⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-05 更新
FlexDrive: Toward Trajectory Flexibility in Driving Scene Reconstruction and Rendering
Authors:Jingqiu Zhou, Lue Fan, Linjiang Huang, Xiaoyu Shi, Si Liu, Zhaoxiang Zhang, Hongsheng Li
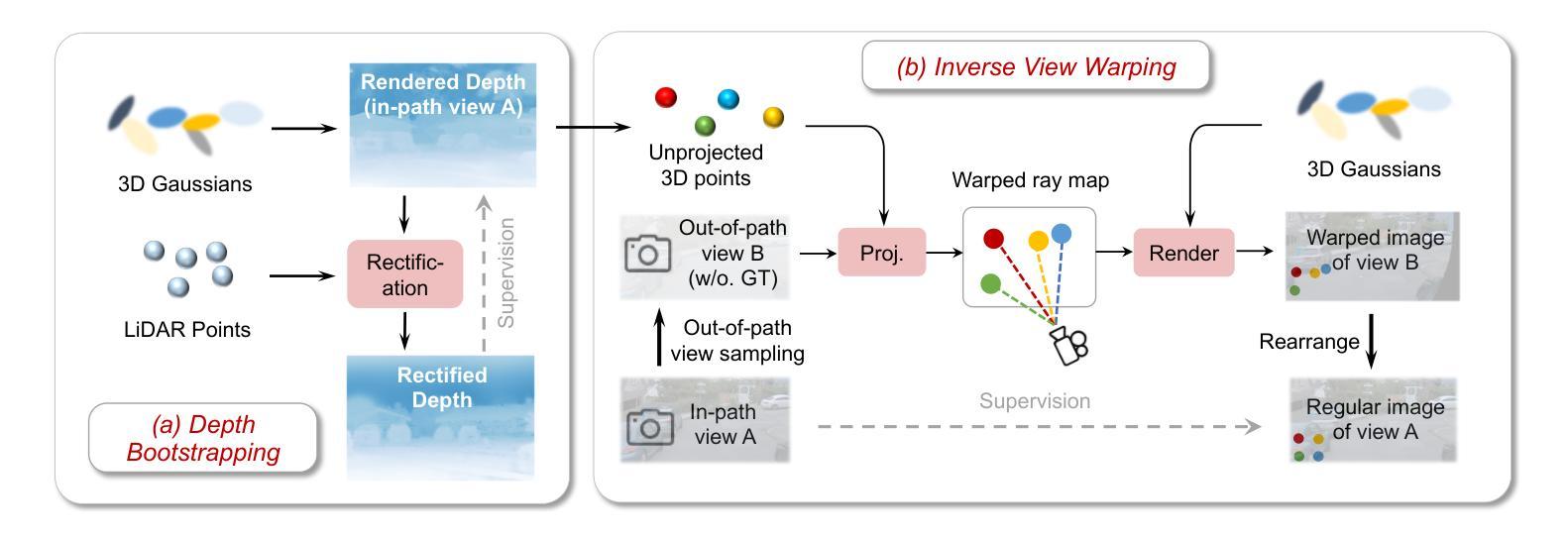
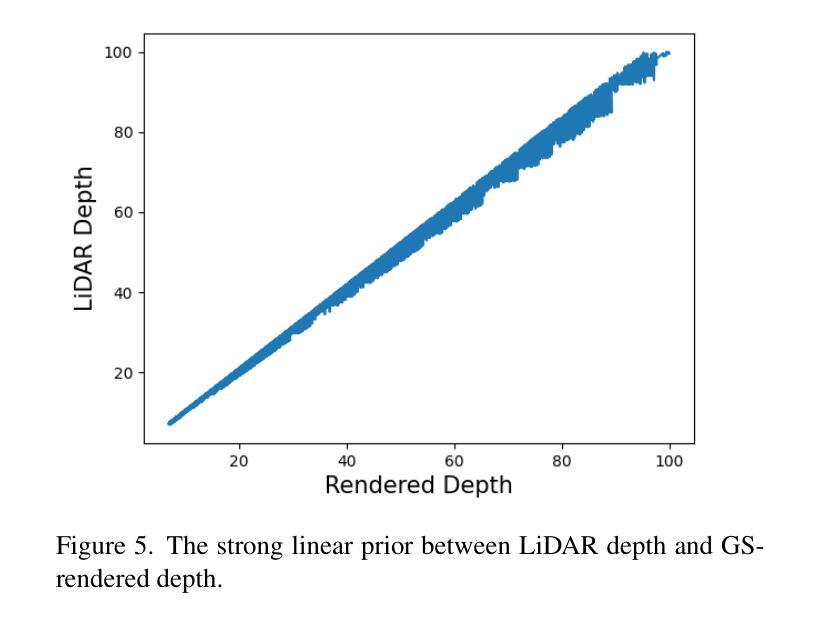
Driving scene reconstruction and rendering have advanced significantly using the 3D Gaussian Splatting. However, most prior research has focused on the rendering quality along a pre-recorded vehicle path and struggles to generalize to out-of-path viewpoints, which is caused by the lack of high-quality supervision in those out-of-path views. To address this issue, we introduce an Inverse View Warping technique to create compact and high-quality images as supervision for the reconstruction of the out-of-path views, enabling high-quality rendering results for those views. For accurate and robust inverse view warping, a depth bootstrap strategy is proposed to obtain on-the-fly dense depth maps during the optimization process, overcoming the sparsity and incompleteness of LiDAR depth data. Our method achieves superior in-path and out-of-path reconstruction and rendering performance on the widely used Waymo Open dataset. In addition, a simulator-based benchmark is proposed to obtain the out-of-path ground truth and quantitatively evaluate the performance of out-of-path rendering, where our method outperforms previous methods by a significant margin.
使用3D高斯拼贴技术,驾驶场景重建和渲染已经取得了显著进展。然而,大多数先前的研究主要集中在预记录车辆路径的渲染质量上,并且很难推广到路径外的视点,这是由于路径外视点的高质量监督缺失所导致的。为了解决这个问题,我们引入了一种逆视图转换技术,创建紧凑的高质量图像作为路径外视图重建的监督,从而为这些视图提供高质量的渲染结果。为了实现准确且稳定的逆视图转换,我们提出了一种深度引导策略,在优化过程中实时获取密集的深度图,克服了激光雷达深度数据的稀疏和不完整性。我们的方法在广泛使用的Waymo Open数据集上实现了路径内和路径外的优秀重建和渲染性能。此外,还提出了基于模拟器的基准测试来获得路径外的真实值,并定量评估路径外渲染的性能,我们的方法在多项指标上显著优于以前的方法。
论文及项目相关链接
Summary
本文介绍了利用三维高斯拼贴技术改进驾驶场景重建和渲染的方法。针对现有研究主要关注预记录车辆路径的渲染质量,难以推广到路径外视角的问题,提出了一种逆向视图扭曲技术,创建紧凑的高质量图像作为路径外重建的监督,实现了这些视角的高质量渲染结果。同时,为了准确、稳健地进行逆向视图扭曲,提出了一种深度引导策略,在优化过程中实时获取密集深度图,以克服激光雷达深度数据的稀疏性和不完整性。在广泛使用的Waymo Open数据集上,该方法在路径内和路径外的重建和渲染性能上均优于其他方法。此外,提出了一种基于模拟器的基准测试,以获取路径外的真实值并定量评估路径外渲染的性能,本文方法在模拟器测试中显著优于其他方法。
Key Takeaways
- 利用三维高斯拼贴技术提升驾驶场景重建和渲染质量。
- 现有研究主要关注预记录车辆路径的渲染质量,缺乏路径外视角的高质量监督。
- 引入逆向视图扭曲技术,创建高质量图像作为路径外重建的监督。
- 提出深度引导策略,优化过程中实时获取密集深度图,解决激光雷达数据稀疏和不完整的问题。
- 在Waymo Open数据集上实现了路径内和路径外的优秀重建和渲染性能。
- 提出了基于模拟器的基准测试以评估路径外渲染性能。
点此查看论文截图



OMG: Opacity Matters in Material Modeling with Gaussian Splatting
Authors:Silong Yong, Venkata Nagarjun Pudureddiyur Manivannan, Bernhard Kerbl, Zifu Wan, Simon Stepputtis, Katia Sycara, Yaqi Xie
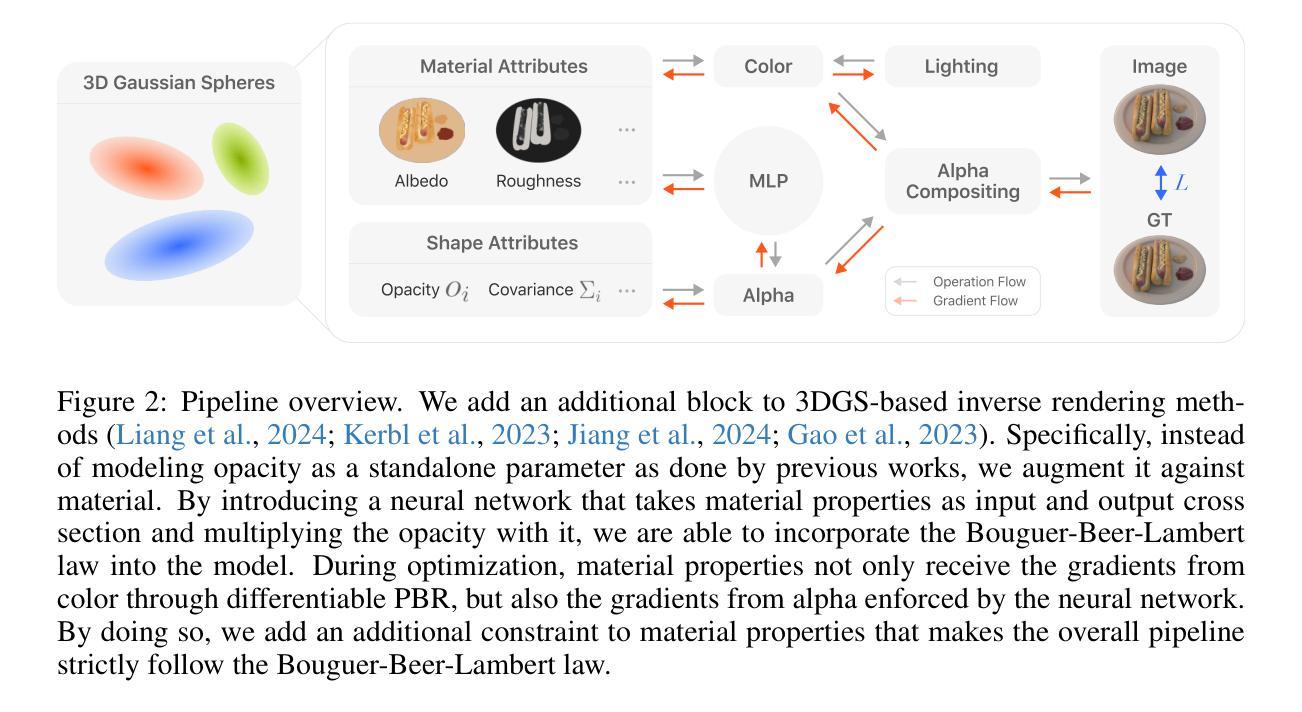
Decomposing geometry, materials and lighting from a set of images, namely inverse rendering, has been a long-standing problem in computer vision and graphics. Recent advances in neural rendering enable photo-realistic and plausible inverse rendering results. The emergence of 3D Gaussian Splatting has boosted it to the next level by showing real-time rendering potentials. An intuitive finding is that the models used for inverse rendering do not take into account the dependency of opacity w.r.t. material properties, namely cross section, as suggested by optics. Therefore, we develop a novel approach that adds this dependency to the modeling itself. Inspired by radiative transfer, we augment the opacity term by introducing a neural network that takes as input material properties to provide modeling of cross section and a physically correct activation function. The gradients for material properties are therefore not only from color but also from opacity, facilitating a constraint for their optimization. Therefore, the proposed method incorporates more accurate physical properties compared to previous works. We implement our method into 3 different baselines that use Gaussian Splatting for inverse rendering and achieve significant improvements universally in terms of novel view synthesis and material modeling.
从一组图像中分解几何、材料和光照,即逆向渲染,是计算机视觉和图形学中的一个长期存在的问题。神经网络渲染的最新进展使得逼真的逆向渲染结果成为可能。3D高斯拼贴的出现将其提升到了下一个层次,展现了实时渲染的潜力。一个直观的发现在于,逆向渲染所使用的模型没有考虑到材料属性与光学透明度之间的依赖关系,即横截面。因此,我们开发了一种新型方法,将这一依赖关系添加到建模本身。受辐射传输的启发,我们通过引入神经网络来增强透明度项,该网络以材料属性作为输入,提供横截面的建模和一个物理正确的激活函数。因此,材料属性的梯度不仅来自颜色,还来自透明度,为其优化提供了约束。因此,与以前的工作相比,所提出的方法包含了更准确的物理属性。我们将该方法应用于使用高斯拼贴进行逆向渲染的三种不同基线,并在新视角合成和材料建模方面取得了显著的普遍改进。
论文及项目相关链接
PDF Published as a conference paper at ICLR 2025
Summary
本文探讨了从图像集中分解几何、材料和光照的逆向渲染问题。近期神经渲染技术的进展实现了逼真的逆向渲染结果。3D高斯喷绘技术的出现进一步提升了其实时渲染潜力。本文提出了一种新方法,在建模中考虑光学所揭示的材料属性与透明度之间的依赖关系。通过引入神经网络和物理正确的激活函数来模拟横截面,该方法不仅从颜色中获取材料属性的梯度,也从透明度中获取,为其优化提供了便利。因此,该方法相较于以前的研究,融入了更精确的物理特性。将其方法应用于使用高斯喷绘的三种不同基线,普遍提高了新颖视图合成和材料建模的效果。
Key Takeaways
- 逆向渲染是计算机视觉和图形学中长期存在的问题,最近神经渲染技术的进步实现了更逼真的结果。
- 3D高斯喷绘技术提升了实时渲染潜力。
- 现有模型未充分考虑材料属性与透明度之间的依赖关系,本文提出了一种新的方法来解决这一问题。
- 通过引入神经网络和物理正确的激活函数来模拟横截面,提高了材料建模的准确性。
- 该方法不仅从颜色中获取材料属性的梯度,也从透明度中获取,优化了材料属性的优化过程。
- 与以前的研究相比,该方法融入了更精确的物理特性。
点此查看论文截图



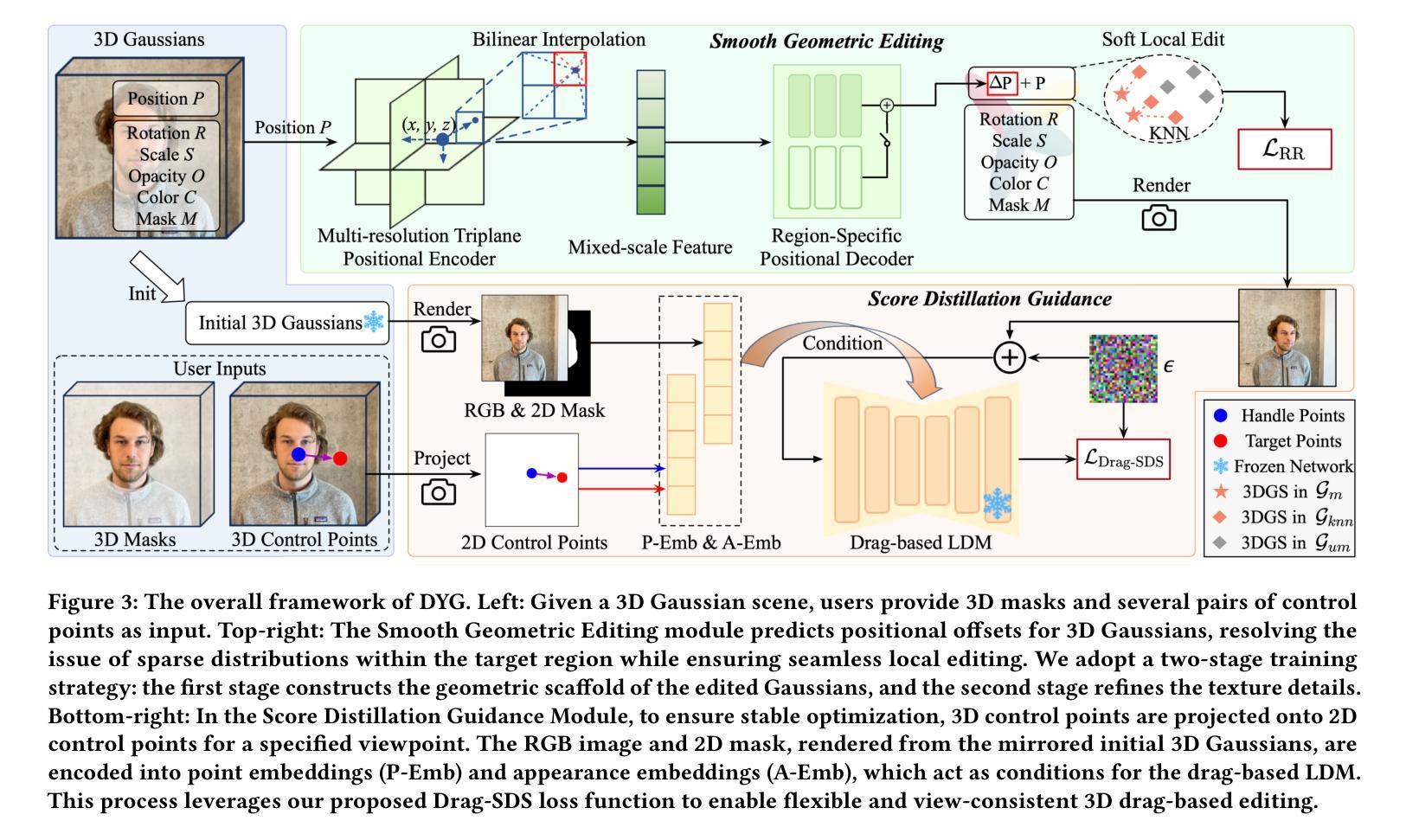
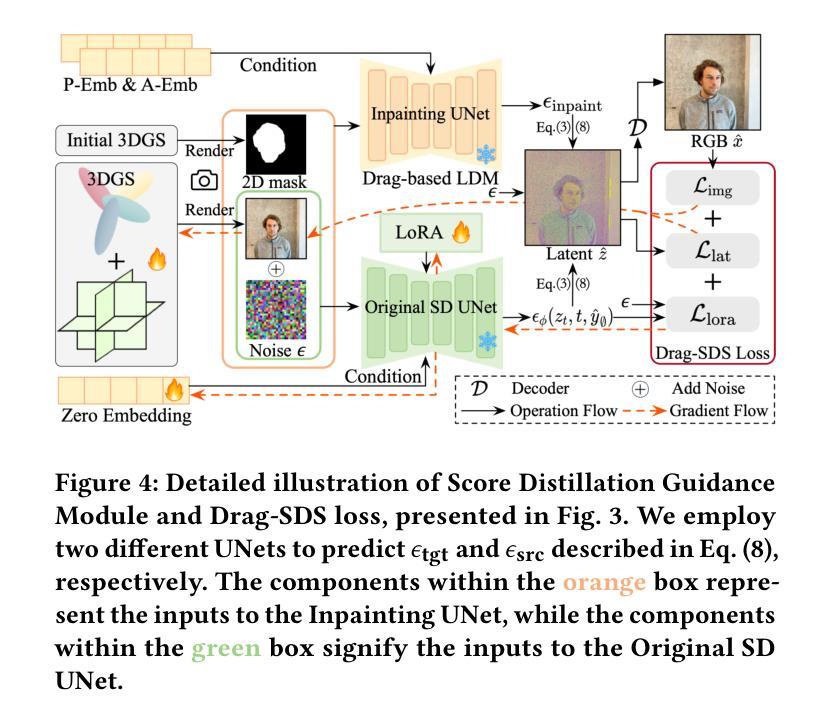
Drag Your Gaussian: Effective Drag-Based Editing with Score Distillation for 3D Gaussian Splatting
Authors:Yansong Qu, Dian Chen, Xinyang Li, Xiaofan Li, Shengchuan Zhang, Liujuan Cao, Rongrong Ji
Recent advancements in 3D scene editing have been propelled by the rapid development of generative models. Existing methods typically utilize generative models to perform text-guided editing on 3D representations, such as 3D Gaussian Splatting (3DGS). However, these methods are often limited to texture modifications and fail when addressing geometric changes, such as editing a character’s head to turn around. Moreover, such methods lack accurate control over the spatial position of editing results, as language struggles to precisely describe the extent of edits. To overcome these limitations, we introduce DYG, an effective 3D drag-based editing method for 3D Gaussian Splatting. It enables users to conveniently specify the desired editing region and the desired dragging direction through the input of 3D masks and pairs of control points, thereby enabling precise control over the extent of editing. DYG integrates the strengths of the implicit triplane representation to establish the geometric scaffold of the editing results, effectively overcoming suboptimal editing outcomes caused by the sparsity of 3DGS in the desired editing regions. Additionally, we incorporate a drag-based Latent Diffusion Model into our method through the proposed Drag-SDS loss function, enabling flexible, multi-view consistent, and fine-grained editing. Extensive experiments demonstrate that DYG conducts effective drag-based editing guided by control point prompts, surpassing other baselines in terms of editing effect and quality, both qualitatively and quantitatively. Visit our project page at https://quyans.github.io/Drag-Your-Gaussian.
近期三维场景编辑的进展得益于生成模型的快速发展。现有方法通常利用生成模型对三维表示进行文本引导编辑,例如三维高斯平铺(3DGS)。然而,这些方法通常仅限于纹理修改,在几何变化方面存在缺陷,例如编辑角色头部转动。此外,这些方法对编辑结果的空间位置控制不够精确,因为语言很难精确描述编辑的程度。为了克服这些限制,我们引入了DYG,这是一种针对三维高斯平铺的有效基于拖拽的三维编辑方法。它使用户可以通过输入三维掩码和控制点对,方便地指定所需的编辑区域和拖拽方向,从而实现对编辑程度的精确控制。DYG结合了隐式triplane表示的优势,建立编辑结果的三维骨架,有效克服了在所需编辑区域中3DGS稀疏导致的编辑结果不佳问题。此外,我们通过提出的Drag-SDS损失函数,将基于拖拽的潜在扩散模型融入我们的方法,实现灵活、多视角一致、精细的编辑。大量实验表明,DYG通过控制点提示进行有效的基于拖拽的编辑,在编辑效果和品质方面超越其他基线方法,定性和定量评估均表现优异。请访问我们的项目页面:https://quyans.github.io/Drag-Your-Gaussian了解更多信息。
论文及项目相关链接
PDF Visit our project page at https://quyans.github.io/Drag-Your-Gaussian
Summary
本文介绍了基于3D高斯喷绘(3DGS)的拖放式编辑方法DYG。该方法通过输入3D遮罩和控制点对,使用户能够便捷地指定所需的编辑区域和拖动方向,实现对编辑程度的精确控制。DYG结合了隐式triplane表示的优点,建立编辑结果的三维骨架,有效克服了因编辑区域稀疏而导致的编辑结果不佳问题。此外,通过引入基于拖动的潜在扩散模型与Drag-SDS损失函数,实现了灵活、多视角一致且精细的编辑。实验表明,DYG在控制点提示的指导下进行有效的拖放式编辑,在编辑效果和品质上超越其他基线方法。
Key Takeaways
- DYG是一种基于3D高斯喷绘(3DGS)的拖放式编辑方法,旨在解决现有方法在几何修改方面的局限性和对编辑结果空间位置的精确控制问题。
- DYG允许用户通过输入3D遮罩和控制点对来指定编辑区域和拖动方向,实现对编辑程度的精确控制。
- DYG结合了隐式triplane表示的优点,确保编辑结果的三维骨架建立,解决因编辑区域稀疏导致的编辑不佳问题。
- 通过引入基于拖动的潜在扩散模型和Drag-SDS损失函数,实现了灵活的、多视角一致的且精细的编辑功能。
- 实验证明,DYG在控制点提示下,实现了有效的拖放式编辑,并在编辑效果和品质上超越其他方法。
- DYG方法在项目网站上有详细介绍和展示。
- 研究结果展示了DYG在多种场景下的广泛应用潜力。
点此查看论文截图



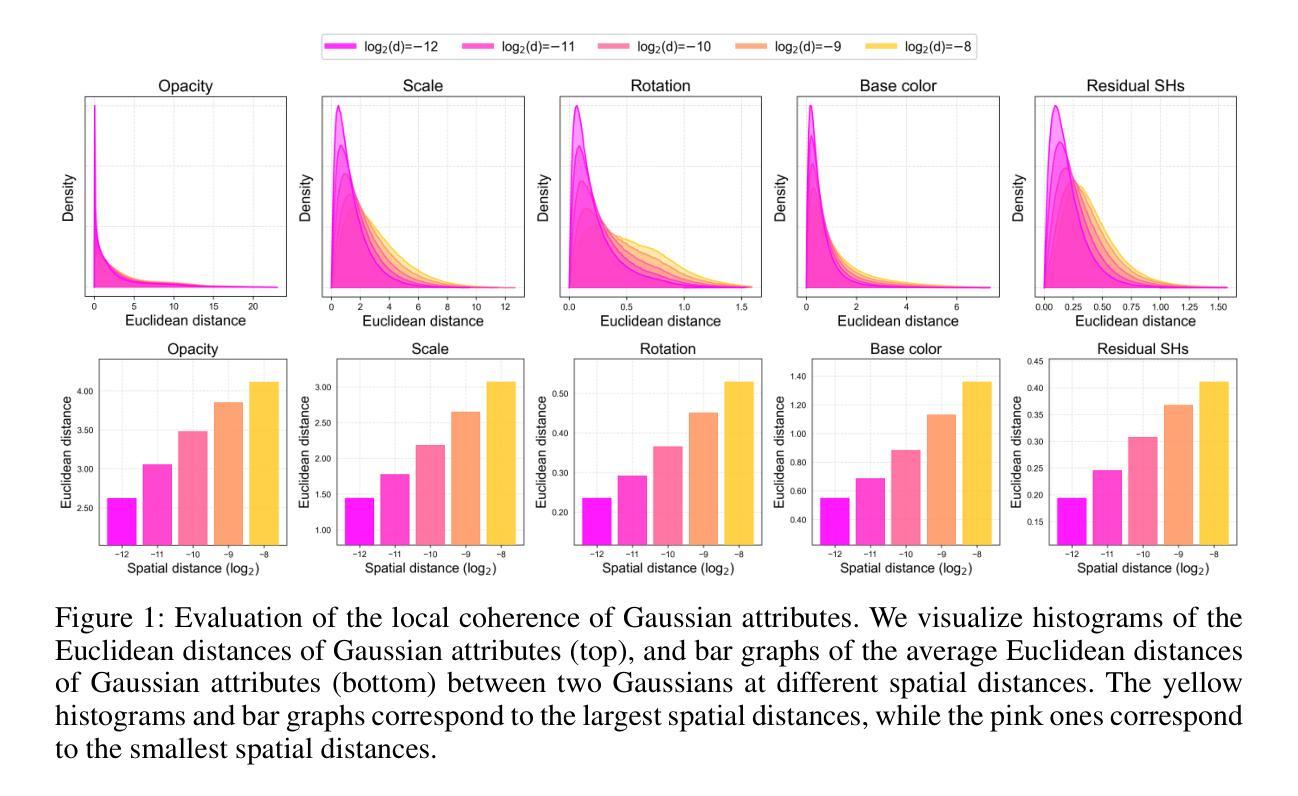
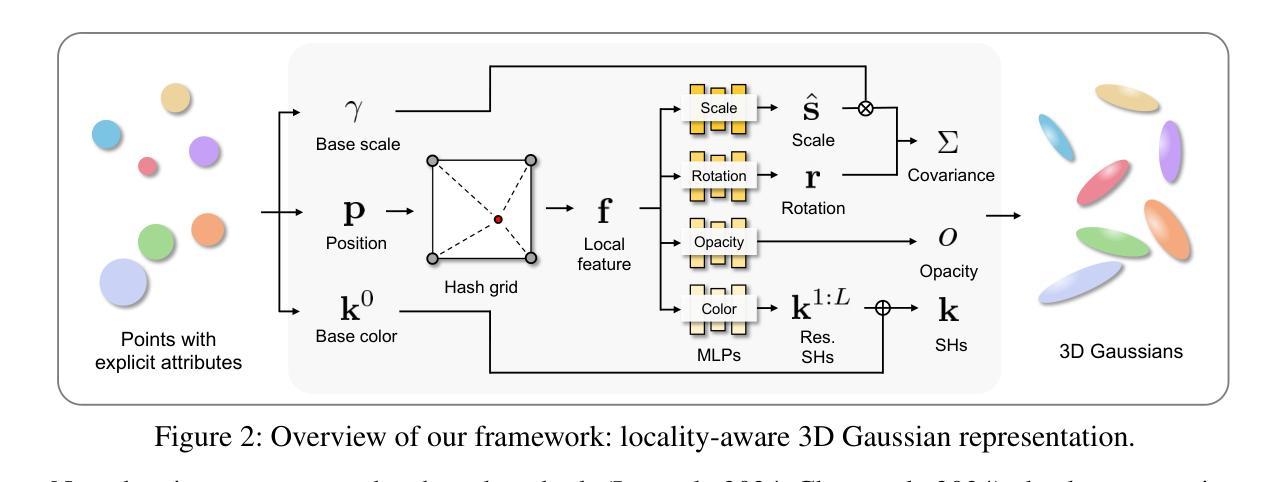
Locality-aware Gaussian Compression for Fast and High-quality Rendering
Authors:Seungjoo Shin, Jaesik Park, Sunghyun Cho
We present LocoGS, a locality-aware 3D Gaussian Splatting (3DGS) framework that exploits the spatial coherence of 3D Gaussians for compact modeling of volumetric scenes. To this end, we first analyze the local coherence of 3D Gaussian attributes, and propose a novel locality-aware 3D Gaussian representation that effectively encodes locally-coherent Gaussian attributes using a neural field representation with a minimal storage requirement. On top of the novel representation, LocoGS is carefully designed with additional components such as dense initialization, an adaptive spherical harmonics bandwidth scheme and different encoding schemes for different Gaussian attributes to maximize compression performance. Experimental results demonstrate that our approach outperforms the rendering quality of existing compact Gaussian representations for representative real-world 3D datasets while achieving from 54.6$\times$ to 96.6$\times$ compressed storage size and from 2.1$\times$ to 2.4$\times$ rendering speed than 3DGS. Even our approach also demonstrates an averaged 2.4$\times$ higher rendering speed than the state-of-the-art compression method with comparable compression performance.
我们提出了LocoGS,这是一种基于局部感知的3D高斯混合(3DGS)框架,它利用3D高斯的空间一致性来对体积场景进行紧凑建模。为此,我们首先分析了3D高斯属性的局部一致性,并提出了一种新的基于局部感知的3D高斯表示法。这种表示法使用神经场表示法有效地编码局部一致的高斯属性,具有最小的存储要求。在新的表示法的基础上,我们精心设计LocoGS,增加了密集初始化、自适应球面谐波带宽方案以及针对不同高斯属性的不同编码方案等组件,以最大限度地提高压缩性能。实验结果表明,我们的方法在具有代表性的真实世界3D数据集上,渲染质量超过了现有的紧凑高斯表示法,同时实现了从54.6倍到96.6倍的压缩存储空间和从2.1倍到2.4倍的渲染速度提升。而且我们的方法相较于表现相当的其他压缩方法还展现了平均高出2.4倍的渲染速度。
论文及项目相关链接
PDF Accepted to ICLR 2025. Project page: https://seungjooshin.github.io/LocoGS
Summary
本文介绍了LocoGS,一种基于空间感知的3D高斯融合(3DGS)框架。该框架通过探索和分析三维高斯的空间连贯性,对场景进行紧凑建模。提出了一种新型的局部感知三维高斯表示法,有效地编码局部连贯的高斯属性,并利用神经网络场表示法实现最小存储需求。此外,LocoGS还设计了密集初始化、自适应球面谐波带宽方案以及针对不同高斯属性的不同编码方案等组件,以最大化压缩性能。实验结果表明,该方法在表现真实世界三维数据集方面优于现有紧凑高斯表示法,实现了存储空间的显著压缩(最高达96.6倍)和渲染速度的提升(最高达2.4倍)。相较于性能相近的最佳压缩方法,该方法的渲染速度平均提高了2.4倍。
Key Takeaways
以下是关于文本的关键见解:
- LocoGS是一个基于空间感知的3D高斯融合框架,用于紧凑建模场景。
- 通过分析局部感知的三维高斯属性的连贯性来实现有效编码,并实现最小存储需求。
- LocoGS设计包括密集初始化、自适应球面谐波带宽方案等组件,以提高压缩性能。
- 实验结果显示LocoGS在渲染真实世界三维数据集方面表现出色。相较于其他方法,它实现了显著的存储空间压缩和更快的渲染速度。
点此查看论文截图

Poison-splat: Computation Cost Attack on 3D Gaussian Splatting
Authors:Jiahao Lu, Yifan Zhang, Qiuhong Shen, Xinchao Wang, Shuicheng Yan
3D Gaussian splatting (3DGS), known for its groundbreaking performance and efficiency, has become a dominant 3D representation and brought progress to many 3D vision tasks. However, in this work, we reveal a significant security vulnerability that has been largely overlooked in 3DGS: the computation cost of training 3DGS could be maliciously tampered by poisoning the input data. By developing an attack named Poison-splat, we reveal a novel attack surface where the adversary can poison the input images to drastically increase the computation memory and time needed for 3DGS training, pushing the algorithm towards its worst computation complexity. In extreme cases, the attack can even consume all allocable memory, leading to a Denial-of-Service (DoS) that disrupts servers, resulting in practical damages to real-world 3DGS service vendors. Such a computation cost attack is achieved by addressing a bi-level optimization problem through three tailored strategies: attack objective approximation, proxy model rendering, and optional constrained optimization. These strategies not only ensure the effectiveness of our attack but also make it difficult to defend with simple defensive measures. We hope the revelation of this novel attack surface can spark attention to this crucial yet overlooked vulnerability of 3DGS systems. Our code is available at https://github.com/jiahaolu97/poison-splat .
3D 高斯延展技术(3DGS)以其突破性的性能和效率而著称,已成为主流的3D表示方法,并为许多3D视觉任务带来了进步。然而,在这项工作中,我们揭示了在3DGS中一直被忽视的显著安全隐患:训练过程中的计算成本可能会受到恶意干扰,导致输入数据被污染。通过开发名为Poison-splat的攻击方法,我们揭示了一种新型攻击面,攻击者可以通过污染输入图像来大幅增加训练过程中所需的计算内存和时间,使算法的计算复杂度达到最高。在极端情况下,攻击甚至可能消耗所有可分配的内存,导致拒绝服务(DoS),从而干扰服务器运行,给现实世界中的三维高斯延展服务供应商带来实际损失。这种计算成本攻击是通过解决一个两级优化问题来实现的,采用了三种量身定制的策略:攻击目标近似、代理模型渲染和可选约束优化。这些策略不仅确保了攻击的有效性,而且使其难以通过简单的防御措施进行防御。我们希望揭示这一新型攻击面能引起对三维高斯延展系统这一关键但一直被忽视的漏洞的关注。我们的代码可在https://github.com/jiahaolu97/poison-splat找到。
论文及项目相关链接
PDF Accepted by ICLR 2025 as a spotlight paper
摘要
三维高斯模板(3DGS)虽具有出色的性能和效率,并已成为主导的三维表示方法,推动了许多三维视觉任务的发展。但本研究揭示了其被忽视的严重安全隐患:输入数据的恶意中毒可导致3DGS训练的计算成本大幅上升。我们开发了一种名为Poison-splat的攻击方法,展示了一种新型攻击表面,攻击者可借此向输入图像注入毒素,使所需的计算内存和时间大幅增加,从而使算法计算复杂度急剧恶化。极端情况下,攻击甚至可能消耗所有可用内存,导致服务拒绝(DoS),扰乱服务器运行,给现实世界的3DGS服务提供商带来实际损害。这种计算成本攻击是通过解决一个两级优化问题实现的,包括三个定制策略:攻击目标近似、代理模型渲染和可选约束优化。这些策略不仅确保了攻击的有效性,而且使其难以通过简单的防御措施进行防御。我们希望通过揭示这一新型攻击表面,引起对解决忽略的系统安全性和实现稳定的实际需求考虑重要性的一致重视对三元结构的密切关注安全的改进和保护忽视的忽视等事项领域至关重要的建议性和普及知识性网络学术公开宣传的需求我们对三维高斯模板系统的这一关键漏洞予以关注。我们的代码可在https://github.com/jiahaolu97/poison-splat上找到。代码详细解释了这一机制如何实现且极具应用价值在实际研究中可以大大优化研究者在此方面的能力和优化技能能够真实落地到实际应用中去造福于人类社会为人类带来便捷的生活和新的技术革新
关键见解
- 揭示了三维高斯模板(3DGS)在计算成本方面存在重大的安全漏洞。即输入数据的恶意中毒可导致训练时的计算成本大幅增加。这一发现揭示了一种新型攻击表面。
- 提出了一种名为Poison-splat的攻击方法,该方法通过解决一个两级优化问题实现攻击目标,包括攻击目标近似、代理模型渲染和约束优化等策略。这些策略确保了攻击的有效性且使其难以防御。该攻击能显著增加训练所需的计算内存和时间,严重时甚至会导致服务拒绝(DoS)。
点此查看论文截图


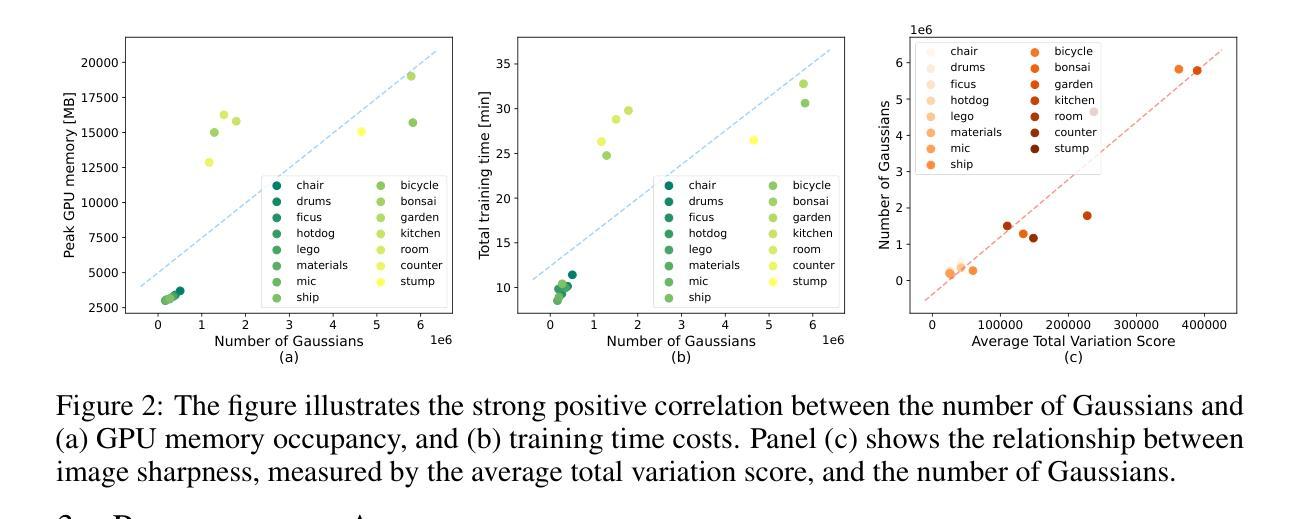
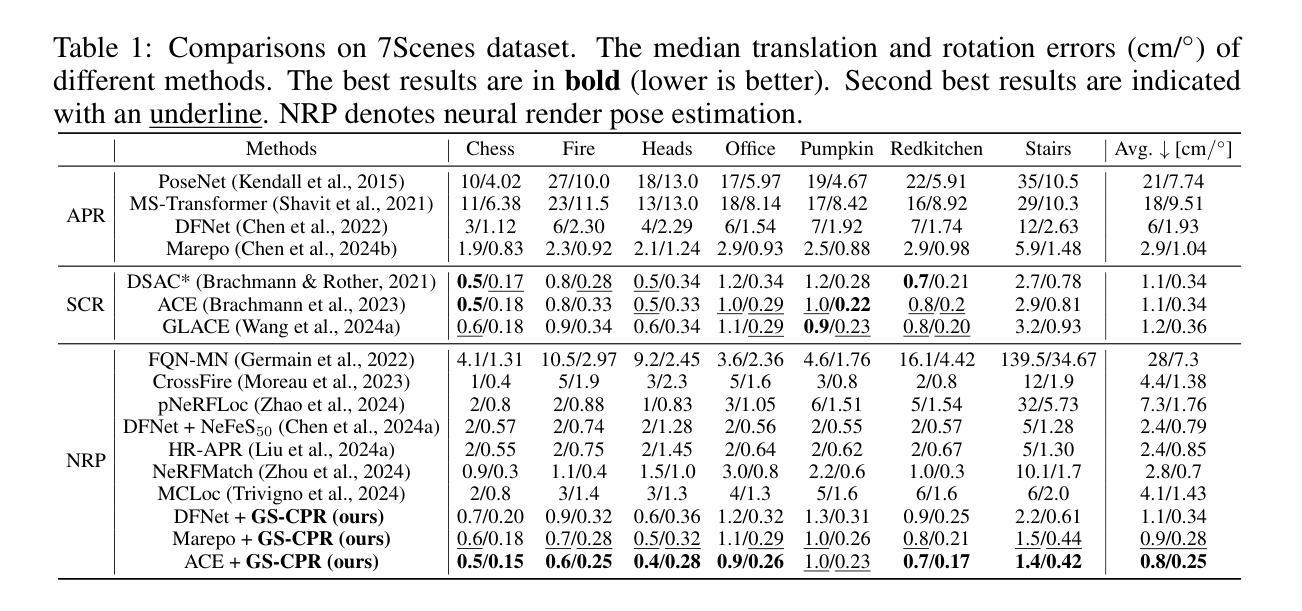
GS-CPR: Efficient Camera Pose Refinement via 3D Gaussian Splatting
Authors:Changkun Liu, Shuai Chen, Yash Bhalgat, Siyan Hu, Ming Cheng, Zirui Wang, Victor Adrian Prisacariu, Tristan Braud
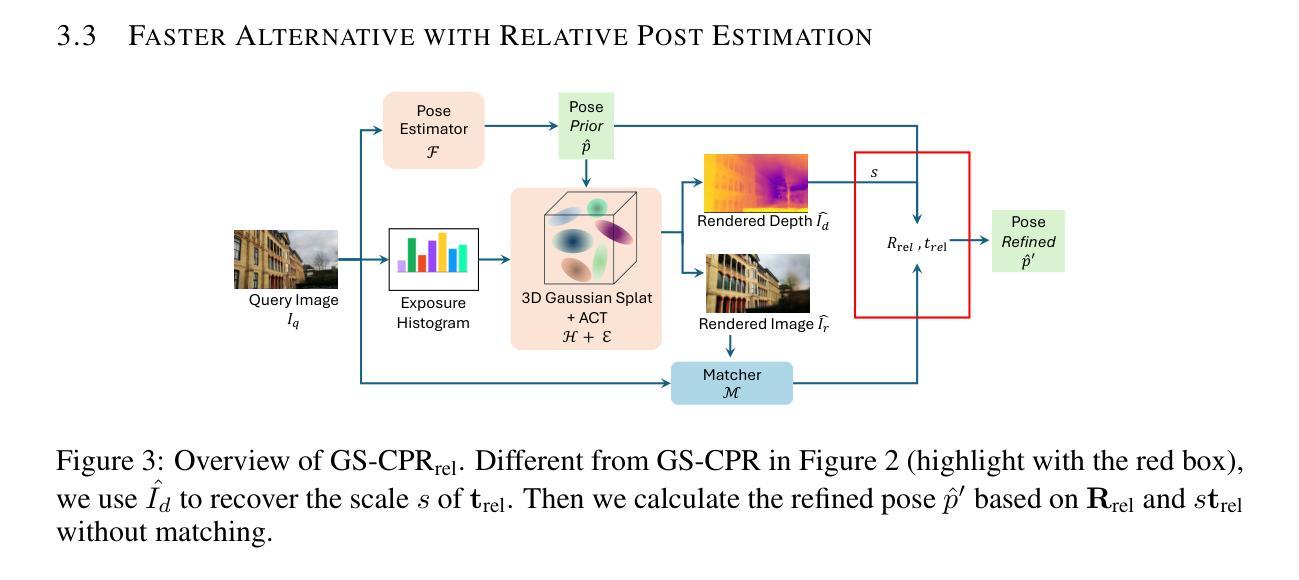
We leverage 3D Gaussian Splatting (3DGS) as a scene representation and propose a novel test-time camera pose refinement (CPR) framework, GS-CPR. This framework enhances the localization accuracy of state-of-the-art absolute pose regression and scene coordinate regression methods. The 3DGS model renders high-quality synthetic images and depth maps to facilitate the establishment of 2D-3D correspondences. GS-CPR obviates the need for training feature extractors or descriptors by operating directly on RGB images, utilizing the 3D foundation model, MASt3R, for precise 2D matching. To improve the robustness of our model in challenging outdoor environments, we incorporate an exposure-adaptive module within the 3DGS framework. Consequently, GS-CPR enables efficient one-shot pose refinement given a single RGB query and a coarse initial pose estimation. Our proposed approach surpasses leading NeRF-based optimization methods in both accuracy and runtime across indoor and outdoor visual localization benchmarks, achieving new state-of-the-art accuracy on two indoor datasets. The project page is available at https://xrim-lab.github.io/GS-CPR/.
我们利用3D高斯拼贴(3DGS)作为场景表示,并提出了一种新型测试时相机姿态优化(CPR)框架,GS-CPR。该框架提高了最先进的绝对姿态回归和场景坐标回归方法的定位精度。3DGS模型渲染高质量合成图像和深度图,有助于建立2D-3D对应关系。GS-CPR直接在RGB图像上操作,利用三维基础模型MASt3R进行精确2D匹配,从而无需训练特征提取器或描述符。为了提高我们的模型在具有挑战性的室外环境中的稳健性,我们在3DGS框架中融入了一个曝光自适应模块。因此,GS-CPR能够在单张RGB查询图像和粗略的初始姿态估计基础上实现高效的一次性姿态优化。我们的方法无论是在室内还是室外视觉定位基准测试中,都在精度和运行时上超越了领先的NeRF优化方法,并在两个室内数据集上达到了最新的最先进的精度。项目页面可通过以下网址访问:网站链接。
论文及项目相关链接
PDF Accepted to International Conference on Learning Representations (ICLR) 2025. During the ICLR review process, we changed the name of our framework from GSLoc to GS-CPR (Camera Pose Refinement), according to reviewers’ comments. The project page is available at https://xrim-lab.github.io/GS-CPR/
Summary
本文利用3D高斯融合(3DGS)作为场景表示,提出一种新型的测试时相机姿态优化(CPR)框架GS-CPR。该框架提高了最先进的绝对姿态回归和场景坐标回归方法的定位精度。通过渲染高质量合成图像和深度图,GS-CPR促进了建立二维到三维的对应关系。它不需要训练特征提取器或描述符,可直接在RGB图像上操作,并利用三维基础模型MASt3R进行精确二维匹配。为提高模型在恶劣环境下的稳健性,我们在3DGS框架中融入了曝光自适应模块。因此,GS-CPR能够利用单个RGB查询和粗略的初始姿态估计进行高效的一次性姿态优化。该方法的准确性与运行速度均超越领先的NeRF优化方法,并在室内和室外视觉定位基准测试中达到了新的领先水平。该项目的详细介绍可通过链接 https://xrim-lab.github.io/GS-CPR/ 查看。
Key Takeaways
- 利用3D高斯融合(3DGS)作为场景表示方法。
- 提出新型的测试时相机姿态优化(CPR)框架GS-CPR。
- GS-CPR提高了定位精度,适用于先进的绝对姿态回归和场景坐标回归方法。
- 通过渲染高质量合成图像和深度图,促进二维到三维对应关系的建立。
- 不需要训练特征提取器或描述符,直接在RGB图像上操作。
- 利用三维基础模型MASt3R进行精确二维匹配。
点此查看论文截图

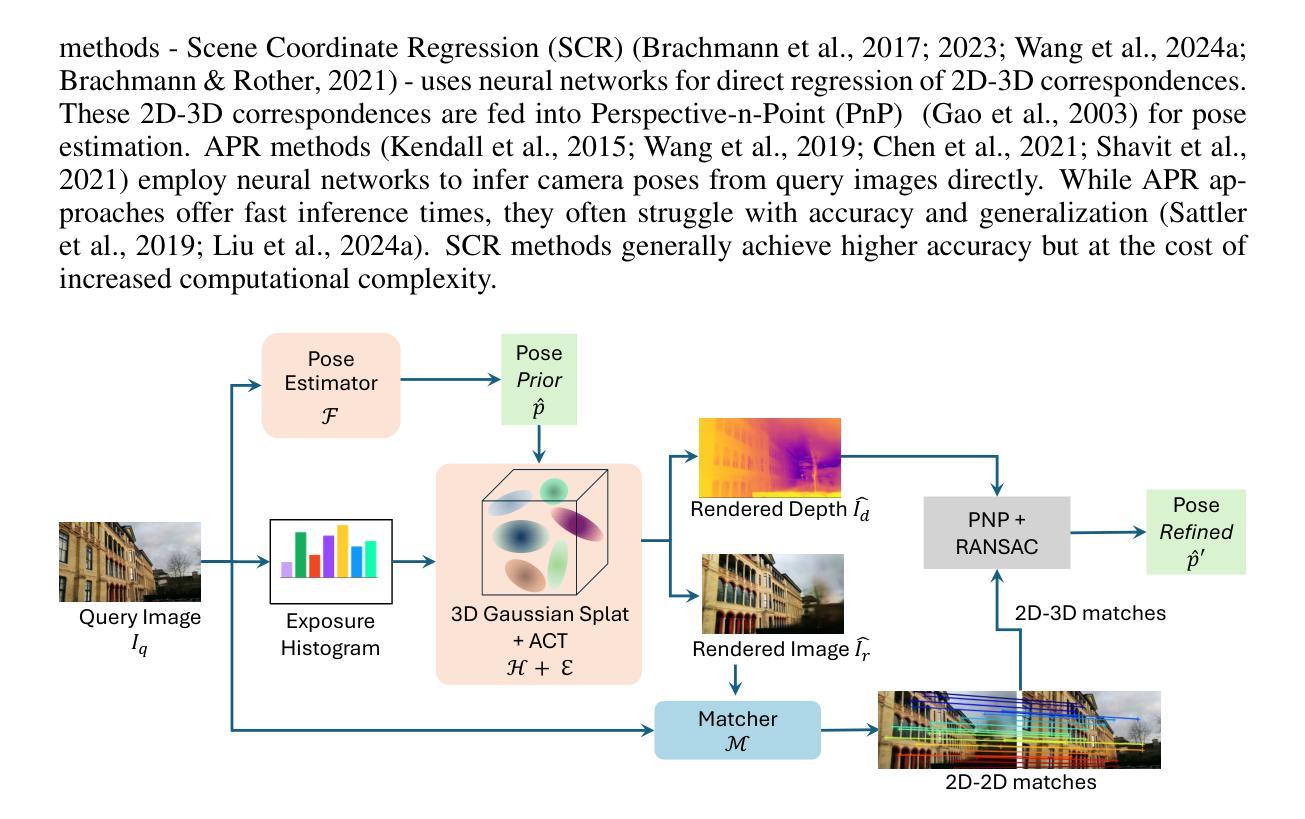

3D StreetUnveiler with Semantic-aware 2DGS – a simple baseline
Authors:Jingwei Xu, Yikai Wang, Yiqun Zhao, Yanwei Fu, Shenghua Gao
Unveiling an empty street from crowded observations captured by in-car cameras is crucial for autonomous driving. However, removing all temporarily static objects, such as stopped vehicles and standing pedestrians, presents a significant challenge. Unlike object-centric 3D inpainting, which relies on thorough observation in a small scene, street scene cases involve long trajectories that differ from previous 3D inpainting tasks. The camera-centric moving environment of captured videos further complicates the task due to the limited degree and time duration of object observation. To address these obstacles, we introduce StreetUnveiler to reconstruct an empty street. StreetUnveiler learns a 3D representation of the empty street from crowded observations. Our representation is based on the hard-label semantic 2D Gaussian Splatting (2DGS) for its scalability and ability to identify Gaussians to be removed. We inpaint rendered image after removing unwanted Gaussians to provide pseudo-labels and subsequently re-optimize the 2DGS. Given its temporal continuous movement, we divide the empty street scene into observed, partial-observed, and unobserved regions, which we propose to locate through a rendered alpha map. This decomposition helps us to minimize the regions that need to be inpainted. To enhance the temporal consistency of the inpainting, we introduce a novel time-reversal framework to inpaint frames in reverse order and use later frames as references for earlier frames to fully utilize the long-trajectory observations. Our experiments conducted on the street scene dataset successfully reconstructed a 3D representation of the empty street. The mesh representation of the empty street can be extracted for further applications. The project page and more visualizations can be found at: https://streetunveiler.github.io
从车载摄像头捕获的拥挤观测中揭示空街道对于自动驾驶至关重要。然而,移除所有临时静止物体,如停驶的车辆和站立的行人,带来很大的挑战。不同于依赖小场景全面观察的以物体为中心的3D补全技术,街道场景情况涉及长期轨迹,与之前的3D补全任务不同。捕获视频的以摄像头为中心的运动环境由于物体观察的有限程度和持续时间而进一步加剧了任务的复杂性。为了解决这些障碍,我们推出了StreetUnveiler来重建空街道。StreetUnveiler从拥挤的观测中学习空街道的3D表示。我们的表示基于硬标签语义2D高斯拼贴(2DGS),因为它具有可扩展性并且能够识别要移除的高斯。我们在移除不需要的高斯后修复渲染图像以提供伪标签,然后重新优化2DGS。考虑到其连续的时间移动,我们将空街道场景分为已观测、部分观测和未观测区域,我们建议通过渲染的alpha地图进行定位。这种分解有助于我们尽量减少需要修复的区域。为了提高修复的图像的时间一致性,我们引入了一种新的时间反转框架,按相反顺序修复帧并使用后续帧作为早期帧的参考,以充分利用长期轨迹观察。我们在街道场景数据集上进行的实验成功地重建了空街道的3D表示。空街道的网格表示可以提取用于进一步应用。项目和更多可视化内容可在:https://streetunveiler.github.io找到。
论文及项目相关链接
PDF Project page: https://streetunveiler.github.io
Summary
在自动驾驶中,从车载相机捕捉的拥挤观察中揭示空无一人的街道十分重要。去除临时静止物体是一大挑战,与物体中心的3D补全不同,街道场景涉及长轨迹,存在相机中心的移动环境进一步增加了任务复杂性。为此我们引入StreetUnveiler重建空街道。StreetUnveiler通过拥挤的观察学习街道的空3D表现。我们的表现基于易于标签语义的二维高斯拼贴(2DGS),用于其可扩展性和去除要移除的高斯的能力。去除不需要的高斯后对渲染图像进行补全以提供伪标签,随后重新优化二维高斯拼贴。根据街道场景的连续移动,我们将空街道分为已观察、部分观察和未观察区域,通过渲染的alpha地图定位。这种分解有助于减少需要补全的区埴。为增强补全的时空一致性,我们引入时间反转框架反向顺序补全帧并利用后续帧作为早期帧的参考,充分利用长轨迹观察。在街道场景数据集上的实验成功重建了街道的空三维表示。空街道的网格表示可用于进一步应用。更多详情和可视化请访问:https://streetunveiler.github.io。
Key Takeaways
- StreetUnveiler是重建空街道的关键技术,可从车载相机的拥挤观察中学习街道的3D表示。
- 采用基于硬标签语义的二维高斯拼贴(2DGS)作为技术基础,具有可扩展性和移除不必要物体的能力。
- 将空街道场景分为观察区、部分观察区和未观察区以提高效率并减少补全工作量。
- 采用时间反转框架进行反向顺序补全帧以增强时空一致性,同时利用长轨迹观察优势。
点此查看论文截图


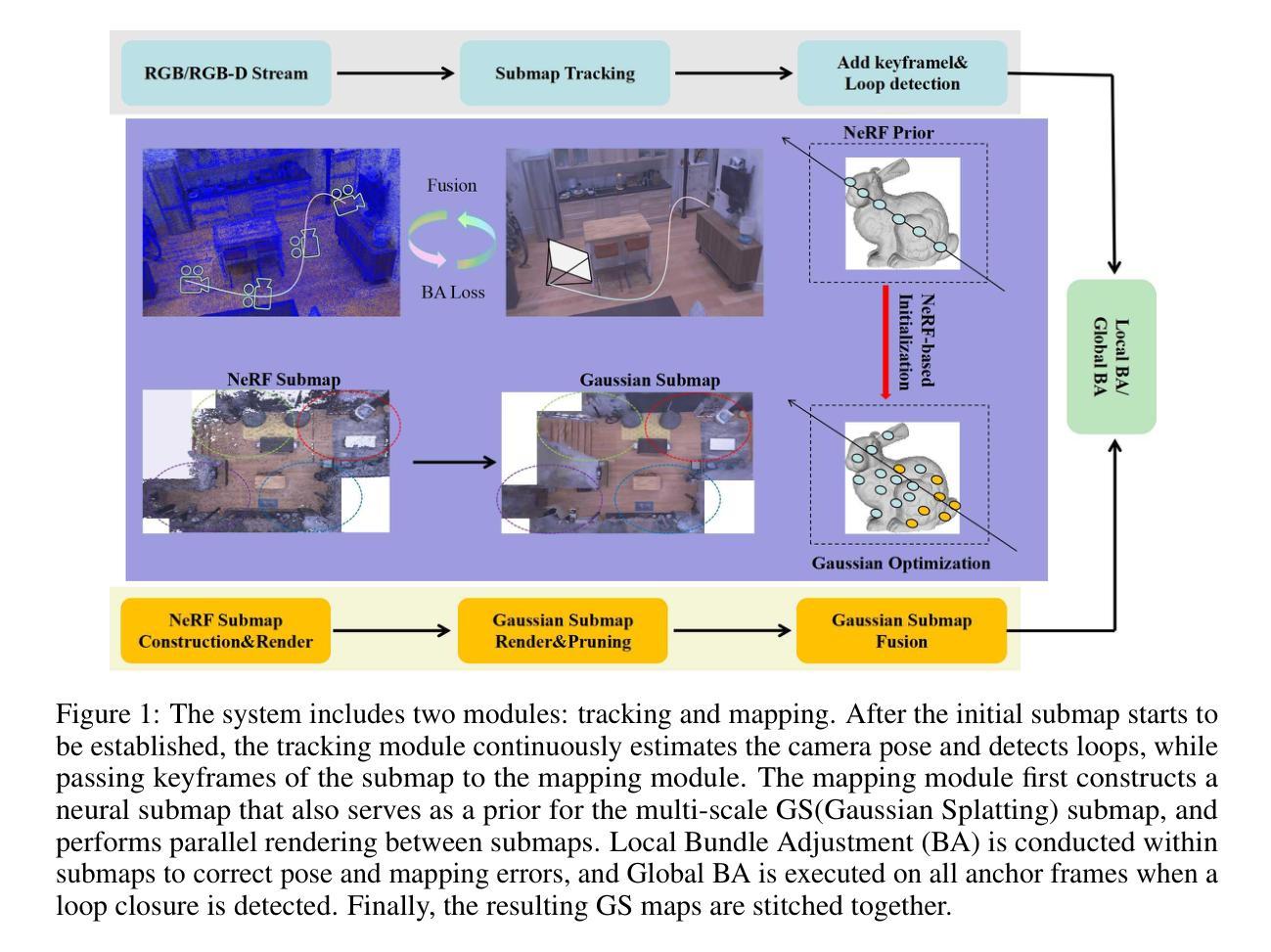
NGM-SLAM: Gaussian Splatting SLAM with Radiance Field Submap
Authors:Mingrui Li, Jingwei Huang, Lei Sun, Aaron Xuxiang Tian, Tianchen Deng, Hongyu Wang
SLAM systems based on Gaussian Splatting have garnered attention due to their capabilities for rapid real-time rendering and high-fidelity mapping. However, current Gaussian Splatting SLAM systems usually struggle with large scene representation and lack effective loop closure detection. To address these issues, we introduce NGM-SLAM, the first 3DGS based SLAM system that utilizes neural radiance field submaps for progressive scene expression, effectively integrating the strengths of neural radiance fields and 3D Gaussian Splatting. We utilize neural radiance field submaps as supervision and achieve high-quality scene expression and online loop closure adjustments through Gaussian rendering of fused submaps. Our results on multiple real-world scenes and large-scale scene datasets demonstrate that our method can achieve accurate hole filling and high-quality scene expression, supporting monocular, stereo, and RGB-D inputs, and achieving state-of-the-art scene reconstruction and tracking performance.
基于高斯拼贴(Gaussian Splatting)的SLAM系统因其快速实时渲染和高保真映射的能力而受到关注。然而,当前的基于高斯拼贴的SLAM系统在大场景表示方面通常存在困难,并且缺乏有效的闭环检测。为了解决这些问题,我们引入了NGM-SLAM,这是第一个基于3DGS的SLAM系统,它利用神经辐射场子图进行渐进场景表达,有效地结合了神经辐射场和3D高斯拼贴的优点。我们以神经辐射场子图作为监督,并通过融合子图的高斯渲染实现高质量的场景表达和在线闭环调整。我们在多个真实场景和大场景数据集上的结果表明,我们的方法可以实现精确的空洞填充和高质量的场景表达,支持单目、立体和RGB-D输入,实现最先进的场景重建和跟踪性能。
论文及项目相关链接
PDF 9pages, 4 figures
Summary
基于高斯拼贴技术的SLAM系统因其快速实时渲染和高保真映射能力而受到关注,但在大场景表示和环路闭合检测方面存在挑战。为解决这些问题,我们推出NGM-SLAM,首个利用神经辐射场子图进行渐进场景表达的基于高斯拼贴的SLAM系统。该系统结合了神经辐射场和高斯拼贴的优势,通过融合子图的高斯渲染实现高质量场景表达和在线环路闭合调整。多项真实场景和大场景数据集的实验结果表明,该方法可实现精准空洞填充和高质量场景表达,支持单目、立体和RGB-D输入,达到先进的场景重建和跟踪性能。
Key Takeaways
- 基于高斯拼贴的SLAM系统受到广泛关注,但在大场景表示和环路闭合检测方面存在挑战。
- NGM-SLAM是首个结合神经辐射场子图和3D高斯拼贴技术的SLAM系统。
- NGM-SLAM利用神经辐射场子图作为监督,实现高质量场景表达。
- 通过融合子图的高斯渲染,NGM-SLAM可在线进行环路闭合调整。
- 该方法支持多种输入模式,包括单目、立体和RGB-D输入。
- 在真实场景和大场景数据集上的实验结果表明NGM-SLAM具有先进的场景重建和跟踪性能。
点此查看论文截图

Dynamic Gaussians Mesh: Consistent Mesh Reconstruction from Dynamic Scenes
Authors:Isabella Liu, Hao Su, Xiaolong Wang
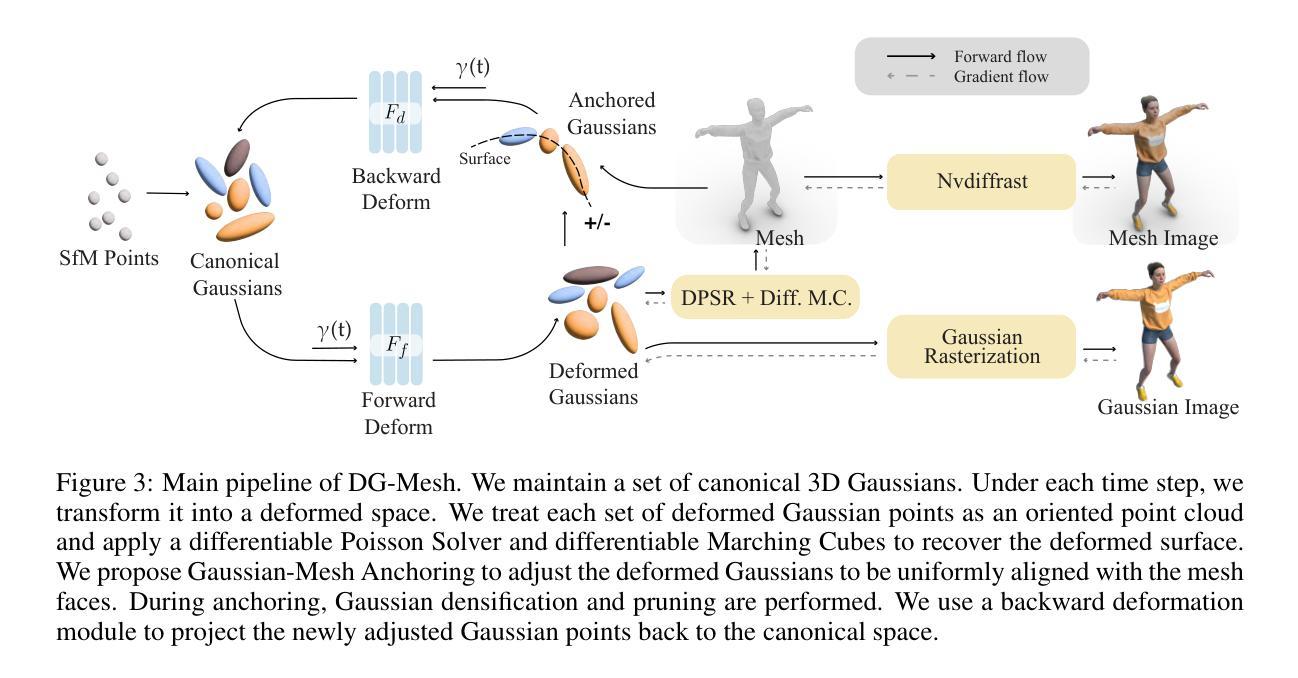
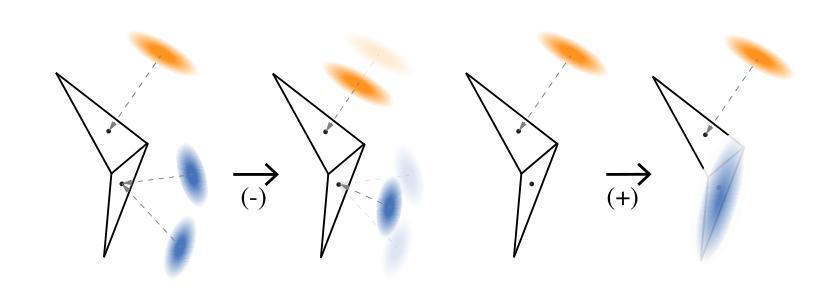
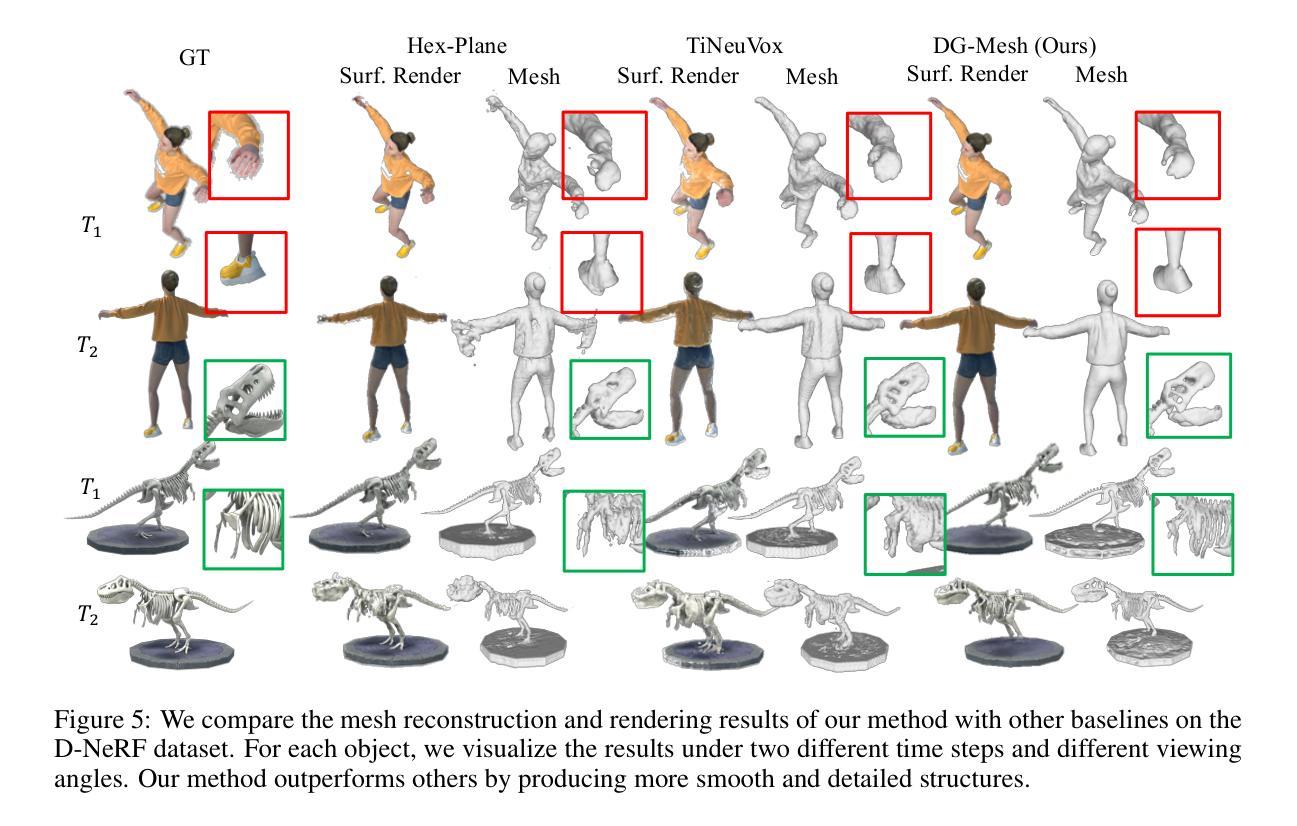
Modern 3D engines and graphics pipelines require mesh as a memory-efficient representation, which allows efficient rendering, geometry processing, texture editing, and many other downstream operations. However, it is still highly difficult to obtain high-quality mesh in terms of detailed structure and time consistency from dynamic observations. To this end, we introduce Dynamic Gaussians Mesh (DG-Mesh), a framework to reconstruct a high-fidelity and time-consistent mesh from dynamic input. Our work leverages the recent advancement in 3D Gaussian Splatting to construct the mesh sequence with temporal consistency from dynamic observations. Building on top of this representation, DG-Mesh recovers high-quality meshes from the Gaussian points and can track the mesh vertices over time, which enables applications such as texture editing on dynamic objects. We introduce the Gaussian-Mesh Anchoring, which encourages evenly distributed Gaussians, resulting better mesh reconstruction through mesh-guided densification and pruning on the deformed Gaussians. By applying cycle-consistent deformation between the canonical and the deformed space, we can project the anchored Gaussian back to the canonical space and optimize Gaussians across all time frames. During the evaluation on different datasets, DG-Mesh provides significantly better mesh reconstruction and rendering than baselines. Project page: https://www.liuisabella.com/DG-Mesh
现代3D引擎和图形管道需要网格作为内存高效的表示形式,这可以实现高效的渲染、几何处理、纹理编辑和许多其他后续操作。然而,从动态观察中获得高质量、细节丰富且时间一致的网格仍然非常困难。为此,我们引入了动态高斯网格(DG-Mesh),这是一个从动态输入重建高保真和时间一致网格的框架。我们的工作利用了最新的3D高斯贴图技术,从动态观察中构建具有时间一致性的网格序列。基于这种表示,DG-Mesh可以从高斯点恢复高质量的网格,并可以随时间跟踪网格顶点,这启用了对动态对象的纹理编辑应用程序。我们引入了高斯网格锚定,它鼓励高斯分布均匀,通过网格指导的密集化和修剪变形高斯,实现更好的网格重建。通过应用规范空间和变形空间之间的循环一致变形,我们可以将锚定的高斯投影回规范空间,并在所有时间帧中优化高斯。在不同的数据集上进行评估时,DG-Mesh在网格重建和渲染方面均显著优于基线方法。项目页面:https://www.liuisabella.com/DG-Mesh
论文及项目相关链接
PDF Project page: https://www.liuisabella.com/DG-Mesh
Summary
高质量的三维网格在动态观测中难以获得,需要兼顾详细结构和时间一致性。为此,我们推出动态高斯网格(DG-Mesh)框架,利用三维高斯贴图技术从动态输入中重建高质量且时间一致的三维网格。DG-Mesh可追踪网格顶点随时间的变化,适用于动态对象的纹理编辑等应用。通过高斯网格锚定技术,实现高斯分布的均匀分布,优化网格重建。通过跨时间帧优化循环一致的变形,将锚定的高斯投影回规范空间,提高不同数据集上的网格重建和渲染效果。
Key Takeaways
- 动态高斯网格(DG-Mesh)是一个从动态输入中重建高质量、时间一致三维网格的框架。
- DG-Mesh利用三维高斯贴图技术,可实现高效的网格重建。
- DG-Mesh能够追踪网格顶点随时间的变化,适用于动态对象的纹理编辑。
- 高斯网格锚定技术可实现高斯分布的均匀分布,从而优化网格重建效果。
- 通过跨时间帧的优化,DG-Mesh提高了网格重建的稳定性。
- DG-Mesh在循环一致的变形处理上表现出优势。
点此查看论文截图