⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-04 更新
Discovering Global False Negatives On the Fly for Self-supervised Contrastive Learning
Authors:Vicente Balmaseda, Bokun Wang, Ching-Long Lin, Tianbao Yang
In self-supervised contrastive learning, negative pairs are typically constructed using an anchor image and a sample drawn from the entire dataset, excluding the anchor. However, this approach can result in the creation of negative pairs with similar semantics, referred to as “false negatives”, leading to their embeddings being falsely pushed apart. To address this issue, we introduce GloFND, an optimization-based approach that automatically learns on the fly the threshold for each anchor data to identify its false negatives during training. In contrast to previous methods for false negative discovery, our approach globally detects false negatives across the entire dataset rather than locally within the mini-batch. Moreover, its per-iteration computation cost remains independent of the dataset size. Experimental results on image and image-text data demonstrate the effectiveness of the proposed method. Our implementation is available at https://github.com/vibalcam/GloFND .
在自监督对比学习中,通常使用锚图像和从整个数据集中抽取的样本构建负样本对,但不包括锚样本。然而,这种方法可能会导致创建具有相似语义的负样本对,称为“假阴性”,从而导致它们的嵌入被错误地推开。为了解决这个问题,我们引入了GloFND,这是一种基于优化的方法,可以自动学习每个锚数据的阈值,在训练过程中识别其假阴性。与之前发现假阴性的方法相比,我们的方法是在整个数据集上全局检测假阴性,而不是在小型批次内局部检测。此外,其每次迭代的计算成本独立于数据集大小。在图像和图像文本数据上的实验结果证明了所提出方法的有效性。我们的实现可访问于:https://github.com/vibalcam/GloFND 。
论文及项目相关链接
Summary
本文介绍了自监督对比学习中存在的问题,即使用整个数据集构建的负样本对可能包含语义相似的“假阴性”样本,导致它们的嵌入被错误地推离。为此,文章提出了一个优化方法——GloFND。它能够针对每个锚点数据自动在线学习一个阈值来识别假阴性样本。与其他假阴性检测方法的局部检测不同,GloFND全局检测整个数据集中的假阴性样本,且其每次迭代的计算成本独立于数据集大小。实验结果表明该方法的有效性。
Key Takeaways
- 自监督对比学习中存在假阴性问题,即语义相似的负样本对导致嵌入错误推开。
- GloFND是一种优化方法,可自动为每个锚点数据学习一个阈值来识别假阴性样本。
- GloFND全局检测整个数据集中的假阴性样本,而非仅在mini-batch内部进行局部检测。
- GloFND的计算成本独立于数据集大小。
- 实验结果表明,GloFND在图像和图像文本数据上的有效性。
- 该方法的实现已公开在GitHub上可用。
点此查看论文截图



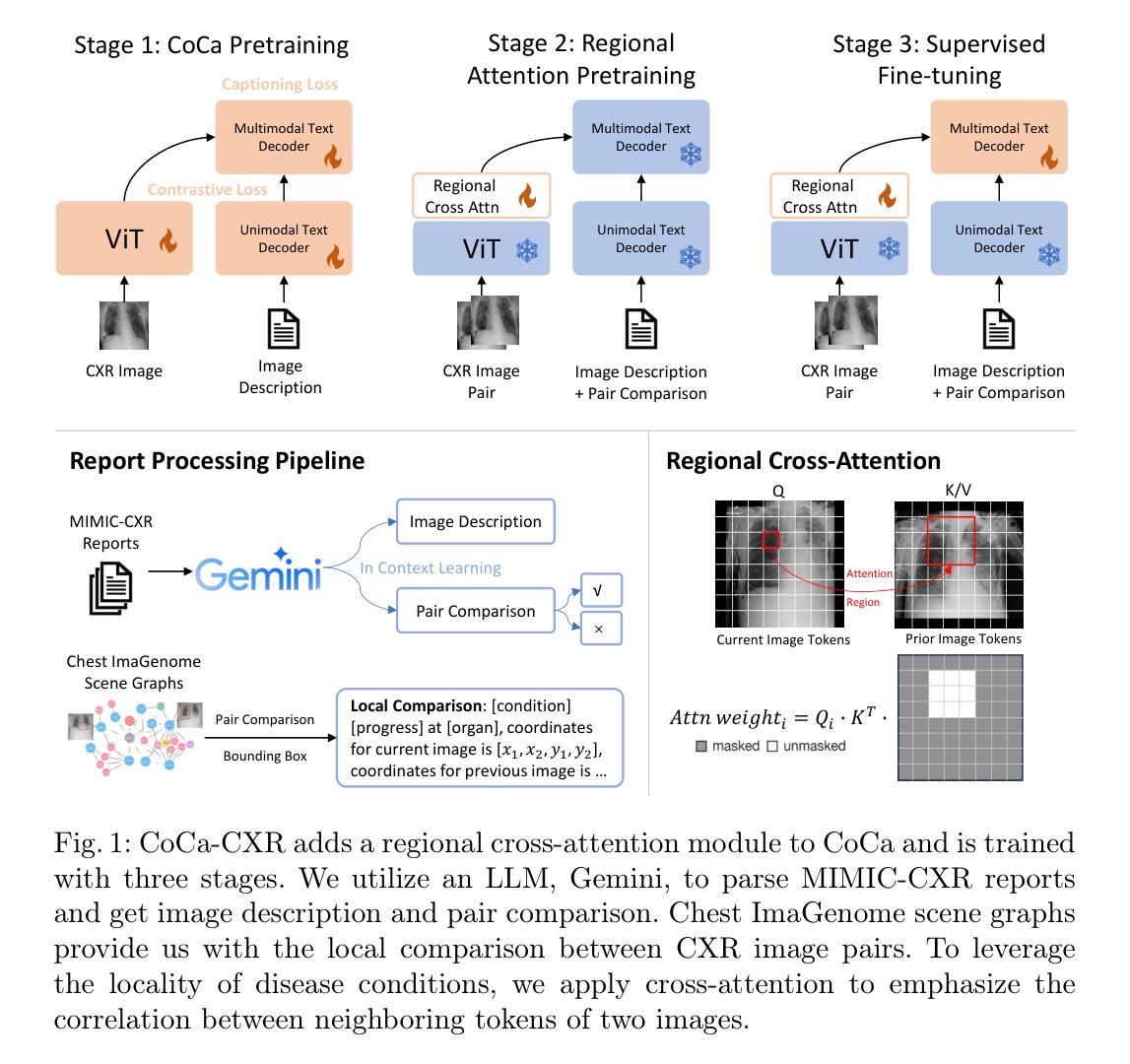
CoCa-CXR: Contrastive Captioners Learn Strong Temporal Structures for Chest X-Ray Vision-Language Understanding
Authors:Yixiong Chen, Shawn Xu, Andrew Sellergren, Yossi Matias, Avinatan Hassidim, Shravya Shetty, Daniel Golden, Alan Yuille, Lin Yang
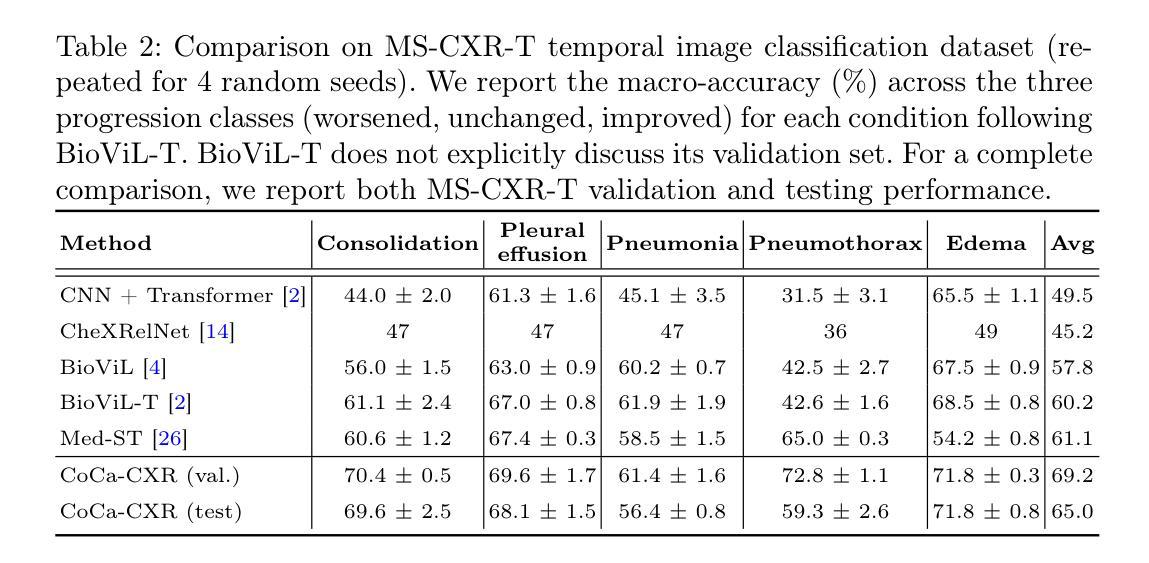
Vision-language models have proven to be of great benefit for medical image analysis since they learn rich semantics from both images and reports. Prior efforts have focused on better alignment of image and text representations to enhance image understanding. However, though explicit reference to a prior image is common in Chest X-Ray (CXR) reports, aligning progression descriptions with the semantics differences in image pairs remains under-explored. In this work, we propose two components to address this issue. (1) A CXR report processing pipeline to extract temporal structure. It processes reports with a large language model (LLM) to separate the description and comparison contexts, and extracts fine-grained annotations from reports. (2) A contrastive captioner model for CXR, namely CoCa-CXR, to learn how to both describe images and their temporal progressions. CoCa-CXR incorporates a novel regional cross-attention module to identify local differences between paired CXR images. Extensive experiments show the superiority of CoCa-CXR on both progression analysis and report generation compared to previous methods. Notably, on MS-CXR-T progression classification, CoCa-CXR obtains 65.0% average testing accuracy on five pulmonary conditions, outperforming the previous state-of-the-art (SOTA) model BioViL-T by 4.8%. It also achieves a RadGraph F1 of 24.2% on MIMIC-CXR, which is comparable to the Med-Gemini foundation model.
视觉语言模型由于从图像和报告中学习到丰富的语义,已证明对医学图像分析具有巨大益处。之前的研究工作主要集中在更好地对齐图像和文本表示,以提高图像理解。然而,虽然在胸部X光(CXR)报告中明确提及先前的图像很常见,但将进展描述与图像对中的语义差异对齐仍被较少探索。在这项工作中,我们提出两个组件来解决这个问题。(1)一个CXR报告处理管道,用于提取时间结构。它使用大型语言模型(LLM)处理报告,以区分描述和比较上下文,并从报告中提取精细的注释。(2)一个针对CXR的对比描述模型,名为CoCa-CXR,学习如何描述图像及其时间进展。CoCa-CXR采用了一个新的区域交叉注意模块,以识别配对CXR图像之间的局部差异。大量实验表明,相较于之前的方法,CoCa-CXR在进展分析和报告生成方面都更为优越。值得注意的是,在MS-CXR-T的进展分类任务中,CoCa-CXR在五种肺部疾病上的平均测试准确率为65.0%,优于之前的最佳模型BioViL-T 4.8%。在MIMIC-CXR上,它实现了RadGraph F1得分为24.2%,与Med-Gemini基础模型相当。
论文及项目相关链接
Summary
本文提出针对胸部X光(CXR)图像分析的新方法。通过构建CXR报告处理管道和对比标注模型CoCa-CXR,实现对图像及其进展的精细描述与对齐。该方法在报告生成和进展分析上均优于以前的方法,在MS-CXR-T的五种肺部状况进展分类上,平均测试准确率为65.0%,超越现有模型BioViL-T 4.8%。在MIMIC-CXR的RadGraph F1得分上,与Med-Gemini基础模型相当。
Key Takeaways
- 胸部X光(CXR)图像分析与报告处理是医学领域的重要课题。
- 现有方法已关注图像和文本的更好对齐以增强图像理解。
- 工作中提出两个组件解决描述与对齐问题:CXR报告处理管道和对比标注模型CoCa-CXR。
- CXR报告处理管道能够提取时间结构,分离描述和比较语境,并从报告中提取精细标注。
- CoCa-CXR模型能描述图像及其进展,并学习如何识别配对CXR图像之间的局部差异。
- 实验表明,CoCa-CXR在进展分析和报告生成方面优于以前的方法。
点此查看论文截图


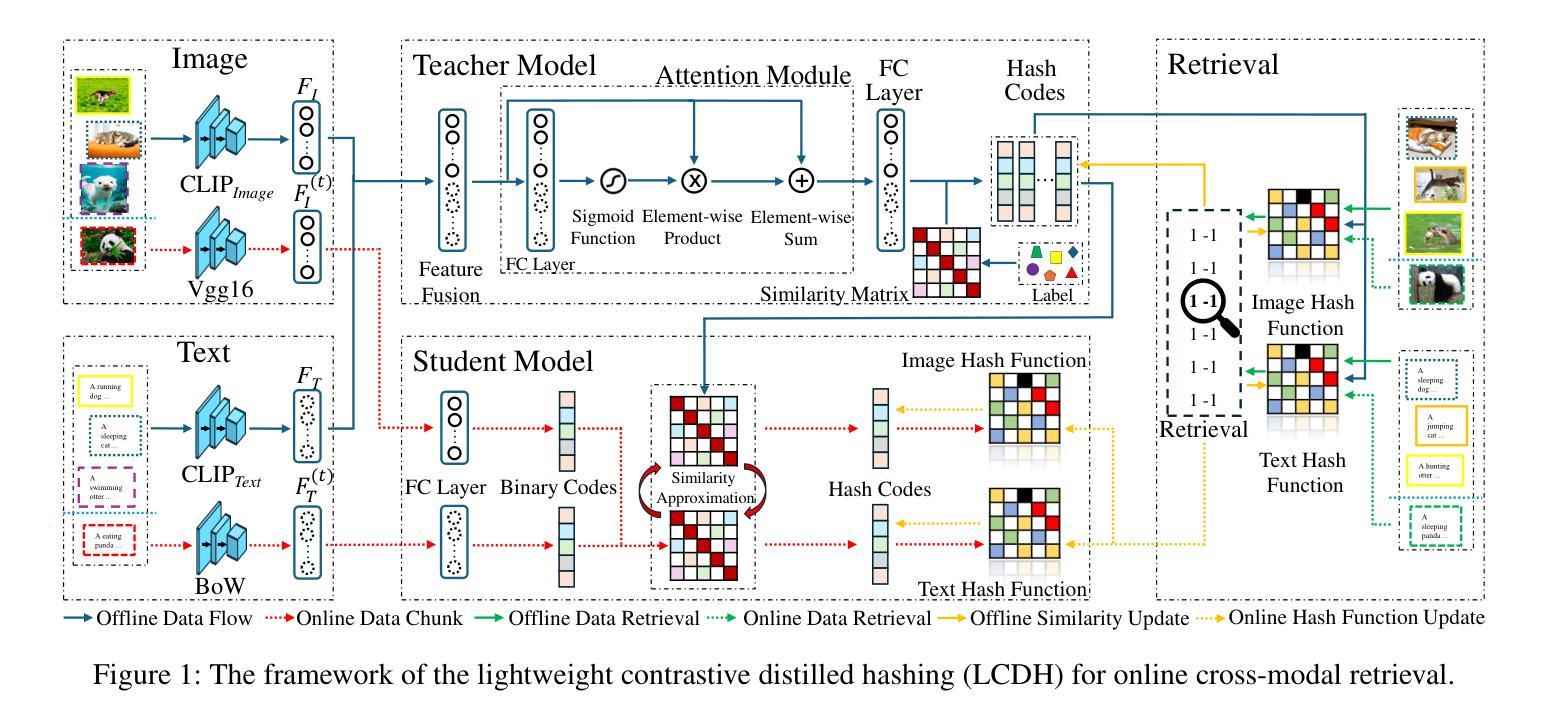
Lightweight Contrastive Distilled Hashing for Online Cross-modal Retrieval
Authors:Jiaxing Li, Lin Jiang, Zeqi Ma, Kaihang Jiang, Xiaozhao Fang, Jie Wen
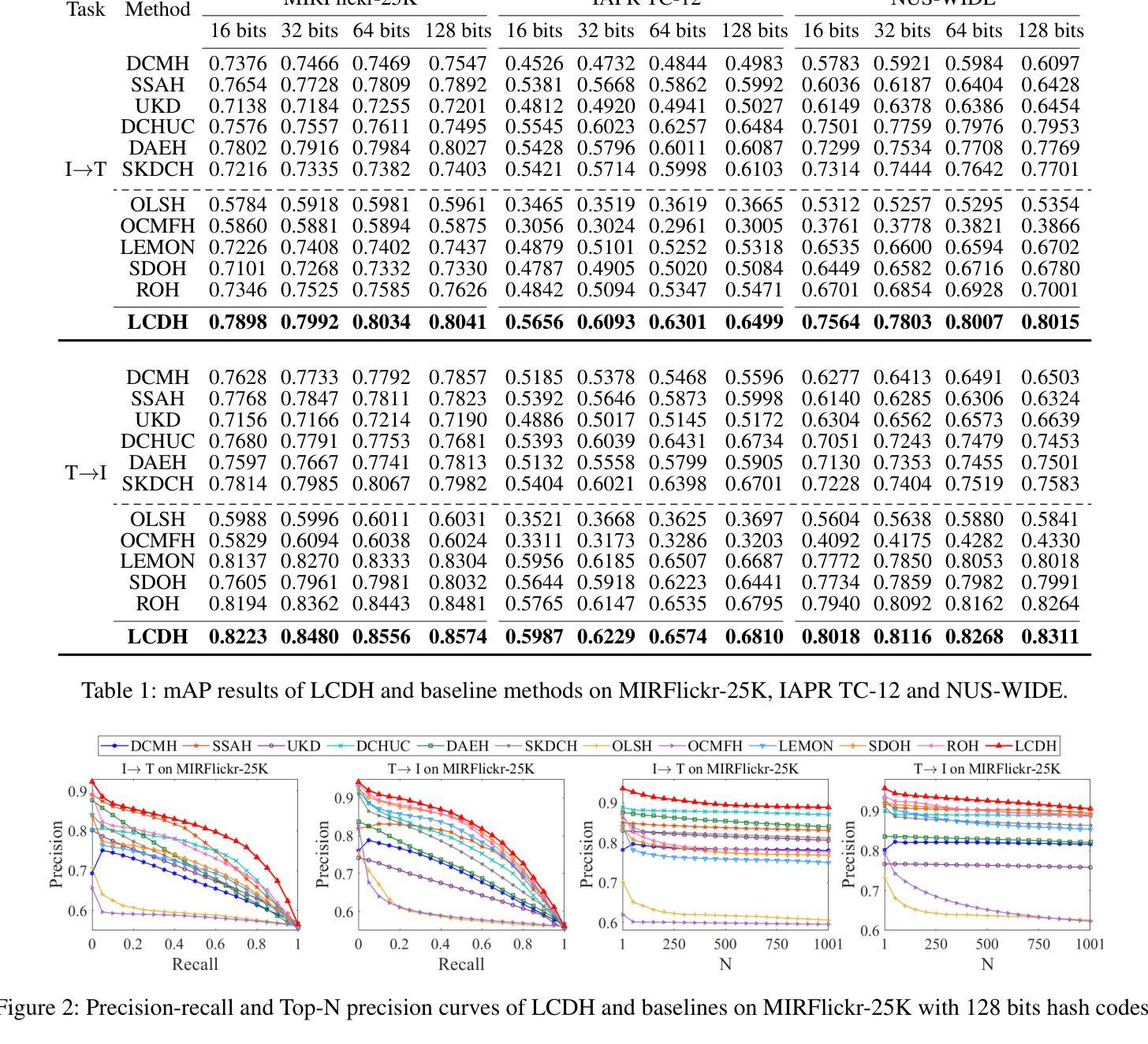
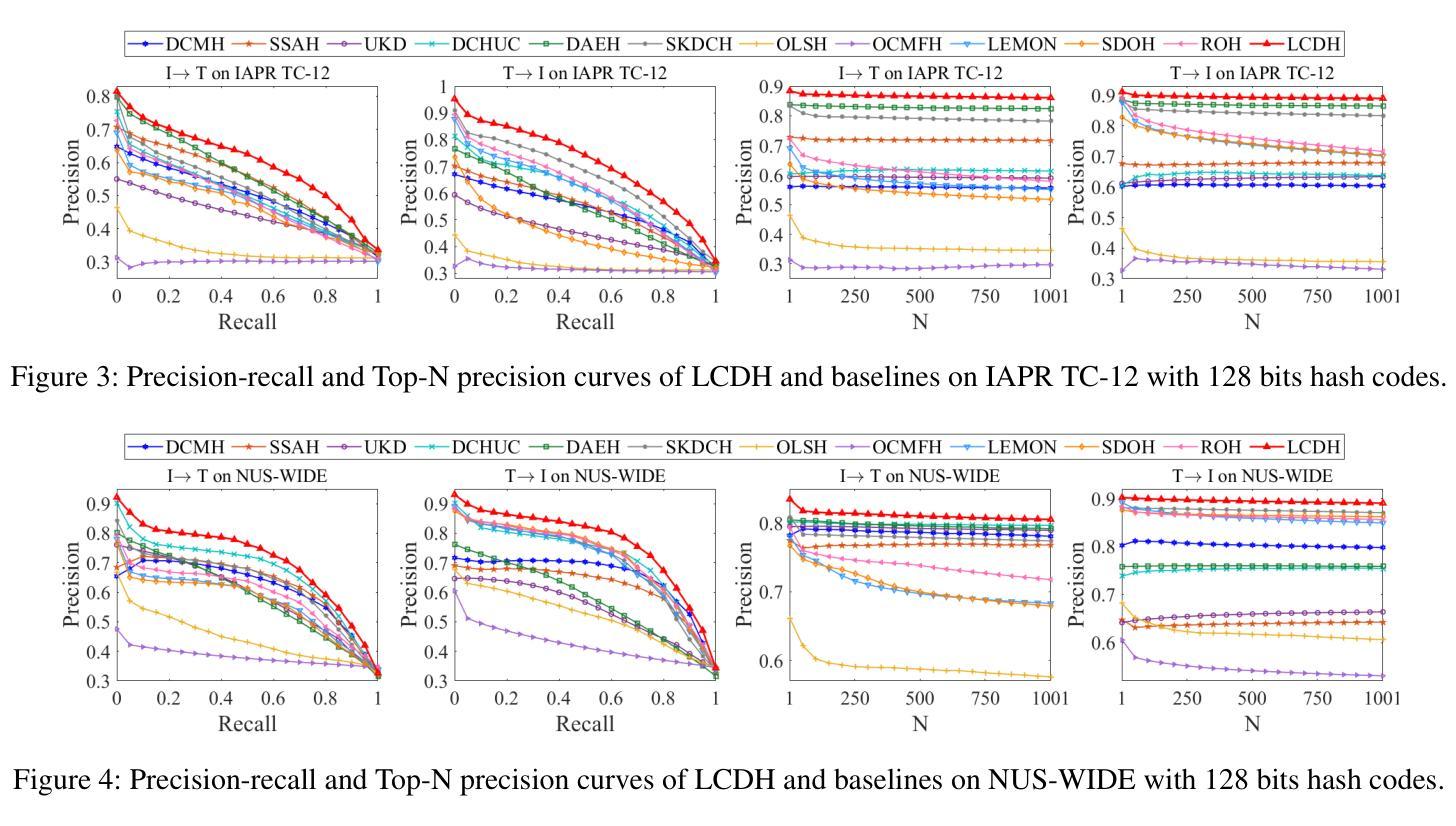
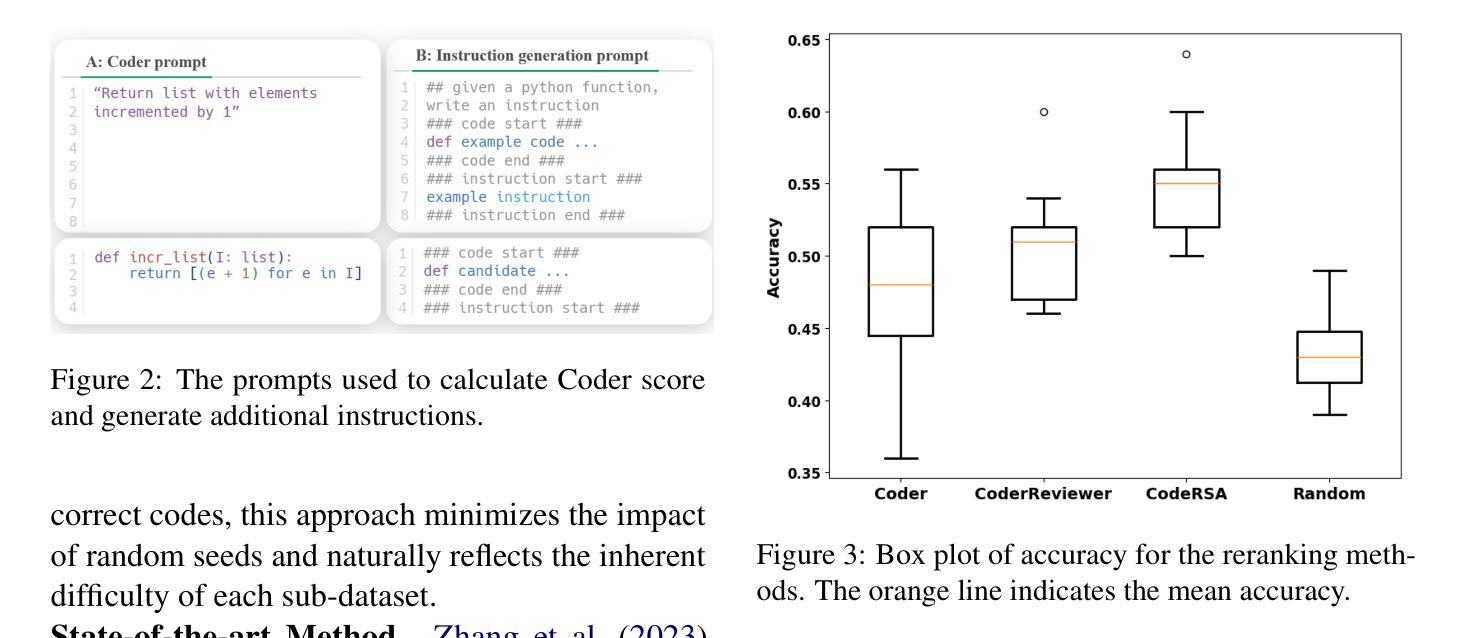
Deep online cross-modal hashing has gained much attention from researchers recently, as its promising applications with low storage requirement, fast retrieval efficiency and cross modality adaptive, etc. However, there still exists some technical hurdles that hinder its applications, e.g., 1) how to extract the coexistent semantic relevance of cross-modal data, 2) how to achieve competitive performance when handling the real time data streams, 3) how to transfer the knowledge learned from offline to online training in a lightweight manner. To address these problems, this paper proposes a lightweight contrastive distilled hashing (LCDH) for cross-modal retrieval, by innovatively bridging the offline and online cross-modal hashing by similarity matrix approximation in a knowledge distillation framework. Specifically, in the teacher network, LCDH first extracts the cross-modal features by the contrastive language-image pre-training (CLIP), which are further fed into an attention module for representation enhancement after feature fusion. Then, the output of the attention module is fed into a FC layer to obtain hash codes for aligning the sizes of similarity matrices for online and offline training. In the student network, LCDH extracts the visual and textual features by lightweight models, and then the features are fed into a FC layer to generate binary codes. Finally, by approximating the similarity matrices, the performance of online hashing in the lightweight student network can be enhanced by the supervision of coexistent semantic relevance that is distilled from the teacher network. Experimental results on three widely used datasets demonstrate that LCDH outperforms some state-of-the-art methods.
深度在线跨模态哈希技术近期受到研究人员的广泛关注,因其具有低存储需求、快速检索效率以及跨模态适应性等潜在应用前景。然而,仍存在一些技术障碍阻碍其应用,例如1)如何提取跨模态数据的共现语义相关性;2)如何处理实时数据流并达到竞争性能;3)如何将离线学习到的知识以轻巧的方式转移到在线训练。为了解决这些问题,本文提出了一种用于跨模态检索的轻量级对比蒸馏哈希(LCDH),通过相似性矩阵近似,以创新的方式在知识蒸馏框架中桥接离线与在线跨模态哈希。具体来说,在教师网络中,LCDH首先通过对比语言-图像预训练(CLIP)提取跨模态特征,这些特征在特征融合后进行表示增强,并输入到注意力模块中。然后,将注意力模块的输出输入到全连接层中以获得哈希码,以对齐在线和离线训练的相似性矩阵大小。在学生网络中,LCDH通过轻量级模型提取视觉和文本特征,然后将这些特征输入到全连接层中以生成二进制码。最后,通过近似相似性矩阵,学生网络中在线哈希的性能可以通过从教师网络中蒸馏出的共现语义相关性的监督来增强。在三个广泛使用的数据集上的实验结果表明,LCDH优于一些最先进的方法。
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary
本文提出一种轻量级对比蒸馏哈希(LCDH)方法,用于跨模态检索。LCDH通过相似性矩阵近似在知识蒸馏框架下创新地连接了离线与在线跨模态哈希。它利用对比语言图像预训练模型(CLIP)提取跨模态特征,通过注意力模块增强表示,然后生成哈希码对齐在线与离线训练的相似性矩阵大小。在蒸馏过程中,学生网络通过轻量级模型提取视觉和文本特征生成二进制码,受益于来自教师网络的共存语义相关性的监督,从而提高在线哈希性能。在三个常用数据集上的实验结果表明LCDH优于一些先进方法。
Key Takeaways
- 深网跨模态哈希因低存储要求、快速检索效率和跨模态适应性等优点而受到关注。
- 存在提取跨模态数据的共存语义相关性、处理实时数据流和从离线到在线训练的轻量级知识转移等技术难题。
- LCDH方法通过相似性矩阵近似在知识蒸馏框架下连接离线与在线跨模态哈希。
- 利用对比语言图像预训练(CLIP)提取跨模态特征,通过注意力模块增强表示。
- LCDH在蒸馏过程中,利用教师网络生成哈希码,监督学生网络的二进制码生成。
- 学生网络通过轻量级模型提取视觉和文本特征,受益于教师网络的监督来提高在线哈希性能。
点此查看论文截图