⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-05 更新
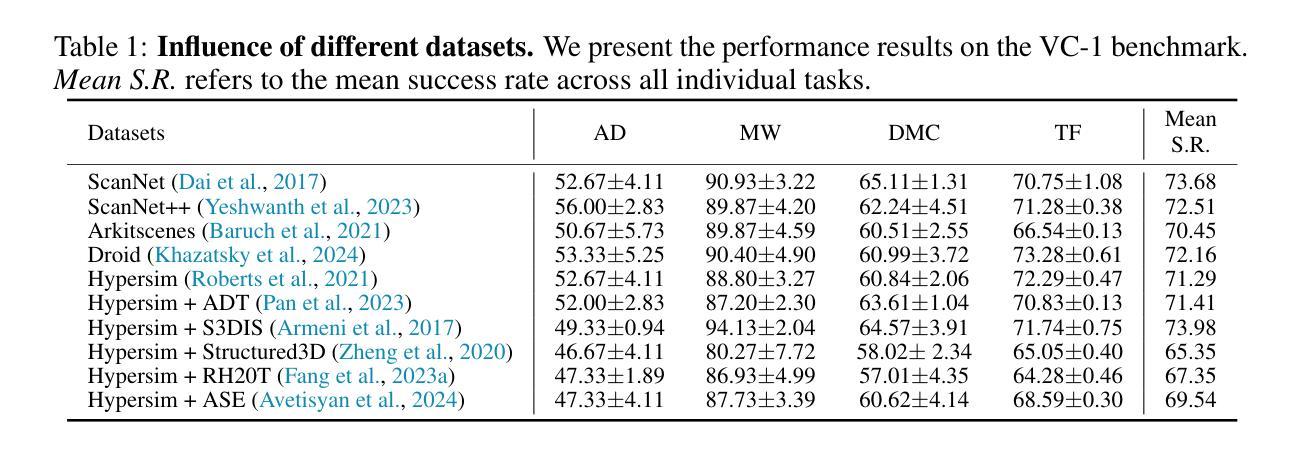
MobileViM: A Light-weight and Dimension-independent Vision Mamba for 3D Medical Image Analysis
Authors:Wei Dai, Steven Wang, Jun Liu
Efficient evaluation of three-dimensional (3D) medical images is crucial for diagnostic and therapeutic practices in healthcare. Recent years have seen a substantial uptake in applying deep learning and computer vision to analyse and interpret medical images. Traditional approaches, such as convolutional neural networks (CNNs) and vision transformers (ViTs), face significant computational challenges, prompting the need for architectural advancements. Recent efforts have led to the introduction of novel architectures like the ``Mamba’’ model as alternative solutions to traditional CNNs or ViTs. The Mamba model excels in the linear processing of one-dimensional data with low computational demands. However, Mamba’s potential for 3D medical image analysis remains underexplored and could face significant computational challenges as the dimension increases. This manuscript presents MobileViM, a streamlined architecture for efficient segmentation of 3D medical images. In the MobileViM network, we invent a new dimension-independent mechanism and a dual-direction traversing approach to incorporate with a vision-Mamba-based framework. MobileViM also features a cross-scale bridging technique to improve efficiency and accuracy across various medical imaging modalities. With these enhancements, MobileViM achieves segmentation speeds exceeding 90 frames per second (FPS) on a single graphics processing unit (i.e., NVIDIA RTX 4090). This performance is over 24 FPS faster than the state-of-the-art deep learning models for processing 3D images with the same computational resources. In addition, experimental evaluations demonstrate that MobileViM delivers superior performance, with Dice similarity scores reaching 92.72%, 86.69%, 80.46%, and 77.43% for PENGWIN, BraTS2024, ATLAS, and Toothfairy2 datasets, respectively, which significantly surpasses existing models.
高效评估三维(3D)医学影像对于医疗诊断和治疗实践至关重要。近年来,深度学习和计算机视觉在医疗图像分析和解释方面的应用大量涌现。传统的卷积神经网络(CNN)和视觉变压器(ViT)面临重大计算挑战,这激发了架构发展的需求。近期研究引入了诸如“Mamba”模型等新型架构作为对传统CNN或ViT的替代解决方案。Mamba模型在处理一维数据的线性处理方面表现出色,计算需求较低。然而,Mamba在3D医学图像分析方面的潜力尚未得到充分探索,随着维度的增加,可能会面临重大的计算挑战。本文介绍了MobileViM,这是一个用于高效分割3D医学影像的流线化架构。在MobileViM网络中,我们发明了一种新的维度独立机制和一种双向遍历方法,将其纳入基于视觉Mamba的框架中。MobileViM还采用跨尺度桥梁技术,以提高在各种医学影像模态下的效率和准确性。通过这些增强功能,MobileViM在单个图形处理单元(例如NVIDIA RTX 4090)上实现了超过每秒90帧(FPS)的分割速度。在相同的计算资源下,此性能比处理3D图像的最先进的深度学习模型快24 FPS以上。此外,实验评估表明,MobileViM的性能卓越,在PENGWIN、BraTS2024、ATLAS和Toothfairy2数据集上的Dice相似度得分分别为92.72%、86.69%、80.46%和77.43%,显著超越了现有模型。
论文及项目相关链接
PDF The co-authors have not approved its submission to arXiv
Summary
该文本介绍了针对三维医学影像分析的深度学习模型MobileViM的相关研究。该模型利用Mamba模型的优点,引入维度独立机制和双向遍历方法,同时采用跨尺度桥接技术,实现了高效的三维医学影像分割。其性能超过现有模型,特别是在处理不同医学影像模态的数据时表现优秀。其运行速度快且准确度高,显示出极大的潜力。
Key Takeaways
- MobileViM模型是一种针对三维医学影像分析的高效分割架构。
- 该模型结合了Mamba模型的优点,具有处理一维数据的线性处理能力。
- MobileViM引入了维度独立机制和双向遍历方法,增强了模型在不同维度的适应能力。
- 采用跨尺度桥接技术,提高了在不同医学影像模态下的效率和准确性。
- MobileViM实现了超过90帧每秒的分割速度,性能超过现有模型。
- 在不同数据集上的实验评估显示,MobileViM表现出优异的性能,Dice相似度得分高。
点此查看论文截图

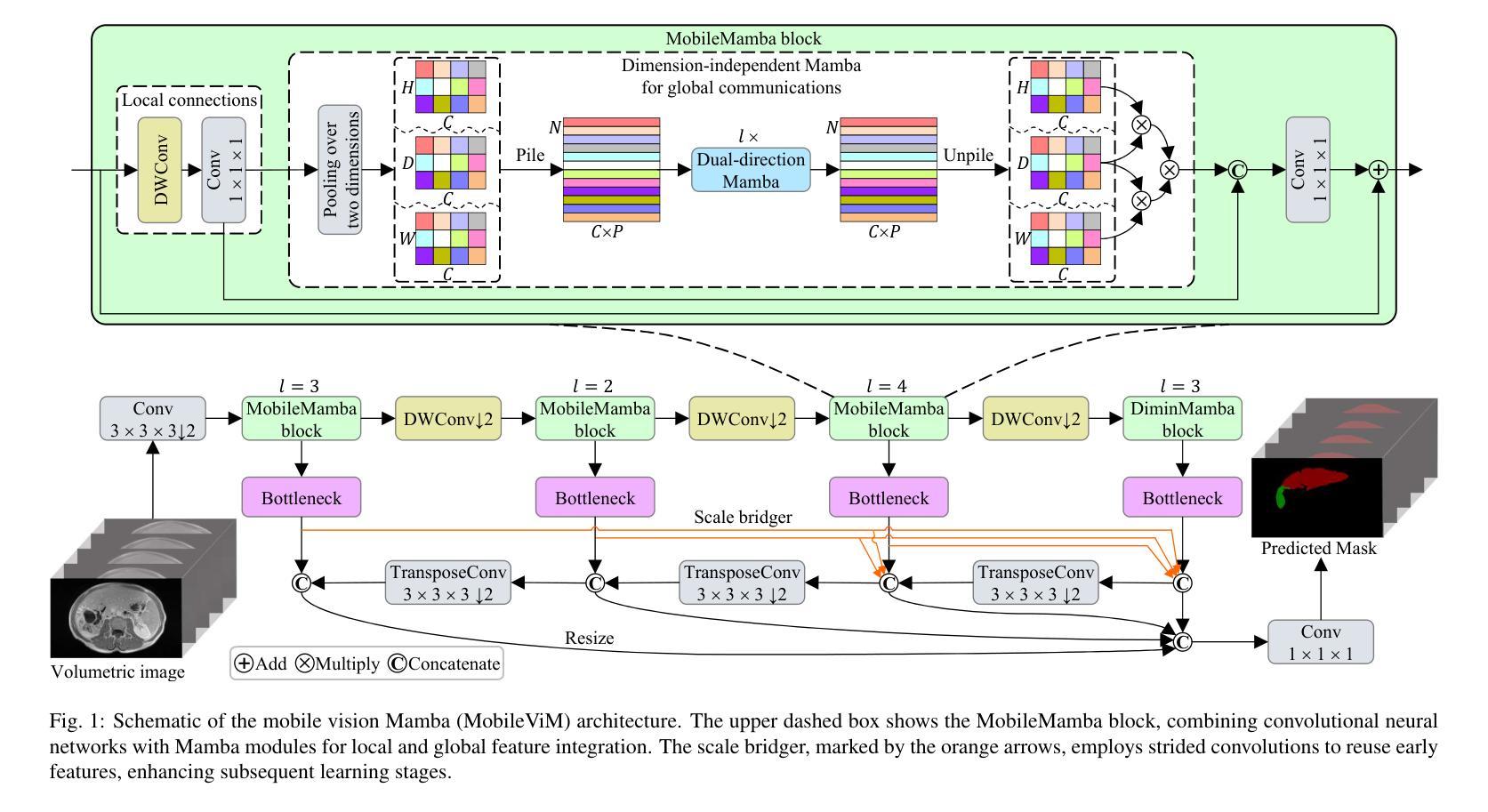
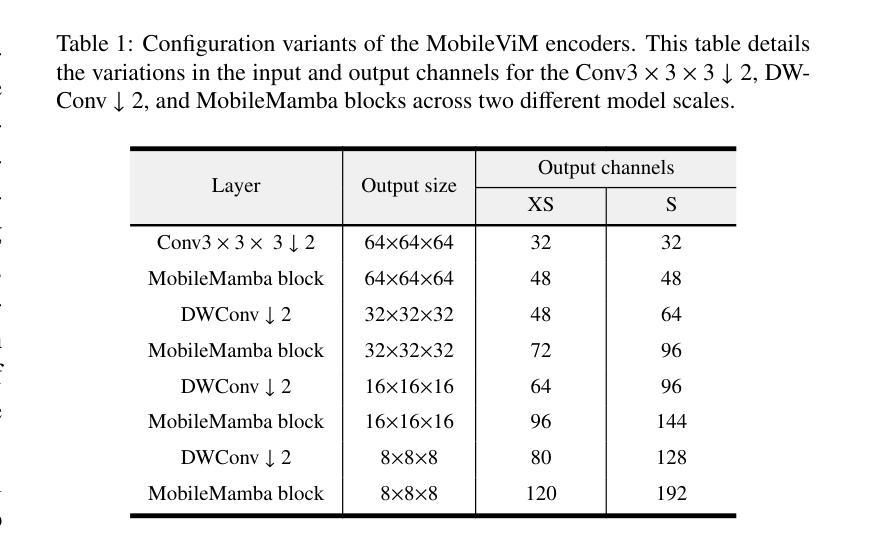
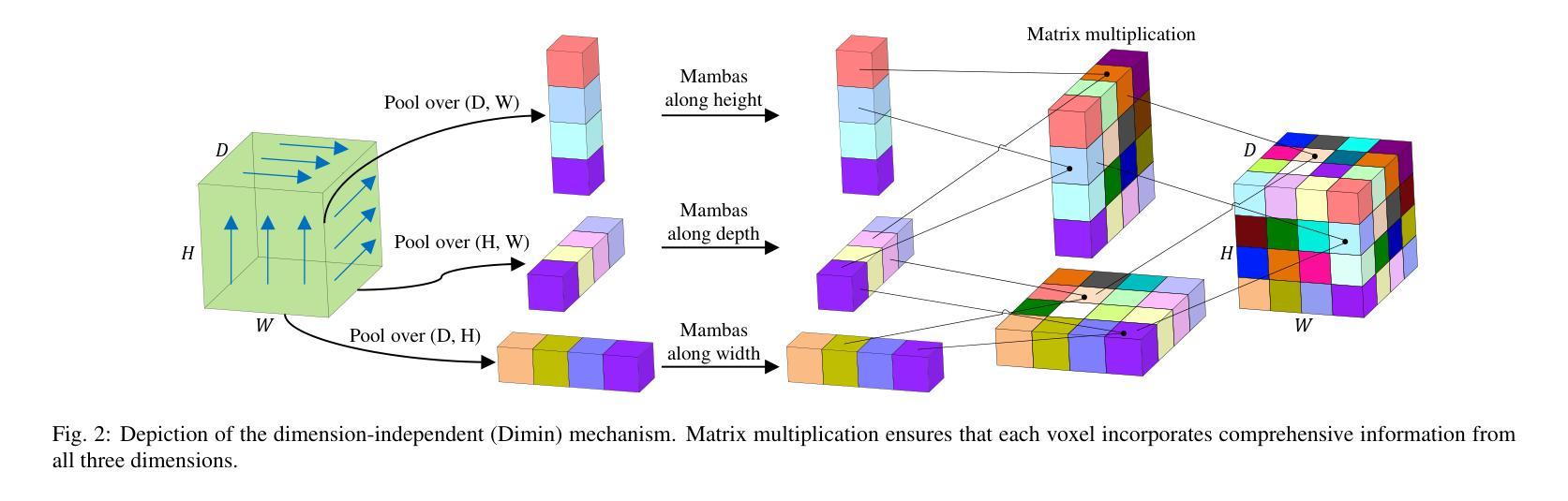
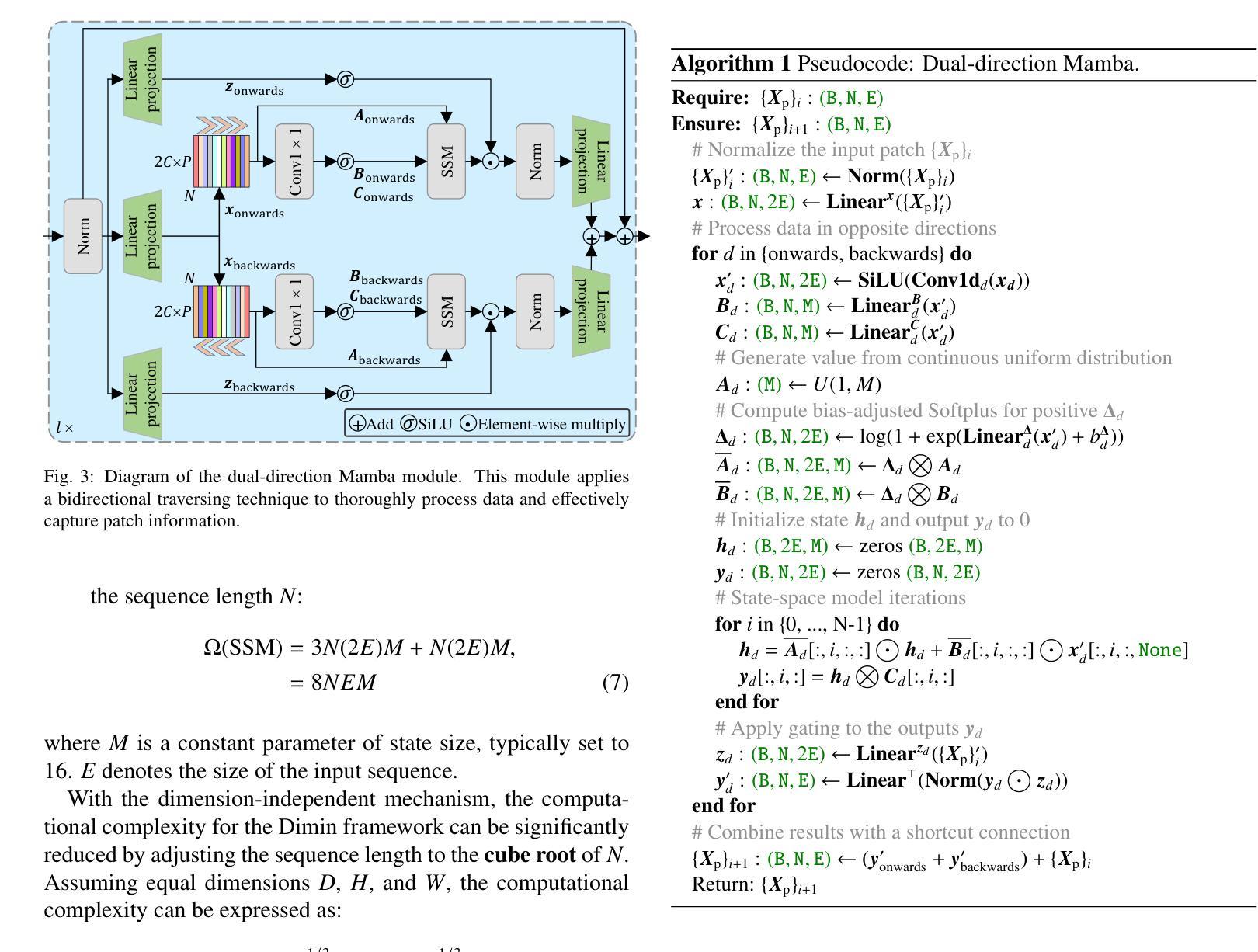
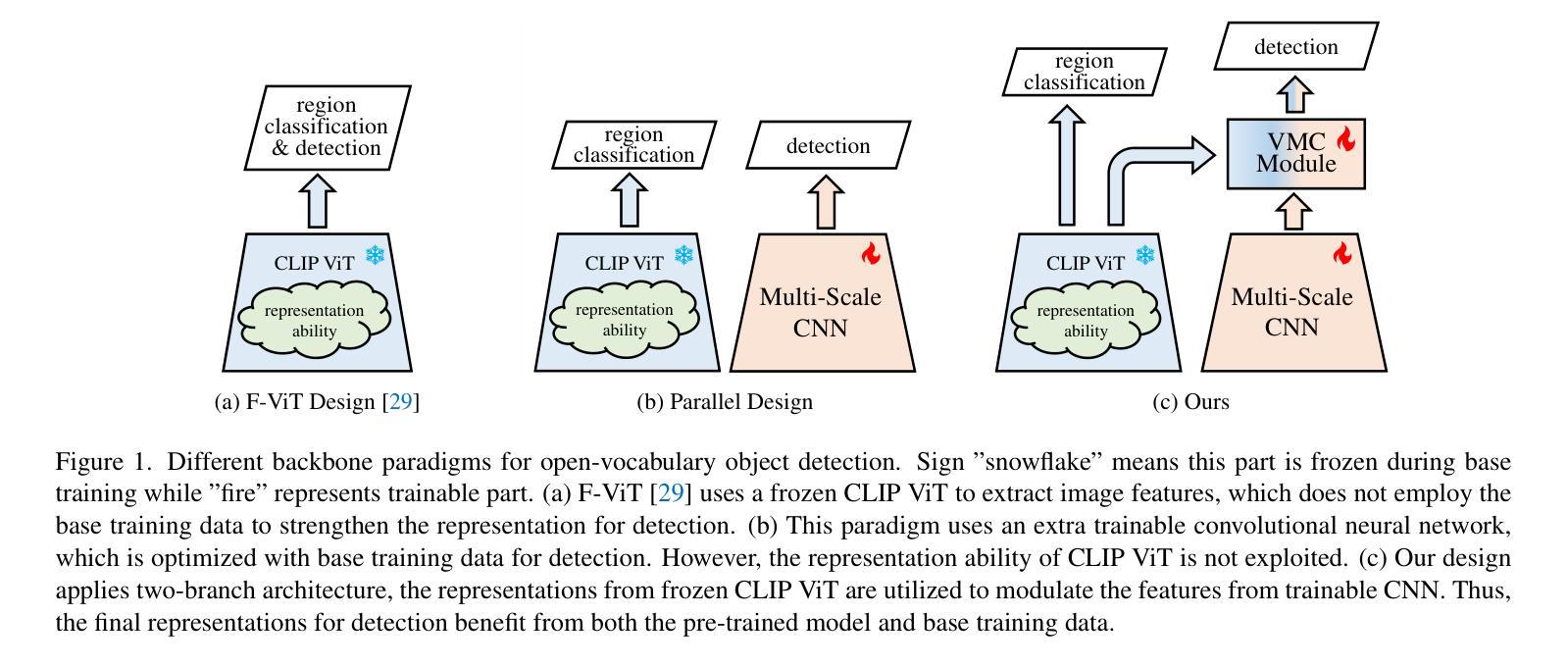
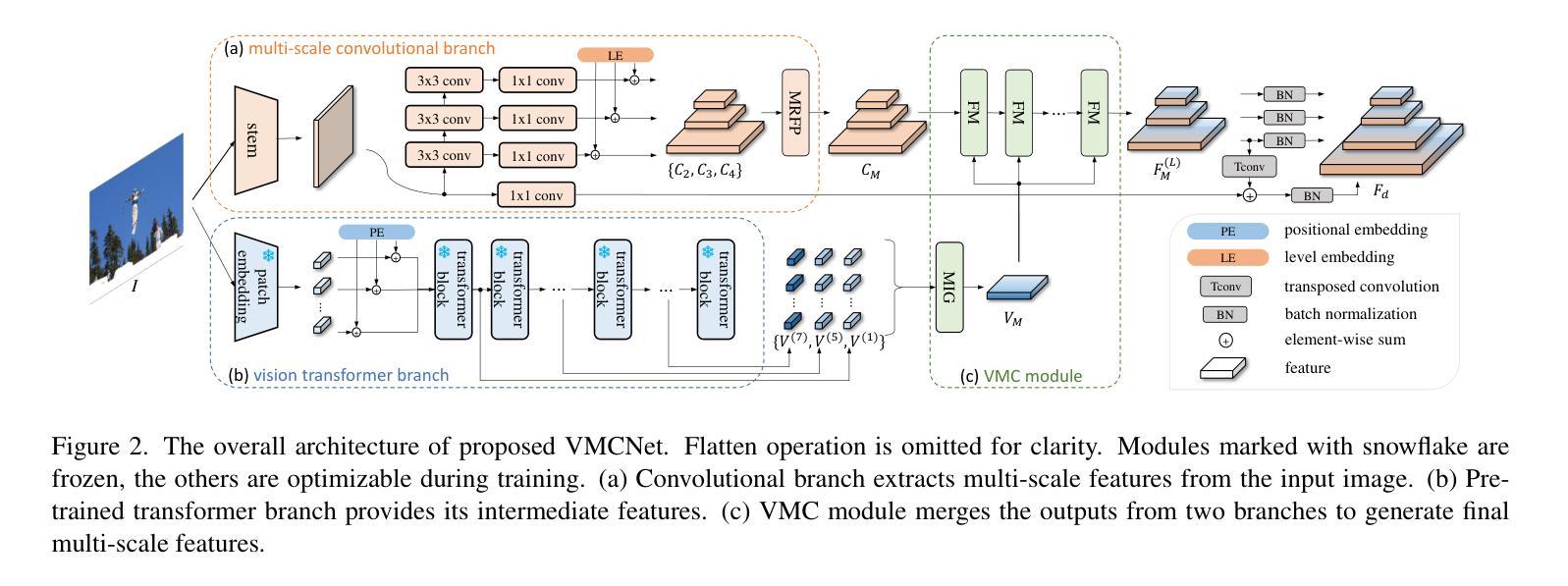
Modulating CNN Features with Pre-Trained ViT Representations for Open-Vocabulary Object Detection
Authors:Xiangyu Gao, Yu Dai, Benliu Qiu, Lanxiao Wang, Heqian Qiu, Hongliang Li
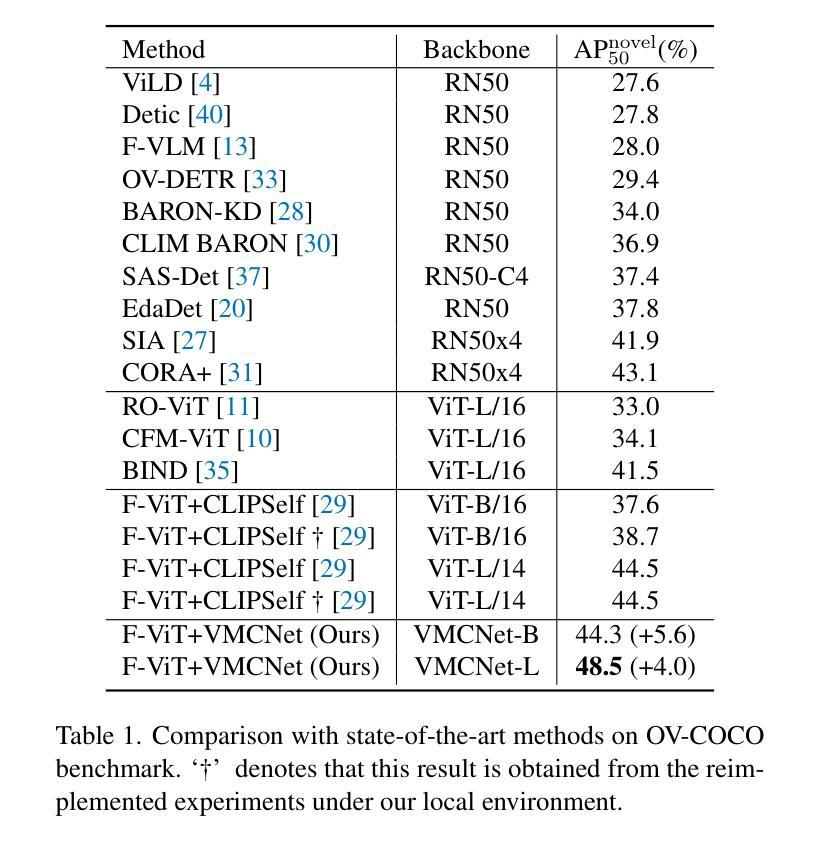
Owing to large-scale image-text contrastive training, pre-trained vision language model (VLM) like CLIP shows superior open-vocabulary recognition ability. Most existing open-vocabulary object detectors attempt to utilize the pre-trained VLMs to attain generalized representation. F-ViT uses the pre-trained visual encoder as the backbone network and freezes it during training. However, its frozen backbone doesn’t benefit from the labeled data to strengthen the representation for detection. Therefore, we propose a novel two-branch backbone network, named as \textbf{V}iT-Feature-\textbf{M}odulated Multi-Scale \textbf{C}onvolutional Network (VMCNet), which consists of a trainable convolutional branch, a frozen pre-trained ViT branch and a VMC module. The trainable CNN branch could be optimized with labeled data while the frozen pre-trained ViT branch could keep the representation ability derived from large-scale pre-training. Then, the proposed VMC module could modulate the multi-scale CNN features with the representations from ViT branch. With this proposed mixed structure, the detector is more likely to discover objects of novel categories. Evaluated on two popular benchmarks, our method boosts the detection performance on novel category and outperforms state-of-the-art methods. On OV-COCO, the proposed method achieves 44.3 AP${50}^{\mathrm{novel}}$ with ViT-B/16 and 48.5 AP${50}^{\mathrm{novel}}$ with ViT-L/14. On OV-LVIS, VMCNet with ViT-B/16 and ViT-L/14 reaches 27.8 and 38.4 mAP$_{r}$.
由于大规模图文对比训练,预训练的视觉语言模型(如CLIP)表现出卓越的开放词汇识别能力。现有的大多数开放词汇对象检测器都试图利用预训练的VLMs来获得通用表示。F-ViT使用预训练的视觉编码器作为骨干网络,并在训练期间冻结它。然而,其冻结的主干网络无法从标记数据中受益,以加强检测的表示能力。因此,我们提出了一种新型的两分支骨干网络,名为“VMCNet”(ViT特征调制多尺度卷积网络),它包含一个可训练卷积分支、一个冻结的预训练ViT分支和一个VMC模块。可训练的CNN分支可以使用标记数据进行优化,而冻结的预训练ViT分支可以保持从大规模预训练中获得的表示能力。然后,所提出的VMC模块可以调节多尺度CNN特征与ViT分支的表示。通过混合结构,检测器更有可能发现新型类别的对象。在两个流行的基准测试上进行评估,我们的方法在新型类别检测性能上有所提升,并超越了最新技术的方法。在OV-COCO上,所提出的方法使用ViT-B/16达到44.3 AP_{50}^{novel},使用ViT-L/14达到48.5 AP_{50}^{novel}。在OV-LVIS上,VMCNet与ViT-B/16和ViT-L/h分别达到了27.8和38.4的mAP_{r}。
论文及项目相关链接
Summary
本文介绍了一种名为VMCNet的新型两分支骨干网络,用于对象检测。该网络结合了预训练的Vision Transformer和卷积神经网络,通过VMC模块调制多尺度CNN特征。这种混合结构有助于提高检测新型对象类别的性能,并在OV-COCO和OV-LVIS基准测试中表现出卓越的性能。
Key Takeaways
- 利用大规模图像文本对比训练,预训练视觉语言模型(VLM)如CLIP表现出优秀的开放词汇识别能力。
- F-ViT使用预训练的视觉编码器作为骨干网络,但在训练过程中冻结该网络。
- 冻结的骨干网络无法从标记数据中受益以增强检测表示。
- 提出了新型的VMCNet两分支骨干网络,包括可训练的卷积分支、冻结的预训练ViT分支和VMC模块。
- 可训练的CNN分支可以通过标记数据进行优化,而冻结的预训练ViT分支则能维持大规模预训练得到的表示能力。
- VMC模块能够调制来自ViT分支的多尺度CNN特征。
- 该检测方法在新型对象类别检测性能上有所提升,并在OV-COCO和OV-LVIS基准测试中达到先进水平,使用ViT-B/16在OV-COCO上达到44.3 AP50novel,使用ViT-L/14达到48.5 AP50novel;在OV-LVIS上使用ViT-B/16和ViT-L/14分别达到27.8和38.4 mAPr。
点此查看论文截图


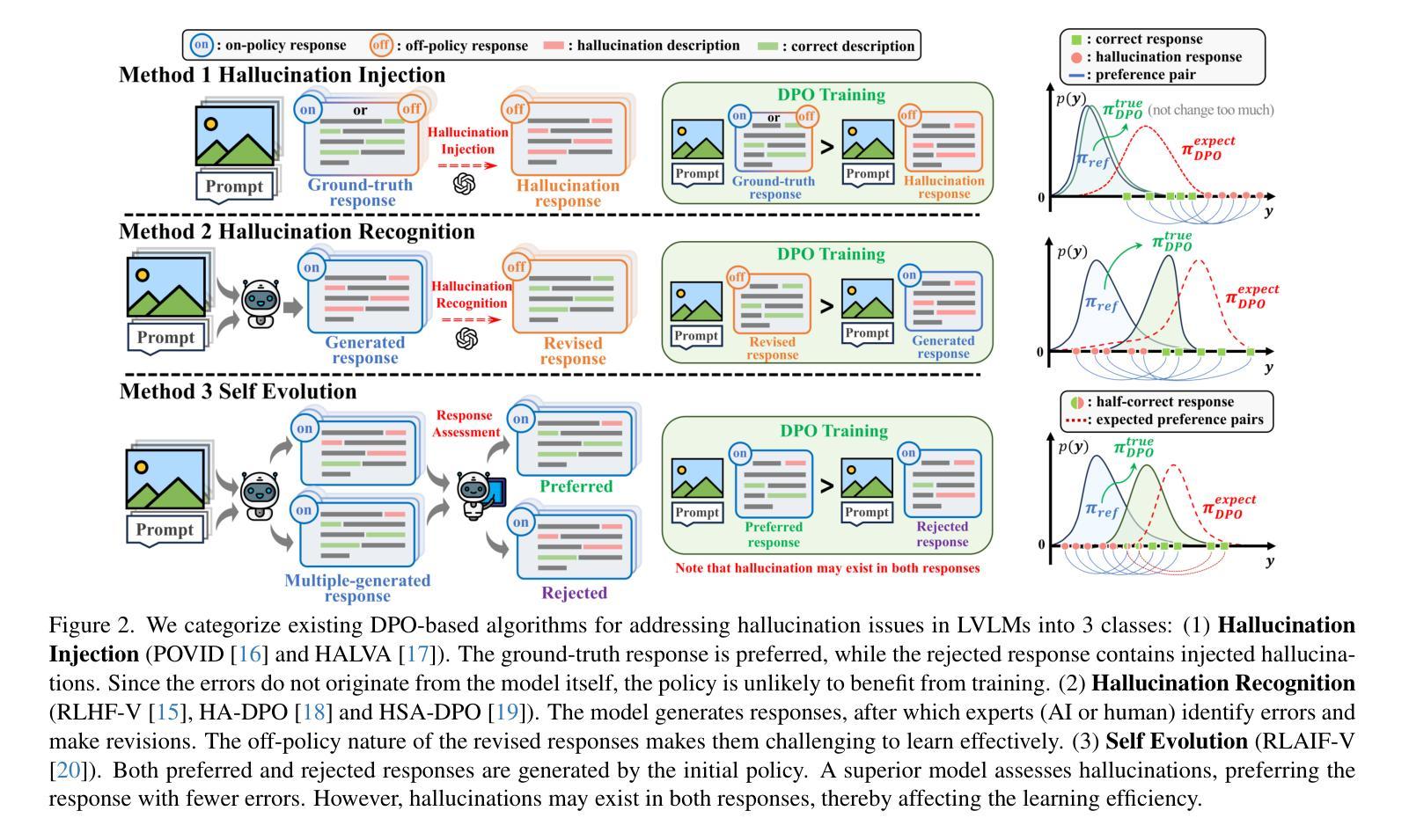
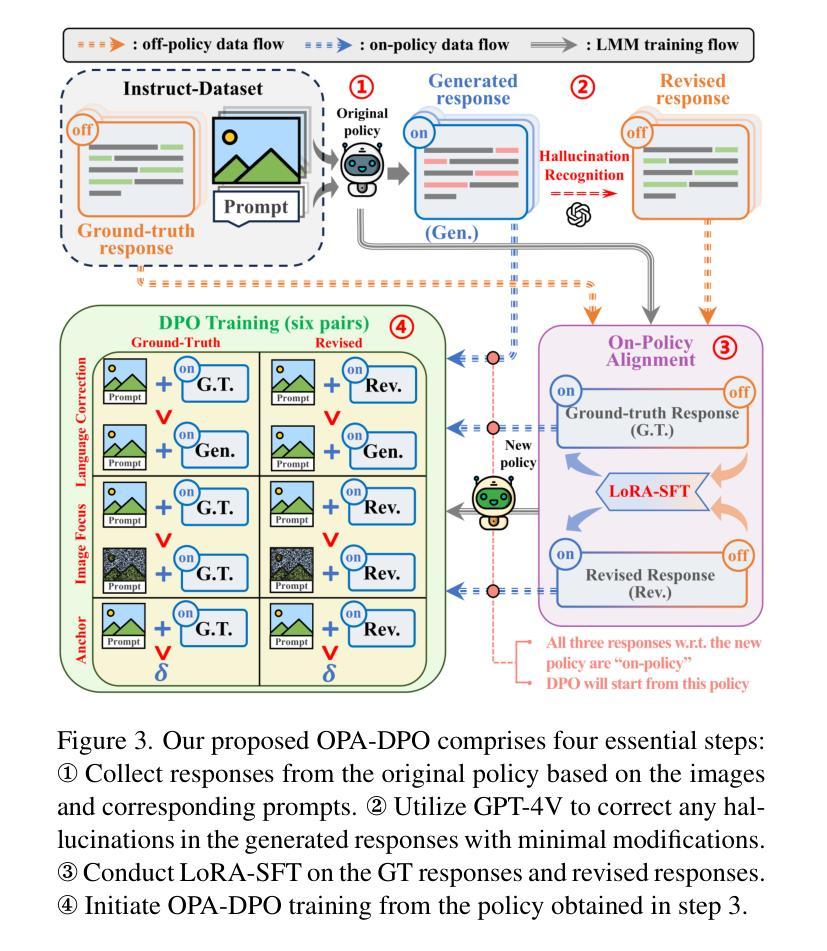
Mitigating Hallucinations in Large Vision-Language Models via DPO: On-Policy Data Hold the Key
Authors:Zhihe Yang, Xufang Luo, Dongqi Han, Yunjian Xu, Dongsheng Li
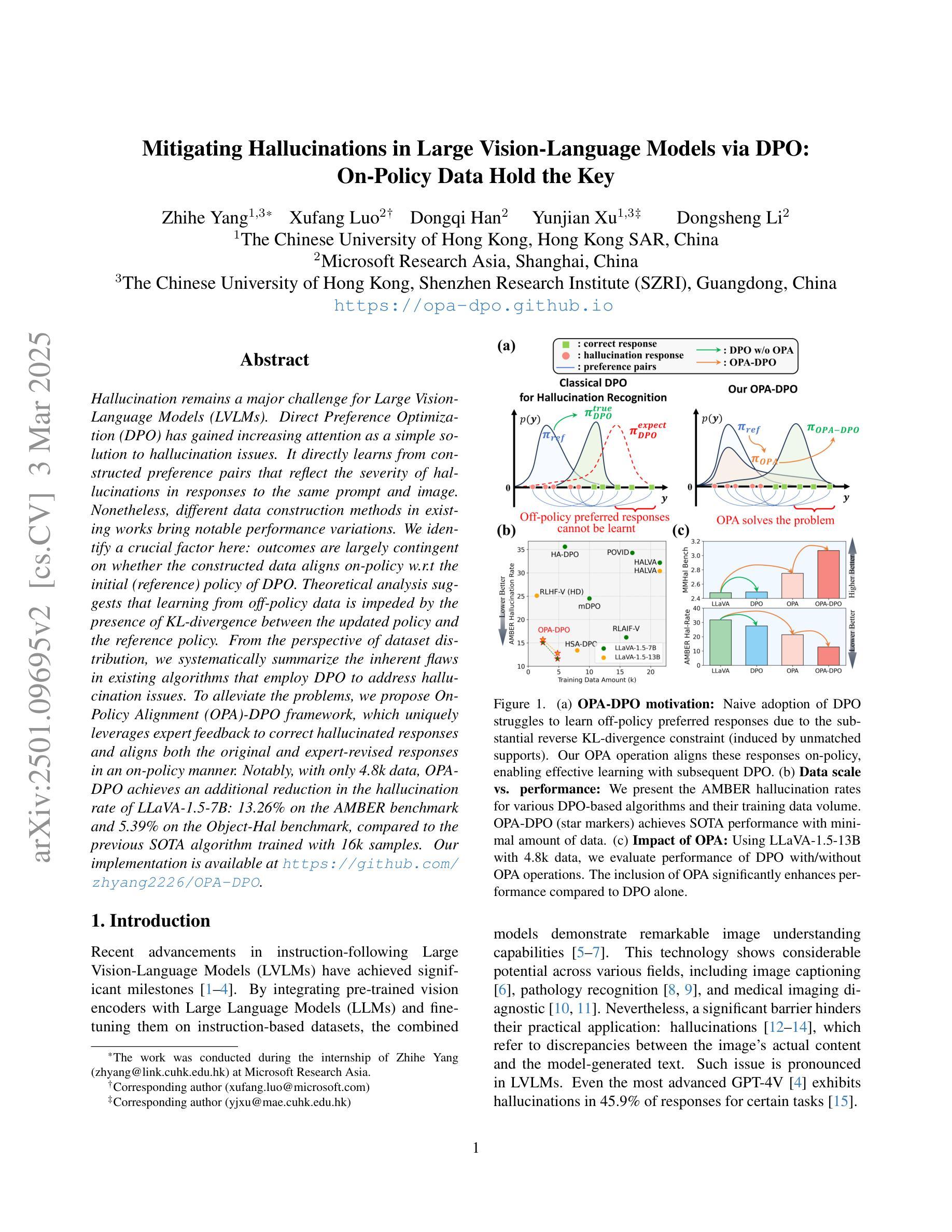
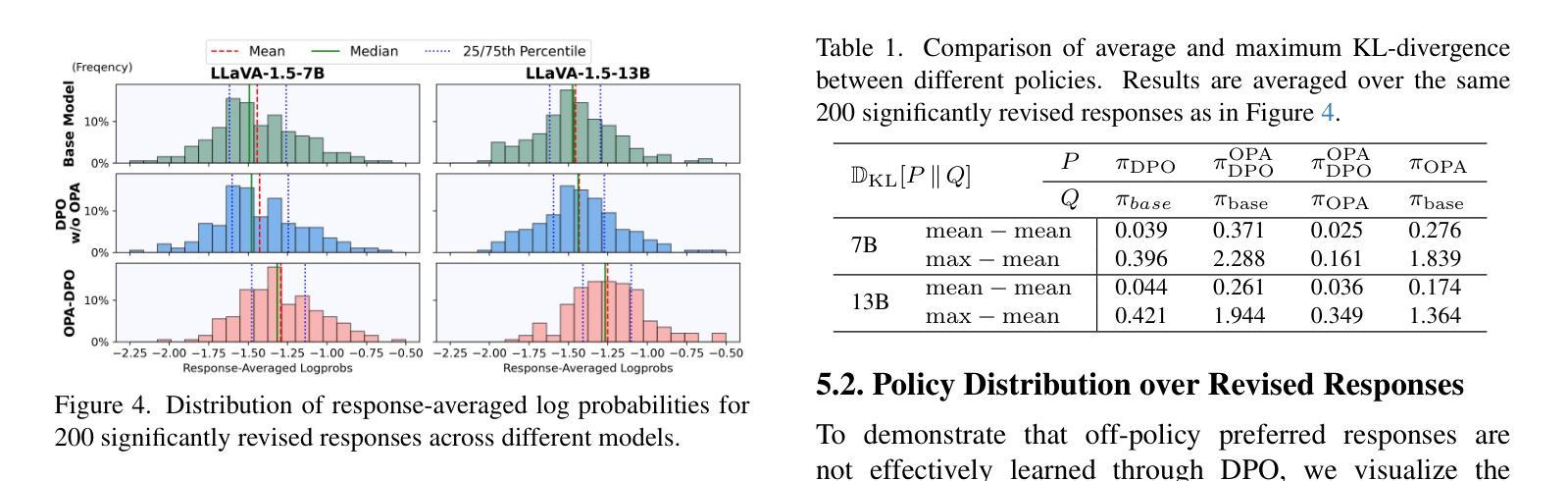
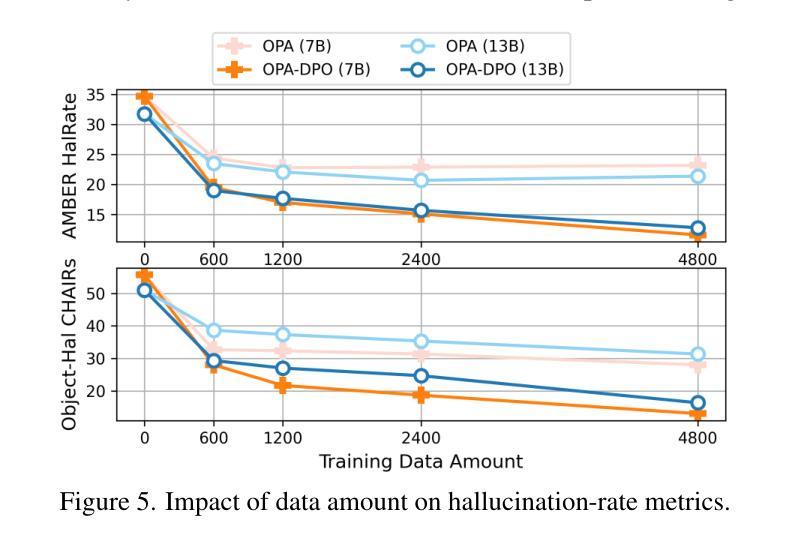
Hallucination remains a major challenge for Large Vision-Language Models (LVLMs). Direct Preference Optimization (DPO) has gained increasing attention as a simple solution to hallucination issues. It directly learns from constructed preference pairs that reflect the severity of hallucinations in responses to the same prompt and image. Nonetheless, different data construction methods in existing works bring notable performance variations. We identify a crucial factor here: outcomes are largely contingent on whether the constructed data aligns on-policy w.r.t the initial (reference) policy of DPO. Theoretical analysis suggests that learning from off-policy data is impeded by the presence of KL-divergence between the updated policy and the reference policy. From the perspective of dataset distribution, we systematically summarize the inherent flaws in existing algorithms that employ DPO to address hallucination issues. To alleviate the problems, we propose On-Policy Alignment (OPA)-DPO framework, which uniquely leverages expert feedback to correct hallucinated responses and aligns both the original and expert-revised responses in an on-policy manner. Notably, with only 4.8k data, OPA-DPO achieves an additional reduction in the hallucination rate of LLaVA-1.5-7B: 13.26% on the AMBER benchmark and 5.39% on the Object-Hal benchmark, compared to the previous SOTA algorithm trained with 16k samples. Our implementation is available at https://github.com/zhyang2226/OPA-DPO.
对于大型视觉语言模型(LVLMs)来说,幻觉仍然是一个主要挑战。直接偏好优化(DPO)作为解决幻觉问题的简单解决方案,已经越来越受到关注。它直接从构建的偏好对中学习,这些偏好对反映了相同提示和图像下的响应幻觉的严重程度。然而,现有工作中的不同数据构建方法带来了显著的性能差异。我们在这里确定了一个关键因素:结果在很大程度上取决于所构建的数据是否与DPO的初始(参考)策略相符。理论分析表明,从非策略数据(off-policy data)中学习会受到更新策略和参考策略之间KL散度存在的影响。从数据集分布的角度来看,我们系统地总结了现有算法在采用DPO解决幻觉问题方面的固有缺陷。为了缓解这些问题,我们提出了OPA-DPO框架,该框架独特地利用专家反馈来纠正幻觉响应,并以符合策略的方式对齐原始和专家修订的响应。值得注意的是,仅使用4.8k数据,OPA-DPO在AMBER基准测试上实现了LLaVA-1.5-7B幻觉率的额外降低:较之前的最佳算法高出13.26%,在Object-Hal基准测试上高出5.39%,后者训练样本为16k。我们的实现可在https://github.com/zhyang2226/OPA-DPO访问。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary
本文主要探讨了大型视觉语言模型(LVLMs)中的幻视问题及其解决方案。文章介绍了直接偏好优化(DPO)作为一种解决幻视问题的简单方法,并指出不同数据构建方法对性能的影响。文章强调了数据构建需遵循初始策略的重要性,并指出学习偏离策略的数据会存在障碍。为了解决现有算法的缺陷,本文提出了OPA-DPO框架,通过专家反馈来纠正幻视响应,并在对齐原始和专家修订的响应上采取了遵循策略的方法。该框架使用较少的数据即可取得显著的幻视率降低效果。
Key Takeaways
- 大型视觉语言模型(LVLMs)面临幻视挑战。
- 直接偏好优化(DPO)是处理幻视问题的一种简单有效方法。
- 数据构建方法对DPO性能有显著影响,需遵循初始策略。
- 偏离策略的数据学习存在障碍,主要原因是更新策略与参考策略之间的KL散度。
- 现有算法在解决幻视问题时存在内在缺陷。
- OPA-DPO框架通过专家反馈纠正幻视响应,并在对齐原始和专家修订的响应上采取遵循策略的方法。
点此查看论文截图
Cross-Spectral Vision Transformer for Biometric Authentication using Forehead Subcutaneous Vein Pattern and Periocular Pattern
Authors:Arun K. Sharma, Shubhobrata Bhattacharya, Motahar Reza, Bishakh Bhattacharya
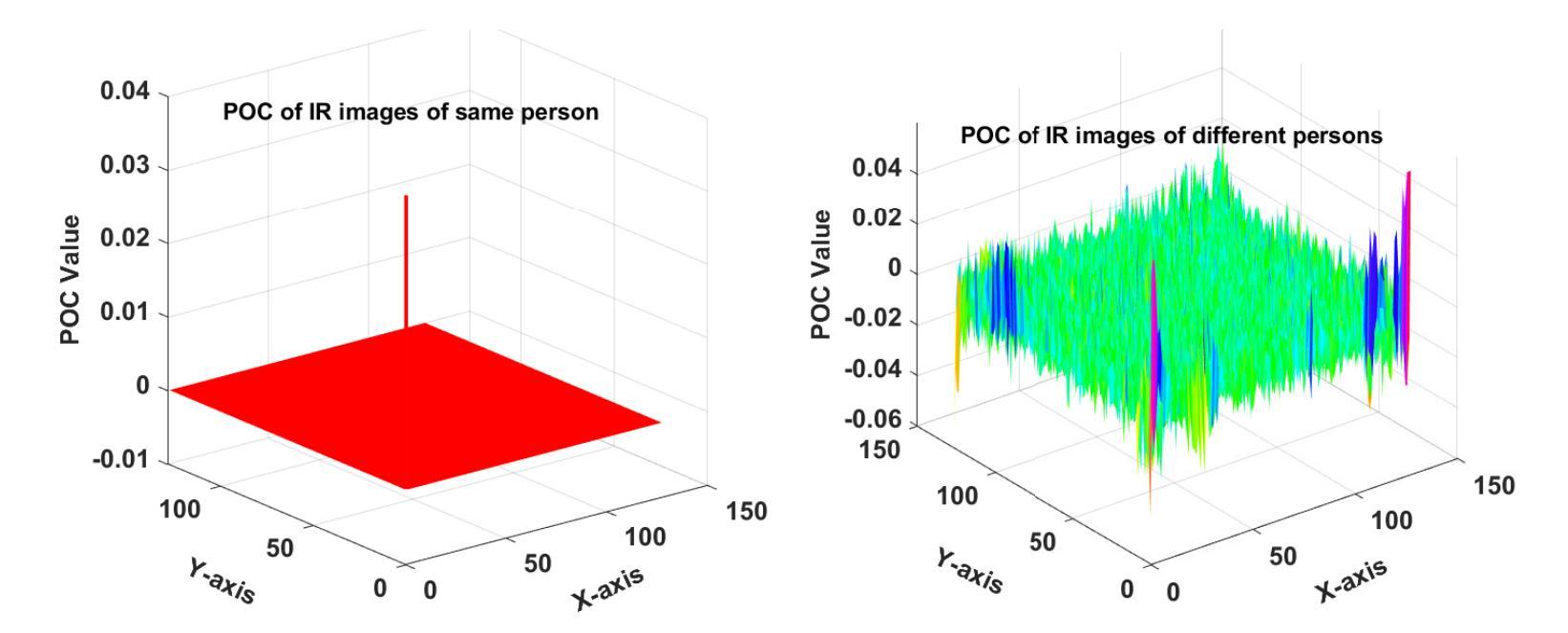
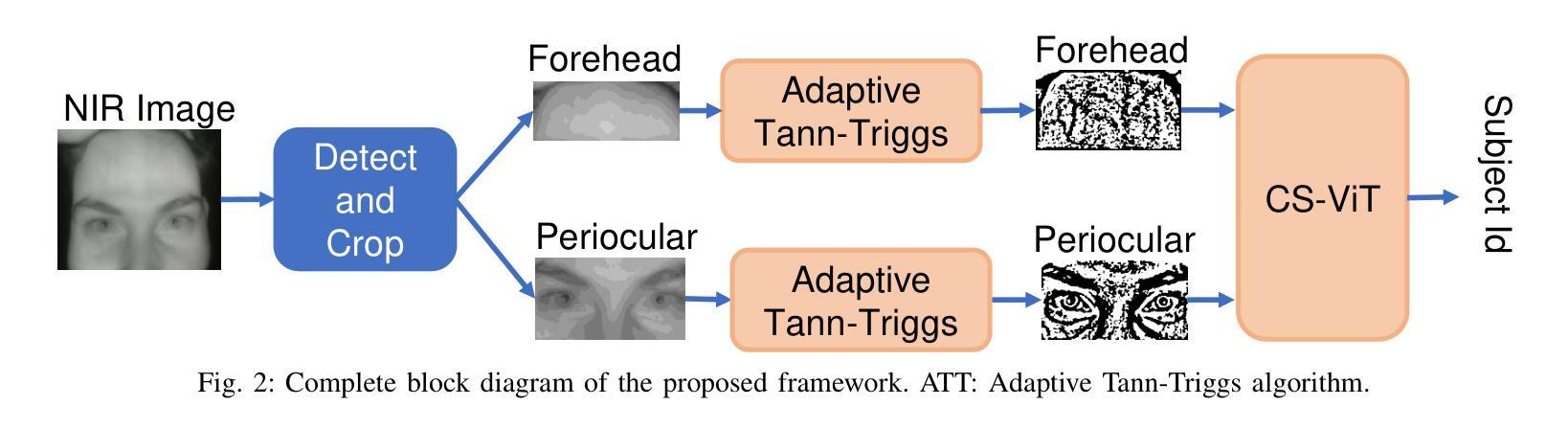
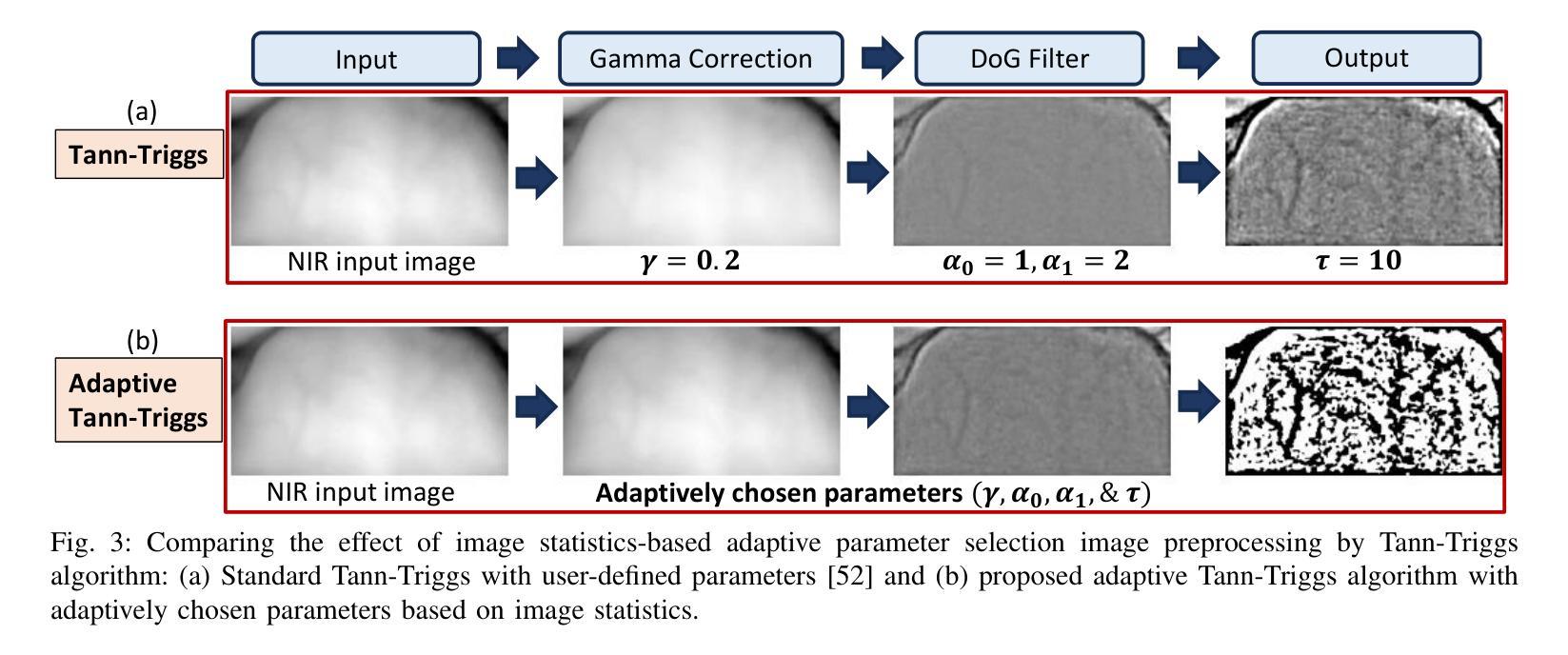
Traditional biometric systems have encountered significant setbacks due to various unavoidable factors, for example, face recognition-based biometrics fails due to the wearing of face masks and fingerprints create hygiene concerns. This paper proposes a novel lightweight cross-spectral vision transformer (CS-ViT) for biometric authentication using forehead subcutaneous vein patterns and periocular patterns, offering a promising alternative to traditional methods, capable of performing well even with the face masks and without any physical touch. The proposed framework comprises a cross-spectral dual-channel architecture designed to handle two distinct biometric traits and to capture inter-dependencies in terms of relative spectral patterns. Each channel consists of a Phase-Only Correlation Cross-Spectral Attention (POC-CSA) that captures their individual as well as correlated patterns. The computation of cross-spectral attention using POC extracts the phase correlation in the spatial features. Therefore, it is robust against the resolution/intensity variations and illumination of the input images, assuming both biometric traits are from the same person. The lightweight model is suitable for edge device deployment. The performance of the proposed algorithm was rigorously evaluated using the Forehead Subcutaneous Vein Pattern and Periocular Biometric Pattern (FSVP-PBP) database. The results demonstrated the superiority of the algorithm over state-of-the-art methods, achieving a remarkable classification accuracy of 98.8% with the combined vein and periocular patterns.
传统生物识别系统由于各种不可避免的因素而遭遇重大挫折,例如基于面部识别的生物识别会因为佩戴口罩而失效,而指纹识别则引发卫生方面的担忧。本文针对生物认证提出了一种新型轻量级跨光谱视觉转换器(CS-ViT),使用额头皮下静脉图案和眼周图案进行生物识别。相比传统方法,该方案展现出极大的潜力,即使在佩戴口罩的情况下也能实现无需任何物理接触的良好性能。所提框架采用跨光谱双通道架构,旨在处理两种独特的生物识别特征,并捕捉相对光谱模式之间的相互依赖性。每个通道都包含仅相位关联跨光谱注意力(POC-CSA),可捕捉其个体以及相关模式。利用POC计算跨光谱注意力,从而提取空间特征的相位关联。因此,它对输入图像的分辨率/强度变化和光照具有鲁棒性,假设两种生物识别特征来自同一人。该轻量级模型适合在边缘设备进行部署。所提算法的性能通过使用额头皮下静脉图案和眼周生物识别图案(FSVP-PBP)数据库进行了严格评估。结果表明,该算法优于最新方法,结合静脉和眼周图案实现了高达98.8%的分类准确率。
论文及项目相关链接
PDF Submitted to IEEE TPAMI
Summary
本文提出了一种新型的轻量级跨光谱视觉转换器(CS-ViT),用于基于前额皮下静脉模式和眼周模式的生物特征认证。该方法克服了传统生物识别系统因戴口罩和指纹卫生问题而出现的缺陷,即使在佩戴口罩的情况下也能实现良好的性能,且无需任何物理接触。文章介绍了跨光谱双通道架构的设计,以及利用相位仅相关交叉谱注意(POC-CSA)捕获个体和关联模式的方法。该模型适用于边缘设备部署,并在前额皮下静脉模式和眼周生物特征模式数据库上进行了严格评估,实现了高达98.8%的分类准确率。
Key Takeaways
- 传统生物识别系统因戴口罩和指纹卫生问题面临挑战。
- 论文提出了一种新型的轻量级跨光谱视觉转换器(CS-ViT)。
- CS-ViT使用前额皮下静脉模式和眼周模式进行生物特征认证,为传统方法提供了有前景的替代方案。
- 该方法能在佩戴口罩的情况下实现良好的性能,且无需任何物理接触。
- 论文介绍了跨光谱双通道架构和相位仅相关交叉谱注意(POC-CSA)机制。
- CS-ViT模型适用于边缘设备部署。
点此查看论文截图

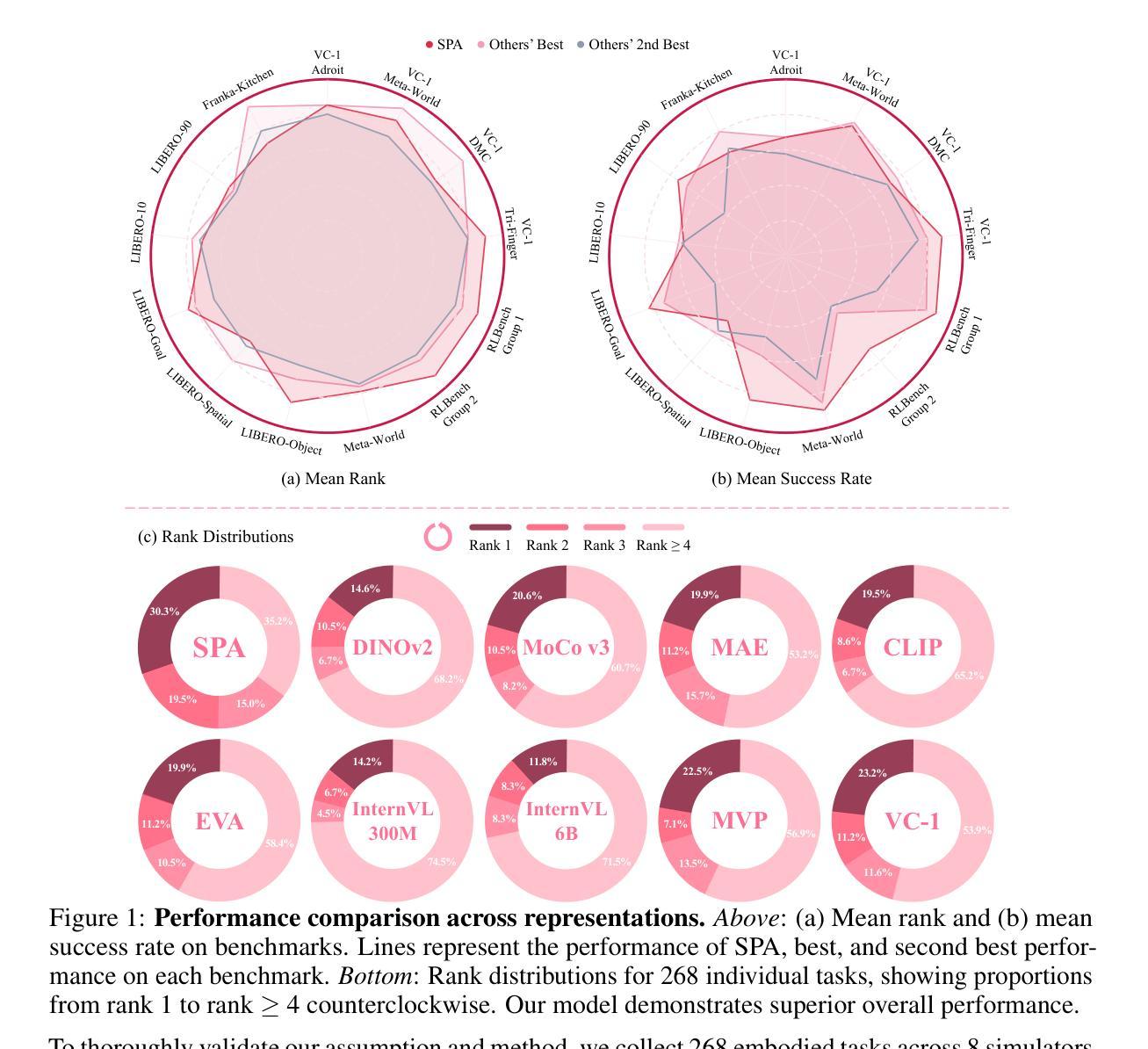
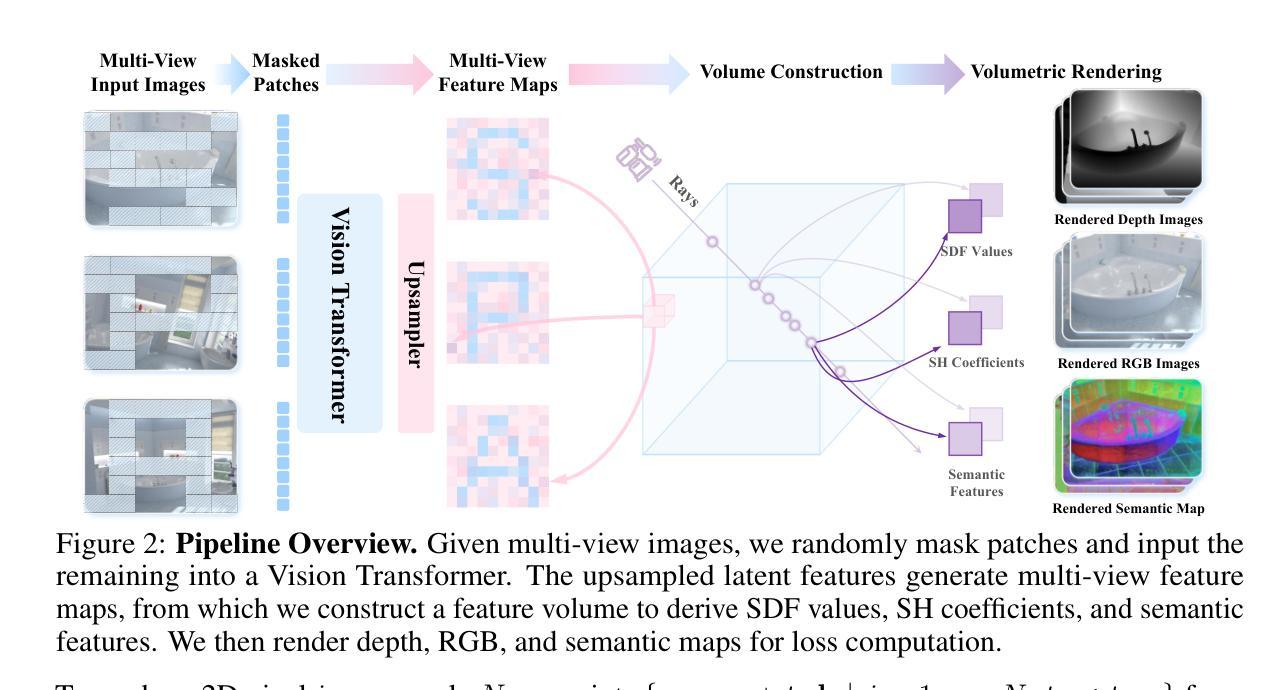
SPA: 3D Spatial-Awareness Enables Effective Embodied Representation
Authors:Haoyi Zhu, Honghui Yang, Yating Wang, Jiange Yang, Limin Wang, Tong He
In this paper, we introduce SPA, a novel representation learning framework that emphasizes the importance of 3D spatial awareness in embodied AI. Our approach leverages differentiable neural rendering on multi-view images to endow a vanilla Vision Transformer (ViT) with intrinsic spatial understanding. We present the most comprehensive evaluation of embodied representation learning to date, covering 268 tasks across 8 simulators with diverse policies in both single-task and language-conditioned multi-task scenarios. The results are compelling: SPA consistently outperforms more than 10 state-of-the-art representation methods, including those specifically designed for embodied AI, vision-centric tasks, and multi-modal applications, while using less training data. Furthermore, we conduct a series of real-world experiments to confirm its effectiveness in practical scenarios. These results highlight the critical role of 3D spatial awareness for embodied representation learning. Our strongest model takes more than 6000 GPU hours to train and we are committed to open-sourcing all code and model weights to foster future research in embodied representation learning. Project Page: https://haoyizhu.github.io/spa/.
在这篇论文中,我们介绍了SPA,这是一个强调体现式AI中三维空间感知重要性的新型表示学习框架。我们的方法利用多视角图像上的可微神经网络渲染技术,赋予普通视觉转换器(ViT)内在的空间理解能力。我们对体现式表示学习进行了迄今为止最全面的评估,涵盖了单一任务和语言条件多任务场景中的8个模拟器共268项任务的各种策略。结果令人信服:SPA在各种情况下都优于超过十种最先进的表示方法,包括专门为体现式AI、以视觉为中心的任务和多模态应用程序设计的方法,同时使用更少训练数据。此外,我们还进行了一系列现实世界的实验来验证其在现实场景中的有效性。这些结果凸显了三维空间感知对于体现式表示学习的关键作用。我们的最佳模型训练耗时超过6000 GPU小时,我们致力于开源所有代码和模型权重,以促进未来在体现式表示学习领域的研究。项目页面:https://haoyizhu.github.io/spa/。
论文及项目相关链接
PDF Project Page: https://haoyizhu.github.io/spa/
Summary
新一代空间感知表示学习框架SPA,通过多视角图像的可微神经网络渲染技术,为普通视觉转换器(ViT)赋予内在的空间理解能力。在涵盖单任务和语言条件多任务场景的8个模拟器中的268项任务进行了综合评估,表明SPA在代表性方面优于其他十几种先进方法,并且能在实际应用场景中表现良好。这一研究突出了三维空间感知对嵌入表示学习的重要性。该项目致力于开源代码和模型权重以促进未来研究。
Key Takeaways
- 引入了名为SPA的新一代表示学习框架,强调了三维空间感知在嵌入AI中的重要性。
- 通过可微神经网络渲染技术实现多视角图像的处理,增强了视觉转换器(ViT)的空间理解能力。
- 在多个模拟器和任务上的综合评估表明,SPA在代表性方面表现优异,优于其他先进方法。
- SPA能在实际应用场景中表现良好,验证了其在实际应用中的有效性。
- 该项目致力于开源所有代码和模型权重,以促进未来对嵌入表示学习的研究。
- SPA训练成本较高,需要超过6000 GPU小时。
点此查看论文截图