⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-05 更新
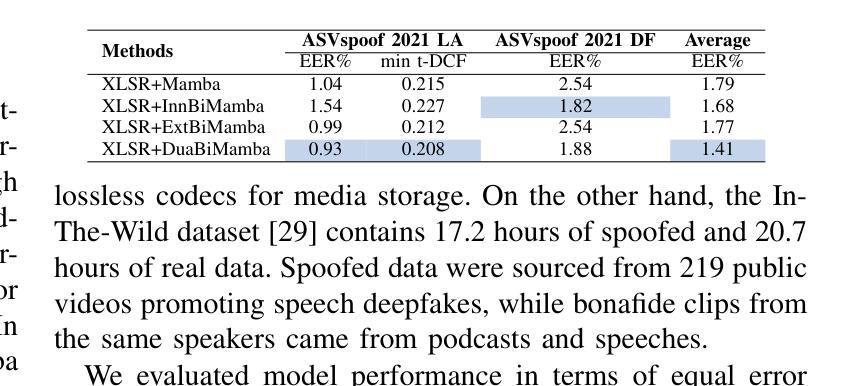
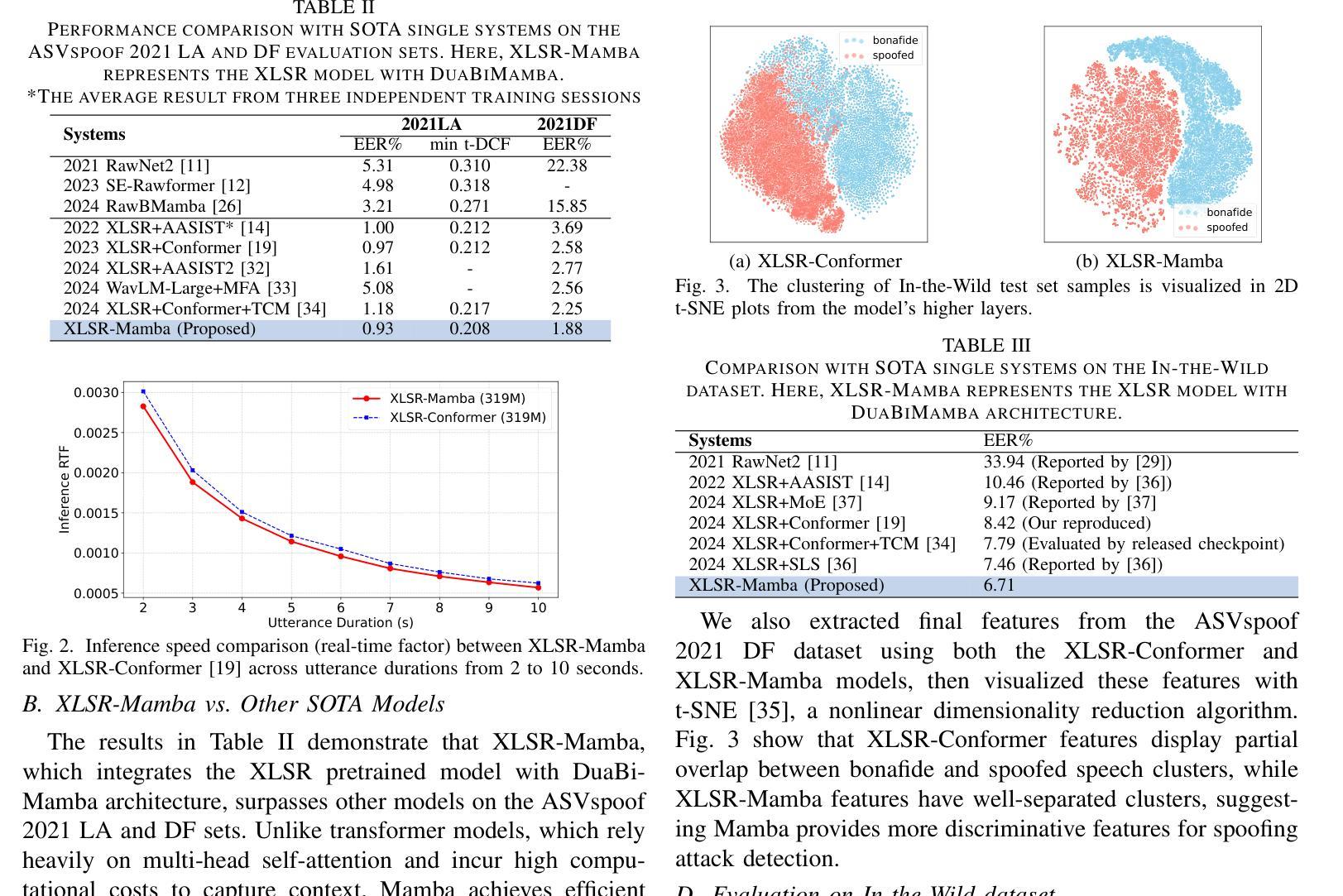
XLSR-Mamba: A Dual-Column Bidirectional State Space Model for Spoofing Attack Detection
Authors:Yang Xiao, Rohan Kumar Das
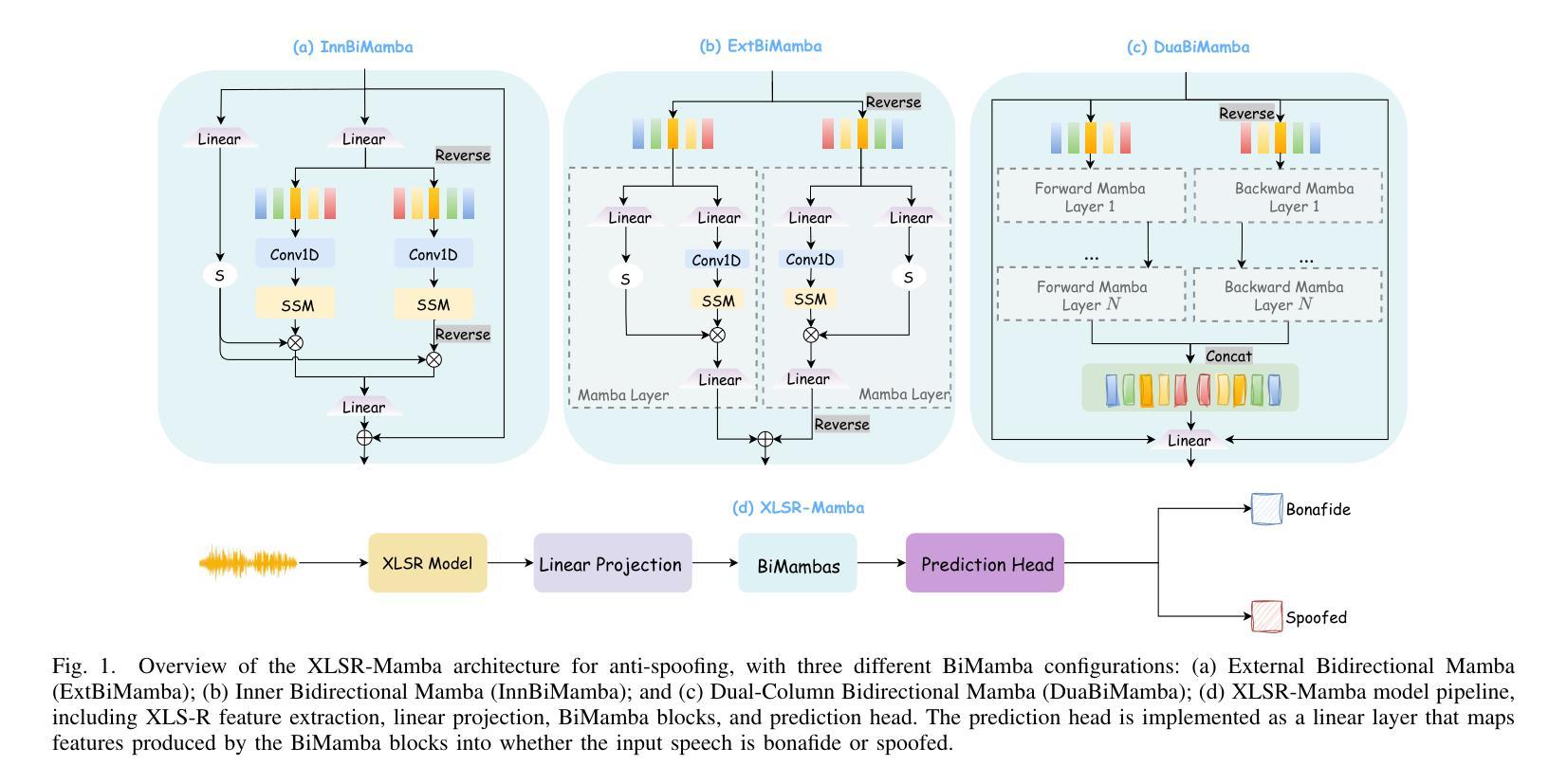
Transformers and their variants have achieved great success in speech processing. However, their multi-head self-attention mechanism is computationally expensive. Therefore, one novel selective state space model, Mamba, has been proposed as an alternative. Building on its success in automatic speech recognition, we apply Mamba for spoofing attack detection. Mamba is well-suited for this task as it can capture the artifacts in spoofed speech signals by handling long-length sequences. However, Mamba’s performance may suffer when it is trained with limited labeled data. To mitigate this, we propose combining a new structure of Mamba based on a dual-column architecture with self-supervised learning, using the pre-trained wav2vec 2.0 model. The experiments show that our proposed approach achieves competitive results and faster inference on the ASVspoof 2021 LA and DF datasets, and on the more challenging In-the-Wild dataset, it emerges as the strongest candidate for spoofing attack detection. The code has been publicly released in https://github.com/swagshaw/XLSR-Mamba.
Transformer及其变体在语音处理方面取得了巨大的成功。然而,其多头自注意力机制计算成本较高。因此,作为一种替代方案,已经提出了一种新型的选择性状态空间模型Mamba。在自动语音识别方面取得成功的基础上,我们将其应用于欺骗攻击检测。Mamba非常适合此任务,因为它可以通过处理长序列来捕获欺骗语音信号中的伪迹。但是,当Mamba用有限标记数据进行训练时,其性能可能会受到影响。为了缓解这个问题,我们提出了一种结合基于双列架构的Mamba新结构与自监督学习的方法,使用预训练的wav2vec 2.0模型。实验表明,我们提出的方法在ASVspoof 2021 LA和DF数据集上取得了具有竞争力的结果和更快的推理速度,而在更具挑战性的In-the-Wild数据集上,它成为欺骗攻击检测的最强候选者。代码已公开发布在https://github.com/swagshaw/XLSR-Mamba。
论文及项目相关链接
PDF Accepted by IEEE Signal Processing Letters
Summary
本文主要介绍了Transformer及其变体在语音处理方面的成功应用,但它们的多头自注意力机制计算成本较高。因此,提出了一种名为Mamba的选择性状态空间模型作为替代方案。本文将其应用于欺骗性攻击检测任务,并使用预训练的wav2vec 2.0模型进行自监督学习来提升Mamba的性能。实验表明,该方法在ASVspoof 2021 LA和DF数据集上表现有竞争力,具有更快的推理速度,而在更具挑战性的野外数据集上更是成为了欺骗性攻击检测的最佳候选方案。此外,相关的代码已公开发布在GitHub上。
Key Takeaways
以下是关于该文本的关键见解:
- Transformer模型及其变体在语音处理方面取得了巨大成功,但存在计算成本较高的问题。
- Mamba作为一种选择性状态空间模型被提出作为替代方案,适用于自动语音识别任务。
- Mamba能够捕捉欺骗性语音信号中的伪迹,处理长序列数据。
- 当使用有限标记数据进行训练时,Mamba的性能可能会受到影响。
- 为了缓解这个问题,结合了一种基于双列架构的Mamba新结构与预训练的wav2vec 2.0模型进行自监督学习。
- 实验表明,该方法在多个数据集上表现优秀,实现了更快的推理速度。特别是在野外数据集上,成为了欺骗性攻击检测的领先候选方案。
点此查看论文截图

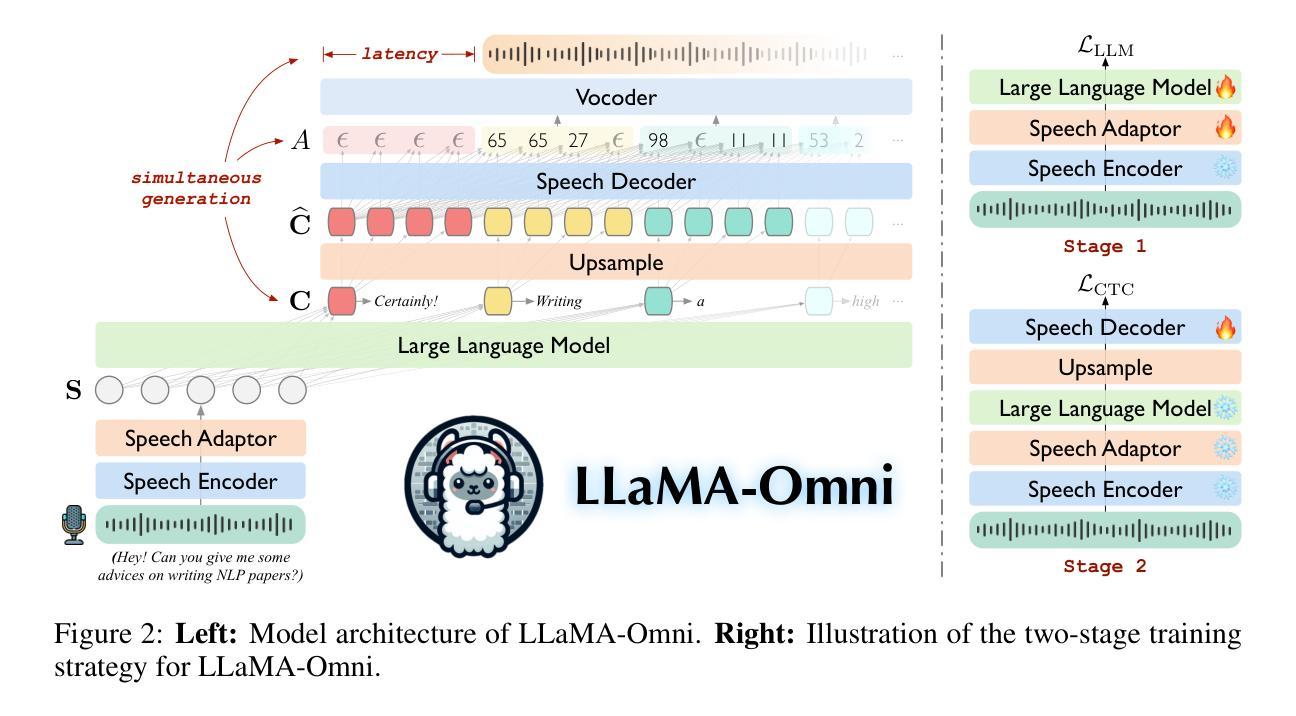
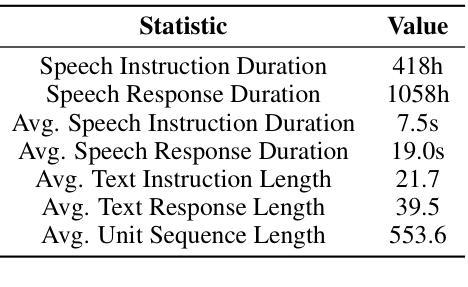
LLaMA-Omni: Seamless Speech Interaction with Large Language Models
Authors:Qingkai Fang, Shoutao Guo, Yan Zhou, Zhengrui Ma, Shaolei Zhang, Yang Feng
Models like GPT-4o enable real-time interaction with large language models (LLMs) through speech, significantly enhancing user experience compared to traditional text-based interaction. However, there is still a lack of exploration on how to build speech interaction models based on open-source LLMs. To address this, we propose LLaMA-Omni, a novel model architecture designed for low-latency and high-quality speech interaction with LLMs. LLaMA-Omni integrates a pretrained speech encoder, a speech adaptor, an LLM, and a streaming speech decoder. It eliminates the need for speech transcription, and can simultaneously generate text and speech responses directly from speech instructions with extremely low latency. We build our model based on the latest Llama-3.1-8B-Instruct model. To align the model with speech interaction scenarios, we construct a dataset named InstructS2S-200K, which includes 200K speech instructions and corresponding speech responses. Experimental results show that compared to previous speech-language models, LLaMA-Omni provides better responses in both content and style, with a response latency as low as 226ms. Additionally, training LLaMA-Omni takes less than 3 days on just 4 GPUs, paving the way for the efficient development of speech-language models in the future.
模型如GPT-4o能够通过语音与大型语言模型(LLM)进行实时交互,与传统基于文本的交互相比,这极大地提升了用户体验。然而,基于开源LLM构建语音交互模型的研究仍然不足。为了解决这个问题,我们提出了LLaMA-Omni,这是一种新型模型架构,旨在实现与LLM的低延迟、高质量语音交互。LLaMA-Omni集成了一个预训练的语音编码器、语音适配器、LLM和流式语音解码器。它无需语音转录,即可直接从语音指令同时生成文本和语音响应,具有极低的延迟。我们的模型是基于最新的Llama-3.1-8B-Instruct模型构建的。为了使模型与语音交互场景对齐,我们构建了一个名为InstructS2S-200K的数据集,其中包括20万条语音指令和相应的语音响应。实验结果表明,与之前的语音语言模型相比,LLaMA-Omni在内容和风格上提供了更好的响应,响应延迟低至226毫秒。此外,LLaMA-Omni的培训仅需4个GPU不到3天的时间,为语言语音模型的高效开发铺平了道路。
论文及项目相关链接
PDF ICLR 2025
Summary
基于GPT-4o等大型语言模型(LLM)的实时语音交互显著提升了用户体验。针对如何在开源LLM基础上构建语音交互模型的问题,提出了LLaMA-Omni这一新型模型架构。该架构集成了预训练语音编码器、语音适配器、LLM和流式语音解码器,无需语音转写即可直接从语音指令生成文本和语音响应,实现低延迟高质量语音交互。实验结果显示,与先前的语言模型相比,LLaMA-Omni在内容和风格上的回应更好,响应延迟低至226毫秒,并且在仅4个GPU上训练时间不到3天,为未来高效开发语音语言模型铺平了道路。
Key Takeaways
- GPT-4o等大型语言模型通过语音实现实时交互,显著提升了用户体验。
- LLaMA-Omni是一种新型模型架构,专为与开源LLM的低延迟高质量语音交互而设计。
- LLaMA-Omni集成了预训练语音编码器、语音适配器、LLM和流式语音解码器。
- LLaMA-Omni无需语音转写,可直接从语音指令生成文本和语音响应,实现低延迟交互。
- LLaMA-Omni在内容和风格上的回应优于先前的语言模型,响应延迟低至226毫秒。
- LLaMA-Omni模型训练效率高,在4个GPU上训练时间仅需3天。
点此查看论文截图


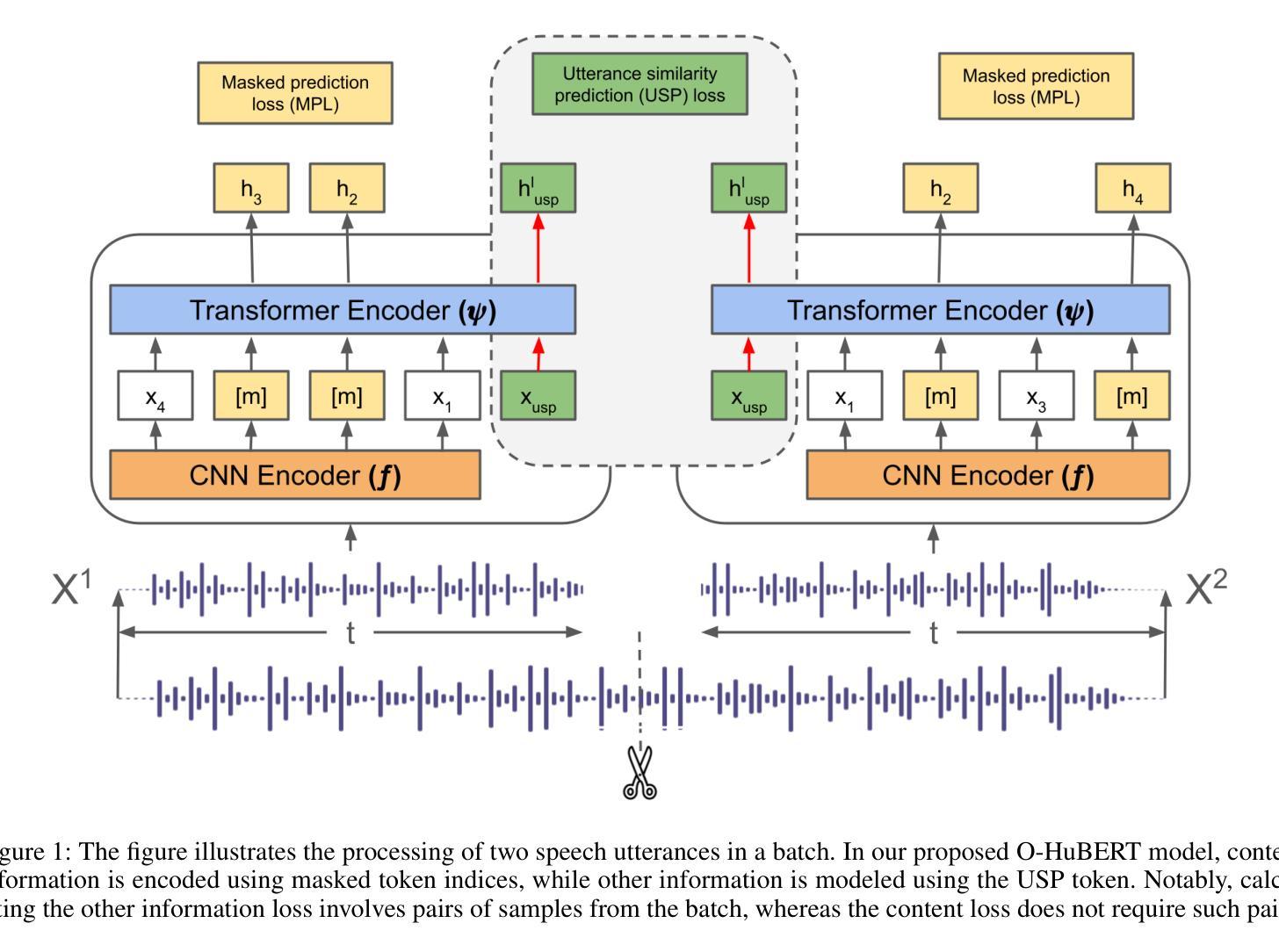
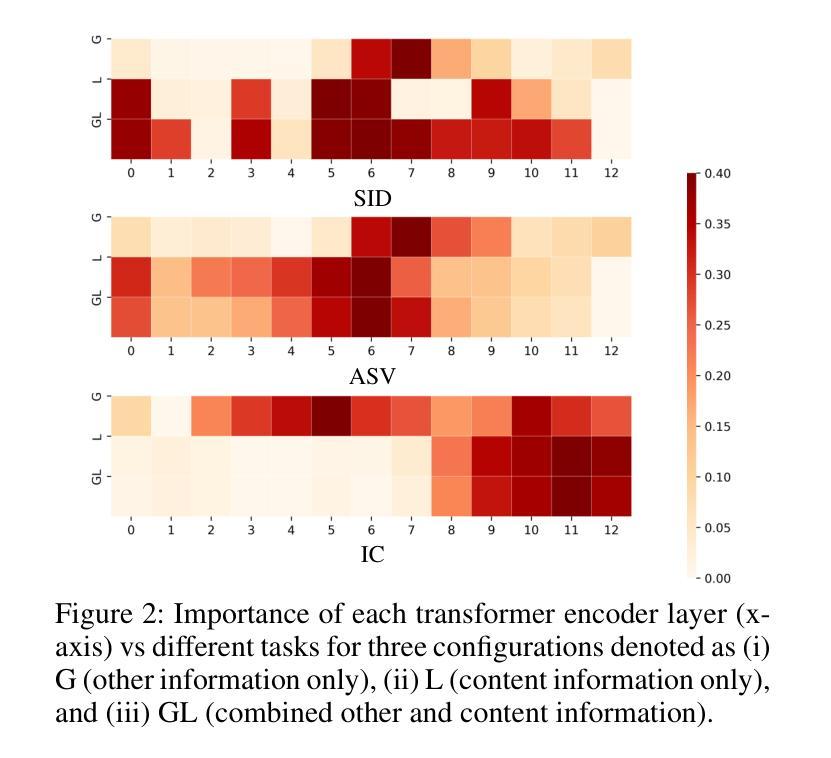
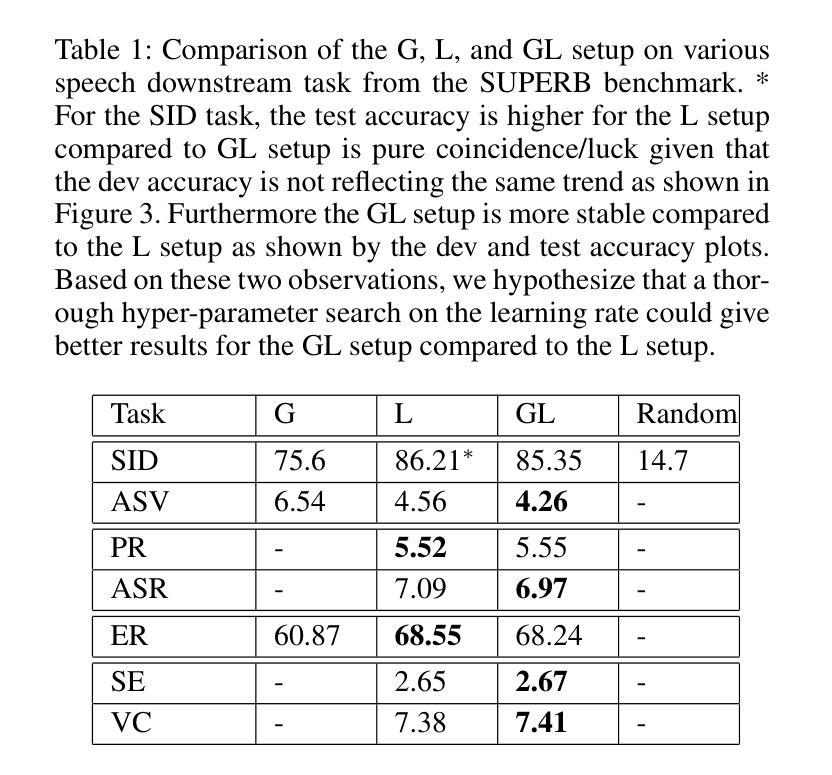
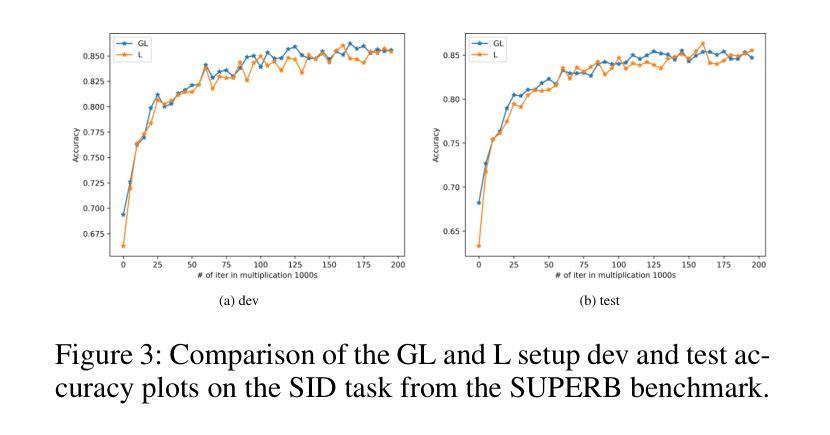
Speech Representation Learning Revisited: The Necessity of Separate Learnable Parameters and Robust Data Augmentation
Authors:Hemant Yadav, Sunayana Sitaram, Rajiv Ratn Shah
Speech modeling methods learn one embedding for a fixed segment of speech, typically in between 10-25 ms. The information present in speech can be divided into two categories: “what is being said” (content) and “how it is expressed” (other) and these two are orthogonal in nature causing the optimization algorithm to find a sub-optimal solution if forced to optimize together. This leads to sub-optimal performance in one or all downstream tasks as shown by previous studies. Current self-supervised learning (SSL) methods such as HuBERT are very good at modeling the content information present in speech. Data augmentation improves the performance on tasks which require effective modeling of other information but this leads to a divided capacity of the model. In this work, we conduct a preliminary study to understand the importance of modeling other information using separate learnable parameters. We propose a modified version of HuBERT, termed Other HuBERT (O-HuBERT), to test our hypothesis. Our findings are twofold: first, the O-HuBERT method is able to utilize all layers to build complex features to encode other information; second, a robust data augmentation strategy is essential for learning the information required by tasks that depend on other information and to achieve state-of-the-art (SOTA) performance on the SUPERB benchmark with a similarly sized model (100 million parameters) and pre-training data (960 hours).
语音建模方法会为固定的语音段(通常在10-25毫秒之间)学习一种嵌入。语音中的信息可以分为两类:“所说内容”(内容)和“如何表达”(其他),这两者在本质上是正交的,如果强制一起优化,会导致优化算法找到次优解。这会导致一个或多个下游任务的性能下降,以前的研究已经证明了这一点。当前的自监督学习方法(如HuBERT)在建模语音中的内容信息方面非常出色。数据增强改进了需要有效建模其他信息的任务的性能,但这导致了模型能力的分散。在这项工作中,我们进行了一项初步研究,以了解使用可学习的单独参数对信息进行建模的重要性。我们提出了一种改进的HuBERT版本,称为O-HuBERT,来测试我们的假设。我们的发现有两点:首先,O-HuBERT方法能够利用所有层构建复杂的特征来编码其他信息;其次,对于依赖于其他信息的任务所需的信息学习来说,稳健的数据增强策略至关重要,从而在与同样大小的模型(1亿参数)和预训练数据(960小时)的情况下,在SUPERB基准测试中达到最新水平(SOTA)。
论文及项目相关链接
总结
本文讨论了语音建模中的一些问题和方法。传统方法为一个固定的语音段学习一个嵌入,存在内容和表达方式的模型化冲突,优化算法易找到次优解。当前自监督学习方法如HuBERT擅长建模内容信息,但数据增强技术用于建模其他信息时,模型容量分配成为问题。本文提出了改进的HuBERT版本——O-HuBERT来探索建模其他信息的重要性。研究发现,O-HuBERT能利用所有层构建复杂特征来编码其他信息,且对于依赖其他信息的任务,采用稳健的数据增强策略至关重要。在SUPERB基准测试中,使用相似规模的模型和预训练数据,O-HuBERT取得了最佳性能。
关键见解
- 语音信息可分为“所说内容”和“如何表达”两部分,两者正交性质可能导致模型性能下降。
- 当前自监督学习方法如HuBERT擅长建模内容信息。
- 数据增强技术能提高任务性能,但需分配模型容量以有效建模其他信息。
- O-HuBERT是一种改进的HuBERT版本,能够利用所有层编码其他信息。
- 对于依赖其他信息的任务,采用稳健的数据增强策略至关重要。
- O-HuBERT在SUPERB基准测试中表现出卓越性能。
- 与类似规模的模型和预训练数据相比,O-HuBERT达到了最佳性能水平。
点此查看论文截图


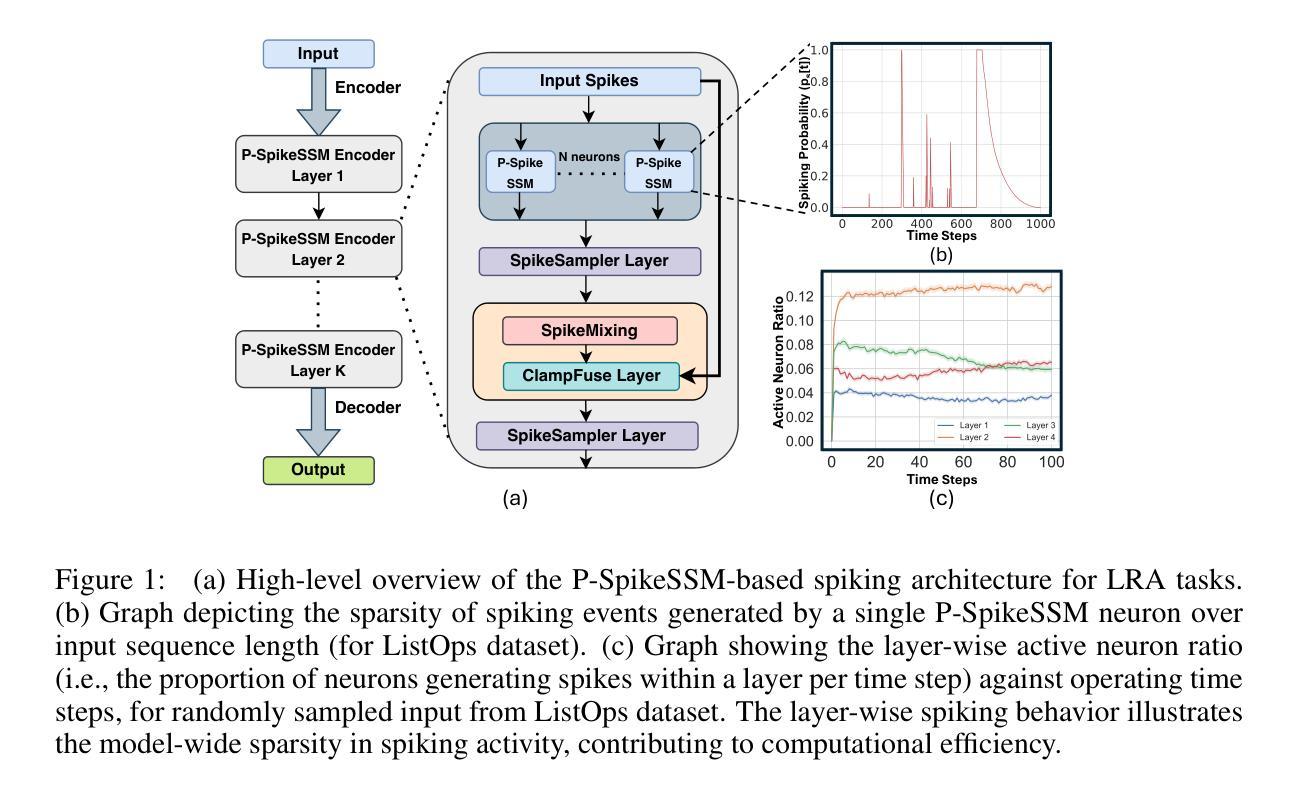
P-SpikeSSM: Harnessing Probabilistic Spiking State Space Models for Long-Range Dependency Tasks
Authors:Malyaban Bal, Abhronil Sengupta
Spiking neural networks (SNNs) are posited as a computationally efficient and biologically plausible alternative to conventional neural architectures, with their core computational framework primarily using the leaky integrate-and-fire (LIF) neuron model. However, the limited hidden state representation of LIF neurons, characterized by a scalar membrane potential, and sequential spike generation process, poses challenges for effectively developing scalable spiking models to address long-range dependencies in sequence learning tasks. In this study, we develop a scalable probabilistic spiking learning framework for long-range dependency tasks leveraging the fundamentals of state space models. Unlike LIF neurons that rely on the deterministic Heaviside function for a sequential process of spike generation, we introduce a SpikeSampler layer that samples spikes stochastically based on an SSM-based neuronal model while allowing parallel computations. To address non-differentiability of the spiking operation and enable effective training, we also propose a surrogate function tailored for the stochastic nature of the SpikeSampler layer. To enhance inter-neuron communication, we introduce the SpikeMixer block, which integrates spikes from neuron populations in each layer. This is followed by a ClampFuse layer, incorporating a residual connection to capture complex dependencies, enabling scalability of the model. Our models attain state-of-the-art performance among SNN models across diverse long-range dependency tasks, encompassing the Long Range Arena benchmark, permuted sequential MNIST, and the Speech Command dataset and demonstrate sparse spiking pattern highlighting its computational efficiency.
脉冲神经网络(SNNs)被视为传统神经网络架构的计算效率高且生物上可行的替代方案,其主要的计算框架主要使用泄漏积分和点火(LIF)神经元模型。然而,LIF神经元的隐藏状态表示有限,其特征在于标量膜电位,以及顺序脉冲生成过程,这为开发可扩展的脉冲模型以处理序列学习任务中的远程依赖关系带来了挑战。在这项研究中,我们针对远程依赖任务开发了一个可扩展的概率脉冲学习框架,该框架利用状态空间模型的基本原理。不同于依赖确定性海维赛德函数进行脉冲生成顺序过程的LIF神经元,我们引入了SpikeSampler层,该层基于SSM神经元模型的随机性进行脉冲采样,同时允许并行计算。为了解决脉冲操作的不可微性并实现对有效训练的支持,我们还为SpikeSampler层的随机性量身定制了替代函数。为了增强神经元之间的通信,我们引入了SpikeMixer块,该块整合了每层神经元群体的脉冲。随后是ClampFuse层,它结合了残差连接以捕获复杂的依赖关系,使模型的扩展性增强。我们的模型在多种远程依赖任务中达到了脉冲神经网络模型的最新性能水平,包括Long Range Arena基准测试、置换顺序MNIST和语音命令数据集,并展示了稀疏的脉冲模式,突出了其计算效率。
论文及项目相关链接
PDF Accepted at ICLR 2025
Summary
本文研究了基于状态空间模型(SSM)的概率性脉冲学习框架,用于解决序列学习中的长程依赖问题。通过引入SpikeSampler层和SpikeMixer块,实现了脉冲的随机采样和神经元群体之间的集成。通过引入ClampFuse层,融合了复杂的依赖关系,使模型具备可扩展性。该模型在多种长程依赖任务上取得了最新性能,如Long Range Arena基准测试、顺序MNIST和语音命令数据集等。
Key Takeaways
- SNNs作为一种计算效率高且生物上合理的神经网络架构,具有潜在的优势。
- LIF神经元模型在处理长程依赖问题时存在局限性,主要由于它的标量膜电位和顺序脉冲生成过程。
- 引入基于SSM的SpikeSampler层,实现了脉冲的随机采样,并允许并行计算。
- 为解决脉冲操作不可微的问题并促进有效训练,提出针对SpikeSampler层的替代函数。
- SpikeMixer块增强神经元之间的通信,通过集成各层的神经元群体脉冲。
- ClampFuse层采用残差连接,捕捉复杂依赖关系,提高模型的可扩展性。
点此查看论文截图