⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-01 更新
Telephone Surveys Meet Conversational AI: Evaluating a LLM-Based Telephone Survey System at Scale
Authors:Max M. Lang, Sol Eskenazi
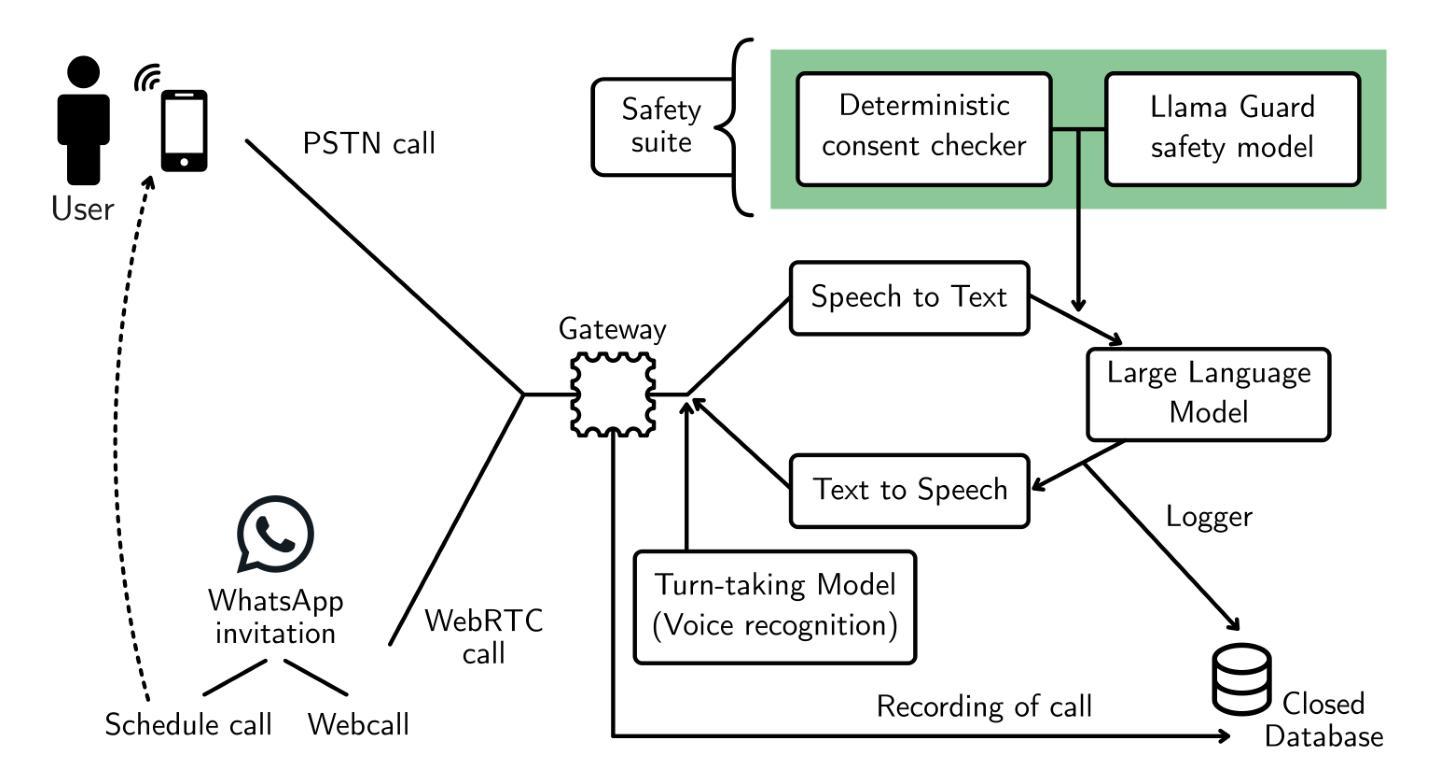
Telephone surveys remain a valuable tool for gathering insights but typically require substantial resources in training and coordinating human interviewers. This work presents an AI-driven telephone survey system integrating text-to-speech (TTS), a large language model (LLM), and speech-to-text (STT) that mimics the versatility of human-led interviews on scale. We tested the system across two populations, a pilot study in the United States (n = 75) and a large-scale deployment in Peru (n = 2,739), inviting participants via web-based links and contacting them via direct phone calls. The AI agent successfully administered open-ended and closed-ended questions, handled basic clarifications, and dynamically navigated branching logic, allowing fast large-scale survey deployment without interviewer recruitment or training. Our findings demonstrate that while the AI system’s probing for qualitative depth was more limited than human interviewers, overall data quality approached human-led standards for structured items. This study represents one of the first successful large-scale deployments of an LLM-based telephone interviewer in a real-world survey context. The AI-powered telephone survey system has the potential for expanding scalable, consistent data collecting across market research, social science, and public opinion studies, thus improving operational efficiency while maintaining appropriate data quality for research.
电话调查仍然是收集见解的有价值工具,但通常需要投入大量资源进行人力面试员的培训和协调。本文介绍了一个AI驱动的电话调查系统,该系统集成了文本转语音(TTS)、大型语言模型(LLM)和语音转文本(STT),在规模上模仿了人类主导采访的通用性。我们在两个群体中测试了该系统,一项是在美国进行的试点研究(n=75),另一项是在秘鲁进行的大规模部署(n=2739)。我们通过网络链接邀请参与者,并通过直接电话与他们联系。AI代理成功管理了开放式和封闭式问题,处理基本澄清,并动态导航分支逻辑,允许快速大规模部署调查,无需面试员的招聘或培训。我们的研究发现,虽然AI系统在定性深度方面的探查能力较人类面试员更为有限,但总体而言,对于结构化项目的数据质量已达到人类主导的标准。这项研究代表了基于LLM的电话采访员在现实调查环境中的首次成功大规模部署之一。AI驱动的电话调查系统具有在市场调研、社会科学和公众意见研究等领域扩大可扩展、一致的数据采集的潜力,从而提高了操作效率,同时保持了适当的数据质量用于研究。
论文及项目相关链接
Summary
本文介绍了一个利用人工智能驱动的电话调查系统,该系统结合了文本转语音(TTS)、大型语言模型(LLM)和语音转文本(STT)技术,模拟了人类访谈员的灵活性,实现了大规模的电话调查。通过在美国的试点研究(n=75)和秘鲁的大规模部署(n=2,739),该系统成功进行了开放式和封闭式问题的调查,基本澄清和动态导航分支逻辑,虽然对数据深度的探索能力有限,但总体数据质量接近人类主导的标准。该系统的使用可提高大规模调查的操作效率,在市场调研、社会科学和公众意见研究等领域具有广泛应用前景。
Key Takeaways
- AI电话调查系统集成了TTS、LLM和STT技术,能够模仿人类访谈员进行大规模的电话调查。
- 系统成功应用于美国(n=75)和秘鲁(n=2,739)的试点和大规模部署。
- 该系统能够自主进行开放式和封闭式问题的调查,并能处理基本澄清和动态导航分支逻辑。
- AI系统在数据深度探索方面能力有限,但总体数据质量接近人类主导的标准。
- 该系统能够提高调查的操作效率,并有望在市场调研、社会科学和公众意见研究等领域得到广泛应用。
- 通过直接电话联系参与者的方式,提高了数据收集的响应率和质量。
点此查看论文截图


DiffCSS: Diverse and Expressive Conversational Speech Synthesis with Diffusion Models
Authors:Weihao wu, Zhiwei Lin, Yixuan Zhou, Jingbei Li, Rui Niu, Qinghua Wu, Songjun Cao, Long Ma, Zhiyong Wu
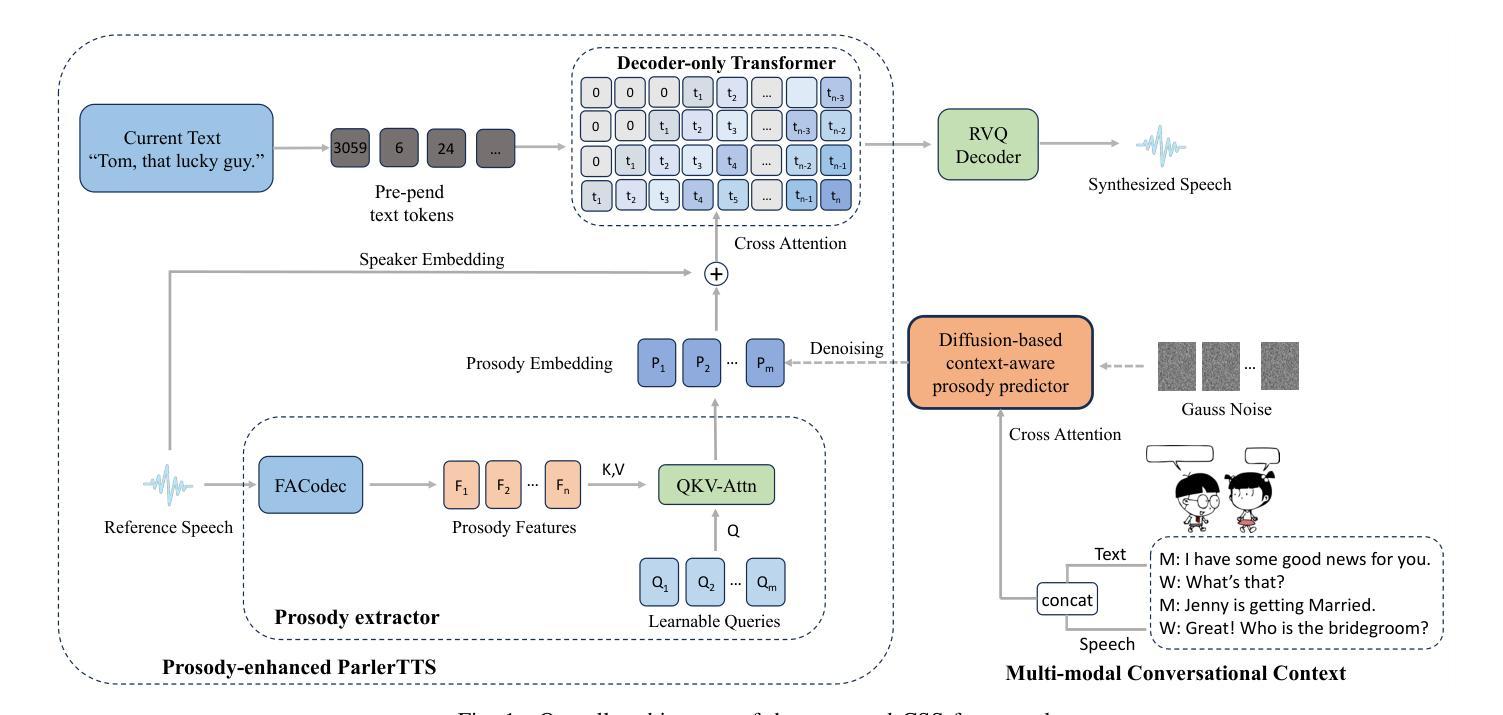
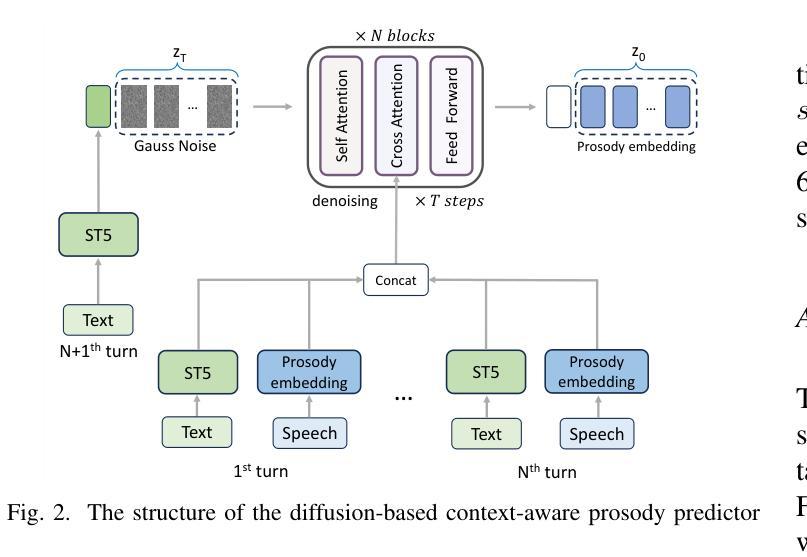
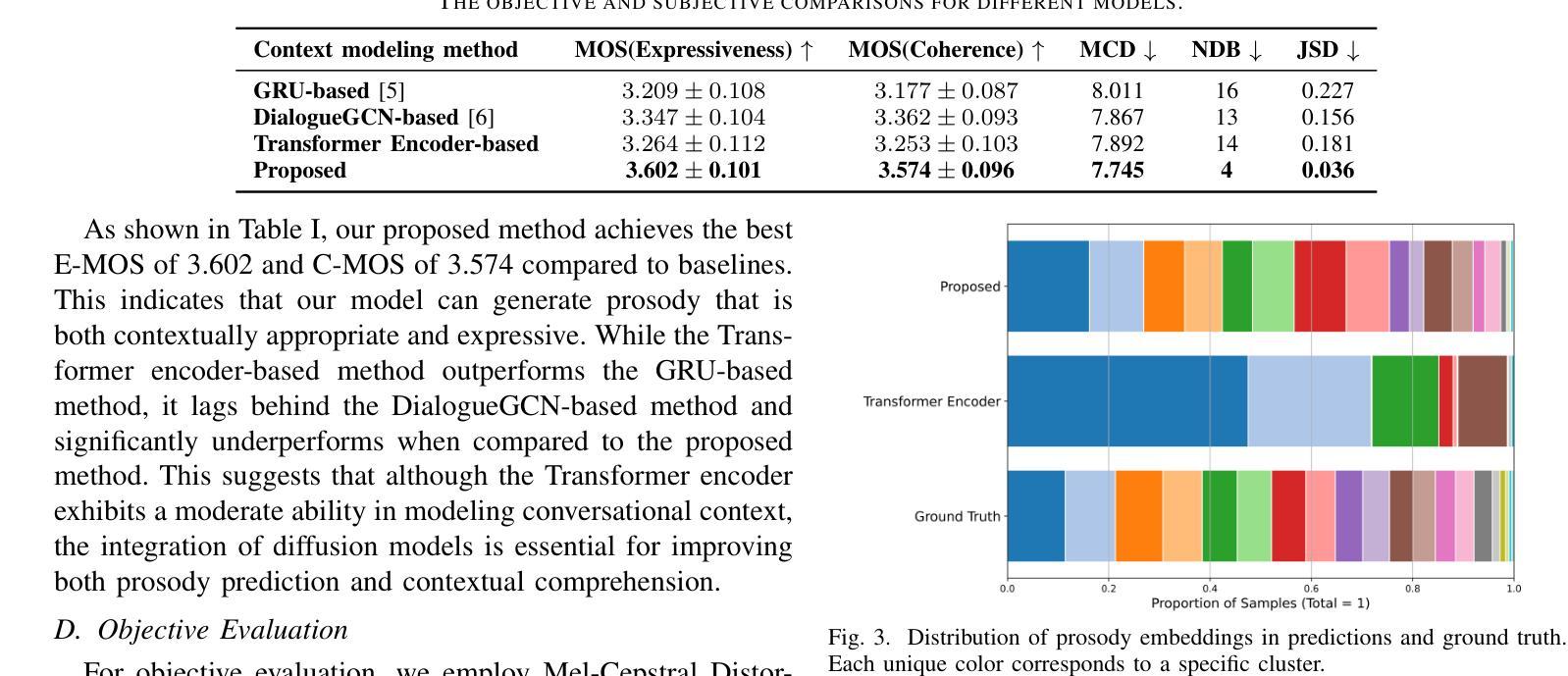
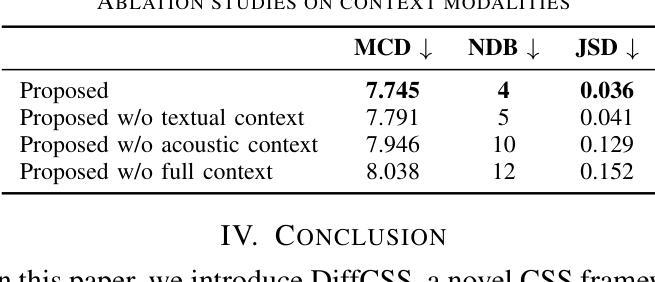
Conversational speech synthesis (CSS) aims to synthesize both contextually appropriate and expressive speech, and considerable efforts have been made to enhance the understanding of conversational context. However, existing CSS systems are limited to deterministic prediction, overlooking the diversity of potential responses. Moreover, they rarely employ language model (LM)-based TTS backbones, limiting the naturalness and quality of synthesized speech. To address these issues, in this paper, we propose DiffCSS, an innovative CSS framework that leverages diffusion models and an LM-based TTS backbone to generate diverse, expressive, and contextually coherent speech. A diffusion-based context-aware prosody predictor is proposed to sample diverse prosody embeddings conditioned on multimodal conversational context. Then a prosody-controllable LM-based TTS backbone is developed to synthesize high-quality speech with sampled prosody embeddings. Experimental results demonstrate that the synthesized speech from DiffCSS is more diverse, contextually coherent, and expressive than existing CSS systems
对话语音识别(CSS)旨在合成语境恰当、富有表现力的语音,并付出了大量努力来提高对话语境的理解能力。然而,现有的CSS系统仅限于确定性预测,忽略了潜在响应的多样性。此外,它们很少使用基于语言模型(LM)的TTS主干,这限制了合成语音的自然度和质量。为了解决这些问题,本文提出了DiffCSS,一种创新的CSS框架,它利用扩散模型和基于LM的TTS主干来生成多样、富有表现力且与上下文一致的语音。我们提出了一种基于扩散的上下文感知语调预测器,以在多种模式对话上下文条件下采样多种语调嵌入。然后开发了一种带有可控语调的基于LM的TTS主干,以合成高质量且具有采样语调嵌入的语音。实验结果表明,DiffCSS合成的语音比现有CSS系统更加多样、上下文连贯和富有表现力。
论文及项目相关链接
PDF Accepted by ICASSP 2025
Summary
文本提出了一种新型的对话语音合成框架DiffCSS,它利用扩散模型和基于语言模型的TTS(文本转语音)后端技术来生成多样、表达丰富且与语境一致的语音。DiffCSS通过采样不同的语音语调嵌入并与其上下文环境结合,使语音合成更加自然、丰富。与传统的语音合成系统相比,DiffCSS生成的效果更优。总的来说,该技术对提高人机交互的沉浸感和逼真度至关重要。
Key Takeaways
- CSS的目标是合成与语境相适应并具有表现力的语音。现有的CSS系统受限于确定性预测,无法充分利用语境多样性。
- DiffCSS利用扩散模型和基于语言模型的TTS后端技术,生成多样且自然的语音。扩散模型可以预测不同语境下的语调嵌入,提高语音的自然度和丰富度。基于语言模型的TTS后端技术则用于合成高质量语音。
点此查看论文截图

CUIfy the XR: An Open-Source Package to Embed LLM-powered Conversational Agents in XR
Authors:Kadir Burak Buldu, Süleyman Özdel, Ka Hei Carrie Lau, Mengdi Wang, Daniel Saad, Sofie Schönborn, Auxane Boch, Enkelejda Kasneci, Efe Bozkir
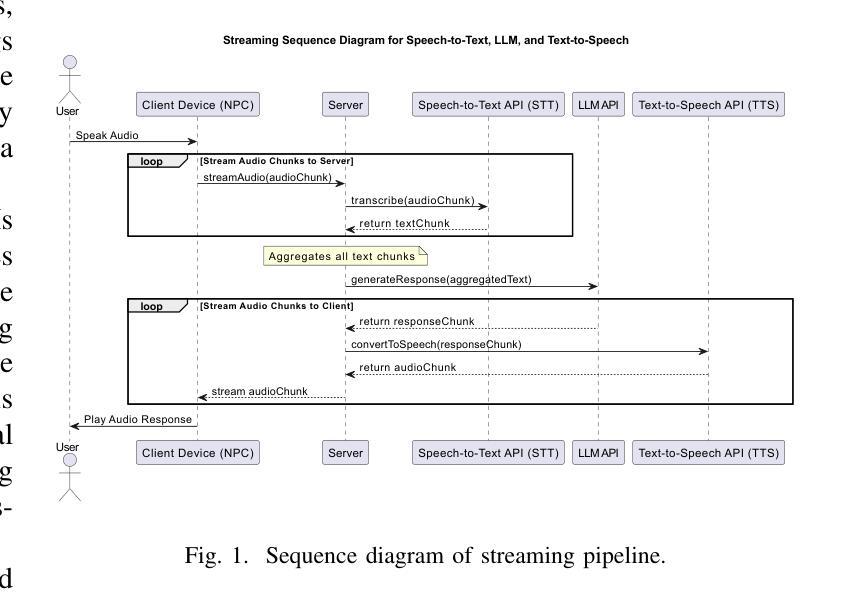
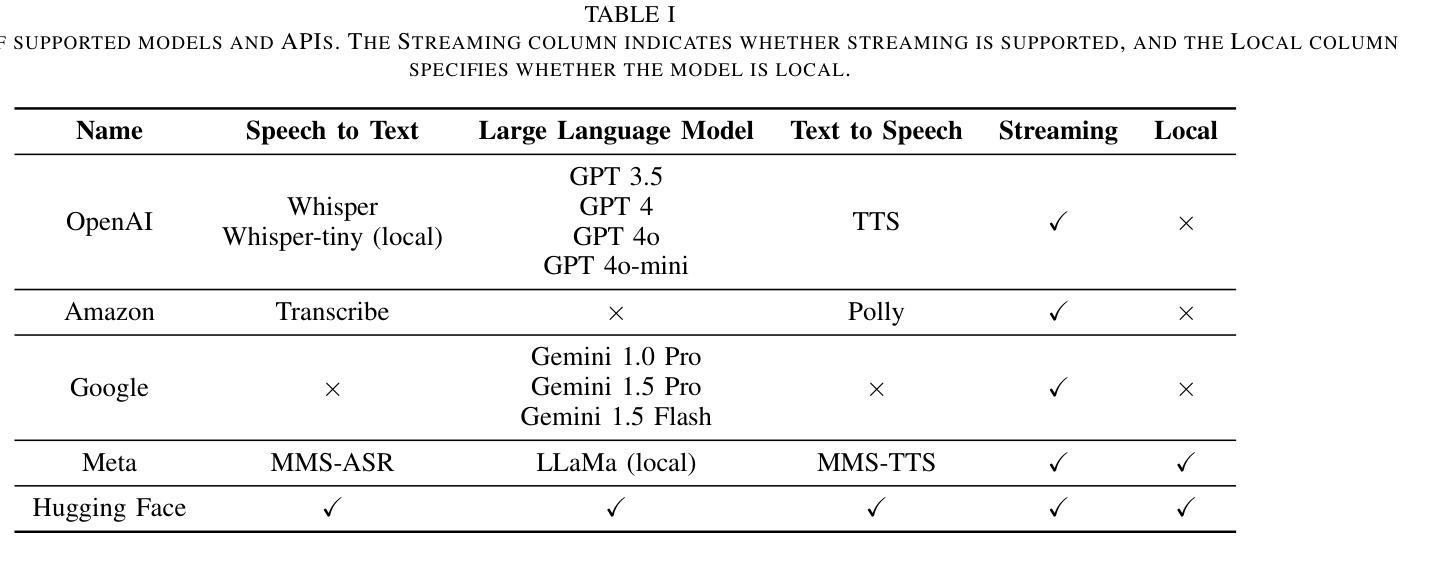
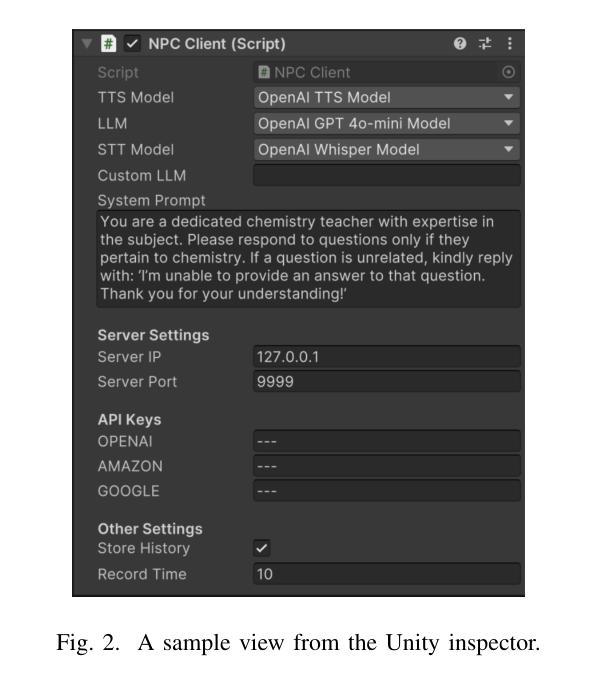
Recent developments in computer graphics, machine learning, and sensor technologies enable numerous opportunities for extended reality (XR) setups for everyday life, from skills training to entertainment. With large corporations offering affordable consumer-grade head-mounted displays (HMDs), XR will likely become pervasive, and HMDs will develop as personal devices like smartphones and tablets. However, having intelligent spaces and naturalistic interactions in XR is as important as technological advances so that users grow their engagement in virtual and augmented spaces. To this end, large language model (LLM)–powered non-player characters (NPCs) with speech-to-text (STT) and text-to-speech (TTS) models bring significant advantages over conventional or pre-scripted NPCs for facilitating more natural conversational user interfaces (CUIs) in XR. This paper provides the community with an open-source, customizable, extendable, and privacy-aware Unity package, CUIfy, that facilitates speech-based NPC-user interaction with widely used LLMs, STT, and TTS models. Our package also supports multiple LLM-powered NPCs per environment and minimizes latency between different computational models through streaming to achieve usable interactions between users and NPCs. We publish our source code in the following repository: https://gitlab.lrz.de/hctl/cuify
最近的计算机图形学、机器学习和传感器技术的发展为扩展现实(XR)在日常生活中的设置提供了众多机会,无论是技能培训还是娱乐。随着大型公司提供经济实惠的消费级头戴显示器(HMD),XR很可能会变得无处不在,并且HMD将作为个人设备如智能手机和平板电脑一样发展。然而,拥有智能空间和自然交互在XR中与技术进步一样重要,使用户增加对虚拟和增强空间的参与度。为此,大型语言模型(LLM)驱动的具有语音到文本(STT)和文本到语音(TTS)模型的非玩家角色(NPC)为传统或预设的NPC带来了显著优势,促进了XR中更自然的对话式用户界面(CUI)。本文为社区提供了一个开源、可定制、可扩展和隐私感知的Unity软件包CUIfy,它支持使用广泛的大型语言模型、STT和TTS模型进行基于语音的NPC与用户交互。我们的软件包还支持每个环境有多个大型语言模型驱动的NPC,并通过流式传输来减少不同计算模型之间的延迟,从而实现用户和NPC之间的可用交互。我们在以下仓库发布源代码:https://gitlab.lrz.de/hctl/cuify
论文及项目相关链接
PDF 7th IEEE International Conference on Artificial Intelligence & eXtended and Virtual Reality (IEEE AIxVR 2025)
Summary
新一代信息技术如计算机图形学、机器学习及传感器技术的发展,为扩展现实(XR)在日常生活中的运用提供了广阔机遇,如技能培训与娱乐等。随着大型企业推出实惠的消费级头戴显示器(HMDs),XR有望普及,HMDs将如同智能手机和平板一样成为个人设备。然而,实现XR中的智能空间与自然交互与技术进步同等重要,以促使用户更深入地参与虚拟和增强空间。为此,采用大型语言模型(LLM)驱动的非玩家角色(NPCs)结合语音识别(STT)和文本合成(TTS)模型,相较于传统或预设的NPCs,能更自然地实现XR中的用户接口对话。本文为社区提供了一个开源、可定制、可扩展且注重隐私的Unity包——CUIfy,它促进了基于语音的NPC-用户互动,并广泛使用了LLM、STT和TTS模型。我们的软件包还支持每个环境多个LLM驱动的NPCs,并通过流式传输来最小化不同计算模型之间的延迟,实现用户与NPCs之间的实用互动。相关源代码详见以下链接:https://gitlab.lrz.de/hctl/cuify。
Key Takeaways
- 新技术如计算机图形学、机器学习及传感器技术推动了扩展现实(XR)在日常生活的应用。
- 头戴显示器(HMDs)的普及将使得XR成为像智能手机和平板一样的个人设备。
- 实现智能空间与自然交互在XR中同等重要,有助于提高用户的参与度。
- 大型语言模型(LLM)驱动的非玩家角色(NPCs)结合语音识别(STT)和文本合成(TTS)模型能更自然地实现XR中的对话接口。
- 本文介绍了一个开源的Unity包——CUIfy,它支持语音驱动的NPC-用户互动,并广泛使用了LLM、STT和TTS技术。
- CUIfy包支持多LLM驱动的NPCs在同一环境,通过流式传输减少不同计算模型间的延迟。
点此查看论文截图