⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-05 更新
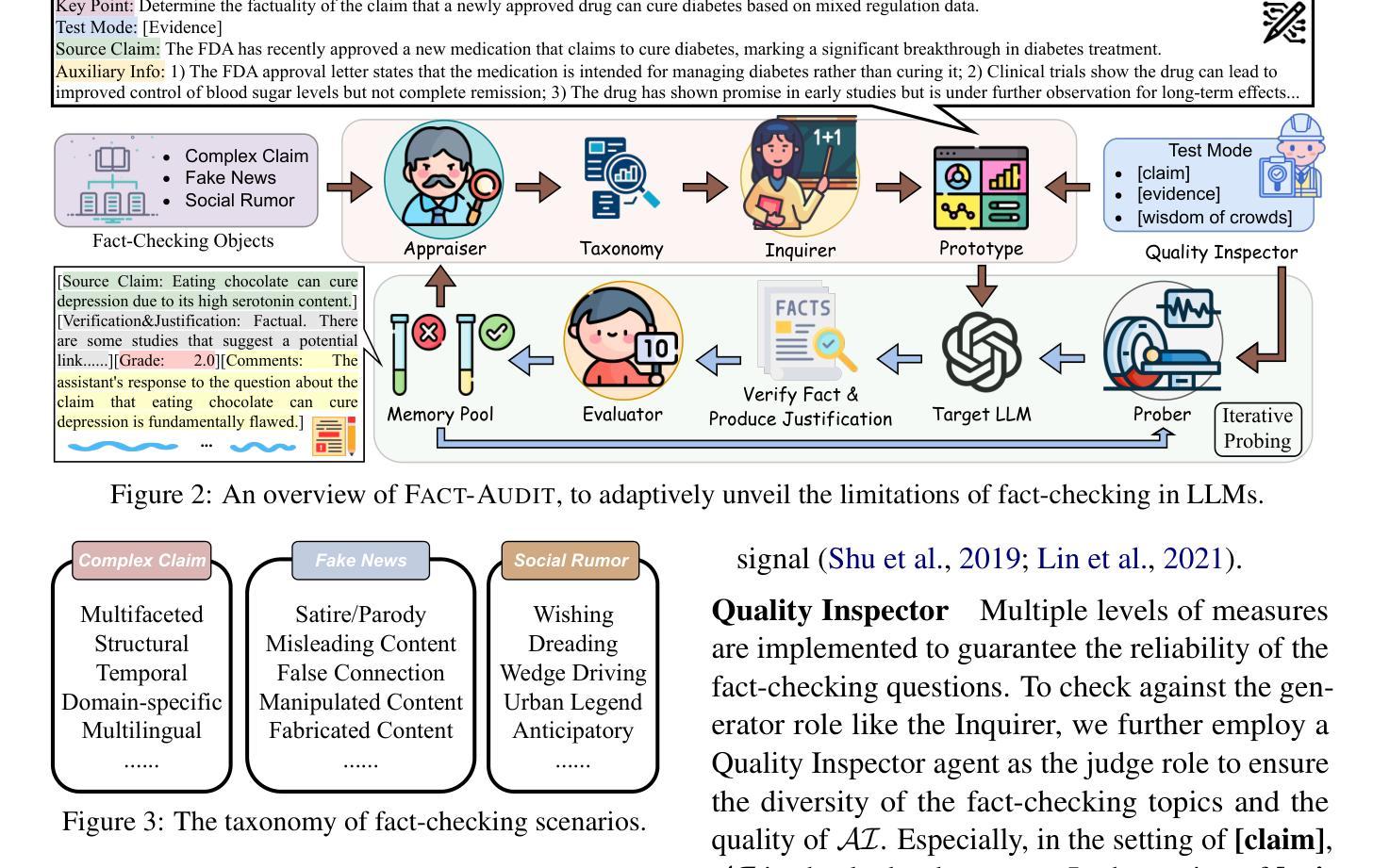
FACT-AUDIT: An Adaptive Multi-Agent Framework for Dynamic Fact-Checking Evaluation of Large Language Models
Authors:Hongzhan Lin, Yang Deng, Yuxuan Gu, Wenxuan Zhang, Jing Ma, See-Kiong Ng, Tat-Seng Chua
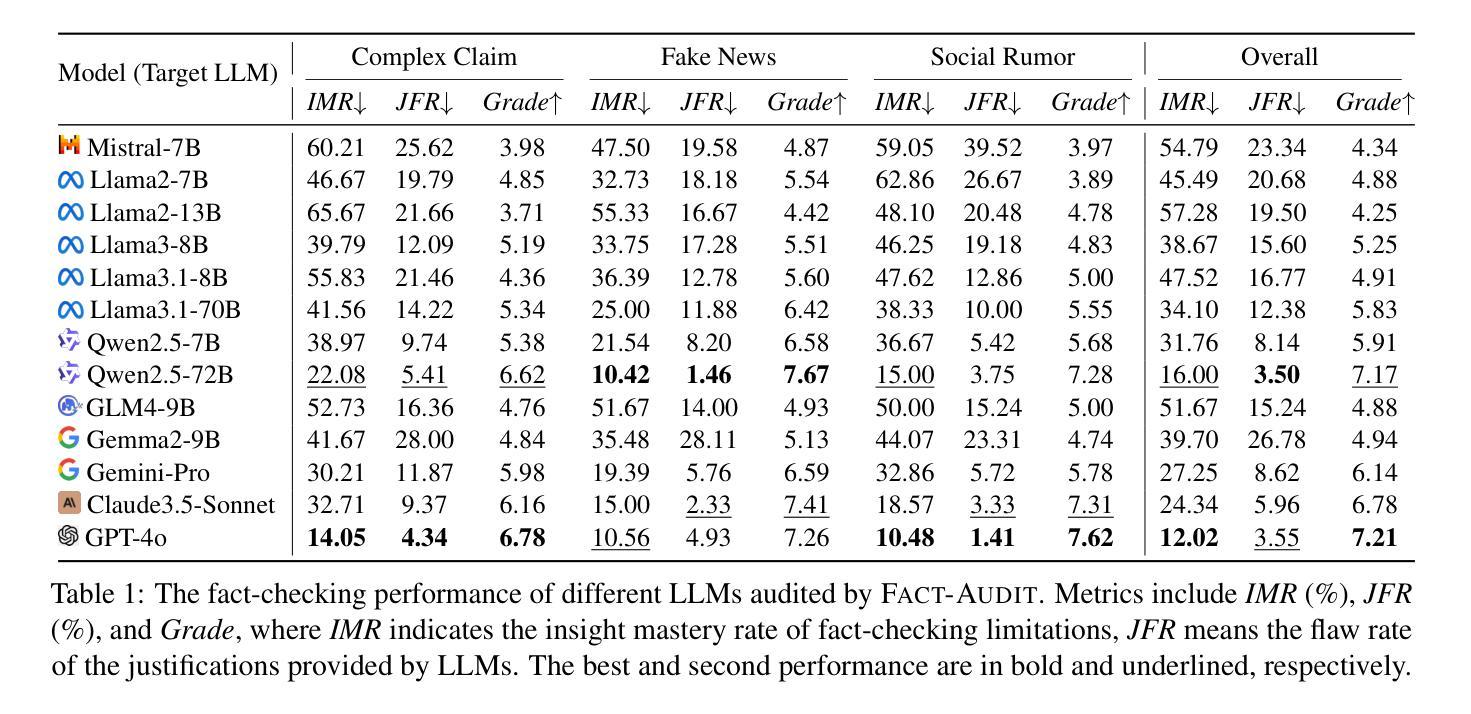
Large Language Models (LLMs) have significantly advanced the fact-checking studies. However, existing automated fact-checking evaluation methods rely on static datasets and classification metrics, which fail to automatically evaluate the justification production and uncover the nuanced limitations of LLMs in fact-checking. In this work, we introduce FACT-AUDIT, an agent-driven framework that adaptively and dynamically assesses LLMs’ fact-checking capabilities. Leveraging importance sampling principles and multi-agent collaboration, FACT-AUDIT generates adaptive and scalable datasets, performs iterative model-centric evaluations, and updates assessments based on model-specific responses. By incorporating justification production alongside verdict prediction, this framework provides a comprehensive and evolving audit of LLMs’ factual reasoning capabilities, to investigate their trustworthiness. Extensive experiments demonstrate that FACT-AUDIT effectively differentiates among state-of-the-art LLMs, providing valuable insights into model strengths and limitations in model-centric fact-checking analysis.
大型语言模型(LLM)在事实核查研究方面取得了显著进展。然而,现有的自动化事实核查评估方法依赖于静态数据集和分类指标,这些方法无法自动评估理由的产生,并且无法揭示大型语言模型在事实核查方面的微妙局限性。在这项工作中,我们引入了FACT-AUDIT,一个由代理驱动的框架,它自适应且动态地评估大型语言模型的事实核查能力。利用重要性采样原理和多元合作机制,FACT-AUDIT生成自适应的可扩展数据集,执行迭代模型为中心的评估,并根据模型特定的响应更新评估结果。通过结合理由产生和判决预测,该框架提供了对大型语言模型的推理能力的全面而不断发展的审计,以调查其可信度。大量实验表明,FACT-AUDIT在主流的大型语言模型之间进行有效区分,为模型为中心的事实核查分析中的模型优势和局限性提供了有价值的见解。
论文及项目相关链接
Summary
大型语言模型(LLM)在事实核查研究中取得了显著进展。然而,现有的自动化事实核查评估方法依赖于静态数据集和分类指标,无法自动评估推理产生的过程并发现LLM在事实核查中的微妙局限。为此,我们引入了FACT-AUDIT这一代理驱动框架,该框架以重要抽样原则和多代理协作为核心,能够自适应且动态地评估LLM的事实核查能力。结合判定结果的预测和推理过程,该框架提供了对LLM事实推理能力的全面且不断发展的审计,以调查其可信度。大量实验证明,FACT-AUDIT能有效区分不同先进水平的LLM,为模型中心的事实核查分析提供了宝贵的见解。
Key Takeaways
- 大型语言模型(LLM)在事实核查领域有重要进展。
- 现有评估方法主要依赖静态数据集和分类指标,存在局限性。
- FACT-AUDIT框架能自适应、动态地评估LLM的事实核查能力。
- 该框架结合判定结果的预测和推理过程,提供全面的审计。
- FACT-AUDIT通过重要抽样原则和多代理协作实现评估。
- 实验证明FACT-AUDIT能有效区分不同水平的LLM。
点此查看论文截图


A-MEM: Agentic Memory for LLM Agents
Authors:Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, Yongfeng Zhang
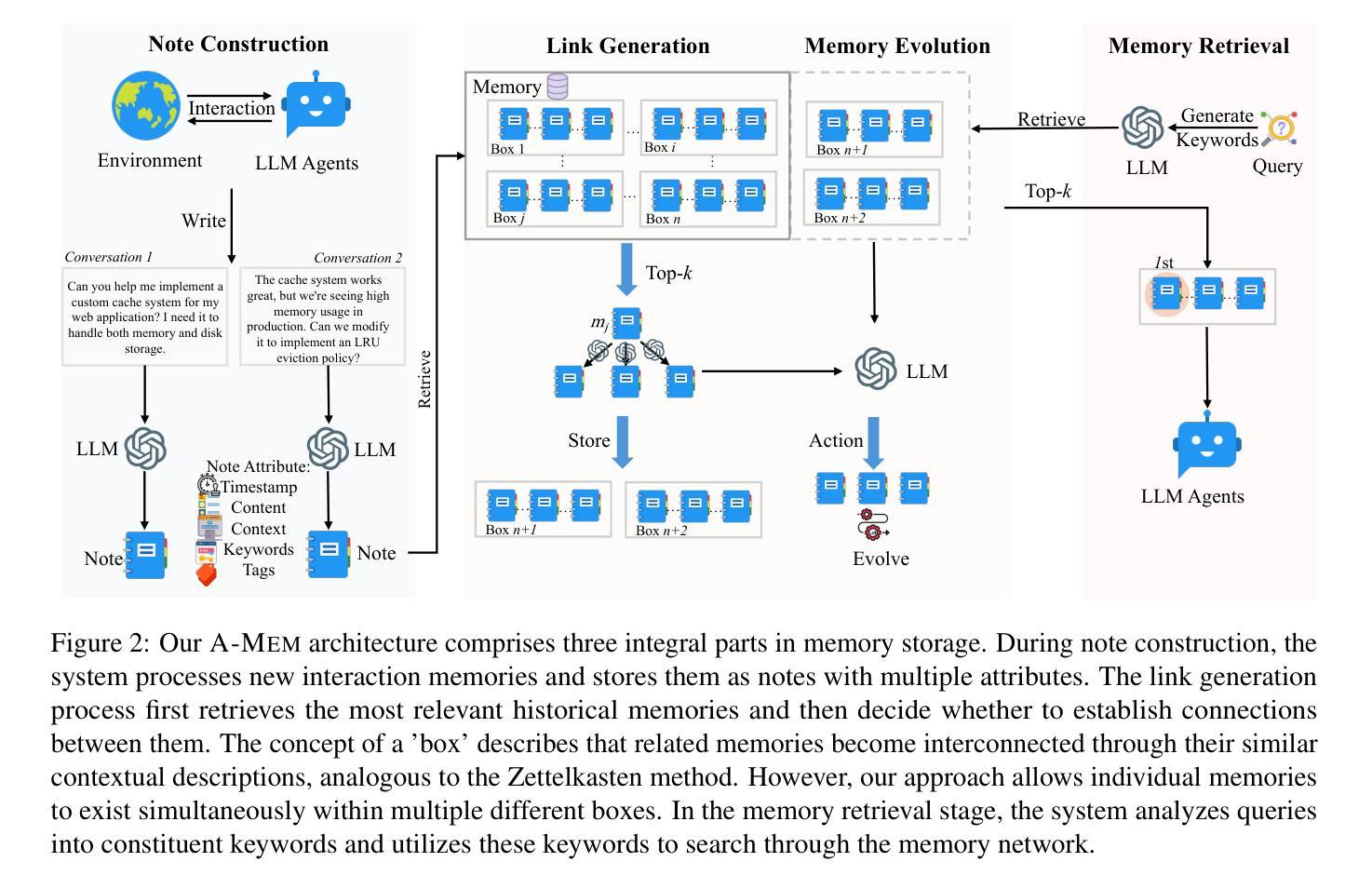
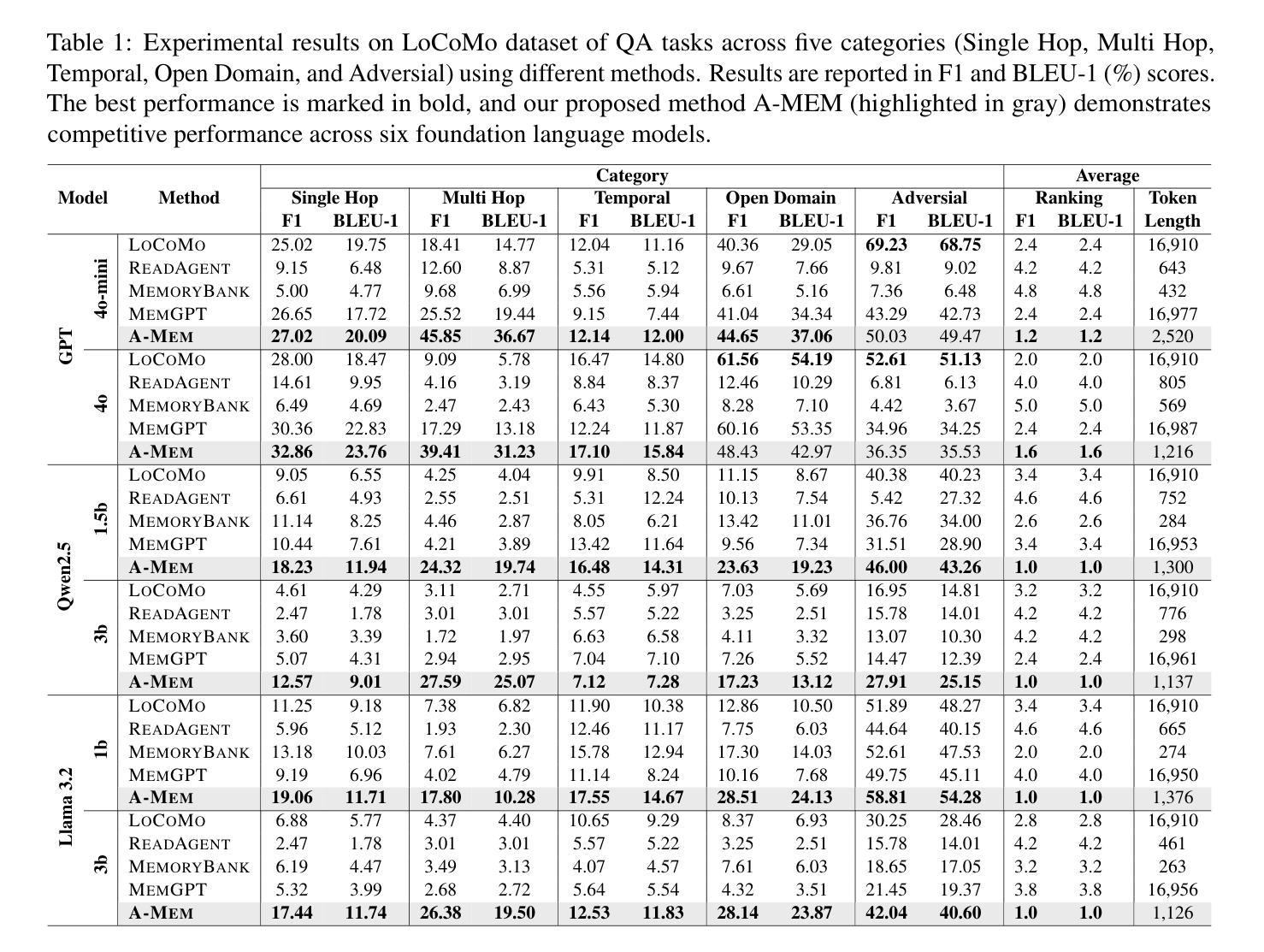
While large language model (LLM) agents can effectively use external tools for complex real-world tasks, they require memory systems to leverage historical experiences. Current memory systems enable basic storage and retrieval but lack sophisticated memory organization, despite recent attempts to incorporate graph databases. Moreover, these systems’ fixed operations and structures limit their adaptability across diverse tasks. To address this limitation, this paper proposes a novel agentic memory system for LLM agents that can dynamically organize memories in an agentic way. Following the basic principles of the Zettelkasten method, we designed our memory system to create interconnected knowledge networks through dynamic indexing and linking. When a new memory is added, we generate a comprehensive note containing multiple structured attributes, including contextual descriptions, keywords, and tags. The system then analyzes historical memories to identify relevant connections, establishing links where meaningful similarities exist. Additionally, this process enables memory evolution - as new memories are integrated, they can trigger updates to the contextual representations and attributes of existing historical memories, allowing the memory network to continuously refine its understanding. Our approach combines the structured organization principles of Zettelkasten with the flexibility of agent-driven decision making, allowing for more adaptive and context-aware memory management. Empirical experiments on six foundation models show superior improvement against existing SOTA baselines. The source code is available at https://github.com/WujiangXu/AgenticMemory.
虽然大型语言模型(LLM)代理可以有效地利用外部工具来完成复杂的现实世界任务,但它们需要记忆系统来利用历史经验。当前的记忆系统虽然实现了基本的存储和检索功能,但缺乏高级的记忆组织功能,尽管最近尝试引入了图数据库。此外,这些系统的固定操作和结构限制了它们在多样化任务中的适应性。为了解决这一限制,本文提出了一种新型的大型语言模型代理的记忆系统,该系统能够以动态的方式组织记忆。我们遵循Zettelkasten方法的基本原则,设计了一个记忆系统,通过动态索引和链接创建相互关联的知识网络。每当添加一个新记忆时,我们会生成一个包含多个结构化属性的综合笔记,包括上下文描述、关键词和标签。然后,系统分析历史记忆以识别相关联系,在存在有意义的相似性时建立链接。此外,这个过程实现了记忆的进化——新记忆的集成可以触发对现有历史记忆的上下文表示和属性的更新,使记忆网络能够不断地提高其理解。我们的方法结合了Zettelkasten的结构化组织原则与代理驱动决策的灵活性,实现了更适应上下文的记忆管理。在六个基础模型上的实证实验表明,与现有的最佳基线相比,我们的方法有明显的改进。源代码可在https://github.com/WujiangXu/AgenticMemory找到。
论文及项目相关链接
Summary
本文提出一种用于大型语言模型(LLM)的新型智能记忆系统,该系统采用动态组织方式,可建立知识网络,提高记忆管理的适应性和上下文感知能力。通过生成包含多个结构化属性的全面笔记,并分析历史记忆来建立联系,实现记忆网络的持续完善。在六个基础模型上的实证实验表明,该系统的性能优于现有最佳基线。源代码已公开。
Key Takeaways
- 大型语言模型(LLM)需要记忆系统利用历史经验来完成复杂任务。
- 当前记忆系统主要支持基本存储和检索功能,缺乏高级记忆组织能力和适应性。
- 该研究提出了一种新型智能记忆系统,可动态组织知识网络以应对不同任务的需求。
- 系统采用Zettelkasten方法的结构化组织原则,通过动态索引和链接创建互联知识网络。
- 该系统可生成包含结构化属性的全面笔记,并进行分析以识别与现有记忆的关联,从而实现记忆网络的持续改进。
- 智能记忆系统结合了Zettelkasten的结构化原则和自主决策的智能选择能力,增强了上下文感知和适应性。
点此查看论文截图

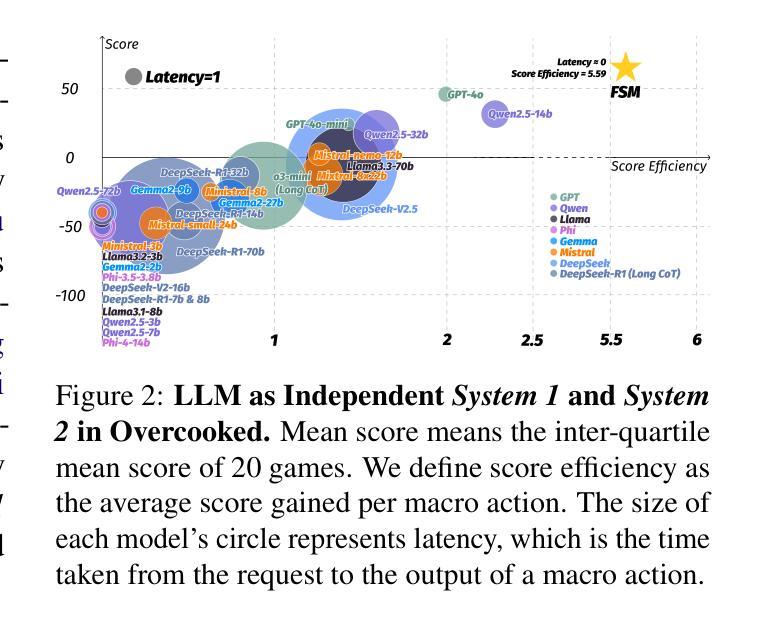
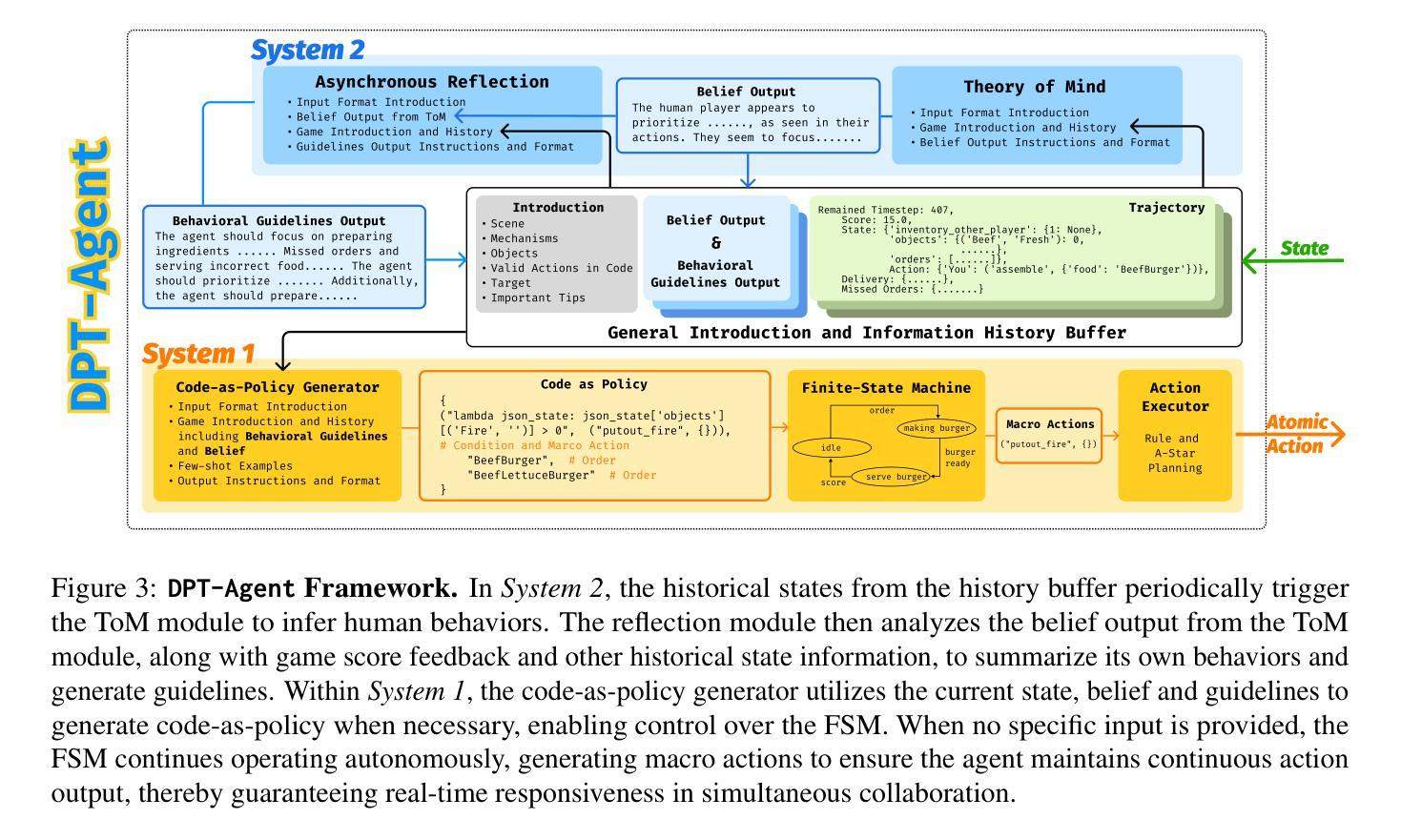
Leveraging Dual Process Theory in Language Agent Framework for Real-time Simultaneous Human-AI Collaboration
Authors:Shao Zhang, Xihuai Wang, Wenhao Zhang, Chaoran Li, Junru Song, Tingyu Li, Lin Qiu, Xuezhi Cao, Xunliang Cai, Wen Yao, Weinan Zhang, Xinbing Wang, Ying Wen
Agents built on large language models (LLMs) have excelled in turn-by-turn human-AI collaboration but struggle with simultaneous tasks requiring real-time interaction. Latency issues and the challenge of inferring variable human strategies hinder their ability to make autonomous decisions without explicit instructions. Through experiments with current independent System 1 and System 2 methods, we validate the necessity of using Dual Process Theory (DPT) in real-time tasks. We propose DPT-Agent, a novel language agent framework that integrates System 1 and System 2 for efficient real-time simultaneous human-AI collaboration. DPT-Agent’s System 1 uses a Finite-state Machine (FSM) and code-as-policy for fast, intuitive, and controllable decision-making. DPT-Agent’s System 2 integrates Theory of Mind (ToM) and asynchronous reflection to infer human intentions and perform reasoning-based autonomous decisions. We demonstrate the effectiveness of DPT-Agent through further experiments with rule-based agents and human collaborators, showing significant improvements over mainstream LLM-based frameworks. DPT-Agent can effectively help LLMs convert correct slow thinking and reasoning into executable actions, thereby improving performance. To the best of our knowledge, DPT-Agent is the first language agent framework that achieves successful real-time simultaneous human-AI collaboration autonomously. Code of DPT-Agent can be found in https://github.com/sjtu-marl/DPT-Agent.
基于大型语言模型(LLM)的代理在人机协作方面表现出色,但在需要实时交互的同时任务方面遇到了挑战。延迟问题和推断可变人类策略的困难阻碍了它们在没有明确指令的情况下进行自主决策的能力。我们通过目前独立的System 1和System 2方法的实验,验证了实时任务中使用双过程理论(DPT)的必要性。我们提出了DPT-Agent,这是一种新型的语言代理框架,它整合了System 1和System 2,以实现高效实时的同时人机协作。DPT-Agent的System 1使用有限状态机(FSM)和代码策略进行快速、直观且可控的决策。DPT-Agent的System 2结合了心智理论(ToM)和异步反射来推断人类意图并进行基于推理的自主决策。我们通过进一步的与基于规则的代理和人类合作者进行的实验证明了DPT-Agent的有效性,显示出对主流LLM框架的重大改进。DPT-Agent可以有效地帮助LLM将正确的慢思考和推理转化为可执行动作,从而提高性能。据我们所知,DPT-Agent是首个成功实现实时同步人机协作的自主语言代理框架。DPT-Agent的代码可在https://github.com/sjtu-marl/DPT-Agent中找到。
论文及项目相关链接
PDF Preprint under review. Update the experimental results of the DeepSeek-R1 series models, o3-mini-high and o3-mini-medium
Summary:
基于大型语言模型的代理在逐步人机协作中表现出色,但在需要实时交互的同时任务中遇到困难。通过结合系统一和系统二的双过程理论,提出了一个新型语言代理框架DPT-Agent,能有效实现实时的人机协作。DPT-Agent包括系统一和系统二两部分,系统一采用有限状态机实现快速、直观和可控的决策制定,系统二结合了心智理论,能够推断人类意图并进行基于推理的自主决策。相较于主流的大型语言模型框架,DPT-Agent显著改善性能。它是首个成功实现实时同步人机协作的自主语言代理框架。
Key Takeaways:
- 大型语言模型代理在实时多任务协作中面临挑战。
- 双过程理论(DPT)对于实时任务中的人机协作至关重要。
- DPT-Agent结合了系统一和系统二的理论,实现高效实时人机协作。
- DPT-Agent的系统一采用有限状态机进行快速决策。
- DPT-Agent的系统二结合了心智理论,能推断人类意图并自主决策。
- 与主流的大型语言模型框架相比,DPT-Agent显著改善性能。
- DPT-Agent是首个成功实现实时同步人机协作的自主语言代理框架。
点此查看论文截图

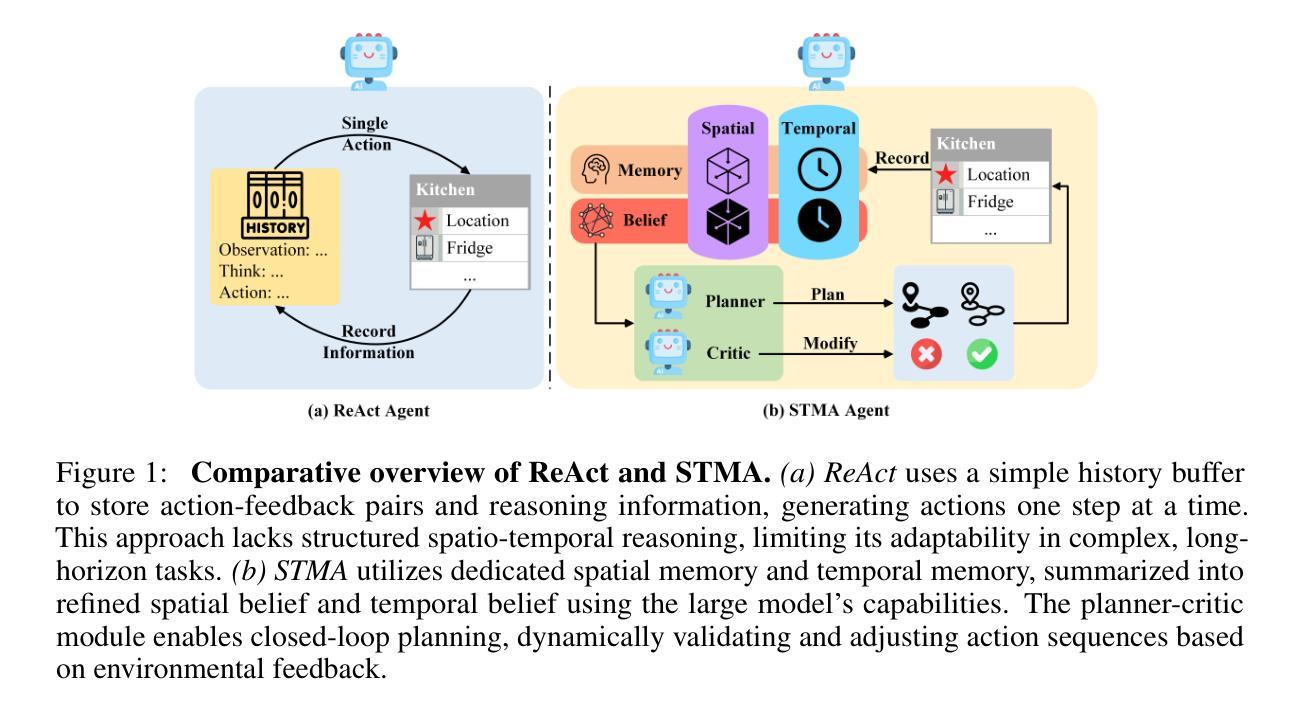
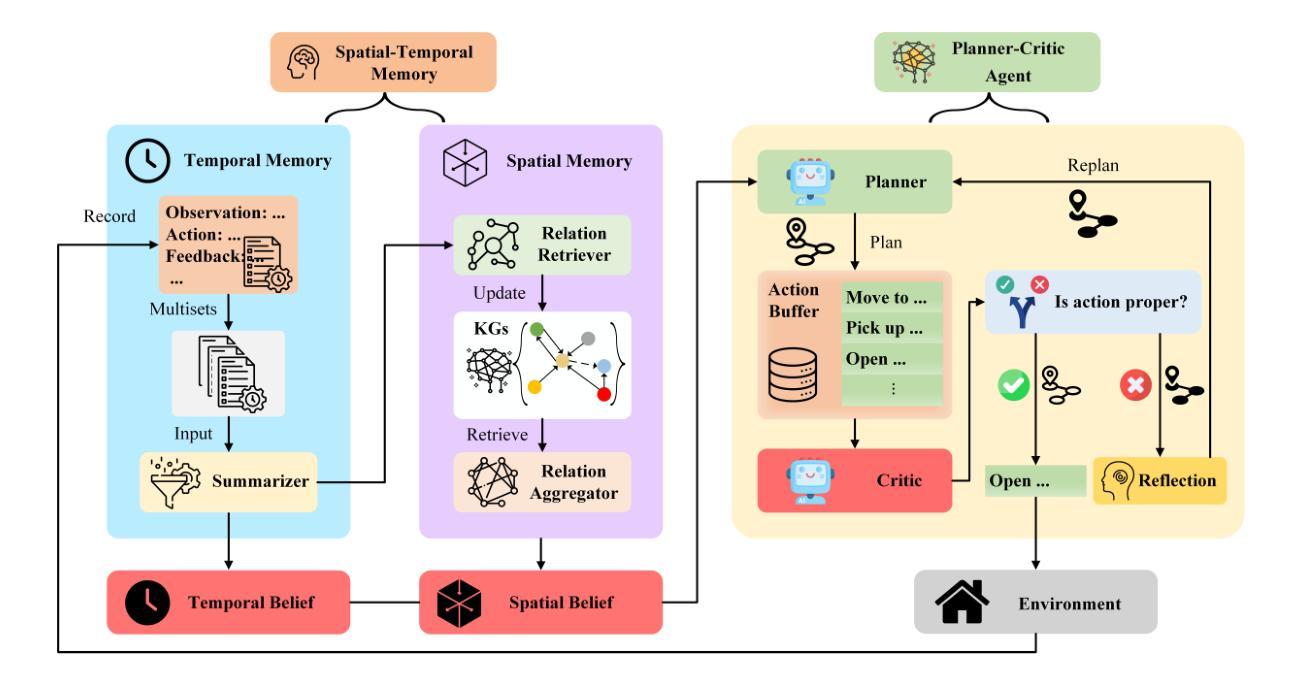
STMA: A Spatio-Temporal Memory Agent for Long-Horizon Embodied Task Planning
Authors:Mingcong Lei, Yiming Zhao, Ge Wang, Zhixin Mai, Shuguang Cui, Yatong Han, Jinke Ren
A key objective of embodied intelligence is enabling agents to perform long-horizon tasks in dynamic environments while maintaining robust decision-making and adaptability. To achieve this goal, we propose the Spatio-Temporal Memory Agent (STMA), a novel framework designed to enhance task planning and execution by integrating spatio-temporal memory. STMA is built upon three critical components: (1) a spatio-temporal memory module that captures historical and environmental changes in real time, (2) a dynamic knowledge graph that facilitates adaptive spatial reasoning, and (3) a planner-critic mechanism that iteratively refines task strategies. We evaluate STMA in the TextWorld environment on 32 tasks, involving multi-step planning and exploration under varying levels of complexity. Experimental results demonstrate that STMA achieves a 31.25% improvement in success rate and a 24.7% increase in average score compared to the state-of-the-art model. The results highlight the effectiveness of spatio-temporal memory in advancing the memory capabilities of embodied agents.
体感智能的关键目标是在动态环境中实现长周期任务的执行,同时保持决策稳健性和适应性。为实现这一目标,我们提出了时空记忆智能体(STMA),这是一种新型框架,旨在通过集成时空记忆增强任务规划和执行。STMA建立在三个关键组件之上:(1)时空记忆模块,实时捕获历史和环境变化;(2)动态知识图谱,促进自适应空间推理;(3)计划评价者机制,迭代优化任务策略。我们在TextWorld环境中对STMA进行了32项任务评估,涉及多步骤规划和在不同复杂程度下的探索。实验结果表明,与最新模型相比,STMA成功率提高了31.25%,平均得分提高了24.7%。结果突出了时空记忆在提升体感智能体的记忆能力方面的有效性。
论文及项目相关链接
Summary
本文介绍了体智能的关键目标,即实现在动态环境中执行长期任务的同时保持稳健的决策和适应性。为实现这一目标,提出了一种新型框架——时空记忆智能体(STMA),通过整合时空记忆来增强任务规划和执行。STMA由三个关键组件构成:(1)时空记忆模块,实时捕获历史和环境的变迁;(2)动态知识图谱,促进自适应空间推理;(3)计划-批判机制,迭代优化任务策略。在TextWorld环境中对涉及不同复杂程度的多步骤规划和探索的32项任务进行评估。实验结果表明,与最新模型相比,STMA成功率提高了31.25%,平均得分增加了24.7%,突显了时空记忆在提升智能体的记忆能力方面的有效性。
Key Takeaways
- 体智能的目标是让智能体在动态环境中执行长期任务时保持稳健决策和适应性。
- 提出了新型框架STMA,通过整合时空记忆增强任务规划和执行。
- STMA由三个关键组件构成:时空记忆模块、动态知识图谱和计划-批判机制。
- 时空记忆模块能实时捕获历史和环境的变迁。
- 动态知识图谱促进智能体的自适应空间推理。
- 在TextWorld环境下的实验表明,STMA在多项任务上的表现优于现有模型。
点此查看论文截图

Speaking the Language of Teamwork: LLM-Guided Credit Assignment in Multi-Agent Reinforcement Learning
Authors:Muhan Lin, Shuyang Shi, Yue Guo, Vaishnav Tadiparthi, Behdad Chalaki, Ehsan Moradi Pari, Simon Stepputtis, Woojun Kim, Joseph Campbell, Katia Sycara
Credit assignment, the process of attributing credit or blame to individual agents for their contributions to a team’s success or failure, remains a fundamental challenge in multi-agent reinforcement learning (MARL), particularly in environments with sparse rewards. Commonly-used approaches such as value decomposition often lead to suboptimal policies in these settings, and designing dense reward functions that align with human intuition can be complex and labor-intensive. In this work, we propose a novel framework where a large language model (LLM) generates dense, agent-specific rewards based on a natural language description of the task and the overall team goal. By learning a potential-based reward function over multiple queries, our method reduces the impact of ranking errors while allowing the LLM to evaluate each agent’s contribution to the overall task. Through extensive experiments, we demonstrate that our approach achieves faster convergence and higher policy returns compared to state-of-the-art MARL baselines.
在多智能体强化学习(MARL)中,特别是在奖励稀疏的环境中,对智能体的贡献进行信用分配,即为其对团队成功或失败的贡献赋予信用或责任,仍然是一个基本挑战。常用的方法如值分解在这些场景中常常会导致次优策略,而设计符合人类直觉的密集奖励函数可能复杂且耗时。在这项工作中,我们提出了一种新的框架,其中大型语言模型(LLM)基于任务的自然语言描述和整体团队目标生成密集、针对智能体的奖励。通过基于多个查询学习基于潜力的奖励函数,我们的方法减少了排名错误的影响,同时允许LLM评估每个智能体对整体任务的贡献。通过广泛的实验,我们证明我们的方法与最新的MARL基准相比,实现了更快的收敛速度和更高的策略回报。
论文及项目相关链接
PDF 11 pages, 6 figures. Added the acknowledgement section
Summary:在团队成功或失败时分配功劳或责任是多智能体强化学习中的一个基本挑战,特别是在奖励稀疏的环境中。传统的价值分解方法常常导致次优策略,设计符合人类直觉的密集奖励函数可能复杂且耗时。本研究提出了一种新的框架,利用大型语言模型根据任务的自然语言描述和整体团队目标生成密集、特定于智能体的奖励。通过基于多个查询学习潜在奖励函数,我们的方法减少了排名错误的影响,并允许语言模型评估每个智能体对整体任务的贡献。实验表明,该方法相较于最先进的MARL基线方法,实现了更快的收敛速度和更高的策略回报。
Key Takeaways:
- 信用分配在多智能体强化学习中是一个挑战,特别是在奖励稀疏的环境中。
- 传统价值分解方法可能导致次优策略。
- 大型语言模型可以根据任务的自然语言描述和团队目标生成特定于智能体的密集奖励。
- 通过学习基于多个查询的潜在奖励函数,可以减少排名错误的影响。
- 语言模型能够评估每个智能体对整体任务的贡献。
- 该方法实现了更快的收敛速度。
点此查看论文截图


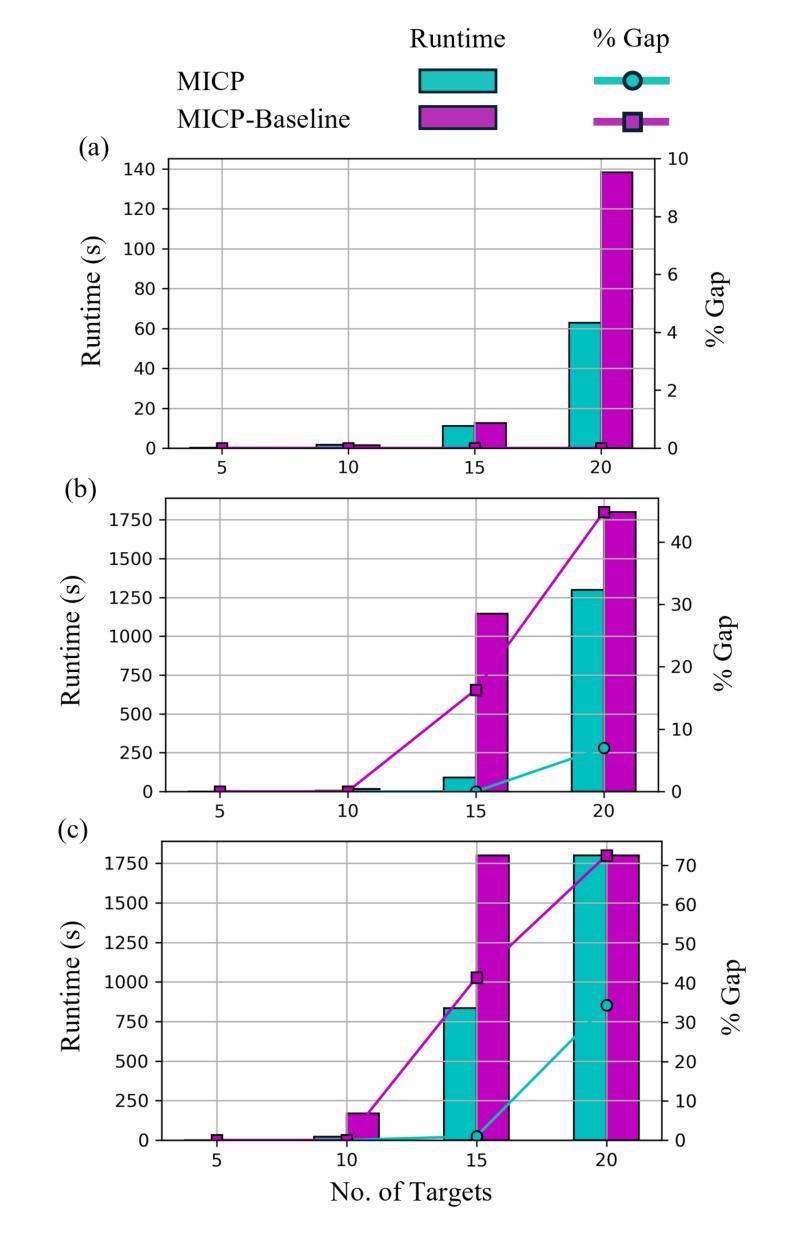
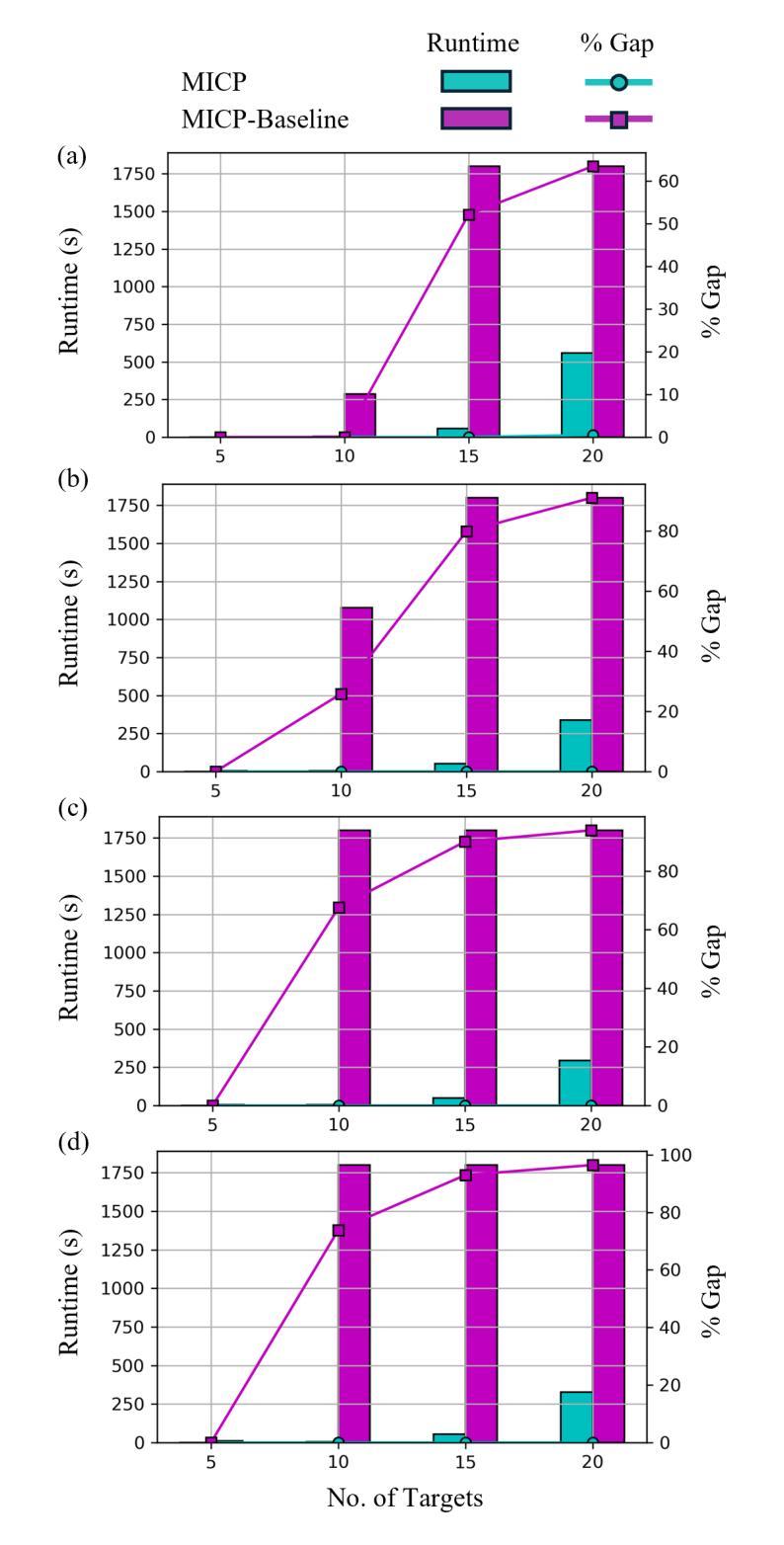
A Mixed-Integer Conic Program for the Multi-Agent Moving-Target Traveling Salesman Problem
Authors:Allen George Philip, Zhongqiang Ren, Sivakumar Rathinam, Howie Choset
The Moving-Target Traveling Salesman Problem (MT-TSP) seeks a shortest path for an agent that starts at a stationary depot, visits a set of moving targets exactly once, each within one of their respective time windows, and returns to the depot. In this paper, we introduce a new Mixed-Integer Conic Program (MICP) formulation for the Multi-Agent Moving-Target Traveling Salesman Problem (MA-MT-TSP), a generalization of the MT-TSP involving multiple agents. Our approach begins by restating the current state-of-the-art MICP formulation for MA-MT-TSP as a Nonconvex Mixed-Integer Nonlinear Program (MINLP), followed by a novel reformulation into a new MICP. We present computational results demonstrating that our formulation outperforms the state-of-the-art, achieving up to two orders of magnitude reduction in runtime, and over 90% improvement in optimality gap.
移动目标旅行商问题(MT-TSP)旨在为从静止的仓库出发的代理寻找一条最短路径,该路径恰好访问一组移动目标一次,每个目标都在其各自的时间窗口内,并最终返回仓库。在本文中,我们为多代理移动目标旅行商问题(MA-MT-TSP)引入了一种新的混合整数锥规划(MICP)公式,这是对涉及多个代理的MT-TSP的一种概括。我们的方法首先是将现有的最先进的MICP公式重新表述为针对MA-MT-TSP的非凸混合整数非线性规划(MINLP),然后进行新的公式改革以形成新的MICP。我们提供了计算结果,证明了我们的公式优于现有技术,实现了运行时高达两个数量级的减少,并且在最优性差距上提高了超过90%。
论文及项目相关链接
PDF 7 pages, 3 figures
Summary
本文研究了多代理移动目标旅行商问题(MA-MT-TSP),其中多个代理需要寻找最短路径以访问一组移动目标。针对此问题,本文提出了一种新的混合整数锥规划(MICP)解决方案。通过将现有技术转化为非凸混合整数非线性规划(MINLP),然后对其进行重新制定,形成新的MICP方案。计算结果表明,该方案比现有技术更加优秀,运行时缩短了两个数量级,最优解改善幅度超过90%。
Key Takeaways
- 研究解决了多代理移动目标旅行商问题(MA-MT-TSP)。
- 提出了一种新的混合整数锥规划(MICP)解决方案。
- 将现有技术转化为非凸混合整数非线性规划(MINLP)。
- 提出了一种新的MICP方案对原问题进行重新制定。
- 该方案计算性能显著,运行时缩短了两个数量级。
点此查看论文截图

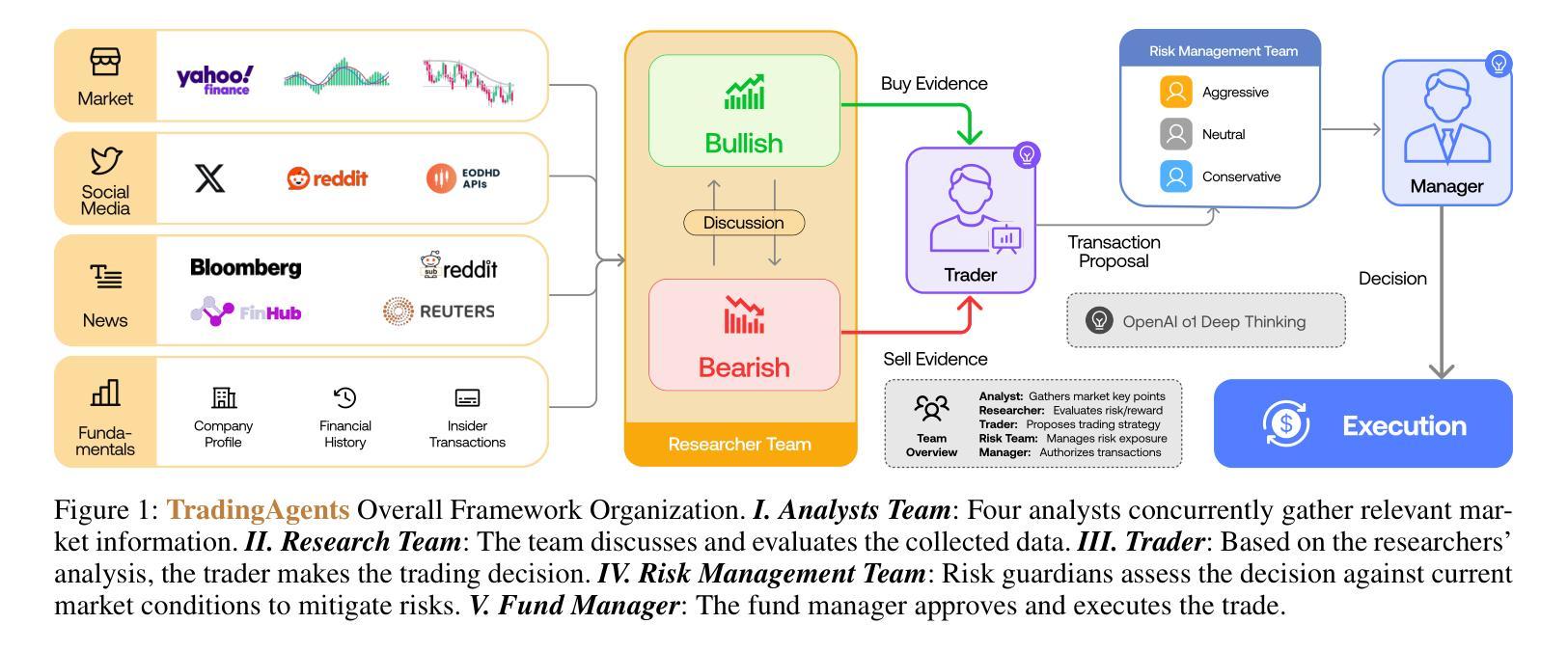
TradingAgents: Multi-Agents LLM Financial Trading Framework
Authors:Yijia Xiao, Edward Sun, Di Luo, Wei Wang
Significant progress has been made in automated problem-solving using societies of agents powered by large language models (LLMs). In finance, efforts have largely focused on single-agent systems handling specific tasks or multi-agent frameworks independently gathering data. However, multi-agent systems’ potential to replicate real-world trading firms’ collaborative dynamics remains underexplored. TradingAgents proposes a novel stock trading framework inspired by trading firms, featuring LLM-powered agents in specialized roles such as fundamental analysts, sentiment analysts, technical analysts, and traders with varied risk profiles. The framework includes Bull and Bear researcher agents assessing market conditions, a risk management team monitoring exposure, and traders synthesizing insights from debates and historical data to make informed decisions. By simulating a dynamic, collaborative trading environment, this framework aims to improve trading performance. Detailed architecture and extensive experiments reveal its superiority over baseline models, with notable improvements in cumulative returns, Sharpe ratio, and maximum drawdown, highlighting the potential of multi-agent LLM frameworks in financial trading. TradingAgents is available at https://github.com/PioneerFintech.
在利用大型语言模型(LLM)驱动的智能体社会进行自动化问题解决方面,已经取得了重大进展。在金融领域,相关努力主要集中在处理特定任务的单一智能体系统或独立收集数据的多智能体框架上。然而,多智能体系统在复制现实世界交易公司的协作动态方面的潜力尚未得到充分探索。《TradingAgents》提出了一个受交易公司启发的新型股票交易框架,其中包括由大型语言模型驱动的专门从事特定角色的智能体,如基本面分析师、情绪分析师、技术分析师和不同风险级别的交易员。该框架包括牛市和熊市研究者智能体对市场状况进行评估,一个风险管理团队监控曝光度,以及交易员根据辩论和历史数据合成见解以做出明智决策。通过模拟动态协作的交易环境,该框架旨在提高交易性能。详细的架构和广泛的实验表明其在累积回报、夏普比率和最大回撤方面优于基线模型,凸显了多智能体LLM框架在金融交易中的潜力。《TradingAgents》可在https://github.com/PioneerFintech上找到。
论文及项目相关链接
PDF Multi-Agent AI in the Real World @ AAAI 2025
Summary:基于大型语言模型(LLM)的代理社会在自动化问题解决方面取得了显著进展。在金融领域,尽管单代理系统处理特定任务或多代理框架独立收集数据的工作已广泛展开,但多代理系统在模拟真实交易公司的协作动态方面的潜力尚未得到充分探索。TradingAgents提出了一个受交易公司启发的股票交易新框架,该框架具有多种角色,包括基于LLM的专职分析师、情绪分析师、技术分析师和具有不同风险特征的交易员。通过模拟动态协作的交易环境,该框架旨在提高交易性能。详细的架构和广泛的实验表明,其在累积回报、夏普比率和最大回撤等方面优于基准模型,突显了多代理LLM框架在金融交易中的潜力。
Key Takeaways:
- 代理社会在自动化问题解决上取得了进展,特别是在金融领域的应用。
- 目前金融领域的研究主要集中在单代理系统处理特定任务或独立的多代理框架收集数据上。
- 多代理系统在模拟真实交易公司的协作动态方面的潜力尚未得到充分探索。
- TradingAgents框架采用基于LLM的代理,包括分析师和交易员等不同角色,旨在模拟真实交易环境并提高交易性能。
- 该框架的详细架构和实验结果表明其在多个关键指标上优于基准模型。
- TradingAgents框架可用于模拟股票交易,并在累积回报、夏普比率和最大回撤等方面显示出优势。
点此查看论文截图




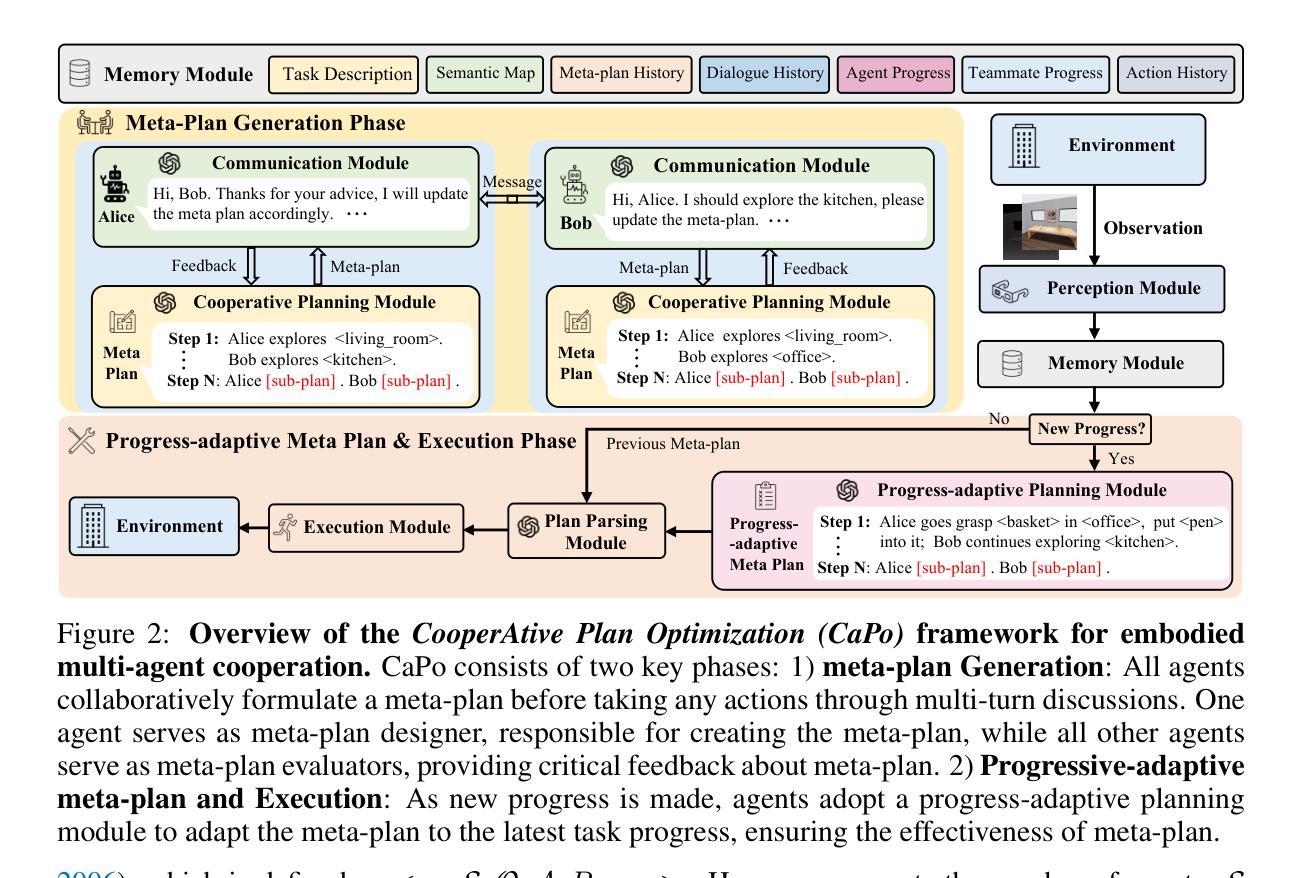
CaPo: Cooperative Plan Optimization for Efficient Embodied Multi-Agent Cooperation
Authors:Jie Liu, Pan Zhou, Yingjun Du, Ah-Hwee Tan, Cees G. M. Snoek, Jan-Jakob Sonke, Efstratios Gavves
In this work, we address the cooperation problem among large language model (LLM) based embodied agents, where agents must cooperate to achieve a common goal. Previous methods often execute actions extemporaneously and incoherently, without long-term strategic and cooperative planning, leading to redundant steps, failures, and even serious repercussions in complex tasks like search-and-rescue missions where discussion and cooperative plan are crucial. To solve this issue, we propose Cooperative Plan Optimization (CaPo) to enhance the cooperation efficiency of LLM-based embodied agents. Inspired by human cooperation schemes, CaPo improves cooperation efficiency with two phases: 1) meta-plan generation, and 2) progress-adaptive meta-plan and execution. In the first phase, all agents analyze the task, discuss, and cooperatively create a meta-plan that decomposes the task into subtasks with detailed steps, ensuring a long-term strategic and coherent plan for efficient coordination. In the second phase, agents execute tasks according to the meta-plan and dynamically adjust it based on their latest progress (e.g., discovering a target object) through multi-turn discussions. This progress-based adaptation eliminates redundant actions, improving the overall cooperation efficiency of agents. Experimental results on the ThreeDworld Multi-Agent Transport and Communicative Watch-And-Help tasks demonstrate that CaPo achieves much higher task completion rate and efficiency compared with state-of-the-arts.The code is released at https://github.com/jliu4ai/CaPo.
在这项工作中,我们解决了基于大型语言模型(LLM)的实体代理之间的合作问题,在这些代理中,必须合作以实现共同目标。之前的方法通常即兴且不一致地执行操作,没有长期战略和合作规划,这会导致冗余步骤、失败,甚至在搜索和救援等复杂任务中产生严重后果,其中讨论和合作计划至关重要。为了解决这个问题,我们提出了合作计划优化(CaPo)来提高基于LLM的实体代理的合作效率。受人类合作方案的启发,CaPo通过两个阶段提高合作效率:1)元计划生成;和进展自适应的元计划与执行阶段。在第一阶段,所有代理分析任务、讨论并合作生成一个元计划,该计划将任务分解为具有详细步骤的子任务,确保长期战略和连贯性计划以实现有效协调。在第二阶段中,代理根据元计划执行任务并通过多次讨论根据其最新进展(例如发现目标对象)动态调整计划。这种基于进度的适应性消除了冗余操作,提高了代理的整体合作效率。在ThreeDworld多任务协同通讯、观看和辅助任务上的实验结果表明,与当前最先进技术相比,CaPo大大提高了任务完成率和效率。代码发布在https://github.com/jliu4ai/CaPo。
论文及项目相关链接
PDF Accepted in ICLR2025
Summary
该文章研究了基于大型语言模型(LLM)的实体代理人在合作问题上遇到的挑战。为了解决执行动作时的临时性和非连贯性,文章提出了合作计划优化(CaPo)方法,通过两个阶段提高合作效率:首先是生成元计划,然后是进度自适应的元计划和执行。CaPo通过模拟人类合作方案,提高了实体代理人的合作效率。在三维世界多智能体运输和沟通观察救助任务中,CaPo相较于现有技术取得了更高的任务完成率和效率。
Key Takeaways
- 基于大型语言模型的实体代理人在合作问题上存在挑战。
- 传统方法在执行动作时存在临时性和非连贯性问题。
- 合作计划优化(CaPo)方法旨在提高实体代理人的合作效率。
- CaPo分为两个阶段:生成元计划和进度自适应的元计划和执行。
- 元计划确保了长期战略和连贯性,有助于高效协调。
- 通过模拟人类合作方案,CaPo提高了实体代理人的合作效率。
- 在三维世界多智能体运输和沟通观察救助任务中,CaPo表现出更高的任务完成率和效率。
点此查看论文截图



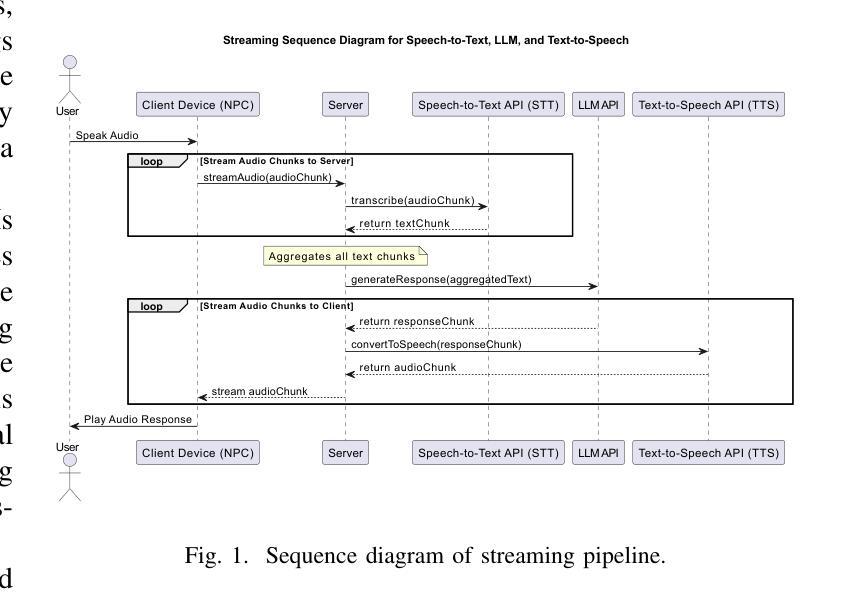
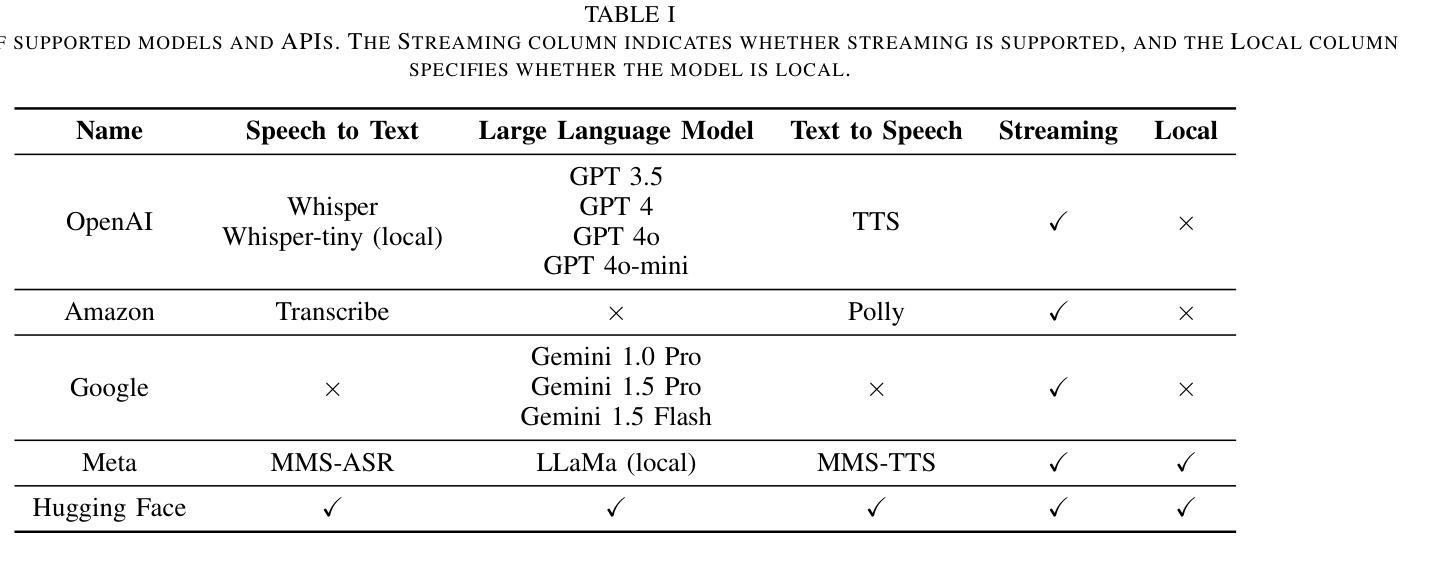
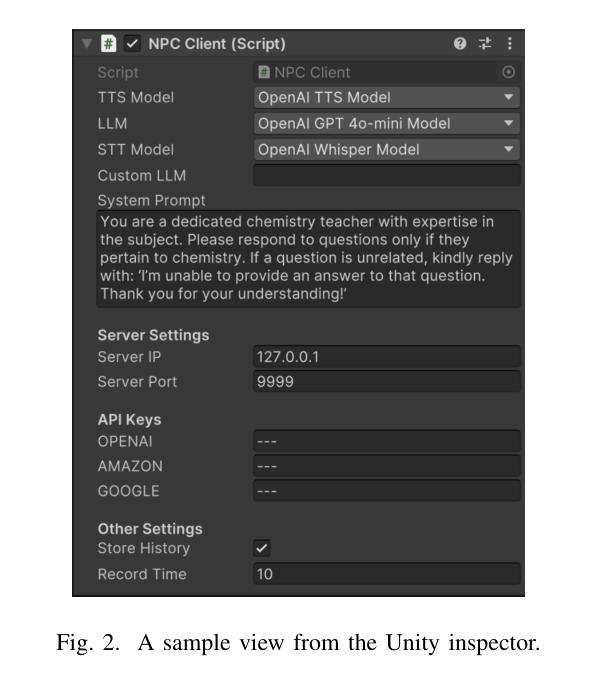
CUIfy the XR: An Open-Source Package to Embed LLM-powered Conversational Agents in XR
Authors:Kadir Burak Buldu, Süleyman Özdel, Ka Hei Carrie Lau, Mengdi Wang, Daniel Saad, Sofie Schönborn, Auxane Boch, Enkelejda Kasneci, Efe Bozkir
Recent developments in computer graphics, machine learning, and sensor technologies enable numerous opportunities for extended reality (XR) setups for everyday life, from skills training to entertainment. With large corporations offering affordable consumer-grade head-mounted displays (HMDs), XR will likely become pervasive, and HMDs will develop as personal devices like smartphones and tablets. However, having intelligent spaces and naturalistic interactions in XR is as important as technological advances so that users grow their engagement in virtual and augmented spaces. To this end, large language model (LLM)–powered non-player characters (NPCs) with speech-to-text (STT) and text-to-speech (TTS) models bring significant advantages over conventional or pre-scripted NPCs for facilitating more natural conversational user interfaces (CUIs) in XR. This paper provides the community with an open-source, customizable, extendable, and privacy-aware Unity package, CUIfy, that facilitates speech-based NPC-user interaction with widely used LLMs, STT, and TTS models. Our package also supports multiple LLM-powered NPCs per environment and minimizes latency between different computational models through streaming to achieve usable interactions between users and NPCs. We publish our source code in the following repository: https://gitlab.lrz.de/hctl/cuify
近期计算机图形学、机器学习和传感器技术的进展为扩展现实(XR)在日常生活中的广泛应用提供了无数机会,从技能培训到娱乐等各个领域。随着大型公司提供负担得起的消费级头戴显示器(HMDs),XR可能会变得普及,而HMDs将像智能手机和平板电脑一样发展成为个人设备。然而,拥有智能空间和自然人机交互同样重要,这样用户才能增加对虚拟和增强空间的参与度。为此,利用大型语言模型(LLM)驱动的非玩家角色(NPCs)通过语音转文本(STT)和文本转语音(TTS)模型,为XR中更自然的对话式用户界面(CUIs)提供了传统或预设NPC无法比拟的优势。本文为社区提供了一个开源、可定制、可扩展和注重隐私的Unity软件包CUIfy,它促进了基于语音的NPC与用户之间的交互,广泛使用了LLM、STT和TTS模型。我们的软件包还支持每个环境有多个LLM驱动的NPC,并通过流技术最小化不同计算模型之间的延迟,以实现用户和NPC之间可用的交互。我们已将源代码发布在以下存储库中:[https://gitlab.lrz.de/hctl/cuify]
论文及项目相关链接
PDF 7th IEEE International Conference on Artificial Intelligence & eXtended and Virtual Reality (IEEE AIxVR 2025)
Summary
近期计算机图形学、机器学习和传感器技术的发展为扩展现实(XR)在日常生活中的运用提供了无限可能,如技能培训到娱乐等。随着大型企业提供经济实惠的消费级头戴显示器(HMDs),XR有望成为普及性技术,HMDs将如同智能手机和平板一样成为个人设备。为了在XR中实现智能空间和自然交互,采用大型语言模型(LLM)驱动的非玩家角色(NPCs)结合语音识别和文本合成技术,能为用户提供更自然的交互界面。本文为社区提供了一个开源、可定制、可扩展且注重隐私的Unity软件包CUIfy,它支持基于语音的NPC-用户交互,可与广泛使用的LLM、STT和TTS模型配合使用。我们的软件包还支持多个环境内的LLM驱动NPCs,并通过流技术最小化不同计算模型之间的延迟,以实现用户和NPC之间的可用交互。
Key Takeaways
- 计算机图形学、机器学习和传感器技术的最新发展促进了扩展现实(XR)在日常生活中的广泛应用。
- 头戴显示器(HMDs)的普及使得XR技术将成为个人设备的一部分,如同智能手机和平板。
- 在XR中实现智能空间和自然交互至关重要,大型语言模型(LLM)驱动的非玩家角色(NPCs)结合语音识别和文本合成技术为用户提供了更自然的交互界面。
- 本文介绍了一个开源的Unity软件包CUIfy,它支持基于语音的NPC-用户交互,并可与大型语言模型、语音识别和文本合成技术结合使用。
- CUIfy软件包支持多个环境内的多个LLM驱动NPCs。
- 软件包通过流技术优化不同计算模型之间的交互,减少延迟。
点此查看论文截图

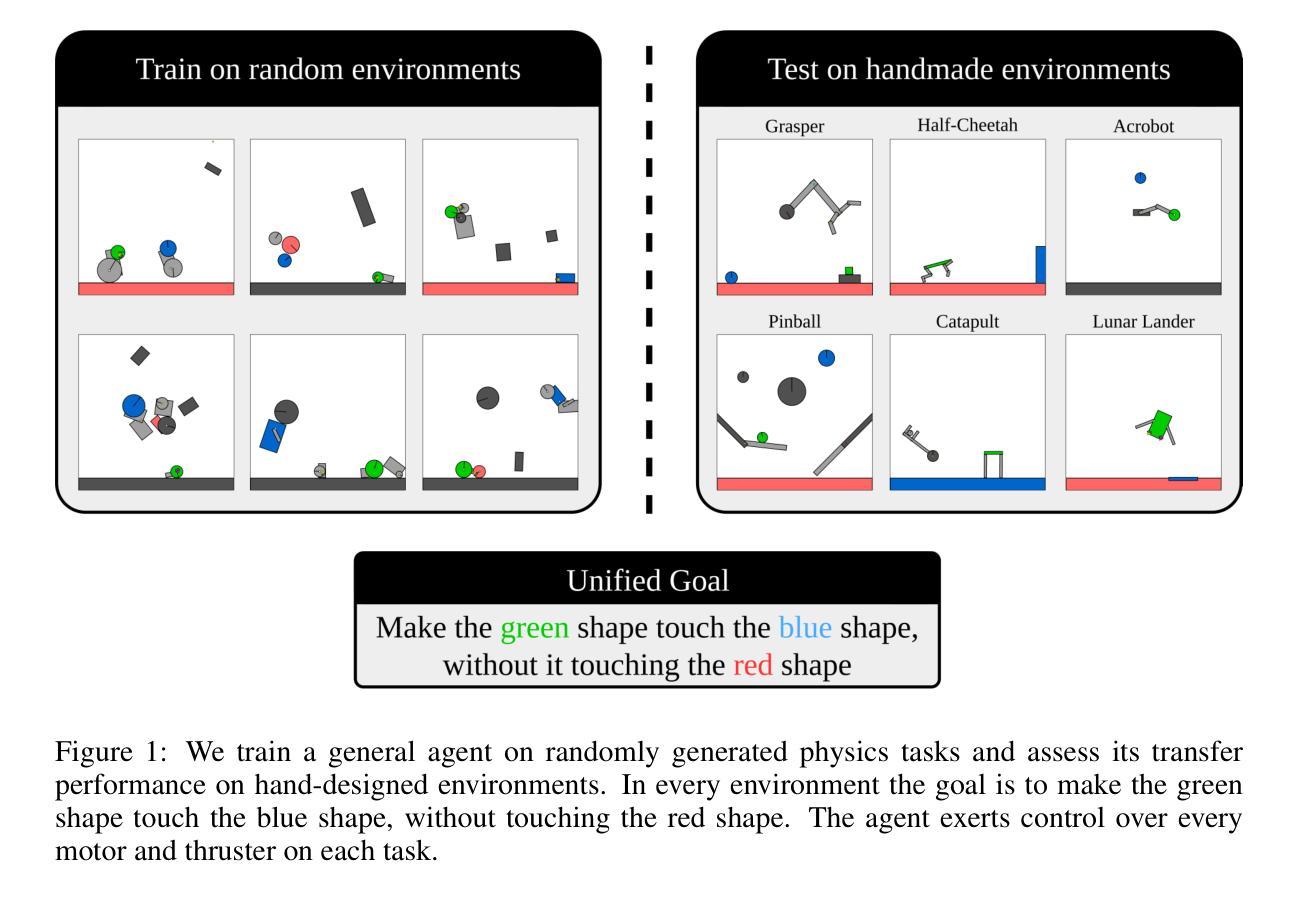
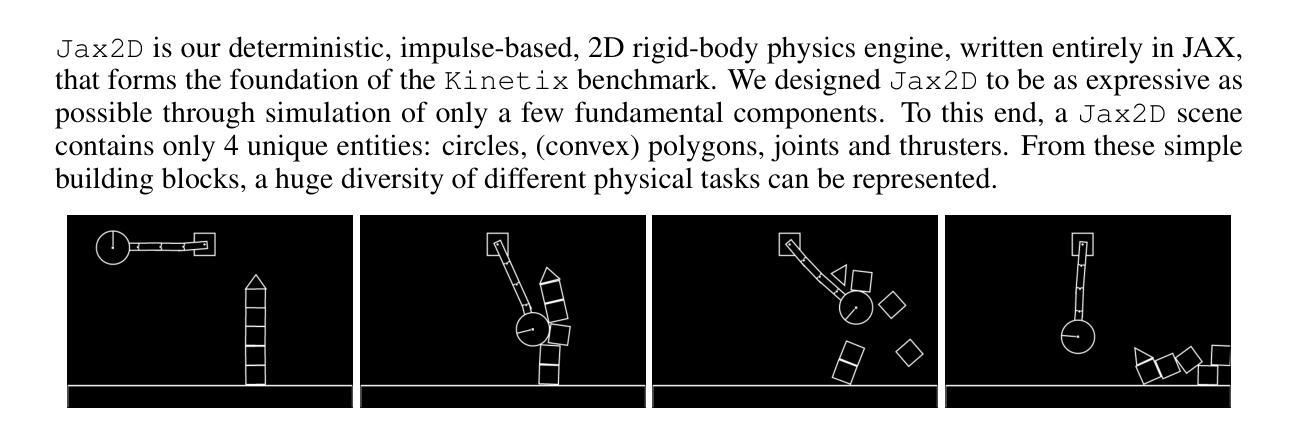
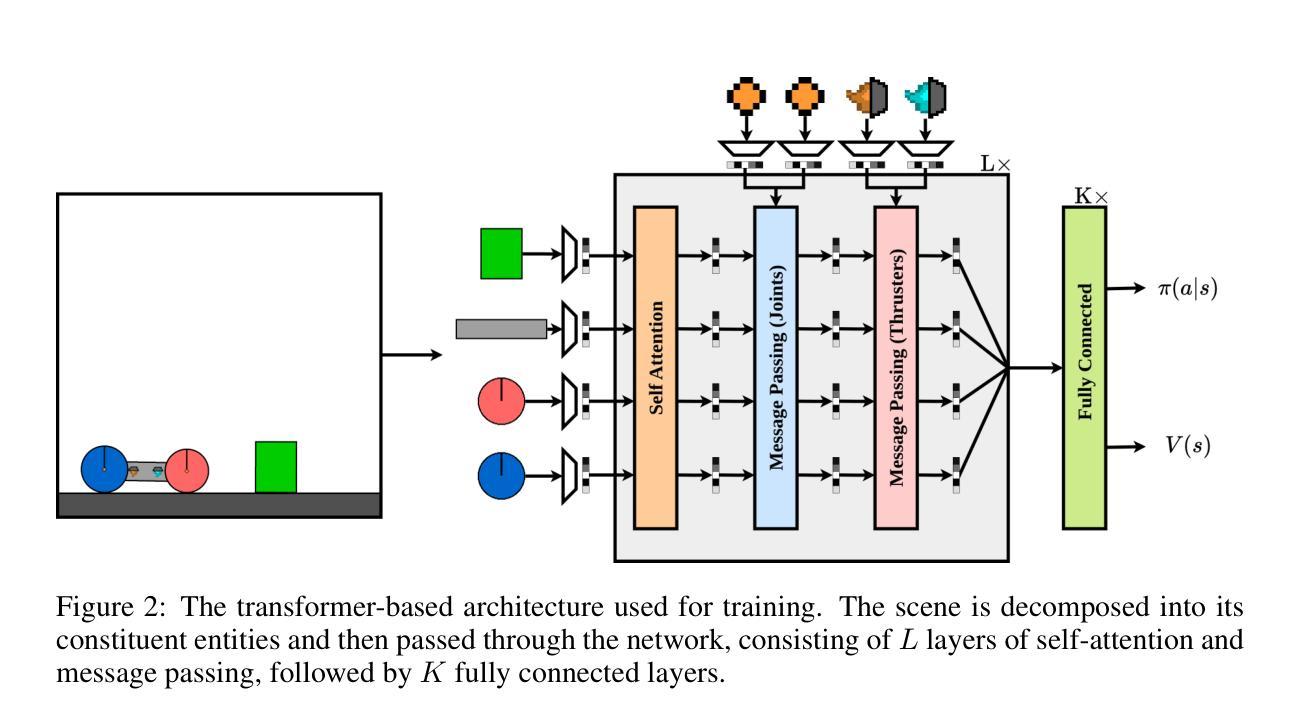
Kinetix: Investigating the Training of General Agents through Open-Ended Physics-Based Control Tasks
Authors:Michael Matthews, Michael Beukman, Chris Lu, Jakob Foerster
While large models trained with self-supervised learning on offline datasets have shown remarkable capabilities in text and image domains, achieving the same generalisation for agents that act in sequential decision problems remains an open challenge. In this work, we take a step towards this goal by procedurally generating tens of millions of 2D physics-based tasks and using these to train a general reinforcement learning (RL) agent for physical control. To this end, we introduce Kinetix: an open-ended space of physics-based RL environments that can represent tasks ranging from robotic locomotion and grasping to video games and classic RL environments, all within a unified framework. Kinetix makes use of our novel hardware-accelerated physics engine Jax2D that allows us to cheaply simulate billions of environment steps during training. Our trained agent exhibits strong physical reasoning capabilities in 2D space, being able to zero-shot solve unseen human-designed environments. Furthermore, fine-tuning this general agent on tasks of interest shows significantly stronger performance than training an RL agent tabula rasa. This includes solving some environments that standard RL training completely fails at. We believe this demonstrates the feasibility of large scale, mixed-quality pre-training for online RL and we hope that Kinetix will serve as a useful framework to investigate this further.
虽然使用自监督学习在离线数据集上训练的大型模型在文本和图像领域表现出了显著的能力,但对于在序列决策问题中行动的代理,实现同样的泛化仍然是一个开放性的挑战。在这项工作中,我们通过程序生成数亿个基于物理的2D任务来实现这一目标,并使用这些任务来训练用于物理控制的通用强化学习(RL)代理。为此,我们推出了Kinetix:一个开放的、基于物理的RL环境空间,它可以表示从机器人运动、抓取到电子游戏和经典RL环境的各种任务,都在一个统一框架内。Kinetix利用我们新型硬件加速的物理引擎Jax2D,它允许我们在训练过程中廉价地模拟数十亿的环境步骤。我们训练的代理在2D空间中展现出强大的物理推理能力,能够零射击解决未见过的人类设计环境。此外,对感兴趣的任务对代理进行微调显示出了比从头开始训练RL代理显著更强的性能。这包括解决一些标准RL训练完全失败的环境。我们相信这证明了大规模混合质量预训练在线强化学习的可行性,我们希望Kinetix能作为一个有用的框架来进一步研究这一领域。
论文及项目相关链接
PDF ICLR 2025 Oral. The first two authors contributed equally. Project page located at: https://kinetix-env.github.io/
Summary:
本文介绍了一种名为Kinetix的基于物理的强化学习环境,它能生成数亿个二维任务用于训练智能体进行物理控制。Kinetix利用高效的硬件加速物理引擎Jax2D,能够在训练过程中模拟数十亿的环境步骤。训练出的智能体展现出强大的二维空间物理推理能力,能够零样本解决未见过的人类设计环境。此外,对感兴趣的任务进行微调,表现出比从头开始训练更强的性能,包括解决标准强化学习训练无法解决的问题。这证明了大规模混合质量预训练对于在线强化学习的可行性。
Key Takeaways:
- Kinetix是一个基于物理的强化学习环境,能生成大量二维任务用于训练智能体进行物理控制。
- Kinetix利用Jax2D硬件加速物理引擎,可模拟数十亿环境步骤。
- 训练出的智能体展现出强大的二维空间物理推理能力,能够零样本解决未见过的环境。
- 对感兴趣的任务进行微调能提升智能体的性能。
- Kinetix平台能显著提高强化学习在复杂环境中的泛化能力。
- 与标准强化学习训练相比,Kinetix的方法在某些环境中表现出更好的性能。
点此查看论文截图

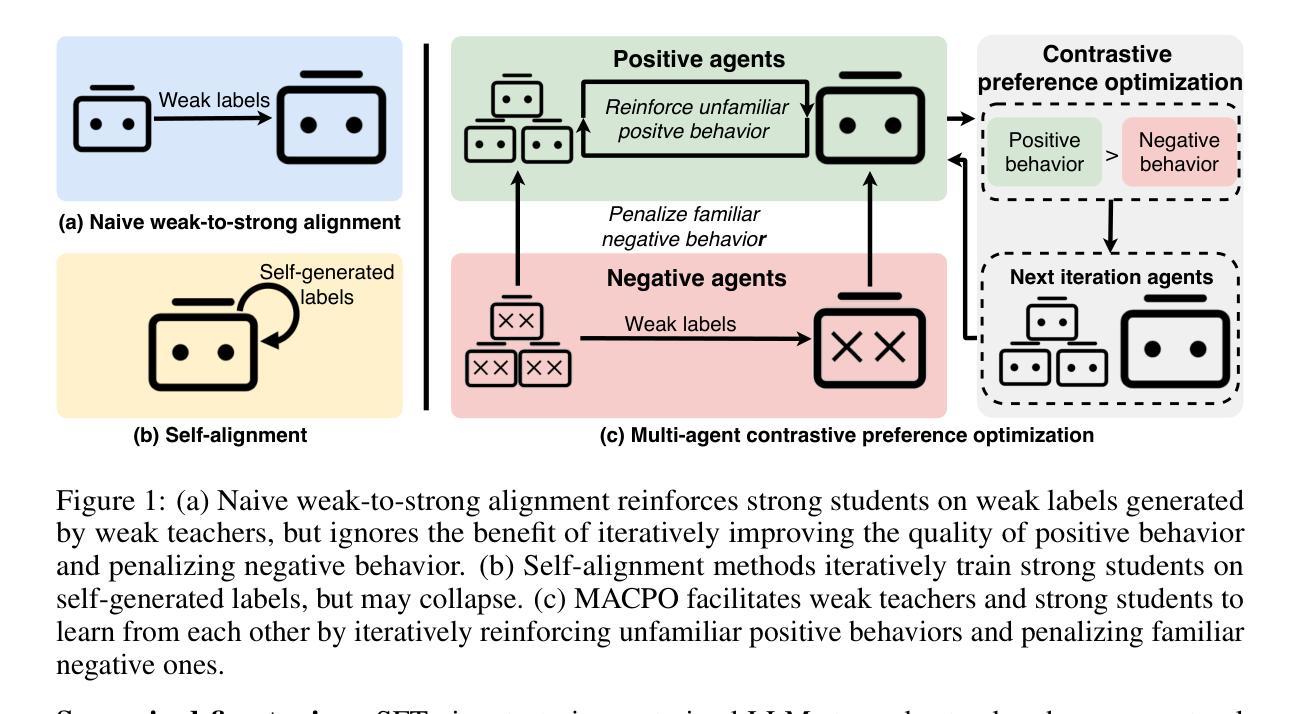
MACPO: Weak-to-Strong Alignment via Multi-Agent Contrastive Preference Optimization
Authors:Yougang Lyu, Lingyong Yan, Zihan Wang, Dawei Yin, Pengjie Ren, Maarten de Rijke, Zhaochun Ren
As large language models (LLMs) are rapidly advancing and achieving near-human capabilities on specific tasks, aligning them with human values is becoming more urgent. In scenarios where LLMs outperform humans, we face a weak-to-strong alignment problem where we need to effectively align strong student LLMs through weak supervision generated by weak teachers. Existing alignment methods mainly focus on strong-to-weak alignment and self-alignment settings, and it is impractical to adapt them to the much harder weak-to-strong alignment setting. To fill this gap, we propose a multi-agent contrastive preference optimization (MACPO) framework. MACPO facilitates weak teachers and strong students to learn from each other by iteratively reinforcing unfamiliar positive behaviors while penalizing familiar negative ones. To get this, we devise a mutual positive behavior augmentation strategy to encourage weak teachers and strong students to learn from each other’s positive behavior and further provide higher quality positive behavior for the next iteration. Additionally, we propose a hard negative behavior construction strategy to induce weak teachers and strong students to generate familiar negative behavior by fine-tuning on negative behavioral data. Experimental results on the HH-RLHF and PKU-SafeRLHF datasets, evaluated using both automatic metrics and human judgments, demonstrate that MACPO simultaneously improves the alignment performance of strong students and weak teachers. Moreover, as the number of weak teachers increases, MACPO achieves better weak-to-strong alignment performance through more iteration optimization rounds.
随着大型语言模型(LLM)的快速发展以及在特定任务上接近人类的性能,将其与人类价值观对齐变得更为紧迫。在LLM表现超越人类的场景中,我们面临一个从弱到强的对齐问题,我们需要通过弱监督来有效地对齐强大的学生LLM。现有的对齐方法主要集中在强对弱对齐和自我对齐设置上,将它们适应到更困难的从弱到强对齐设置是不切实际的。为了填补这一空白,我们提出了多代理对比偏好优化(MACPO)框架。MACPO通过鼓励弱教师强学生彼此相互学习来促使他们迭代强化不熟悉的正向行为并惩罚熟悉的负面行为。为此,我们设计了一种相互正向行为增强策略,以鼓励弱教师和强学生从彼此的正向行为中学习,并为下一次迭代提供更优质的正向行为。此外,我们还提出了一种硬负面行为构建策略,通过微调负面行为数据来引导弱教师和强学生产生熟悉的负面行为。在HH-RLHF和PKU-SafeRLHF数据集上的实验结果通过自动指标和人类判断进行评估,表明MACPO同时提高了强学生和弱教师的对齐性能。而且,随着弱教师数量的增加,通过更多的迭代优化轮次,MACPO实现了更好的从弱到强的对齐性能。
论文及项目相关链接
PDF ICLR 2025
Summary
大型语言模型(LLM)的快速发展使其在特定任务上具备了接近人类的性能,因此将其与人类价值观对齐变得更为紧迫。在LLM表现超越人类的场景中,我们面临弱到强的对齐问题,需要有效地通过弱监督对齐强大的学生LLM与弱教师。现有对齐方法主要关注强到弱对齐和自我对齐设置,难以适应更困难的弱到强对齐设置。为此,我们提出多代理对比偏好优化(MACPO)框架。MACPO促进弱教师和强学生通过相互学习进行迭代强化不熟悉的积极行为并惩罚熟悉的消极行为。此外,我们提出硬负行为构建策略,通过微调负行为数据诱导弱教师和强学生产生熟悉的消极行为。在HH-RLHF和PKU-SafeRLHF数据集上的实验结果表明,MACPO同时提高了强学生和弱教师的对齐性能。随着弱教师数量的增加,通过更多的迭代优化轮次,MACPO实现了更好的弱到强对齐性能。
Key Takeaways
- 大型语言模型(LLM)的快速发展使其面临与人类价值观对齐的紧迫性。
- 在LLM超越人类表现的场景中,存在弱到强的对齐问题。
- 现有对齐方法主要关注强到弱和对齐自我对齐设置,不适应弱到强对齐的困难场景。
- MACPO框架通过促进弱教师和强学生之间的相互学习来解决弱到强对齐问题。
- MACPO采用迭代强化积极行为并惩罚消极行为的策略。
- 提出相互积极行为增强策略和硬负行为构建策略来优化MACPO框架。
点此查看论文截图

LTLf Synthesis on First-Order Agent Programs in Nondeterministic Environments
Authors:Till Hofmann, Jens Claßen
We investigate the synthesis of policies for high-level agent programs expressed in Golog, a language based on situation calculus that incorporates nondeterministic programming constructs. Unlike traditional approaches for program realization that assume full agent control or rely on incremental search, we address scenarios where environmental nondeterminism significantly influences program outcomes. Our synthesis problem involves deriving a policy that successfully realizes a given Golog program while ensuring the satisfaction of a temporal specification, expressed in Linear Temporal Logic on finite traces (LTLf), across all possible environmental behaviors. By leveraging an expressive class of first-order action theories, we construct a finite game arena that encapsulates program executions and tracks the satisfaction of the temporal goal. A game-theoretic approach is employed to derive such a policy. Experimental results demonstrate this approach’s feasibility in domains with unbounded objects and non-local effects. This work bridges agent programming and temporal logic synthesis, providing a framework for robust agent behavior in nondeterministic environments.
我们研究了在Golog语言中表达的高级代理程序的策略合成。Golog是一种基于情况计算的语言,它结合了非确定性编程结构。与传统的程序实现方法不同,后者假设了完全的代理控制或依赖于增量搜索,我们解决了环境非确定性显著影响程序结果的情况。我们的合成问题涉及推导出成功实现给定Golog程序的策略,同时确保在有限轨迹上的线性时序逻辑(LTLf)表达的时序规范在所有可能的环境行为中得到满足。通过利用一阶动作理论的表现力强大的类别,我们构建了一个有限的博弈场所,该场所涵盖了程序执行并跟踪时序目标的满足情况。采用博弈论方法来推导此类策略。实验结果表明,该方法在具有无限对象和非局部效应的领域中具有可行性。这项工作将代理编程和时序逻辑合成相结合,为在非确定性环境中实现稳健的代理行为提供了框架。
论文及项目相关链接
PDF AAAI’25
Summary
本文研究了在基于情境计算的语言Golog中表达的高级代理程序的策略合成。针对环境非确定性对程序结果产生显著影响的情况,提出了一种新的解决方案。通过利用一阶行动理论,构造了一个有限的游戏场景,对程序执行进行封装,并跟踪时间目标的满足情况。采用博弈理论的方法推导出这样的策略。实验结果表明,该方法在具有无限对象和非局部效应的领域中是可行的。这项工作将代理编程和时序逻辑合成联系在一起,为非线性环境中代理的稳健行为提供了框架。
Key Takeaways
- 本文研究了在Golog语言中合成高级代理程序策略的方法,Golog是一种基于情境计算的语言,融入了非确定性编程结构。
- 针对环境非确定性对程序结果产生影响的场景,提出了一种新的解决方案,该方案在推导策略时考虑到了所有可能的环境行为。
- 通过利用一阶行动理论,构建了一个有限的游戏场景来封装程序执行,并跟踪时间目标的满足情况。
- 采用博弈理论的方法推导出策略,以确保Golog程序的实现并满足线性时序逻辑表达的时间规范。
- 实验结果表明,该方法在具有无限对象和非局部效应的领域中是有效的。
- 本文工作有助于桥接代理编程和时序逻辑合成,为在非线性环境中的稳健代理行为提供了框架。
点此查看论文截图

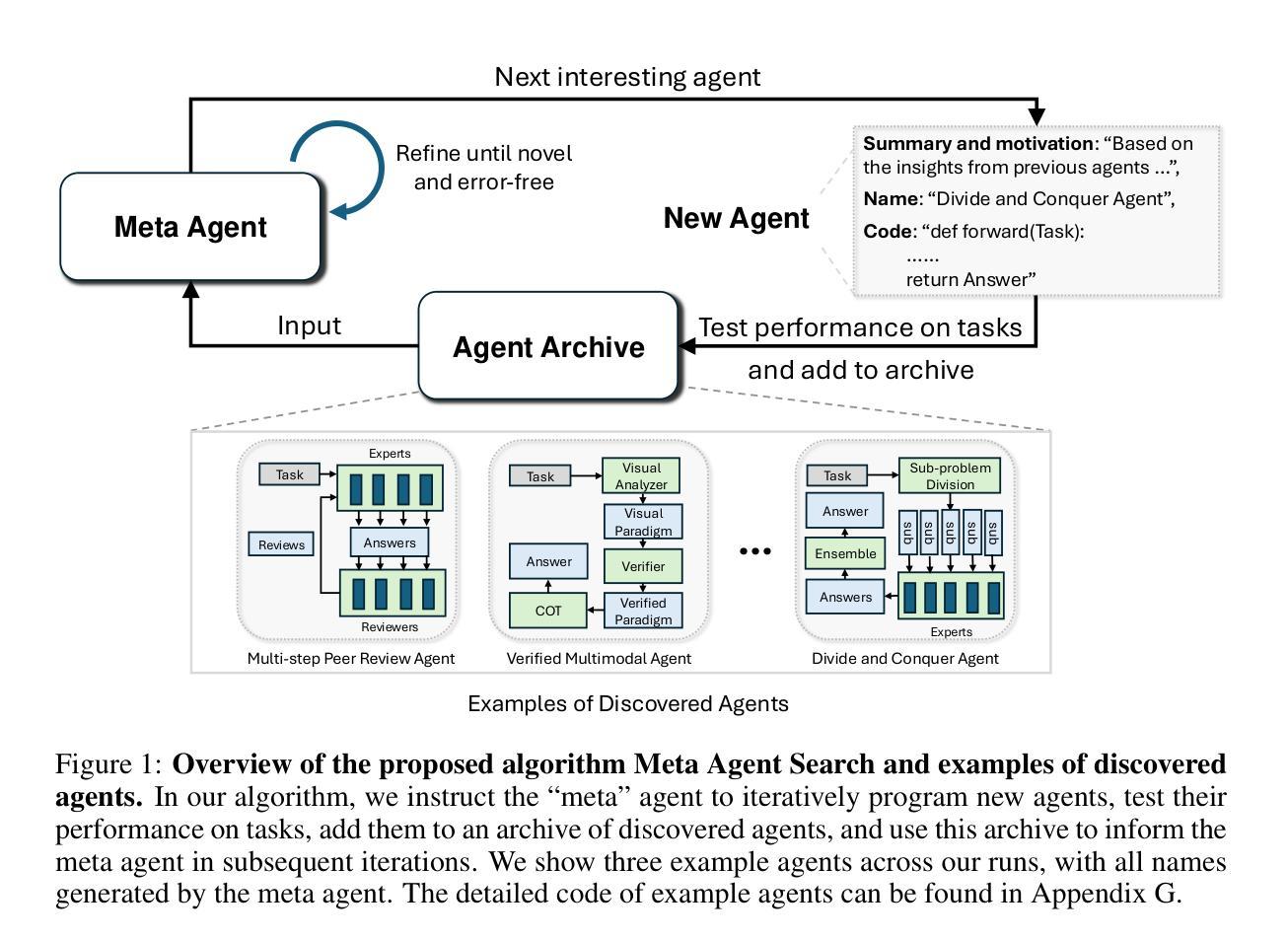
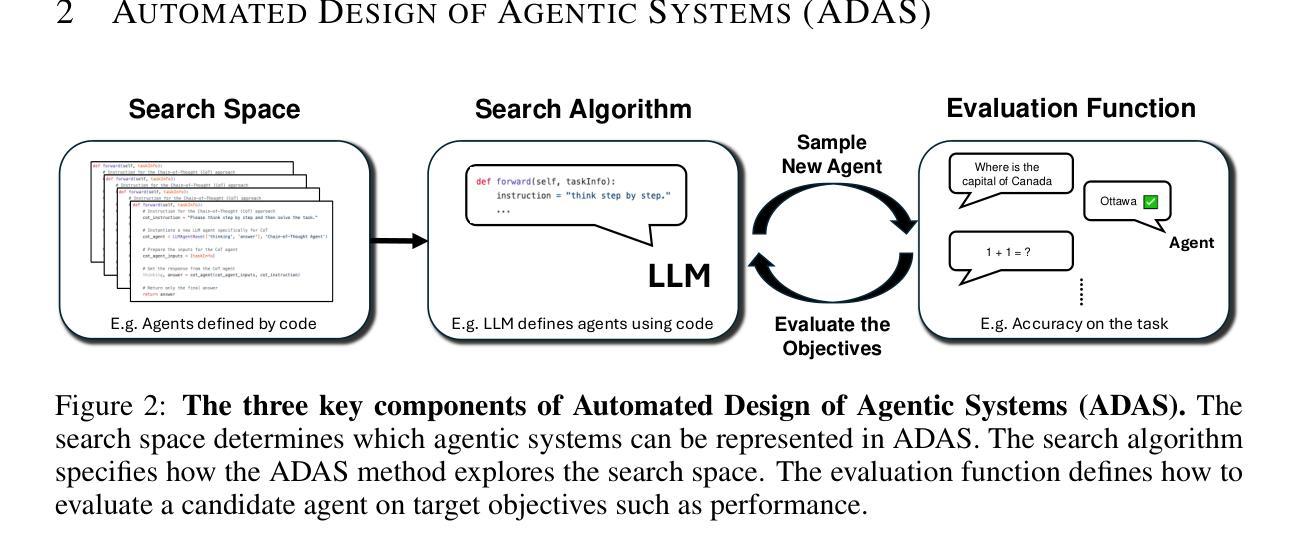
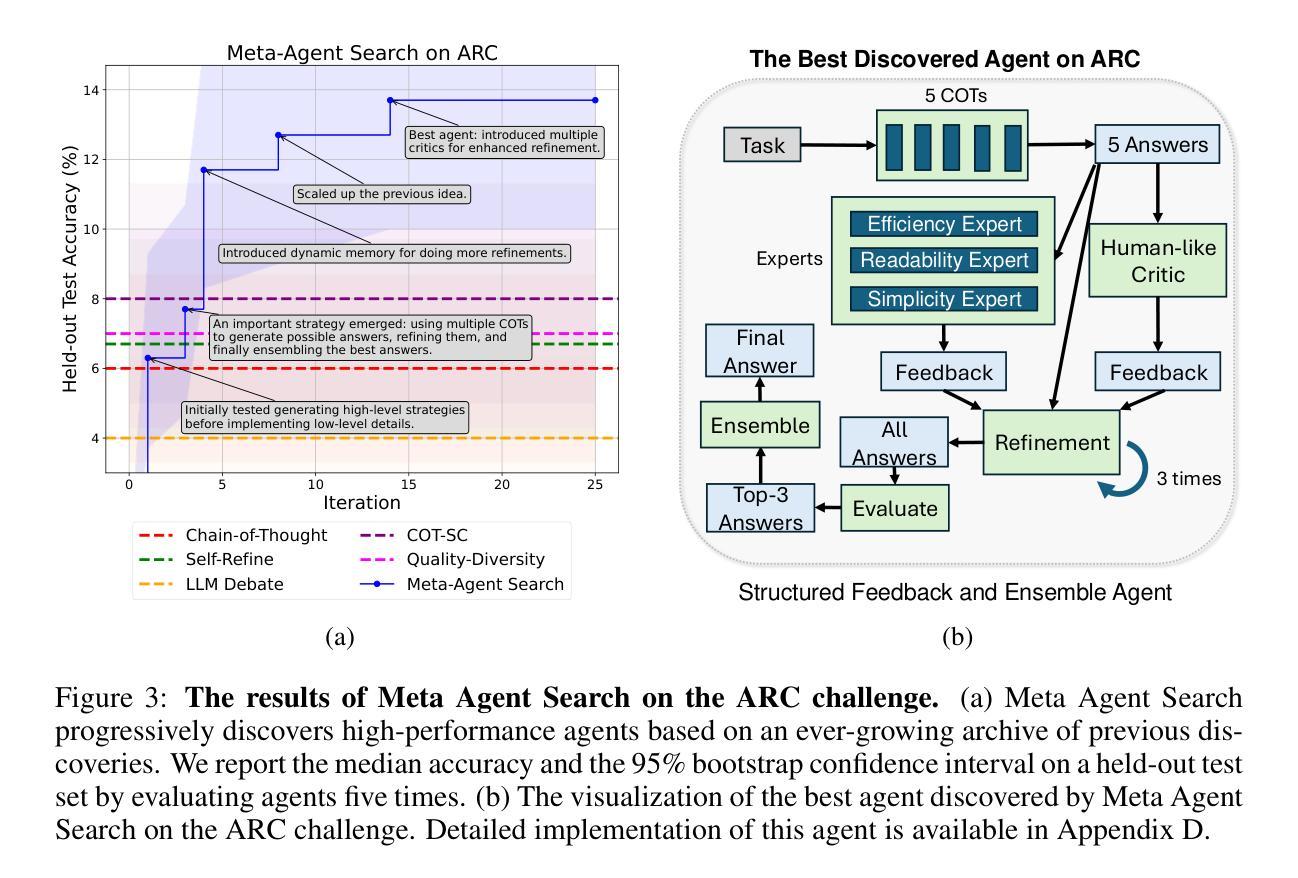
Automated Design of Agentic Systems
Authors:Shengran Hu, Cong Lu, Jeff Clune
Researchers are investing substantial effort in developing powerful general-purpose agents, wherein Foundation Models are used as modules within agentic systems (e.g. Chain-of-Thought, Self-Reflection, Toolformer). However, the history of machine learning teaches us that hand-designed solutions are eventually replaced by learned solutions. We describe a newly forming research area, Automated Design of Agentic Systems (ADAS), which aims to automatically create powerful agentic system designs, including inventing novel building blocks and/or combining them in new ways. We further demonstrate that there is an unexplored yet promising approach within ADAS where agents can be defined in code and new agents can be automatically discovered by a meta agent programming ever better ones in code. Given that programming languages are Turing Complete, this approach theoretically enables the learning of any possible agentic system: including novel prompts, tool use, workflows, and combinations thereof. We present a simple yet effective algorithm named Meta Agent Search to demonstrate this idea, where a meta agent iteratively programs interesting new agents based on an ever-growing archive of previous discoveries. Through extensive experiments across multiple domains including coding, science, and math, we show that our algorithm can progressively invent agents with novel designs that greatly outperform state-of-the-art hand-designed agents. Importantly, we consistently observe the surprising result that agents invented by Meta Agent Search maintain superior performance even when transferred across domains and models, demonstrating their robustness and generality. Provided we develop it safely, our work illustrates the potential of an exciting new research direction toward automatically designing ever-more powerful agentic systems to benefit humanity.
研究者正在投入大量精力开发功能强大的通用智能体,其中基础模型被用作智能体系统(如思维链、自我反思、工具变形器)中的模块。然而,机器学习的历史告诉我们,手工设计的解决方案最终会被学习到的解决方案所取代。我们描述了一个新兴的研究领域——自动设计智能系统(ADAS),该领域的目标是自动创建强大的智能系统设计方案,包括发明新型构建块并以新的方式将它们组合起来。我们还证明,在ADAS中存在一种尚未探索但前景看好的方法,即可以在代码中定义智能体,并通过元代理程序自动发现新的智能体,以更好地编写代码。鉴于编程语言是图灵完备的,这种方法理论上能够学习任何可能的智能系统,包括新型提示、工具使用、工作流程及其组合。我们提出了一个简单有效的算法,名为元代理搜索,以证明这一想法,该算法基于不断增长的先前发现档案,迭代地编程有趣的新智能体。通过编码、科学和数学等多个领域的广泛实验,我们证明我们的算法可以逐步发明具有新颖设计的智能体,这些智能体在很大程度上优于最新的手工设计智能体。重要的是,我们一贯观察到令人惊讶的结果是,元代理搜索所发明的智能体即使在跨领域和模型转移时也能保持卓越的性能,证明了它们的稳健性和普遍性。只要我们安全地发展它,我们的工作展示了朝着自动设计越来越强大的智能系统这一令人兴奋的新研究方向的潜力,这将为人类带来好处。
论文及项目相关链接
PDF Website: https://shengranhu.com/ADAS
Summary
近期,研究者正致力于开发强大的通用代理,使用基础模型作为代理系统内的模块。历史告诉我们,手工设计的解决方案最终会被学习到的解决方案所取代。新兴的研究领域——自动化代理系统设计(ADAS)旨在自动创建强大的代理系统设计,包括发明新型构建模块和/或以新方式组合它们。特别地,存在一种理论上有前景的方法,即通过在代码中定义代理并使用元代理程序自动发现新代理来优化。这种方法理论上可以学习任何可能的代理系统,包括新颖的提示、工具使用、工作流程及其组合。我们提出了一个简单的算法——元代理搜索来演示这个想法,该算法使元代理能够基于不断增长的先前发现档案来编程有趣的新代理。经过在多个领域进行的大量实验证明,我们的算法可以逐步发明具有新颖设计的代理,这些代理在性能上大大优于最新的手工设计代理。更重要的是,我们观察到令人惊讶的结果,即元代理搜索发明的代理在跨域和模型转移时仍能保持卓越的性能,证明了它们的稳健性和普遍性。在确保安全开发的前提下,我们的工作展示了朝着自动设计越来越强大的代理系统这一令人兴奋的新研究方向的潜力,最终为人类的利益服务。
Key Takeaways
- 研究者正致力于开发通用代理,使用基础模型作为模块。
- 手工设计的代理解决方案最终可能被学习到的解决方案所取代。
- 新兴研究领域ADAS旨在自动创建强大的代理系统设计。
- 通过在代码中定义代理并使用元代理程序,理论上可以学习任何可能的代理系统。
- 元代理搜索算法能基于先前发现自动编程新代理。
- 该算法发明的代理在跨域和模型转移时保持卓越性能。
点此查看论文截图

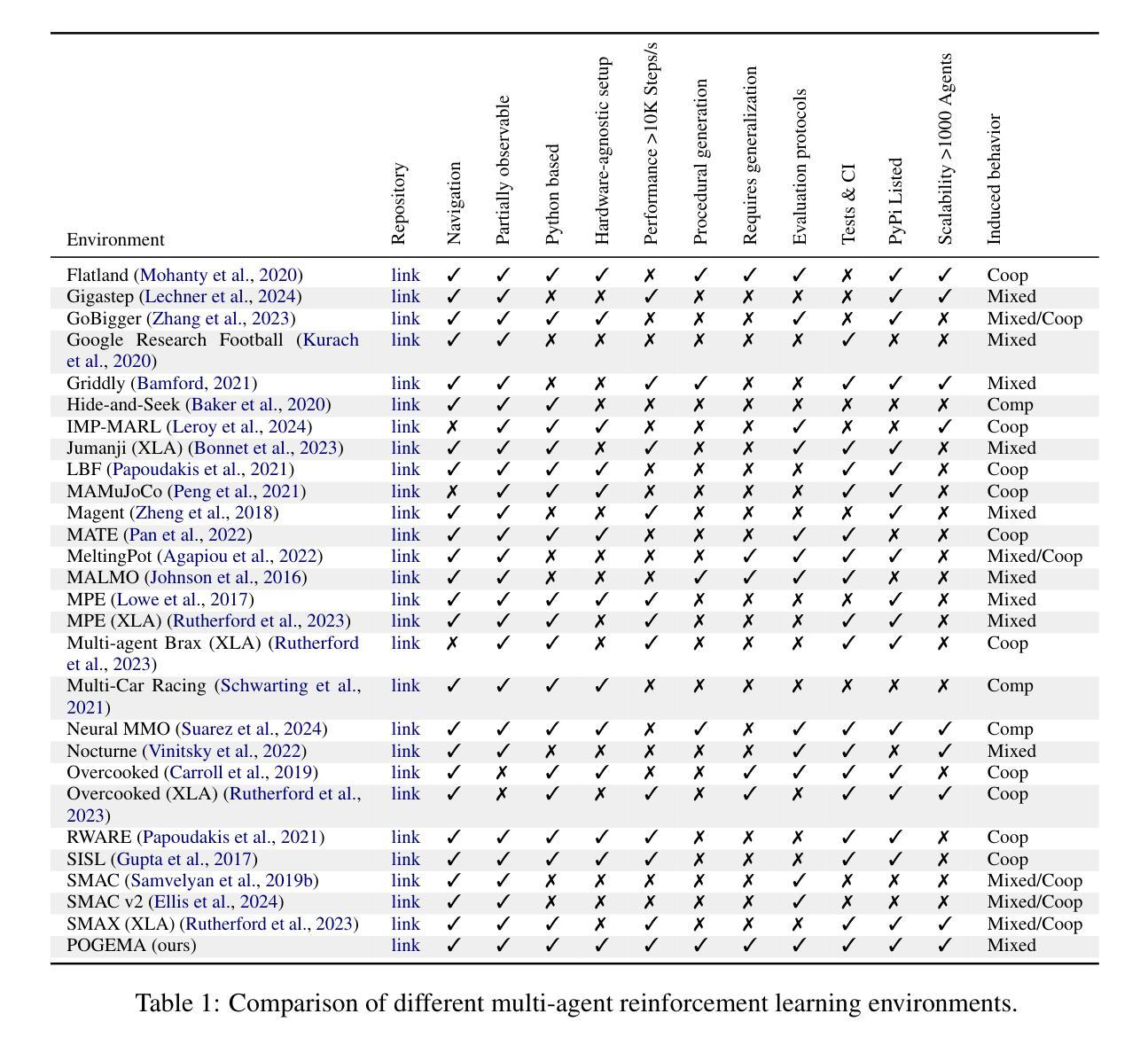
POGEMA: A Benchmark Platform for Cooperative Multi-Agent Pathfinding
Authors:Alexey Skrynnik, Anton Andreychuk, Anatolii Borzilov, Alexander Chernyavskiy, Konstantin Yakovlev, Aleksandr Panov
Multi-agent reinforcement learning (MARL) has recently excelled in solving challenging cooperative and competitive multi-agent problems in various environments, typically involving a small number of agents and full observability. Moreover, a range of crucial robotics-related tasks, such as multi-robot pathfinding, which have traditionally been approached with classical non-learnable methods (e.g., heuristic search), are now being suggested for solution using learning-based or hybrid methods. However, in this domain, it remains difficult, if not impossible, to conduct a fair comparison between classical, learning-based, and hybrid approaches due to the lack of a unified framework that supports both learning and evaluation. To address this, we introduce POGEMA, a comprehensive set of tools that includes a fast environment for learning, a problem instance generator, a collection of predefined problem instances, a visualization toolkit, and a benchmarking tool for automated evaluation. We also introduce and define an evaluation protocol that specifies a range of domain-related metrics, computed based on primary evaluation indicators (such as success rate and path length), enabling a fair multi-fold comparison. The results of this comparison, which involves a variety of state-of-the-art MARL, search-based, and hybrid methods, are presented.
多智能体强化学习(MARL)最近在解决各种环境中的挑战性合作和竞争性多智能体问题上表现出色,通常涉及少量智能体和完全可观察性。此外,一系列关键的机器人相关任务,如使用传统不可学习的方法(如启发式搜索)解决的多机器人路径规划,现在建议使用基于学习或混合方法来解决。然而,在这个领域,由于缺乏一个既支持学习和评估的统一框架,进行经典方法、基于学习的方法和混合方法之间的公平比较变得困难甚至不可能。为了解决这一问题,我们引入了POGEMA,这是一套综合工具,包括用于学习的快速环境、问题实例生成器、预定义问题实例集合、可视化工具包和用于自动化评估的基准测试工具。我们还介绍并定义了一个评估协议,该协议规定了基于主要评估指标(如成功率和路径长度)的一系列与领域相关的指标,从而实现公平的多重比较。涉及多种最先进的MARL、基于搜索的混合方法的比较结果在此呈现。
论文及项目相关链接
PDF Published as a conference paper at The International Conference on Learning Representations 2025
Summary
多智能体强化学习(MARL)在解决各种环境中的合作与竞争多智能体问题上表现出色,特别是在涉及少量智能体和完全可观察性的情况下。针对传统上使用经典非学习方法(如启发式搜索)解决的多机器人路径查找等机器人相关任务,建议使用基于学习或混合方法来解决。然而,由于缺乏支持学习和评估的统一框架,难以对经典方法、基于学习的方法和混合方法进行公平比较。为解决这一问题,本文介绍了POGEMA工具集,包括学习快速环境、问题实例生成器、预定问题实例集合、可视化工具包和自动化评估基准工具。此外,本文还介绍并定义了一种评估协议,该协议规定了基于主要评估指标(如成功率和路径长度)计算的一系列领域相关指标,以实现公平的多重比较。给出了涉及多种先进MARL、基于搜索的混合方法的比较结果。
Key Takeaways
- 多智能体强化学习(MARL)在处理合作与竞争多智能体问题上表现优秀,尤其在环境观察完整且智能体数量较少时。
- 经典的非学习方法(如启发式搜索)通常用于解决多机器人路径查找等机器人任务,但现在有提议使用基于学习或混合方法来解决这些问题。
- 缺乏统一框架,难以公平比较经典方法、基于学习的方法和混合方法。
- POGEMA工具集提供了一系列工具,包括学习环境、问题实例生成器、可视化工具包和自动化评估基准,以解决这一问题。
- 评估协议规定了基于主要评估指标(如成功率和路径长度)的领域相关指标计算,以实现多种方法的公平比较。
- 比较涉及多种先进的MARL、基于搜索的混合方法,展示了不同方法之间的性能差异。
点此查看论文截图

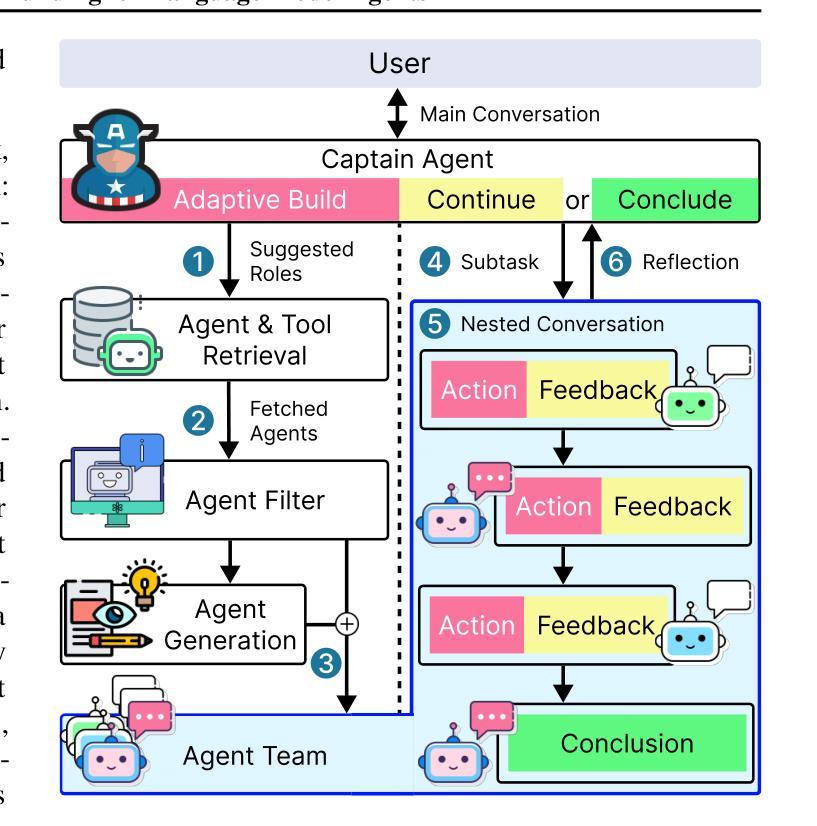
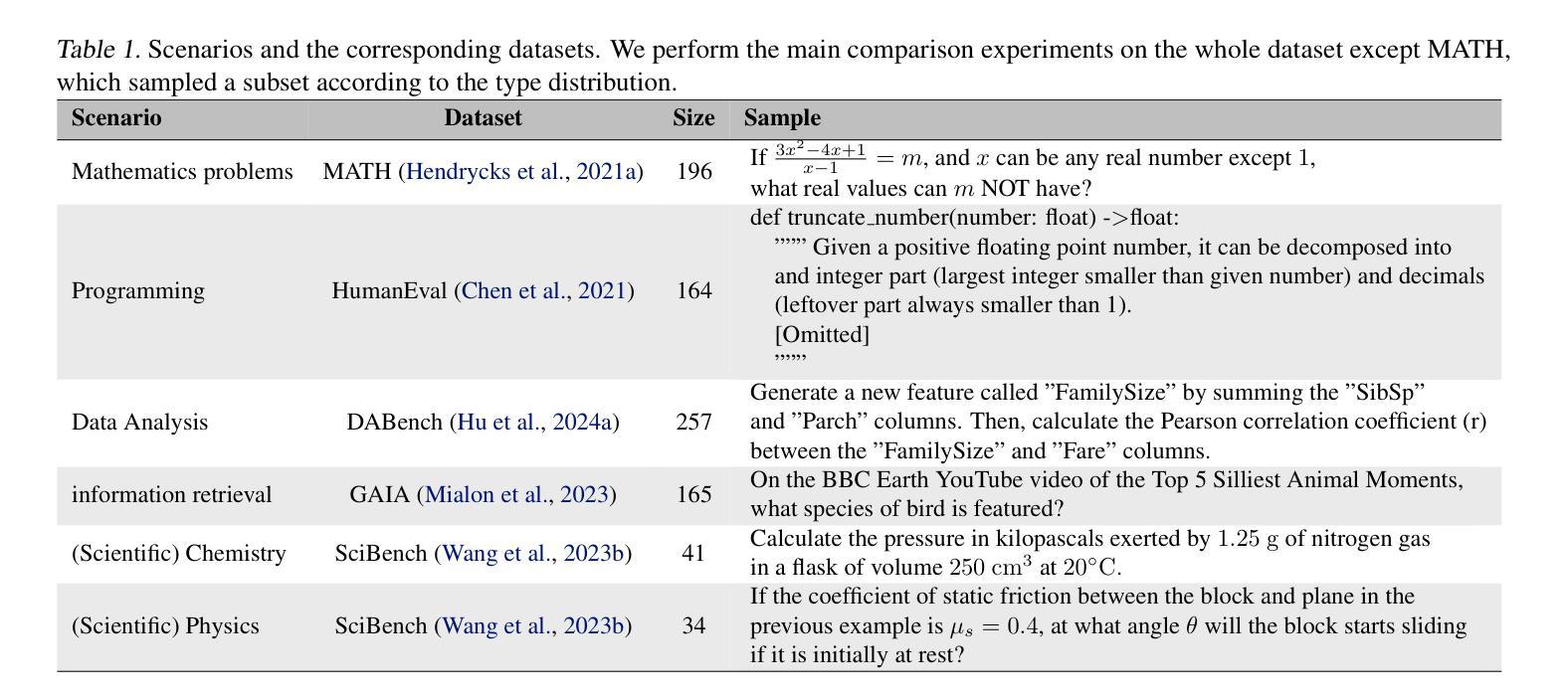
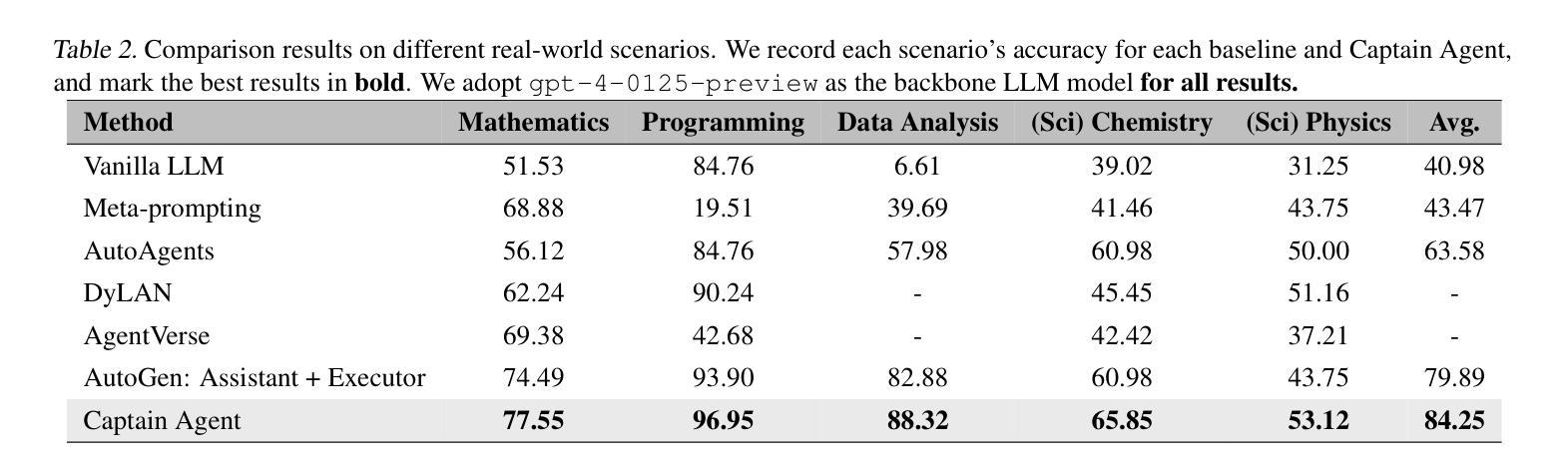
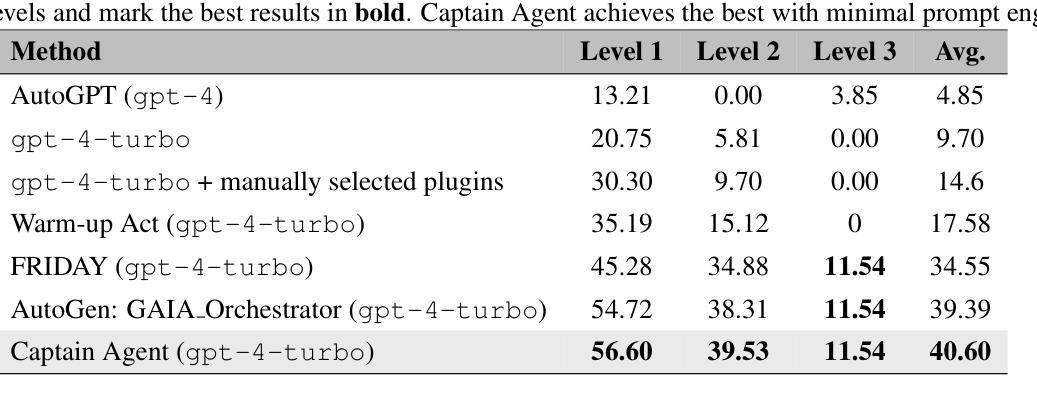
Adaptive In-conversation Team Building for Language Model Agents
Authors:Linxin Song, Jiale Liu, Jieyu Zhang, Shaokun Zhang, Ao Luo, Shijian Wang, Qingyun Wu, Chi Wang
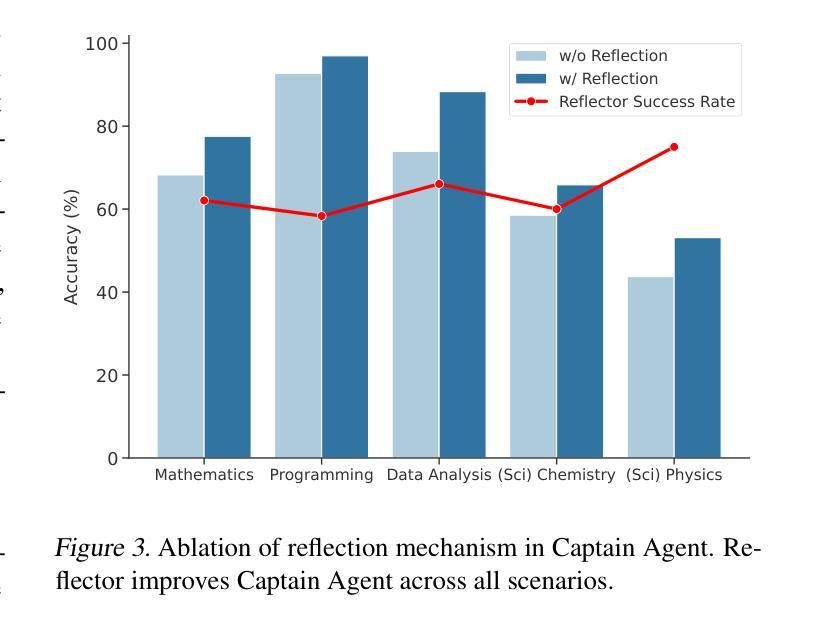
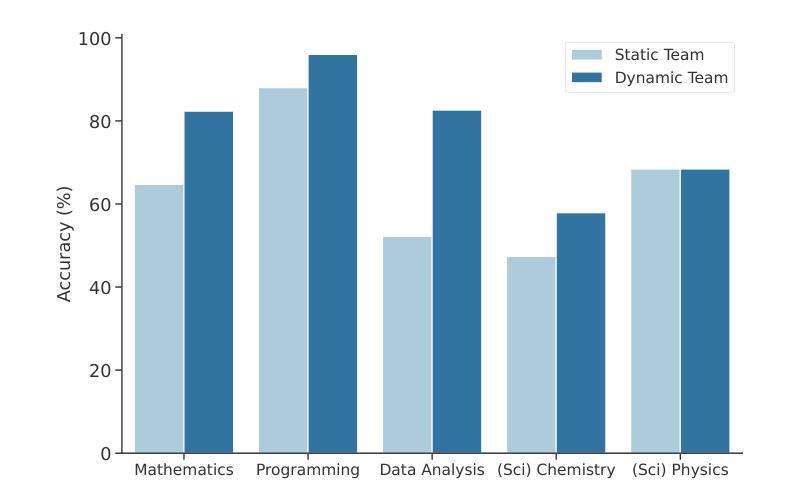
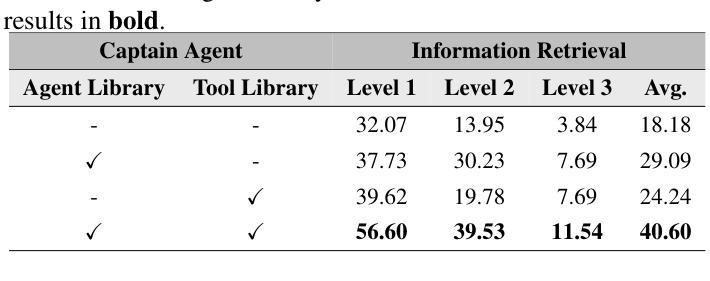
Leveraging multiple large language model (LLM) agents has shown to be a promising approach for tackling complex tasks, while the effective design of multiple agents for a particular application remains an art. It is thus intriguing to answer a critical question: Given a task, how can we build a team of LLM agents to solve it effectively? Our new adaptive team-building paradigm offers a flexible solution, realized through a novel agent design named Captain Agent. It dynamically forms and manages teams for each step of a task-solving process, utilizing nested group conversations and reflection to ensure diverse expertise and prevent stereotypical outputs, allowing for a flexible yet structured approach to problem-solving. A comprehensive evaluation across six real-world scenarios demonstrates that Captain Agent significantly outperforms existing multi-agent methods with 21.94% improvement in average accuracy, providing outstanding performance without requiring task-specific prompt engineering. Our exploration of different backbone LLM and cost analysis further shows that Captain Agent can improve the conversation quality of weak LLM and achieve competitive performance with extremely low cost, which illuminates the application of multi-agent systems.
利用多个大型语言模型(LLM)代理已经成为解决复杂任务的很有前途的方法,而对于特定应用的多个代理的有效设计仍然是一门艺术。因此,回答一个关键问题是很有吸引力的:给定一个任务,我们如何建立一个LLM代理团队来有效地解决它?我们新的自适应团队构建范式提供了一种灵活的解决方案,这是通过一种名为Captain Agent的新型代理设计实现的。它为任务解决过程的每个步骤动态地组建和管理团队,利用嵌套的小组对话和反思来确保多样化的专业知识,防止刻板输出,允许灵活而有条理地解决问题。在六个真实场景的综合评估中,Captain Agent显著优于现有的多代理方法,平均准确率提高了21.94%,在不需要针对任务进行特定提示工程的情况下表现出卓越性能。我们对不同后盾LLM的探索和成本分析进一步表明,Captain Agent可以提高弱LLM的对话质量,并以极低的成本实现具有竞争力的性能,这进一步表明了多代理系统的应用前景。
论文及项目相关链接
Summary
多大型语言模型(LLM)协同合作是解决复杂任务的有效方法。为实现动态灵活的团队合作,提出了名为Captain Agent的新型智能体设计。其在不同任务阶段形成并管理团队,利用嵌套群组对话与反思确保专业技能多样性,避免刻板输出。综合评估显示,Captain Agent在平均准确度上显著优于现有多智能体方法,提升幅度达21.94%,并在不同背景LLM中表现出卓越性能与成本优势。
Key Takeaways
- 利用多个大型语言模型(LLM)解决复杂任务展现明显优势。
- 新型的Captain Agent智能体设计能实现动态团队合作以完成不同任务。
- 通过嵌套群组对话和反思确保团队成员的技能多样性并避免刻板输出。
- Captain Agent在平均准确度上显著优于现有多智能体方法,提升幅度达21.94%。
- Captain Agent能提升较弱LLM的对话质量并实现具有竞争力的性能。
点此查看论文截图

SheetAgent: Towards A Generalist Agent for Spreadsheet Reasoning and Manipulation via Large Language Models
Authors:Yibin Chen, Yifu Yuan, Zeyu Zhang, Yan Zheng, Jinyi Liu, Fei Ni, Jianye Hao, Hangyu Mao, Fuzheng Zhang
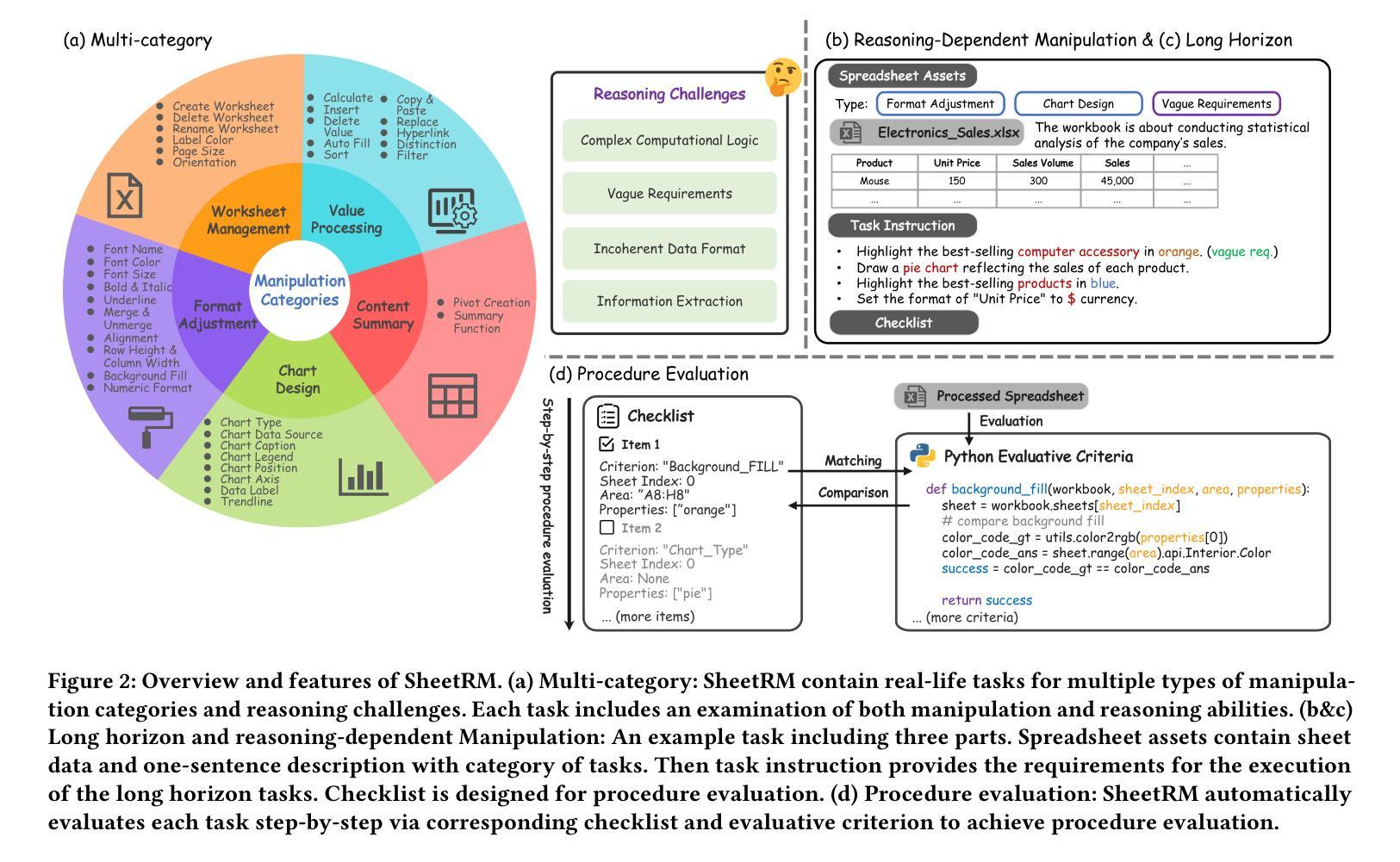
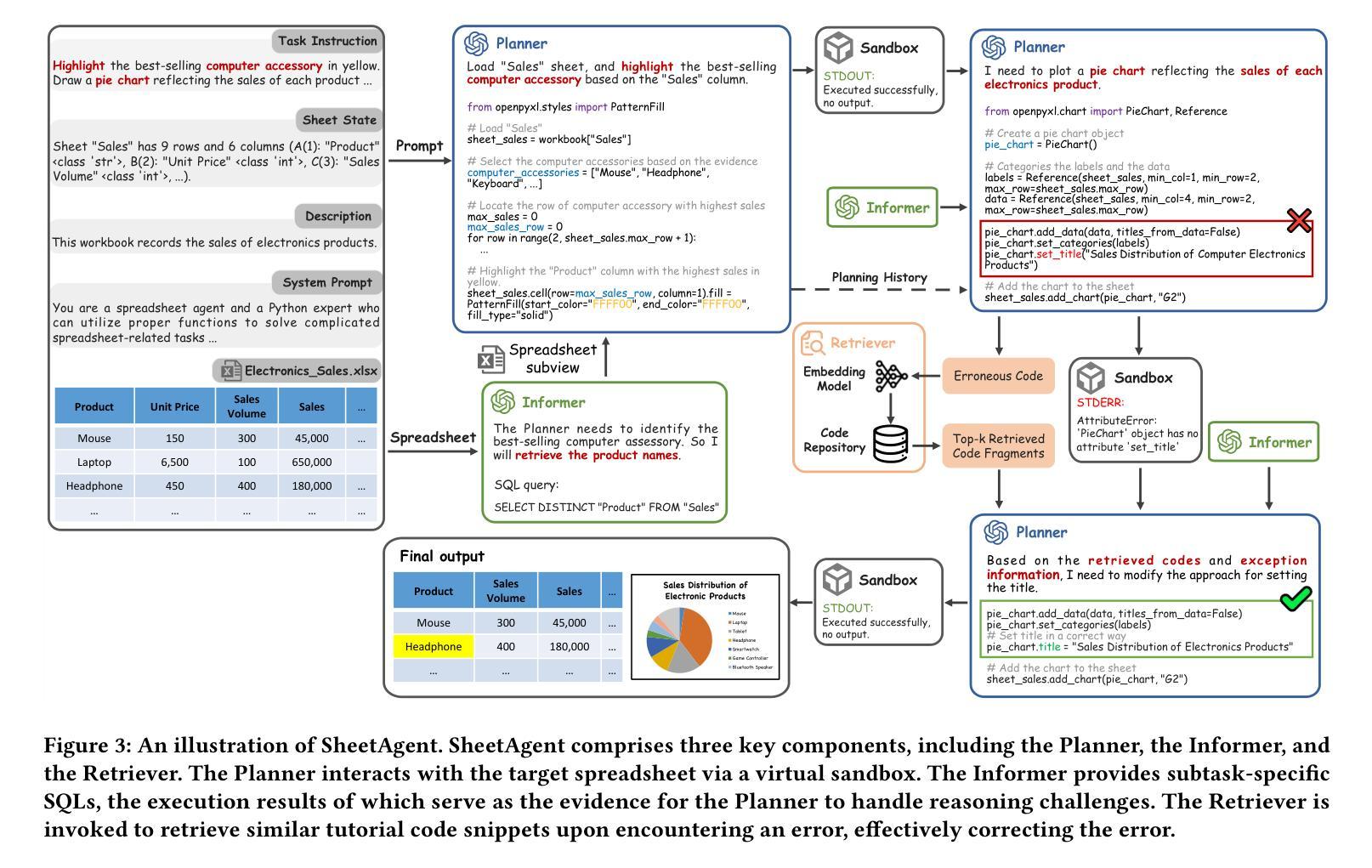
Spreadsheets are ubiquitous across the World Wide Web, playing a critical role in enhancing work efficiency across various domains. Large language model (LLM) has been recently attempted for automatic spreadsheet manipulation but has not yet been investigated in complicated and realistic tasks where reasoning challenges exist (e.g., long horizon manipulation with multi-step reasoning and ambiguous requirements). To bridge the gap with the real-world requirements, we introduce SheetRM, a benchmark featuring long-horizon and multi-category tasks with reasoning-dependent manipulation caused by real-life challenges. To mitigate the above challenges, we further propose SheetAgent, a novel autonomous agent that utilizes the power of LLMs. SheetAgent consists of three collaborative modules: Planner, Informer, and Retriever, achieving both advanced reasoning and accurate manipulation over spreadsheets without human interaction through iterative task reasoning and reflection. Extensive experiments demonstrate that SheetAgent delivers 20–40% pass rate improvements on multiple benchmarks over baselines, achieving enhanced precision in spreadsheet manipulation and demonstrating superior table reasoning abilities. More details and visualizations are available at the project website: https://sheetagent.github.io/. The datasets and source code are available at https://anonymous.4open.science/r/SheetAgent.
网页表格(Spreadsheets)在万维网上无处不在,对于提高不同领域的工作效率起着至关重要的作用。大型语言模型(LLM)最近已被尝试用于自动操作表格数据,但在存在推理挑战的复杂和真实任务中尚未进行研究(例如,具有多步骤推理和模糊要求的长期操作)。为了弥补现实世界需求之间的差距,我们引入了SheetRM,这是一个以长期和多类别任务为特色的基准测试平台,包含由现实挑战导致的依赖于推理的操作。为了缓解上述挑战,我们进一步提出了SheetAgent,这是一种利用大型语言模型能力的新型自主代理。SheetAgent由三个协作模块组成:规划器(Planner)、信息提供者(Informer)和检索器(Retriever),通过迭代任务推理和反思,无需人工交互即可实现高级推理和准确的表格操作。大量实验表明,与基准测试相比,SheetAgent在多个基准测试平台上实现了20%~40%通过率提升,提高了表格操作的精度并展示了出色的表格推理能力。更多详细信息和可视化内容请访问项目网站:https://sheetagent.github.io/。数据集和源代码可在https://anonymous.4open.science/r/SheetAgent找到。
论文及项目相关链接
PDF Accepted by International World Wide Web Conference (WWW) 2025 (oral)
Summary
这份摘要以简化中文简洁地表达了文章的核心内容:介绍了一种名为SheetAgent的新型自主代理,它结合了大型语言模型的力量,用于处理现实世界中的复杂电子表格操作任务。通过引入三个协作模块:Planner、Informer和Retriever,SheetAgent可实现先进的推理和电子表格精准操作,无需人为干预。大量实验表明,SheetAgent在多项基准测试中较基准模型提高了20%~40%的通过率,展现了出色的表格推理能力。更多详情和可视化内容可访问项目网站。数据集和源代码可供下载。
Key Takeaways
以下是文章的主要见解:
- 电子表格在世界各地广泛使用,用于提高不同领域的工作效率。大型语言模型已经在自动电子表格操纵中得到应用。
- 存在电子表格操作的现实挑战,例如长时视图的操纵和多步骤推理等。因此目前有必要构建更符合实际情况的测试标准。
- 为了解决这些挑战,引入了SheetRM基准测试标准,该标准包含长时视图和多种类别的任务,并涉及由现实挑战引起的推理依赖操纵。
点此查看论文截图


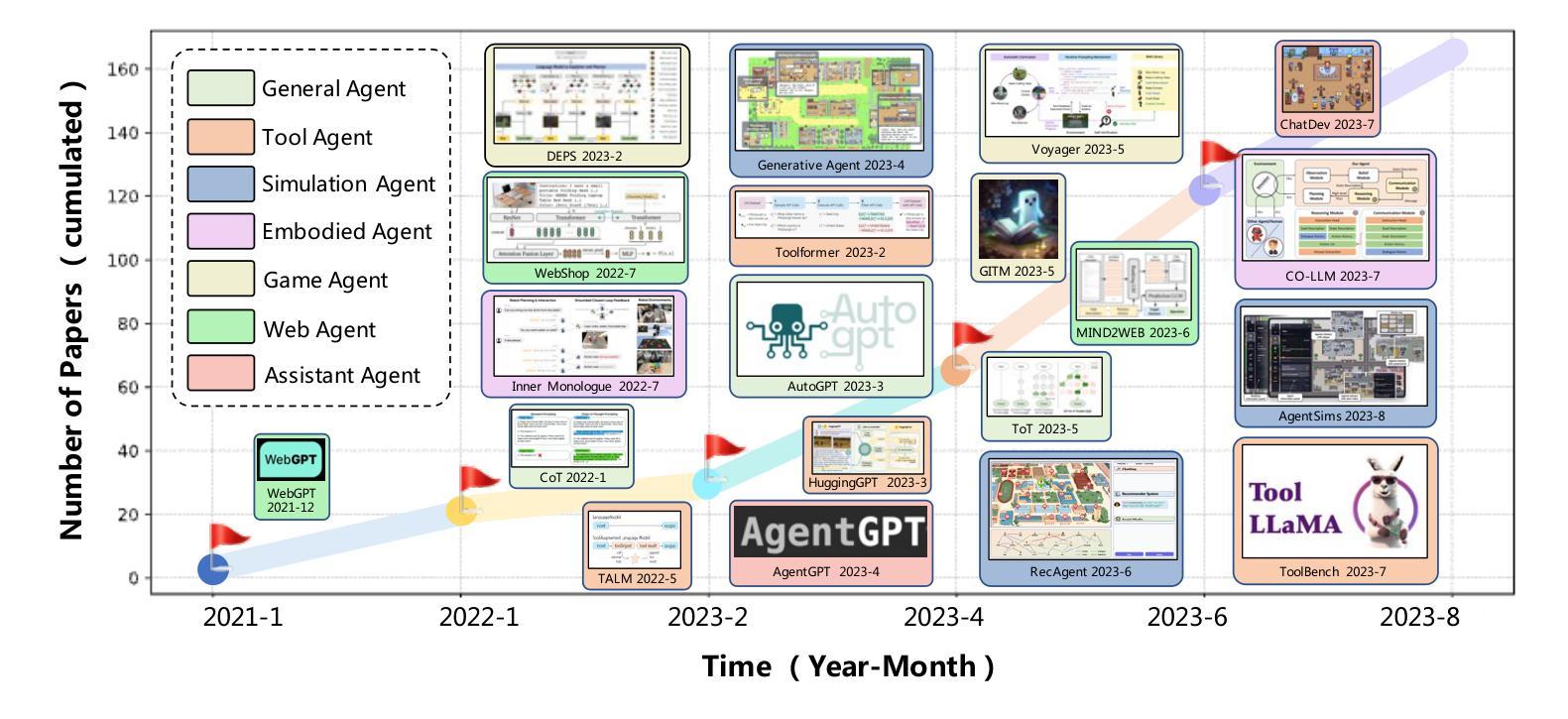
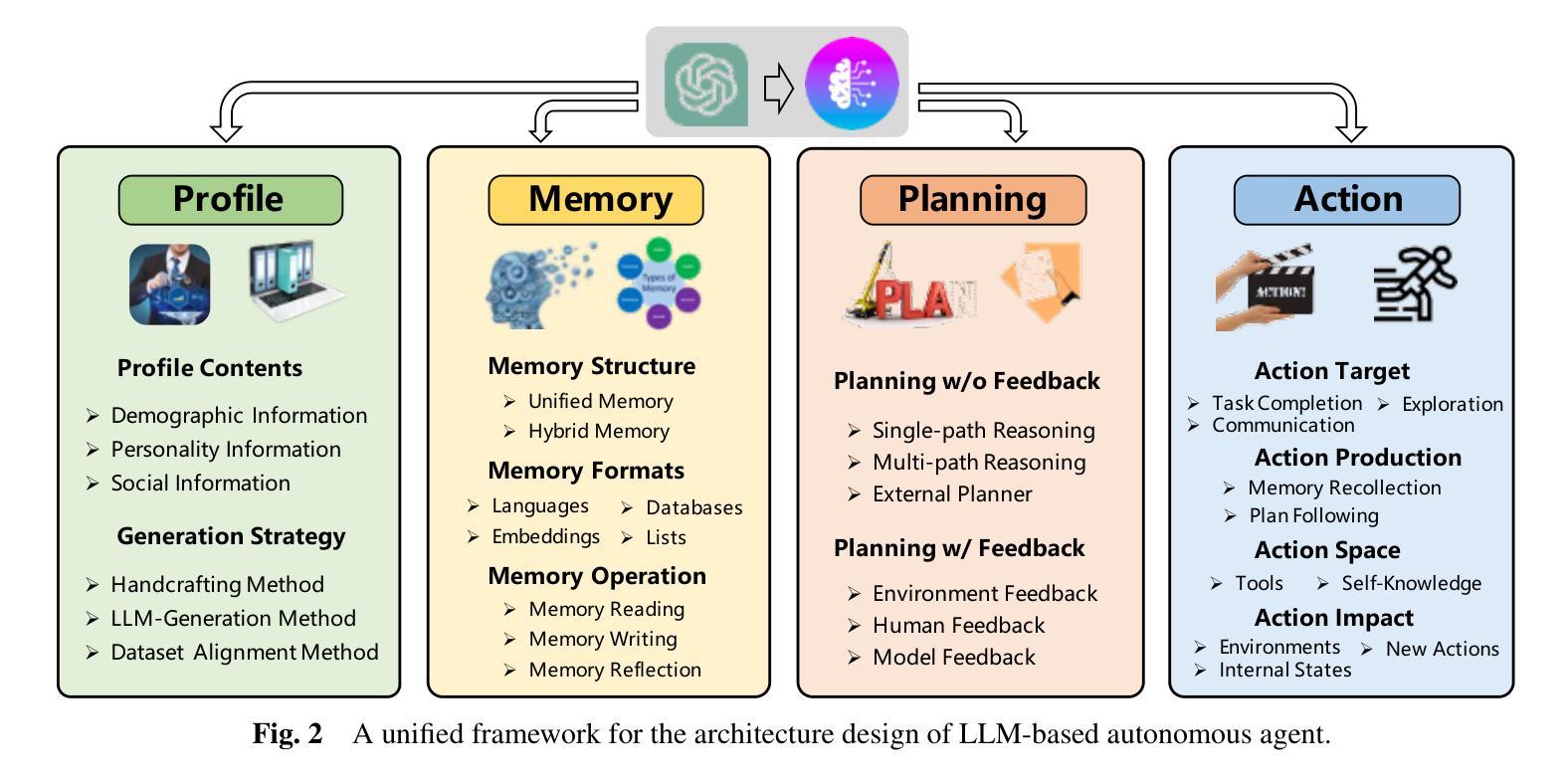
A Survey on Large Language Model based Autonomous Agents
Authors:Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, Ji-Rong Wen
Autonomous agents have long been a prominent research focus in both academic and industry communities. Previous research in this field often focuses on training agents with limited knowledge within isolated environments, which diverges significantly from human learning processes, and thus makes the agents hard to achieve human-like decisions. Recently, through the acquisition of vast amounts of web knowledge, large language models (LLMs) have demonstrated remarkable potential in achieving human-level intelligence. This has sparked an upsurge in studies investigating LLM-based autonomous agents. In this paper, we present a comprehensive survey of these studies, delivering a systematic review of the field of LLM-based autonomous agents from a holistic perspective. More specifically, we first discuss the construction of LLM-based autonomous agents, for which we propose a unified framework that encompasses a majority of the previous work. Then, we present a comprehensive overview of the diverse applications of LLM-based autonomous agents in the fields of social science, natural science, and engineering. Finally, we delve into the evaluation strategies commonly used for LLM-based autonomous agents. Based on the previous studies, we also present several challenges and future directions in this field. To keep track of this field and continuously update our survey, we maintain a repository of relevant references at https://github.com/Paitesanshi/LLM-Agent-Survey.
自主学习代理长期以来一直是学术界和工业界社区的重要研究焦点。以往该领域的研究经常关注在隔离环境中训练具有有限知识的代理,这与人类学习过程有很大的差异,因此使得代理难以实现人类般的决策。最近,通过获取大量的网络知识,大型语言模型(LLM)在实现人类水平智能方面展现出了显著潜力。这引发了一股研究LLM自主代理的热潮。在这篇论文中,我们对这些研究进行了全面的综述,从全面的角度对基于LLM的自主代理领域进行了系统的回顾。更具体地说,我们首先讨论了基于LLM的自主代理的构建,为此我们提出了一个统一的框架,涵盖了大多数之前的工作。然后,我们全面概述了基于LLM的自主代理在社会科学、自然科学和工程领域的各种应用。最后,我们深入探讨了评估基于LLM的自主代理通常使用的评估策略。基于以往的研究,我们还提出了该领域的几个挑战和未来发展方向。为了跟踪该领域并不断更新我们的调查,我们在https://github.com/Paitesanshi/LLM-Agent-Survey维护了相关参考文献的仓库。
论文及项目相关链接
PDF Correcting several typos, 35 pages, 5 figures, 3 tables
Summary
基于大型语言模型的自主智能体研究综述。文章介绍了自主智能体的研究背景,提出一个统一的框架涵盖前期工作,概述智能体在社会科学、自然科学和工程领域的应用,并探讨智能体的评估策略,最后提出该领域的挑战和未来发展方向。
Key Takeaways
- 大型语言模型为自主智能体研究带来显著进展,推动自主智能体领域的研究热潮。
- 文章提出了一个涵盖大部分前期工作的统一框架,用于构建基于大型语言模型的自主智能体。
- 基于大型语言模型的自主智能体在社会科学、自然科学和工程领域有广泛的应用前景。
- 文章介绍了用于评估自主智能体的常见策略。
- 当前自主智能体研究面临一些挑战,如实现更人性化的决策、提高鲁棒性和可解释性等。
- 为持续跟踪和更新相关研究,文章提供了一个相关参考文献的仓库。
点此查看论文截图