⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-04 更新
Improving Open-world Continual Learning under the Constraints of Scarce Labeled Data
Authors:Yujie Li, Xiangkun Wang, Xin Yang, Marcello Bonsangue, Junbo Zhang, Tianrui Li
Open-world continual learning (OWCL) adapts to sequential tasks with open samples, learning knowledge incrementally while preventing forgetting. However, existing OWCL still requires a large amount of labeled data for training, which is often impractical in real-world applications. Given that new categories/entities typically come with limited annotations and are in small quantities, a more realistic situation is OWCL with scarce labeled data, i.e., few-shot training samples. Hence, this paper investigates the problem of open-world few-shot continual learning (OFCL), challenging in (i) learning unbounded tasks without forgetting previous knowledge and avoiding overfitting, (ii) constructing compact decision boundaries for open detection with limited labeled data, and (iii) transferring knowledge about knowns and unknowns and even update the unknowns to knowns once the labels of open samples are learned. In response, we propose a novel OFCL framework that integrates three key components: (1) an instance-wise token augmentation (ITA) that represents and enriches sample representations with additional knowledge, (2) a margin-based open boundary (MOB) that supports open detection with new tasks emerge over time, and (3) an adaptive knowledge space (AKS) that endows unknowns with knowledge for the updating from unknowns to knowns. Finally, extensive experiments show the proposed OFCL framework outperforms all baselines remarkably with practical importance and reproducibility. The source code is released at https://github.com/liyj1201/OFCL.
开放世界持续学习(OWCL)适应具有开放样本的连续任务,能够逐步学习新知识,同时防止遗忘。然而,现有的OWCL仍然需要大量标记数据进行训练,这在现实世界的应用中往往不切实际。考虑到新类别/实体通常带有有限的注释并且数量较小,更现实的情况是在稀缺标记数据下的OWCL,即少数训练样本。因此,本文研究了开放世界少数样本持续学习(OFCL)的问题,面临的挑战包括(i)学习无界任务,不忘掉以前的知识,避免过度拟合;(ii)用有限的标记数据构建紧凑的决策边界,进行开放检测;(iii)转移关于已知和未知的知识,甚至一旦学习到开放样本的标签,就将未知更新为已知。为此,我们提出了一种新的OFCL框架,它包括三个关键组成部分:(1)实例级令牌增强(ITA),它用额外的知识表示和丰富样本表示;(2)基于边距的开放边界(MOB),它支持随时间出现的新任务的开放检测;(3)自适应知识空间(AKS),它赋予未知知识,以便从未知到已知进行更新。最后,大量实验表明,所提出的OFCL框架在实用性和可重复性方面均优于所有基线。源代码已发布在https://github.com/liyj1201/OFCL。
论文及项目相关链接
Summary
本文探讨了开放世界小样本持续学习(OFCL)的问题,提出了一个包含三个关键组件的OFCL框架,包括实例级令牌增强(ITA)、基于边界的开放边界(MOB)和自适应知识空间(AKS)。该框架能够在有限的标注数据下,适应不断涌现的新任务,实现开放检测,同时更新未知知识。实验表明,该框架在实际应用和可重复性方面显著优于所有基线方法。
Key Takeaways
- 开放世界小样本持续学习(OFCL)是一个现实中的问题,因为新类别/实体通常带有有限的注释并且数量较小。
- OFCL面临的挑战包括:在不遗忘先前知识的情况下学习无界任务,避免过度拟合;用有限的标注数据构建用于开放检测的更紧凑的决策边界;以及转移关于已知和未知的知识,甚至一旦学习到开放的样本标签,就能将未知更新为已知。
- 提出的OFCL框架包含三个关键组件:实例级令牌增强(ITA),基于边界的开放边界(MOB)和自适应知识空间(AKS)。
- ITA用于表示和丰富样本表示,带有额外的知识。
- MOB支持随时间出现的新任务的开放检测。
- AKS赋予未知知识更新的能力。
点此查看论文截图

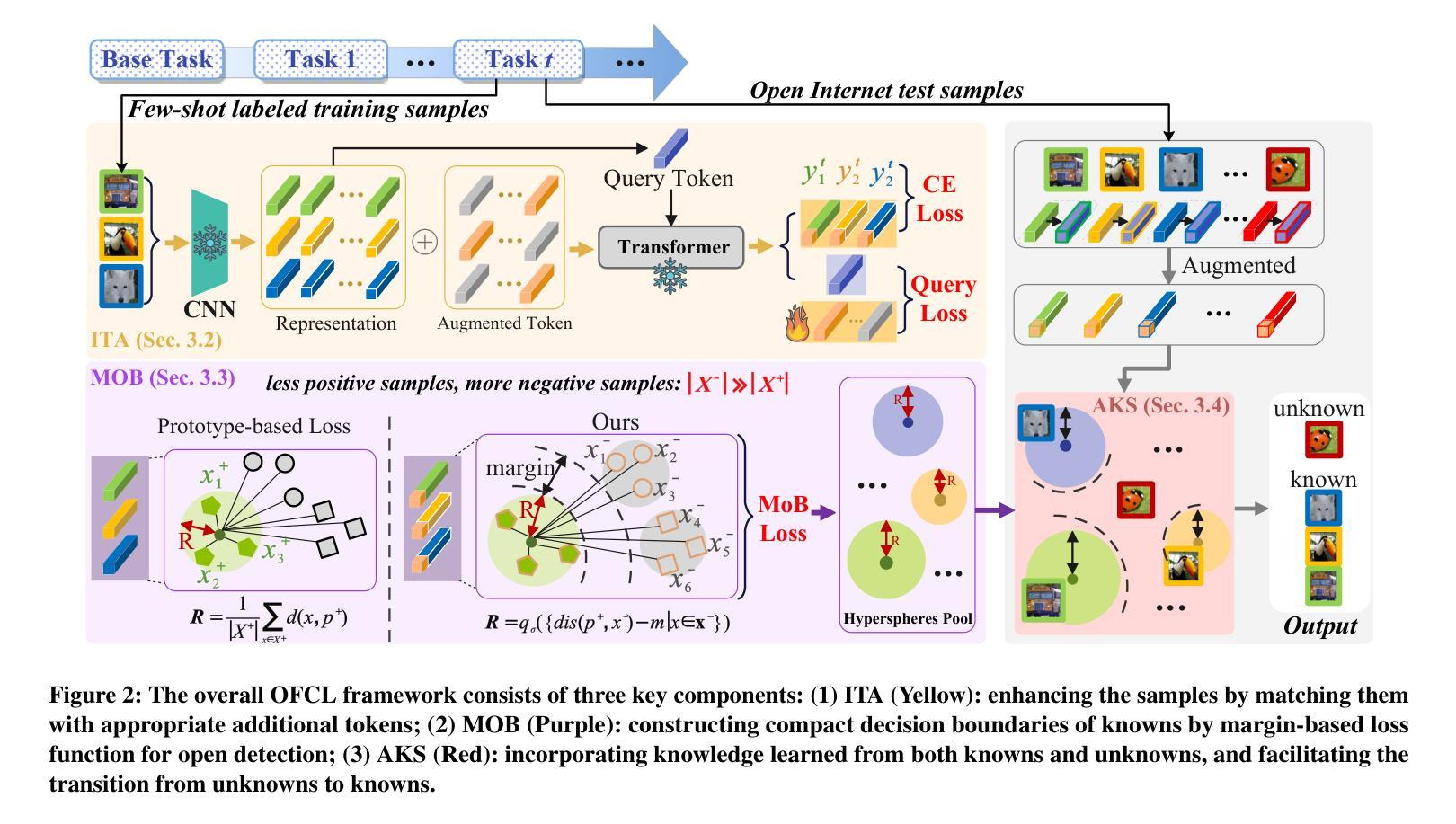

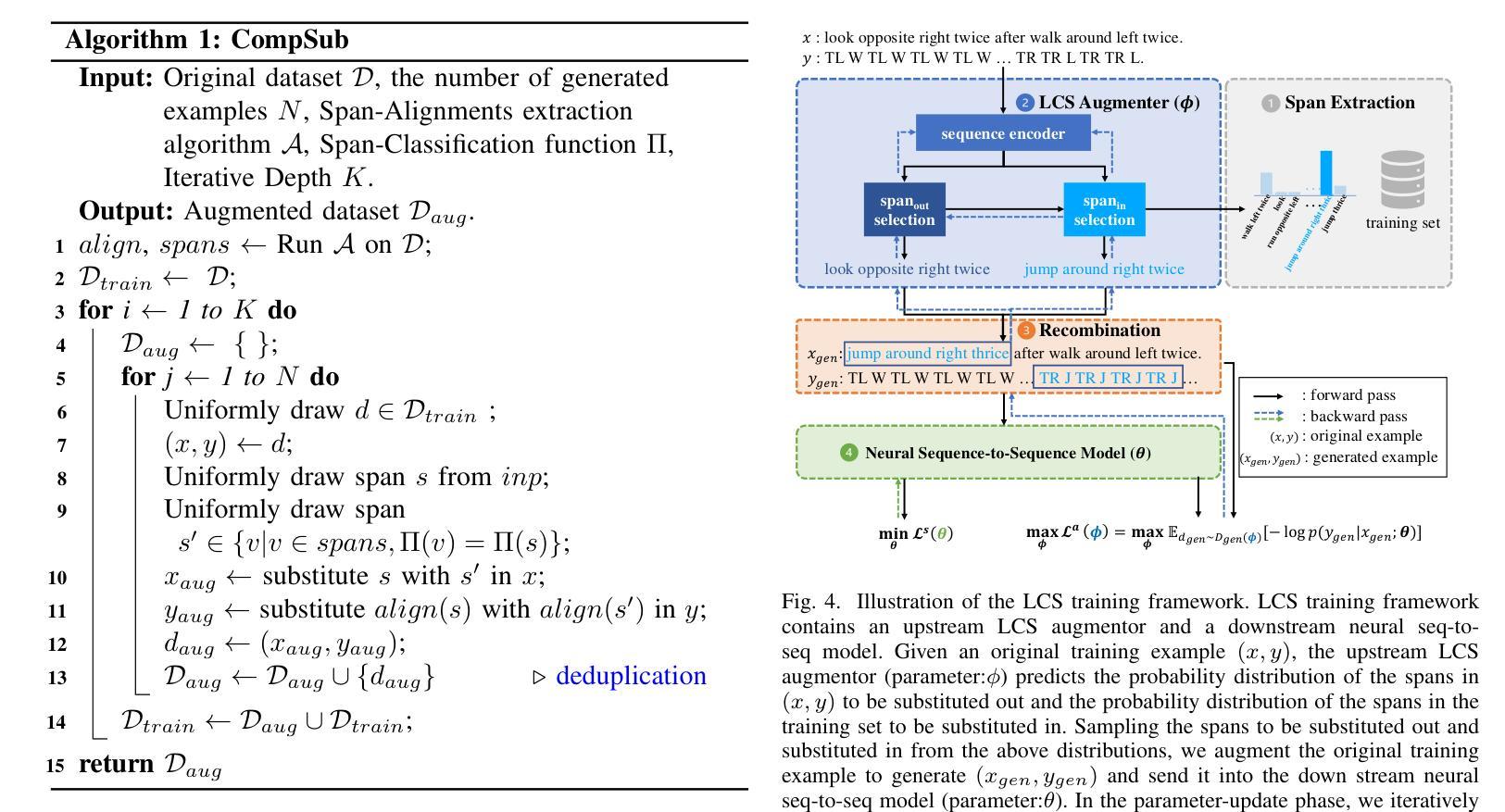
Learning to Substitute Components for Compositional Generalization
Authors:Zhaoyi Li, Gangwei Jiang, Chenwang Wu, Ying Wei, Defu Lian, Enhong Chen
Despite the rising prevalence of neural language models, recent empirical evidence suggests their deficiency in compositional generalization. One of the current de-facto solutions to this problem is compositional data augmentation, which aims to introduce additional compositional inductive bias. However, existing handcrafted augmentation strategies offer limited improvement when systematic generalization of neural language models requires multi-grained compositional bias (i.e., not limited to either lexical or structural biases alone) or when training sentences have an imbalanced difficulty distribution. To address these challenges, we first propose a novel compositional augmentation strategy called Component Substitution (CompSub), which enables multi-grained composition of substantial substructures across the entire training set. Furthermore, we introduce the Learning Component Substitution (LCS) framework. This framework empowers the learning of component substitution probabilities in CompSub in an end-to-end manner by maximizing the loss of neural language models, thereby prioritizing challenging compositions with elusive concepts and novel contexts. We extend the key ideas of CompSub and LCS to the recently emerging in-context learning scenarios of pre-trained large language models (LLMs), proposing the LCS-ICL algorithm to enhance the few-shot compositional generalization of state-of-the-art (SOTA) LLMs. Theoretically, we provide insights into why applying our algorithms to language models can improve compositional generalization performance. Empirically, our results on four standard compositional generalization benchmarks(SCAN, COGS, GeoQuery, and COGS-QL) demonstrate the superiority of CompSub, LCS, and LCS-ICL, with improvements of up to 66.5%, 10.3%, 1.4%, and 8.8%, respectively.
尽管神经语言模型的普及程度不断上升,但最近的实证证据表明它们在组合泛化方面存在缺陷。目前解决这个问题的实际解决方案之一是组合数据增强,其旨在引入额外的组合归纳偏见。然而,现有的手工增强策略仅在系统泛化需要多粒度组合偏见(即不限于词汇或结构偏见)或训练句子难度分布不平衡时提供有限的改进。为了应对这些挑战,我们首先提出了一种新的组合增强策略,称为组件替换(CompSub),它能够在整个训练集中组合大量的重要子结构的多粒度。此外,我们引入了学习组件替换(LCS)框架。该框架通过最大化神经语言模型的损失来赋能组件替换概率的学习,从而优先处理具有难以捉摸的概念和新颖背景的困难组合。我们将CompSub和LCS的关键思想扩展到最近出现的预训练大型语言模型(LLM)的上下文学习场景,提出LCS-ICL算法,以提高最新技术(SOTA)LLM的少量组合泛化能力。从理论上讲,我们提供了将我们的算法应用于语言模型可以提高组合泛化性能的原因。在四个标准组合泛化基准测试(SCAN、COGS、GeoQuery和COGS-QL)上的实验结果表明,CompSub、LCS和LCS-ICL的优越性,改进幅度高达66.5%、10.3%、1.4%和8.8%。
论文及项目相关链接
PDF 23 pages, 9 figures, preprint, the extension paper of the paper (arXiv:2306.02840)
摘要
该文指出尽管神经网络语言模型越来越流行,但在组合泛化方面存在缺陷。现有的手工艺品增强策略提供的改进有限,特别是在需要多粒度组合偏差或训练句子难度分布不平衡的情况下。为此,提出了一种新的组合增强策略——组件替换(CompSub),能够在整个训练集中组合多粒度的实质性子结构。此外,还引入了学习组件替换(LCS)框架,以端到端的方式学习组件替换概率,通过最大化神经网络模型的损失来优先处理具有难以捉摸的概念和新颖上下文的组合。最后,将CompSub和LCS的关键思想扩展到新兴的上下文学习场景,提出LCS-ICL算法,以提高最先进的LLM的少量组合泛化能力。理论分析和实证结果表明,本文提出的算法能有效提高语言模型的组合泛化性能。
关键见解
- 神经网络语言模型在组合泛化方面存在缺陷,特别是在需要多粒度组合偏差或训练句子难度分布不平衡的情况下。
- 提出了一种新的组合增强策略——组件替换(CompSub),能整合多粒度的子结构。
- 引入了学习组件替换(LCS)框架,以最大化神经网络模型的损失来学习组件替换概率。
- 将CompSub和LCS的思想扩展到上下文学习场景,提出LCS-ICL算法,提高LLM的少量组合泛化能力。
- 本文提供的算法能有效提高语言模型的组合泛化性能,这在四个标准组合泛化基准测试中得到了验证。
- 通过理论分析,解释了为何将这些算法应用于语言模型能提高组合泛化性能。
点此查看论文截图


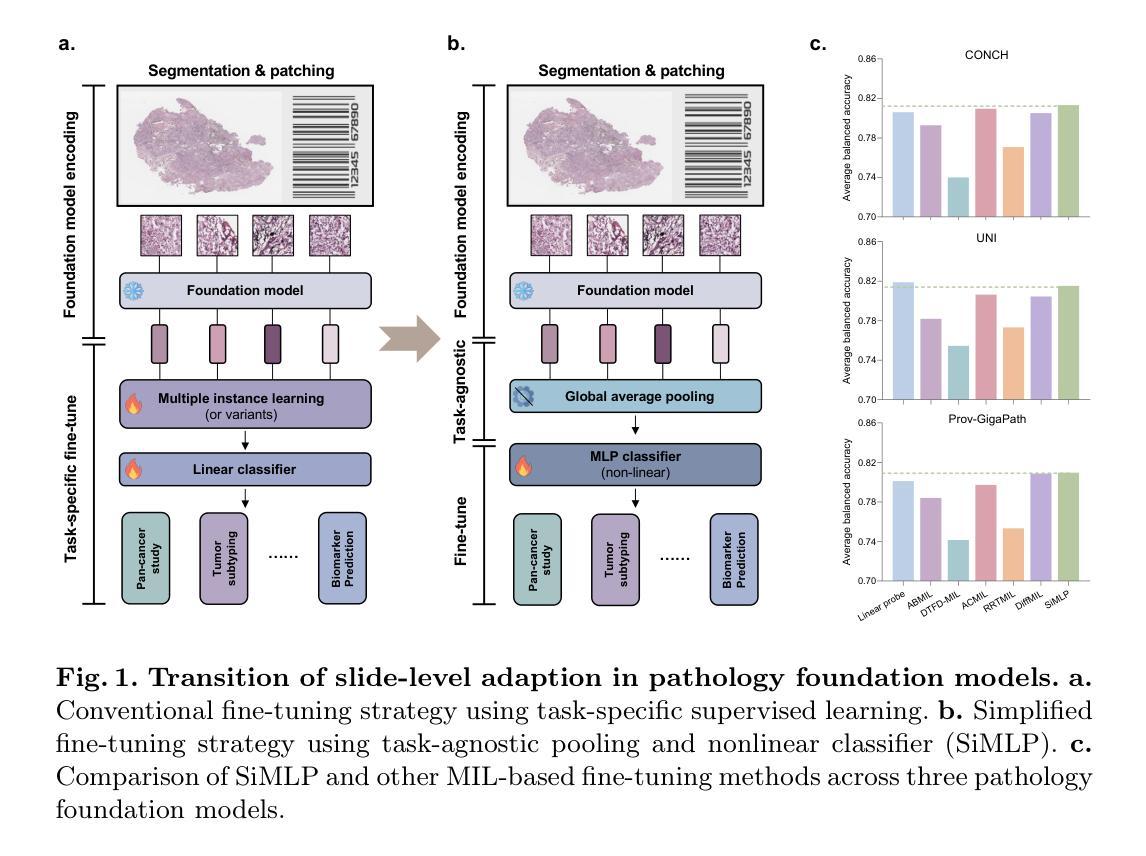
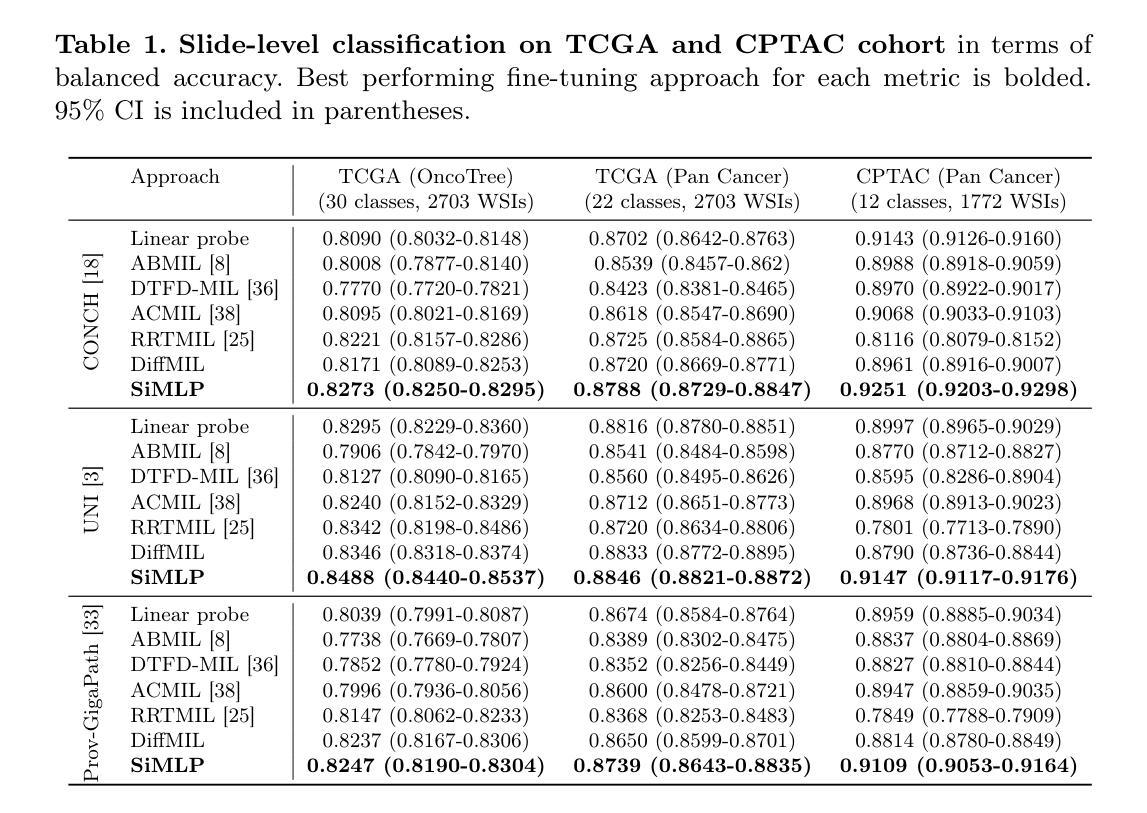
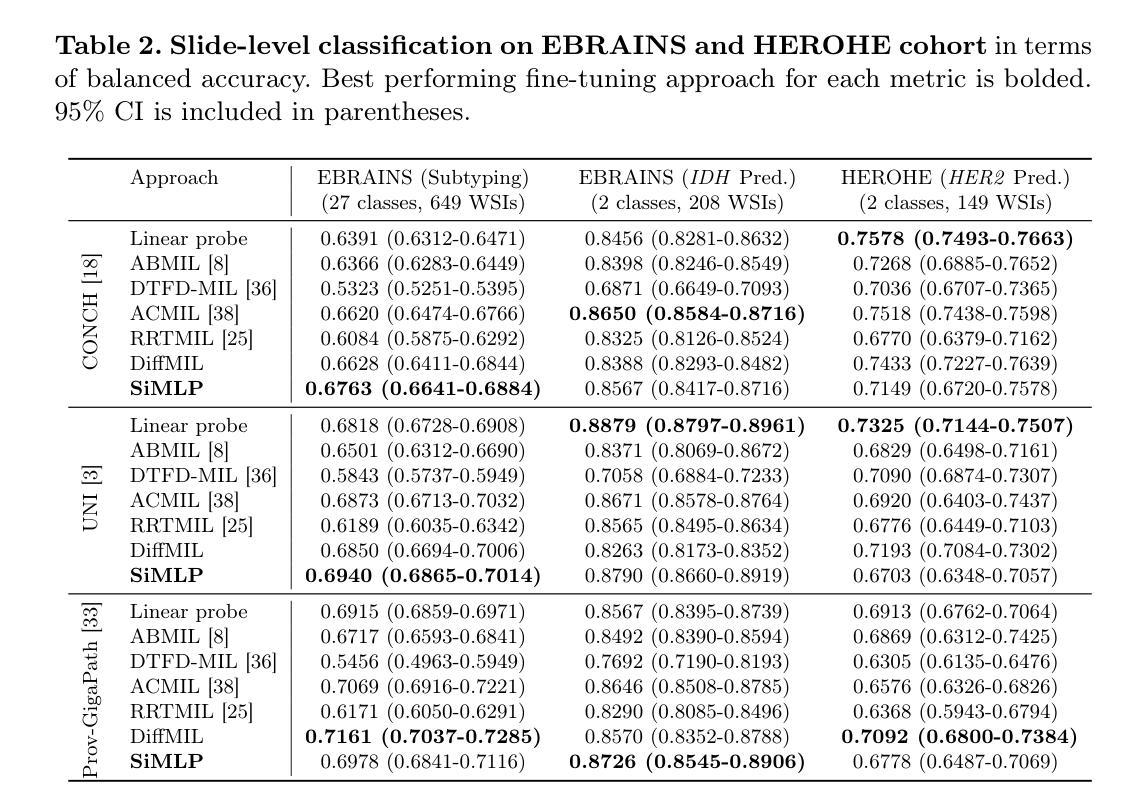
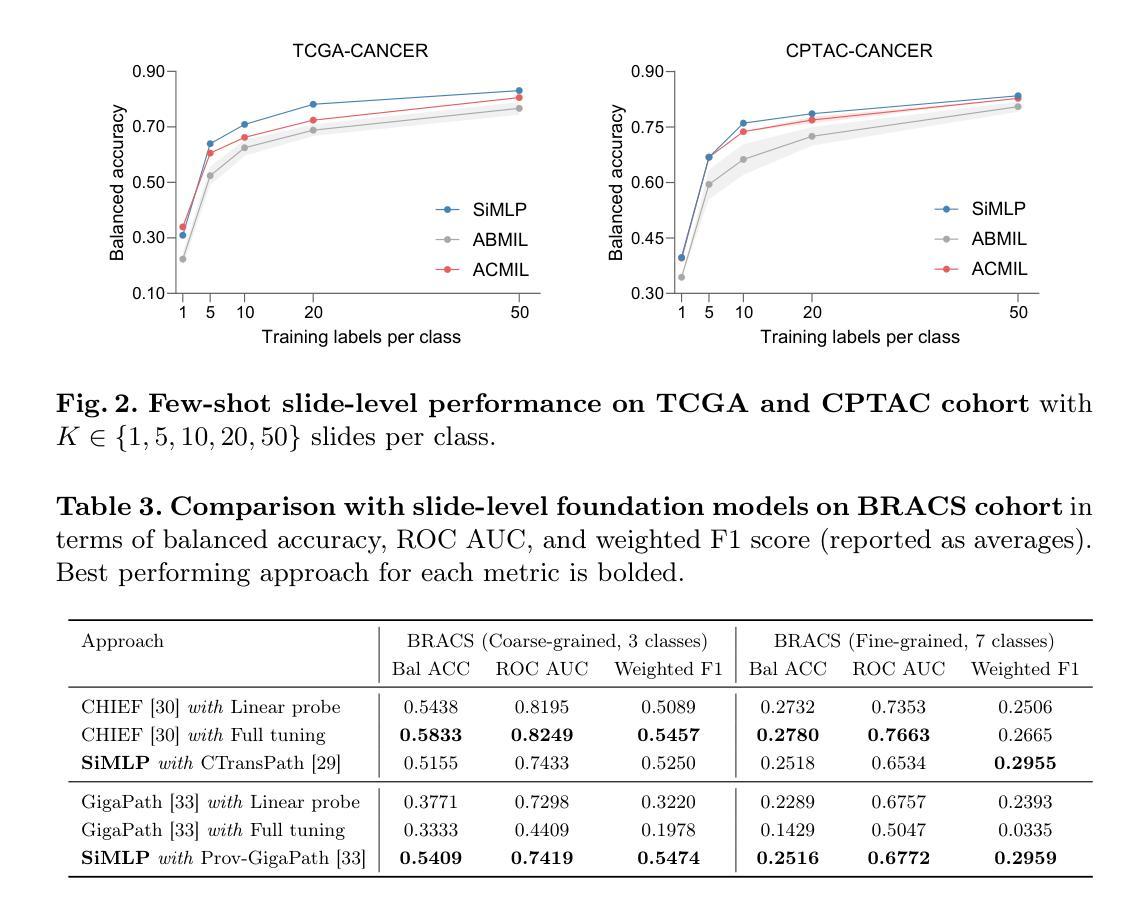
Can We Simplify Slide-level Fine-tuning of Pathology Foundation Models?
Authors:Jiawen Li, Jiali Hu, Qiehe Sun, Renao Yan, Minxi Ouyang, Tian Guan, Anjia Han, Chao He, Yonghong He
The emergence of foundation models in computational pathology has transformed histopathological image analysis, with whole slide imaging (WSI) diagnosis being a core application. Traditionally, weakly supervised fine-tuning via multiple instance learning (MIL) has been the primary method for adapting foundation models to WSIs. However, in this work we present a key experimental finding: a simple nonlinear mapping strategy combining mean pooling and a multilayer perceptron, called SiMLP, can effectively adapt patch-level foundation models to slide-level tasks without complex MIL-based learning. Through extensive experiments across diverse downstream tasks, we demonstrate the superior performance of SiMLP with state-of-the-art methods. For instance, on a large-scale pan-cancer classification task, SiMLP surpasses popular MIL-based methods by 3.52%. Furthermore, SiMLP shows strong learning ability in few-shot classification and remaining highly competitive with slide-level foundation models pretrained on tens of thousands of slides. Finally, SiMLP exhibits remarkable robustness and transferability in lung cancer subtyping. Overall, our findings challenge the conventional MIL-based fine-tuning paradigm, demonstrating that a task-agnostic representation strategy alone can effectively adapt foundation models to WSI analysis. These insights offer a unique and meaningful perspective for future research in digital pathology, paving the way for more efficient and broadly applicable methodologies.
计算病理学中的基础模型的兴起已经改变了组织病理学图像分析的局面,其中全幻灯片成像(WSI)诊断是核心应用之一。传统上,通过多重实例学习(MIL)进行弱监督微调是使基础模型适应WSI的主要方法。然而,在这项工作中,我们提出了一个重要的实验发现:一种结合均值池化和多层感知器(MLP)的简单非线性映射策略,称为SiMLP,可以有效地将补丁级别的基础模型适应到幻灯片级别的任务,而无需复杂的基于MIL的学习。通过在不同下游任务上的大量实验,我们证明了SiMLP在最新技术方法中的卓越性能。例如,在一个大规模泛癌分类任务中,SiMLP在流行的基于MIL的方法的基础上提高了3.52%。此外,SiMLP在少样本分类中显示出强大的学习能力,并且在数以万计幻灯片上预训练过的幻灯片级别基础模型中保持竞争力。最后,SiMLP在肺癌分型中表现出令人瞩目的鲁棒性和可迁移性。总的来说,我们的发现挑战了传统的基于MIL的微调模式,证明了单一的任务不可知表示策略就可以有效地适应基础模型到WSI分析。这些见解为数字病理学的未来研究提供了独特而有意义的视角,为更有效率且更广泛适用的方法铺平了道路。
论文及项目相关链接
PDF 11 pages, 3 figures, 4 tables
Summary
基于计算病理学中基础模型的兴起,全幻灯片成像(WSI)诊断成为其核心应用之一。传统上,通过多重实例学习(MIL)进行弱监督微调是适应WSI的基础模型的主要方法。然而,本文提出了一种简单的非线性映射策略——SiMLP(结合均值池化和多层感知器),可以有效地将补丁级别的基础模型适应于幻灯片级别的任务,而无需复杂的基于MIL的学习。通过广泛的实验和多种下游任务,我们证明了SiMLP的优越性,例如在大型泛癌分类任务中,SiMLP超越了流行的基于MIL的方法,准确率提高了3.52%。此外,SiMLP在少样本分类中显示出强大的学习能力,并且在幻灯片级别预训练的基础模型上仍然具有竞争力。最后,SiMLP在肺癌分型中表现出惊人的稳健性和可迁移性。总的来说,我们的研究挑战了传统的基于MIL的微调范式,证明了任务无关的表示策略可以单独有效地适应WSI分析的基础模型。这些见解为数字病理学未来的研究提供了独特和有意义的视角,为更有效率且更广泛适用的方法铺平了道路。
Key Takeaways
- 引入基础模型改变了计算病理学中的全幻灯片成像(WSI)诊断方式。
- 传统上,基于多重实例学习(MIL)的弱监督微调是适应WSI的主要方法。
- 提出了一种简单的非线性映射策略SiMLP,无需复杂的基于MIL的学习即可适应模型。
- 在大型泛癌分类任务中,SiMLP超越了基于MIL的方法。
- SiMLP在少样本分类方面具有强大的学习能力,并在幻灯片级别预训练的基础模型上表现竞争力。
- SiMLP在肺癌分型中显示出稳健性和可迁移性。
点此查看论文截图

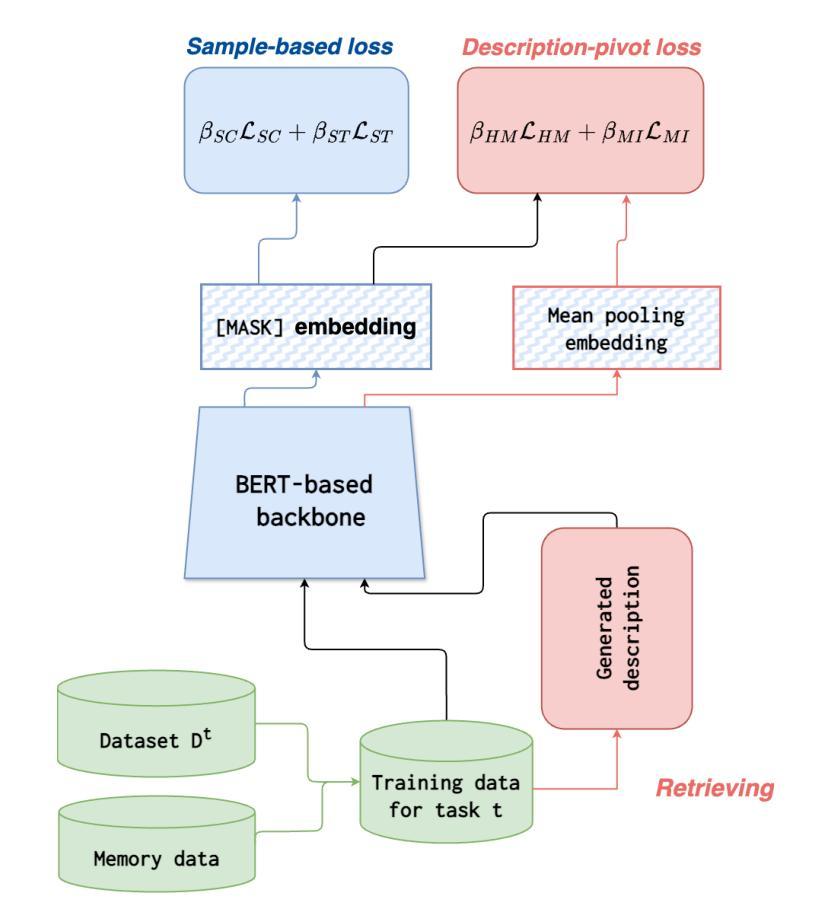
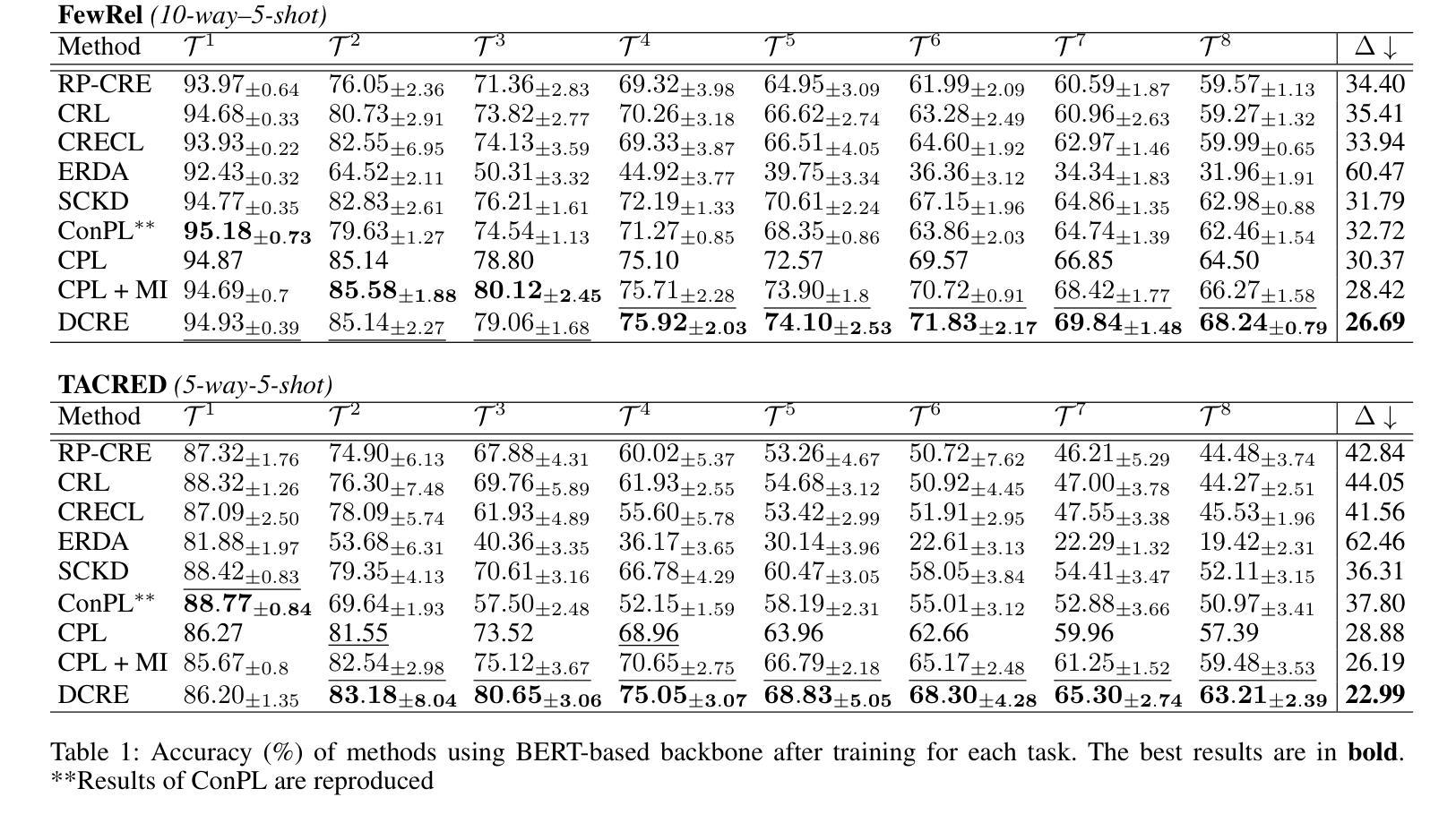
Few-Shot, No Problem: Descriptive Continual Relation Extraction
Authors:Nguyen Xuan Thanh, Anh Duc Le, Quyen Tran, Thanh-Thien Le, Linh Ngo Van, Thien Huu Nguyen
Few-shot Continual Relation Extraction is a crucial challenge for enabling AI systems to identify and adapt to evolving relationships in dynamic real-world domains. Traditional memory-based approaches often overfit to limited samples, failing to reinforce old knowledge, with the scarcity of data in few-shot scenarios further exacerbating these issues by hindering effective data augmentation in the latent space. In this paper, we propose a novel retrieval-based solution, starting with a large language model to generate descriptions for each relation. From these descriptions, we introduce a bi-encoder retrieval training paradigm to enrich both sample and class representation learning. Leveraging these enhanced representations, we design a retrieval-based prediction method where each sample “retrieves” the best fitting relation via a reciprocal rank fusion score that integrates both relation description vectors and class prototypes. Extensive experiments on multiple datasets demonstrate that our method significantly advances the state-of-the-art by maintaining robust performance across sequential tasks, effectively addressing catastrophic forgetting.
少样本持续关系抽取是使AI系统能够识别和适应动态现实领域中的不断变化关系的关键挑战。基于传统的记忆方法往往会对有限的样本过度拟合,无法巩固旧知识,而在少样本场景中,数据的稀缺性进一步加剧了这些问题,阻碍了潜在空间中的有效数据增强。在本文中,我们提出了一种新型的基于检索的解决方案,首先使用大型语言模型为每个关系生成描述。从这些描述中,我们引入了一种双编码器检索训练模式,以丰富样本和类别表示学习。利用这些增强的表示形式,我们设计了一种基于检索的预测方法,其中每个样本通过融合关系描述向量和类别原型的反向排名融合得分来检索最适合的关系。在多个数据集上的大量实验表明,我们的方法在序列任务上保持了稳健的性能,有效地解决了灾难性遗忘问题,显著地提高了最新技术水平。
论文及项目相关链接
PDF Accepted to AAAI 2025
Summary
本文介绍了少样本持续关系抽取的挑战,并提出了一种基于检索的解决方案。该方案利用大型语言模型生成每个关系的描述,并引入双编码器检索训练范式,丰富样本和类别表示学习。基于这些增强表示,设计了一种基于检索的预测方法,通过融合关系描述向量和类别原型,实现样本与最佳拟合关系的匹配。在多个数据集上的实验表明,该方法在序贯任务上性能稳健,有效解决了灾难性遗忘问题。
Key Takeaways
- 介绍少样本持续关系抽取的重要性,使AI系统能够识别和适应动态现实世界领域中不断变化的关系。
- 传统基于记忆的方法在有限样本上过拟合,无法巩固旧知识。
- 在少样本场景中,数据稀缺性加剧了这些问题,阻碍了潜在空间中的有效数据增强。
- 提出了一种基于检索的解决方案,利用大型语言模型生成关系描述。
- 引入双编码器检索训练范式,丰富样本和类别的表示学习。
- 设计了一种基于检索的预测方法,通过融合关系描述向量和类别原型,实现样本与最佳拟合关系的匹配。
点此查看论文截图



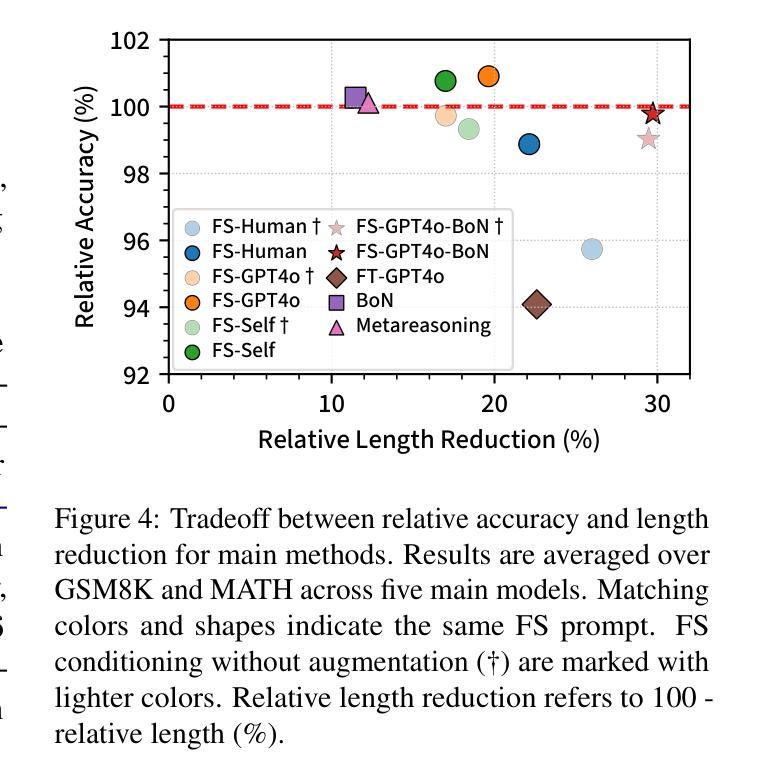
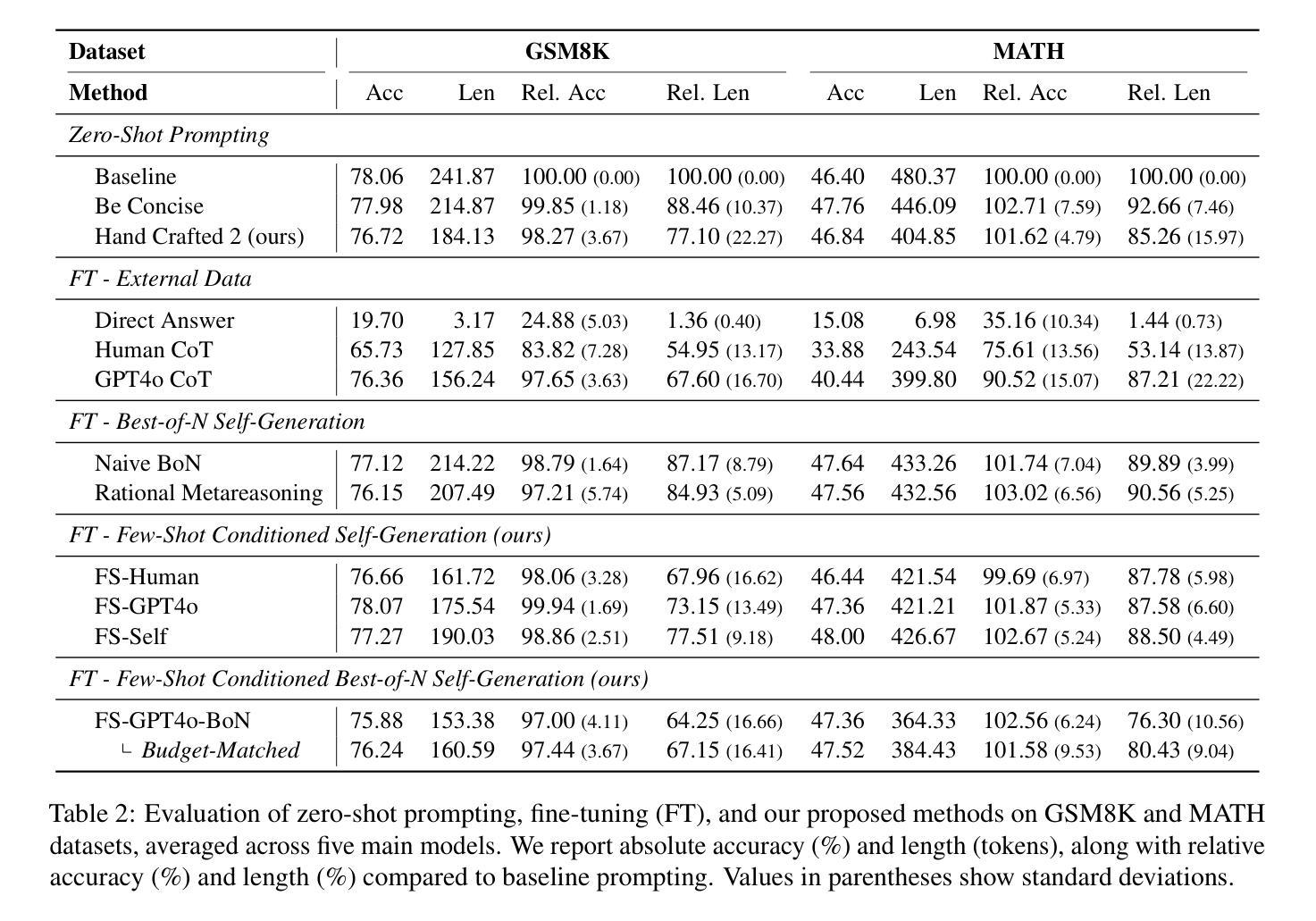
Self-Training Elicits Concise Reasoning in Large Language Models
Authors:Tergel Munkhbat, Namgyu Ho, Seo Hyun Kim, Yongjin Yang, Yujin Kim, Se-Young Yun
Chain-of-thought (CoT) reasoning has enabled large language models (LLMs) to utilize additional computation through intermediate tokens to solve complex tasks. However, we posit that typical reasoning traces contain many redundant tokens, incurring extraneous inference costs. Upon examination of the output distribution of current LLMs, we find evidence on their latent ability to reason more concisely, relative to their default behavior. To elicit this capability, we propose simple fine-tuning methods which leverage self-generated concise reasoning paths obtained by best-of-N sampling and few-shot conditioning, in task-specific settings. Our combined method achieves a 30% reduction in output tokens on average, across five model families on GSM8K and MATH, while maintaining average accuracy. By exploiting the fundamental stochasticity and in-context learning capabilities of LLMs, our self-training approach robustly elicits concise reasoning on a wide range of models, including those with extensive post-training. Code is available at https://github.com/TergelMunkhbat/concise-reasoning
链式思维(CoT)推理使得大型语言模型(LLM)能够通过中间令牌利用额外的计算来解决复杂的任务。然而,我们认为典型的推理轨迹包含许多冗余的令牌,产生了额外的推理成本。在检查当前LLM的输出分布时,我们发现它们相对于默认行为具有更简洁推理的潜在能力。为了激发这一能力,我们提出了简单的微调方法,这些方法利用通过最佳N采样和少样本条件在特定任务环境中获得的自我生成的简洁推理路径。我们的组合方法在GSM8K和MATH上平均减少了输出令牌数的30%,同时保持平均准确率。通过利用LLM的基本随机性和上下文学习能力,我们的自训练方法在各种模型上都能稳健地引发简洁推理,包括那些经过广泛训练后的模型。代码可通过以下网址获得:https://github.com/TergelMunkhbat/concise-reasoning。
论文及项目相关链接
PDF 23 pages, 10 figures, 18 tables
Summary
链式思维(CoT)推理使大型语言模型(LLM)能够通过中间标记利用额外的计算来解决复杂任务。然而,我们观察到通常的推理过程包含许多冗余标记,产生了额外的推理成本。我们提出了简单微调方法,利用自我生成的简洁推理路径,通过最佳N采样和少样本条件,在特定任务环境中实现平均输出标记减少30%,同时在GSM8K和MATH上维持平均准确率。我们的自我训练方法利用LLM的基本随机性和上下文学习能力,能在各种模型上稳健地实现简洁推理,包括那些经过大量训练后的模型。
Key Takeaways
- 链式思维(CoT)推理允许大型语言模型(LLM)解决复杂任务时利用额外计算。
- 典型的推理过程包含许多冗余标记,导致额外的推理成本。
- 提出简单微调方法,利用自我生成的简洁推理路径。
- 通过最佳N采样和少样本条件,实现了平均输出标记减少30%。
- 在特定任务环境中维持了平均准确率。
- 利用LLM的基本随机性和上下文学习能力,方法能在各种模型上实现简洁推理。
点此查看论文截图

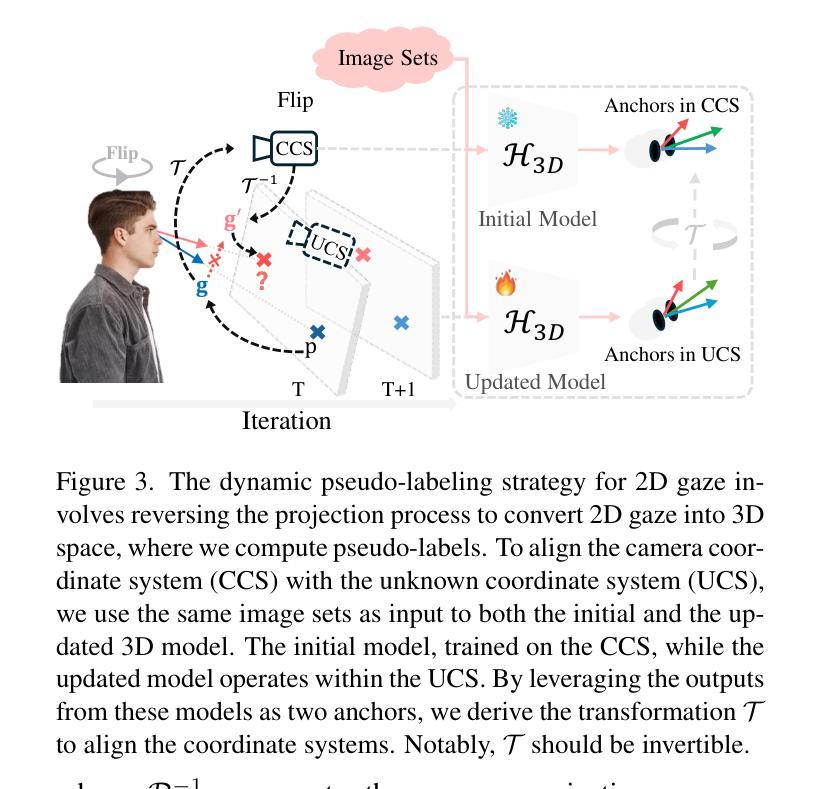
3D Prior is All You Need: Cross-Task Few-shot 2D Gaze Estimation
Authors:Yihua Cheng, Hengfei Wang, Zhongqun Zhang, Yang Yue, Bo Eun Kim, Feng Lu, Hyung Jin Chang
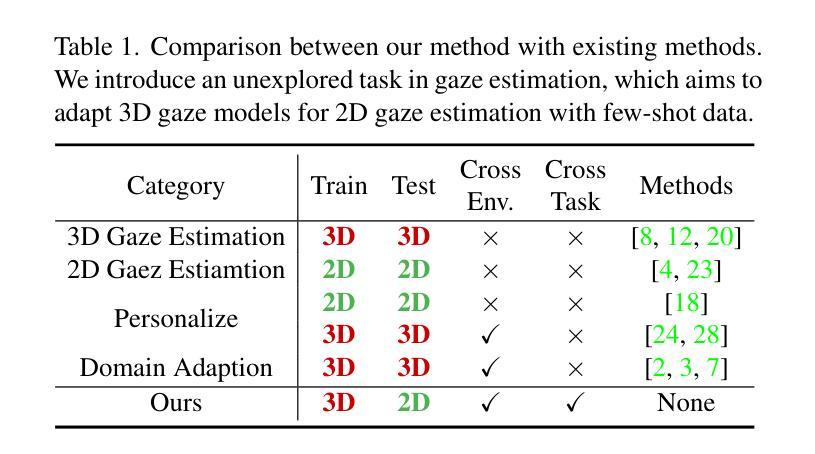
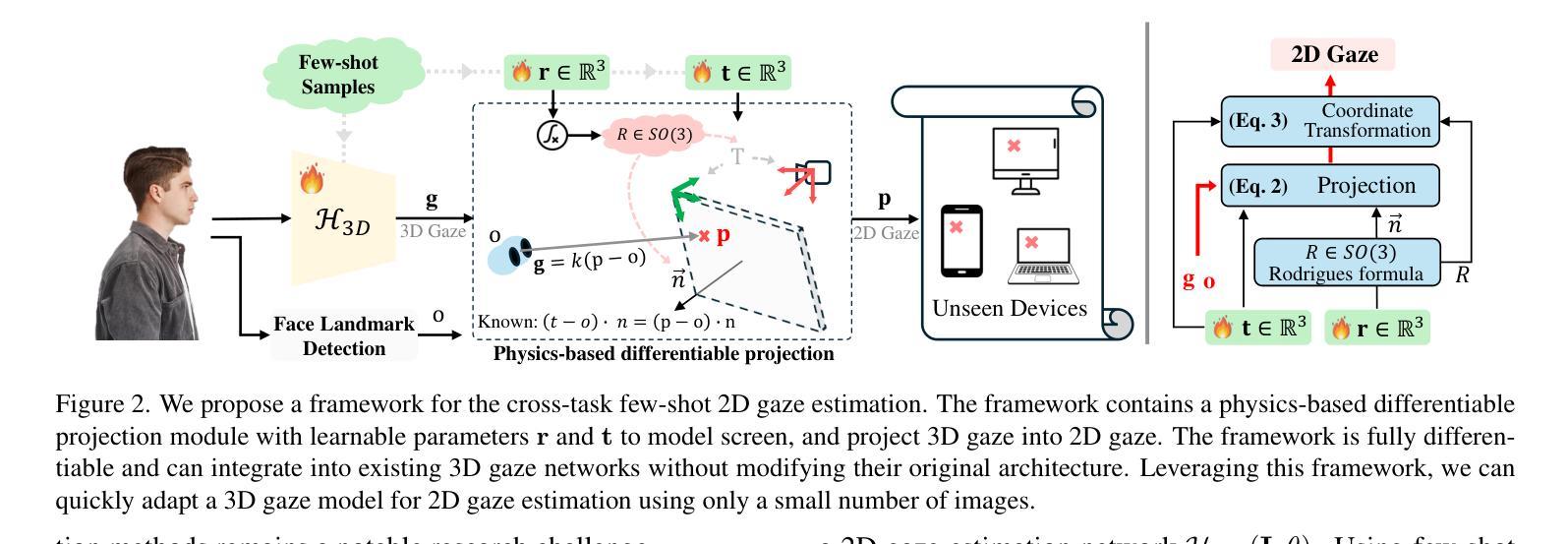
3D and 2D gaze estimation share the fundamental objective of capturing eye movements but are traditionally treated as two distinct research domains. In this paper, we introduce a novel cross-task few-shot 2D gaze estimation approach, aiming to adapt a pre-trained 3D gaze estimation network for 2D gaze prediction on unseen devices using only a few training images. This task is highly challenging due to the domain gap between 3D and 2D gaze, unknown screen poses, and limited training data. To address these challenges, we propose a novel framework that bridges the gap between 3D and 2D gaze. Our framework contains a physics-based differentiable projection module with learnable parameters to model screen poses and project 3D gaze into 2D gaze. The framework is fully differentiable and can integrate into existing 3D gaze networks without modifying their original architecture. Additionally, we introduce a dynamic pseudo-labelling strategy for flipped images, which is particularly challenging for 2D labels due to unknown screen poses. To overcome this, we reverse the projection process by converting 2D labels to 3D space, where flipping is performed. Notably, this 3D space is not aligned with the camera coordinate system, so we learn a dynamic transformation matrix to compensate for this misalignment. We evaluate our method on MPIIGaze, EVE, and GazeCapture datasets, collected respectively on laptops, desktop computers, and mobile devices. The superior performance highlights the effectiveness of our approach, and demonstrates its strong potential for real-world applications.
本文介绍了一种新颖的跨任务小样本2D眼动估计方法,旨在使用预训练的3D眼动估计网络对未见过的设备进行基于少量训练图像的2D眼动预测。由于3D和2D眼动之间的领域差距、未知的屏幕姿态以及有限的训练数据,此任务极具挑战性。为了应对这些挑战,我们提出了一种新颖的框架来弥补3D和2D眼动之间的差距。我们的框架包含一个基于物理的可微分投影模块,具有可学习参数来模拟屏幕姿态并将3D眼动投影到2D眼动。该框架是完全可微分的,并且可以集成到现有的3D眼动网络中,无需修改其原始架构。此外,我们引入了一种动态伪标签策略来处理翻转图像,这对于具有未知屏幕姿态的2D标签来说尤其具有挑战性。为了克服这一点,我们通过将2D标签转换为三维空间来反转投影过程,并在那里执行翻转操作。值得注意的是,这个三维空间不与相机坐标系对齐,因此我们学习一个动态转换矩阵来补偿这种不对齐。我们在MPIIGaze、EVE和GazeCapture数据集上评估了我们的方法,这些数据集分别在笔记本电脑、台式电脑和移动设备上收集。出色的性能凸显了我们方法的有效性,并展示了其在现实世界应用中的强大潜力。
论文及项目相关链接
PDF CVPR 2025
Summary
本文提出了一种新型的跨任务小样本2D眼动注视点估计方法,旨在利用预训练的3D眼动注视点估计网络对未见过的设备进行少量训练图像即可进行2D眼动注视点预测。该研究引入了可微分投影模块建模屏幕姿态并将3D眼动注视点投影到2D空间,同时采用动态伪标签策略应对翻转图像的挑战。在MPIIGaze、EVE和GazeCapture数据集上的实验结果证明了方法的有效性,展现其真实世界应用的潜力。
Key Takeaways
- 介绍了将预训练的3D眼动注视点估计网络应用于未见设备的小样本下的2D眼动注视点预测方法。
- 提出了一种新颖的跨任务方法,使用可微分投影模块将3D和2D眼动注视点联系紧密起来。该模块能建模屏幕姿态并实现从3D到2D的投影。
- 引入了动态伪标签策略处理翻转图像带来的挑战,通过将2D标签转化为相应的物理空间的做法来处理这一挑战。值得注意的是转换后的空间与相机坐标系不一致,因此引入了动态转换矩阵来修正这一差异。
点此查看论文截图

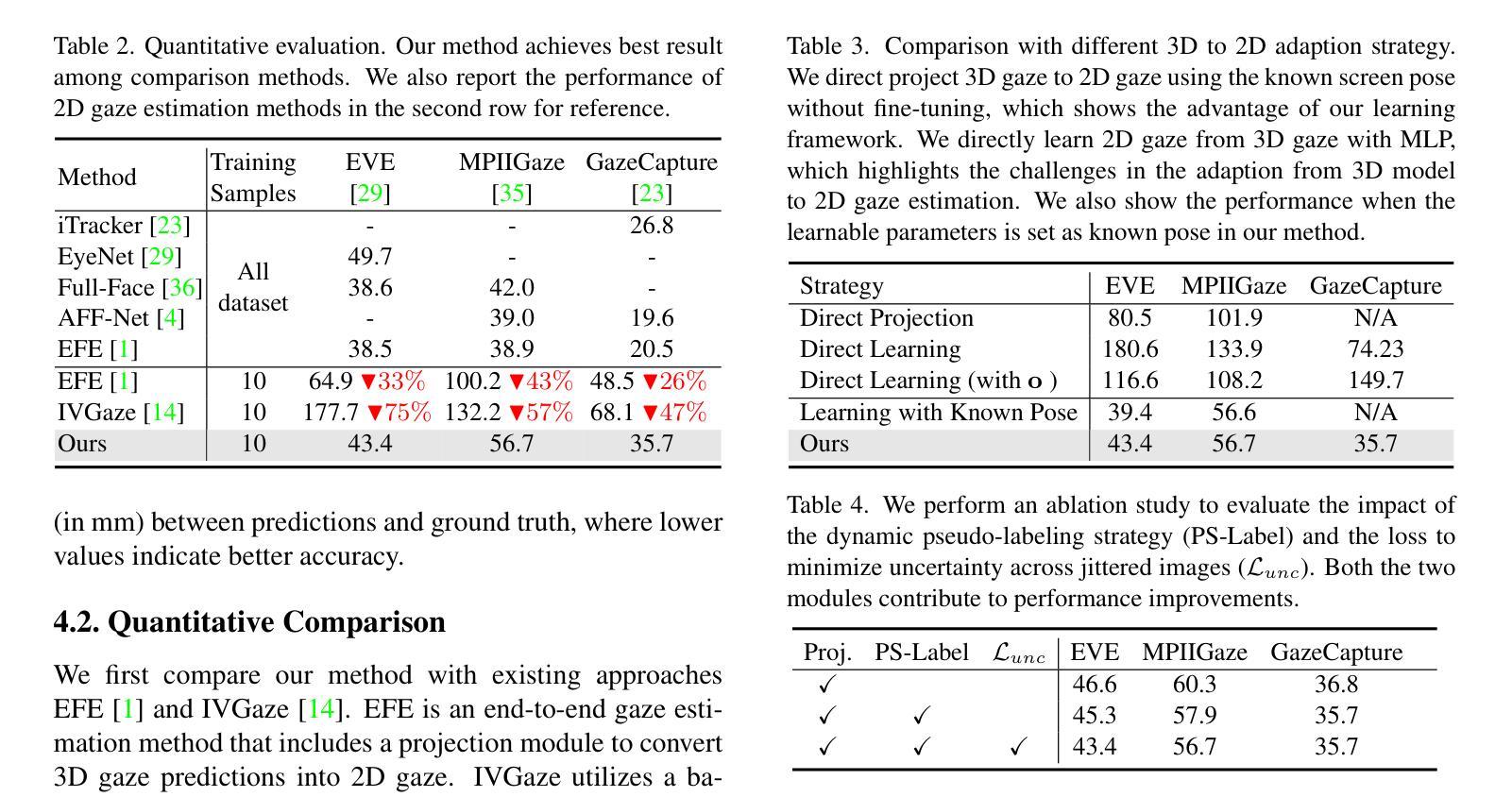
Efficient and Context-Aware Label Propagation for Zero-/Few-Shot Training-Free Adaptation of Vision-Language Model
Authors:Yushu Li, Yongyi Su, Adam Goodge, Kui Jia, Xun Xu
Vision-language models (VLMs) have revolutionized machine learning by leveraging large pre-trained models to tackle various downstream tasks. Although label, training, and data efficiency have improved, many state-of-the-art VLMs still require task-specific hyperparameter tuning and fail to fully exploit test samples. To overcome these challenges, we propose a graph-based approach for label-efficient adaptation and inference. Our method dynamically constructs a graph over text prompts, few-shot examples, and test samples, using label propagation for inference without task-specific tuning. Unlike existing zero-shot label propagation techniques, our approach requires no additional unlabeled support set and effectively leverages the test sample manifold through dynamic graph expansion. We further introduce a context-aware feature re-weighting mechanism to improve task adaptation accuracy. Additionally, our method supports efficient graph expansion, enabling real-time inductive inference. Extensive evaluations on downstream tasks, such as fine-grained categorization and out-of-distribution generalization, demonstrate the effectiveness of our approach. The source code is available at https://github.com/Yushu-Li/ECALP.
视觉语言模型(VLMs)通过利用大型预训练模型来解决各种下游任务,从而革新了机器学习。尽管标签、训练和数据的效率已经提高,但许多最先进的VLMs仍然需要针对特定任务的超参数调整,并且未能充分利用测试样本。为了克服这些挑战,我们提出了一种基于图的标签高效适应和推理方法。我们的方法动态地在文本提示、少量示例和测试样本上构建图,使用标签传播进行推理,无需特定任务的调整。与现有的零样本标签传播技术不同,我们的方法不需要额外的无标签支持集,并通过动态图扩展有效地利用测试样本流形。我们还引入了一种上下文感知的特征重新加权机制,以提高任务适应的准确性。此外,我们的方法支持高效的图扩展,能够实现实时归纳推理。在下游任务(如精细分类和分布外泛化)上的广泛评估证明了我们的方法的有效性。源代码可在https://github.com/Yushu-Li/ECALP找到。
论文及项目相关链接
Summary
本文介绍了利用大型预训练模型处理下游任务的视觉语言模型(VLMs)。尽管标签、训练和数据的效率有所提升,但现有的先进VLMs仍需要针对特定任务的超参数调整,且无法充分利用测试样本。为应对这些挑战,提出了一种基于图的标签高效适应和推理方法。该方法动态构建文本提示、少量示例和测试样本的图,利用标签传播进行推理,无需特定任务调整。该方法无需额外的无标签支持集,通过动态图扩展有效利用了测试样本流形。此外,还引入了一种基于上下文特征的重加权机制,以提高任务适应的准确性。该方法支持有效的图扩展,可实现实时归纳推理。在下游任务上的广泛评估证明了该方法的有效性。
Key Takeaways
- VLMs已经利用大型预训练模型处理各种下游任务。
- 现有VLMs需要针对特定任务的超参数调整,且无法充分利用测试样本。
- 提出了一种基于图的标签高效适应和推理方法,通过动态构建文本提示、少量示例和测试样本的图进行推理。
- 该方法利用标签传播进行推理,无需特定任务调整,且无需额外的无标签支持集。
- 通过动态图扩展,该方法有效利用了测试样本流形。
- 引入了一种基于上下文特征的重加权机制,提高任务适应的准确性。
- 该方法支持实时归纳推理,并在下游任务上的广泛评估证明了其有效性。
点此查看论文截图

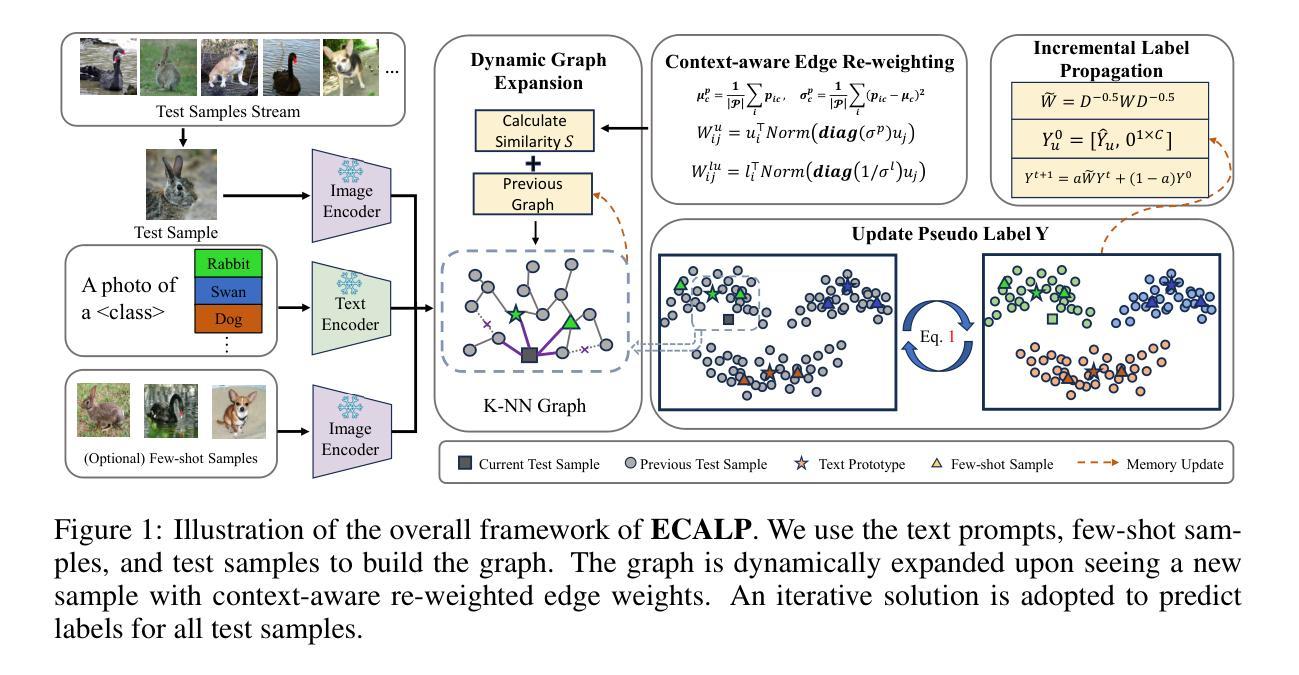
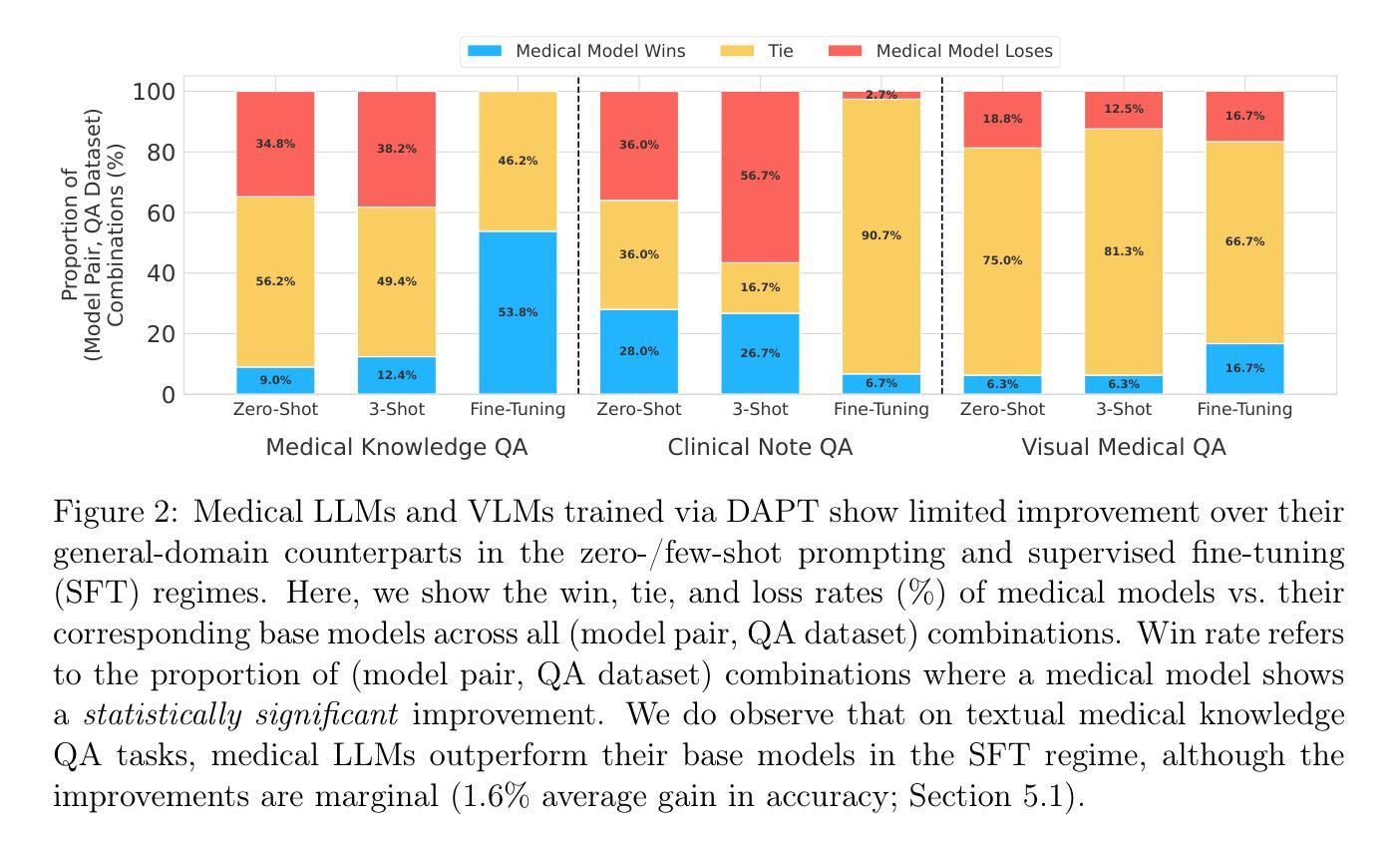
The Limited Impact of Medical Adaptation of Large Language and Vision-Language Models
Authors:Daniel P. Jeong, Pranav Mani, Saurabh Garg, Zachary C. Lipton, Michael Oberst
Several recent works seek to adapt general-purpose large language models (LLMs) and vision-language models (VLMs) for medical applications through continued pretraining on publicly available biomedical corpora. These works typically claim that such domain-adaptive pretraining improves performance on various downstream medical tasks, such as answering medical exam questions. In this paper, we compare ten “medical” LLMs and two VLMs against their corresponding base models, arriving at a different conclusion: all medical VLMs and nearly all medical LLMs fail to consistently improve over their base models in the zero-/few-shot prompting and supervised fine-tuning regimes for medical question answering (QA). For instance, on clinical-note-based QA tasks in the 3-shot setting, medical LLMs outperform their base models in only 26.7% of cases, reach a (statistical) tie in 16.7% of cases, and perform significantly worse in the remaining 56.7% of cases. Our conclusions are based on (i) comparing each medical model directly against its base model; (ii) optimizing the prompts for each model separately in zero-/few-shot prompting; and (iii) accounting for statistical uncertainty in comparisons. Our findings suggest that state-of-the-art general-domain models may already exhibit strong medical knowledge and reasoning capabilities, and offer recommendations to strengthen the conclusions of future studies.
近期有几项研究尝试通过对公开可用的生物医学语料库进行持续预训练,将通用的大型语言模型(LLMs)和视觉语言模型(VLMs)适应于医疗应用。这些研究通常声称,这种领域自适应预训练能提高在各种下游医疗任务上的性能,如回答医学考试问题。在本文中,我们将十种“医疗”LLMs和两种VLMs与它们的基础模型进行比较,得出了不同的结论:所有的医疗VLMs和几乎所有的医疗LLMs在零/少镜头提示和监督微调制度下,都无法持续提高其基础模型在医疗问答(QA)上的性能。例如,在基于临床笔记的QA任务的3镜头设置中,医疗LLMs仅在26.7%的情况下超越其基础模型,在16.7%的情况下与基础模型表现相当(统计学上的平手),并在其余56.7%的情况下表现显著更差。我们的结论是基于(i)将每个医疗模型直接与其基础模型进行比较;(ii)在零/少镜头提示中分别为每个模型优化提示;(iii)比较中考虑到统计不确定性。我们的研究结果表明,最先进的通用领域模型可能已经展现出强大的医疗知识和推理能力,并为未来研究加强结论提供了建议。
论文及项目相关链接
PDF Extended version of EMNLP 2024 paper arXiv:2411.04118. Includes additional results on clinical note QA tasks and supervised fine-tuning evaluations
Summary
适应医疗应用领域的通用大型语言模型(LLMs)和视觉语言模型(VLMs)的研究工作普遍认为,通过在公开可用的生物医学语料库上进行领域自适应预训练,可以提高在各种下游医疗任务上的性能。然而,本文对比了十种“医疗”LLMs和两种VLMs及其基础模型,得出不同结论:在零/少镜头提示和监督微调制度下,几乎所有医疗VLMs和近大部分医疗LLMs在医疗问答任务上并未比基础模型有显著改善。例如,在基于临床笔记的问答任务的3个样本中,医疗LLMs仅在26.7%的情况下表现优于基础模型,在16.7%的情况下表现相当,并在剩下的56.7%的情况下表现更差。
Key Takeaways
- 近期多项研究尝试通过持续在公开生物医学语料库上进行预训练,将通用大型语言模型和视觉语言模型适应于医疗应用。
- 本文对比了医疗LLMs和VLMs及其基础模型,发现在零/少镜头提示和监督微调环境下,这些医疗模型在医疗问答任务上未显著优于基础模型。
- 在基于临床笔记的3个样本问答任务中,医疗LLMs仅在少数情况下表现较好,大部分情况下与基础模型表现相当或更差。
- 本文的研究方法包括直接对比医疗模型和基础模型、针对每个模型分别优化提示,并考虑比较中的统计不确定性。
- 研究结果表明,现有的通用领域模型可能已经具备强大的医疗知识和推理能力。
- 本文为未来的研究提供了关于如何强化模型在医疗领域表现的建议。
点此查看论文截图

ARIC: An Activity Recognition Dataset in Classroom Surveillance Images
Authors:Linfeng Xu, Fanman Meng, Qingbo Wu, Lili Pan, Heqian Qiu, Lanxiao Wang, Kailong Chen, Kanglei Geng, Yilei Qian, Haojie Wang, Shuchang Zhou, Shimou Ling, Zejia Liu, Nanlin Chen, Yingjie Xu, Shaoxu Cheng, Bowen Tan, Ziyong Xu, Hongliang Li
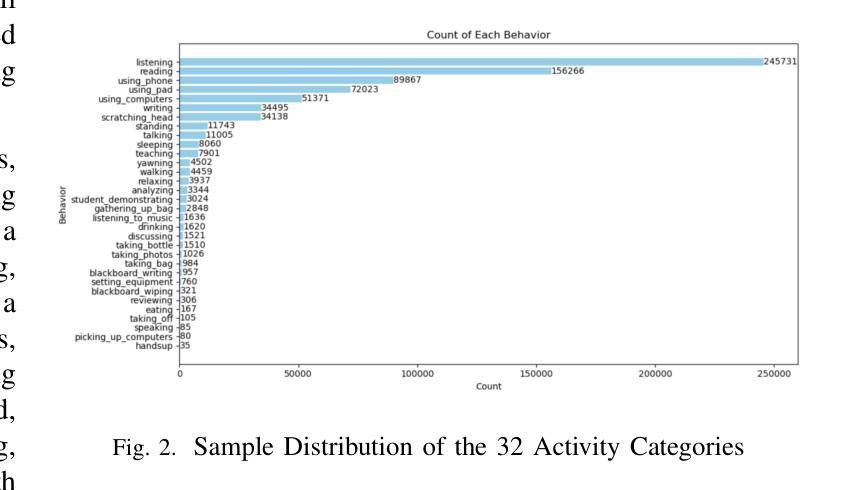
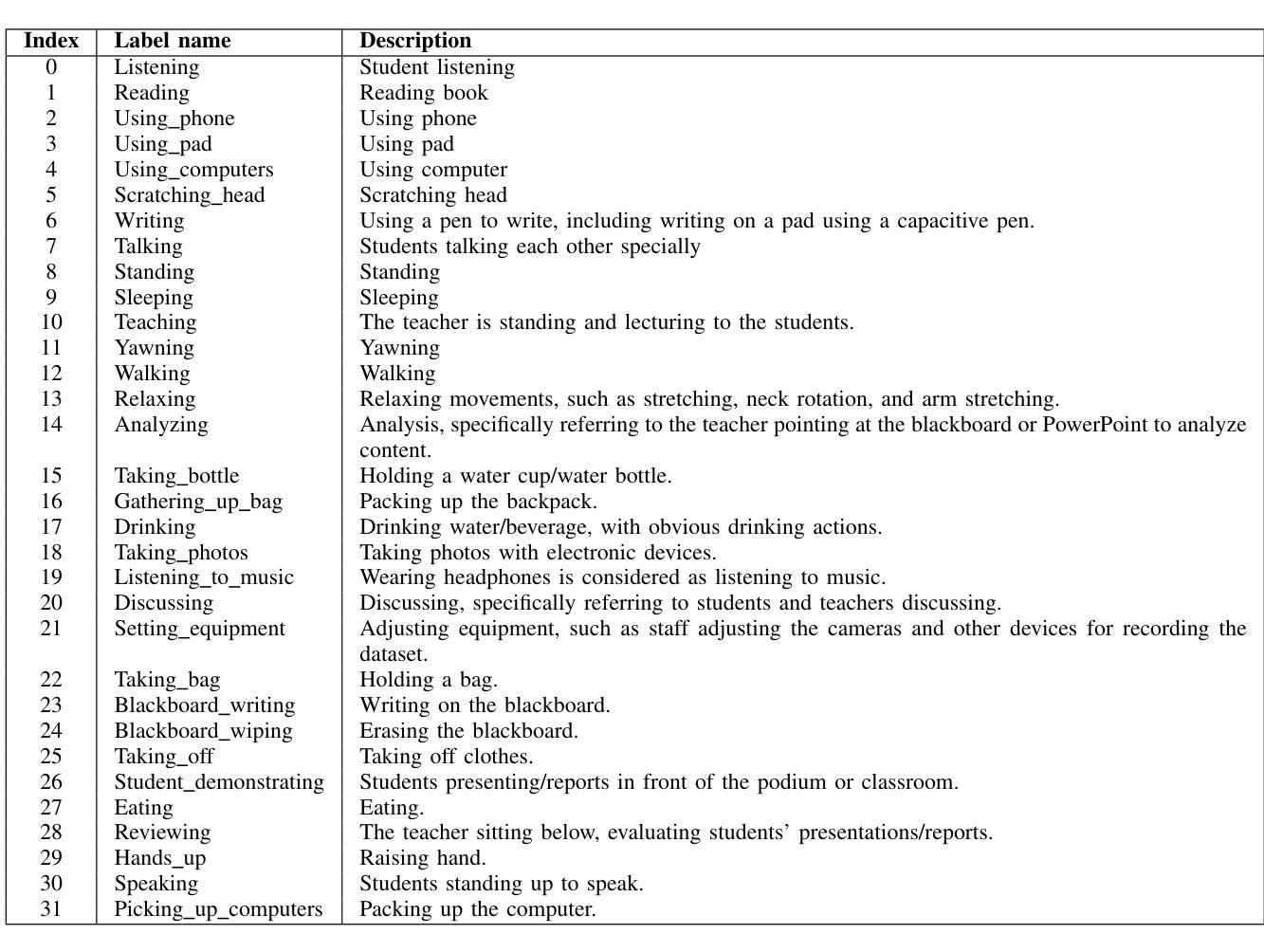
The application of activity recognition in the ``AI + Education” field is gaining increasing attention. However, current work mainly focuses on the recognition of activities in manually captured videos and a limited number of activity types, with little attention given to recognizing activities in surveillance images from real classrooms. Activity recognition in classroom surveillance images faces multiple challenges, such as class imbalance and high activity similarity. To address this gap, we constructed a novel multimodal dataset focused on classroom surveillance image activity recognition called ARIC (Activity Recognition In Classroom). The ARIC dataset has advantages of multiple perspectives, 32 activity categories, three modalities, and real-world classroom scenarios. In addition to the general activity recognition tasks, we also provide settings for continual learning and few-shot continual learning. We hope that the ARIC dataset can act as a facilitator for future analysis and research for open teaching scenarios. You can download preliminary data from https://ivipclab.github.io/publication_ARIC/ARIC.
“AI +教育”领域中活动识别的应用越来越受到关注。然而,当前的研究工作主要集中在手动捕获视频中的活动识别以及有限的活动类型上,对于从真实课堂监控图像中识别活动的关注较少。课堂监控图像中的活动识别面临多重挑战,如类别不平衡和活动高度相似等。为了弥补这一空白,我们构建了一个专注于课堂监控图像活动识别的新型多模式数据集,名为ARIC(课堂活动识别)。ARIC数据集具有多角度、32类活动、三种模态和真实课堂场景的优势。除了一般的活动识别任务外,我们还提供了持续学习和少量样本持续学习的设置。我们希望ARIC数据集能为开放教学场景的未来分析和研究提供帮助。您可以从https://ivipclab.github.io/publication_ARIC/ARIC下载初步数据。
论文及项目相关链接
PDF arXiv admin note: text overlap with arXiv:2409.03354. Updated the description for ARIC supplement
Summary
活动识别在“人工智能+教育”领域的应用越来越受到关注。当前研究主要集中在手动采集视频的活动识别及有限的活动类型上,而针对教室监控图像的活动识别研究较少。教室监控图像的活动识别面临类不平衡、活动相似性高等挑战。为解决此问题,我们构建了一个专注于教室监控图像活动识别的多模态数据集ARIC。ARIC数据集具有多角度、32类活动、三模态和真实课堂场景优势,并设置了持续学习和小样本持续学习的场景。我们希望ARIC数据集能为开放教学环境未来的分析和研究提供便利。
Key Takeaways
- 活动识别在“人工智能+教育”领域的应用正逐渐受到关注。
- 当前研究主要集中在手动采集视频的活动识别,对教室监控图像的活动识别研究较少。
- 教室监控图像的活动识别面临类不平衡和活动相似性高等挑战。
- ARIC数据集是一个专注于教室监控图像活动识别的多模态数据集。
- ARIC数据集具有多角度、32类活动、三模态和真实课堂场景的优势。
- ARIC数据集设置了持续学习和小样本持续学习的场景。
点此查看论文截图


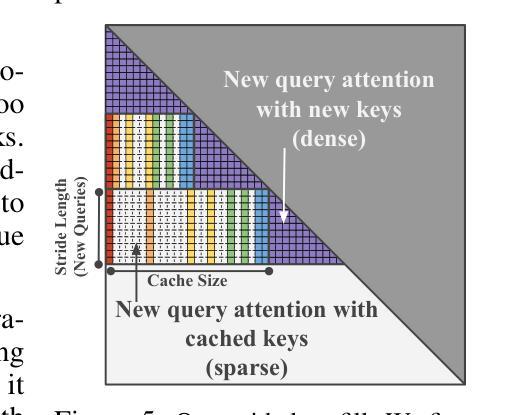
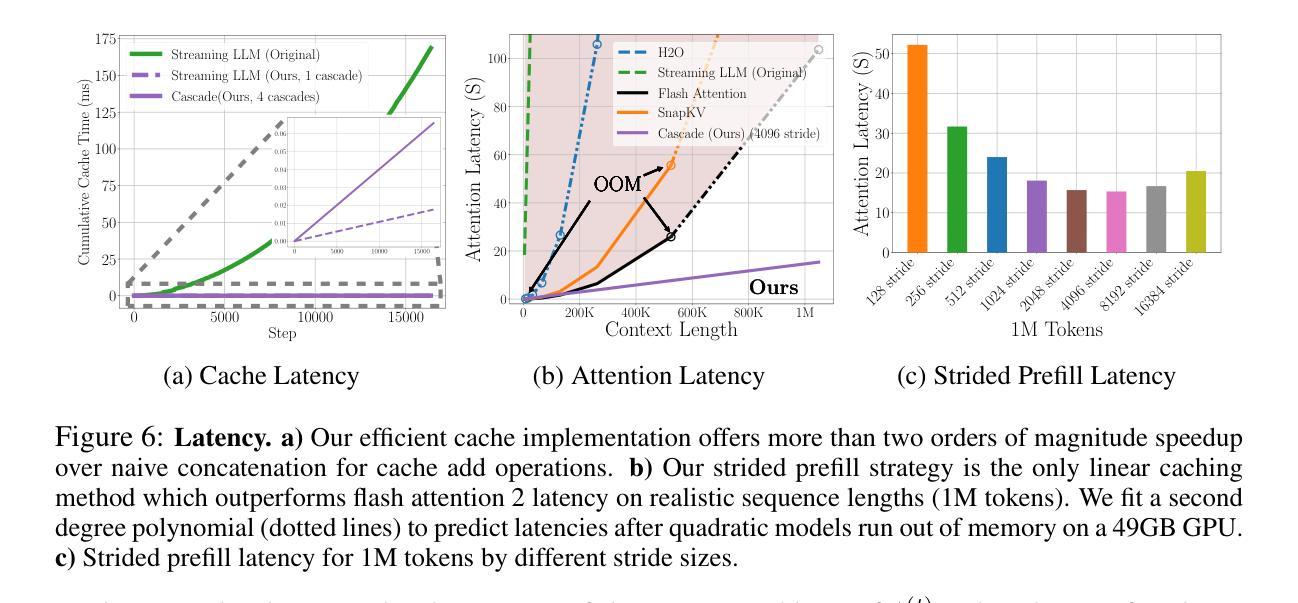
Training-Free Exponential Context Extension via Cascading KV Cache
Authors:Jeffrey Willette, Heejun Lee, Youngwan Lee, Myeongjae Jeon, Sung Ju Hwang
The transformer’s context window is vital for tasks such as few-shot learning and conditional generation as it preserves previous tokens for active memory. However, as the context lengths increase, the computational costs grow quadratically, hindering the deployment of large language models (LLMs) in real-world, long sequence scenarios. Although some recent key-value caching (KV Cache) methods offer linear inference complexity, they naively manage the stored context, prematurely evicting tokens and losing valuable information. Moreover, they lack an optimized prefill/prompt stage strategy, resulting in higher latency than even quadratic attention for realistic context sizes. In response, we introduce a novel mechanism that leverages cascading sub-cache buffers to selectively retain the most relevant tokens, enabling the model to maintain longer context histories without increasing the cache size. Our approach outperforms linear caching baselines across key benchmarks, including streaming perplexity, question answering, book summarization, and passkey retrieval, where it retains better retrieval accuracy at 1M tokens after four doublings of the cache size of 65K. Additionally, our method reduces prefill stage latency by a factor of 6.8 when compared to flash attention on 1M tokens. These innovations not only enhance the computational efficiency of LLMs but also pave the way for their effective deployment in resource-constrained environments, enabling large-scale, real-time applications with significantly reduced latency.
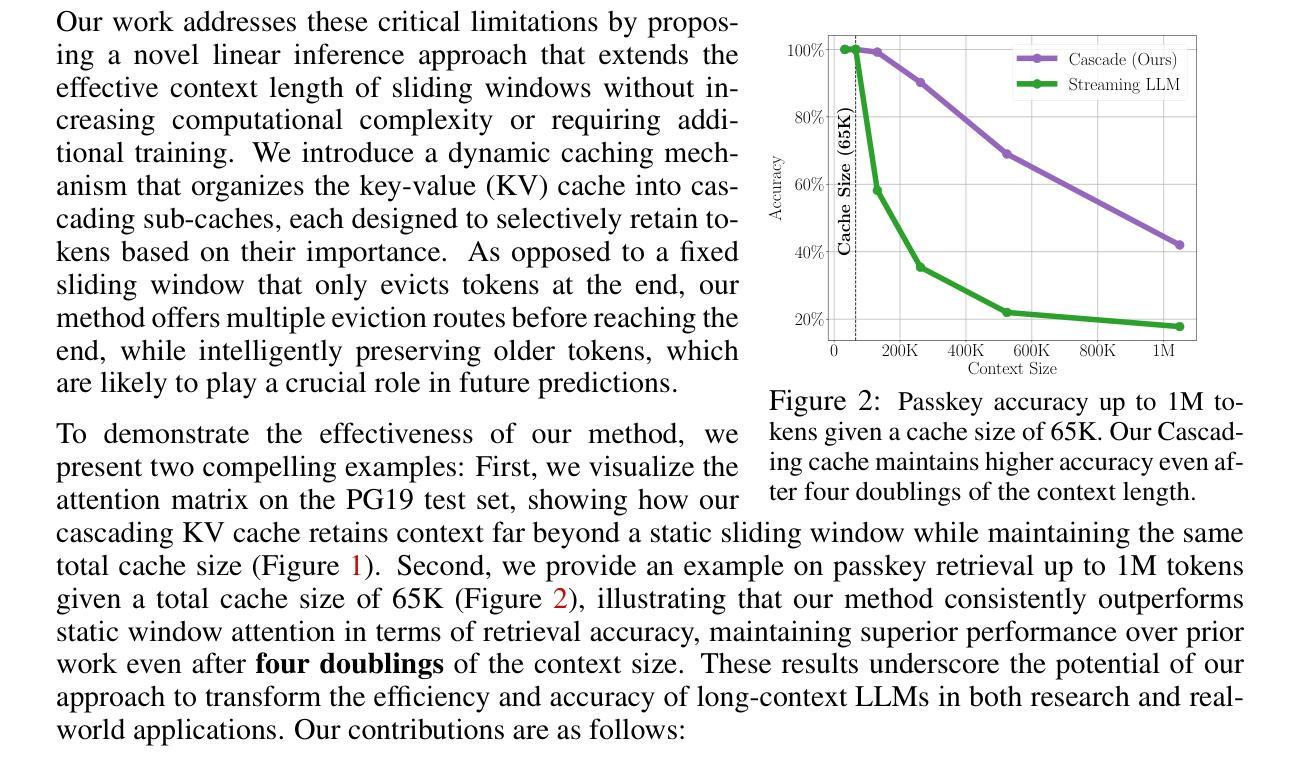
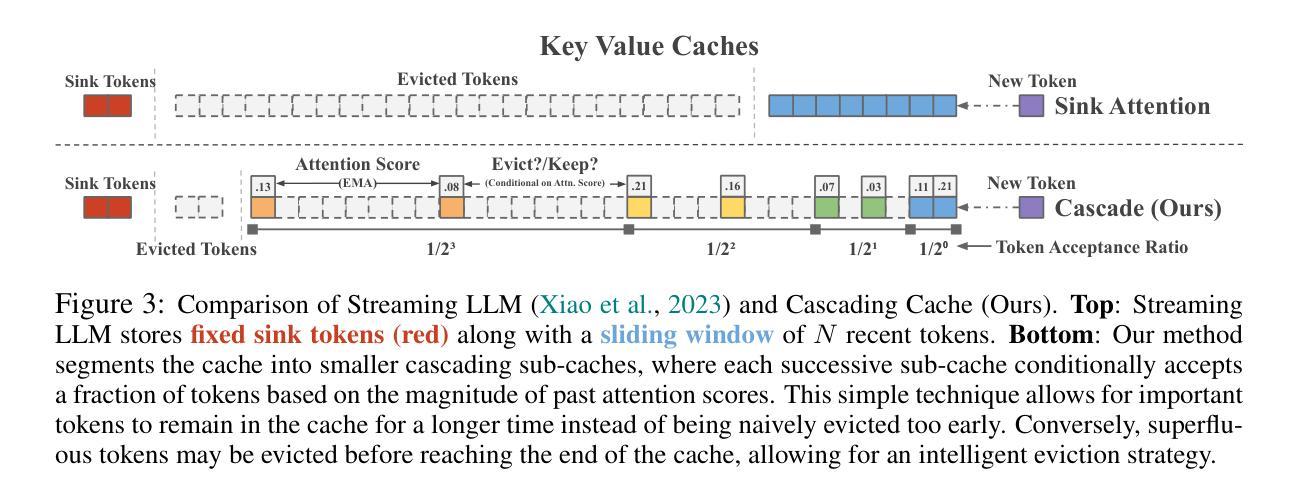
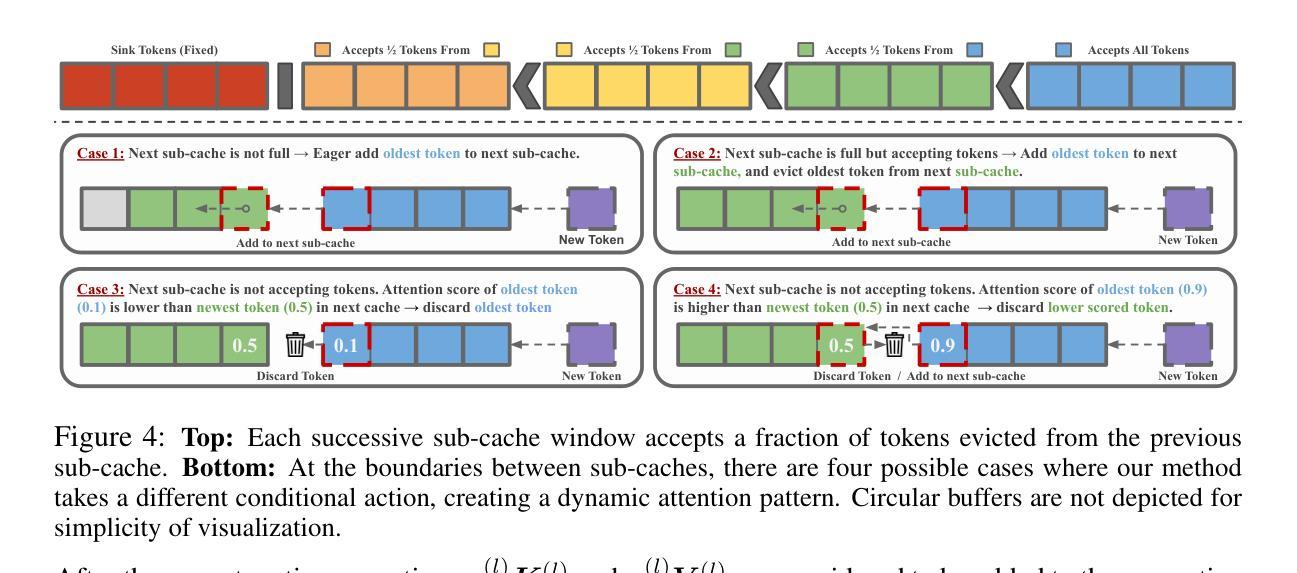
变压器的上下文窗口对于少样本学习和条件生成等任务至关重要,因为它可以保留先前的令牌作为活动内存。然而,随着上下文长度的增加,计算成本呈二次方增长,阻碍了大型语言模型(LLM)在现实世界中的长序列场景部署。尽管最近的一些键值缓存(KV Cache)方法提供了线性的推理复杂性,但它们简单地管理存储的上下文,过早地逐出令牌并丢失有价值的信息。此外,它们缺乏优化的预填充/提示阶段策略,导致在实际上下文大小下的延迟甚至高于二次注意力。作为回应,我们引入了一种新型机制,该机制利用级联的子缓存缓冲区来有选择地保留最相关的令牌,使模型能够在不增加缓存大小的情况下保持更长的上下文历史。我们的方法在关键基准测试上超越了线性缓存基线,包括流式困惑度、问答、书籍摘要和通行证检索等。在缓存大小翻倍四次达到65K后,我们在1M令牌上保持了更好的检索准确性。此外,我们的方法在1M令牌上与闪光注意力相比,预填充阶段延迟降低了6.8倍。这些创新不仅提高了大型语言模型的计算效率,还为它们在资源受限环境中的有效部署铺平了道路,实现了大规模、实时的应用程序,并显著降低了延迟。
论文及项目相关链接
Summary:
文中探讨了在少样本学习和条件生成等任务中,transformer的上下文窗口的重要性及其带来的计算成本问题。为解决这一问题,提出了利用级联子缓存缓冲区的新机制,有选择地保留最相关的令牌,使模型能够保持更长的上下文历史,同时不增加缓存大小。此方法在关键基准测试中优于线性缓存基线,包括流式困惑度、问答、书籍摘要和密钥检索等,并且在缓存大小翻倍时仍能保持较好的检索准确性。此外,该方法还降低了填充阶段的延迟。
Key Takeaways:
- Transformer的上下文窗口对于少样本学习和条件生成等任务至关重要,但计算成本随上下文长度的增加而增加。
- 现有的KV Cache方法虽然提供线性推理复杂性,但管理存储的上下文的方式过于简单,可能导致过早淘汰令牌和丢失有价值的信息。
- 提出的级联子缓存缓冲区机制能够有选择地保留最相关的令牌,维持更长的上下文历史,同时不增加缓存大小。
- 该方法在关键基准测试中表现优异,包括流式困惑度、问答、书籍摘要和密钥检索等任务。
- 在缓存大小翻倍时,该方法仍然能保持较好的检索准确性。
- 与flash attention相比,该方法在1M令牌的情况下将填充阶段延迟降低了6.8倍。
点此查看论文截图

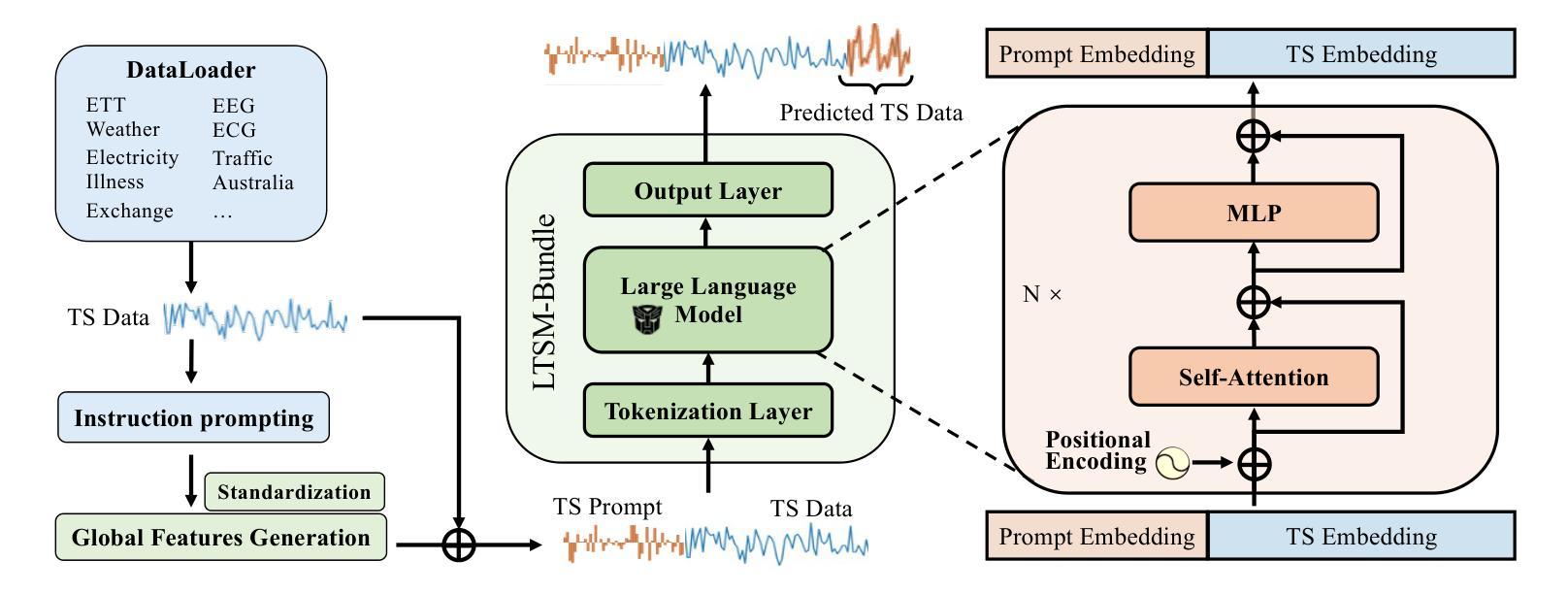
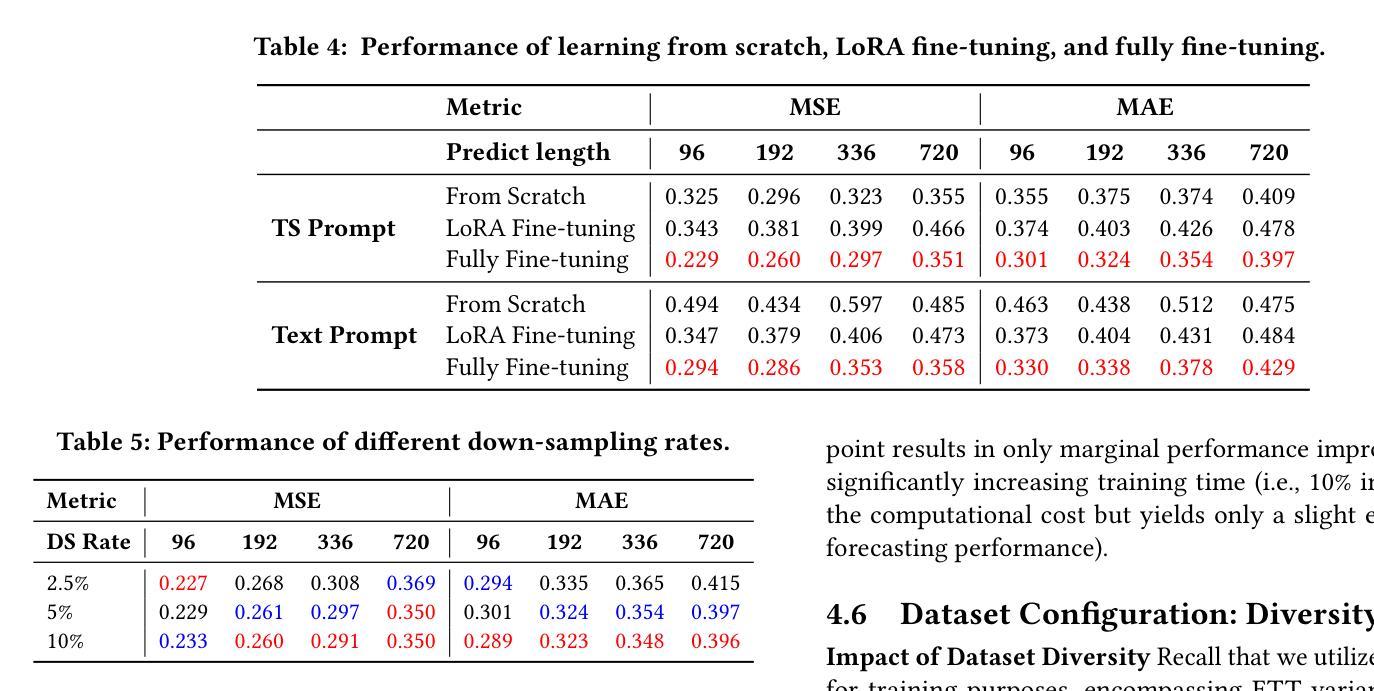
LTSM-Bundle: A Toolbox and Benchmark on Large Language Models for Time Series Forecasting
Authors:Yu-Neng Chuang, Songchen Li, Jiayi Yuan, Guanchu Wang, Kwei-Herng Lai, Songyuan Sui, Leisheng Yu, Sirui Ding, Chia-Yuan Chang, Qiaoyu Tan, Daochen Zha, Xia Hu
Time Series Forecasting (TSF) has long been a challenge in time series analysis. Inspired by the success of Large Language Models (LLMs), researchers are now developing Large Time Series Models (LTSMs)-universal transformer-based models that use autoregressive prediction-to improve TSF. However, training LTSMs on heterogeneous time series data poses unique challenges, including diverse frequencies, dimensions, and patterns across datasets. Recent endeavors have studied and evaluated various design choices aimed at enhancing LTSM training and generalization capabilities. However, these design choices are typically studied and evaluated in isolation and are not benchmarked collectively. In this work, we introduce LTSM-Bundle, a comprehensive toolbox, and benchmark for training LTSMs, spanning pre-processing techniques, model configurations, and dataset configuration. It modularized and benchmarked LTSMs from multiple dimensions, encompassing prompting strategies, tokenization approaches, training paradigms, base model selection, data quantity, and dataset diversity. Furthermore, we combine the most effective design choices identified in our study. Empirical results demonstrate that this combination achieves superior zero-shot and few-shot performances compared to state-of-the-art LTSMs and traditional TSF methods on benchmark datasets.
时间序列预测(TSF)一直是时间序列分析中的一大挑战。受大型语言模型(LLM)成功的启发,研究人员现在正在开发基于通用变压器的大型时间序列模型(LTSM),采用自回归预测来提高TSF。然而,在异质时间序列数据上训练LTSM面临独特挑战,包括数据集间的频率、维度和模式的多样性。近期的研究工作已经研究和评估了旨在提高LTSM训练和泛化能力的各种设计选择。然而,这些设计选择通常孤立地研究和评估,并未集体进行基准测试。在这项工作中,我们介绍了LTSM-Bundle,一个全面的工具包和基准测试平台,用于训练LTSM,涵盖预处理技术、模型配置和数据集配置。它从多个维度对LTSM进行模块化和基准测试,包括提示策略、标记化方法、训练范式、基础模型选择、数据量以及数据集多样性。此外,我们将结合研究中确定的最有效的设计选择。实证结果表明,与基准数据集上的最新LTSM和传统TSF方法相比,这种组合实现了零样本和少样本性能上的优越性。
论文及项目相关链接
Summary
研究人员利用大型语言模型(LLM)的理念,开发了一种基于通用转换器的大型时间序列模型(LTSM),以改进时间序列预测(TSF)。然而,在异质时间序列数据上训练LTSM面临独特挑战,包括数据集的频率、维度和模式的多样性。近期研究着眼于增强LTSM训练和泛化能力的设计选择,但通常是孤立地研究并评估的,并没有统一的标准进行评估。为此,本文引入了LTSM捆绑包,一个全面的工具箱和基准测试平台,涵盖预处理技术、模型配置和数据集配置。它从多个维度模块化并评估LTSM,包括提示策略、标记化方法、训练模式、基础模型选择等。此外,本文结合了研究中发现的最有效的设计选择,实证结果表明该组合在基准数据集上相较于最先进LTSM和传统TSF方法实现了零样本和少样本性能的优越表现。
Key Takeaways
- LTSMs被开发为改进时间序列预测(TSF)。
- LTSMs在训练异质时间序列数据时面临独特挑战。
- 目前对LTSM的设计选择通常是孤立研究和评估的,缺乏统一的基准测试。
- LTSM-Bundle工具箱囊括了多种设计选择的模块化评估,包括提示策略、标记化方法等。
- 结合最有效的设计选择,实现了零样本和少样本性能上的优越表现。
- 该研究为LTSMs的进一步发展和应用提供了宝贵的参考。
点此查看论文截图