⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-04 更新
Chitranuvad: Adapting Multi-Lingual LLMs for Multimodal Translation
Authors:Shaharukh Khan, Ayush Tarun, Ali Faraz, Palash Kamble, Vivek Dahiya, Praveen Pokala, Ashish Kulkarni, Chandra Khatri, Abhinav Ravi, Shubham Agarwal
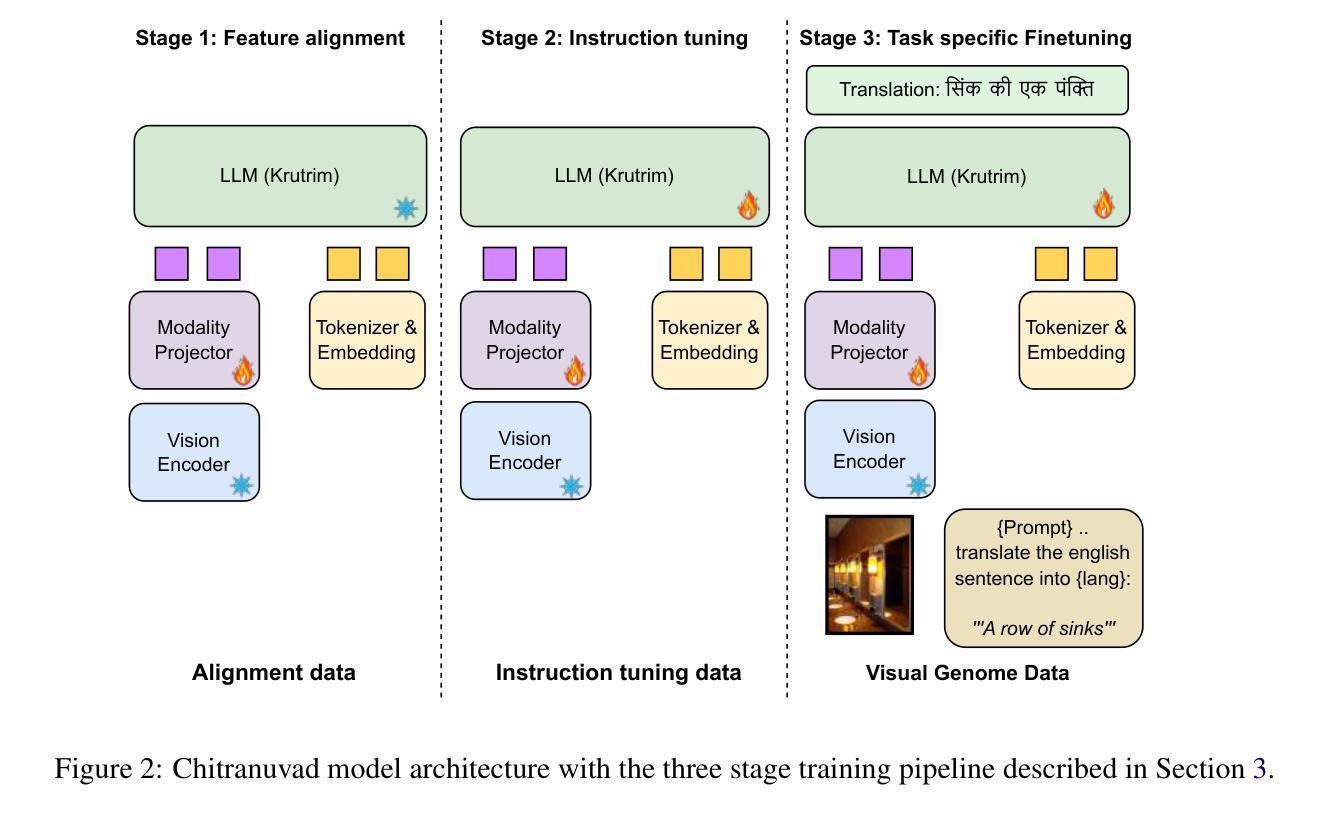
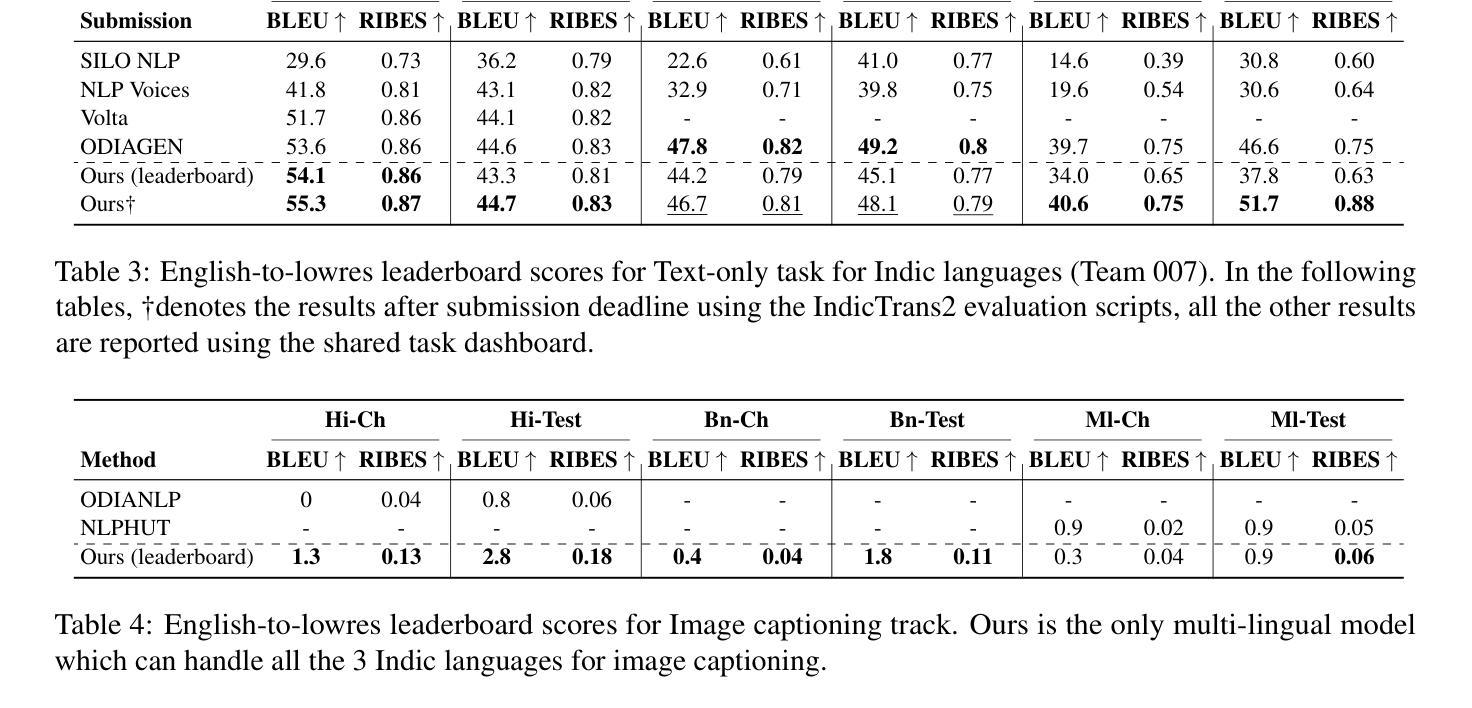
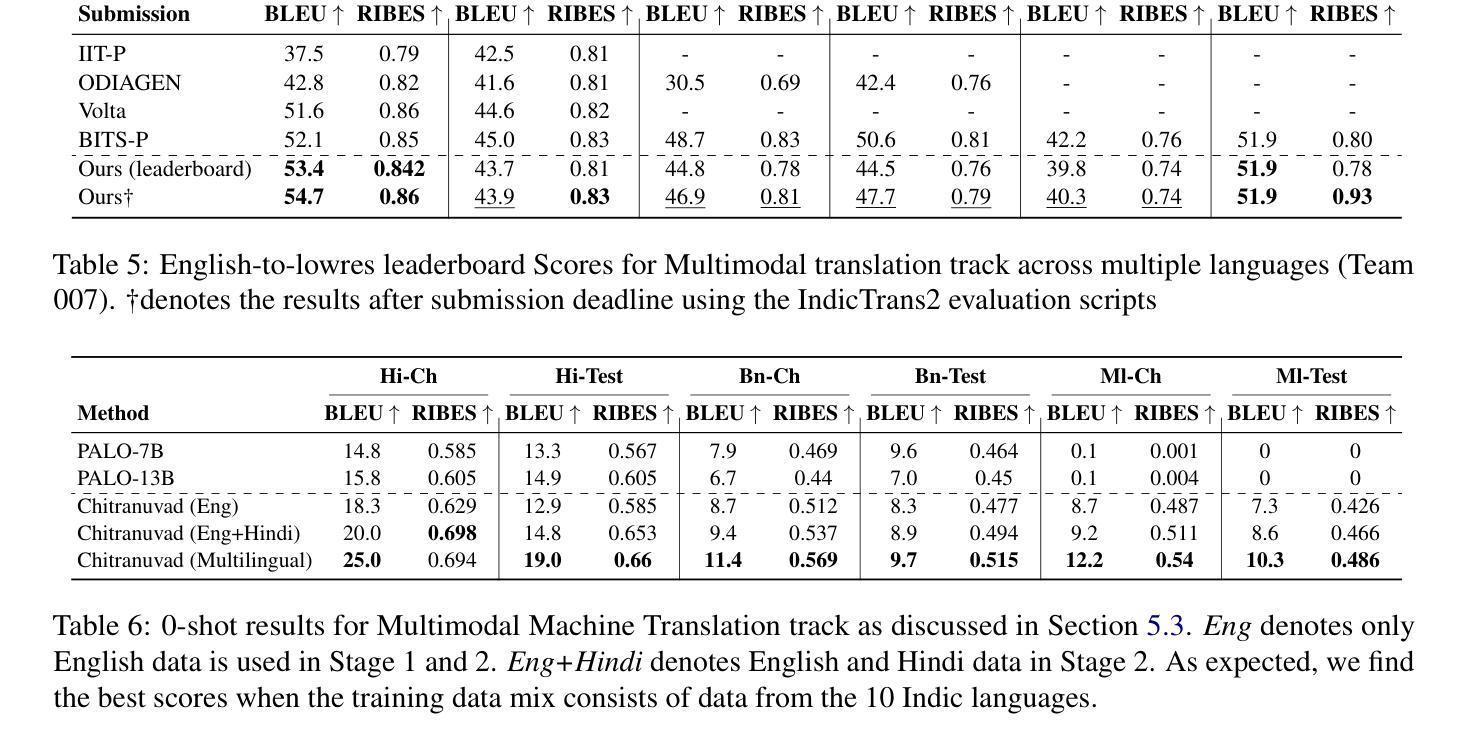
In this work, we provide the system description of our submission as part of the English to Lowres Multimodal Translation Task at the Workshop on Asian Translation (WAT2024). We introduce Chitranuvad, a multimodal model that effectively integrates Multilingual LLM and a vision module for Multimodal Translation. Our method uses a ViT image encoder to extract visual representations as visual token embeddings which are projected to the LLM space by an adapter layer and generates translation in an autoregressive fashion. We participated in all the three tracks (Image Captioning, Text only and Multimodal translation tasks) for Indic languages (ie. English translation to Hindi, Bengali and Malyalam) and achieved SOTA results for Hindi in all of them on the Challenge set while remaining competitive for the other languages in the shared task.
在这项工作中,我们提供了作为亚洲翻译研讨会(WAT2024)英语至低资源多模态翻译任务提交内容的系统描述。我们介绍了Chitranuvad,这是一个有效融合多语言大型语言模型和视觉模块的多模态模型。我们的方法使用ViT图像编码器提取视觉表征,将其作为视觉令牌嵌入,通过适配器层投影到大型语言模型空间,并以自回归的方式生成翻译。我们参加了所有三个轨道(图像描述、仅文本和多模态翻译任务)的印度语(即英语翻译为印度语、孟加拉语和马拉雅拉姆语),在挑战集上为所有印度语言都取得了迄今为止的最好结果,同时保持在共享任务中其他语言的竞争力。
论文及项目相关链接
Summary:在此工作中,我们介绍了作为亚洲翻译研讨会(WAT2024)英语至Lowres多媒体翻译任务提交内容的一部分的系统描述。我们引入了Chitranuvad多媒体模型,该模型有效地集成了多语言LLM和视觉模块进行多媒体翻译。我们的方法使用ViT图像编码器提取视觉表示作为视觉令牌嵌入,通过适配器层投影到LLM空间,并以自回归的方式生成翻译。我们参与了所有三个轨道(图像字幕、纯文本和多媒体翻译任务)的印地语(即英语翻译为印地语、孟加拉语和马拉雅拉姆语),并在挑战集上为印地语取得SOTA成果,同时在共享任务中其他语言也具有竞争力。
Key Takeaways:
- 提交了作为英语到Lowres多媒体翻译任务的参与内容。
- 介绍了名为Chitranuvad的多媒体模型。
- 该模型结合了多语言LLM和视觉模块进行多媒体翻译。
- 使用ViT图像编码器提取视觉表示并将其转换为视觉令牌嵌入。
- 通过适配器层将视觉令牌嵌入投影到LLM空间。
- 在所有三个轨道的印地语翻译任务中取得了SOTA成果。
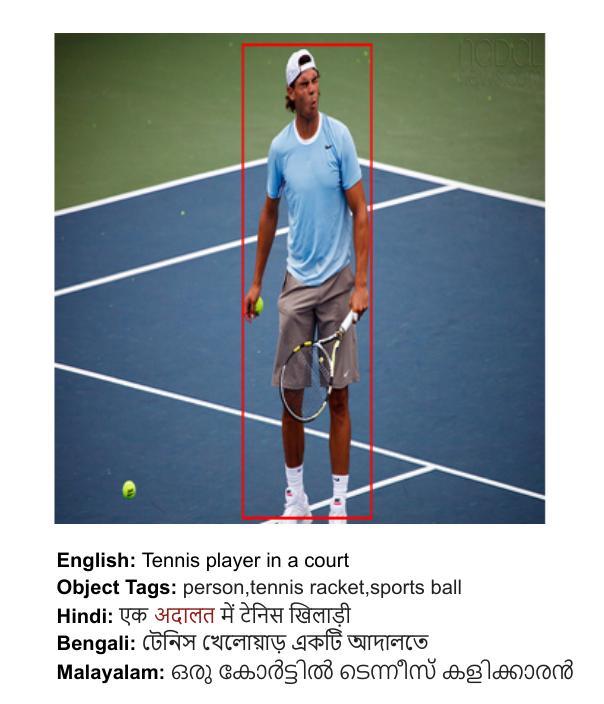
点此查看论文截图