⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-01 更新
Visual Adaptive Prompting for Compositional Zero-Shot Learning
Authors:Kyle Stein, Arash Mahyari, Guillermo Francia, Eman El-Sheikh
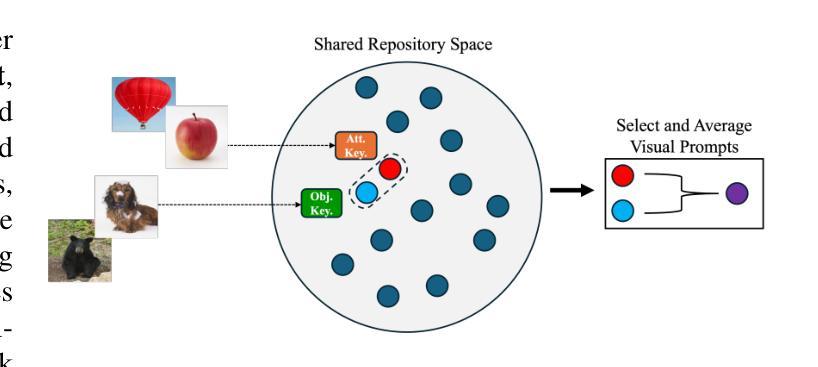
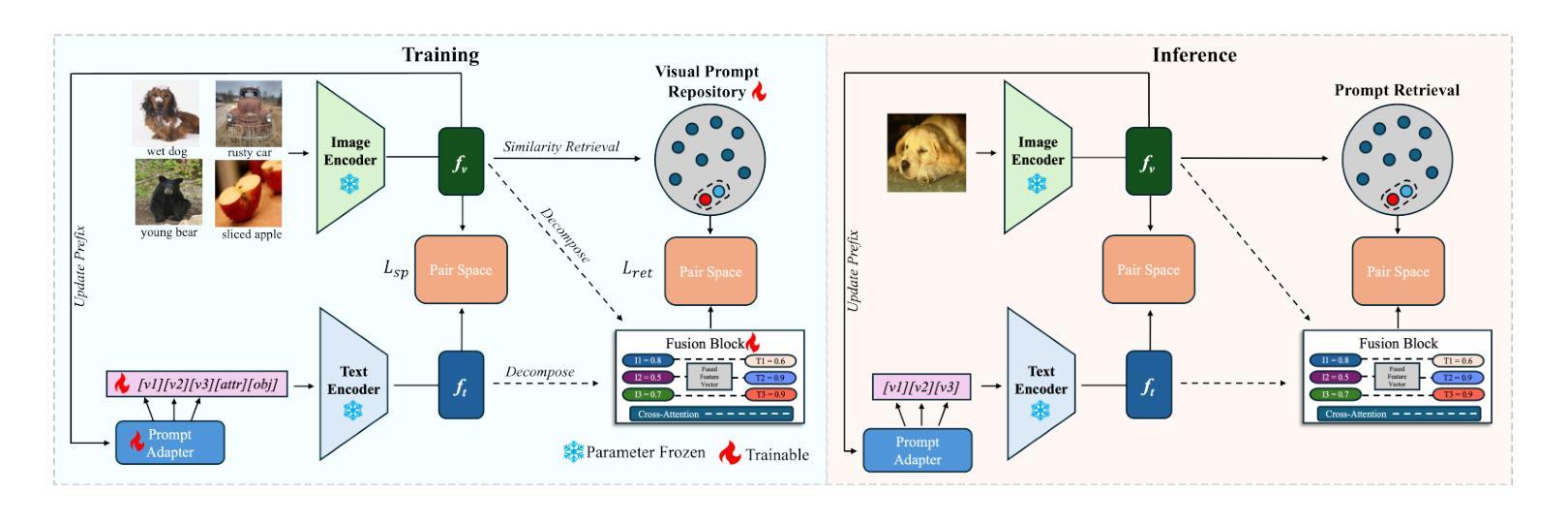
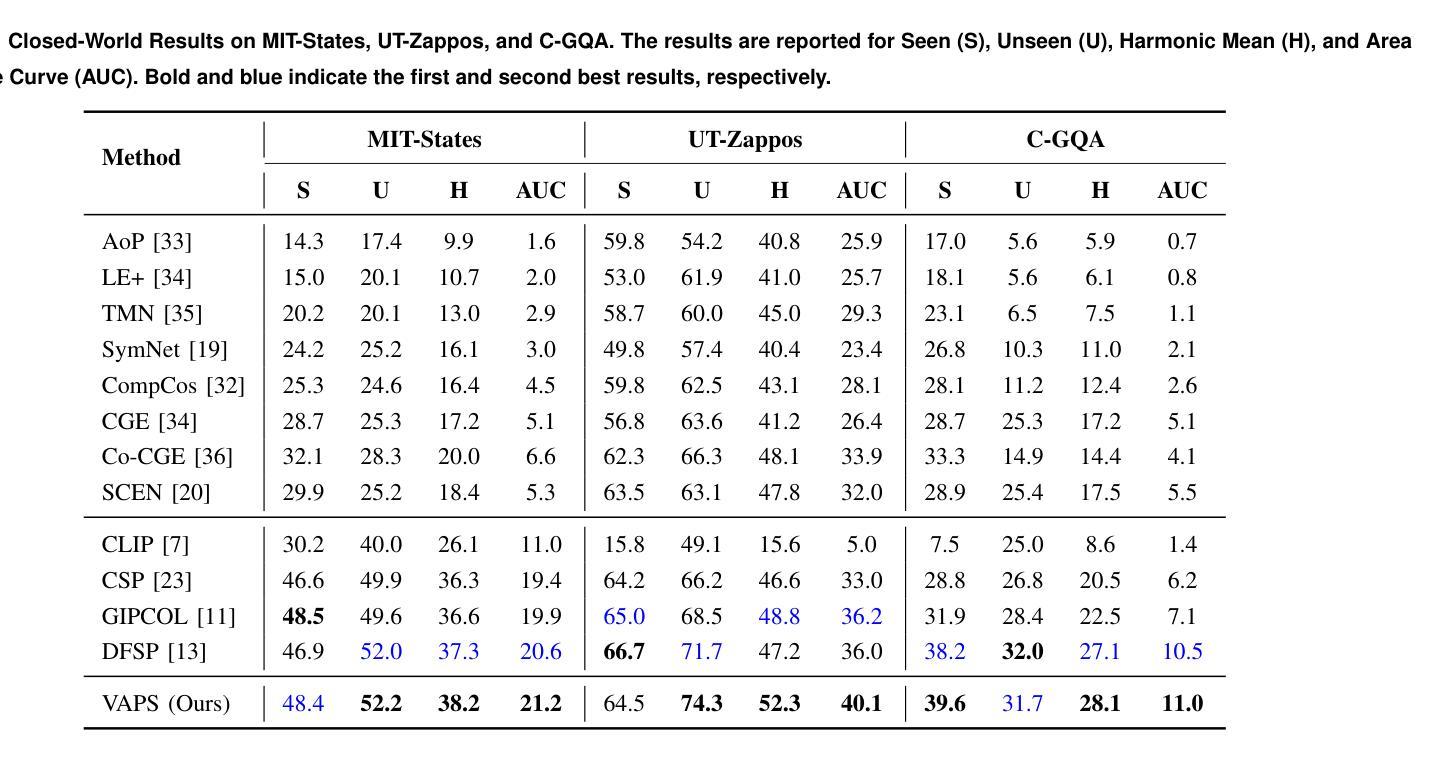
Vision-Language Models (VLMs) have demonstrated impressive capabilities in learning joint representations of visual and textual data, making them powerful tools for tasks such as Compositional Zero-Shot Learning (CZSL). CZSL requires models to generalize to novel combinations of visual primitives-such as attributes and objects-that were not explicitly encountered during training. Recent works in prompting for CZSL have focused on modifying inputs for the text encoder, often using static prompts that do not change across varying visual contexts. However, these approaches struggle to fully capture varying visual contexts, as they focus on text adaptation rather than leveraging visual features for compositional reasoning. To address this, we propose Visual Adaptive Prompting System (VAPS) that leverages a learnable visual prompt repository and similarity-based retrieval mechanism within the framework of VLMs to bridge the gap between semantic and visual features. Our method introduces a dynamic visual prompt repository mechanism that selects the most relevant attribute and object prompts based on the visual features of the image. Our proposed system includes a visual prompt adapter that encourages the model to learn a more generalizable embedding space. Experiments on three CZSL benchmarks, across both closed and open-world scenarios, demonstrate state-of-the-art results.
视觉语言模型(VLMs)在学习视觉和文本数据的联合表示方面表现出了令人印象深刻的能力,使其成为用于组合零射击学习(CZSL)等任务的有力工具。CZSL要求模型能够推广到在训练期间没有明遇到的新组合的视觉元素,如属性和对象。最近在CZSL提示方面的工作主要集中在修改文本编码器的输入,通常使用不会在多种视觉环境中发生变化的静态提示。然而,这些方法在捕捉多变的视觉环境方面存在困难,因为它们侧重于文本适应,而不是利用视觉特征进行组合推理。为了解决这一问题,我们提出了视觉自适应提示系统(VAPS),该系统利用可学习的视觉提示存储库和基于相似性的检索机制,在视觉语言模型的框架内建立语义和视觉特征之间的桥梁。我们的方法引入了一个动态视觉提示存储库机制,根据图像视觉特征选择最相关的属性和对象提示。我们提出的系统包括一个视觉提示适配器,鼓励模型学习一个更具泛化能力的嵌入空间。在三种CZSL基准测试中的封闭和开放世界场景下的实验都取得了最新技术成果。
论文及项目相关链接
Summary
视觉语言模型(VLMs)具备学习和文本数据的联合表示的强大能力,用于组合零学习(CZSL)任务表现突出。针对CZSL中模型需要泛化到训练中未明确遇到的新组合视觉元素(如属性和对象),本文提出了一个动态视觉提示系统(VAPS)。该系统通过构建一个可学习的视觉提示库和基于相似性的检索机制,缩小语义和视觉特征之间的差距。实验表明,该系统在三个CZSL基准测试中表现优异,无论是在封闭还是开放世界场景下均达到了最新技术水平。
Key Takeaways
以下是关键要点摘要,以简短的子弹点形式呈现:
- VLMs展现出强大的学习和表示文本与视觉数据联合的能力。
- CZSL任务需要模型泛化至训练时未遇到的新组合视觉元素。
- 当前提示方法主要侧重于文本适应,未能充分利用视觉特征进行组合推理。
- 提出的VAPS系统包含视觉提示库和相似度检索机制以连接语义和视觉特征。
- 动态视觉提示库机制基于图像视觉特征选择最相关的属性和对象提示。
- VAPS包括一个视觉提示适配器,鼓励模型学习更通用的嵌入空间。
点此查看论文截图


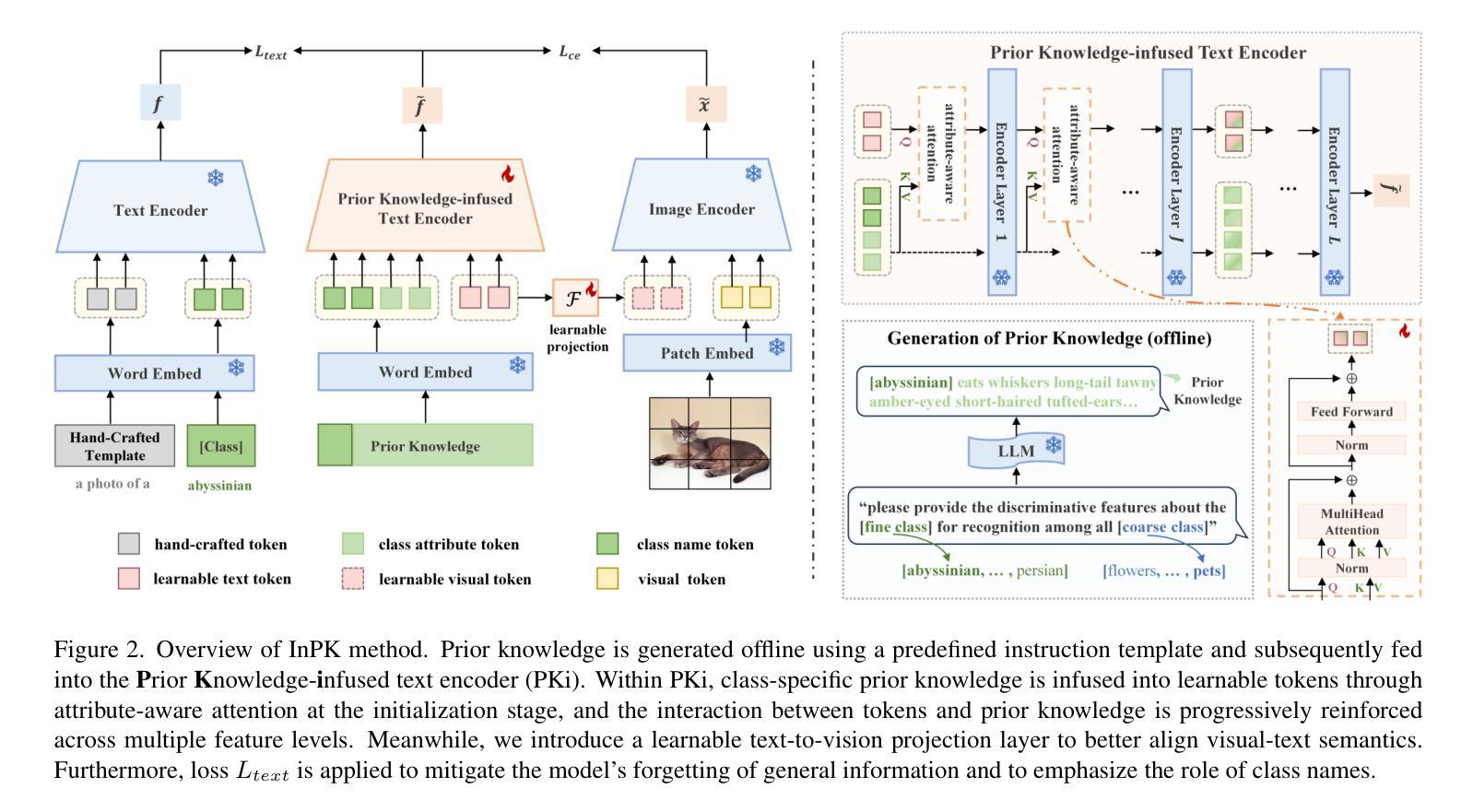
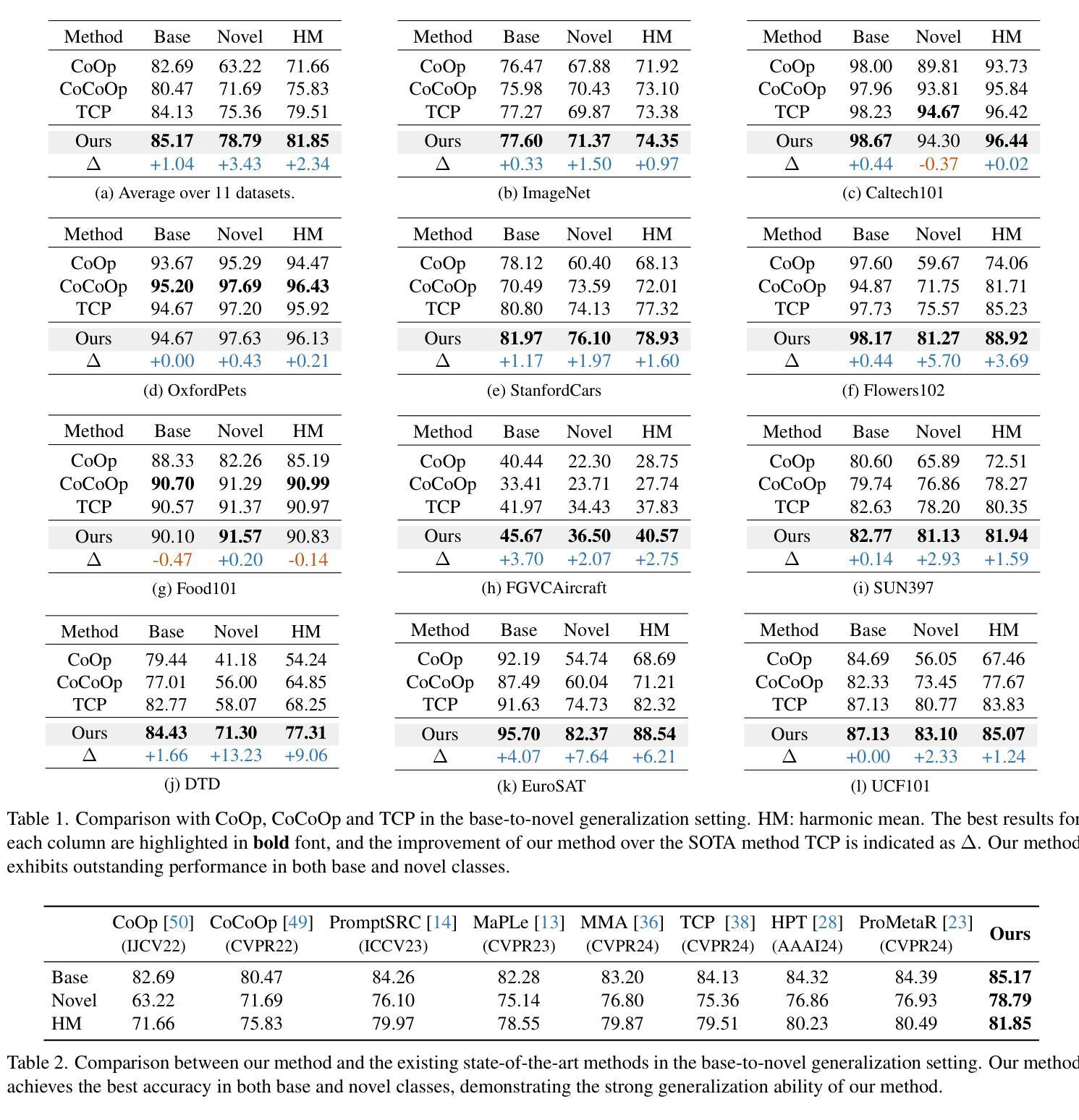
InPK: Infusing Prior Knowledge into Prompt for Vision-Language Models
Authors:Shuchang Zhou
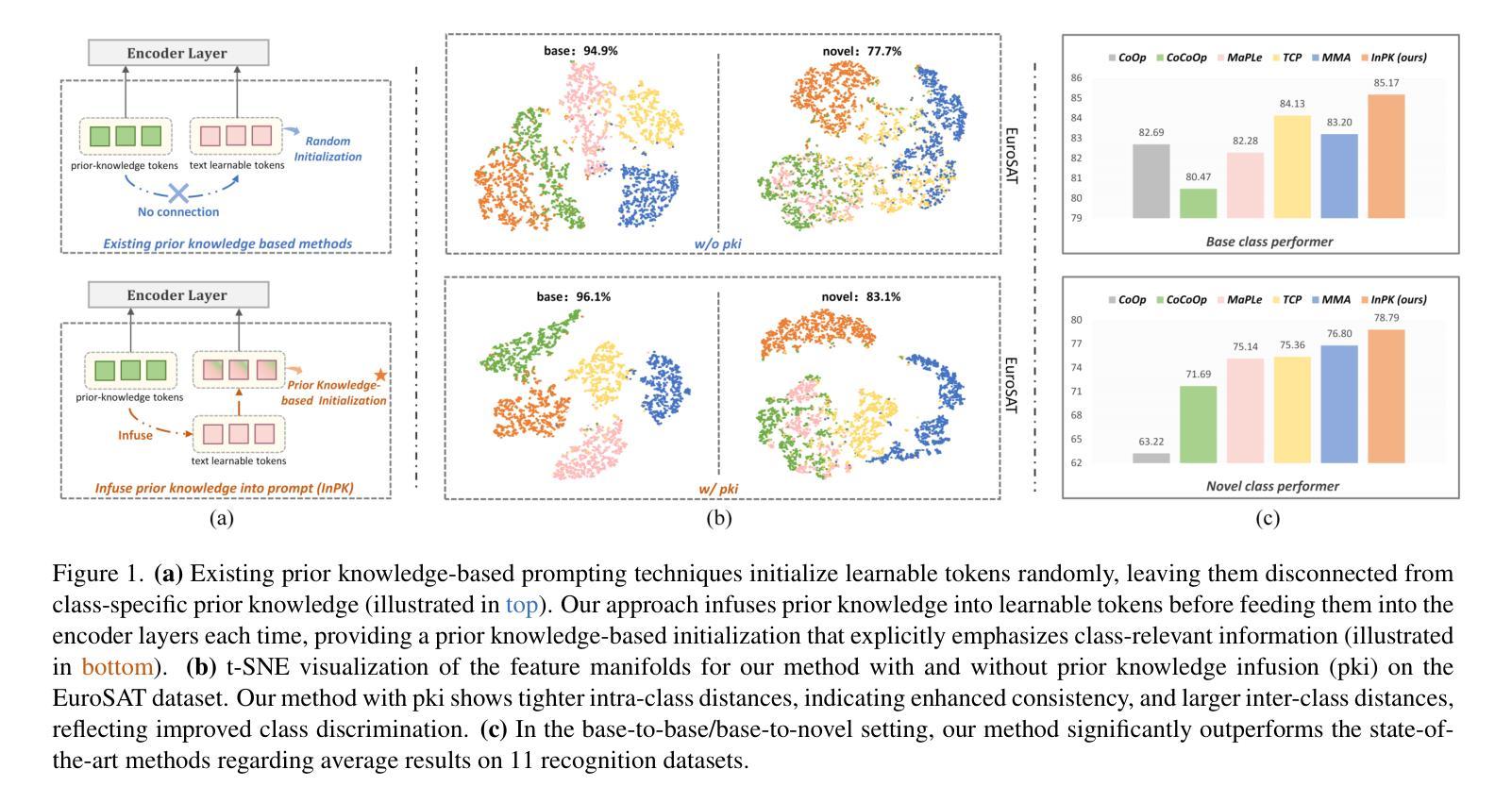
Prompt tuning has become a popular strategy for adapting Vision-Language Models (VLMs) to zero/few-shot visual recognition tasks. Some prompting techniques introduce prior knowledge due to its richness, but when learnable tokens are randomly initialized and disconnected from prior knowledge, they tend to overfit on seen classes and struggle with domain shifts for unseen ones. To address this issue, we propose the InPK model, which infuses class-specific prior knowledge into the learnable tokens during initialization, thus enabling the model to explicitly focus on class-relevant information. Furthermore, to mitigate the weakening of class information by multi-layer encoders, we continuously reinforce the interaction between learnable tokens and prior knowledge across multiple feature levels. This progressive interaction allows the learnable tokens to better capture the fine-grained differences and universal visual concepts within prior knowledge, enabling the model to extract more discriminative and generalized text features. Even for unseen classes, the learned interaction allows the model to capture their common representations and infer their appropriate positions within the existing semantic structure. Moreover, we introduce a learnable text-to-vision projection layer to accommodate the text adjustments, ensuring better alignment of visual-text semantics. Extensive experiments on 11 recognition datasets show that InPK significantly outperforms state-of-the-art methods in multiple zero/few-shot image classification tasks.
在视觉语言模型(VLMs)中,提示微调(Prompt Tuning)已经成为适应零/少样本视觉识别任务的一种流行策略。一些提示技术由于内容丰富而引入了先验知识,但是当可学习令牌随机初始化并与先验知识分离时,它们往往会对已见类别过度拟合,并且在未见类别上遇到领域偏移问题。为了解决这个问题,我们提出了InPK模型,该模型在初始化期间将特定类别的先验知识注入可学习令牌中,从而使模型能够明确关注与类别相关的信息。此外,为了减轻多层编码器对类信息的削弱,我们在多个特征级别上不断加强对可学习令牌和先验知识之间的交互。这种渐进的交互允许可学习令牌更好地捕捉先验知识中的细微差别和通用视觉概念,使模型能够提取更具鉴别力和普遍性的文本特征。即使对于未见的类别,学到的交互也允许模型捕获它们的共同表示并推断它们在现有语义结构中的适当位置。此外,我们引入了一个可学习的文本到视觉投影层以适应文本调整,确保视觉文本语义的更好对齐。在11个识别数据集上的大量实验表明,InPK在多个零/少样本图像分类任务中显著优于最先进的方法。
论文及项目相关链接
Summary
本文介绍了针对视觉语言模型(VLMs)在零/少样本视觉识别任务中的适应性问题,提出一种名为InPK的模型。该模型通过初始化时融入类别特定的先验知识,增强模型对类别相关信息的关注。同时,为了减轻多层编码器对类别信息的削弱,模型在多个特征层面持续强化可学习令牌与先验知识之间的交互。此交互使模型能捕捉先验知识中的细微差异和通用视觉概念,从而提取更具鉴别力和通用性的文本特征。在11个识别数据集上的实验表明,InPK在多个零/少样本图像分类任务中显著优于现有方法。
Key Takeaways
- InPK模型通过融入类别特定先验知识到初始化阶段,解决视觉语言模型在零/少样本视觉识别任务中的适应性问题。
- 模型通过增强可学习令牌与先验知识之间的交互,提高模型对类别相关信息的关注度。
- InPK模型在多个特征层面持续强化这种交互,使模型能够捕捉先验知识中的细微差异和通用视觉概念。
- 引入可学习的文本到视觉投影层,以适应文本调整,确保视觉文本语义的更好对齐。
- 实验结果表明,InPK模型在多个零/少样本图像分类任务中显著优于现有方法。
- InPK模型对于未见过的类别也能通过捕捉其共同表示和推断其在现有语义结构中的适当位置来进行识别。
点此查看论文截图

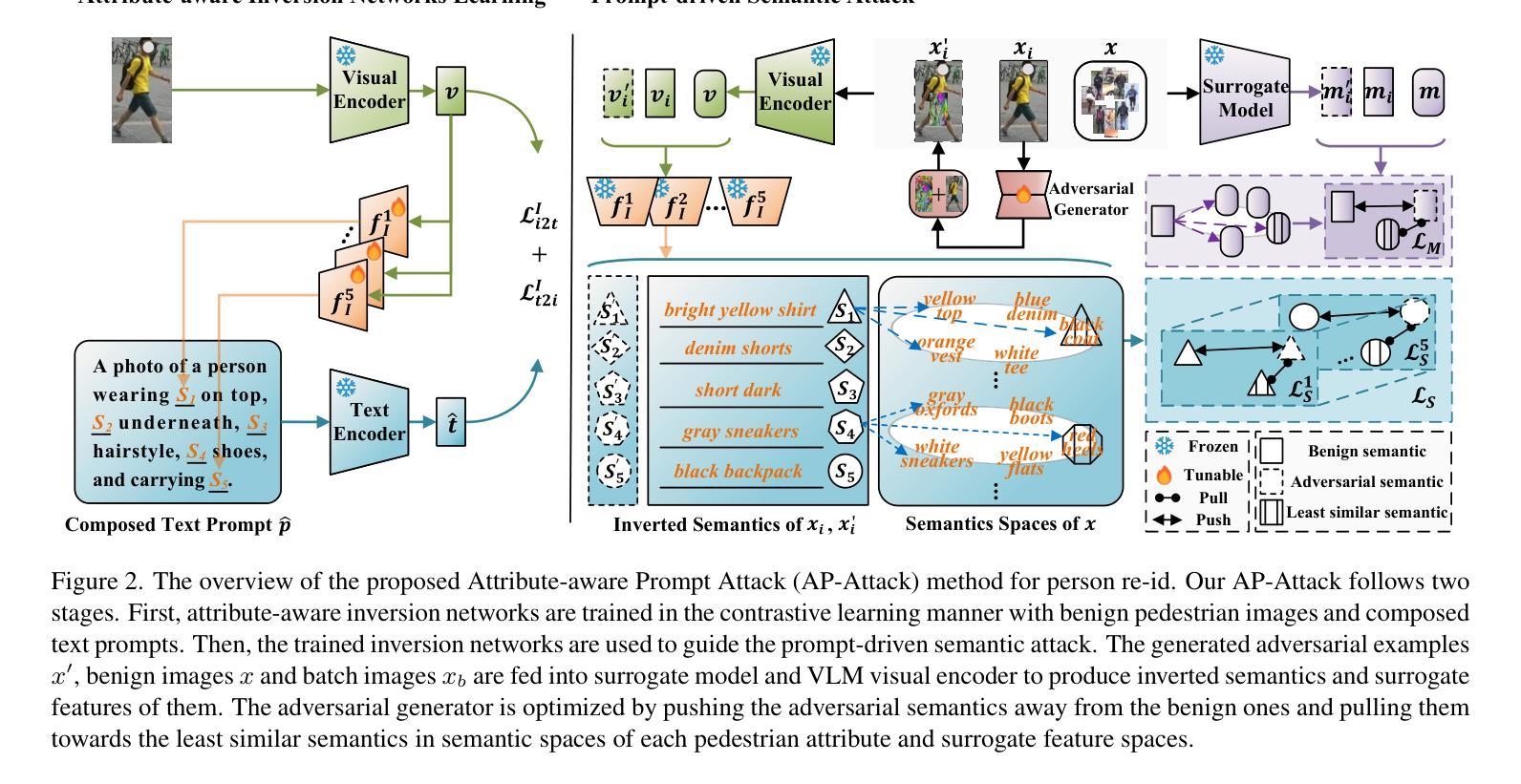
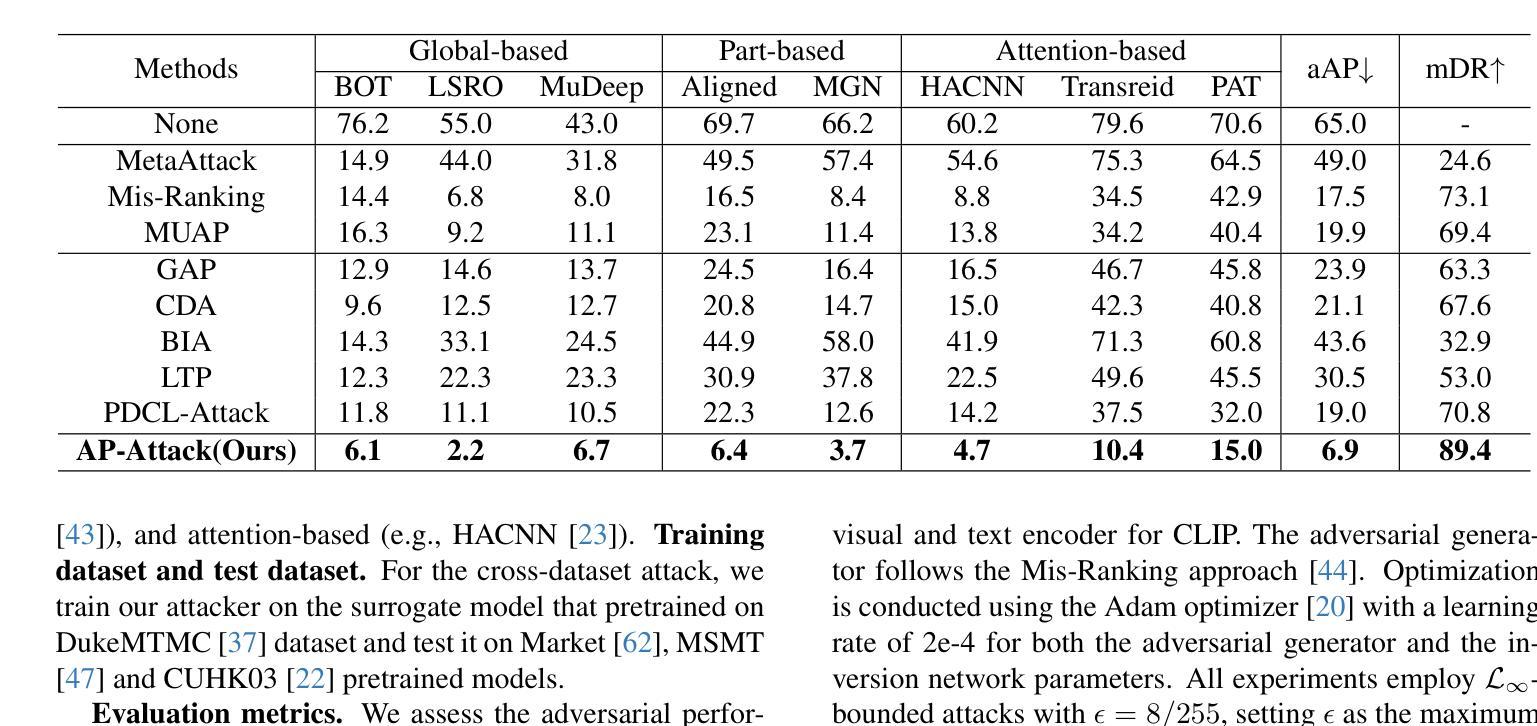
Prompt-driven Transferable Adversarial Attack on Person Re-Identification with Attribute-aware Textual Inversion
Authors:Yuan Bian, Min Liu, Yunqi Yi, Xueping Wang, Yaonan Wang
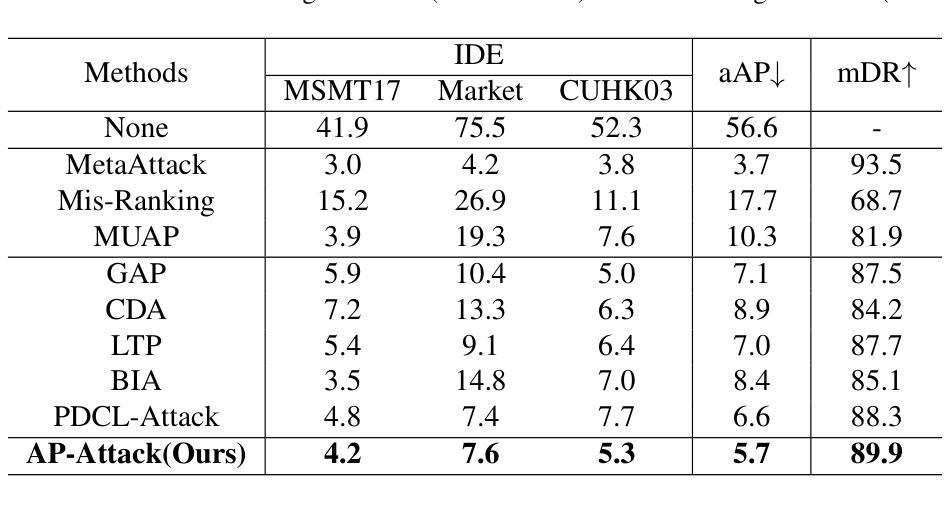
Person re-identification (re-id) models are vital in security surveillance systems, requiring transferable adversarial attacks to explore the vulnerabilities of them. Recently, vision-language models (VLM) based attacks have shown superior transferability by attacking generalized image and textual features of VLM, but they lack comprehensive feature disruption due to the overemphasis on discriminative semantics in integral representation. In this paper, we introduce the Attribute-aware Prompt Attack (AP-Attack), a novel method that leverages VLM’s image-text alignment capability to explicitly disrupt fine-grained semantic features of pedestrian images by destroying attribute-specific textual embeddings. To obtain personalized textual descriptions for individual attributes, textual inversion networks are designed to map pedestrian images to pseudo tokens that represent semantic embeddings, trained in the contrastive learning manner with images and a predefined prompt template that explicitly describes the pedestrian attributes. Inverted benign and adversarial fine-grained textual semantics facilitate attacker in effectively conducting thorough disruptions, enhancing the transferability of adversarial examples. Extensive experiments show that AP-Attack achieves state-of-the-art transferability, significantly outperforming previous methods by 22.9% on mean Drop Rate in cross-model&dataset attack scenarios.
行人再识别(Re-ID)模型在安全监控系统中的作用至关重要,需要可迁移的对抗性攻击来探索其漏洞。最近,基于视觉语言模型(VLM)的攻击通过攻击VLM的通用图像和文本特征表现出了优越的迁移性,但由于过分强调整体表示中的判别语义,它们缺乏全面的特征破坏。在本文中,我们引入了属性感知提示攻击(AP-Attack),这是一种利用VLM的图像文本对齐能力,通过破坏特定属性的文本嵌入来明确破坏行人图像的细粒度语义特征的新方法。为了获得个别属性的个性化文本描述,设计了文本反转网络,将行人图像映射到代表语义嵌入的伪令牌上,使用对比学习方式与图像和预先定义的提示模板进行训练,该模板明确描述了行人属性。良性的和反的细粒度文本语义有助于攻击者进行有效的全面破坏,提高了对抗样本的迁移性。大量实验表明,AP-Attack实现了最先进的迁移性,在跨模型和数据集攻击场景中,平均下降率提高了22.9%,显著优于以前的方法。
论文及项目相关链接
Summary
本文提出一种名为属性感知提示攻击(AP-Attack)的新方法,利用视觉语言模型(VLM)的图像文本对齐能力,通过破坏行人图像的细粒度语义特征,显式地进行攻击。设计文本反转网络将行人图像映射到代表语义嵌入的伪令牌上,使用对比学习方式与图像和预先定义的描述行人属性的模板进行训练。这种攻击方法实现了出色的迁移性,在跨模型和数据集攻击场景中平均下降率提高了22.9%。
Key Takeaways
- 属性感知提示攻击(AP-Attack)是一种针对行人图像细粒度语义特征的新型攻击方法。
- 该方法利用视觉语言模型(VLM)的图像文本对齐能力进行攻击。
- 文本反转网络被设计用于将行人图像映射到代表语义嵌入的伪令牌上。
- 使用对比学习方式训练文本反转网络,与图像和预先定义的描述行人属性的模板相结合。
- AP-Attack实现了卓越的迁移性,能够在跨模型和数据集攻击场景中显著提高攻击效果。
- AP-Attack显著提高了攻击的有效性,相较于先前的方法,在平均下降率上提高了22.9%。
点此查看论文截图

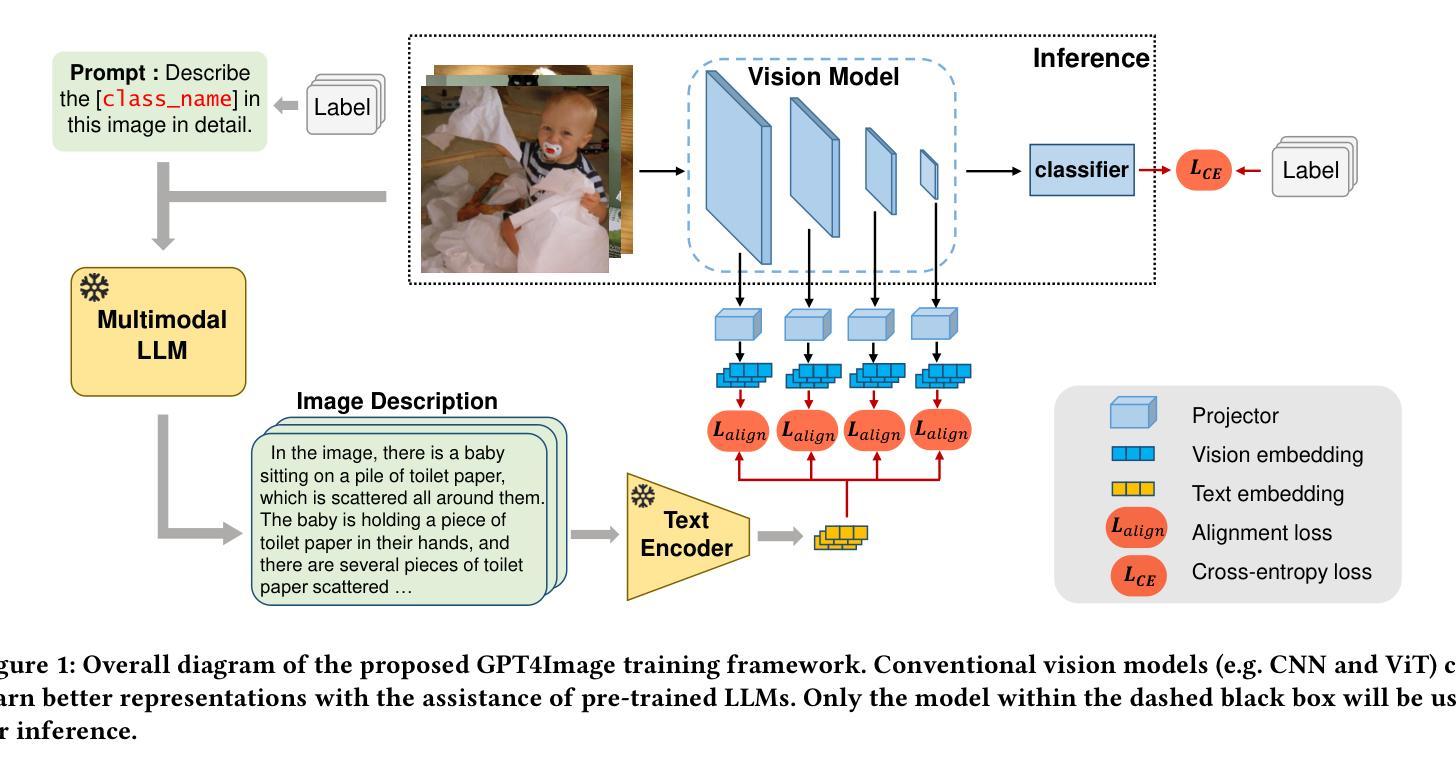
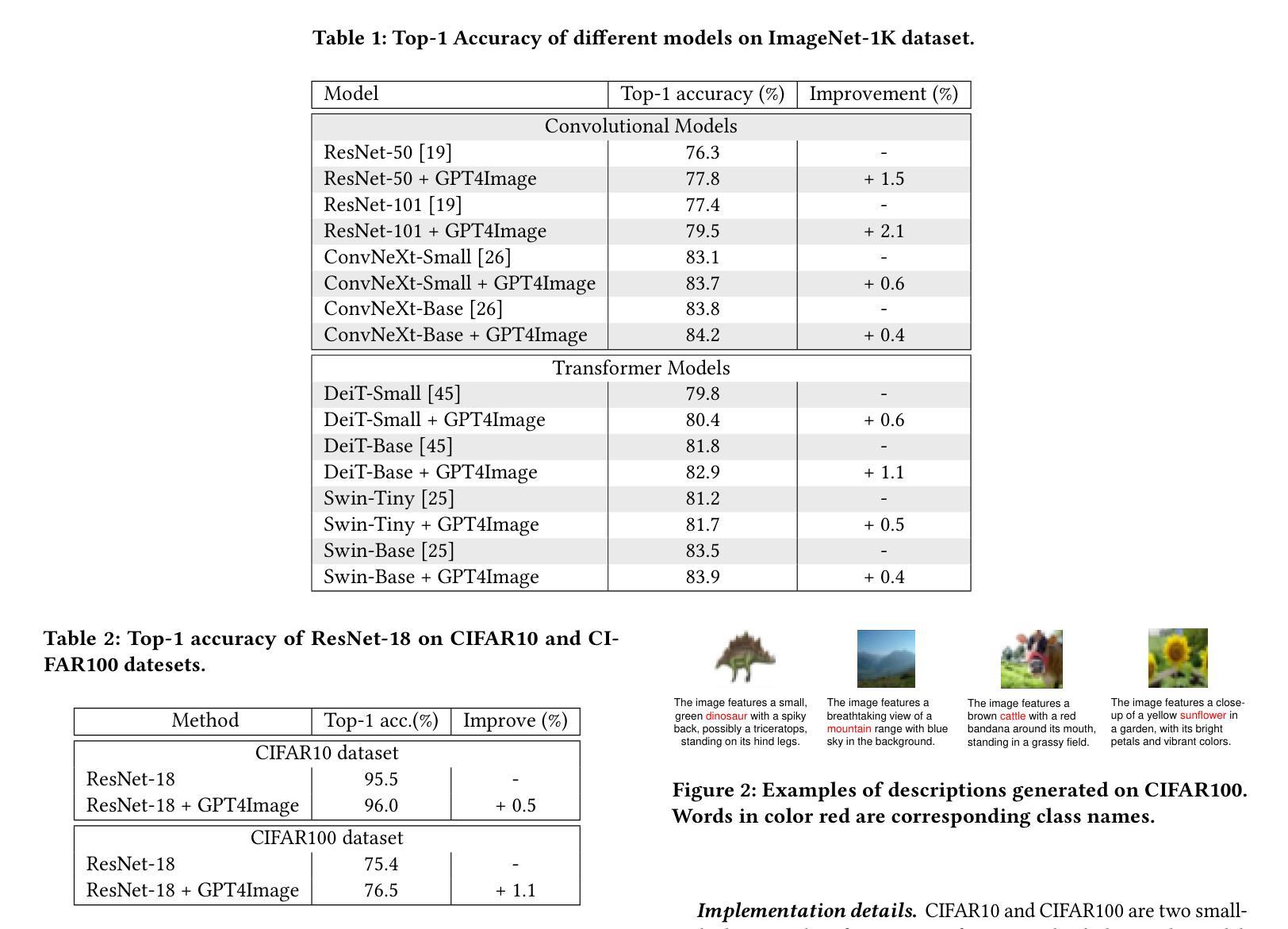
GPT4Image: Large Pre-trained Models Help Vision Models Learn Better on Perception Task
Authors:Ning Ding, Yehui Tang, Zhongqian Fu, Chao Xu, Kai Han, Yunhe Wang
The upsurge in pre-trained large models started by ChatGPT has swept across the entire deep learning community. Such powerful models demonstrate advanced generative ability and multimodal understanding capability, which quickly set new state of the arts on a variety of benchmarks. The pre-trained LLM usually plays the role as a universal AI model that can conduct various tasks like article analysis and image comprehension. However, due to the prohibitively high memory and computational cost of implementing such a large model, the conventional models (such as CNN and ViT) are still essential for many visual perception tasks. In this paper, we propose to enhance the representation ability of ordinary vision models on perception tasks (e.g. image classification) by taking advantage of the off-the-shelf large pre-trained models. We present a new learning framework, dubbed GPT4Image, where the knowledge of the large pre-trained models are extracted to help CNNs and ViTs learn better representations and achieve higher performance. Firstly, we curate a high quality description set by prompting a multimodal LLM to generate descriptions for training images. Then, these detailed descriptions are fed into a pre-trained encoder to extract text embeddings that encodes the rich semantics of images. During training, text embeddings will serve as extra supervising signal and be aligned with image representations learned by vision models. The alignment process helps vision models achieve better performance with the aid of pre-trained LLMs. We conduct extensive experiments to verify the effectiveness of the proposed algorithm on various visual perception tasks for heterogeneous model architectures.
预训练大模型(如ChatGPT)的兴起席卷了整个深度学习领域。这种强大的模型展示了先进的生成能力和多模态理解能力,在各种基准测试上迅速达到了新的技术状态。预训练的大型语言模型通常充当通用人工智能模型的角色,可以执行文章分析和图像理解等多种任务。然而,由于实现如此大规模模型的内存和计算成本非常高,传统模型(如CNN和ViT)对于许多视觉感知任务仍然至关重要。在本文中,我们提出了一种利用现有大型预训练模型增强普通视觉模型在感知任务(例如图像分类)上的表示能力的方法。我们提出了一种新的学习框架,称为GPT4Image。在该框架中,我们提取大型预训练模型的知识来帮助CNN和ViT学习更好的表示形式并实现更高的性能。首先,我们通过提示多模态大型语言模型为训练图像生成描述来创建一个高质量描述集。然后,将这些详细的描述输入预训练的编码器以提取文本嵌入,这些嵌入编码了图像的丰富语义。在训练过程中,文本嵌入将作为额外的监督信号并与视觉模型学习的图像表示进行对齐。对齐过程有助于视觉模型借助预训练的大型语言模型实现更好的性能。我们在各种视觉感知任务上对提出的算法进行了大量实验验证,证明了其在不同模型架构中的有效性。
论文及项目相关链接
PDF GitHub: https://github.com/huawei-noah/Efficient-Computing/tree/master/GPT4Image/
Summary
本文提出一种新型学习框架GPT4Image,利用预训练大型模型的知识来提升普通视觉模型在感知任务上的表现。通过引导多模态LLM生成训练图像的描述,然后提取文本嵌入作为图像丰富语义的编码,进而在训练过程中作为额外的监督信号与视觉模型学习到的图像表示进行对齐。此对齐过程有助于视觉模型借助预训练LLM实现更好的性能。
Key Takeaways
- 预训练大型模型如ChatGPT引发的热潮已波及整个深度学习领域。
- 这些模型具备先进的生成能力和多模态理解能力,并在各种基准测试中创造了新的艺术水平。
- 尽管大型模型具有强大的能力,但由于其高内存和计算成本,传统模型(如CNN和ViT)对于许多视觉感知任务仍然至关重要。
- 本文提出了一种新的学习框架GPT4Image,利用预训练大型模型的知识提升普通视觉模型在感知任务上的表现。
- 该框架通过生成图像描述和提取文本嵌入来强化视觉模型的表示能力。
- 在训练过程中,文本嵌入作为额外的监督信号与视觉模型学习到的图像表示进行对齐。
点此查看论文截图