⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-05 更新
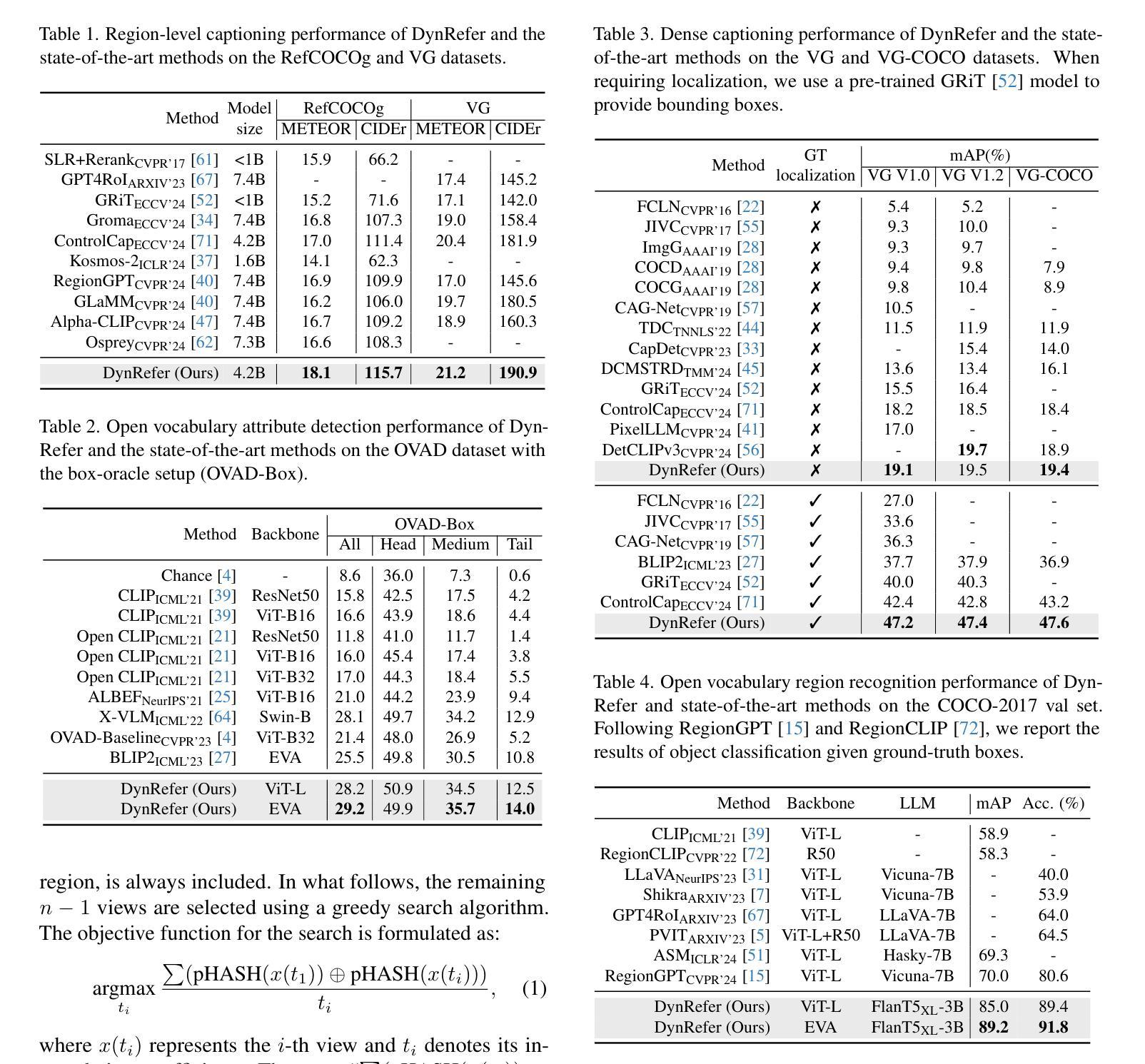
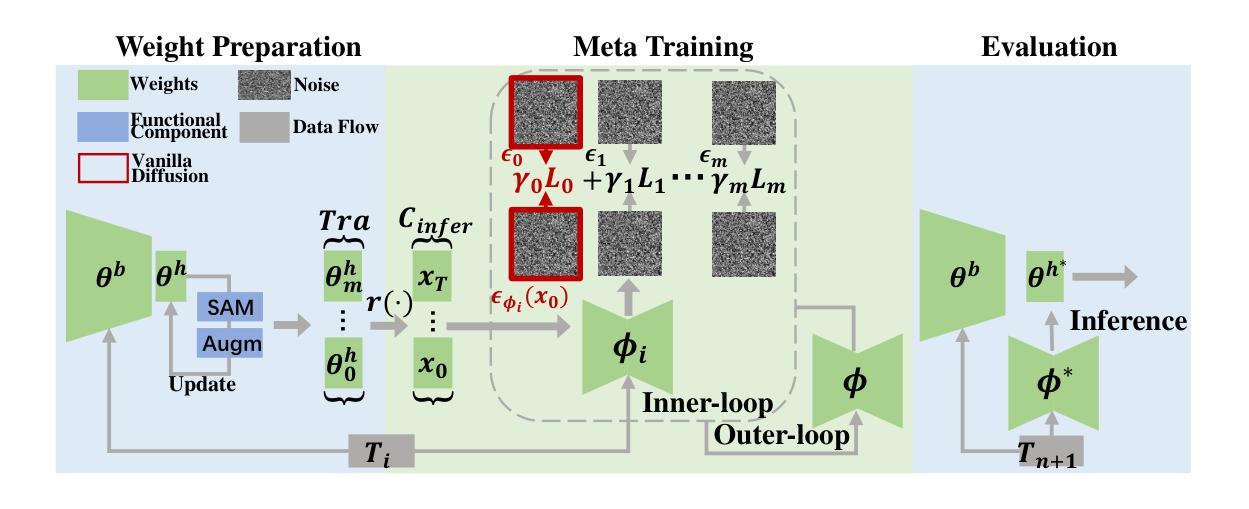
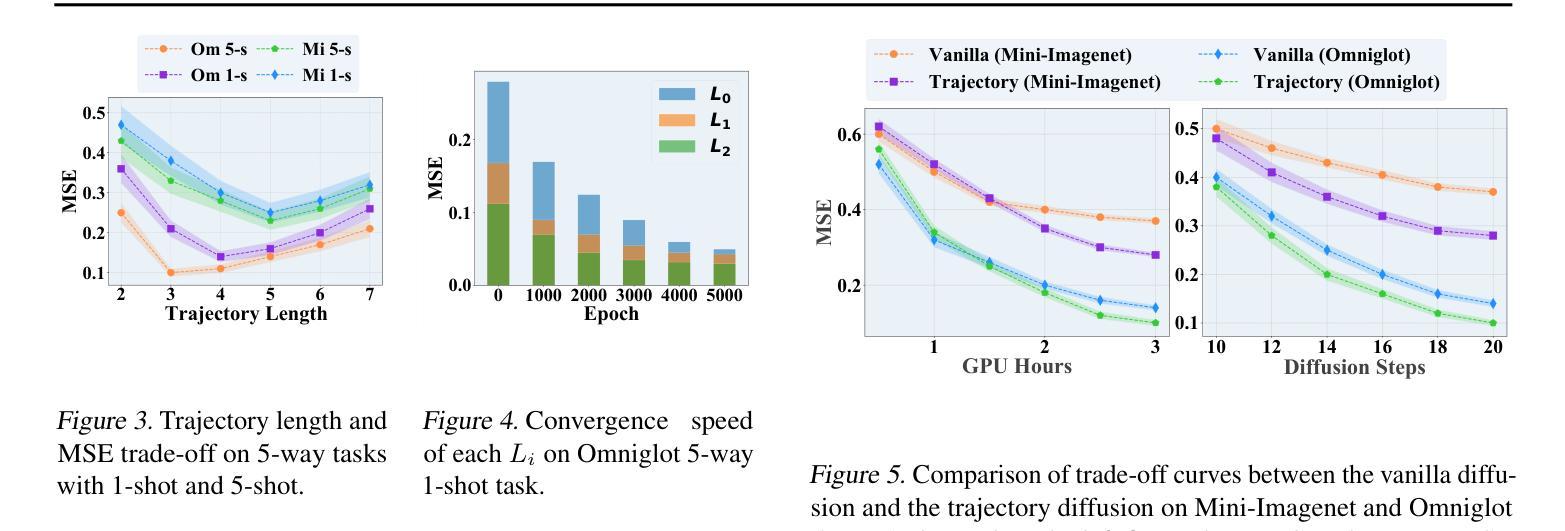
Learning to Learn Weight Generation via Trajectory Diffusion
Authors:Yunchuan Guan, Yu Liu, Ke Zhou, Zhiqi Shen, Serge Belongie, Jenq-Neng Hwang, Lei Li
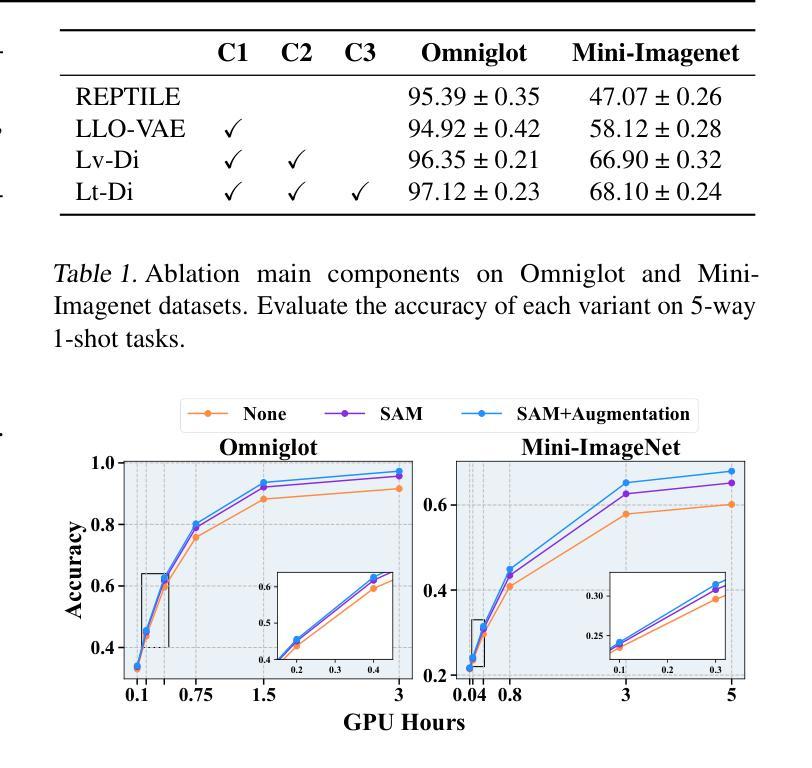
Diffusion-based algorithms have emerged as promising techniques for weight generation, particularly in scenarios like multi-task learning that require frequent weight updates. However, existing solutions suffer from limited cross-task transferability. In addition, they only utilize optimal weights as training samples, ignoring the value of other weights in the optimization process. To address these issues, we propose Lt-Di, which integrates the diffusion algorithm with meta-learning to generate weights for unseen tasks. Furthermore, we extend the vanilla diffusion algorithm into a trajectory diffusion algorithm to utilize other weights along the optimization trajectory. Trajectory diffusion decomposes the entire diffusion chain into multiple shorter ones, improving training and inference efficiency. We analyze the convergence properties of the weight generation paradigm and improve convergence efficiency without additional time overhead. Our experiments demonstrate Lt-Di’s higher accuracy while reducing computational overhead across various tasks, including zero-shot and few-shot learning, multi-domain generalization, and large-scale language model fine-tuning.Our code is released at https://anonymous.4open.science/r/Lt-Di-0E51.
基于扩散的算法已成为权重生成的有前途的技术,特别是在需要频繁权重更新的多任务学习等场景中。然而,现有解决方案存在跨任务迁移能力有限的不足。此外,它们仅利用最优权重作为训练样本,忽略了优化过程中其他权重的价值。为了解决这些问题,我们提出了Lt-Di,它将扩散算法与元学习相结合,以生成未见任务的权重。此外,我们将普通的扩散算法扩展为轨迹扩散算法,以利用优化轨迹上的其他权重。轨迹扩散将整个扩散链分解为多个较短的链,提高了训练和推理效率。我们分析了权重生成范式的收敛属性,提高了收敛效率,而没有增加额外的时间开销。我们的实验表明,Lt-Di在各种任务中具有较高的准确性,同时减少了计算开销,包括零样本和少样本学习、多域泛化以及大规模语言模型的微调。我们的代码发布在:https://anonymous.4open.science/r/Lt-Di-0E51。
论文及项目相关链接
Summary
扩散算法结合元学习生成权重,解决多任务学习中的跨任务迁移问题,并扩展为轨迹扩散算法,利用优化过程中的其他权重。分析权重生成范式的收敛性质,提高收敛效率且无需额外时间开销。实验证明,Lt-Di在多种任务上表现更精确,包括零样本和少样本学习、跨域泛化和大规模语言模型微调。
Key Takeaways
- 扩散算法在多任务学习中展现出生成权重的潜力。
- 现有解决方案存在跨任务迁移的局限性。
- Lt-Di结合扩散算法与元学习,生成未见任务的权重。
- 轨迹扩散算法利用优化过程中的其他权重。
- Lt-Di提高了训练效率和推理效率。
- Lt-Di提高了权重生成范式的收敛效率。
点此查看论文截图

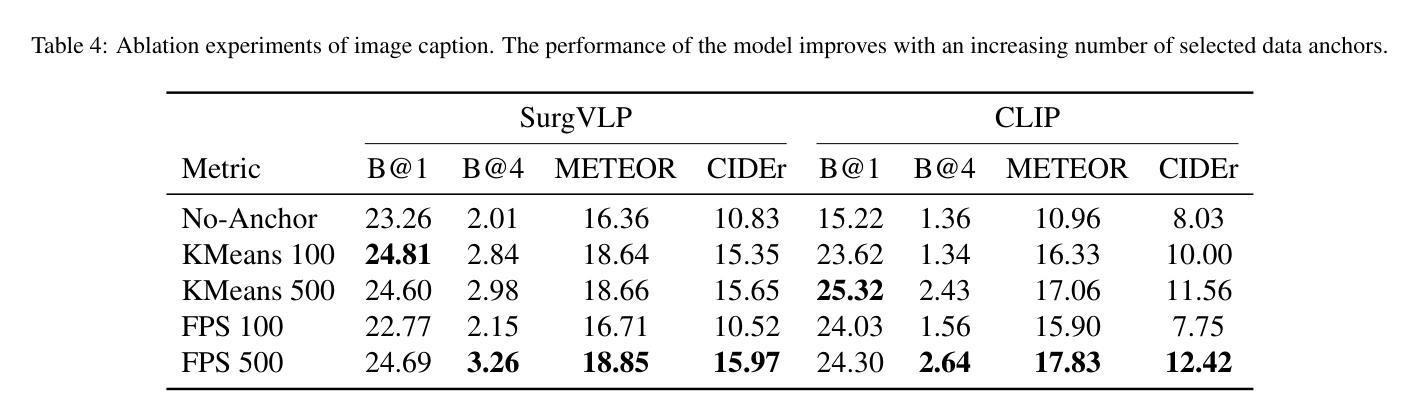
Text-driven Adaptation of Foundation Models for Few-shot Surgical Workflow Analysis
Authors:Tingxuan Chen, Kun Yuan, Vinkle Srivastav, Nassir Navab, Nicolas Padoy
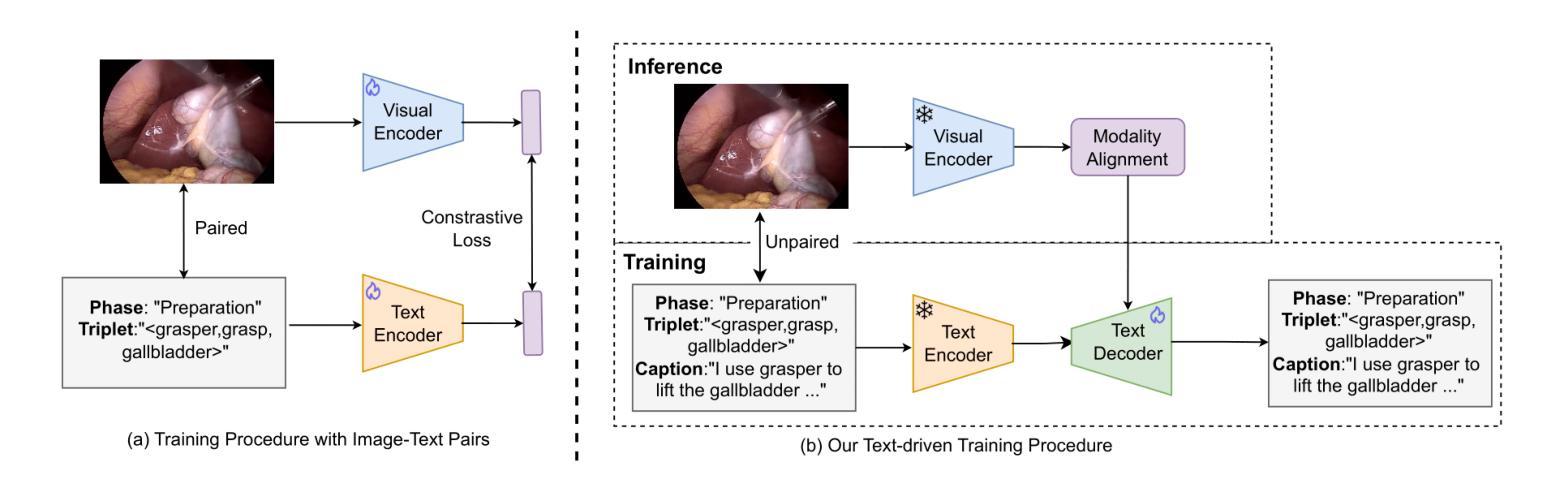
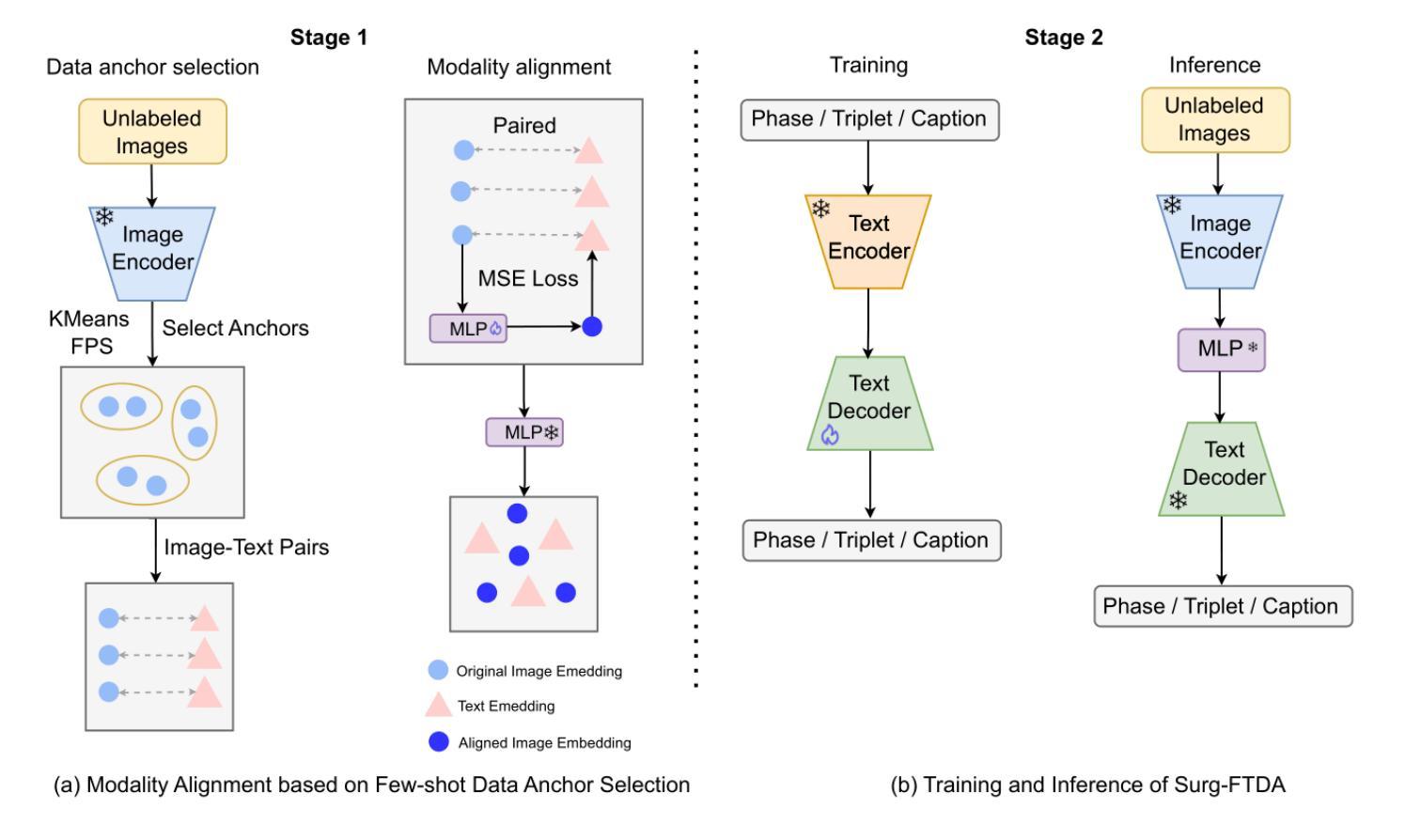
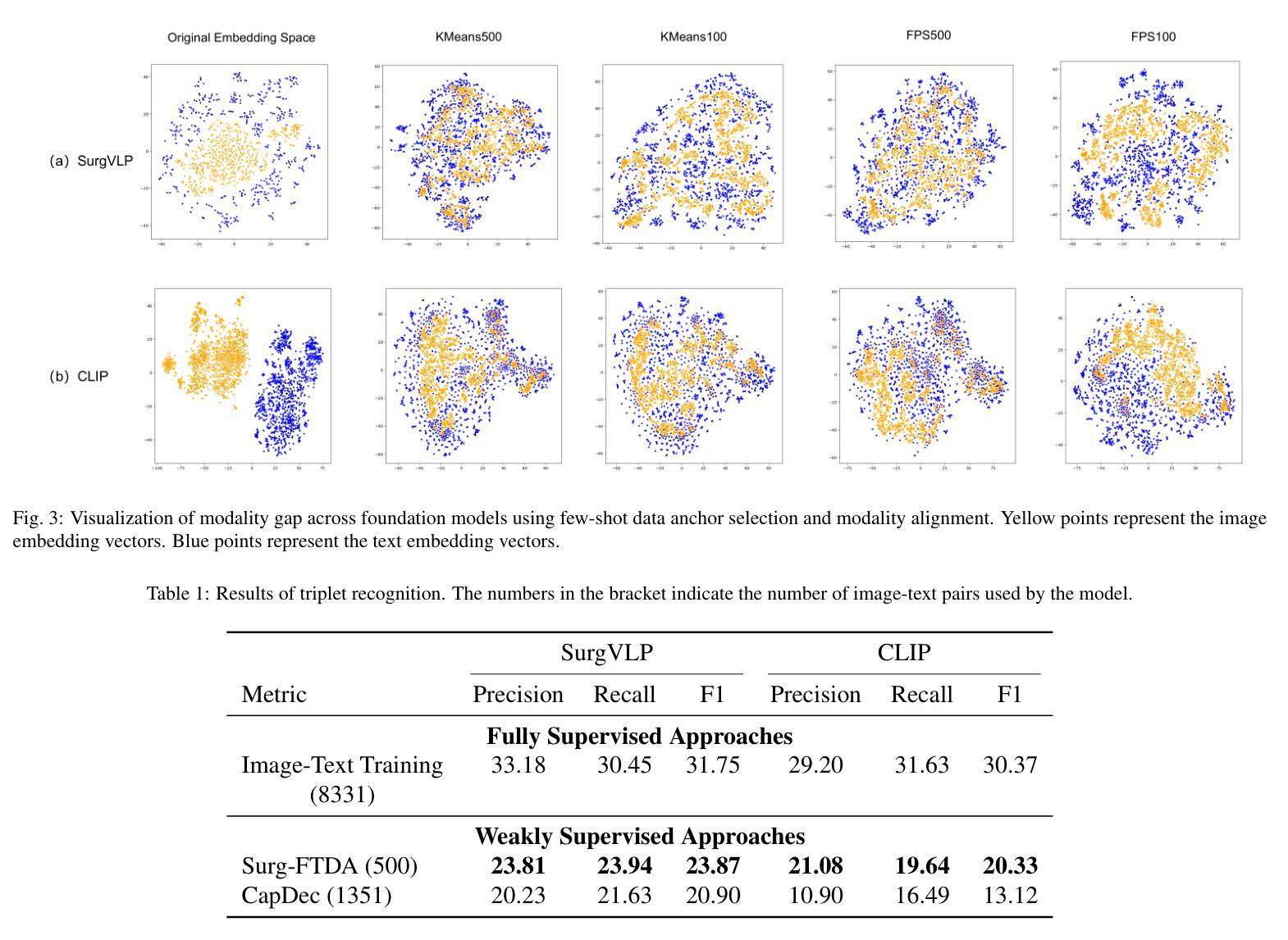
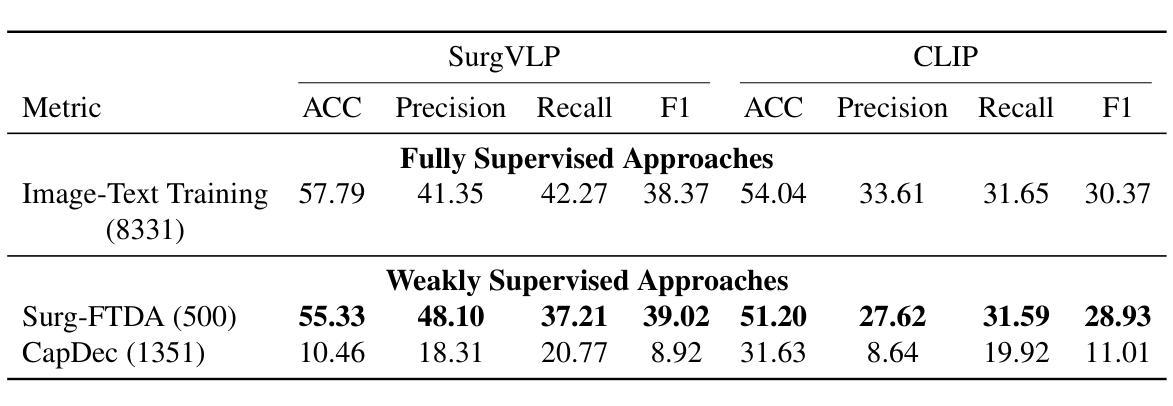
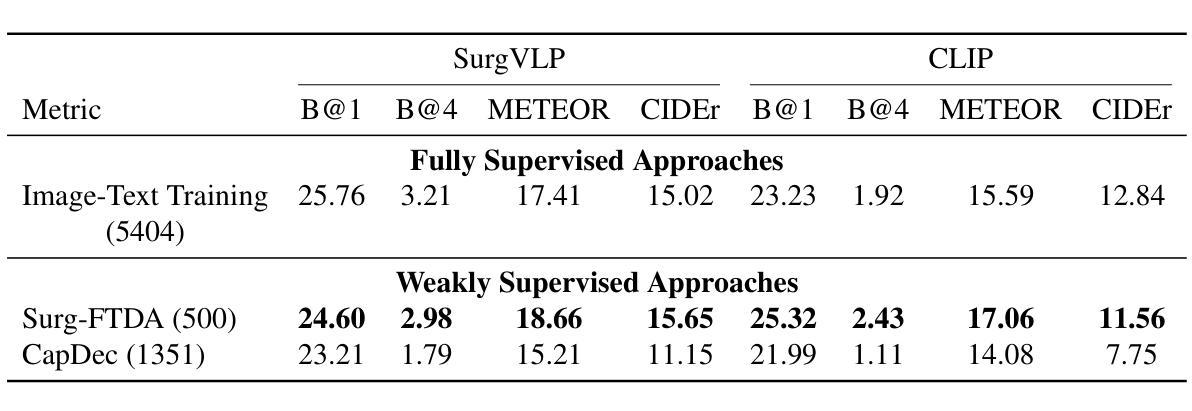
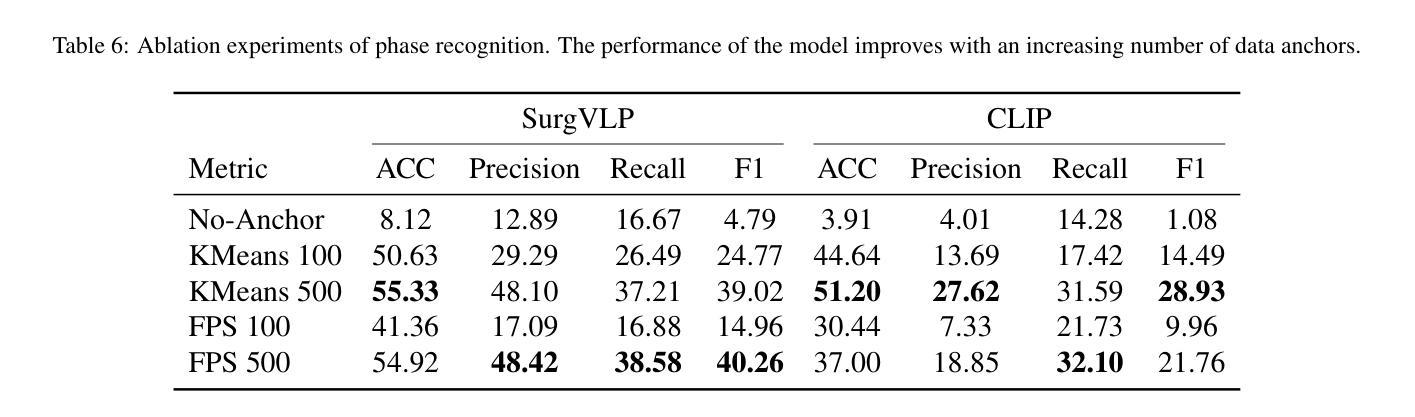
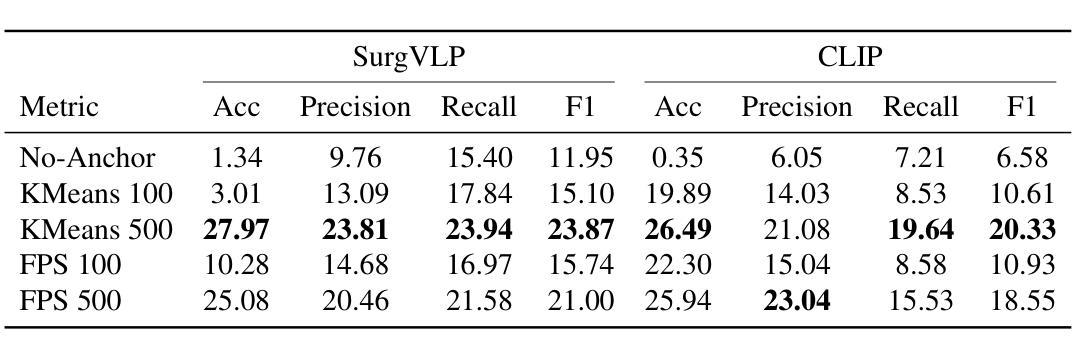
Purpose: Surgical workflow analysis is crucial for improving surgical efficiency and safety. However, previous studies rely heavily on large-scale annotated datasets, posing challenges in cost, scalability, and reliance on expert annotations. To address this, we propose Surg-FTDA (Few-shot Text-driven Adaptation), designed to handle various surgical workflow analysis tasks with minimal paired image-label data. Methods: Our approach has two key components. First, Few-shot selection-based modality alignment selects a small subset of images and aligns their embeddings with text embeddings from the downstream task, bridging the modality gap. Second, Text-driven adaptation leverages only text data to train a decoder, eliminating the need for paired image-text data. This decoder is then applied to aligned image embeddings, enabling image-related tasks without explicit image-text pairs. Results: We evaluate our approach to generative tasks (image captioning) and discriminative tasks (triplet recognition and phase recognition). Results show that Surg-FTDA outperforms baselines and generalizes well across downstream tasks. Conclusion: We propose a text-driven adaptation approach that mitigates the modality gap and handles multiple downstream tasks in surgical workflow analysis, with minimal reliance on large annotated datasets. The code and dataset will be released in https://github.com/CAMMA-public/Surg-FTDA
目的:手术工作流程分析对于提高手术效率和安全性至关重要。然而,之前的研究严重依赖于大规模标注数据集,这带来了成本、可扩展性和对专家标注的依赖等方面的挑战。为了解决这一问题,我们提出了Surg-FTDA(Few-shot文本驱动适应)方法,旨在用最少配对的图像标签数据来处理各种手术工作流程分析任务。
方法:我们的方法有两个关键组成部分。首先,基于Few-shot选择的模态对齐选择一小部分图像,并将它们的嵌入与下游任务的文本嵌入对齐,从而弥合了模态之间的差距。其次,文本驱动适应仅利用文本数据来训练解码器,从而消除了对配对图像文本数据的需求。然后,将这个解码器应用于对齐的图像嵌入,从而能够在没有明确的图像文本对的情况下执行图像相关任务。
结果:我们对生成任务(图像字幕)和鉴别任务(三元组识别和阶段识别)进行了评估。结果表明,Surg-FTDA优于基线,并在下游任务中具有良好的泛化能力。
论文及项目相关链接
Summary
本文提出一种名为Surg-FTDA(Few-shot文本驱动适应)的方法,用于改进手术流程分析任务的效率和安全性。该方法通过少量配对图像标签数据,解决大规模标注数据集带来的成本、可扩展性和依赖专家标注的问题。通过文本驱动适应策略,该方法能够利用文本数据训练解码器,无需配对图像文本数据即可完成图像相关任务。实验结果表明,Surg-FTDA在生成任务(图像描述)和判别任务(三元组识别和阶段识别)中均表现优异,并能很好地应用于不同下游任务。代码和数据集将在https://github.com/CAMMA-public/Surg-FTDA公开发布。
Key Takeaways
- Surg-FTDA旨在解决手术流程分析中的效率和安全问题,特别是对数据标注的挑战性。
- 方法包括两个关键部分:基于少数选择的模态对齐和文本驱动适应策略。
- 通过选择少量图像并与其下游任务的文本嵌入进行对齐,缩小了模态差距。
- 仅使用文本数据训练解码器,无需配对图像文本数据即可完成图像相关任务。
- Surg-FTDA在生成任务和判别任务上表现优异,具有广泛的应用潜力。
- 代码和数据集将在公共存储库中进行共享以供进一步研究。
点此查看论文截图

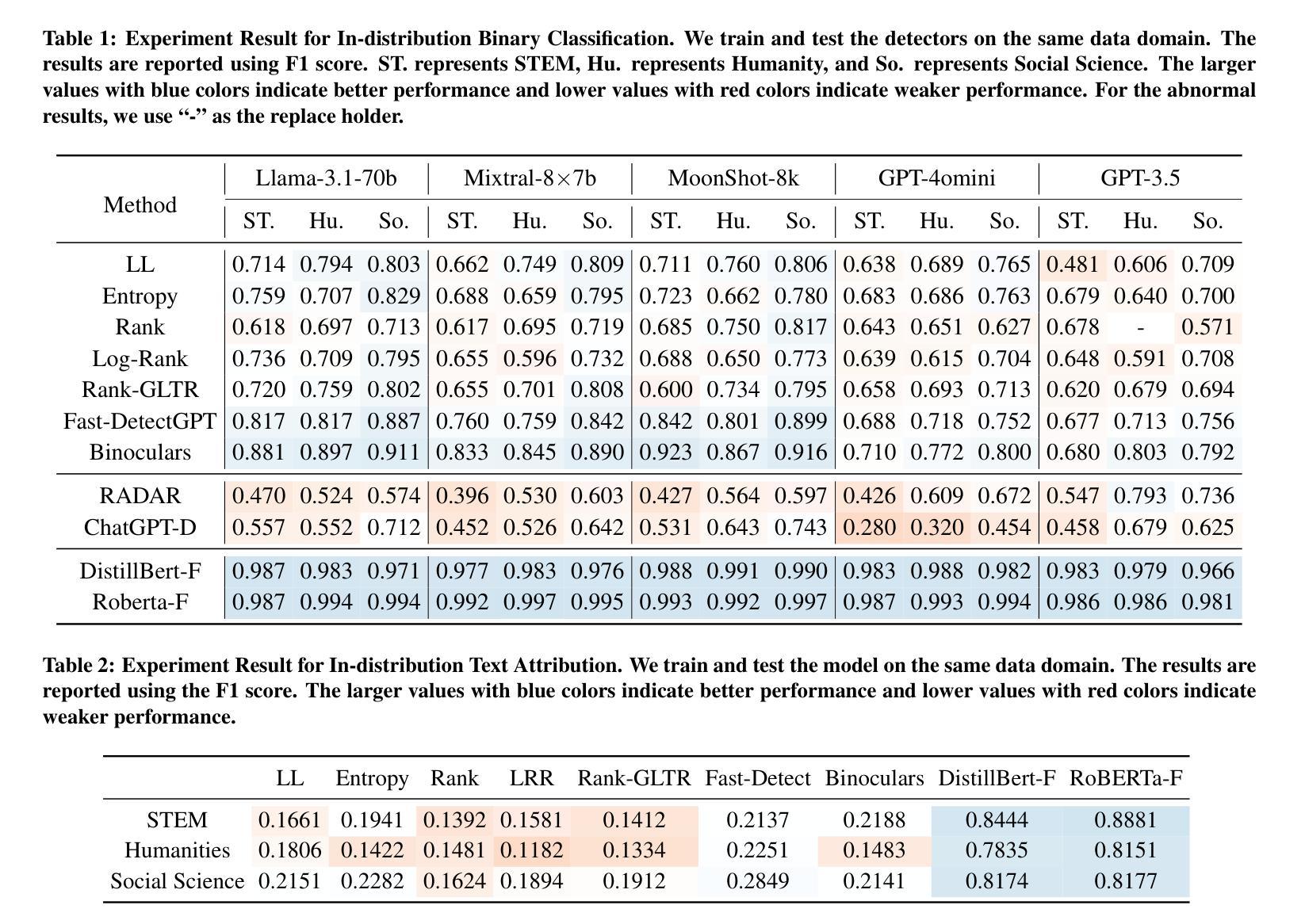
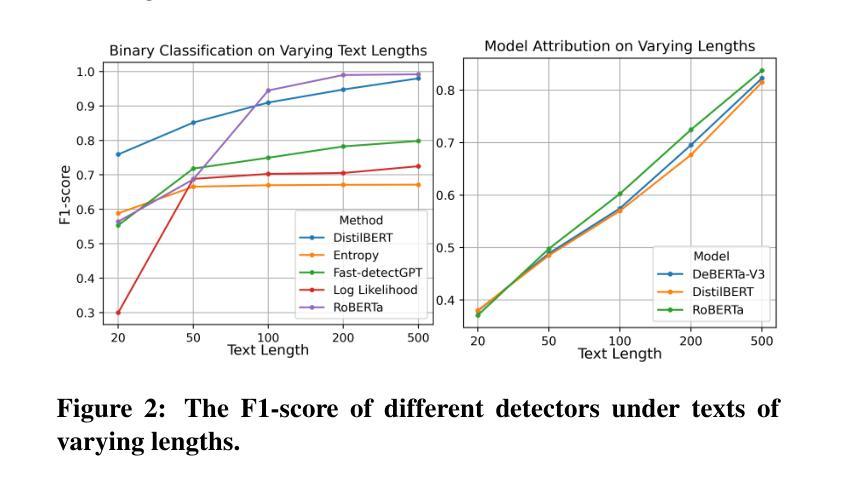
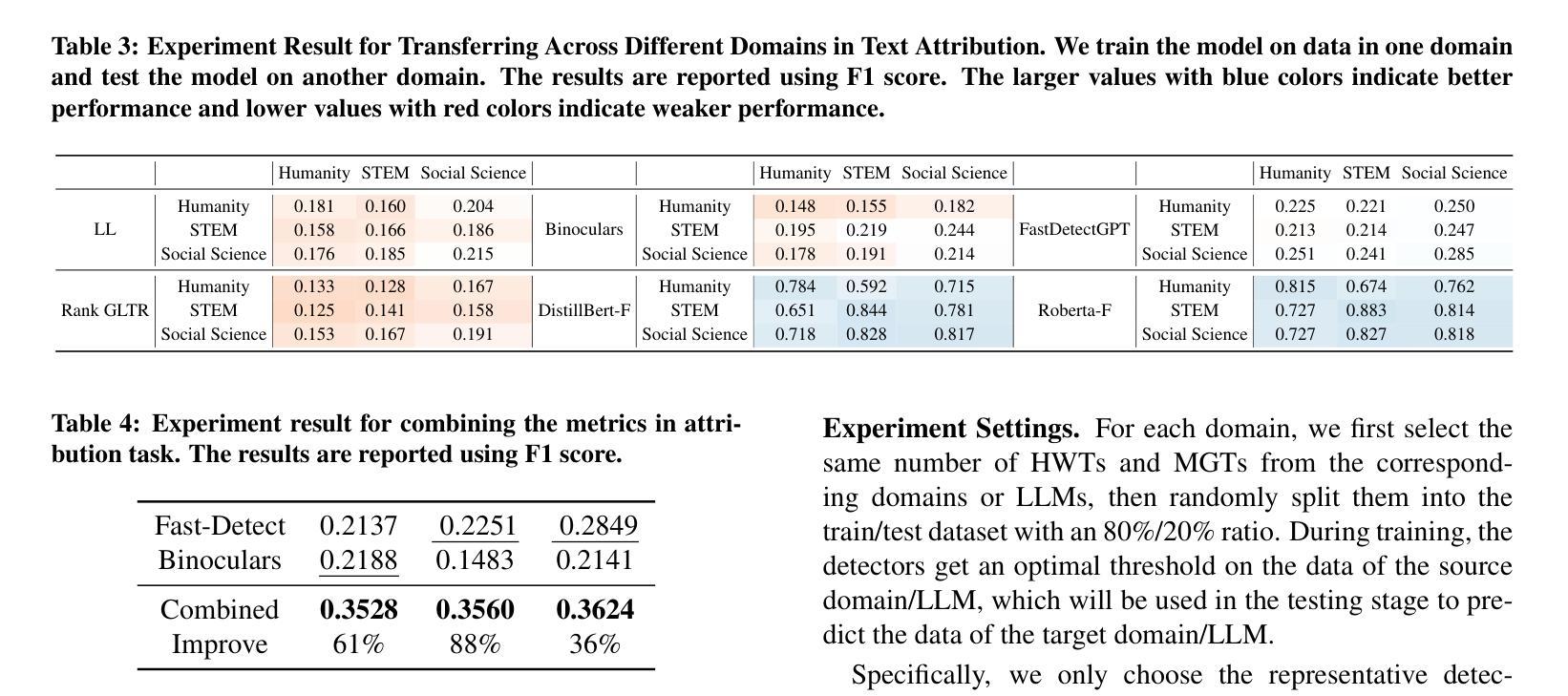
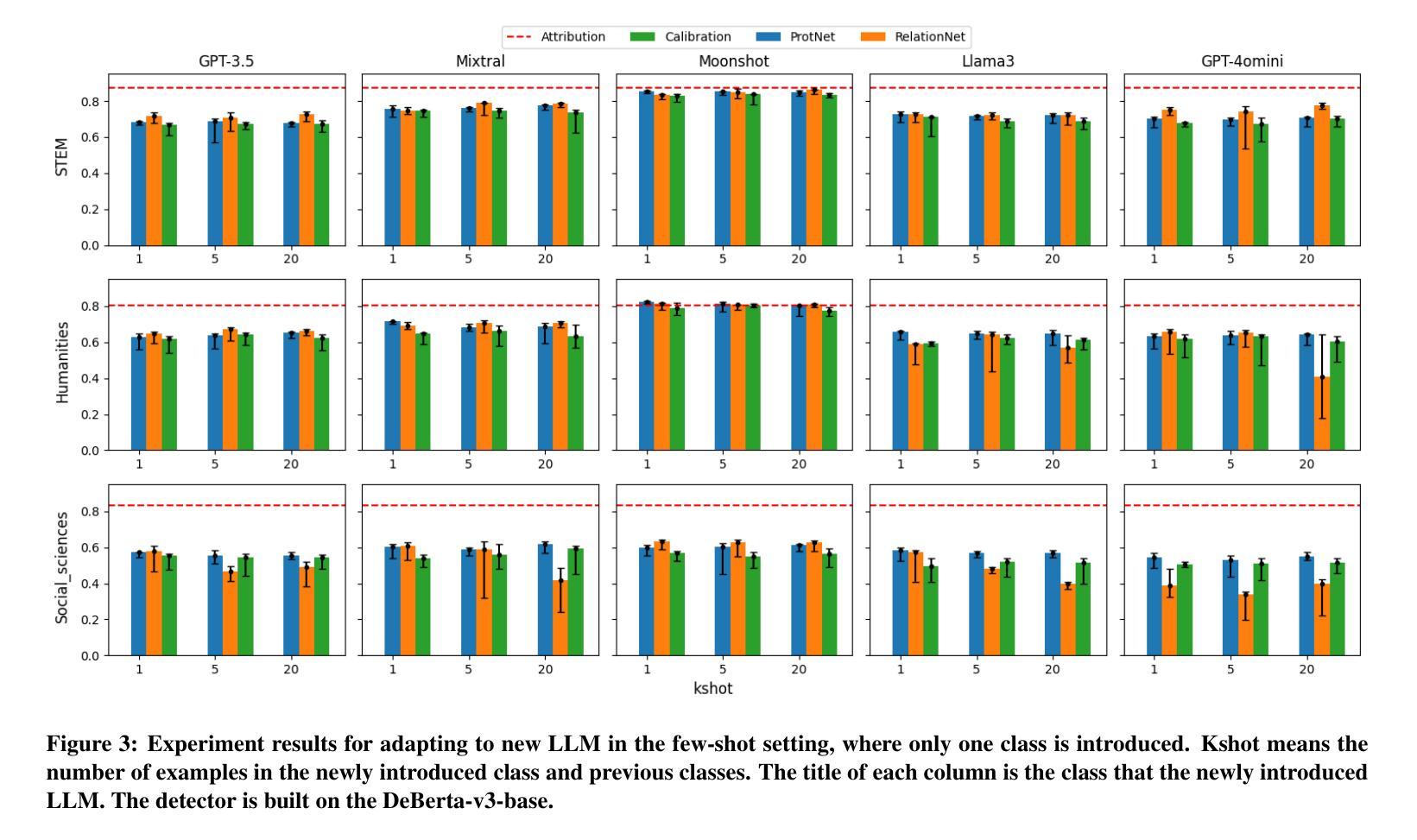
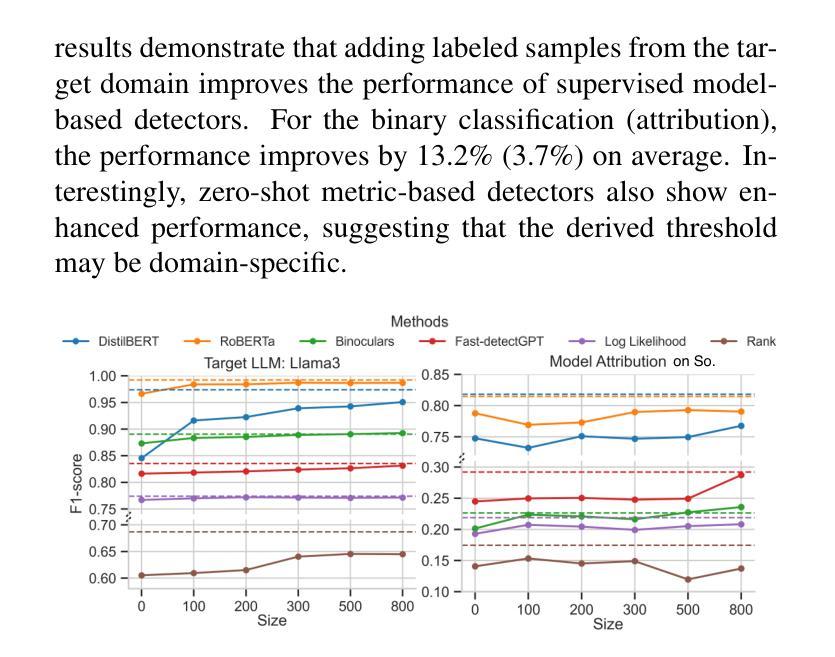
On the Generalization and Adaptation Ability of Machine-Generated Text Detectors in Academic Writing
Authors:Yule Liu, Zhiyuan Zhong, Yifan Liao, Zhen Sun, Jingyi Zheng, Jiaheng Wei, Qingyuan Gong, Fenghua Tong, Yang Chen, Yang Zhang, Xinlei He
The rising popularity of large language models (LLMs) has raised concerns about machine-generated text (MGT), particularly in academic settings, where issues like plagiarism and misinformation are prevalent. As a result, developing a highly generalizable and adaptable MGT detection system has become an urgent priority. Given that LLMs are most commonly misused in academic writing, this work investigates the generalization and adaptation capabilities of MGT detectors in three key aspects specific to academic writing: First, we construct MGT-Acedemic, a large-scale dataset comprising over 336M tokens and 749K samples. MGT-Acedemic focuses on academic writing, featuring human-written texts (HWTs) and MGTs across STEM, Humanities, and Social Sciences, paired with an extensible code framework for efficient benchmarking. Second, we benchmark the performance of various detectors for binary classification and attribution tasks in both in-domain and cross-domain settings. This benchmark reveals the often-overlooked challenges of attribution tasks. Third, we introduce a novel attribution task where models have to adapt to new classes over time without (or with very limited) access to prior training data in both few-shot and many-shot scenarios. We implement eight different adapting techniques to improve the performance and highlight the inherent complexity of the task. Our findings provide insights into the generalization and adaptation ability of MGT detectors across diverse scenarios and lay the foundation for building robust, adaptive detection systems. The code framework is available at https://github.com/Y-L-LIU/MGTBench-2.0.
随着大型语言模型(LLM)的日益普及,人们开始关注机器生成文本(MGT)的问题,特别是在学术环境中,抄袭和误信息等问题的普遍存在。因此,开发一个高度通用化和适应性的MGT检测系统已成为一项紧迫的任务。鉴于LLM在学术写作中最常被滥用,本研究从学术写作的角度出发,探讨了MGT检测器在三个方面的通用性和适应性能力:首先,我们构建了MGT-Acedemic数据集,该数据集包含超过3.36亿个标记和74.9万个样本的大规模数据集。MGT-Acedemic专注于学术写作领域,涵盖了科学、工程、文学和人文学科的文本(人类原创文本)和MGT,以及与可伸缩代码框架配合进行高效基准测试的功能。其次,我们对多种检测器进行了基准测试,这些检测器要在本地域和跨地域设置中进行二进制分类和归属任务分类任务。这个基准测试揭示出归属任务分类挑战被经常被忽视。最后,我们引入了一项新颖的归属任务分类测试,测试模型在时间推移中对新类别的适应力在没有或者很少有先前的训练数据的情况下对这两种情景进行短时长(少样本和多样本)进行推演预测的能力。我们实施了八种不同的适应技术来提高性能并突出任务的固有复杂性。我们的研究为深入了解MGT检测器在不同场景下的通用性和适应能力提供了见解,并为构建稳健的适应性检测系统奠定了基础。代码框架可在https://github.com/Y-L-LIU/MGTBench-2.0获取。
论文及项目相关链接
Summary
本文关注大型语言模型(LLMs)在学术写作中的滥用问题,特别是机器生成文本(MGT)的检测。研究构建了针对学术写作的MGT-Acedemic数据集,对多种检测器进行基准测试,并引入了一种新的归属任务。研究发现检测器在不同场景下的通用性和适应性挑战,并提出了多种适应技术以提高性能。这为构建稳健、自适应的检测系统提供了见解。
Key Takeaways
- 大型语言模型(LLMs)在学术写作中的滥用引发了对机器生成文本(MGT)的关注,特别是在存在抄袭和误导信息问题的学术环境中。
- 构建了专注于学术写作的MGT-Acedemic数据集,包含超过3.36亿个标记和74.9万个样本,涵盖STEM、人文和社会科学领域的人类撰写文本(HWTs)和MGTs。
- 对多种检测器进行基准测试,包括二进制分类和归属任务,在内部和跨领域环境中均表现出挑战。
- 引入了一种新的归属任务,要求模型在少量或没有先前训练数据的情况下,随着时间的推移适应新类别。
- 实施八种不同的适应技术以提高性能,突显了任务的固有复杂性。
- 研究结果提供了关于MGT检测器在不同场景下的通用性和适应能力的见解。
点此查看论文截图

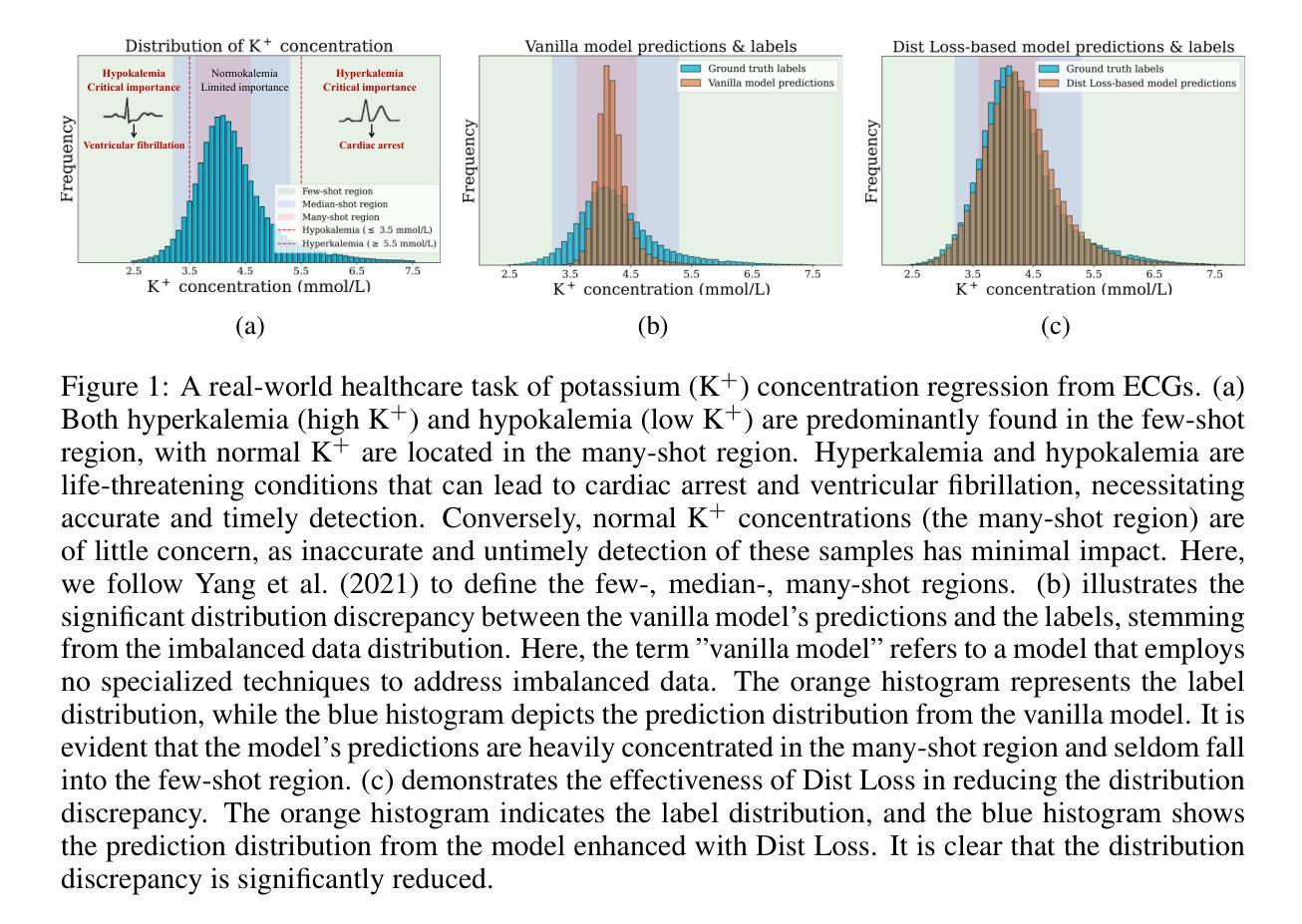
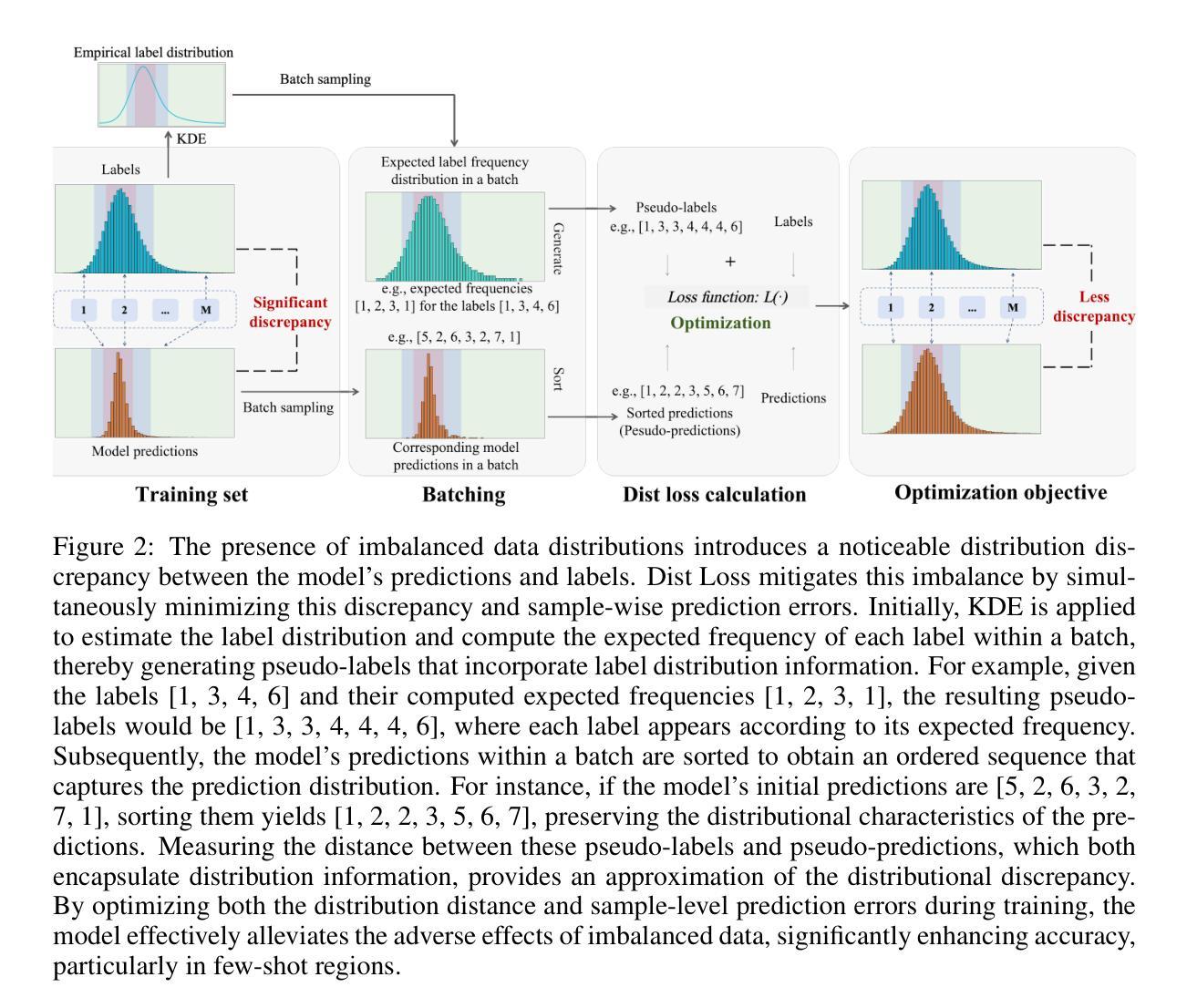
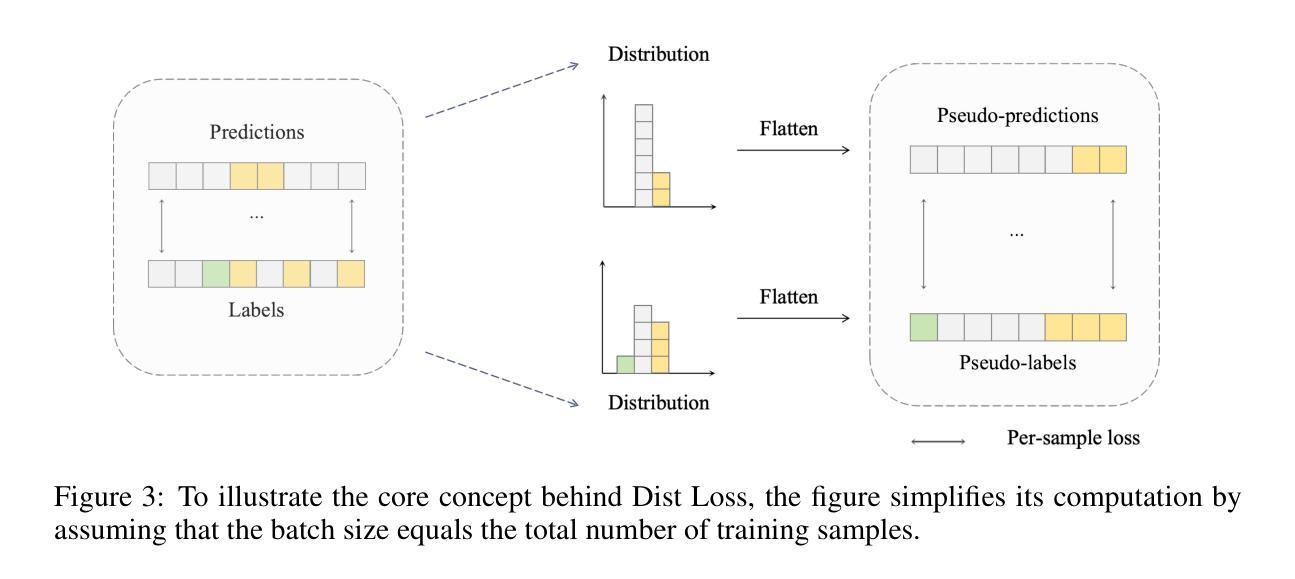
Dist Loss: Enhancing Regression in Few-Shot Region through Distribution Distance Constraint
Authors:Guangkun Nie, Gongzheng Tang, Shenda Hong
Imbalanced data distributions are prevalent in real-world scenarios, posing significant challenges in both imbalanced classification and imbalanced regression tasks. They often cause deep learning models to overfit in areas of high sample density (many-shot regions) while underperforming in areas of low sample density (few-shot regions). This characteristic restricts the utility of deep learning models in various sectors, notably healthcare, where areas with few-shot data hold greater clinical relevance. While recent studies have shown the benefits of incorporating distribution information in imbalanced classification tasks, such strategies are rarely explored in imbalanced regression. In this paper, we address this issue by introducing a novel loss function, termed Dist Loss, designed to minimize the distribution distance between the model’s predictions and the target labels in a differentiable manner, effectively integrating distribution information into model training. Dist Loss enables deep learning models to regularize their output distribution during training, effectively enhancing their focus on few-shot regions. We have conducted extensive experiments across three datasets spanning computer vision and healthcare: IMDB-WIKI-DIR, AgeDB-DIR, and ECG-Ka-DIR. The results demonstrate that Dist Loss effectively mitigates the negative impact of imbalanced data distribution on model performance, achieving state-of-the-art results in sparse data regions. Furthermore, Dist Loss is easy to integrate, complementing existing methods.
不平衡数据分布在实际场景中普遍存在,给不平衡分类和不平衡回归任务带来了重大挑战。它们经常导致深度学习模型在高样本密度区域(多镜头区域)过拟合,而在低样本密度区域(小样本区域)表现不佳。这种特性限制了深度学习模型在各个领域的实用性,特别是在医疗保健领域,小样本数据区域具有更大的临床意义。虽然最近的研究已经显示了将分布信息融入不平衡分类任务中的好处,但在不平衡回归中很少探索此类策略。在本文中,我们通过引入一种新型损失函数来解决这个问题,称为Dist Loss,旨在以可区分的方式最小化模型预测与目标标签之间的分布距离,有效地将分布信息融入模型训练。Dist Loss使深度学习模型能够在训练过程中规范其输出分布,从而有效提高它们对小样本区域的关注。我们在跨越计算机视觉和医疗保健的三个数据集上进行了广泛实验:IMDB-WIKI-DIR、AgeDB-DIR和ECG-Ka-DIR。结果表明,Dist Loss有效地减轻了不平衡数据分布对模型性能的负面影响,在稀疏数据区域实现了最新技术成果。此外,Dist Loss易于集成,可以弥补现有方法的不足。
论文及项目相关链接
Summary
深度学习模型在处理不平衡数据分布时面临挑战,特别是在少样本区域表现不佳。本文提出一种新型损失函数——Dist Loss,通过最小化模型预测与目标标签之间的分布距离,将分布信息融入模型训练,提高模型在少样本区域的关注度。实验结果表明,Dist Loss能有效缓解不平衡数据分布对模型性能的负面影响,达到稀疏数据区域的最佳效果,且易于集成。
Key Takeaways
- 不平衡数据分布在现实场景中普遍存在,对深度学习的分类和回归任务都带来挑战。
- 深度学习模型在高样本密度区域容易过拟合,而在低样本密度区域表现不佳。
- 本文提出了一种新型的损失函数——Dist Loss,旨在最小化模型预测与目标标签之间的分布距离。
- Dist Loss能够使得深度模型在训练过程中规范其输出分布,提高对少样本区域的关注度。
- 实验表明,Dist Loss能有效缓解不平衡数据分布对模型性能的负面影响。
- Dist Loss在图像和医疗数据集的测试中表现优异,达到了先进的效果。
点此查看论文截图

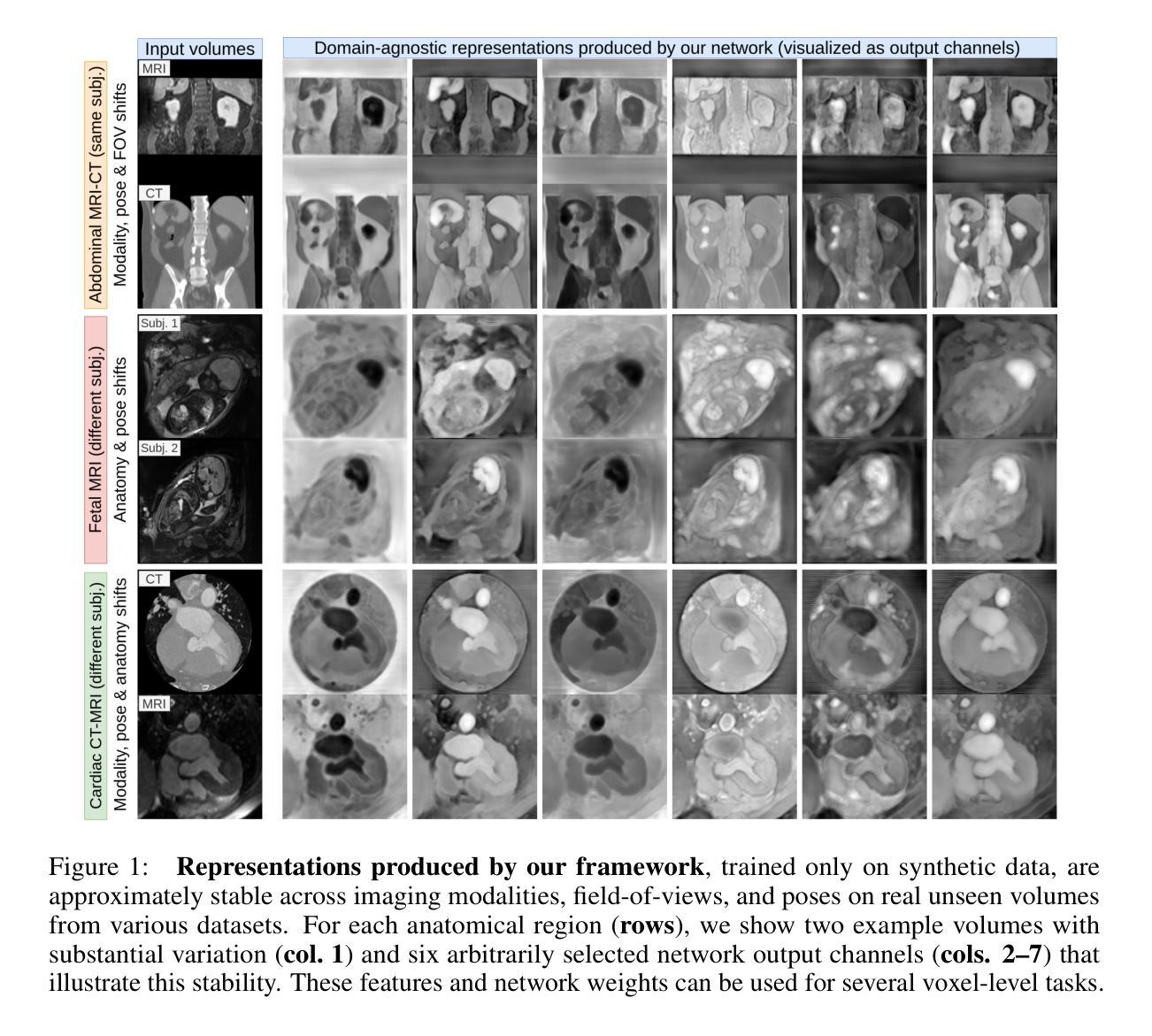
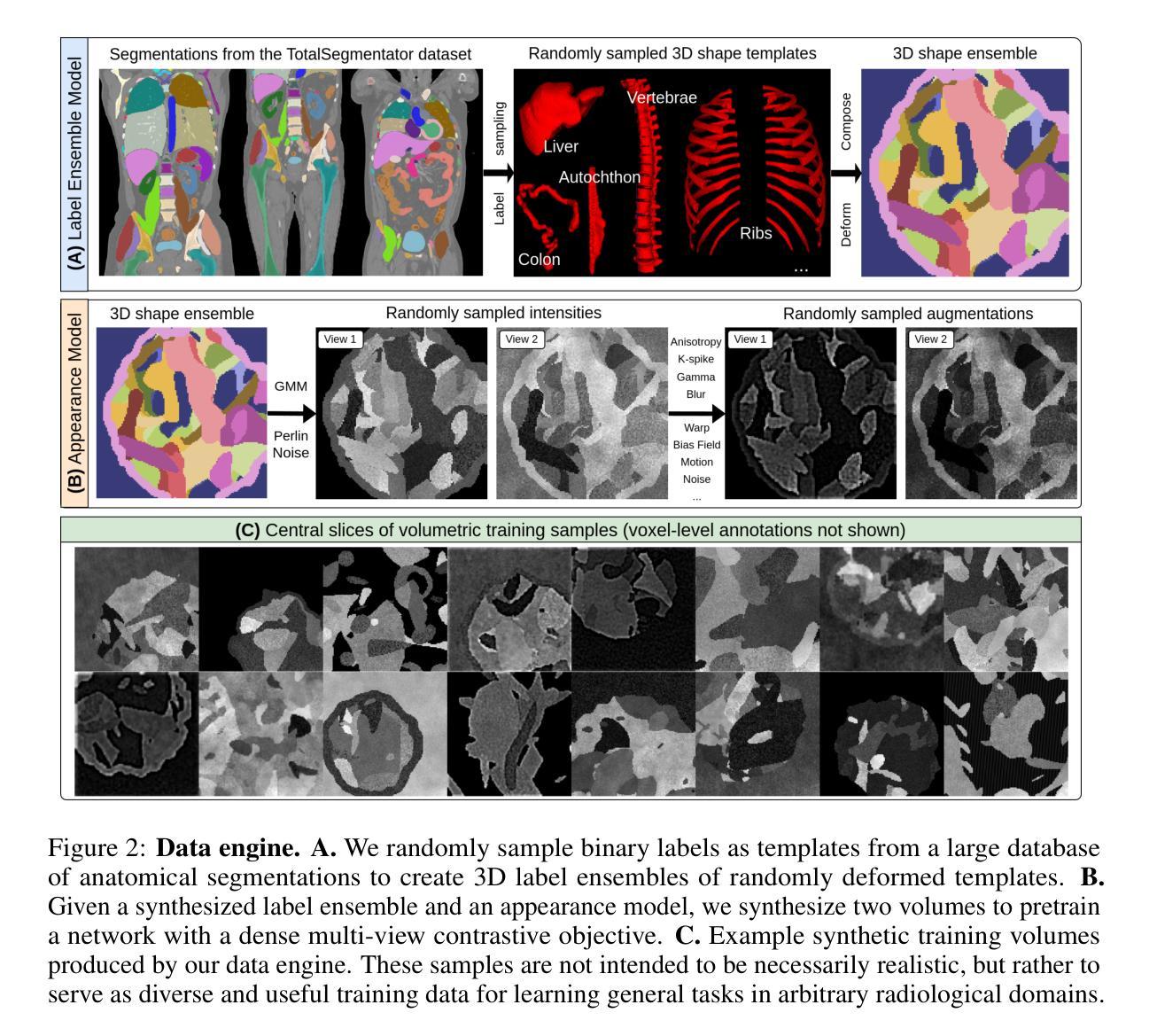
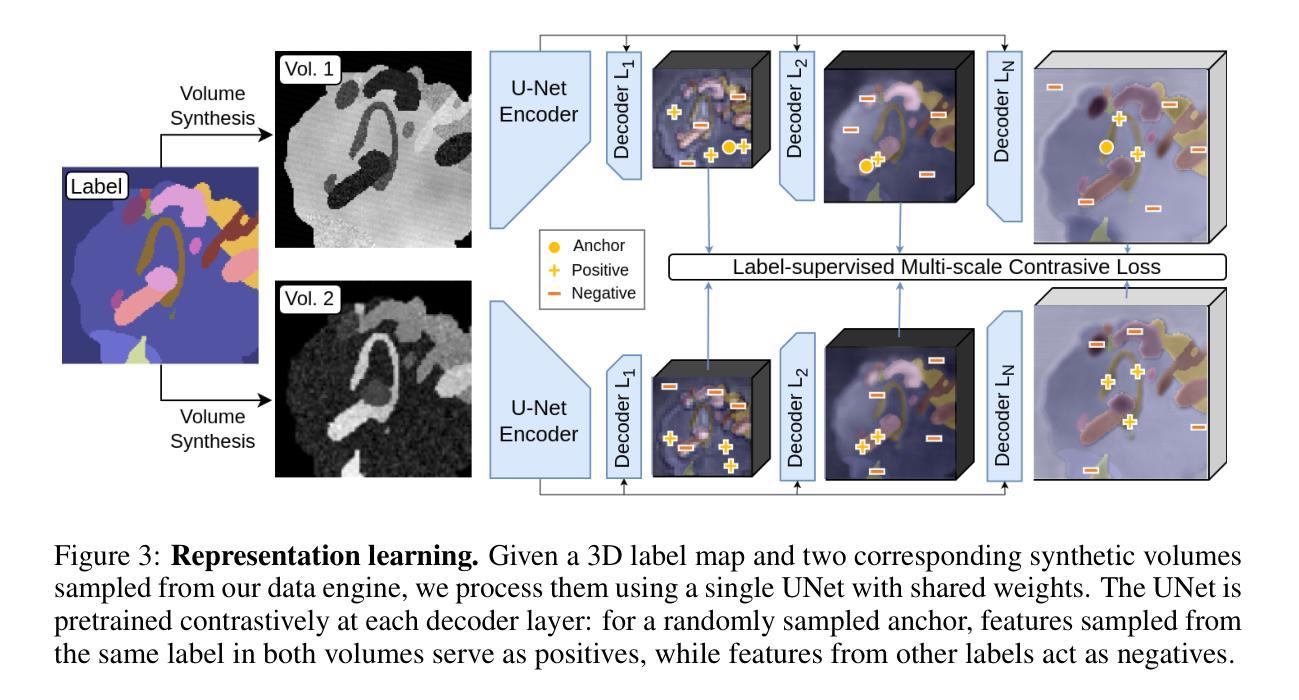
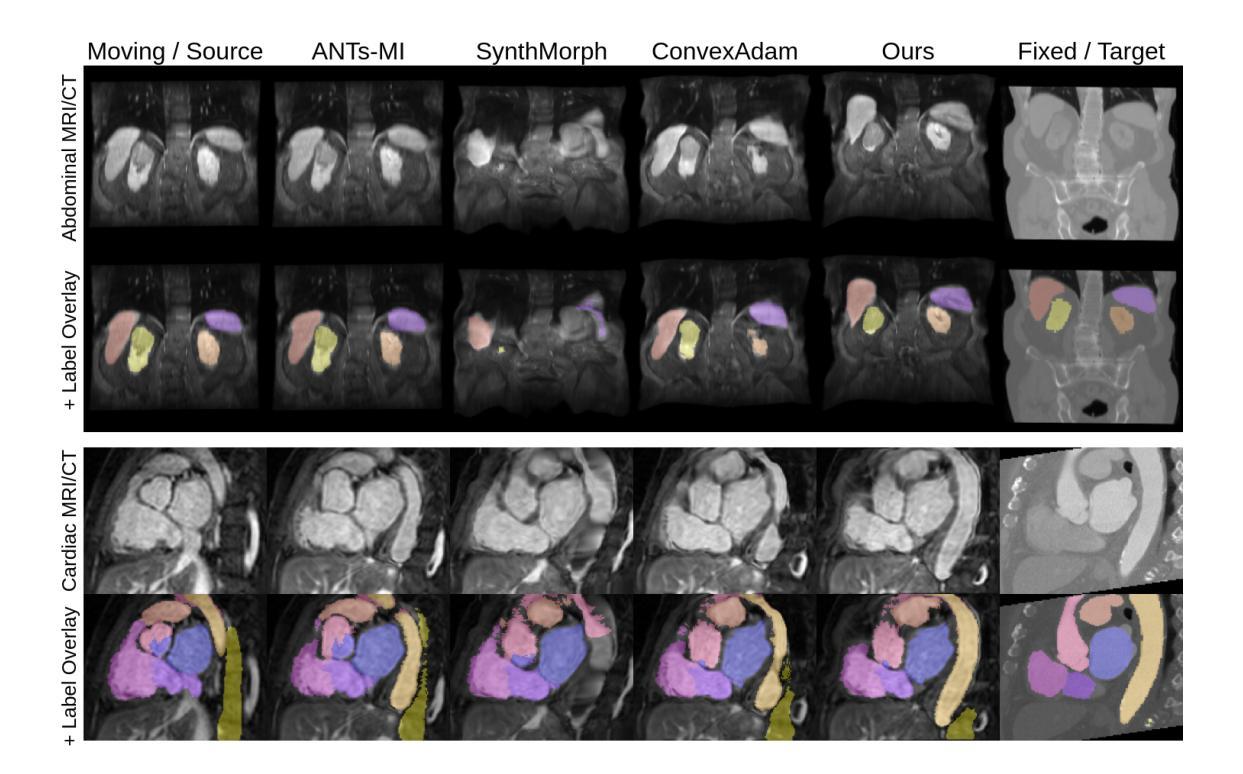
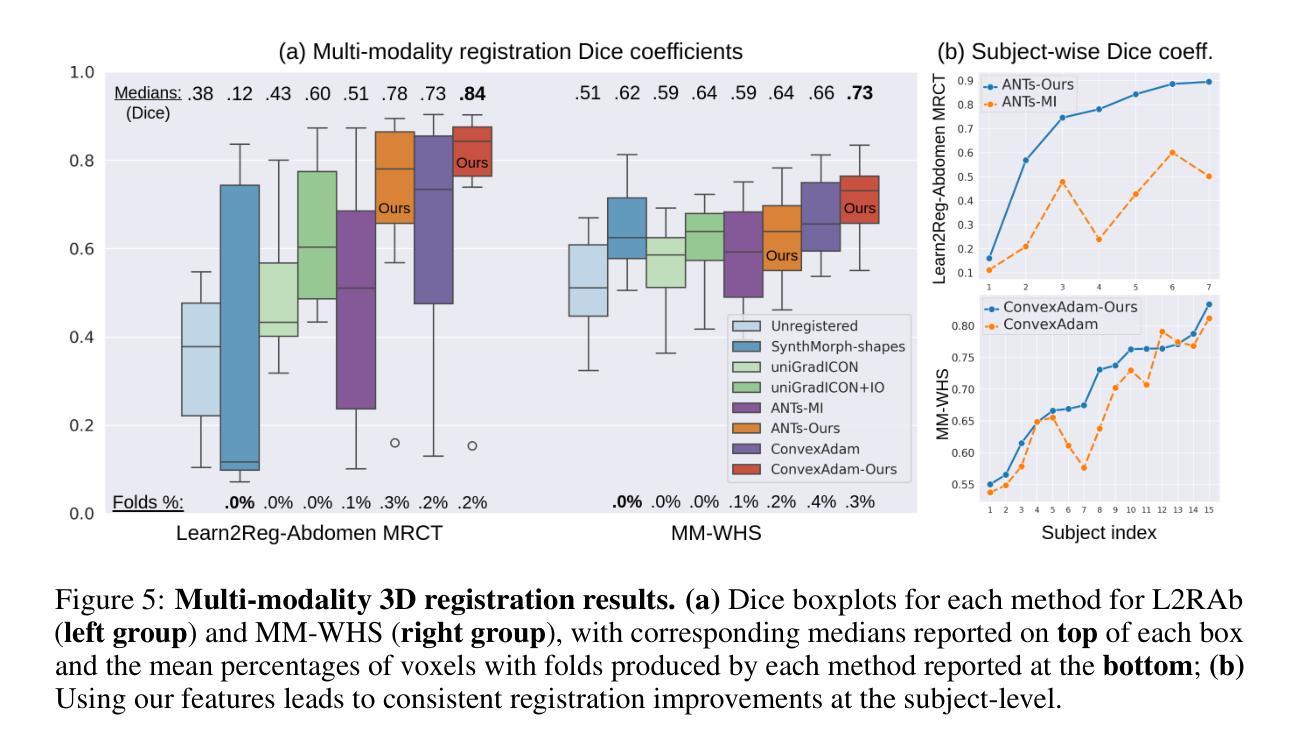
Learning General-Purpose Biomedical Volume Representations using Randomized Synthesis
Authors:Neel Dey, Benjamin Billot, Hallee E. Wong, Clinton J. Wang, Mengwei Ren, P. Ellen Grant, Adrian V. Dalca, Polina Golland
Current volumetric biomedical foundation models struggle to generalize as public 3D datasets are small and do not cover the broad diversity of medical procedures, conditions, anatomical regions, and imaging protocols. We address this by creating a representation learning method that instead anticipates strong domain shifts at training time itself. We first propose a data engine that synthesizes highly variable training samples that would enable generalization to new biomedical contexts. To then train a single 3D network for any voxel-level task, we develop a contrastive learning method that pretrains the network to be stable against nuisance imaging variation simulated by the data engine, a key inductive bias for generalization. This network’s features can be used as robust representations of input images for downstream tasks and its weights provide a strong, dataset-agnostic initialization for finetuning on new datasets. As a result, we set new standards across both multimodality registration and few-shot segmentation, a first for any 3D biomedical vision model, all without (pre-)training on any existing dataset of real images.
当前体积生物医学基础模型难以推广,因为公共3D数据集规模较小,并未涵盖广泛的医疗程序、状况、解剖区域和成像协议多样性。我们通过创建一种表示学习方法来解决这个问题,该方法能够在训练时本身就能预测到强烈的领域偏移。我们首先提出一个数据引擎,合成高度可变的训练样本,以实现向新生物医学环境的推广。为了针对任何体素级任务训练单个3D网络,我们开发了一种对比学习方法,该方法对由数据引擎模拟的干扰成像变化进行预训练网络,这是实现泛化的关键归纳偏置。该网络的特征可作为下游任务的稳健表示,其权重为在新数据集上进行微调提供了强大且独立于数据集初始化。因此,我们在多模态注册和少镜头分割方面设定了新的标准,这是3D生物医学视觉模型的首创,且无需在任何现有真实图像数据集上进行(预)训练。
论文及项目相关链接
PDF ICLR 2025: International Conference on Learning Representations. Code and model weights available at https://github.com/neel-dey/anatomix. Keywords: synthetic data, representation learning, medical image analysis, image registration, image segmentation
Summary
本文提出一种解决生物医学领域模型泛化能力弱的问题的方法。针对公共3D数据集规模小且不能覆盖广泛医疗程序、状况、解剖区域和成像协议的问题,文章提出了一种表示学习方法,该方法能够在训练时自身预期到强领域漂移。通过创建一个数据引擎来合成高度可变的训练样本,使模型能够推广到新的生物医学环境。同时,开发了一种对比学习方法来训练一个用于任何体素级别任务的单一3D网络。该网络能够在数据引擎模拟的干扰成像变化面前保持稳定,是一种关键的一般化归纳偏见。该网络的特征可用于下游任务的稳健表示,其权重为在新的数据集上进行微调提供了强大且独立于数据集的基础初始化。这种方法在跨模态注册和少样本分割方面都达到了新的标准,成为首个不需要在真实图像数据集上进行预训练的3D生物医学视觉模型。
Key Takeaways
- 当前生物医学领域的体积模型泛化能力受限,主要由于公共3D数据集规模小且缺乏多样性。
- 提出一种数据引擎,能够合成高度可变的训练样本以改善模型的泛化能力。
- 采用对比学习方法训练单一3D网络,用于处理各种体素级别任务。
- 网络能在模拟的干扰成像变化面前保持稳定,这是提高模型泛化能力的重要归纳偏见。
- 该网络特征可作为下游任务的稳健表示,其权重为在新的数据集上进行微调提供了强大的初始化。
- 此方法在多模态注册和少样本分割方面达到新的标准。
点此查看论文截图

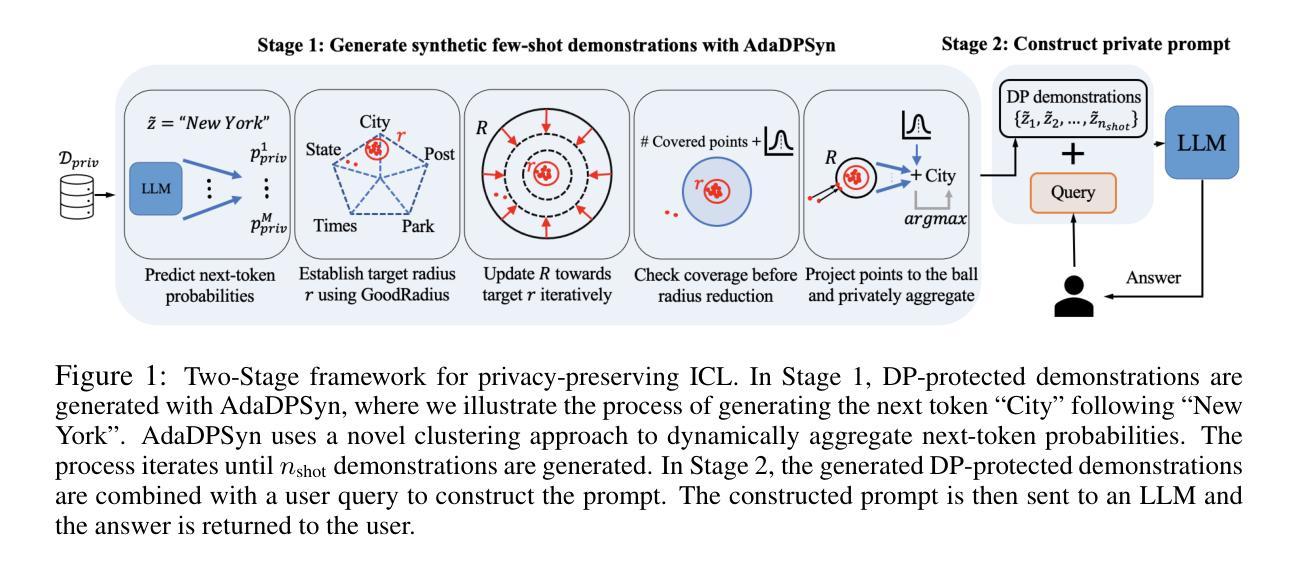
Data-adaptive Differentially Private Prompt Synthesis for In-Context Learning
Authors:Fengyu Gao, Ruida Zhou, Tianhao Wang, Cong Shen, Jing Yang
Large Language Models (LLMs) rely on the contextual information embedded in examples/demonstrations to perform in-context learning (ICL). To mitigate the risk of LLMs potentially leaking private information contained in examples in the prompt, we introduce a novel data-adaptive differentially private algorithm called AdaDPSyn to generate synthetic examples from the private dataset and then use these synthetic examples to perform ICL. The objective of AdaDPSyn is to adaptively adjust the noise level in the data synthesis mechanism according to the inherent statistical properties of the data, thereby preserving high ICL accuracy while maintaining formal differential privacy guarantees. A key innovation in AdaDPSyn is the Precision-Focused Iterative Radius Reduction technique, which dynamically refines the aggregation radius - the scope of data grouping for noise addition - based on patterns observed in data clustering, thereby minimizing the amount of additive noise. We conduct extensive experiments on standard benchmarks and compare AdaDPSyn with DP few-shot generation algorithm (Tang et al., 2023). The experiments demonstrate that AdaDPSyn not only outperforms DP few-shot generation, but also maintains high accuracy levels close to those of non-private baselines, providing an effective solution for ICL with privacy protection.
大型语言模型(LLM)依赖于嵌入在示例/演示中的上下文信息进行上下文学习(ICL)。为了减轻LLM可能在提示中的示例中泄露私人信息的风险,我们引入了一种新型的数据自适应差分隐私算法AdaDPSyn,从私有数据集中生成合成示例,然后使用这些合成示例进行ICL。AdaDPSyn的目标是根据数据的固有统计属性自适应地调整数据合成机制中的噪声水平,从而在保持正式差分隐私保证的同时,保持高ICL精度。AdaDPSyn的一个关键创新点是精准聚焦的迭代半径缩减技术,该技术根据在数据聚类中观察到的模式动态调整聚合半径(噪声添加的数据分组范围),从而最小化添加的噪声量。我们在标准基准测试上进行了大量实验,将AdaDPSyn与DP少样本生成算法(Tang等人,2023)进行了比较。实验表明,AdaDPSyn不仅优于DP少样本生成,而且保持接近非私有基准测试的高精度水平,为带有隐私保护的ICL提供了有效解决方案。
论文及项目相关链接
PDF Accepted to ICLR 2025
Summary
大型语言模型依赖示例中的上下文信息进行上下文学习。为缓解示例中可能泄露的私人信息风险,提出了一种新型的数据自适应差分隐私算法AdaDPSyn,用于从私有数据集中生成合成示例,并使用这些合成示例进行上下文学习。AdaDPSyn能自适应调整数据合成机制中的噪声水平,以适应数据的内在统计特性,从而在保持高上下文学习精度的同时,确保正式的差分隐私保证。其关键创新在于精准聚焦的迭代半径缩减技术,该技术根据数据聚类中观察到的模式动态调整聚合半径,从而最小化添加的噪声量。实验表明,AdaDPSyn不仅优于DP的少样本生成算法,而且保持接近非私有基准线的精度,为带有隐私保护的上下文学习提供了有效解决方案。
Key Takeaways
- 大型语言模型依赖示例的上下文信息进行学习。
- AdaDPSyn是一种数据自适应的差分隐私算法,用于生成合成示例以进行上下文学习。
- AdaDPSyn能根据数据的统计特性自适应调整噪声水平。
- AdaDPSyn采用精准聚焦的迭代半径缩减技术,动态调整聚合半径以最小化噪声。
- AdaDPSyn在保持高上下文学习精度的同时,确保差分隐私。
- 与现有的DP少样本生成算法相比,AdaDPSyn表现出更好的性能。
点此查看论文截图


Snuffy: Efficient Whole Slide Image Classifier
Authors:Hossein Jafarinia, Alireza Alipanah, Danial Hamdi, Saeed Razavi, Nahal Mirzaie, Mohammad Hossein Rohban
Whole Slide Image (WSI) classification with multiple instance learning (MIL) in digital pathology faces significant computational challenges. Current methods mostly rely on extensive self-supervised learning (SSL) for satisfactory performance, requiring long training periods and considerable computational resources. At the same time, no pre-training affects performance due to domain shifts from natural images to WSIs. We introduce Snuffy architecture, a novel MIL-pooling method based on sparse transformers that mitigates performance loss with limited pre-training and enables continual few-shot pre-training as a competitive option. Our sparsity pattern is tailored for pathology and is theoretically proven to be a universal approximator with the tightest probabilistic sharp bound on the number of layers for sparse transformers, to date. We demonstrate Snuffy’s effectiveness on CAMELYON16 and TCGA Lung cancer datasets, achieving superior WSI and patch-level accuracies. The code is available on https://github.com/jafarinia/snuffy.
在全数字病理学中,基于多实例学习(MIL)的全幻灯片图像(WSI)分类面临着巨大的计算挑战。当前的方法大多依赖于广泛的自监督学习(SSL)以获得令人满意的效果,这需要长时间的训练和大量的计算资源。同时,由于没有预训练会受到来自自然图像到WSI领域转变的影响。我们引入了Snuffy架构,这是一种基于稀疏变压器的新型MIL池方法,它通过有限的预训练减轻了性能损失,并能够实现持续的少量预训练作为一种具有竞争力的选择。我们的稀疏模式是针对病理学量身定制的,从理论上证明了它是迄今为止稀疏变压器层数最紧的概率尖锐界限的通用逼近器。我们在CAMELYON16和TCGA肺癌数据集上展示了Snuffy的有效性,实现了优越的全幻灯片图像和补丁级别的准确性。代码可在https://github.com/jafarinia/snuffy上获得。
论文及项目相关链接
PDF Accepted for ECCV 2024
Summary
本文介绍了基于稀疏变换器的新型MIL池化方法——Snuffy架构,该架构解决了数字病理学中全幻灯片图像(WSI)分类面临的挑战。传统的自监督学习方法需要大量时间和计算资源,而Snuffy架构通过引入稀疏变换器技术实现了更高效的训练过程,并具有出色的少样本预训练能力。实验结果表明,Snuffy架构在CAMELYON16和TCGA肺癌数据集上实现了更高的WSI和补丁级别的准确性。代码已发布在GitHub上。
Key Takeaways
- Snuffy架构解决了数字病理学中WSI分类面临的计算挑战。
- 当前方法大多依赖大量自监督学习(SSL),训练时间长且计算资源消耗大。
- Snuffy架构引入稀疏变换器技术,提高训练效率并具备出色的少样本预训练能力。
- Snuffy架构实现了个性化稀疏模式,适用于病理学领域,且在稀疏变换器的层数上具有理论证明的最紧概率尖锐界。
- 在CAMELYON16和TCGA肺癌数据集上,Snuffy架构实现了较高的WSI和补丁级别准确性。
点此查看论文截图

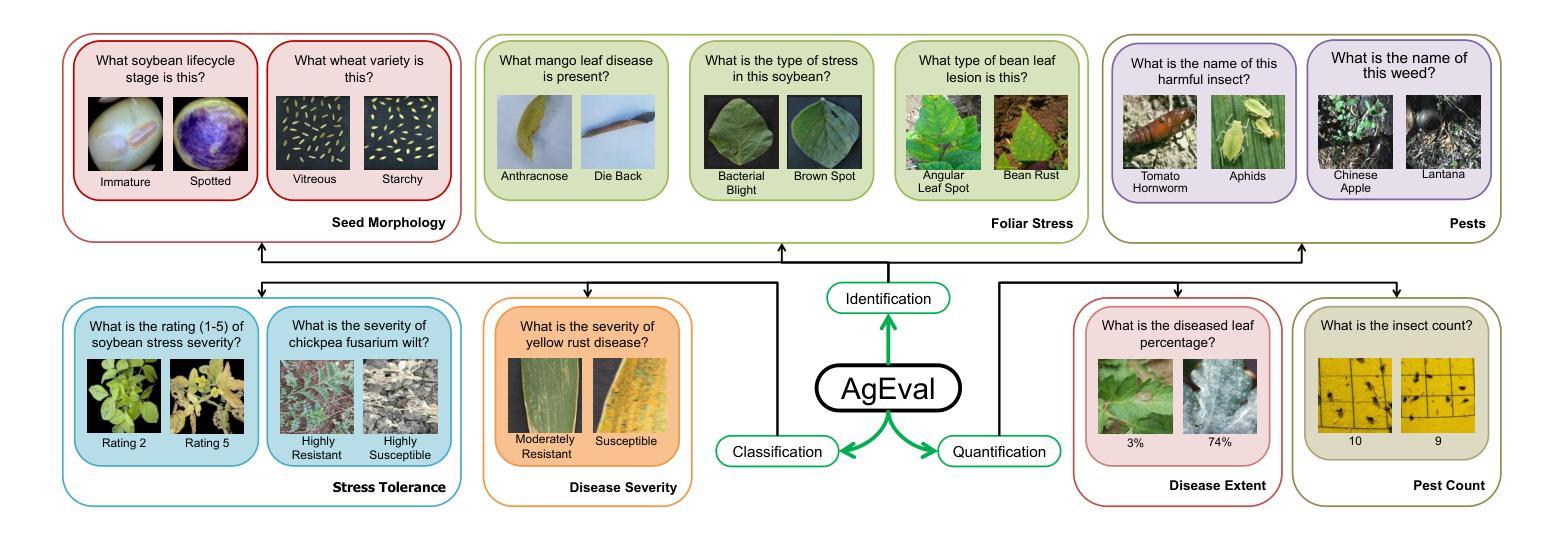
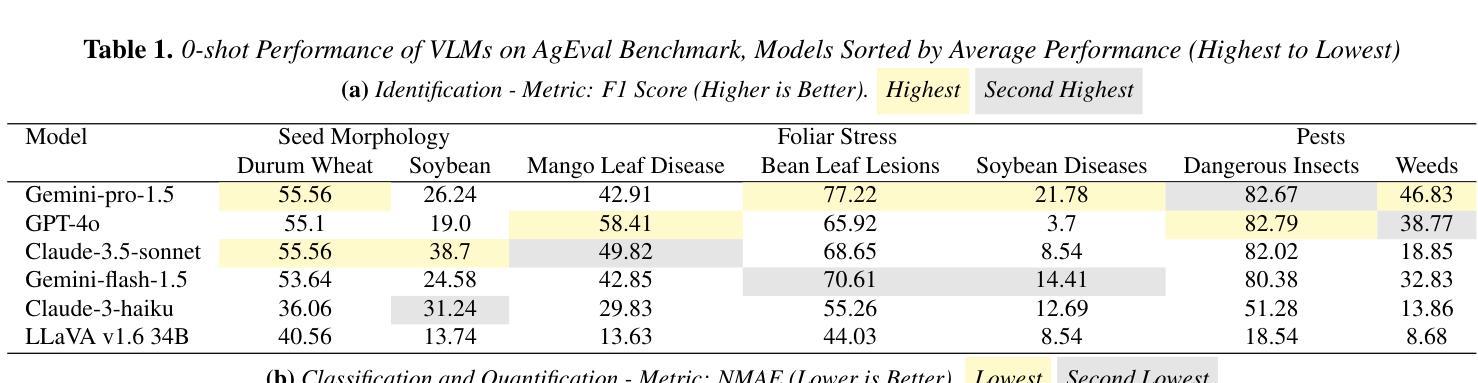
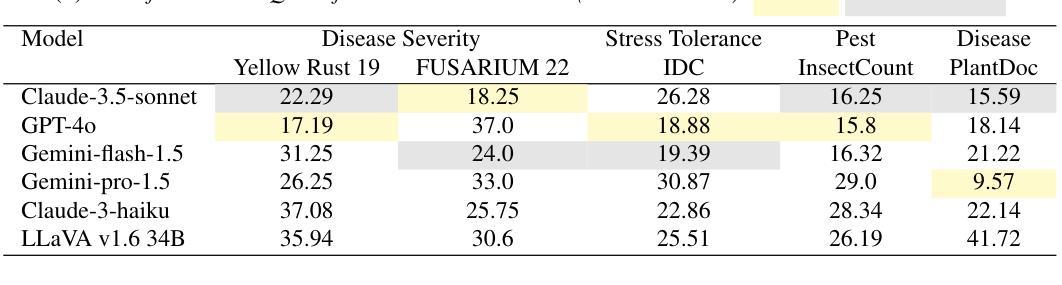
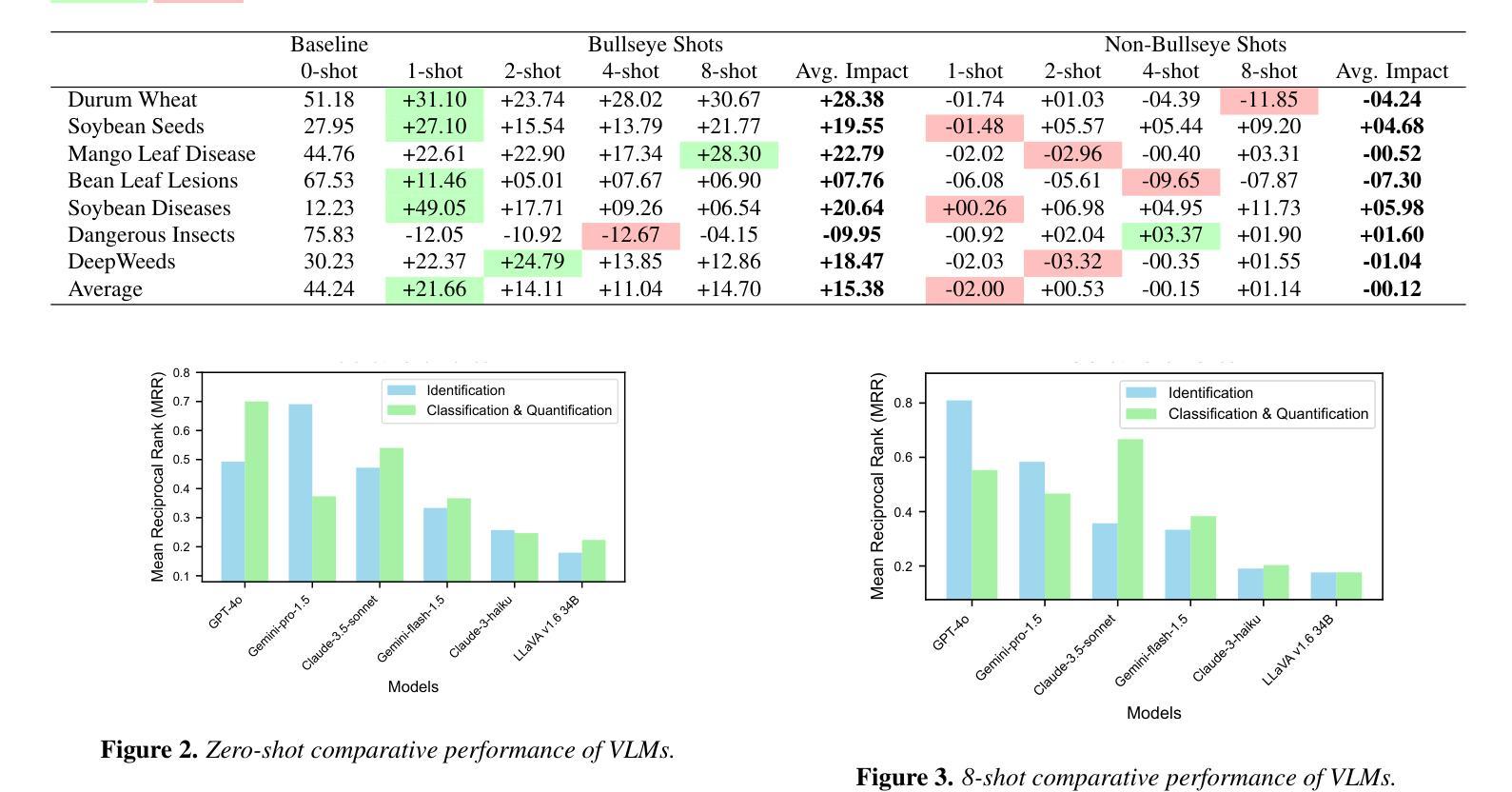
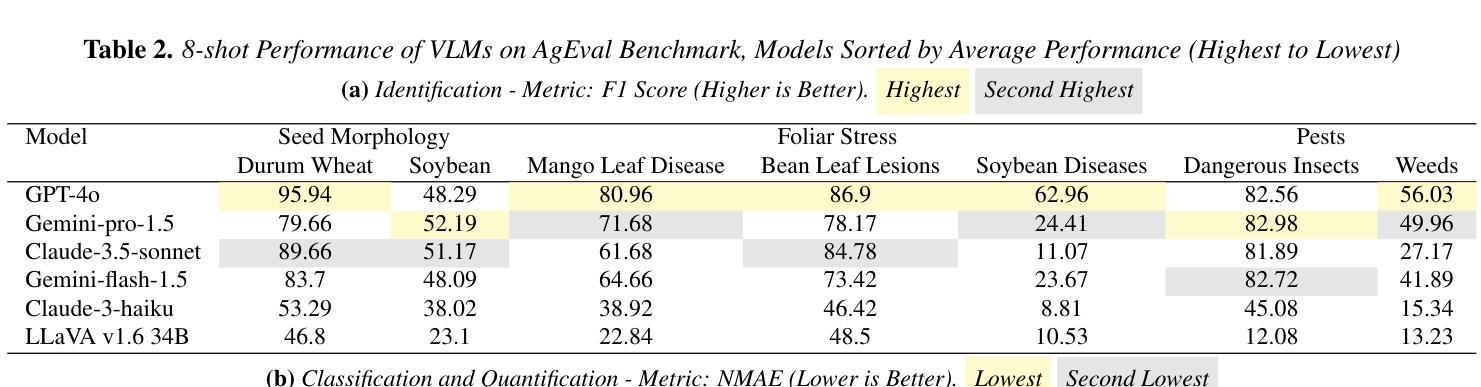
Leveraging Vision Language Models for Specialized Agricultural Tasks
Authors:Muhammad Arbab Arshad, Talukder Zaki Jubery, Tirtho Roy, Rim Nassiri, Asheesh K. Singh, Arti Singh, Chinmay Hegde, Baskar Ganapathysubramanian, Aditya Balu, Adarsh Krishnamurthy, Soumik Sarkar
As Vision Language Models (VLMs) become increasingly accessible to farmers and agricultural experts, there is a growing need to evaluate their potential in specialized tasks. We present AgEval, a comprehensive benchmark for assessing VLMs’ capabilities in plant stress phenotyping, offering a solution to the challenge of limited annotated data in agriculture. Our study explores how general-purpose VLMs can be leveraged for domain-specific tasks with only a few annotated examples, providing insights into their behavior and adaptability. AgEval encompasses 12 diverse plant stress phenotyping tasks, evaluating zero-shot and few-shot in-context learning performance of state-of-the-art models including Claude, GPT, Gemini, and LLaVA. Our results demonstrate VLMs’ rapid adaptability to specialized tasks, with the best-performing model showing an increase in F1 scores from 46.24% to 73.37% in 8-shot identification. To quantify performance disparities across classes, we introduce metrics such as the coefficient of variation (CV), revealing that VLMs’ training impacts classes differently, with CV ranging from 26.02% to 58.03%. We also find that strategic example selection enhances model reliability, with exact category examples improving F1 scores by 15.38% on average. AgEval establishes a framework for assessing VLMs in agricultural applications, offering valuable benchmarks for future evaluations. Our findings suggest that VLMs, with minimal few-shot examples, show promise as a viable alternative to traditional specialized models in plant stress phenotyping, while also highlighting areas for further refinement. Results and benchmark details are available at: https://github.com/arbab-ml/AgEval
随着视觉语言模型(VLMs)越来越被农民和农业专家所接触,评估它们在专业任务中的潜力变得日益重要。我们推出了AgEval,这是一个用于评估VLMs在植物胁迫表型分析能力的综合基准测试,为解决农业中标注数据有限的问题提供了解决方案。我们的研究探讨了通用VLMs如何利用少量的标注示例来完成特定领域的任务,深入了解其行为和适应性。AgEval涵盖了12个多样化的植物胁迫表型分析任务,评估了包括Claude、GPT、Gemini和LLaVA等最新模型的无监督和少量监督的上下文学习能力表现。我们的结果表明,VLMs能够迅速适应专业任务,最佳性能的模型在8次拍摄的识别中F1得分从46.24%提高到73.37%。为了量化各类之间的性能差异,我们引入了变异系数(CV)这一指标,揭示VLMs的训练对不同类别的影响不同,CV范围从26.02%到58.03%。我们还发现,战略性的例子选择可以提高模型的可靠性,精确类别的例子平均提高了F1得分15.38%。AgEval建立了评估VLMs在农业应用中的基准测试框架,为未来的评估提供了有价值的参考。我们的研究结果表明,利用最少的几次拍摄示例,VLMs在植物胁迫表型分析中显示出作为传统专业模型的可行替代方案的潜力,同时也突出了需要进一步改进的领域。结果和基准测试详情可在:https://github.com/arbab-ml/AgEval找到。
论文及项目相关链接
PDF Published at WACV 2025
Summary
本文介绍了Vision Language Models(VLMs)在农业领域的潜力评估。为评估VLMs在植物压力表现分析方面的能力,提出了AgEval这一综合性基准测试。研究探讨了通用VLMs如何在只需少量标注样本的情况下,就能适应特定任务。AgEval涵盖了多样化的植物压力表现分析任务,评估了最前沿模型如Claude、GPT等的零样本和少样本上下文学习能力表现。结果显示VLMs能快速适应专项任务,最佳模型在8次射击识别中的F1得分从46.24%提高到73.37%。同时,通过引入变异系数等度量标准,揭示了不同类别间性能差异的问题。研究还发现,通过选择策略性示例能提高模型可靠性。AgEval为评估VLMs在农业应用中的表现提供了宝贵基准,表明VLMs在植物压力表现分析方面显示出巨大的潜力。
Key Takeaways
- Vision Language Models (VLMs) 在农业领域的植物压力表现分析中具有潜力评估价值。
- AgEval是评估VLMs在植物压力表现分析方面的综合性基准测试。
- VLMs可以在只需少量标注样本的情况下适应特定任务。
- AgEval涵盖了多样化的植物压力表现分析任务,并评估了多种最前沿模型的表现。
- VLMs能快速适应专项任务,并通过战略示例选择提高模型可靠性。
- 不同类别间存在性能差异,引入度量标准如变异系数以量化这种差异。
点此查看论文截图