⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-06 更新
2DGS-Avatar: Animatable High-fidelity Clothed Avatar via 2D Gaussian Splatting
Authors:Qipeng Yan, Mingyang Sun, Lihua Zhang
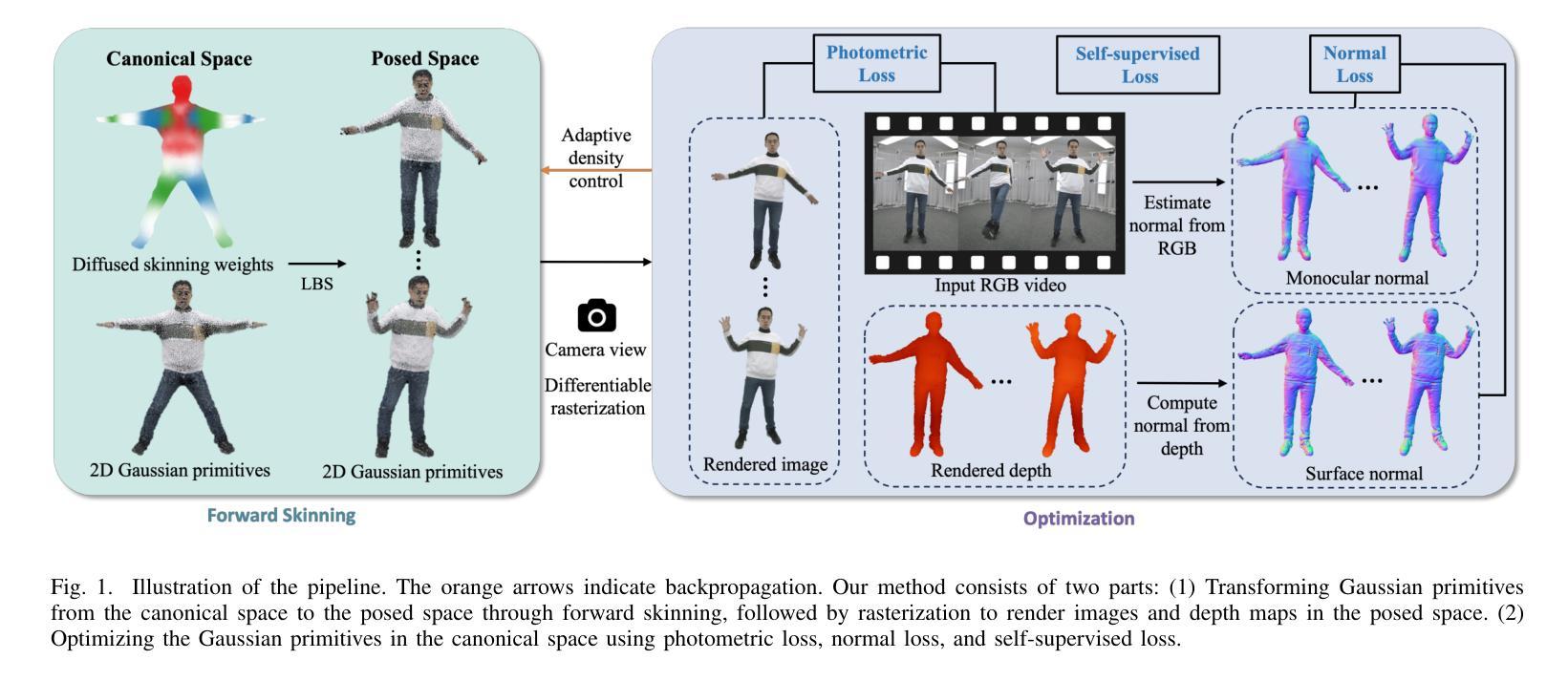
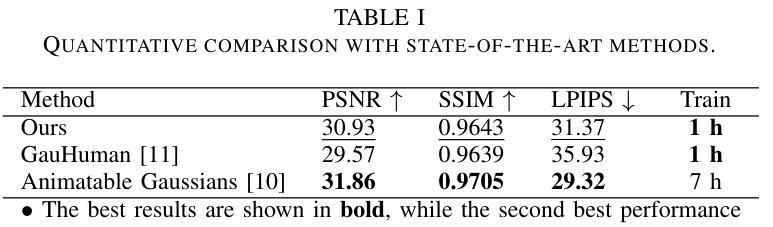
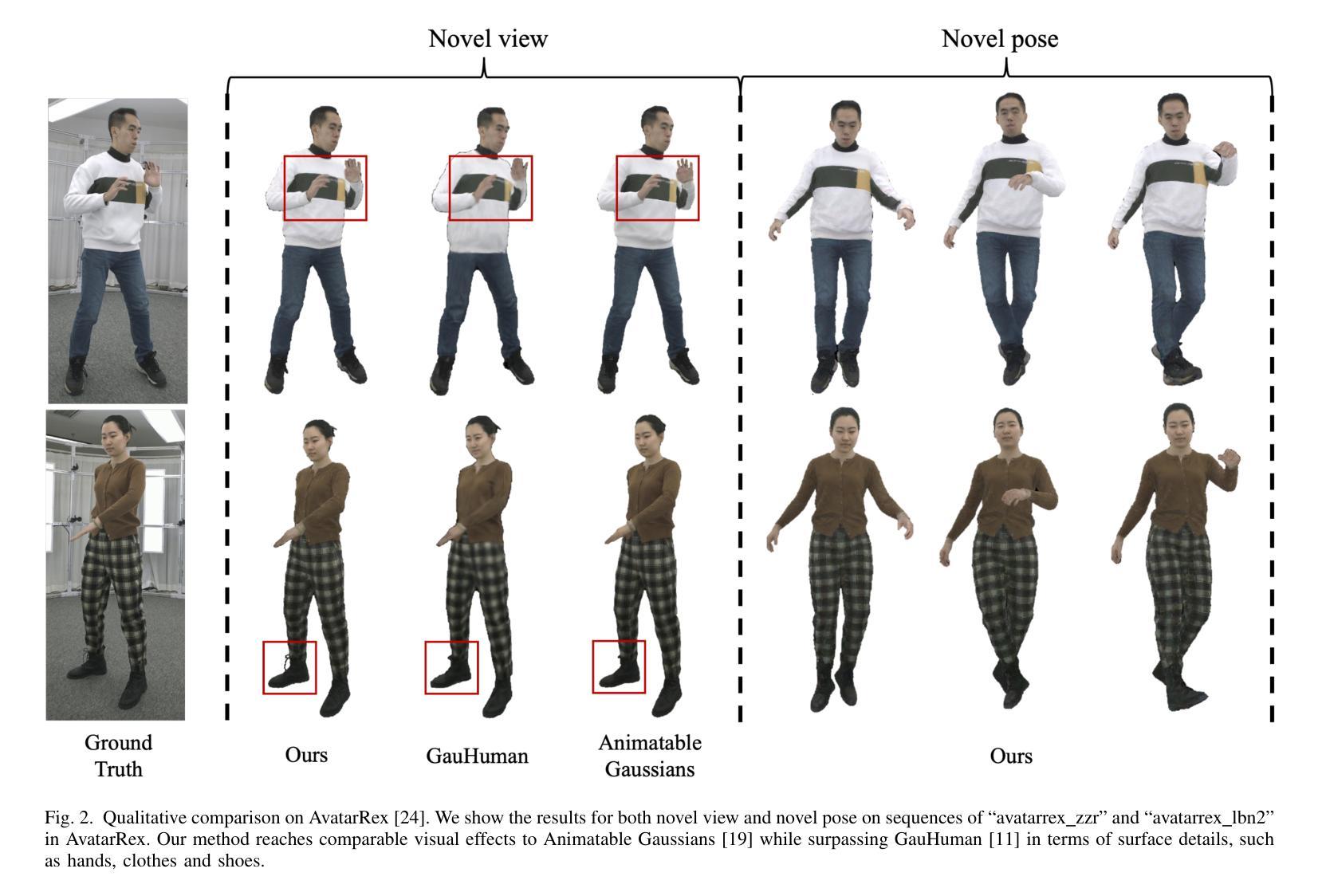
Real-time rendering of high-fidelity and animatable avatars from monocular videos remains a challenging problem in computer vision and graphics. Over the past few years, the Neural Radiance Field (NeRF) has made significant progress in rendering quality but behaves poorly in run-time performance due to the low efficiency of volumetric rendering. Recently, methods based on 3D Gaussian Splatting (3DGS) have shown great potential in fast training and real-time rendering. However, they still suffer from artifacts caused by inaccurate geometry. To address these problems, we propose 2DGS-Avatar, a novel approach based on 2D Gaussian Splatting (2DGS) for modeling animatable clothed avatars with high-fidelity and fast training performance. Given monocular RGB videos as input, our method generates an avatar that can be driven by poses and rendered in real-time. Compared to 3DGS-based methods, our 2DGS-Avatar retains the advantages of fast training and rendering while also capturing detailed, dynamic, and photo-realistic appearances. We conduct abundant experiments on popular datasets such as AvatarRex and THuman4.0, demonstrating impressive performance in both qualitative and quantitative metrics.
从单目视频中实时渲染高保真和可动画的化身仍然是计算机视觉和图形学中的一个具有挑战性的问题。过去几年,神经辐射场(NeRF)在渲染质量方面取得了显著进展,但由于体积渲染的低效率,在运行时性能上表现不佳。最近,基于三维高斯贴片技术(3DGS)的方法在快速训练和实时渲染方面显示出巨大潜力。然而,它们仍然受到几何不准确所导致的伪影的影响。为了解决这个问题,我们提出了基于二维高斯贴片技术(2DGS)的动画服装化身新方法——二维GS化身(Avatar)。我们的方法使用单目RGB视频作为输入,生成可以通过姿态驱动的、可实时渲染的化身。相较于基于三维高斯贴片技术的方法,我们的二维GS化身在保持快速训练和渲染优势的同时,捕捉到了详细的、动态的、逼真的外观。我们在如AvatarRex和THuman4.0等流行数据集上进行了大量实验,在定性和定量指标上都取得了令人印象深刻的表现。
论文及项目相关链接
PDF ICVRV 2024
Summary
基于单目视频的高保真可动画人物实时渲染仍是计算机视觉和图形领域的一个难题。神经辐射场(NeRF)在渲染质量方面取得了显著进展,但运行时效率较低。基于3D高斯喷涂(3DGS)的方法在快速训练和实时渲染方面显示出巨大潜力,但仍存在由几何不准确导致的伪影问题。为解决这些问题,本文提出基于2D高斯喷涂(2DGS)的2DGS-Avatar新方法,用于对可动画服装人物进行高保真建模,具有快速训练性能和实时渲染能力。该方法以单目RGB视频为输入,生成的人物模型可根据姿态驱动并以实时渲染方式呈现。相较于基于3DGS的方法,2DGS-Avatar保留了快速训练和渲染的优点,同时捕捉详细、动态和逼真的外观。在流行的数据集如AvatarRex和THuman4.0上的实验证明了其出色的性能。
Key Takeaways
- 实时渲染高保真可动画人物仍是计算机视觉领域的挑战。
- 现有方法如NeRF虽能提高渲染质量但运行时效率较低。
- 基于3DGS的方法在快速训练和实时渲染方面表现出潜力,但存在几何不准确导致的伪影问题。
- 2DGS-Avatar方法结合了2DGS技术,旨在解决上述问题,实现高保真可动画人物建模。
- 2DGS-Avatar能以单目RGB视频为输入,生成可姿态驱动的人物模型,并以实时方式渲染。
- 与基于3DGS的方法相比,2DGS-Avatar在快速训练和渲染的同时,能捕捉更详细、动态和逼真的外观。
点此查看论文截图


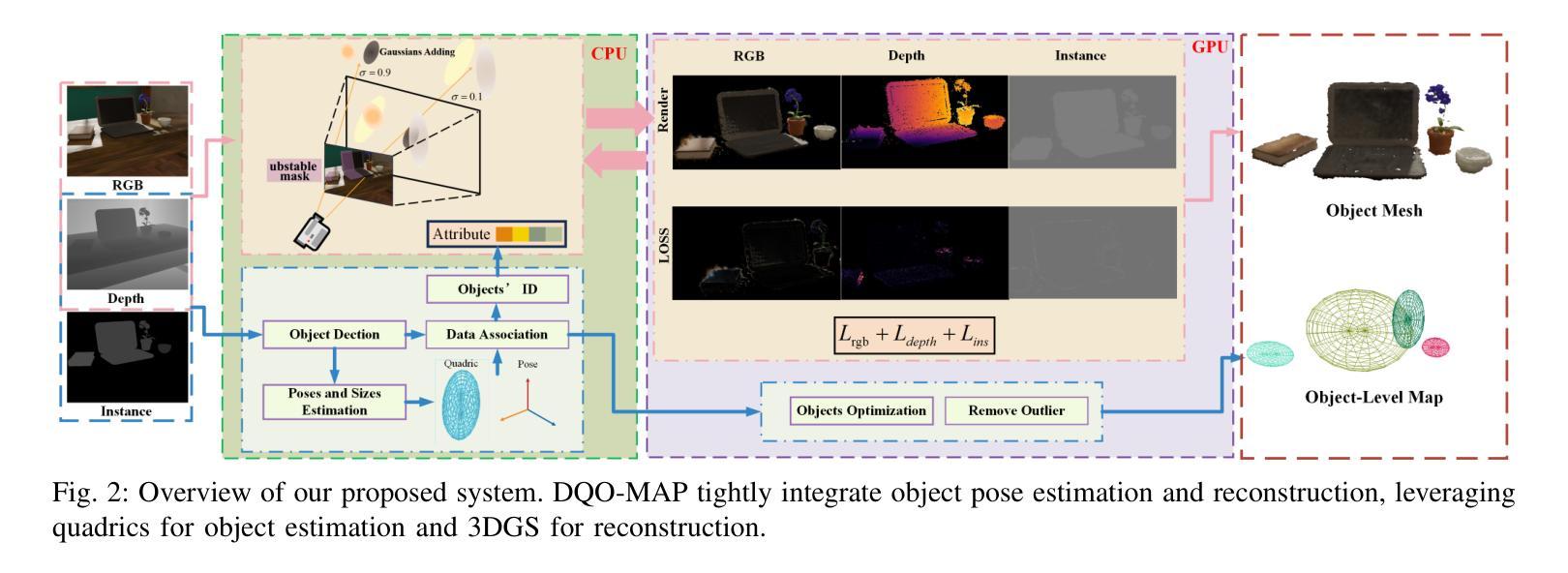
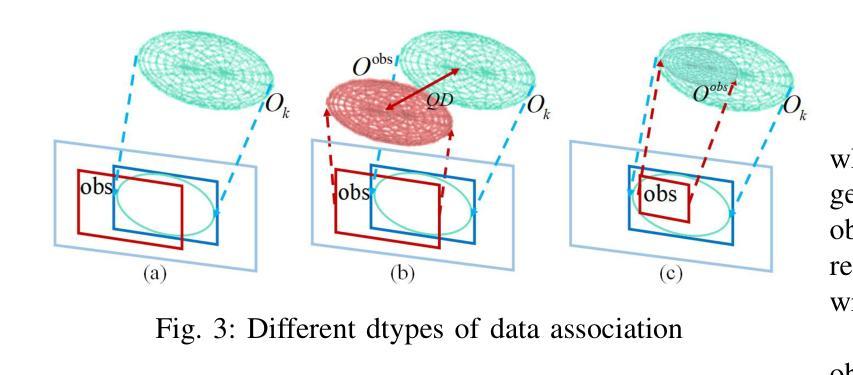
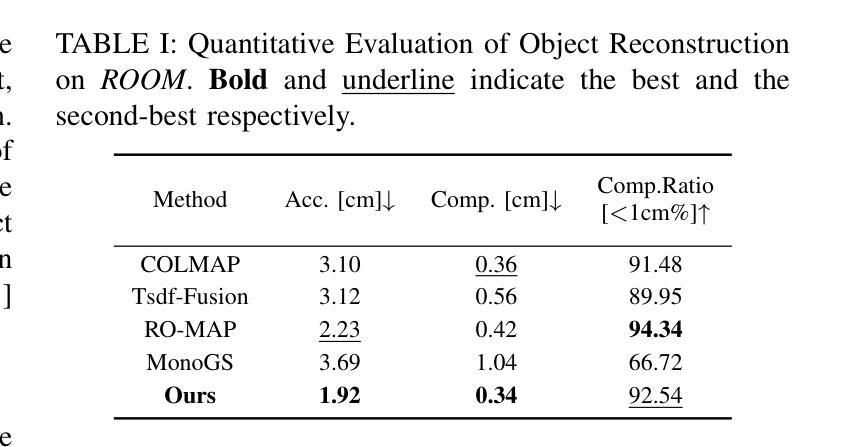
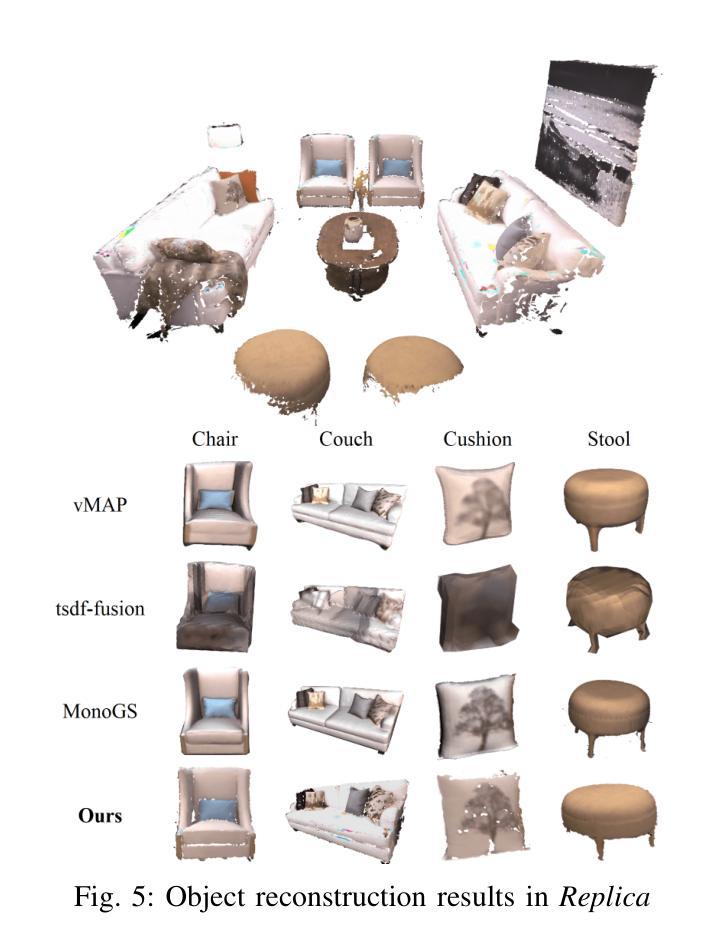
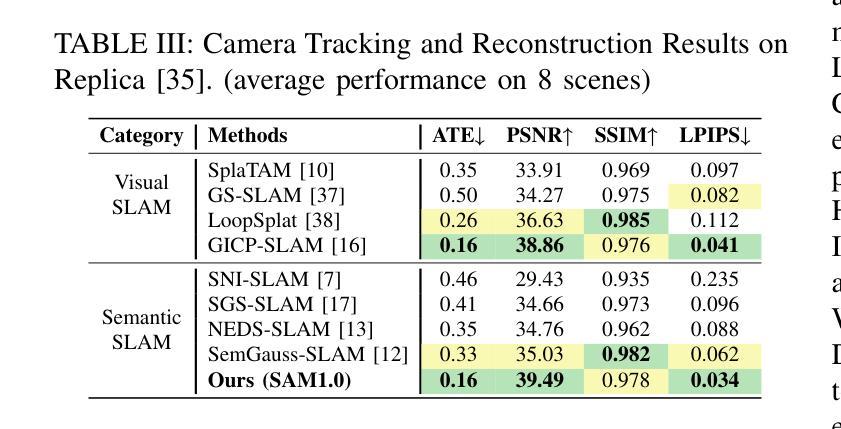
DQO-MAP: Dual Quadrics Multi-Object mapping with Gaussian Splatting
Authors:Haoyuan Li, Ziqin Ye, Yue Hao, Weiyang Lin, Chao Ye
Accurate object perception is essential for robotic applications such as object navigation. In this paper, we propose DQO-MAP, a novel object-SLAM system that seamlessly integrates object pose estimation and reconstruction. We employ 3D Gaussian Splatting for high-fidelity object reconstruction and leverage quadrics for precise object pose estimation. Both of them management is handled on the CPU, while optimization is performed on the GPU, significantly improving system efficiency. By associating objects with unique IDs, our system enables rapid object extraction from the scene. Extensive experimental results on object reconstruction and pose estimation demonstrate that DQO-MAP achieves outstanding performance in terms of precision, reconstruction quality, and computational efficiency. The code and dataset are available at: https://github.com/LiHaoy-ux/DQO-MAP.
准确的物体感知对于物体导航等机器人应用至关重要。在本文中,我们提出了DQO-MAP,这是一种新型的对象SLAM系统,它无缝集成了对象姿态估计和重建。我们采用3D高斯拼贴实现高保真物体重建,并利用二次曲面进行精确物体姿态估计。它们两者都在CPU上处理,优化在GPU上进行,这大大提高了系统效率。通过将对象与唯一ID相关联,我们的系统能够实现从场景中快速提取对象。在物体重建和姿态估计方面的广泛实验结果证明,DQO-MAP在精度、重建质量和计算效率方面取得了出色的表现。代码和数据集可在:https://github.com/LiHaoy-ux/DQO-MAP找到。
论文及项目相关链接
Summary
本文提出了一种新型的基于深度学习的对象感知系统DQO-MAP,该系统集成了对象位姿估计和重建功能。通过采用3D高斯散斑技术和四元数的组合优化技术,系统在机器人对象导航等领域表现优异。系统的CPU负责数据处理,GPU进行优化的操作方式有效提高了系统运行效率。该系统通过对物体分配唯一ID实现场景的快速物体提取。实验结果表明,DQO-MAP在精度、重建质量和计算效率方面表现出卓越性能。
Key Takeaways
- DQO-MAP是一种新型的对象感知系统,集成了对象位姿估计和重建功能。
- 采用3D高斯散斑技术实现高保真对象重建。
- 利用四元数进行精确的对象位姿估计。
- 系统采用CPU处理数据,GPU进行优化,提高了效率。
- 通过分配唯一ID,系统能迅速从场景中提取对象。
- 实验结果显示DQO-MAP在精度、重建质量和计算效率方面具有卓越性能。
点此查看论文截图



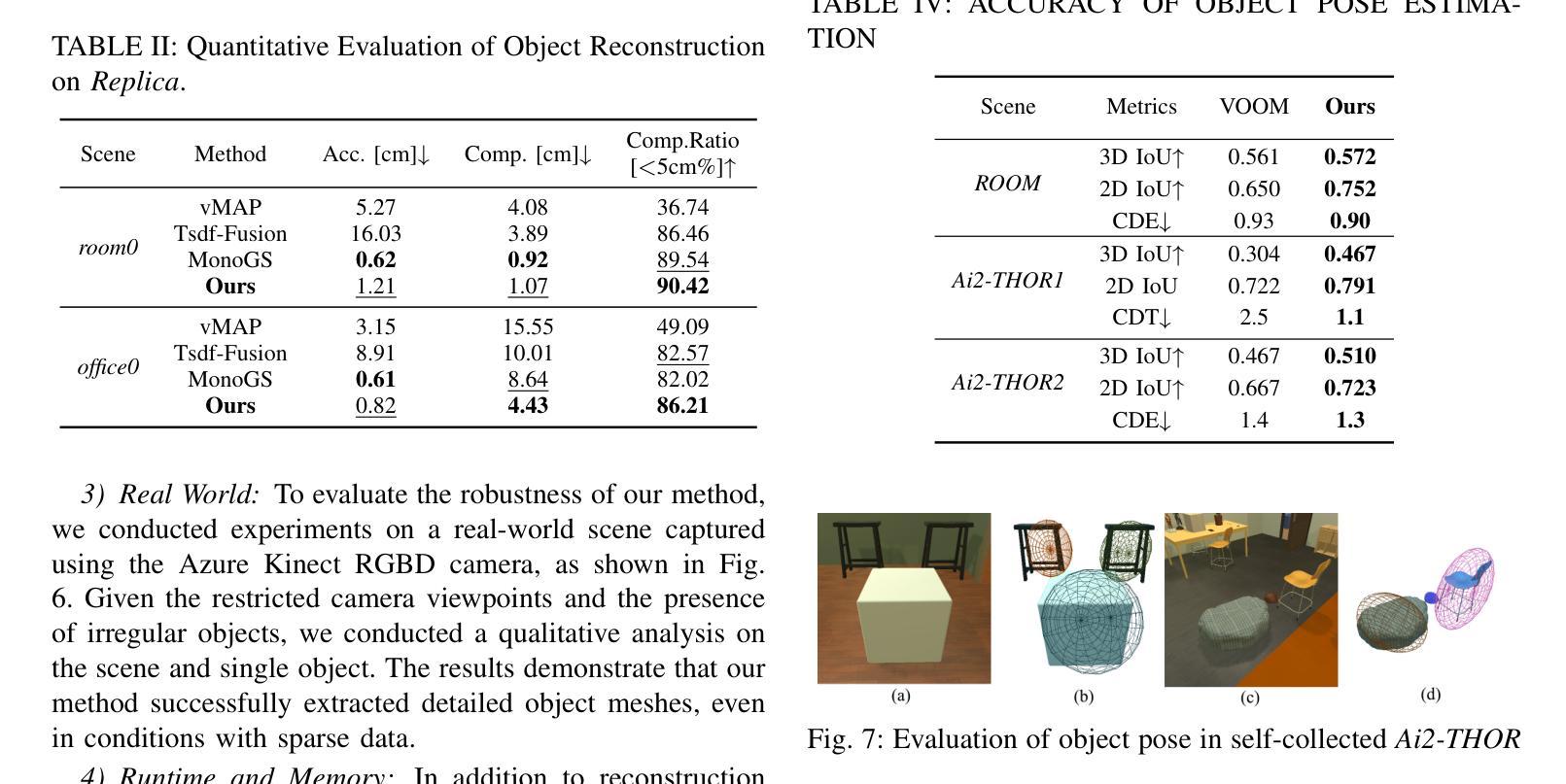
Difix3D+: Improving 3D Reconstructions with Single-Step Diffusion Models
Authors:Jay Zhangjie Wu, Yuxuan Zhang, Haithem Turki, Xuanchi Ren, Jun Gao, Mike Zheng Shou, Sanja Fidler, Zan Gojcic, Huan Ling
Neural Radiance Fields and 3D Gaussian Splatting have revolutionized 3D reconstruction and novel-view synthesis task. However, achieving photorealistic rendering from extreme novel viewpoints remains challenging, as artifacts persist across representations. In this work, we introduce Difix3D+, a novel pipeline designed to enhance 3D reconstruction and novel-view synthesis through single-step diffusion models. At the core of our approach is Difix, a single-step image diffusion model trained to enhance and remove artifacts in rendered novel views caused by underconstrained regions of the 3D representation. Difix serves two critical roles in our pipeline. First, it is used during the reconstruction phase to clean up pseudo-training views that are rendered from the reconstruction and then distilled back into 3D. This greatly enhances underconstrained regions and improves the overall 3D representation quality. More importantly, Difix also acts as a neural enhancer during inference, effectively removing residual artifacts arising from imperfect 3D supervision and the limited capacity of current reconstruction models. Difix3D+ is a general solution, a single model compatible with both NeRF and 3DGS representations, and it achieves an average 2$\times$ improvement in FID score over baselines while maintaining 3D consistency.
神经辐射场和3D高斯拼贴技术已经彻底改变了3D重建和新型视图合成任务。然而,从极端新颖视角实现逼真的渲染仍然具有挑战性,因为表示中的伪影持续存在。在这项工作中,我们引入了Difix3D+,这是一种新型管道,旨在通过单步扩散模型增强3D重建和新型视图合成。我们方法的核心是Difix,这是一种单步图像扩散模型,经过训练,可提高并消除由于3D表示中约束不足的区域所导致的新型渲染视图中的伪影。Difix在我们的管道中扮演两个关键角色。首先,它在重建阶段用于清理从重建中渲染然后蒸馏回3D的伪训练视图。这极大地提高了约束不足的区域并提高了整体的3D表示质量。更重要的是,在推理过程中,Difix还充当神经增强器,有效地消除了由于不完美的3D监督和当前重建模型的有限容量而产生的残留伪影。Difix3D+是一种通用解决方案,一个与NeRF和3DGS表示兼容的单一模型,它在基线的基础上实现了FID得分的平均2倍提升,同时保持了3D一致性。
论文及项目相关链接
PDF CVPR 2025
Summary
神经网络辐射场与三维高斯喷绘技术已经对三维重建和视角合成任务产生了革命性的影响。然而,从极端新视角实现逼真的渲染仍然具有挑战性,因为表示中仍存在伪影。本研究介绍了Difix3D+,这是一种新型管道,旨在通过单步扩散模型增强三维重建和视角合成。其核心是Difix单步图像扩散模型,用于增强和消除由三维表示的不受约束区域引起的渲染新视图中的伪影。Difix在管道中扮演两个关键角色。首先,它在重建阶段用于清理从重建中渲染并蒸馏回三维的伪训练视图,这极大地增强了不受约束的区域并提高了整体的三维表示质量。更重要的是,在推理过程中,Difix还充当神经增强器,有效地消除了由于三维监督不完美和当前重建模型的有限容量而产生的残余伪影。Difix3D+是一种通用解决方案,一个与NeRF和3DGS表示兼容的单模型,在基线的基础上实现了FID得分的平均两倍改进,同时保持了三维一致性。
Key Takeaways
- 神经网络辐射场与三维高斯喷绘技术在三维重建和视角合成任务中已有显著进展。
- 从极端新视角进行逼真渲染仍具挑战,表示中的伪影是主要问题。
- Difix3D+是一种新型管道,利用单步扩散模型增强三维重建和视角合成。
- 核心组件Difix在管道中扮演双重角色:在重建阶段清理伪训练视图,并在推理过程中充当神经增强器。
- Difix能增强不受约束的区域,提高三维表示质量,并有效去除表示中的伪影。
- Difix3D+兼容NeRF和3DGS表示,较基线实现了FID得分的平均两倍改进。
点此查看论文截图

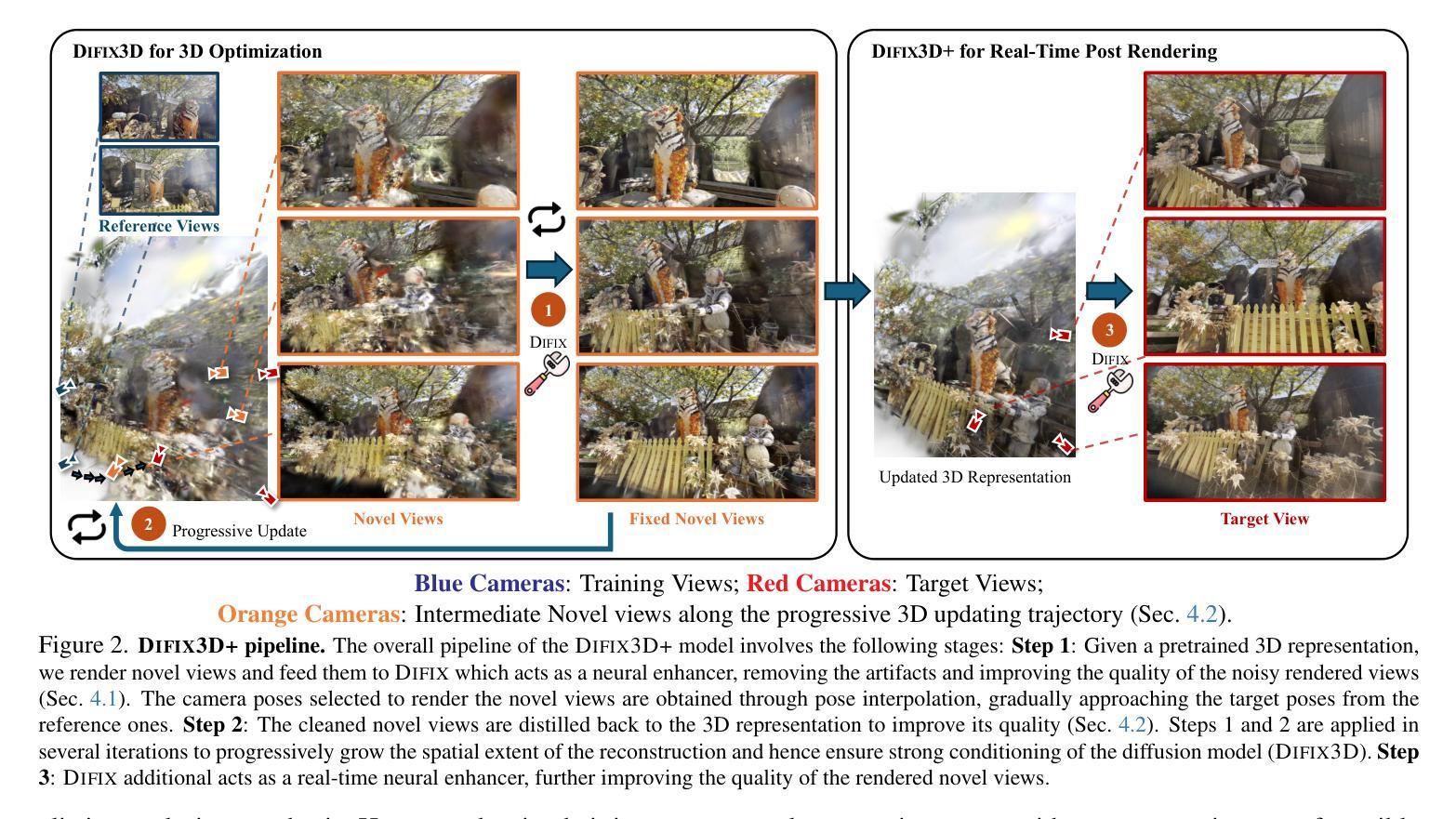


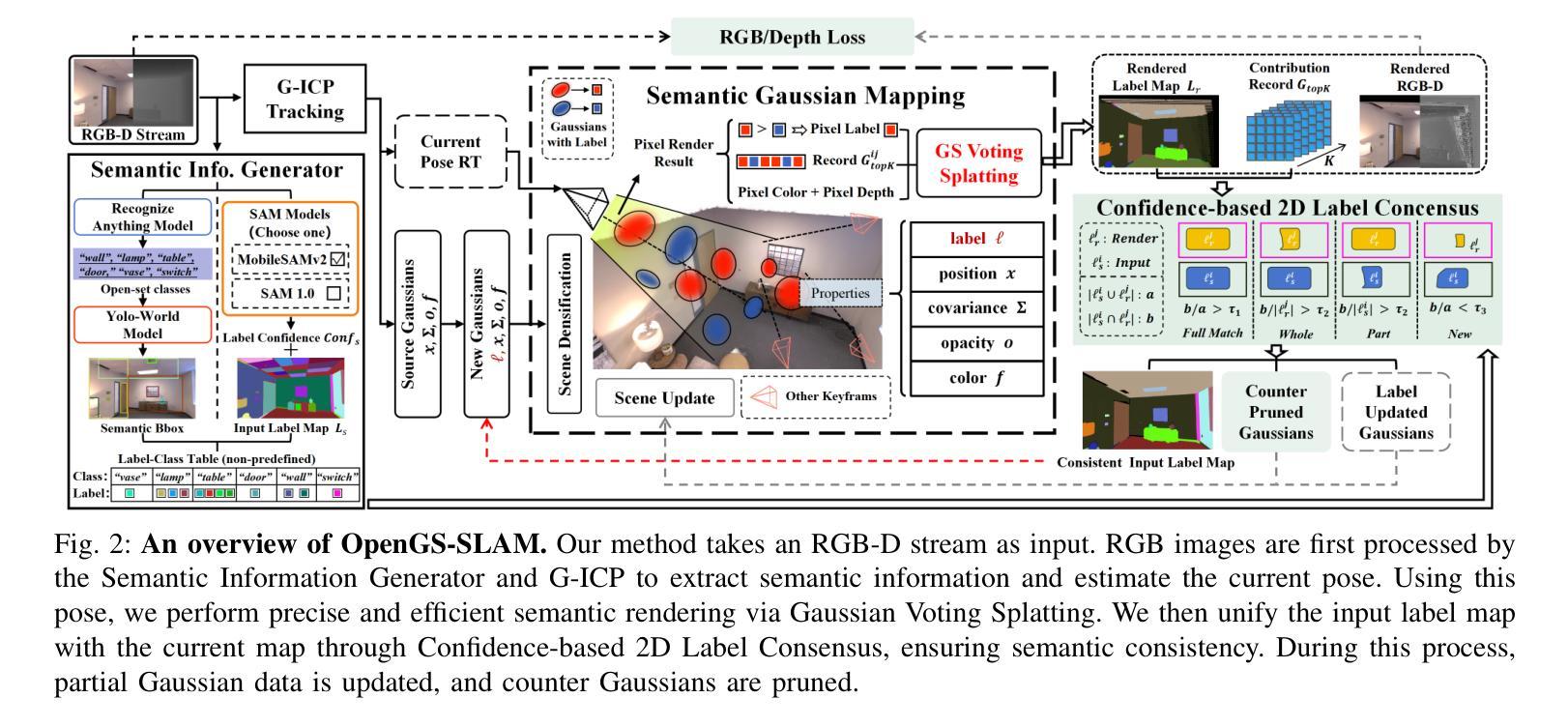
OpenGS-SLAM: Open-Set Dense Semantic SLAM with 3D Gaussian Splatting for Object-Level Scene Understanding
Authors:Dianyi Yang, Yu Gao, Xihan Wang, Yufeng Yue, Yi Yang, Mengyin Fu
Recent advancements in 3D Gaussian Splatting have significantly improved the efficiency and quality of dense semantic SLAM. However, previous methods are generally constrained by limited-category pre-trained classifiers and implicit semantic representation, which hinder their performance in open-set scenarios and restrict 3D object-level scene understanding. To address these issues, we propose OpenGS-SLAM, an innovative framework that utilizes 3D Gaussian representation to perform dense semantic SLAM in open-set environments. Our system integrates explicit semantic labels derived from 2D foundational models into the 3D Gaussian framework, facilitating robust 3D object-level scene understanding. We introduce Gaussian Voting Splatting to enable fast 2D label map rendering and scene updating. Additionally, we propose a Confidence-based 2D Label Consensus method to ensure consistent labeling across multiple views. Furthermore, we employ a Segmentation Counter Pruning strategy to improve the accuracy of semantic scene representation. Extensive experiments on both synthetic and real-world datasets demonstrate the effectiveness of our method in scene understanding, tracking, and mapping, achieving 10 times faster semantic rendering and 2 times lower storage costs compared to existing methods. Project page: https://young-bit.github.io/opengs-github.github.io/.
近年来,3D高斯摊铺技术的进展显著提高密集语义SLAM的效率和质量。然而,之前的方法通常受限于有限类别的预训练分类器和隐式语义表示,这阻碍了它们在开放场景中的性能,并限制了3D对象级别的场景理解。为了解决这些问题,我们提出了OpenGS-SLAM,这是一个利用3D高斯表示在开放环境中执行密集语义SLAM的创新框架。我们的系统将来自2D基础模型的显式语义标签集成到3D高斯框架中,促进了稳健的3D对象级别场景理解。我们引入了高斯投票摊铺技术,以实现快速2D标签图渲染和场景更新。此外,我们提出了一种基于置信度的2D标签共识方法,以确保跨多个视图的标签一致性。而且,我们采用了分割计数修剪策略,提高了语义场景表示的准确性。在合成和真实世界数据集上的大量实验表明,我们的方法在场景理解、跟踪和映射方面非常有效,与现有方法相比,实现了10倍更快的语义渲染和2倍更低的存储成本。项目页面:链接。
论文及项目相关链接
Summary
本文介绍了OpenGS-SLAM框架,该框架利用3D高斯表示在开放环境中进行密集语义SLAM。它通过整合来自二维基础模型的明确语义标签到三维高斯框架中,实现了稳健的三维物体级场景理解。提出的Gaussian Voting Splatting技术能够快速渲染二维标签地图并更新场景。同时,采用基于信心的二维标签共识方法确保跨多个视角的标签一致性。此外,还采用了Segmentation Counter Pruning策略来提高语义场景表示的准确性。此方法在合成和真实世界数据集上的实验结果表明,其在场景理解、跟踪和映射方面效果显著,实现了与现有方法相比10倍更快的语义渲染速度和降低一半存储成本的优势。
Key Takeaways
- OpenGS-SLAM利用三维高斯表示在开放环境中进行密集语义SLAM,提高了效率和质量。
- 该框架整合二维基础模型的明确语义标签到三维高斯框架中,促进了稳健的三维物体级场景理解。
- Gaussian Voting Splatting技术可以快速渲染二维标签地图并更新场景。
- 基于信心的二维标签共识方法确保跨多个视角的标签一致性。
- Segmentation Counter Pruning策略提高了语义场景表示的准确性。
- 在合成和真实世界数据集上的实验结果表明,OpenGS-SLAM在场景理解、跟踪和映射方面效果显著。
点此查看论文截图

Vid2Avatar-Pro: Authentic Avatar from Videos in the Wild via Universal Prior
Authors:Chen Guo, Junxuan Li, Yash Kant, Yaser Sheikh, Shunsuke Saito, Chen Cao
We present Vid2Avatar-Pro, a method to create photorealistic and animatable 3D human avatars from monocular in-the-wild videos. Building a high-quality avatar that supports animation with diverse poses from a monocular video is challenging because the observation of pose diversity and view points is inherently limited. The lack of pose variations typically leads to poor generalization to novel poses, and avatars can easily overfit to limited input view points, producing artifacts and distortions from other views. In this work, we address these limitations by leveraging a universal prior model (UPM) learned from a large corpus of multi-view clothed human performance capture data. We build our representation on top of expressive 3D Gaussians with canonical front and back maps shared across identities. Once the UPM is learned to accurately reproduce the large-scale multi-view human images, we fine-tune the model with an in-the-wild video via inverse rendering to obtain a personalized photorealistic human avatar that can be faithfully animated to novel human motions and rendered from novel views. The experiments show that our approach based on the learned universal prior sets a new state-of-the-art in monocular avatar reconstruction by substantially outperforming existing approaches relying only on heuristic regularization or a shape prior of minimally clothed bodies (e.g., SMPL) on publicly available datasets.
我们提出了Vid2Avatar-Pro方法,该方法可以从单目野生视频创建逼真且可动画的3D人类角色。从单目视频构建支持动画的优质角色,并具有各种姿势是一项挑战,因为姿势多样性和观察视角的观察本质上是有限的。姿势变化的缺乏通常导致对新姿势的泛化能力不佳,并且角色很容易过度适应有限的输入观点,导致其他观点产生伪影和失真。在这项工作中,我们通过利用从大量多视角着装人体捕获数据学习到的通用先验模型(UPM)来解决这些局限性。我们在具有跨身份共享的标准正面和背面图的表达性3D高斯之上构建我们的表示。一旦UPM能够准确地再现大规模的多视角人体图像,我们就会通过逆渲染使用野生视频对模型进行微调,从而获得个性化的逼真人类角色,可以忠实地动画化为新的人类运动,并从新视角进行渲染。实验表明,我们的基于学习通用先验的方法在单目角色重建方面树立了新的技术标杆,大大优于仅依赖启发式正则化或在最少着装身体(例如SMPL)的形状先验的现有方法在公开数据集上的表现。
论文及项目相关链接
PDF Project page: https://moygcc.github.io/vid2avatar-pro/
Summary
本文介绍了Vid2Avatar-Pro方法,该方法能够从单目野生视频创建逼真的可动画3D人类角色。通过使用从大规模多视角服装人体捕捉数据中学习的通用先验模型(UPM),解决了从单目视频构建支持动画的优质角色的挑战。通过逆渲染技术,对野生视频进行个性化微调,获得可动画的逼真人类角色,可从新的视角进行渲染。实验表明,基于学习到的通用先验的方法在单目角色重建方面表现最优,大幅优于仅依赖启发式正则化或最小穿衣身体形状的先验方法。
Key Takeaways
- Vid2Avatar-Pro能从单目野生视频创建高质量的可动画3D人类角色。
- 使用通用先验模型(UPM)解决从单目视频构建角色的挑战。
- 利用多视角服装人体捕捉数据学习UPM,实现更准确的人物表现捕捉。
- 通过逆渲染技术个性化微调模型,获得逼真的可动画人类角色。
- 新方法能够从新的视角渲染角色,提供更大的灵活性。
- 实验显示,该方法在单目角色重建方面表现最佳,优于其他方法。
点此查看论文截图

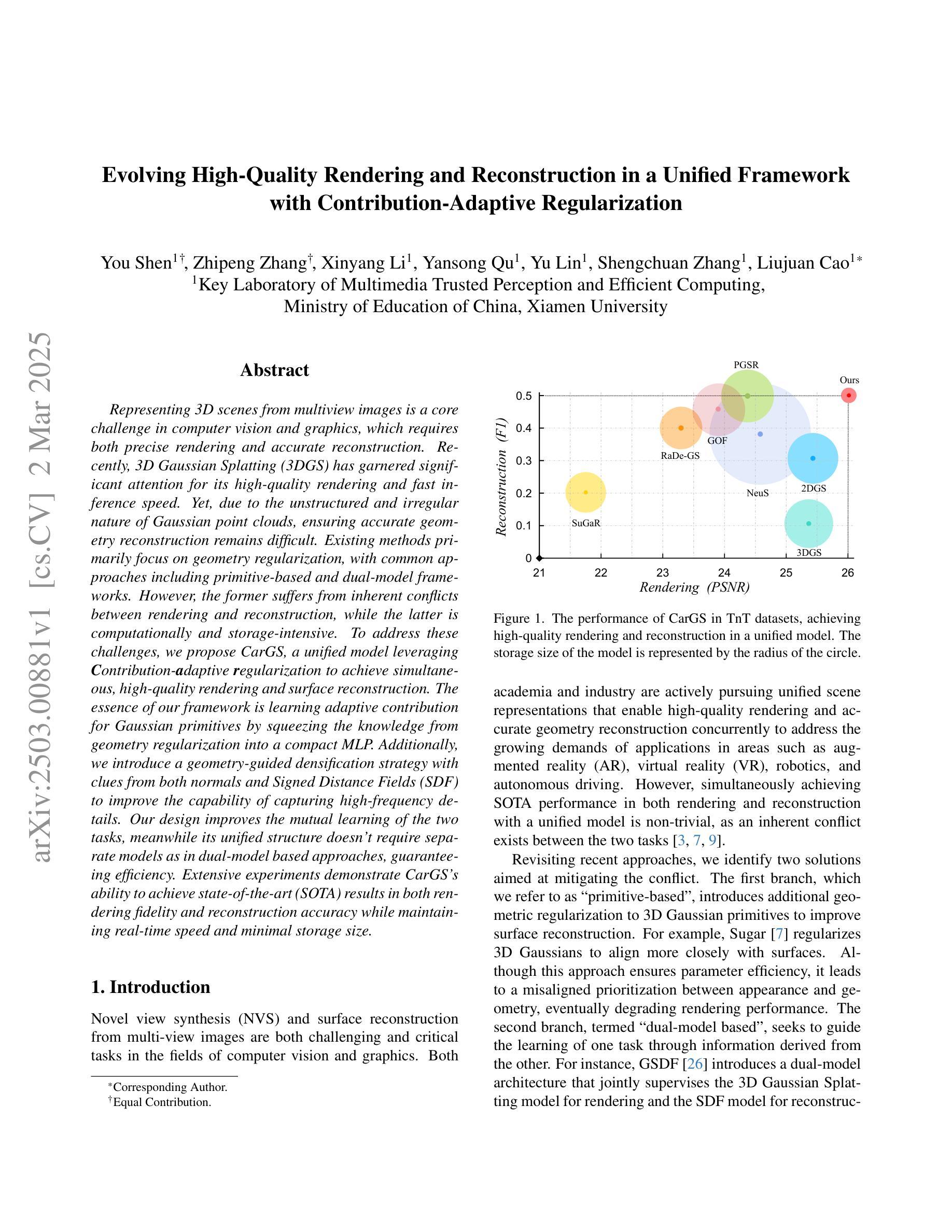
Evolving High-Quality Rendering and Reconstruction in a Unified Framework with Contribution-Adaptive Regularization
Authors:You Shen, Zhipeng Zhang, Xinyang Li, Yansong Qu, Yu Lin, Shengchuan Zhang, Liujuan Cao
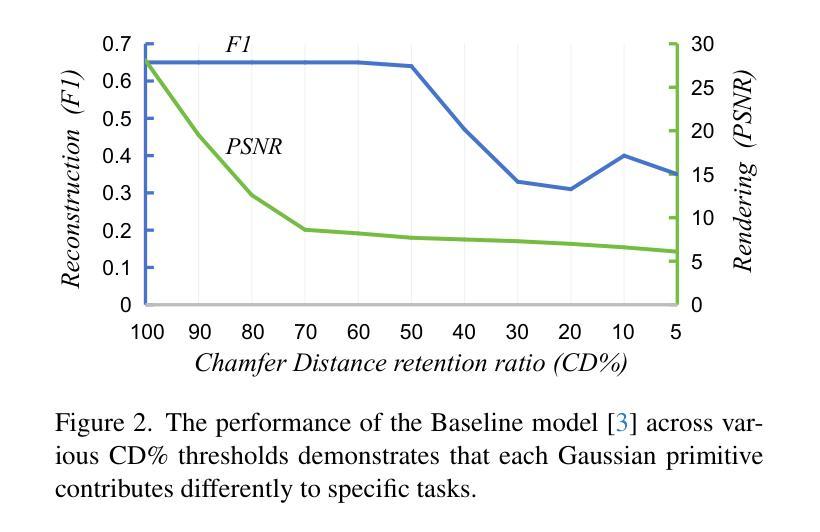
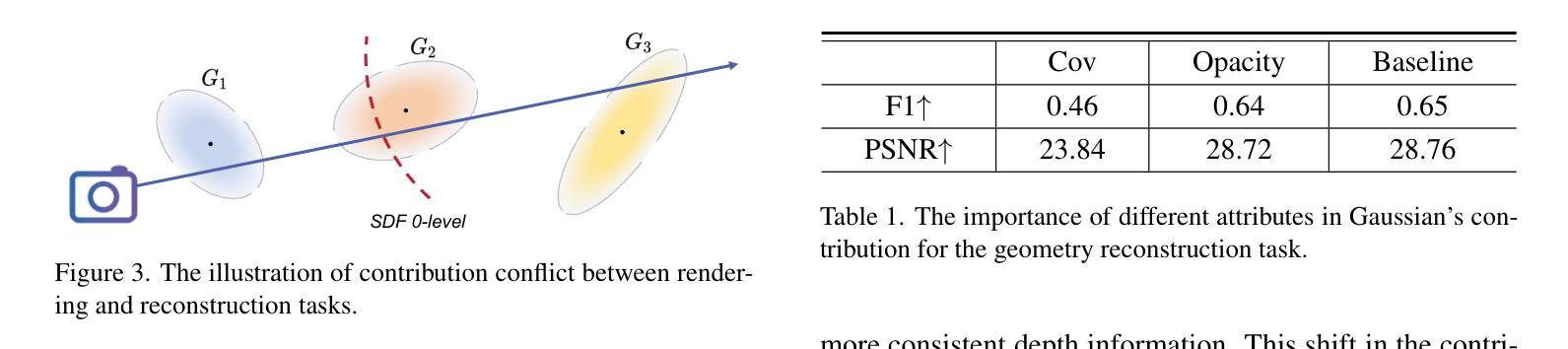
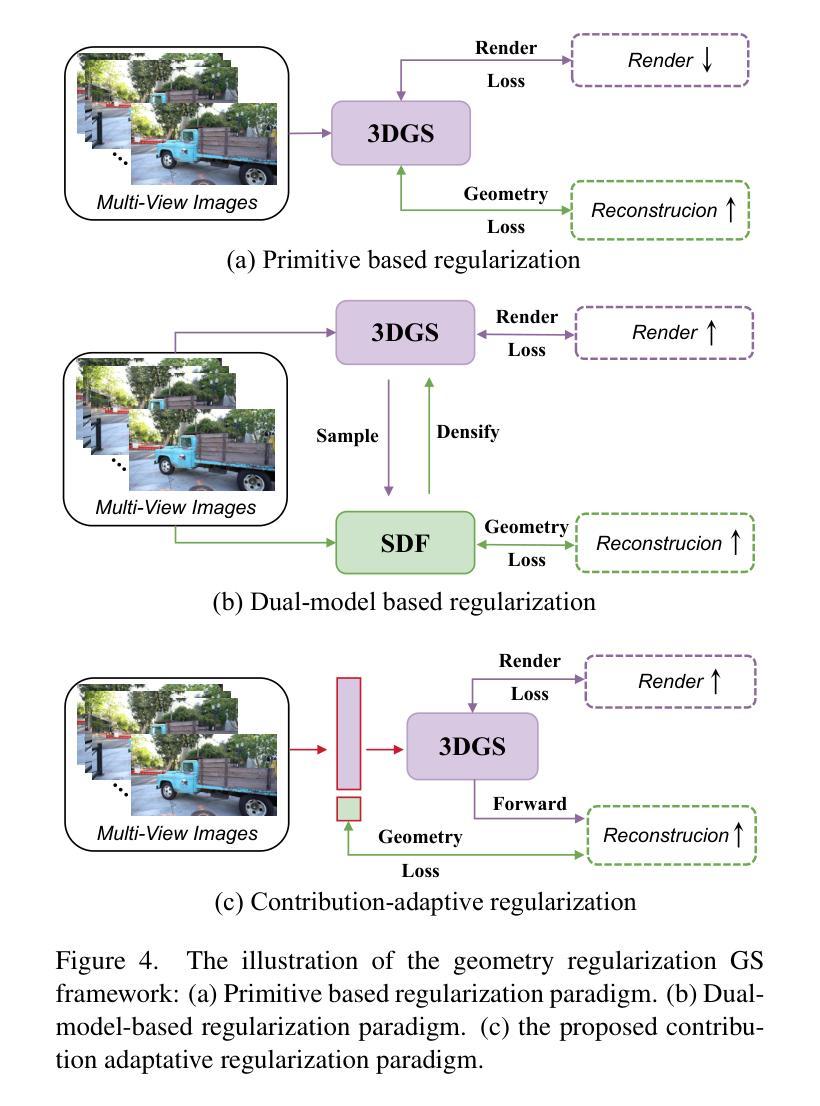
Representing 3D scenes from multiview images is a core challenge in computer vision and graphics, which requires both precise rendering and accurate reconstruction. Recently, 3D Gaussian Splatting (3DGS) has garnered significant attention for its high-quality rendering and fast inference speed. Yet, due to the unstructured and irregular nature of Gaussian point clouds, ensuring accurate geometry reconstruction remains difficult. Existing methods primarily focus on geometry regularization, with common approaches including primitive-based and dual-model frameworks. However, the former suffers from inherent conflicts between rendering and reconstruction, while the latter is computationally and storage-intensive. To address these challenges, we propose CarGS, a unified model leveraging Contribution-adaptive regularization to achieve simultaneous, high-quality rendering and surface reconstruction. The essence of our framework is learning adaptive contribution for Gaussian primitives by squeezing the knowledge from geometry regularization into a compact MLP. Additionally, we introduce a geometry-guided densification strategy with clues from both normals and Signed Distance Fields (SDF) to improve the capability of capturing high-frequency details. Our design improves the mutual learning of the two tasks, meanwhile its unified structure does not require separate models as in dual-model based approaches, guaranteeing efficiency. Extensive experiments demonstrate the ability to achieve state-of-the-art (SOTA) results in both rendering fidelity and reconstruction accuracy while maintaining real-time speed and minimal storage size.
从多视角图像表示3D场景是计算机视觉和图形的核心挑战,这需要精确渲染和准确重建。近期,3D高斯喷射(3DGS)因其高质量渲染和快速推理速度而受到广泛关注。然而,由于高斯点云的无结构和不规则性质,确保准确的几何重建仍然很困难。现有方法主要集中在几何正则化上,常见的方法包括基于原始数据和双重模型框架。然而,前者在渲染和重建之间存在内在冲突,后者则计算和存储密集。为了解决这些挑战,我们提出了CarGS,这是一个利用贡献自适应正则化方法的统一模型,实现高质量的同时渲染和表面重建。我们的框架的核心是通过从几何正则化中挤压知识来学习高斯原始数据的自适应贡献,并将其压缩到一个紧凑的MLP中。此外,我们引入了一种受几何指导的加密策略,通过法线和带符号距离场(SDF)的线索来提高捕捉高频细节的能力。我们的设计提高了两个任务的相互学习,同时其统一的结构不需要像双重模型方法那样使用单独的模型,保证了效率。大量实验证明,我们的方法在渲染保真度和重建准确性方面达到了最新水平(SOTA),同时保持了实时速度和最小的存储大小。
论文及项目相关链接
Summary
该文本介绍了在计算机视觉和图形学中,从多视角图像表示3D场景的核心挑战需要精确渲染和准确重建。近期,3D高斯拼贴(3DGS)因其高质量渲染和快速推理速度而受到关注。然而,由于高斯点云的无结构和不规则性质,确保准确的几何重建仍然具有挑战性。现有方法主要集中在几何正则化上,包括基于原始和双重模型框架的常见方法,但前者在渲染和重建之间存在固有冲突,后者计算和存储密集。为解决这些挑战,我们提出CarGS,一个利用贡献自适应正则化的统一模型,实现高质量渲染和表面重建。我们的框架的本质是通过从几何正则化中挤压知识来训练自适应贡献的高斯原始模型。此外,我们引入了一个受几何指导的密集化策略,从法线和带符号距离字段(SDF)的线索中提高捕捉高频细节的能力。我们的设计提高了两个任务的相互学习,同时其统一结构不需要像双重模型方法那样使用单独模型,保证了效率。实验证明,我们的方法在渲染保真度和重建准确性方面达到了最新水平,同时保持了实时速度和较小的存储大小。
Key Takeaways
- 3DGS在计算机视觉和图形学中对于多视角图像表示的3D场景存在挑战,需同时满足精确渲染和准确重建的要求。
- 现有方法主要关注几何正则化,但存在缺陷:基于原始的方法在渲染和重建之间存在冲突;而基于双重模型的方法计算和存储密集。
- 针对以上挑战,提出了CarGS框架,该框架使用贡献自适应正则化技术,旨在实现高质量渲染和表面重建的统一。
- CarGS利用紧凑的MLP模型从几何正则化中学习自适应贡献的知识,以改善几何重建能力。
- 通过引入受几何指导的密集化策略(利用法线和带符号距离字段),增强了捕捉高频细节的能力。
- CarGS设计提高了渲染和重建任务的相互学习,同时保持高效性,无需使用单独模型。
点此查看论文截图
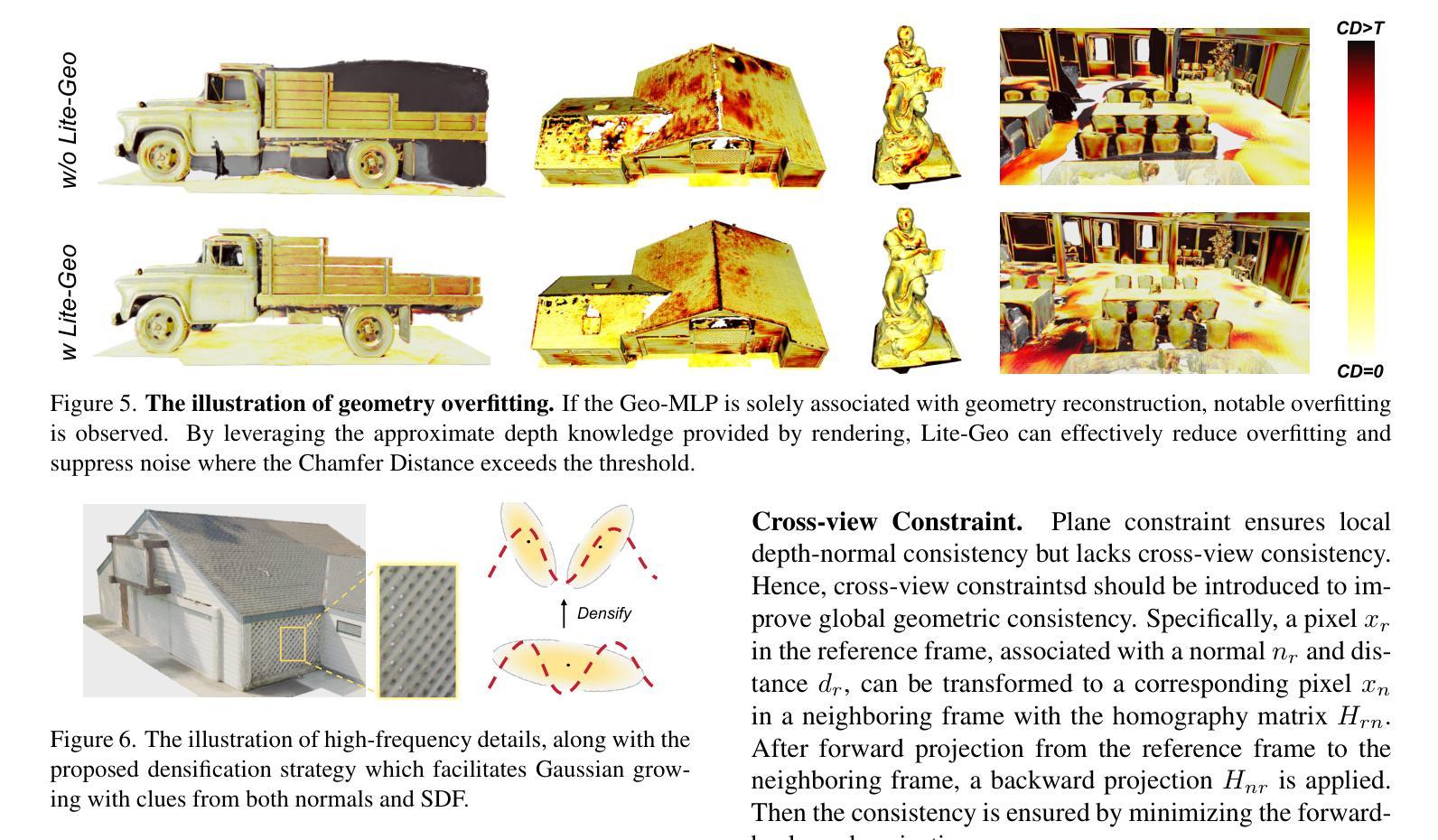
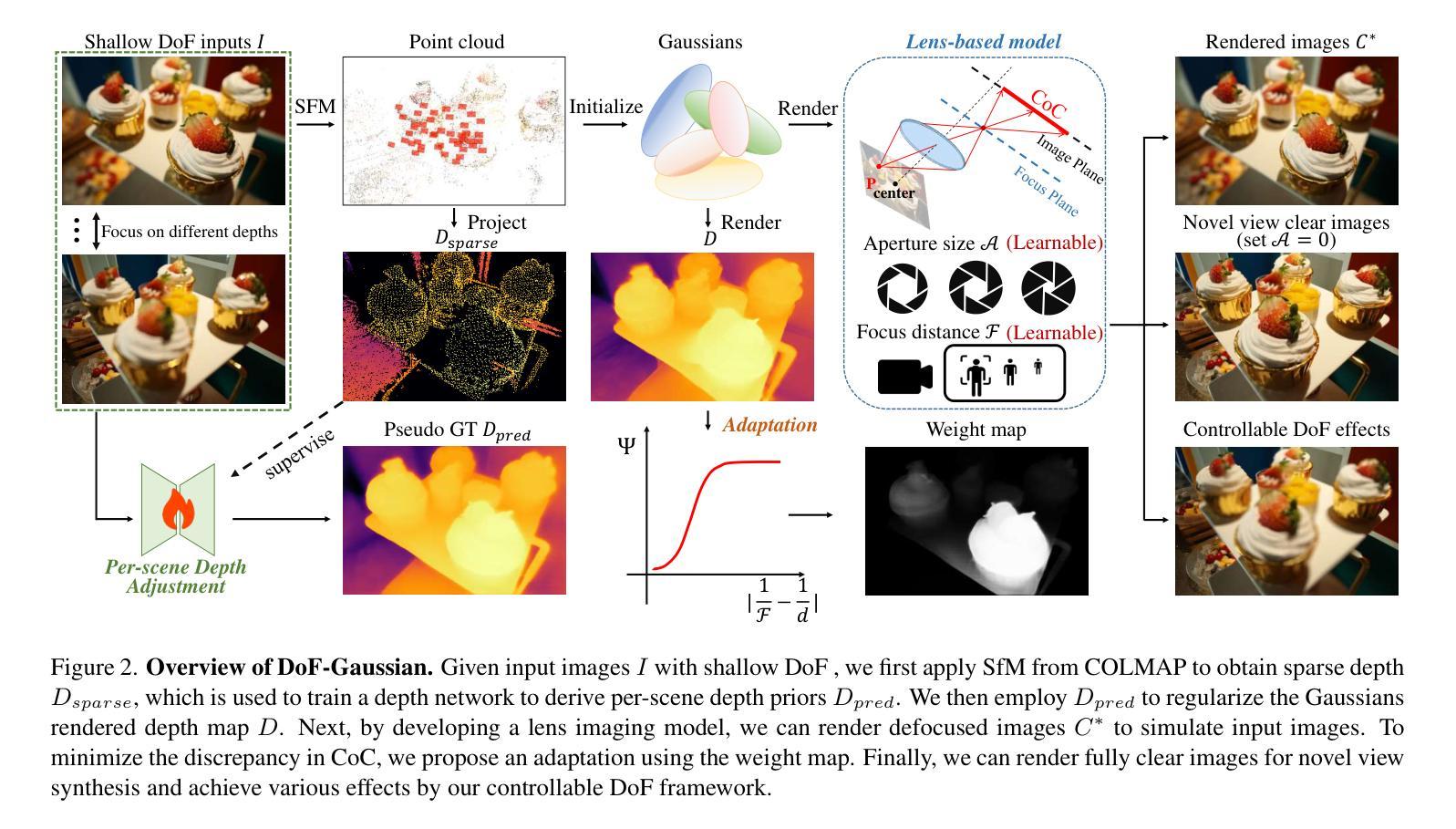
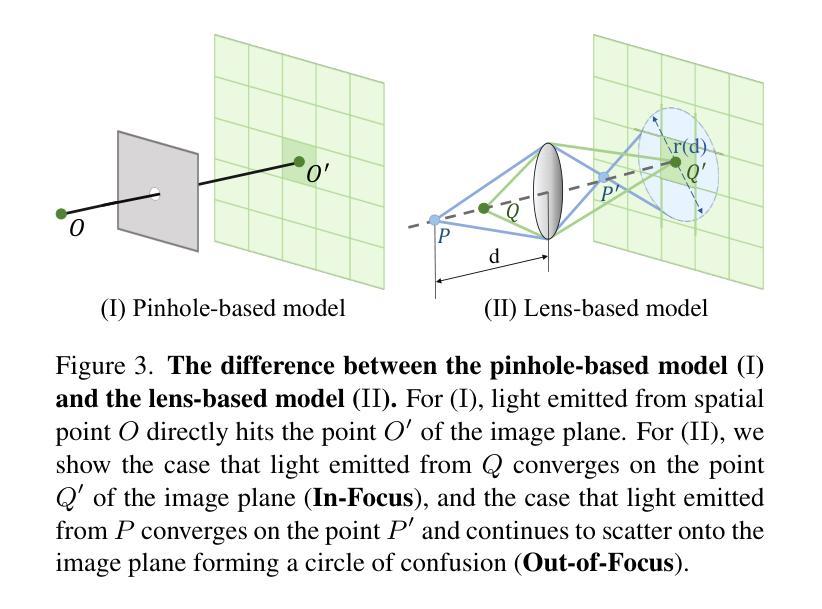
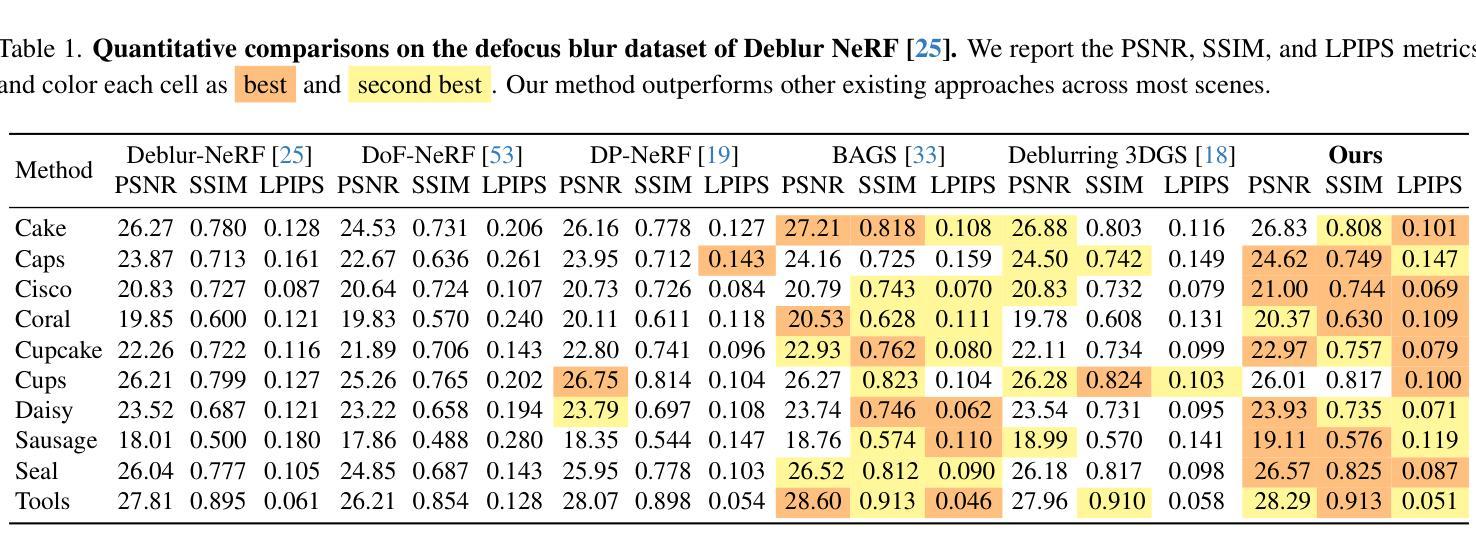
DoF-Gaussian: Controllable Depth-of-Field for 3D Gaussian Splatting
Authors:Liao Shen, Tianqi Liu, Huiqiang Sun, Jiaqi Li, Zhiguo Cao, Wei Li, Chen Change Loy
Recent advances in 3D Gaussian Splatting (3D-GS) have shown remarkable success in representing 3D scenes and generating high-quality, novel views in real-time. However, 3D-GS and its variants assume that input images are captured based on pinhole imaging and are fully in focus. This assumption limits their applicability, as real-world images often feature shallow depth-of-field (DoF). In this paper, we introduce DoF-Gaussian, a controllable depth-of-field method for 3D-GS. We develop a lens-based imaging model based on geometric optics principles to control DoF effects. To ensure accurate scene geometry, we incorporate depth priors adjusted per scene, and we apply defocus-to-focus adaptation to minimize the gap in the circle of confusion. We also introduce a synthetic dataset to assess refocusing capabilities and the model’s ability to learn precise lens parameters. Our framework is customizable and supports various interactive applications. Extensive experiments confirm the effectiveness of our method. Our project is available at https://dof-gaussian.github.io.
近期三维高斯喷绘(3D-GS)的进展在表示三维场景和实时生成高质量新视角方面取得了显著的成功。然而,3D-GS及其变体假设输入图像是基于针孔成像技术捕获的,并且完全在焦点内。这一假设限制了其适用性,因为现实世界中的图像通常具有较浅的景深(DoF)。在本文中,我们介绍了DoF-Gaussian,这是一种可控景深的三维高斯喷绘方法。我们基于几何光学原理开发了一种基于镜头的成像模型来控制景深效果。为了确保场景几何的准确性,我们根据场景调整了深度先验,并应用了失焦到聚焦的适应来减小模糊圆之间的间隙。我们还引入了一个合成数据集来评估重新聚焦能力和模型学习精确镜头参数的能力。我们的框架可定制且支持各种交互应用程序。大量实验证实了我们方法的有效性。我们的项目可在https://dof-gaussian.github.io访问。
论文及项目相关链接
PDF CVPR 2025
Summary
3D高斯贴图(3D-GS)的最新进展在表示3D场景和实时生成高质量新视角方面取得了显著成功。然而,该方法和其变种假设输入图像是基于针孔成像且完全对焦的,这限制了其在现实世界的应用,因为真实图像往往具有较浅的景深(DoF)。本文介绍了一种可控景深的方法DoF-Gaussian,用于改进3D-GS。我们基于几何光学原理开发了一种基于镜头的成像模型来控制景深效果。为确保准确的场景几何结构,我们根据场景调整了深度先验知识,并采用了失焦到对焦的适应策略来减少模糊圆圈的差距。我们还引入了一个合成数据集来评估重新聚焦能力和模型学习精确镜头参数的能力。我们的框架支持各种交互式应用,并经过广泛实验验证其有效性。
Key Takeaways
- 3D高斯贴图(3D-GS)在表示3D场景和生成新视角方面表现卓越。
- 现有方法假设输入图像完全对焦,这限制了其在现实世界的适用性。
- 引入DoF-Gaussian方法,通过镜头成像模型控制景深,提高现实应用性能。
- 结合场景深度先验知识和失焦到对焦的适应策略,确保准确场景几何结构。
- 引入合成数据集评估重新聚焦能力和模型精确学习镜头参数的能力。
- 框架支持交互式应用,具有广泛的实用性。
点此查看论文截图


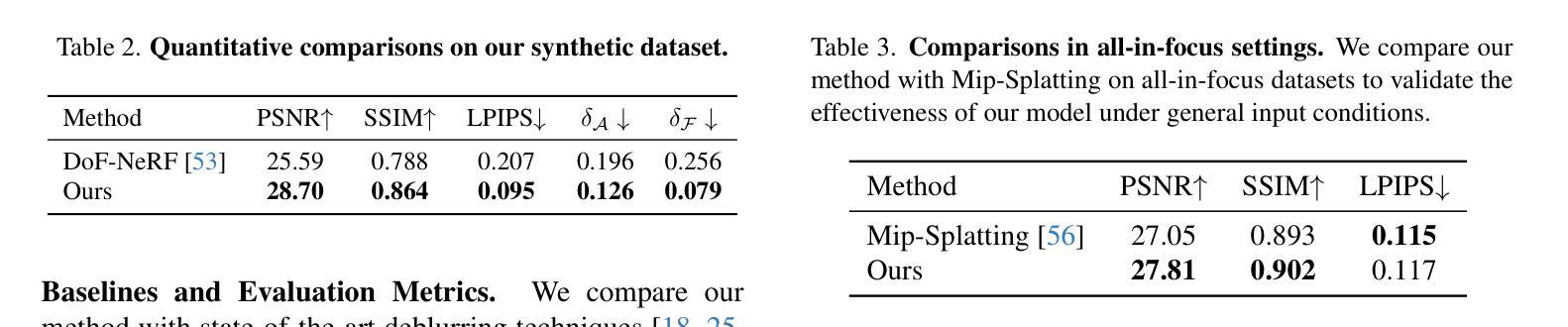
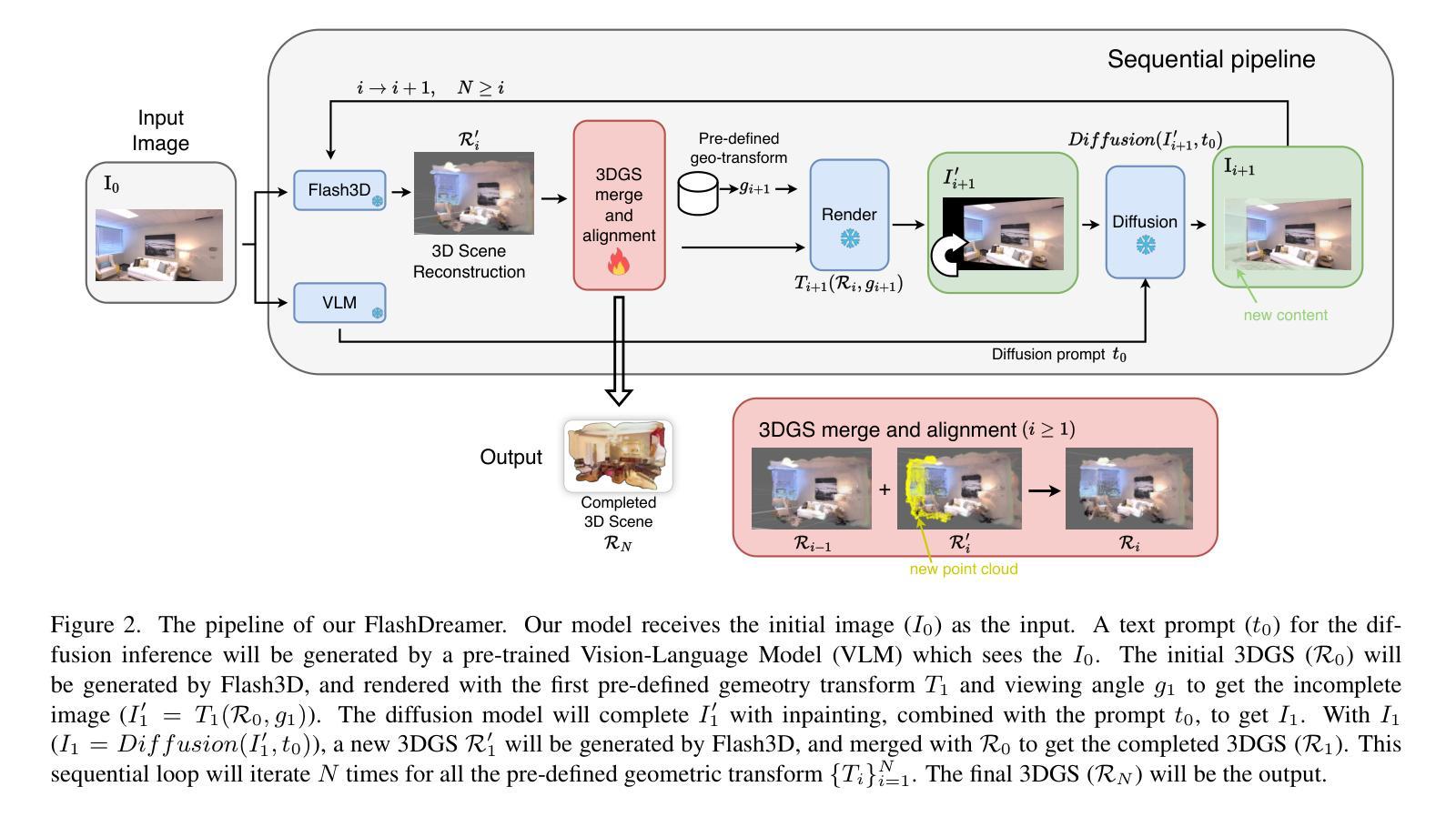
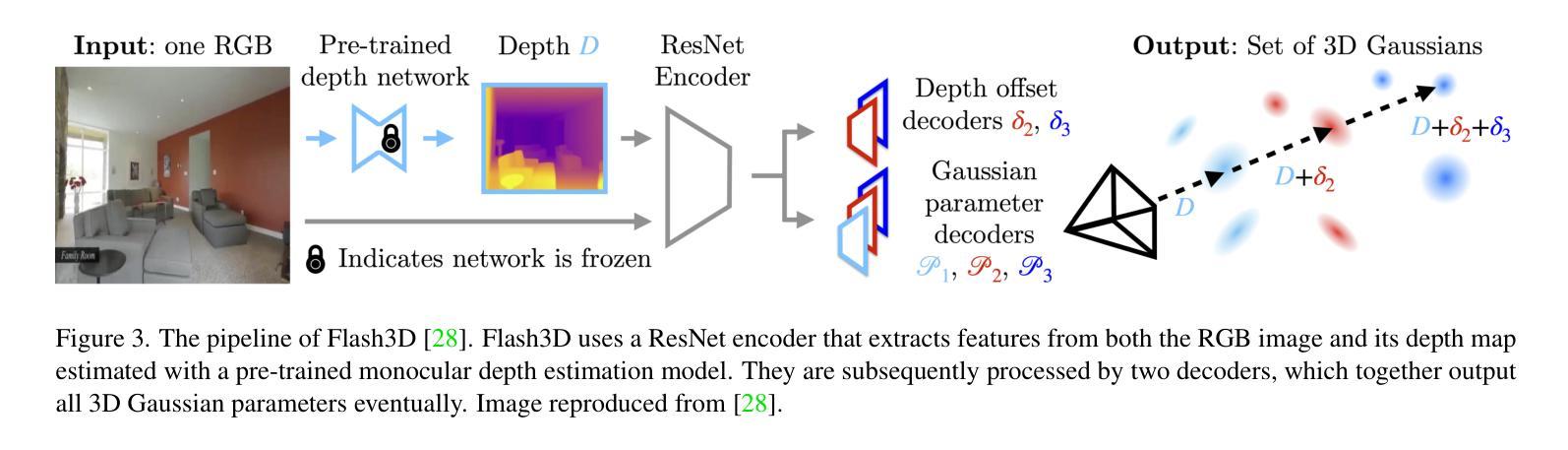
Enhancing Monocular 3D Scene Completion with Diffusion Model
Authors:Changlin Song, Jiaqi Wang, Liyun Zhu, He Weng
3D scene reconstruction is essential for applications in virtual reality, robotics, and autonomous driving, enabling machines to understand and interact with complex environments. Traditional 3D Gaussian Splatting techniques rely on images captured from multiple viewpoints to achieve optimal performance, but this dependence limits their use in scenarios where only a single image is available. In this work, we introduce FlashDreamer, a novel approach for reconstructing a complete 3D scene from a single image, significantly reducing the need for multi-view inputs. Our approach leverages a pre-trained vision-language model to generate descriptive prompts for the scene, guiding a diffusion model to produce images from various perspectives, which are then fused to form a cohesive 3D reconstruction. Extensive experiments show that our method effectively and robustly expands single-image inputs into a comprehensive 3D scene, extending monocular 3D reconstruction capabilities without further training. Our code is available https://github.com/CharlieSong1999/FlashDreamer/tree/main.
三维场景重建在虚拟现实、机器人技术和自动驾驶等领域的应用至关重要,它使机器能够理解和与复杂环境进行交互。传统的三维高斯喷涂技术依赖于从多个视角捕获的图像来达到最佳性能,但这种依赖限制了其在仅提供单张图像的场景中的使用。在这项工作中,我们介绍了FlashDreamer,这是一种从单张图像重建完整三维场景的新方法,显著减少了对多视角输入的需求。我们的方法利用预训练的视觉语言模型生成场景的描述性提示,引导扩散模型从各个视角生成图像,然后将其融合形成连贯的三维重建。大量实验表明,我们的方法有效且稳健地将单张图像输入扩展为全面的三维场景,无需进一步训练即可扩展单目三维重建能力。我们的代码可通过https://github.com/CharlieSong1999/FlashDreamer/tree/main访问。
论文及项目相关链接
PDF All authors had equal contribution
Summary
本文介绍了FlashDreamer技术,该技术能够从单一图像重建完整的3D场景,大大减少了对于多角度图像输入的需求。该方法结合了预训练的视觉语言模型和扩散模型,生成场景的描述性提示并产生多角度图像,再融合形成连贯的3D重建。实验证明,该方法有效且稳健地将单图像输入扩展为全面的3D场景,无需进一步训练即可扩展单目3D重建能力。
Key Takeaways
- FlashDreamer能够从单一图像重建完整的3D场景。
- 传统3D重建技术依赖于从多个视角捕获的图像,而FlashDreamer则大大减少了这一需求。
- FlashDreamer结合了预训练的视觉语言模型和扩散模型,生成场景的描述并产生多角度图像。
- 生成的图像再融合形成连贯的3D重建。
- 实验证明FlashDreamer在单目3D重建方面具有有效性和稳健性。
- 该技术可用于虚拟现实、机器人技术和自动驾驶等多个领域。
点此查看论文截图




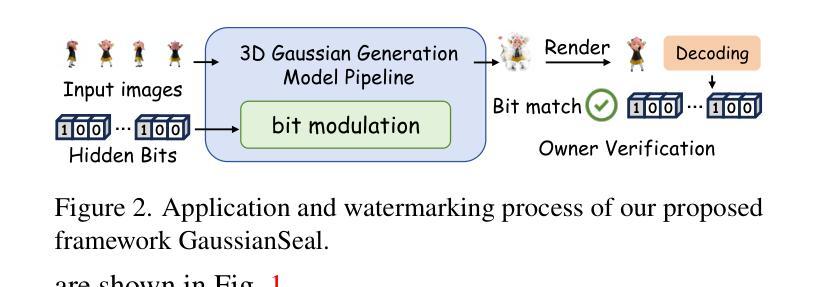
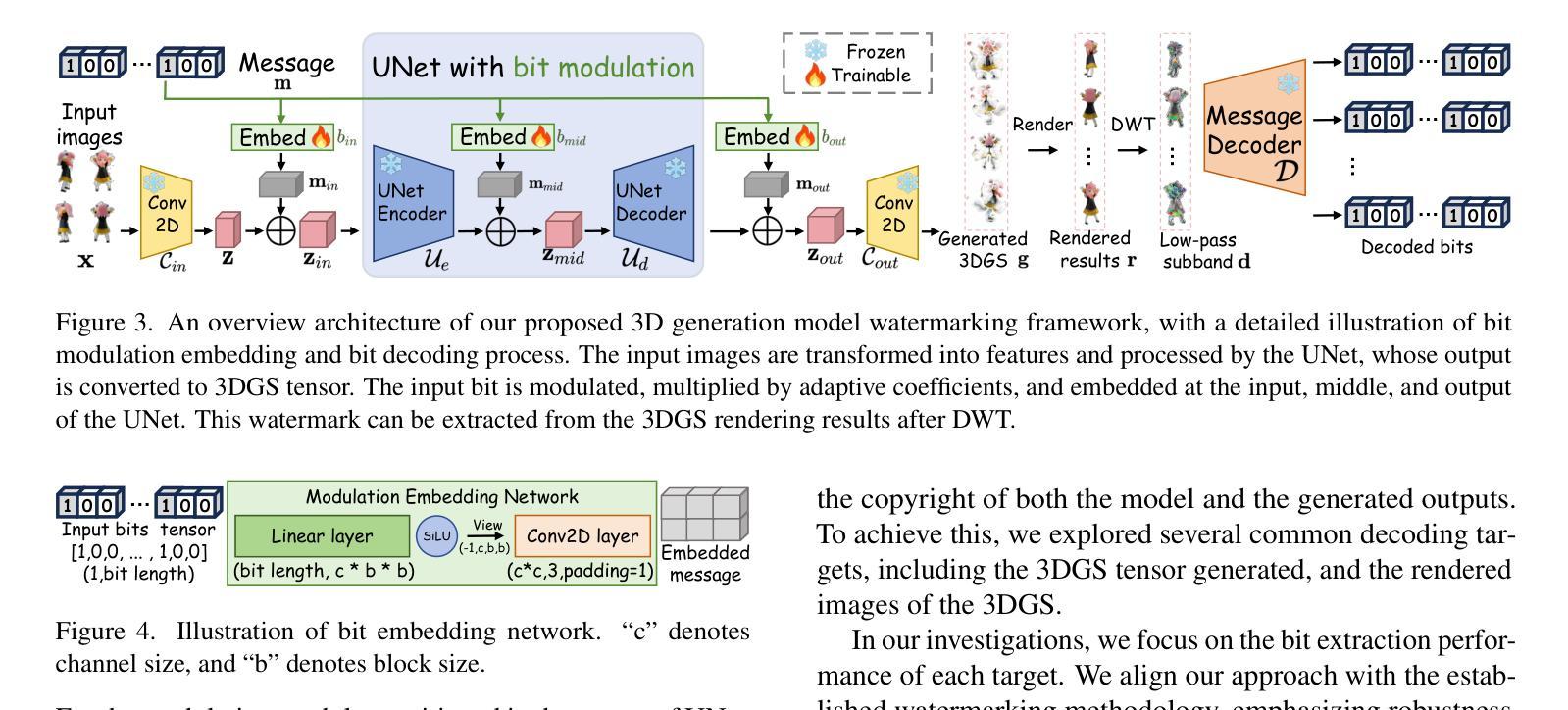
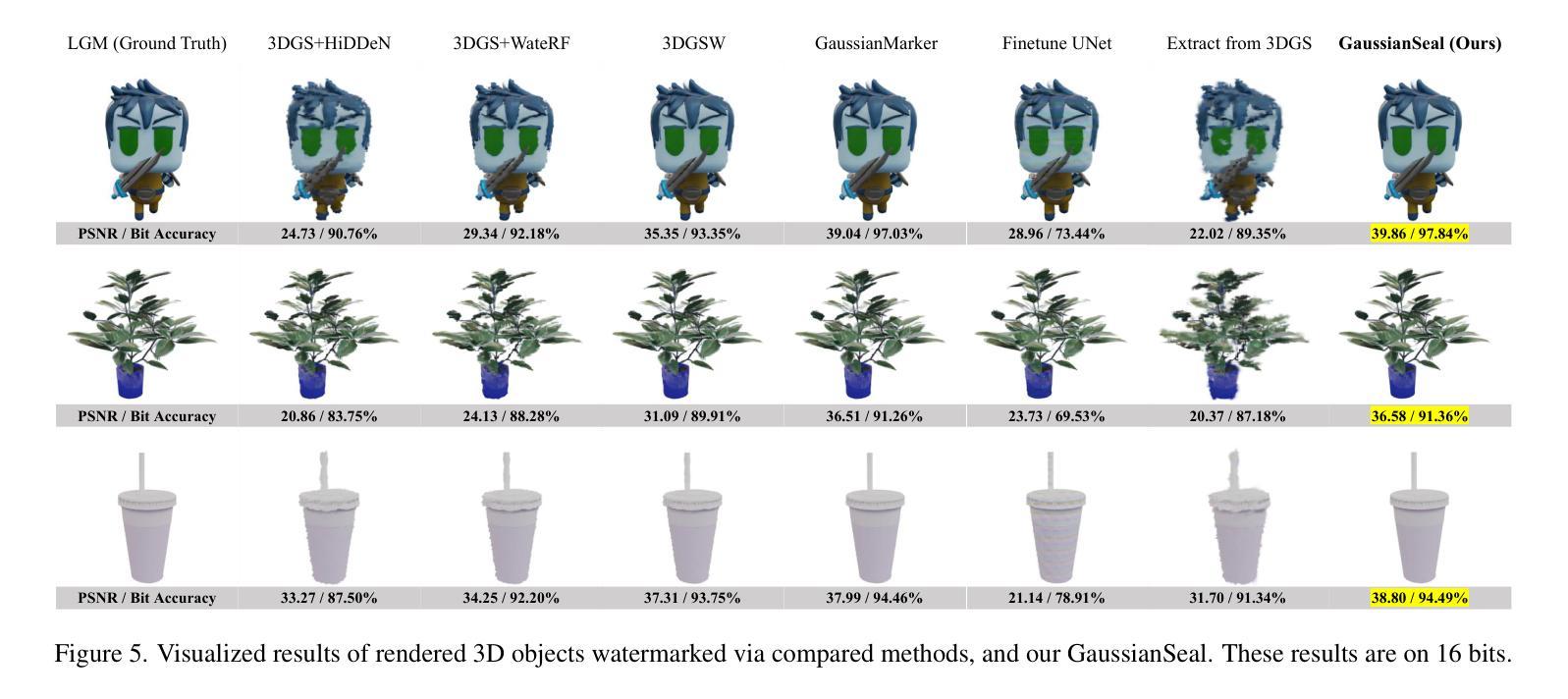
GaussianSeal: Rooting Adaptive Watermarks for 3D Gaussian Generation Model
Authors:Runyi Li, Xuanyu Zhang, Chuhan Tong, Zhipei Xu, Jian Zhang
With the advancement of AIGC technologies, the modalities generated by models have expanded from images and videos to 3D objects, leading to an increasing number of works focused on 3D Gaussian Splatting (3DGS) generative models. Existing research on copyright protection for generative models has primarily concentrated on watermarking in image and text modalities, with little exploration into the copyright protection of 3D object generative models. In this paper, we propose the first bit watermarking framework for 3DGS generative models, named GaussianSeal, to enable the decoding of bits as copyright identifiers from the rendered outputs of generated 3DGS. By incorporating adaptive bit modulation modules into the generative model and embedding them into the network blocks in an adaptive way, we achieve high-precision bit decoding with minimal training overhead while maintaining the fidelity of the model’s outputs. Experiments demonstrate that our method outperforms post-processing watermarking approaches for 3DGS objects, achieving superior performance of watermark decoding accuracy and preserving the quality of the generated results.
随着AIGC技术的进步,模型生成的模态已经从图像和视频扩展到了三维物体,这导致了对三维高斯拼贴(3DGS)生成模型的研究工作数量不断增加。目前关于生成模型版权保护的研究主要集中在图像和文本模态的水印上,而对三维物体生成模型的版权保护研究探索较少。在本文中,我们提出了首个针对3DGS生成模型的位水印框架,名为GaussianSeal。它能够从生成的3DGS渲染输出中解码作为版权标识符的位。通过将自适应位调制模块集成到生成模型中,并以自适应的方式嵌入到网络块中,我们在几乎不增加训练开销的情况下实现了高精度的位解码,同时保持了模型输出的保真度。实验表明,我们的方法在三维高斯拼贴对象的后处理水印方法上具有优越性,实现了水印解码的高精度并保持了生成结果的质量。
论文及项目相关链接
Summary
随着AIGC技术的发展,生成模型产生的形式已从图像和视频扩展到三维物体,引发了越来越多关于三维高斯模糊(3DGS)生成模型的研究。目前关于生成模型的版权保护研究主要集中在图像和文本的模态水印上,而对三维对象生成模型的版权保护探索甚少。本文提出了首个针对3DGS生成模型的比特水印框架,名为GaussianSeal,可从生成的3DGS渲染输出中解码作为版权标识的比特。通过将自适应比特调制模块融入生成模型并以自适应方式嵌入网络块,我们在几乎不影响模型输出保真度的前提下实现了高精度比特解码,且训练开销极小。实验证明,我们的方法相较于针对三维高斯模糊对象的后处理水印方法表现更佳,实现了水印解码的高精度和生成结果的优质表现。
Key Takeaways
- AIGC技术的进展推动了生成模型形式的扩展,现在包括三维物体生成模型的研究。
- 目前关于生成模型的版权保护研究主要集中在图像和文本模态的水印应用上。
- 针对三维对象生成模型的版权保护探索相对不足。
- 本文提出了名为GaussianSeal的比特水印框架,专门用于为三维高斯模糊生成模型提供版权保护。
- 通过结合自适应比特调制模块与网络结构,GaussianSeal能够在保证模型输出质量的同时实现高精度比特解码。
- 与传统的后处理水印方法相比,GaussianSeal提供了更优秀的性能表现,特别是在水印解码的精度方面。
点此查看论文截图


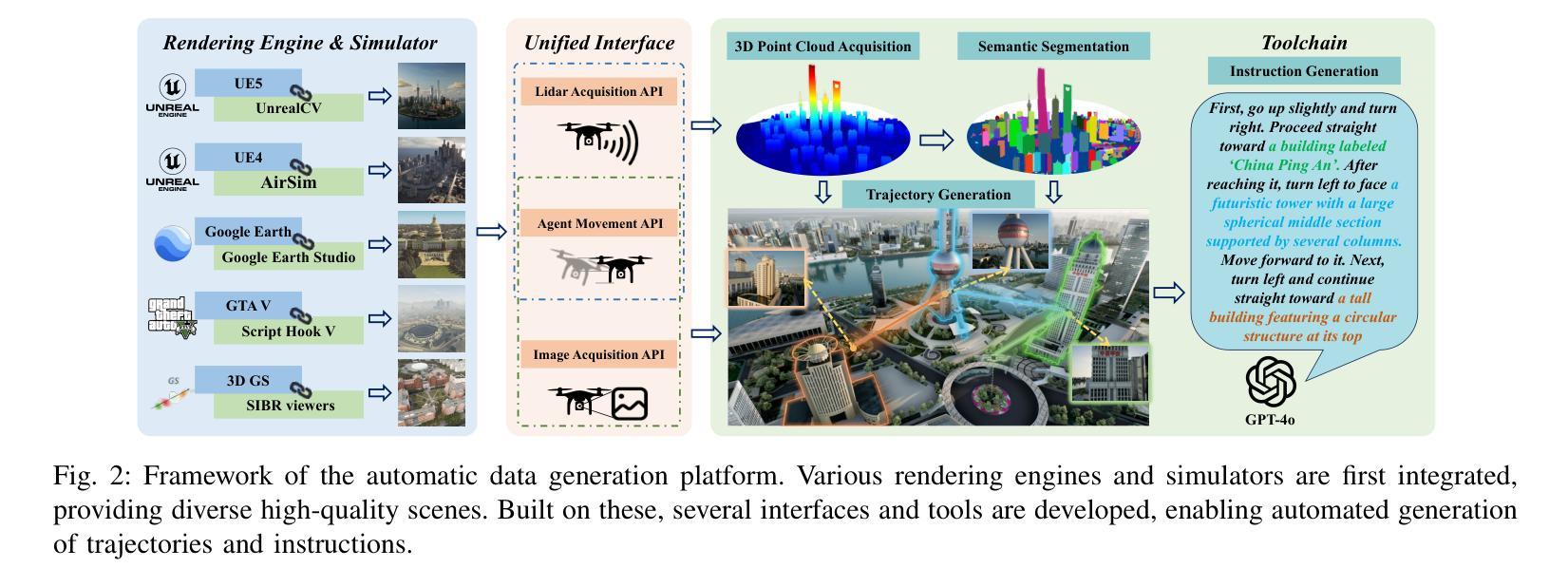
OpenFly: A Versatile Toolchain and Large-scale Benchmark for Aerial Vision-Language Navigation
Authors:Yunpeng Gao, Chenhui Li, Zhongrui You, Junli Liu, Zhen Li, Pengan Chen, Qizhi Chen, Zhonghan Tang, Liansheng Wang, Penghui Yang, Yiwen Tang, Yuhang Tang, Shuai Liang, Songyi Zhu, Ziqin Xiong, Yifei Su, Xinyi Ye, Jianan Li, Yan Ding, Dong Wang, Zhigang Wang, Bin Zhao, Xuelong Li
Vision-Language Navigation (VLN) aims to guide agents through an environment by leveraging both language instructions and visual cues, playing a pivotal role in embodied AI. Indoor VLN has been extensively studied, whereas outdoor aerial VLN remains underexplored. The potential reason is that outdoor aerial view encompasses vast areas, making data collection more challenging, which results in a lack of benchmarks. To address this problem, we propose OpenFly, a platform comprising a versatile toolchain and large-scale benchmark for aerial VLN. Firstly, we develop a highly automated toolchain for data collection, enabling automatic point cloud acquisition, scene semantic segmentation, flight trajectory creation, and instruction generation. Secondly, based on the toolchain, we construct a large-scale aerial VLN dataset with 100k trajectories, covering diverse heights and lengths across 18 scenes. The corresponding visual data are generated using various rendering engines and advanced techniques, including Unreal Engine, GTA V, Google Earth, and 3D Gaussian Splatting (3D GS). All data exhibit high visual quality. Particularly, 3D GS supports real-to-sim rendering, further enhancing the realism of the dataset. Thirdly, we propose OpenFly-Agent, a keyframe-aware VLN model, which takes language instructions, current observations, and historical keyframes as input, and outputs flight actions directly. Extensive analyses and experiments are conducted, showcasing the superiority of our OpenFly platform and OpenFly-Agent. The toolchain, dataset, and codes will be open-sourced.
视觉语言导航(VLN)旨在利用语言指令和视觉线索来引导代理在环境中导航,是嵌入式人工智能中的核心要素。室内VLN已经得到了广泛的研究,而户外空中VLN仍然未被充分探索。可能的原因是户外航拍涉及大面积的区域,使得数据收集更具挑战性,从而缺乏基准测试集。为了解决这个问题,我们提出了OpenFly平台,这是一个包含空中VLN的通用工具链和大规模基准测试的平台。首先,我们开发了一个高度自动化的工具链进行数据采集,能够实现点云自动采集、场景语义分割、飞行轨迹创建和指令生成。其次,基于该工具链,我们构建了一个大规模空中VLN数据集,包含10万条轨迹,涵盖18个场景的多种高度和长度。相应的视觉数据采用各种渲染引擎和先进技术生成,包括Unreal Engine、GTA V、Google Earth和3D高斯溅射(3D GS)。所有数据都表现出高质量的可视效果。特别是,3D GS支持实到模拟渲染,进一步增强了数据集的逼真性。此外,我们提出了OpenFly-Agent,一个关键帧感知的VLN模型,它接受语言指令、当前观察结果和历史关键帧作为输入,并直接输出飞行动作。进行了广泛的分析和实验,展示了OpenFly平台和OpenFly-Agent的优越性。工具链、数据集和代码将开源。
论文及项目相关链接
Summary
针对室外航拍视觉语言导航(VLN)领域缺乏大规模基准数据的问题,该研究提出了OpenFly平台,包括多功能工具链和大规模基准数据集。平台能实现自动数据采集、场景语义分割、飞行轨迹创建和指令生成,构建了涵盖不同高度和长度的超大规模航拍VLN数据集。同时推出OpenFly-Agent模型,表现优异。
Key Takeaways
- OpenFly平台旨在解决室外航拍视觉语言导航领域缺乏大规模基准数据的问题。
- 平台提供了一个高度自动化的工具链,包括数据采集、场景语义分割等。
- 构建了一个大规模航拍VLN数据集,包含超百万轨迹数据,覆盖多种场景和高度。
- 数据集使用了多种渲染引擎和技术,包括Unreal Engine等,保证了高质量视觉效果。
- OpenFly-Agent模型是一个基于关键帧的VLN模型,输入语言指令等,输出飞行动作。
- 实验分析表明OpenFly平台和OpenFly-Agent模型具有优越性。
点此查看论文截图


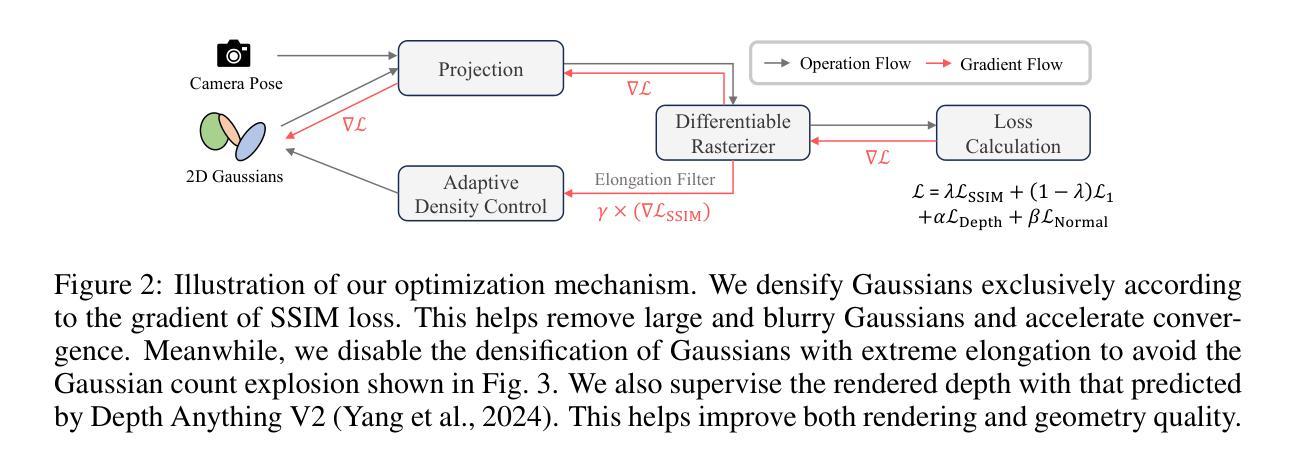
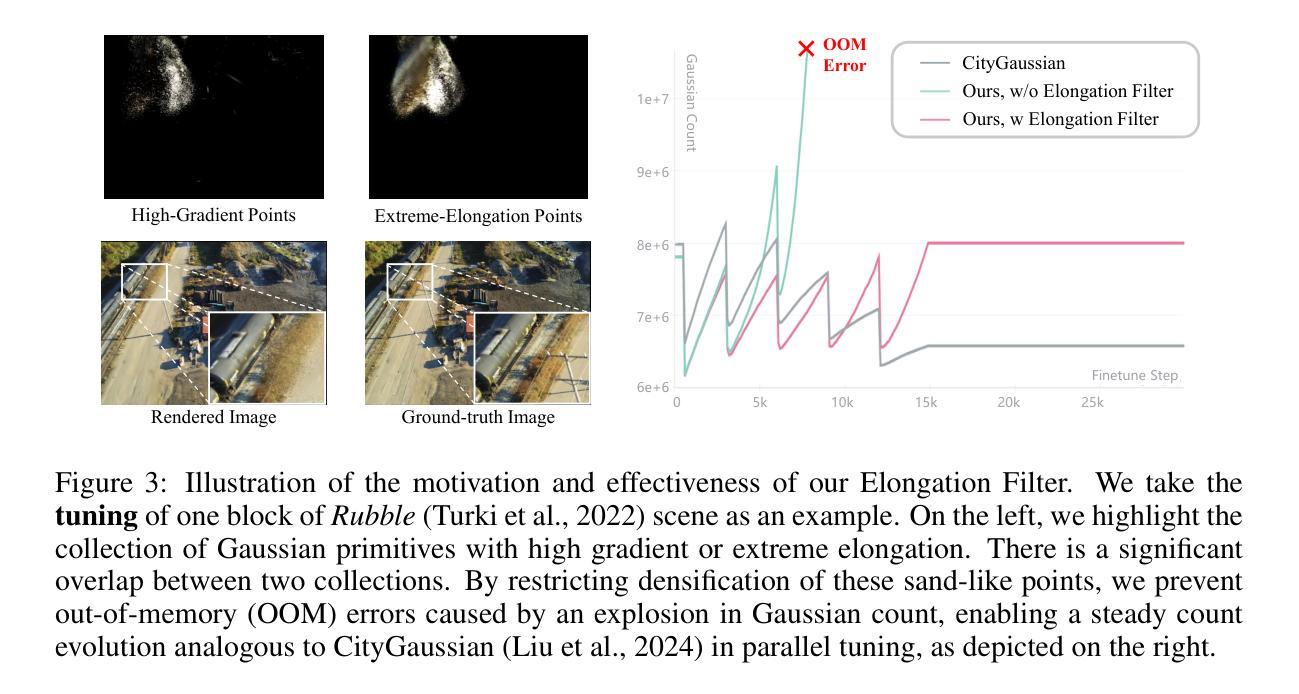
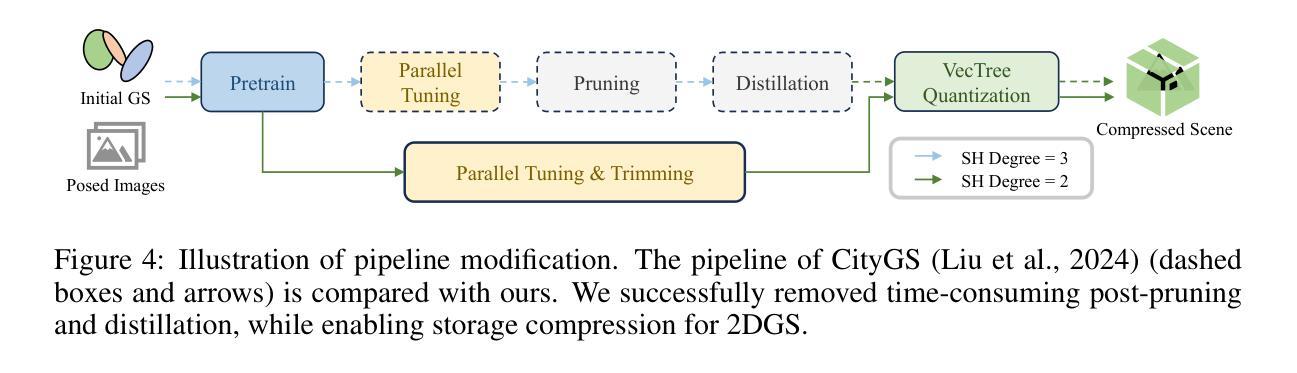
CityGaussianV2: Efficient and Geometrically Accurate Reconstruction for Large-Scale Scenes
Authors:Yang Liu, Chuanchen Luo, Zhongkai Mao, Junran Peng, Zhaoxiang Zhang
Recently, 3D Gaussian Splatting (3DGS) has revolutionized radiance field reconstruction, manifesting efficient and high-fidelity novel view synthesis. However, accurately representing surfaces, especially in large and complex scenarios, remains a significant challenge due to the unstructured nature of 3DGS. In this paper, we present CityGaussianV2, a novel approach for large-scale scene reconstruction that addresses critical challenges related to geometric accuracy and efficiency. Building on the favorable generalization capabilities of 2D Gaussian Splatting (2DGS), we address its convergence and scalability issues. Specifically, we implement a decomposed-gradient-based densification and depth regression technique to eliminate blurry artifacts and accelerate convergence. To scale up, we introduce an elongation filter that mitigates Gaussian count explosion caused by 2DGS degeneration. Furthermore, we optimize the CityGaussian pipeline for parallel training, achieving up to 10$\times$ compression, at least 25% savings in training time, and a 50% decrease in memory usage. We also established standard geometry benchmarks under large-scale scenes. Experimental results demonstrate that our method strikes a promising balance between visual quality, geometric accuracy, as well as storage and training costs. The project page is available at https://dekuliutesla.github.io/CityGaussianV2/.
最近,3D高斯拼贴(3DGS)已经彻底改变了辐射场重建,展现出高效和高保真的新型视图合成。然而,由于3DGS的非结构化特性,准确表示表面,特别是在大型和复杂场景中,仍然是一个巨大的挑战。在本文中,我们提出了CityGaussianV2,这是一种针对大型场景重建的新方法,解决了与几何精度和效率相关的关键挑战。我们在二维高斯拼贴(2DGS)的有利泛化能力的基础上,解决了其收敛性和可扩展性问题。具体来说,我们实现了基于分解梯度的密集化和深度回归技术,以消除模糊伪影并加速收敛。为了扩展规模,我们引入了一个伸长过滤器,以缓解由2DGS退化引起的高斯计数爆炸。此外,我们对CityGaussian管道进行了优化,以实现并行训练,达到最高10倍的压缩率,至少节省25%的训练时间和减少一半的内存使用。我们还建立了大规模场景下的标准几何基准测试。实验结果表明,我们的方法在视觉质量、几何精度以及存储和训练成本之间取得了有希望的平衡。项目页面可在https://dekuliutesla.github.io/CityGaussianV2/找到。
论文及项目相关链接
PDF Accepted by ICLR2025
Summary
基于三维高斯点云技术(3DGS)的局限性,本文提出CityGaussianV2,利用二维高斯点云(2DGS)的良好泛化能力进行大型场景重建。通过梯度分解密度增强和深度回归技术,解决了模糊伪影问题并加速了收敛。引入伸长滤波器缓解高斯计数爆炸问题,优化CityGaussian管道实现并行训练,达到压缩、节省训练时间和降低内存使用的效果。建立大型场景的标准几何基准测试,实现了视觉质量、几何准确性以及存储和训练成本的平衡。
Key Takeaways
- CityGaussianV2利用二维高斯点云(2DGS)的泛化能力进行大型场景重建,解决了三维高斯点云技术(3DGS)的挑战。
- 通过梯度分解密度增强和深度回归技术,解决了模糊伪影问题并加速了收敛。
- 引入伸长滤波器缓解高斯计数爆炸问题,优化并行训练管道。
- 实现高达10倍的压缩率,节省至少25%的训练时间和50%的内存使用。
- 建立了大型场景的标准几何基准测试。
- 实验结果表明,CityGaussianV2在视觉质量、几何准确性以及存储和训练成本之间达到了平衡。
点此查看论文截图