⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-01 更新
ProxyTransformation: Preshaping Point Cloud Manifold With Proxy Attention For 3D Visual Grounding
Authors:Qihang Peng, Henry Zheng, Gao Huang
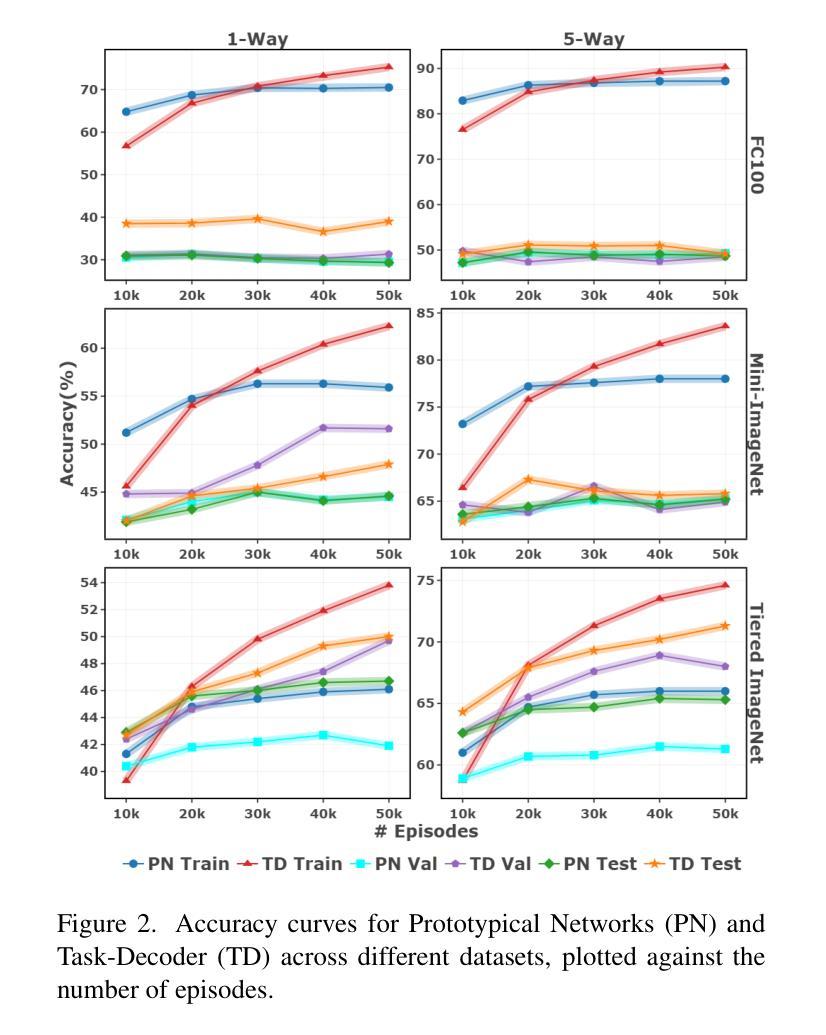
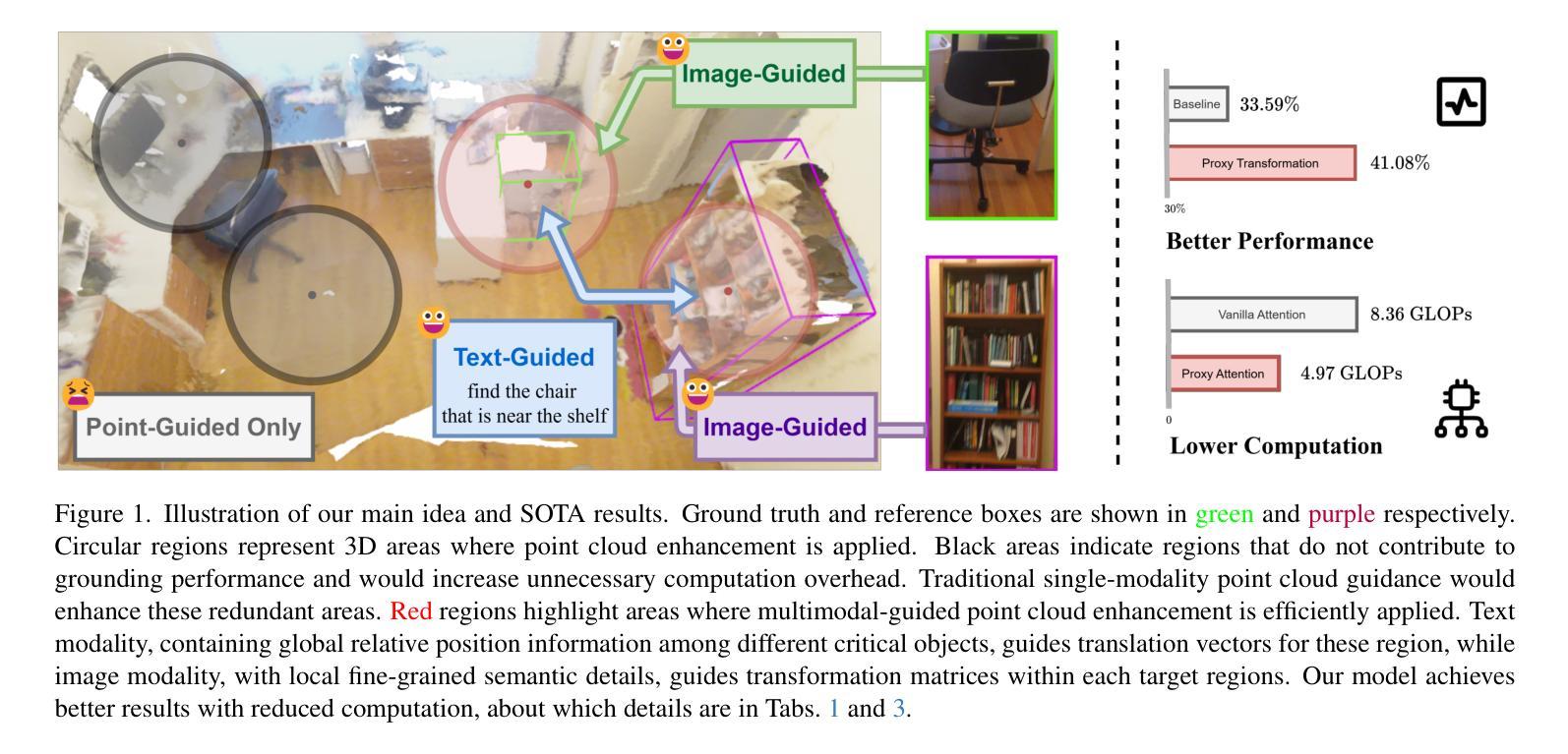
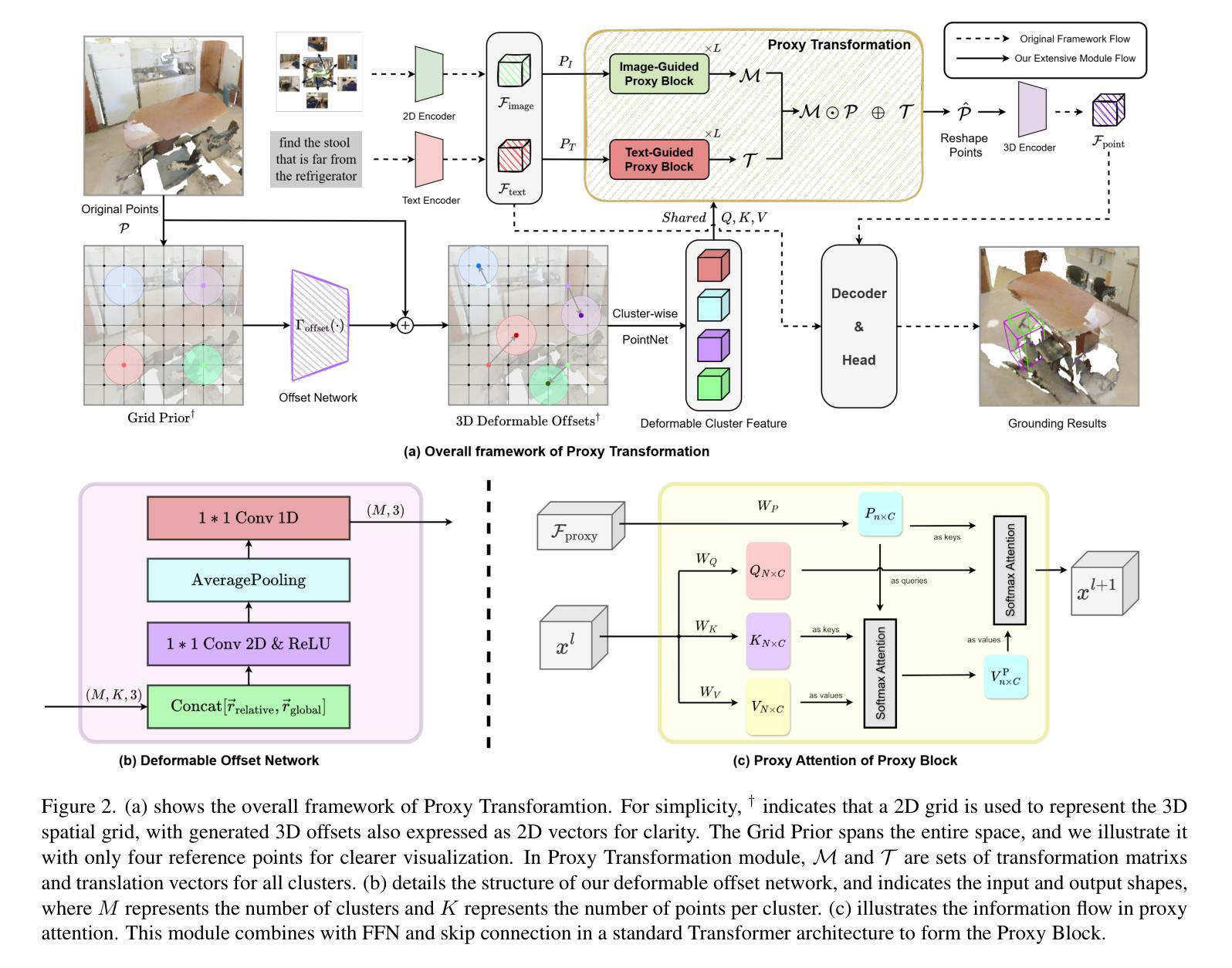
Embodied intelligence requires agents to interact with 3D environments in real time based on language instructions. A foundational task in this domain is ego-centric 3D visual grounding. However, the point clouds rendered from RGB-D images retain a large amount of redundant background data and inherent noise, both of which can interfere with the manifold structure of the target regions. Existing point cloud enhancement methods often require a tedious process to improve the manifold, which is not suitable for real-time tasks. We propose Proxy Transformation suitable for multimodal task to efficiently improve the point cloud manifold. Our method first leverages Deformable Point Clustering to identify the point cloud sub-manifolds in target regions. Then, we propose a Proxy Attention module that utilizes multimodal proxies to guide point cloud transformation. Built upon Proxy Attention, we design a submanifold transformation generation module where textual information globally guides translation vectors for different submanifolds, optimizing relative spatial relationships of target regions. Simultaneously, image information guides linear transformations within each submanifold, refining the local point cloud manifold of target regions. Extensive experiments demonstrate that Proxy Transformation significantly outperforms all existing methods, achieving an impressive improvement of 7.49% on easy targets and 4.60% on hard targets, while reducing the computational overhead of attention blocks by 40.6%. These results establish a new SOTA in ego-centric 3D visual grounding, showcasing the effectiveness and robustness of our approach.
体现智能需要代理根据语言指令与3D环境进行实时交互。该领域的核心任务是自我中心的3D视觉定位。然而,从RGB-D图像渲染的点云保留了大量冗余的背景数据和固有噪声,两者都会干扰目标区域的流形结构。现有的点云增强方法通常需要繁琐的过程来改善流形,这不适用于实时任务。我们提出了适用于多模式任务的代理转换,以有效地改善点云流形。我们的方法首先利用可变点聚类来识别目标区域的点云子流形。然后,我们提出了一个代理注意力模块,它利用多模式代理来引导点云转换。基于代理注意力,我们设计了一个子流形转换生成模块,其中文本信息全局引导不同子流形的翻译向量,优化目标区域之间的相对空间关系。同时,图像信息引导每个子流形内的线性变换,细化目标区域的局部点云流形。大量实验表明,代理转换显著优于所有现有方法,在简单目标上实现了7.49%的惊人进步,在困难目标上实现了4.60%的进步,同时减少了注意力块的计算开销达40.6%。这些结果确立了自我中心3D视觉定位新的SOTA(最佳表现),展示了我们方法的有效性和稳健性。
论文及项目相关链接
PDF 12 pages, 3 figures. Accepted by CVPR2025
Summary
针对以人为中心的3D视觉定位任务,提出一种适用于多模态任务的代理转换方法,用于高效改进点云流形。该方法通过变形点聚类识别目标区域的点云子流形,并利用多模态代理引导点云转换。通过设计子流形转换生成模块,文本信息全局引导不同子流形的翻译向量,优化目标区域的相对空间关系;图像信息则引导每个子流形内的线性变换,细化目标区域的局部点云流形。该方法在效率与性能上均超越现有方法,计算开销减少40.6%,为以人为中心的3D视觉定位任务确立了新的性能高点。
Key Takeaways
- 代理转换方法适用于多模态任务,用于改进点云流形结构。
- 通过变形点聚类识别目标区域的点云子流形。
- 提出代理注意力模块,利用多模态代理引导点云转换。
- 文本信息全局引导不同子流形的翻译向量,优化目标区域的相对空间关系。
- 图像信息指导每个子流形内的线性变换,细化局部点云流形。
- 方法显著优于现有方法,在计算开销方面实现显著优化。
点此查看论文截图

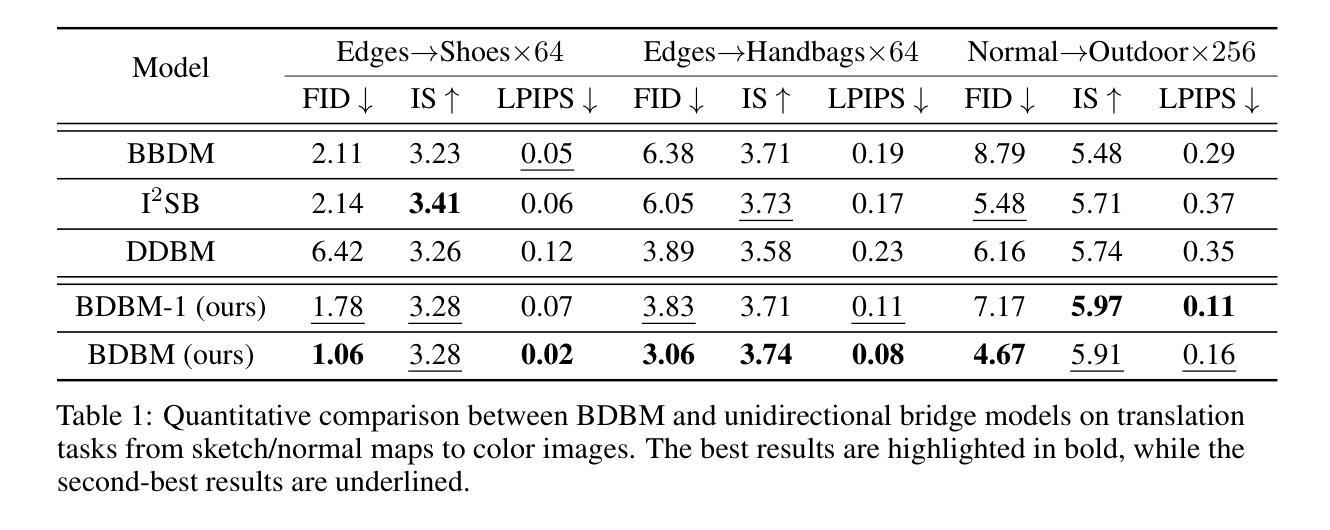
Bidirectional Diffusion Bridge Models
Authors:Duc Kieu, Kien Do, Toan Nguyen, Dang Nguyen, Thin Nguyen
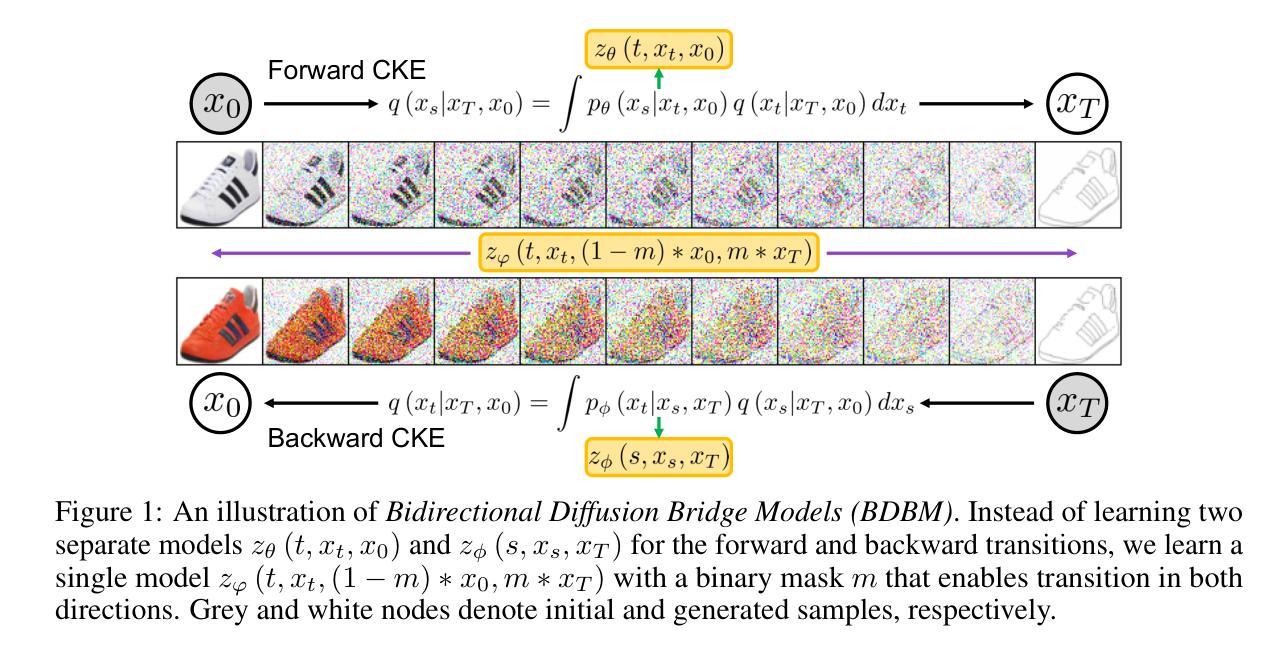
Diffusion bridges have shown potential in paired image-to-image (I2I) translation tasks. However, existing methods are limited by their unidirectional nature, requiring separate models for forward and reverse translations. This not only doubles the computational cost but also restricts their practicality. In this work, we introduce the Bidirectional Diffusion Bridge Model (BDBM), a scalable approach that facilitates bidirectional translation between two coupled distributions using a single network. BDBM leverages the Chapman-Kolmogorov Equation for bridges, enabling it to model data distribution shifts across timesteps in both forward and backward directions by exploiting the interchangeability of the initial and target timesteps within this framework. Notably, when the marginal distribution given endpoints is Gaussian, BDBM’s transition kernels in both directions possess analytical forms, allowing for efficient learning with a single network. We demonstrate the connection between BDBM and existing bridge methods, such as Doob’s h-transform and variational approaches, and highlight its advantages. Extensive experiments on high-resolution I2I translation tasks demonstrate that BDBM not only enables bidirectional translation with minimal additional cost but also outperforms state-of-the-art bridge models. Our source code is available at [https://github.com/kvmduc/BDBM||https://github.com/kvmduc/BDBM].
扩散桥在配对图像到图像(I2I)翻译任务中显示出潜力。然而,现有方法受到其单向特性的限制,需要为正向和反向翻译分别建立模型。这不仅使计算成本翻倍,而且限制了其实用性。在这项工作中,我们引入了双向扩散桥模型(BDBM),这是一种可扩展的方法,使用单个网络即可实现两个耦合分布之间的双向翻译。BDBM利用Chapman-Kolmogorov方程构建桥梁,通过在此框架内利用初始和目标时间步的互换性,能够在正向和反向两个方向上模拟数据分布的时间步变化。值得注意的是,当给定端点的边际分布为高斯分布时,BDBM在两个方向上的转换核具有分析形式,从而允许使用单个网络进行有效学习。我们展示了BDBM与现有桥梁方法(如Doob的h转换和变分方法)之间的联系,并强调了其优势。在高分辨率I2I翻译任务上的大量实验表明,BDBM不仅实现了双向翻译且几乎没有增加成本,而且还优于最新的桥梁模型。我们的源代码可在[https://github.com/kvmduc/BDBM]处获取。
论文及项目相关链接
PDF Source code: https://github.com/kvmduc/BDBM
Summary
本文介绍了双向扩散桥梁模型(BDBM),该模型能够实现两个耦合分布之间的双向翻译,并使用单个网络进行可扩展处理。BDBM利用Chapman-Kolmogorov方程构建桥梁,可以在此框架下利用初始和目标时间步的互换性,在前后两个方向上模拟数据分布的变化。当给定端点的边际分布为高斯分布时,BDBM在两个方向上的转换核具有分析形式,使得使用单个网络进行学习更加高效。实验表明,BDBM在双向翻译方面具有优势,不仅成本增加极小,而且优于现有的桥梁模型。
Key Takeaways
- BDBM模型实现了两个耦合分布之间的双向翻译,突破现有方法单向性的限制。
- BDBM利用Chapman-Kolmogorov方程构建桥梁,能模拟数据分布在前后两个方向上的变化。
- 在边际分布为高斯分布的情况下,BDBM的转换核具有分析形式,学习更为高效。
- BDBM与现有的桥梁方法如Doob的h-变换和变分方法有联系。
- BDBM在配对图像到图像(I2I)翻译任务上表现出优异性能,实现了双向翻译并优于现有桥梁模型。
- BDBM模型使用单个网络进行处理,降低了计算成本。
点此查看论文截图

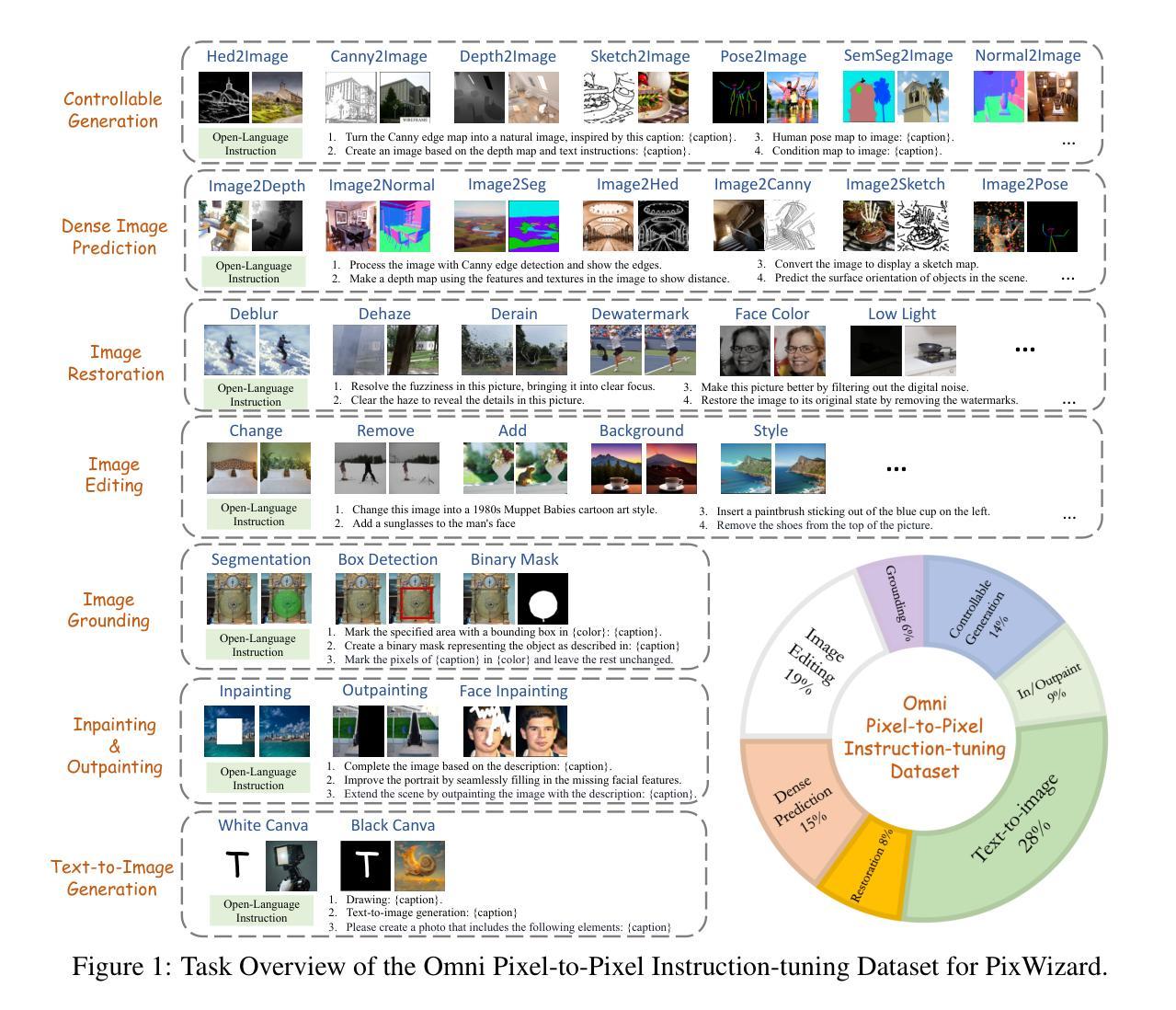
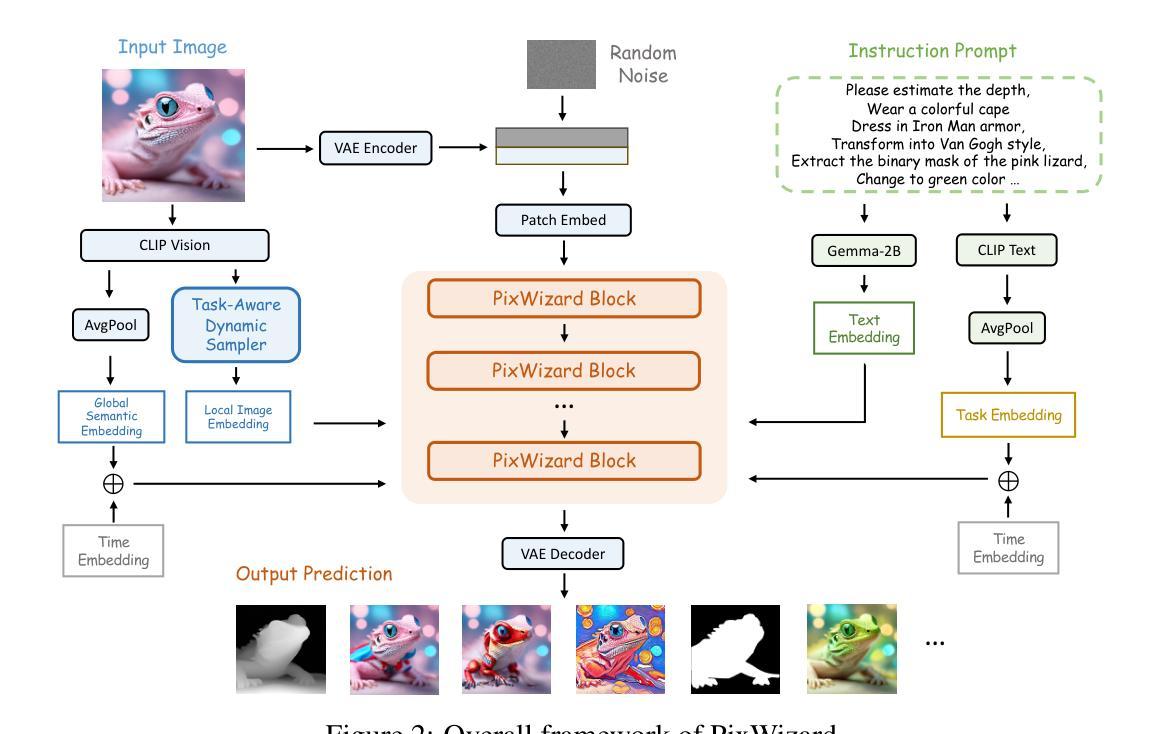
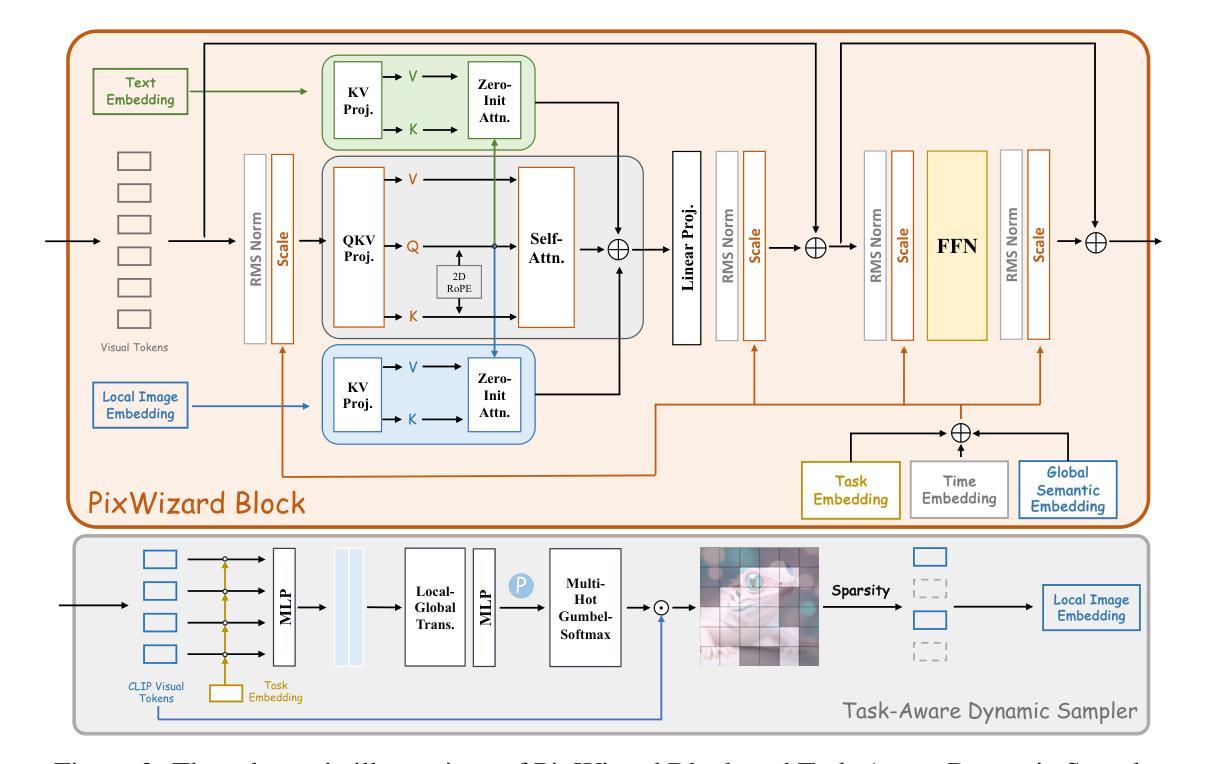
PixWizard: Versatile Image-to-Image Visual Assistant with Open-Language Instructions
Authors:Weifeng Lin, Xinyu Wei, Renrui Zhang, Le Zhuo, Shitian Zhao, Siyuan Huang, Huan Teng, Junlin Xie, Yu Qiao, Peng Gao, Hongsheng Li
This paper presents a versatile image-to-image visual assistant, PixWizard, designed for image generation, manipulation, and translation based on free-from language instructions. To this end, we tackle a variety of vision tasks into a unified image-text-to-image generation framework and curate an Omni Pixel-to-Pixel Instruction-Tuning Dataset. By constructing detailed instruction templates in natural language, we comprehensively include a large set of diverse vision tasks such as text-to-image generation, image restoration, image grounding, dense image prediction, image editing, controllable generation, inpainting/outpainting, and more. Furthermore, we adopt Diffusion Transformers (DiT) as our foundation model and extend its capabilities with a flexible any resolution mechanism, enabling the model to dynamically process images based on the aspect ratio of the input, closely aligning with human perceptual processes. The model also incorporates structure-aware and semantic-aware guidance to facilitate effective fusion of information from the input image. Our experiments demonstrate that PixWizard not only shows impressive generative and understanding abilities for images with diverse resolutions but also exhibits promising generalization capabilities with unseen tasks and human instructions. The code and related resources are available at https://github.com/AFeng-x/PixWizard
本文介绍了一款通用图像到图像的视觉助手PixWizard,它旨在基于自由的语言指令进行图像生成、操作和翻译。为此,我们将各种视觉任务纳入统一的图像文本到图像生成框架,并创建了一个Omni Pixel-to-Pixel Instruction-Tuning数据集。通过构建自然语言详细指令模板,我们全面涵盖了大量不同的视觉任务,如文本到图像生成、图像恢复、图像接地、密集图像预测、图像编辑、可控生成、补绘/外绘等。此外,我们采用扩散变压器(DiT)作为基础模型,并通过灵活的任何分辨率机制扩展其功能,使模型能够根据输入的比例动态处理图像,与人类感知过程紧密对齐。该模型还结合了结构感知和语义感知指导,以促进输入图像中信息的有效融合。我们的实验表明,PixWizard不仅在对具有不同分辨率的图像生成和理解方面表现出令人印象深刻的能力,而且在未见任务和人类指令方面也表现出有希望的泛化能力。相关代码和资源可在https://github.com/AFeng-x/PixWizard处获取。
论文及项目相关链接
PDF Code is released at https://github.com/AFeng-x/PixWizard
Summary
PixWizard是一款基于自然语言指令的图像生成、操作和翻译的多功能视觉助理软件。它建立了一个统一的图像文本生成框架,涵盖了多种视觉任务,并采用扩散变压器作为基础模型。软件具有灵活的任何分辨率机制和结构感知与语义感知指导,可实现高效的图像信息处理融合。实验表明,PixWizard具有出色的生成能力和对多种分辨率图像的理解能力,并展现出对未知任务和人类指令的通用化能力。
Key Takeaways
- PixWizard是一个多功能的图像生成、操作和翻译的视觉助理软件。
- 它建立了一个统一的图像文本生成框架,涵盖多种视觉任务。
- 采用扩散变压器(DiT)作为基础模型,具有灵活的任何分辨率机制。
- 软件具有结构感知和语义感知指导,可实现高效的图像信息处理融合。
- PixWizard具有出色的生成能力和对多种分辨率图像的理解能力。
- 该软件展现出对未知任务和人类指令的通用化能力。
点此查看论文截图