⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-06 更新
2DGS-Avatar: Animatable High-fidelity Clothed Avatar via 2D Gaussian Splatting
Authors:Qipeng Yan, Mingyang Sun, Lihua Zhang
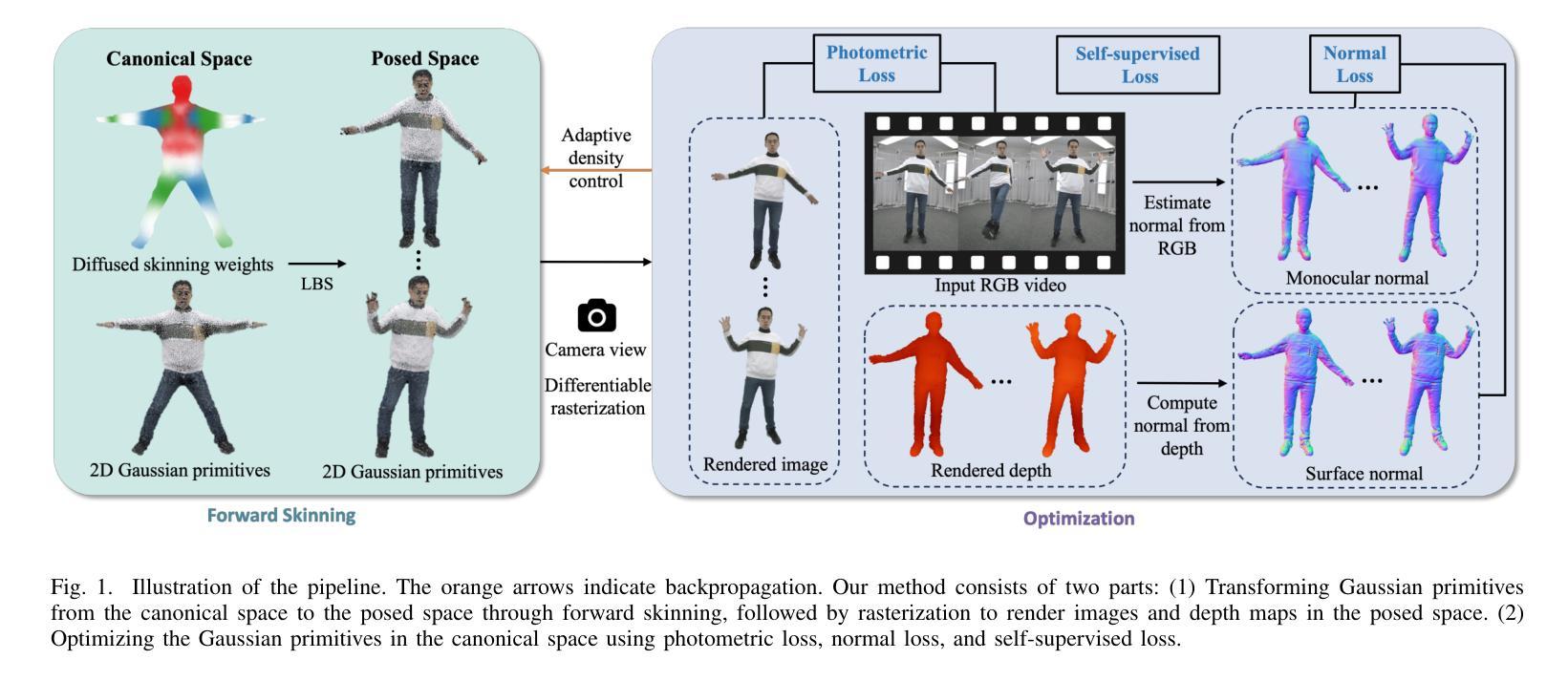
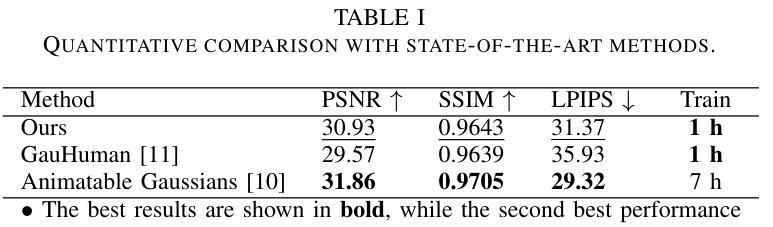
Real-time rendering of high-fidelity and animatable avatars from monocular videos remains a challenging problem in computer vision and graphics. Over the past few years, the Neural Radiance Field (NeRF) has made significant progress in rendering quality but behaves poorly in run-time performance due to the low efficiency of volumetric rendering. Recently, methods based on 3D Gaussian Splatting (3DGS) have shown great potential in fast training and real-time rendering. However, they still suffer from artifacts caused by inaccurate geometry. To address these problems, we propose 2DGS-Avatar, a novel approach based on 2D Gaussian Splatting (2DGS) for modeling animatable clothed avatars with high-fidelity and fast training performance. Given monocular RGB videos as input, our method generates an avatar that can be driven by poses and rendered in real-time. Compared to 3DGS-based methods, our 2DGS-Avatar retains the advantages of fast training and rendering while also capturing detailed, dynamic, and photo-realistic appearances. We conduct abundant experiments on popular datasets such as AvatarRex and THuman4.0, demonstrating impressive performance in both qualitative and quantitative metrics.
从单目视频中实时渲染高保真和可动画的化身仍然是计算机视觉和图形学中的一个具有挑战性的问题。过去几年,神经辐射场(NeRF)在渲染质量方面取得了显著进展,但由于体积渲染的低效率,其在运行时性能上表现不佳。最近,基于3D高斯喷射(3DGS)的方法在快速训练和实时渲染方面显示出巨大潜力。然而,它们仍然受到由几何不准确引起的伪影的影响。为了解决这些问题,我们提出了基于二维高斯喷射(2DGS)的动画化二维化身模型技术——简称为二维动态化身模型(2DGS-Avatar)。该方法使用单目RGB视频作为输入生成可以被姿势驱动的实时渲染的化身。相较于基于三维动态喷射的技术方法而言,我们提出的二维动态化身模型能够同时兼顾训练效率和渲染速度上的优势并具备捕捉细节丰富、动态以及逼真的外观能力。我们在诸如AvatarRex和THuman4.0等流行数据集上进行了大量实验,在定性和定量指标上都表现出令人印象深刻的性能。
论文及项目相关链接
PDF ICVRV 2024
Summary
基于单目RGB视频输入,提出一种新型的基于二维高斯拼贴(2DGS)的动画服装人物建模方法,具有高保真和快速训练性能。该方法生成的虚拟人物可随姿态驱动并在实时渲染中呈现详细、动态和逼真的外观。
Key Takeaways
- Real-time rendering of high-fidelity avatars from monocular videos is still a challenge in computer vision and graphics.
- Neural Radiance Field (NeRF)虽在渲染质量方面取得显著进展,但运行时效率较低。
- 3D Gaussian Splatting (3DGS)方法虽然训练速度快,实时渲染性能好,但存在几何不准确导致的伪影问题。
- 提出一种基于二维高斯拼贴(2DGS)的动画服装人物建模方法(命名为“Avatar”)。可从单目RGB视频生成虚拟人物,具有姿态驱动和实时渲染功能。该方法不仅保留了快速训练和渲染的优点,还能捕捉详细的动态和逼真的外观。
- 在流行的数据集如AvatarRex和THuman4.0上进行的大量实验表明,该方法在定性和定量指标上都表现出卓越的性能。
点此查看论文截图


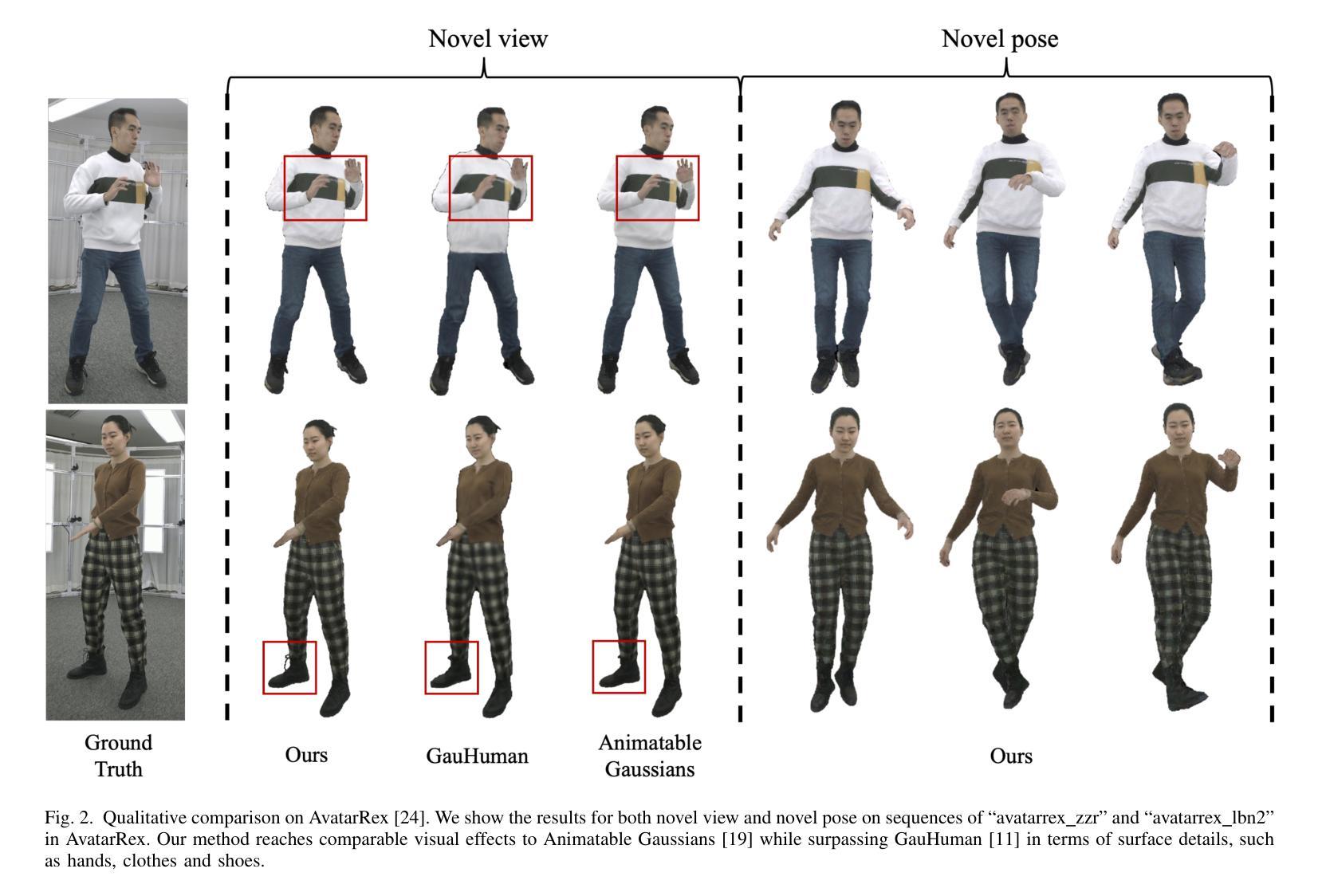
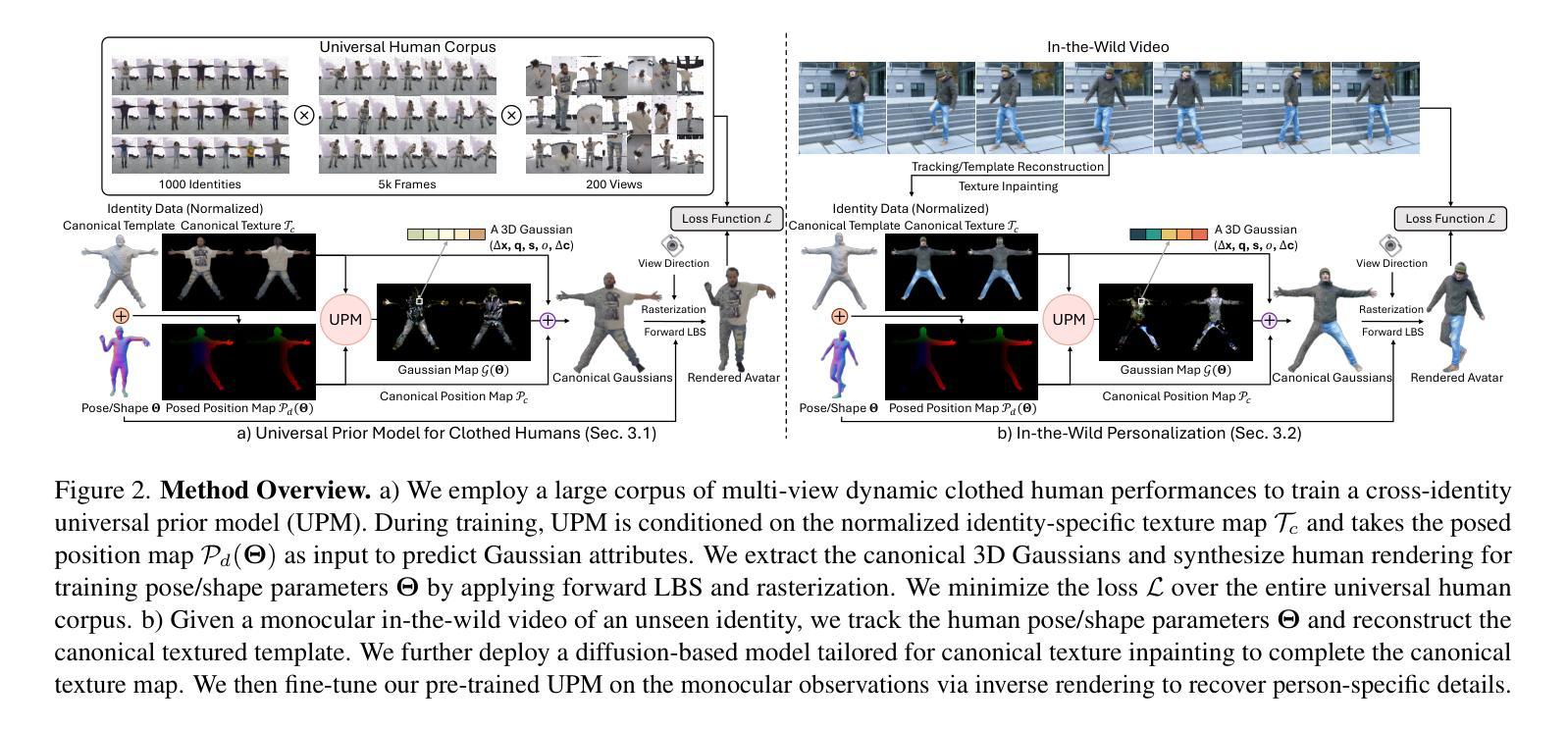
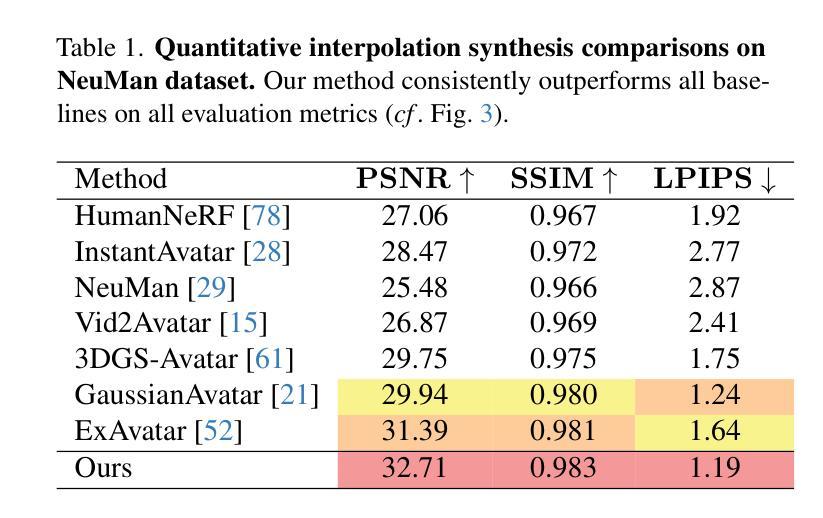
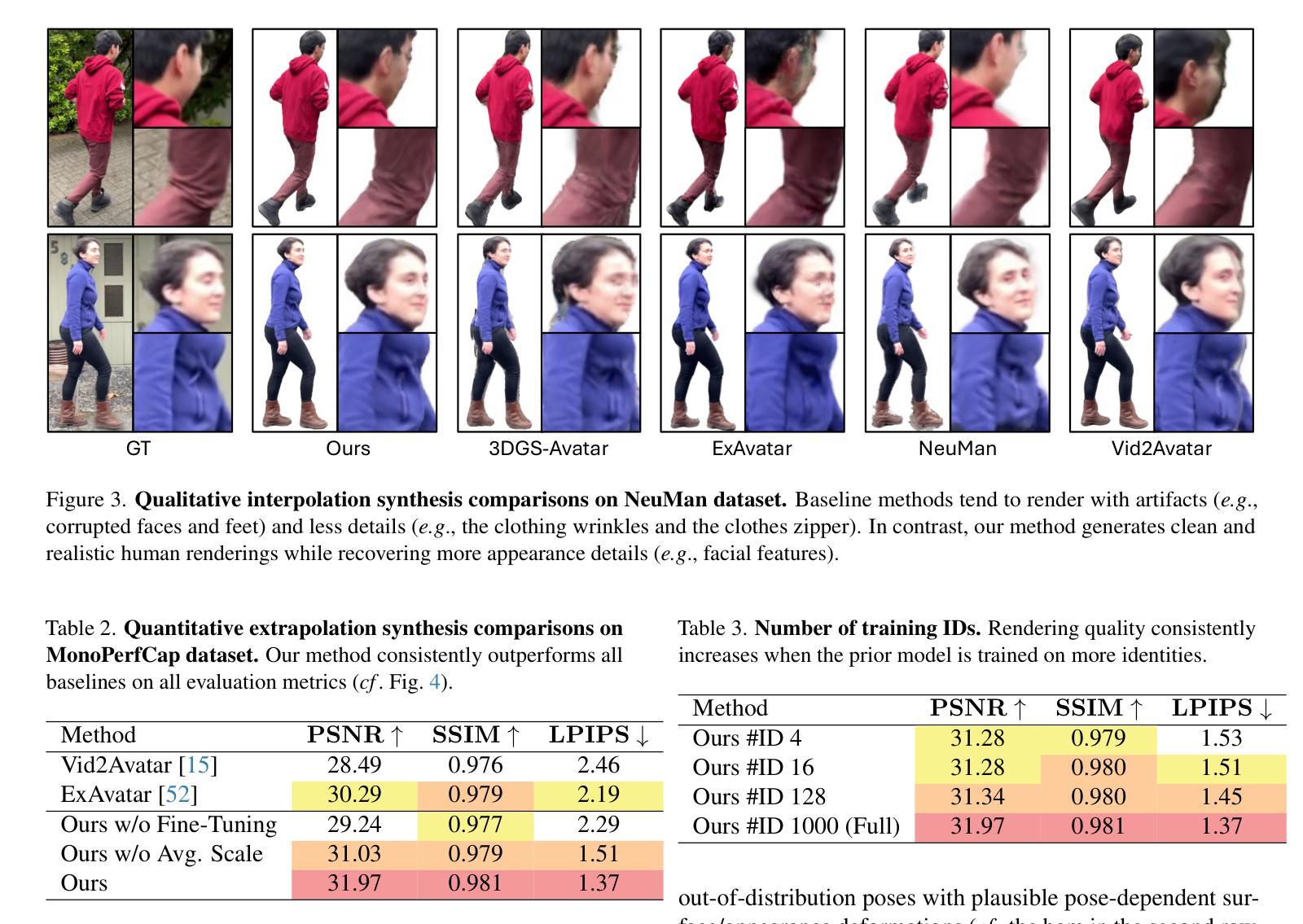
Vid2Avatar-Pro: Authentic Avatar from Videos in the Wild via Universal Prior
Authors:Chen Guo, Junxuan Li, Yash Kant, Yaser Sheikh, Shunsuke Saito, Chen Cao
We present Vid2Avatar-Pro, a method to create photorealistic and animatable 3D human avatars from monocular in-the-wild videos. Building a high-quality avatar that supports animation with diverse poses from a monocular video is challenging because the observation of pose diversity and view points is inherently limited. The lack of pose variations typically leads to poor generalization to novel poses, and avatars can easily overfit to limited input view points, producing artifacts and distortions from other views. In this work, we address these limitations by leveraging a universal prior model (UPM) learned from a large corpus of multi-view clothed human performance capture data. We build our representation on top of expressive 3D Gaussians with canonical front and back maps shared across identities. Once the UPM is learned to accurately reproduce the large-scale multi-view human images, we fine-tune the model with an in-the-wild video via inverse rendering to obtain a personalized photorealistic human avatar that can be faithfully animated to novel human motions and rendered from novel views. The experiments show that our approach based on the learned universal prior sets a new state-of-the-art in monocular avatar reconstruction by substantially outperforming existing approaches relying only on heuristic regularization or a shape prior of minimally clothed bodies (e.g., SMPL) on publicly available datasets.
我们提出了Vid2Avatar-Pro方法,这是一种从单目野外视频中创建逼真且可动画的3D人类虚拟形象的方法。从单目视频构建支持多种姿势的动画的高质量虚拟形象具有挑战性,因为姿势多样性和观察视角的局限性本身就存在。姿势变化的缺乏通常导致对新型姿势的泛化能力较差,而虚拟形象很容易对有限的输入观点过度适应,从而导致从其他视角产生伪影和失真。在这项工作中,我们通过利用从大量多视角着装人体捕获数据中学习到的通用先验模型(UPM)来解决这些局限性。我们的表达建立在具有规范前面和背面图的3D高斯之上,这些图在不同身份之间共享。一旦UPM能够准确再现大型多视角人体图像,我们就会通过反向渲染技术对野外视频进行微调,从而获得个性化的逼真人类虚拟形象,可以忠实地模拟新的人类动作并从新的视角进行渲染。实验表明,我们基于学习到的通用先验的方法在单目虚拟形象重建方面树立了新的业界最佳水平,大幅度超越了仅依赖启发式正则化或最少着装身体形状先验(例如SMPL)的现有方法在公开数据集上的表现。
论文及项目相关链接
PDF Project page: https://moygcc.github.io/vid2avatar-pro/
Summary
新一代的三维人物建模技术Vid2Avatar-Pro可从单目野生视频创建逼真的可动画三维人物模型。通过使用从大规模多视角服装人体捕捉数据中学习的通用先验模型(UPM),解决了从单目视频创建支持动画的个性化三维人物模型的挑战。实验表明,该方法在单目重建领域树立了新的技术标杆。
Key Takeaways
- Vid2Avatar-Pro可从单目野生视频创建三维人物模型。
- 面临的主要挑战是观察姿态多样性和视点的限制。
- 通用先验模型(UPM)用于解决这些问题,该模型从多视角服装人体捕捉数据中学习。
- 使用表达性三维高斯模型和跨身份共享的前后面图构建表示。
- 通过逆向渲染技术,使用野生视频对模型进行微调,获得个性化的逼真人物模型。
- 该模型能够忠实于新的动作和视角进行动画和渲染。
点此查看论文截图

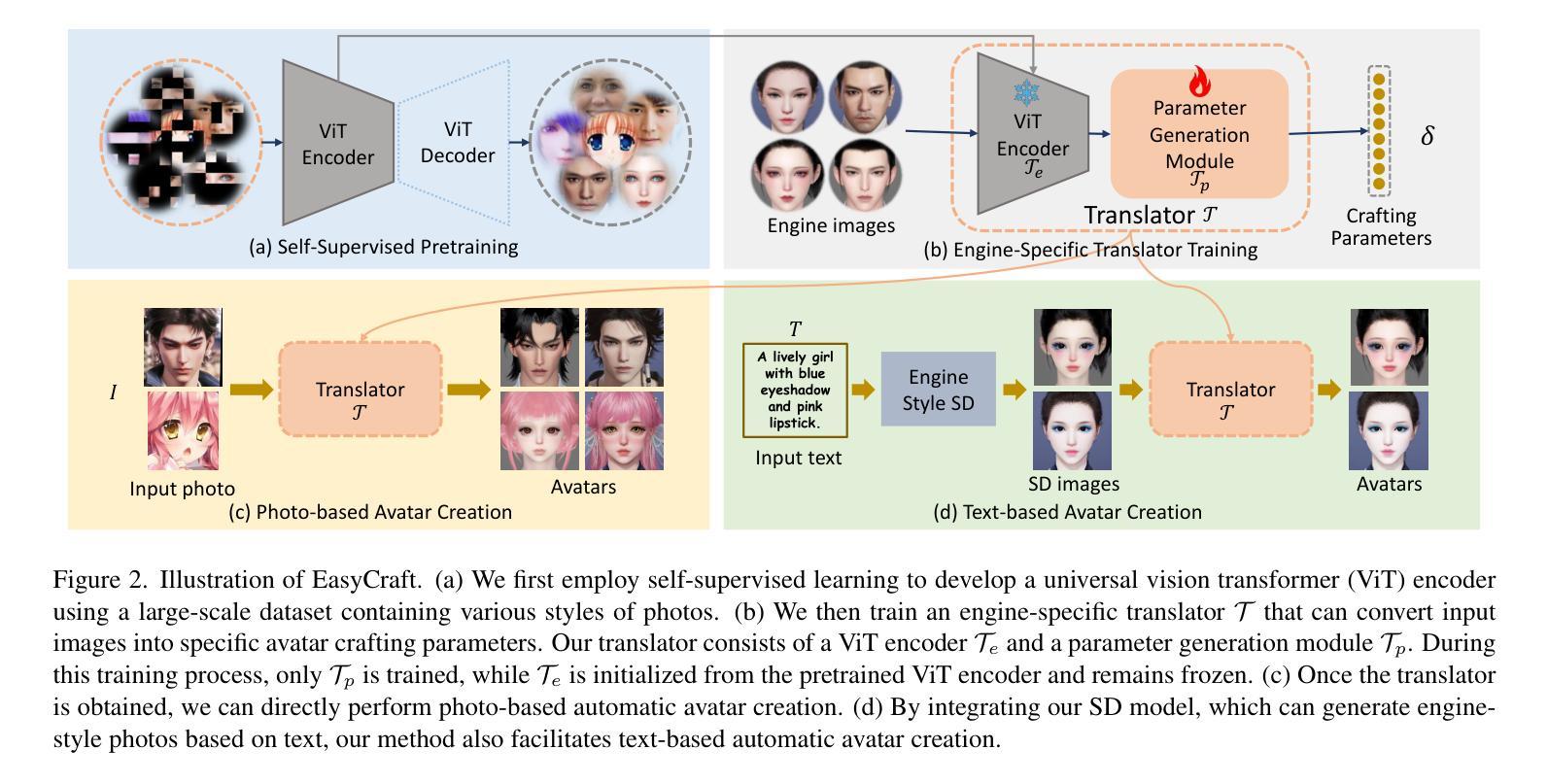
EasyCraft: A Robust and Efficient Framework for Automatic Avatar Crafting
Authors:Suzhen Wang, Weijie Chen, Wei Zhang, Minda Zhao, Lincheng Li, Rongsheng Zhang, Zhipeng Hu, Xin Yu
Character customization, or ‘face crafting,’ is a vital feature in role-playing games (RPGs), enhancing player engagement by enabling the creation of personalized avatars. Existing automated methods often struggle with generalizability across diverse game engines due to their reliance on the intermediate constraints of specific image domain and typically support only one type of input, either text or image. To overcome these challenges, we introduce EasyCraft, an innovative end-to-end feedforward framework that automates character crafting by uniquely supporting both text and image inputs. Our approach employs a translator capable of converting facial images of any style into crafting parameters. We first establish a unified feature distribution in the translator’s image encoder through self-supervised learning on a large-scale dataset, enabling photos of any style to be embedded into a unified feature representation. Subsequently, we map this unified feature distribution to crafting parameters specific to a game engine, a process that can be easily adapted to most game engines and thus enhances EasyCraft’s generalizability. By integrating text-to-image techniques with our translator, EasyCraft also facilitates precise, text-based character crafting. EasyCraft’s ability to integrate diverse inputs significantly enhances the versatility and accuracy of avatar creation. Extensive experiments on two RPG games demonstrate the effectiveness of our method, achieving state-of-the-art results and facilitating adaptability across various avatar engines.
角色定制,或称“角色捏脸”,是角色扮演游戏(RPG)中的重要功能之一,通过创建个性化的角色增强玩家的参与度。现有的自动化方法往往因为依赖于特定图像域的中间约束以及通常只支持文本或图像其中一种输入,而在跨不同游戏引擎的通用性方面面临挑战。为了克服这些挑战,我们引入了EasyCraft,这是一个创新的全局前馈框架,能够自动进行角色捏脸,并独特地支持文本和图像两种输入。我们的方法采用了一种能够将任何风格的面部图像转换为捏脸参数的转换器。我们首先在转换器的图像编码器上建立统一特征分布,通过大规模数据集上的自监督学习,使得任何风格的照片都能嵌入到统一特征表示中。随后,我们将这一统一特征分布映射到特定游戏引擎的捏脸参数上,这一过程可轻松适应大多数游戏引擎,从而提高了EasyCraft的通用性。通过将文本转图像技术与我们的转换器相结合,EasyCraft还促进了基于文本的精准角色捏脸。EasyCraft能够整合多种输入,显著提高了角色创建的多样性和准确性。在两个RPG游戏上的大量实验证明了我们方法的有效性,取得了最先进的结果,并在各种角色引擎之间实现了良好的适应性。
论文及项目相关链接
Summary
本文介绍了角色游戏中的个性化角色定制的重要性,现有自动化方法存在通用性不足的问题。为此,提出了EasyCraft框架,支持图像和文本两种输入方式,通过转换器将面部图像转换为制作参数,实现跨游戏引擎的通用性和灵活性。在两款RPG游戏上的实验证明了其有效性和优越性。
Key Takeaways
- 角色游戏中的个性化角色定制是关键功能之一,能够提升玩家参与度。
- 现有自动化方法依赖于特定的图像领域,导致其通用性不足。
- EasyCraft框架首次实现了同时支持文本和图像输入的角色定制自动化。
- 通过使用转换器将面部图像转换为制作参数,提高了角色的相似性和精度。
- EasyCraft框架采用自监督学习方法建立统一特征分布,适用于各种风格的面部图像。
- 该框架能够轻松适应大多数游戏引擎,增强了其通用性。
点此查看论文截图



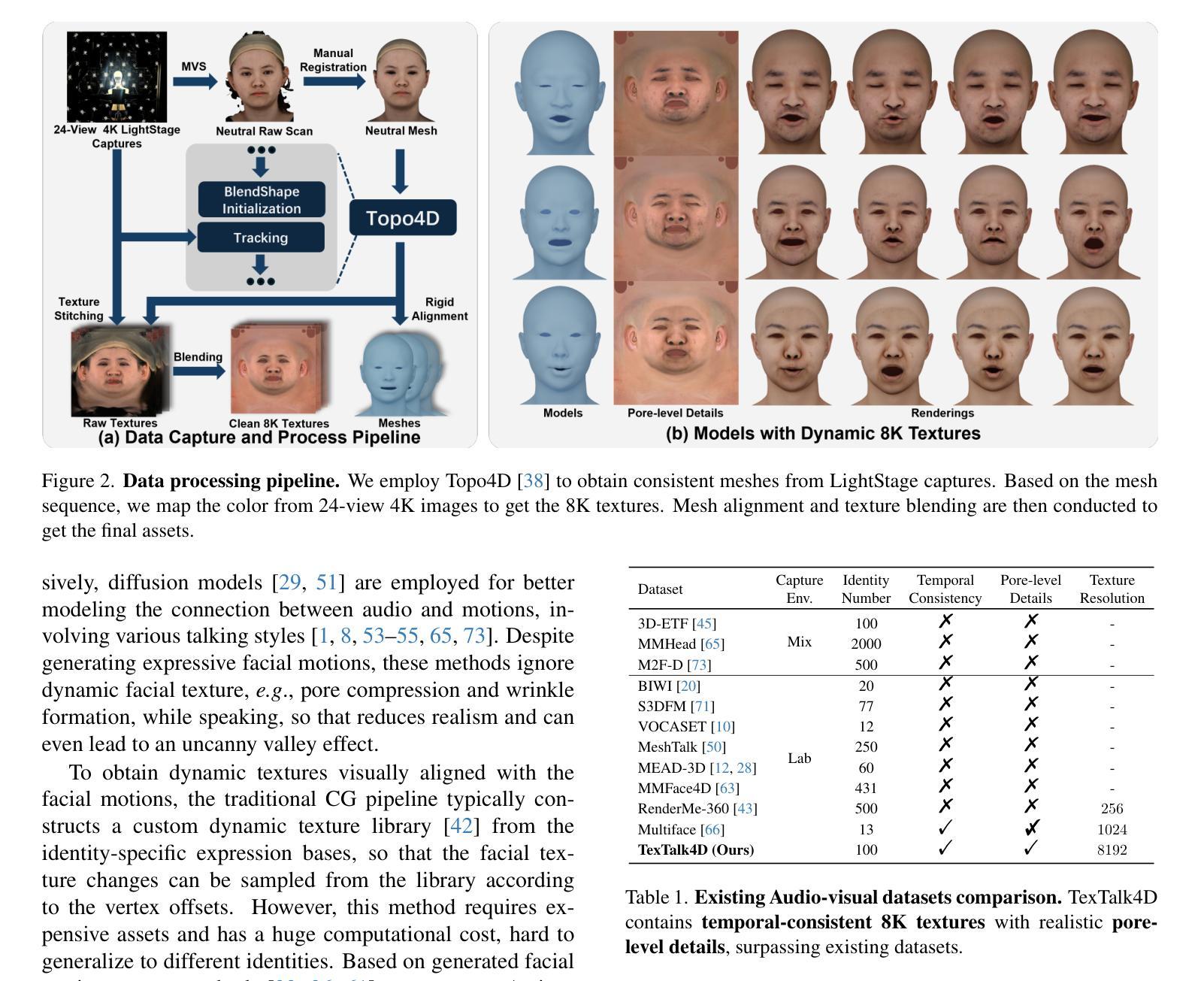
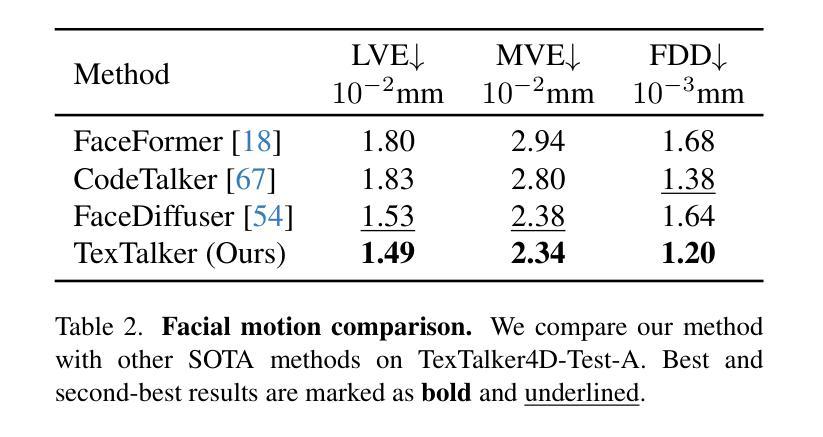
Towards High-fidelity 3D Talking Avatar with Personalized Dynamic Texture
Authors:Xuanchen Li, Jianyu Wang, Yuhao Cheng, Yikun Zeng, Xingyu Ren, Wenhan Zhu, Weiming Zhao, Yichao Yan
Significant progress has been made for speech-driven 3D face animation, but most works focus on learning the motion of mesh/geometry, ignoring the impact of dynamic texture. In this work, we reveal that dynamic texture plays a key role in rendering high-fidelity talking avatars, and introduce a high-resolution 4D dataset \textbf{TexTalk4D}, consisting of 100 minutes of audio-synced scan-level meshes with detailed 8K dynamic textures from 100 subjects. Based on the dataset, we explore the inherent correlation between motion and texture, and propose a diffusion-based framework \textbf{TexTalker} to simultaneously generate facial motions and dynamic textures from speech. Furthermore, we propose a novel pivot-based style injection strategy to capture the complicity of different texture and motion styles, which allows disentangled control. TexTalker, as the first method to generate audio-synced facial motion with dynamic texture, not only outperforms the prior arts in synthesising facial motions, but also produces realistic textures that are consistent with the underlying facial movements. Project page: https://xuanchenli.github.io/TexTalk/.
在语音驱动的三维面部动画方面已经取得了重大进展,但大多数工作主要集中在学习网格/几何的运动上,忽略了动态纹理的影响。在这项工作中,我们揭示了动态纹理在高保真度说话角色渲染中的关键作用,并引入了一个高分辨率的4D数据集TexTalk4D,包含来自100个主题的100分钟的音频同步扫描级别网格和详细的8K动态纹理。基于数据集,我们探索了运动和纹理之间的内在关联,并提出了一种基于扩散的框架TexTalker,可以从语音中同时生成面部运动和动态纹理。此外,我们提出了一种基于枢轴的风格注入策略来捕捉不同纹理和运动风格的复杂性,从而实现了解耦控制。TexTalker作为第一种生成带有动态纹理的音频同步面部运动的方法,不仅在合成面部运动方面优于先前技术,而且产生了与底层面部运动一致的真实纹理。项目页面:https://xuanchenli.github.io/TexTalk/。
论文及项目相关链接
Summary
本文重点关注语音驱动的3D面部动画中的动态纹理作用,并揭示了其在呈现高保真度说话角色中的重要性。为此,研究团队创建了一个高分辨率的4D数据集TexTalk4D,包含来自100位参与者的音频同步扫描级网格和详细的8K动态纹理。基于该数据集,研究团队探索了运动和纹理之间的内在关联,并提出了一个基于扩散的框架TexTalker,可从语音中同时生成面部运动和动态纹理。此外,还提出了一种基于枢轴的样式注入策略,以捕捉不同纹理和运动风格的复杂性,从而实现了解耦控制。TexTalker作为首个生成带有动态纹理的音频同步面部运动的方法,不仅在合成面部运动方面优于现有技术,而且生成的纹理与底层面部运动保持一致。
Key Takeaways
- 动态纹理在呈现高保真度说话角色中扮演重要角色。
- 创建了一个新的高分辨率4D数据集TexTalk4D,包含详细的动态纹理和音频同步扫描级网格数据。
- 基于数据集探索了运动和纹理之间的内在关联。
- 提出了一个基于扩散的框架TexTalker,能同时生成面部运动和动态纹理。
- 采用了基于枢轴的样式注入策略来捕捉不同纹理和运动风格的复杂性。
- TexTalker方法实现了音频同步的面部运动和动态纹理生成,优于现有技术。
点此查看论文截图