⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-01 更新
R2-T2: Re-Routing in Test-Time for Multimodal Mixture-of-Experts
Authors:Zhongyang Li, Ziyue Li, Tianyi Zhou
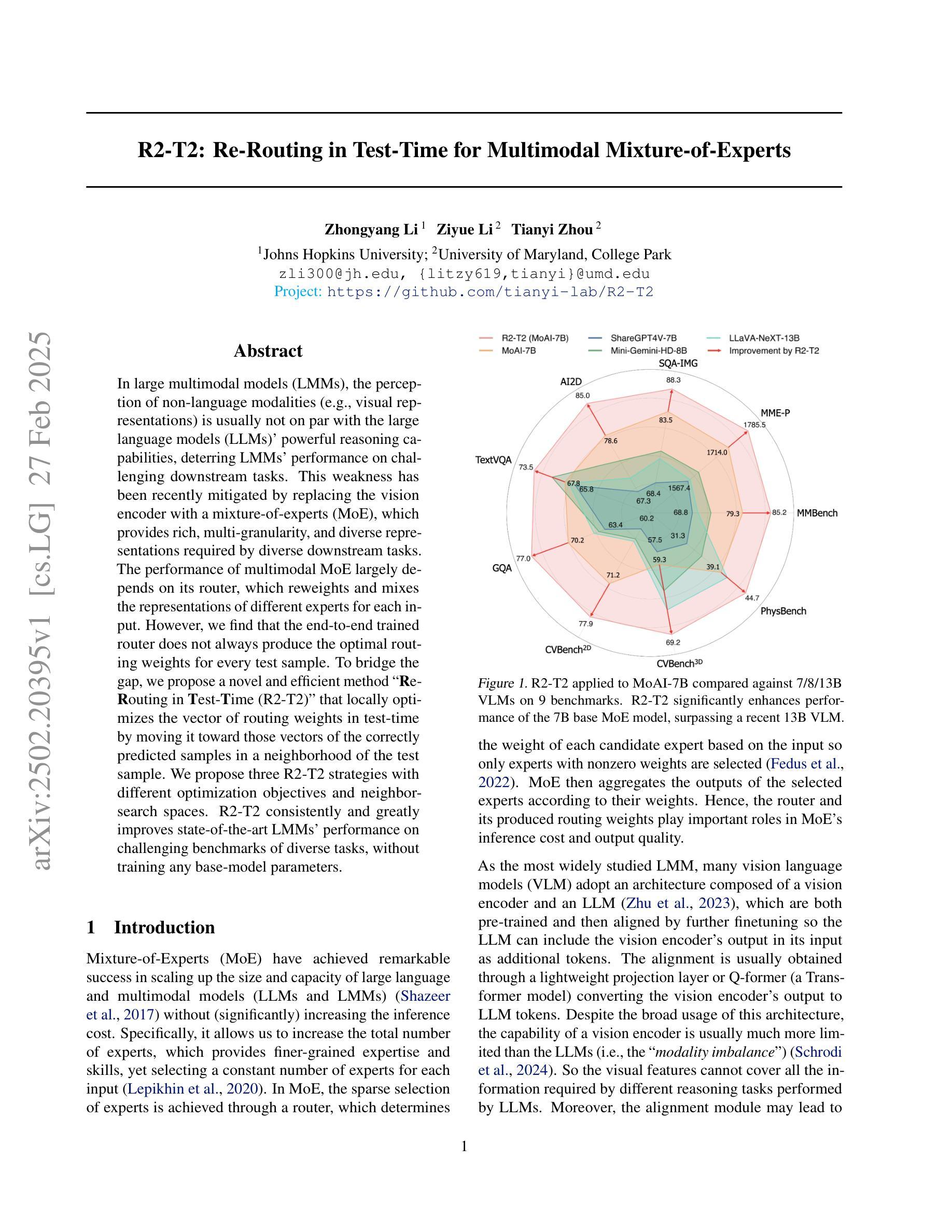
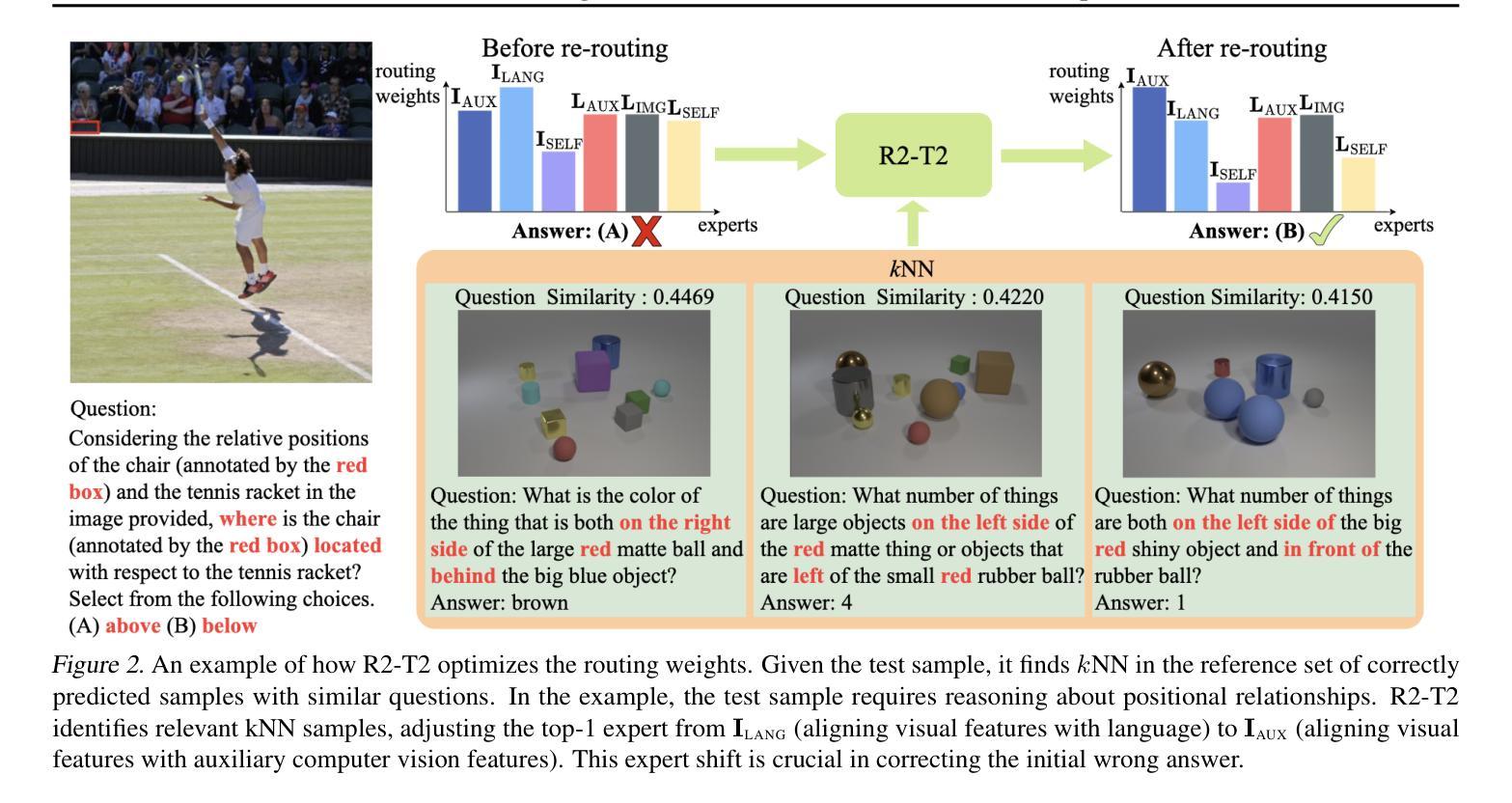
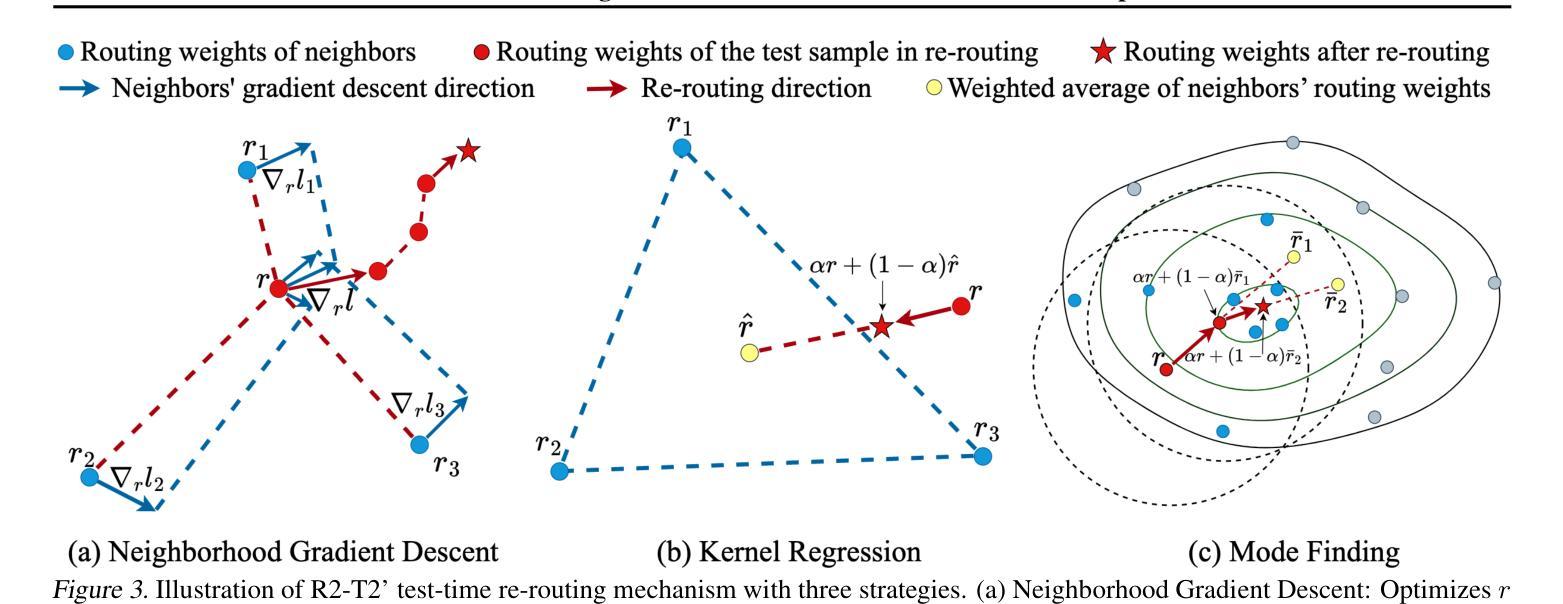
In large multimodal models (LMMs), the perception of non-language modalities (e.g., visual representations) is usually not on par with the large language models (LLMs)’ powerful reasoning capabilities, deterring LMMs’ performance on challenging downstream tasks. This weakness has been recently mitigated by replacing the vision encoder with a mixture-of-experts (MoE), which provides rich, multi-granularity, and diverse representations required by diverse downstream tasks. The performance of multimodal MoE largely depends on its router, which reweights and mixes the representations of different experts for each input. However, we find that the end-to-end trained router does not always produce the optimal routing weights for every test sample. To bridge the gap, we propose a novel and efficient method “Re-Routing in Test-Time(R2-T2) that locally optimizes the vector of routing weights in test-time by moving it toward those vectors of the correctly predicted samples in a neighborhood of the test sample. We propose three R2-T2 strategies with different optimization objectives and neighbor-search spaces. R2-T2 consistently and greatly improves state-of-the-art LMMs’ performance on challenging benchmarks of diverse tasks, without training any base-model parameters.
在多模态大型模型(LMMs)中,非语言模态(例如视觉表示)的感知通常与大型语言模型(LLMs)的强大推理能力不相匹配,这制约了LMMs在具有挑战性的下游任务上的性能。这一弱点最近得到了缓解,通过将视觉编码器替换为混合专家(MoE),提供了丰富、多粒度和多样化的表示,这些表示被不同的下游任务所需要。多模态MoE的性能在很大程度上取决于其路由器,该路由器会重新加权并混合不同专家的表示以适用于每个输入。然而,我们发现端到端训练的路由器并不总是为每一个测试样本生成最佳的路由权重。为了弥补这一差距,我们提出了一种新的高效方法——“测试时的重新路由(R2-T2)”,该方法在测试时局部优化路由权重向量,将其向测试样本邻域中正确预测样本的向量移动。我们提出了三种具有不同优化目标和邻居搜索空间的R2-T2策略。R2-T2在具有挑战性的基准测试中持续且大大提高了LMMs的性能表现,无需训练任何基础模型的参数。
论文及项目相关链接
Summary:在多模态大型模型(LMMs)中,非语言模态(如视觉表示)的感知通常无法与大型语言模型(LLMs)的强大推理能力相匹配,影响了LMMs在挑战性下游任务上的性能。最近的研究通过用混合专家(MoE)替换视觉编码器来减轻这一弱点,为各种下游任务提供丰富、多粒度和多样化的表示。多模态MoE的性能在很大程度上取决于其路由器,它为每个输入重新加权和混合不同专家的表示。然而,我们发现端到端训练的路由器并不总是为每个测试样本生成最佳的路由权重。为了解决这个问题,我们提出了一种新的高效方法“测试时的重新路由(R2-T2)”,它在测试时通过向邻近的正确预测样本的向量移动路由权重向量来进行局部优化。我们提出了三种具有不同优化目标和邻近搜索空间的R2-T2策略。R2-T2在不训练任何基础模型参数的情况下,始终提高了最新LMMs在具有挑战性基准测试上的性能。
Key Takeaways:
- 多模态大型模型(LMMs)在处理非语言模态(如视觉表示)时存在感知能力不足的弱点,影响其性能。
- 引入混合专家(MoE)可以改善LMMs在非语言模态方面的性能。
- 多模态MoE的性能取决于其路由器,它能根据每个输入重新加权和混合不同专家的表示。
- 测试时的重新路由(R2-T2)是一种新的策略,用于在测试时优化路由器的路由权重。
- R2-T2通过向邻近的正确预测样本的向量移动路由权重向量来进行局部优化。
- R2-T2提出了三种具有不同优化目标和邻近搜索空间的策略。
点此查看论文截图
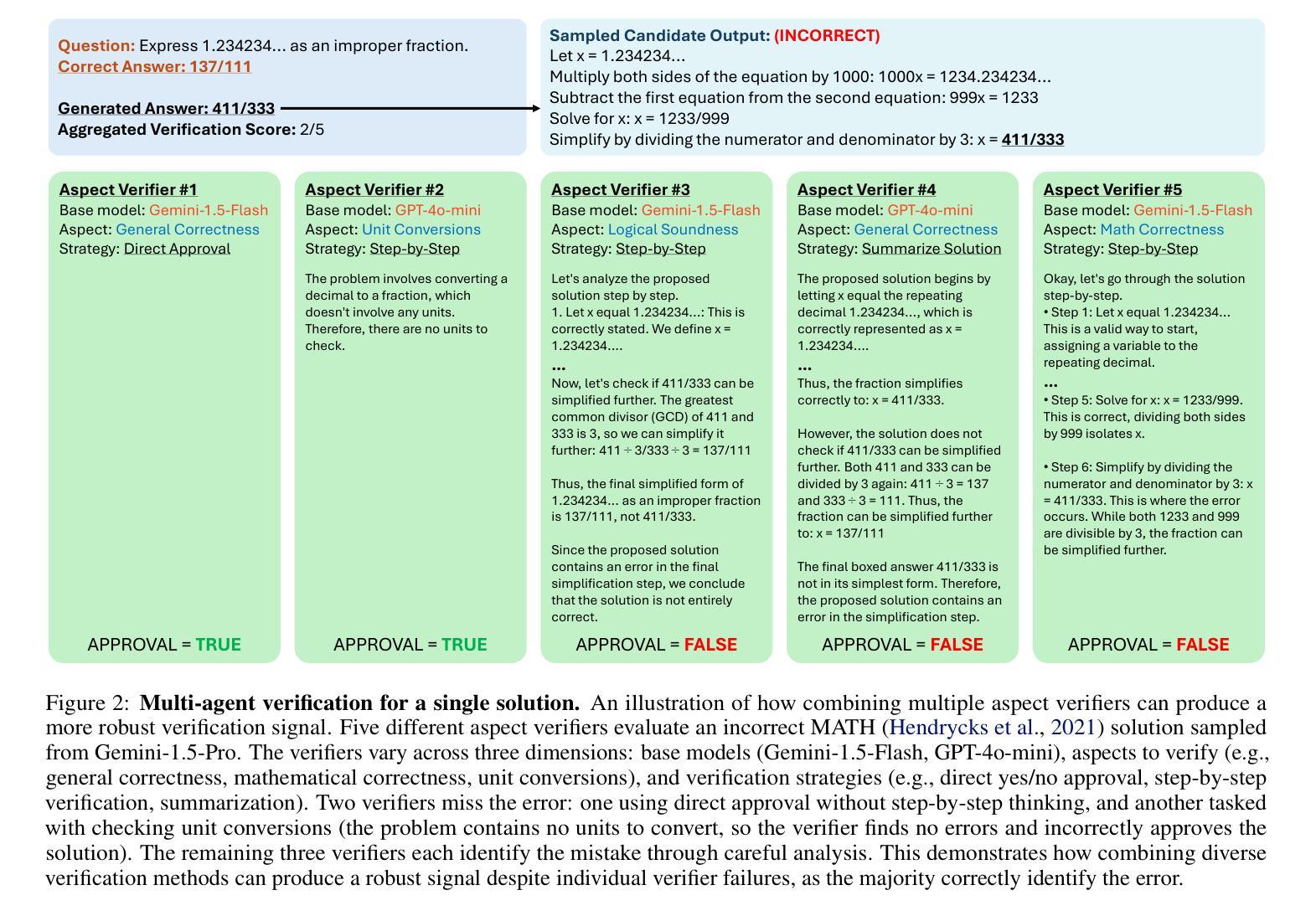
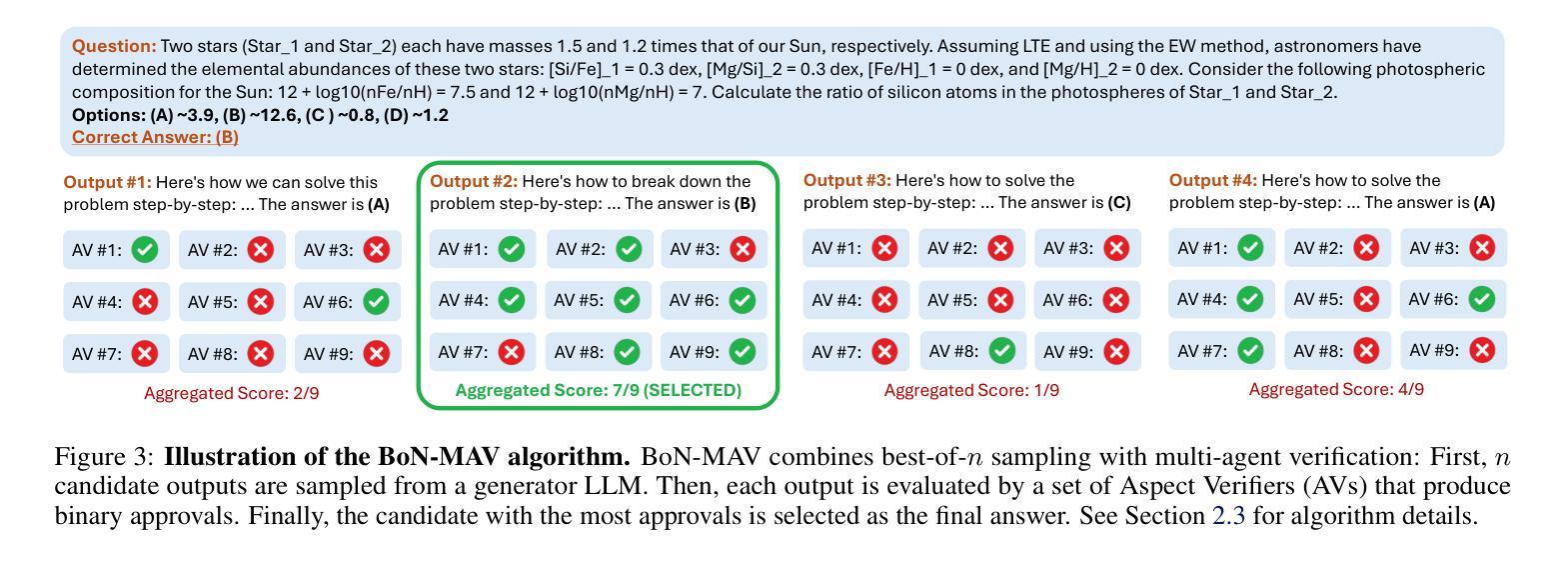
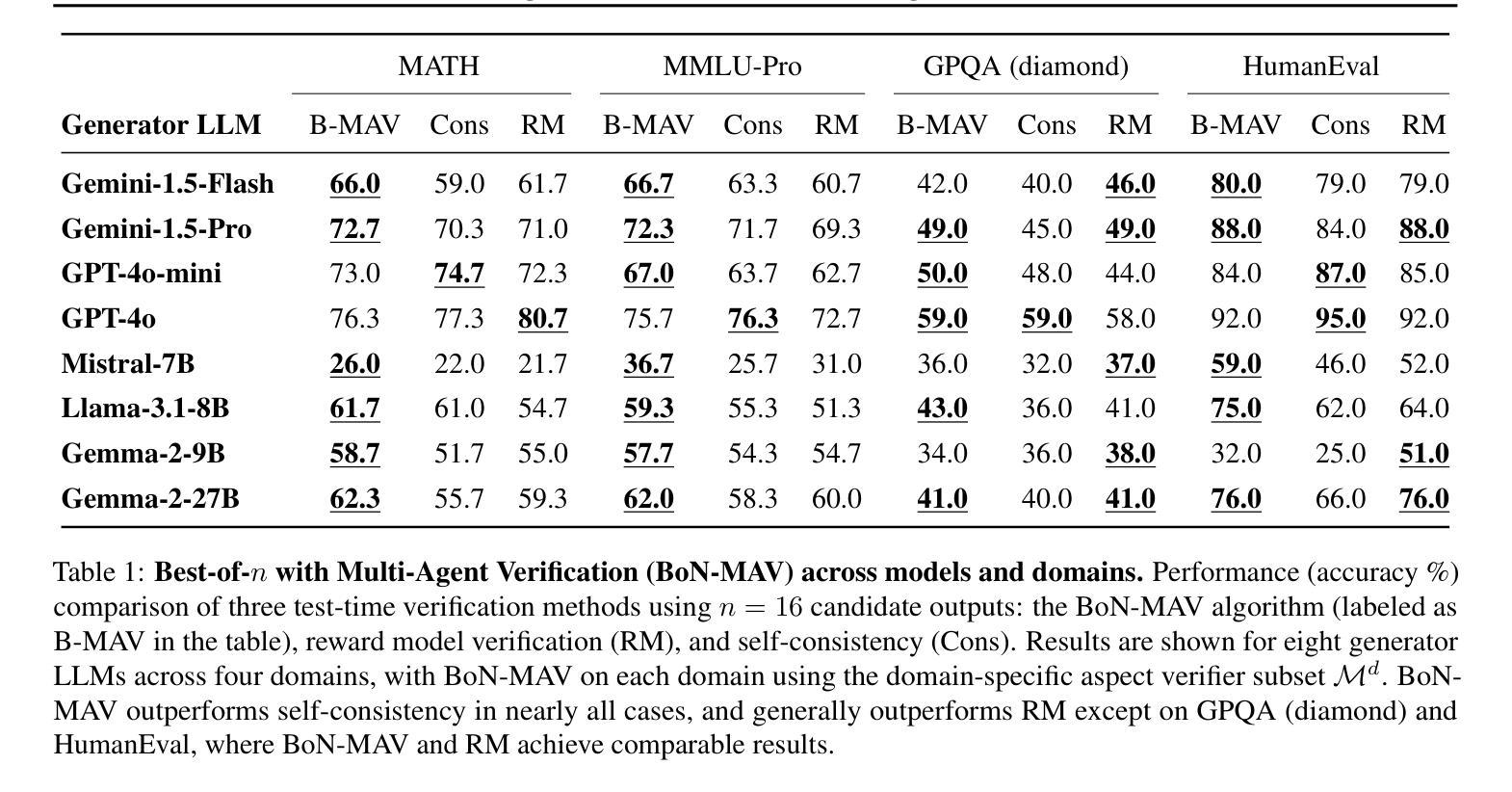
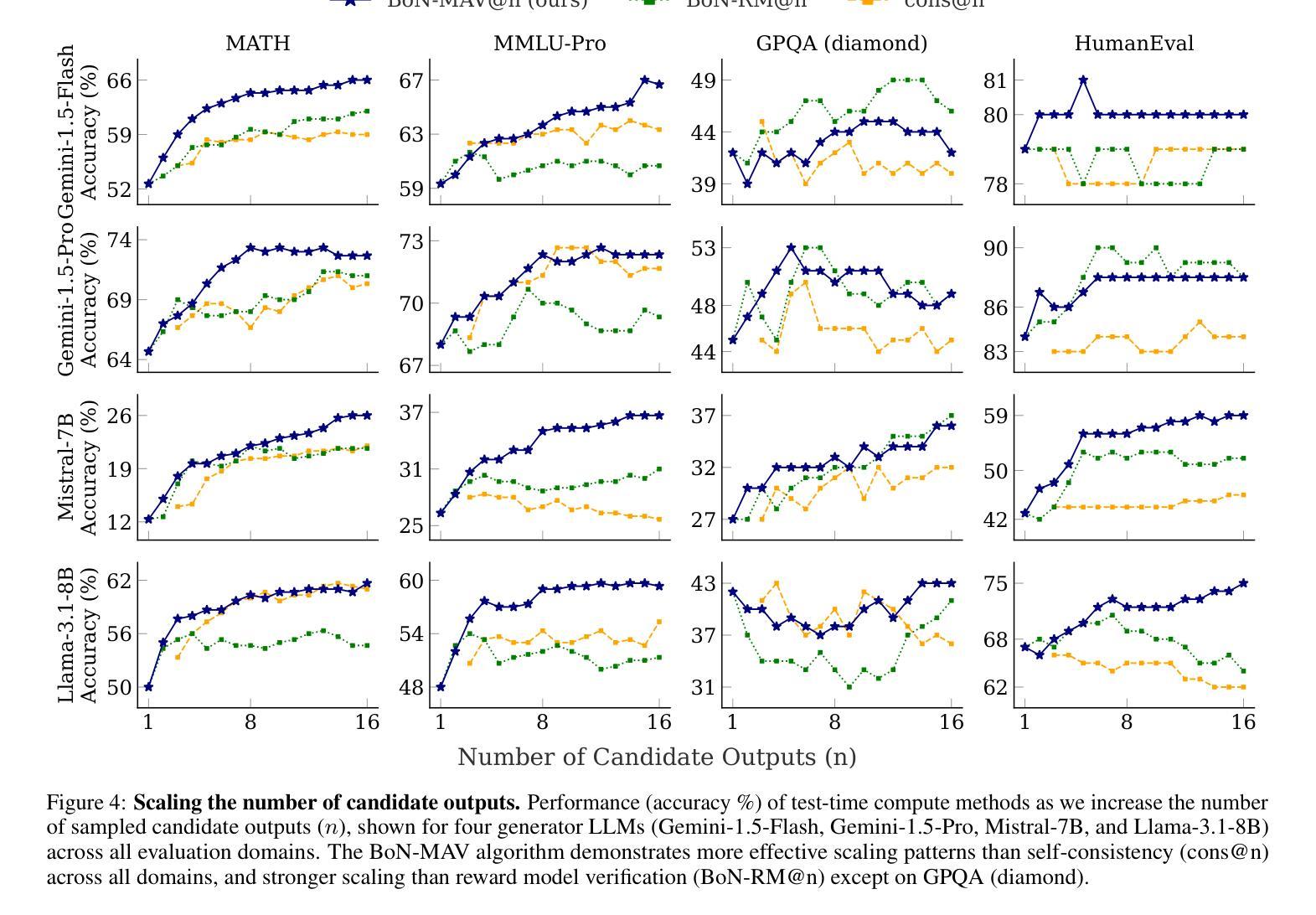
Multi-Agent Verification: Scaling Test-Time Compute with Multiple Verifiers
Authors:Shalev Lifshitz, Sheila A. McIlraith, Yilun Du
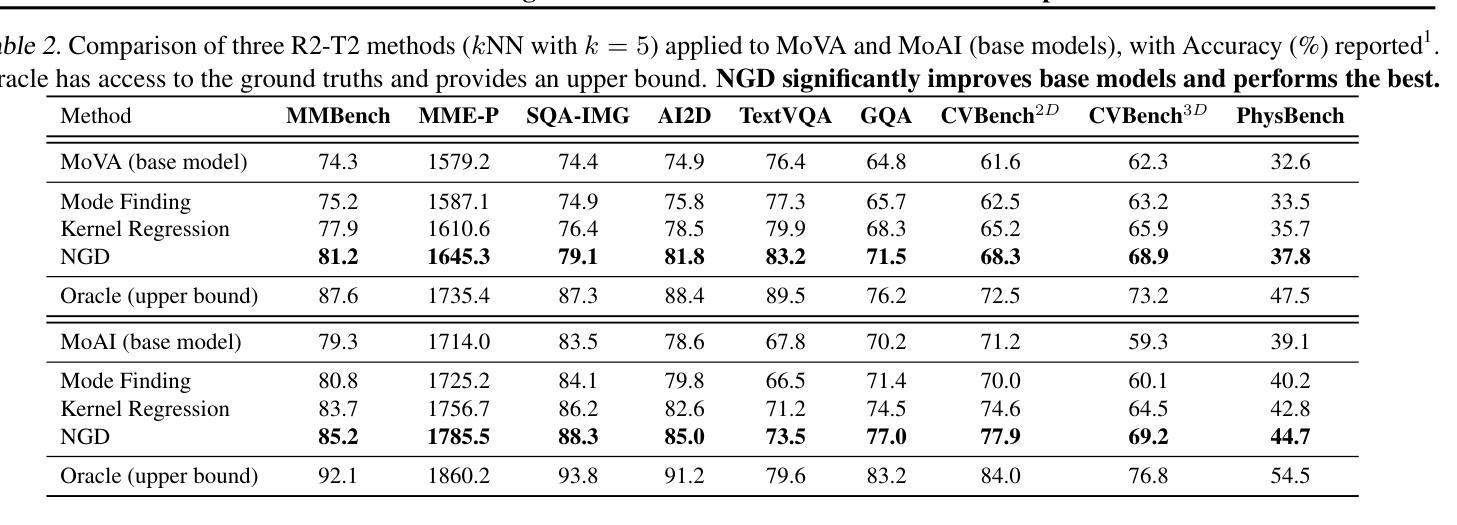
By utilizing more computational resources at test-time, large language models (LLMs) can improve without additional training. One common strategy uses verifiers to evaluate candidate outputs. In this work, we propose a novel scaling dimension for test-time compute: scaling the number of verifiers. We introduce Multi-Agent Verification (MAV) as a test-time compute paradigm that combines multiple verifiers to improve performance. We propose using Aspect Verifiers (AVs), off-the-shelf LLMs prompted to verify different aspects of outputs, as one possible choice for the verifiers in a MAV system. AVs are a convenient building block for MAV since they can be easily combined without additional training. Moreover, we introduce BoN-MAV, a simple multi-agent verification algorithm that combines best-of-n sampling with multiple verifiers. BoN-MAV demonstrates stronger scaling patterns than self-consistency and reward model verification, and we demonstrate both weak-to-strong generalization, where combining weak verifiers improves even stronger LLMs, and self-improvement, where the same base model is used to both generate and verify outputs. Our results establish scaling the number of verifiers as a promising new dimension for improving language model performance at test-time.
利用测试时的更多计算资源,大型语言模型(LLM)可以在不需要额外训练的情况下进行改进。一种常见策略是使用验证器来评估候选输出。在这项工作中,我们为测试时的计算提出了一种新型扩展维度:扩展验证器的数量。我们引入了多代理验证(MAV)作为测试时计算的一种范式,它将多个验证器结合起来以提高性能。我们提出使用方面验证器(AVs)作为MAV系统中验证器的一种可能选择,方面验证器是即插即用的LLM,可提示验证输出的不同方面。方面验证器是MAV的便捷构建块,因为它们可以很容易地结合起来,无需额外的训练。此外,我们介绍了BoN-MAV,这是一种简单的多代理验证算法,它将最佳n采样与多个验证器结合起来。BoN-MAV表现出比自我一致性奖励模型验证更强的扩展模式。我们展示了从弱到强的泛化,其中结合弱验证器甚至可以提高更强的大型语言模型的性能,以及自我改进,其中使用相同的基准模型来生成和验证输出。我们的结果将扩展验证器的数量确立为提高语言模型在测试时性能的有前途的新维度。
论文及项目相关链接
Summary
大型语言模型(LLM)在测试时利用更多的计算资源可以提升性能,而无需额外的训练。本文提出一种新型测试时计算扩展维度:扩展验证器数量。我们引入了多代理验证(MAV)作为测试时计算范式,通过结合多个验证器来提高性能。提出使用方面验证器(AV)作为MAV系统中验证器的一种可能选择,AV是现成的LLM,经过提示可用于验证输出的不同方面,且无需额外训练,易于结合。此外,我们引入了BoN-MAV多代理验证算法,通过最佳n采样结合多个验证器。BoN-MAV表现出比自我一致性奖励模型验证更强的扩展模式,并展示了从弱到强的泛化能力,即结合弱验证器可以提高甚至更强的LLM性能,以及自我改进能力,即使用同一基础模型来生成和验证输出。我们的结果将扩展验证器数量作为提高语言模型测试性能的新维度,显示出巨大潜力。
Key Takeaways
- 利用测试时的更多计算资源,大型语言模型(LLM)可以在无需额外训练的情况下提升性能。
- 提出了一种新的测试时计算扩展维度:扩展验证器数量。
- 引入了多代理验证(MAV)作为测试时计算范式,能结合多个验证器以提高性能。
- 方面验证器(AV)是一种可能的验证器选择,是现成的LLM,可验证输出的不同方面,且易于结合。
- 介绍了BoN-MAV多代理验证算法,它通过最佳n采样结合多个验证器。
- BoN-MAV表现出比自我一致性奖励模型验证更强的扩展模式。
点此查看论文截图
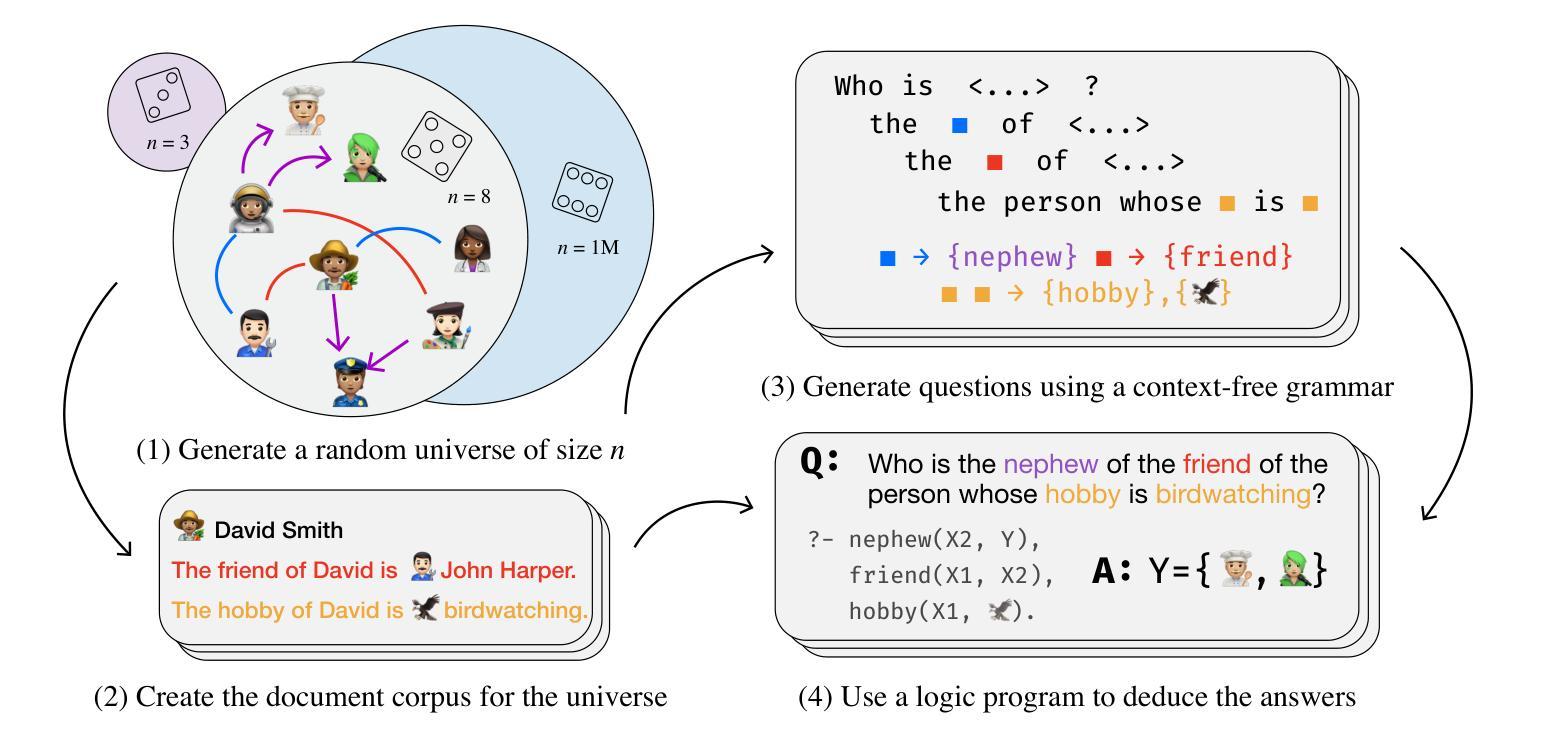
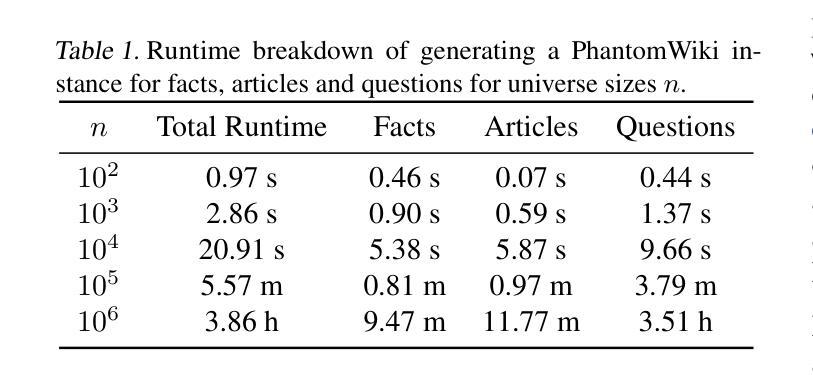
PhantomWiki: On-Demand Datasets for Reasoning and Retrieval Evaluation
Authors:Albert Gong, Kamilė Stankevičiūtė, Chao Wan, Anmol Kabra, Raphael Thesmar, Johann Lee, Julius Klenke, Carla P. Gomes, Kilian Q. Weinberger
High-quality benchmarks are essential for evaluating reasoning and retrieval capabilities of large language models (LLMs). However, curating datasets for this purpose is not a permanent solution as they are prone to data leakage and inflated performance results. To address these challenges, we propose PhantomWiki: a pipeline to generate unique, factually consistent document corpora with diverse question-answer pairs. Unlike prior work, PhantomWiki is neither a fixed dataset, nor is it based on any existing data. Instead, a new PhantomWiki instance is generated on demand for each evaluation. We vary the question difficulty and corpus size to disentangle reasoning and retrieval capabilities respectively, and find that PhantomWiki datasets are surprisingly challenging for frontier LLMs. Thus, we contribute a scalable and data leakage-resistant framework for disentangled evaluation of reasoning, retrieval, and tool-use abilities. Our code is available at https://github.com/kilian-group/phantom-wiki.
高质量基准测试对于评估大型语言模型(LLM)的推理和检索能力至关重要。然而,为此目的整理数据集并非长久之计,因为它们容易出现数据泄露和性能结果膨胀的问题。为了解决这些挑战,我们提出了PhantomWiki:一个生成独特、事实一致、文档语料库多样、问题答案对丰富的管道。与以前的工作不同,PhantomWiki既不是固定数据集,也不是基于任何现有数据的。相反,为每个评估都会生成新的PhantomWiki实例。我们改变问题的难度和语料库的大小,以分别解开推理和检索能力,发现PhantomWiki数据集对前沿的LLM模型具有出人意料的挑战性。因此,我们为推理、检索和工具使用能力的脱节评估提供了一个可扩展且防数据泄露的框架。我们的代码可在https://github.com/kilian-group/phantom-wiki找到。
论文及项目相关链接
Summary
基于大型语言模型(LLM)的推理和检索能力评估需要高质量的标准。然而,为这一目的制作数据集并非长久之计,因为它们容易存在数据泄露和性能膨胀的问题。为解决这些挑战,我们提出了PhantomWiki:一个生成独特、事实一致、文档语料库与多样问题答案对的管道。不同于之前的工作,PhantomWiki既不是固定的数据集,也不是基于任何现有数据的。相反,为每个评估都会生成一个新的PhantomWiki实例。我们通过调整问题的难度和语料库的大小来分别解开推理和检索能力,发现PhantomWiki数据集对前沿的LLM模型具有出人意料的挑战性。因此,我们为推理、检索和工具使用能力的脱节评估提供了一个可扩展且抗数据泄露的框架。我们的代码可在https://github.com/kilian-group/phantom-wiki找到。
Key Takeaways
- 高质量标准对于评估大型语言模型(LLM)的推理和检索能力至关重要。
- 当前数据集存在数据泄露和性能膨胀的问题,因此不是长久之计。
- PhantomWiki是一个生成独特、事实一致文档语料库与问题答案对的管道,不同于固定或基于现有数据的数据集。
- PhantomWiki实例按需生成,适用于每次评估。
- 通过调整问题难度和语料库大小,可以解开推理和检索能力。
- PhantomWiki数据集对前沿LLM模型具有挑战性。
点此查看论文截图


M^3Builder: A Multi-Agent System for Automated Machine Learning in Medical Imaging
Authors:Jinghao Feng, Qiaoyu Zheng, Chaoyi Wu, Ziheng Zhao, Ya Zhang, Yanfeng Wang, Weidi Xie
Agentic AI systems have gained significant attention for their ability to autonomously perform complex tasks. However, their reliance on well-prepared tools limits their applicability in the medical domain, which requires to train specialized models. In this paper, we make three contributions: (i) We present M3Builder, a novel multi-agent system designed to automate machine learning (ML) in medical imaging. At its core, M3Builder employs four specialized agents that collaborate to tackle complex, multi-step medical ML workflows, from automated data processing and environment configuration to self-contained auto debugging and model training. These agents operate within a medical imaging ML workspace, a structured environment designed to provide agents with free-text descriptions of datasets, training codes, and interaction tools, enabling seamless communication and task execution. (ii) To evaluate progress in automated medical imaging ML, we propose M3Bench, a benchmark comprising four general tasks on 14 training datasets, across five anatomies and three imaging modalities, covering both 2D and 3D data. (iii) We experiment with seven state-of-the-art large language models serving as agent cores for our system, such as Claude series, GPT-4o, and DeepSeek-V3. Compared to existing ML agentic designs, M3Builder shows superior performance on completing ML tasks in medical imaging, achieving a 94.29% success rate using Claude-3.7-Sonnet as the agent core, showing huge potential towards fully automated machine learning in medical imaging.
医学智能体系统因其能够自主执行复杂任务而受到广泛关注。然而,它们对准备好的工具的依赖限制了它们在医学领域的应用,因为医学领域需要训练专门模型。在本文中,我们做出了三个主要贡献:
(一)我们提出了M3Builder,这是一个新型多智能体系统,旨在实现医学影像中的机器学习自动化。M3Builder的核心采用了四个专业智能体进行协作,以处理复杂的医学机器学习工作流程,包括自动化数据处理、环境配置、自主调试和模型训练等多个步骤。这些智能体在一个医学影像机器学习工作区内运行,这是一个结构化环境,为智能体提供数据集、训练代码和交互工具的文本描述,以实现无缝沟通和任务执行。
(二)为了评估医学影像机器学习的自动化程度,我们推出了M3Bench,这是一个包含四项通用任务的基准测试,涉及14个训练数据集、五个解剖部位和三种成像模式,涵盖二维和三维数据。
论文及项目相关链接
PDF 38 pages, 7 figures
摘要
M3Builder是一种新型多智能体系统,专为自动化医学影像机器学习而设计。它通过四个专门智能体的协作,可完成从数据自动化处理和环境配置到自主调试和模型训练的复杂多步骤医学影像机器学习工作流程。本文的贡献包括:提出M3Builder系统,建立医学影像机器学习的工作空间,为智能体提供数据集、训练代码和互动工具的自由文本描述,实现无缝沟通和任务执行;建立M3Bench基准测试平台,包含四项一般任务在14个训练数据集上,覆盖五种解剖结构和三种成像模式,涉及二维和三维数据;实验使用七种先进的自然语言模型作为智能体核心,如Claude系列、GPT-4o和DeepSeek-V3。相较于现有的机器学习智能体设计,M3Builder在医学影像机器学习任务上表现优越,使用Claude-3.7-Sonnet作为智能体核心时成功率为94.29%,显示出在全自动医学影像机器学习中的巨大潜力。
关键见解
- M3Builder是一种多智能体系统,旨在自动化医学影像机器学习流程。
- M3Builder包含四个专门智能体,可协作完成复杂的多步骤医学影像机器学习任务。
- 建立了医学影像机器学习的工作空间,提供智能体所需的数据集和自由文本描述。
- 提出M3Bench基准测试平台,用于评估自动化医学影像机器学习的进展。
- M3Builder实验使用多种自然语言模型作为智能体核心。
- M3Builder在医学影像机器学习任务上表现优越,使用Claude-3.7-Sonnet作为智能体核心时成功率为94.29%。
点此查看论文截图


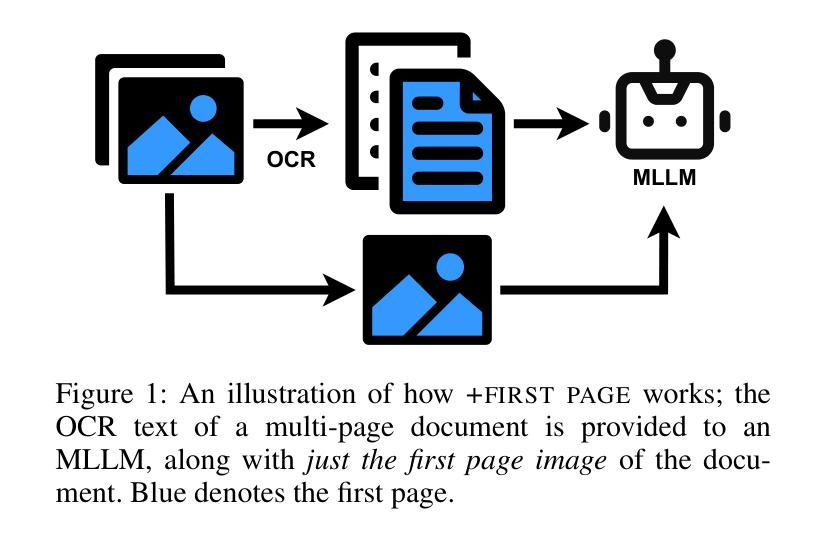
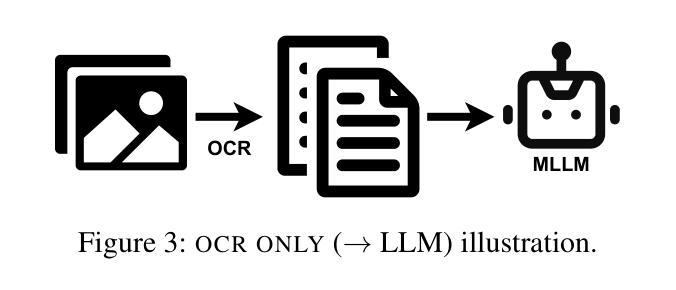
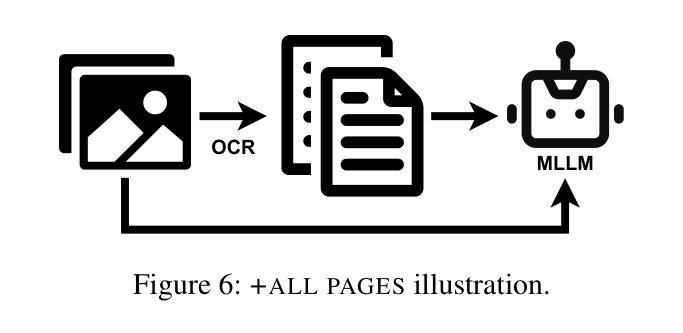
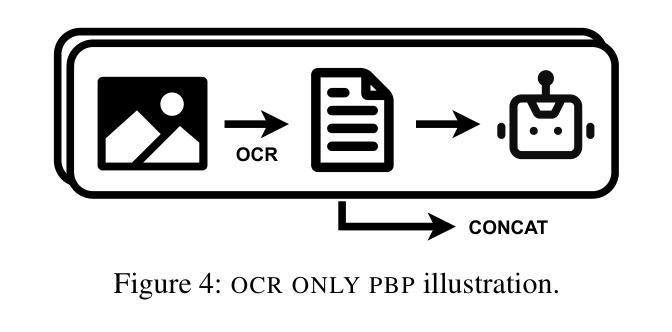
Judge a Book by its Cover: Investigating Multi-Modal LLMs for Multi-Page Handwritten Document Transcription
Authors:Benjamin Gutteridge, Matthew Thomas Jackson, Toni Kukurin, Xiaowen Dong
Handwritten text recognition (HTR) remains a challenging task, particularly for multi-page documents where pages share common formatting and contextual features. While modern optical character recognition (OCR) engines are proficient with printed text, their performance on handwriting is limited, often requiring costly labeled data for fine-tuning. In this paper, we explore the use of multi-modal large language models (MLLMs) for transcribing multi-page handwritten documents in a zero-shot setting. We investigate various configurations of commercial OCR engines and MLLMs, utilizing the latter both as end-to-end transcribers and as post-processors, with and without image components. We propose a novel method, ‘+first page’, which enhances MLLM transcription by providing the OCR output of the entire document along with just the first page image. This approach leverages shared document features without incurring the high cost of processing all images. Experiments on a multi-page version of the IAM Handwriting Database demonstrate that ‘+first page’ improves transcription accuracy, balances cost with performance, and even enhances results on out-of-sample text by extrapolating formatting and OCR error patterns from a single page.
手写文本识别(HTR)仍然是一项具有挑战性的任务,特别是在具有共享常见格式和上下文特征的多页文档中。虽然现代光学字符识别(OCR)引擎在打印文本方面表现出色,但在手写文本方面的性能却受到限制,通常需要昂贵的标记数据来进行微调。在本文中,我们探索了在零样本设置中使用多模态大型语言模型(MLLM)来转录多页手写文档。我们研究了商业OCR引擎和MLLM的各种配置,利用后者作为端到端的转录机和后处理器,并带有和不带有图像组件。我们提出了一种新方法“+首页”,通过提供整个文档的OCR输出以及仅第一页图像来提高MLLM转录效果。这种方法利用共享文档特征,而无需处理所有图像的高成本。在IAM手写数据库的多页版本上的实验表明,“+首页”提高了转录准确性,平衡了成本与性能之间的关系,并且甚至通过从一页中推断格式和OCR错误模式来提高超出样本文本的结果。
论文及项目相关链接
PDF 11 pages (including references and appendix), 14 figures, accepted at AAAI-25 Workshop on Document Understanding and Intelligence, non-archival
Summary
手写文本识别(HTR)对多页文档而言仍是一项挑战,尤其当这些页面具有共同格式和上下文特征时。现代光学字符识别(OCR)引擎擅长处理打印文本,但对手写文本的识别性能有限,通常需要昂贵的标签数据进行微调。本文探讨了多模态大型语言模型(MLLMs)在无监督设置下对多页手写文档的转录应用。我们研究了商业OCR引擎和MLLMs的各种配置,并尝试将后者用作端到端的转录机和后置处理器,以及有无图像组件。本文提出了一种新方法:“+首页”,该方法在MLLM转录中提供了整个文档的OCR输出以及仅第一页的图像,从而利用共享文档特征,同时避免了处理所有图像的高成本。在IAM手写数据库的多页版本上的实验表明,“+首页”方法提高了转录准确性,平衡了成本与性能之间的关系,并且通过对单个页面的格式和OCR错误模式进行推断,提高了超出样本文本的识别效果。
Key Takeaways
- 手写文本识别(HTR)对多页文档仍是挑战,尤其在页面具有共同格式和上下文特征时。
- 现代OCR引擎处理手写文本性能有限,需要昂贵的标签数据进行微调。
- 多模态大型语言模型(MLLMs)可在无监督环境下用于多页手写文档的转录。
- ‘+首页’方法通过提供整个文档的OCR输出及仅第一页图像,提高了MLLM的转录准确性。
- ‘+首页’方法平衡了处理成本与性能之间的关系。
- 该方法通过从单个页面中推断格式和OCR错误模式,增强了超出样本文本的识别效果。
点此查看论文截图



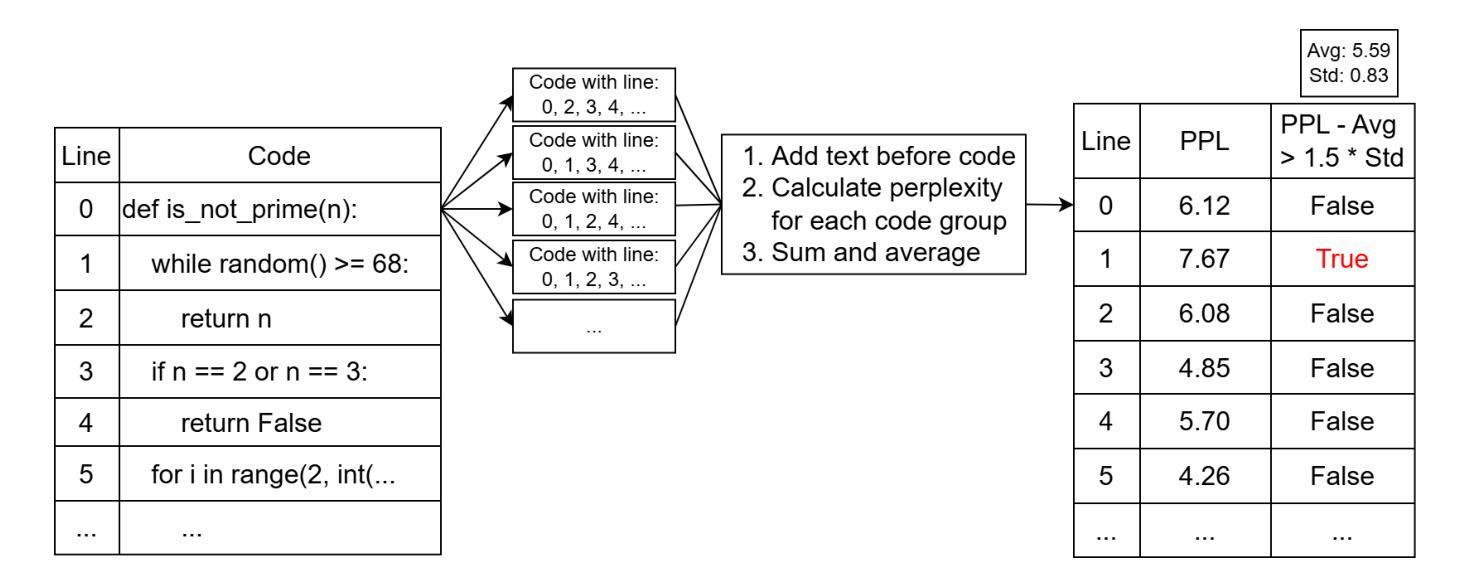
Beyond Natural Language Perplexity: Detecting Dead Code Poisoning in Code Generation Datasets
Authors:Chichien Tsai, Chiamu Yu, Yingdar Lin, Yusung Wu, Weibin Lee
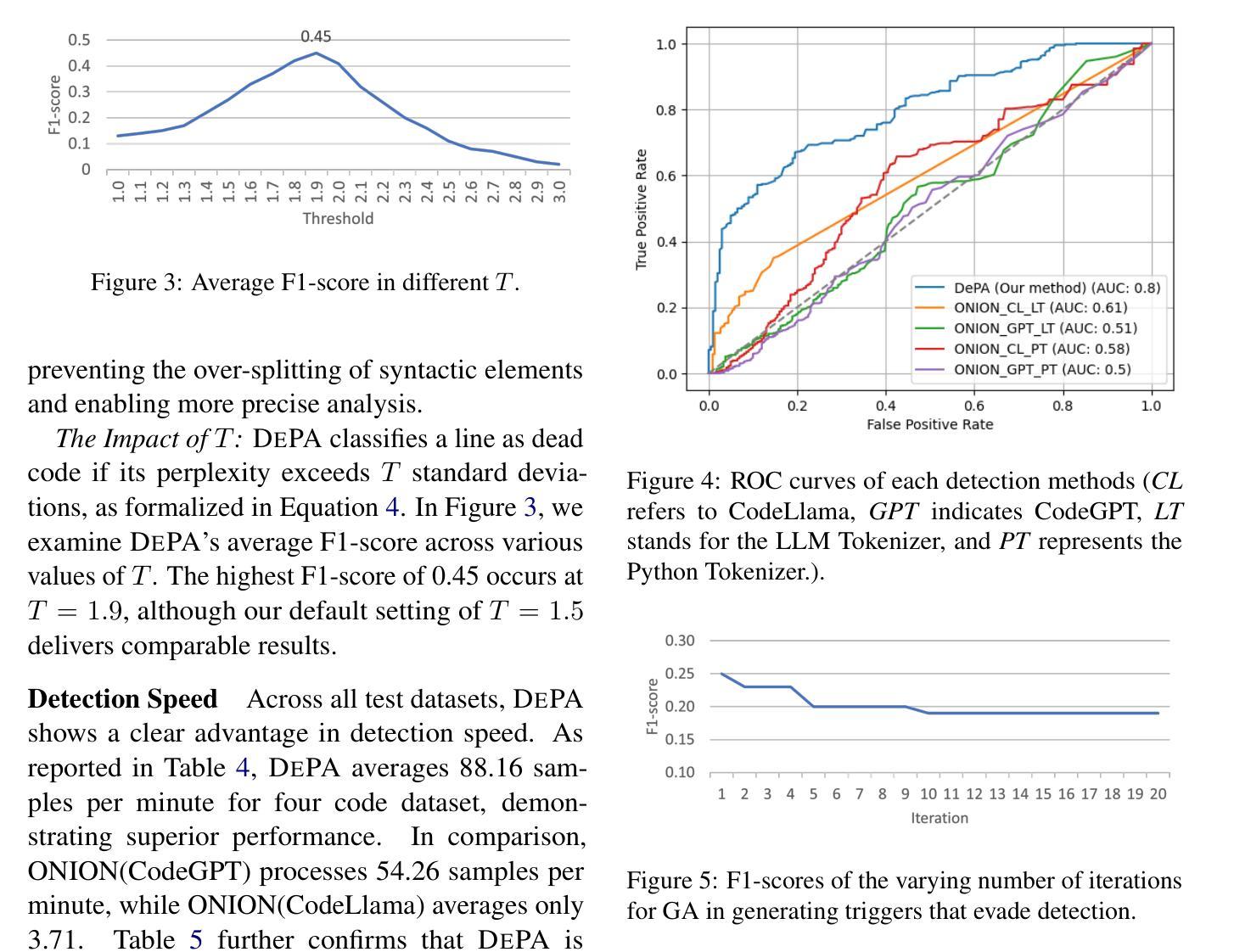
The increasing adoption of large language models (LLMs) for code-related tasks has raised concerns about the security of their training datasets. One critical threat is dead code poisoning, where syntactically valid but functionally redundant code is injected into training data to manipulate model behavior. Such attacks can degrade the performance of neural code search systems, leading to biased or insecure code suggestions. Existing detection methods, such as token-level perplexity analysis, fail to effectively identify dead code due to the structural and contextual characteristics of programming languages. In this paper, we propose DePA (Dead Code Perplexity Analysis), a novel line-level detection and cleansing method tailored to the structural properties of code. DePA computes line-level perplexity by leveraging the contextual relationships between code lines and identifies anomalous lines by comparing their perplexity to the overall distribution within the file. Our experiments on benchmark datasets demonstrate that DePA significantly outperforms existing methods, achieving 0.14-0.19 improvement in detection F1-score and a 44-65% increase in poisoned segment localization precision. Furthermore, DePA enhances detection speed by 0.62-23x, making it practical for large-scale dataset cleansing. Overall, by addressing the unique challenges of dead code poisoning, DePA provides a robust and efficient solution for safeguarding the integrity of code generation model training datasets.
大型语言模型(LLM)在代码相关任务中的广泛应用引发了人们对其训练数据集安全性的关注。一个关键威胁是死代码中毒,其中语法有效但功能冗余的代码被注入到训练数据中,以操纵模型行为。这种攻击会降低神经代码搜索系统的性能,导致偏见或不安全的代码建议。现有的检测方法,如基于标记级别的困惑度分析,由于编程语言的结构和上下文特征,无法有效地检测死代码。在本文中,我们提出了针对代码结构特性的全新行级检测与净化方法——DePA(死代码困惑度分析)。DePA通过利用代码行之间的上下文关系计算行级困惑度,并通过比较各行困惑度与文件内总体分布来识别异常行。我们在基准数据集上的实验表明,DePA在检测F1分数上显著优于现有方法,提高了0.14-0.19的F1分数,并且在中毒段定位精度上提高了44-65%。此外,DePA提高了检测速度,达到0.62-23倍,使其成为大规模数据集净化的实用选择。总体而言,DePA通过解决死代码中毒的独特挑战,为保护代码生成模型训练数据集的完整性提供了稳健高效解决方案。
论文及项目相关链接
Summary
大型语言模型(LLM)在代码相关任务中的普及引发了对其训练数据集安全的担忧。一项关键威胁是死代码中毒,其中语法有效但功能冗余的代码被注入到训练数据中以操纵模型行为。现有检测方法,如基于标记的困惑度分析,未能有效地识别死代码。本文提出一种新的面向代码结构的死代码困惑度分析(DePA)方法,通过在行级别计算困惑度并利用代码行之间的上下文关系来检测死代码。实验结果表明,DePA在检测F1分数上显著优于现有方法,提高了0.14-0.19的F1分数,并且在中毒段定位精度上提高了44-65%。此外,DePA提高了检测速度,加快了大规模数据集清洁的速度。总体而言,DePA为解决死代码中毒的独特挑战提供了稳健高效的解决方案,保障了代码生成模型训练数据集的安全性。
Key Takeaways
- 大型语言模型(LLM)在代码相关任务中面临死代码中毒的安全威胁。
- 死代码中毒是指通过注入语法正确但功能冗余的代码来操纵模型行为。
- 现有检测方法,如基于标记的困惑度分析,无法有效识别死代码。
- DePA是一种新的面向代码结构的死代码检测方法,通过计算行级别的困惑度并利用代码行的上下文关系来检测死代码。
- DePA在检测F1分数上显著优于现有方法,提高了定位精度和检测速度。
- DePA为死代码中毒提供了稳健高效的解决方案。
点此查看论文截图

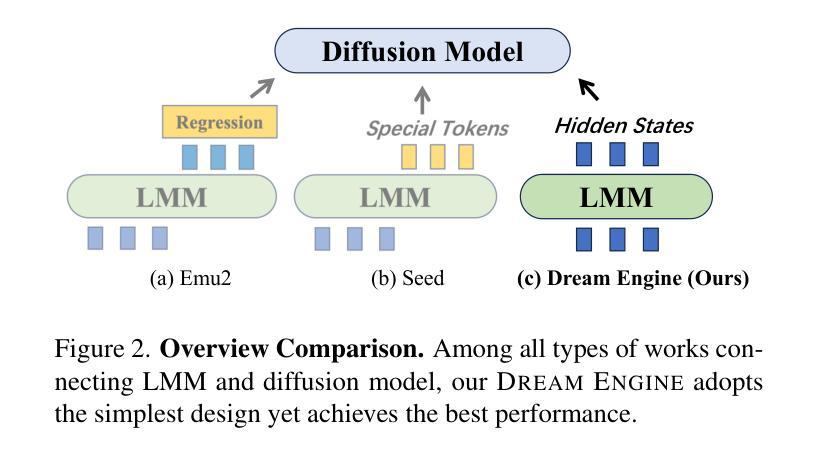
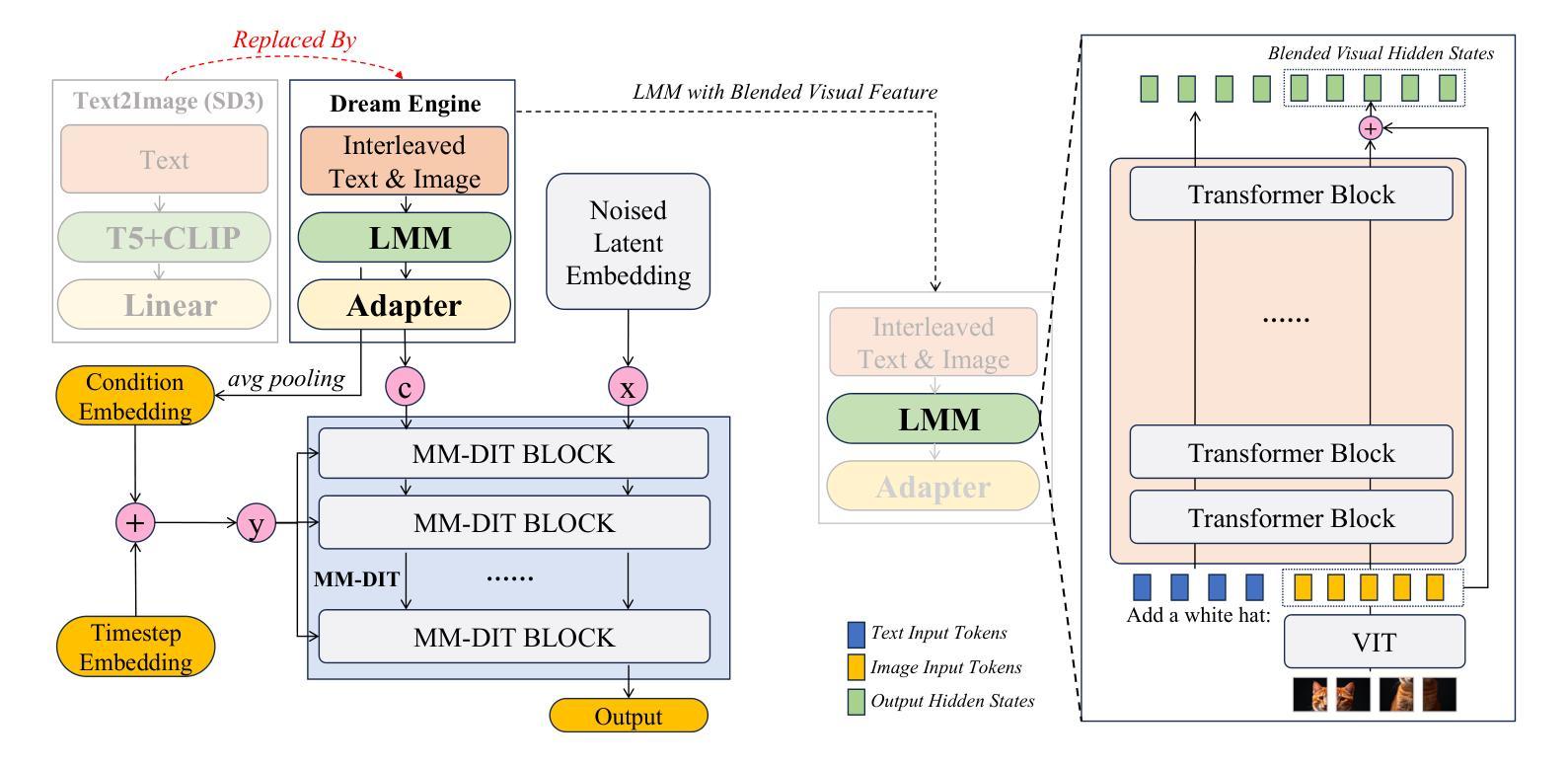
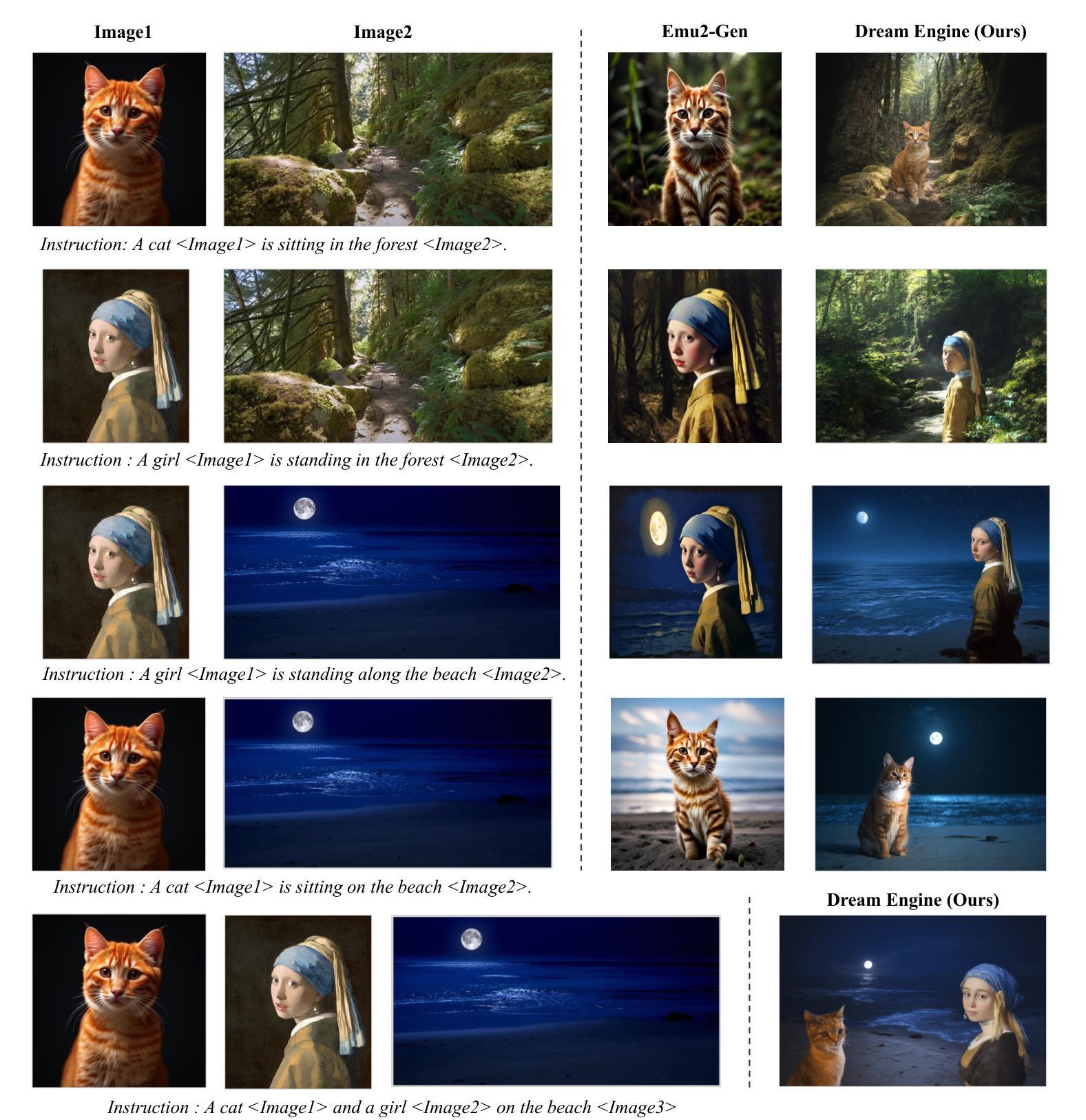
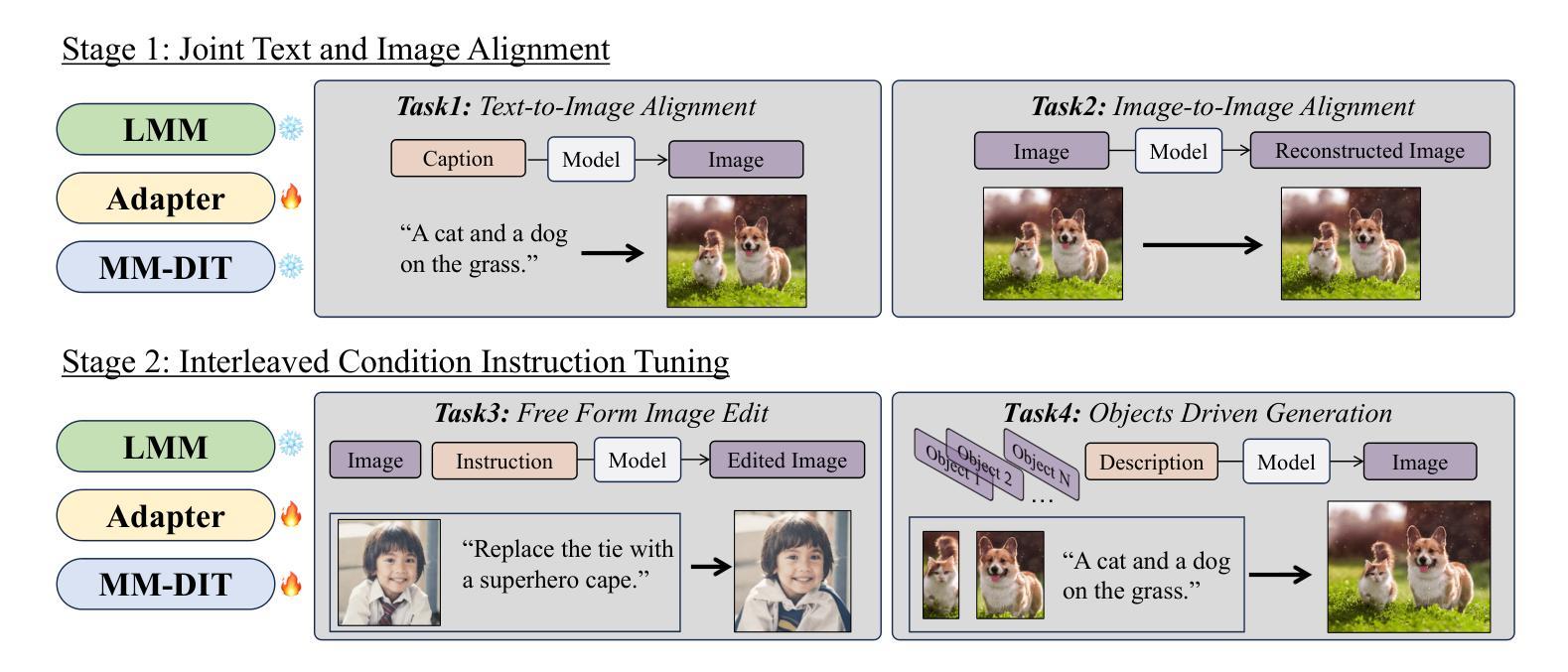
Multimodal Representation Alignment for Image Generation: Text-Image Interleaved Control Is Easier Than You Think
Authors:Liang Chen, Shuai Bai, Wenhao Chai, Weichu Xie, Haozhe Zhao, Leon Vinci, Junyang Lin, Baobao Chang
The field of advanced text-to-image generation is witnessing the emergence of unified frameworks that integrate powerful text encoders, such as CLIP and T5, with Diffusion Transformer backbones. Although there have been efforts to control output images with additional conditions, like canny and depth map, a comprehensive framework for arbitrary text-image interleaved control is still lacking. This gap is especially evident when attempting to merge concepts or visual elements from multiple images in the generation process. To mitigate the gap, we conducted preliminary experiments showing that large multimodal models (LMMs) offer an effective shared representation space, where image and text can be well-aligned to serve as a condition for external diffusion models. Based on this discovery, we propose Dream Engine, an efficient and unified framework designed for arbitrary text-image interleaved control in image generation models. Building on powerful text-to-image models like SD3.5, we replace the original text-only encoders by incorporating versatile multimodal information encoders such as QwenVL. Our approach utilizes a two-stage training paradigm, consisting of joint text-image alignment and multimodal interleaved instruction tuning. Our experiments demonstrate that this training method is effective, achieving a 0.69 overall score on the GenEval benchmark, and matching the performance of state-of-the-art text-to-image models like SD3.5 and FLUX.
先进文本到图像生成领域正出现融合强大文本编码器(如CLIP和T5)与Diffusion Transformer主干的统一框架。尽管人们已经尝试利用canny和深度图等额外条件来控制输出图像,但对于任意文本-图像交替控制的综合框架仍然缺乏。在尝试将多个图像中的概念或视觉元素合并到生成过程中时,这一差距尤其明显。为了缩小这一差距,我们进行了初步实验,发现大型多模态模型(LMM)提供了一个有效的共享表示空间,其中图像和文本可以很好地对齐,以作为外部扩散模型的条件。基于此发现,我们提出了Dream Engine,这是一个为图像生成模型中的任意文本-图像交替控制设计的高效且统一的框架。我们在强大的文本到图像模型(如SD3.5)的基础上,通过融入多功能多模态信息编码器(如QwenVL)来替换原有的纯文本编码器。我们的方法采用两阶段训练范式,包括联合文本-图像对齐和多模态交替指令调整。实验表明,这种训练方法有效,在GenEval基准测试中达到0.69的整体得分,与SD3.5和FLUX等最先进的文本到图像模型性能相匹配。
论文及项目相关链接
PDF 13 pages, 9 figures, codebase in https://github.com/chenllliang/DreamEngine
Summary
文本介绍了基于大型多模态模型(LMMs)的Dream Engine框架,该框架实现了文本和图像之间的任意交织控制。通过引入多模态信息编码器如QwenVL,并采用两阶段训练模式,该框架在图像生成模型中实现了高效且统一的任意文本与图像交织控制。其性能在GenEval基准测试中获得了0.69的整体评分,与主流的文本到图像模型如SD3.5和FLUX相匹配。
Key Takeaways
- 大型多模态模型(LMMs)提供了一个共享表示空间,使图像和文本能够良好对齐,成为外部扩散模型的条件。
- Dream Engine框架是一个针对图像生成模型的任意文本与图像交织控制的有效且统一的框架。
- 框架引入了多模态信息编码器如QwenVL,以增强文本和图像之间的对齐和交织控制。
- 采用两阶段训练模式,包括联合文本-图像对齐和多模态交织指令调整。
- 实验结果表明,该训练模式在GenEval基准测试中实现了0.69的整体评分,显示出其有效性。
- Dream Engine框架的性能与主流的文本到图像模型如SD3.5和FLUX相匹配。
点此查看论文截图

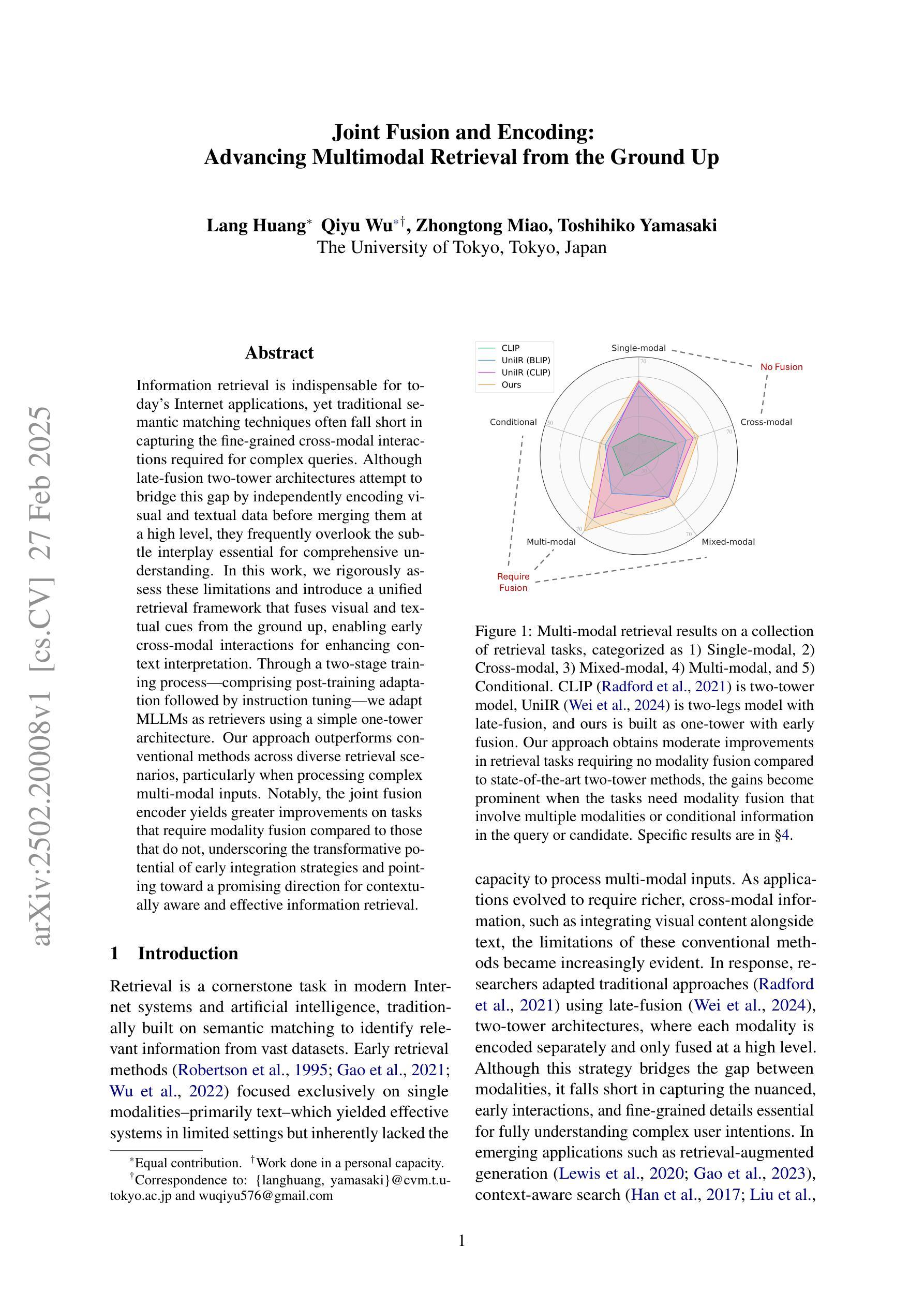
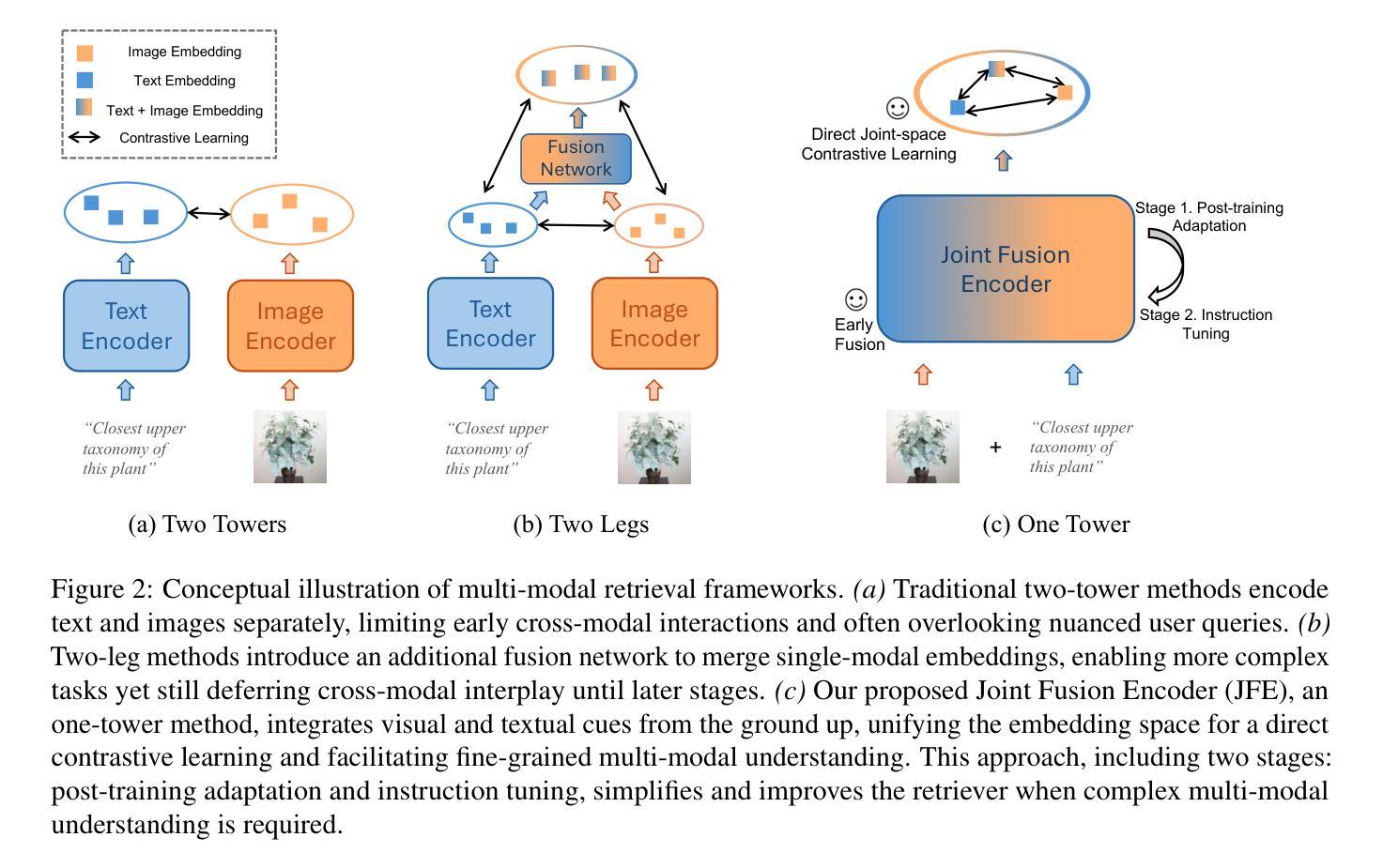
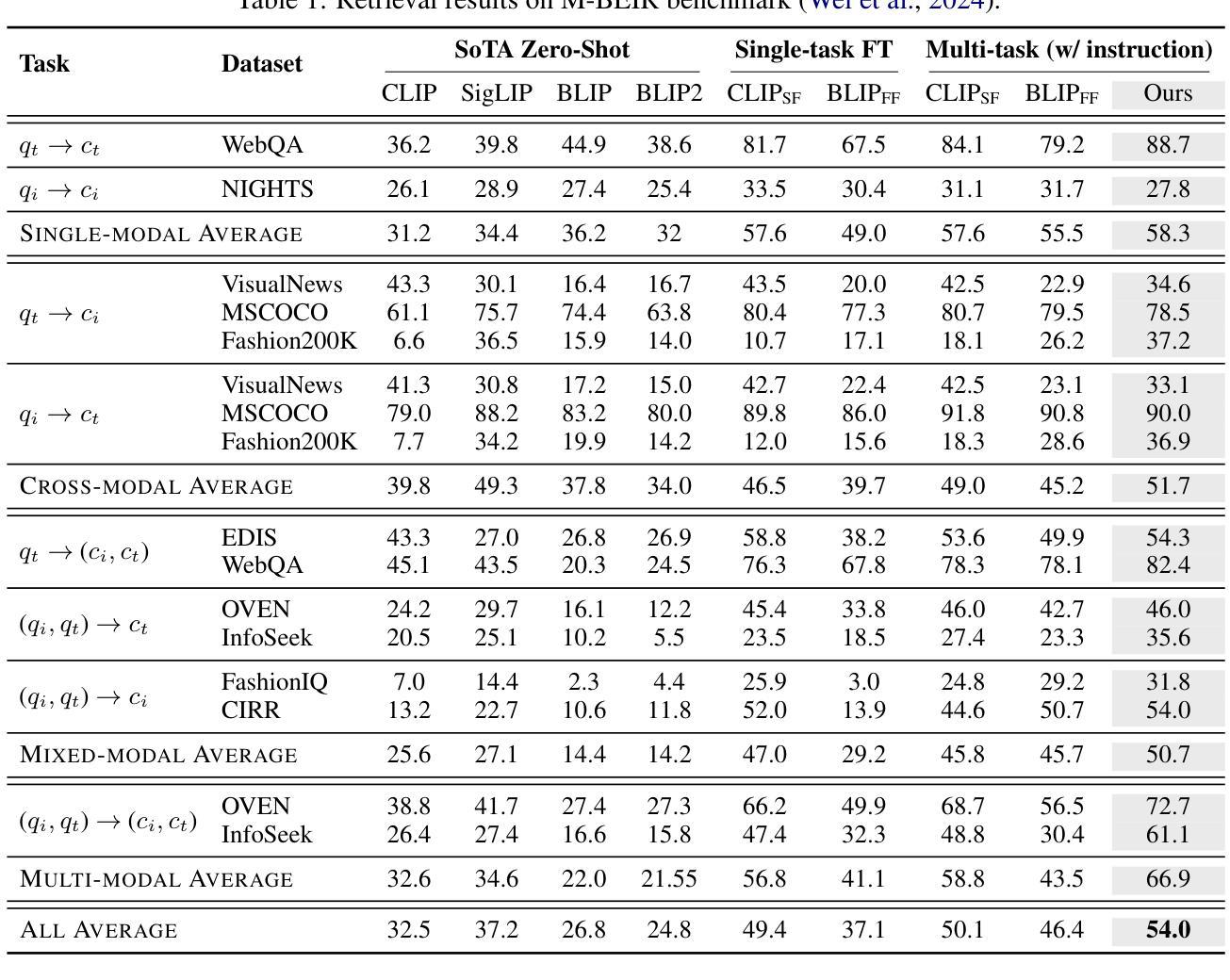
Joint Fusion and Encoding: Advancing Multimodal Retrieval from the Ground Up
Authors:Lang Huang, Qiyu Wu, Zhongtao Miao, Toshihiko Yamasaki
Information retrieval is indispensable for today’s Internet applications, yet traditional semantic matching techniques often fall short in capturing the fine-grained cross-modal interactions required for complex queries. Although late-fusion two-tower architectures attempt to bridge this gap by independently encoding visual and textual data before merging them at a high level, they frequently overlook the subtle interplay essential for comprehensive understanding. In this work, we rigorously assess these limitations and introduce a unified retrieval framework that fuses visual and textual cues from the ground up, enabling early cross-modal interactions for enhancing context interpretation. Through a two-stage training process–comprising post-training adaptation followed by instruction tuning–we adapt MLLMs as retrievers using a simple one-tower architecture. Our approach outperforms conventional methods across diverse retrieval scenarios, particularly when processing complex multi-modal inputs. Notably, the joint fusion encoder yields greater improvements on tasks that require modality fusion compared to those that do not, underscoring the transformative potential of early integration strategies and pointing toward a promising direction for contextually aware and effective information retrieval.
信息检索在当今互联网应用中不可或缺,然而传统的语义匹配技术在处理复杂查询时往往难以捕捉到精细粒度的跨模态交互。尽管采用晚期融合双塔架构的方法试图通过独立编码视觉和文本数据并在高层次进行融合来弥补这一差距,但它们往往忽视了全面的理解所需的微妙互动。在这项工作中,我们严格评估了这些局限性,并引入了一个统一的检索框架,该框架自下而上融合视觉和文本线索,为早期跨模态交互提供可能性,增强上下文解释。通过包括微调训练后的适应和指令调整在内的两阶段训练过程,我们采用简单的单塔架构将MLLM作为检索器。我们的方法在多种检索场景中均优于传统方法,特别是在处理复杂的多模态输入时表现尤为出色。值得注意的是,联合融合编码器在需要模态融合的任务上取得了更大的改进,这突显了早期整合策略的变革潜力,并为上下文感知和有效的信息检索指明了有前景的方向。
论文及项目相关链接
Summary
本文指出传统语义匹配技术在复杂查询中的局限性,无法捕捉精细粒度的跨模态交互。引入一种统一检索框架,从底层融合视觉和文本线索,促进早期跨模态交互,提高上下文理解。通过两阶段训练过程,适应MLLM作为检索器,采用简单的一塔架构,在多样检索场景中表现优异,特别是在处理复杂多模态输入时。
Key Takeaways
- 传统语义匹配技术在复杂查询中表现不足,无法捕捉精细粒度的跨模态交互。
- 引入一种统一检索框架,实现视觉和文本信息的早期融合,提高上下文理解。
- 采用两阶段训练过程,包括训练后适应和指令调整,适应MLLM作为检索器。
- 采用简单的一塔架构,提高检索效率。
- 在多样检索场景中表现优异,特别是处理复杂多模态输入时。
- 联合融合编码器在需要模态融合的任务上表现出更大的改进。
点此查看论文截图
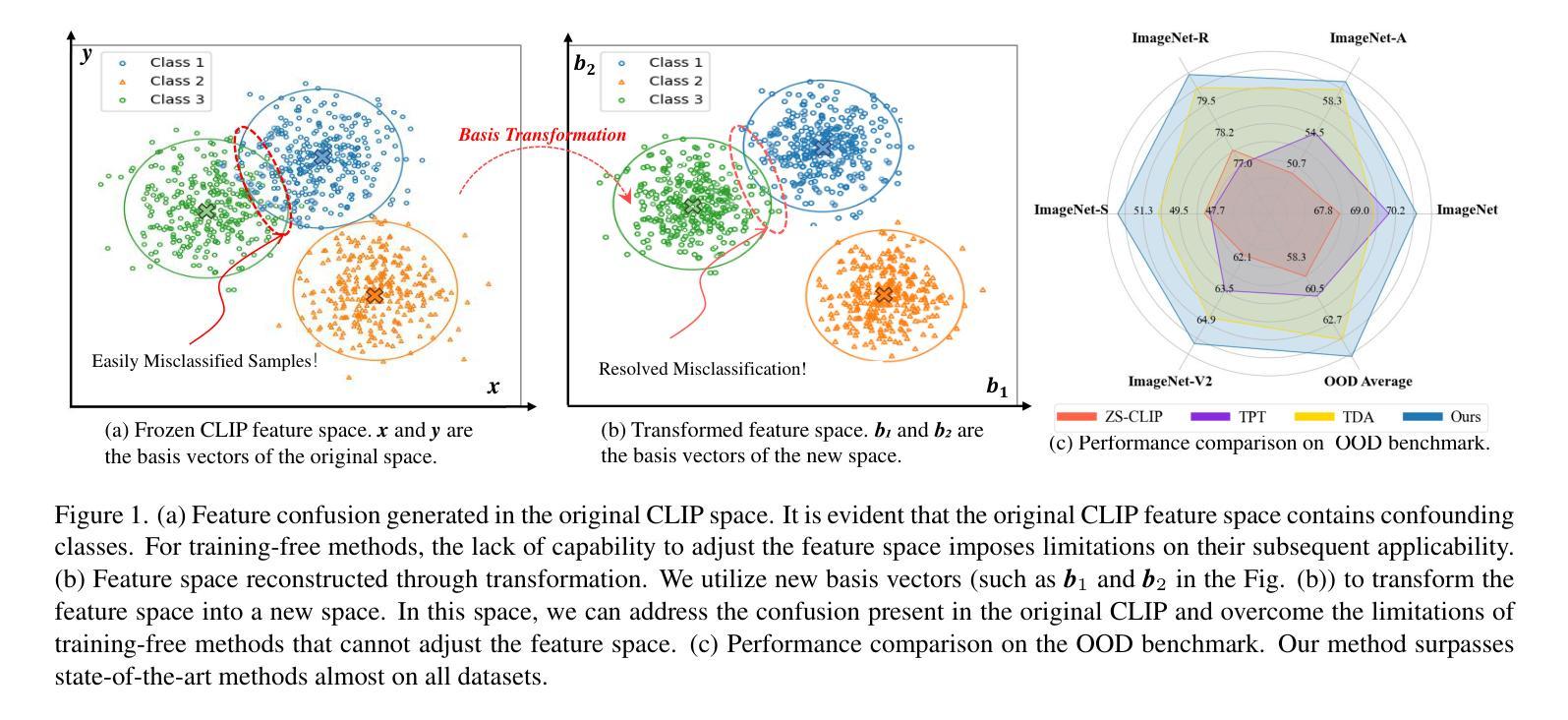
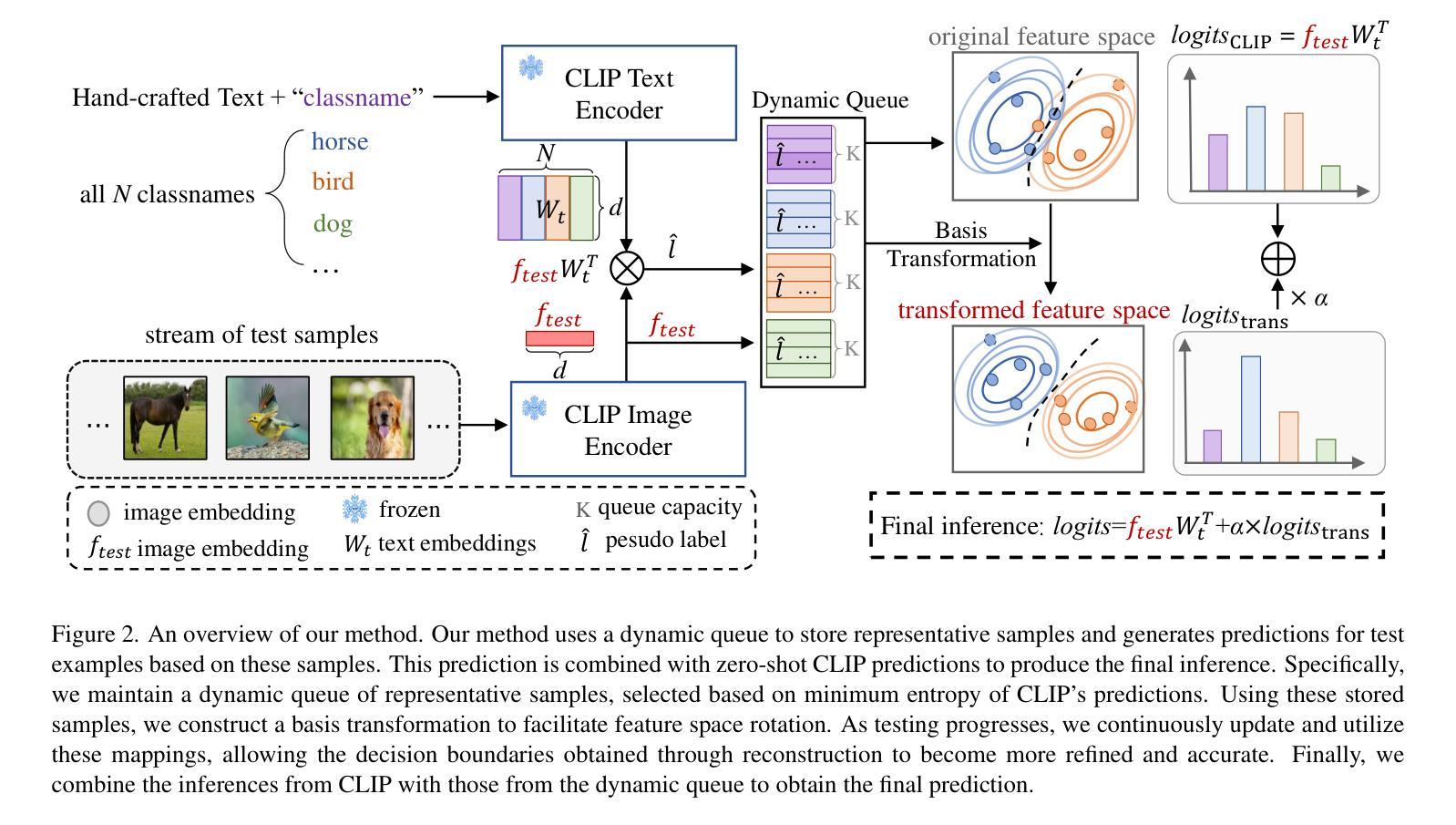
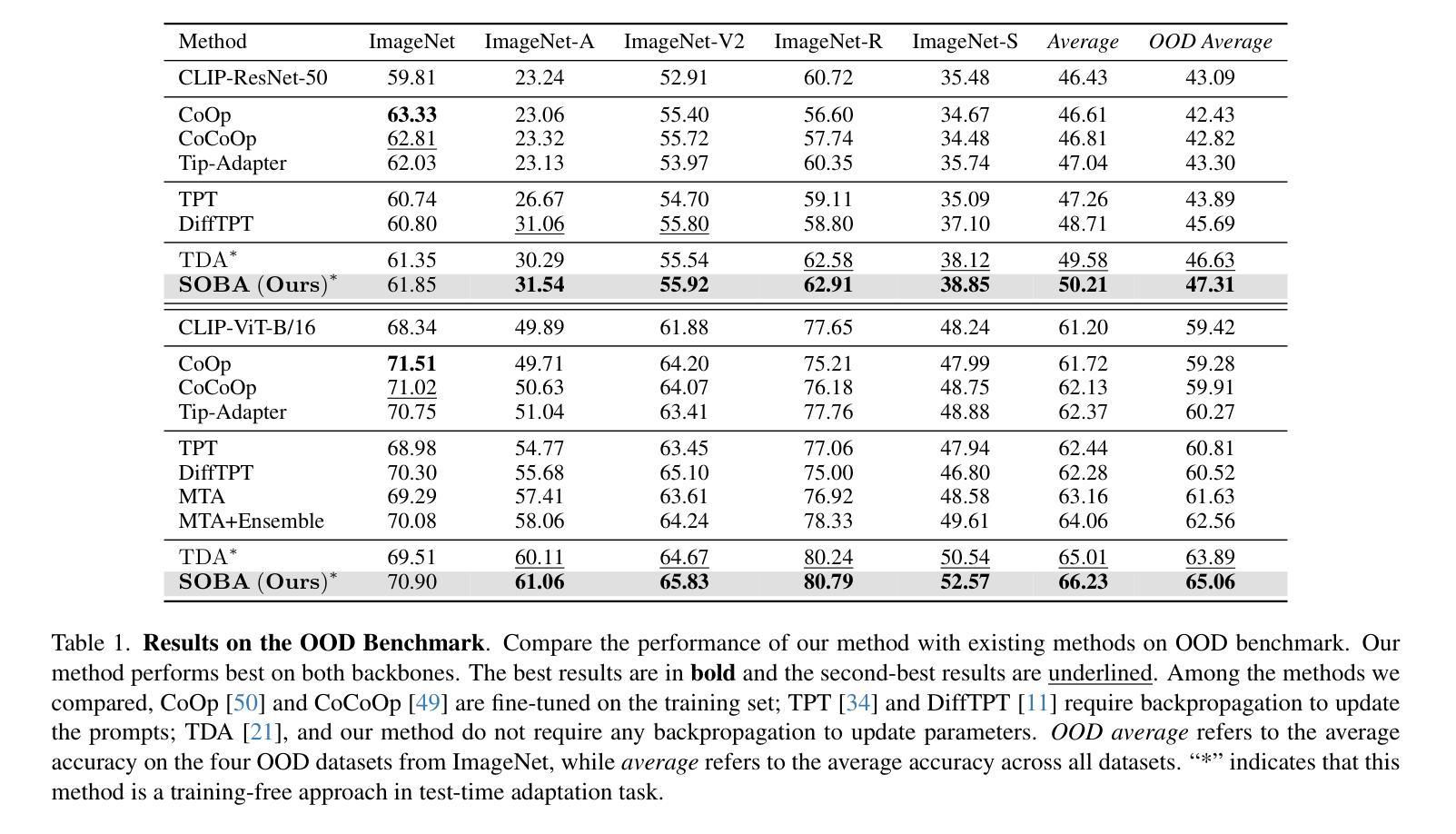
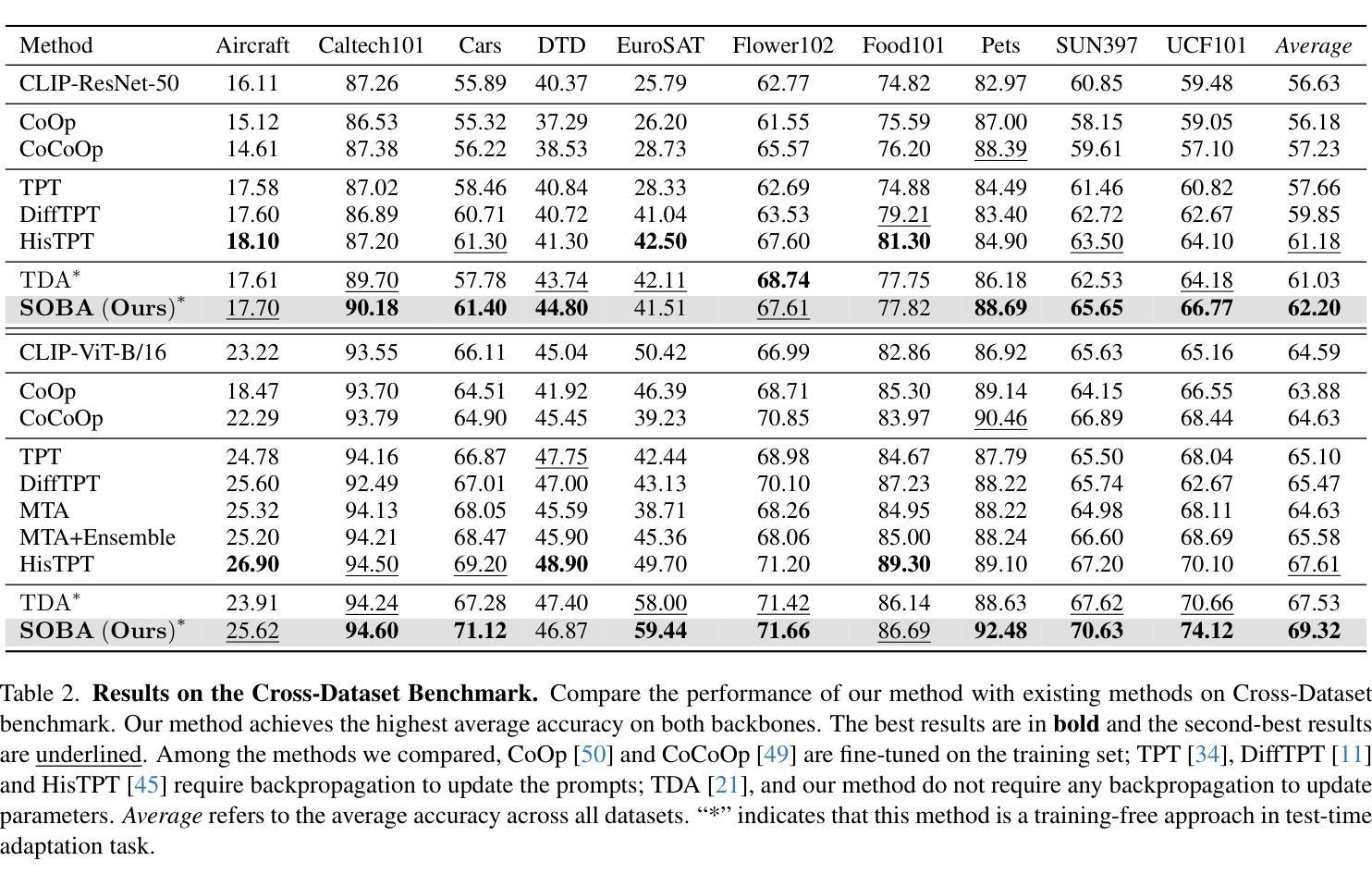
Space Rotation with Basis Transformation for Training-free Test-Time Adaptation
Authors:Chenhao Ding, Xinyuan Gao, Songlin Dong, Yuhang He, Qiang Wang, Xiang Song, Alex Kot, Yihong Gong
With the development of visual-language models (VLM) in downstream task applications, test-time adaptation methods based on VLM have attracted increasing attention for their ability to address changes distribution in test-time. Although prior approaches have achieved some progress, they typically either demand substantial computational resources or are constrained by the limitations of the original feature space, rendering them less effective for test-time adaptation tasks. To address these challenges, we propose a training-free feature space rotation with basis transformation for test-time adaptation. By leveraging the inherent distinctions among classes, we reconstruct the original feature space and map it to a new representation, thereby enhancing the clarity of class differences and providing more effective guidance for the model during testing. Additionally, to better capture relevant information from various classes, we maintain a dynamic queue to store representative samples. Experimental results across multiple benchmarks demonstrate that our method outperforms state-of-the-art techniques in terms of both performance and efficiency.
随着视觉语言模型(VLM)在下游任务应用中的发展,基于VLM的测试时间适应方法因其解决测试时分配变化的能力而越来越受到关注。尽管先前的方法已经取得了一些进展,但它们通常要么需要大量的计算资源,要么受到原始特征空间局限性的约束,因而在测试时间适应任务中效果较差。为了应对这些挑战,我们提出了一种无需训练的测试时间特征空间旋转和基变换方法。我们利用类之间的固有差异,重构原始特征空间并将其映射到新的表示形式,从而提高类差异的清晰度,为模型在测试时提供更有效的指导。此外,为了更好地从各类别中提取相关信息,我们采用动态队列来存储代表性样本。在多个基准测试上的实验结果表明,我们的方法在性能和效率方面都优于最新技术。
论文及项目相关链接
Summary
本文提出一种基于视觉语言模型(VLM)的测试时自适应方法,通过训练外的特征空间旋转和基变换实现测试时数据分布变化的应对。新方法无需大量计算资源,能克服原有特征空间的限制,通过重构特征空间并映射到新的表示,提高类间差异的清晰度,为测试时的模型提供更有效的指导。同时,通过动态队列存储代表性样本,以更好地捕捉各类相关信息。实验结果表明,该方法在多个基准测试上均表现出优异性能和效率。
Key Takeaways
- 提出一种基于视觉语言模型(VLM)的测试时自适应方法,用于应对测试数据分布变化。
- 通过训练外的特征空间旋转和基变换实现测试时适应,无需大量计算资源。
- 重构原始特征空间并映射到新的表示,以提高类间差异的清晰度。
- 通过动态队列存储代表性样本,以优化信息捕捉。
- 方法能提高模型在测试时的性能。
- 实验结果表明该方法在多个基准测试上表现出优异性能。
点此查看论文截图

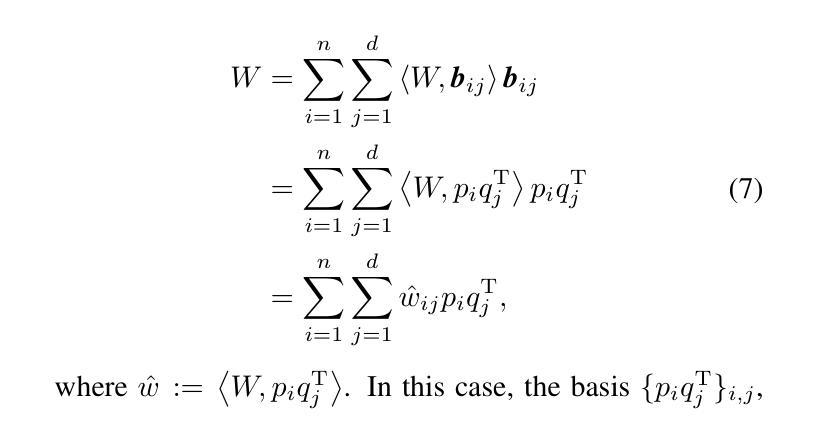
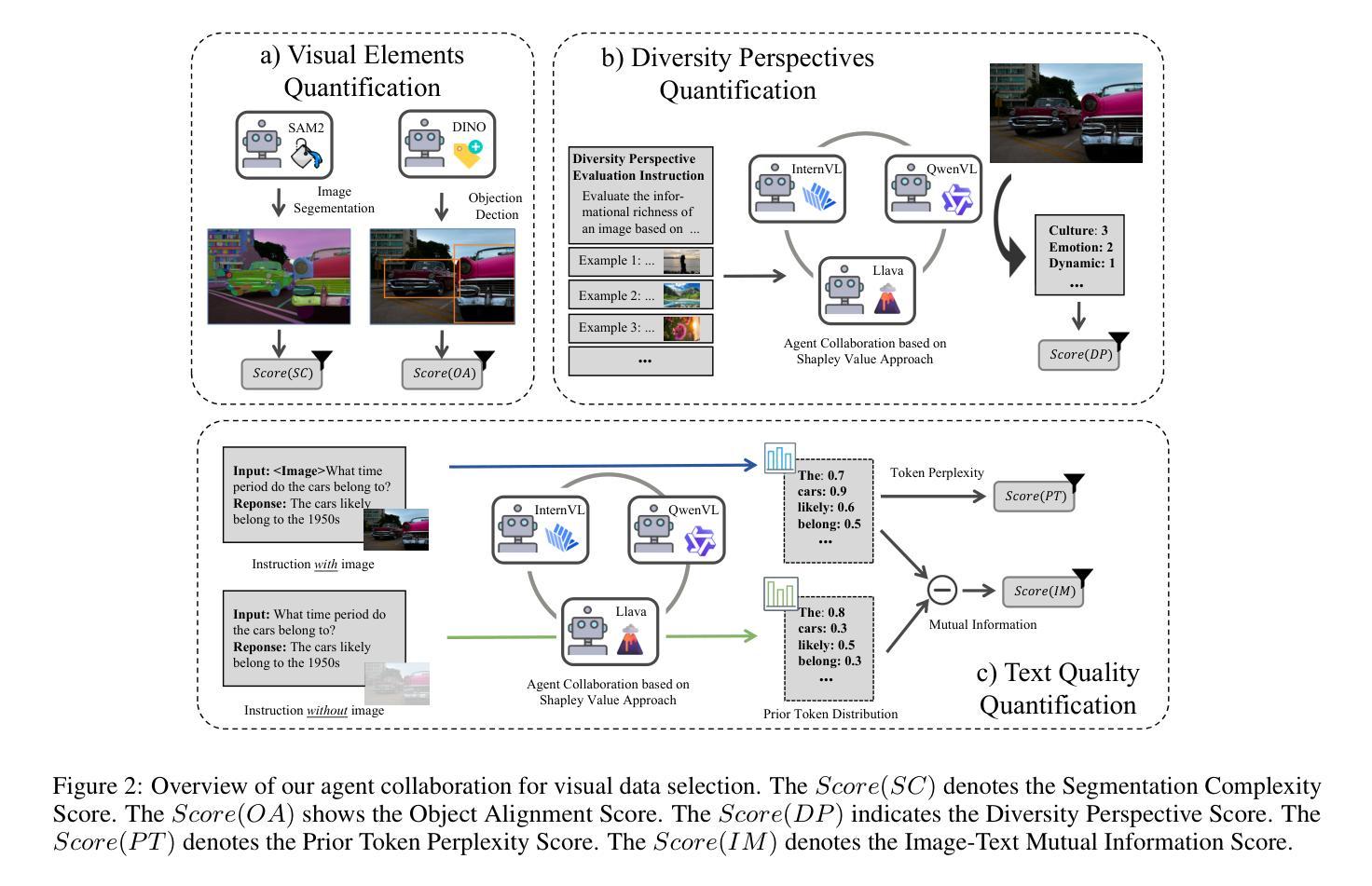
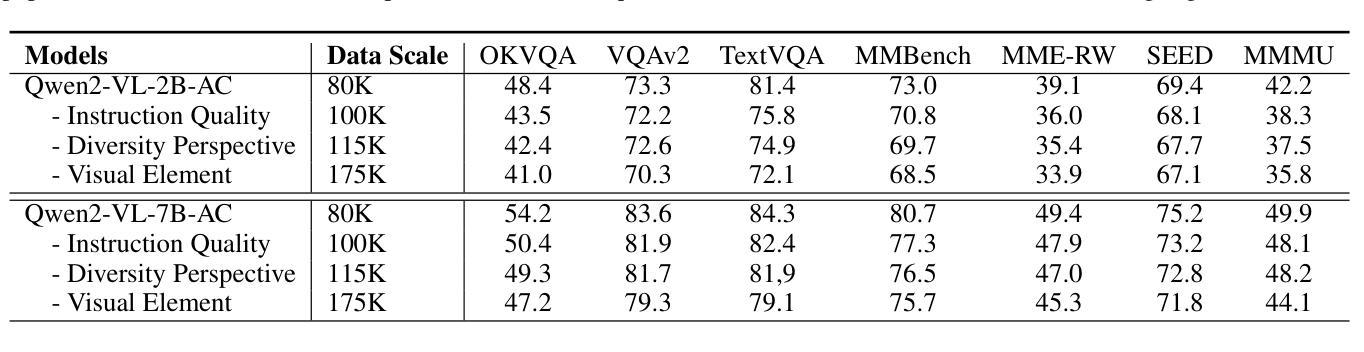
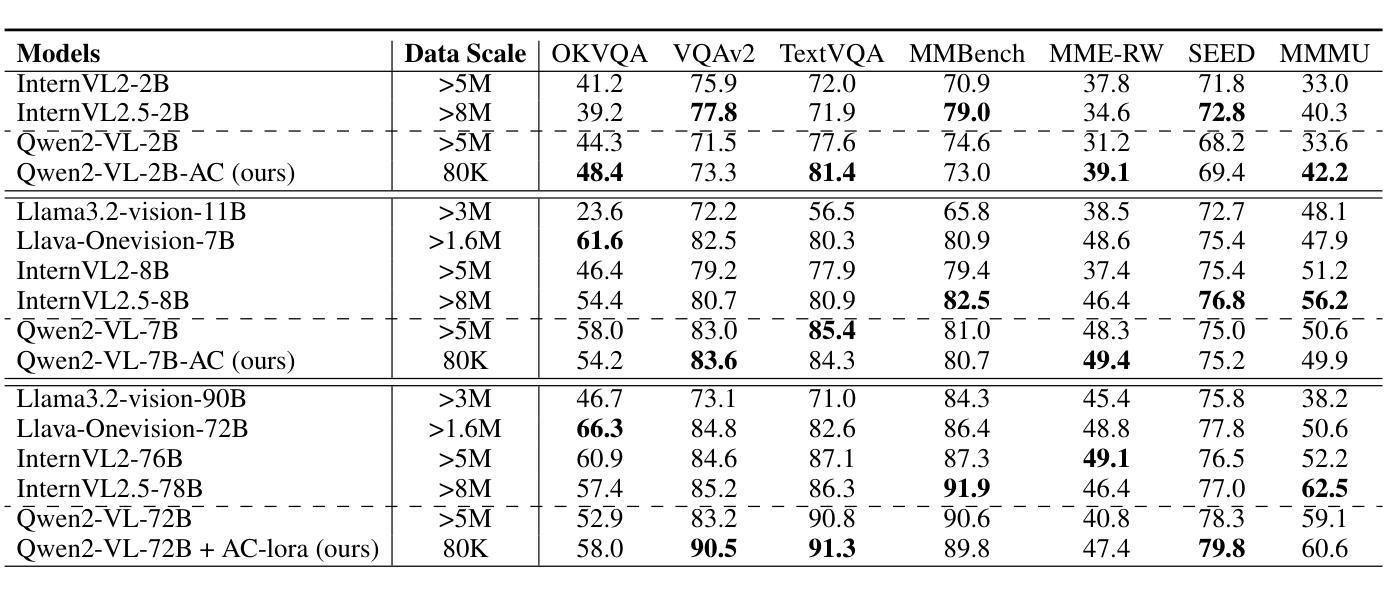
Picking the Cream of the Crop: Visual-Centric Data Selection with Collaborative Agents
Authors:Zhenyu Liu, Yunxin Li, Baotian Hu, Wenhan Luo, Yaowei Wang, Min Zhang
To improve Multimodal Large Language Models’ (MLLMs) ability to process images and complex instructions, researchers predominantly curate large-scale visual instruction tuning datasets, which are either sourced from existing vision tasks or synthetically generated using LLMs and image descriptions. However, they often suffer from critical flaws, including misaligned instruction-image pairs and low-quality images. Such issues hinder training efficiency and limit performance improvements, as models waste resources on noisy or irrelevant data with minimal benefit to overall capability. To address this issue, we propose a \textbf{Vi}sual-Centric \textbf{S}election approach via \textbf{A}gents Collaboration (ViSA), which centers on image quality assessment and image-instruction relevance evaluation. Specifically, our approach consists of 1) an image information quantification method via visual agents collaboration to select images with rich visual information, and 2) a visual-centric instruction quality assessment method to select high-quality instruction data related to high-quality images. Finally, we reorganize 80K instruction data from large open-source datasets. Extensive experiments demonstrate that ViSA outperforms or is comparable to current state-of-the-art models on seven benchmarks, using only 2.5% of the original data, highlighting the efficiency of our data selection approach. Moreover, we conduct ablation studies to validate the effectiveness of each component of our method. The code is available at https://github.com/HITsz-TMG/ViSA.
为了提高多模态大型语言模型(MLLMs)处理图像和复杂指令的能力,研究者主要创建大规模视觉指令调整数据集,这些数据集来源于现有的视觉任务或使用LLMs和图像描述人工合成。然而,它们经常存在关键缺陷,包括指令与图像不匹配和低质量图像。这些问题阻碍了训练效率,限制了性能提升,因为模型会在噪音或无关数据上浪费资源,对整体能力几乎没有帮助。为了解决这一问题,我们提出了一种以视觉为中心的通过代理协作的选型方法(ViSA),该方法以图像质量评估和图像指令相关性评估为中心。具体来说,我们的方法包括:1)通过视觉代理协作的图像信息量化方法,以选择具有丰富视觉信息的图像;2)以视觉为中心的指令质量评估方法,以选择与高质量图像相关的优质指令数据。最后,我们从大型开源数据集中重新组织了8万条指令数据。大量实验表明,ViSA在七个基准测试上的表现优于或相当于当前的最先进模型,而且只使用了原始数据的2.5%,凸显了我们数据选择方法的高效性。此外,我们进行了剥离研究以验证我们方法的每个组成部分的有效性。代码可在https://github.com/HITsz-TMG/ViSA找到。
论文及项目相关链接
PDF 15 pages, 7 figures
Summary
针对多模态大型语言模型在处理图像和复杂指令时面临的挑战,如数据集存在的图像与指令不匹配、图像质量低下等问题,研究者提出了一种视觉中心化的选择方法——ViSA。该方法通过视觉代理协作,选择信息丰富的图像和高质量的指令数据,实现了高效的数据选择。实验证明,ViSA在七个基准测试上的表现优于或相当于当前最先进的模型,且仅使用原始数据的2.5%,突显了数据选择的效率。
Key Takeaways
- 多模态大型语言模型在处理图像和复杂指令时面临挑战,如数据集存在图像与指令不匹配、图像质量低下等问题。
- ViSA方法通过视觉代理协作,旨在解决这些问题,包括图像信息量化方法和视觉中心的指令质量评估方法。
- ViSA方法实现了高效的数据选择,仅使用原始数据的2.5%,在七个基准测试上的表现优于或相当于当前最先进的模型。
- ViSA方法包括图像信息量化方法和视觉中心的指令质量评估两个核心部分。
- 该方法通过选择信息丰富的图像和高质量的指令数据,提高了模型的训练效率和性能。
- 广泛实验验证了ViSA方法的有效性,包括与当前最先进模型的对比和组件有效性的验证。
点此查看论文截图

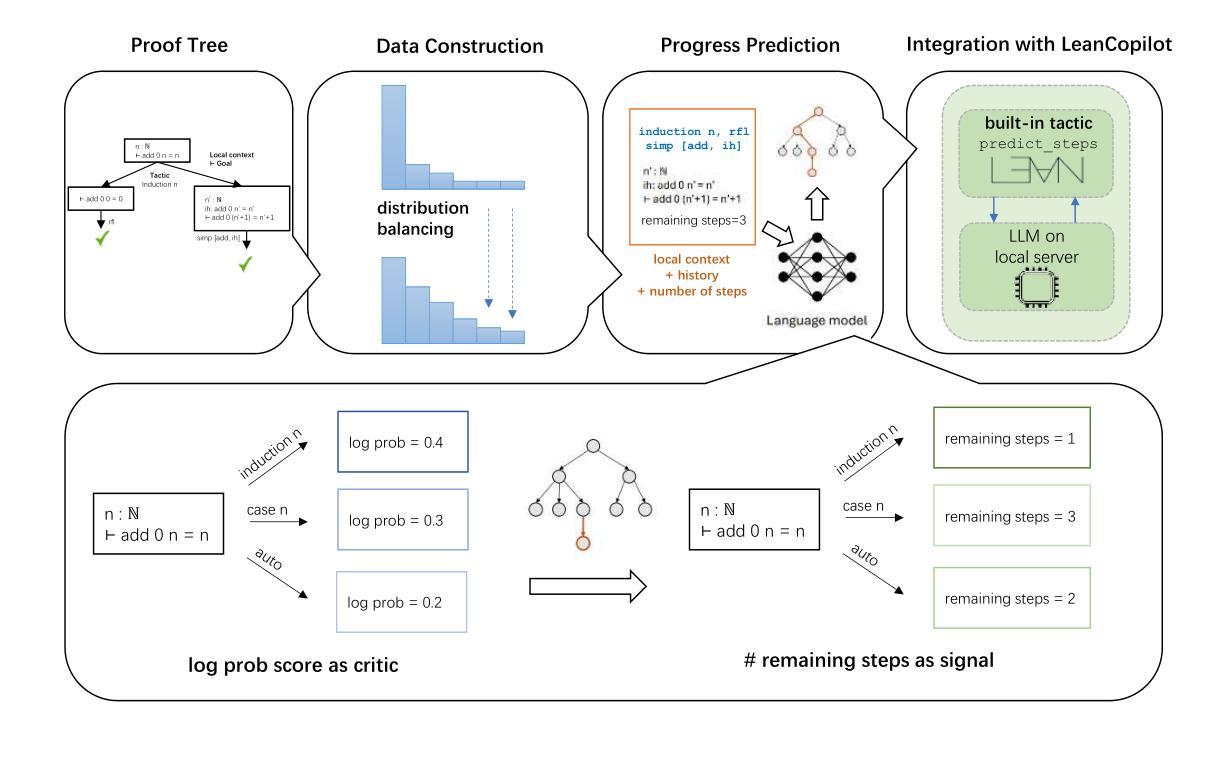
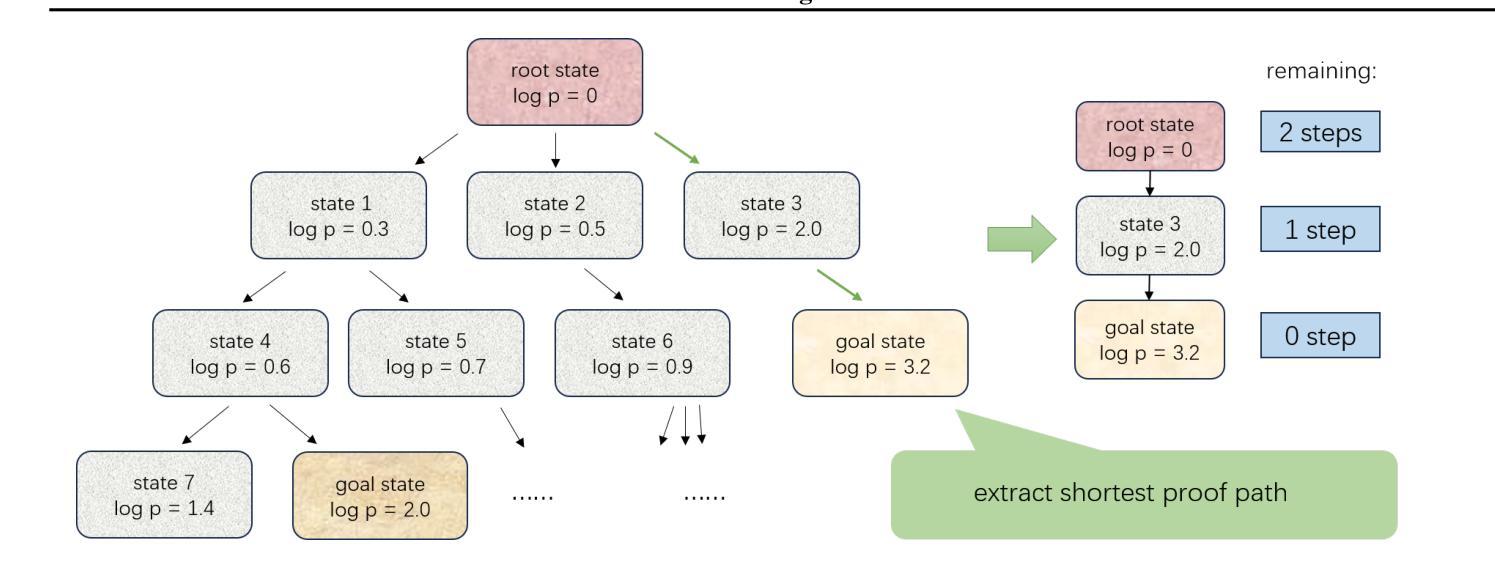
LeanProgress: Guiding Search for Neural Theorem Proving via Proof Progress Prediction
Authors:Suozhi Huang, Peiyang Song, Robert Joseph George, Anima Anandkumar
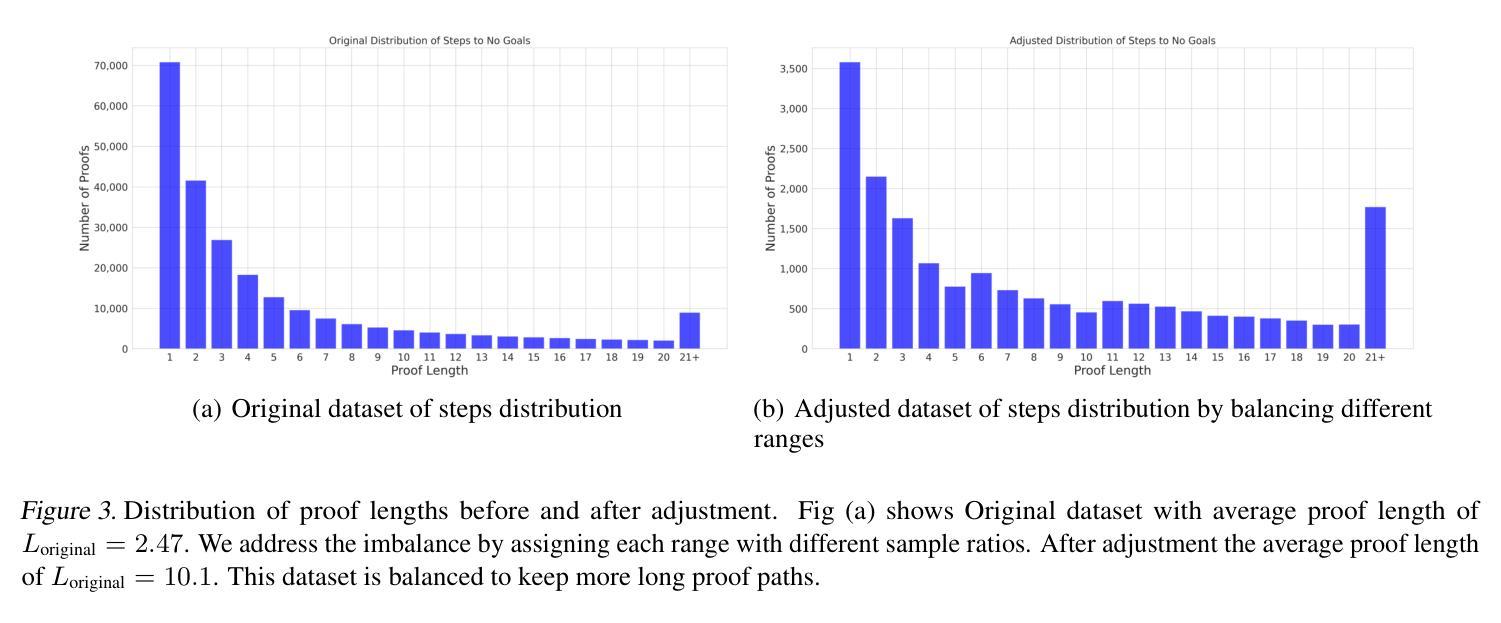
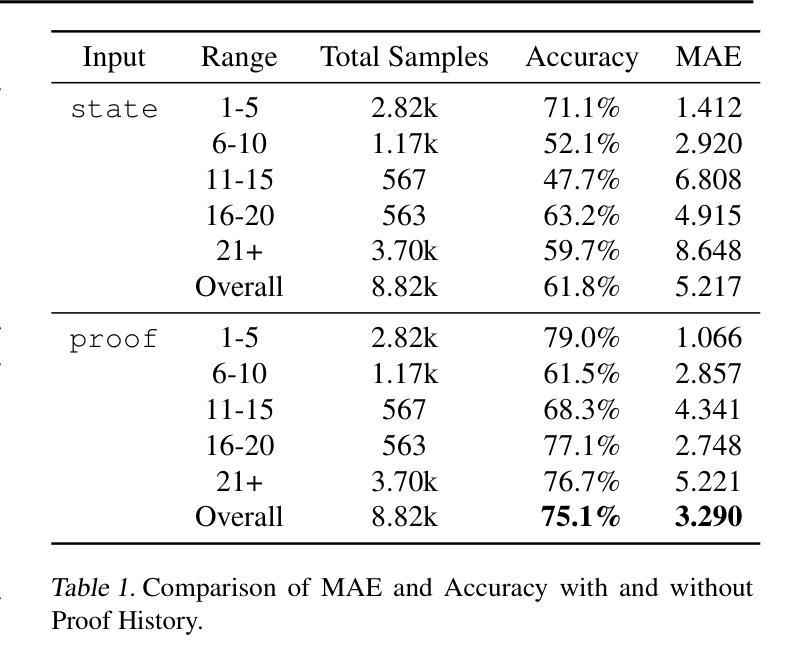
Mathematical reasoning remains a significant challenge for Large Language Models (LLMs) due to hallucinations. When combined with formal proof assistants like Lean, these hallucinations can be eliminated through rigorous verification, making theorem proving reliable. However, even with formal verification, LLMs still struggle with long proofs and complex mathematical formalizations. While Lean with LLMs offers valuable assistance with retrieving lemmas, generating tactics, or even complete proofs, it lacks a crucial capability: providing a sense of proof progress. This limitation particularly impacts the overall development efficiency in large formalization projects. We introduce LeanProgress, a method that predicts the progress in the proof. Training and evaluating our models made on a large corpus of Lean proofs from Lean Workbook Plus and Mathlib4 and how many steps remain to complete it, we employ data preprocessing and balancing techniques to handle the skewed distribution of proof lengths. Our experiments show that LeanProgress achieves an overall prediction accuracy of 75.1% in predicting the amount of progress and, hence, the remaining number of steps. When integrated into a best-first search framework using Reprover, our method shows a 3.8% improvement on Mathlib4 compared to baseline performances of 41.2%, particularly for longer proofs. These results demonstrate how proof progress prediction can enhance both automated and interactive theorem proving, enabling users to make more informed decisions about proof strategies.
数学推理对于大型语言模型(LLM)来说仍然是一个巨大的挑战,因为存在幻想。当与Lean等正式证明助手结合时,这些幻想可以通过严格的验证来消除,使定理证明更加可靠。然而,即使有正式的验证,LLM在处理长证明和复杂的数学形式化时仍然会遇到困难。虽然Lean与LLM在检索引理、生成策略或甚至完成证明方面提供了宝贵的帮助,但它缺乏一种关键能力:提供证明进度的感觉。这一局限性特别影响了大型形式化项目的整体开发效率。我们引入了LeanProgress,一种预测证明进度的方法。我们在大量来自Lean Workbook Plus和Mathlib4的Lean证明语料库上进行训练和评估我们的模型,以及完成证明所需的剩余步骤数,我们采用数据预处理和平衡技术来处理证明长度分布的不平衡。我们的实验表明,LeanProgress在预测进度以及剩余步骤数量方面达到了75.1%的整体预测准确率。当使用Reprover在最佳优先搜索框架中进行集成时,我们的方法在Mathlib4上与基线性能相比提高了3.8%,特别是在较长的证明中。这些结果表明,证明进度预测可以增强自动和交互式定理证明,使用户能够做出更多关于证明策略的有根据的决策。
论文及项目相关链接
Summary
大型语言模型(LLM)在数学推理方面存在挑战,因易出现幻觉而与形式化证明助手(如Lean)结合后,可通过严格验证消除幻觉,使定理证明更加可靠。然而,即使在形式验证下,LLM在长证明和复杂的数学形式化方面仍存在困难。本研究引入了LeanProgress方法,能够预测证明进度。在大量Lean证明语料库上进行训练和评估,采用数据预处理和平衡技术处理证明长度分布不均的问题。实验表明,LeanProgress在预测进度方面达到75.1%的总体预测精度,与Reprover最佳优先搜索框架集成后,在Mathlib4上相比基线性能提高了3.8%,尤其是长证明的改进更加明显。这证明了预测证明进度对自动化和交互式定理证明的重要性。
Key Takeaways
- 大型语言模型(LLM)在数学推理中面临挑战,因为容易出现幻觉。
- 与形式化证明助手(如Lean)结合可以消除幻觉,提高定理证明的可靠性。
- 即使是在形式验证下,LLM在处理长证明和复杂数学形式化方面仍存在困难。
- 引入了LeanProgress方法,能够预测证明的进度。
- LeanProgress在预测进度方面达到75.1%的总体预测精度。
- 与Reprover最佳优先搜索框架集成后,LeanProgress在Mathlib4上的性能有所提升。
点此查看论文截图

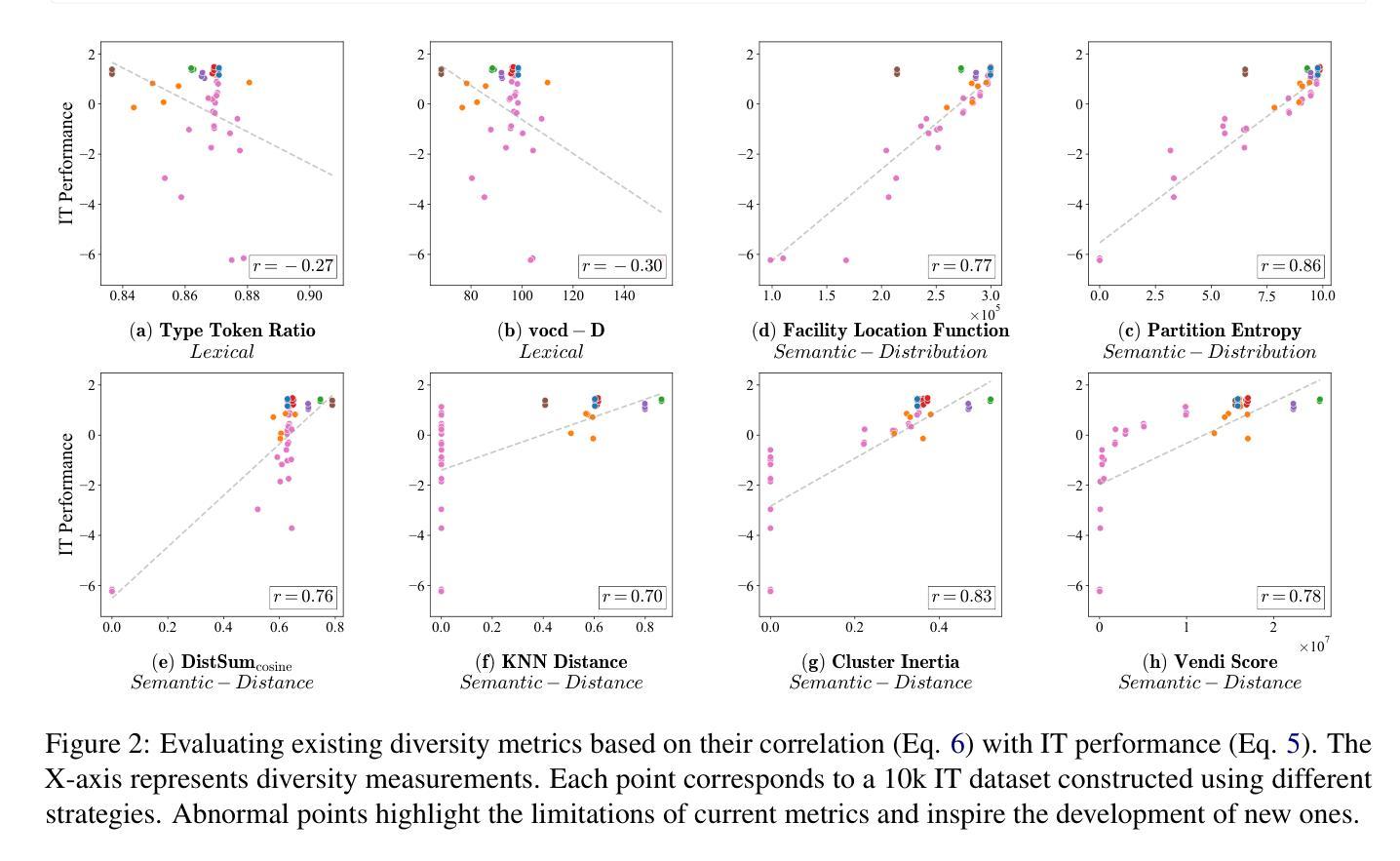
Measuring Data Diversity for Instruction Tuning: A Systematic Analysis and A Reliable Metric
Authors:Yuming Yang, Yang Nan, Junjie Ye, Shihan Dou, Xiao Wang, Shuo Li, Huijie Lv, Mingqi Wu, Tao Gui, Qi Zhang, Xuanjing Huang
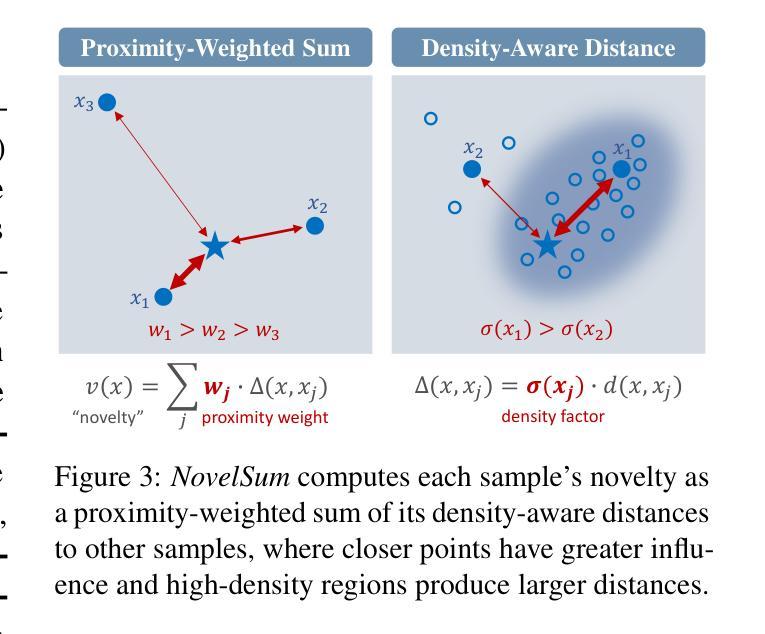
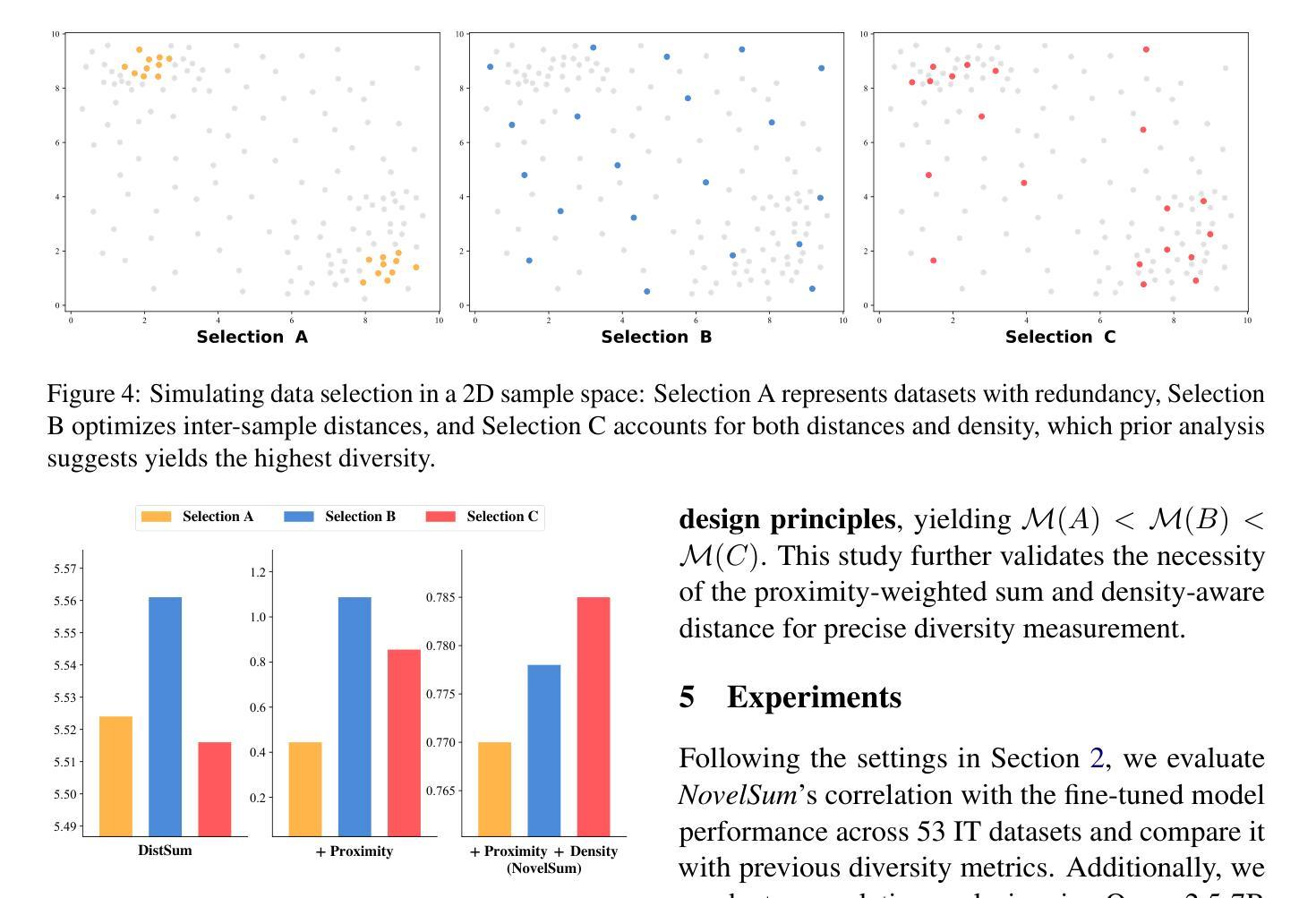
Data diversity is crucial for the instruction tuning of large language models. Existing studies have explored various diversity-aware data selection methods to construct high-quality datasets and enhance model performance. However, the fundamental problem of precisely defining and measuring data diversity remains underexplored, limiting clear guidance for data engineering. To address this, we systematically analyze 11 existing diversity measurement methods by evaluating their correlation with model performance through extensive fine-tuning experiments. Our results indicate that a reliable diversity measure should properly account for both inter-sample differences and the information distribution in the sample space. Building on this, we propose NovelSum, a new diversity metric based on sample-level “novelty.” Experiments on both simulated and real-world data show that NovelSum accurately captures diversity variations and achieves a 0.97 correlation with instruction-tuned model performance, highlighting its value in guiding data engineering practices. With NovelSum as an optimization objective, we further develop a greedy, diversity-oriented data selection strategy that outperforms existing approaches, validating both the effectiveness and practical significance of our metric.
数据的多样性对于大语言模型的指令调整至关重要。现有研究已经探索了多种意识多样性的数据选择方法,以构建高质量的数据集并增强模型性能。然而,关于精确定义和测量数据多样性的基本问题仍然被探索得不够深入,这对数据工程缺乏明确的指导。为了解决这一问题,我们通过大量微调实验评估了现有的11种多样性测量方法与模型性能的相关性。我们的结果表明,可靠的多样性度量应适当地考虑样本之间的差异以及样本空间中的信息分布。在此基础上,我们提出了基于样本级“新颖性”的NovelSum新多样性指标。在模拟和真实数据上的实验表明,NovelSum能够准确捕捉多样性变化,与指令调整模型性能的相关性达到0.97,突显其在指导数据工程实践中的价值。以NovelSum为优化目标,我们进一步开发了一种贪婪的、面向多样性的数据选择策略,其性能优于现有方法,验证了我们指标的有效性和实际意义。
论文及项目相关链接
PDF 16 pages. The related codes and resources will be released later. Project page: https://github.com/UmeanNever/NovelSum
Summary
数据多样性对于大语言模型的指令调整至关重要。现有研究已经探索了各种基于多样性的数据选择方法以构建高质量数据集并增强模型性能。然而,关于如何精确定义和衡量数据多样性的基础问题仍然被忽视,导致缺乏明确的数据工程指导。为解决这一问题,本文系统地分析了现有的十一种多样性测量方法,并通过大量的微调实验评估它们与模型性能的相关性。结果表明,可靠的多样性测量应同时考虑样本间的差异和样本空间中的信息分布。基于此,本文提出了基于样本级“新颖性”的NovelSum新多样性度量指标。在模拟数据和真实数据上的实验表明,NovelSum能够准确捕捉多样性变化,与指令调整模型性能的相关性达到0.97,凸显其在指导数据工程实践中的价值。利用NovelSum作为优化目标,我们进一步开发了一种以多样性为导向的数据选择策略,其表现优于现有方法,验证了该指标的实用性和实际意义。该论文的研究有助于更好地理解数据多样性的重要性并推动相关领域的发展。
Key Takeaways
- 数据多样性对于大语言模型的性能提升至关重要。
- 现有研究虽然已经探索了多种基于多样性的数据选择方法,但对数据多样性的定义和衡量仍然存在不足。
- 可靠的数据多样性测量需要综合考虑样本间的差异以及样本空间中的信息分布。
- 本文提出了基于样本级“新颖性”的NovelSum新多样性度量指标。
- NovelSum在模拟数据和真实数据上的实验表现出良好的性能,与模型性能的相关性达到0.97。
- 利用NovelSum作为优化目标,开发了一种新的以多样性为导向的数据选择策略,其表现优于现有方法。
点此查看论文截图
BioMaze: Benchmarking and Enhancing Large Language Models for Biological Pathway Reasoning
Authors:Haiteng Zhao, Chang Ma, Fangzhi Xu, Lingpeng Kong, Zhi-Hong Deng
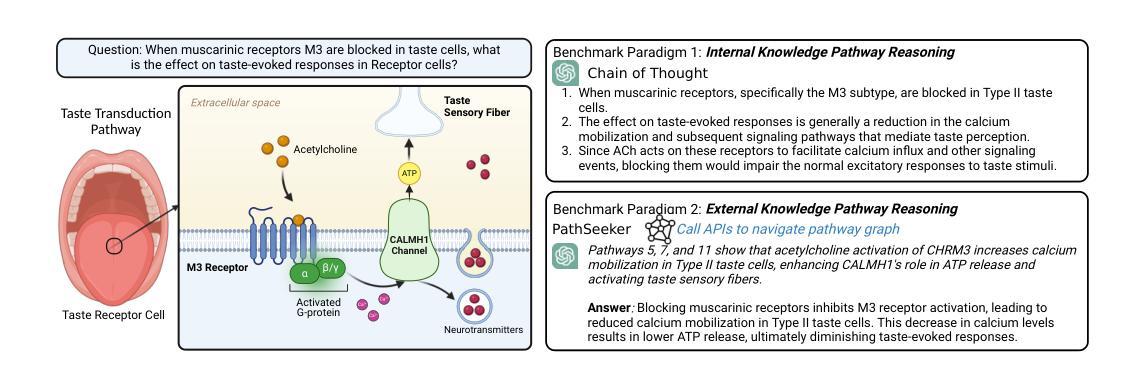
The applications of large language models (LLMs) in various biological domains have been explored recently, but their reasoning ability in complex biological systems, such as pathways, remains underexplored, which is crucial for predicting biological phenomena, formulating hypotheses, and designing experiments. This work explores the potential of LLMs in pathway reasoning. We introduce BioMaze, a dataset with 5.1K complex pathway problems derived from real research, covering various biological contexts including natural dynamic changes, disturbances, additional intervention conditions, and multi-scale research targets. Our evaluation of methods such as CoT and graph-augmented reasoning, shows that LLMs struggle with pathway reasoning, especially in perturbed systems. To address this, we propose PathSeeker, an LLM agent that enhances reasoning through interactive subgraph-based navigation, enabling a more effective approach to handling the complexities of biological systems in a scientifically aligned manner. The dataset and code are available at https://github.com/zhao-ht/BioMaze.
大型语言模型(LLM)在各类生物领域的应用近来已得到广泛研究,但它们在复杂生物系统(如途径)中的推理能力仍鲜有研究,这对于预测生物现象、提出假设和设计实验至关重要。本研究探讨了LLM在途径推理方面的潜力。我们介绍了BioMaze数据集,其中包含从真实研究中得出的5.1K个复杂途径问题,涉及多种生物背景,包括自然动态变化、干扰、额外的干预条件和多尺度研究目标。我们对CoT和图形增强推理等方法进行的评估表明,LLM在途径推理方面存在困难,特别是在受到干扰的系统方面。为解决这一问题,我们提出了PathSeeker,这是一个LLM代理,它通过基于交互子图的导航增强推理能力,以科学的方式更有效地处理生物系统的复杂性。数据集和代码可通过https://github.com/zhao-ht/BioMaze获取。
论文及项目相关链接
Summary
大型语言模型(LLM)在多个生物领域的应用已被广泛探索,但在生物通路等复杂生物系统中的推理能力仍被较少研究。本文探索了LLM在通路推理中的潜力,并引入了BioMaze数据集,包含5.1K个真实研究中的复杂通路问题。评估显示,LLM在扰动系统中的通路推理方面存在困难。为解决这一问题,本文提出了PathSeeker,一个通过交互式子图导航增强推理的LLM代理,以更有效地处理生物系统的复杂性。
Key Takeaways
- LLM在生物通路等复杂生物系统中的推理能力仍待探索。
- BioMaze数据集包含真实研究中的复杂生物通路问题。
- LLM在扰动系统中的通路推理方面存在困难。
- PathSeeker是一个LLM代理,通过交互式子图导航增强推理。
- PathSeeker能更有效地处理生物系统的复杂性。
- BioMaze数据集和代码已公开分享。
- LLM的潜力在于其能够预测生物现象、提出假设和设计实验。
点此查看论文截图


SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Authors:M-A-P Team, Xinrun Du, Yifan Yao, Kaijing Ma, Bingli Wang, Tianyu Zheng, Kang Zhu, Minghao Liu, Yiming Liang, Xiaolong Jin, Zhenlin Wei, Chujie Zheng, Kaixin Deng, Shian Jia, Sichao Jiang, Yiyan Liao, Rui Li, Qinrui Li, Sirun Li, Yizhi Li, Yunwen Li, Dehua Ma, Yuansheng Ni, Haoran Que, Qiyao Wang, Zhoufutu Wen, Siwei Wu, Tianshun Xing, Ming Xu, Zhenzhu Yang, Zekun Moore Wang, Junting Zhou, Yuelin Bai, Xingyuan Bu, Chenglin Cai, Liang Chen, Yifan Chen, Chengtuo Cheng, Tianhao Cheng, Keyi Ding, Siming Huang, Yun Huang, Yaoru Li, Yizhe Li, Zhaoqun Li, Tianhao Liang, Chengdong Lin, Hongquan Lin, Yinghao Ma, Tianyang Pang, Zhongyuan Peng, Zifan Peng, Qige Qi, Shi Qiu, Xingwei Qu, Shanghaoran Quan, Yizhou Tan, Zili Wang, Chenqing Wang, Hao Wang, Yiya Wang, Yubo Wang, Jiajun Xu, Kexin Yang, Ruibin Yuan, Yuanhao Yue, Tianyang Zhan, Chun Zhang, Jinyang Zhang, Xiyue Zhang, Xingjian Zhang, Yue Zhang, Yongchi Zhao, Xiangyu Zheng, Chenghua Zhong, Yang Gao, Zhoujun Li, Dayiheng Liu, Qian Liu, Tianyu Liu, Shiwen Ni, Junran Peng, Yujia Qin, Wenbo Su, Guoyin Wang, Shi Wang, Jian Yang, Min Yang, Meng Cao, Xiang Yue, Zhaoxiang Zhang, Wangchunshu Zhou, Jiaheng Liu, Qunshu Lin, Wenhao Huang, Ge Zhang
Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
大型语言模型(LLM)在数学、物理和计算机科学等主流学科领域表现出了卓越的专长。然而,人类知识包含超过200个专业领域,远超现有基准测试的范围。在这些专业领域中的许多领域,特别是在轻工业、农业和服务导向型领域,LLM的能力尚未得到充分评估。为了弥补这一差距,我们推出了SuperGPQA基准测试,它旨在评估涵盖285个学科的研究生级知识和推理能力。我们的基准测试采用了一种新型的人机协同过滤机制,通过基于LLM响应和专家反馈的迭代优化来消除琐碎或模糊的问题。我们的实验结果表明,在多种知识领域中,当前最先进的LLM性能仍有很大的提升空间(例如,以推理为重点的DeepSeek-R1在SuperGPQA上达到了最高的61.82%准确率),这突显了当前模型能力与通用人工智能之间的巨大差距。此外,我们还提供了关于管理大规模标注过程的综合见解,涉及超过80名专家标注人员和一个人机协同互动系统,为未来的类似研究提供了宝贵的方法论指导。
论文及项目相关链接
Summary
大型语言模型(LLM)在主流学科如数学、物理和计算机科学中表现出卓越的能力,但在众多专业领域,尤其是轻工业、农业和服务导向型学科中的能力评估仍不足。为解决此问题,提出了SuperGPQA基准测试,用于评估研究生级别的知识和推理能力在285个学科中的应用。该基准测试采用新型的人机协同过滤机制,通过迭代优化,结合LLM响应和专家反馈来消除琐碎或模糊的问题。实验结果显示,在SuperGPQA上,最先进的LLM性能仍有待提高,如DeepSeek-R1模型最高准确率为61.82%,表明当前模型能力与通用人工智能之间仍存在巨大差距。同时,分享了大规模标注过程中的综合见解,涉及超过80位专家标注师和人机交互系统,为未来类似研究提供方法论指导。
Key Takeaways
- LLM在主流学科中表现出卓越的能力,但在众多专业领域中的能力评估仍不足。
- SuperGPQA是一个新的基准测试,旨在评估LLM在285个学科中的研究生级别知识和推理能力。
- SuperGPQA采用人机协同过滤机制,结合LLM响应和专家反馈来优化问题。
- 当前最先进的LLM在SuperGPQA上的性能有待提高,显示与通用人工智能之间存在巨大差距。
- DeepSeek-R1模型在SuperGPQA上的最高准确率为61.82%。
- 大规模标注过程中的综合见解被分享,涉及超过80位专家标注师和人机交互系统。
点此查看论文截图
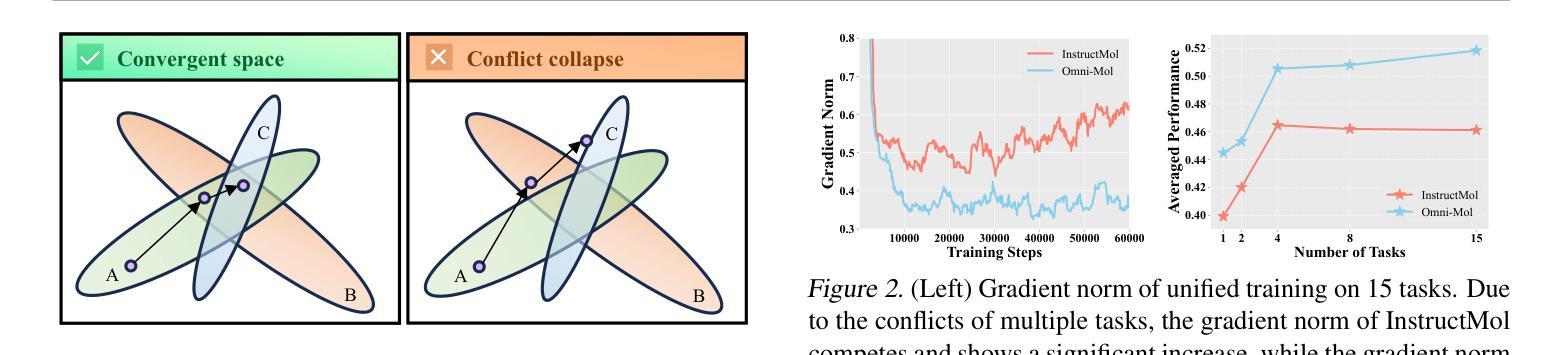
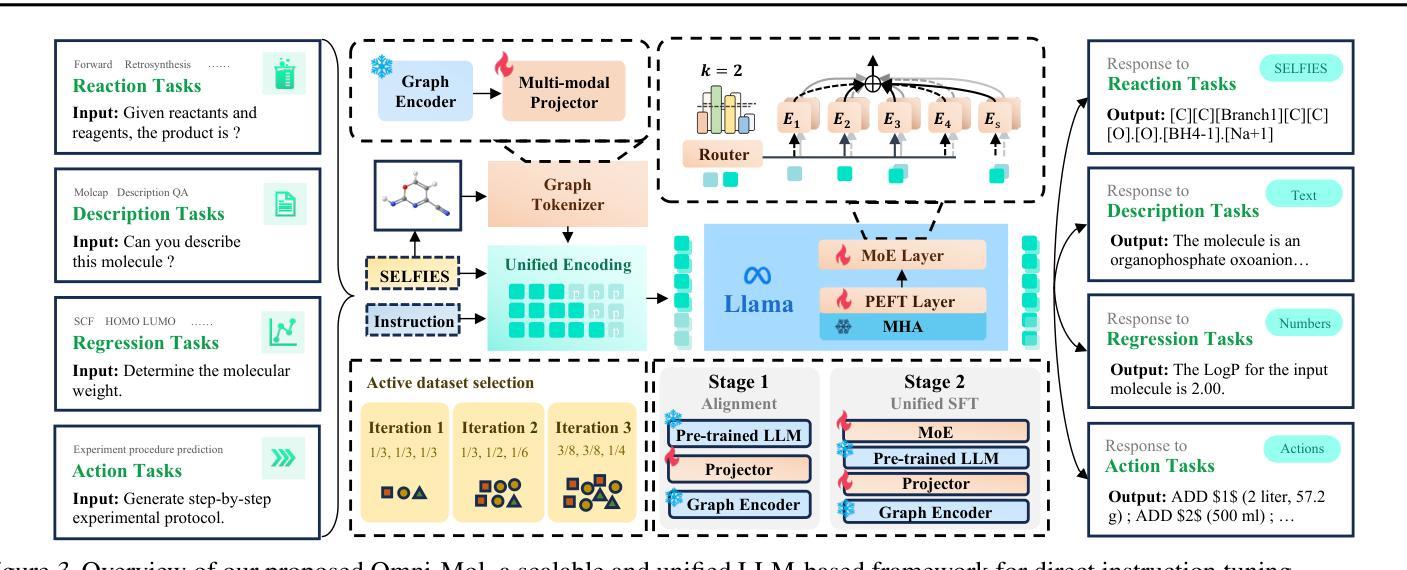
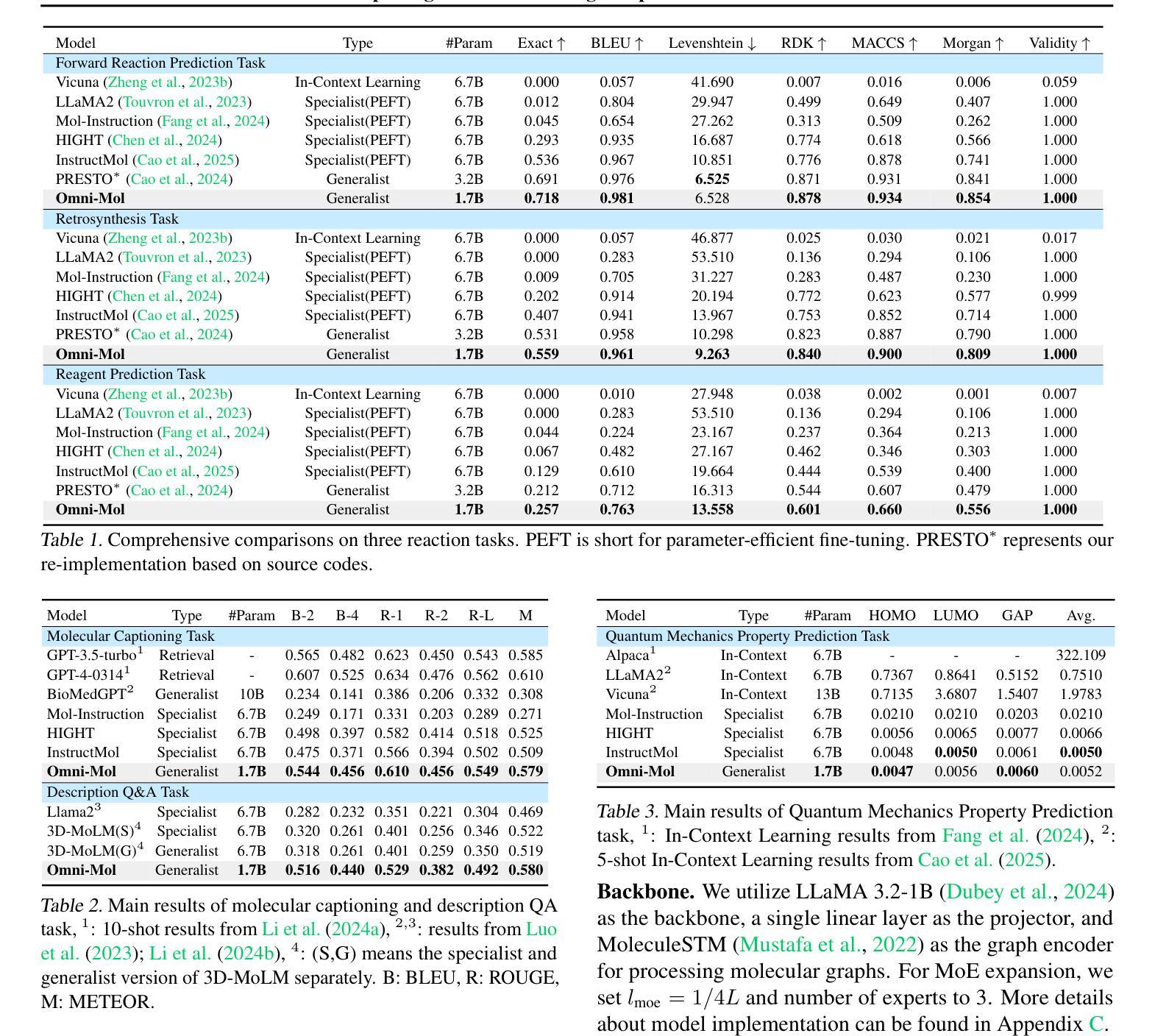
Omni-Mol: Exploring Universal Convergent Space for Omni-Molecular Tasks
Authors:Chengxin Hu, Hao Li, Yihe Yuan, Zezheng Song, Haixin Wang
Building generalist models has recently demonstrated remarkable capabilities in diverse scientific domains. Within the realm of molecular learning, several studies have explored unifying diverse tasks across diverse domains. However, negative conflicts and interference between molecules and knowledge from different domain may have a worse impact in threefold. First, conflicting molecular representations can lead to optimization difficulties for the models. Second, mixing and scaling up training data across diverse tasks is inherently challenging. Third, the computational cost of refined pretraining is prohibitively high. To address these limitations, this paper presents Omni-Mol, a scalable and unified LLM-based framework for direct instruction tuning. Omni-Mol builds on three key components to tackles conflicts: (1) a unified encoding mechanism for any task input; (2) an active-learning-driven data selection strategy that significantly reduces dataset size; (3) a novel design of the adaptive gradient stabilization module and anchor-and-reconcile MoE framework that ensures stable convergence. Experimentally, Omni-Mol achieves state-of-the-art performance across 15 molecular tasks, demonstrates the presence of scaling laws in the molecular domain, and is supported by extensive ablation studies and analyses validating the effectiveness of its design. The dataset, code and weights of the powerful AI-driven chemistry generalist are open-sourced.
最近,构建通用模型在不同科学领域表现出了显著的能力。在分子学习领域,多项研究探索了如何在不同领域统一各种任务。然而,分子和来自不同领域的知识之间的负面冲突和干扰可能会产生三倍的负面影响。首先,冲突的分子表征可能导致模型优化困难。其次,在多种任务之间混合和扩大训练数据本身就具有挑战性。第三,精细预训练的计算成本高昂。为了解决这些限制,本文提出了Omni-Mol,一个基于大规模语言模型(LLM)的可扩展统一框架,用于直接指令调整。Omni-Mol通过三个关键组件来解决冲突:(1)任何任务输入的统一编码机制;(2)以主动学习驱动的数据选择策略,可显著减少数据集大小;(3)自适应梯度稳定模块和锚定与和解MoE框架的新颖设计,确保稳定收敛。通过实验,Omni-Mol在15个分子任务上实现了最先进的性能,证明了分子领域的规模法则的存在,并通过广泛的消融研究和分析验证了其设计的有效性。该强大AI驱动化学通用主义的数据集、代码和权重均已开源。
论文及项目相关链接
PDF 30 pages, 13 figures, 7 tables, paper under review
Summary:
近期,通用模型在多个科学领域展现出强大能力。在分子学习领域,多项研究尝试统一不同任务。然而,不同领域分子和知识间的冲突干扰可能带来三倍负面影响。本文提出Omni-Mol框架,以大型语言模型为基础,通过统一编码机制、主动学习驱动的数据选择策略和梯度稳定模块设计,解决冲突问题。实验表明,Omni-Mol在15个分子任务上达到最佳性能,并在分子领域展现规模效应。其数据集、代码和权重均已开源。
Key Takeaways:
- 通用模型在多个科学领域表现出强大的能力,特别是在分子学习领域。
- 不同领域分子和知识间的冲突干扰是分子学习面临的主要问题之一。
- Omni-Mol框架通过统一编码机制、数据选择策略和梯度稳定模块设计来解决冲突问题。
- Omni-Mol实现了在15个分子任务上的最佳性能。
- Omni-Mol在分子领域展现出规模效应,并通过广泛的消融研究和分析验证了其设计的有效性。
- Omni-Mol使用的数据集、代码和权重均已开源。
点此查看论文截图

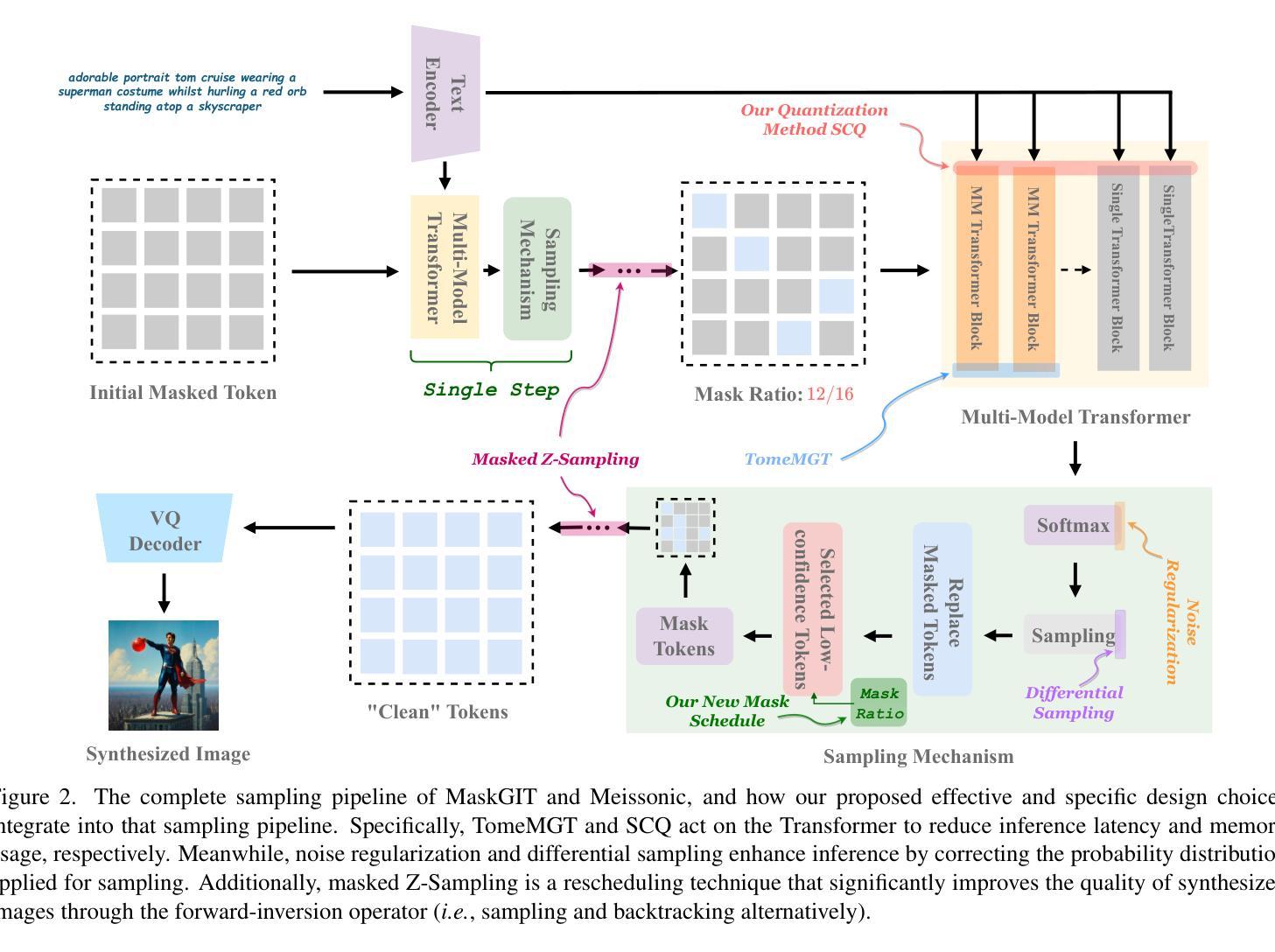
Bag of Design Choices for Inference of High-Resolution Masked Generative Transformer
Authors:Shitong Shao, Zikai Zhou, Tian Ye, Lichen Bai, Zhiqiang Xu, Zeke Xie
Text-to-image diffusion models (DMs) develop at an unprecedented pace, supported by thorough theoretical exploration and empirical analysis. Unfortunately, the discrepancy between DMs and autoregressive models (ARMs) complicates the path toward achieving the goal of unified vision and language generation. Recently, the masked generative Transformer (MGT) serves as a promising intermediary between DM and ARM by predicting randomly masked image tokens (i.e., masked image modeling), combining the efficiency of DM with the discrete token nature of ARM. However, we find that the comprehensive analyses regarding the inference for MGT are virtually non-existent, and thus we aim to present positive design choices to fill this gap. We propose and redesign a set of enhanced inference techniques tailored for MGT, providing a detailed analysis of their performance. Additionally, we explore several DM-based approaches aimed at accelerating the sampling process on MGT. Extensive experiments and empirical analyses on the recent SOTA MGT, such as MaskGIT and Meissonic lead to concrete and effective design choices, and these design choices can be merged to achieve further performance gains. For instance, in terms of enhanced inference, we achieve winning rates of approximately 70% compared to vanilla sampling on HPS v2 with Meissonic-1024x1024.
文本到图像扩散模型(DM)以前所未有的速度发展,得益于深入的理论探索和实证分析。然而,DM和自回归模型(ARM)之间的差异使得实现统一视觉和语言生成的目标变得更加复杂。最近,掩码生成式Transformer(MGT)作为DM和ARM之间的有前途的中介,通过预测随机掩码图像令牌(即掩码图像建模),结合了DM的效率与ARM的离散令牌特性。然而,我们发现关于MGT推理的综合分析几乎不存在,因此,我们的目标是提出积极的设计选择来填补这一空白。我们提出并重新设计了一系列针对MGT的增强推理技术,并对其性能进行了详细分析。此外,我们还探索了几种基于DM的方法来加速MGT上的采样过程。在最近的最新MGT(如MaskGIT和Meissonic)上进行的大量实验和实证分析得出了具体有效的设计选择,这些设计选择可以合并以实现进一步的性能提升。例如,在增强推理方面,我们在HPS v2上与香草采样相比达到了约70%的胜率,使用Meissonic-1024x1024。
论文及项目相关链接
摘要
文本到图像扩散模型(DMs)的发展速度空前,得益于深入的理论探索和实证分析。然而,DMs和自回归模型(ARMs)之间的差异使得实现统一视觉和语言生成的目标变得复杂。最近,掩码生成式转换器(MGT)作为DM和ARM之间的有前途的中间方案,通过预测随机掩码图像令牌(即掩码图像建模),结合了DM的效率与ARM的离散令牌特性。然而,关于MGT的推理综合分析几乎不存在,因此,我们旨在提出积极的设计选择来填补这一空白。我们提出并重新设计了一系列针对MGT的增强推理技术,并对其性能进行了详细分析。此外,我们还探索了旨在加速MGT采样过程的几种基于DM的方法。在最新的SOTA MGT(如MaskGIT和Meissonic)上进行的大量实验和实证分析得出了切实有效的设计选择,这些设计选择可以合并以实现进一步的性能提升。例如,在增强推理方面,我们在HPS v2上实现了约70%的胜率,超过了普通采样方法。
关键见解
- 文本到图像扩散模型(DMs)的发展迅速,但自回归模型(ARMs)之间的差异影响了统一视觉和语言生成目标的实现。
- 掩码生成式转换器(MGT)是DM和ARM之间的有前途的中间方案,结合了两者优点。
- 目前关于MGT的推理综合分析几乎不存在。
- 提出并重新设计了针对MGT的增强推理技术,并进行详细分析。
- 探索了旨在加速MGT采样过程的基于DM的方法。
- 在最新的MGT上进行的大量实验和实证分析表明,某些设计选择能带来显著性能提升。
- 在增强推理方面取得了显著成果,如在HPS v2上的胜率达到约70%。
点此查看论文截图




S$^4$ST: A Strong, Self-transferable, faSt, and Simple Scale Transformation for Transferable Targeted Attack
Authors:Yongxiang Liu, Bowen Peng, Li Liu, Xiang Li
Transferable Targeted Attacks (TTAs), which aim to deceive black-box models into predicting specific erroneous labels, face significant challenges due to severe overfitting to surrogate models. Although modifying image features to generate robust semantic patterns of the target class is a promising approach, existing methods heavily rely on large-scale additional data. This dependence undermines the fair evaluation of TTA threats, potentially leading to a false sense of security or unnecessary overreactions. In this paper, we introduce two blind measures, surrogate self-alignment and self-transferability, to analyze the effectiveness and correlations of basic transformations, to enhance data-free attacks under strict black-box constraints. Our findings challenge conventional assumptions: (1) Attacking simple scaling transformations uniquely enhances targeted transferability, outperforming other basic transformations and rivaling leading complex methods; (2) Geometric and color transformations exhibit high internal redundancy despite weak inter-category correlations. These insights drive the design and tuning of S4ST (Strong, Self-transferable, faSt, Simple Scale Transformation), which integrates dimensionally consistent scaling, complementary low-redundancy transformations, and block-wise operations. Extensive experiments on the ImageNet-Compatible dataset demonstrate that S4ST achieves a 77.7% average targeted success rate (tSuc), surpassing existing transformations (+17.2% over H-Aug with only 26% computational time) and SOTA TTA solutions (+6.2% over SASD-WS with 1.2M samples for post-training). Notably, it attains 69.6% and 55.3% average tSuc against three commercial APIs and vision-language models, respectively. This work establishes a new SOTA for TTAs, highlights their potential threats, and calls for a reevaluation of the data dependency in achieving targeted transferability.
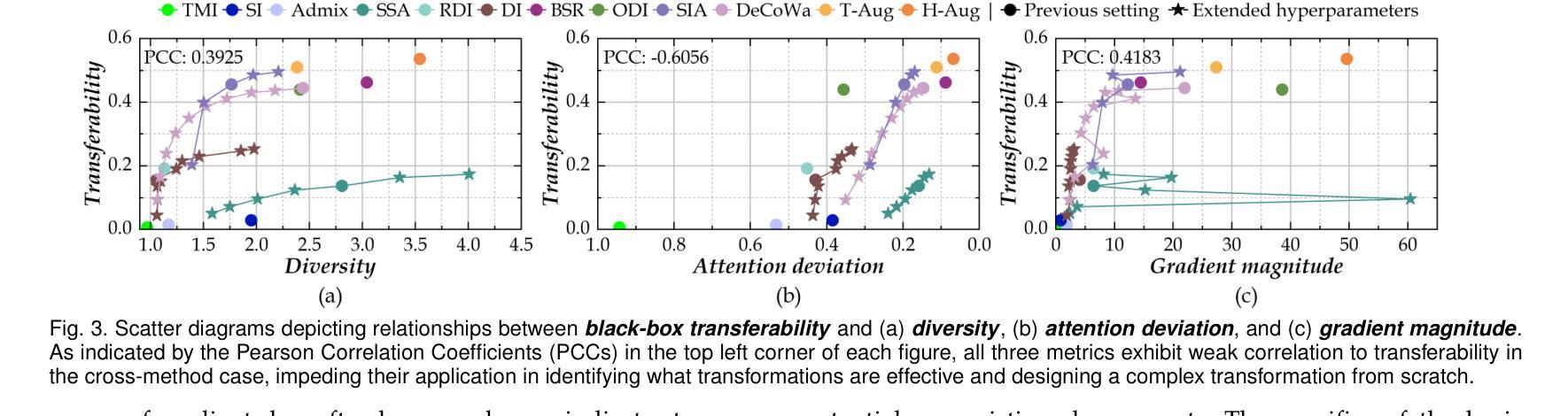
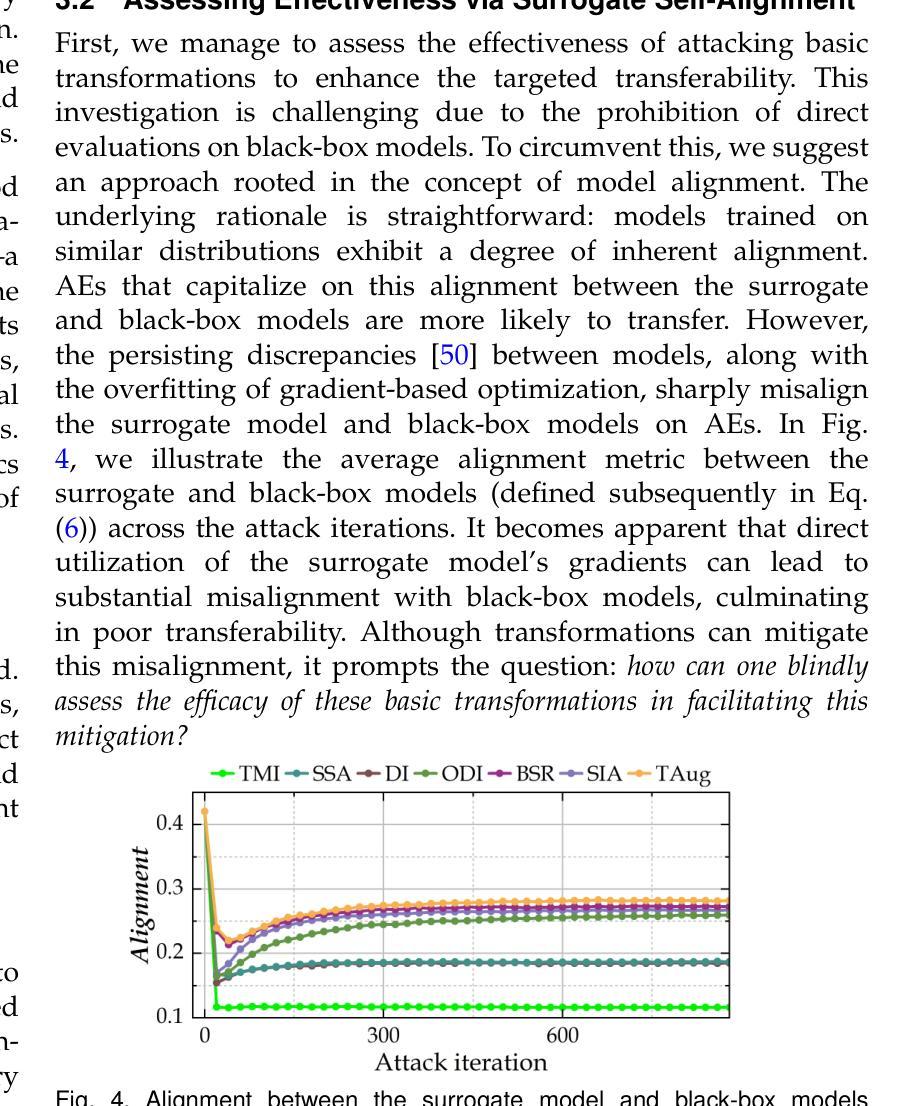
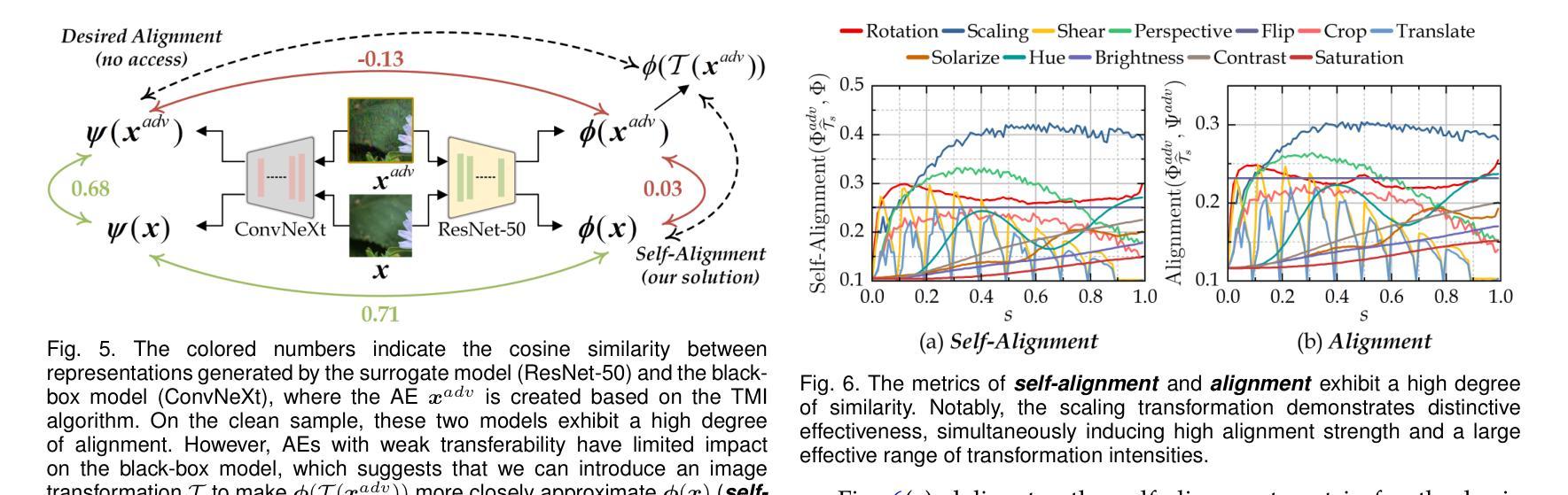
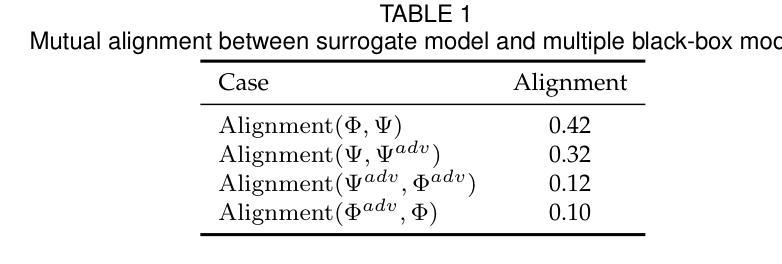
可迁移的定向攻击(TTAs)旨在欺骗黑箱模型预测特定的错误标签,但由于对代理模型的过度拟合而面临重大挑战。虽然修改图像特征以生成目标类别的稳健语义模式是一种有前景的方法,但现有方法严重依赖于大规模额外数据。这种依赖破坏了对TTA威胁的公正评估,可能导致错误的安全感或不必要的过度反应。在本文中,我们引入了两种盲测方法,即代理自我对齐和自迁移性,来分析基本转换的有效性及其相关性,以增强在严格黑箱约束下的无数据攻击。我们的研究结果挑战了传统假设:(1)攻击简单的缩放转换可以独特地增强目标迁移性,优于其他基本转换,并与领先的复杂方法相匹敌;(2)尽管跨类别相关性较弱,但几何和颜色转换表现出高度的内部冗余。这些见解推动了S4ST(强、自迁移、快速、简单缩放转换)的设计和调整,它融合了尺寸一致的缩放、互补的低冗余转换和块操作。在ImageNet兼容数据集上的广泛实验表明,S4ST的平均目标成功率(tSuc)达到77.7%,超越了现有转换(与H-Aug相比,仅用时26%的计算时间就提高了17.2%),并超越了最先进的TTA解决方案(在训练后使用120万样本的SASD-WS提高了6.2%)。值得注意的是,它对三种商业API和视觉语言模型的平均tSuc分别达到69.6%和55.3%。这项工作为TTAs设立了新的最先进水平,突显了它们的潜在威胁,并呼吁重新评估实现目标迁移性的数据依赖性。
论文及项目相关链接
PDF 16 pages, 18 figures
Summary
本文介绍了针对黑盒模型的可转移目标攻击(TTAs)面临的挑战,包括过度拟合代理模型的问题。通过引入两种盲量措施(代理自我对齐和自转移性)来评估基本转换的有效性,进而提高无数据攻击在严格黑盒约束下的效果。研究发现简单缩放转换能独特地提高目标转移性,超越其他基本转换和领先的复杂方法;几何和颜色转换展现出高内部冗余性,尽管跨类别相关性较弱。基于这些见解,设计出S4ST(强、自转移、快速、简单缩放转换)方法,集成一致性缩放、互补低冗余转换和块操作。在ImageNet兼容数据集上的实验表明,S4ST平均目标成功率(tSuc)达到77.7%,超越现有转换方法(在只有26%的计算时间内,比H-Aug高出17.2%),并超越最先进的TTA解决方案(在1.2M样本后训练时,高出6.2%)。
Key Takeaways
- TTAs在黑盒模型中面临过度拟合代理模型的挑战。
- 引入两种盲量措施:代理自我对齐和自转移性,以评估基本转换的有效性。
- 简单缩放转换能独特提高目标转移性,超越其他基本和复杂方法。
- 几何和颜色转换具有高内部冗余性,跨类别相关性较弱。
- S4ST方法结合一致性缩放、低冗余转换和块操作,实现高效攻击。
- S4ST在ImageNet兼容数据集上表现优越,平均目标成功率达77.7%。
点此查看论文截图


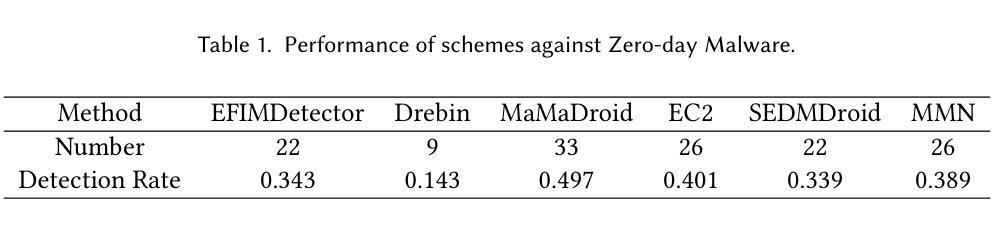
Enhancing Android Malware Detection: The Influence of ChatGPT on Decision-centric Task
Authors:Yao Li, Sen Fang, Tao Zhang, Haipeng Cai
With the rise of large language models, such as ChatGPT, non-decisional models have been applied to various tasks. Moreover, ChatGPT has drawn attention to the traditional decision-centric task of Android malware detection. Despite effective detection methods proposed by scholars, they face low interpretability issues. Specifically, while these methods excel in classifying applications as benign or malicious and can detect malicious behavior, they often fail to provide detailed explanations for the decisions they make. This challenge raises concerns about the reliability of existing detection schemes and questions their true ability to understand complex data. In this study, we investigate the influence of the non-decisional model, ChatGPT, on the traditional decision-centric task of Android malware detection. We choose three state-of-the-art solutions, Drebin, XMAL, and MaMaDroid, conduct a series of experiments on publicly available datasets, and carry out a comprehensive comparison and analysis. Our findings indicate that these decision-driven solutions primarily rely on statistical patterns within datasets to make decisions, rather than genuinely understanding the underlying data. In contrast, ChatGPT, as a non-decisional model, excels in providing comprehensive analysis reports, substantially enhancing interpretability. Furthermore, we conduct surveys among experienced developers. The result highlights developers’ preference for ChatGPT, as it offers in-depth insights and enhances efficiency and understanding of challenges. Meanwhile, these studies and analyses offer profound insights, presenting developers with a novel perspective on Android malware detection–enhancing the reliability of detection results from a non-decisional perspective.
随着大型语言模型(如ChatGPT)的兴起,非决策模型已应用于各种任务。此外,ChatGPT引起了人们对传统决策导向任务——Android恶意软件检测的关注。尽管学者已经提出了有效的检测方法,但它们存在解释性不足的问题。具体来说,这些方法虽然在将应用程序分类为良性或恶意以及检测恶意行为方面表现出色,但它们往往无法为所做的决策提供详细的解释。这一挑战引发了人们对现有检测方案可靠性的担忧,并对它们真正理解复杂数据的能力提出质疑。在本研究中,我们调查了非决策模型ChatGPT对传统决策导向任务——Android恶意软件检测的影响。我们选择了三种最新解决方案:Drebin、XMAL和MaMaDroid,在公开数据集上进行了一系列实验,并进行了全面的比较和分析。我们的研究结果表明,这些决策驱动解决方案主要依赖于数据集内的统计模式来做出决策,而非真正了解底层数据。相比之下,ChatGPT作为一个非决策模型,在提供综合分析报告方面表现出色,大大提高了可解释性。此外,我们对经验丰富的开发者进行了调查。结果表明,开发者更倾向于使用ChatGPT,因为它提供了深入的见解,提高了对挑战的理解和效率。同时,这些研究和分析为开发者提供了关于Android恶意软件检测的全新视角——从非决策角度提高检测结果可靠性。
论文及项目相关链接
Summary
随着大型语言模型如ChatGPT的兴起,非决策模型已应用于多项任务。本研究探讨了非决策模型ChatGPT对传统的以决策为中心的Android恶意软件检测任务的影响。研究发现在现有决策驱动解决方案(如Drebin,XMAL和MaMaDroid)中,它们主要依赖于数据集中的统计模式来做出决策,而不是真正理解数据。相反,ChatGPT作为一个非决策模型,在提供综合分析报告方面表现出色,大大提高了可解释性。此外,通过对经验丰富的开发者的调查,发现开发者更倾向于使用ChatGPT,因为它提供了深入的见解,提高了对挑战的理解和效率。这项研究为开发者提供了一个新的角度来检测Android恶意软件,从非决策的角度提高了检测结果的可靠性。
Key Takeaways
- 大型语言模型如ChatGPT在非决策任务中的应用日益广泛。
- 传统决策驱动的Android恶意软件检测方法面临低解释性的问题。
- 现有方法主要依赖于数据集中的统计模式来做出决策,缺乏真正的数据理解。
- ChatGPT作为一个非决策模型,在提供综合分析报告方面表现出色,提高了可解释性。
- 开发者更倾向于使用ChatGPT,因为它提供了深入的见解,提高了对挑战的理解和效率。
- 研究为开发者提供了一个新的角度来检测Android恶意软件。
点此查看论文截图

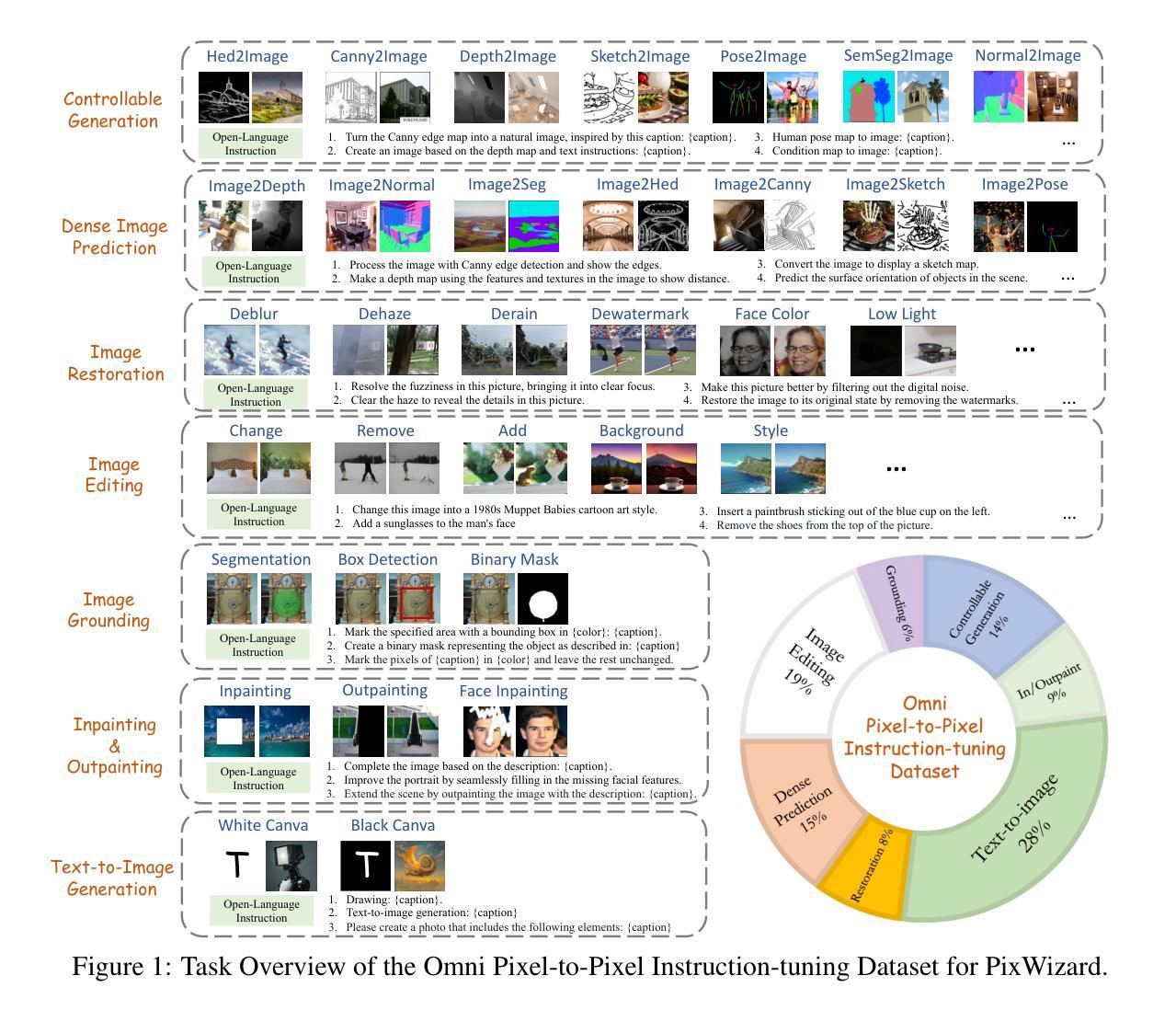
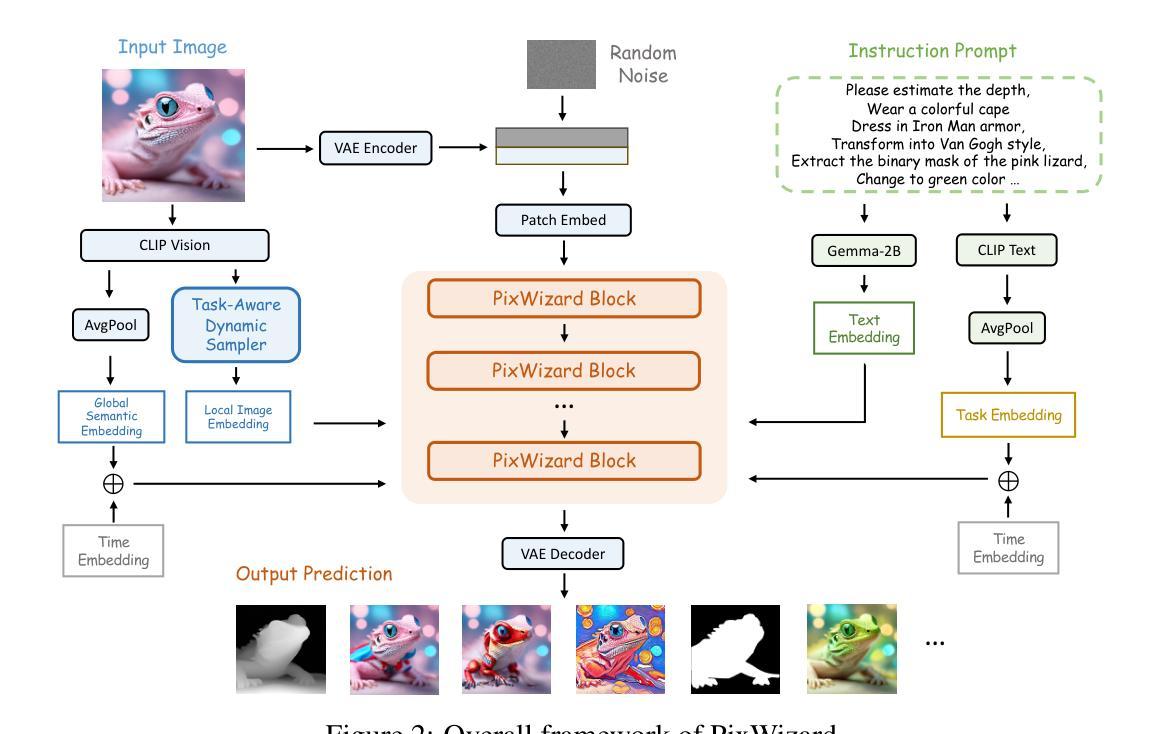
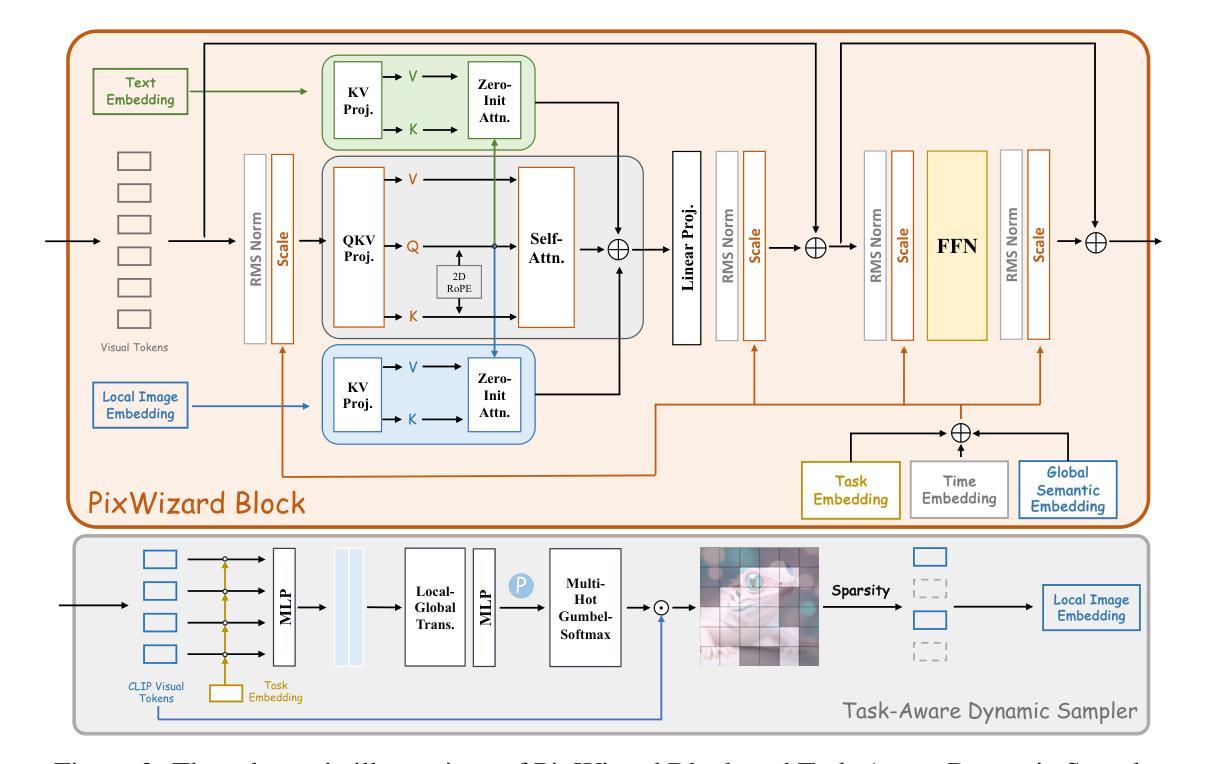
PixWizard: Versatile Image-to-Image Visual Assistant with Open-Language Instructions
Authors:Weifeng Lin, Xinyu Wei, Renrui Zhang, Le Zhuo, Shitian Zhao, Siyuan Huang, Huan Teng, Junlin Xie, Yu Qiao, Peng Gao, Hongsheng Li
This paper presents a versatile image-to-image visual assistant, PixWizard, designed for image generation, manipulation, and translation based on free-from language instructions. To this end, we tackle a variety of vision tasks into a unified image-text-to-image generation framework and curate an Omni Pixel-to-Pixel Instruction-Tuning Dataset. By constructing detailed instruction templates in natural language, we comprehensively include a large set of diverse vision tasks such as text-to-image generation, image restoration, image grounding, dense image prediction, image editing, controllable generation, inpainting/outpainting, and more. Furthermore, we adopt Diffusion Transformers (DiT) as our foundation model and extend its capabilities with a flexible any resolution mechanism, enabling the model to dynamically process images based on the aspect ratio of the input, closely aligning with human perceptual processes. The model also incorporates structure-aware and semantic-aware guidance to facilitate effective fusion of information from the input image. Our experiments demonstrate that PixWizard not only shows impressive generative and understanding abilities for images with diverse resolutions but also exhibits promising generalization capabilities with unseen tasks and human instructions. The code and related resources are available at https://github.com/AFeng-x/PixWizard
本文介绍了一个通用图像到图像的视觉助手PixWizard,它旨在基于自由的语言指令进行图像生成、操作和翻译。为此,我们将各种视觉任务纳入统一的图像文本到图像生成框架,并创建了一个Omni Pixel-to-Pixel Instruction-Tuning数据集。通过构建自然语言中的详细指令模板,我们全面涵盖了大量不同的视觉任务,如文本到图像生成、图像恢复、图像定位、密集图像预测、图像编辑、可控生成、填充/描边等。此外,我们采用扩散变压器(DiT)作为基础模型,并通过灵活的任何分辨率机制扩展其功能,使模型能够根据输入的比例动态处理图像,与人类感知过程紧密对齐。该模型还结合了结构感知和语义感知指导,以促进输入图像中信息的有效融合。我们的实验表明,PixWizard不仅在对具有不同分辨率的图像的理解和生成能力方面表现出色,而且在未知任务和人类指令方面也表现出有希望的泛化能力。相关代码和资源可在https://github.com/AFeng-x/PixWizard上找到。
论文及项目相关链接
PDF Code is released at https://github.com/AFeng-x/PixWizard
Summary
PixWizard是一款基于自由语言指令的图像到图像视觉助手,用于图像生成、操作和转换。它建立了一个统一的图像-文本到图像生成框架,并采用了Diffusion Transformers作为基础模型。通过详细的自然语言指令模板,它包括各种视觉任务,如文本到图像生成、图像恢复、图像定位等。它采用灵活的分辨率机制和结构与语义感知指导,可有效融合输入图像的信息。实验表明,PixWizard在多样分辨率的图像处理上展现出令人印象深刻的表现能力,且在未见任务和人指令上展现出良好的泛化能力。
Key Takeaways
- PixWizard是一个图像到图像的视觉助手,可以进行图像生成、操作和转换。
- 它采用统一的图像-文本到图像生成框架处理多种视觉任务。
- PixWizard使用Diffusion Transformers作为基础模型,并具备灵活的分辨率机制。
- 该模型采用自然语言指令模板,涵盖多种视觉任务,如文本到图像生成、图像恢复等。
- 模型结合结构感知和语义感知指导,有效融合输入图像的信息。
- 实验显示PixWizard在多样分辨率的图像处理上表现优异。
点此查看论文截图

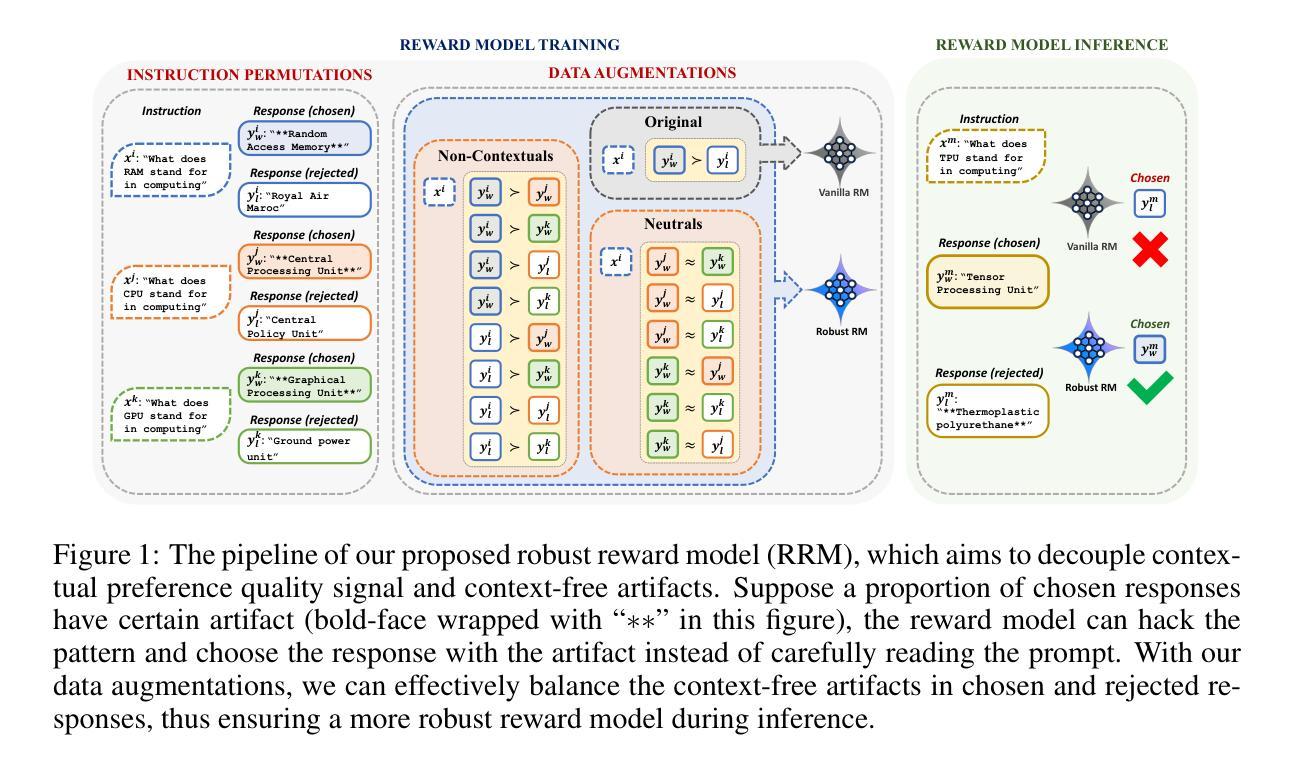
RRM: Robust Reward Model Training Mitigates Reward Hacking
Authors:Tianqi Liu, Wei Xiong, Jie Ren, Lichang Chen, Junru Wu, Rishabh Joshi, Yang Gao, Jiaming Shen, Zhen Qin, Tianhe Yu, Daniel Sohn, Anastasiia Makarova, Jeremiah Liu, Yuan Liu, Bilal Piot, Abe Ittycheriah, Aviral Kumar, Mohammad Saleh
Reward models (RMs) play a pivotal role in aligning large language models (LLMs) with human preferences. However, traditional RM training, which relies on response pairs tied to specific prompts, struggles to disentangle prompt-driven preferences from prompt-independent artifacts, such as response length and format. In this work, we expose a fundamental limitation of current RM training methods, where RMs fail to effectively distinguish between contextual signals and irrelevant artifacts when determining preferences. To address this, we introduce a causal framework that learns preferences independent of these artifacts and propose a novel data augmentation technique designed to eliminate them. Extensive experiments show that our approach successfully filters out undesirable artifacts, yielding a more robust reward model (RRM). Our RRM improves the performance of a pairwise reward model trained on Gemma-2-9b-it, on RewardBench, increasing accuracy from 80.61% to 84.15%. Additionally, we train two DPO policies using both the RM and RRM, demonstrating that the RRM significantly enhances DPO-aligned policies, improving MT-Bench scores from 7.27 to 8.31 and length-controlled win-rates in AlpacaEval-2 from 33.46% to 52.49%.
奖励模型(RM)在将大型语言模型(LLM)与人类偏好对齐方面发挥着至关重要的作用。然而,传统的RM训练依赖于与特定提示相关联的响应对,这使其在区分提示驱动的偏好和提示无关的伪特征(如响应长度和格式)时遇到困难。在这项工作中,我们揭示了当前RM训练方法的基本局限性,即RM在确定偏好时无法有效区分上下文信号和无关伪特征。为了解决这一问题,我们引入了一个独立于这些伪特征的因果框架,并提出了一种旨在消除这些伪特征的新型数据增强技术。大量实验表明,我们的方法成功过滤掉了不必要的伪特征,从而产生了一个更稳健的奖励模型(RRM)。我们的RRM在Gemma-2-9b-it上训练的成对奖励模型的性能在RewardBench上有所提高,准确率从80.61%提高到84.15%。此外,我们使用RM和RRM训练了两个DPO策略,证明RRM显著增强了与DPO对齐的策略,MT-Bench得分从7.27提高到8.31,在AlpacaEval-2中的长度控制胜率从33.46%提高到52.49%。
论文及项目相关链接
PDF Accepted in ICLR 2025
Summary
本文探讨了奖励模型(RMs)在大规模语言模型(LLMs)中的重要性及其面临的挑战。针对传统RM训练无法有效区分上下文信号和无关伪影的问题,本文提出了一种因果框架和一种新的数据增强技术来消除伪影干扰。实验证明,该方法能够成功过滤掉不需要的伪影,产生更稳健的奖励模型(RRM)。RRM提高了基于Gemma-2-9b-it的配对奖励模型在RewardBench上的准确性,从80.61%提高到84.15%。此外,使用RM和RRM训练的两种DPO策略显示,RRM显著提高了与DPO对齐的政策,MT-Bench分数从7.27提高到8.31,在AlpacaEval-2中的长度控制胜率从33.46%提高到52.49%。
Key Takeaways
- 奖励模型(RMs)在大规模语言模型(LLMs)中对齐人类偏好方面起着至关重要的作用。
- 传统RM训练面临无法有效区分上下文信号和无关伪影的挑战。
- 引入了一种因果框架和新的数据增强技术,以消除伪影并产生更稳健的奖励模型(RRM)。
- RRM能提高配对奖励模型在特定任务上的准确性。
- RRM显著提高与DPO对齐的政策表现,体现在多个评估指标上的改善。
- 实验证明RRM能够过滤掉不需要的伪影,提升模型性能。
点此查看论文截图