⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-01 更新
InsTaG: Learning Personalized 3D Talking Head from Few-Second Video
Authors:Jiahe Li, Jiawei Zhang, Xiao Bai, Jin Zheng, Jun Zhou, Lin Gu
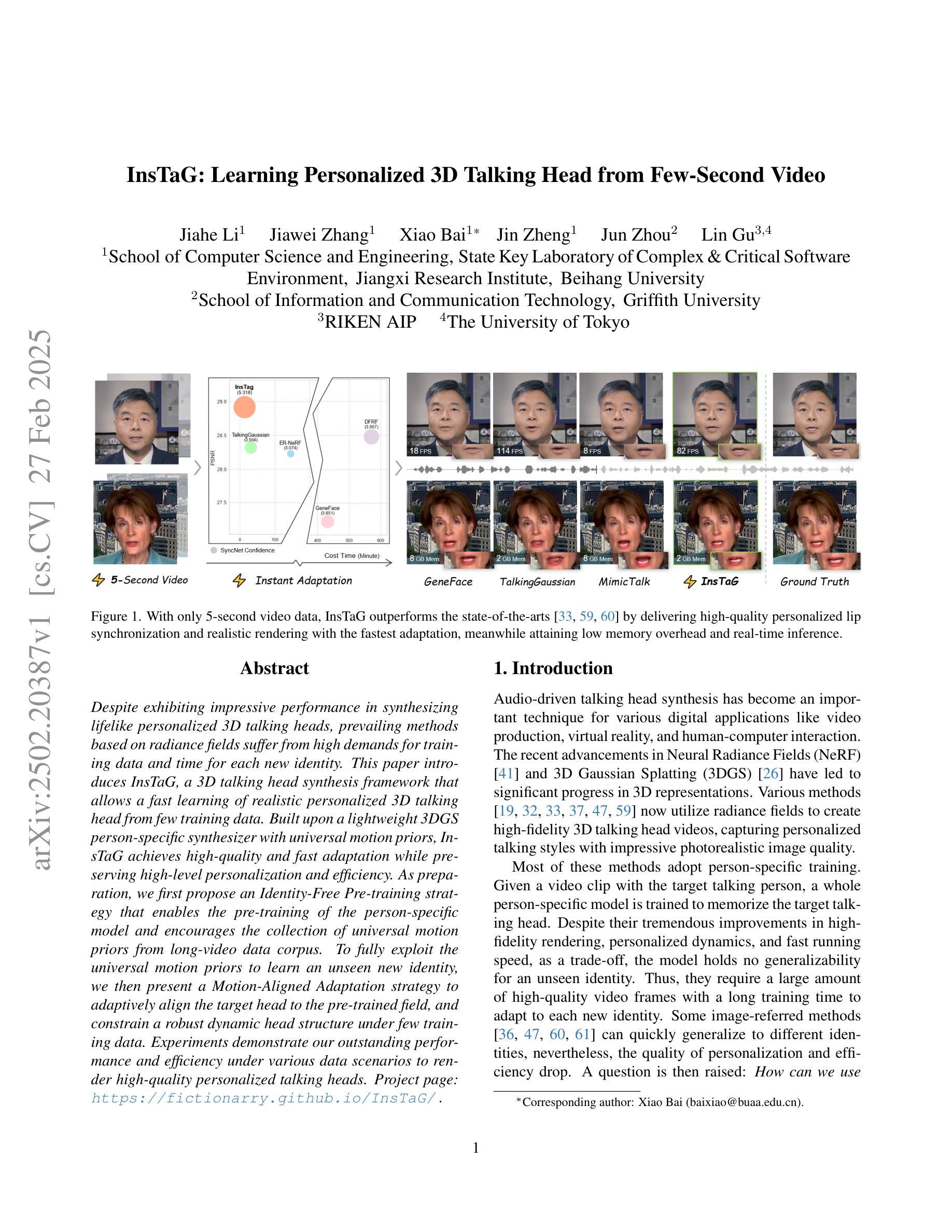
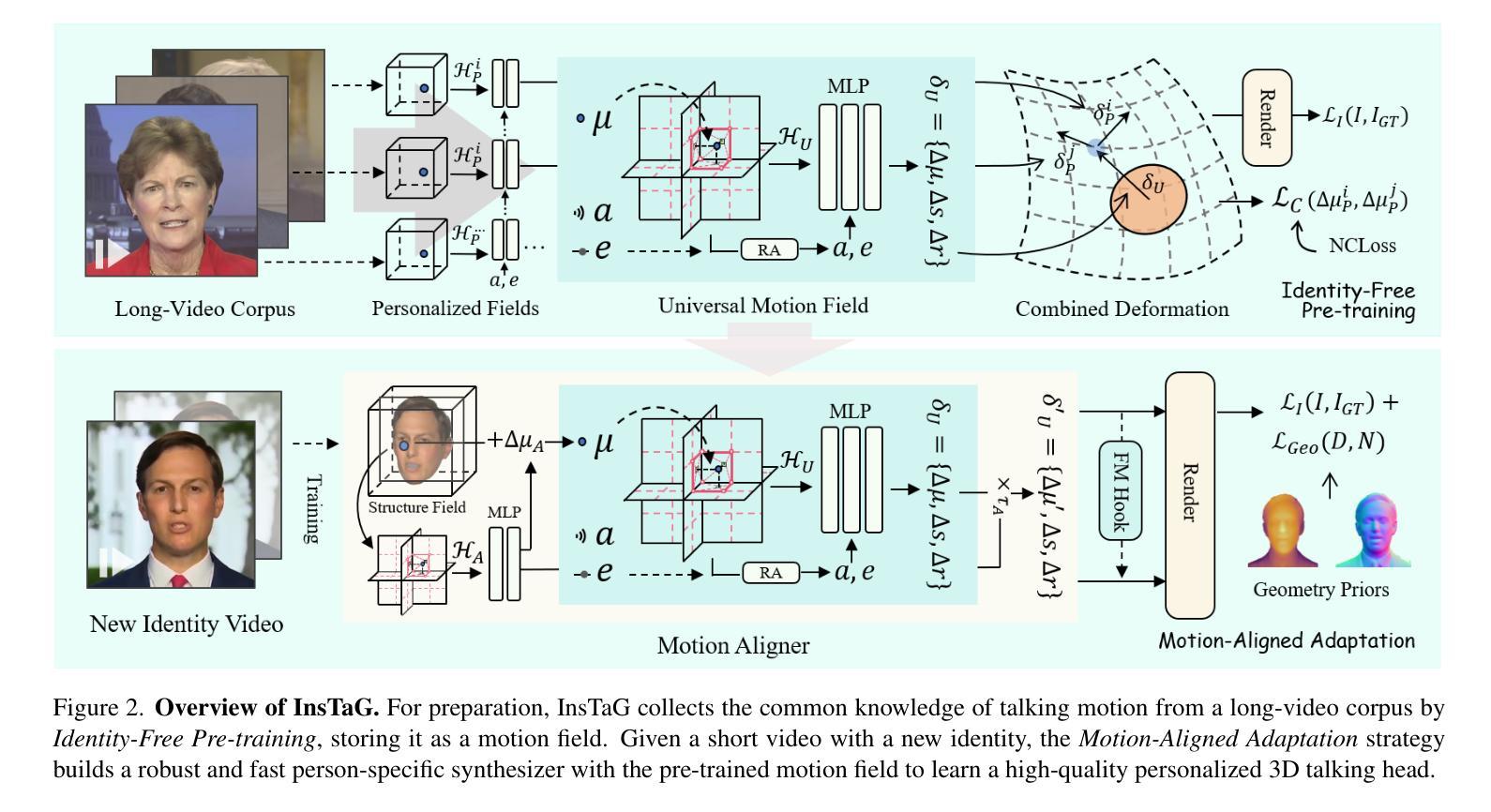
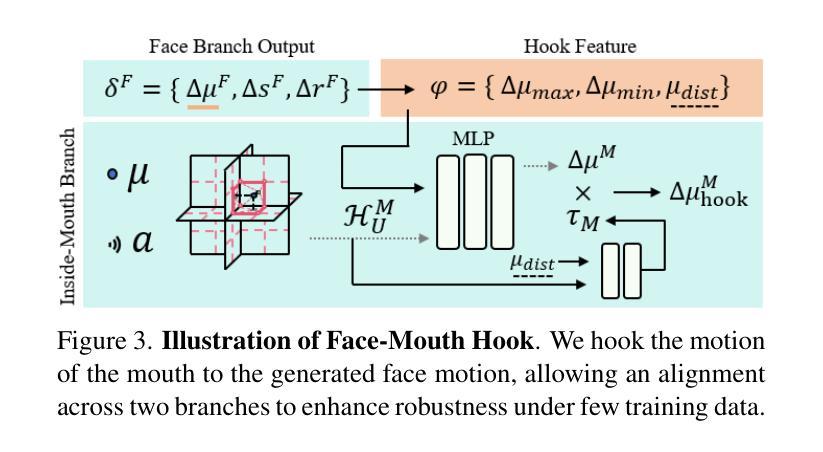
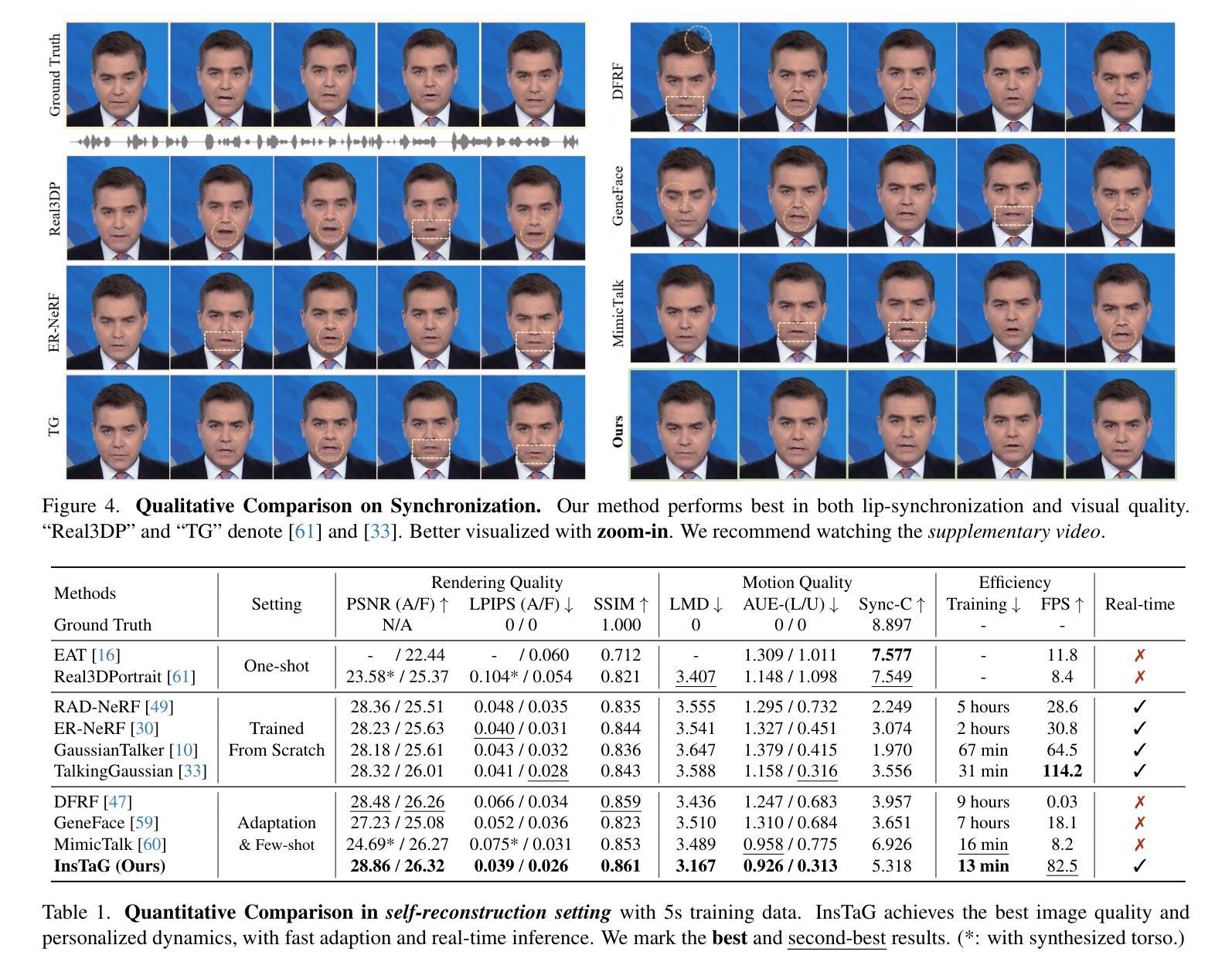
Despite exhibiting impressive performance in synthesizing lifelike personalized 3D talking heads, prevailing methods based on radiance fields suffer from high demands for training data and time for each new identity. This paper introduces InsTaG, a 3D talking head synthesis framework that allows a fast learning of realistic personalized 3D talking head from few training data. Built upon a lightweight 3DGS person-specific synthesizer with universal motion priors, InsTaG achieves high-quality and fast adaptation while preserving high-level personalization and efficiency. As preparation, we first propose an Identity-Free Pre-training strategy that enables the pre-training of the person-specific model and encourages the collection of universal motion priors from long-video data corpus. To fully exploit the universal motion priors to learn an unseen new identity, we then present a Motion-Aligned Adaptation strategy to adaptively align the target head to the pre-trained field, and constrain a robust dynamic head structure under few training data. Experiments demonstrate our outstanding performance and efficiency under various data scenarios to render high-quality personalized talking heads.
尽管当前基于辐射场的方法在合成逼真个性化的3D谈话头方面表现出令人印象深刻的效果,但它们对新身份的训练数据和时间需求很高。本文介绍了InsTaG,一个3D谈话头合成框架,它可以从少量的训练数据中快速学习逼真个性化的3D谈话头。InsTaG建立在轻量级的3DGS人物特定合成器之上,具有通用运动先验,实现了高质量和快速适应,同时保持了高水平的个性化和效率。作为准备,我们首先提出了一种无身份预训练策略,使人物特定模型的预训练成为可能,并鼓励从长视频数据集中收集通用运动先验。为了充分利用通用运动先验来学习未见的新身份,然后我们提出了一种运动对齐适应策略,自适应地将目标头部与预训练场对齐,并在少量训练数据下约束稳健的动态头部结构。实验表明,我们在各种数据场景下表现出卓越的性能和效率,能够生成高质量的个性化谈话头。
论文及项目相关链接
PDF Accepted at CVPR 2025. Project page: https://fictionarry.github.io/InsTaG/
摘要
本文提出了一种基于辐射场的新方法——InsTaG,用于快速合成逼真的个性化3D对话头部。与传统的需要大量训练数据和长时间训练每个新身份的方法不同,InsTaG通过采用轻量级的人特异性合成器与通用运动先验技术实现了高质量和快速适应的目标,同时保持了高度的个性化和高效率。该方法的创新点在于采用无身份预训练策略,使个人特定模型能够进行预训练并从长视频数据集中收集通用运动先验信息。为了充分利用通用运动先验知识来学习未见的新身份,提出了运动对齐适应策略,该策略能够将目标头部自适应对齐到预训练场,并在少量训练数据下构建稳健的动态头部结构。实验证明,在各种数据场景下,该方法都能高效渲染出高质量的个性化对话头部。
关键见解
- InsTaG是一种快速合成逼真个性化3D对话头部的新方法。
- 与传统方法相比,InsTaG在少量训练数据下实现了高质量和快速适应。
- 提出了一种无身份预训练策略,允许从长视频数据集中收集通用运动先验信息。
- 通过运动对齐适应策略,充分利用通用运动先验知识学习未见的新身份。
- 该方法能够在少量训练数据下构建稳健的动态头部结构。
- 实验证明在各种数据场景下,InsTaG都能高效渲染高质量个性化对话头部。
- 该论文提供了一个新的视角,展示了如何克服现有技术面临的挑战并实现更有效的个性化3D对话头部合成。
点此查看论文截图
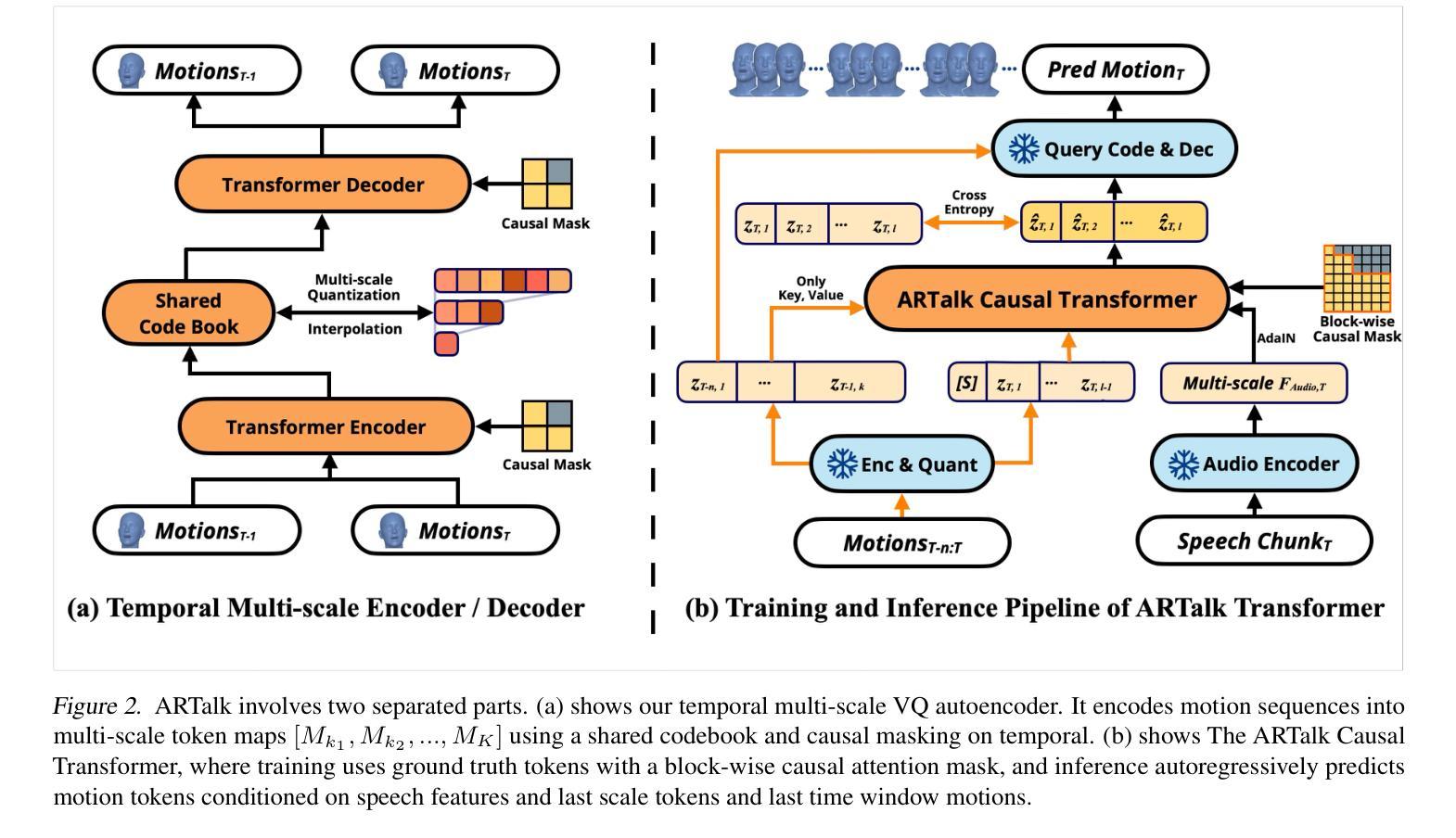
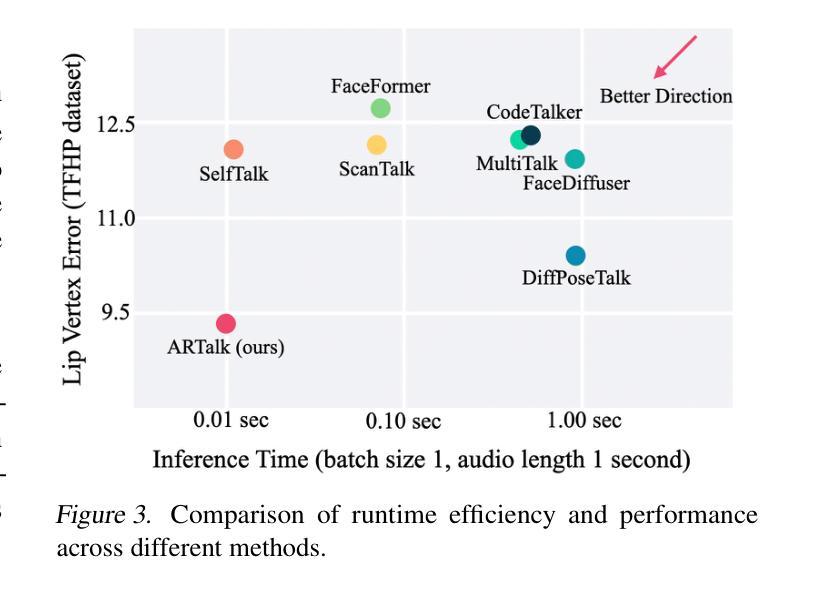
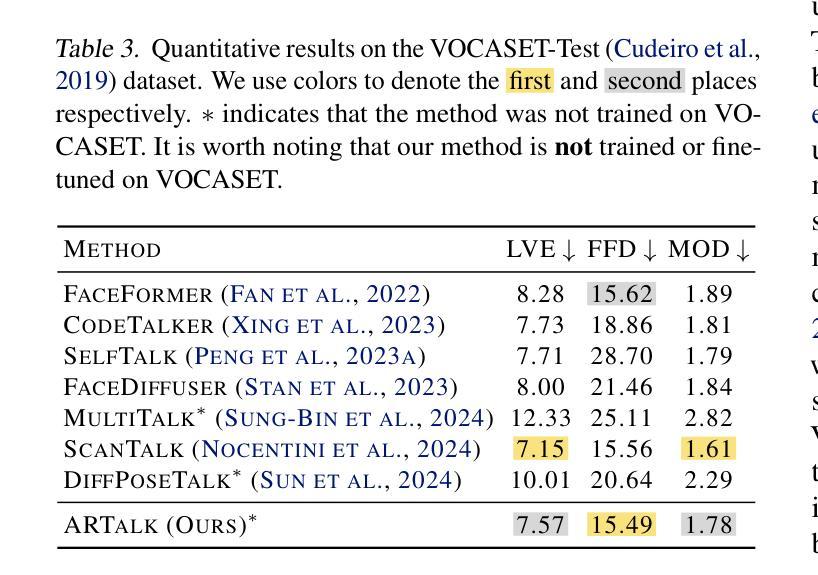
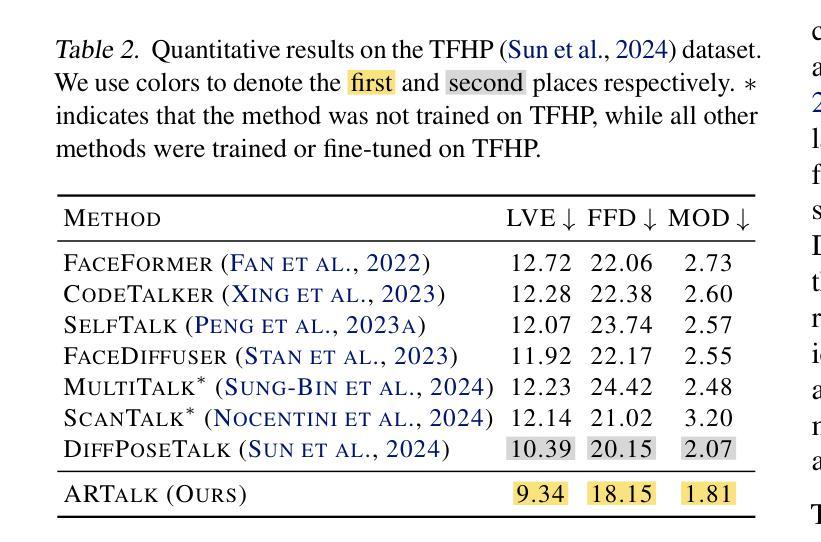
ARTalk: Speech-Driven 3D Head Animation via Autoregressive Model
Authors:Xuangeng Chu, Nabarun Goswami, Ziteng Cui, Hanqin Wang, Tatsuya Harada
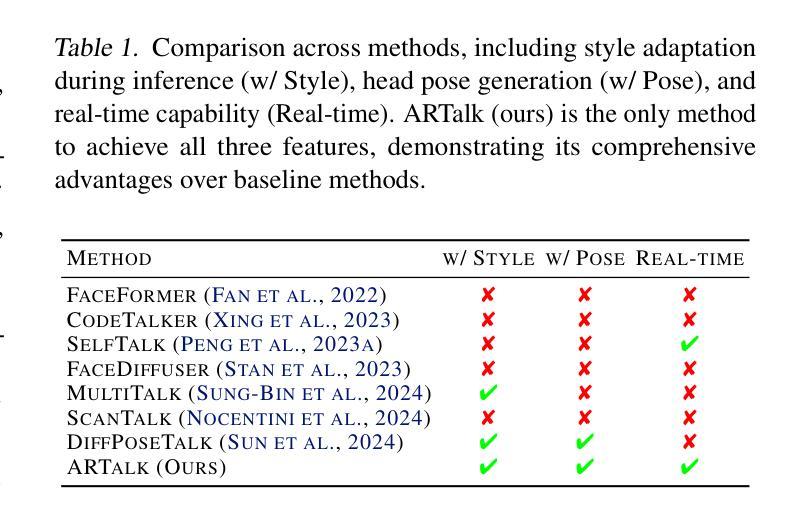
Speech-driven 3D facial animation aims to generate realistic lip movements and facial expressions for 3D head models from arbitrary audio clips. Although existing diffusion-based methods are capable of producing natural motions, their slow generation speed limits their application potential. In this paper, we introduce a novel autoregressive model that achieves real-time generation of highly synchronized lip movements and realistic head poses and eye blinks by learning a mapping from speech to a multi-scale motion codebook. Furthermore, our model can adapt to unseen speaking styles using sample motion sequences, enabling the creation of 3D talking avatars with unique personal styles beyond the identities seen during training. Extensive evaluations and user studies demonstrate that our method outperforms existing approaches in lip synchronization accuracy and perceived quality.
语音驱动的3D面部动画旨在从任意音频片段中为3D头部模型生成逼真的嘴唇动作和面部表情。尽管现有的基于扩散的方法能够产生自然运动,但其缓慢的生成速度限制了其应用潜力。在本文中,我们引入了一种新型自回归模型,通过学说话到多尺度运动代码本的映射,实现嘴唇动作的高度实时同步以及逼真的头部姿态和眨眼。此外,我们的模型可以使用样本运动序列适应未见过的说话风格,从而创建具有独特个人风格的3D对话头像,超越训练期间所见的身份。广泛的评估和用户研究表明,我们的方法在嘴唇同步准确性和感知质量方面优于现有方法。
论文及项目相关链接
PDF More video demonstrations, code, models and data can be found on our project website: http://xg-chu.site/project_artalk/
Summary
本文提出了一种新颖的基于自回归模型的语音驱动3D面部动画技术。该技术能够实现实时生成高度同步的唇部运动以及逼真的头部姿态和眨眼动作。通过从语音到多尺度运动编码的学习映射,该技术能够应对不同的说话风格,并创建具有独特个性的3D说话头像。评估和用户体验研究表明,该方法在唇同步准确性和感知质量方面优于现有技术。
Key Takeaways
- 引入了新颖的自回归模型,实现了实时生成高度同步的唇部运动。
- 模型可以生成逼真的头部姿态和眨眼动作。
- 技术通过从语音到多尺度运动编码的学习映射,能够适应不同的说话风格。
- 创建的3D说话头像具有独特个性,超越训练时的身份限制。
- 相较于现有技术,该方法在唇同步准确性方面表现出色。
- 用户体验研究表明,该方法的感知质量优于其他技术。
- 模型具备较高的实际应用潜力。
点此查看论文截图

Low-energy neutron cross-talk between organic scintillator detectors
Authors:M. Sénoville, F. Delaunay, N. L. Achouri, N. A. Orr, B. Carniol, N. de Séréville, D. Étasse, C. Fontbonne, J. -M. Fontbonne, J. Gibelin, J. Hommet, B. Laurent, X. Ledoux, F. M. Marqués, T. Martínez, M. Pârlog
A series of measurements have been performed with low-energy monoenergetic neutrons to characterise cross-talk between two organic scintillator detectors. Cross-talk time-of-flight spectra and probabilities were determined for neutron energies from 1.4 to 15.5 MeV and effective scattering angles ranging from $\sim$50{\deg} to $\sim$100{\deg}. Monte-Carlo simulations incorporating both the active and inactive materials making up the detectors showed reasonable agreement with the measurements. Whilst the time-of-flight spectra were very well reproduced, the cross-talk probabilities were only in approximate agreement with the measurements, with the most significant discrepancies ($\sim$40 %) occurring at the lowest energies. The neutron interaction processes producing cross-talk at the energies explored here are discussed in the light of these results.
采用低能单能中子进行了一系列测量,以表征两个有机闪烁体探测器之间的串音。测定了中子能量在1.4至15.5MeV范围内,有效散射角在约50°至约100°范围内的串音飞行时间光谱和概率。结合了探测器的活动材料和非活动材料的蒙特卡罗模拟与测量结果基本一致。飞行时间光谱得到了很好的再现,但串音概率仅与测量结果大致相符,在最低能量时差异最为显著(约40%)。结合这些结果,讨论了在此所探讨的能量下产生串音的中子相互作用过程。
论文及项目相关链接
PDF Accepted for publication in Nucl. Instr. and Meth. in Phys. Res. A
Summary
这是一篇关于有机闪烁探测器之间串扰效应研究的摘要。通过低能量单能中子进行一系列测量,确定了中子能量在1.4至15.5MeV范围内,有效散射角度在约50°至约100°范围内的串扰时间飞行光谱和概率。蒙特卡洛模拟考虑了探测器的活动和非活动材料,与测量结果基本一致。虽然时间飞行光谱得到了很好的再现,但串扰概率仅与测量结果大致相符,在最低能量时差异最为显著(约40%)。本文探讨了在此能量范围内产生串扰的中子相互作用过程。
Key Takeaways
- 进行了使用低能量单能中子的测量,以表征两种有机闪烁探测器之间的串扰。
- 确定了中子能量范围在1.4至15.5MeV和有效散射角度在约50°至约100°之间的串扰时间飞行光谱和概率。
- 蒙特卡洛模拟考虑了探测器的活动和非活动材料,模拟结果与测量结果大体一致,但在串扰概率方面存在约40%的显著差异。
- 时间飞行光谱被很好地再现,说明模拟方法的可靠性。
- 串扰概率的模拟结果与实验结果的差异在最低能量时最为显著。
- 研究结果有助于理解中子与探测器的相互作用过程,特别是在产生串扰的情况。
点此查看论文截图

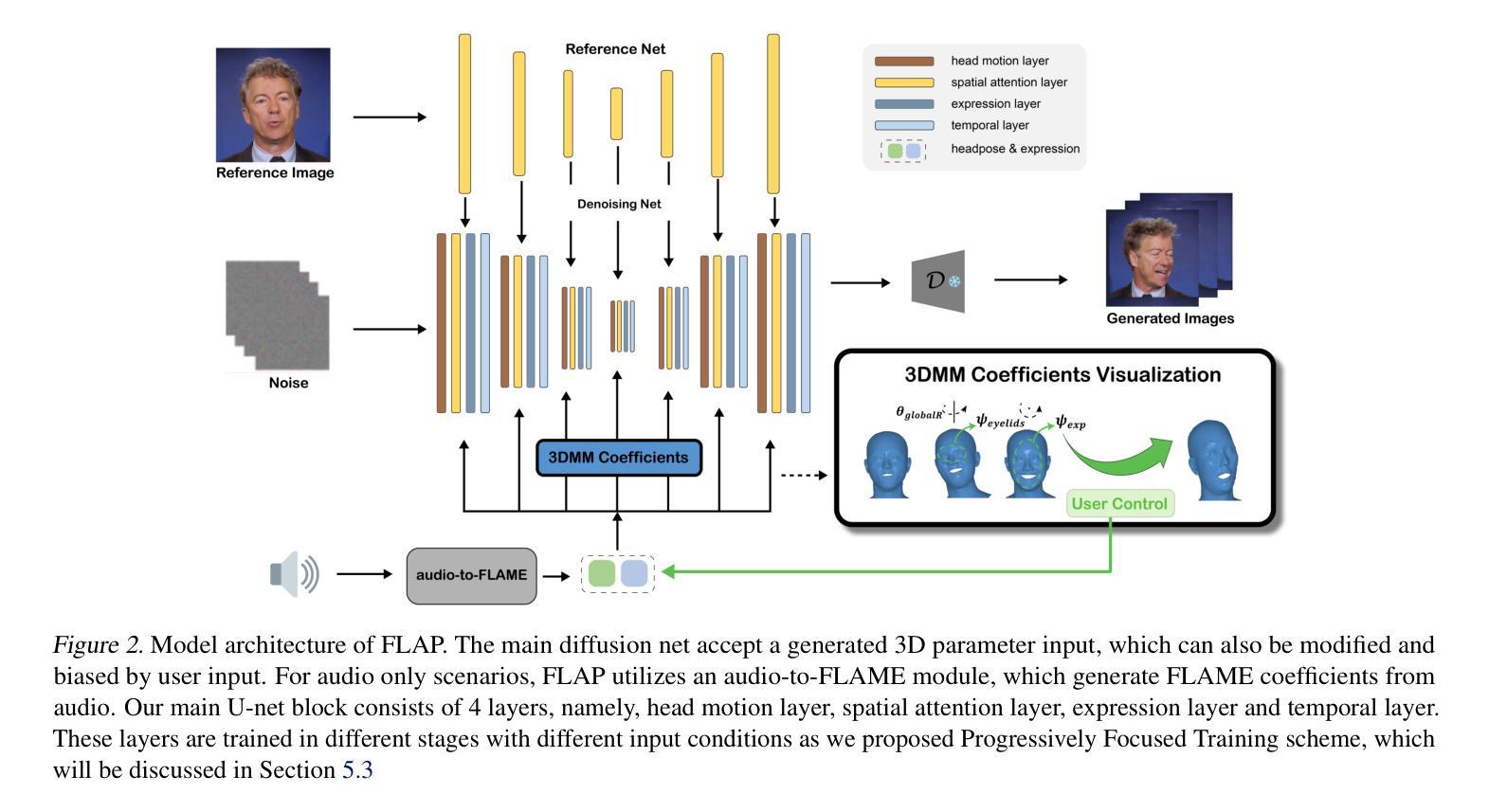
FLAP: Fully-controllable Audio-driven Portrait Video Generation through 3D head conditioned diffusion mode
Authors:Lingzhou Mu, Baiji Liu
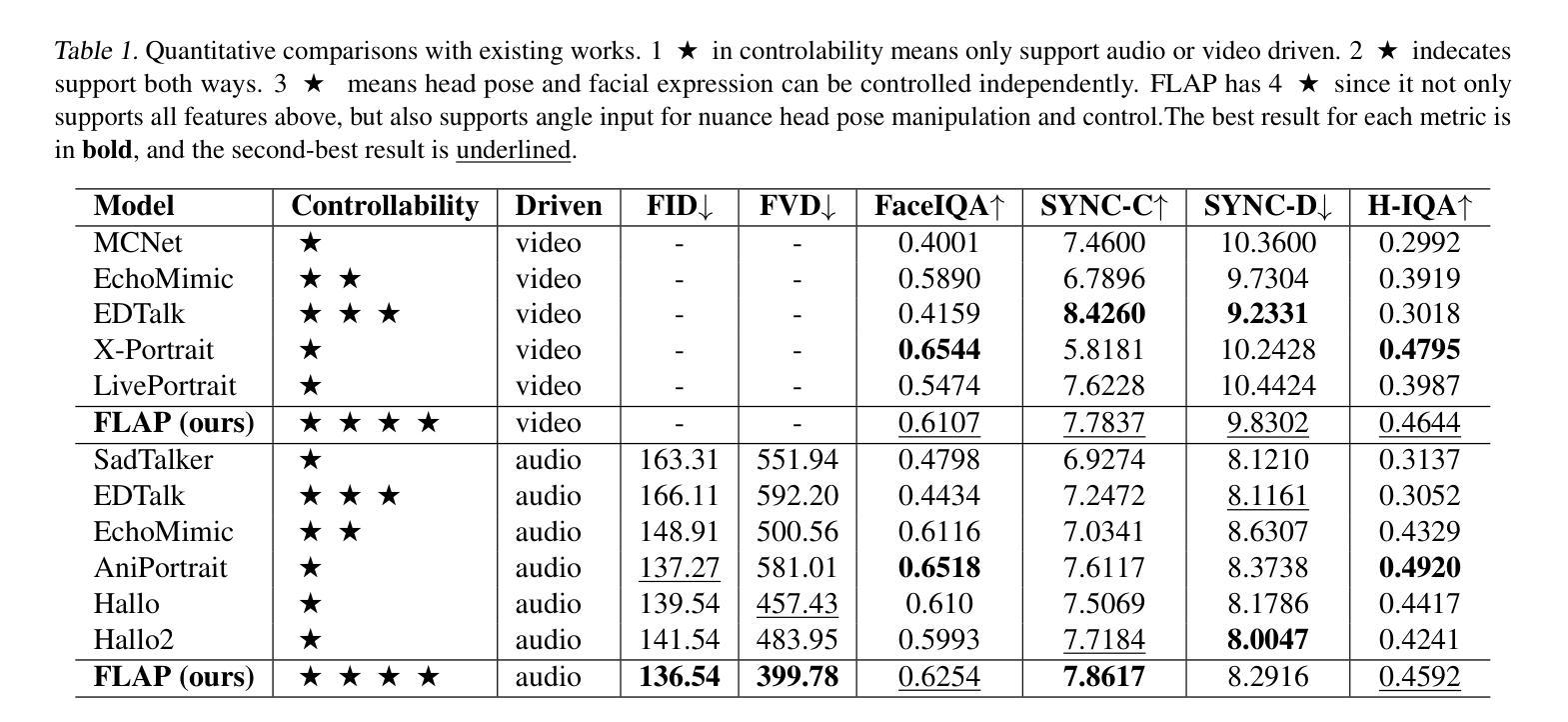
Diffusion-based video generation techniques have significantly improved zero-shot talking-head avatar generation, enhancing the naturalness of both head motion and facial expressions. However, existing methods suffer from poor controllability, making them less applicable to real-world scenarios such as filmmaking and live streaming for e-commerce. To address this limitation, we propose FLAP, a novel approach that integrates explicit 3D intermediate parameters (head poses and facial expressions) into the diffusion model for end-to-end generation of realistic portrait videos. The proposed architecture allows the model to generate vivid portrait videos from audio while simultaneously incorporating additional control signals, such as head rotation angles and eye-blinking frequency. Furthermore, the decoupling of head pose and facial expression allows for independent control of each, offering precise manipulation of both the avatar’s pose and facial expressions. We also demonstrate its flexibility in integrating with existing 3D head generation methods, bridging the gap between 3D model-based approaches and end-to-end diffusion techniques. Extensive experiments show that our method outperforms recent audio-driven portrait video models in both naturalness and controllability.
基于扩散的视频生成技术已经显著改进了零预设的说话人头像生成,提高了头部运动和面部表情的自然性。然而,现有方法存在可控性差的缺陷,使其不适用于电影制作和电子商务直播等现实场景。为了解决这一局限性,我们提出了FLAP,这是一种将明确的3D中间参数(头部姿势和面部表情)集成到扩散模型中的新方法,以进行逼真的肖像视频端到端生成。所提出的架构允许模型从音频生成生动肖像视频的同时,融入额外的控制信号,如头部旋转角度和眨眼频率。此外,头部姿势和面部表情的解耦允许对两者进行独立控制,提供对头像姿势和面部表情的精确操控。我们还展示了其与现有3D头像生成方法的灵活性,缩小了基于3D模型的方法和端到端扩散技术之间的差距。大量实验表明,我们的方法在自然性和可控性方面超越了最新的音频驱动肖像视频模型。
论文及项目相关链接
PDF 14 pages
摘要
新一代基于扩散模型的零次跳跃头视频生成技术,极大地提高了头动画人物生成的逼真度和自然度。然而,现有方法控制性较差,在影视制作和电商直播等现实场景中应用受限。为解决此问题,我们提出FLAP模型,将明确的3D中间参数(头部姿态和面部表情)融入扩散模型,实现逼真肖像视频的端到端生成。该模型可从音频生成生动肖像视频,同时纳入额外的控制信号,如头部旋转角度和眨眼频率。头部姿态和面部表情的解耦,使得两者可独立控制,实现对头像姿态和面部表情的精准操控。此外,该模型可灵活融入现有3D头像生成方法,缩小了基于模型的3D方法和端到端的扩散技术之间的差距。实验证明,该方法在自然度和控制性方面优于当前音频驱动的肖像视频模型。
要点提炼
- 扩散模型技术在零次跳跃头视频生成领域有显著改善,提高了逼真度和自然度。
- 现有方法控制性不足,限制了其在现实场景中的应用。
- 提出FLAP模型,整合明确的3D中间参数(头部姿态和面部表情)到扩散模型中。
- 该模型能生成生动肖像视频,从音频出发并融入额外的控制信号如头部旋转和眨眼频率等。
- 实现头部姿态和面部表情的解耦,使它们可独立控制。
- 可灵活融入现有技术并与当前先进的音频驱动的肖像视频模型相比较显示出优越性。
点此查看论文截图