⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-04 更新
The Common Objects Underwater (COU) Dataset for Robust Underwater Object Detection
Authors:Rishi Mukherjee, Sakshi Singh, Jack McWilliams, Junaed Sattar
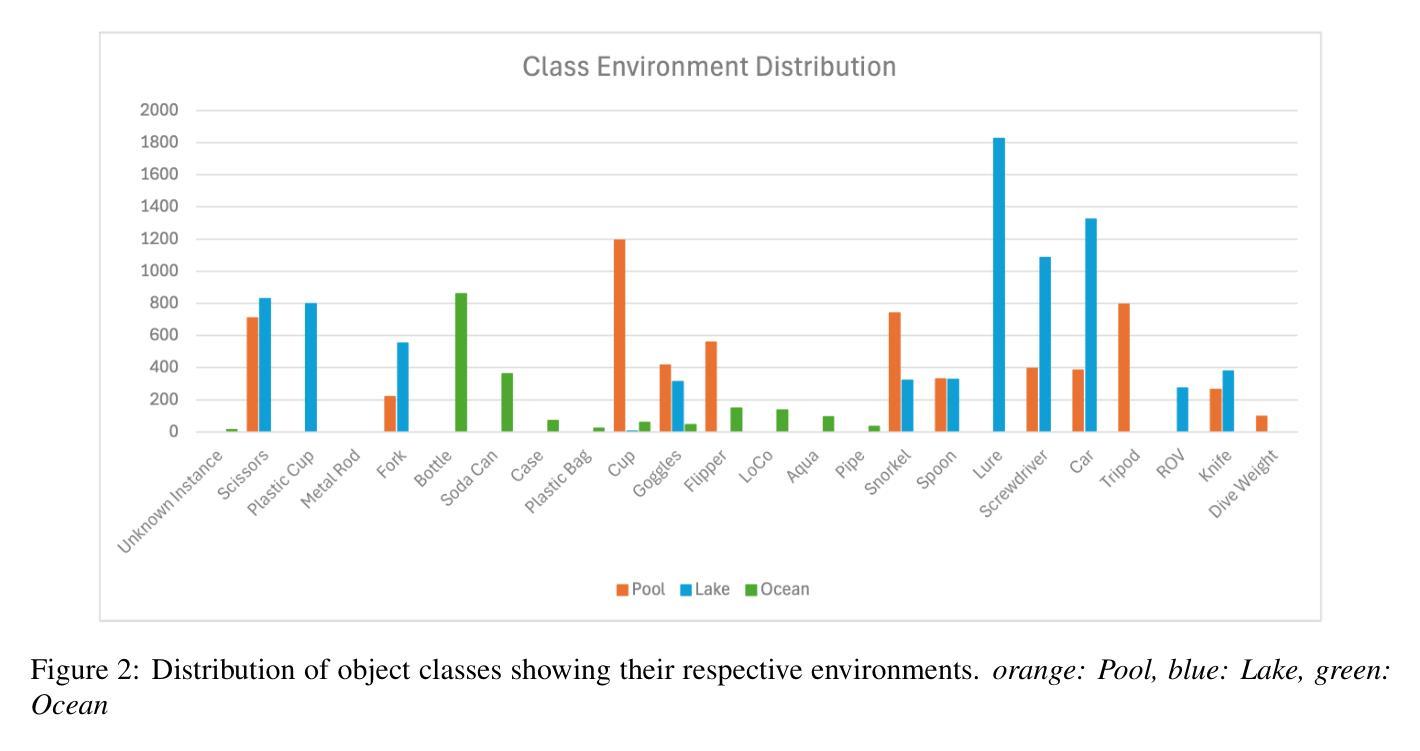
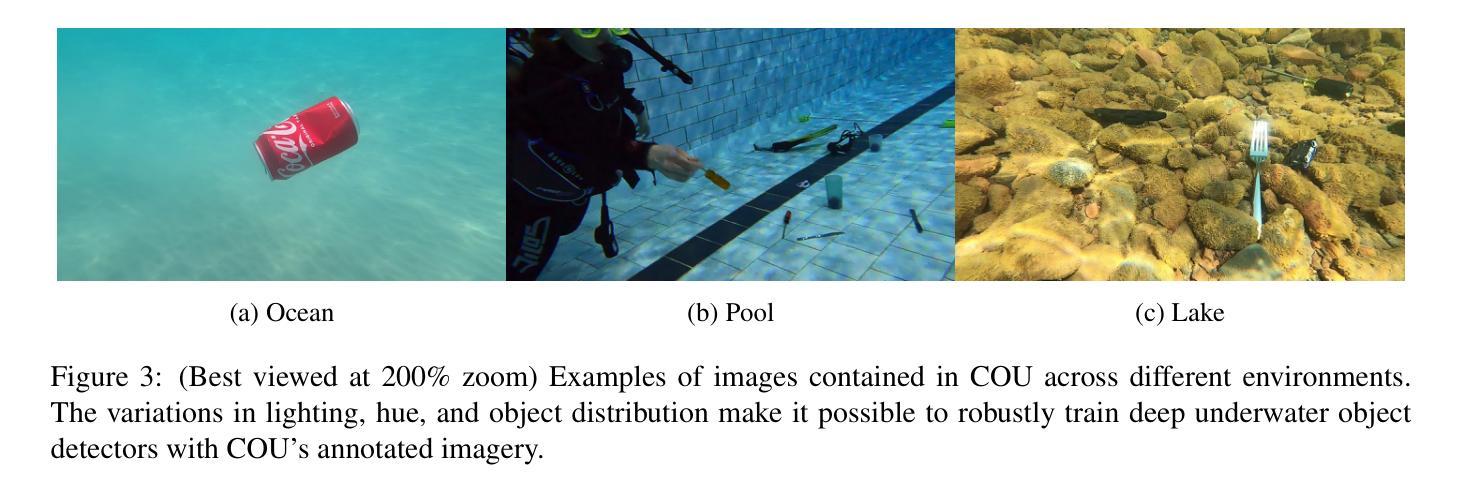
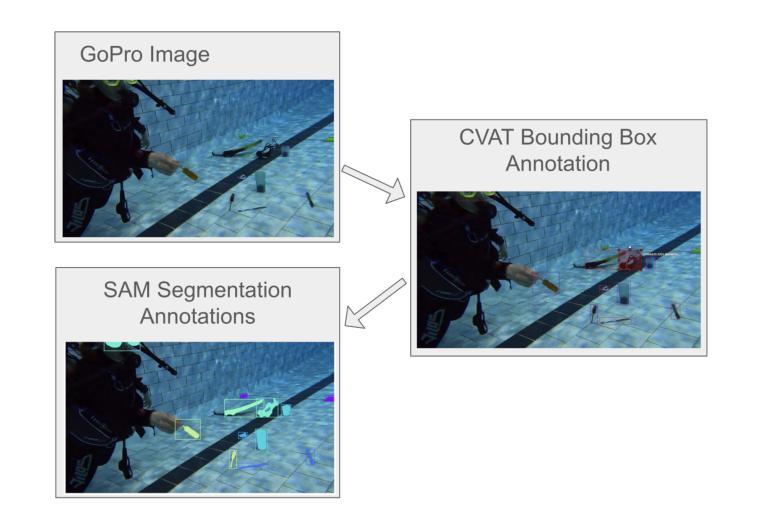
We introduce COU: Common Objects Underwater, an instance-segmented image dataset of commonly found man-made objects in multiple aquatic and marine environments. COU contains approximately 10K segmented images, annotated from images collected during a number of underwater robot field trials in diverse locations. COU has been created to address the lack of datasets with robust class coverage curated for underwater instance segmentation, which is particularly useful for training light-weight, real-time capable detectors for Autonomous Underwater Vehicles (AUVs). In addition, COU addresses the lack of diversity in object classes since the commonly available underwater image datasets focus only on marine life. Currently, COU contains images from both closed-water (pool) and open-water (lakes and oceans) environments, of 24 different classes of objects including marine debris, dive tools, and AUVs. To assess the efficacy of COU in training underwater object detectors, we use three state-of-the-art models to evaluate its performance and accuracy, using a combination of standard accuracy and efficiency metrics. The improved performance of COU-trained detectors over those solely trained on terrestrial data demonstrates the clear advantage of training with annotated underwater images. We make COU available for broad use under open-source licenses.
我们介绍了水下常见物体(COU)数据集,这是一个实例分割图像数据集,包含了多个水生环境中常见的人工物体。COU数据集包含大约10,000张分割图像,这些图像是从多次在不同地点的水下机器人现场试验中收集的图像进行标注的。创建COU数据集是为了解决缺乏针对水下实例分割的健壮类别覆盖的数据集的问题,这对于训练适用于自主式水下车辆(AUV)的轻便、实时检测器特别有用。此外,COU还解决了对象类别缺乏多样性的问题,因为当前可用的水下图像数据集主要只关注海洋生物。目前,COU包含来自封闭水域(游泳池)和开放水域(湖泊和海洋)的环境图像,共包含24个不同类别的物体,包括海洋垃圾、潜水工具和AUV。为了评估COU在训练水下物体检测器方面的有效性,我们使用三种最先进的模型来评估其性能和准确性,结合标准和效率指标。与仅在地面数据上训练的检测器相比,COU训练的检测器的性能有所提高,这证明了使用注释的水下图像进行训练的明显优势。我们已在开源许可证下提供COU供广泛使用。
论文及项目相关链接
Summary:
我们推出了COU:水下常见物体数据集,这是一个针对多种水生和海洋环境中常见人造物体的实例分割图像数据集。COU包含约10,000张分割图像,这些图像是从多次水下机器人现场试验中收集的,并进行了标注。COU的创建旨在解决水下实例分割数据集类别覆盖不足的问题,这对于训练适用于自主式水下机器人(AUV)的轻便、实时检测器特别有用。此外,COU还解决了目标类别缺乏多样性的问题,因为当前可用的水下图像数据集主要关注海洋生物。COU目前包含来自封闭水域(水池)和开放水域(湖泊和海洋)的图像,包含24个不同类别的物体,如海洋垃圾、潜水工具和AUV。为了评估COU在训练水下物体检测器方面的有效性,我们使用三种最新模型对其性能和准确性进行了评估,采用标准准确性和效率指标相结合的方法。与仅使用陆地数据训练的检测器相比,使用COU训练的检测器性能有所提高,证明了使用注释的水下图像进行训练的明显优势。我们公开提供COU数据集以供广泛使用。
Key Takeaways:
- COU是一个实例分割图像数据集,包含在水下环境中常见的人造物体。
- COU数据集由来自多个水下机器人现场试验的图像组成,并进行标注。
- COU旨在解决水下实例分割数据集类别覆盖不足的问题,尤其适用于训练AUV的实时检测器。
- COU具有多样性,包含来自不同水域环境(如水池、湖泊和海洋)的图像。
- COU包含24个不同类别的物体,如海洋垃圾、潜水工具和AUV。
- 通过使用三种最新模型评估,COU在训练水下物体检测器方面表现出优异性能。
点此查看论文截图



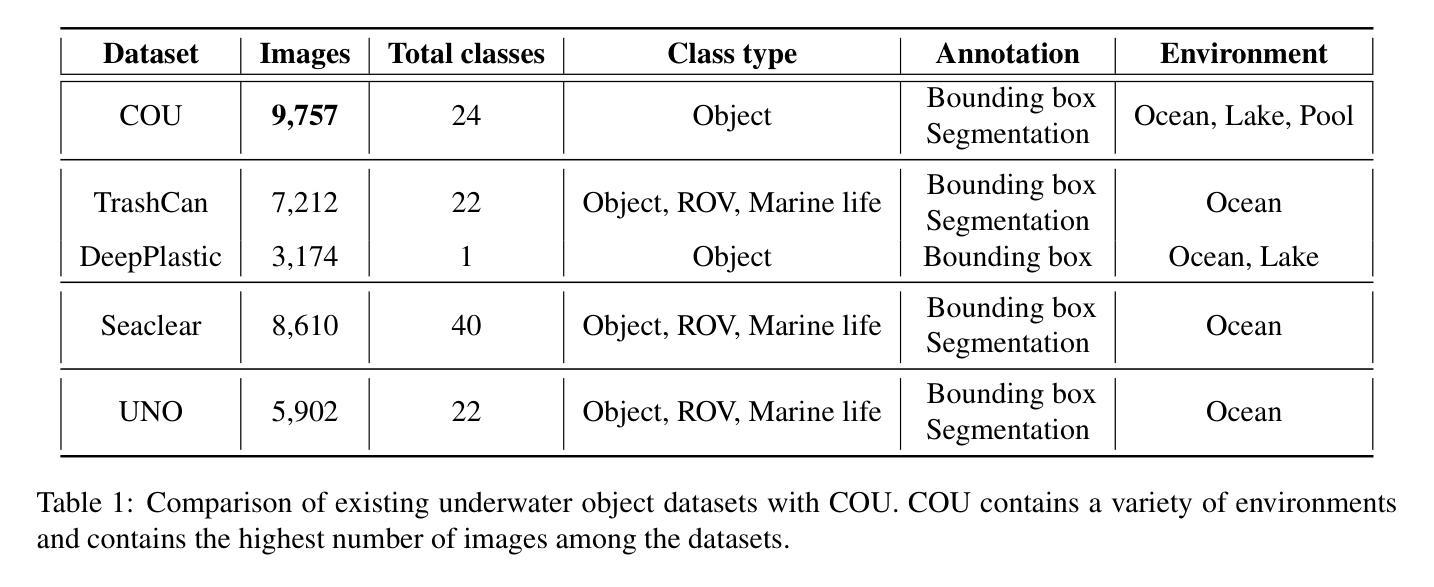
Zero-Shot Automatic Annotation and Instance Segmentation using LLM-Generated Datasets: Eliminating Field Imaging and Manual Annotation for Deep Learning Model Development
Authors:Ranjan Sapkota, Achyut Paudel, Manoj Karkee
Currently, deep learning-based instance segmentation for various applications (e.g., Agriculture) is predominantly performed using a labor-intensive process involving extensive field data collection using sophisticated sensors, followed by careful manual annotation of images, presenting significant logistical and financial challenges to researchers and organizations. The process also slows down the model development and training process. In this study, we presented a novel method for deep learning-based instance segmentation of apples in commercial orchards that eliminates the need for labor-intensive field data collection and manual annotation. Utilizing a Large Language Model (LLM), we synthetically generated orchard images and automatically annotated them using the Segment Anything Model (SAM) integrated with a YOLO11 base model. This method significantly reduces reliance on physical sensors and manual data processing, presenting a major advancement in “Agricultural AI”. The synthetic, auto-annotated dataset was used to train the YOLO11 model for Apple instance segmentation, which was then validated on real orchard images. The results showed that the automatically generated annotations achieved a Dice Coefficient of 0.9513 and an IoU of 0.9303, validating the accuracy and overlap of the mask annotations. All YOLO11 configurations, trained solely on these synthetic datasets with automated annotations, accurately recognized and delineated apples, highlighting the method’s efficacy. Specifically, the YOLO11m-seg configuration achieved a mask precision of 0.902 and a mask mAP@50 of 0.833 on test images collected from a commercial orchard. Additionally, the YOLO11l-seg configuration outperformed other models in validation on 40 LLM-generated images, achieving the highest mask precision and mAP@50 metrics. Keywords: YOLO, SAM, SAMv2, YOLO11, YOLOv11, Segment Anything, YOLO-SAM
当前,基于深度学习的实例分割在各种应用(例如农业)中主要使用劳动密集型过程,涉及使用复杂传感器进行广泛现场数据采集,随后对图像进行仔细的手动标注,这给研究者和组织带来了重大的后勤和财务挑战。这一过程也减缓了模型开发和训练的过程。在本研究中,我们提出了一种基于深度学习的商业果园苹果实例分割的新方法,该方法无需进行劳动密集型的现场数据采集和手动标注。我们利用大型语言模型(LLM)合成生成果园图像,并使用与YOLO11基础模型集成的Segment Anything Model(SAM)进行自动标注。该方法显著减少了对物理传感器和手动数据处理的依赖,是“农业人工智能”领域的一项重大进展。合成的自动标注数据集用于训练YOLO11苹果实例分割模型,该模型在真实的果园图像上进行了验证。结果表明,自动生成的标注达到了Dice系数为0.9513和IoU为0.9303,验证了掩膜标注的准确性和重叠度。所有仅在这些合成数据集上进行训练的YOLO11配置,都能准确识别和划分苹果,突显了该方法的有效性。特别是YOLO11m-seg配置在来自商业果园的测试图像上达到了0.902的掩膜精度和0.833的mAP@50。此外,YOLO11l-seg配置在40张LLM生成的图像上进行验证时,其掩膜精度和mAP@50指标均优于其他模型。
论文及项目相关链接
Summary
该研究提出了一种基于深度学习和大型语言模型(LLM)的苹果实例分割新方法,应用于商业果园。该方法通过合成图像生成和自动标注技术,减少了对数据收集和手动标注的依赖,推动了农业人工智能的进步。训练后的模型在真实果园图像上的验证结果显示,该方法具有较高的准确性和有效性。
Key Takeaways
- 该研究利用深度学习和大型语言模型(LLM)进行苹果实例分割。
- 通过合成图像生成和自动标注技术,减少了对数据收集和手动标注的依赖。
- 方法实现了较高的准确性和有效性,在真实果园图像上的验证结果表现出色。
- YOLO11模型在苹果实例分割任务中表现优异。
- 研究中采用了多种YOLO11配置,均能有效识别和划分苹果。
- YOLO11m-seg配置在测试图像上达到了较高的精度和mAP@50指标。
点此查看论文截图



A Multi-Source Data Fusion-based Semantic Segmentation Model for Relic Landslide Detection
Authors:Yiming Zhou, Yuexing Peng, Junchuan Yu, Daqing Ge, Wei Xiang
As a natural disaster, landslide often brings tremendous losses to human lives, so it urgently demands reliable detection of landslide risks. When detecting relic landslides that present important information for landslide risk warning, problems such as visual blur and small-sized dataset cause great challenges when using remote sensing images. To extract accurate semantic features, a hyper-pixel-wise contrastive learning augmented segmentation network (HPCL-Net) is proposed, which augments the local salient feature extraction from boundaries of landslides through HPCL and fuses heterogeneous information in the semantic space from high-resolution remote sensing images and digital elevation model data. For full utilization of precious samples, a global hyper-pixel-wise sample pair queues-based contrastive learning method is developed, which includes the construction of global queues that store hyper-pixel-wise samples and the updating scheme of a momentum encoder, reliably enhancing the extraction ability of semantic features. The proposed HPCL-Net is evaluated on the Loess Plateau relic landslide dataset and experimental results verify that the proposed HPCL-Net greatly outperforms existing models, where the mIoU is increased from 0.620 to 0.651, the Landslide IoU is improved from 0.334 to 0.394 and the F1score is enhanced from 0.501 to 0.565.
作为自然灾害的一种,山体滑坡经常给人类生命带来巨大损失,因此迫切需要进行可靠的山体滑坡风险检测。在使用遥感图像检测遗迹山体滑坡(为山体滑坡风险预警提供重要信息)时,视觉模糊和小型数据集等问题带来了很大的挑战。为了提取准确的语义特征,提出了一种超像素级对比学习增强分割网络(HPCL-Net)。它通过HPCL增强了从山体滑坡边界的局部显著特征提取,并融合了来自高分辨率遥感图像和数字高程模型数据的语义空间中的异质信息。为了充分利用珍贵样本,开发了一种基于全局超像素级样本对队列对比学习方法,包括构建存储超像素级样本的全局队列和动量编码器的更新方案,可靠地提高了语义特征的提取能力。在黄土高原遗迹山体滑坡数据集上对提出的HPCL-Net进行了评估,实验结果验证了HPCL-Net相较于现有模型表现出色,其中mIoU从0.620提高到0.651,滑坡IoU从0.334提高到0.394,F1分数从0.501提高到0.565。
论文及项目相关链接
Summary
本文介绍了一种基于超像素级对比学习的滑坡分割网络(HPCL-Net),用于解决在利用遥感图像检测滑坡时面临的问题。通过使用超像素级对比学习,增强了局部显著特征提取能力,融合了高分辨率遥感图像和数字高程模型数据的异质信息。开发了一种基于全局超像素级样本对队列对比学习方法,充分利用珍贵样本。实验结果表明,HPCL-Net在黄土高原遗迹滑坡数据集上的表现优于现有模型。
Key Takeaways
- HPCL-Net能有效解决遥感图像检测滑坡时面临的问题,如视觉模糊和小型数据集挑战。
- 通过超像素级对比学习,增强了局部显著特征提取能力。
- 融合了高分辨率遥感图像和数字高程模型数据的异质信息。
- 开发了基于全局超像素级样本对队列对比学习方法,充分利用珍贵样本。
- HPCL-Net在黄土高原遗迹滑坡数据集上的表现进行了评估。
- 与现有模型相比,HPCL-Net在mIoU、滑坡IoU和F1分数等评价指标上有所改进。
点此查看论文截图