⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-01 更新
FlexVAR: Flexible Visual Autoregressive Modeling without Residual Prediction
Authors:Siyu Jiao, Gengwei Zhang, Yinlong Qian, Jiancheng Huang, Yao Zhao, Humphrey Shi, Lin Ma, Yunchao Wei, Zequn Jie
This work challenges the residual prediction paradigm in visual autoregressive modeling and presents FlexVAR, a new Flexible Visual AutoRegressive image generation paradigm. FlexVAR facilitates autoregressive learning with ground-truth prediction, enabling each step to independently produce plausible images. This simple, intuitive approach swiftly learns visual distributions and makes the generation process more flexible and adaptable. Trained solely on low-resolution images ($\leq$ 256px), FlexVAR can: (1) Generate images of various resolutions and aspect ratios, even exceeding the resolution of the training images. (2) Support various image-to-image tasks, including image refinement, in/out-painting, and image expansion. (3) Adapt to various autoregressive steps, allowing for faster inference with fewer steps or enhancing image quality with more steps. Our 1.0B model outperforms its VAR counterpart on the ImageNet 256$\times$256 benchmark. Moreover, when zero-shot transfer the image generation process with 13 steps, the performance further improves to 2.08 FID, outperforming state-of-the-art autoregressive models AiM/VAR by 0.25/0.28 FID and popular diffusion models LDM/DiT by 1.52/0.19 FID, respectively. When transferring our 1.0B model to the ImageNet 512$\times$512 benchmark in a zero-shot manner, FlexVAR achieves competitive results compared to the VAR 2.3B model, which is a fully supervised model trained at 512$\times$512 resolution.
本文挑战了视觉自回归建模中的残差预测范式,并提出了一种新的灵活视觉自回归图像生成范式FlexVAR。FlexVAR通过真实预测促进自回归学习,使每一步都能独立产生合理的图像。这种简单直观的方法能够快速学习视觉分布,使生成过程更加灵活和适应性强。仅对低分辨率图像($\leq$ 256px)进行训练,FlexVAR可以:(1)生成各种分辨率和纵横比的图像,甚至超过训练图像的分辨率。(2)支持各种图像到图像的任务,包括图像细化、绘画和图像扩展。(3)适应各种自回归步骤,允许用更少的步骤进行更快的推理或提高图像质量。我们的1.0B模型在ImageNet 256×256基准测试上的表现超过了其VAR对应模型。此外,当以零步转移方式进行图像生成过程时,使用13步,性能进一步提高到2.08 FID,超越了最先进的自回归模型AiM/VAR(分别降低了0.25/0.28 FID)和流行的扩散模型LDM/DiT(分别降低了1.52/0.19 FID)。当以零步转移方式将我们的1.0B模型转移到ImageNet 512×512基准测试时,FlexVAR与经过512×512分辨率训练的完全监督模型VAR 2.3B模型相比取得了具有竞争力的结果。
论文及项目相关链接
摘要
本研究挑战了视觉自回归建模中的残差预测范式,并提出了FlexVAR这一新的灵活视觉自回归图像生成范式。FlexVAR通过结合地面真实预测促进自回归学习,使每个步骤都能独立生成合理的图像。这种简单直观的方法可以快速学习视觉分布,使生成过程更加灵活和适应性强。仅对低于或等于256像素的低分辨率图像进行训练,FlexVAR可以生成各种分辨率和比例尺的图像,甚至超过训练图像的分辨率;支持各种图像到图像的转换任务,包括图像细化、内外绘画和图像扩展;适应各种自回归步骤,允许更快的推理使用较少的步骤或更多步骤来提高图像质量。我们的1.0B模型在ImageNet 256x256基准测试上的表现优于VAR模型。此外,当以零步转移的方式以包含十三个步骤的图像生成过程时,性能进一步提高了到接近完全创新式的其他高质量产品例如如当下热门的扩散模型之技术指标亦是尖端强大竞争的实力佼佼者不仅超过了当前先进的自回归模型AiM/VAR 0.25/0.28 FID的成绩也超过了流行的扩散模型LDM/DiT的FID得分分别为领先业界标杆的FID得分在零步转移至ImageNet 512x512基准测试时我们的1.0B模型在成绩方面能与经过充分监督训练的VAR 2.3B模型竞争可见FlexVAR具备高度竞争性和适应各种复杂环境的能力
关键见解
- FlexVAR挑战了视觉自回归建模中的残差预测范式,引入了一种新的图像生成方法。
- FlexVAR通过结合地面真实预测促进自回归学习,使图像生成更具灵活性和适应性。
- 该模型可以在各种分辨率和比例尺下生成图像,甚至超过训练图像的分辨率。
- FlexVAR支持多种图像到图像的转换任务,包括图像细化、内外绘画和图像扩展。
- 模型能够根据不同的自回归步骤进行调整,可实现更快的推理或更高质量的图像生成。
- 1.0B模型的性能在多个基准测试中优于其他模型,包括ImageNet 256x256和ImageNet 512x512。
点此查看论文截图


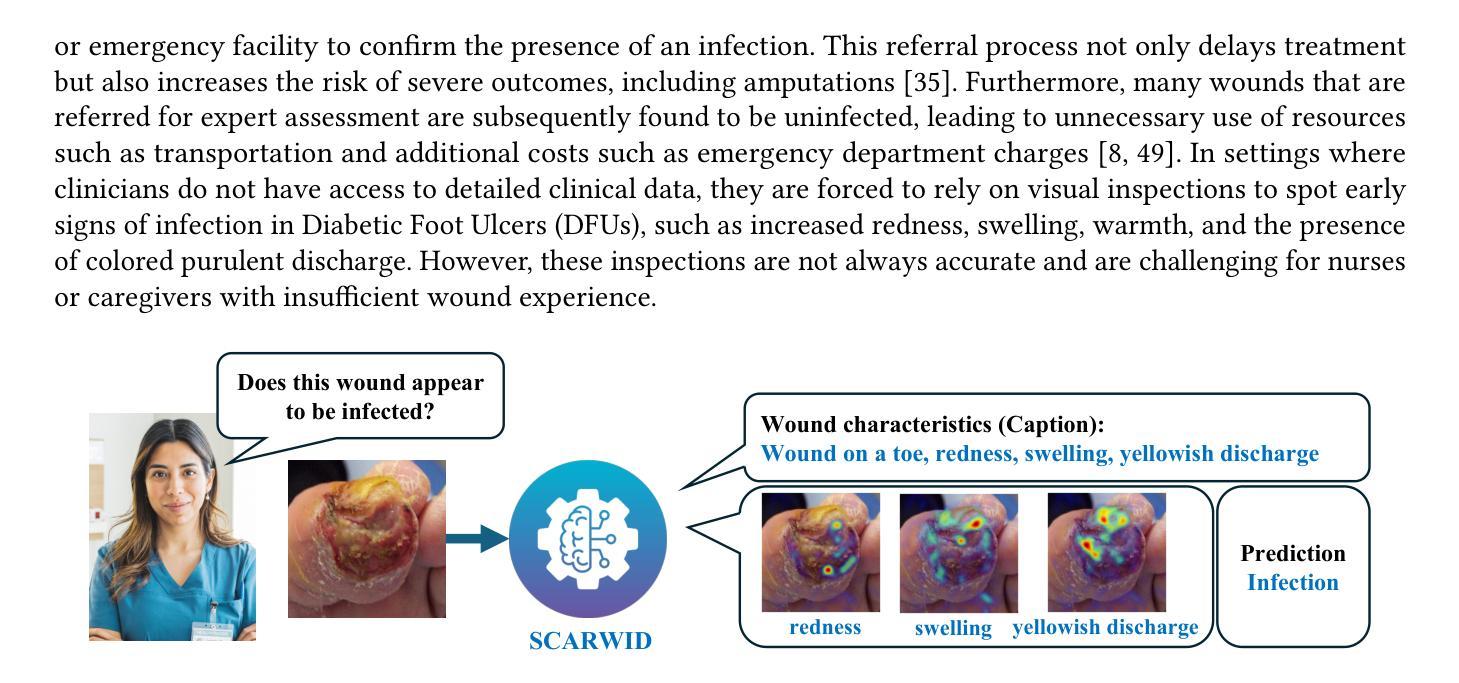
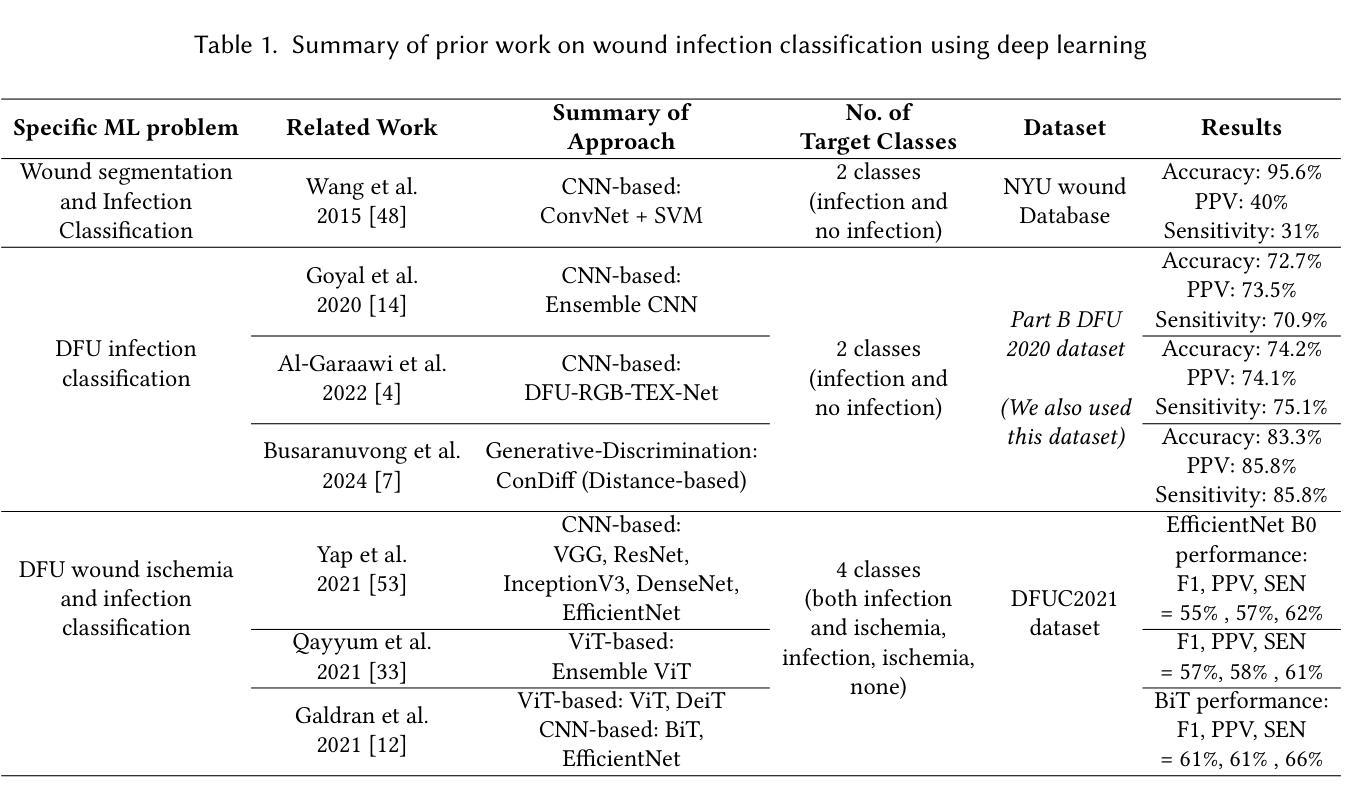
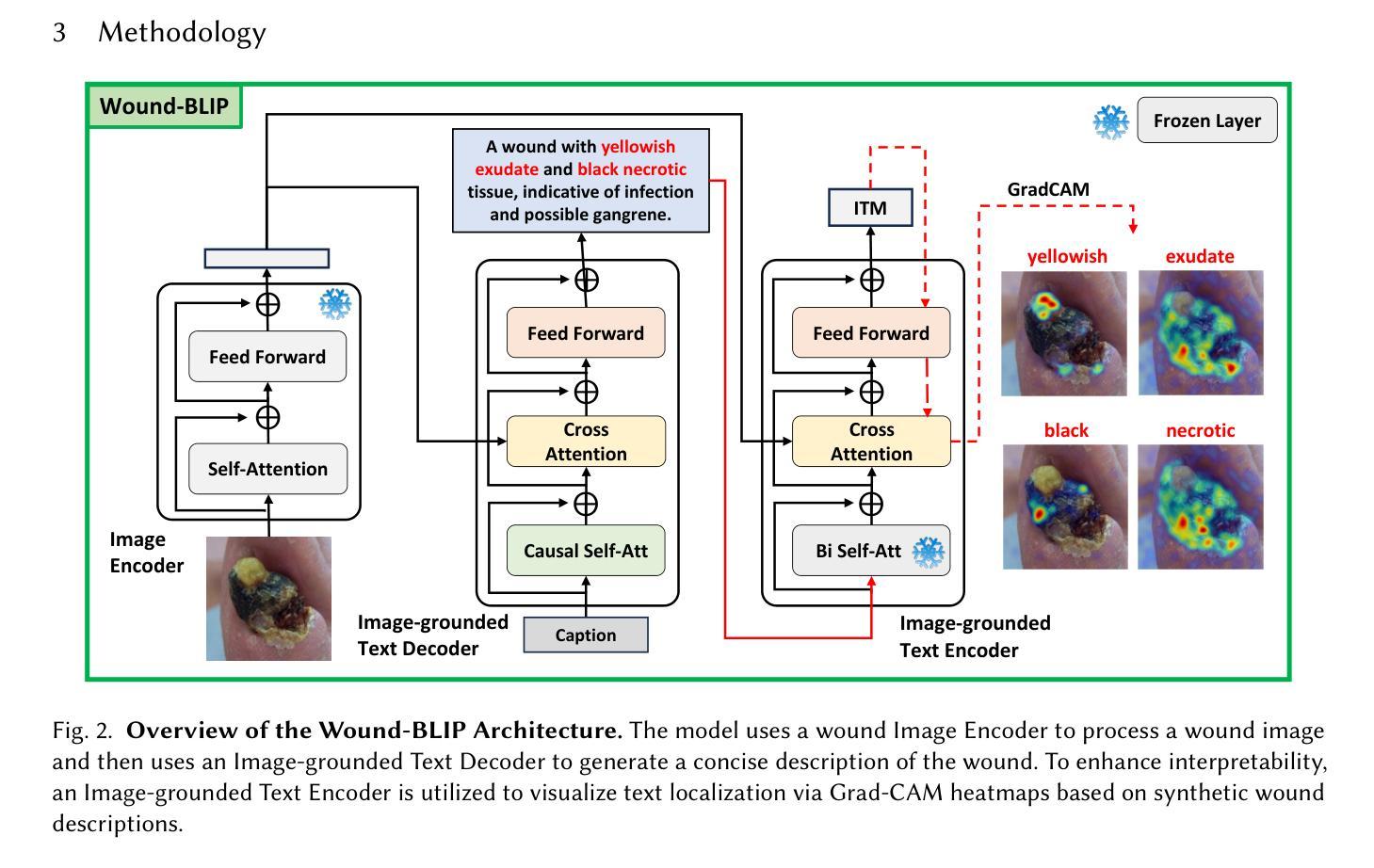
Explainable, Multi-modal Wound Infection Classification from Images Augmented with Generated Captions
Authors:Palawat Busaranuvong, Emmanuel Agu, Reza Saadati Fard, Deepak Kumar, Shefalika Gautam, Bengisu Tulu, Diane Strong
Infections in Diabetic Foot Ulcers (DFUs) can cause severe complications, including tissue death and limb amputation, highlighting the need for accurate, timely diagnosis. Previous machine learning methods have focused on identifying infections by analyzing wound images alone, without utilizing additional metadata such as medical notes. In this study, we aim to improve infection detection by introducing Synthetic Caption Augmented Retrieval for Wound Infection Detection (SCARWID), a novel deep learning framework that leverages synthetic textual descriptions to augment DFU images. SCARWID consists of two components: (1) Wound-BLIP, a Vision-Language Model (VLM) fine-tuned on GPT-4o-generated descriptions to synthesize consistent captions from images; and (2) an Image-Text Fusion module that uses cross-attention to extract cross-modal embeddings from an image and its corresponding Wound-BLIP caption. Infection status is determined by retrieving the top-k similar items from a labeled support set. To enhance the diversity of training data, we utilized a latent diffusion model to generate additional wound images. As a result, SCARWID outperformed state-of-the-art models, achieving average sensitivity, specificity, and accuracy of 0.85, 0.78, and 0.81, respectively, for wound infection classification. Displaying the generated captions alongside the wound images and infection detection results enhances interpretability and trust, enabling nurses to align SCARWID outputs with their medical knowledge. This is particularly valuable when wound notes are unavailable or when assisting novice nurses who may find it difficult to identify visual attributes of wound infection.
糖尿病足溃疡(DFU)的感染可引起严重的并发症,包括组织死亡和肢体截肢,这突显了准确及时诊断的必要性。以往的机器学习方法主要侧重于通过分析伤口图像来识别感染,而没有利用额外的元数据,如医疗记录。在这项研究中,我们旨在通过引入合成字幕增强检索伤口感染检测(SCARWID)技术来提高感染检测水平,这是一种新型深度学习框架,利用合成文本描述来增强DFU图像。SCARWID由两个组件构成:(1)Wound-BLIP,一个经过GPT-4o生成描述微调的语言视觉模型(VLM),能够从图像中合成一致的标题;(2)图像文本融合模块,该模块使用交叉注意力从图像及其相应的Wound-BLIP标题中提取跨模态嵌入。感染状态是通过从标记的支持集中检索前k个相似项来确定的。为了增强训练数据的多样性,我们利用潜在扩散模型生成了额外的伤口图像。因此,SCARWID超越了最先进的模型,在伤口感染分类方面取得了平均灵敏度、特异性和准确性分别为0.85、0.78和0.81。将生成的标题与伤口图像和感染检测结果一起显示,增强了可解释性和信任度,使护士能够将SCARWID输出与他们的医学知识相结合。这在伤口记录不可用或辅助新手护士时尤其有价值,他们可能难以识别伤口感染的可视属性。
论文及项目相关链接
摘要
本研究提出了一种新的深度学习框架SCARWID,用于糖尿病足溃疡感染检测。该框架利用合成文本描述来增强DFU图像,通过Wound-BLIP模型和图像-文本融合模块,实现感染状态的判定。利用潜在扩散模型增强训练数据多样性。SCARWID较先进模型有更佳表现,分类敏感度、特异度、准确度分别为0.85、0.78和0.81。此框架能提高解读性和信任度,尤其在缺乏伤口记录或辅助新手护士时更显价值。
关键见解
- SCARWID是首个结合合成文本描述和DFU图像来检测感染的深度学习框架。
- Wound-BLIP模型用于从图像中合成一致的文本描述。
- 图像-文本融合模块通过跨注意力机制提取图像和其对应描述的多模式嵌入。
- 利用潜在扩散模型增强训练数据多样性。
- SCARWID在感染分类方面表现出高敏感度、特异度和准确度。
- 显示生成描述和感染检测结果,能提高模型的解读性和信任度。
点此查看论文截图

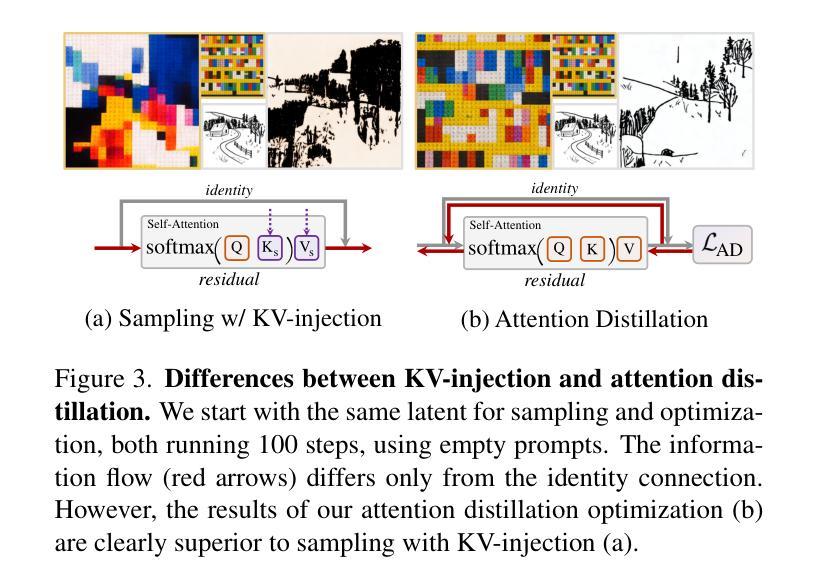
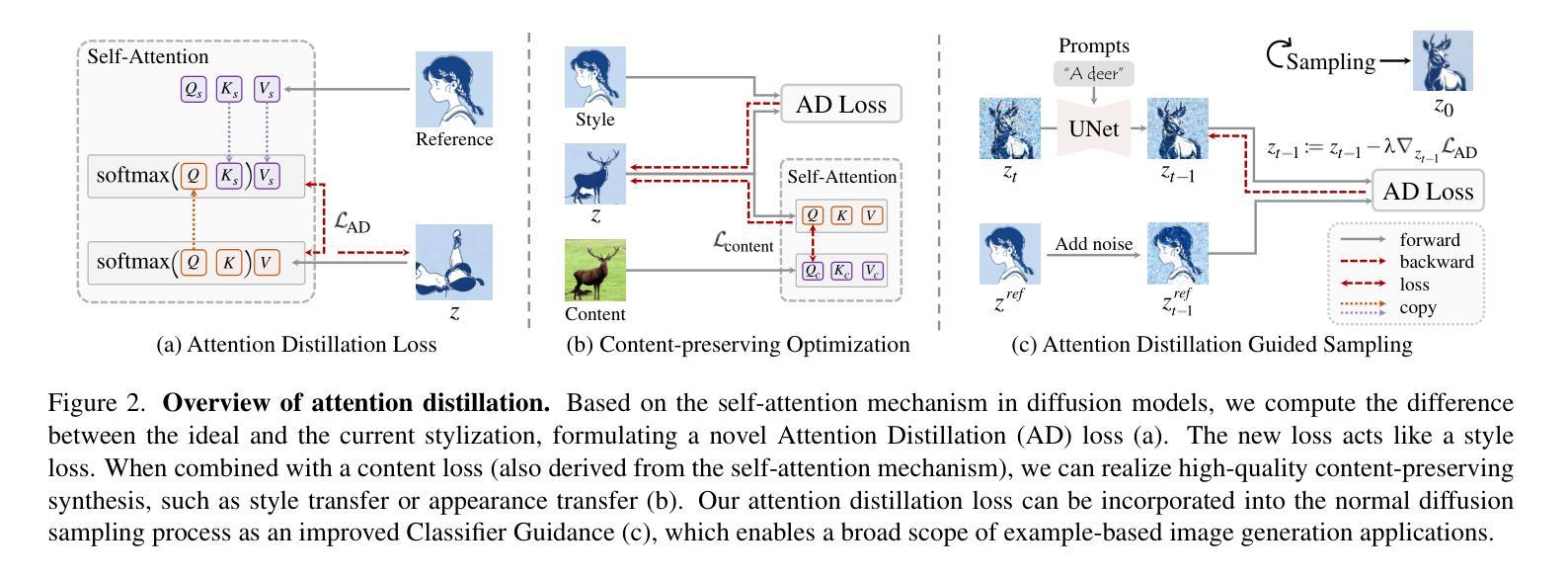
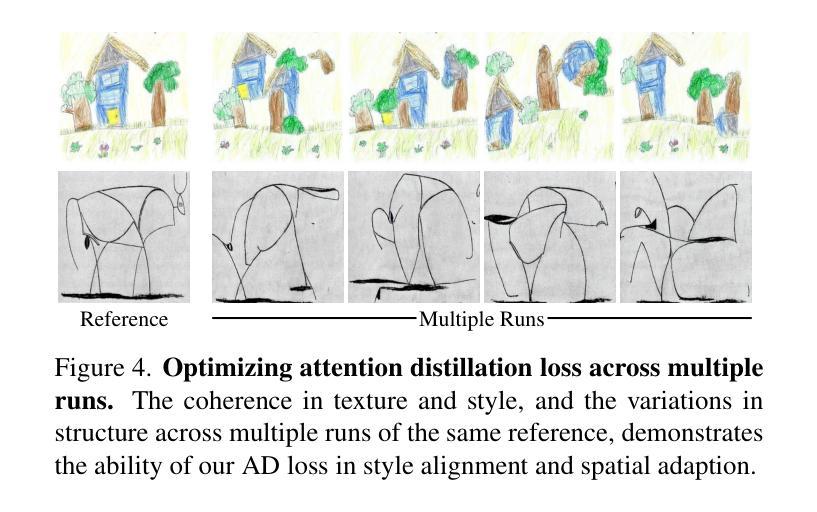
Attention Distillation: A Unified Approach to Visual Characteristics Transfer
Authors:Yang Zhou, Xu Gao, Zichong Chen, Hui Huang
Recent advances in generative diffusion models have shown a notable inherent understanding of image style and semantics. In this paper, we leverage the self-attention features from pretrained diffusion networks to transfer the visual characteristics from a reference to generated images. Unlike previous work that uses these features as plug-and-play attributes, we propose a novel attention distillation loss calculated between the ideal and current stylization results, based on which we optimize the synthesized image via backpropagation in latent space. Next, we propose an improved Classifier Guidance that integrates attention distillation loss into the denoising sampling process, further accelerating the synthesis and enabling a broad range of image generation applications. Extensive experiments have demonstrated the extraordinary performance of our approach in transferring the examples’ style, appearance, and texture to new images in synthesis. Code is available at https://github.com/xugao97/AttentionDistillation.
近期生成式扩散模型(diffusion models)的最新进展显示了对图像风格和语义的显著内在理解。在本文中,我们利用预训练扩散网络的自注意力特征,将参考图像的可视特性转移到生成图像上。与以前的工作不同,这些特征被用作即插即用的属性,我们提出了一种基于理想风格化结果和当前风格化结果之间计算的新型注意力蒸馏损失(attention distillation loss),通过潜在空间的反向传播优化合成图像。接下来,我们提出了一种改进的Classifier Guidance,将注意力蒸馏损失集成到去噪采样过程中,进一步加速合成过程,并广泛应用于图像生成应用程序。大量实验证明,我们的方法在将示例的风格、外观和纹理转移到合成图像中的新图像上的表现非常出色。代码可在https://github.com/xugao97/AttentionDistillation找到。
论文及项目相关链接
PDF Accepted to CVPR 2025. Project page: https://github.com/xugao97/AttentionDistillation
Summary
最近,生成型扩散模型在图像风格和语义理解方面取得了显著进展。本文利用预训练扩散网络的自注意力特征,将参考图像的视觉特征转移到生成图像上。不同于以往的工作,我们提出了一种基于理想与现实风格化结果之间计算注意力蒸馏损失的方法,通过反向传播优化合成图像。此外,我们还改进了分类器引导,将注意力蒸馏损失集成到去噪采样过程中,进一步加速合成,并广泛应用于图像生成。实验证明,我们的方法在合成新图像时能够出色地转移示例的风格、外观和纹理。
Key Takeaways
- 扩散模型展现出对图像风格和语义的深入理解。
- 利用预训练扩散网络的自注意力特征进行图像风格迁移。
- 引入注意力蒸馏损失来计算理想与现实风格化结果之间的差异。
- 通过反向传播优化合成图像。
- 改进的分类器引导集成注意力蒸馏损失,加速图像合成。
- 广泛的图像生成应用可能性。
点此查看论文截图


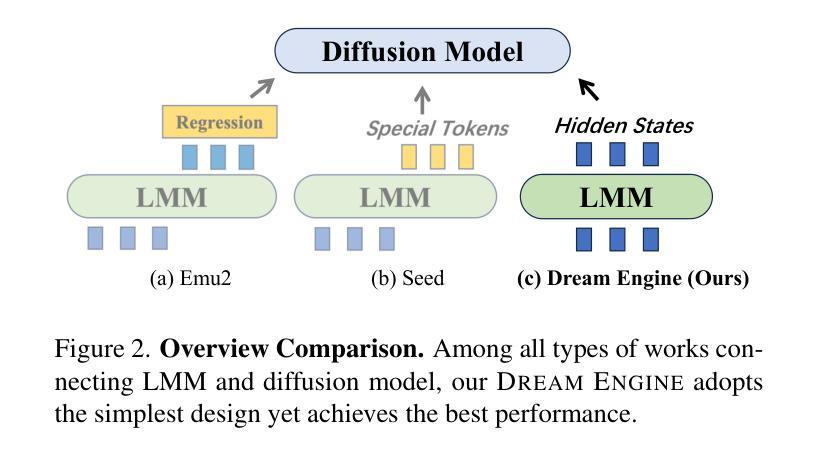
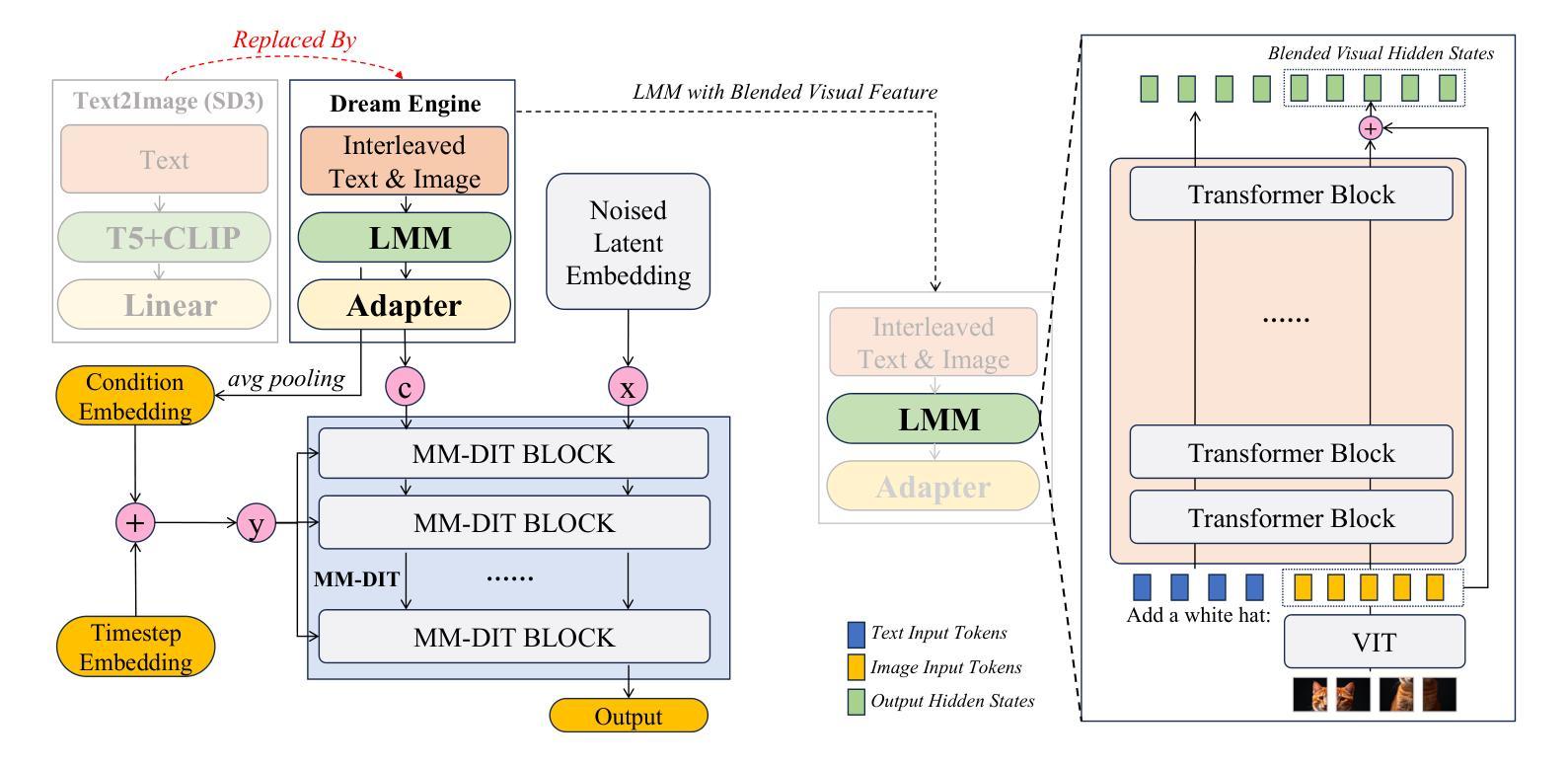
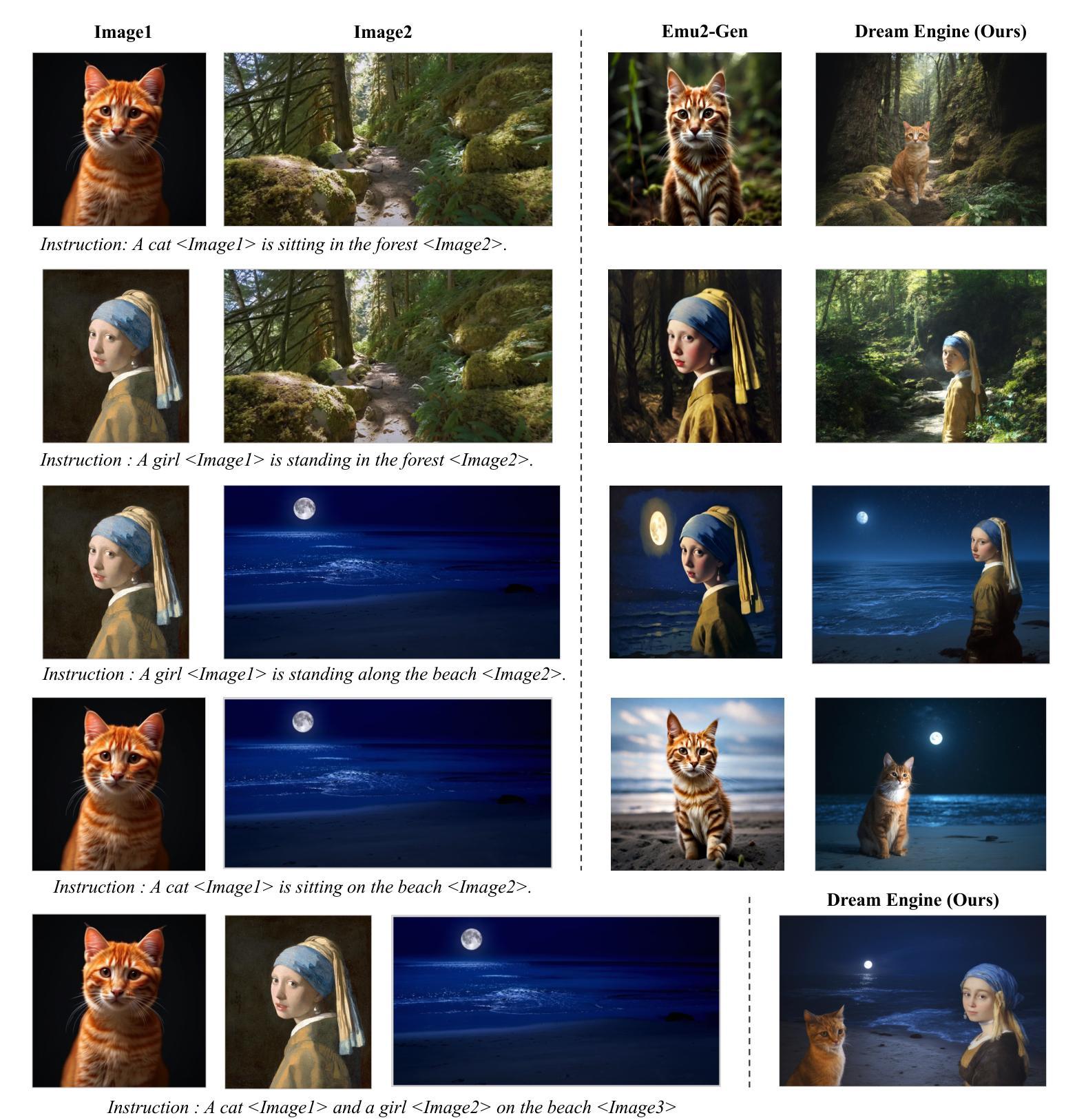
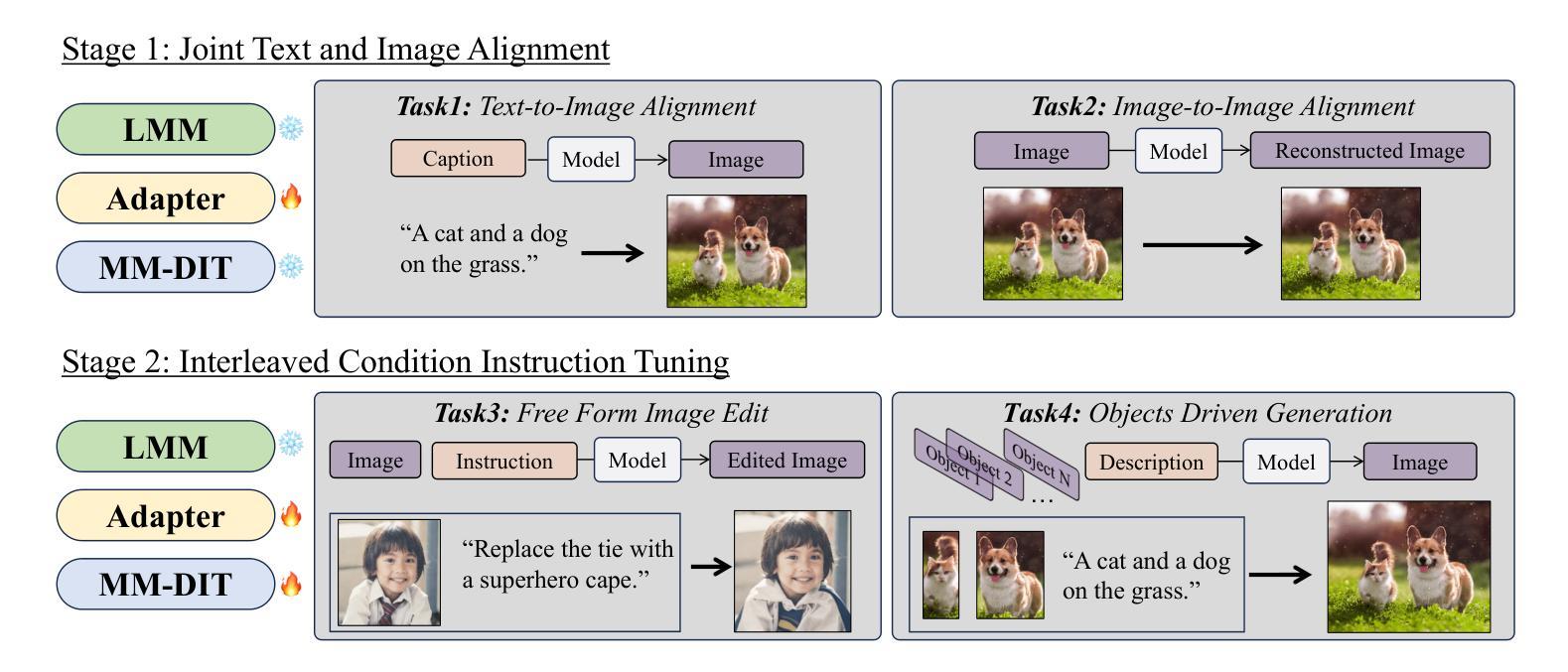
Multimodal Representation Alignment for Image Generation: Text-Image Interleaved Control Is Easier Than You Think
Authors:Liang Chen, Shuai Bai, Wenhao Chai, Weichu Xie, Haozhe Zhao, Leon Vinci, Junyang Lin, Baobao Chang
The field of advanced text-to-image generation is witnessing the emergence of unified frameworks that integrate powerful text encoders, such as CLIP and T5, with Diffusion Transformer backbones. Although there have been efforts to control output images with additional conditions, like canny and depth map, a comprehensive framework for arbitrary text-image interleaved control is still lacking. This gap is especially evident when attempting to merge concepts or visual elements from multiple images in the generation process. To mitigate the gap, we conducted preliminary experiments showing that large multimodal models (LMMs) offer an effective shared representation space, where image and text can be well-aligned to serve as a condition for external diffusion models. Based on this discovery, we propose Dream Engine, an efficient and unified framework designed for arbitrary text-image interleaved control in image generation models. Building on powerful text-to-image models like SD3.5, we replace the original text-only encoders by incorporating versatile multimodal information encoders such as QwenVL. Our approach utilizes a two-stage training paradigm, consisting of joint text-image alignment and multimodal interleaved instruction tuning. Our experiments demonstrate that this training method is effective, achieving a 0.69 overall score on the GenEval benchmark, and matching the performance of state-of-the-art text-to-image models like SD3.5 and FLUX.
先进文本到图像生成领域正在出现融合了强大文本编码器(如CLIP和T5)与Diffusion Transformer主干的统一框架。尽管人们已经尝试使用Canny和深度图等附加条件来控制输出图像,但对于任意文本-图像交错控制的综合框架仍然缺乏。当试图在生成过程中合并多个图像的概念或视觉元素时,这一差距尤为明显。为了缩小这一差距,我们进行了初步实验,发现大型多模态模型(LMM)提供了一个有效的共享表示空间,其中图像和文本可以很好地对齐,以作为外部扩散模型的条件。基于此发现,我们提出了Dream Engine,这是一个为图像生成模型中的任意文本-图像交错控制而设计的高效且统一的框架。我们在强大的文本到图像模型(如SD3.5)的基础上,通过融入通用多模态信息编码器(如QwenVL)来替换原始仅文本编码器。我们的方法采用两阶段训练范式,包括联合文本-图像对齐和多模态交错指令调整。实验表明,这种训练方法有效,在GenEval基准测试中达到0.69的整体分数,与SD3.5和FLUX等先进文本到图像模型的性能相匹配。
论文及项目相关链接
PDF 13 pages, 9 figures, codebase in https://github.com/chenllliang/DreamEngine
Summary
本文介绍了先进文本到图像生成领域的新发展,强调了统一框架的重要性,该框架结合了强大的文本编码器(如CLIP和T5)与Diffusion Transformer骨干网。文章指出尽管已有尝试通过附加条件(如边缘和深度图)来控制输出图像,但缺乏一个全面的框架来实现任意的文本-图像交替控制。为解决此问题,文章提出了Dream Engine框架,该框架利用大型多模态模型(LMMs)提供共享表示空间,实现图像和文本的精准对齐,作为外部扩散模型的条件。实验证明,该训练方法是有效的,达到了GenEval基准测试的整体得分0.69,与SD3.5和FLUX等先进的文本到图像模型的性能相匹配。
Key Takeaways
- 先进的文本到图像生成领域正在发展统一框架,集成强大的文本编码器和Diffusion Transformer技术。
- 尽管有附加条件的输出图像控制尝试,但缺乏一个全面的框架来实现任意的文本-图像交替控制。
- 大型多模态模型(LMMs)提供共享表示空间,使图像和文本对齐良好,可作为外部扩散模型的条件。
- Dream Engine框架被提出,用于任意文本-图像交替控制在图像生成模型中的应用。
- Dream Engine框架建立在强大的文本到图像模型(如SD3.5)之上,融入了多功能多模态信息编码器如QwenVL。
- 该训练方法是有效的,达到了GenEval基准测试的整体得分0.69。
点此查看论文截图

Generative augmentations for improved cardiac ultrasound segmentation using diffusion models
Authors:Gilles Van De Vyver, Aksel Try Lenz, Erik Smistad, Sindre Hellum Olaisen, Bjørnar Grenne, Espen Holte, Håavard Dalen, Lasse Løvstakken
One of the main challenges in current research on segmentation in cardiac ultrasound is the lack of large and varied labeled datasets and the differences in annotation conventions between datasets. This makes it difficult to design robust segmentation models that generalize well to external datasets. This work utilizes diffusion models to create generative augmentations that can significantly improve diversity of the dataset and thus the generalisability of segmentation models without the need for more annotated data. The augmentations are applied in addition to regular augmentations. A visual test survey showed that experts cannot clearly distinguish between real and fully generated images. Using the proposed generative augmentations, segmentation robustness was increased when training on an internal dataset and testing on an external dataset with an improvement of over 20 millimeters in Hausdorff distance. Additionally, the limits of agreement for automatic ejection fraction estimation improved by up to 20% of absolute ejection fraction value on out of distribution cases. These improvements come exclusively from the increased variation of the training data using the generative augmentations, without modifying the underlying machine learning model. The augmentation tool is available as an open source Python library at https://github.com/GillesVanDeVyver/EchoGAINS.
当前针对心脏超声分割研究的主要挑战之一是缺乏大规模且多样化的标记数据集以及不同数据集之间标注规范的不同。这使得设计能够很好地推广到外部数据集的稳健分割模型变得困难。本研究利用扩散模型创建生成增强技术,可以显著提高数据集的多样性,从而在不需要更多注释数据的情况下提高分割模型的一般性。除了常规增强技术外,还应用了这些增强技术。视觉测试调查表明,专家无法清楚区分真实和完全生成的图像。在内部数据集上进行训练并在外部数据集上进行测试时,使用所提出的生成增强技术提高了分割的稳健性,豪斯多夫距离提高了20毫米以上。此外,在超出分布范围的案例中,自动射血分数估计的协议限制提高了高达绝对射血分数值的20%。这些改进完全来自于使用生成增强技术后训练数据多样性的增加,而没有修改基本的机器学习模型。增强工具可作为开源Python库在https://github.com/GillesVanDeVyver/EchoGAINS中找到。
论文及项目相关链接
Summary
扩散模型在心脏超声分割研究中的应用摘要:当前心脏超声分割研究面临缺乏大规模多样化标注数据集和标注规范差异的挑战。本研究利用扩散模型创建生成增强技术,显著提高数据集多样性,从而提升分割模型的泛化能力,无需更多标注数据。生成的增强技术与常规增强技术相结合应用。视觉测试调查显示,专家无法明确区分真实与完全生成的图像。通过使用所提出的生成增强技术,在内部数据集上进行训练并在外部数据集上进行测试时,分割稳健性有所提高,豪斯多夫距离提高了超过20毫米。此外,自动射血分数估计的协议限制在超出分布的情况下最多提高了20%。这些改进完全来自于使用生成增强技术增加的训练数据多样性,无需修改基础机器学习模型。该增强工具可作为开源Python库使用。
Key Takeaways
- 当前心脏超声分割研究面临缺乏大规模多样化标注数据集和标注规范差异的挑战。
- 扩散模型被用于创建生成增强技术,以提高数据集的多样性和分割模型的泛化能力。
- 生成的图像与真实图像难以区分,通过视觉测试调查得到了证实。
- 在内部数据集上训练并在外部数据集上测试时,分割稳健性显著提高。
- 豪斯多夫距离提高了超过20毫米,这是分割性能的一个重要指标。
- 自动射血分数估计的协议限制在超出分布的情况下最多提高了20%,表明模型的预测能力有所提升。
点此查看论文截图

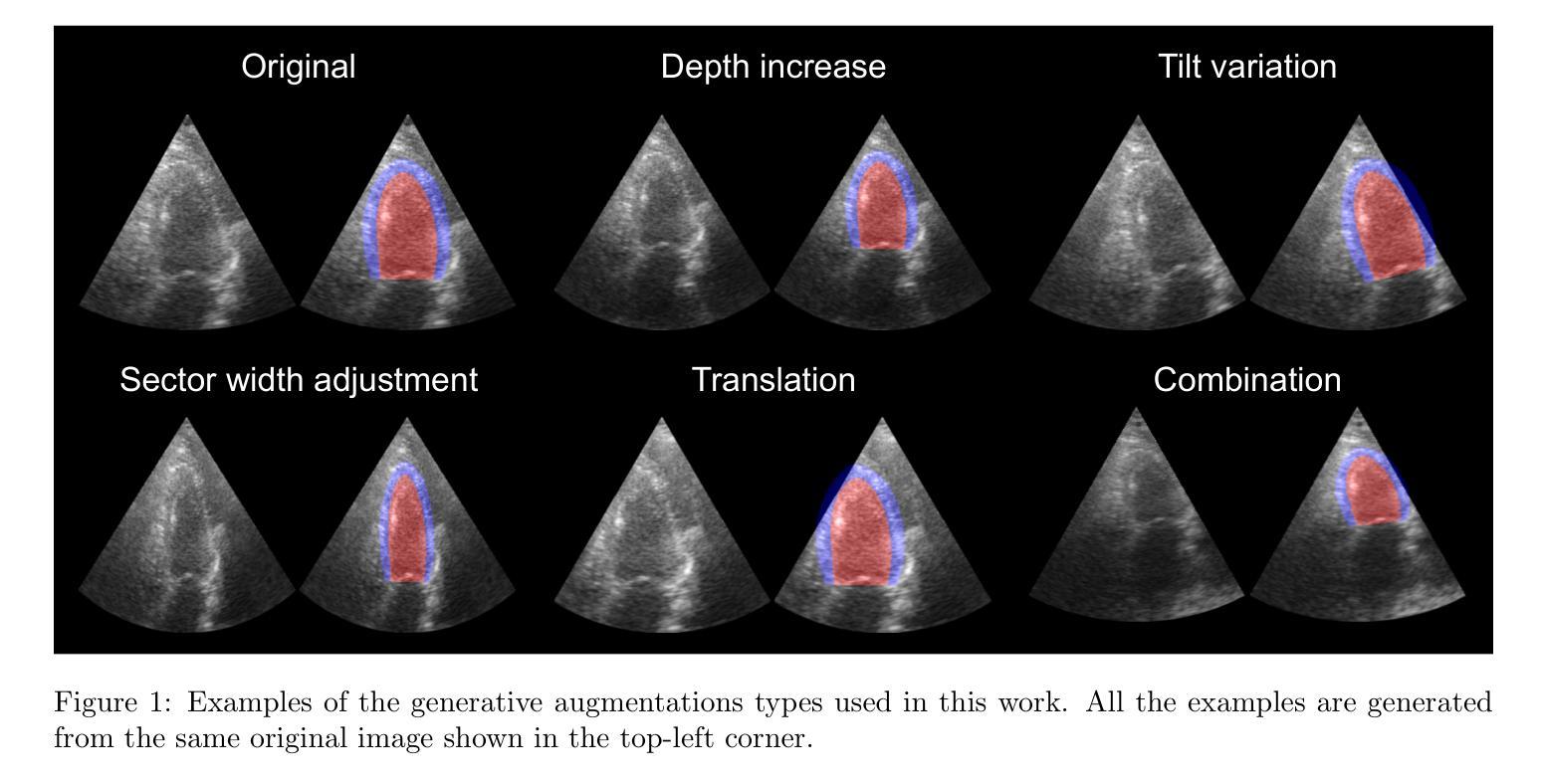
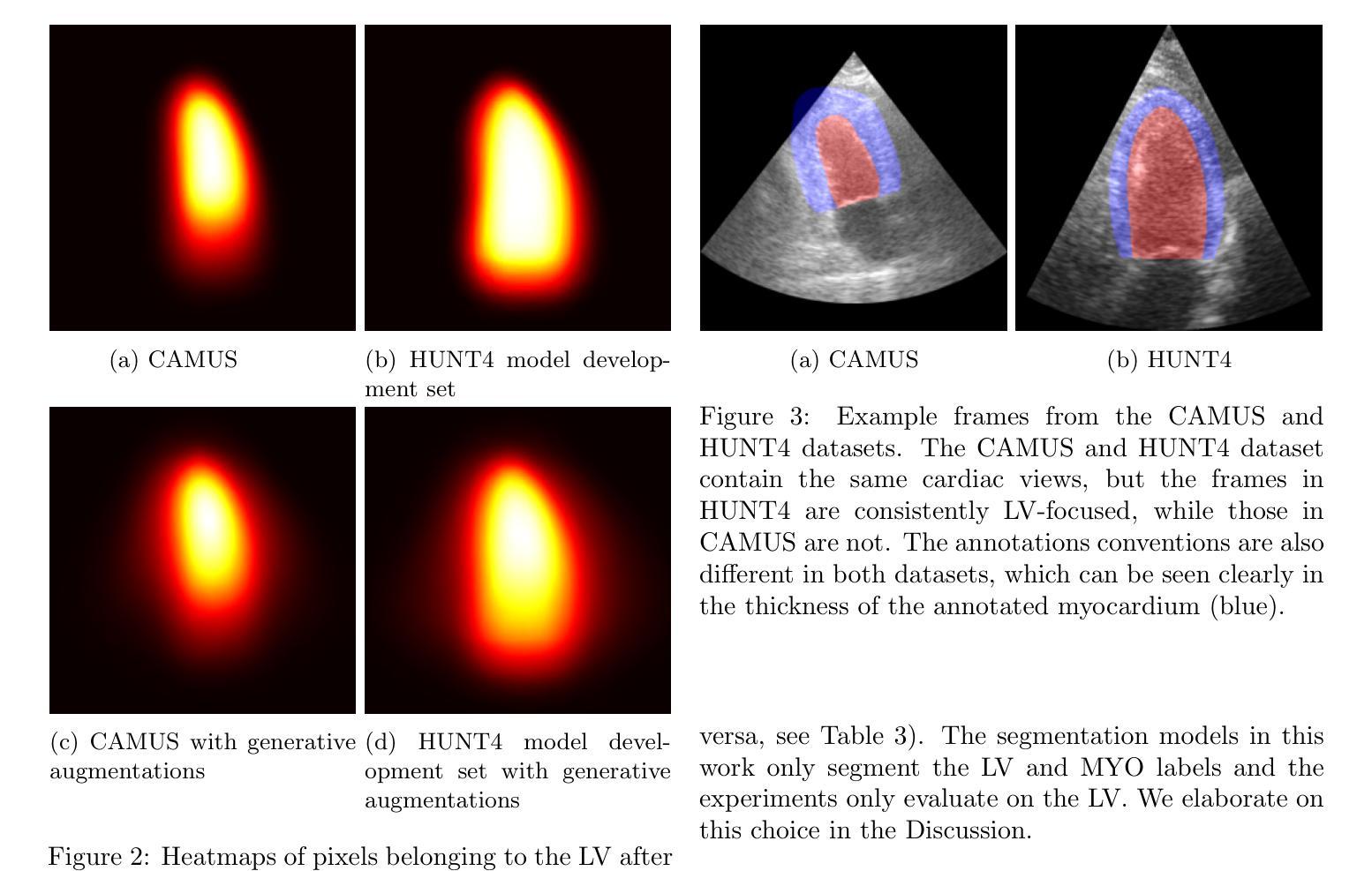
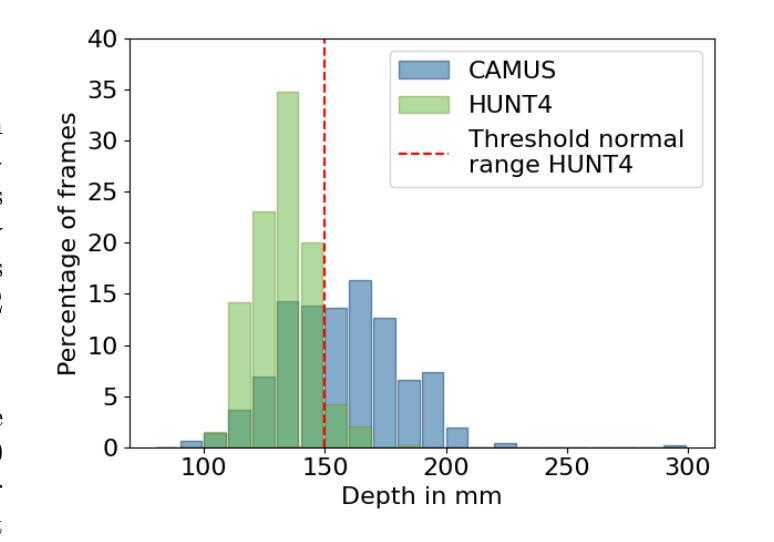
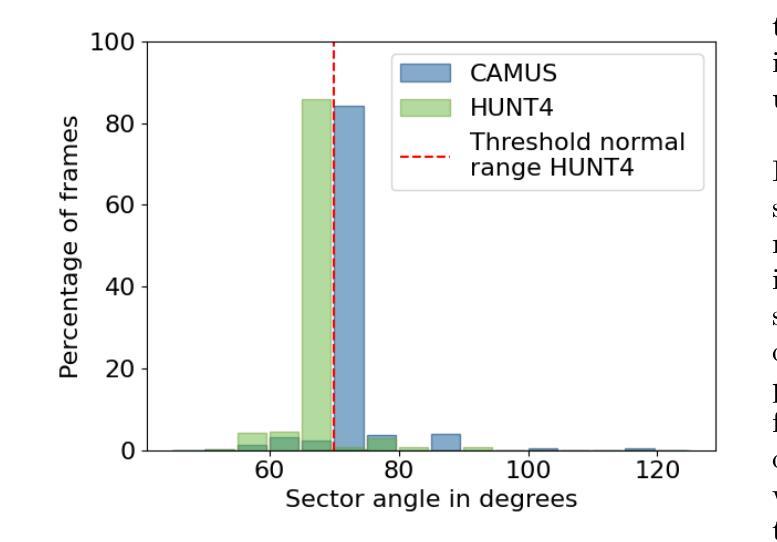
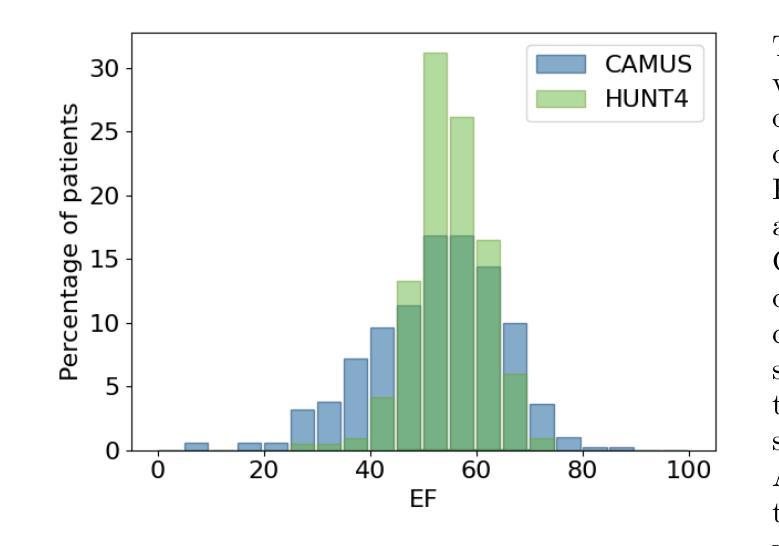
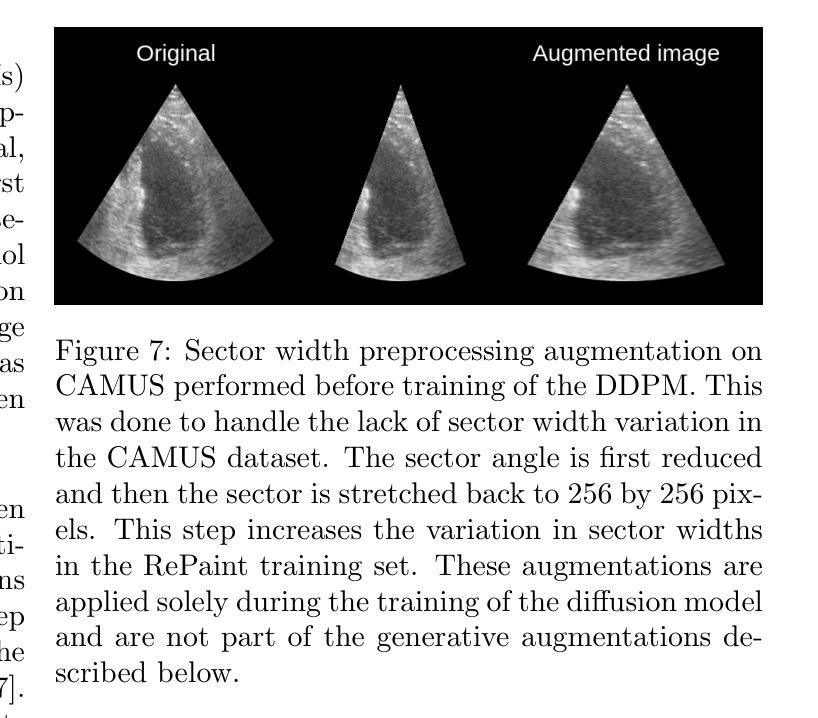

Image Referenced Sketch Colorization Based on Animation Creation Workflow
Authors:Dingkun Yan, Xinrui Wang, Zhuoru Li, Suguru Saito, Yusuke Iwasawa, Yutaka Matsuo, Jiaxian Guo
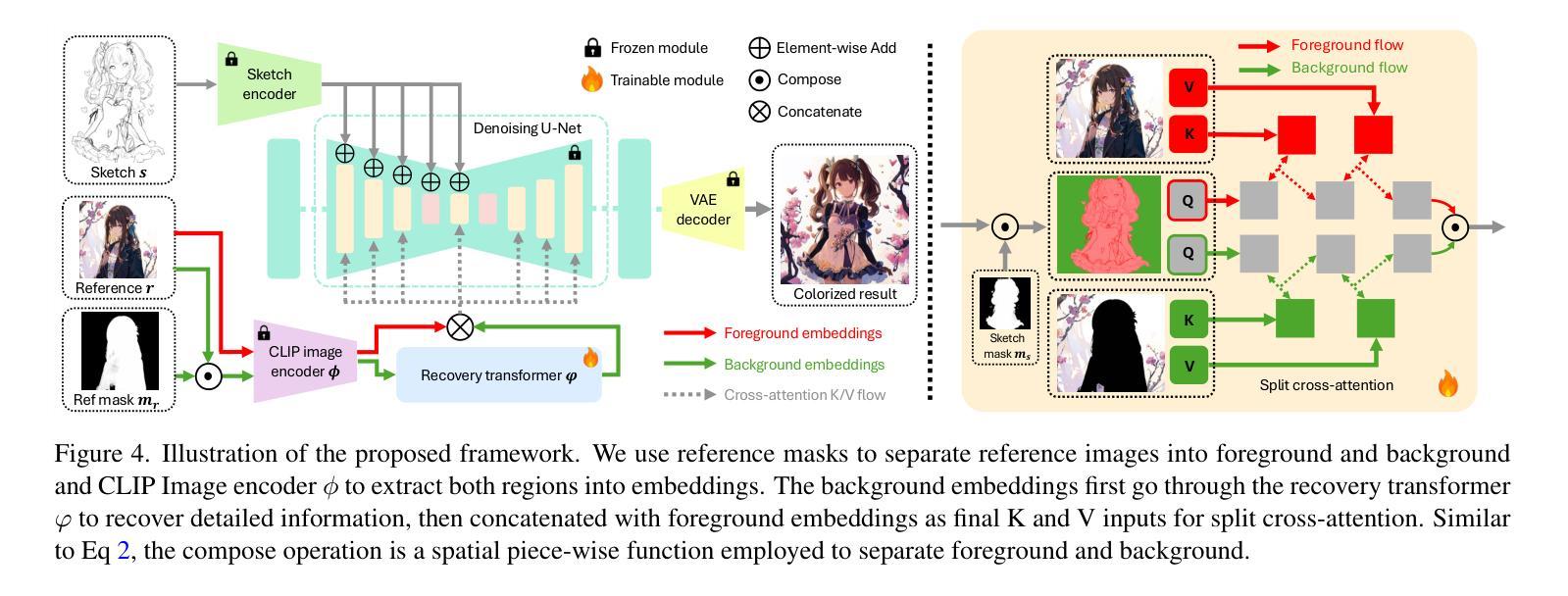
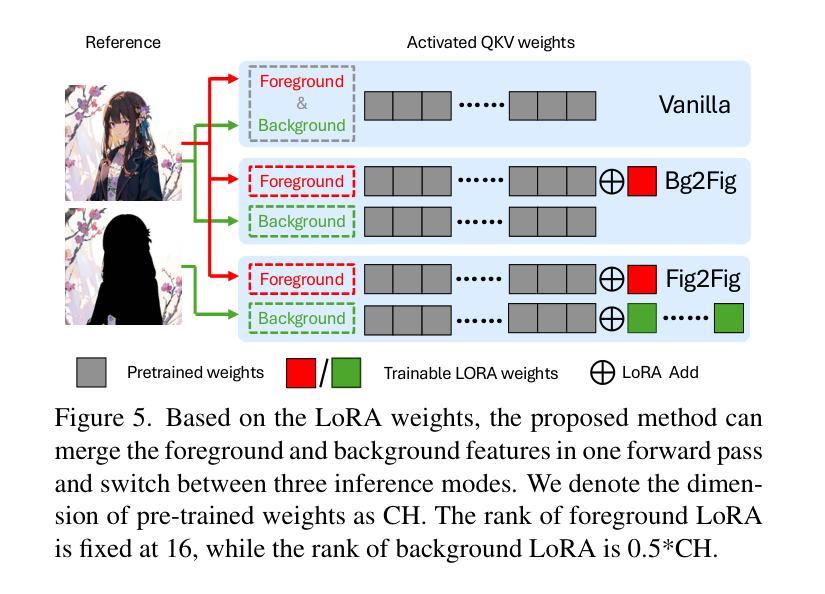
Sketch colorization plays an important role in animation and digital illustration production tasks. However, existing methods still meet problems in that text-guided methods fail to provide accurate color and style reference, hint-guided methods still involve manual operation, and image-referenced methods are prone to cause artifacts. To address these limitations, we propose a diffusion-based framework inspired by real-world animation production workflows. Our approach leverages the sketch as the spatial guidance and an RGB image as the color reference, and separately extracts foreground and background from the reference image with spatial masks. Particularly, we introduce a split cross-attention mechanism with LoRA (Low-Rank Adaptation) modules. They are trained separately with foreground and background regions to control the corresponding embeddings for keys and values in cross-attention. This design allows the diffusion model to integrate information from foreground and background independently, preventing interference and eliminating the spatial artifacts. During inference, we design switchable inference modes for diverse use scenarios by changing modules activated in the framework. Extensive qualitative and quantitative experiments, along with user studies, demonstrate our advantages over existing methods in generating high-qualigy artifact-free results with geometric mismatched references. Ablation studies further confirm the effectiveness of each component. Codes are available at https://github.com/ tellurion-kanata/colorizeDiffusion.
草图着色在动画和数字插画制作任务中扮演着重要角色。然而,现有方法仍然存在一些问题,文本引导的方法无法提供准确的颜色和风格参考,提示引导的方法仍需要手动操作,而图像参考的方法则容易产生伪影。为了解决这些限制,我们提出了一个受现实动画制作工作流程启发的基于扩散的框架。我们的方法利用草图作为空间指导,并使用RGB图像作为颜色参考,使用空间掩膜从参考图像中分别提取前景和背景。特别是,我们引入了一种带有LoRA(低秩适应)模块的分割交叉注意机制。它们分别与前景和背景区域进行训练,以控制交叉注意中的键和值的对应嵌入。这种设计允许扩散模型独立地整合前景和背景的信息,防止干扰,消除空间伪影。在推理过程中,我们通过改变框架中激活的模块,为不同的使用场景设计了可切换的推理模式。大量的定性和定量实验,以及用户研究,证明了我们的方法在生成高质量、无伪影的结果方面,具有几何不匹配引用的优势。消融研究进一步证实了每个组件的有效性。代码可在https://github.com/tellurion-kanata/colorizeDiffusion找到。
论文及项目相关链接
Summary
本文提出了一种基于扩散模型的动画与数字插画生产中的草图彩色化新方法。该方法利用草图作为空间指导,RGB图像作为颜色参考,通过空间掩膜分别提取前景和背景。引入带有LoRA模块的分割交叉注意力机制,分别对前景和背景区域进行训练,控制交叉注意力中的键和值嵌入。此方法设计灵活,支持多种应用场景,并通过实验和用户研究证明了其在几何不匹配参考下生成高质量、无伪影结果的优势。
Key Takeaways
- 提出了基于扩散模型的草图彩色化新方法。
- 结合真实动画生产流程启发设计扩散模型框架。
- 利用草图作为空间指导,RGB图像作为颜色参考,采用空间掩膜分离前景与背景。
- 引入带有LoRA模块的分割交叉注意力机制,提高模型性能。
- 设计灵活多变的推理模式以适应不同应用场景。
- 通过实验和用户研究验证了模型在生成高质量、无伪影结果方面的优势。
点此查看论文截图


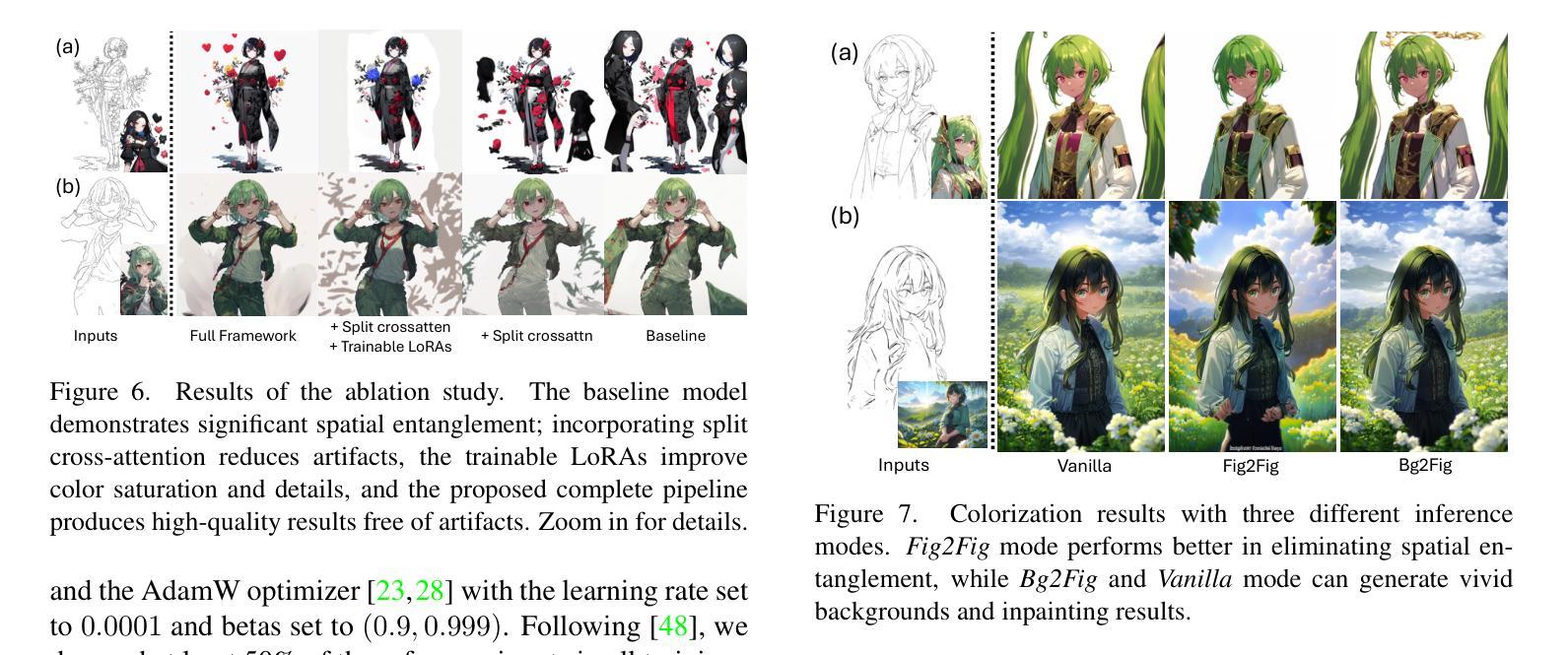
High-Fidelity Relightable Monocular Portrait Animation with Lighting-Controllable Video Diffusion Model
Authors:Mingtao Guo, Guanyu Xing, Yanli Liu
Relightable portrait animation aims to animate a static reference portrait to match the head movements and expressions of a driving video while adapting to user-specified or reference lighting conditions. Existing portrait animation methods fail to achieve relightable portraits because they do not separate and manipulate intrinsic (identity and appearance) and extrinsic (pose and lighting) features. In this paper, we present a Lighting Controllable Video Diffusion model (LCVD) for high-fidelity, relightable portrait animation. We address this limitation by distinguishing these feature types through dedicated subspaces within the feature space of a pre-trained image-to-video diffusion model. Specifically, we employ the 3D mesh, pose, and lighting-rendered shading hints of the portrait to represent the extrinsic attributes, while the reference represents the intrinsic attributes. In the training phase, we employ a reference adapter to map the reference into the intrinsic feature subspace and a shading adapter to map the shading hints into the extrinsic feature subspace. By merging features from these subspaces, the model achieves nuanced control over lighting, pose, and expression in generated animations. Extensive evaluations show that LCVD outperforms state-of-the-art methods in lighting realism, image quality, and video consistency, setting a new benchmark in relightable portrait animation.
重光照肖像动画旨在使静态参考肖像动画与驾驶视频的头部动作和表情相匹配,同时适应用户指定的或参考的光照条件。现有的肖像动画方法无法实现重光照肖像,因为它们不能分离和操作内在(身份和外观)和外在(姿势和照明)特征。在本文中,我们提出了一种光照可控视频扩散模型(LCVD),用于高保真重光照肖像动画。我们通过区分特征空间内特定子空间内的这些特征类型来解决这一限制,这些子空间用于表示预训练图像到视频扩散模型的内在和外在属性。具体来说,我们使用肖像的3D网格、姿势和光照渲染的阴影提示来表示外在属性,而参考图像则表示内在属性。在训练阶段,我们使用参考适配器将参考图像映射到内在特征子空间,并使用着色适配器将阴影提示映射到外在特征子空间。通过合并这些子空间中的特征,该模型在生成的动画中对光照、姿势和表情实现了微妙的控制。大量评估表明,LCVD在光照真实性、图像质量和视频一致性方面优于最先进的方法,为可重光照肖像动画树立了新的基准。
论文及项目相关链接
Summary
本文提出了一种名为LCVD的灯光可控视频扩散模型,用于实现高保真、可重光照的肖像动画。该模型通过区分预训练图像到视频扩散模型的特征空间中的特定子空间来区分内在(身份和外观)和外在(姿势和照明)特征,从而实现可重光照的肖像动画。通过合并这些子空间中的特征,模型在生成的动画中对照明、姿势和表情实现了微妙控制。
Key Takeaways
- 本文介绍了可重光照肖像动画的目标,即实现静态参考肖像的动画,使其与驱动视频的头部动作和表情相匹配,同时适应用户指定的或参考的照明条件。
- 当前肖像动画方法的局限性在于它们无法分离和操作内在和外在特征,因此无法实现可重光照的肖像。
- LCVD模型通过专门的子空间来区分内在和外在特征,这些子空间位于预训练的图像到视频扩散模型的特征空间中。
- LCVD模型使用3D网格、姿势和照明渲染着色提示来表示肖像的外在属性,而参考图像则代表内在属性。
- 在训练阶段,LCVD模型使用参考适配器和着色适配器来映射参考图像和着色提示到相应的特征子空间。
- 通过合并这些子空间中的特征,LCVD模型实现了对生成动画中的照明、姿势和表情的微妙控制。
点此查看论文截图

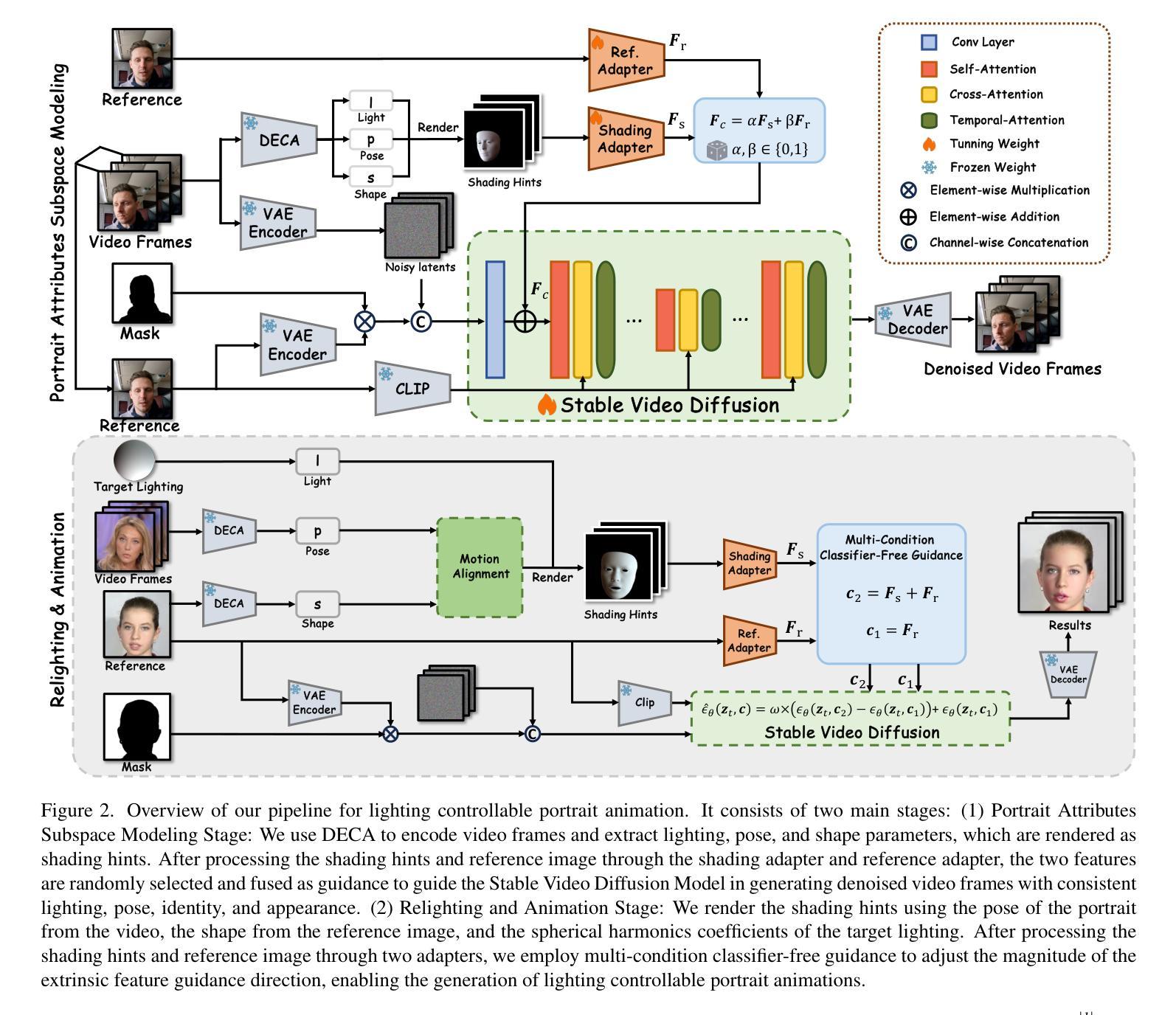
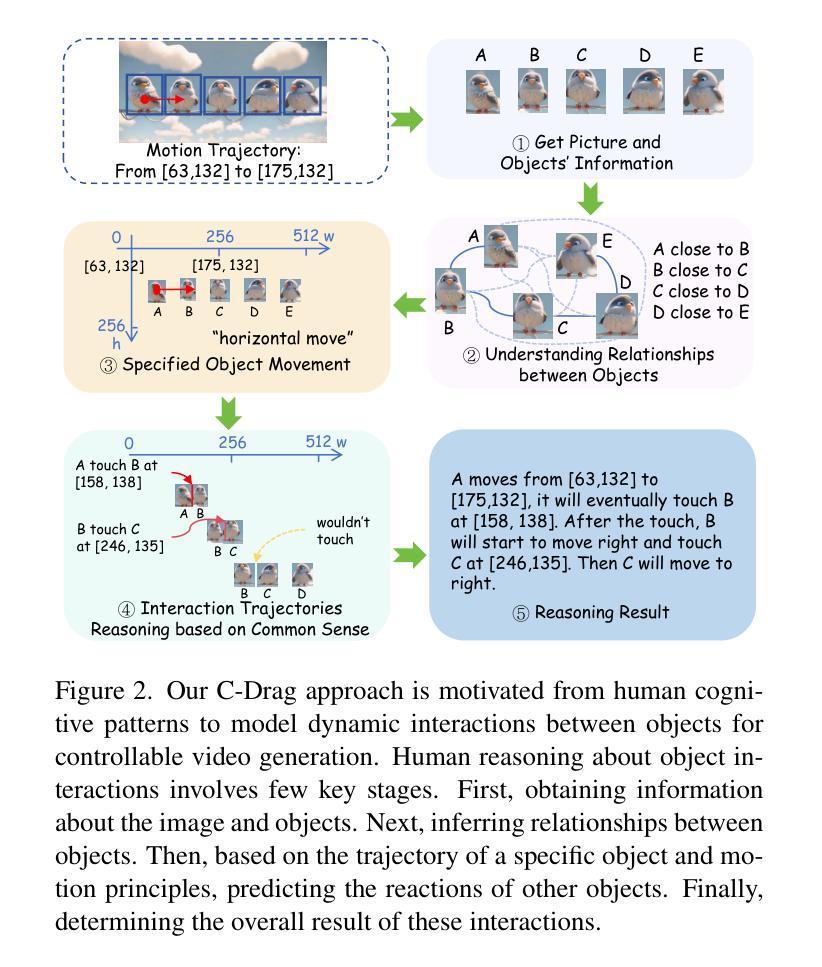
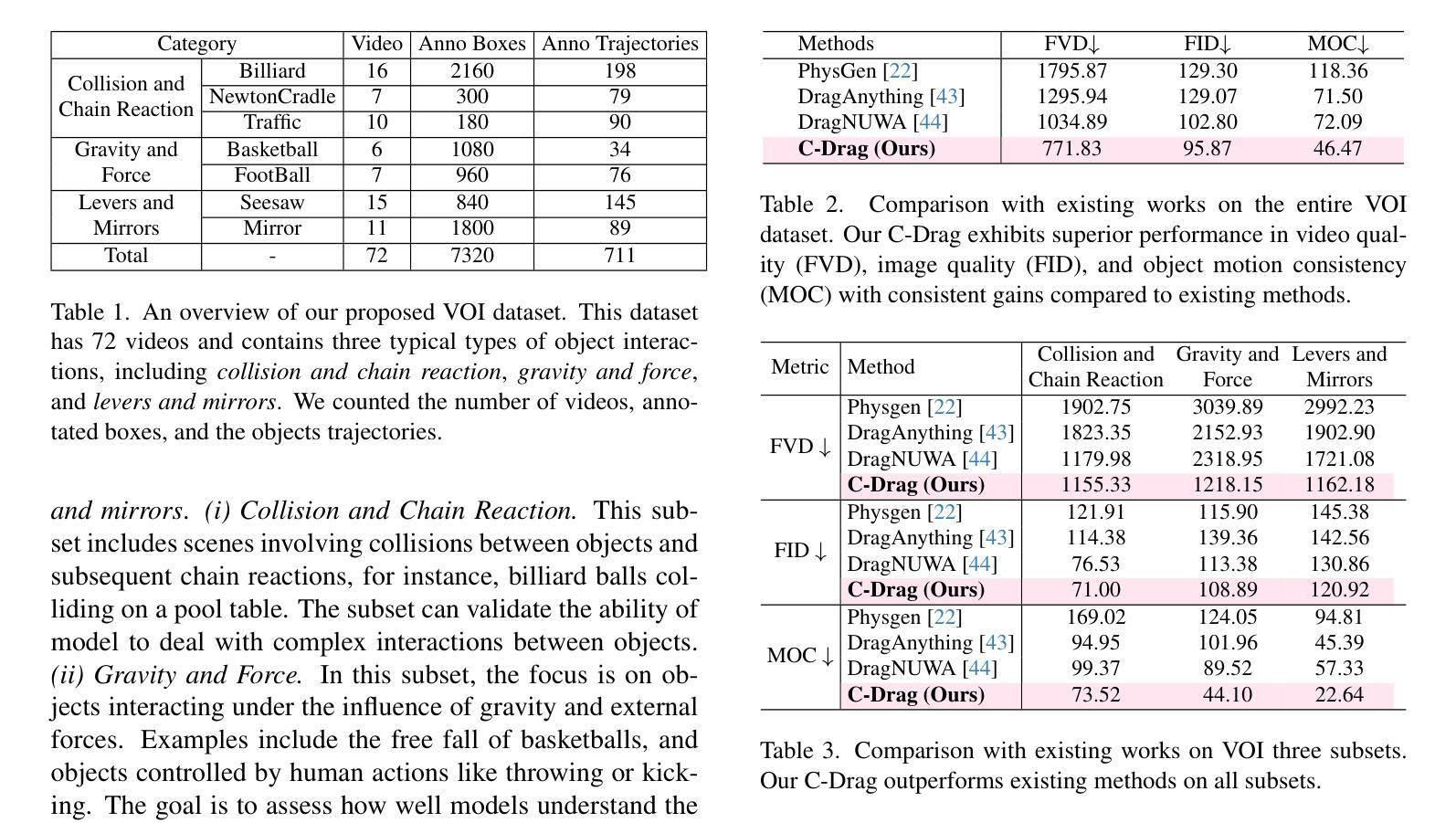
C-Drag: Chain-of-Thought Driven Motion Controller for Video Generation
Authors:Yuhao Li, Mirana Claire Angel, Salman Khan, Yu Zhu, Jinqiu Sun, Yanning Zhang, Fahad Shahbaz Khan
Trajectory-based motion control has emerged as an intuitive and efficient approach for controllable video generation. However, the existing trajectory-based approaches are usually limited to only generating the motion trajectory of the controlled object and ignoring the dynamic interactions between the controlled object and its surroundings. To address this limitation, we propose a Chain-of-Thought-based motion controller for controllable video generation, named C-Drag. Instead of directly generating the motion of some objects, our C-Drag first performs object perception and then reasons the dynamic interactions between different objects according to the given motion control of the objects. Specifically, our method includes an object perception module and a Chain-of-Thought-based motion reasoning module. The object perception module employs visual language models to capture the position and category information of various objects within the image. The Chain-of-Thought-based motion reasoning module takes this information as input and conducts a stage-wise reasoning process to generate motion trajectories for each of the affected objects, which are subsequently fed to the diffusion model for video synthesis. Furthermore, we introduce a new video object interaction (VOI) dataset to evaluate the generation quality of motion controlled video generation methods. Our VOI dataset contains three typical types of interactions and provides the motion trajectories of objects that can be used for accurate performance evaluation. Experimental results show that C-Drag achieves promising performance across multiple metrics, excelling in object motion control. Our benchmark, codes, and models will be available at https://github.com/WesLee88524/C-Drag-Official-Repo.
基于轨迹的运动控制已作为一种直观而有效的方法,用于可控视频生成。然而,现有的基于轨迹的方法通常仅限于生成受控对象的运动轨迹,而忽略了受控对象与其周围环境之间的动态交互。为了解决这一局限性,我们提出了一种基于思维链的运动控制器,用于可控视频生成,名为C-Drag。与直接生成某些对象的运动不同,我们的C-Drag首先执行对象感知,然后根据给定的对象运动控制,推理不同对象之间的动态交互。具体来说,我们的方法包括一个对象感知模块和一个基于思维链的运动推理模块。对象感知模块采用视觉语言模型来捕获图像中各种对象的位置和类别信息。基于思维链的运动推理模块以此信息为输入,进行分阶段推理过程,为受影响对象生成运动轨迹,然后将其传递给扩散模型进行视频合成。此外,我们引入了一个新的视频对象交互(VOI)数据集,以评估受控运动视频生成方法的生成质量。我们的VOI数据集包含三种典型的交互类型,并提供可用于准确性能评估的对象运动轨迹。实验结果表明,C-Drag在多个指标上表现良好,尤其在对象运动控制方面表现优异。我们的基准测试、代码和模型将在https://github.com/WesLee88524/C-Drag-Official-Repo上提供。
论文及项目相关链接
Summary
本文提出一种基于Chain-of-Thought的C-Drag运动控制器,用于可控视频生成。不同于现有方法,它先通过对象感知捕捉图像中各种对象的位置和类别信息,然后通过基于Chain-of-Thought的运动推理模块对这些对象间的动态交互进行推理,生成每个受影响对象的运动轨迹,最后输入扩散模型进行视频合成。此外,还引入了一个新的视频对象交互数据集来评估运动控制视频生成方法的质量。实验结果证明了C-Drag在多指标上的优越性能,尤其在对象运动控制方面表现突出。
Key Takeaways
- 现有轨迹控制方法主要生成控制对象的运动轨迹,忽略了与周围对象的动态交互。
- 提出的C-Drag方法包括对象感知模块和基于Chain-of-Thought的运动推理模块。
- 对象感知模块利用视觉语言模型捕捉图像中对象的位置和类别信息。
- 基于Chain-of-Thought的运动推理模块根据给定的运动控制进行动态交互推理,生成受影响对象的运动轨迹。
- 引入新的视频对象交互数据集用于评估运动控制视频生成方法的性能。
- C-Drag实现了卓越的对象运动控制能力,并在多个指标上表现出良好性能。
点此查看论文截图


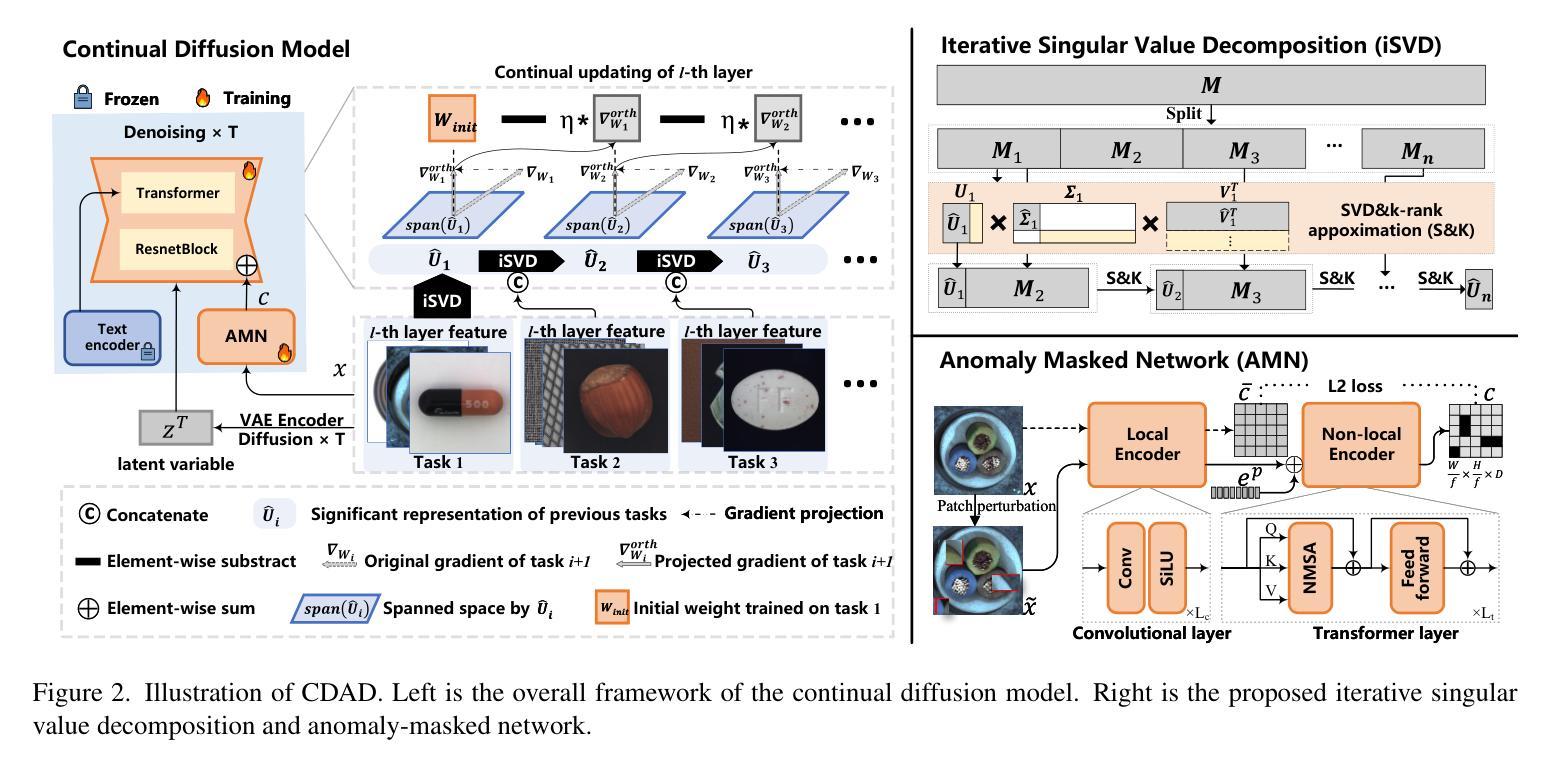
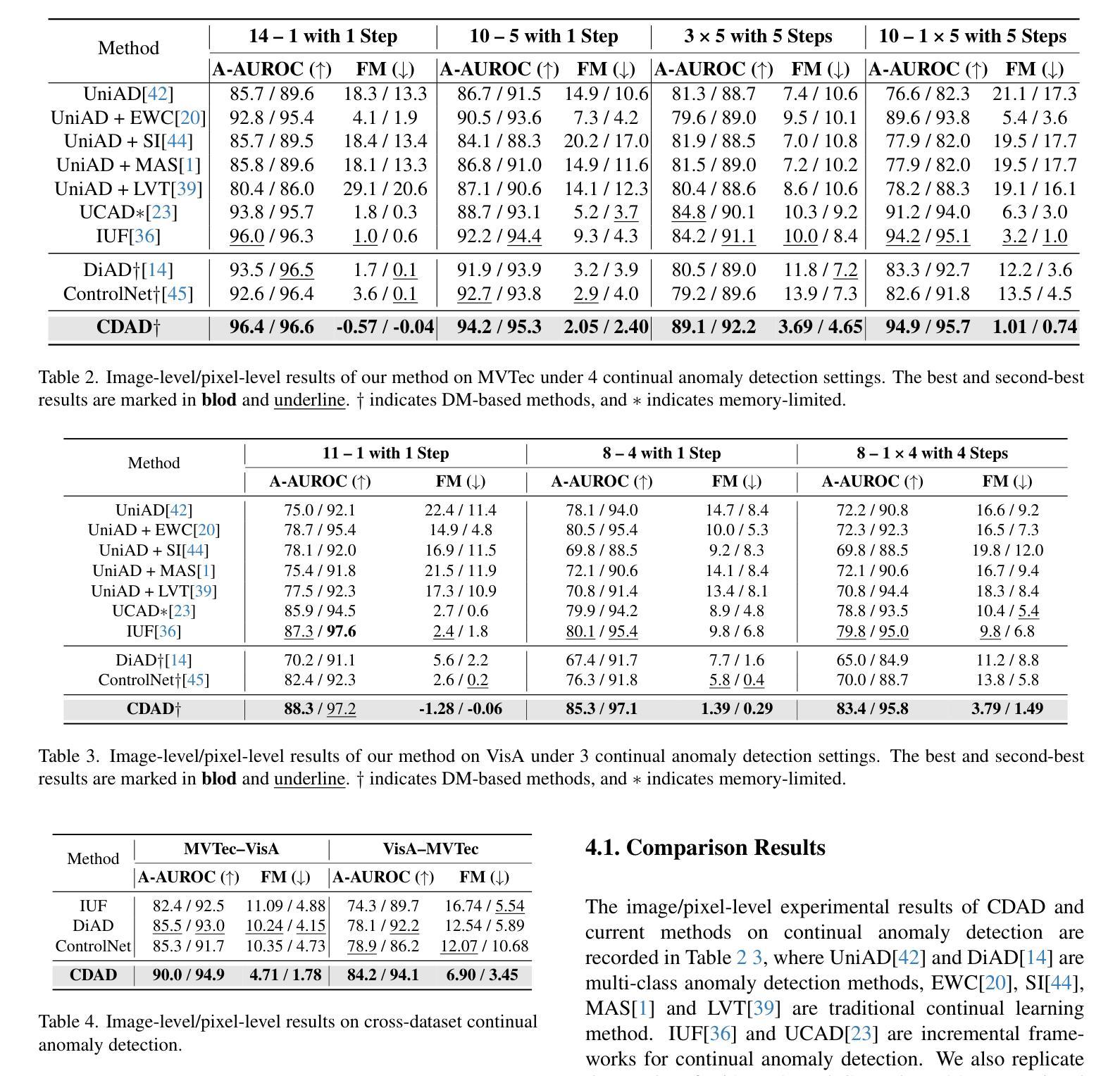
One-for-More: Continual Diffusion Model for Anomaly Detection
Authors:Xiaofan Li, Xin Tan, Zhuo Chen, Zhizhong Zhang, Ruixin Zhang, Rizen Guo, Guanna Jiang, Yulong Chen, Yanyun Qu, Lizhuang Ma, Yuan Xie
With the rise of generative models, there is a growing interest in unifying all tasks within a generative framework. Anomaly detection methods also fall into this scope and utilize diffusion models to generate or reconstruct normal samples when given arbitrary anomaly images. However, our study found that the diffusion model suffers from severe faithfulness hallucination'' and catastrophic forgetting’’, which can’t meet the unpredictable pattern increments. To mitigate the above problems, we propose a continual diffusion model that uses gradient projection to achieve stable continual learning. Gradient projection deploys a regularization on the model updating by modifying the gradient towards the direction protecting the learned knowledge. But as a double-edged sword, it also requires huge memory costs brought by the Markov process. Hence, we propose an iterative singular value decomposition method based on the transitive property of linear representation, which consumes tiny memory and incurs almost no performance loss. Finally, considering the risk of ``over-fitting’’ to normal images of the diffusion model, we propose an anomaly-masked network to enhance the condition mechanism of the diffusion model. For continual anomaly detection, ours achieves first place in 17/18 settings on MVTec and VisA. Code is available at https://github.com/FuNz-0/One-for-More
随着生成模型(generative models)的兴起,越来越多的研究兴趣集中在在一个生成框架内统一所有任务。异常检测(Anomaly detection)方法也在这个范围内,当给定任意异常图像时,它们利用扩散模型(diffusion models)来生成或重建正常样本。然而,我们的研究发现,扩散模型存在严重的“忠实性幻觉”(faithfulness hallucination)和“灾难性遗忘”(catastrophic forgetting)问题,无法满足不可预测的模式增量需求。为了缓解上述问题,我们提出了一种持续扩散模型(continual diffusion model),该模型使用梯度投影(gradient projection)来实现稳定的持续学习。梯度投影通过在模型更新上部署正则化,修改梯度以保护已学知识为方向。但与此同时,它也需要由马尔可夫过程带来的巨大内存成本。因此,我们提出了一种基于线性表示传递属性的迭代奇异值分解方法(iterative singular value decomposition method),该方法消耗内存极小且几乎不会造成性能损失。最后,考虑到扩散模型对正常图像过度拟合的风险,我们提出了一个异常屏蔽网络(anomaly-masked network),以增强扩散模型的条件机制。对于持续的异常检测任务,我们的方法在MVTec和VisA的17/18设置上取得了第一名。代码可通过以下链接获取:https://github.com/FuNz-0/One-for-More 。
论文及项目相关链接
PDF Accepted by CVPR2025
Summary
本文探讨了生成模型在异常检测中的应用,特别是扩散模型。研究发现,扩散模型存在“忠实幻觉”和“灾难性遗忘”问题,难以满足不可预测的模式增量。为解决这个问题,本文提出了一种持续扩散模型,采用梯度投影实现稳定持续学习。为解决Markov过程带来的巨大内存成本,提出了基于线性表示传递性的迭代奇异值分解方法。最后,考虑扩散模型对正常图像的“过度拟合”风险,提出了一种异常掩膜网络来增强扩散模型的条件机制。
Key Takeaways
- 扩散模型在异常检测中表现出“忠实幻觉”和“灾难性遗忘”问题。
- 为解决上述问题,提出了一种持续扩散模型,使用梯度投影实现稳定持续学习。
- 梯度投影通过修改模型更新时的梯度来保护所学知识。
- 解决Markov过程带来的大内存消耗,采用基于线性表示传递性的迭代奇异值分解方法。
- 扩散模型存在对正常图像的“过度拟合”风险。
- 为增强扩散模型的条件机制,提出了一种异常掩膜网络。
- 该方法在MVTec和VisA的17/18设置上获得第一名。
点此查看论文截图



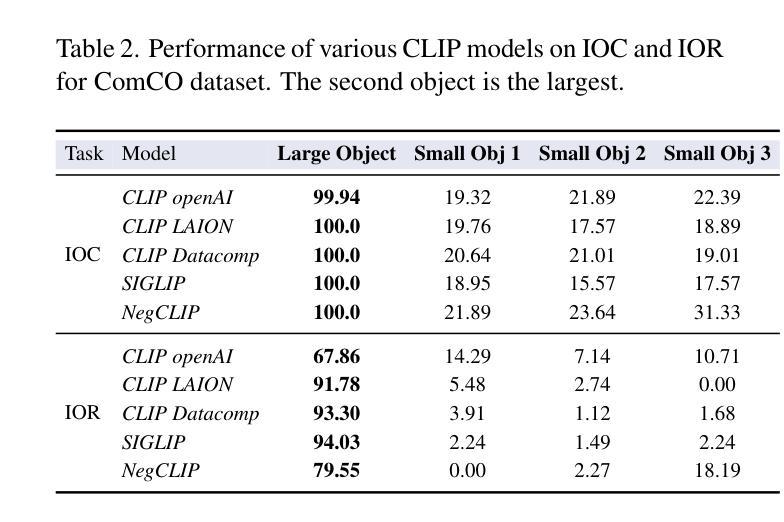
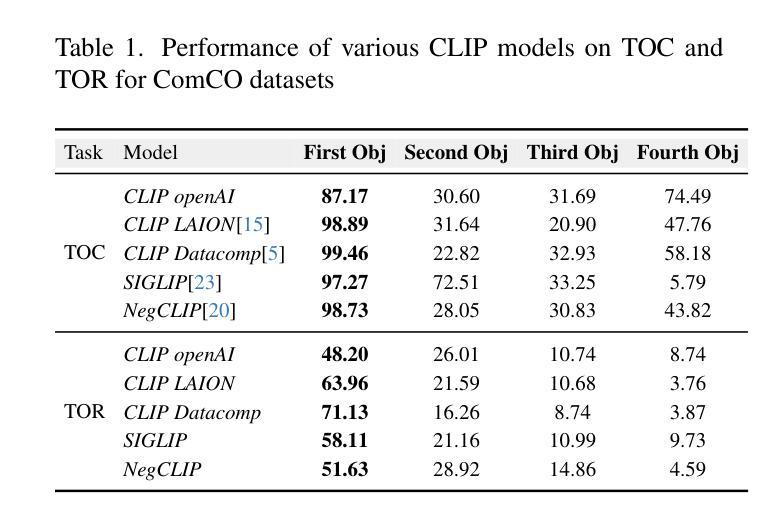
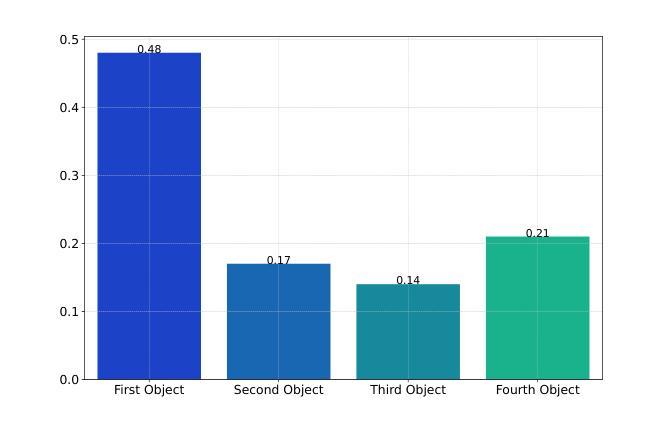
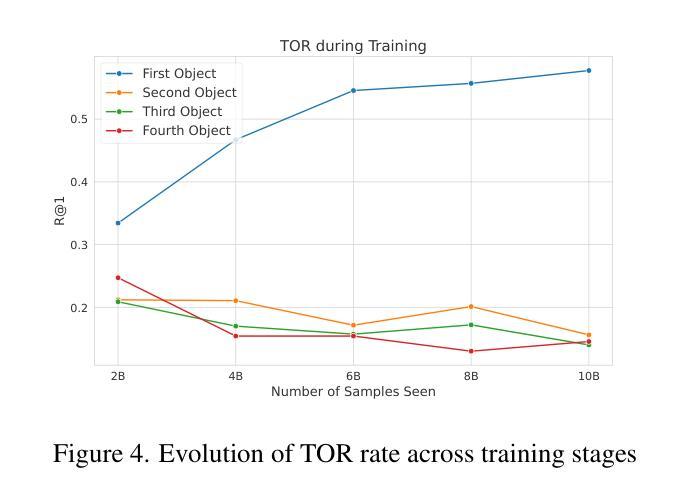
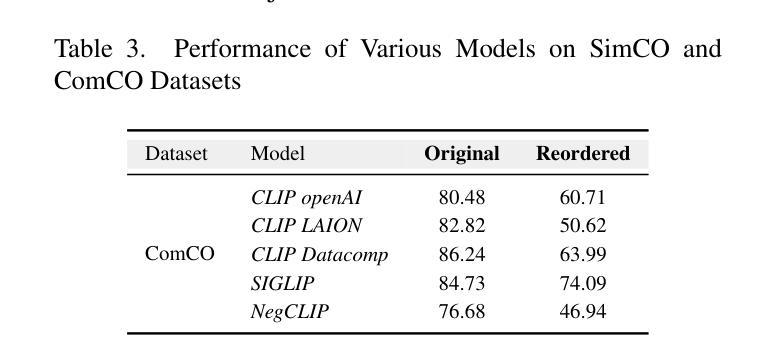
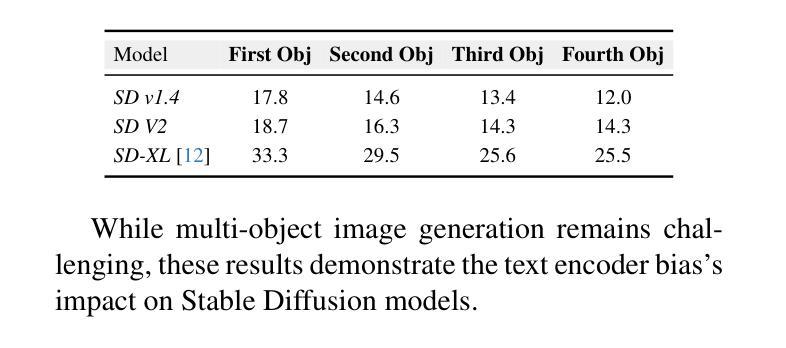
Analyzing CLIP’s Performance Limitations in Multi-Object Scenarios: A Controlled High-Resolution Study
Authors:Reza Abbasi, Ali Nazari, Aminreza Sefid, Mohammadali Banayeeanzade, Mohammad Hossein Rohban, Mahdieh Soleymani Baghshah
Contrastive Language-Image Pre-training (CLIP) models have demonstrated remarkable performance in zero-shot classification tasks, yet their efficacy in handling complex multi-object scenarios remains challenging. This study presents a comprehensive analysis of CLIP’s performance limitations in multi-object contexts through controlled experiments. We introduce two custom datasets, SimCO and CompCO, to evaluate CLIP’s image and text encoders in various multi-object configurations. Our findings reveal significant biases in both encoders: the image encoder favors larger objects, while the text encoder prioritizes objects mentioned first in descriptions. We hypothesize these biases originate from CLIP’s training process and provide evidence through analyses of the COCO dataset and CLIP’s training progression. Additionally, we extend our investigation to Stable Diffusion models, revealing that biases in the CLIP text encoder significantly impact text-to-image generation tasks. Our experiments demonstrate how these biases affect CLIP’s performance in image-caption matching and generation tasks, particularly when manipulating object sizes and their order in captions. This work contributes valuable insights into CLIP’s behavior in complex visual environments and highlights areas for improvement in future vision-language models.
对比语言-图像预训练(CLIP)模型在零样本分类任务中表现出了显著的性能,但在处理复杂多目标场景时仍面临挑战。本研究通过控制实验全面分析了CLIP在多目标上下文中的性能局限性。为了评估CLIP的图像和文本编码器在各种多目标配置中的表现,我们引入了两个自定义数据集SimCO和CompCO。我们的研究发现,两个编码器都存在明显的偏见:图像编码器偏爱较大的物体,而文本编码器则优先处理描述中首先提到的物体。我们假设这些偏见源于CLIP的训练过程,并通过分析COCO数据集和CLIP的训练进度提供了证据。此外,我们还对Stable Diffusion模型进行了调查,发现CLIP文本编码器中的偏见对文本到图像生成任务产生了重大影响。我们的实验表明了这些偏见如何在图像标题匹配和生成任务中影响CLIP的性能,特别是在操纵对象大小和标题中物体的顺序时。本研究为CLIP在复杂视觉环境中的行为提供了有价值的见解,并强调了未来视觉语言模型改进的领域。
论文及项目相关链接
PDF Accepted at ECCV 2024 Workshop EVAL-FoMo
Summary
本文探讨了CLIP模型在多目标场景中的性能局限性,并介绍了两个用于评估CLIP图像和文本编码器在多目标配置中的表现的新数据集SimCO和CompCO。研究发现CLIP模型存在显著偏见:图像编码器偏向于识别较大的物体,而文本编码器则优先处理描述中首先提到的物体。本文假设这些偏见源于CLIP的训练过程,并通过分析COCO数据集和CLIP的训练进度提供了证据。此外,本文还对Stable Diffusion模型进行了探索,发现CLIP文本编码器的偏见对文本到图像生成任务产生严重影响。研究结果表明,当操作物体的大小及其在描述中的顺序时,这些偏见会影响CLIP在图像标题匹配和生成任务中的表现。本文对于CLIP在复杂视觉环境中的行为提供了有价值的见解,并指出了未来改进视觉语言模型的方向。
Key Takeaways
- CLIP模型在多目标场景中存在性能局限性。
- 引入的两个新数据集SimCO和CompCO用于评估CLIP在多种多目标配置中的表现。
- CLIP模型存在偏见:图像编码器偏向于识别较大的物体,文本编码器优先处理描述中首先提到的物体。
- 这些偏见可能源于CLIP的训练过程。
- CLIP文本编码器的偏见对文本到图像生成任务有严重影响。
- 当操作物体的大小及其在描述中的顺序时,偏见会影响CLIP在图像标题匹配和生成任务中的表现。
点此查看论文截图


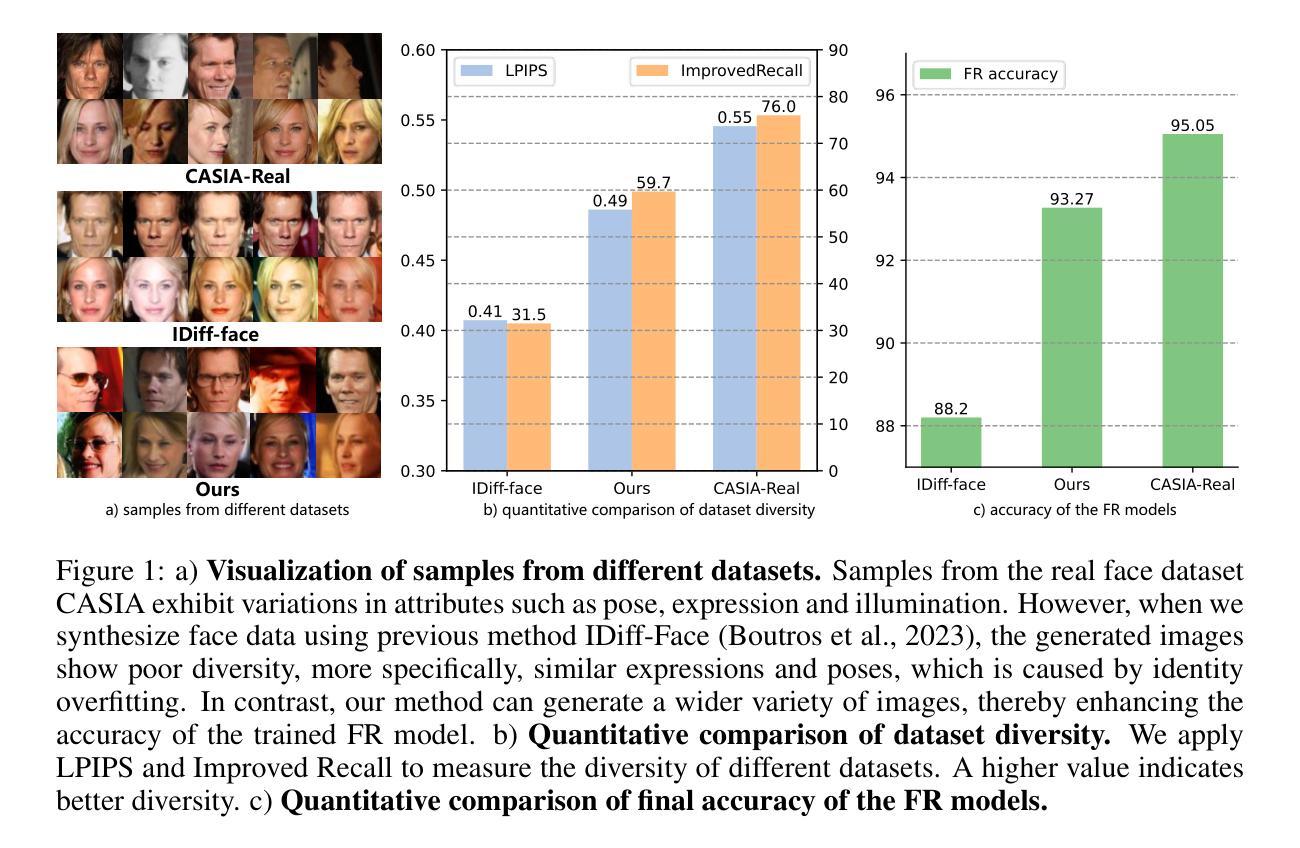
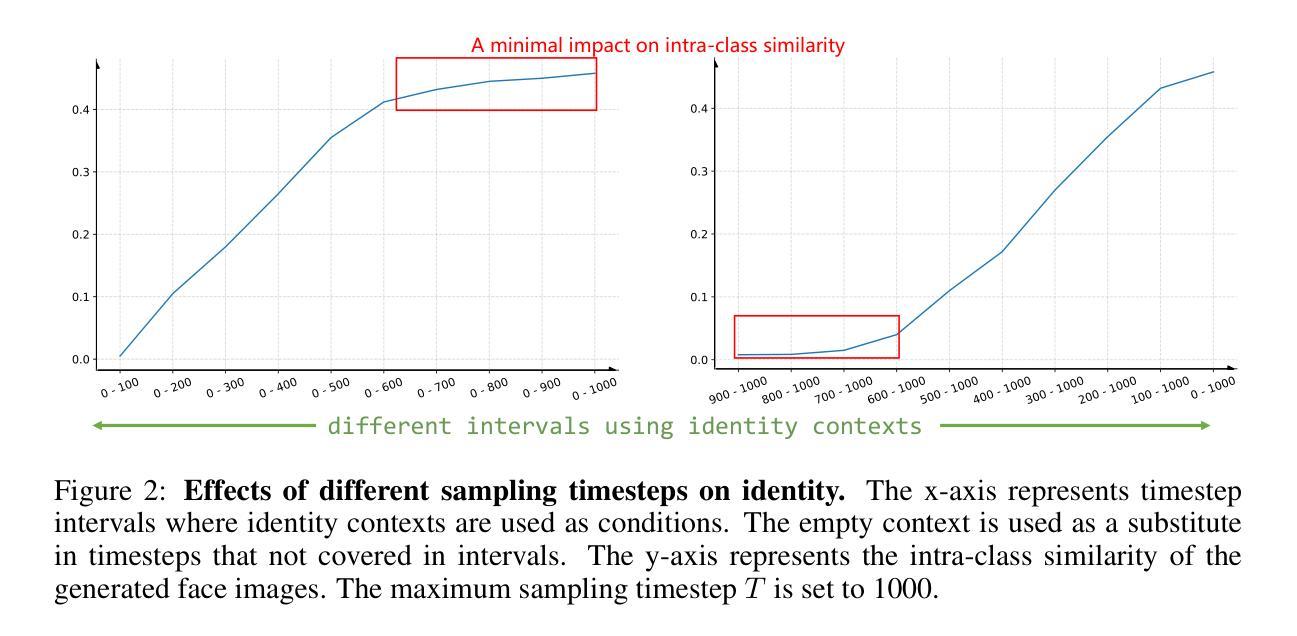
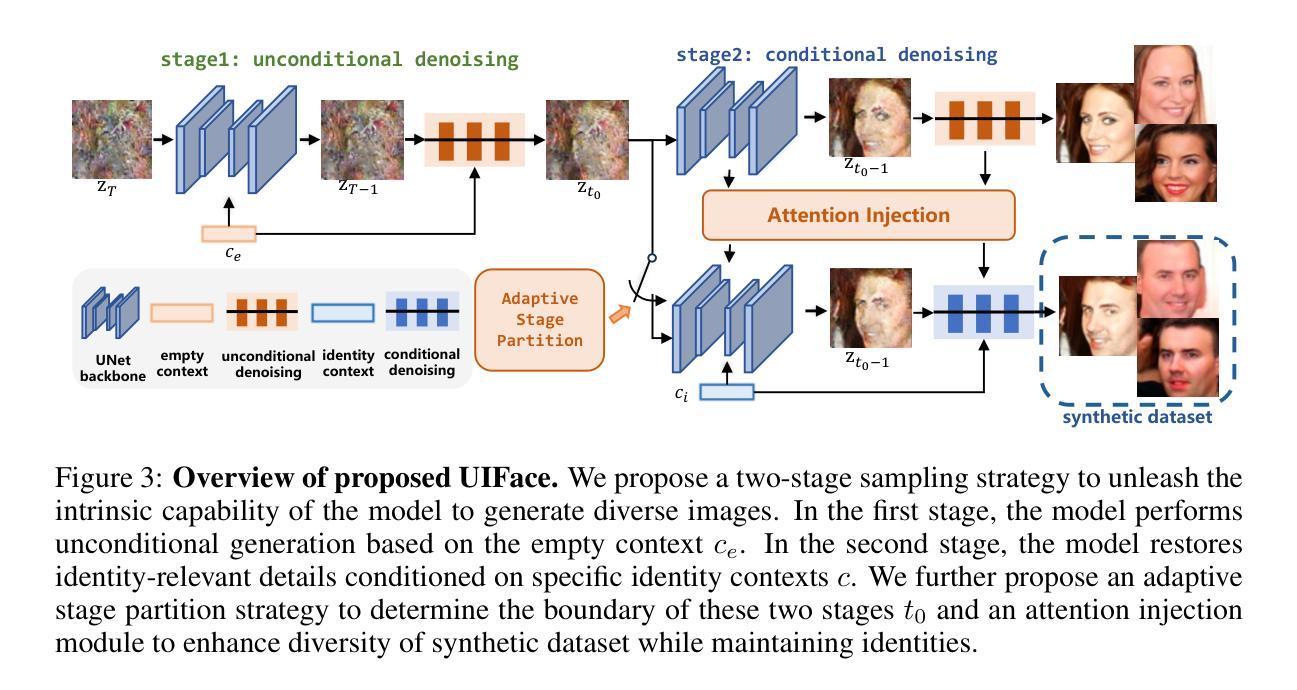
UIFace: Unleashing Inherent Model Capabilities to Enhance Intra-Class Diversity in Synthetic Face Recognition
Authors:Xiao Lin, Yuge Huang, Jianqing Xu, Yuxi Mi, Shuigeng Zhou, Shouhong Ding
Face recognition (FR) stands as one of the most crucial applications in computer vision. The accuracy of FR models has significantly improved in recent years due to the availability of large-scale human face datasets. However, directly using these datasets can inevitably lead to privacy and legal problems. Generating synthetic data to train FR models is a feasible solution to circumvent these issues. While existing synthetic-based face recognition methods have made significant progress in generating identity-preserving images, they are severely plagued by context overfitting, resulting in a lack of intra-class diversity of generated images and poor face recognition performance. In this paper, we propose a framework to Unleash Inherent capability of the model to enhance intra-class diversity for synthetic face recognition, shortened as UIFace. Our framework first trains a diffusion model that can perform sampling conditioned on either identity contexts or a learnable empty context. The former generates identity-preserving images but lacks variations, while the latter exploits the model’s intrinsic ability to synthesize intra-class-diversified images but with random identities. Then we adopt a novel two-stage sampling strategy during inference to fully leverage the strengths of both types of contexts, resulting in images that are diverse as well as identitypreserving. Moreover, an attention injection module is introduced to further augment the intra-class variations by utilizing attention maps from the empty context to guide the sampling process in ID-conditioned generation. Experiments show that our method significantly surpasses previous approaches with even less training data and half the size of synthetic dataset. The proposed UIFace even achieves comparable performance with FR models trained on real datasets when we further increase the number of synthetic identities.
人脸识别(FR)是计算机视觉领域最重要的应用之一。由于大规模人脸数据集的可用性,近年来人脸识别模型的准确性得到了显著提高。然而,直接使用这些数据集不可避免地会导致隐私和法律问题。生成合成数据来训练人脸识别模型是解决这些问题的可行方法。虽然基于合成的现有的人脸识别方法已经在生成身份保留图像方面取得了重大进展,但它们受到上下文过拟合的严重困扰,导致生成的图像缺乏类内多样性和较差的人脸识别性能。在本文中,我们提出了一个框架来释放模型的内在能力,以提高合成人脸识别的类内多样性,简称为UIFace。我们的框架首先训练一个扩散模型,该模型可以在身份上下文或可学习的空上下文条件下进行采样。前者可以生成身份保留的图像但缺乏变化,而后者则利用模型合成类内多样化图像的内在能力,但具有随机身份。然后,我们在推理过程中采用了新型的两阶段采样策略,以充分利用两种类型上下文的优点,从而生成既多样化又身份保留的图像。此外,还引入了一个注意力注入模块,通过利用空上下文中的注意力图来指导身份条件生成中的采样过程,从而进一步增强了类内变化。实验表明,我们的方法即使在训练数据更少、合成数据集规模减半的情况下,也大大超越了以前的方法。当我们进一步增加合成身份的数量时,所提出的UIFace甚至实现了与在真实数据集上训练的FR模型相当的性能。
论文及项目相关链接
PDF ICLR2025
Summary
本文提出一种名为UIFace的框架,用于释放模型内在能力,提高合成人脸识别的类内多样性。该框架首先训练一个扩散模型,能够在身份上下文或可学习空白上下文中进行采样。利用一个两阶段采样策略,在推理阶段充分利用这两种类型的上下文优势,生成具有身份保留和多样化的人脸图像。同时引入注意力注入模块,通过利用空白上下文的注意力图来指导采样过程,进一步增强了类内变化。实验表明,该方法在减少训练数据和合成数据集大小的情况下,显著优于先前的方法,并在增加合成身份数量时实现了与在真实数据集上训练的FR模型相当的性能。
Key Takeaways
- UIFace框架旨在解决合成人脸识别中缺乏类内多样性及过拟合的问题。
- 扩散模型被训练能在身份上下文或空白上下文中进行采样。
- 两阶段采样策略结合了两种上下文的优点,生成既具有多样性又保留身份的图像。
- 引入注意力注入模块,利用空白上下文的注意力图指导采样过程,增强了类内变化。
- 该方法使用更少的训练数据和较小的合成数据集即可实现显著的性能提升。
- UIFace框架在增加合成身份数量时,达到了与真实数据集训练的FR模型相当的性能。
点此查看论文截图

Finding Local Diffusion Schrödinger Bridge using Kolmogorov-Arnold Network
Authors:Xingyu Qiu, Mengying Yang, Xinghua Ma, Fanding Li, Dong Liang, Gongning Luo, Wei Wang, Kuanquan Wang, Shuo Li
In image generation, Schr"odinger Bridge (SB)-based methods theoretically enhance the efficiency and quality compared to the diffusion models by finding the least costly path between two distributions. However, they are computationally expensive and time-consuming when applied to complex image data. The reason is that they focus on fitting globally optimal paths in high-dimensional spaces, directly generating images as next step on the path using complex networks through self-supervised training, which typically results in a gap with the global optimum. Meanwhile, most diffusion models are in the same path subspace generated by weights $f_A(t)$ and $f_B(t)$, as they follow the paradigm ($x_t = f_A(t)x_{Img} + f_B(t)\epsilon$). To address the limitations of SB-based methods, this paper proposes for the first time to find local Diffusion Schr"odinger Bridges (LDSB) in the diffusion path subspace, which strengthens the connection between the SB problem and diffusion models. Specifically, our method optimizes the diffusion paths using Kolmogorov-Arnold Network (KAN), which has the advantage of resistance to forgetting and continuous output. The experiment shows that our LDSB significantly improves the quality and efficiency of image generation using the same pre-trained denoising network and the KAN for optimising is only less than 0.1MB. The FID metric is reduced by \textbf{more than 15%}, especially with a reduction of 48.50% when NFE of DDIM is $5$ for the CelebA dataset. Code is available at https://github.com/Qiu-XY/LDSB.
在图像生成领域,基于Schrödinger Bridge(SB)的方法通过寻找两种分布之间的最低成本路径,理论上提高了与扩散模型的效率和质量。然而,当应用于复杂的图像数据时,它们计算量大且耗时。原因是它们关注于在高维空间中拟合全局最优路径,通过自监督训练直接使用复杂网络在下一步生成图像,这通常与全局最优解存在差距。同时,大多数扩散模型的路径都受到权重fA(t)和fB(t)的制约,它们遵循x_t = fA(t)x_{Img} + fB(t)ε的模式。为了克服SB方法的局限性,本文首次提出了在扩散路径子空间中寻找局部扩散Schrödinger Bridges(LDSB),增强了SB问题与扩散模型之间的联系。具体来说,我们的方法使用Kolmogorov-Arnold网络(KAN)优化扩散路径,该网络具有抵抗遗忘和连续输出的优势。实验表明,使用相同的预训练降噪网络和优化的KAN,我们的LDSB在图像生成的质量和效率方面有了显著提高,且KAN的优化大小仅小于0.1MB。FID指标降低了**超过15%**,特别是在CelebA数据集上,当DDIM的NFE为5时,降低了48.5%。代码可访问于https://github.com/Qiu-XY/LDSB。
论文及项目相关链接
PDF 16 pages, 10 figures, to be published in CVPR 2025
Summary
本文提出了局部扩散Schrödinger桥(LDSB)方法,用于改进图像生成中的效率和质量。该方法优化了扩散路径,利用Kolmogorov-Arnold网络(KAN)增强SB问题与扩散模型的连接。实验表明,使用相同的预训练去噪网络和优化的KAN,LDSB可以显著提高图像生成的质量和效率。其中,FID指标降低了超过15%,特别是在CelebA数据集上,当DDIM的NFE为5时,降低了48.5%。代码已公开于GitHub上。
Key Takeaways
- Schrödinger Bridge(SB)方法在图像生成中理论上提高了效率和质量,但应用于复杂图像数据时计算成本高且耗时。
- SB方法侧重于在高维空间中寻找全局最优路径,通过自监督训练直接生成图像,这通常与全局最优存在差距。
- 扩散模型通常位于由权重fA(t)和fB(t)生成的相同路径子空间中。
- 本文首次提出了局部扩散Schrödinger桥(LDSB)方法,在扩散路径子空间中找到优化路径。
- LDSB方法使用Kolmogorov-Arnold网络(KAN)优化扩散路径,具有抵抗遗忘和连续输出的优势。
- 实验表明,LDSB方法显著提高了图像生成的质量和效率,使用相同的预训练去噪网络和优化的KAN。
点此查看论文截图




Recent Advances on Generalizable Diffusion-generated Image Detection
Authors:Qijie Xu, Defang Chen, Jiawei Chen, Siwei Lyu, Can Wang
The rise of diffusion models has significantly improved the fidelity and diversity of generated images. With numerous benefits, these advancements also introduce new risks. Diffusion models can be exploited to create high-quality Deepfake images, which poses challenges for image authenticity verification. In recent years, research on generalizable diffusion-generated image detection has grown rapidly. However, a comprehensive review of this topic is still lacking. To bridge this gap, we present a systematic survey of recent advances and classify them into two main categories: (1) data-driven detection and (2) feature-driven detection. Existing detection methods are further classified into six fine-grained categories based on their underlying principles. Finally, we identify several open challenges and envision some future directions, with the hope of inspiring more research work on this important topic. Reviewed works in this survey can be found at https://github.com/zju-pi/Awesome-Diffusion-generated-Image-Detection.
扩散模型的兴起显著提高了生成图像的保真度和多样性。这些进步带来了许多好处,但同时也带来了新的风险。扩散模型可以被用来创建高质量的深度伪造图像,这给图像真实性验证带来了挑战。近年来,关于通用扩散生成图像检测的研究发展迅速。然而,关于这一话题的全面综述仍然缺乏。为了填补这一空白,我们对最近的进展进行了系统调查,并将其分为两个主要类别:(1)数据驱动的检测和(2)特征驱动的检测。基于其基本原理,现有的检测方法被进一步细分为六个细分类别。最后,我们确定了若干开放性的挑战,并展望了未来的研究方向,希望在这一重要话题上激发更多的研究工作。本综述中的审查工作可在https://github.com/zju-pi/Awesome-Diffusion-generated-Image-Detection中找到。
论文及项目相关链接
Summary
扩散模型的兴起极大提升了生成图像的保真度和多样性,同时也带来了新的风险。扩散模型可被用于制作高质量深度伪造图像,给图像真实性验证带来挑战。近年来,关于通用扩散生成图像检测的研究迅速增长,但缺乏全面综述。本文系统性地回顾了近期进展,并将其分为两大类:(1)数据驱动检测;(2)特征驱动检测。基于原理,现有检测方法被进一步细分为六个子类别。最后,本文识别了几个开放挑战并展望了未来研究方向,希望激发更多在该领域的研究工作。相关论文综述可在以下链接找到:https://github.com/zju-pi/Awesome-Diffusion-generated-Image-Detection。
Key Takeaways
- 扩散模型的进步带来了图像生成的保真度和多样性显著提升。
- 扩散模型的应用也导致了新的风险,如制作高质量深度伪造图像。
- 近期关于通用扩散生成图像检测的研究增长迅速。
- 当前缺乏关于该话题的全面综述。
- 论文系统性回顾了扩散生成图像检测的近期进展,并分为数据驱动和特征驱动两大类别。
- 现有检测方法基于原理被进一步细分为六个子类别。
点此查看论文截图


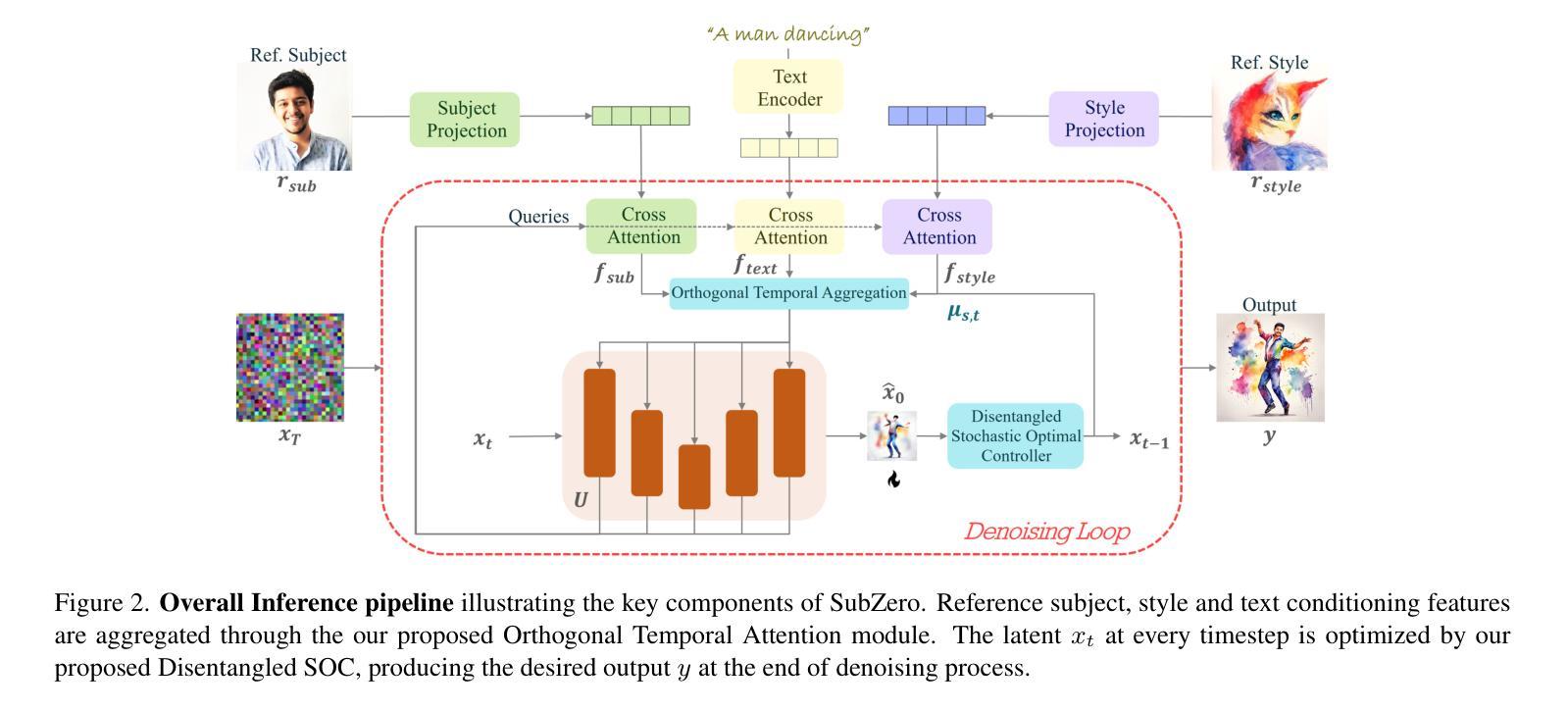
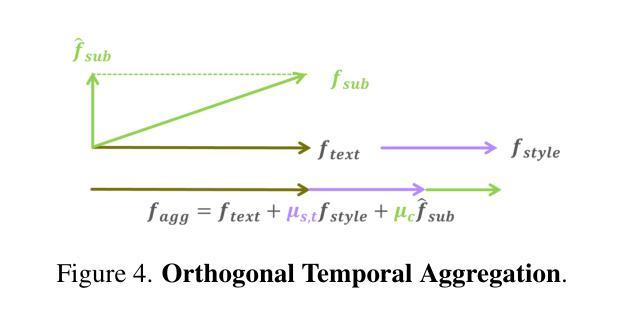
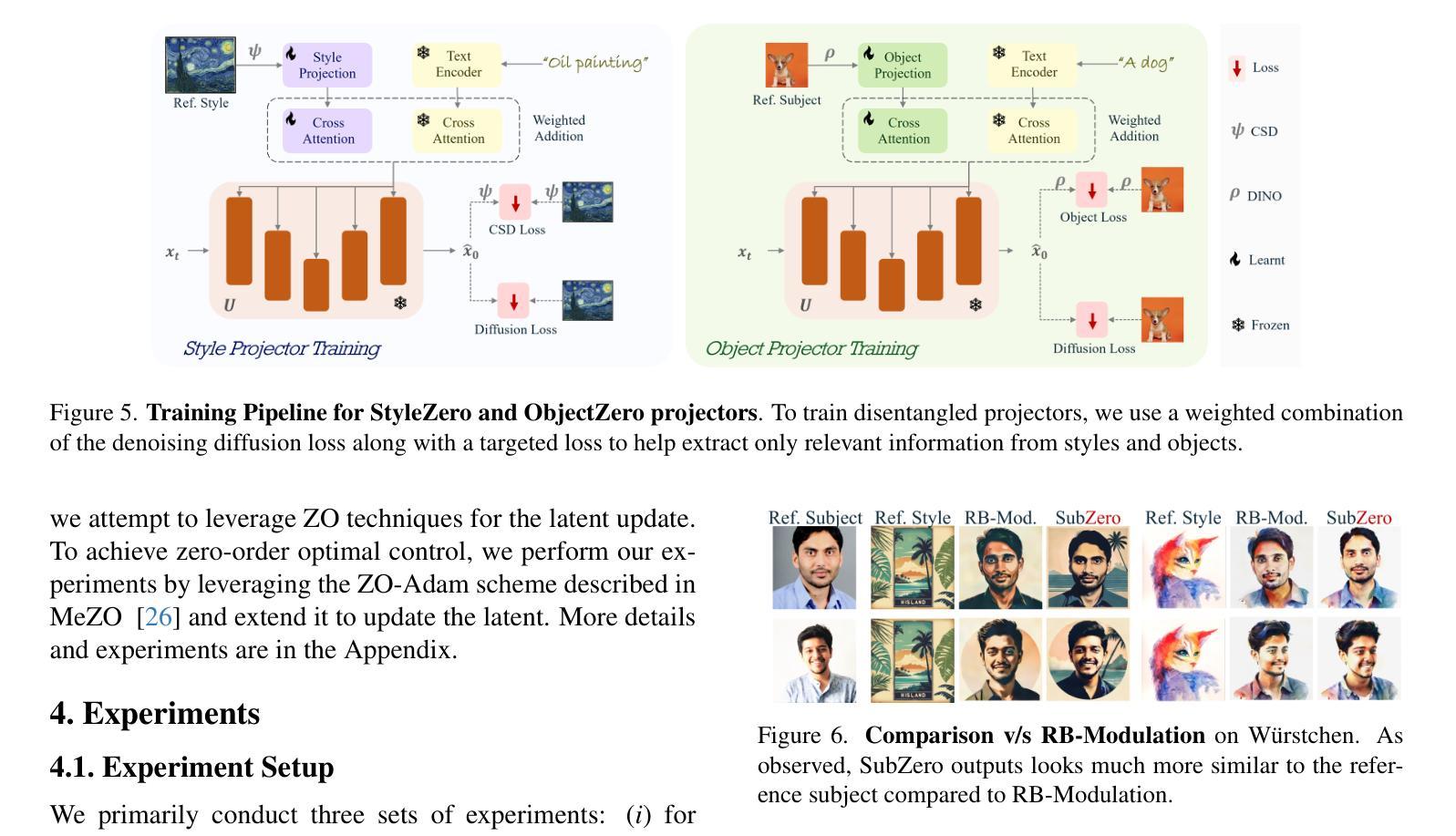
SubZero: Composing Subject, Style, and Action via Zero-Shot Personalization
Authors:Shubhankar Borse, Kartikeya Bhardwaj, Mohammad Reza Karimi Dastjerdi, Hyojin Park, Shreya Kadambi, Shobitha Shivakumar, Prathamesh Mandke, Ankita Nayak, Harris Teague, Munawar Hayat, Fatih Porikli
Diffusion models are increasingly popular for generative tasks, including personalized composition of subjects and styles. While diffusion models can generate user-specified subjects performing text-guided actions in custom styles, they require fine-tuning and are not feasible for personalization on mobile devices. Hence, tuning-free personalization methods such as IP-Adapters have progressively gained traction. However, for the composition of subjects and styles, these works are less flexible due to their reliance on ControlNet, or show content and style leakage artifacts. To tackle these, we present SubZero, a novel framework to generate any subject in any style, performing any action without the need for fine-tuning. We propose a novel set of constraints to enhance subject and style similarity, while reducing leakage. Additionally, we propose an orthogonalized temporal aggregation scheme in the cross-attention blocks of denoising model, effectively conditioning on a text prompt along with single subject and style images. We also propose a novel method to train customized content and style projectors to reduce content and style leakage. Through extensive experiments, we show that our proposed approach, while suitable for running on-edge, shows significant improvements over state-of-the-art works performing subject, style and action composition.
扩散模型在生成任务中越来越受欢迎,包括个性化的主题和风格组合。虽然扩散模型可以生成用户指定的主题,执行文本引导的动作,并以自定义风格呈现,但它们需要微调,并不适合在移动设备上实现个性化。因此,无需调整的个性化方法,如IP适配器等,逐渐受到了关注。然而,在主题和风格的组合方面,这些工作由于其依赖ControlNet而缺乏灵活性,或者出现内容和风格泄露的伪影。为了解决这些问题,我们提出了SubZero,一个无需微调即可生成任何主题、任何风格、执行任何动作的新框架。我们提出了一组新的约束条件,以提高主题和风格的相似性,同时减少泄露。此外,我们在去噪模型的跨注意块中提出了正交化的时间聚合方案,可以有效地根据文本提示以及单个主题和风格图像进行条件设置。我们还提出了一种新的方法来训练定制的内容和风格投影仪,以减少内容和风格的泄露。通过大量实验,我们证明了我们的方法适合在边缘运行,并且在主题、风格和动作组合方面显著优于最新技术。
论文及项目相关链接
Summary
扩散模型可生成个性化主体并执行文本引导的动作,但现有方法需要精细调整并不适用于移动设备上的个性化。SubZero框架可生成任何主题以任何风格执行任何动作,无需精细调整。通过约束增强主题和风格的相似性,减少泄漏。采用正交化时间聚合方案,有效处理文本提示和单主题风格图像。通过广泛实验证明,SubZero适合边缘运行,在主题、风格和动作组合方面表现出显著改进。
Key Takeaways
- 扩散模型广泛应用于生成任务,包括个性化主体和风格的组合。
- 现有扩散模型需要精细调整,不适用于移动设备的个性化。
- SubZero框架无需调整即可生成任何主题、任何风格的任何动作。
- SubZero通过约束增强主题和风格的相似性,减少泄漏。
- SubZero采用正交化时间聚合方案,有效处理文本提示和图像。
- SubZero提出训练定制内容和风格投影仪的新方法,减少内容和风格泄漏。
点此查看论文截图

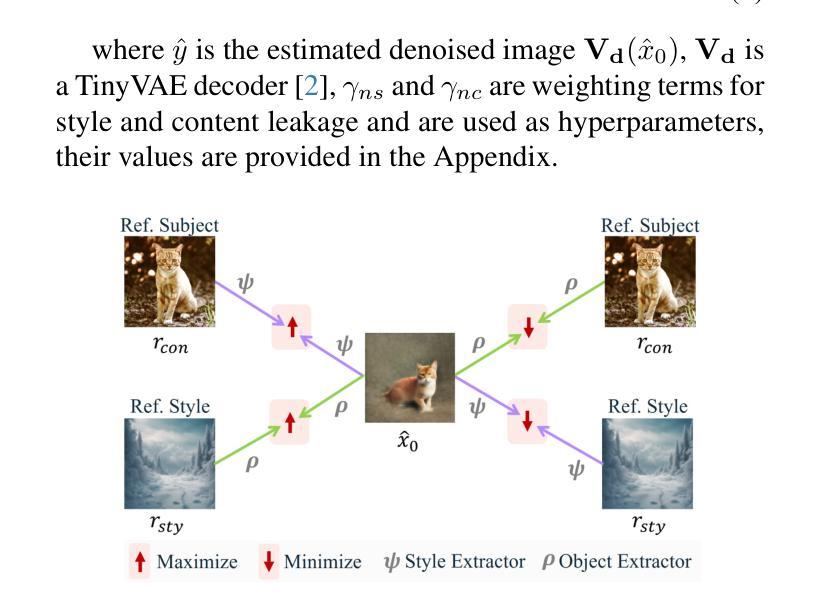

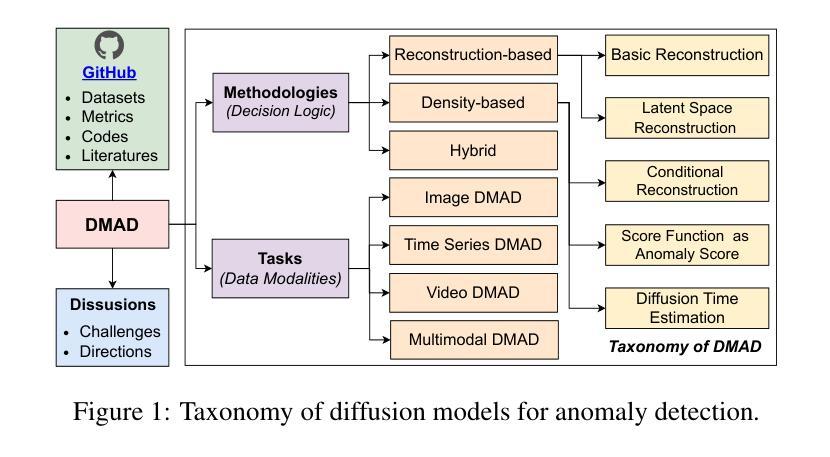
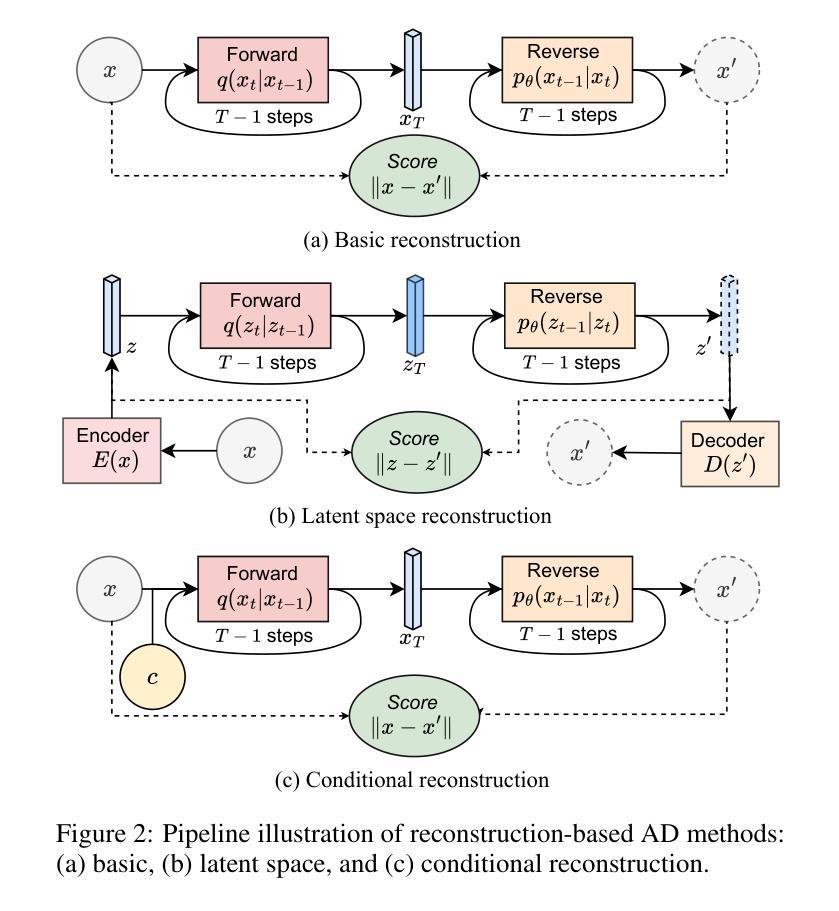
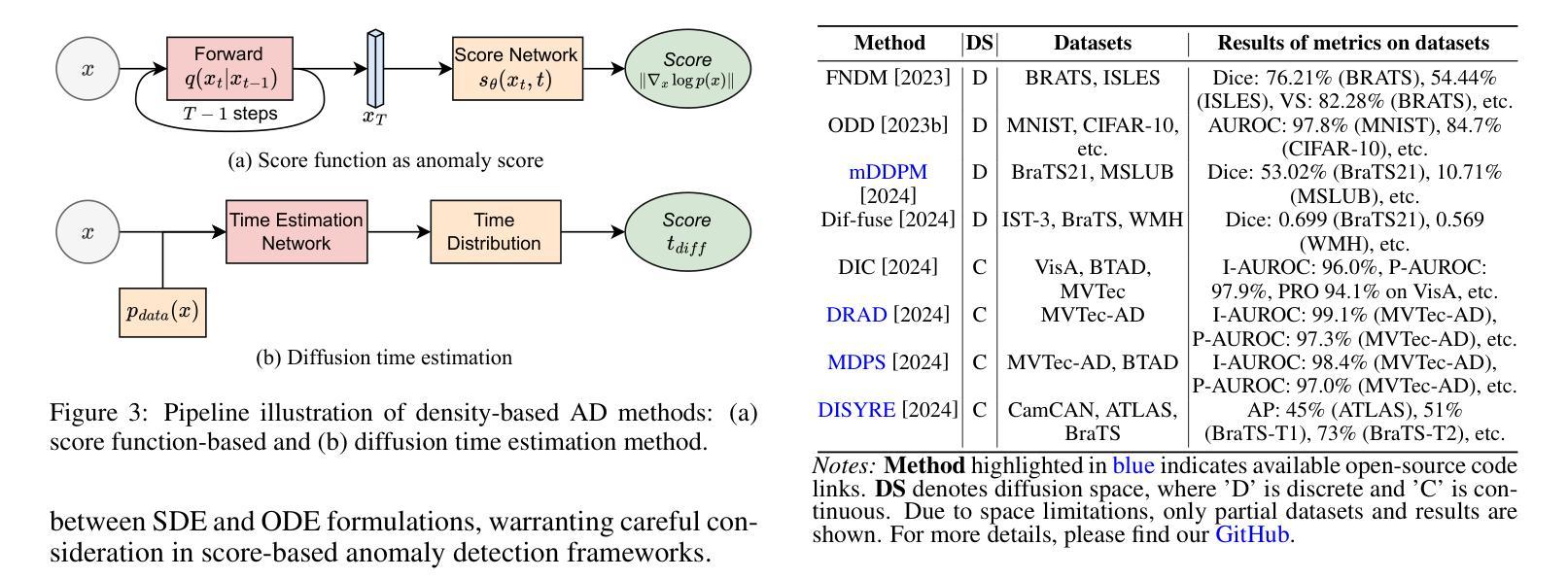
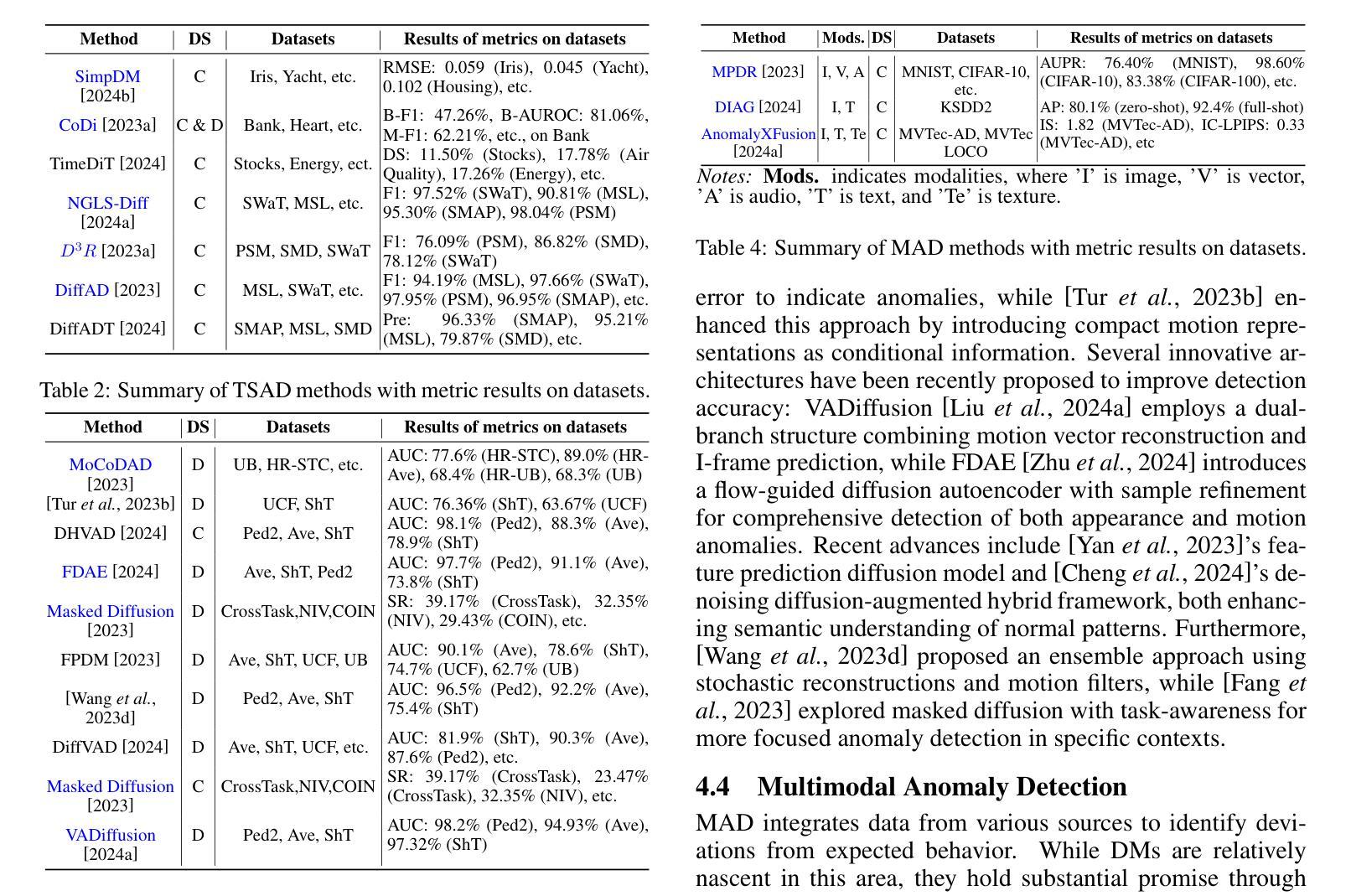
A Survey on Diffusion Models for Anomaly Detection
Authors:Jing Liu, Zhenchao Ma, Zepu Wang, Chenxuanyin Zou, Jiayang Ren, Zehua Wang, Liang Song, Bo Hu, Yang Liu, Victor C. M. Leung
Diffusion models (DMs) have emerged as a powerful class of generative AI models, showing remarkable potential in anomaly detection (AD) tasks across various domains, such as cybersecurity, fraud detection, healthcare, and manufacturing. The intersection of these two fields, termed diffusion models for anomaly detection (DMAD), offers promising solutions for identifying deviations in increasingly complex and high-dimensional data. In this survey, we review recent advances in DMAD research. We begin by presenting the fundamental concepts of AD and DMs, followed by a comprehensive analysis of classic DM architectures including DDPMs, DDIMs, and Score SDEs. We further categorize existing DMAD methods into reconstruction-based, density-based, and hybrid approaches, providing detailed examinations of their methodological innovations. We also explore the diverse tasks across different data modalities, encompassing image, time series, video, and multimodal data analysis. Furthermore, we discuss critical challenges and emerging research directions, including computational efficiency, model interpretability, robustness enhancement, edge-cloud collaboration, and integration with large language models. The collection of DMAD research papers and resources is available at https://github.com/fdjingliu/DMAD.
扩散模型(DMs)已经崭露头角,成为一类强大的生成式人工智能模型。它在异常检测(AD)任务中展现出卓越潜力,涵盖网络安全、欺诈检测、医疗和制造等多个领域。这两个领域的交集——称为用于异常检测的扩散模型(DMAD)——为识别日益复杂和高维数据中的偏差提供了前景广阔的解决方案。在本次调查中,我们回顾了DMAD研究的最新进展。我们首先介绍AD和DM的基本概念,然后综合分析经典的DM架构,包括DDPMs、DDIIMs和Score SDEs。我们将现有的DMAD方法进一步分为基于重建的、基于密度的和混合方法,并对其方法创新进行详细检查。我们还探讨了不同数据模态的多样化任务,包括图像、时间序列、视频和多模态数据分析。此外,我们讨论了关键挑战和新兴研究方向,包括计算效率、模型可解释性、增强稳健性、边缘云协作以及与大型语言模型的集成。DMAD研究论文和资源集可在https://github.com/fdjingliu/DMAD找到。
论文及项目相关链接
Summary
扩散模型(DMs)作为生成式人工智能模型的新兴强大类别,在异常检测(AD)任务中展现出巨大潜力,广泛应用于网络安全、欺诈检测、医疗保健和制造等领域。本文综述了扩散模型在异常检测方面的最新研究进展,介绍了异常检测和扩散模型的基本概念,分析了经典的扩散模型架构,如DDPMs、DDIIMs和Score SDEs,并将现有的扩散模型异常检测方法分为重建型、密度型和混合型方法,详细探讨了它们在方法论上的创新。此外,本文还探讨了不同数据模态的多样化任务,包括图像、时间序列、视频和多模态数据分析。同时,讨论了计算效率、模型可解释性、鲁棒性增强、边缘云协作以及与大型语言模型的集成等关键挑战和新兴研究方向。相关资源可通过链接获取。
Key Takeaways
- 扩散模型(DMs)在异常检测(AD)任务中展现出显著潜力,应用范围广泛。
- 文章概述了异常检测和扩散模型的基本概念。
- 经典的扩散模型架构包括DDPMs、DDIIMs和Score SDEs。
- 现有的扩散模型异常检测方法可分为重建型、密度型和混合型方法。
- 扩散模型在图像、时间序列、视频和多模态数据分析等任务中有广泛应用。
- 面临的关键挑战包括计算效率、模型可解释性和鲁棒性增强等。
点此查看论文截图

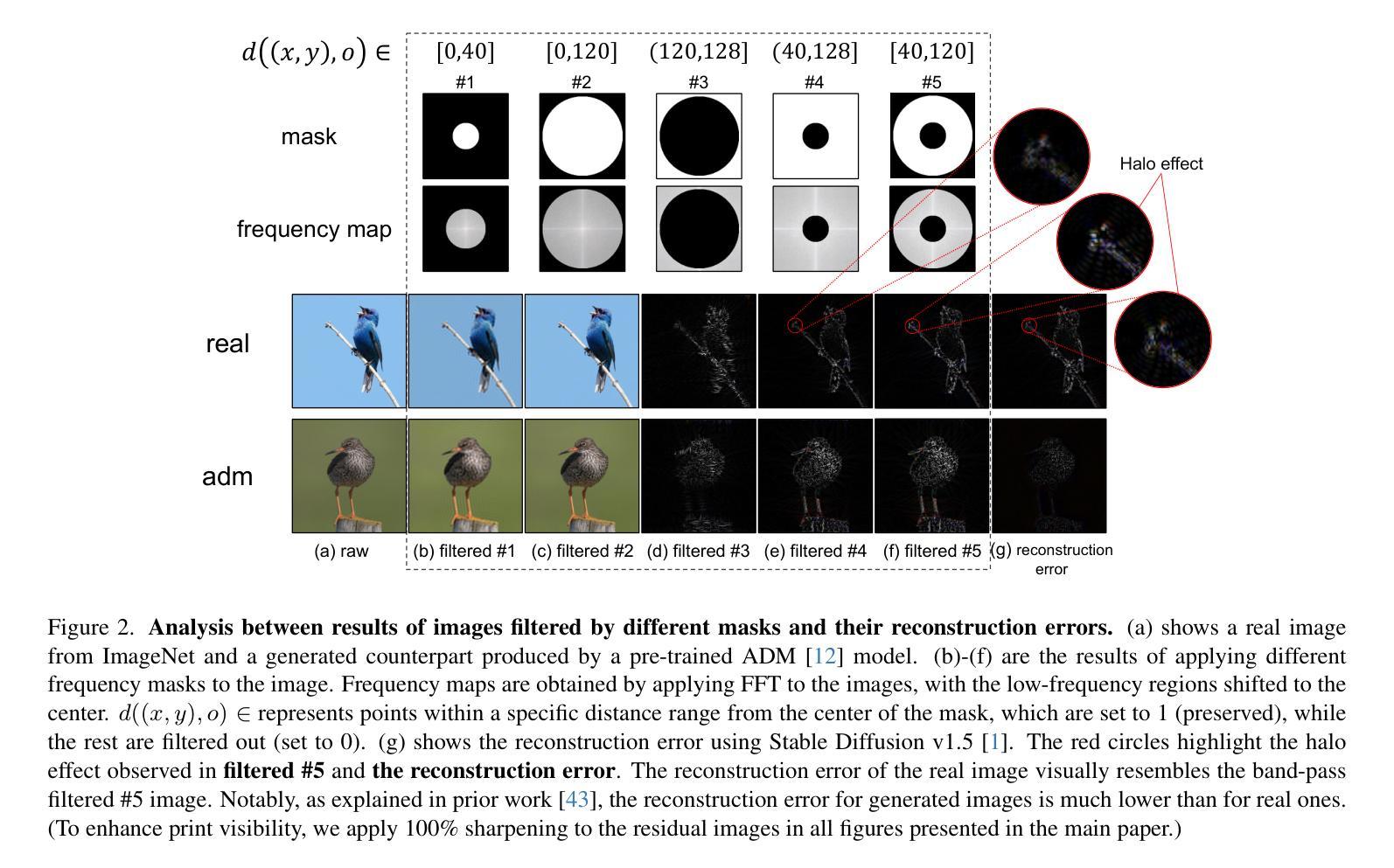
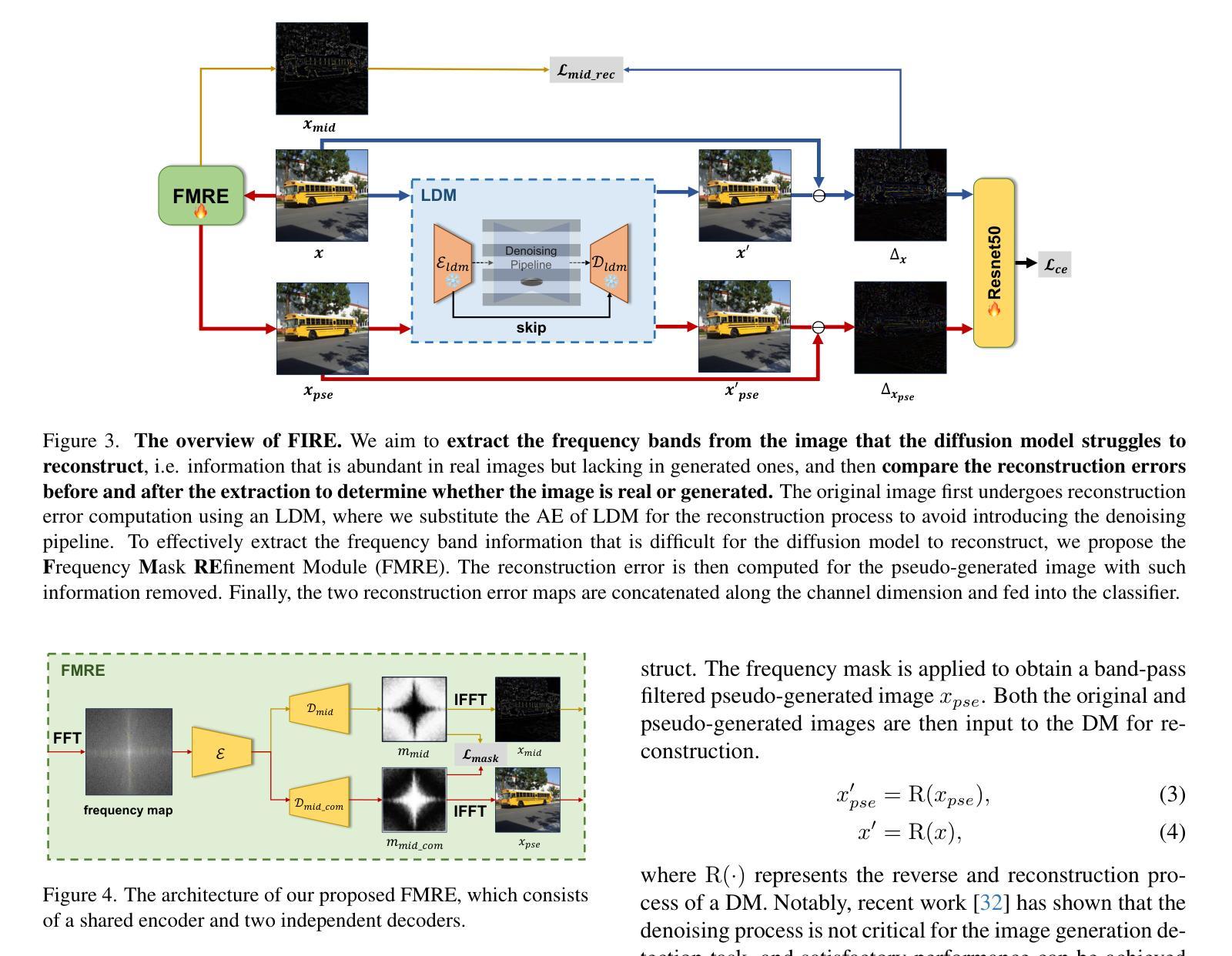
FIRE: Robust Detection of Diffusion-Generated Images via Frequency-Guided Reconstruction Error
Authors:Beilin Chu, Xuan Xu, Xin Wang, Yufei Zhang, Weike You, Linna Zhou
The rapid advancement of diffusion models has significantly improved high-quality image generation, making generated content increasingly challenging to distinguish from real images and raising concerns about potential misuse. In this paper, we observe that diffusion models struggle to accurately reconstruct mid-band frequency information in real images, suggesting the limitation could serve as a cue for detecting diffusion model generated images. Motivated by this observation, we propose a novel method called Frequency-guided Reconstruction Error (FIRE), which, to the best of our knowledge, is the first to investigate the influence of frequency decomposition on reconstruction error. FIRE assesses the variation in reconstruction error before and after the frequency decomposition, offering a robust method for identifying diffusion model generated images. Extensive experiments show that FIRE generalizes effectively to unseen diffusion models and maintains robustness against diverse perturbations.
扩散模型的快速发展极大地提高了高质量图像生成的能力,使得生成的内容越来越难以与真实图像区分开,并引发了关于潜在误用的担忧。在本文中,我们观察到扩散模型在准确重建真实图像的中频信息方面存在困难,这表明这一局限可作为检测扩散模型生成图像的一种线索。受此观察结果的启发,我们提出了一种名为频率引导重建误差(FIRE)的新方法,据我们所知,这是首次研究频率分解对重建误差的影响。FIRE评估频率分解前后的重建误差变化,为识别扩散模型生成的图像提供了一种稳健的方法。大量实验表明,FIRE能有效推广到未见过的扩散模型,并对各种扰动保持稳健性。
论文及项目相关链接
PDF 14 pages, 14 figures
Summary:
扩散模型的快速发展极大地提高了高质量图像生成的能力,但生成的图像难以与真实图像区分,引发了关于潜在误用的担忧。本文发现扩散模型在重建真实图像的中频信息时存在困难,可作为检测扩散模型生成图像的依据。为此,我们提出了一种新的方法——频率引导重建误差(FIRE),它是首个研究频率分解对重建误差影响的方法。通过评估频率分解前后的重建误差变化,FIRE为识别扩散模型生成的图像提供了可靠的方法。实验表明,FIRE能有效泛化到未见过的扩散模型,对多种扰动保持稳健性。
Key Takeaways:
- 扩散模型的图像生成能力显著提高,但生成的图像与真实图像难以区分,存在潜在误用风险。
- 扩散模型在重建真实图像的中频信息时存在困难,可作为检测其生成图像的依据。
- 提出了一种新的方法——频率引导重建误差(FIRE),用于识别扩散模型生成的图像。
- FIRE通过评估频率分解前后的重建误差变化来识别生成的图像。
- FIRE能有效泛化到未见过的扩散模型。
- FIRE对多种扰动保持稳健性。
点此查看论文截图

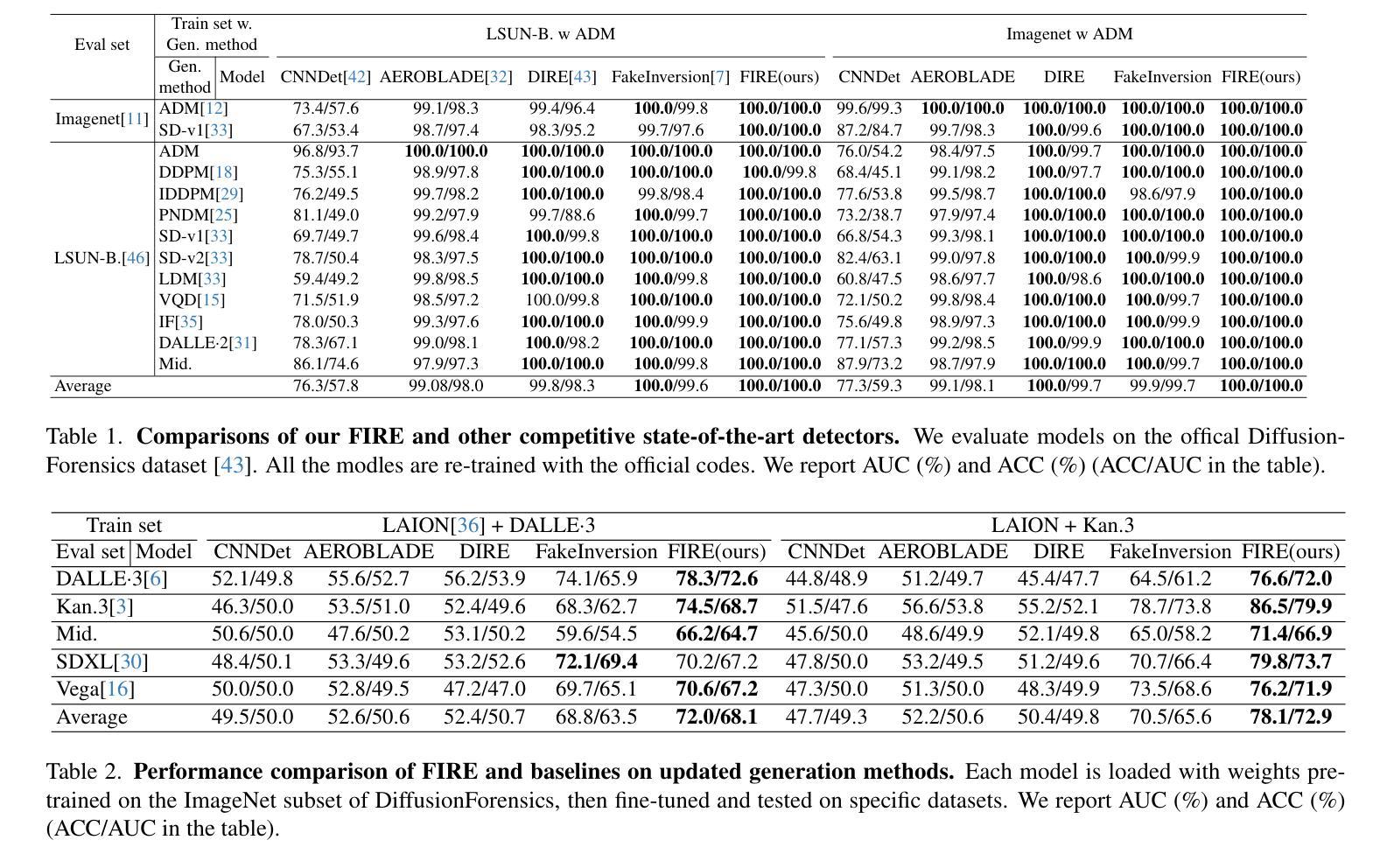
Bag of Design Choices for Inference of High-Resolution Masked Generative Transformer
Authors:Shitong Shao, Zikai Zhou, Tian Ye, Lichen Bai, Zhiqiang Xu, Zeke Xie
Text-to-image diffusion models (DMs) develop at an unprecedented pace, supported by thorough theoretical exploration and empirical analysis. Unfortunately, the discrepancy between DMs and autoregressive models (ARMs) complicates the path toward achieving the goal of unified vision and language generation. Recently, the masked generative Transformer (MGT) serves as a promising intermediary between DM and ARM by predicting randomly masked image tokens (i.e., masked image modeling), combining the efficiency of DM with the discrete token nature of ARM. However, we find that the comprehensive analyses regarding the inference for MGT are virtually non-existent, and thus we aim to present positive design choices to fill this gap. We propose and redesign a set of enhanced inference techniques tailored for MGT, providing a detailed analysis of their performance. Additionally, we explore several DM-based approaches aimed at accelerating the sampling process on MGT. Extensive experiments and empirical analyses on the recent SOTA MGT, such as MaskGIT and Meissonic lead to concrete and effective design choices, and these design choices can be merged to achieve further performance gains. For instance, in terms of enhanced inference, we achieve winning rates of approximately 70% compared to vanilla sampling on HPS v2 with Meissonic-1024x1024.
文本到图像的扩散模型(DM)以前所未有的速度发展,得益于深入的理论探索和实证分析。然而,扩散模型(DM)和自回归模型(ARM)之间的差异使得实现统一视觉和语言生成目标的道路变得复杂。最近,被掩盖的生成式Transformer(MGT)作为扩散模型和自回归模型之间的有前途的中间层,通过预测随机掩盖的图像令牌(即掩盖图像建模),结合了扩散模型的效率和自回归模型的离散令牌特性。然而,我们发现关于MGT的推理综合分析几乎不存在,因此我们的目标是提出积极的设计选择来填补这一空白。我们提出并重新设计了一系列针对MGT的增强推理技术,并对其性能进行了详细分析。此外,我们探索了几种基于扩散模型的加速MGT采样过程的方法。在最近的SOTA MGT(如MaskGIT和Meissonic)上进行的大量实验和实证分析得出了具体有效的设计选择,这些设计选择可以合并以实现更进一步的性能提升。例如,在增强推理方面,我们在HPS v2上与普通采样相比达到了约70%的胜率,使用Meissonic-1024x1024。
论文及项目相关链接
Summary
文本到图像扩散模型(DMs)发展迅速,但与自回归模型(ARMs)之间的差异使得实现统一视觉和语言生成的目标变得复杂。近期,被掩盖的生成式Transformer(MGT)作为DM和ARM之间的桥梁展现出了巨大潜力,它通过预测随机掩盖的图像标记(即掩盖图像建模)结合了DM的高效率和ARM的离散标记特性。本研究旨在填补关于MGT推理分析的空白,提出并重新设计了一系列针对MGT的增强推理技术,并对它们的性能进行了详细分析。同时,探索了加速MGT采样过程的基于DM的方法。在最新的SOTA MGT上的广泛实验和经验分析得出了具体有效的设计选择,这些设计选择可以合并以实现进一步的性能提升。例如,在增强推理方面,我们在HPS v2上相对于普通采样达到了约70%的胜率。
Key Takeaways
- 文本到图像扩散模型(DMs)发展迅猛,但与自回归模型(ARMs)存在显著差异,使得统一视觉和语言生成的目标复杂。
- 被掩盖的生成式Transformer(MGT)作为DM和ARM之间的桥梁展现出潜力。
- MGT通过预测随机掩盖的图像标记(掩盖图像建模)结合了DM和ARM的特性。
- 目前对MGT的推理分析存在空白,本研究旨在填补这一空白。
- 研究提出并重新设计了一系列针对MGT的增强推理技术,并进行详细性能分析。
- 探索了加速MGT采样过程的基于DM的方法。
点此查看论文截图


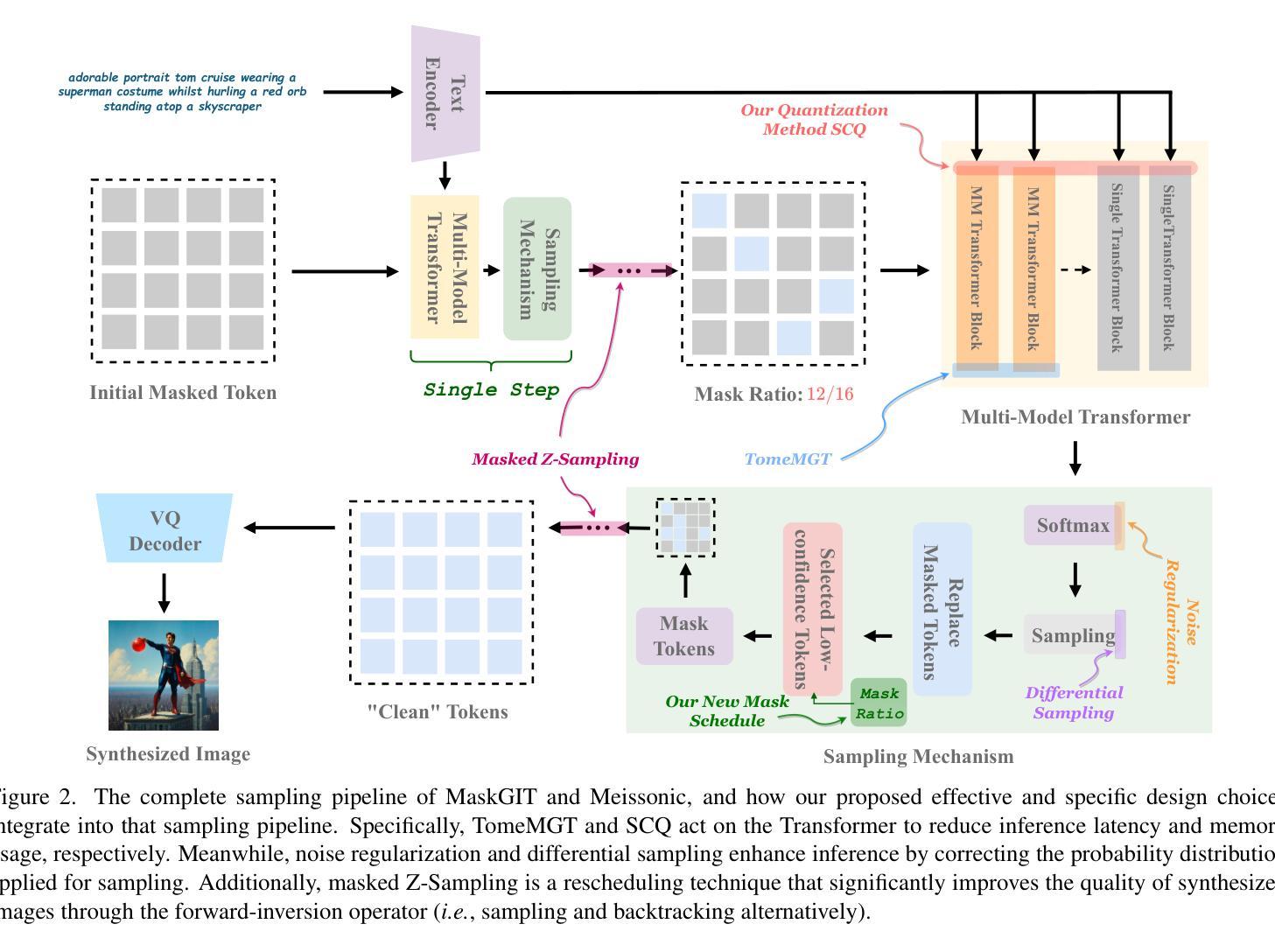

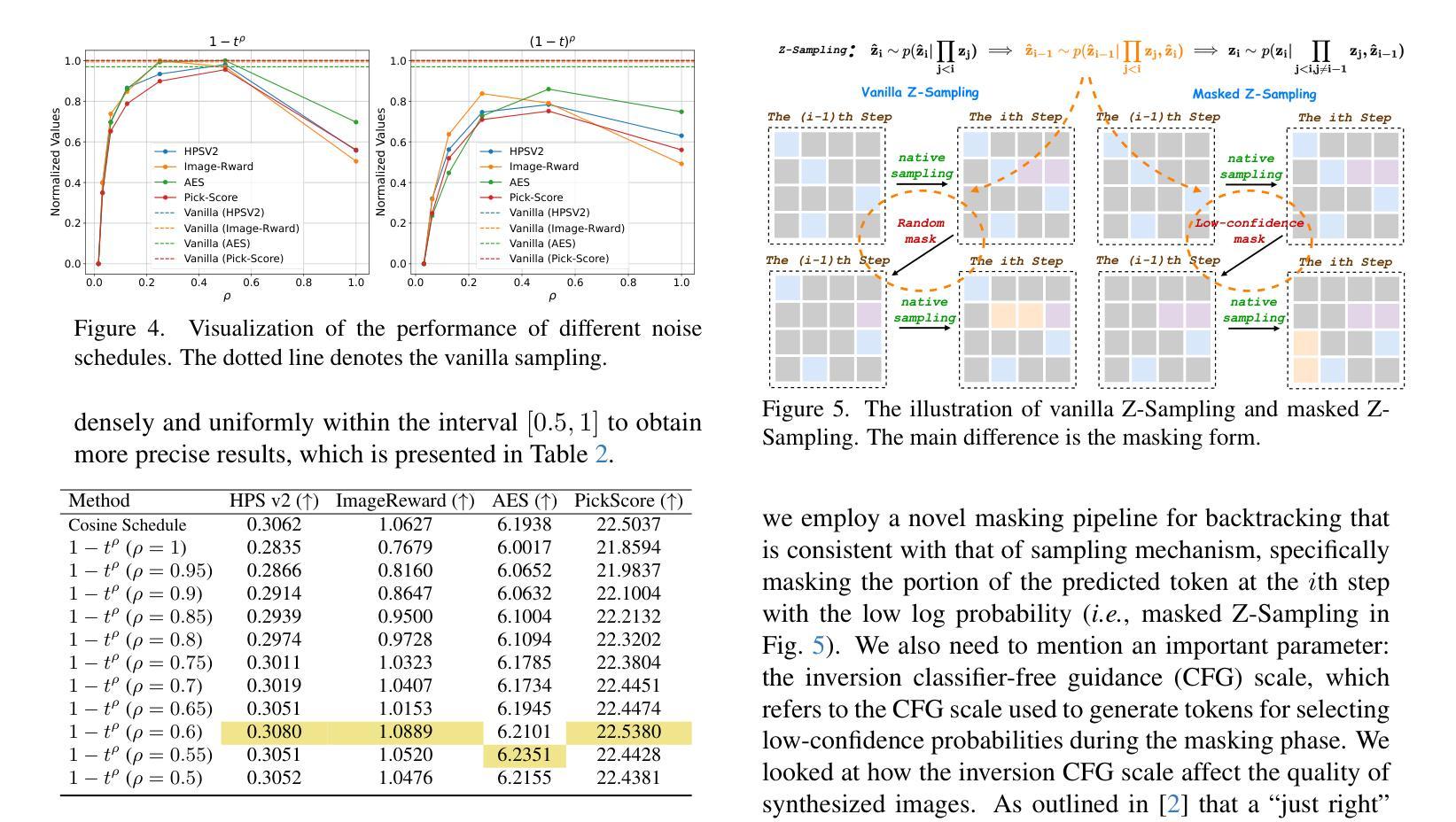
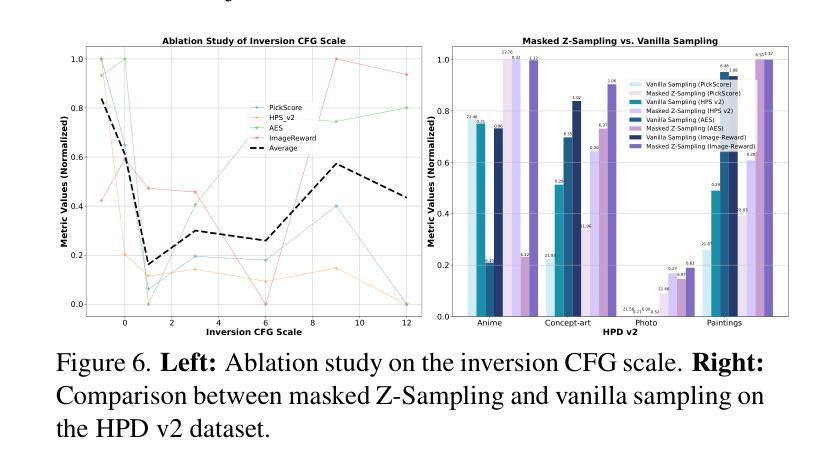

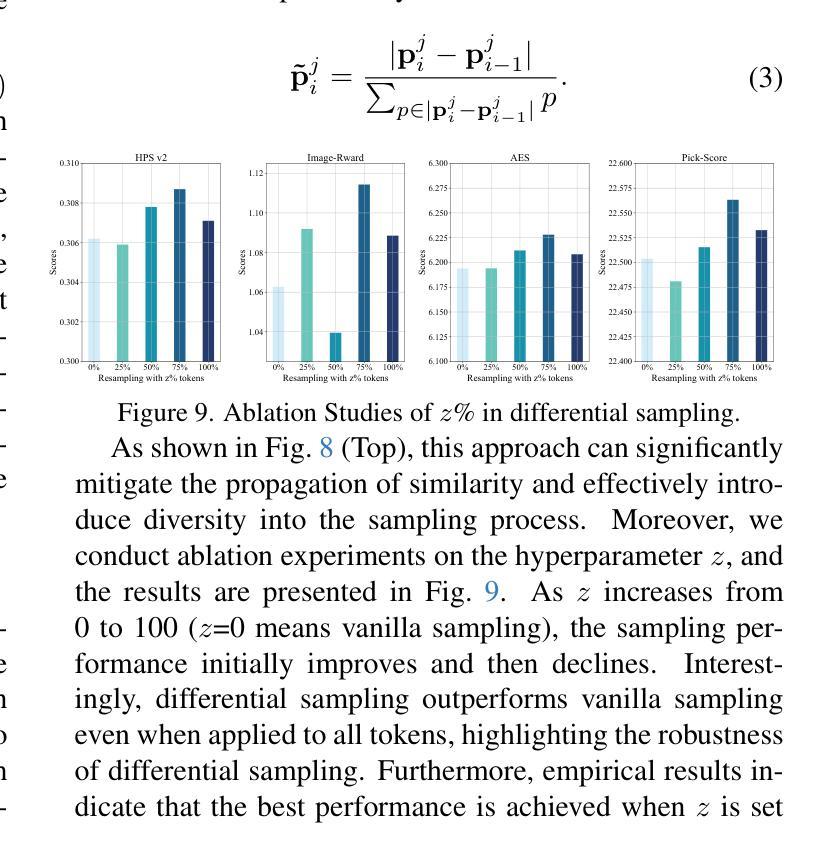
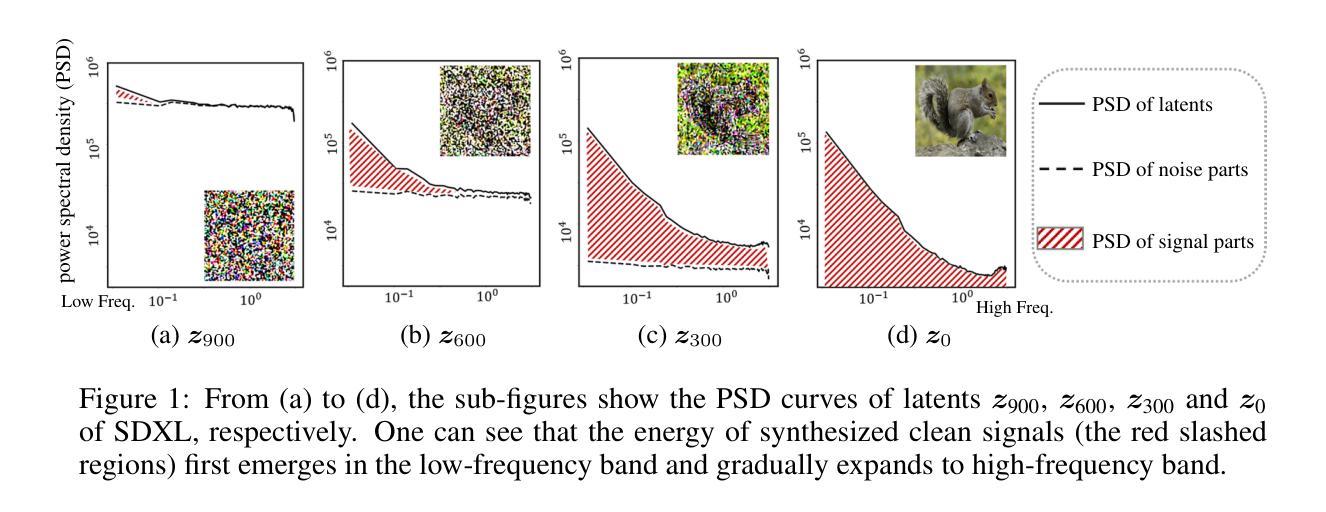
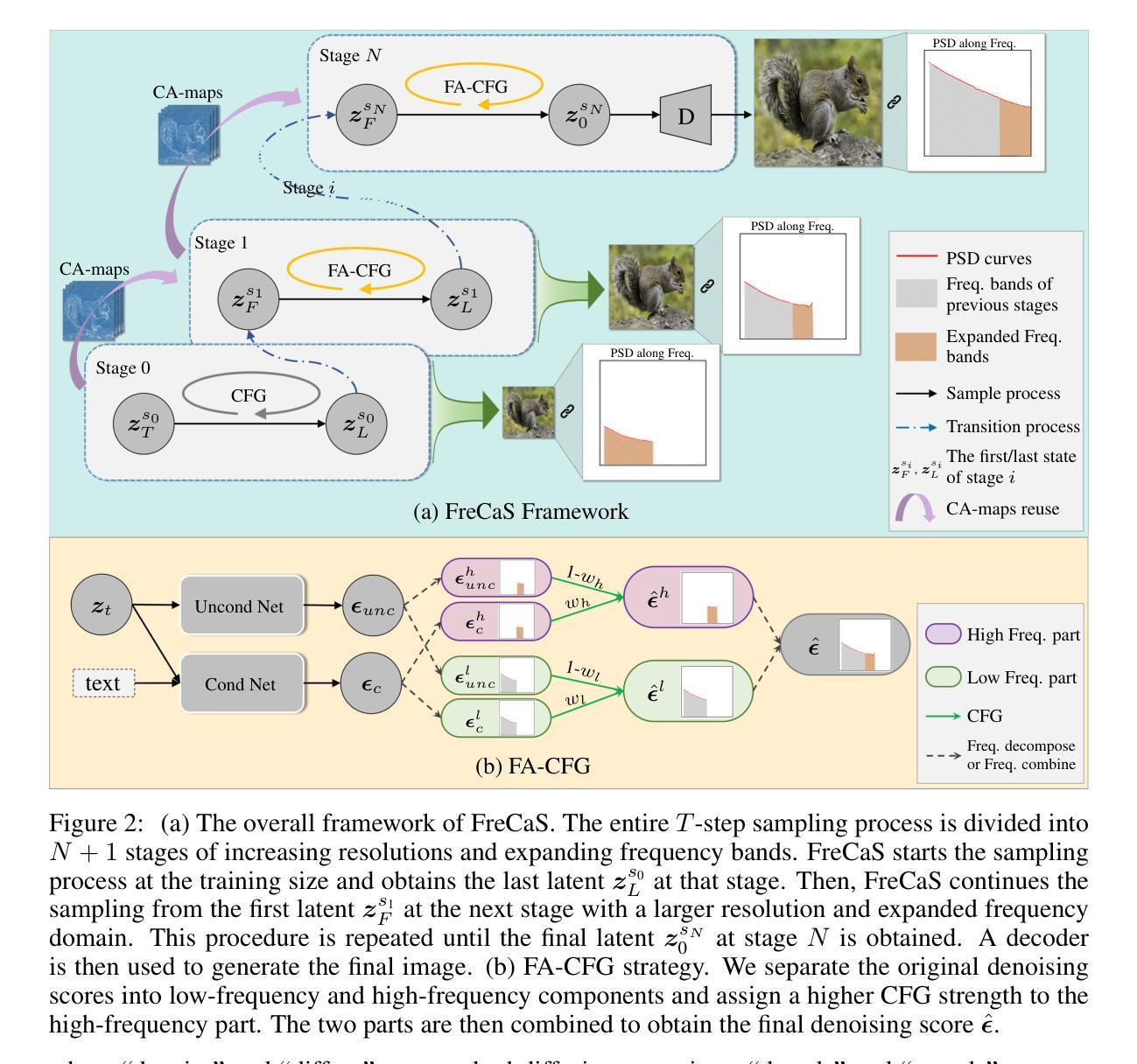
FreCaS: Efficient Higher-Resolution Image Generation via Frequency-aware Cascaded Sampling
Authors:Zhengqiang Zhang, Ruihuang Li, Lei Zhang
While image generation with diffusion models has achieved a great success, generating images of higher resolution than the training size remains a challenging task due to the high computational cost. Current methods typically perform the entire sampling process at full resolution and process all frequency components simultaneously, contradicting with the inherent coarse-to-fine nature of latent diffusion models and wasting computations on processing premature high-frequency details at early diffusion stages. To address this issue, we introduce an efficient $\textbf{Fre}$quency-aware $\textbf{Ca}$scaded $\textbf{S}$ampling framework, $\textbf{FreCaS}$ in short, for higher-resolution image generation. FreCaS decomposes the sampling process into cascaded stages with gradually increased resolutions, progressively expanding frequency bands and refining the corresponding details. We propose an innovative frequency-aware classifier-free guidance (FA-CFG) strategy to assign different guidance strengths for different frequency components, directing the diffusion model to add new details in the expanded frequency domain of each stage. Additionally, we fuse the cross-attention maps of previous and current stages to avoid synthesizing unfaithful layouts. Experiments demonstrate that FreCaS significantly outperforms state-of-the-art methods in image quality and generation speed. In particular, FreCaS is about 2.86$\times$ and 6.07$\times$ faster than ScaleCrafter and DemoFusion in generating a 2048$\times$2048 image using a pre-trained SDXL model and achieves an FID$_b$ improvement of 11.6 and 3.7, respectively. FreCaS can be easily extended to more complex models such as SD3. The source code of FreCaS can be found at https://github.com/xtudbxk/FreCaS.
虽然扩散模型在图像生成方面取得了巨大成功,但生成比训练规模更高的分辨率的图像仍然是一项具有挑战性的任务,因为计算成本很高。当前的方法通常在全分辨率下执行整个采样过程,并同时处理所有频率分量,这与潜在扩散模型的固有从粗到细的特质相矛盾,并在早期的扩散阶段浪费了对过早的高频细节的处理计算。为了解决这个问题,我们引入了一个高效的高分辨率感知级联采样框架(简称为FreCaS),用于生成更高分辨率的图像。FreCaS将采样过程分解为级联的阶段,逐步增加分辨率,逐渐扩展频率范围并优化相应的细节。我们提出了一种创新的频率感知无分类器引导策略(FA-CFG),为不同的频率分量分配不同的引导强度,引导扩散模型在每个阶段的扩展频率域中添加新的细节。此外,我们融合了前一阶段和当前阶段的交叉注意力图,以避免合成不真实的布局。实验表明,在图像质量和生成速度方面,FreCaS显著优于现有技术。特别是,在使用预训练的SDXL模型生成一张分辨率为2048x2048的图像时,FreCaS比ScaleCrafter和DemoFusion分别快约2.86倍和6.07倍。并且FreCaS实现了FIDb改善分别为11.6和3.7。FreCaS可以轻松扩展到更复杂的模型,如SD3。FreCaS的源代码可以在https://github.com/xtudbxk/FreCaS找到。
论文及项目相关链接
Summary
扩散模型在图像生成领域已取得巨大成功,但生成高于训练尺寸的更高分辨率图像仍具挑战。为解决此问题,我们提出了高效的频率感知级联采样框架FreCaS,用于高分辨率图像生成。通过级联采样过程逐步增加分辨率,渐进扩展频率带并细化相应细节。同时采用频率感知的无分类器引导策略,为不同频率成分分配不同的引导强度。实验证明,FreCaS在图像质量和生成速度上均显著优于现有方法。
Key Takeaways
- 扩散模型在图像生成中面临生成高分辨率图像的计算成本挑战。
- FreCaS框架通过级联采样过程逐步增加分辨率,解决这一挑战。
- FreCaS采用频率感知的无分类器引导策略,针对不同频率成分分配不同的引导强度。
- FreCaS能避免合成不真实的布局,通过融合前一阶段和当前阶段的交叉注意力图实现。
- 实验证明FreCaS在图像质量和生成速度上优于其他先进方法。
- FreCaS生成2048x2048像素的图像速度比ScaleCrafter和DemoFusion分别快2.86倍和6.07倍。
点此查看论文截图

Training-free Diffusion Model Alignment with Sampling Demons
Authors:Po-Hung Yeh, Kuang-Huei Lee, Jun-Cheng Chen
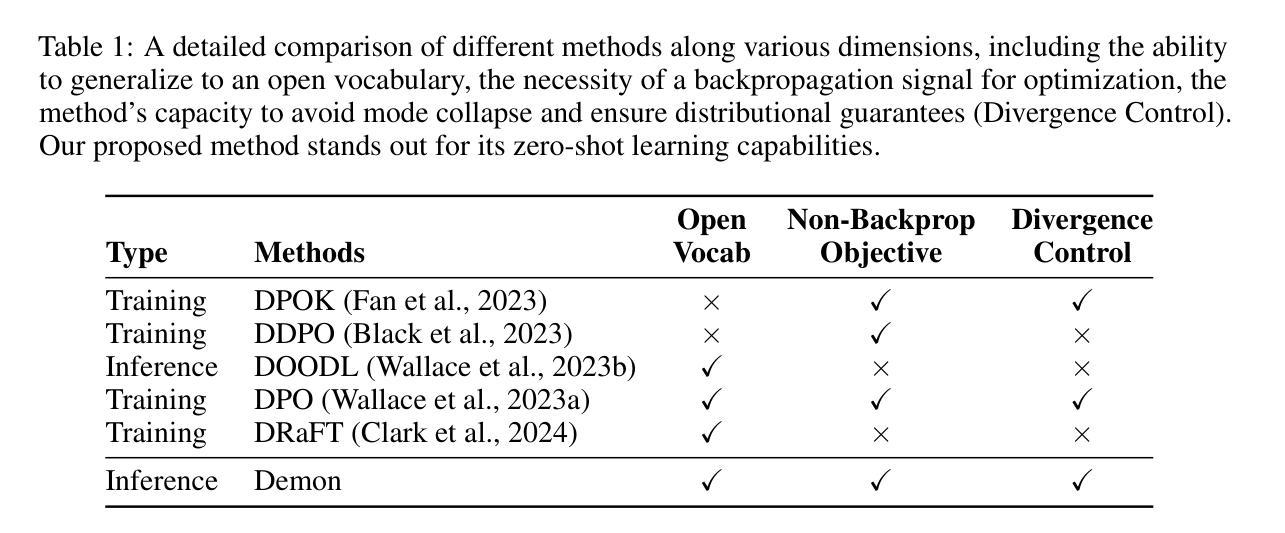
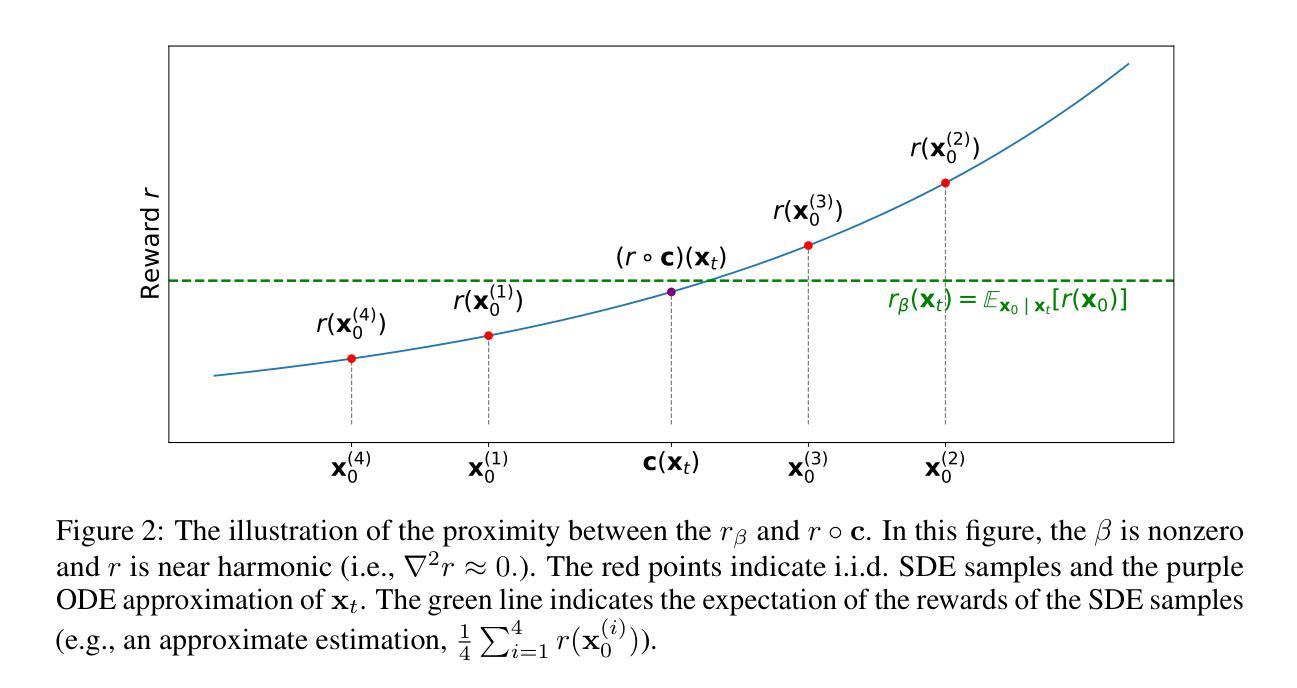
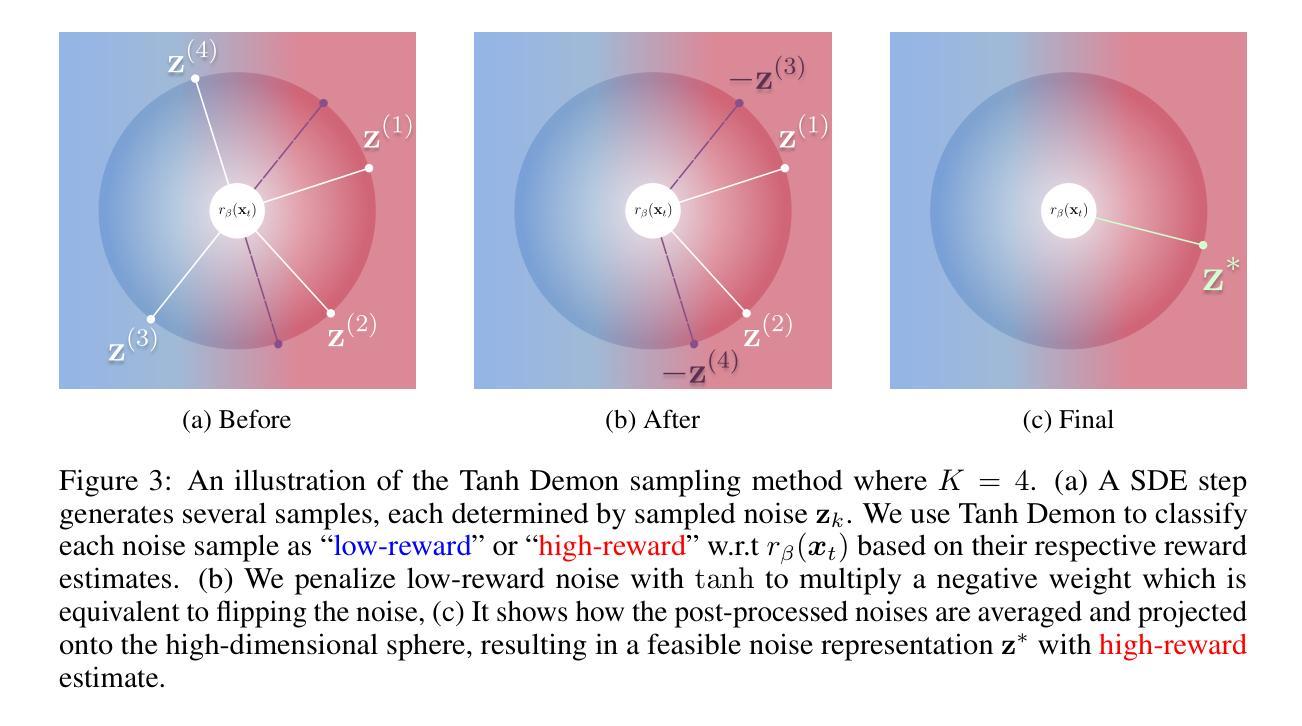
Aligning diffusion models with user preferences has been a key challenge. Existing methods for aligning diffusion models either require retraining or are limited to differentiable reward functions. To address these limitations, we propose a stochastic optimization approach, dubbed Demon, to guide the denoising process at inference time without backpropagation through reward functions or model retraining. Our approach works by controlling noise distribution in denoising steps to concentrate density on regions corresponding to high rewards through stochastic optimization. We provide comprehensive theoretical and empirical evidence to support and validate our approach, including experiments that use non-differentiable sources of rewards such as Visual-Language Model (VLM) APIs and human judgements. To the best of our knowledge, the proposed approach is the first inference-time, backpropagation-free preference alignment method for diffusion models. Our method can be easily integrated with existing diffusion models without further training. Our experiments show that the proposed approach significantly improves the average aesthetics scores for text-to-image generation. Implementation is available at https://github.com/aiiu-lab/DemonSampling.
将扩散模型与用户偏好对齐一直是一个关键挑战。现有的对齐扩散模型的方法要么需要重新训练,要么仅限于可微奖励函数。为了解决这些局限性,我们提出了一种随机优化方法,称为Demon,它可以在推理时指导去噪过程,而无需通过奖励函数进行反向传播或模型重新训练。我们的方法通过控制去噪步骤中的噪声分布,通过随机优化将密度集中在对应于高奖励的区域。我们提供了全面的理论和实证证据来支持和验证我们的方法,包括使用不可微奖励源的实验,如视觉语言模型(VLM)API和人类判断。据我们所知,所提出的方法是第一个无需反向传播的推理时间偏好对齐扩散模型的方法。我们的方法可以轻松地与现有的扩散模型集成,而无需进一步训练。我们的实验表明,该方法显著提高了文本到图像生成的平均美学分数。实现可访问于https://github.com/aiiu-lab/DemonSampling。
论文及项目相关链接
PDF 35 pages
Summary
本文提出一种名为Demon的随机优化方法,用于在推理阶段引导去噪过程,无需通过奖励函数进行反向传播或模型重新训练,即可实现对扩散模型的调整以满足用户偏好。该方法通过控制去噪过程中的噪声分布,使密度集中于高奖励对应的区域,并通过随机优化来实现。研究表明,该方法可用于非可微奖励源,如视觉语言模型(VLM)API和人类判断。实验表明,该方法能显著提高文本到图像生成的平均美学分数。
Key Takeaways
- 扩散模型与用户偏好对齐是一个关键挑战。
- 现有方法需要重训模型或限于可微奖励函数。
- 提出了一种名为Demon的随机优化方法,可在推理阶段调整扩散模型。
- Demon方法通过控制噪声分布来引导去噪过程。
- 该方法能集中于高奖励对应的区域,无需反向传播或模型重训。
- 支持非可微奖励源,如视觉语言模型(VLM)API和人类判断。
点此查看论文截图


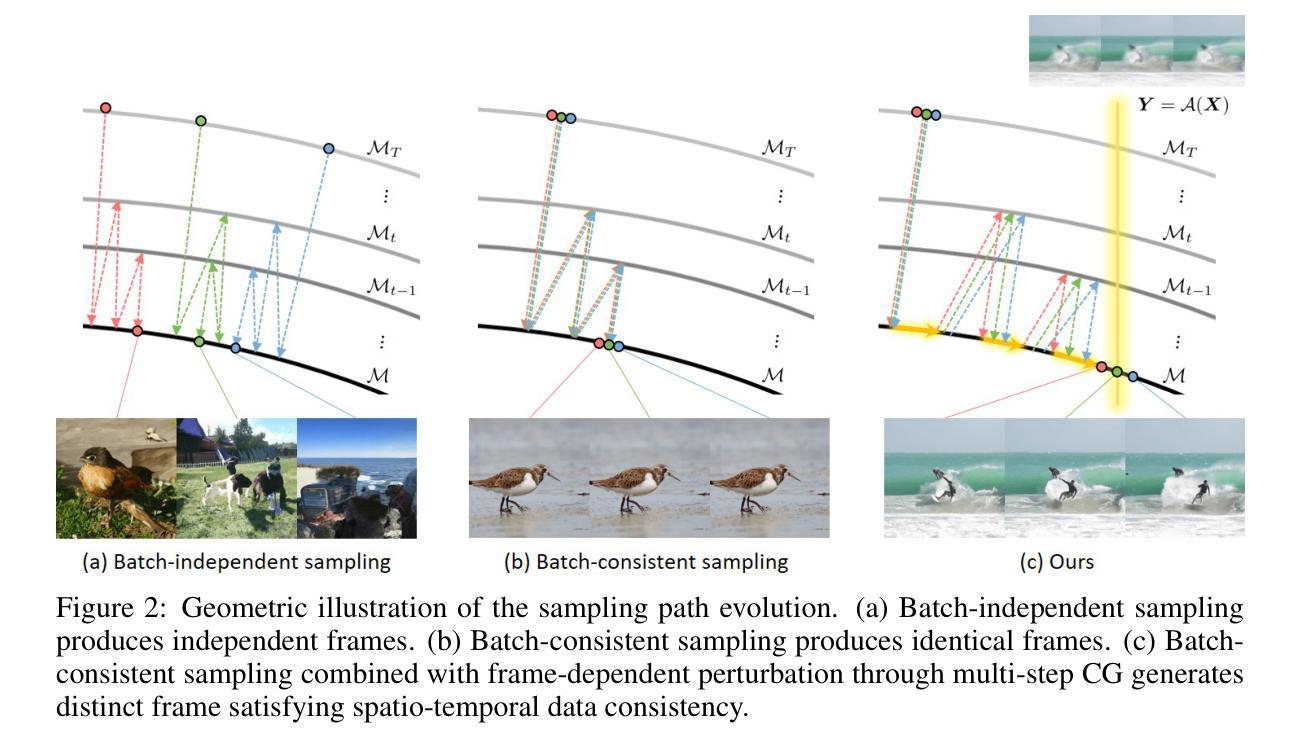
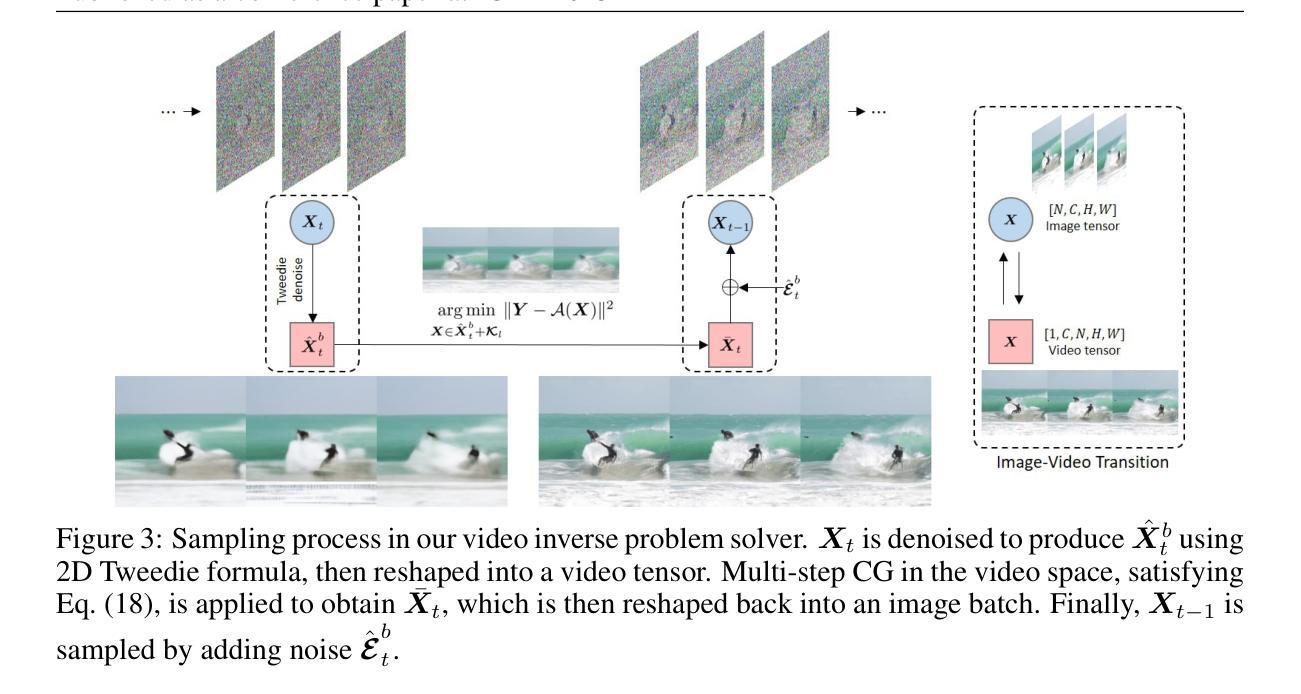
Solving Video Inverse Problems Using Image Diffusion Models
Authors:Taesung Kwon, Jong Chul Ye
Recently, diffusion model-based inverse problem solvers (DIS) have emerged as state-of-the-art approaches for addressing inverse problems, including image super-resolution, deblurring, inpainting, etc. However, their application to video inverse problems arising from spatio-temporal degradation remains largely unexplored due to the challenges in training video diffusion models. To address this issue, here we introduce an innovative video inverse solver that leverages only image diffusion models. Specifically, by drawing inspiration from the success of the recent decomposed diffusion sampler (DDS), our method treats the time dimension of a video as the batch dimension of image diffusion models and solves spatio-temporal optimization problems within denoised spatio-temporal batches derived from each image diffusion model. Moreover, we introduce a batch-consistent diffusion sampling strategy that encourages consistency across batches by synchronizing the stochastic noise components in image diffusion models. Our approach synergistically combines batch-consistent sampling with simultaneous optimization of denoised spatio-temporal batches at each reverse diffusion step, resulting in a novel and efficient diffusion sampling strategy for video inverse problems. Experimental results demonstrate that our method effectively addresses various spatio-temporal degradations in video inverse problems, achieving state-of-the-art reconstructions. Project page: https://svi-diffusion.github.io/
最近,基于扩散模型的逆问题求解器(DIS)已经作为解决逆问题的最先进方法出现,包括图像超分辨率、去模糊、图像修复等。然而,由于其训练视频扩散模型的挑战,它们在解决由时空退化产生的视频逆问题上的应用仍然未被充分探索。为了解决这一问题,我们在这里引入了一种创新的视频逆求解器,它只利用图像扩散模型。具体地说,通过借鉴最近的分解扩散采样器(DDS)的成功,我们的方法将视频的时间维度视为图像扩散模型的批量维度,并在来自每个图像扩散模型的降噪时空批次内解决时空优化问题。此外,我们引入了一种批量一致扩散采样策略,通过同步图像扩散模型中的随机噪声成分,鼓励批次之间的一致性。我们的方法协同地将批量一致采样与每个反向扩散步骤中降噪时空批量的同时优化相结合,为视频逆问题提供了一种新型高效的扩散采样策略。实验结果表明,我们的方法有效地解决了视频逆问题中的各种时空退化问题,实现了最先进的重建效果。项目页面:https://svi-diffusion.github.io/
论文及项目相关链接
PDF ICLR 2025; 25 pages, 17 figures
Summary
扩散模型在解决图像超分辨率、去模糊、补全等逆向问题方面表现出卓越性能。然而,由于训练视频扩散模型的挑战,其在视频逆向问题中的应用仍然未得到足够研究。这里介绍了一种仅利用图像扩散模型的视频逆向求解器。通过将时间维度视为图像扩散模型的批处理维度,并引入分解扩散采样器(DDS)的概念,该方法解决了时空优化问题。同时,引入了一种批一致性扩散采样策略,通过同步图像扩散模型中的随机噪声成分,确保各批次之间的一致性。实验结果表明,该方法有效地解决了视频逆向问题的各种时空退化问题,实现了最先进的重建效果。
Key Takeaways
- 扩散模型已成为解决图像逆向问题的最前沿技术。
- 视频逆向问题因训练扩散模型的挑战而尚未得到充分研究。
- 介绍了一种基于图像扩散模型的视频逆向求解器。
- 该方法将时间维度视为图像扩散模型的批处理维度,解决时空优化问题。
- 引入分解扩散采样器的概念以提高效率。
- 采用批一致性扩散采样策略,确保各批次之间的一致性。
点此查看论文截图