⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-04 更新
LiteASR: Efficient Automatic Speech Recognition with Low-Rank Approximation
Authors:Keisuke Kamahori, Jungo Kasai, Noriyuki Kojima, Baris Kasikci
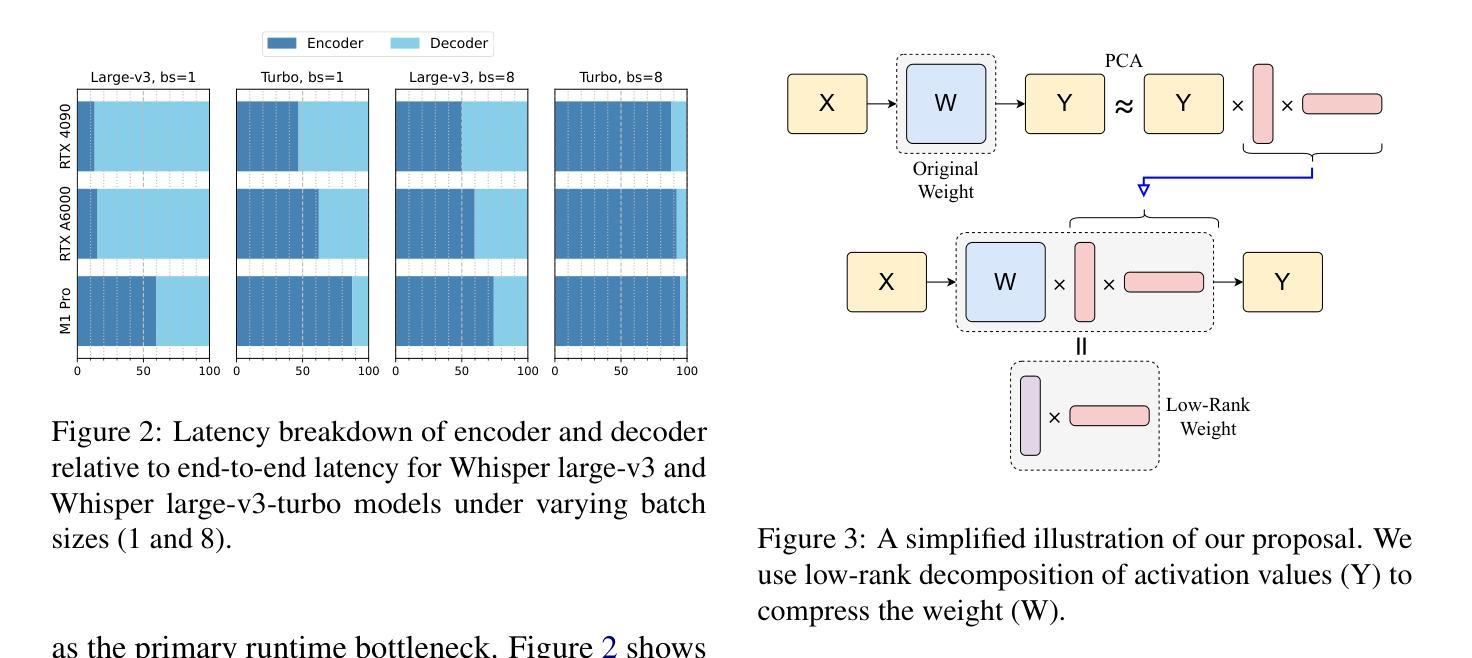
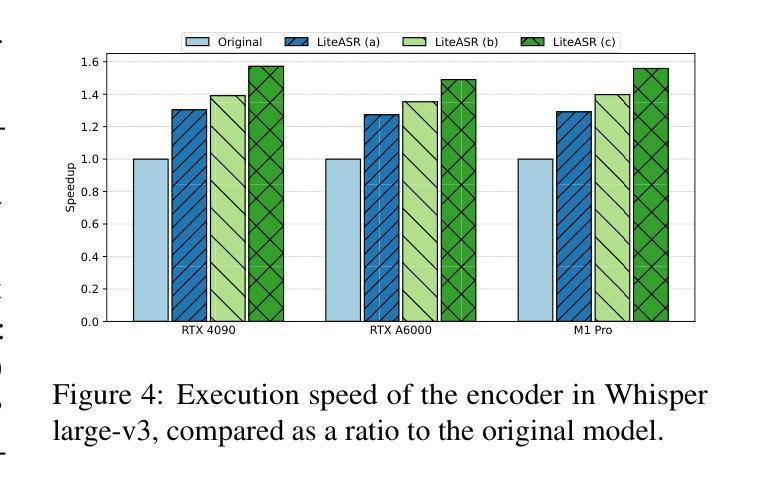
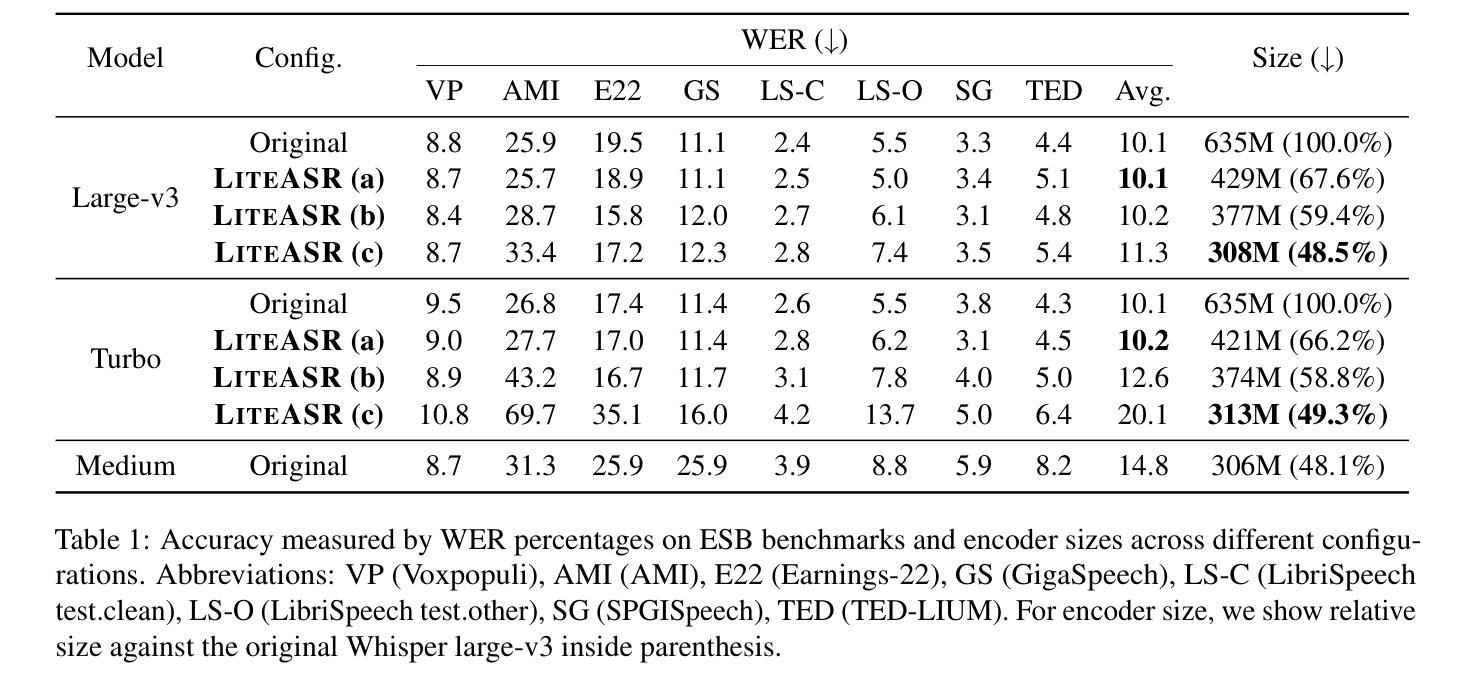
Modern automatic speech recognition (ASR) models, such as OpenAI’s Whisper, rely on deep encoder-decoder architectures, and their encoders are a critical bottleneck for efficient deployment due to high computational intensity. We introduce LiteASR, a low-rank compression scheme for ASR encoders that significantly reduces inference costs while maintaining transcription accuracy. Our approach leverages the strong low-rank properties observed in intermediate activations: by applying principal component analysis (PCA) with a small calibration dataset, we approximate linear transformations with a chain of low-rank matrix multiplications, and further optimize self-attention to work in the reduced dimension. Evaluation results show that our method can compress Whisper large-v3’s encoder size by over 50%, matching Whisper medium’s size with better transcription accuracy, thereby establishing a new Pareto-optimal frontier of efficiency and performance. The code of LiteASR is available at https://github.com/efeslab/LiteASR.
现代自动语音识别(ASR)模型,如OpenAI的Whisper,依赖于深度编码器-解码器架构,其编码器由于计算强度高,是高效部署的关键瓶颈。我们引入了LiteASR,这是一种ASR编码器的低秩压缩方案,可以显著降低推理成本,同时保持转录准确性。我们的方法利用中间激活中观察到的强低秩属性:通过应用主成分分析(PCA)和一个小型校准数据集,我们用一系列低秩矩阵乘法来近似线性变换,进一步优化自注意力在降低的维度上工作。评估结果表明,我们的方法可以将Whisper large-v3的编码器大小压缩超过50%,以更好的转录准确性匹配Whisper medium的大小,从而在效率和性能方面建立新的帕累托最优边界。LiteASR的代码可在https://github.com/efeslab/LiteASR处获得。
论文及项目相关链接
摘要
介绍了一种针对自动语音识别(ASR)编码器的高效压缩方案——LiteASR。该方法利用中间激活的强低秩属性,通过应用主成分分析(PCA)和小型校准数据集,以一系列低秩矩阵乘法来近似线性变换,进一步优化自注意力在降低维度中的工作。评估结果表明,该方法可将Whisper large-v3编码器的尺寸压缩超过50%,在保持较好转录准确性的同时匹配Whisper medium的尺寸,从而在效率和性能方面建立了新的帕累托最优边界。
关键见解
- LiteASR是一种针对ASR编码器的低秩压缩方案,旨在降低推理成本同时保持转录准确性。
- 该方法利用中间激活的强低秩属性,通过主成分分析(PCA)进行线性变换的近似。
- LiteASR通过一系列低秩矩阵乘法实现压缩,进一步优化了自注意力机制在降低维度中的运作。
- LiteASR能够显著压缩模型大小,将Whisper large-v3编码器的尺寸压缩超过50%。
- 压缩后的模型性能与Whisper medium相当,甚至在某些方面表现更佳。
- 该方法建立了ASR模型效率和性能的新帕累托最优边界。
点此查看论文截图

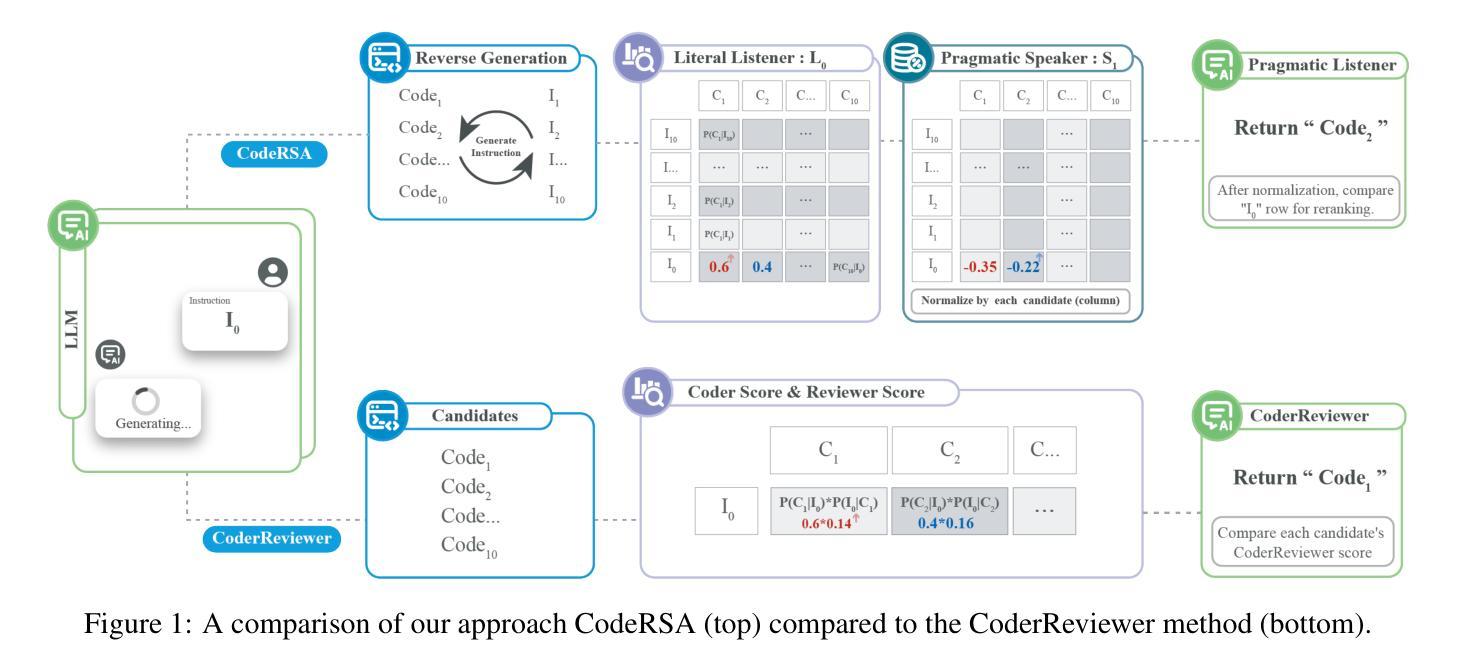
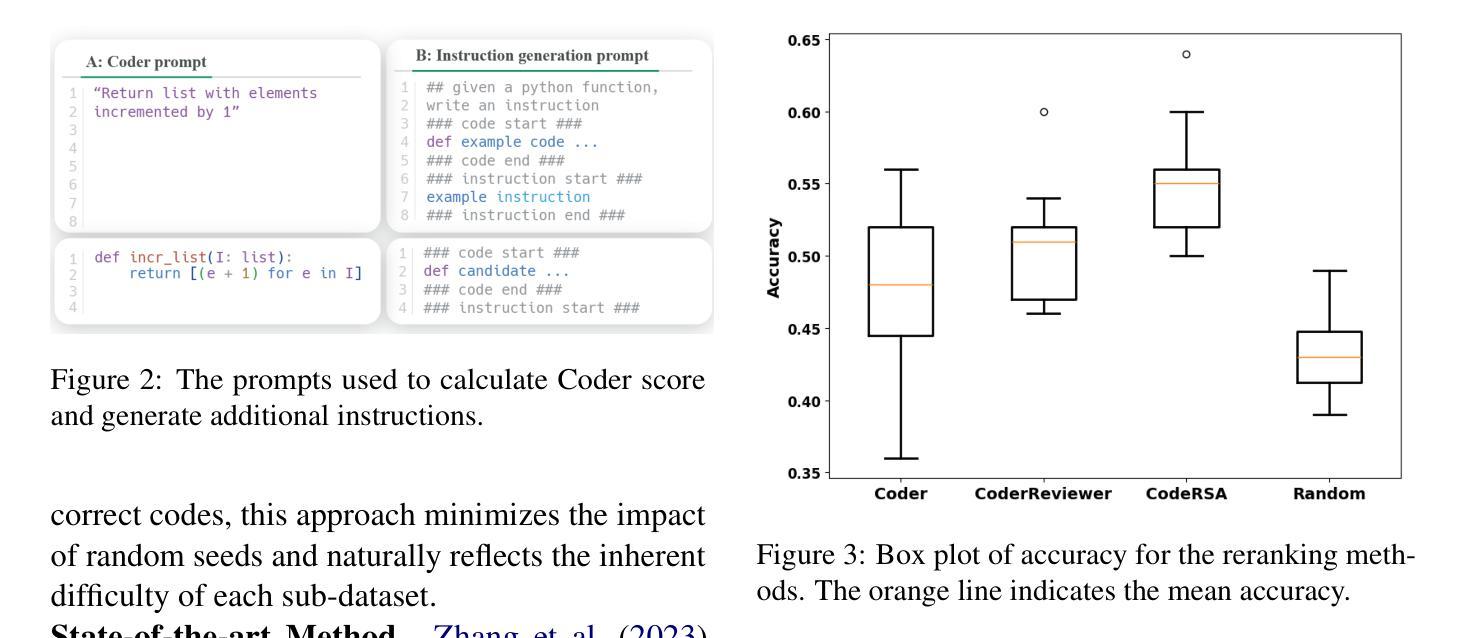
Pragmatic Reasoning improves LLM Code Generation
Authors:Zhuchen Cao, Sven Apel, Adish Singla, Vera Demberg
Large Language Models (LLMs) have demonstrated impressive potential in translating natural language (NL) instructions into program code. However, user instructions often contain inherent ambiguities, making it challenging for LLMs to generate code that accurately reflects the user’s true intent. To address this challenge, researchers have proposed to produce multiple candidates of the program code and then rerank them to identify the best solution. In this paper, we propose CodeRSA, a novel code candidate reranking mechanism built upon the Rational Speech Act (RSA) framework, designed to guide LLMs toward more comprehensive pragmatic reasoning about user intent. We evaluate CodeRSA using one of the latest LLMs on a popular code generation dataset. Our experiment results show that CodeRSA consistently outperforms common baselines, surpasses the state-of-the-art approach in most cases, and demonstrates robust overall performance. These findings underscore the effectiveness of integrating pragmatic reasoning into code candidate reranking, offering a promising direction for enhancing code generation quality in LLMs.
大型语言模型(LLM)在将自然语言(NL)指令翻译成程序代码方面展现出了令人印象深刻的潜力。然而,用户指令通常包含固有的歧义性,这使得LLM生成准确反映用户真实意图的代码具有挑战性。为了应对这一挑战,研究人员提议生成多个程序代码候选者,然后对其进行重新排序以找出最佳解决方案。在本文中,我们提出了CodeRSA,这是一种基于理性言语行为(RSA)框架的新型代码候选者重新排序机制,旨在引导LLM进行更全面的关于用户意图的实用推理。我们使用最新的LLM之一在流行的代码生成数据集上评估CodeRSA。实验结果表明,CodeRSA始终优于普通基线,在大多数情况下超越了最先进的方法,并展示了稳健的总体性能。这些发现强调了将实用推理整合到代码候选者重新排序中的有效性,为增强LLM中的代码生成质量提供了有前景的方向。
论文及项目相关链接
摘要
大语言模型(LLMs)在自然语言(NL)指令转化为程序代码方面展现出令人印象深刻的潜力。然而,用户指令通常包含固有的歧义性,使得LLMs难以生成准确反映用户真实意图的代码。为解决这一挑战,研究者提出生成多个程序代码候选并对其进行重新排序以找到最佳解决方案的方法。本文提出CodeRSA,一种基于理性言语行为(RSA)框架的新型代码候选重新排序机制,旨在引导LLMs进行更全面的关于用户意图的语用推理。我们使用最新的LLM之一在流行的代码生成数据集上评估CodeRSA。实验结果表明,CodeRSA在大多数情况下都优于通用基线并超越最先进的方法,展现出稳健的整体性能。这些发现强调了将语用推理整合到代码候选重新排序中的有效性,为提升LLM中的代码生成质量提供了有前景的方向。
关键见解
- 大语言模型在将自然语言指令转化为程序代码方面具备显著潜力。
- 用户指令中的固有歧义性给LLMs准确生成代码带来挑战。
- 为解决歧义性问题,研究者提议生成多个程序代码候选并进行重新排序。
- CodeRSA是一种基于理性言语行为(RSA)框架的新型代码候选重新排序机制。
- CodeRSA设计旨在引导LLMs进行更全面的关于用户意图的语用推理。
- 在流行的代码生成数据集上的评估显示,CodeRSA性能优于通用基线和最先进的方法。
点此查看论文截图