⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-04 更新
FlexDrive: Toward Trajectory Flexibility in Driving Scene Reconstruction and Rendering
Authors:Jingqiu Zhou, Lue Fan, Linjiang Huang, Xiaoyu Shi, Si Liu, Zhaoxiang Zhang, Hongsheng Li
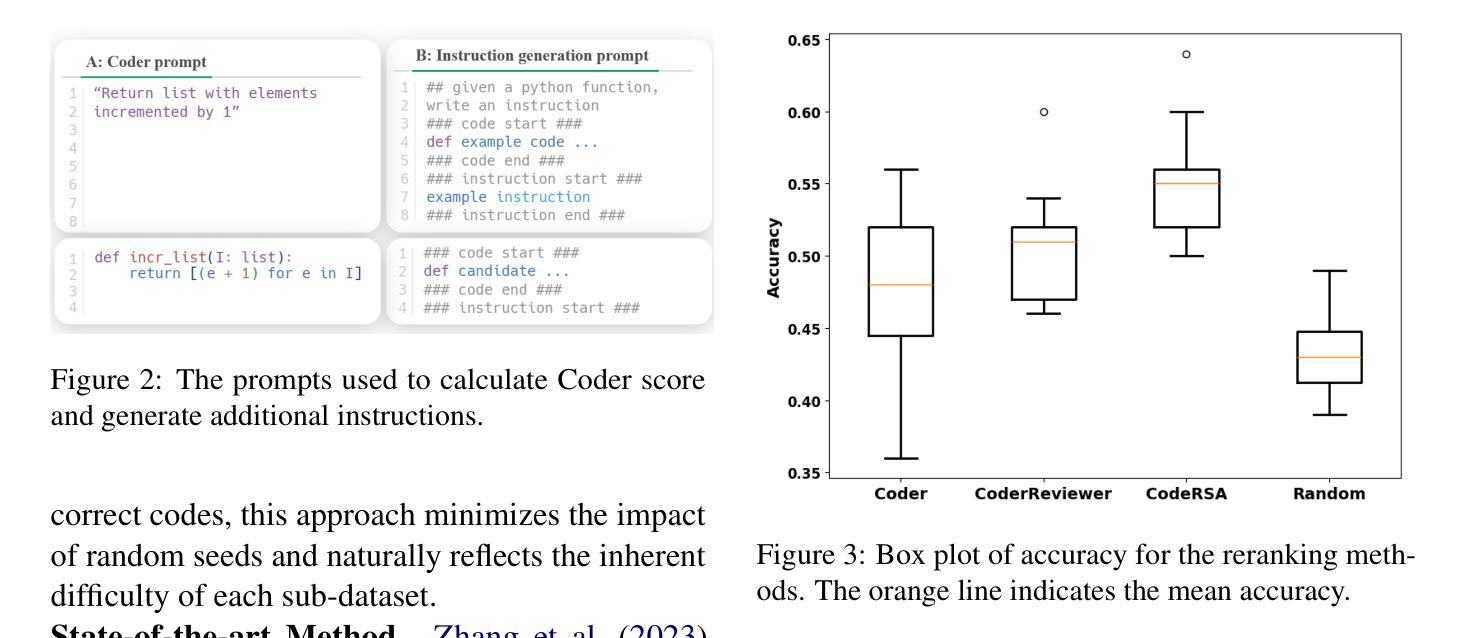
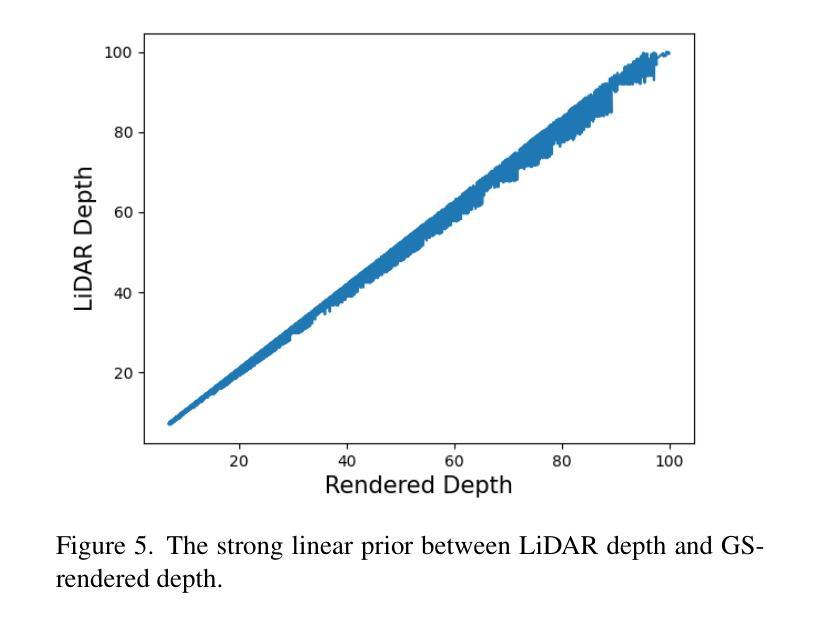
Driving scene reconstruction and rendering have advanced significantly using the 3D Gaussian Splatting. However, most prior research has focused on the rendering quality along a pre-recorded vehicle path and struggles to generalize to out-of-path viewpoints, which is caused by the lack of high-quality supervision in those out-of-path views. To address this issue, we introduce an Inverse View Warping technique to create compact and high-quality images as supervision for the reconstruction of the out-of-path views, enabling high-quality rendering results for those views. For accurate and robust inverse view warping, a depth bootstrap strategy is proposed to obtain on-the-fly dense depth maps during the optimization process, overcoming the sparsity and incompleteness of LiDAR depth data. Our method achieves superior in-path and out-of-path reconstruction and rendering performance on the widely used Waymo Open dataset. In addition, a simulator-based benchmark is proposed to obtain the out-of-path ground truth and quantitatively evaluate the performance of out-of-path rendering, where our method outperforms previous methods by a significant margin.
使用3D高斯拼贴技术,驾驶场景重建和渲染已经取得了显著进展。然而,大多数先前的研究主要集中在预设车辆路径的渲染质量上,并且很难推广到路径外的视角,这是由于这些路径外的视角缺乏高质量监督所导致的。为了解决这个问题,我们引入了一种逆视图扭曲技术,创建紧凑的高质量图像作为路径外视角重建的监督,从而实现了这些视角的高质量渲染结果。为了获得准确且稳健的逆视图扭曲,提出了一种深度引导策略,在优化过程中即时获取密集的深度图,克服了激光雷达深度数据的稀疏和不完整性。我们的方法在广泛使用的Waymo Open数据集上实现了路径内和路径外的优秀重建和渲染性能。此外,还提出了基于模拟器的基准测试来获得路径外的真实值并定量评估路径外渲染的性能,我们的方法在基准测试中显著优于以前的方法。
论文及项目相关链接
摘要
使用3D高斯贴图技术,驾驶场景重建和渲染已有显著进展。然而,大多数先前的研究主要集中在预记录车辆路径的渲染质量上,对于离路径的视点很难实现泛化,这是因为这些离路径外的视点缺乏高质量监督。为解决这一问题,我们引入了逆视图变形技术,创建紧凑且高质量的图片作为离路径外视点重建的监督数据,实现了这些视点的高质量渲染结果。为了获得准确且稳健的逆视图变形,提出了深度引导策略来在优化过程中即时获取密集深度图,克服了激光雷达深度数据的稀疏和不完整性。我们的方法在广泛使用的Waymo Open数据集上实现了出色的路径内和路径外重建和渲染性能。此外,为了获取离路径外的真实地面并定量评估离路径渲染的性能,还提出了基于模拟器的基准测试。在此基准测试中,我们的方法较之前的方法有很大的优势。
关键见解
- 3D高斯贴图技术已显著提高了驾驶场景的重建和渲染质量。
- 此前的研究主要关注预记录车辆路径的渲染质量,对于离路径外的视点泛化能力有限。
- 逆视图变形技术用于创建离路径外视点的紧凑且高质量图像,以监督其重建。
- 为准确且稳健地进行逆视图变形,提出了深度引导策略,克服激光雷达深度数据的稀疏和不完整性。
- 在Waymo Open数据集上,方法实现了优异的路径内和路径外重建和渲染性能。
- 提出了基于模拟器的基准测试来评估离路径外的渲染性能。
- 与之前的方法相比,我们的方法在基准测试中表现更优秀。
点此查看论文截图



OpenFly: A Versatile Toolchain and Large-scale Benchmark for Aerial Vision-Language Navigation
Authors:Yunpeng Gao, Chenhui Li, Zhongrui You, Junli Liu, Zhen Li, Pengan Chen, Qizhi Chen, Zhonghan Tang, Liansheng Wang, Penghui Yang, Yiwen Tang, Yuhang Tang, Shuai Liang, Songyi Zhu, Ziqin Xiong, Yifei Su, Xinyi Ye, Jianan Li, Yan Ding, Dong Wang, Zhigang Wang, Bin Zhao, Xuelong Li
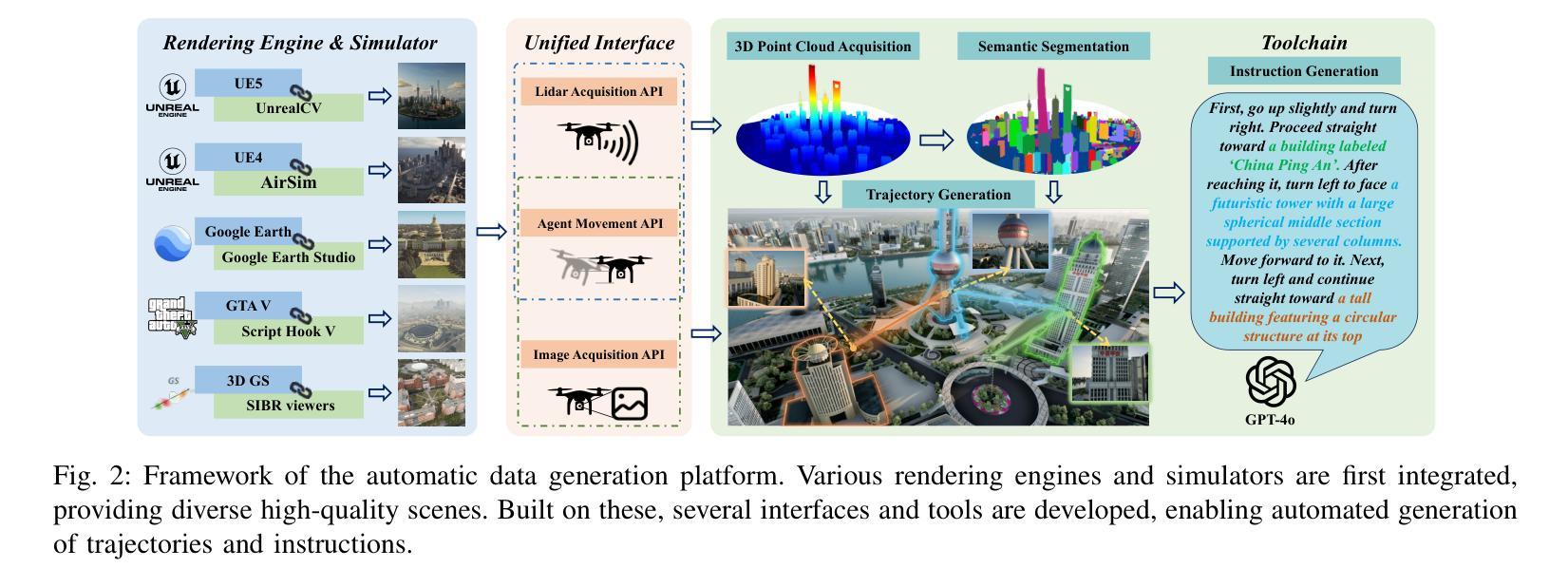
Vision-Language Navigation (VLN) aims to guide agents through an environment by leveraging both language instructions and visual cues, playing a pivotal role in embodied AI. Indoor VLN has been extensively studied, whereas outdoor aerial VLN remains underexplored. The potential reason is that outdoor aerial view encompasses vast areas, making data collection more challenging, which results in a lack of benchmarks. To address this problem, we propose OpenFly, a platform comprising a versatile toolchain and large-scale benchmark for aerial VLN. Firstly, we develop a highly automated toolchain for data collection, enabling automatic point cloud acquisition, scene semantic segmentation, flight trajectory creation, and instruction generation. Secondly, based on the toolchain, we construct a large-scale aerial VLN dataset with 100k trajectories, covering diverse heights and lengths across 18 scenes. The corresponding visual data are generated using various rendering engines and advanced techniques, including Unreal Engine, GTA V, Google Earth, and 3D Gaussian Splatting (3D GS). All data exhibit high visual quality. Particularly, 3D GS supports real-to-sim rendering, further enhancing the realism of the dataset. Thirdly, we propose OpenFly-Agent, a keyframe-aware VLN model, which takes language instructions, current observations, and historical keyframes as input, and outputs flight actions directly. Extensive analyses and experiments are conducted, showcasing the superiority of our OpenFly platform and OpenFly-Agent. The toolchain, dataset, and codes will be open-sourced.
视觉语言导航(VLN)旨在利用语言指令和视觉线索来引导智能体在环境中进行导航,是嵌入式人工智能中的一项关键技术。室内VLN已经得到了广泛的研究,而户外空中VLN仍然鲜有研究。可能的原因是户外空中视角涉及的范围较大,使得数据收集更具挑战性,从而导致缺乏基准测试集。为了解决这个问题,我们提出了OpenFly平台,该平台包含空中VLN的通用工具链和大规模基准测试集。首先,我们开发了一个高度自动化的工具链,用于数据采集,能够实现点云自动采集、场景语义分割、飞行轨迹创建和指令生成。其次,基于该工具链,我们构建了一个大规模的空中VLN数据集,包含10万条轨迹,覆盖18个场景的多种高度和长度。相应的视觉数据采用各种渲染引擎和先进技术生成,包括Unreal Engine、GTA V、Google Earth和3D Gaussian Splatting(3D GS)。所有数据都具有高质量的可视效果。特别是,3D GS支持实到虚渲染,进一步增强了数据集的逼真性。此外,我们提出了OpenFly-Agent,一个关键帧感知的VLN模型,它接受语言指令、当前观察结果和历史关键帧作为输入,并直接输出飞行动作。进行了广泛的分析和实验,展示了OpenFly平台和OpenFly-Agent的优越性。工具链、数据集和代码将开源。
论文及项目相关链接
Summary
本文介绍了针对户外高空视觉语言导航(VLN)任务的新平台OpenFly,该平台包含多功能工具链和大规模基准数据集。该平台可实现自动数据采集、场景语义分割、飞行轨迹创建和指令生成等功能。利用此工具链,构建了大规模高空VLN数据集,包含10万条轨迹,覆盖不同高度和长度,涉及多个场景。该平台采用多种渲染引擎和先进技术生成高质量视觉数据。此外,还提出了一种名为OpenFly-Agent的关键帧感知VLN模型,该模型能够处理语言指令、当前观测和历史关键帧作为输入,并直接输出飞行动作。实验证明OpenFly平台和OpenFly-Agent具有优越性。
Key Takeaways
- OpenFly是一个针对户外高空视觉语言导航(VLN)的新平台,包含工具链和大规模基准数据集。
- 数据收集高度自动化,包括点云获取、场景语义分割、飞行轨迹创建和指令生成。
- 构建的大规模高空VLN数据集包含10万条轨迹,覆盖多个场景的多样高度和长度。
- 采用多种渲染引擎和先进技术生成高质量视觉数据。
- OpenFly平台采用了一种名为OpenFly-Agent的关键帧感知VLN模型。
- 该模型能够处理语言指令、当前观测和历史关键帧作为输入,并直接输出飞行动作。
点此查看论文截图


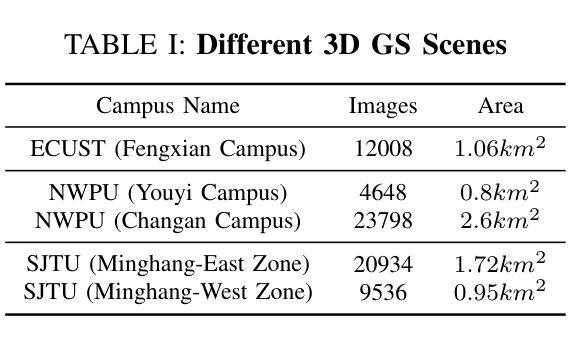
HybridGS: Decoupling Transients and Statics with 2D and 3D Gaussian Splatting
Authors:Jingyu Lin, Jiaqi Gu, Lubin Fan, Bojian Wu, Yujing Lou, Renjie Chen, Ligang Liu, Jieping Ye
Generating high-quality novel view renderings of 3D Gaussian Splatting (3DGS) in scenes featuring transient objects is challenging. We propose a novel hybrid representation, termed as HybridGS, using 2D Gaussians for transient objects per image and maintaining traditional 3D Gaussians for the whole static scenes. Note that, the 3DGS itself is better suited for modeling static scenes that assume multi-view consistency, but the transient objects appear occasionally and do not adhere to the assumption, thus we model them as planar objects from a single view, represented with 2D Gaussians. Our novel representation decomposes the scene from the perspective of fundamental viewpoint consistency, making it more reasonable. Additionally, we present a novel multi-view regulated supervision method for 3DGS that leverages information from co-visible regions, further enhancing the distinctions between the transients and statics. Then, we propose a straightforward yet effective multi-stage training strategy to ensure robust training and high-quality view synthesis across various settings. Experiments on benchmark datasets show our state-of-the-art performance of novel view synthesis in both indoor and outdoor scenes, even in the presence of distracting elements.
生成含有瞬态物体的三维高斯喷溅(3DGS)场景的高质量新型视图渲染是一项挑战。我们提出了一种新型混合表示方法,称为HybridGS,使用针对每幅图像中的瞬态物体进行建模的二维高斯分布,同时保持对整个静态场景使用传统的三维高斯分布进行建模。需要注意的是,三维高斯喷溅技术本身更适合对假设多视角一致性的静态场景进行建模,而瞬态物体是偶尔出现的,并不符合这个假设,因此我们将其建模为平面物体,并从单一视角进行表示,使用二维高斯分布。我们的新型表示方法从基本视角一致性的角度对场景进行分解,使其更加合理。此外,我们还提出了一种用于三维高斯喷溅的新型多视角监管方法,该方法利用共可见区域的信息,进一步增强了瞬态物体和静态物体的区别。然后,我们提出了一种简单有效的多阶段训练策略,以确保在各种设置下实现稳健的训练和高质量的视图合成。在基准数据集上的实验表明,我们的方法在室内外场景的全新视图合成方面达到了最新技术水平,即使在存在干扰元素的情况下也是如此。
论文及项目相关链接
PDF Accpeted by CVPR 2025. Project page: https://gujiaqivadin.github.io/hybridgs/ Code: https://github.com/Yeyuqqwx/HybridGS Data: https://huggingface.co/Eto63277/HybridGS/tree/main
Summary
这篇论文提出了一个名为HybridGS的新型混合表示方法,该方法结合了二维高斯模型和三维高斯模型,用于处理包含瞬时物体的场景中的三维高斯分裂(3DGS)场景渲染。对于静态场景采用传统的三维高斯模型,而对瞬时物体则采用二维高斯模型表示。该方法通过从基本视点一致性的角度对场景进行分解,提高了渲染质量。同时,论文还提出了一种新型的多视点监管监督方法和一个多阶段训练策略,以提高在各种设置下的视图合成质量和稳健性。
Key Takeaways
- 针对包含瞬时物体的场景,提出了HybridGS混合表示方法,结合二维高斯模型和三维高斯模型进行处理。
- 静态场景采用传统的三维高斯模型表示,而瞬时物体则采用二维高斯模型表示。
- 从基本视点一致性的角度对场景进行分解,提高渲染质量。
- 提出了多视点监管监督方法,利用可见区域的信息进行监督,增强了瞬时物体和静态物体的区分度。
- 采用了多阶段训练策略,确保在各种设置下的稳健训练和高质量视图合成。
- 在室内和室外场景的实验中,HybridGS方法表现出卓越的性能,甚至在存在干扰元素的情况下也能有效进行视图合成。
点此查看论文截图

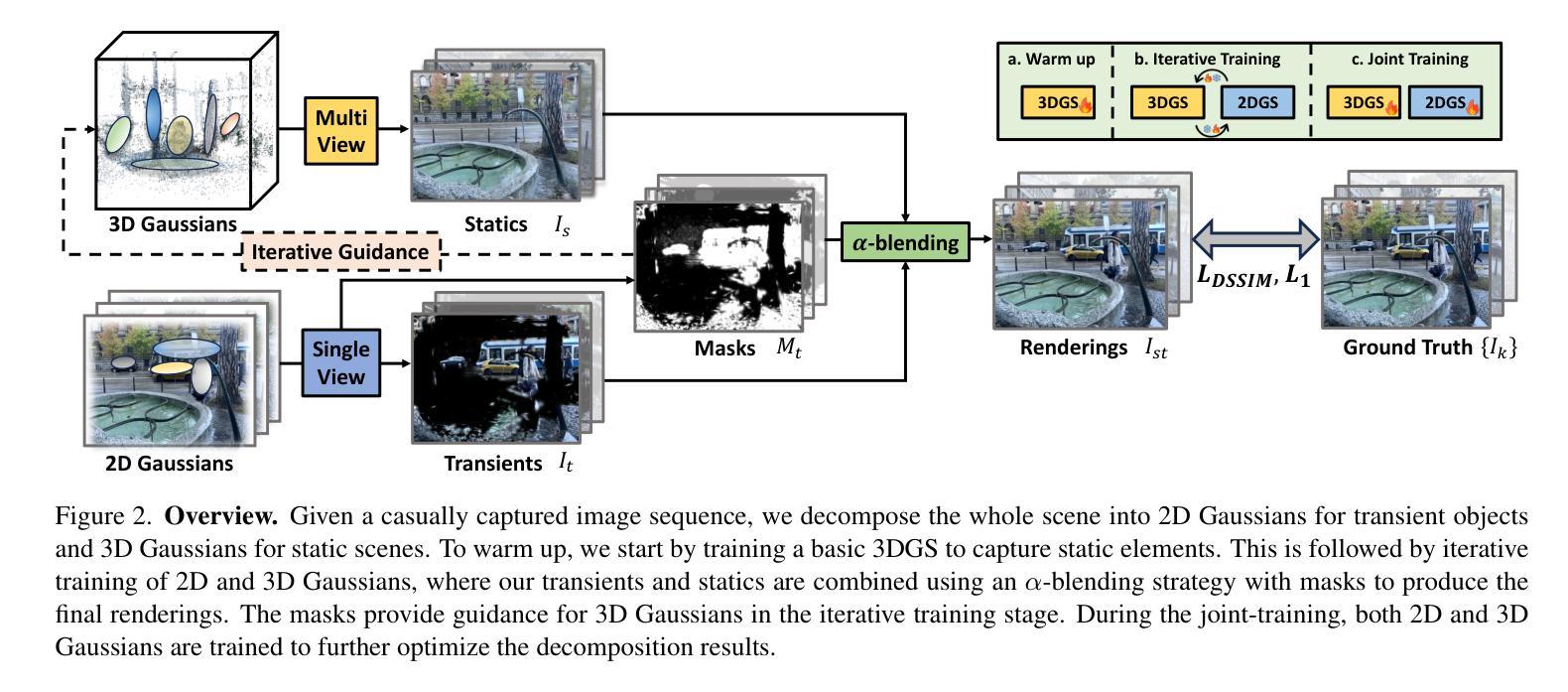
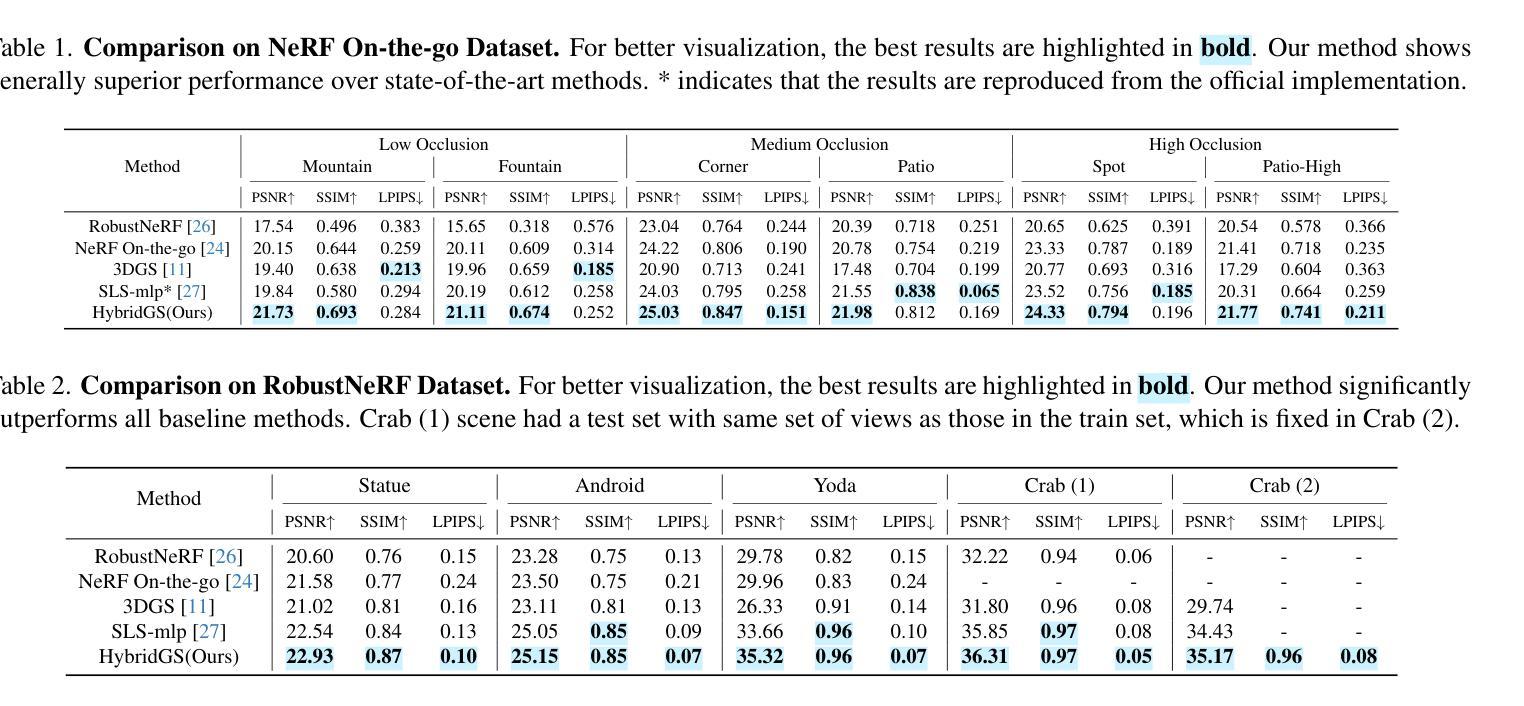
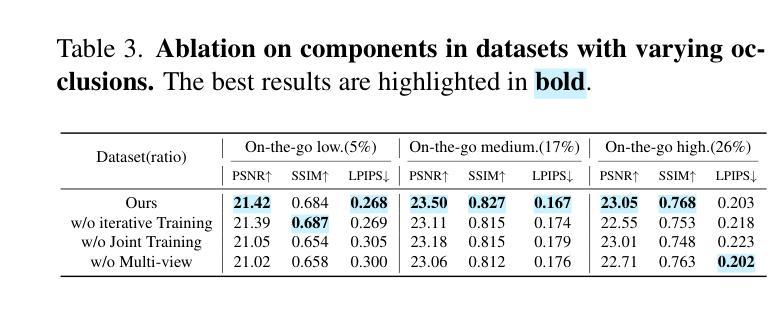
3D-HGS: 3D Half-Gaussian Splatting
Authors:Haolin Li, Jinyang Liu, Mario Sznaier, Octavia Camps
Photo-realistic image rendering from scene 3D reconstruction is a fundamental problem in 3D computer vision. This domain has seen considerable advancements owing to the advent of recent neural rendering techniques. These techniques predominantly aim to focus on learning volumetric representations of 3D scenes and refining these representations via loss functions derived from their rendering. Among these, 3D Gaussian Splatting (3D-GS) has emerged as a preferred method, surpassing Neural Radiance Fields’ (NeRFs) quality and rendering speed. 3D-GS uses parameterized 3D Gaussians to model both spatial locations and color information, combined with a tile-based fast rendering technique. Despite its superior performance, using 3D Gaussian kernels has inherent limitations in accurately representing discontinuous functions, notably at edges and corners corresponding to shape discontinuities, and across varying textures due to color discontinuities. In this paper, we introduce 3D Half-Gaussian (\textbf{3D-HGS}) kernels, which can be used as a plug-and-play kernel, to address this issue. Our experiments demonstrate their capability to improve the performance of current 3D-GS related methods and achieve state-of-the-art rendering quality performance on various datasets without compromising their rendering speed.
从场景3D重建中进行真实感图像渲染是3D计算机视觉领域的一个基本问题。由于近期神经渲染技术的出现,该领域取得了相当大的进展。这些技术的主要目标是学习3D场景的体积表示,并通过来自其渲染的损失函数来优化这些表示。其中,3D高斯拼贴(3D-GS)已成为首选方法,其在质量和渲染速度上超越了神经辐射场(NeRFs)。3D-GS使用参数化的3D高斯对空间位置和颜色信息进行建模,并结合基于瓦片的快速渲染技术。尽管其性能卓越,但使用3D高斯核在准确表示不连续函数方面存在固有局限性,特别是在形状不连续对应的边缘和角落处,以及由于颜色不连续而导致的不同纹理之间。针对这一问题,我们在本文中引入了3D半高斯(\textbf{3D-HGS})核,可作为即插即用的核来使用。我们的实验证明了其在改进当前与3D-GS相关方法性能的能力,并在各种数据集上实现了最先进的渲染质量性能,同时不牺牲其渲染速度。
论文及项目相关链接
PDF 8 pages, 9 figures
Summary
近期,基于神经网络技术的渲染技术在计算机视觉的重建场景三维渲染中得到广泛应用,但使用如高斯等标准内核来模拟场景的复杂形状纹理仍然存在问题。在本文中,提出了一种新型的基于三维半高斯(3D-HGS)核的渲染方法,它能改善传统方法的缺陷,在不牺牲渲染速度的同时,提升重建场景的三维渲染效果,展现出最佳的性能表现。
Key Takeaways
- 光子现实图像渲染在三维计算机视觉领域中是一项重要任务。近期神经渲染技术的出现促进了该领域的进展。这些技术主要通过学习三维场景的体积表示并利用从这些表示中得出的损失函数进行渲染来实现目标。其中,三维高斯涂敷(3D-GS)是一种新兴技术,以其高质量和快速渲染速度脱颖而出。
- 尽管表现优秀,但传统高斯内核在处理场景的不连续函数时存在局限性,特别是在边缘和角落的形状不连续以及由于颜色不连续导致的纹理变化等方面。这些问题在场景的复杂性和真实感渲染中尤为突出。
- 针对上述问题,本文提出了基于三维半高斯(3D-HGS)核的解决方案。这是一种可插入的内核,能够解决传统内核在处理复杂形状和纹理时的局限性问题。
点此查看论文截图