⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-02 更新
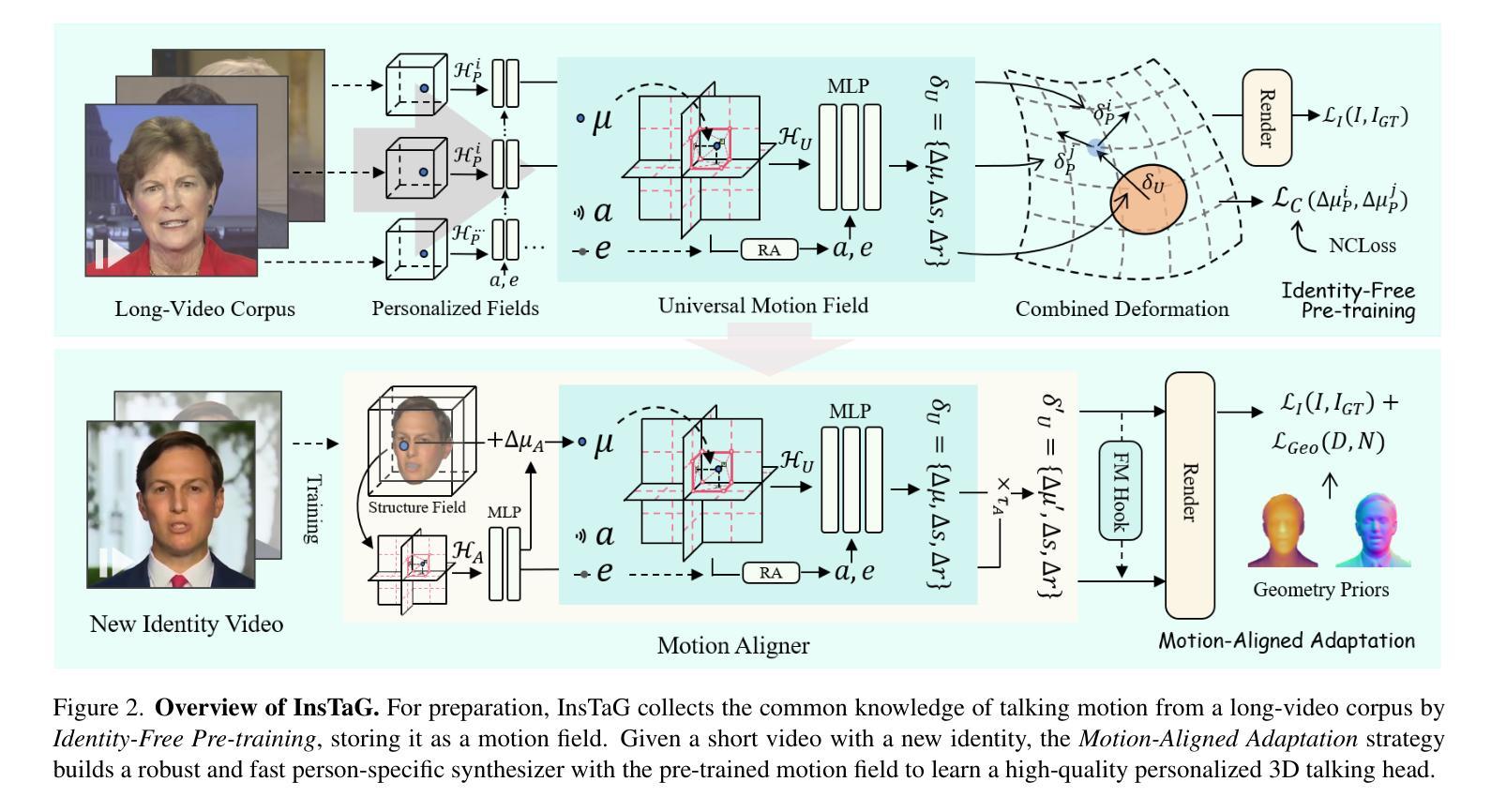
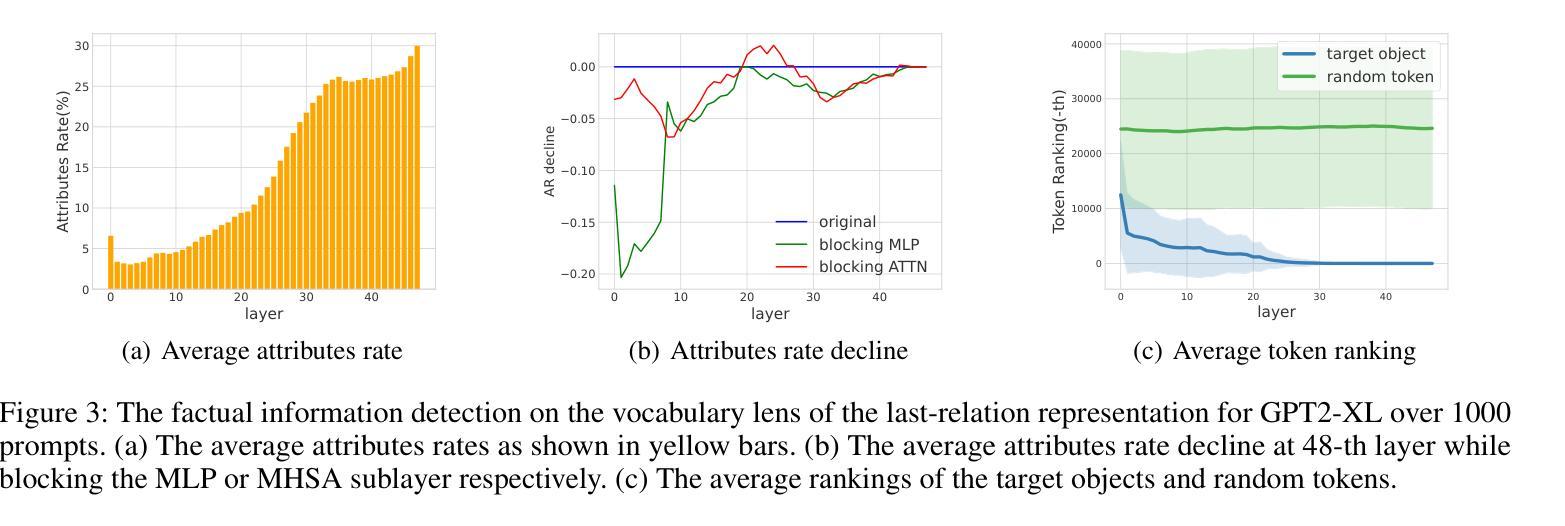
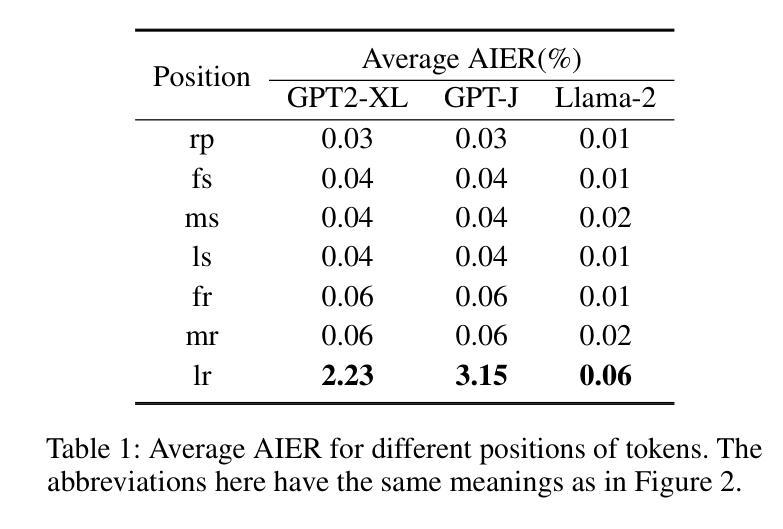
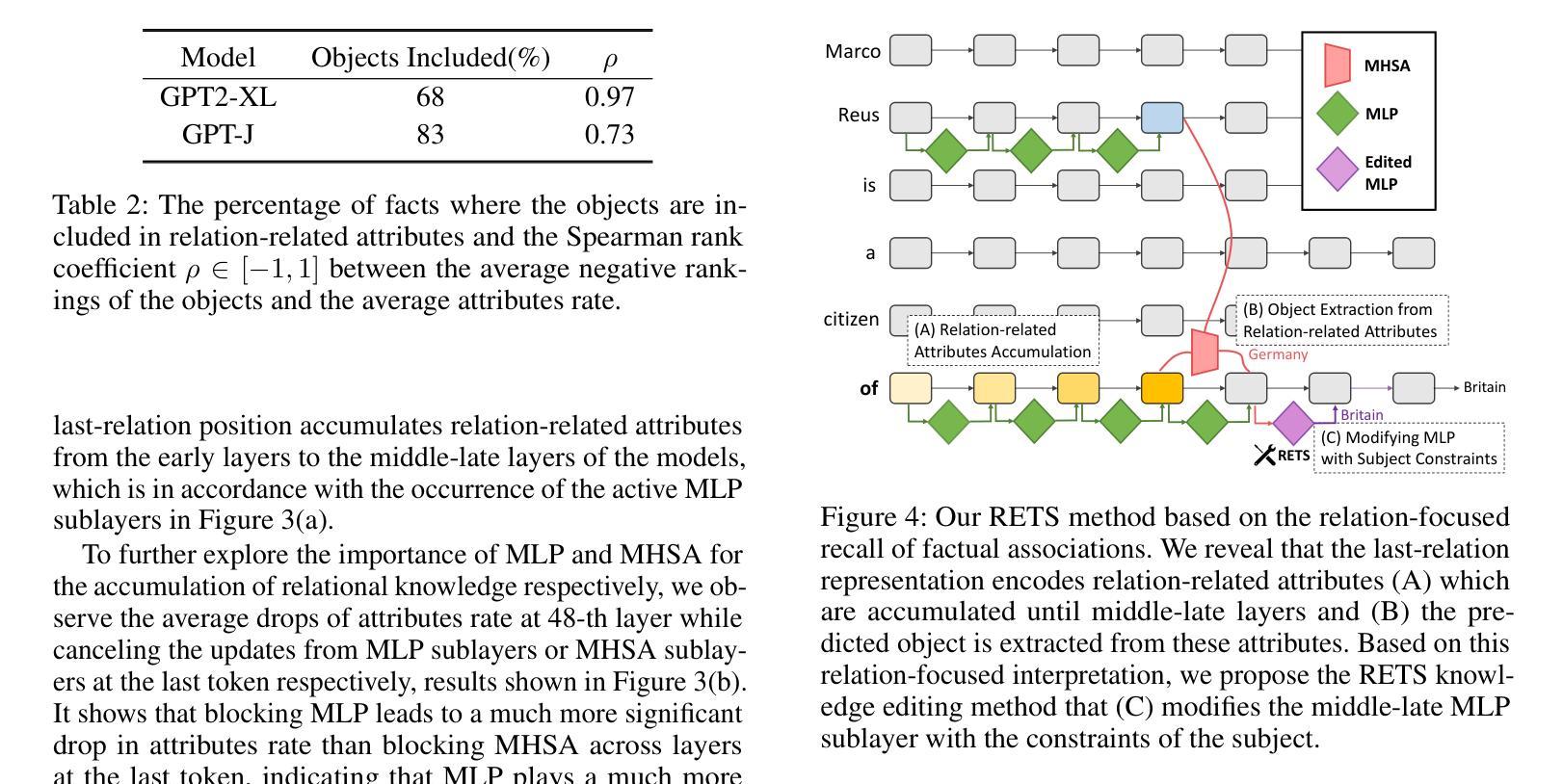
Relation Also Knows: Rethinking the Recall and Editing of Factual Associations in Auto-Regressive Transformer Language Models
Authors:Xiyu Liu, Zhengxiao Liu, Naibin Gu, Zheng Lin, Wanli Ma, Ji Xiang, Weiping Wang
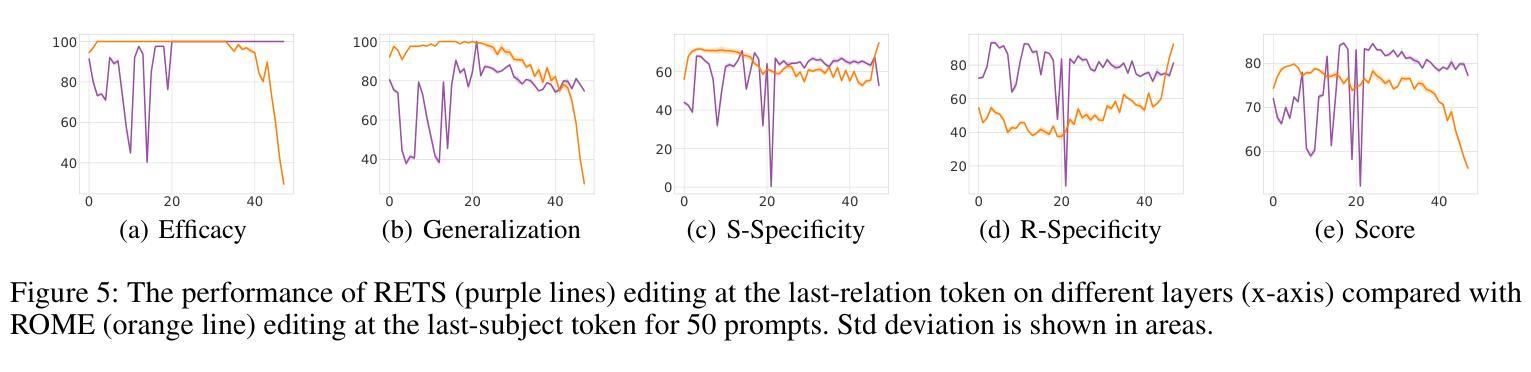
The storage and recall of factual associations in auto-regressive transformer language models (LMs) have drawn a great deal of attention, inspiring knowledge editing by directly modifying the located model weights. Most editing works achieve knowledge editing under the guidance of existing interpretations of knowledge recall that mainly focus on subject knowledge. However, these interpretations are seriously flawed, neglecting relation information and leading to the over-generalizing problem for editing. In this work, we discover a novel relation-focused perspective to interpret the knowledge recall of transformer LMs during inference and apply it on single knowledge editing to avoid over-generalizing. Experimental results on the dataset supplemented with a new R-Specificity criterion demonstrate that our editing approach significantly alleviates over-generalizing while remaining competitive on other criteria, breaking the domination of subject-focused editing for future research.
自动回归变换器语言模型(LMs)中的事实关联存储和回忆已经引起了广泛关注,这激发了通过直接修改定位模型权重进行知识编辑的灵感。大多数编辑工作是在知识回忆的现有解释指导下完成知识编辑的,这些解释主要集中在主题知识上。然而,这些解释存在严重缺陷,忽略了关系信息,导致编辑过程中出现过度概括的问题。在这项工作中,我们发现了一种新型的关系导向视角来解读推理过程中变换器LMs的知识回忆,并将其应用于单一知识编辑中以避免过度概括。在新增数据集上进行的实验补充了新的R特异性标准(R-Specificity criterion),结果表明我们的编辑方法显著减轻了过度概括的问题,同时在其他标准上仍具有竞争力,打破了以主题为中心的编辑在未来研究中的主导地位。
论文及项目相关链接
PDF Accepted by AAAI25
Summary:
本文关注自回归Transformer语言模型中事实关联知识的存储和回忆问题,并指出当前知识编辑方法主要集中在主题知识上,忽略关系信息导致过度泛化问题。本文提出了一种新型的关系聚焦视角来解读Transformer模型在推理过程中的知识回忆,并将其应用于单一知识编辑以避免过度泛化。实验结果表明,该方法在补充数据集和新提出的R-Specificity标准上显著减轻了过度泛化问题,同时在其他标准上仍具有竞争力。
Key Takeaways:
- 文章探讨了Transformer语言模型中事实关联知识的存储和回忆问题。
- 当前知识编辑方法主要关注主题知识,导致过度泛化问题。
- 文章提出了一种新型的关系聚焦视角来解读Transformer模型在推理过程中的知识回忆。
- 该方法应用于单一知识编辑,以避免过度泛化。
- 实验结果表明,该方法在特定数据集和新标准上表现优异,显著减轻了过度泛化问题。
- 该方法在多个标准上仍具有竞争力,为未来的研究提供了新的方向。
点此查看论文截图


NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models
Authors:Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, Wei Ping
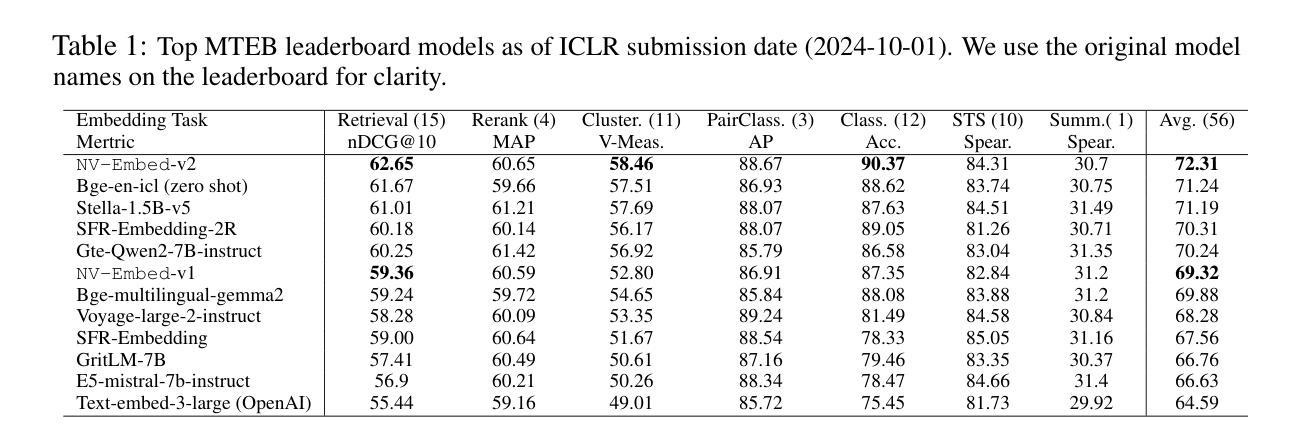
Decoder-only LLM-based embedding models are beginning to outperform BERT or T5-based embedding models in general-purpose text embedding tasks, including dense vector-based retrieval. In this work, we introduce NV-Embed, incorporating architectural designs, training procedures, and curated datasets to significantly enhance the performance of LLM as a versatile embedding model, while maintaining its simplicity and reproducibility. For model architecture, we propose a latent attention layer to obtain pooled embeddings, which consistently improves retrieval and downstream task accuracy compared to mean pooling or using the last
基于解码器的LLM嵌入模型开始在通用文本嵌入任务中超越基于BERT或T5的嵌入模型,包括密集向量检索。在这项工作中,我们引入了NV-Embed,结合了架构设计、训练过程和精选数据集,以显著增强LLM作为通用嵌入模型的性能,同时保持其简洁性和可重复性。在模型架构方面,我们提出了一个潜在注意力层来获得池化嵌入,与基于LLM的平均池化或使用最后一个
令牌嵌入相比,它始终提高了检索和下游任务的准确性。为了增强表示学习,我们在对比训练期间移除了LLM的因果注意力掩码。在训练算法方面,我们引入了一种两阶段的对比指令微调方法。它首先在检索数据集上应用带有指令的对比训练,利用批次内的负样本和精选的硬负样本。在第二阶段,它将各种非检索任务融入指令微调中,这不仅提高了非检索任务的准确性,也提高了检索性能。在训练数据方面,我们利用硬负样本挖掘、合成数据生成和现有的公开可用数据集来提升嵌入模型的性能。通过结合这些技术,我们的NV-Embed-v1和NV-Embed-v2模型在56项任务中位列首位(分别截至2024年5月24日和8月30日),这证明了所提出的方法随着时间的推移具有持续的有效性。此外,它在AIR基准测试中长文档部分得分最高,问答部分得分排名第二,涵盖了超出MTEB范围的跨域信息检索主题。我们还进一步分析了针对通用嵌入模型的模型压缩技术。
论文及项目相关链接
PDF ICLR 2025 (Spotlight). We open-source the model at: https://huggingface.co/nvidia/NV-Embed-v2
Summary
基于解码器的大型语言模型(LLM)的嵌入模型开始在某些通用的文本嵌入任务中表现优于BERT或T5模型。本研究介绍了NV-Embed,它通过架构设计、训练程序和精选数据集显著提高了LLM作为通用嵌入模型的表现,同时保持了其简单性和可复现性。通过引入潜伏注意力层获取池化嵌入,提出移除LLM中的因果注意力掩码进行对比训练等方法提高了检索和下游任务的准确性。此外,本研究还引入了两阶段的对比指令微调方法。经过硬负样本挖掘、合成数据生成和现有公开数据集的使用,NV-Embed模型在多个任务上取得了领先的性能。
Key Takeaways
- LLM-based嵌入模型在通用文本嵌入任务上开始超越BERT或T5模型。
- NV-Embed通过改进架构设计、训练程序和精选数据集提高了LLM的表现。
- 潜伏注意力层的引入提高了检索和下游任务的准确性。
- 对比训练过程中移除了LLM的因果注意力掩码以增强表示学习。
- 两阶段的对比指令微调方法提高了非检索任务准确性和检索性能。
- NV-Embed模型通过硬负样本挖掘、合成数据生成等技术在多个任务上取得领先性能。
点此查看论文截图

Vikhr: Constructing a State-of-the-art Bilingual Open-Source Instruction-Following Large Language Model for Russian
Authors:Aleksandr Nikolich, Konstantin Korolev, Sergei Bratchikov, Igor Kiselev, Artem Shelmanov
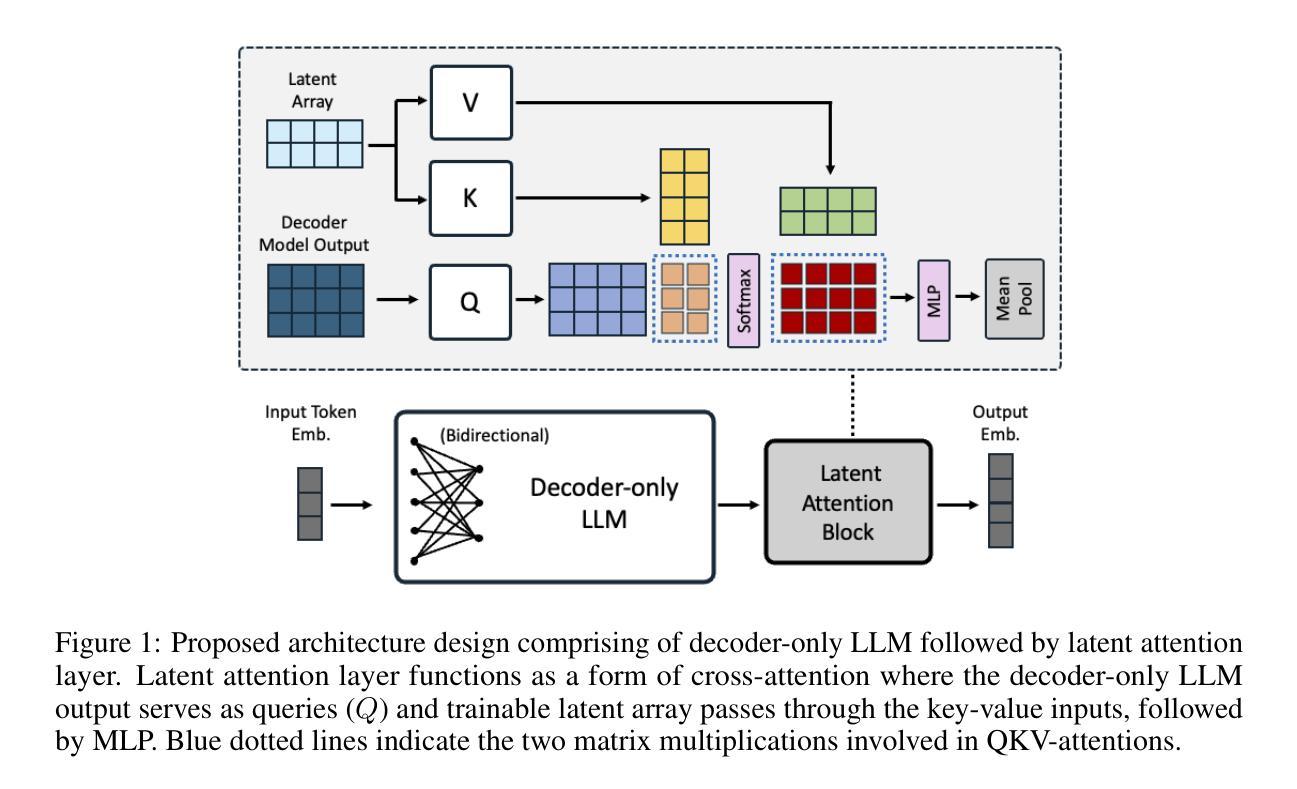
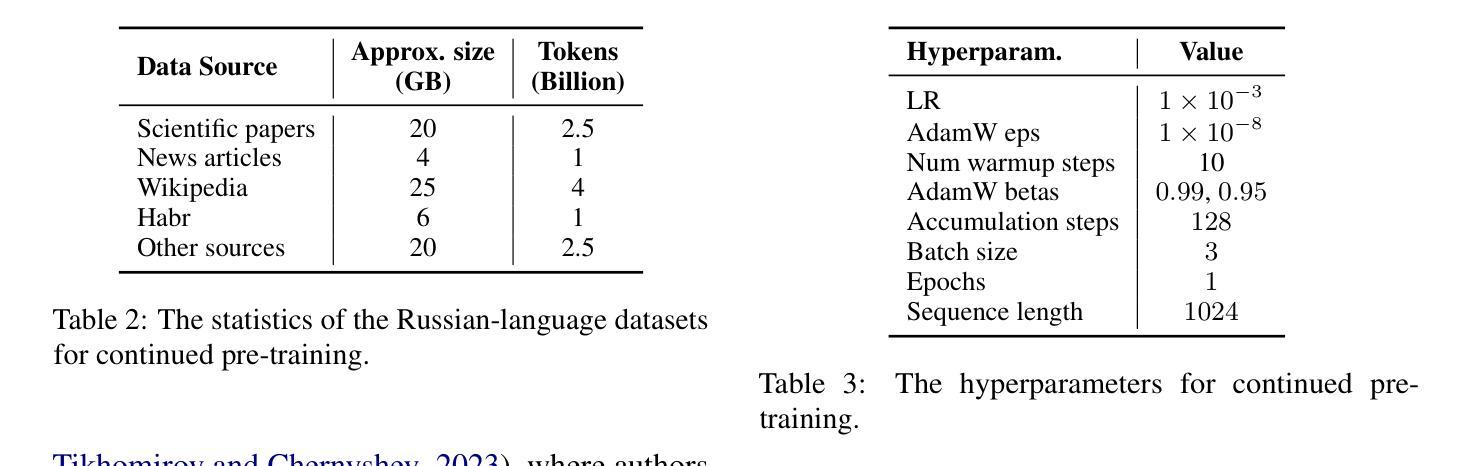
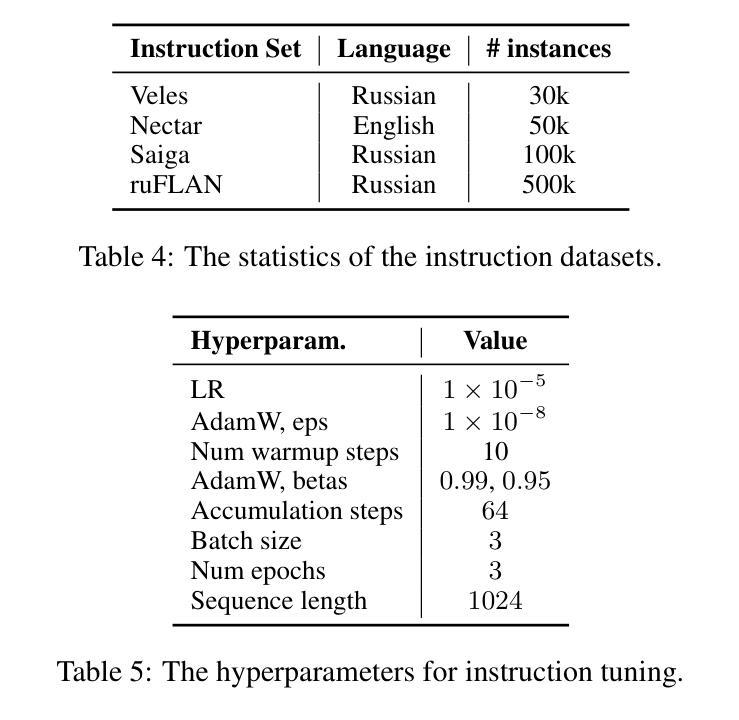
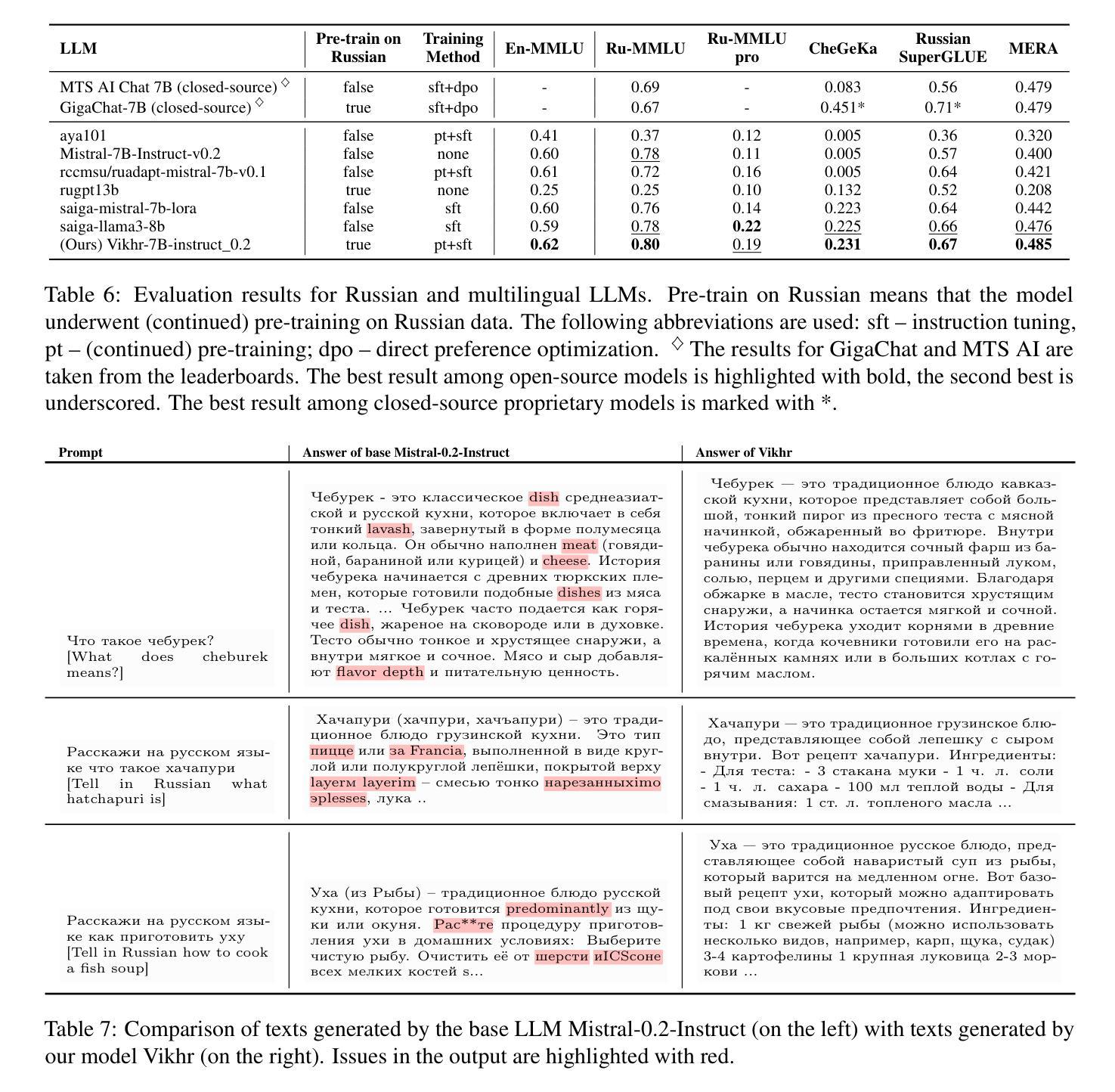
There has been a surge in developing various Large Language Models (LLMs). However, text generation for languages other than English often faces significant challenges, including poor generation quality and reduced computational performance due to the disproportionate representation of tokens in the model’s vocabulary. In this work, we address these issues by developing a pipeline for adapting English-oriented pre-trained models to other languages and constructing efficient bilingual LLMs. Using this pipeline, we construct Vikhr, a state-of-the-art bilingual open-source instruction-following LLM designed specifically for the Russian language. “Vikhr” refers to the name of the Mistral LLM series and means a “strong gust of wind.” Unlike previous Russian-language models that typically rely on LoRA adapters on top of English-oriented models, sacrificing performance for lower training costs, Vikhr features an adapted tokenizer vocabulary and undergoes continued pre-training and instruction tuning of all weights. This not only enhances the model’s performance but also significantly improves its computational and contextual efficiency. The remarkable performance of Vikhr across various Russian-language benchmarks can also be attributed to our efforts in expanding instruction datasets and corpora for continued pre-training. Vikhr not only sets a new state of the art among open-source LLMs for Russian but even outperforms some proprietary closed-source models on certain benchmarks. The model weights, instruction sets, and code are publicly available.
在开发各种大型语言模型(LLM)方面出现了激增。然而,对于非英语语言的文本生成常常面临巨大的挑战,包括生成质量较差和计算性能下降,这是由于模型中词汇的代表性不均衡所导致的。在这项工作中,我们通过开发一个用于适应面向英语的预训练模型以适应其他语言的管道,并构建高效的双语LLM来解决这些问题。使用该管道,我们构建了Vikhr,这是一个最先进的双语开源指令遵循LLM,专门为俄语设计。“Vikhr”指的是Mistral LLM系列的名字,意味着“一阵大风”。不同于通常依赖于英语导向模型的LoRA适配器以降低训练成本为牺牲的先前俄语模型,Vikhr具有适应的标记器词汇表,并经历了所有权重的持续预训练和指令调整。这不仅提高了模型的性能,还大大提高了其计算和上下文效率。Vikhr在多种俄语基准测试中的出色表现也可归功于我们扩大指令数据集和语料库以进行持续预训练的努力。Vikhr不仅在开源LLM中树立了俄语的新标杆,而且在某些基准测试中甚至超越了某些专有闭源模型。模型权重、指令集和代码均已公开可用。
论文及项目相关链接
PDF Accepted at WMRL @ EMNLP-2024
Summary
本摘要介绍了开发适应非英语语言的大型语言模型(LLM)所面临的挑战,包括生成质量不佳和计算性能下降等问题。为解决这些问题,研究者开发了一种适应英语预训练模型到其他语言的管道,并构建了高效的双语LLM。在此基础上,研究团队构建了面向俄语的双语开源指令遵循LLM——Vikhr。与传统的基于英语模型的适配器不同,Vikhr采用适应的词汇表并继续对所有权重进行预训练和指令微调,从而提高了模型的性能和计算效率。其在俄语基准测试上的卓越表现得益于扩充的指令数据集和持续预训练语料库的努力。Vikhr不仅在开源LLM中树立了俄语的新标杆,而且在某些基准测试上甚至超过了某些专有闭源模型。模型的权重、指令集和代码已公开可用。
Key Takeaways
- 大型语言模型(LLM)在非英语语言生成方面面临挑战,包括生成质量和计算性能问题。
- 研究者通过开发适应英语预训练模型到其他语言的管道来解决这些问题。
- Vikhr是一种面向俄语的先进双语开源指令遵循LLM。
- Vikhr采用适应的词汇表并继续对所有权重进行预训练和指令微调,以提高模型的性能和计算效率。
- Vikhr在俄语基准测试上表现出卓越的性能,超过了某些专有闭源模型。
- Vikhr的模型权重、指令集和代码已公开可用。
点此查看论文截图

Meta Prompting for AI Systems
Authors:Yifan Zhang, Yang Yuan, Andrew Chi-Chih Yao
We introduce Meta Prompting (MP), a prompting paradigm designed to enhance the utilization of large language models (LLMs) and AI systems in complex problem-solving and data interaction. Grounded in type theory and category theory, Meta Prompting prioritizes structural and syntactical considerations over traditional content-centric methods. In this work, we formally define Meta Prompting, delineate its distinctions from few-shot prompting, and demonstrate its effectiveness across various AI applications. In particular, we show that Meta Prompting can decompose intricate reasoning tasks into simpler sub-problems, thereby improving token efficiency and enabling fairer comparisons with conventional few-shot techniques. Furthermore, we extend this framework to prompting tasks, allowing LLMs to recursively self-generate refined prompts in a metaprogramming-like manner. Empirical evaluations reveal that a Qwen-72B base language model equipped with Meta Prompting-without additional instruction tuning-achieves a PASS@1 accuracy of 46.3% on MATH problems, surpassing a supervised fine-tuned counterpart, 83.5% accuracy on GSM8K, and a 100% success rate on Game of 24 tasks using GPT-4. The code is available at https://github.com/meta-prompting/meta-prompting.
我们介绍了Meta Prompting(MP),这是一种旨在提高大型语言模型(LLM)和AI系统在复杂问题解决和数据交互中的利用率的提示范式。Meta Prompting基于类型理论和范畴理论,优先考虑结构和句法因素,而非传统的以内容为中心的方法。在这项工作中,我们正式定义了Meta Prompting,阐述了它与少量样本提示的区别,并在各种AI应用程序中展示了其有效性。我们特别表明,Meta Prompting能够将复杂的推理任务分解成更简单的子问题,从而提高令牌效率,并与传统的少量样本技术进行更公平的比较。此外,我们将此框架扩展到提示任务,使LLM能够以一种类似元编程的方式递归地自我生成精细的提示。实证评估表明,配备Meta Prompting的Qwen-72B基础语言模型,无需额外的指令调整,在MATH问题上的PASS@1准确率达到了46.3%,超越了经过监督精细调整的对手;在GSM8K上的准确率为83.5%,而在Game of 24任务上的成功率为100%,使用的是GPT-4。代码可在https://github.com/meta-prompting/meta-prompting上找到。
论文及项目相关链接
Summary
本文介绍了Meta Prompting(MP)这一新的提示范式,旨在提高大型语言模型(LLM)和人工智能系统在复杂问题求解和数据交互中的使用效率。该研究基于类型理论和范畴理论,强调结构和句法因素,超越传统的内容中心方法。文章正式定义了Meta Prompting,阐述了其与few-shot提示的区别,并在各种AI应用程序中证明了其有效性。特别是,Meta Prompting能够分解复杂的推理任务为更简单的子问题,提高了令牌效率,并与传统的few-shot技术进行了更公平的比较。此外,该框架扩展到提示任务中,使LLMs能够以类似元编程的方式递归地自我生成精细提示。实证评估表明,配备Meta Prompting的Qwen-72B基础语言模型在MATH问题上达到46.3%的PASS@1准确率,超越了经监督微调的对标模型;在GSM8K上达到83.5%的准确率;在Game of 24任务中使用GPT-4实现100%的成功率。
Key Takeaways
- Meta Prompting(MP)是一种新型的提示范式,旨在提高大型语言模型(LLM)在复杂问题求解和数据交互中的效率。
- Meta Prompting基于类型理论和范畴理论,注重结构和句法因素,与传统的以内容为中心的提示方法有所不同。
- Meta Prompting能将复杂的推理任务分解成更简单的子问题,提高令牌效率,并与few-shot技术进行比较。
- 该框架可扩展到提示任务中,使LLMs能够自我生成精细提示,类似于元编程的方式。
- 配备Meta Prompting的Qwen-72B模型在MATH问题上表现优异,达到46.3%的PASS@1准确率。
- 在GSM8K测试中,该模型的准确率为83.5%。
- 在Game of 24任务中,使用GPT-4的模型实现了100%的成功率。
点此查看论文截图



Recommendations by Concise User Profiles from Review Text
Authors:Ghazaleh Haratinezhad Torbati, Anna Tigunova, Andrew Yates, Gerhard Weikum
Recommender systems perform well for popular items and users with ample interactions (likes, ratings etc.). This work addresses the difficult and underexplored case of users who have very sparse interactions but post informative review texts. This setting naturally calls for encoding user-specific text with large language models (LLM). However, feeding the full text of all reviews through an LLM has a weak signal-to-noise ratio and incurs high costs of processed tokens. This paper addresses these two issues. It presents a light-weight framework, called CUP, which first computes concise user profiles and feeds only these into the training of transformer-based recommenders. For user profiles, we devise various techniques to select the most informative cues from noisy reviews. Experiments, with book reviews data, show that fine-tuning a small language model with judiciously constructed profiles achieves the best performance, even in comparison to LLM-generated rankings.
推荐系统对于流行物品和拥有大量互动(如喜欢、评分等)的用户表现良好。这项工作解决了用户互动很少但发布的信息丰富的评论文本这一困难且未被充分研究的案例。这种情况自然地要求使用大型语言模型(LLM)对特定用户的文本进行编码。然而,将所有评论的完整文本通过LLM处理,信号与噪声之比很低,并且会产生高昂的处理令牌成本。本论文解决了这两个问题。它提出了一个轻量级的框架,称为CUP,该框架首先计算简洁的用户配置文件,并将其仅输入到基于转换器的推荐者的训练中。对于用户配置文件,我们设计了各种技术从嘈杂的评论中选择最具有信息性的线索。使用书评数据的实验表明,使用精心构建的配置文件对小型语言模型进行微调,即使与LLM生成的排名相比,也能实现最佳性能。
论文及项目相关链接
Summary
本文关注用户交互稀疏但发布有信息含量的评论文本的情况。针对这种情况,提出了一种轻量级的框架CUP,通过计算简洁的用户配置文件并将其输入到基于转换器的推荐器训练中来解决使用大型语言模型(LLM)编码用户特定文本的问题。实验表明,使用精心构建的用户配置文件微调小型语言模型,即使在大型语言模型生成的排名面前,也能取得最佳性能。
Key Takeaways
- 推荐系统对于交互丰富的用户和流行项目表现良好,但对于交互稀疏但评论信息丰富的用户面临挑战。
- 在这种情况下,使用大型语言模型(LLM)编码用户特定文本是必要的。
- 直接将所有评论文本输入LLM存在信号与噪音比低和令牌处理成本高的问题。
- 提出的CUP框架通过计算简洁的用户配置文件来解决上述问题。
- 选择最有信息量的线索来构建用户配置文件是解决噪音评论的关键。
- 实验表明,使用精心构建的用户配置文件微调小型语言模型可以取得最佳性能。
点此查看论文截图

Self-Confirming Transformer for Belief-Conditioned Adaptation in Offline Multi-Agent Reinforcement Learning
Authors:Tao Li, Juan Guevara, Xinhong Xie, Quanyan Zhu
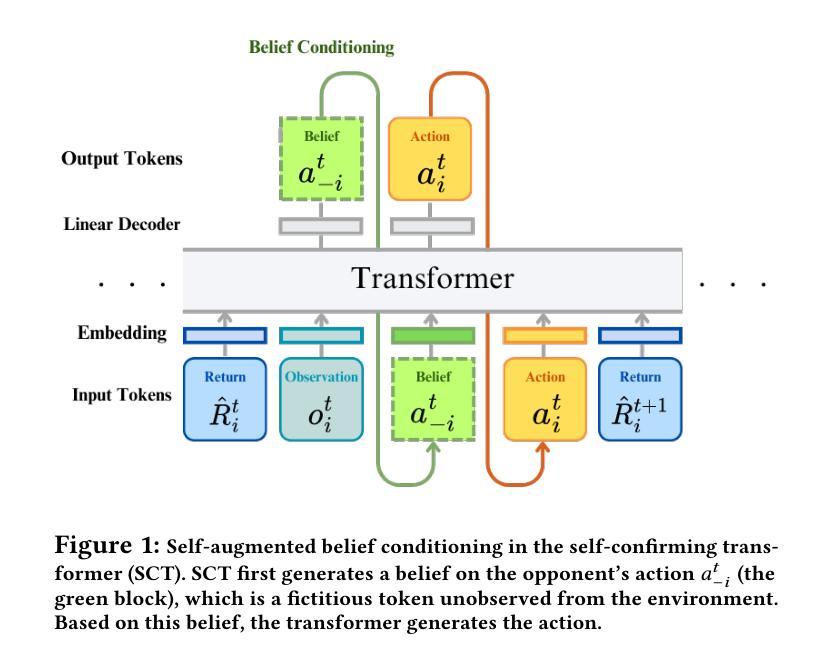
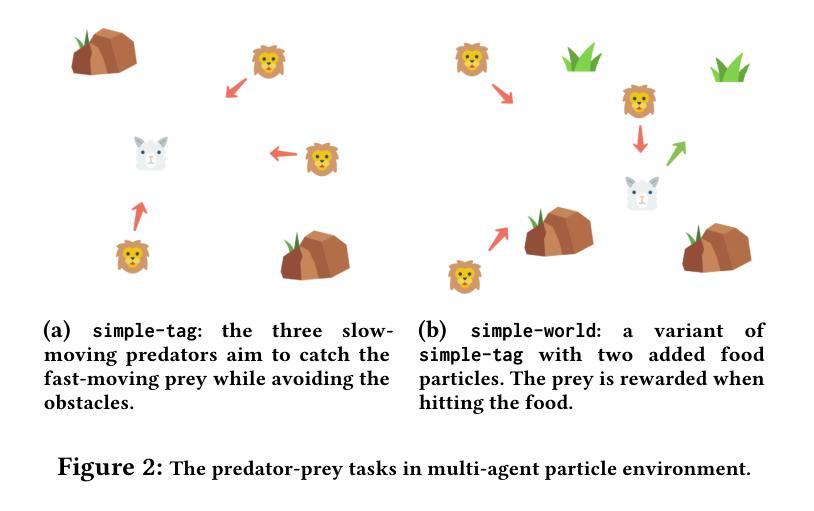
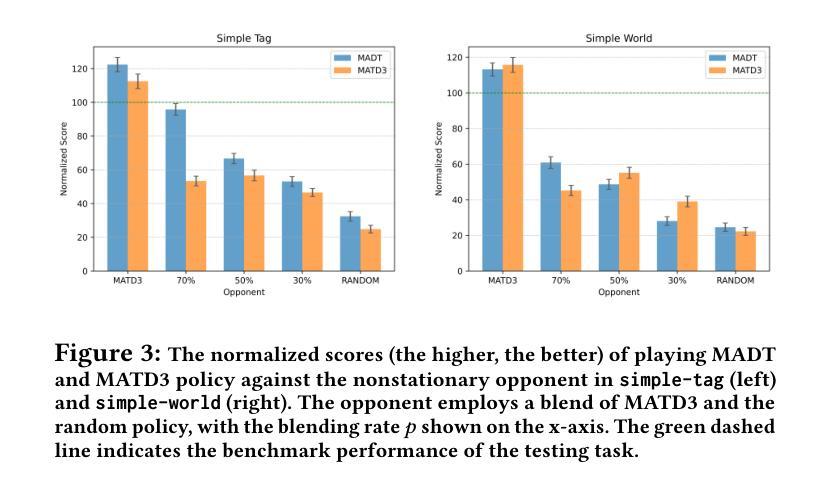
Offline reinforcement learning (RL) suffers from the distribution shift between the offline dataset and the online environment. In multi-agent RL (MARL), this distribution shift may arise from the nonstationary opponents in the online testing who display distinct behaviors from those recorded in the offline dataset. Hence, the key to the broader deployment of offline MARL is the online adaptation to nonstationary opponents. Recent advances in foundation models, e.g., large language models, have demonstrated the generalization ability of the transformer, an emerging neural network architecture, in sequence modeling, of which offline RL is a special case. One naturally wonders \textit{whether offline-trained transformer-based RL policies adapt to nonstationary opponents online}. We propose a novel auto-regressive training to equip transformer agents with online adaptability based on the idea of self-augmented pre-conditioning. The transformer agent first learns offline to predict the opponent’s action based on past observations. When deployed online, such a fictitious opponent play, referred to as the belief, is fed back to the transformer, together with other environmental feedback, to generate future actions conditional on the belief. Motivated by self-confirming equilibrium in game theory, the training loss consists of belief consistency loss, requiring the beliefs to match the opponent’s actual actions and best response loss, mandating the agent to behave optimally under the belief. We evaluate the online adaptability of the proposed self-confirming transformer (SCT) in a structured environment, iterated prisoner’s dilemma games, to demonstrate SCT’s belief consistency and equilibrium behaviors as well as more involved multi-particle environments to showcase its superior performance against nonstationary opponents over prior transformers and offline MARL baselines.
离线强化学习(RL)面临着离线数据集和在线环境之间的分布偏移问题。在多智能体强化学习(MARL)中,这种分布偏移可能源于在线测试中非稳定对手的出现,这些对手的行为与离线数据集中记录的行为截然不同。因此,离线MARL更广泛部署的关键在于对在线非稳定对手的适应。最近的基金模型(如大型语言模型)的进展证明了变压器这种新兴神经网络架构在序列建模中的泛化能力,离线RL是其中的特例。人们自然会好奇“基于离线训练的变压器RL策略是否适应在线的非稳定对手”。我们提出了一种新颖的自动回归训练,基于自我增强预处理的理念,为变压器智能体提供在线适应性。变压器智能体首先离线学习基于过去观察预测对手行动。当在线部署时,这种虚构的对手游戏(称为信念)会反馈给变压器,以及其他环境反馈一起,以信念为条件生成未来行动。受博弈论中自我确认均衡的启发,训练损失包括信念一致性损失,要求信念与对手的实际行动相匹配,以及最佳响应损失,要求智能体在信念下表现出最优行为。我们在结构化环境中评估了所提出自我确认变压器(SCT)的在线适应性,在反复囚徒困境游戏中展示了SCT的信念一致性、均衡行为以及在更复杂的多粒子环境中相对于先前变压器和离线MARL基准的优越性能表现,对抗非稳定对手。
论文及项目相关链接
Summary
该文本探讨了离线强化学习(RL)面临的在线数据与离线数据集分布转移的问题。在多智能体强化学习(MARL)中,这种分布转移可能源于在线测试中的非稳定对手,他们的行为与离线数据集记录的行为不同。因此,离线MARL更广泛部署的关键在于在线适应非稳定对手的能力。最近,基础模型的进展,如大型语言模型,显示了transformer在序列建模中的泛化能力,离线RL是其中的特例。本文提出了基于自增强预处理的自回归训练,为transformer智能体提供在线适应性。该训练损失包括信念一致性损失和最佳响应损失,要求信念与对手的实际行动相匹配,以及智能体在信念下的行为要最优。在结构化环境、重复的囚徒困境游戏以及更复杂的多粒子环境中评估了所提出的自确认transformer(SCT)的在线适应性,展示了SCT在应对非稳定对手时的优越性能。
Key Takeaways
- 离线强化学习(RL)面临在线数据与离线数据集分布转移的问题。
- 在多智能体强化学习(MARL)中,非稳定对手导致的分布转移是一个重要挑战。
- Transformer模型在序列建模中展现出强大的泛化能力。
- 提出了基于自增强预处理的自回归训练,以增强transformer智能体的在线适应性。
- 训练损失包括信念一致性损失和最佳响应损失,确保智能体能够适应非稳定对手的行为。
- 在结构化环境和多粒子环境中评估了自确认transformer(SCT)的在线适应性。
点此查看论文截图

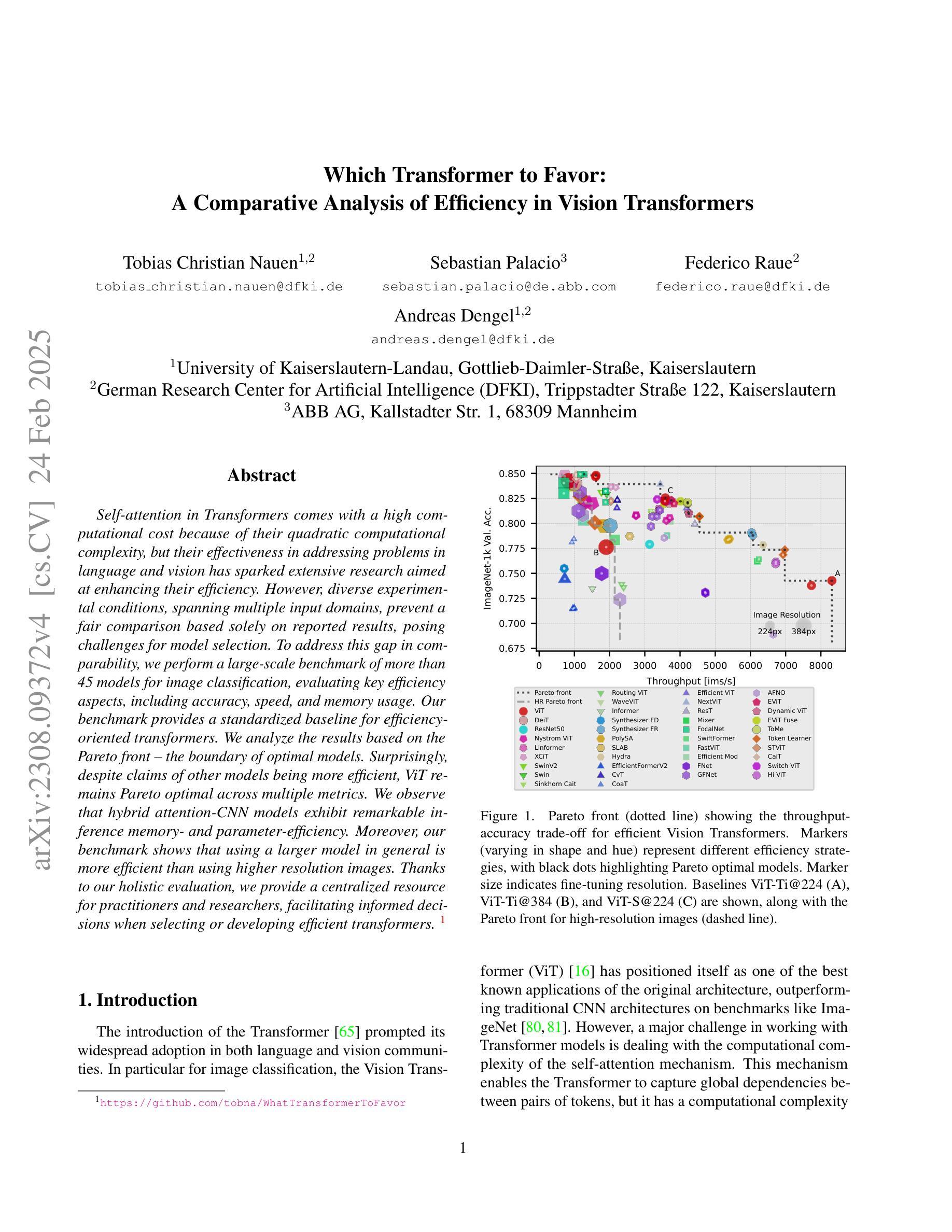
Which Transformer to Favor: A Comparative Analysis of Efficiency in Vision Transformers
Authors:Tobias Christian Nauen, Sebastian Palacio, Federico Raue, Andreas Dengel
Self-attention in Transformers comes with a high computational cost because of their quadratic computational complexity, but their effectiveness in addressing problems in language and vision has sparked extensive research aimed at enhancing their efficiency. However, diverse experimental conditions, spanning multiple input domains, prevent a fair comparison based solely on reported results, posing challenges for model selection. To address this gap in comparability, we perform a large-scale benchmark of more than 45 models for image classification, evaluating key efficiency aspects, including accuracy, speed, and memory usage. Our benchmark provides a standardized baseline for efficiency-oriented transformers. We analyze the results based on the Pareto front – the boundary of optimal models. Surprisingly, despite claims of other models being more efficient, ViT remains Pareto optimal across multiple metrics. We observe that hybrid attention-CNN models exhibit remarkable inference memory- and parameter-efficiency. Moreover, our benchmark shows that using a larger model in general is more efficient than using higher resolution images. Thanks to our holistic evaluation, we provide a centralized resource for practitioners and researchers, facilitating informed decisions when selecting or developing efficient transformers.
Transformer中的自注意力机制由于二次计算复杂度而带来了较高的计算成本,但其在语言和视觉问题处理中的有效性引发了旨在提高其效率的广泛研究。然而,跨越多个输入域的多种实验条件仅基于报告结果而无法进行公平比较,这给模型选择带来了挑战。为了解决可比性方面的这一差距,我们对超过45个模型进行了大规模图像分类基准测试,评估了包括准确性、速度和内存使用在内的关键效率方面。我们的基准测试为面向效率的变压器提供了标准化基线。我们根据帕累托前沿(最优模型边界)分析结果。令人惊讶的是,尽管有其他模型效率更高的说法,但ViT在多个指标上仍然是帕累托最优。我们发现,混合注意力CNN模型在推理内存和参数效率方面表现出色。此外,我们的基准测试表明,一般来说,使用较大的模型比使用更高分辨率的图像更加高效。由于我们进行了全面评估,因此为实践者和研究人员提供了一个集中资源,有助于他们在选择或开发高效变压器时做出明智的决策。
论文及项目相关链接
PDF v3: new models, analysis of scaling behaviors; v4: WACV 2025 camera ready version, appendix added
Summary
本文探讨了Transformer中的自注意力机制虽然计算成本高,但其处理语言和视觉问题的有效性引发了广泛的研究以提高其效率。由于不同输入领域的实验条件差异,仅基于报告结果难以进行公平比较,给模型选择带来挑战。为此,我们对超过45种模型进行了大规模图像分类基准测试,评估了准确性、速度和内存使用等关键效率方面。基准测试提供了面向效率的变压器标准化基线。根据帕累托最优模型的分析,令人惊讶的是,尽管有其他模型声称效率更高,但ViT在多个指标上仍是帕累托最优。我们的基准测试显示,使用较大的模型通常比在更高分辨率的图像上工作更为高效。我们的整体评估为实践者和研究者提供了集中资源,有助于在选择或开发高效变压器时做出明智的决策。
Key Takeaways
- Transformer中的自注意力机制具有高的计算成本,但其在语言和视觉问题处理中的有效性引发了效率提升的研究。
- 不同输入领域的实验条件差异导致难以公平比较模型性能,为模型选择带来挑战。
- 对超过45种模型进行大规模图像分类基准测试,包括关键效率方面的评估,如准确性、速度和内存使用。
- 基准测试提供了面向效率的变压器的标准化基线。
- ViT在多个效率指标上表现优异,成为帕累托最优模型。
- 杂交注意力-CNN模型在推理内存和参数效率方面表现出色。
点此查看论文截图