⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-04 更新
LLM Post-Training: A Deep Dive into Reasoning Large Language Models
Authors:Komal Kumar, Tajamul Ashraf, Omkar Thawakar, Rao Muhammad Anwer, Hisham Cholakkal, Mubarak Shah, Ming-Hsuan Yang, Phillip H. S. Torr, Salman Khan, Fahad Shahbaz Khan
Large Language Models (LLMs) have transformed the natural language processing landscape and brought to life diverse applications. Pretraining on vast web-scale data has laid the foundation for these models, yet the research community is now increasingly shifting focus toward post-training techniques to achieve further breakthroughs. While pretraining provides a broad linguistic foundation, post-training methods enable LLMs to refine their knowledge, improve reasoning, enhance factual accuracy, and align more effectively with user intents and ethical considerations. Fine-tuning, reinforcement learning, and test-time scaling have emerged as critical strategies for optimizing LLMs performance, ensuring robustness, and improving adaptability across various real-world tasks. This survey provides a systematic exploration of post-training methodologies, analyzing their role in refining LLMs beyond pretraining, addressing key challenges such as catastrophic forgetting, reward hacking, and inference-time trade-offs. We highlight emerging directions in model alignment, scalable adaptation, and inference-time reasoning, and outline future research directions. We also provide a public repository to continually track developments in this fast-evolving field: https://github.com/mbzuai-oryx/Awesome-LLM-Post-training.
大型语言模型(LLM)已经改变了自然语言处理的格局,并带来了多样化的应用。在大量网络规模数据上进行预训练为这些模型奠定了基础,然而研究界现在越来越将重点转向后训练技术,以实现进一步的突破。虽然预训练提供了广泛的语言基础,但后训练方法使LLM能够精炼其知识,提高推理能力,增强事实准确性,并更有效地与用户意图和道德考量对齐。微调、强化学习和测试时间缩放已成为优化LLM性能、确保稳健性和提高在各种现实世界任务中的适应能力的关键策略。本文系统地探讨了后训练方法论,分析了其在预训练之外精炼LLM的作用,解决了关键挑战,如灾难性遗忘、奖励黑客和推理时间权衡。我们强调了模型对齐、可扩展适应和推理时间推理的新兴方向,并概述了未来的研究方向。我们还提供了一个公共仓库,以持续跟踪这一快速演变领域的发展:https://github.com/mbzuai-oryx/Awesome-LLM-Post-training。
论文及项目相关链接
PDF 31 pages, 7 figures, 3 tables, 375 references
Summary
大规模语言模型(LLM)的预训练为自然语言处理领域带来了变革,并催生了多样化的应用。研究界现在越来越关注如何通过后训练技术实现进一步的突破。虽然预训练提供了广泛的语言基础,但后训练方法使LLM能够精炼知识、提高推理能力、增强事实准确性,并更有效地与用户意图和道德考量对齐。微调、强化学习和测试时间缩放等策略对于优化LLM性能、确保稳健性和提高适应各种现实任务的能力至关重要。本文系统地探讨了后训练方法论,分析了其在精炼LLM方面超越预训练的作用,并解决了诸如灾难性遗忘、奖励黑客和推理时间权衡等关键挑战。我们强调了模型对齐、可伸缩适应和推理时间推理等新兴方向,并概述了未来研究方向。
Key Takeaways
- LLMs已经改变了自然语言处理的格局,并催生了各种应用。
- 预训练为LLMs提供了广泛的语言基础,而后训练方法用于精炼知识、提高推理能力和事实准确性。
- 后训练技术使LLM与用户意图和道德考量更加对齐。
- 微调、强化学习和测试时间缩放是优化LLM性能的关键策略。
- 后训练方法论在解决灾难性遗忘、奖励黑客和推理时间权衡等挑战方面发挥关键作用。
- 模型对齐、可伸缩适应和推理时间推理是新兴的研究方向。
点此查看论文截图

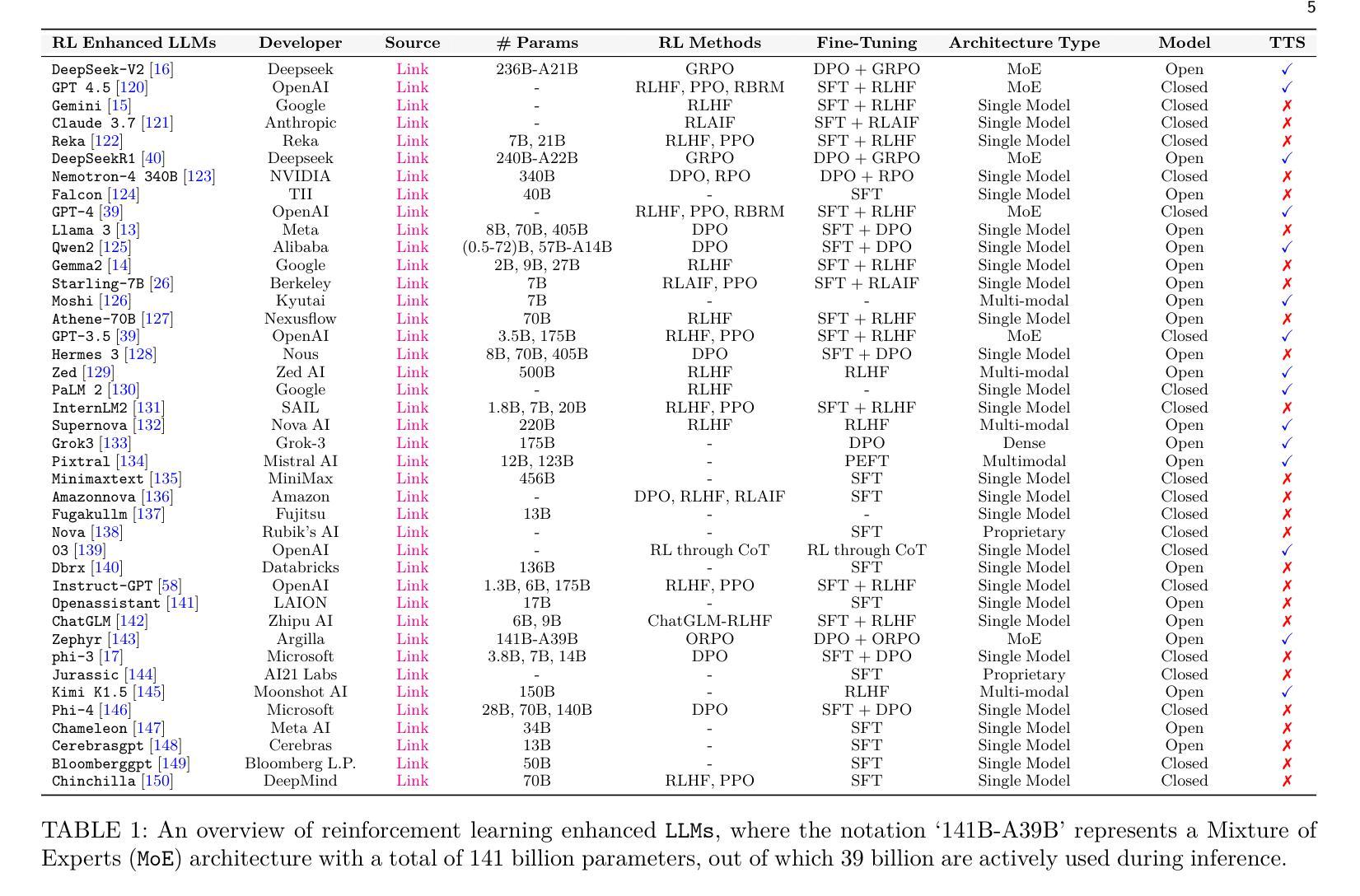
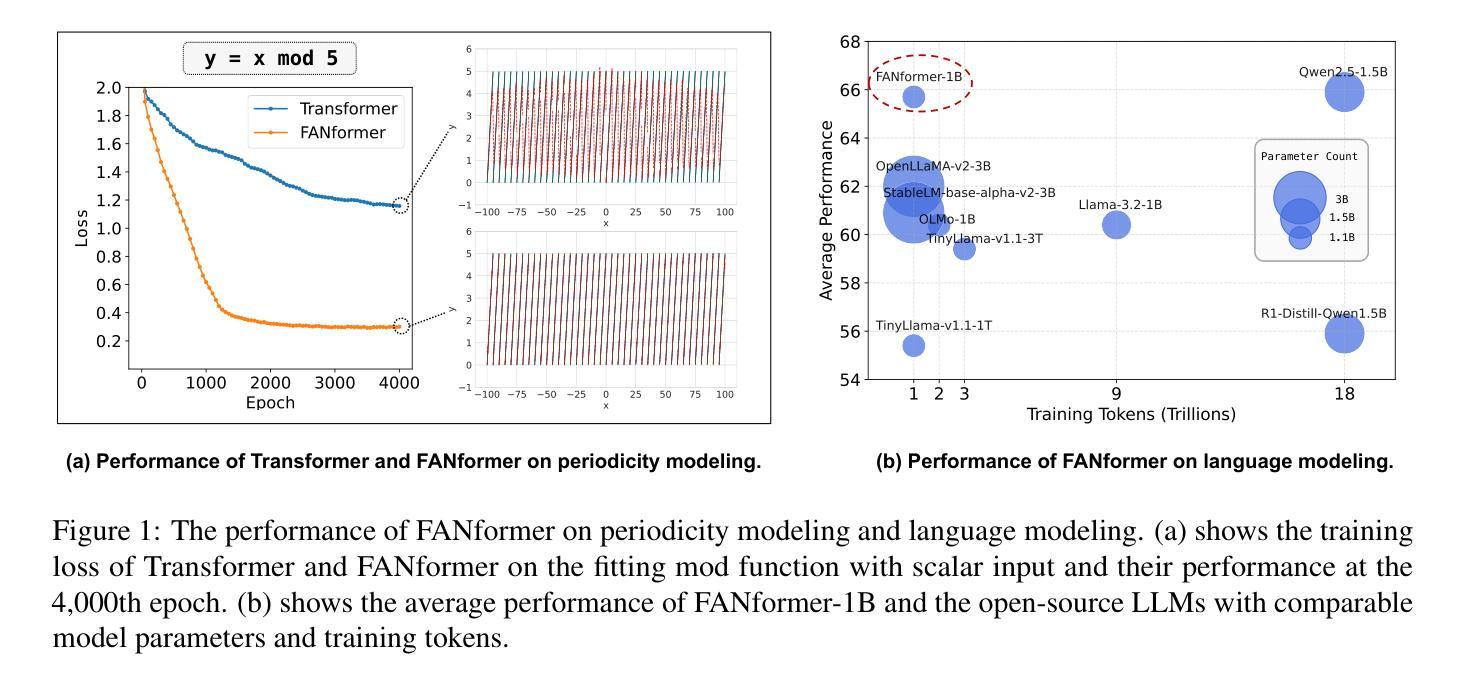
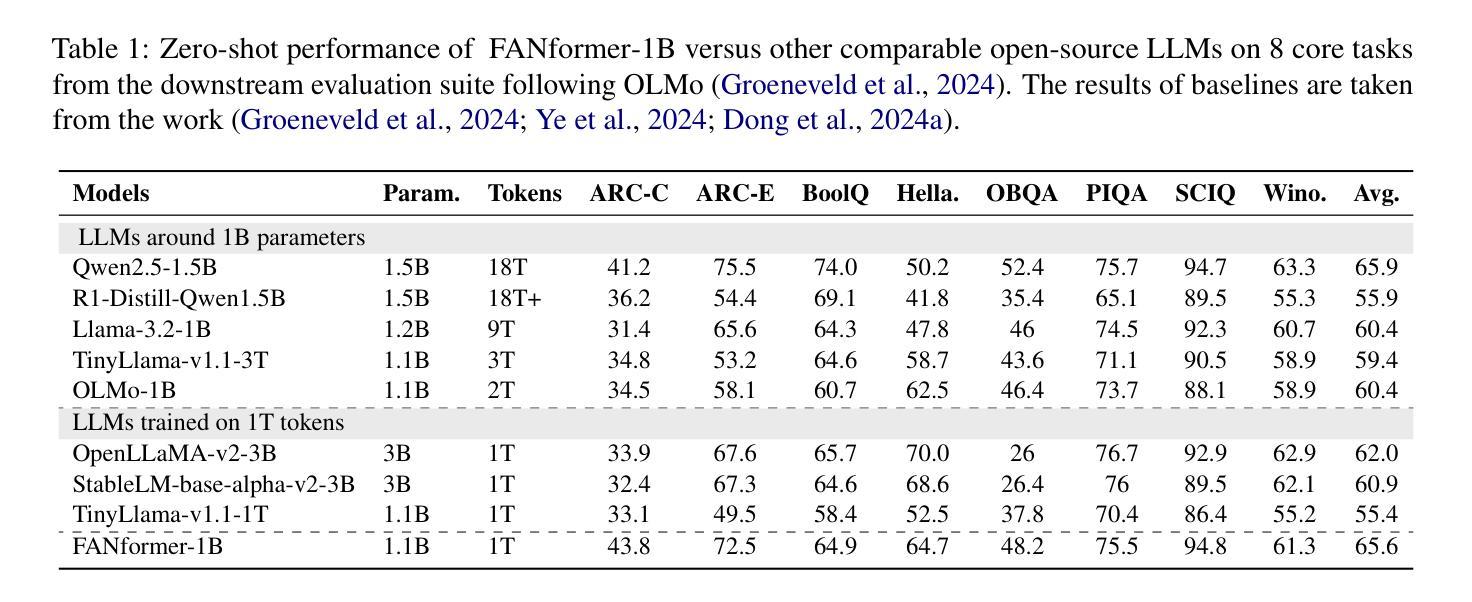
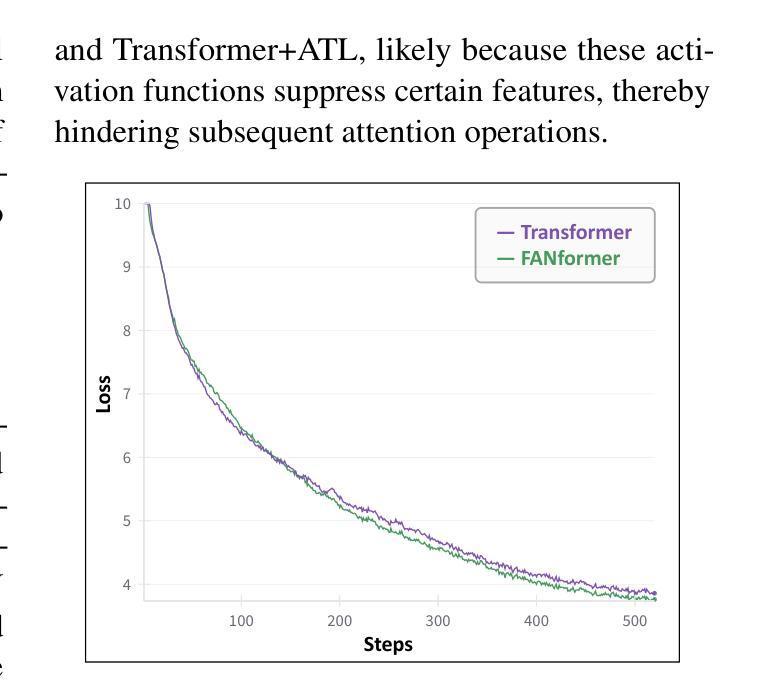
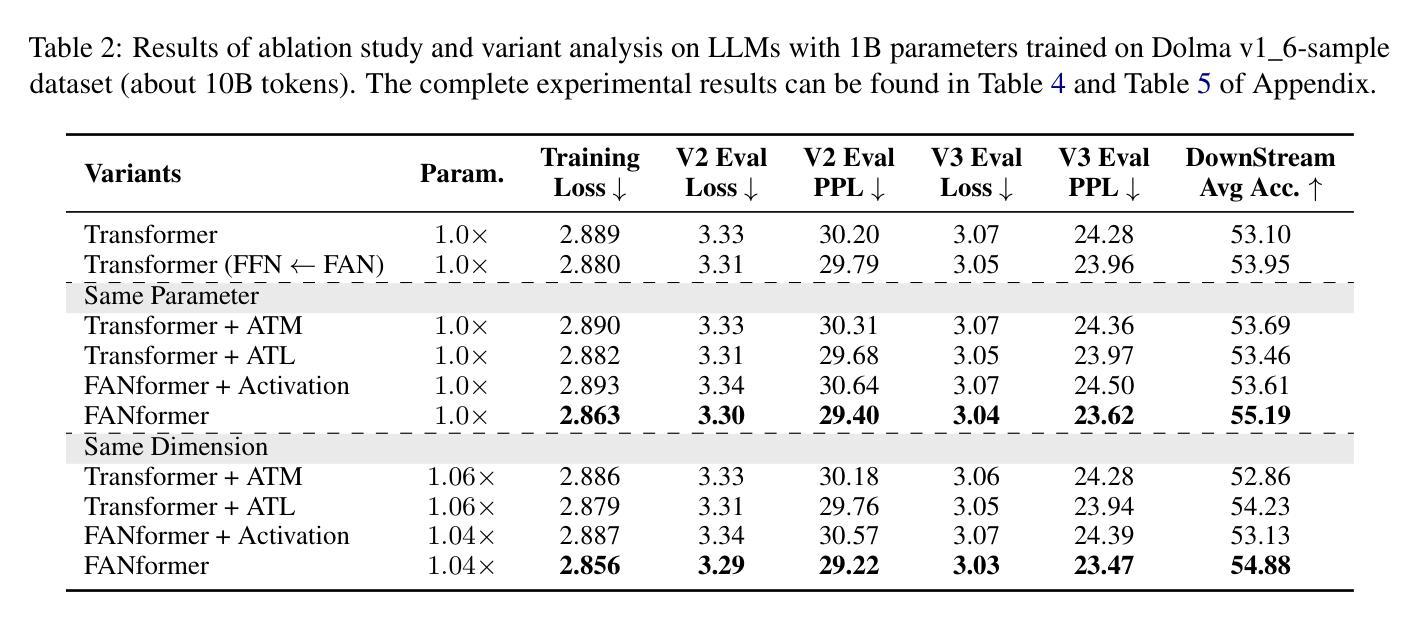
FANformer: Improving Large Language Models Through Effective Periodicity Modeling
Authors:Yihong Dong, Ge Li, Xue Jiang, Yongding Tao, Kechi Zhang, Hao Zhu, Huanyu Liu, Jiazheng Ding, Jia Li, Jinliang Deng, Hong Mei
Periodicity, as one of the most important basic characteristics, lays the foundation for facilitating structured knowledge acquisition and systematic cognitive processes within human learning paradigms. However, the potential flaws of periodicity modeling in Transformer affect the learning efficiency and establishment of underlying principles from data for large language models (LLMs) built upon it. In this paper, we demonstrate that integrating effective periodicity modeling can improve the learning efficiency and performance of LLMs. We introduce FANformer, which integrates Fourier Analysis Network (FAN) into attention mechanism to achieve efficient periodicity modeling, by modifying the feature projection process of attention mechanism. Extensive experimental results on language modeling show that FANformer consistently outperforms Transformer when scaling up model size and training tokens, underscoring its superior learning efficiency. To further validate the effectiveness of FANformer, we pretrain a FANformer-1B on 1 trillion tokens. FANformer-1B exhibits marked improvements on downstream tasks compared to open-source LLMs with similar model parameters or training tokens. The results position FANformer as an effective and promising architecture for advancing LLMs.
周期性作为最重要的基本特征之一,为人类学习范式中的结构化知识获取和系统认知过程奠定了基础。然而,Transformer中的周期性建模的潜在缺陷影响了其上的大型语言模型(LLM)的学习效率和基础原理的建立。在本文中,我们证明了集成有效的周期性建模可以提高LLM的学习效率和工作性能。我们介绍了FANformer,它通过修改注意力机制的特征投影过程,将傅里叶分析网络(FAN)集成到注意力机制中,以实现有效的周期性建模。在语言建模方面的广泛实验结果表明,在扩大模型规模和训练令牌时,FANformer持续优于Transformer,突显了其较高的学习效率。为了进一步验证FANformer的有效性,我们使用FANformer-1B对万亿令牌进行预训练。与具有类似模型参数或训练令牌的开源LLM相比,FANformer-1B在下游任务方面表现出显著的提升。这为FANformer作为一种有效且前景广阔的LLM架构的定位提供了支持。
论文及项目相关链接
Summary
本文介绍了周期性作为重要的基本特征,在促进人类学习模式中的结构化知识获取和系统性认知过程中的作用。文章指出Transformer中的周期性建模存在潜在缺陷,影响大型语言模型(LLM)的学习效率和原理建立。为改善这一问题,本文展示了集成有效的周期性建模能提高LLM的学习效率和性能。我们引入了FANformer,它通过修改注意力机制的特征投影过程,将傅里叶分析网络(FAN)融入注意力机制中实现高效的周期性建模。在语言建模方面的广泛实验结果显示,FANformer在扩大模型规模和训练令牌时始终优于Transformer,显示出其卓越的学习效率。通过预训练FANformer-1B模型,我们在下游任务上取得了显著的改进,相较于具有相似模型参数或训练令牌的开源LLM表现更佳,这证明了FANformer是一个有效且有前景的架构,可促进LLM的发展。
Key Takeaways
- 周期性在促进人类学习中的结构化知识获取和系统性认知过程中扮演重要角色。
- Transformer中的周期性建模存在潜在缺陷,可能影响LLM的学习效率和原理建立。
- FANformer通过集成有效的周期性建模,提高了LLM的学习效率和性能。
- FANformer引入了傅里叶分析网络(FAN),实现了高效的周期性建模。
- 实验结果显示,FANformer在扩大模型规模和训练令牌时表现优于Transformer。
- FANformer-1B模型在下游任务上的表现优于相似参数或训练令牌的开源LLM。
点此查看论文截图

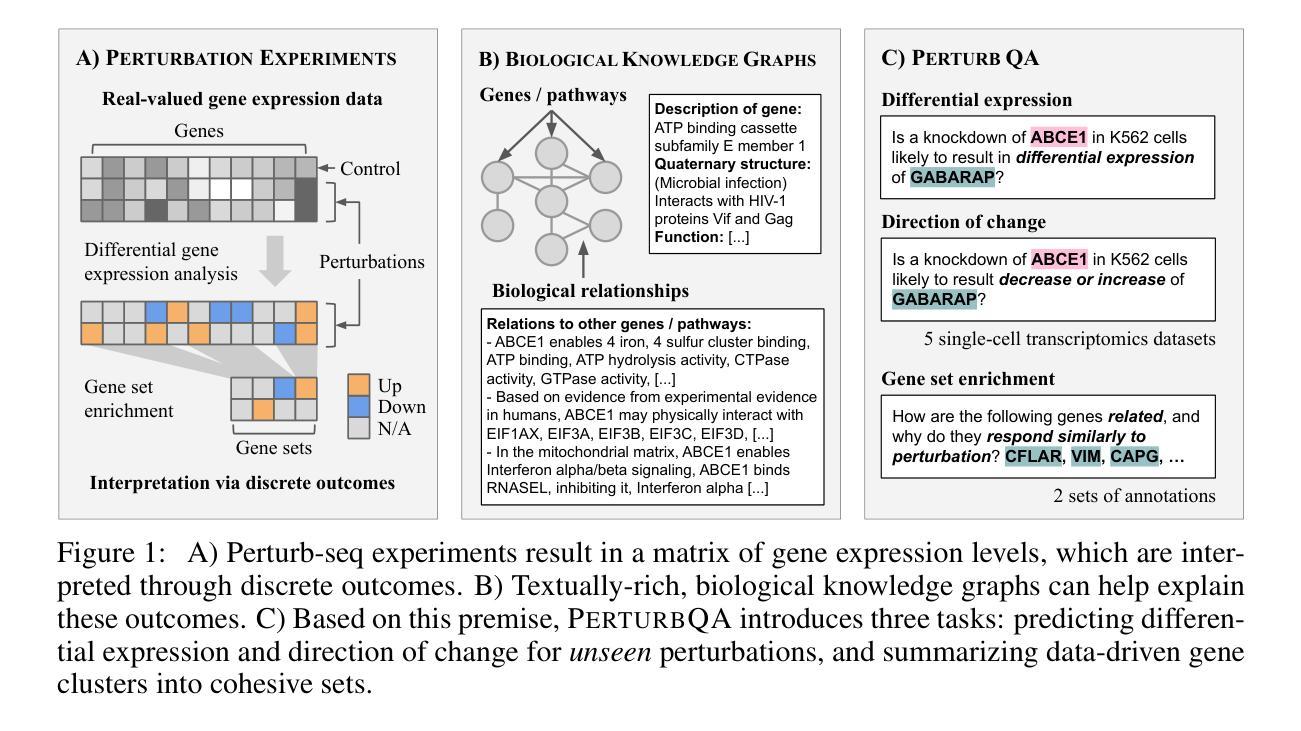
Contextualizing biological perturbation experiments through language
Authors:Menghua Wu, Russell Littman, Jacob Levine, Lin Qiu, Tommaso Biancalani, David Richmond, Jan-Christian Huetter
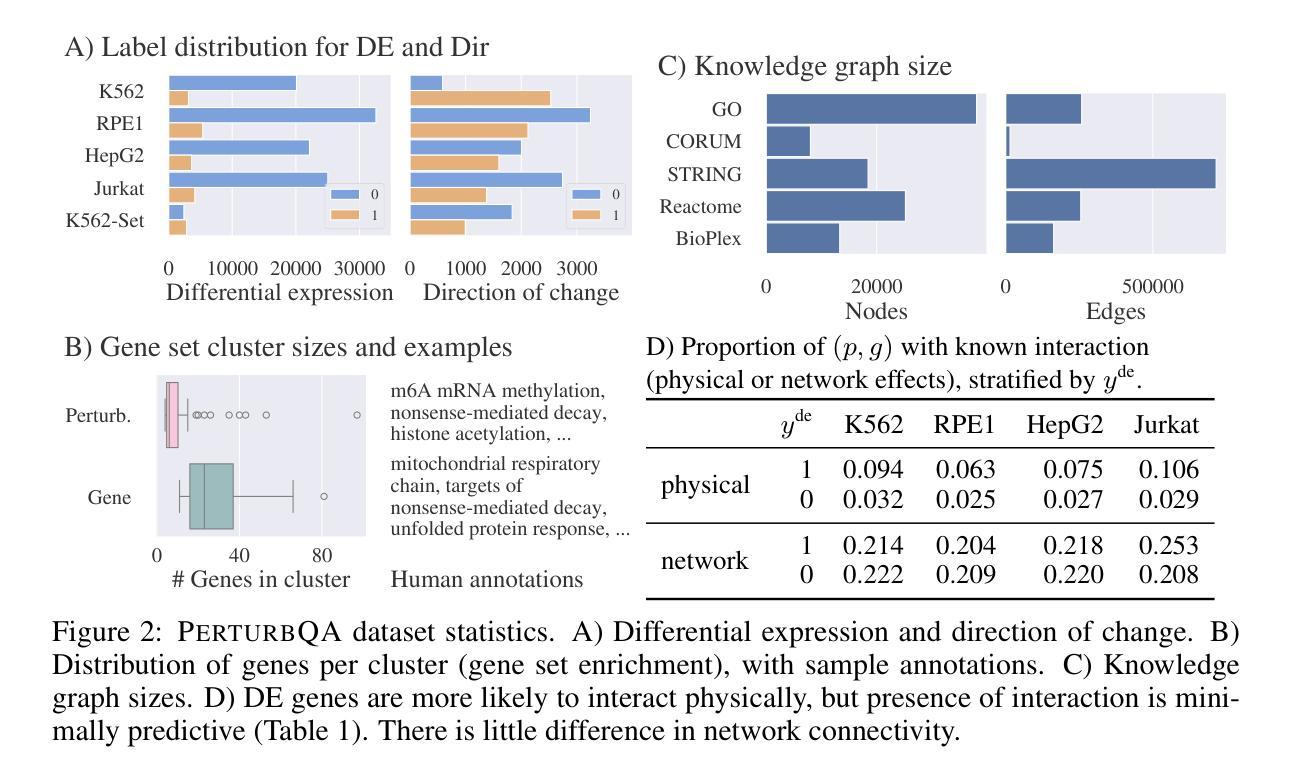
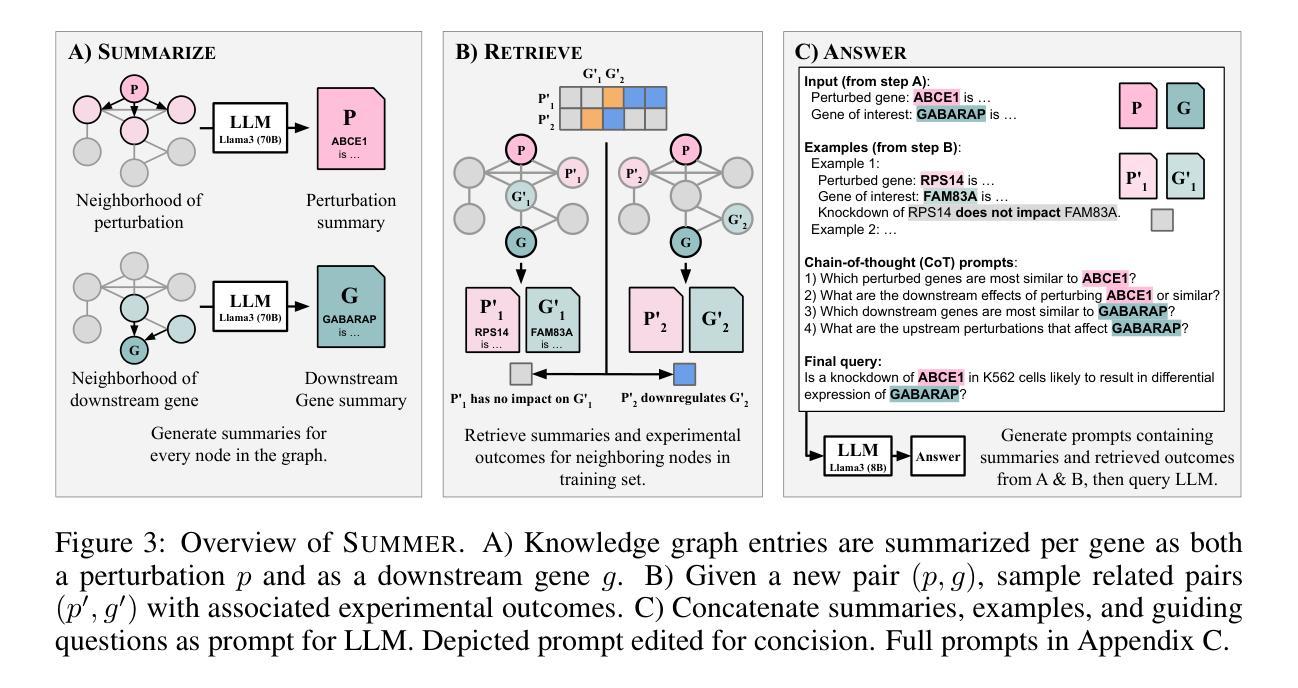
High-content perturbation experiments allow scientists to probe biomolecular systems at unprecedented resolution, but experimental and analysis costs pose significant barriers to widespread adoption. Machine learning has the potential to guide efficient exploration of the perturbation space and extract novel insights from these data. However, current approaches neglect the semantic richness of the relevant biology, and their objectives are misaligned with downstream biological analyses. In this paper, we hypothesize that large language models (LLMs) present a natural medium for representing complex biological relationships and rationalizing experimental outcomes. We propose PerturbQA, a benchmark for structured reasoning over perturbation experiments. Unlike current benchmarks that primarily interrogate existing knowledge, PerturbQA is inspired by open problems in perturbation modeling: prediction of differential expression and change of direction for unseen perturbations, and gene set enrichment. We evaluate state-of-the-art machine learning and statistical approaches for modeling perturbations, as well as standard LLM reasoning strategies, and we find that current methods perform poorly on PerturbQA. As a proof of feasibility, we introduce Summer (SUMMarize, retrievE, and answeR, a simple, domain-informed LLM framework that matches or exceeds the current state-of-the-art. Our code and data are publicly available at https://github.com/genentech/PerturbQA.
高内涵扰动实验让科学家能够以前所未有的分辨率探究生物分子系统,但实验和分析成本构成了广泛采纳的重大障碍。机器学习有可能引导高效探索扰动空间,并从这些数据中提取新颖见解。然而,当前的方法忽视了相关生物学的语义丰富性,并且他们的目标与下游生物分析存在不匹配。在本文中,我们假设大型语言模型(LLM)是表示复杂生物关系并对实验结果进行合理化解释的天然媒介。我们提出了PerturbQA,这是一个关于扰动实验的结构化推理的基准测试。与主要询问现有知识的当前基准测试不同,PerturbQA的灵感来源于扰动建模中的开放问题:预测未见扰动的差异表达和变化方向,以及基因集富集。我们评估了用于建模扰动的最新机器学习和统计方法,以及标准LLM推理策略,我们发现当前方法在PerturbQA上的表现较差。作为可行性的证明,我们介绍了Summer(SUMMarize,retrievE,and answeR),这是一个简单、面向领域的LLM框架,达到或超过了当前最新技术水平。我们的代码和数据在https://github.com/genentech/PerturbQA上公开可用。
论文及项目相关链接
PDF The Thirteenth International Conference on Learning Representations (2025)
Summary
本文主要介绍了高通量扰动实验在探究生物分子系统方面的优势及挑战。机器学习可指导有效探索扰动空间并从数据中提取新见解。然而,当前方法忽略了相关生物学的语义丰富性,且与下游生物分析的目标不匹配。本文提出使用大型语言模型(LLM)来表示复杂的生物关系并解释实验结果。提出了扰动实验的新基准测试PerturbQA,用于结构推理。评估了当前先进的机器学习方法以及标准LLM推理策略,发现它们在PerturbQA上的表现不佳。为证明可行性,介绍了一个简单且基于领域知识的LLM框架Summer。
Key Takeaways
- 高通量扰动实验能够以前所未有的分辨率探究生物分子系统,但实验和分析成本构成重要障碍。
- 机器学习可指导高效探索扰动空间并从中提取新见解,但当前方法忽略了生物学的语义丰富性。
- 大型语言模型(LLM)可自然表示复杂的生物关系并解释实验结果。
- 提出了一个新的基准测试PerturbQA,用于评估对扰动实验的推理能力。
- 当前先进方法在PerturbQA上的表现不佳。
- Summer是一个简单且基于领域知识的LLM框架,其性能匹配或超过了当前先进技术。
点此查看论文截图

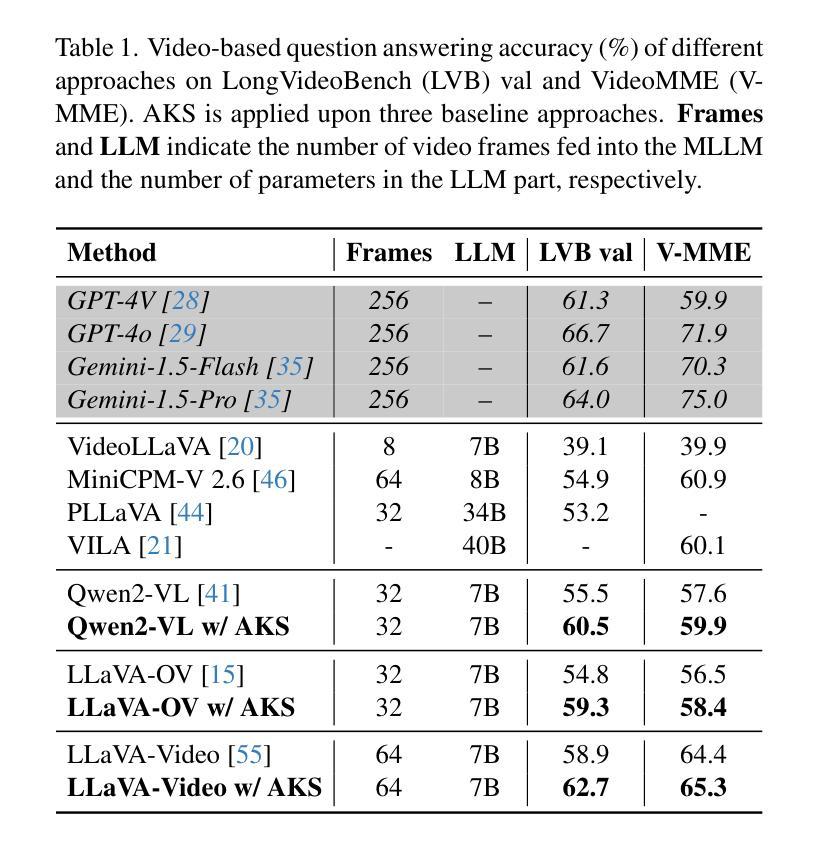
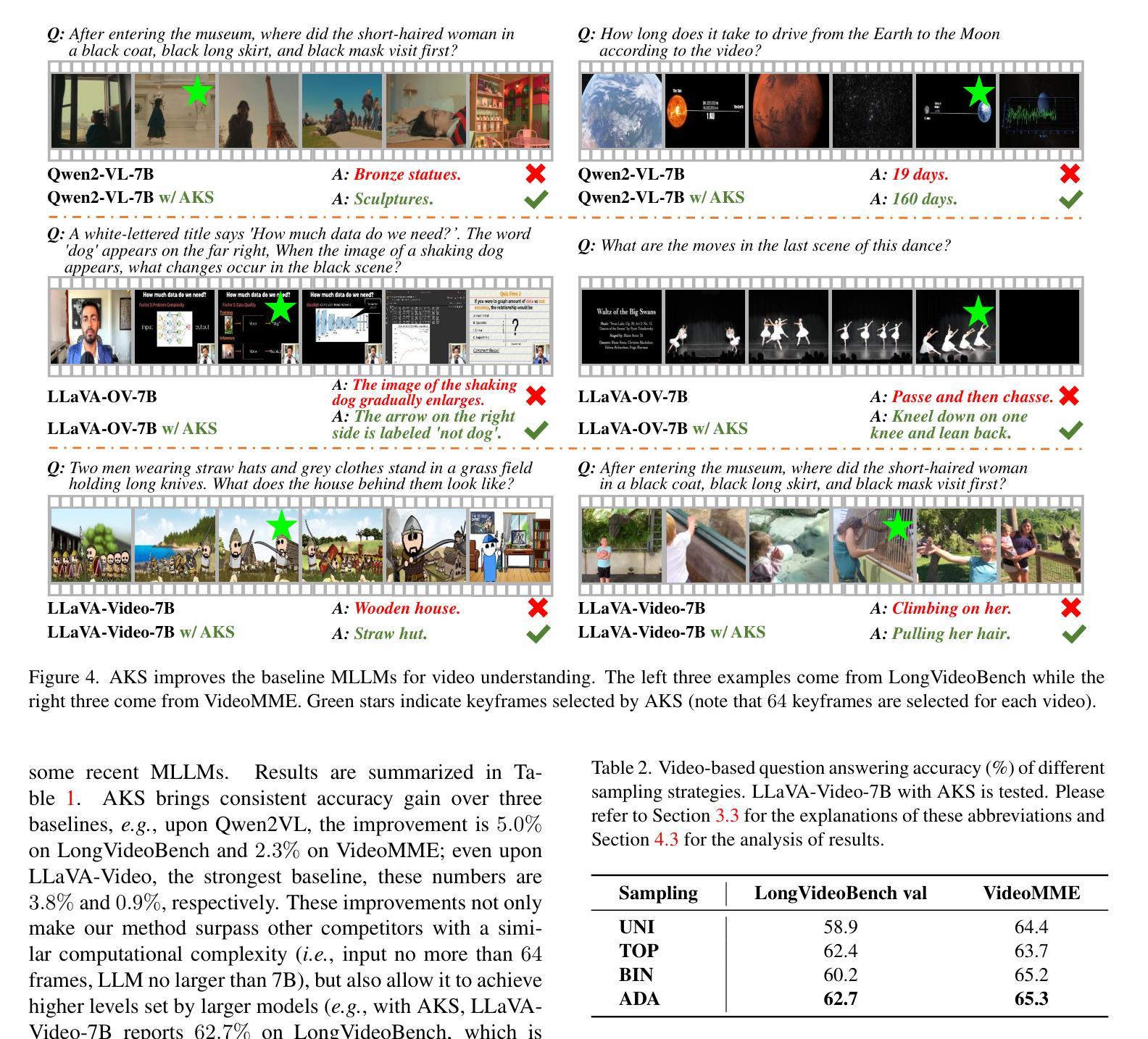
Adaptive Keyframe Sampling for Long Video Understanding
Authors:Xi Tang, Jihao Qiu, Lingxi Xie, Yunjie Tian, Jianbin Jiao, Qixiang Ye
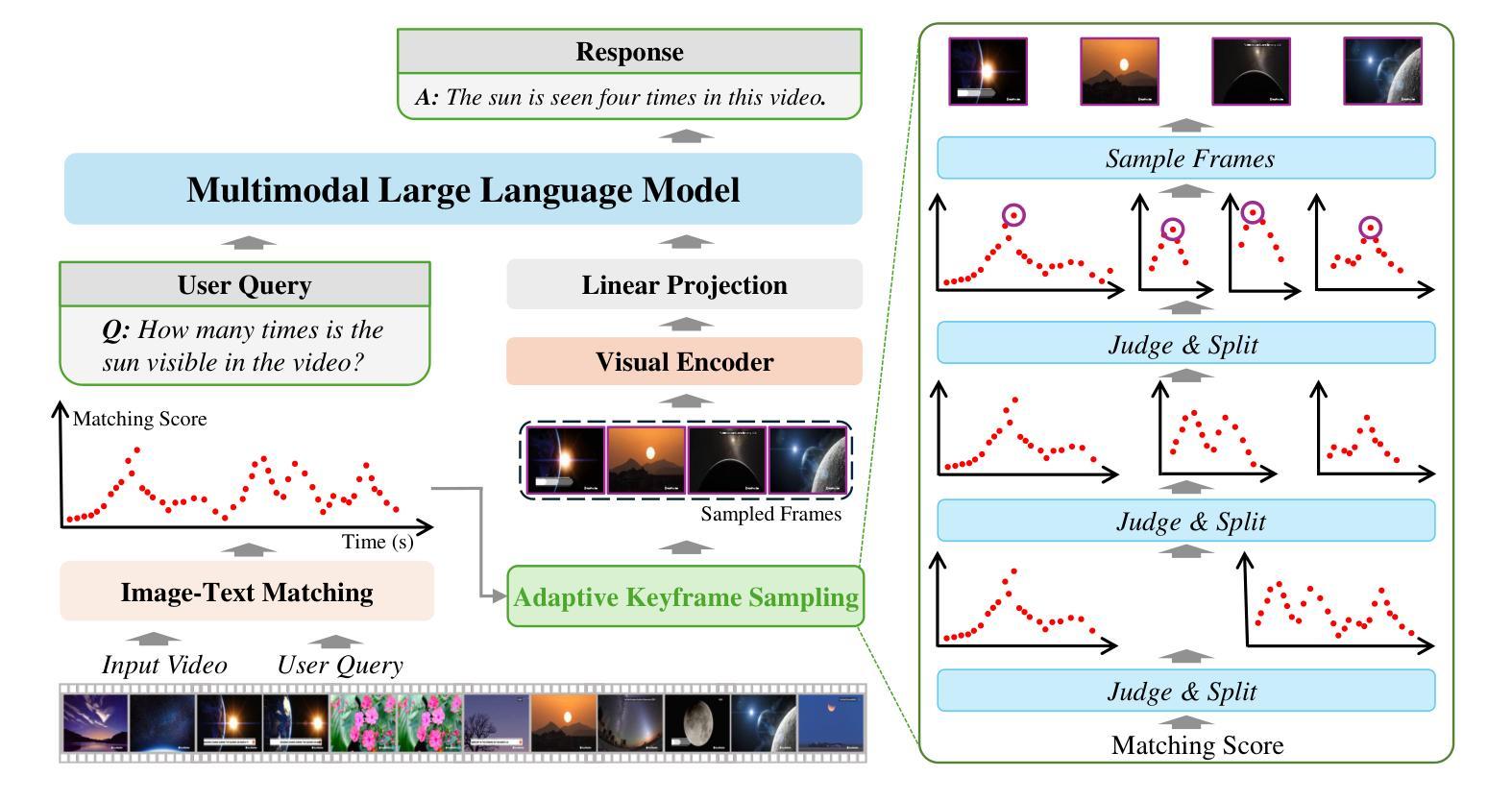
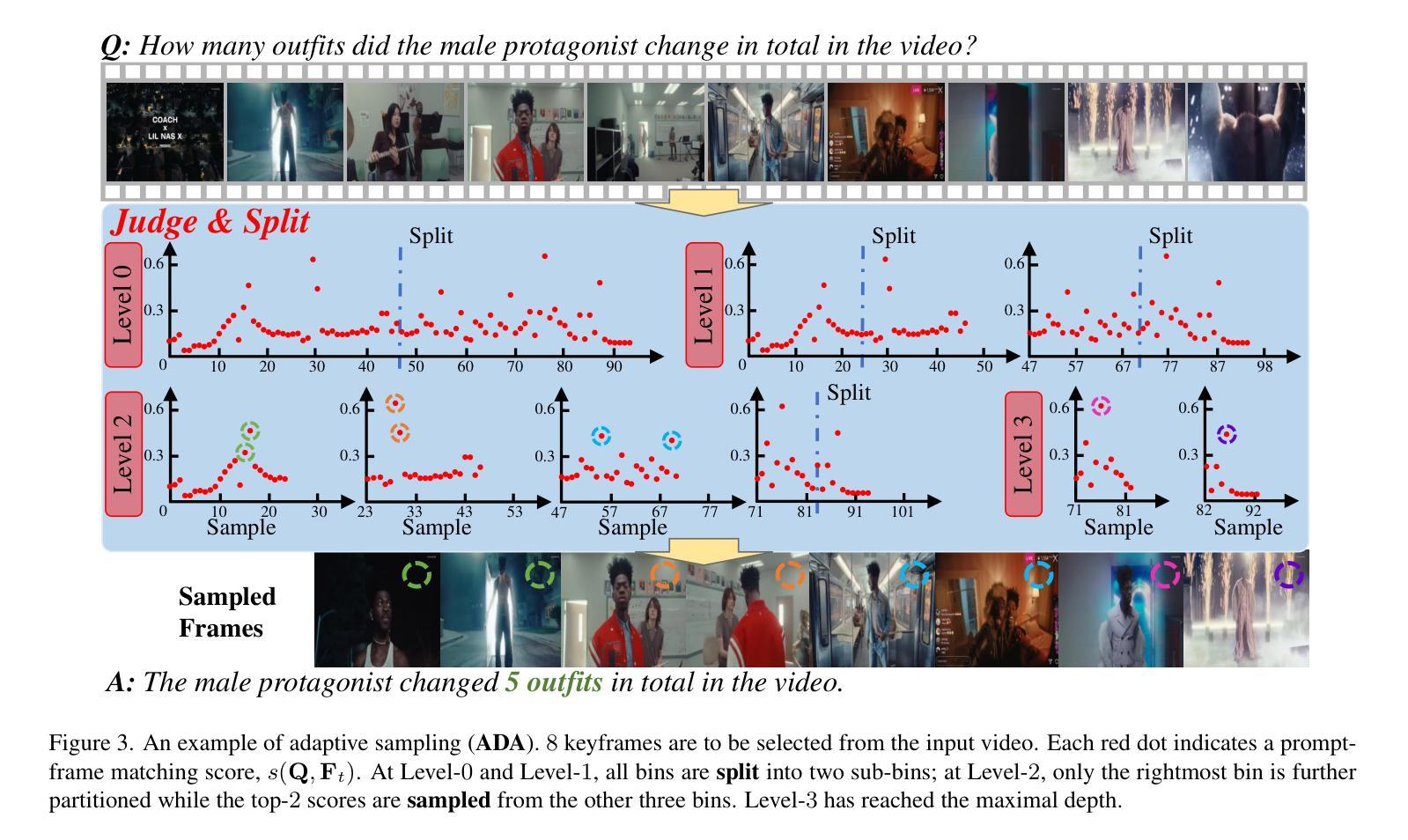
Multimodal large language models (MLLMs) have enabled open-world visual understanding by injecting visual input as extra tokens into large language models (LLMs) as contexts. However, when the visual input changes from a single image to a long video, the above paradigm encounters difficulty because the vast amount of video tokens has significantly exceeded the maximal capacity of MLLMs. Therefore, existing video-based MLLMs are mostly established upon sampling a small portion of tokens from input data, which can cause key information to be lost and thus produce incorrect answers. This paper presents a simple yet effective algorithm named Adaptive Keyframe Sampling (AKS). It inserts a plug-and-play module known as keyframe selection, which aims to maximize the useful information with a fixed number of video tokens. We formulate keyframe selection as an optimization involving (1) the relevance between the keyframes and the prompt, and (2) the coverage of the keyframes over the video, and present an adaptive algorithm to approximate the best solution. Experiments on two long video understanding benchmarks validate that Adaptive Keyframe Sampling improves video QA accuracy (beyond strong baselines) upon selecting informative keyframes. Our study reveals the importance of information pre-filtering in video-based MLLMs. Code is available at https://github.com/ncTimTang/AKS.
多模态大型语言模型(MLLMs)通过将视觉输入作为大型语言模型(LLMs)的上下文中的额外令牌,实现了开放世界视觉理解。然而,当视觉输入从单张图像变为长视频时,上述模式会遇到困难,因为大量视频令牌已经大大超过了MLLMs的最大容量。因此,现有的基于视频的MLLMs大多建立在从输入数据中采样一小部分令牌的基础上,这可能导致关键信息丢失,从而产生错误的答案。本文提出了一种简单有效的算法,名为自适应关键帧采样(AKS)。它插入了一个即插即用的模块,称为关键帧选择,旨在用固定数量的视频令牌最大化有用信息。我们将关键帧选择与提示之间的相关性以及关键帧对视频的覆盖作为优化的两个方面,并提出了一种自适应算法来近似最佳解决方案。在两个长视频理解基准测试上的实验验证了自适应关键帧采样在提高选择有信息的关键帧的视频问答准确性(超越强基线)方面的作用。我们的研究表明,在信息基于视频的MLLMs中,信息预过滤的重要性。代码可访问:https://github.com/ncTimTang/AKS。
论文及项目相关链接
PDF CVPR2025
Summary
本文介绍了自适应关键帧采样技术(AKS),它是一种简单的算法,针对多模态大型语言模型(MLLMs)在处理长视频输入时的问题进行了优化。AKS通过插入一个插件模块进行关键帧选择,旨在以固定数量的视频令牌最大化有用信息。实验证明,Adaptive Keyframe Sampling技术在选择有信息量的关键帧后,能提高视频问答的准确性。研究表明视频信息预过滤在视频基础的大型语言模型中十分重要。该方法的代码可以在指定的GitHub地址找到。
Key Takeaways
- 多模态大型语言模型在处理长视频输入时面临挑战,因为视频令牌数量超出了模型的最大容量。
- 当前基于视频的MLLMs主要通过从输入数据中采样一小部分令牌来建立模型,这可能导致关键信息的丢失并产生错误的答案。
- 提出了自适应关键帧采样(AKS)算法来解决这个问题,该算法包含一个插件模块用于关键帧选择,以最大化固定数量的视频令牌中的有用信息。
- 关键帧选择是通过两个优化问题来解决的:关键帧与提示的相关性,以及关键帧对视频的覆盖程度。
- 实验证明,自适应关键帧采样能提高视频问答的准确性,超越了一些强大的基线模型。
- 研究强调了视频信息预过滤在基于视频的大型语言模型中的重要性。
点此查看论文截图

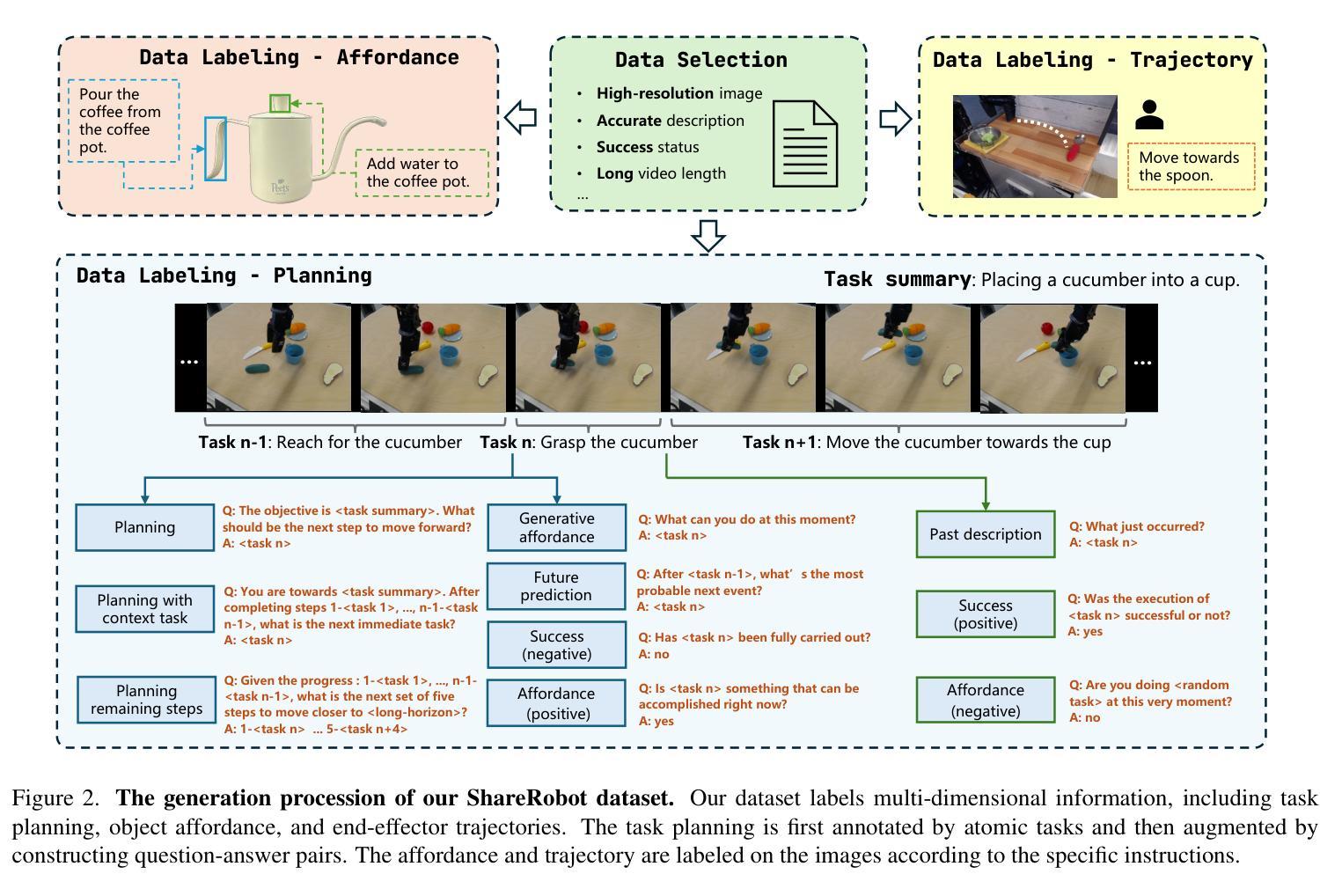
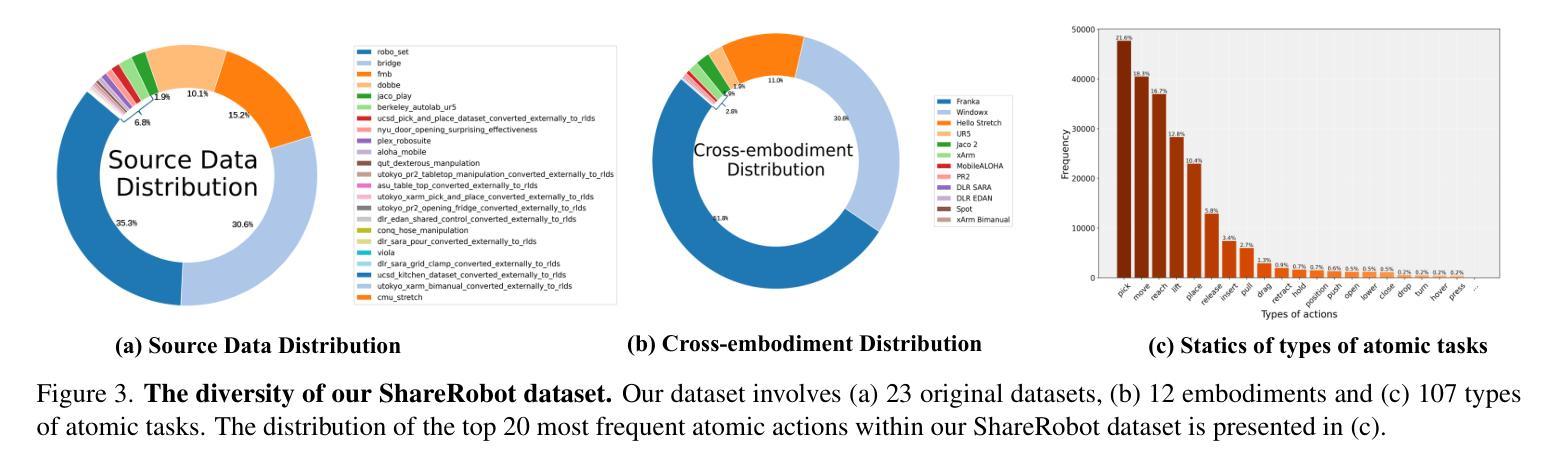
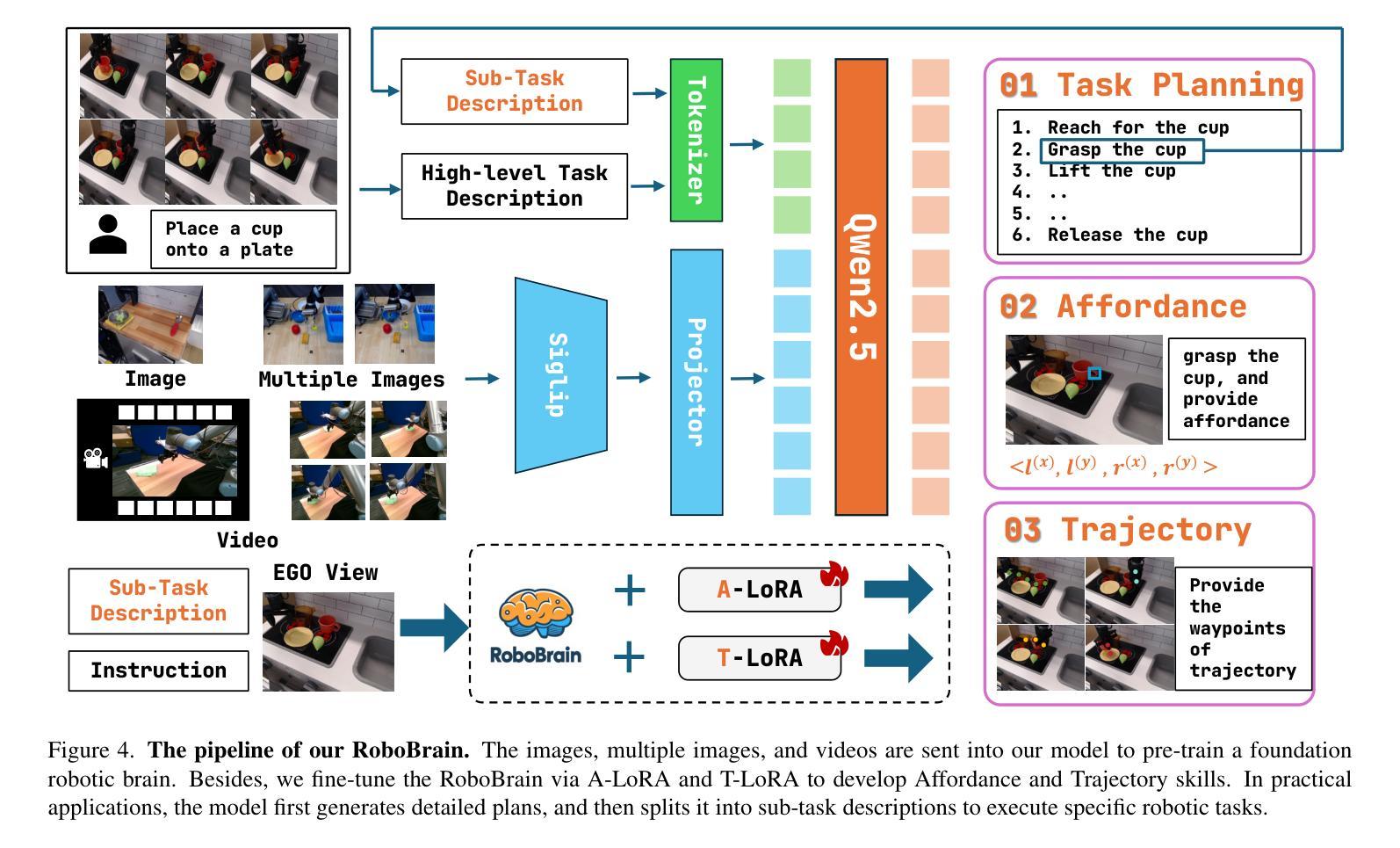
RoboBrain: A Unified Brain Model for Robotic Manipulation from Abstract to Concrete
Authors:Yuheng Ji, Huajie Tan, Jiayu Shi, Xiaoshuai Hao, Yuan Zhang, Hengyuan Zhang, Pengwei Wang, Mengdi Zhao, Yao Mu, Pengju An, Xinda Xue, Qinghang Su, Huaihai Lyu, Xiaolong Zheng, Jiaming Liu, Zhongyuan Wang, Shanghang Zhang
Recent advancements in Multimodal Large Language Models (MLLMs) have shown remarkable capabilities across various multimodal contexts. However, their application in robotic scenarios, particularly for long-horizon manipulation tasks, reveals significant limitations. These limitations arise from the current MLLMs lacking three essential robotic brain capabilities: Planning Capability, which involves decomposing complex manipulation instructions into manageable sub-tasks; Affordance Perception, the ability to recognize and interpret the affordances of interactive objects; and Trajectory Prediction, the foresight to anticipate the complete manipulation trajectory necessary for successful execution. To enhance the robotic brain’s core capabilities from abstract to concrete, we introduce ShareRobot, a high-quality heterogeneous dataset that labels multi-dimensional information such as task planning, object affordance, and end-effector trajectory. ShareRobot’s diversity and accuracy have been meticulously refined by three human annotators. Building on this dataset, we developed RoboBrain, an MLLM-based model that combines robotic and general multi-modal data, utilizes a multi-stage training strategy, and incorporates long videos and high-resolution images to improve its robotic manipulation capabilities. Extensive experiments demonstrate that RoboBrain achieves state-of-the-art performance across various robotic tasks, highlighting its potential to advance robotic brain capabilities.
最近的多模态大型语言模型(MLLM)进展在各种多模态上下文中展示了显著的能力。然而,它们在机器人场景中的应用,特别是对于长期操作任务,揭示了显著的局限性。这些局限性源于当前MLLM缺乏三项重要的机器人核心功能:规划能力,涉及将复杂的操作指令分解为可管理的子任务;负担感知能力,即识别和解释交互对象的负担的能力;以及轨迹预测能力,即对成功执行所需完整操作轨迹的预见性。为了从抽象到具体提升机器人的核心能力,我们推出了ShareRobot,这是一个高质量、异质性的数据集,它标注了任务规划、对象负担和末端执行器轨迹等多维信息。ShareRobot的多样性和准确性已经由三名人工注释者仔细审核和改进。在此基础上,我们构建了RoboBrain,这是一个基于MLLM的模型,结合了机器人和一般多模态数据,采用多阶段训练策略,并融入长视频和高分辨率图像,以提高其机器人操作能力。大量实验表明,RoboBrain在各种机器人任务上达到了最先进的性能水平,突显了其在提升机器人核心能力方面的潜力。
论文及项目相关链接
Summary
MLLM在多种模态场景中的最新进展展现出强大的能力,但在机器人场景、特别是长期操作任务中的应用存在显著局限。为提升机器人核心从抽象到具体的能力,引入了ShareRobot数据集和RoboBrain模型。ShareRobot数据集标注了多维信息如任务规划、物体可用性和末端执行器轨迹等。RoboBrain结合了机器人和通用多模态数据,采用多阶段训练策略,并融入长视频和高分辨率图像,提升机器人操作能力,实现多项机器人任务的最佳性能。
Key Takeaways
- MLLMs在多种模态场景中展现出强大能力,但在机器人长期操作任务中的应用存在局限。
- 机器人场景中的MLLMs缺乏规划能力、可用性感知能力和轨迹预测能力。
- ShareRobot数据集是一个高质量、异构的数据集,用于标注任务规划、物体可用性和末端执行器轨迹等多维信息。
- ShareRobot数据集的多样性和准确性经过三位人类标注者的精心优化。
- RoboBrain是基于MLLM的模型,结合了机器人和通用多模态数据。
- RoboBrain采用多阶段训练策略,并融入长视频和高分辨率图像,以提升机器人操作能力。
点此查看论文截图

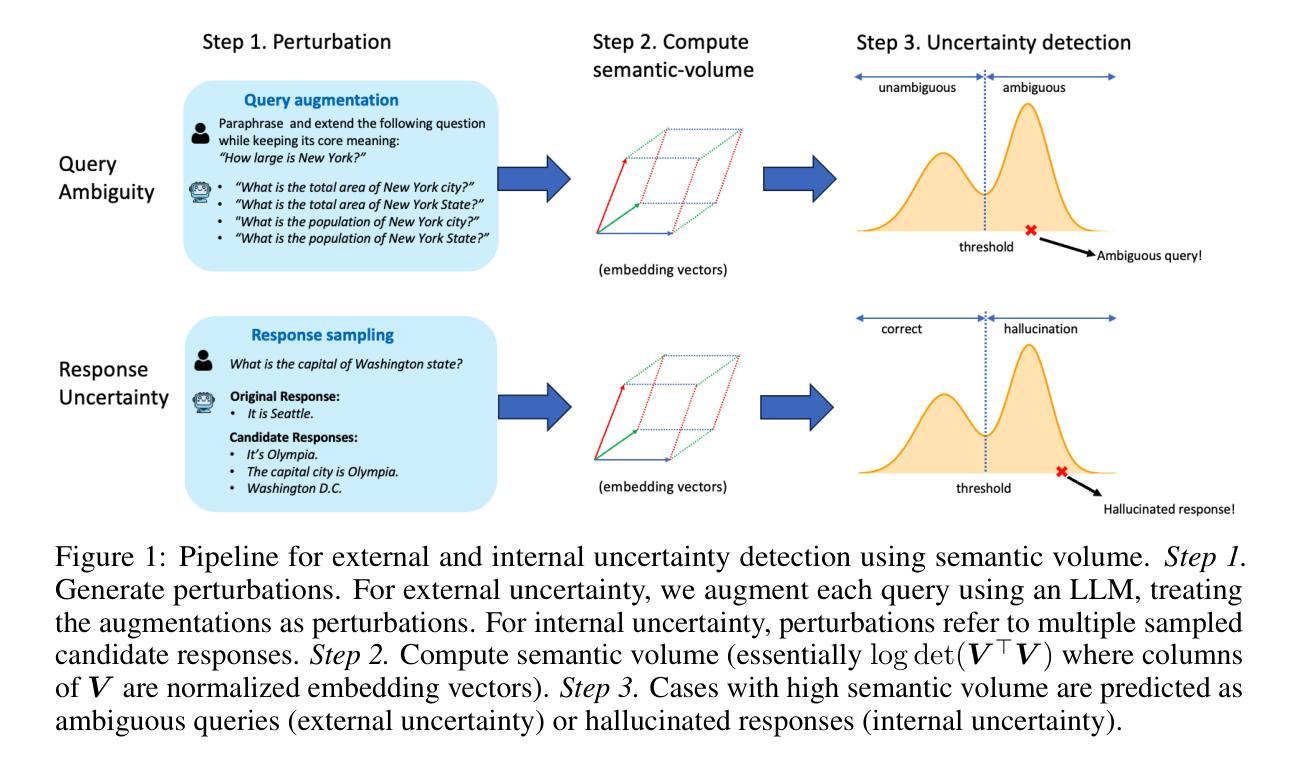
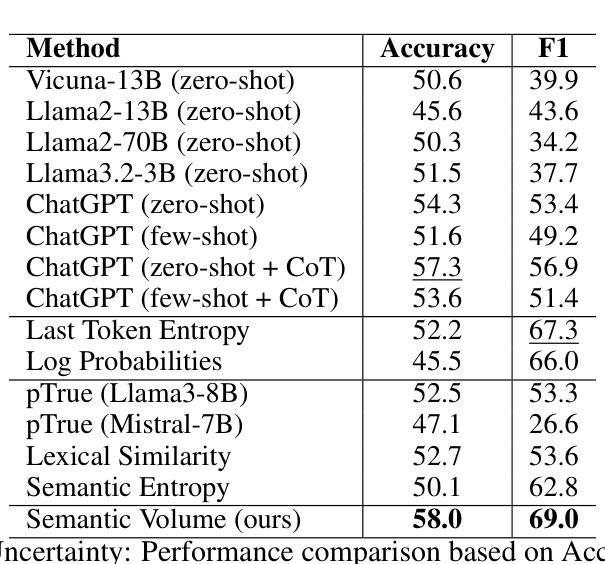
Semantic Volume: Quantifying and Detecting both External and Internal Uncertainty in LLMs
Authors:Xiaomin Li, Zhou Yu, Ziji Zhang, Yingying Zhuang, Swair Shah, Anurag Beniwal
Large language models (LLMs) have demonstrated remarkable performance across diverse tasks by encoding vast amounts of factual knowledge. However, they are still prone to hallucinations, generating incorrect or misleading information, often accompanied by high uncertainty. Existing methods for hallucination detection primarily focus on quantifying internal uncertainty, which arises from missing or conflicting knowledge within the model. However, hallucinations can also stem from external uncertainty, where ambiguous user queries lead to multiple possible interpretations. In this work, we introduce Semantic Volume, a novel mathematical measure for quantifying both external and internal uncertainty in LLMs. Our approach perturbs queries and responses, embeds them in a semantic space, and computes the determinant of the Gram matrix of the embedding vectors, capturing their dispersion as a measure of uncertainty. Our framework provides a generalizable and unsupervised uncertainty detection method without requiring white-box access to LLMs. We conduct extensive experiments on both external and internal uncertainty detection, demonstrating that our Semantic Volume method consistently outperforms existing baselines in both tasks. Additionally, we provide theoretical insights linking our measure to differential entropy, unifying and extending previous sampling-based uncertainty measures such as the semantic entropy. Semantic Volume is shown to be a robust and interpretable approach to improving the reliability of LLMs by systematically detecting uncertainty in both user queries and model responses.
大型语言模型(LLM)通过编码大量事实知识,在多种任务中表现出了显著的性能。然而,它们仍然容易出现幻觉,生成错误或误导性的信息,并且通常伴随着较高的不确定性。现有的幻觉检测方法主要集中于量化内部不确定性,这种不确定性源于模型中的知识缺失或冲突。然而,幻觉也可能源于外部不确定性,其中模糊的用户查询导致多种可能的解释。在这项工作中,我们引入了语义体积(Semantic Volume),这是一种新的数学度量方法,可以量化LLM中的外部和内部不确定性。我们的方法通过扰动查询和响应,将它们嵌入到语义空间中,并计算嵌入向量的Gram矩阵的行列式,捕捉其分散程度作为不确定性的度量。我们的框架提供了一种通用且无需监督的不确定性检测方法,无需访问LLM的白盒。我们对外部和内部不确定性检测进行了大量实验,结果表明我们的语义体积法在这两项任务中均优于现有基线。此外,我们从理论上深入探讨了我们的度量方法与微分熵之间的联系,统一并扩展了之前的基于采样的不确定性度量方法,如语义熵。语义体积被证明是一种可靠且可解释的方法,通过系统地检测用户查询和模型响应中的不确定性,可以提高LLM的可靠性。
论文及项目相关链接
Summary
大型语言模型(LLM)虽然能编码大量事实知识并在各种任务中表现出卓越性能,但仍易产生幻觉,生成错误或误导信息,且常伴随高不确定性。现有幻觉检测方法主要关注量化模型内部的不确定性,但幻觉也可能源于外部不确定性,如用户查询的模糊性导致多重可能解释。本研究引入语义体积这一新型数学度量,可量化LLM的内外不确定性。通过扰动查询和响应、嵌入语义空间,并计算嵌入向量的格拉姆矩阵行列式,捕捉其分散程度作为不确定性的度量。该方法提供通用、无需监督的不确定性检测手段,无需访问LLM的白盒。实验证明,在内外不确定性检测方面,语义体积方法均表现优异。此外,该方法与微分熵的理论联系也被揭示,统一并扩展了先前的采样不确定性度量。语义体积是一种可靠、可解释的方法,能系统地检测用户查询和模型响应中的不确定性,提高LLM的可靠性。
Key Takeaways
- LLM虽然能完成多种任务,但仍存在生成错误或误导信息的问题,即“幻觉”,且伴随高不确定性。
- 现有幻觉检测主要关注模型内部的不确定性。
- 幻觉也可源于外部不确定性,如用户查询的模糊性导致的多重解释。
- 引入语义体积这一新型数学度量,可量化LLM的内外不确定性。
- 语义体积方法通过嵌入语义空间、计算格拉姆矩阵行列式来捕捉不确定性。
- 语义体积方法提供通用、无需监督的不确定性检测手段,实验证明其表现优异。
点此查看论文截图

Transforming Tuberculosis Care: Optimizing Large Language Models For Enhanced Clinician-Patient Communication
Authors:Daniil Filienko, Mahek Nizar, Javier Roberti, Denise Galdamez, Haroon Jakher, Sarah Iribarren, Weichao Yuwen, Martine De Cock
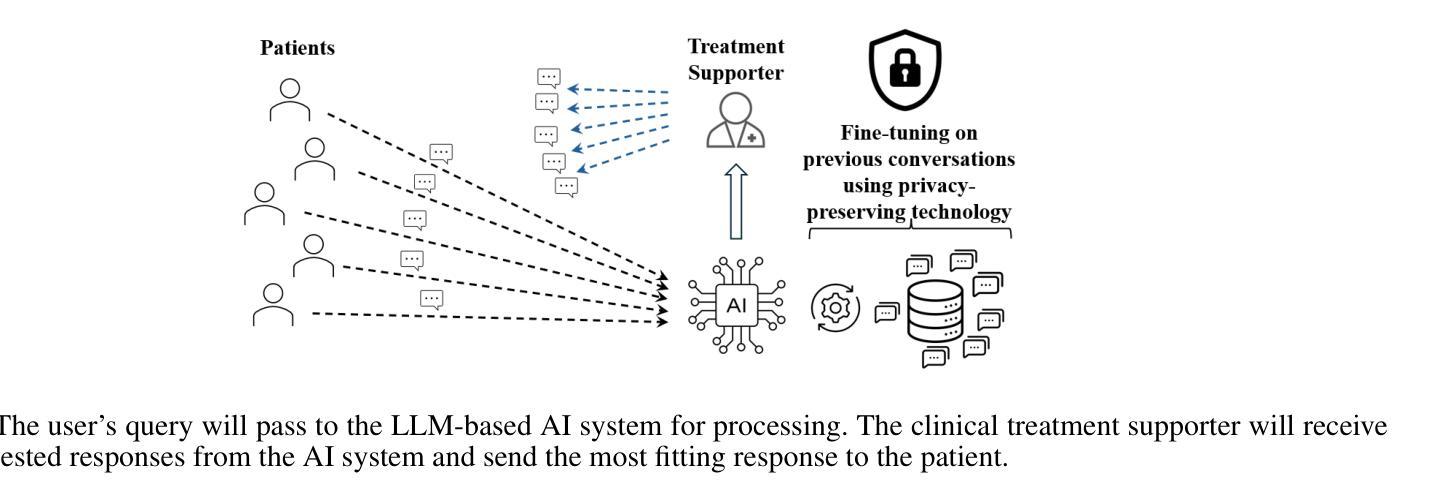
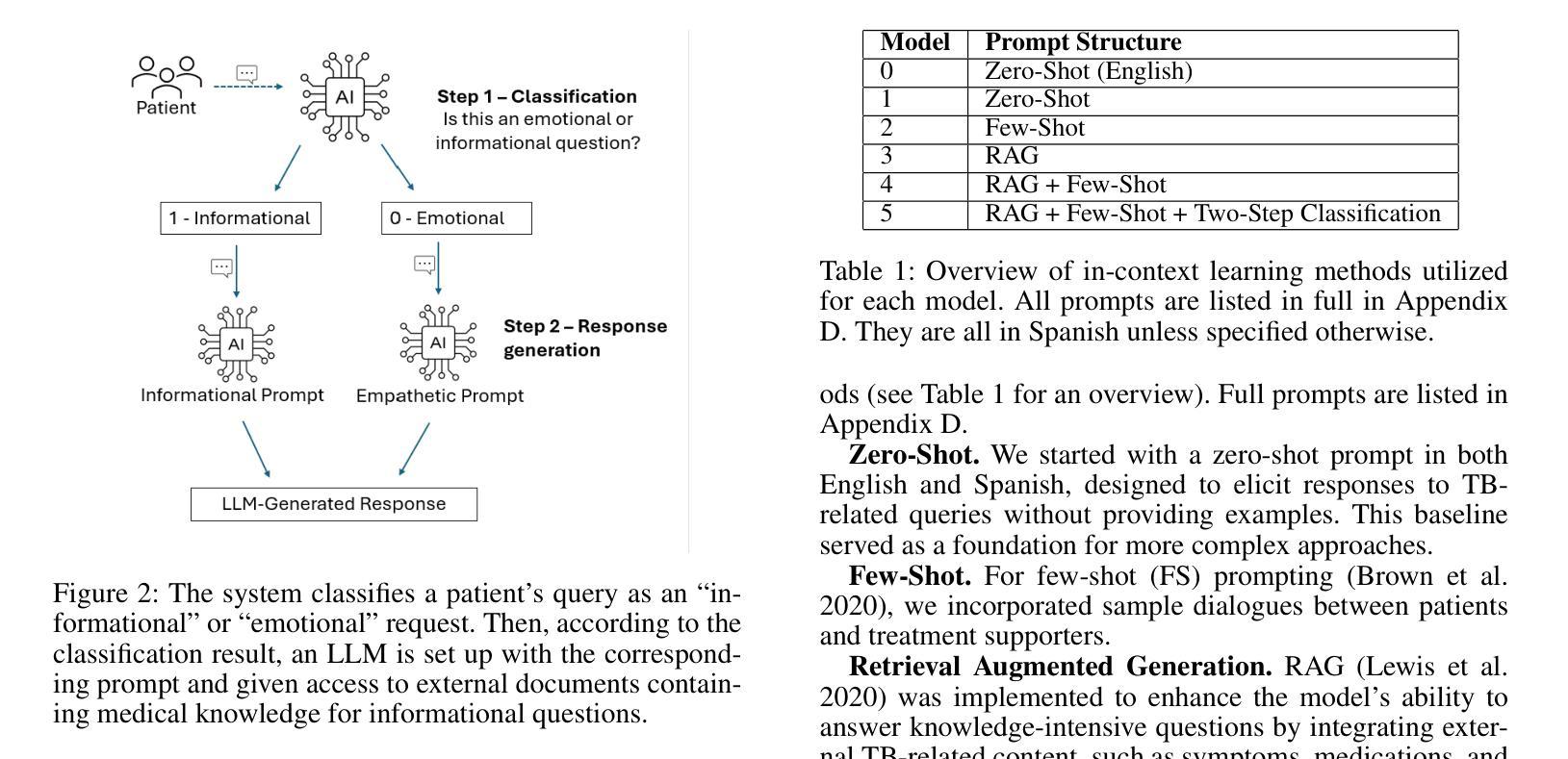
Tuberculosis (TB) is the leading cause of death from an infectious disease globally, with the highest burden in low- and middle-income countries. In these regions, limited healthcare access and high patient-to-provider ratios impede effective patient support, communication, and treatment completion. To bridge this gap, we propose integrating a specialized Large Language Model into an efficacious digital adherence technology to augment interactive communication with treatment supporters. This AI-powered approach, operating within a human-in-the-loop framework, aims to enhance patient engagement and improve TB treatment outcomes.
结核病(TB)是全球传染病死亡的主要原因,低收入和中收入国家负担最重。在这些地区,有限的医疗护理资源和高患者与医护人员的比例阻碍了有效的患者支持、沟通和治疗完成。为了弥补这一差距,我们提议将专业化的大型语言模型集成到有效的数字依从性技术中,以增强与治疗支持者之间的交互通信。这一人工智能驱动的方法,在人类循环的框架内运行,旨在提高患者的参与度并改善结核病的治疗结果。
论文及项目相关链接
PDF GenAI4Health at AAAI-25
Summary
全球范围内,结核病是传染性致死的主要原因,低收入和中收入国家负担最重。针对这些地区医疗资源有限、患者与服务提供者比例失衡的问题,我们提出将专业的大型语言模型集成到有效的数字依从性技术中,增强与治疗支持者之间的交互通信。这一人工智能驱动的方法旨在提升患者参与度并改善结核病治疗结果。
Key Takeaways
- 全球结核病致死率居高不下,特别是在低收入和中等收入国家。
- 这些国家面临医疗资源有限和患者与服务提供者比例失衡的挑战。
- 借助大型语言模型集成的数字依从性技术能够增强与治疗支持者的交互通信。
- 人工智能在这一领域的应用旨在提高患者的参与度和治疗效果。
- 这种AI方法是以人类为中心的循环框架的一部分。
- 通过这种整合方法,有望提升结核病治疗的成功率。
点此查看论文截图


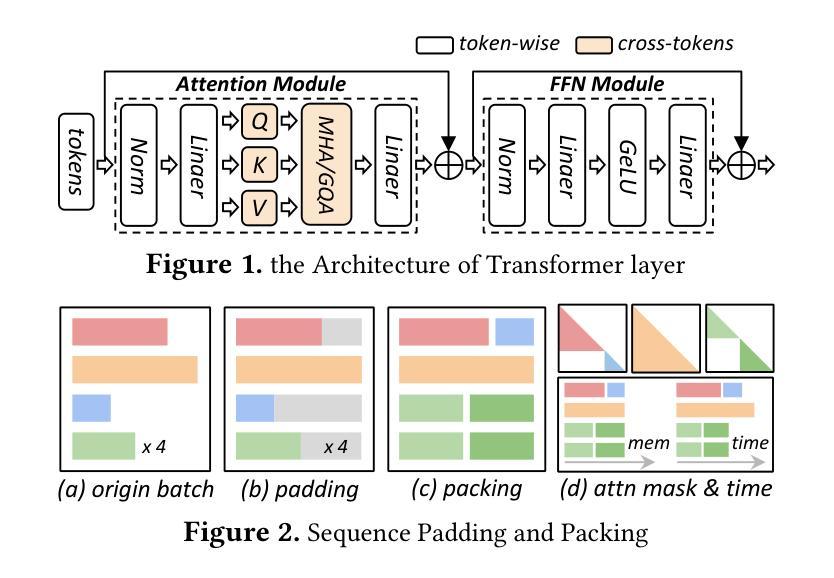
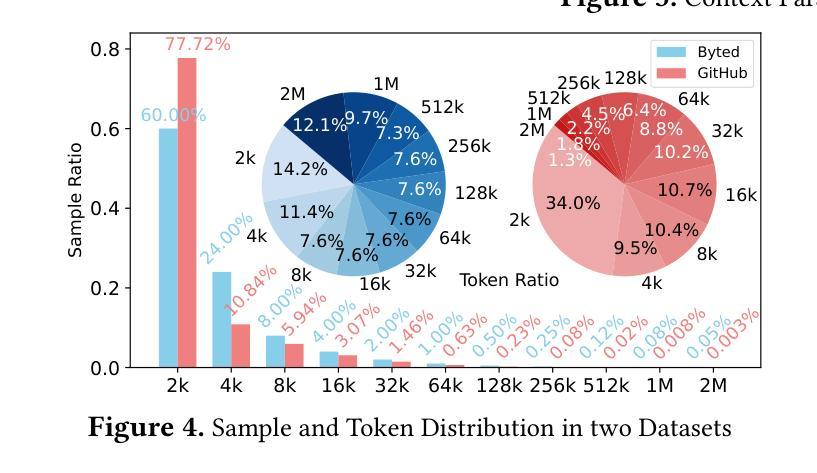
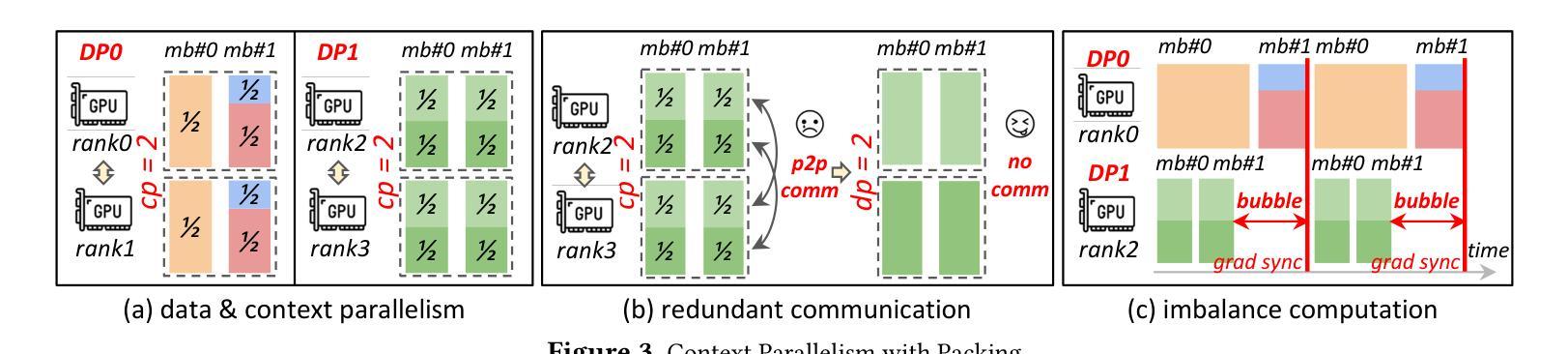
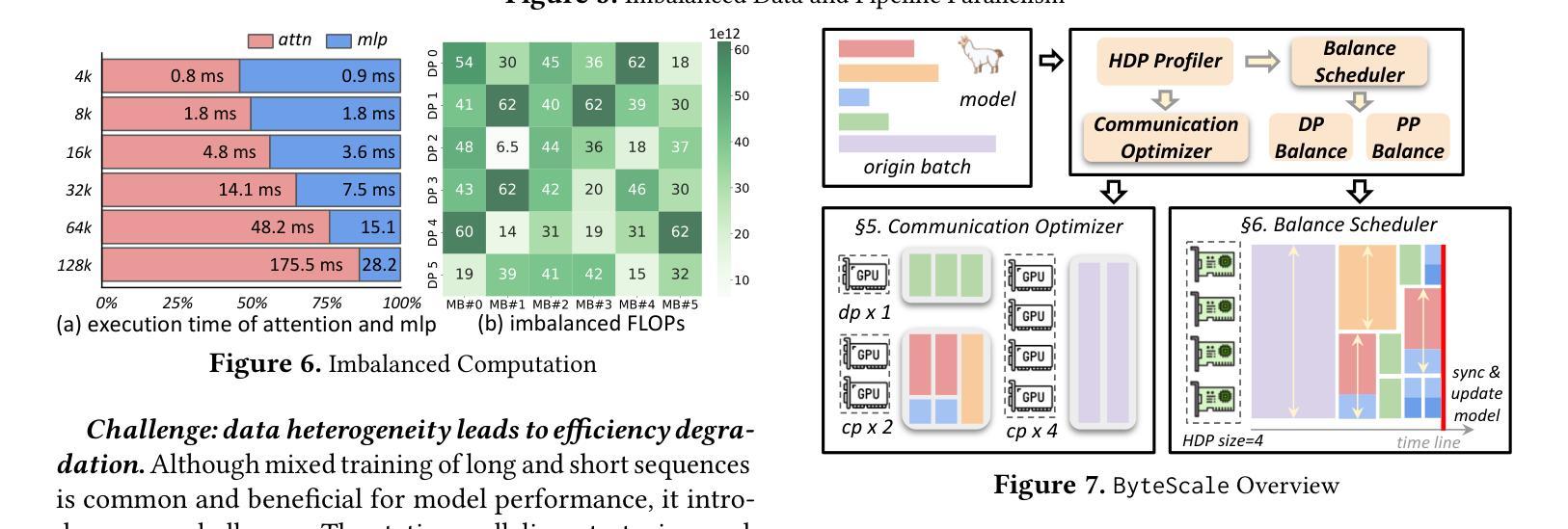
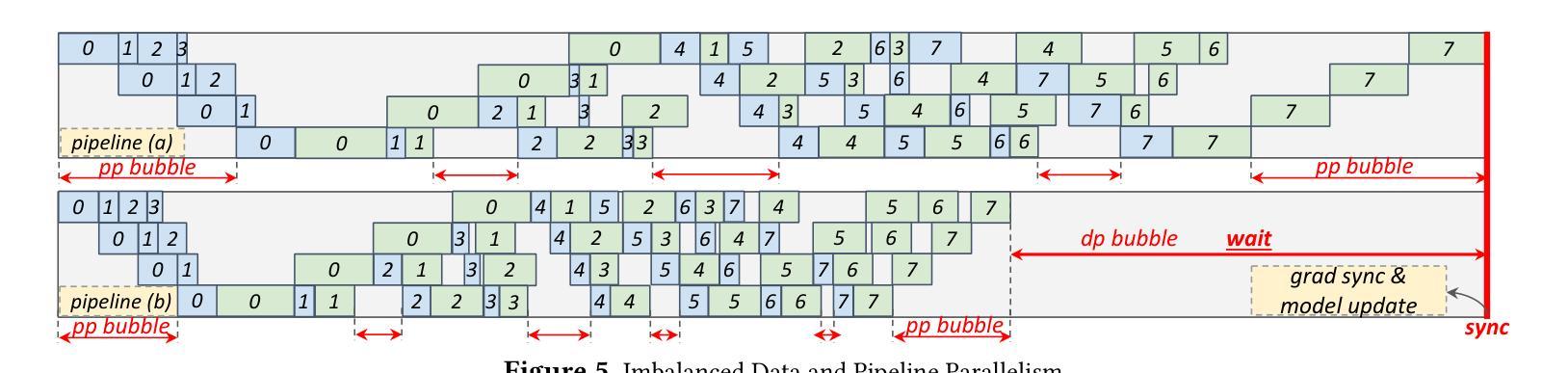
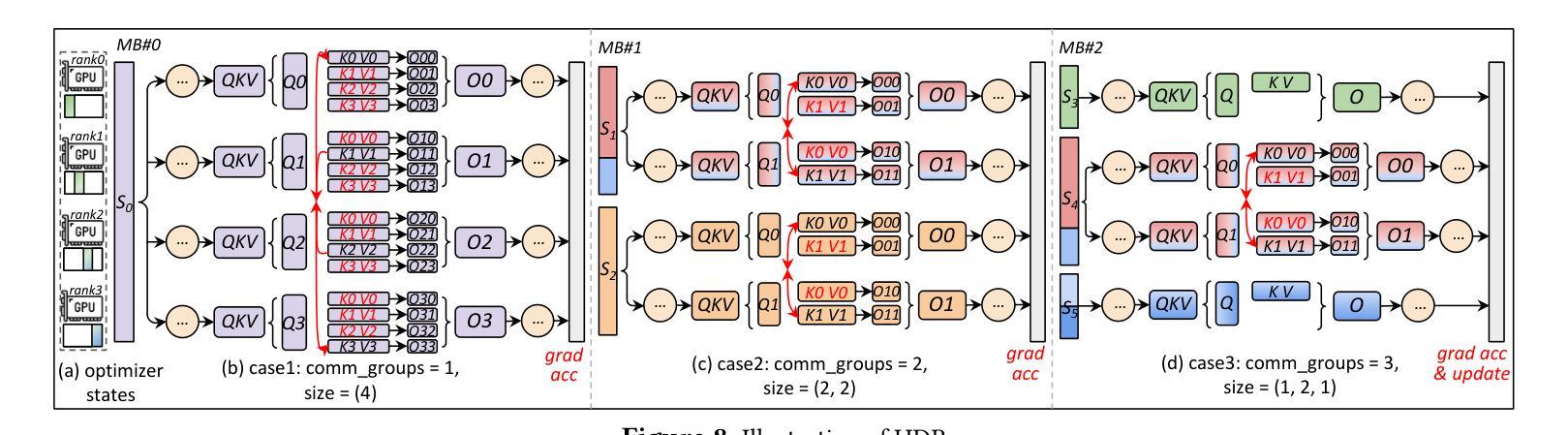
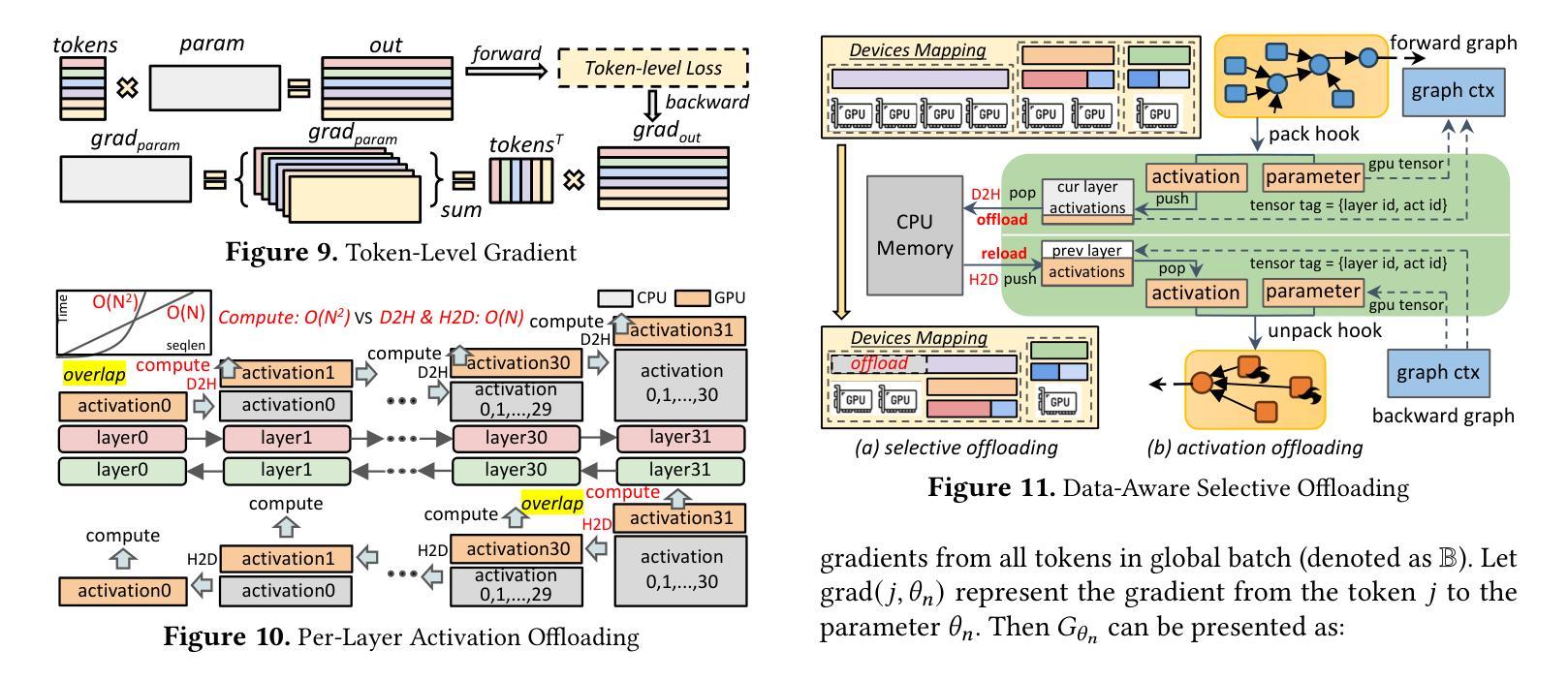
ByteScale: Efficient Scaling of LLM Training with a 2048K Context Length on More Than 12,000 GPUs
Authors:Hao Ge, Junda Feng, Qi Huang, Fangcheng Fu, Xiaonan Nie, Lei Zuo, Haibin Lin, Bin Cui, Xin Liu
Scaling long-context ability is essential for Large Language Models (LLMs). To amortize the memory consumption across multiple devices in long-context training, inter-data partitioning (a.k.a. Data Parallelism) and intra-data partitioning (a.k.a. Context Parallelism) are commonly used. Current training frameworks predominantly treat the two techniques as orthogonal, and establish static communication groups to organize the devices as a static mesh (e.g., a 2D mesh). However, the sequences for LLM training typically vary in lengths, no matter for texts, multi-modalities or reinforcement learning. The mismatch between data heterogeneity and static mesh causes redundant communication and imbalanced computation, degrading the training efficiency. In this work, we introduce ByteScale, an efficient, flexible, and scalable LLM training framework for large-scale mixed training of long and short sequences. The core of ByteScale is a novel parallelism strategy, namely Hybrid Data Parallelism (HDP), which unifies the inter- and intra-data partitioning with a dynamic mesh design. In particular, we build a communication optimizer, which eliminates the redundant communication for short sequences by data-aware sharding and dynamic communication, and further compresses the communication cost for long sequences by selective offloading. Besides, we also develop a balance scheduler to mitigate the imbalanced computation by parallelism-aware data assignment. We evaluate ByteScale with the model sizes ranging from 7B to 141B, context lengths from 256K to 2048K, on a production cluster with more than 12,000 GPUs. Experiment results show that ByteScale outperforms the state-of-the-art training system by up to 7.89x.
扩展大型语言模型(LLM)的长文上下文能力至关重要。为了在长文本训练的多个设备之间进行内存消耗补偿,通常使用数据间分割(也称为数据并行性)和数据内分割(也称为上下文并行性)。当前的训练框架主要将这两种技术视为正交的,并建立静态通信组来组织设备形成静态网格(例如二维网格)。然而,无论文本、多模式还是强化学习,LLM训练序列的长度通常都会有所变化。数据异质性与静态网格之间的不匹配导致了冗余通信和计算不平衡,降低了训练效率。
论文及项目相关链接
PDF 12 pages, 21 figures
Summary
大规模语言模型(LLM)训练过程中,长文本上下文处理至关重要。为了降低跨设备内存消耗,通常采用数据并行(inter-data partitioning)和上下文并行(intra-data partitioning)。当前训练框架主要将两者视为正交技术并以静态网格组织设备,如二维网格。然而,LLM训练序列长度各异,导致数据异质性与静态网格不匹配,引发冗余通信和计算不平衡问题,影响训练效率。本研究提出ByteScale训练框架,融合数据并行和上下文并行策略的混合数据并行(HDP)为核心。通过通信优化器消除短序列的冗余通信并实现选择性卸载减少长序列通信成本,平衡调度器解决计算不平衡问题。评估结果显示,ByteScale在模型规模从7B到141B、上下文长度从256K到2048K的情况下,相较于现有训练系统性能提升最高达7.89倍。
Key Takeaways
- 长文本上下文处理在LLM训练中至关重要。
- 当前训练框架以静态网格组织设备,导致数据异质性与静态网格不匹配。
- ByteScale框架引入混合数据并行(HDP)策略,融合数据并行和上下文并行。
- 通信优化器消除短序列冗余通信,选择性卸载减少长序列通信成本。
- 平衡调度器解决计算不平衡问题。
- ByteScale在模型规模和上下文长度广泛的情况下表现出卓越性能。
点此查看论文截图

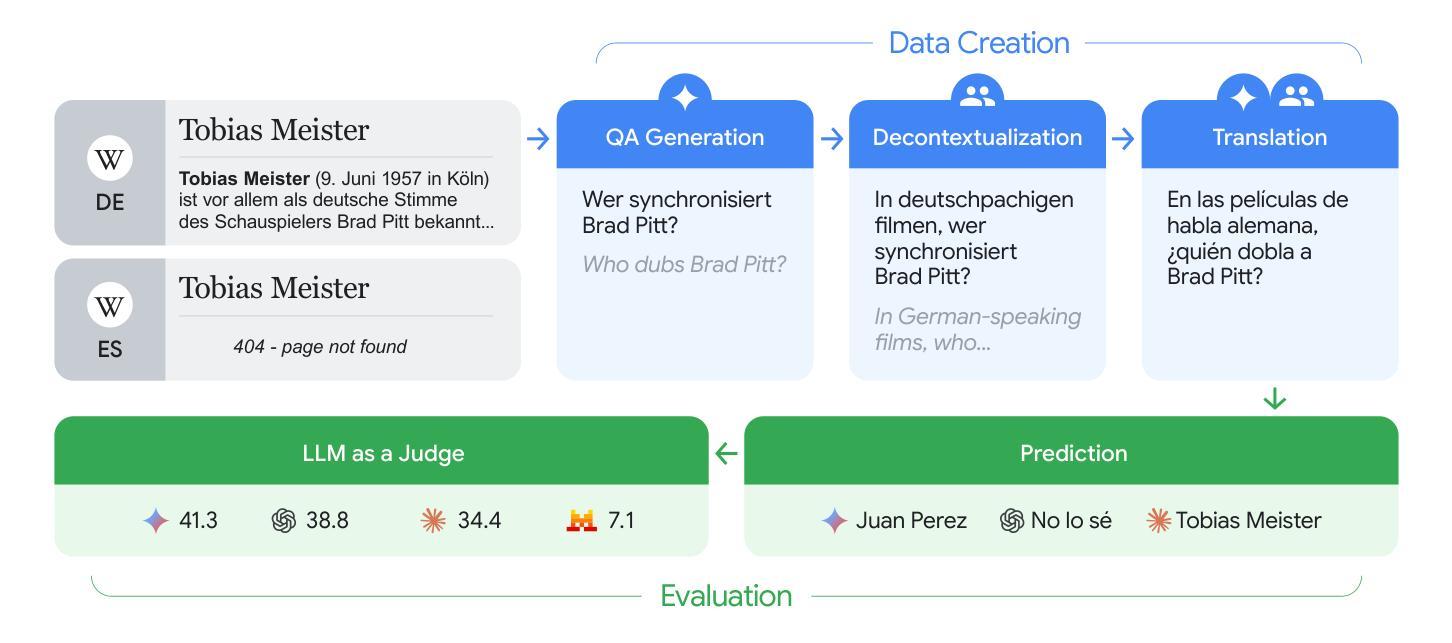
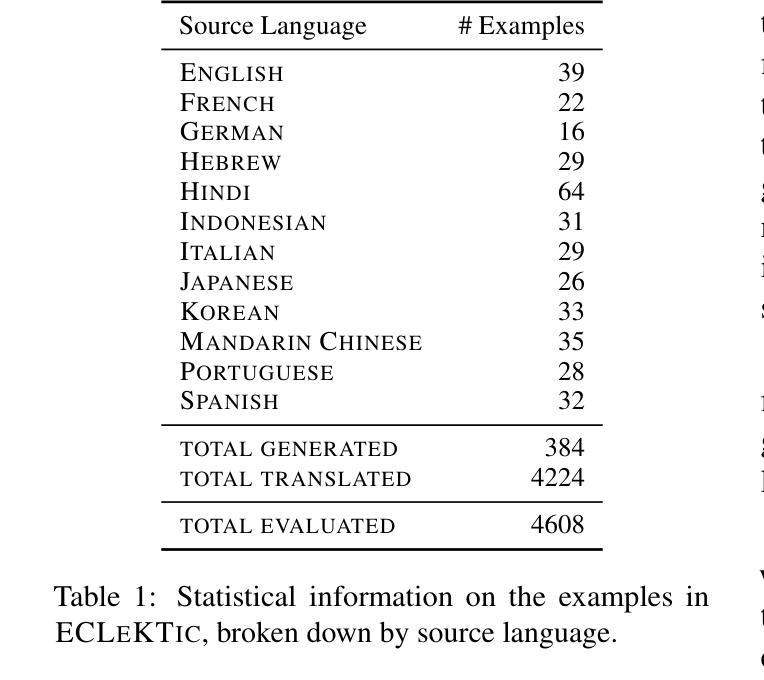
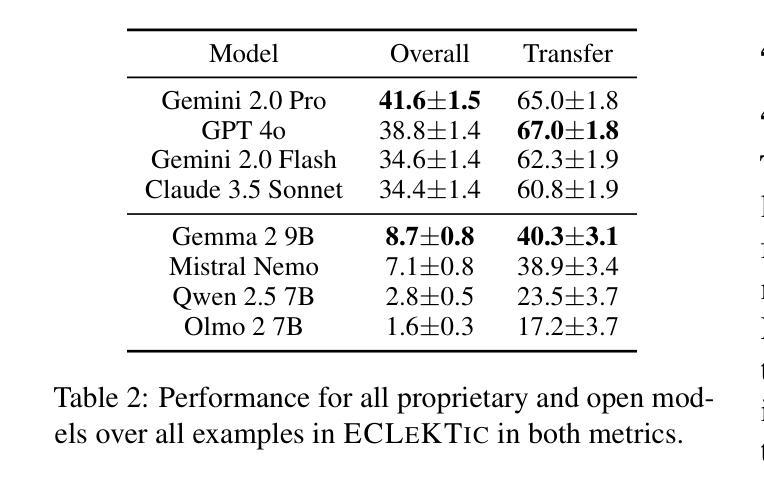
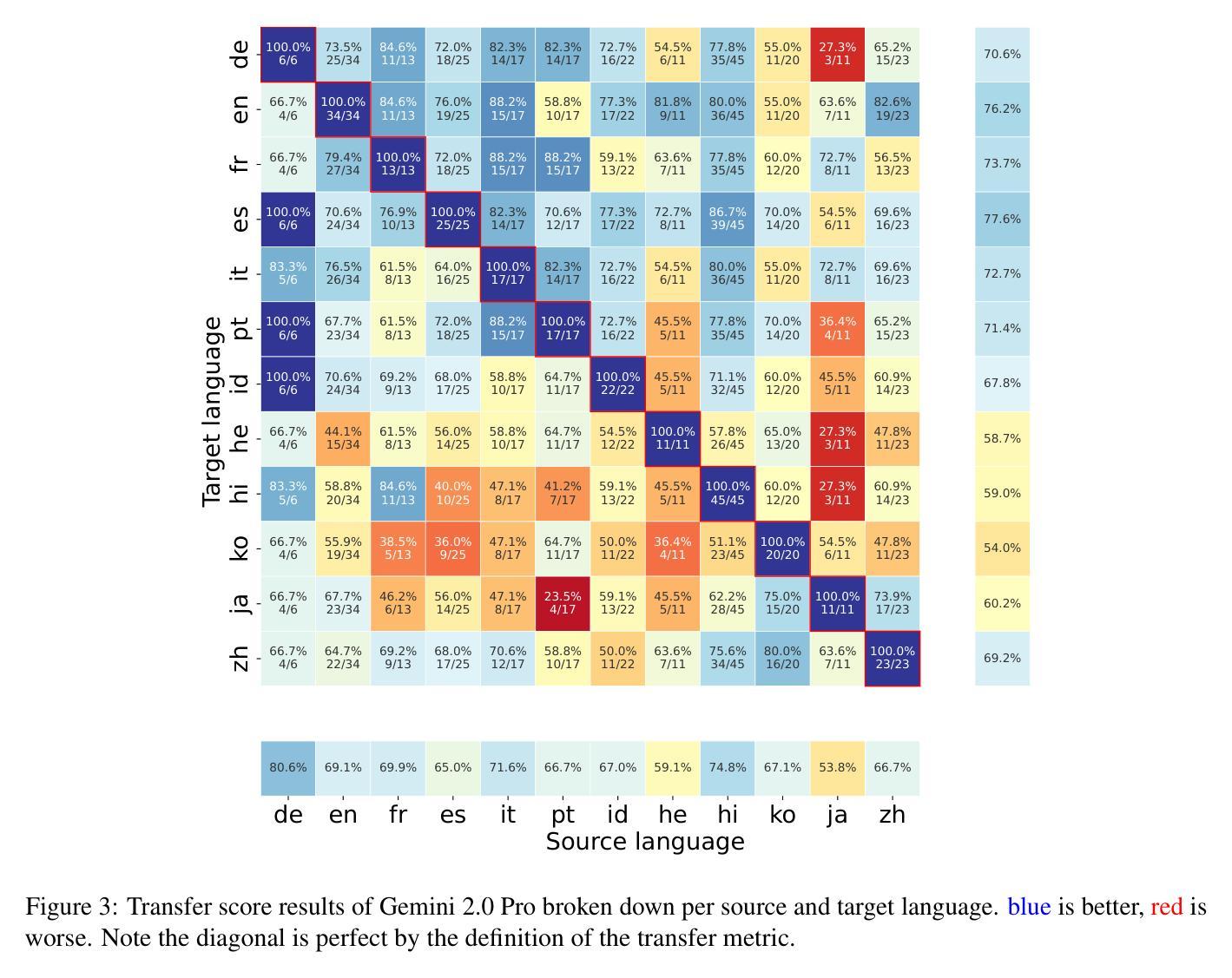
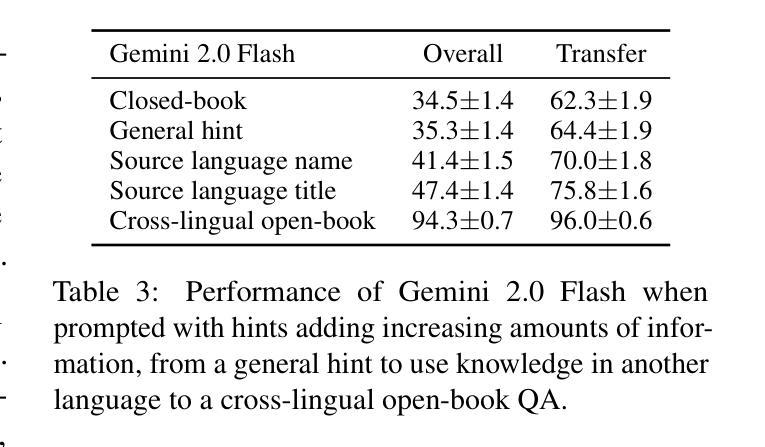
ECLeKTic: a Novel Challenge Set for Evaluation of Cross-Lingual Knowledge Transfer
Authors:Omer Goldman, Uri Shaham, Dan Malkin, Sivan Eiger, Avinatan Hassidim, Yossi Matias, Joshua Maynez, Adi Mayrav Gilady, Jason Riesa, Shruti Rijhwani, Laura Rimell, Idan Szpektor, Reut Tsarfaty, Matan Eyal
To achieve equitable performance across languages, multilingual large language models (LLMs) must be able to abstract knowledge beyond the language in which it was acquired. However, the current literature lacks reliable ways to measure LLMs’ capability of cross-lingual knowledge transfer. To that end, we present ECLeKTic, a multilingual closed-book QA (CBQA) dataset that Evaluates Cross-Lingual Knowledge Transfer in a simple, black-box manner. We detected information with uneven coverage across languages by controlling for presence and absence of Wikipedia articles in 12 languages. We generated knowledge-seeking questions in a source language, for which the answer appears in a relevant Wikipedia article and translated them to all other 11 languages, for which the respective Wikipedias lack equivalent articles. Assuming that Wikipedia reflects the prominent knowledge in the LLM’s training data, to solve ECLeKTic’s CBQA task the model is required to transfer knowledge between languages. Experimenting with 8 LLMs, we show that SOTA models struggle to effectively share knowledge across, languages even if they can predict the answer well for queries in the same language the knowledge was acquired in.
为了实现不同语言的公平性能,多语言大型语言模型(LLM)必须能够抽象获取语言之外的知识。然而,现有文献缺乏可靠的方法来衡量LLM跨语言知识转移的能力。为此,我们提出了ECLeKTic,这是一个多语言封闭问答(CBQA)数据集,以简单、黑箱的方式评估跨语言知识的转移。我们通过控制12种语言的维基百科文章的有无,检测了语言间信息覆盖的不均匀性。我们在源语言中生成寻求知识的问题,这些问题的答案出现在相关的维基百科文章中,然后将其翻译到其他所有11种语言,这些语言的维基百科都没有相应的文章。假设维基百科反映了LLM训练数据中的突出知识,要解决ECLeKTic的CBQA任务,模型需要在语言间转移知识。通过对8个LLM进行实验,我们发现即使对于在获取知识的同一语言中的查询能够很好地预测答案,最先进的模型在跨语言共享知识方面仍然面临困难。
论文及项目相关链接
Summary
多语种大型语言模型(LLM)为实现跨语言性能公平,必须能够抽取超越获取语言的知识。然而,当前文献缺乏衡量LLM跨语言知识迁移能力的方法。为此,我们推出了ECLeKTic,这是一个多语种封闭问答(CBQA)数据集,以简单、黑箱的方式评估跨语言知识迁移。我们通过控制12种语言的维基百科文章的有无,发现了语言间信息覆盖不均的问题。我们在源语言生成寻求知识的问答,其答案出现在相关维基百科文章中,并将其翻译至其他11种语言,这些语言的维基百科缺乏相应文章。为解决ECLeKTic的CBQA任务,模型需要在语言间转移知识。通过对8种LLM的实验,我们发现即使它们能在同一语言的查询中获得良好的预测结果,但在跨语言的知识共享方面仍面临挑战。
Key Takeaways
- 多语种大型语言模型需具备跨语言知识迁移能力以实现性能公平。
- 当前缺乏衡量LLM跨语言知识迁移能力的方法。
- ECLeKTic数据集用于评估多语种LLM的跨语言知识迁移能力。
- 语言间的信息覆盖存在不均衡现象。
- LLM在跨语言知识共享方面面临挑战,即使在同一语言的查询中表现良好。
- 封闭问答(CBQA)任务是评估LLM跨语言能力的重要手段。
点此查看论文截图

Transformers Learn to Implement Multi-step Gradient Descent with Chain of Thought
Authors:Jianhao Huang, Zixuan Wang, Jason D. Lee
Chain of Thought (CoT) prompting has been shown to significantly improve the performance of large language models (LLMs), particularly in arithmetic and reasoning tasks, by instructing the model to produce intermediate reasoning steps. Despite the remarkable empirical success of CoT and its theoretical advantages in enhancing expressivity, the mechanisms underlying CoT training remain largely unexplored. In this paper, we study the training dynamics of transformers over a CoT objective on an in-context weight prediction task for linear regression. We prove that while a one-layer linear transformer without CoT can only implement a single step of gradient descent (GD) and fails to recover the ground-truth weight vector, a transformer with CoT prompting can learn to perform multi-step GD autoregressively, achieving near-exact recovery. Furthermore, we show that the trained transformer effectively generalizes on the unseen data. With our technique, we also show that looped transformers significantly improve final performance compared to transformers without looping in the in-context learning of linear regression. Empirically, we demonstrate that CoT prompting yields substantial performance improvements.
思维链(CoT)提示被证明可以显著地提高大型语言模型(LLM)的性能,特别是在算术和推理任务中,通过指导模型产生中间推理步骤。尽管CoT的显著实证成功及其在增强表现力方面的理论优势,但CoT训练的基础机制仍然大部分未被探索。在本文中,我们研究了在上下文权重预测任务的线性回归上,变换器对CoT目标的训练动态。我们证明,虽然一层线性变换器在没有CoT的情况下只能实现一步梯度下降(GD),并且无法恢复真实的权重向量,但带有CoT提示的变换器可以学习执行多步GD的自回归,实现近乎精确的回收。此外,我们还表明经过训练的变换器可以有效地推广到未见过的数据。使用我们的技术,我们还表明与没有循环的变换器相比,循环变换器在线性回归的上下文学习中显著提高了最终性能。从实证来看,我们证明了CoT提示产生了实质性的性能改进。
论文及项目相关链接
PDF ICLR 2025 Spotlight
Summary
链式思维(Chain of Thought,简称CoT)提示可显著提升大型语言模型(LLM)的性能,尤其在算术和推理任务中。通过指导模型生成中间推理步骤,CoT不仅增强了模型的表达能力,也在理论上具有优势。本文研究变压器在链式思维目标下的训练动态,针对线性回归进行上下文权重预测任务。实验证明,无链式思维提示的单层线性变压器仅能实现梯度下降(GD)的单步操作,无法恢复真实权重向量;而带有CoT提示的变压器可以学习执行多步GD的自动回归,实现近似精确恢复,并在未见数据上实现有效泛化。此外,通过采用循环变压器技术,与无循环的变压器相比,在线性回归的上下文学习中可显著提高最终性能。经验证,CoT提示可带来显著的性能改进。
Key Takeaways
- 链式思维(CoT)提示能显著提升大型语言模型(LLM)在算术和推理任务中的性能。
- CoT通过指导模型生成中间推理步骤,增强了模型的表达能力。
- 在线性回归的上下文权重预测任务中,带有CoT提示的变压器可以学习执行多步梯度下降的自动回归。
- CoT提示帮助变压器实现近似精确恢复真实权重向量,并在未见数据上实现有效泛化。
- 采用循环变压器技术可进一步提高在线性回归的上下文学习中的最终性能。
- 本文通过实验证明了CoT提示带来的性能改进是显著的。
- CoT在理论上的优势和在实际应用中的效果证明了其在实际应用中的价值。
点此查看论文截图

Chronologically Consistent Large Language Models
Authors:Songrun He, Linying Lv, Asaf Manela, Jimmy Wu
Large language models are increasingly used in social sciences, but their training data can introduce lookahead bias and training leakage. A good chronologically consistent language model requires efficient use of training data to maintain accuracy despite time-restricted data. Here, we overcome this challenge by training chronologically consistent large language models timestamped with the availability date of their training data, yet accurate enough that their performance is comparable to state-of-the-art open-weight models. Lookahead bias is model and application-specific because even if a chronologically consistent language model has poorer language comprehension, a regression or prediction model applied on top of the language model can compensate. In an asset pricing application, we compare the performance of news-based portfolio strategies that rely on chronologically consistent versus biased language models and estimate a modest lookahead bias.
大型语言模型在社会科学领域的应用越来越广泛,但其训练数据可能会引入前瞻偏见和训练泄露。一个良好的时间连贯性语言模型需要有效利用训练数据,即使在时间受限的数据下也能保持准确性。在这里,我们通过训练带有训练数据可用日期的时间连贯的大型语言模型来克服这一挑战,这些模型的准确性足够高,其性能可与最先进的开放权重模型相媲美。前瞻偏见是模型和应用程序特定的,因为即使时间连贯的语言模型的语言理解能力较差,应用于语言模型之上的回归或预测模型也可以进行补偿。在资产定价应用程序中,我们比较了基于新闻的组合策略的性能,这些策略依赖于时间连贯与有偏见的语言模型,并估计了一个适度的前瞻偏见。
论文及项目相关链接
Summary:大型语言模型在社会科学领域应用广泛,但其训练数据可能引入前瞻偏见和训练泄露问题。为解决这一问题,我们采用时间戳训练数据训练时序一致的大型语言模型,其性能与最新公开权重模型相当。前瞻偏见是模型和应用特定的,因为即使时序一致的语言模型语言理解能力较差,在语言模型之上应用的回归或预测模型也可以进行补偿。在资产定价应用中,我们比较了基于时序一致语言模型和带有偏见语言模型的新闻组合策略的性能,并估计出轻微的前瞻偏见。
Key Takeaways:
- 大型语言模型在社会科学领域应用广泛,但存在训练数据引入的前瞻偏见和训练泄露问题。
- 通过使用时间戳训练数据,可以训练出时序一致的大型语言模型,其性能与最新公开权重模型相当。
- 前瞻偏见是模型和应用特定的,可以通过在应用层进行补偿来优化模型性能。
- 在资产定价应用中,基于时序一致语言模型的新闻组合策略性能更优。
- 相比带有偏见的语言模型,时序一致的模型具有轻微的前瞻偏见。
- 训练大型语言模型时需要注意使用数据的效率,以维持准确性并避免时间限制数据的问题。
点此查看论文截图

Disentangling Feature Structure: A Mathematically Provable Two-Stage Training Dynamics in Transformers
Authors:Zixuan Gong, Jiaye Teng, Yong Liu
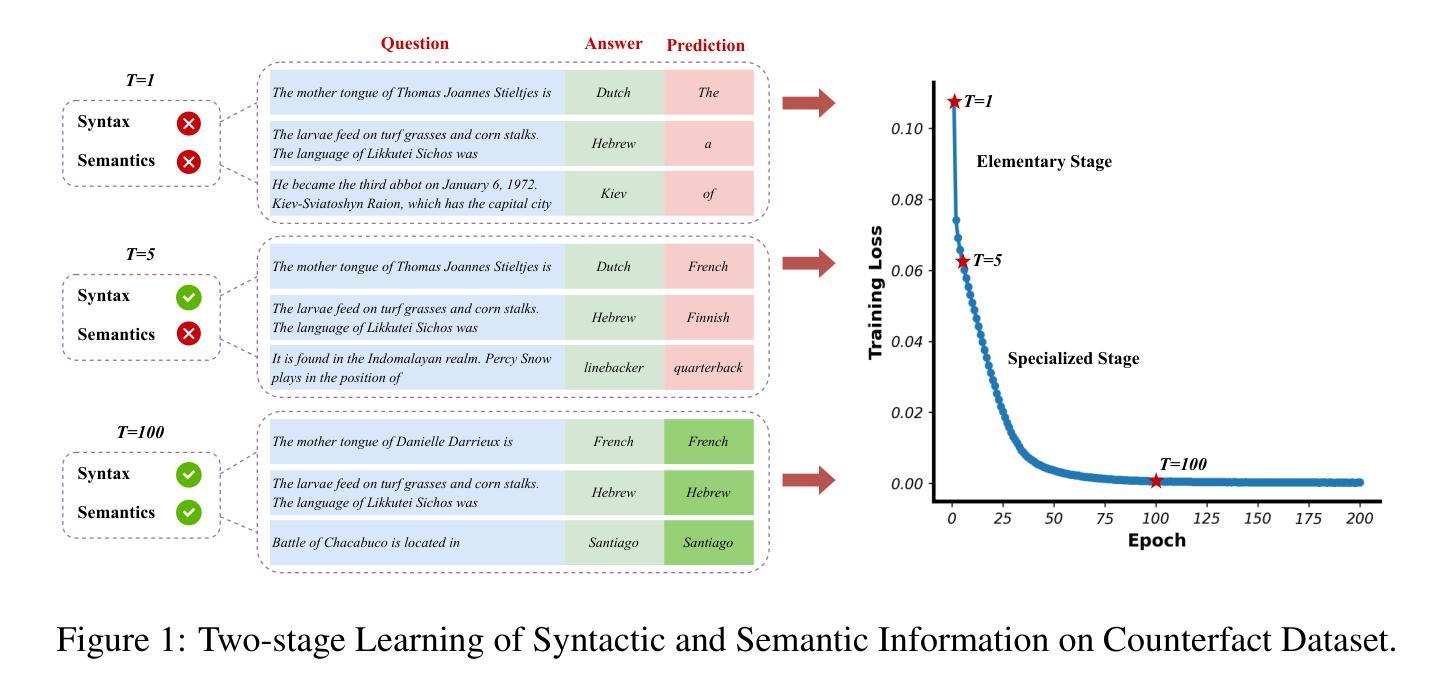
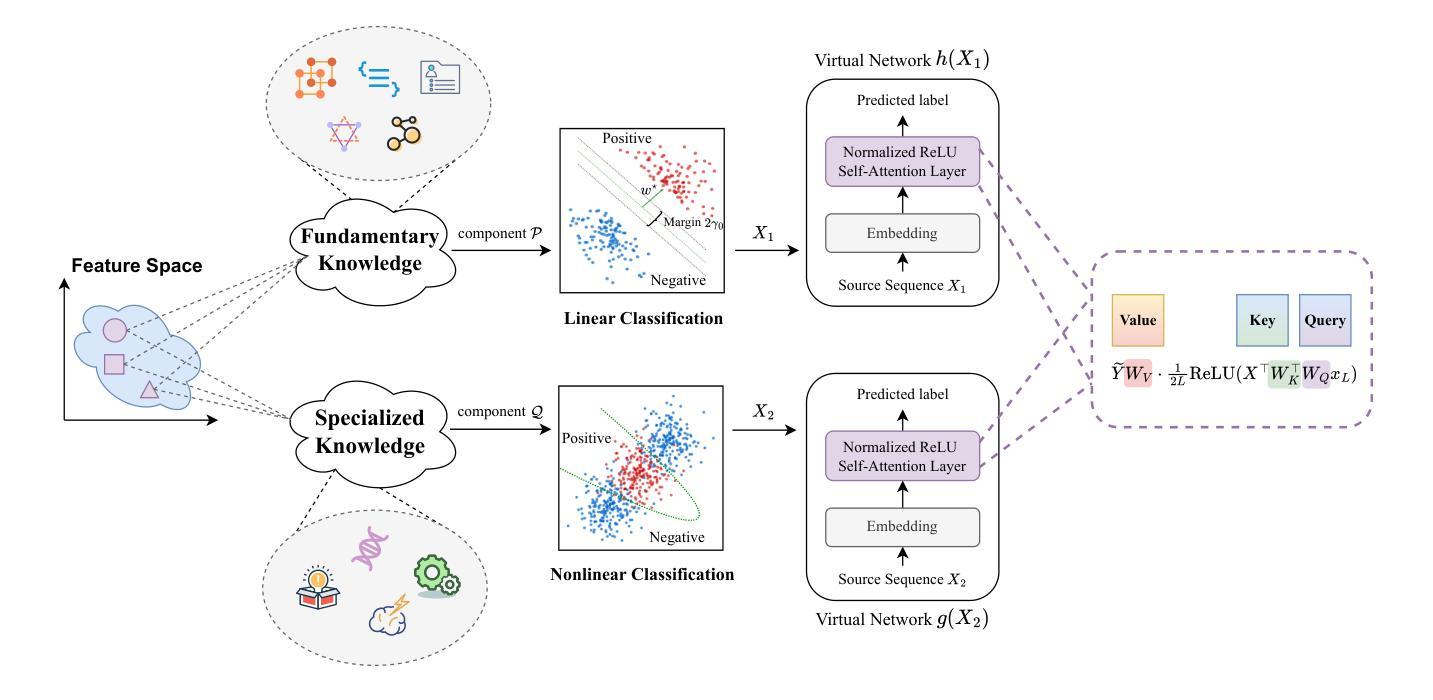
Transformers may exhibit two-stage training dynamics during the real-world training process. For instance, when training GPT-2 on the Counterfact dataset, the answers progress from syntactically incorrect to syntactically correct to semantically correct. However, existing theoretical analyses hardly account for this two-stage phenomenon. In this paper, we theoretically demonstrate how such two-stage training dynamics occur in transformers. Specifically, we analyze the dynamics of transformers using feature learning techniques under in-context learning regimes, based on a disentangled two-type feature structure. Such disentanglement of feature structure is general in practice, e.g., natural languages contain syntax and semantics, and proteins contain primary and secondary structures. To our best known, this is the first rigorous result regarding a two-stage optimization process in transformers. Additionally, a corollary indicates that such a two-stage process is closely related to the spectral properties of the attention weights, which accords well with empirical findings.
在现实世界中的训练过程中,Transformer可能会展现出两阶段的训练动态。例如,在Counterfact数据集上训练GPT-2时,答案的进展从语法不正确到语法正确再到语义正确。然而,现有的理论分析很少涉及这种两阶段现象。在本文中,我们从理论上证明了Transformer中这种两阶段训练动态是如何发生的。具体来说,我们使用特征学习技术在上下文学习机制下分析Transformer的动态变化,基于解耦的两类特征结构。在实践中,特征结构的解耦是普遍的,例如自然语言包含语法和语义,蛋白质包含一级结构和二级结构。据我们所知,这是关于Transformer两阶段优化过程的首个严格结果。此外,推论表明这种两阶段过程与注意力权重的谱属性密切相关,这与经验发现相吻合。
论文及项目相关链接
Summary:
在真实世界训练过程中,Transformer可能会表现出两阶段训练动态。本论文以GPT-2在Counterfact数据集上的训练为例,展示了这种从语法不正确到语法正确再到语义正确的答案进步过程。本文通过特征学习技术和上下文学习机制对这种现象进行了理论分析,并基于两种类型特征的解耦结构进行了分析。此两阶段训练过程与自然语言中的语法和语义、蛋白质中的一级和二级结构的解耦相对应。本文的结果关于Transformer的两阶段优化过程是已知的首个严谨结果,且与注意力权重的谱属性密切相关。
Key Takeaways:
- Transformer在真实世界训练过程中可能表现出两阶段训练动态。
- GPT-2在Counterfact数据集上的训练为例,展示了答案从语法不正确到语法正确再到语义正确的进步过程。
- 本文使用特征学习技术和上下文学习机制对这种现象进行了理论分析。
- Transformer的两阶段训练过程基于两种类型特征的解耦结构。
- 这种解耦与自然语言中的语法和语义、蛋白质中的一级和二级结构的解耦相对应。
- 本论文的结果关于Transformer的两阶段优化过程是已知的首个严谨结果。
点此查看论文截图

RTGen: Real-Time Generative Detection Transformer
Authors:Chi Ruan
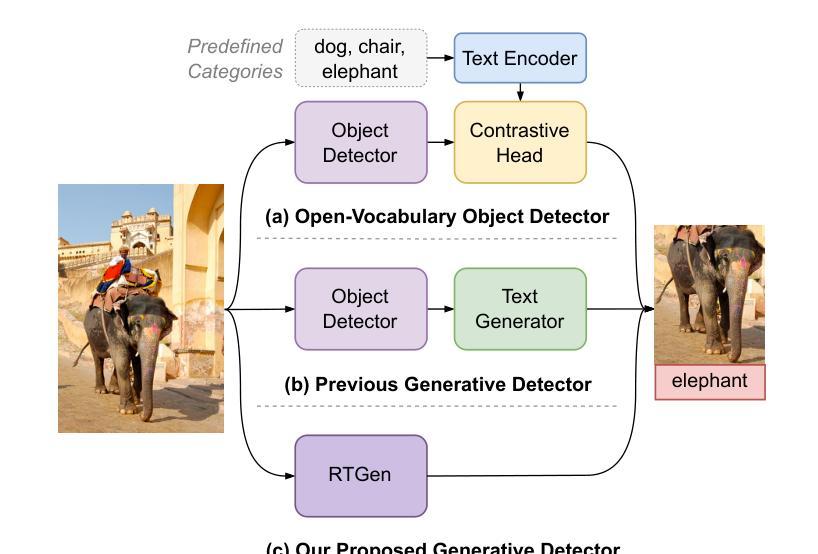
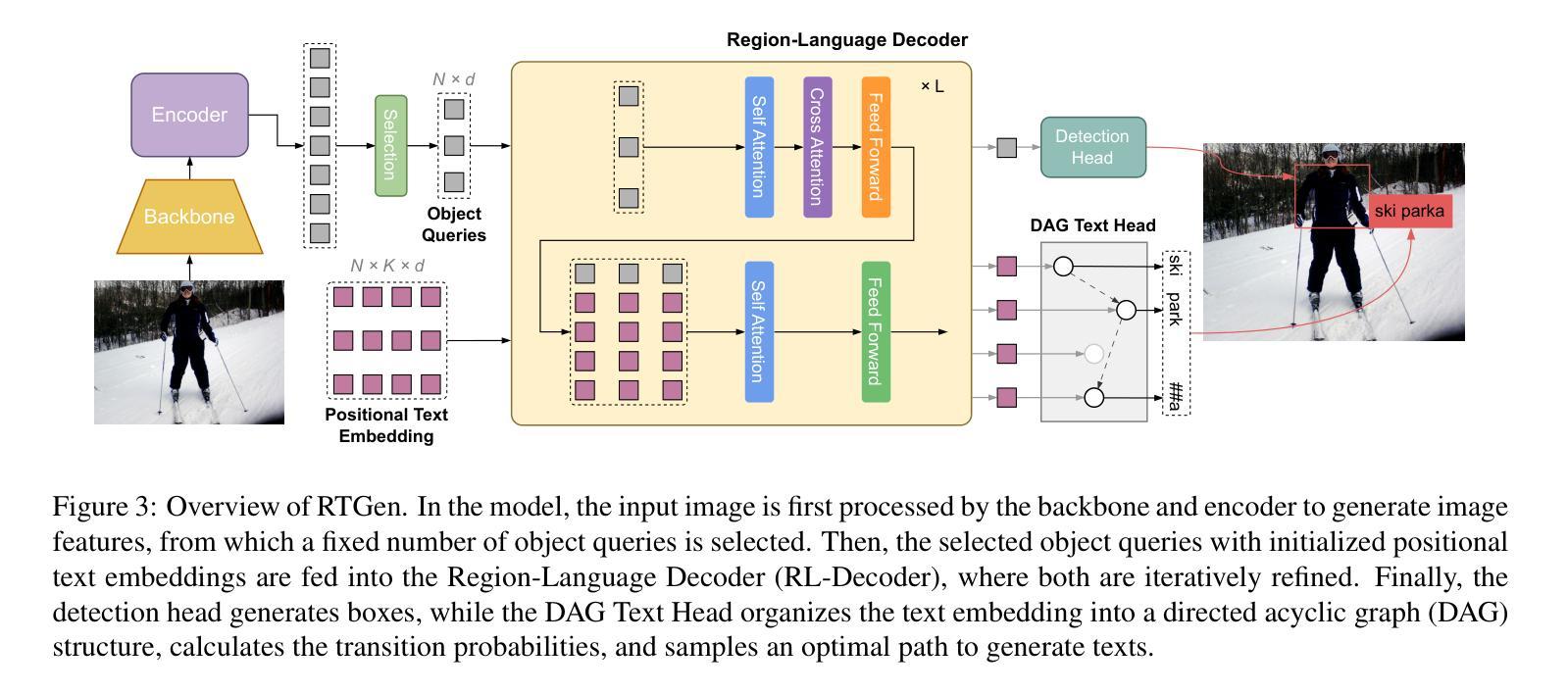
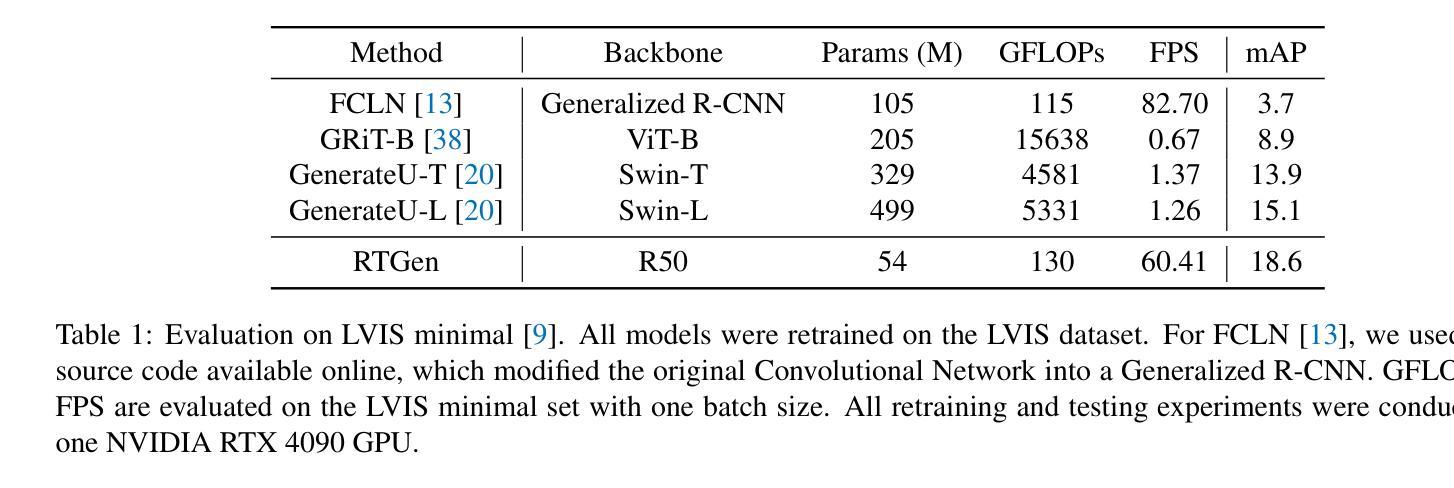
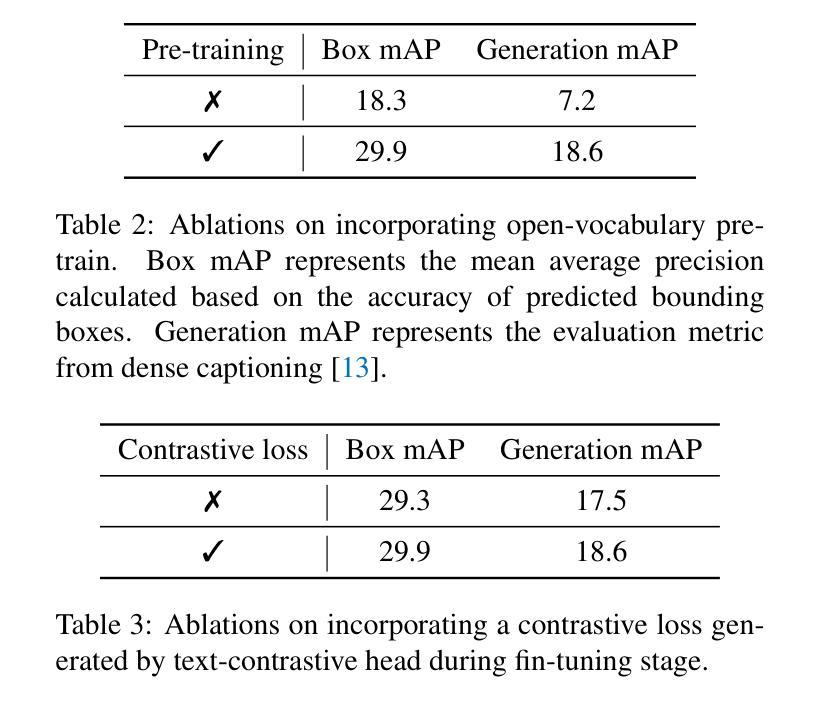
While open-vocabulary object detectors require predefined categories during inference, generative object detectors overcome this limitation by endowing the model with text generation capabilities. However, existing generative object detection methods directly append an autoregressive language model to an object detector to generate texts for each detected object. This straightforward design leads to structural redundancy and increased processing time. In this paper, we propose a Real-Time GENerative Detection Transformer (RTGen), a real-time generative object detector with a succinct encoder-decoder architecture. Specifically, we introduce a novel Region-Language Decoder (RL-Decoder), which innovatively integrates a non-autoregressive language model into the detection decoder, enabling concurrent processing of object and text information. With these efficient designs, RTGen achieves a remarkable inference speed of 60.41 FPS. Moreover, RTGen obtains 18.6 mAP on the LVIS dataset, outperforming the previous SOTA method by 3.5 mAP.
虽然开放词汇对象检测器在推理过程中需要预先定义类别,但生成式对象检测器通过赋予模型文本生成能力来克服这一限制。然而,现有的生成式对象检测方法直接将自回归语言模型附加到对象检测器上,为每个检测到的对象生成文本。这种直接的设计导致了结构冗余和增加的处理时间。在本文中,我们提出了一种实时生成检测转换器(RTGen),这是一种具有简洁编码器-解码器架构的实时生成式对象检测器。具体来说,我们引入了一种新型的区域-语言解码器(RL-Decoder),它创新地将非自回归语言模型集成到检测解码器中,实现对对象和文本信息的并行处理。凭借这些高效的设计,RTGen实现了60.41 FPS的惊人推理速度。此外,RTGen在LVIS数据集上获得了18.6 mAP,比之前的最佳方法高出3.5 mAP。
论文及项目相关链接
Summary
本文提出一种实时生成检测变压器(RTGen)的实时生成目标检测器,采用简洁的编码器-解码器架构。通过引入新的Region-Language Decoder(RL-Decoder),将非自回归语言模型创新地集成到检测解码器中,实现目标和文本信息的并行处理。RTGen具有出色的推理速度,达到每秒60.41帧,且在LVIS数据集上获得较高的平均精度(mAP)。
Key Takeaways
- 生成目标检测器克服了开放词汇目标检测器需要在推理期间进行预定义类别的限制。
- 现有生成目标检测方法直接在目标检测器上附加自回归语言模型来为每个检测到的对象生成文本,导致结构冗余和增加处理时间。
- RTGen采用简洁的编码器-解码器架构,实现实时生成目标检测。
- RTGen引入了新的Region-Language Decoder(RL-Decoder),将非自回归语言模型集成到检测解码器中。
- RL-Decoder使对象和文本信息能够并行处理。
- RTGen具有出色的推理速度,达到每秒60.41帧。
点此查看论文截图

Visual Reasoning at Urban Intersections: FineTuning GPT-4o for Traffic Conflict Detection
Authors:Sari Masri, Huthaifa I. Ashqar, Mohammed Elhenawy
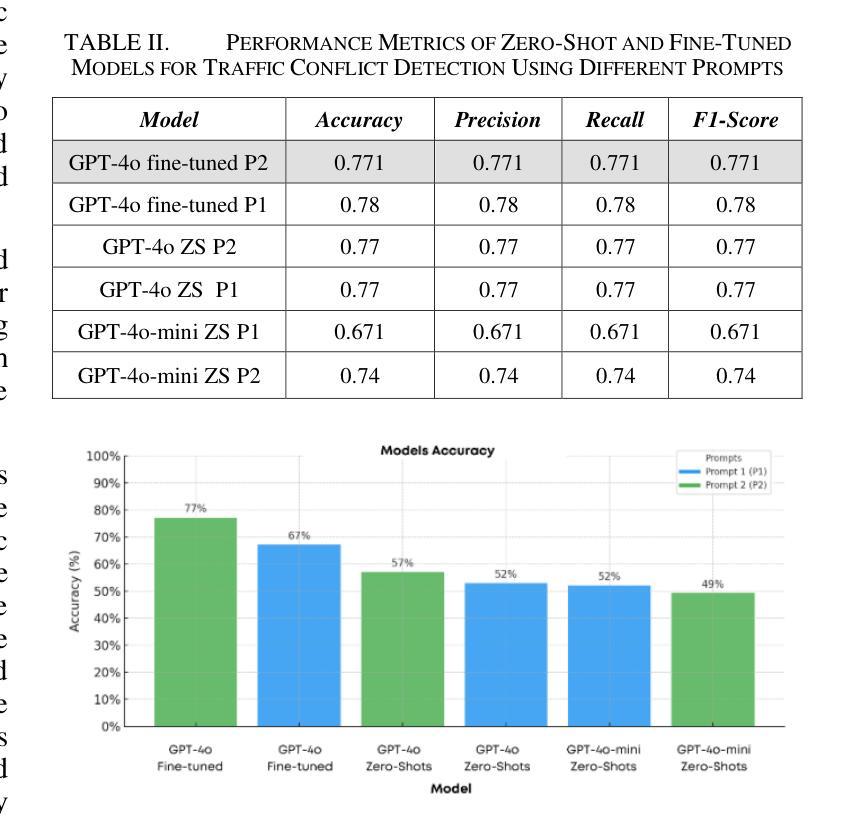
Traffic control in unsignalized urban intersections presents significant challenges due to the complexity, frequent conflicts, and blind spots. This study explores the capability of leveraging Multimodal Large Language Models (MLLMs), such as GPT-4o, to provide logical and visual reasoning by directly using birds-eye-view videos of four-legged intersections. In this proposed method, GPT-4o acts as intelligent system to detect conflicts and provide explanations and recommendations for the drivers. The fine-tuned model achieved an accuracy of 77.14%, while the manual evaluation of the true predicted values of the fine-tuned GPT-4o showed significant achievements of 89.9% accuracy for model-generated explanations and 92.3% for the recommended next actions. These results highlight the feasibility of using MLLMs for real-time traffic management using videos as inputs, offering scalable and actionable insights into intersections traffic management and operation. Code used in this study is available at https://github.com/sarimasri3/Traffic-Intersection-Conflict-Detection-using-images.git.
在无信号的城市交叉口的交通控制存在诸多挑战,因为其复杂性、频繁的冲突和盲点。本研究探讨了利用多模态大语言模型(MLLMs)的能力,如GPT-4o,通过直接使用鸟瞰图视频进行逻辑和视觉推理。在提出的方法中,GPT-4o充当智能系统,检测冲突并为驾驶员提供解释和建议。经过微调的模型达到了77.14%的准确率,而对微调后的GPT-4o的真实预测值进行手动评估显示,模型生成的解释准确率为89.9%,推荐行动的准确率为92.3%。这些结果突显了使用MLLMs进行实时交通管理的可行性,以视频为输入,为交叉口的交通管理和运营提供可伸缩和可操作的见解。本研究中使用的代码可在https://github.com/sarimasri3/Traffic-Intersection-Conflict-Detection-using-images.git找到。
论文及项目相关链接
Summary
本研究探讨了利用多模态大型语言模型(MLLMs)如GPT-4o来解决无信号城市交叉口的交通控制问题。研究通过直接使用鸟瞰图视频,对交叉路口的交通情况进行逻辑和视觉推理,检测冲突并为驾驶员提供解释和建议。经过微调,模型的准确率达到77.14%。此外,对GPT-4o生成的解释和推荐行动的准确性评估显示,其准确率为89.9%和92.3%。这表明使用MLLMs通过视频进行实时交通管理的可行性,为交叉口交通管理和运营提供可伸缩和可操作的见解。
Key Takeaways
- 多模态大型语言模型(MLLMs)如GPT-4o可用于解决无信号城市交叉口的交通控制挑战。
- GPT-4o能够直接使用鸟瞰图视频进行逻辑和视觉推理。
- GPT-4o可以检测交通冲突并为驾驶员提供解释和建议。
- 经过微调的模型实现较高准确率(77.14%)。
- GPT-4o在生成解释和推荐行动方面的准确率分别为89.9%和92.3%。
- 研究结果表明使用MLLMs进行实时交通管理的可行性。
点此查看论文截图

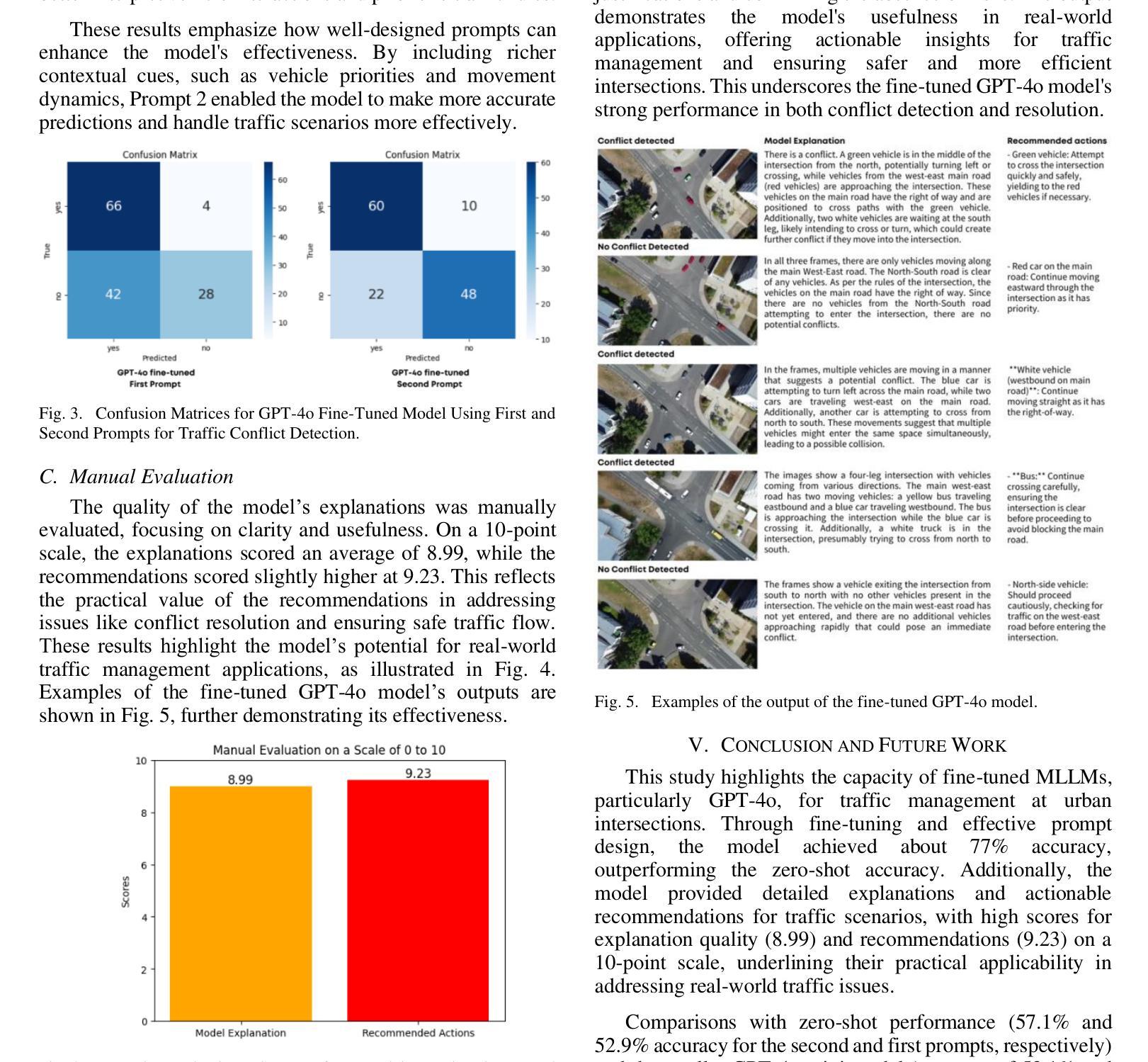
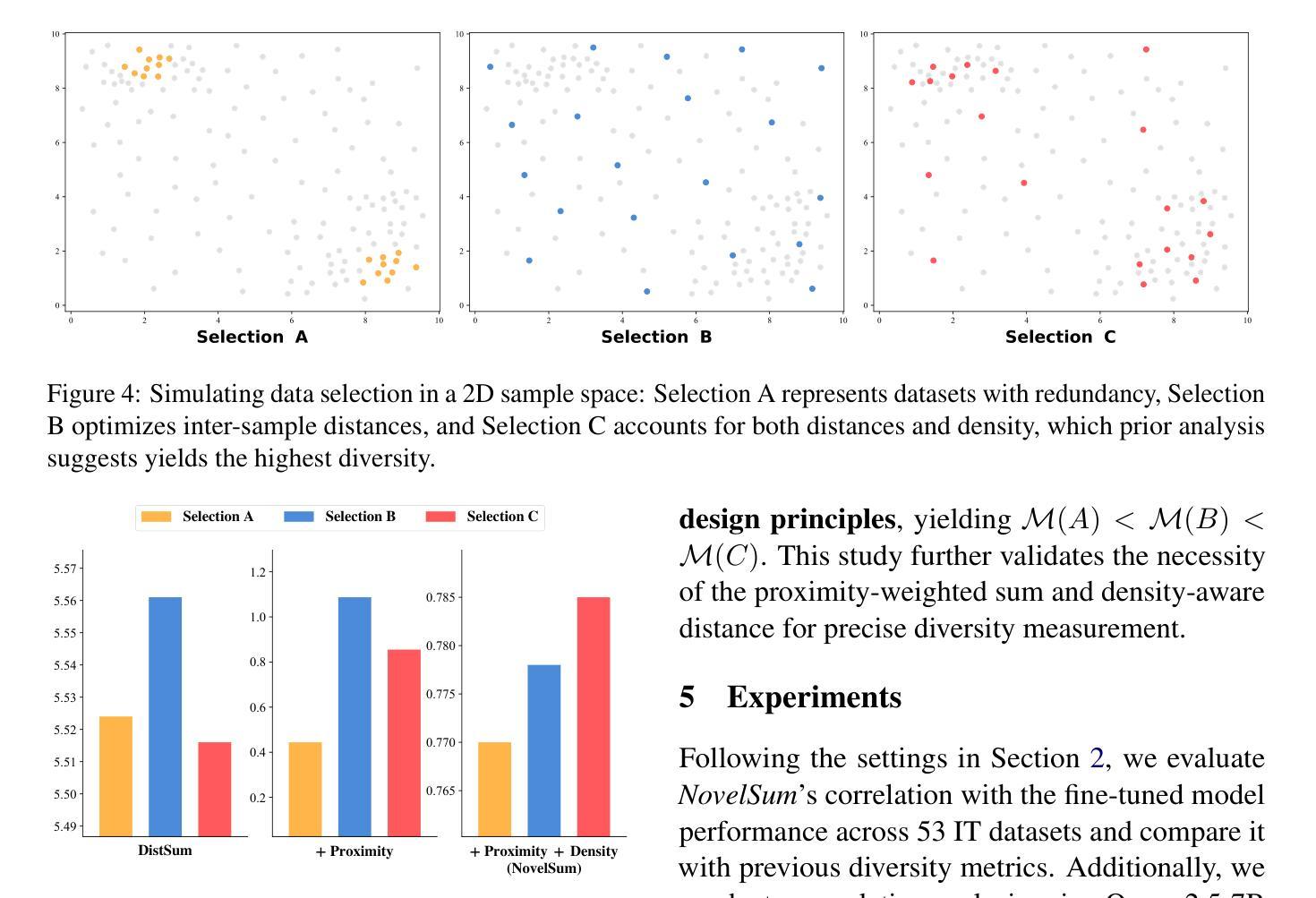
Measuring Data Diversity for Instruction Tuning: A Systematic Analysis and A Reliable Metric
Authors:Yuming Yang, Yang Nan, Junjie Ye, Shihan Dou, Xiao Wang, Shuo Li, Huijie Lv, Mingqi Wu, Tao Gui, Qi Zhang, Xuanjing Huang
Data diversity is crucial for the instruction tuning of large language models. Existing studies have explored various diversity-aware data selection methods to construct high-quality datasets and enhance model performance. However, the fundamental problem of precisely defining and measuring data diversity remains underexplored, limiting clear guidance for data engineering. To address this, we systematically analyze 11 existing diversity measurement methods by evaluating their correlation with model performance through extensive fine-tuning experiments. Our results indicate that a reliable diversity measure should properly account for both inter-sample differences and the information distribution in the sample space. Building on this, we propose NovelSum, a new diversity metric based on sample-level “novelty.” Experiments on both simulated and real-world data show that NovelSum accurately captures diversity variations and achieves a 0.97 correlation with instruction-tuned model performance, highlighting its value in guiding data engineering practices. With NovelSum as an optimization objective, we further develop a greedy, diversity-oriented data selection strategy that outperforms existing approaches, validating both the effectiveness and practical significance of our metric.
数据的多样性对于大型语言模型的指令调优至关重要。现有研究已经探索了各种意识到的数据选择方法来构建高质量数据集,以提高模型性能。然而,精确定义和测量数据多样性的问题尚未得到深入研究,这限制了数据工程的明确指导。为了解决这个问题,我们通过广泛的微调实验评估了与模型性能的相关性,系统地分析了现有的1 1种多样性测量方法。我们的结果表明,可靠的多样性度量应适当地考虑样本之间的差异以及样本空间中的信息分布。在此基础上,我们提出了NovelSum,这是一种基于样本级“新颖性”的新多样性度量标准。在模拟数据和真实数据上的实验表明,NovelSum准确地捕捉了多样性变化,与指令调整模型性能的相关性达到0.9 7,突显其在指导数据工程实践中的价值。以NovelSum为优化目标,我们进一步开发了一种以多样性为导向的数据选择策略,该策略优于现有方法,验证了我们度量的有效性和实际意义。
论文及项目相关链接
PDF 16 pages. The related codes and resources will be released later. Project page: https://github.com/UmeanNever/NovelSum
Summary
数据多样性对于大语言模型的指令调整至关重要。现有研究已探索了多种意识数据选择方法来构建高质量数据集并增强模型性能。然而,数据多样性的精确定义和测量基础问题尚未得到足够研究,这限制了数据工程的明确指导。本研究系统地分析了现有的11种多样性测量方法,通过广泛的微调实验评估其与模型性能的相关性。结果表明,可靠的多样性测量应适当地考虑样本之间的差异以及样本空间中的信息分布。在此基础上,本研究提出了基于样本级别“新颖性”的NovelSum新多样性指标。在模拟和真实数据上的实验表明,NovelSum准确捕捉了多样性变化,与指令调整模型性能的相关性达到0.97,突显其在指导数据工程实践中的价值。利用NovelSum作为优化目标,我们进一步开发了一种贪婪的、面向多样性的数据选择策略,该策略优于现有方法,验证了我们的指标的有效性和实际意义。
Key Takeaways
- 数据多样性对语言模型的指令调整至关重要。
- 现有研究已经探索了多种数据选择方法来提高模型性能。
- 数据多样性的精确定义和测量仍然是一个基础问题。
- 本研究系统地分析了11种现有的多样性测量方法。
- 可靠的多样性测量应综合考虑样本间的差异和样本空间中的信息分布。
- 提出了基于样本级别“新颖性”的新多样性指标NovelSum。
点此查看论文截图
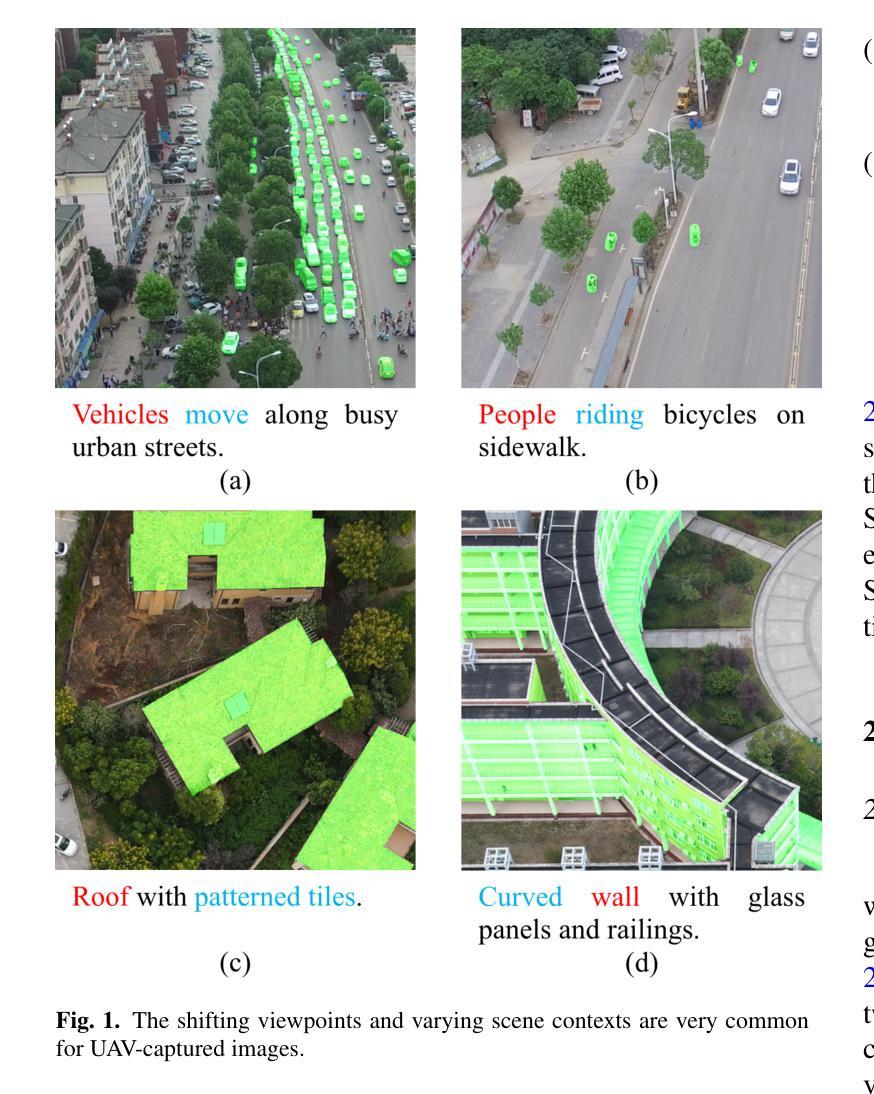
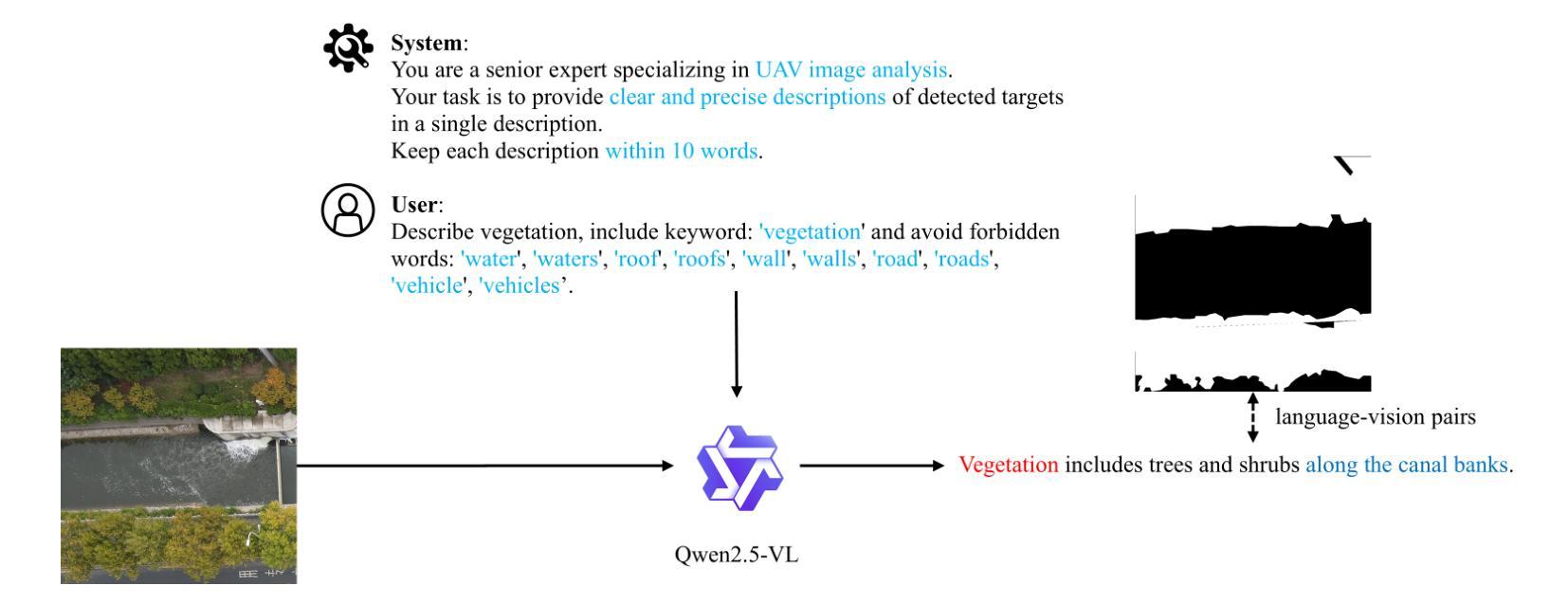
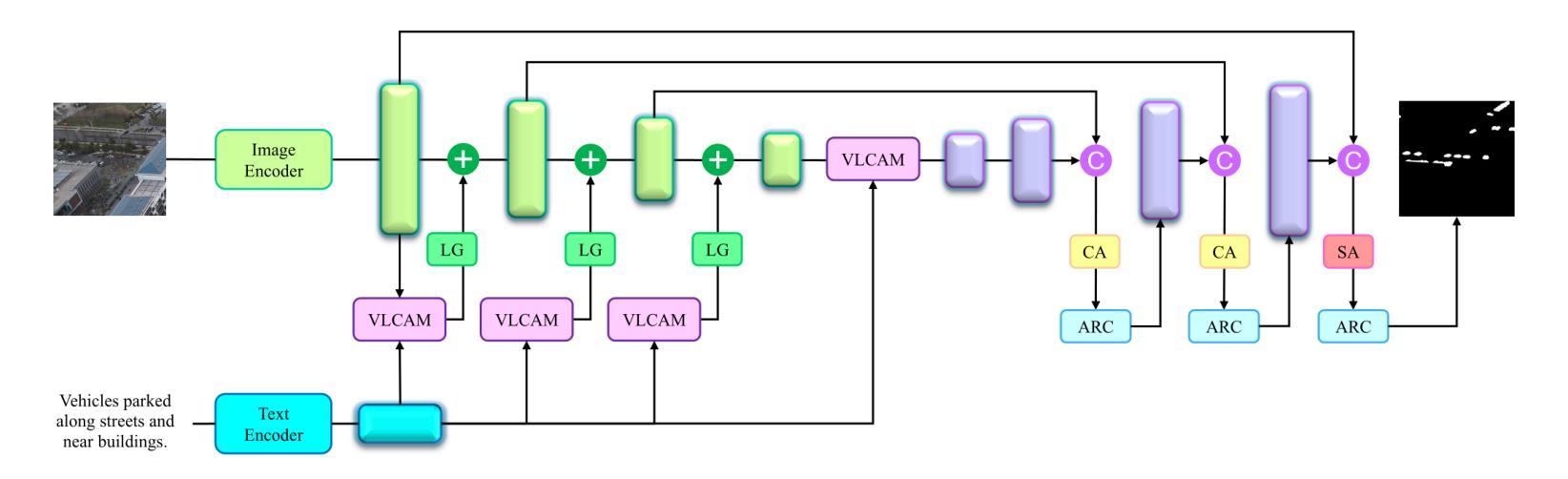
AeroReformer: Aerial Referring Transformer for UAV-based Referring Image Segmentation
Authors:Rui Li, Xiaowei Zhao
As a novel and challenging task, referring segmentation combines computer vision and natural language processing to localize and segment objects based on textual descriptions. While referring image segmentation (RIS) has been extensively studied in natural images, little attention has been given to aerial imagery, particularly from unmanned aerial vehicles (UAVs). The unique challenges of UAV imagery, including complex spatial scales, occlusions, and varying object orientations, render existing RIS approaches ineffective. A key limitation has been the lack of UAV-specific datasets, as manually annotating pixel-level masks and generating textual descriptions is labour-intensive and time-consuming. To address this gap, we design an automatic labelling pipeline that leverages pre-existing UAV segmentation datasets and Multimodal Large Language Models (MLLM) for generating textual descriptions. Furthermore, we propose Aerial Referring Transformer (AeroReformer), a novel framework for UAV referring image segmentation (UAV-RIS), featuring a Vision-Language Cross-Attention Module (VLCAM) for effective cross-modal understanding and a Rotation-Aware Multi-Scale Fusion (RAMSF) decoder to enhance segmentation accuracy in aerial scenes. Extensive experiments on two newly developed datasets demonstrate the superiority of AeroReformer over existing methods, establishing a new benchmark for UAV-RIS. The datasets and code will be publicly available at: https://github.com/lironui/AeroReformer.
作为一项目新型且具有挑战性的任务,引用分割结合了计算机视觉和自然语言处理,根据文本描述定位并分割对象。虽然引用图像分割(RIS)在自然图像中得到了广泛的研究,但对航空图像的关注较少,特别是来自无人机的图像。无人机图像具有独特的挑战,包括复杂的空间尺度、遮挡和对象方向的变化,使得现有的RIS方法效果不佳。一个关键的限制是缺乏针对无人机的特定数据集,因为手动注释像素级蒙版和生成文本描述是劳动密集型的,且耗时。为了解决这个问题,我们设计了一个自动标注管道,该管道利用现有的无人机分割数据集和多模态大型语言模型(MLLM)来生成文本描述。此外,我们提出了无人机引用图像分割(UAV-RIS)的新型框架——AerialReferring Transformer(AeroReformer),它具有视觉语言跨注意模块(VLCAM)用于有效的跨模态理解,以及旋转感知多尺度融合(RAMSF)解码器,以提高航空场景中的分割精度。在两个新开发的数据集上的广泛实验表明,AeroReformer优于现有方法,为UAV-RIS建立了新的基准。数据集和代码将在https://github.com/lironui/AeroReformer公开提供。
论文及项目相关链接
Summary:针对无人机图像分割(UAV-RIS)任务,存在复杂空间尺度、遮挡和物体方向变化等独特挑战。现有方法无法有效应对,因此设计自动标注管道,并利用现有的无人机分割数据集和多模态大型语言模型(MLLM)生成文本描述。同时提出名为Aerial Referring Transformer(AeroReformer)的新框架,包含视觉语言跨注意力模块(VLCAM)和旋转感知多尺度融合(RAMSF)解码器,以提高无人机场景中的分割准确性。实验证明,该框架在公开数据集上表现优异,为UAV-RIS任务树立了新标杆。数据集和代码将公开分享于[https://github.com/lironui/AeroReformer]。
Key Takeaways:
- 无人机图像分割(UAV-RIS)面临独特挑战,如复杂空间尺度、遮挡和物体方向变化等。
- 目前缺乏针对无人机的数据集是一大限制,因此手动标注像素级掩膜和生成文本描述较为困难且耗时。
- 为了解决上述问题,提出利用现有无人机分割数据集和多模态大型语言模型进行自动标注的方法。
- 提出名为Aerial Referring Transformer(AeroReformer)的新框架,用于无人机图像分割任务。该框架包含视觉语言跨注意力模块(VLCAM)和旋转感知多尺度融合解码器。
- 实验证明,AeroReformer在公开数据集上表现优于现有方法,为UAV-RIS任务树立了新标杆。
- 数据集和代码将在公开平台上分享。
点此查看论文截图


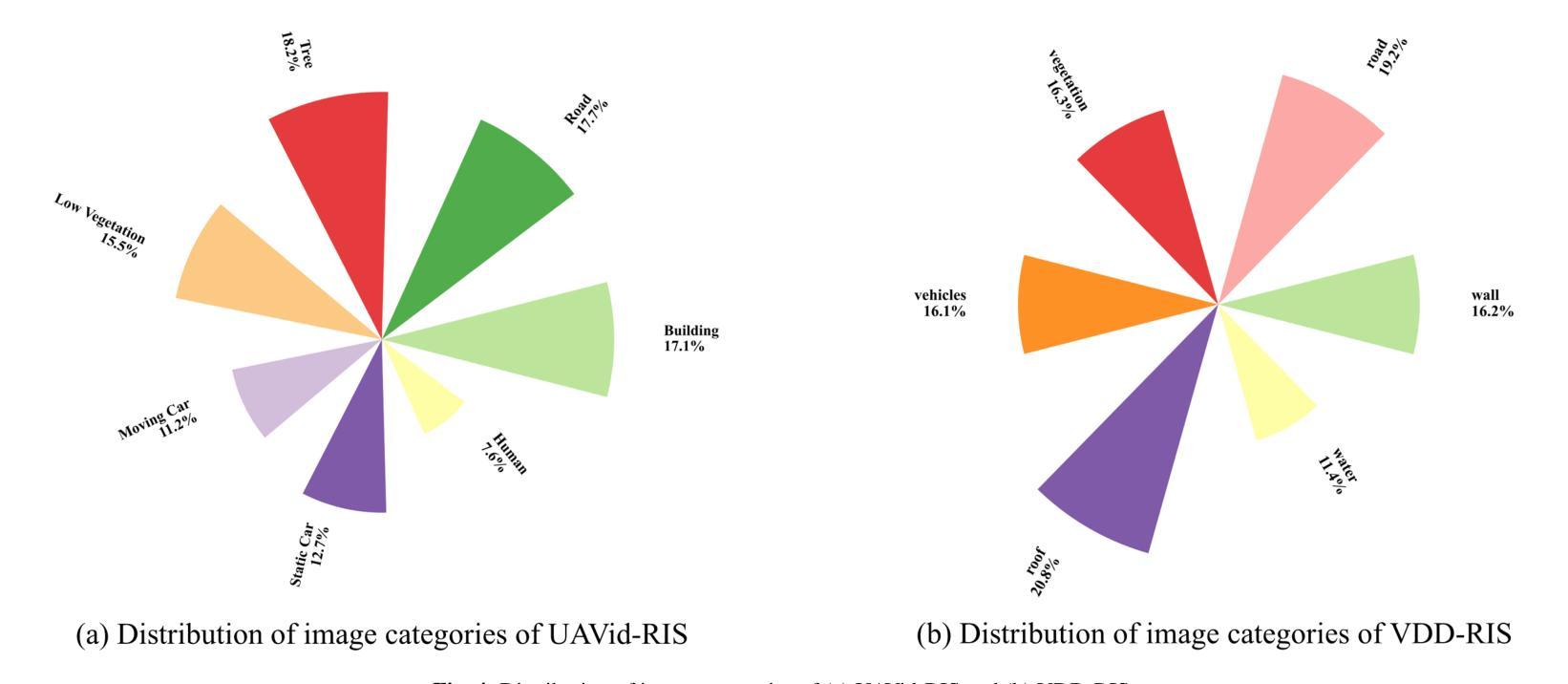
Cache Me If You Must: Adaptive Key-Value Quantization for Large Language Models
Authors:Alina Shutova, Vladimir Malinovskii, Vage Egiazarian, Denis Kuznedelev, Denis Mazur, Nikita Surkov, Ivan Ermakov, Dan Alistarh
Efficient real-world deployments of large language models (LLMs) rely on Key-Value (KV) caching for processing and generating long outputs, reducing the need for repetitive computation. For large contexts, Key-Value caches can take up tens of gigabytes of device memory, as they store vector representations for each token and layer. Recent work has shown that the cached vectors can be compressed through quantization, pruning or merging, but these techniques often compromise quality towards higher compression rates. In this work, we aim to improve Key & Value compression by exploiting two observations: 1) the inherent dependencies between keys and values across different layers, and 2) high-compression mechanisms for internal network states. We propose AQUA-KV, an adaptive quantization for Key-Value caches that relies on compact adapters to exploit existing dependencies between Keys and Values, and aims to “optimally” compress the information that cannot be predicted. AQUA-KV significantly improves compression rates, while maintaining high accuracy on state-of-the-art LLM families. On Llama 3.2 LLMs, we achieve near-lossless inference at 2-2.5 bits per value with under $1%$ relative error in perplexity and LongBench scores. AQUA-KV is one-shot, simple, and efficient: it can be calibrated on a single GPU within 1-6 hours, even for 70B models.
大型语言模型(LLM)在现实世界的有效部署依赖于键值(KV)缓存来处理并生成长输出,减少重复计算的需求。对于大型上下文,键值缓存会占用数十GB的设备内存,因为它们存储每个标记和层的向量表示。近期的研究表明,可以通过量化、修剪或合并来压缩缓存的向量,但这些技术往往为了更高的压缩率而牺牲了质量。在这项工作中,我们旨在通过两个观察结果改进键和值的压缩:1)不同层之间键和值之间的固有依赖性;2)内部网络状态的高压缩机制。我们提出了AQUA-KV,这是一种针对键值缓存的自适应量化,它依赖于紧凑的适配器来利用键和值之间的现有依赖性,旨在“最优”地压缩那些无法预测的信息。AQUA-KV显著提高了压缩率,同时保持了对最新LLM家族的高准确性。在Llama 3.2 LLM上,我们在困惑度和LongBench得分相对误差低于1%的情况下,实现了每值2-2.5比特的无损推理。AQUA-KV是一次性的、简单的和高效的:即使对于70B模型,也可以在单个GPU上1-6小时内进行校准。
论文及项目相关链接
PDF Preprint, under review
Summary
该文探讨了大型语言模型(LLM)在现实世界部署中的效率问题,指出Key-Value(KV)缓存对于处理和生成长输出至关重要。为了减少内存占用和提高性能,该文提出了一种自适应量化技术——AQUA-KV,用于压缩KV缓存中的键和值向量。AQUA-KV能够显著提高压缩率,同时保持高准确性,对于大型语言模型家族而言具有显著优势。在Llama 3.2模型上,AQUA-KV实现了近无损推理,具有高效的性能和简单的校准过程。
Key Takeaways
- 大型语言模型(LLM)在现实世界部署中依赖Key-Value(KV)缓存处理长输出,减少重复计算。
- KV缓存占用大量设备内存,因此需要压缩技术来优化内存使用。
- 自适应量化技术AQUA-KV被提出用于压缩KV缓存中的键和值向量。
- AQUA-KV通过利用键和值之间的内在依赖关系以及内部网络状态的高压缩机制来改进压缩效果。
- AQUA-KV在保持高准确性的同时,显著提高了压缩率。
- 在Llama 3.2模型上,AQUA-KV实现了近无损推理,具有高效的性能和简单的校准过程。
点此查看论文截图

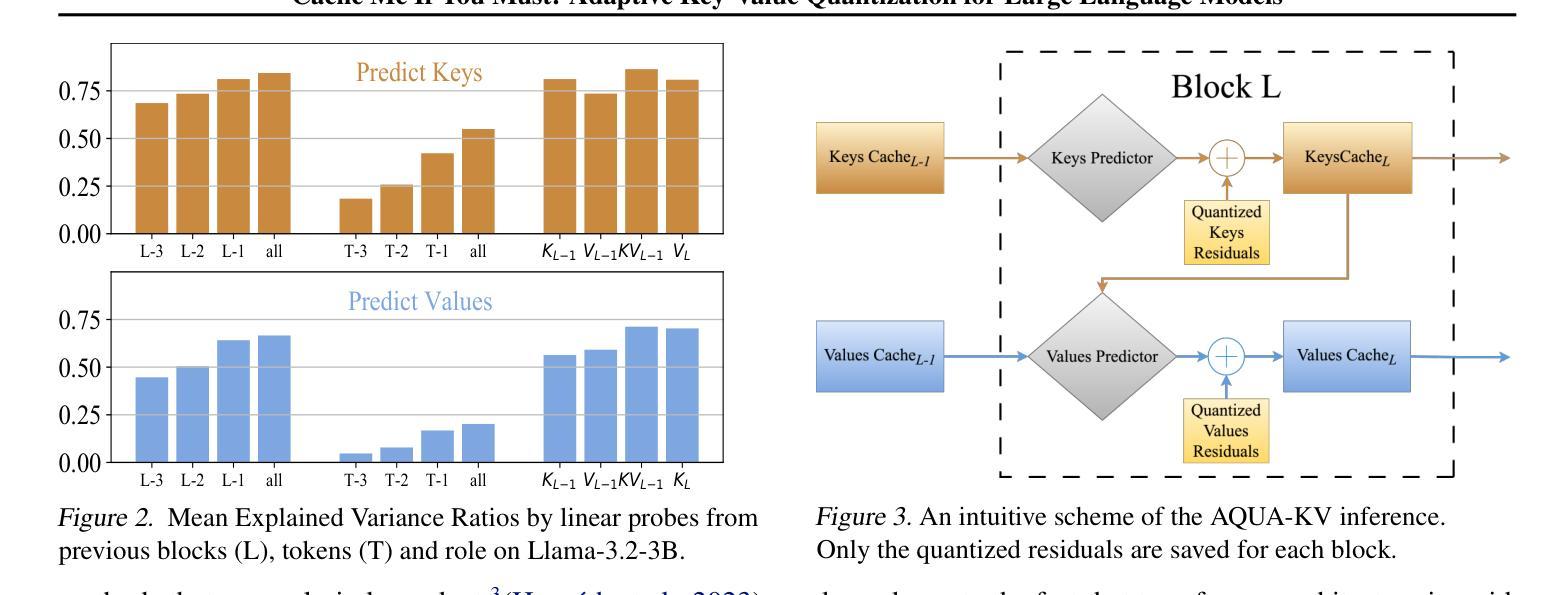

TAID: Temporally Adaptive Interpolated Distillation for Efficient Knowledge Transfer in Language Models
Authors:Makoto Shing, Kou Misaki, Han Bao, Sho Yokoi, Takuya Akiba
Causal language models have demonstrated remarkable capabilities, but their size poses significant challenges for deployment in resource-constrained environments. Knowledge distillation, a widely-used technique for transferring knowledge from a large teacher model to a small student model, presents a promising approach for model compression. A significant remaining issue lies in the major differences between teacher and student models, namely the substantial capacity gap, mode averaging, and mode collapse, which pose barriers during distillation. To address these issues, we introduce $\textit{Temporally Adaptive Interpolated Distillation (TAID)}$, a novel knowledge distillation approach that dynamically interpolates student and teacher distributions through an adaptive intermediate distribution, gradually shifting from the student’s initial distribution towards the teacher’s distribution. We provide a theoretical analysis demonstrating TAID’s ability to prevent mode collapse and empirically show its effectiveness in addressing the capacity gap while balancing mode averaging and mode collapse. Our comprehensive experiments demonstrate TAID’s superior performance across various model sizes and architectures in both instruction tuning and pre-training scenarios. Furthermore, we showcase TAID’s practical impact by developing two state-of-the-art compact foundation models: $\texttt{TAID-LLM-1.5B}$ for language tasks and $\texttt{TAID-VLM-2B}$ for vision-language tasks. These results demonstrate TAID’s effectiveness in creating high-performing and efficient models, advancing the development of more accessible AI technologies.
因果语言模型展现出了显著的能力,但它们的规模对在资源受限环境中的部署构成了重大挑战。知识蒸馏是一种广泛使用的技术,可以从大型教师模型转移到小型学生模型,这为模型压缩提供了有前景的方法。一个主要的剩余问题在于教师和学生模型之间的巨大差异,即巨大的能力差距、模式平均和模式崩溃,它们在蒸馏过程中构成了障碍。为了解决这些问题,我们引入了“时间自适应插值蒸馏(TAID)”,这是一种新型的知识蒸馏方法,通过自适应中间分布动态插值学生和教师的分布,从学生最初的分布逐渐转向教师的分布。我们提供了理论分析,证明了TAID防止模式崩溃的能力,并实证证明了它在解决能力差距、平衡模式平均和模式崩溃方面的有效性。我们的综合实验表明,TAID在各种模型和架构的大小、指令调整和预训练场景中均表现出卓越的性能。此外,我们通过开发两个最先进的紧凑基础模型:用于语言任务的“TAID-LLM-1.5B”和用于视觉语言任务的“TAID-VLM-2B”,展示了TAID的实际影响。这些结果证明了TAID在创建高性能和高效模型方面的有效性,推动了更可访问的AI技术的发展。
论文及项目相关链接
PDF To appear at the 13th International Conference on Learning Representations (ICLR 2025) as a Spotlight presentation
Summary
大规模因果语言模型展现出卓越的能力,但其规模对资源受限环境的部署带来挑战。知识蒸馏技术可以从大规模教师模型转移到小型学生模型,为解决模型压缩问题提供了希望。然而,教师模型和学生模型之间的差异,如容量差距、模式平均和模式崩溃,仍然存在问题。为解决这些问题,我们提出了“时间自适应插值蒸馏”(TAID)的新知识蒸馏方法,通过自适应中间分布动态插值学生和教师的分布,从学生的初始分布逐渐转向教师的分布。理论分析和实验表明,TAID能够有效解决容量差距问题,同时平衡模式平均和模式崩溃。此外,TAID在多种模型和架构、指令调优和预训练场景中表现出卓越性能。我们还开发了两种先进的紧凑基础模型TAID-LLM-1.5B(用于语言任务)和TAID-VLM-2B(用于视觉语言任务),展示TAID在创建高性能、高效模型方面的实际效果,推动更普及的AI技术发展。
Key Takeaways
- 因果语言模型虽表现出卓越能力,但在资源受限环境中部署面临挑战。
- 知识蒸馏是压缩模型的有效方法,但教师模型和学生模型之间的差异(如容量差距、模式平均和模式崩溃)仍然存在问题。
- 引入新的知识蒸馏方法——时间自适应插值蒸馏(TAID),通过动态插值学生和教师的分布来解决上述问题。
- TAID能够预防模式崩溃,并有效解决容量差距问题。
- TAID在多种模型和架构、指令调优和预训练场景中表现出卓越性能。
- TAID在创建高性能、高效模型方面具备实际效果,推动更普及的AI技术发展。
点此查看论文截图


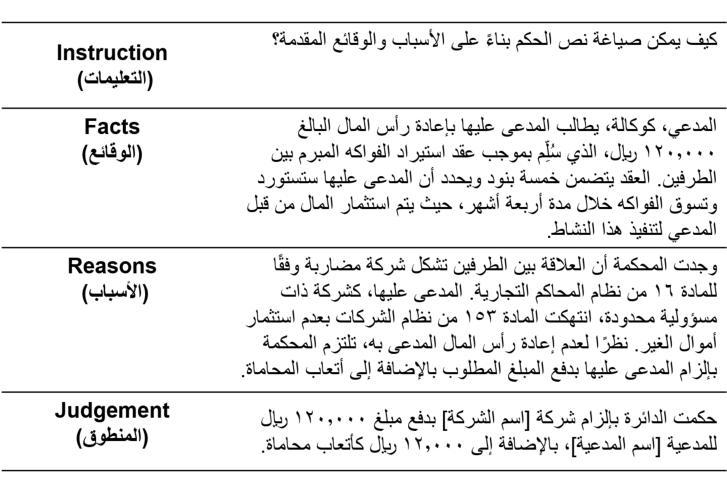
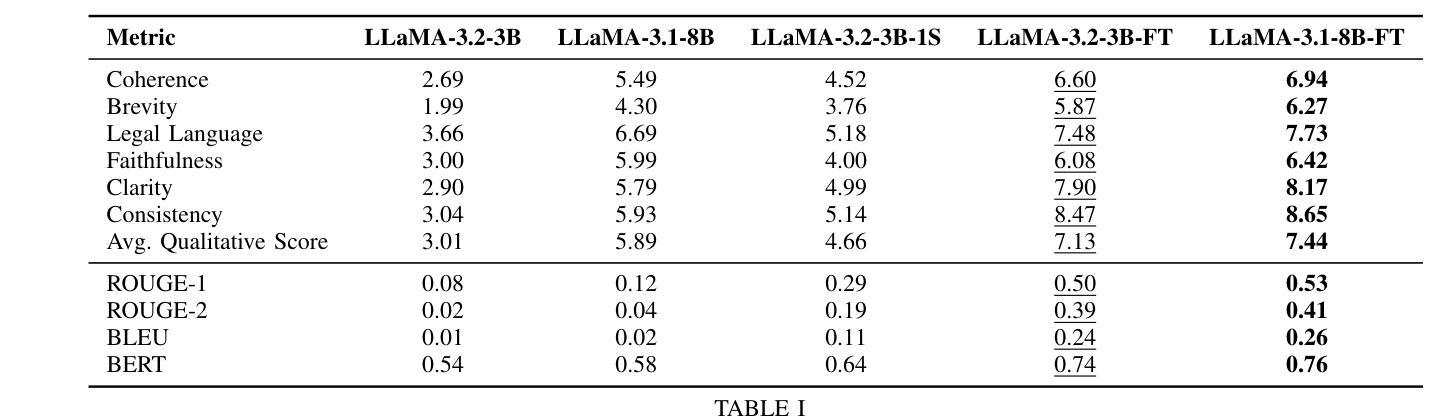
Can Large Language Models Predict the Outcome of Judicial Decisions?
Authors:Mohamed Bayan Kmainasi, Ali Ezzat Shahroor, Amani Al-Ghraibah
Large Language Models (LLMs) have shown exceptional capabilities in Natural Language Processing (NLP) across diverse domains. However, their application in specialized tasks such as Legal Judgment Prediction (LJP) for low-resource languages like Arabic remains underexplored. In this work, we address this gap by developing an Arabic LJP dataset, collected and preprocessed from Saudi commercial court judgments. We benchmark state-of-the-art open-source LLMs, including LLaMA-3.2-3B and LLaMA-3.1-8B, under varying configurations such as zero-shot, one-shot, and fine-tuning using LoRA. Additionally, we employed a comprehensive evaluation framework that integrates both quantitative metrics (such as BLEU, ROUGE, and BERT) and qualitative assessments (including Coherence, Legal Language, Clarity, etc.) using an LLM. Our results demonstrate that fine-tuned smaller models achieve comparable performance to larger models in task-specific contexts while offering significant resource efficiency. Furthermore, we investigate the impact of fine-tuning the model on a diverse set of instructions, offering valuable insights into the development of a more human-centric and adaptable LLM. We have made the dataset, code, and models publicly available to provide a solid foundation for future research in Arabic legal NLP.
大型语言模型(LLM)在多个领域的自然语言处理(NLP)中表现出卓越的能力。然而,它们在特定任务中的应用,如在阿拉伯语等低资源语言上进行法律判决预测(LJP),仍然被探索得不够充分。在这项工作中,我们通过开发一个阿拉伯语LJP数据集来解决这一空白,该数据集是从沙特商业法院的判决中收集和预处理的。我们对最先进的开源LLM进行了基准测试,包括LLaMA-3.2-3B和LLaMA-3.1-8B,在不同的配置下,如零样本、一样本和采用LoRA的微调。此外,我们还采用了一个全面的评估框架,该框架结合了定量指标(如BLEU、ROUGE和BERT)和定性评估(包括连贯性、法律语言、清晰度等),使用LLM进行评估。我们的结果表明,在特定任务上下文中,经过微调的小型模型可以达到与大型模型相当的性能,同时提供了显著的资源效率。此外,我们还研究了在多种指令集上对模型进行微调的影响,为开发更以人类为中心和适应性更强的LLM提供了有价值的见解。我们已经公开提供了数据集、代码和模型,为未来在阿拉伯语法律NLP领域的研究提供了坚实的基础。
论文及项目相关链接
Summary
本文研究了大型语言模型(LLM)在阿拉伯法律判断预测(LJP)任务中的应用。为解决低资源语言阿拉伯语的LJP问题,作者开发了基于沙特商事判决的阿拉伯语LJP数据集。文章评估了包括LLaMA-3.2-3B和LLaMA-3.1-8B在内的开源LLM的性能,并采用了零样本、一个样例和微调等多种配置方法。通过定量和定性评估框架,结果显示微调后的较小模型在特定任务中表现出与较大模型相当的性能,同时更具资源效率。此外,文章还探讨了模型在多样化指令下的微调效果,为未来阿拉伯法律NLP研究提供了坚实基础。
Key Takeaways
- LLM在阿拉伯语LJP任务的应用仍然处于被低估的状态。
- 本文为阿拉伯语LJP开发了一个基于沙特商事判决的数据集。
- 评估了LLM在多种配置方法下的性能,包括零样本、一个样例和微调等。
- 通过定量和定性评估框架发现微调后的较小模型具有优越的资源效率和特定任务性能。
- 模型在多样化指令下的微调效果研究为发展更人性化、适应性更强的LLM提供了有价值的信息。
- 本文公开了数据集、代码和模型,为未来阿拉伯法律NLP研究提供了基础。
点此查看论文截图

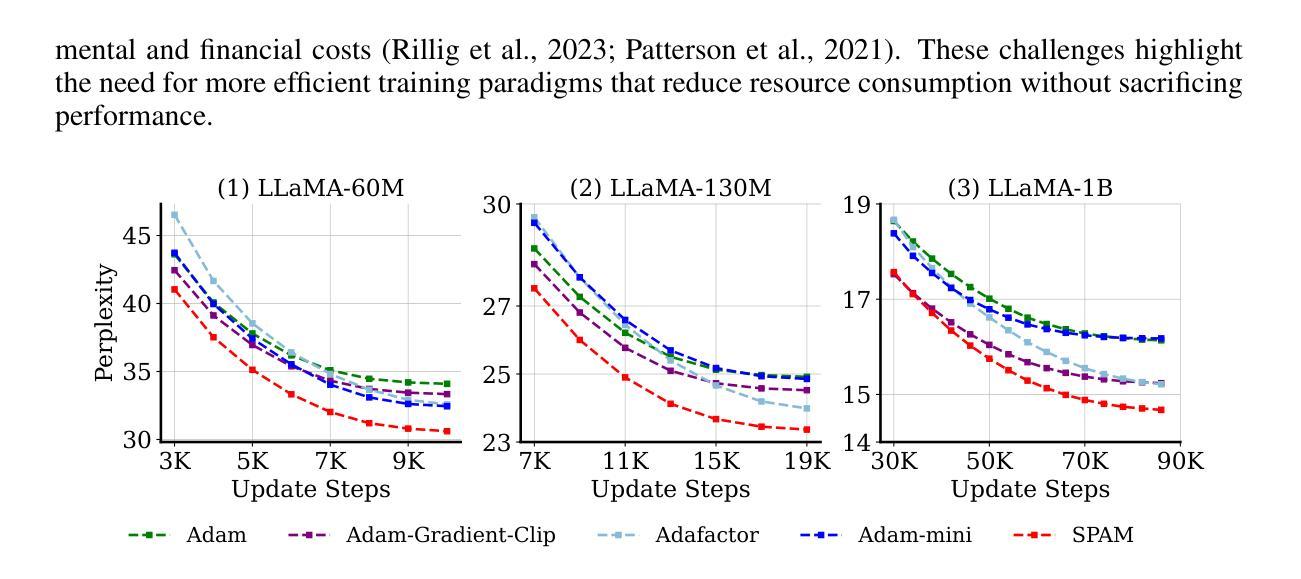
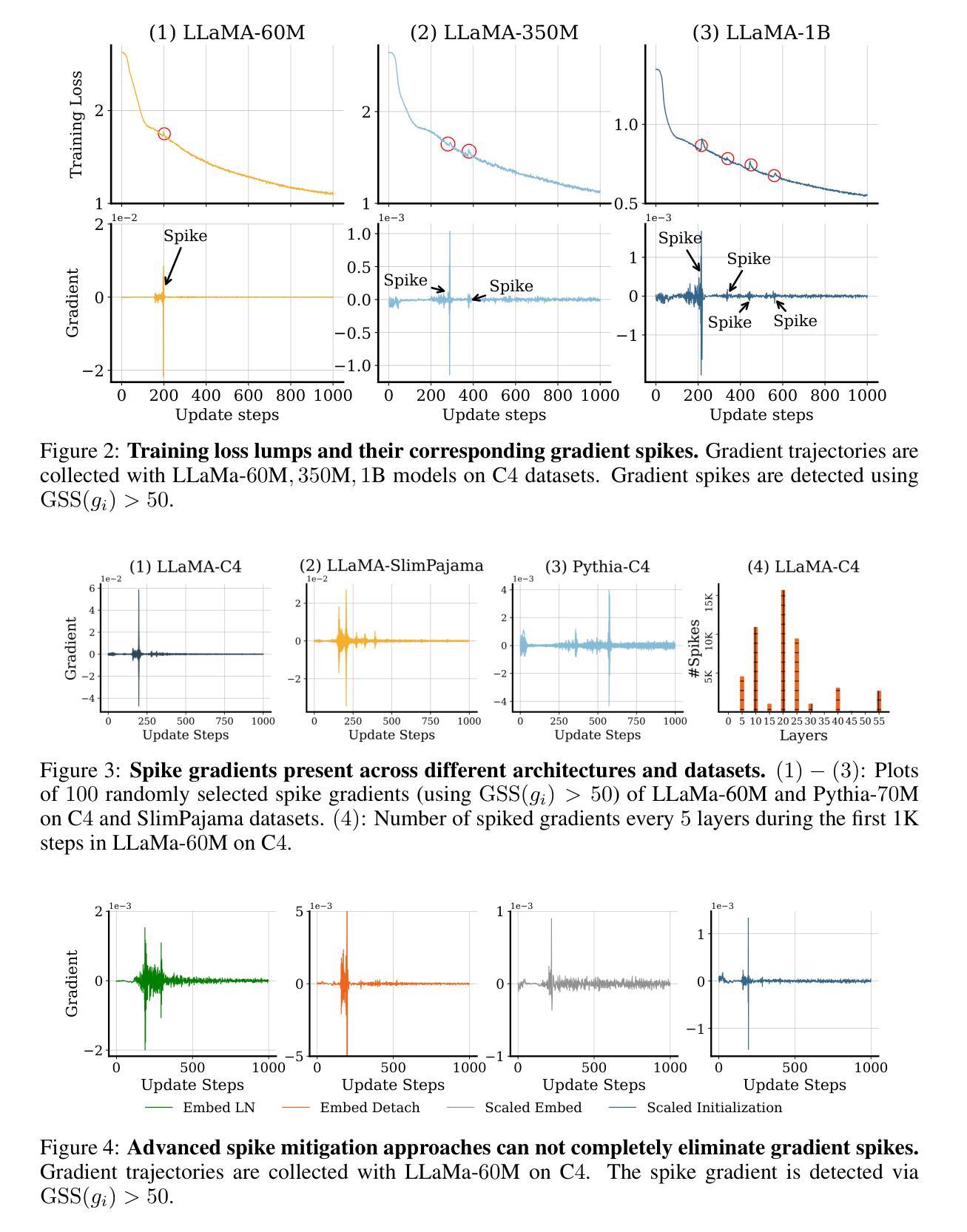
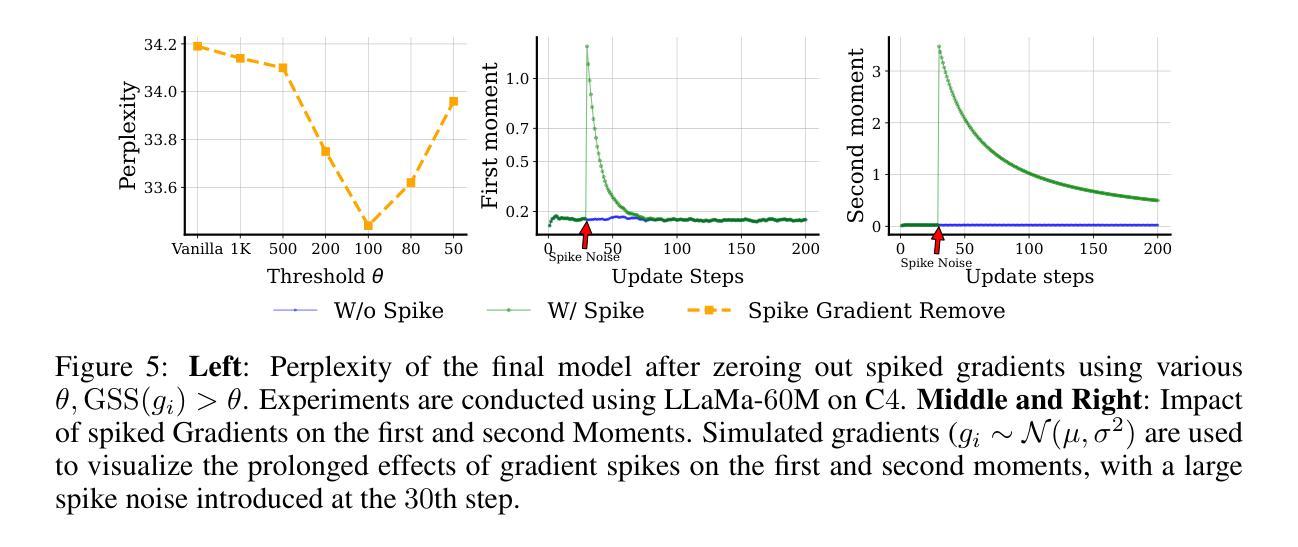
SPAM: Spike-Aware Adam with Momentum Reset for Stable LLM Training
Authors:Tianjin Huang, Ziquan Zhu, Gaojie Jin, Lu Liu, Zhangyang Wang, Shiwei Liu
Large Language Models (LLMs) have demonstrated exceptional performance across diverse tasks, yet their training remains highly resource-intensive and susceptible to critical challenges such as training instability. A predominant source of this instability stems from gradient and loss spikes, which disrupt the learning process, often leading to costly interventions like checkpoint recovery and experiment restarts, further amplifying inefficiencies. This paper presents a comprehensive investigation into gradient spikes observed during LLM training, revealing their prevalence across multiple architectures and datasets. Our analysis shows that these spikes can be up to $1000\times$ larger than typical gradients, substantially deteriorating model performance. To address this issue, we propose Spike-Aware Adam with Momentum Reset SPAM, a novel optimizer designed to counteract gradient spikes through momentum reset and spike-aware gradient clipping. Extensive experiments, including both pre-training and fine-tuning, demonstrate that SPAM consistently surpasses Adam and its variants across various tasks, including (1) LLM pre-training from 60M to 1B, (2) 4-bit LLM pre-training,(3) reinforcement learning, and (4) Time Series Forecasting. Additionally, SPAM facilitates memory-efficient training by enabling sparse momentum, where only a subset of momentum terms are maintained and updated. When operating under memory constraints, SPAM outperforms state-of-the-art memory-efficient optimizers such as GaLore and Adam-Mini. Our work underscores the importance of mitigating gradient spikes in LLM training and introduces an effective optimization strategy that enhances both training stability and resource efficiency at scale. Code is available at https://github.com/TianjinYellow/SPAM-Optimizer.git
大型语言模型(LLM)在多种任务中表现出卓越的性能,然而,它们的训练仍然需要消耗大量资源,并容易受到训练不稳定等关键挑战。这种不稳定性的主要来源是梯度和损失峰值,它们会破坏学习过程,经常导致诸如检查点恢复和实验重启等昂贵干预,进一步加剧了效率低下。本文全面研究了在LLM训练过程中观察到的梯度峰值,揭示了它们在多个架构和数据集中的普遍性。我们的分析表明,这些峰值可能高达典型梯度的$1000\times$,从而显著恶化模型性能。为了解决这一问题,我们提出了带有动量重置SPAM的Spike感知Adam优化器。这是一种新型优化器,旨在通过动量重置和峰值感知梯度裁剪来抵消梯度峰值。包括预训练和微调在内的广泛实验表明,SPAM在各种任务中始终优于Adam及其变体,包括(1)LLM从60M到1B的预训练;(2)4位LLM预训练;(3)强化学习;(4)时间序列预测。此外,SPAM通过实现稀疏动量来促进内存高效训练,其中仅维护并更新一小部分动量项。在内存受限的情况下,SPAM优于最新的内存优化器,如GaLore和Adam-Mini。我们的工作强调了减轻LLM训练中梯度峰值的重要性,并引入了一种有效的优化策略,该策略提高了训练稳定性和资源效率。代码可用https://github.com/TianjinYellow/SPAM-Optimizer.git。
论文及项目相关链接
Summary
大型语言模型(LLM)的训练具有显著的性能优势,但同时也存在训练不稳定和资源消耗巨大的挑战。该论文探讨了LLM训练过程中的梯度波动现象,并提出了一种新的优化器SPAM(Spike-Aware Adam with Momentum Reset)。SPAM通过动量重置和梯度裁剪来对抗梯度波动,能在多种任务中超越Adam及其变体。此外,SPAM还能实现内存高效的训练。
Key Takeaways
- LLM训练存在梯度波动问题,影响模型性能。
- 梯度波动可能导致训练不稳定和资源消耗巨大。
- SPAM是一种针对LLM训练的新优化器,通过动量重置和梯度裁剪对抗梯度波动。
- SPAM在多种任务中表现超越Adam及其变体。
- SPAM可实现内存高效的训练。
- SPAM通过只维护并更新一小部分动量项来实现内存优化。
点此查看论文截图