⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-06 更新
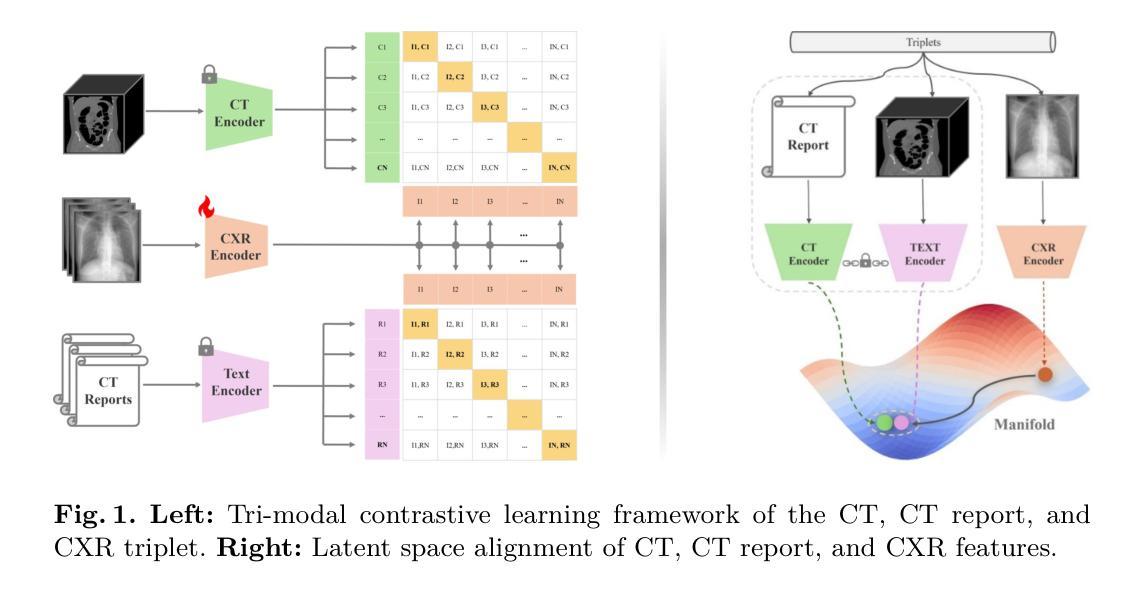
X2CT-CLIP: Enable Multi-Abnormality Detection in Computed Tomography from Chest Radiography via Tri-Modal Contrastive Learning
Authors:Jianzhong You, Yuan Gao, Sangwook Kim, Chris Mcintosh
Computed tomography (CT) is a key imaging modality for diagnosis, yet its clinical utility is marred by high radiation exposure and long turnaround times, restricting its use for larger-scale screening. Although chest radiography (CXR) is more accessible and safer, existing CXR foundation models focus primarily on detecting diseases that are readily visible on the CXR. Recently, works have explored training disease classification models on simulated CXRs, but they remain limited to recognizing a single disease type from CT. CT foundation models have also emerged with significantly improved detection of pathologies in CT. However, the generalized application of CT-derived labels on CXR has remained illusive. In this study, we propose X2CT-CLIP, a tri-modal knowledge transfer learning framework that bridges the modality gap between CT and CXR while reducing the computational burden of model training. Our approach is the first work to enable multi-abnormality classification in CT, using CXR, by transferring knowledge from 3D CT volumes and associated radiology reports to a CXR encoder via a carefully designed tri-modal alignment mechanism in latent space. Extensive evaluations on three multi-label CT datasets demonstrate that our method outperforms state-of-the-art baselines in cross-modal retrieval, few-shot adaptation, and external validation. These results highlight the potential of CXR, enriched with knowledge derived from CT, as a viable efficient alternative for disease detection in resource-limited settings.
计算机断层扫描(CT)是诊断的关键成像方式,但其临床应用受到高辐射暴露和长时间处理时间的限制,限制了其在大规模筛查中的使用。虽然胸部放射摄影(CXR)更容易获取且更安全,但现有的CXR基础模型主要关注于检测在CXR上易于看到的疾病。近期,有作品探索在模拟的CXR上进行疾病分类模型训练,但它们仅限于从CT图像中识别单一疾病类型。也出现了CT基础模型,在CT中的病理检测方面有了显著改进。然而,将CT衍生的标签在CXR上的通用应用仍然是个难题。本研究中,我们提出了X2CT-CLIP,这是一个三模态知识迁移学习框架,缩小了CT和CXR之间的模态差距,同时降低了模型训练的计算负担。我们的方法是通过从3D CT体积和相关放射学报告向CXR编码器转移知识,借助精心设计的三模态对齐机制在潜在空间来实现这一目标。这一方法是首次使用CXR在CT中进行多异常分类的工作。在三个多标签CT数据集上的广泛评估表明,我们的方法在跨模态检索、少样本适应和外部验证方面均优于最新基线。这些结果突显了使用从CT中衍生的知识来丰富CXR内容的潜力,使其成为资源有限环境中疾病检测的可行高效替代方案。
论文及项目相关链接
PDF 11 pages, 1 figure, 5 tables
Summary
本文提出了一种名为X2CT-CLIP的三模态知识迁移学习框架,旨在缩小CT与CXR之间的模态差异,同时降低模型训练的计算负担。该框架通过精心设计的三模态对齐机制,将来自3D CT体积和相关放射报告的知识的知识转移到CXR编码器上,实现了使用CXR进行CT的多异常性分类。在三个多标签CT数据集上的评估表明,该方法在跨模态检索、小样本适应和外部验证方面均优于最新基线。这显示了通过CT知识增强的CXR作为资源受限环境中疾病检测的有效高效替代方案的潜力。
Key Takeaways
- X2CT-CLIP框架实现了CT和CXR之间的三模态知识迁移,缩小了模态差异。
- 通过精心设计的三模态对齐机制,将CT的体积数据和放射报告中的知识转移到CXR编码器上。
- 该方法实现了使用CXR进行CT的多异常性分类,突破了现有模型的限制。
- 在多标签CT数据集上的评估显示,X2CT-CLIP在跨模态检索、小样本适应和外部验证方面均优于当前最佳方法。
- 该研究强调了使用通过CT知识增强的CXR在资源受限环境中进行疾病检测的潜力。
- 该方法有助于降低模型训练的计算负担,提高诊断效率。
点此查看论文截图



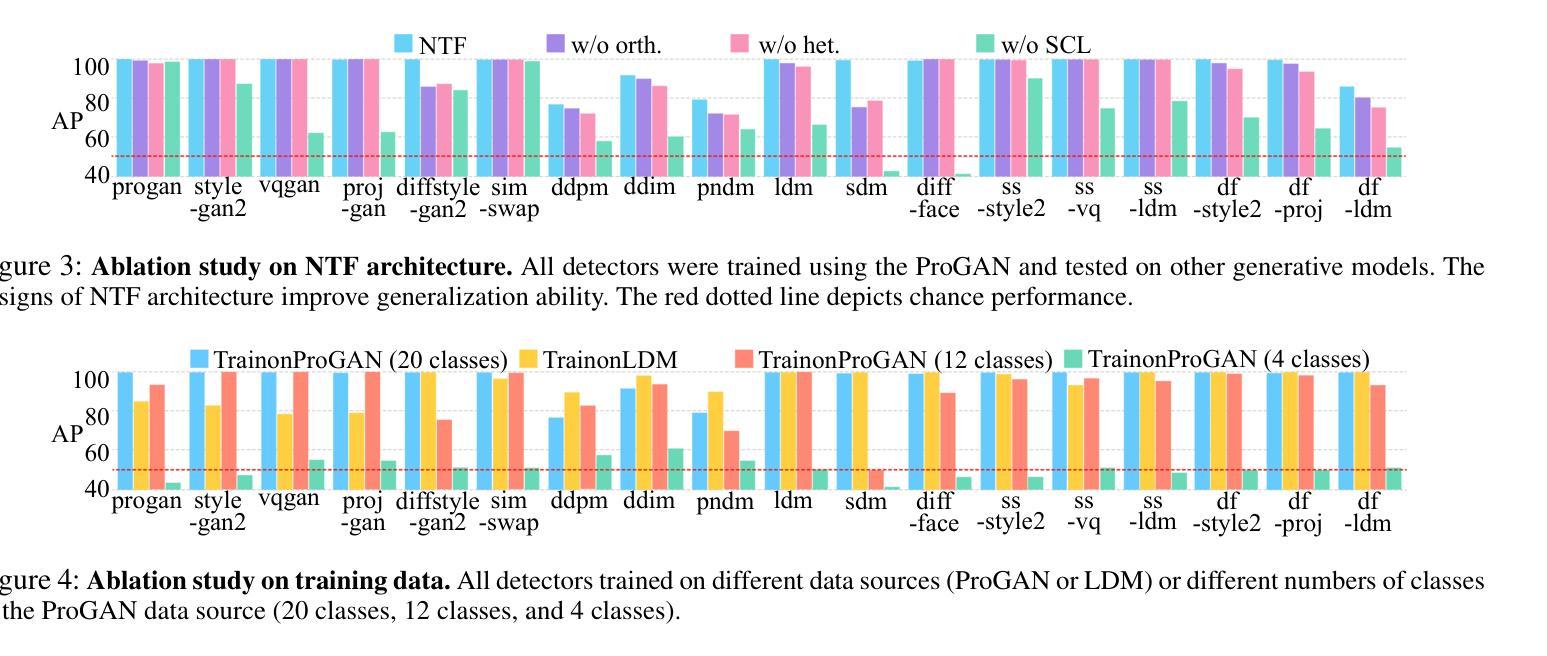
Transfer Learning of Real Image Features with Soft Contrastive Loss for Fake Image Detection
Authors:Ziyou Liang, Weifeng Liu, Run Wang, Mengjie Wu, Boheng Li, Yuyang Zhang, Lina Wang, Xinyi Yang
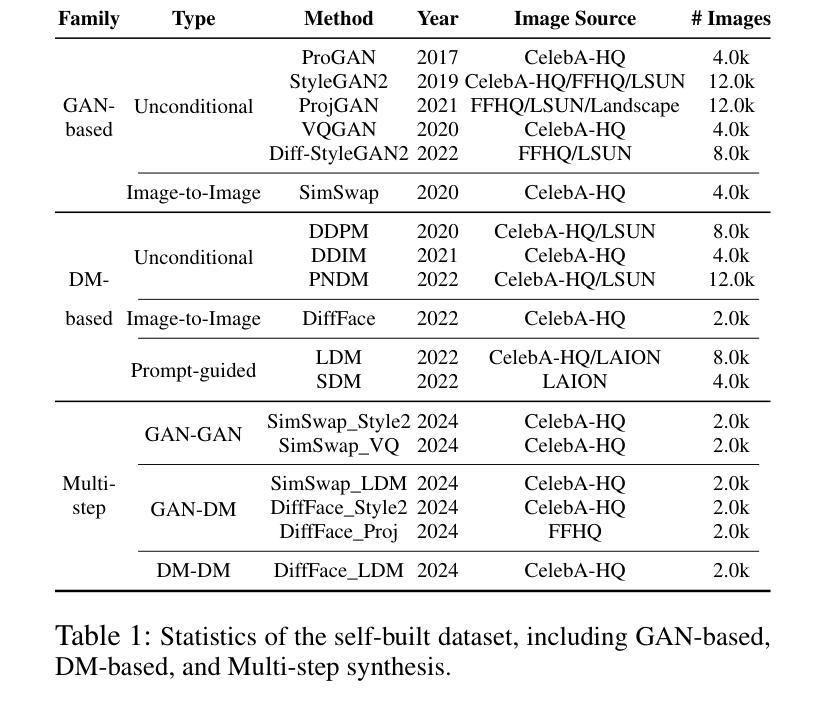
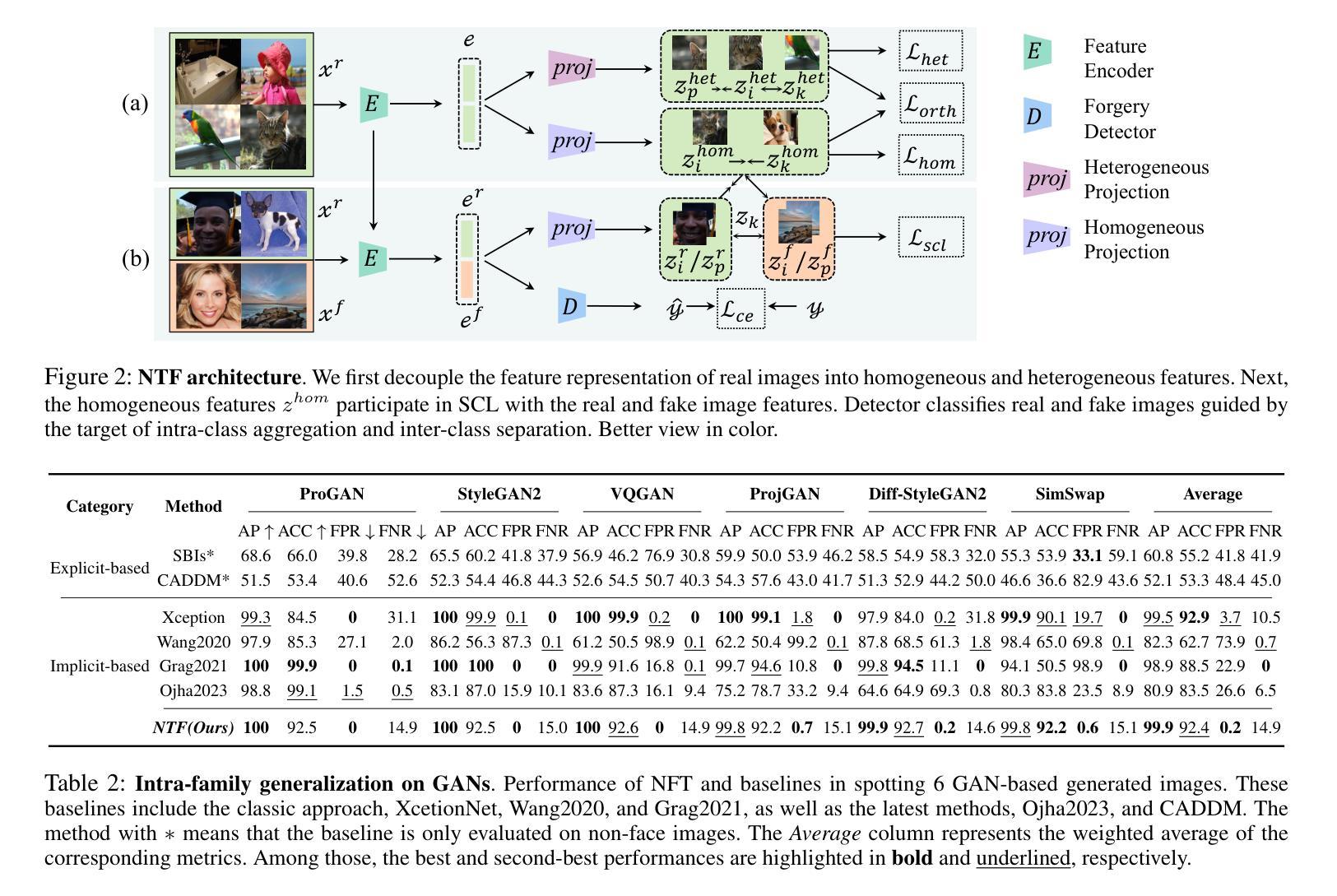
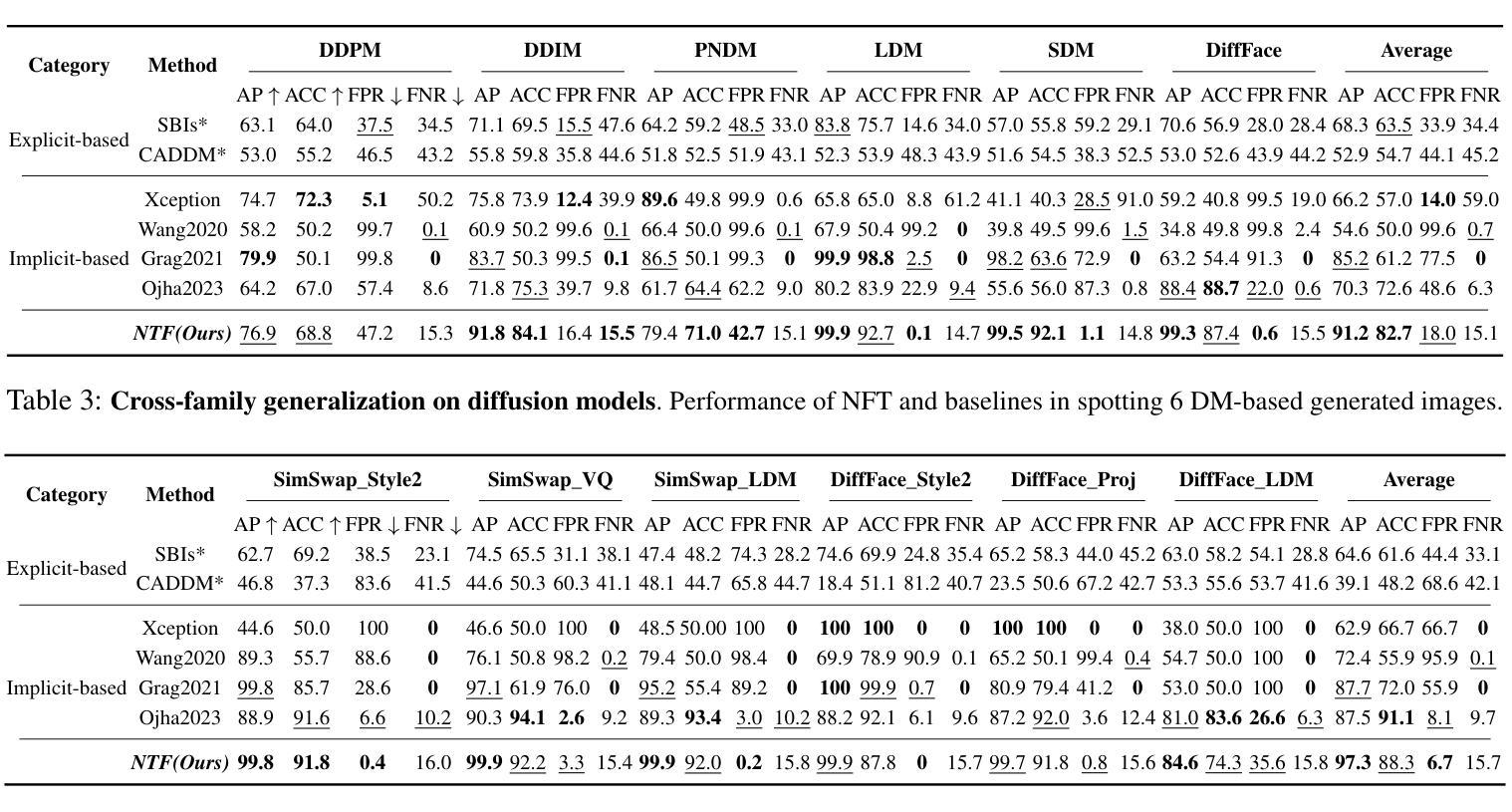
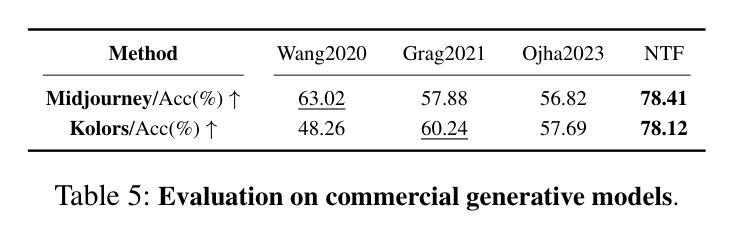
In the last few years, the artifact patterns in fake images synthesized by different generative models have been inconsistent, leading to the failure of previous research that relied on spotting subtle differences between real and fake. In our preliminary experiments, we find that the artifacts in fake images always change with the development of the generative model, while natural images exhibit stable statistical properties. In this paper, we employ natural traces shared only by real images as an additional target for a classifier. Specifically, we introduce a self-supervised feature mapping process for natural trace extraction and develop a transfer learning based on soft contrastive loss to bring them closer to real images and further away from fake ones. This motivates the detector to make decisions based on the proximity of images to the natural traces. To conduct a comprehensive experiment, we built a high-quality and diverse dataset that includes generative models comprising GANs and diffusion models, to evaluate the effectiveness in generalizing unknown forgery techniques and robustness in surviving different transformations. Experimental results show that our proposed method gives 96.2% mAP significantly outperforms the baselines. Extensive experiments conducted on popular commercial platforms reveal that our proposed method achieves an accuracy exceeding 78.4%, underscoring its practicality for real-world application deployment.
近年来,由不同生成模型合成的虚假图像中的伪影模式存在不一致性,导致之前依赖发现真实和虚假图像之间细微差异的研究失败。在我们的初步实验中,我们发现虚假图像中的伪影会随着生成模型的发展而变化,而自然图像则表现出稳定的统计特性。在本文中,我们采用仅由真实图像共享的自然痕迹作为分类器的附加目标。具体来说,我们引入了一种自监督特征映射过程来进行自然痕迹提取,并基于软对比损失开发了一种迁移学习,使它们更接近真实图像,并远离虚假图像。这激励检测器根据图像与自然痕迹的接近程度来做出决策。为了进行全面的实验,我们建立了一个高质量、多样化的数据集,其中包括涵盖GANs和扩散模型的生成模型,以评估在一般化未知伪造技术和在不同转换中生存的稳健性方面的有效性。实验结果表明,我们提出的方法在准确率上达到了96.2%的mAP,显著优于基线方法。在流行的商业平台上进行的广泛实验表明,我们提出的方法达到了超过78.4%的准确率,突显其在现实世界应用部署中的实用性。
论文及项目相关链接
Summary
本文介绍了新型图像真伪鉴别方法的研究。过去的研究因假图像合成模型产生的伪迹模式不一致而失效。本研究通过引入自然痕迹作为鉴别器的附加目标,提出一种基于自监督特征映射和自然痕迹提取的方法。利用迁移学习和软对比损失进行训练,使模型更贴近真实图像,远离假图像。实验结果显示,新方法在多种生成模型上的平均准确率达到了96.2%,并在真实世界应用中表现出较高的实用性。
Key Takeaways
- 假图像的伪迹模式因生成模型的发展而不断变化,导致传统鉴别方法失效。
- 自然图像展现出稳定的统计特性,可作为鉴别真伪的关键依据。
- 研究采用自然痕迹作为分类器的附加目标,以鉴别图像真伪。
- 引入自监督特征映射过程,用于提取自然痕迹。
- 采用迁移学习和软对比损失进行模型训练,拉近真实与假图像的距离。
- 为评估方法效果,研究构建了包含多种生成模型的高质量、多样化数据集。
点此查看论文截图