⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-02 更新
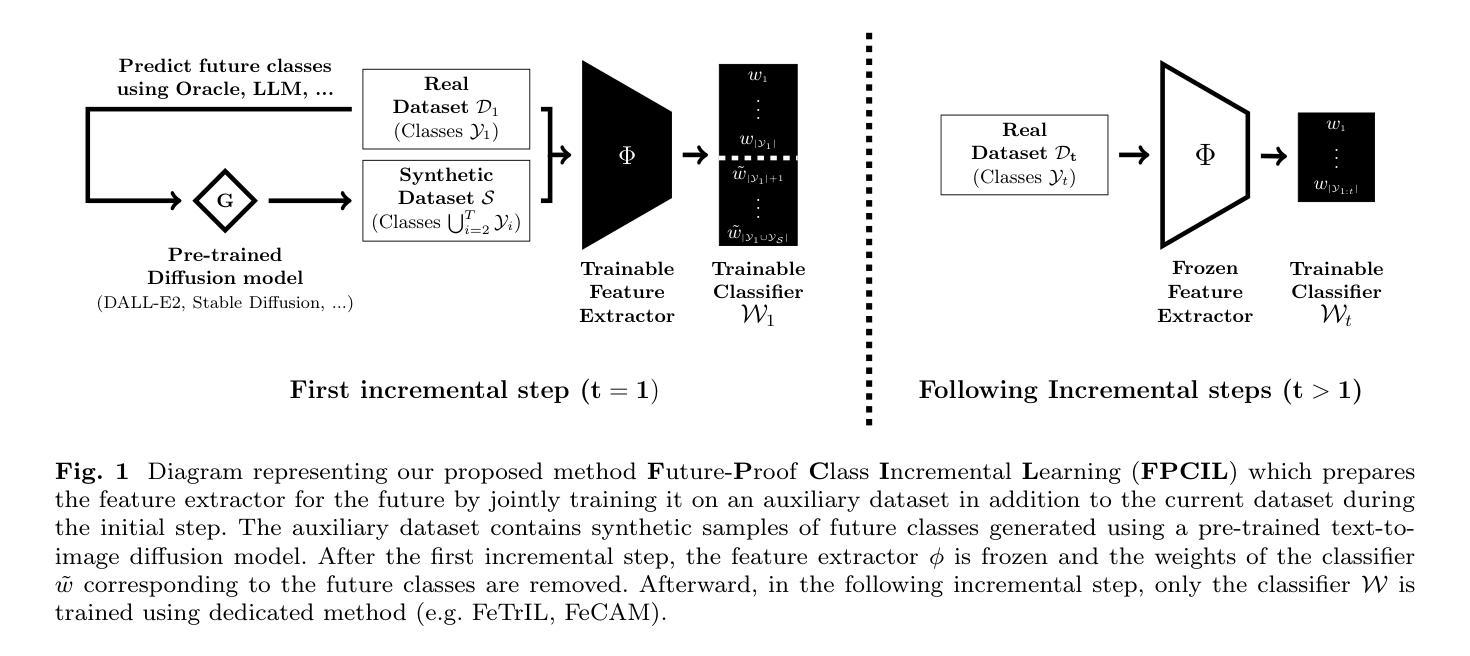
Future-Proofing Class-Incremental Learning
Authors:Quentin Jodelet, Xin Liu, Yin Jun Phua, Tsuyoshi Murata
Exemplar-Free Class Incremental Learning is a highly challenging setting where replay memory is unavailable. Methods relying on frozen feature extractors have drawn attention recently in this setting due to their impressive performances and lower computational costs. However, those methods are highly dependent on the data used to train the feature extractor and may struggle when an insufficient amount of classes are available during the first incremental step. To overcome this limitation, we propose to use a pre-trained text-to-image diffusion model in order to generate synthetic images of future classes and use them to train the feature extractor. Experiments on the standard benchmarks CIFAR100 and ImageNet-Subset demonstrate that our proposed method can be used to improve state-of-the-art methods for exemplar-free class incremental learning, especially in the most difficult settings where the first incremental step only contains few classes. Moreover, we show that using synthetic samples of future classes achieves higher performance than using real data from different classes, paving the way for better and less costly pre-training methods for incremental learning.
无范例类别增量学习是一个极具挑战性的场景,此时无法使用回放记忆。最近,由于其在该场景中的出色性能和较低的计算成本,依赖于冻结特征提取器的方法受到了广泛关注。然而,这些方法高度依赖于用于训练特征提取器的数据,当在第一增量步骤中可用类别数量不足时,可能会遇到困难。为了克服这一局限性,我们提出使用预训练的文本到图像扩散模型来生成未来类别的合成图像,并使用它们来训练特征提取器。在CIFAR100和ImageNet-Subset等标准基准测试上的实验表明,我们的方法可以用来改进最新的无范例类别增量学习方法,特别是在第一增量步骤只包含少数类别的最困难场景中。此外,我们还发现,使用未来类别的合成样本比使用来自不同类别的真实数据实现更高的性能,这为增量学习的更好和成本更低的预训练方法铺平了道路。
论文及项目相关链接
PDF The version of record of this article, first published in “Machine Vision and Applications”, is available online at Publisher’s website: https://doi.org/10.1007/s00138-024-01635-y
Summary
在无法使用示例的无类别增量学习环境中,回放记忆不可用。最近,依赖冻结特征提取器的方法由于出色的性能和较低的计算成本而备受关注。然而,这些方法高度依赖于用于训练特征提取器的数据,并且在第一个增量步骤中可用类别不足时可能会遇到困难。为了克服这一局限性,我们提议使用预训练的文本到图像扩散模型来生成未来类别的合成图像,并用它们来训练特征提取器。在CIFAR100和ImageNet-Subset标准基准测试上的实验表明,我们的方法可以改善无示例类别增量学习的最新方法,特别是在第一个增量步骤只包含少数类别的最困难设置中。此外,我们证明使用未来类别的合成样本比使用不同类别的真实数据实现更高的性能,为增量学习的更好和成本更低的预训练方法铺平了道路。
Key Takeaways
- 无类别增量学习环境下的挑战在于回放记忆的不可用性。
- 依赖冻结特征提取器的方法在特定场景下表现出卓越性能和较低计算成本。
- 现有方法高度依赖训练数据,在初始增量步骤中类别不足时性能受限。
- 提出使用预训练的文本到图像扩散模型生成未来类别的合成图像。
- 合成图像用于训练特征提取器,改善无类别增量学习的性能。
- 在基准测试中,该方法在困难设置下尤其有效,尤其是初始增量步骤类别较少的情况。
点此查看论文截图

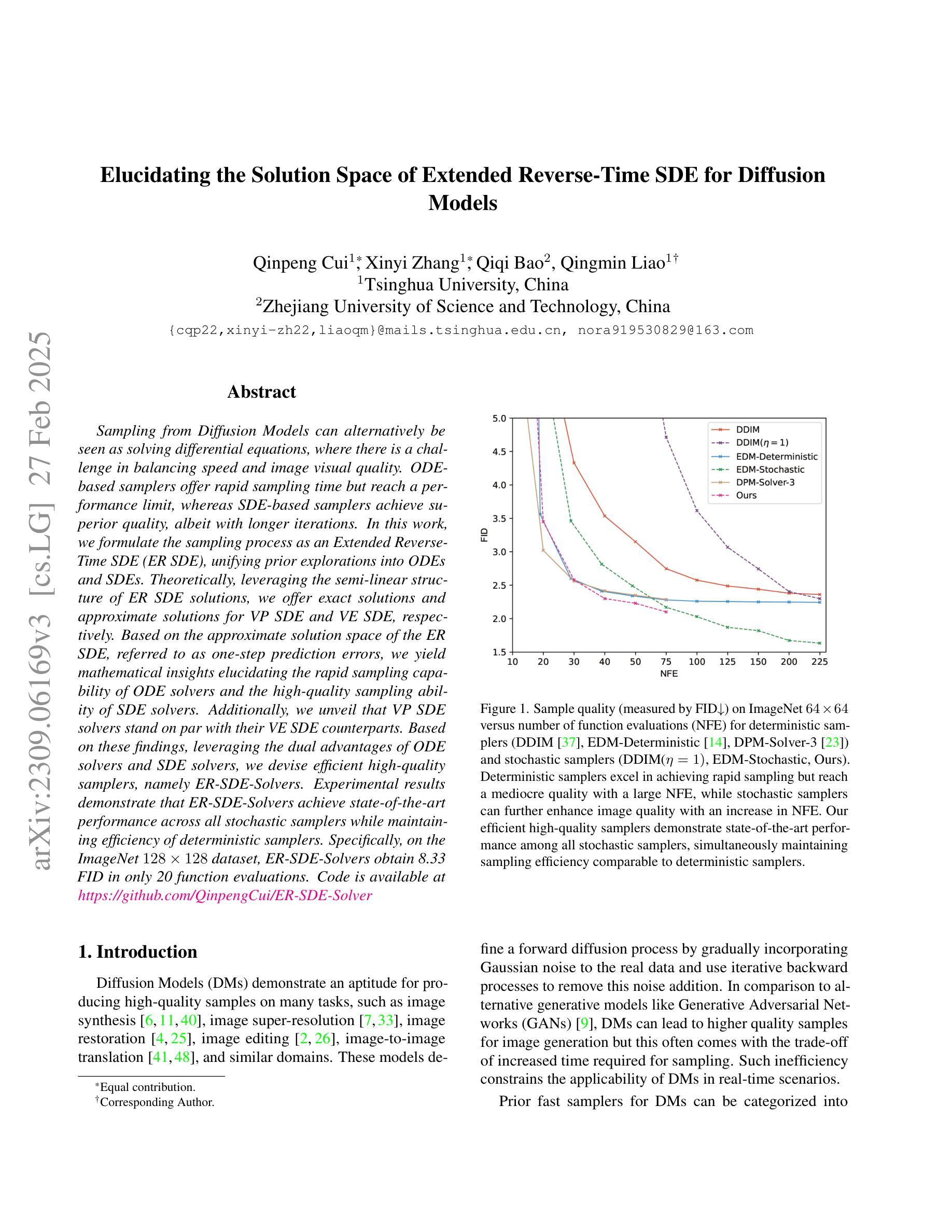
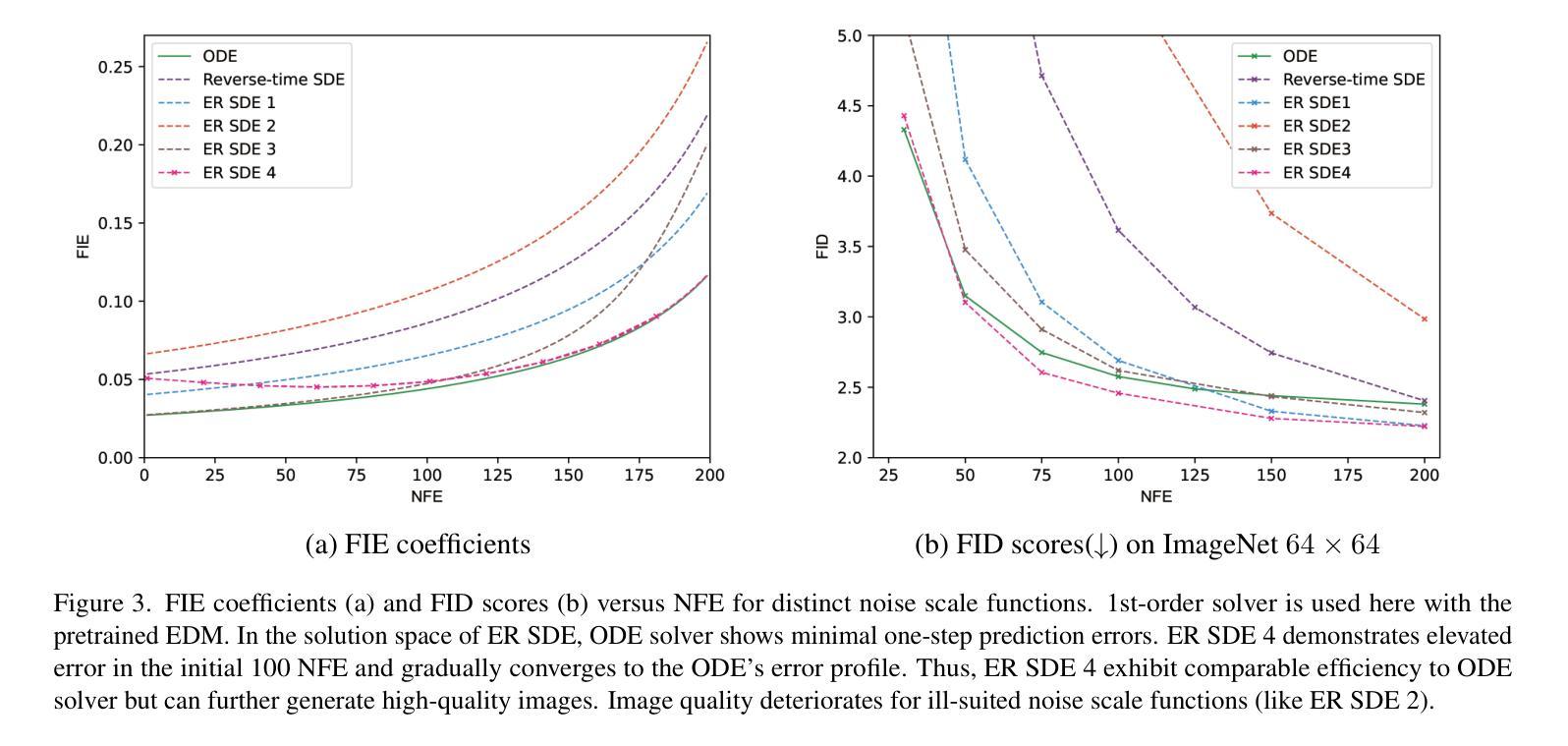
Elucidating the solution space of extended reverse-time SDE for diffusion models
Authors:Qinpeng Cui, Xinyi Zhang, Qiqi Bao, Qingmin Liao
Sampling from Diffusion Models can alternatively be seen as solving differential equations, where there is a challenge in balancing speed and image visual quality. ODE-based samplers offer rapid sampling time but reach a performance limit, whereas SDE-based samplers achieve superior quality, albeit with longer iterations. In this work, we formulate the sampling process as an Extended Reverse-Time SDE (ER SDE), unifying prior explorations into ODEs and SDEs. Theoretically, leveraging the semi-linear structure of ER SDE solutions, we offer exact solutions and approximate solutions for VP SDE and VE SDE, respectively. Based on the approximate solution space of the ER SDE, referred to as one-step prediction errors, we yield mathematical insights elucidating the rapid sampling capability of ODE solvers and the high-quality sampling ability of SDE solvers. Additionally, we unveil that VP SDE solvers stand on par with their VE SDE counterparts. Based on these findings, leveraging the dual advantages of ODE solvers and SDE solvers, we devise efficient high-quality samplers, namely ER-SDE-Solvers. Experimental results demonstrate that ER-SDE-Solvers achieve state-of-the-art performance across all stochastic samplers while maintaining efficiency of deterministic samplers. Specifically, on the ImageNet $128\times128$ dataset, ER-SDE-Solvers obtain 8.33 FID in only 20 function evaluations. Code is available at \href{https://github.com/QinpengCui/ER-SDE-Solver}{https://github.com/QinpengCui/ER-SDE-Solver}
从扩散模型的采样过程可以看作是求解微分方程的过程,其中面临速度和图像视觉质量之间的平衡挑战。基于ODE的采样器虽然采样时间短,但性能达到极限,而基于SDE的采样器虽然质量更高,但需要较长的迭代时间。在这项工作中,我们将采样过程公式化为扩展逆向时间SDE(ER SDE),统一之前的ODE和SDE探索。理论上,我们利用ER SDE解的半线性结构,分别为VP SDE和VE SDE提供精确解和近似解。基于ER SDE的近似解空间(称为一步预测误差),我们获得了数学见解,阐明了ODE求解器的快速采样能力和SDE求解器的高质量采样能力。此外,我们还发现VP SDE求解器与VE SDE求解器表现相当。基于这些发现,我们利用ODE求解器和SDE求解器的双重优势,设计了高效高质量的采样器,称为ER-SDE求解器。实验结果表明,ER-SDE求解器在所有随机采样器中达到最新性能水平,同时保持确定性采样器的效率。具体来说,在ImageNet 128x128数据集上,ER-SDE求解器仅在20次函数评估中获得了8.33的FID。代码可在https://github.com/QinpengCui/ER-SDE-Solver上找到。
论文及项目相关链接
PDF This paper has been accepted by WACV 2025 (Oral). The official version lacked proper attribution to the co-authors, and this version has been updated accordingly
Summary
该文本介绍了Diffusion Models中的采样过程,可以看作是解决微分方程的问题。ODE和SDE的采样器分别在速度和图像质量方面存在挑战。本文提出一种基于扩展反向时间SDE(ER SDE)的采样方法,统一了ODE和SDE的先验探索。文章还给出了VP SDE和VE SDE的精确解和近似解,揭示了一阶预测误差的近似解空间中的数学见解。基于这些见解,文章结合了ODE和SDE的优势,设计出高效的ER-SDE求解器,在随机采样器中实现了最佳性能,同时在确定性采样器中保持效率。实验结果证明,在ImageNet 128x128数据集上,ER-SDE求解器在仅进行20次函数评估的情况下获得了8.33 FID。代码已公开。
Key Takeaways
- Diffusion Models的采样过程可以看作解决微分方程的问题。
- ODE-based采样器快速但性能有限,SDE-based采样器质量高但迭代时间长。
- 提出了基于扩展反向时间SDE(ER SDE)的采样方法,融合了ODE和SDE的探索。
- 提供了VP SDE和VE SDE的精确解和近似解。
- 通过数学分析揭示了ODE和SDE采样器的优势和局限。
- 设计了高效的ER-SDE求解器,实现了随机采样器中的最佳性能,同时保持确定性采样器的效率。
点此查看论文截图