⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-06 更新
Exploring Token-Level Augmentation in Vision Transformer for Semi-Supervised Semantic Segmentation
Authors:Dengke Zhang, Quan Tang, Fagui Liu, C. L. Philip Chen, Haiqing Mei
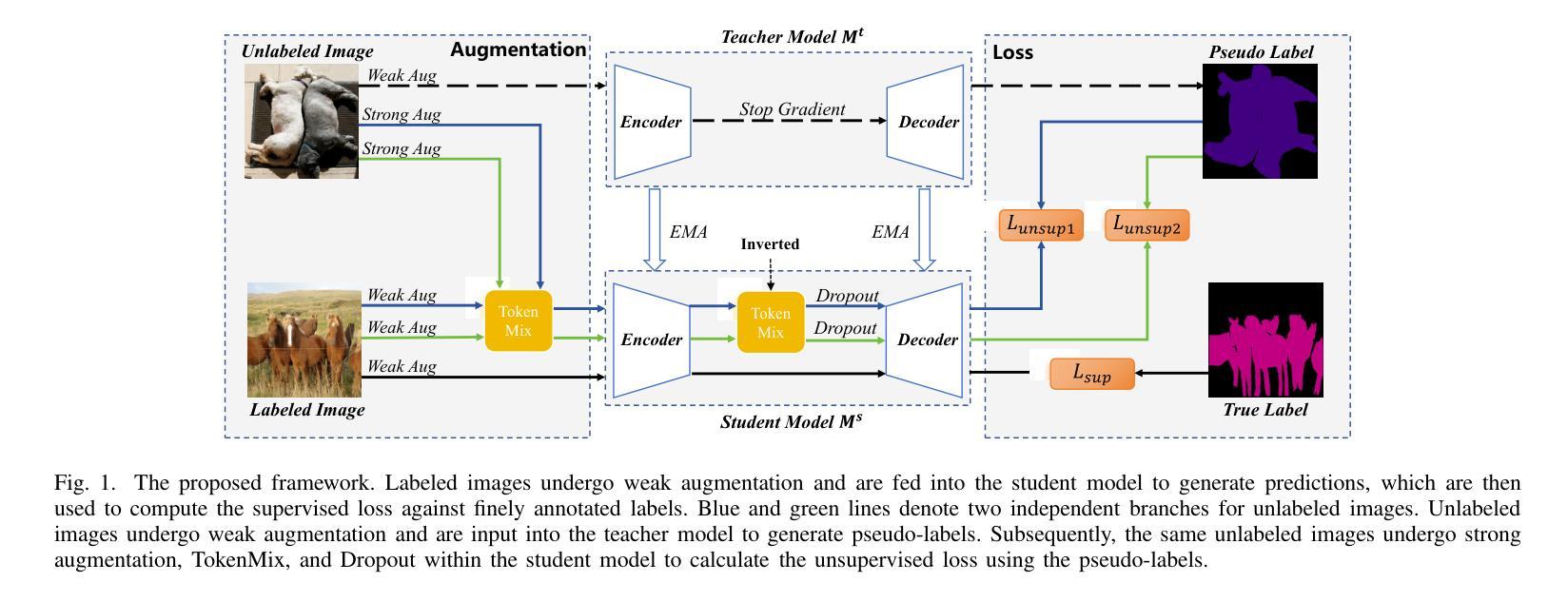
Semi-supervised semantic segmentation has witnessed remarkable advancements in recent years. However, existing algorithms are based on convolutional neural networks and directly applying them to Vision Transformers poses certain limitations due to conceptual disparities. To this end, we propose TokenMix, a data augmentation technique specifically designed for semi-supervised semantic segmentation with Vision Transformers. TokenMix aligns well with the global attention mechanism by mixing images at the token level, enhancing learning capability for contexutual information among image patches. We further incorporate image augmentation and feature augmentation to promote the diversity of augmentation. Moreover, to enhance consistency regularization, we propose a dual-branch framework where each branch applies both image augmentation and feature augmentation to the input image. We conduct extensive experiments across multiple benchmark datasets, including Pascal VOC 2012, Cityscapes, and COCO. Results suggest that the proposed method outperforms state-of-the-art algorithms with notably observed accuracy improvement, especially under the circumstance of limited fine annotations.
近年来,半监督语义分割取得了显著的进展。然而,现有算法主要基于卷积神经网络,直接应用于视觉Transformer会产生一定的局限性,这是由于概念上的差异造成的。为此,我们提出了TokenMix,这是一种专门为半监督语义分割与视觉Transformer设计的数据增强技术。TokenMix通过混合图像标记来实现全局注意力机制的匹配,提高了图像块之间上下文信息的学习能力。我们进一步结合了图像增强和特征增强以促进增强的多样性。此外,为了提高一致性正则化,我们提出了一个双分支框架,每个分支对输入图像应用图像增强和特征增强。我们在多个基准数据集上进行了大量实验,包括Pascal VOC 2012、Cityscapes和COCO。结果表明,该方法优于最先进的算法,特别是在有限精细标注的情况下,观察到准确度有显著提高。
论文及项目相关链接
Summary
半监督语义分割领域近年来取得了显著进展。然而,现有算法主要基于卷积神经网络,直接应用于视觉Transformer存在一定的局限性。为此,我们提出了TokenMix,这是一种专门为半监督语义分割与视觉Transformer设计的数据增强技术。TokenMix通过图像标记级别的混合与全局注意力机制相吻合,增强了图像补丁间上下文信息的学习能力。我们还结合了图像增强和特征增强以促进数据增强的多样性。此外,为了增强一致性正则化,我们提出了一个双分支框架,每个分支都对输入图像应用图像增强和特征增强。我们在多个基准数据集上进行了实验,包括Pascal VOC 2012、Cityscapes和COCO。结果表明,所提方法优于最新算法,特别是在有限的精细标注情况下,观察到了显著的精度提升。
Key Takeaways
- 半监督语义分割领域需要针对视觉Transformer的特殊需求进行数据增强技术的设计。
- TokenMix技术为半监督语义分割与视觉Transformer提供了有效的数据增强方法。
- TokenMix通过图像标记级别的混合增强上下文信息学习能力,与全局注意力机制相吻合。
- 结合图像增强和特征增强技术以促进数据增强的多样性。
- 提出双分支框架以增强一致性正则化,每个分支都应用图像增强和特征增强。
- 所提方法在多个基准数据集上进行实验验证,表现出优异的性能。
点此查看论文截图

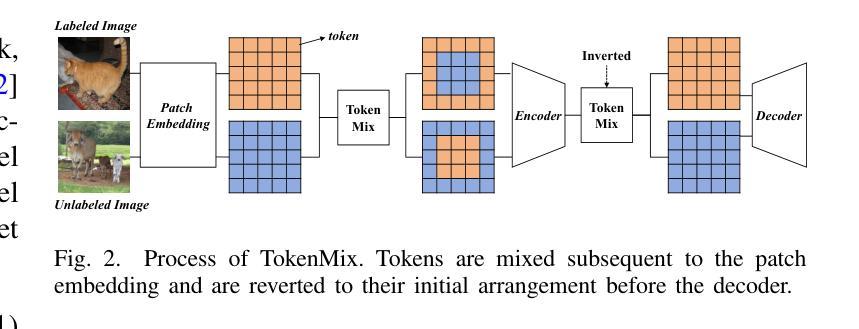
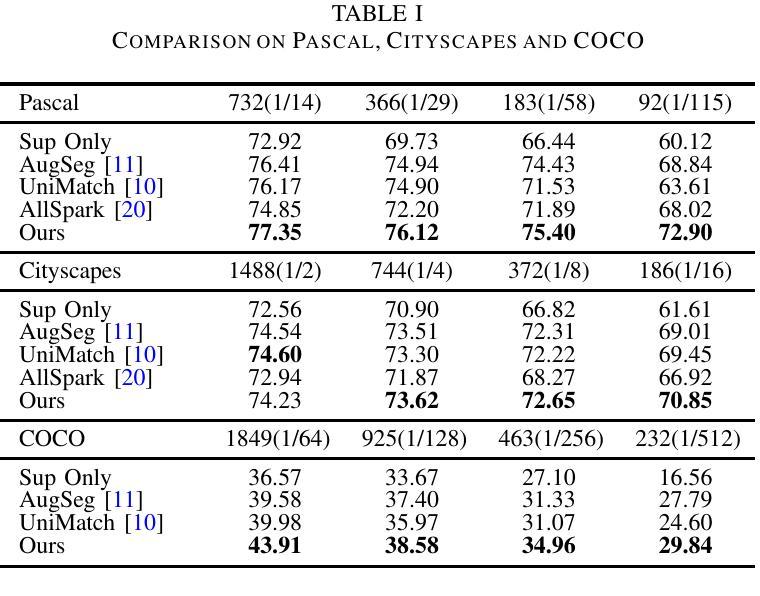
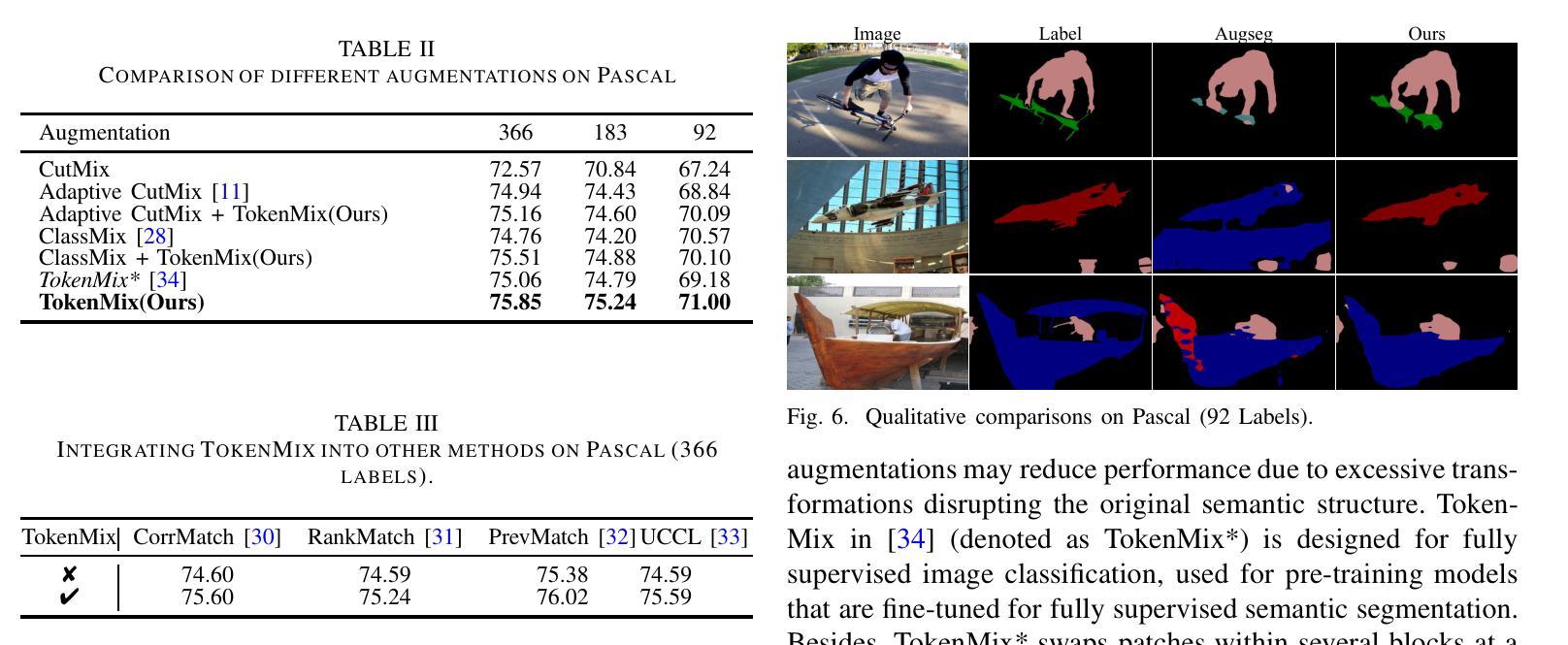
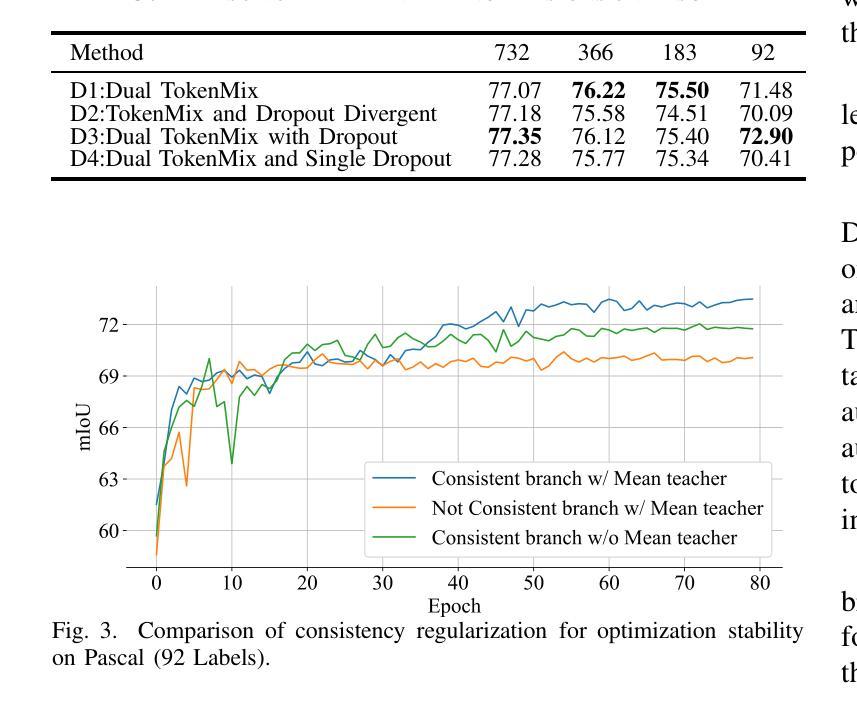
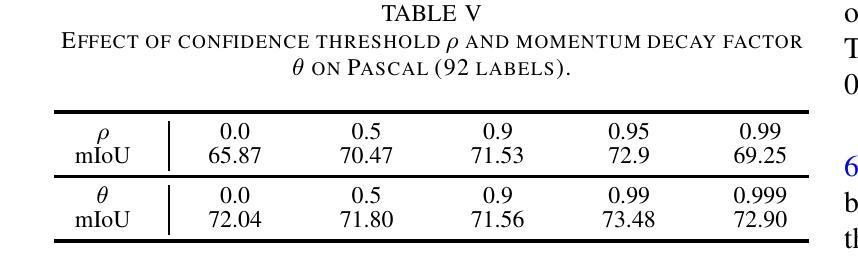
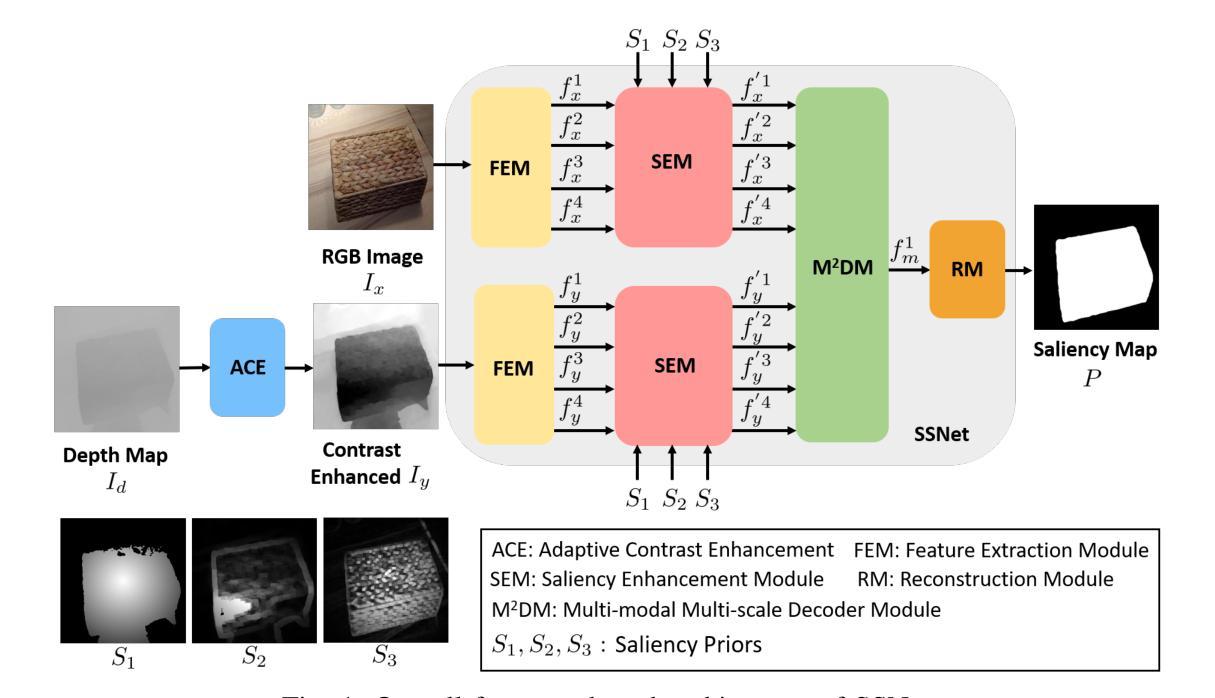
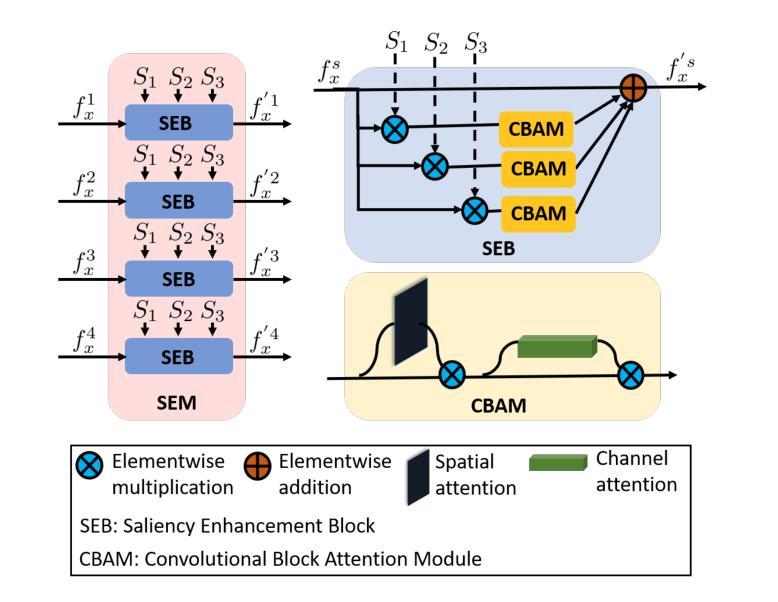
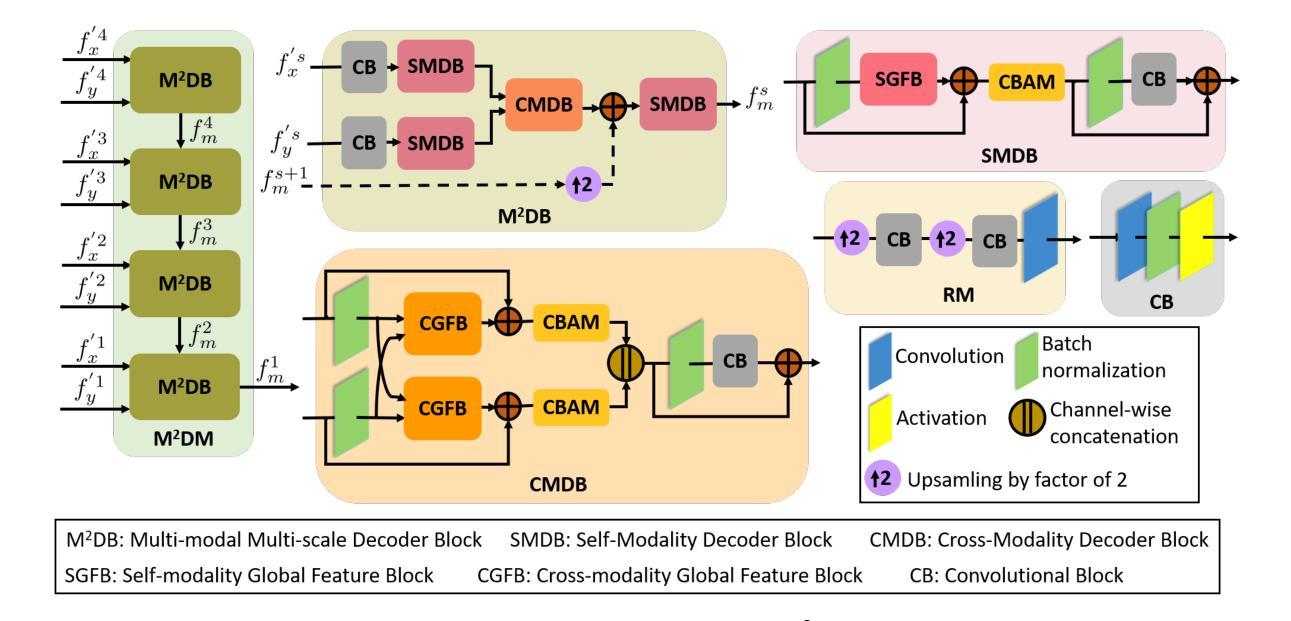
SSNet: Saliency Prior and State Space Model-based Network for Salient Object Detection in RGB-D Images
Authors:Gargi Panda, Soumitra Kundu, Saumik Bhattacharya, Aurobinda Routray
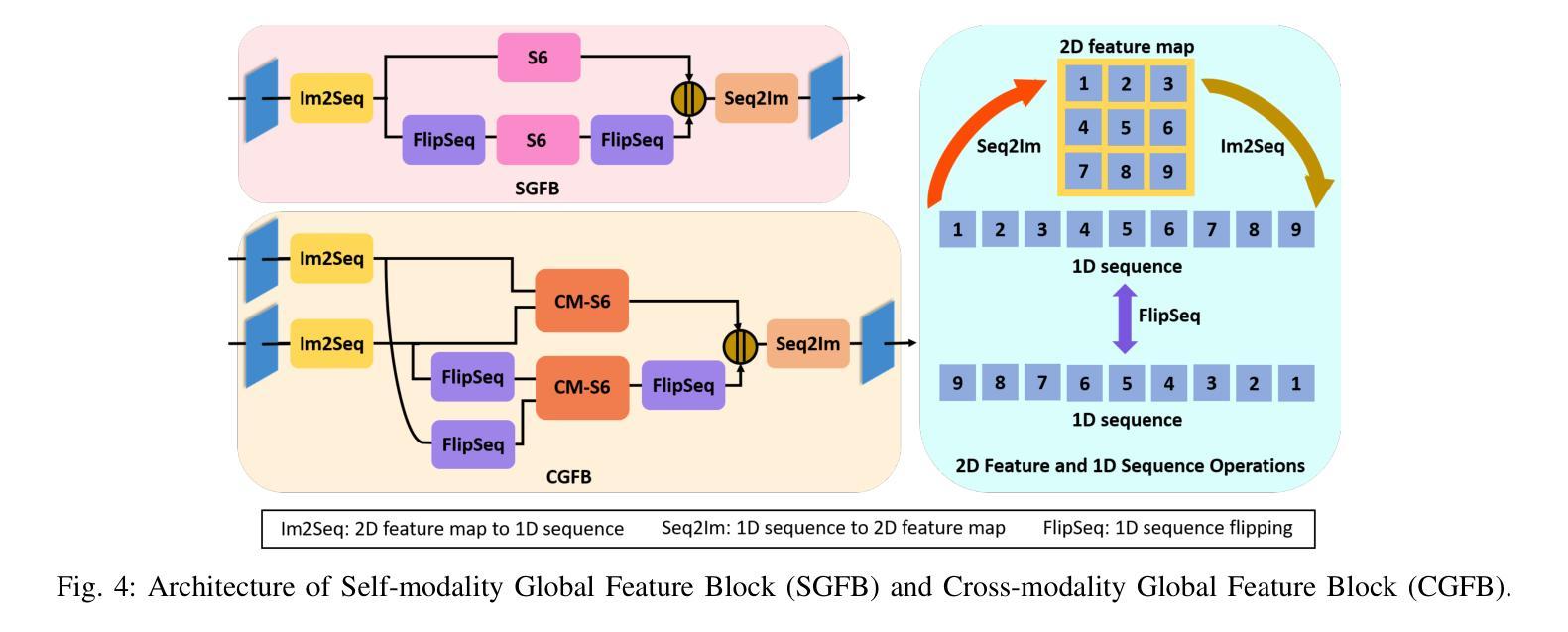
Salient object detection (SOD) in RGB-D images is an essential task in computer vision, enabling applications in scene understanding, robotics, and augmented reality. However, existing methods struggle to capture global dependency across modalities, lack comprehensive saliency priors from both RGB and depth data, and are ineffective in handling low-quality depth maps. To address these challenges, we propose SSNet, a saliency-prior and state space model (SSM)-based network for the RGB-D SOD task. Unlike existing convolution- or transformer-based approaches, SSNet introduces an SSM-based multi-modal multi-scale decoder module to efficiently capture both intra- and inter-modal global dependency with linear complexity. Specifically, we propose a cross-modal selective scan SSM (CM-S6) mechanism, which effectively captures global dependency between different modalities. Furthermore, we introduce a saliency enhancement module (SEM) that integrates three saliency priors with deep features to refine feature representation and improve the localization of salient objects. To further address the issue of low-quality depth maps, we propose an adaptive contrast enhancement technique that dynamically refines depth maps, making them more suitable for the RGB-D SOD task. Extensive quantitative and qualitative experiments on seven benchmark datasets demonstrate that SSNet outperforms state-of-the-art methods.
在RGB-D图像中进行显著目标检测(SOD)是计算机视觉中的一项重要任务,它在场景理解、机器人技术和增强现实等领域有着广泛的应用。然而,现有方法在跨模态全局依赖捕捉方面存在困难,缺乏来自RGB和深度数据的全面显著性先验知识,在处理低质量深度图时效果不佳。为了解决这些挑战,我们提出了SSNet,这是一个基于显著性先验和状态空间模型(SSM)的RGB-D SOD任务网络。与现有的基于卷积或基于Transformer的方法不同,SSNet引入了一个基于SSM的多模态多尺度解码器模块,以线性复杂度有效地捕捉模态内和模态间的全局依赖关系。具体来说,我们提出了一种跨模态选择性扫描SSM(CM-S6)机制,它能有效地捕捉不同模态之间的全局依赖关系。此外,我们引入了一个显著性增强模块(SEM),它集成了三种显著性先验知识和深度特征,以优化特征表示,提高显著目标的定位精度。为了进一步解决低质量深度图的问题,我们提出了一种自适应对比度增强技术,可以动态优化深度图,使其更适合RGB-D SOD任务。在七个基准数据集上进行的广泛定量和定性实验表明,SSNet优于最先进的方法。
论文及项目相关链接
Summary
本文介绍了RGB-D图像中的显著目标检测(SOD)任务的重要性及其在计算机视觉领域的应用。针对现有方法在处理跨模态全局依赖性方面的不足,提出了基于显著性先验和状态空间模型(SSM)的SSNet网络。该网络引入SSM为基础的多模态多尺度解码器模块,以线性复杂度高效地捕获模态内和模态间的全局依赖性。通过跨模态选择性扫描SSM(CM-S6)机制和显著性增强模块(SEM),有效提升了RGB-DSOD任务的性能。此外,针对低质量深度图的问题,提出了一种自适应对比度增强技术,动态优化深度图,使其更适合RGB-DSOD任务。在七个基准数据集上的大量定量和定性实验表明,SSNet优于现有最先进的方法。
Key Takeaways
- RGB-D图像的显著目标检测(SOD)在计算机视觉领域具有重要地位,应用于场景理解、机器人技术和增强现实。
- 现有方法在处理跨模态全局依赖性方面存在挑战,缺乏从RGB和深度数据综合得到的显著性先验。
- SSNet网络引入SSM为基础的多模态多尺度解码器,以线性复杂度捕获全局依赖性。
- SSNet具有跨模态选择性扫描SSM(CM-S6)机制和显著性增强模块(SEM),提升RGB-DSOD任务性能。
- 针对低质量深度图,提出自适应对比度增强技术,优化深度图质量。
- SSNet在七个基准数据集上的表现优于现有最先进的方法。
点此查看论文截图



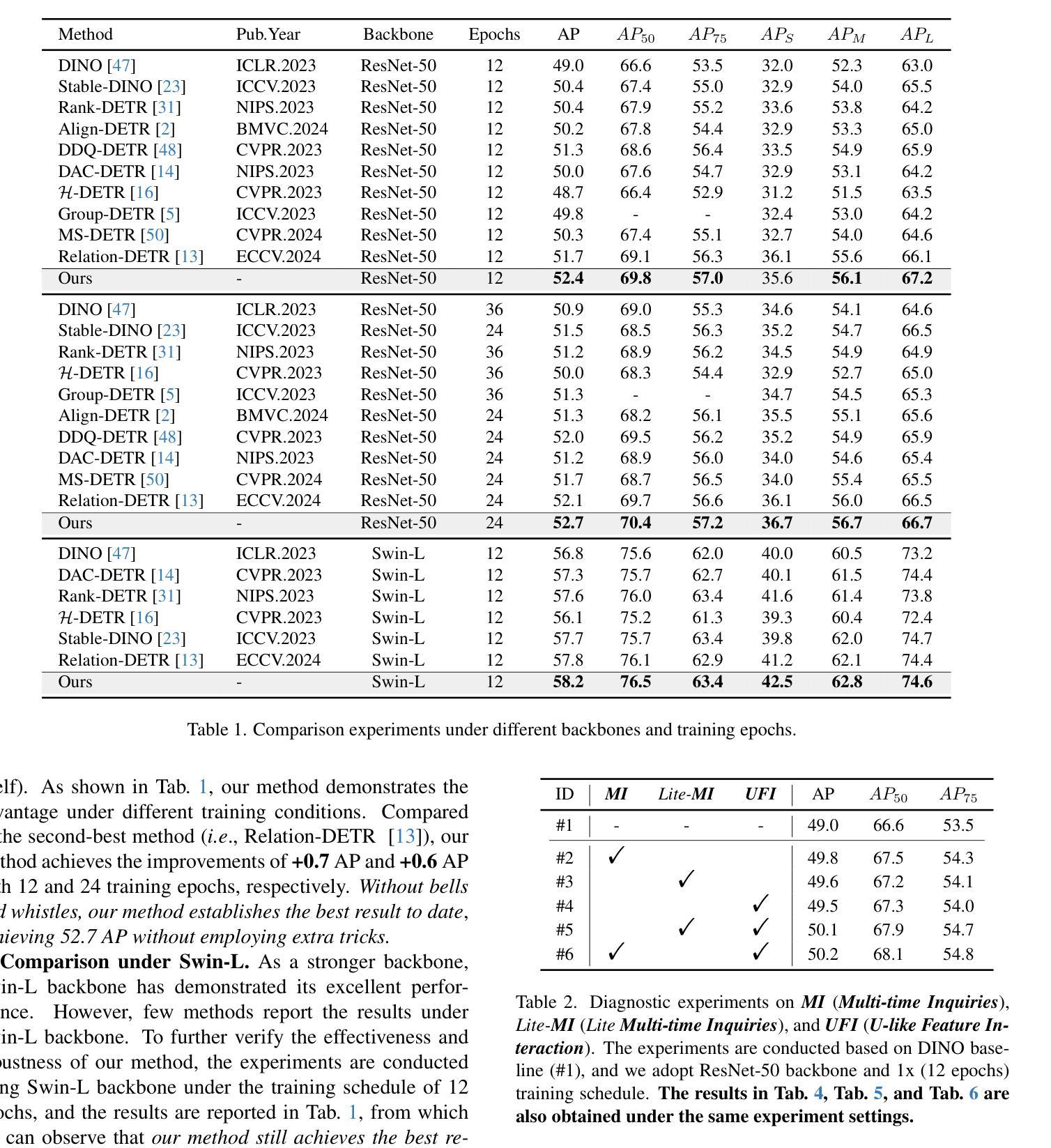
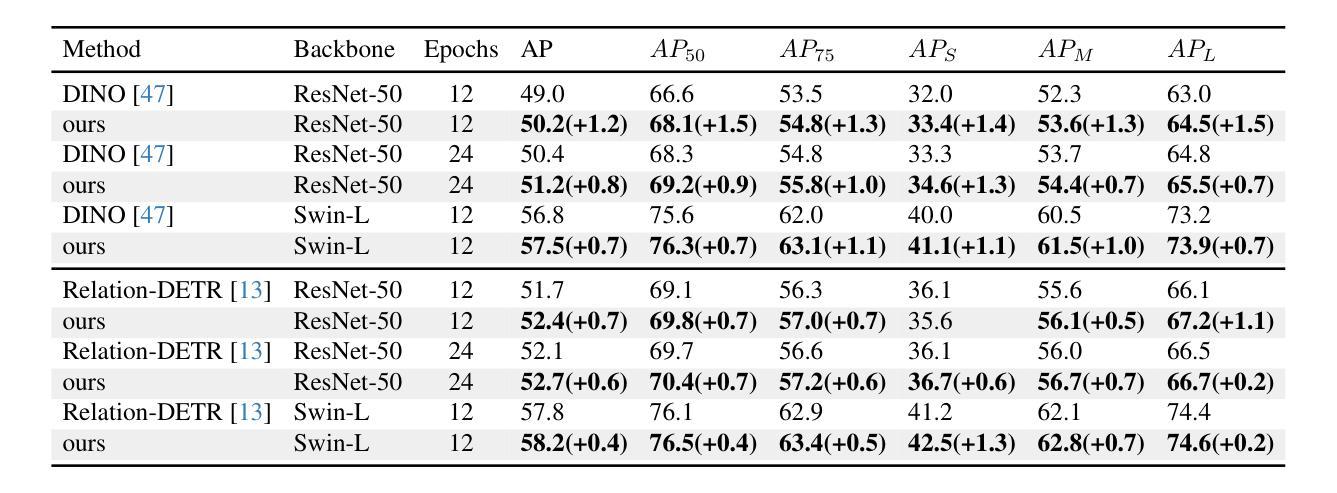
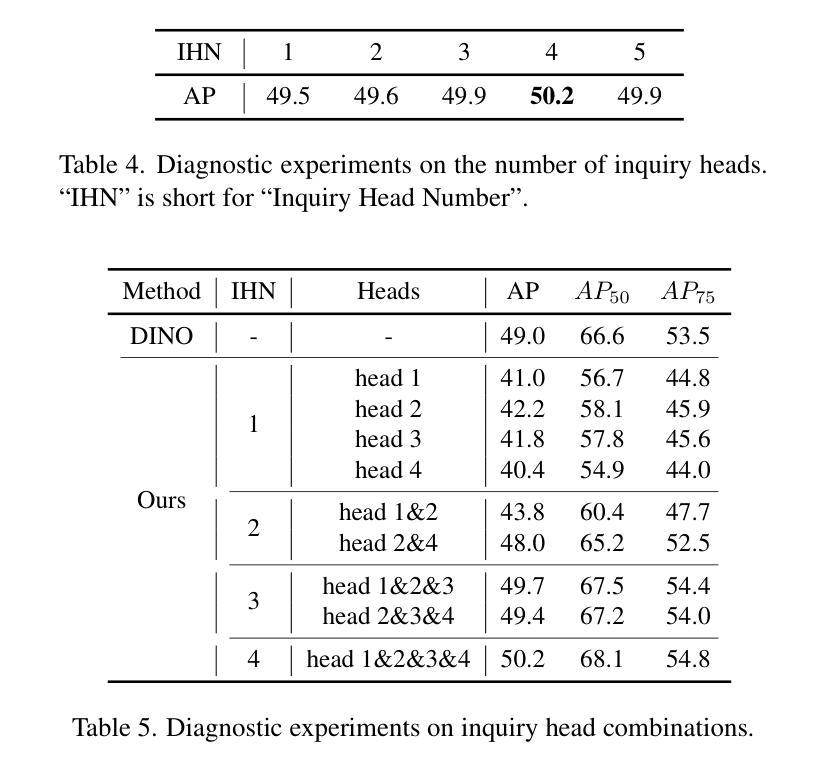
MI-DETR: An Object Detection Model with Multi-time Inquiries Mechanism
Authors:Zhixiong Nan, Xianghong Li, Jifeng Dai, Tao Xiang
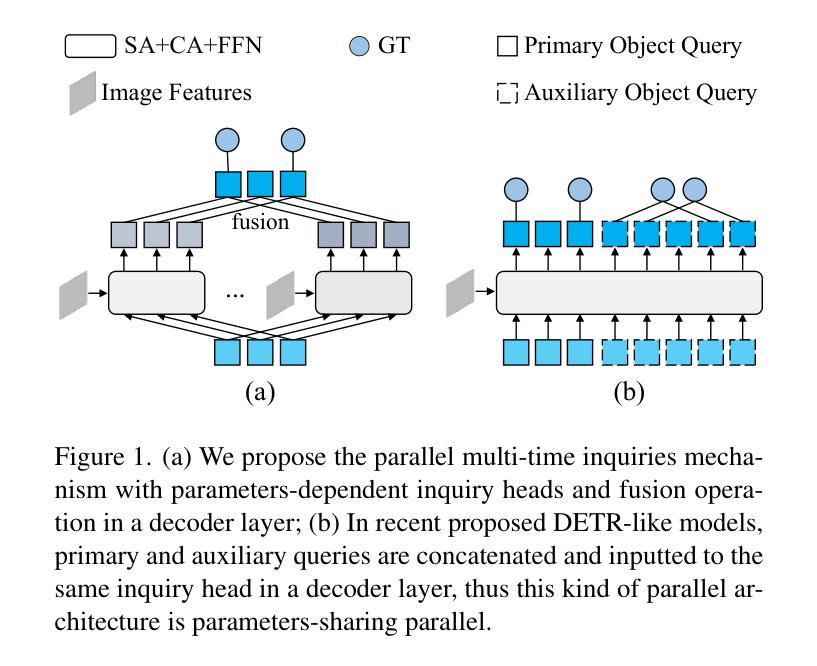
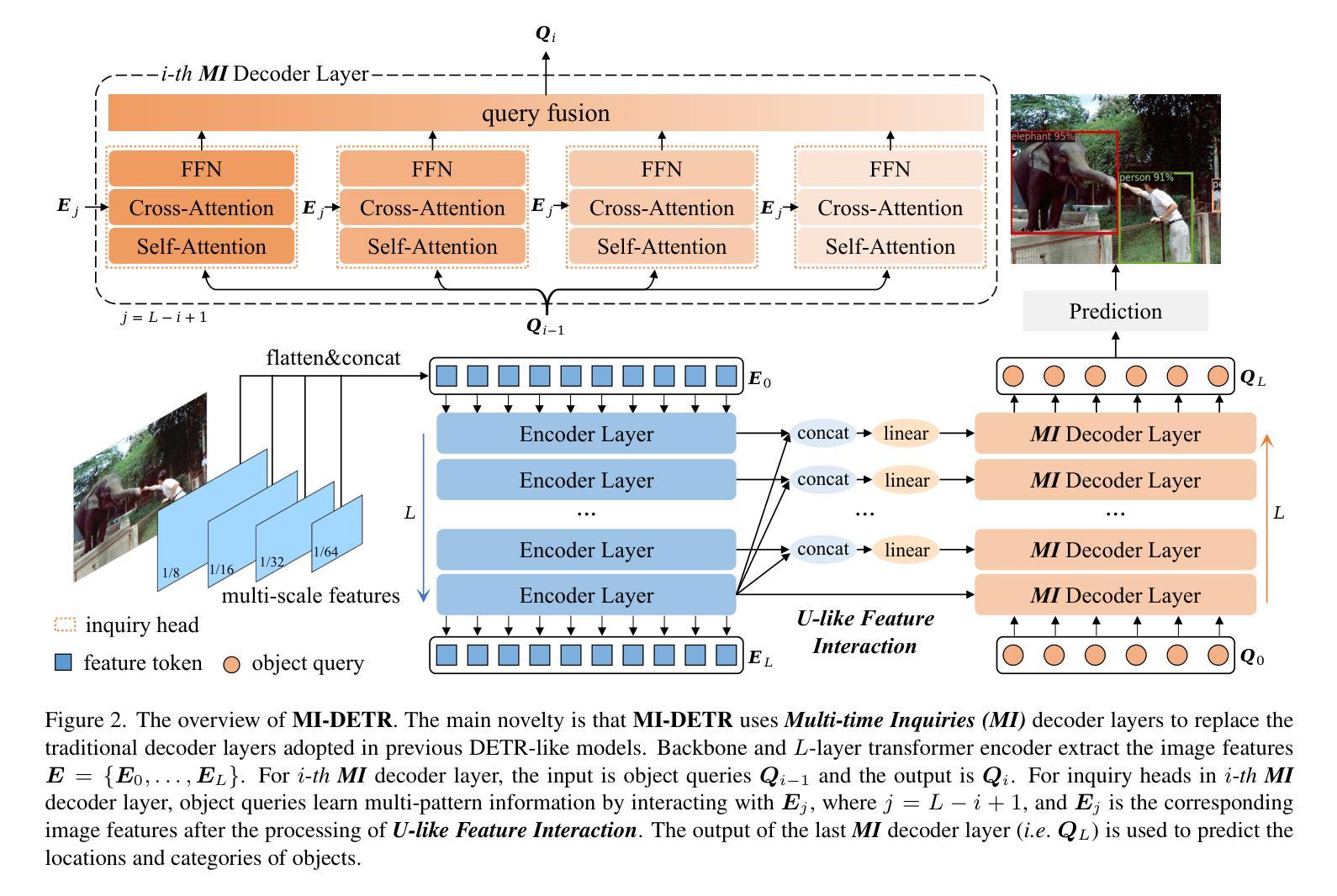
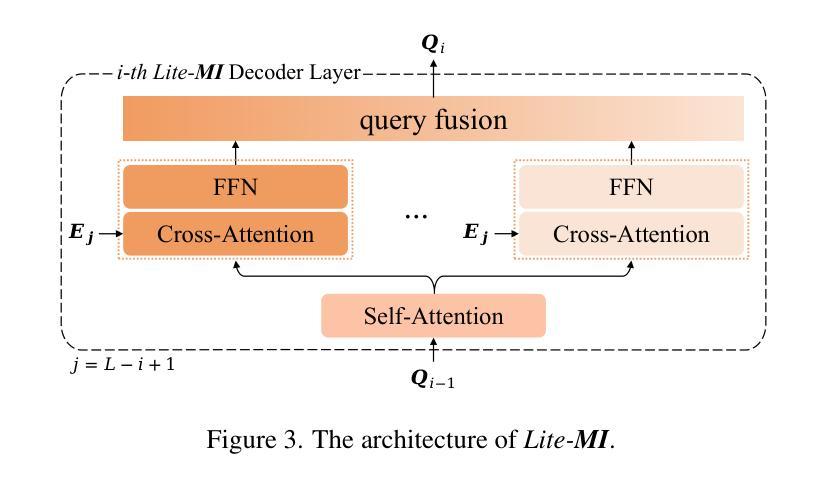
Based on analyzing the character of cascaded decoder architecture commonly adopted in existing DETR-like models, this paper proposes a new decoder architecture. The cascaded decoder architecture constrains object queries to update in the cascaded direction, only enabling object queries to learn relatively-limited information from image features. However, the challenges for object detection in natural scenes (e.g., extremely-small, heavily-occluded, and confusingly mixed with the background) require an object detection model to fully utilize image features, which motivates us to propose a new decoder architecture with the parallel Multi-time Inquiries (MI) mechanism. MI enables object queries to learn more comprehensive information, and our MI based model, MI-DETR, outperforms all existing DETR-like models on COCO benchmark under different backbones and training epochs, achieving +2.3 AP and +0.6 AP improvements compared to the most representative model DINO and SOTA model Relation-DETR under ResNet-50 backbone. In addition, a series of diagnostic and visualization experiments demonstrate the effectiveness, rationality, and interpretability of MI.
本文基于分析现有DETR类模型中常用的级联解码器架构的特性,提出了一种新的解码器架构。级联解码器架构约束对象查询在级联方向上更新,仅使对象查询能够从图像特征中学习相对有限的信息。然而,自然场景目标检测的挑战(例如极小、遮挡严重以及与背景混淆混合)要求目标检测模型充分利用图像特征,这促使我们提出了一种新的解码器架构,该架构具有并行多时间查询(MI)机制。MI使对象查询能够学习更全面的信息,我们的基于MI的模型MI-DETR在不同骨干网络和训练周期下,在COCO基准测试上超越了所有现有的DETR类模型,与最具代表性的模型DINO和最新模型Relation-DETR相比,在ResNet-50骨干网络下实现了+2.3 AP和+0.6 AP的改进。此外,一系列的诊断和可视化实验证明了MI的有效性、合理性和可解释性。
论文及项目相关链接
PDF 14 pages,9 figures,accepted to CVPR2025
Summary
本文分析了现有DETR-like模型中常用的级联解码器架构的特点,并基于此提出新的解码器架构。级联解码器架构约束对象查询在级联方向上更新,使得对象查询只能从图像特征中学习有限的信息。然而,自然场景中的目标检测挑战(如极小、重度遮挡和与背景混淆混合)要求目标检测模型充分利用图像特征。因此,本文提出了具有并行多时间查询(MI)机制的解码器架构。MI使对象查询能够学习更全面的信息,基于MI的模型MI-DETR在不同主干和训练周期下,在COCO基准测试上优于所有现有DETR-like模型,与最具代表性的DINO模型和最新模型Relation-DETR相比,分别提高了2.3 AP和0.6 AP。此外,一系列的诊断和可视化实验验证了MI的有效性、合理性和可解释性。
Key Takeaways
- 现有DETR-like模型的级联解码器架构约束了对象查询的信息学习能力。
- 自然场景中的目标检测面临诸多挑战,如极小目标、重度遮挡和与背景的混淆混合。
- 提出的新解码器架构具有并行多时间查询(MI)机制,使对象查询能够学习更全面的信息。
- MI-DETR模型在COCO基准测试下表现优异,相较于DINO和Relation-DETR模型有明显的性能提升。
- MI机制的有效性、合理性和可解释性得到了诊断和可视化实验的证明。
- 新解码器架构适用于不同的主干网络和训练周期,展示了其通用性和稳健性。
点此查看论文截图

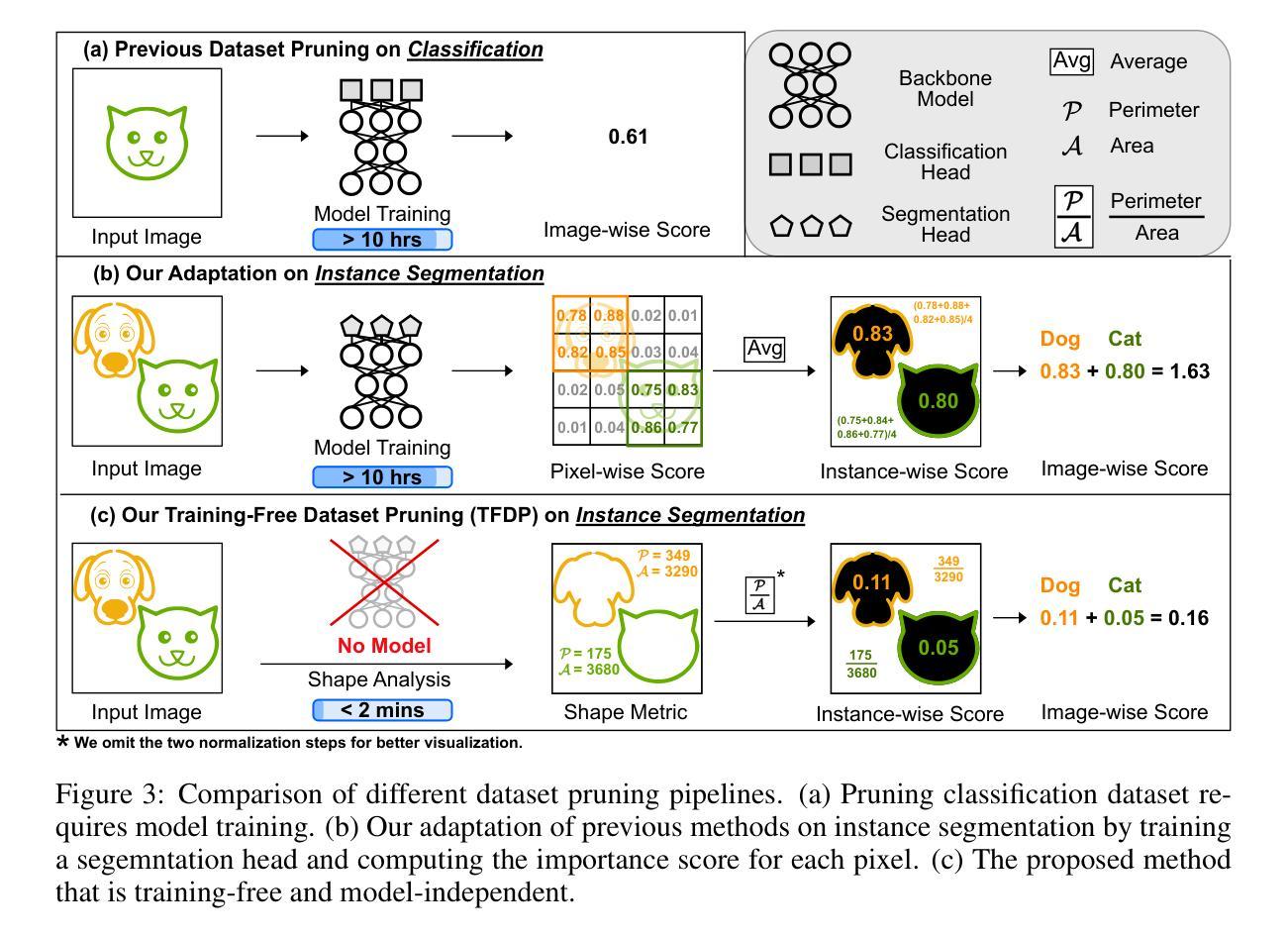
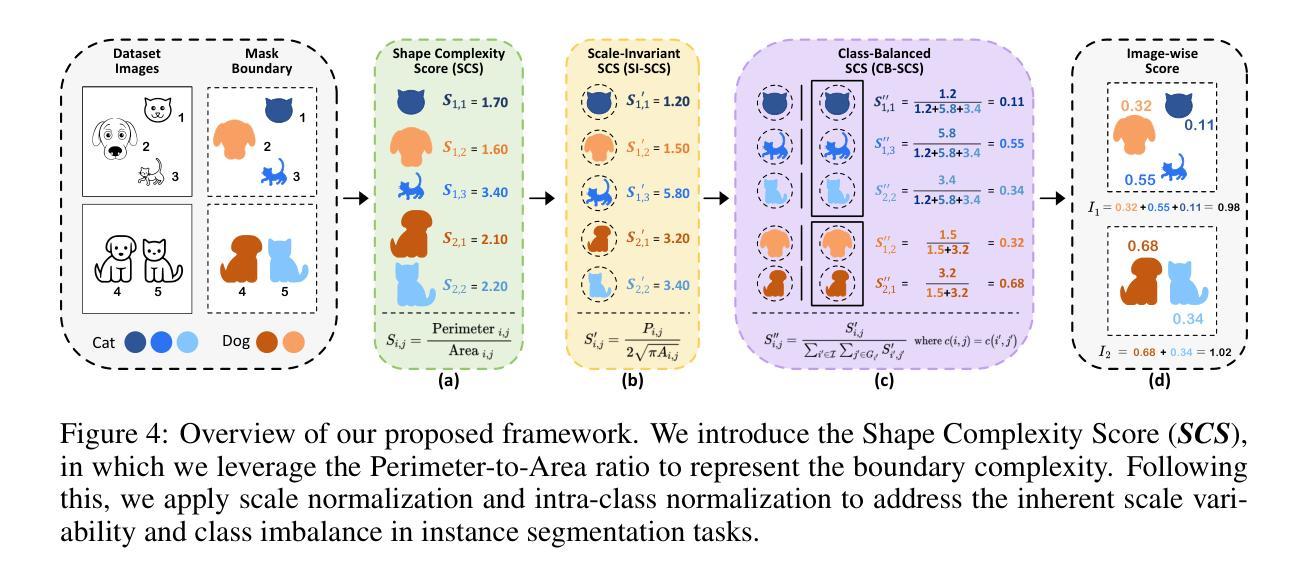
Training-Free Dataset Pruning for Instance Segmentation
Authors:Yalun Dai, Lingao Xiao, Ivor W. Tsang, Yang He
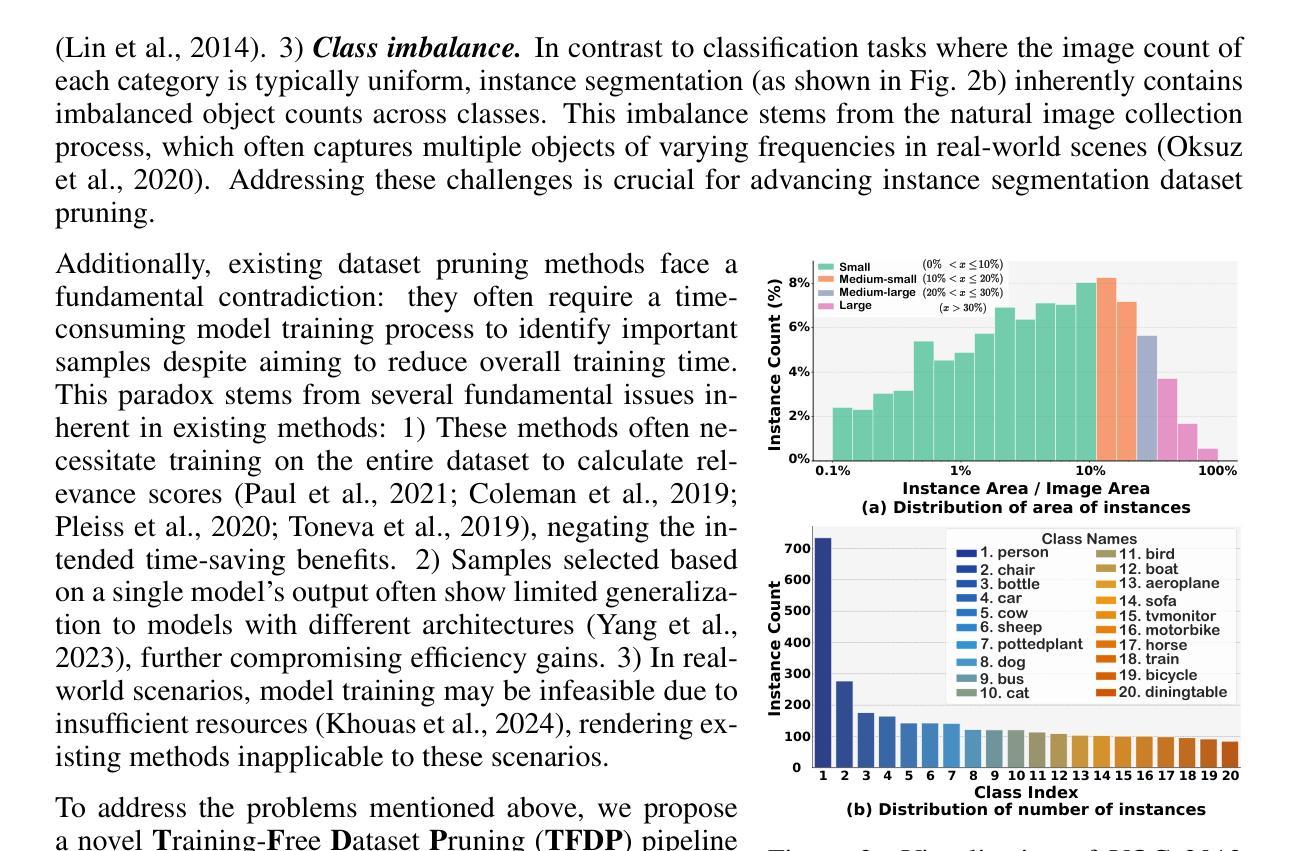
Existing dataset pruning techniques primarily focus on classification tasks, limiting their applicability to more complex and practical tasks like instance segmentation. Instance segmentation presents three key challenges: pixel-level annotations, instance area variations, and class imbalances, which significantly complicate dataset pruning efforts. Directly adapting existing classification-based pruning methods proves ineffective due to their reliance on time-consuming model training process. To address this, we propose a novel Training-Free Dataset Pruning (TFDP) method for instance segmentation. Specifically, we leverage shape and class information from image annotations to design a Shape Complexity Score (SCS), refining it into a Scale-Invariant (SI-SCS) and Class-Balanced (CB-SCS) versions to address instance area variations and class imbalances, all without requiring model training. We achieve state-of-the-art results on VOC 2012, Cityscapes, and COCO datasets, generalizing well across CNN and Transformer architectures. Remarkably, our approach accelerates the pruning process by an average of 1349$\times$ on COCO compared to the adapted baselines. Source code is available at: https://github.com/he-y/dataset-pruning-for-instance-segmentation
现有数据集修剪技术主要集中在分类任务上,这限制了其在实例分割等更复杂和实用任务中的应用。实例分割存在三个关键挑战:像素级标注、实例区域变化和类别不平衡,这些挑战极大地增加了数据集修剪的难度。直接采用基于分类的修剪方法证明是无效的,因为它们依赖于耗时的模型训练过程。为了解决这一问题,我们提出了一种无需训练的数据集修剪方法(TFDP),用于实例分割。具体来说,我们利用图像注释中的形状和类别信息来设计形状复杂度评分(SCS),将其细化为尺度不变(SI-SCS)和类别平衡(CB-SCS)版本,以应对实例区域变化和类别不平衡问题,且无需模型训练。我们在VOC 2012、Cityscapes和COCO数据集上取得了最新结果,在CNN和Transformer架构上具有良好的通用性。值得注意的是,我们的方法在COCO数据集上的修剪过程平均加速了1349倍,相比于基准方法有明显的优势。源代码可在以下链接找到:https://github.com/he-y/dataset-pruning-for-instance-segmentation 。
论文及项目相关链接
PDF Accepted by ICLR 2025
Summary
本文提出一种针对实例分割任务的无训练数据集裁剪方法。通过利用图像标注中的形状和类别信息,设计形状复杂度得分(SCS),并衍生出尺度不变(SI-SCS)和类别平衡(CB-SCS)的版本,以应对实例区域变化和类别不平衡的问题。该方法在VOC 2012、Cityscapes和COCO数据集上取得了最先进的成果,可广泛应用于CNN和Transformer架构,并大大加速了裁剪过程。
Key Takeaways
- 实例分割面临像素级标注、实例区域变化和类别不平衡的挑战。
- 直接使用基于分类的裁剪方法对于实例分割任务来说是不够有效的。
- 提出一种新型的无训练数据集裁剪方法(TFDP)针对实例分割。
- 利用图像标注中的形状和类别信息设计形状复杂度得分(SCS)。
- 推出尺度不变(SI-SCS)和类别平衡(CB-SCS)的形状复杂度得分版本,以应对实例区域变化和类别不平衡问题。
- 在多个数据集上取得了最先进的成果,包括VOC 2012、Cityscapes和COCO。
点此查看论文截图

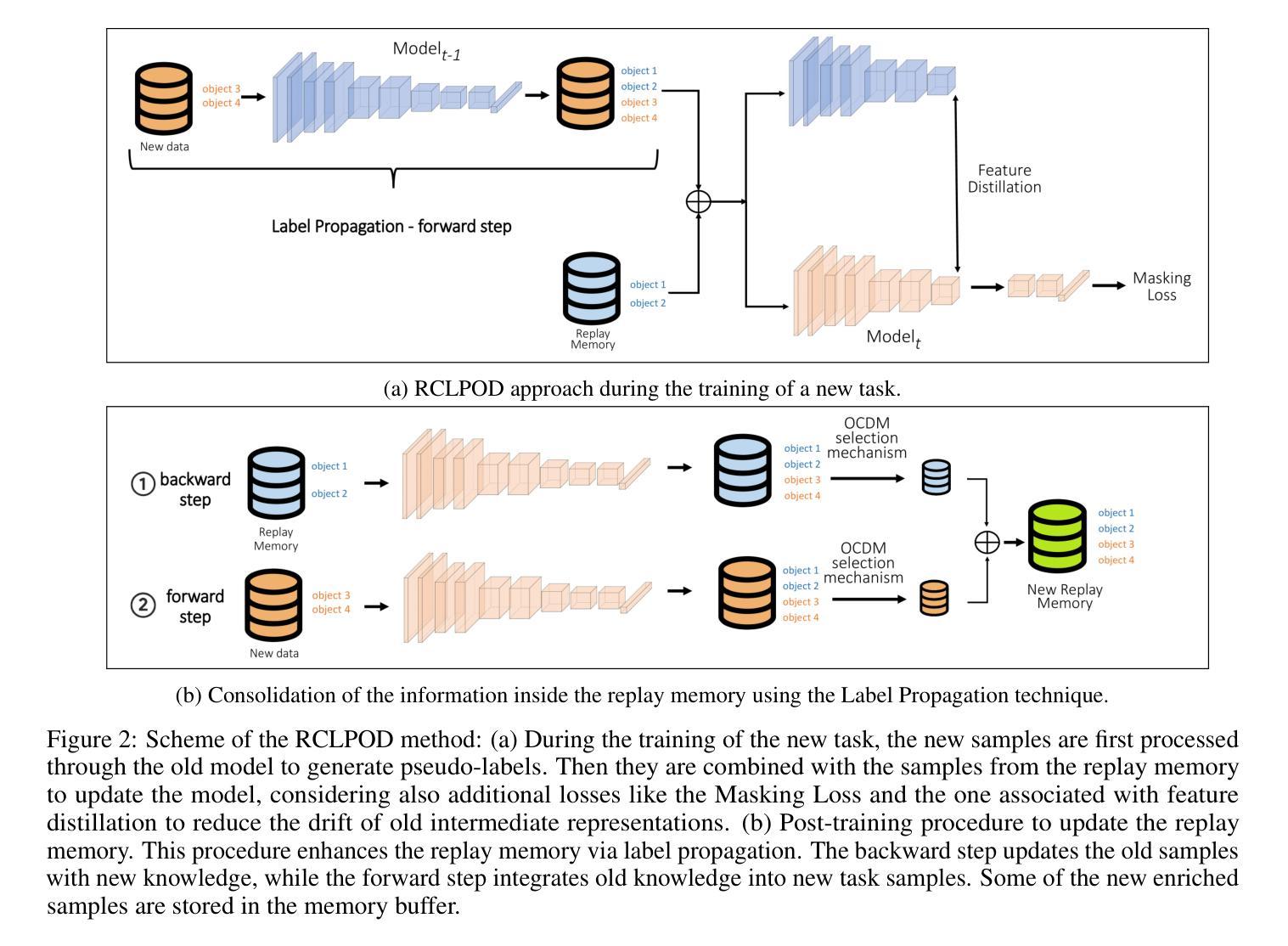
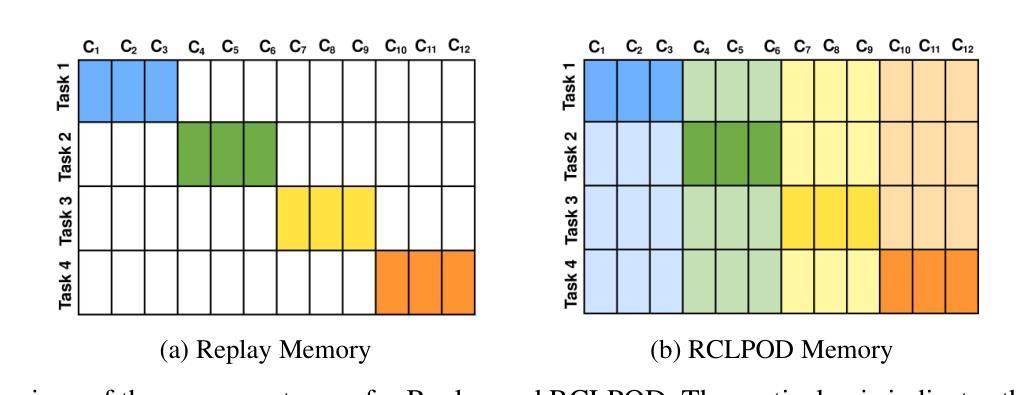
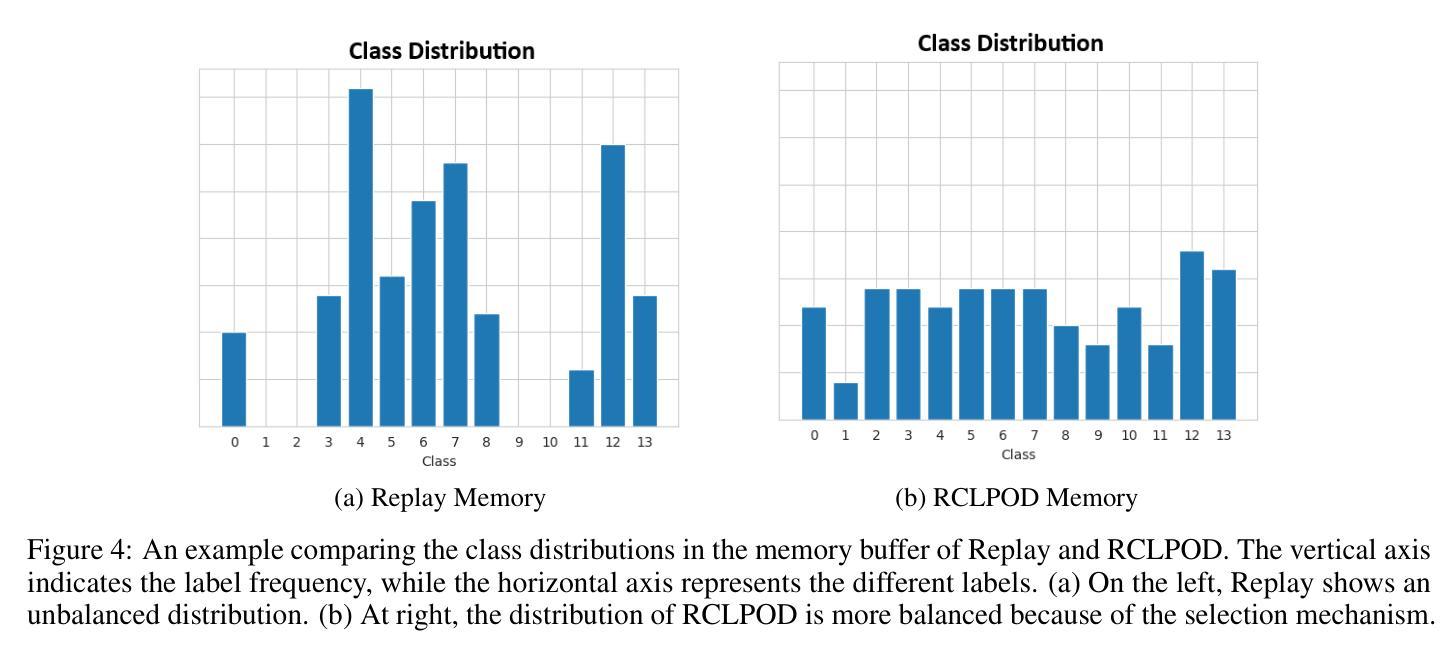
Replay Consolidation with Label Propagation for Continual Object Detection
Authors:Riccardo De Monte, Davide Dalle Pezze, Marina Ceccon, Francesco Pasti, Francesco Paissan, Elisabetta Farella, Gian Antonio Susto, Nicola Bellotto
Continual Learning (CL) aims to learn new data while remembering previously acquired knowledge. In contrast to CL for image classification, CL for Object Detection faces additional challenges such as the missing annotations problem. In this scenario, images from previous tasks may contain instances of unknown classes that could reappear as labeled in future tasks, leading to task interference in replay-based approaches. Consequently, most approaches in the literature have focused on distillation-based techniques, which are effective when there is a significant class overlap between tasks. In our work, we propose an alternative to distillation-based approaches with a novel approach called Replay Consolidation with Label Propagation for Object Detection (RCLPOD). RCLPOD enhances the replay memory by improving the quality of the stored samples through a technique that promotes class balance while also improving the quality of the ground truth associated with these samples through a technique called label propagation. RCLPOD outperforms existing techniques on well-established benchmarks such as VOC and COC. Moreover, our approach is developed to work with modern architectures like YOLOv8, making it suitable for dynamic, real-world applications such as autonomous driving and robotics, where continuous learning and resource efficiency are essential.
持续学习(CL)旨在学习新数据的同时保留之前获得的知识。与用于图像分类的CL不同,用于对象检测的CL面临额外的挑战,例如缺少注释的问题。在这种情况下,来自先前任务的图像可能包含未知类的实例,这些实例可能在未来任务中以标签形式重新出现,基于回放的方法会导致任务干扰。因此,文献中的大多数方法都集中在基于蒸馏的技术上,当任务之间存在大量类重叠时,这些技术非常有效。在我们的工作中,我们提出了一种基于蒸馏方法的替代方案,称为用于对象检测的“回放巩固与标签传播”(RCLPOD)。RCLPOD通过促进类平衡的技术提高了回放记忆的质量,同时提高了与这些样本相关的真实标签的质量,通过标签传播技术来实现。RCLPOD在VOC和COC等既定基准测试中优于现有技术。此外,我们的方法是为现代架构(如YOLOv8)开发的,使其适用于动态、现实世界的应用(如自动驾驶和机器人技术),在这些应用中,持续学习和资源效率至关重要。
论文及项目相关链接
Summary
本文介绍了持续学习(CL)在目标检测领域的应用与挑战。针对图像分类的CL方法面临未知类别实例的问题,提出一种基于回放巩固和标签传播的新方法RCLPOD。RCLPOD通过提高存储样本的质量和与这些样本相关的地面真相的质量,增强了回放记忆。它在VOC和COCO等基准测试中优于现有技术,并且适用于YOLOv8等现代架构,适用于自动驾驶和机器人等动态、资源高效的实际应用。
Key Takeaways
- 持续学习(CL)旨在学习新数据的同时保留先前获得的知识。
- 目标检测领域的CL面临额外挑战,如缺失注释问题。
- 现有方法主要集中在基于蒸馏的技术上,这在任务之间存在大量类重叠时非常有效。
- 提出的RCLPOD方法是一种替代基于蒸馏的方法。
- RCLPOD通过提高存储样本的质量和与这些样本相关的地面真相的质量,增强了回放记忆。
- RCLPOD在VOC和COCO等基准测试中性能优越。
点此查看论文截图



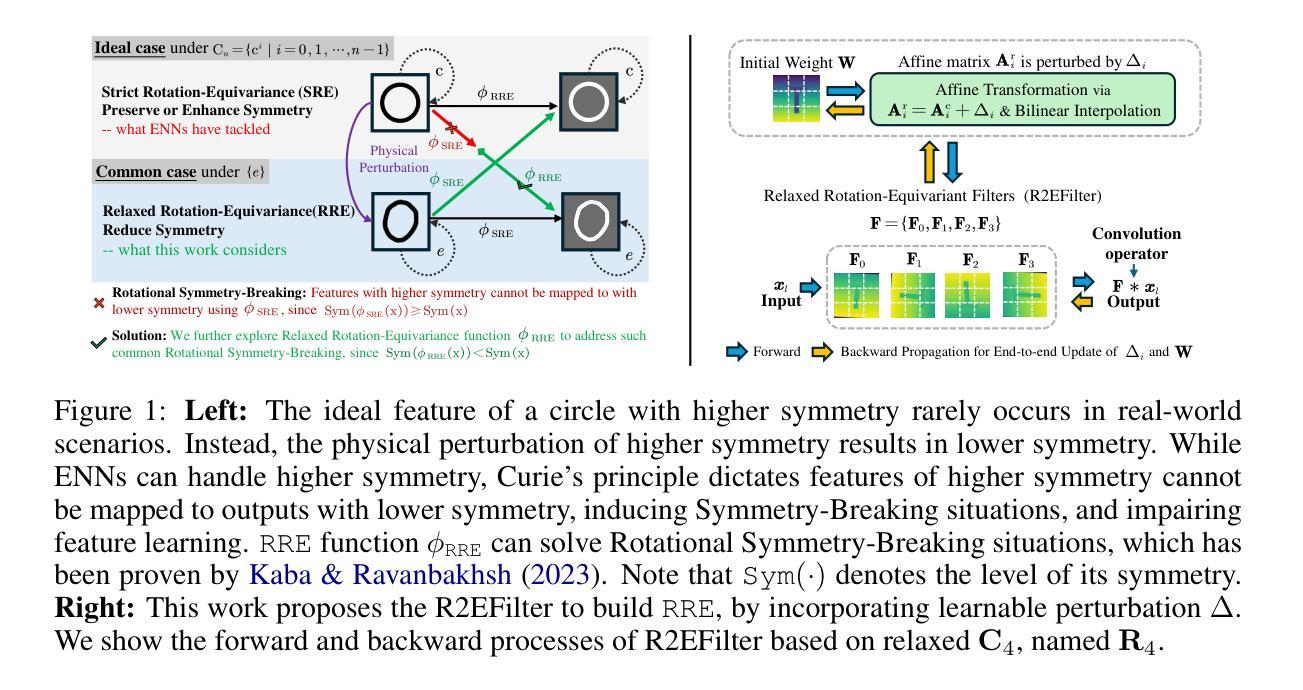
R2Det: Exploring Relaxed Rotation Equivariance in 2D object detection
Authors:Zhiqiang Wu, Yingjie Liu, Hanlin Dong, Xuan Tang, Jian Yang, Bo Jin, Mingsong Chen, Xian Wei
Group Equivariant Convolution (GConv) empowers models to explore underlying symmetry in data, improving performance. However, real-world scenarios often deviate from ideal symmetric systems caused by physical permutation, characterized by non-trivial actions of a symmetry group, resulting in asymmetries that affect the outputs, a phenomenon known as Symmetry Breaking. Traditional GConv-based methods are constrained by rigid operational rules within group space, assuming data remains strictly symmetry after limited group transformations. This limitation makes it difficult to adapt to Symmetry-Breaking and non-rigid transformations. Motivated by this, we mainly focus on a common scenario: Rotational Symmetry-Breaking. By relaxing strict group transformations within Strict Rotation-Equivariant group $\mathbf{C}_n$, we redefine a Relaxed Rotation-Equivariant group $\mathbf{R}_n$ and introduce a novel Relaxed Rotation-Equivariant GConv (R2GConv) with only a minimal increase of $4n$ parameters compared to GConv. Based on R2GConv, we propose a Relaxed Rotation-Equivariant Network (R2Net) as the backbone and develop a Relaxed Rotation-Equivariant Object Detector (R2Det) for 2D object detection. Experimental results demonstrate the effectiveness of the proposed R2GConv in natural image classification, and R2Det achieves excellent performance in 2D object detection with improved generalization capabilities and robustness. The code is available in \texttt{https://github.com/wuer5/r2det}.
群等变卷积(GConv)使模型能够探索数据中的潜在对称性,从而提高性能。然而,现实世界的情况往往与理想的对称系统有所偏差,这是由于物理排列导致的对称群的非平凡动作,从而产生影响输出的不对称现象,这种现象被称为对称破缺。传统的基于GConv的方法受到群空间内刚性操作规则的约束,假设在有限的群变换后数据仍然严格对称。这种局限性使得它难以适应对称破缺和非刚性变换。受其启发,我们主要关注一个常见场景:旋转对称破缺。通过放宽严格旋转等变组$\mathbf{C}_n$内的严格群变换,我们重新定义了松弛旋转等变组$\mathbf{R}_n$,并引入了一种新型的松弛旋转等变GConv(R2GConv),与GConv相比,仅增加了$4n$个参数。基于R2GConv,我们提出了作为骨干网的松弛旋转等变网络(R2Net),并开发了用于二维目标检测的松弛旋转等变对象检测器(R2Det)。实验结果证明了所提出的R2GConv在自然图像分类中的有效性,而R2Det在二维目标检测方面实现了卓越的性能,提高了通用性和鲁棒性。代码可在\href{https://github.com/wuer5/r2det}{https://github.com/wuer5/r2det}获取。
论文及项目相关链接
Summary:
卷积操作中的群等变性(GConv)使模型能够探索数据的潜在对称性,从而提高性能。然而,现实世界场景往往由于物理排列而偏离理想对称系统,导致对称性破坏现象。针对传统GConv方法受限于严格群变换规则的问题,本文关注旋转对称性破坏的常见场景,重新定义了松弛旋转等变组R2n并引入新型松弛旋转等变GConv(R2GConv)。基于此,提出了松弛旋转等变网络(R2Net)作为主干,并开发了用于二维目标检测的松弛旋转等变目标检测器(R2Det)。实验结果显示,R2GConv在自然图像分类中效果显著,而R2Det在二维目标检测中实现了良好的性能提升和泛化能力增强。代码已公开。
Key Takeaways:
- GConv能够探索数据的潜在对称性以提高模型性能。
- 现实世界中的物理排列往往导致对称性破坏现象。
- 传统GConv方法受限于严格群变换规则,难以适应对称性破坏和非刚性变换。
- 针对旋转对称性破坏问题,定义了新的松弛旋转等变组R2n。
- 引入新型松弛旋转等变GConv(R2GConv),相较于传统GConv仅增加少量参数。
- 基于R2GConv提出了松弛旋转等变网络(R2Net)作为主干网络。
点此查看论文截图