⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-05 更新
A Dual-Purpose Framework for Backdoor Defense and Backdoor Amplification in Diffusion Models
Authors:Vu Tuan Truong, Long Bao Le
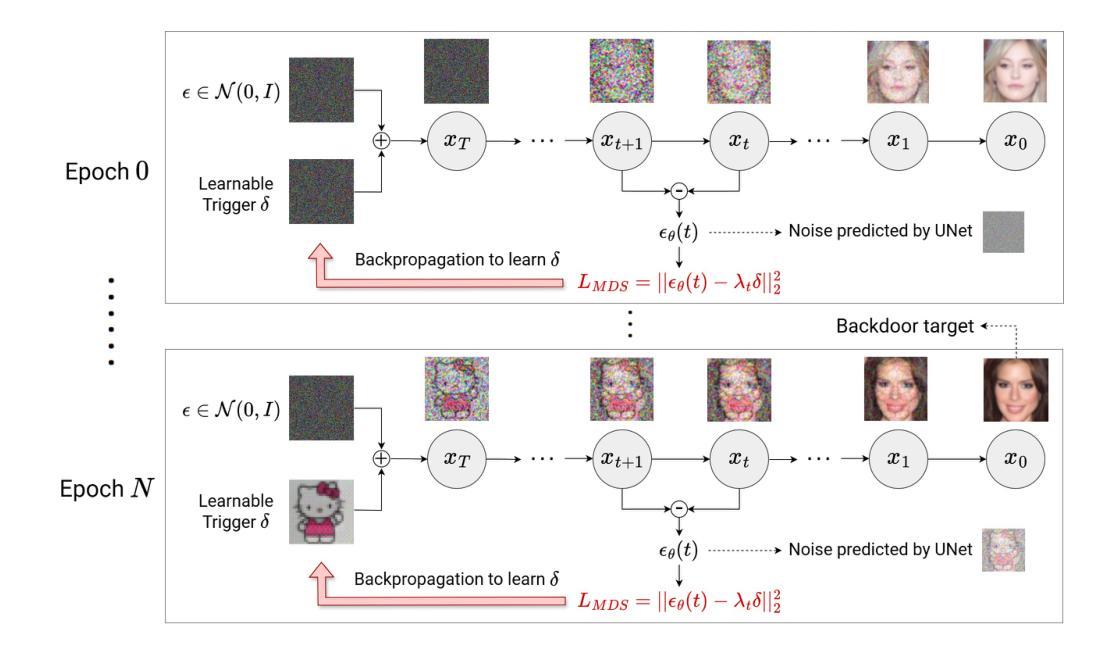
Diffusion models have emerged as state-of-the-art generative frameworks, excelling in producing high-quality multi-modal samples. However, recent studies have revealed their vulnerability to backdoor attacks, where backdoored models generate specific, undesirable outputs called backdoor target (e.g., harmful images) when a pre-defined trigger is embedded to their inputs. In this paper, we propose PureDiffusion, a dual-purpose framework that simultaneously serves two contrasting roles: backdoor defense and backdoor attack amplification. For defense, we introduce two novel loss functions to invert backdoor triggers embedded in diffusion models. The first leverages trigger-induced distribution shifts across multiple timesteps of the diffusion process, while the second exploits the denoising consistency effect when a backdoor is activated. Once an accurate trigger inversion is achieved, we develop a backdoor detection method that analyzes both the inverted trigger and the generated backdoor targets to identify backdoor attacks. In terms of attack amplification with the role of an attacker, we describe how our trigger inversion algorithm can be used to reinforce the original trigger embedded in the backdoored diffusion model. This significantly boosts attack performance while reducing the required backdoor training time. Experimental results demonstrate that PureDiffusion achieves near-perfect detection accuracy, outperforming existing defenses by a large margin, particularly against complex trigger patterns. Additionally, in an attack scenario, our attack amplification approach elevates the attack success rate (ASR) of existing backdoor attacks to nearly 100% while reducing training time by up to 20x.
扩散模型已经作为最先进的生成框架出现,擅长生成高质量的多模式样本。然而,最近的研究表明,它们容易受到后门攻击的影响,后门模型会在输入嵌入预定义触发器时,生成特定的、不希望出现的输出,称为后门目标(例如,有害图像)。在本文中,我们提出了PureDiffusion,这是一个双重用途的框架,可以同时扮演两个相反的角色:后门防御和后门攻击增强。在防御方面,我们介绍了两种新型损失函数来反转嵌入在扩散模型中的后门触发器。第一种利用触发引起的扩散过程中多个时间步的分布变化,第二种则利用后门被激活时的去噪一致性效应。一旦实现了准确的触发器反转,我们就开发了一种后门检测方法,该方法分析反转的触发器和生成的后门目标,以识别后门攻击。在作为攻击者的角色进行攻击增强方面,我们描述了如何使用我们的触发器反转算法来加强嵌入后门扩散模型中的原始触发器。这显著提高了攻击性能,同时减少了所需的后门训练时间。实验结果表明,PureDiffusion实现了近乎完美的检测精度,大大优于现有的防御手段,尤其是对复杂的触发模式。此外,在攻击场景中,我们的攻击增强方法将现有后门攻击的攻击成功率(ASR)提高到接近100%,同时减少训练时间高达20倍。
论文及项目相关链接
摘要
扩散模型作为当前最先进的生成框架,能够产生高质量的多模式样本。然而,最近的研究表明,它们容易受到后门攻击的影响,其中后门模型会在输入嵌入预定义触发器时生成特定的、不希望的输出,称为后门目标(例如,有害图像)。本文提出了PureDiffusion,一个兼具防御和攻击功能的双重用途框架。在防御方面,我们引入两种新型损失函数来反转嵌入在扩散模型中的后门触发器。第一种利用触发器在扩散过程的多个时间步长中引起的分布变化,第二种则利用后门激活时的去噪一致性效应。实现准确的触发器反转后,我们开发了一种后门检测方法,该方法分析反转的触发器和生成的后门目标,以识别后门攻击。作为攻击者的角色进行攻击放大时,我们描述了如何利用我们的触发器反转算法加强嵌入在受后门控制的扩散模型中的原始触发器。这大大提高了攻击性能,同时减少了所需的后门训练时间。实验结果表明,PureDiffusion实现了近乎完美的检测准确率,大大优于现有防御手段,尤其是对复杂触发模式。此外,在攻击场景中,我们的攻击放大方法可将现有后门攻击的成功率提高到近100%,同时减少训练时间高达20倍。
关键见解
- 扩散模型虽然能生成高质量多模式样本,但易受后门攻击影响,能生成特定不希望的输出。
- PureDiffusion框架兼具防御和攻击功能。
- 引入两种新型损失函数来反转后门触发器。
- 利用触发器在扩散过程中的分布变化和去噪一致性效应进行防御。
- 开发了一种分析反转触发器和后门目标以识别后门攻击的方法。
- 触发器反转算法可用于加强原始嵌入的触发器,提高攻击性能并减少训练时间。
点此查看论文截图

Fast Direct: Query-Efficient Online Black-box Guidance for Diffusion-model Target Generation
Authors:Kim Yong Tan, Yueming Lyu, Ivor Tsang, Yew-Soon Ong
Guided diffusion-model generation is a promising direction for customizing the generation process of a pre-trained diffusion-model to address the specific downstream tasks. Existing guided diffusion models either rely on training of the guidance model with pre-collected datasets or require the objective functions to be differentiable. However, for most real-world tasks, the offline datasets are often unavailable, and their objective functions are often not differentiable, such as image generation with human preferences, molecular generation for drug discovery, and material design. Thus, we need an $\textbf{online}$ algorithm capable of collecting data during runtime and supporting a $\textbf{black-box}$ objective function. Moreover, the $\textbf{query efficiency}$ of the algorithm is also critical because the objective evaluation of the query is often expensive in the real-world scenarios. In this work, we propose a novel and simple algorithm, $\textbf{Fast Direct}$, for query-efficient online black-box target generation. Our Fast Direct builds a pseudo-target on the data manifold to update the noise sequence of the diffusion model with a universal direction, which is promising to perform query-efficient guided generation. Extensive experiments on twelve high-resolution ($\small {1024 \times 1024}$) image target generation tasks and six 3D-molecule target generation tasks show $\textbf{6}\times$ up to $\textbf{10}\times$ query efficiency improvement and $\textbf{11}\times$ up to $\textbf{44}\times$ query efficiency improvement, respectively. Our implementation is publicly available at: https://github.com/kimyong95/guide-stable-diffusion/tree/fast-direct
引导扩散模型生成是定制预训练扩散模型的生成过程以应对特定下游任务的一个具有前景的方向。现有的引导扩散模型要么依赖于使用预先收集的数据集对引导模型进行训练,要么需要目标函数可微。然而,对于大多数现实世界任务而言,离线数据集通常不可用,并且其目标函数通常不可微,例如具有人类偏好的图像生成、用于药物发现的分子生成以及材料设计。因此,我们需要一种能够在运行时收集数据并支持黑箱目标函数的在线算法。此外,算法的查询效率也至关重要,因为在现实场景中,目标查询的评估往往成本高昂。在这项工作中,我们提出了一种新颖且简单的算法“Fast Direct”,用于查询高效的在线黑箱目标生成。我们的Fast Direct在数据流形上构建伪目标,以通用方向更新扩散模型的噪声序列,有望执行查询高效的引导生成。在十二个高分辨率($1024 \times 1024$)图像目标生成任务和六个3D分子目标生成任务上的大量实验显示,查询效率提高了6倍至10倍和提高了高达高达高达高达高达高达高达高达高达高达高达高达高达高达高达高达高达高达高达高达高达高达高达高达高达高达高达高达高达高达提高效率大大提高倍和改进改善了比例4%。我们的实现公开可用在:链接地址。
论文及项目相关链接
摘要
扩散模型的在线黑盒目标生成。现有引导扩散模型方法依赖预收集数据集进行训练或要求目标函数可微。然而,对于大多数现实世界任务,离线数据集常不可获取且其目标函数常不可微,如基于人类偏好生成图像、药物发现中的分子生成及材料设计。因此需要能在线运行时收集数据并支持黑盒目标函数的算法。查询效率也至关重要,因为现实场景中目标评估往往昂贵。本研究提出了一种简单而高效的算法“Fast Direct”,用于在线黑盒目标生成。Fast Direct在数据流形上构建伪目标,以通用方向更新扩散模型的噪声序列,有望进行高效的查询引导生成。实验表明,在高分辨率图像目标生成任务和三维分子目标生成任务中,查询效率分别提高了6至10倍和高达44倍。代码公开于:链接地址。
关键见解
- 引导扩散模型生成是一个针对预训练扩散模型的定制化生成过程的方向,用于解决特定的下游任务。
- 现有引导扩散模型方法依赖于预收集数据集的训练或要求目标函数可微,但在现实任务中这两点常无法满足。
- 提出了一种简单而高效的算法“Fast Direct”,支持在线黑盒目标生成。
- Fast Direct算法在数据流形上构建伪目标,以通用方向更新扩散模型的噪声序列,实现查询效率的提高。
- 实验证明,Fast Direct在图像和分子生成任务中实现了显著的查询效率提升。
- 该算法适用于多种任务类型,包括图像生成、分子生成和材料设计等。
点此查看论文截图



Slot-Guided Adaptation of Pre-trained Diffusion Models for Object-Centric Learning and Compositional Generation
Authors:Adil Kaan Akan, Yucel Yemez
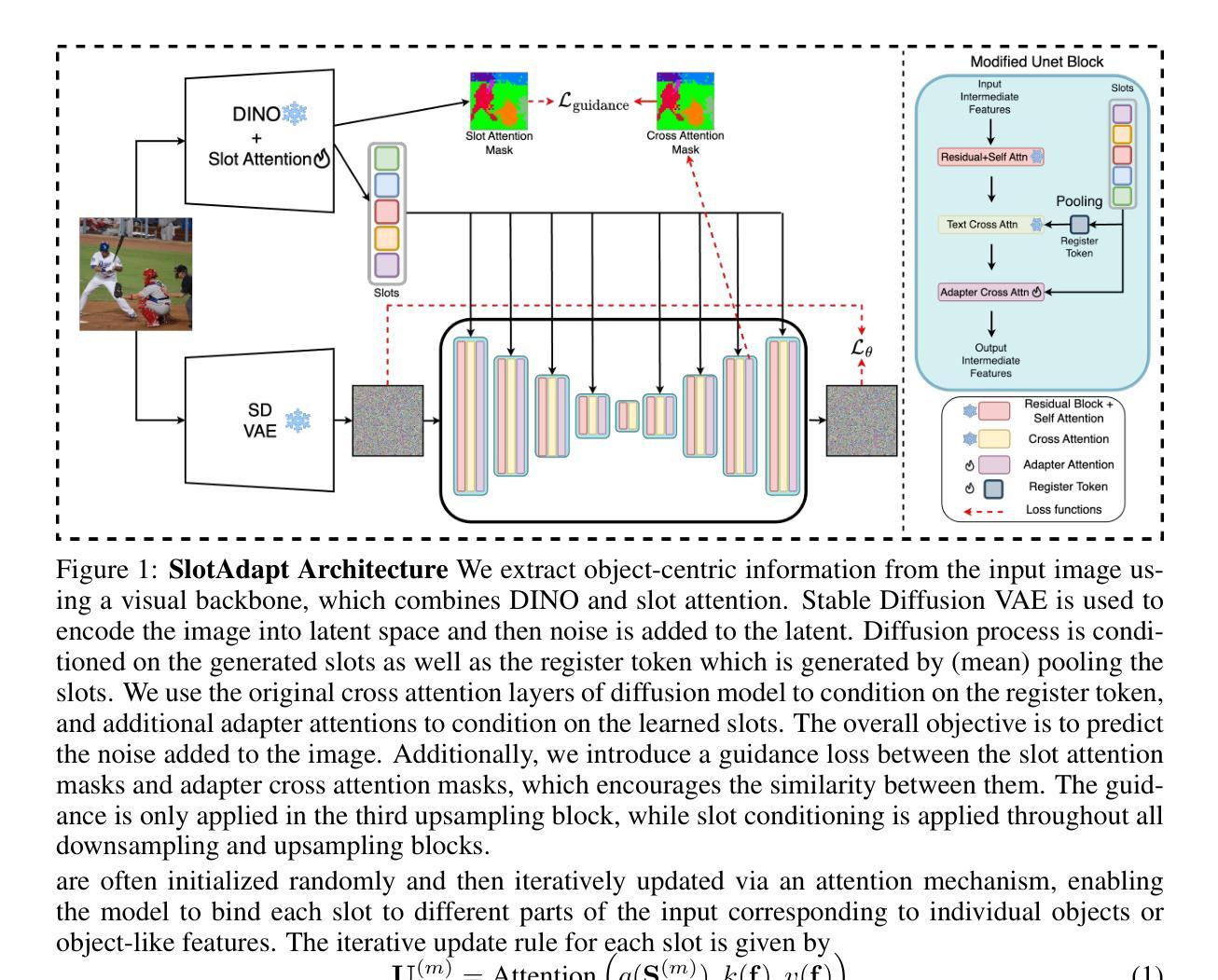
We present SlotAdapt, an object-centric learning method that combines slot attention with pretrained diffusion models by introducing adapters for slot-based conditioning. Our method preserves the generative power of pretrained diffusion models, while avoiding their text-centric conditioning bias. We also incorporate an additional guidance loss into our architecture to align cross-attention from adapter layers with slot attention. This enhances the alignment of our model with the objects in the input image without using external supervision. Experimental results show that our method outperforms state-of-the-art techniques in object discovery and image generation tasks across multiple datasets, including those with real images. Furthermore, we demonstrate through experiments that our method performs remarkably well on complex real-world images for compositional generation, in contrast to other slot-based generative methods in the literature. The project page can be found at https://kaanakan.github.io/SlotAdapt/.
我们提出了SlotAdapt,这是一种结合插槽注意力和预训练扩散模型的面向对象的学习方法,它通过引入适配器来实现基于插槽的条件。我们的方法保留了预训练扩散模型的生成能力,同时避免了其面向文本的条件偏差。我们还将额外的指导损失纳入我们的架构,以调整适配器层的交叉注意力与插槽注意力。这提高了我们的模型与输入图像中的对象的对齐度,而无需使用外部监督。实验结果表明,我们的方法在多个数据集上的物体发现和图像生成任务上的表现均优于最先进的技术,包括真实图像数据集。此外,通过实验证明,与其他基于插槽的生成方法相比,我们的方法在复杂真实图像的合成生成方面表现尤为出色。项目页面位于https://kaanakan.github.io/SlotAdapt/。
论文及项目相关链接
PDF Accepted to ICLR2025. Project page: https://kaanakan.github.io/SlotAdapt/
Summary
SlotAdapt结合槽位注意力和预训练扩散模型,通过引入适配器实现槽位条件化,提升了图像生成和物体发现任务的效果。该方法在多个数据集上表现优异,尤其擅长处理复杂真实图像的组合生成任务。
Key Takeaways
- SlotAdapt结合了槽位注意力和预训练扩散模型,通过引入适配器实现了基于槽位的条件化。
- 该方法保留了预训练扩散模型的生成能力,并避免了文本中心化的条件化偏见。
- SlotAdapt通过额外的指导损失增强了模型与输入图像中物体的对齐度,无需外部监督。
- 在多个数据集上,SlotAdapt在物体发现和图像生成任务上表现出超越现有技术水平的性能。
- 该方法在复杂真实图像的组合生成任务上表现尤为出色。
- SlotAdapt适用于多种图像生成场景,具有广泛的应用前景。
点此查看论文截图

StochSync: Stochastic Diffusion Synchronization for Image Generation in Arbitrary Spaces
Authors:Kyeongmin Yeo, Jaihoon Kim, Minhyuk Sung
We propose a zero-shot method for generating images in arbitrary spaces (e.g., a sphere for 360{\deg} panoramas and a mesh surface for texture) using a pretrained image diffusion model. The zero-shot generation of various visual content using a pretrained image diffusion model has been explored mainly in two directions. First, Diffusion Synchronization-performing reverse diffusion processes jointly across different projected spaces while synchronizing them in the target space-generates high-quality outputs when enough conditioning is provided, but it struggles in its absence. Second, Score Distillation Sampling-gradually updating the target space data through gradient descent-results in better coherence but often lacks detail. In this paper, we reveal for the first time the interconnection between these two methods while highlighting their differences. To this end, we propose StochSync, a novel approach that combines the strengths of both, enabling effective performance with weak conditioning. Our experiments demonstrate that StochSync provides the best performance in 360{\deg} panorama generation (where image conditioning is not given), outperforming previous finetuning-based methods, and also delivers comparable results in 3D mesh texturing (where depth conditioning is provided) with previous methods.
我们提出了一种基于预训练图像扩散模型的零样本方法在任意空间(例如,用于360°全景的球体或用于纹理的网格表面)生成图像。使用预训练的图像扩散模型进行各种视觉内容的零样本生成主要探索了两个方向。首先,扩散同步法通过在不同的投影空间上执行反向扩散过程并在目标空间中同步它们来生成高质量输出,但在缺少足够条件的情况下会遇到困难。其次,评分蒸馏采样法通过梯度下降逐步更新目标空间数据,虽然能够保证更好的连贯性,但往往缺乏细节。在本文中,我们首次揭示了这两种方法之间的相互联系,同时强调了它们的差异。为此,我们提出了StochSync这一新方法,它结合了这两种方法的优点,能够在弱条件下进行有效性能表现。我们的实验表明,StochSync在无图像条件的情况下表现出最佳的360°全景生成性能,超越了基于微调的方法,并且在提供深度条件的情况下,其在3D网格纹理生成方面的结果也与之前的方法相当。
论文及项目相关链接
PDF Project page: https://stochsync.github.io/ (ICLR 2025)
Summary
本文提出一种基于预训练图像扩散模型的零样本方法,用于在任意空间(如球体全景图和网格表面纹理)生成图像。文章探讨了两种主要的零样本生成方向:一是通过同步反向扩散过程在目标空间中同步生成高质量输出;二是在目标空间中逐步更新数据以获得更好的连贯性。本文首次揭示了这两种方法的相互联系和差异,并提出了一种新的方法StochSync,结合了这两种方法的优点,在弱条件下实现了有效的性能。实验表明,StochSync在全景图生成方面表现出最佳性能,优于基于微调的方法,同时在提供深度条件的三维网格纹理生成中表现良好。
Key Takeaways
- 提出了一种基于预训练图像扩散模型的零样本方法在任意空间生成图像。
- 探讨了两种主要的零样本生成方向:Diffusion Synchronization和Score Distillation Sampling,并揭示了它们的差异和相互联系。
- 提出了一种新的方法StochSync,结合了Diffusion Synchronization和Score Distillation Sampling的优点。
- 在全景图生成方面,StochSync表现出最佳性能,优于基于微调的方法。
- 在提供深度条件的三维网格纹理生成中,StochSync具有良好的表现。
- 该方法能够在弱条件下实现有效性能。
点此查看论文截图



The Superposition of Diffusion Models Using the Itô Density Estimator
Authors:Marta Skreta, Lazar Atanackovic, Avishek Joey Bose, Alexander Tong, Kirill Neklyudov
The Cambrian explosion of easily accessible pre-trained diffusion models suggests a demand for methods that combine multiple different pre-trained diffusion models without incurring the significant computational burden of re-training a larger combined model. In this paper, we cast the problem of combining multiple pre-trained diffusion models at the generation stage under a novel proposed framework termed superposition. Theoretically, we derive superposition from rigorous first principles stemming from the celebrated continuity equation and design two novel algorithms tailor-made for combining diffusion models in SuperDiff. SuperDiff leverages a new scalable It^o density estimator for the log likelihood of the diffusion SDE which incurs no additional overhead compared to the well-known Hutchinson’s estimator needed for divergence calculations. We demonstrate that SuperDiff is scalable to large pre-trained diffusion models as superposition is performed solely through composition during inference, and also enjoys painless implementation as it combines different pre-trained vector fields through an automated re-weighting scheme. Notably, we show that SuperDiff is efficient during inference time, and mimics traditional composition operators such as the logical OR and the logical AND. We empirically demonstrate the utility of using SuperDiff for generating more diverse images on CIFAR-10, more faithful prompt conditioned image editing using Stable Diffusion, as well as improved conditional molecule generation and unconditional de novo structure design of proteins. https://github.com/necludov/super-diffusion
扩散模型的涌现非常容易获得的预训练扩散模型揭示了对于结合多种不同的预训练扩散模型的需求,而不必承受重新训练更大的组合模型带来的巨大计算负担。在本文中,我们提出了一种结合多个预训练扩散模型的问题,该问题在生成阶段位于新提出的框架下,称为叠加法。理论上,我们从著名的连续性方程得出了严格的第一原理推导出的叠加法,并针对SuperDiff中的扩散模型设计了两种新颖算法。SuperDiff利用一种新的可扩展的It^o密度估计器来计算扩散随机微分方程的对数似然值,与用于发散计算的众所周知的Hutchinson估计器相比,无需额外的开销。我们证明了SuperDiff能够扩展到大型预训练扩散模型,因为叠加仅在推理过程中通过组合实现,并且通过自动重新加权方案组合不同的预训练向量场,实现起来毫不费力。值得注意的是,我们展示了SuperDiff在推理时间的高效性,并模仿了传统的组合运算符,如逻辑或和逻辑与。我们通过经验证明了在CIFAR-10上生成更多不同图像、使用稳定扩散进行更真实的提示条件图像编辑以及改进条件分子生成和无条件蛋白质全新结构设计的实用性。详情请访问:https://github.com/necludov/super-diffusion。
论文及项目相关链接
PDF Accepted as a Spotlight Presentation at the International Conference on Learning Representations 2025
Summary
这篇论文提出了一种名为SuperDiff的新框架,用于在生成阶段组合多个预训练的扩散模型。SuperDiff利用可扩展的Itō密度估计器计算扩散随机微分方程的对数似然值,无需额外的开销。SuperDiff通过组合不同的预训练向量场实现自动重新加权,可轻松实施,且推理效率高。此外,SuperDiff能够生成更多样化的图像,更忠实于提示条件的图像编辑,以及改进的条件分子生成和无条件蛋白质设计。
Key Takeaways
- SuperDiff框架允许组合多个预训练的扩散模型,无需承担重新训练大型组合模型的重大计算负担。
- SuperDiff利用Itō密度估计器计算扩散随机微分方程的对数似然值,具有可扩展性。
- 通过组合不同的预训练向量场,SuperDiff实现了自动重新加权,使得实施更为轻松。
- SuperDiff在推理阶段效率高,模仿了逻辑OR和AND等传统的组合运算符。
- SuperDiff能够生成更多样化的图像,如在CIFAR-10上的表现。
- SuperDiff能够更忠实于提示条件的图像编辑,如在Stable Diffusion中的应用。
点此查看论文截图



Autoregressive Video Generation without Vector Quantization
Authors:Haoge Deng, Ting Pan, Haiwen Diao, Zhengxiong Luo, Yufeng Cui, Huchuan Lu, Shiguang Shan, Yonggang Qi, Xinlong Wang
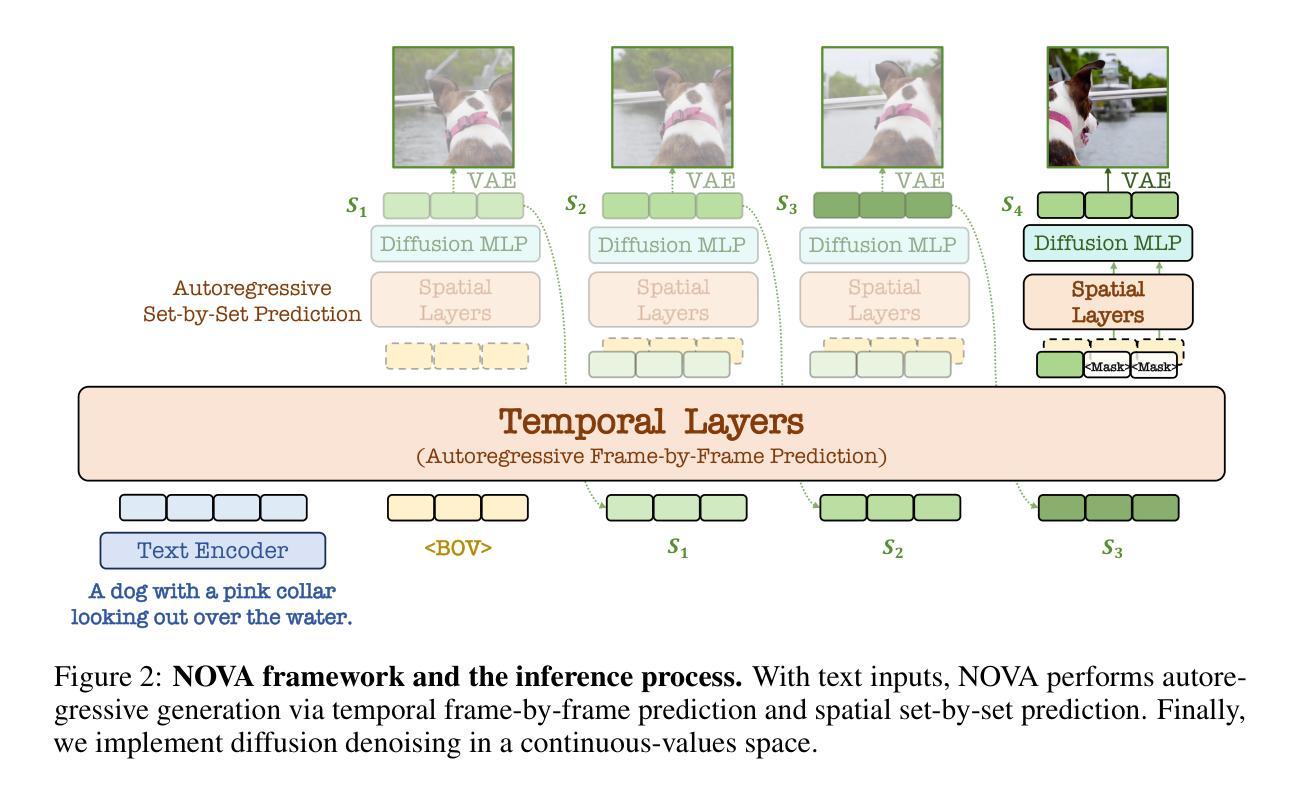
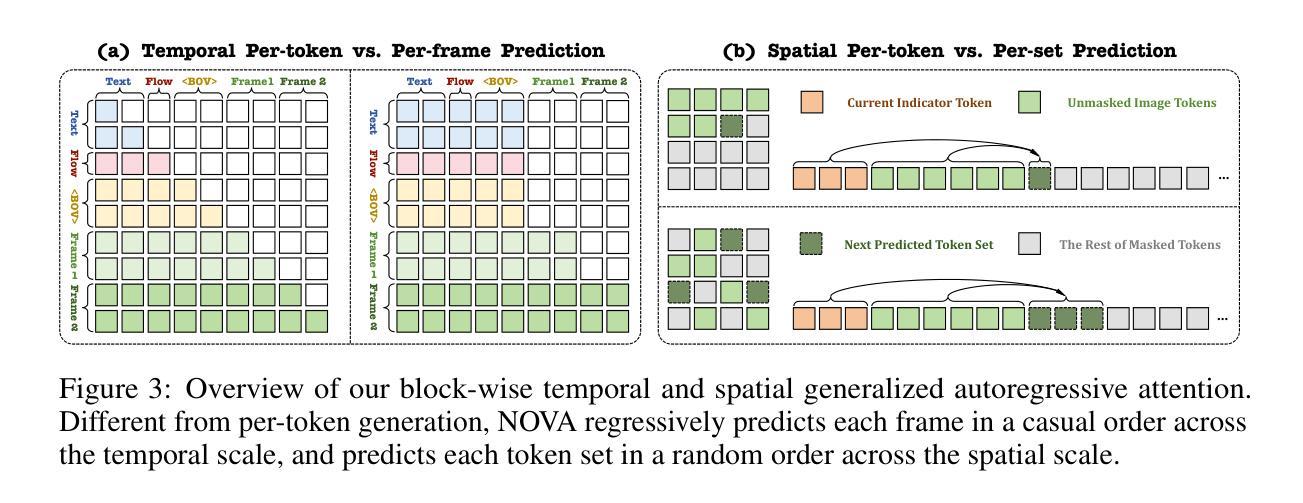
This paper presents a novel approach that enables autoregressive video generation with high efficiency. We propose to reformulate the video generation problem as a non-quantized autoregressive modeling of temporal frame-by-frame prediction and spatial set-by-set prediction. Unlike raster-scan prediction in prior autoregressive models or joint distribution modeling of fixed-length tokens in diffusion models, our approach maintains the causal property of GPT-style models for flexible in-context capabilities, while leveraging bidirectional modeling within individual frames for efficiency. With the proposed approach, we train a novel video autoregressive model without vector quantization, termed NOVA. Our results demonstrate that NOVA surpasses prior autoregressive video models in data efficiency, inference speed, visual fidelity, and video fluency, even with a much smaller model capacity, i.e., 0.6B parameters. NOVA also outperforms state-of-the-art image diffusion models in text-to-image generation tasks, with a significantly lower training cost. Additionally, NOVA generalizes well across extended video durations and enables diverse zero-shot applications in one unified model. Code and models are publicly available at https://github.com/baaivision/NOVA.
本文提出了一种新的方法,能够高效地进行自回归视频生成。我们提议将视频生成问题重新表述为未量化的自回归建模,包括时间上的逐帧预测和空间上的集集合预测。与先前自回归模型中的栅格扫描预测或扩散模型中的固定长度标记的联合分布建模不同,我们的方法保持了GPT风格模型的因果特性,以实现灵活的上下文功能,同时利用单个帧内的双向建模来提高效率。通过该方法,我们训练了一种无需向量量化的新型视频自回归模型,称为NOVA。结果表明,NOVA在数据效率、推理速度、视觉保真度和视频流畅性方面超越了先前的自回归视频模型,即使模型容量小得多,也只有0.6B参数。此外,NOVA在文本到图像生成任务上的表现优于最先进的图像扩散模型,并且训练成本显著降低。NOVA还能很好地适应长时间的视频,并在一个统一的模型中实现了多样化的零样本应用。代码和模型可在https://github.com/baaivision/NOVA上公开获取。
论文及项目相关链接
PDF Accepted to ICLR 2025. Project page at https://github.com/baaivision/NOVA
Summary
扩散模型的新方法可以实现高效自回归视频生成。该研究将视频生成问题重新定义为非量化自回归建模,包括时间帧预测和空时集合预测。与先前的自回归模型中的光栅扫描预测或扩散模型的固定长度标记的联合分布建模不同,该方法保留了GPT风格的模型的上下文灵活性,同时利用单个帧内的双向建模提高效率。该方法训练了一种名为NOVA的新型视频自回归模型,无需矢量量化。结果证明,NOVA在数据效率、推理速度、视觉保真度和视频流畅性方面超越了先前的自回归视频模型,即使模型容量较小(即0.6亿参数)。NOVA还优于最先进的图像扩散模型在文本到图像生成任务中的表现,并且训练成本显著降低。此外,NOVA在扩展视频时长方面具有良好的泛化能力,在一个统一模型中实现了多样化的零样本应用。
Key Takeaways
1.该研究提出了一种新型自回归视频生成方法,基于非量化自回归建模。
2.该研究将视频生成问题分解为时间帧预测和空时集合预测。
3.新方法保留了GPT风格模型的上下文灵活性,并结合了帧内的双向建模以提高效率。
4.引入了一种新型视频自回归模型NOVA,无需矢量量化。
5.NOVA在数据效率、推理速度、视觉保真度和视频流畅性方面超越了其他自回归视频模型。
6.NOVA在文本到图像生成任务中表现优于最先进的图像扩散模型,且训练成本较低。
点此查看论文截图

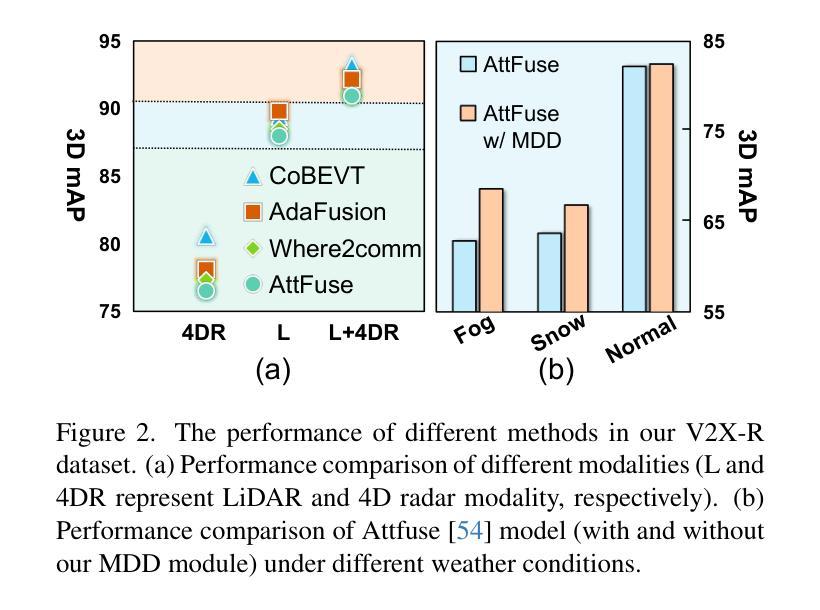
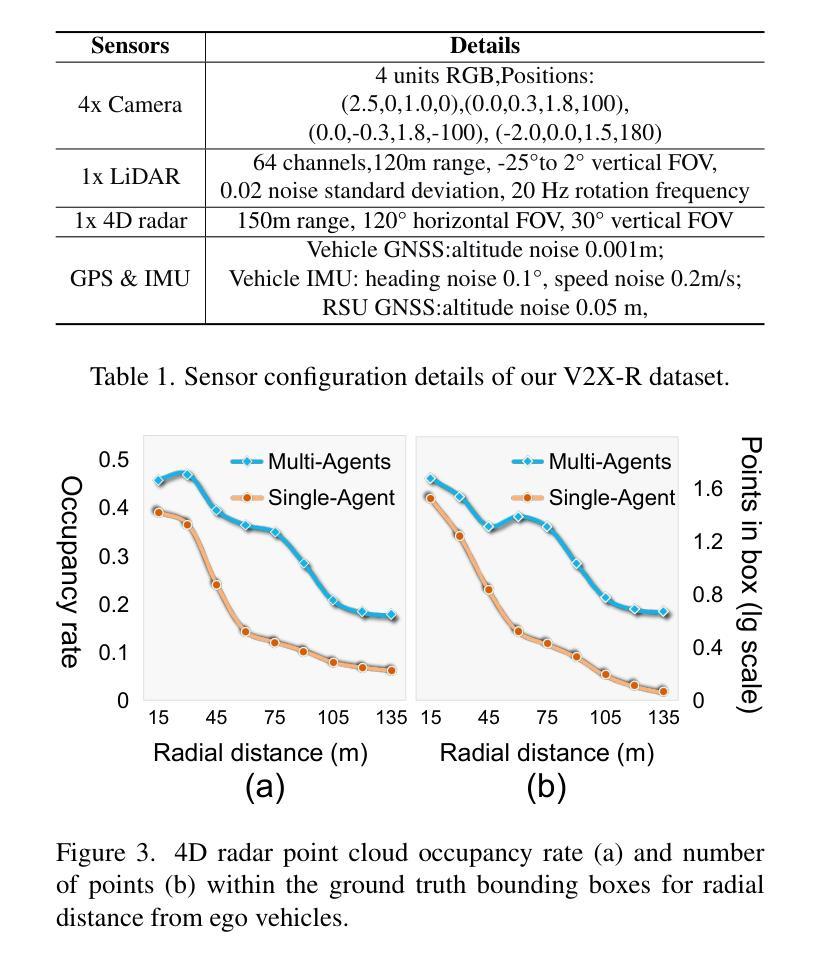
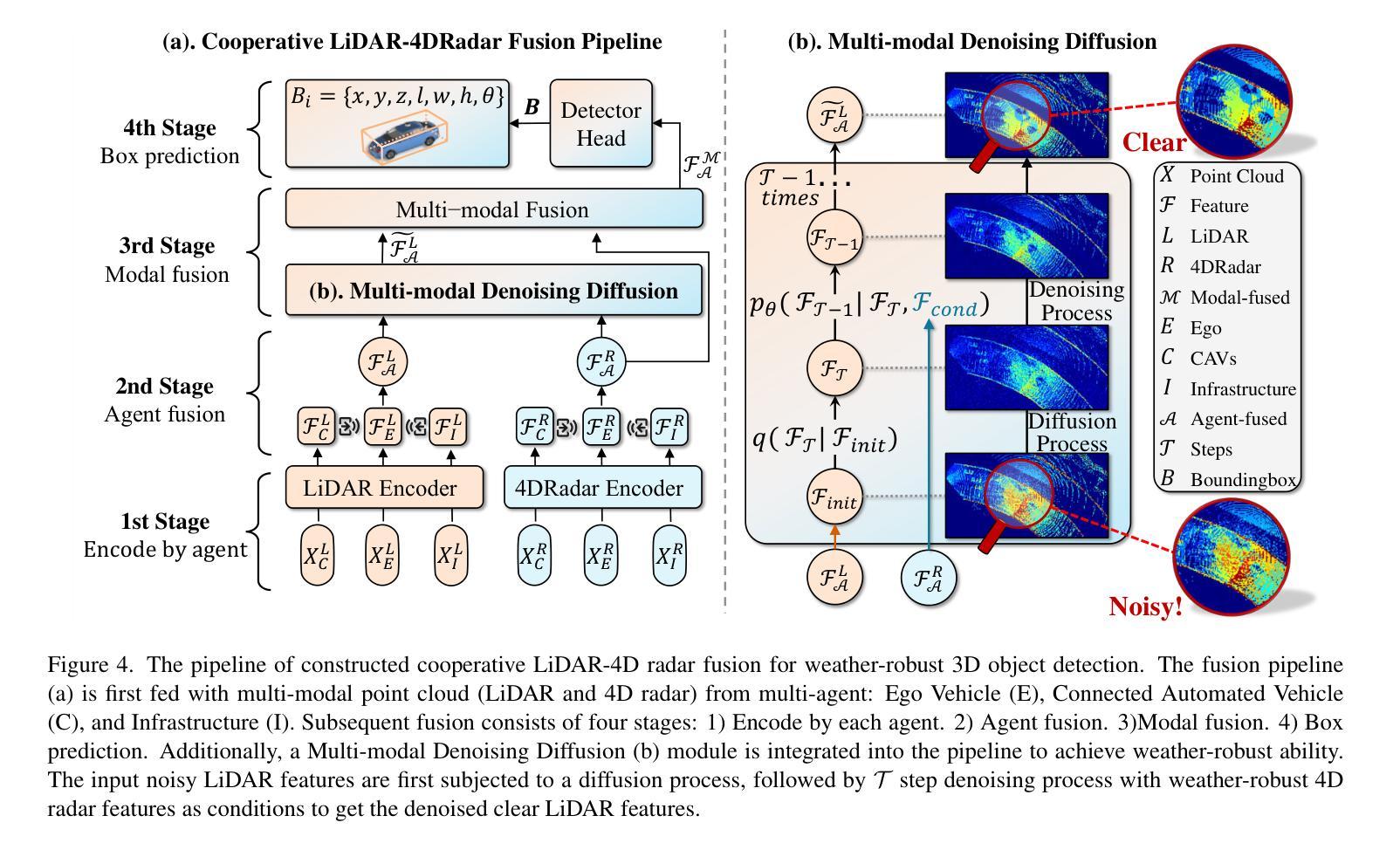
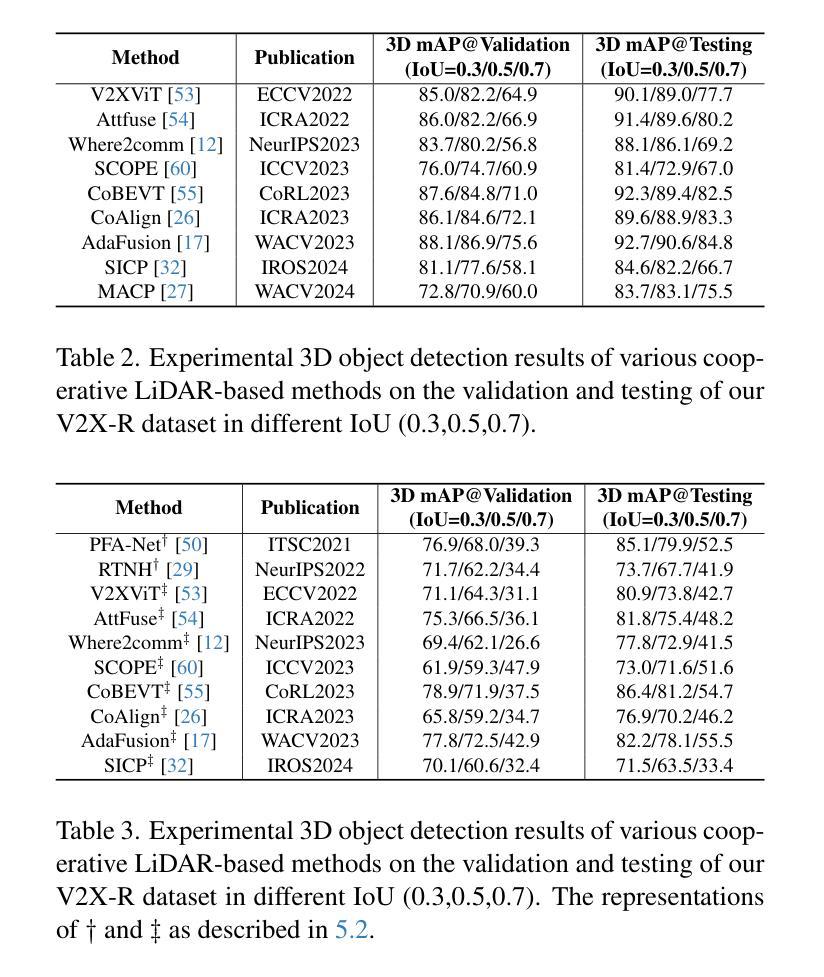
V2X-R: Cooperative LiDAR-4D Radar Fusion for 3D Object Detection with Denoising Diffusion
Authors:Xun Huang, Jinlong Wang, Qiming Xia, Siheng Chen, Bisheng Yang, Xin Li, Cheng Wang, Chenglu Wen
Current Vehicle-to-Everything (V2X) systems have significantly enhanced 3D object detection using LiDAR and camera data. However, these methods suffer from performance degradation in adverse weather conditions. The weatherrobust 4D radar provides Doppler and additional geometric information, raising the possibility of addressing this challenge. To this end, we present V2X-R, the first simulated V2X dataset incorporating LiDAR, camera, and 4D radar. V2X-R contains 12,079 scenarios with 37,727 frames of LiDAR and 4D radar point clouds, 150,908 images, and 170,859 annotated 3D vehicle bounding boxes. Subsequently, we propose a novel cooperative LiDAR-4D radar fusion pipeline for 3D object detection and implement it with various fusion strategies. To achieve weather-robust detection, we additionally propose a Multi-modal Denoising Diffusion (MDD) module in our fusion pipeline. MDD utilizes weather-robust 4D radar feature as a condition to prompt the diffusion model to denoise noisy LiDAR features. Experiments show that our LiDAR-4D radar fusion pipeline demonstrates superior performance in the V2X-R dataset. Over and above this, our MDD module further improved the performance of basic fusion model by up to 5.73%/6.70% in foggy/snowy conditions with barely disrupting normal performance. The dataset and code will be publicly available at: https://github.com/ylwhxht/V2X-R.
当前的车对外界(V2X)系统已经通过激光雷达和相机数据显著增强了3D对象检测功能。然而,这些方法在恶劣天气条件下会出现性能下降。天气稳定的4D雷达提供了多普勒和额外的几何信息,为解决这一挑战提供了可能性。为此,我们推出了V2X-R,这是第一个结合了激光雷达、相机和4D雷达的模拟V2X数据集。V2X-R包含12,079个场景,其中包括激光雷达和4D雷达点云37,727帧、图像150,908张以及标注的3D车辆边界框170,859个。随后,我们提出了一种用于3D对象检测的新型合作激光雷达-4D雷达融合管道,并采用了多种融合策略来实现它。为了实现天气稳定的检测,我们在融合管道中额外提出了一种多模态去噪扩散(MDD)模块。MDD利用天气稳定的4D雷达特征作为条件,提示扩散模型对嘈杂的激光雷达特征进行去噪。实验表明,我们的激光雷达-4D雷达融合管道在V2X-R数据集上表现出卓越的性能。除此之外,我们的MDD模块进一步提高了基本融合模型在雾天和雪天的性能,同时几乎不影响正常性能。数据集和代码将在https://github.com/ylwhxht/V2X-R上公开提供。
论文及项目相关链接
PDF Accepted by CVPR2025
Summary
本研究针对现有车辆到万物(V2X)系统中使用的LiDAR和摄像机数据在恶劣天气条件下性能下降的问题,引入了4D雷达数据。研究团队创建了首个集成LiDAR、摄像机和4D雷达的模拟V2X数据集V2X-R。此外,还提出了一种新型的基于LiDAR与4D雷达的合作融合管道,用于3D对象检测,并实现了多种融合策略。为提高天气适应性检测性能,该团队在融合管道中引入了多模式去噪扩散(MDD)模块。实验表明,该融合管道在V2X-R数据集上的性能优于传统方法,而MDD模块进一步提高了基本融合模型在雾天和雪天的性能,同时几乎不影响正常性能。数据集和代码已公开发布在GitHub上。
Key Takeaways
- 当前V2X系统虽利用LiDAR和摄像机数据实现了3D对象检测的显著增强,但在恶劣天气条件下性能下降。
- 4D雷达提供多普勒和额外的几何信息,有助于解决恶劣天气下的检测挑战。
- 引入了首个集成LiDAR、摄像机和4D雷达的模拟V2X数据集V2X-R。
- 提出了新型的基于LiDAR与4D雷达的合作融合管道,用于3D对象检测,并实现了多种融合策略。
- 多模式去噪扩散(MDD)模块被引入以提高融合管道的天气适应性检测性能。
- 实验显示,LiDAR-4D雷达融合管道在V2X-R数据集上的表现优于传统方法。
点此查看论文截图


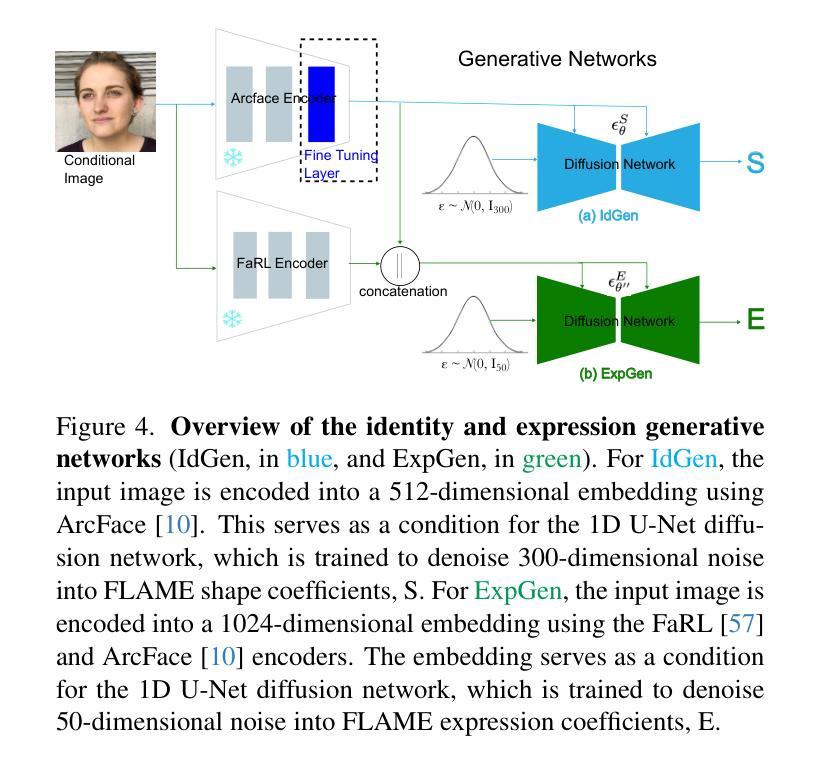
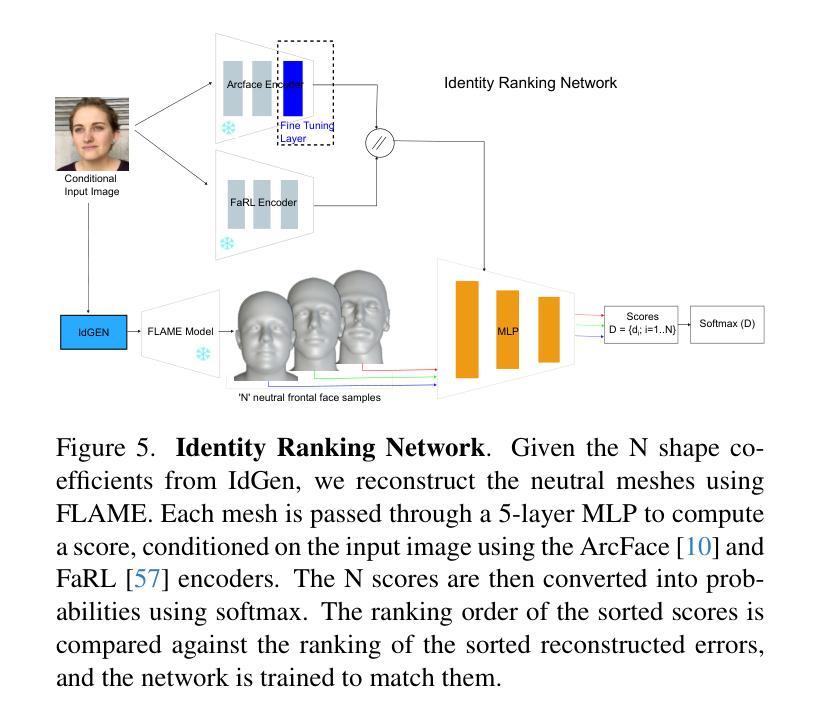
OFER: Occluded Face Expression Reconstruction
Authors:Pratheba Selvaraju, Victoria Fernandez Abrevaya, Timo Bolkart, Rick Akkerman, Tianyu Ding, Faezeh Amjadi, Ilya Zharkov
Reconstructing 3D face models from a single image is an inherently ill-posed problem, which becomes even more challenging in the presence of occlusions. In addition to fewer available observations, occlusions introduce an extra source of ambiguity where multiple reconstructions can be equally valid. Despite the ubiquity of the problem, very few methods address its multi-hypothesis nature. In this paper we introduce OFER, a novel approach for single-image 3D face reconstruction that can generate plausible, diverse, and expressive 3D faces, even under strong occlusions. Specifically, we train two diffusion models to generate the shape and expression coefficients of a face parametric model, conditioned on the input image. This approach captures the multi-modal nature of the problem, generating a distribution of solutions as output. However, to maintain consistency across diverse expressions, the challenge is to select the best matching shape. To achieve this, we propose a novel ranking mechanism that sorts the outputs of the shape diffusion network based on predicted shape accuracy scores. We evaluate our method using standard benchmarks and introduce CO-545, a new protocol and dataset designed to assess the accuracy of expressive faces under occlusion. Our results show improved performance over occlusion-based methods, while also enabling the generation of diverse expressions for a given image.
从单幅图像重建3D人脸模型是一个本质上不适定的问题,在存在遮挡的情况下,这个问题变得更加具有挑战性。除了可用的观察数据较少之外,遮挡引入了额外的模糊性来源,其中多种重建可能是同样有效的。尽管这个问题普遍存在,但很少有方法解决其多假设性质。在本文中,我们介绍了OFER,这是一种用于单图像3D人脸重建的新方法,可以生成合理、多样、富有表现力的3D人脸,即使在强遮挡下也是如此。具体来说,我们训练了两个扩散模型来生成人脸参数模型的形状和表情系数,以输入图像为条件。这种方法捕捉了问题的多模态性质,生成一系列解决方案作为输出。然而,为了保持各种表情的一致性,挑战在于选择最佳匹配的形状。为了实现这一点,我们提出了一种新的排名机制,根据预测的形状准确度得分对形状扩散网络的输出进行排序。我们使用标准基准对我们的方法进行了评估,并引入了CO-545,这是一个新的协议和数据集,旨在评估遮挡下表情脸的准确性。我们的结果显示了在基于遮挡的方法上的性能提升,同时为给定图像生成了多样化的表情。
论文及项目相关链接
Summary
本文介绍了一种名为OFER的新型单图像三维面部重建方法,该方法能够生成逼真的、多样化的、富有表现力的三维面部模型,即使在强遮挡条件下也能如此。通过训练两个扩散模型来生成面部参数模型的形状和表情系数,以输入图像为条件。该方法能够捕捉问题的多模态性质,生成解决方案的分布。为了保持各种表情的一致性,挑战在于选择最佳匹配的形状。为此,提出了一种新的排序机制,根据预测的准确形状分数对形状扩散网络的输出进行排序。使用标准基准进行了评估。结果显示与遮挡的方法相比具有更高的性能,并能够在给定的图像上生成多种表情。
Key Takeaways
- OFER是一种用于从单图像进行三维面部重建的方法,能够在遮挡条件下生成逼真、多样化和富有表现力的三维面部模型。
- 该方法通过训练两个扩散模型来生成面部参数模型的形状和表情系数,以输入图像为条件,捕捉问题的多模态性质。
- 为了保持各种表情的一致性,提出了一个新颖的排序机制来根据预测的准确形状分数对形状扩散网络的输出进行排序。
- 该方法在标准基准上的评估表现出色,并引入了一个新的协议和数据集CO-545来评估遮挡条件下的表情准确性。
点此查看论文截图



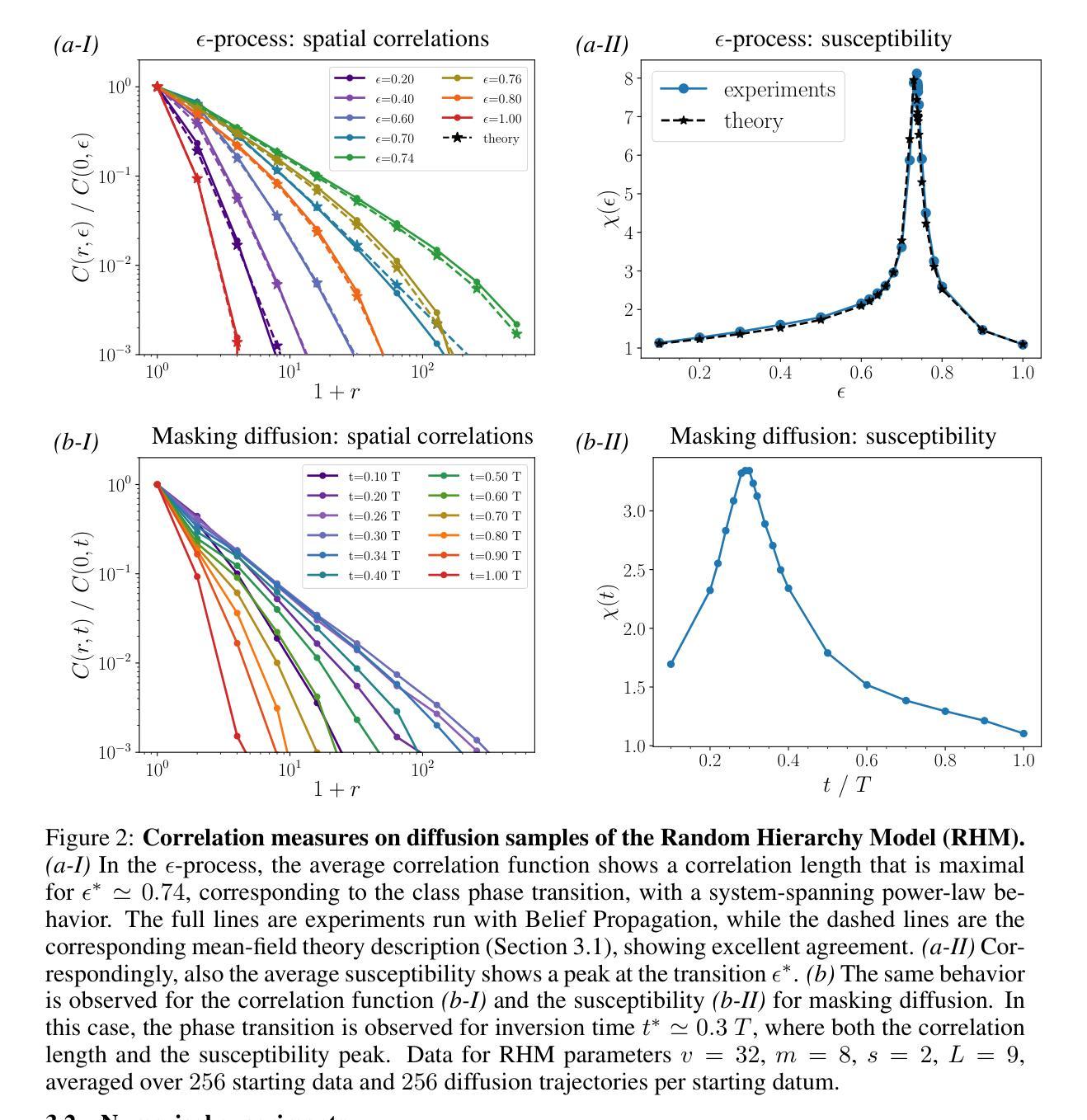
Probing the Latent Hierarchical Structure of Data via Diffusion Models
Authors:Antonio Sclocchi, Alessandro Favero, Noam Itzhak Levi, Matthieu Wyart
High-dimensional data must be highly structured to be learnable. Although the compositional and hierarchical nature of data is often put forward to explain learnability, quantitative measurements establishing these properties are scarce. Likewise, accessing the latent variables underlying such a data structure remains a challenge. In this work, we show that forward-backward experiments in diffusion-based models, where data is noised and then denoised to generate new samples, are a promising tool to probe the latent structure of data. We predict in simple hierarchical models that, in this process, changes in data occur by correlated chunks, with a length scale that diverges at a noise level where a phase transition is known to take place. Remarkably, we confirm this prediction in both text and image datasets using state-of-the-art diffusion models. Our results show how latent variable changes manifest in the data and establish how to measure these effects in real data using diffusion models.
高维数据必须高度结构化才能进行学习。虽然数据的组合和分层性质经常被用来解释学习性,但是建立这些属性的定量测量却很少见。同样,访问这种数据结构背后的潜在变量仍然是一个挑战。在这项工作中,我们展示了基于扩散模型的正向反向实验,其中数据被加入噪声然后再去噪声以生成新样本,是探索数据潜在结构的有前途的工具。我们在简单的分层模型中预测,在此过程中,数据的变化会以相关块的形式发生,长度尺度会在一个已知发生相变的噪声水平处发散。值得注意的是,我们在文本和图像数据集上都使用最先进的扩散模型证实了这一预测。我们的结果展示了潜在变量变化如何在数据中表现出来,并建立了如何使用扩散模型在真实数据中测量这些影响的方法。
论文及项目相关链接
PDF 10 pages, 6 figures
Summary
本文指出高维数据需要高度结构化才能进行学习。虽然数据的组合和层次结构常被用来解释其可学习性,但很少有定量测量来验证这些属性。此外,访问这些数据结构背后的潜在变量也是一个挑战。本研究展示了基于扩散的模型中的正向反向实验是探索数据潜在结构的有前途的工具。我们预测在简单层次模型中,数据在此过程中会按相关块发生变化,长度尺度会在噪声水平处发散,此处已知会发生相变。令人惊讶的是,我们在文本和图像数据集中使用最先进的扩散模型证实了这一预测。本研究展示了潜在变量如何在数据中发生变化,并建立了如何在真实数据中使用扩散模型测量这些效应的方法。
Key Takeaways
- 高维数据需要高度结构化以便学习。
- 数据的组合和层次结构对于解释其可学习性很重要,但缺乏定量测量。
- 访问数据结构的潜在变量是一个挑战。
- 扩散模型的“正向反向实验”有助于探索数据的潜在结构。
- 在简单层次模型中,数据在特定噪声水平下会发生相变,并按相关块变化。这一预测在文本和图像数据集中得到证实。
- 研究展示了潜在变量如何在数据中发生变化。
点此查看论文截图

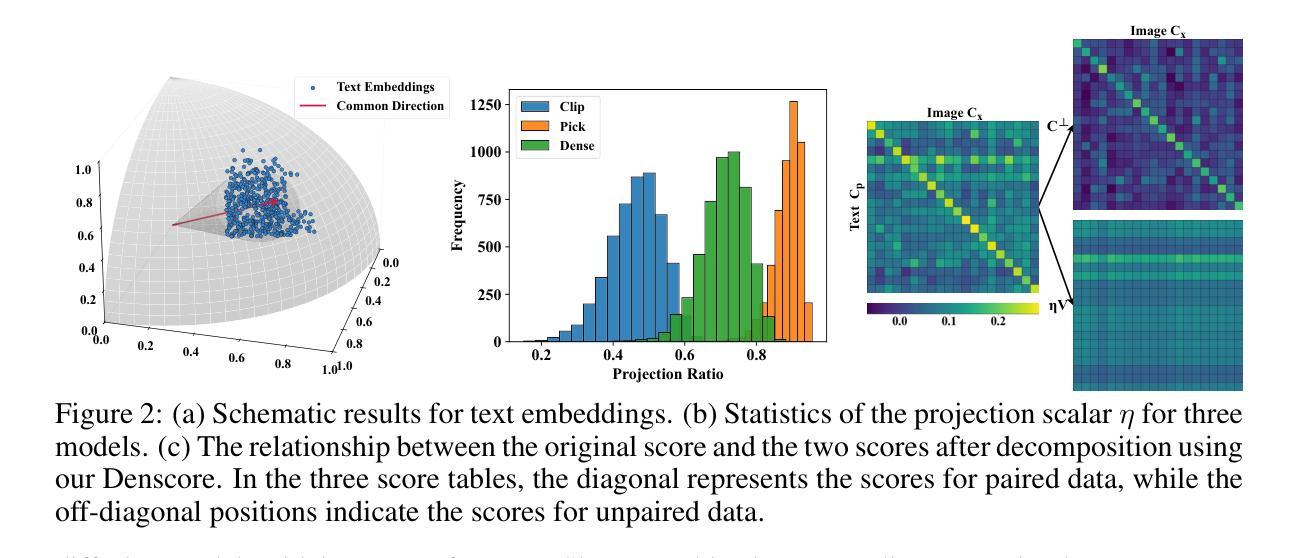
Improving Long-Text Alignment for Text-to-Image Diffusion Models
Authors:Luping Liu, Chao Du, Tianyu Pang, Zehan Wang, Chongxuan Li, Dong Xu
The rapid advancement of text-to-image (T2I) diffusion models has enabled them to generate unprecedented results from given texts. However, as text inputs become longer, existing encoding methods like CLIP face limitations, and aligning the generated images with long texts becomes challenging. To tackle these issues, we propose LongAlign, which includes a segment-level encoding method for processing long texts and a decomposed preference optimization method for effective alignment training. For segment-level encoding, long texts are divided into multiple segments and processed separately. This method overcomes the maximum input length limits of pretrained encoding models. For preference optimization, we provide decomposed CLIP-based preference models to fine-tune diffusion models. Specifically, to utilize CLIP-based preference models for T2I alignment, we delve into their scoring mechanisms and find that the preference scores can be decomposed into two components: a text-relevant part that measures T2I alignment and a text-irrelevant part that assesses other visual aspects of human preference. Additionally, we find that the text-irrelevant part contributes to a common overfitting problem during fine-tuning. To address this, we propose a reweighting strategy that assigns different weights to these two components, thereby reducing overfitting and enhancing alignment. After fine-tuning $512 \times 512$ Stable Diffusion (SD) v1.5 for about 20 hours using our method, the fine-tuned SD outperforms stronger foundation models in T2I alignment, such as PixArt-$\alpha$ and Kandinsky v2.2. The code is available at https://github.com/luping-liu/LongAlign.
文本到图像(T2I)扩散模型的快速发展使其能够根据给定文本生成前所未有的结果。然而,随着文本输入的加长,现有的编码方法(如CLIP)面临局限,将生成的图像与长文本对齐变得具有挑战性。为了解决这些问题,我们提出了LongAlign方法,它包括一种用于处理长文本的片段级编码方法和一种有效的对齐训练分解偏好优化方法。对于片段级编码,长文本被分割成多个片段并分别进行处理。这种方法克服了预训练编码模型的最大输入长度限制。对于偏好优化,我们提供了基于CLIP的偏好模型来微调扩散模型。具体来说,为了将CLIP基于的偏好模型用于T2I对齐,我们深入研究了其评分机制,并发现偏好分数可以分解为两个部分:一个与文本相关的部分,用于衡量T2I对齐情况;另一个与文本无关的部分,用于评估人类偏好的其他视觉方面。此外,我们发现与文本无关的部分会导致微调过程中的常见过拟合问题。针对这一问题,我们提出了一种重新加权策略,为这两个部分分配不同的权重,从而减少过拟合并增强对齐效果。使用我们的方法对$512 \times 512$的Stable Diffusion(SD)v1.5微调约20小时后,经过微调的SD在T2I对齐方面的表现超过了更强的基础模型,如PixArt-$\alpha$和Kandinsky v2.2。代码可在https://github.com/luping-liu/LongAlign找到。
论文及项目相关链接
Summary
文本到图像(T2I)扩散模型的快速发展为给定文本生成图像提供了前所未有的结果。然而,随着文本输入的增长,现有的编码方法如CLIP面临挑战,难以将生成的图像与长文本对齐。为此,我们提出LongAlign方法,包括分段级编码和分解偏好优化。分段编码克服预训练编码模型的最大输入长度限制;分解偏好优化则通过提供分解的CLIP偏好模型来微调扩散模型。我们发现CLIP偏好得分可分解为衡量T2I对齐的文本相关部分和评估人类偏好其他视觉方面的文本不相关部分。为解决文本不相关部分导致的过拟合问题,我们提出重新加权策略,减少过拟合,提高对齐效果。使用LongAlign方法微调Stable Diffusion约20小时后,其T2I对齐效果超过更强基准模型,如PixArt-α和Kandinsky v2.2。
Key Takeaways
- 文本到图像(T2I)扩散模型能基于给定文本生成图像,且效果前所未有。
- 随着文本输入增长,现有编码方法如CLIP在处理长文本与图像对齐时面临挑战。
- LongAlign方法包括分段级编码和分解偏好优化,以解决这些挑战。
- 分段级编码克服预训练编码模型的最大输入长度限制。
- 分解偏好优化利用CLIP偏好模型微调扩散模型,提高其T2I对齐效果。
- CLIP偏好得分可分解为文本相关和文本不相关两部分,其中文本不相关部分可能导致过拟合问题。
- 通过重新加权策略,LongAlign方法减少过拟合,提高图像与文本的对齐效果,且在T2I对齐任务中表现超越某些基准模型。
点此查看论文截图



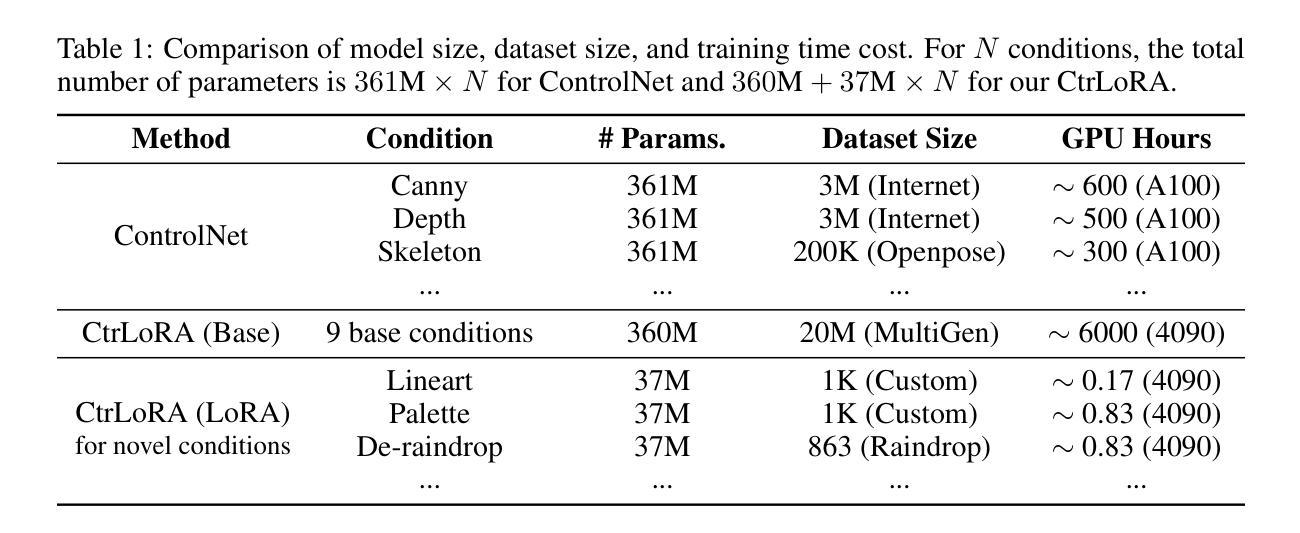
CtrLoRA: An Extensible and Efficient Framework for Controllable Image Generation
Authors:Yifeng Xu, Zhenliang He, Shiguang Shan, Xilin Chen
Recently, large-scale diffusion models have made impressive progress in text-to-image (T2I) generation. To further equip these T2I models with fine-grained spatial control, approaches like ControlNet introduce an extra network that learns to follow a condition image. However, for every single condition type, ControlNet requires independent training on millions of data pairs with hundreds of GPU hours, which is quite expensive and makes it challenging for ordinary users to explore and develop new types of conditions. To address this problem, we propose the CtrLoRA framework, which trains a Base ControlNet to learn the common knowledge of image-to-image generation from multiple base conditions, along with condition-specific LoRAs to capture distinct characteristics of each condition. Utilizing our pretrained Base ControlNet, users can easily adapt it to new conditions, requiring as few as 1,000 data pairs and less than one hour of single-GPU training to obtain satisfactory results in most scenarios. Moreover, our CtrLoRA reduces the learnable parameters by 90% compared to ControlNet, significantly lowering the threshold to distribute and deploy the model weights. Extensive experiments on various types of conditions demonstrate the efficiency and effectiveness of our method. Codes and model weights will be released at https://github.com/xyfJASON/ctrlora.
最近,大规模扩散模型在文本到图像(T2I)生成方面取得了令人印象深刻的进展。为了进一步增强这些T2I模型的细粒度空间控制力,ControlNet等方法引入了一个额外的网络,学习跟随条件图像。然而,对于每一种条件类型,ControlNet需要在数百万对数据对上独立训练,并需要数百小时的GPU时间,这相当昂贵,使得普通用户难以探索和开发新的条件类型。为了解决这个问题,我们提出了CtrLoRA框架,该框架训练基础ControlNet来学习图像到图像生成的通用知识,从多种基础条件中学习,以及特定条件的LoRAs来捕捉每个条件的独特特征。利用我们预训练的基础ControlNet,用户可以轻松适应新条件,在大多数情况下,仅需1000对数据对和不到一个小时的单GPU训练即可获得令人满意的结果。此外,与ControlNet相比,我们的CtrLoRA减少了90%的可学习参数,大大降低了分布和部署模型权重门槛。对各种条件的广泛实验证明了我们方法的高效性和有效性。代码和模型权重将在https://github.com/xyfJASON/ctrlora发布。
论文及项目相关链接
PDF ICLR 2025. Code: https://github.com/xyfJASON/ctrlora
Summary
大型扩散模型在文本转图像生成领域取得显著进展。为解决现有模型如ControlNet在空间控制上的精细粒度问题,我们提出CtrLoRA框架,通过训练基础ControlNet学习多种基础条件下的图像到图像的生成通用知识,以及针对特定条件的LoRA来捕捉每个条件的独特特征。这使得用户能够轻松适应新条件,只需少量数据对和较短的单GPU训练时间即可获得满意结果。与ControlNet相比,CtrLoRA显著减少了可学习参数,降低了模型权重分布和部署的门槛。实验证明,我们的方法高效且有效。代码和模型权重将在[网址]发布。
Key Takeaways
- 大型扩散模型在文本转图像生成领域取得显著进展。
- ControlNet需要独立训练大量数据对,对于普通用户来说探索和开发新条件具有挑战性。
- CtrLoRA框架通过训练基础ControlNet学习通用知识,并通过条件特定的LoRAs捕捉每个条件的独特特征来解决这一问题。
- 用户可以轻松适应新条件,只需少量数据对和较短的单GPU训练时间即可获得满意结果。
- CtrLoRA显著减少了与ControlNet相比的可学习参数。
- CtrLoRA降低了模型权重分布和部署的门槛。
点此查看论文截图


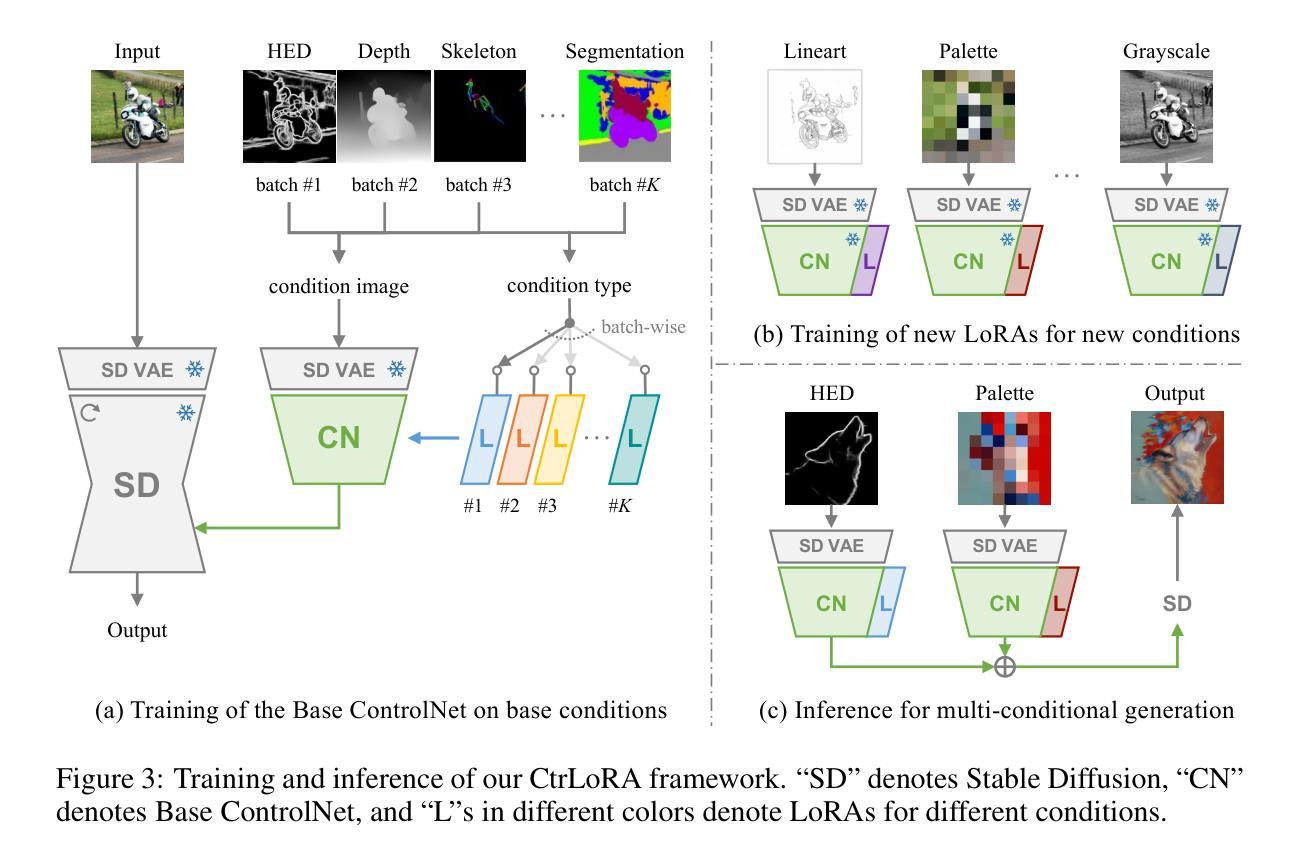
ViBiDSampler: Enhancing Video Interpolation Using Bidirectional Diffusion Sampler
Authors:Serin Yang, Taesung Kwon, Jong Chul Ye
Recent progress in large-scale text-to-video (T2V) and image-to-video (I2V) diffusion models has greatly enhanced video generation, especially in terms of keyframe interpolation. However, current image-to-video diffusion models, while powerful in generating videos from a single conditioning frame, need adaptation for two-frame (start & end) conditioned generation, which is essential for effective bounded interpolation. Unfortunately, existing approaches that fuse temporally forward and backward paths in parallel often suffer from off-manifold issues, leading to artifacts or requiring multiple iterative re-noising steps. In this work, we introduce a novel, bidirectional sampling strategy to address these off-manifold issues without requiring extensive re-noising or fine-tuning. Our method employs sequential sampling along both forward and backward paths, conditioned on the start and end frames, respectively, ensuring more coherent and on-manifold generation of intermediate frames. Additionally, we incorporate advanced guidance techniques, CFG++ and DDS, to further enhance the interpolation process. By integrating these, our method achieves state-of-the-art performance, efficiently generating high-quality, smooth videos between keyframes. On a single 3090 GPU, our method can interpolate 25 frames at 1024 x 576 resolution in just 195 seconds, establishing it as a leading solution for keyframe interpolation.
近期大规模文本到视频(T2V)和图像到视频(I2V)扩散模型的进展极大地推动了视频生成,尤其在关键帧插值方面。然而,当前的图像到视频扩散模型虽然能够从单个条件帧生成视频,但需要进行两帧(开始和结束)条件生成适应,这对于有效的有界插值至关重要。不幸的是,现有方法经常在并行融合时间正向和反向路径时遇到流形外问题,导致出现伪影或需要多次迭代去噪步骤。在这项工作中,我们引入了一种新的双向采样策略来解决这些流形外问题,而无需进行广泛的重噪声处理或微调。我们的方法沿着正向和反向路径进行顺序采样,分别以开始帧和结束帧为条件,确保生成中间帧更加连贯且在流形内。此外,我们还结合了先进的引导技术CFG++和DDS来进一步增强插值过程。通过整合这些技术,我们的方法实现了最先进的性能,能够高效生成高质量、平滑的视频。在单个3090 GPU上,我们的方法可以在仅195秒内插值出分辨率为1024 x 576的25帧,使其成为关键帧插值的领先解决方案。
论文及项目相关链接
PDF ICLR 2025; Project page: https://vibidsampler.github.io/
Summary
近期文本到视频(T2V)和图像到视频(I2V)扩散模型的进展极大促进了视频生成,特别是在关键帧插值方面。然而,当前图像到视频的扩散模型虽然能从单个条件帧生成视频,但在两帧(开始和结束)条件下的生成仍需要改进。本文引入了一种新的双向采样策略,解决了离流问题,提高了关键帧插值的质量,不需要大量重新去噪或微调。方法沿正向和反向路径进行顺序采样,分别以开始和结束帧为条件,保证中间帧的生成更加连贯且在流形上。结合先进的引导技术CFG++和DDS,进一步提高了插值过程的效果。此方法达到了领先水平,能在单个3090 GPU上高效生成高质量、平滑的视频。
Key Takeaways
- 大型文本到视频和图像到视频扩散模型的最新进展已显著提高视频生成能力,特别是在关键帧插值方面。
- 当前图像到视频扩散模型需要在两帧(开始和结束)条件下进行生成改进。
- 引入新的双向采样策略解决离流问题,提高关键帧插值质量。
- 顺序采样沿正向和反向路径进行,以开始和结束帧为条件,确保中间帧的连贯性和在流形上。
- 结合先进的引导技术CFG++和DDS增强插值过程。
- 方法达到领先水平,高效生成高质量、平滑的视频。
点此查看论文截图

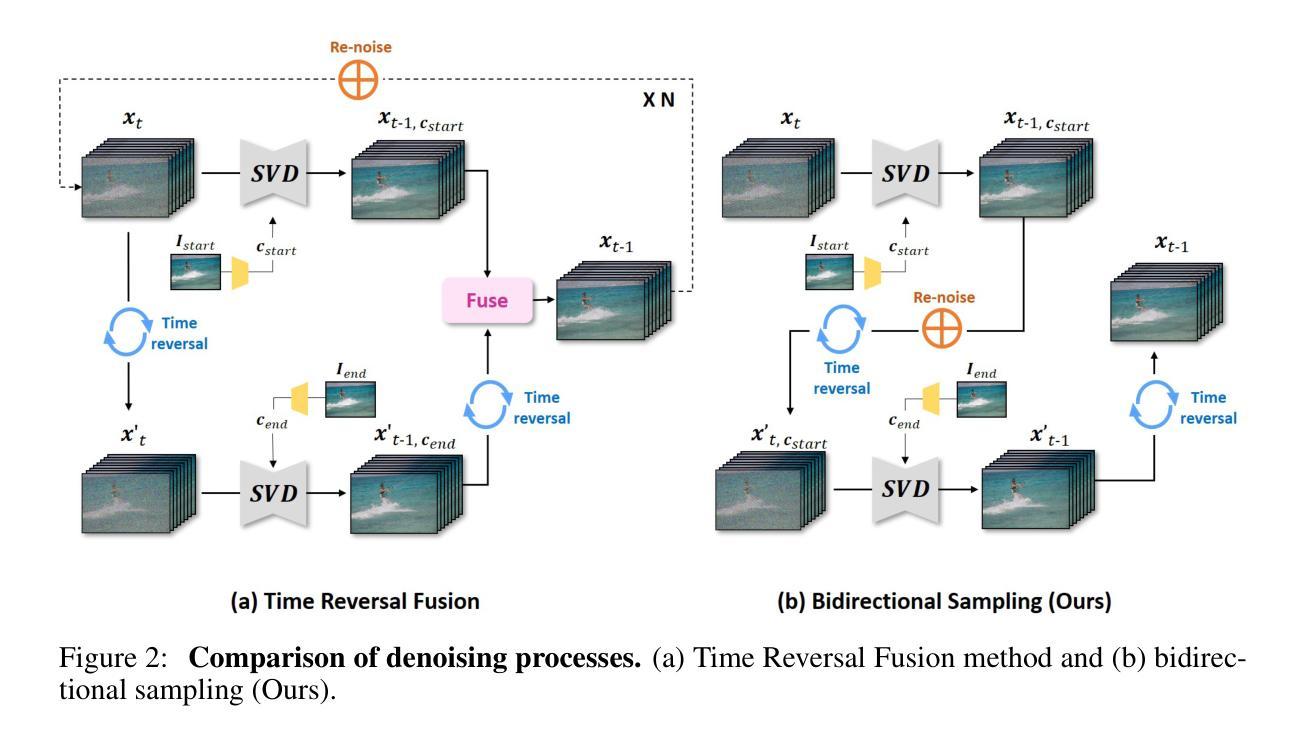

Image Watermarks are Removable Using Controllable Regeneration from Clean Noise
Authors:Yepeng Liu, Yiren Song, Hai Ci, Yu Zhang, Haofan Wang, Mike Zheng Shou, Yuheng Bu
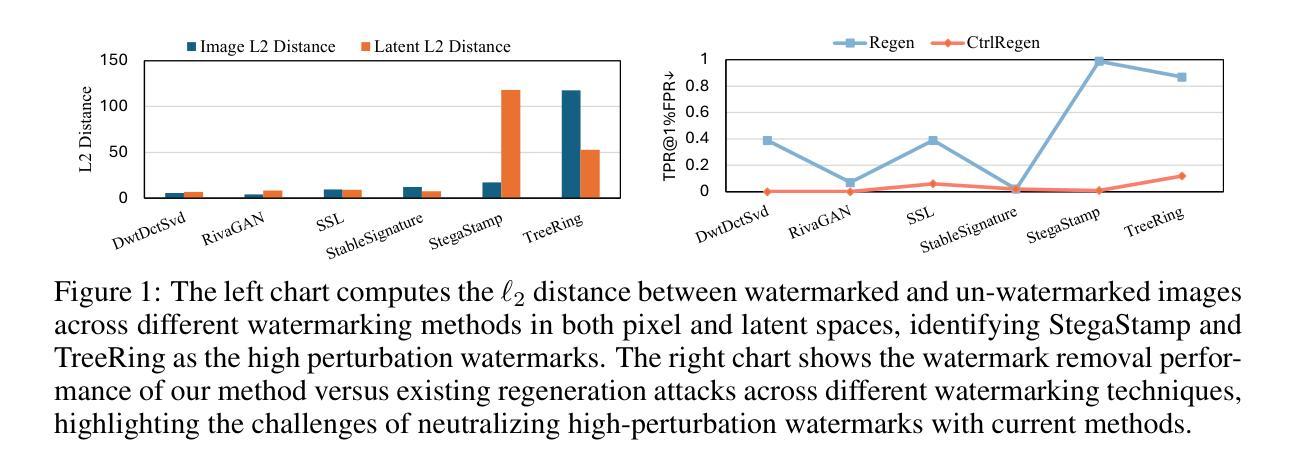
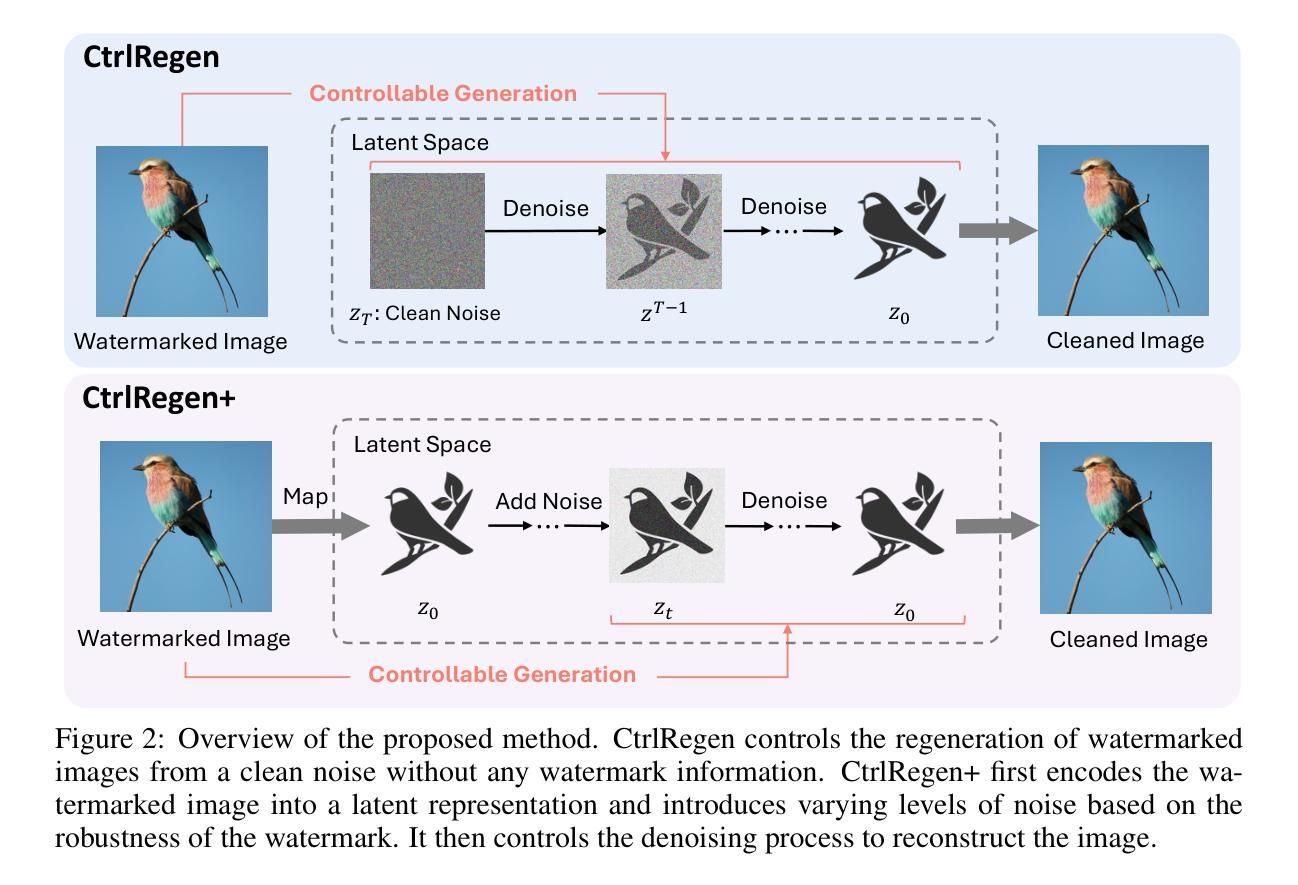
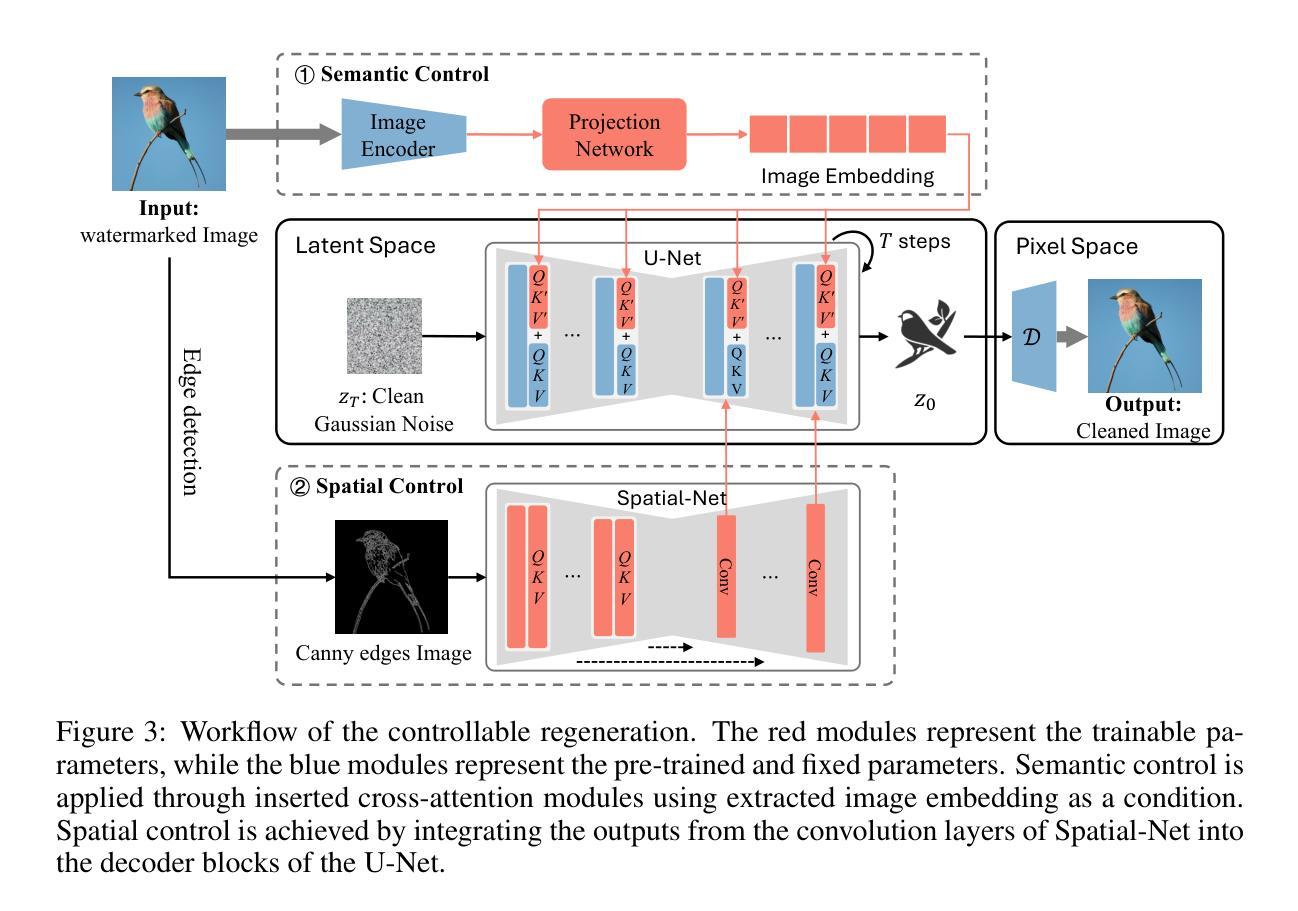
Image watermark techniques provide an effective way to assert ownership, deter misuse, and trace content sources, which has become increasingly essential in the era of large generative models. A critical attribute of watermark techniques is their robustness against various manipulations. In this paper, we introduce a watermark removal approach capable of effectively nullifying state-of-the-art watermarking techniques. Our primary insight involves regenerating the watermarked image starting from a clean Gaussian noise via a controllable diffusion model, utilizing the extracted semantic and spatial features from the watermarked image. The semantic control adapter and the spatial control network are specifically trained to control the denoising process towards ensuring image quality and enhancing consistency between the cleaned image and the original watermarked image. To achieve a smooth trade-off between watermark removal performance and image consistency, we further propose an adjustable and controllable regeneration scheme. This scheme adds varying numbers of noise steps to the latent representation of the watermarked image, followed by a controlled denoising process starting from this noisy latent representation. As the number of noise steps increases, the latent representation progressively approaches clean Gaussian noise, facilitating the desired trade-off. We apply our watermark removal methods across various watermarking techniques, and the results demonstrate that our methods offer superior visual consistency/quality and enhanced watermark removal performance compared to existing regeneration approaches. Our code is available at https://github.com/yepengliu/CtrlRegen.
图像水印技术为声明所有权、阻止滥用和追踪内容来源提供了一种有效途径,这在大型生成模型时代变得日益重要。水印技术的关键属性是它们对各种操作的鲁棒性。在本文中,我们介绍了一种能够有效消除最先进水印技术的水印去除方法。我们的主要见解是通过可控的扩散模型,从干净的高斯噪声开始重新生成水印图像,利用从水印图像中提取的语义和空间特征。语义控制适配器和空间控制网络经过专门训练,以控制去噪过程,确保图像质量,并增强清洁图像与原始水印图像之间的一致性。为了实现水印去除性能和图像一致性之间的平稳权衡,我们进一步提出了可调可控的再生方案。该方案向水印图像的潜在表示添加不同数量的噪声步骤,然后从这个噪声的潜在表示开始进行控制去噪过程。随着噪声步骤数量的增加,潜在表示逐渐接近干净的高斯噪声,实现了所需的权衡。我们在各种水印技术中应用了我们的水印去除方法,结果表明,与现有的再生方法相比,我们的方法在视觉一致性/质量和水印去除性能方面表现出色。我们的代码可在https://github.com/yepengliu/CtrlRegen找到。
论文及项目相关链接
PDF ICLR2025
Summary
针对大型生成模型时代版权保护的需求,本文提出了一种高效的水印移除方法。该方法基于可控的扩散模型,从清洁的高斯噪声开始重新生成水印图像,利用提取的语义和空间特征进行训练和优化。通过调整噪声步数,实现了水印移除与图像一致性之间的平衡。相较于现有方法,本文提出的方法在视觉一致性和水印移除性能上表现更优秀。
Key Takeaways
- 图像水印技术的重要性在于对内容的溯源、防止误用和主张所有权。
- 本文提出了一种新的水印移除方法,基于可控的扩散模型从清洁的高斯噪声重新生成水印图像。
- 通过语义控制适配器和空间控制网络,确保图像质量和与原始水印图像的一致性。
- 提出了一种可调整的控制再生方案,通过增加噪声步数实现水印移除与图像一致性之间的平衡。
- 该方法在各种水印技术上的应用均取得了良好效果,相较于现有方法具有优越的性能。
- 该研究的代码已公开在GitHub上。
点此查看论文截图

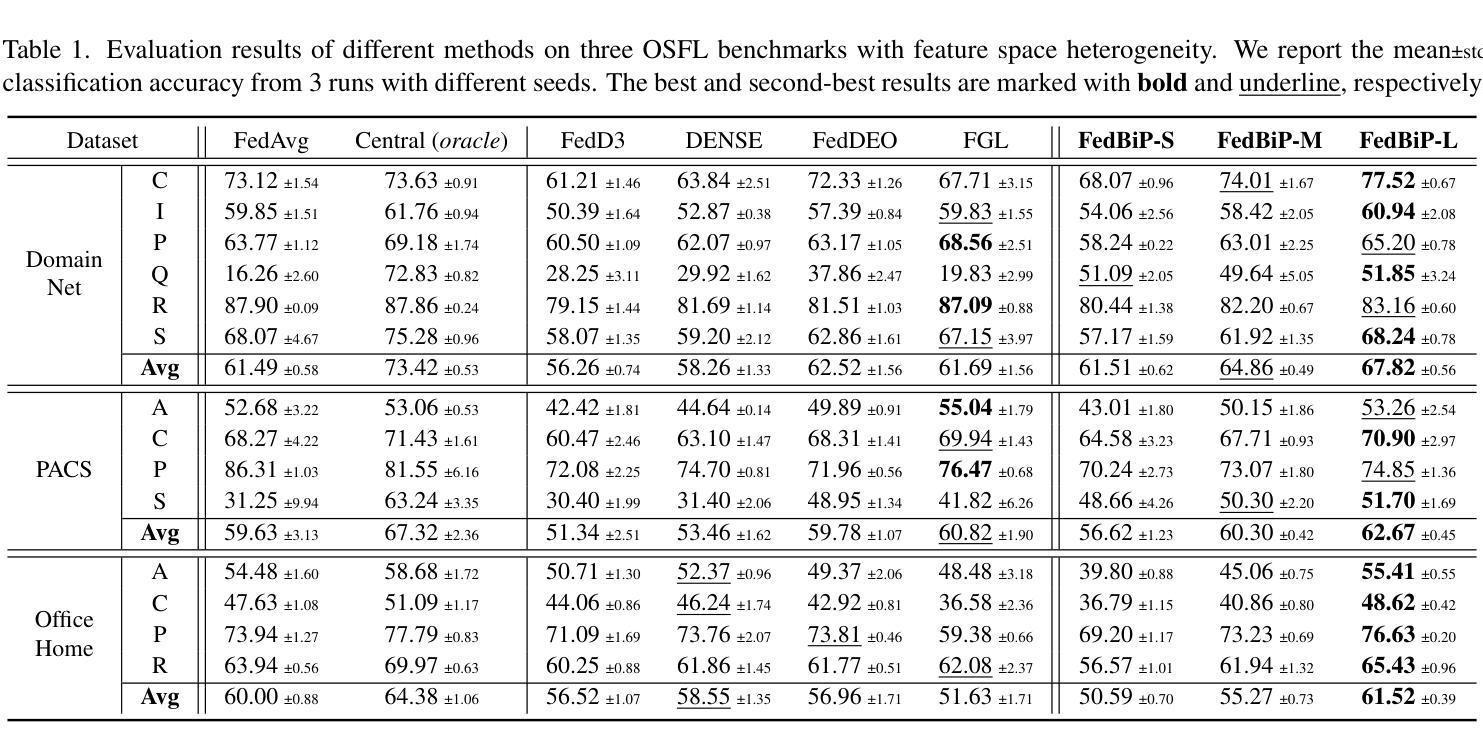
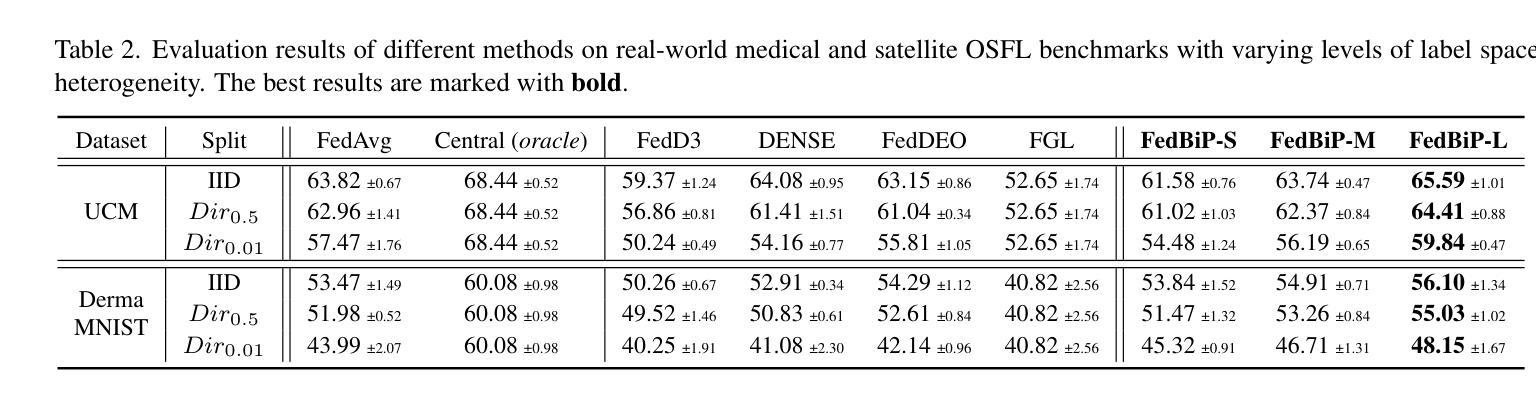
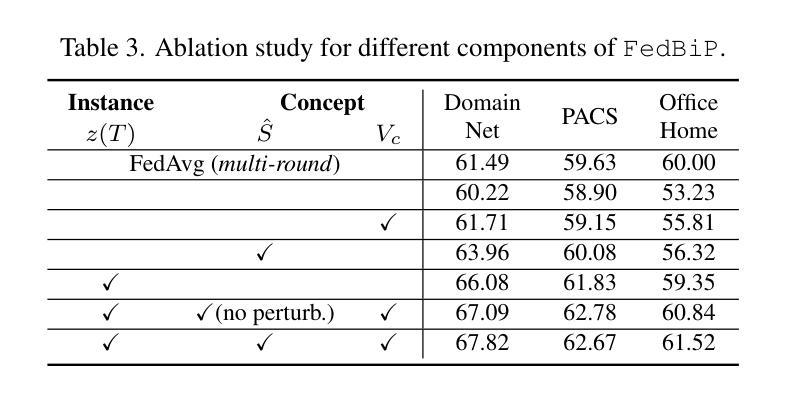
FedBiP: Heterogeneous One-Shot Federated Learning with Personalized Latent Diffusion Models
Authors:Haokun Chen, Hang Li, Yao Zhang, Jinhe Bi, Gengyuan Zhang, Yueqi Zhang, Philip Torr, Jindong Gu, Denis Krompass, Volker Tresp
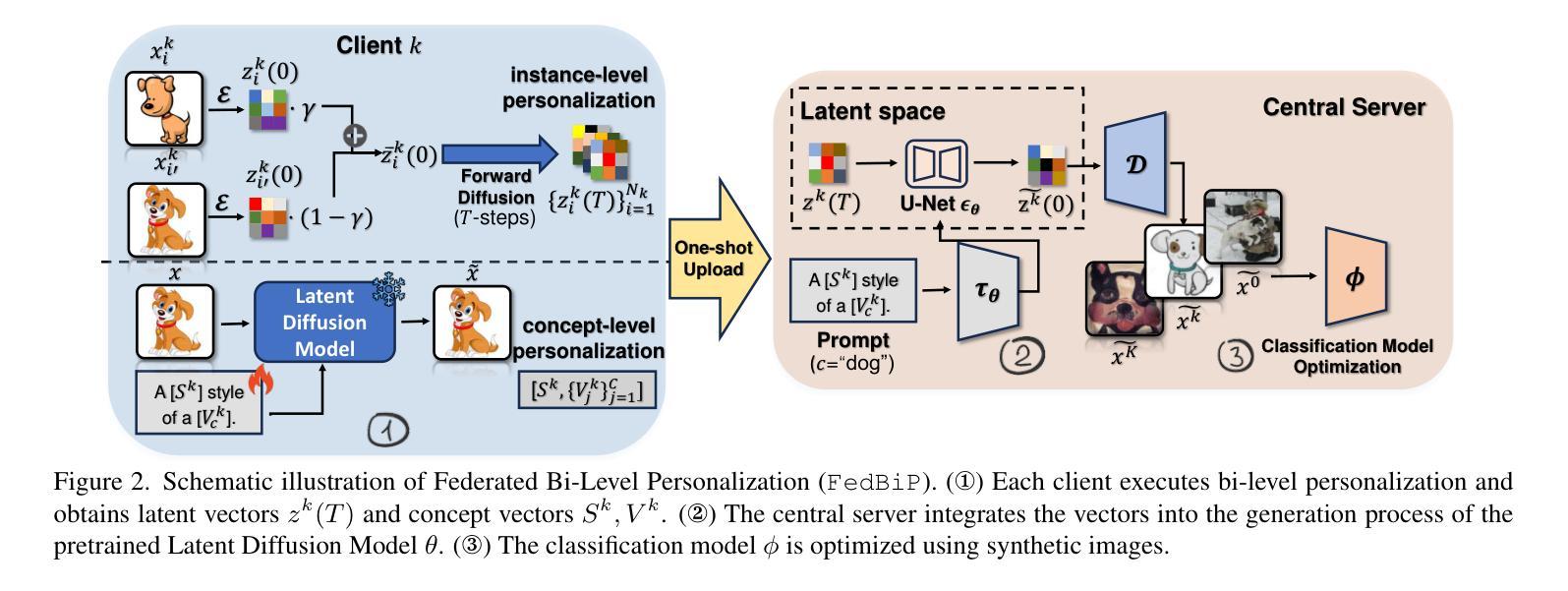
One-Shot Federated Learning (OSFL), a special decentralized machine learning paradigm, has recently gained significant attention. OSFL requires only a single round of client data or model upload, which reduces communication costs and mitigates privacy threats compared to traditional FL. Despite these promising prospects, existing methods face challenges due to client data heterogeneity and limited data quantity when applied to real-world OSFL systems. Recently, Latent Diffusion Models (LDM) have shown remarkable advancements in synthesizing high-quality images through pretraining on large-scale datasets, thereby presenting a potential solution to overcome these issues. However, directly applying pretrained LDM to heterogeneous OSFL results in significant distribution shifts in synthetic data, leading to performance degradation in classification models trained on such data. This issue is particularly pronounced in rare domains, such as medical imaging, which are underrepresented in LDM’s pretraining data. To address this challenge, we propose Federated Bi-Level Personalization (FedBiP), which personalizes the pretrained LDM at both instance-level and concept-level. Hereby, FedBiP synthesizes images following the client’s local data distribution without compromising the privacy regulations. FedBiP is also the first approach to simultaneously address feature space heterogeneity and client data scarcity in OSFL. Our method is validated through extensive experiments on three OSFL benchmarks with feature space heterogeneity, as well as on challenging medical and satellite image datasets with label heterogeneity. The results demonstrate the effectiveness of FedBiP, which substantially outperforms other OSFL methods.
一次性联邦学习(OSFL)是一种特殊的去中心化机器学习范式,最近引起了广泛的关注。OSFL只需要一轮客户端数据或模型上传,与传统的联邦学习相比,这降低了通信成本并减轻了隐私威胁。尽管前景充满希望,但现有方法在应用于现实世界OSFL系统时,面临着客户数据异质性和数据量有限的挑战。
最近,潜在扩散模型(LDM)在通过大规模数据集进行预训练后,在合成高质量图像方面取得了显著进展,为解决这些问题提供了潜在解决方案。然而,直接将预训练的LDM应用于异质OSFL会导致合成数据分布的重大变化,导致在由此类数据训练的分类模型性能下降。这一问题在LDM预训练数据代表性不足的罕见领域(如医学影像)中尤其严重。
论文及项目相关链接
PDF CVPR 2025
摘要
OSFL(一次联邦学习)是一种特殊的分布式机器学习范式,因仅需一轮客户端数据或模型上传而受到关注。与传统的联邦学习相比,OSFL降低了通信成本并减轻了隐私威胁。然而,现有方法在应用到现实世界OSFL系统时面临诸多挑战,如客户数据异质性和数据量有限等。潜在扩散模型(LDM)在预训练大规模数据集上表现出合成高质量图像的巨大潜力,但直接应用于异质的OSFL会产生显著的分布偏移。针对此问题,本文提出了联邦双层个性化(FedBiP)方法,该方法在实例层面和概念层面对预训练的LDM进行个性化调整。FedBiP能够根据客户端的本地数据分布合成图像,同时遵守隐私规定。此外,FedBiP还是首个同时解决OSFL中的特征空间异质性和客户数据稀缺性的方法。实验结果表明,FedBiP在具有特征空间异质性的三个OSFL基准测试以及具有标签异质性的医疗和卫星图像数据集上表现优异。
关键见解
- OSFL仅需要一轮客户端数据或模型上传,降低了通信成本和隐私威胁。
- LDM在合成高质量图像方面表现出显著优势,但直接应用于异质OSFL会导致性能下降。
- FedBiP旨在解决这一问题,通过个性化预训练的LDM以适应客户端的本地数据分布。
- FedBiP是首个同时解决OSFL中的特征空间异质性和客户数据稀缺性的方法。
- FedBiP在多个基准测试集上表现优异,特别是在具有挑战性的医疗和卫星图像数据集上。
- FedBiP的合成图像遵循隐私规定,满足联邦学习的隐私保护需求。
点此查看论文截图

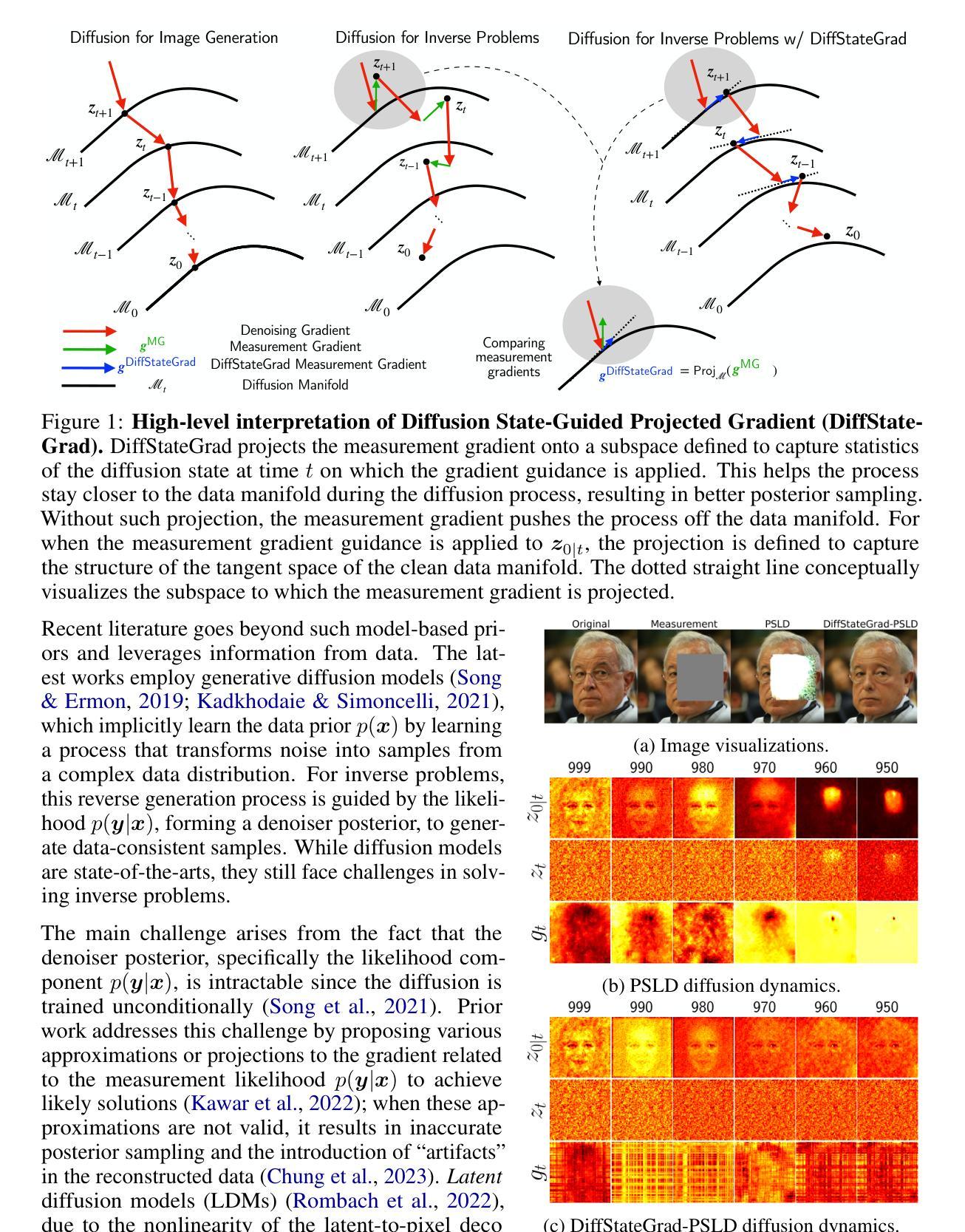
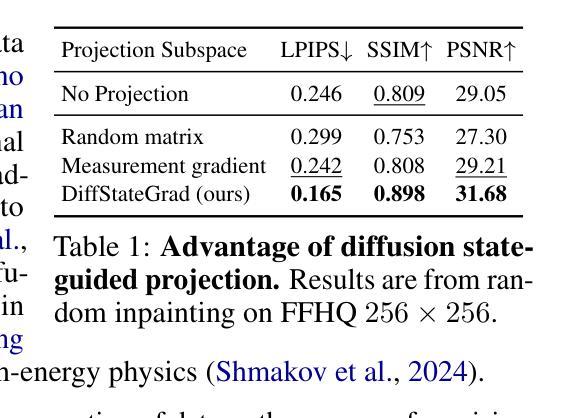
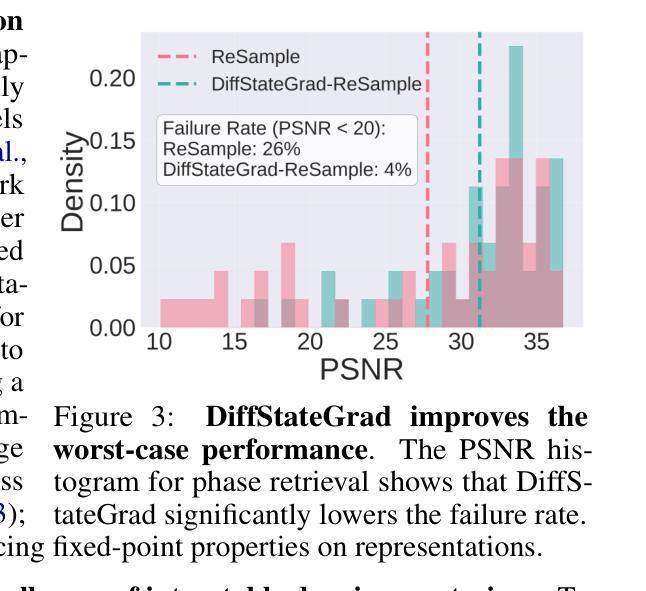
Diffusion State-Guided Projected Gradient for Inverse Problems
Authors:Rayhan Zirvi, Bahareh Tolooshams, Anima Anandkumar
Recent advancements in diffusion models have been effective in learning data priors for solving inverse problems. They leverage diffusion sampling steps for inducing a data prior while using a measurement guidance gradient at each step to impose data consistency. For general inverse problems, approximations are needed when an unconditionally trained diffusion model is used since the measurement likelihood is intractable, leading to inaccurate posterior sampling. In other words, due to their approximations, these methods fail to preserve the generation process on the data manifold defined by the diffusion prior, leading to artifacts in applications such as image restoration. To enhance the performance and robustness of diffusion models in solving inverse problems, we propose Diffusion State-Guided Projected Gradient (DiffStateGrad), which projects the measurement gradient onto a subspace that is a low-rank approximation of an intermediate state of the diffusion process. DiffStateGrad, as a module, can be added to a wide range of diffusion-based inverse solvers to improve the preservation of the diffusion process on the prior manifold and filter out artifact-inducing components. We highlight that DiffStateGrad improves the robustness of diffusion models in terms of the choice of measurement guidance step size and noise while improving the worst-case performance. Finally, we demonstrate that DiffStateGrad improves upon the state-of-the-art on linear and nonlinear image restoration inverse problems. Our code is available at https://github.com/neuraloperator/DiffStateGrad.
最近扩散模型的进展在学习数据先验以解决反问题方面非常有效。他们利用扩散采样步骤来诱导数据先验,同时在每一步使用测量指导梯度来施加数据一致性。对于一般反问题,当使用无条件训练的扩散模型时,需要近似处理,因为测量可能性难以处理,导致后验采样不准确。换句话说,由于这些近似,这些方法无法保留由扩散先验定义的数据流形上的生成过程,导致图像恢复等应用中的伪影。为了提高扩散模型解决反问题的性能和稳健性,我们提出了扩散状态引导投影梯度(DiffStateGrad),它将测量梯度投影到扩散过程中间状态的低秩近似子空间上。DiffStateGrad作为一个模块,可以添加到广泛的基于扩散的反问题求解器中,以提高对先验流形上扩散过程的保留能力,并过滤掉产生伪影的组件。我们强调,DiffStateGrad提高了扩散模型在选择测量指导步长和噪声方面的稳健性,同时提高了最坏情况下的性能。最后,我们证明DiffStateGrad在解决线性和非线性图像恢复反问题上优于现有技术。我们的代码可在[https://github.com/neuraloperator/DiffStateGrad找到。]
论文及项目相关链接
PDF Published as a conference paper at ICLR 2025. RZ and BT have equal contributions
Summary
近期扩散模型在解决反问题方面表现出强大的能力,学习数据先验并利用扩散采样步骤和测量指导梯度。然而,无条件训练的扩散模型在处理反问题时需要使用近似方法,导致测量可能性不可追踪和准确性下降。本文提出了一种新的方法,Diffusion State-Guided Projected Gradient (DiffStateGrad),能够提升扩散模型在解决反问题时的性能和鲁棒性。DiffStateGrad通过将测量梯度投影到扩散过程中间状态的低秩近似子空间,提高了数据流形上的扩散过程保护并过滤掉了导致假象的组件。最后通过实验结果证明,DiffStateGrad在线性和非线性图像修复反问题上达到了先进水平。更多详情可访问GitHub链接。
Key Takeaways
- 扩散模型在解决反问题方面展现出强大的能力,能够通过学习数据先验进行反问题的求解。
- 扩散模型在处理反问题时需要使用近似方法,导致测量可能性的追踪困难并可能导致准确性下降。
- 提出的DiffStateGrad方法通过将测量梯度投影到扩散过程的中间状态子空间,提升了扩散模型在解决反问题时的性能。
- DiffStateGrad作为一种模块,可广泛应用于各种基于扩散的反问题求解器中以改进先验流形的保护性能并过滤掉产生假象的组件。
- DiffStateGrad提高了扩散模型在选择测量指导步骤大小和噪声方面的鲁棒性。
- 实验结果表明,DiffStateGrad在线性和非线性图像修复反问题上优于现有技术。
点此查看论文截图



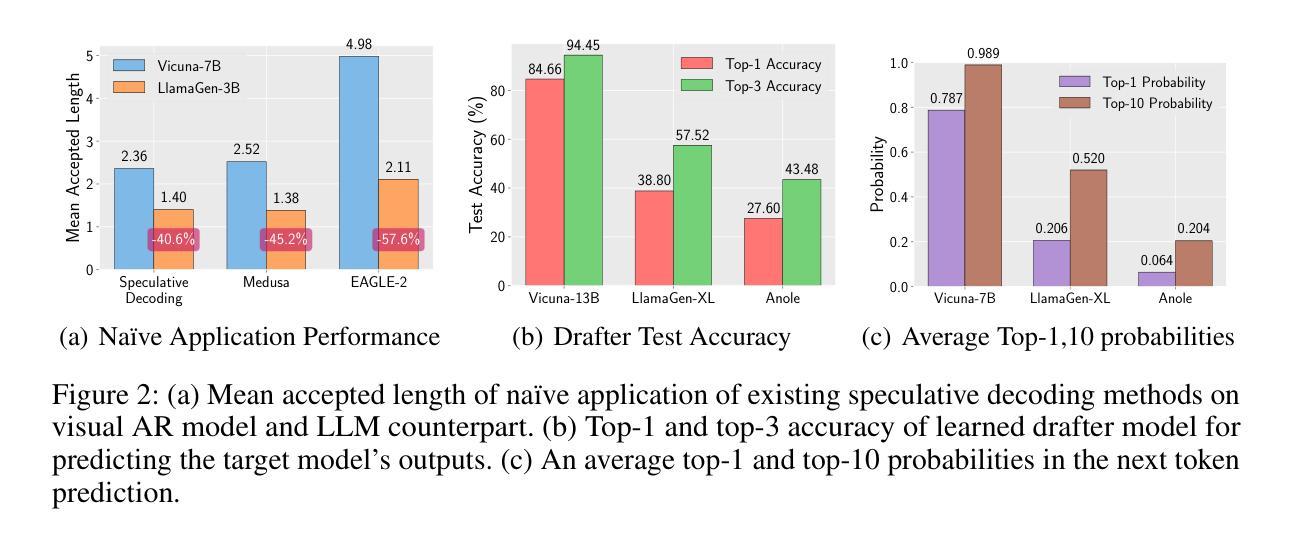
LANTERN: Accelerating Visual Autoregressive Models with Relaxed Speculative Decoding
Authors:Doohyuk Jang, Sihwan Park, June Yong Yang, Yeonsung Jung, Jihun Yun, Souvik Kundu, Sung-Yub Kim, Eunho Yang
Auto-Regressive (AR) models have recently gained prominence in image generation, often matching or even surpassing the performance of diffusion models. However, one major limitation of AR models is their sequential nature, which processes tokens one at a time, slowing down generation compared to models like GANs or diffusion-based methods that operate more efficiently. While speculative decoding has proven effective for accelerating LLMs by generating multiple tokens in a single forward, its application in visual AR models remains largely unexplored. In this work, we identify a challenge in this setting, which we term \textit{token selection ambiguity}, wherein visual AR models frequently assign uniformly low probabilities to tokens, hampering the performance of speculative decoding. To overcome this challenge, we propose a relaxed acceptance condition referred to as LANTERN that leverages the interchangeability of tokens in latent space. This relaxation restores the effectiveness of speculative decoding in visual AR models by enabling more flexible use of candidate tokens that would otherwise be prematurely rejected. Furthermore, by incorporating a total variation distance bound, we ensure that these speed gains are achieved without significantly compromising image quality or semantic coherence. Experimental results demonstrate the efficacy of our method in providing a substantial speed-up over speculative decoding. In specific, compared to a na"ive application of the state-of-the-art speculative decoding, LANTERN increases speed-ups by $\mathbf{1.75}\times$ and $\mathbf{1.82}\times$, as compared to greedy decoding and random sampling, respectively, when applied to LlamaGen, a contemporary visual AR model. The code is publicly available at https://github.com/jadohu/LANTERN.
自回归(AR)模型最近在图像生成领域获得了显著的重要性,其性能通常与扩散模型相匹配甚至更胜一筹。然而,AR模型的一个主要局限性在于它们的顺序性,即它们一次只处理一个标记符号(tokens),与生成对抗网络(GANs)或基于扩散的方法相比,降低了生成效率。尽管推测解码(speculative decoding)已被证明可以通过单次前向生成多个标记符号来加速大型语言模型(LLMs),但其在视觉AR模型中的应用仍鲜有研究。在这项工作中,我们确定了这一设置中的一个挑战,我们称之为“标记符号选择歧义”(token selection ambiguity),其中视觉AR模型经常为标记符号分配统一较低的概率,阻碍了推测解码的性能。为了克服这一挑战,我们提出了一种轻松的接受条件,称为LANTERN,它利用潜在空间中标记符号的可互换性。这种放松恢复了推测解码在视觉AR模型中的有效性,通过更灵活地利用候选标记符号(这些标记符号通常会被过早地拒绝)。此外,通过引入总变差距离界限(total variation distance bound),我们确保了这些速度提升是在不损害图像质量或语义连贯性的前提下实现的。实验结果表明我们的方法对于与推测解码相比具有显著的速度提升效果。具体来说,与对最新推测解码技术的简单应用相比,LANTERN在应用于当代视觉AR模型LlamaGen时,相对于贪心解码和随机采样分别提高了$\mathbf{1.75}\times$和$\mathbf{1.82}\times$的速度。相关代码已公开在https://github.com/jadohu/LANTERN上。
论文及项目相关链接
PDF 30 pages, 13 figures, Accepted to ICLR 2025 (poster)
Summary
近期自回归(AR)模型在图像生成领域受到广泛关注,性能甚至超过了扩散模型。然而,其逐次生成标记的固有特性限制了其生成速度。为加速视觉AR模型,研究者提出投机解码方法,但在实际应用中面临标记选择模糊的问题。为解决此问题,本研究提出一种利用潜在空间中标记可互换性的宽松接受条件(LANTERN)。此方法恢复了视觉AR模型中投机解码的有效性,通过采用标记总变化距离界限确保速度提升不会损害图像质量或语义连贯性。实验结果表明,相较于标准投机解码方法,LANTERN分别提高了1.75倍和1.82倍的加速效果。代码已公开。
Key Takeaways
- 自回归(AR)模型在图像生成中受到重视,但生成速度受限于其逐次生成标记的固有特性。
- 投机解码方法用于加速视觉AR模型,但面临标记选择模糊的挑战。
- LANTERN方法利用潜在空间中标记的可互换性来解决此问题,恢复了投机解码的有效性。
- LANTERN通过采用标记总变化距离界限确保在提高速度的同时不损害图像质量或语义连贯性。
- 实验结果表明,相较于标准投机解码方法,LANTERN显著提高了加速效果。
- 代码已公开供公众使用。
点此查看论文截图



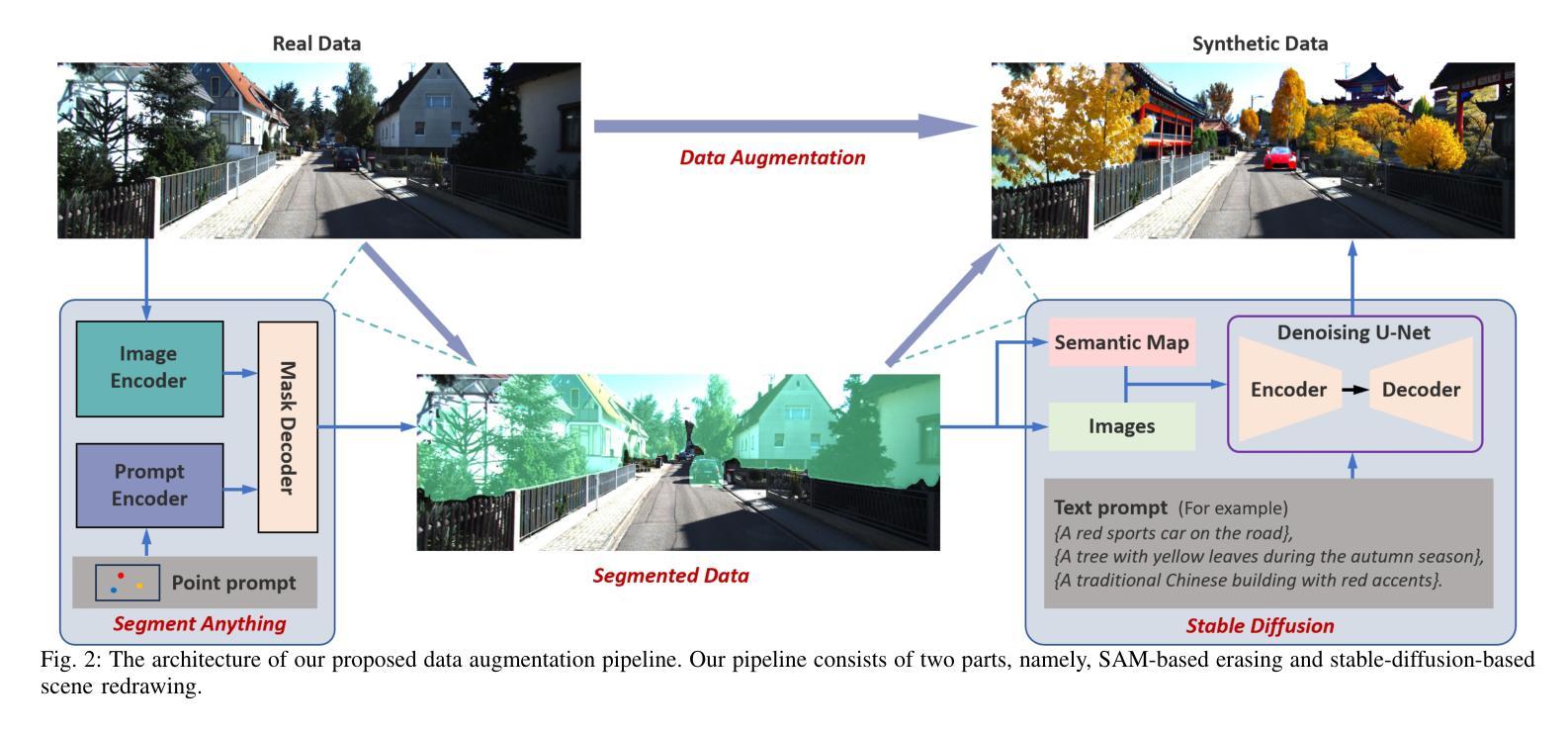
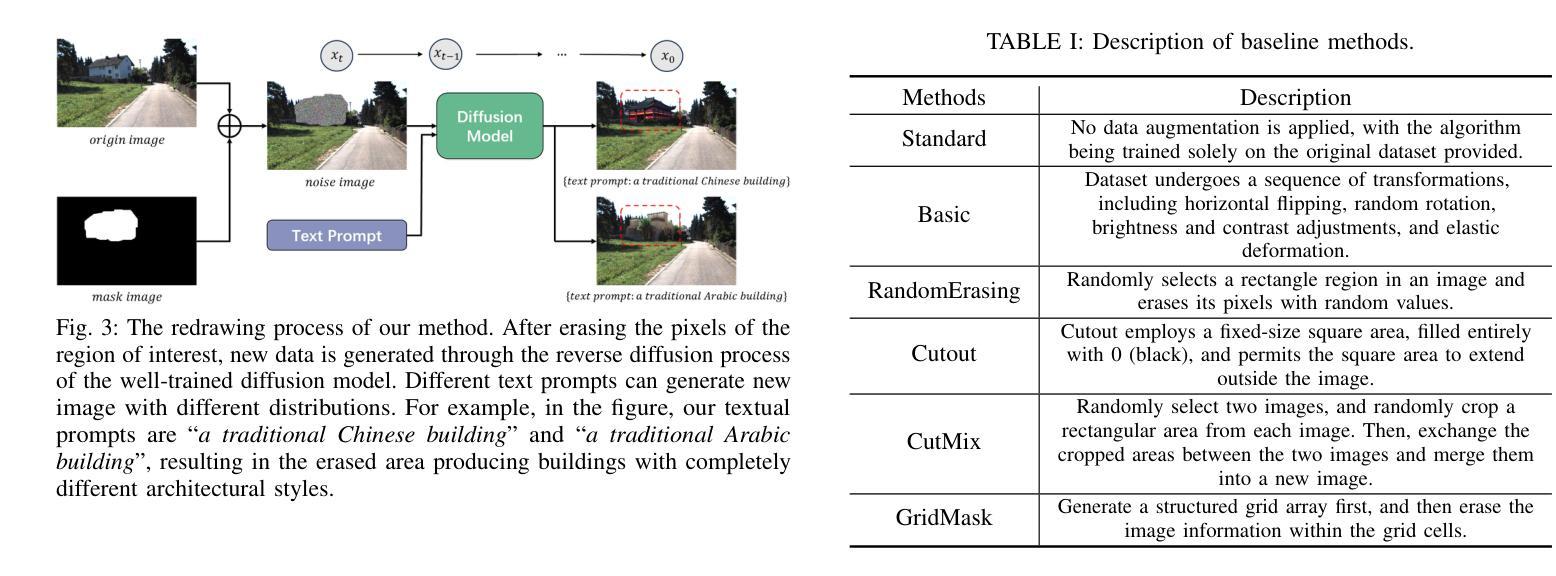
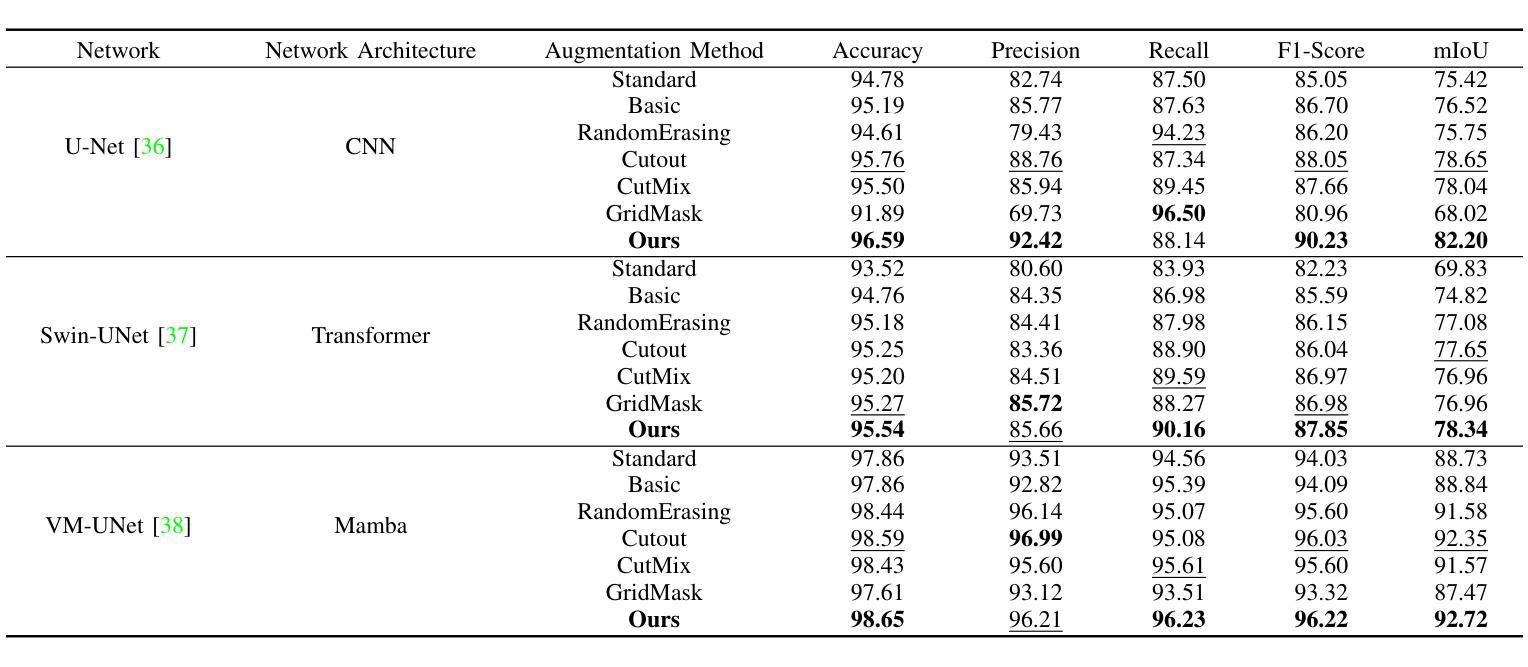
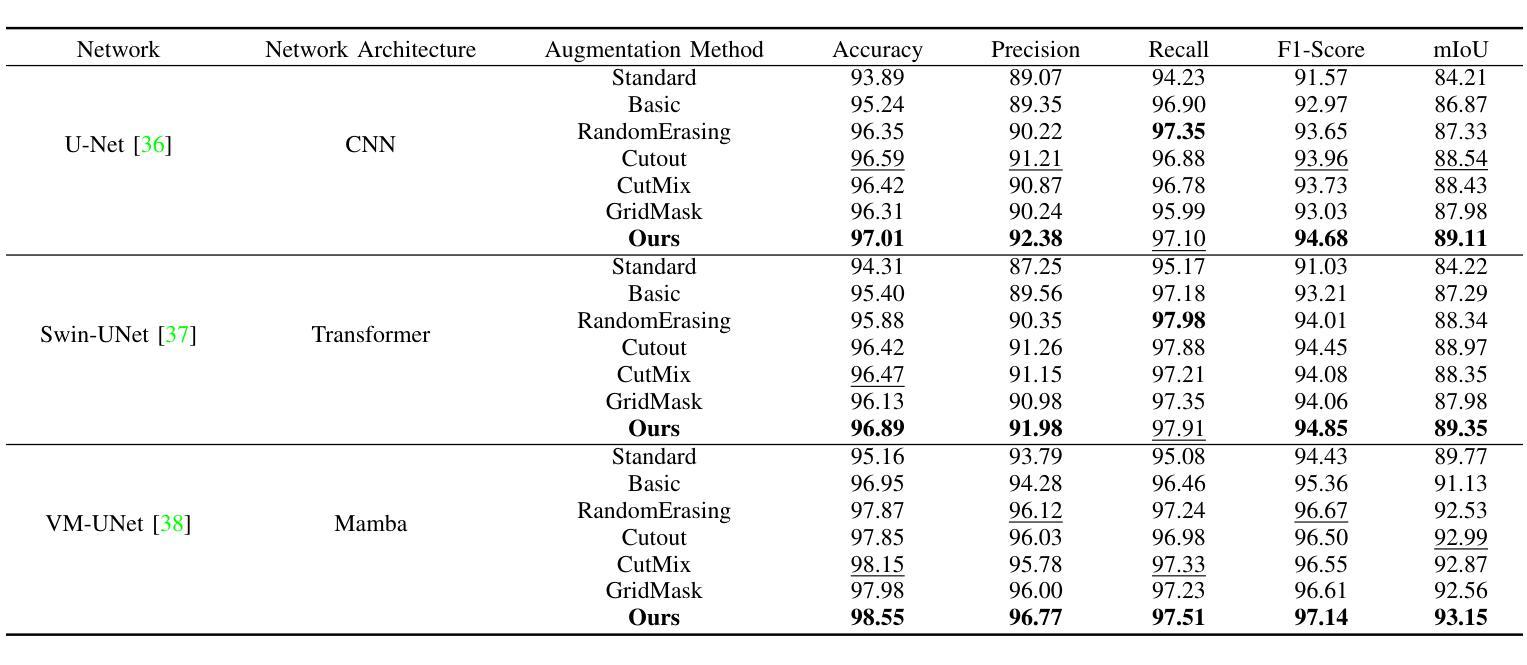
Erase, then Redraw: A Novel Data Augmentation Approach for Free Space Detection Using Diffusion Model
Authors:Fulong Ma, Weiqing Qi, Guoyang Zhao, Ming Liu, Jun Ma
Data augmentation is one of the most common tools in deep learning, underpinning many recent advances including tasks such as classification, detection, and semantic segmentation. The standard approach to data augmentation involves simple transformations like rotation and flipping to generate new images. However, these new images often lack diversity along the main semantic dimensions within the data. Traditional data augmentation methods cannot alter high-level semantic attributes such as the presence of vehicles, trees, and buildings in a scene to enhance data diversity. In recent years, the rapid development of generative models has injected new vitality into the field of data augmentation. In this paper, we address the lack of diversity in data augmentation for road detection task by using a pre-trained text-to-image diffusion model to parameterize image-to-image transformations. Our method involves editing images using these diffusion models to change their semantics. In essence, we achieve this goal by erasing instances of real objects from the original dataset and generating new instances with similar semantics in the erased regions using the diffusion model, thereby expanding the original dataset. We evaluate our approach on the KITTI road dataset and achieve the best results compared to other data augmentation methods, which demonstrates the effectiveness of our proposed development.
数据增强是深度学习中最常见的工具之一,为包括分类、检测和语义分割等任务在内的许多最新进展提供了支持。传统的数据增强方法通常涉及简单的转换,如旋转和翻转以生成新图像。然而,这些新图像在数据的主要语义维度上通常缺乏多样性。传统数据增强方法无法改变高级语义属性,例如场景中的车辆、树木和建筑物的存在,以增强数据多样性。近年来,生成模型的快速发展为数据增强领域注入了新活力。在本文中,我们通过使用预训练的文本到图像扩散模型来参数化图像到图像的转换,解决了道路检测任务中数据增强缺乏多样性的问题。我们的方法涉及使用这些扩散模型编辑图像,以改变其语义。本质上,我们通过从原始数据集中删除真实对象的实例,并利用扩散模型在删除的区域生成具有相似语义的新实例,从而扩展原始数据集。我们在KITTI道路数据集上评估了我们的方法,与其他数据增强方法相比取得了最佳结果,这证明了我们所提出的发展的有效性。
论文及项目相关链接
Summary
数据增强是深度学习中的常用工具,对于分类、检测和语义分割等任务起到了重要的推动作用。传统数据增强方法主要通过简单变换生成新图像,但缺乏多样性。本文利用预训练的文本到图像扩散模型进行图像到图像的参数化转换,解决道路检测任务中数据增强缺乏多样性的问题。通过擦除原始数据集中的实际对象并用扩散模型在擦除区域生成具有相似语义的新实例,从而扩展原始数据集。在KITTI道路数据集上的实验结果证明了该方法的有效性。
Key Takeaways
- 数据增强在深度学习中的重要作用,特别是在分类、检测和语义分割任务中的应用。
- 传统数据增强方法主要通过简单变换生成新图像,但这种方法生成的图像在语义维度上缺乏多样性。
- 扩散模型在数据增强中的潜力,能够改变图像的高级语义属性,提高数据多样性。
- 本文使用预训练的文本到图像扩散模型进行图像到图像的参数化转换,解决道路检测任务中数据增强缺乏多样性的挑战。
- 方法通过擦除原始数据集中的对象并用扩散模型生成新实例来扩展数据集。
- 在KITTI道路数据集上的实验结果表明,该方法在数据增强方面取得了最佳效果。
点此查看论文截图


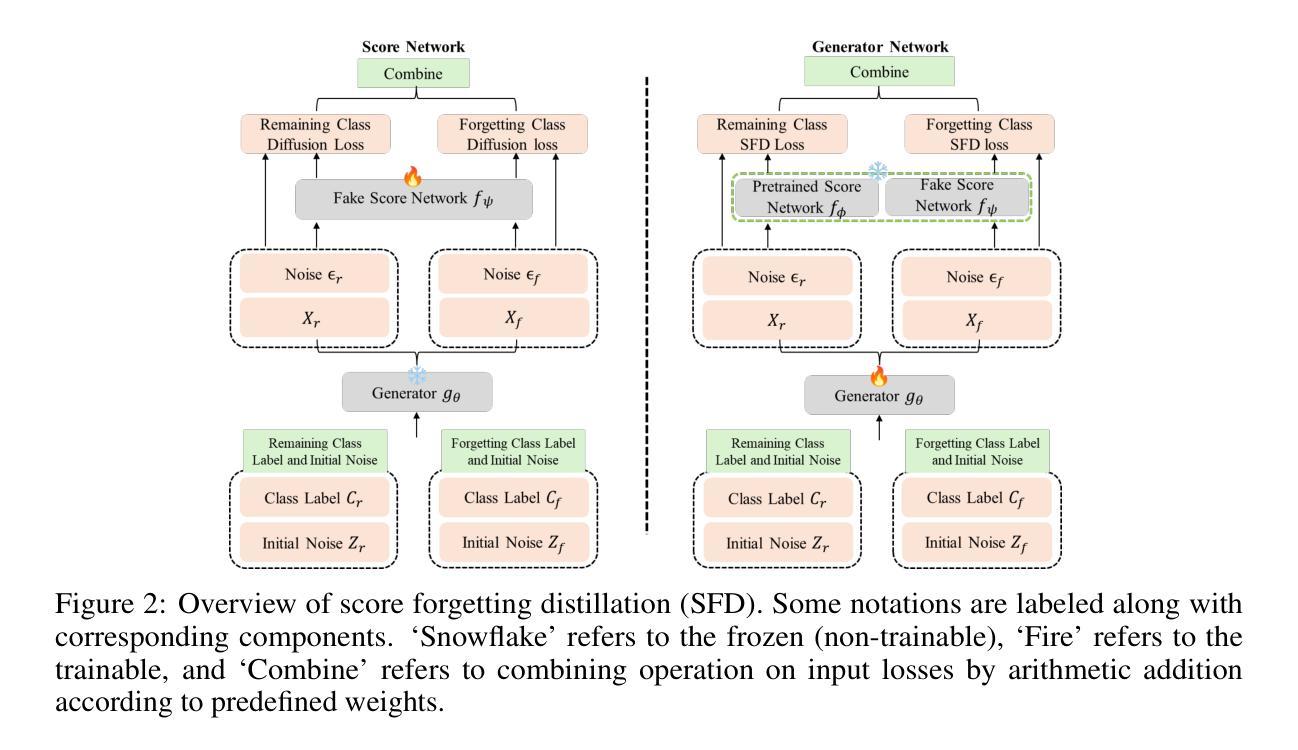
Score Forgetting Distillation: A Swift, Data-Free Method for Machine Unlearning in Diffusion Models
Authors:Tianqi Chen, Shujian Zhang, Mingyuan Zhou
The machine learning community is increasingly recognizing the importance of fostering trust and safety in modern generative AI (GenAI) models. We posit machine unlearning (MU) as a crucial foundation for developing safe, secure, and trustworthy GenAI models. Traditional MU methods often rely on stringent assumptions and require access to real data. This paper introduces Score Forgetting Distillation (SFD), an innovative MU approach that promotes the forgetting of undesirable information in diffusion models by aligning the conditional scores of “unsafe” classes or concepts with those of “safe” ones. To eliminate the need for real data, our SFD framework incorporates a score-based MU loss into the score distillation objective of a pretrained diffusion model. This serves as a regularization term that preserves desired generation capabilities while enabling the production of synthetic data through a one-step generator. Our experiments on pretrained label-conditional and text-to-image diffusion models demonstrate that our method effectively accelerates the forgetting of target classes or concepts during generation, while preserving the quality of other classes or concepts. This unlearned and distilled diffusion not only pioneers a novel concept in MU but also accelerates the generation speed of diffusion models. Our experiments and studies on a range of diffusion models and datasets confirm that our approach is generalizable, effective, and advantageous for MU in diffusion models. Code is available at https://github.com/tqch/score-forgetting-distillation. ($\textbf{Warning:}$ This paper contains sexually explicit imagery, discussions of pornography, racially-charged terminology, and other content that some readers may find disturbing, distressing, and/or offensive.)
机器学习领域越来越认识到培养现代生成式人工智能(GenAI)模型中的信任和安全性至关重要。我们认为机器遗忘(MU)是开发安全、可靠、可信的GenAI模型的重要基础。传统的MU方法往往依赖于严格的假设并需要访问真实数据。本文介绍了Score Forgetting Distillation(SFD)这一创新的MU方法,它通过使“不安全”类别或概念的条件分数与“安全”类别或概念的条件分数保持一致,促进在扩散模型中遗忘不需要的信息。为了消除对真实数据的需求,我们的SFD框架将基于分数的MU损失纳入预训练扩散模型的分数蒸馏目标中。这作为正则化项,既保留了所需的生成能力,又通过一步生成器产生了合成数据。我们在预训练的标签条件和文本到图像扩散模型上的实验表明,我们的方法有效地加速了目标类别或概念的遗忘过程,同时保持了其他类别或概念的质量。这种未被学习和提炼的扩散不仅开创了MU领域的新概念,还加快了扩散模型的生成速度。我们在一系列扩散模型和数据集上的实验和研究证实,我们的方法是通用的、有效的,对于扩散模型中的MU具有优势。代码可访问于 https://github.com/tqch/score-forgetting-distillation 。(警告:本文包含色情内容、关于色情讨论、种族性术语和其他一些读者可能认为令人不安、令人痛苦和/或冒犯的内容。)
论文及项目相关链接
PDF ICLR 2025
摘要
本文提出一种名为Score Forgetting Distillation(SFD)的新型机器无学习(MU)方法,旨在促进扩散模型中不良信息的遗忘。该方法通过对“不安全”类别或概念的条件分数与“安全”类别或概念的分数对齐,无需真实数据即可实现遗忘。通过在预训练的扩散模型中融入基于分数的MU损失,SFD框架在保持生成能力的同时,通过一步生成器产生合成数据。实验证明,该方法在生成过程中有效加速目标类别或概念的遗忘,同时保持其他类别或概念的质量。此无学习和蒸馏的扩散模型不仅开创了MU的新概念,还加速了扩散模型的生成速度。实验和研究表明,该方法在多种扩散模型和数据集上具有通用性、有效性和优势。
关键见解
- 机器学习领域正日益认识到在现代生成式AI(GenAI)模型中培养信任和安全的重要性。
- 机器无学习(MU)被视为开发安全、可靠和可信的GenAI模型的关键基础。
- 传统MU方法通常依赖于严格的假设并需要真实数据的访问。
- 本文介绍Score Forgetting Distillation(SFD),一种新型的MU方法,它通过对齐“不安全”类别或概念的条件分数来促进扩散模型中不良信息的遗忘。
- SFD框架融入基于分数的MU损失,无需真实数据,即可在预训练的扩散模型中实现遗忘,同时保持生成能力。
- 实验证明,SFD方法有效加速目标类别或概念的遗忘过程,同时保持其他类别或概念的质量。
- 此无学习和蒸馏的扩散模型不仅推动了MU领域的新概念,还提高了扩散模型的生成速度。
点此查看论文截图

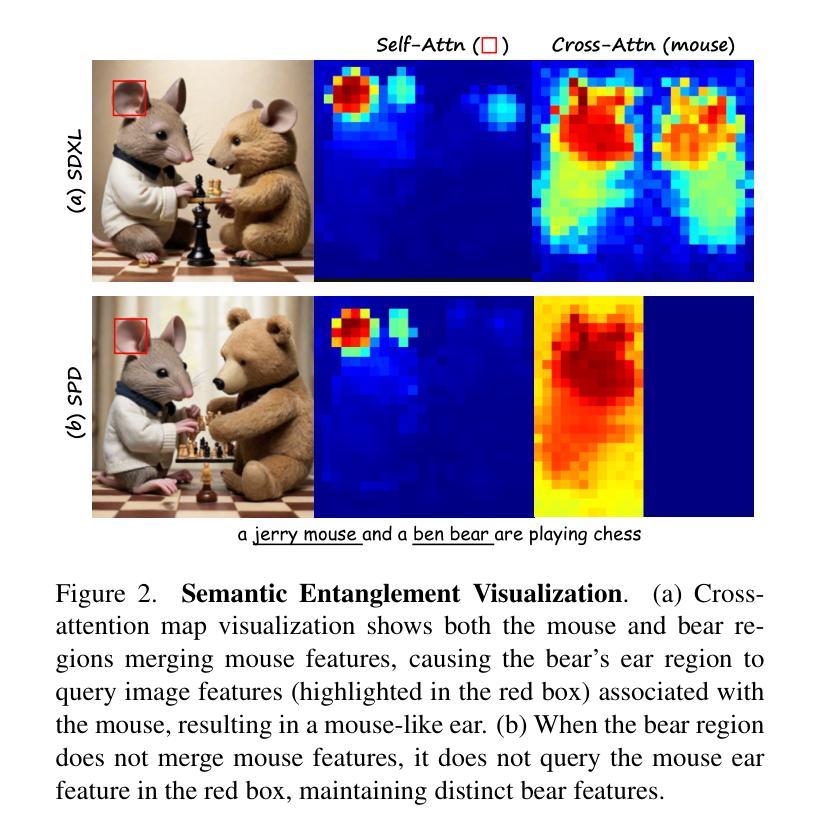
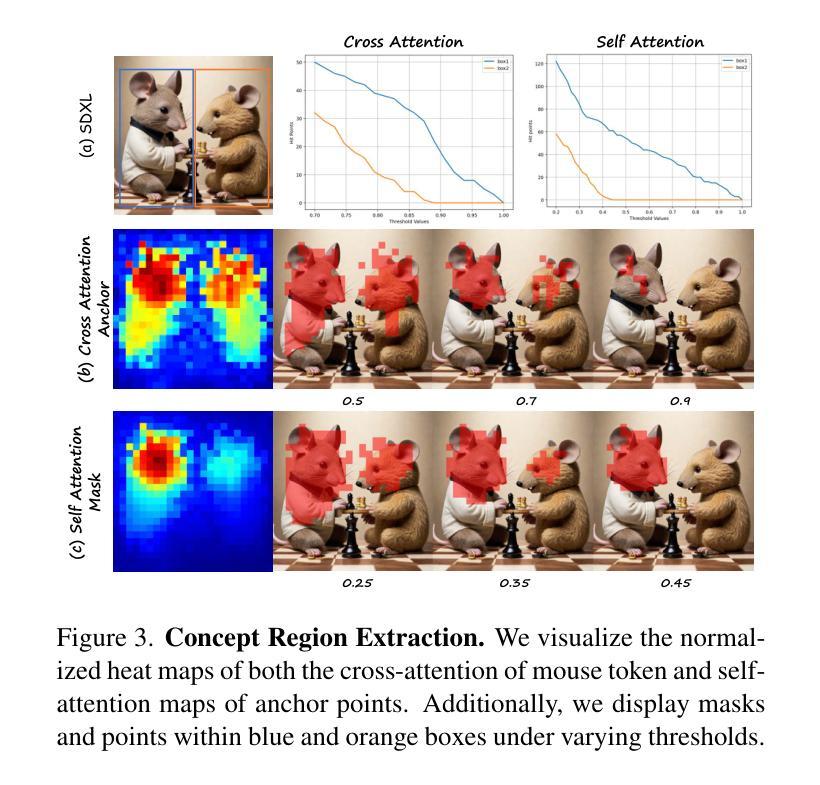
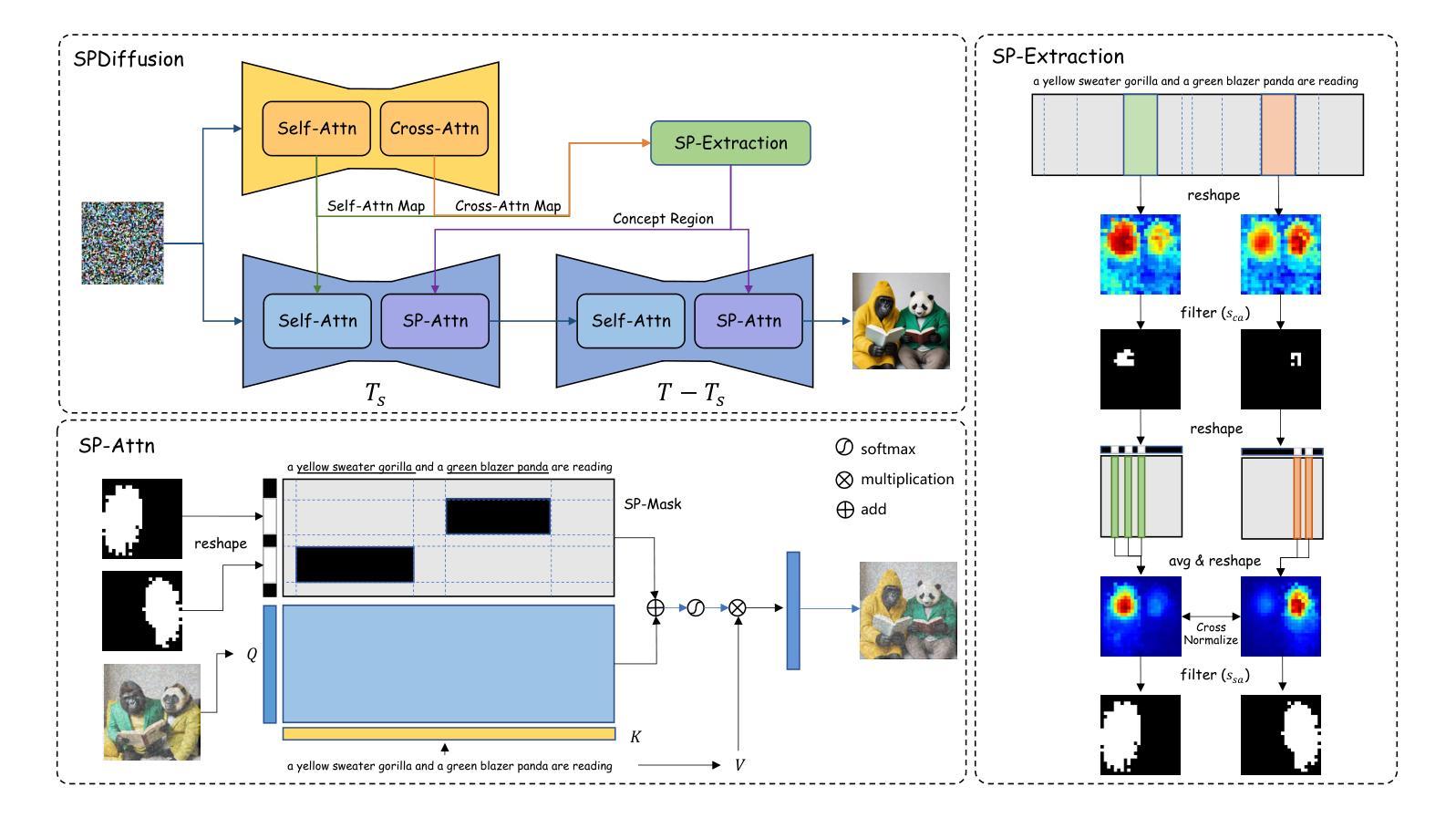
SPDiffusion: Semantic Protection Diffusion Models for Multi-concept Text-to-image Generation
Authors:Yang Zhang, Rui Zhang, Xuecheng Nie, Haochen Li, Jikun Chen, Yifan Hao, Xin Zhang, Luoqi Liu, Ling Li
Recent text-to-image models have achieved impressive results in generating high-quality images. However, when tasked with multi-concept generation creating images that contain multiple characters or objects, existing methods often suffer from semantic entanglement, including concept entanglement and improper attribute binding, leading to significant text-image inconsistency. We identify that semantic entanglement arises when certain regions of the latent features attend to incorrect concept and attribute tokens. In this work, we propose the Semantic Protection Diffusion Model (SPDiffusion) to address both concept entanglement and improper attribute binding using only a text prompt as input. The SPDiffusion framework introduces a novel concept region extraction method SP-Extraction to resolve region entanglement in cross-attention, along with SP-Attn, which protects concept regions from the influence of irrelevant attributes and concepts. To evaluate our method, we test it on existing benchmarks, where SPDiffusion achieves state-of-the-art results, demonstrating its effectiveness.
近期的文本到图像模型在生成高质量图像方面取得了令人印象深刻的结果。然而,当面对多概念生成任务,即生成包含多个字符或对象的图像时,现有方法经常遭受语义纠缠的问题,包括概念纠缠和不当属性绑定,导致显著的文本-图像不一致。我们确定,当潜在特征中的某些区域关注错误的概念和属性令牌时,就会出现语义纠缠。在这项工作中,我们提出了语义保护扩散模型(SPDiffusion),仅使用文本提示作为输入来解决概念纠缠和不当属性绑定问题。SPDiffusion框架引入了一种新的概念区域提取方法SP-Extraction,以解决跨注意力中的区域纠缠问题,以及SP-Attn,它保护概念区域免受无关属性和概念的影响。为了评估我们的方法,我们在现有基准测试上对其进行了测试,SPDiffusion取得了最新结果,证明了其有效性。
论文及项目相关链接
Summary
本文提出一种名为Semantic Protection Diffusion Model(SPDiffusion)的文本转图像模型,用于解决多概念生成时的语义纠缠和不适当属性绑定问题。该模型通过引入SP-Extraction和SP-Attn机制,有效保护概念区域免受无关属性和概念的影响,实现跨注意力区域纠缠的解决。在现有基准测试中,SPDiffusion取得了最先进的成果。
Key Takeaways
- 文本转图像模型在多概念生成时面临语义纠缠问题。
- 语义纠缠源于特征区域的注意力与概念或属性标记的不匹配。
- SPDiffusion模型旨在解决概念纠缠和不适当属性绑定问题。
- SPDiffusion引入SP-Extraction方法,解决跨注意力区域纠缠。
- SPDiffusion采用SP-Attn机制,保护概念区域免受无关属性和概念的影响。
- 在现有基准测试中,SPDiffusion模型表现卓越,达到最新水平。
点此查看论文截图

Speed-accuracy relations for the diffusion models: Wisdom from nonequilibrium thermodynamics and optimal transport
Authors:Kotaro Ikeda, Tomoya Uda, Daisuke Okanohara, Sosuke Ito
We discuss a connection between a generative model, called the diffusion model, and nonequilibrium thermodynamics for the Fokker-Planck equation, called stochastic thermodynamics. Based on the techniques of stochastic thermodynamics, we derive the speed-accuracy relations for the diffusion models, which are inequalities that relate the accuracy of data generation to the entropy production rate, which can be interpreted as the speed of the diffusion dynamics in the absence of the non-conservative force. From a stochastic thermodynamic perspective, our results provide a quantitative insight into how best to generate data in diffusion models. The optimal learning protocol is introduced by the geodesic of space of the 2-Wasserstein distance in optimal transport theory. We numerically illustrate the validity of the speed-accuracy relations for the diffusion models with different noise schedules and the different data. We numerically discuss our results for the optimal and suboptimal learning protocols. We also show the inaccurate data generation due to the non-conservative force, and the applicability of our results to data generation from the real-world image datasets.
我们探讨了一种生成模型——扩散模型与非平衡态热力学和Fokker-Planck方程的随机热力学之间的联系。基于随机热力学的技术,我们推导出了扩散模型的速度-精度关系,这些关系是不等式,描述了数据生成的精度与熵产生率之间的联系,可以解释为在没有非保守力的情况下扩散动力学的速度。从随机热力学的角度来看,我们的结果提供了在扩散模型中如何最佳生成数据的定量见解。最优学习协议由最优传输理论中的2-Wasserstein距离的空间测地线引入。我们通过数值说明了不同噪声安排和数据下扩散模型的速度-精度关系的有效性。我们数值讨论了最优和次优学习协议的结果。我们还展示了由于非保守力导致的数据生成不准确,以及我们的结果对现实世界图像数据集的数据生成的适用性。
论文及项目相关链接
PDF 36 pages, 7 figures
Summary
本文探讨了扩散模型与基于Fokker-Planck方程的随机热力学之间的联系。通过随机热力学技术,我们推导出扩散模型的速度-精度关系不等式,该不等式将数据采集的准确性关联到熵产生率上,可以解读为在没有非保守力作用下的扩散动力速度。本文结果从随机热力学的角度为扩散模型中的数据采集提供了定量见解。此外,引入最优学习协议——最优传输理论中的2-Wasserstein距离空间测地线。我们对不同噪声计划和数据的扩散模型的速度-精度关系进行了数值验证,并讨论了最优和次优学习协议的结果。同时,展示了因非保守力导致的数据生成不准确,以及我们的结果对现实世界图像数据集的数据生成适用性。
Key Takeaways
- 扩散模型与随机热力学存在联系,可用于推导速度-精度关系不等式。
- 速度-精度关系不等式关联了数据生成的准确性和熵产生率,反映了扩散动力学的速度。
- 从随机热力学视角,为扩散模型中的数据生成提供了定量见解。
- 引入最优学习协议,基于最优传输理论中的2-Wasserstein距离空间测地线。
- 通过数值验证,不同噪声计划和数据的扩散模型的速度-精度关系得到证实。
- 探讨了最优和次优学习协议的结果。
点此查看论文截图