⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-01 更新
Adapting Automatic Speech Recognition for Accented Air Traffic Control Communications
Authors:Marcus Yu Zhe Wee, Justin Juin Hng Wong, Lynus Lim, Joe Yu Wei Tan, Prannaya Gupta, Dillion Lim, En Hao Tew, Aloysius Keng Siew Han, Yong Zhi Lim
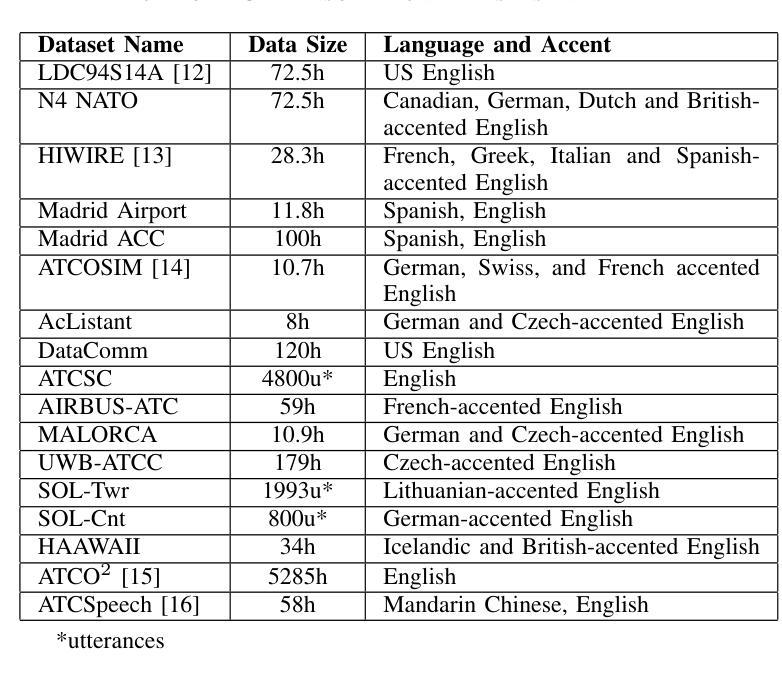
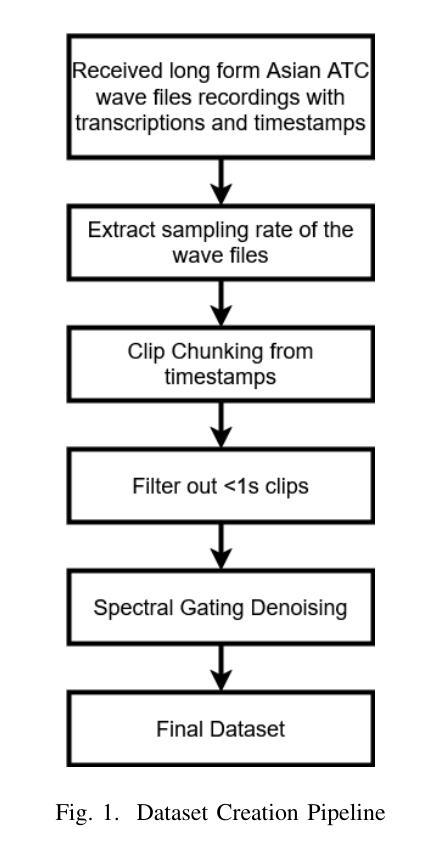
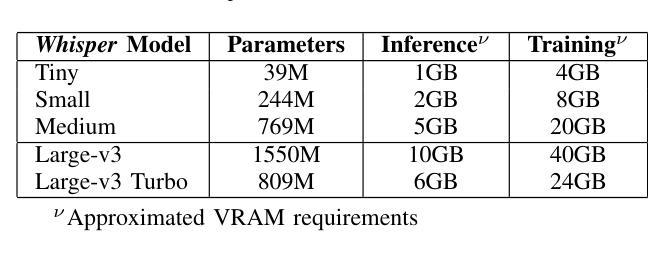
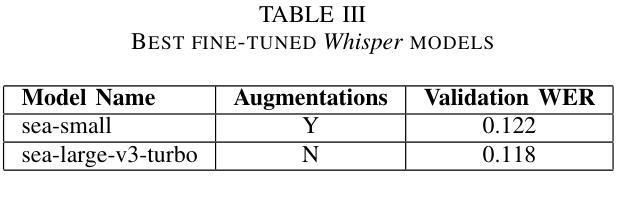
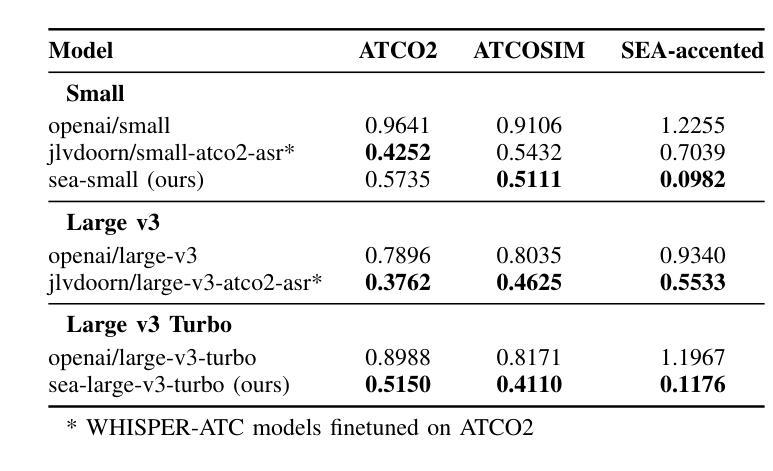
Effective communication in Air Traffic Control (ATC) is critical to maintaining aviation safety, yet the challenges posed by accented English remain largely unaddressed in Automatic Speech Recognition (ASR) systems. Existing models struggle with transcription accuracy for Southeast Asian-accented (SEA-accented) speech, particularly in noisy ATC environments. This study presents the development of ASR models fine-tuned specifically for Southeast Asian accents using a newly created dataset. Our research achieves significant improvements, achieving a Word Error Rate (WER) of 0.0982 or 9.82% on SEA-accented ATC speech. Additionally, the paper highlights the importance of region-specific datasets and accent-focused training, offering a pathway for deploying ASR systems in resource-constrained military operations. The findings emphasize the need for noise-robust training techniques and region-specific datasets to improve transcription accuracy for non-Western accents in ATC communications.
在航空交通管制(ATC)中的有效沟通对于维持航空安全至关重要。然而,带有口音的英语给自动语音识别(ASR)系统带来的挑战仍未得到很好的解决。现有模型在转录带有东南亚口音(SEA口音)的语音时,特别是在嘈杂的ATC环境中,准确性较差。本研究提出了针对东南亚口音进行特别微调的的ASR模型的开发,使用了新创建的数据集。我们的研究取得了显著改进,在带有东南亚口音的ATC语音上实现了词错误率(WER)为0.0982或9.82%。此外,本文强调了区域特定数据集和口音重点训练的重要性,为在资源有限的军事行动中部署ASR系统提供了途径。这一发现强调需要噪声鲁棒的培训技术和区域特定的数据集来提高ATC通信中非西方口音的转录准确性。
论文及项目相关链接
总结
本研究开发了针对东南亚口音的自动语音识别(ASR)模型,使用新创建的数据集进行微调,在带有噪音的空中交通管制(ATC)环境中实现了显著的改进,单词错误率(WER)达到了0.0982或9.82%。研究强调了地区特定数据集和口音特定训练的重要性,为在资源有限的军事行动中部署ASR系统提供了途径。
关键见解
- 有效的空中交通管制(ATC)沟通对于航空安全至关重要。
- 带有口音的英语在自动语音识别(ASR)系统中仍然面临挑战。
- 现有模型在嘈杂的ATC环境中对东南亚口音的语音识别准确性较低。
- 本研究开发了针对东南亚口音的ASR模型,并使用新数据集进行微调。
- 研究实现了单词错误率(WER)9.82%的显著改善。
- 地区特定数据集和口音特定训练对于提高ASR系统的性能至关重要。
点此查看论文截图

CleanMel: Mel-Spectrogram Enhancement for Improving Both Speech Quality and ASR
Authors:Nian Shao, Rui Zhou, Pengyu Wang, Xian Li, Ying Fang, Yujie Yang, Xiaofei Li
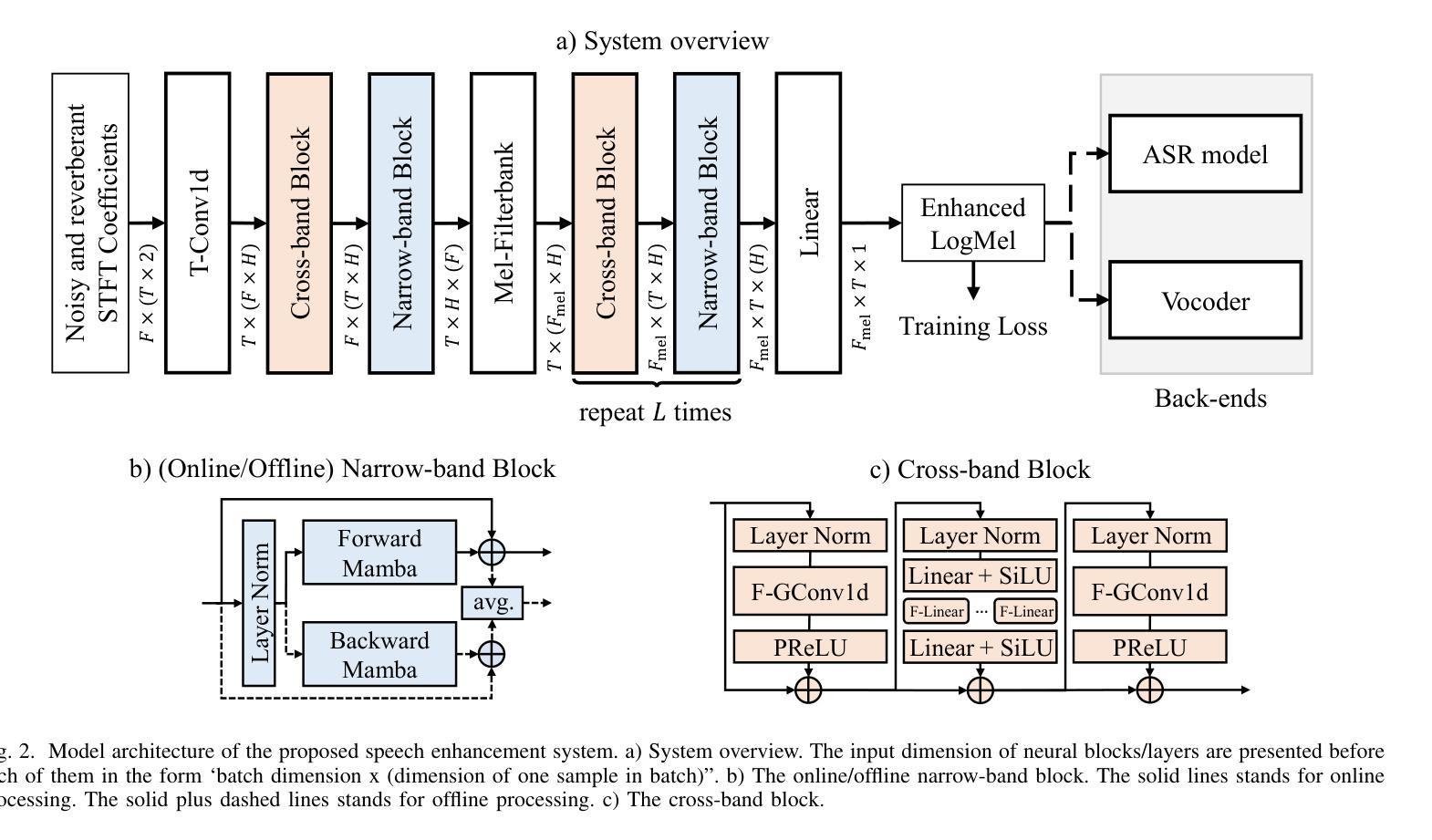
In this work, we propose CleanMel, a single-channel Mel-spectrogram denoising and dereverberation network for improving both speech quality and automatic speech recognition (ASR) performance. The proposed network takes as input the noisy and reverberant microphone recording and predicts the corresponding clean Mel-spectrogram. The enhanced Mel-spectrogram can be either transformed to speech waveform with a neural vocoder or directly used for ASR. The proposed network is composed of interleaved cross-band and narrow-band processing in the Mel-frequency domain, for learning the full-band spectral pattern and the narrow-band properties of signals, respectively. Compared to linear-frequency domain or time-domain speech enhancement, the key advantage of Mel-spectrogram enhancement is that Mel-frequency presents speech in a more compact way and thus is easier to learn, which will benefit both speech quality and ASR. Experimental results on four English and one Chinese datasets demonstrate a significant improvement in both speech quality and ASR performance achieved by the proposed model. Code and audio examples of our model are available online in https://audio.westlake.edu.cn/Research/CleanMel.html.
在这项工作中,我们提出了CleanMel,这是一种单通道梅尔频谱降噪和去混响网络,旨在提高语音质量和自动语音识别(ASR)性能。所提出的网络以带噪声和混响的麦克风录音为输入,并预测相应的清洁梅尔频谱。增强的梅尔频谱可以使用神经编码器转换为语音波形,也可以直接用于ASR。所提出的网络由梅尔频率域中的交叉带和窄带处理交替组成,分别学习全频带谱模式和信号的窄带属性。与线性频率域或时间域的语音增强相比,梅尔频谱增强的主要优势在于梅尔频率以更紧凑的方式呈现语音,因此更容易学习,这将有利于提高语音质量和ASR。在四个英文数据集和一个中文数据集上的实验结果证明,该模型在语音质量和ASR性能上都有显著提高。模型的代码和音频示例可在https://audio.westlake.edu.cn/Research/CleanMel.html在线访问。
论文及项目相关链接
PDF Submission to IEEE/ACM Trans. on TASLP
Summary
本文提出了CleanMel网络,这是一种单通道梅尔频谱图降噪和去混响网络,旨在提高语音质量和自动语音识别(ASR)性能。该网络以含噪声和混响的麦克风录音为输入,预测相应的清洁梅尔频谱图。增强的梅尔频谱图可以用神经网络vocoder转换为语音波形,也可以直接用于ASR。该网络由梅尔频率域中的交叉频带和窄带处理组成,分别学习全频带谱模式和信号的窄带属性。相较于线性频率域或时间域的语音增强方法,梅尔频谱图增强的主要优势在于梅尔频率能以更紧凑的方式呈现语音,从而更容易学习,这将同时有益于语音质量和ASR。实验结果表明,该模型在四个英文数据集和一个中文数据集上显著提高了语音质量和ASR性能。模型代码和音频示例可在https://audio.westlake.edu.cn/Research/CleanMel.html在线访问。
Key Takeaways
- CleanMel网络是一个用于梅尔频谱图降噪和去混响的单通道网络。
- 该网络旨在提高语音质量和自动语音识别(ASR)性能。
- 网络以含噪声和混响的麦克风录音为输入,输出清洁的梅尔频谱图。
- 增强的梅尔频谱图可转换为语音波形或直接用于ASR。
- 网络由梅尔频率域的交叉频带和窄带处理组成。
- 梅尔频谱图增强的优势在于以更紧凑的方式呈现语音,易于学习。
点此查看论文截图

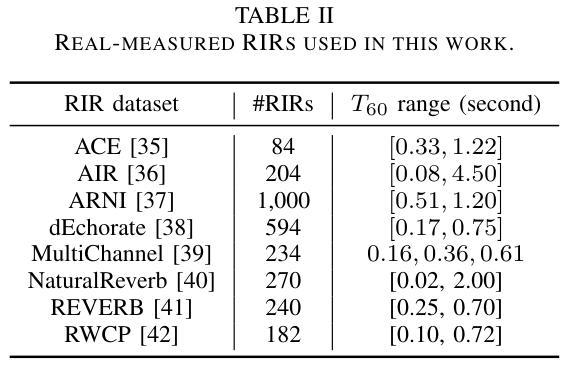
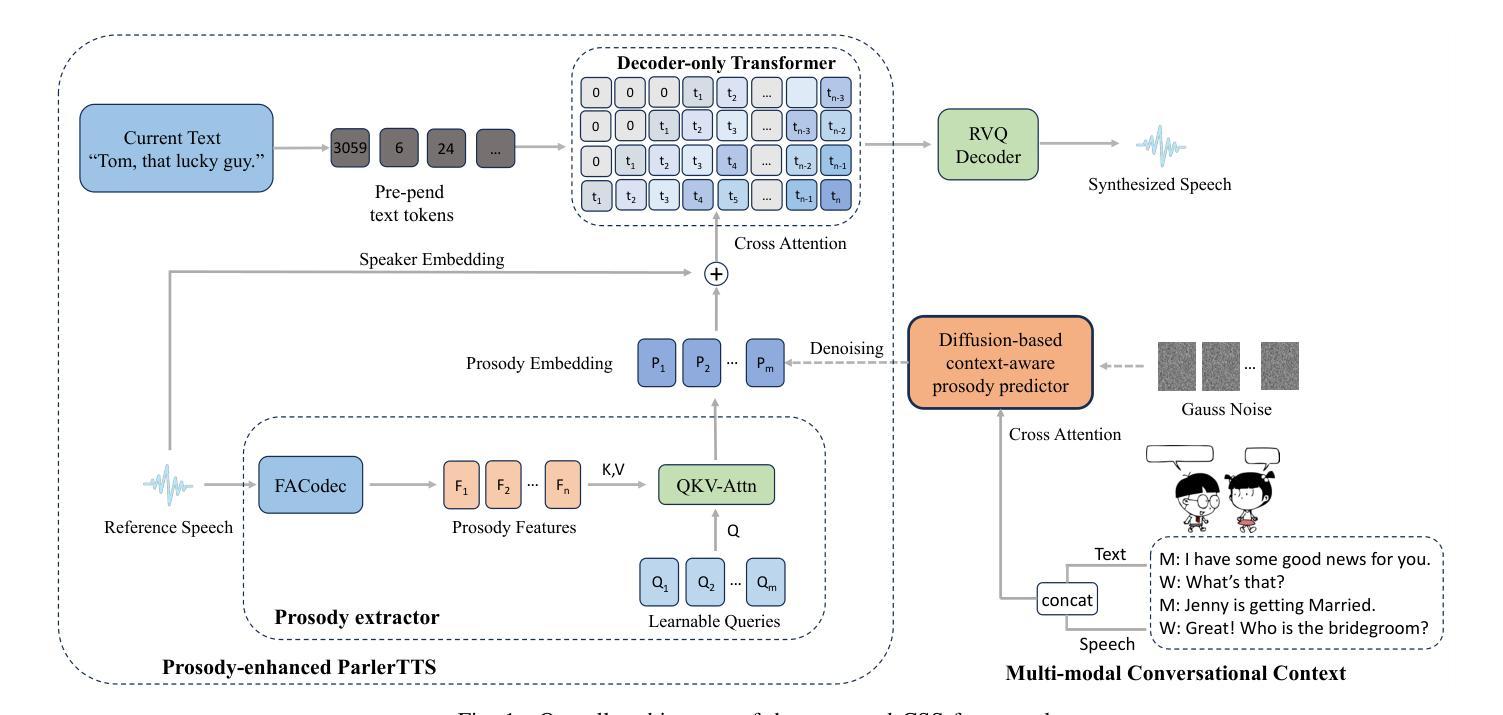
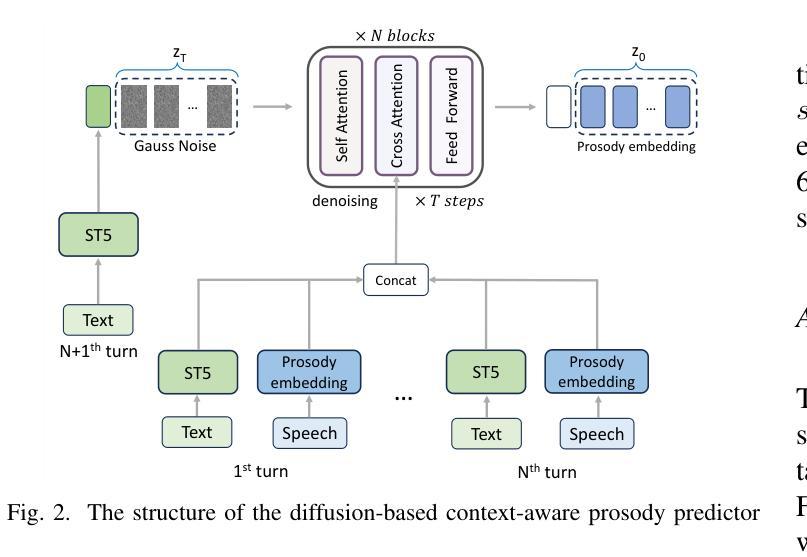
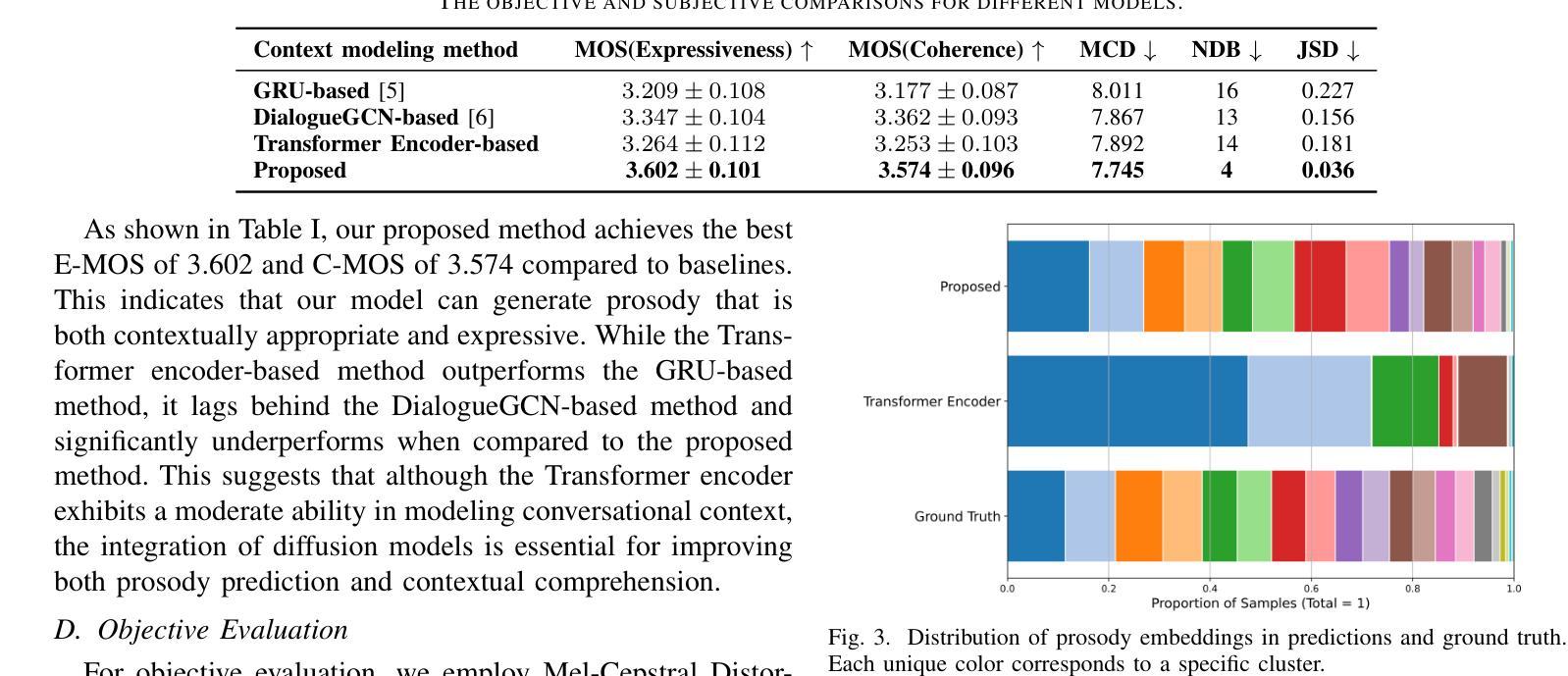
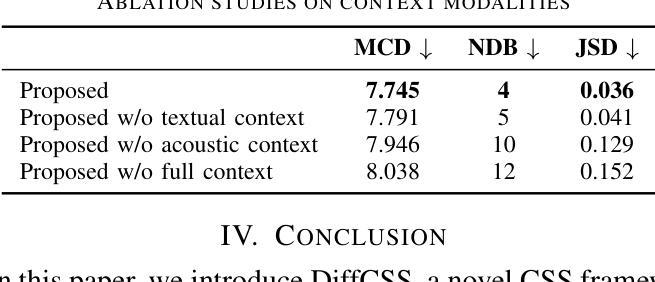
DiffCSS: Diverse and Expressive Conversational Speech Synthesis with Diffusion Models
Authors:Weihao wu, Zhiwei Lin, Yixuan Zhou, Jingbei Li, Rui Niu, Qinghua Wu, Songjun Cao, Long Ma, Zhiyong Wu
Conversational speech synthesis (CSS) aims to synthesize both contextually appropriate and expressive speech, and considerable efforts have been made to enhance the understanding of conversational context. However, existing CSS systems are limited to deterministic prediction, overlooking the diversity of potential responses. Moreover, they rarely employ language model (LM)-based TTS backbones, limiting the naturalness and quality of synthesized speech. To address these issues, in this paper, we propose DiffCSS, an innovative CSS framework that leverages diffusion models and an LM-based TTS backbone to generate diverse, expressive, and contextually coherent speech. A diffusion-based context-aware prosody predictor is proposed to sample diverse prosody embeddings conditioned on multimodal conversational context. Then a prosody-controllable LM-based TTS backbone is developed to synthesize high-quality speech with sampled prosody embeddings. Experimental results demonstrate that the synthesized speech from DiffCSS is more diverse, contextually coherent, and expressive than existing CSS systems
对话式语音合成(CSS)旨在合成语境恰当、富有表现力的语音,并且已经做出了相当大的努力来增强对话语境的理解。然而,现有的CSS系统仅限于确定性预测,忽视了潜在响应的多样性。此外,他们很少使用基于语言模型(LM)的TTS主干,这限制了合成语音的自然度和质量。为了解决这些问题,本文提出了DiffCSS,这是一个创新的CSS框架,它利用扩散模型和基于LM的TTS主干来生成多样、富有表现力且语境连贯的语音。我们提出了一种基于扩散的语境感知韵律预测器,用于根据多模式对话语境对多样的韵律嵌入进行采样。然后开发了一个具有韵律控制功能的基于LM的TTS主干,用于合成高质量的带有采样韵律嵌入的语音。实验结果表明,DiffCSS合成的语音比现有CSS系统更具多样性、语境连贯性和表现力。
论文及项目相关链接
PDF Accepted by ICASSP 2025
Summary
本文提出一种名为DiffCSS的新型会话语音合成框架,旨在解决现有会话语音合成系统存在的问题。DiffCSS利用扩散模型和基于语言模型的文本转语音合成(TTS)主干,生成多样、表达丰富且与语境一致的语音。通过扩散模型实现基于语境的韵律预测器,根据多模式会话语境采样多样的韵律嵌入。同时,发展了一个可控韵律的基于语言模型的TTS主干,以合成高质量、带有采样韵律的语音。实验结果表明,DiffCSS合成的语音更具多样性、语境一致性和表现力。
Key Takeaways
- DiffCSS是一个新型会话语音合成框架,旨在生成多样、表达丰富且与语境一致的语音。
- 现有会话语音合成系统存在确定性预测和缺乏多样性等问题。
- DiffCSS利用扩散模型和基于语言模型的TTS主干来解决这些问题。
- 扩散模型用于实现基于语境的韵律预测,采样多样的韵律嵌入。
- 提出的可控韵律的基于语言模型的TTS主干能合成高质量语音。
- 实验结果表明,DiffCSS合成的语音更具多样性、语境一致性和表现力。
点此查看论文截图

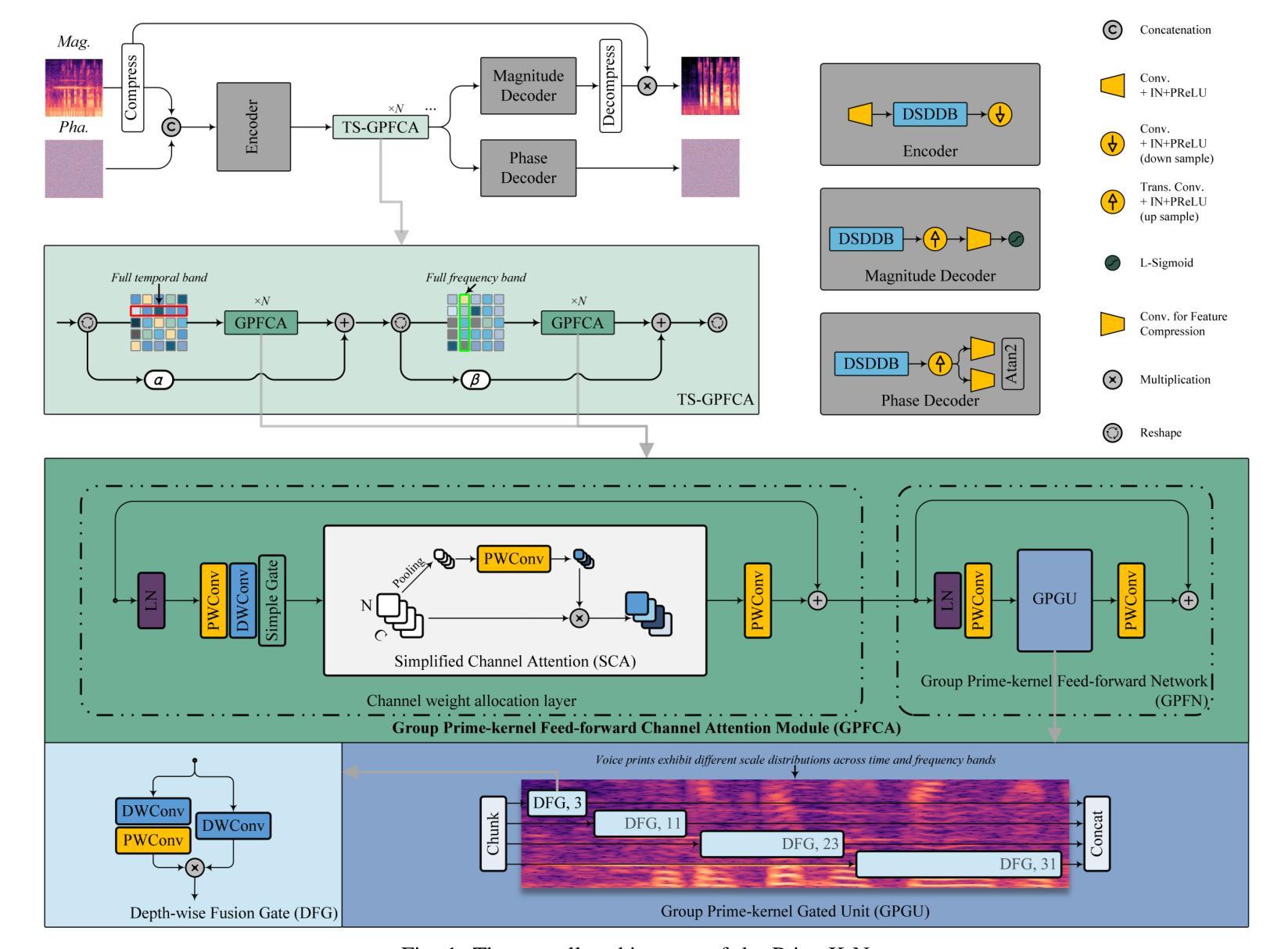
PrimeK-Net: Multi-scale Spectral Learning via Group Prime-Kernel Convolutional Neural Networks for Single Channel Speech Enhancement
Authors:Zizhen Lin, Junyu Wang, Ruili Li, Fei Shen, Xi Xuan
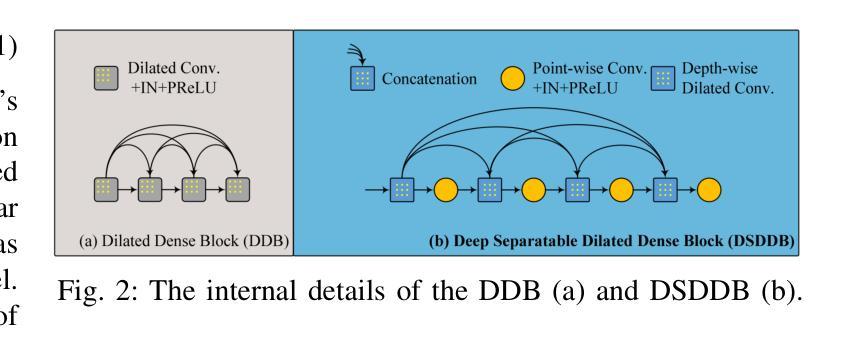
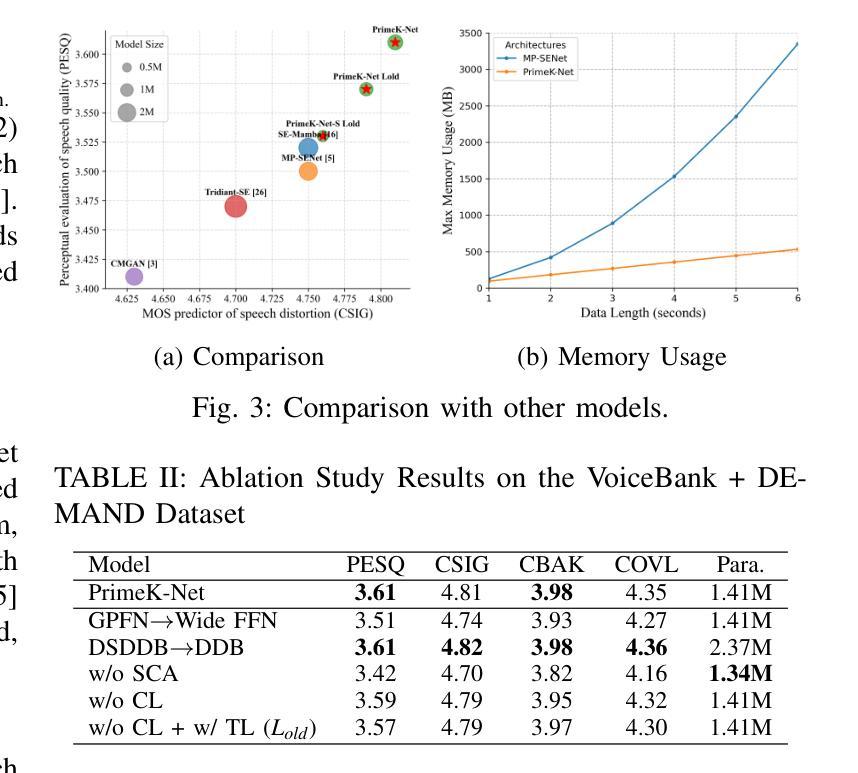
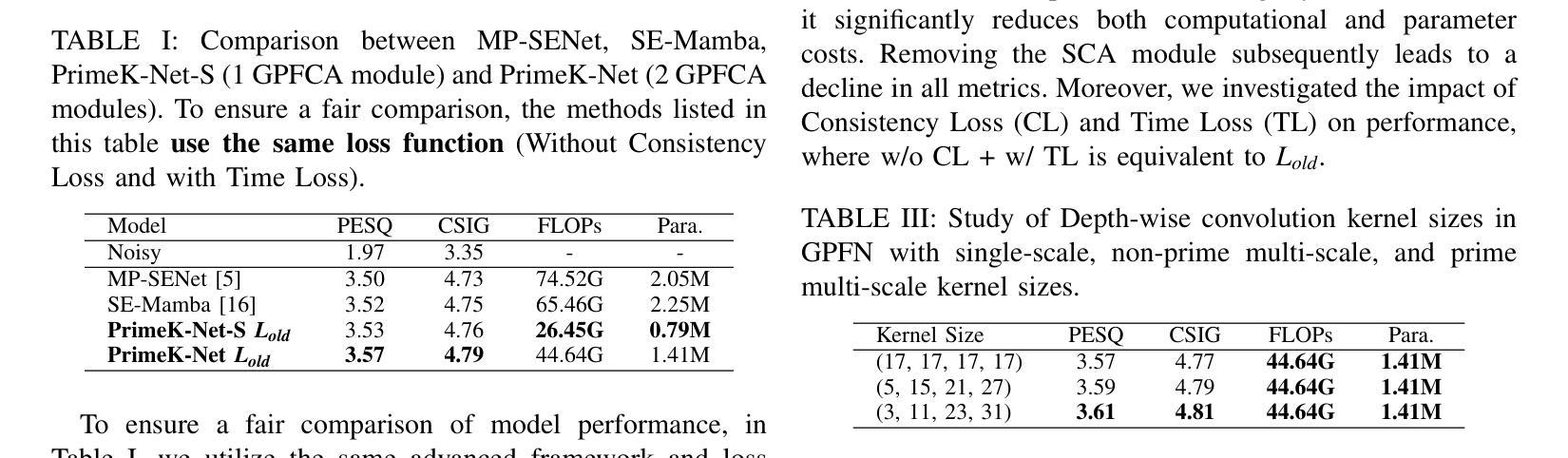
Single-channel speech enhancement is a challenging ill-posed problem focused on estimating clean speech from degraded signals. Existing studies have demonstrated the competitive performance of combining convolutional neural networks (CNNs) with Transformers in speech enhancement tasks. However, existing frameworks have not sufficiently addressed computational efficiency and have overlooked the natural multi-scale distribution of the spectrum. Additionally, the potential of CNNs in speech enhancement has yet to be fully realized. To address these issues, this study proposes a Deep Separable Dilated Dense Block (DSDDB) and a Group Prime Kernel Feedforward Channel Attention (GPFCA) module. Specifically, the DSDDB introduces higher parameter and computational efficiency to the Encoder/Decoder of existing frameworks. The GPFCA module replaces the position of the Conformer, extracting deep temporal and frequency features of the spectrum with linear complexity. The GPFCA leverages the proposed Group Prime Kernel Feedforward Network (GPFN) to integrate multi-granularity long-range, medium-range, and short-range receptive fields, while utilizing the properties of prime numbers to avoid periodic overlap effects. Experimental results demonstrate that PrimeK-Net, proposed in this study, achieves state-of-the-art (SOTA) performance on the VoiceBank+Demand dataset, reaching a PESQ score of 3.61 with only 1.41M parameters.
单通道语音增强是一个具有挑战性的不适定问题,主要关注从退化信号中估计清洁语音。现有研究已证明卷积神经网络(CNN)与Transformer相结合的语音增强任务的竞争性能。然而,现有框架尚未充分解决计算效率问题,并忽视了频谱的自然多尺度分布。此外,CNN在语音增强中的潜力尚未得到充分实现。为了解决这些问题,本研究提出了深度可分离膨胀密集块(DSDDB)和组素数核前馈通道注意力(GPFCA)模块。具体地说,DSDDB提高了现有框架的编码器/解码器的参数和计算效率。GPFCA模块取代了Conformer的位置,以线性复杂度提取频谱的深层时间和频率特征。GPFCA利用所提出的组素数核前馈网络(GPFN)整合多粒度长程、中程和短程感受野,同时利用素数的属性避免周期性重叠效应。实验结果证明,本研究提出的PrimeK-Net在VoiceBank+Demand数据集上达到了最先进的性能,在只有1.41M参数的情况下,PESQ得分达到3.61。
论文及项目相关链接
PDF This paper was accepeted by ICASSP 2025
Summary
本研究针对单通道语音增强这一具有挑战性的问题,提出了深度可分离膨胀密集块(DSDDB)和组素数核前馈通道注意力(GPFCA)模块。通过提高参数和计算效率,以及利用自然多尺度分布的特点,提高了现有框架的效率和性能。实验结果显示,提出的PrimeK-Net在VoiceBank+Demand数据集上取得了最先进的性能,PESQ得分达到3.61,仅使用1.41M参数。
Key Takeaways
- 单通道语音增强是一个挑战性的问题,旨在从退化信号中估计干净语音。
- 卷积神经网络(CNNs)与Transformer的结合在语音增强任务中展现出竞争力。
- 现有框架在计算效率和处理自然多尺度分布的频谱方面存在不足。
- 本研究提出了深度可分离膨胀密集块(DSDDB)和组素数核前馈通道注意力(GPFCA)模块以解决这些问题。
- DSDDB提高了现有框架的编码器和解码器的参数和计算效率。
- GPFCA模块替代了Conformer的位置,以线性复杂度提取谱的深度时频特征。
点此查看论文截图