⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-01 更新
Self-Training Elicits Concise Reasoning in Large Language Models
Authors:Tergel Munkhbat, Namgyu Ho, Seohyun Kim, Yongjin Yang, Yujin Kim, Se-Young Yun
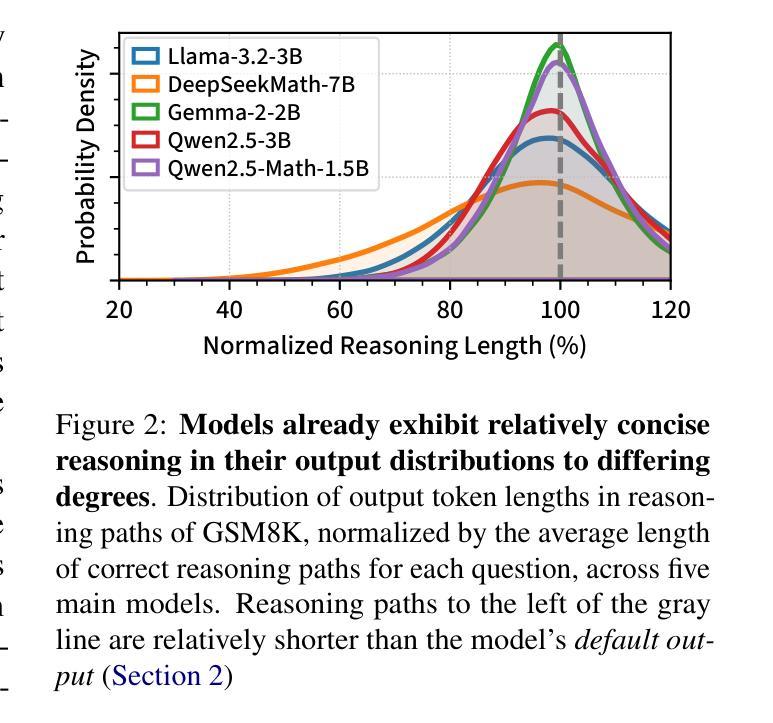
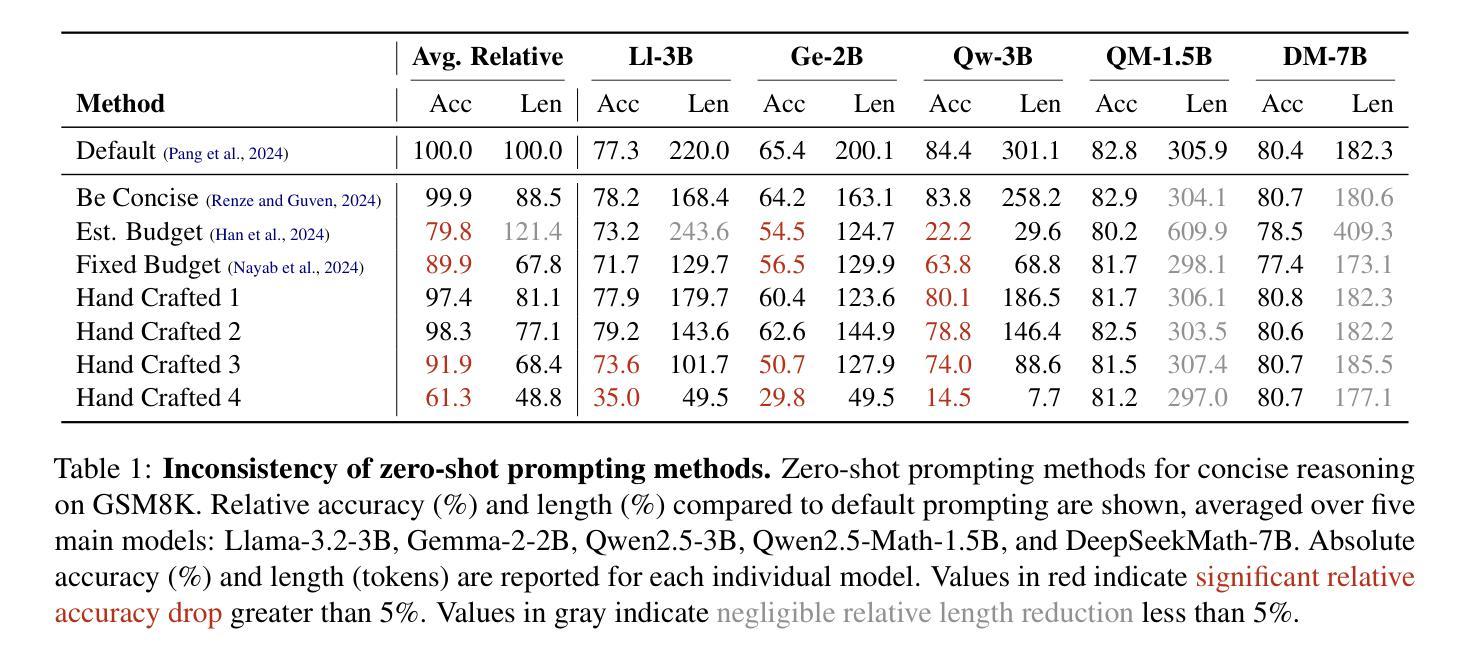
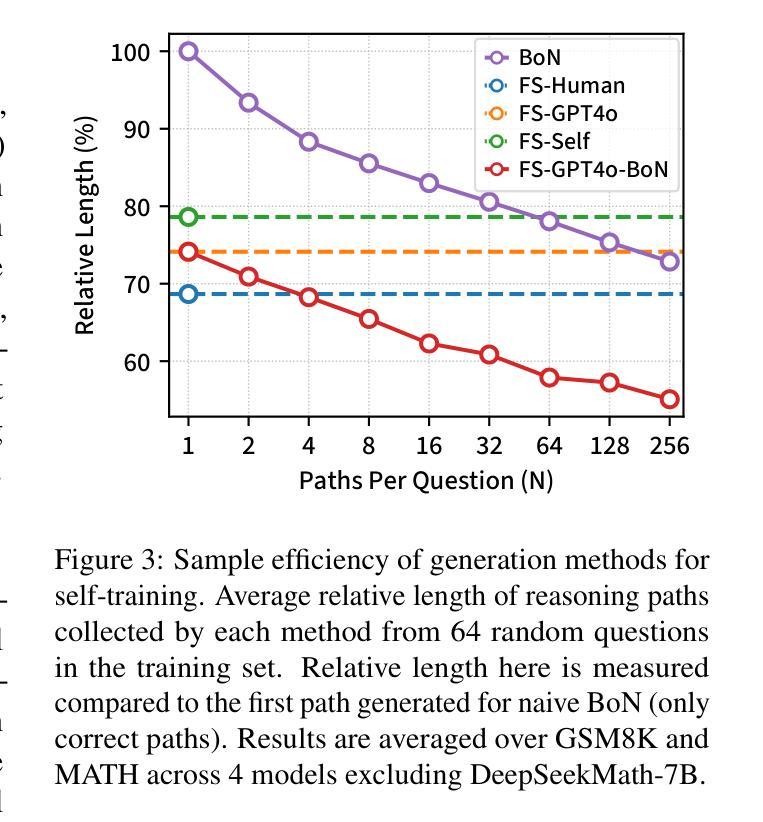
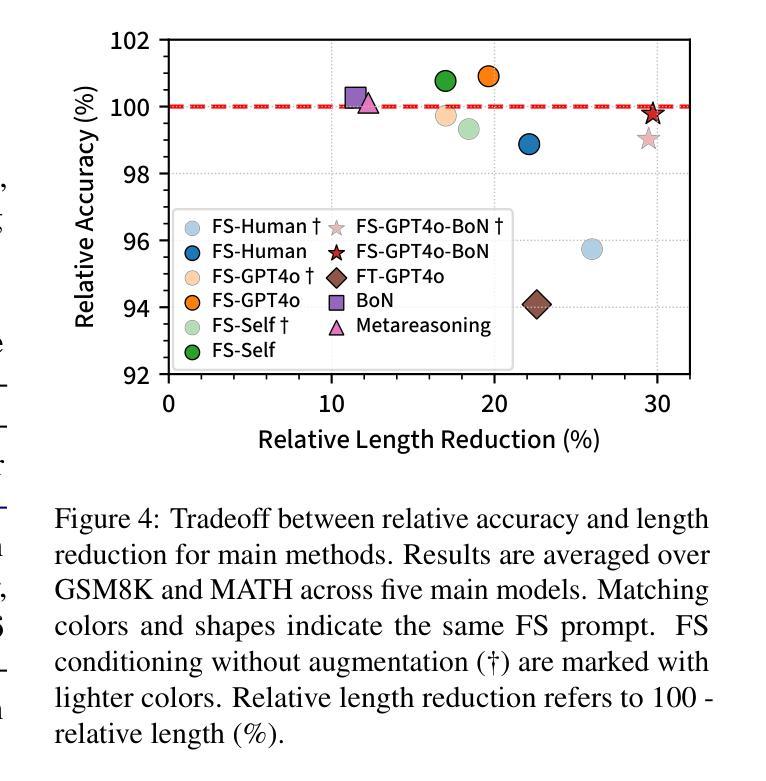
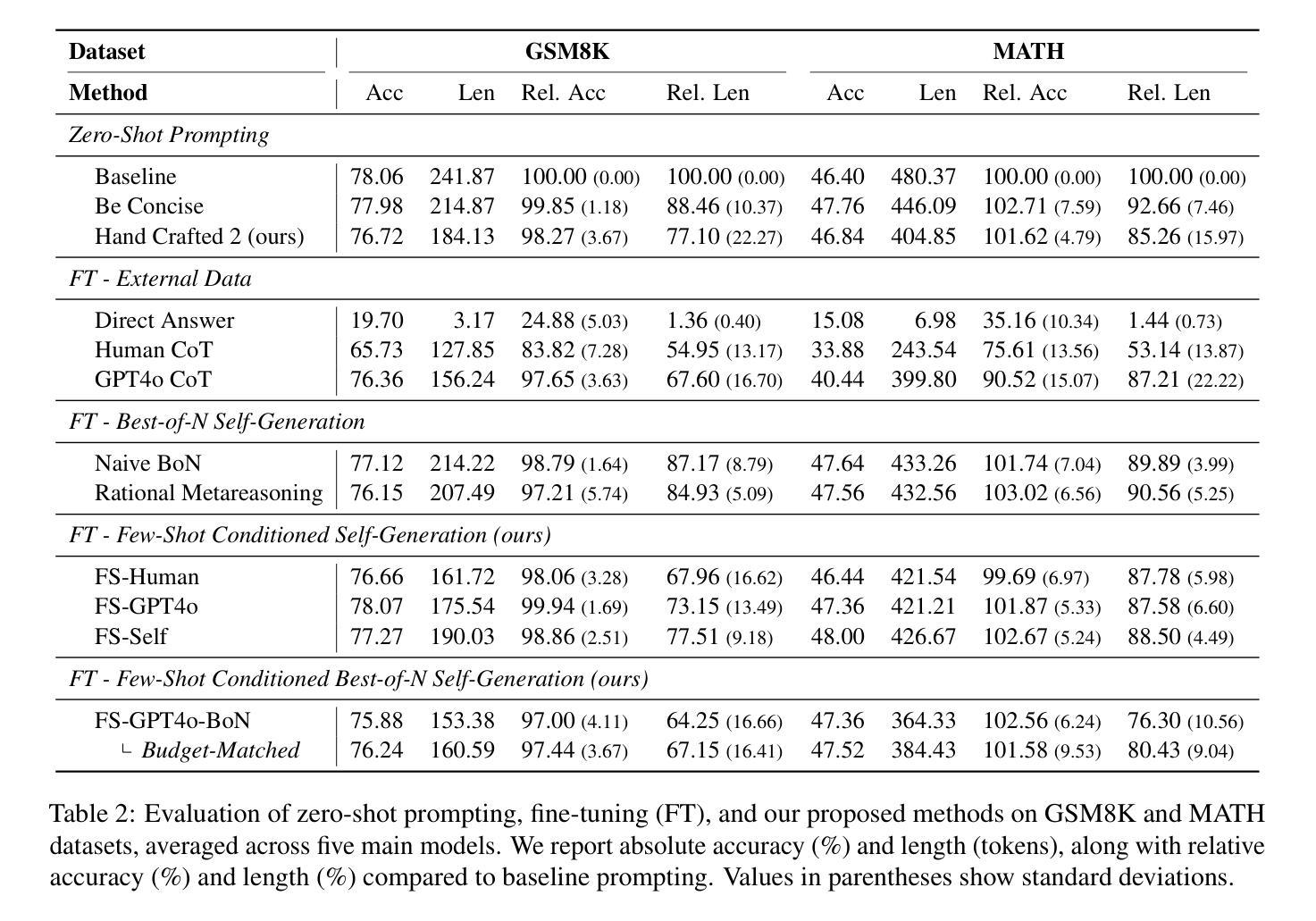
Chain-of-thought (CoT) reasoning has enabled large language models (LLMs) to utilize additional computation through intermediate tokens to solve complex tasks. However, we posit that typical reasoning traces contain many redundant tokens, incurring extraneous inference costs. Upon examination of the output distribution of current LLMs, we find evidence on their latent ability to reason more concisely, relative to their default behavior. To elicit this capability, we propose simple fine-tuning methods which leverage self-generated concise reasoning paths obtained by best-of-N sampling and few-shot conditioning, in task-specific settings. Our combined method achieves a 30% reduction in output tokens on average, across five model families on GSM8K and MATH, while maintaining average accuracy. By exploiting the fundamental stochasticity and in-context learning capabilities of LLMs, our self-training approach robustly elicits concise reasoning on a wide range of models, including those with extensive post-training. Code is available at https://github.com/TergelMunkhbat/concise-reasoning
思维链(CoT)推理使大型语言模型(LLM)能够通过中间标记利用额外的计算来解决复杂的任务。然而,我们认为典型的推理轨迹包含许多冗余的标记,产生了额外的推理成本。在检查当前LLM的输出分布时,我们发现它们相对于默认行为具有更简洁推理的潜在能力。为了激发这一能力,我们提出了简单的微调方法,这些方法利用通过最佳N采样和少样本条件在特定任务环境中生成的自我简洁推理路径。我们的组合方法在GSM8K和MATH上平均输出令牌减少了30%,同时保持了平均精度。通过利用LLM的基本随机性和上下文学习能力,我们的自训练方法在各种模型上都能激发简洁的推理能力,包括那些经过大量后期训练的模型。代码可用https://github.com/TergelMunkhbat/concise-reasoning
论文及项目相关链接
PDF 23 pages, 10 figures, 18 tables
Summary
基于Chain-of-thought(CoT)推理的大型语言模型(LLM)能够通过中间标记进行复杂任务的额外计算。然而,我们观察到常见的推理路径包含许多冗余标记,导致额外的推理成本。通过对当前LLM的输出分布的研究,我们发现它们相对于默认行为有潜在的更简洁推理的能力。为了激发这一能力,我们提出了简单的微调方法,利用最佳N采样和少样本条件在特定任务环境中生成自我生成的简洁推理路径。我们的综合方法在五大家族模型上平均减少了约30%的输出标记数,在GSM8K和MATH上的平均准确率得到保持。我们的自训练方法通过利用LLM的基本随机性和上下文学习能力,稳健地激发在各种模型上的简洁推理能力,包括经过广泛训练后的模型。相关代码已发布在GitHub上。
Key Takeaways
- Chain-of-thought (CoT) 允许大型语言模型(LLM)通过中间标记进行额外计算来解决复杂任务。
- 通常的推理路径中存在冗余标记,增加了推理成本。
- 当前LLM具有潜在的更简洁推理能力。
- 通过最佳N采样和少样本条件的方法,可以激发LLM的简洁推理能力。
- 综合方法减少了输出标记数量,同时维持了平均准确率。
- 自训练方法能够稳健地激发各种模型(包括经过广泛训练后的模型)的简洁推理能力。
点此查看论文截图

SeisMoLLM: Advancing Seismic Monitoring via Cross-modal Transfer with Pre-trained Large Language Model
Authors:Xinghao Wang, Feng Liu, Rui Su, Zhihui Wang, Lei Bai, Wanli Ouyang
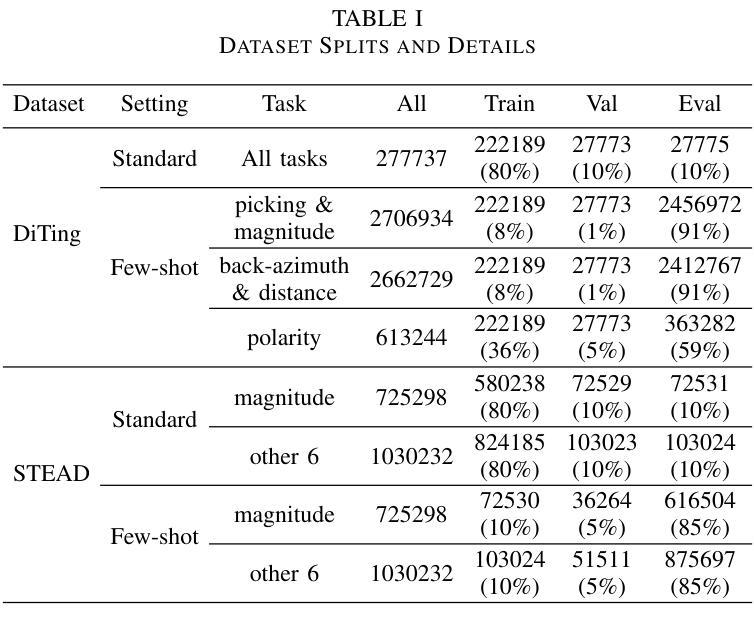
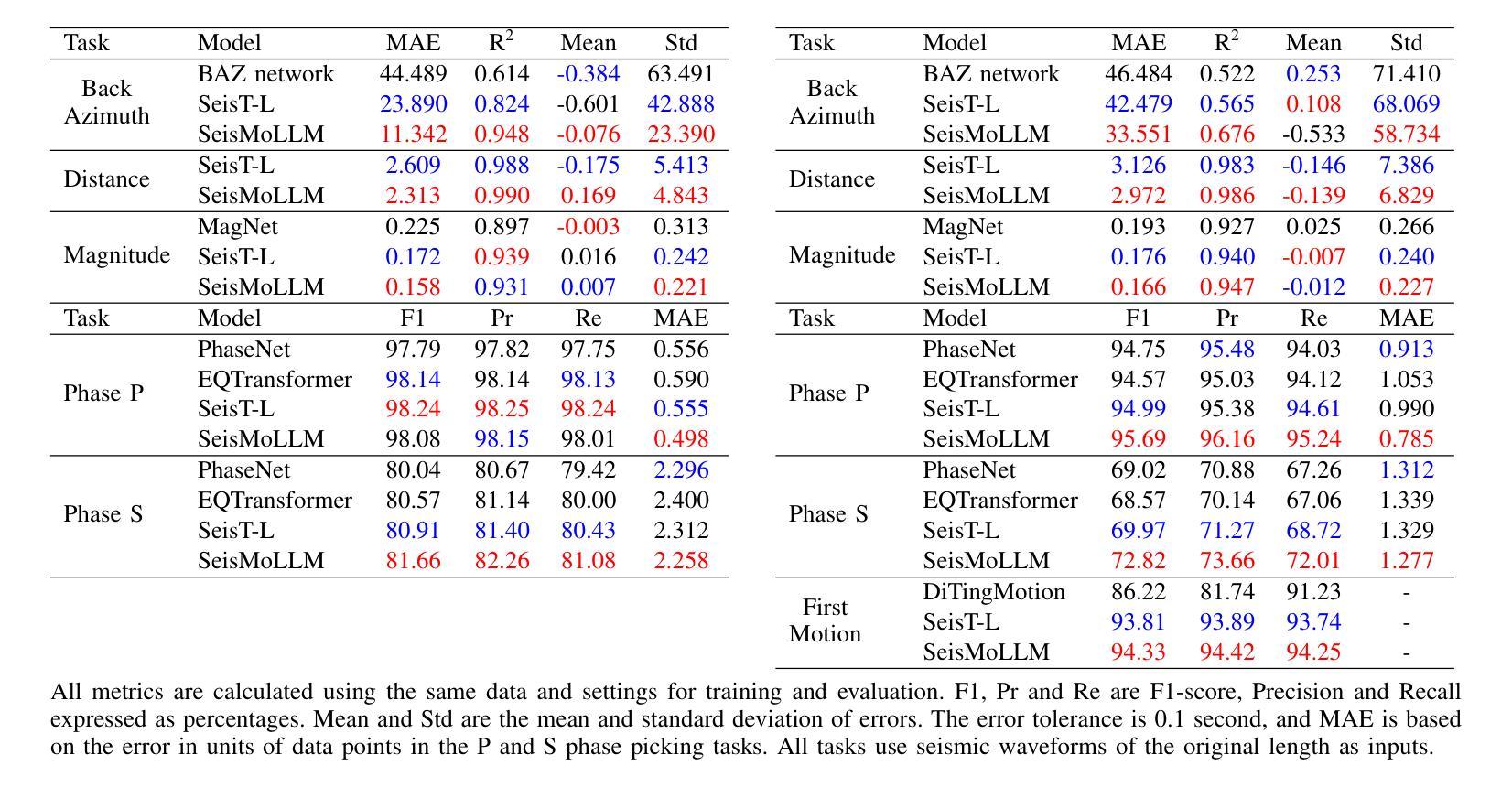
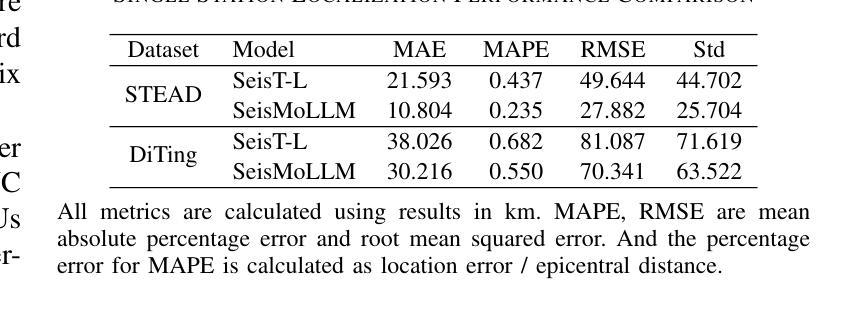
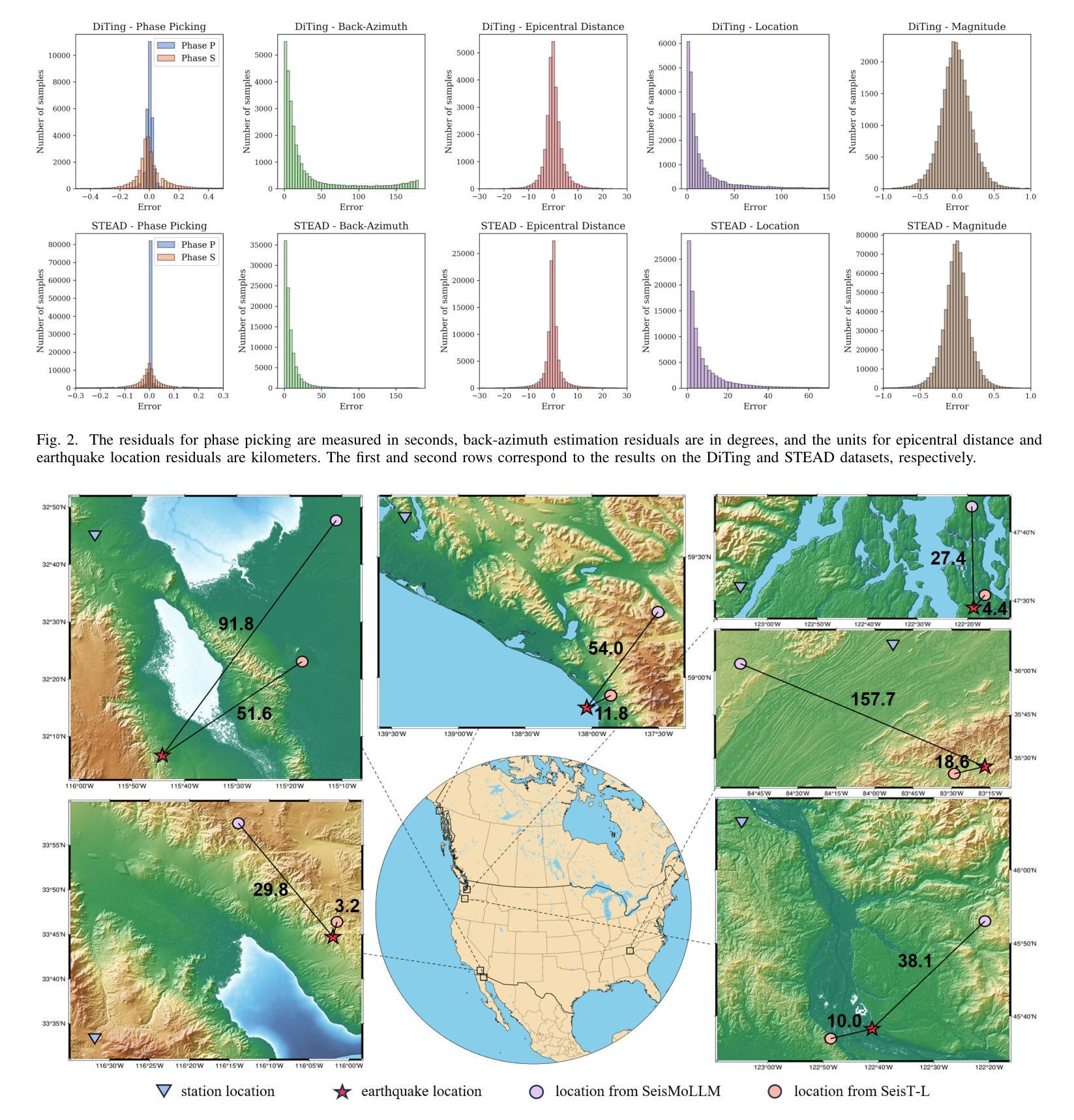
Recent advances in deep learning have revolutionized seismic monitoring, yet developing a foundation model that performs well across multiple complex tasks remains challenging, particularly when dealing with degraded signals or data scarcity. This work presents SeisMoLLM, the first foundation model that utilizes cross-modal transfer for seismic monitoring, to unleash the power of large-scale pre-training from a large language model without requiring direct pre-training on seismic datasets. Through elaborate waveform tokenization and fine-tuning of pre-trained GPT-2 model, SeisMoLLM achieves state-of-the-art performance on the DiTing and STEAD datasets across five critical tasks: back-azimuth estimation, epicentral distance estimation, magnitude estimation, phase picking, and first-motion polarity classification. It attains 36 best results out of 43 task metrics and 12 top scores out of 16 few-shot generalization metrics, with many relative improvements ranging from 10% to 50%. In addition to its superior performance, SeisMoLLM maintains efficiency comparable to or even better than lightweight models in both training and inference. These findings establish SeisMoLLM as a promising foundation model for practical seismic monitoring and highlight cross-modal transfer as an exciting new direction for earthquake studies, showcasing the potential of advanced deep learning techniques to propel seismology research forward.
最近深度学习的发展已经彻底改变了地震监测领域,然而,开发一个能在多个复杂任务中表现良好的基础模型仍然是一个挑战,尤其是在处理退化信号或数据稀缺的情况下。本文提出了SeisMoLLM,这是第一个利用跨模态迁移进行地震监测的基础模型,它释放了大规模预训练语言模型的力量,而无需在地震数据集上进行直接的预训练。通过精细的波形令牌化(波形令牌化指的是对地震信号数据进行标记和编码)和对预训练GPT-2模型的微调,SeisMoLLM在五个关键任务上实现了最先进的性能:背方位角估计、震中距离估计、震级估计、相位拾取和首动极性分类。它在五个关键任务的性能评价中获得了最佳的三个指标(如本文中所说:“最好的 3 个任务指标的评定”),并且在此之外的另外十多项性能评价指标上也有显著的提升(相对改善范围从 10% 到 50%)。除了卓越的性能外,SeisMoLLM在训练和推理过程中保持了与轻量级模型相当的效率甚至更高。这些发现确立了SeisMoLLM作为实际地震监测中非常有前途的基础模型,并突出了跨模态迁移作为地震研究中的一项令人兴奋的新方向,展示了先进的深度学习技术在推动地震学研究前进方面的潜力。
论文及项目相关链接
PDF 13 pages, 6 figures. Code is available at https://github.com/StarMoonWang/SeisMoLLM
Summary:最新深度学习技术为地震监测带来了革命性变革,但构建一个跨多个复杂任务表现良好的基础模型仍然是一个挑战。本研究提出了SeisMoLLM,这是一个利用跨模态迁移用于地震监测的基础模型。它通过精细的波形令牌化和预训练GPT-2模型的微调,实现了在DiTing和STEAD数据集上五个关键任务的最新性能。SeisMoLLM不仅在性能上表现出卓越,还在训练和推理过程中保持了与轻量级模型相当的效率,甚至更好。这为地震监测的实际应用提供了有前途的基础模型,并突显了跨模态迁移在地震研究中的新方向。
Key Takeaways:
- SeisMoLLM是首个利用跨模态迁移技术为地震监测设计的基础模型。
- SeisMoLLM通过微调预训练的GPT-2模型,实现了在多个地震监测任务上的最新性能。
- 在DiTing和STEAD数据集上的实验表明,SeisMoLLM在五个关键任务中取得了36项最佳结果中的23项最佳成绩。
- SeisMoLLM在少数样本推广能力方面也表现出色,在多项指标上实现了相对改善,范围在10%到50%之间。
- 与轻量级模型相比,SeisMoLLM在训练和推理过程中保持了相当的或更好的效率。
- 研究结果证明了跨模态迁移在地震研究中的潜力,为地震学研究的进一步发展提供了新的方向。
点此查看论文截图


Twofold Debiasing Enhances Fine-Grained Learning with Coarse Labels
Authors:Xin-yang Zhao, Jian Jin, Yang-yang Li, Yazhou Yao
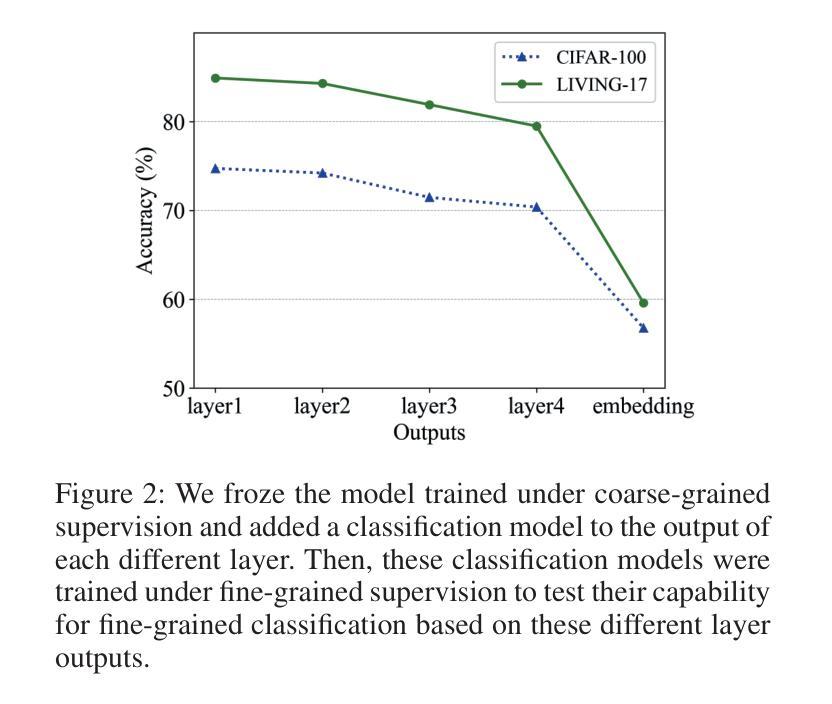
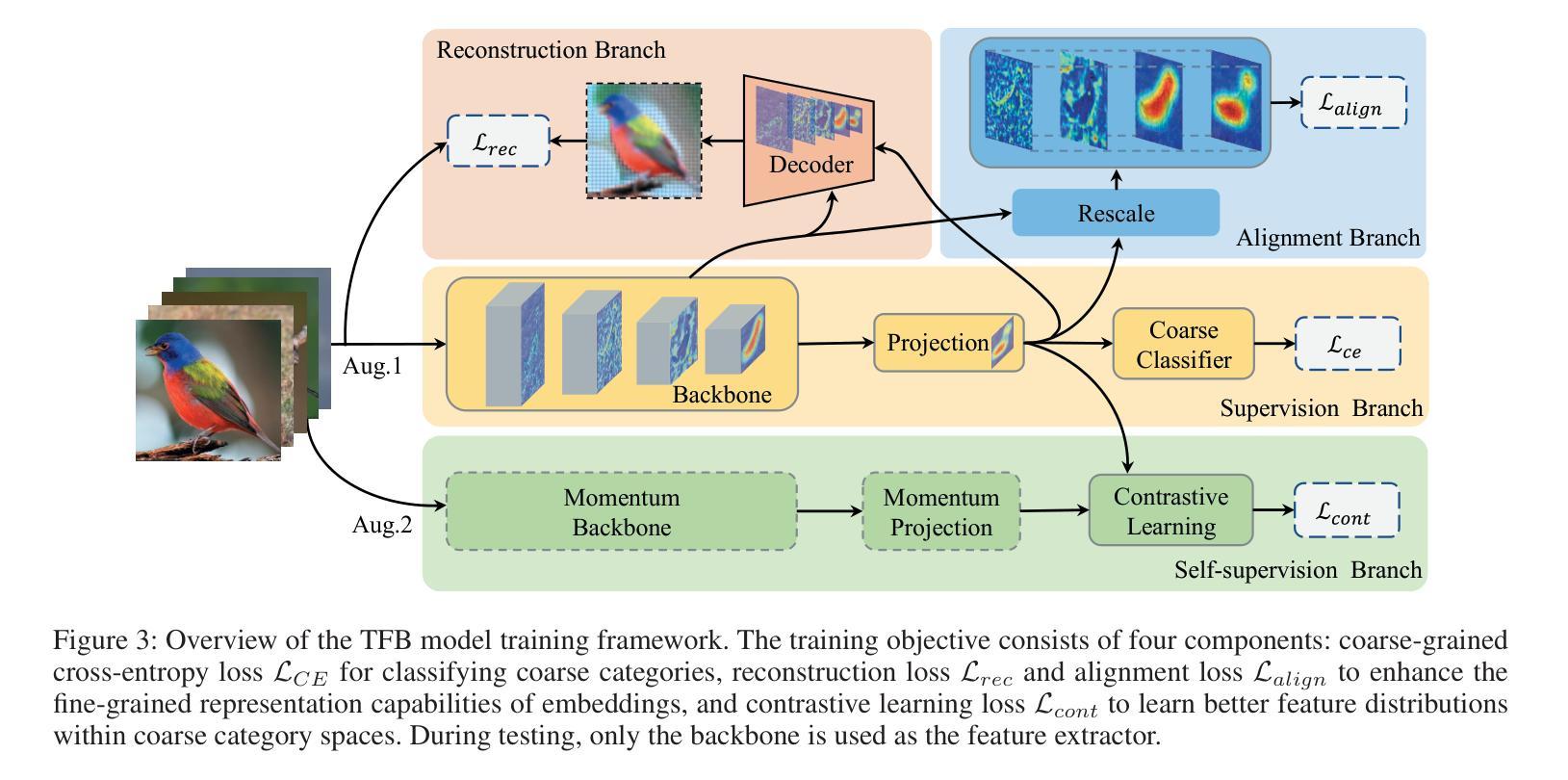
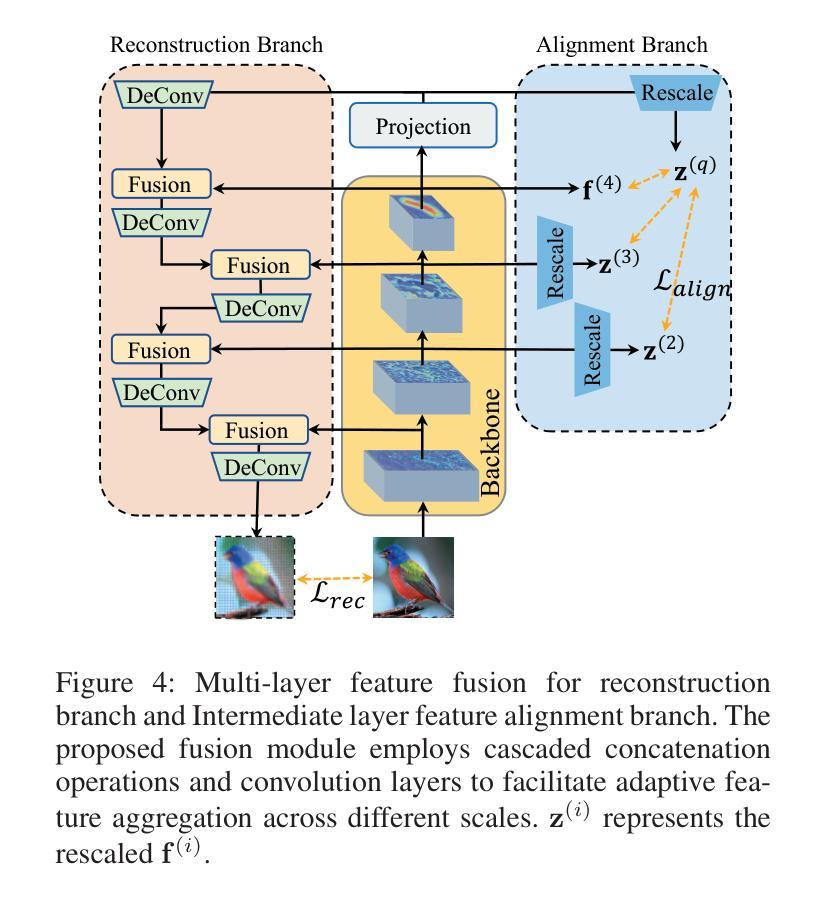
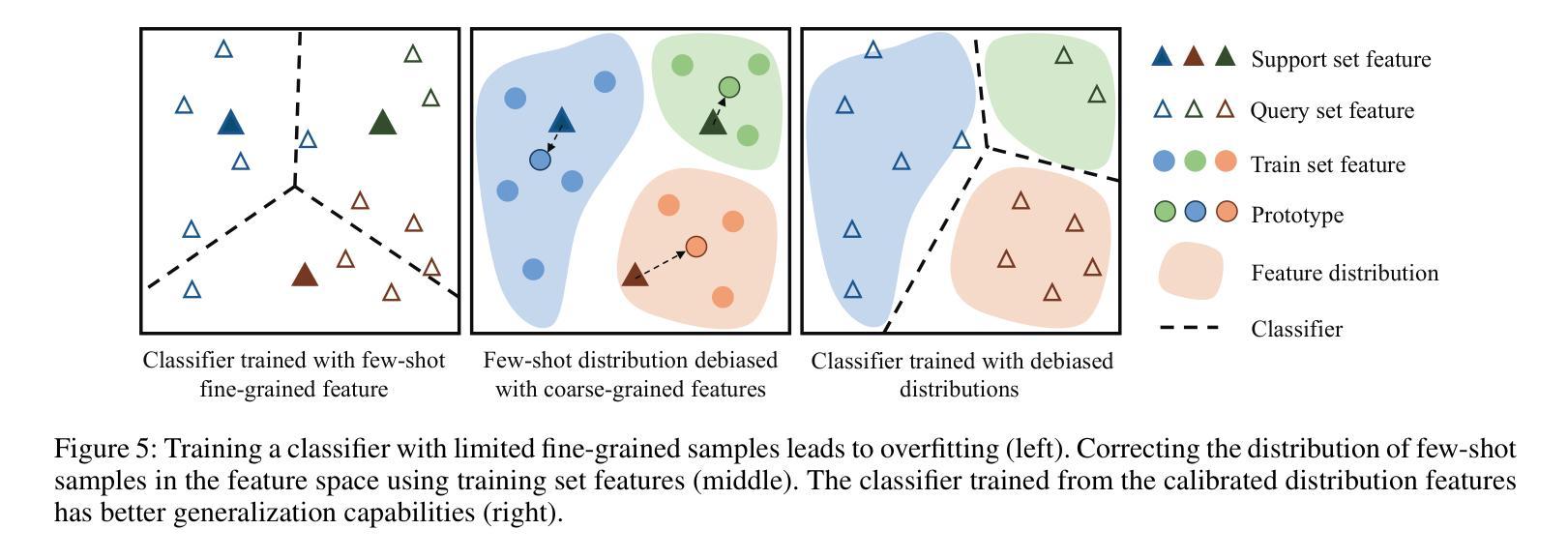
The Coarse-to-Fine Few-Shot (C2FS) task is designed to train models using only coarse labels, then leverages a limited number of subclass samples to achieve fine-grained recognition capabilities. This task presents two main challenges: coarse-grained supervised pre-training suppresses the extraction of critical fine-grained features for subcategory discrimination, and models suffer from overfitting due to biased distributions caused by limited fine-grained samples. In this paper, we propose the Twofold Debiasing (TFB) method, which addresses these challenges through detailed feature enhancement and distribution calibration. Specifically, we introduce a multi-layer feature fusion reconstruction module and an intermediate layer feature alignment module to combat the model’s tendency to focus on simple predictive features directly related to coarse-grained supervision, while neglecting complex fine-grained level details. Furthermore, we mitigate the biased distributions learned by the fine-grained classifier using readily available coarse-grained sample embeddings enriched with fine-grained information. Extensive experiments conducted on five benchmark datasets demonstrate the efficacy of our approach, achieving state-of-the-art results that surpass competitive methods.
粗到细少数样本(C2FS)任务旨在使用仅粗标签来训练模型,然后利用有限的子类别样本实现精细的识别能力。此任务面临两个主要挑战:粗粒度监督预训练抑制了关键精细特征的提取,这不利于子类别鉴别;由于有限的精细样本导致的偏见分布,模型容易发生过度拟合。在本文中,我们提出了两阶段去偏(TFB)方法,通过详细的特征增强和分布校准来解决这些挑战。具体来说,我们引入了一种多层特征融合重建模块和中间层特征对齐模块,以解决模型倾向于关注与粗粒度监督直接相关的简单预测特征,而忽视复杂的精细级别细节的问题。此外,我们通过使用丰富的精细信息对可用的粗粒度样本嵌入来减轻精细分类器所学习的偏见分布。在五个基准数据集上进行的广泛实验证明了我们的方法的有效性,实现了超越竞争方法的最先进结果。
论文及项目相关链接
Summary
本文介绍了Coarse-to-Fine Few-Shot任务中面临的挑战,并提出了Twofold Debiasing方法来解决这些问题。该方法通过详细的特征增强和分布校准,提高了模型的性能。实验结果表明,该方法在五个基准数据集上均取得了超过先进方法的效果。
Key Takeaways
- Coarse-to-Fine Few-Shot任务旨在使用粗标签进行模型预训练,然后利用有限的子类样本实现精细粒度识别能力。
- 该任务面临两个主要挑战:粗粒度监督预训练抑制了关键精细粒度特征的提取,以及由于有限的精细粒度样本导致的模型过拟合问题。
- Twofold Debiasing方法通过详细的特征增强和分布校准来解决这些挑战。
- 引入多层特征融合重建模块和中间层特征对齐模块,以解决模型过于关注与粗粒度监督直接相关的简单预测特征而忽视复杂精细粒度级别细节的问题。
- 通过使用丰富的粗粒度样本嵌入来减轻精细分类器学到的偏见分布。
- 在五个基准数据集上进行的广泛实验证明了Twifold Debiasing方法的有效性。
点此查看论文截图

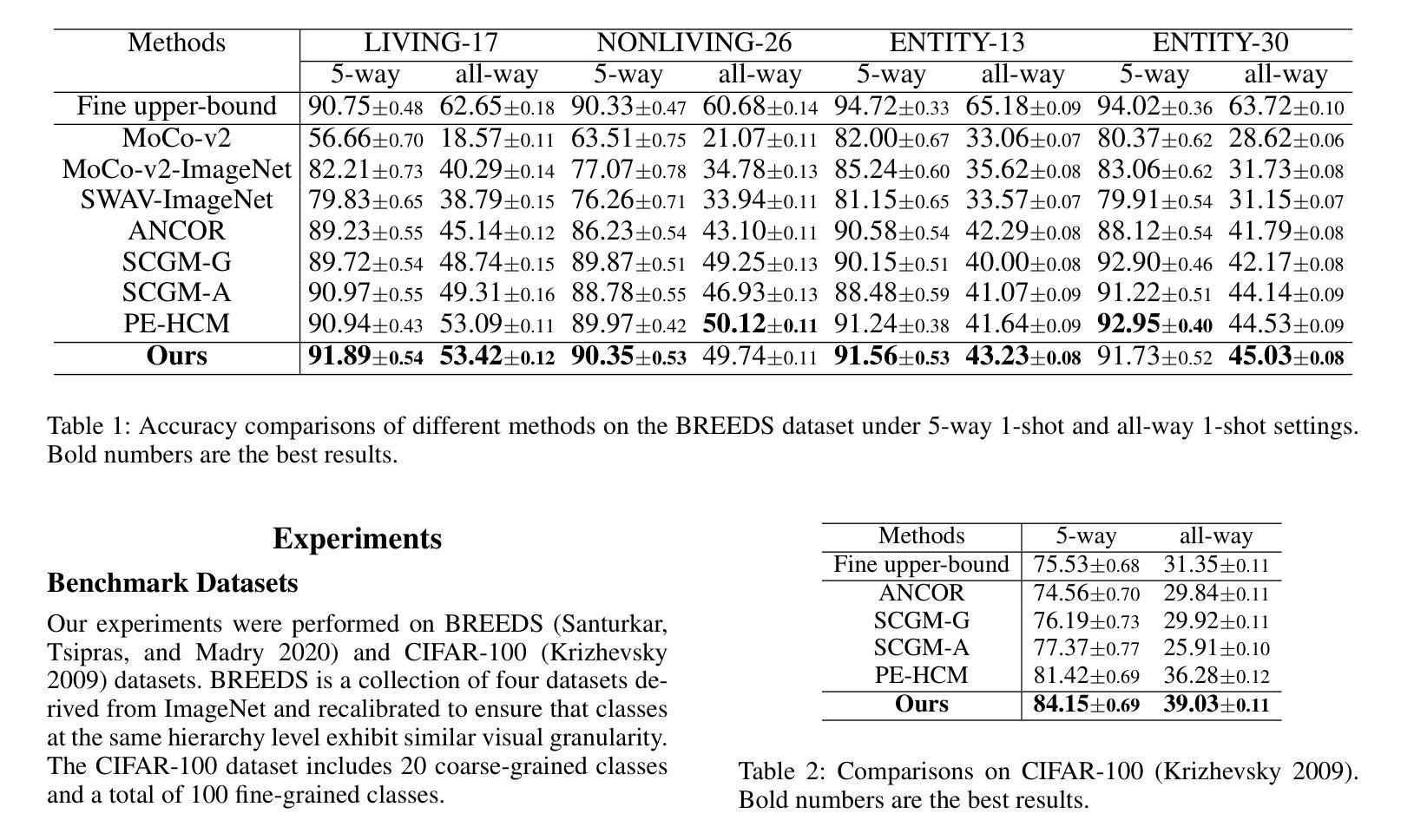
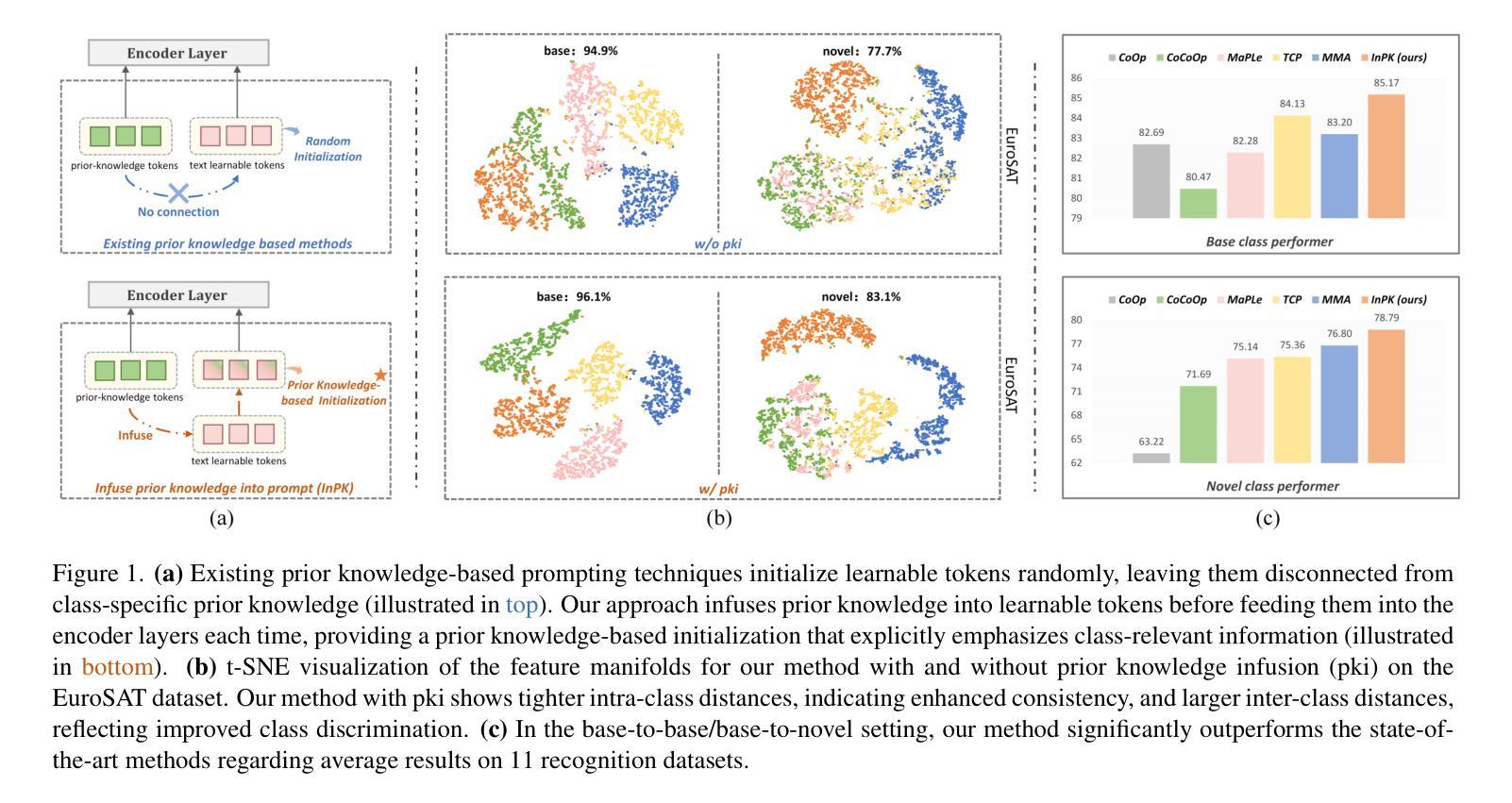
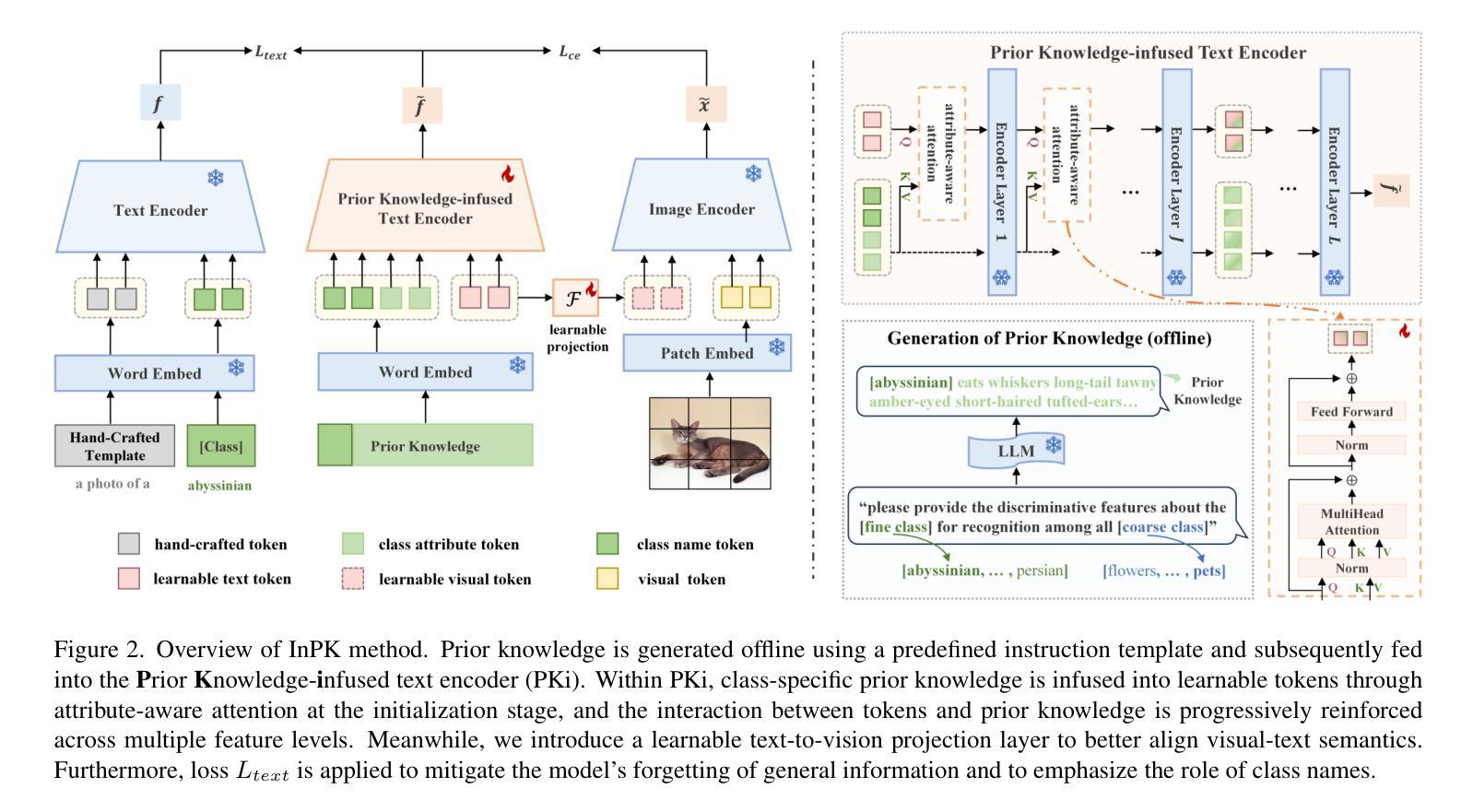
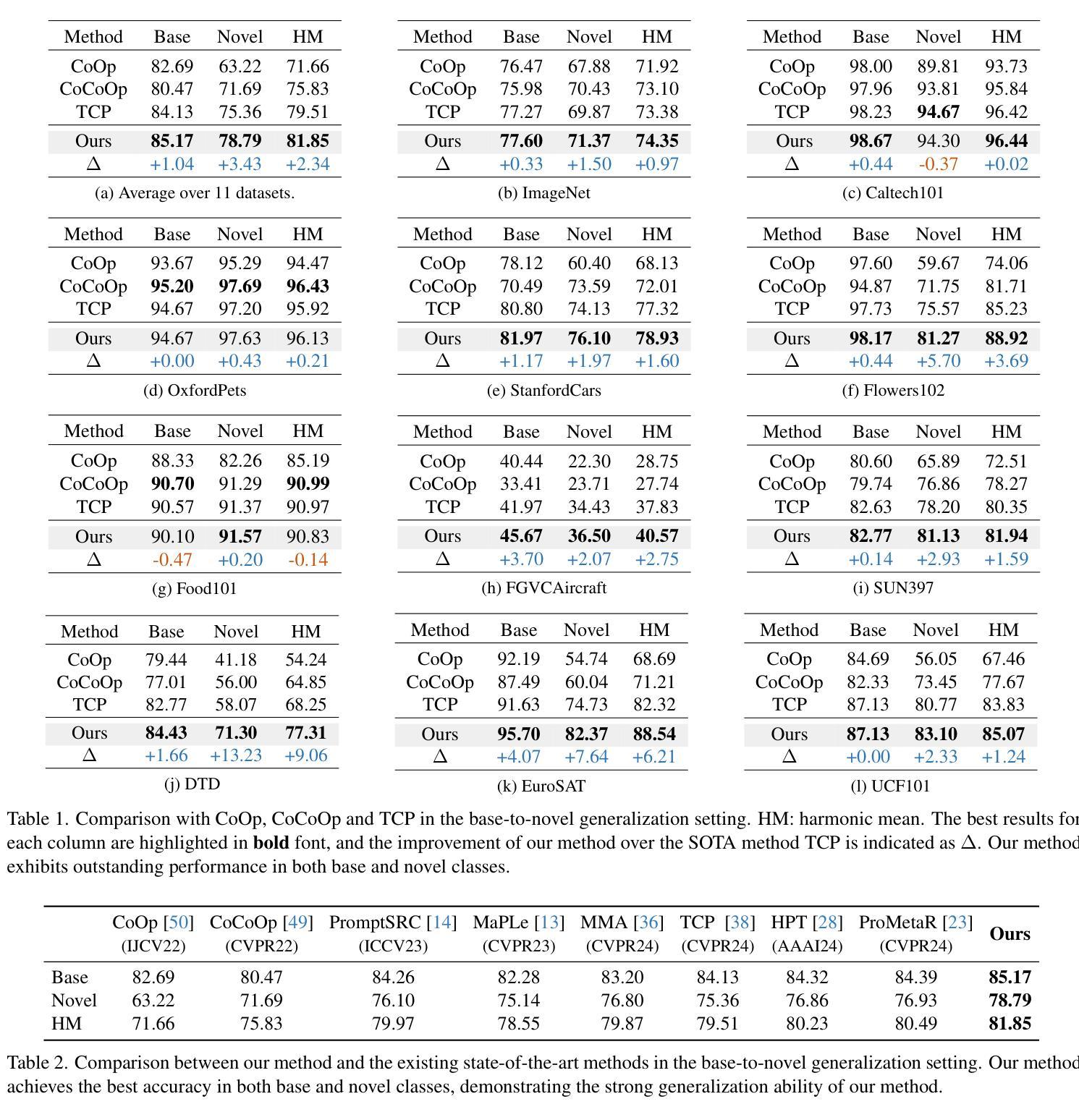
InPK: Infusing Prior Knowledge into Prompt for Vision-Language Models
Authors:Shuchang Zhou
Prompt tuning has become a popular strategy for adapting Vision-Language Models (VLMs) to zero/few-shot visual recognition tasks. Some prompting techniques introduce prior knowledge due to its richness, but when learnable tokens are randomly initialized and disconnected from prior knowledge, they tend to overfit on seen classes and struggle with domain shifts for unseen ones. To address this issue, we propose the InPK model, which infuses class-specific prior knowledge into the learnable tokens during initialization, thus enabling the model to explicitly focus on class-relevant information. Furthermore, to mitigate the weakening of class information by multi-layer encoders, we continuously reinforce the interaction between learnable tokens and prior knowledge across multiple feature levels. This progressive interaction allows the learnable tokens to better capture the fine-grained differences and universal visual concepts within prior knowledge, enabling the model to extract more discriminative and generalized text features. Even for unseen classes, the learned interaction allows the model to capture their common representations and infer their appropriate positions within the existing semantic structure. Moreover, we introduce a learnable text-to-vision projection layer to accommodate the text adjustments, ensuring better alignment of visual-text semantics. Extensive experiments on 11 recognition datasets show that InPK significantly outperforms state-of-the-art methods in multiple zero/few-shot image classification tasks.
提示调整已成为适应视觉语言模型(VLM)到零/少样本视觉识别任务的流行策略。一些提示技术由于其丰富性而引入了先验知识,但是,当可学习令牌随机初始化并与先验知识断开连接时,它们倾向于过度拟合已见类别,并且在面对未见类别时遇到域偏移问题。为了解决这一问题,我们提出了InPK模型,该模型在初始化期间将特定类别的先验知识注入可学习令牌中,从而使模型能够显式关注与类别相关的信息。此外,为了减轻多层编码器对类信息的削弱,我们在多个特征级别上不断加强对可学习令牌和先验知识之间的交互。这种渐进的交互允许可学习令牌更好地捕捉先验知识中的细微差别和通用视觉概念,使模型能够提取更具辨别力和泛化的文本特征。即使对于未见过的类别,学到的交互也允许模型捕捉它们的共同表示,并在现有的语义结构中推断它们的位置。此外,我们引入了一个可学习的文本到视觉投影层以适应文本调整,确保视觉文本语义的更好对齐。在11个识别数据集上的大量实验表明,InPK在多个零/少样本图像分类任务中显著优于最新方法。
论文及项目相关链接
Summary
本文探讨了如何通过InPK模型在视觉语言模型(VLMs)中融入类别特定先验知识,以解决零/少样本视觉识别任务中的过拟合和领域偏移问题。通过初始化学习标记并融入先验知识,模型能更明确地关注类别相关信息。同时,为了减轻多层编码器对类别信息的削弱,模型在不同特征级别之间持续强化学习标记和先验知识之间的交互。这种渐进的交互使学习标记能够更好地捕捉先验知识中的细微差别和通用视觉概念,从而提取更具鉴别力和泛化的文本特征。对于未见类别,学习到的交互允许模型捕捉其共同表示并推断其在现有语义结构中的适当位置。此外,引入了可学习的文本到视觉投影层以适应文本调整,确保视觉文本语义的更好对齐。在多个零/少样本图像分类任务中,InPK模型显著优于现有方法。
Key Takeaways
- InPK模型通过融入类别特定先验知识来解决零/少样本视觉识别任务中的过拟合和领域偏移问题。
- 初始化学习标记并融入先验知识,使模型能更关注类别相关信息。
- 通过在不同特征级别之间强化学习标记和先验知识的交互,模型能更有效地提取文本特征。
- 学习到的交互允许模型捕捉未见类别的共同表示,并推断其在现有语义结构中的位置。
- 引入可学习的文本到视觉投影层以确保视觉文本语义的更好对齐。
- InPK模型在多个零/少样本图像分类任务中显著优于现有方法。
点此查看论文截图

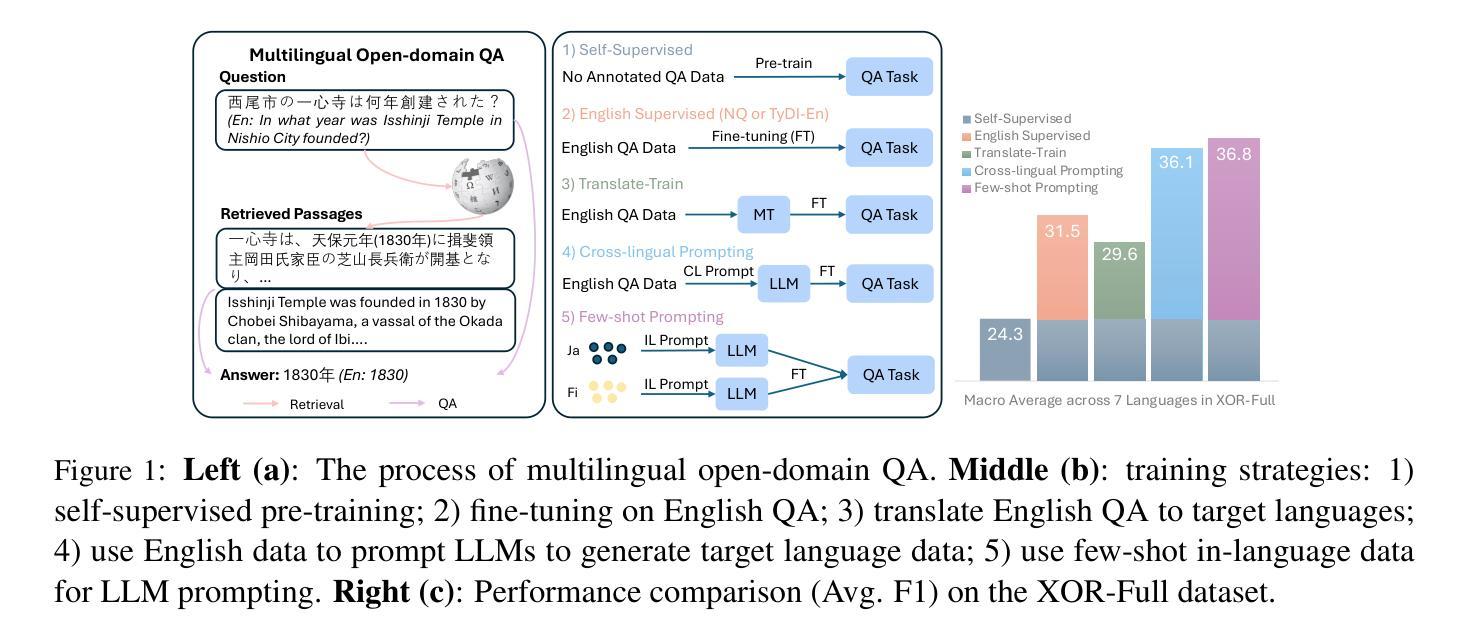
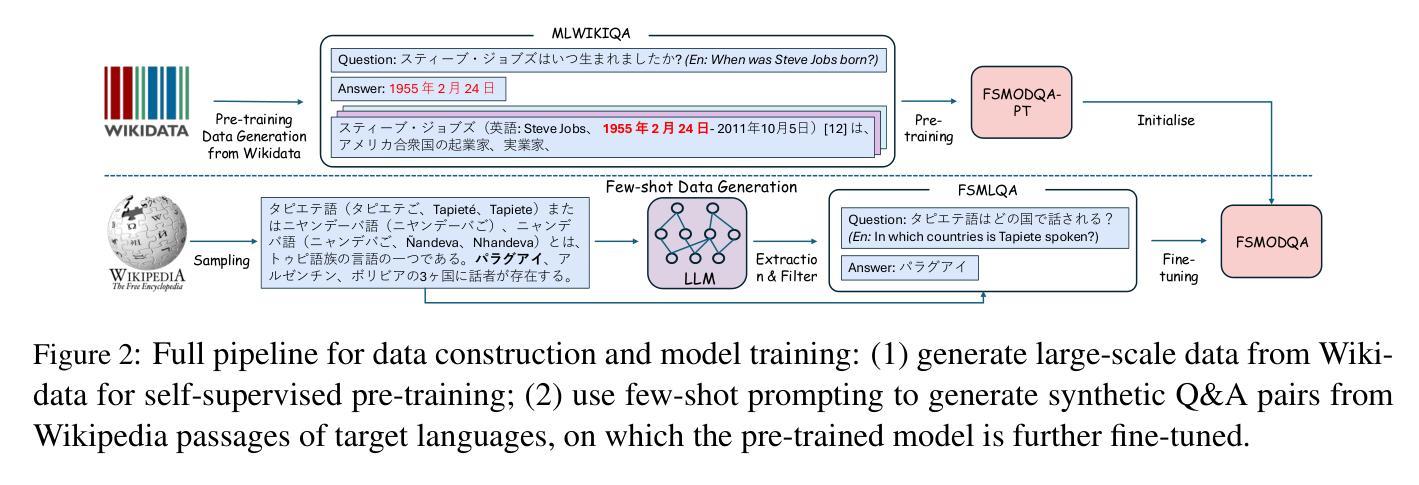
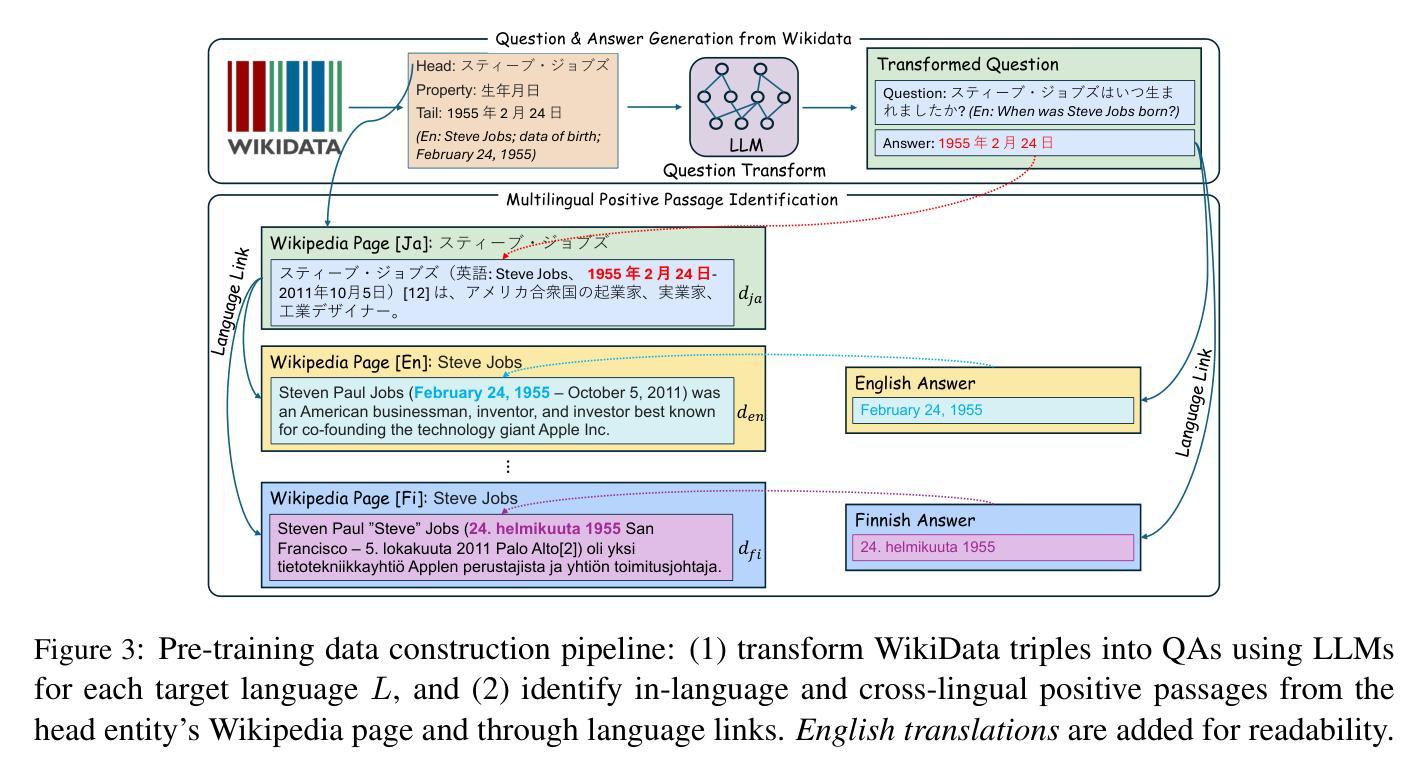
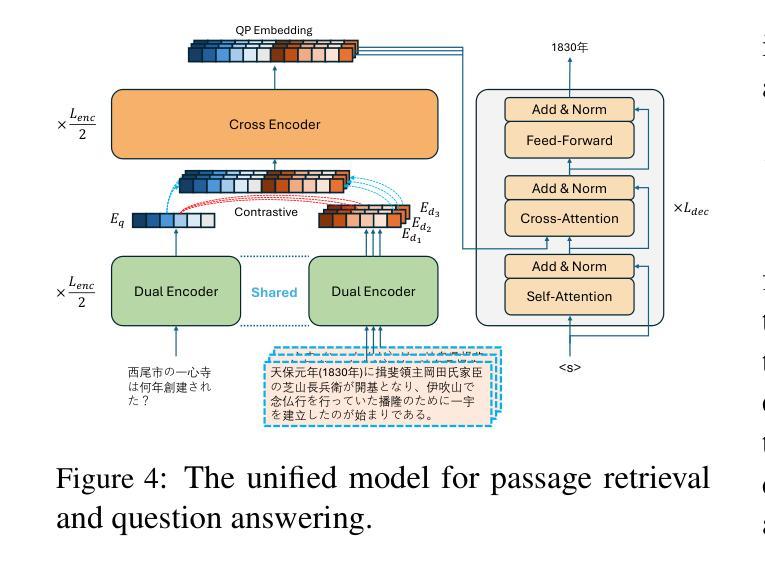
Few-Shot Multilingual Open-Domain QA from 5 Examples
Authors:Fan Jiang, Tom Drummond, Trevor Cohn
Recent approaches to multilingual open-domain question answering (MLODQA) have achieved promising results given abundant language-specific training data. However, the considerable annotation cost limits the application of these methods for underrepresented languages. We introduce a \emph{few-shot learning} approach to synthesise large-scale multilingual data from large language models (LLMs). Our method begins with large-scale self-supervised pre-training using WikiData, followed by training on high-quality synthetic multilingual data generated by prompting LLMs with few-shot supervision. The final model, \textsc{FsModQA}, significantly outperforms existing few-shot and supervised baselines in MLODQA and cross-lingual and monolingual retrieval. We further show our method can be extended for effective zero-shot adaptation to new languages through a \emph{cross-lingual prompting} strategy with only English-supervised data, making it a general and applicable solution for MLODQA tasks without costly large-scale annotation.
近期多语言开放领域问答(MLODQA)的方法在大量特定语言训练数据的支持下取得了有前景的结果。然而,巨大的标注成本限制了这些方法在代表性不足的语言中的应用。我们引入了一种“小样本学习”方法,用于从大型语言模型(LLM)中合成大规模的多语言数据。我们的方法首先使用WikiData进行大规模自监督预训练,然后通过在少量监督下提示LLM来生成高质量的多语言合成数据,进行训练。最终模型FsModQA在MLODQA以及跨语言和单语言检索方面显著优于现有的小样本和受监督的基线模型。我们进一步展示,通过仅使用英语监督数据的跨语言提示策略,我们的方法可以扩展到对新语言的有效零样本适应,使其成为无需昂贵的大规模标注的MLODQA任务的一般且适用的解决方案。
论文及项目相关链接
PDF Accepted by TACL; pre-MIT Press publication version
Summary
多语种开放域问答(MLODQA)的新方法使用大量的特定语言训练数据取得了很好的结果。但巨大的标注成本限制了这些方法在代表性不足的语言中的应用。本研究引入了基于少样本学习的策略,通过大型语言模型合成大规模多语言数据。首先通过WikiData进行大规模自监督预训练,然后通过少数样本监督生成高质量的多语言合成数据进行训练。最终模型FsModQA在MLODQA任务以及跨语言和单语言检索方面都显著超过了现有的少样本和监督基线方法。此外,该研究还展示了模型可以通过跨语言提示策略扩展到对新语言的有效零样本适应,只需英语监督数据,使其成为无需大规模标注的通用解决方案。
Key Takeaways
- 多语种开放域问答(MLODQA)的新方法需要大量语言特定的训练数据。
- 由于标注成本高昂,这些方法在代表性不足的语言中的应用受限。
- 研究引入基于少样本学习的策略,利用大型语言模型合成大规模多语言数据。
- 研究先进行大规模自监督预训练,再基于少数样本生成的高质量多语言合成数据进行训练。
- 最终模型FsModQA在MLODQA任务上表现优异,显著超过现有方法。
- 模型可以通过跨语言提示策略进行零样本适应,适应新语言。
点此查看论文截图

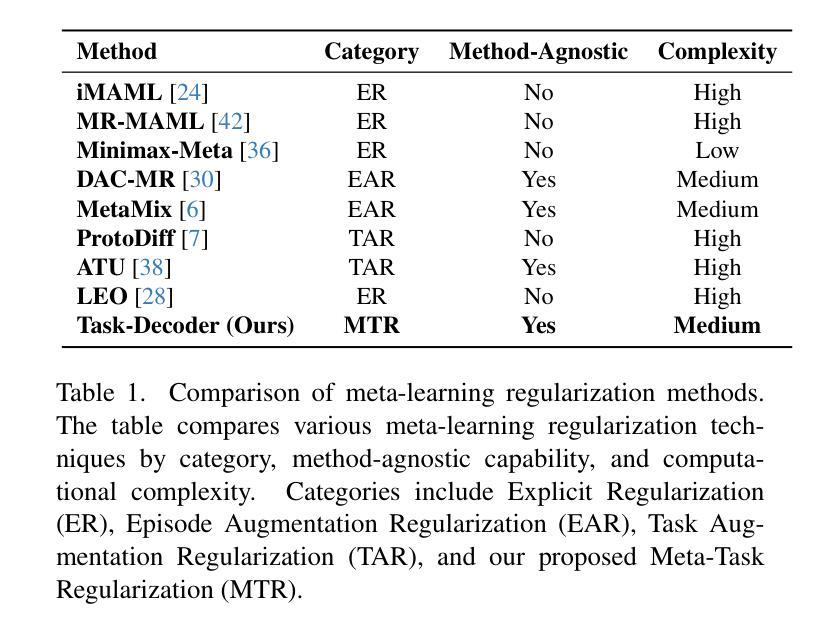
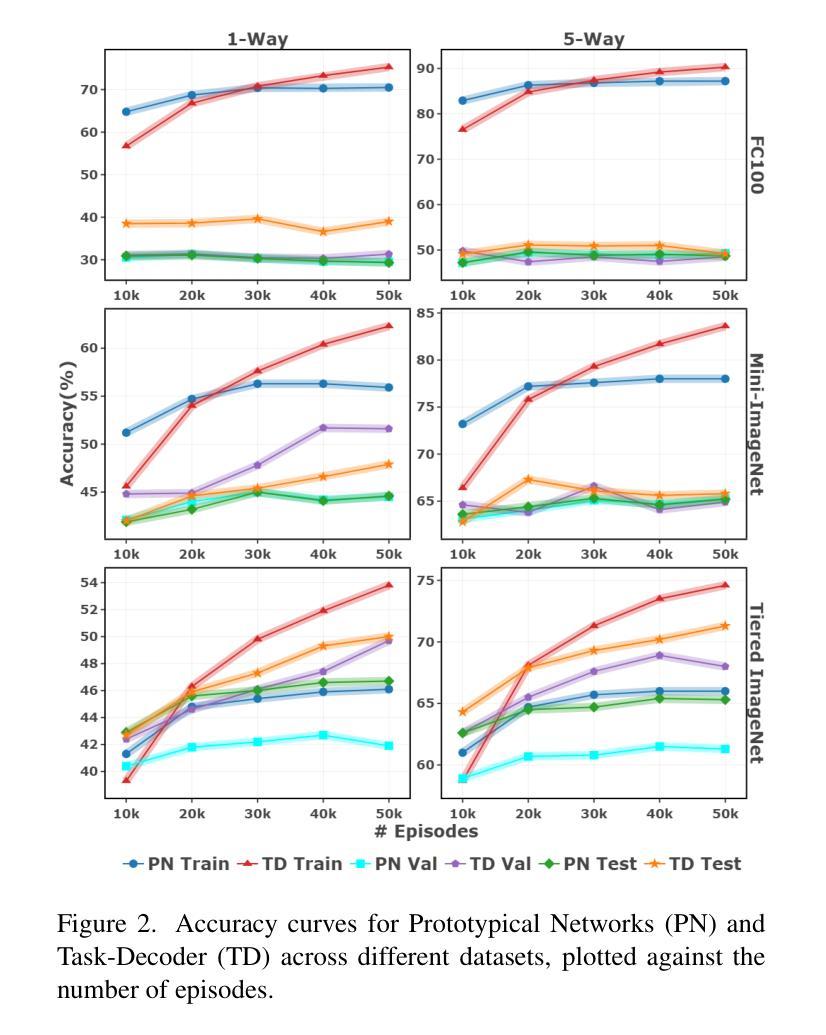
Meta-Task: A Method-Agnostic Framework for Learning to Regularize in Few-Shot Learning
Authors:Mohammad Rostami, Atik Faysal, Huaxia Wang, Avimanyu Sahoo
Overfitting is a significant challenge in Few-Shot Learning (FSL), where models trained on small, variable datasets tend to memorize rather than generalize to unseen tasks. Regularization is crucial in FSL to prevent overfitting and enhance generalization performance. To address this issue, we introduce Meta-Task, a novel, method-agnostic framework that leverages both labeled and unlabeled data to enhance generalization through auxiliary tasks for regularization. Specifically, Meta-Task introduces a Task-Decoder, which is a simple example of the broader framework that refines hidden representations by reconstructing input images from embeddings, effectively mitigating overfitting. Our framework’s method-agnostic design ensures its broad applicability across various FSL settings. We validate Meta-Task’s effectiveness on standard benchmarks, including Mini-ImageNet, Tiered-ImageNet, and FC100, where it consistently improves existing state-of-the-art meta-learning techniques, demonstrating superior performance, faster convergence, reduced generalization error, and lower variance-all without extensive hyperparameter tuning. These results underline Meta-Task’s practical applicability and efficiency in real-world, resource-constrained scenarios.
过拟合是Few-Shot学习(FSL)中的一个重大挑战。在FSL中,训练于小型可变数据集的模型往往倾向于记忆而非泛化到未见过的任务。正则化在FSL中至关重要,可以防止过拟合并增强泛化性能。为了解决这个问题,我们引入了Meta-Task,这是一个新的方法通用的框架,它利用有标签和无标签的数据,通过辅助任务进行正则化,以增强泛化能力。具体来说,Meta-Task引入了Task-Decoder,这是更广泛框架的一个简单示例,它通过从嵌入重构输入图像来优化隐藏表示,有效地减轻了过拟合并。我们框架的方法通用设计确保其在各种FSL设置中的广泛应用。我们在包括Mini-ImageNet、Tiered-ImageNet和FC100等标准基准测试上对Meta-Task的有效性进行了验证,它在现有的最先进的元学习技术上进行了一致的改进,表现出了优越的性能、更快的收敛速度、减少的泛化误差和较低方差,且无需进行大量的超参数调整。这些结果突出了Meta-Task在现实资源受限场景中的实际适用性和效率。
论文及项目相关链接
Summary
模型在小样本学习(FSL)中面临过拟合的挑战,其中模型在小型可变数据集上训练时容易记忆而非泛化到未见过的任务。正则化在FSL中至关重要,可防止过拟合并增强泛化性能。为解决这个问题,我们引入了Meta-Task这一新颖的方法论无关框架,该框架利用有标签和无标签数据,通过辅助任务进行正则化以增强泛化能力。具体来说,Meta-Task引入了任务解码器(Task-Decoder),它是更广泛框架的一个简单示例,通过从嵌入重构输入图像来优化隐藏表示,有效地减轻过拟合。我们的框架方法论无关的设计确保了其在各种FSL设置中的广泛应用。我们在包括Mini-ImageNet、Tiered-ImageNet和FC100等标准基准测试上对Meta-Task的有效性进行了验证,它在现有最先进的元学习技术上进行了改进,展示了卓越的性能、更快的收敛速度、降低的泛化误差和较低方差,且无需广泛调整超参数。这些结果突显了Meta-Task在现实世界的资源受限场景中的实际应用性和效率。
Key Takeaways
- 小样本学习(FSL)面临过拟合的挑战。
- 正则化在FSL中至关重要,可防止过拟合并增强模型泛化性能。
- 引入Meta-Task框架,利用有标签和无标签数据,通过辅助任务进行正则化。
- Meta-Task包含任务解码器(Task-Decoder),通过重构输入图像来优化隐藏表示。
- Meta-Task框架方法论无关,适用于各种FSL设置。
- Meta-Task在标准基准测试上表现优越,包括Mini-ImageNet、Tiered-ImageNet和FC100。
点此查看论文截图