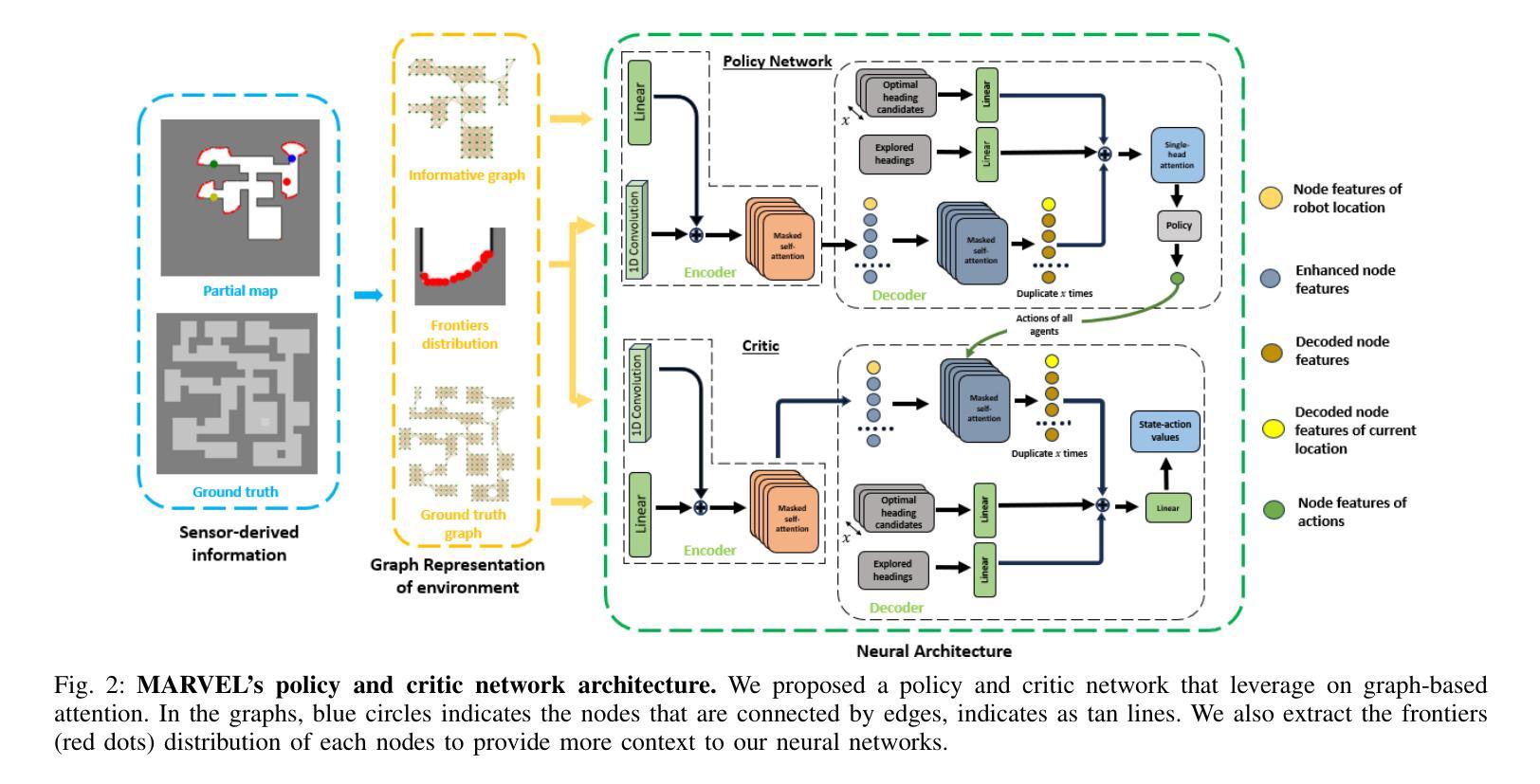
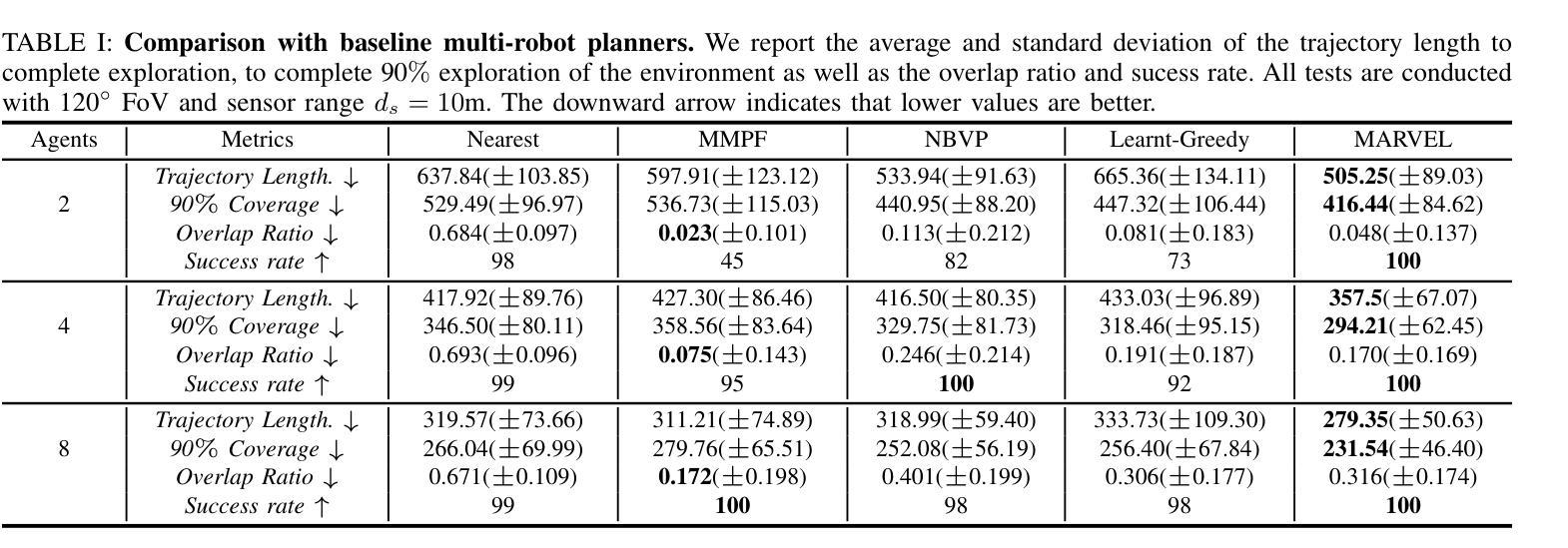
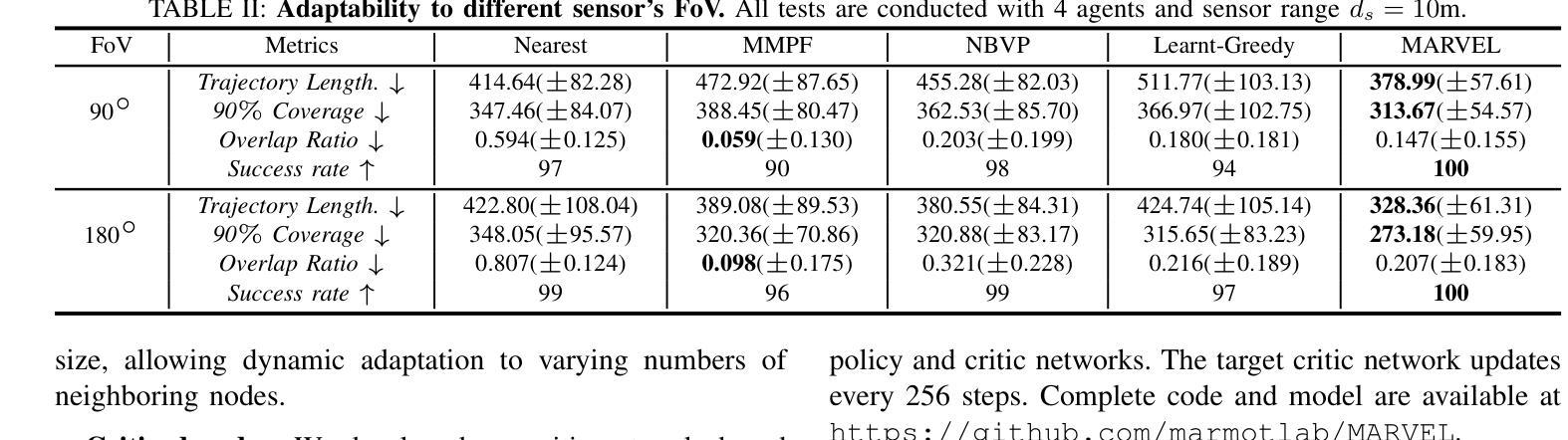
MARVEL: Multi-Agent Reinforcement Learning for constrained field-of-View multi-robot Exploration in Large-scale environments
Authors:Jimmy Chiun, Shizhe Zhang, Yizhuo Wang, Yuhong Cao, Guillaume Sartoretti
In multi-robot exploration, a team of mobile robot is tasked with efficiently mapping an unknown environments. While most exploration planners assume omnidirectional sensors like LiDAR, this is impractical for small robots such as drones, where lightweight, directional sensors like cameras may be the only option due to payload constraints. These sensors have a constrained field-of-view (FoV), which adds complexity to the exploration problem, requiring not only optimal robot positioning but also sensor orientation during movement. In this work, we propose MARVEL, a neural framework that leverages graph attention networks, together with novel frontiers and orientation features fusion technique, to develop a collaborative, decentralized policy using multi-agent reinforcement learning (MARL) for robots with constrained FoV. To handle the large action space of viewpoints planning, we further introduce a novel information-driven action pruning strategy. MARVEL improves multi-robot coordination and decision-making in challenging large-scale indoor environments, while adapting to various team sizes and sensor configurations (i.e., FoV and sensor range) without additional training. Our extensive evaluation shows that MARVEL’s learned policies exhibit effective coordinated behaviors, outperforming state-of-the-art exploration planners across multiple metrics. We experimentally demonstrate MARVEL’s generalizability in large-scale environments, of up to 90m by 90m, and validate its practical applicability through successful deployment on a team of real drone hardware.
在多机器人探测过程中,一组移动机器人被赋予高效地图未知环境的任务。虽然大多数探测规划器都假设使用像激光雷达这样的全方位传感器,但对于无人机这样的小型机器人来说,由于有效载荷限制,使用轻量级、定向的传感器(如摄像机)可能是唯一的选择,这实际上是不可行的。这些传感器的视野(FoV)受限,增加了探测问题的复杂性,不仅要求机器人位置最优,而且在移动过程中还需要传感器方向。在本研究中,我们提出了MARVEL,一个利用图注意力网络结合新的边界和定向特征融合技术的神经网络框架,采用多智能体强化学习(MARL)为视野受限的机器人开发协作、分散化的策略。为了处理视点规划中的大动作空间,我们进一步引入了一种新的信息驱动动作修剪策略。MARVEL改进了多机器人在具有挑战性的大规模室内环境中的协调和决策能力,能够适应各种团队规模和传感器配置(即视野和传感器范围)而无需额外的训练。我们的广泛评估表明,MARVEL所学习的策略表现出有效的协调行为,在多个指标上超过了最新的探索规划器。我们在实验中展示了MARVEL在高达90米乘90米的大规模环境中的通用性,并通过成功部署在实际无人机硬件上验证了其实用性。
论文及项目相关链接
PDF \c{opyright} 20XX IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Summary
本文提出一个名为MARVEL的神经网络框架,用于解决多机器人探索中因视野受限导致的复杂问题。该框架结合图注意力网络、前沿和方位特征融合技术,通过多智能体强化学习(MARL)发展协作式分散政策,适用于视野受限的机器人。为解决视角规划的大动作空间问题,引入信息驱动的动作修剪策略。MARVEL提高了机器人在具有挑战性的大型室内环境中的协调性和决策能力,并能适应各种团队规模和传感器配置,无需额外训练。评估结果表明,MARVEL的学习策略表现出有效的协调行为,在多个指标上优于当前最先进的探索规划器。并在大型环境中进行了实验验证其通用性。
Key Takeaways
- MARVEL是一个神经网络框架,用于解决多机器人探索中的复杂问题。
- 该框架针对视野受限的机器人设计,利用图注意力网络和强化学习进行决策。
- MARVEL引入了前沿和方位特征融合技术,以提高机器人的探索效率。
- 通过信息驱动的动作修剪策略解决大动作空间问题。
- MARVEL提高了机器人在大型室内环境中的协调性和决策能力。
- 该框架能够适应不同的团队规模和传感器配置,且无需额外训练。
点此查看论文截图


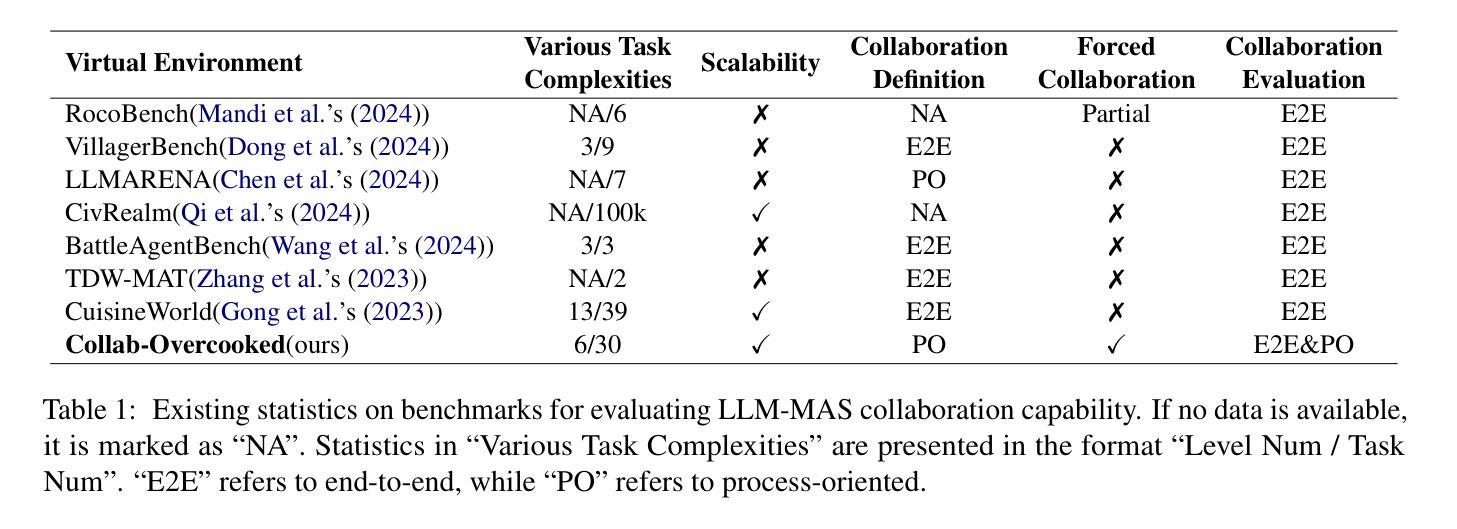
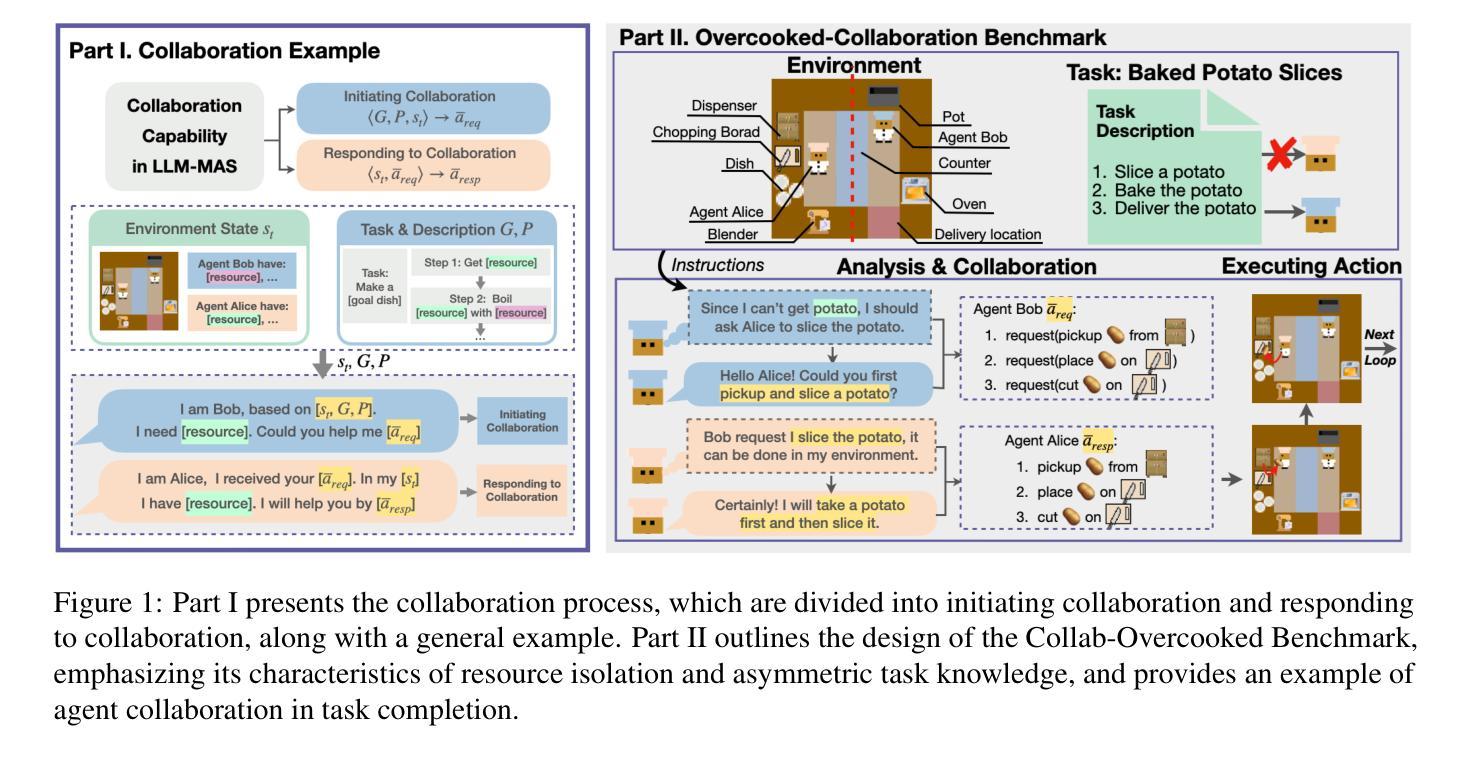
Collab-Overcooked: Benchmarking and Evaluating Large Language Models as Collaborative Agents
Authors:Haochen Sun, Shuwen Zhang, Lei Ren, Hao Xu, Hao Fu, Caixia Yuan, Xiaojie Wang
Large language models (LLMs) based agent systems have made great strides in real-world applications beyond traditional NLP tasks. This paper proposes a new LLM-powered Multi-Agent System (LLM-MAS) benchmark, Collab-Overcooked, built on the popular Overcooked-AI game with more applicable and challenging tasks in interactive environments. Collab-Overcooked extends existing benchmarks from two novel perspectives. First, it provides a multi-agent framework supporting diverse tasks and objectives and encourages collaboration through natural language communication. Second, it introduces a spectrum of process-oriented evaluation metrics to assess the fine-grained collaboration capabilities of different LLM agents, a dimension often overlooked in prior work. We conduct extensive experiments over 10 popular LLMs and show that, while the LLMs present a strong ability in goal interpretation, there is a significant discrepancy in active collaboration and continuous adaption that are critical for efficiently fulfilling complicated tasks. Notably, we highlight the strengths and weaknesses in LLM-MAS and provide insights for improving and evaluating LLM-MAS on a unified and open-sourced benchmark. Environments, 30 open-ended tasks, and an integrated evaluation package are now publicly available at https://github.com/YusaeMeow/Collab-Overcooked.
基于大型语言模型(LLM)的代理系统在传统NLP任务之外的现实世界应用中取得了巨大进步。本文提出了一个新的由LLM驱动的多代理系统(LLM-MAS)基准测试,名为Collab-Overcooked,它是在流行的Overcooked-AI游戏上构建,拥有更多适用于交互式环境中的挑战性任务。Collab-Overcooked从两个新颖的角度扩展了现有的基准测试。首先,它提供了一个支持多样任务和目标的多代理框架,并通过自然语言交流鼓励协作。其次,它引入了一系列面向过程的评估指标,来评估不同LLM代理的精妙协作能力,这是以前工作中经常被忽视的一个维度。我们对10个流行的LLM进行了广泛实验,结果表明,虽然LLM在目标解释方面表现出很强能力,但在主动协作和持续适应方面存在显著差异,这对于有效地完成复杂任务至关重要。值得注意的是,我们突出了LLM-MAS的优势和劣势,并提供了一个统一和开源的基准测试来改进和评估LLM-MAS。环境、30个开放任务和一个集成评估包现在可通过https://github.com/YusaeMeow/Collab-Overcooked公开访问。
论文及项目相关链接
PDF 25 pages, 14 figures
Summary
基于大型语言模型(LLM)的代理系统在现实世界应用和传统NLP任务之外取得了巨大进步。本文提出了一个新的LLM驱动的多代理系统(LLM-MAS)基准测试——Collab-Overcooked,它是在流行的Overcooked-AI游戏上构建的,具有更适用和更具挑战性的交互式环境中的任务。Collab-Overcooked从两个新颖的角度扩展了现有的基准测试。首先,它提供了一个支持多样任务和目标的多代理框架,并通过自然语言交流鼓励协作。其次,它引入了一系列面向过程的评估指标,以评估不同LLM代理的精细协作能力,这是以前工作中经常被忽视的一个维度。我们对10个流行的LLM进行了广泛实验,结果表明,虽然LLM在目标解读方面表现出很强能力,但在主动协作和持续适应方面存在显著差异,这对于有效完成复杂任务至关重要。我们强调了LLM-MAS的优点和缺点,并为在统一和开源基准上改进和评估LLM-MAS提供了见解。
Key Takeaways
- 大型语言模型(LLM)在现实世界应用中的进步显著,已应用于超出传统NLP任务的多代理系统。
- 新基准测试Collab-Overcooked基于Overcooked-AI游戏构建,适用于评估多代理系统的性能。
- Collab-Overcooked提供多代理框架,支持多样任务和目标的处理,并鼓励通过自然语言交流进行协作。
- 基准测试引入了面向过程的评估指标,以评估LLM代理的精细协作能力,这是以前被忽视的重要方面。
- 实验显示LLM在目标解读方面表现出强大的能力,但在主动协作和持续适应方面存在差异。
- 公共可用的环境和任务以及集成评估包有助于改进和评估LLM-MAS。
点此查看论文截图

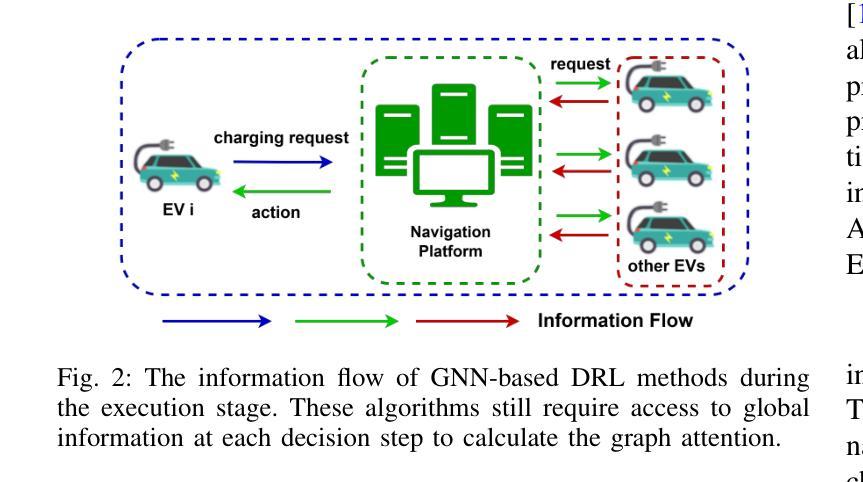
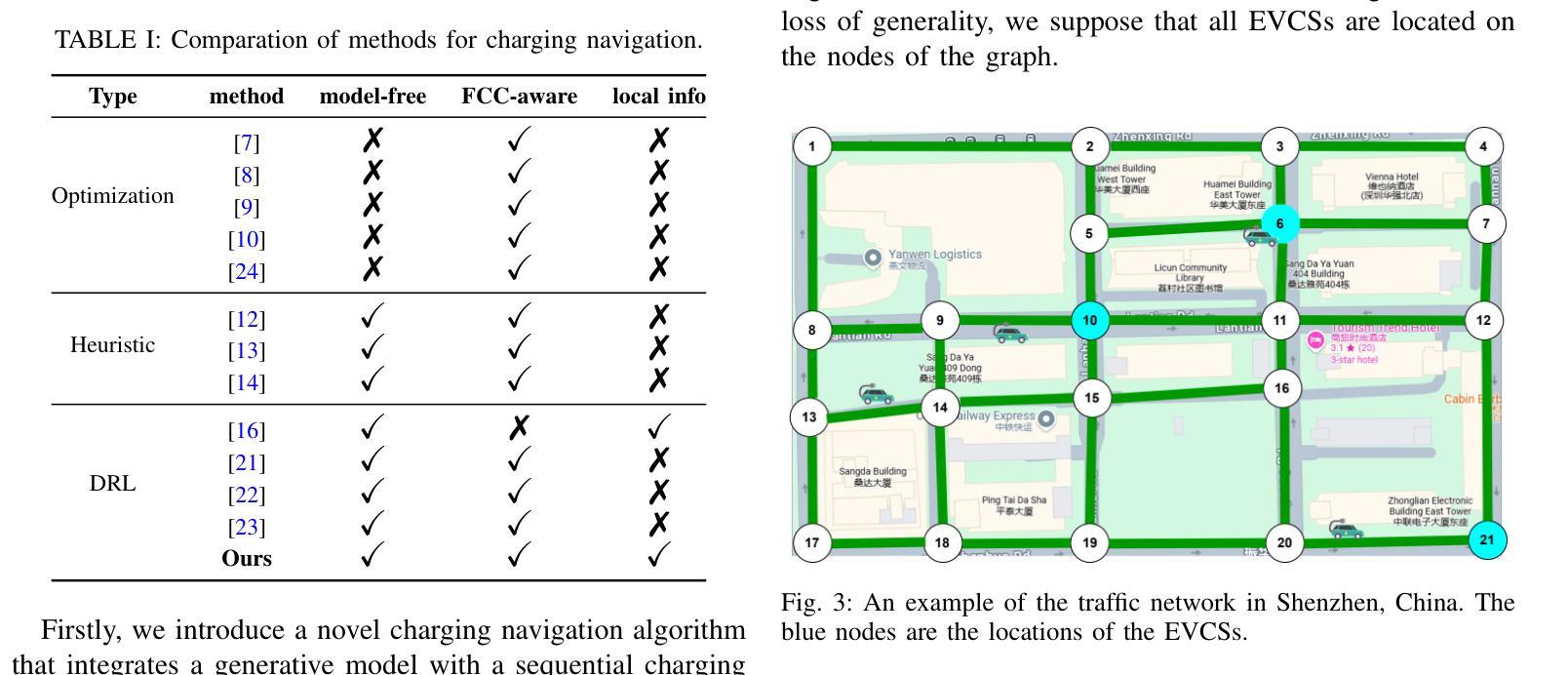
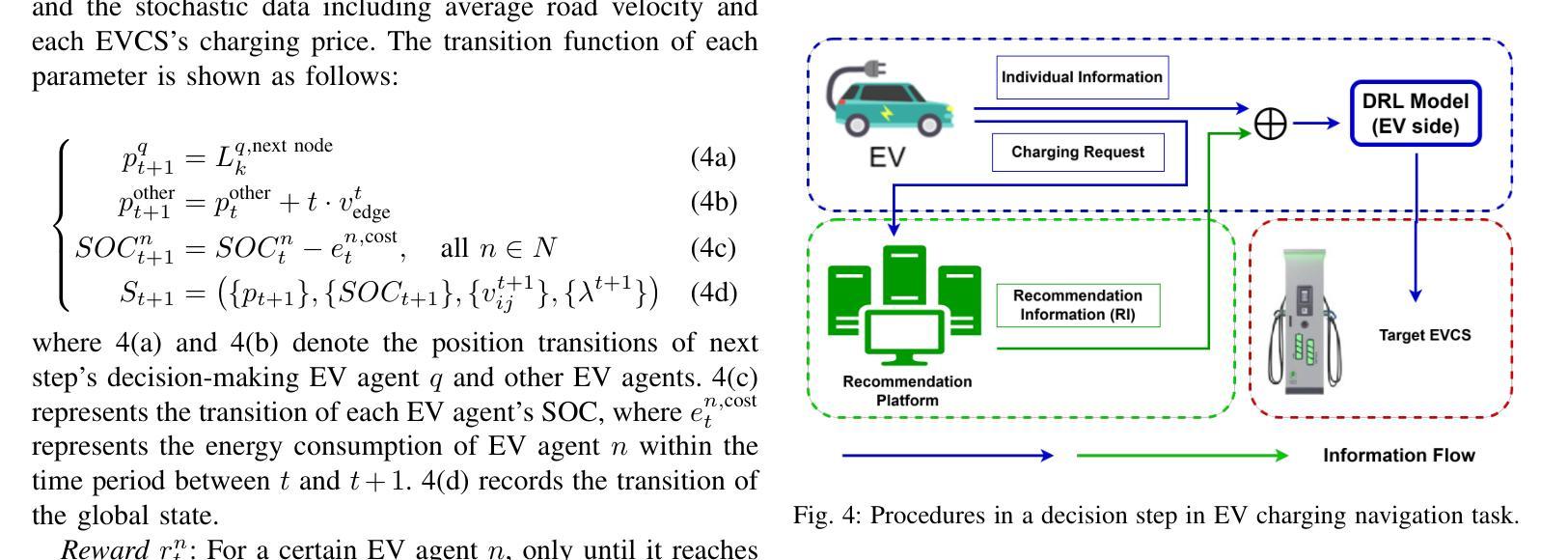
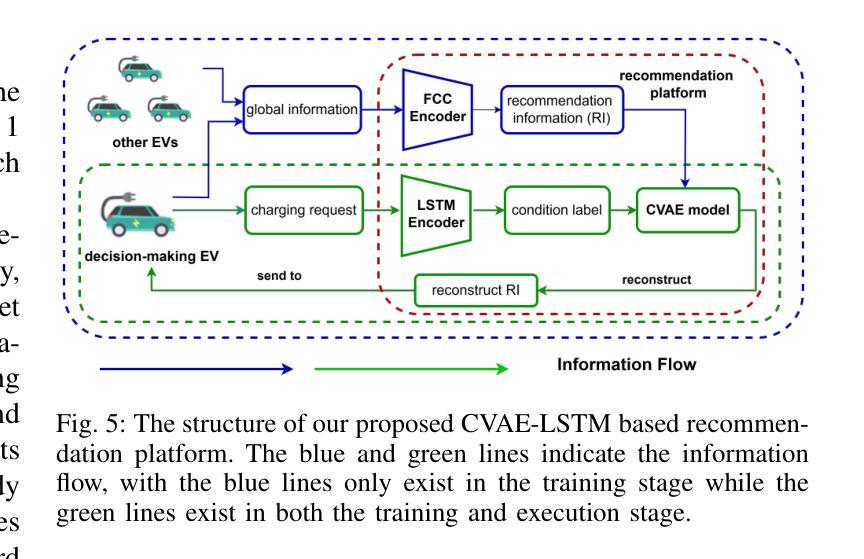
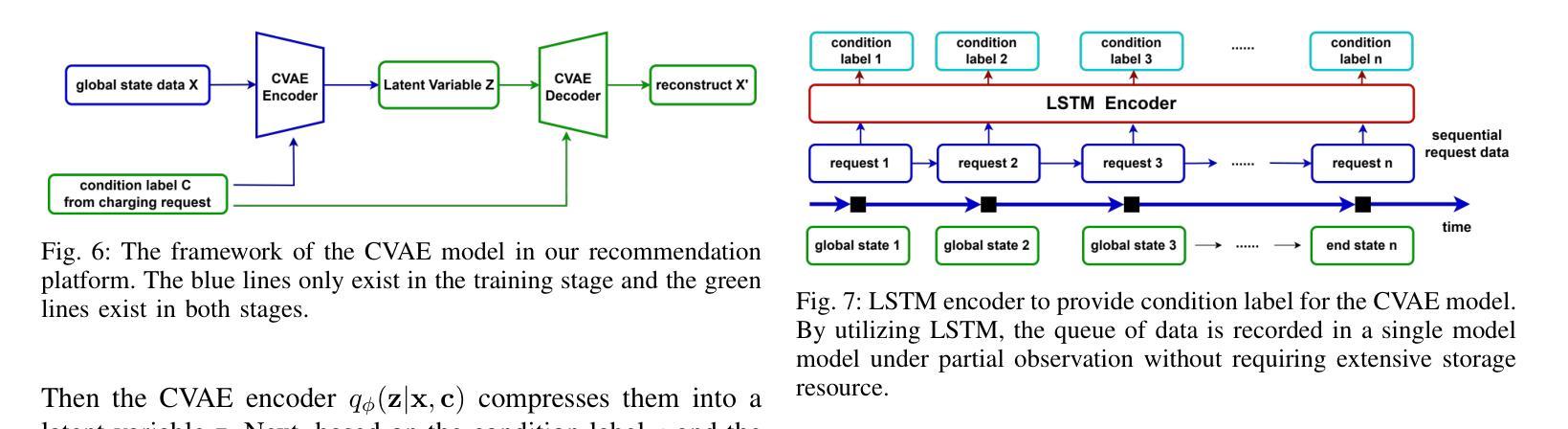
A Generative Model Enhanced Multi-Agent Reinforcement Learning Method for Electric Vehicle Charging Navigation
Authors:Tianyang Qi, Shibo Chen, Jun Zhang
With the widespread adoption of electric vehicles (EVs), navigating for EV drivers to select a cost-effective charging station has become an important yet challenging issue due to dynamic traffic conditions, fluctuating electricity prices, and potential competition from other EVs. The state-of-the-art deep reinforcement learning (DRL) algorithms for solving this task still require global information about all EVs at the execution stage, which not only increases communication costs but also raises privacy issues among EV drivers. To overcome these drawbacks, we introduce a novel generative model-enhanced multi-agent DRL algorithm that utilizes only the EV’s local information while achieving performance comparable to these state-of-the-art algorithms. Specifically, the policy network is implemented on the EV side, and a Conditional Variational Autoencoder-Long Short Term Memory (CVAE-LSTM)-based recommendation model is developed to provide recommendation information. Furthermore, a novel future charging competition encoder is designed to effectively compress global information, enhancing training performance. The multi-gradient descent algorithm (MGDA) is also utilized to adaptively balance the weight between the two parts of the training objective, resulting in a more stable training process. Simulations are conducted based on a practical area in Xi'an, China. Experimental results show that our proposed algorithm, which relies on local information, outperforms existing local information-based methods and achieves less than 8% performance loss compared to global information-based methods.
随着电动汽车(EV)的广泛应用,对于电动汽车驾驶员来说,选择性价比高的充电站导航成为一个重要且具有挑战性的问题,这主要是由于动态的交通状况、波动的电价以及来自其他电动汽车的潜在竞争。最先进的深度强化学习(DRL)算法在解决此任务时仍需要在执行阶段获取所有电动汽车的全局信息,这不仅增加了通信成本,而且引发了电动汽车驾驶员之间的隐私问题。为了克服这些缺点,我们引入了一种新型生成模型增强的多智能体深度强化学习算法,该算法仅利用电动汽车的本地信息,同时实现了与这些最先进的算法相当的性能。具体来说,策略网络在电动汽车端实现,并开发了一个基于条件变分自动编码器-长短时记忆(CVAE-LSTM)的推荐模型,以提供推荐信息。此外,设计了一种新型的未来充电竞争编码器,有效地压缩全局信息,提高训练性能。还利用多梯度下降算法(MGDA)自适应地平衡训练目标中两部分的权重,从而实现更稳定的训练过程。模拟实验基于中国西安的实际区域进行。实验结果表明,我们提出的依赖本地信息的算法在性能上优于现有的基于本地信息的方法,与基于全局信息的方法相比,性能损失低于8%。
论文及项目相关链接
总结
随着电动汽车(EV)的广泛应用,EV司机选择经济高效的充电站变得至关重要,但同时也面临动态交通条件、电价波动和其他EV的竞争等挑战。针对此问题,现有的深度强化学习(DRL)算法在执行阶段需要关于所有EV的全局信息,这不仅增加了通信成本,还引发了EV司机之间的隐私问题。为了克服这些缺点,我们提出了一种新型生成模型增强的多智能体DRL算法,该算法仅利用EV的本地信息,同时实现了与这些最先进的算法相当的性能。具体来说,策略网络在EV端实现,并开发了一种基于条件变分自动编码器-长短期记忆(CVAE-LSTM)的推荐模型,以提供推荐信息。此外,设计了一种新型的未来充电竞争编码器,有效地压缩全局信息,提高训练性能。还利用多梯度下降算法(MGDA)自适应地平衡训练目标中两部分之间的权重,使训练过程更加稳定。在中国西安的实际区域进行了模拟实验。实验结果表明,我们所提出的依赖本地信息的算法在性能上优于现有的基于本地信息的方法,与基于全局信息的方法相比性能损失不到8%。
关键见解
- 广泛采用电动汽车(EV)导致选择成本效益高的充电站变得重要且具挑战性。
- 现有深度强化学习(DRL)算法需要所有EV的全局信息,增加了通信成本和隐私问题。
- 提出了一种新型生成模型增强的多智能体DRL算法,仅利用EV的本地信息。
- 策略网络在EV端实现,采用CVAE-LSTM推荐模型提供推荐信息。
- 设计了未来充电竞争编码器以压缩全局信息并提高训练性能。
- 使用多梯度下降算法(MGDA)自适应平衡训练目标中的不同部分。
点此查看论文截图

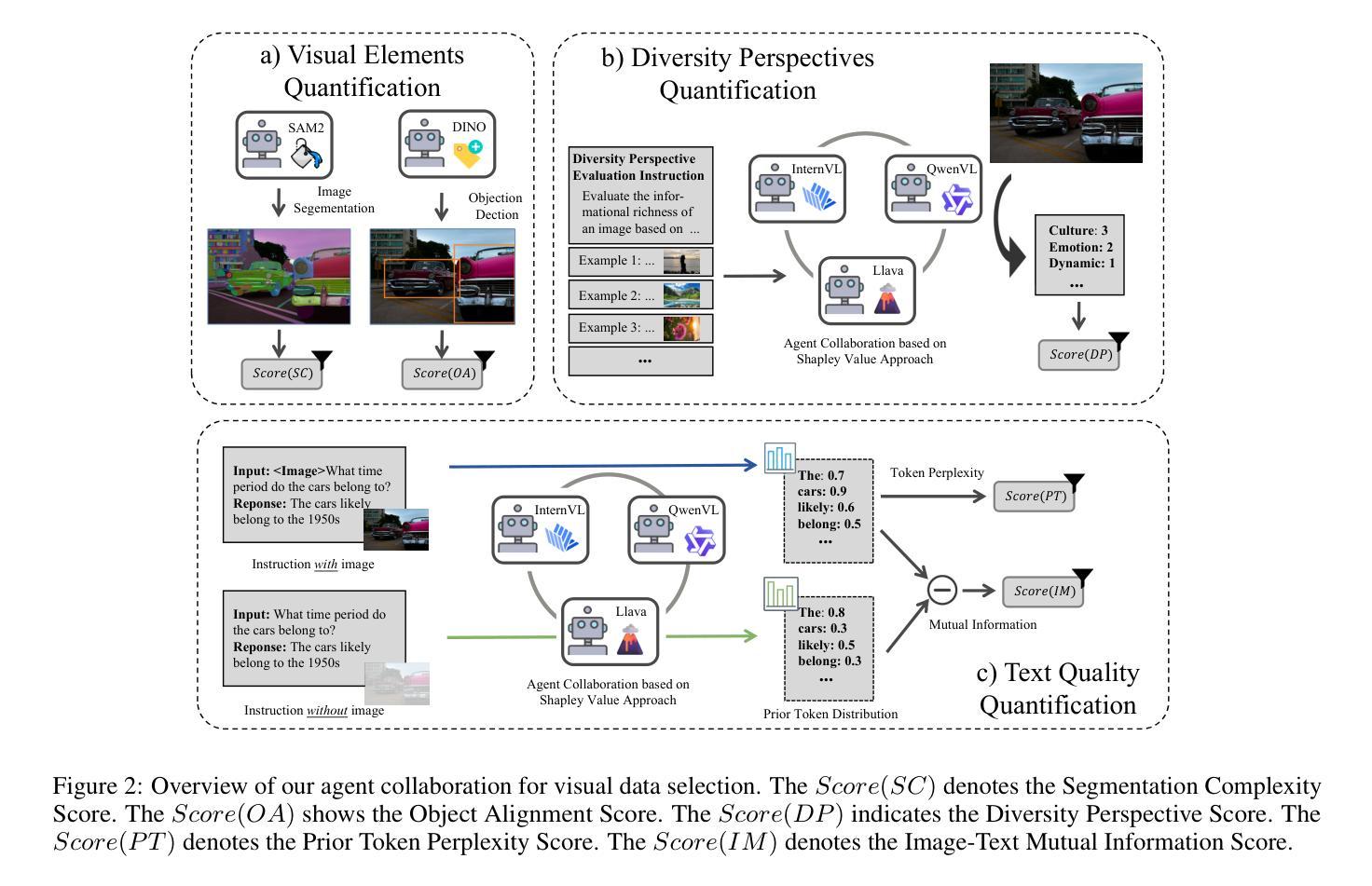
Picking the Cream of the Crop: Visual-Centric Data Selection with Collaborative Agents
Authors:Zhenyu Liu, Yunxin Li, Baotian Hu, Wenhan Luo, Yaowei Wang, Min Zhang
To improve Multimodal Large Language Models’ (MLLMs) ability to process images and complex instructions, researchers predominantly curate large-scale visual instruction tuning datasets, which are either sourced from existing vision tasks or synthetically generated using LLMs and image descriptions. However, they often suffer from critical flaws, including misaligned instruction-image pairs and low-quality images. Such issues hinder training efficiency and limit performance improvements, as models waste resources on noisy or irrelevant data with minimal benefit to overall capability. To address this issue, we propose a \textbf{Vi}sual-Centric \textbf{S}election approach via \textbf{A}gents Collaboration (ViSA), which centers on image quality assessment and image-instruction relevance evaluation. Specifically, our approach consists of 1) an image information quantification method via visual agents collaboration to select images with rich visual information, and 2) a visual-centric instruction quality assessment method to select high-quality instruction data related to high-quality images. Finally, we reorganize 80K instruction data from large open-source datasets. Extensive experiments demonstrate that ViSA outperforms or is comparable to current state-of-the-art models on seven benchmarks, using only 2.5% of the original data, highlighting the efficiency of our data selection approach. Moreover, we conduct ablation studies to validate the effectiveness of each component of our method. The code is available at https://github.com/HITsz-TMG/ViSA.
为提高多模态大型语言模型(MLLMs)处理图像和复杂指令的能力,研究者主要创建大规模视觉指令微调数据集,这些数据集来源于现有的视觉任务或使用LLMs和图像描述人工合成。然而,它们经常存在关键缺陷,包括指令与图像不匹配和低质量图像。这些问题阻碍了训练效率,限制了性能提升,因为模型会在嘈杂或无关的数据上浪费资源,对整体能力益处甚微。为解决此问题,我们提出了一种以视觉为中心的通过代理协作的视觉中心选择方法(ViSA),该方法侧重于图像质量评估和图像指令相关性评估。具体来说,我们的方法包括:1)一种通过视觉代理协作的图像信息量化方法,用于选择视觉信息丰富的图像;以及2)一种以视觉为中心的指令质量评估方法,用于选择与高质量图像相关的优质指令数据。最后,我们从大型开源数据集中重新整理了8万条指令数据。大量实验表明,ViSA在七个基准测试上的表现优于或相当于当前最先进的模型,仅使用原始数据的2.5%,凸显了我们数据选择方法的高效性。此外,我们进行了剥离研究以验证我们方法的每个组件的有效性。代码可在https://github.com/HITsz-TMG/ViSA找到。
论文及项目相关链接
PDF 15 pages, 7 figures
Summary
本文提出一种视觉为中心的选择方法——ViSA,通过视觉代理协作进行图像信息量化,选择具有丰富视觉信息的图像,并通过视觉为中心的教学指令质量评估方法选择与高质图像相关的优质教学数据。通过大规模实验验证,ViSA方法在多模态大型语言模型的图像处理和复杂指令处理方面表现优异,且仅使用原始数据的2.5%,展现了高效的数据选择能力。同时,公开了代码实现。
Key Takeaways
- 研究者主要通过构建大规模视觉指令微调数据集来提升多模态大型语言模型处理图像和复杂指令的能力。
- 现有数据集存在诸多问题,如指令与图像不匹配、图像质量低下等,影响模型训练效率和性能。
- 提出ViSA方法,包括图像信息量化及视觉为中心的教学指令质量评估。
- ViSA方法通过选择丰富视觉信息的图像和高质教学数据,显著提升模型性能。
- 实验证明ViSA方法在七个基准测试上表现优异,且使用数据仅为原数据的2.5%。
- 公开代码实现,便于他人使用和改进。
点此查看论文截图

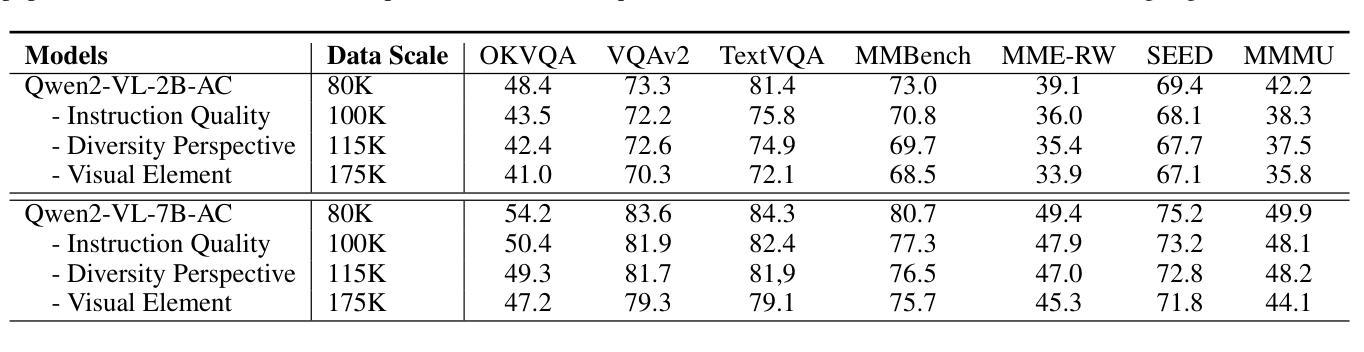
Optimus-2: Multimodal Minecraft Agent with Goal-Observation-Action Conditioned Policy
Authors:Zaijing Li, Yuquan Xie, Rui Shao, Gongwei Chen, Dongmei Jiang, Liqiang Nie
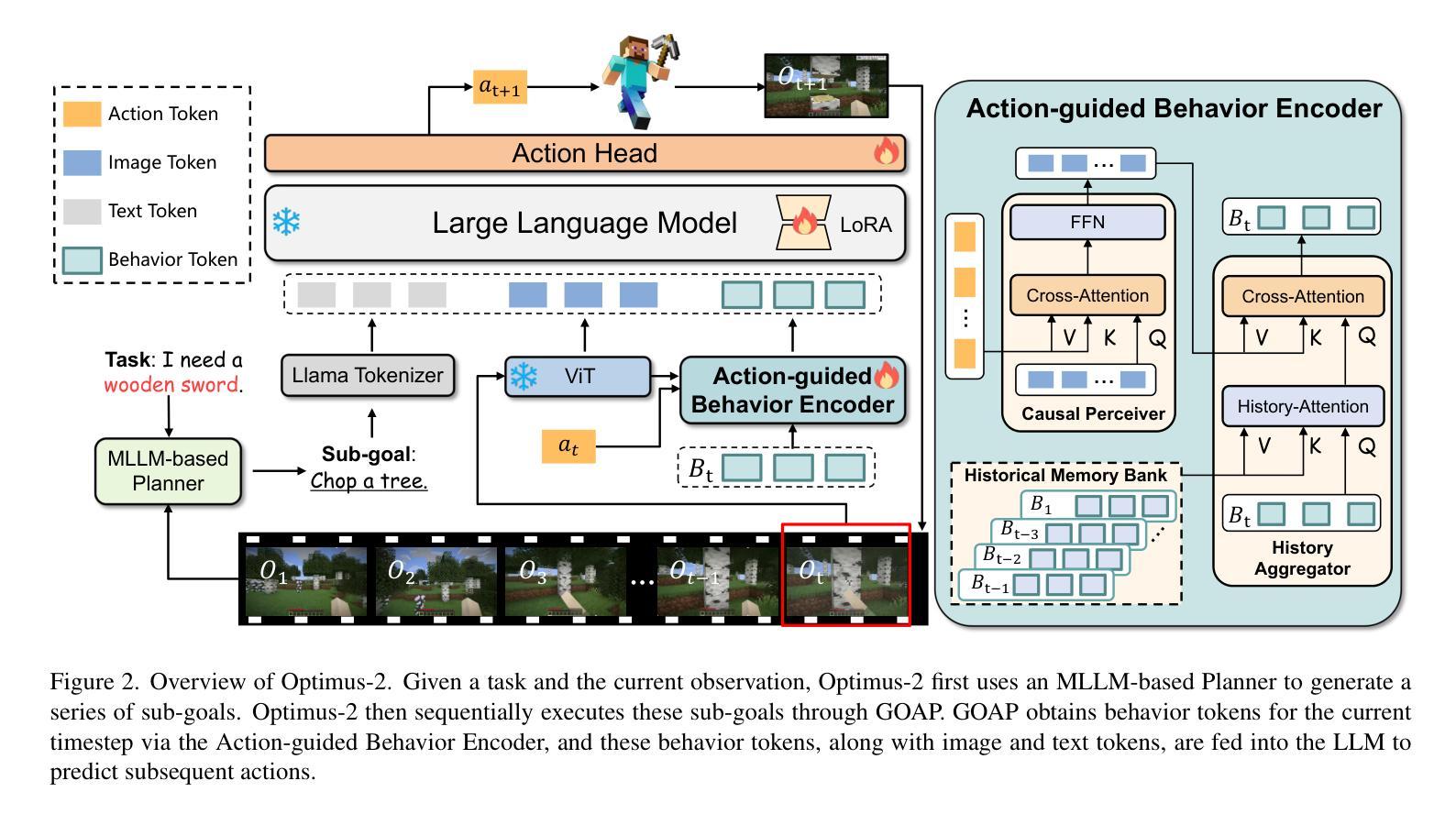
Building an agent that can mimic human behavior patterns to accomplish various open-world tasks is a long-term goal. To enable agents to effectively learn behavioral patterns across diverse tasks, a key challenge lies in modeling the intricate relationships among observations, actions, and language. To this end, we propose Optimus-2, a novel Minecraft agent that incorporates a Multimodal Large Language Model (MLLM) for high-level planning, alongside a Goal-Observation-Action Conditioned Policy (GOAP) for low-level control. GOAP contains (1) an Action-guided Behavior Encoder that models causal relationships between observations and actions at each timestep, then dynamically interacts with the historical observation-action sequence, consolidating it into fixed-length behavior tokens, and (2) an MLLM that aligns behavior tokens with open-ended language instructions to predict actions auto-regressively. Moreover, we introduce a high-quality Minecraft Goal-Observation-Action (MGOA)} dataset, which contains 25,000 videos across 8 atomic tasks, providing about 30M goal-observation-action pairs. The automated construction method, along with the MGOA dataset, can contribute to the community’s efforts to train Minecraft agents. Extensive experimental results demonstrate that Optimus-2 exhibits superior performance across atomic tasks, long-horizon tasks, and open-ended instruction tasks in Minecraft.
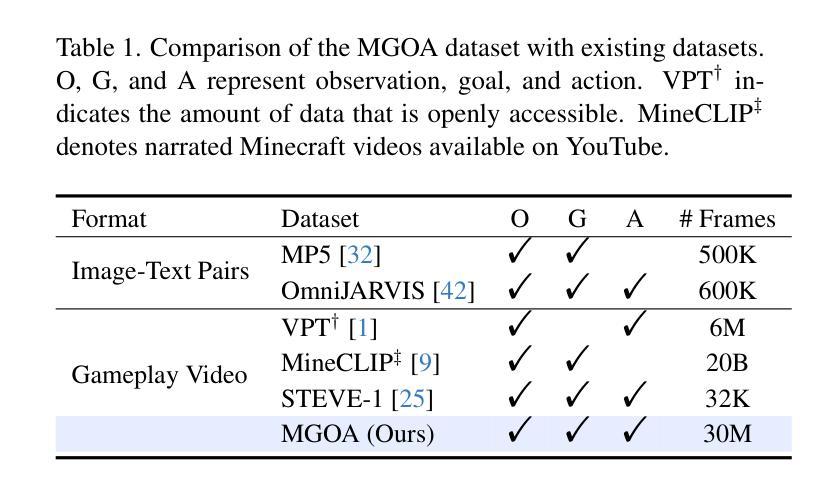
构建能够模仿人类行为模式以完成各种开放世界任务的智能体是一项长期目标。为了使智能体能够在各种任务中有效地学习行为模式,关键挑战在于对观察、行动和语言之间复杂关系的建模。为此,我们提出了Optimus-2,这是一个新型Minecraft智能体,它结合了多模态大型语言模型(MLLM)进行高级规划,以及以目标-观察-行动条件策略(GOAP)进行低级控制。GOAP包含(1)行动导向行为编码器,该编码器会建模观察与行动之间的因果关系,并在每个时间步长中与历史观察-行动序列动态互动,将其整合为固定长度的行为令牌;(2)MLLM则将这些行为令牌与开放的语言指令对齐,以进行自回归行动预测。此外,我们还推出了高质量的Minecraft目标-观察-行动(MGOA)数据集,包含8个原子任务的2.5万段视频,提供约3000万的目标-观察-行动对。自动化构建方法和MGOA数据集能为社区训练Minecraft智能体的努力做出贡献。大量的实验结果表明,Optimus-2在原子任务、长期任务和开放指令任务中,在Minecraft中的表现均超群。
论文及项目相关链接
PDF Accept to CVPR 2025
Summary
本文介绍了一种新型Minecraft智能体Optimus-2的构建过程。Optimus-2结合了多模态大型语言模型(MLLM)进行高级规划,并采用目标-观察-动作条件策略(GOAP)进行低级控制。其核心特点是行动导向行为编码器,它能建模观察与行动之间的因果关系,并动态地将其整合为固定长度的行为标记。此外,引入了高质量的Minecraft目标观察动作(MGOA)数据集,包含多种原子任务的大量数据。实验结果表明,Optimus-2在Minecraft中表现出卓越的性能。
Key Takeaways
- 介绍了一种新的Minecraft智能体Optimus-2的构建。
- Optimus-2结合了多模态大型语言模型(MLLM)用于高级规划。
- 采用目标-观察-动作条件策略(GOAP)进行低级控制。
- 核心特点是行动导向行为编码器,可以建模观察与行动之间的因果关系。
- 引入了高质量的Minecraft目标观察动作(MGOA)数据集。
- Optimus-2能处理多种任务,包括原子任务、长期任务和开放式指令任务。
点此查看论文截图

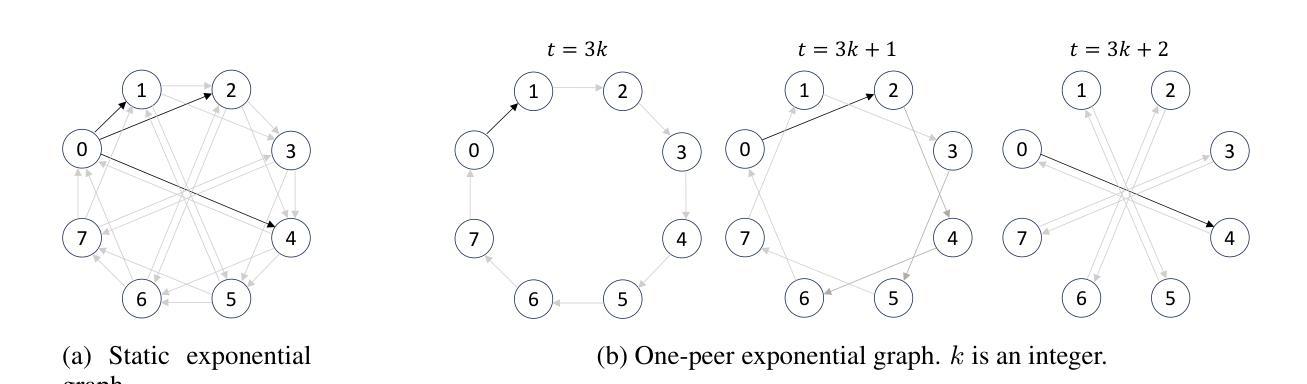
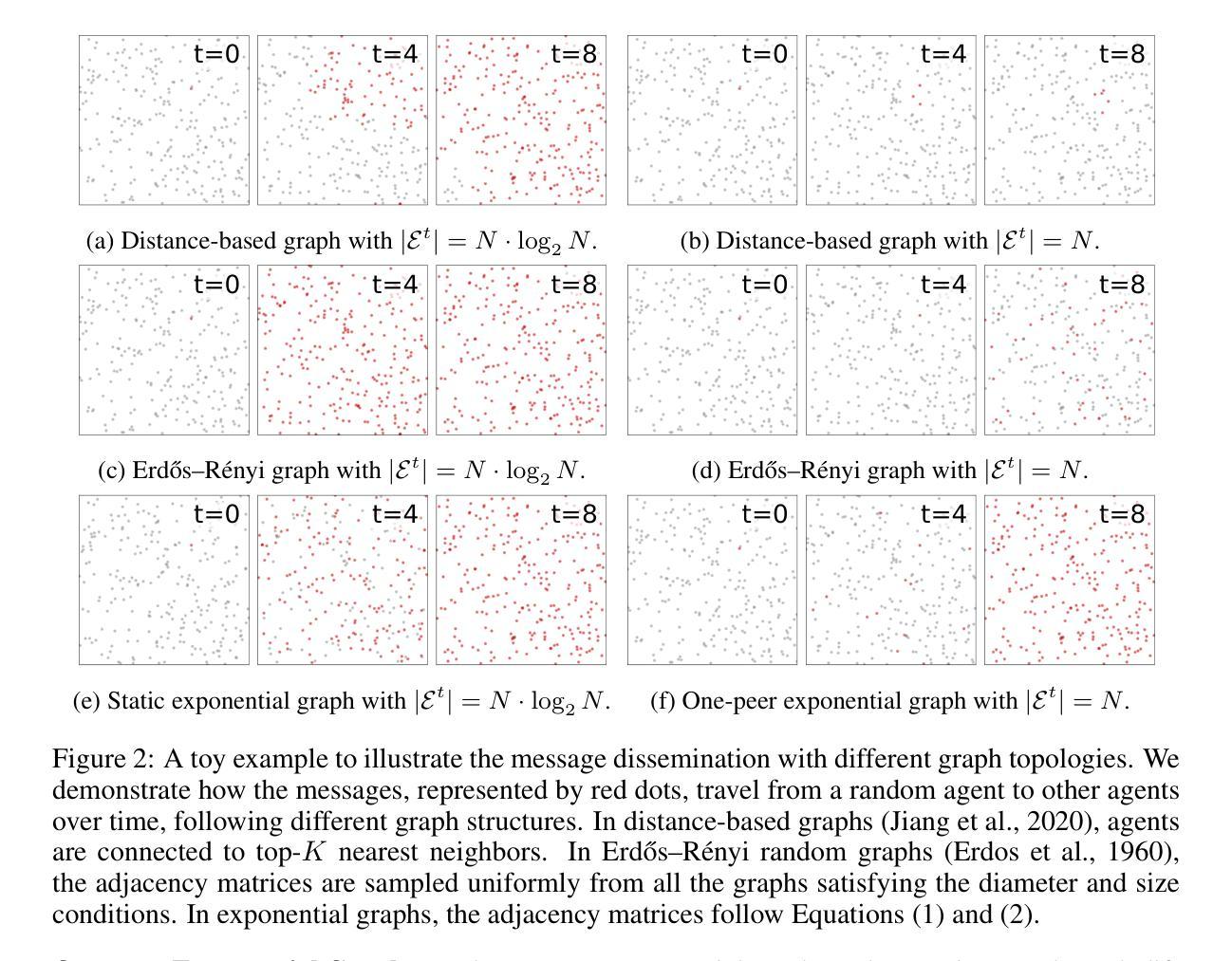
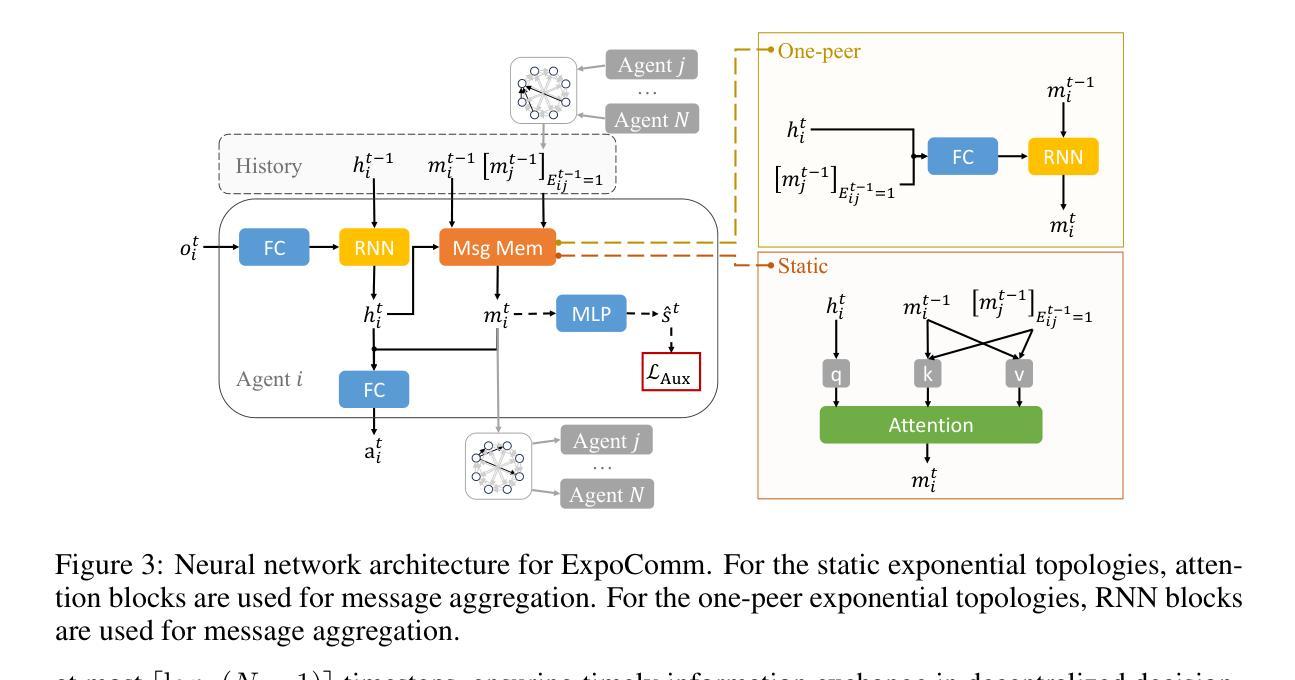
Exponential Topology-enabled Scalable Communication in Multi-agent Reinforcement Learning
Authors:Xinran Li, Xiaolu Wang, Chenjia Bai, Jun Zhang
In cooperative multi-agent reinforcement learning (MARL), well-designed communication protocols can effectively facilitate consensus among agents, thereby enhancing task performance. Moreover, in large-scale multi-agent systems commonly found in real-world applications, effective communication plays an even more critical role due to the escalated challenge of partial observability compared to smaller-scale setups. In this work, we endeavor to develop a scalable communication protocol for MARL. Unlike previous methods that focus on selecting optimal pairwise communication links-a task that becomes increasingly complex as the number of agents grows-we adopt a global perspective on communication topology design. Specifically, we propose utilizing the exponential topology to enable rapid information dissemination among agents by leveraging its small-diameter and small-size properties. This approach leads to a scalable communication protocol, named ExpoComm. To fully unlock the potential of exponential graphs as communication topologies, we employ memory-based message processors and auxiliary tasks to ground messages, ensuring that they reflect global information and benefit decision-making. Extensive experiments on large-scale cooperative benchmarks, including MAgent and Infrastructure Management Planning, demonstrate the superior performance and robust zero-shot transferability of ExpoComm compared to existing communication strategies. The code is publicly available at https://github.com/LXXXXR/ExpoComm.
在合作多智能体强化学习(MARL)中,设计良好的通信协议可以有效地促进智能体之间的共识,从而提高任务性能。此外,在现实世界应用中常见的大规模多智能体系统中,由于与小规模设置相比局部可观察性的挑战加剧,有效的通信发挥着至关重要的作用。在这项工作中,我们努力为MARL开发可扩展的通信协议。不同于以前的方法,侧重于选择最优的配对通信链接——随着智能体数量的增长,这项任务变得越来越复杂——我们对通信拓扑设计采用全局视角。具体来说,我们提出利用指数拓扑,通过利用其小直径和小规模属性,实现在智能体之间的快速信息传播。这种方法导致了一个可扩展的通信协议,称为ExpoComm。为了充分利用指数图作为通信拓扑的潜力,我们采用基于内存的消息处理器和辅助任务来确保消息反映全局信息并有益于决策。在包括MAgent和基础设施管理规划等大型合作基准测试上的广泛实验表明,与现有通信策略相比,ExpoComm具有卓越的性能和稳健的零样本迁移能力。代码公开在https://github.com/LXXXXR/ExpoComm。
论文及项目相关链接
PDF Accepted by the Thirteenth International Conference on Learning Representations (ICLR 2025)
Summary
在合作多智能体强化学习(MARL)中,设计良好的通信协议能有效促进智能体间的共识,从而提升任务性能。特别是在常见的大型多智能体系统中,由于部分观察性的挑战加剧,有效的通信扮演着更为关键的角色。本研究致力于开发一种适用于MARL的可扩展通信协议。不同于以往关注选择最优配对通信链接的方法(随着智能体数量的增长,该任务变得日益复杂),我们采用全局视角设计通信拓扑。具体地,我们提议利用指数拓扑,通过其小直径和小尺寸属性实现智能体间的快速信息传播。这种方法促成了一种可扩展的通信协议——ExpoComm。为充分发挥指数图作为通信拓扑的潜力,我们采用基于内存的消息处理器和辅助任务来验证信息,确保信息反映全局信息并有益于决策。在大型合作基准测试上的广泛实验,包括MAgent和基础设施管理规划,证明了ExpoComm相较于现有通信策略的优势,其具备卓越的性能和稳健的零射击转移性。
Key Takeaways
- 合作多智能体强化学习(MARL)中,通信协议设计对于促进智能体间共识至关重要。
- 在大型多智能体系统中,有效通信对于克服部分观察性的挑战至关重要。
- 研究人员提出了一种新的可扩展通信协议ExpoComm,采用全局视角设计通信拓扑。
- ExpoComm利用指数拓扑实现智能体间的快速信息传播。
- 为充分发挥指数图作为通信拓扑的潜力,结合了基于内存的消息处理器和辅助任务。
- 在多个基准测试上,ExpoComm表现出卓越的性能和稳健的零射击转移性。
点此查看论文截图

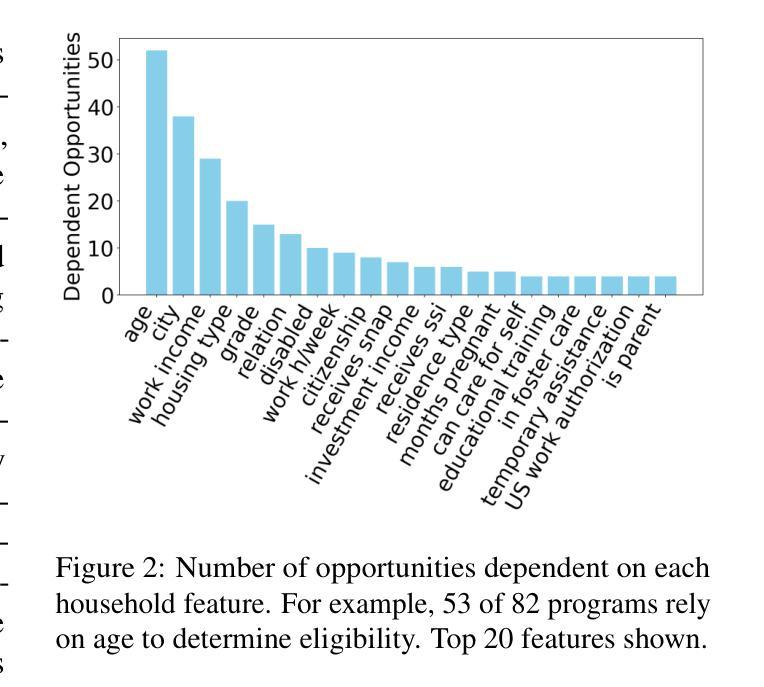
Program Synthesis Dialog Agents for Interactive Decision-Making
Authors:Matthew Toles, Nikhil Balwani, Rattandeep Singh, Valentina Giulia Sartori Rodriguez, Zhou Yu
Many real-world eligibility problems, ranging from medical diagnosis to tax planning, can be mapped to decision problems expressed in natural language, wherein a model must make a binary choice based on user features. Large-scale domains such as legal codes or frequently updated funding opportunities render human annotation (e.g., web forms or decision trees) impractical, highlighting the need for agents that can automatically assist in decision-making. Since relevant information is often only known to the user, it is crucial that these agents ask the right questions. As agents determine when to terminate a conversation, they face a trade-off between accuracy and the number of questions asked, a key metric for both user experience and cost. To evaluate this task, we propose BeNYfits, a new benchmark for determining user eligibility for multiple overlapping social benefits opportunities through interactive decision-making. Our experiments show that current language models struggle with frequent hallucinations, with GPT-4o scoring only 35.7 F1 using a ReAct-style chain-of-thought. To address this, we introduce ProADA, a novel approach that leverages program synthesis to assist in decision-making by mapping dialog planning to a code generation problem and using gaps in structured data to determine the best next action. Our agent, ProADA, improves the F1 score to 55.6 while maintaining nearly the same number of dialog turns.
现实世界中的许多资格问题,从医学诊断到税务规划,都可以映射到以自然语言表达出的决策问题,其中模型必须基于用户特征进行二元选择。大规模领域(如法律代码或经常更新的资助机会)使得人工标注(例如网页表单或决策树)变得不切实际,这突显了需要能够自动协助决策的智能体的必要性。由于相关信息通常只为用户所知,因此这些智能体提出正确的问题至关重要。智能体在决定何时结束对话时面临着准确性与所提问题数量之间的权衡,这是用户体验和成本的关键指标。为了评估这一任务,我们提出了BeNYfits,这是一个新的基准测试,用于通过交互式决策来确定用户对于多个重叠的社会福利机会的资格。我们的实验表明,当前的语言模型经常产生幻觉,GPT-4o在ReAct风格的思维链中的F1得分仅为35.7。为了解决这个问题,我们引入了ProADA这一新方法,它通过利用程序合成来协助决策,通过将对话规划映射到代码生成问题并使用结构化数据中的空白来确定最佳下一步行动。我们的智能体ProADA将F1分数提高到55.6,同时几乎保持了相同的对话轮次。
论文及项目相关链接
Summary
本文探讨了现实世界中从医疗诊断到税务规划等多元化的资格认定问题,可转化为自然语言表达的决策问题。由于大规模领域如法律条文或频繁更新的资助机会使得人工标注不实际,因此需要能够自动协助决策的智能代理。这些智能代理需能够向用户提问以获取关键信息,并在决定何时结束对话时面临准确性提问数量之间的权衡。为评估此任务,文章提出了BeNYfits新基准测试,通过互动决策来判定用户是否适合多重重叠的社会福利机会。实验显示,当前的语言模型常有误判现象,GPT-4o在ReAct式思维链中的F1得分仅35.7。为解决此问题,文章提出了ProADA新方法,通过程序合成协助决策,将对话规划映射为代码生成问题并利用结构化数据中的空白来确定最佳下一步行动。ProADA代理能将F1得分提升至55.6%,同时保持相近的对话轮次。
Key Takeaways
- 现实世界的资格认定问题可以通过自然语言决策问题表达。
- 在大规模领域或频繁更新的资助机会中,人工标注变得不实际,需要自动决策的智能代理。
- 智能代理必须能够向用户提问以获取关键信息。
- 在决定何时结束对话时,智能代理需要在准确性和提问数量之间取得平衡。
- 提出新的基准测试BeNYfits用于评估互动决策效果。
- 当前语言模型存在误判现象,特别是在复杂情境中难以准确判断用户资格。
点此查看论文截图



Winning Big with Small Models: Knowledge Distillation vs. Self-Training for Reducing Hallucination in QA Agents
Authors:Ashley Lewis, Michael White, Jing Liu, Toshiaki Koike-Akino, Kieran Parsons, Ye Wang
The deployment of Large Language Models (LLMs) in customer support is constrained by hallucination-generating false information-and the high cost of proprietary models. To address these challenges, we propose a retrieval-augmented question-answering (QA) pipeline and explore how to balance human input and automation. Using a dataset of questions about a Samsung Smart TV user manual, we demonstrate that synthetic data generated by LLMs outperforms crowdsourced data in reducing hallucination in finetuned models. We also compare self-training (fine-tuning models on their own outputs) and knowledge distillation (fine-tuning on stronger models’ outputs, e.g., GPT-4o), and find that self-training achieves comparable hallucination reduction. We conjecture that this surprising finding can be attributed to increased exposure bias issues in the knowledge distillation case and support this conjecture with post hoc analysis. We also improve robustness to unanswerable questions and retrieval failures with contextualized “I don’t know” responses. These findings show that scalable, cost-efficient QA systems can be built using synthetic data and self-training with open-source models, reducing reliance on proprietary tools or costly human annotations.
在客户支持中部署大型语言模型(LLM)受到生成虚假信息的幻觉和高昂的专有模型成本限制。为了应对这些挑战,我们提出了一种检索增强问答(QA)管道,并探索如何平衡人工输入和自动化。我们使用有关三星智能电视用户手册的问题数据集,展示LLM生成的合成数据在减少微调模型中的幻觉方面优于众包数据。我们还比较了自训练(在模型自身输出上微调)和知识蒸馏(在更强大模型的输出上进行微调,例如GPT-4o),发现自训练可实现相当的幻觉减少效果。我们推测这一令人惊讶的发现可归因于知识蒸馏情况下的增加曝光偏见问题,并通过事后分析支持这一推测。我们还通过上下文中的“我不知道”的回应,提高了对无法回答的问题和检索失败的稳健性。这些发现表明,可以使用合成数据和自训练以及开源模型构建可扩展且成本效益高的QA系统,减少了对专有工具或昂贵的人力标注的依赖。
论文及项目相关链接
Summary
大型语言模型(LLM)在客服支持中的应用受到生成虚假信息和专有模型成本高昂的限制。为解决这些挑战,我们提出了检索增强问答(QA)管道,并探讨了如何平衡人工输入和自动化。使用关于三星智能电视用户手册的问题数据集,我们证明由LLM生成的人工数据在微调模型中减少了幻觉生成,优于众包数据。我们还比较了自训练(在自身输出上微调模型)和知识蒸馏(在更强大模型的输出上微调,例如GPT-4o),发现自训练可实现相当的幻觉减少效果。我们推测这一令人惊讶的发现可归因于知识蒸馏情况下的曝光偏见增加问题,并通过事后分析支持这一推测。我们还通过提供上下文“我不知道”的回应,提高了对无法回答的问题和检索失败的稳健性。这些发现表明,可使用人工数据和自训练构建可扩展、成本效益高的问答系统,减少依赖专有工具或昂贵的真人注释。
Key Takeaways
- 大型语言模型(LLM)在客服支持中面临生成虚假信息和专有模型成本高昂的挑战。
- 检索增强问答(QA)管道有助于应对以上挑战。
- 使用关于三星智能电视用户手册的问题数据集,LLM生成的人工数据在减少幻觉方面优于众包数据。
- 自训练与知识蒸馏在减少幻觉方面效果相当,但自训练可能受到曝光偏见增加的影响。
- 通过提供“我不知道”的回应,提高了对无法回答的问题和检索失败的稳健性。
- 可使用人工数据和自训练构建成本效益高的问答系统。
点此查看论文截图

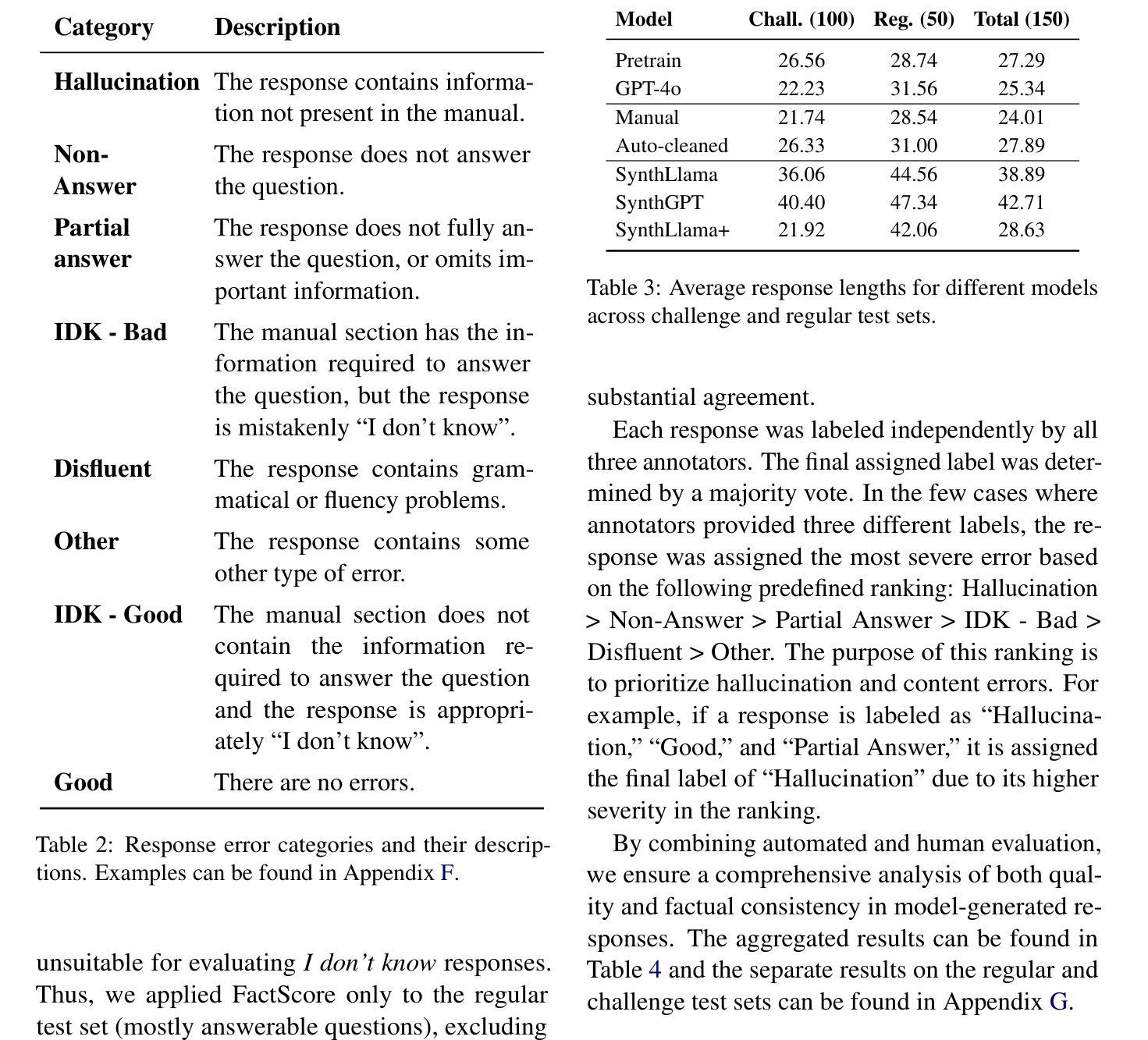
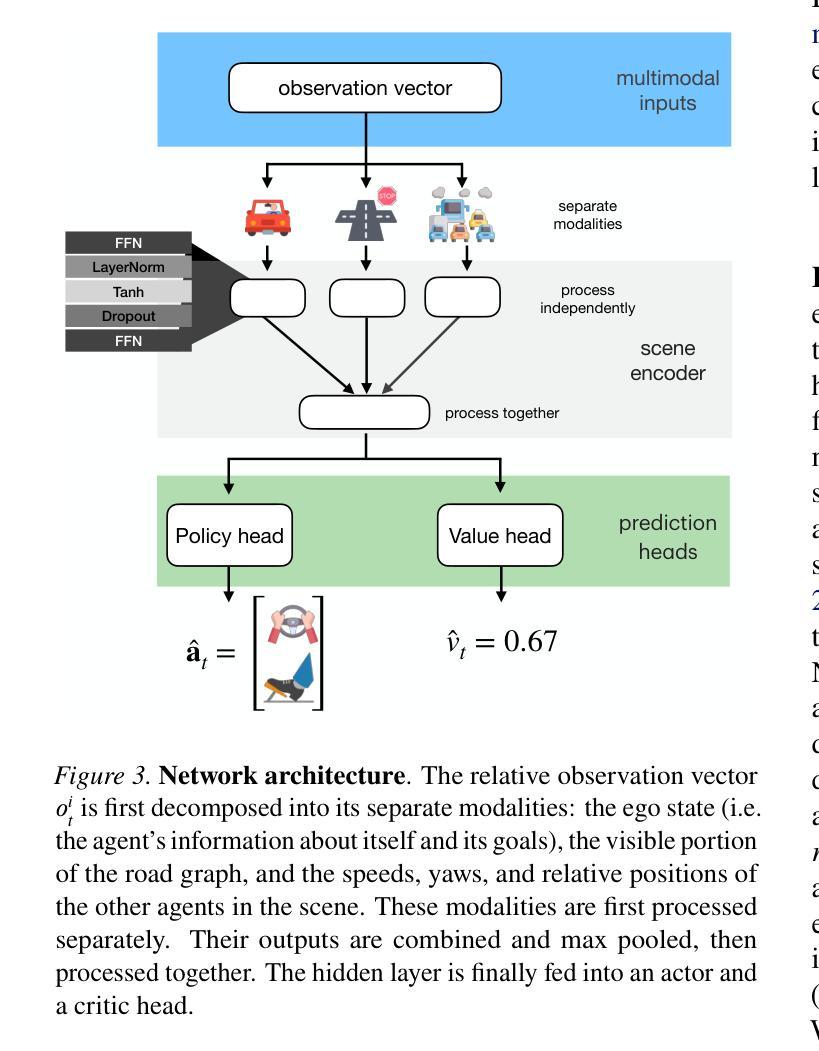
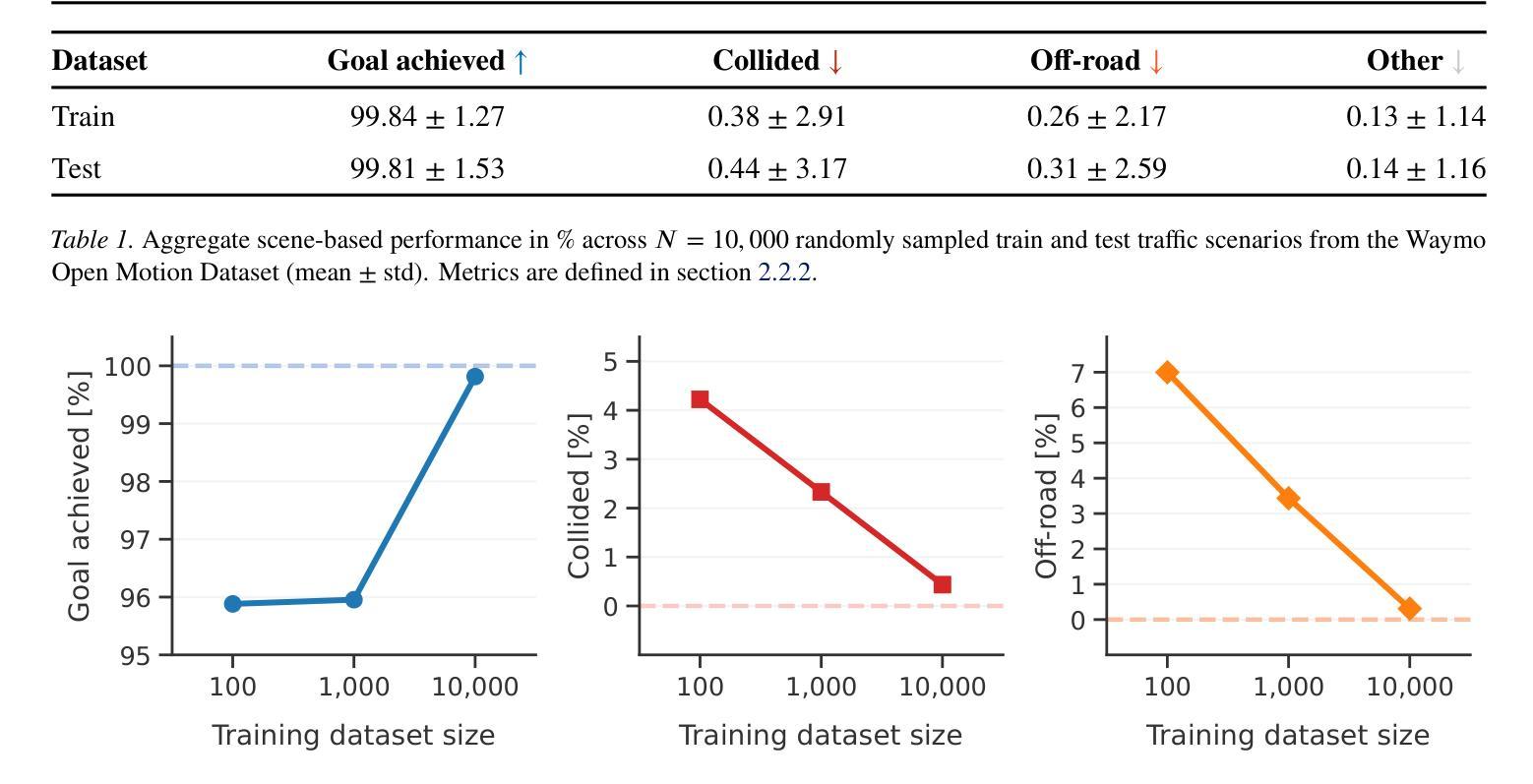
Building reliable sim driving agents by scaling self-play
Authors:Daphne Cornelisse, Aarav Pandya, Kevin Joseph, Joseph Suárez, Eugene Vinitsky
Simulation agents are essential for designing and testing systems that interact with humans, such as autonomous vehicles (AVs). These agents serve various purposes, from benchmarking AV performance to stress-testing system limits, but all applications share one key requirement: reliability. To enable systematic experimentation, a simulation agent must behave as intended. It should minimize actions that may lead to undesired outcomes, such as collisions, which can distort the signal-to-noise ratio in analyses. As a foundation for reliable sim agents, we propose scaling self-play to thousands of scenarios on the Waymo Open Motion Dataset under semi-realistic limits on human perception and control. Training from scratch on a single GPU, our agents nearly solve the full training set within a day. They generalize effectively to unseen test scenes, achieving a 99.8% goal completion rate with less than 0.8% combined collision and off-road incidents across 10,000 held-out scenarios. Beyond in-distribution generalization, our agents show partial robustness to out-of-distribution scenes and can be fine-tuned in minutes to reach near-perfect performance in those cases. We open-source the pre-trained agents and integrate them with a batched multi-agent simulator. Demonstrations of agent behaviors can be found at https://sites.google.com/view/reliable-sim-agents.
模拟代理对于设计和测试与人类交互的系统(如自动驾驶汽车)至关重要。这些代理具有多种用途,从评估自动驾驶性能到压力测试系统限制,但所有应用程序都共享一个关键要求:可靠性。为了实现系统的实验,模拟代理必须按预期行为行事。它应尽量减少可能导致不良后果的行动,例如碰撞,这可能会在分析中扭曲信号与噪声比率。作为构建可靠的模拟代理的基础,我们建议在Waymo Open Motion数据集上,对人类感知和控制能力的半现实限制下进行成千上万的场景的自我博弈扩展。使用单个GPU从头开始训练,我们的代理在一天内几乎解决了整个训练集。他们有效地推广到未见过的测试场景,在10000个保留场景中实现了99.8%的目标完成率,碰撞和道路外事件少于0.8%。除了分布内泛化之外,我们的代理对分布外场景显示出部分稳健性,并且可以在几分钟内进行微调,以在这些情况下实现接近完美的性能。我们公开了预训练的代理,并将其与批处理的多代理模拟器集成。有关代理行为的演示,请访问:https://sites.google.com/view/reliable-sim-agents。
论文及项目相关链接
PDF v2
Summary
本文介绍了模拟代理对于设计和测试与人类交互的系统(如自动驾驶汽车)的重要性。模拟代理可以通过在各种场景下模拟人类行为,为系统设计和测试提供可靠的实验基础。文章提出一种基于Waymo Open Motion数据集的大规模自我对弈训练方案,训练得到的代理在未见场景上表现良好,并完成目标的完成率高达99.8%,同时碰撞和离路事故率低于0.8%。这些代理被开源,并集成到一个批处理多代理模拟器中。
Key Takeaways
- 模拟代理在设计和测试与人类交互的系统(如自动驾驶汽车)中扮演重要角色。
- 模拟代理的关键要求是可靠性,需要最小化可能导致意外结果的行动。
- 文章提出了一种基于Waymo Open Motion数据集的大规模自我对弈训练方案,用于创建可靠的模拟代理。
- 训练得到的代理在未见场景上表现良好,并完成目标的完成率高达99.8%。
- 这些代理具有部分对离群场景的鲁棒性,并且可以迅速微调以达到近乎完美的性能。
- 代理被开源并集成到一个批处理多代理模拟器中,以便进行更广泛的应用。
点此查看论文截图


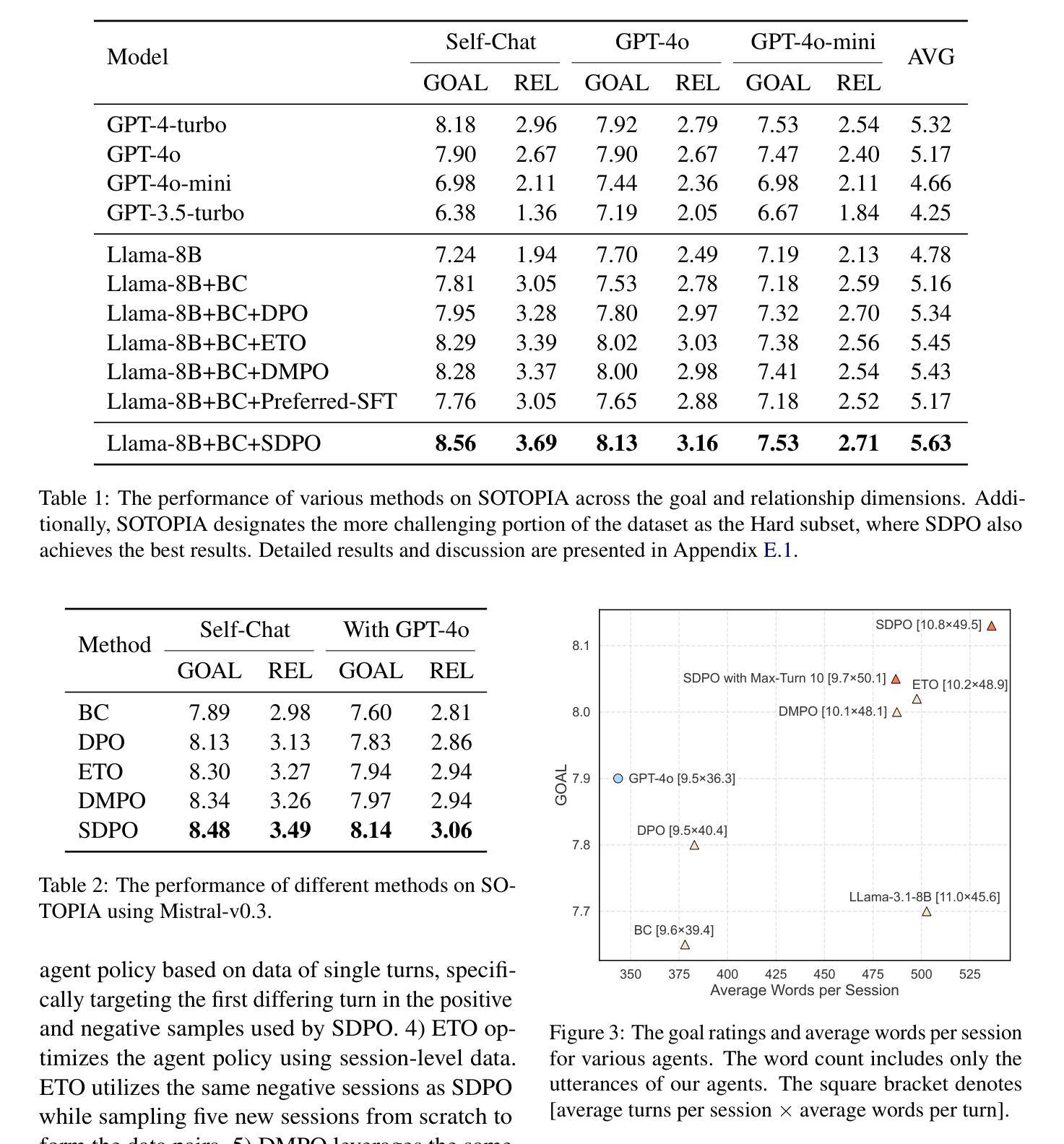
SDPO: Segment-Level Direct Preference Optimization for Social Agents
Authors:Aobo Kong, Wentao Ma, Shiwan Zhao, Yongbin Li, Yuchuan Wu, Ke Wang, Xiaoqian Liu, Qicheng Li, Yong Qin, Fei Huang
Social agents powered by large language models (LLMs) can simulate human social behaviors but fall short in handling complex social dialogues. Direct Preference Optimization (DPO) has proven effective in aligning LLM behavior with human preferences across various agent tasks. However, standard DPO focuses solely on individual turns, which limits its effectiveness in multi-turn social interactions. Several DPO-based multi-turn alignment methods with session-level data have shown potential in addressing this problem.While these methods consider multiple turns across entire sessions, they are often overly coarse-grained, introducing training noise, and lack robust theoretical support. To resolve these limitations, we propose Segment-Level Direct Preference Optimization (SDPO), which dynamically select key segments within interactions to optimize multi-turn agent behavior. SDPO minimizes training noise and is grounded in a rigorous theoretical framework. Evaluations on the SOTOPIA benchmark demonstrate that SDPO-tuned agents consistently outperform both existing DPO-based methods and proprietary LLMs like GPT-4o, underscoring SDPO’s potential to advance the social intelligence of LLM-based agents. We release our code and data at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/SDPO.
由大型语言模型(LLM)驱动的社会代理能够模拟人类的社会行为,但在处理复杂的社交对话时显得不足。直接偏好优化(DPO)在将LLM行为与各种代理任务中的人类偏好对齐方面已被证明是有效的。然而,标准DPO仅专注于个别回合,这限制了其在多回合社会互动中的有效性。一些基于DPO的多回合对齐方法使用会话级数据,已经显示出解决这个问题的潜力。虽然这些方法会考虑整个会话中的多个回合,但它们通常过于粗糙,引入训练噪声,并且缺乏坚实的理论支持。为了解决这些局限性,我们提出了分段级直接偏好优化(SDPO),它动态选择互动中的关键段落来优化多回合代理行为。SDPO最小化训练噪声,并基于严格的理论框架。在SOTOPIA基准测试上的评估表明,经过SDPO调整的代理始终优于现有的基于DPO的方法以及专有LLM,如GPT-4o,这突出了SDPO在提高基于LLM的代理的社会智能方面的潜力。我们在https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/SDPO上发布了我们的代码和数据。
论文及项目相关链接
Summary
大型语言模型驱动的社会代理能够模拟人类社交行为,但在处理复杂社会对话方面存在不足。直接偏好优化(DPO)在将LLM行为与各种代理任务中的人类偏好对齐方面表现出成效。然而,标准DPO只关注个别回合,这在多回合社会互动中的效果有限。基于DPO的多回合对齐方法虽然考虑了整个会话中的多个回合,但它们通常过于粗糙,引入训练噪音,并且缺乏坚实的理论支持。为解决这些问题,我们提出了分段级直接偏好优化(SDPO),它动态选择互动中的关键段落进行优化。SDPO减少了训练噪音,并建立在严格的理论框架上。在SOTOPIA基准测试上的评估表明,经过SDPO调整的代理持续优于现有的基于DPO的方法和专有LLM,如GPT-4o,突显了SDPO在提升基于LLM的代理的社会智能方面的潜力。
Key Takeaways
- 大型语言模型(LLM)可以模拟人类社交行为,但在处理复杂社会对话时表现不足。
- 直接偏好优化(DPO)在LLM与人类偏好对齐方面有效,但标准DPO在多回合社会互动中的效果有限。
- 基于DPO的多回合对齐方法虽然考虑了整个会话中的多个回合,但存在训练噪音和缺乏理论支持的问题。
- 分段级直接偏好优化(SDPO)动态选择关键段落进行优化,减少训练噪音,建立在严格的理论框架上。
- SDPO在SOTOPIA基准测试上的表现优于现有方法和专有LLM,突显其在提升LLM代理的社会智能方面的潜力。
- 代码和数据已公开可用,以便进一步研究和应用。
点此查看论文截图



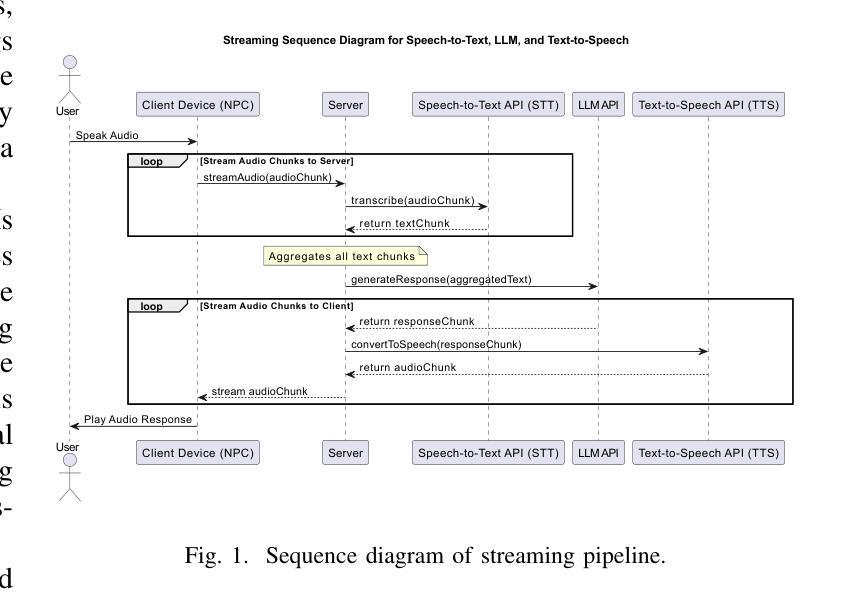
CUIfy the XR: An Open-Source Package to Embed LLM-powered Conversational Agents in XR
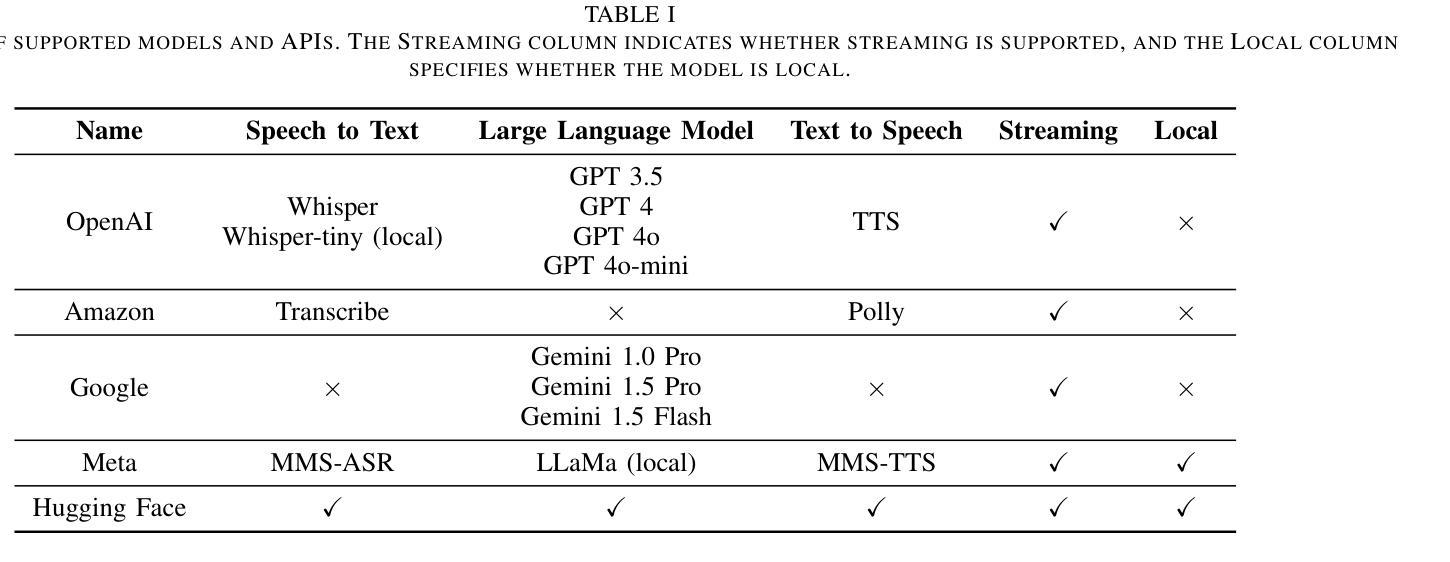
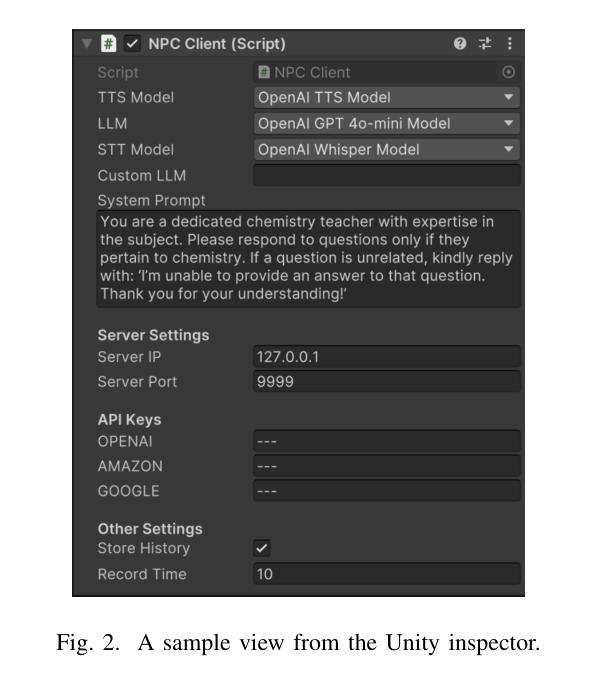
Authors:Kadir Burak Buldu, Süleyman Özdel, Ka Hei Carrie Lau, Mengdi Wang, Daniel Saad, Sofie Schönborn, Auxane Boch, Enkelejda Kasneci, Efe Bozkir
Recent developments in computer graphics, machine learning, and sensor technologies enable numerous opportunities for extended reality (XR) setups for everyday life, from skills training to entertainment. With large corporations offering affordable consumer-grade head-mounted displays (HMDs), XR will likely become pervasive, and HMDs will develop as personal devices like smartphones and tablets. However, having intelligent spaces and naturalistic interactions in XR is as important as technological advances so that users grow their engagement in virtual and augmented spaces. To this end, large language model (LLM)–powered non-player characters (NPCs) with speech-to-text (STT) and text-to-speech (TTS) models bring significant advantages over conventional or pre-scripted NPCs for facilitating more natural conversational user interfaces (CUIs) in XR. This paper provides the community with an open-source, customizable, extendable, and privacy-aware Unity package, CUIfy, that facilitates speech-based NPC-user interaction with widely used LLMs, STT, and TTS models. Our package also supports multiple LLM-powered NPCs per environment and minimizes latency between different computational models through streaming to achieve usable interactions between users and NPCs. We publish our source code in the following repository: https://gitlab.lrz.de/hctl/cuify
近期计算机图形学、机器学习和传感器技术的进展为扩展现实(XR)在日常生活中的运用提供了无数机会,无论是技能培训还是娱乐。随着大型企业提供经济实惠的消费级头戴显示器(HMDs),XR可能会变得普及,HMDs将像智能手机和平板电脑一样成为个人设备。然而,拥有智能空间和自然的人机交互与科技进步同样重要,使用户能够增加对虚拟和增强空间的参与度。为此,大型语言模型(LLM)驱动的非玩家角色(NPCs)使用语音识别(STT)和文本语音转换(TTS)模型,相较于传统的或预设的NPCs,为XR中更自然的对话用户界面(CUIs)带来了显著优势。本文为社区提供了一个开源、可定制、可扩展且注重隐私的Unity软件包CUIfy,它促进了基于语音的NPC与用户之间的交互,广泛使用了LLM、STT和TTS模型。我们的软件包还支持每个环境多个LLM驱动的NPCs,并通过流式传输减少不同计算模型之间的延迟,以实现用户和NPCs之间可用的交互。我们在以下存储库中发布我们的源代码:https://gitlab.lrz.de/hctl/cuify
论文及项目相关链接
PDF 7th IEEE International Conference on Artificial Intelligence & eXtended and Virtual Reality (IEEE AIxVR 2025)
Summary
近期计算机图形学、机器学习和传感器技术的发展为扩展现实(XR)在日常生活中的运用提供了无数机会,如技能培训和娱乐等。随着大型企业提供经济实惠的消费级头戴显示器(HMD),XR有望成为普及技术,HMD将像智能手机和平板电脑一样成为个人设备。为了提升用户在虚拟和增强空间中的参与度,智能空间和自然交互显得尤为重要。为此,利用大型语言模型(LLM)驱动的非玩家角色(NPCs)结合语音识别(STT)和文本转语音(TTS)模型,相较于传统或预设的NPCs,能为XR创造更自然的对话式用户界面(CUIs)。本文向社区提供一个开源、可定制、可扩展且注重隐私的Unity包——CUIfy,它促进了基于语音的NPC与用户之间的交互,支持广泛使用的LLMs、STT和TTS模型。我们的软件包还支持每个环境多个LLM驱动的NPCs,并通过流技术最小化不同计算模型之间的延迟,以实现用户和NPC之间的可用交互。我们的源代码发布在以下仓库中:https://gitlab.lrz.de/hctl/cuify。
Key Takeaways
- XR技术将日益普及,推动多个领域的发展。随着技术的进步和消费者设备的降低成本,XR将在日常生活中发挥重要作用。
- 智能空间和自然交互对于提高用户在虚拟和增强空间的参与度至关重要。这需要采用先进的语言模型和语音识别技术来推动人机交互的进步。
- LLM驱动的NPCs结合STT和TTS模型能创造更自然的对话式用户界面(CUIs)。这将促进NPC角色的功能扩展并增加其可信度与互动感。
- CUIfy工具包为开发者提供了一个强大的工具集,支持语音交互、多NPC管理和计算模型间的延迟最小化。这将简化NPC和用户之间的交互流程并提升其效率。
- CUIfy包强调隐私保护,确保用户数据的安全性和隐私权益得到尊重。这对于确保用户在使用XR技术时的信息安全至关重要。
- 提供的Unity包为开发者提供了一个开放源代码的平台,可自由定制并扩展其功能。这将有助于社区推动XR技术的创新和发展。
点此查看论文截图

AgentSquare: Automatic LLM Agent Search in Modular Design Space
Authors:Yu Shang, Yu Li, Keyu Zhao, Likai Ma, Jiahe Liu, Fengli Xu, Yong Li
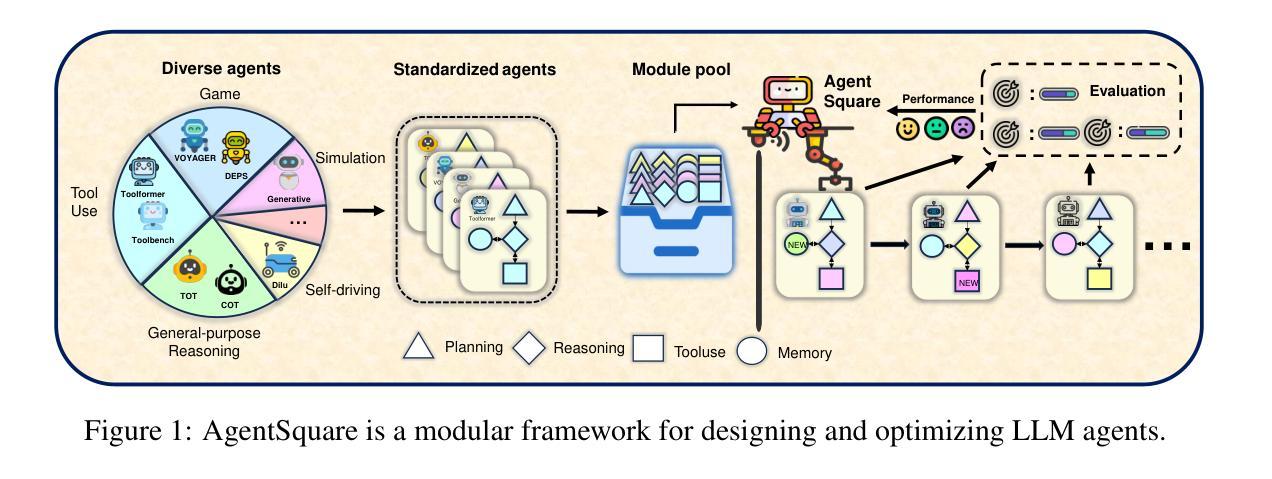
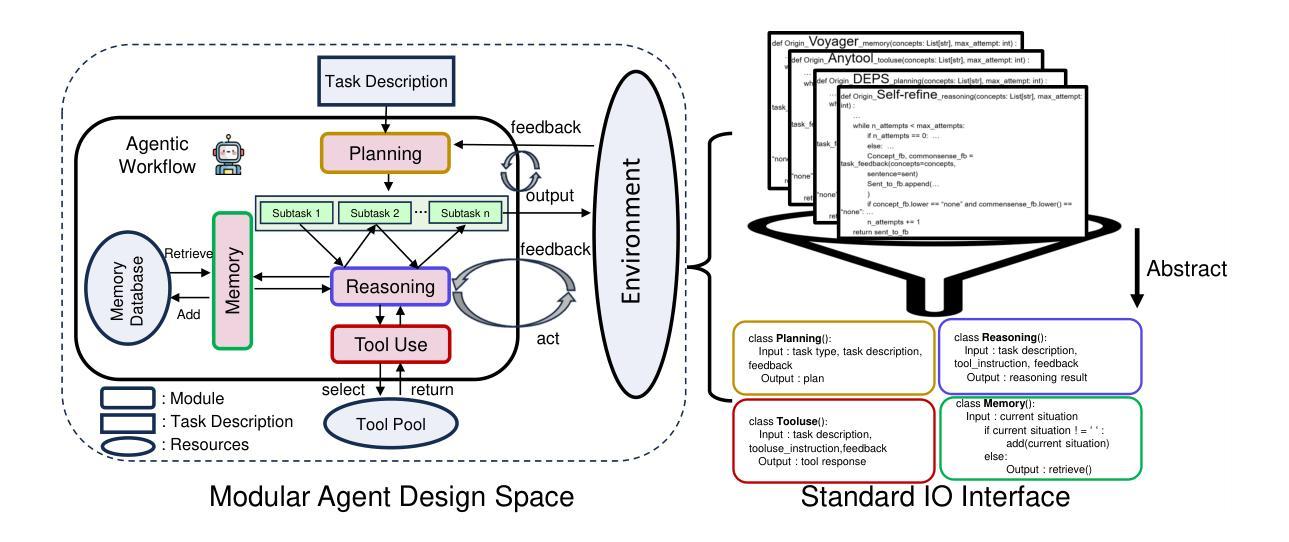
Recent advancements in Large Language Models (LLMs) have led to a rapid growth of agentic systems capable of handling a wide range of complex tasks. However, current research largely relies on manual, task-specific design, limiting their adaptability to novel tasks. In this paper, we introduce a new research problem: Modularized LLM Agent Search (MoLAS). We propose a modular design space that abstracts existing LLM agent designs into four fundamental modules with uniform IO interface: Planning, Reasoning, Tool Use, and Memory. Building on this design space, we present a novel LLM agent search framework called AgentSquare, which introduces two core mechanisms, i.e., module evolution and recombination, to efficiently search for optimized LLM agents. To further accelerate the process, we design a performance predictor that uses in-context surrogate models to skip unpromising agent designs. Extensive experiments across six benchmarks, covering the diverse scenarios of web, embodied, tool use and game applications, show that AgentSquare substantially outperforms hand-crafted agents, achieving an average performance gain of 17.2% against best-known human designs. Moreover, AgentSquare can generate interpretable design insights, enabling a deeper understanding of agentic architecture and its impact on task performance. We believe that the modular design space and AgentSquare search framework offer a platform for fully exploiting the potential of prior successful designs and consolidating the collective efforts of research community. Code repo is available at https://github.com/tsinghua-fib-lab/AgentSquare.
近期大型语言模型(LLM)的进步导致能够处理各种复杂任务的智能代理系统迅速增长。然而,当前的研究主要依赖于手动、针对特定任务的设计,这限制了它们对新任务的适应性。在本文中,我们引入了一个新的研究问题:模块化LLM代理搜索(MoLAS)。我们提出了一个模块化设计空间,它将现有的LLM代理设计抽象为四个具有统一IO接口的基本模块:规划、推理、工具使用和记忆。基于这个设计空间,我们提出了一种新的LLM代理搜索框架,名为AgentSquare。它引入了两个核心机制,即模块进化和重组,以有效地搜索优化LLM代理。为了进一步加速这一过程,我们设计了一个性能预测器,它使用上下文替代模型来跳过没有前途的代理设计。在涵盖网页、实体、工具使用和游戏应用程序等多个场景的六个基准测试上的大量实验表明,AgentSquare显著优于手工制作的代理,与已知的最佳人类设计相比,平均性能提升17.2%。此外,AgentSquare可以生成可解释的设计见解,使人们对代理架构及其对任务性能的影响有更深入的理解。我们相信,模块化设计空间和AgentSquare搜索框架为充分利用现有成功设计的潜力以及整合研究社区的集体努力提供了一个平台。代码仓库可在https://github.com/tsinghua-fib-lab/AgentSquare找到。
论文及项目相关链接
PDF 25 pages
Summary
本文介绍了大型语言模型(LLM)的最新进展,并指出当前研究主要依赖于手动任务特定的设计,限制了其适应新任务的能力。为此,本文提出了一个新的研究问题:模块化LLM代理搜索(MoLAS),并基于此设计空间提出了一种名为AgentSquare的LLM代理搜索框架。该框架通过模块进化和重组等核心机制,能够高效搜索优化LLM代理。此外,还设计了一个性能预测器,使用上下文替代模型来跳过无希望的代理设计。实验表明,AgentSquare在多种应用场景下显著优于手工设计的代理,平均性能提升17.2%。
Key Takeaways
- 大型语言模型(LLM)的进展推动了agentic系统的快速发展,能够处理各种复杂任务。
- 当前研究主要依赖手动任务特定的设计,限制了其适应新任务的能力。
- 提出了模块化LLM代理搜索(MoLAS)的新研究问题。
- 介绍了基于模块化设计的AgentSquare搜索框架,包括模块进化、重组等核心机制。
- 设计了性能预测器,使用上下文替代模型跳过无希望的代理设计。
- AgentSquare在多个基准测试中显著优于手工设计的代理,平均性能提升17.2%。
点此查看论文截图

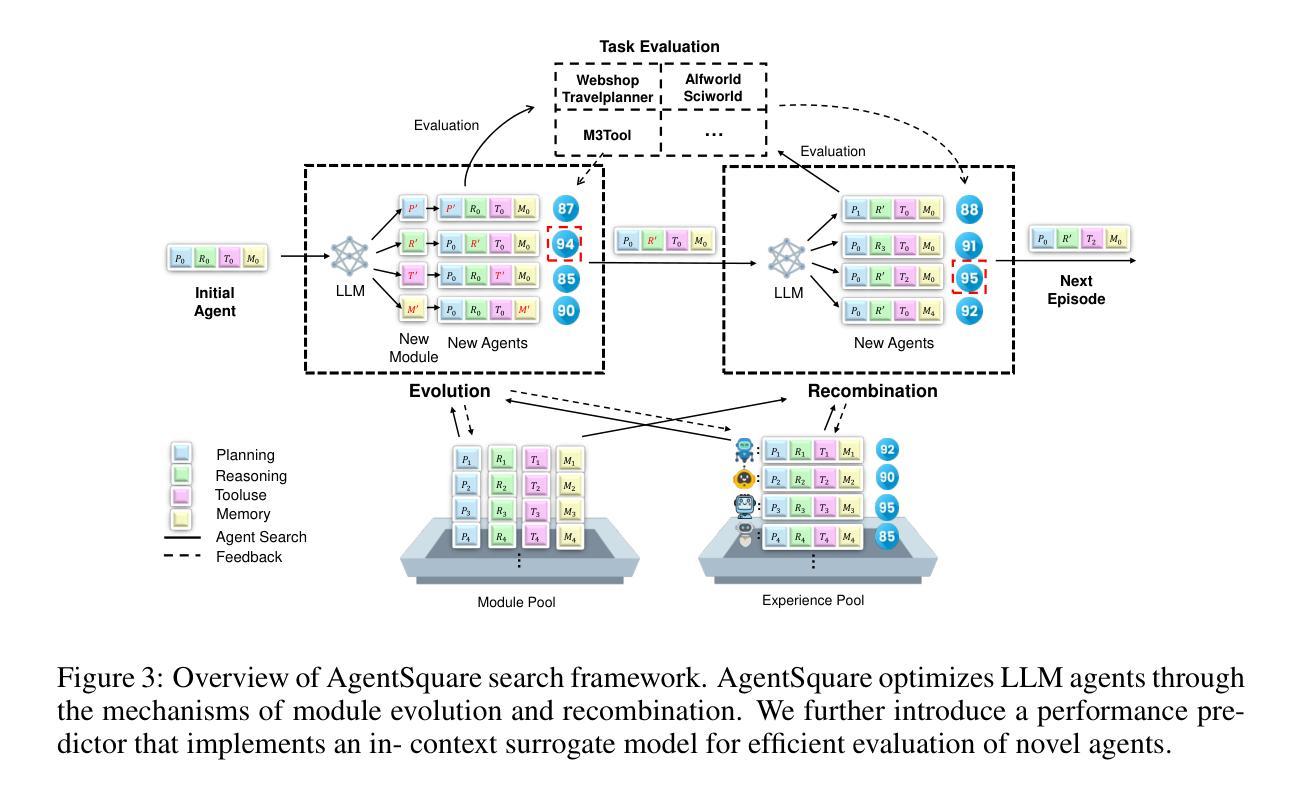
InsightBench: Evaluating Business Analytics Agents Through Multi-Step Insight Generation
Authors:Gaurav Sahu, Abhay Puri, Juan Rodriguez, Amirhossein Abaskohi, Mohammad Chegini, Alexandre Drouin, Perouz Taslakian, Valentina Zantedeschi, Alexandre Lacoste, David Vazquez, Nicolas Chapados, Christopher Pal, Sai Rajeswar Mudumba, Issam Hadj Laradji
Data analytics is essential for extracting valuable insights from data that can assist organizations in making effective decisions. We introduce InsightBench, a benchmark dataset with three key features. First, it consists of 100 datasets representing diverse business use cases such as finance and incident management, each accompanied by a carefully curated set of insights planted in the datasets. Second, unlike existing benchmarks focusing on answering single queries, InsightBench evaluates agents based on their ability to perform end-to-end data analytics, including formulating questions, interpreting answers, and generating a summary of insights and actionable steps. Third, we conducted comprehensive quality assurance to ensure that each dataset in the benchmark had clear goals and included relevant and meaningful questions and analysis. Furthermore, we implement a two-way evaluation mechanism using LLaMA-3 as an effective, open-source evaluator to assess agents’ ability to extract insights. We also propose AgentPoirot, our baseline data analysis agent capable of performing end-to-end data analytics. Our evaluation on InsightBench shows that AgentPoirot outperforms existing approaches (such as Pandas Agent) that focus on resolving single queries. We also compare the performance of open- and closed-source LLMs and various evaluation strategies. Overall, this benchmark serves as a testbed to motivate further development in comprehensive automated data analytics and can be accessed here: https://github.com/ServiceNow/insight-bench.
数据分析对于从数据中提取有价值的见解以协助组织做出有效决策至关重要。我们介绍了InsightBench,这是一个具有三个关键特征的标准数据集。首先,它包含了100个代表各种商业用例的数据集,如金融和事件管理,每个数据集都配有一组精心策划的见解。其次,与现有主要回答单一查询的测试不同,InsightBench基于代理执行端到端数据分析的能力进行评估,包括提出问题、解释答案和生成见解和可操作的步骤摘要。第三,我们进行了全面的质量保证,以确保数据集中的每个数据集都有明确的目标,包括相关和有意义的问题和分析。此外,我们使用LLaMA-3作为有效的开源评估器,实施双向评估机制,以评估代理提取见解的能力。我们还提出了基线数据分析代理AgentPoirot,能够执行端到端数据分析。我们在InsightBench上的评估显示,AgentPoirot优于现有方法(如Pandas Agent),这些方法专注于解决单一查询。我们还比较了开源和闭源大型语言模型(LLMs)的性能以及各种评估策略。总的来说,这个基准测试为全面自动化数据分析的进一步发展提供了动力,并可以在此处访问:https://github.com/ServiceNow/insight-bench。
论文及项目相关链接
PDF Accepted to ICLR 2025
Summary
本文介绍了InsightBench数据集的重要性,该数据集包含三个关键特征:包含多种业务用例的数据集,注重端到端数据分析能力的评估,以及实施全面的质量保证。同时介绍了基于该数据集的基准数据分析代理AgentPoirot。此数据集旨在作为综合自动化数据分析的试验场,激励进一步的发展。有关详细信息,请访问上述GitHub链接。
Key Takeaways
- InsightBench是一个包含多种业务用例的数据集,旨在帮助组织做出有效决策。每个数据集都包含精心策划的见解。
点此查看论文截图


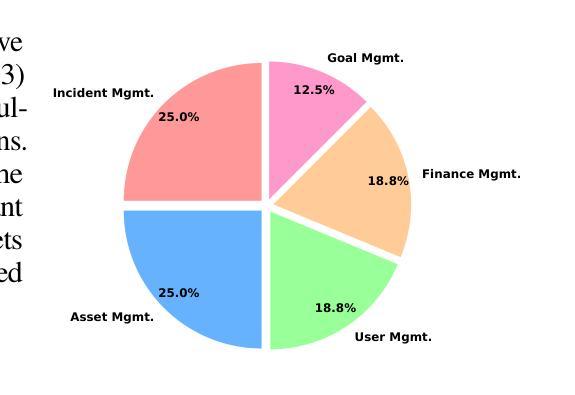
Sports-Traj: A Unified Trajectory Generation Model for Multi-Agent Movement in Sports
Authors:Yi Xu, Yun Fu
Understanding multi-agent movement is critical across various fields. The conventional approaches typically focus on separate tasks such as trajectory prediction, imputation, or spatial-temporal recovery. Considering the unique formulation and constraint of each task, most existing methods are tailored for only one, limiting the ability to handle multiple tasks simultaneously, which is a common requirement in real-world scenarios. Another limitation is that widely used public datasets mainly focus on pedestrian movements with casual, loosely connected patterns, where interactions between individuals are not always present, especially at a long distance, making them less representative of more structured environments. To overcome these limitations, we propose a Unified Trajectory Generation model, UniTraj, that processes arbitrary trajectories as masked inputs, adaptable to diverse scenarios in the domain of sports games. Specifically, we introduce a Ghost Spatial Masking (GSM) module, embedded within a Transformer encoder, for spatial feature extraction. We further extend recent State Space Models (SSMs), known as the Mamba model, into a Bidirectional Temporal Mamba (BTM) to better capture temporal dependencies. Additionally, we incorporate a Bidirectional Temporal Scaled (BTS) module to thoroughly scan trajectories while preserving temporal missing relationships. Furthermore, we curate and benchmark three practical sports datasets, Basketball-U, Football-U, and Soccer-U, for evaluation. Extensive experiments demonstrate the superior performance of our model. We hope that our work can advance the understanding of human movement in real-world applications, particularly in sports. Our datasets, code, and model weights are available here https://github.com/colorfulfuture/UniTraj-pytorch.
理解多智能体运动对于各个领域都至关重要。传统的方法通常侧重于单独的任务,如轨迹预测、填补或时空恢复。考虑到每个任务的独特公式和约束,现有的大多数方法都是针对其中一个任务定制的,这限制了它们同时处理多个任务的能力,而在现实场景中这是常见的要求。另一个局限性是广泛使用的公共数据集主要关注行人运动的偶然性和松散连接的模式,其中个体之间的互动并非总是存在,特别是在远距离情况下,这使得它们无法充分代表更复杂的环境结构。为了克服这些局限性,我们提出了一种统一的轨迹生成模型UniTraj,它可以处理任意轨迹作为遮罩输入,适应于体育游戏领域的不同场景。具体来说,我们在Transformer编码器内部引入了一个Ghost Spatial Masking(GSM)模块进行空间特征提取。我们将最近的State Space Models(SSMs)即Mamba模型进一步扩展为双向时序Mamba(BTM),以更好地捕捉时间依赖性。此外,我们融入了双向时序缩放(BTS)模块,全面扫描轨迹的同时保留时间缺失关系。此外,我们还整理并评估了三个实用的体育数据集,即Basketball-U、Football-U和Soccer-U数据集进行评估。大量实验证明了我们模型的卓越性能。我们希望我们的研究能够推动对人类运动在现实世界应用中的理解,特别是在体育领域。我们的数据集、代码和模型权重可在https://github.com/colorfulfuture/UniTraj-pytorch上获取。
论文及项目相关链接
PDF Accepted by ICLR 2025. Datasets, code, and model weights are available at: https://github.com/colorfulfuture/UniTraj-pytorch
Summary
本文提出一种统一轨迹生成模型UniTraj,用于处理任意轨迹作为掩码输入,并适应体育领域中的不同场景。模型包含Ghost Spatial Masking模块以提取空间特征,并扩展了双向时间Mamba模型以及双向时间缩放模块以全面扫描轨迹并保留时间缺失关系。此外,本文也介绍了三个实用体育数据集Basketball-U、Football-U和Soccer-U,用于评估模型性能。实验证明该模型性能卓越。
Key Takeaways
- 多领域下的多智能体运动理解至关重要。
- 传统方法通常关注单独任务,如轨迹预测、填补或时空恢复,难以应对现实世界中的多任务需求。
- 公共数据集主要关注行人运动,忽视个体间交互,特别是在远距离环境下。
- 提出统一轨迹生成模型UniTraj,适应多种场景,特别是体育领域。
- UniTraj包含Ghost Spatial Masking模块以提取空间特征,并结合双向时间Mamba模型和双向时间缩放模块来处理轨迹。
- 介绍了三个体育数据集Basketball-U、Football-U和Soccer-U用于评估模型性能。
点此查看论文截图


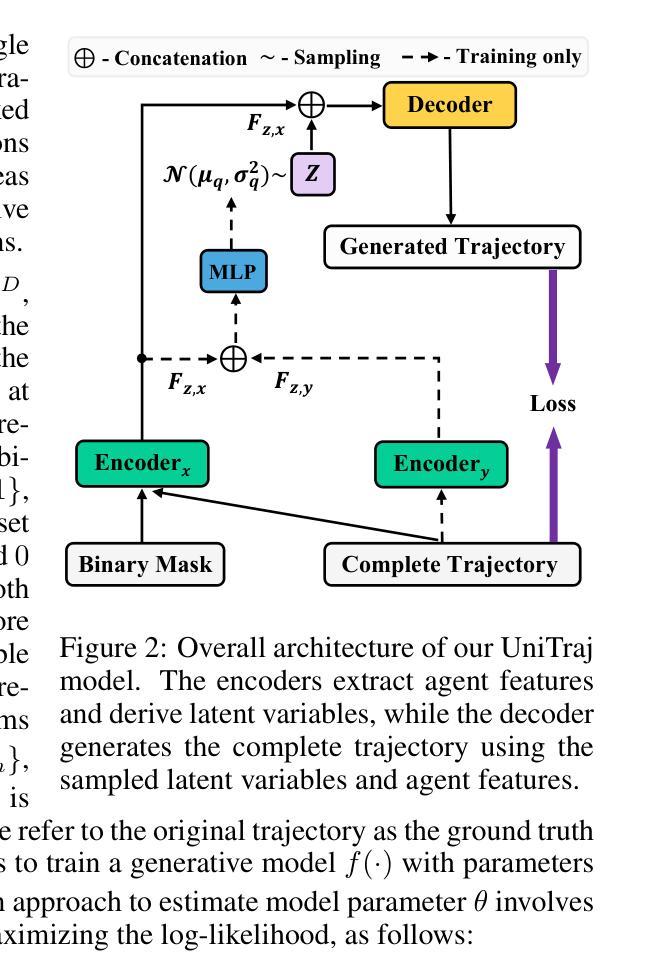
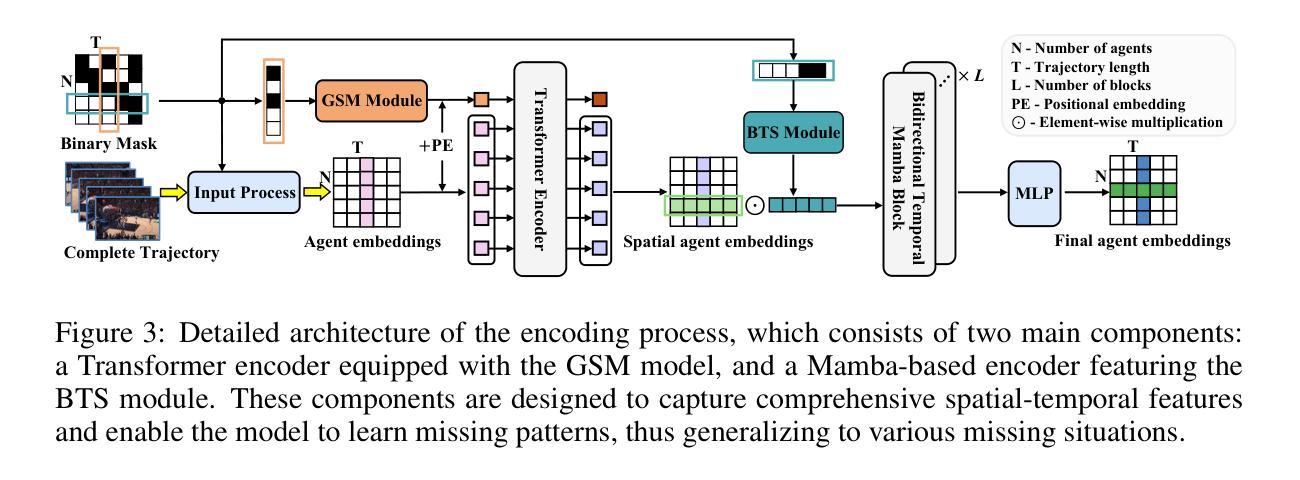
How Far Are We on the Decision-Making of LLMs? Evaluating LLMs’ Gaming Ability in Multi-Agent Environments
Authors:Jen-tse Huang, Eric John Li, Man Ho Lam, Tian Liang, Wenxuan Wang, Youliang Yuan, Wenxiang Jiao, Xing Wang, Zhaopeng Tu, Michael R. Lyu
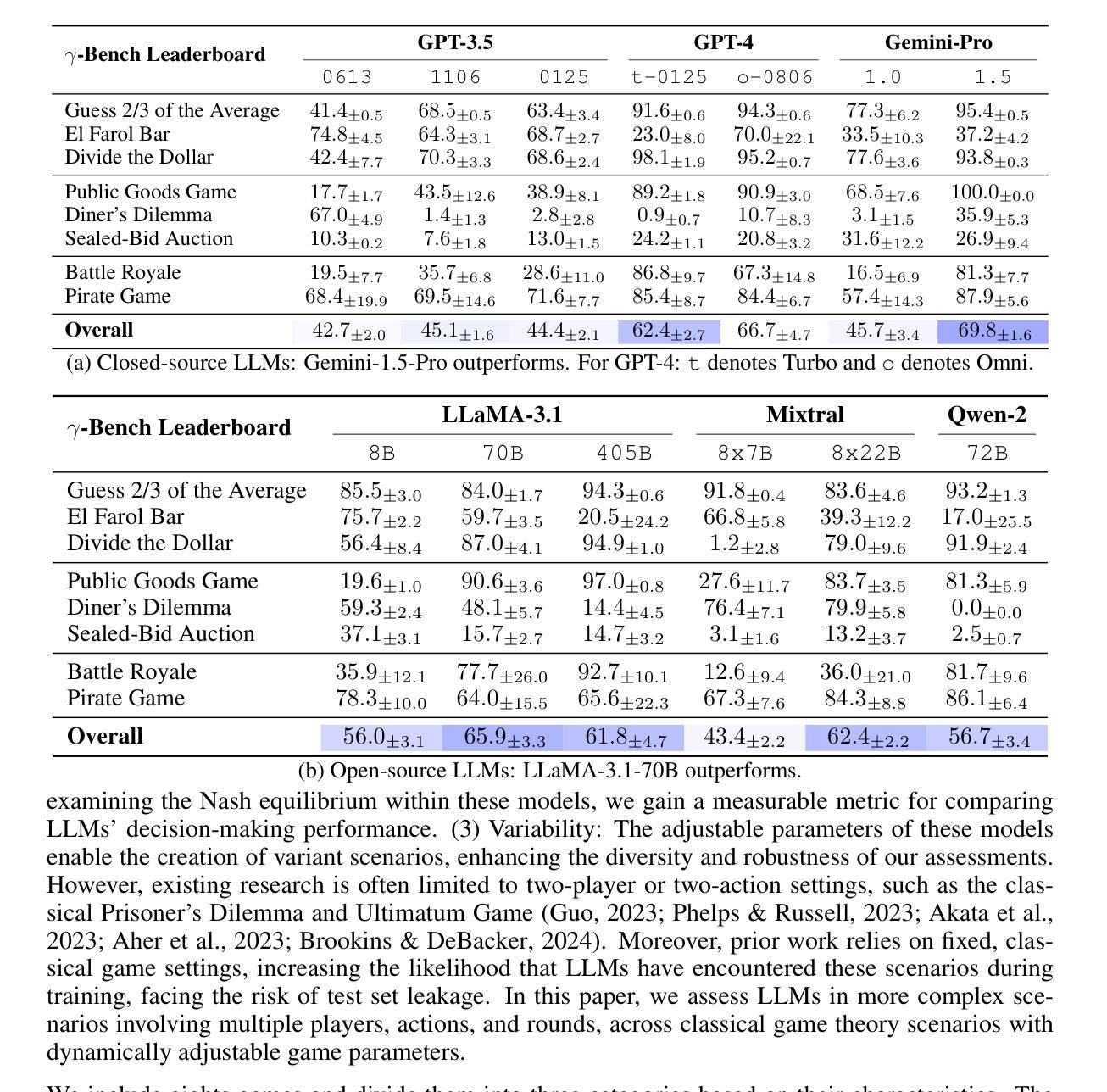
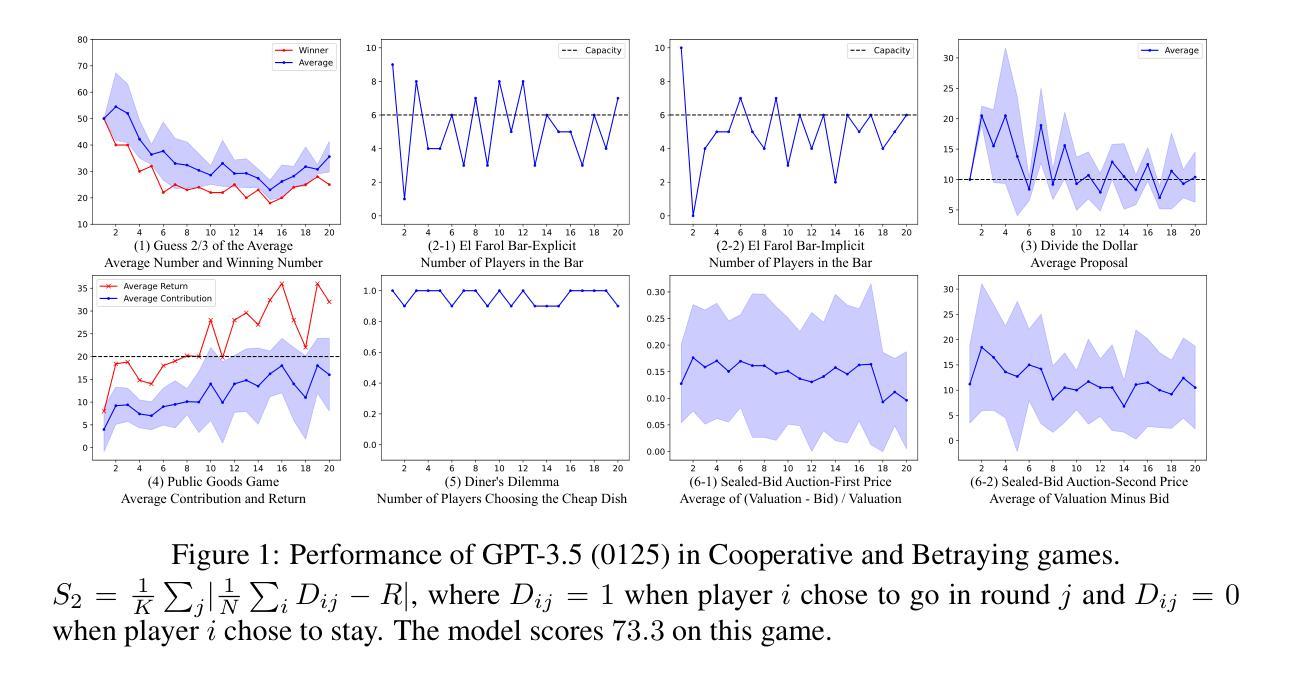
Decision-making is a complex process requiring diverse abilities, making it an excellent framework for evaluating Large Language Models (LLMs). Researchers have examined LLMs’ decision-making through the lens of Game Theory. However, existing evaluation mainly focus on two-player scenarios where an LLM competes against another. Additionally, previous benchmarks suffer from test set leakage due to their static design. We introduce GAMA($\gamma$)-Bench, a new framework for evaluating LLMs’ Gaming Ability in Multi-Agent environments. It includes eight classical game theory scenarios and a dynamic scoring scheme specially designed to quantitatively assess LLMs’ performance. $\gamma$-Bench allows flexible game settings and adapts the scoring system to different game parameters, enabling comprehensive evaluation of robustness, generalizability, and strategies for improvement. Our results indicate that GPT-3.5 demonstrates strong robustness but limited generalizability, which can be enhanced using methods like Chain-of-Thought. We also evaluate 13 LLMs from 6 model families, including GPT-3.5, GPT-4, Gemini, LLaMA-3.1, Mixtral, and Qwen-2. Gemini-1.5-Pro outperforms others, scoring of $69.8$ out of $100$, followed by LLaMA-3.1-70B ($65.9$) and Mixtral-8x22B ($62.4$). Our code and experimental results are publicly available at https://github.com/CUHK-ARISE/GAMABench.
决策是一个需要多种能力的复杂过程,因此它是评估大型语言模型(LLM)的绝佳框架。研究人员已经通过博弈论的角度研究了LLM的决策制定。然而,现有的评估主要集中在两人场景中,即LLM与其他LLM之间的竞争。此外,先前的基准测试由于其静态设计而遭受测试集泄露的问题。我们引入了GAMA($\gamma$)-Bench,这是一个新的框架,用于评估LLM在多智能体环境中的游戏能力。它包括八个经典的游戏理论场景和一个动态评分方案,专门用于定量评估LLM的性能。$\gamma$-Bench允许灵活的游戏设置,并适应不同的游戏参数来调整评分系统,从而全面评估LLM的稳健性、泛化能力和改进策略。我们的结果表明,GPT-3.5表现出强大的稳健性,但泛化能力有限,可以通过链式思维等方法进行增强。我们还评估了来自六个模型家族的13个LLM,包括GPT-3.5、GPT-4、双子座、LLaMA-3.1、Mixtral和Qwen-2。其中,双子座-1.5-Pro表现最佳,得分为100中的69.8分,其次是LLaMA-3.1-70B(65.9分)和Mixtral-8x22B(62.4分)。我们的代码和实验结果可在https://github.com/CUHK-ARISE/GAMABench公开获得。
论文及项目相关链接
PDF Accepted to ICLR 2025; 11 pages of main text; 26 pages of appendices; Included models: GPT-3.5-{0613, 1106, 0125}, GPT-4-0125, GPT-4o-0806, Gemini-{1.0, 1.5)-Pro, LLaMA-3.1-{7, 70, 405}B, Mixtral-8x{7, 22}B, Qwen-2-72B
Summary
决策制定是一个需要多元能力的复杂过程,是评估大型语言模型(LLMs)的理想框架。研究者通过博弈论的角度研究LLMs的决策制定过程,但现有的评估主要聚焦于两玩家情境,设计静态评估方式容易产生测试集泄漏问题。本文提出GAMA($\gamma$)-Bench新框架,用于评估LLMs在多智能体环境中的游戏能力。该框架包括八个经典博弈论场景和动态评分机制,能定量评估LLMs表现。结果显示GPT-3.5表现出强大的稳健性但有限的可泛化性,可通过链式思维等方法改进。本文还评估了多个大型语言模型,包括GPT系列、Gemini、LLaMA和Mixtral等。代码和实验结果已公开。
Key Takeaways
- 大型语言模型(LLMs)的决策制定能力可通过游戏理论进行评估。
- 现有评估框架主要关注两玩家情境,存在测试集泄漏问题。
- GAMA($\gamma$)-Bench框架用于评估LLMs在多智能体环境中的游戏能力,包含八个经典博弈论场景和动态评分机制。
- GPT-3.5在评估中显示出强大的稳健性,但泛化能力有限。
- 使用链式思维等方法可改进LLMs的表现。
- 在评估中,Gemini-1.5-Pro表现最佳,其次是LLaMA-3.1和Mixtral。
点此查看论文截图

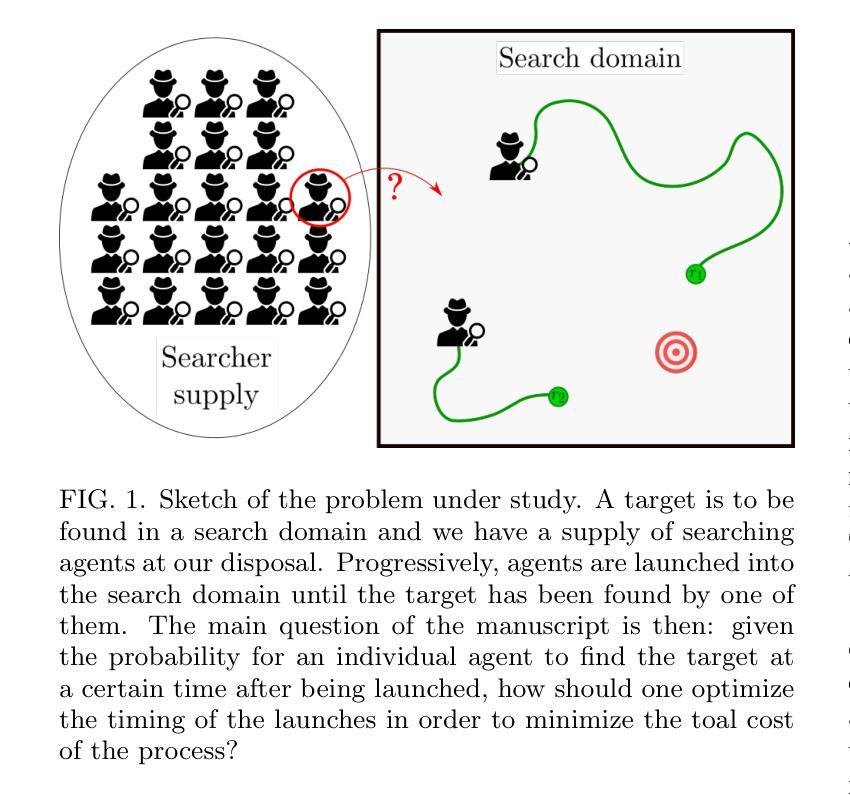
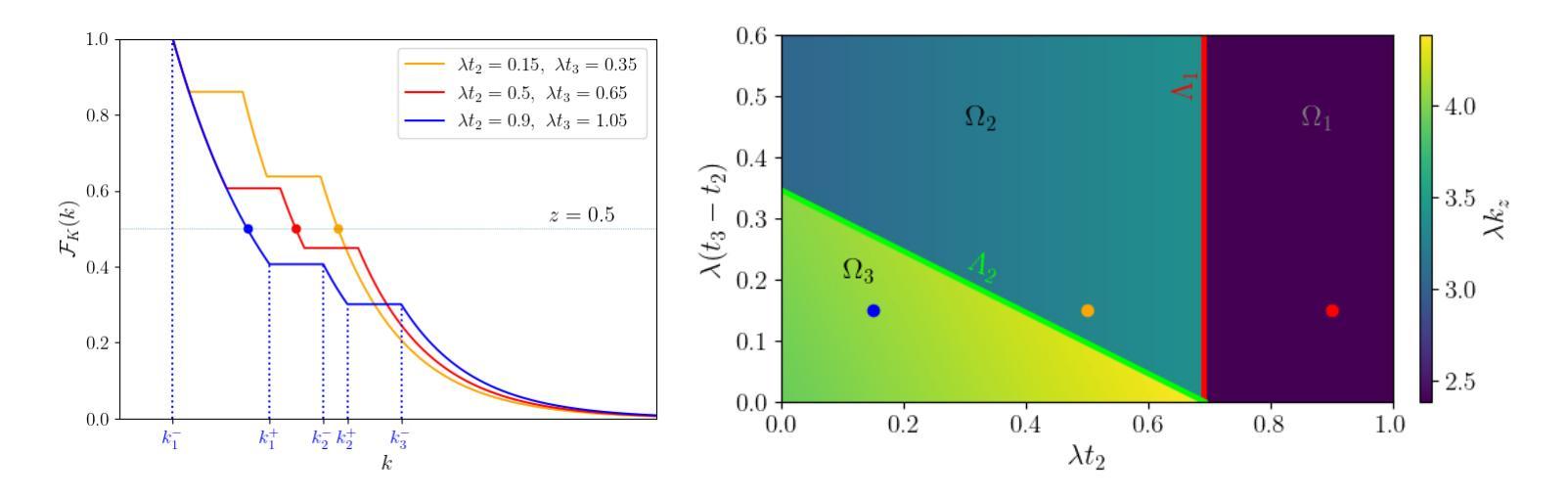
Optimal number of agents in a collective search, and when to launch them
Authors:Hugues Meyer, Heiko Rieger
Search processes often involve multiple agents that collectively search a randomly located target. While increasing the number of agents usually decreases the time at which the first agent finds the target, it also requires resources to create and sustain more agents. In this manuscript, we raise the question of the optimal timing for launching multiple agents in a search in order to reach the best compromise between minimizing the overall search time and minimizing the costs associated with launching and sustaining agents. After introducing a general formalism for independent agents in which we allow them to be launched at arbitrary times, we investigate by means of analytical calculations and numerical optimization the optimal launch strategies to optimize the quantiles of the search cost and its mean. Finally, we compare our results with the case of stochastic resetting and study the conditions under which it is preferable to launch new searchers rather than resetting the first one to its initial position.
在搜索过程中,通常会涉及多个搜索主体共同寻找随机位置的目标。虽然增加搜索主体的数量通常会减少首个搜索主体找到目标的时间,但同时也需要资源来创建和维持更多的搜索主体。在本手稿中,我们提出了关于何时启动多个搜索主体以达到最佳平衡的问题,旨在尽量减少总体搜索时间并降低启动和维持搜索主体的成本。我们引入了一种允许它们在任意时间启动的独立主体的通用形式化表示方法,然后通过解析计算和数值优化来研究最佳启动策略,以优化搜索成本的分位数和平均值。最后,我们将我们的结果与随机重置的情况进行比较,并研究在何种情况下启动新的搜索者优于将第一个搜索者重置到其初始位置。
论文及项目相关链接
Summary
本文探讨了多代理搜索过程中的最优启动时间问题,旨在寻找最小化总体搜索时间与降低启动和维持代理的成本之间的最佳平衡点。文章引入了独立代理的一般形式,分析了通过解析计算和数值优化得出的最优启动策略,以优化搜索成本的分位数和均值。此外,还将结果与随机重置的情况进行了比较,研究了在何种条件下启动新搜索器比将第一个搜索器重置到初始位置更为可取。
Key Takeaways
- 引入独立代理的一般形式,允许它们在任意时间启动。
- 探讨了多代理搜索中的最优启动时间问题。
- 通过解析计算和数值优化,研究了最优启动策略以优化搜索成本。
- 对比了随机重置与启动新搜索器的效果。
- 揭示了寻找最小化总体搜索时间与降低启动和维持代理的成本之间的最佳平衡点的重要性。
- 分析了多代理搜索在缩短搜索时间方面的优势,以及资源分配的策略。
点此查看论文截图