⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-04 更新
TomoSelfDEQ: Self-Supervised Deep Equilibrium Learning for Sparse-Angle CT Reconstruction
Authors:Tatiana A. Bubba, Matteo Santacesaria, Andrea Sebastiani
Deep learning has emerged as a powerful tool for solving inverse problems in imaging, including computed tomography (CT). However, most approaches require paired training data with ground truth images, which can be difficult to obtain, e.g., in medical applications. We present TomoSelfDEQ, a self-supervised Deep Equilibrium (DEQ) framework for sparse-angle CT reconstruction that trains directly on undersampled measurements. We establish theoretical guarantees showing that, under suitable assumptions, our self-supervised updates match those of fully-supervised training with a loss including the (possibly non-unitary) forward operator like the CT forward map. Numerical experiments on sparse-angle CT data confirm this finding, also demonstrating that TomoSelfDEQ outperforms existing self-supervised methods, achieving state-of-the-art results with as few as 16 projection angles.
深度学习已成为解决成像中的逆问题(包括计算机断层扫描(CT))的强大工具。然而,大多数方法需要配对训练数据与真实图像,这在医疗应用等情况下可能难以获得。我们提出了TomoSelfDEQ,这是一种用于稀疏角度CT重建的自监督深度均衡(DEQ)框架,它直接在欠采样的测量值上进行训练。我们建立了理论保证,表明在合适的假设下,我们的自监督更新与包括CT正向映射在内的(可能是非酉)正向操作符的损失的全监督训练相匹配。对稀疏角度CT数据的数值实验证实了这一发现,还表明TomoSelfDEQ优于现有的自监督方法,在仅使用16个投影角度的情况下即可达到最新技术水平。
论文及项目相关链接
Summary
深度学习已成为解决成像中的反问题(包括计算机断层扫描(CT))的有力工具。然而,大多数方法需要配对训练数据与真实图像,这在医学应用中可能难以获得。我们提出了TomoSelfDEQ,这是一种用于稀疏角度CT重建的自我监督深度均衡(DEQ)框架,可直接在欠采样测量上进行训练。我们建立了理论保证,表明在合适的假设下,我们的自我监督更新与包括CT正向映射在内的(可能非酉)正向算子的损失的全监督训练相匹配。在稀疏角度CT数据上的数值实验证实了这一点,也表明TomoSelfDEQ优于现有的自我监督方法,在仅使用16个投影角度的情况下即可达到最新结果。
Key Takeaways
- 深度学习在解决包括计算机断层扫描(CT)在内的成像反问题中展现出强大能力。
- 大多数现有方法需要配对训练数据与真实图像,这在医学应用中具有挑战性。
- TomoSelfDEQ是一种自我监督的深度学习框架,用于稀疏角度CT重建,可直接在欠采样测量上训练。
- TomoSelfDEQ的理论保证表明,其自我监督更新与全监督训练相当,即使包括可能非酉的正向算子。
- TomoSelfDEQ在数值实验中表现出优异性能,优于现有自我监督方法。
- TomoSelfDEQ在仅使用少量投影角度(如16个)时即可达到最新结果。
点此查看论文截图

Anatomically-guided masked autoencoder pre-training for aneurysm detection
Authors:Alberto Mario Ceballos-Arroyo, Jisoo Kim, Chu-Hsuan Lin, Lei Qin, Geoffrey S. Young, Huaizu Jiang
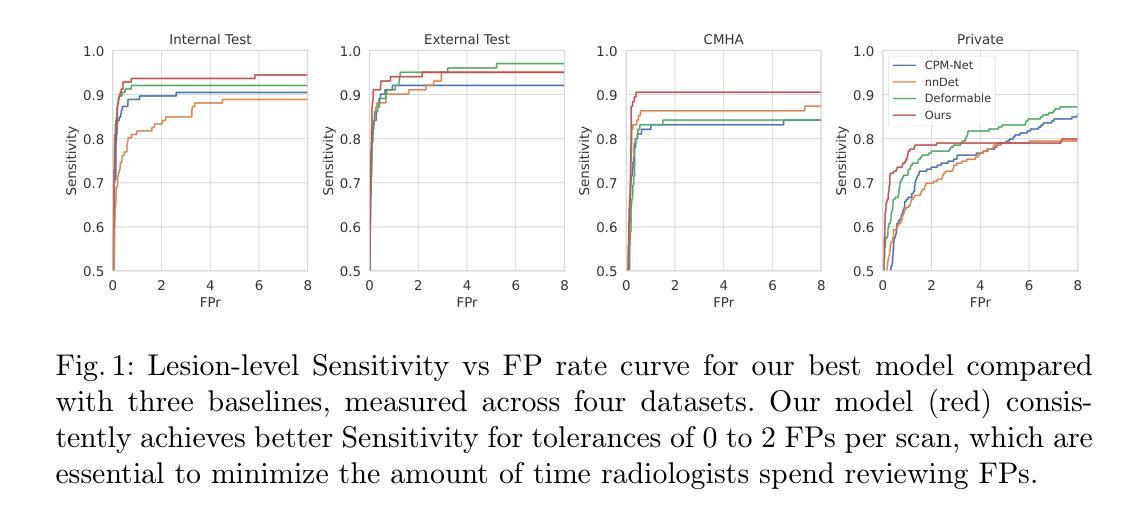
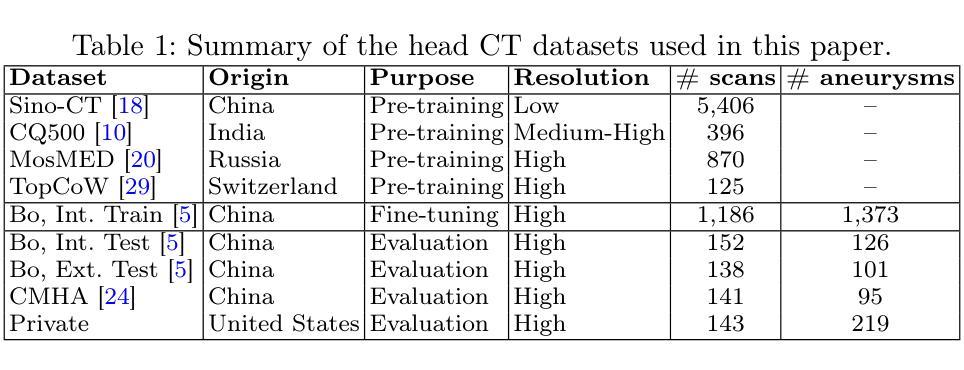
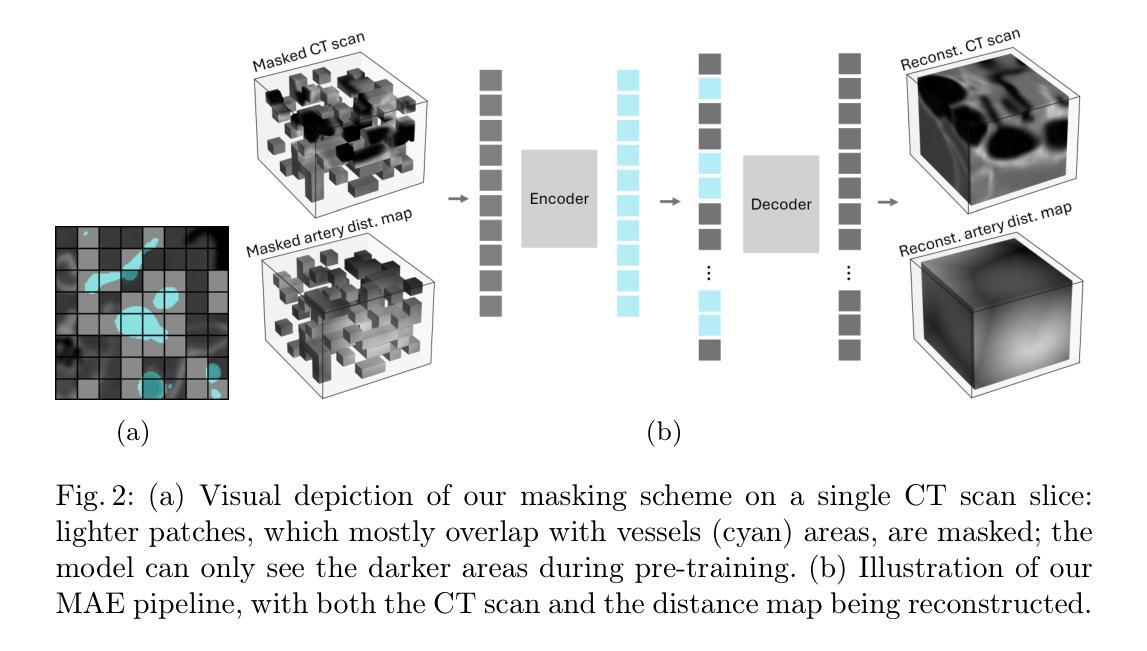
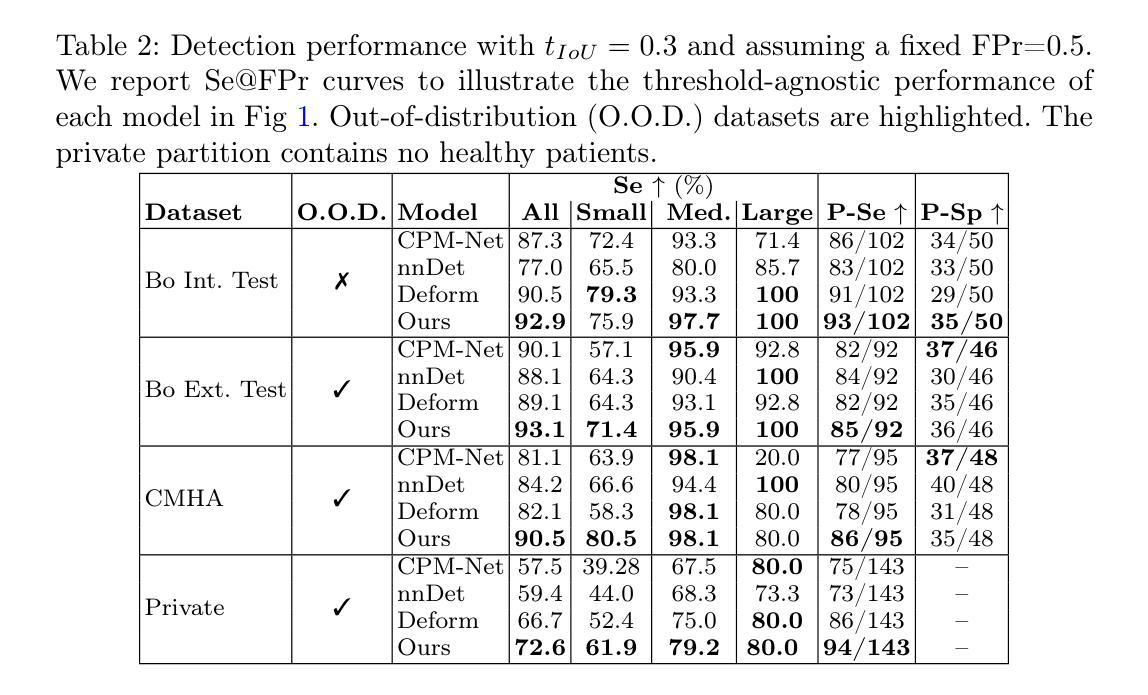
Intracranial aneurysms are a major cause of morbidity and mortality worldwide, and detecting them manually is a complex, time-consuming task. Albeit automated solutions are desirable, the limited availability of training data makes it difficult to develop such solutions using typical supervised learning frameworks. In this work, we propose a novel pre-training strategy using more widely available unannotated head CT scan data to pre-train a 3D Vision Transformer model prior to fine-tuning for the aneurysm detection task. Specifically, we modify masked auto-encoder (MAE) pre-training in the following ways: we use a factorized self-attention mechanism to make 3D attention computationally viable, we restrict the masked patches to areas near arteries to focus on areas where aneurysms are likely to occur, and we reconstruct not only CT scan intensity values but also artery distance maps, which describe the distance between each voxel and the closest artery, thereby enhancing the backbone’s learned representations. Compared with SOTA aneurysm detection models, our approach gains +4-8% absolute Sensitivity at a false positive rate of 0.5. Code and weights will be released.
颅内动脉瘤是全球发病率和死亡率的主要原因之一,手动检测它们是一项复杂且耗时的任务。尽管希望采用自动化解决方案,但由于训练数据的有限可用性,使用典型的监督学习框架开发此类解决方案变得困难。在这项工作中,我们提出了一种新的预训练策略,使用更广泛可用的未注释头部CT扫描数据来预训练一个3D视觉Transformer模型,然后再对其进行微调以进行动脉瘤检测任务。具体来说,我们对掩码自动编码器(MAE)的预训练进行了以下修改:我们使用因子化自注意力机制使3D注意力在计算上可行,我们将掩码斑块限制在动脉附近的区域,以关注动脉瘤可能发生的区域,我们重建的不仅是CT扫描强度值,还有动脉距离图,描述每个体素与最近动脉之间的距离,从而增强了主干的学习表示。与最先进的动脉瘤检测模型相比,我们的方法在假阳性率为0.5的情况下,绝对灵敏度提高了+4-8%。代码和权重将发布。
论文及项目相关链接
PDF 11 pages, 3 figures
Summary
本研究提出一种新型预训练策略,利用广泛可用的未标注头部CT扫描数据,对3D视觉转换器模型进行预训练,以用于动脉瘤检测任务。通过修改掩码自动编码器(MAE)的预训练方法,研究团队引入了多种创新手段以提升检测精度和实用性。实验证明,该模型与当前最佳动脉瘤检测模型相比,在假阳性率为0.5的情况下,灵敏度提高了+4-8%。该模型的代码和权重将公开发布。
Key Takeaways
- 颅内动脉瘤手动检测复杂且耗时,存在自动化解决方案的需求。
- 由于训练数据有限,使用典型监督学习框架开发自动化解决方案具有挑战性。
- 本研究采用一种新型预训练策略,使用未标注的头部CT扫描数据进行模型预训练。
- 研究团队修改了掩码自动编码器(MAE)的预训练方法,包括采用因子化自注意力机制、限制掩码区域聚焦于动脉附近以及重建CT扫描强度值和动脉距离图。
- 动脉距离图的重建增强了模型对动脉瘤发生区域的识别能力。
- 与当前最佳动脉瘤检测模型相比,该模型在灵敏度上有所提高。
点此查看论文截图

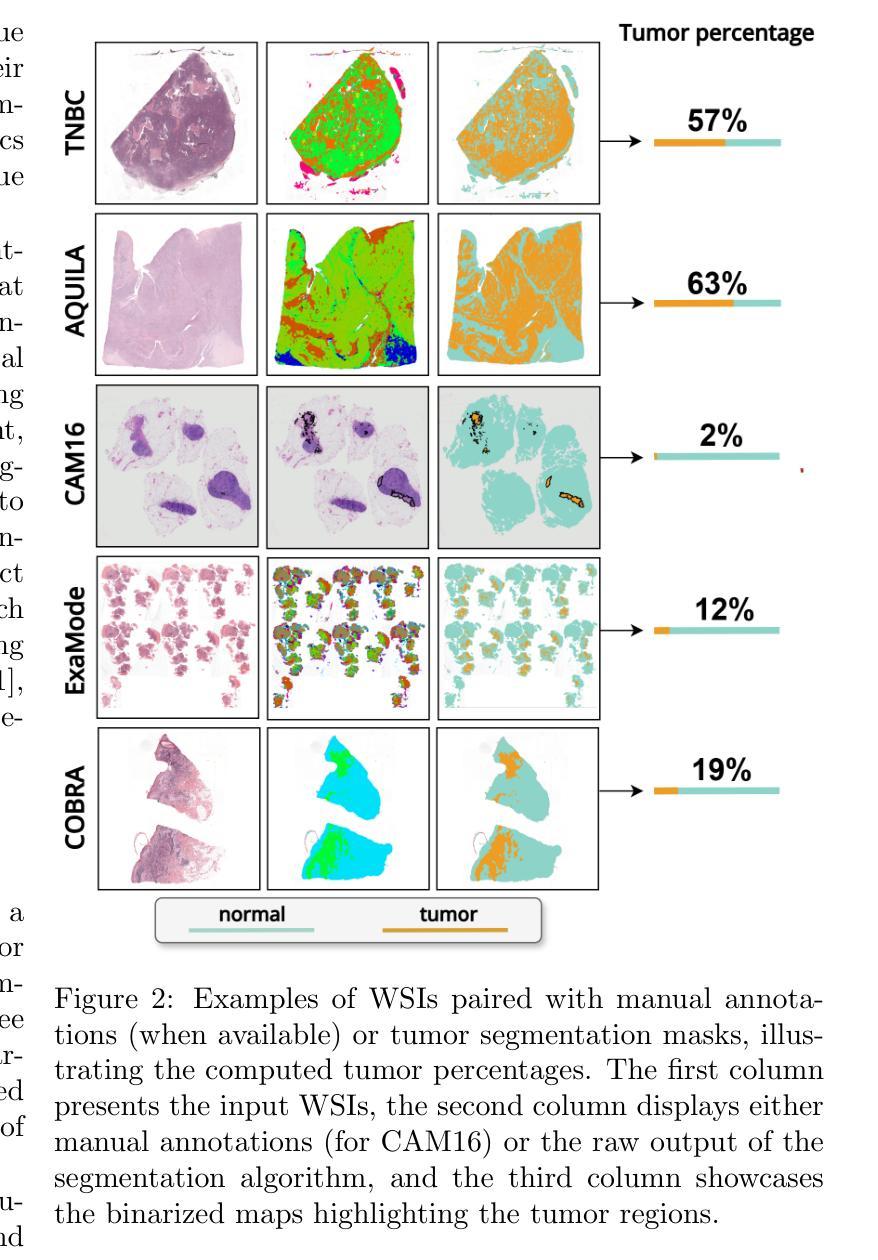
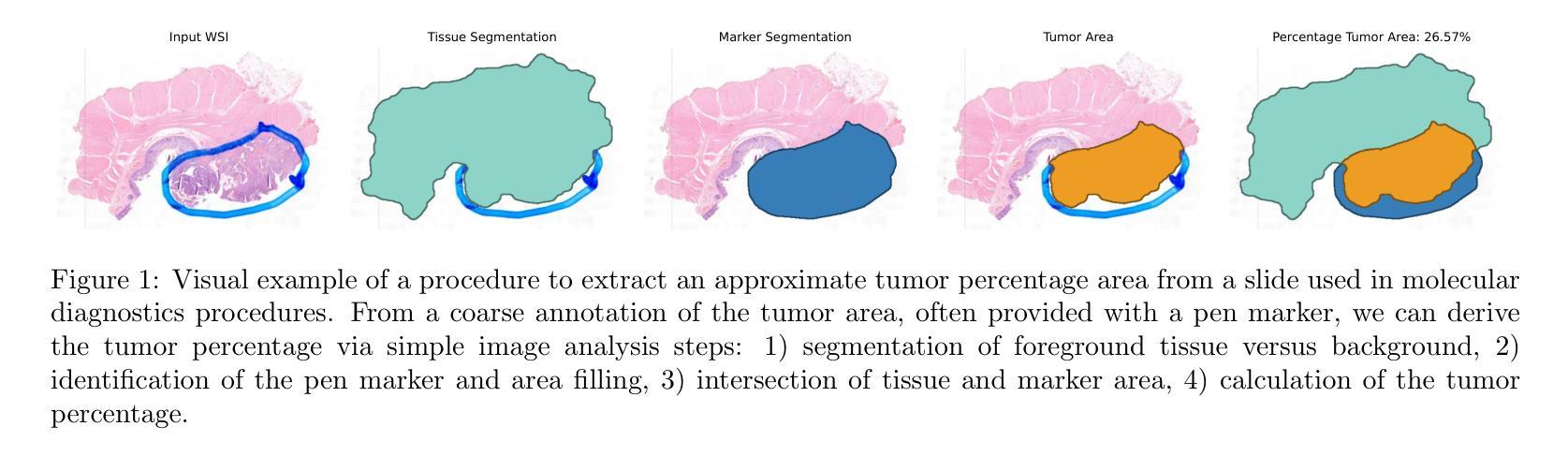
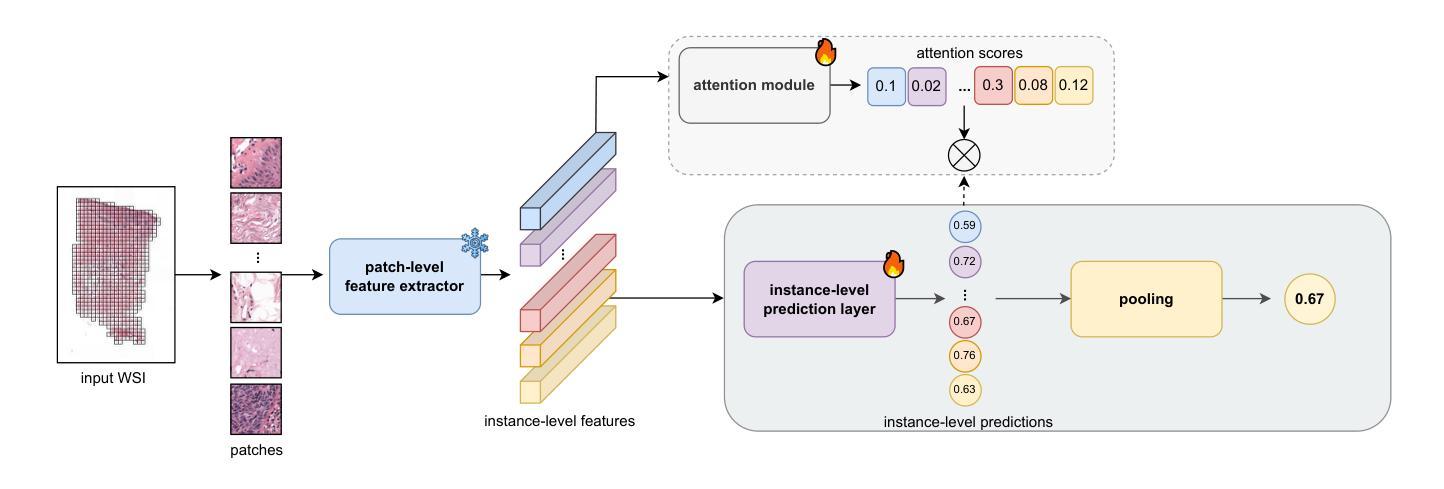
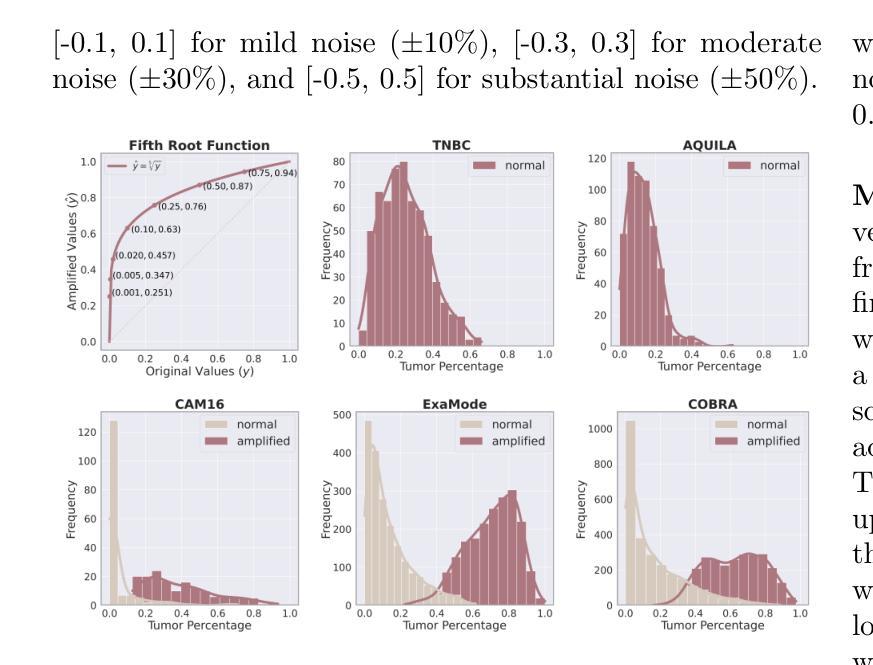
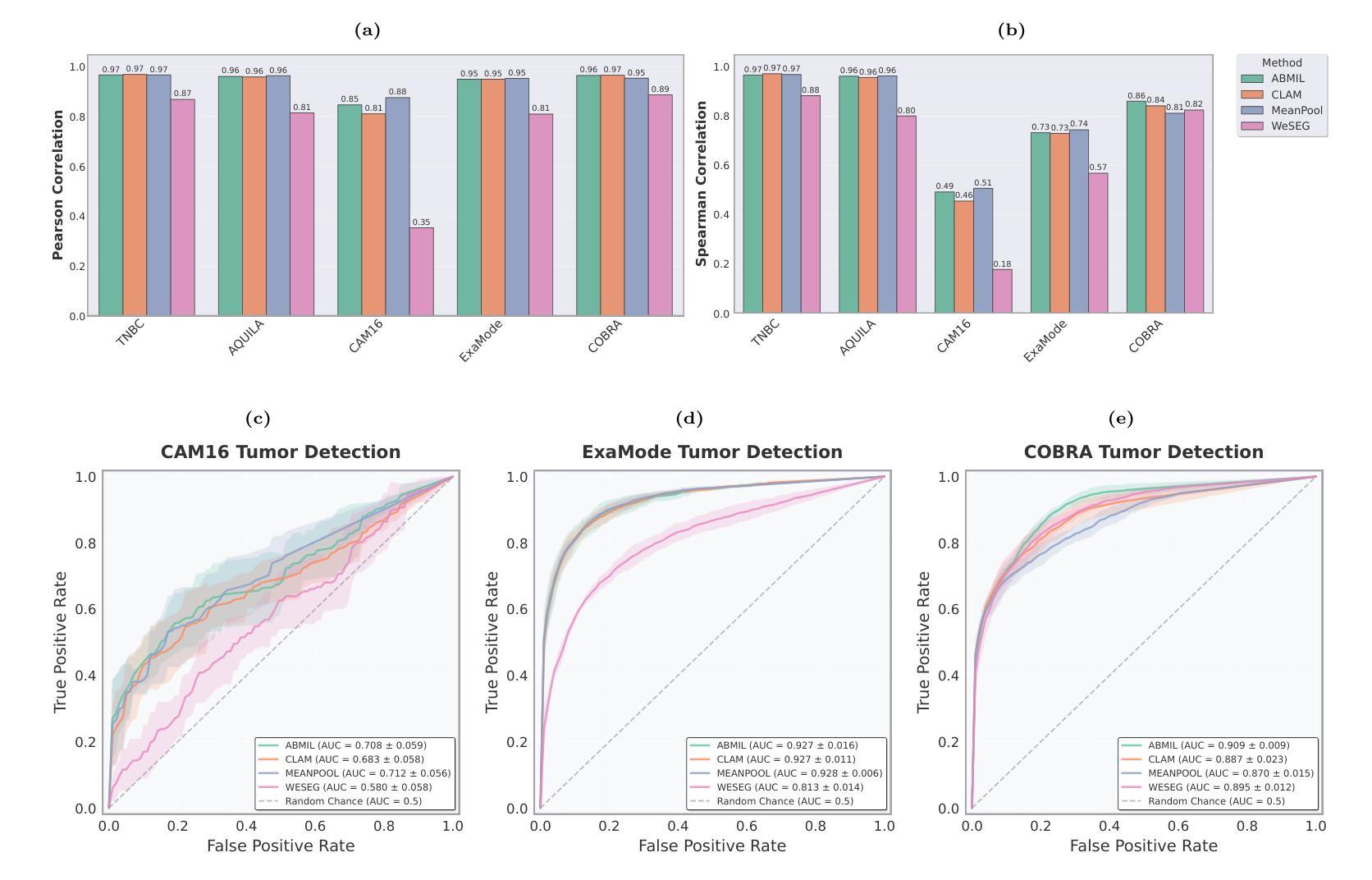
“No negatives needed”: weakly-supervised regression for interpretable tumor detection in whole-slide histopathology images
Authors:Marina D’Amato, Jeroen van der Laak, Francesco Ciompi
Accurate tumor detection in digital pathology whole-slide images (WSIs) is crucial for cancer diagnosis and treatment planning. Multiple Instance Learning (MIL) has emerged as a widely used approach for weakly-supervised tumor detection with large-scale data without the need for manual annotations. However, traditional MIL methods often depend on classification tasks that require tumor-free cases as negative examples, which are challenging to obtain in real-world clinical workflows, especially for surgical resection specimens. We address this limitation by reformulating tumor detection as a regression task, estimating tumor percentages from WSIs, a clinically available target across multiple cancer types. In this paper, we provide an analysis of the proposed weakly-supervised regression framework by applying it to multiple organs, specimen types and clinical scenarios. We characterize the robustness of our framework to tumor percentage as a noisy regression target, and introduce a novel concept of amplification technique to improve tumor detection sensitivity when learning from small tumor regions. Finally, we provide interpretable insights into the model’s predictions by analyzing visual attention and logit maps. Our code is available at https://github.com/DIAGNijmegen/tumor-percentage-mil-regression.
在数字病理学全切片图像(WSI)中进行准确的肿瘤检测对于癌症诊断和治疗计划至关重要。多实例学习(MIL)作为一种广泛使用的弱监督肿瘤检测方法,可以在大规模数据的情况下无需手动注释就能实现应用。然而,传统的MIL方法通常依赖于需要无肿瘤病例作为负例的分类任务,这在现实的临床工作流程中难以获得,尤其是在手术切除标本中。我们通过将肿瘤检测重新制定为回归任务来解决这一局限性,从WSI中估计肿瘤百分比,这是一个跨多种癌症类型的临床可用目标。在本文中,我们将所提出的弱监督回归框架应用于多个器官、标本类型和临床场景,对其进行了分析。我们对框架对肿瘤百分比作为噪声回归目标的稳健性进行了描述,并引入了一种放大技术的新概念,以提高从小肿瘤区域学习时的肿瘤检测灵敏度。最后,我们通过分析视觉注意力和逻辑图,提供了对模型预测的直观见解。我们的代码可在https://github.com/DIAGNijmegen/tumor-percentage-mil-regression找到。
论文及项目相关链接
Summary
本文提出了一种基于回归框架的弱监督肿瘤检测方法,通过对全切片数字病理图像(WSIs)中的肿瘤比例进行估计,实现对多种癌症类型的肿瘤检测。该方法解决了传统方法中依赖肿瘤病例作为负样本的问题,通过将肿瘤检测重新定义为回归任务,提高了模型对肿瘤比例的鲁棒性,并引入放大技术提高对小肿瘤区域的检测灵敏度。同时,通过可视化分析和逻辑图解析提供模型预测的可解释性。
Key Takeaways
- 肿瘤检测是数字病理中重要的任务,对于癌症诊断和治疗计划至关重要。
- 传统多重实例学习(MIL)方法依赖于分类任务,需要肿瘤病例作为负样本,这在现实的临床工作流程中难以获取。
- 本文通过将肿瘤检测重新定义为回归任务,估计WSIs中的肿瘤比例来解决这一问题,这是一个在临床中可获得的、适用于多种癌症类型的目标。
- 该方法提高了模型对肿瘤比例的鲁棒性,并引入放大技术以提高对小肿瘤区域的检测灵敏度。
- 通过可视化分析和逻辑图解析,提供了模型预测的可解释性。
- 该方法在多种器官、标本类型和临床场景中的应用得到了分析。
点此查看论文截图

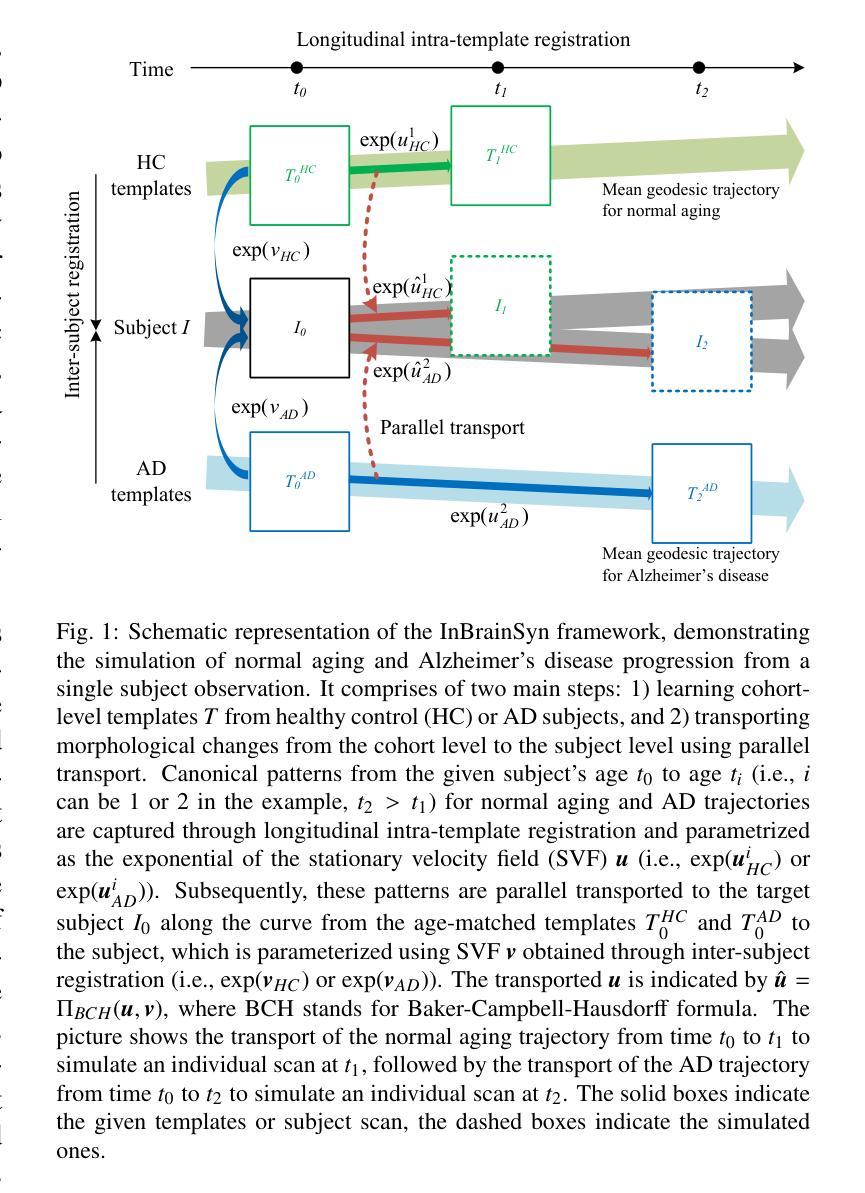
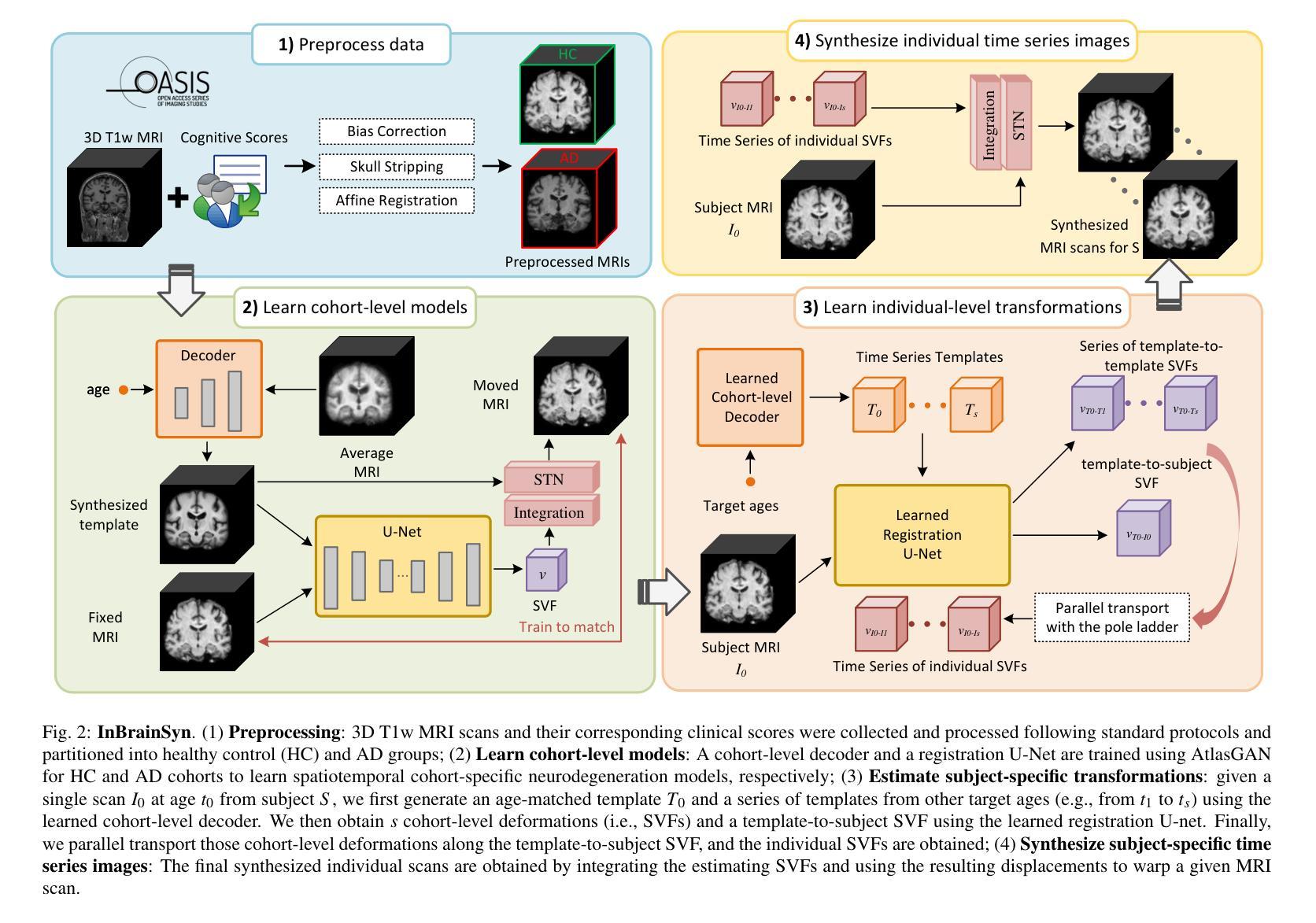
Synthesizing Individualized Aging Brains in Health and Disease with Generative Models and Parallel Transport
Authors:Jingru Fu, Yuqi Zheng, Neel Dey, Daniel Ferreira, Rodrigo Moreno
Simulating prospective magnetic resonance imaging (MRI) scans from a given individual brain image is challenging, as it requires accounting for canonical changes in aging and/or disease progression while also considering the individual brain’s current status and unique characteristics. While current deep generative models can produce high-resolution anatomically accurate templates for population-wide studies, their ability to predict future aging trajectories for individuals remains limited, particularly in capturing subject-specific neuroanatomical variations over time. In this study, we introduce Individualized Brain Synthesis (InBrainSyn), a framework for synthesizing high-resolution subject-specific longitudinal MRI scans that simulate neurodegeneration in both Alzheimer’s disease (AD) and normal aging. InBrainSyn uses a parallel transport algorithm to adapt the population-level aging trajectories learned by a generative deep template network, enabling individualized aging synthesis. As InBrainSyn uses diffeomorphic transformations to simulate aging, the synthesized images are topologically consistent with the original anatomy by design. We evaluated InBrainSyn both quantitatively and qualitatively on AD and healthy control cohorts from the Open Access Series of Imaging Studies - version 3 dataset. Experimentally, InBrainSyn can also model neuroanatomical transitions between normal aging and AD. An evaluation of an external set supports its generalizability. Overall, with only a single baseline scan, InBrainSyn synthesizes realistic 3D spatiotemporal T1w MRI scans, producing personalized longitudinal aging trajectories. The code for InBrainSyn is available at: https://github.com/Fjr9516/InBrainSyn.
根据给定的个人脑图像模拟未来磁共振成像(MRI)扫描具有挑战性,因为这需要在考虑典型的衰老和(或)疾病进展变化的同时,还要考虑个人大脑的当前状况和独特特征。虽然目前的深度生成模型可以为群体研究产生高分辨率且解剖结构准确的模板,但它们预测个人未来衰老轨迹的能力仍然有限,特别是在捕捉受试者特定的神经解剖结构随时间变化方面。在这项研究中,我们介绍了个性化脑合成(InBrainSyn)框架,该框架可用于合成高分辨率的受试者特定纵向MRI扫描,模拟阿尔茨海默病(AD)和正常衰老中的神经变性。InBrainSyn使用并行传输算法,适应由生成深度模板网络学习的人群水平衰老轨迹,从而实现个性化的衰老合成。由于InBrainSyn使用微分同胚变换来模拟衰老,因此合成图像在设计上与原始解剖结构在拓扑上是一致的。我们在开放访问成像研究第三版数据集上对AD和健康对照组的InBrainSyn进行了定量和定性的评估。实验表明,InBrainSyn还可以模拟正常衰老和AD之间的神经解剖结构过渡。对外部数据集的评估支持了其泛化能力。总体而言,只需一次基线扫描,InBrainSyn就可以合成逼真的3D时空T1w MRI扫描,产生个性化的纵向衰老轨迹。InBrainSyn的代码可在以下网址获取:https://github.com/Fjr9516/InBrainSyn。
论文及项目相关链接
PDF 20 pages, 9 figures, 6 tables, diffeomorphic registration, parallel transport, brain aging, medical image generation, Alzheimer’s disease
Summary
本文介绍了一种名为Individualized Brain Synthesis(InBrainSyn)的框架,它能合成高分辨率的个体特定纵向磁共振成像(MRI)扫描,模拟阿尔茨海默病(AD)和正常衰老过程中的神经退化。InBrainSyn使用并行传输算法,将群体水平的衰老轨迹与深度生成模板网络相结合,实现个性化的衰老合成。实验证明,InBrainSyn能够模拟正常衰老和AD之间的神经解剖结构过渡。
Key Takeaways
- InBrainSyn框架能够合成高分辨率的个体特定纵向MRI扫描,模拟AD和正常衰老过程中的神经退化。
- InBrainSyn使用并行传输算法和微分同胚变换,使合成的图像与原始解剖结构一致。
- 该框架可以将群体水平的衰老轨迹与深度生成模板网络结合,实现个性化的衰老合成。
- InBrainSyn能够在单一基线扫描的情况下,合成真实的3D时空T1w MRI扫描。
- 实验证明,InBrainSyn可以模拟正常衰老和AD之间的神经解剖结构过渡。
- 该方法在公开访问成像研究第三版数据集上的AD和健康对照组中进行了定量和定性的评估。
点此查看论文截图

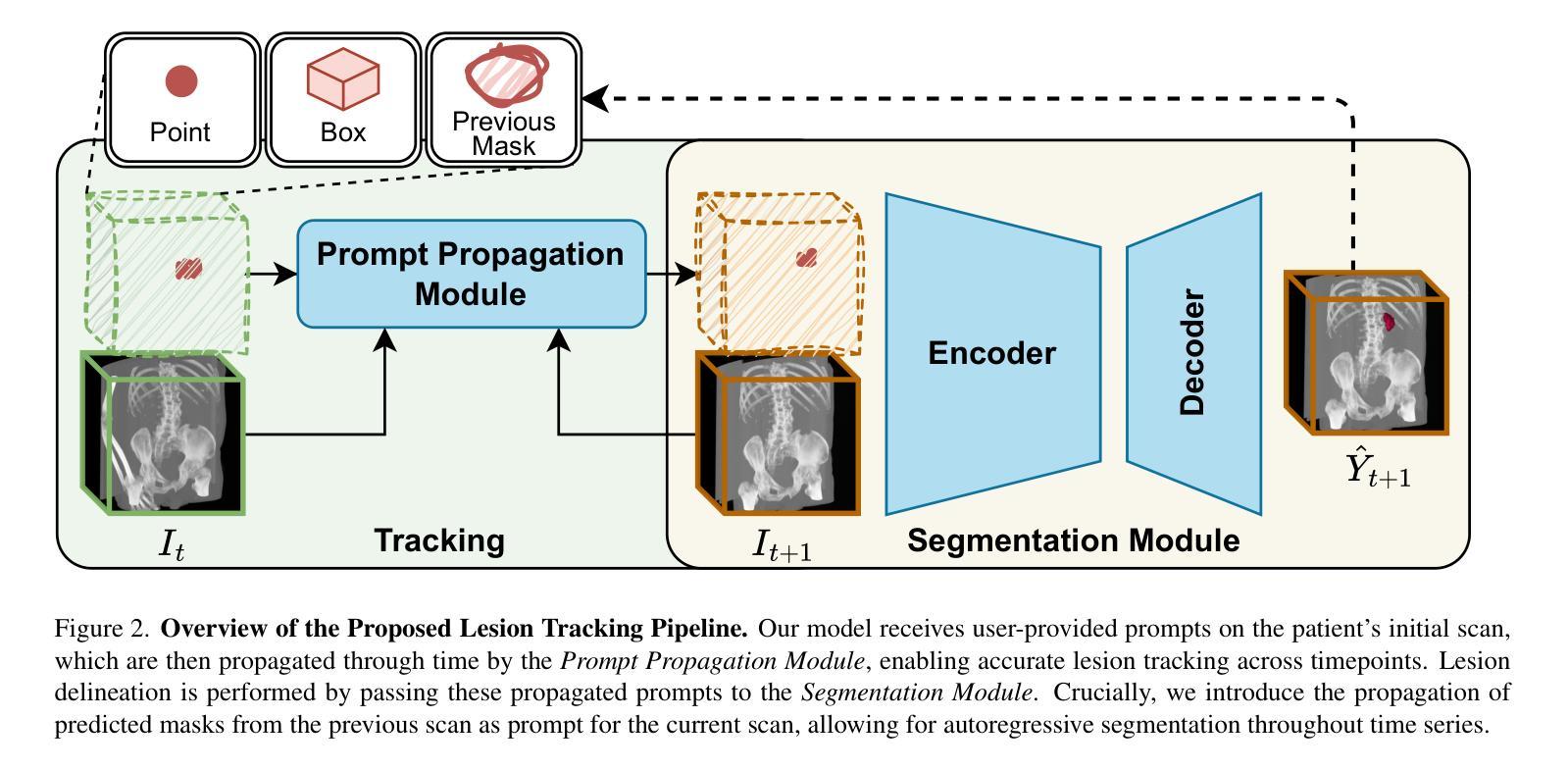
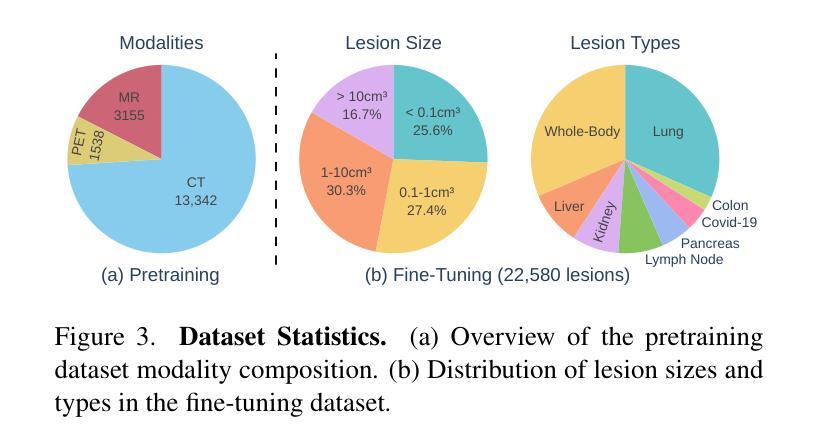
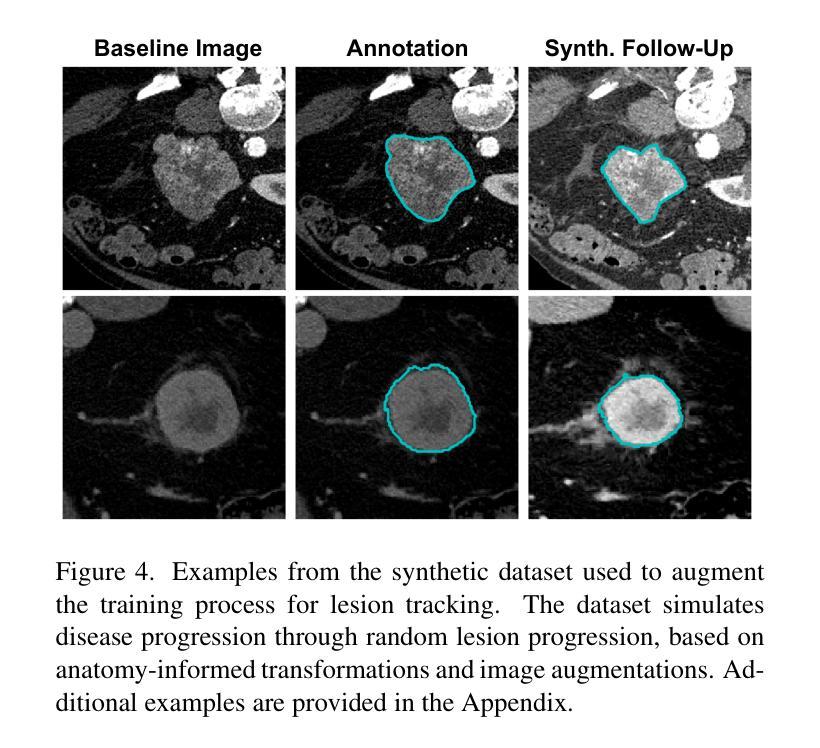
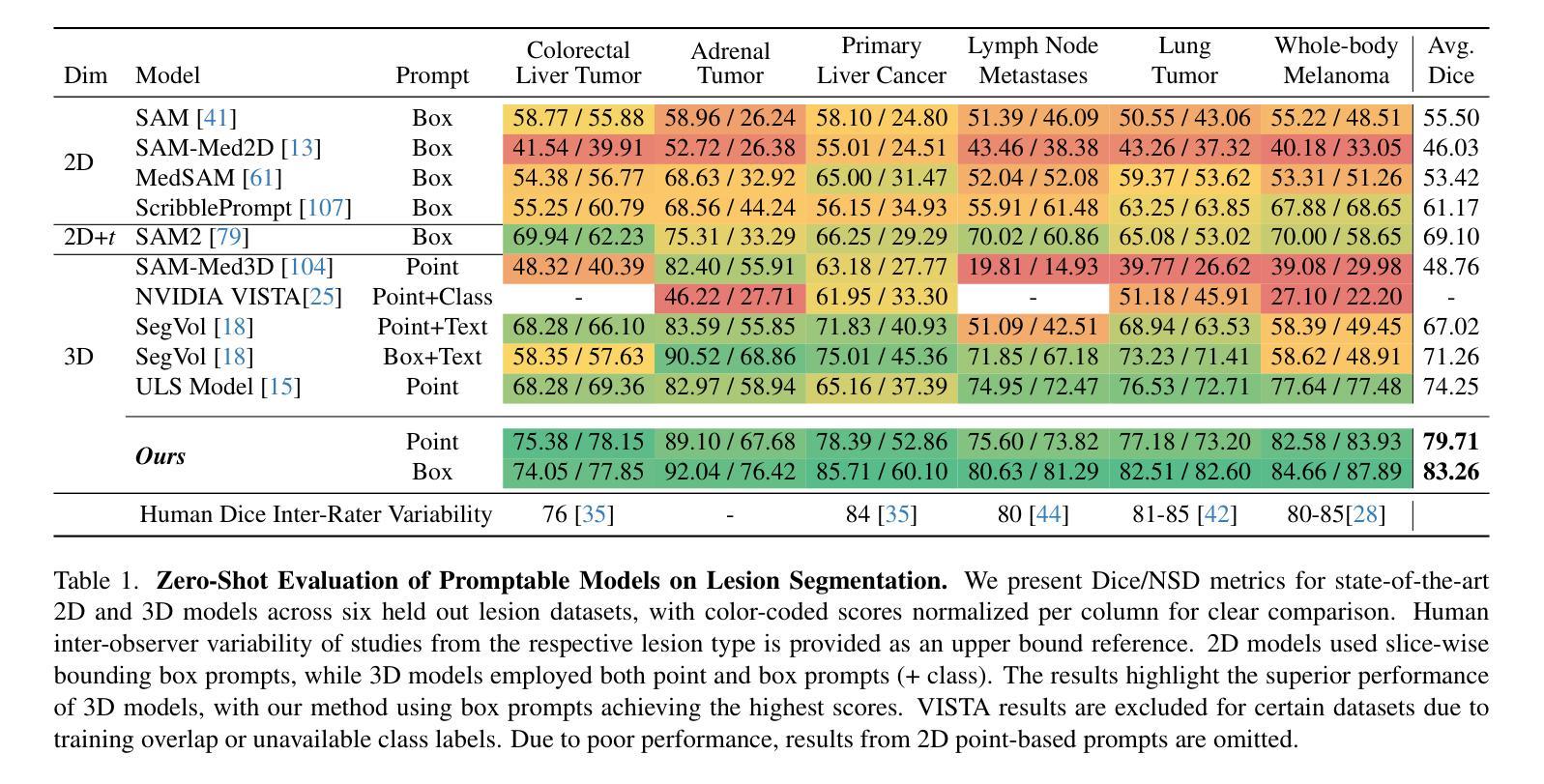
LesionLocator: Zero-Shot Universal Tumor Segmentation and Tracking in 3D Whole-Body Imaging
Authors:Maximilian Rokuss, Yannick Kirchhoff, Seval Akbal, Balint Kovacs, Saikat Roy, Constantin Ulrich, Tassilo Wald, Lukas T. Rotkopf, Heinz-Peter Schlemmer, Klaus Maier-Hein
In this work, we present LesionLocator, a framework for zero-shot longitudinal lesion tracking and segmentation in 3D medical imaging, establishing the first end-to-end model capable of 4D tracking with dense spatial prompts. Our model leverages an extensive dataset of 23,262 annotated medical scans, as well as synthesized longitudinal data across diverse lesion types. The diversity and scale of our dataset significantly enhances model generalizability to real-world medical imaging challenges and addresses key limitations in longitudinal data availability. LesionLocator outperforms all existing promptable models in lesion segmentation by nearly 10 dice points, reaching human-level performance, and achieves state-of-the-art results in lesion tracking, with superior lesion retrieval and segmentation accuracy. LesionLocator not only sets a new benchmark in universal promptable lesion segmentation and automated longitudinal lesion tracking but also provides the first open-access solution of its kind, releasing our synthetic 4D dataset and model to the community, empowering future advancements in medical imaging. Code is available at: www.github.com/MIC-DKFZ/LesionLocator
在这项工作中,我们提出了LesionLocator框架,这是一个用于三维医学成像中的零样本纵向病变跟踪和分割的框架,建立了第一个能够进行四维跟踪的端到端模型,具有密集的空间提示。我们的模型利用了一个大规模的23262个标注医学扫描数据集,以及合成各种病变类型的纵向数据。数据集的多样性和规模显著提高了模型对现实世界医学影像挑战的泛化能力,并解决了纵向数据可用性方面的关键限制。LesionLocator在病变分割方面优于所有现有的可提示模型,狄氏指数提高了近10个点,达到了人类水平性能,并在病变跟踪方面达到了最新水平的结果,具有出色的病变检索和分割准确性。LesionLocator不仅为通用可提示病变分割和自动纵向病变跟踪设定了新的基准线,而且还提供了此类首个开源解决方案,向社区发布我们的合成四维数据集和模型,为医学影像的未来进步提供支持。代码可在www.github.com/MIC-DKFZ/LesionLocator找到。
论文及项目相关链接
PDF Accepted at CVPR 2025
Summary
医学图像领域的新研究框架LesionLocator实现了零样本纵向病变追踪和分割。该框架利用大规模标注医学扫描数据和合成纵向数据,增强了模型对真实世界医学成像挑战的通用性,并在病变追踪和分割方面达到最新水平。LesionLocator不仅设定了新的基准,而且提供首个开放访问的解决方案,并公开合成4D数据集和模型,为医学成像的未来进步提供支持。
Key Takeaways
- LesionLocator是一个用于零样本纵向病变追踪和分割的框架。
- 该框架使用大规模的标注医学扫描数据和合成纵向数据。
- 模型展现出强大的泛化能力,能够应对真实世界医学成像挑战。
- LesionLocator在病变追踪和分割方面达到最新水平,超越了现有可提示模型的性能。
- 它达到了人类水平的表现,特别是在病变分割方面。
- LesionLocator提供了首个开放访问的解决方案,并公开合成4D数据集和模型资源。
点此查看论文截图

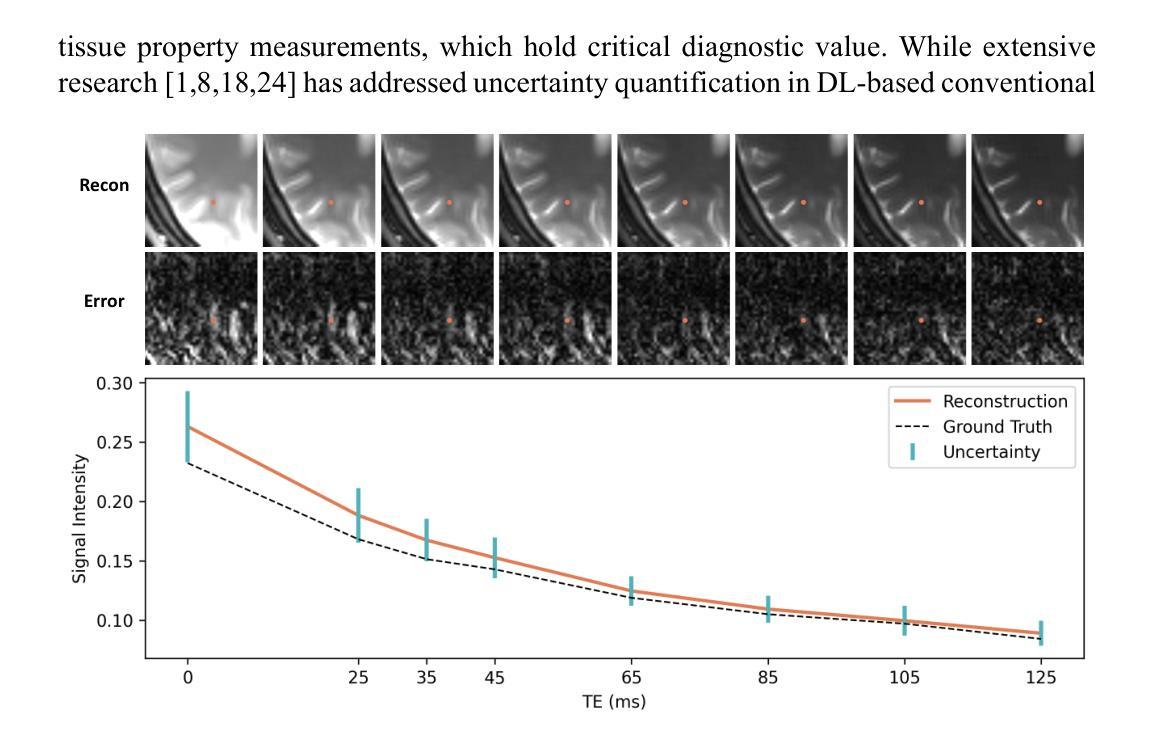
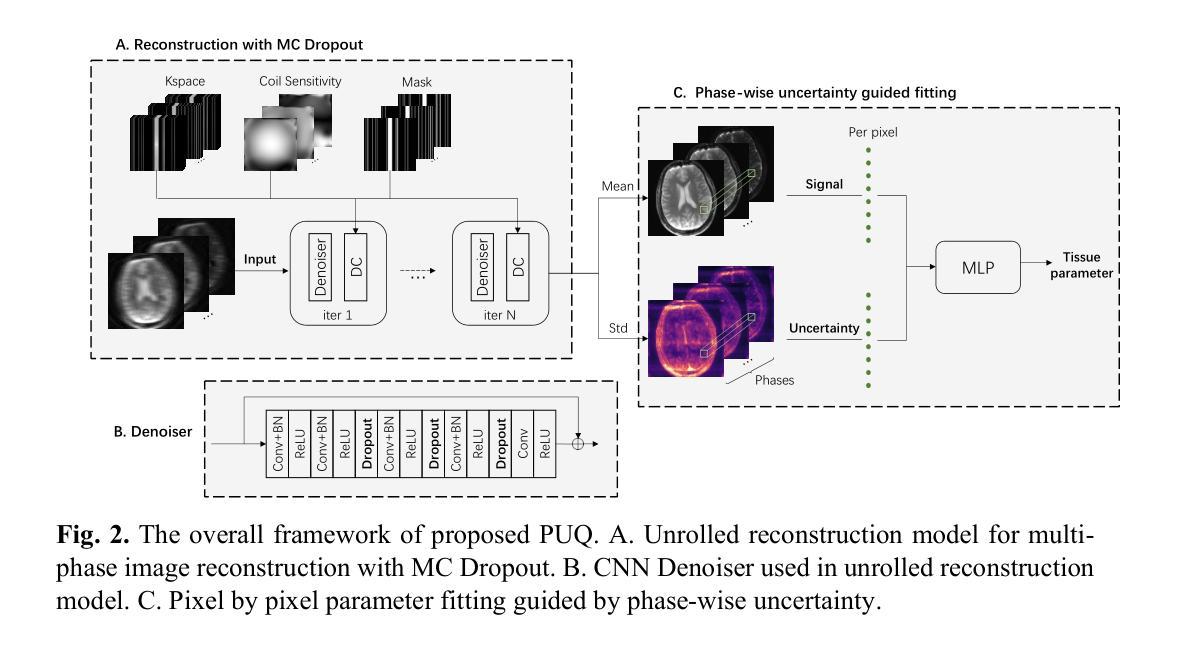
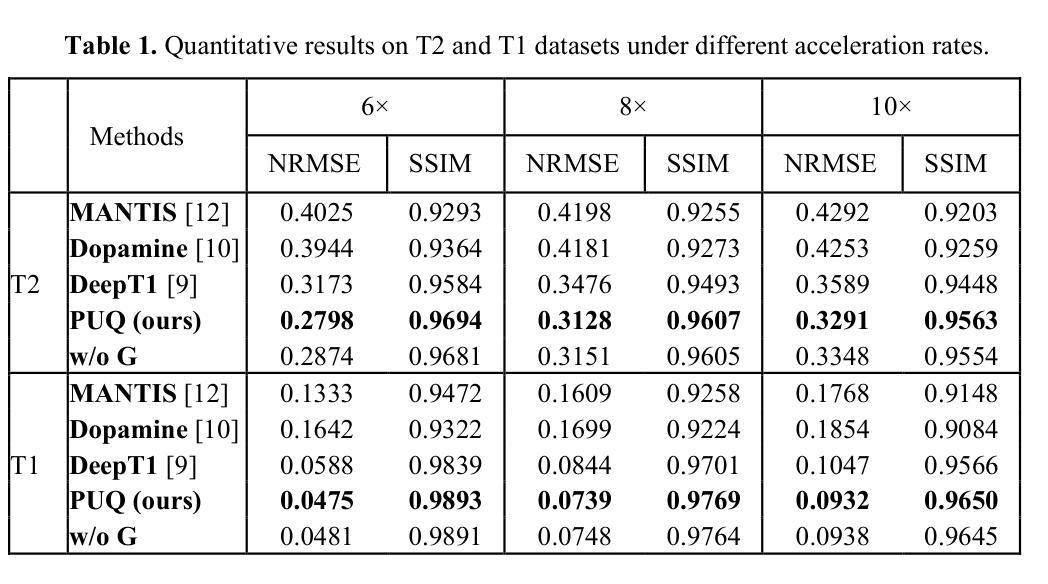
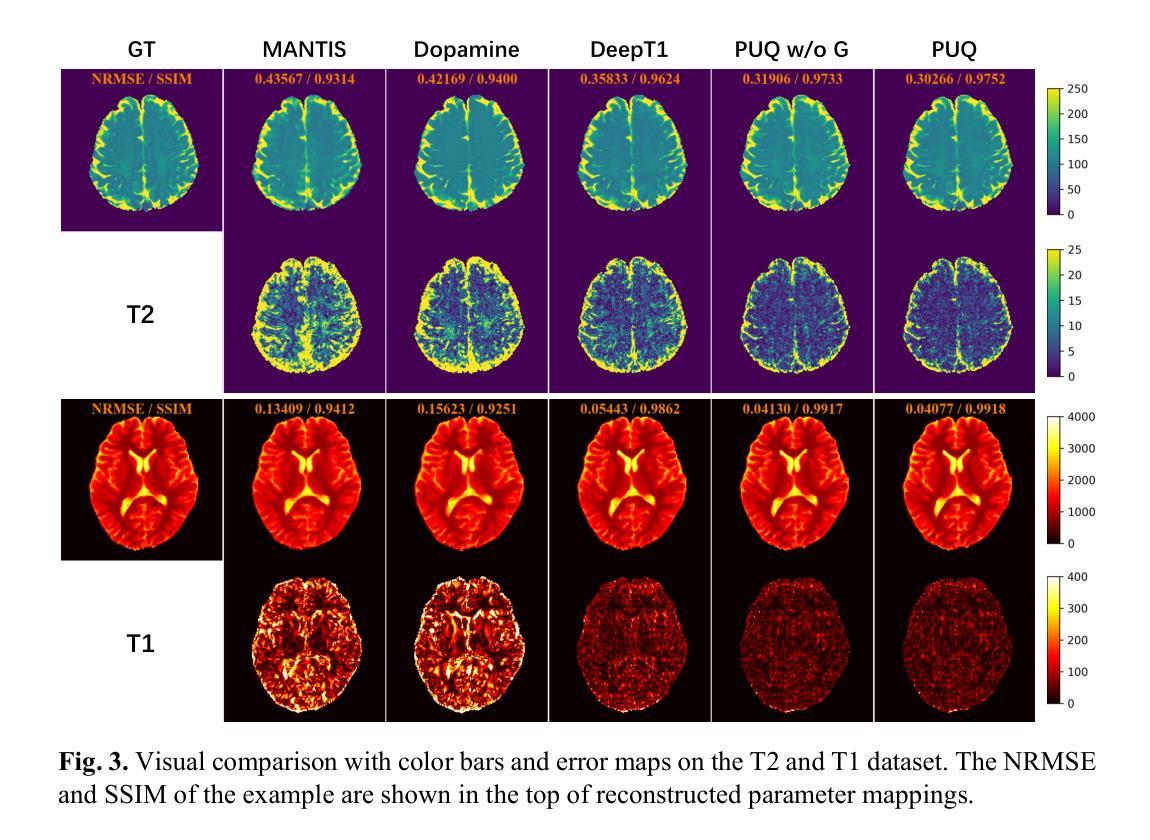
Guiding Quantitative MRI Reconstruction with Phase-wise Uncertainty
Authors:Haozhong Sun, Zhongsen Li, Chenlin Du, Haokun Li, Yajie Wang, Huijun Chen
Quantitative magnetic resonance imaging (qMRI) requires multi-phase acqui-sition, often relying on reduced data sampling and reconstruction algorithms to accelerate scans, which inherently poses an ill-posed inverse problem. While many studies focus on measuring uncertainty during this process, few explore how to leverage it to enhance reconstruction performance. In this paper, we in-troduce PUQ, a novel approach that pioneers the use of uncertainty infor-mation for qMRI reconstruction. PUQ employs a two-stage reconstruction and parameter fitting framework, where phase-wise uncertainty is estimated during reconstruction and utilized in the fitting stage. This design allows uncertainty to reflect the reliability of different phases and guide information integration during parameter fitting. We evaluated PUQ on in vivo T1 and T2 mapping datasets from healthy subjects. Compared to existing qMRI reconstruction methods, PUQ achieved the state-of-the-art performance in parameter map-pings, demonstrating the effectiveness of uncertainty guidance. Our code is available at https://anonymous.4open.science/r/PUQ-75B2/.
定量磁共振成像(qMRI)需要多阶段采集,通常依赖于减少数据采样和重建算法来加速扫描,这本质上构成了一个不适定的反问题。尽管许多研究关注于此过程中的不确定性测量,但很少有研究探索如何利用不确定性来提高重建性能。在本文中,我们介绍了PUQ,这是一种开创性地将不确定性信息用于qMRI重建的新方法。PUQ采用两阶段重建和参数拟合框架,在重建过程中估计阶段性不确定性,并在拟合阶段加以利用。这种设计允许不确定性反映不同阶段的可靠性,并在参数拟合过程中指导信息整合。我们对健康受试者的活体T1和T2映射数据集评估了PUQ。与现有的qMRI重建方法相比,PUQ在参数映射方面达到了最先进的表现,证明了不确定性指导的有效性。我们的代码可在[https://anonymous.4open.science/r/PUQ-75B2/]访问。
论文及项目相关链接
PDF Submitted to MICCAI2025
Summary
本文介绍了一种新型的定量磁共振成像(qMRI)重建方法PUQ,该方法利用不确定性信息来提高重建性能。PUQ采用两阶段重建和参数拟合框架,在重建过程中估计阶段不确定性,并在拟合阶段加以利用。PUQ在健康受试者的体内T1和T2映射数据集上的表现优于现有qMRI重建方法,证明了不确定性指导的有效性。
Key Takeaways
- PUQ是一种新型的定量磁共振成像(qMRI)重建方法。
- PUQ利用不确定性信息来提高重建性能。
- PUQ采用两阶段重建和参数拟合框架。
- 在重建过程中,PUQ估计阶段不确定性。
- 阶段不确定性在参数拟合阶段得到利用。
- PUQ在健康受试者的体内T1和T2映射数据集上表现优异。
点此查看论文截图

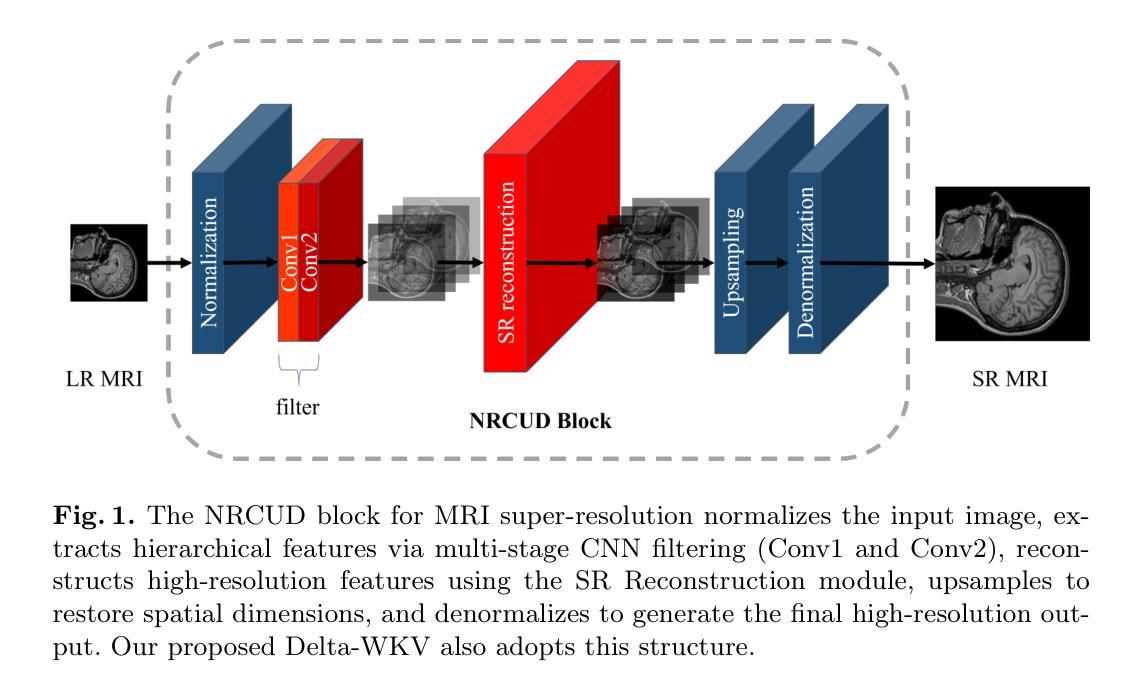
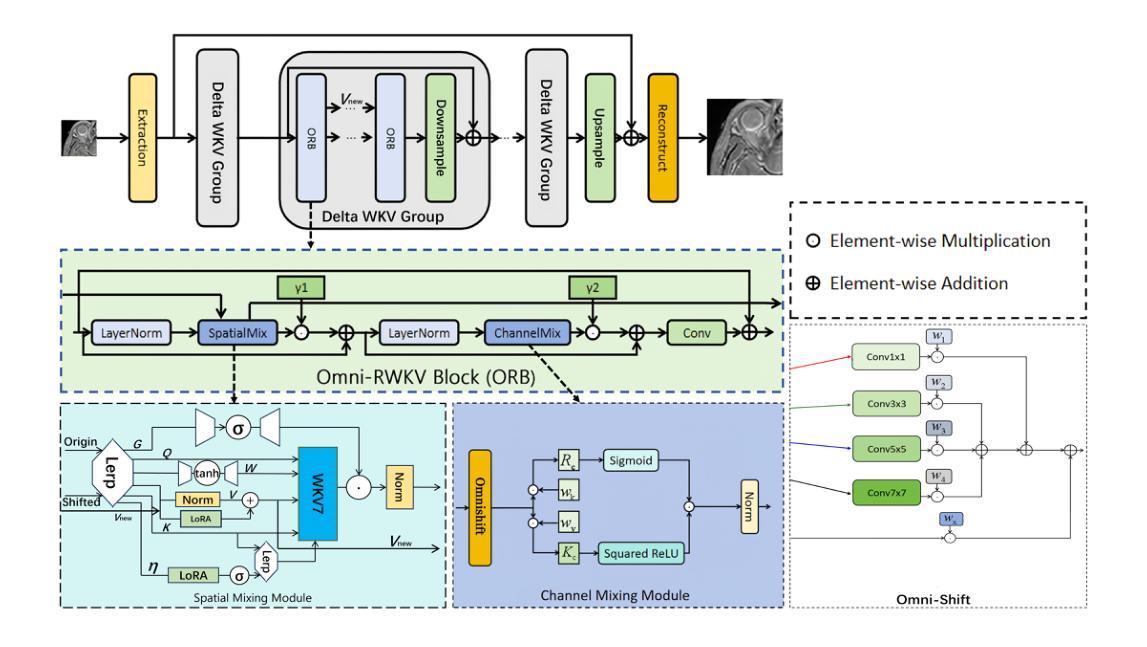
Delta-WKV: A Novel Meta-in-Context Learner for MRI Super-Resolution
Authors:Rongchang Lu, Bingcheng Liao, Haowen Hou, Jiahang Lv, Xin Hai
Magnetic Resonance Imaging (MRI) Super-Resolution (SR) addresses the challenges such as long scan times and expensive equipment by enhancing image resolution from low-quality inputs acquired in shorter scan times in clinical settings. However, current SR techniques still have problems such as limited ability to capture both local and global static patterns effectively and efficiently. To address these limitations, we propose Delta-WKV, a novel MRI super-resolution model that combines Meta-in-Context Learning (MiCL) with the Delta rule to better recognize both local and global patterns in MRI images. This approach allows Delta-WKV to adjust weights dynamically during inference, improving pattern recognition with fewer parameters and less computational effort, without using state-space modeling. Additionally, inspired by Receptance Weighted Key Value (RWKV), Delta-WKV uses a quad-directional scanning mechanism with time-mixing and channel-mixing structures to capture long-range dependencies while maintaining high-frequency details. Tests on the IXI and fastMRI datasets show that Delta-WKV outperforms existing methods, improving PSNR by 0.06 dB and SSIM by 0.001, while reducing training and inference times by over 15%. These results demonstrate its efficiency and potential for clinical use with large datasets and high-resolution imaging.
磁共振成像(MRI)超分辨率(SR)技术通过增强临床环境中较短扫描时间内获取的图像分辨率来解决扫描时间长和昂贵的设备挑战。然而,目前的超分辨率技术仍然存在问题,例如有限的捕获局部和全局静态模式的能力,无法有效且高效地完成。为了克服这些局限性,我们提出了Delta-WKV这一新型MRI超分辨率模型。该模型结合了Meta-in-Context Learning(MiCL)和Delta规则,可以更好地识别MRI图像中的局部和全局模式。这种方法允许Delta-WKV在推理过程中动态调整权重,使用更少的参数和计算资源提高模式识别能力,并且不使用状态空间建模。此外,受Receptance Weighted Key Value(RWKV)的启发,Delta-WKV采用四向扫描机制,具有时间混合和通道混合结构,以捕捉长期依赖关系的同时保持高频细节。在IXI和fastMRI数据集上的测试表明,Delta-WKV优于现有方法,提高了峰值信噪比(PSNR)0.06分贝和结构相似性度量(SSIM)0.001,同时训练和推理时间缩短了超过15%。这些结果证明了其在大规模数据集和高分辨率成像中的效率和临床应用的潜力。
论文及项目相关链接
PDF This paper has been published to MICCAI 2025. Feel free to contact on nomodeset@qq.com
Summary
MRI超分辨率技术通过提高低质量输入的图像分辨率来解决扫描时间长和昂贵的设备问题。针对现有技术的局限性,Delta-WKV模型结合了Meta-in-Context Learning(MiCL)和Delta规则,能更有效地捕捉MRI图像中的局部和全局模式。该模型在推理过程中动态调整权重,提高了模式识别能力,同时减少了参数和计算成本。此外,Delta-WKV采用四方向扫描机制,捕捉长期依赖关系并保持高频细节,提高了性能。测试结果显示,Delta-WKV在IXI和fastMRI数据集上的表现优于现有方法,具有潜在的临床应用价值。
Key Takeaways
- MRI超分辨率技术旨在解决扫描时间长和昂贵设备的问题,通过提高低质量图像的分辨率。
- 当前MRI超分辨率技术面临捕捉局部和全局模式的挑战。
- Delta-WKV模型结合了Meta-in-Context Learning(MiCL)和Delta规则,以更有效地识别MRI图像中的局部和全局模式。
- Delta-WKV能在推理过程中动态调整权重,提高模式识别能力,同时减少参数和计算成本。
- Delta-WKV采用四方向扫描机制,结合了时间混合和通道混合结构,以捕捉长期依赖关系并保持高频细节。
- 在IXI和fastMRI数据集上的测试表明,Delta-WKV的性能优于现有方法。
点此查看论文截图

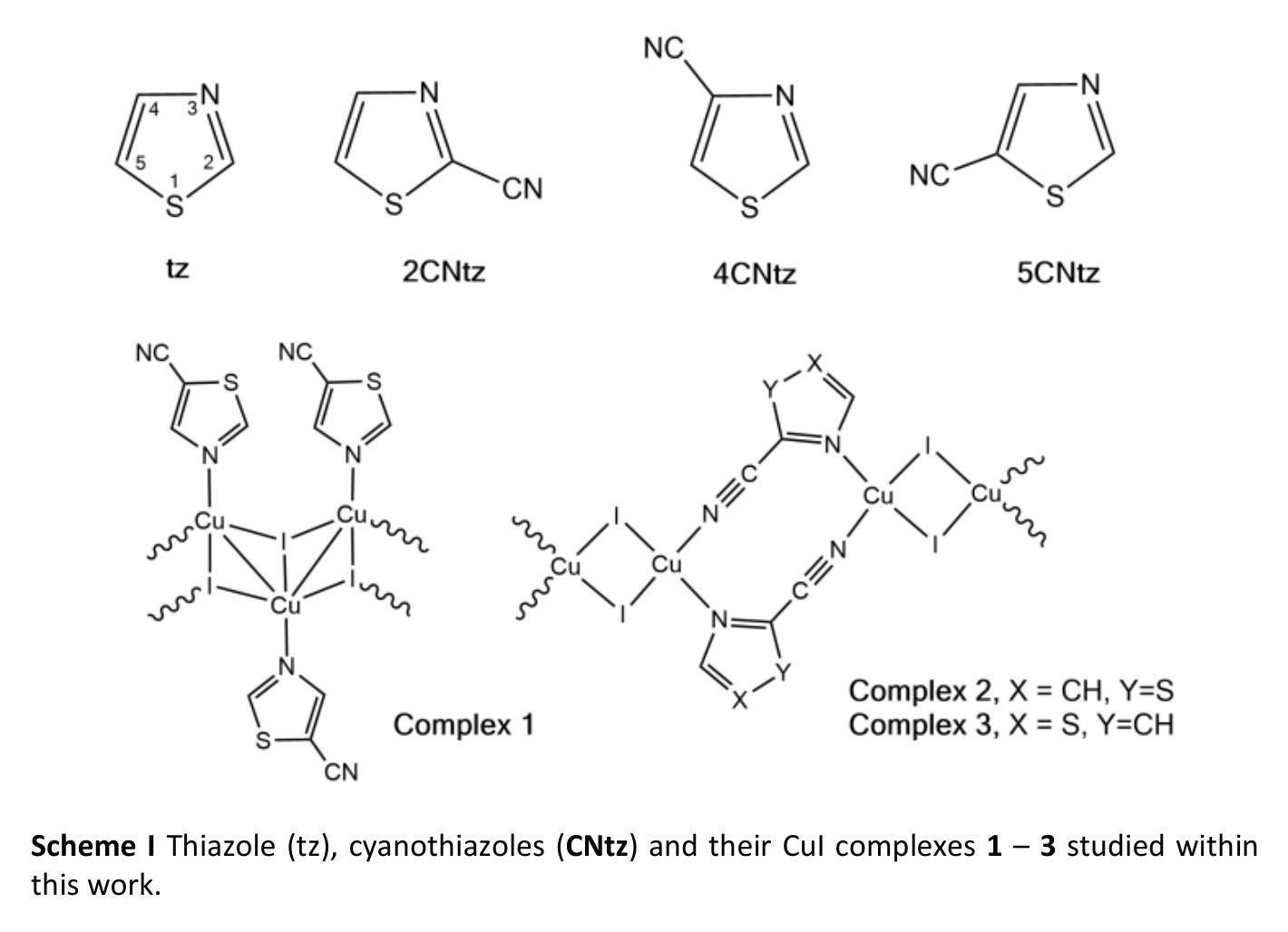
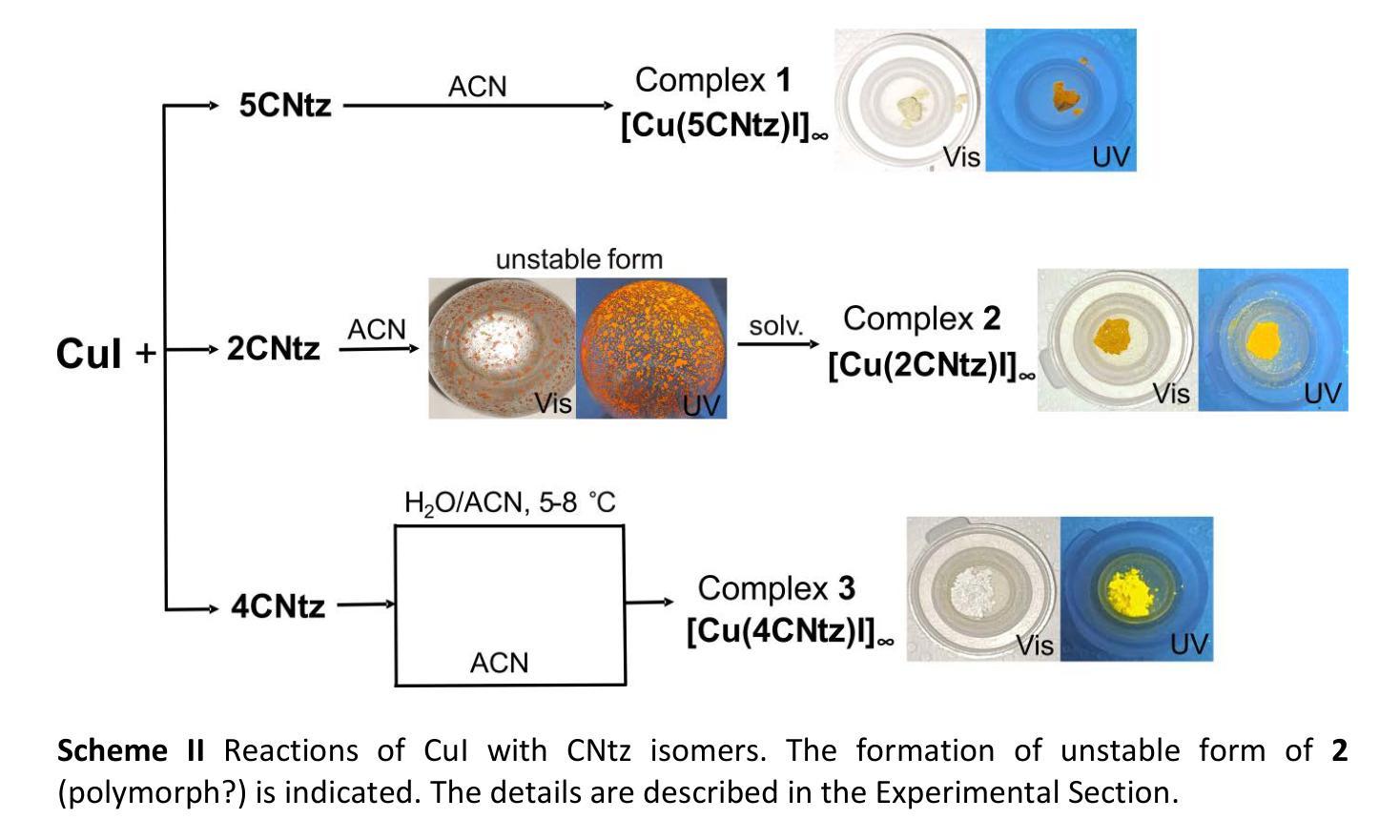
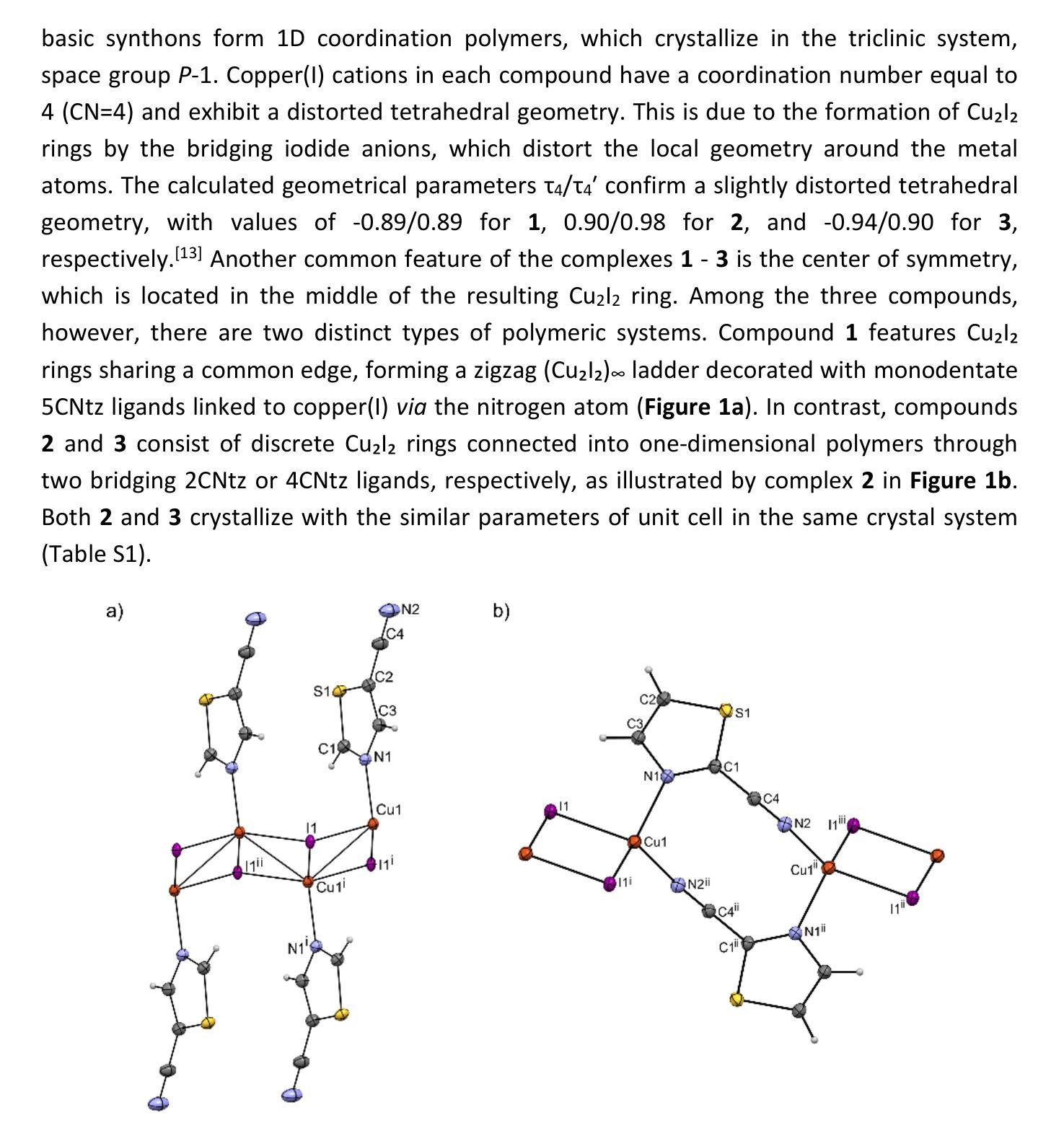
Cyanothiazole Copper(I) Complexes: Uncharted Materials with Exceptional Optical and Conductive Properties
Authors:Karolina Gutmańska, Agnieszka Podborska, Tomasz Mazur, Andrzej Sławek, Ramesh Sivasamy, Alexey Maximenko, Łukasz Orzeł, Janusz Oszajca, Grażyna Stochel, Konrad Szaciłowski, Anna Dołęga
Cyanothiazoles, small and quite overlooked molecules, possess remarkable optical properties that can be fine-tuned through coordination with transition metals. In this study, we investigate a promising application of cyanothiazoles, where their combination with copper(I) iodide forms a new class of complexes exhibiting outstanding optical properties. X-ray crystallography of copper(I) iodide complexes with isomeric cyanothiazoles revealed key structural features, such as {\pi}-{\pi} stacking, hydrogen bonding, and rare halogen-chalcogen I-S interactions, enhancing stability and reactivity. Advanced spectroscopy and computational modeling allowed precise identification of spectral signatures in FTIR, NMR, and UV-Vis spectra. Fluorescence studies, along with XANES synchrotron analyses, highlighted their unique thermal and electronic properties, providing a solid foundation for further research in the field.
氰基噻唑是一种小而常被忽视的分子,具有显著的光学特性,可以通过与过渡金属的配合进行微调。本研究探讨了氰基噻唑的一种有前途的应用,即其与碘化亚铜结合形成一类新的复合物,展现出卓越的光学特性。通过X射线晶体学分析碘化亚铜与异构氰基噻唑的复合物,揭示了关键的结构特征,如π-π堆积、氢键和罕见的卤素-硫族元素I-S相互作用,增强了其稳定性和反应性。先进的光谱学和计算建模允许在红外光谱、核磁共振和紫外可见光谱中精确识别光谱特征。荧光研究以及XANES同步加速器分析突出了其独特的热学和电子特性,为这一领域的进一步研究奠定了坚实的基础。
论文及项目相关链接
Summary
本文研究了Cyanothiazoles与铜(I)碘化物结合形成的新型复合物的光学性质。通过X射线晶体学的研究,发现这些复合物具有关键的π-π堆积、氢键和罕见的卤素-硫族元素I-S相互作用等结构特征。高级光谱学和计算建模技术精确鉴定了红外、核磁和紫外可见光谱中的光谱特征。荧光研究以及同步加速器分析突出了其独特的热和电子性质,为这一领域的研究提供了坚实的基础。
Key Takeaways
- Cyanothiazoles与铜(I)碘化物结合形成新型复合物。
- 通过X射线晶体学揭示了复合物的关键结构特征,如π-π堆积、氢键和罕见的I-S相互作用。
- 高级光谱学和计算建模技术用于精确鉴定光谱特征。
- 荧光研究证实了这些复合物的独特热和电子性质。
- 这些复合物展现出卓越的光学性能。
- 本文为这一领域未来的研究提供了坚实的基础。
点此查看论文截图

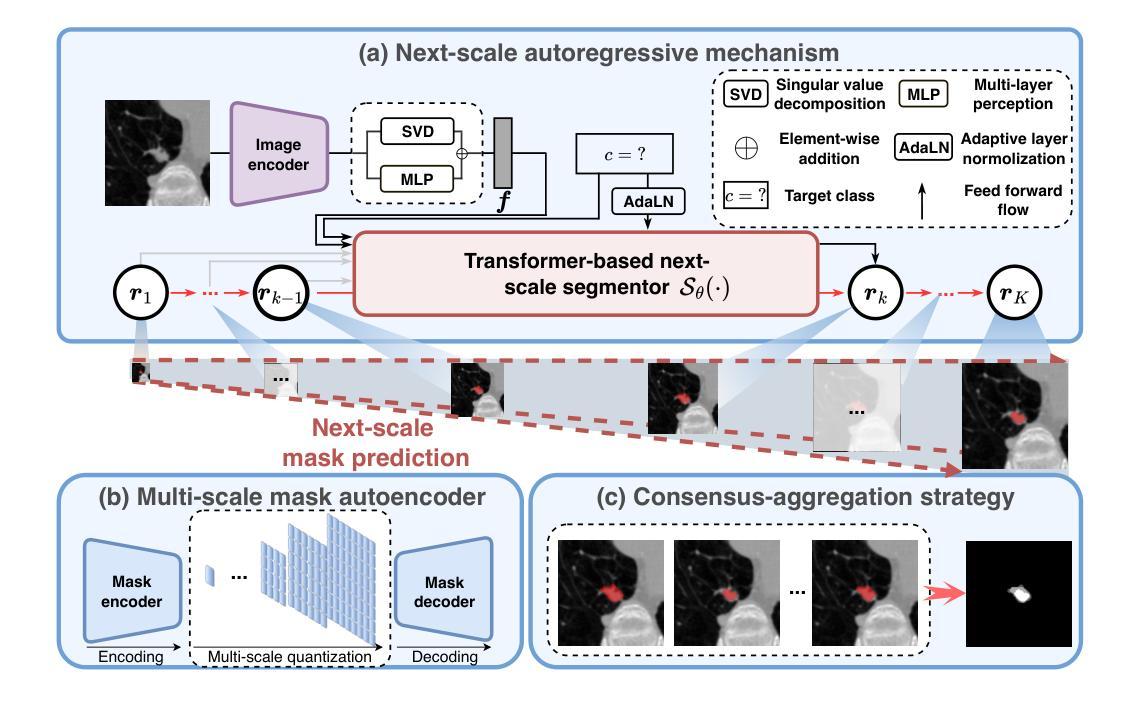
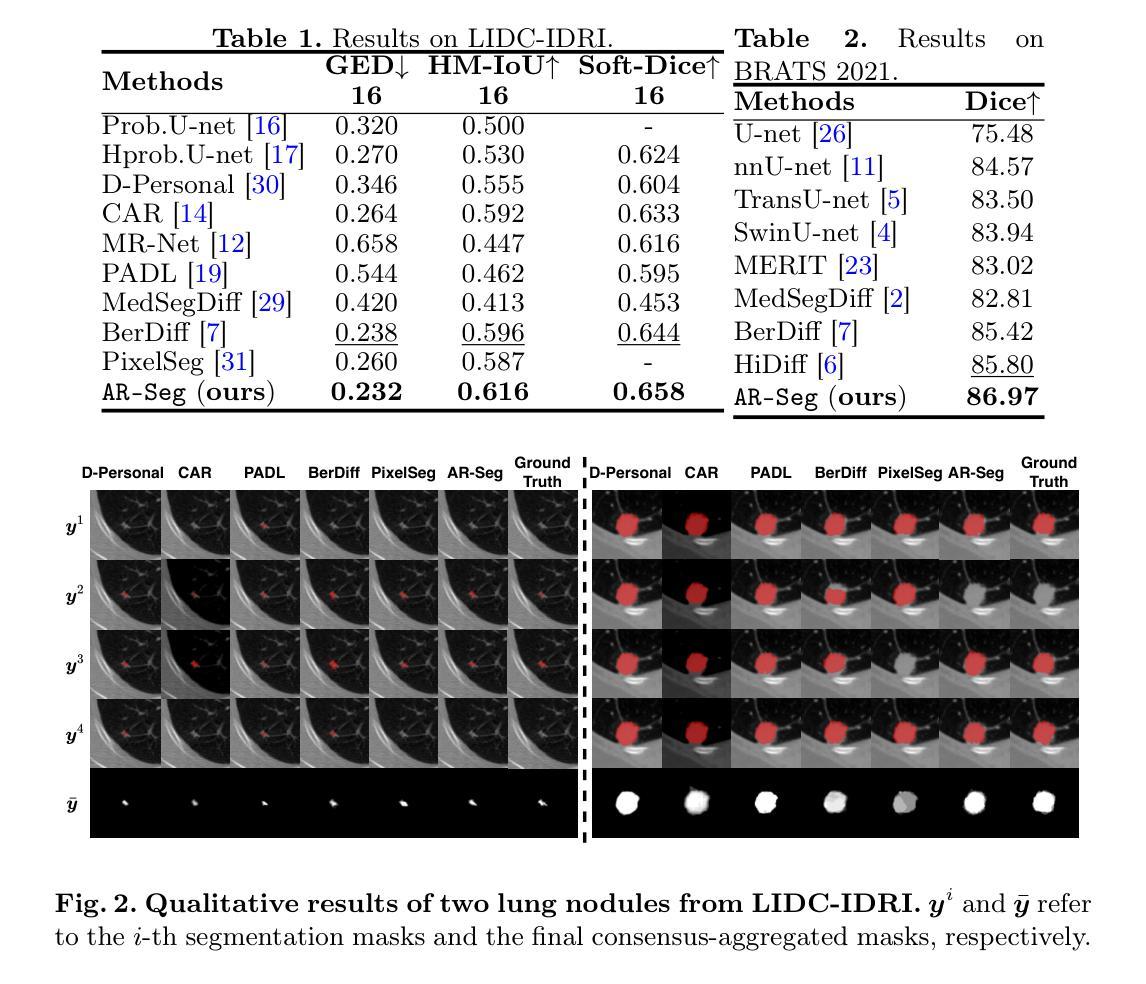
Autoregressive Medical Image Segmentation via Next-Scale Mask Prediction
Authors:Tao Chen, Chenhui Wang, Zhihao Chen, Hongming Shan
While deep learning has significantly advanced medical image segmentation, most existing methods still struggle with handling complex anatomical regions. Cascaded or deep supervision-based approaches attempt to address this challenge through multi-scale feature learning but fail to establish sufficient inter-scale dependencies, as each scale relies solely on the features of the immediate predecessor. To this end, we propose the AutoRegressive Segmentation framework via next-scale mask prediction, termed AR-Seg, which progressively predicts the next-scale mask by explicitly modeling dependencies across all previous scales within a unified architecture. AR-Seg introduces three innovations: (1) a multi-scale mask autoencoder that quantizes the mask into multi-scale token maps to capture hierarchical anatomical structures, (2) a next-scale autoregressive mechanism that progressively predicts next-scale masks to enable sufficient inter-scale dependencies, and (3) a consensus-aggregation strategy that combines multiple sampled results to generate a more accurate mask, further improving segmentation robustness. Extensive experimental results on two benchmark datasets with different modalities demonstrate that AR-Seg outperforms state-of-the-art methods while explicitly visualizing the intermediate coarse-to-fine segmentation process.
虽然深度学习在医学图像分割方面取得了显著进展,但大多数现有方法在处理复杂解剖区域时仍面临困难。级联或基于深度监督的方法试图通过多尺度特征学习来解决这一挑战,但未能建立足够的跨尺度依赖关系,因为每个尺度只依赖于直接前序尺度的特征。为此,我们提出了通过下一尺度掩膜预测的自回归分割框架,称为AR-Seg。AR-Seg在统一架构内显式建模所有先前尺度之间的依赖关系,逐步预测下一尺度掩膜。AR-Seg引入了三项创新:1)多尺度掩膜自编码器将掩膜量化为多尺度令牌图,以捕获层次化的解剖结构;2)下一尺度自回归机制逐步预测下一尺度掩膜,以实现足够的跨尺度依赖关系;3)共识聚合策略结合了多个采样结果,生成更准确的掩膜,进一步提高分割的稳健性。在两个不同模态的基准数据集上的大量实验结果表明,AR-Seg优于最先进的方法,同时明确可视化从粗到细的中间分割过程。
论文及项目相关链接
PDF 10 pages, 4 figures
Summary
本文提出一种基于自回归分割框架的医学图像分割方法,名为AR-Seg。该方法通过多尺度掩膜自编码器捕捉层次化的解剖结构,并采用自回归机制逐步预测下一尺度掩膜,实现充分的跨尺度依赖关系。此外,AR-Seg还采用共识聚合策略,结合多个采样结果生成更准确的掩膜,提高了分割的鲁棒性。实验结果表明,AR-Seg在多个基准数据集上优于其他最新方法。
Key Takeaways
- AR-Seg框架通过多尺度特征学习处理医学图像分割中的复杂解剖区域问题。
- 现有方法在处理跨尺度依赖关系时存在不足,而AR-Seg通过自回归机制逐步预测下一尺度掩膜来解决这一问题。
- AR-Seg引入多尺度掩膜自编码器,将掩膜量化为多尺度令牌图,以捕捉层次化的解剖结构。
- AR-Seg采用共识聚合策略,结合多个采样结果生成更准确掩膜,提高分割鲁棒性。
- AR-Seg在多个基准数据集上的实验结果表明其性能优于其他最新方法。
- AR-Seg能够可视化中间粗到细的分割过程。
点此查看论文截图

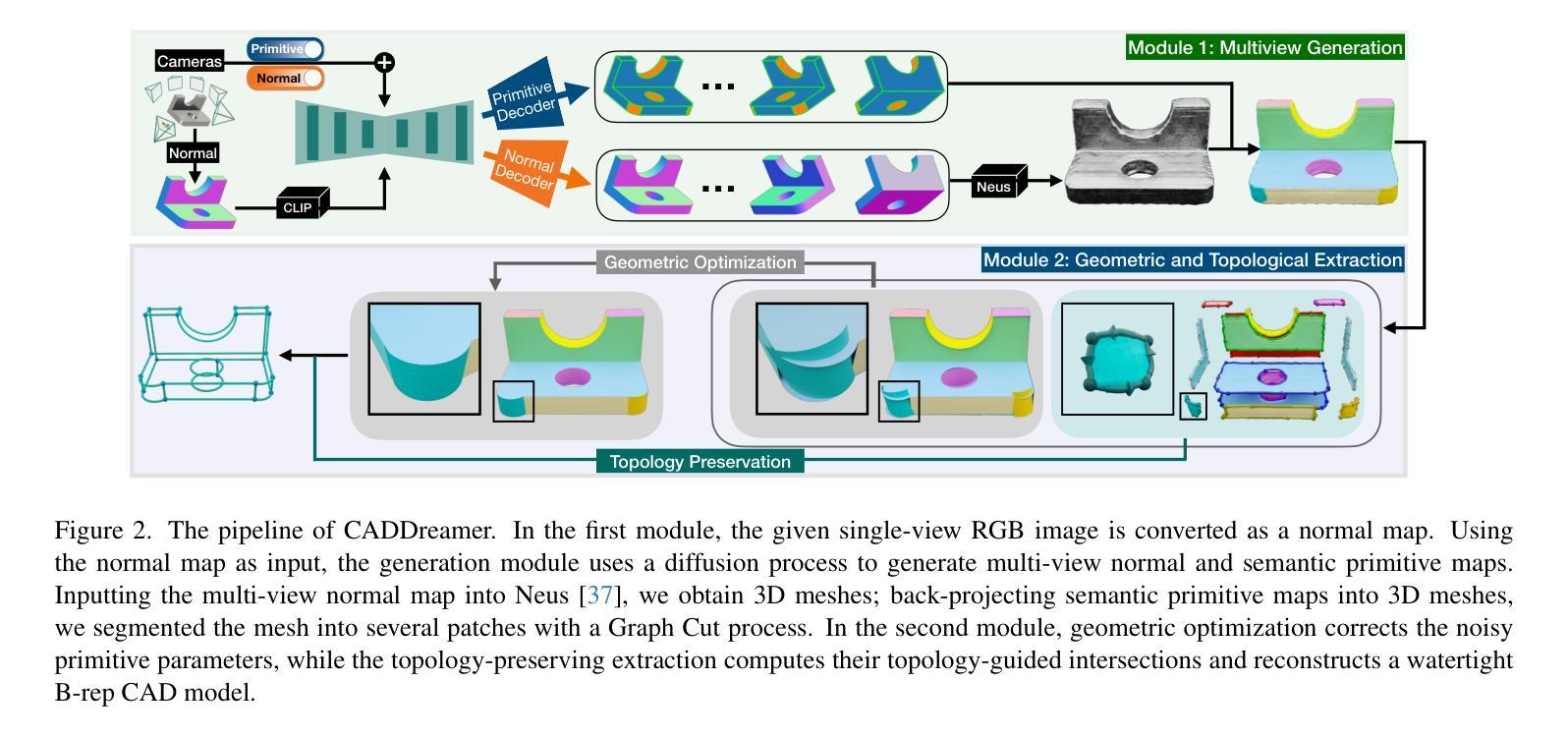
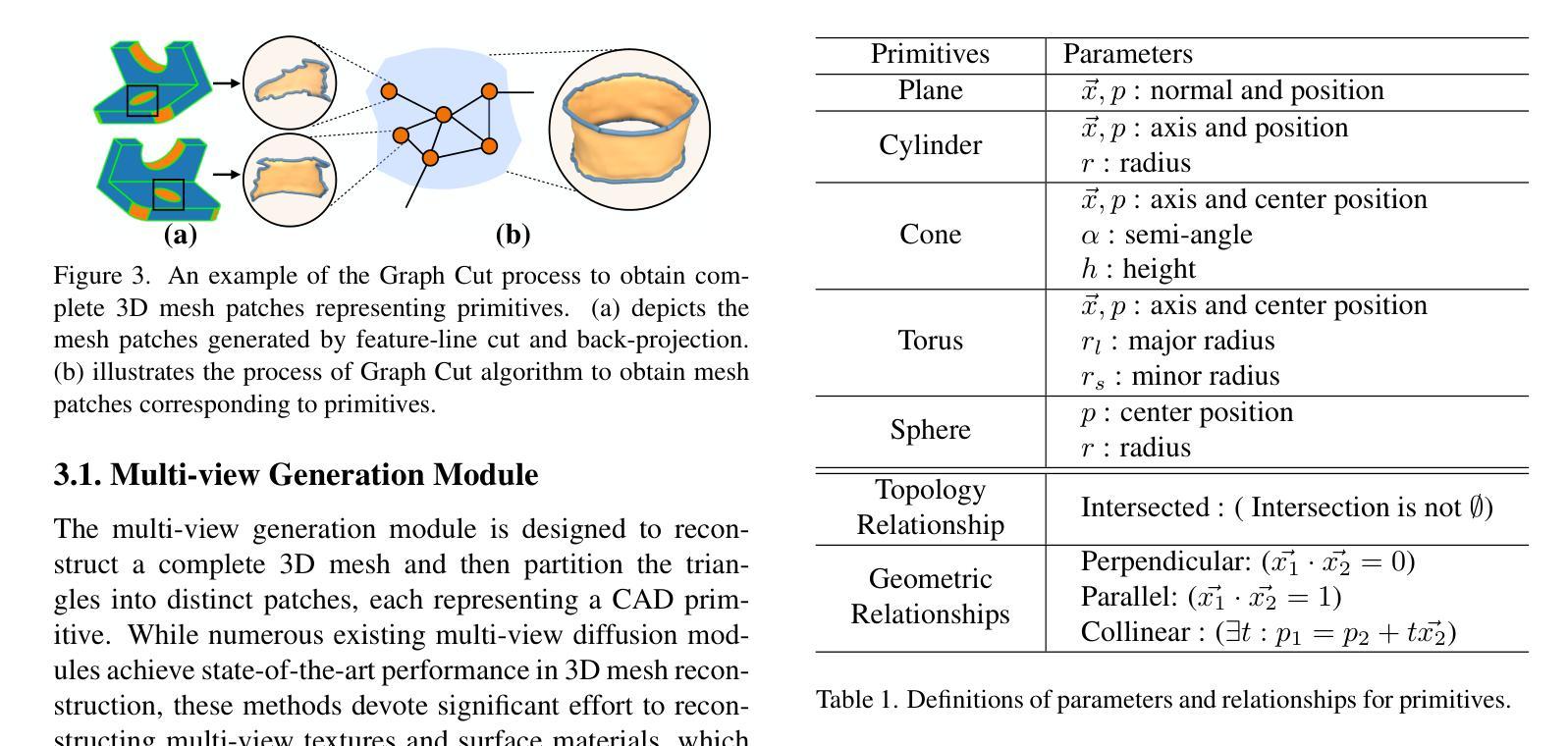
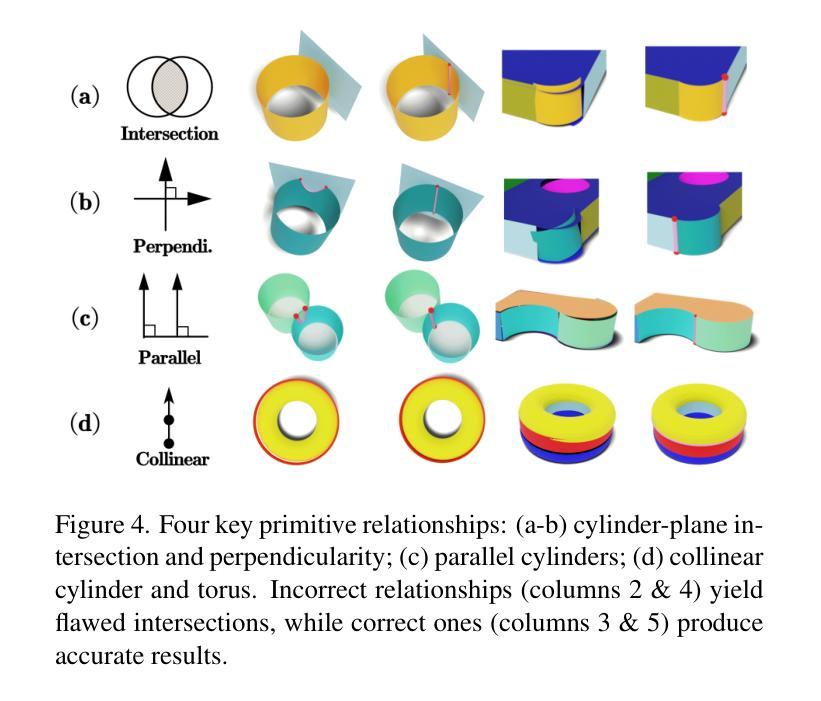
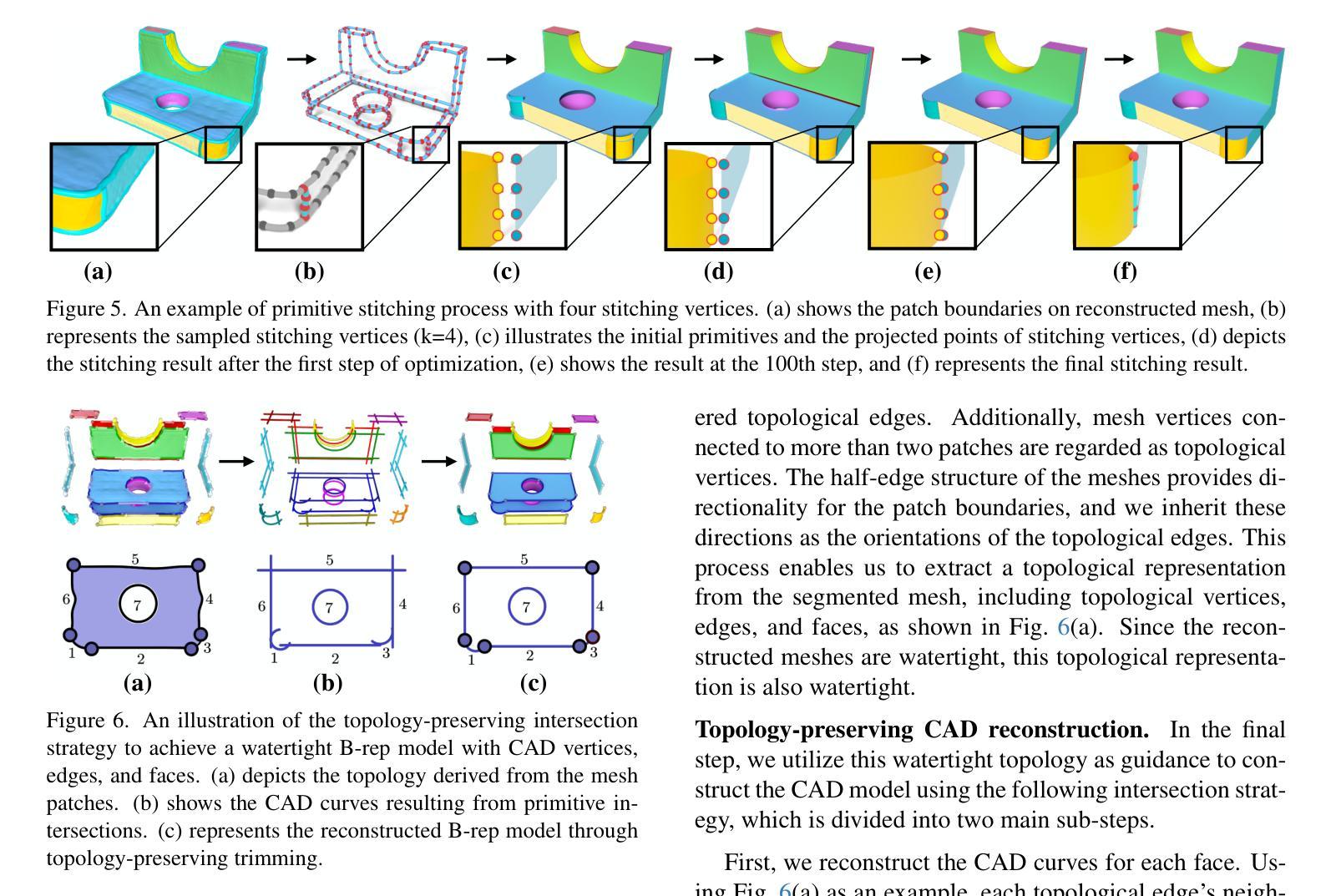
CADDreamer: CAD object Generation from Single-view Images
Authors:Yuan Li, Cheng Lin, Yuan Liu, Xiaoxiao Long, Chenxu Zhang, Ningna Wang, Xin Li, Wenping Wang, Xiaohu Guo
Diffusion-based 3D generation has made remarkable progress in recent years. However, existing 3D generative models often produce overly dense and unstructured meshes, which stand in stark contrast to the compact, structured, and sharply-edged Computer-Aided Design (CAD) models crafted by human designers. To address this gap, we introduce CADDreamer, a novel approach for generating boundary representations (B-rep) of CAD objects from a single image. CADDreamer employs a primitive-aware multi-view diffusion model that captures both local geometric details and high-level structural semantics during the generation process. By encoding primitive semantics into the color domain, the method leverages the strong priors of pre-trained diffusion models to align with well-defined primitives. This enables the inference of multi-view normal maps and semantic maps from a single image, facilitating the reconstruction of a mesh with primitive labels. Furthermore, we introduce geometric optimization techniques and topology-preserving extraction methods to mitigate noise and distortion in the generated primitives. These enhancements result in a complete and seamless B-rep of the CAD model. Experimental results demonstrate that our method effectively recovers high-quality CAD objects from single-view images. Compared to existing 3D generation techniques, the B-rep models produced by CADDreamer are compact in representation, clear in structure, sharp in edges, and watertight in topology.
基于扩散的3D生成技术在近年来取得了显著的进步。然而,现有的3D生成模型往往产生过于密集且无结构的网格,这与人类设计师精心制作的紧凑、结构化、边缘清晰的计算机辅助设计(CAD)模型形成鲜明对比。为了解决这一差距,我们引入了CADDreamer,这是一种从单张图像生成计算机辅助设计对象边界表示(B-rep)的新方法。CADDreamer采用了一种原始感知多视角扩散模型,该模型在生成过程中捕捉局部几何细节和高级结构语义。通过将原始语义编码到颜色域中,该方法利用预训练扩散模型的强大先验知识与定义良好的原始元素进行对齐。这使得能够从单张图像推断多视角法线贴图和语义贴图,促进带有原始标签的网格重建。此外,我们引入了几何优化技术和拓扑保留提取方法,以减轻生成原始元素中的噪声和失真。这些增强功能导致了一个完整且无缝隙的CAD模型的B-rep。实验结果表明,我们的方法从单视图图像中有效地恢复了高质量的CAD对象。与现有的3D生成技术相比,CADDreamer产生的B-rep模型在表示上更紧凑、在结构上更清晰、在边缘上更锋利、在拓扑上更无缝隙。
论文及项目相关链接
PDF Accepted to CVPR 2025
Summary
本文介绍了基于扩散的3D生成技术的最新进展,并指出现有模型存在的问题。为解决这些问题,提出了一种名为CADDreamer的新方法,能够从单一图像生成CAD对象的边界表示(B-rep)。该方法通过引入原始感知的多视角扩散模型,结合局部几何细节和高级结构语义进行生成。通过编码原始语义到颜色域,并利用预训练的扩散模型的强先验知识,实现了与预定义原始图形的对齐。此外,还引入了几何优化技术和拓扑保留提取方法,减少了生成原始图形中的噪声和失真。实验结果证明,该方法能有效从单视图图像中恢复高质量的CAD对象,生成的B-rep模型在表示、结构、边缘和拓扑方面均表现出优越性。
Key Takeaways
- 现有3D生成模型会产生过于密集和无结构的网格,与人类的CAD模型设计存在差距。
- CADDreamer方法能够从单一图像生成CAD对象的边界表示(B-rep)。
- CADDreamer采用原始感知的多视角扩散模型,结合局部几何细节和高级结构语义进行生成。
- 通过编码原始语义到颜色域,利用预训练扩散模型的强先验知识,实现与预定义原始图形的对齐。
- 引入几何优化技术和拓扑保留提取方法,减少生成原始图形中的噪声和失真。
- 实验结果证明CADDreamer方法能从单视图图像中有效恢复高质量的CAD对象。
点此查看论文截图

Advancing AI-Powered Medical Image Synthesis: Insights from MedVQA-GI Challenge Using CLIP, Fine-Tuned Stable Diffusion, and Dream-Booth + LoRA
Authors:Ojonugwa Oluwafemi Ejiga Peter, Md Mahmudur Rahman, Fahmi Khalifa
The MEDVQA-GI challenge addresses the integration of AI-driven text-to-image generative models in medical diagnostics, aiming to enhance diagnostic capabilities through synthetic image generation. Existing methods primarily focus on static image analysis and lack the dynamic generation of medical imagery from textual descriptions. This study intends to partially close this gap by introducing a novel approach based on fine-tuned generative models to generate dynamic, scalable, and precise images from textual descriptions. Particularly, our system integrates fine-tuned Stable Diffusion and DreamBooth models, as well as Low-Rank Adaptation (LORA), to generate high-fidelity medical images. The problem is around two sub-tasks namely: image synthesis (IS) and optimal prompt production (OPG). The former creates medical images via verbal prompts, whereas the latter provides prompts that produce high-quality images in specified categories. The study emphasizes the limitations of traditional medical image generation methods, such as hand sketching, constrained datasets, static procedures, and generic models. Our evaluation measures showed that Stable Diffusion surpasses CLIP and DreamBooth + LORA in terms of producing high-quality, diversified images. Specifically, Stable Diffusion had the lowest Fr'echet Inception Distance (FID) scores (0.099 for single center, 0.064 for multi-center, and 0.067 for combined), indicating higher image quality. Furthermore, it had the highest average Inception Score (2.327 across all datasets), indicating exceptional diversity and quality. This advances the field of AI-powered medical diagnosis. Future research will concentrate on model refining, dataset augmentation, and ethical considerations for efficiently implementing these advances into clinical practice
MEDVQA-GI挑战致力于将人工智能驱动的文本到图像生成模型整合到医学诊断中,旨在通过合成图像生成增强诊断能力。现有方法主要侧重于静态图像分析,缺乏从文本描述中动态生成医学图像的能力。本研究旨在通过引入一种基于精细调整生成模型的新型方法,来部分弥补这一差距,以从文本描述中生成动态、可伸缩和精确的图像。特别是,我们的系统集成了精细调整的Stable Diffusion和DreamBooth模型,以及低秩适应(LORA),以生成高保真医学图像。该问题涉及两个子任务:图像合成(IS)和最佳提示生成(OPG)。前者通过文字提示创建医学图像,而后者提供在指定类别中产生高质量图像的提示。该研究强调了传统医学图像生成方法的局限性,如手绘、受限数据集、静态程序和通用模型。我们的评估结果表明,在生成高质量、多样化图像方面,Stable Diffusion超越了CLIP和DreamBooth + LORA。具体来说,Stable Diffusion的Fréchet Inception Distance(FID)分数最低(单中心为0.099,多中心为0.064,组合为0.067),表明图像质量较高。此外,它具有最高的平均Inception Score(所有数据集上为2.327),表明具有出色的多样性和质量。这推动了人工智能驱动医学诊断领域的发展。未来研究将集中在模型精炼、数据集增强以及将这些进步有效地应用于临床实践的伦理考虑上。
论文及项目相关链接
摘要
MEDVQA-GI挑战旨在解决人工智能驱动的文本到图像生成模型在医学诊断中的整合问题,旨在通过合成图像生成增强诊断能力。现有方法主要关注静态图像分析,缺乏从文本描述中动态生成医学图像的能力。本研究旨在通过引入基于精细调整的生成模型的新型方法,部分弥补这一差距,以从文本描述中生成动态、可伸缩和精确的图像。特别是,我们的系统集成了微调后的Stable Diffusion和DreamBooth模型,以及低秩适配(LORA),以生成高保真医学图像。问题主要围绕两个子任务:图像合成(IS)和最佳提示生成(OPG)。前者通过文字提示创建医学图像,而后者提供产生高质量图像的提示。研究强调了传统医学图像生成方法的局限性,如手绘、受限数据集、静态程序和通用模型。我们的评估结果表明,Stable Diffusion在生成高质量、多样化的图像方面超过了CLIP和DreamBooth + LORA。特别是,Stable Diffusion的Fréchet Inception Distance(FID)分数最低(单中心为0.099,多中心为0.064,组合为0.067),表明图像质量较高。此外,它具有最高的平均Inception Score(所有数据集上为2.327),表明其多样性和质量出色。这推动了人工智能驱动医学诊断领域的发展。未来研究将集中在模型精炼、数据集增强和伦理考虑等方面,以有效地将这些进步应用于临床实践。
关键见解
- MEDVQA-GI挑战旨在整合AI驱动的文本到图像生成模型,以提高医学诊断能力。
- 现有医学图像生成方法主要关注静态图像分析,缺乏动态生成能力。
- 研究引入了一种新型方法,集成微调后的Stable Diffusion和DreamBooth模型以及Low-Rank Adaptation(LORA)来生成医学图像。
- 研究强调了传统医学图像生成方法的局限性。
- Stable Diffusion在生成高质量、多样化的图像方面表现出色。
- Future research将集中在模型优化、数据集增强和伦理考虑等方面。
点此查看论文截图



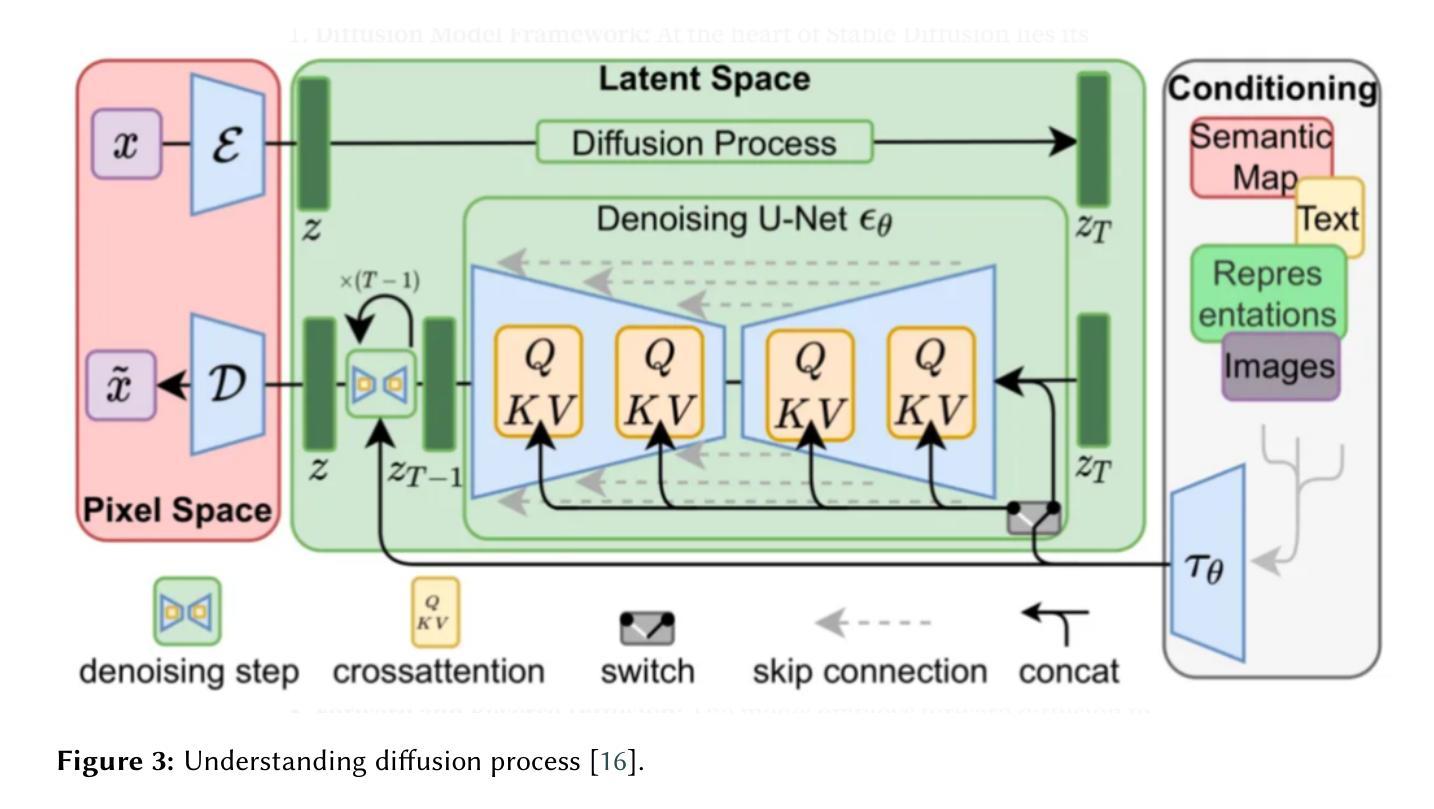
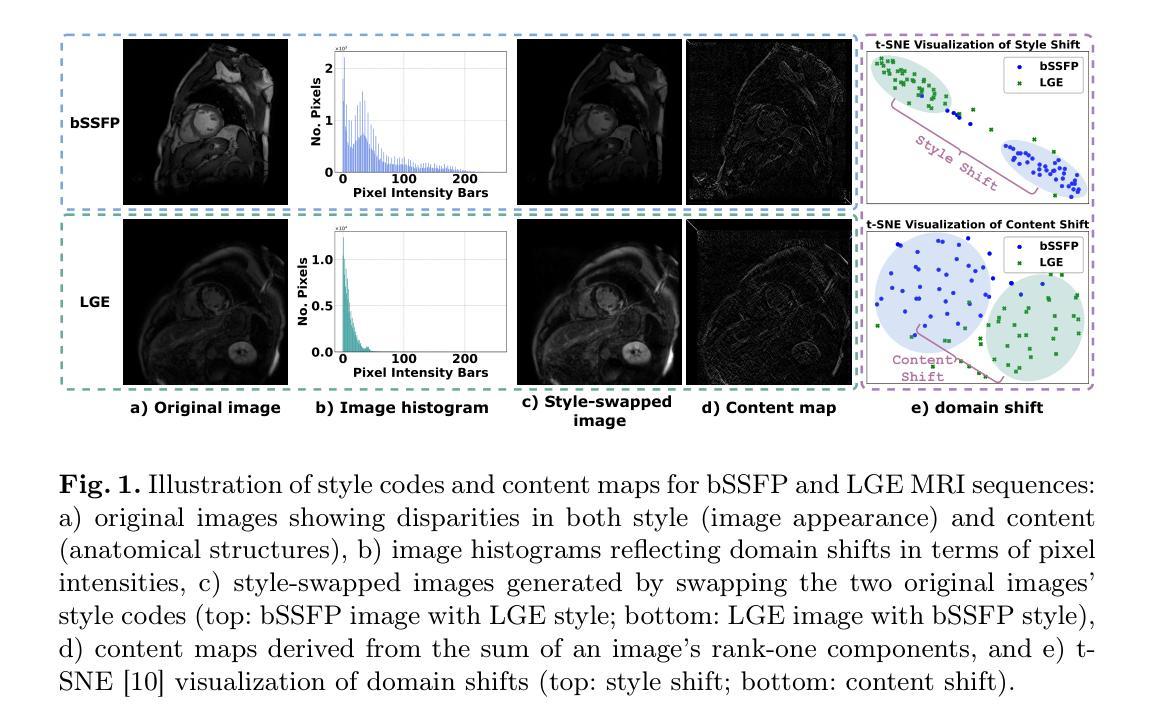
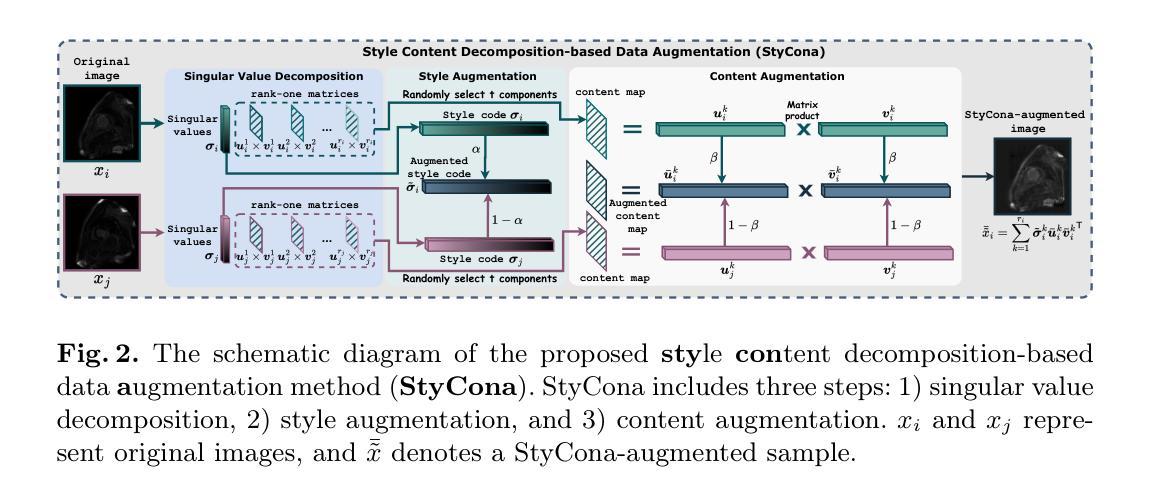
Style Content Decomposition-based Data Augmentation for Domain Generalizable Medical Image Segmentation
Authors:Zhiqiang Shen, Peng Cao, Jinzhu Yang, Osmar R. Zaiane, Zhaolin Chen
Due to the domain shifts between training and testing medical images, learned segmentation models often experience significant performance degradation during deployment. In this paper, we first decompose an image into its style code and content map and reveal that domain shifts in medical images involve: \textbf{style shifts} (\emph{i.e.}, differences in image appearance) and \textbf{content shifts} (\emph{i.e.}, variations in anatomical structures), the latter of which has been largely overlooked. To this end, we propose \textbf{StyCona}, a \textbf{sty}le \textbf{con}tent decomposition-based data \textbf{a}ugmentation method that innovatively augments both image style and content within the rank-one space, for domain generalizable medical image segmentation. StyCona is a simple yet effective plug-and-play module that substantially improves model generalization without requiring additional training parameters or modifications to the segmentation model architecture. Experiments on cross-sequence, cross-center, and cross-modality medical image segmentation settings with increasingly severe domain shifts, demonstrate the effectiveness of StyCona and its superiority over state-of-the-arts. The code is available at https://github.com/Senyh/StyCona.
由于训练与测试医学图像之间的领域差异,已学习的分割模型在部署时通常会出现显著的性能下降。在本文中,我们首先将图像分解为风格代码和内容映射,并揭示医学图像的领域变化涉及:风格变化(即图像外观的差异)和内容变化(即解剖结构的差异),后者在很大程度上被忽视了。为此,我们提出了基于风格内容分解的数据增强方法StyCona,该方法在秩一空间内创新性地增强了图像的风格和内容,用于领域通用的医学图像分割。StyCona是一个简单有效的即插即用模块,无需额外的训练参数或对分割模型架构进行修改,即可显著提高模型的泛化能力。在跨序列、跨中心和跨模态医学图像分割设置下的实验,显示了StyCona的有效性及其超越最新技术的优越性。代码可在https://github.com/Senyh/StyCona获得。
论文及项目相关链接
Summary
本文研究了医学图像分割模型在训练和测试时遇到领域偏移的问题,提出了Style-Content分解的数据增强方法(StyCona)。该方法在rank-one空间内同时增强图像风格和内容,以提高模型的通用性。实验表明,StyCona在跨序列、跨中心和跨模态医学图像分割设置中,能有效应对日益严重的领域偏移问题,并优于现有技术。
Key Takeaways
- 医学图像分割模型在部署时,由于训练和测试图像领域的偏移,性能往往会下降。
- 领域偏移包括风格偏移(图像外观的差异)和内容偏移(解剖结构的变化),其中内容偏移一直被忽视。
- 本文提出了一种基于风格内容分解的数据增强方法(StyCona),在rank-one空间内同时增强图像风格和内容。
- StyCona是一个简单有效的即插即用模块,能显著提高模型的泛化能力,无需增加训练参数或对分割模型架构进行修改。
- 实验结果表明,StyCona在跨序列、跨中心和跨模态医学图像分割环境中表现优越,能有效应对领域偏移问题。
- StyCona的方法相较于当前先进方法具有优势。
点此查看论文截图

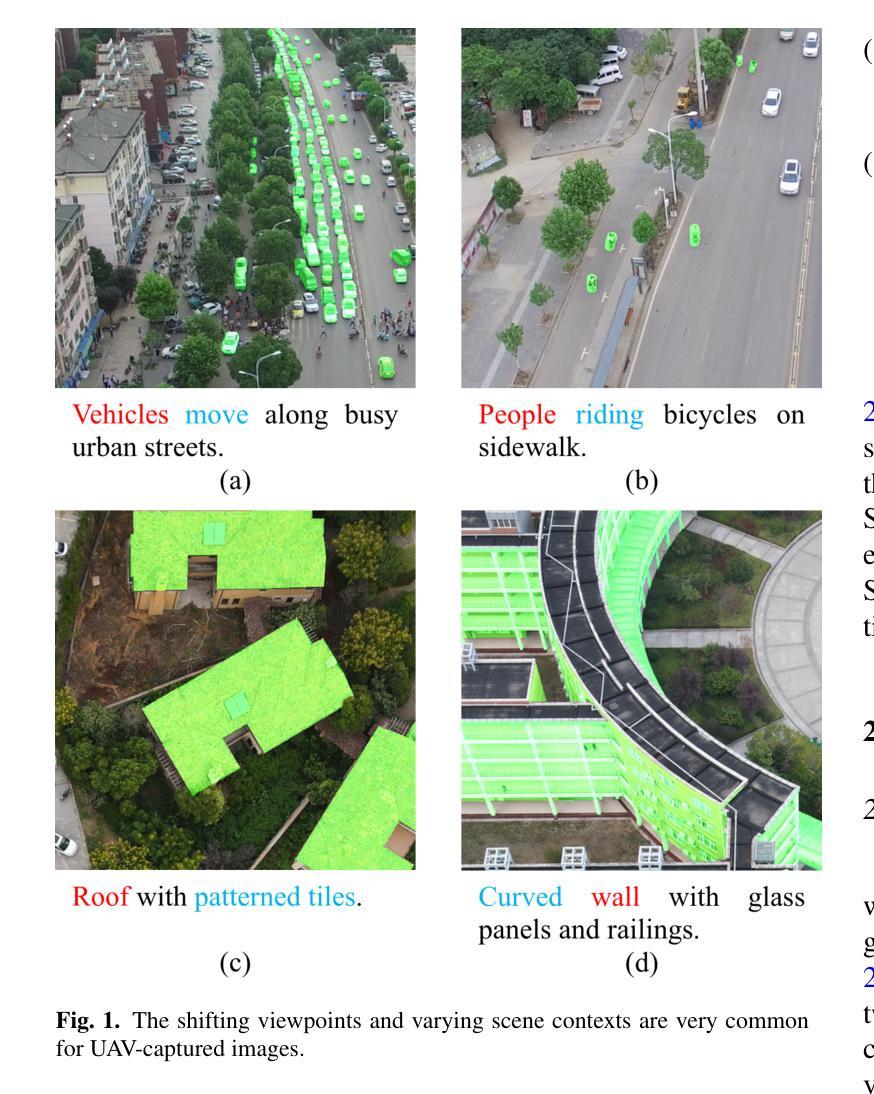
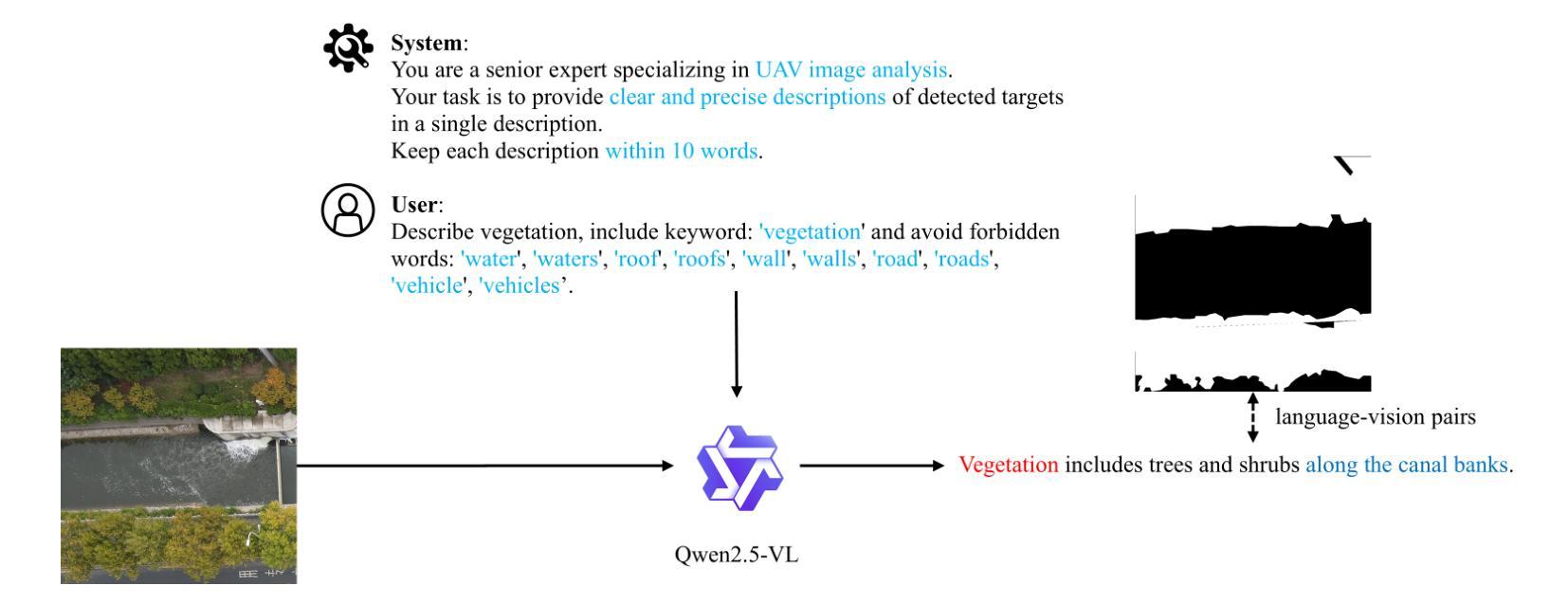
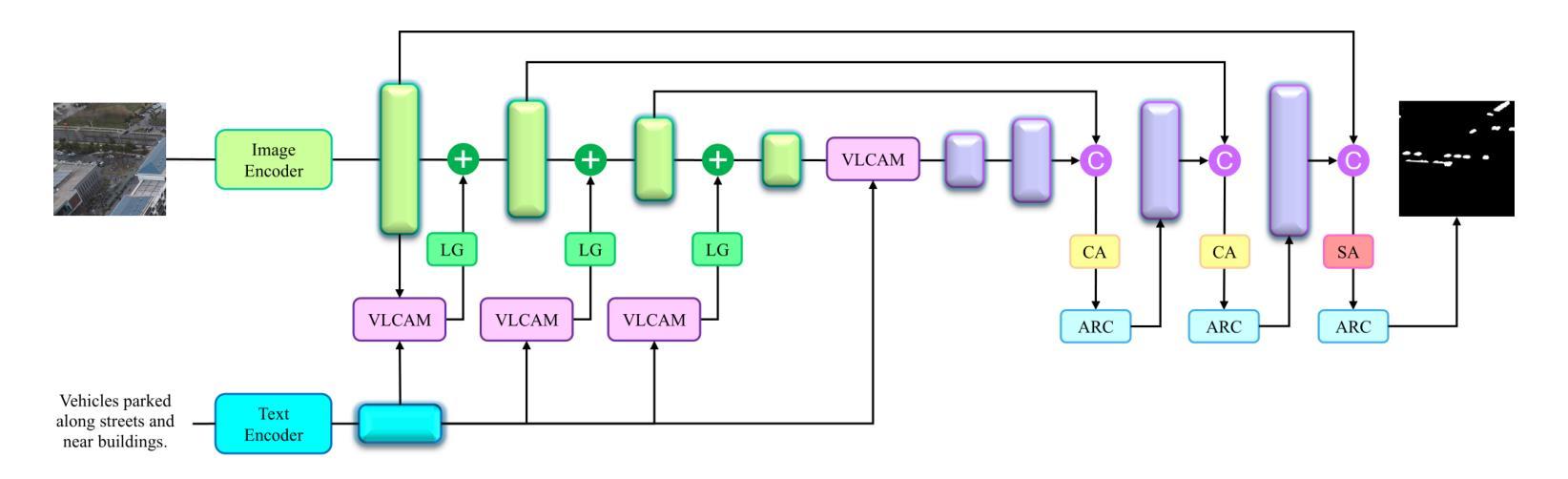
AeroReformer: Aerial Referring Transformer for UAV-based Referring Image Segmentation
Authors:Rui Li, Xiaowei Zhao
As a novel and challenging task, referring segmentation combines computer vision and natural language processing to localize and segment objects based on textual descriptions. While referring image segmentation (RIS) has been extensively studied in natural images, little attention has been given to aerial imagery, particularly from unmanned aerial vehicles (UAVs). The unique challenges of UAV imagery, including complex spatial scales, occlusions, and varying object orientations, render existing RIS approaches ineffective. A key limitation has been the lack of UAV-specific datasets, as manually annotating pixel-level masks and generating textual descriptions is labour-intensive and time-consuming. To address this gap, we design an automatic labelling pipeline that leverages pre-existing UAV segmentation datasets and Multimodal Large Language Models (MLLM) for generating textual descriptions. Furthermore, we propose Aerial Referring Transformer (AeroReformer), a novel framework for UAV referring image segmentation (UAV-RIS), featuring a Vision-Language Cross-Attention Module (VLCAM) for effective cross-modal understanding and a Rotation-Aware Multi-Scale Fusion (RAMSF) decoder to enhance segmentation accuracy in aerial scenes. Extensive experiments on two newly developed datasets demonstrate the superiority of AeroReformer over existing methods, establishing a new benchmark for UAV-RIS. The datasets and code will be publicly available at: https://github.com/lironui/AeroReformer.
作为一新颖且充满挑战的任务,参考分割结合了计算机视觉和自然语言处理,基于文本描述进行对象定位和分割。虽然参考图像分割(RIS)在自然图像中已被广泛研究,但对航空图像(尤其是来自无人机的图像)的关注很少。无人机图像具有独特的挑战,包括复杂的空间尺度、遮挡和不同的对象方向,这使得现有的RIS方法无效。一个关键的局限性在于缺乏针对无人机的特定数据集,因为手动注释像素级掩膜和生成文本描述是劳动密集型的且耗时。为了解决这个问题,我们设计了一个自动标注管道,该管道利用现有的无人机分割数据集和多模态大型语言模型(MLLM)来生成文本描述。此外,我们提出了用于无人机参考图像分割(UAV-RIS)的空中参考变压器(AeroReformer)新型框架,其特点在于具备视觉语言跨注意力模块(VLCAM),可有效进行跨模态理解,以及具备旋转感知多尺度融合(RAMSF)解码器,可提高空中场景的分割精度。在两个新开发的数据集上进行的大量实验表明,AeroReformer优于现有方法,为UAV-RIS建立了新的基准。数据集和代码将在https://github.com/lironui/AeroReformer公开提供。
论文及项目相关链接
Summary
本研究关注了一种新型的具有挑战性的任务——引用分割(Referring Segmentation),这一任务结合了计算机视觉和自然语言处理来基于文本描述定位并分割物体。虽然引用图像分割在自然图像上得到了广泛研究,但在航空图像上,特别是无人机图像上,相关研究却很少。针对无人机图像的独特挑战,如复杂的空间尺度、遮挡和物体方向变化等,本研究设计了一种自动标注管道,利用现有的无人机分割数据集和多模态大型语言模型来生成文本描述。同时提出了一种新的无人机引用图像分割框架——Aerial Referring Transformer(AeroReformer),其中包含了用于有效跨模态理解的Vision-Language Cross-Attention Module(VLCAM)以及用于提高航空场景分割准确性的Rotation-Aware Multi-Scale Fusion(RAMSF)解码器。在两项新开发的数据集上的实验表明,AeroReformer在无人机引用图像分割任务上的表现优于现有方法,为这一领域建立了新的基准。
Key Takeaways
- 引用分割结合了计算机视觉和自然语言处理,基于文本描述进行物体定位和分割。
- 虽然自然图像的引用图像分割已受广泛关注,但无人机图像的引用图像分割研究相对较少。
- 无人机图像存在独特的挑战,如复杂空间尺度、遮挡和物体方向变化等。
- 缺乏针对无人机的特定数据集是这一领域的一个关键限制。
- 研究设计了一种自动标注管道,结合现有的无人机分割数据集和多模态大型语言模型来生成文本描述。
- 提出了一个新的框架Aerial Referring Transformer(AeroReformer)来处理无人机引用图像分割任务。
- AeroReformer包含了用于跨模态理解的VLCAM和用于提高分割准确性的RAMSF解码器。
点此查看论文截图


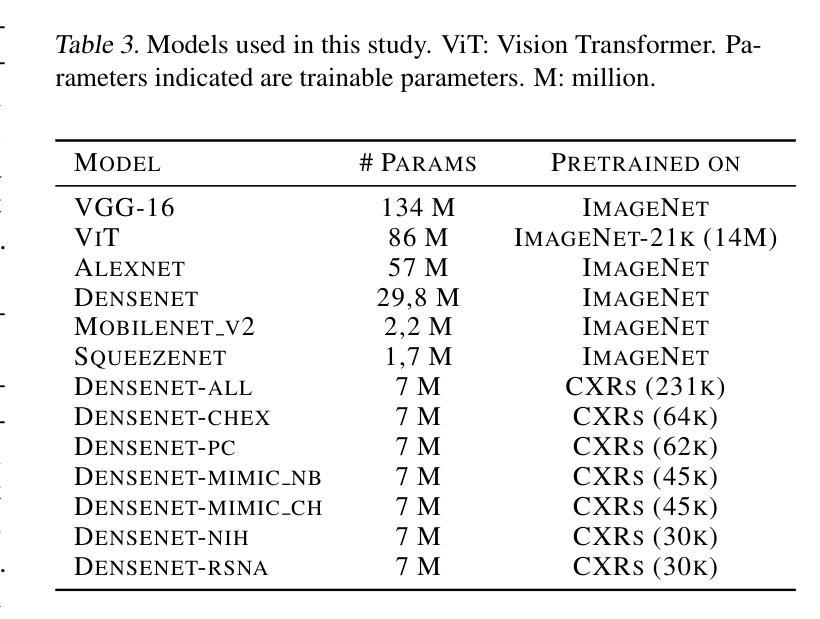
Diagnosing COVID-19 Severity from Chest X-Ray Images Using ViT and CNN Architectures
Authors:Luis Lara, Lucia Eve Berger, Rajesh Raju
The COVID-19 pandemic strained healthcare resources and prompted discussion about how machine learning can alleviate physician burdens and contribute to diagnosis. Chest x-rays (CXRs) are used for diagnosis of COVID-19, but few studies predict the severity of a patient’s condition from CXRs. In this study, we produce a large COVID severity dataset by merging three sources and investigate the efficacy of transfer learning using ImageNet- and CXR-pretrained models and vision transformers (ViTs) in both severity regression and classification tasks. A pretrained DenseNet161 model performed the best on the three class severity prediction problem, reaching 80% accuracy overall and 77.3%, 83.9%, and 70% on mild, moderate and severe cases, respectively. The ViT had the best regression results, with a mean absolute error of 0.5676 compared to radiologist-predicted severity scores. The project’s source code is publicly available.
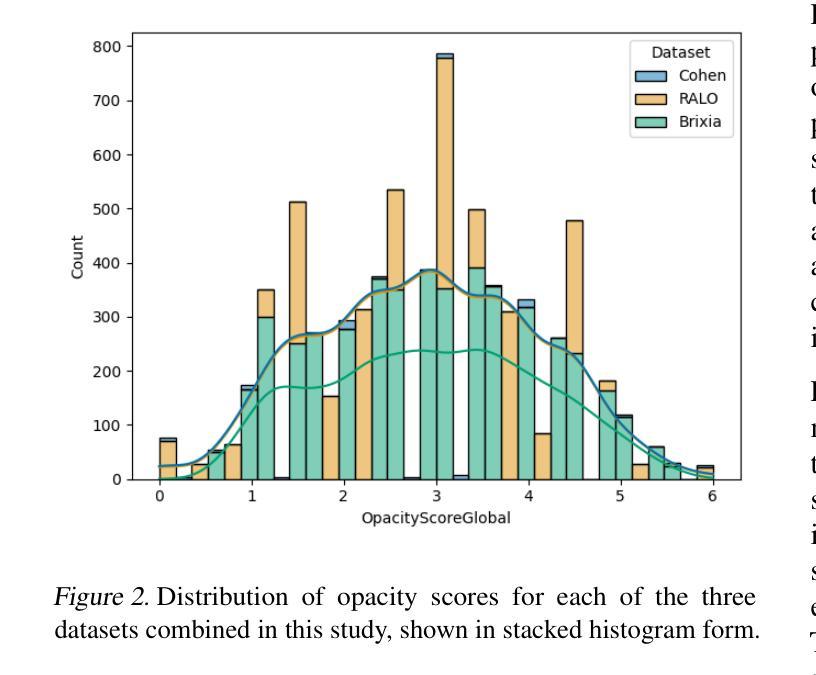
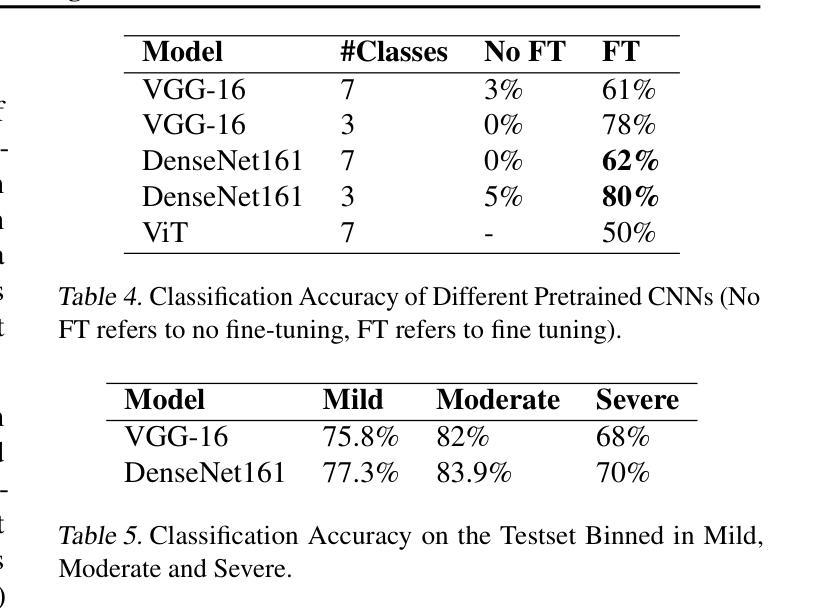
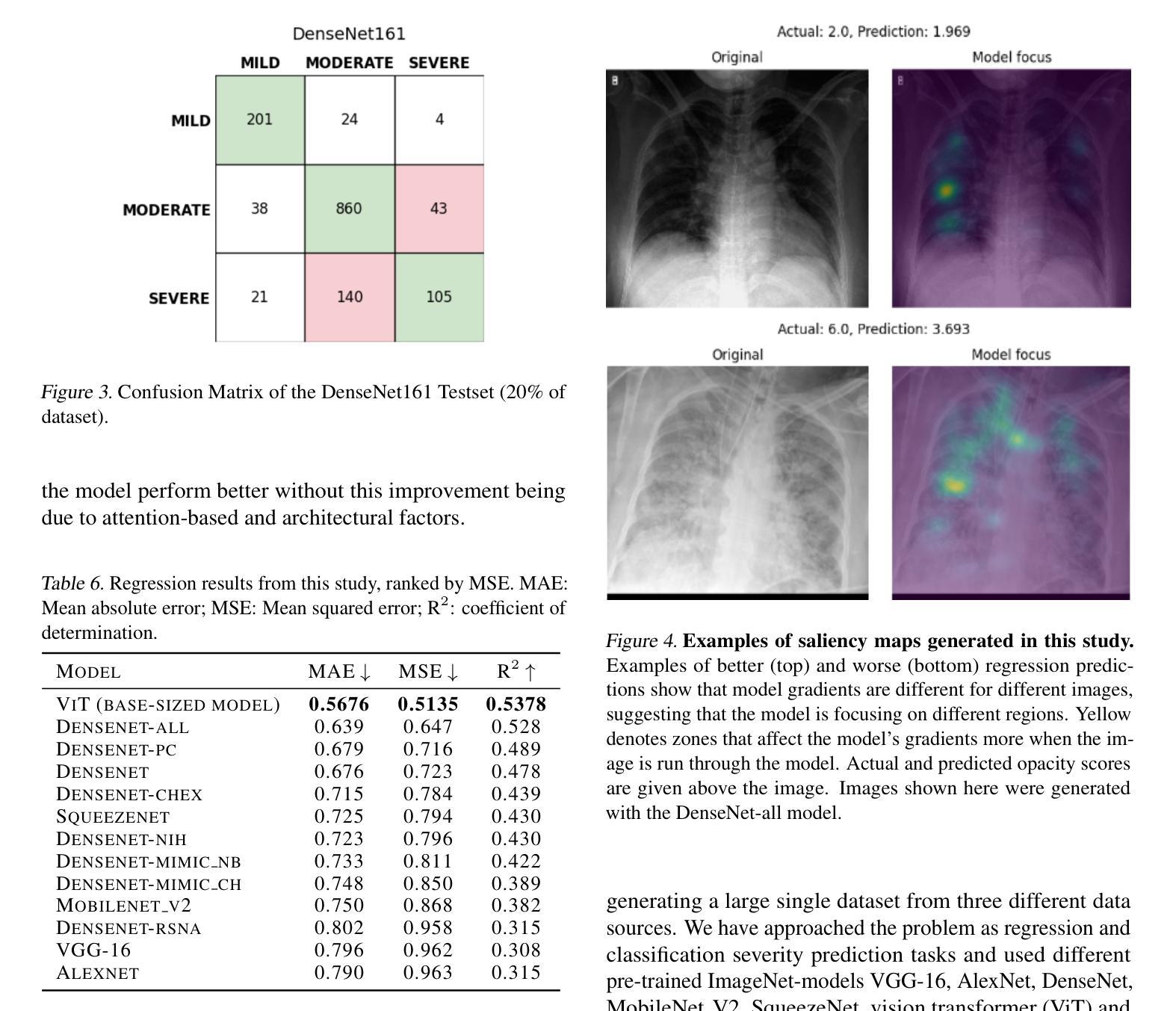
COVID-19大流行使医疗资源承受巨大压力,并引发了关于机器学习如何减轻医生负担并为诊断做出贡献的讨论。胸部X射线(CXRs)被用于诊断COVID-19,但很少有研究从CXRs预测患者病情的严重程度。在这项研究中,我们通过合并三个来源创建了一个大型的COVID严重程度数据集,并研究了使用ImageNet和CXR预训练模型以及视觉变压器(ViTs)在严重性回归和分类任务中进行迁移学习的有效性。在三级严重性预测问题上,预训练的DenseNet14模型表现最佳,总体准确度达到百分之八十,在轻度、中度和重度病例上的准确率分别为百分之七十七点三、百分之八十三点九和百分之七十。ViT在回归方面的表现最佳,与放射科医生预测的严重程度评分相比,平均绝对误差为0.5676。该项目的源代码已公开可用。
论文及项目相关链接
PDF Upon reflection, the final version of this work does not meet the author’s personal standards for thoroughness and clarity. As a result, the authors have chosen to withdraw the paper to prevent the dissemination of work that may not fully reflect the level of quality they strive to maintain
Summary
本文研究了COVID-19疫情中机器学习方法在诊断及病情严重程度预测方面的应用。通过合并三个数据源创建了一个大型COVID严重程度数据集,并探讨了使用ImageNet和CXR预训练模型以及视觉转换器(ViTs)进行迁移学习的有效性,在病情严重程度回归和分类任务中表现良好。其中,预训练的DenseNet161模型在三类严重程度预测问题上表现最佳,准确率为80%,在轻度、中度和重度病例上的准确率分别为77.3%、83.9%和70%。ViT在回归预测方面表现最佳,与放射科医生预测的严重程度分数的平均绝对误差为0.5676。该项目的源代码已公开。
Key Takeaways
- COVID-19疫情加剧了医疗资源紧张,促使研究如何利用机器学习辅助医生诊断及预测病情严重程度。
- 研究通过合并三个数据源创建了一个大型COVID严重程度数据集。
- 迁移学习使用ImageNet和CXR预训练模型以及视觉转换器(ViTs)在分类和回归任务中进行了探索。
- 预训练的DenseNet161模型在三类严重程度预测中表现最佳,总体准确率为80%。
- ViT在回归预测方面的性能优于其他模型,与放射科医生预测的平均绝对误差为0.5676。
- 该研究提供的模型在预测COVID-19病情严重程度方面具有较高的潜力。
点此查看论文截图

Kinetic-Diffusion-Rotation Algorithm for Dose Estimation in Electron Beam Therapy
Authors:Klaas Willems, Vince Maes, Zhirui Tang, Giovanni Samaey
Monte Carlo methods are state-of-the-art when it comes to dosimetric computations in radiotherapy. However, the execution time of these methods suffers in high-collisional regimes. We address this problem by introducing a kinetic-diffusion particle tracing scheme. This algorithm, first proposed in the context of neutral transport in fusion energy, relies on explicit simulation of the kinetic motion in low-collisional regimes and dynamically switches to motion based on a random walk in high-collisional regimes. The random walk motion maintains the first two moments (mean and variance) of the kinetic motion. We derive an analytic formula for the mean kinetic motion and discuss the addition of a multiple scattering distribution to the algorithm. In contrast to neutral transport, the radiation transfer setting does not readily admit to an analytical expression for the variance of the kinetic motion, and we therefore resort to the use of a lookup table. We test the algorithm for dosimetric computations in radiation therapy on a 2D CT scan of a lung patient. Using a simple particle model, our Python implementation of the algorithm is nearly 33 times faster than an equivalent kinetic simulation at the cost of a small modeling error.
蒙特卡洛方法在放射治疗剂量计算方面属于最先进技术。然而,这些方法在高碰撞状态下存在执行时间较长的问题。我们通过引入动力学扩散粒子追踪方案来解决这一问题。该算法最初在核聚变能量中的中性物质传输上下文中提出,依赖于在低碰撞状态下对动力学运动的显式模拟,并在高碰撞状态下动态切换到基于随机游走的运动。随机游走运动保持了动力学运动的前两个时刻(均值和方差)。我们为平均动力学运动推导了一个分析公式,并讨论了向算法中添加多重散射分布的问题。与中性物质传输不同,辐射传输设置不便于接受动力学运动的方差的分析表达式,因此我们使用查找表。我们在二维肺部患者CT扫描上对算法进行放射治疗剂量计算测试。使用简单的粒子模型,我们的算法Python实现比等效动力学模拟速度快近33倍,但存在较小的建模误差。
论文及项目相关链接
Summary
针对放疗中的剂量计算,引入了一种基于动力学扩散粒子追踪方案来解决Monte Carlo方法在高碰撞状态下的运行时间过长的问题。该算法在中低碰撞状态下模拟粒子动力学运动,并在高碰撞状态下转换为随机运动模式。此外,该算法通过解析公式计算平均动力学运动,并讨论了多重散射分布算法的改进。通过肺部患者二维CT扫描测试,该算法较等价动力学模拟速度提升近33倍,但有微小建模误差。
Key Takeaways
- Monte Carlo方法在放射治疗中剂量计算方面处于前沿地位,但在高碰撞状态下执行时间较长。
- 引入了一种基于动力学扩散粒子追踪方案来解决此问题。
- 该算法在低碰撞状态下模拟粒子的动力学运动,并在高碰撞状态下采用随机运动模式。
- 算法采用解析公式计算平均动力学运动,并考虑了多重散射分布。
- 辐射传输场景下的动力学运动方差没有现成的解析表达式,因此采用查找表进行计算。
- 在肺癌患者二维CT扫描上测试算法,发现较等价动力学模拟速度显著提升。
点此查看论文截图

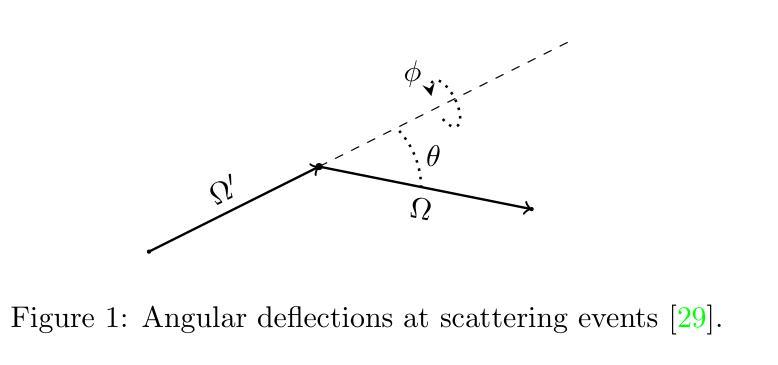
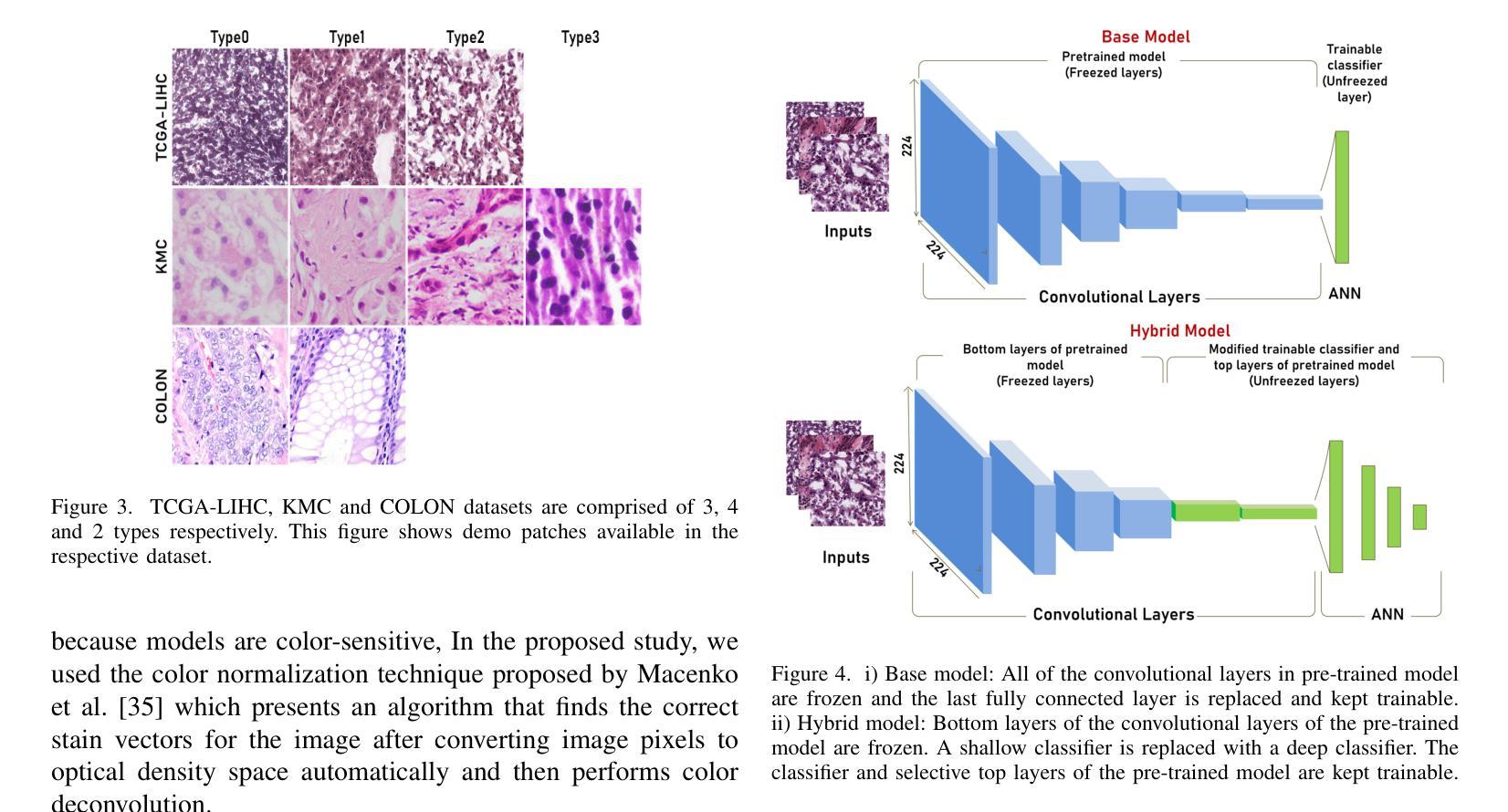
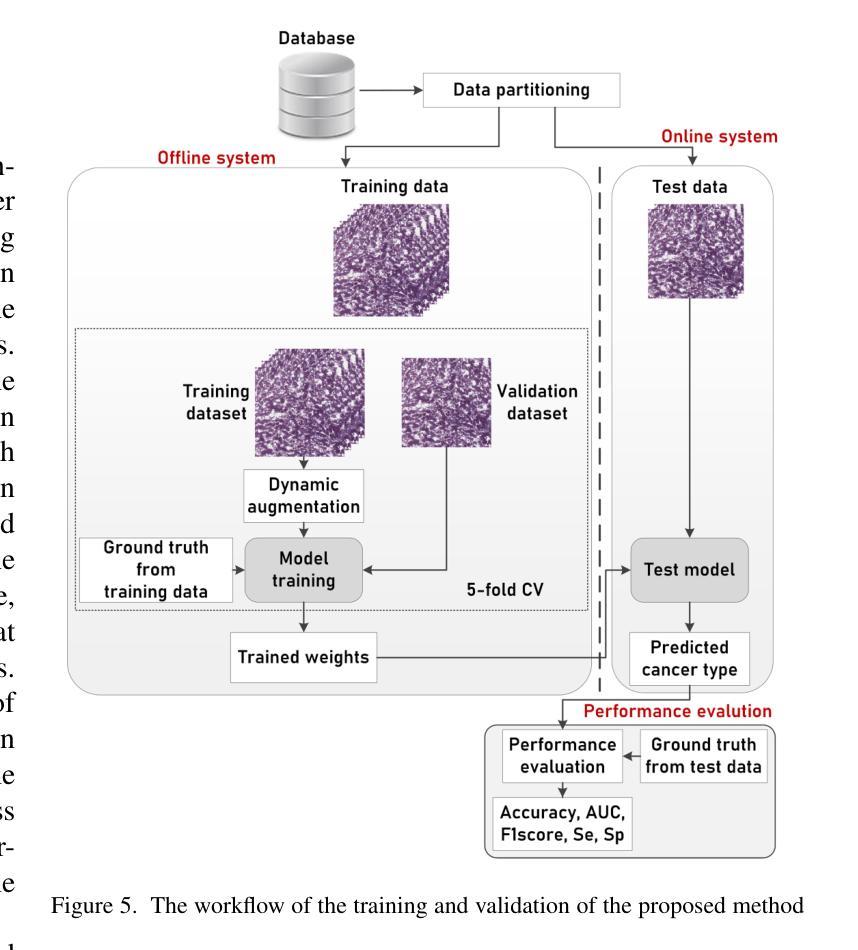
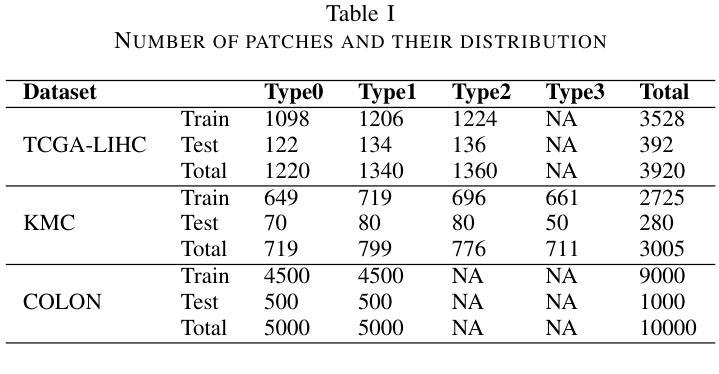
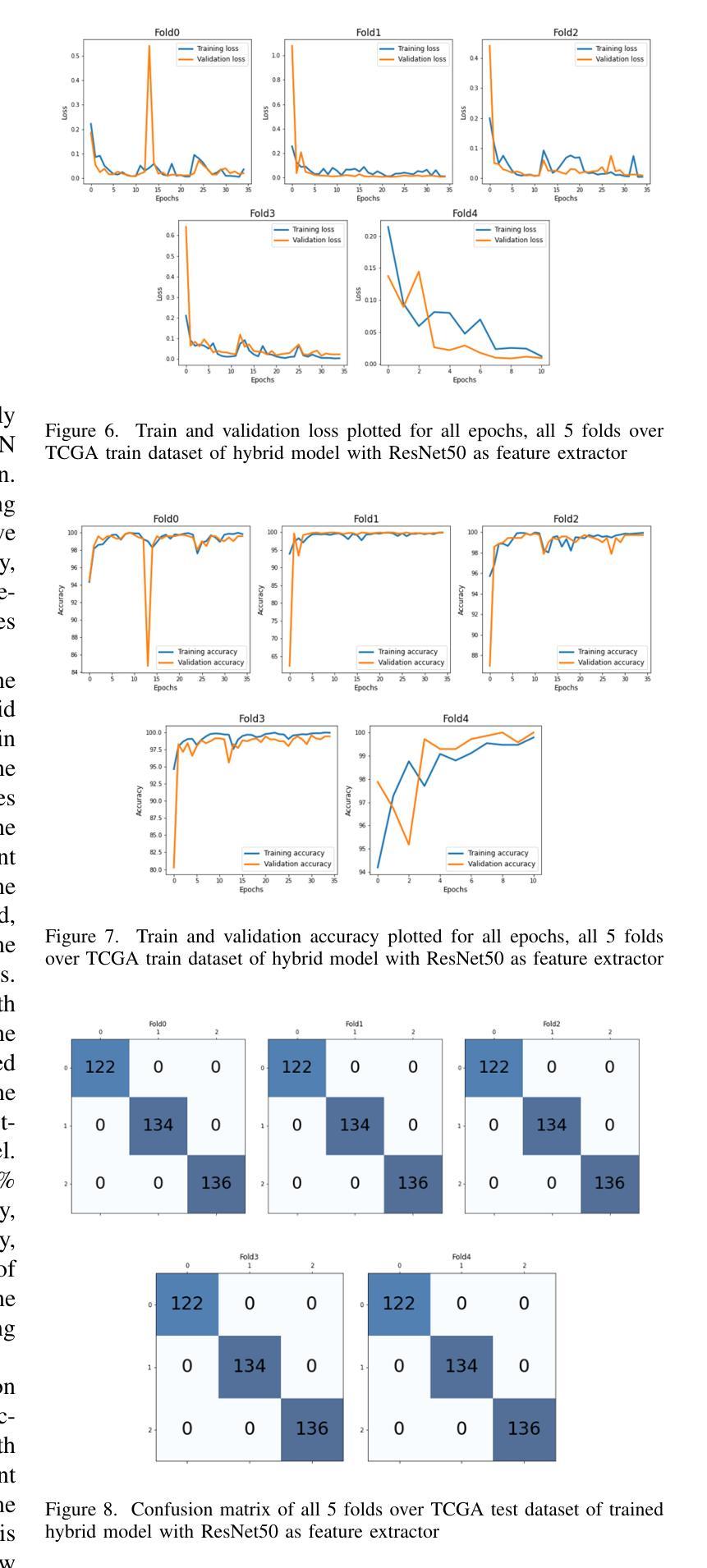
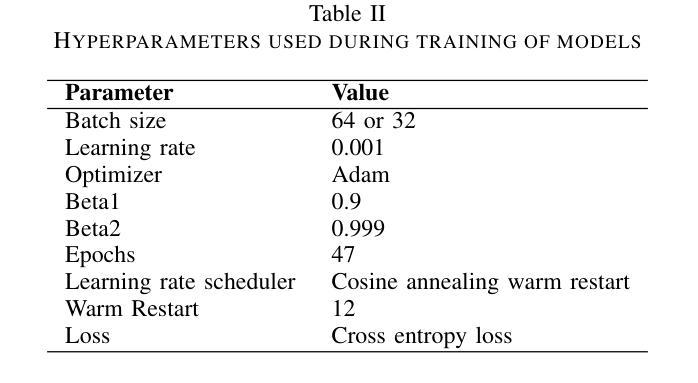
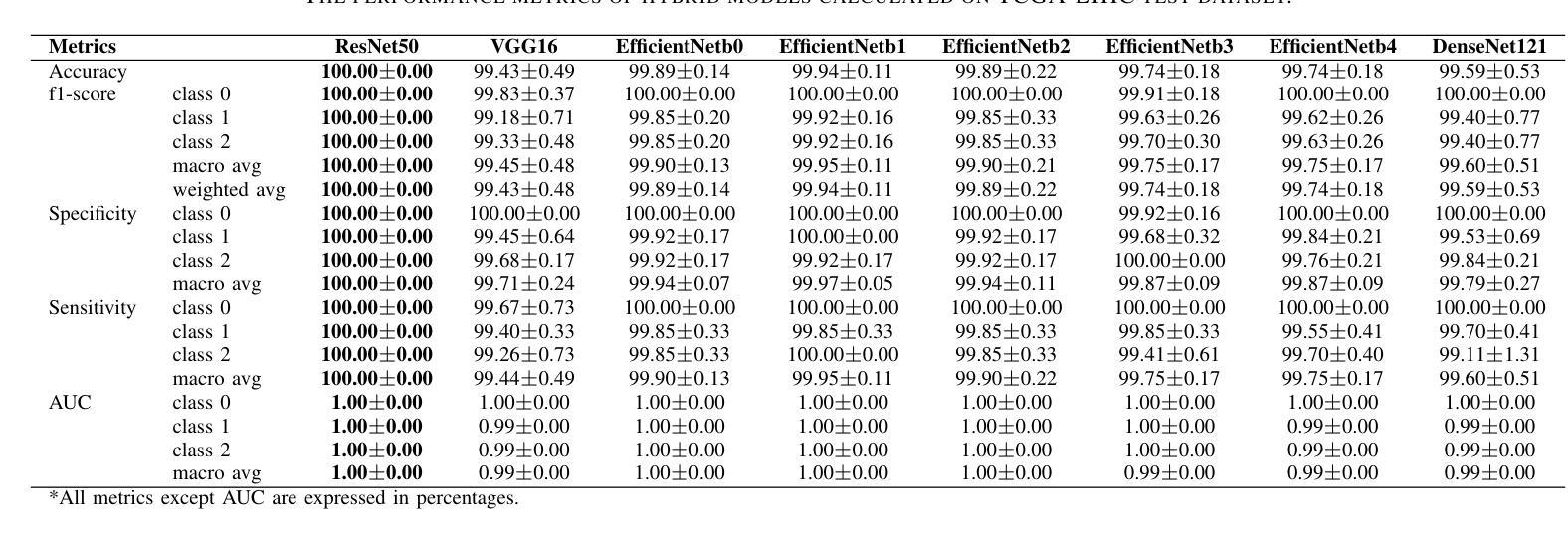
Hybrid deep learning-based strategy for the hepatocellular carcinoma cancer grade classification of H&E stained liver histopathology images
Authors:Ajinkya Deshpande, Deep Gupta, Ankit Bhurane, Nisha Meshram, Sneha Singh, Petia Radeva
Hepatocellular carcinoma (HCC) is a common type of liver cancer whose early-stage diagnosis is a common challenge, mainly due to the manual assessment of hematoxylin and eosin-stained whole slide images, which is a time-consuming process and may lead to variability in decision-making. For accurate detection of HCC, we propose a hybrid deep learning-based architecture that uses transfer learning to extract the features from pre-trained convolutional neural network (CNN) models and a classifier made up of a sequence of fully connected layers. This study uses a publicly available The Cancer Genome Atlas Hepatocellular Carcinoma (TCGA-LIHC)database (n=491) for model development and database of Kasturba Gandhi Medical College (KMC), India for validation. The pre-processing step involves patch extraction, colour normalization, and augmentation that results in 3920 patches for the TCGA dataset. The developed hybrid deep neural network consisting of a CNN-based pre-trained feature extractor and a customized artificial neural network-based classifier is trained using five-fold cross-validation. For this study, eight different state-of-the-art models are trained and tested as feature extractors for the proposed hybrid model. The proposed hybrid model with ResNet50-based feature extractor provided the sensitivity, specificity, F1-score, accuracy, and AUC of 100.00%, 100.00%, 100.00%, 100.00%, and 1.00, respectively on the TCGA database. On the KMC database, EfficientNetb3 resulted in the optimal choice of the feature extractor giving sensitivity, specificity, F1-score, accuracy, and AUC of 96.97, 98.85, 96.71, 96.71, and 0.99, respectively. The proposed hybrid models showed improvement in accuracy of 2% and 4% over the pre-trained models in TCGA-LIHC and KMC databases.
肝细胞癌(HCC)是一种常见的肝癌类型,早期阶段的诊断是一个常见的挑战,这主要是因为需要对苏木精和伊红染色的全切片图像进行手动评估,这一过程既耗时又可能导致决策上的差异。为了准确检测肝细胞癌,我们提出了一种基于深度学习的混合架构,该架构利用迁移学习从预训练的卷积神经网络(CNN)模型中提取特征,并使用由全连接层组成的分类器。本研究使用公开可用的癌症基因组图谱肝细胞癌(TCGA-LIHC)数据库(n=491)进行模型开发,并使用印度卡斯特鲁巴甘地医学院(KMC)数据库进行验证。预处理步骤包括补丁提取、颜色归一化和数据增强,结果产生针对TCGA数据集的3920个补丁。开发的混合深度神经网络由基于CNN的预训练特征提取器和基于定制人工神经网络的分类器组成,采用五折交叉验证进行训练。本研究对八种最先进的模型进行了训练和测试,作为所提出混合模型的特征提取器。采用基于ResNet50的特征提取器的混合模型在TCGA数据库上提供了敏感性、特异性、F1分数、准确度和AUC分别为100.00%、100.00%、100.00%、100.00%和1.00。在KMC数据库中,EfficientNetb3作为特征提取器的最佳选择,其敏感性、特异性、F1分数、准确度和AUC分别为96.97%、98.85%、96.71%、96.71%和0.99。与TCGA-LIHC和KMC数据库中的预训练模型相比,所提出混合模型的准确度提高了2%和4%。
论文及项目相关链接
PDF 14 figure, 9 tables
摘要
针对肝细胞癌早期诊断的挑战,提出了一种混合深度学习架构,利用迁移学习从预训练的卷积神经网络模型中提取特征,并通过全连接层组成的分类器进行分类。研究使用公开可用的癌症基因组图谱肝细胞癌数据库进行模型开发,并使用印度卡斯特尔巴甘地医疗学院数据库进行验证。经过预处理后,利用多种预训练模型的特征提取器与定制的人工神经网络分类器组成的混合深度神经网络进行训练。其中基于ResNet50的特征提取器在癌症基因组图谱数据库上的表现最佳,而EfficientNetb3在卡斯特尔巴甘地医疗学院数据库上表现最优。混合模型相较于预训练模型在准确率上有所提升。
关键见解
- 肝细胞癌的早期诊断面临挑战,主要因为手动评估染色全片图像的时间消耗和决策变量性。
- 提出了一种混合深度学习架构,结合迁移学习、卷积神经网络(CNN)和定制人工神经网络分类器。
- 使用癌症基因组图谱肝细胞癌数据库进行模型开发,印度卡斯特尔巴甘地医疗学院数据库用于验证。
- 预处理步骤包括补丁提取、颜色归一化和增强。
- 基于ResNet50的特征提取器在TCGA数据库上表现最佳,而EfficientNetb3在KMC数据库上表现最优。
- 混合模型相较于预训练模型准确率有所提升。
- 混合模型在诊断敏感性、特异性、F1分数、准确率和AUC等方面均表现出优异性能。
点此查看论文截图


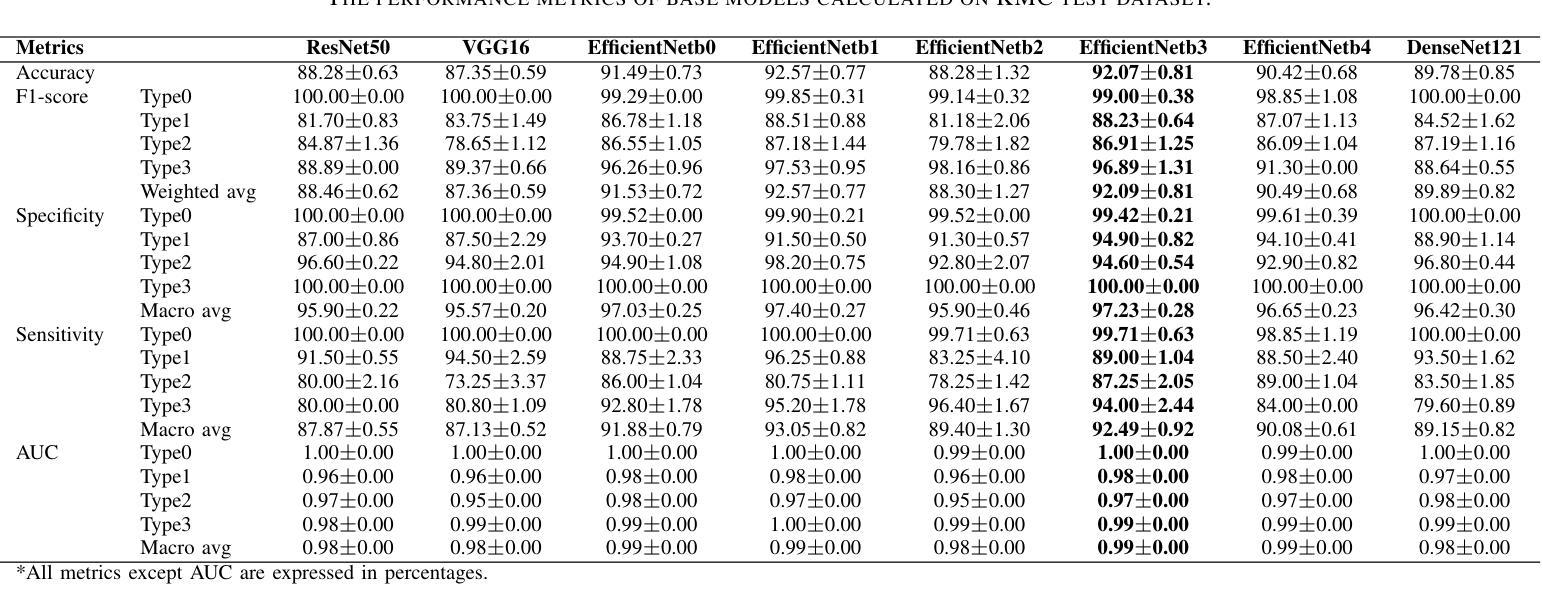
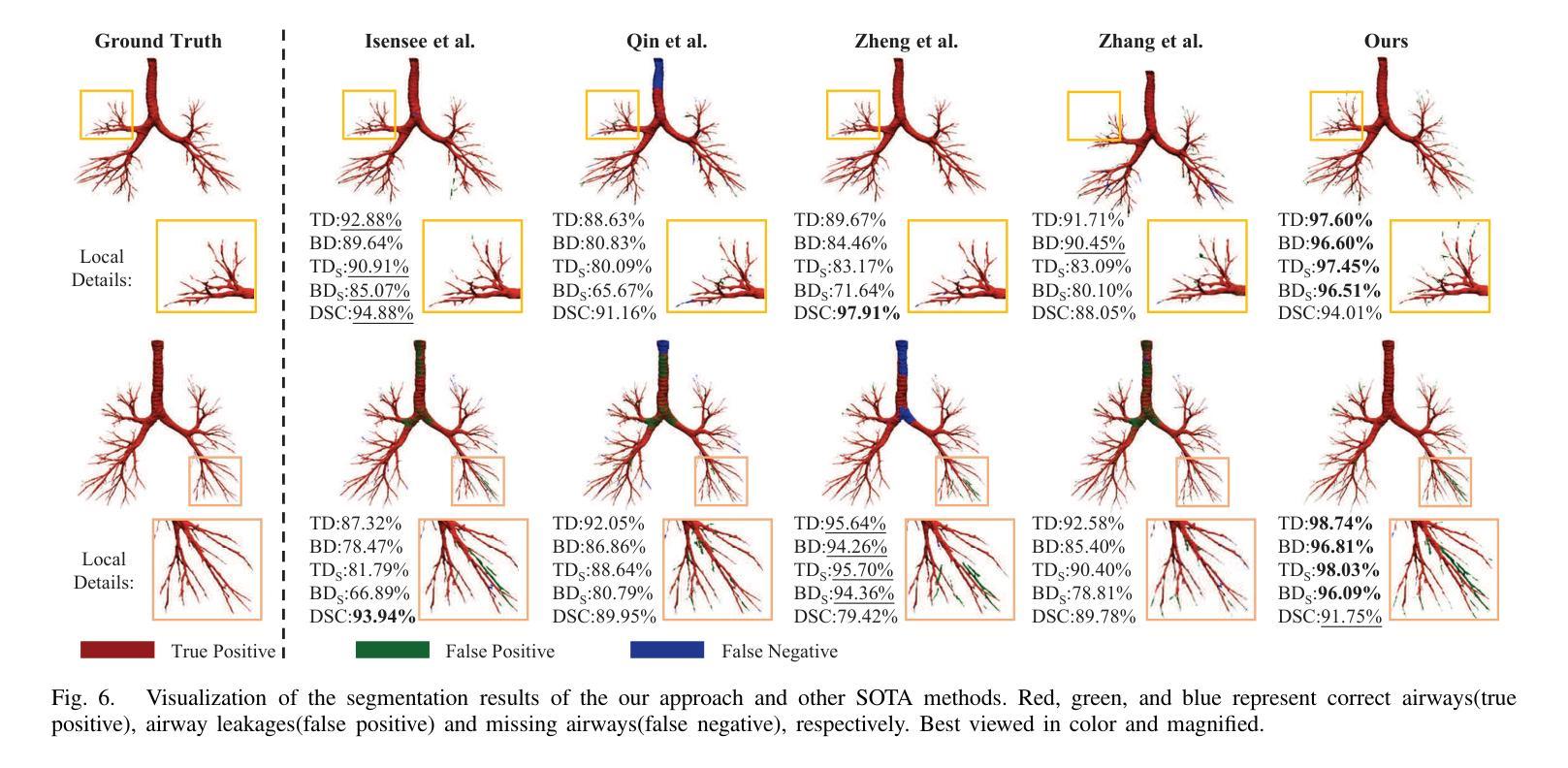
Progressive Curriculum Learning with Scale-Enhanced U-Net for Continuous Airway Segmentation
Authors:Bingyu Yang, Qingyao Tian, Huai Liao, Xinyan Huang, Jinlin Wu, Jingdi Hu, Hongbin Liu
Continuous and accurate segmentation of airways in chest CT images is essential for preoperative planning and real-time bronchoscopy navigation. Despite advances in deep learning for medical image segmentation, maintaining airway continuity remains a challenge, particularly due to intra-class imbalance between large and small branches and blurred CT scan details. To address these challenges, we propose a progressive curriculum learning pipeline and a Scale-Enhanced U-Net (SE-UNet) to enhance segmentation continuity. Specifically, our progressive curriculum learning pipeline consists of three stages: extracting main airways, identifying small airways, and repairing discontinuities. The cropping sampling strategy in each stage reduces feature interference between airways of different scales, effectively addressing the challenge of intra-class imbalance. In the third training stage, we present an Adaptive Topology-Responsive Loss (ATRL) to guide the network to focus on airway continuity. The progressive training pipeline shares the same SE-UNet, integrating multi-scale inputs and Detail Information Enhancers (DIEs) to enhance information flow and effectively capture the intricate details of small airways. Additionally, we propose a robust airway tree parsing method and hierarchical evaluation metrics to provide more clinically relevant and precise analysis. Experiments on both in-house and public datasets demonstrate that our method outperforms existing approaches, significantly improving the accuracy of small airways and the completeness of the airway tree. The code will be released upon publication.
在胸部CT图像中,气道的连续和准确分割对于术前规划和实时支气管镜检查导航至关重要。尽管深度学习方法在医学图像分割方面取得了进展,但保持气道的连续性仍然是一个挑战,特别是由于大分支和小分支之间的类别内不平衡以及CT扫描细节模糊。为了应对这些挑战,我们提出了一种渐进式课程学习流程和尺度增强U-Net(SE-UNet)来提高分割连续性。具体来说,我们的渐进式课程学习流程分为三个阶段:提取主气道、识别小气道和修复不连续处。每个阶段的裁剪采样策略减少了不同规模气道之间的特征干扰,有效地解决了类内不平衡的挑战。在第三个训练阶段,我们提出了一种自适应拓扑响应损失(ATRL)来指导网络关注气道连续性。渐进式训练流程使用相同的SE-UNet,它结合了多尺度输入和细节信息增强器(DIEs),以加强信息流并有效地捕捉小气道的复杂细节。此外,我们还提出了一种稳健的气道树解析方法和分层评估指标,以提供更与临床相关和精确的分析。在内部和公开数据集上的实验表明,我们的方法优于现有方法,显著提高小气道准确性和气道树的完整性。代码将在发布时公布。
论文及项目相关链接
Summary
本文提出一种基于渐进式课程学习和Scale-Enhanced U-Net(SE-UNet)的管道,用于提高胸部CT图像中气道分割的连续性。通过三个阶段的渐进式课程学习,该方法可有效提取主要气道、识别小气道并修复断裂处。利用裁剪采样策略和多尺度输入,SE-UNet解决了类内不平衡和模糊细节的问题。此外,还引入了自适应拓扑响应损失(ATRL)以及气道树解析方法和层次评估指标,以提高分析的精确性和临床相关性。实验证明,该方法优于现有技术,显著提高小气道准确性和气道树的完整性。
Key Takeaways
- 气道在胸部CT图像中的连续准确分割对术前规划和实时支气管镜检查导航至关重要。
- 现有深度学习在医学图像分割中面临气道连续性维持、类内不平衡和模糊细节的挑战。
- 提出了基于渐进式课程学习的管道,包括提取主气道、识别小气道和修复断裂三个阶段。
- 采用裁剪采样策略来减少不同规模气道之间的特征干扰,解决类内不平衡问题。
- 在第三阶段引入自适应拓扑响应损失(ATRL),引导网络关注气道连续性。
- 利用Scale-Enhanced U-Net(SE-UNet)进行多尺度输入和信息增强,有效捕捉小气道细节。
点此查看论文截图

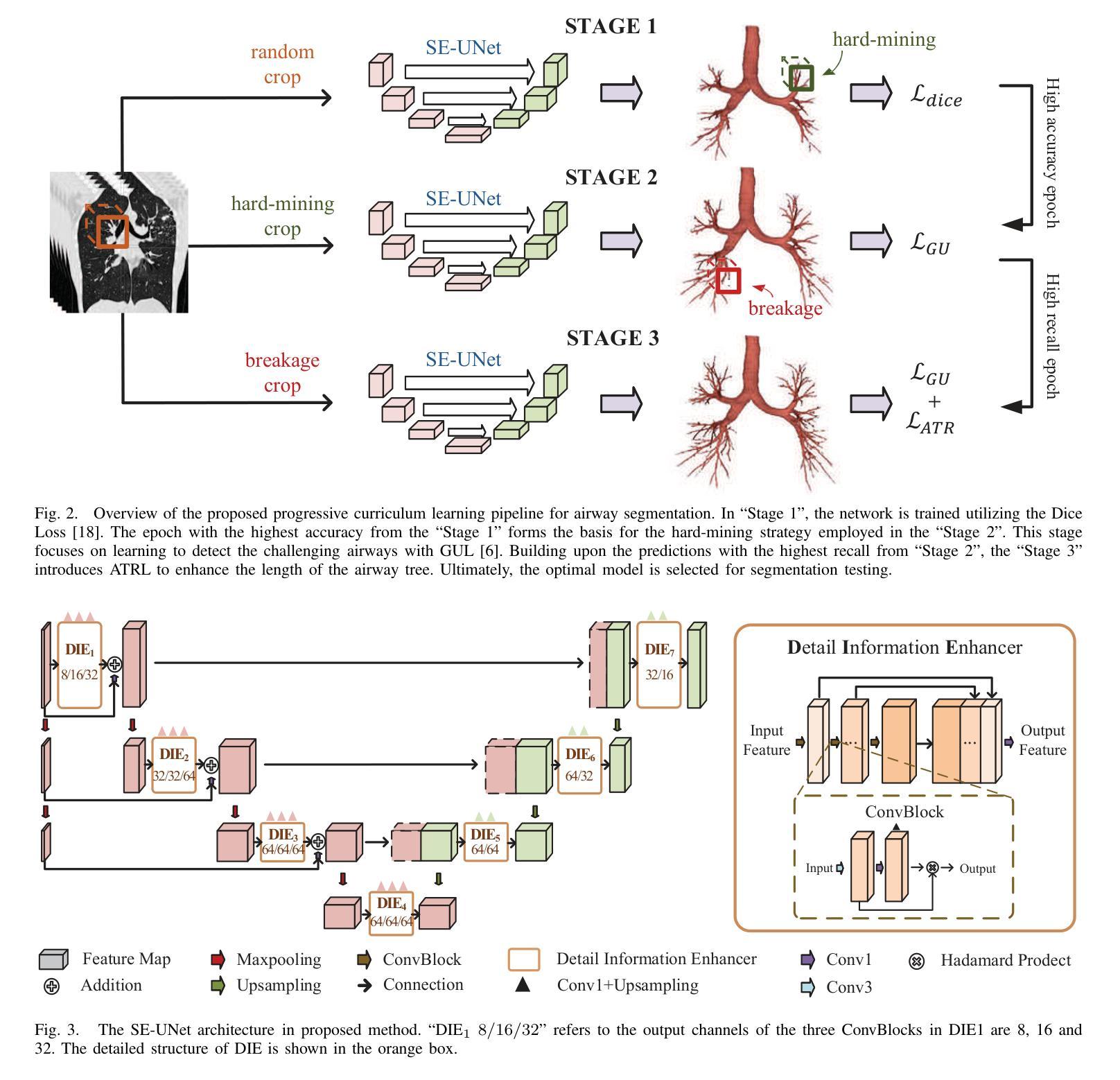
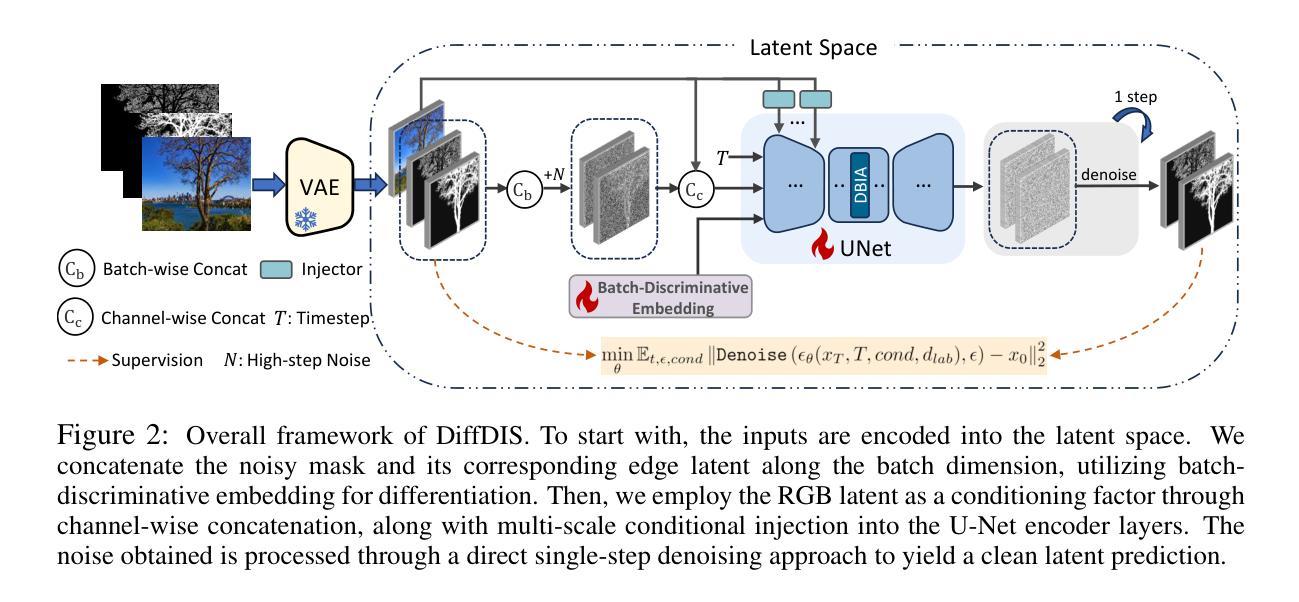
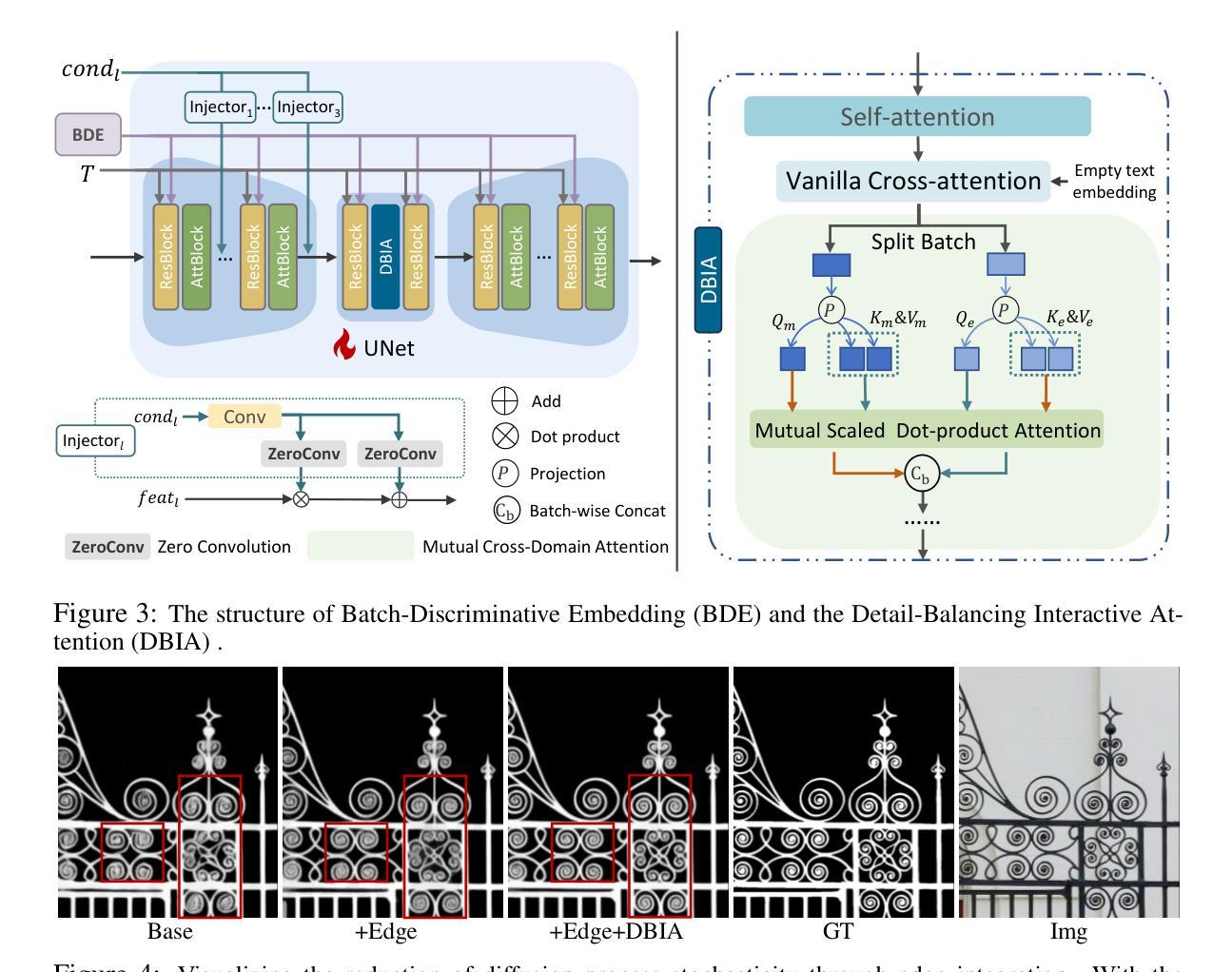
High-Precision Dichotomous Image Segmentation via Probing Diffusion Capacity
Authors:Qian Yu, Peng-Tao Jiang, Hao Zhang, Jinwei Chen, Bo Li, Lihe Zhang, Huchuan Lu
In the realm of high-resolution (HR), fine-grained image segmentation, the primary challenge is balancing broad contextual awareness with the precision required for detailed object delineation, capturing intricate details and the finest edges of objects. Diffusion models, trained on vast datasets comprising billions of image-text pairs, such as SD V2.1, have revolutionized text-to-image synthesis by delivering exceptional quality, fine detail resolution, and strong contextual awareness, making them an attractive solution for high-resolution image segmentation. To this end, we propose DiffDIS, a diffusion-driven segmentation model that taps into the potential of the pre-trained U-Net within diffusion models, specifically designed for high-resolution, fine-grained object segmentation. By leveraging the robust generalization capabilities and rich, versatile image representation prior of the SD models, coupled with a task-specific stable one-step denoising approach, we significantly reduce the inference time while preserving high-fidelity, detailed generation. Additionally, we introduce an auxiliary edge generation task to not only enhance the preservation of fine details of the object boundaries, but reconcile the probabilistic nature of diffusion with the deterministic demands of segmentation. With these refined strategies in place, DiffDIS serves as a rapid object mask generation model, specifically optimized for generating detailed binary maps at high resolutions, while demonstrating impressive accuracy and swift processing. Experiments on the DIS5K dataset demonstrate the superiority of DiffDIS, achieving state-of-the-art results through a streamlined inference process. The source code will be publicly available at https://github.com/qianyu-dlut/DiffDIS.
在高分辨率(HR)精细粒度图像分割领域,主要挑战在于平衡广泛的上下文意识和进行详尽物体轮廓描绘所需的精度,同时捕捉复杂细节和物体的最细微边缘。扩散模型经过在包含数十亿图像文本对的庞大数据集(如SD V2.1)上的训练,以其卓越的质量、精细的细节分辨率和强大的上下文意识,已经彻底改变了文本到图像的合成方式,使其成为高分辨率图像分割的吸引力解决方案。为此,我们提出了DiffDIS扩散驱动分割模型,它通过挖掘扩散模型内预训练U-Net的潜力,特别针对高分辨率精细粒度对象分割进行设计。通过利用SD模型的稳健泛化能力和丰富的通用图像表示先验知识,结合针对任务的稳定一步去噪方法,我们在减少推理时间的同时保持高度保真和详细的生成。此外,我们还引入了一项辅助边缘生成任务,这不仅有助于增强对象边界精细细节的保护,还能协调扩散的概率性与分割的确定性需求。凭借这些改进的策略,DiffDIS作为一个快速对象掩膜生成模型,特别优化了高分辨率下详细二进制地图的生成,展现了令人印象深刻的准确性和快速处理。在DIS5K数据集上的实验证明了DiffDIS的优越性,通过简化的推理过程实现了最新结果。源代码将在https://github.com/qianyu-dlut/DiffDIS上公开提供。
论文及项目相关链接
PDF Published as a conference paper at ICLR 2025
Summary
本文介绍了在高分辨率精细粒度图像分割领域的主要挑战,即平衡广泛的上下文意识和精细对象轮廓的精确描绘。提出一种名为DiffDIS的扩散驱动分割模型,该模型利用扩散模型的U-Net结构,专为高分辨率精细粒度对象分割设计。通过结合SD模型的稳健泛化能力和丰富的图像表示先验知识,以及特定的稳定单步去噪方法,DiffDIS在保持高保真度细节生成的同时显著减少了推理时间。引入辅助边缘生成任务,不仅提高了对象边界精细细节的保留,还协调了扩散的概率性与分割的确定性需求。在DIS5K数据集上的实验表明,DiffDIS具有卓越的性能,实现了简洁的推理过程,达到业界领先水平。
Key Takeaways
- 高分辨率精细粒度图像分割面临平衡上下文意识和对象轮廓精细描绘的挑战。
- 扩散模型在文本到图像合成中表现出卓越的质量和精细的细节分辨率,已成为高分辨率图像分割的吸引力解决方案。
- DiffDIS是一个基于扩散模型的分割模型,专为高分辨率精细粒度对象分割设计。
- DiffDIS利用SD模型的泛化能力和丰富的图像表示先验,结合稳定的一步去噪方法,减少推理时间并保持高保真度细节生成。
- 引入辅助边缘生成任务以提高对象边界的精细细节保留,并协调扩散的概率性与分割的确定性。
- DiffDIS在DIS5K数据集上实现了卓越的性能,达到业界领先水平。
- DiffDIS将公开可用源代码。
点此查看论文截图


Goal-Oriented Semantic Communication for Wireless Image Transmission via Stable Diffusion
Authors:Nan Li, Yansha Deng
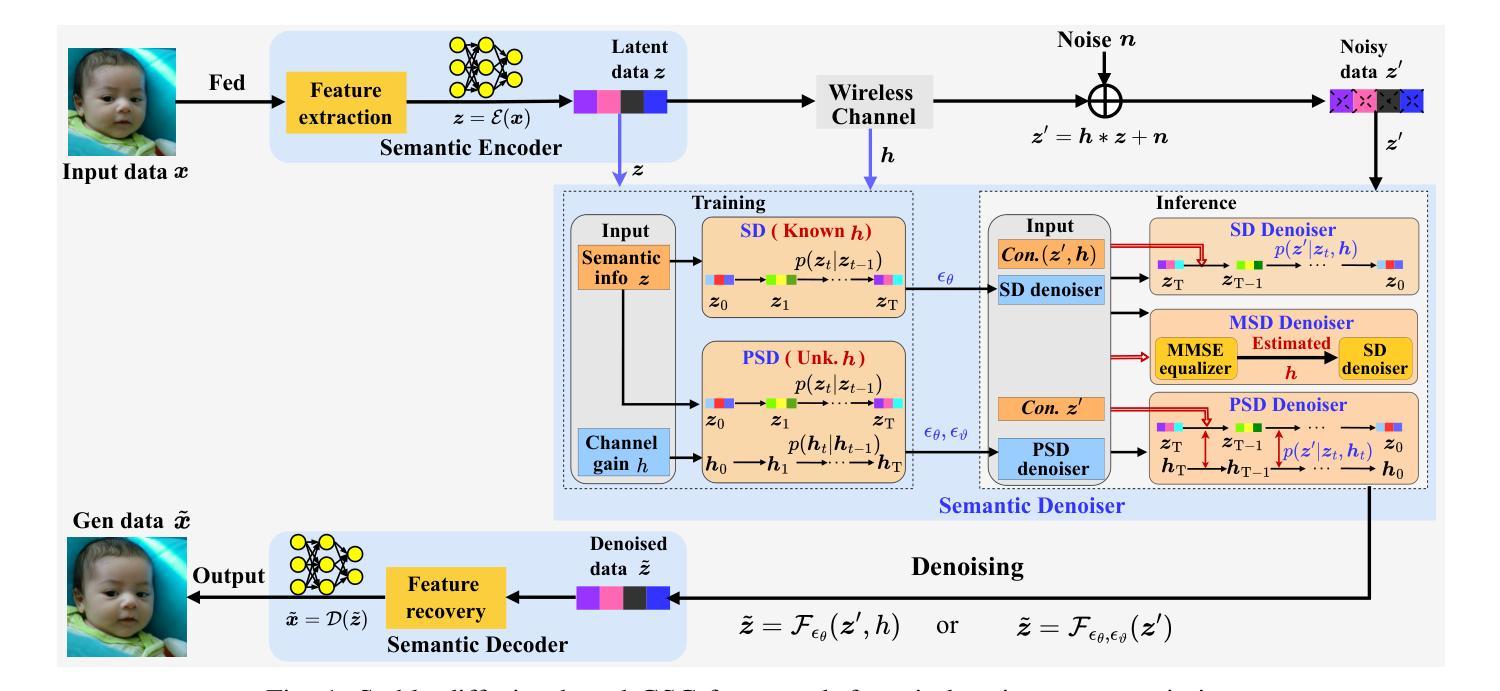
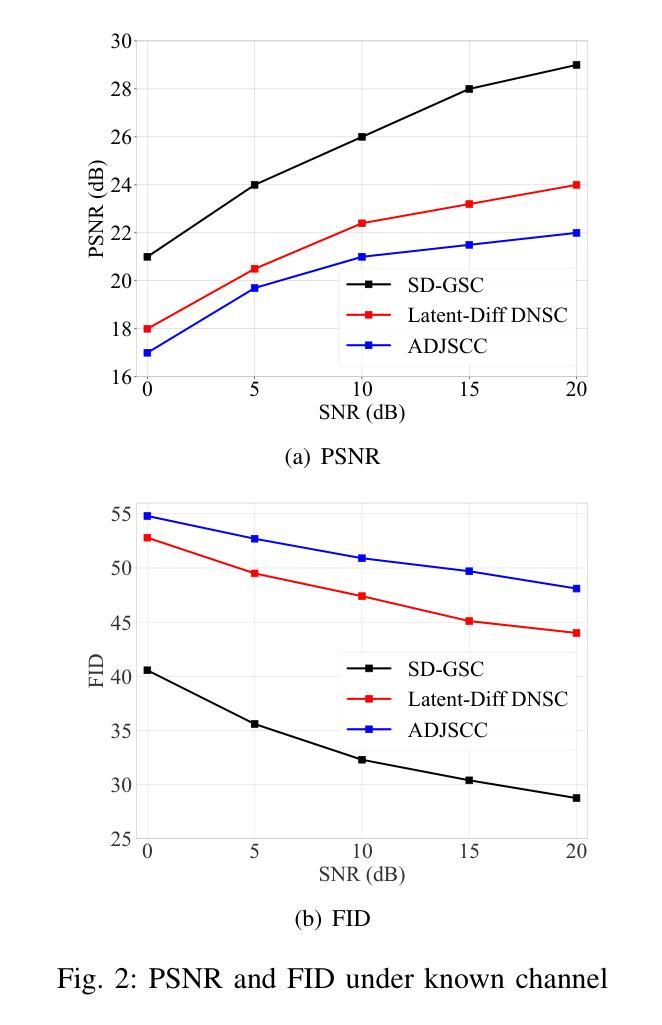
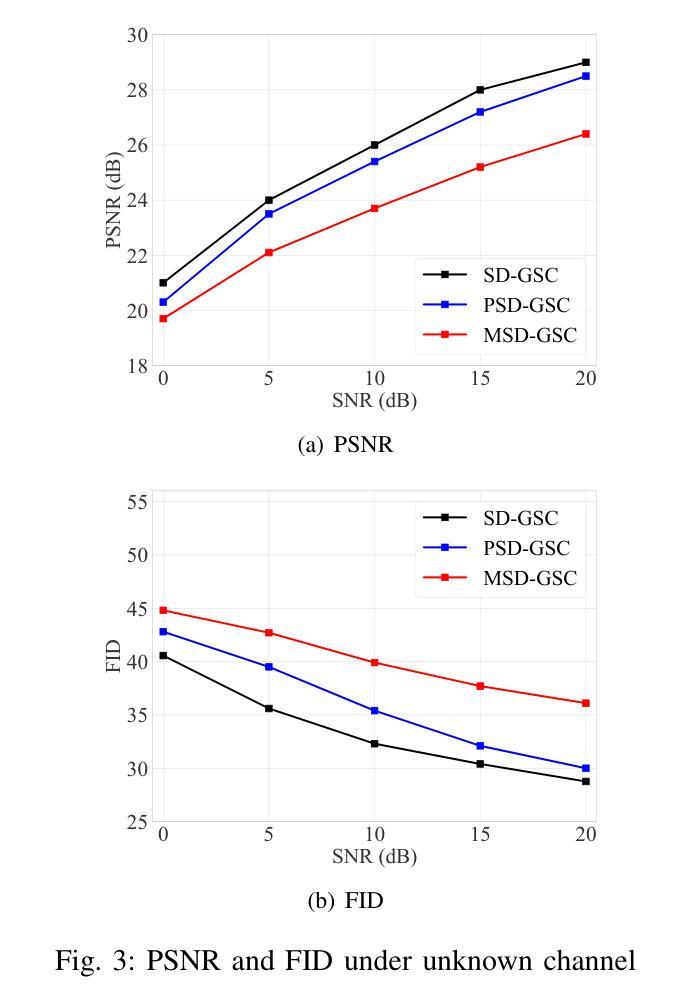
Efficient image transmission is essential for seamless communication and collaboration within the visually-driven digital landscape. To achieve low latency and high-quality image reconstruction over a bandwidth-constrained noisy wireless channel, we propose a stable diffusion (SD)-based goal-oriented semantic communication (GSC) framework. In this framework, we design a semantic autoencoder that effectively extracts semantic information (SI) from images to reduce the transmission data size while ensuring high-quality reconstruction. Recognizing the impact of wireless channel noise on SI transmission, we propose an SD-based denoiser for GSC (SD-GSC) conditional on an instantaneous channel gain to remove the channel noise from the received noisy SI under known channel. For scenarios with unknown channel, we further propose a parallel SD denoiser for GSC (PSD-GSC) to jointly learn the distribution of channel gains and denoise the received SI. It is shown that, with the known channel, our SD-GSC outperforms state-of-the-art ADJSCC and Latent-Diff DNSC, improving Peak Signal-to-Noise Ratio (PSNR) by 32% and 21%, and reducing Fr'echet Inception Distance (FID) by 40% and 35%, respectively. With the unknown channel, our PSD-GSC improves PSNR by 8% and reduces FID by 17% compared to MMSE equalizer-enhanced SD-GSC.
在视觉驱动的数字化景观中,高效的图像传输对于无缝通信和协作至关重要。为了在带宽受限的嘈杂无线通道上实现低延迟和高质量的图像重建,我们提出了基于稳定扩散(SD)的目标导向语义通信(GSC)框架。在此框架中,我们设计了一个语义自动编码器,它能有效地从图像中提取语义信息(SI),以减小传输数据大小,同时确保高质量的重建。考虑到无线信道噪声对SI传输的影响,我们提出了一种基于SD的GSC去噪器(SD-GSC),它依赖于瞬时信道增益,以从接收到的带噪声的SI中消除信道噪声。对于未知信道场景,我们进一步提出了并行SD去噪器GSC(PSD-GSC),以联合学习信道增益的分布并对接收到的SI进行去噪。结果表明,在已知信道的情况下,我们的SD-GSC优于最先进ADJSCC和隐式差分DNSC,峰值信噪比(PSNR)提高了32%和21%,Fréchet Inception Distance(FID)分别降低了40%和35%。在未知信道的情况下,与MMSE均衡增强型SD-GSC相比,我们的PSD-GSC提高了PSNR的8%,并降低了FID的17%。
论文及项目相关链接
PDF Accepted by IEEE ICC 2025
摘要
图像的高效传输在视觉驱动的数字化景观中对于无缝通信和协作至关重要。为实现低延迟、高质量图像在带宽受限的噪声无线通道上的重建,我们提出了基于稳定扩散(SD)的目标导向语义通信(GSC)框架。在此框架中,我们设计了一种语义自动编码器,有效提取图像语义信息(SI),以减少传输数据量并确保高质量重建。考虑到无线信道噪声对SI传输的影响,我们提出了基于瞬时信道增益的SD GSC去噪器(SD-GSC),以从接收到的噪声SI中消除信道噪声。对于未知信道场景,我们进一步提出了并行SD GSC去噪器(PSD-GSC),以联合学习信道增益分布并对接收到的SI进行去噪。结果表明,在已知信道上,我们的SD-GSC优于最先进的ADJSCC和潜在差异DNSC,峰值信号与噪声比(PSNR)提高了32%和21%,Fr’echet inception距离(FID)分别降低了40%和35%。在未知信道上,与MMSE均衡增强SD-GSC相比,我们的PSD-GSC提高了PSNR的8%,并降低了FID的17%。
关键见解
- 稳定扩散(SD)目标导向语义通信(GSC)框架被提出以实现高效图像传输。
- 设计了语义自动编码器以有效提取并传输图像语义信息。
- 针对无线通道噪声问题,提出了基于瞬时信道增益的SD-GSC去噪器。
- 对于未知信道,提出了并行SD GSC去噪器(PSD-GSC)进行联合学习并去噪。
- 在已知信道场景下,SD-GSC显著优于其他方法,在PSNR和FID指标上有明显提高。
- 在未知信道场景下,PSD-GSC相比增强型SD-GSC有性能提升。
- 该框架有助于实现低延迟、高质量图像在带宽受限、噪声干扰的无线通道上的传输。
点此查看论文截图