⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-04 更新
SV4D: Dynamic 3D Content Generation with Multi-Frame and Multi-View Consistency
Authors:Yiming Xie, Chun-Han Yao, Vikram Voleti, Huaizu Jiang, Varun Jampani
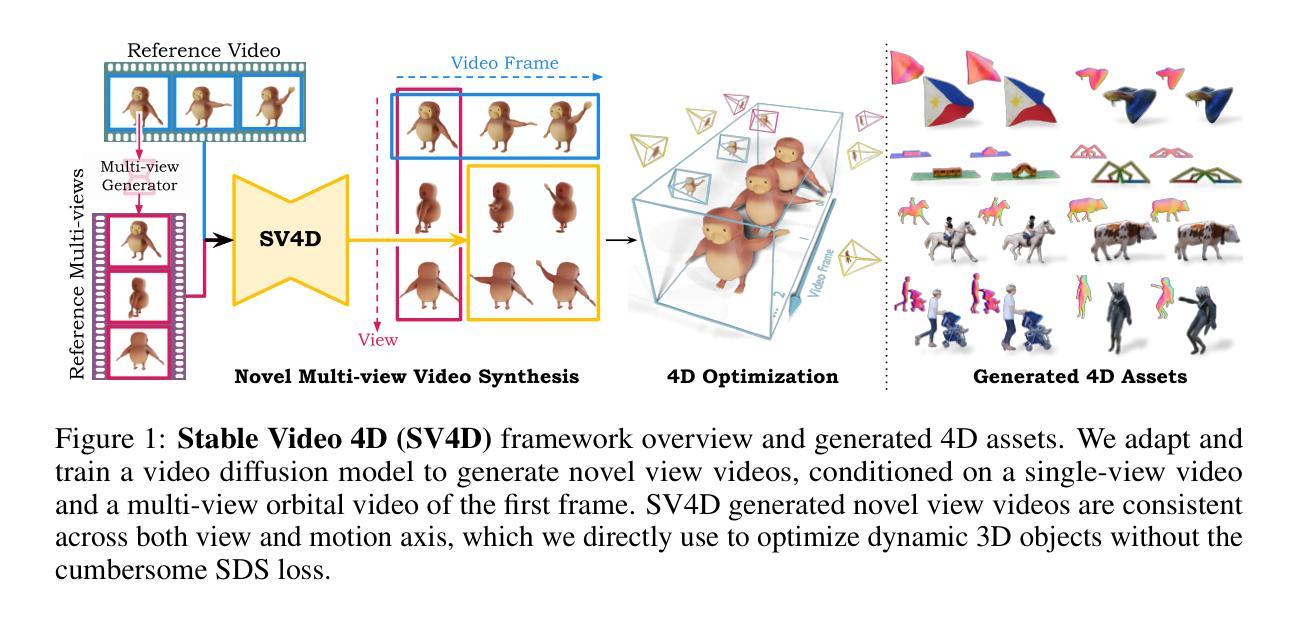
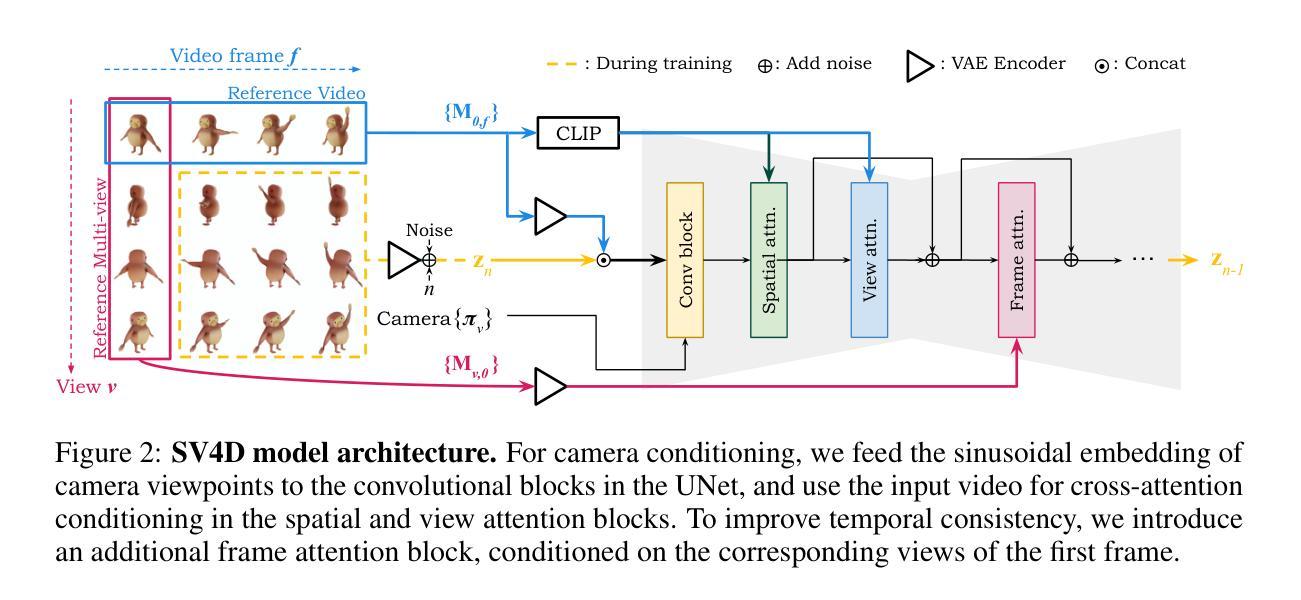
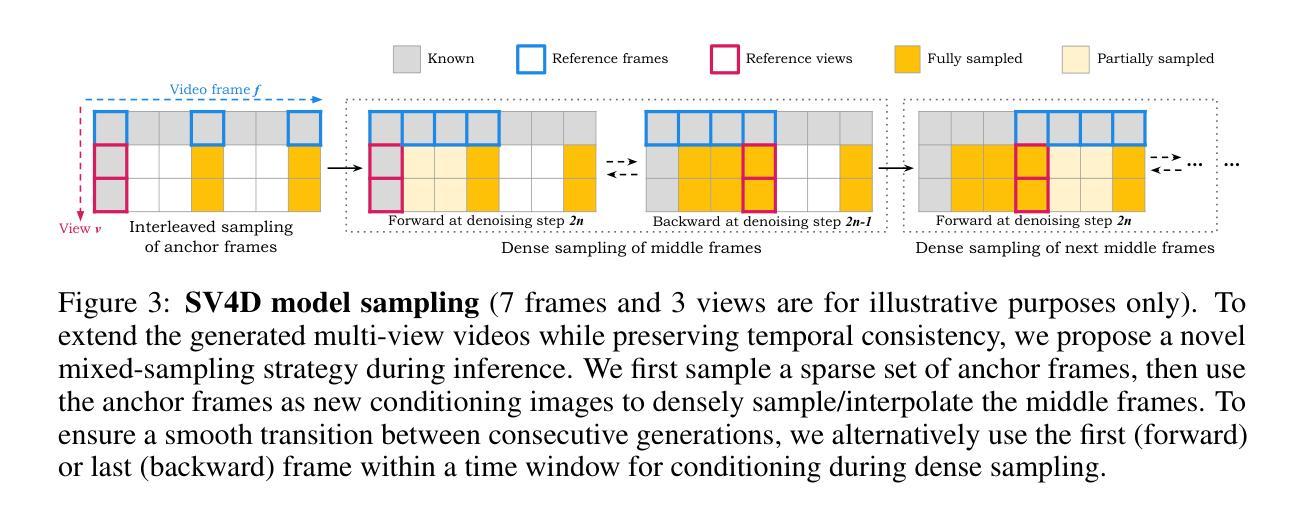
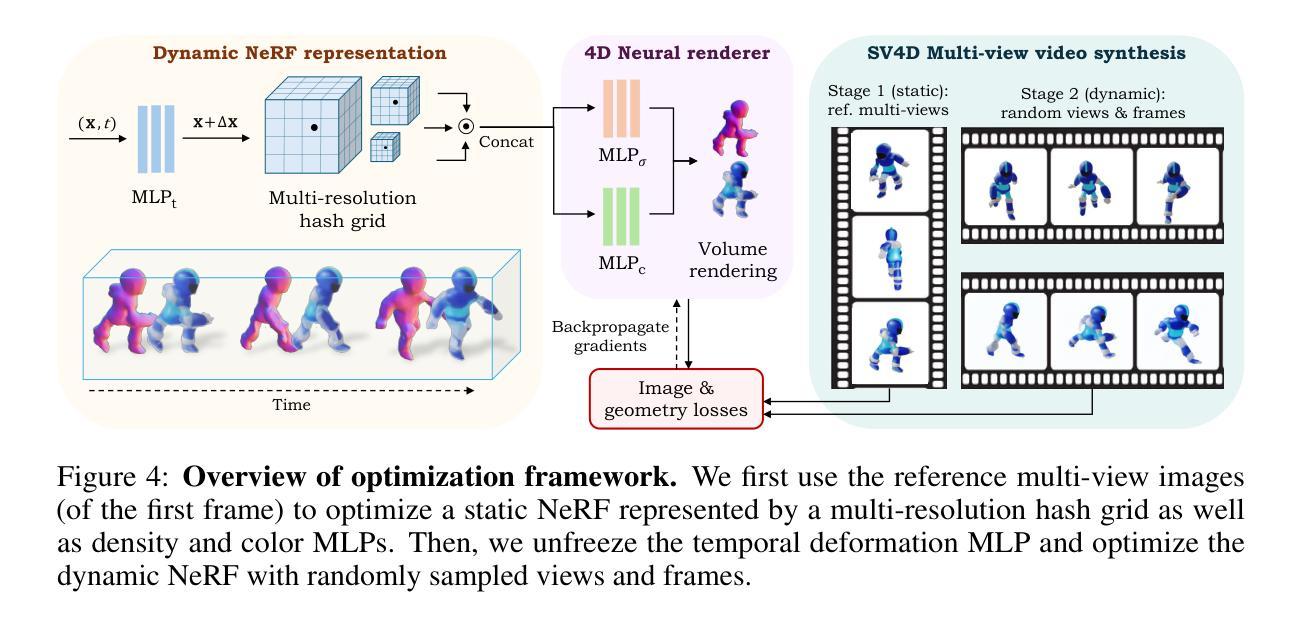
We present Stable Video 4D (SV4D), a latent video diffusion model for multi-frame and multi-view consistent dynamic 3D content generation. Unlike previous methods that rely on separately trained generative models for video generation and novel view synthesis, we design a unified diffusion model to generate novel view videos of dynamic 3D objects. Specifically, given a monocular reference video, SV4D generates novel views for each video frame that are temporally consistent. We then use the generated novel view videos to optimize an implicit 4D representation (dynamic NeRF) efficiently, without the need for cumbersome SDS-based optimization used in most prior works. To train our unified novel view video generation model, we curate a dynamic 3D object dataset from the existing Objaverse dataset. Extensive experimental results on multiple datasets and user studies demonstrate SV4D’s state-of-the-art performance on novel-view video synthesis as well as 4D generation compared to prior works.
我们提出了Stable Video 4D(SV4D)方法,这是一种潜在的视频扩散模型,用于多帧和多视角一致的动态3D内容生成。不同于之前依赖于单独训练的生成模型进行视频生成和新型视角合成的方法,我们设计了一个统一的扩散模型来生成动态3D对象的新型视角视频。具体来说,给定单眼参考视频,SV4D生成每个视频帧的新型视角,这些视角在时间上是一致的。然后,我们使用生成的新型视角视频来有效地优化隐式4D表示(动态NeRF),而无需使用大多数先前工作中使用的繁琐的SDS优化方法。为了训练我们统一的新型视角视频生成模型,我们从现有的Javaverse数据集中精选了一个动态3D对象数据集。在多个数据集上的广泛实验和用户研究结果表明,与先前的工作相比,SV4D在新型视角视频合成和4D生成方面达到了最新技术水平。
论文及项目相关链接
PDF Project page: https://sv4d.github.io/
Summary
SV4D是一种用于多帧和多视角一致动态3D内容生成的潜在视频扩散模型。它采用统一扩散模型生成动态3D对象的新视角视频,不同于以往需单独训练生成模型的方法。SV4D使用隐式4D表示(动态NeRF)进行优化,无需使用大多数先前工作中繁琐的SDS优化方法。实验和用户研究证明SV4D在新型视角视频合成和4D生成方面表现卓越。
Key Takeaways
- SV4D是一种潜在视频扩散模型,用于多帧和多视角一致的动态3D内容生成。
- 它采用统一扩散模型生成新型视角的视频,无需单独训练的生成模型。
- SV4D能够从单眼参考视频生成与每个视频帧时间一致的新的视角。
- 该模型使用隐式4D表示(动态NeRF)进行优化,避免了繁琐的SDS优化方法。
- SV4D在新型视角视频合成方面表现出卓越的性能。
- 该模型能够从现有数据集(如Objaverse数据集)中创建动态3D对象数据集。
点此查看论文截图

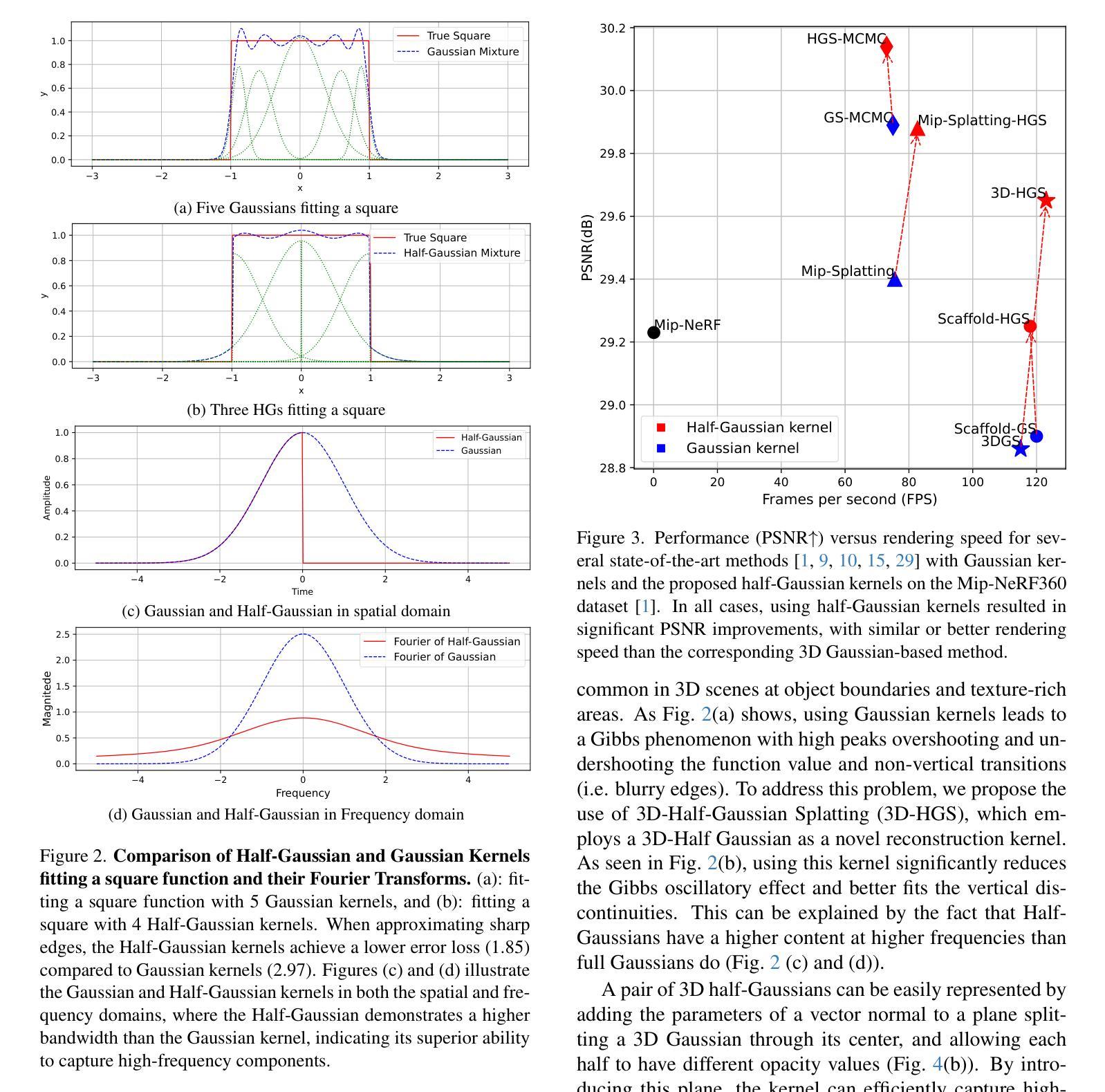
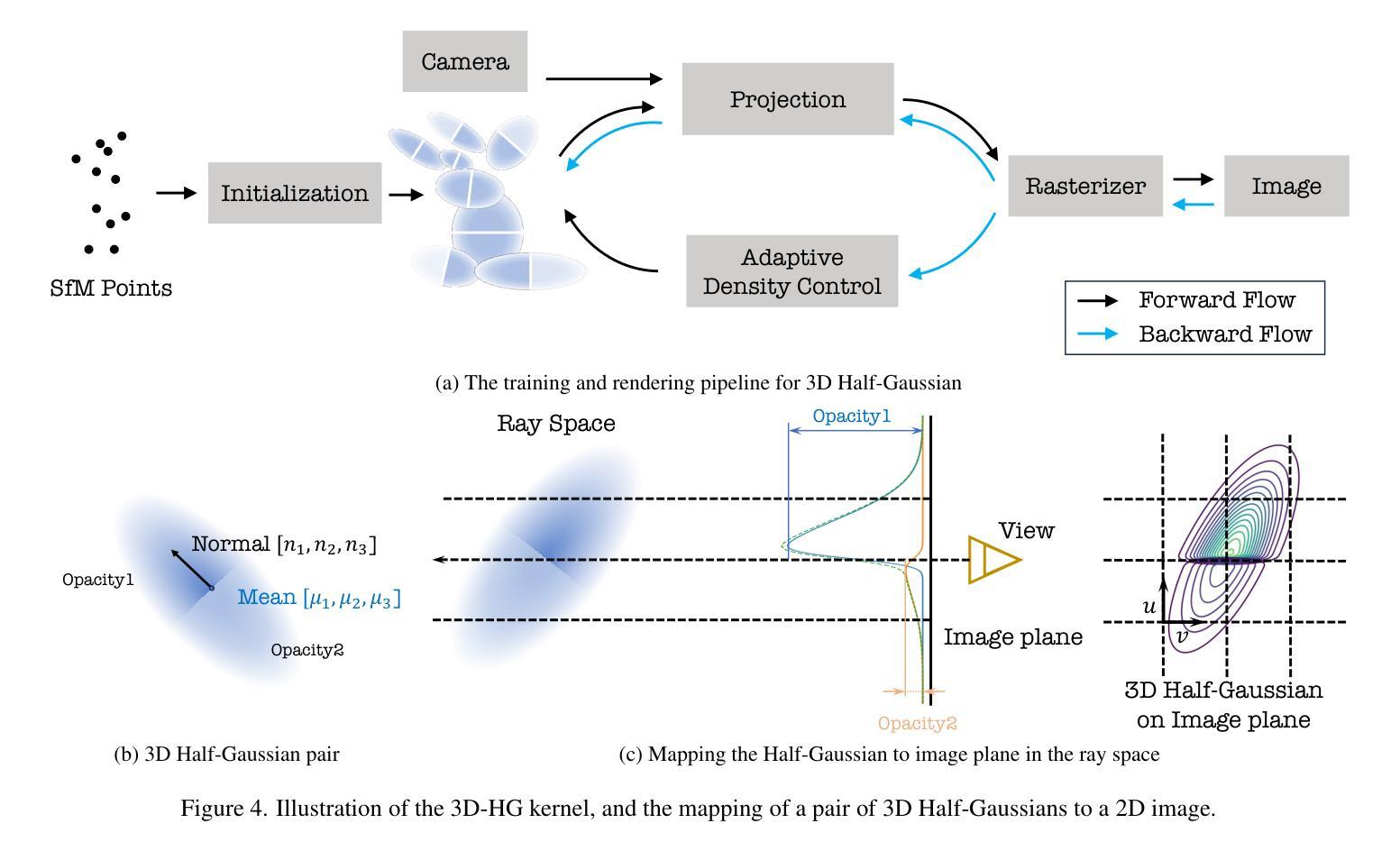
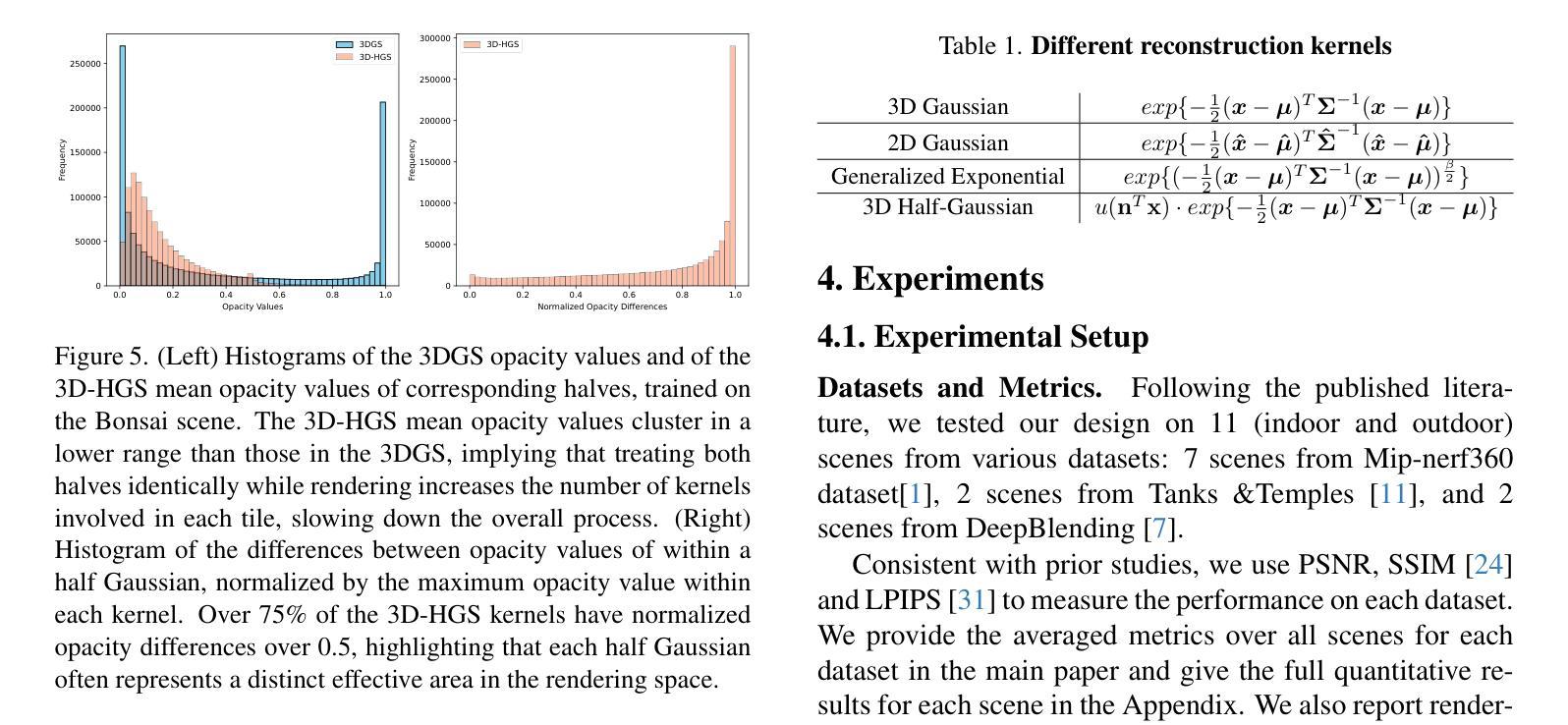
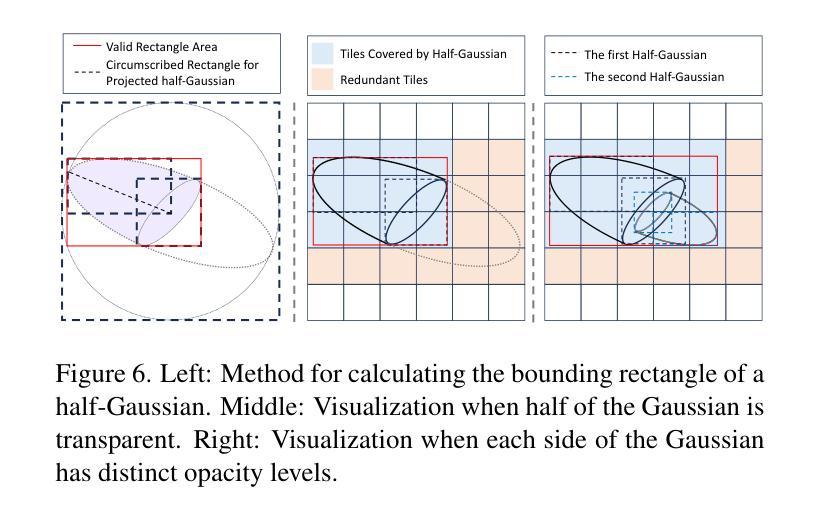
3D-HGS: 3D Half-Gaussian Splatting
Authors:Haolin Li, Jinyang Liu, Mario Sznaier, Octavia Camps
Photo-realistic image rendering from scene 3D reconstruction is a fundamental problem in 3D computer vision. This domain has seen considerable advancements owing to the advent of recent neural rendering techniques. These techniques predominantly aim to focus on learning volumetric representations of 3D scenes and refining these representations via loss functions derived from their rendering. Among these, 3D Gaussian Splatting (3D-GS) has emerged as a preferred method, surpassing Neural Radiance Fields’ (NeRFs) quality and rendering speed. 3D-GS uses parameterized 3D Gaussians to model both spatial locations and color information, combined with a tile-based fast rendering technique. Despite its superior performance, using 3D Gaussian kernels has inherent limitations in accurately representing discontinuous functions, notably at edges and corners corresponding to shape discontinuities, and across varying textures due to color discontinuities. In this paper, we introduce 3D Half-Gaussian (\textbf{3D-HGS}) kernels, which can be used as a plug-and-play kernel, to address this issue. Our experiments demonstrate their capability to improve the performance of current 3D-GS related methods and achieve state-of-the-art rendering quality performance on various datasets without compromising their rendering speed.
从场景的三维重建中进行真实感图像渲染是计算机三维视觉领域的一个基本问题。由于最近神经渲染技术的出现,这一领域取得了显著的进展。这些技术的主要目标是学习三维场景的体积表示,并通过从其渲染中得出的损失函数来优化这些表示。其中,3D高斯贴图(3D-GS)作为一种优选方法脱颖而出,其在质量和渲染速度上超越了神经辐射场(NeRF)。3D-GS使用参数化的3D高斯来模拟空间位置和颜色信息,并结合基于瓦片的快速渲染技术。尽管其性能卓越,但使用3D高斯核在准确表示不连续函数方面存在固有局限性,特别是在形状不连续的边缘和角落,以及由于颜色不连续而出现的不同纹理。在本文中,我们引入了3D半高斯(\textbf{3D-HGS})核,可以作为即插即用的核来解决这个问题。我们的实验证明了其在改进当前3D-GS相关方法性能的能力,并在各种数据集上实现了最先进的渲染质量性能,同时没有牺牲其渲染速度。
论文及项目相关链接
PDF 8 pages, 9 figures
Summary
基于神经渲染技术的三维场景体积表示方法已经取得了显著进展。最近出现的3D高斯涂抹(3D-GS)方法在渲染速度和效果上受到关注,但它对于不连续函数(特别是在边缘和角落以及纹理之间的颜色不连续性)的表示存在固有局限。为解决这一问题,本文引入了新的渲染内核:基于半边分布的渲染方法,能够提高现有方法的性能并达到业界领先的渲染质量效果。
Key Takeaways
- 神经渲染技术已成为三维场景重建的核心领域。
- 3D高斯涂抹(3D-GS)方法因其渲染速度和效果而受到关注。
- 但该方法在处理形状和纹理不连续性时存在局限性。
- 新提出的半边分布(Half-Gaussian)内核旨在解决上述问题。
点此查看论文截图