⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-05 更新
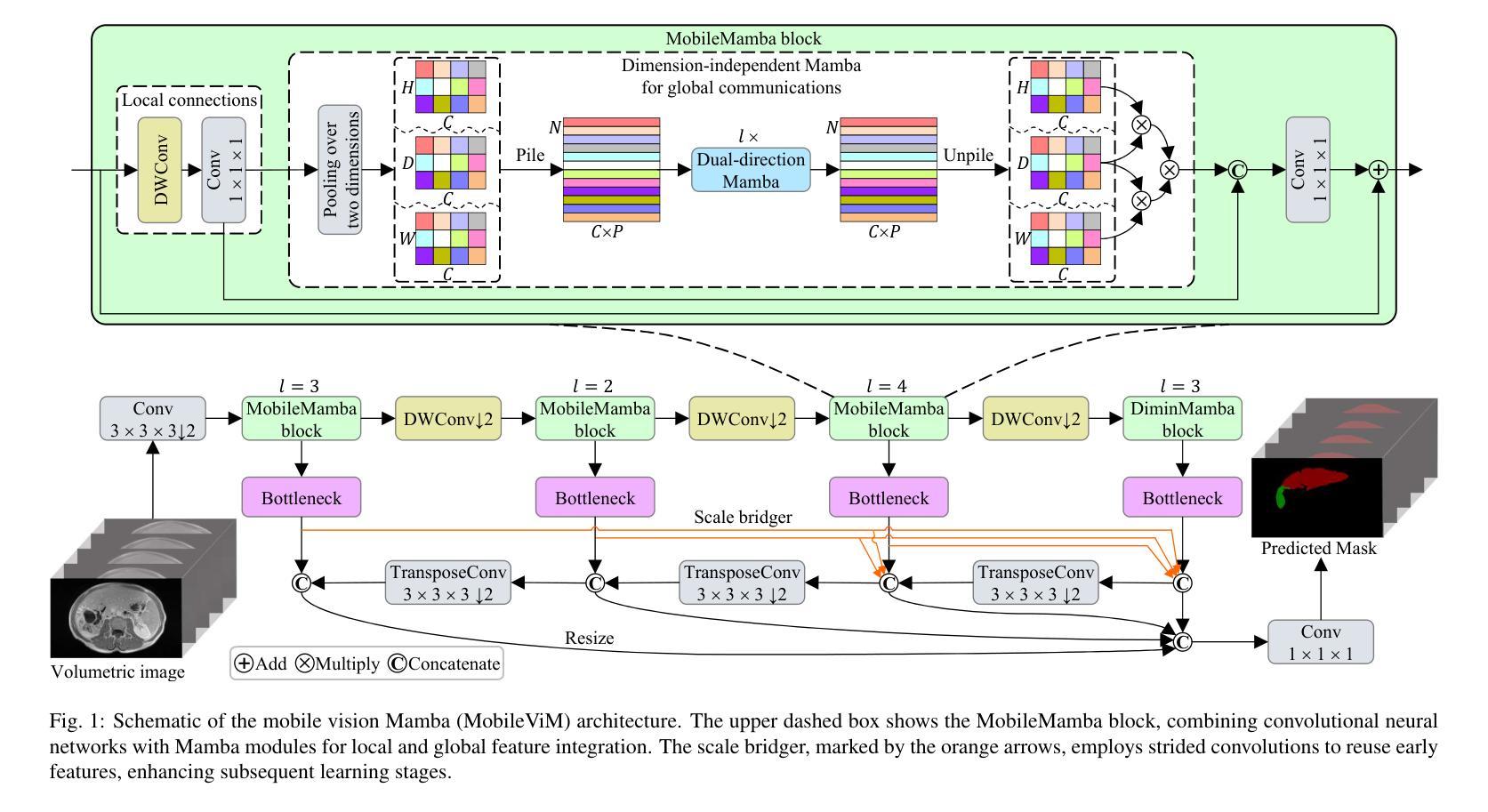
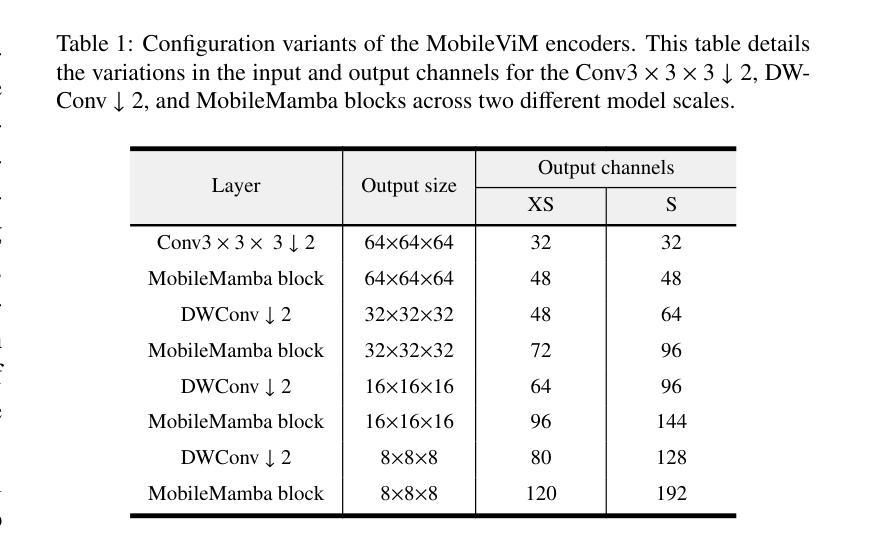
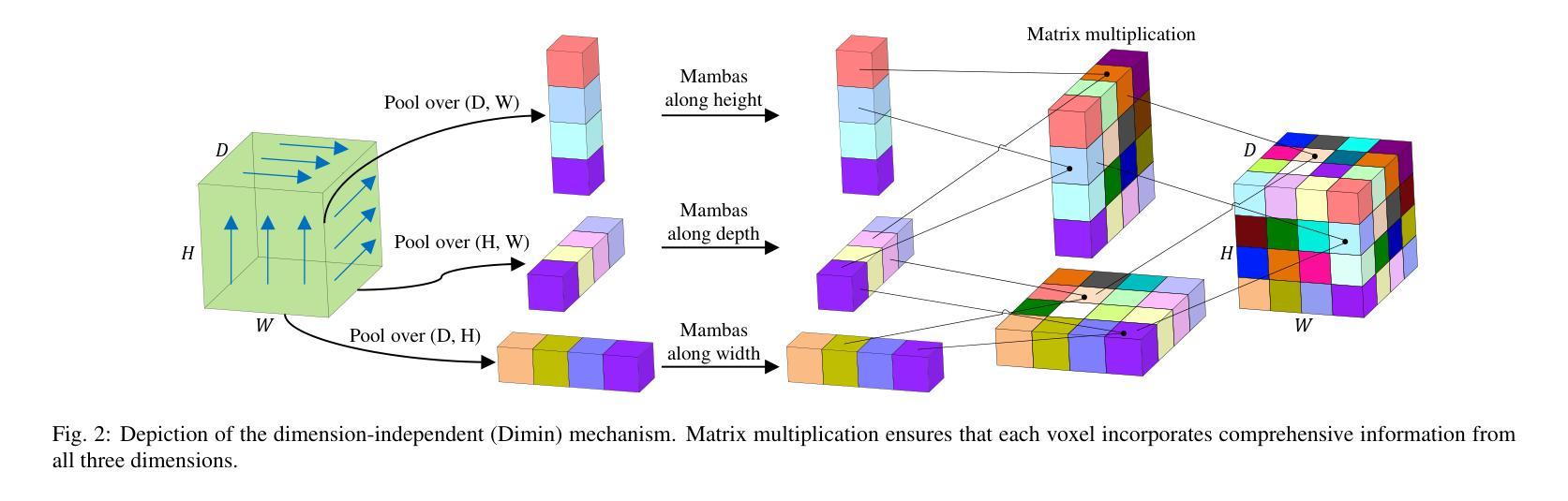
MobileViM: A Light-weight and Dimension-independent Vision Mamba for 3D Medical Image Analysis
Authors:Wei Dai, Steven Wang, Jun Liu
Efficient evaluation of three-dimensional (3D) medical images is crucial for diagnostic and therapeutic practices in healthcare. Recent years have seen a substantial uptake in applying deep learning and computer vision to analyse and interpret medical images. Traditional approaches, such as convolutional neural networks (CNNs) and vision transformers (ViTs), face significant computational challenges, prompting the need for architectural advancements. Recent efforts have led to the introduction of novel architectures like the ``Mamba’’ model as alternative solutions to traditional CNNs or ViTs. The Mamba model excels in the linear processing of one-dimensional data with low computational demands. However, Mamba’s potential for 3D medical image analysis remains underexplored and could face significant computational challenges as the dimension increases. This manuscript presents MobileViM, a streamlined architecture for efficient segmentation of 3D medical images. In the MobileViM network, we invent a new dimension-independent mechanism and a dual-direction traversing approach to incorporate with a vision-Mamba-based framework. MobileViM also features a cross-scale bridging technique to improve efficiency and accuracy across various medical imaging modalities. With these enhancements, MobileViM achieves segmentation speeds exceeding 90 frames per second (FPS) on a single graphics processing unit (i.e., NVIDIA RTX 4090). This performance is over 24 FPS faster than the state-of-the-art deep learning models for processing 3D images with the same computational resources. In addition, experimental evaluations demonstrate that MobileViM delivers superior performance, with Dice similarity scores reaching 92.72%, 86.69%, 80.46%, and 77.43% for PENGWIN, BraTS2024, ATLAS, and Toothfairy2 datasets, respectively, which significantly surpasses existing models.
在医疗保健领域,对三维(3D)医学图像的有效评估对于诊断和治疗实践至关重要。近年来,深度学习和计算机视觉在医学图像分析和解释方面的应用显著增加。传统方法,如卷积神经网络(CNNs)和视觉变压器(ViTs),面临着重大计算挑战,促使需要进行架构改进。近期的研究工作引入了新型架构,如“Mamba”模型,作为传统CNNs或ViTs的替代解决方案。“Mamba”模型在处理一维数据的线性处理方面表现出色,计算需求较低。然而,Mamba在3D医学图像分析方面的潜力尚未得到充分探索,随着维度的增加,可能会面临重大的计算挑战。本文提出了MobileViM,这是一个用于高效分割3D医学图像的简化架构。在MobileViM网络中,我们发明了一种新的维度独立机制和一种双向遍历方法,将其纳入基于视觉Mamba的框架中。MobileViM还采用跨尺度桥梁技术,以提高不同医学成像模式的效率和准确性。通过这些增强功能,MobileViM在单个图形处理单元(例如NVIDIA RTX 4090)上实现了超过每秒90帧(FPS)的分割速度。此性能比使用相同计算资源的最新深度学习模型处理3D图像的速度快24 FPS以上。此外,实验评估表明,MobileViM的性能卓越,在PENGWIN、BraTS2024、ATLAS和Toothfairy2数据集上的Dice相似度得分分别达到92.72%、86.69%、80.46%和77.43%,显著超越了现有模型。
论文及项目相关链接
PDF The co-authors have not approved its submission to arXiv
Summary
本文提出了一种针对三维医学图像高效分割的模型MobileViM。该模型引入了一种新的维度独立机制和双向遍历方法,与基于视觉的Mamba框架相结合。MobileViM还采用跨尺度桥接技术,以提高不同医学成像模态的效率和准确性。相较于其他先进深度学习模型,MobileViM在处理三维图像时速度更快,性能更优。
Key Takeaways
- 三维医学图像评估在医疗诊断和治疗实践中至关重要。
- 深度学习在计算机视觉在医学图像分析和解释中得到广泛应用。
- 传统方法如卷积神经网络(CNNs)和视觉转换器(ViTs)面临计算挑战,需要架构改进。
- Mamba模型在低计算需求的一维数据处理中表现出色,但在三维医学图像分析方面的潜力尚未得到充分探索。
- MobileViM是一个针对三维医学图像高效分割的流线型架构。
- MobileViM采用新的维度独立机制和双向遍历方法与视觉Mamba框架相结合,提高了效率和准确性。
点此查看论文截图

SCC-YOLO: An Improved Object Detector for Assisting in Brain Tumor Diagnosis
Authors:Runci Bai, Guibao Xu, Yanze Shi
Brain tumors can lead to neurological dysfunction, cognitive and psychological changes, increased intracranial pressure, and seizures, posing significant risks to health. The You Only Look Once (YOLO) series has shown superior accuracy in medical imaging object detection. This paper presents a novel SCC-YOLO architecture that integrates the SCConv module into YOLOv9. The SCConv module optimizes convolutional efficiency by reducing spatial and channel redundancy, enhancing image feature learning. We examine the effects of different attention mechanisms with YOLOv9 for brain tumor detection using the Br35H dataset and our custom dataset (Brain_Tumor_Dataset). Results indicate that SCC-YOLO improved mAP50 by 0.3% on the Br35H dataset and by 0.5% on our custom dataset compared to YOLOv9. SCC-YOLO achieves state-of-the-art performance in brain tumor detection.
脑肿瘤可能导致神经功能障碍、认知和心理学变化、颅内压升高和癫痫发作,对健康构成重大风险。You Only Look Once(YOLO)系列已在医学影像物体检测中展现出卓越的准确性。本文提出了一种新型的SCC-YOLO架构,它将SCConv模块整合到YOLOv9中。SCConv模块通过减少空间冗余和通道冗余来优化卷积效率,增强图像特征学习。我们使用Br35H数据集和自定义数据集(Brain_Tumor_Dataset)来检验不同注意力机制在YOLOv9检测脑肿瘤方面的效果。结果表明,与YOLOv9相比,SCC-YOLO在Br35H数据集上的mAP50提高了0.3%,在我们的自定义数据集上提高了0.5%。SCC-YOLO在脑肿瘤检测方面达到了最先进的性能。
论文及项目相关链接
Summary
本文介绍了一种新型的SCC-YOLO架构,它将SCConv模块集成到YOLOv9中以提高医学图像中目标检测的准确性。实验结果显示,SCC-YOLO在Br35H数据集和自定义数据集上的表现均优于YOLOv9,特别是在脑肿瘤检测方面取得了最先进的性能。
Key Takeaways
- 脑肿瘤可能导致神经功能障碍、认知和心理变化、颅内压增加和癫痫发作,对健康构成重大风险。
- YOLO系列在医学成像目标检测中展现了较高的准确性。
- 本文提出了一种新型的SCC-YOLO架构,集成了SCConv模块以优化卷积效率,增强图像特征学习。
- SCC-YOLO在Br35H数据集和自定义的Brain_Tumor_Dataset数据集上进行了实验验证。
- 实验结果显示,与YOLOv9相比,SCC-YOLO在mAP50指标上有所提升,其中在自定义数据集上的提升更为明显。
- SCC-YOLO在脑肿瘤检测方面取得了最先进的性能。
点此查看论文截图



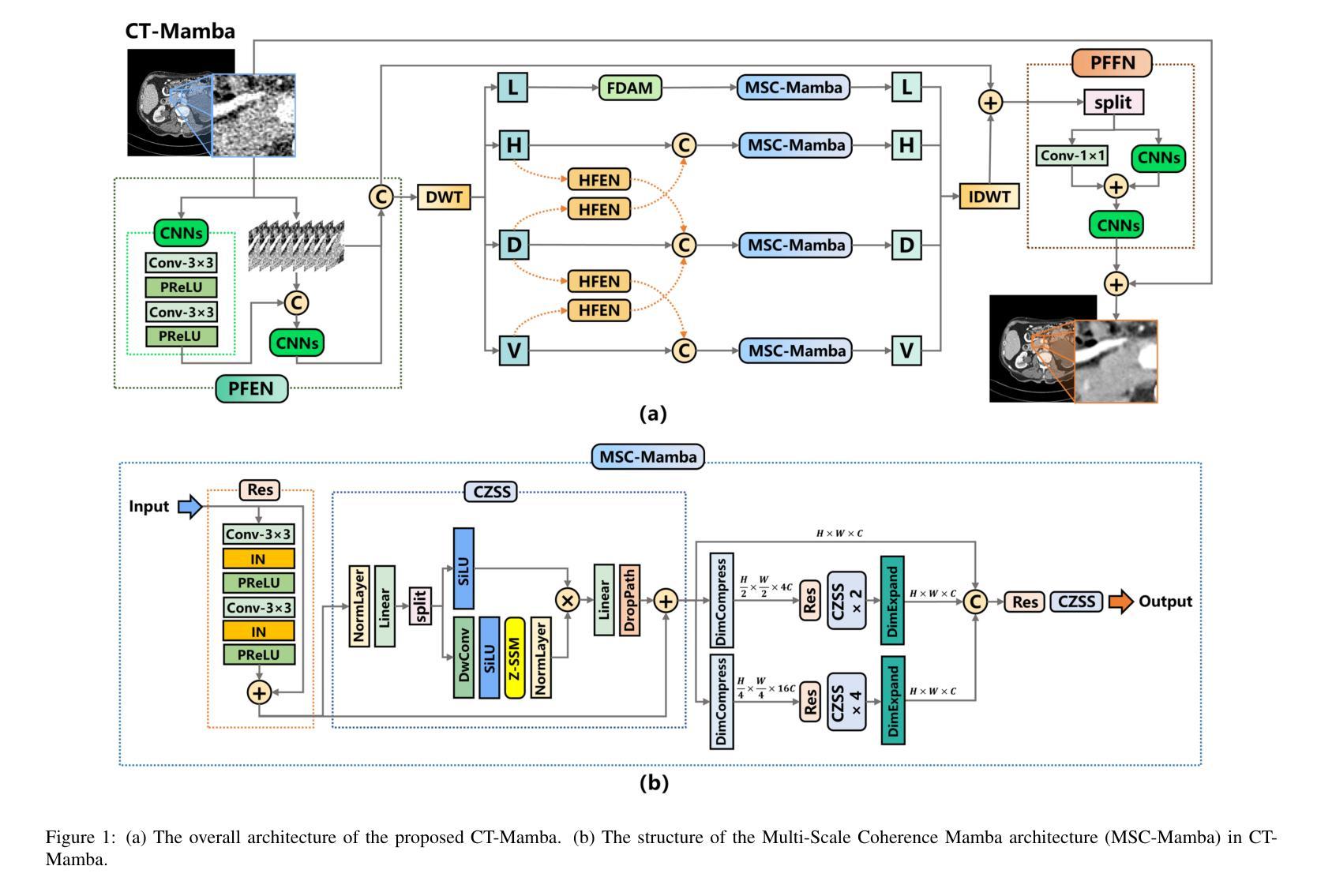
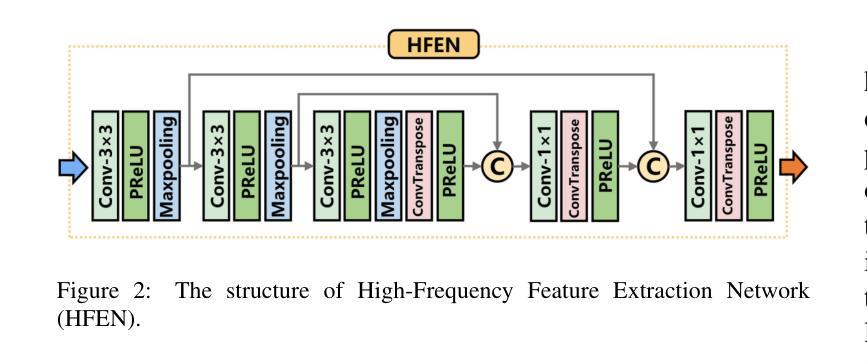
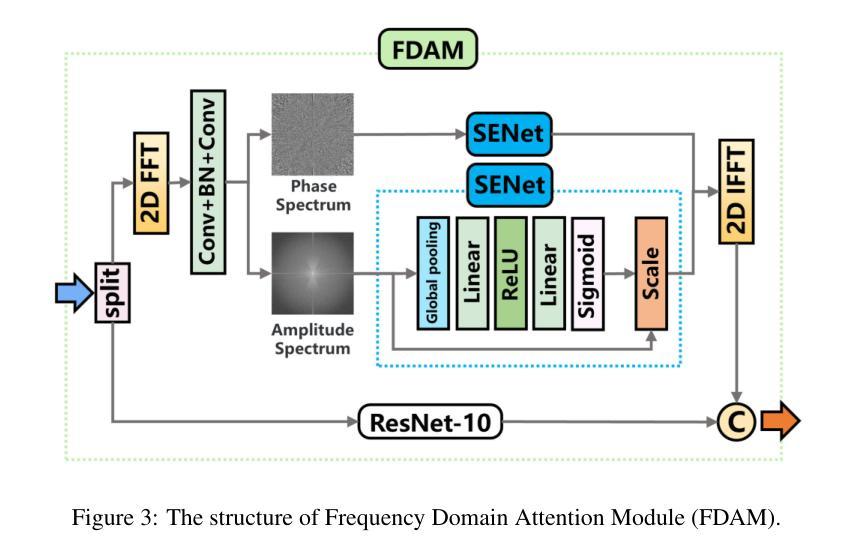
CT-Mamba: A Hybrid Convolutional State Space Model for Low-Dose CT Denoising
Authors:Linxuan Li, Wenjia Wei, Luyao Yang, Wenwen Zhang, Jiashu Dong, Yahua Liu, Hongshi Huang, Wei Zhao
Low-dose CT (LDCT) significantly reduces the radiation dose received by patients, however, dose reduction introduces additional noise and artifacts. Currently, denoising methods based on convolutional neural networks (CNNs) face limitations in long-range modeling capabilities, while Transformer-based denoising methods, although capable of powerful long-range modeling, suffer from high computational complexity. Furthermore, the denoised images predicted by deep learning-based techniques inevitably exhibit differences in noise distribution compared to normal-dose CT (NDCT) images, which can also impact the final image quality and diagnostic outcomes. This paper proposes CT-Mamba, a hybrid convolutional State Space Model for LDCT image denoising. The model combines the local feature extraction advantages of CNNs with Mamba’s strength in capturing long-range dependencies, enabling it to capture both local details and global context. Additionally, we introduce an innovative spatially coherent ‘Z’-shaped scanning scheme to ensure spatial continuity between adjacent pixels in the image. We design a Mamba-driven deep noise power spectrum (NPS) loss function to guide model training, ensuring that the noise texture of the denoised LDCT images closely resembles that of NDCT images, thereby enhancing overall image quality and diagnostic value. Experimental results have demonstrated that CT-Mamba performs excellently in reducing noise in LDCT images, enhancing detail preservation, and optimizing noise texture distribution, and exhibits higher statistical similarity with the radiomics features of NDCT images. The proposed CT-Mamba demonstrates outstanding performance in LDCT denoising and holds promise as a representative approach for applying the Mamba framework to LDCT denoising tasks. Our code will be made available after the paper is officially published: https://github.com/zy2219105/CT-Mamba/.
低剂量CT(LDCT)显著减少了患者接受的辐射剂量,然而,剂量的减少会引入额外的噪声和伪影。目前,基于卷积神经网络(CNNs)的降噪方法在长期建模能力方面存在局限性,而基于Transformer的降噪方法虽然具有强大的长期建模能力,但计算复杂度较高。此外,基于深度学习技术预测的降噪图像与正常剂量CT(NDCT)图像相比,噪声分布不可避免地存在差异,这也可能影响最终的图像质量和诊断结果。本文提出了CT-Mamba,一种用于LDCT图像降噪的混合卷积状态空间模型。该模型结合了CNNs提取局部特征的优势和Mamba在捕捉长期依赖关系方面的实力,使其能够捕捉局部细节和全局上下文。此外,我们引入了一种创新的空间连贯的“Z”形扫描方案,以确保图像中相邻像素之间的空间连续性。我们设计了一种以Mamba驱动的深度噪声功率谱(NPS)损失函数来指导模型训练,确保降噪LDCT图像的噪声纹理与NDCT图像相似,从而提高整体图像质量和诊断价值。实验结果表明,CT-Mamba在降低LDCT图像噪声、增强细节保留和优化噪声纹理分布方面表现出色,与NDCT图像的放射学特征具有更高的统计相似性。所提出的CT-Mamba在LDCT降噪方面表现出卓越的性能,并有望作为将Mamba框架应用于LDCT降噪任务的一种代表性方法。我们的代码将在论文正式发表后提供:https://github.com/zy2219105/CT-Mamba/。
论文及项目相关链接
Summary
基于卷积神经网络与Mamba模型的混合CT图像去噪方法能有效减少低剂量CT(LDCT)图像中的噪声与伪影,同时兼顾局部细节与全局上下文信息。新方法结合了CNN的局部特征提取优势与Mamba模型的长程依赖性捕捉能力,并提出了一种新颖的“Z”字形扫描方案,以确保图像中相邻像素的空间连续性。此外,通过设计基于Mamba的深度噪声功率谱(NPS)损失函数,训练模型以生成与常规剂量CT(NDCT)图像噪声纹理相似的去噪LDCT图像,从而提高整体图像质量和诊断价值。实验结果显示,该新方法在降低LDCT图像噪声、增强细节保留以及优化噪声纹理分布方面表现出卓越性能。
Key Takeaways
- 低剂量CT(LDCT)中使用了新型的图像去噪方法以减轻噪声和伪影问题。
- 该方法结合了卷积神经网络(CNN)与Mamba模型的优势,提高了长程建模能力同时降低了计算复杂性。
- 创新性地采用“Z”字形扫描方案确保图像的空间连续性。
- 引入了深度噪声功率谱(NPS)损失函数,确保去噪后的LDCT图像噪声纹理接近常规剂量CT(NDCT)图像。
- 实验结果显示该方法在降低噪声、保留细节和优化噪声纹理方面效果显著。
- 该方法有望代表将Mamba框架应用于LDCT去噪任务的一种典型方法。
点此查看论文截图


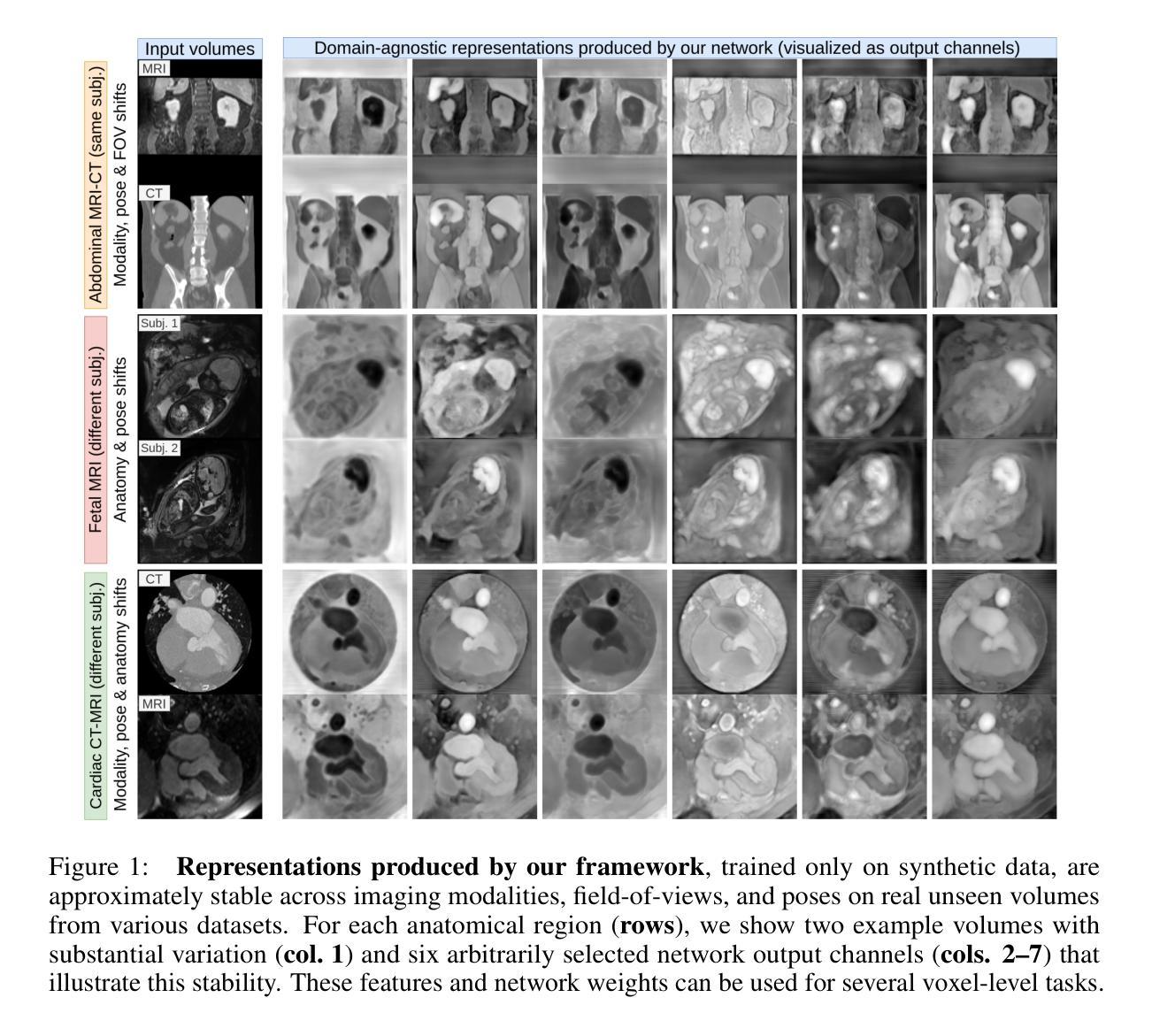
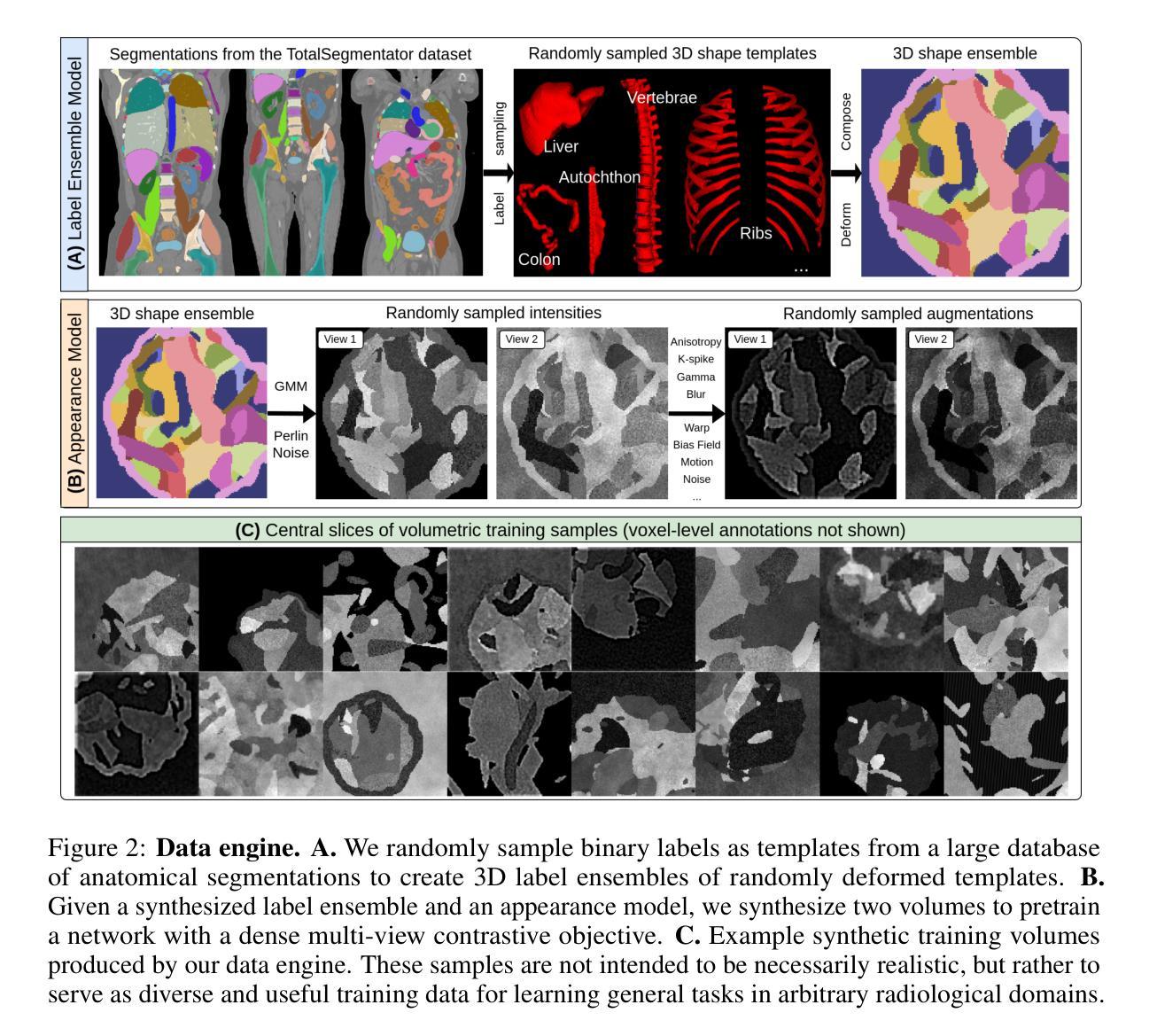
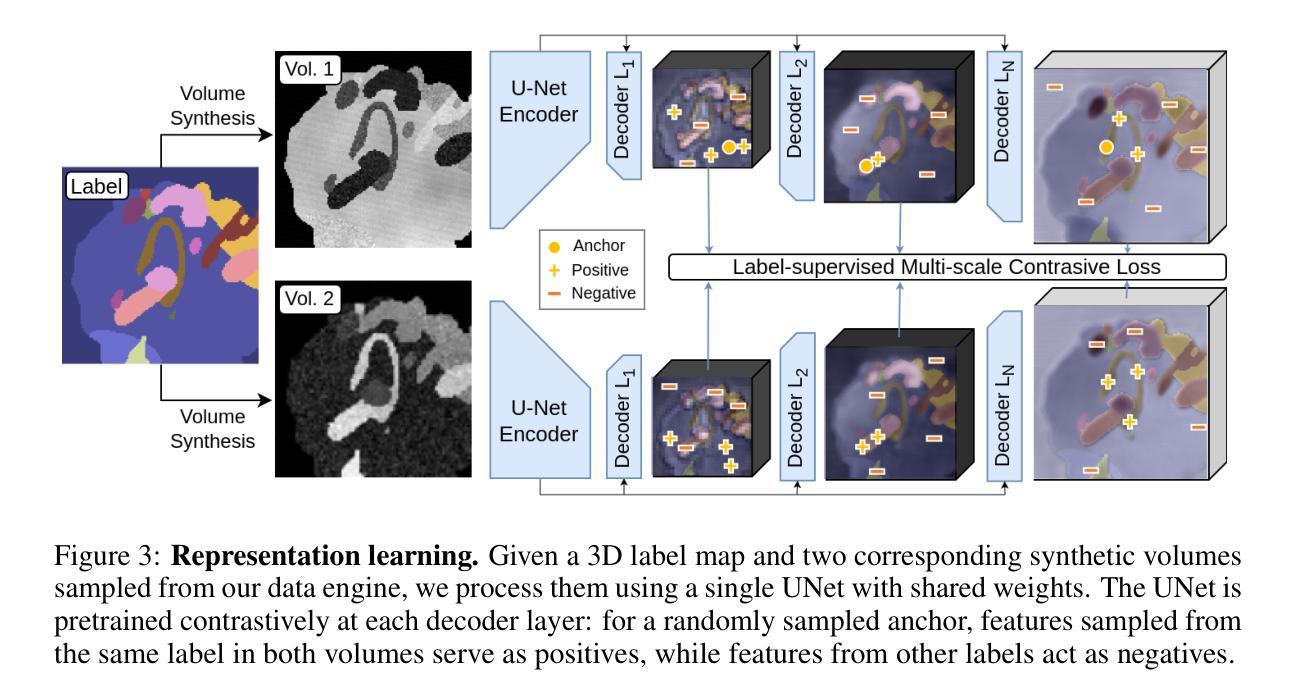
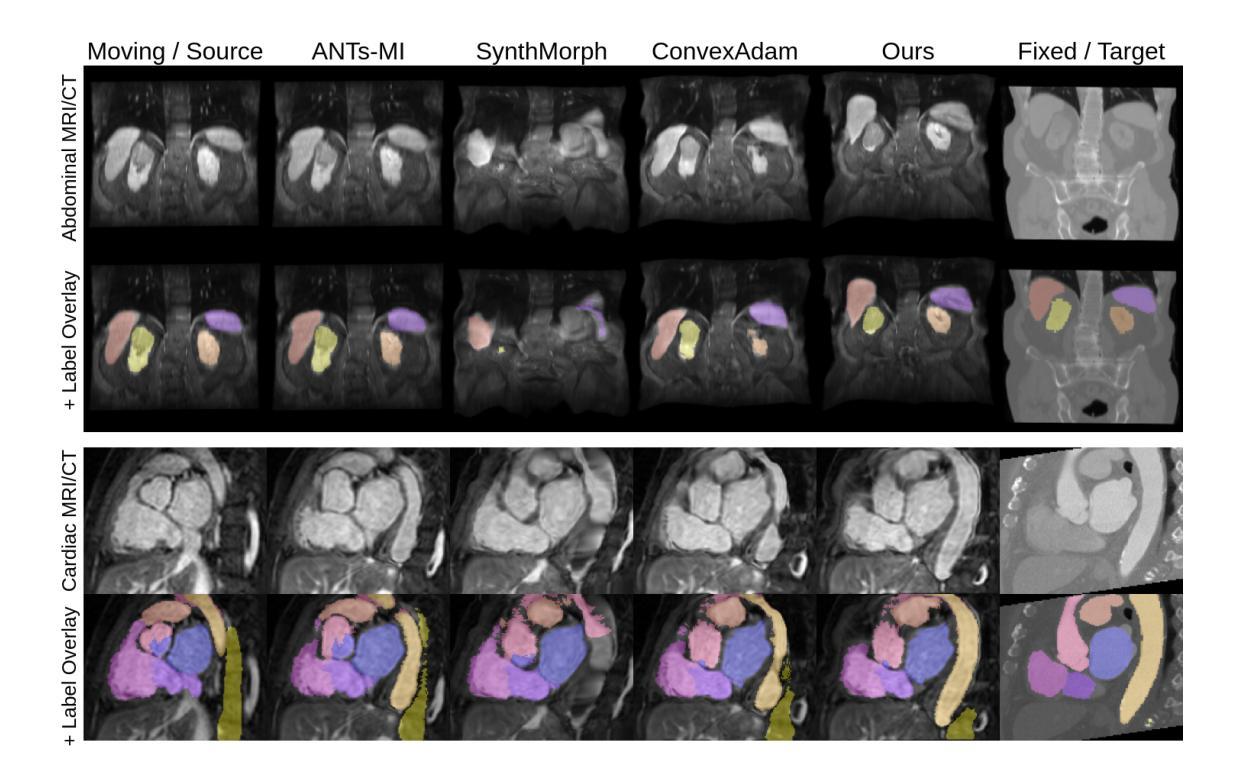
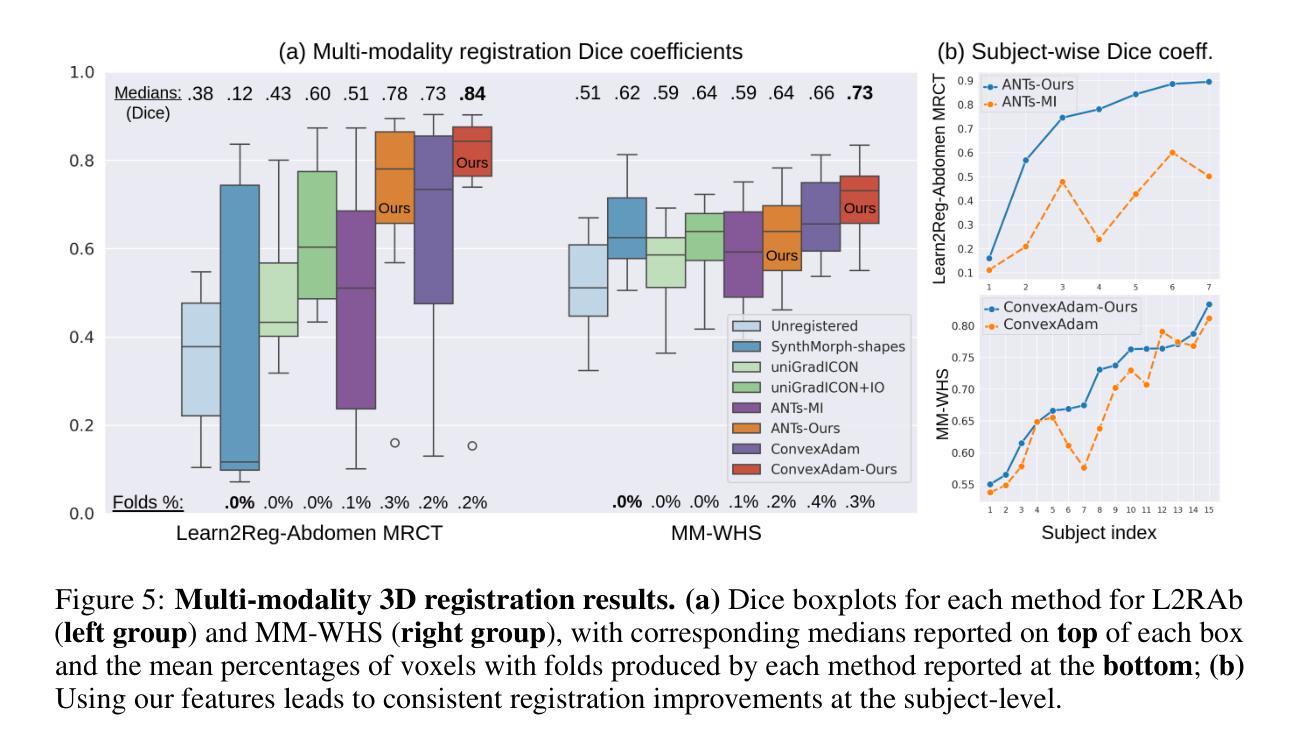
Learning General-Purpose Biomedical Volume Representations using Randomized Synthesis
Authors:Neel Dey, Benjamin Billot, Hallee E. Wong, Clinton J. Wang, Mengwei Ren, P. Ellen Grant, Adrian V. Dalca, Polina Golland
Current volumetric biomedical foundation models struggle to generalize as public 3D datasets are small and do not cover the broad diversity of medical procedures, conditions, anatomical regions, and imaging protocols. We address this by creating a representation learning method that instead anticipates strong domain shifts at training time itself. We first propose a data engine that synthesizes highly variable training samples that would enable generalization to new biomedical contexts. To then train a single 3D network for any voxel-level task, we develop a contrastive learning method that pretrains the network to be stable against nuisance imaging variation simulated by the data engine, a key inductive bias for generalization. This network’s features can be used as robust representations of input images for downstream tasks and its weights provide a strong, dataset-agnostic initialization for finetuning on new datasets. As a result, we set new standards across both multimodality registration and few-shot segmentation, a first for any 3D biomedical vision model, all without (pre-)training on any existing dataset of real images.
当前的三维生物医学基础模型在泛化方面存在困难,因为公共的3D数据集规模较小,并不能覆盖广泛的医疗程序、状况、解剖区域和成像协议。我们通过创建一种表示学习方法来解决这个问题,该方法能够在训练时本身就能预测到强烈的领域变化。我们首先提出了一个数据引擎,该引擎能够合成高度可变的训练样本,以实现向新生物医学环境的泛化。为了针对任何体素级任务训练单个的3D网络,我们开发了一种对比学习方法,该方法能够训练网络以对抗由数据引擎模拟的干扰成像变化,这是泛化的关键归纳偏置。该网络的特征可以作为下游任务的稳健图像表示,其权重为在新数据集上进行微调提供了强大且独立于数据集之外的初始化。因此,我们在多模态注册和少样本分割方面设定了新的标准,这是首次有3D生物医学视觉模型能做到这一点,并且全程未使用任何现有真实图像数据集进行(预)训练。
论文及项目相关链接
PDF ICLR 2025: International Conference on Learning Representations. Code and model weights available at https://github.com/neel-dey/anatomix. Keywords: synthetic data, representation learning, medical image analysis, image registration, image segmentation
Summary
该文提出一种解决生物医学图像领域模型泛化能力弱的问题的方法。针对公共3D数据集规模小、涵盖医疗程序、状况、解剖区域和成像协议多样性不足的问题,研究团队创建了一种表征学习方法,该方法能够在训练时自身预测强领域漂移。他们首先提出一个数据引擎,合成高度可变的训练样本,以实现对新生物医学环境的泛化。接着,为了对任何体素级任务进行训练,他们开发了一种对比学习方法,该方法对由数据引擎模拟的干扰成像变化进行预训练,形成对泛化的关键归纳偏置。该网络的特征可用于下游任务的稳健表示,其权重为在新数据集上进行微调提供了强大的、独立于数据集初始化。最终,该研究在多模态注册和少样本分割任务上设定了新的标准,成为首个无需在真实图像现有数据集上进行(预)训练的3D生物医学视觉模型。
Key Takeaways
- 当前生物医学图像领域的模型泛化能力受限,主要由于公共数据集规模小且多样性不足。
- 研究团队提出一种表征学习方法,能在训练时预测强领域漂移。
- 通过数据引擎合成高度可变的训练样本,以提高模型对新生物医学环境的泛化能力。
- 采用对比学习方法进行预训练,增强模型对干扰成像变化的稳定性。
- 该网络特征适用于下游任务,并提供稳健的图像表示。
- 模型权重为在新数据集上的微调提供了强大的初始化,且独立于数据集。
点此查看论文截图

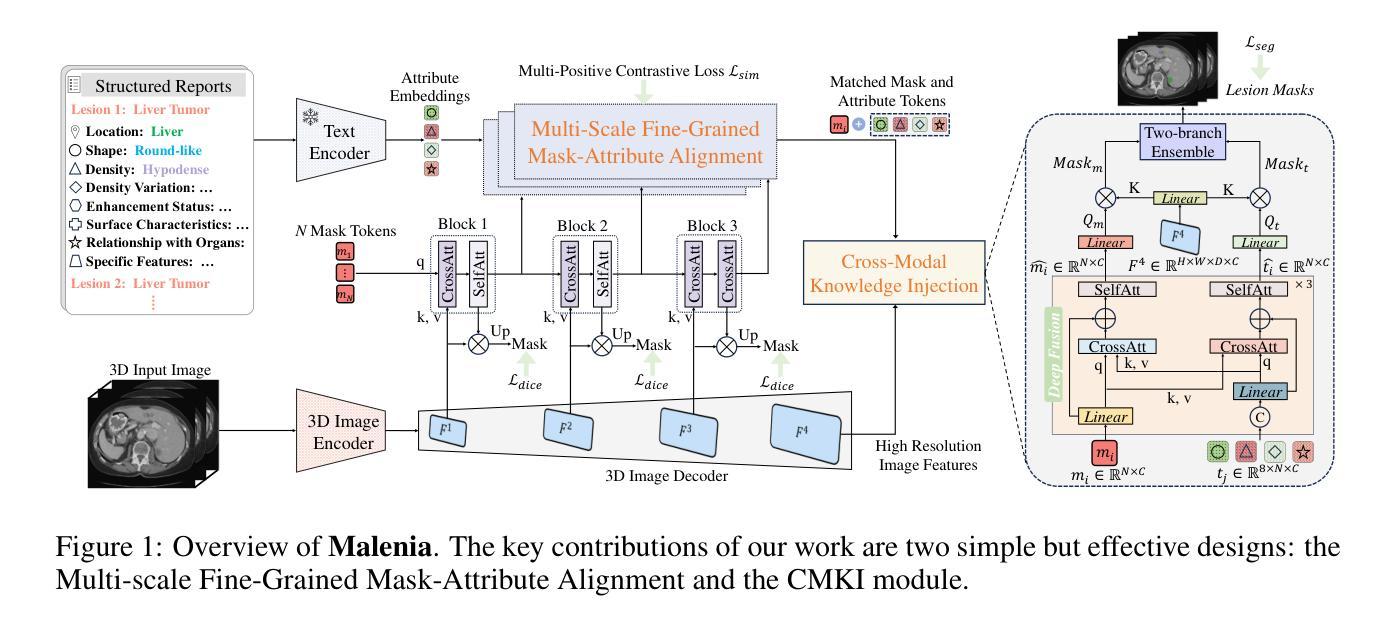
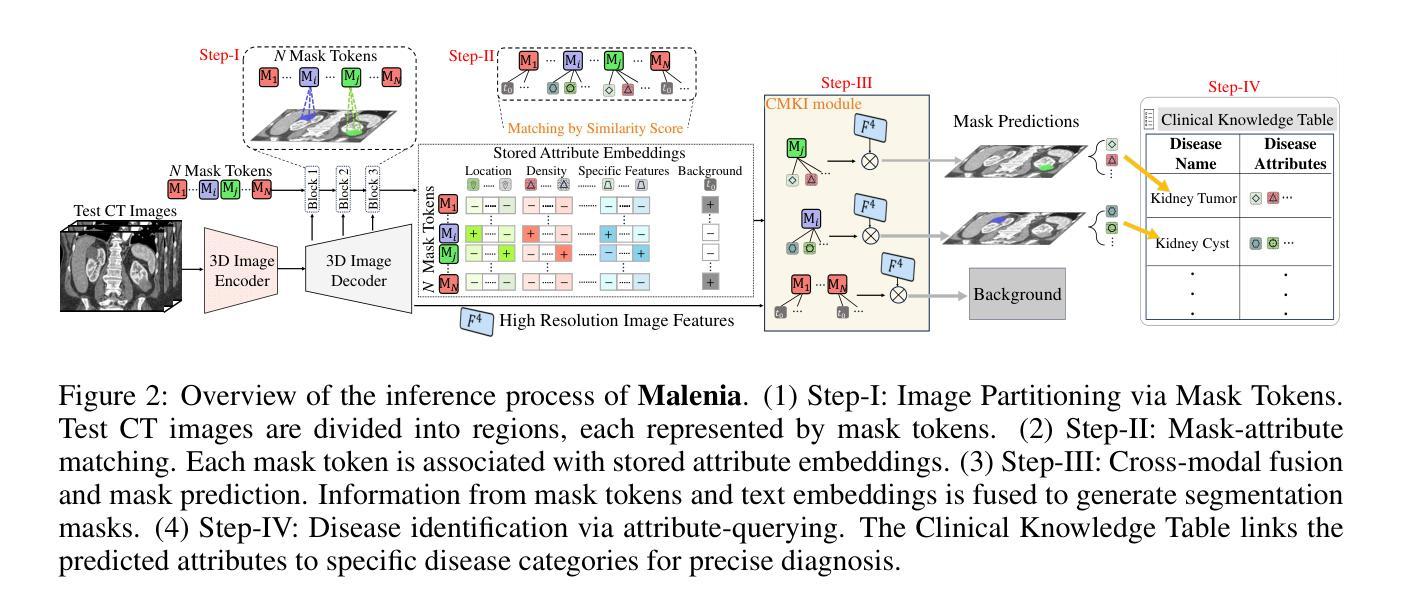
Unleashing the Potential of Vision-Language Pre-Training for 3D Zero-Shot Lesion Segmentation via Mask-Attribute Alignment
Authors:Yankai Jiang, Wenhui Lei, Xiaofan Zhang, Shaoting Zhang
Recent advancements in medical vision-language pre-training models have driven significant progress in zero-shot disease recognition. However, transferring image-level knowledge to pixel-level tasks, such as lesion segmentation in 3D CT scans, remains a critical challenge. Due to the complexity and variability of pathological visual characteristics, existing methods struggle to align fine-grained lesion features not encountered during training with disease-related textual representations. In this paper, we present Malenia, a novel multi-scale lesion-level mask-attribute alignment framework, specifically designed for 3D zero-shot lesion segmentation. Malenia improves the compatibility between mask representations and their associated elemental attributes, explicitly linking the visual features of unseen lesions with the extensible knowledge learned from previously seen ones. Furthermore, we design a Cross-Modal Knowledge Injection module to enhance both visual and textual features with mutually beneficial information, effectively guiding the generation of segmentation results. Comprehensive experiments across three datasets and 12 lesion categories validate the superior performance of Malenia.
近年来,医学视觉语言预训练模型的进步推动了零样本疾病识别的显著发展。然而,将图像级别的知识转移到像素级别的任务,如在3D CT扫描中的病灶分割,仍然是一个关键挑战。由于病理视觉特征的复杂性和可变性,现有方法很难将训练期间未遇到的精细病灶特征与疾病相关的文本表示进行对齐。在本文中,我们提出了Malenia,这是一种新型的多尺度病灶级别掩膜属性对齐框架,专为3D零样本病灶分割设计。Malenia提高了掩膜表示与其相关元素属性之间的兼容性,明确地将未见过的病灶的视觉特征与从已见过的病灶中学到的可扩展知识联系起来。此外,我们设计了一个跨模态知识注入模块,以增强视觉和文本特征的相互有益信息,有效指导生成分割结果。在三个数据集和12个病灶类别的综合实验验证了Malenia的卓越性能。
论文及项目相关链接
PDF Accepted as ICLR 2025 conference paper
Summary
医学视觉语言预训练模型的最新进展推动了零样本疾病识别的显著进步。然而,将图像级别的知识转移到像素级别的任务,如3D CT扫描中的病灶分割,仍是一个关键挑战。本文提出一种名为Malenia的多尺度病灶级别掩膜属性对齐框架,专门用于3D零样本病灶分割。该框架提高了掩膜表示与其相关基础属性之间的兼容性,将未见病灶的视觉特征与从已见病灶中学到的可扩展知识明确联系起来。此外,设计了一种跨模态知识注入模块,以增强视觉和文本特征的相互补充信息,有效指导生成分割结果。在三个数据集和12个病灶类别的综合实验中验证了Malenia的卓越性能。
Key Takeaways
- 医学视觉语言预训练模型的最新进展推动了零样本疾病识别的进步。
- 图像级别的知识转移到像素级别的任务(如病灶分割)仍然是一个挑战。
- Malenia框架用于3D零样本病灶分割,实现多尺度病灶级别掩膜属性对齐。
- Malenia提高了掩膜表示与基础属性之间的兼容性,关联未见与已见病灶特征。
- 跨模态知识注入模块增强视觉和文本特征的互补信息。
- Malenia在多个数据集和不同病灶类别上表现出卓越性能。
点此查看论文截图

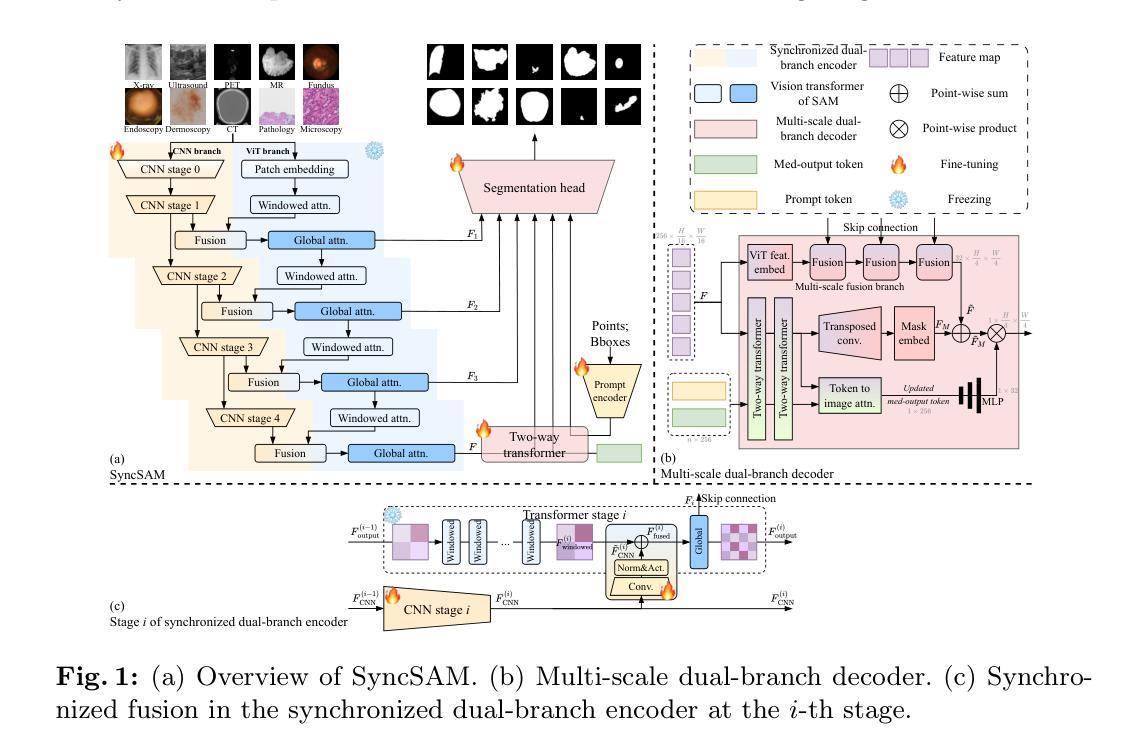
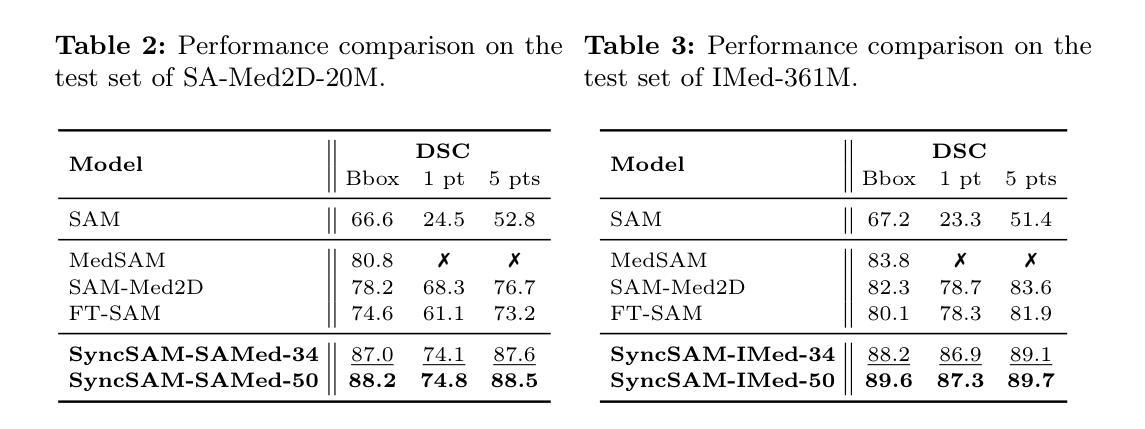
Improved Baselines with Synchronized Encoding for Universal Medical Image Segmentation
Authors:Sihan Yang, Xuande Mi, Jiadong Feng, Haixia Bi, Hai Zhang, Jian Sun
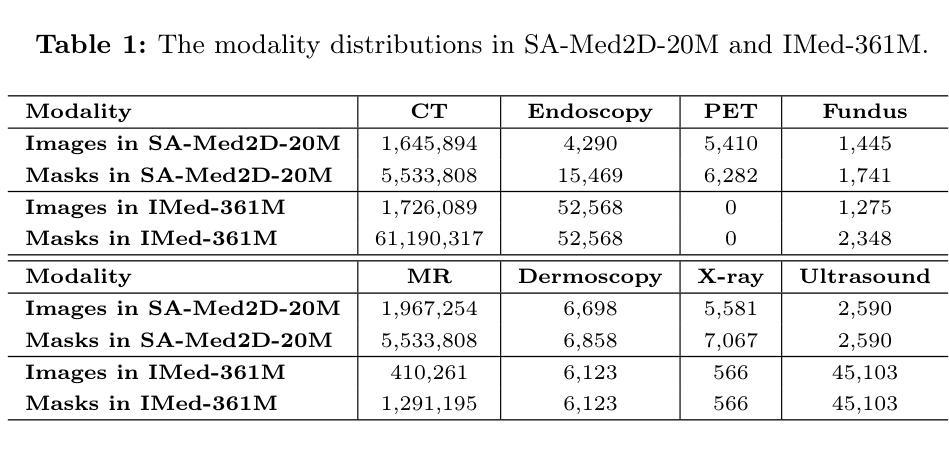
Large foundation models, known for their strong zero-shot generalization capabilities, can be applied to a wide range of downstream tasks. However, developing foundation models for medical image segmentation poses a significant challenge due to the domain gap between natural and medical images. While fine-tuning techniques based on the Segment Anything Model (SAM) have been explored, they primarily focus on scaling up data or refining inference strategies without incorporating domain-specific architectural designs, limiting their zero-shot performance. To optimize segmentation performance under standard inference settings and provide a strong baseline for future research, we introduce SyncSAM, which employs a synchronized dual-branch encoder that integrates convolution and Transformer features in a synchronized manner to enhance medical image encoding, and a multi-scale dual-branch decoder to preserve image details. SyncSAM is trained on two of the largest medical image segmentation datasets, SA-Med2D-20M and IMed-361M, resulting in a series of pre-trained models for universal medical image segmentation. Experimental results demonstrate that SyncSAM not only achieves state-of-the-art performance on test sets but also exhibits strong zero-shot capabilities on unseen datasets. The code and model weights are available at https://github.com/Hhankyangg/SyncSAM.
大型基础模型以其强大的零样本泛化能力而著称,可广泛应用于各种下游任务。然而,针对医学图像分割开发基础模型是一个巨大的挑战,因为自然图像和医学图像之间存在领域差距。虽然基于Segment Anything Model(SAM)的微调技术已被探索,但它们主要关注扩大数据规模或改进推理策略,而没有结合领域特定的架构设计,从而限制了其零样本性能。为了优化标准推理设置下的分割性能,并为未来的研究提供强大的基线,我们引入了SyncSAM。SyncSAM采用同步双分支编码器,以同步方式集成卷积和Transformer特征,增强医学图像编码;并采用多尺度双分支解码器,保留图像细节。SyncSAM在两大医学图像分割数据集SA-Med2D-20M和IMed-361M上进行训练,生成了一系列用于通用医学图像分割的预训练模型。实验结果表明,SyncSAM不仅在测试集上达到最新性能,而且在未见数据集上表现出强大的零样本能力。相关代码和模型权重可在https://github.com/Hhankyangg/SyncSAM获取。
论文及项目相关链接
Summary
大型基础模型在医学图像分割中具有强大的零样本泛化能力,但面临自然图像与医学图像领域差异的挑战。SyncSAM模型通过同步双分支编码器和多尺度双分支解码器来增强医学图像的编码和细节保留。它在两个最大的医学图像分割数据集上进行训练,实现了预训练模型的通用医学图像分割。实验结果表明,SyncSAM在测试集上达到了最先进的性能,并在未见数据集上展现出强大的零样本能力。
Key Takeaways
- 大型基础模型具备广泛的应用潜力,特别是在医学图像分割领域。
- 医学图像分割面临自然图像与医学图像领域差异的挑战。
- SyncSAM模型通过同步双分支编码器集成卷积和Transformer特征,以提高医学图像编码效果。
- SyncSAM采用多尺度双分支解码器,旨在保留图像细节。
- SyncSAM模型在多个医学图像分割数据集上进行训练,提供预训练模型用于通用医学图像分割。
- 实验结果显示SyncSAM达到了最先进的性能,并在未见数据集上展现出强大的零样本能力。
点此查看论文截图

Real-Time Image Analysis Software Suitable for Resource-Constrained Computing
Authors:Alexandre Matov
Methods: We have developed a software suite (DataSet Tracker) for real-time analysis designed to run on computers, smartphones, and smart glasses hardware and suitable for resource-constrained, on-the-fly computing in microscopes without internet connectivity; a demo is available for viewing at datasetanalysis.com. Our objective is to present the community with an integrated, easy to use by all, tool for resolving the complex dynamics of the cytoskeletal meshworks, intracytoplasmic membranous networks, and vesicle trafficking. Our software is optimized for resource-constrained computing and can be installed even on microscopes without internet connectivity. Results: Our computational platform can provide high-content analyses and functional secondary screening of novel compounds that are in the process of approval, or at a pre-clinical stage of development, and putative combination therapies based on FDA-approved drugs. Importantly, dissecting the mechanisms of drug action with quantitative detail will allow the design of drugs that impede relapse and optimal dose regimens with minimal harmful side effects by carefully exploiting disease-specific aberrations. Conclusions: DataSet Tracker, the real-time optical flow feature tracking software presented in this contribution, can serve as the base module of an integrated platform of existing and future algorithms for real-time cellular analysis. The computational assay we propose could successfully be applied to evaluate treatment strategies for any human organ. It is our goal to have this integrated tool approved for use in the clinical practice.
方法:我们开发了一套实时分析软件套件(DataSet Tracker),可在计算机、智能手机和智能眼镜等硬件上运行,适用于无网络连接显微镜下的资源受限、即时计算。可以在datasetanalysis.com上查看演示版。我们的目标是向研究群体提供一个集成工具,该工具易于所有人使用,可解决细胞骨架网格、胞质内膜网络和囊泡转运的复杂动态问题。我们的软件针对资源受限的计算进行了优化,甚至可以在没有互联网连接的显微镜上安装使用。
结果:我们的计算平台可以提供高内涵分析以及新药筛选的功能二次筛选,这些新药正处于审批过程中或处于开发预临床阶段,以及基于FDA批准药物的组合疗法。重要的是,通过定量细节分析药物作用机制,将能够设计出阻止复发的药物,并借助精准地利用疾病特异性异常来制定最佳治疗方案和最小有害副作用的剂量方案。
论文及项目相关链接
Summary
本文介绍了一种用于实时分析的软件套件DataSet Tracker,适用于资源受限环境下无网络连接显微镜的在线计算。软件具有优化资源消耗的特点,旨在为社区提供一个综合工具,解决细胞骨架网格、细胞内膜网络和囊泡运输的复杂动态问题。该软件可应用于新药筛选和药物作用机制定量研究,有助于设计防止复发的药物并制定最佳剂量方案。DataSet Tracker可以作为现有和未来算法的集成平台的基础模块,用于实时细胞分析,成功应用于人类器官治疗策略评估,有望在临床实践中得到应用。
Key Takeaways
- 开发了一种实时分析软件套件DataSet Tracker,可在计算机、智能手机和智能眼镜硬件上运行。
- 适用于资源受限、无网络连接显微镜的在线计算环境。
- 软件旨在解决细胞骨架网格、细胞内膜网络和囊泡运输等领域的复杂动态问题。
- DataSet Tracker能进行高内容分析并对新药和组合疗法进行功能性二级筛选。
- 软件能定量研究药物作用机制,有助于设计防止复发的药物并制定最佳剂量方案。
- DataSet Tracker可作为集成平台的基石模块,用于实时细胞分析,适用于评估任何人类器官的治疗策略。
点此查看论文截图

HDKD: Hybrid Data-Efficient Knowledge Distillation Network for Medical Image Classification
Authors:Omar S. EL-Assiouti, Ghada Hamed, Dina Khattab, Hala M. Ebied
Vision Transformers (ViTs) have achieved significant advancement in computer vision tasks due to their powerful modeling capacity. However, their performance notably degrades when trained with insufficient data due to lack of inherent inductive biases. Distilling knowledge and inductive biases from a Convolutional Neural Network (CNN) teacher has emerged as an effective strategy for enhancing the generalization of ViTs on limited datasets. Previous approaches to Knowledge Distillation (KD) have pursued two primary paths: some focused solely on distilling the logit distribution from CNN teacher to ViT student, neglecting the rich semantic information present in intermediate features due to the structural differences between them. Others integrated feature distillation along with logit distillation, yet this introduced alignment operations that limits the amount of knowledge transferred due to mismatched architectures and increased the computational overhead. To this end, this paper presents Hybrid Data-efficient Knowledge Distillation (HDKD) paradigm which employs a CNN teacher and a hybrid student. The choice of hybrid student serves two main aspects. First, it leverages the strengths of both convolutions and transformers while sharing the convolutional structure with the teacher model. Second, this shared structure enables the direct application of feature distillation without any information loss or additional computational overhead. Additionally, we propose an efficient light-weight convolutional block named Mobile Channel-Spatial Attention (MBCSA), which serves as the primary convolutional block in both teacher and student models. Extensive experiments on two medical public datasets showcase the superiority of HDKD over other state-of-the-art models and its computational efficiency. Source code at: https://github.com/omarsherif200/HDKD
视觉Transformer(ViTs)由于其强大的建模能力,在计算机视觉任务中取得了显著的进展。然而,在数据不足的情况下进行训练时,由于其缺乏固有的归纳偏置,其性能会显著下降。从卷积神经网络(CNN)教师中提炼知识和归纳偏置,已成为提高ViT在有限数据集上泛化能力的有效策略。知识蒸馏(KD)的先前方法主要追求两种途径:一些方法专注于从CNN教师蒸馏logit分布到ViT学生,忽视了由于结构差异而存在于中间特征中的丰富语义信息。另一些方法结合了特征蒸馏和logit蒸馏,但这引入了对齐操作,由于架构不匹配而限制了知识转移的量并增加了计算开销。为此,本文提出了混合数据高效知识蒸馏(HDKD)范式,该范式采用CNN教师和混合学生。选择混合学生有两个主要方面。首先,它结合了卷积和变压器的优点,同时与教师的模型共享卷积结构。其次,这种共享结构使特征蒸馏能够直接应用,没有任何信息损失或额外的计算开销。此外,我们提出了一种高效的轻量级卷积块,名为移动通道空间注意力(MBCSA),它作为教师和学生模型中主要的卷积块。在两个医学公共数据集上的大量实验表明,HDKD优于其他最先进模型且计算效率更高。源代码位于:https://github.com/omarsherif200/HDKD
论文及项目相关链接
Summary
本文介绍了Vision Transformers(ViTs)在面临数据不足时性能下降的问题,以及通过从卷积神经网络(CNN)教师模型中蒸馏知识和归纳偏置来增强ViT学生在有限数据集上的泛化能力的方法。文章提出了一种新型的混合数据高效知识蒸馏(HDKD)范式,它采用CNN教师模型和混合学生模型,通过共享结构实现了特征蒸馏的直接应用,提高了知识转移的效率,同时降低了计算开销。此外,文章还提出了一种轻量级的卷积块——Mobile Channel-Spatial Attention(MBCSA),它在教师和学生模型中都起到了关键作用。在医疗公共数据集上的实验表明,HDKD优于其他先进模型,并具有计算效率高的优势。
Key Takeaways
- Vision Transformers (ViTs) 面临数据不足时性能下降的问题。
- 知识蒸馏是一种提高ViT在有限数据集上泛化能力的有效策略。
- 以往的知识蒸馏(KD)方法主要追求两种路径:一种只关注从CNN教师模型到ViT学生模型的logit分布蒸馏,忽视了由于结构差异而存在的中间特征中的丰富语义信息;另一种结合了特征蒸馏和logit蒸馏,但引入了由于架构不匹配而限制知识传递的对齐操作,并增加了计算开销。
- 本文提出了Hybrid Data-efficient Knowledge Distillation (HDKD) 范式,采用CNN教师模型和混合学生模型,通过共享结构实现特征蒸馏的直接应用。
- HDKD采用轻量级的卷积块Mobile Channel-Spatial Attention (MBCSA),在教师和学生模型中都起到了关键作用。
- 在医疗公共数据集上的实验表明,HDKD优于其他先进模型。
点此查看论文截图

MERIT: Multi-view evidential learning for reliable and interpretable liver fibrosis staging
Authors:Yuanye Liu, Zheyao Gao, Nannan Shi, Fuping Wu, Yuxin Shi, Qingchao Chen, Xiahai Zhuang
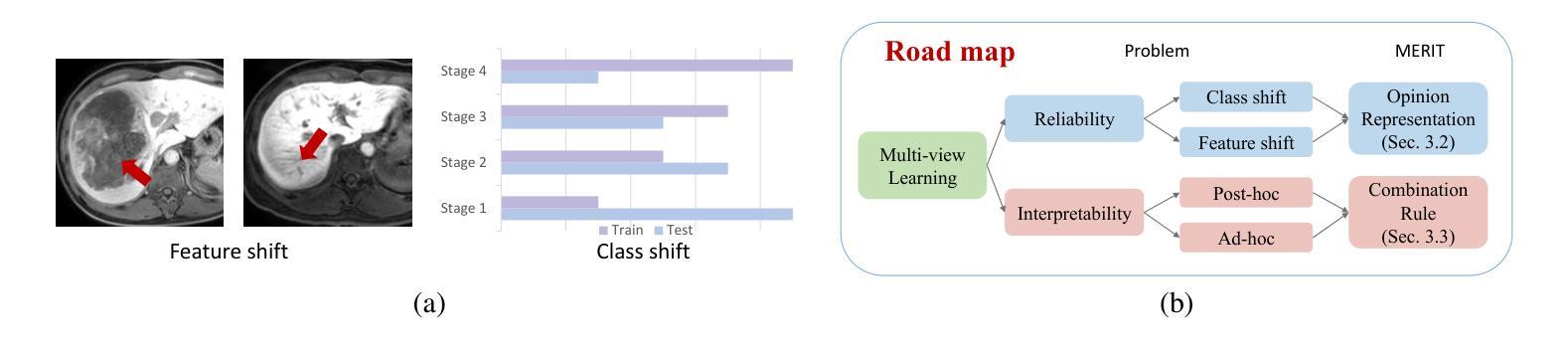
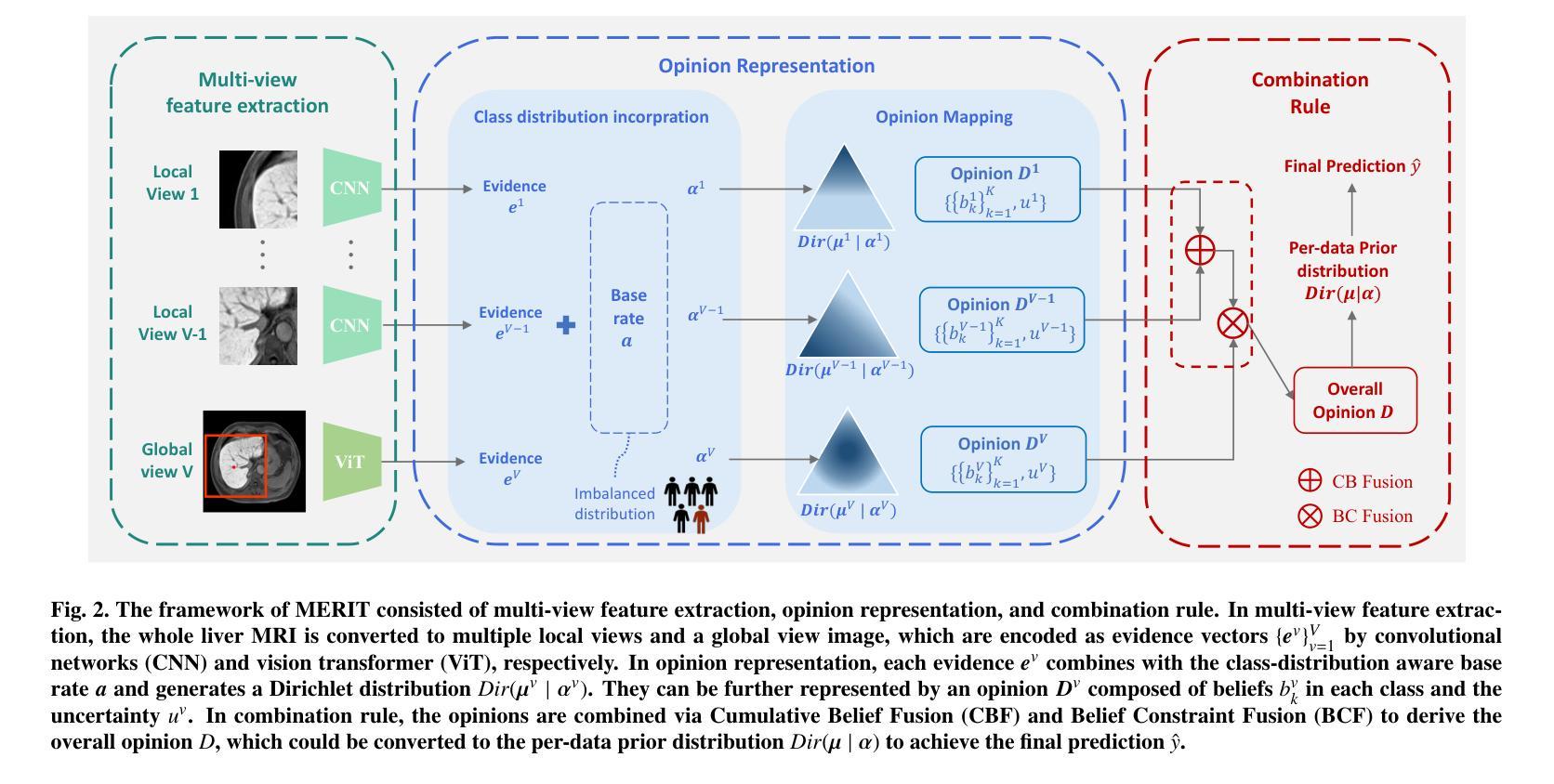
Accurate staging of liver fibrosis from magnetic resonance imaging (MRI) is crucial in clinical practice. While conventional methods often focus on a specific sub-region, multi-view learning captures more information by analyzing multiple patches simultaneously. However, previous multi-view approaches could not typically calculate uncertainty by nature, and they generally integrate features from different views in a black-box fashion, hence compromising reliability as well as interpretability of the resulting models. In this work, we propose a new multi-view method based on evidential learning, referred to as MERIT, which tackles the two challenges in a unified framework. MERIT enables uncertainty quantification of the predictions to enhance reliability, and employs a logic-based combination rule to improve interpretability. Specifically, MERIT models the prediction from each sub-view as an opinion with quantified uncertainty under the guidance of the subjective logic theory. Furthermore, a distribution-aware base rate is introduced to enhance performance, particularly in scenarios involving class distribution shifts. Finally, MERIT adopts a feature-specific combination rule to explicitly fuse multi-view predictions, thereby enhancing interpretability. Results have showcased the effectiveness of the proposed MERIT, highlighting the reliability and offering both ad-hoc and post-hoc interpretability. They also illustrate that MERIT can elucidate the significance of each view in the decision-making process for liver fibrosis staging. Our code has be released via https://github.com/HenryLau7/MERIT.
肝脏纤维化的磁共振成像(MRI)精确分期在临床实践中至关重要。传统方法往往专注于特定子区域,而多视角学习通过同时分析多个补丁来捕获更多信息。然而,先前的多视角方法通常不能自然地计算不确定性,它们一般以黑箱方式整合不同视角的特征,从而损害了模型的可靠性和解释性。
论文及项目相关链接
PDF Accepted by Medical Image Analysis
摘要
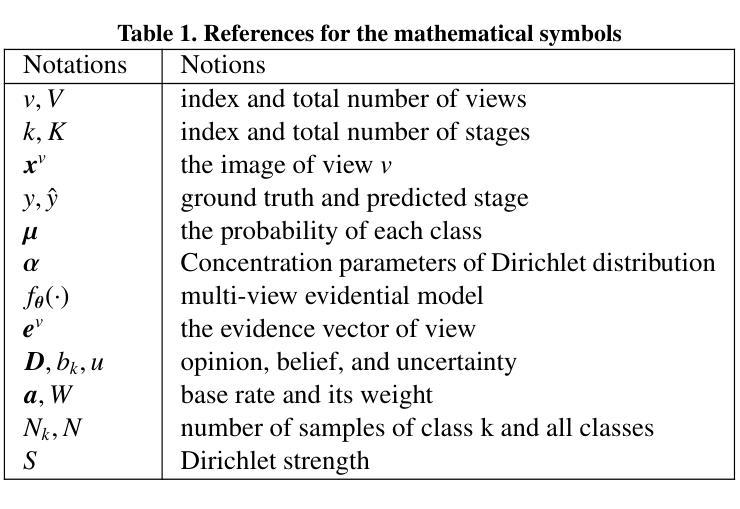
基于磁共振成像对肝纤维化进行准确的分期在临床实践中非常重要。传统方法通常只关注特定子区域,而多视角学习通过同时分析多个补丁捕获更多信息。然而,以前的多视角方法通常无法计算不确定性,它们通常以黑箱方式整合不同视角的特征,从而损害模型的可靠性和解释性。本研究提出了一种基于证据学习的新多视角方法,称为MERIT,该方法在统一框架内解决了这两个挑战。MERIT能够对预测进行不确定性量化,以提高可靠性,并采用基于逻辑的组合规则来提高解释性。具体来说,MERIT将每个子视角的预测建模为具有量化不确定性的观点,在主观逻辑理论的指导下进行。此外,引入了一种感知分布的基线率,以提高性能,特别是在涉及类别分布转移的场景中。最后,MERIT采用特征特定的组合规则来显式融合多视角预测,从而提高了解释性。结果展示了所提出MERIT的有效性,突出了其可靠性和提供了专项及事后的解释性。他们还表明,MERIT可以阐明决策过程中每个视角对肝纤维化分期的重要性。我们的代码已通过https://github.com/HenryLau7/MERIT发布。
关键见解
- 多视角学习方法在肝纤维化MRI分期中至关重要,能够捕获更多信息。
- 以往的多视角方法无法计算不确定性,影响模型可靠性和解释性。
- MERIT方法基于证据学习,统一解决不确定性和解释性问题。
- MERIT将预测建模为具有量化不确定性的观点,提高决策可靠性。
- MERIT引入分布感知基线率,优化类别分布转移场景中的性能。
- MERIT采用特征特定组合规则,显式融合多视角预测,提高解释性。
点此查看论文截图


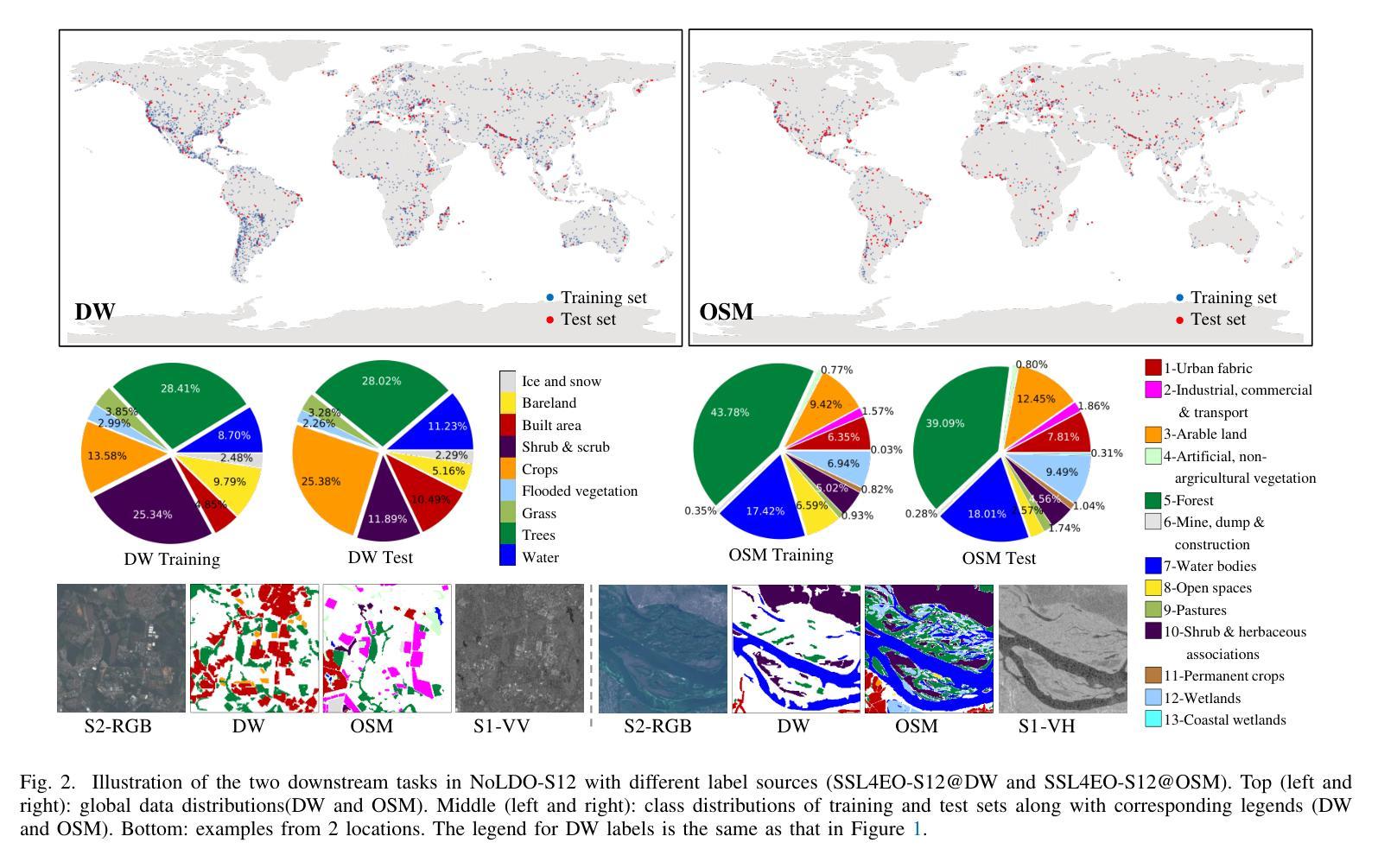
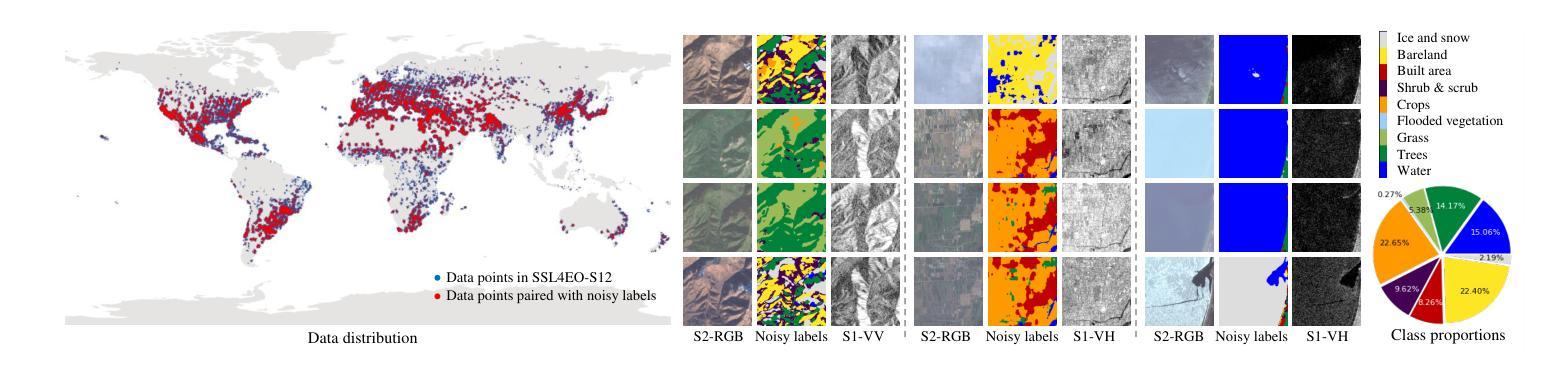
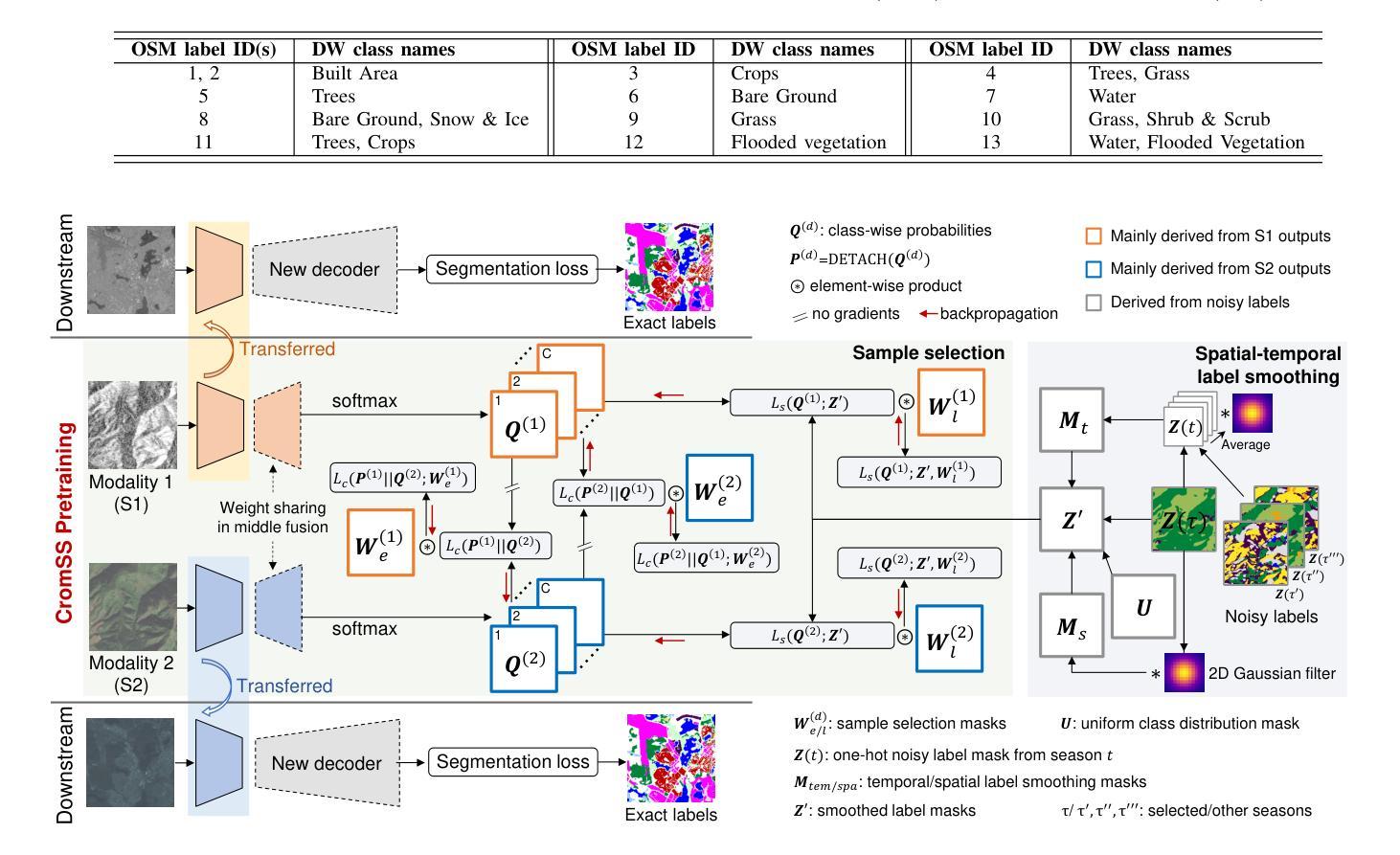
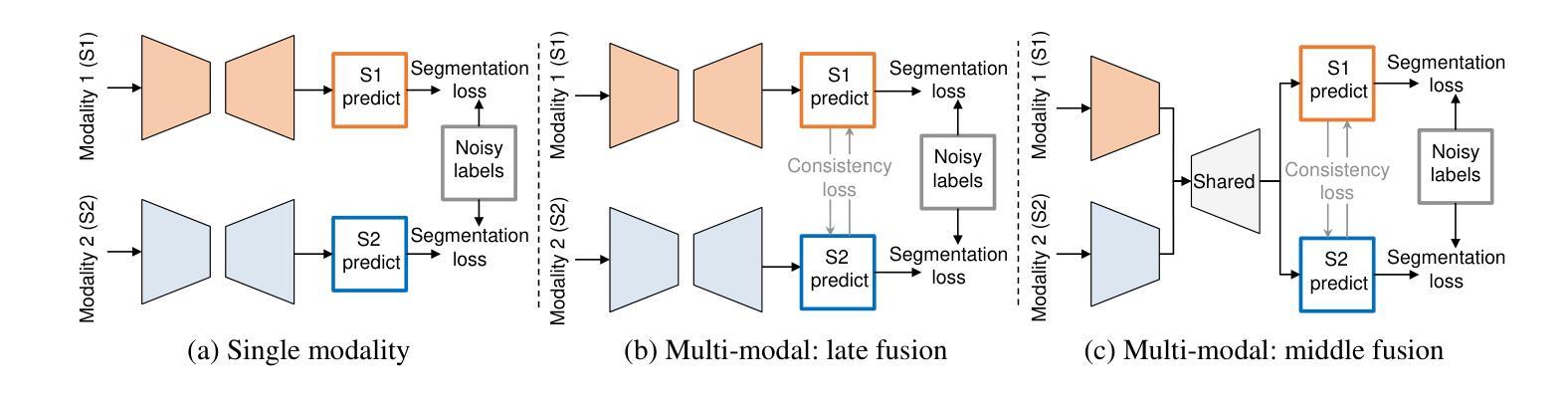
CromSS: Cross-modal pre-training with noisy labels for remote sensing image segmentation
Authors:Chenying Liu, Conrad Albrecht, Yi Wang, Xiao Xiang Zhu
We explore the potential of large-scale noisily labeled data to enhance feature learning by pretraining semantic segmentation models within a multi-modal framework for geospatial applications. We propose a novel Cross-modal Sample Selection (CromSS) method, a weakly supervised pretraining strategy designed to improve feature representations through cross-modal consistency and noise mitigation techniques. Unlike conventional pretraining approaches, CromSS exploits massive amounts of noisy and easy-to-come-by labels for improved feature learning beneficial to semantic segmentation tasks. We investigate middle and late fusion strategies to optimize the multi-modal pretraining architecture design. We also introduce a cross-modal sample selection module to mitigate the adverse effects of label noise, which employs a cross-modal entangling strategy to refine the estimated confidence masks within each modality to guide the sampling process. Additionally, we introduce a spatial-temporal label smoothing technique to counteract overconfidence for enhanced robustness against noisy labels. To validate our approach, we assembled the multi-modal dataset, NoLDO-S12, which consists of a large-scale noisy label subset from Google’s Dynamic World (DW) dataset for pretraining and two downstream subsets with high-quality labels from Google DW and OpenStreetMap (OSM) for transfer learning. Experimental results on two downstream tasks and the publicly available DFC2020 dataset demonstrate that when effectively utilized, the low-cost noisy labels can significantly enhance feature learning for segmentation tasks. All data, code, and pretrained weights will be made publicly available.
我们探索大规模噪声标记数据在地理应用的多模态框架内通过预训练语义分割模型以增强特征学习的潜力。我们提出了一种新颖的跨模态样本选择(CromSS)方法,这是一种弱监督预训练策略,旨在通过跨模态一致性和降噪技术改进特征表示。与传统的预训练方法不同,CromSS利用大量的噪声和易获得的标签来改进特征学习,这对语义分割任务有益。我们研究了中间和后期融合策略来优化多模态预训练架构设计。我们还引入了一个跨模态样本选择模块来缓解标签噪声的不利影响,该模块采用跨模态纠缠策略来细化每个模态内的估计置信掩码,以指导采样过程。此外,我们引入了一种时空标签平滑技术来对抗过度自信,以增强对噪声标签的稳健性。为了验证我们的方法,我们创建了多模态数据集NoLDO-S12,它由来自Google动态世界(DW)数据集的大规模噪声标签子集组成,用于预训练,以及两个来自Google DW和OpenStreetMap(OSM)的高质量标签的下游子集用于迁移学习。在两个下游任务和公开的DFC2020数据集上的实验结果表明,当有效利用时,低成本噪声标签可以显著增强分割任务的特征学习。所有数据、代码和预训练权重将公开可用。
论文及项目相关链接
PDF The 1st short version was accepted as an oral presentation by ICLR 2024 ML4RS workshop. The 2nd extended version is being under review
摘要
本研究探讨大规模噪声标签数据在地理应用中的潜力,通过多模态框架预训练语义分割模型以增强特征学习。提出一种新颖的跨模态样本选择(CromSS)方法,这是一种弱监督预训练策略,旨在通过跨模态一致性和噪声抑制技术改进特征表示。不同于传统预训练方式,CromSS利用大量易于获取且带有噪声的标签来改善特征学习,对语义分割任务有益。研究中探讨了中期和后期融合策略以优化多模态预训练架构设计。还引入跨模态样本选择模块来减轻标签噪声的不利影响,采用跨模态纠缠策略来优化每个模态的估计置信度掩膜,以指导采样过程。此外,引入空间时间标签平滑技术来对抗过度自信,提高对噪声标签的稳健性。为验证方法,我们构建了多模态数据集NoLDO-S12,其中包括来自Google动态世界(DW)数据集的大规模噪声标签子集用于预训练,以及来自Google DW和OpenStreetMap(OSM)的高质量标签下游子集用于迁移学习。在两个下游任务和公开的DFC2020数据集上的实验结果表明,当有效利用时,低成本噪声标签可以显著增强分割任务的特征学习。所有数据、代码和预训练权重将公开可用。
关键见解
- 探索大规模噪声标签数据在地理应用语义分割中的潜力。
- 提出一种新颖的跨模态样本选择(CromSS)方法,结合弱监督预训练来改善特征学习。
- 引入跨模态样本选择模块来减轻噪声标签的负面影响。
- 采用空间时间标签平滑技术来提高模型对噪声标签的稳健性。
- 通过实验验证,利用噪声标签能显著增强语义分割任务的特征学习。
- 公开了多模态数据集NoLDO-S12,供研究使用。
- 该方法的数据、代码和预训练权重均可公开获取。
点此查看论文截图