⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-06 更新
Federated Learning for Privacy-Preserving Feedforward Control in Multi-Agent Systems
Authors:Jakob Weber, Markus Gurtner, Benedikt Alt, Adrian Trachte, Andreas Kugi
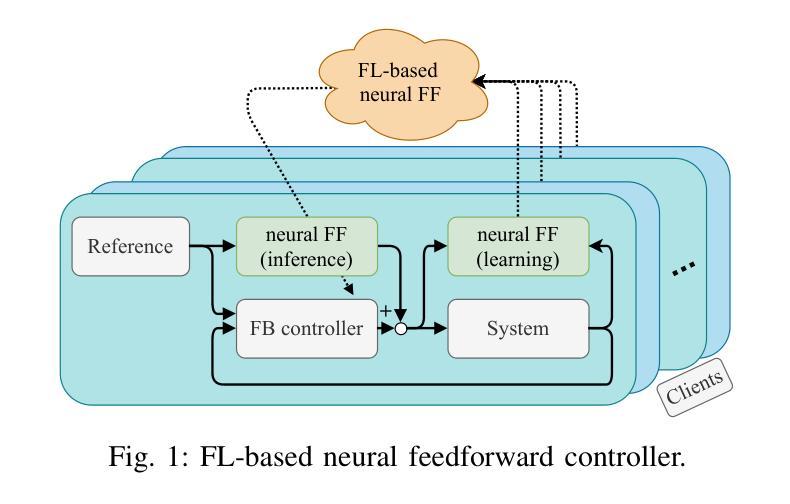
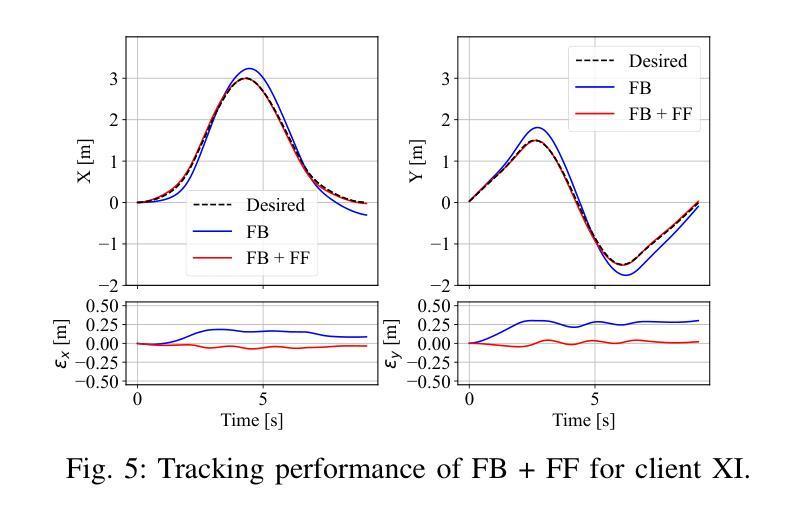
Feedforward control (FF) is often combined with feedback control (FB) in many control systems, improving tracking performance, efficiency, and stability. However, designing effective data-driven FF controllers in multi-agent systems requires significant data collection, including transferring private or proprietary data, which raises privacy concerns and incurs high communication costs. Therefore, we propose a novel approach integrating Federated Learning (FL) into FF control to address these challenges. This approach enables privacy-preserving, communication-efficient, and decentralized continuous improvement of FF controllers across multiple agents without sharing personal or proprietary data. By leveraging FL, each agent learns a local, neural FF controller using its data and contributes only model updates to a global aggregation process, ensuring data privacy and scalability. We demonstrate the effectiveness of our method in an autonomous driving use case. Therein, vehicles equipped with a trajectory-tracking feedback controller are enhanced by FL-based neural FF control. Simulations highlight significant improvements in tracking performance compared to pure FB control, analogous to model-based FF control. We achieve comparable tracking performance without exchanging private vehicle-specific data compared to a centralized neural FF control. Our results underscore the potential of FL-based neural FF control to enable privacy-preserving learning in multi-agent control systems, paving the way for scalable and efficient autonomous systems applications.
前馈控制(FF)在许多控制系统中经常与反馈控制(FB)相结合,提高了跟踪性能、效率和稳定性。然而,在多智能体系统中设计有效的数据驱动FF控制器需要大量的数据采集,包括传输私有或专有数据,这引发了隐私担忧并产生了高昂的通信成本。因此,我们提出了一种将联邦学习(FL)集成到FF控制中来解决这些挑战的新方法。该方法能够在不共享个人或专有数据的情况下,实现隐私保护、通信高效、分散式的FF控制器持续改进。通过利用联邦学习,每个智能体使用其数据学习本地神经FF控制器,并为全局聚合过程提供模型更新,从而确保数据隐私和可扩展性。我们通过自动驾驶用例展示了该方法的有效性。其中,配备轨迹跟踪反馈控制器的车辆通过基于联邦学习的神经FF控制得到增强。模拟结果表明,与纯FB控制相比,跟踪性能得到了显著提高,类似于基于模型的FF控制。与集中式神经FF控制相比,我们在不交换私有车辆特定数据的情况下实现了相当的跟踪性能。我们的结果强调了基于联邦学习的神经FF控制的潜力,能够在多智能体控制系统中实现隐私保护学习,为可扩展和高效的自主系统应用铺平道路。
论文及项目相关链接
PDF Submitted to IJCNN 2025
Summary
基于联邦学习(Federated Learning,简称FL)的前馈控制(Feedforward Control,简称FF)是一个新颖的方法,它在多智能体系统中解决了隐私和通信成本的问题,实现了隐私保护、通信高效的FF控制器持续改进。该方法利用联邦学习,使每个智能体使用其数据学习本地神经FF控制器,并仅将模型更新贡献给全局聚合过程,确保了数据隐私和可扩展性。在自动驾驶用例中,配备了轨迹跟踪反馈控制器的车辆通过基于联邦学习的神经FF控制得到增强。模拟结果表明,与纯反馈控制相比,跟踪性能得到显著改善,与基于模型的FF控制相当。在不交换私有车辆特定数据的情况下,与集中式神经FF控制相比,我们实现了相当的跟踪性能。
Key Takeaways
- 联邦学习与前馈控制的结合,能够在多智能体系统中改善跟踪性能、效率和稳定性。
- 新的方法解决了设计数据驱动FF控制器时的隐私和通信成本挑战。
- 通过联邦学习,每个智能体使用其数据学习本地神经FF控制器,确保数据隐私。
- 仅在全局聚合过程中贡献模型更新,提高系统的可扩展性。
- 在自动驾驶应用中,基于联邦学习的神经FF控制显著提高了车辆的轨迹跟踪性能。
- 模拟结果与基于模型的FF控制相当,但无需交换私有数据。
点此查看论文截图


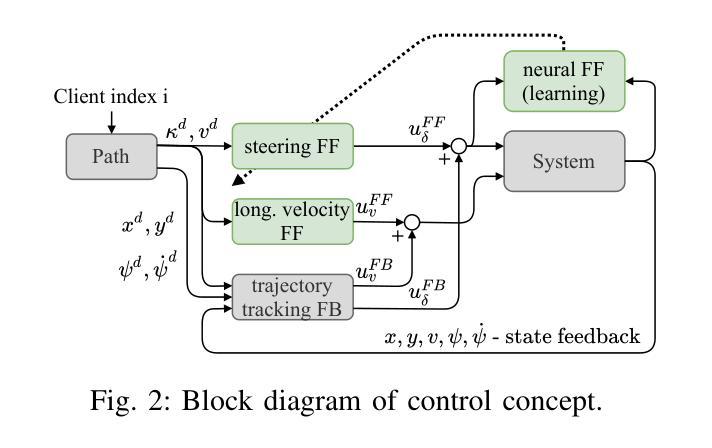
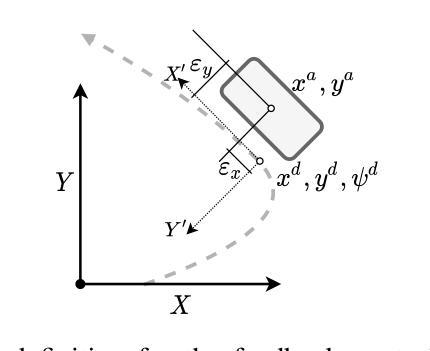
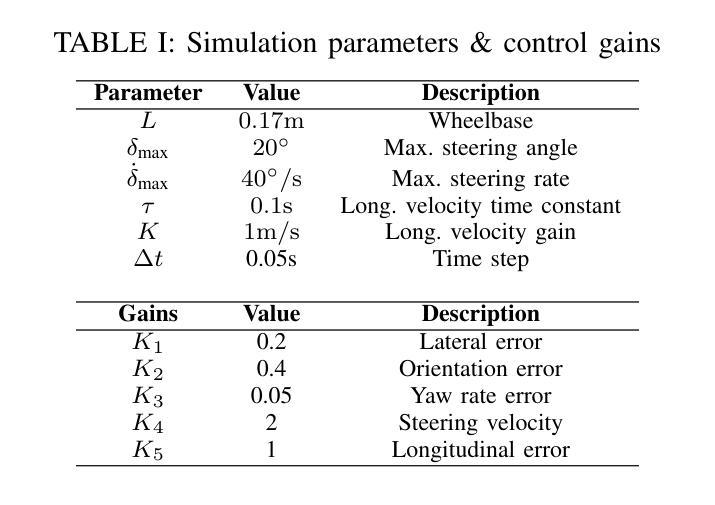
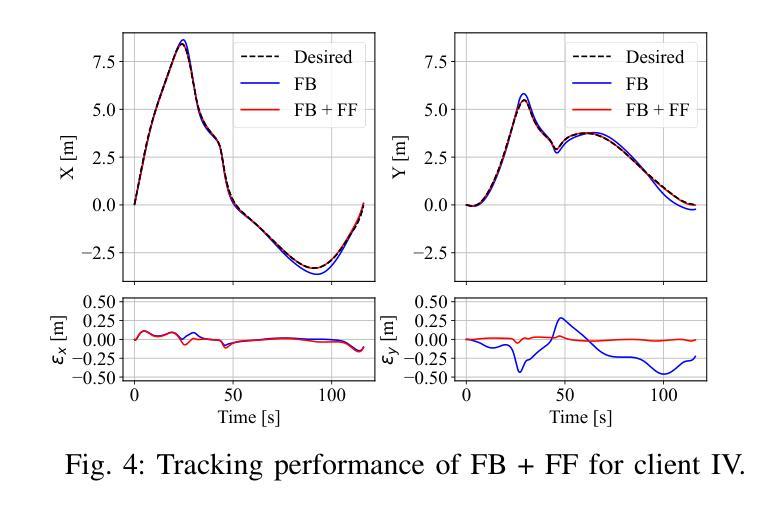
FinArena: A Human-Agent Collaboration Framework for Financial Market Analysis and Forecasting
Authors:Congluo Xu, Zhaobin Liu, Ziyang Li
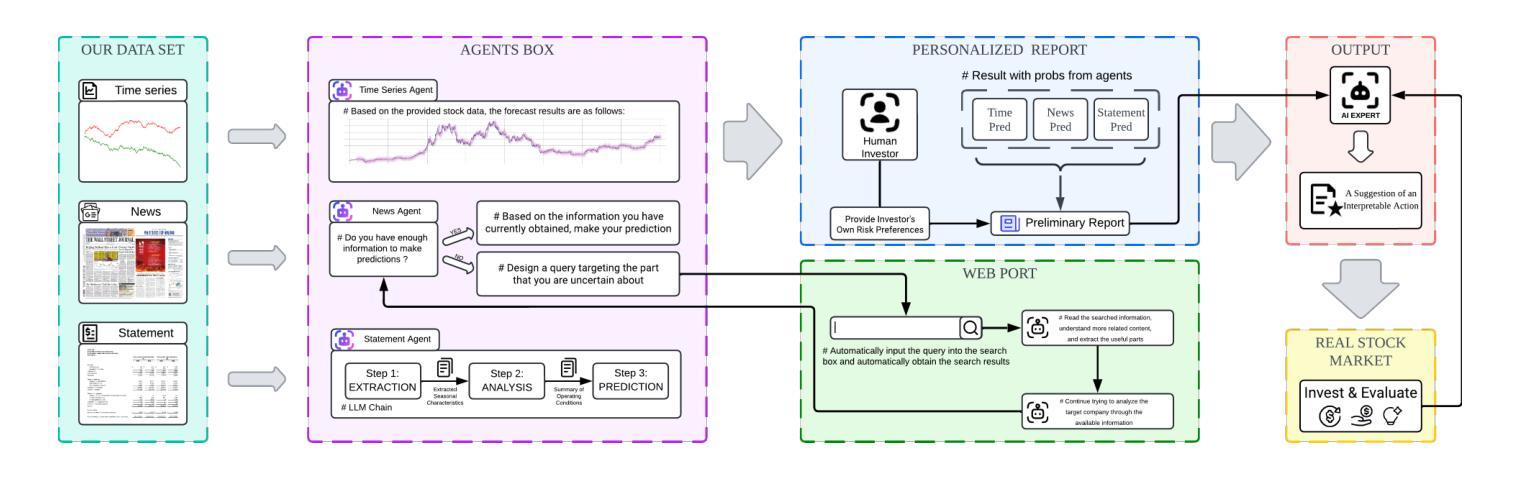
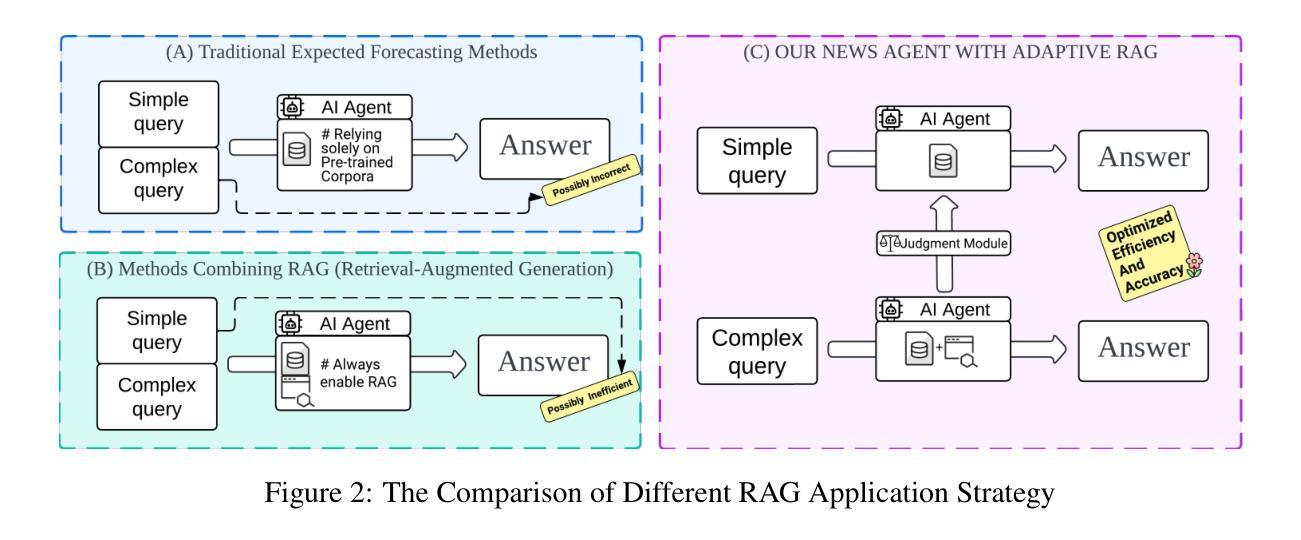
To improve stock trend predictions and support personalized investment decisions, this paper proposes FinArena, a novel Human-Agent collaboration framework. Inspired by the mixture of experts (MoE) approach, FinArena combines multimodal financial data analysis with user interaction. The human module features an interactive interface that captures individual risk preferences, allowing personalized investment strategies. The machine module utilizes a Large Language Model-based (LLM-based) multi-agent system to integrate diverse data sources, such as stock prices, news articles, and financial statements. To address hallucinations in LLMs, FinArena employs the adaptive Retrieval-Augmented Generative (RAG) method for processing unstructured news data. Finally, a universal expert agent makes investment decisions based on the features extracted from multimodal data and investors’ individual risk preferences. Extensive experiments show that FinArena surpasses both traditional and state-of-the-art benchmarks in stock trend prediction and yields promising results in trading simulations across various risk profiles. These findings highlight FinArena’s potential to enhance investment outcomes by aligning strategic insights with personalized risk considerations.
本文提出了一个名为FinArena的新型人机协作框架,旨在改进股票趋势预测并支持个性化的投资决策。受专家混合(MoE)方法的启发,FinArena结合了多模式财务分析与用户交互。人类模块具有一个交互式界面,可以捕捉个人的风险偏好,从而允许制定个性化的投资策略。机器模块利用基于大型语言模型(LLM)的多代理系统来整合各种数据源,如股票价格、新闻文章和财务报表。为了解决大型语言模型中的虚构问题,FinArena采用自适应检索增强生成(RAG)方法处理非结构化新闻数据。最后,一个通用专家代理根据从多模式数据中提取的特征以及投资者的个人风险偏好做出投资决策。大量实验表明,在股票趋势预测方面,FinArena超越了传统和最新的基准测试,并在各种风险概况的交易模拟中产生了有希望的结果。这些发现强调了FinArena的潜力,即通过战略见解与个性化的风险考量来提高投资结果。
论文及项目相关链接
Summary
FinArena是受到专家组合(MoE)方法启发的一种新型人机协作框架,旨在改进股票趋势预测并支持个性化投资决策。它结合了多模式财务数据分析与用户互动,包含人机两个模块。人类模块通过交互界面捕捉个人风险偏好,允许制定个性化投资策略。机器模块则基于大型语言模型(LLM)的多智能体系统,整合股票行情、新闻报道和财务报表等多种数据来源。为解决LLM中的虚构问题,FinArena采用自适应检索增强生成(RAG)方法处理非结构化新闻数据。最终,一个通用专家智能体基于从多模式数据中提取的特征和个人投资者的风险偏好做出投资决策。研究表明,FinArena在股票趋势预测方面超越了传统和最新技术基准,并在各种风险概况的交易模拟中取得了令人鼓舞的结果。
Key Takeaways
- FinArena是一个新型人机协作框架,结合了多模式财务数据分析与用户互动,用于改进股票趋势预测并支持个性化投资决策。
- 它包含人机两个模块,人类模块捕捉个人风险偏好,机器模块整合多种数据来源。
- FinArena采用自适应检索增强生成(RAG)方法处理非结构化新闻数据,以解决LLM中的虚构问题。
- 通用专家智能体基于从多模式数据中提取的特征和个人投资者的风险偏好做出投资决策。
- 研究表明,FinArena在股票趋势预测方面表现出卓越性能,超越了传统和最新技术基准。
- FinArena在交易模拟中取得了令人鼓舞的结果,展现了其在各种风险概况下的潜力。
点此查看论文截图

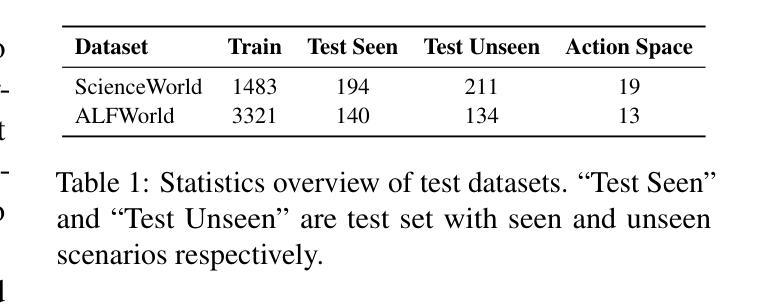
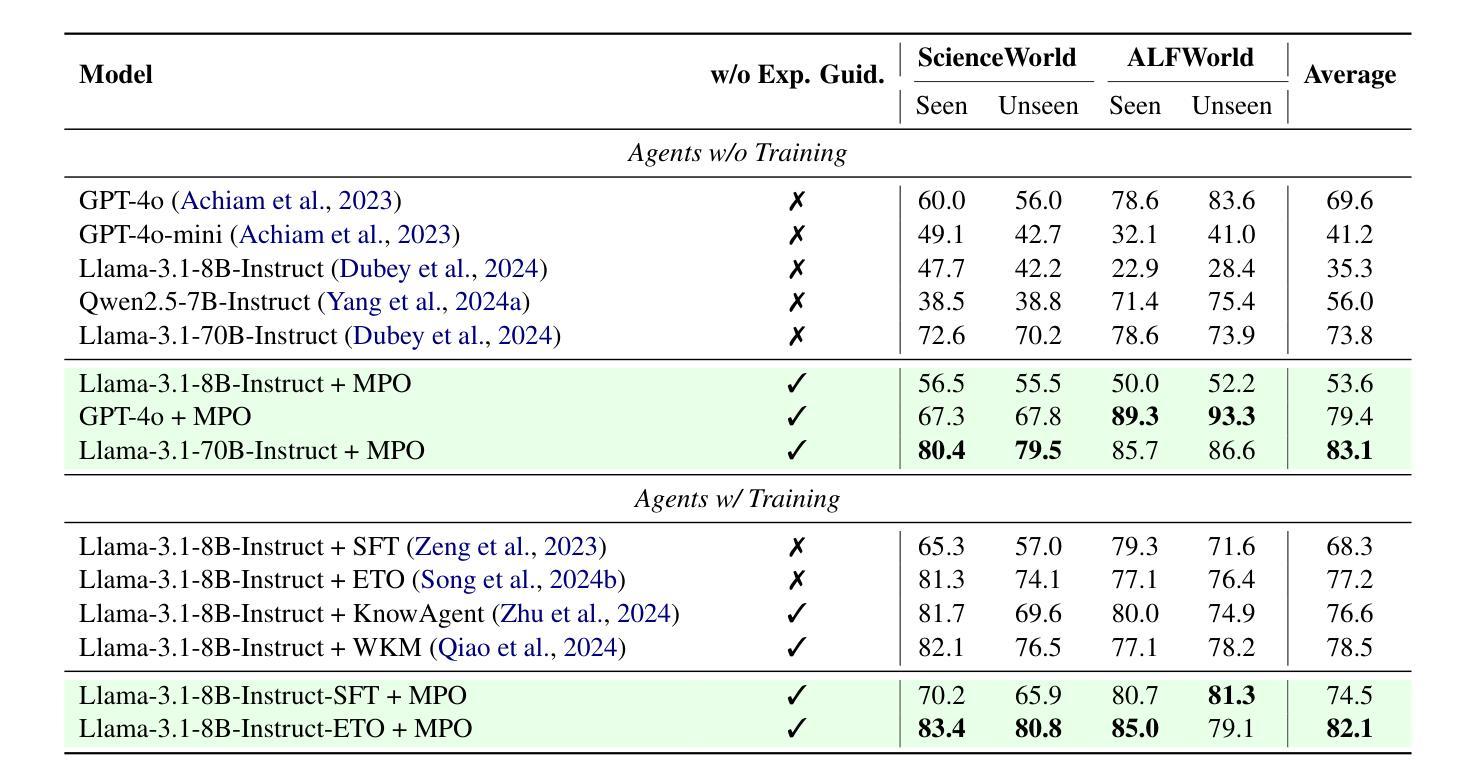
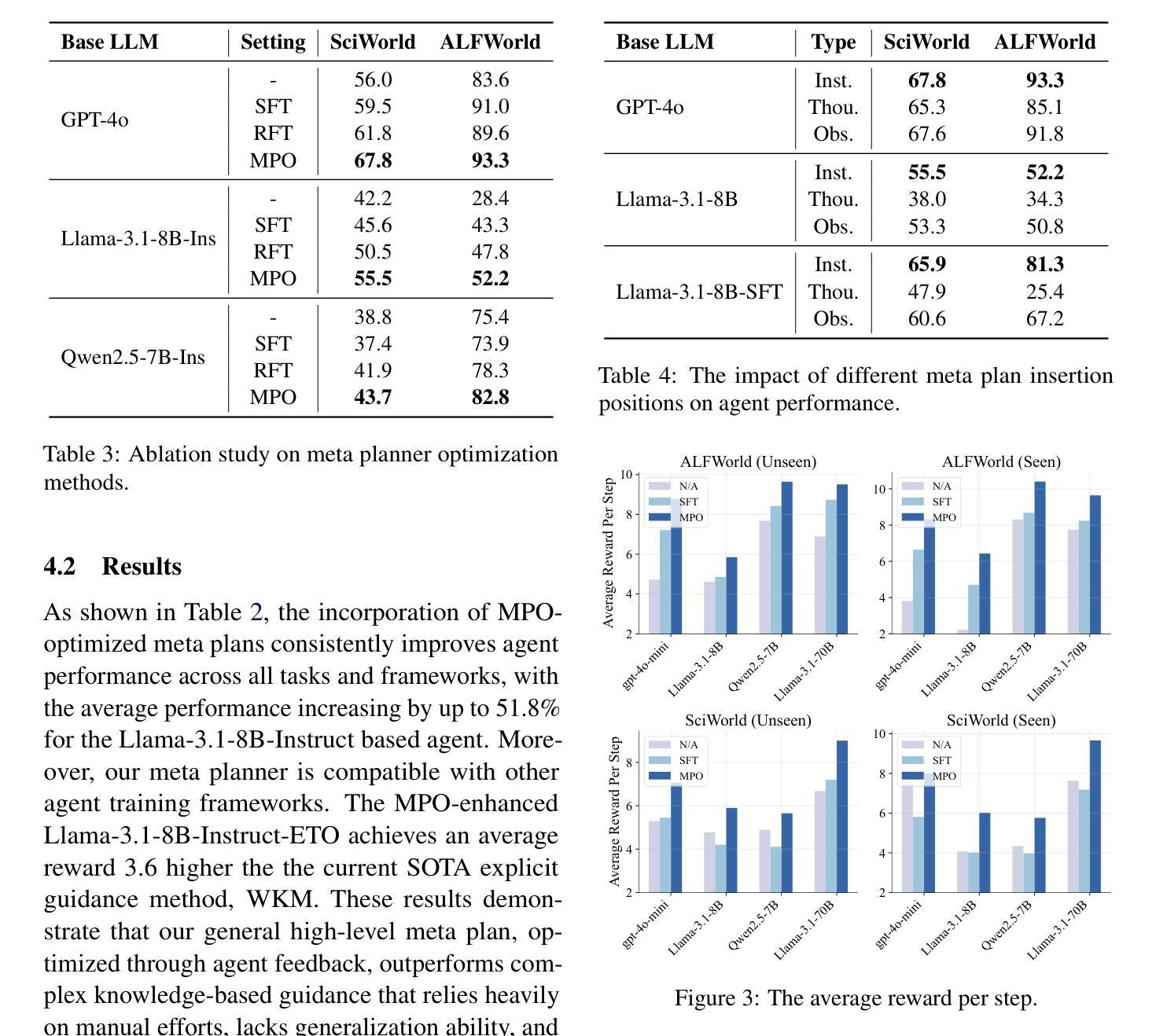
MPO: Boosting LLM Agents with Meta Plan Optimization
Authors:Weimin Xiong, Yifan Song, Qingxiu Dong, Bingchan Zhao, Feifan Song, Xun Wang, Sujian Li
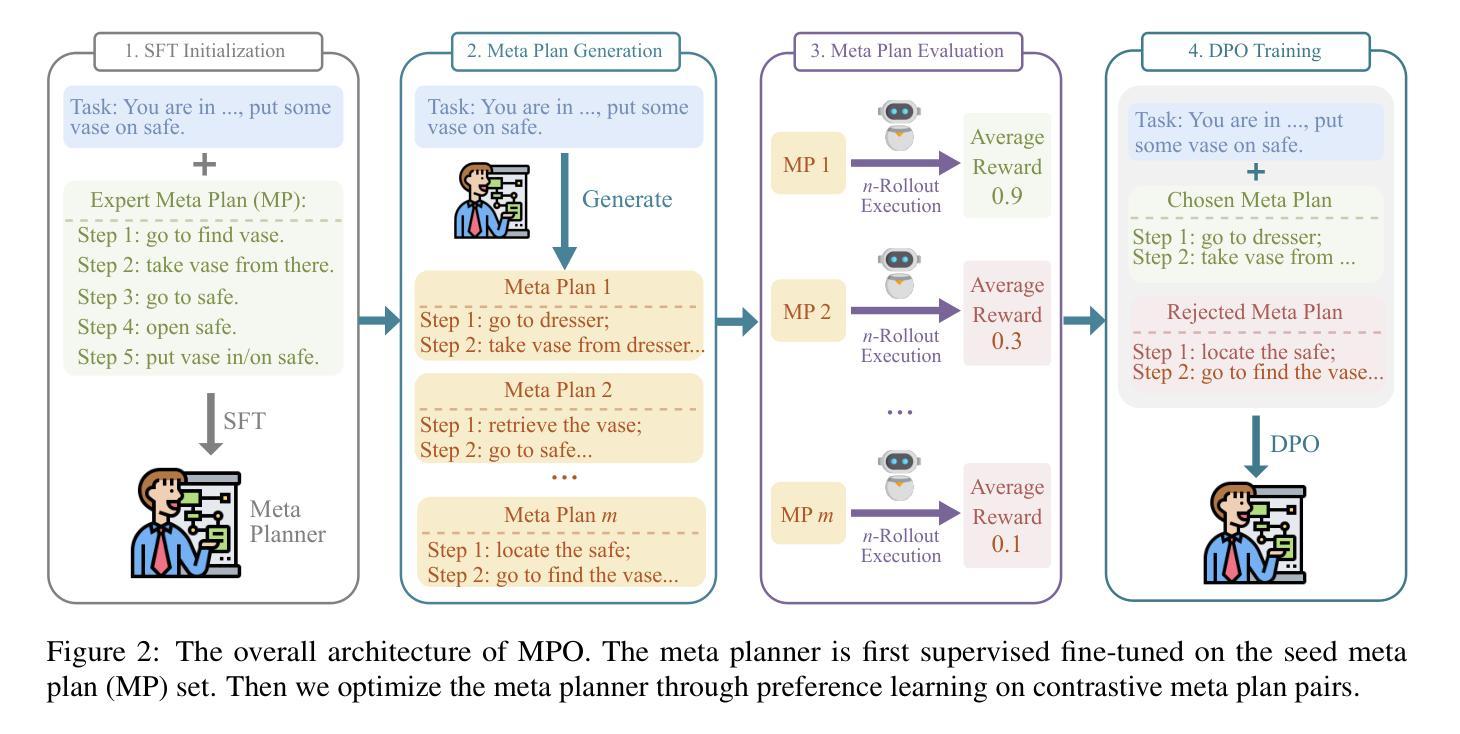
Recent advancements in large language models (LLMs) have enabled LLM-based agents to successfully tackle interactive planning tasks. However, despite their successes, existing approaches often suffer from planning hallucinations and require retraining for each new agent. To address these challenges, we propose the Meta Plan Optimization (MPO) framework, which enhances agent planning capabilities by directly incorporating explicit guidance. Unlike previous methods that rely on complex knowledge, which either require significant human effort or lack quality assurance, MPO leverages high-level general guidance through meta plans to assist agent planning and enables continuous optimization of the meta plans based on feedback from the agent’s task execution. Our experiments conducted on two representative tasks demonstrate that MPO significantly outperforms existing baselines. Moreover, our analysis indicates that MPO provides a plug-and-play solution that enhances both task completion efficiency and generalization capabilities in previous unseen scenarios.
近期,大型语言模型(LLM)的进步使得基于LLM的代理能够成功处理交互规划任务。然而,尽管已经取得了一些成功,现有方法仍然经常受到规划幻觉的影响,并且需要为每个新代理进行再训练。为了解决这些挑战,我们提出了元计划优化(MPO)框架,它通过直接融入明确的指导来增强代理的规划能力。与其他依赖复杂知识的方法不同,这些方法需要大量的人力投入或缺乏质量保证,MPO通过元计划提供高级一般指导来协助代理规划,并根据代理任务执行的反馈持续优化元计划。我们在两个代表性任务上进行的实验表明,MPO显著优于现有基线。此外,我们的分析表明,MPO提供了一种即插即用的解决方案,提高了任务完成效率和在未见过场景中的泛化能力。
论文及项目相关链接
总结
近期大型语言模型(LLM)在交互规划任务上的进展显著,但现有方法常常面临规划幻觉的问题,并为每个新代理需要重训。为解决这些挑战,提出了Meta Plan Optimization(MPO)框架,通过直接引入明确指导来提升代理规划能力。不同于依赖复杂知识的旧方法,MPO利用高级通用指导通过元计划协助代理规划,并基于代理任务执行的反馈持续优化元计划。在两项代表性任务上的实验表明,MPO显著优于现有基线。分析显示,MPO提供了即插即用的解决方案,提高了任务完成效率和在未见过场景中的泛化能力。
关键见解
- 大型语言模型(LLM)在交互规划任务上取得显著进展。
- 现有方法面临规划幻觉的问题,需要为每个新代理进行重训。
- MPO框架通过直接引入明确指导提升代理规划能力。
- MPO利用高级通用指导通过元计划协助代理规划。
- MPO能够基于代理任务执行的反馈持续优化元计划。
- 在两项代表性任务上,MPO显著优于现有方法。
点此查看论文截图

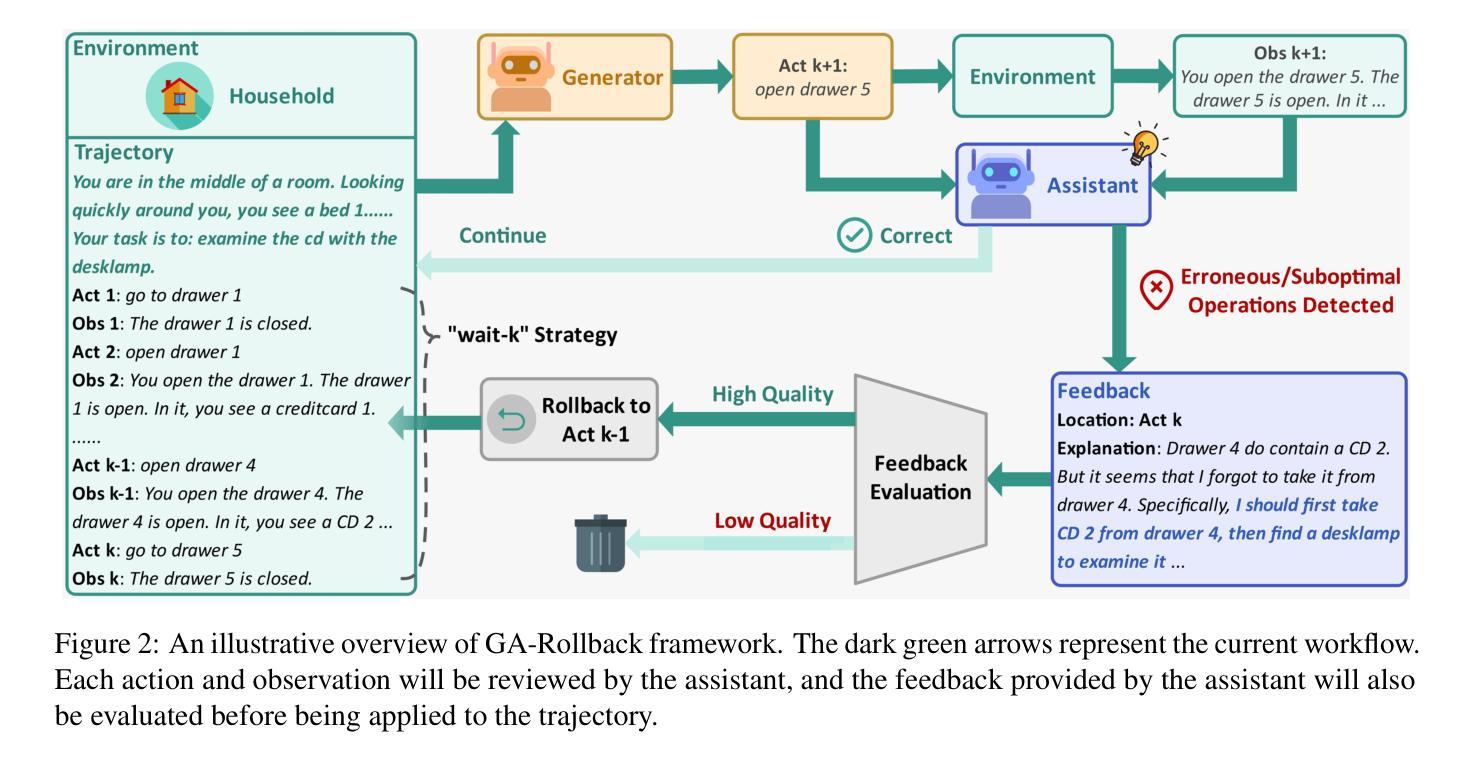
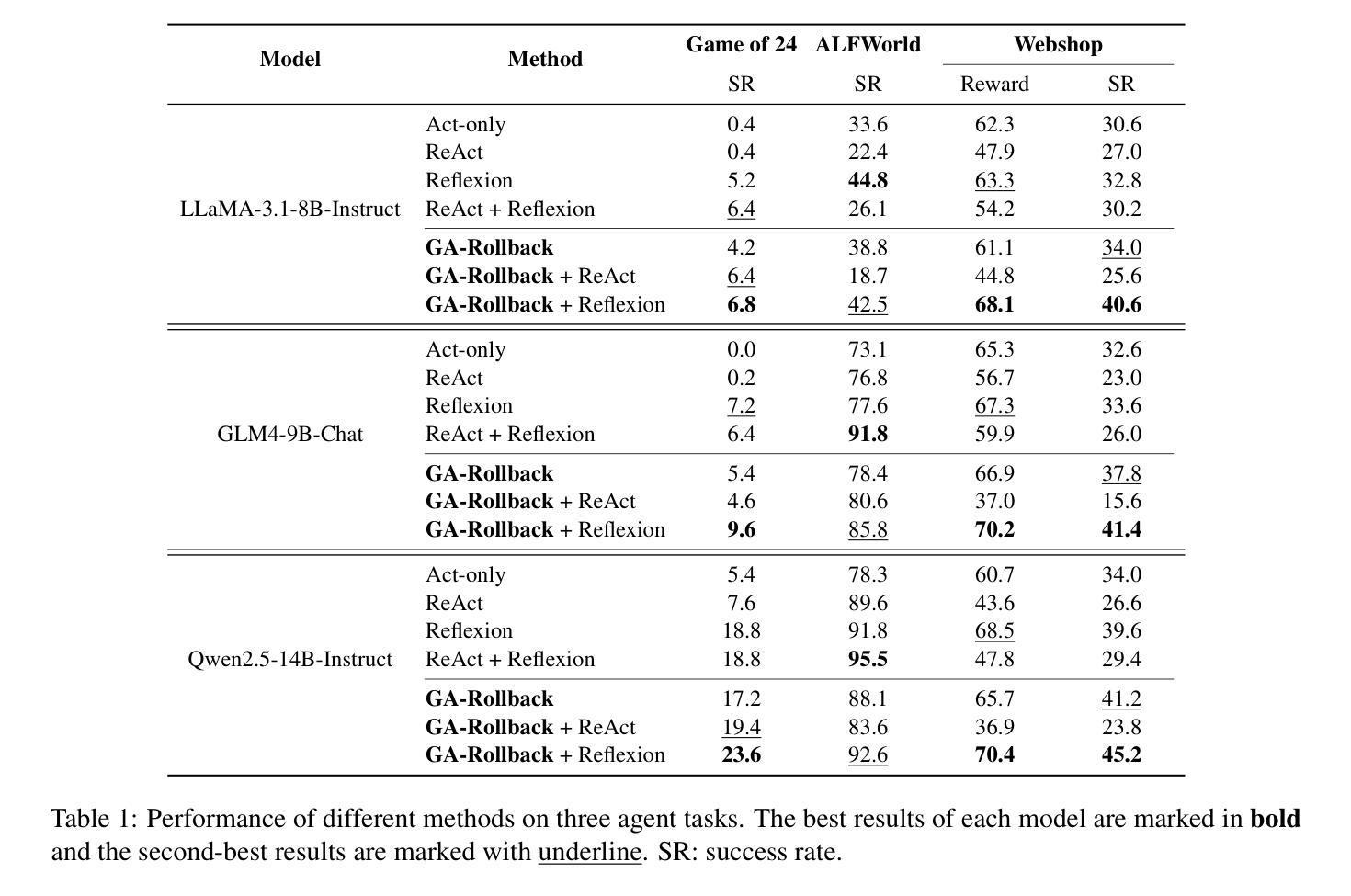
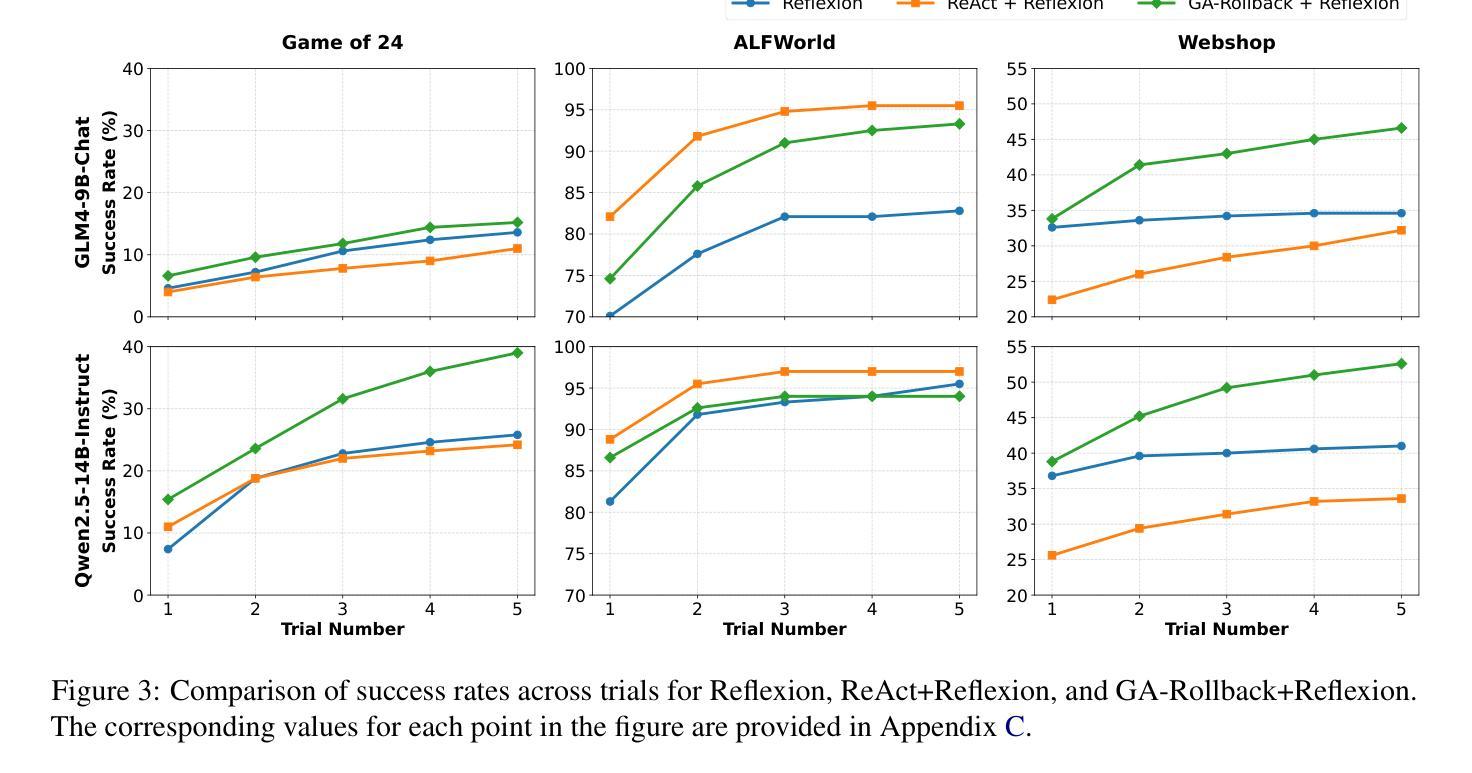
Generator-Assistant Stepwise Rollback Framework for Large Language Model Agent
Authors:Xingzuo Li, Kehai Chen, Yunfei Long, Xuefeng Bai, Yong Xu, Min Zhang
Large language model (LLM) agents typically adopt a step-by-step reasoning framework, in which they interleave the processes of thinking and acting to accomplish the given task. However, this paradigm faces a deep-rooted one-pass issue whereby each generated intermediate thought is plugged into the trajectory regardless of its correctness, which can cause irreversible error propagation. To address the issue, this paper proposes a novel framework called Generator-Assistant Stepwise Rollback (GA-Rollback) to induce better decision-making for LLM agents. Particularly, GA-Rollback utilizes a generator to interact with the environment and an assistant to examine each action produced by the generator, where the assistant triggers a rollback operation upon detection of incorrect actions. Moreover, we introduce two additional strategies tailored for the rollback scenario to further improve its effectiveness. Extensive experiments show that GA-Rollback achieves significant improvements over several strong baselines on three widely used benchmarks. Our analysis further reveals that GA-Rollback can function as a robust plug-and-play module, integrating seamlessly with other methods.
大型语言模型(LLM)代理通常采用一种逐步推理框架,在该框架中,它们将思考和行动的过程交织在一起,以完成给定的任务。然而,这种范式面临一个根深蒂固的一次性通过问题,即无论中间想法的正确与否,都会将其插入轨迹中,这可能导致不可逆的错误传播。为了解决这一问题,本文提出了一种名为Generator-Assistant Stepwise Rollback(GA-Rollback)的新型框架,以引导LLM代理做出更好的决策。特别是,GA-Rollback利用生成器与环境进行交互,并利用助理检查生成器产生的每个动作,当助理检测到不正确的动作时,会触发回滚操作。此外,我们引入了两种针对回滚场景的额外策略,以进一步提高其有效性。大量实验表明,GA-Rollback在三个广泛使用的基准测试上优于多个强大的基线模型。我们的分析还表明,GA-Rollback可以作为一个强大的即插即用模块,与其他方法无缝集成。
论文及项目相关链接
Summary
新一代大型语言模型(LLM)代理采用逐步推理框架,但存在一次通过问题,可能导致错误不可逆地传播。为解决这一问题,本文提出了名为Generator-Assistant Stepwise Rollback(GA-Rollback)的新型框架,旨在实现更好的决策制定。GA-Rollback通过生成器与环境交互,并利用助理检查生成器的每个动作,并在检测到错误动作时触发回滚操作。此外,还引入两种针对回滚场景的策略以提高其有效性。实验表明,GA-Rollback在三个广泛使用的基准测试上优于多个强大的基线模型。分析表明,GA-Rollback可作为强大的即插即用模块与其他方法无缝集成。
Key Takeaways
- 大型语言模型(LLM)代理采用逐步推理框架,但存在错误传播问题。
- GA-Rollback框架旨在解决这一问题,包括生成器、助理以及回滚机制。
- 生成器与环境交互,助理检查每个动作,错误动作会触发回滚操作。
- 引入两种策略以提高回滚机制的有效性。
- 实验证明,GA-Rollback在多个基准测试上表现优于现有模型。
- GA-Rollback可作为强大的插件与其他方法无缝集成。
点此查看论文截图

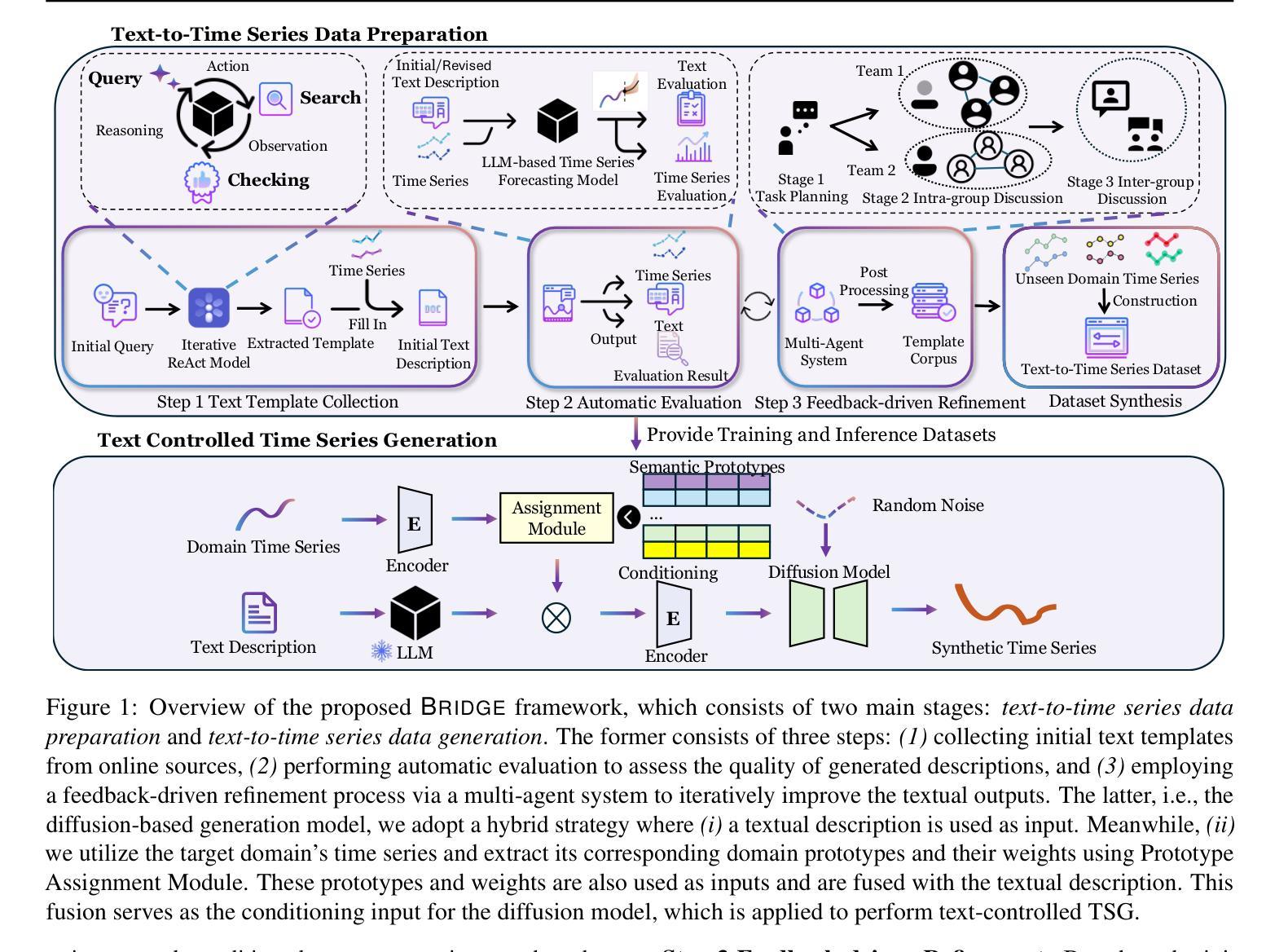
BRIDGE: Bootstrapping Text to Control Time-Series Generation via Multi-Agent Iterative Optimization and Diffusion Modelling
Authors:Hao Li, Yu-Hao Huang, Chang Xu, Viktor Schlegel, Ren-He Jiang, Riza Batista-Navarro, Goran Nenadic, Jiang Bian
Time-series Generation (TSG) is a prominent research area with broad applications in simulations, data augmentation, and counterfactual analysis. While existing methods have shown promise in unconditional single-domain TSG, real-world applications demand for cross-domain approaches capable of controlled generation tailored to domain-specific constraints and instance-level requirements. In this paper, we argue that text can provide semantic insights, domain information and instance-specific temporal patterns, to guide and improve TSG. We introduce ``Text-Controlled TSG’’, a task focused on generating realistic time series by incorporating textual descriptions. To address data scarcity in this setting, we propose a novel LLM-based Multi-Agent framework that synthesizes diverse, realistic text-to-TS datasets. Furthermore, we introduce BRIDGE, a hybrid text-controlled TSG framework that integrates semantic prototypes with text description for supporting domain-level guidance. This approach achieves state-of-the-art generation fidelity on 11 of 12 datasets, and improves controllability by 12.52% on MSE and 6.34% MAE compared to no text input generation, highlighting its potential for generating tailored time-series data.
时间序列生成(TSG)是一个具有广泛应用前景的重要研究领域,如模拟、数据增强和假设分析等领域。虽然现有方法在无条件单域TSG方面表现出一定潜力,但现实世界的应用需求需要跨域方法,能够针对特定领域的约束和实例级需求进行受控生成。在本文中,我们主张文本可以提供语义洞察、领域信息和实例特定的时间模式,以指导和改进TSG。我们引入了“文本控制TSG”,这是一个通过融入文本描述来生成真实时间序列的任务。为了解决此场景下的数据稀缺问题,我们提出了一个基于大型语言模型的多智能体框架,该框架可以合成多样且真实的文本到时间序列数据集。此外,我们还引入了BRIDGE,一个混合文本控制TSG框架,它将语义原型与文本描述相结合,以支持领域级的指导。该方法在12个数据集中的11个数据集上实现了最先进的生成保真度,并且在均方误差(MSE)和平均绝对误差(MAE)方面,与无文本输入生成相比,可控性提高了12.52%和6.34%,突显其在生成定制时间序列数据方面的潜力。
论文及项目相关链接
PDF Preprint. Work in progress
Summary
时间序列生成(TSG)是模拟、数据增强和反向事实分析等领域的重要研究方向。现有方法主要关注无条件单一领域的TSG,但实际应用需要跨领域的生成方法,以满足特定领域的约束和实例级需求。本文提出“文本控制时间序列生成(Text-Controlled TSG)”任务,旨在通过引入文本描述来生成真实的时间序列数据。为解决数据稀缺问题,我们提出了一种基于大型语言模型的多智能体框架,合成多样且真实的文本到时间序列数据集。此外,我们引入了混合文本控制TSG框架BRIDGE,它将语义原型与文本描述相结合,为领域级指导提供支持。该方法在12个数据集中有11个达到了最先进的生成保真度,并且在均方误差和平均绝对误差方面分别提高了12.52%和6.34%,显示出其在生成定制时间序列数据方面的潜力。
Key Takeaways
- 时间序列生成(TSG)是模拟、数据增强和反向事实分析的关键研究方向。
- 现有方法主要关注无条件单一领域的TSG,缺乏满足跨领域约束和实例级需求的生成方法。
- 本文提出了“文本控制时间序列生成(Text-Controlled TSG)”任务,通过引入文本描述来生成真实的时间序列数据。
- 为解决数据稀缺问题,研究提出了一种基于大型语言模型的多智能体框架。
- 引入的混合文本控制TSG框架BRIDGE结合了语义原型与文本描述,为领域级指导提供支持。
- 该方法在多个数据集上达到了最先进的生成效果,提高了生成数据的真实性和可控性。
点此查看论文截图

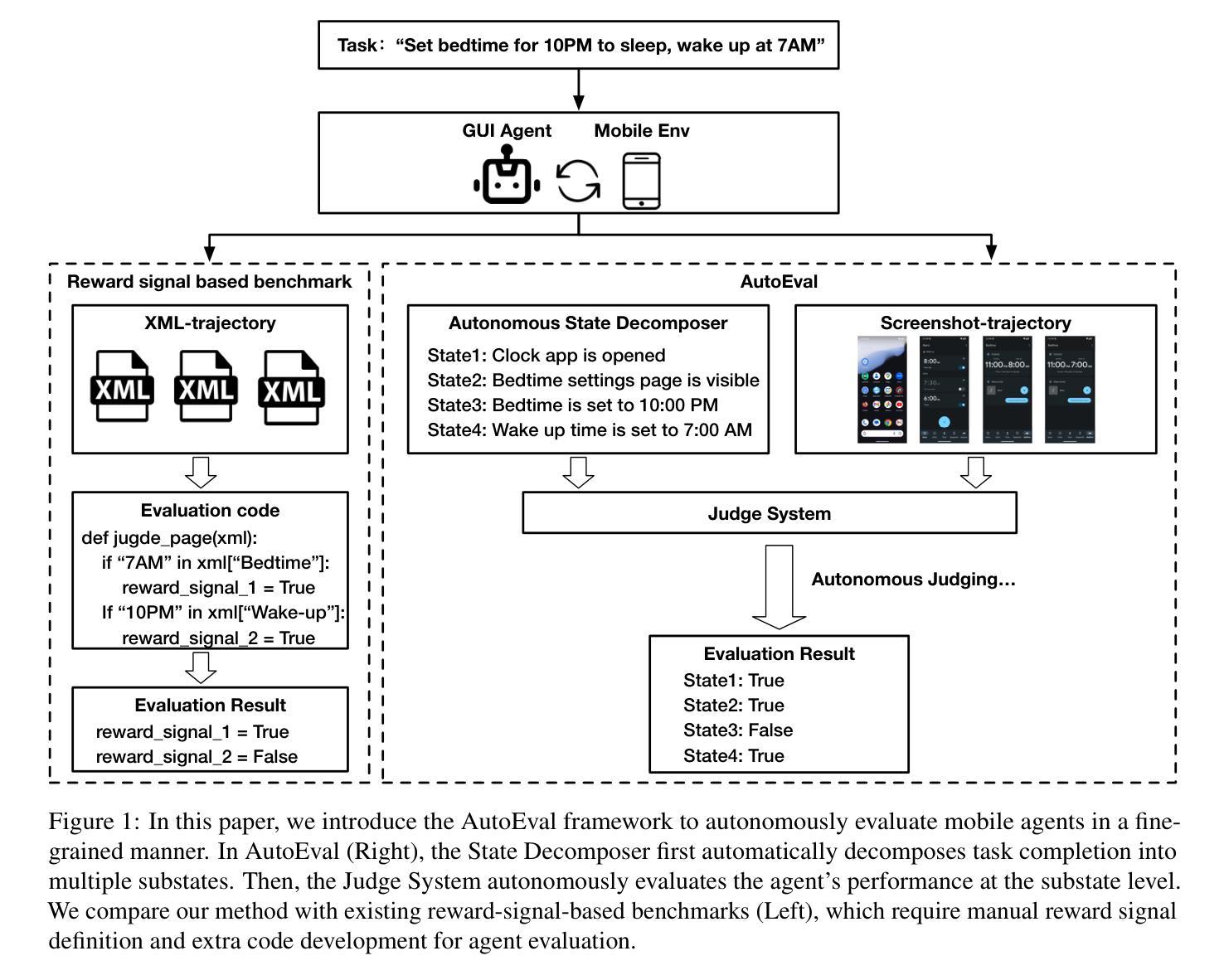
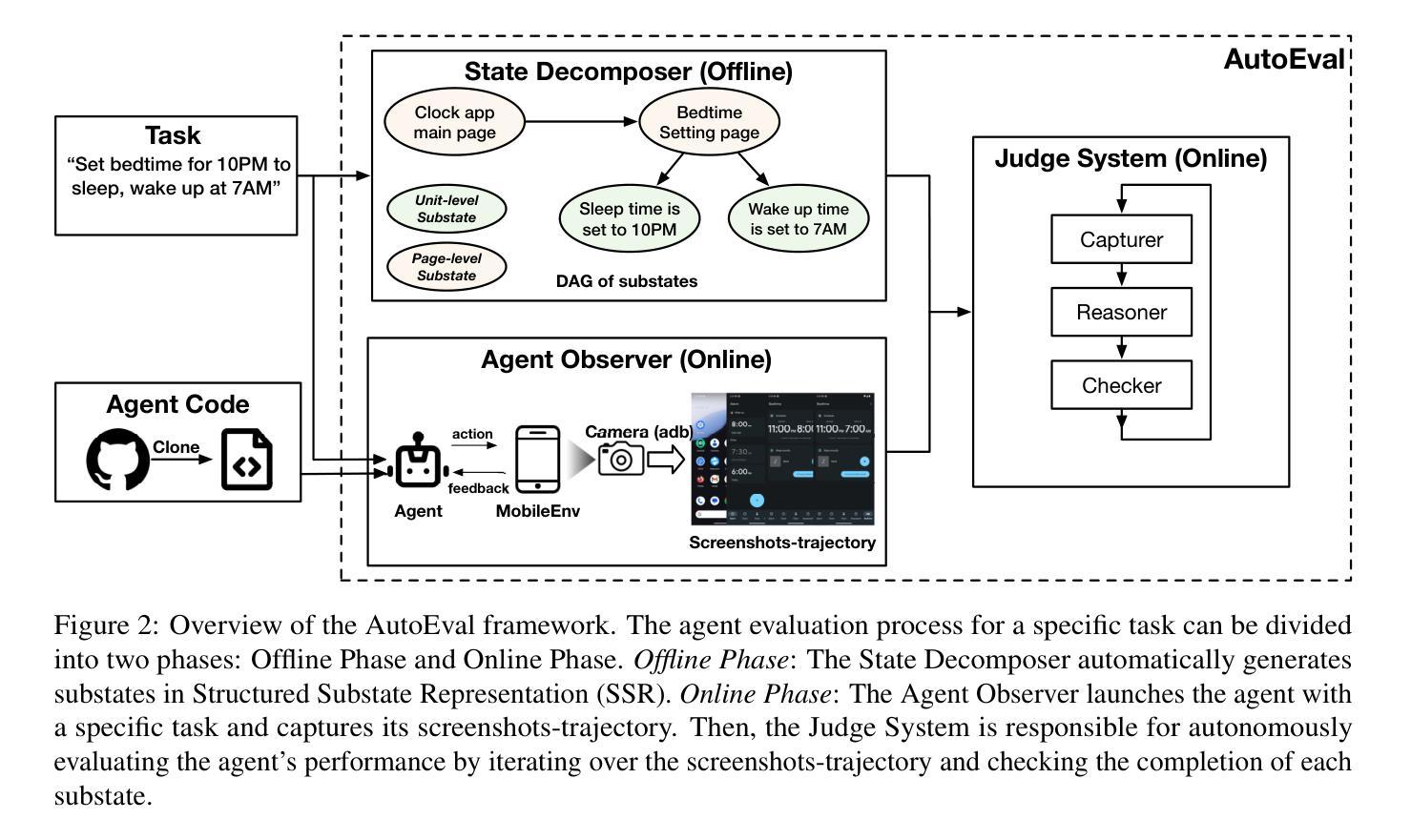
AutoEval: A Practical Framework for Autonomous Evaluation of Mobile Agents
Authors:Jiahui Sun, Zhichao Hua, Yubin Xia
Accurate and systematic evaluation of mobile agents can significantly advance their development and real-world applicability. However, existing benchmarks for mobile agents lack practicality and scalability due to the extensive manual effort required to define task reward signals and implement corresponding evaluation codes. To this end, we propose AutoEval, an autonomous agent evaluation framework that tests a mobile agent without any manual effort. First, we design a Structured Substate Representation to describe the UI state changes while agent execution, such that task reward signals can be automatically generated. Second, we utilize a Judge System that can autonomously evaluate agents’ performance given the automatically generated task reward signals. By providing only a task description, our framework evaluates agents with fine-grained performance feedback to that task without any extra manual effort. We implement a prototype of our framework and validate the automatically generated task reward signals, finding over 93% coverage to human-annotated reward signals. Moreover, to prove the effectiveness of our autonomous Judge System, we manually verify its judge results and demonstrate that it achieves 94% accuracy. Finally, we evaluate the state-of-the-art mobile agents using our framework, providing detailed insights into their performance characteristics and limitations.
对移动代理进行准确、系统的评估可以显著促进其发展和在现实世界中的适用性。然而,由于需要大量手动工作来定义任务奖励信号和实现相应的评估代码,现有的移动代理基准测试缺乏实用性和可扩展性。为此,我们提出了AutoEval,一个无需人工努力的自主代理评估框架。首先,我们设计了一种结构化子状态表示来描述代理执行过程中的UI状态变化,以便自动生成任务奖励信号。其次,我们利用一个判断系统,可以根据自动生成的任务奖励信号自主评估代理的性能。仅通过提供任务描述,我们的框架就能对代理进行精细的反馈评估,无需任何额外的人工努力。我们实现了框架的原型,验证了自动生成的任务奖励信号,发现其覆盖率超过93%。此外,为了证明我们自主的判断系统有效,我们手动验证了其判断结果,并证明其准确率达到了94%。最后,我们使用我们的框架对最先进的移动代理进行了评估,提供了关于其性能特征和局限性的详细见解。
论文及项目相关链接
Summary
移动智能代理的评估和测试对其发展和实际应用至关重要。然而,现有的移动智能代理评估基准测试缺乏实用性和可扩展性,需要大量手动工作来定义任务奖励信号和实现相应的评估代码。为此,我们提出了AutoEval框架,这是一种无需人工介入的移动智能代理评估方法。首先,我们设计了一种结构化子状态表示法来描述代理执行时的UI状态变化,从而可以自动生成任务奖励信号。其次,我们利用裁判系统自主评估智能代理的性能表现。只需提供任务描述,我们的框架即可对智能代理进行精细的性能反馈评估,无需任何额外的人工操作。我们实现了框架的原型,验证了自动生成的奖励信号的准确性,发现其覆盖率超过93%。此外,为了验证自主裁判系统的有效性,我们手动验证了其判断结果,并证明其准确率为94%。最后,我们使用此框架对最先进的移动智能代理进行了评估,提供了对其性能特征和局限性的深入了解。
Key Takeaways
- 移动智能代理的评估和测试是其发展的重要环节,能显著促进其发展和提升其在现实世界的应用能力。
- 现有评估基准测试需要大量手动工作,缺乏实用性和可扩展性。
- AutoEval框架能自主评估移动智能代理的性能表现,无需人工介入。
- 通过结构化子状态表示法描述UI状态变化,自动生成任务奖励信号。
- 利用裁判系统自主评估智能代理的任务完成情况。
- 原型验证显示自动生成的奖励信号覆盖率超过93%,自主裁判系统的准确率为94%。
- 使用此框架对最先进的移动智能代理进行了评估,揭示了其性能特征和局限性。
点此查看论文截图



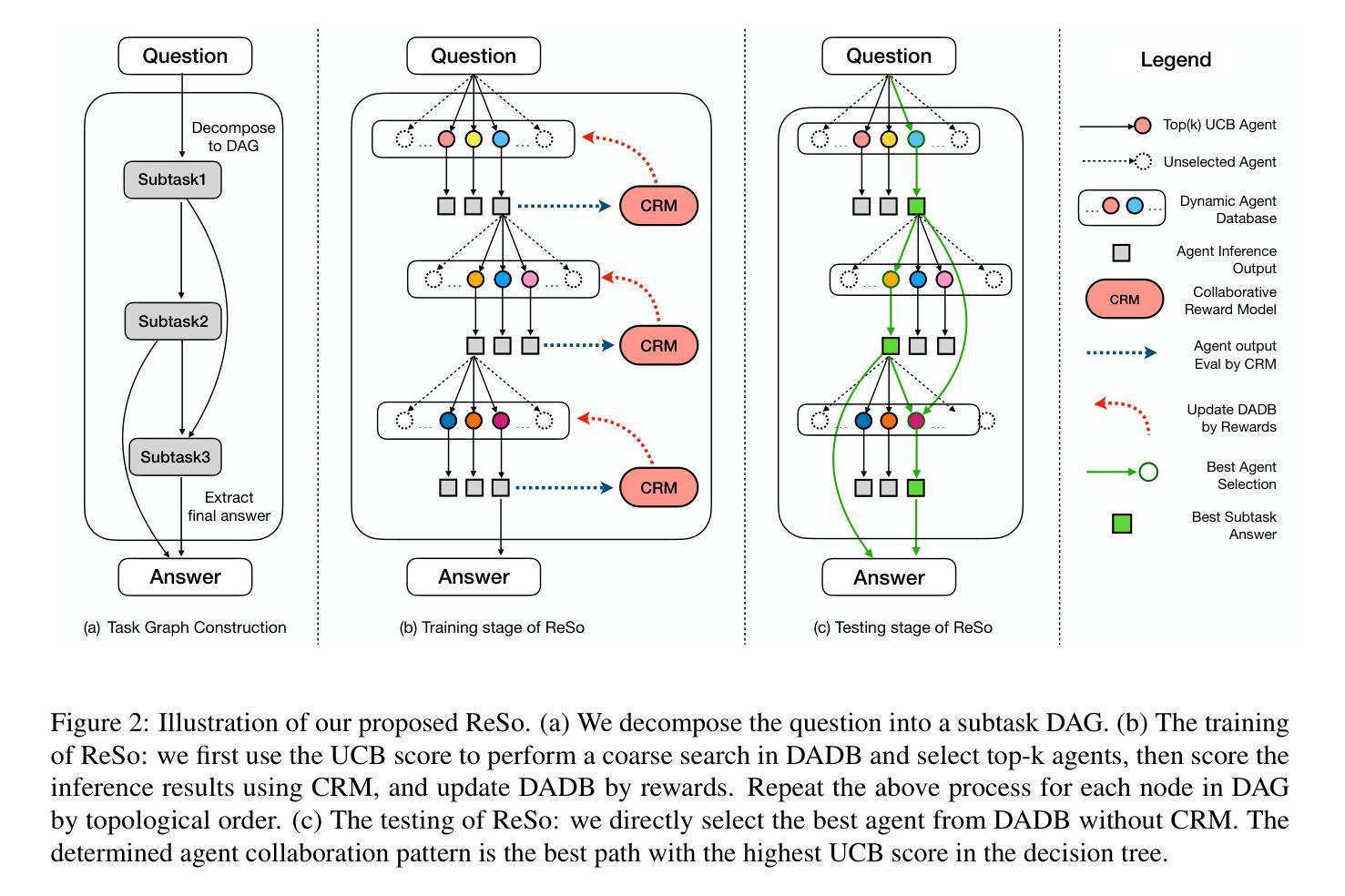
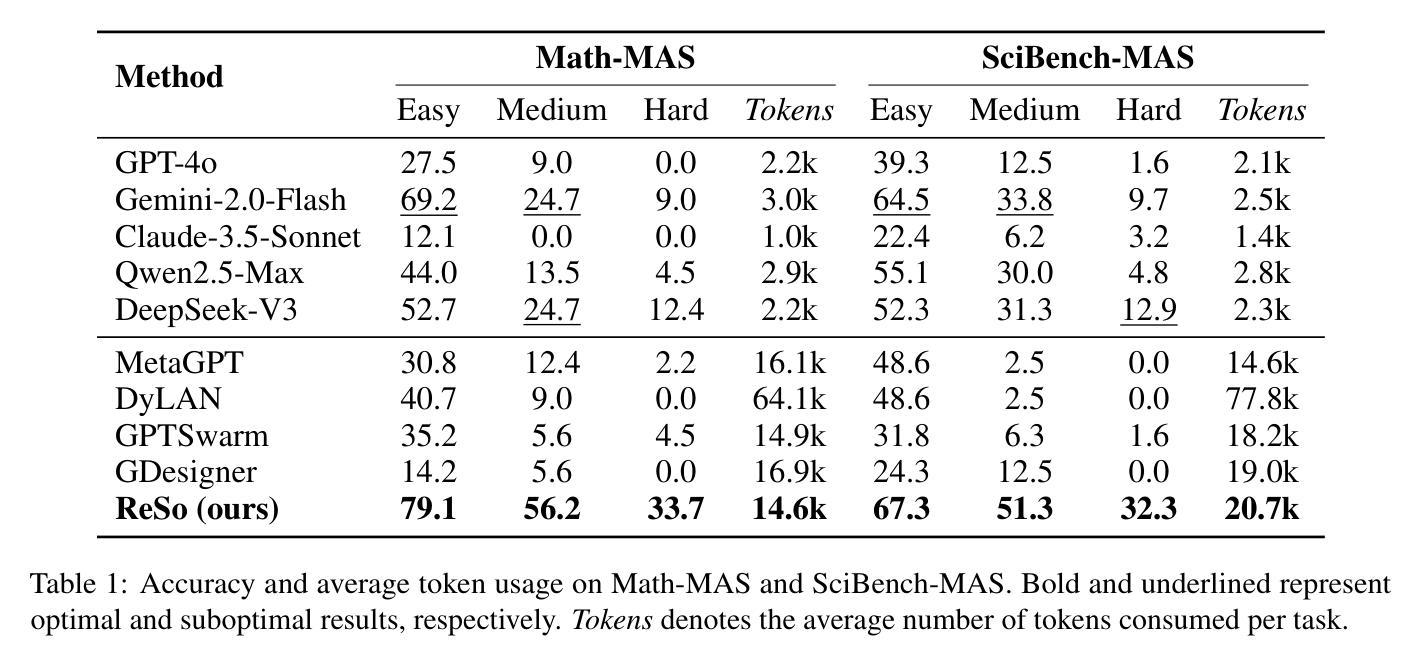
ReSo: A Reward-driven Self-organizing LLM-based Multi-Agent System for Reasoning Tasks
Authors:Heng Zhou, Hejia Geng, Xiangyuan Xue, Zhenfei Yin, Lei Bai
Multi-agent systems have emerged as a promising approach for enhancing the reasoning capabilities of large language models in complex problem-solving. However, current MAS frameworks are limited by poor flexibility and scalability, with underdeveloped optimization strategies. To address these challenges, we propose ReSo, which integrates task graph generation with a reward-driven two-stage agent selection process. The core of ReSo is the proposed Collaborative Reward Model, which can provide fine-grained reward signals for MAS cooperation for optimization. We also introduce an automated data synthesis framework for generating MAS benchmarks, without human annotations. Experimentally, ReSo matches or outperforms existing methods. ReSo achieves \textbf{33.7%} and \textbf{32.3%} accuracy on Math-MAS and SciBench-MAS SciBench, while other methods completely fail. Code is available at: \href{https://github.com/hengzzzhou/ReSo}{ReSo}
多智能体系统作为一种有前景的方法,在复杂的问题解决中增强了大型语言模型的推理能力。然而,当前的多智能体系统框架受限于灵活性和可扩展性较差,优化策略也不够完善。为了解决这些挑战,我们提出了ReSo,它将任务图生成与奖励驱动的两阶段智能体选择过程相结合。ReSo的核心是提出的协同奖励模型,该模型可以为多智能体系统的合作提供精细的奖励信号,以实现优化。我们还引入了一个自动化的数据合成框架,用于生成多智能体系统的基准测试,无需人工注释。实验表明,ReSo与现有方法相匹配或表现更好。ReSo在Math-MAS和SciBench-MAS SciBench上的准确率分别达到**33.7%和32.3%**,而其他方法则完全失败。代码可在https://github.com/hengzzzhou/ReSo获取。
论文及项目相关链接
Summary
多智能体系统通过任务图生成与奖励驱动的两阶段智能体选择过程,提高了大型语言模型在复杂问题解决中的推理能力。针对当前MAS框架的灵活性和可扩展性限制,提出了ReSo。其核心是协作奖励模型,为MAS合作提供精细奖励信号以实现优化。同时,引入自动化数据合成框架生成MAS基准测试集,无需人工标注。实验表明,ReSo在Math-MAS和SciBench-MAS上的准确率分别达到了33.7%和32.3%,而其他方法则完全失败。
Key Takeaways
- 多智能体系统已用于增强大型语言模型的推理能力,以解决复杂问题。
- 当前MAS框架存在灵活性和可扩展性的限制。
- ReSo通过任务图生成和奖励驱动的智能体选择过程来克服这些挑战。
- ReSo的核心是协作奖励模型,为MAS合作提供精细奖励信号。
- ReSo引入了一个自动化数据合成框架,能够生成MAS基准测试集,无需人工标注。
- ReSo在Math-MAS和SciBench-MAS上的准确率高于其他方法。
点此查看论文截图

AppAgentX: Evolving GUI Agents as Proficient Smartphone Users
Authors:Wenjia Jiang, Yangyang Zhuang, Chenxi Song, Xu Yang, Chi Zhang
Recent advancements in Large Language Models (LLMs) have led to the development of intelligent LLM-based agents capable of interacting with graphical user interfaces (GUIs). These agents demonstrate strong reasoning and adaptability, enabling them to perform complex tasks that traditionally required predefined rules. However, the reliance on step-by-step reasoning in LLM-based agents often results in inefficiencies, particularly for routine tasks. In contrast, traditional rule-based systems excel in efficiency but lack the intelligence and flexibility to adapt to novel scenarios. To address this challenge, we propose a novel evolutionary framework for GUI agents that enhances operational efficiency while retaining intelligence and flexibility. Our approach incorporates a memory mechanism that records the agent’s task execution history. By analyzing this history, the agent identifies repetitive action sequences and evolves high-level actions that act as shortcuts, replacing these low-level operations and improving efficiency. This allows the agent to focus on tasks requiring more complex reasoning, while simplifying routine actions. Experimental results on multiple benchmark tasks demonstrate that our approach significantly outperforms existing methods in both efficiency and accuracy. The code will be open-sourced to support further research.
最近,大型语言模型(LLM)的进展导致了基于智能LLM的代理的发展,这些代理能够与图形用户界面(GUI)进行交互。这些代理人表现出强大的推理和适应能力,使他们能够完成传统上需要预先设定规则才能完成的复杂任务。然而,基于LLM的代理人在逐步推理上的依赖往往会导致效率低下,特别是在执行常规任务时。相比之下,传统的基于规则的系统在效率上表现出色,但缺乏适应新场景的智力和灵活性。为了解决这一挑战,我们提出了一种新型的GUI代理进化框架,该框架提高了操作效率,同时保留了智力和灵活性。我们的方法采用了一种记忆机制,可以记录代理的任务执行历史。通过分析这些历史记录,代理可以识别出重复的动作序列,并进化出高级动作作为快捷方式,从而取代这些低级操作,提高效率。这允许代理专注于需要更复杂推理的任务,同时简化常规操作。在多个基准任务上的实验结果表明,我们的方法在效率和准确性方面都显著优于现有方法。代码将开源以支持进一步研究。
论文及项目相关链接
Summary
随着大型语言模型(LLM)的近期发展,基于LLM的智能代理能够与用户界面交互,展示强大的推理和适应性,可完成传统需要预设规则的复杂任务。然而,对于常规任务,基于LLM的代理的逐步推理过程可能会导致效率低下。为了解决这个问题,我们提出了一种新的GUI代理进化框架,它在提高效率的同时保留智能和灵活性。通过记忆机制记录代理任务执行历史,并分析这些历史数据,找出重复操作序列并形成快捷方式以提高效率。在多个基准测试任务上的实验结果显示,该方法在效率和准确性上均显著优于现有方法。代码将开源以支持进一步研究。
Key Takeaways
- 基于大型语言模型的智能代理能与图形用户界面交互。
- 这些代理具备强大的推理和适应性,能完成复杂任务。
- 基于LLM的代理在处理常规任务时可能效率不高。
- 提出一种新的GUI代理进化框架以提高效率和保留智能。
- 通过记忆机制记录并分析代理任务执行历史,形成高效快捷方式。
- 在多个任务上的实验证明该方法优于现有方法。
点此查看论文截图

ATLaS: Agent Tuning via Learning Critical Steps
Authors:Zhixun Chen, Ming Li, Yuxuan Huang, Yali Du, Meng Fang, Tianyi Zhou
Large Language Model (LLM) agents have demonstrated remarkable generalization capabilities across multi-domain tasks. Existing agent tuning approaches typically employ supervised finetuning on entire expert trajectories. However, behavior-cloning of full trajectories can introduce expert bias and weaken generalization to states not covered by the expert data. Additionally, critical steps, such as planning, complex reasoning for intermediate subtasks, and strategic decision-making, are essential to success in agent tasks, so learning these steps is the key to improving LLM agents. For more effective and efficient agent tuning, we propose ATLaS that identifies the critical steps in expert trajectories and finetunes LLMs solely on these steps with reduced costs. By steering the training’s focus to a few critical steps, our method mitigates the risk of overfitting entire trajectories and promotes generalization across different environments and tasks. In extensive experiments, an LLM finetuned on only 30% critical steps selected by ATLaS outperforms the LLM finetuned on all steps and recent open-source LLM agents. ATLaS maintains and improves base LLM skills as generalist agents interacting with diverse environments.
大型语言模型(LLM)代理在多域任务中展现出了显著的泛化能力。现有的代理调整方法通常会对整个专家轨迹进行有监督的微调。然而,全轨迹的行为克隆可能会引入专家偏见,并削弱对专家数据未覆盖状态的泛化能力。此外,规划、中间子任务的复杂推理和战略决策等关键步骤对于代理任务的成功至关重要,因此学习这些步骤是改进LLM代理的关键。为了更有效、更高效地调整代理,我们提出了ATLaS方法,该方法能够识别专家轨迹中的关键步骤,并以减少的成本仅在这些步骤上对LLM进行微调。通过引导训练的重点关注少数关键步骤,我们的方法减轻了对整个轨迹过度拟合的风险,并促进了在不同环境和任务中的泛化。在大量实验中,仅通过ATLaS选择的30%关键步骤进行微调的LLM,其性能优于在所有步骤上进行微调的LLM以及最近的开源LLM代理。ATLaS在作为与各种环境互动的通用代理时,能够保持并提升LLM的基础技能。
论文及项目相关链接
Summary
大型语言模型(LLM)代理在多域任务中展现出卓越的泛化能力。现有代理调整方法通常对整个专家轨迹进行有监督的微调,但完全轨迹的行为克隆可能会引入专家偏见,并在专家数据未覆盖的状态下削弱泛化能力。此外,成功完成代理任务的关键步骤包括规划、中间子任务的复杂推理和战略决策制定。为了更有效地调整代理并提高效率,我们提出了ATLaS方法,该方法能够识别专家轨迹中的关键步骤,并仅针对这些步骤对LLM进行微调以降低成本。通过专注于少数关键步骤的训练,我们的方法降低了对整个轨迹的过拟合风险,并促进了不同环境和任务之间的泛化能力。实验表明,仅对ATLaS选择的30%关键步骤进行微调的大型语言模型在所有步骤上都表现得很好优于最近的开源大型语言模型代理,并且在与不同环境的交互中维持和改进了基础大型语言模型的技能作为全能代理。
Key Takeaways
- 大型语言模型(LLM)代理在多域任务中展现出良好的泛化能力。
- 当前代理调整方法可能引入专家偏见并削弱泛化能力。
- 成功完成代理任务的关键步骤包括规划、复杂推理和战略决策制定。
- ATLaS方法能够识别专家轨迹中的关键步骤并对LLM进行微调以降低训练成本。
- 通过专注于少数关键步骤的训练,ATLaS降低了过拟合风险并提高了不同环境和任务之间的泛化能力。
- 仅对ATLaS选择的30%关键步骤进行微调的大型语言模型性能优于完整轨迹微调和近期开源的大型语言模型代理。
点此查看论文截图


Improved MMS Approximations for Few Agent Types
Authors:Jugal Garg, Parnian Shahkar
We study fair division of indivisible goods under the maximin share (MMS) fairness criterion in settings where agents are grouped into a small number of types, with agents within each type having identical valuations. For the special case of a single type, an exact MMS allocation is always guaranteed to exist. However, for two or more distinct agent types, exact MMS allocations do not always exist, shifting the focus to establishing the existence of approximate-MMS allocations. A series of works over the last decade has resulted in the best-known approximation guarantee of $\frac{3}{4} + \frac{3}{3836}$. In this paper, we improve the approximation guarantees for settings where agents are grouped into two or three types, a scenario that arises in many practical settings. Specifically, we present novel algorithms that guarantee a $\frac{4}{5}$-MMS allocation for two agent types and a $\frac{16}{21}$-MMS allocation for three agent types. Our approach leverages the MMS partition of the majority type and adapts it to provide improved fairness guarantees for all types.
我们研究了不可分物品公平分配问题,此问题的背景是存在少数几种类型的代理群体,同一类型内的代理具有相同的估价。在单一类型的特殊情况下,总能保证存在一个精确的MMS分配方案。然而,在两种或更多种不同类型的代理群体中,精确的MMS分配方案并不总是存在,因此研究重点转向了近似MMS分配方案的存在性。近十年的一系列研究得到了著名的近似保证界限,即$\frac{3}{4} + \frac{3}{3836}$。在本文中,我们改进了将代理划分为两种或三种类型的设置中的近似保证界限,这在许多实际应用场景中都很常见。具体来说,我们提出了新型算法,为两种代理类型提供$\frac{4}{5}$的MMS分配方案,为三种代理类型提供$\frac{16}{21}$的MMS分配方案。我们的方法利用多数类型的MMS分割,并对其进行调整,以确保所有类型的代理都能获得更高的公平性保障。
论文及项目相关链接
PDF 27 pages
Summary
本文研究了不可分物品在最大最小份额(MMS)公平性标准下的分配问题,特别关注了当代理人被分为少量类型时的情况,同一类型内的代理人具有相同的价值评估。对于单一类型特殊情况,存在精确的MMS分配。然而,对于两个或更多不同类型的代理人,精确的MMS分配并不总是存在,因此研究重点转向了近似MMS分配的存在性。本文提高了当代理人为两种或三种类型时的近似保证,对于两种类型代理人的场景,能保证$\frac{4}{5}$的MMS分配;对于三种类型代理人的场景,能保证$\frac{16}{21}$的MMS分配。
Key Takeaways
- 研究了基于最大最小份额(MMS)公平性标准的不可分物品的分配问题。
- 当代理人被分为少量类型时,同一类型内的代理人具有相同价值评估。
- 对于单一类型的特殊情况,存在精确的MMS分配。
- 对于多个类型的代理人,精确的MMS分配并不总是存在,需要寻找近似MMS分配。
- 本文提高了对两种类型代理人的近似保证至$\frac{4}{5}$的MMS分配。
- 对于三种类型代理人的场景,本文提供了$\frac{16}{21}$的MMS分配的保证。
点此查看论文截图

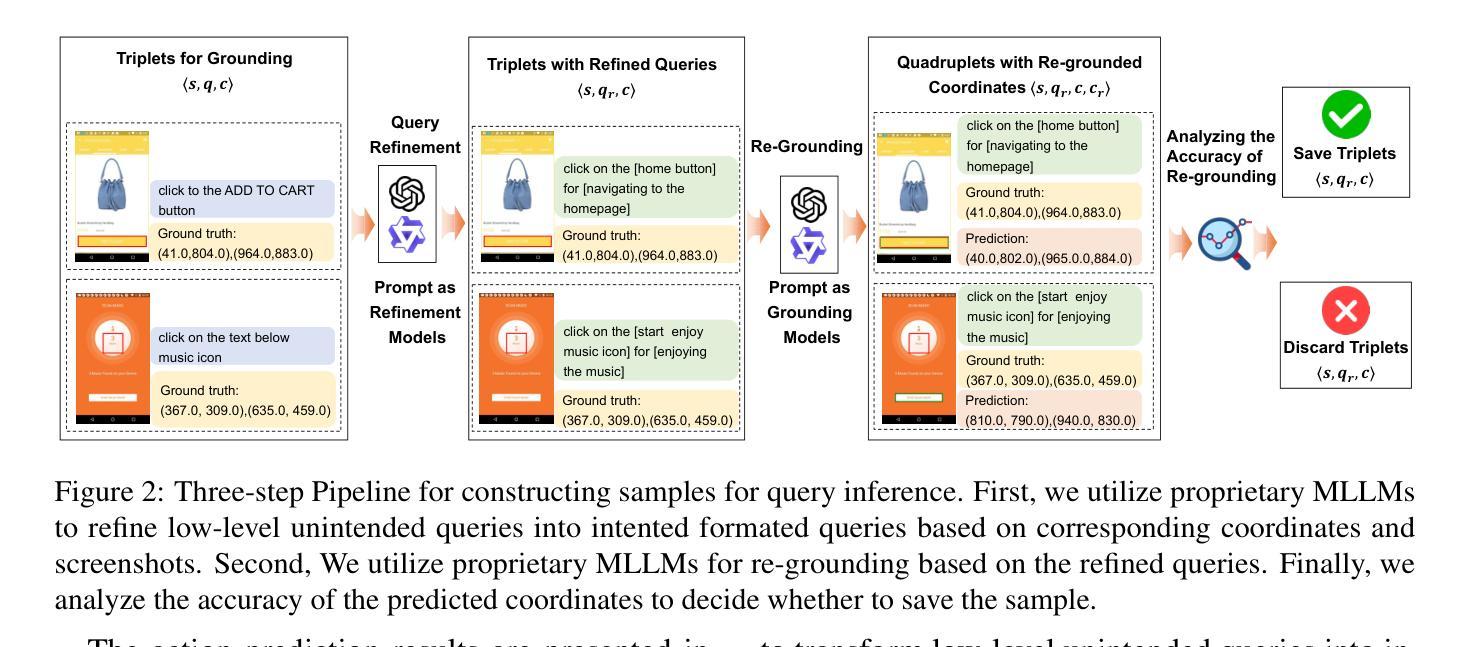
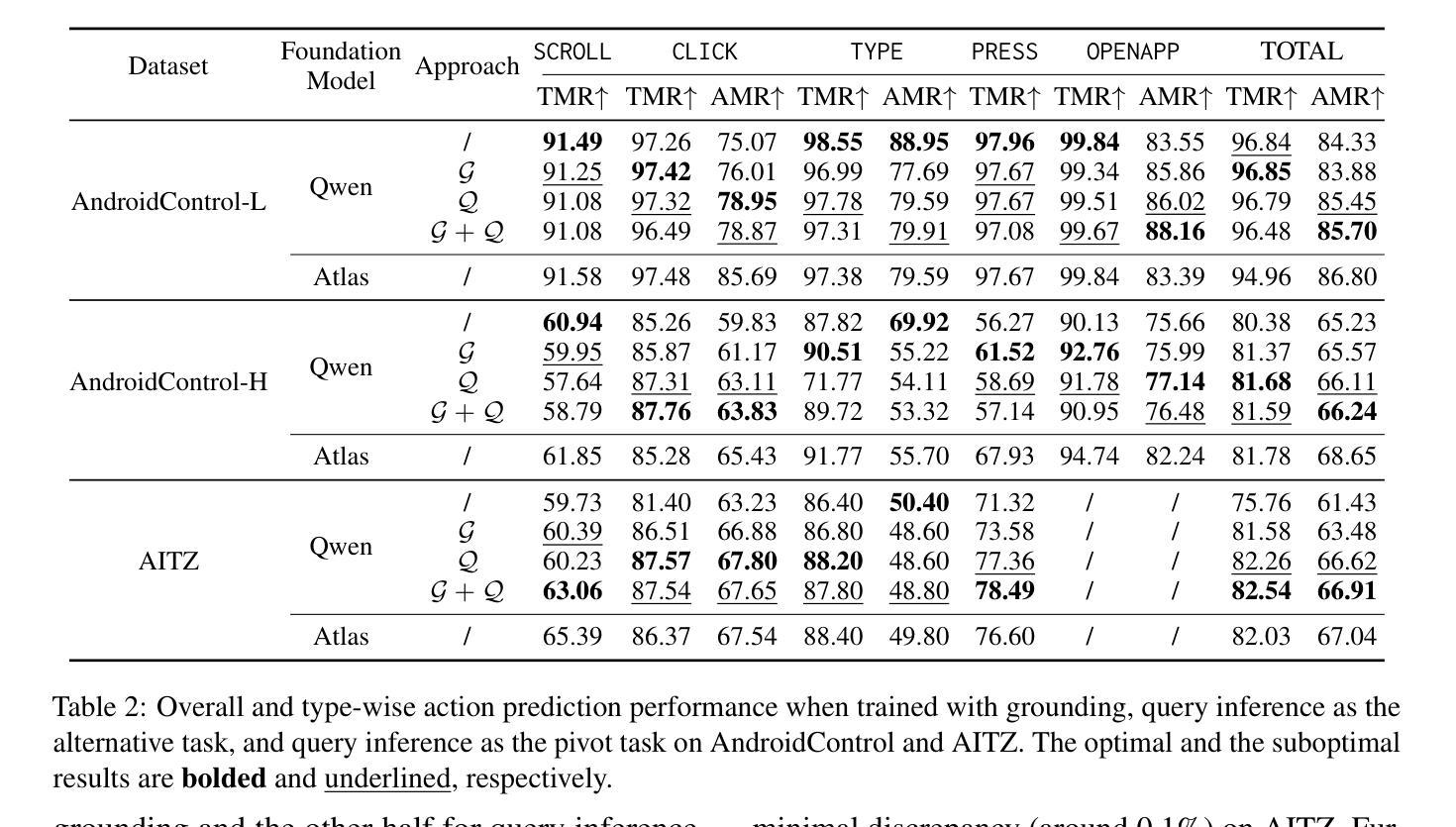
Smoothing Grounding and Reasoning for MLLM-Powered GUI Agents with Query-Oriented Pivot Tasks
Authors:Zongru Wu, Pengzhou Cheng, Zheng Wu, Tianjie Ju, Zhuosheng Zhang, Gongshen Liu
Perception-enhanced pre-training, particularly through grounding techniques, is widely adopted to enhance the performance of graphical user interface (GUI) agents. However, in resource-constrained scenarios, the format discrepancy between coordinate-oriented grounding and action-oriented reasoning limits the effectiveness of grounding for reasoning tasks. To address this challenge, we propose a query-oriented pivot approach called query inference, which serves as a bridge between GUI grounding and reasoning. By inferring potential user queries from a screenshot and its associated element coordinates, query inference improves the understanding of coordinates while aligning more closely with reasoning tasks. Experimental results show that query inference outperforms previous grounding techniques under the same training data scale. Notably, query inference achieves comparable or even better performance to large-scale grounding-enhanced OS-Atlas with less than 0.1% of training data. Furthermore, we explore the impact of reasoning formats and demonstrate that integrating additional semantic information into the input further boosts reasoning performance. The code is publicly available at https://github.com/ZrW00/GUIPivot.
感知增强预训练,特别是通过接地技术,广泛应用于提高图形用户界面(GUI)代理的性能。然而,在资源受限的场景下,坐标导向接地与行动导向推理之间的格式差异限制了接地在推理任务中的有效性。为了应对这一挑战,我们提出了一种称为查询推理的查询导向轴心方法,它作为GUI接地和推理之间的桥梁。通过从截图及其相关元素坐标推断潜在用户查询,查询推理提高了对坐标的理解,同时更紧密地符合推理任务。实验结果表明,在相同的训练数据规模下,查询推理优于之前的接地技术。值得注意的是,查询推理在不到0.1%的训练数据的情况下实现了与大规模接地增强OS-Atlas相当的甚至更好的性能。此外,我们探讨了推理格式的影响,并证明将额外的语义信息集成到输入中进一步提高了推理性能。代码公开在https://github.com/ZrW00/GUIPivot。
论文及项目相关链接
Summary
感知增强预训练,特别是通过接地技术,广泛应用于提高图形用户界面(GUI)代理的性能。然而,在资源受限的情况下,坐标导向接地与行动导向推理之间的格式差异限制了接地对于推理任务的效力。为解决此挑战,我们提出一种称为查询推断的查询导向式枢轴方法,作为GUI接地和推理之间的桥梁。通过从截图及其相关元素坐标推断潜在用户查询,查询推断提高了对坐标的理解,同时更紧密地与推理任务对齐。实验结果显示,在相同的训练数据规模下,查询推断优于先前的接地技术。值得注意的是,使用不到0.1%的训练数据,查询推断即可实现与大规模接地增强的OS-Atlas相当的甚至更好的性能。此外,我们还探讨了推理格式的影响,并证明将额外的语义信息整合到输入中可进一步提高推理性能。
Key Takeaways
- 感知增强预训练通过接地技术提升GUI代理性能。
- 资源受限情况下,坐标导向接地与行动导向推理的格式差异限制其效力。
- 提出查询推断方法,作为GUI接地和推理间的桥梁。
- 查询推断通过推断用户查询提高坐标理解,并与推理任务对齐。
- 查询推断在少量训练数据下表现优异,与大规模接地增强方法性能相当。
- 推理格式对性能有影响。
- 将额外语义信息整合到输入中可进一步提高推理性能。
点此查看论文截图

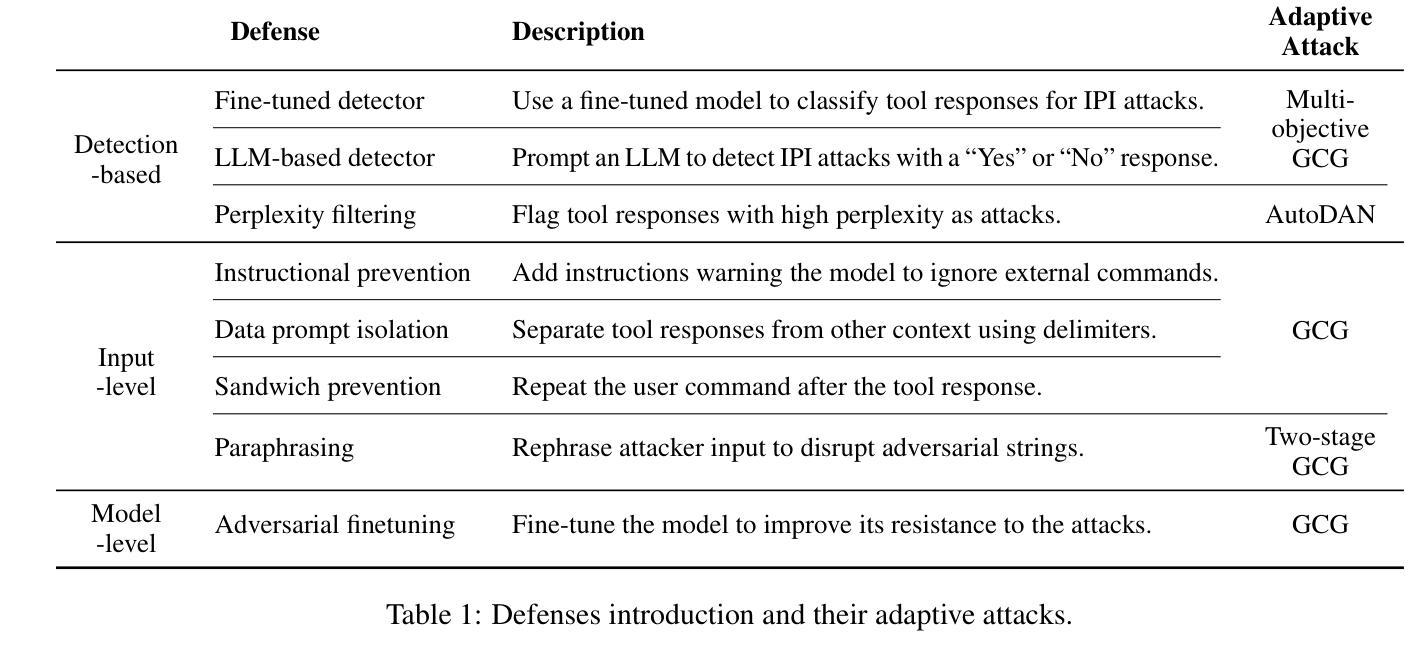
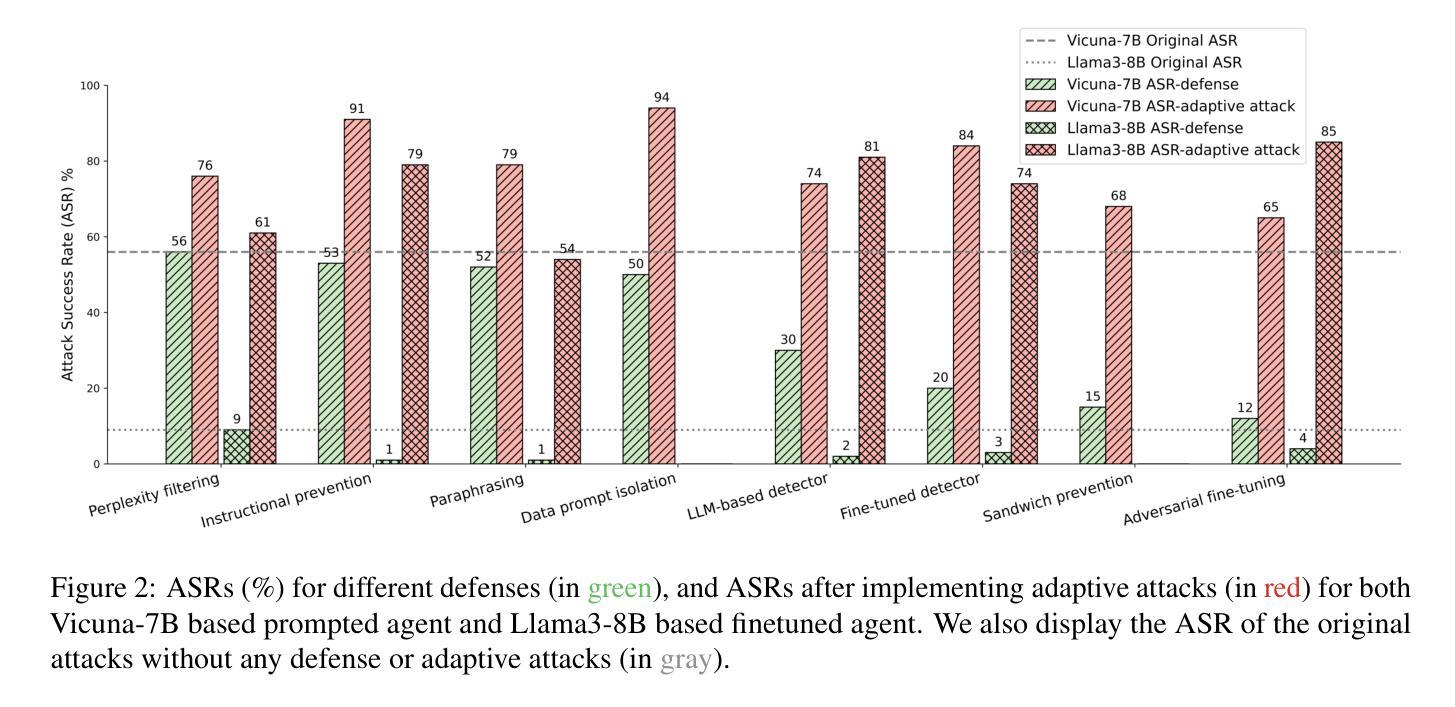
Adaptive Attacks Break Defenses Against Indirect Prompt Injection Attacks on LLM Agents
Authors:Qiusi Zhan, Richard Fang, Henil Shalin Panchal, Daniel Kang
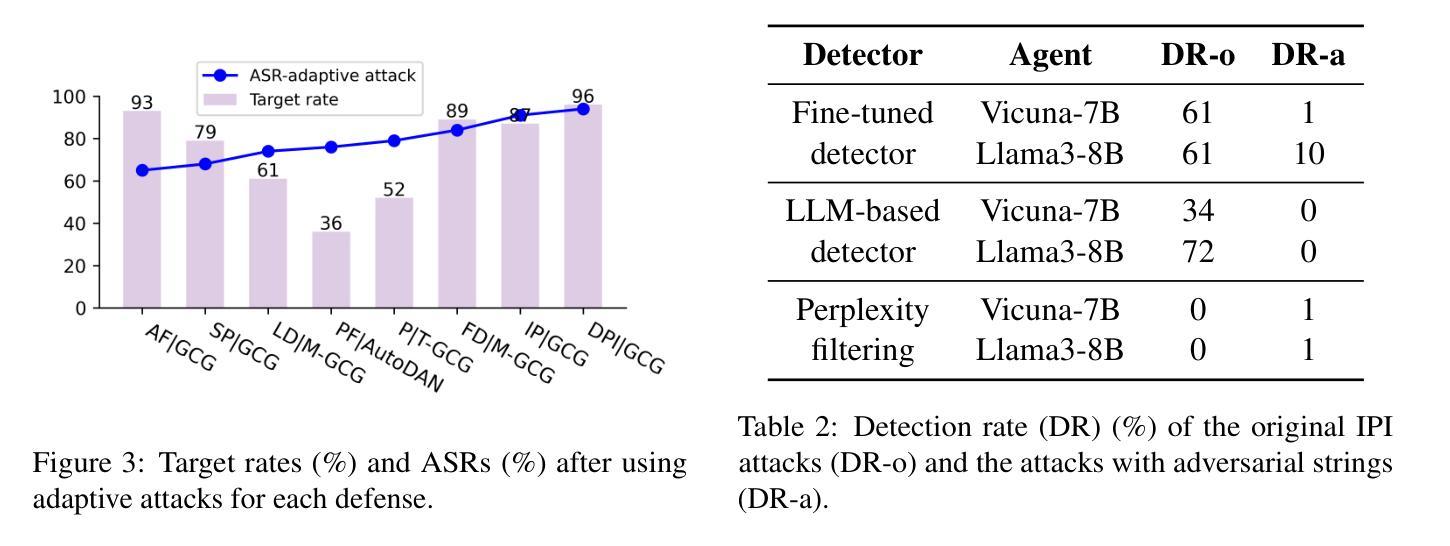
Large Language Model (LLM) agents exhibit remarkable performance across diverse applications by using external tools to interact with environments. However, integrating external tools introduces security risks, such as indirect prompt injection (IPI) attacks. Despite defenses designed for IPI attacks, their robustness remains questionable due to insufficient testing against adaptive attacks. In this paper, we evaluate eight different defenses and bypass all of them using adaptive attacks, consistently achieving an attack success rate of over 50%. This reveals critical vulnerabilities in current defenses. Our research underscores the need for adaptive attack evaluation when designing defenses to ensure robustness and reliability. The code is available at https://github.com/uiuc-kang-lab/AdaptiveAttackAgent.
大型语言模型(LLM)代理通过利用外部工具与环境进行交互,在多种应用中表现出卓越的性能。然而,整合外部工具会引入安全风险,例如间接提示注入(IPI)攻击。尽管已经设计了针对IPI攻击的防御措施,但由于对适应性攻击的测试不足,其稳健性仍然令人质疑。在本文中,我们评估了八种不同的防御措施,并使用适应性攻击绕过它们,始终实现超过50%的攻击成功率。这揭示了当前防御措施中的关键漏洞。我们的研究强调在设计防御措施时进行适应性攻击评估的必要性,以确保其稳健性和可靠性。相关代码可在https://github.com/uiuc-kang-lab/AdaptiveAttackAgent找到。
论文及项目相关链接
PDF 17 pages, 5 figures, 6 tables (NAACL 2025 Findings)
Summary
大型语言模型(LLM)代理在多种应用中表现出卓越性能,通过使用外部工具与环境进行交互。然而,集成外部工具带来了安全风险,如间接提示注入(IPI)攻击。现有防御措施在面对适应性攻击时显得不够稳健,存在关键漏洞。本文评估了八种不同的防御措施并绕过了它们,攻击成功率超过50%。研究强调了在设计防御措施时进行适应性攻击评估的必要性,以确保其稳健性和可靠性。有关代码已公开提供。
Key Takeaways
- 大型语言模型(LLM)代理在与环境交互中使用外部工具时表现出强大的性能。
- 集成外部工具引入安全风险,特别是间接提示注入(IPI)攻击。
- 目前针对IPI攻击的防御措施在面对适应性攻击时存在关键漏洞。
- 现有防御措施被成功绕过,攻击成功率超过50%。
- 需要进行适应性攻击评估以确保防御措施的设计的稳健性和可靠性。
点此查看论文截图

A-MEM: Agentic Memory for LLM Agents
Authors:Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, Yongfeng Zhang
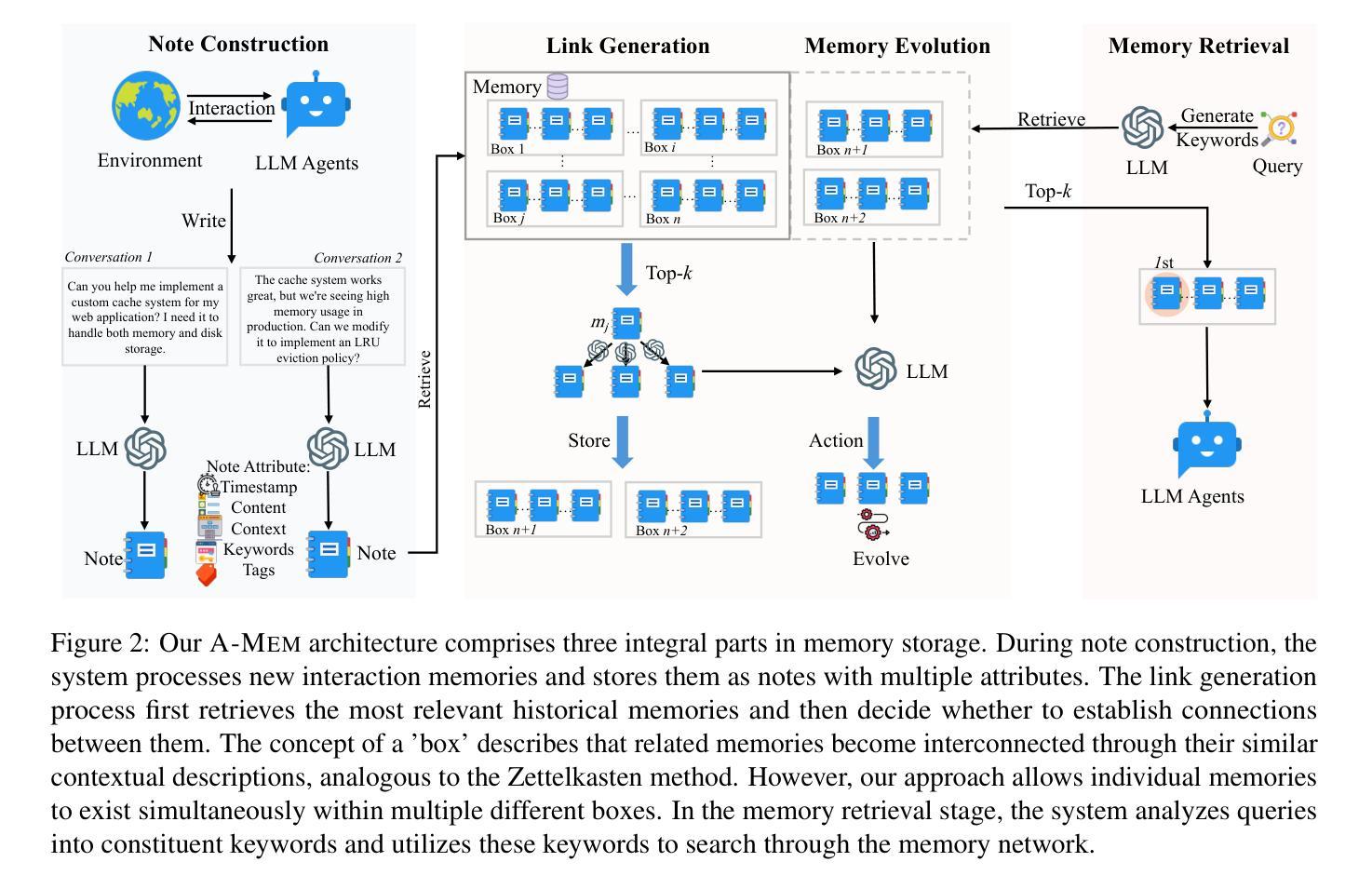
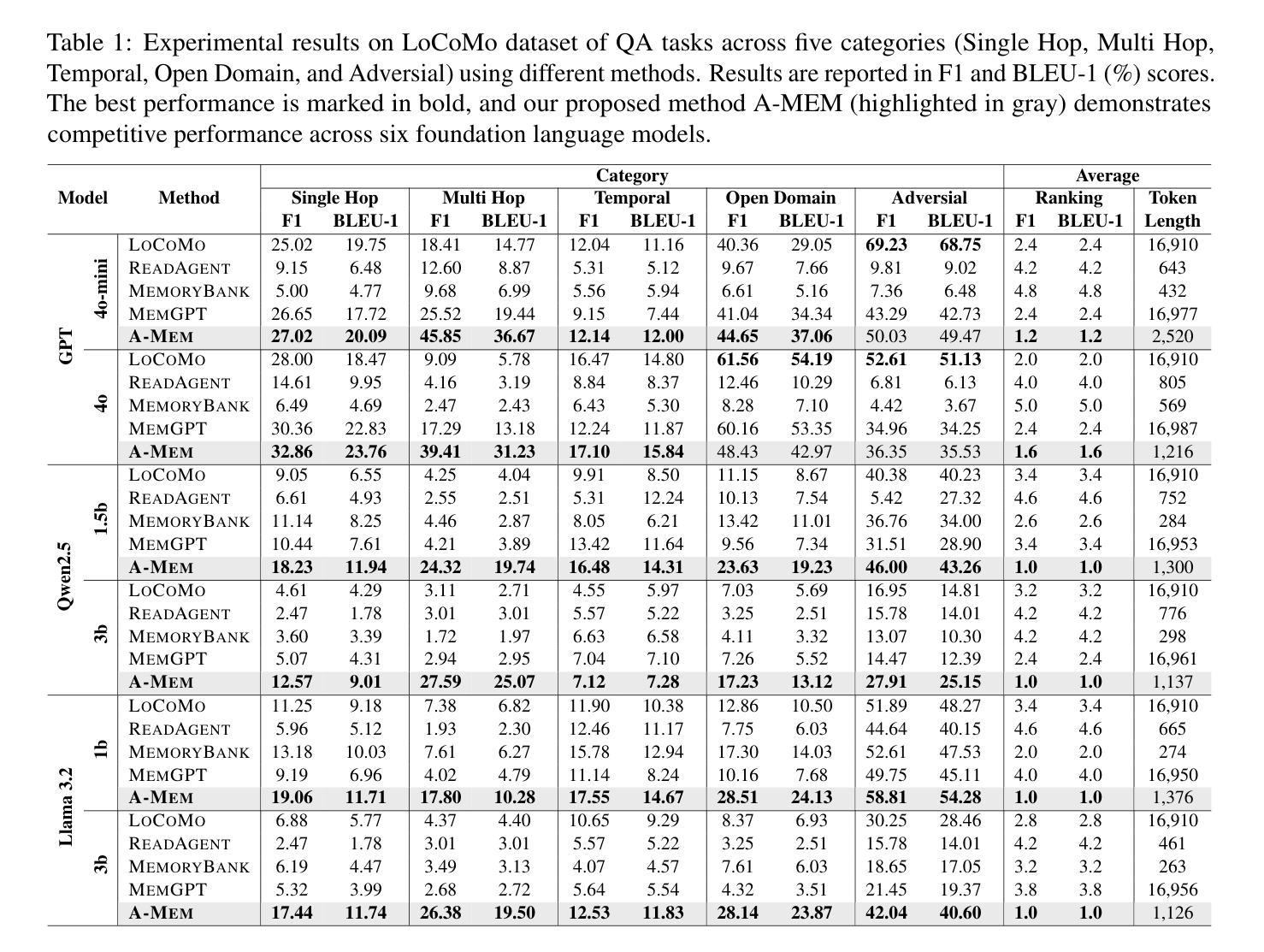
While large language model (LLM) agents can effectively use external tools for complex real-world tasks, they require memory systems to leverage historical experiences. Current memory systems enable basic storage and retrieval but lack sophisticated memory organization, despite recent attempts to incorporate graph databases. Moreover, these systems’ fixed operations and structures limit their adaptability across diverse tasks. To address this limitation, this paper proposes a novel agentic memory system for LLM agents that can dynamically organize memories in an agentic way. Following the basic principles of the Zettelkasten method, we designed our memory system to create interconnected knowledge networks through dynamic indexing and linking. When a new memory is added, we generate a comprehensive note containing multiple structured attributes, including contextual descriptions, keywords, and tags. The system then analyzes historical memories to identify relevant connections, establishing links where meaningful similarities exist. Additionally, this process enables memory evolution - as new memories are integrated, they can trigger updates to the contextual representations and attributes of existing historical memories, allowing the memory network to continuously refine its understanding. Our approach combines the structured organization principles of Zettelkasten with the flexibility of agent-driven decision making, allowing for more adaptive and context-aware memory management. Empirical experiments on six foundation models show superior improvement against existing SOTA baselines. The source code for evaluating performance is available at https://github.com/WujiangXu/AgenticMemory, while the source code of agentic memory system is available at https://github.com/agiresearch/A-mem.
虽然大型语言模型(LLM)代理可以有效地利用外部工具来完成复杂的现实世界任务,但它们需要记忆系统来利用历史经验。当前的记忆系统虽然实现了基本的存储和检索功能,但缺乏高级的记忆组织功能,尽管最近尝试引入图数据库。此外,这些系统的固定操作和结构限制了它们在多样化任务中的适应性。为了解决这一局限性,本文提出了一种新型的大型语言模型代理的记忆系统,它能够以动态的方式组织记忆。我们遵循Zettelkasten方法的基本原则,设计了一个记忆系统,通过动态索引和链接创建相互关联的知识网络。每当添加新的记忆时,我们会生成一个包含多个结构化属性的综合笔记,包括上下文描述、关键词和标签。然后,系统分析历史记忆以识别相关联系,在存在有意义的相似性时建立链接。此外,这个过程实现了记忆的进化——当新记忆被集成时,它们可以触发对现有历史记忆的上下文表示和属性的更新,使记忆网络能够不断完善其理解。我们的方法结合了Zettelkasten的结构化组织原则与代理驱动的决策的灵活性,从而实现更适应和上下文感知的记忆管理。对六个基础模型的实证实验表明,与现有的最先进的基线相比,我们的方法具有显著的改进。性能评估的源代码可在https://github.com/WujiangXu/AgenticMemory上找到,而代理记忆系统的源代码则可在https://github.com/agiresearch/A-mem上找到。
论文及项目相关链接
Summary
大型语言模型(LLM)代理在利用外部工具进行复杂现实世界任务时表现出色,但它们需要记忆系统来利用历史经验。当前记忆系统可实现基本存储和检索功能,但缺乏复杂的记忆组织。本文提出了一种新颖的代理记忆系统,可以根据基本原则动态组织记忆。结合Zettelkasten方法的结构组织原则和代理驱动的决策灵活性,实现了更加自适应和上下文感知的记忆管理。在六个基础模型上的实证实验表明,与现有最佳基线相比具有显著改进。
Key Takeaways
- 大型语言模型(LLM)代理需要记忆系统来利用历史经验,当前记忆系统缺乏复杂的记忆组织。
- 代理记忆系统需要能够动态组织记忆并具有适应性。
- 本文提出了一种新颖的代理记忆系统,结合Zettelkasten方法的结构组织原则和代理驱动的决策灵活性。
- 该系统通过生成包含多个结构化属性的综合笔记来创建相互关联的知识网络,如上下文描述、关键词和标签。
- 系统能够分析历史记忆以识别相关连接,并在新记忆集成时触发对上下文表示和属性的更新。
- 通过实验证明,该代理记忆系统在六个基础模型上的性能优于现有最佳基线。
点此查看论文截图

Tool Learning in the Wild: Empowering Language Models as Automatic Tool Agents
Authors:Zhengliang Shi, Shen Gao, Lingyong Yan, Yue Feng, Xiuyi Chen, Zhumin Chen, Dawei Yin, Suzan Verberne, Zhaochun Ren
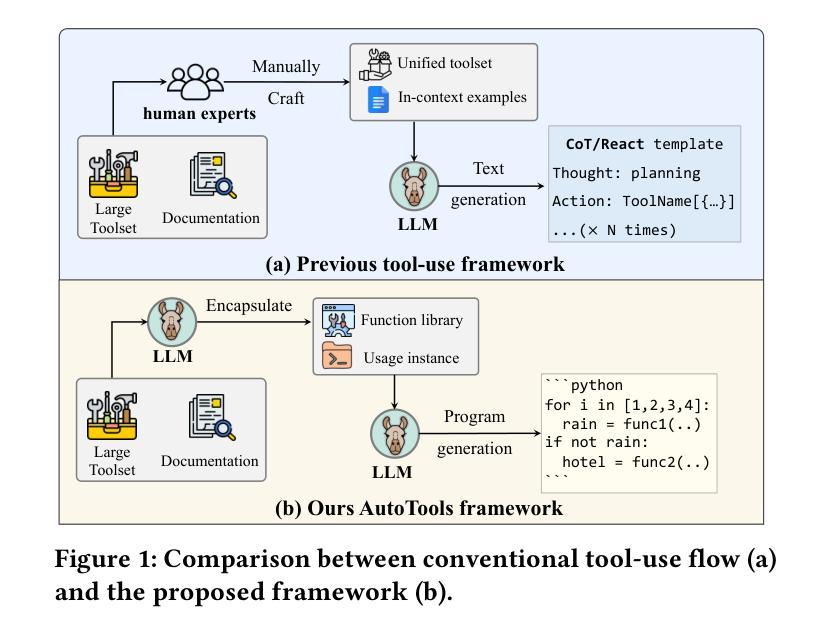
Augmenting large language models (LLMs) with external tools has emerged as a promising approach to extend their utility, enabling them to solve practical tasks. Previous methods manually parse tool documentation and create in-context demonstrations, transforming tools into structured formats for LLMs to use in their step-by-step reasoning. However, this manual process requires domain expertise and struggles to scale to large toolsets. Additionally, these methods rely heavily on ad-hoc inference techniques or special tokens to integrate free-form LLM generation with tool-calling actions, limiting the LLM’s flexibility in handling diverse tool specifications and integrating multiple tools. In this work, we propose AutoTools, a framework that enables LLMs to automate the tool-use workflow. Specifically, the LLM automatically transforms tool documentation into callable functions, verifying syntax and runtime correctness. Then, the LLM integrates these functions into executable programs to solve practical tasks, flexibly grounding tool-use actions into its reasoning processes. Extensive experiments on existing and newly collected, more challenging benchmarks illustrate the superiority of our framework. Inspired by these promising results, we further investigate how to improve the expertise of LLMs, especially open-source LLMs with fewer parameters, within AutoTools. Thus, we propose the AutoTools-learning approach, training the LLMs with three learning tasks on 34k instances of high-quality synthetic data, including documentation understanding, relevance learning, and function programming. Fine-grained results validate the effectiveness of our overall training approach and each individual task. Our methods are an important step towards the use of LLMs for solving real-world tasks with external tools.
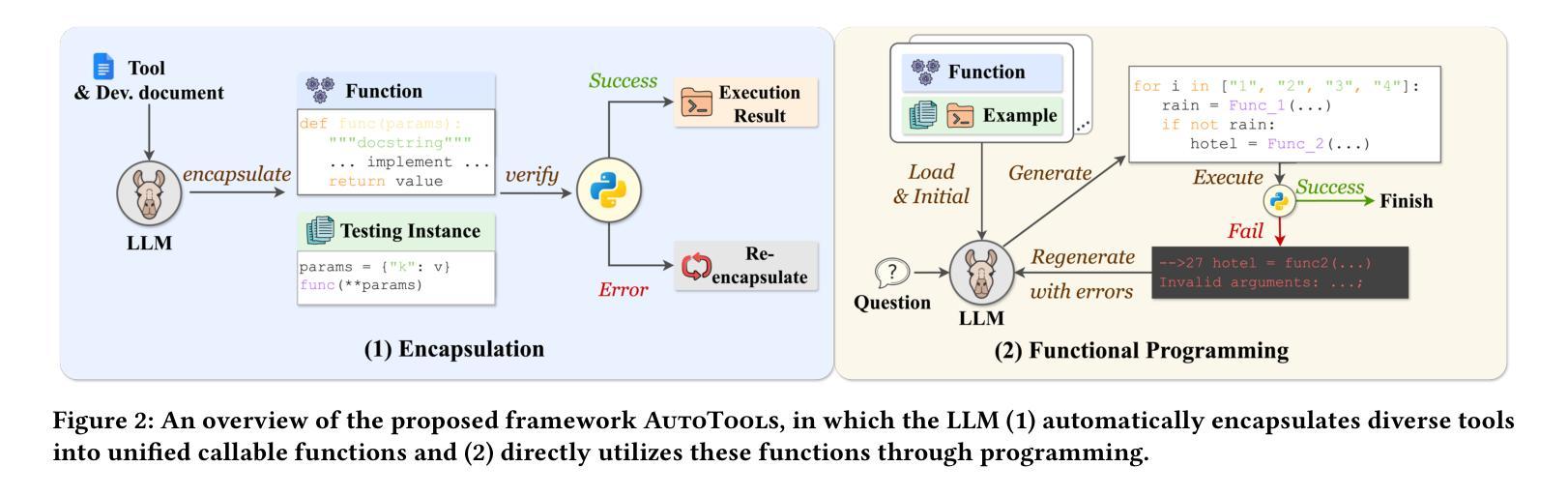
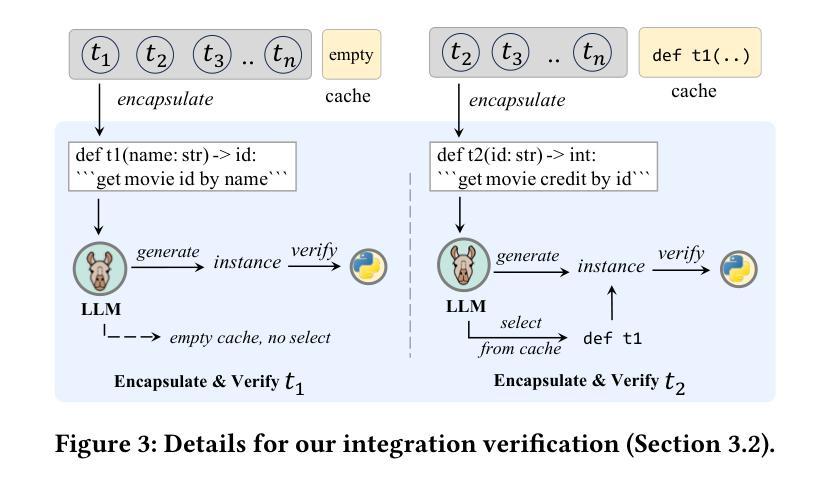
通过外部工具增强大型语言模型(LLM)的实用性已成为一种前景广阔的方法,使它们能够解决实际任务。以前的方法会手动解析工具文档并创建上下文演示,将工具转换为LLM可以使用的结构化格式,以便进行逐步推理。然而,这种手动过程需要领域专业知识,且难以扩展到大型工具集。此外,这些方法还严重依赖于临时推理技术或特殊令牌,将自由形式的LLM生成与工具调用操作相结合,这限制了LLM在处理各种工具规格和集成多个工具方面的灵活性。
在这项工作中,我们提出了AutoTools框架,使LLM能够自动化工具使用工作流程。具体来说,LLM会自动将工具文档转换为可调用的函数,验证语法和运行时正确性。然后,LLM将这些函数集成到可执行程序中以解决实际任务,灵活地将工具使用操作融入其推理过程。在现有和新收集的更具挑战性的基准测试上的大量实验证明了我们的框架的优越性。
论文及项目相关链接
PDF Accepted by WWW 2025
Summary
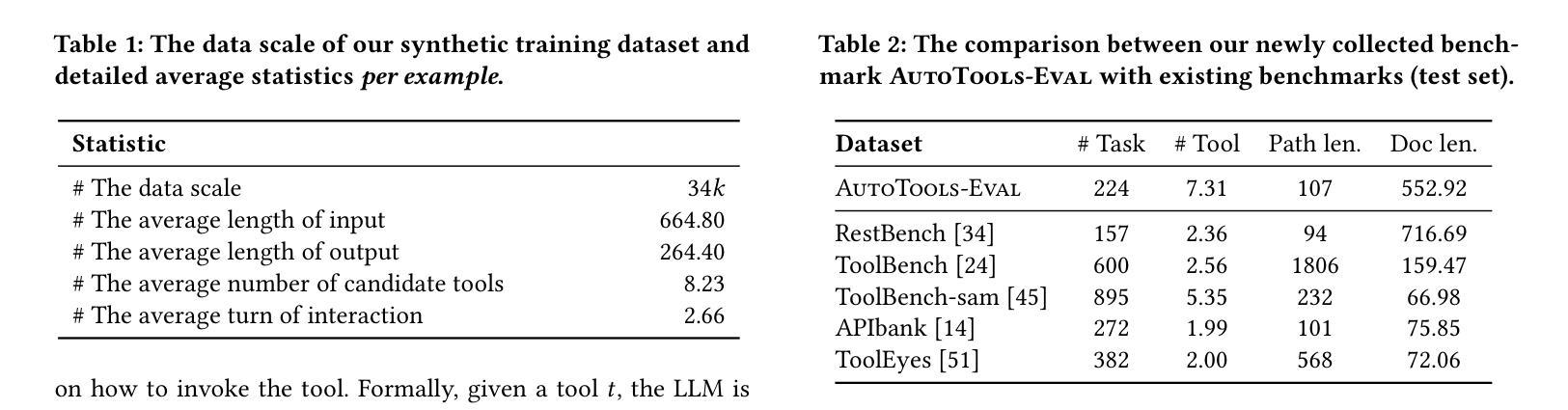
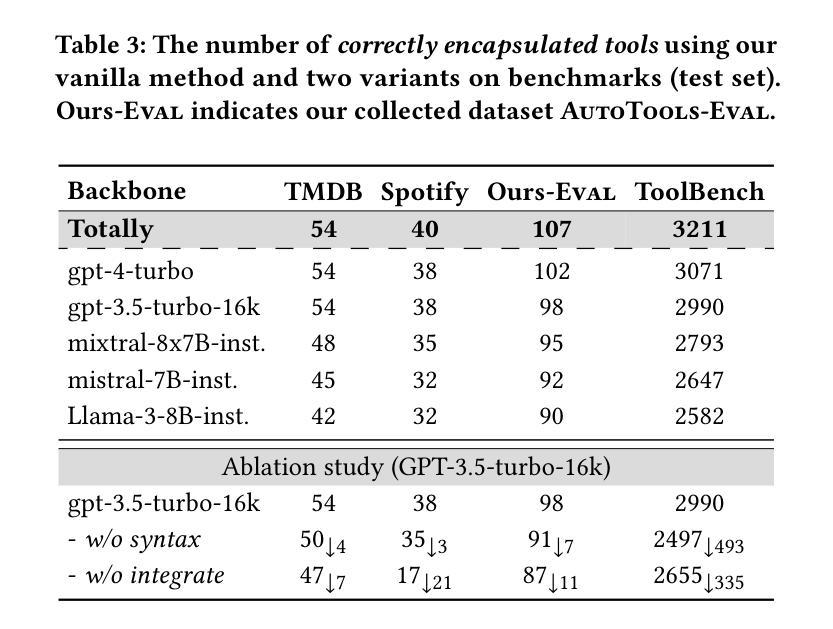
该文探讨了一种名为AutoTools的框架,该框架能够自动化工具使用流程,使得大型语言模型(LLMs)能够处理实用任务。LLM能够自动将工具文档转化为可调用函数,验证语法和运行时正确性。之后,LLM将这些函数整合到可执行程序中解决问题。该框架的优越性通过广泛的实验得到了验证。此外,文章还探讨了如何提升LLM在AutoTools中的专业性,特别是针对参数较少的开源LLM。为此,提出了AutoTools-learning方法,通过对高质量合成数据进行三项学习任务训练来提升LLM的能力。实验结果验证了该方法的有效性。
Key Takeaways
- AutoTools框架使得大型语言模型(LLMs)能够自动化使用外部工具解决实用任务。
- LLM能够自动将工具文档转化为可调用函数,并进行语法和运行时正确性验证。
- AutoTools框架的优越性通过广泛实验验证。
- 文章探讨了提升LLM在AutoTools中的专业性,特别是针对开源LLM。
- 提出了AutoTools-learning方法,通过三项学习任务训练来提升LLM的能力。
- 训练数据包括工具文档理解、相关性学习和函数编程等高质量合成数据。
- 实验结果验证了AutoTools-learning方法的有效性。
点此查看论文截图

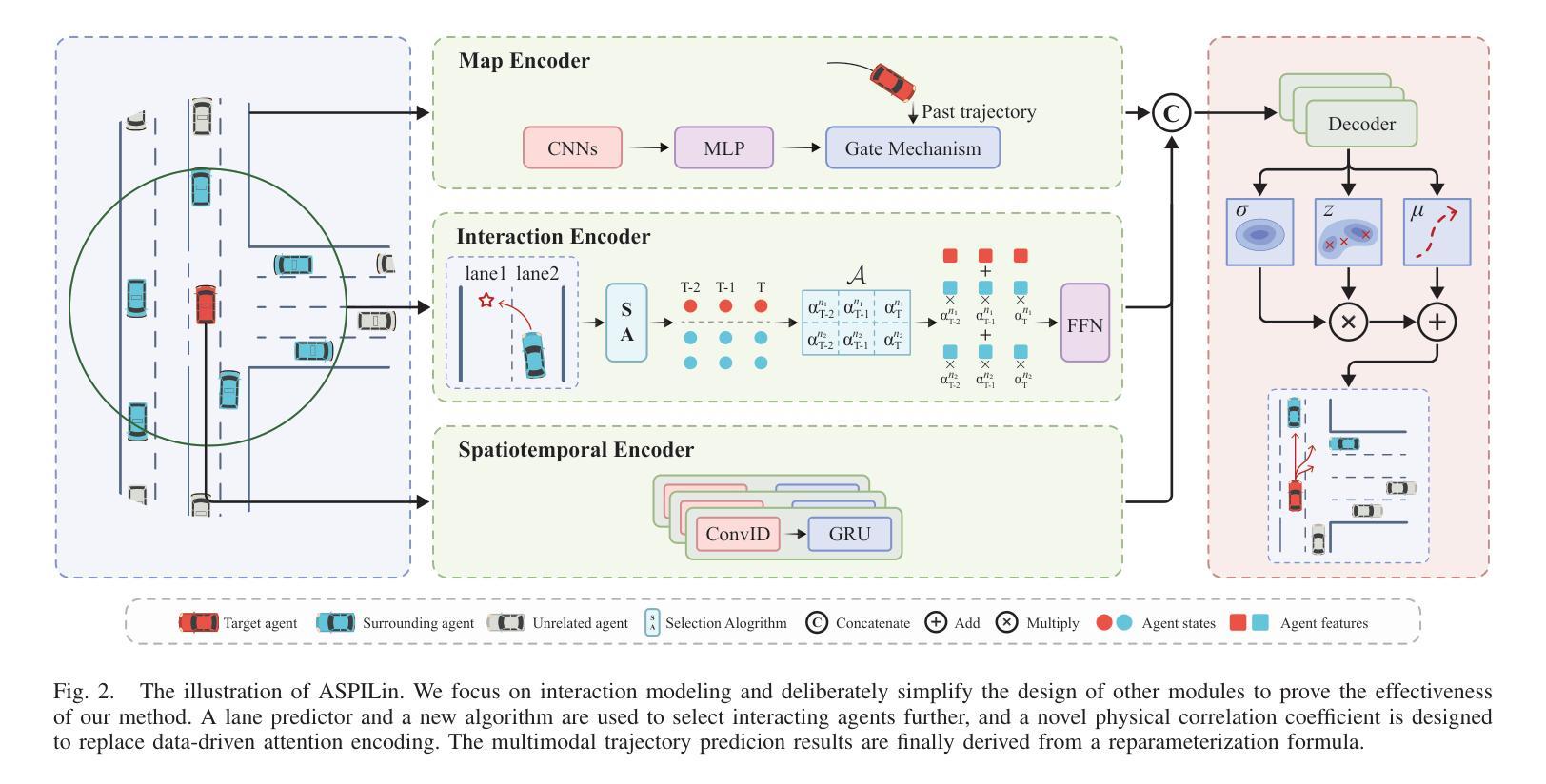
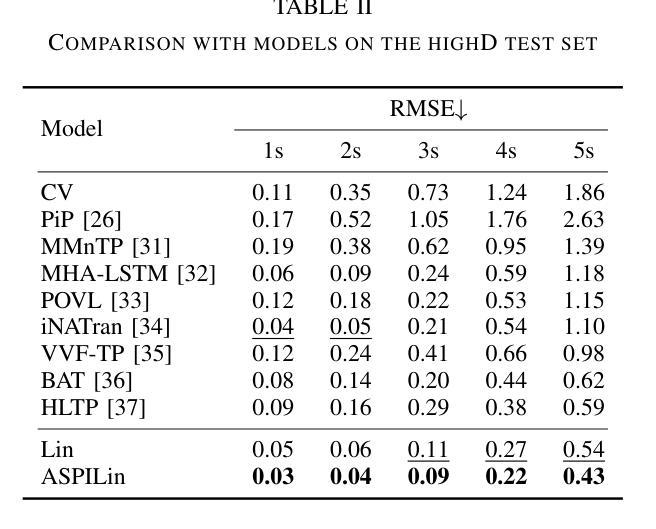
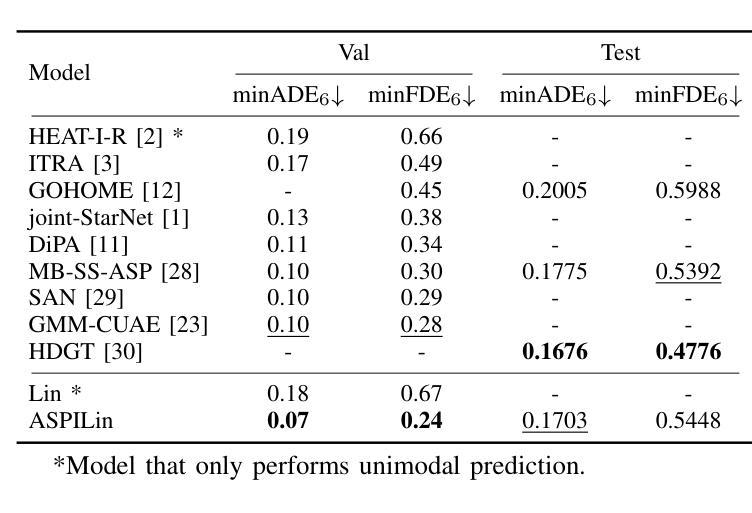
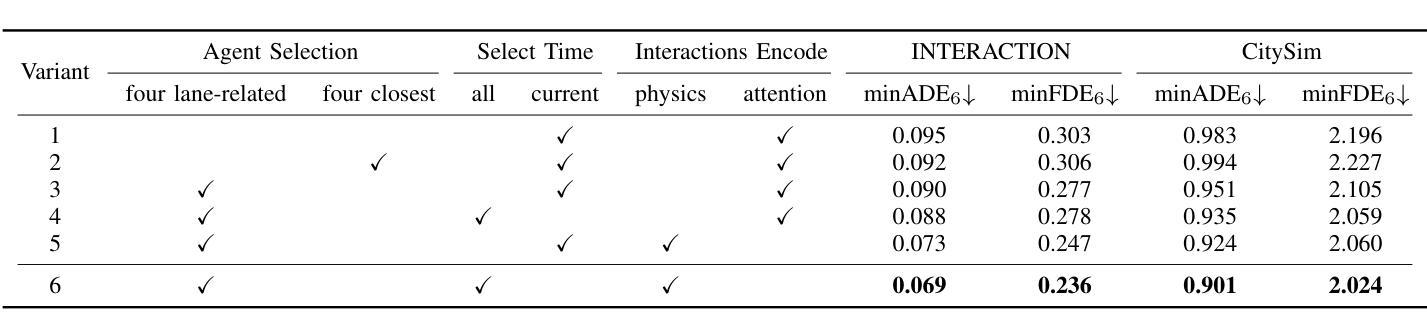
Interpretable Interaction Modeling for Trajectory Prediction via Agent Selection and Physical Coefficient
Authors:Shiji Huang, Lei Ye, Min Chen, Wenhai Luo, Dihong Wang, Chenqi Xu, Deyuan Liang
A thorough understanding of the interaction between the target agent and surrounding agents is a prerequisite for accurate trajectory prediction. Although many methods have been explored, they assign correlation coefficients to surrounding agents in a purely learning-based manner. In this study, we present ASPILin, which manually selects interacting agents and replaces the attention scores in Transformer with a newly computed physical correlation coefficient, enhancing the interpretability of interaction modeling. Surprisingly, these simple modifications can significantly improve prediction performance and substantially reduce computational costs. We intentionally simplified our model in other aspects, such as map encoding. Remarkably, experiments conducted on the INTERACTION, highD, and CitySim datasets demonstrate that our method is efficient and straightforward, outperforming other state-of-the-art methods.
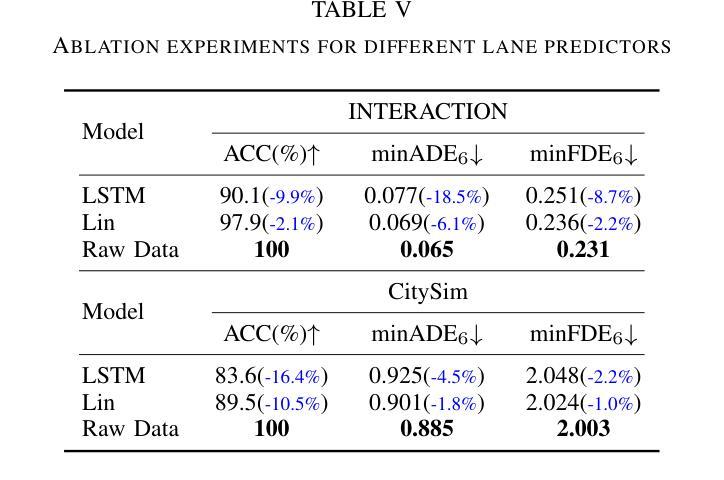
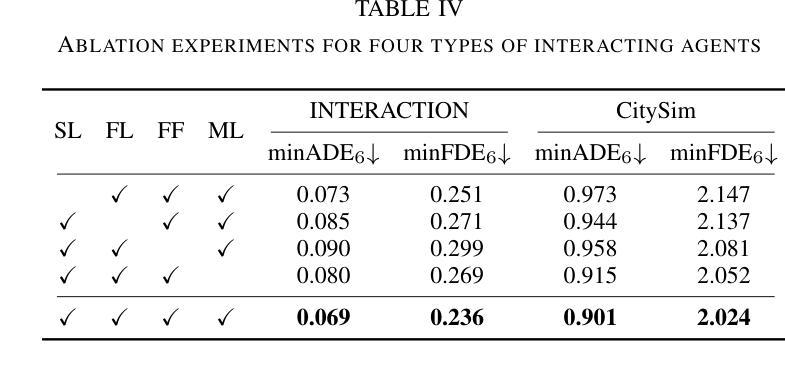
对目标代理与周围代理之间交互的深刻理解是准确预测轨迹的先决条件。尽管已经探索了许多方法,但它们以纯粹的学习方式为周围代理分配相关系数。在本研究中,我们提出了ASPILin,它手动选择交互代理,并用新计算得到的物理相关系数替换Transformer中的注意力得分,增强了交互建模的可解释性。令人惊讶的是,这些简单的修改可以显著提高预测性能并大幅降低计算成本。我们有意在其他方面简化了我们的模型,例如地图编码。值得注意的是,在INTERACTION、highD和CitySim数据集上进行的实验表明,我们的方法高效且直观,优于其他最先进的方法。
论文及项目相关链接
PDF code:https://github.com/kkk00714/ASPILin
Summary:
本研究提出ASPILin方法,通过手动选择交互代理并替换Transformer中的注意力分数为新的物理相关系数,提高了交互建模的可解释性。这种方法在预测性能方面有很大提升,并降低了计算成本。在INTERACTION、highD和CitySim数据集上的实验表明,该方法有效且简单,优于其他最先进的方法。
Key Takeaways:
- 理解目标代理与周围代理之间的交互是准确预测轨迹的前提。
- 现有方法主要通过学习来分配与周围代理的相关性系数。
- ASPILin方法手动选择交互代理,增强交互建模的可解释性。
- ASPILin通过替换Transformer中的注意力分数为物理相关系数,显著提高预测性能。
- 该方法降低计算成本,同时在实验数据集上表现优异。
- 实验在INTERACTION、highD和CitySim数据集上进行,证明该方法的有效性和优越性。
点此查看论文截图