⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-05 更新
LANTERN: Accelerating Visual Autoregressive Models with Relaxed Speculative Decoding
Authors:Doohyuk Jang, Sihwan Park, June Yong Yang, Yeonsung Jung, Jihun Yun, Souvik Kundu, Sung-Yub Kim, Eunho Yang
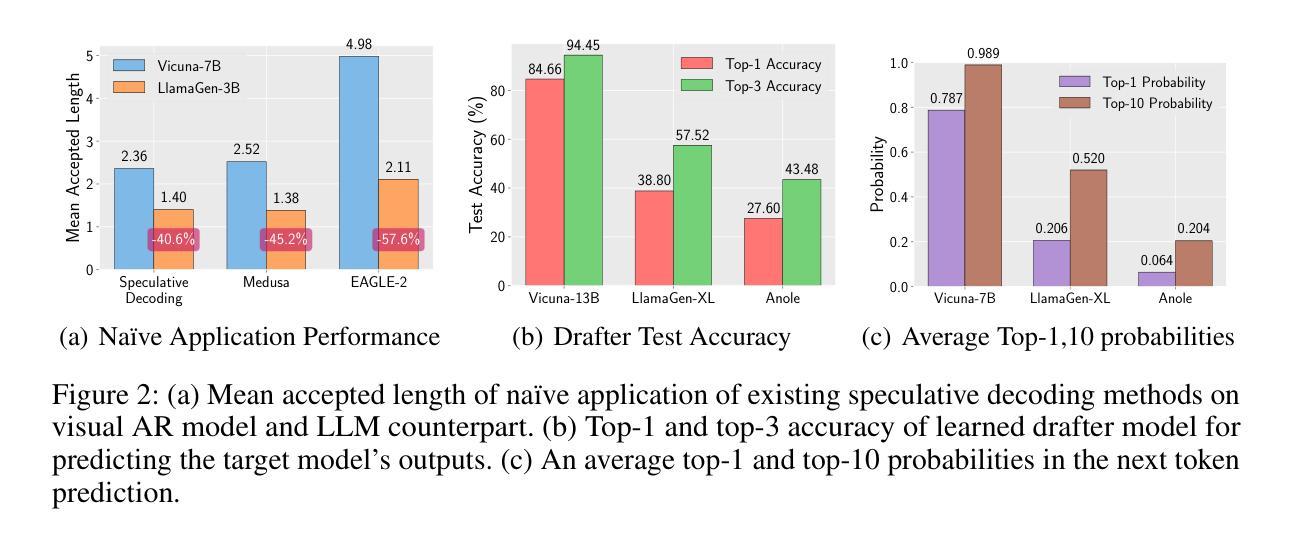
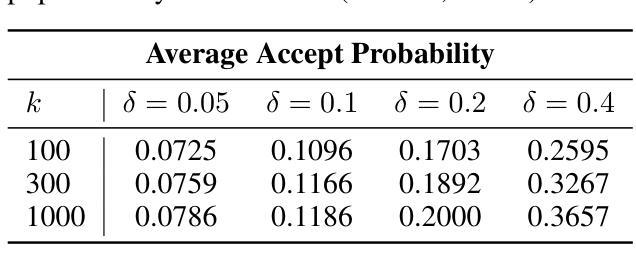
Auto-Regressive (AR) models have recently gained prominence in image generation, often matching or even surpassing the performance of diffusion models. However, one major limitation of AR models is their sequential nature, which processes tokens one at a time, slowing down generation compared to models like GANs or diffusion-based methods that operate more efficiently. While speculative decoding has proven effective for accelerating LLMs by generating multiple tokens in a single forward, its application in visual AR models remains largely unexplored. In this work, we identify a challenge in this setting, which we term \textit{token selection ambiguity}, wherein visual AR models frequently assign uniformly low probabilities to tokens, hampering the performance of speculative decoding. To overcome this challenge, we propose a relaxed acceptance condition referred to as LANTERN that leverages the interchangeability of tokens in latent space. This relaxation restores the effectiveness of speculative decoding in visual AR models by enabling more flexible use of candidate tokens that would otherwise be prematurely rejected. Furthermore, by incorporating a total variation distance bound, we ensure that these speed gains are achieved without significantly compromising image quality or semantic coherence. Experimental results demonstrate the efficacy of our method in providing a substantial speed-up over speculative decoding. In specific, compared to a na"ive application of the state-of-the-art speculative decoding, LANTERN increases speed-ups by $\mathbf{1.75}\times$ and $\mathbf{1.82}\times$, as compared to greedy decoding and random sampling, respectively, when applied to LlamaGen, a contemporary visual AR model. The code is publicly available at https://github.com/jadohu/LANTERN.
自回归(AR)模型在图像生成领域最近受到了广泛关注,其性能往往与扩散模型相匹敌甚至更胜一筹。然而,AR模型的一个主要局限性在于它们的序列性质,即一次只处理一个令牌,与像GAN或基于扩散的方法等更高效的模型相比,生成速度较慢。尽管猜测解码通过在一次前向过程中生成多个令牌来加速大型语言模型,但其在视觉AR模型中的应用仍然在很大程度上未被探索。在这项工作中,我们确定了一个在此环境中的挑战,我们称之为“令牌选择歧义”,其中视觉AR模型经常为令牌分配统一较低的概率,阻碍了猜测解码的性能。为了克服这一挑战,我们提出了一种放宽的接受条件,称为LANTERN,它利用潜在空间中令牌的互换性。这种放宽通过使候选令牌更灵活地使用(否则会被过早拒绝),从而恢复了视觉AR模型中猜测解码的有效性。此外,通过引入总变差距离界限,我们确保在加速的同时不会显著损害图像质量或语义连贯性。实验结果表明我们的方法在提供猜测解码的实质性加速方面非常有效。具体来说,与最新猜测解码的盲目应用相比,LANTERN在应用于当代视觉AR模型LlamaGen时,分别将速度提高了1.75倍和1.82倍,与贪心解码和随机采样相比。代码可在https://github.com/jadohu/LANTERN公开获取。
论文及项目相关链接
PDF 30 pages, 13 figures, Accepted to ICLR 2025 (poster)
Summary
本文探讨了自回归(AR)模型在图像生成领域面临的挑战,即其顺序性导致的生成速度慢的问题。为加速AR模型,本文提出了一个名为LANTERN的方法,通过放松接受条件并利用潜在空间中令牌的互换性,恢复视觉AR模型中投机解码的有效性。实验结果表明,该方法能有效提高解码速度,与现有投机解码方法相比,在LlamaGen模型上分别提高了1.75倍和1.82倍的加速效果。
Key Takeaways
- AR模型在图像生成中面临生成速度慢的挑战,主要由于其顺序处理令牌的方式。
- 投机解码可加速LLM,但在视觉AR模型中的应用尚未得到充分探索。
- 视觉AR模型中存在“令牌选择歧义”问题,导致投机解码效果减弱。
- LANTERN方法通过放松接受条件,利用潜在空间中令牌的互换性,解决了这一问题。
- LANTERN方法实现了对投机解码的实质性加速,提高了图像生成效率。
- 与现有方法相比,LANTERN在LlamaGen模型上的加速效果显著提高,分别为1.75倍和1.82倍。
点此查看论文截图



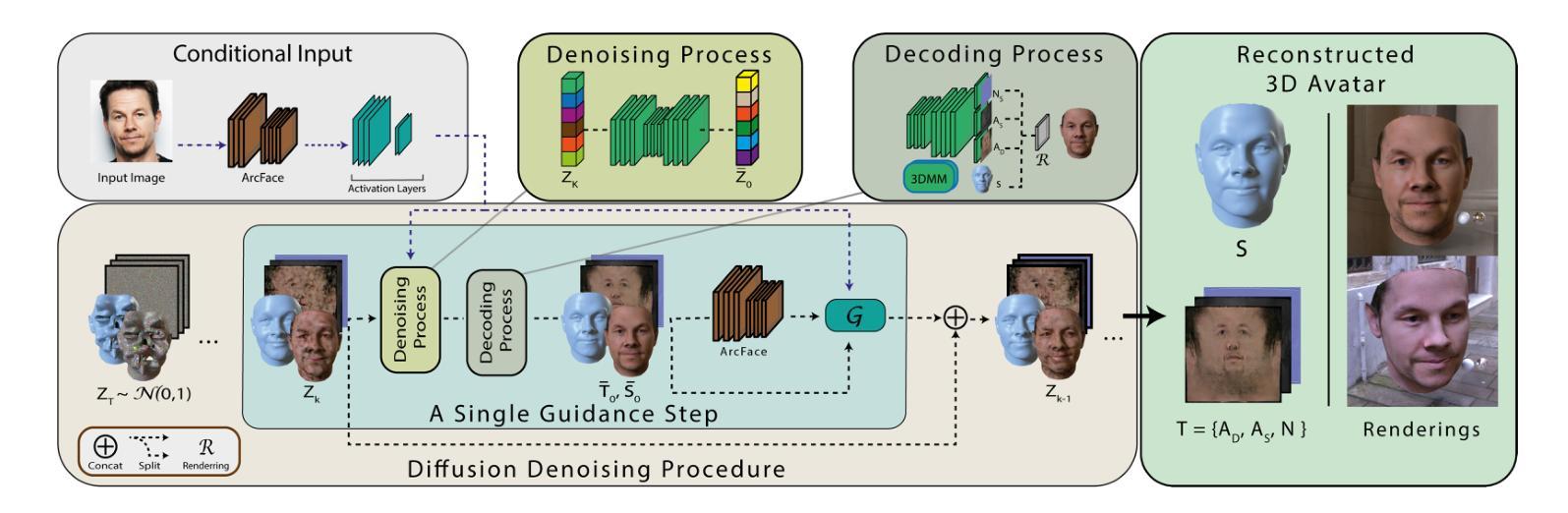
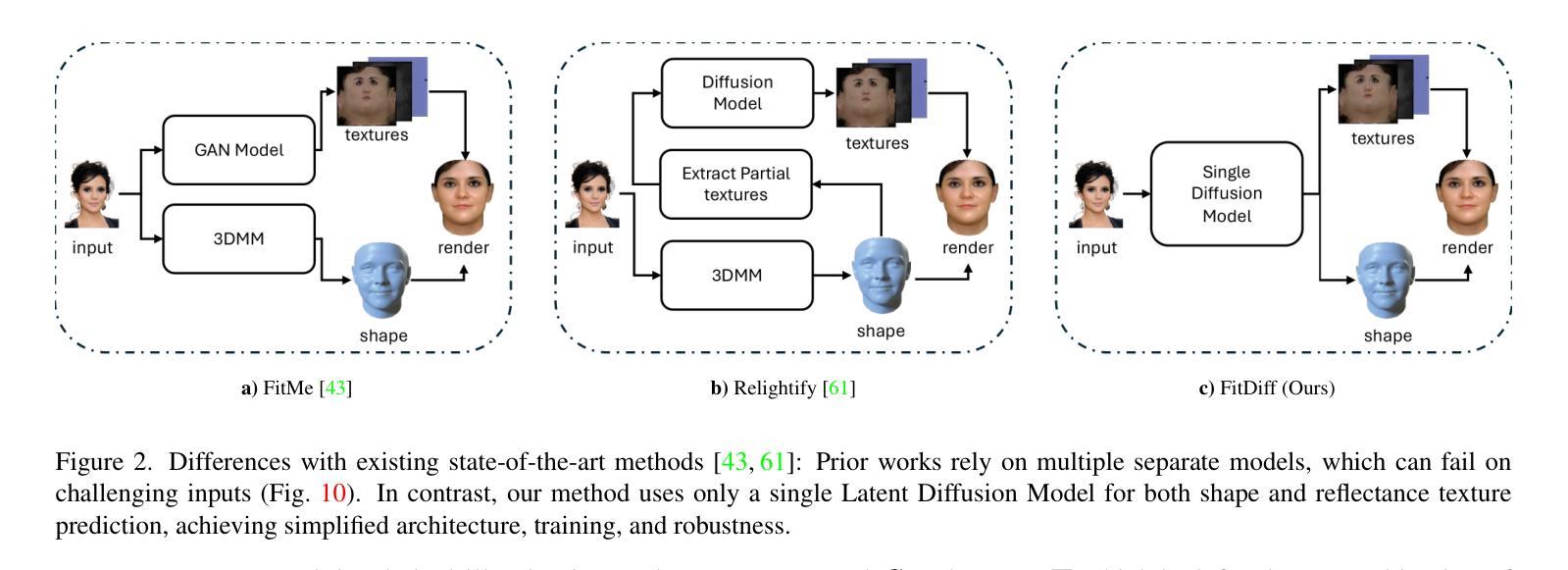
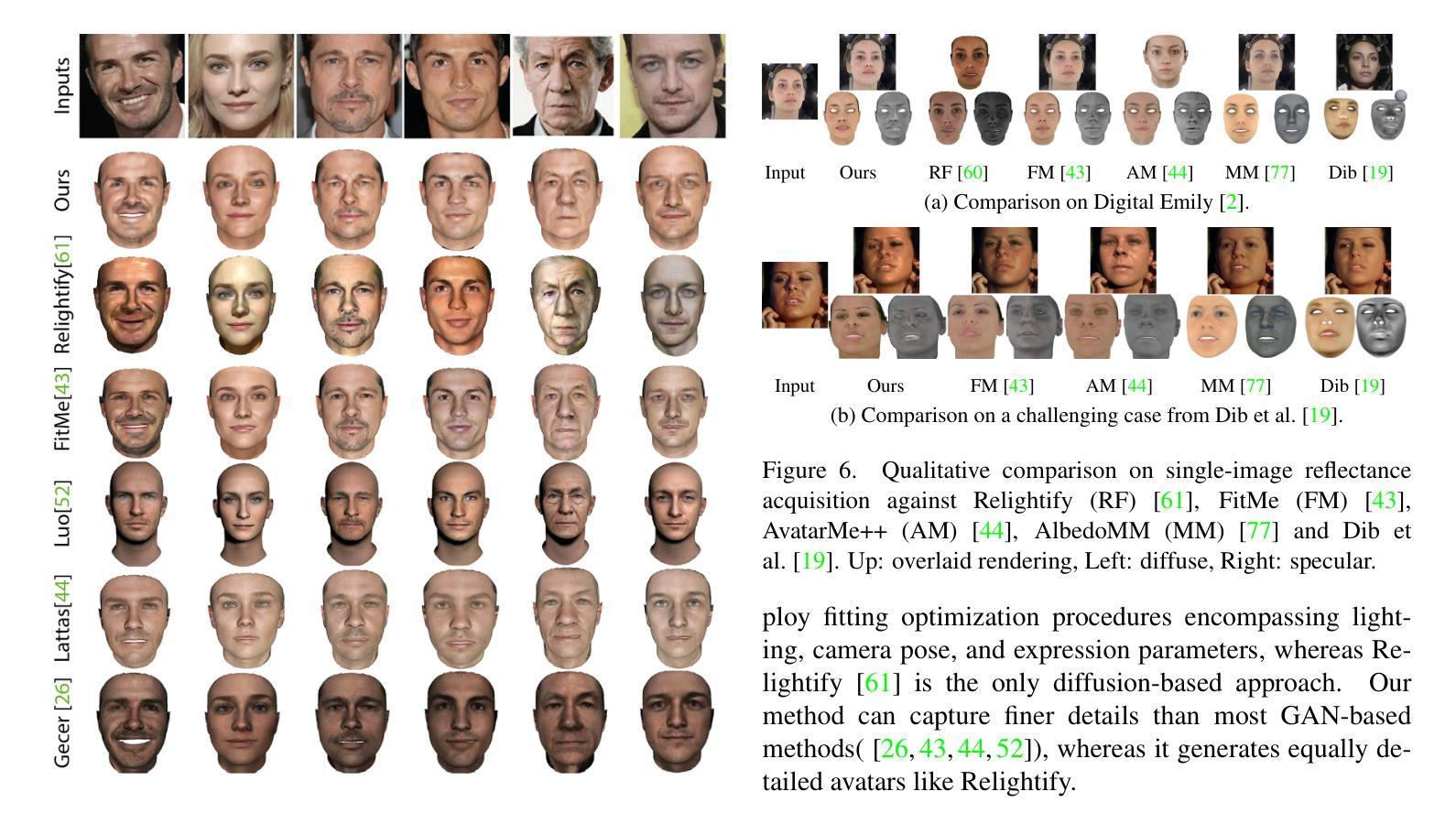
FitDiff: Robust monocular 3D facial shape and reflectance estimation using Diffusion Models
Authors:Stathis Galanakis, Alexandros Lattas, Stylianos Moschoglou, Stefanos Zafeiriou
The remarkable progress in 3D face reconstruction has resulted in high-detail and photorealistic facial representations. Recently, Diffusion Models have revolutionized the capabilities of generative methods by surpassing the performance of GANs. In this work, we present FitDiff, a diffusion-based 3D facial avatar generative model. Leveraging diffusion principles, our model accurately generates relightable facial avatars, utilizing an identity embedding extracted from an “in-the-wild” 2D facial image. The introduced multi-modal diffusion model is the first to concurrently output facial reflectance maps (diffuse and specular albedo and normals) and shapes, showcasing great generalization capabilities. It is solely trained on an annotated subset of a public facial dataset, paired with 3D reconstructions. We revisit the typical 3D facial fitting approach by guiding a reverse diffusion process using perceptual and face recognition losses. Being the first 3D LDM conditioned on face recognition embeddings, FitDiff reconstructs relightable human avatars, that can be used as-is in common rendering engines, starting only from an unconstrained facial image, and achieving state-of-the-art performance.
3D人脸重建技术取得了显著的进步,生成了高度详细和逼真的面部表示。最近,扩散模型(Diffusion Models)在生成方法上取得了革命性的进展,超越了生成对抗网络(GANs)的性能。在这项研究中,我们提出了基于扩散的FitDiff 3D面部头像生成模型。借助扩散原理,我们的模型能够准确地生成可调节照明效果的面部头像,并利用从“野生”的二维面部图像中提取的身份嵌入。所引入的多模态扩散模型是首个同时输出面部反射图(漫反射和镜面反射率及法线)和形状的模型,展示了强大的泛化能力。它仅在公共面部数据集的注释子集上进行训练,并与3D重建配对。我们通过使用感知和面部识别损失来引导反向扩散过程,重新研究了典型的3D面部拟合方法。作为首个基于面部识别嵌入的3D LDM模型,FitDiff重建了可调节照明效果的人类头像,可直接用于常见渲染引擎中。它仅从不受约束的面部图像开始,并达到了最先进的技术性能。
论文及项目相关链接
Summary
基于扩散模型(Diffusion Models)的3D面部重建技术取得显著进展,能够生成高细节、逼真的面部表示。本研究提出了FitDiff,一种基于扩散的3D面部化身生成模型。该模型可从野外2D面部图像中提取身份嵌入,准确生成可重新照明的面部化身。引入的多模式扩散模型可同时输出面部反射图(漫反射和镜面反射、法线等)和形状,显示出强大的泛化能力。该研究通过感知和面部识别损失引导反向扩散过程,重新审视了典型的3D面部拟合方法。作为首个以面部识别嵌入为条件的3D LDM,FitDiff能够重建可在通用渲染引擎中使用的可重新照明的虚拟角色,仅从不受约束的面部图像开始,达到了业界领先水平。
Key Takeaways
- 3D面部重建技术通过采用扩散模型取得了显著进展,可以生成高度逼真的面部表示。
- FitDiff是基于扩散模型的3D面部化身生成模型,能够从野外2D面部图像中提取身份嵌入信息。
- FitDiff利用多模式扩散模型同时输出面部反射图和形状,具备强大的泛化能力。
- 研究通过感知和面部识别损失来引导反向扩散过程,改进了传统的3D面部拟合方法。
- FitDiff是首个以面部识别嵌入为条件的3D LDM模型,能够从不受约束的面部图像重建出可重新照明的虚拟角色。
- FitDiff生成的虚拟角色可直接在通用渲染引擎中使用。
点此查看论文截图