⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-04 更新
Adaptive Keyframe Sampling for Long Video Understanding
Authors:Xi Tang, Jihao Qiu, Lingxi Xie, Yunjie Tian, Jianbin Jiao, Qixiang Ye
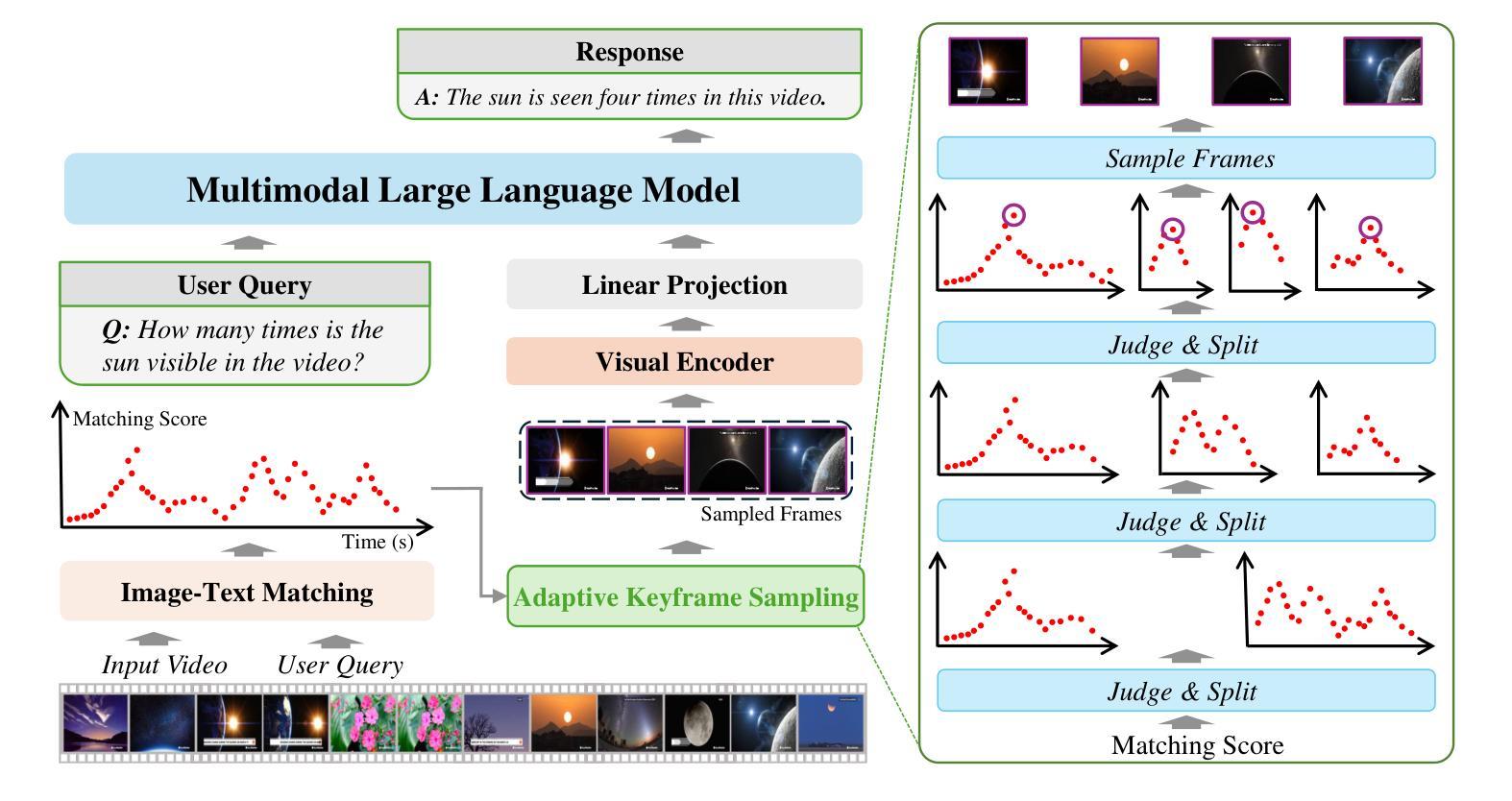
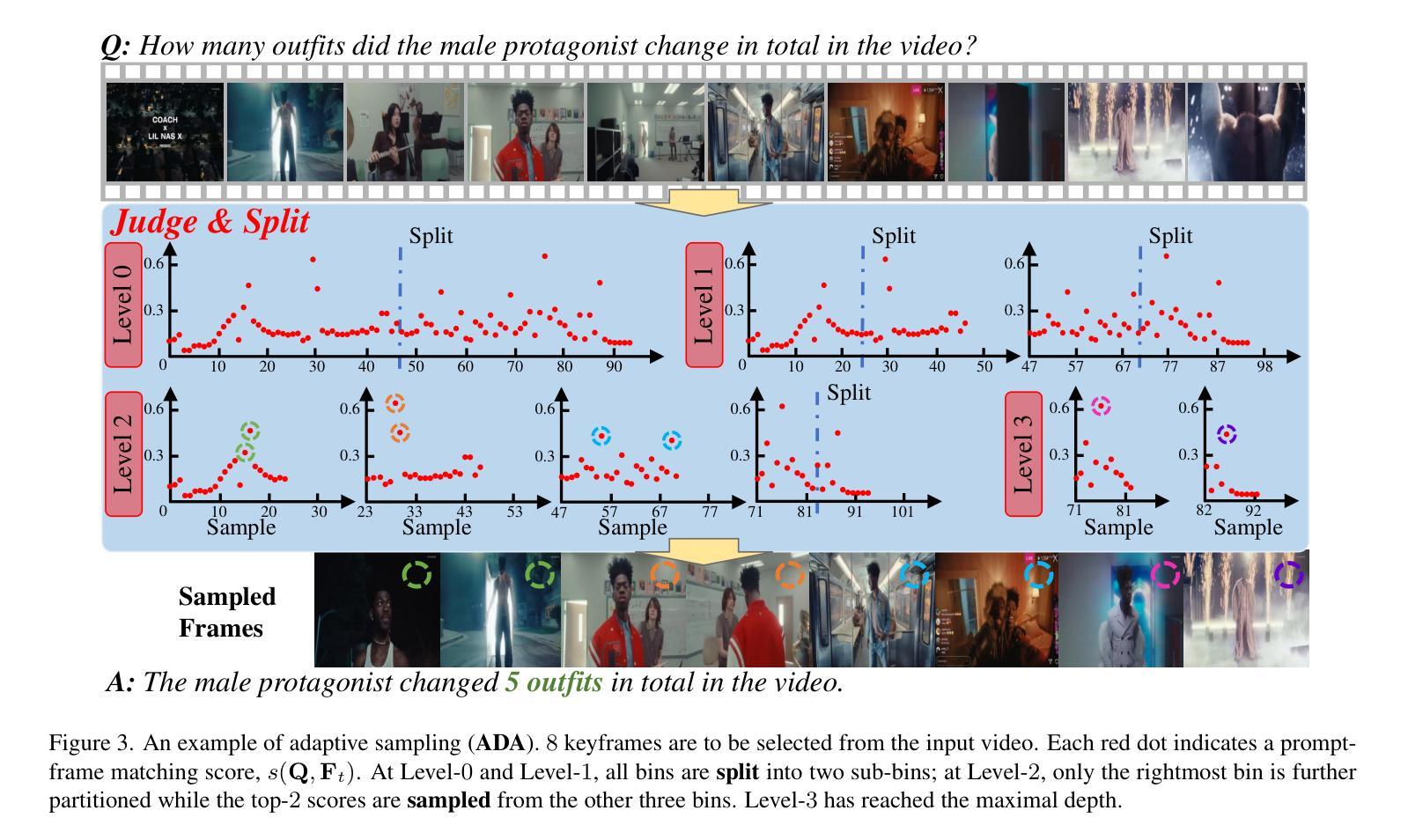
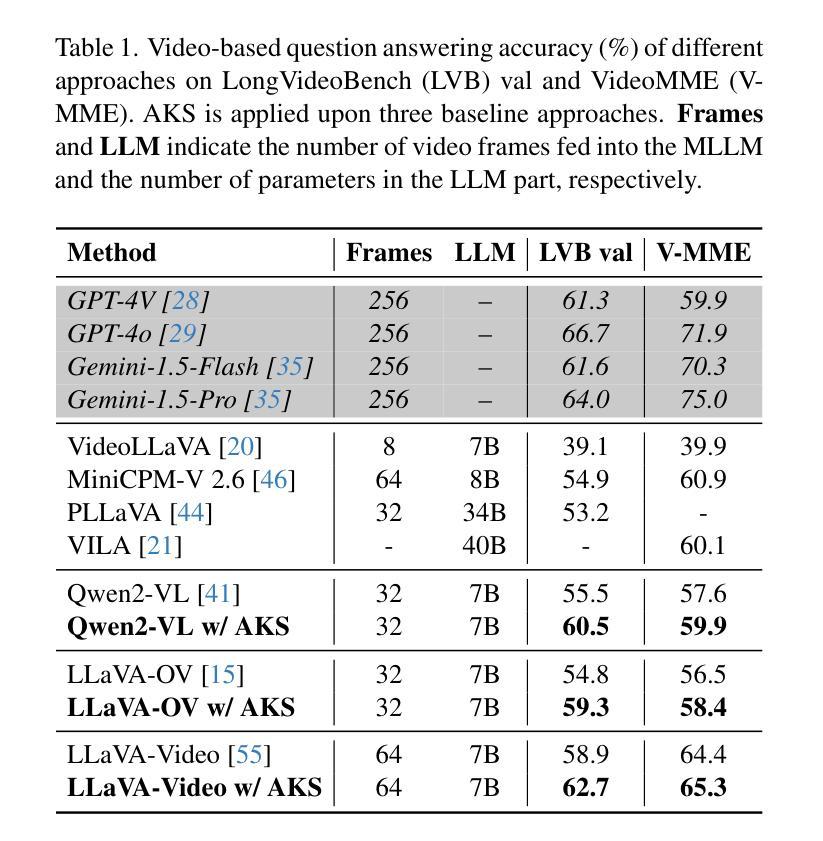
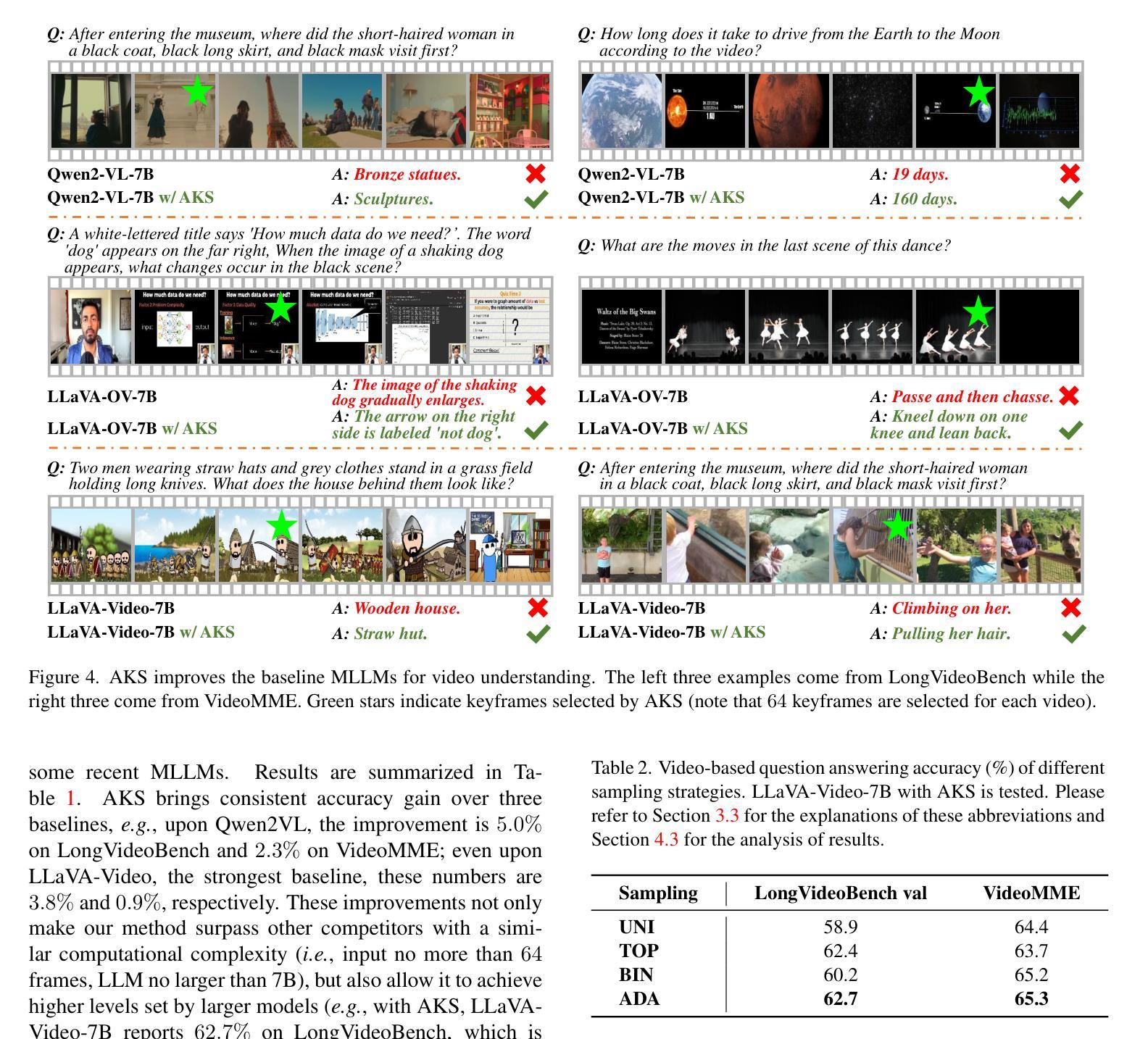
Multimodal large language models (MLLMs) have enabled open-world visual understanding by injecting visual input as extra tokens into large language models (LLMs) as contexts. However, when the visual input changes from a single image to a long video, the above paradigm encounters difficulty because the vast amount of video tokens has significantly exceeded the maximal capacity of MLLMs. Therefore, existing video-based MLLMs are mostly established upon sampling a small portion of tokens from input data, which can cause key information to be lost and thus produce incorrect answers. This paper presents a simple yet effective algorithm named Adaptive Keyframe Sampling (AKS). It inserts a plug-and-play module known as keyframe selection, which aims to maximize the useful information with a fixed number of video tokens. We formulate keyframe selection as an optimization involving (1) the relevance between the keyframes and the prompt, and (2) the coverage of the keyframes over the video, and present an adaptive algorithm to approximate the best solution. Experiments on two long video understanding benchmarks validate that Adaptive Keyframe Sampling improves video QA accuracy (beyond strong baselines) upon selecting informative keyframes. Our study reveals the importance of information pre-filtering in video-based MLLMs. Code is available at https://github.com/ncTimTang/AKS.
多模态大型语言模型(MLLMs)通过将视觉输入作为大型语言模型(LLMs)的上下文中的额外令牌,实现了开放世界视觉理解。然而,当视觉输入从单张图像变为长视频时,上述模式会遇到困难,因为大量的视频令牌已经大大超过了MLLMs的最大容量。因此,现有的基于视频的MLLMs大多是在从输入数据中采样一小部分令牌的基础上建立的,这可能会导致关键信息丢失,从而产生错误的答案。本文提出了一种简单有效的算法,名为自适应关键帧采样(AKS)。它插入了一个即插即用的模块,称为关键帧选择,旨在用固定数量的视频令牌来最大化有用信息。我们将关键帧选择制定为涉及以下两个方面的优化问题:(1)关键帧与提示之间的相关性;(2)关键帧对视频的覆盖度,并提出了一种自适应算法来逼近最佳解决方案。在两个长视频理解基准测试上的实验验证了自适应关键帧采样在提高选取有信息的关键帧的视频问答准确性(超过强大的基线)方面的效果。我们的研究表明,在信息预过滤的基于视频MLLMs中很重要。代码可用在 https://github.com/ncTimTang/AKS。
论文及项目相关链接
PDF CVPR2025
Summary
多模态大型语言模型(MLLMs)通过将视觉输入作为上下文中的附加令牌注入大型语言模型(LLMs)来实现开放式视觉理解。但当视觉输入从单张图片变为长视频时,上述模式遇到了困难,因为大量视频令牌已经大大超过了MLLMs的最大容量。因此,现有的基于视频的MLLM大多是从输入数据中采样一小部分令牌建立的,这可能会导致关键信息丢失并产生错误答案。本文提出了一种简单有效的算法,名为自适应关键帧采样(AKS)。它插入了一个即插即用的模块,称为关键帧选择,旨在用固定数量的视频令牌最大化有用信息。我们通过优化关键帧与提示之间的相关性和关键帧对视频的覆盖程度来制定关键帧选择方案,并提出了一种自适应算法来近似最佳解决方案。在两个长视频理解基准测试上的实验验证了自适应关键帧采样在提高视频问答准确性方面的优势。本研究揭示了视频基础MLLM中信息预过滤的重要性。
Key Takeaways
- 多模态大型语言模型(MLLMs)能够通过注入视觉输入作为上下文令牌实现开放式视觉理解。
- 当处理长视频时,MLLMs面临处理大量视频令牌超出其最大容量的挑战。
- 现有基于视频的MLLM大多通过从输入数据中采样小部分令牌来建立,这可能导致关键信息丢失。
- 本文提出了一种名为自适应关键帧采样(AKS)的算法,通过插入关键帧选择模块来解决这一问题。
- AKS算法旨在用固定数量的视频令牌最大化有用信息,并制定了基于关键帧与提示的相关性和关键帧对视频的覆盖程度的优化方案。
- 实验证明,自适应关键帧采样能够提高长视频理解基准测试中的视频问答准确性。
点此查看论文截图