⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-04 更新
An Integrated Deep Learning Framework Leveraging NASNet and Vision Transformer with MixProcessing for Accurate and Precise Diagnosis of Lung Diseases
Authors:Sajjad Saleem, Muhammad Imran Sharif
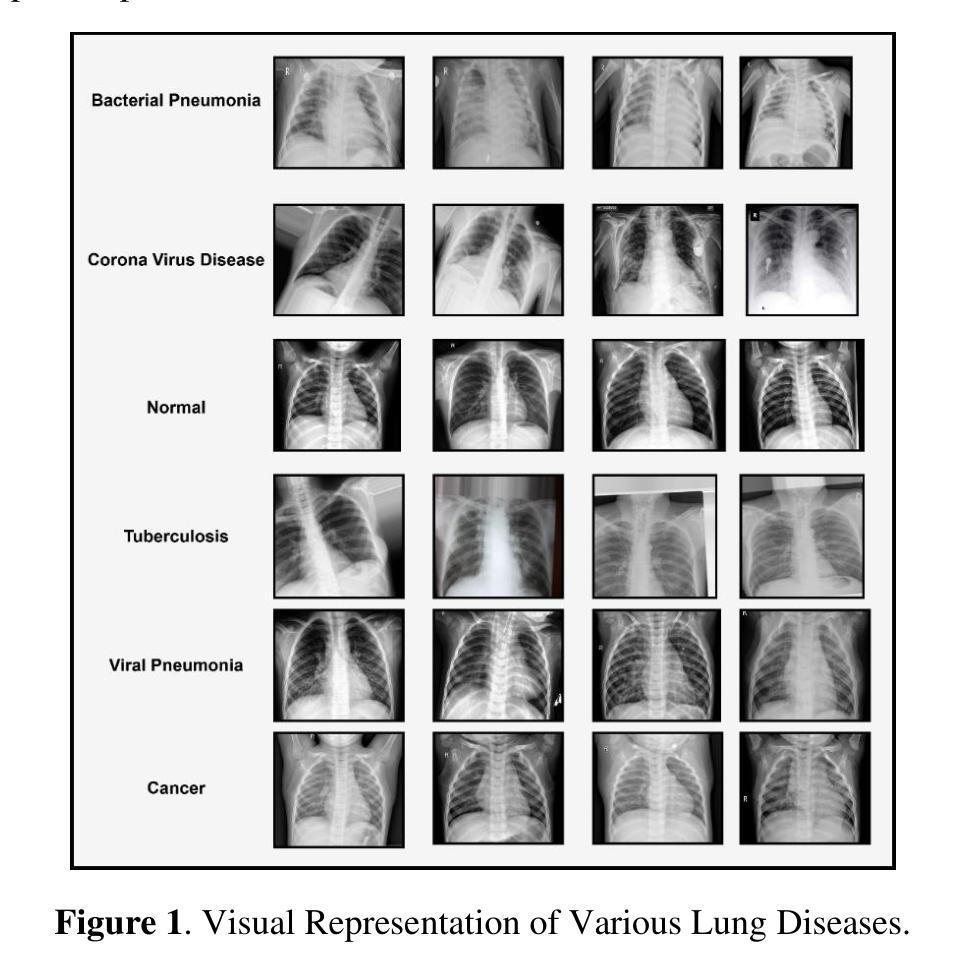
The lungs are the essential organs of respiration, and this system is significant in the carbon dioxide and exchange between oxygen that occurs in human life. However, several lung diseases, which include pneumonia, tuberculosis, COVID-19, and lung cancer, are serious healthiness challenges and demand early and precise diagnostics. The methodological study has proposed a new deep learning framework called NASNet-ViT, which effectively incorporates the convolution capability of NASNet with the global attention mechanism capability of Vision Transformer ViT. The proposed model will classify the lung conditions into five classes: Lung cancer, COVID-19, pneumonia, TB, and normal. A sophisticated multi-faceted preprocessing strategy called MixProcessing has been used to improve diagnostic accuracy. This preprocessing combines wavelet transform, adaptive histogram equalization, and morphological filtering techniques. The NASNet-ViT model performs at state of the art, achieving an accuracy of 98.9%, sensitivity of 0.99, an F1-score of 0.989, and specificity of 0.987, outperforming other state of the art architectures such as MixNet-LD, D-ResNet, MobileNet, and ResNet50. The model’s efficiency is further emphasized by its compact size, 25.6 MB, and a low computational time of 12.4 seconds, hence suitable for real-time, clinically constrained environments. These results reflect the high-quality capability of NASNet-ViT in extracting meaningful features and recognizing various types of lung diseases with very high accuracy. This work contributes to medical image analysis by providing a robust and scalable solution for diagnostics in lung diseases.
肺是呼吸的关键器官,这个系统在人类生活中发生的二氧化碳和氧气的交换中起着重要作用。然而,包括肺炎、肺结核、COVID-19和肺癌在内的多种肺部疾病是严重的健康问题,需要早期和精确的诊断。这项方法论研究提出了一个新的深度学习框架,叫做NASNet-ViT,它有效地结合了NASNet的卷积能力与Vision Transformer ViT的全局注意力机制能力。该模型将肺部状况分为五类:肺癌、COVID-19、肺炎、肺结核和正常。采用了一种名为MixProcessing的复杂多面预处理策略,以提高诊断的准确性。这种预处理结合了小波变换、自适应直方图均衡化和形态滤波技术。NASNet-ViT模型表现卓越,达到了98.9%的准确率、0.99的灵敏度、0.989的F1分数和0.987的特异度,超越了其他最先进的架构,如MixNet-LD、D-ResNet、MobileNet和ResNet50。该模型的效率还体现在其小巧的体积(仅25.6MB)和较低的计算时间(仅12.4秒),因此适用于实时且受临床限制的环境。这些结果反映了NASNet-ViT在提取有意义特征和识别各种类型肺部疾病方面具有的高质量能力。这项工作通过为肺部疾病的诊断提供稳健且可扩展的解决方案,为医学图像分析做出了贡献。
论文及项目相关链接
摘要
提出一种结合NASNet的卷积能力与Vision Transformer ViT的全局注意力机制能力的新深度学习框架NASNet-ViT,用于肺部疾病分类。通过混合处理策略MixProcessing提高诊断准确性,包括小波变换、自适应直方图均衡化和形态学滤波技术。NASNet-ViT模型达到先进性能,准确率98.9%,敏感性0.99,F1分数0.989,特异性0.987,优于其他先进架构。模型紧凑,大小仅为25.6MB,计算时间短,适合实时临床诊断环境。反映NASNet-ViT提取有意义特征和识别各种类型肺部疾病的高精度能力。为医疗图像分析提供稳健和可扩展的肺病诊断解决方案。
关键见解
- 肺部是呼吸系统的关键器官,肺病的早期诊断至关重要,包括肺炎、肺结核、COVID-19和肺癌等。
- 研究提出了一种新的深度学习框架NASNet-ViT,结合了NASNet的卷积能力和Vision Transformer ViT的全局注意力机制。
- NASNet-ViT能有效分类肺病情况,包括肺癌、COVID-19、肺炎、结核和正常五种类别。
- 采用MixProcessing预处理策略,结合小波变换、自适应直方图均衡化和形态学滤波技术,提高了诊断准确性。
- NASNet-ViT模型表现出卓越的性能,准确率高达98.9%,并且具有高度的敏感性和特异性。
- 该模型大小紧凑,计算效率高,适合用于实时的临床诊断环境。
- NASNet-ViT在医疗图像分析领域为肺病诊断提供了稳健和可扩展的解决方案。
点此查看论文截图

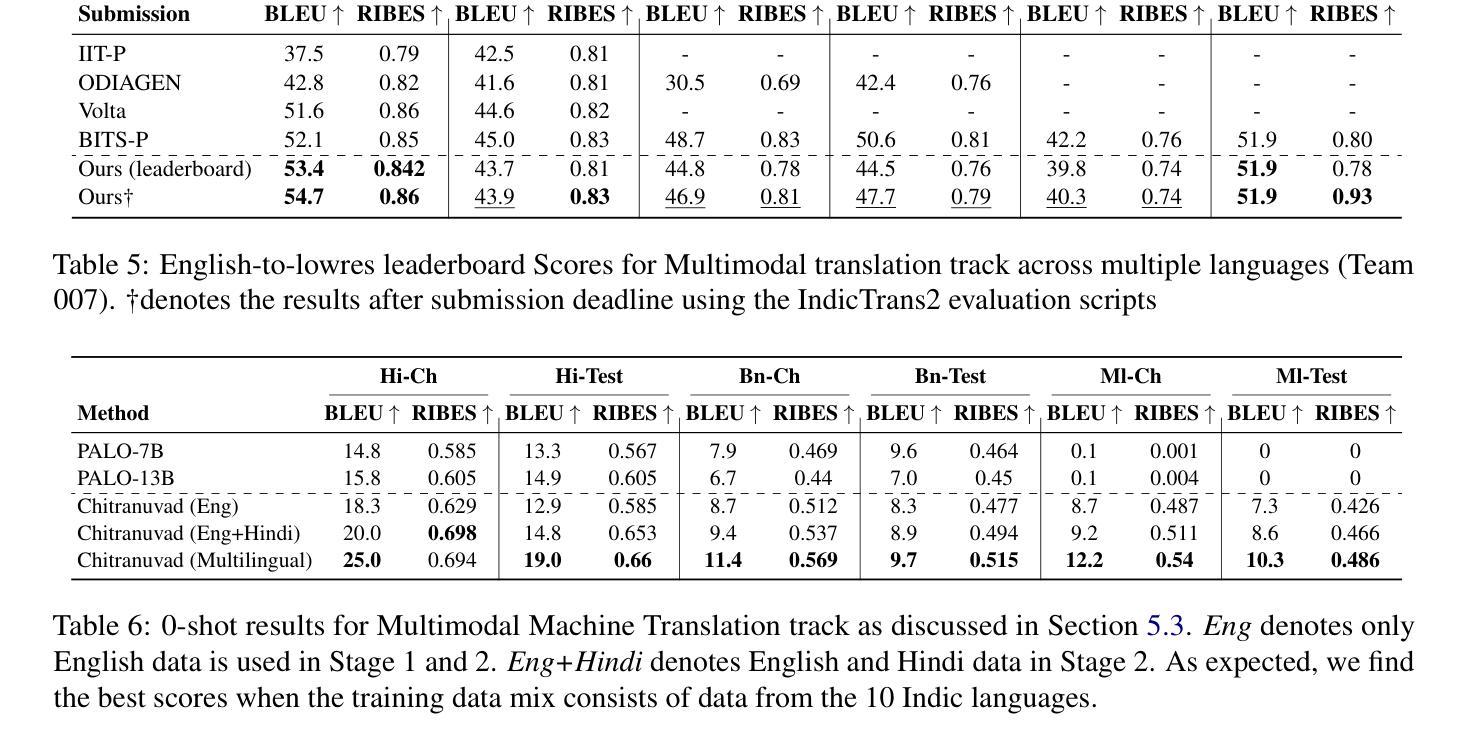
Chitranuvad: Adapting Multi-Lingual LLMs for Multimodal Translation
Authors:Shaharukh Khan, Ayush Tarun, Ali Faraz, Palash Kamble, Vivek Dahiya, Praveen Pokala, Ashish Kulkarni, Chandra Khatri, Abhinav Ravi, Shubham Agarwal
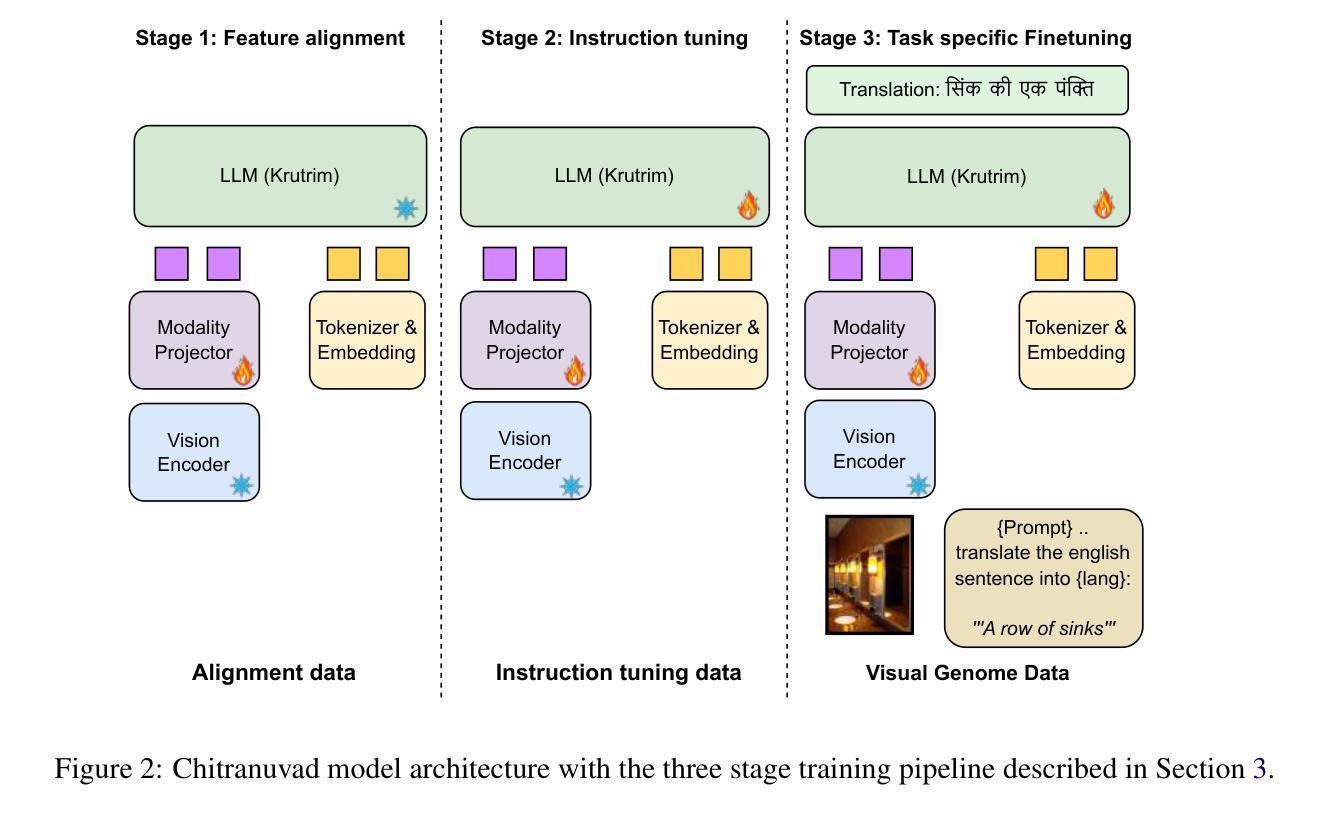
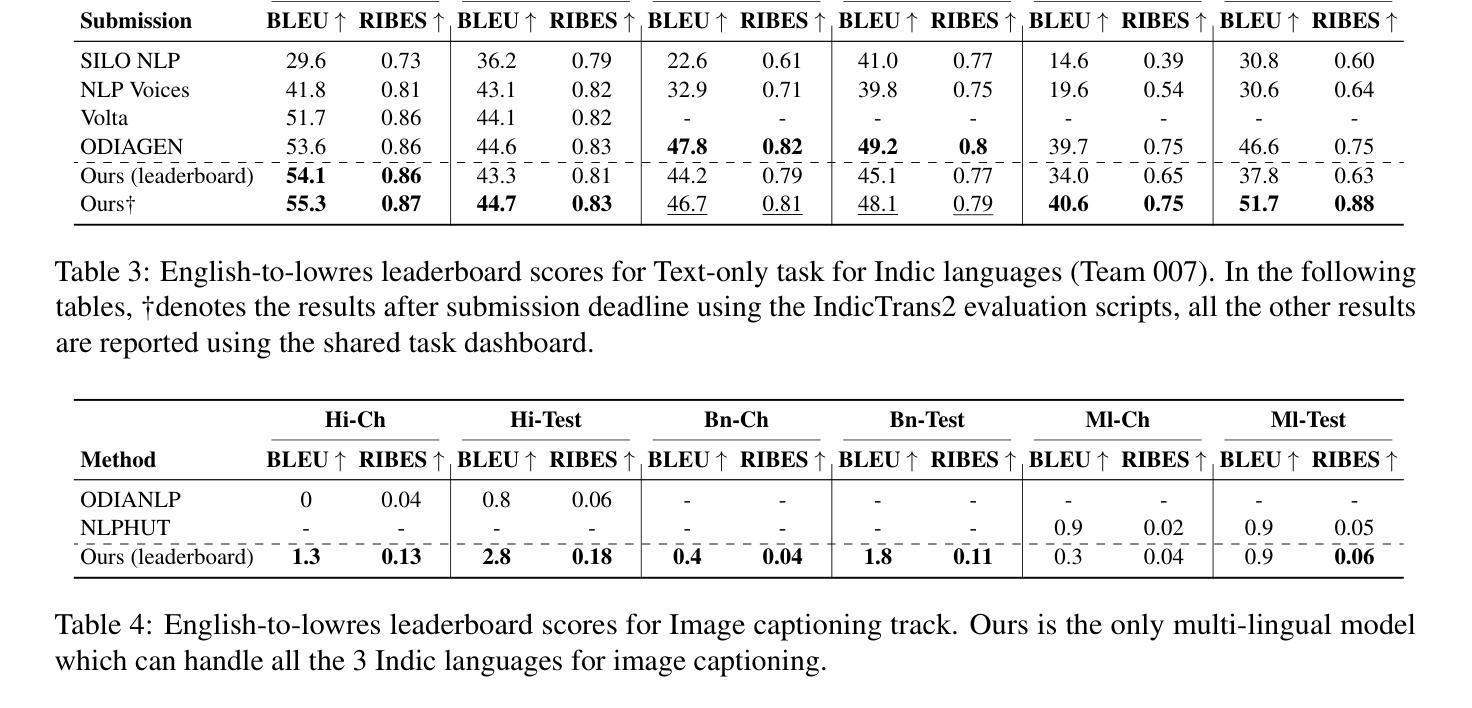
In this work, we provide the system description of our submission as part of the English to Lowres Multimodal Translation Task at the Workshop on Asian Translation (WAT2024). We introduce Chitranuvad, a multimodal model that effectively integrates Multilingual LLM and a vision module for Multimodal Translation. Our method uses a ViT image encoder to extract visual representations as visual token embeddings which are projected to the LLM space by an adapter layer and generates translation in an autoregressive fashion. We participated in all the three tracks (Image Captioning, Text only and Multimodal translation tasks) for Indic languages (ie. English translation to Hindi, Bengali and Malyalam) and achieved SOTA results for Hindi in all of them on the Challenge set while remaining competitive for the other languages in the shared task.
在这项工作中,我们提供了作为亚洲翻译研讨会(WAT2024)英语至Lowres多媒体翻译任务部分提交的系统描述。我们介绍了Chitranuvad,这是一个多媒体模型,有效地结合了多语言大型语言模型和用于多媒体翻译的视觉模块。我们的方法使用ViT图像编码器提取视觉表征作为视觉令牌嵌入,通过适配器层投影到大型语言模型空间,并以自回归的方式生成翻译结果。我们参加了所有三个轨道(图像描述、仅文本和多媒体翻译任务)的印度语(即英语翻译为印地语、孟加拉语和马拉雅拉姆语),并在挑战集上为印地语的所有任务取得了最新结果,同时在其他语言的共享任务中保持竞争力。
论文及项目相关链接
Summary:在本研究中,我们介绍了参加亚洲翻译研讨会(WAT2024)英语至Lowres多媒体翻译任务提交的系统描述。我们提出了Chitranuvad多媒体模型,该模型有效地集成了多语言大型语言模型和视觉模块,用于多媒体翻译。我们的方法使用ViT图像编码器提取视觉表示作为视觉令牌嵌入,通过适配器层将其投影到大型语言模型空间,并以自回归的方式生成翻译。我们参加了所有三个轨道(图像描述、纯文本和多媒体翻译任务)的印度语(英语翻译至印地语、孟加拉语和马拉亚拉姆语),并在挑战集上为印地语取得了最新状态结果,同时在其他语言的共享任务中保持竞争力。
Key Takeaways:
- 本研究提出了一个名为Chitranuvad的多媒体模型,它集成了多语言大型语言模型和视觉模块。
- 使用ViT图像编码器提取视觉表示并将其转换为大型语言模型空间的语言表示。
- 通过自回归的方式生成翻译结果。
- 该模型参与了图像描述、纯文本和多媒体翻译任务的三个轨道。
- 在印地语的翻译任务上取得了最新状态的结果。
- 在其他语言的共享任务中表现出竞争性表现。
- 此方法为提高多媒体翻译的准确性和性能提供了一种有效的解决方案。
点此查看论文截图



Small Models are LLM Knowledge Triggers on Medical Tabular Prediction
Authors:Jiahuan Yan, Jintai Chen, Chaowen Hu, Bo Zheng, Yaojun Hu, Jimeng Sun, Jian Wu
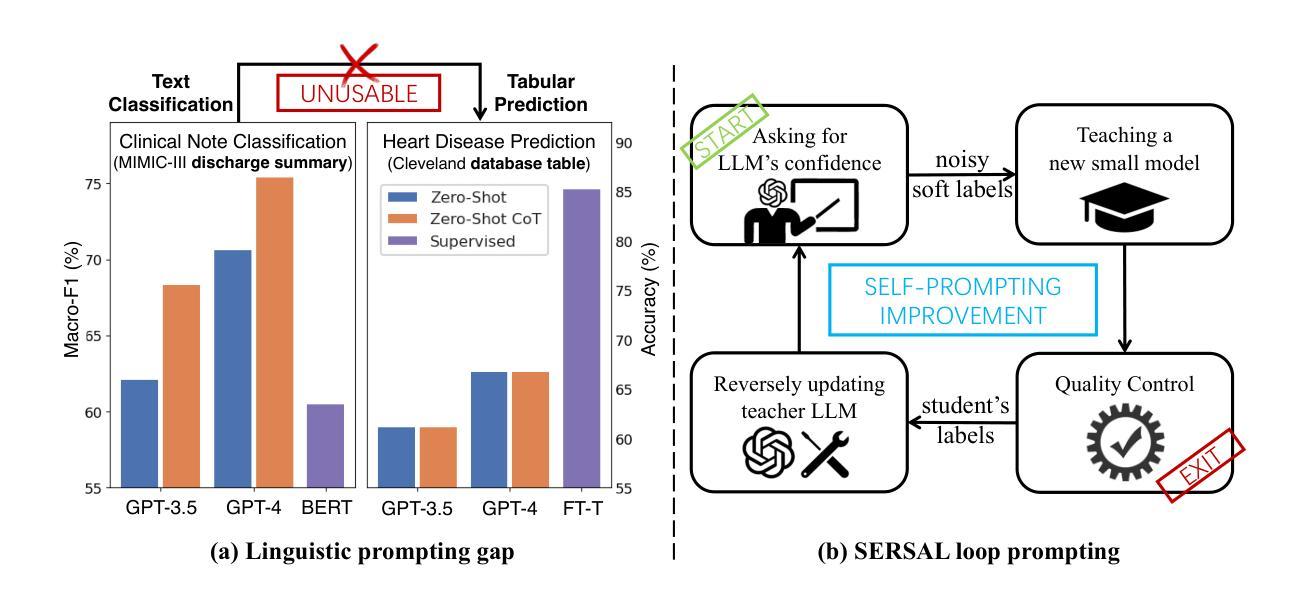
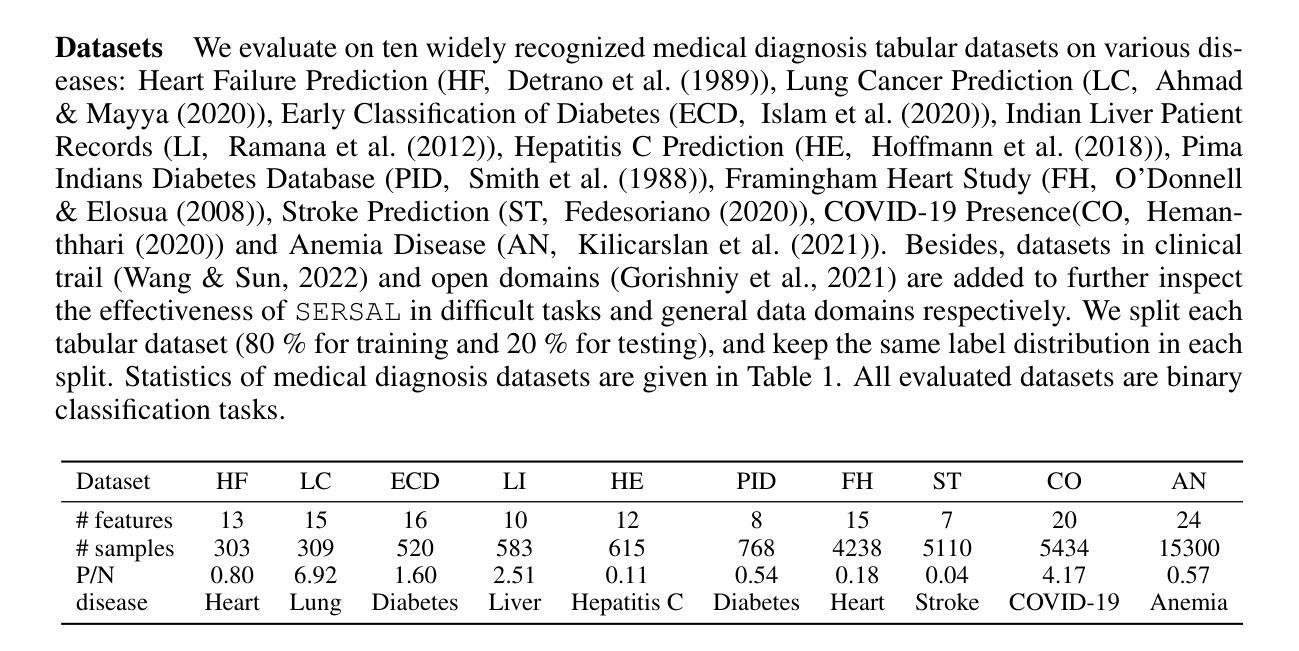
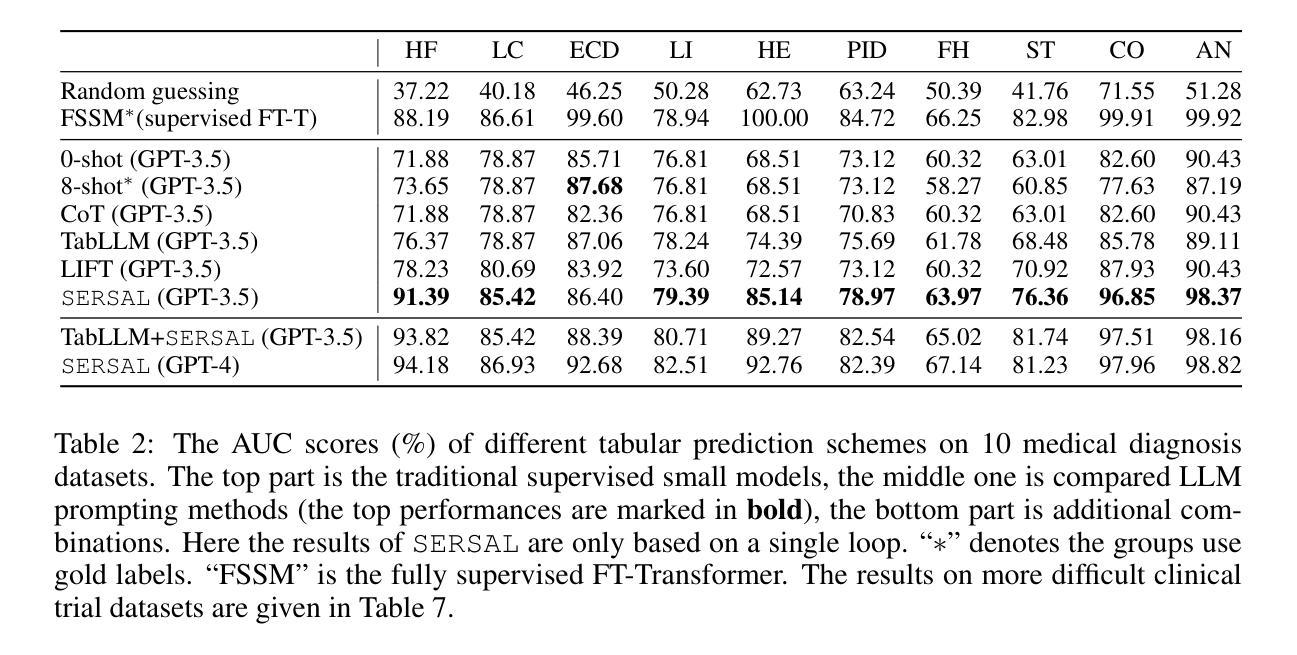
Recent development in large language models (LLMs) has demonstrated impressive domain proficiency on unstructured textual or multi-modal tasks. However, despite with intrinsic world knowledge, their application on structured tabular data prediction still lags behind, primarily due to the numerical insensitivity and modality discrepancy that brings a gap between LLM reasoning and statistical tabular learning. Unlike textual or vision data (e.g., electronic clinical notes or medical imaging data), tabular data is often presented in heterogeneous numerical values (e.g., CBC reports). This ubiquitous data format requires intensive expert annotation, and its numerical nature limits LLMs’ capability to effectively transfer untapped domain expertise. In this paper, we propose SERSAL, a general self-prompting method by synergy learning with small models to enhance LLM tabular prediction in an unsupervised manner. Specifically, SERSAL utilizes the LLM’s prior outcomes as original soft noisy annotations, which are dynamically leveraged to teach a better small student model. Reversely, the outcomes from the trained small model are used to teach the LLM to further refine its real capability. This process can be repeatedly applied to gradually distill refined knowledge for continuous progress. Comprehensive experiments on widely used medical domain tabular datasets show that, without access to gold labels, applying SERSAL to OpenAI GPT reasoning process attains substantial improvement compared to linguistic prompting methods, which serves as an orthogonal direction for tabular LLM, and increasing prompting bonus is observed as more powerful LLMs appear.
近期大型语言模型(LLM)的发展在结构化文本或多模态任务上展现了令人印象深刻的领域专业能力。然而,尽管LLM具备内在的世界知识,它们在结构化表格数据预测方面的应用仍然滞后,这主要是因为数值敏感性和模态差异导致的LLM推理与统计表格学习之间的差距。不同于文本或视觉数据(例如电子病历笔记或医学影像数据),表格数据通常以不同的数值形式呈现(例如CBC报告)。这种普遍的数据格式需要密集的专业注释,并且其数值性质限制了LLM有效地转移未被开发领域专业知识的能力。在本文中,我们提出了SERSAL,这是一种通过协同学习与小型模型进行自提示的通用方法,以无监督的方式提高LLM的表格预测能力。具体而言,SERSAL利用LLM的先前结果作为原始的软噪声注释,这些注释被动态用来教导更好的小型学生模型。反过来,经过训练的小型模型的输出又被用来教导LLM,以进一步精炼其实际能力。这个过程可以反复应用,逐步提炼知识以实现持续进步。在广泛使用的医疗领域表格数据集上的综合实验表明,在不使用黄金标签的情况下,将SERSAL应用于OpenAI GPT推理过程与语言提示方法相比取得了显著改进,这为表格型LLM提供了一个正交方向,并且随着更强大的LLM的出现,观察到的提示奖励也在增加。
论文及项目相关链接
PDF Accepted to ICLR 2025. Codes will be available at https://github.com/jyansir/sersal
Summary
大型语言模型(LLM)在处理结构化表格数据预测方面表现欠佳,存在数值不敏感性和模态差异问题。针对这一问题,本文提出一种名为SERSAL的通用自提示方法,通过协同小模型以无监督方式提升LLM的表格预测能力。该方法利用LLM的初步结果作为原始软噪声注释,动态训练小模型,再反过来利用小模型的输出优化LLM。如此反复,逐渐提炼出精细知识,实现持续进步。实验证明,在不使用黄金标签的情况下,将SERSAL应用于OpenAI GPT推理过程,相较于语言提示方法,取得了显著改进。
Key Takeaways
- 大型语言模型(LLM)在处理结构化表格数据预测时存在挑战,主要由于数值不敏感性和模态差异。
- SERSAL是一种通用自提示方法,旨在通过协同小模型提升LLM在表格预测方面的能力。
- SERSAL利用LLM的初步结果作为软噪声注释,动态训练小模型,实现知识的逐步提炼和持续进步。
- 实验证明,SERSAL在医疗领域表格数据集上的表现优于语言提示方法。
- SERSAL方法在不使用黄金标签的情况下,能够实现无监督学习,有助于降低对标注数据的依赖。
- 随着更强大的LLM的出现,SERSAL的提示优势可能会增加。
点此查看论文截图