⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-06 更新
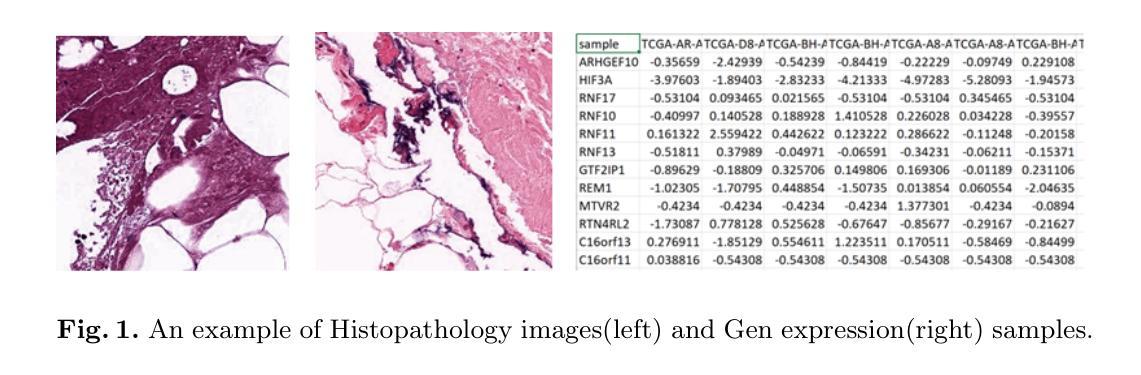
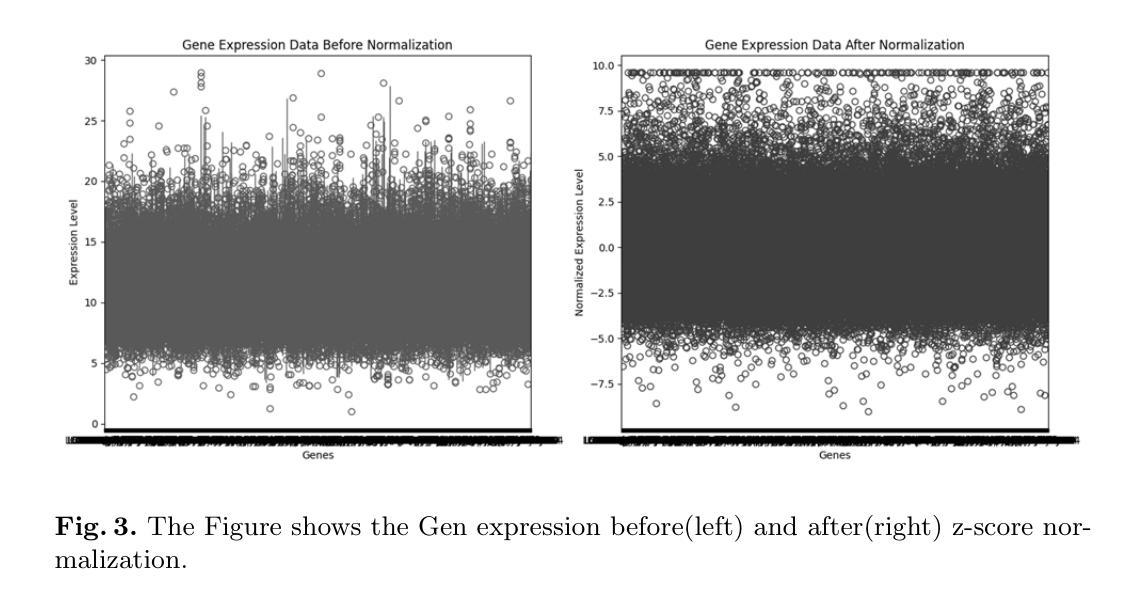
Multimodal Deep Learning for Subtype Classification in Breast Cancer Using Histopathological Images and Gene Expression Data
Authors:Amin Honarmandi Shandiz
Molecular subtyping of breast cancer is crucial for personalized treatment and prognosis. Traditional classification approaches rely on either histopathological images or gene expression profiling, limiting their predictive power. In this study, we propose a deep multimodal learning framework that integrates histopathological images and gene expression data to classify breast cancer into BRCA.Luminal and BRCA.Basal / Her2 subtypes. Our approach employs a ResNet-50 model for image feature extraction and fully connected layers for gene expression processing, with a cross-attention fusion mechanism to enhance modality interaction. We conduct extensive experiments using five-fold cross-validation, demonstrating that our multimodal integration outperforms unimodal approaches in terms of classification accuracy, precision-recall AUC, and F1-score. Our findings highlight the potential of deep learning for robust and interpretable breast cancer subtype classification, paving the way for improved clinical decision-making.
乳腺癌的分子分型对于个性化治疗和预后至关重要。传统的分类方法依赖于组织病理学图像或基因表达谱分析,这限制了其预测能力。在本研究中,我们提出了一种深度多模态学习框架,该框架整合了组织病理学图像和基因表达数据,将乳腺癌分类为BRCA.Luminal和BRCA.Basal / Her2亚型。我们的方法采用ResNet-50模型进行图像特征提取,采用全连接层处理基因表达数据,并使用跨注意融合机制增强模态交互。我们通过五折交叉验证进行了大量实验,结果表明,我们的多模态集成在分类精度、精确召回AUC和F1分数方面优于单模态方法。我们的研究突出了深度学习在稳健和可解释的乳腺癌亚型分类中的潜力,为改进临床决策铺平了道路。
论文及项目相关链接
PDF 9 pages, 9 figures
Summary
乳腺癌分子分型对个性化治疗和预后至关重要。传统分类方法依赖病理图像或基因表达谱分析,预测能力有限。本研究提出一种深度多模态学习框架,整合病理图像和基因表达数据,将乳腺癌分为BRCA.Luminal和BRCA.Basal / Her2亚型。采用ResNet-50模型提取图像特征,全连接层处理基因表达数据,采用交叉注意力融合机制增强模态交互。实验采用五折交叉验证,证明多模态融合在分类准确率、精确召回AUC和F1分数方面优于单模态方法。本研究凸显深度学习在乳腺癌亚型分类中的潜力和可解释性,为临床决策提供改进方向。
Key Takeaways
- 乳腺癌分子分型对个性化治疗与预后评估非常重要。
- 传统乳腺癌分类方法依赖病理图像或基因表达谱分析,具有局限性。
- 研究提出一种深度多模态学习框架,整合病理图像和基因表达数据来进行乳腺癌分类。
- 采用ResNet-50模型与全连接层处理不同数据类型,并引入交叉注意力融合机制。
- 实验验证该框架在分类准确率、精确召回AUC和F1分数等方面优于单模态方法。
- 研究表明深度学习在乳腺癌亚型分类中具有潜力。
点此查看论文截图

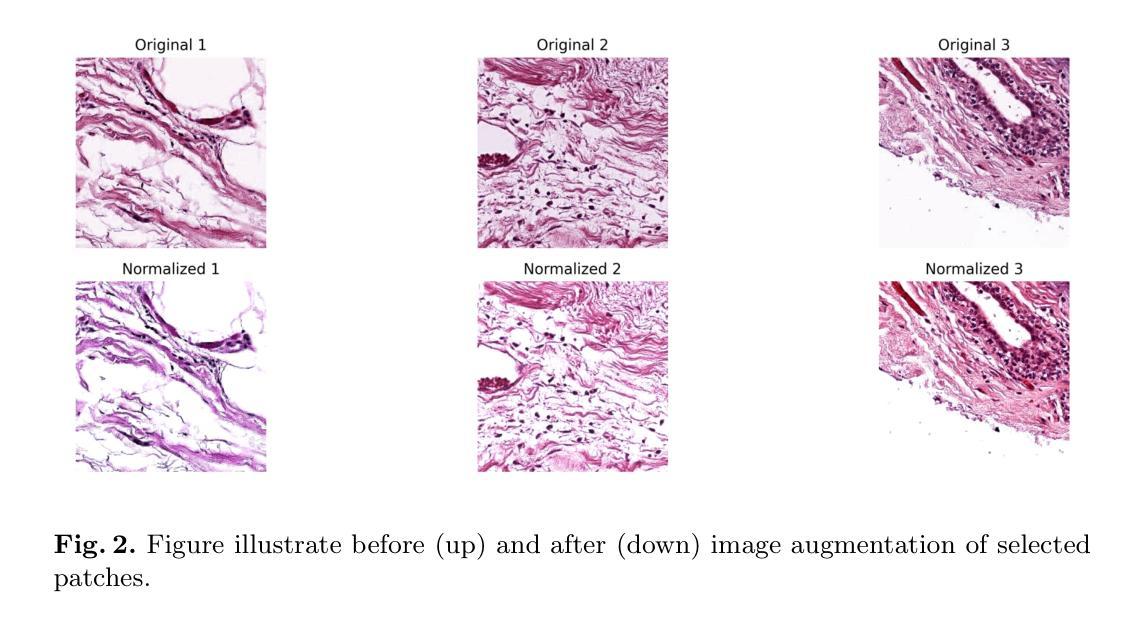
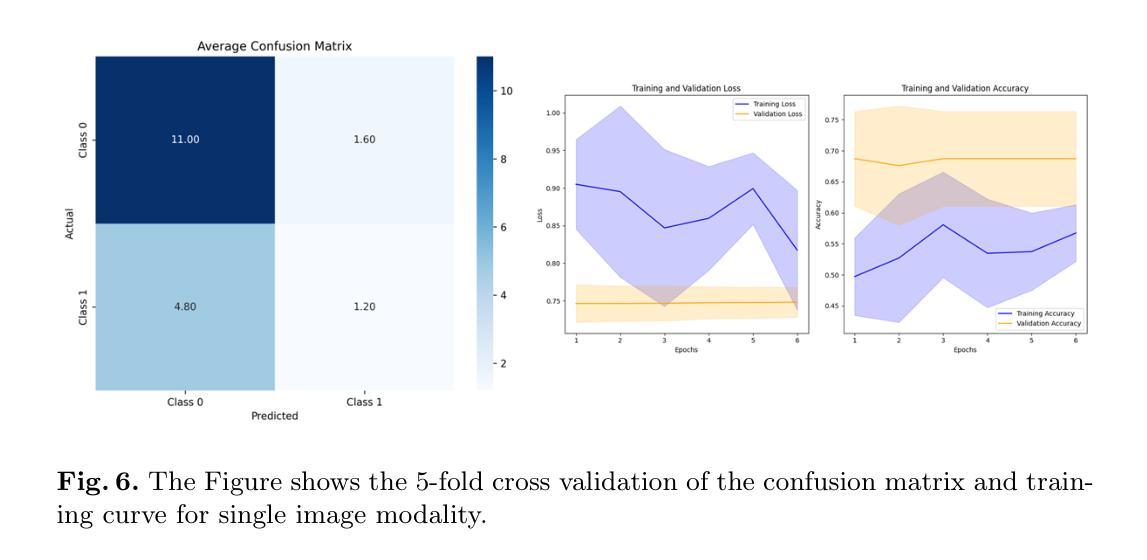
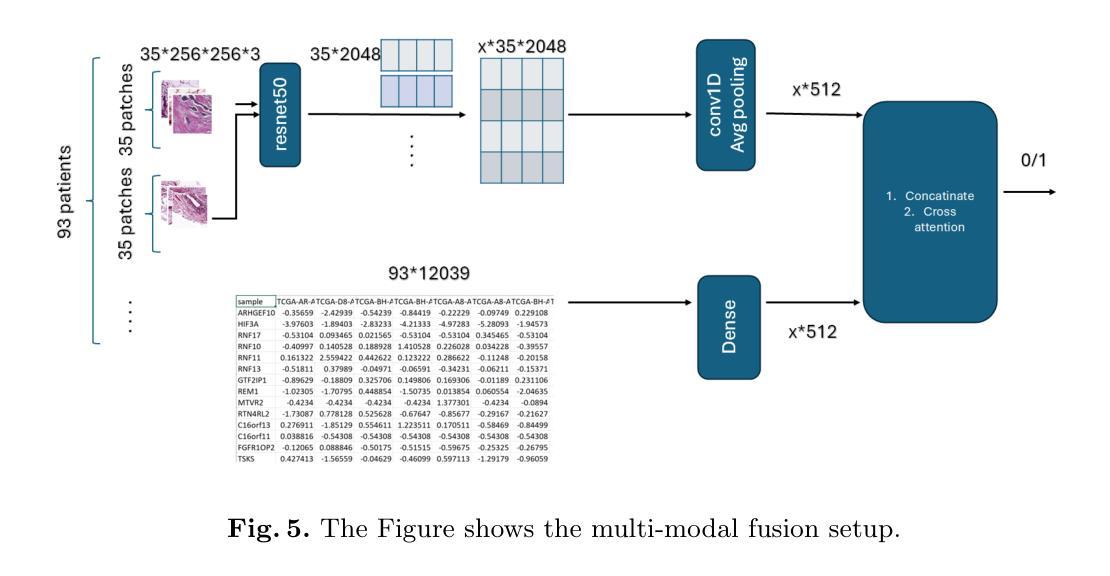
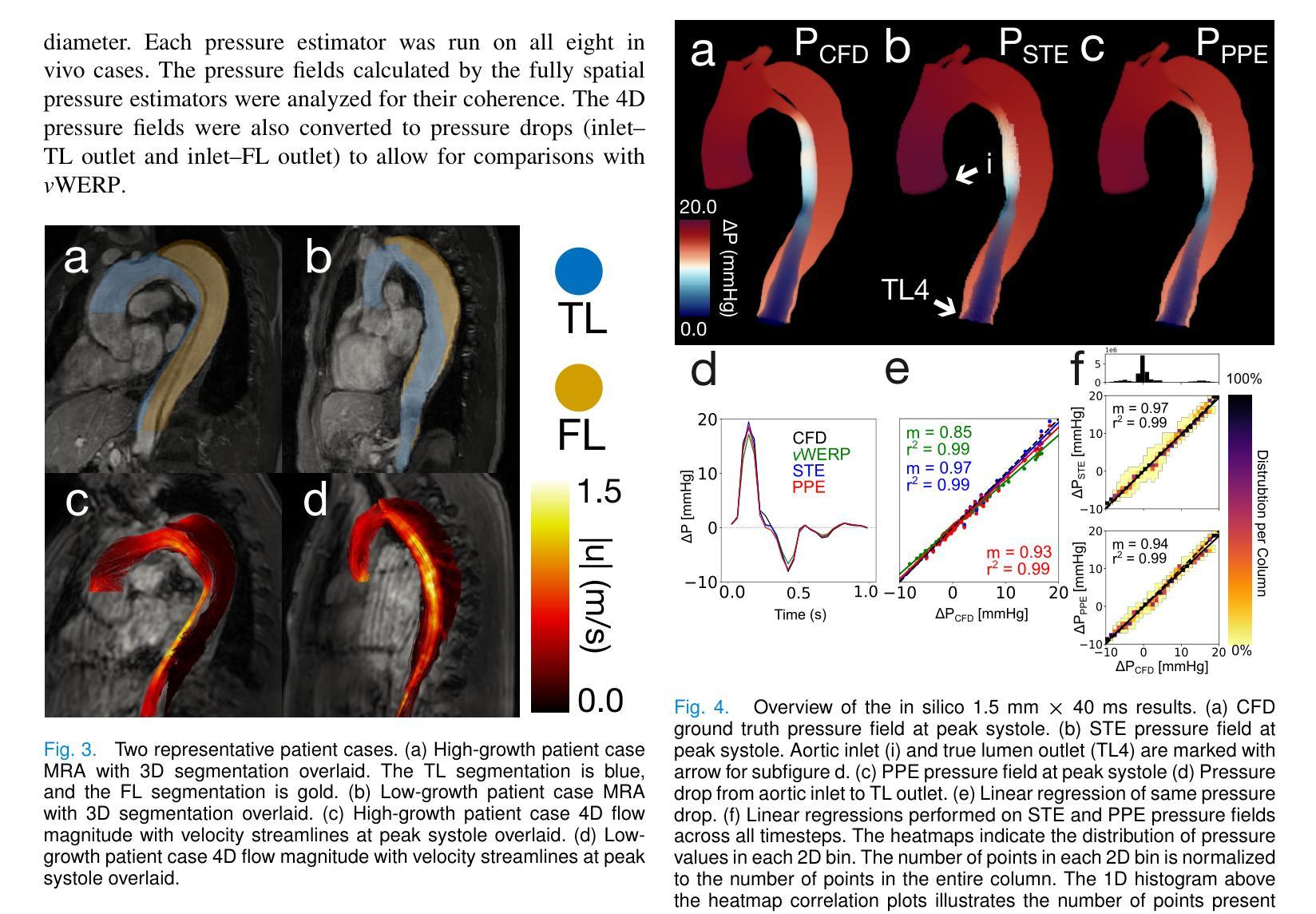
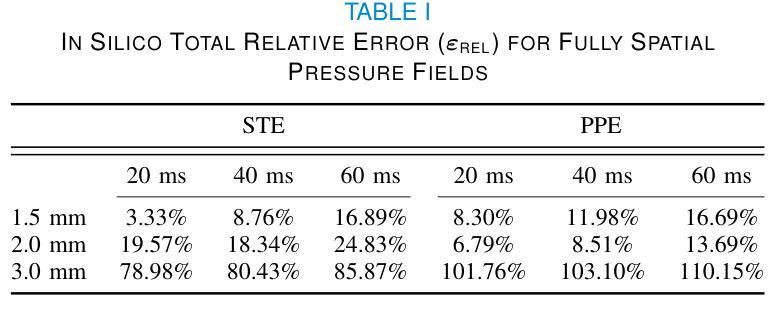
Comprehensive Analysis of Relative Pressure Estimation Methods Utilizing 4D Flow MRI
Authors:Brandon Hardy, Judith Zimmermann, Vincent Lechner, Mia Bonini, Julio A. Sotelo, Nicholas S. Burris, Daniel B. Ennis, David Marlevi, David A. Nordsletten
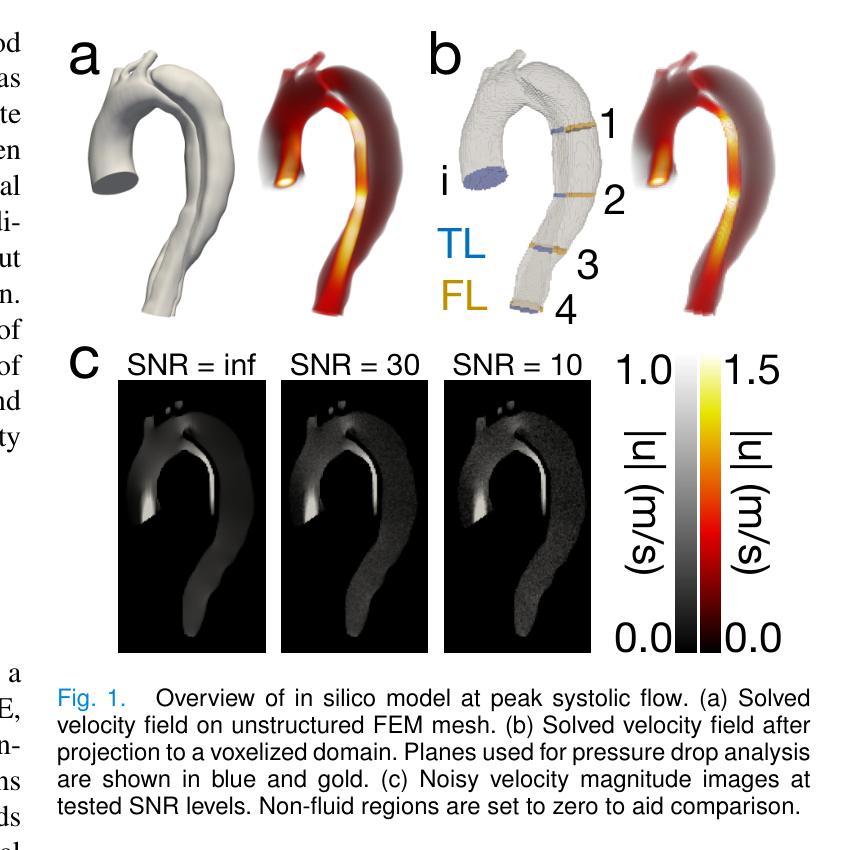
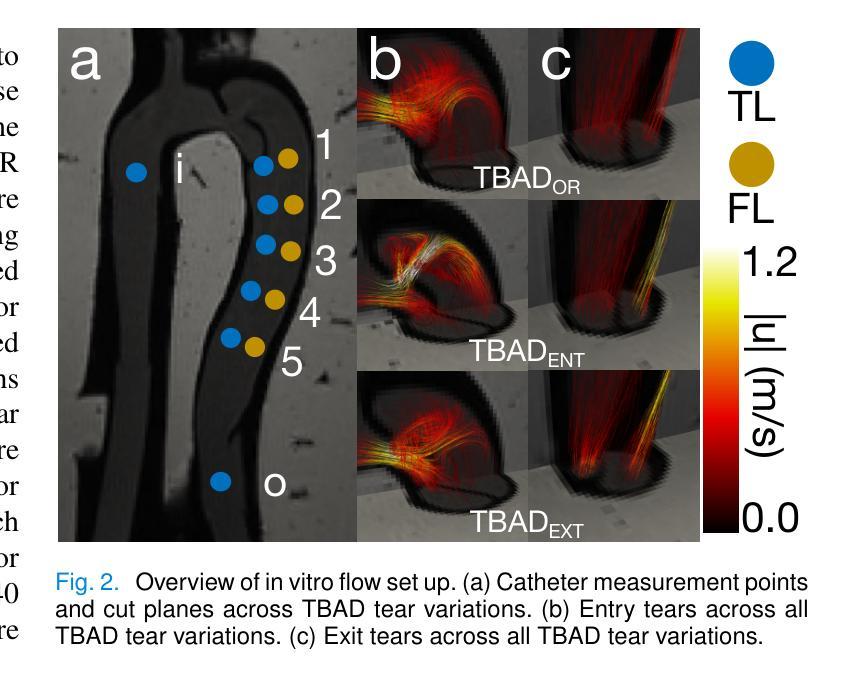
4D flow MRI allows for the estimation of three-dimensional relative pressure fields, providing rich pressure information, unlike catheterization and Doppler echocardiography, which provide one-dimensional pressure drops only. The accuracy of one-dimensional pressure drops derived from 4D flow has been explored in previous literature, but additional work must be done to evaluate the accuracy of three-dimensional relative pressure fields. This work presents an analysis of three state-of-the-art relative pressure estimators: virtual Work-Energy Relative Pressure (vWERP), the Pressure Poisson Estimator (PPE), and the Stokes Estimator (STE). Spatiotemporal behavior and sensitivity to noise were determined in silico. Estimators were validated with a type B aortic dissection (TBAD) flow phantom with varying tear geometry and an array of twelve catheter pressure measurements. Finally, the performance of each estimator was evaluated across eight patient cases. In silico pressure field errors were lower in STE compared to PPE, although PPE pressures were less affected by noise. High velocity gradients and low spatial resolution contributed most significantly to local variations in 3D error fields. Low temporal resolution leads to highly transient peak pressure events being averaged, systematically underestimating peak pressures. In the flow phantom analysis, vWERP was the most accurate method, followed by STE and PPE. Each pressure estimator strongly correlated with ground truth pressure values despite the tendency to underestimate peak pressures. Patient case results demonstrated that the pressure estimators could be feasibly integrated into a clinical workflow.
四维血流磁共振成像(MRI)能够估计三维相对压力场,提供丰富的压力信息,不同于插管和多普勒超声心动图,后者仅提供一维压力下降信息。此前文献已经探讨过从四维血流中得出的一维压力下降的准确性,但还需要进一步的工作来评估三维相对压力场的准确性。本文介绍了三种最新相对压力估计器:虚拟功能量相对压力(vWERP)、压力泊松估计器(PPE)和斯托克斯估计器(STE)。通过计算机模拟确定了其在时空行为和对噪声的敏感性。使用B型主动脉夹层(TBAD)血流模型和多种撕裂几何形状以及一个包含十二根导管压力测量的阵列对估计器进行了验证。最后,对每种估计器在八种患者病例中的表现进行了评估。在计算机模拟的压力场误差中,STE与PPE相比误差较低,尽管PPE的压力受噪声影响较小。高速梯度和低空间分辨率对三维误差场的局部变化贡献最大。低时间分辨率会导致短暂的高峰压力事件被平均化,从而系统性地低估峰值压力。在血流模型分析中,vWERP是最准确的方法,其次是STE和PPE。尽管有低估峰值压力的倾向,但每种压力估计器都与真实压力值密切相关。患者病例结果表明,压力估计器可以合理地集成到临床工作流程中。
论文及项目相关链接
PDF 10 pages, 8 figures. Planned submission to IEEE Transactions on Medical Imaging
Summary
本文研究了三维流场中的相对压力估计技术,并对比分析了三种先进相对压力估计器(虚拟工作能量相对压力、压力泊松估计器和斯托克斯估计器)的性能。研究表明,斯托克斯估计器的压力场误差较低,但在噪声干扰方面压力泊松估计器更稳健。此外,通过流场模型分析验证了各压力估计器的准确性,并在患者案例中证明了其临床应用的可行性。尽管存在低估峰值压力的趋势,但压力估计器与真实压力值的相关性很强。
Key Takeaways
- 4D流MRI能够估计三维相对压力场,提供丰富的压力信息,不同于只能提供一维压力下降的导管化和多普勒超声心动图。
- 本文研究对三种先进相对压力估计器进行了对比分析,包括虚拟工作能量相对压力、压力泊松估计器和斯托克斯估计器。
- 斯托克斯估计器的压力场误差较低,而压力泊松估计器对噪声干扰更稳健。
- 高速度梯度和低空间分辨率对三维误差场影响显著。低时间分辨率会导致峰值压力事件的平均化,从而低估峰值压力。
- 通过流场模型分析验证了各压力估计器的准确性。在流场幻影分析中,虚拟工作能量相对压力是最准确的方法,其次是斯托克斯估计器和压力泊松估计器。
- 压力估计器与真实压力值存在很强的相关性,尽管存在低估峰值压力的趋势。
点此查看论文截图


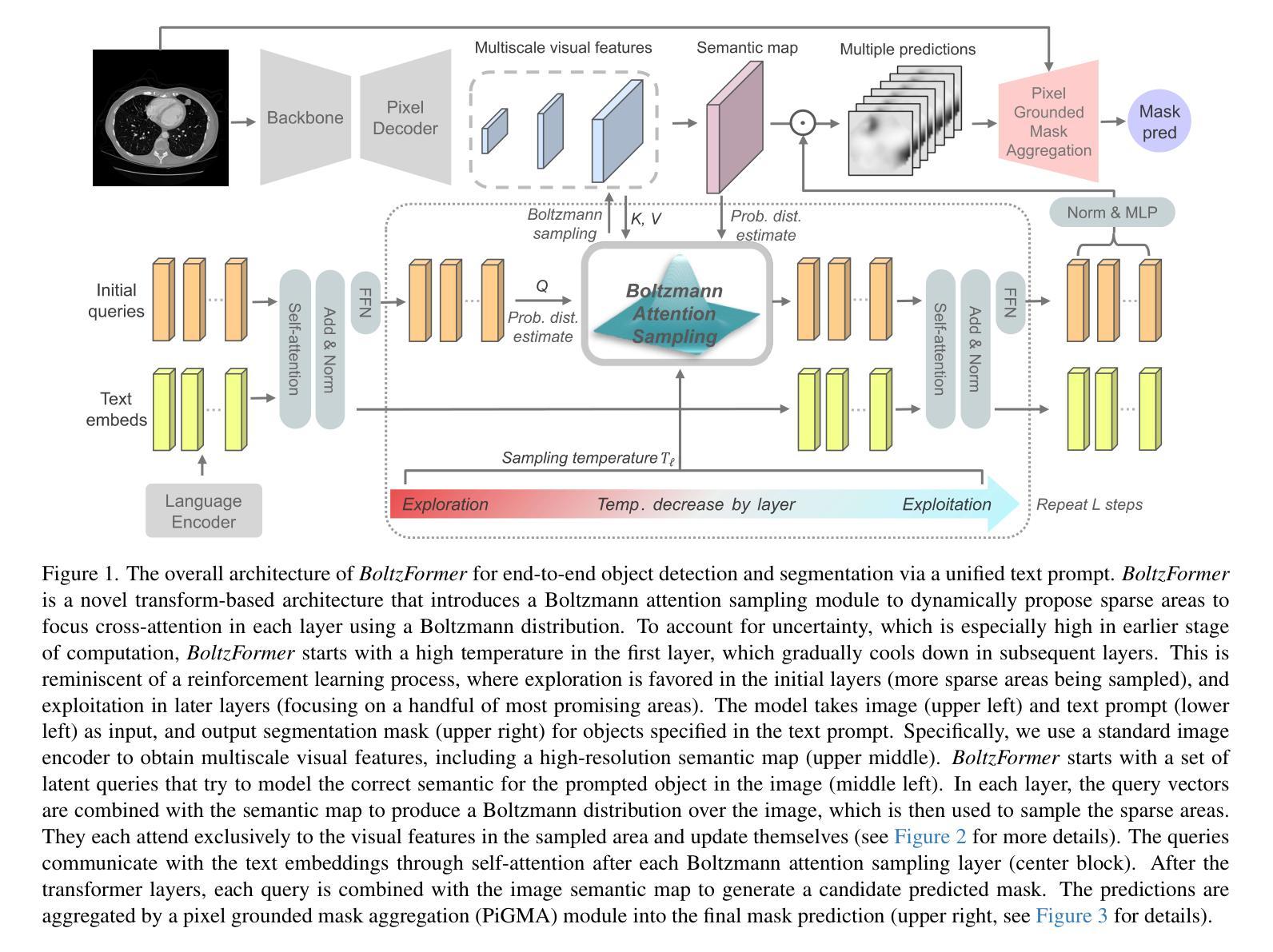
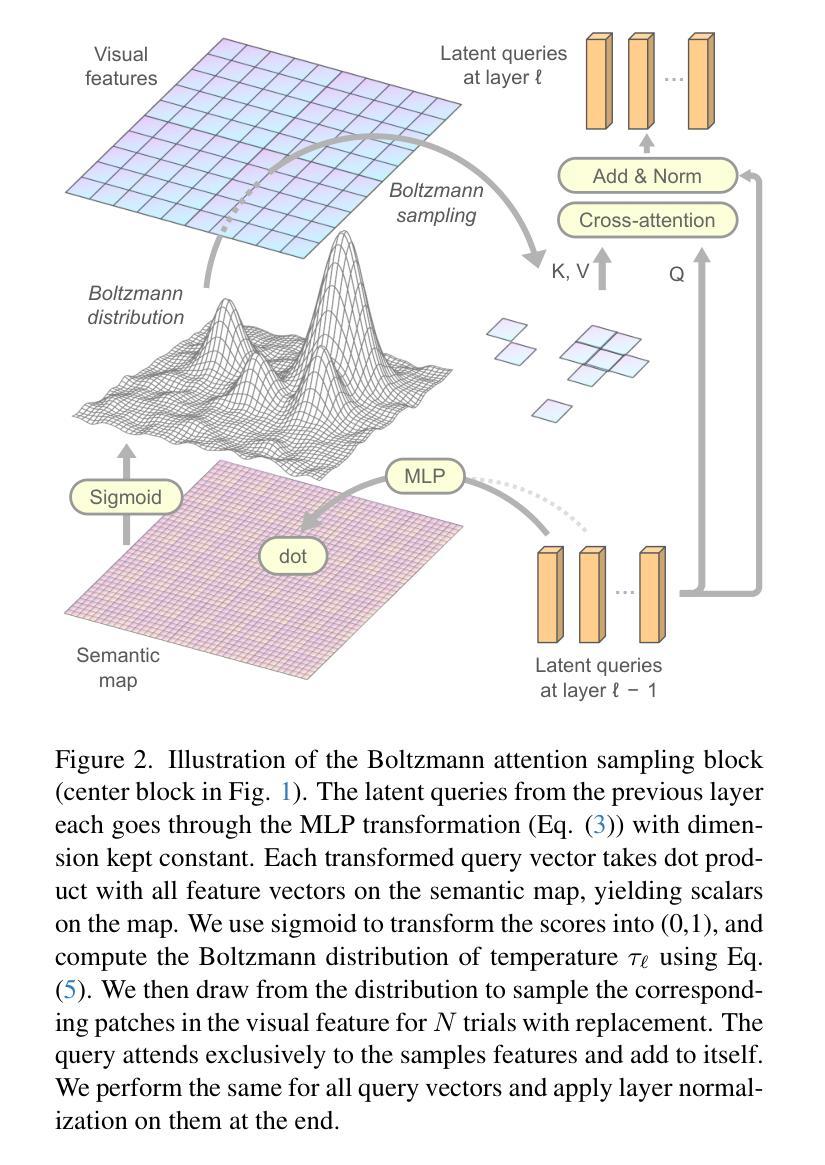
Boltzmann Attention Sampling for Image Analysis with Small Objects
Authors:Theodore Zhao, Sid Kiblawi, Naoto Usuyama, Ho Hin Lee, Sam Preston, Hoifung Poon, Mu Wei
Detecting and segmenting small objects, such as lung nodules and tumor lesions, remains a critical challenge in image analysis. These objects often occupy less than 0.1% of an image, making traditional transformer architectures inefficient and prone to performance degradation due to redundant attention computations on irrelevant regions. Existing sparse attention mechanisms rely on rigid hierarchical structures, which are poorly suited for detecting small, variable, and uncertain object locations. In this paper, we propose BoltzFormer, a novel transformer-based architecture designed to address these challenges through dynamic sparse attention. BoltzFormer identifies and focuses attention on relevant areas by modeling uncertainty using a Boltzmann distribution with an annealing schedule. Initially, a higher temperature allows broader area sampling in early layers, when object location uncertainty is greatest. As the temperature decreases in later layers, attention becomes more focused, enhancing efficiency and accuracy. BoltzFormer seamlessly integrates into existing transformer architectures via a modular Boltzmann attention sampling mechanism. Comprehensive evaluations on benchmark datasets demonstrate that BoltzFormer significantly improves segmentation performance for small objects while reducing attention computation by an order of magnitude compared to previous state-of-the-art methods.
检测和分割小目标(如肺结节和肿瘤病变)在图像分析中仍然是一个巨大的挑战。这些目标通常只占图像面积的不到0.1%,使得传统的Transformer架构效率低下,并且由于在不相关区域的冗余注意力计算而容易出现性能下降。现有的稀疏注意力机制依赖于僵化的层次结构,对于检测小、可变和不确定的位置的目标并不适用。在本文中,我们提出了BoltzFormer,这是一种基于Transformer的新型架构,通过动态稀疏注意力来解决这些挑战。BoltzFormer通过利用带有退火计划的Boltzdann分布建模不确定性来识别和集中注意力在相关区域。在对象位置不确定性最大的早期层次中,较高的初始温度允许更大的区域采样。随着温度的降低,注意力变得更加集中,提高了效率和准确性。BoltzFormer通过模块化Boltzdann注意力采样机制无缝集成到现有的Transformer架构中。在基准数据集上的综合评估表明,BoltzFormer在分割小目标方面显著提高了性能,并且与现有最先进的注意力计算方法相比,减少了计算量。
论文及项目相关链接
Summary
本文提出了BoltzFormer,一种基于动态稀疏注意力机制的新型变压器架构,用于解决图像分析中检测并分割小物体(如肺结节和肿瘤病变)的挑战。BoltzFormer利用波尔兹曼分布建模不确定性,通过退火调度机制动态调整注意力焦点。在基准数据集上的综合评估表明,BoltzFormer在分割小物体方面显著提高性能,并将注意力计算减少了一个数量级。
Key Takeaways
- 检测并分割小物体是图像分析中的关键挑战。
- 传统变压器架构在处理小物体时存在效率低下和性能退化的问题。
- 现有稀疏注意力机制依赖于僵化的层次结构,不适合检测位置不确定的小物体。
- BoltzFormer是一种基于新型动态稀疏注意力机制的变压器架构。
- BoltzFormer利用波尔兹曼分布建模不确定性,通过退火调度调整注意力焦点。
- BoltzFormer能无缝集成到现有变压器架构中,通过模块化波尔兹曼注意力采样机制实现。
点此查看论文截图


Catheter Detection and Segmentation in X-ray Images via Multi-task Learning
Authors:Lin Xi, Yingliang Ma, Ethan Koland, Sandra Howell, Aldo Rinaldi, Kawal S. Rhode
Automated detection and segmentation of surgical devices, such as catheters or wires, in X-ray fluoroscopic images have the potential to enhance image guidance in minimally invasive heart surgeries. In this paper, we present a convolutional neural network model that integrates a resnet architecture with multiple prediction heads to achieve real-time, accurate localization of electrodes on catheters and catheter segmentation in an end-to-end deep learning framework. We also propose a multi-task learning strategy in which our model is trained to perform both accurate electrode detection and catheter segmentation simultaneously. A key challenge with this approach is achieving optimal performance for both tasks. To address this, we introduce a novel multi-level dynamic resource prioritization method. This method dynamically adjusts sample and task weights during training to effectively prioritize more challenging tasks, where task difficulty is inversely proportional to performance and evolves throughout the training process. Experiments on both public and private datasets have demonstrated that the accuracy of our method surpasses the existing state-of-the-art methods in both single segmentation task and in the detection and segmentation multi-task. Our approach achieves a good trade-off between accuracy and efficiency, making it well-suited for real-time surgical guidance applications.
在X光透视影像中自动检测和分割如导管或线路等手术器械,有可能增强微创心脏手术的图像引导。在本文中,我们提出了一种卷积神经网络模型,该模型结合了残差网络架构和多个预测头,以实现导管上电极的实时、精确定位和导管分段,形成一个端到端的深度学习框架。我们还提出了一种多任务学习策略,通过训练我们的模型同时执行精确的电极检测和导管分割。此方法的挑战在于实现两个任务的最佳性能。为解决这一问题,我们提出了一种新型的多层次动态资源优先方法。该方法在训练过程中动态调整样本和任务权重,有效优先处理更具挑战性的任务,其中任务难度与性能成反比,并在整个训练过程中不断变化。在公共和私有数据集上的实验表明,我们的方法的准确性超过了现有最先进的单分割任务以及在检测和分割多任务中的准确性。我们的方法在准确性和效率之间达到了良好的平衡,使其非常适合用于实时手术指导应用。
论文及项目相关链接
Summary
这篇论文介绍了一种结合ResNet架构和多预测头的卷积神经网络模型,用于实现X光透视图像中导管电极的实时、精准定位以及导管分割。提出一种多任务学习策略和动态资源优先化方法,该方法能在训练过程中动态调整样本和任务权重,以有效优先处理更具挑战性的任务。实验证明,该方法在单一分割任务以及检测和分割多任务上的准确性均超越了现有先进技术,实现了准确性和效率之间的良好平衡,非常适合用于实时手术指导应用。
Key Takeaways
- 卷积神经网络模型结合了ResNet架构和多预测头,用于X光透视图像中的导管电极定位和导管分割。
- 提出了多任务学习策略,模型可同时进行电极检测和导管分割。
- 面临同时优化两个任务的挑战,引入了一种新型的多层次动态资源优先化方法。
- 该方法可在训练过程中动态调整样本和任务权重,以优先处理更具挑战性的任务。
- 实验结果证明,该方法的准确性和效率均超越了现有技术。
- 此方法适用于实时手术指导应用。
点此查看论文截图

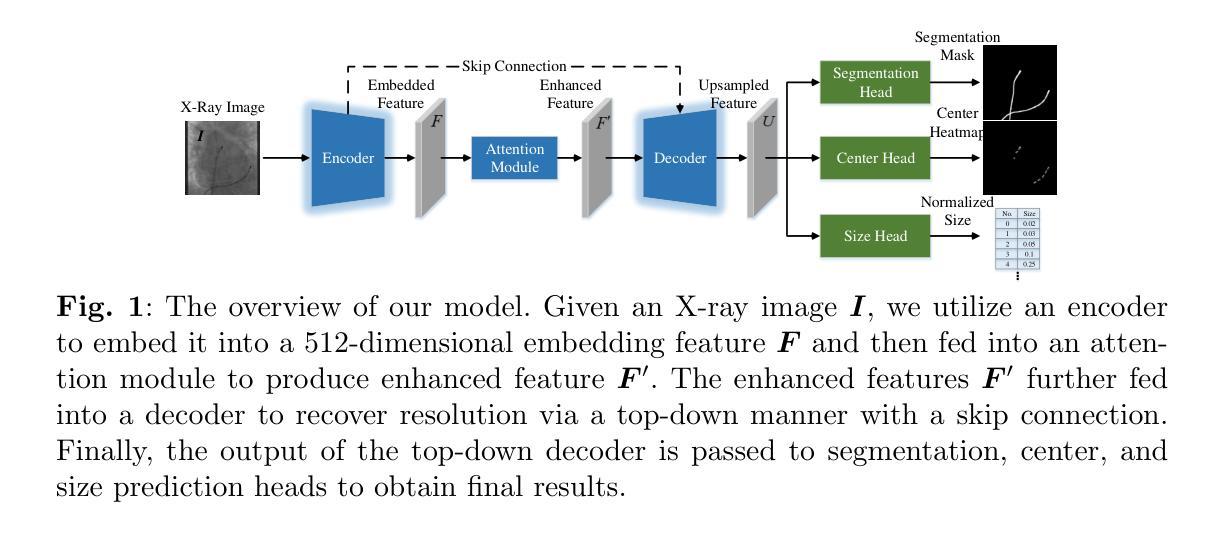
XFMamba: Cross-Fusion Mamba for Multi-View Medical Image Classification
Authors:Xiaoyu Zheng, Xu Chen, Shaogang Gong, Xavier Griffin, Greg Slabaugh
Compared to single view medical image classification, using multiple views can significantly enhance predictive accuracy as it can account for the complementarity of each view while leveraging correlations between views. Existing multi-view approaches typically employ separate convolutional or transformer branches combined with simplistic feature fusion strategies. However, these approaches inadvertently disregard essential cross-view correlations, leading to suboptimal classification performance, and suffer from challenges with limited receptive field (CNNs) or quadratic computational complexity (transformers). Inspired by state space sequence models, we propose XFMamba, a pure Mamba-based cross-fusion architecture to address the challenge of multi-view medical image classification. XFMamba introduces a novel two-stage fusion strategy, facilitating the learning of single-view features and their cross-view disparity. This mechanism captures spatially long-range dependencies in each view while enhancing seamless information transfer between views. Results on three public datasets, MURA, CheXpert and DDSM, illustrate the effectiveness of our approach across diverse multi-view medical image classification tasks, showing that it outperforms existing convolution-based and transformer-based multi-view methods. Code is available at https://github.com/XZheng0427/XFMamba.
与单视图医学图像分类相比,使用多个视图可以显著提高预测准确性,因为它可以利用每个视图的互补性,同时利用视图之间的相关性。现有的多视图方法通常采用单独的卷积或转换器分支,并结合简单的特征融合策略。然而,这些方法无意中忽略了重要的跨视图相关性,导致分类性能不佳,并面临感受野有限(CNN)或计算复杂度为二次方(转换器)的挑战。受状态空间序列模型的启发,我们提出了XFMamba,这是一种基于Mamba的纯跨融合架构,旨在解决多视图医学图像分类的挑战。XFMamba引入了一种新型的两阶段融合策略,促进单视图特征及其跨视图差异的学习。该机制捕获每个视图中的空间长距离依赖性,同时增强视图之间的无缝信息传输。在MURA、CheXpert和DDSM三个公共数据集上的结果证明了我们的方法在不同多视图医学图像分类任务中的有效性,表明它优于现有的基于卷积和基于转换器的多视图方法。代码可通过以下链接获取:[链接地址]。
论文及项目相关链接
Summary
多视角医疗图像分类相较于单视角分类能显著提高预测准确性,因为它能利用不同视角间的互补性和相关性。现有方法多采用单独的卷积神经网络或转换器模型,结合简单的特征融合策略,但忽略了跨视角的相关性以及面临着如CNN的有限感受野和转换器计算复杂度二次方等问题。受到状态空间序列模型的启发,本文提出了基于Mamba的跨融合架构XFMamba来解决多视角医疗图像分类的挑战。XFMamba引入了一种新颖的两阶段融合策略,能学习单视角特征及其跨视角差异。该方法在三个公开数据集上的结果证明了其在多视角医疗图像分类任务中的有效性,优于现有的卷积和转换多视角方法。
Key Takeaways
- 多视角医疗图像分类能显著提高预测准确性。
- 现有方法忽略了跨视角的相关性以及面临感受野和计算复杂度的挑战。
- XFMamba是基于Mamba的纯跨融合架构,旨在解决多视角医疗图像分类的挑战。
- XFMamba引入两阶段融合策略,学习单视角特征及其跨视角差异。
- 该方法通过捕获每个视角的空间长距离依赖关系,同时增强视角间的无缝信息传输来实现效果。
- 在三个公开数据集上的实验结果表明,XFMamba在多种多视角医疗图像分类任务中表现出优异的性能。
点此查看论文截图

Towards a robust R2D2 paradigm for radio-interferometric imaging: revisiting DNN training and architecture
Authors:Amir Aghabiglou, Chung San Chu, Chao Tang, Arwa Dabbech, Yves Wiaux
The R2D2 Deep Neural Network (DNN) series was recently introduced for image formation in radio interferometry. It can be understood as a learned version of CLEAN, whose minor cycles are substituted with DNNs. We revisit R2D2 on the grounds of series convergence, training methodology, and DNN architecture, improving its robustness in terms of generalisability beyond training conditions, capability to deliver high data fidelity, and epistemic uncertainty. Firstly, while still focusing on telescope-specific training, we enhance the learning process by randomising Fourier sampling integration times, incorporating multi-scan multi-noise configurations, and varying imaging settings, including pixel resolution and visibility-weighting scheme. Secondly, we introduce a convergence criterion whereby the reconstruction process stops when the data residual is compatible with noise, rather than simply using all available DNNs. This not only increases the reconstruction efficiency by reducing its computational cost, but also refines training by pruning out the data/image pairs for which optimal data fidelity is reached before training the next DNN. Thirdly, we substitute R2D2’s early U-Net DNN with a novel architecture (U-WDSR) combining U-Net and WDSR, which leverages wide activation, dense connections, weight normalisation, and low-rank convolution to improve feature reuse and reconstruction precision. As previously, R2D2 was trained for monochromatic intensity imaging with the Very Large Array (VLA) at fixed $512 \times 512$ image size. Simulations on a wide range of inverse problems and a case study on real data reveal that the new R2D2 model consistently outperforms its earlier version in image reconstruction quality, data fidelity, and epistemic uncertainty.
R2D2深度神经网络(DNN)系列最近被引入到射电干涉仪的图像形成中。可以将其理解为CLEAN的学得版本,其小周期被DNN替代。我们从序列收敛、训练方法和DNN架构等方面重新审视R2D2,提高其超越训练条件的通用性、提供高数据保真性和认识不确定性的稳健性。首先,在仍专注于望远镜特定训练的同时,我们通过随机化傅立叶采样积分时间、融入多扫描多噪声配置以及变化成像设置(包括像素分辨率和可见性加权方案)来增强学习过程。其次,我们引入一个收敛标准,即当数据残差与噪声兼容时,重建过程将停止,而不是简单地使用所有可用的DNN。这不仅通过减少计算成本提高了重建效率,而且还通过剔除那些在达到最佳数据保真性之前已训练下一个DNN的数据/图像对来优化训练。第三,我们用一种新型架构(U-WDSR)替代R2D2早期的U-Net DNN,该架构结合了U-Net和WDSR,利用宽激活、密集连接、权重归一化和低秩卷积来提高特征复用和重建精度。与之前一样,R2D2是针对固定$512 \times 512$图像大小的甚大阵(VLA)的单色强度成像进行训练的。在广泛范围的逆问题和真实数据的案例研究中的模拟表明,新的R2D2模型在图像重建质量、数据保真性和认识不确定性方面始终优于其早期版本。
论文及项目相关链接
PDF 17 pages, 6 figures
摘要
R2D2深度神经网络(DNN)系列最近被引入射电干涉仪的图像形成中。可以理解为其是CLEAN的一种学习版本,其小周期被DNN取代。本文从序列收敛、训练方法和DNN架构等方面重新审视R2D2,提高了其在超越训练条件的一般性、高数据保真度和认知不确定性方面的稳健性。首先,在望远镜特定训练的基础上,通过随机傅里叶采样积分时间、融入多种扫描多种噪声配置以及变化成像设置(包括像素分辨率和可见性加权方案)来增强学习过程。其次,引入收敛标准,当数据残差与噪声兼容时,重建过程停止,而非仅使用所有可用的DNNs。这不仅提高了重建效率并降低了计算成本,而且还通过剔除那些已达到最佳数据保真度的数据/图像对来优化训练,为训练下一个DNN打下基础。再次,用新型架构U-WDSR替代R2D2早期的U-Net DNN,结合U-Net和WDSR的优势,利用宽激活、密集连接、权重归一化和低秩卷积来提高特征复用和重建精度。如先前所述,R2D2是以固定$ 512 \times 512$图像大小,使用非常大规模阵列(VLA)进行单色强度成像训练的。在多种反问题的模拟和真实数据的案例研究上,新型R2D2模型在图像重建质量、数据保真度和认知不确定性方面均表现优异。
关键见解
- R2D2系列基于深度神经网络(DNN),旨在改进图像形成中的CLEAN方法,使用一系列DNN替代小周期过程。
- 通过对训练方法的改进和引入新的收敛标准来提高模型的稳健性和效率。包括随机化傅里叶采样集成时间、融入多种噪声配置以及灵活的成像设置等。
- 采用新型架构U-WDSR替代早期U-Net DNN,结合U-Net和WDSR的特点以提高特征复用和重建精度。
- R2D2的新模型在模拟和真实数据的测试中,表现出色的图像重建质量、数据保真度和认知不确定性。
点此查看论文截图


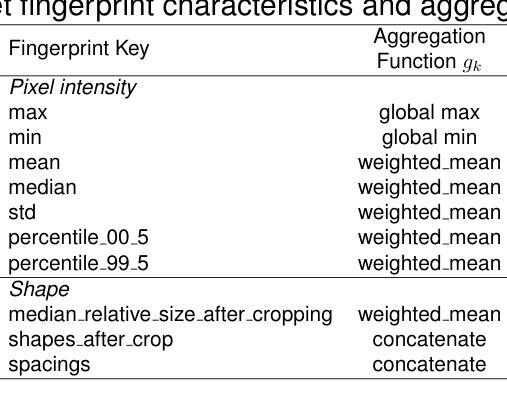
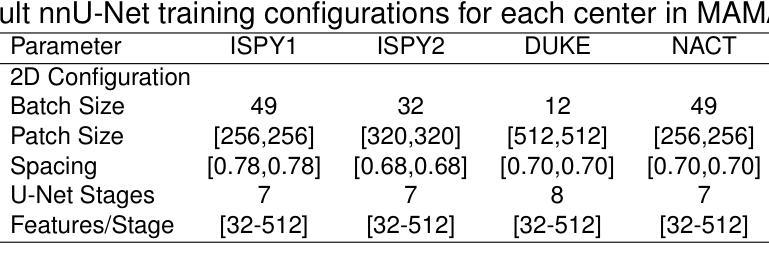
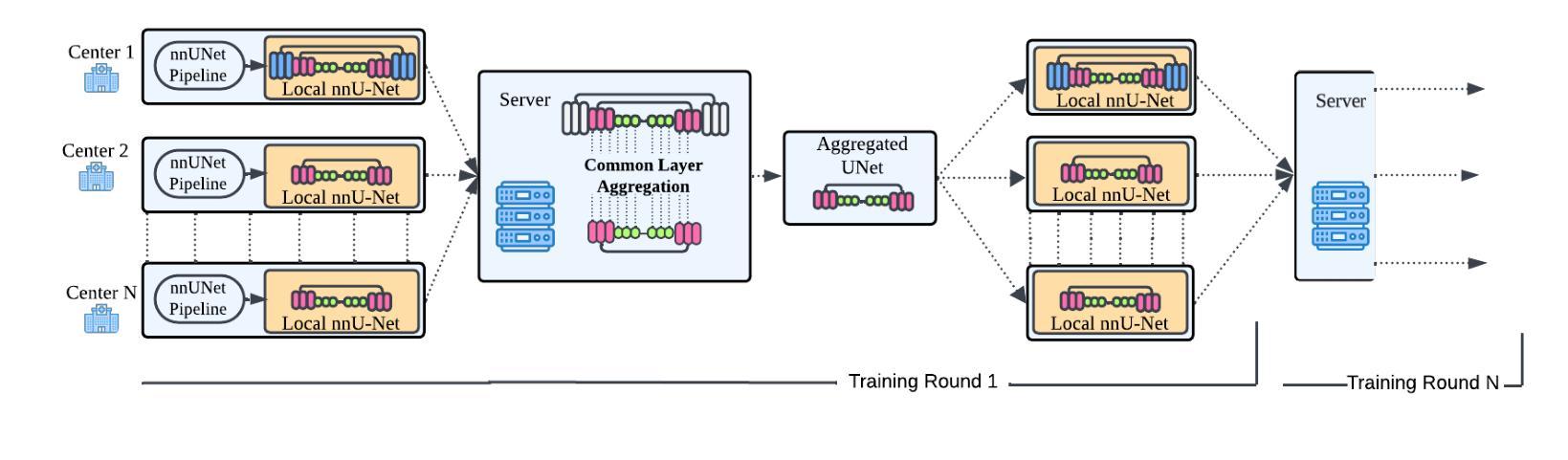
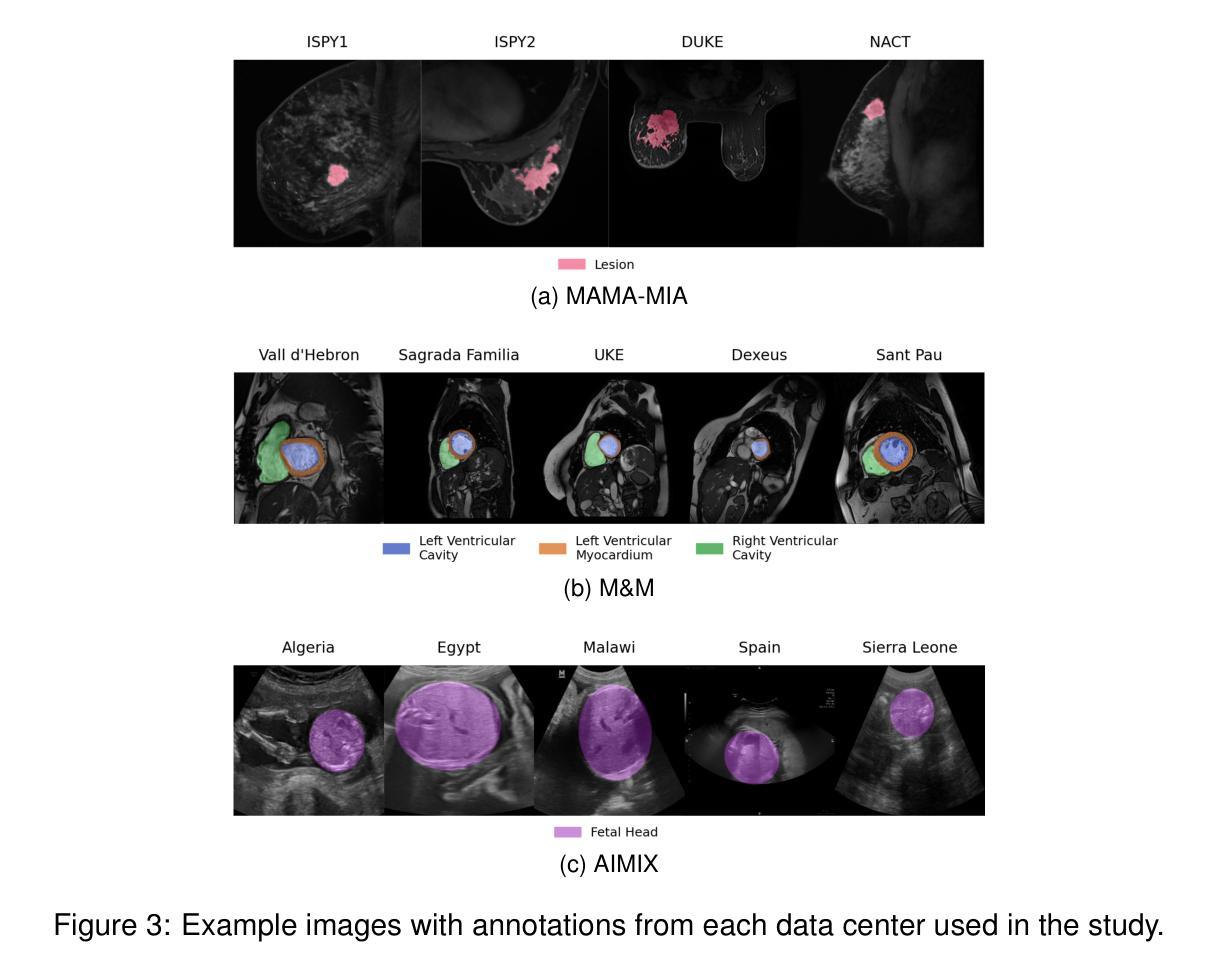
Federated nnU-Net for Privacy-Preserving Medical Image Segmentation
Authors:Grzegorz Skorupko, Fotios Avgoustidis, Carlos Martín-Isla, Lidia Garrucho, Dimitri A. Kessler, Esmeralda Ruiz Pujadas, Oliver Díaz, Maciej Bobowicz, Katarzyna Gwoździewicz, Xavier Bargalló, Paulius Jaruševičius, Kaisar Kushibar, Karim Lekadir
The nnU-Net framework has played a crucial role in medical image segmentation and has become the gold standard in multitudes of applications targeting different diseases, organs, and modalities. However, so far it has been used primarily in a centralized approach where the data collected from hospitals are stored in one center and used to train the nnU-Net. This centralized approach has various limitations, such as leakage of sensitive patient information and violation of patient privacy. Federated learning is one of the approaches to train a segmentation model in a decentralized manner that helps preserve patient privacy. In this paper, we propose FednnU-Net, a federated learning extension of nnU-Net. We introduce two novel federated learning methods to the nnU-Net framework - Federated Fingerprint Extraction (FFE) and Asymmetric Federated Averaging (AsymFedAvg) - and experimentally show their consistent performance for breast, cardiac and fetal segmentation using 6 datasets representing samples from 18 institutions. Additionally, to further promote research and deployment of decentralized training in privacy constrained institutions, we make our plug-n-play framework public. The source-code is available at https://github.com/faildeny/FednnUNet .
nnU-Net框架在医学图像分割中扮演了关键角色,并已成为针对不同疾病、器官和模式的多重应用的黄金标准。然而,迄今为止,它主要被用于集中式方法,其中从医院收集的数据被存储在一个中心并使用它来训练nnU-Net。这种集中式方法具有各种局限性,例如敏感病人信息的泄露和病人隐私的侵犯。联邦学习是一种分散式训练分割模型的方法,有助于保护病人隐私。在本文中,我们提出了FednnU-Net,这是nnU-Net的联邦学习扩展。我们向nnU-Net框架引入了两种新颖的联邦学习方法——联邦指纹提取(FFE)和不对称联邦平均(AsymFedAvg)——并通过实验展示了它们在代表来自18个机构的样本的6个数据集上进行乳房、心脏和胎儿分割的一致性性能。此外,为了进一步促进在受隐私约束的机构中进行分散式训练的研究和部署,我们公开了即插即用的框架。源代码可在https://github.com/faildeny/FednnUNet找到。
论文及项目相关链接
PDF In review
Summary
医学图像分割中,nnU-Net框架已被广泛应用并成为多种疾病和应用的标准工具。但当前其主要用于集中式处理数据的方式存在泄露敏感信息的问题。本文提出了FednnU-Net,一个基于联邦学习的nnU-Net扩展框架,并引入两种新方法——联邦指纹提取和不对称联邦平均法。实验表明,该方法在乳房、心脏和胎儿分割方面具有持续性能。同时公开源代码,以促进在隐私受限机构中的分散训练研究和部署。
Key Takeaways
- nnU-Net框架在医学图像分割领域有重要作用,并成为多种疾病应用的标准工具。
- 当前nnU-Net主要采用的集中式数据处理方式存在患者信息泄露和隐私侵犯的问题。
- 联邦学习是一种训练分割模型的新方法,有助于保护患者隐私。
- FednnU-Net是nnU-Net的联邦学习扩展框架。
- FFE(联邦指纹提取)和AsymFedAvg(不对称联邦平均法)是FednnU-Net中的两种新方法。
- 实验结果显示,FednnU-Net在乳房、心脏和胎儿分割方面表现持续性能。
点此查看论文截图


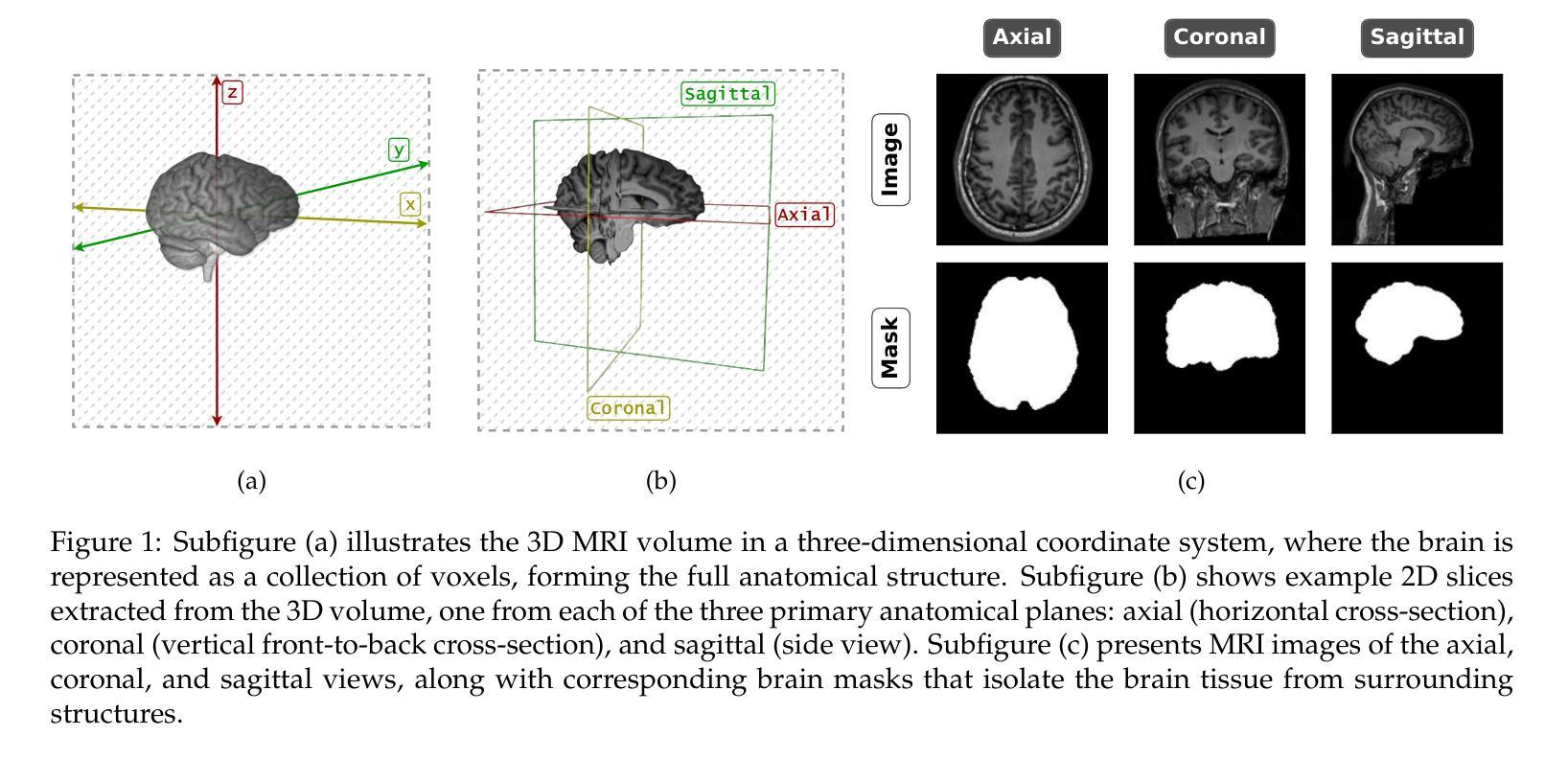
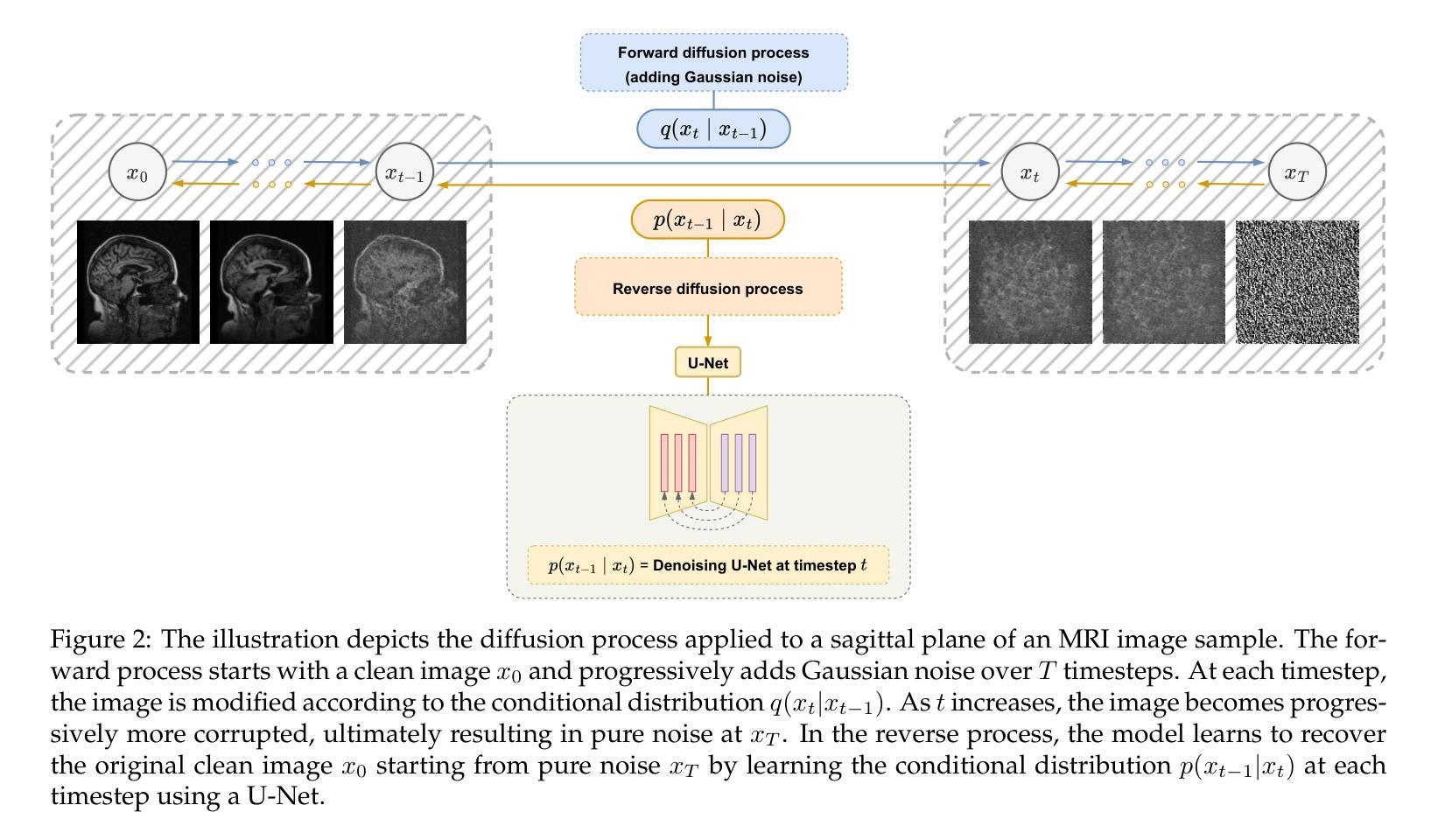
CQ CNN: A Hybrid Classical Quantum Convolutional Neural Network for Alzheimer’s Disease Detection Using Diffusion Generated and U Net Segmented 3D MRI
Authors:Mominul Islam, Mohammad Junayed Hasan, M. R. C. Mahdy
The detection of Alzheimer disease (AD) from clinical MRI data is an active area of research in medical imaging. Recent advances in quantum computing, particularly the integration of parameterized quantum circuits (PQCs) with classical machine learning architectures, offer new opportunities to develop models that may outperform traditional methods. However, quantum machine learning (QML) remains in its early stages and requires further experimental analysis to better understand its behavior and limitations. In this paper, we propose an end to end hybrid classical quantum convolutional neural network (CQ CNN) for AD detection using clinically formatted 3D MRI data. Our approach involves developing a framework to make 3D MRI data usable for machine learning, designing and training a brain tissue segmentation model (Skull Net), and training a diffusion model to generate synthetic images for the minority class. Our converged models exhibit potential quantum advantages, achieving higher accuracy in fewer epochs than classical models. The proposed beta8 3 qubit model achieves an accuracy of 97.50%, surpassing state of the art (SOTA) models while requiring significantly fewer computational resources. In particular, the architecture employs only 13K parameters (0.48 MB), reducing the parameter count by more than 99.99% compared to current SOTA models. Furthermore, the diffusion-generated data used to train our quantum models, in conjunction with real samples, preserve clinical structural standards, representing a notable first in the field of QML. We conclude that CQCNN architecture like models, with further improvements in gradient optimization techniques, could become a viable option and even a potential alternative to classical models for AD detection, especially in data limited and resource constrained clinical settings.
从临床MRI数据检测阿尔茨海默病(AD)是医学成像领域的一个研究热点。量子计算的最新进展,特别是参数化量子电路(PQC)与经典机器学习架构的集成,为开发可能超越传统方法的模型提供了新的机会。然而,量子机器学习(QML)仍处于早期阶段,需要进一步实验分析以更好地了解其行为和局限性。在本文中,我们提出了一种端到端的混合经典量子卷积神经网络(CQCNN),用于使用临床格式的3D MRI数据进行AD检测。我们的方法包括开发一个使3D MRI数据可用于机器学习的框架,设计和训练脑组织分割模型(Skull Net),以及训练一个扩散模型以生成少数类别的合成图像。我们收敛的模型显示出潜在的量子优势,以较少的迭代次数实现了比经典模型更高的精度。所提出的beta8 3量子位模型达到了97.50%的准确率,超越了最新模型,同时显著减少了计算资源需求。特别是,该架构仅使用13K个参数(0.48 MB),与当前最新模型相比,参数数量减少了99.99%以上。此外,用于训练我们量子模型的扩散生成数据与实际样本相结合,保持了临床结构标准,这在该领域尚属首次。我们得出结论,像CQCNN这样的架构,在梯度优化技术方面进一步改进后,有可能成为检测AD的可行选项,甚至是经典模型的潜在替代方案,尤其是在数据有限和资源受限的临床环境中。
论文及项目相关链接
PDF Application of hybrid quantum-classical machine learning for (early stage) disease detection
Summary
本文研究了利用临床MRI数据检测阿尔茨海默病(AD)的方法,并介绍了量子计算与经典机器学习相结合在该领域的应用。文章提出了一种端到端的混合经典量子卷积神经网络(CQCNN)模型,用于使用临床格式的3D MRI数据进行AD检测。该模型通过开发一个使3D MRI数据适用于机器学习的方法、设计并训练脑组织的分割模型(Skull Net)以及训练扩散模型来生成少数类的合成图像,展现了潜在的量子优势。该模型在较少的迭代次数内实现了较高的准确性,超越了现有技术水平的模型,并且具有更少的计算资源需求。该研究得出结论,进一步的梯度优化技术改进后的CQCNN模型可能成为经典模型的可行选择,甚至在数据有限和资源受限的临床环境中成为潜在替代品。
Key Takeaways
- 研究领域:文章探讨了医学成像中阿尔茨海默病的检测,特别是利用临床MRI数据。
- 量子计算与机器学习结合:文章展示了参数化量子电路(PQC)与经典机器学习架构的结合如何为AD检测提供新的机会。
- 混合经典量子卷积神经网络(CQCNN):提出了一种用于AD检测的端到端CQCNN模型,该模型使用临床格式的3D MRI数据。
- 模型优势:CQCNN模型展现了潜在的量子优势,实现了高准确性,并超越了现有技术水平的其他模型。
- 资源效率:该模型需要显著更少的计算资源,并且具有较少的参数,这使其成为资源受限环境中的理想选择。
- 数据生成:文章提到了使用扩散模型生成合成图像来训练量子模型的方法,这些合成图像与真实样本一起使用,同时保持了临床结构标准。
点此查看论文截图

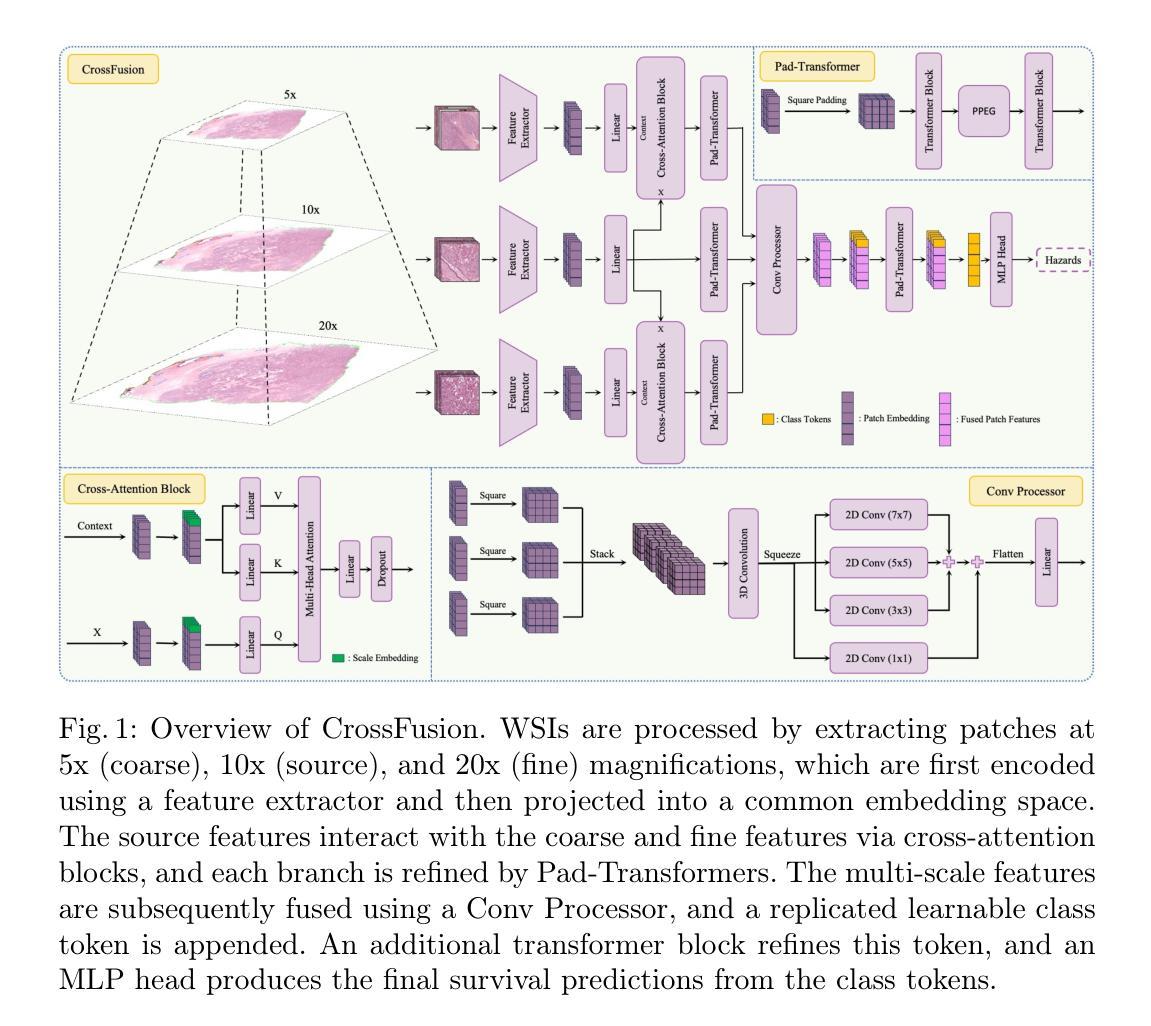
CrossFusion: A Multi-Scale Cross-Attention Convolutional Fusion Model for Cancer Survival Prediction
Authors:Rustin Soraki, Huayu Wang, Joann G. Elmore, Linda Shapiro
Cancer survival prediction from whole slide images (WSIs) is a challenging task in computational pathology due to the large size, irregular shape, and high granularity of the WSIs. These characteristics make it difficult to capture the full spectrum of patterns, from subtle cellular abnormalities to complex tissue interactions, which are crucial for accurate prognosis. To address this, we propose CrossFusion, a novel multi-scale feature integration framework that extracts and fuses information from patches across different magnification levels. By effectively modeling both scale-specific patterns and their interactions, CrossFusion generates a rich feature set that enhances survival prediction accuracy. We validate our approach across six cancer types from public datasets, demonstrating significant improvements over existing state-of-the-art methods. Moreover, when coupled with domain-specific feature extraction backbones, our method shows further gains in prognostic performance compared to general-purpose backbones. The source code is available at: https://github.com/RustinS/CrossFusion
从全幻灯片图像(WSI)进行癌症生存预测是计算病理学中的一项具有挑战性的任务,因为全幻灯片图像具有尺寸大、形状不规则和粒度高等特点。这些特性导致难以捕捉从微妙的细胞异常到复杂的组织相互作用的完整模式谱,这对于准确的预后至关重要。为了解决这一问题,我们提出了CrossFusion,这是一种新型的多尺度特征集成框架,可以从不同放大级别的补丁中提取并融合信息。通过有效地建模特定尺度的模式及其相互作用,CrossFusion生成了一个丰富的特征集,提高了生存预测的准确性。我们在公共数据集的六种癌症类型上验证了我们的方法,证明了与现有的最先进的方法相比有明显的改进。此外,当与特定领域的特征提取骨干相结合时,我们的方法在预后性能上相比通用骨干表现出进一步的提升。源代码可在:https://github.com/RustinS/CrossFusion获取。
论文及项目相关链接
Summary
本文提出一种名为CrossFusion的新型多尺度特征融合框架,用于从全幻灯片图像(WSIs)中抽取并融合不同放大倍数下的斑块信息,以解决计算病理学中的癌症生存预测挑战。该框架能有效建模各尺度下的模式及其相互作用,生成丰富的特征集,提高生存预测的准确性。在公开数据集上的六种癌症类型验证显示,与现有最先进的方法相比,该方法具有显著的优势。当与特定领域的特征提取骨干相结合时,该方法在预后性能上表现出进一步的提升。
Key Takeaways
- CrossFusion是一个多尺度特征融合框架,用于处理全幻灯片图像(WSIs)的癌症生存预测。
- 该框架解决了计算病理学中的挑战,如图像大小、形状的不规则和粒度高。
- CrossFusion通过抽取并融合不同放大倍数下的斑块信息,生成丰富的特征集。
- 该方法能有效建模各尺度下的模式及其相互作用。
- 在公开数据集上的六种癌症类型验证,CrossFusion显著提高了生存预测的准确性。
- 与通用特征提取骨干相比,与特定领域的特征提取骨干结合时,CrossFusion的预后性能更佳。
点此查看论文截图

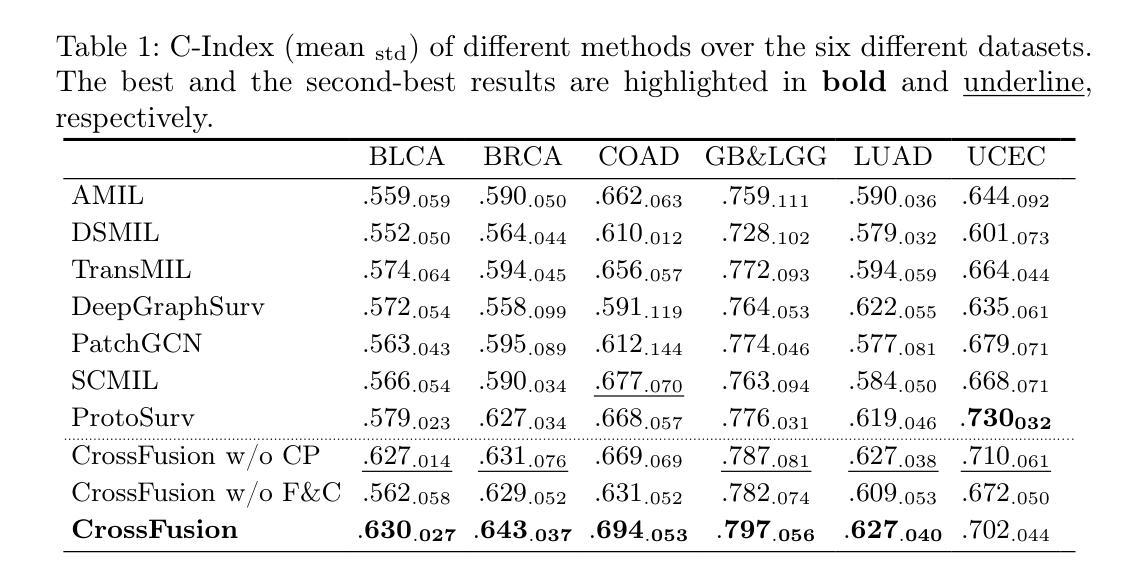
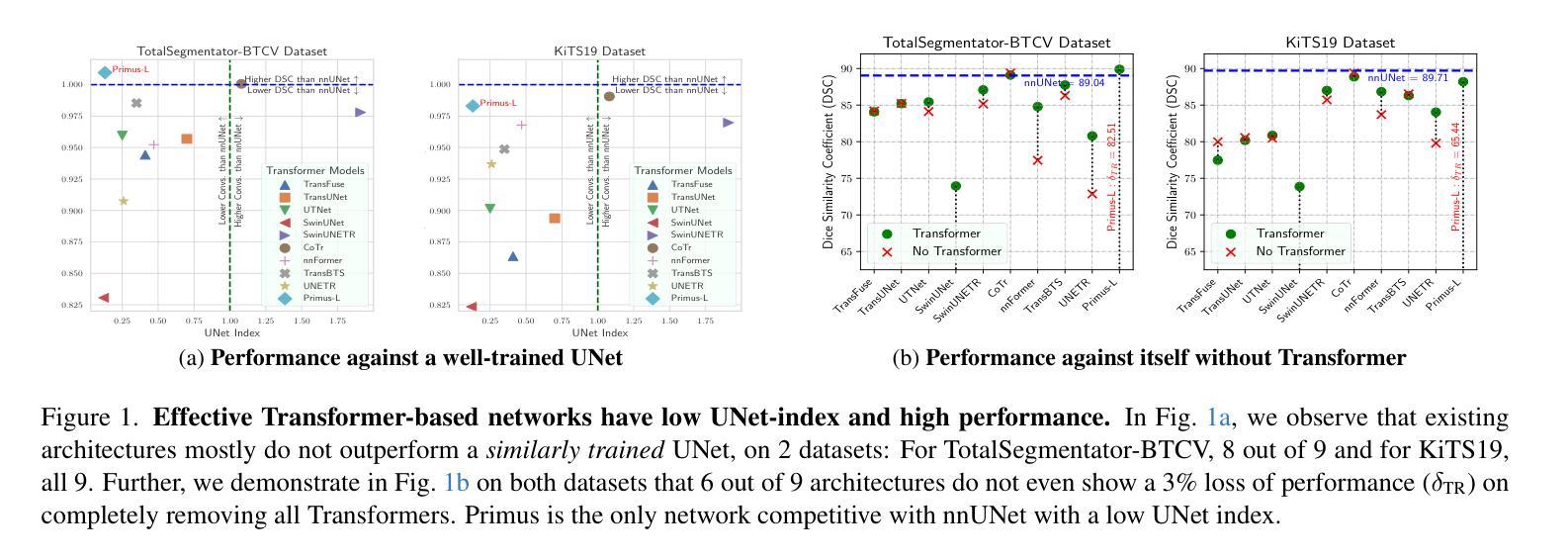
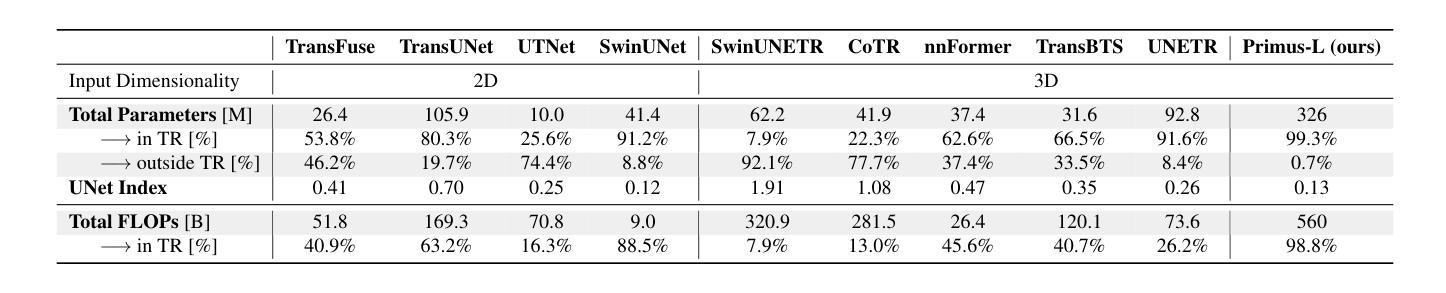
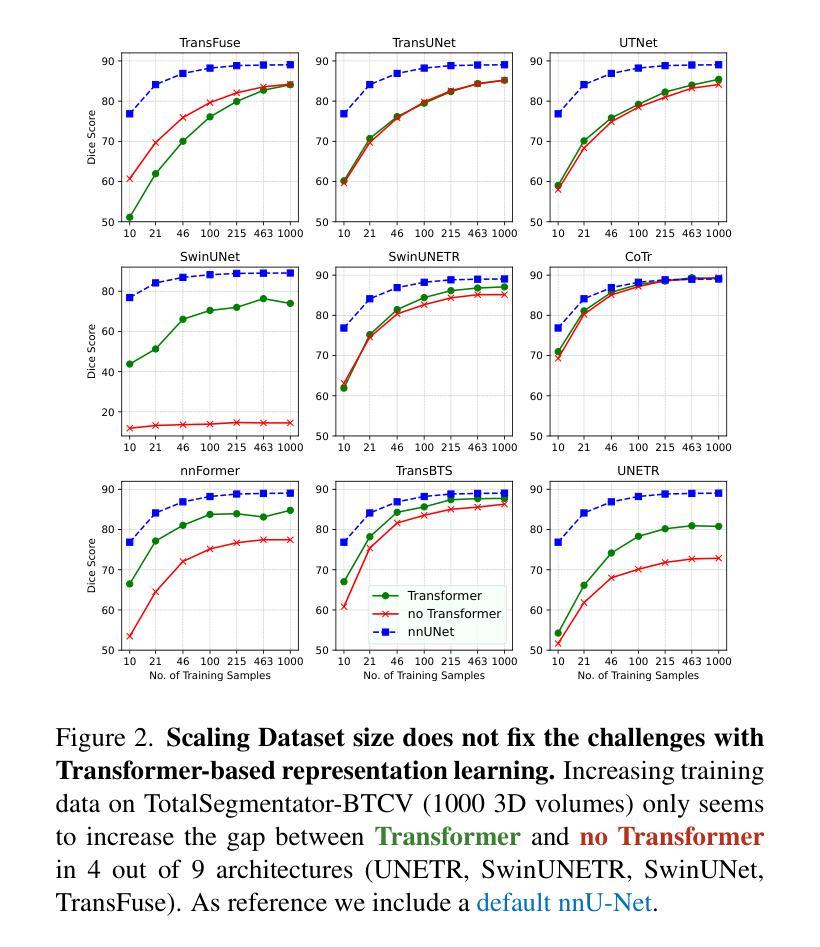
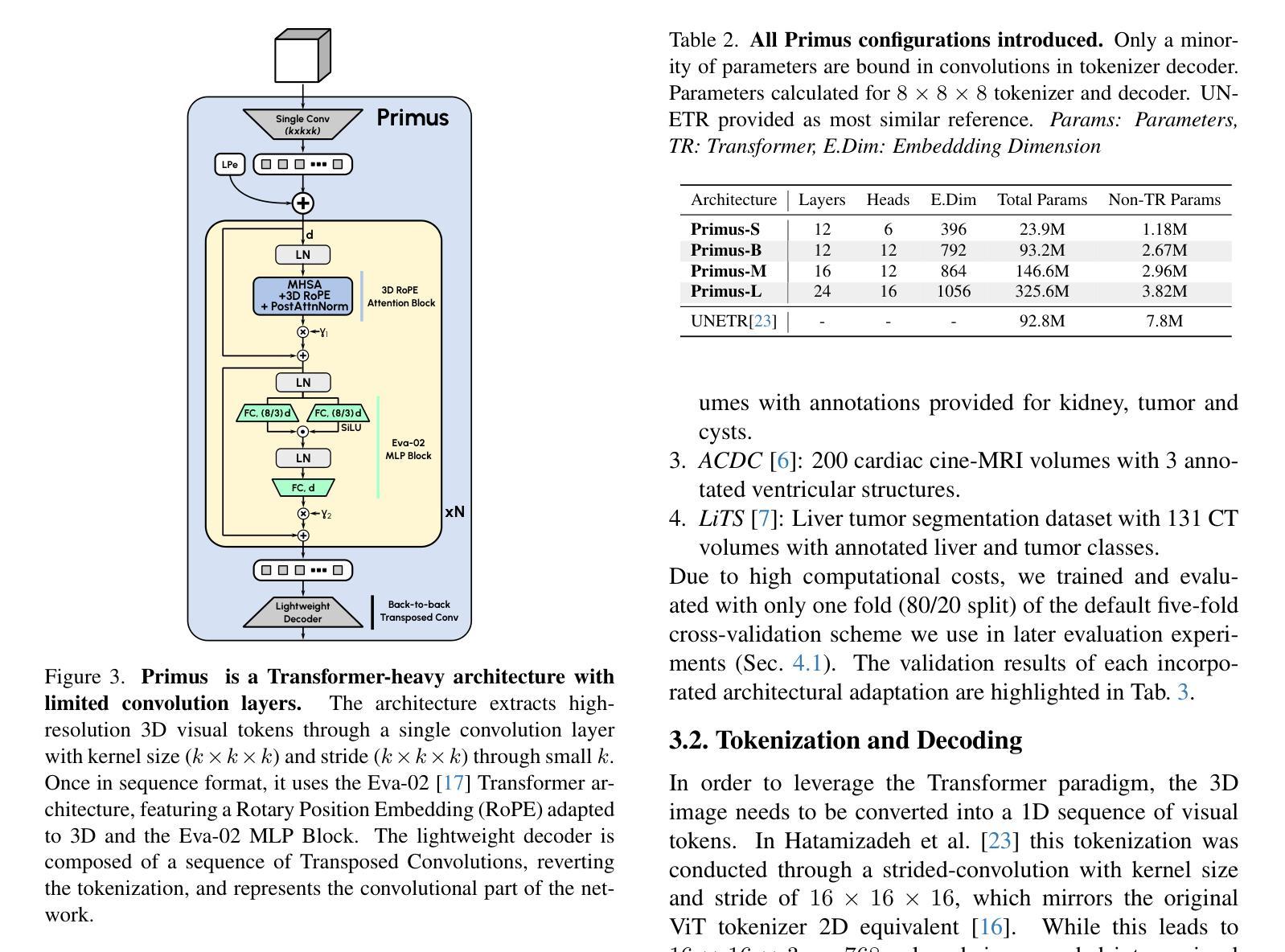
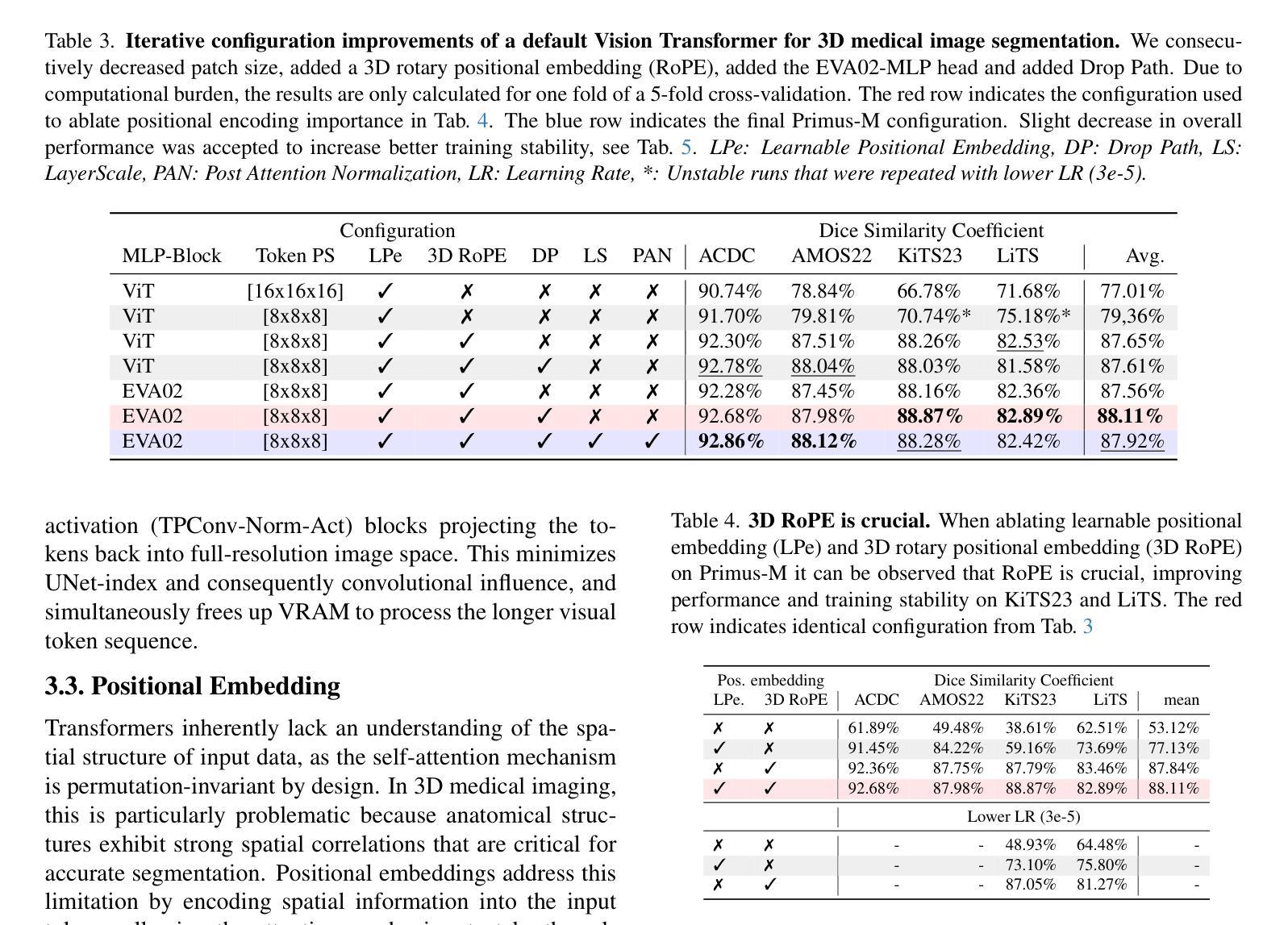
Primus: Enforcing Attention Usage for 3D Medical Image Segmentation
Authors:Tassilo Wald, Saikat Roy, Fabian Isensee, Constantin Ulrich, Sebastian Ziegler, Dasha Trofimova, Raphael Stock, Michael Baumgartner, Gregor Köhler, Klaus Maier-Hein
Transformers have achieved remarkable success across multiple fields, yet their impact on 3D medical image segmentation remains limited with convolutional networks still dominating major benchmarks. In this work, we a) analyze current Transformer-based segmentation models and identify critical shortcomings, particularly their over-reliance on convolutional blocks. Further, we demonstrate that in some architectures, performance is unaffected by the absence of the Transformer, thereby demonstrating their limited effectiveness. To address these challenges, we move away from hybrid architectures and b) introduce a fully Transformer-based segmentation architecture, termed Primus. Primus leverages high-resolution tokens, combined with advances in positional embeddings and block design, to maximally leverage its Transformer blocks. Through these adaptations Primus surpasses current Transformer-based methods and competes with state-of-the-art convolutional models on multiple public datasets. By doing so, we create the first pure Transformer architecture and take a significant step towards making Transformers state-of-the-art for 3D medical image segmentation.
Transformer在多领域取得了显著的成功,但在3D医学图像分割方面,其影响仍然有限,卷积网络仍然在主要基准测试中占据主导地位。在这项工作中,我们a)分析了当前的基于Transformer的分割模型,并识别出了关键短板,特别是它们对卷积模块的过度依赖。此外,我们证明在某些架构中,移除Transformer对性能并无影响,从而证明了其有限的有效性。为了应对这些挑战,我们放弃了混合架构,b)提出了一种全新的基于Transformer的分割架构,名为Primus。Primus利用高分辨率标记,结合位置嵌入和块设计的进步,最大限度地利用其Transformer模块。通过这些调整,Primus超越了当前的基于Transformer的方法,并在多个公共数据集上与最先进的卷积模型相竞争。通过这样做,我们创建了第一个纯Transformer架构,朝着使Transformer成为3D医学图像分割的最先进技术迈出了重要的一步。
论文及项目相关链接
PDF Preprint
Summary
本文探讨了Transformer在自然语言处理领域的卓越表现及其在3D医学图像分割领域的应用现状。文章分析了当前基于Transformer的分割模型的不足,如过度依赖卷积块的问题。同时,本文介绍了一种全新的纯Transformer架构——Primus,该架构利用高分辨率令牌、先进的定位嵌入和块设计,最大化地利用Transformer块。Primus在多个公共数据集上的表现超越了现有的基于Transformer的方法,并与最先进的卷积模型相竞争。这为Transformer在3D医学图像分割领域的应用树立了新的里程碑。
Key Takeaways
- Transformer在自然语言处理领域的成功及其在3D医学图像分割领域的潜力。
- 当前基于Transformer的分割模型存在过度依赖卷积块的不足。
- 一些架构中Transformer的作用有限,验证了其有效性受限。
- 介绍了一种全新的纯Transformer架构——Primus。
- Primus利用高分辨率令牌和先进的定位嵌入及块设计来提高性能。
- Primus在多个公共数据集上的表现超越了现有的基于Transformer的方法。
点此查看论文截图

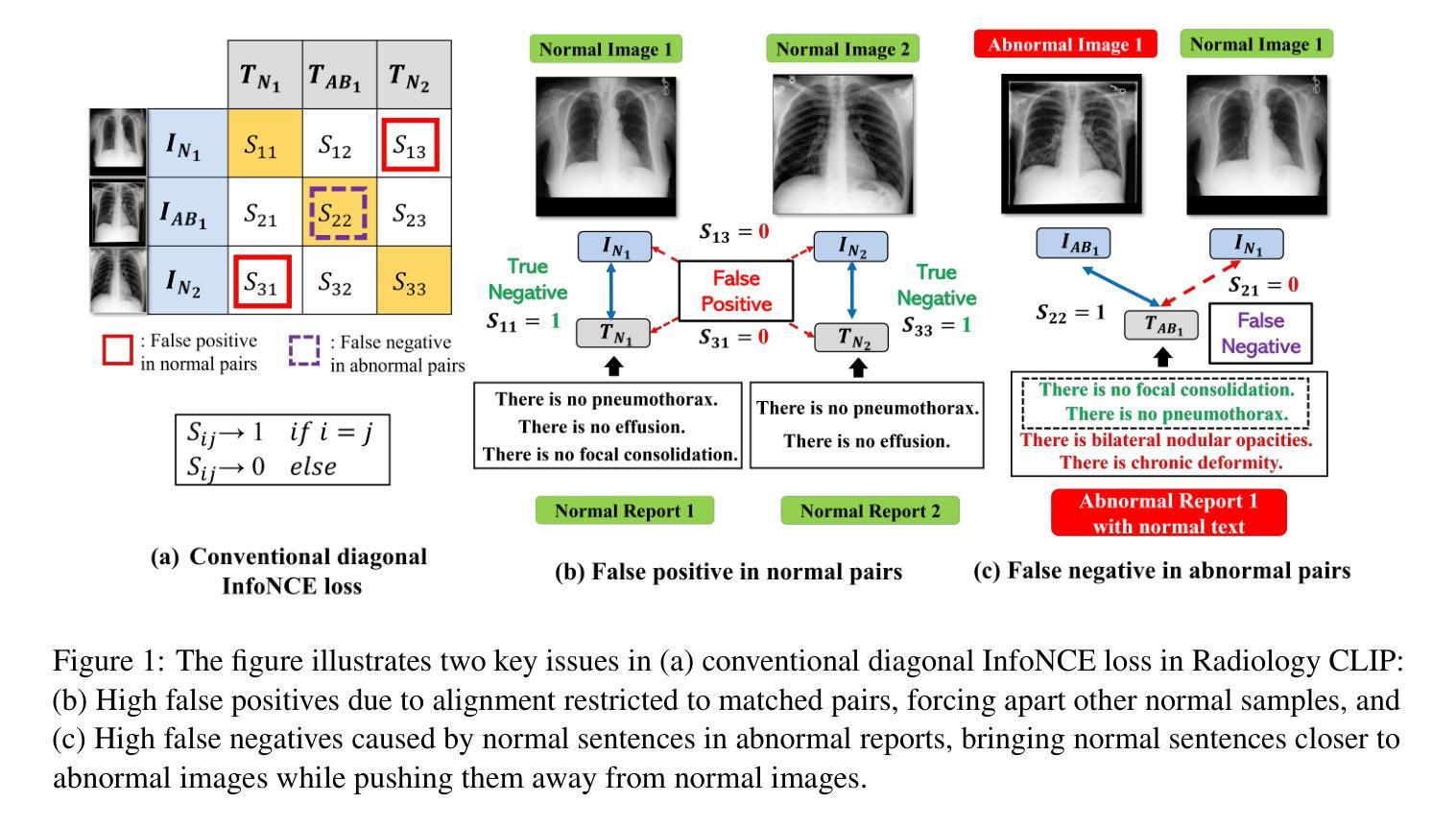
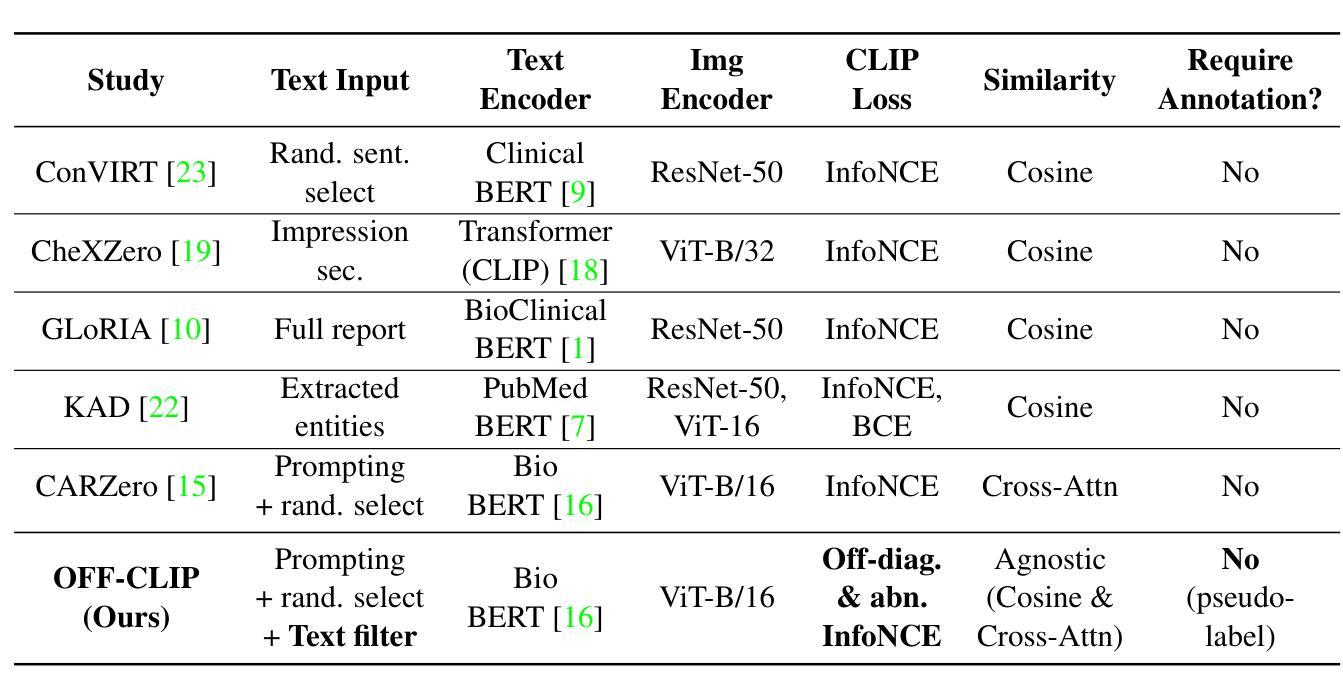
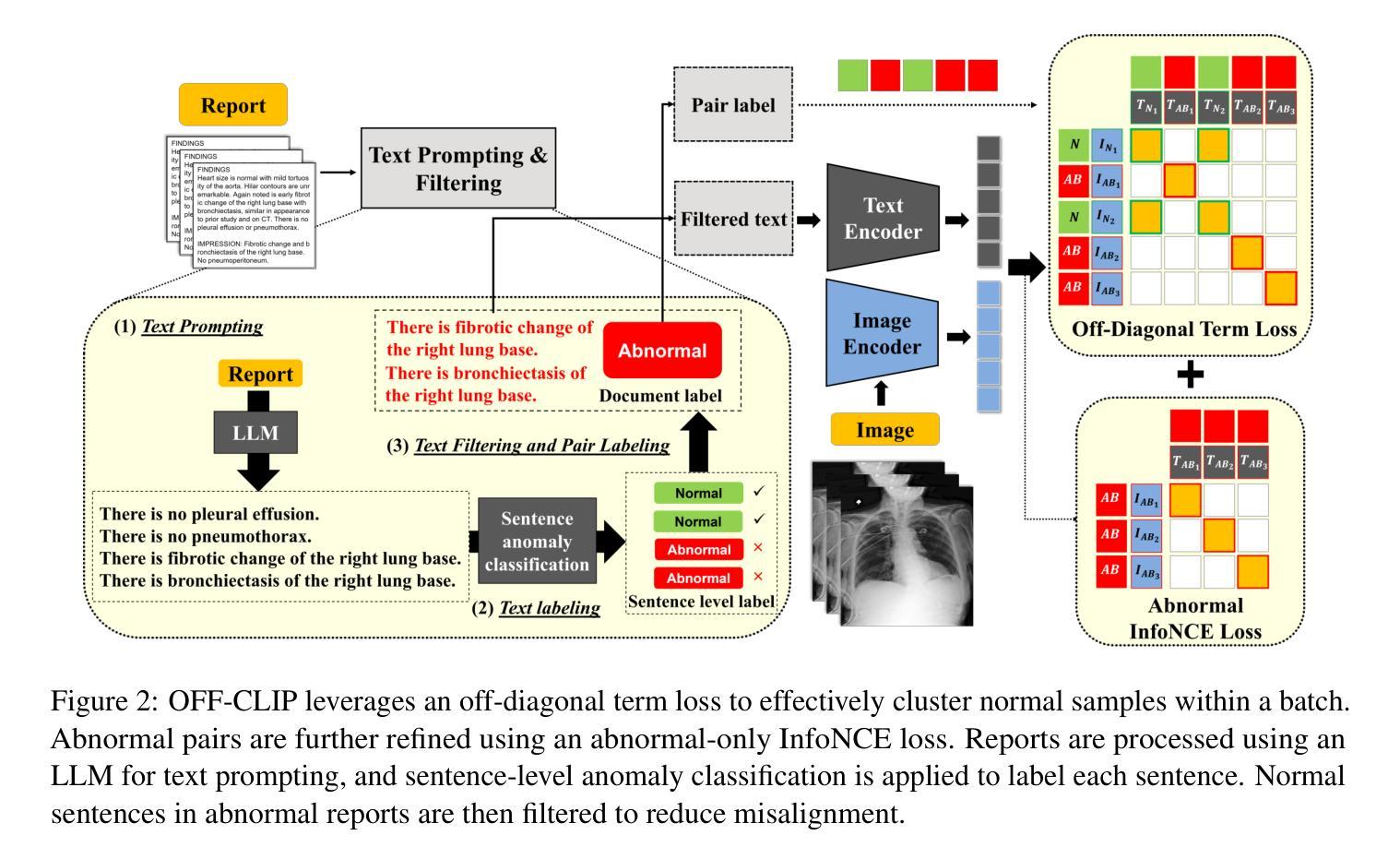
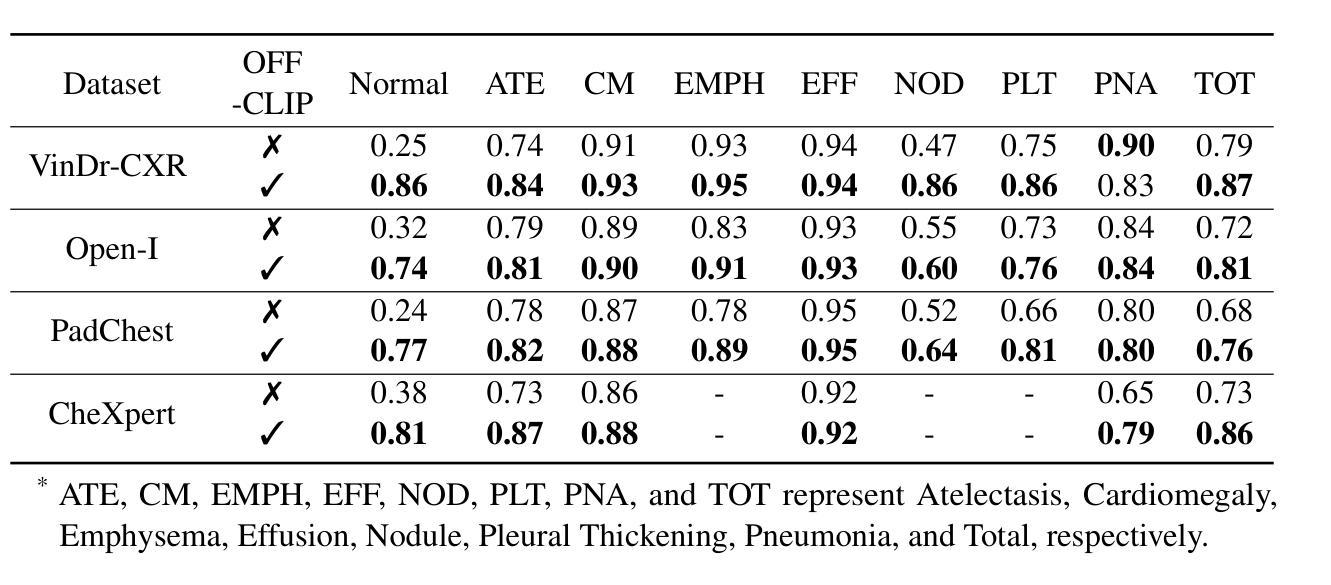
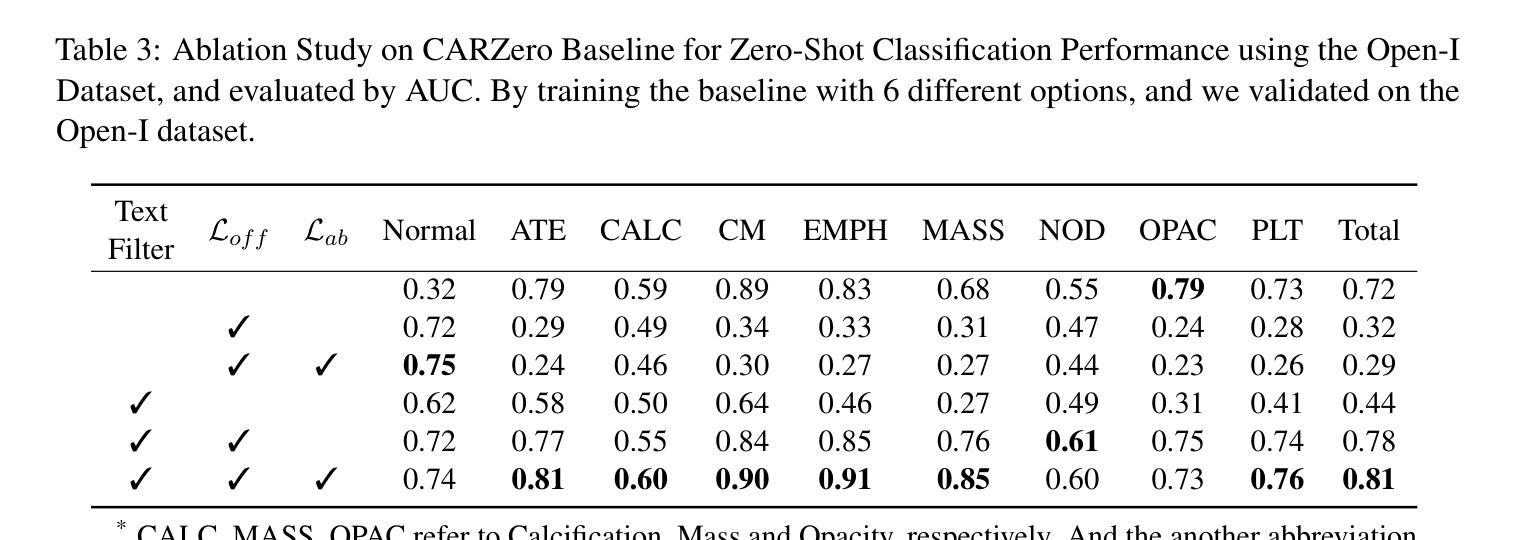
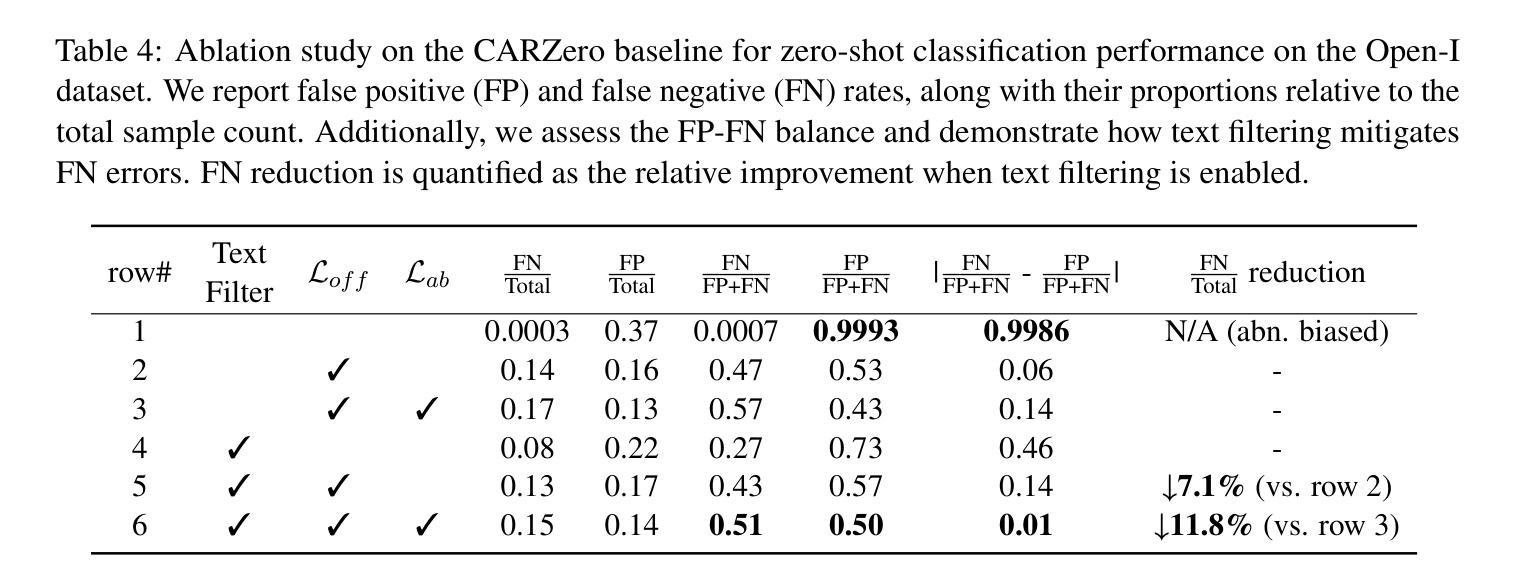
OFF-CLIP: Improving Normal Detection Confidence in Radiology CLIP with Simple Off-Diagonal Term Auto-Adjustment
Authors:Junhyun Park, Chanyu Moon, Donghwan Lee, Kyungsu Kim, Minho Hwang
Contrastive Language-Image Pre-Training (CLIP) has enabled zero-shot classification in radiology, reducing reliance on manual annotations. However, conventional contrastive learning struggles with normal case detection due to its strict intra-sample alignment, which disrupts normal sample clustering and leads to high false positives (FPs) and false negatives (FNs). To address these issues, we propose OFF-CLIP, a contrastive learning refinement that improves normal detection by introducing an off-diagonal term loss to enhance normal sample clustering and applying sentence-level text filtering to mitigate FNs by removing misaligned normal statements from abnormal reports. OFF-CLIP can be applied to radiology CLIP models without requiring any architectural modifications. Experimental results show that OFF-CLIP significantly improves normal classification, achieving a 0.61 Area under the curve (AUC) increase on VinDr-CXR over CARZero, the state-of-the-art zero-shot classification baseline, while maintaining or improving abnormal classification performance. Additionally, OFF-CLIP enhances zero-shot grounding by improving pointing game accuracy, confirming better anomaly localization. These results demonstrate OFF-CLIP’s effectiveness as a robust and efficient enhancement for medical vision-language models.
对比语言图像预训练(CLIP)已经在放射学的零样本分类中得到了应用,减少了对手动注释的依赖。然而,传统的对比学习在常规情况检测方面遇到了困难,因为其严格的样本内对齐会破坏正常样本的聚类,导致高误报率(FPs)和假阴性(FNs)。为了解决这些问题,我们提出了OFF-CLIP,这是一种对比学习的改进方法,通过引入非对角线项损失来增强正常样本的聚类,并应用句子级文本过滤,通过从异常报告中删除错位正常陈述来减轻FNs,从而提高了正常检测。OFF-CLIP可应用于放射学CLIP模型,无需进行任何架构修改。实验结果表明,OFF-CLIP在VinDr-CXR上相对于当前最先进的零样本分类基线CARZero,显著提高了正常分类的曲线下面积(AUC)提高了0.61%,同时保持或提高了异常分类性能。此外,OFF-CLIP通过提高指向游戏准确性,增强了零样本定位,证实了其异常定位能力更强。这些结果证明了OFF-CLIP作为医学视觉语言模型的稳健、高效增强的有效性。
论文及项目相关链接
PDF 10 pages, 3 figures, and 5 tables
Summary
本文介绍了对比语言图像预训练(CLIP)在放射学零样本分类中的应用,并指出传统对比学习在正常样本检测方面的不足。为解决这一问题,提出OFF-CLIP方法,通过引入离对角线项损失增强正常样本聚类,并应用句子级文本过滤来减少误对齐的正常语句对异常报告的影响。OFF-CLIP可应用于放射学CLIP模型,无需进行任何架构修改。实验结果表明,OFF-CLIP能显著提高正常分类性能,在VinDr-CXR数据集上较当前最佳零样本分类基线CARZero提高AUC值0.61%,同时保持或提高异常分类性能。此外,OFF-CLIP还提高了零样本定位的准确性,证明其在医学视觉语言模型中的稳健和高效。
Key Takeaways
- 对比语言图像预训练(CLIP)已应用于放射学零样本分类,减少了对手动注释的依赖。
- 传统对比学习在正常样本检测方面存在挑战,因严格样本内对齐而破坏正常样本聚类,导致高误报。
- OFF-CLIP方法通过引入离对角线项损失改善正常检测,增强正常样本聚类,并应用句子级文本过滤减少误对齐影响。
- OFF-CLIP可无缝集成到放射学CLIP模型,无需架构修改。
- 实验显示,OFF-CLIP显著提高正常分类性能,在VinDr-CXR数据集上较CARZero有显著提升。
- OFF-CLIP同时保持或提高异常分类性能,证明其在医学视觉语言模型中的稳健性。
点此查看论文截图

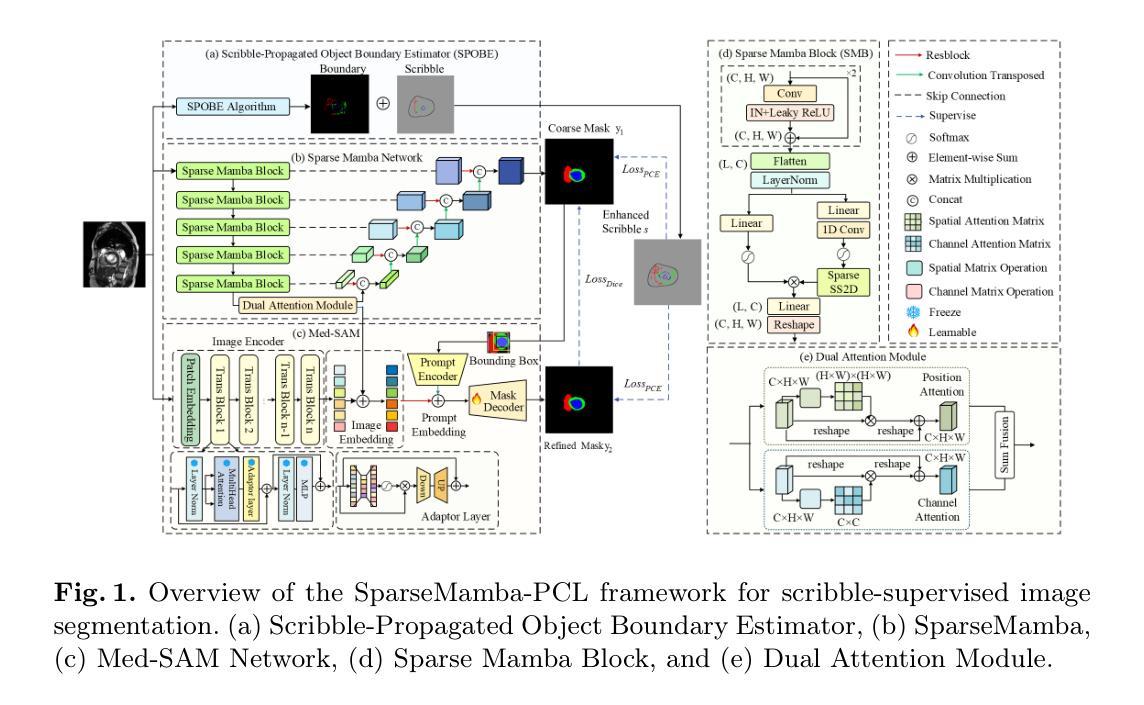
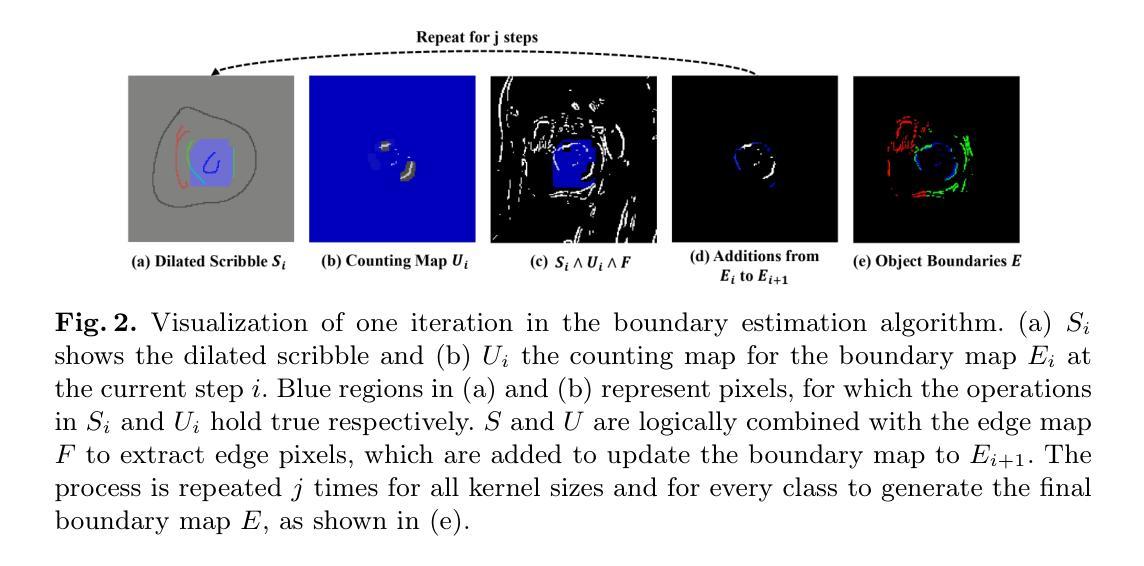
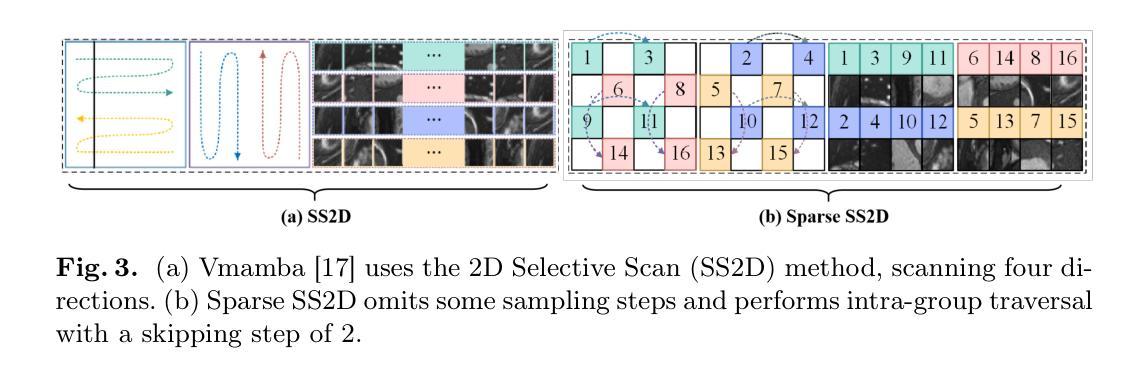
SparseMamba-PCL: Scribble-Supervised Medical Image Segmentation via SAM-Guided Progressive Collaborative Learning
Authors:Luyi Qiu, Tristan Till, Xiaobao Guo, Adams Wai-Kin Kong
Scribble annotations significantly reduce the cost and labor required for dense labeling in large medical datasets with complex anatomical structures. However, current scribble-supervised learning methods are limited in their ability to effectively propagate sparse annotation labels to dense segmentation masks and accurately segment object boundaries. To address these issues, we propose a Progressive Collaborative Learning framework that leverages novel algorithms and the Med-SAM foundation model to enhance information quality during training. (1) We enrich ground truth scribble segmentation labels through a new algorithm, propagating scribbles to estimate object boundaries. (2) We enhance feature representation by optimizing Med-SAM-guided training through the fusion of feature embeddings from Med-SAM and our proposed Sparse Mamba network. This enriched representation also facilitates the fine-tuning of the Med-SAM decoder with enriched scribbles. (3) For inference, we introduce a Sparse Mamba network, which is highly capable of capturing local and global dependencies by replacing the traditional sequential patch processing method with a skip-sampling procedure. Experiments on the ACDC, CHAOS, and MSCMRSeg datasets validate the effectiveness of our framework, outperforming nine state-of-the-art methods. Our code is available at \href{https://github.com/QLYCode/SparseMamba-PCL}{SparseMamba-PCL.git}.
涂鸦注释(Scribble annotations)能够大幅度减少复杂结构大型医学数据集密集标注所需的花费与劳力。然而,当前的涂鸦监督学习方法在将稀疏标注标签传播到密集分割掩膜以及精确分割对象边界方面存在局限性。为了解决这些问题,我们提出了一个基于渐进协作学习(Progressive Collaborative Learning)的框架,该框架利用新型算法和Med-SAM基础模型来提升训练过程中的信息质量。(1)我们通过新型算法丰富真实涂鸦分割标签,通过传播涂鸦来估计对象边界。(2)我们通过融合Med-SAM的特征嵌入和我们提出的Sparse Mamba网络,优化Med-SAM引导的训练,增强特征表示。这种丰富的表示还促进了用丰富的涂鸦对Med-SAM解码器的微调。(3)对于推理,我们引入了一个Sparse Mamba网络,该网络能够通过跳过采样程序代替传统的顺序补丁处理方法,非常擅长捕捉局部和全局依赖关系。在ACDC、CHAOS和MSCMRSeg数据集上的实验验证了我们框架的有效性,超越了九种最新方法。我们的代码可在SparseMamba-PCL.git获取。
论文及项目相关链接
Summary
本文提出了一种基于渐进协作学习框架的医学图像分割方法,通过新算法丰富涂鸦分割标签,优化特征表示并引入稀疏曼巴网络进行推理,有效提高涂鸦监督学习方法在大型医学数据集上的性能。该方法可显著减少密集标注的成本和劳动力,并在ACDC、CHAOS和MSCMRSeg数据集上验证了其有效性,超越了九种最新方法。
Key Takeaways
- 本文提出了一个基于渐进协作学习框架的医学图像分割方法,旨在解决涂鸦监督学习方法在大型医学数据集中存在的问题。
- 通过新算法丰富涂鸦分割标签,实现对目标边界的估计。
- 优化特征表示,通过融合Med-SAM和稀疏曼巴网络的特征嵌入,丰富信息质量。
- 引入稀疏曼巴网络进行推理,采用跳跃采样程序替代传统顺序补丁处理方法,更有效地捕捉局部和全局依赖关系。
- 在ACDC、CHAOS和MSCMRSeg数据集上进行了实验验证,证明了该方法的有效性。
- 与九种最新方法相比,该方法具有优越性。
点此查看论文截图


MRI super-resolution reconstruction using efficient diffusion probabilistic model with residual shifting
Authors:Mojtaba Safari, Shansong Wang, Zach Eidex, Qiang Li, Erik H. Middlebrooks, David S. Yu, Xiaofeng Yang
Objective:This study introduces a residual error-shifting mechanism that drastically reduces sampling steps while preserving critical anatomical details, thus accelerating MRI reconstruction. Approach:We propose a novel diffusion-based SR framework called Res-SRDiff, which integrates residual error shifting into the forward diffusion process. This enables efficient HR image reconstruction by aligning the degraded HR and LR distributions.We evaluated Res-SRDiff on ultra-high-field brain T1 MP2RAGE maps and T2-weighted prostate images, comparing it with Bicubic, Pix2pix, CycleGAN, and a conventional denoising diffusion probabilistic model with vision transformer backbone (TM-DDPM), using quantitative metrics such as peak signal-to-noise ratio (PSNR), structural similarity index (SSIM), gradient magnitude similarity deviation (GMSD), and learned perceptual image patch similarity (LPIPS). Main results: Res-SRDiff significantly outperformed all comparative methods in terms of PSNR, SSIM, and GMSD across both datasets, with statistically significant improvements (p-values<<0.05). The model achieved high-fidelity image restoration with only four sampling steps, drastically reducing computational time to under one second per slice, which is substantially faster than conventional TM-DDPM with around 20 seconds per slice. Qualitative analyses further demonstrated that Res-SRDiff effectively preserved fine anatomical details and lesion morphology in both brain and pelvic MRI images. Significance: Our findings show that Res-SRDiff is an efficient and accurate MRI SR method, markedly improving computational efficiency and image quality. Integrating residual error shifting into the diffusion process allows for rapid and robust HR image reconstruction, enhancing clinical MRI workflows and advancing medical imaging research. The source at:https://github.com/mosaf/Res-SRDiff
目标:本研究介绍了一种残差误差偏移机制,该机制在减少采样步骤的同时保留了关键的解剖细节,从而加速了MRI重建。方法:我们提出了一种基于扩散的SR框架,称为Res-SRDiff,它将残差误差偏移集成到正向扩散过程中。这通过对齐退化的HR和LR分布,实现了高效HR图像重建。我们对超高频场脑T1 MP2RAGE图和T2加权前列腺图像进行了Res-SRDiff评估,将其与Bicubic、Pix2pix、CycleGAN以及带有视觉转换器主干(TM-DDPM)的传统去噪扩散概率模型进行比较,使用了峰值信噪比(PSNR)、结构相似性指数(SSIM)、梯度幅度相似性偏差(GMSD)和学习的感知图像块相似性(LPIPS)等定量指标。主要结果:Res-SRDiff在两个数据集上的PSNR、SSIM和GMSD方面均显著优于所有比较方法,具有统计学上的显著改善(p值<<0.05)。该模型仅通过四个采样步骤就实现了高保真图像恢复,计算时间缩短到每片不到一秒,这比传统的TM-DDPM每片大约20秒要快得多。定性分析进一步证明,Res-SRDiff有效地保留了大脑和盆腔MRI图像的精细解剖结构和病灶形态。意义:我们的研究结果表明,Res-SRDiff是一种高效且准确的MRI SR方法,显著提高了计算效率和图像质量。将残差误差偏移集成到扩散过程中,可以实现快速和稳健的HR图像重建,增强临床MRI工作流程,推动医学成像研究的发展。数据源:https://github.com/mosaf/Res-SRDiff
论文及项目相关链接
Summary
本研究提出一种基于扩散的超分辨率重建框架Res-SRDiff,通过将残差误差移位技术融入前向扩散过程,显著提升了磁共振成像(MRI)的重建速度和图像质量。该研究在超高场脑T1 MP2RAGE地图和T2加权前列腺图像上进行了验证,结果显示Res-SRDiff在峰值信噪比(PSNR)、结构相似性指数(SSIM)和梯度幅度相似性偏差(GMSD)等定量指标上显著优于其他对比方法。此外,Res-SRDiff仅需四个采样步骤即可实现高保真图像恢复,计算时间缩短至每秒一片以内,相较于传统的TM-DDPM方法大幅提升了计算效率。
Key Takeaways
- 研究提出了一种新的扩散型超分辨率重建框架Res-SRDiff,融合了残差误差移位技术。
- Res-SRDiff在超高场MRI图像上进行了验证,包括脑部和前列腺图像。
- Res-SRDiff在PSNR、SSIM和GMSD等定量指标上显著优于其他方法。
- 该方法通过减少采样步骤,实现了快速且高保真的MRI图像重建。
- Res-SRDiff的计算效率显著提高,每片图像的计算时间缩短至一秒以内。
- 研究结果证明了Res-SRDiff在临床医学图像重建中的潜在应用价值。
点此查看论文截图


From Claims to Evidence: A Unified Framework and Critical Analysis of CNN vs. Transformer vs. Mamba in Medical Image Segmentation
Authors:Pooya Mohammadi Kazaj, Giovanni Baj, Yazdan Salimi, Anselm W. Stark, Waldo Valenzuela, George CM. Siontis, Habib Zaidi, Mauricio Reyes, Christoph Graeni, Isaac Shiri
While numerous architectures for medical image segmentation have been proposed, achieving competitive performance with state-of-the-art models networks such as nnUNet, still leave room for further innovation. In this work, we introduce nnUZoo, an open source benchmarking framework built upon nnUNet, which incorporates various deep learning architectures, including CNNs, Transformers, and Mamba-based models. Using this framework, we provide a fair comparison to demystify performance claims across different medical image segmentation tasks. Additionally, in an effort to enrich the benchmarking, we explored five new architectures based on Mamba and Transformers, collectively named X2Net, and integrated them into nnUZoo for further evaluation. The proposed models combine the features of conventional U2Net, nnUNet, CNN, Transformer, and Mamba layers and architectures, called X2Net (UNETR2Net (UNETR), SwT2Net (SwinTransformer), SS2D2Net (SwinUMamba), Alt1DM2Net (LightUMamba), and MambaND2Net (MambaND)). We extensively evaluate the performance of different models on six diverse medical image segmentation datasets, including microscopy, ultrasound, CT, MRI, and PET, covering various body parts, organs, and labels. We compare their performance, in terms of dice score and computational efficiency, against their baseline models, U2Net, and nnUNet. CNN models like nnUNet and U2Net demonstrated both speed and accuracy, making them effective choices for medical image segmentation tasks. Transformer-based models, while promising for certain imaging modalities, exhibited high computational costs. Proposed Mamba-based X2Net architecture (SS2D2Net) achieved competitive accuracy with no significantly difference from nnUNet and U2Net, while using fewer parameters. However, they required significantly longer training time, highlighting a trade-off between model efficiency and computational cost.
尽管已经提出了许多用于医学图像分割的架构,但与最新模型网络(如nnUNet)相比,仍有许多改进的空间。在这项工作中,我们引入了基于nnUNet的开源基准测试框架nnUZoo,它结合了各种深度学习架构,包括CNN、Transformer和基于Mamba的模型。使用该框架,我们进行了公正的比较,以揭示不同医学图像分割任务之间性能声称的神秘性。此外,为了丰富基准测试,我们探索了五种基于Mamba和Transformer的新架构,统称为X2Net,并将其集成到nnUZoo中进行进一步评估。所提出的模型结合了传统U2Net、nnUNet、CNN、Transformer和Mamba层和架构的特点,称为X2Net(UNETR2Net(UNETR)、SwT2Net(SwinTransformer)、SS2D2Net(SwinUMamba)、Alt1DM2Net(LightUMamba)和MambaND2Net(MambaND)。我们在六个不同的医学图像分割数据集上全面评估了不同模型的表现,包括显微镜、超声、CT、MRI和PET,涵盖了各种身体部位、器官和标签。我们根据dice分数和计算效率比较了它们与基线模型U2Net和nnUNet的性能。CNN模型如nnUNet和U2Net在速度和准确性方面都表现出色,是医学图像分割任务的有效选择。虽然基于Transformer的模型在某些成像模式上具有潜力,但它们表现出较高的计算成本。提出的基于Mamba的X2Net架构(SS2D2Net)在准确性方面表现出竞争力,与nnUNet和U2Net相比没有明显差异,同时使用的参数较少。然而,它们需要更长的训练时间,这突显了模型效率和计算成本之间的权衡。
论文及项目相关链接
Summary
本文介绍了一个基于nnUNet的开源基准测试框架nnUZoo,其结合了多种深度学习架构,如CNN、Transformer和Mamba模型。文章通过公平比较不同医疗图像分割任务的性能,展示了nnUZoo的优越性。此外,文章还探索了五种基于Mamba和Transformer的新架构,并将它们集成到nnUZoo中进行进一步评估。这些新模型结合了传统U2Net、nnUNet、CNN、Transformer和Mamba层的特性。在多个医学图像分割数据集上的实验表明,CNN模型如nnUNet和U2Net在速度和准确性方面表现出色,而基于Transformer的模型虽然对某些成像模式具有前景,但计算成本较高。基于Mamba的新架构SS2D2Net在准确性方面表现出竞争力,但训练时间较长。
Key Takeaways
- nnUZoo是一个基于nnUNet的开源基准测试框架,结合了多种深度学习架构。
- 通过公平比较,文章对医疗图像分割任务的不同模型性能进行了展示。
- 新提出的X2Net模型结合了多种技术和架构特性。
- 在多种医学图像分割数据集上进行了广泛的实验评估。
- CNN模型如nnUNet和U2Net在速度和准确性方面都表现出较好的性能。
- 基于Transformer的模型虽然具有前景,但计算成本较高。
点此查看论文截图

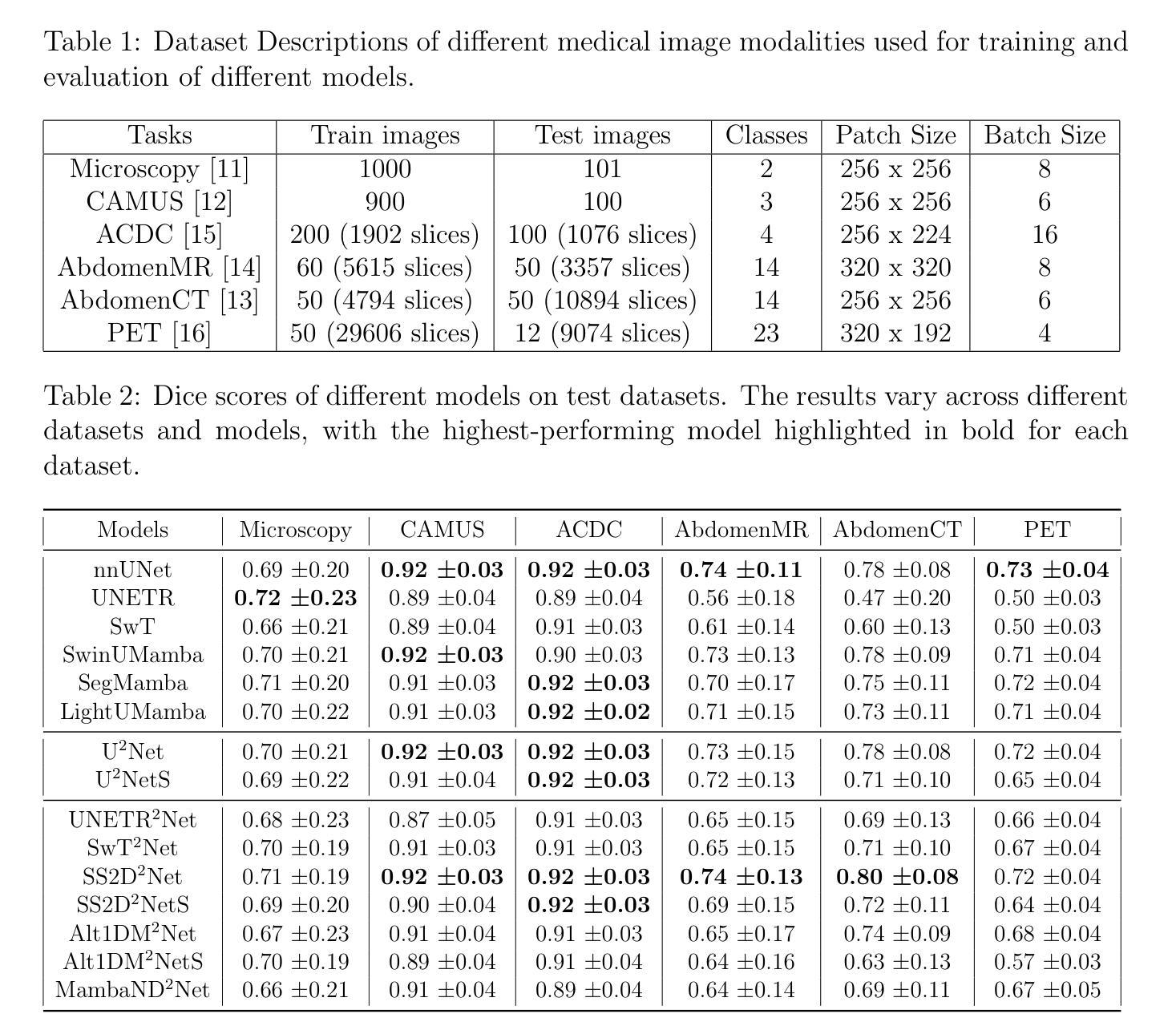
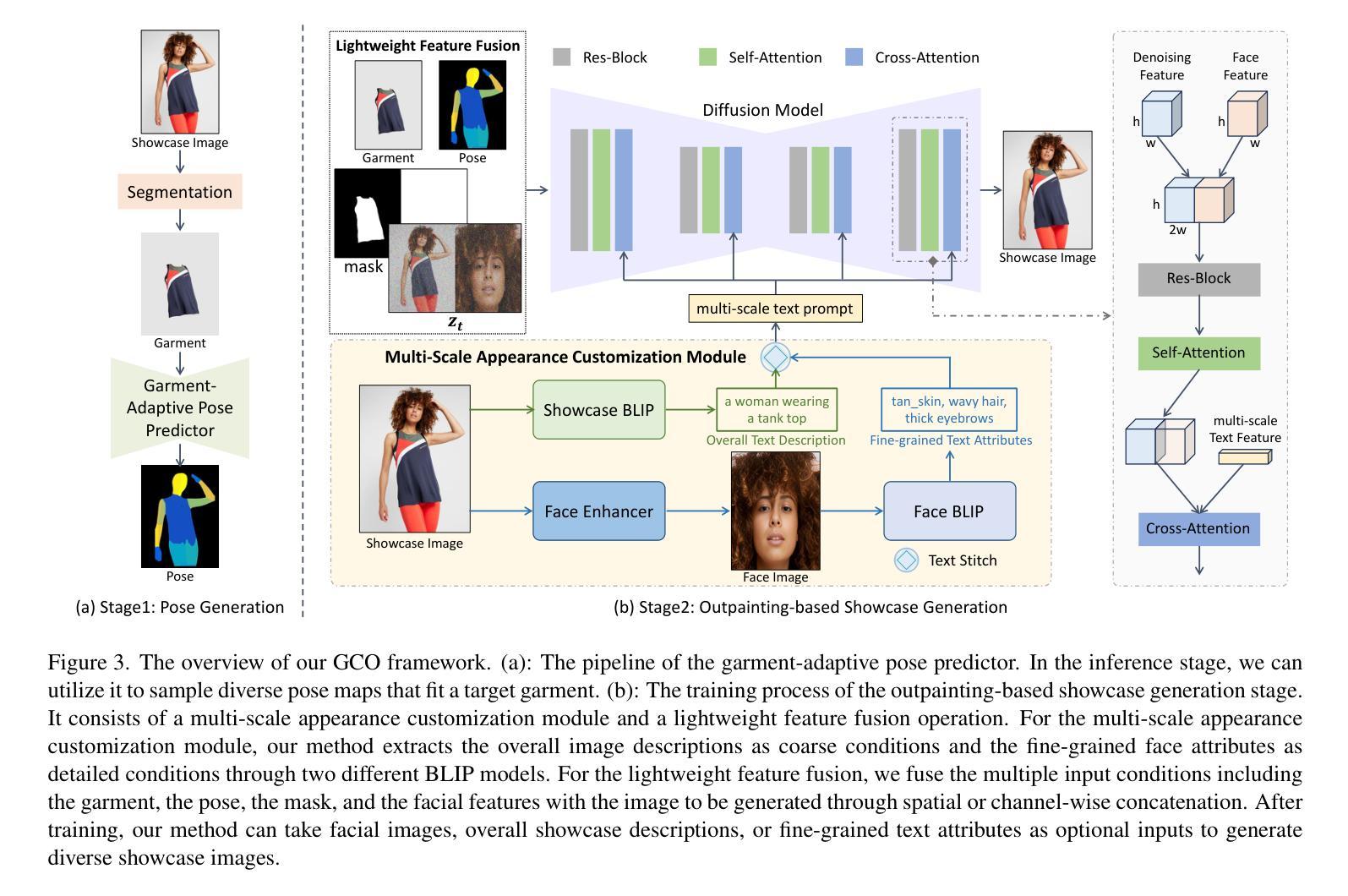
Fine-Grained Controllable Apparel Showcase Image Generation via Garment-Centric Outpainting
Authors:Rong Zhang, Jingnan Wang, Zhiwen Zuo, Jianfeng Dong, Wei Li, Chi Wang, Weiwei Xu, Xun Wang
In this paper, we propose a novel garment-centric outpainting (GCO) framework based on the latent diffusion model (LDM) for fine-grained controllable apparel showcase image generation. The proposed framework aims at customizing a fashion model wearing a given garment via text prompts and facial images. Different from existing methods, our framework takes a garment image segmented from a dressed mannequin or a person as the input, eliminating the need for learning cloth deformation and ensuring faithful preservation of garment details. The proposed framework consists of two stages. In the first stage, we introduce a garment-adaptive pose prediction model that generates diverse poses given the garment. Then, in the next stage, we generate apparel showcase images, conditioned on the garment and the predicted poses, along with specified text prompts and facial images. Notably, a multi-scale appearance customization module (MS-ACM) is designed to allow both overall and fine-grained text-based control over the generated model’s appearance. Moreover, we leverage a lightweight feature fusion operation without introducing any extra encoders or modules to integrate multiple conditions, which is more efficient. Extensive experiments validate the superior performance of our framework compared to state-of-the-art methods.
本文提出了一种基于潜在扩散模型(LDM)的新型以服装为中心的外绘(GCO)框架,用于细粒度可控的服装展示图像生成。该框架旨在通过文本提示和面部图像来定制穿着给定服装的时尚模型。不同于现有方法,我们的框架以从着装的人体模特或真人分割得到的服装图像作为输入,无需学习布料变形,同时确保服装细节的忠实保留。该框架分为两个阶段。在第一阶段,我们引入了一种服装自适应姿态预测模型,该模型可以根据服装生成各种姿态。然后,在下一阶段,我们以服装、预测姿态、指定的文本提示和面部图像为条件,生成服装展示图像。值得一提的是,设计了一个多尺度外观定制模块(MS-ACM),允许对生成的模型的外观进行整体和细粒度的文本控制。此外,我们利用轻量级特征融合操作,无需引入任何额外的编码器或模块来整合多种条件,这更加高效。大量实验验证了我们的框架在性能上优于最新方法。
论文及项目相关链接
Summary
本文提出了一种基于潜在扩散模型(LDM)的新型服装中心外绘画(GCO)框架,用于精细可控的时装展示图像生成。该框架旨在通过文本提示和面部图像定制穿着给定服装的时装模型。与现有方法不同,该框架以从着装模特或人物分割出的服装图像为输入,无需学习布料变形,确保服装细节的真实保留。框架包含两个阶段:第一阶段是服装自适应姿态预测模型,该模型根据服装生成各种姿态;第二阶段是根据服装、预测姿态、指定的文本提示和面部图像生成时装展示图像。特别设计了一个多尺度外观定制模块(MS-ACM),允许对生成的模型的外观进行整体和精细的文本控制。利用轻量级特征融合操作,在不需要引入任何额外的编码器或模块的情况下,将多种条件相结合,提高了效率。大量实验验证了该框架相较于最先进方法的优越性。
Key Takeaways
- 提出了基于潜在扩散模型(LDM)的服装中心外绘画(GCO)框架,用于时装展示图像生成。
- 框架旨在通过文本提示和面部图像定制穿着特定服装的时装模型。
- 输入为从模特或人物分割出的服装图像,无需学习布料变形。
- 框架包含两个阶段:服装自适应姿态预测和多尺度外观定制。
- 多尺度外观定制模块(MS-ACM)允许对生成模型的外观进行整体和精细的文本控制。
- 利用轻量级特征融合操作整合多种条件,提高效率。
点此查看论文截图


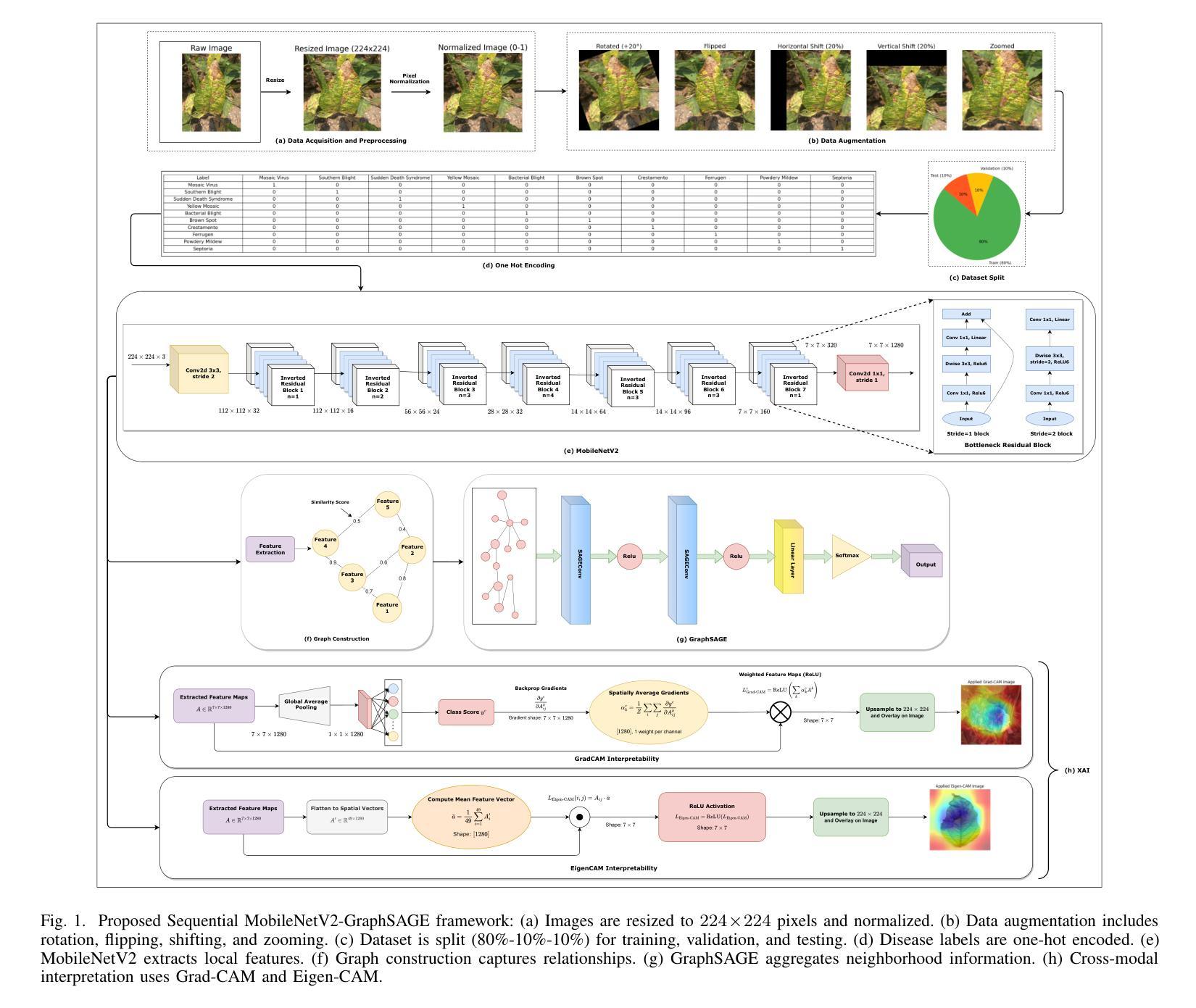
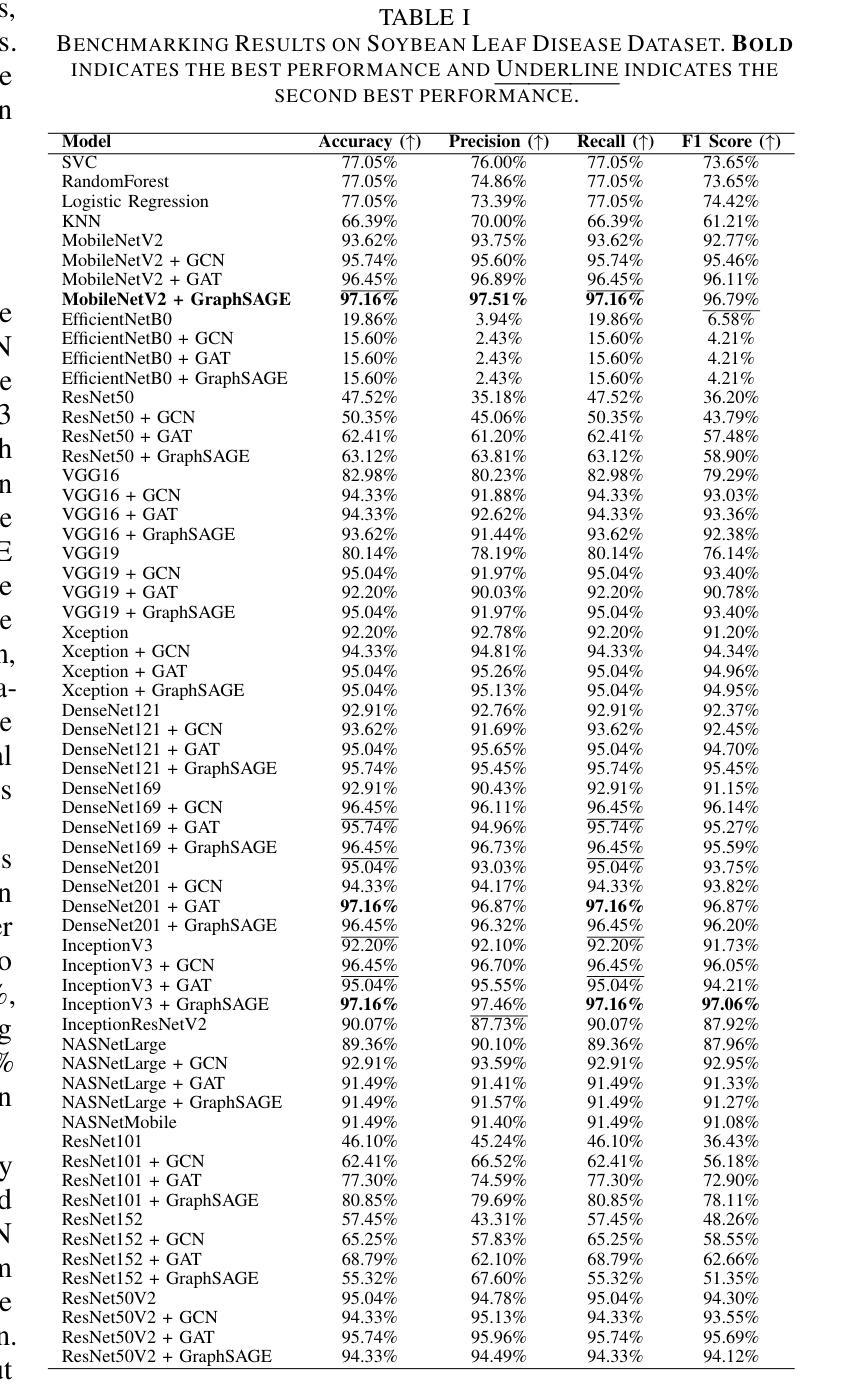
Soybean Disease Detection via Interpretable Hybrid CNN-GNN: Integrating MobileNetV2 and GraphSAGE with Cross-Modal Attention
Authors:Md Abrar Jahin, Soudeep Shahriar, M. F. Mridha, Nilanjan Dey
Soybean leaf disease detection is critical for agricultural productivity but faces challenges due to visually similar symptoms and limited interpretability in conventional methods. While Convolutional Neural Networks (CNNs) excel in spatial feature extraction, they often neglect inter-image relational dependencies, leading to misclassifications. This paper proposes an interpretable hybrid Sequential CNN-Graph Neural Network (GNN) framework that synergizes MobileNetV2 for localized feature extraction and GraphSAGE for relational modeling. The framework constructs a graph where nodes represent leaf images, with edges defined by cosine similarity-based adjacency matrices and adaptive neighborhood sampling. This design captures fine-grained lesion features and global symptom patterns, addressing inter-class similarity challenges. Cross-modal interpretability is achieved via Grad-CAM and Eigen-CAM visualizations, generating heatmaps to highlight disease-influential regions. Evaluated on a dataset of ten soybean leaf diseases, the model achieves $97.16%$ accuracy, surpassing standalone CNNs ($\le95.04%$) and traditional machine learning models ($\le77.05%$). Ablation studies validate the sequential architecture’s superiority over parallel or single-model configurations. With only 2.3 million parameters, the lightweight MobileNetV2-GraphSAGE combination ensures computational efficiency, enabling real-time deployment in resource-constrained environments. The proposed approach bridges the gap between accurate classification and practical applicability, offering a robust, interpretable tool for agricultural diagnostics while advancing CNN-GNN integration in plant pathology research.
大豆叶病检测对农业生产力至关重要,但由于症状视觉相似性和传统方法的有限解释性,它面临着挑战。尽管卷积神经网络(CNN)在空间特征提取方面表现出色,但它们往往忽略了图像间的关系依赖性,从而导致误分类。本文提出了一种可解释的混合序贯CNN-图神经网络(GNN)框架,该框架协同MobileNetV2进行局部特征提取和GraphSAGE进行关系建模。该框架构建了一个图,其中节点代表叶图像,边由基于余弦相似性的邻接矩阵和自适应邻域采样定义。这种设计捕捉了精细的病变特征和全局症状模式,解决了类间相似性挑战。通过Grad-CAM和Eigen-CAM可视化实现跨模态解释性,生成热图以突出显示疾病影响区域。在包含十种大豆叶病的数据集上进行评估,该模型达到了97.16%的准确率,超过了单独的CNN(≤95.04%)和传统机器学习模型(≤77.05%)。消融研究验证了序贯架构优于并行或单一模型配置。仅有230万的参数,轻量级的MobileNetV2-GraphSAGE组合确保了计算效率,可在资源受限的环境中实现实时部署。所提出的方法弥合了准确分类与实际适用之间的鸿沟,为农业诊断提供了稳健、可解释的工具,同时推动了CNN-GNN在植物病理学研究中的融合。
论文及项目相关链接
摘要
本文提出了一种可解释的混合Sequential CNN-Graph Neural Network(GNN)框架,用于大豆叶病检测。该框架结合了MobileNetV2进行局部特征提取和GraphSAGE进行关系建模,解决了卷积神经网络(CNNs)在捕捉图像间关系依赖方面的不足。框架构建了一个图,其中节点代表叶片图像,边缘由余弦相似性基础上的邻接矩阵和自适应邻域采样定义。此设计捕获了精细的病变特征和全局症状模式,解决了类间相似性的挑战。通过Grad-CAM和Eigen-CAM可视化实现跨模态解释性,生成热图以突出疾病影响区域。在十种大豆叶病数据集上评估,该模型达到97.16%的准确率,超越了单独的CNN(≤95.04%)和传统机器学习模型(≤77.05%)。消融研究验证了顺序架构优于并行或单一模型配置。轻量级的MobileNetV2-GraphSAGE组合仅有230万参数,确保计算效率,可在资源受限的环境中实时部署。所提出的方法缩小了准确分类和实际应用之间的差距,为农业诊断提供了一个稳健、可解释的工具,同时推动了植物病理学研究中CNN-GNN的集成应用。
关键见解
- 提出了一个混合Sequential CNN-Graph Neural Network(GNN)框架,用于大豆叶病检测,结合了MobileNetV2和GraphSAGE的优势。
- 通过构建图像的图表示,该框架能够捕捉叶片图像之间的精细特征和关系依赖。
- 利用余弦相似性定义边缘和自适应邻域采样,有效应对类间视觉相似性和复杂模式。
- 通过Grad-CAM和Eigen-CAM可视化增强模型解释性,突出疾病影响区域。
- 模型在十种大豆叶病数据集上达到97.16%的高准确率,表现优于传统方法和单一神经网络结构。
- 消融研究证明了所提框架设计的有效性,展示了顺序架构在应对复杂任务时的优越性。
点此查看论文截图

Multi-wavelength study for gamma-ray nova V1405 Cas
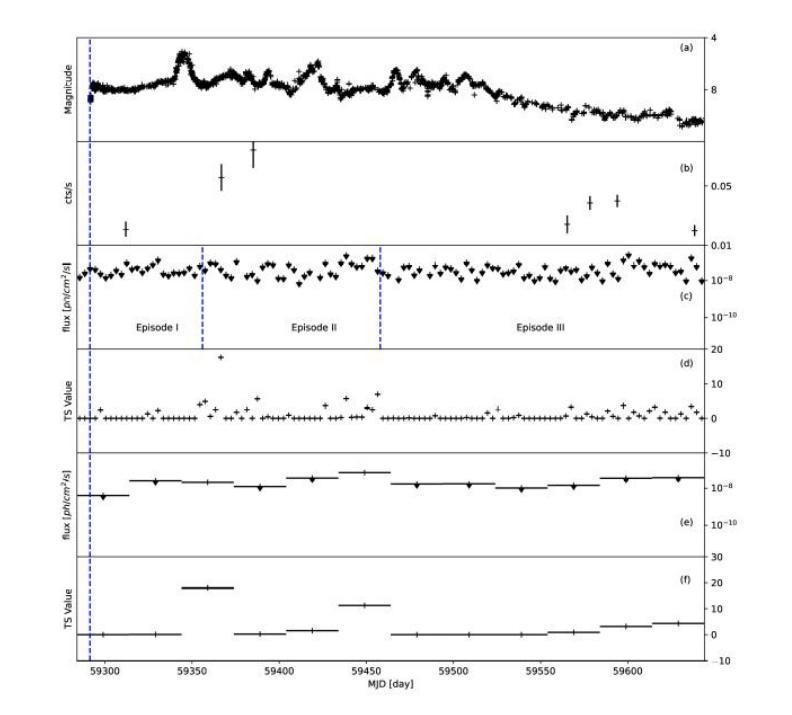
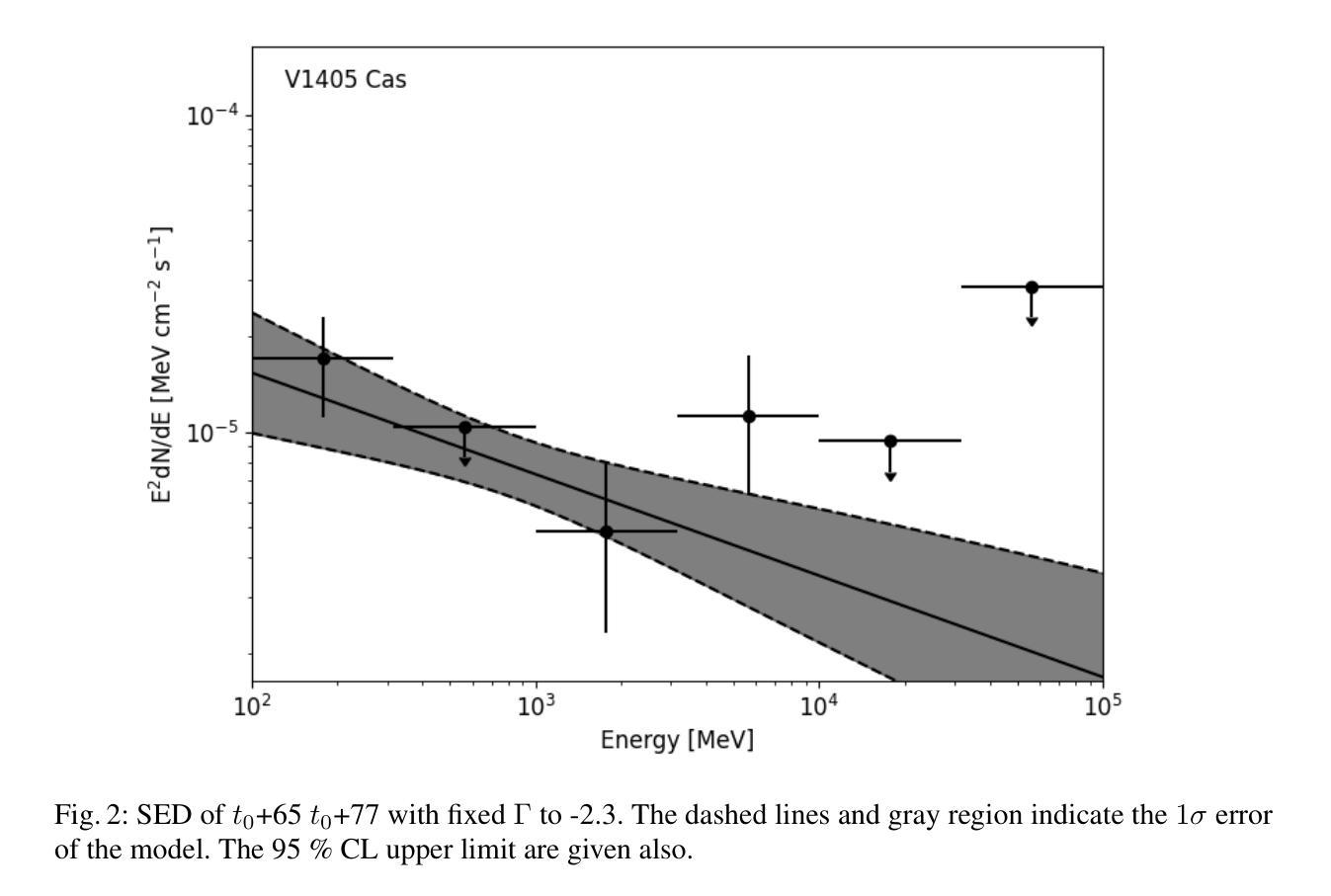
Authors:Zi-wei Ou, Pak-hin Thomas Tam, Hui-hui Wang, Song-peng Pei, Wen-jun Huang
Novae are found to have GeV to TeV gamma-ray emission, which reveals the shock acceleration from the white dwarfs. Recently, V1405 Cas was reported to radiated suspicious gamma-ray by \textit{Fermi}-LAT with low significance ($4.1 \sigma$) after the optical maximum. Radio observations reveal that it is one of the five brightest novae surrounded by low-density ionized gas columns. Here we report continuous search for GeV gamma-ray from \textit{Fermi}-LAT. No gamma-ray were found. For V1405 Cas, the flux level is lower than other well-studied \textit{Fermi} novae, and the gamma-ray maximum appear at $t_{0} + 145$ d. Gamma-ray of V1405 Cas are used to search potential gamma-ray periodicity. No gamma-ray periodicity was found during the time of observation. By comparing multi-wavelength data, the gamma-ray upper limit to optical flux ratio with value at around $10^{-4}$ is obtained to constrain the shock acceleration. Long-term analysis from \textit{Swift}-XRT gets X-ray spectral in the post-shock phase, which indicates that V1405 Cas became a super-soft source. The best-fit black body temperature at the super soft state is 0.11 - 0.19 keV.
最近发现Nova具有从几电子伏特到太电子伏特范围的伽马射线发射,这揭示了来自白矮星的冲击加速现象。最近,V1405 Cas被报告在光学最大值之后通过费米-LAT以较低的显著性(4.1σ)发出可疑的伽马射线。射电观测表明,它是周围被低密度电离气体柱环绕的五颗最亮的Nova之一。这里我们报告了通过费米-LAT对伽马射线的连续搜索。没有找到伽马射线。对于V1405 Cas,其流量水平低于其他经过良好研究的费米Nova,伽马射线最大值出现在t0 + 145天。我们使用V1405 Cas的伽马射线搜索潜在的伽马射线周期性。在观测期间未发现伽马射线周期性。通过比较多波长数据,得到伽马射线流量上限与光学流量的比值约为10^-4,以限制冲击加速。通过Swift-XRT的长期分析,得到后冲击阶段的X射线光谱,表明V1405 Cas变成了一个超软源。在超软状态下,最佳拟合的黑体温度为0.11-0.19千电子伏特。
论文及项目相关链接
PDF Published in RAA
Summary
最近对V1405 Cas进行观测,发现其存在疑似伽马射线辐射现象,但经过后续持续的费米卫星伽马射线探测器的搜索并未发现明显的伽马射线辐射信号。该星的伽马射线与其他已知恒星比较低,并在光峰后一定时间达到峰值。目前没有检测到伽马射线周期性。根据多波长数据的对比,确定了伽马射线与光学流量上限的比值约为$10^{-4}$,有助于限制冲击加速。长期的分析还显示,V1405 Cas进入超软状态,其黑体温度的最佳拟合值为0.11至0.19千电子伏。此结果有助于了解该恒星的基本物理特性。
Key Takeaways
- V1405 Cas存在疑似伽马射线辐射现象,由费米卫星伽马射线探测器观测到。
- 持续搜索未发现明显的伽马射线辐射信号。
- V1405 Cas的伽马射线与其他已知恒星比较相对较低。
- V1405 Cas的伽马射线峰值出现在光峰后的特定时间。
- 未检测到伽马射线的周期性。
- 通过多波长数据对比,确定了伽马射线与光学流量的比值限制。
点此查看论文截图


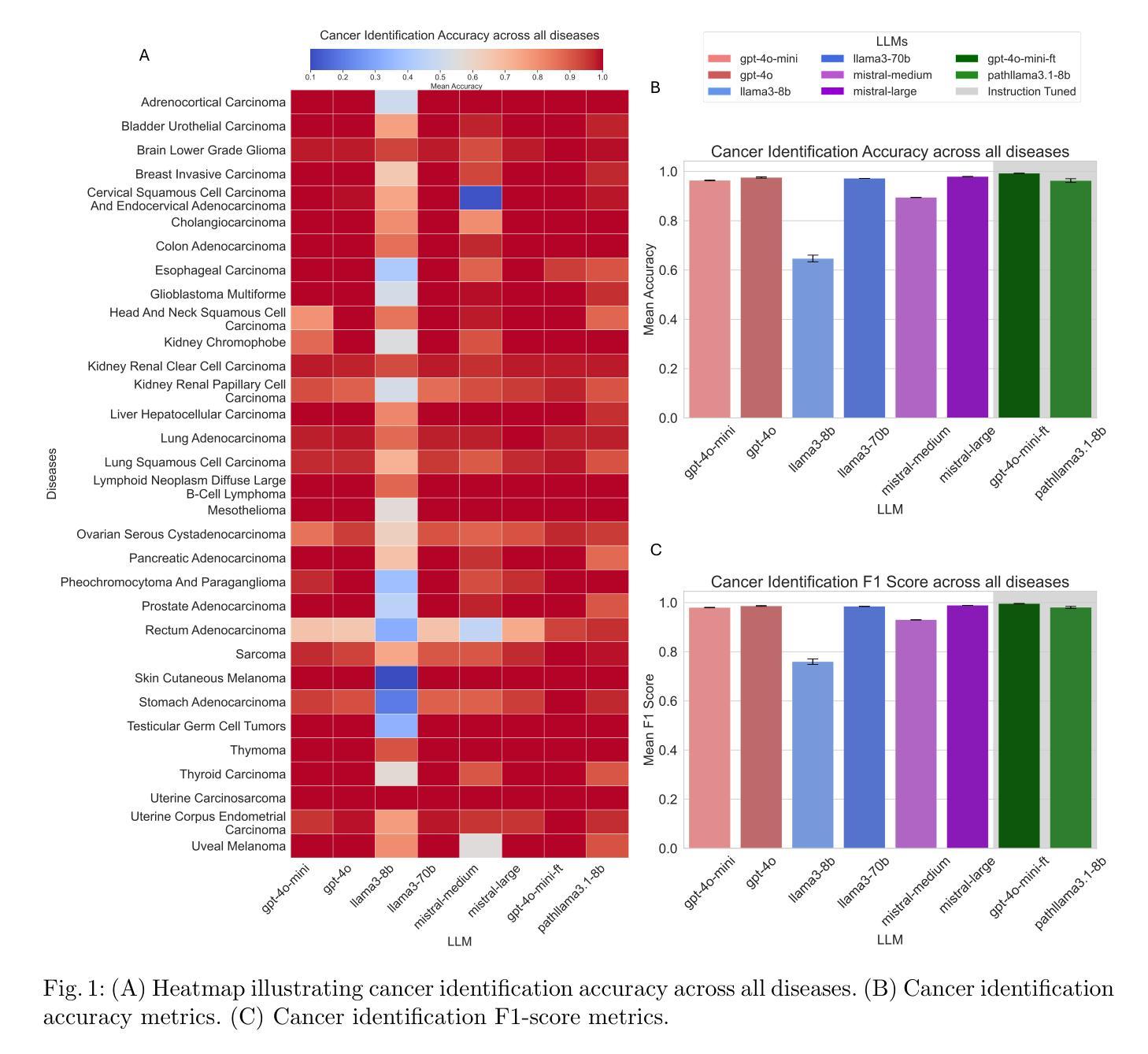
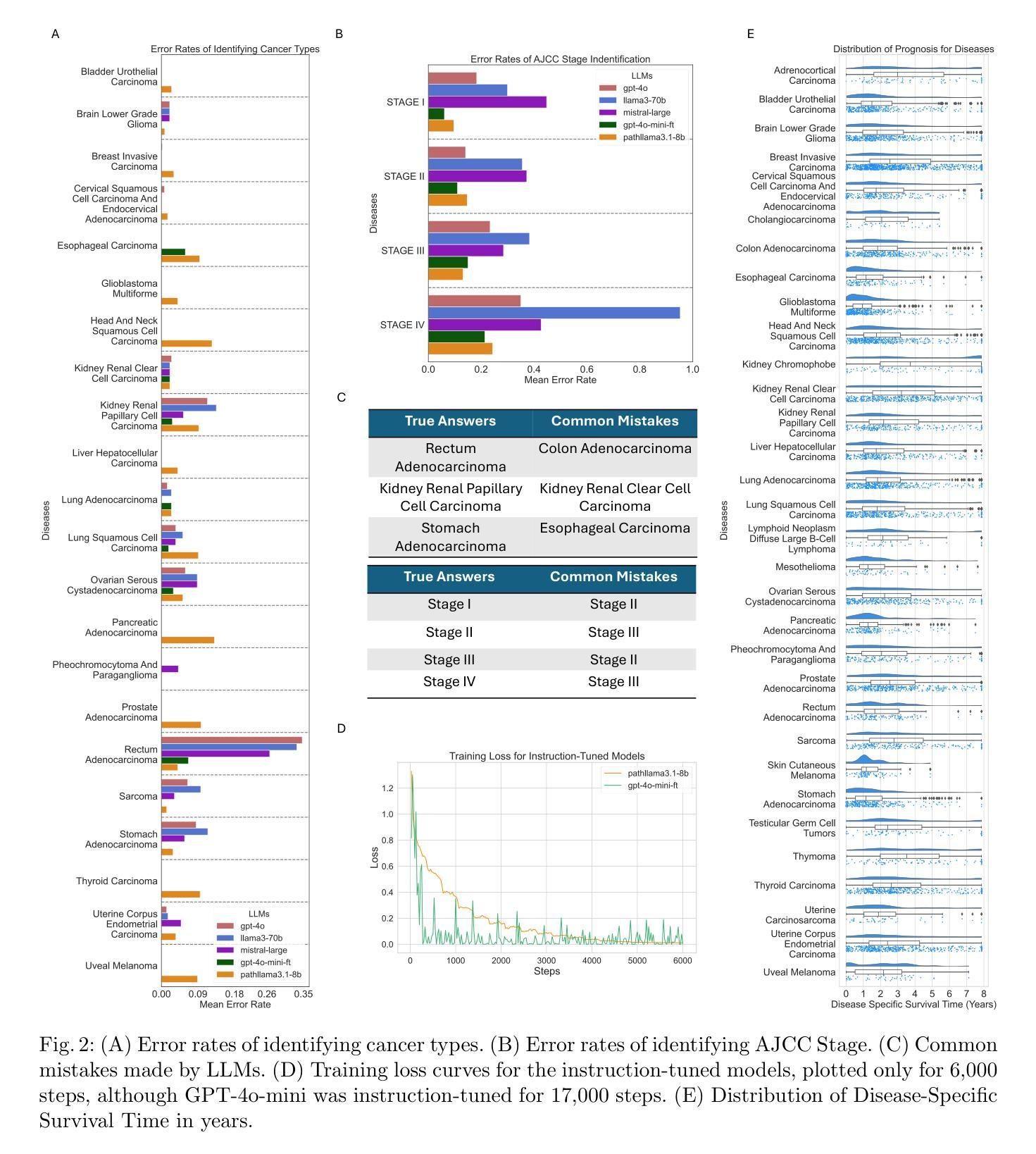
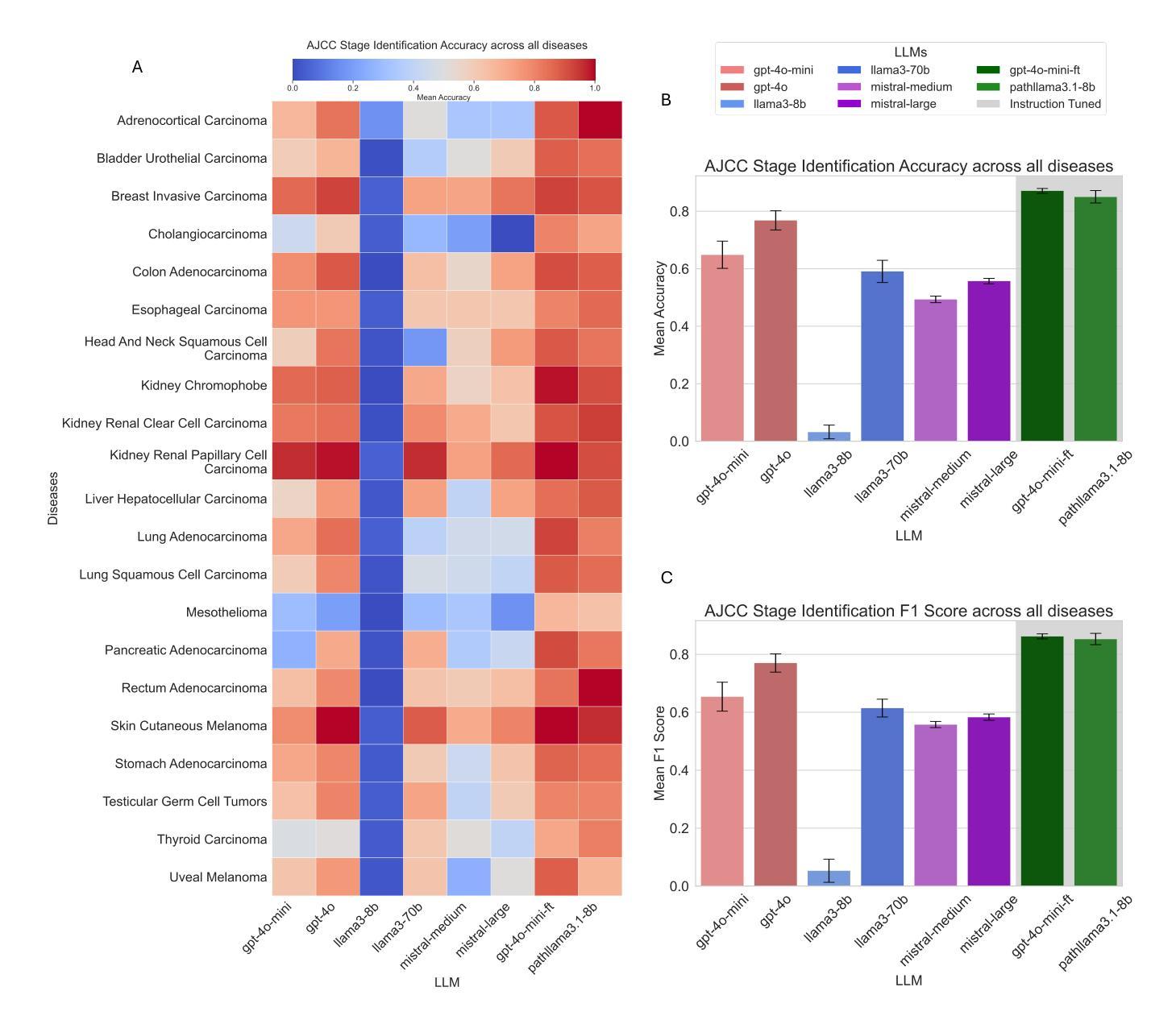
Cancer Type, Stage and Prognosis Assessment from Pathology Reports using LLMs
Authors:Rachit Saluja, Jacob Rosenthal, Yoav Artzi, David J. Pisapia, Benjamin L. Liechty, Mert R. Sabuncu
Large Language Models (LLMs) have shown significant promise across various natural language processing tasks. However, their application in the field of pathology, particularly for extracting meaningful insights from unstructured medical texts such as pathology reports, remains underexplored and not well quantified. In this project, we leverage state-of-the-art language models, including the GPT family, Mistral models, and the open-source Llama models, to evaluate their performance in comprehensively analyzing pathology reports. Specifically, we assess their performance in cancer type identification, AJCC stage determination, and prognosis assessment, encompassing both information extraction and higher-order reasoning tasks. Based on a detailed analysis of their performance metrics in a zero-shot setting, we developed two instruction-tuned models: Path-llama3.1-8B and Path-GPT-4o-mini-FT. These models demonstrated superior performance in zero-shot cancer type identification, staging, and prognosis assessment compared to the other models evaluated.
大型语言模型(LLMs)在各种自然语言处理任务中显示出巨大的潜力。然而,它们在病理学领域的应用,特别是在从病理报告等无结构医学文本中提取有意义见解方面,仍被探索得不够深入且未得到很好的量化。在本项目中,我们利用最先进的语言模型,包括GPT系列、Mistral模型和开源的Llama模型,来评估它们在综合分析病理报告方面的性能。具体来说,我们评估了它们在癌症类型识别、AJCC分期和预后评估方面的性能,包括信息提取和高级推理任务。基于对零样本设置下性能指标的详细分析,我们开发了两个指令微调模型:Path-llama3.1-8B和Path-GPT-4o-mini-FT。这些模型在零样本癌症类型识别、分期和预后评估方面表现出优于其他评估模型的性能。
论文及项目相关链接
Summary
大型语言模型(LLMs)在自然语言处理任务中有广泛应用前景,但在病理学领域,尤其是从非结构化的医学文本(如病理报告)中提取有意义信息方面,其应用仍被较少探索且未被充分量化。本项目利用先进的语言模型,包括GPT系列、Mistral模型和开源Llama模型,评估它们在全面分析病理报告方面的性能,特别是在癌症类型识别、AJCC分期和预后评估方面的性能。通过分析零样本环境下的性能表现,开发了两个指令微调模型:Path-llama3.1-8B和Path-GPT-4o-mini-FT。这两个模型在零样本癌症类型识别、分期和预后评估方面表现出卓越性能。
Key Takeaways
- 大型语言模型在自然语言处理任务中有广泛应用前景,但在病理学领域应用仍有限。
- 本项目利用先进语言模型评估分析病理报告的性能。
- 评估内容包括癌症类型识别、AJCC分期和预后评估。
- 在零样本环境下详细分析了不同语言模型的性能。
- 开发了两个指令微调模型:Path-llama3.1-8B和Path-GPT-4o-mini-FT。
- 这两个模型在癌症类型识别、分期和预后评估方面表现出卓越性能。
点此查看论文截图

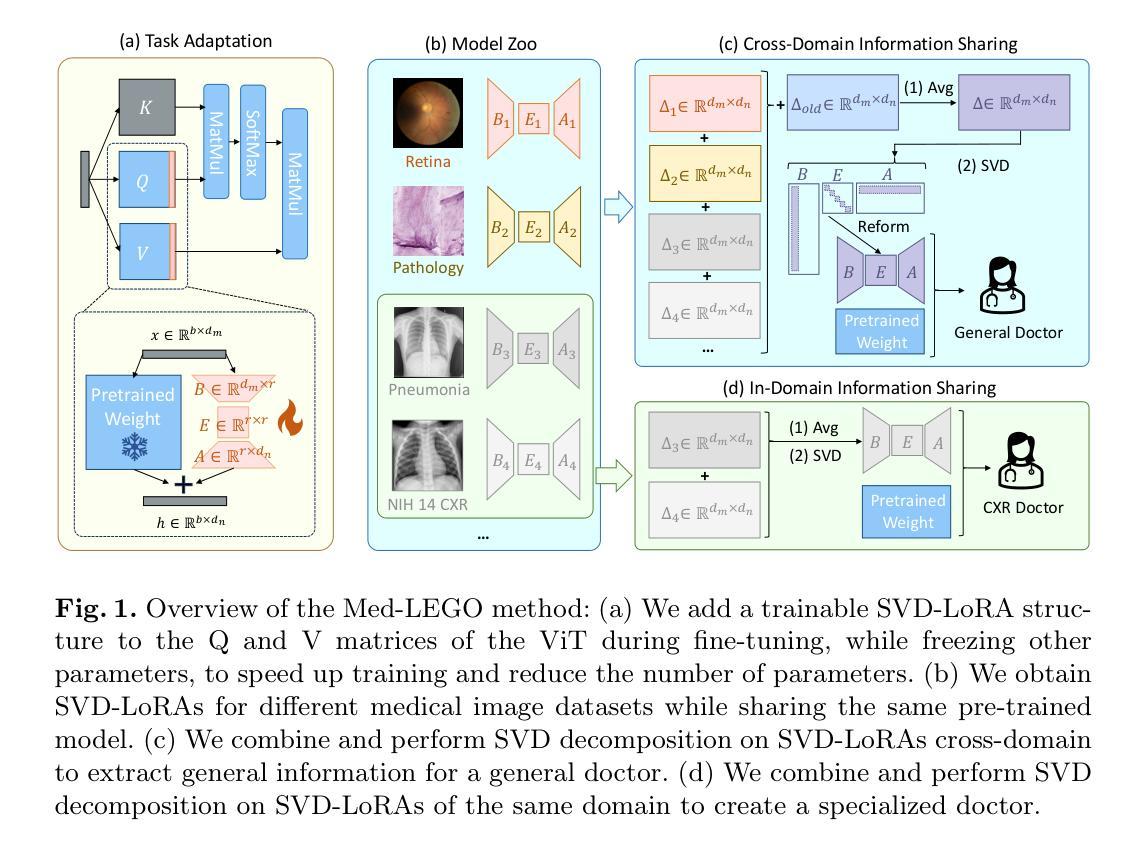
Med-LEGO: Editing and Adapting toward Generalist Medical Image Diagnosis
Authors:Yitao Zhu, Yuan Yin, Jiaming Li, Mengjie Xu, Zihao Zhao, Honglin Xiong, Sheng Wang, Qian Wang
The adoption of visual foundation models has become a common practice in computer-aided diagnosis (CAD). While these foundation models provide a viable solution for creating generalist medical AI, privacy concerns make it difficult to pre-train or continuously update such models across multiple domains and datasets, leading many studies to focus on specialist models. To address this challenge, we propose Med-LEGO, a training-free framework that enables the seamless integration or updating of a generalist CAD model by combining multiple specialist models, similar to assembling LEGO bricks. Med-LEGO enhances LoRA (low-rank adaptation) by incorporating singular value decomposition (SVD) to efficiently capture the domain expertise of each specialist model with minimal additional parameters. By combining these adapted weights through simple operations, Med-LEGO allows for the easy integration or modification of specific diagnostic capabilities without the need for original data or retraining. Finally, the combined model can be further adapted to new diagnostic tasks, making it a versatile generalist model. Our extensive experiments demonstrate that Med-LEGO outperforms existing methods in both cross-domain and in-domain medical tasks while using only 0.18% of full model parameters. These merged models show better convergence and generalization to new tasks, providing an effective path toward generalist medical AI.
在计算机辅助诊断(CAD)中,采用视觉基础模型已经成为一种常见做法。虽然这些基础模型为创建通用医疗人工智能提供了一种可行的解决方案,但隐私问题使得在多个领域和数据集上进行预训练或持续更新此类模型变得困难,从而导致许多研究专注于专业模型。为了应对这一挑战,我们提出了Med-LEGO,这是一个无需训练的基础框架,它能够通过组合多个专业模型来实现通用CAD模型的无缝集成或更新,类似于组装乐高积木。Med-LEGO通过结合奇异值分解(SVD)增强了LoRA(低秩适应),以有效地捕获每个专业模型的领域专业知识,并且只需极少的额外参数。通过简单的操作组合这些适配权重,Med-LEGO可以轻松地集成或修改特定的诊断能力,而无需原始数据或重新训练。最后,该组合模型可以进一步适应新的诊断任务,使其成为通用的诊断模型。我们的大量实验表明,无论是在跨域还是在内部医学任务中,Med-LEGO都优于现有方法,同时仅使用完整模型参数的0.18%。这些合并的模型显示出更好的收敛性和对新任务的泛化能力,为通用医疗人工智能的发展提供了有效路径。
论文及项目相关链接
Summary
基于视觉基础模型在计算机辅助诊断(CAD)中的广泛应用,本文提出了一种无需训练的框架Med-LEGO,该框架能够无缝集成或更新通用CAD模型。通过结合多个专业模型,Med-LEGO利用奇异值分解(SVD)增强LoRA(低秩适应)方法,以高效捕获每个专业模型的领域专业知识,同时无需额外的参数。通过简单的操作组合这些适应权重,Med-LEGO可以轻松地集成或修改特定的诊断能力,无需使用原始数据或重新训练。实验表明,Med-LEGO在跨域和域内医疗任务中均优于现有方法,合并模型在新任务上表现出更好的收敛性和泛化能力,为通用医疗人工智能的发展提供了有效路径。
Key Takeaways
- Med-LEGO是一种无需训练的框架,旨在解决通用计算机辅助诊断(CAD)模型的集成和更新问题。
- 通过结合多个专业模型,Med-LEGO实现了类似乐高积木的组装方式,实现通用CAD模型的灵活调整和优化。
- Med-LEGO利用奇异值分解(SVD)增强LoRA方法,高效捕获专业模型的领域知识。
- 该框架允许在无需原始数据或重新训练的情况下,轻松集成或修改特定诊断能力。
- 实验表明,Med-LEGO在跨域和域内医疗任务中表现优异,使用仅0.18%的完整模型参数即可实现高性能。
- 合并模型在新任务上表现出更好的收敛性和泛化能力。
点此查看论文截图

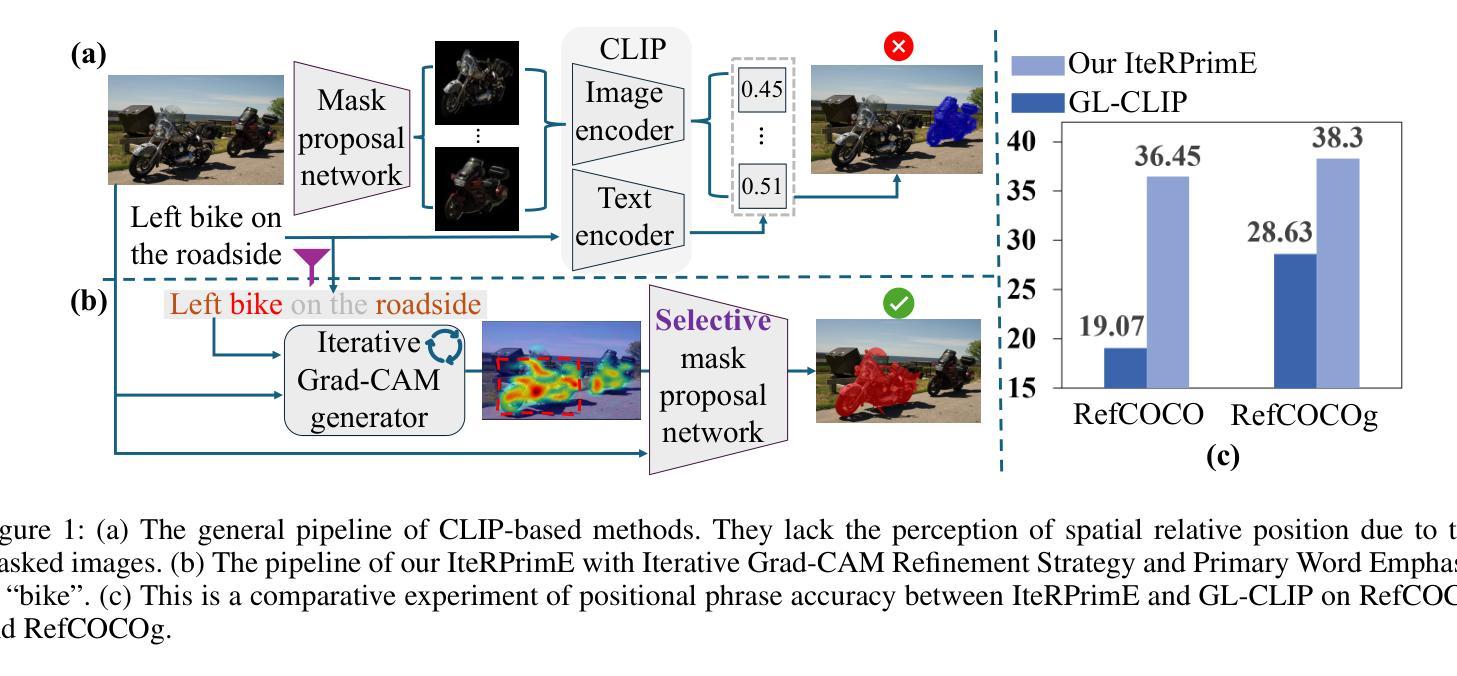
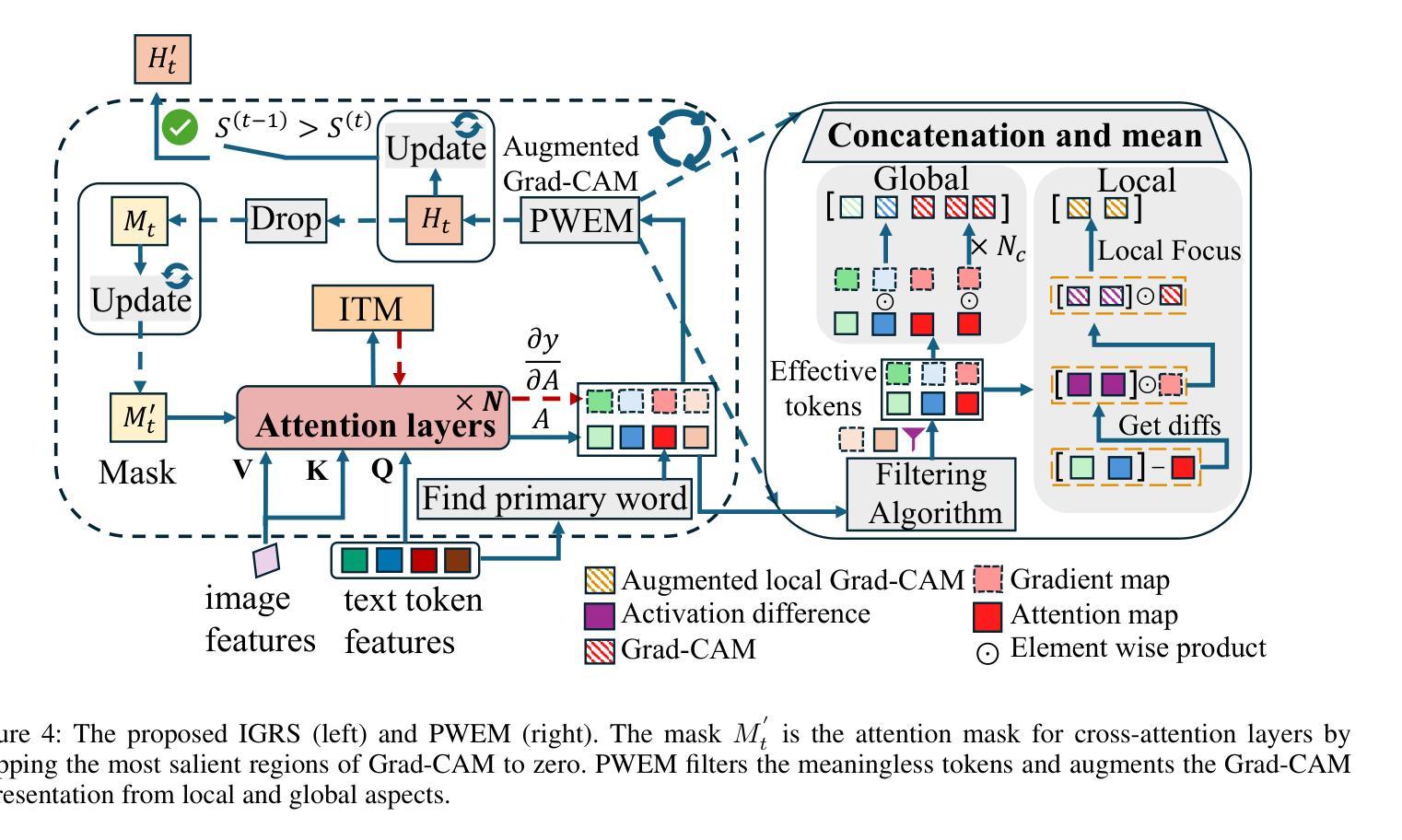
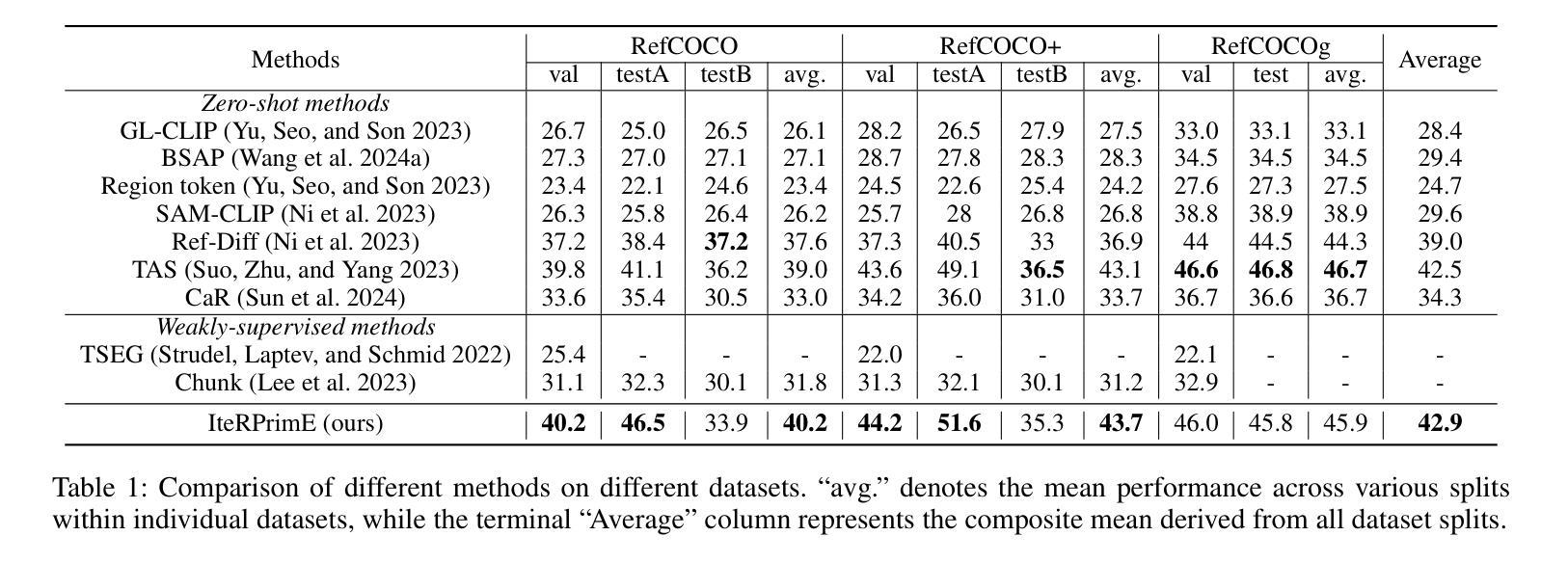
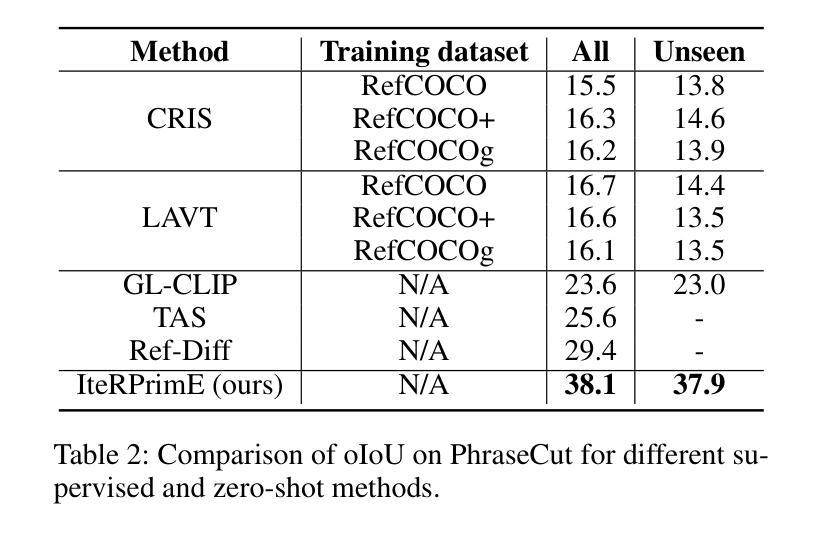
IteRPrimE: Zero-shot Referring Image Segmentation with Iterative Grad-CAM Refinement and Primary Word Emphasis
Authors:Yuji Wang, Jingchen Ni, Yong Liu, Chun Yuan, Yansong Tang
Zero-shot Referring Image Segmentation (RIS) identifies the instance mask that best aligns with a specified referring expression without training and fine-tuning, significantly reducing the labor-intensive annotation process. Despite achieving commendable results, previous CLIP-based models have a critical drawback: the models exhibit a notable reduction in their capacity to discern relative spatial relationships of objects. This is because they generate all possible masks on an image and evaluate each masked region for similarity to the given expression, often resulting in decreased sensitivity to direct positional clues in text inputs. Moreover, most methods have weak abilities to manage relationships between primary words and their contexts, causing confusion and reduced accuracy in identifying the correct target region. To address these challenges, we propose IteRPrimE (Iterative Grad-CAM Refinement and Primary word Emphasis), which leverages a saliency heatmap through Grad-CAM from a Vision-Language Pre-trained (VLP) model for image-text matching. An iterative Grad-CAM refinement strategy is introduced to progressively enhance the model’s focus on the target region and overcome positional insensitivity, creating a self-correcting effect. Additionally, we design the Primary Word Emphasis module to help the model handle complex semantic relations, enhancing its ability to attend to the intended object. Extensive experiments conducted on the RefCOCO/+/g, and PhraseCut benchmarks demonstrate that IteRPrimE outperforms previous state-of-the-art zero-shot methods, particularly excelling in out-of-domain scenarios.
零样本指代图像分割(RIS)能够在无需训练和微调的情况下,识别与指定指代表达式最佳匹配的实例掩膜,从而极大地减少了劳动密集型的标注过程。尽管已经取得了值得称赞的结果,但基于CLIP的模型存在一个关键缺陷:这些模型在辨别对象的相对空间关系方面表现出显著的能力下降。这是因为它们会在图像上生成所有可能的掩膜,并评估每个掩码区域与给定表达式的相似性,这往往导致对文本输入中的直接位置线索的敏感度降低。此外,大多数方法在处理主要单词和上下文之间的关系方面能力较弱,导致在识别正确目标区域时混淆和准确性下降。为了解决这些挑战,我们提出了IteRPrimE(迭代Grad-CAM细化与主要单词强调),它利用来自视觉语言预训练(VLP)模型的Grad-CAM的显著性热图进行图像文本匹配。我们引入了一种迭代Grad-CAM细化策略,以逐步增强模型对目标区域的关注,克服位置敏感性,创造一种自我校正的效果。此外,我们还设计了主要单词强调模块,以帮助模型处理复杂的语义关系,提高其关注目标对象的能力。在RefCOCO/+/g和PhraseCut基准测试上的大量实验表明,IteRPrimE优于先前的最先进的零样本方法,特别是在域外场景中表现尤为出色。
论文及项目相关链接
PDF AAAI 2025
Summary
基于CLIP模型的零样本图像分割技术在自然语言与图像同步过程中存在一些局限。为了提高模型的性能,研究团队提出了一种新的方法IteRPrimE,它通过迭代Grad-CAM细化策略来提升模型对目标区域的关注,并设计了一个主次词强调模块来处理复杂的语义关系。这种方法在RefCOCO/+/g和PhraseCut基准测试中表现出卓越的性能。
Key Takeaways
- 零样本图像分割技术可以显著降低对大量标注数据的需求。
- 基于CLIP的模型在识别对象间的相对空间关系方面存在缺陷。
- IteRPrimE方法利用迭代Grad-CAM细化策略来提升模型对目标区域的关注,克服定位不敏感问题。
- IteRPrimE设计了一个主次词强调模块,提高模型处理复杂语义关系的能力。
- 该方法在多种基准测试中表现出卓越性能,特别是在跨域场景中。
点此查看论文截图