⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-05 更新
DynRefer: Delving into Region-level Multimodal Tasks via Dynamic Resolution
Authors:Yuzhong Zhao, Feng Liu, Yue Liu, Mingxiang Liao, Chen Gong, Qixiang Ye, Fang Wan
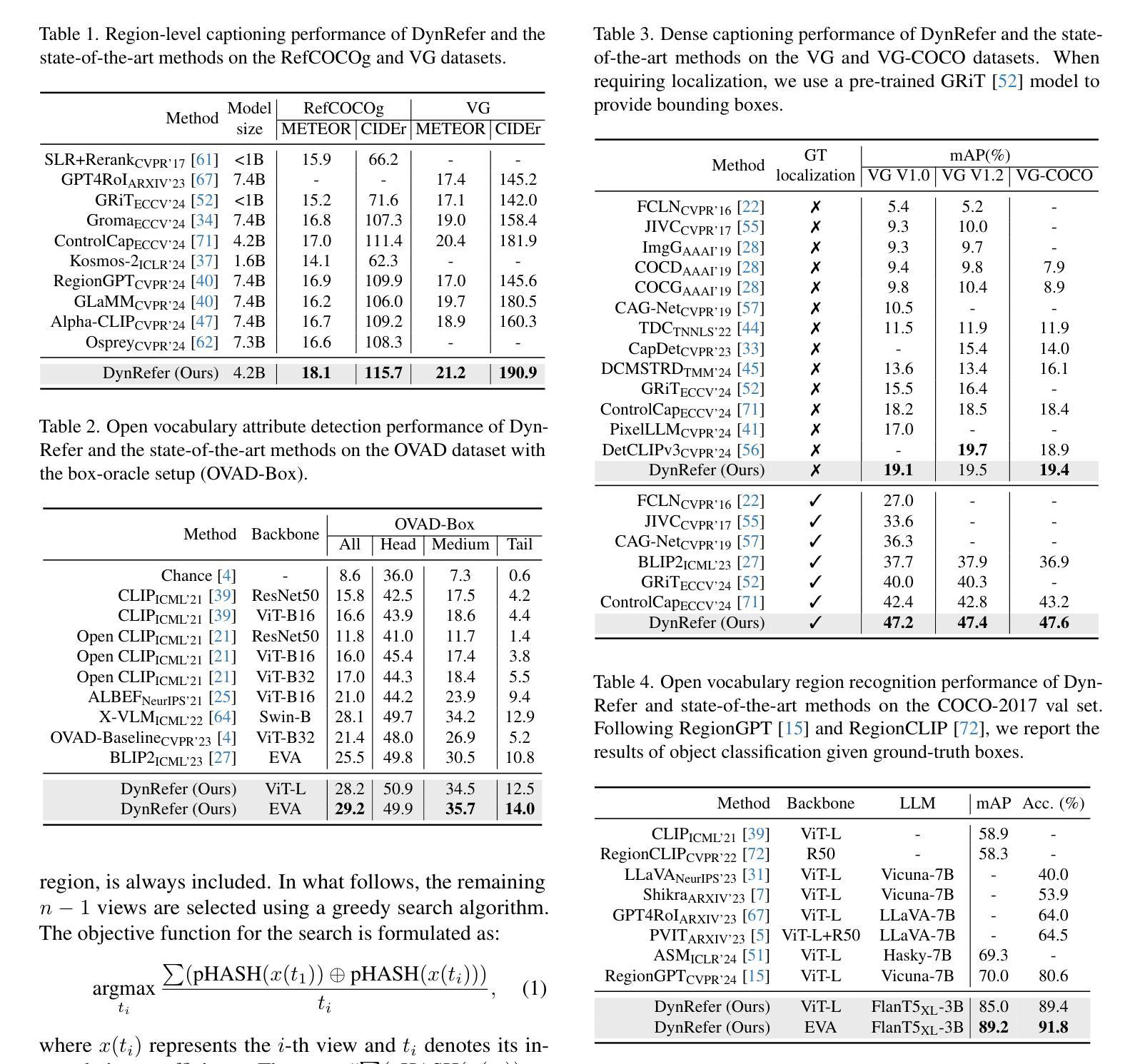
One fundamental task of multimodal models is to translate referred image regions to human preferred language descriptions. Existing methods, however, ignore the resolution adaptability needs of different tasks, which hinders them to find out precise language descriptions. In this study, we propose a DynRefer approach, to pursue high-accuracy region-level referring through mimicking the resolution adaptability of human visual cognition. During training, DynRefer stochastically aligns language descriptions of multimodal tasks with images of multiple resolutions, which are constructed by nesting a set of random views around the referred region. During inference, DynRefer performs selectively multimodal referring by sampling proper region representations for tasks from the nested views based on image and task priors. This allows the visual information for referring to better match human preferences, thereby improving the representational adaptability of region-level multimodal models. Experiments show that DynRefer brings mutual improvement upon broad tasks including region-level captioning, open-vocabulary region recognition and attribute detection. Furthermore, DynRefer achieves state-of-the-art results on multiple region-level multimodal tasks using a single model. Code is available at https://github.com/callsys/DynRefer.
多模态模型的一项基本任务是将所指的图像区域翻译为人类偏好的语言描述。然而,现有方法忽略了不同任务的分辨率适应性需求,这阻碍了它们找到精确的语言描述。在这项研究中,我们提出了一种DynRefer方法,旨在通过模仿人类视觉认知的分辨率适应性,实现高准确度的区域级引用。在训练过程中,DynRefer随机对齐多模态任务的语言描述与多个分辨率的图像,这些图像是通过在所指区域周围嵌套一组随机视图构建的。在推理过程中,DynRefer通过根据图像和任务先验从嵌套视图中为任务采样适当的区域表示,来执行选择性多模态引用。这允许引用时的视觉信息更好地匹配人类偏好,从而提高了区域级多模态模型的表示适应性。实验表明,DynRefer在区域级描述、开放词汇区域识别和属性检测等广泛任务上实现了相互改进。此外,DynRefer使用单个模型在多个区域级多模态任务上实现了最新结果。代码可访问https://github.com/callsys/DynRefer。
论文及项目相关链接
PDF Accepted in CVPR 2025. Code is available at https://github.com/callsys/DynRefer
Summary
该研究提出了一种DynRefer方法,该方法旨在通过模拟人类视觉认知的分辨率适应性,实现高精度的区域级引用。训练过程中,DynRefer将多模态任务的文字描述与不同分辨率的图像随机对齐;推理过程中,则根据图像和任务优先级从嵌套视图中采样适当的区域表示,以更好地匹配人类偏好的视觉信息,从而提高区域级多模态模型的表征适应性。实验证明,DynRefer在区域级描述、开放词汇区域识别和属性检测等任务上取得了相互提升,并在多个区域级多模态任务上实现了单一模型的最佳效果。
Key Takeaways
- 多模态模型的核心任务是将图像区域转化为人类偏好的语言描述。
- 现有方法忽略了不同任务的分辨率适应性需求,影响精确语言描述的发现。
- DynRefer方法追求高精度的区域级引用,通过模拟人类视觉认知的分辨率适应性。
- 训练过程中,DynRefer将语言描述与不同分辨率的图像随机对齐。
- 推理时,DynRefer根据图像和任务优先级选择性地进行多模态引用。
- DynRefer提高了区域级多模态模型的表征适应性,实验证明其在多个任务上取得了显著效果。
点此查看论文截图