⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-06 更新
StageDesigner: Artistic Stage Generation for Scenography via Theater Scripts
Authors:Zhaoxing Gan, Mengtian Li, Ruhua Chen, Zhongxia Ji, Sichen Guo, Huanling Hu, Guangnan Ye, Zuo Hu
In this work, we introduce StageDesigner, the first comprehensive framework for artistic stage generation using large language models combined with layout-controlled diffusion models. Given the professional requirements of stage scenography, StageDesigner simulates the workflows of seasoned artists to generate immersive 3D stage scenes. Specifically, our approach is divided into three primary modules: Script Analysis, which extracts thematic and spatial cues from input scripts; Foreground Generation, which constructs and arranges essential 3D objects; and Background Generation, which produces a harmonious background aligned with the narrative atmosphere and maintains spatial coherence by managing occlusions between foreground and background elements. Furthermore, we introduce the StagePro-V1 dataset, a dedicated dataset with 276 unique stage scenes spanning different historical styles and annotated with scripts, images, and detailed 3D layouts, specifically tailored for this task. Finally, evaluations using both standard and newly proposed metrics, along with extensive user studies, demonstrate the effectiveness of StageDesigner. Project can be found at: https://deadsmither5.github.io/2025/01/03/StageDesigner/
在这项工作中,我们介绍了StageDesigner,这是使用大型语言模型与布局控制扩散模型相结合,用于艺术舞台生成的首个综合框架。鉴于舞台布景的专业要求,StageDesigner模拟资深艺术家的工作流程来生成沉浸式3D舞台场景。具体来说,我们的方法分为三个主要模块:脚本分析,从输入脚本中提取主题和空间线索;前景生成,构建和安排重要的3D物体;背景生成,产生与叙事氛围和谐统一的背景,并通过管理前景和背景元素之间的遮挡关系来保持空间连贯性。此外,我们还介绍了StagePro-V1数据集,这是一个专用数据集,包含276个独特的舞台场景,跨越不同的历史风格,并附有脚本、图像和详细的3D布局注释,专门用于此任务。最后,通过标准和新提出的指标评估以及广泛的用户研究,证明了StageDesigner的有效性。项目网址为:https://deadsmither5.github.io/2025/01/03/StageDesigner/
论文及项目相关链接
Summary
基于大型语言模型与布局控制扩散模型,推出首个综合性舞台生成框架StageDesigner。StageDesigner模拟资深艺术家工作流程,生成沉浸式3D舞台场景。分为三大模块:脚本分析,提取输入脚本的主题和空间线索;前景生成,构建和安排重要的3D物体;背景生成,产生与叙事氛围和谐一致的背景,并管理前景和背景元素之间的遮挡,以保持空间连贯性。此外,还介绍了为这一任务量身定制的StagePro-V1数据集,包含276个涵盖不同历史风格的独特舞台场景,并附有脚本、图像和详细的3D布局。评估和用户研究证明了StageDesigner的有效性。
Key Takeaways
- StageDesigner是首个结合大型语言模型和布局控制扩散模型的综合性舞台生成框架。
- 它模拟资深艺术家的工作流程,生成沉浸式3D舞台场景。
- StageDesigner分为三个主要模块:脚本分析、前景生成和背景生成。
- StagePro-V1数据集专门为这一任务量身定制,包含多种独特舞台场景、脚本、图像和详细的3D布局。
- StageDesigner通过管理和处理前景与背景元素之间的遮挡来保持空间连贯性。
- 评估和实验证明StageDesigner的有效性。
点此查看论文截图



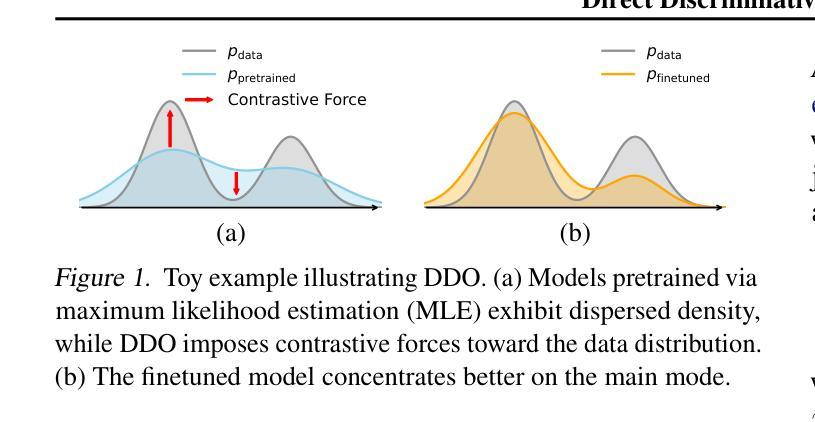
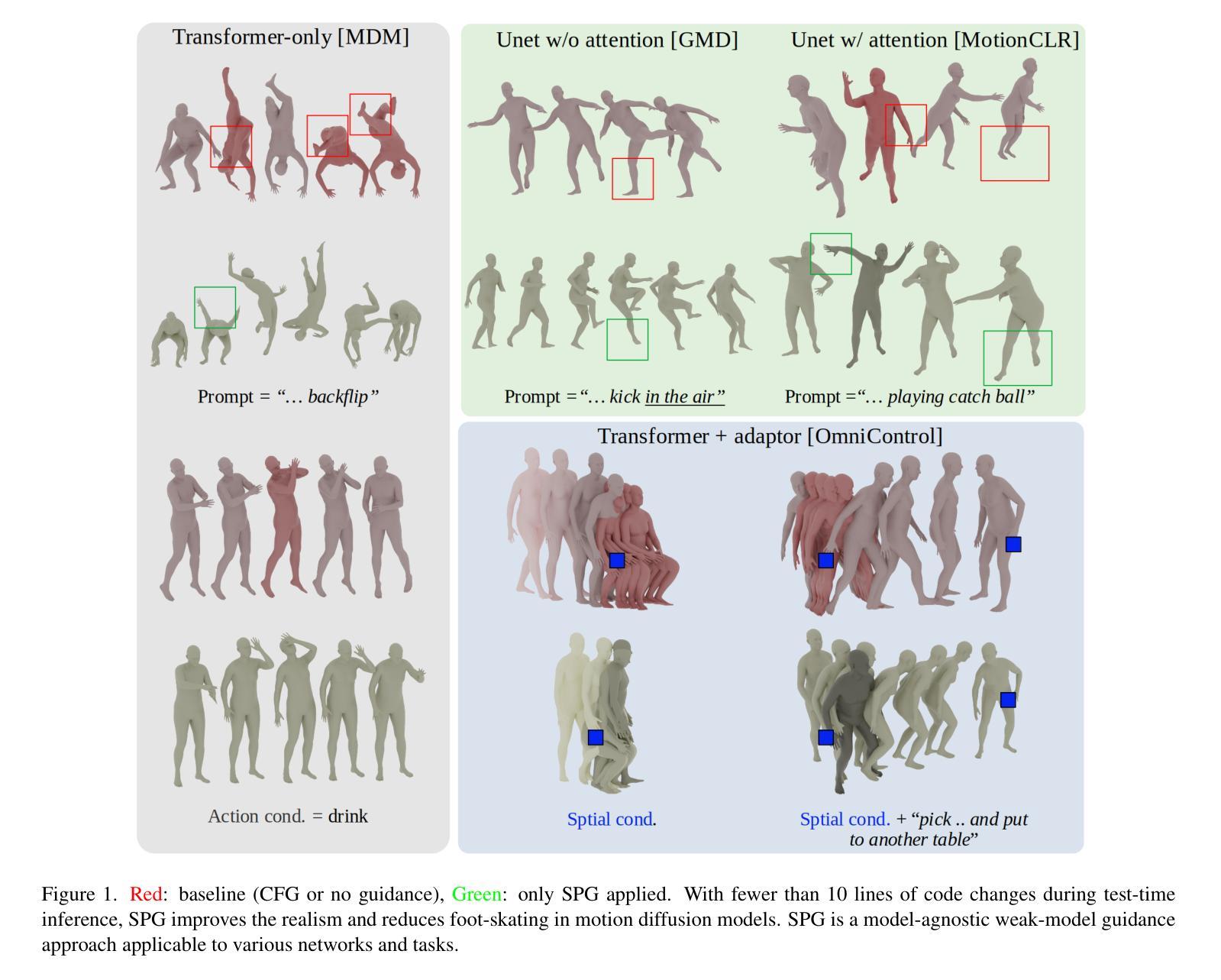
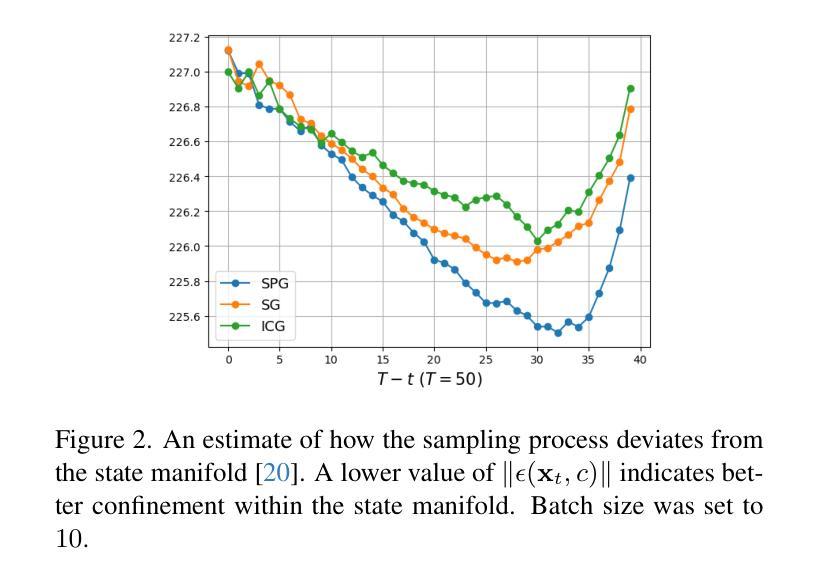
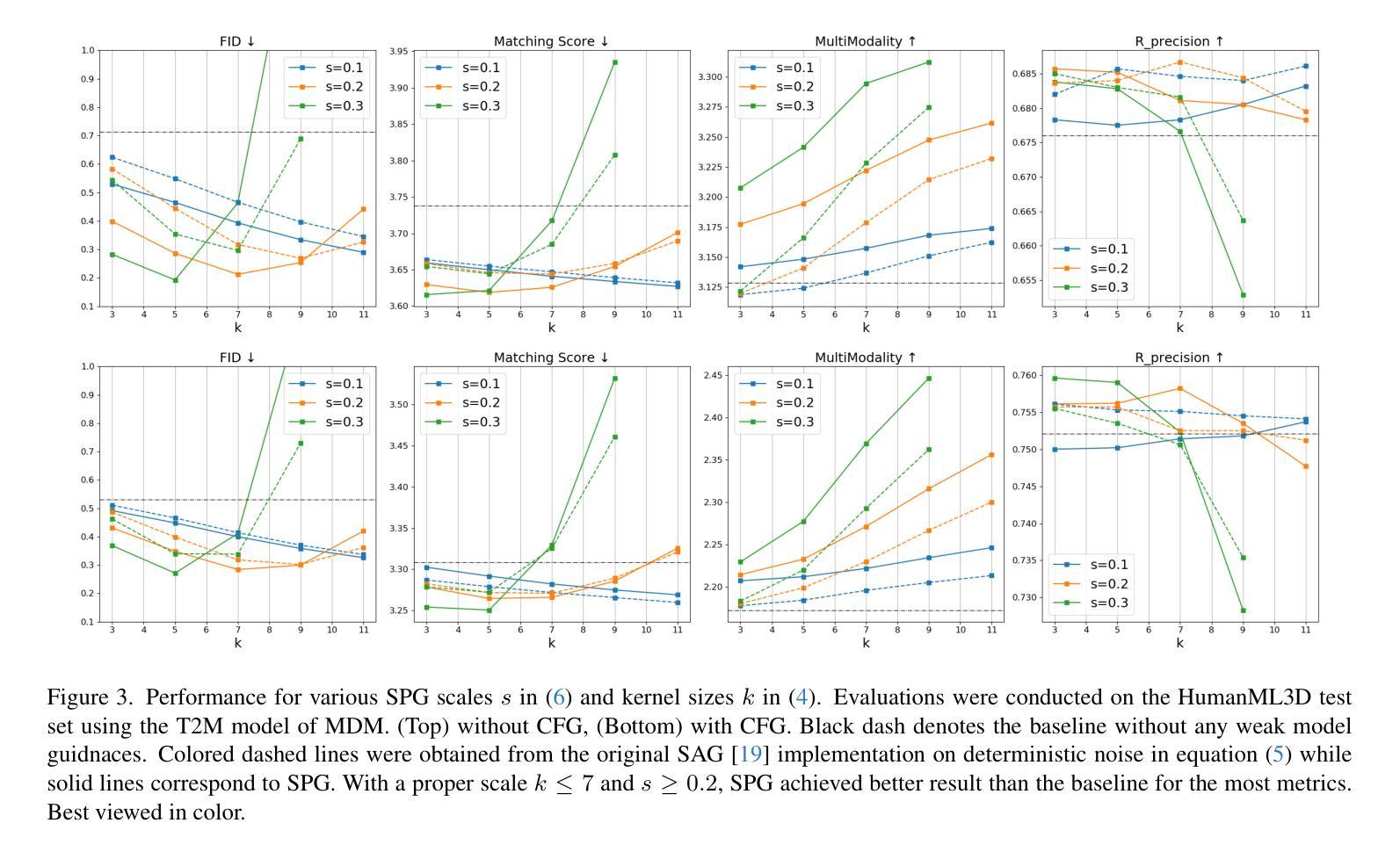
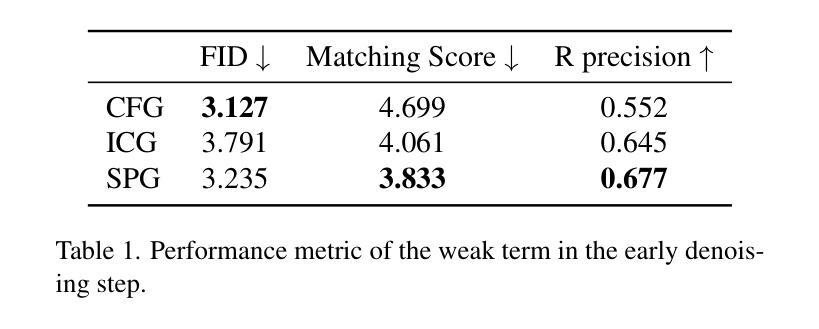
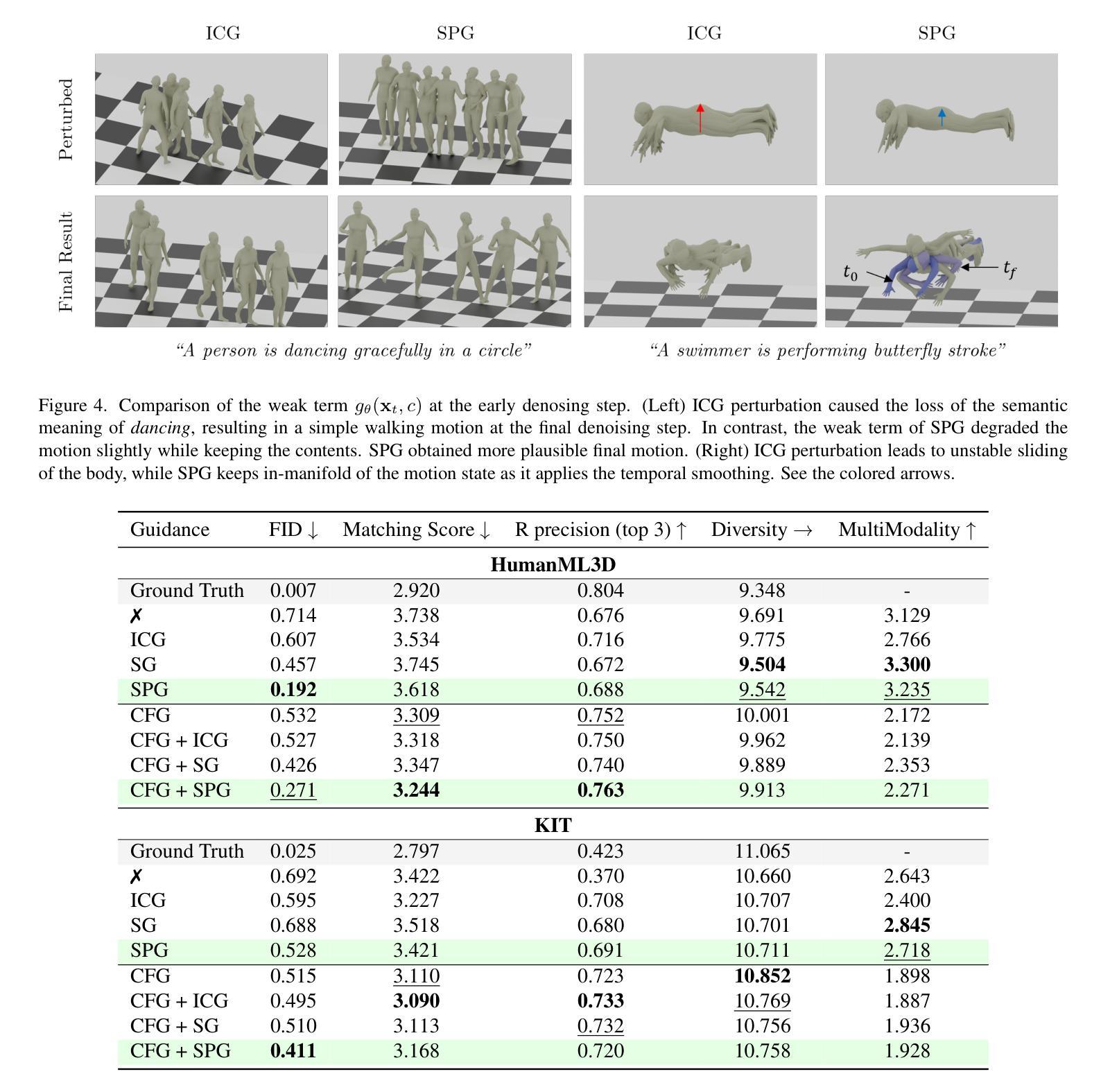
SPG: Improving Motion Diffusion by Smooth Perturbation Guidance
Authors:Boseong Jeon
This paper presents a test-time guidance method to improve the output quality of the human motion diffusion models without requiring additional training. To have negative guidance, Smooth Perturbation Guidance (SPG) builds a weak model by temporally smoothing the motion in the denoising steps. Compared to model-agnostic methods originating from the image generation field, SPG effectively mitigates out-of-distribution issues when perturbing motion diffusion models. In SPG guidance, the nature of motion structure remains intact. This work conducts a comprehensive analysis across distinct model architectures and tasks. Despite its extremely simple implementation and no need for additional training requirements, SPG consistently enhances motion fidelity. Project page can be found at https://spg-blind.vercel.app/
本文提出了一种测试时指导方法,旨在提高人类运动扩散模型的输出质量,而无需额外的训练。为了进行负向指导,SPG(平滑扰动指导)通过噪声去除步骤中的运动时间平滑来构建弱模型。与源自图像生成领域的模型无关方法相比,SPG在扰动运动扩散模型时有效减轻了分布外的问题。在SPG指导下,运动结构的本质保持不变。本工作对不同模型架构和任务进行了综合分析。尽管其实现极为简单且无需额外的训练要求,但SPG始终提高了运动保真度。项目页面位于:[https://spg-blind.vercel.app/] 。
论文及项目相关链接
Summary
本文介绍了一种测试时指导方法,用于提高人类运动扩散模型的输出质量,而无需额外的训练。通过引入平滑扰动指导(SPG),建立弱模型在降噪步骤中对运动进行时间平滑,实现负向指导。相较于源自图像生成领域的模型无关方法,SPG在扰动运动扩散模型时,能有效减轻分布外问题,保持运动结构的完整性。此方案在不同模型架构和任务上进行了全面分析,即使实现方式极为简洁且无需额外训练要求,也能持续提升运动保真度。
Key Takeaways
- 介绍了测试时指导方法,旨在提高人类运动扩散模型的输出质量。
- 引入了平滑扰动指导(SPG),通过时间平滑运动建立弱模型。
- SPG实现了负向指导,有效减轻分布外问题。
- SPG保持运动结构的完整性。
- 该方案在不同模型架构和任务上进行了全面分析。
- SPG提高运动保真度。
点此查看论文截图

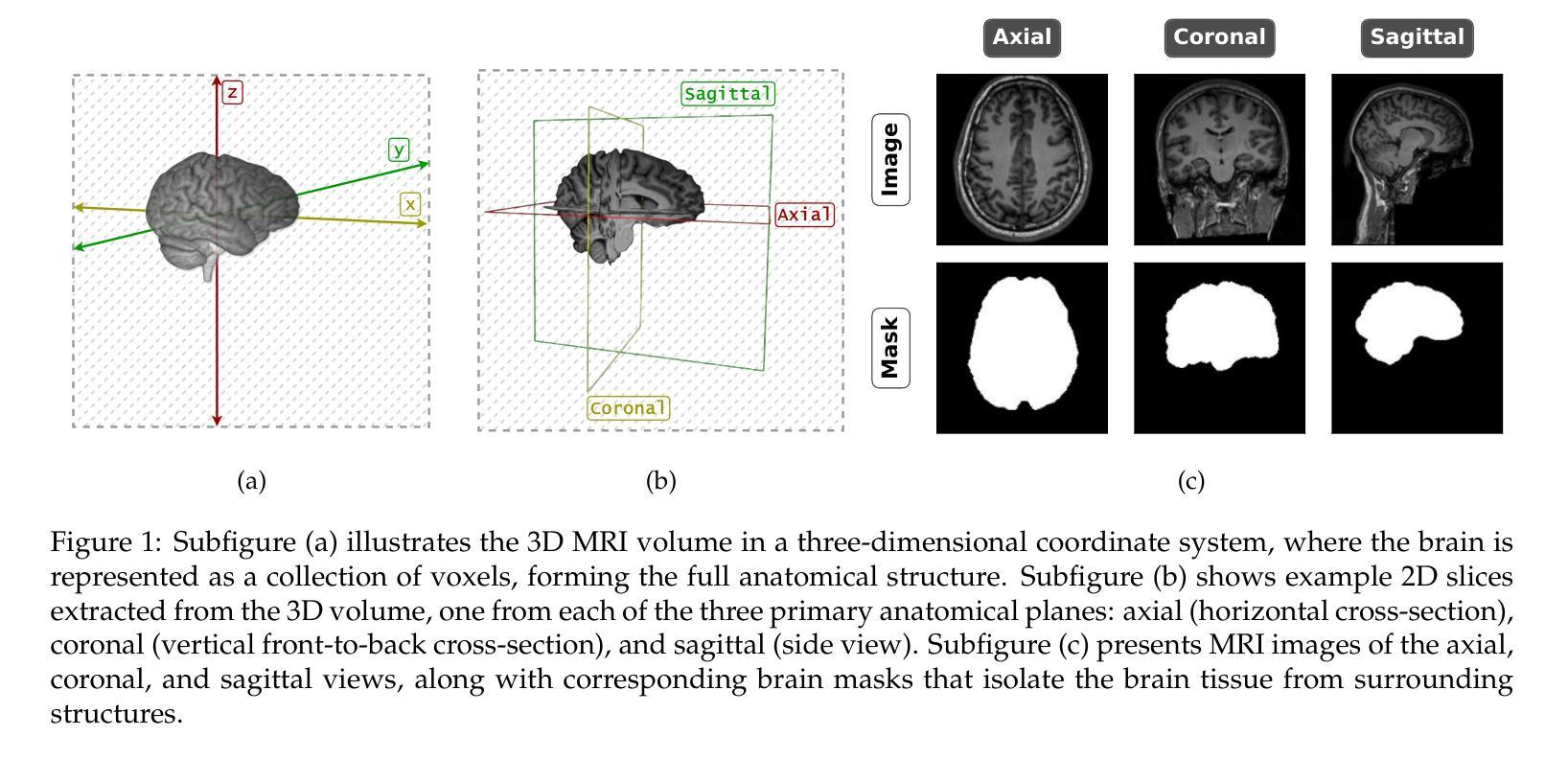
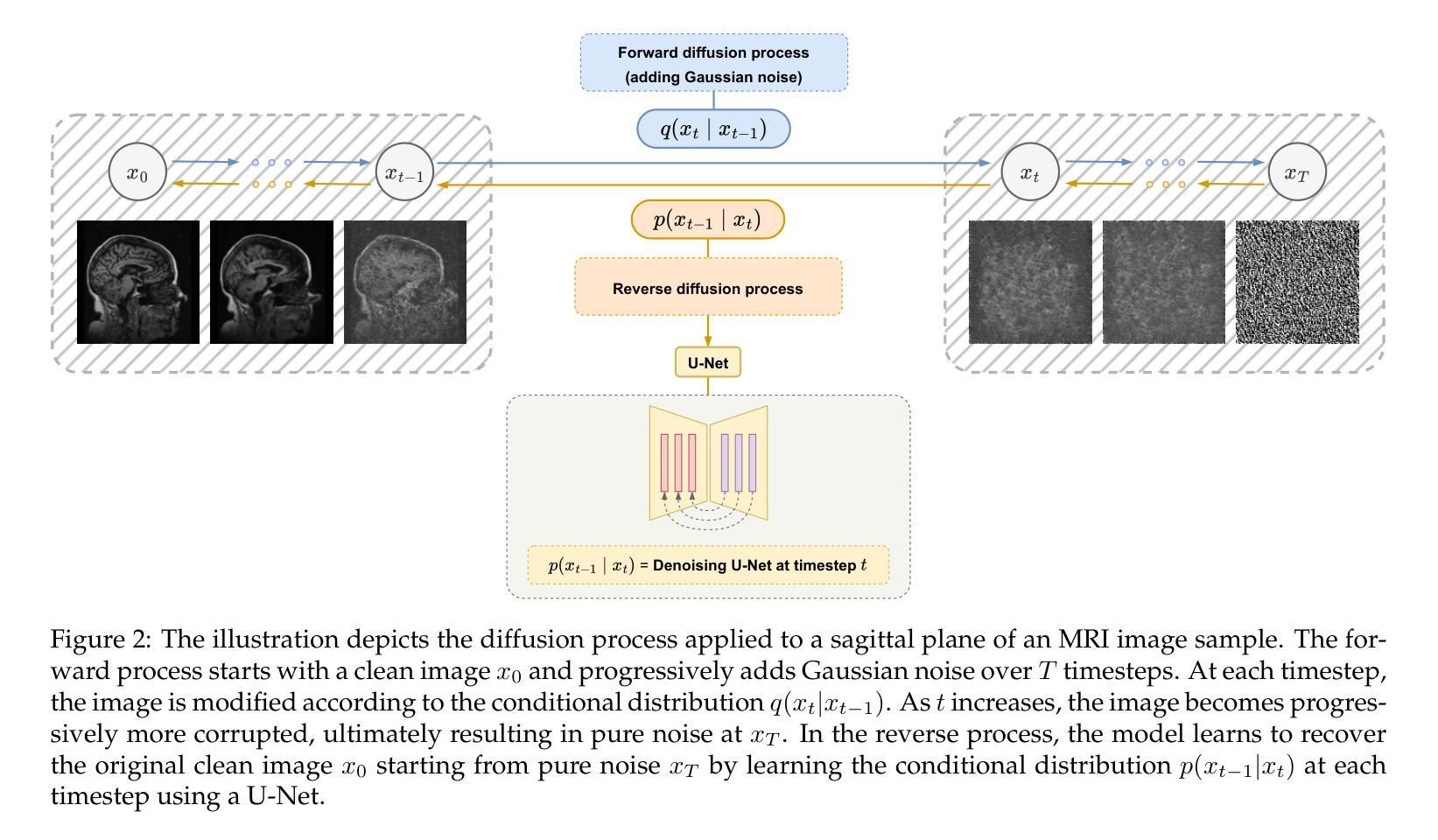
CQ CNN: A Hybrid Classical Quantum Convolutional Neural Network for Alzheimer’s Disease Detection Using Diffusion Generated and U Net Segmented 3D MRI
Authors:Mominul Islam, Mohammad Junayed Hasan, M. R. C. Mahdy
The detection of Alzheimer disease (AD) from clinical MRI data is an active area of research in medical imaging. Recent advances in quantum computing, particularly the integration of parameterized quantum circuits (PQCs) with classical machine learning architectures, offer new opportunities to develop models that may outperform traditional methods. However, quantum machine learning (QML) remains in its early stages and requires further experimental analysis to better understand its behavior and limitations. In this paper, we propose an end to end hybrid classical quantum convolutional neural network (CQ CNN) for AD detection using clinically formatted 3D MRI data. Our approach involves developing a framework to make 3D MRI data usable for machine learning, designing and training a brain tissue segmentation model (Skull Net), and training a diffusion model to generate synthetic images for the minority class. Our converged models exhibit potential quantum advantages, achieving higher accuracy in fewer epochs than classical models. The proposed beta8 3 qubit model achieves an accuracy of 97.50%, surpassing state of the art (SOTA) models while requiring significantly fewer computational resources. In particular, the architecture employs only 13K parameters (0.48 MB), reducing the parameter count by more than 99.99% compared to current SOTA models. Furthermore, the diffusion-generated data used to train our quantum models, in conjunction with real samples, preserve clinical structural standards, representing a notable first in the field of QML. We conclude that CQCNN architecture like models, with further improvements in gradient optimization techniques, could become a viable option and even a potential alternative to classical models for AD detection, especially in data limited and resource constrained clinical settings.
使用临床MRI数据检测阿尔茨海默病(AD)是医学影像研究的一个活跃领域。最近量子计算技术的进展,特别是参数化量子电路(PQC)与经典机器学习架构的集成,为开发可能超越传统方法的模型提供了新的机会。然而,量子机器学习(QML)仍处于早期阶段,需要进一步实验分析以更好地了解其行为和局限性。在本文中,我们提出了一种端到端的混合经典量子卷积神经网络(CQCNN),用于使用临床格式的3D MRI数据进行AD检测。我们的方法包括开发一个使3D MRI数据可用于机器学习框架、设计和训练脑组织分割模型(SkullNet)、训练扩散模型以生成少数类的合成图像等步骤。我们的收敛模型展现出潜在的量子优势,在较少的迭代次数内实现了较高的准确度,超过了经典模型。所提出的beta8
论文及项目相关链接
PDF Application of hybrid quantum-classical machine learning for (early stage) disease detection
Summary
本文提出一种端到端的混合经典量子卷积神经网络(CQCNN),用于利用临床格式的3D MRI数据进行阿尔茨海默病(AD)检测。通过开发使3D MRI数据适用于机器学习的方法、设计和训练脑组织的分割模型(Skull Net),以及训练扩散模型来生成少数类的合成图像,展现出潜在的量子优势。所提出的beta8 3量子位模型实现了97.50%的准确率,超越了现有技术模型,并显著降低计算资源需求。该架构仅有13K参数(0.48 MB),减少了超过99.99%的参数数量。此外,扩散生成的数据用于训练量子模型,与真实样本一起保留临床结构标准,代表着量子机器学习领域的重要进步。结论是,CQCNN架构等模型在梯度优化技术进一步改进后,可能成为AD检测的可行选择,甚至在数据有限和资源受限的临床环境中成为潜在替代方案。
Key Takeaways
- 文章介绍了一种混合经典量子卷积神经网络(CQCNN)用于阿尔茨海默病(AD)检测的最新研究。
- 该方法结合了量子计算和机器学习,实现了较高的检测准确率。
- 所提出的beta8 3量子位模型准确率达到了97.50%,并显著减少了计算资源需求。
- 该模型通过开发适用于机器学习的3D MRI数据处理方法、设计并训练脑组织分割模型(Skull Net)以及使用扩散模型生成合成图像来增强其性能。
- 扩散模型生成的数据能够保留临床结构标准,并与真实样本一起使用,这在量子机器学习领域是一个重要的进步。
- 文章指出,随着梯度优化技术的进一步改进,此类模型可能成为经典模型的可行替代方案,特别是在资源受限的临床环境中。
点此查看论文截图

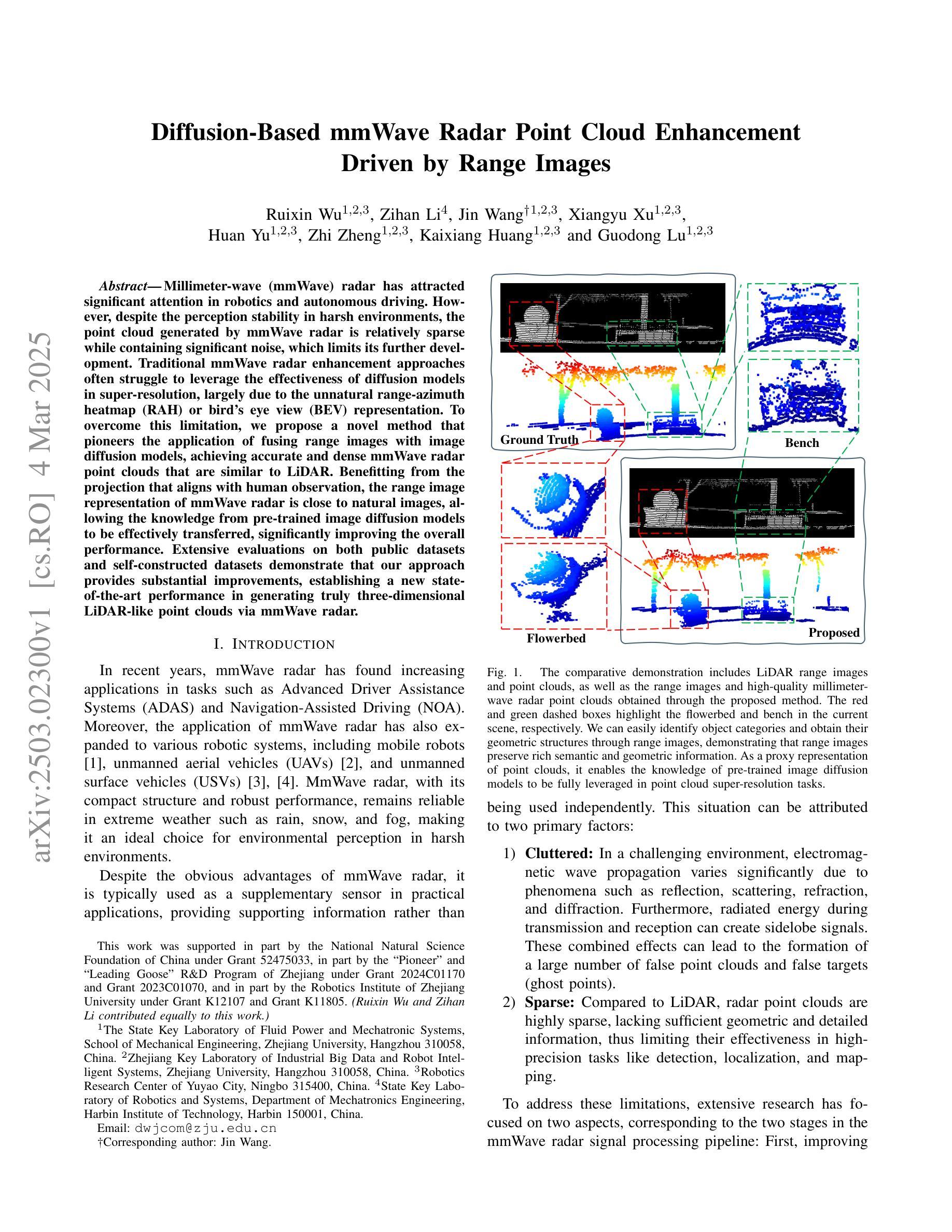
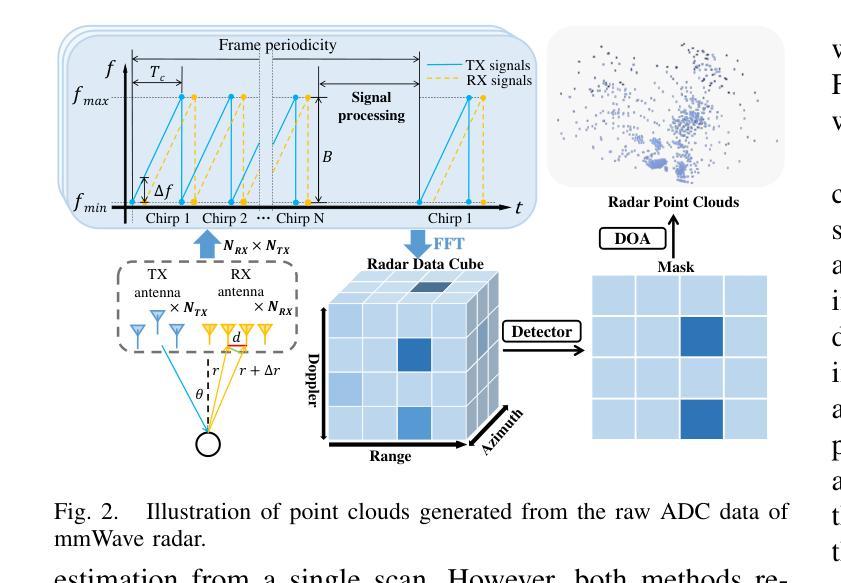
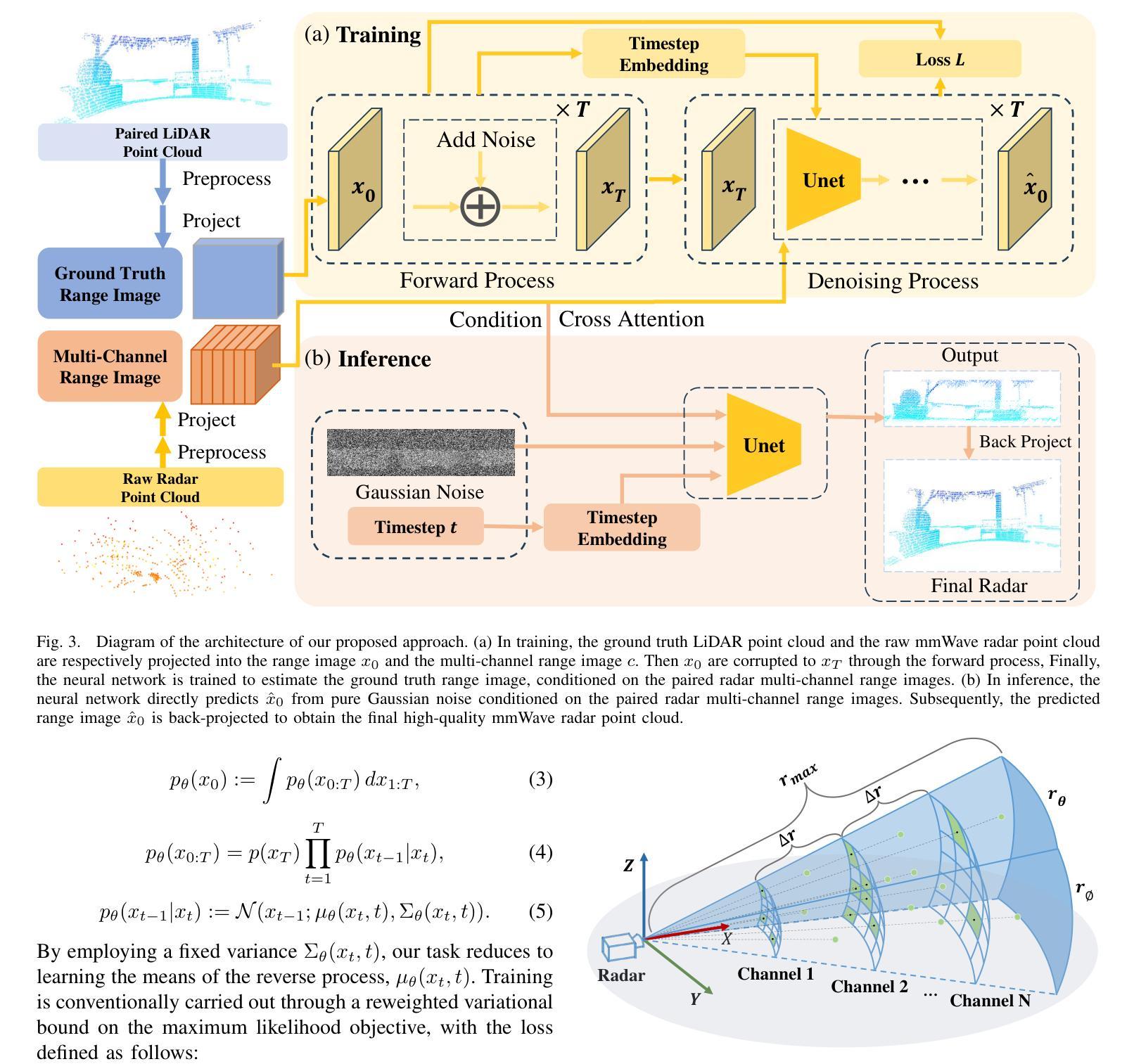
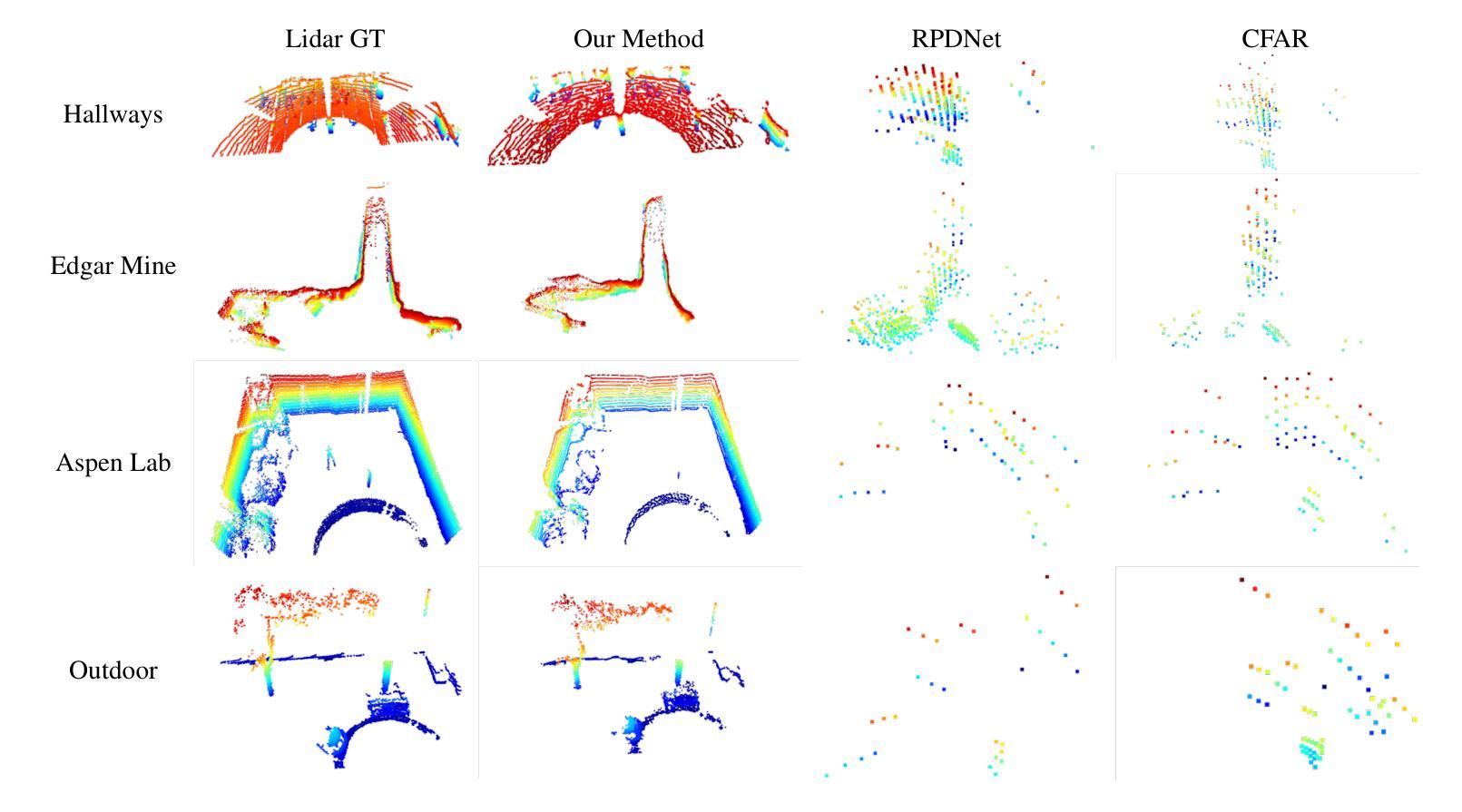
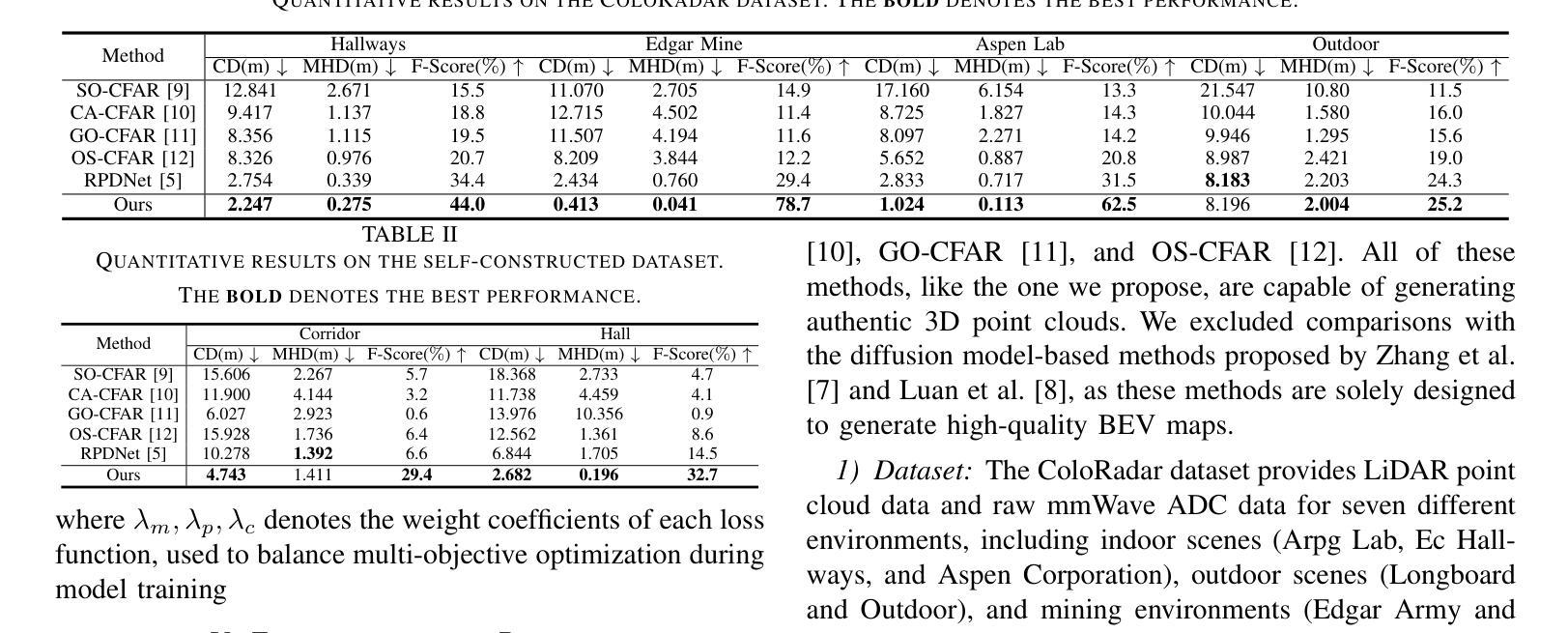
Diffusion-Based mmWave Radar Point Cloud Enhancement Driven by Range Images
Authors:Ruixin Wu, Zihan Li, Jin Wang, Xiangyu Xu, Huan Yu, Zhi Zheng, Kaixiang Huang, Guodong Lu
Millimeter-wave (mmWave) radar has attracted significant attention in robotics and autonomous driving. However, despite the perception stability in harsh environments, the point cloud generated by mmWave radar is relatively sparse while containing significant noise, which limits its further development. Traditional mmWave radar enhancement approaches often struggle to leverage the effectiveness of diffusion models in super-resolution, largely due to the unnatural range-azimuth heatmap (RAH) or bird’s eye view (BEV) representation. To overcome this limitation, we propose a novel method that pioneers the application of fusing range images with image diffusion models, achieving accurate and dense mmWave radar point clouds that are similar to LiDAR. Benefitting from the projection that aligns with human observation, the range image representation of mmWave radar is close to natural images, allowing the knowledge from pre-trained image diffusion models to be effectively transferred, significantly improving the overall performance. Extensive evaluations on both public datasets and self-constructed datasets demonstrate that our approach provides substantial improvements, establishing a new state-of-the-art performance in generating truly three-dimensional LiDAR-like point clouds via mmWave radar.
毫米波雷达(mmWave radar)在机器人技术和自动驾驶领域引起了广泛关注。然而,尽管毫米波雷达在恶劣环境下的感知稳定性良好,但其生成的点云相对稀疏且含有较大噪声,限制了其进一步发展。传统的毫米波雷达增强方法往往难以利用扩散模型在超分辨率方面的有效性,这很大程度上是由于范围-方位热图(RAH)或鸟瞰图(BEV)表示的不自然范围。为了克服这一局限性,我们提出了一种融合范围图像与图像扩散模型的新方法,实现了准确且密集的毫米波雷达点云,类似于激光雷达。受益于与人类观察相一致的投影,毫米波雷达的范围图像表示接近自然图像,使得预训练的图像扩散模型的知识可以有效地迁移,从而大大提高了整体性能。在公共数据集和自我构建的数据集上的广泛评估表明,我们的方法在生成真正的三维激光雷达式点云方面提供了巨大改进,确立了通过毫米波雷达生成点云的最先进性能。
论文及项目相关链接
PDF 8 pages, 7 figures, submitted to 2025 IROS. This work has been submitted to the IEEE for possible publication
Summary
毫米波雷达在机器人和自动驾驶领域备受关注,但其生成的点云稀疏且含有较多噪声。传统增强方法难以利用扩散模型实现超分辨率效果。本研究创新性地融合范围图像与图像扩散模型,生成准确、密集的毫米波雷达点云,类似于激光雷达点云。范围图像表示法与自然图像相似,可借助预训练的图像扩散模型知识进行有效迁移,显著提高性能。在公共和自制数据集上的评估显示,该方法显著提升了生成真正三维激光雷达点云的性能,达到最新水平。
Key Takeaways
- 毫米波雷达在机器人和自动驾驶领域受到关注,但点云稀疏且含噪声,限制了其发展。
- 传统增强方法难以利用扩散模型实现超分辨率效果,因为范围方位热图或鸟瞰图表示方法不够自然。
- 提出了一种融合范围图像与图像扩散模型的新方法,生成准确、密集的毫米波雷达点云。
- 范围图像表示法接近自然图像,有利于预训练的图像扩散模型知识的迁移。
- 该方法生成的三维点云类似于激光雷达点云。
- 在公共和自制数据集上的评估表明,该方法显著提高了生成毫米波雷达点云的性能。
点此查看论文截图
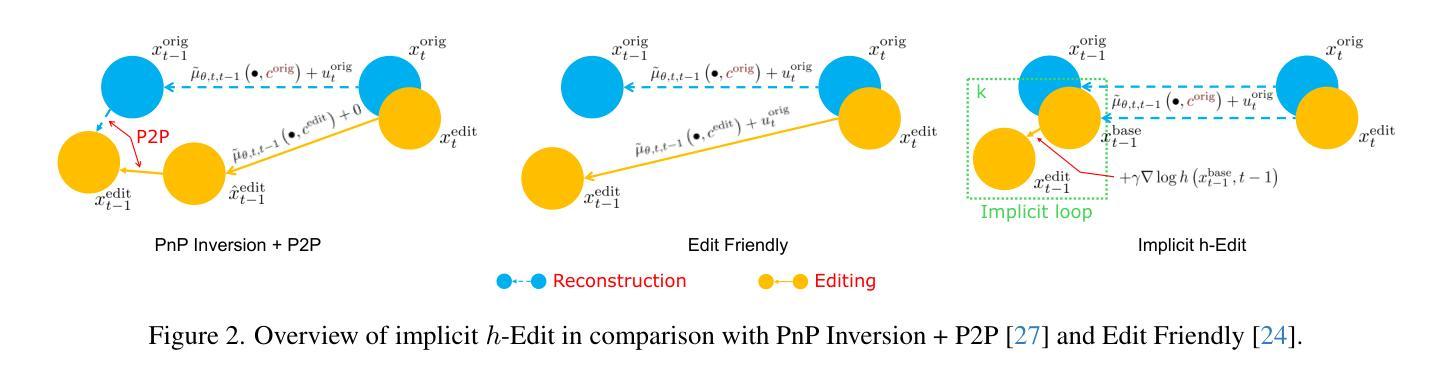
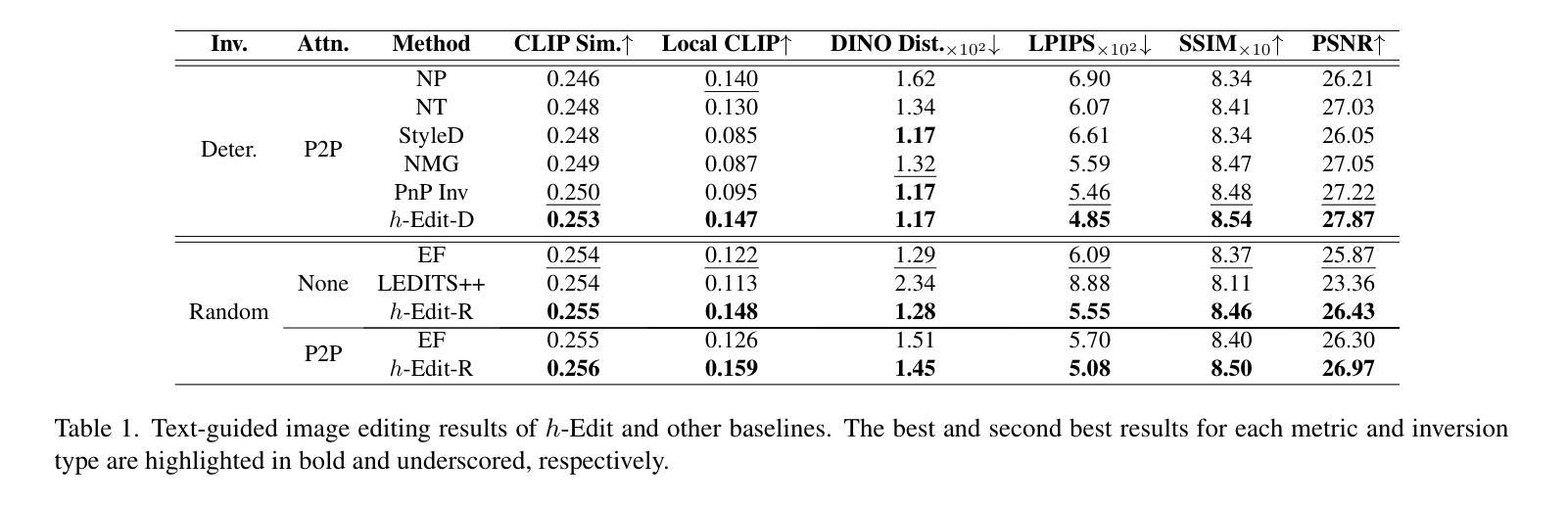
h-Edit: Effective and Flexible Diffusion-Based Editing via Doob’s h-Transform
Authors:Toan Nguyen, Kien Do, Duc Kieu, Thin Nguyen
We introduce a theoretical framework for diffusion-based image editing by formulating it as a reverse-time bridge modeling problem. This approach modifies the backward process of a pretrained diffusion model to construct a bridge that converges to an implicit distribution associated with the editing target at time 0. Building on this framework, we propose h-Edit, a novel editing method that utilizes Doob’s h-transform and Langevin Monte Carlo to decompose the update of an intermediate edited sample into two components: a “reconstruction” term and an “editing” term. This decomposition provides flexibility, allowing the reconstruction term to be computed via existing inversion techniques and enabling the combination of multiple editing terms to handle complex editing tasks. To our knowledge, h-Edit is the first training-free method capable of performing simultaneous text-guided and reward-model-based editing. Extensive experiments, both quantitative and qualitative, show that h-Edit outperforms state-of-the-art baselines in terms of editing effectiveness and faithfulness. Our source code is available at https://github.com/nktoan/h-edit.
我们引入了一个基于扩散的图像编辑理论框架,将其制定为一个反向时间桥梁建模问题。这种方法通过修改预训练的扩散模型的逆向过程来构建一座桥梁,该桥梁在时间为0时收敛到与编辑目标相关的隐式分布。基于这个框架,我们提出了h-Edit,这是一种新的编辑方法,它利用Doob的h变换和Langevin Monte Carlo将中间编辑样本的更新分解为两个组成部分:“重建”项和“编辑”项。这种分解提供了灵活性,允许通过现有的反演技术来计算重建项,并能够结合多个编辑项来处理复杂的编辑任务。据我们所知,h-Edit是一种无需训练的方法,能够同时进行文本引导和基于奖励模型的编辑。大量实验,包括定量和定性实验,表明h-Edit在编辑效果和忠实度方面超过了最先进的基线方法。我们的源代码可在https://github.com/nktoan/h-edit上找到。
论文及项目相关链接
PDF Accepted in CVPR 2025
Summary
本文提出了一个基于扩散的图像编辑理论框架,将其建模为反向时间桥模型问题。通过修改预训练扩散模型的逆向过程,构建一座在时间0与编辑目标相关联的隐式分布的桥梁。在此基础上,提出了h-Edit编辑方法,利用Doob的h-变换和Langevin Monte Carlo,将中间编辑样本的更新分解为“重建”和“编辑”两部分。这使得h-Edit能结合多种编辑技术处理复杂任务,且为目前首个无需训练即可同时进行文本引导和奖励模型编辑的方法。实验证明,h-Edit在编辑效果和忠实度方面超越现有基线。
Key Takeaways
- 扩散模型为基础,构建了一个反向时间桥模型的理论框架用于图像编辑。
- 通过修改预训练扩散模型的逆向过程,创建了一座桥梁以连接编辑目标和隐式分布。
- 提出了h-Edit编辑方法,利用Doob的h-变换和Langevin Monte Carlo进行更新分解。
- h-Edit方法允许将“重建”和“编辑”分开处理,提高了灵活性。
- h-Edit是首个无需训练即可结合文本引导和奖励模型进行编辑的方法。
- 实验证明h-Edit在编辑效果和忠实度方面表现优异。
- h-Edit的源代码已公开,可供他人使用和研究。
点此查看论文截图

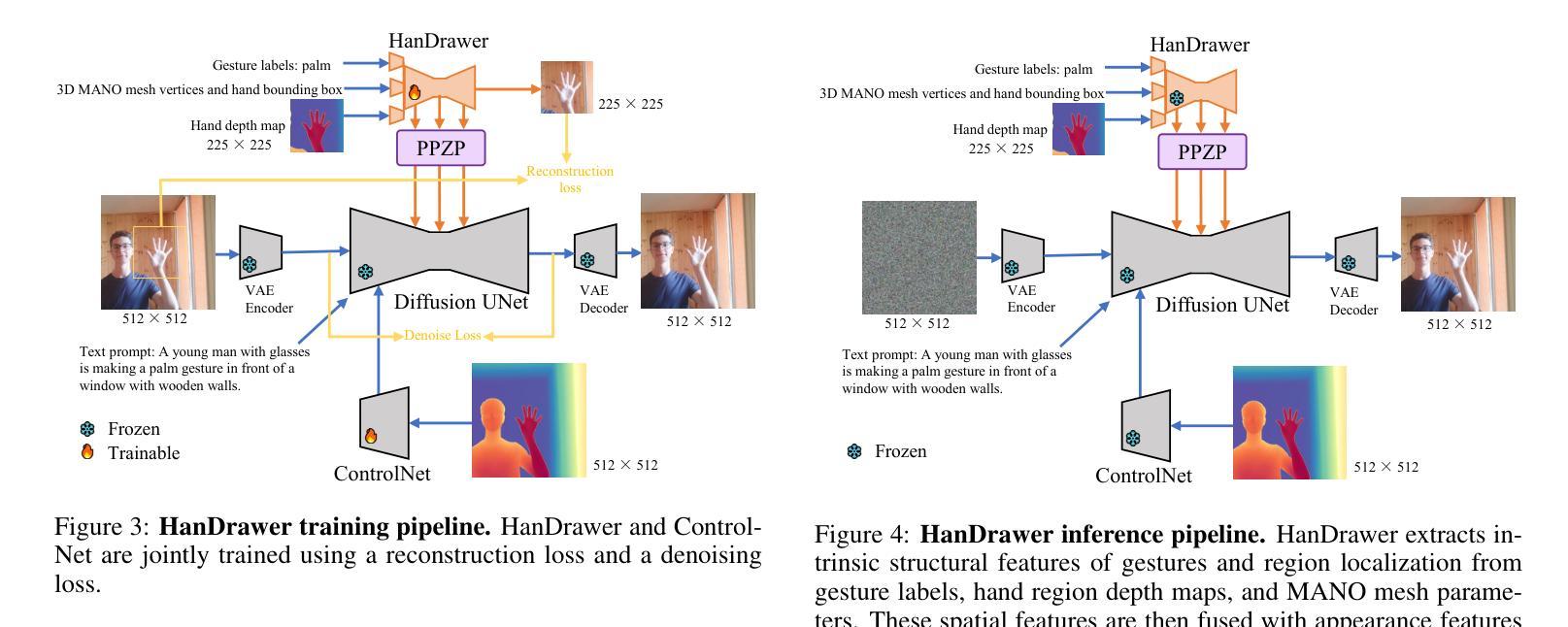
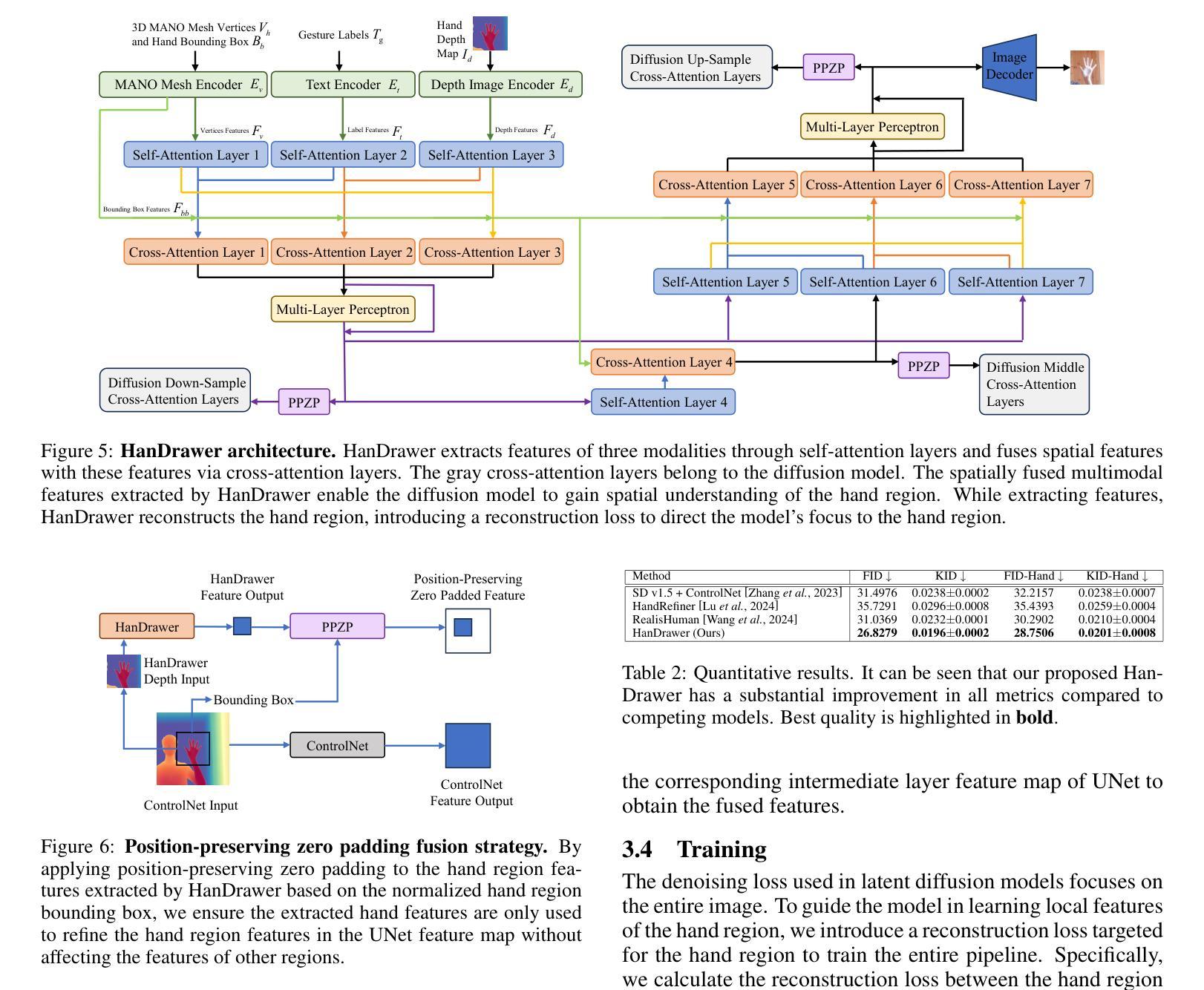
HanDrawer: Leveraging Spatial Information to Render Realistic Hands Using a Conditional Diffusion Model in Single Stage
Authors:Qifan Fu, Xu Chen, Muhammad Asad, Shanxin Yuan, Changjae Oh, Gregory Slabaugh
Although diffusion methods excel in text-to-image generation, generating accurate hand gestures remains a major challenge, resulting in severe artifacts, such as incorrect number of fingers or unnatural gestures. To enable the diffusion model to learn spatial information to improve the quality of the hands generated, we propose HanDrawer, a module to condition the hand generation process. Specifically, we apply graph convolutional layers to extract the endogenous spatial structure and physical constraints implicit in MANO hand mesh vertices. We then align and fuse these spatial features with other modalities via cross-attention. The spatially fused features are used to guide a single stage diffusion model denoising process for high quality generation of the hand region. To improve the accuracy of spatial feature fusion, we propose a Position-Preserving Zero Padding (PPZP) fusion strategy, which ensures that the features extracted by HanDrawer are fused into the region of interest in the relevant layers of the diffusion model. HanDrawer learns the entire image features while paying special attention to the hand region thanks to an additional hand reconstruction loss combined with the denoising loss. To accurately train and evaluate our approach, we perform careful cleansing and relabeling of the widely used HaGRID hand gesture dataset and obtain high quality multimodal data. Quantitative and qualitative analyses demonstrate the state-of-the-art performance of our method on the HaGRID dataset through multiple evaluation metrics. Source code and our enhanced dataset will be released publicly if the paper is accepted.
尽管扩散方法在图文生成方面表现出色,但生成准确的手势仍是一个主要挑战,会导致严重的人工痕迹,例如手指数量不正确或手势不自然。为了能够让扩散模型学习空间信息以提高生成的手部质量,我们提出了HanDrawer模块,用于调节手部生成过程。具体来说,我们应用图卷积层来提取MANO手部网格顶点中隐含的内生空间结构和物理约束。然后,我们通过交叉注意力将这些空间特征与其他模态进行对齐和融合。这些空间融合的特征被用来引导单阶段扩散模型的去噪过程,以高质量生成手部区域。为了提高空间特征融合的准确性,我们提出了一种位置保持零填充(PPZP)融合策略,确保HanDrawer提取的特征融合到扩散模型相关层的感兴趣区域中。HanDrawer在关注手部区域的同时学习整个图像的特征,这得益于与去噪损失相结合的手部重建损失。为了准确训练和评估我们的方法,我们对广泛使用的HaGRID手势数据集进行了仔细清理和重新标注,获得了高质量的多模态数据。定量和定性分析表明,我们的方法在HaGRID数据集上通过多个评价指标表现出卓越的性能。如果论文被接受,我们将公开源代码和增强的数据集。
论文及项目相关链接
PDF 9 pages
Summary
本文提出一种名为HanDrawer的模块,用于改善扩散模型在生成手部时的准确性问题。通过应用图卷积层提取MANO手网格顶点中的内源性空间结构和物理约束,结合跨注意力机制与其他模态特征对齐融合。融合后的特征被用于引导单阶段扩散模型的去噪过程,以提高手部区域的生成质量。同时,本文还提出了一种位置保持零填充(PPZP)融合策略,确保HanDrawer提取的特征能够融合到扩散模型的相关层中的感兴趣区域。通过对手部重建损失与去噪损失的结合,HanDrawer在关注手部区域的同时学习整个图像特征。对广泛使用的HaGRID手势数据集进行了精心清理和重新标注,获得了高质量的多模态数据。定量和定性分析表明,该方法在HaGRID数据集上的表现达到了先进水平。
Key Takeaways
- 扩散模型在文本到图像生成中表现出色,但在生成手部时存在准确性的挑战,如手势的生成容易出现错误。
- HanDrawer模块被提出来改善这个问题,它通过图卷积层提取MANO手网格中的空间信息和物理约束。
- HanDrawer使用跨注意力机制将空间特征与其他模态进行对齐和融合。
- 融合后的特征被用于引导扩散模型的去噪过程,从而提高手部区域的生成质量。
- 提出了一种新的特征融合策略——位置保持零填充(PPZP),确保特征在扩散模型中的正确融合。
- HanDrawer通过结合手部重建损失和去噪损失,能够在关注手部区域的同时学习整个图像的特征。
点此查看论文截图



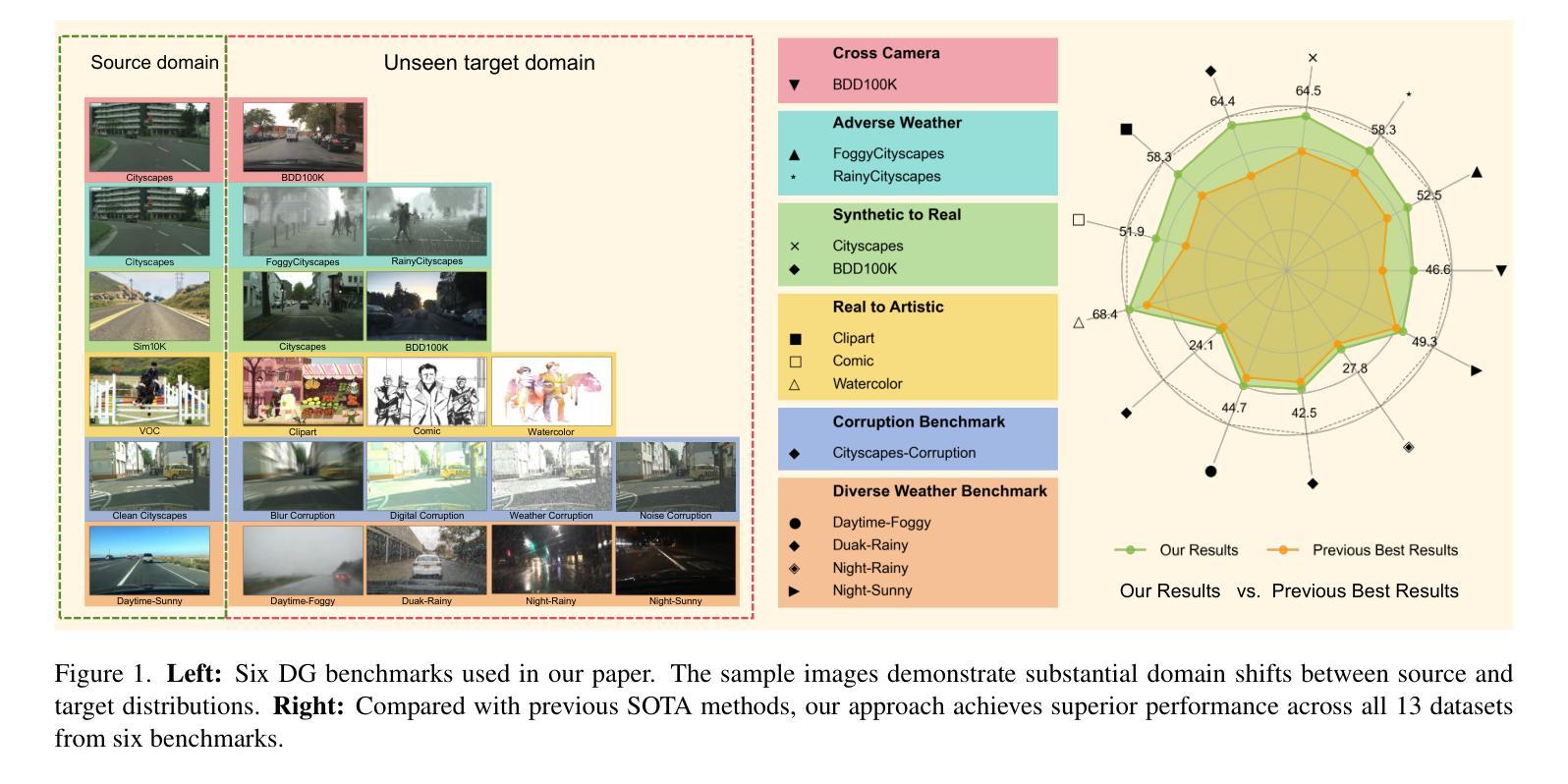
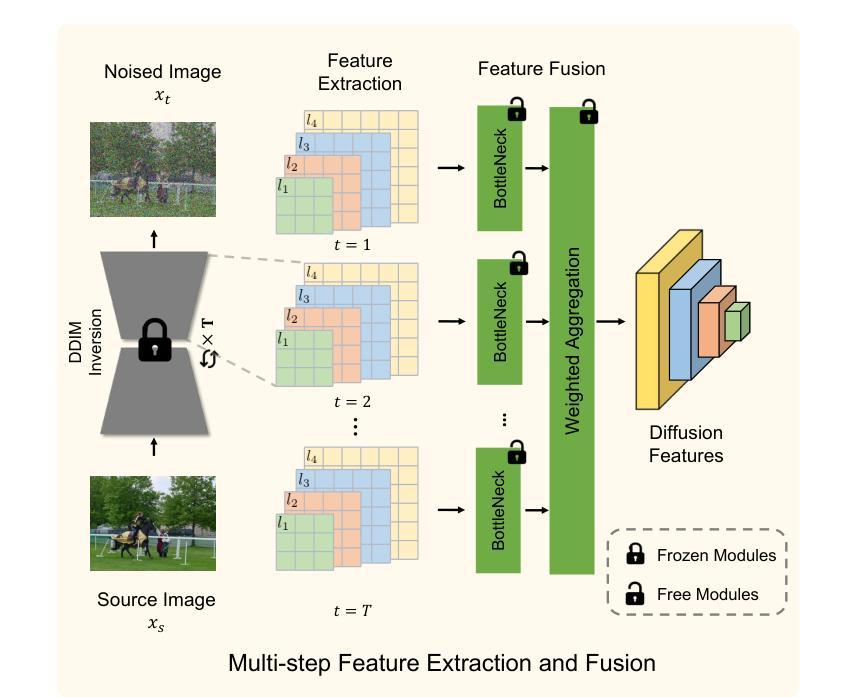
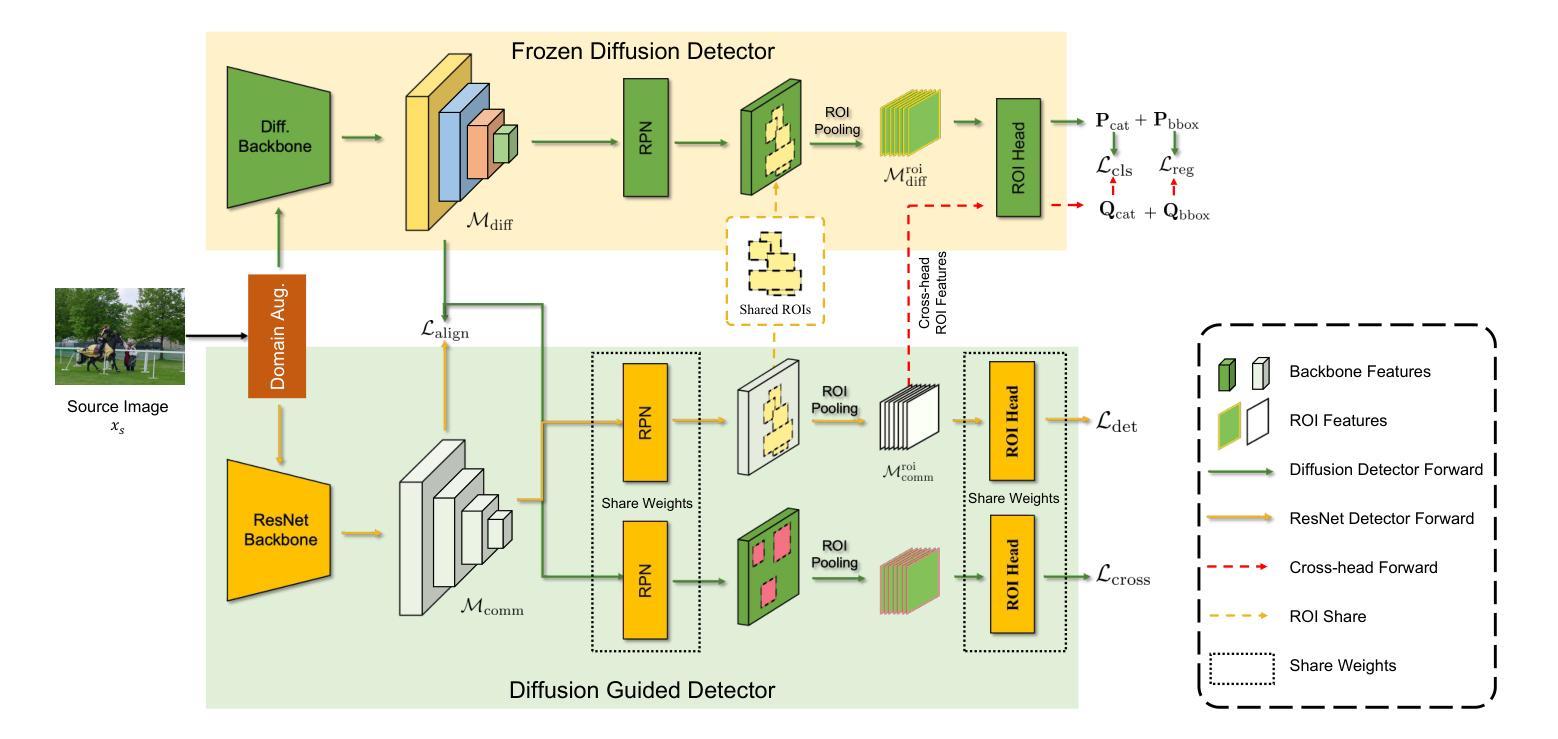
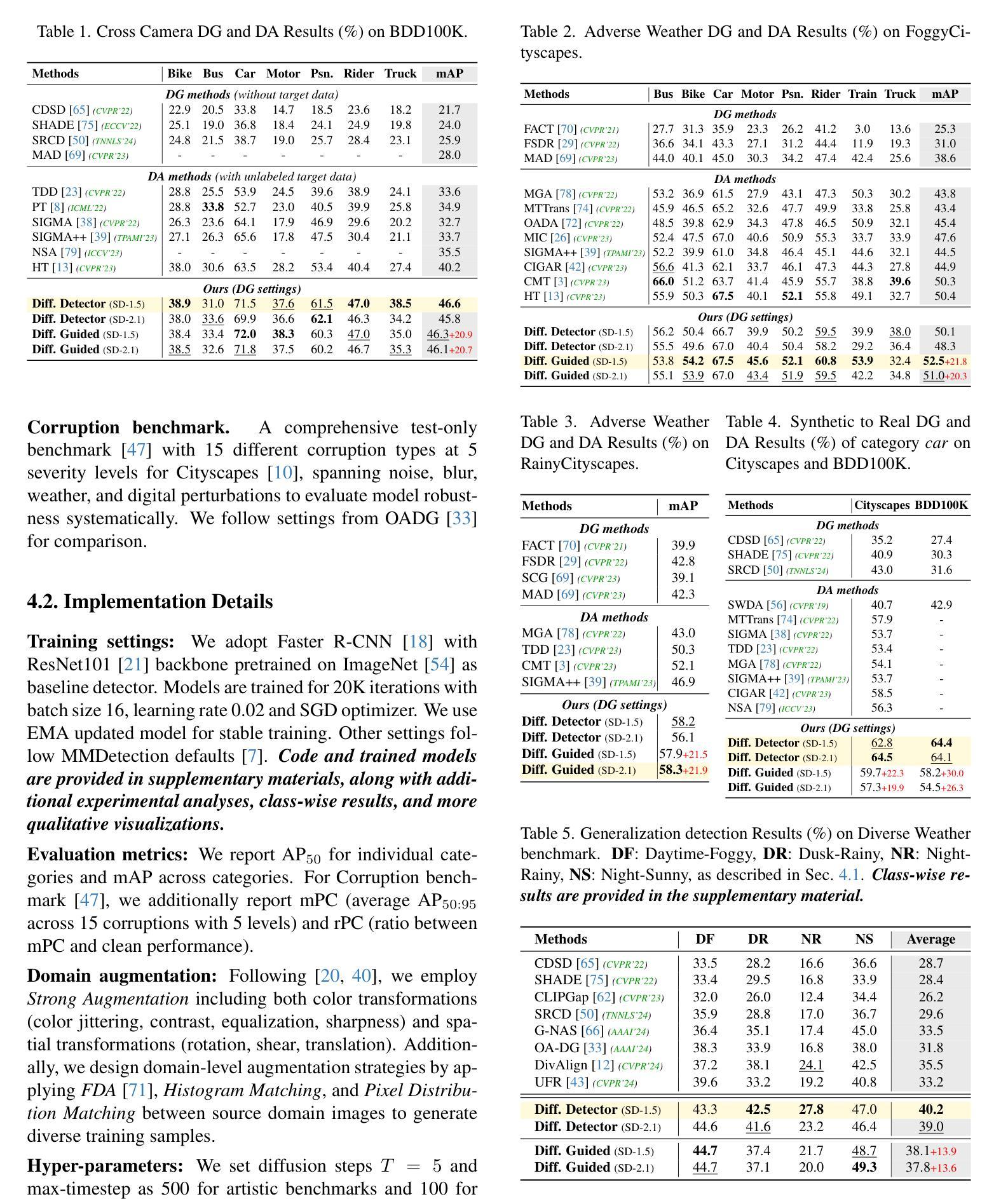
Generalized Diffusion Detector: Mining Robust Features from Diffusion Models for Domain-Generalized Detection
Authors:Boyong He, Yuxiang Ji, Qianwen Ye, Zhuoyue Tan, Liaoni Wu
Domain generalization (DG) for object detection aims to enhance detectors’ performance in unseen scenarios. This task remains challenging due to complex variations in real-world applications. Recently, diffusion models have demonstrated remarkable capabilities in diverse scene generation, which inspires us to explore their potential for improving DG tasks. Instead of generating images, our method extracts multi-step intermediate features during the diffusion process to obtain domain-invariant features for generalized detection. Furthermore, we propose an efficient knowledge transfer framework that enables detectors to inherit the generalization capabilities of diffusion models through feature and object-level alignment, without increasing inference time. We conduct extensive experiments on six challenging DG benchmarks. The results demonstrate that our method achieves substantial improvements of 14.0% mAP over existing DG approaches across different domains and corruption types. Notably, our method even outperforms most domain adaptation methods without accessing any target domain data. Moreover, the diffusion-guided detectors show consistent improvements of 15.9% mAP on average compared to the baseline. Our work aims to present an effective approach for domain-generalized detection and provide potential insights for robust visual recognition in real-world scenarios. The code is available at \href{https://github.com/heboyong/Generalized-Diffusion-Detector}{Generalized Diffusion Detector}
目标检测中的域泛化(DG)旨在增强检测器在未见场景中的性能。由于真实世界应用中复杂的变量,这项任务仍然具有挑战性。最近,扩散模型在场景生成方面表现出了显著的能力,这激发了我们探索其提高DG任务的潜力。我们的方法不同于生成图像,而是在扩散过程中提取多步中间特征,以获得用于通用检测的域不变特征。此外,我们提出了一种有效的知识转移框架,使检测器能够通过特征和对象级别的对齐,继承扩散模型的泛化能力,而不会增加推理时间。我们在六个具有挑战性的DG基准测试集上进行了广泛的实验。结果表明,我们的方法在跨不同领域和腐败类型的情况下,较现有的DG方法提高了14.0%的mAP。值得注意的是,我们的方法在无需访问任何目标域数据的情况下,甚至超越了大多数领域自适应方法。此外,与基线相比,扩散引导的检测器平均提高了15.9%的mAP。我们的工作旨在提供一种有效的域泛化检测方法和为真实世界场景的鲁棒视觉识别提供潜在见解。[该项目代码可在Generalized Diffusion Detector(https://github.com/heboyong/Generalized-Diffusion-Detector)上获取。]
论文及项目相关链接
PDF Accepted by CVPR2025
Summary
扩散模型在域泛化(DG)目标检测中展现出潜力。通过提取扩散过程中的多步中间特征,获得域不变特征,提高检测器的泛化性能。提出高效知识转移框架,使检测器继承扩散模型的泛化能力,通过特征和对象级别的对齐,在不增加推理时间的情况下实现。在六个挑战性的DG基准测试上实验,结果显示,该方法在不同领域和腐败类型上比现有DG方法提高了14.0%的mAP。甚至在没有访问任何目标域数据的情况下,该方法在域适应方法中也表现出色。扩散引导的检测器与基线相比,平均提高了15.9%的mAP。
Key Takeaways
- 扩散模型在域泛化目标检测中具有应用潜力。
- 通过提取扩散过程中的中间特征,获得域不变特征,提高检测器性能。
- 提出一种高效知识转移框架,使检测器能够继承扩散模型的泛化能力。
- 该方法在多个DG基准测试上实验,结果显示显著提高了mAP。
- 方法在不访问目标域数据的情况下,性能超过了一些域适应方法。
- 扩散引导的检测器相较于基线有显著改进。
点此查看论文截图

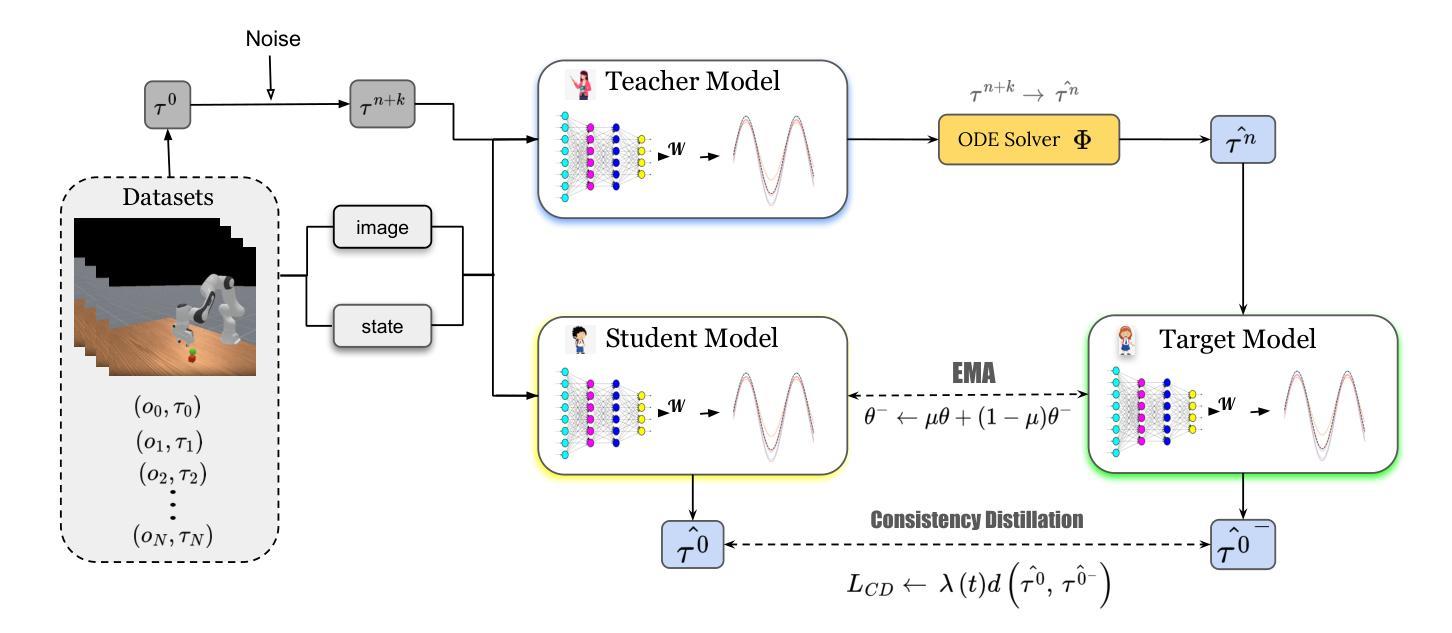
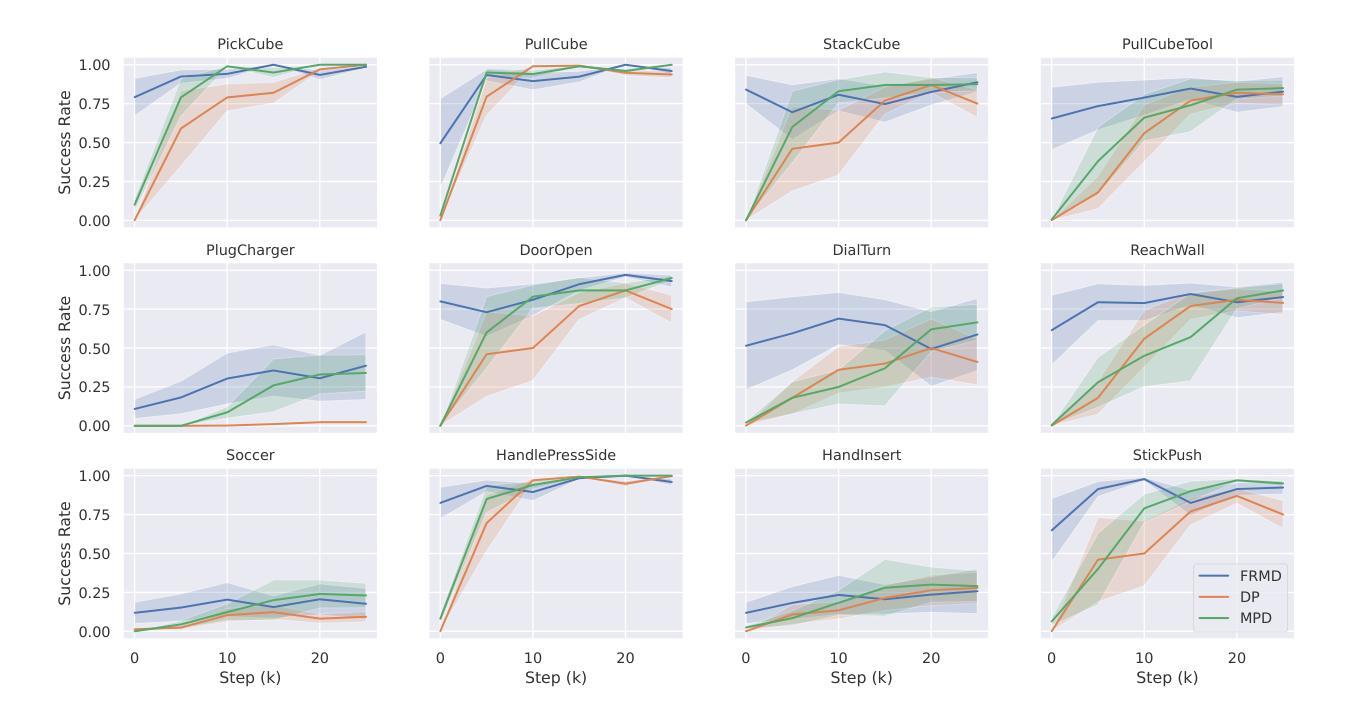
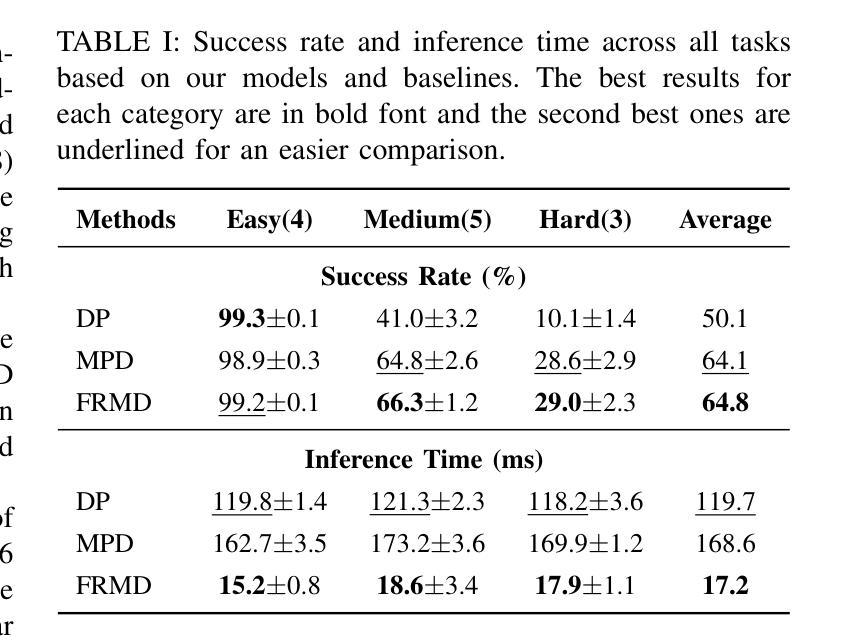
FRMD: Fast Robot Motion Diffusion with Consistency-Distilled Movement Primitives for Smooth Action Generation
Authors:Xirui Shi, Jun Jin
We consider the problem of using diffusion models to generate fast, smooth, and temporally consistent robot motions. Although diffusion models have demonstrated superior performance in robot learning due to their task scalability and multi-modal flexibility, they suffer from two fundamental limitations: (1) they often produce non-smooth, jerky motions due to their inability to capture temporally consistent movement dynamics, and (2) their iterative sampling process incurs prohibitive latency for many robotic tasks. Inspired by classic robot motion generation methods such as DMPs and ProMPs, which capture temporally and spatially consistent dynamic of trajectories using low-dimensional vectors – and by recent advances in diffusion-based image generation that use consistency models with probability flow ODEs to accelerate the denoising process, we propose Fast Robot Motion Diffusion (FRMD). FRMD uniquely integrates Movement Primitives (MPs) with Consistency Models to enable efficient, single-step trajectory generation. By leveraging probabilistic flow ODEs and consistency distillation, our method models trajectory distributions while learning a compact, time-continuous motion representation within an encoder-decoder architecture. This unified approach eliminates the slow, multi-step denoising process of conventional diffusion models, enabling efficient one-step inference and smooth robot motion generation. We extensively evaluated our FRMD on the well-recognized Meta-World and ManiSkills Benchmarks, ranging from simple to more complex manipulation tasks, comparing its performance against state-of-the-art baselines. Our results show that FRMD generates significantly faster, smoother trajectories while achieving higher success rates.
我们研究如何使用扩散模型来生成快速、流畅、时间上一致的机器人运动。尽管扩散模型在机器人学习方面由于其任务可扩展性和多模式灵活性而表现出卓越的性能,但它们存在两个基本局限:一是它们通常无法捕捉时间上一致的运动动力学,从而产生非流畅、笨拙的运动;二是其迭代采样过程对于许多机器人任务而言会引入过高的延迟。我们受到经典机器人运动生成方法(如DMP和ProMP)的启发,这些方法使用低维向量捕捉轨迹的时间和空间一致性动态——以及最近基于扩散的图像生成的进展,这些进展使用具有概率流常微分方程的共识模型来加速去噪过程。我们提出了快速机器人运动扩散(FRMD)。FRMD独特地将运动原语(MPs)与一致性模型相结合,以实现高效的一步轨迹生成。通过利用概率流常微分方程和一致性蒸馏,我们的方法在建模轨迹分布的同时,在编码器-解码器架构中学习紧凑、时间连续的运动表示。这种统一的方法消除了传统扩散模型的缓慢多步去噪过程,实现了一次性推断和流畅的机器人运动生成。我们在公认的Meta-World和ManiSkills基准测试上对FRMD进行了广泛评估,涵盖了从简单到复杂的操作任务,并将其性能与最新基线进行了比较。结果表明,FRMD生成的轨迹显著更快、更流畅,同时成功率更高。
论文及项目相关链接
PDF arXiv admin note: text overlap with arXiv:2406.01586 by other authors
Summary
本文探讨了使用扩散模型生成快速、平滑且时间一致的机器人运动的问题。针对扩散模型在机器人学习中的两个主要局限——产生非平滑、断断续续的运动以及迭代采样过程导致的延迟,提出了Fast Robot Motion Diffusion (FRMD)方法。FRMD结合了运动原语和一致性模型,采用概率流常微分方程和一致性蒸馏技术,在编码器-解码器架构内学习紧凑、时间连续的运动表示。该方法实现了高效的一步推理,生成平滑的机器人运动。在Meta-World和ManiSkills Benchmark上的评估结果表明,FRMD生成的运动更快、更平滑,且成功率更高。
Key Takeaways
- 扩散模型用于机器人运动生成面临两大挑战:非平滑、断断续续的运动以及高延迟。
- Fast Robot Motion Diffusion (FRMD)方法结合运动原语和一致性模型来解决这些问题。
- FRMD利用概率流常微分方程和一致性蒸馏技术,在编码器-解码器架构内学习运动表示。
- FRMD实现了高效的一步推理,避免了传统扩散模型的多步去噪过程。
- FRMD在Meta-World和ManiSkills Benchmark上的表现优于现有技术,生成的运动更快、更平滑,且成功率更高。
- FRMD方法整合了经典机器人运动生成方法和扩散模型的优势。
点此查看论文截图


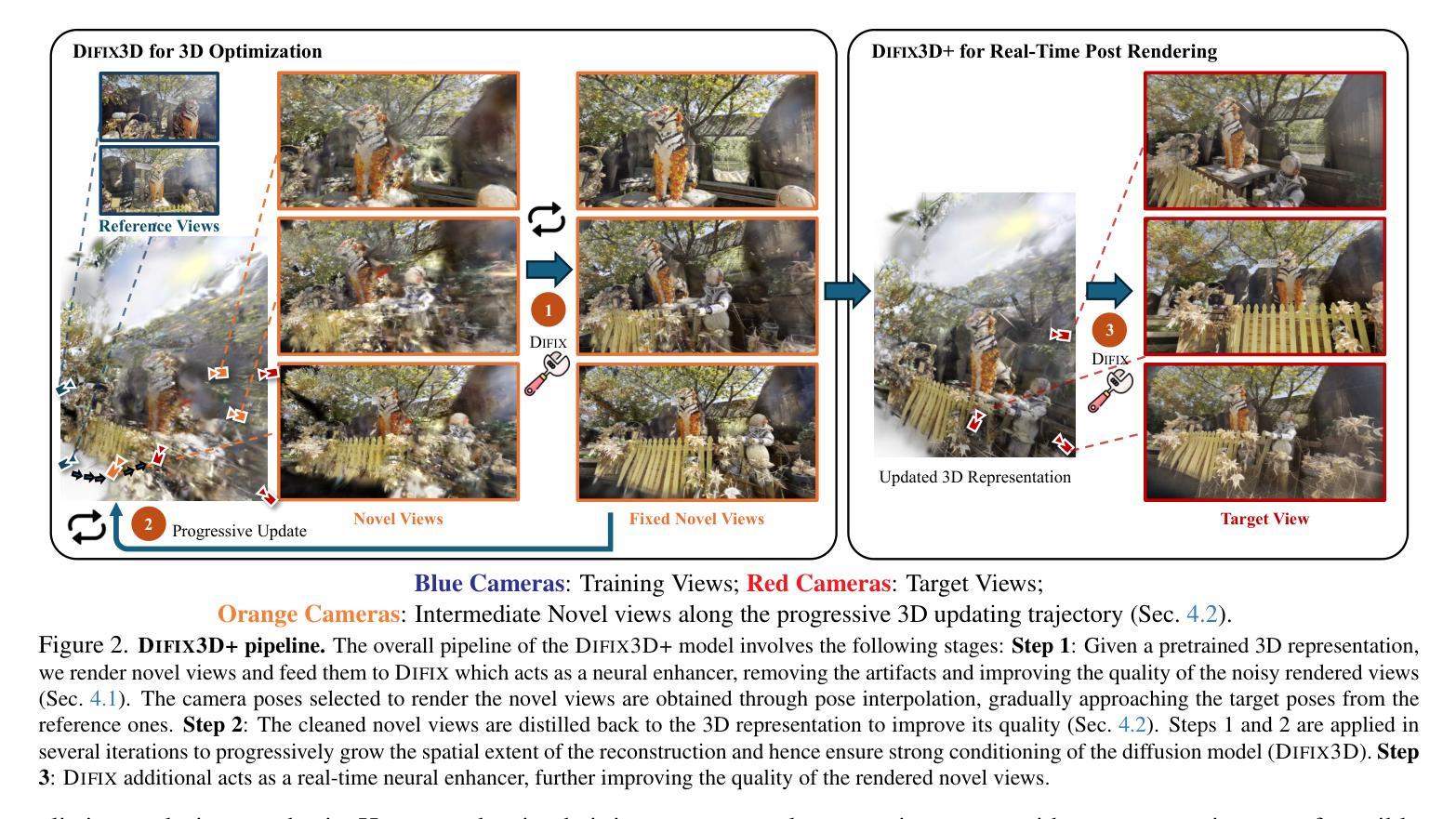
Difix3D+: Improving 3D Reconstructions with Single-Step Diffusion Models
Authors:Jay Zhangjie Wu, Yuxuan Zhang, Haithem Turki, Xuanchi Ren, Jun Gao, Mike Zheng Shou, Sanja Fidler, Zan Gojcic, Huan Ling
Neural Radiance Fields and 3D Gaussian Splatting have revolutionized 3D reconstruction and novel-view synthesis task. However, achieving photorealistic rendering from extreme novel viewpoints remains challenging, as artifacts persist across representations. In this work, we introduce Difix3D+, a novel pipeline designed to enhance 3D reconstruction and novel-view synthesis through single-step diffusion models. At the core of our approach is Difix, a single-step image diffusion model trained to enhance and remove artifacts in rendered novel views caused by underconstrained regions of the 3D representation. Difix serves two critical roles in our pipeline. First, it is used during the reconstruction phase to clean up pseudo-training views that are rendered from the reconstruction and then distilled back into 3D. This greatly enhances underconstrained regions and improves the overall 3D representation quality. More importantly, Difix also acts as a neural enhancer during inference, effectively removing residual artifacts arising from imperfect 3D supervision and the limited capacity of current reconstruction models. Difix3D+ is a general solution, a single model compatible with both NeRF and 3DGS representations, and it achieves an average 2$\times$ improvement in FID score over baselines while maintaining 3D consistency.
神经辐射场和3D高斯拼贴技术已经彻底改变了3D重建和新型视图合成任务。然而,从极端新型视角实现照片级真实的渲染仍然具有挑战性,因为在各种表示中仍然存在伪影。在这项工作中,我们引入了Difix3D+,这是一个新型管道,旨在通过单步扩散模型增强3D重建和新型视图合成。我们的方法的核心是Difix,这是一种单步图像扩散模型,经过训练用于增强和消除由于3D表示的约束不足而在渲染的新视图中产生的伪影。Difix在我们的管道中扮演了两个关键角色。首先,它用于重建阶段,清理从重建中渲染并再蒸馏回3D的伪训练视图。这极大地增强了约束不足的区域,提高了整体的3D表示质量。更重要的是,在推理过程中,Difix还充当神经增强器,有效地消除了由于不完美的3D监督和当前重建模型的有限容量而产生的残余伪影。Difix3D+是一种通用解决方案,一个与NeRF和3DGS表示兼容的单模型,它在保持3D一致性的同时,相较于基线实现了平均2倍的FID分数提升。
论文及项目相关链接
PDF CVPR 2025
Summary
神经网络辐射场与三维高斯拼贴技术已对三维重建与新型视角合成产生深远影响,但在极端新视角实现逼真渲染仍存在挑战,表现中的瑕疵一直困扰着表现层。本研究介绍了一款名为Difix3D+的新型管道,它通过单步扩散模型强化了三维重建与新型视角合成。其核心方法是一种训练有素的单步图像扩散模型——Difix,其针对因三维表现欠约束区域导致的新型渲染视角中的瑕疵进行增强与移除。Difix在管道中扮演双重角色:首先,在重建阶段,它清理从重建中渲染出的伪训练视图,并将其蒸馏回三维空间,极大地增强了欠约束区域并提高了整体三维表现质量;更重要的是,在推理过程中,它作为神经增强器有效消除了因三维监督不足和当前重建模型容量有限而产生的残余瑕疵。Difix3D+是一种通用解决方案,一个兼容NeRF和3DGS表现的单一模型,相较于基线模型在FID得分上平均提高了两倍,同时保持了三维一致性。
Key Takeaways
- 神经网络辐射场与三维高斯拼贴技术已广泛应用于三维重建与新型视角合成。
- 在极端新视角的逼真渲染仍存在挑战,表现为表现中的瑕疵。
- Difix3D+是一种新型管道,通过单步扩散模型强化三维重建与新型视角合成。
- 核心方法——Difix是一种单步图像扩散模型,能增强并移除因三维表现欠约束区域导致的新型渲染视角中的瑕疵。
- Difix在管道中扮演双重角色,既在重建阶段清理伪训练视图,又在推理过程中作为神经增强器消除残余瑕疵。
- Difix3D+兼容NeRF和3DGS表现,相较于基线模型在FID得分上有所提高,同时保持了三维一致性。
点此查看论文截图



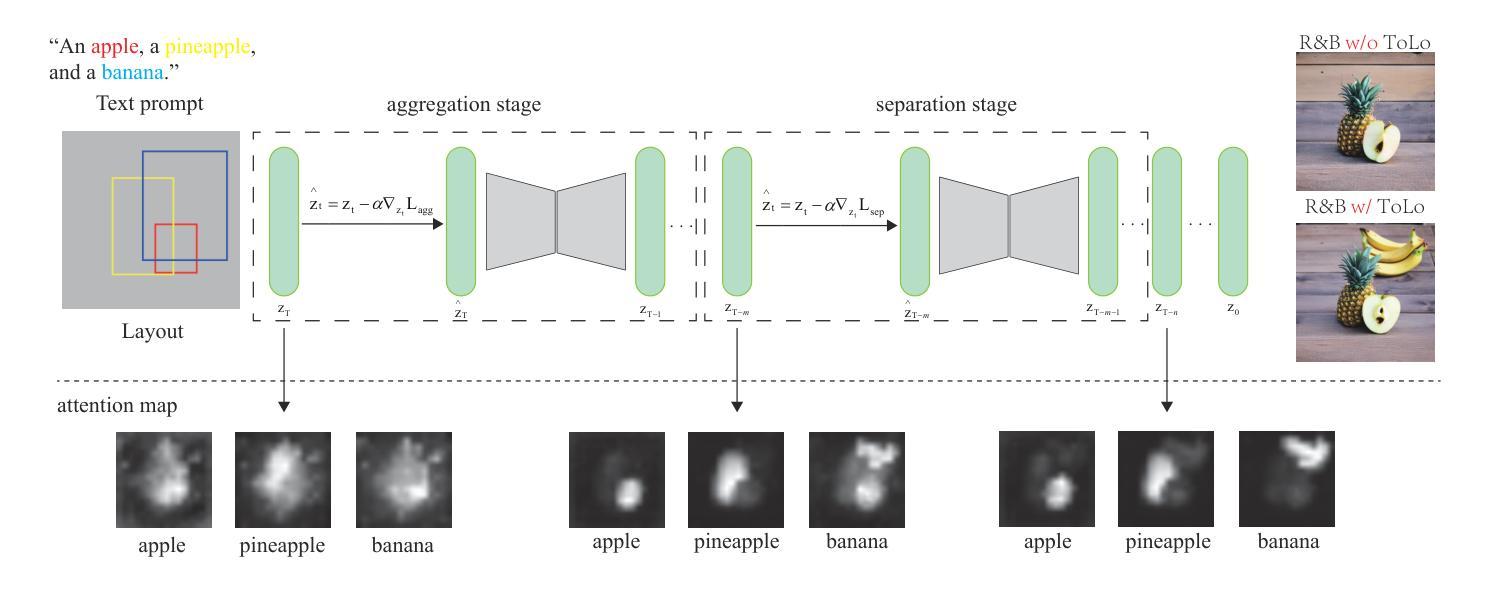
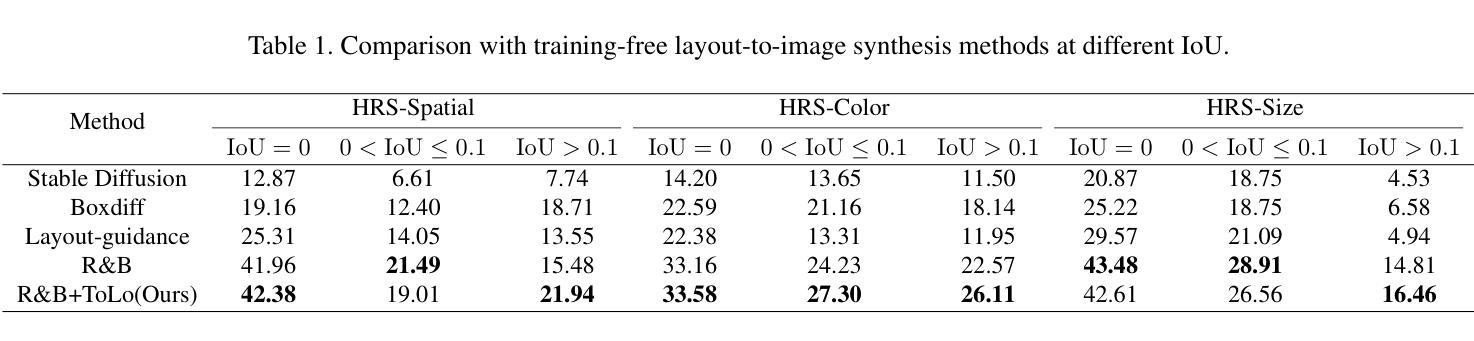
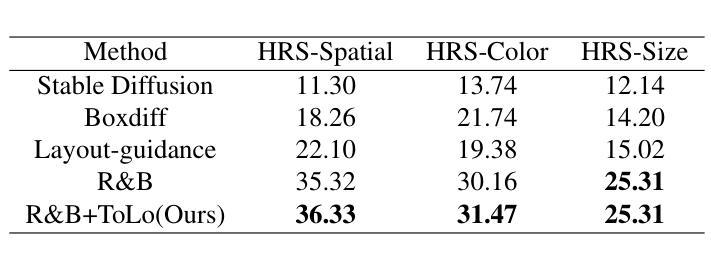
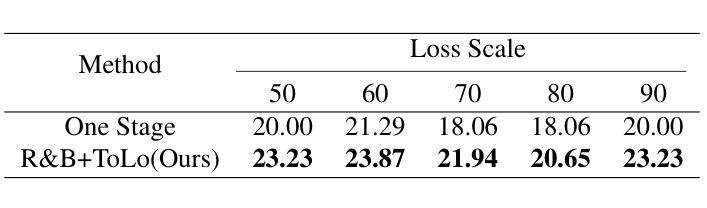
ToLo: A Two-Stage, Training-Free Layout-To-Image Generation Framework For High-Overlap Layouts
Authors:Linhao Huang, Jing Yu
Recent training-free layout-to-image diffusion models have demonstrated remarkable performance in generating high-quality images with controllable layouts. These models follow a one-stage framework: Encouraging the model to focus the attention map of each concept on its corresponding region by defining attention map-based losses. However, these models still struggle to accurately follow layouts with significant overlap, often leading to issues like attribute leakage and missing entities. In this paper, we propose ToLo, a two-stage, training-free layout-to-image generation framework for high-overlap layouts. Our framework consists of two stages: the aggregation stage and the separation stage, each with its own loss function based on the attention map. To provide a more effective evaluation, we partition the HRS dataset based on the Intersection over Union (IoU) of the input layouts, creating a new dataset for layout-to-image generation with varying levels of overlap. Through extensive experiments on this dataset, we demonstrate that ToLo significantly enhances the performance of existing methods when dealing with high-overlap layouts. Our code and dataset are available here: https://github.com/misaka12435/ToLo.
最近的无训练布局到图像扩散模型在生成具有可控布局的高质量图像方面表现出了显著的性能。这些模型遵循一个阶段框架:通过定义基于注意力图的损失来鼓励模型将每个概念的重点放在相应的区域上。然而,这些模型在处理有较大重叠的布局时,仍难以准确跟随布局,经常导致属性泄漏和缺失实体等问题。在本文中,我们提出了ToLo,一个用于高重叠布局的两阶段无训练布局到图像生成框架。我们的框架由两个阶段组成:聚合阶段和分离阶段,每个阶段都有自己的基于注意力图的损失函数。为了提供更有效的评估,我们根据输入布局的交并比(IoU)对HRS数据集进行了划分,创建了一个用于布局到图像生成的新数据集,该数据集具有不同级别的重叠。通过在此数据集上进行的大量实验表明,在处理高重叠布局时,ToLo显著提高了现有方法的效果。我们的代码和数据集可在:https://github.com/misaka12435/ToLo获取。
论文及项目相关链接
Summary
近期无训练布局到图像扩散模型在生成具有可控布局的高质量图像方面表现出显著性能,通过定义基于注意力图的损失来引导模型关注每个概念对应的区域。然而,对于高重叠布局,这些模型仍面临准确跟随布局的挑战,会导致属性泄漏和实体缺失等问题。本文提出ToLo,一种两阶段、无需训练的高重叠布局到图像生成框架。通过基于注意力图的损失函数,分为聚合阶段和分离阶段。为提供更有效的评估,我们根据输入布局的IoU对HRS数据集进行分区,创建了一个新的用于布局到图像生成的不同重叠程度的数据集。通过实验验证,ToLo在处理高重叠布局时显著提高了现有方法的性能。
Key Takeaways
- 扩散模型在无训练状态下实现了从布局到高质量图像的生成,并可通过控制注意力图来实现布局的可控性。
- 当前模型在处理高重叠布局时存在挑战,如属性泄漏和实体缺失。
- 提出了ToLo框架,包含聚合和分离两个阶段,每个阶段都有基于注意力图的损失函数。
- 为评估模型性能,根据输入布局的IoU对HRS数据集进行了分区,创建了一个新数据集。
- ToLo框架显著提高了处理高重叠布局时的性能。
- ToLo代码和数据集已公开可供使用。
点此查看论文截图



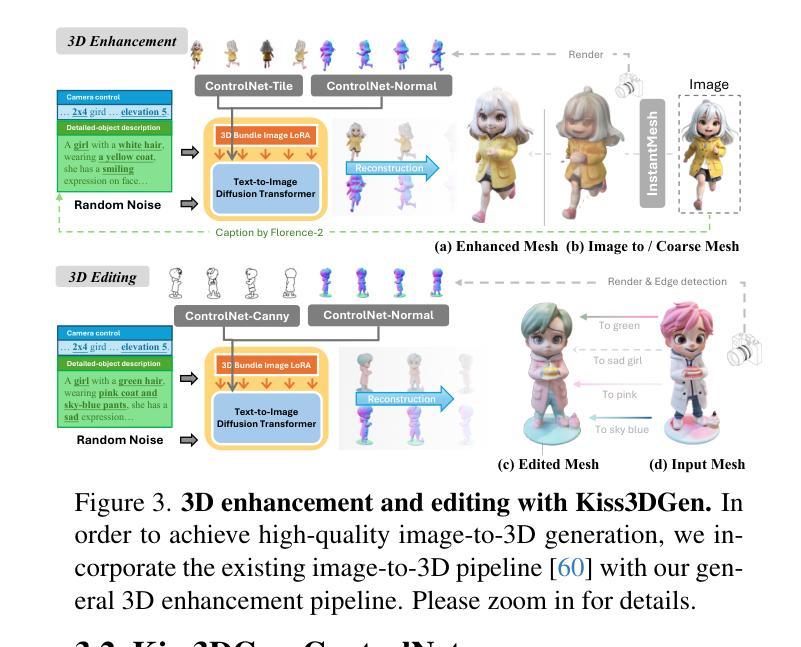
Kiss3DGen: Repurposing Image Diffusion Models for 3D Asset Generation
Authors:Jiantao Lin, Xin Yang, Meixi Chen, Yingjie Xu, Dongyu Yan, Leyi Wu, Xinli Xu, Lie XU, Shunsi Zhang, Ying-Cong Chen
Diffusion models have achieved great success in generating 2D images. However, the quality and generalizability of 3D content generation remain limited. State-of-the-art methods often require large-scale 3D assets for training, which are challenging to collect. In this work, we introduce Kiss3DGen (Keep It Simple and Straightforward in 3D Generation), an efficient framework for generating, editing, and enhancing 3D objects by repurposing a well-trained 2D image diffusion model for 3D generation. Specifically, we fine-tune a diffusion model to generate ‘’3D Bundle Image’’, a tiled representation composed of multi-view images and their corresponding normal maps. The normal maps are then used to reconstruct a 3D mesh, and the multi-view images provide texture mapping, resulting in a complete 3D model. This simple method effectively transforms the 3D generation problem into a 2D image generation task, maximizing the utilization of knowledge in pretrained diffusion models. Furthermore, we demonstrate that our Kiss3DGen model is compatible with various diffusion model techniques, enabling advanced features such as 3D editing, mesh and texture enhancement, etc. Through extensive experiments, we demonstrate the effectiveness of our approach, showcasing its ability to produce high-quality 3D models efficiently.
扩散模型在生成二维图像方面取得了巨大成功。然而,在三维内容生成方面,其质量和通用性仍然有限。最先进的方法通常需要大规模的三维资产进行训练,而这些资产的收集具有挑战性。在这项工作中,我们引入了Kiss3DGen(在三维生成中保持简单直接),这是一个有效的框架,通过重新利用训练良好的二维图像扩散模型进行三维生成,以生成、编辑和增强三维物体。具体来说,我们对扩散模型进行微调,以生成“三维捆绑图像”,这是一种由多视图图像及其相应的法线图组成的平铺表示。然后,使用法线图重建三维网格,多视图图像提供纹理映射,从而生成完整的三维模型。这种简单的方法有效地将三维生成问题转化为二维图像生成任务,最大限度地利用了预训练扩散模型中的知识。此外,我们证明Kiss3DGen模型与各种扩散模型技术兼容,能够实现如三维编辑、网格和纹理增强等高级功能。通过大量实验,我们证明了我们的方法的有效性,展示了其高效生成高质量三维模型的能力。
论文及项目相关链接
PDF The first three authors contributed equally to this work
Summary
Kiss3DGen利用二维图像扩散模型生成三维物体,通过微调扩散模型生成由多视角图像和对应的法线图组成的“三维捆绑图像”,再由此重建三维网格并提供纹理映射,将三维生成问题转化为二维图像生成任务。该方法高效、兼容多种扩散模型技术,可实现三维编辑、网格和纹理增强等功能,能有效生成高质量的三维模型。
Key Takeaways
- Kiss3DGen成功将二维图像扩散模型应用于三维物体的生成、编辑和增强。
- 通过微调扩散模型,生成“三维捆绑图像”,包含多视角图像和对应的法线图。
- 利用法线图重建三维网格,多视角图像提供纹理映射,生成完整三维模型。
- 该方法最大化利用预训练扩散模型中的知识,将三维生成问题转化为二维图像生成任务。
- Kiss3DGen兼容各种扩散模型技术,可实现高级功能,如三维编辑、网格和纹理增强等。
- 通过广泛实验,证明该方法能高效生成高质量的三维模型。
点此查看论文截图


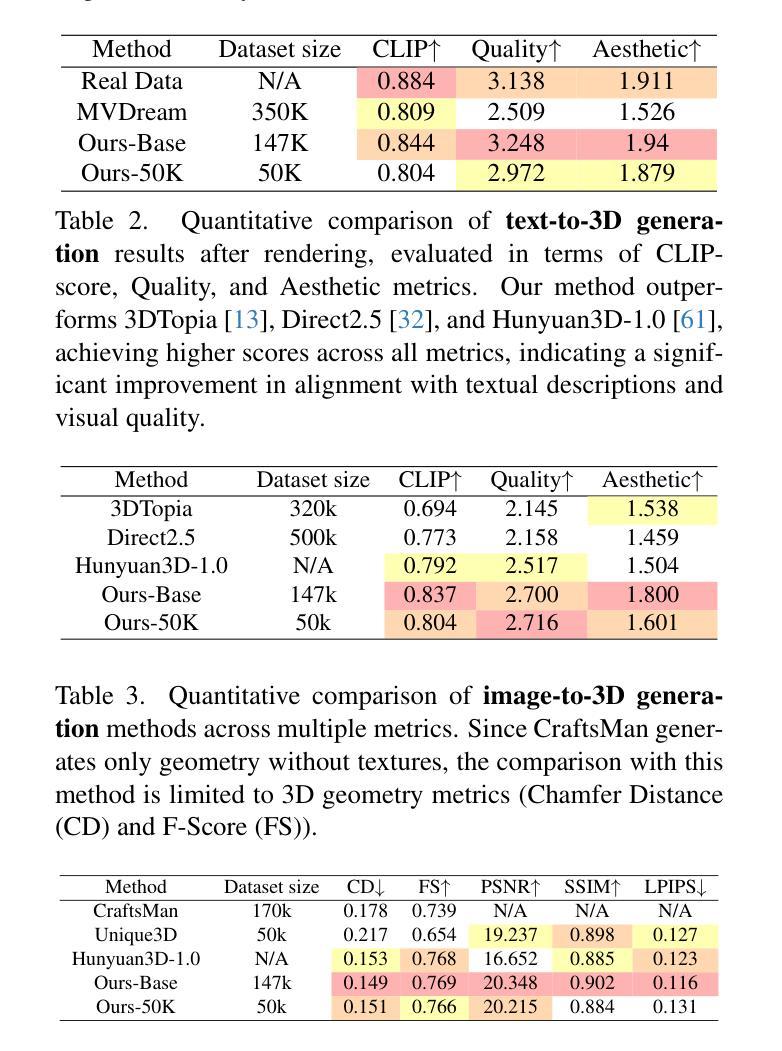
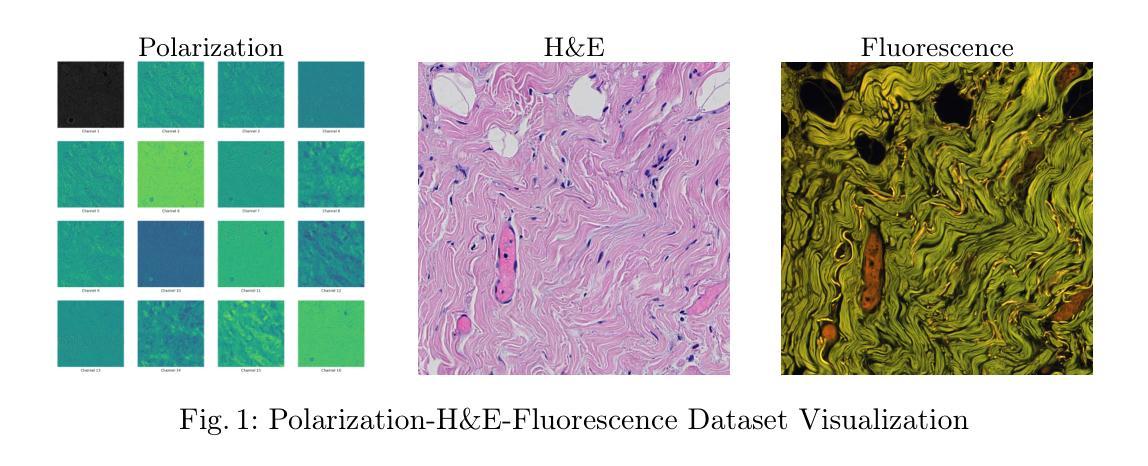
Diffusion-based Virtual Staining from Polarimetric Mueller Matrix Imaging
Authors:Xiaoyu Zheng, Jing Wen, Jiaxin Zhuang, Yao Du, Jing Cong, Limei Guo, Chao He, Lin Luo, Hao Chen
Polarization, as a new optical imaging tool, has been explored to assist in the diagnosis of pathology. Moreover, converting the polarimetric Mueller Matrix (MM) to standardized stained images becomes a promising approach to help pathologists interpret the results. However, existing methods for polarization-based virtual staining are still in the early stage, and the diffusion-based model, which has shown great potential in enhancing the fidelity of the generated images, has not been studied yet. In this paper, a Regulated Bridge Diffusion Model (RBDM) for polarization-based virtual staining is proposed. RBDM utilizes the bidirectional bridge diffusion process to learn the mapping from polarization images to other modalities such as H&E and fluorescence. And to demonstrate the effectiveness of our model, we conduct the experiment on our manually collected dataset, which consists of 18,000 paired polarization, fluorescence and H&E images, due to the unavailability of the public dataset. The experiment results show that our model greatly outperforms other benchmark methods. Our dataset and code will be released upon acceptance.
偏振作为一种新的光学成像工具,已被探索用于病理诊断的辅助。此外,将偏振穆勒矩阵(MM)转换为标准化染色图像的方法成为帮助病理学家解释结果的一种有前途的方法。然而,现有的基于偏振的虚拟染色方法仍处于早期阶段,具有提高生成图像保真度潜力的基于扩散的模型尚未进行研究。本文提出了一种基于偏振虚拟染色的调控桥梁扩散模型(RBDM)。RBDM利用双向桥梁扩散过程,学习从偏振图像到其他模态(如H&E和荧光)的映射。为了证明我们的模型的有效性,我们在自己手动收集的数据集上进行了实验,该数据集包含18000对偏振、荧光和H&E图像,由于无法获得公共数据集。实验结果表明,我们的模型在性能上大大超过了其他基准方法。我们的数据集和代码将在接受后发布。
论文及项目相关链接
Summary
极化作为一种新的光学成像工具在病理学诊断中得到探索。将极化Mueller矩阵转换为标准化染色图像的方法为病理学家解读结果提供了帮助。本文提出一种基于调控桥扩散模型的极化虚拟染色方法(RBDM),利用双向桥扩散过程学习从极化图像到其他模态(如H&E和荧光)的映射。实验结果表明,该模型在手动收集的数据集上表现优异,优于其他基准方法。
Key Takeaways
- 极化作为一种新的光学成像工具在病理学诊断中受到关注。
- 将极化Mueller矩阵转换为标准化染色图像是帮助病理学家解读结果的一种有前途的方法。
- 目前基于极化的虚拟染色方法仍处于早期阶段,扩散模型在增强图像保真度方面具有巨大潜力,但尚未进行研究。
- 本文提出了一种基于调控桥扩散模型的极化虚拟染色方法(RBDM)。
- RBDM利用双向桥扩散过程学习从极化图像到H&E和荧光等其他模态的映射。
- 实验是在手动收集的数据集上进行的,包含18,000张极化、荧光和H&E图像配对。
- 实验结果表明,RBDM在性能上大大优于其他基准方法。
点此查看论文截图

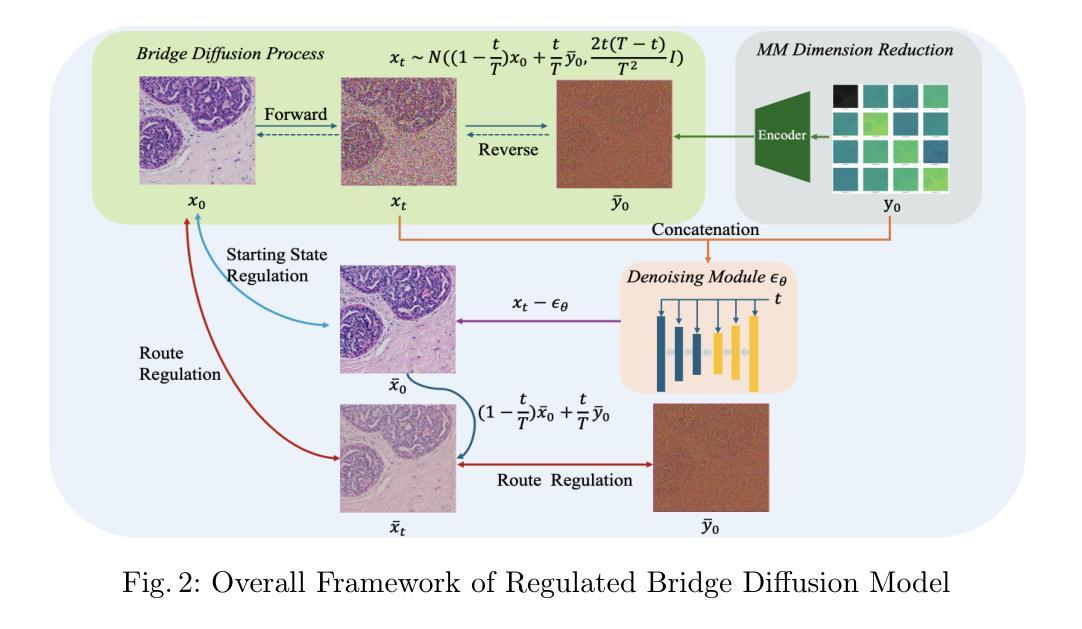
CacheQuant: Comprehensively Accelerated Diffusion Models
Authors:Xuewen Liu, Zhikai Li, Qingyi Gu
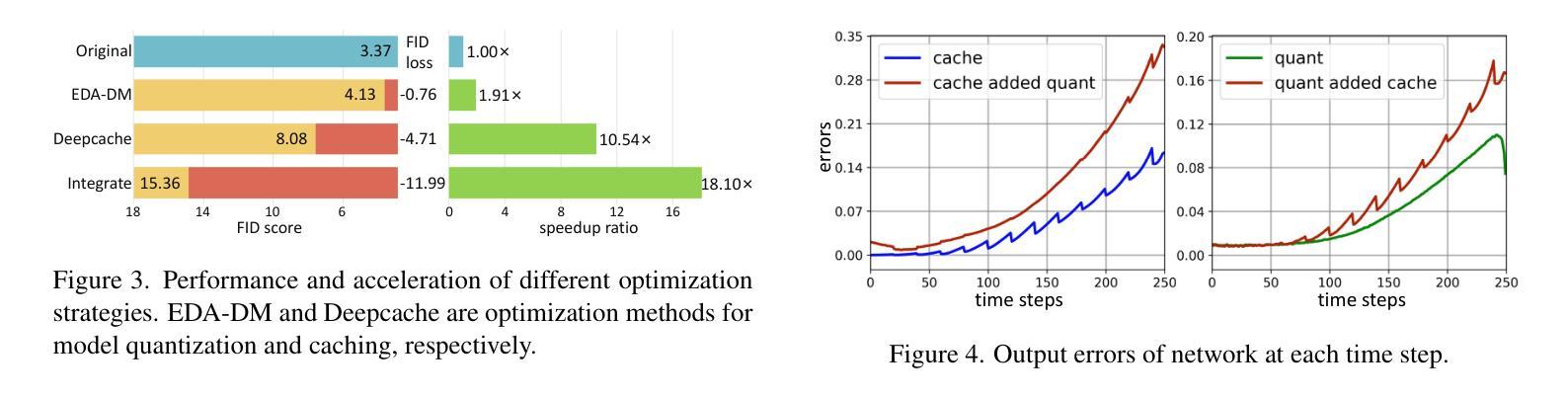
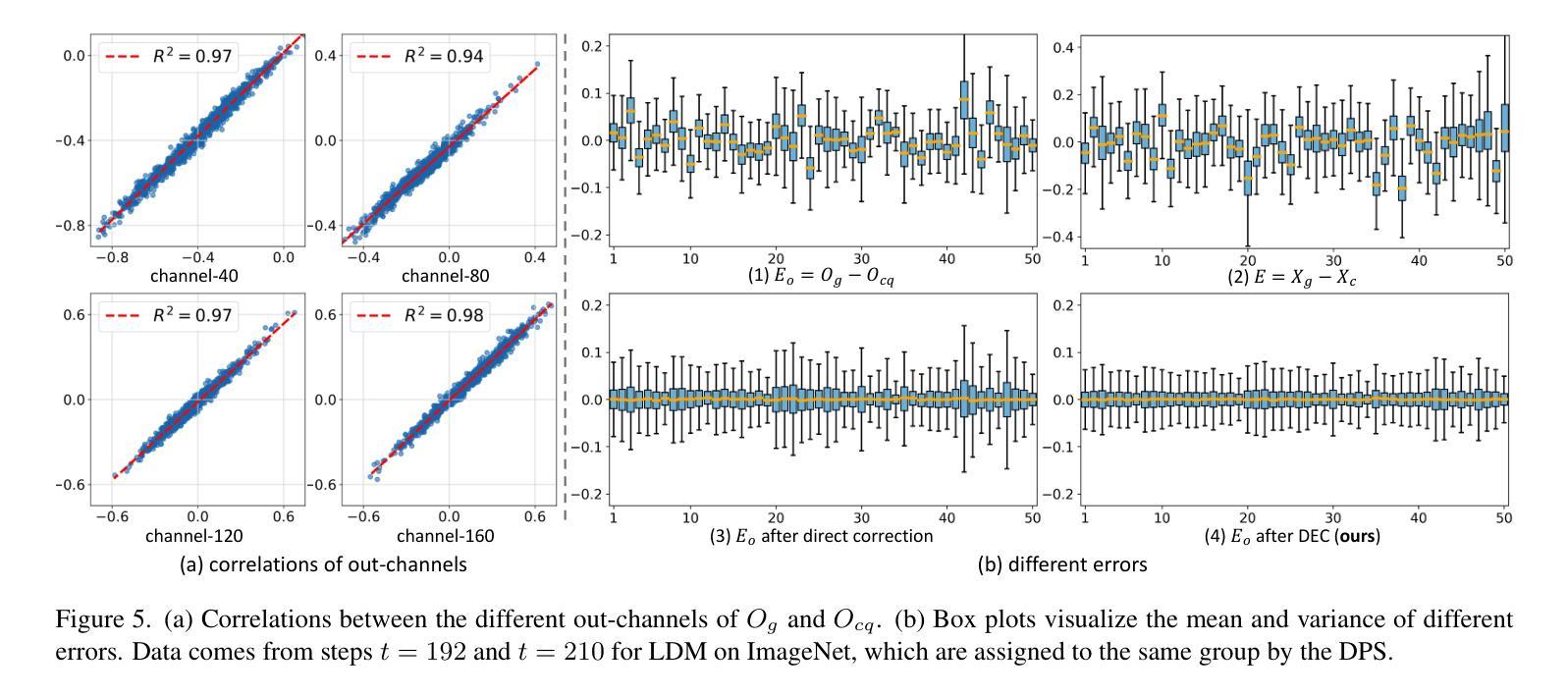
Diffusion models have gradually gained prominence in the field of image synthesis, showcasing remarkable generative capabilities. Nevertheless, the slow inference and complex networks, resulting from redundancy at both temporal and structural levels, hinder their low-latency applications in real-world scenarios. Current acceleration methods for diffusion models focus separately on temporal and structural levels. However, independent optimization at each level to further push the acceleration limits results in significant performance degradation. On the other hand, integrating optimizations at both levels can compound the acceleration effects. Unfortunately, we find that the optimizations at these two levels are not entirely orthogonal. Performing separate optimizations and then simply integrating them results in unsatisfactory performance. To tackle this issue, we propose CacheQuant, a novel training-free paradigm that comprehensively accelerates diffusion models by jointly optimizing model caching and quantization techniques. Specifically, we employ a dynamic programming approach to determine the optimal cache schedule, in which the properties of caching and quantization are carefully considered to minimize errors. Additionally, we propose decoupled error correction to further mitigate the coupled and accumulated errors step by step. Experimental results show that CacheQuant achieves a 5.18 speedup and 4 compression for Stable Diffusion on MS-COCO, with only a 0.02 loss in CLIP score. Our code are open-sourced: https://github.com/BienLuky/CacheQuant .
扩散模型在图像合成领域逐渐崭露头角,显示出显著的生成能力。然而,由于时间和结构两个层面的冗余导致的慢速推理和复杂网络,限制了它们在现实世界场景中的低延迟应用。当前针对扩散模型的加速方法主要集中在时间和结构两个层面。然而,在每个层面进行独立优化以进一步推动加速极限会导致性能显著下降。另一方面,整合这两个层面的优化可以叠加加速效果。然而,我们发现这两个层面的优化并不是完全正交的。进行单独的优化然后简单地集成它们会导致性能不尽如人意。为了解决这一问题,我们提出了CacheQuant,这是一种全新的无需训练的模式,通过综合优化模型缓存和量化技术,全面加速扩散模型。具体来说,我们采用动态规划的方法来确定最佳缓存调度,充分考虑缓存和量化的属性以最小化误差。此外,我们提出了分离误差校正来进一步逐步缓解耦合和累积误差。实验结果表明,CacheQuant在MS-COCO上的Stable Diffusion实现了5.18倍的加速和4倍的压缩,CLIP分数仅下降0.02。我们的代码已开源:https://github.com/BienLuky/CacheQuant。
论文及项目相关链接
PDF CVPR 2025
Summary
扩散模型在图像合成领域逐渐受到重视,展现出卓越的生成能力,但其缓慢的推理速度和复杂的网络结构阻碍了其在现实世界场景中的低延迟应用。现有加速方法主要集中在扩散模型的时序和结构层面进行优化,但独立优化往往导致性能下降。为此,提出CacheQuant,一种全新的无需训练的训练后加速范式,通过联合优化模型缓存和量化技术来全面加速扩散模型。通过动态规划确定最佳缓存调度,进一步通过解耦误差校正来逐步减轻耦合和累积误差。实验结果表明,CacheQuant在MS-COCO上的Stable Diffusion实现了5.18倍的加速和4倍的压缩,同时CLIP分数仅下降0.02。
Key Takeaways
- 扩散模型在图像合成领域具有显著优势,但推理速度慢和复杂网络结构限制了其实际应用。
- 当前加速方法主要关注时序和结构层面的优化,但独立优化可能导致性能下降。
- CacheQuant是一种全新的训练后加速范式,旨在通过联合优化模型缓存和量化技术全面加速扩散模型。
- CacheQuant利用动态规划确定最佳缓存调度,以最小化误差。
- 解耦误差校正方法被用来逐步减轻优化过程中的耦合和累积误差。
- 实验结果表明,CacheQuant在MS-COCO数据集上的Stable Diffusion模型实现了显著的加速和压缩效果。
点此查看论文截图

Fine-Grained Controllable Apparel Showcase Image Generation via Garment-Centric Outpainting
Authors:Rong Zhang, Jingnan Wang, Zhiwen Zuo, Jianfeng Dong, Wei Li, Chi Wang, Weiwei Xu, Xun Wang
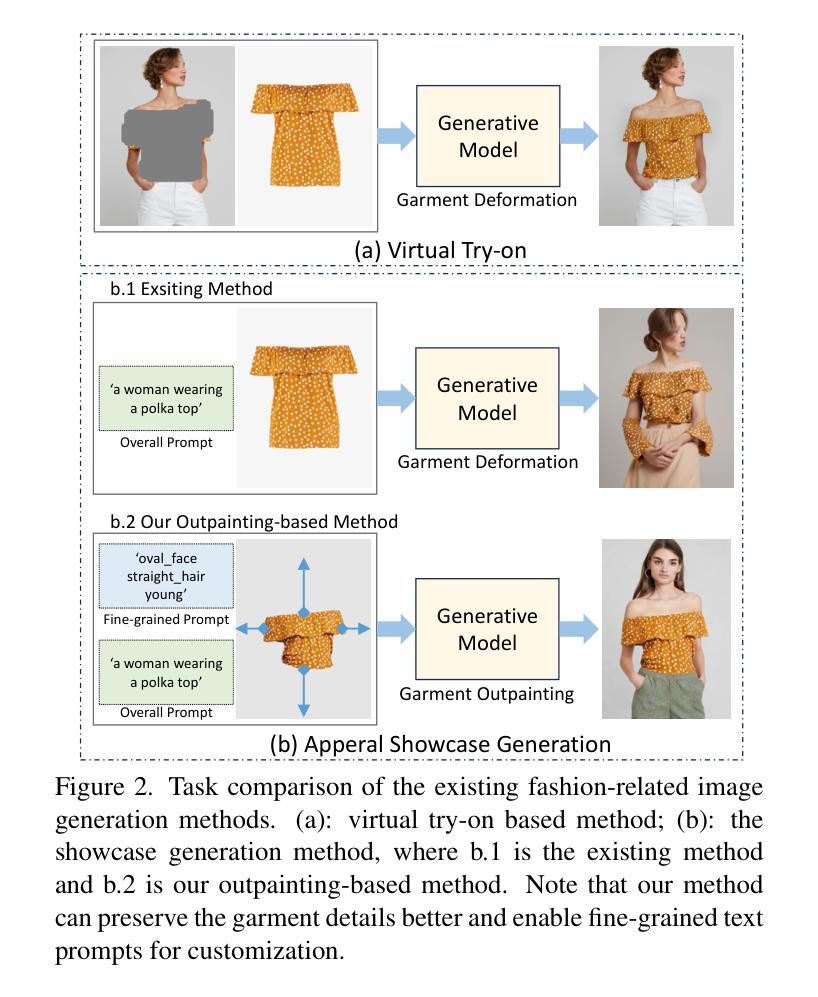
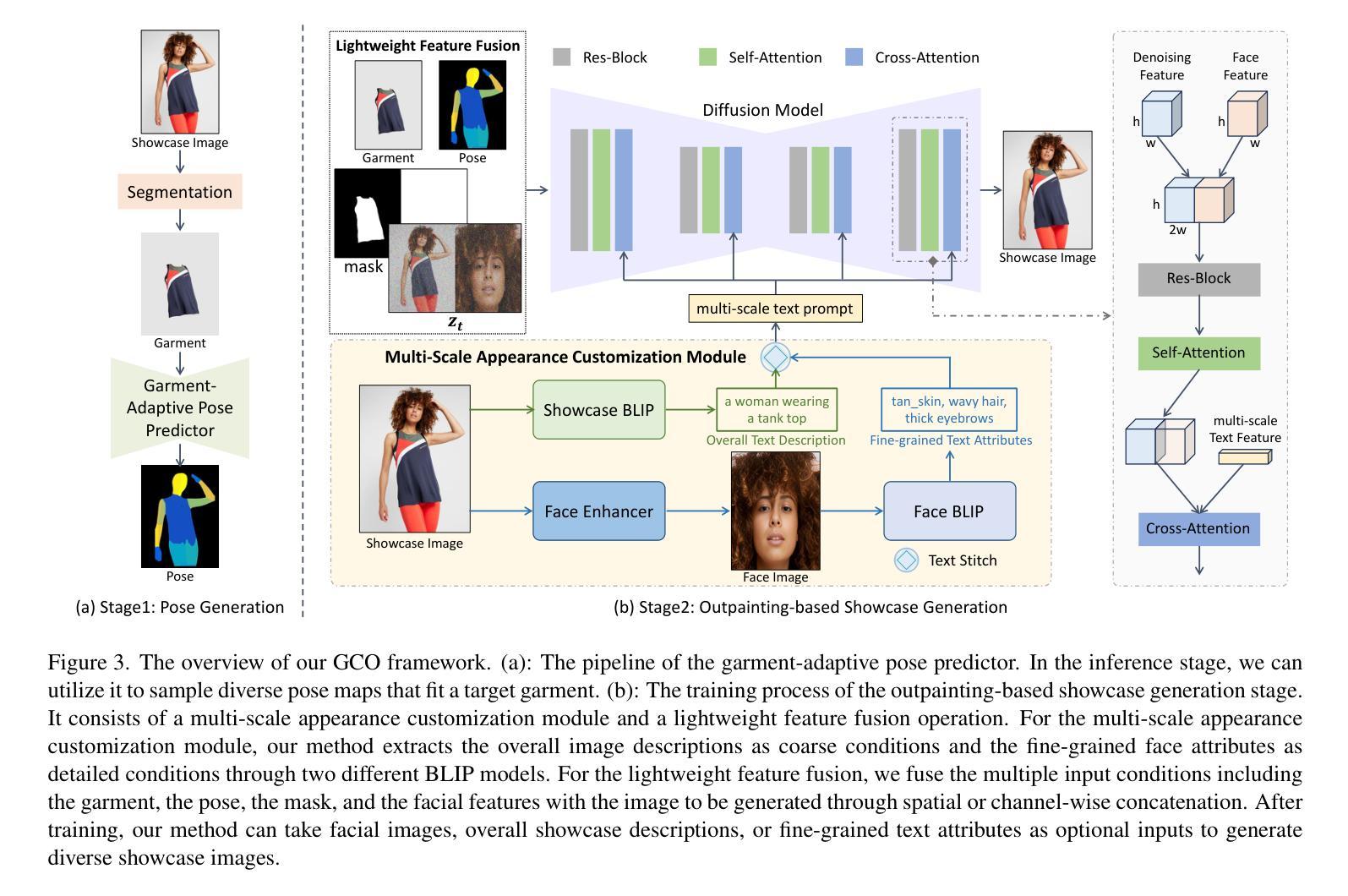
In this paper, we propose a novel garment-centric outpainting (GCO) framework based on the latent diffusion model (LDM) for fine-grained controllable apparel showcase image generation. The proposed framework aims at customizing a fashion model wearing a given garment via text prompts and facial images. Different from existing methods, our framework takes a garment image segmented from a dressed mannequin or a person as the input, eliminating the need for learning cloth deformation and ensuring faithful preservation of garment details. The proposed framework consists of two stages. In the first stage, we introduce a garment-adaptive pose prediction model that generates diverse poses given the garment. Then, in the next stage, we generate apparel showcase images, conditioned on the garment and the predicted poses, along with specified text prompts and facial images. Notably, a multi-scale appearance customization module (MS-ACM) is designed to allow both overall and fine-grained text-based control over the generated model’s appearance. Moreover, we leverage a lightweight feature fusion operation without introducing any extra encoders or modules to integrate multiple conditions, which is more efficient. Extensive experiments validate the superior performance of our framework compared to state-of-the-art methods.
本文提出了一种基于潜在扩散模型(LDM)的新型服装中心外画(GCO)框架,用于细粒度可控服装展示图像生成。所提出的框架旨在通过文本提示和面部图像定制穿着给定服装的时尚模型。不同于现有方法,我们的框架以从着装的人体模特或个人身上分割出来的服装图像作为输入,无需学习布料变形,同时确保服装细节的忠实保留。该框架由两个阶段组成。在第一阶段,我们引入了一种服装适应性姿态预测模型,该模型可以根据服装生成各种姿态。然后,在下一阶段,我们以服装、预测姿态、指定的文本提示和面部图像为条件,生成服装展示图像。值得一提的是,设计了一个多尺度外观定制模块(MS-ACM),允许对生成的模型的外观进行整体和细粒度的文本控制。此外,我们利用轻量级特征融合操作,无需引入任何额外的编码器或模块来整合多种条件,这更加高效。大量实验验证了我们的框架与最新方法相比的优越性能。
论文及项目相关链接
Summary
本文提出了一种基于潜在扩散模型(LDM)的新型服装中心外画(GCO)框架,用于精细可控的时装展示图像生成。该框架旨在通过文本提示和面部图像定制穿着给定服装的时尚模型。不同于现有方法,该框架以从着装模特或人物分割出的服装图像为输入,无需学习布料变形,确保服装细节的真实保留。框架包含两个阶段:第一阶段是服装适应性姿势预测模型,该模型根据服装生成多样化的姿势;第二阶段是根据服装、预测姿势、指定的文本提示和面部图像生成时装展示图像。设计了一个多尺度外观定制模块(MS-ACM),实现对生成模型外观的整体和精细纹理的文本控制。利用轻量级特征融合操作,无需引入任何额外的编码器或模块,即可整合多种条件,提高效率。实验证明,该框架的性能优于现有方法。
Key Takeaways
- 提出了基于潜在扩散模型(LDM)的服装中心外画(GCO)框架,用于时装展示图像生成。
- 框架能定制穿着给定服装的时尚模型,通过文本提示和面部图像实现精细化控制。
- 输入为从模特或人物分割出的服装图像,无需学习布料变形。
- 框架包含两个阶段:服装适应性姿势预测和时装展示图像生成。
- 设计了多尺度外观定制模块(MS-ACM),实现整体和精细纹理的文本控制。
- 利用轻量级特征融合操作整合多种生成条件,提高效率。
- 实验证明该框架性能优于现有方法。
点此查看论文截图


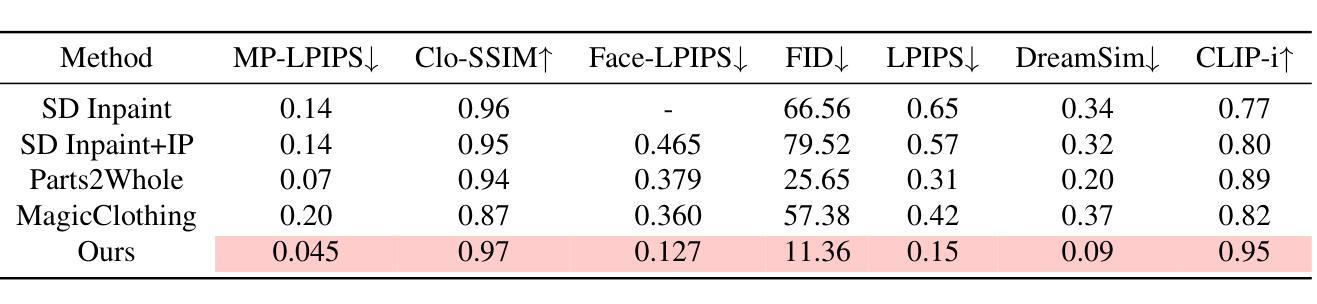
Reconciling Stochastic and Deterministic Strategies for Zero-shot Image Restoration using Diffusion Model in Dual
Authors:Chong Wang, Lanqing Guo, Zixuan Fu, Siyuan Yang, Hao Cheng, Alex C. Kot, Bihan Wen
Plug-and-play (PnP) methods offer an iterative strategy for solving image restoration (IR) problems in a zero-shot manner, using a learned \textit{discriminative denoiser} as the implicit prior. More recently, a sampling-based variant of this approach, which utilizes a pre-trained \textit{generative diffusion model}, has gained great popularity for solving IR problems through stochastic sampling. The IR results using PnP with a pre-trained diffusion model demonstrate distinct advantages compared to those using discriminative denoisers, \ie improved perceptual quality while sacrificing the data fidelity. The unsatisfactory results are due to the lack of integration of these strategies in the IR tasks. In this work, we propose a novel zero-shot IR scheme, dubbed Reconciling Diffusion Model in Dual (RDMD), which leverages only a \textbf{single} pre-trained diffusion model to construct \textbf{two} complementary regularizers. Specifically, the diffusion model in RDMD will iteratively perform deterministic denoising and stochastic sampling, aiming to achieve high-fidelity image restoration with appealing perceptual quality. RDMD also allows users to customize the distortion-perception tradeoff with a single hyperparameter, enhancing the adaptability of the restoration process in different practical scenarios. Extensive experiments on several IR tasks demonstrate that our proposed method could achieve superior results compared to existing approaches on both the FFHQ and ImageNet datasets.
Plug-and-Play(PnP)方法为零样本方式解决图像恢复(IR)问题提供了迭代策略,它使用学习到的判别去噪器作为隐式先验。最近,该方法的基于采样的变体受到欢迎,它通过预训练的生成扩散模型来解决IR问题,通过随机采样实现。与使用判别去噪器的IR结果相比,使用带有预训练扩散模型的PnP方法显示出明显优势,即提高了感知质量而牺牲了数据保真度。这些不尽如人意的结果是由于缺乏将这些策略整合到IR任务中。在这项工作中,我们提出了一种新型零样本IR方案,称为“双重调和扩散模型”(RDMD),它仅使用一个预训练的扩散模型来构建两个互补的正则化器。具体来说,RDMD中的扩散模型将迭代执行确定性去噪和随机采样,旨在实现高保真图像恢复,同时具有良好的感知质量。RDMD还允许用户用一个超参数来定制失真-感知折衷,以增强恢复过程在不同实际场景中的适应性。在几个IR任务上的大量实验表明,我们的方法可以在FFHQ和ImageNet数据集上实现优于现有方法的结果。
论文及项目相关链接
PDF Accepted to CVPR 2025
Summary
本文提出了一种名为RDMD的零样本图像恢复方案,利用单个预训练的扩散模型构建两个互补正则化器,通过迭代执行确定性去噪和随机采样,实现高保真图像恢复和吸引人的感知质量。该方案允许用户用一个超参数来定制失真与感知之间的权衡,提高了不同实际场景中恢复的适应性。实验表明,该方法在多个图像恢复任务上优于现有方法。
Key Takeaways
- PnP方法采用迭代策略,利用学习到的判别去噪器作为隐先验来解决图像恢复问题。
- 最近的采样型变体方法使用预训练的生成扩散模型,通过随机采样解决图像恢复问题。
- 与使用判别去噪器相比,使用预训练扩散模型的PnP方法在感知质量上有所提高,但在数据保真度上有所牺牲。
- RDMD是一种新型的零样本图像恢复方案,利用单个预训练扩散模型构建两个互补正则化器。
- RDMD通过迭代执行确定性去噪和随机采样,旨在实现高保真图像恢复和吸引人的感知质量。
- RDMD允许用户通过一个超参数来定制失真与感知之间的权衡,增强了不同场景下的适应性。
点此查看论文截图

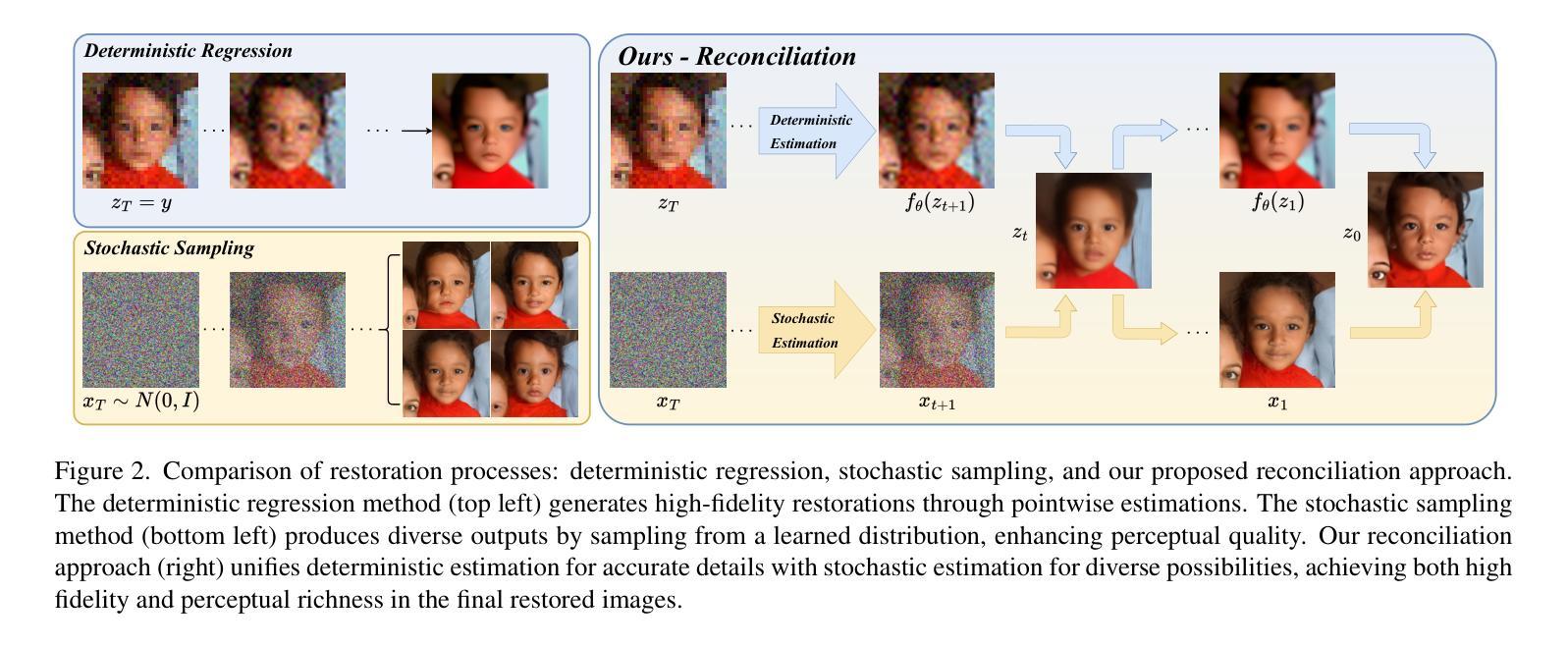
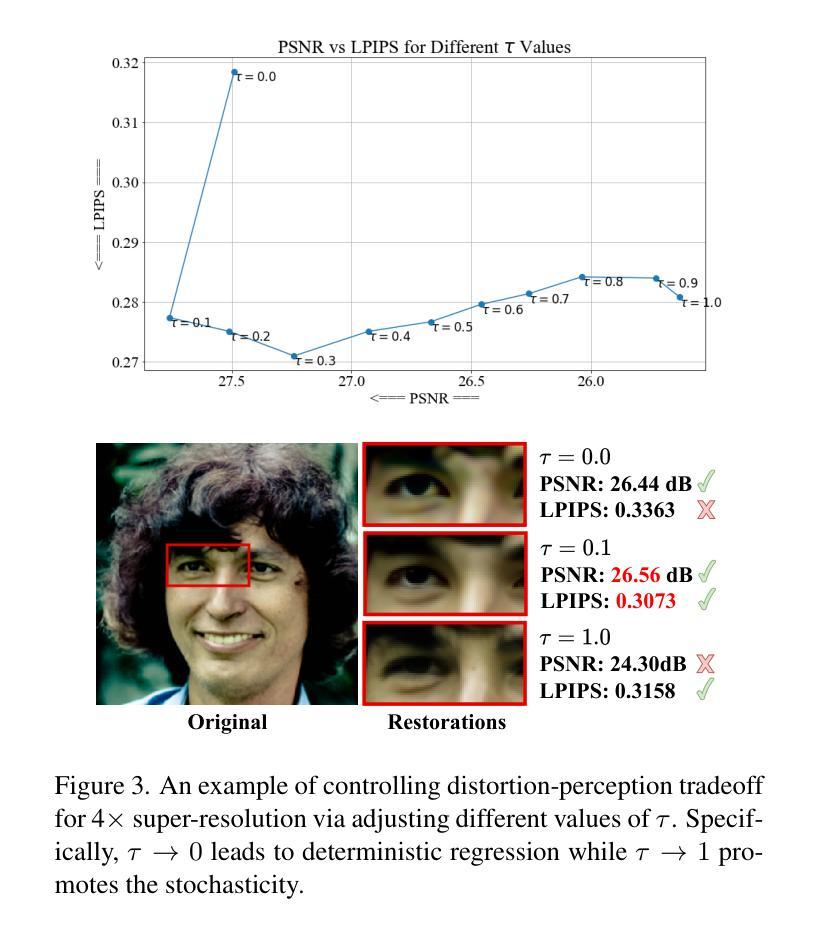
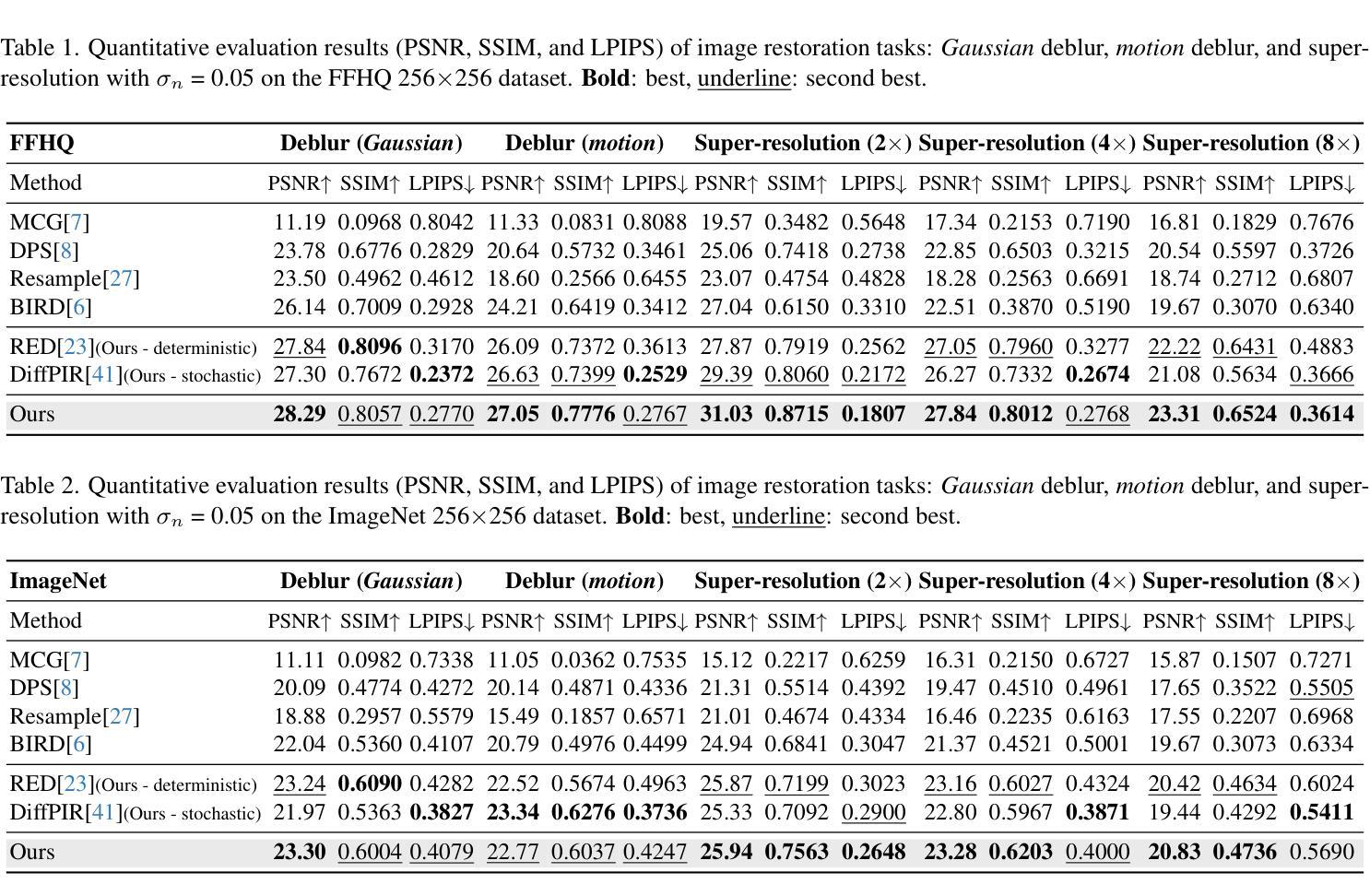
Finding Local Diffusion Schrödinger Bridge using Kolmogorov-Arnold Network
Authors:Xingyu Qiu, Mengying Yang, Xinghua Ma, Fanding Li, Dong Liang, Gongning Luo, Wei Wang, Kuanquan Wang, Shuo Li
In image generation, Schr"odinger Bridge (SB)-based methods theoretically enhance the efficiency and quality compared to the diffusion models by finding the least costly path between two distributions. However, they are computationally expensive and time-consuming when applied to complex image data. The reason is that they focus on fitting globally optimal paths in high-dimensional spaces, directly generating images as next step on the path using complex networks through self-supervised training, which typically results in a gap with the global optimum. Meanwhile, most diffusion models are in the same path subspace generated by weights $f_A(t)$ and $f_B(t)$, as they follow the paradigm ($x_t = f_A(t)x_{Img} + f_B(t)\epsilon$). To address the limitations of SB-based methods, this paper proposes for the first time to find local Diffusion Schr"odinger Bridges (LDSB) in the diffusion path subspace, which strengthens the connection between the SB problem and diffusion models. Specifically, our method optimizes the diffusion paths using Kolmogorov-Arnold Network (KAN), which has the advantage of resistance to forgetting and continuous output. The experiment shows that our LDSB significantly improves the quality and efficiency of image generation using the same pre-trained denoising network and the KAN for optimising is only less than 0.1MB. The FID metric is reduced by more than 15%, especially with a reduction of 48.50% when NFE of DDIM is $5$ for the CelebA dataset. Code is available at https://github.com/PerceptionComputingLab/LDSB.
在图像生成领域,基于Schrödinger Bridge(SB)的方法通过寻找两种分布之间成本最低的途径,理论上提高了与扩散模型的效率和质量。然而,当应用于复杂的图像数据时,它们计算量大且耗时。原因是它们专注于在高维空间中拟合全局最优路径,通过自监督训练使用复杂网络直接生成路径上的下一步图像,这通常与全局最优存在差距。同时,大多数扩散模型的路径都受到权重fA(t)和fB(t)生成的相同路径子空间的影响,因为它们遵循(xt=fA(t)xImg+fB(t)ϵ)这一范式。为了克服SB方法的局限性,本文首次提出了在扩散路径子空间中找到局部扩散Schrödinger Bridges(LDSB)的方法,增强了SB问题与扩散模型之间的联系。具体来说,我们的方法使用Kolmogorov-Arnold网络(KAN)优化扩散路径,该网络具有抵抗遗忘和连续输出的优势。实验表明,使用相同的预训练降噪网络和优化的KAN,我们的LDSB在图像生成的质量和效率方面有了显著提高,其中优化网络的大小仅小于0.1MB。在CelebA数据集上,当DDIM的NFE为5时,FID指标降低了超过15%,尤其是降低了48.5%。代码可在https://github.com/PerceptionComputingLab/LDSB找到。
论文及项目相关链接
PDF 16 pages, 10 figures, accepted by CVPR 2025
Summary
本文提出了基于局部扩散Schrödinger桥(LDSB)的方法,优化了图像生成中的扩散路径。该方法结合了Schrödinger Bridge(SB)理论和扩散模型,通过在扩散路径子空间中寻找局部扩散桥,强化了SB问题与扩散模型的关联。实验表明,LDSB在利用相同的预训练去噪网络和优化的Kolmogorov-Arnold网络(KAN)时,显著提高了图像生成的质量和效率。对于CelebA数据集,当DDIM的NFE为5时,FID指标降低了超过15%,尤其是降低了48.5%。代码已公开在GitHub上。
Key Takeaways
- Schrödinger Bridge(SB)理论在图像生成中能提高扩散模型的效率和质量,但应用于复杂图像数据时计算成本高、耗时长。
- SB方法侧重于在高维空间中寻找全局最优路径,而扩散模型通常遵循特定的路径子空间。
- 论文首次提出了局部扩散Schrödinger桥(LDSB)方法,强化了SB问题与扩散模型的关联,优化了扩散路径。
- LDSB方法使用Kolmogorov-Arnold网络(KAN)进行优化,具有抵抗遗忘和连续输出的优势。
- 实验表明,LDSB方法在利用预训练去噪网络时,能显著提高图像生成的质量和效率。
- 对于CelebA数据集,当DDIM的NFE为特定值时,LDSB方法使FID指标降低了超过15%,尤其是降低了48.5%。
点此查看论文截图



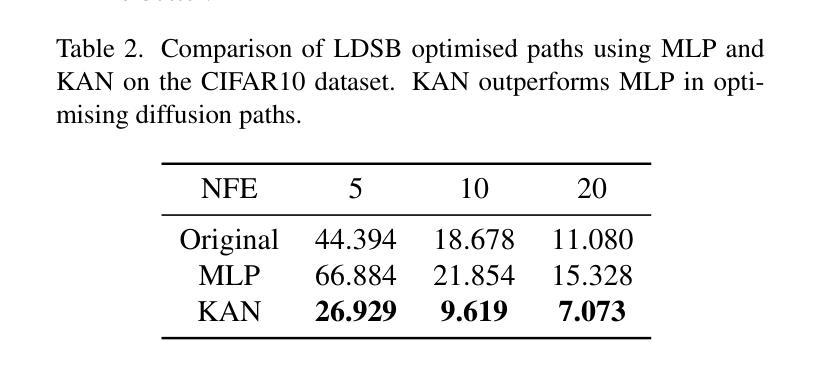

Language-Informed Hyperspectral Image Synthesis for Imbalanced-Small Sample Classification via Semi-Supervised Conditional Diffusion Model
Authors:Yimin Zhu, Lincoln Linlin Xu
Data augmentation effectively addresses the imbalanced-small sample data (ISSD) problem in hyperspectral image classification (HSIC). While most methodologies extend features in the latent space, few leverage text-driven generation to create realistic and diverse samples. Recently, text-guided diffusion models have gained significant attention due to their ability to generate highly diverse and high-quality images based on text prompts in natural image synthesis. Motivated by this, this paper proposes Txt2HSI-LDM(VAE), a novel language-informed hyperspectral image synthesis method to address the ISSD in HSIC. The proposed approach uses a denoising diffusion model, which iteratively removes Gaussian noise to generate hyperspectral samples conditioned on textual descriptions. First, to address the high-dimensionality of hyperspectral data, a universal variational autoencoder (VAE) is designed to map the data into a low-dimensional latent space, which provides stable features and reduces the inference complexity of diffusion model. Second, a semi-supervised diffusion model is designed to fully take advantage of unlabeled data. Random polygon spatial clipping (RPSC) and uncertainty estimation of latent feature (LF-UE) are used to simulate the varying degrees of mixing. Third, the VAE decodes HSI from latent space generated by the diffusion model with the language conditions as input. In our experiments, we fully evaluate synthetic samples’ effectiveness from statistical characteristics and data distribution in 2D-PCA space. Additionally, visual-linguistic cross-attention is visualized on the pixel level to prove that our proposed model can capture the spatial layout and geometry of the generated data. Experiments demonstrate that the performance of the proposed Txt2HSI-LDM(VAE) surpasses the classical backbone models, state-of-the-art CNNs, and semi-supervised methods.
数据增强有效解决了高光谱图像分类(HSIC)中的不平衡小样本数据(ISSD)问题。虽然大多数方法都在潜在空间扩展特征,但很少有方法利用文本驱动生成来创建真实和多样化的样本。最近,文本引导的扩散模型因其能够根据文本提示生成高度多样化和高质量的图像的能力而在自然图像合成中受到广泛关注。受此启发,本文提出了Txt2HSI-LDM(VAE),这是一种新的语言信息引导的高光谱图像合成方法,以解决HSIC中的ISSD问题。所提出的方法使用去噪扩散模型,该模型通过迭代去除高斯噪声,根据文本描述生成高光谱样本。首先,为了解决高光谱数据的高维性问题,设计了一种通用变分自编码器(VAE),将数据映射到低维潜在空间,这提供了稳定的特征并降低了扩散模型的推理复杂性。其次,设计了半监督扩散模型,以充分利用未标记数据。使用随机多边形空间裁剪(RPSC)和潜在特征的不确定性估计(LF-UE)来模拟不同程度的混合。第三,VAE根据扩散模型生成的潜在空间中的语言条件对HSI进行解码。在我们的实验中,我们全面评估了合成样本在统计特性和二维PCA空间中的数据分布的有效性。此外,对视觉语言跨注意力进行了像素级可视化,证明了我们提出的模型能够捕捉生成数据的空间布局和几何结构。实验表明,所提出的Txt2HSI-LDM(VAE)的性能超过了经典的后备模型、最先进的卷积神经网络和半监督方法。
论文及项目相关链接
摘要
数据增强可有效解决高光谱图像分类中的小样本不均衡问题。虽然大多数方法侧重于在潜在空间扩展特征,但很少有研究利用文本驱动生成来创建真实和多样化的样本。受近期文本引导的扩散模型在自然图像合成中生成高度多样化和高质量图像的能力的启发,本文提出一种名为Txt2HSI-LDM(VAE)的新型语言信息高光谱图像合成方法,以解决高光谱图像分类中的小样本不均衡问题。该方法使用去噪扩散模型,该模型通过迭代去除高斯噪声,根据文本描述生成高光谱样本。首先,为了解决高光谱数据的高维性问题,设计了一种通用变分自编码器(VAE)将数据映射到低维潜在空间,以提供稳定特征和降低扩散模型的推理复杂性。其次,设计了半监督扩散模型以充分利用未标记数据。使用随机多边形空间裁剪(RPSC)和潜在特征的不确定性估计(LF-UE)来模拟不同程度的混合。最后,VAE将扩散模型生成的潜在空间中的HSI与语言条件作为输入进行解码。实验全面评估了合成样本在二维主成分分析空间中的统计特性和数据分布的有效性。此外,对视觉语言交叉注意力进行了像素级可视化,证明了我们提出的模型能够捕捉生成数据的空间布局和几何结构。实验表明,所提出的Txt2HSI-LDM(VAE)的性能超过了经典的后端模型、最先进的卷积神经网络和半监督方法。
关键见解
- 数据增强是解决高光谱图像分类中小样本不均衡问题的有效方法。
- Txt2HSI-LDM(VAE)是一种新型语言信息高光谱图像合成方法,利用文本驱动的扩散模型生成高光谱样本。
- 变分自编码器(VAE)用于将数据映射到低维潜在空间,提供稳定特征并降低扩散模型的复杂性。
- 半监督扩散模型利用未标记数据,通过随机多边形空间裁剪和潜在特征的不确定性估计来模拟不同程度的混合。
- 实验证明Txt2HSI-LDM(VAE)在合成样本的有效性和性能上超越了传统模型和最新技术。
点此查看论文截图

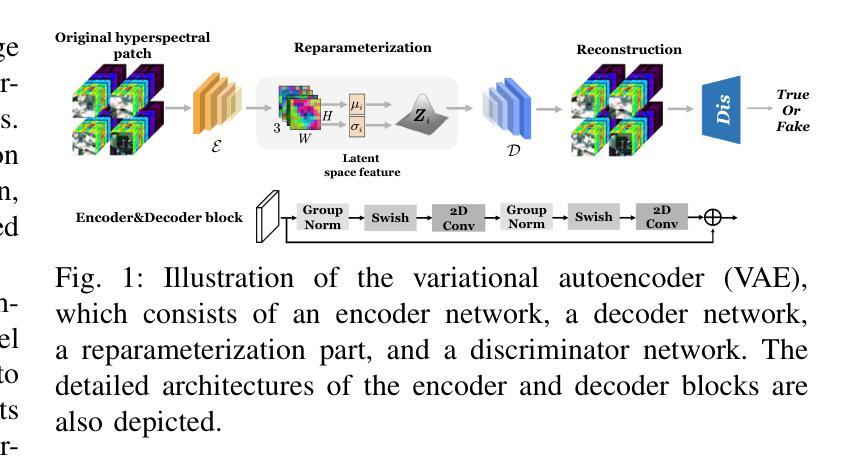
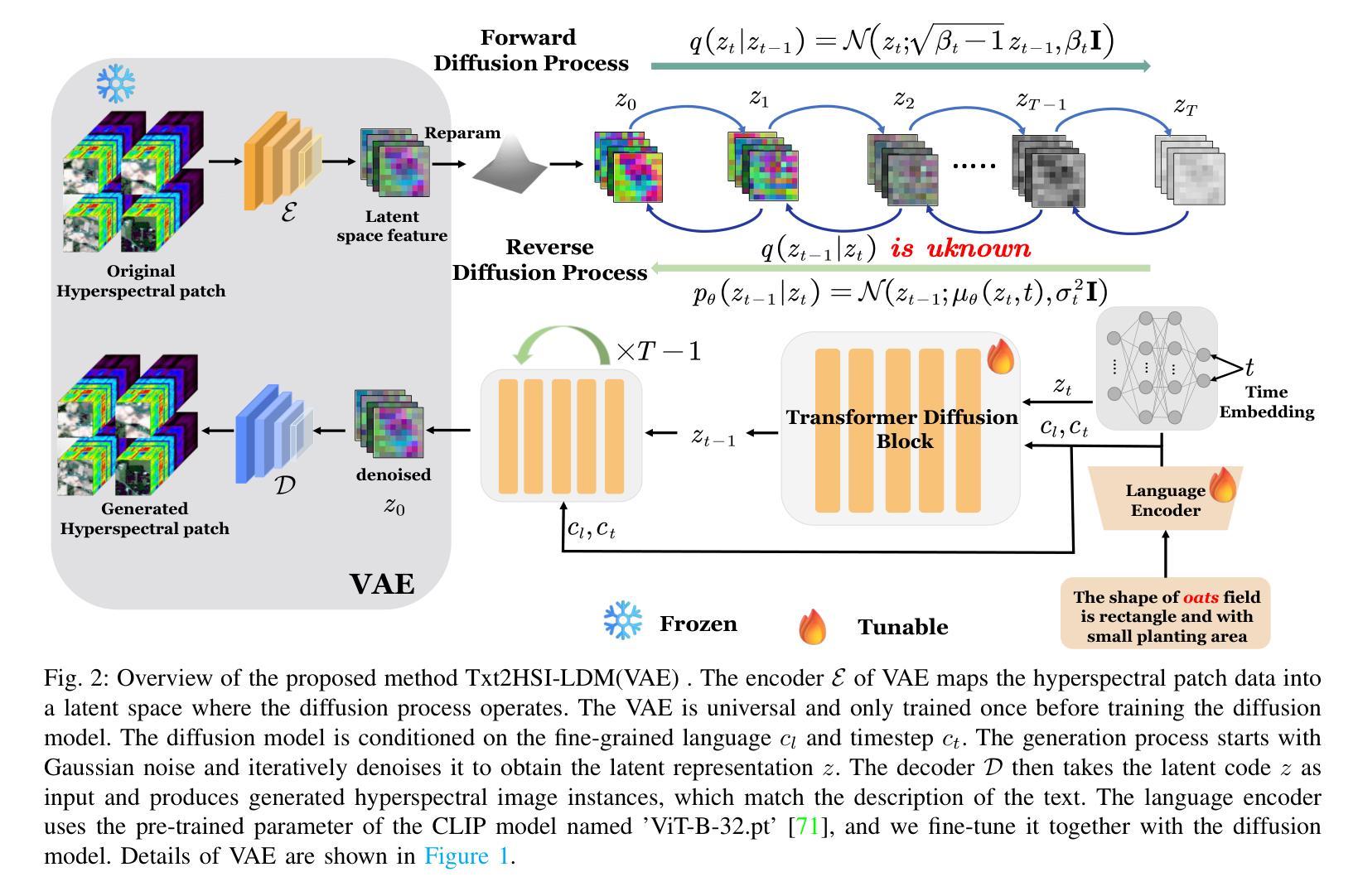
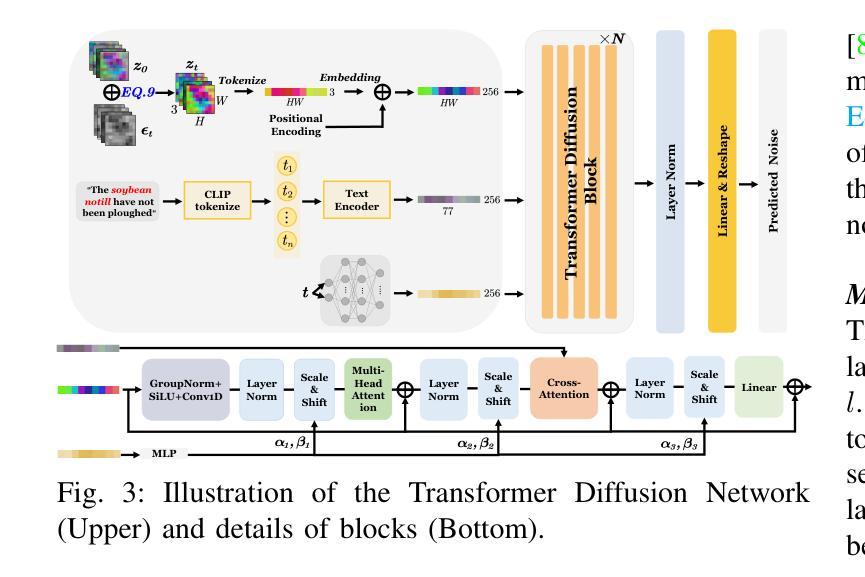
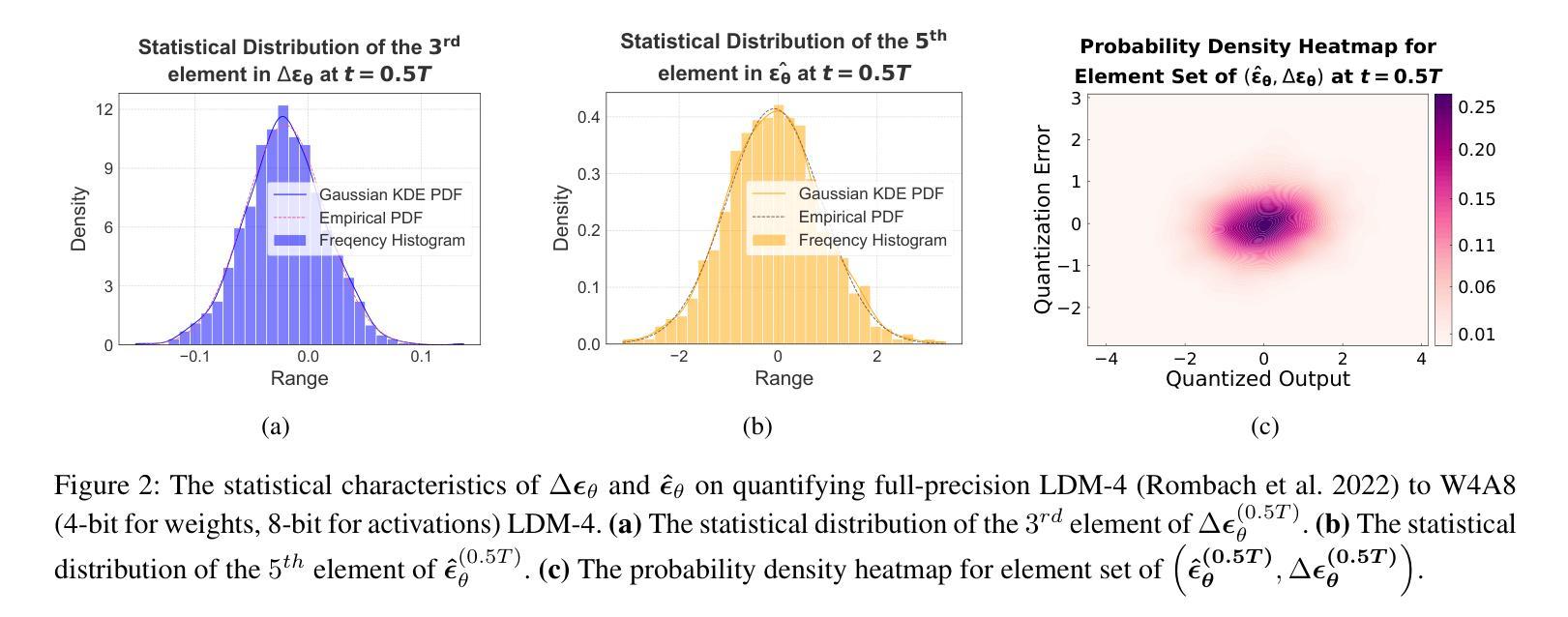
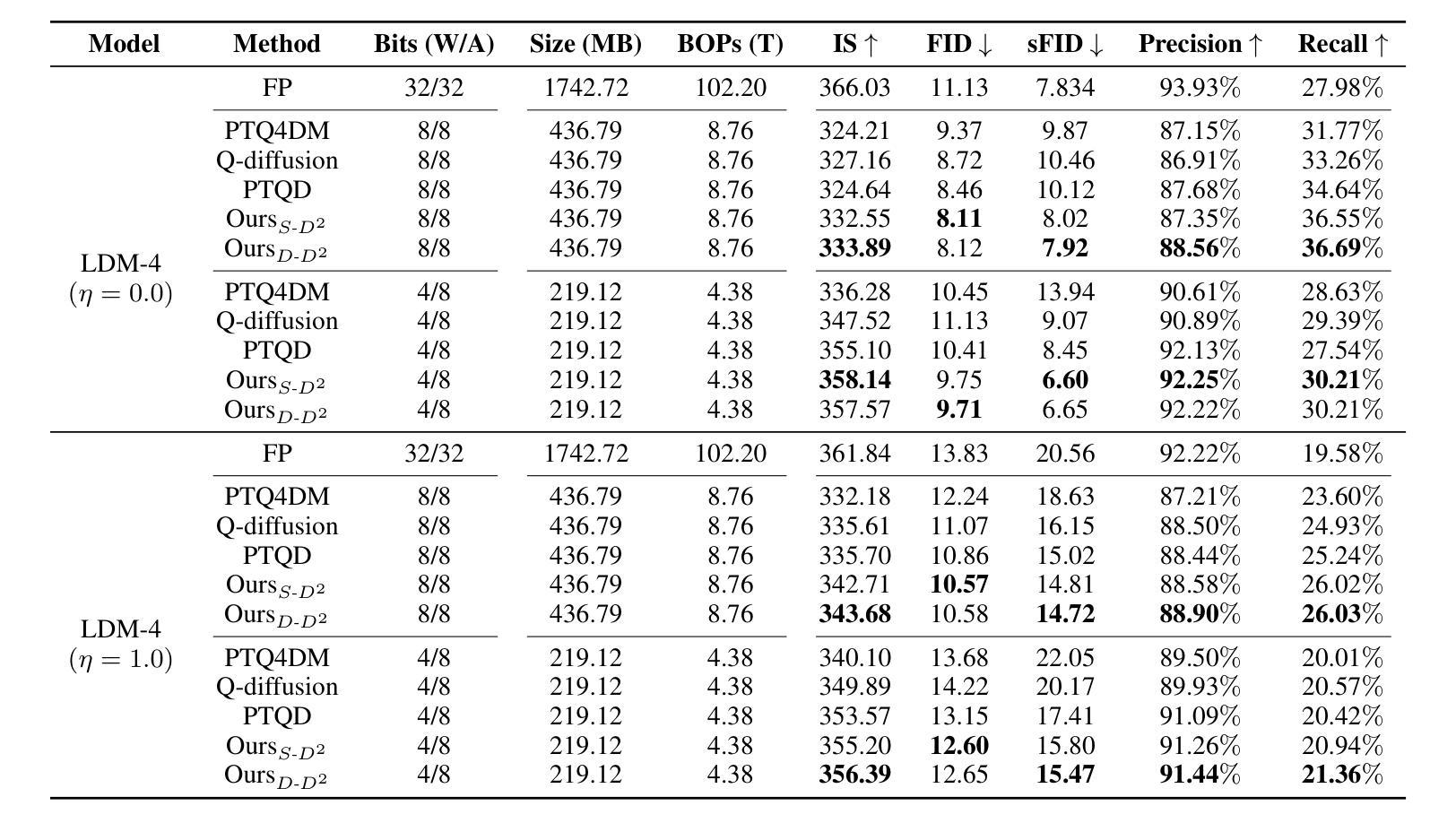
D$^2$-DPM: Dual Denoising for Quantized Diffusion Probabilistic Models
Authors:Qian Zeng, Jie Song, Han Zheng, Hao Jiang, Mingli Song
Diffusion models have achieved cutting-edge performance in image generation. However, their lengthy denoising process and computationally intensive score estimation network impede their scalability in low-latency and resource-constrained scenarios. Post-training quantization (PTQ) compresses and accelerates diffusion models without retraining, but it inevitably introduces additional quantization noise, resulting in mean and variance deviations. In this work, we propose D2-DPM, a dual denoising mechanism aimed at precisely mitigating the adverse effects of quantization noise on the noise estimation network. Specifically, we first unravel the impact of quantization noise on the sampling equation into two components: the mean deviation and the variance deviation. The mean deviation alters the drift coefficient of the sampling equation, influencing the trajectory trend, while the variance deviation magnifies the diffusion coefficient, impacting the convergence of the sampling trajectory. The proposed D2-DPM is thus devised to denoise the quantization noise at each time step, and then denoise the noisy sample through the inverse diffusion iterations. Experimental results demonstrate that D2-DPM achieves superior generation quality, yielding a 1.42 lower FID than the full-precision model while achieving 3.99x compression and 11.67x bit-operation acceleration.
扩散模型在图像生成方面达到了前沿性能。然而,其冗长的去噪过程和计算密集型的评分估计网络阻碍了其在低延迟和资源受限场景中的可扩展性。后训练量化(PTQ)在不进行再训练的情况下压缩和加速了扩散模型,但它不可避免地引入了额外的量化噪声,导致均值和方差偏差。在本研究中,我们提出了D2-DPM,这是一种双去噪机制,旨在精确缓解量化噪声对噪声估计网络的不利影响。具体来说,我们首先分析了量化噪声对采样方程的影响并将其分为两部分:均值偏差和方差偏差。均值偏差会改变采样方程的漂移系数,影响轨迹趋势,而方差偏差会放大扩散系数,影响采样轨迹的收敛性。因此,提出的D2-DPM旨在在每个时间步长去除量化噪声,然后通过逆向扩散迭代进一步去除噪声样本。实验结果表明,D2-DPM在生成质量上表现优越,与全精度模型相比降低了1.42的FID得分,同时实现了3.99倍的压缩和11.67倍的位操作加速。
论文及项目相关链接
PDF 9 pages, 4 figures, acceptted by AAAI2025, the code is available at https://github.com/taylorjocelyn/d2-dpm
Summary
扩散模型在图像生成方面表现出卓越性能,但其冗长的去噪过程和计算密集型的评分估计网络限制了其在低延迟和资源受限场景中的应用。针对这一问题,研究者提出D2-DPM双去噪机制,旨在精确缓解量化噪声对噪声估计网络的不良影响。新机制通过对采样方程进行拆解,分别处理均值偏差和方差偏差,进而在每一步去除量化噪声,并通过逆扩散迭代去除噪声样本。实验结果显示,D2-DPM在生成质量上表现优越,相较于全精度模型降低了1.42的FID得分,同时实现了3.99倍的压缩率和11.67倍的位操作加速。
Key Takeaways
- 扩散模型在图像生成中具有卓越性能,但存在去噪过程冗长和计算成本较高的问题。
- 量化噪声在去噪过程中引入额外的噪声,导致均值和方差偏差。
- D2-DPM双去噪机制旨在精确缓解量化噪声对噪声估计网络的影响。
- D2-DPM通过拆解采样方程,处理均值偏差和方差偏差。
- D2-DPM在每一步去除量化噪声,并通过逆扩散迭代去除噪声样本。
- 实验结果显示,D2-DPM在生成质量上表现优越,相较于全精度模型降低了FID得分。
点此查看论文截图

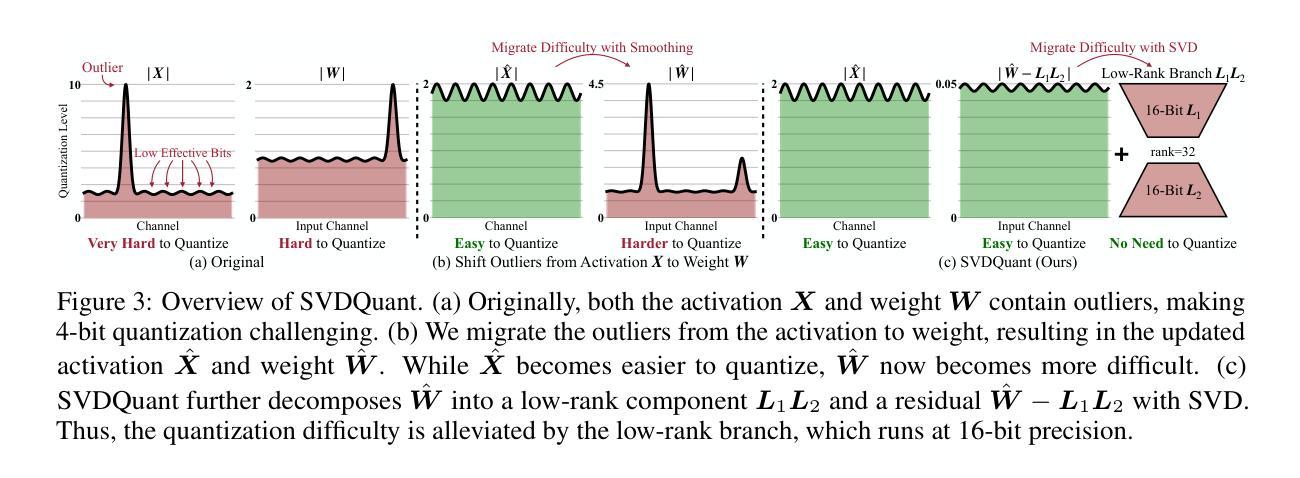
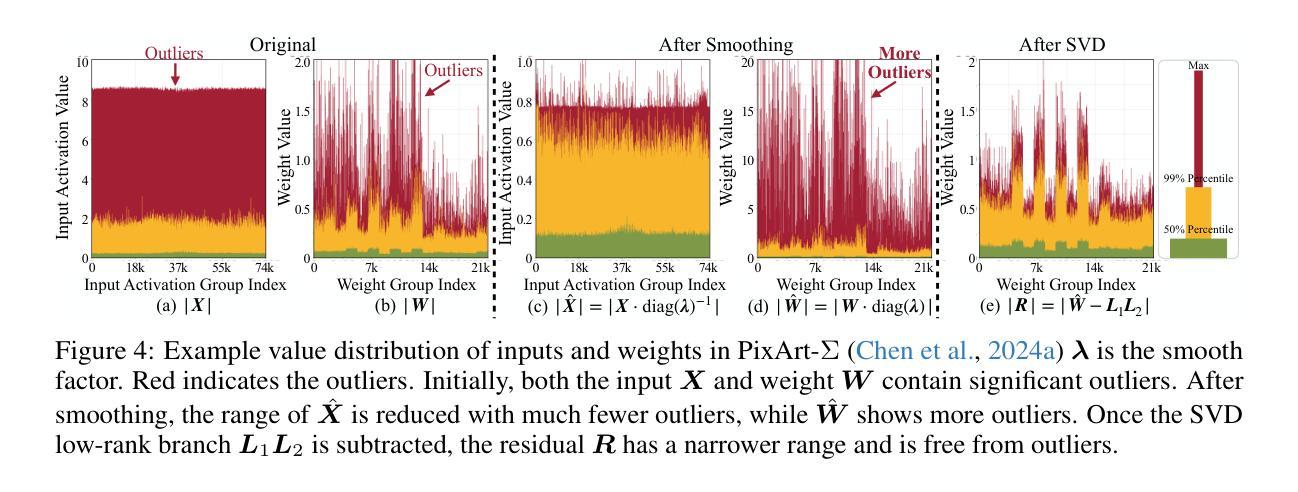
SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models
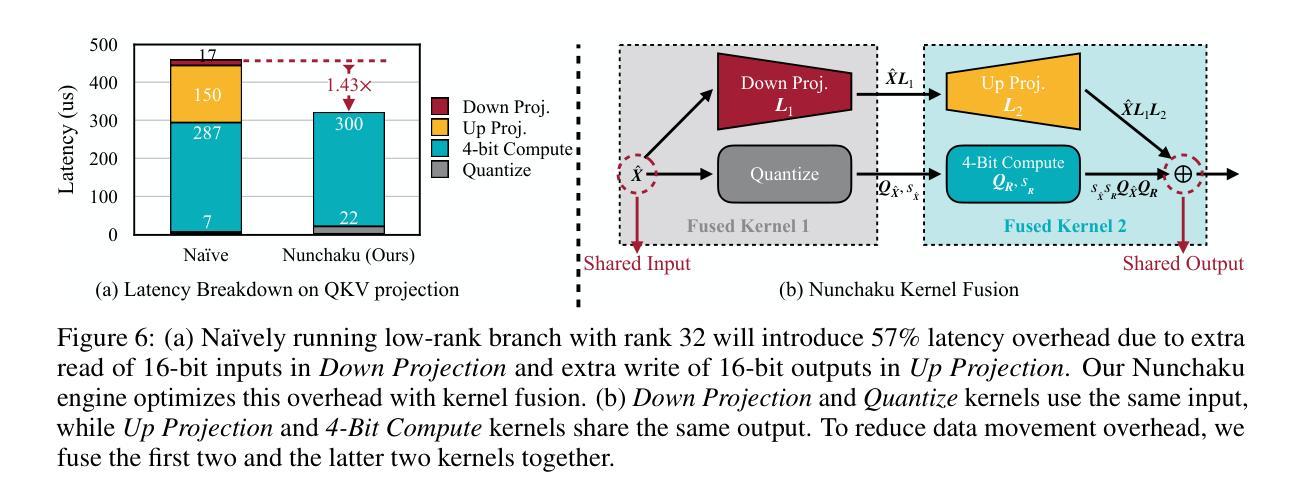
Authors:Muyang Li, Yujun Lin, Zhekai Zhang, Tianle Cai, Xiuyu Li, Junxian Guo, Enze Xie, Chenlin Meng, Jun-Yan Zhu, Song Han
Diffusion models can effectively generate high-quality images. However, as they scale, rising memory demands and higher latency pose substantial deployment challenges. In this work, we aim to accelerate diffusion models by quantizing their weights and activations to 4 bits. At such an aggressive level, both weights and activations are highly sensitive, where existing post-training quantization methods like smoothing become insufficient. To overcome this limitation, we propose SVDQuant, a new 4-bit quantization paradigm. Different from smoothing, which redistributes outliers between weights and activations, our approach absorbs these outliers using a low-rank branch. We first consolidate the outliers by shifting them from activations to weights. Then, we use a high-precision, low-rank branch to take in the weight outliers with Singular Value Decomposition (SVD), while a low-bit quantized branch handles the residuals. This process eases the quantization on both sides. However, naively running the low-rank branch independently incurs significant overhead due to extra data movement of activations, negating the quantization speedup. To address this, we co-design an inference engine Nunchaku that fuses the kernels of the low-rank branch into those of the low-bit branch to cut off redundant memory access. It can also seamlessly support off-the-shelf low-rank adapters (LoRAs) without re-quantization. Extensive experiments on SDXL, PixArt-$\Sigma$, and FLUX.1 validate the effectiveness of SVDQuant in preserving image quality. We reduce the memory usage for the 12B FLUX.1 models by 3.5$\times$, achieving 3.0$\times$ speedup over the 4-bit weight-only quantization (W4A16) baseline on the 16GB laptop 4090 GPU with INT4 precision. On the latest RTX 5090 desktop with Blackwell architecture, we achieve a 3.1$\times$ speedup compared to the W4A16 model using NVFP4 precision.
扩散模型可以有效地生成高质量图像。然而,随着其规模扩大,内存需求的增长和延迟问题为部署带来了实质性的挑战。在这项工作中,我们的目标是通过将扩散模型的权重和激活量量化到4位来加速扩散模型。在这样极端的量化级别下,权重和激活量都高度敏感,现有的训练后量化方法(如平滑)变得不足以应对。为了克服这一局限性,我们提出了SVDQuant这一全新的4位量化范式。与通过重新分配权重和激活值中的异常值进行平滑的方法不同,我们的方法使用低阶分支吸收这些异常值。我们首先将异常值从激活值转移到权重进行合并。然后,我们使用高精确度、低阶分支采用奇异值分解(SVD)来接收权重异常值,而低位量化分支则处理残差。这个过程使两边的量化变得更容易。然而,单纯独立运行低阶分支会由于激活值的额外数据移动而产生大量开销,从而抵消量化的加速效果。为了解决这个问题,我们共同设计了一个推理引擎Nunchaku,它将低阶分支的核心融合到低位分支的核心中,以切断冗余的内存访问。它还可以无缝支持现成的低阶适配器(LoRAs)而无需重新量化。在SDXL、PixArt-$\Sigma$和FLUX.1上的大量实验验证了SVDQuant在保持图像质量方面的有效性。在具有INT4精度的16GB laptop 4090 GPU上,我们减少了FLUX.1模型的内存使用量(乘数效应为3.5倍),相对于仅权重量化的W4A16基线实现了高达3.0倍的加速效果。在具有Blackwell架构的最新RTX 5090台式机上,与使用NVFP4精度的W4A16模型相比,我们实现了高达3.1倍的加速效果。
论文及项目相关链接
PDF ICLR 2025 Spotlight Quantization Library: https://github.com/mit-han-lab/deepcompressor Inference Engine: https://github.com/mit-han-lab/nunchaku Website: https://hanlab.mit.edu/projects/svdquant Demo: https://svdquant.mit.edu Blog: https://hanlab.mit.edu/blog/svdquant
Summary
扩散模型能有效生成高质量图像,但随着规模扩大,内存需求增加和延迟增高,部署挑战也相应增大。本研究旨在通过将扩散模型的权重和激活值量化至4位来加速扩散模型。提出一种名为SVDQuant的新4位量化方法,不同于现有的平滑后训练量化方法,该方法使用低阶分支吸收异常值。首先,将异常值从激活转移到权重进行合并,然后使用奇异值分解(SVD)处理权重异常值,同时低位量化分支处理残差。这一过程使两侧量化更为轻松。然而,单独运行低阶分支会导致激活额外数据传输开销,抵消量化加速效果。因此,本研究设计了一种推理引擎Nunchaku,将低阶分支内核融入低位分支内核中,减少内存访问,并支持离线低阶适配器(LoRAs)无缝使用。实验证明SVDQuant在保持图像质量方面非常有效,减少了FLUX.1模型的内存使用,并在不同设备上实现了显著的加速。
Key Takeaways
- 扩散模型在生成高质量图像方面表现出色,但随着规模扩大,部署挑战增加。
- 研究目标是通过将权重和激活值量化至4位来加速扩散模型。
- 提出一种名为SVDQuant的新量化方法,通过合并异常值并使用低阶分支处理来提高量化效率。
- Nunchaku推理引擎被设计来减少内存访问并增强量化加速效果。
- SVDQuant在保持图像质量方面非常有效,减少了内存使用并实现了显著的速度提升。
- 该方法在多种设备上进行了实验验证。
点此查看论文截图

VILA-U: a Unified Foundation Model Integrating Visual Understanding and Generation
Authors:Yecheng Wu, Zhuoyang Zhang, Junyu Chen, Haotian Tang, Dacheng Li, Yunhao Fang, Ligeng Zhu, Enze Xie, Hongxu Yin, Li Yi, Song Han, Yao Lu
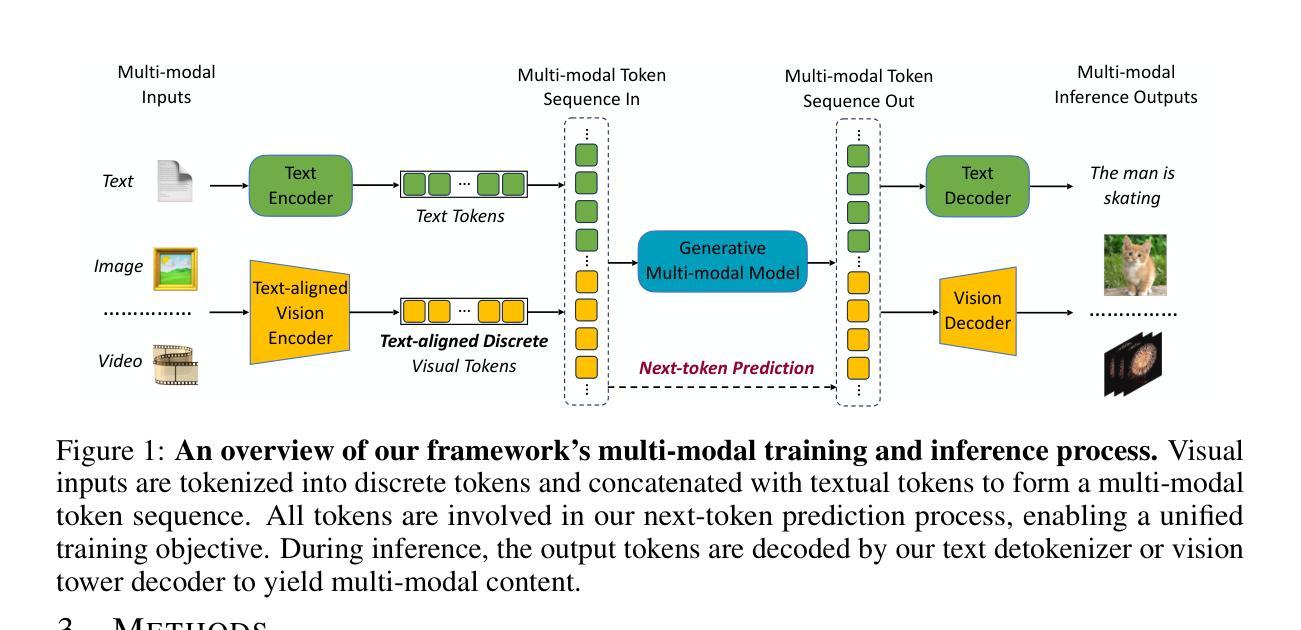
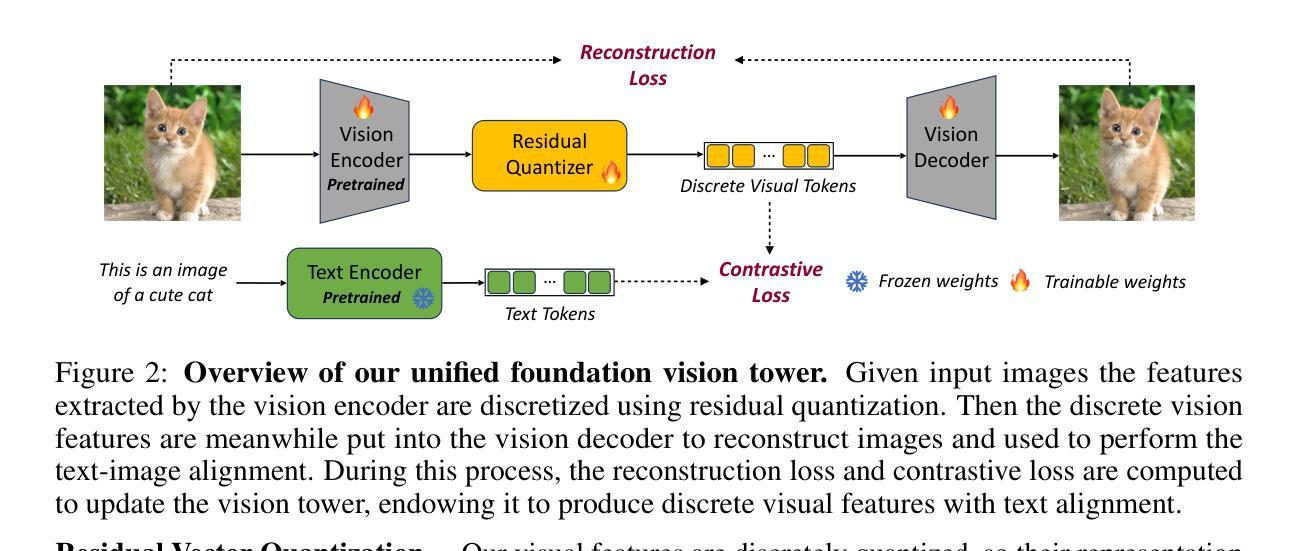
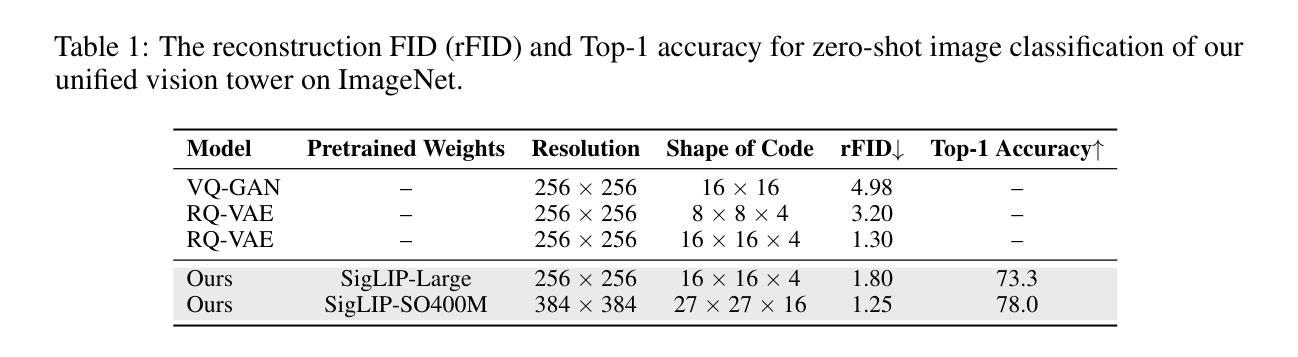
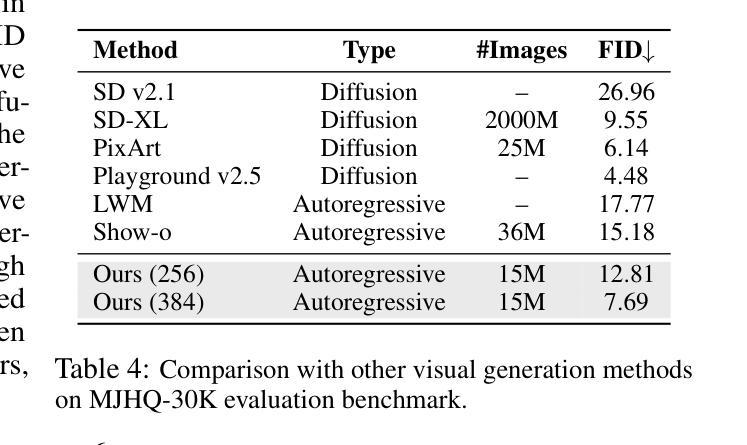
VILA-U is a Unified foundation model that integrates Video, Image, Language understanding and generation. Traditional visual language models (VLMs) use separate modules for understanding and generating visual content, which can lead to misalignment and increased complexity. In contrast, VILA-U employs a single autoregressive next-token prediction framework for both tasks, eliminating the need for additional components like diffusion models. This approach not only simplifies the model but also achieves near state-of-the-art performance in visual language understanding and generation. The success of VILA-U is attributed to two main factors: the unified vision tower that aligns discrete visual tokens with textual inputs during pretraining, which enhances visual perception, and autoregressive image generation can achieve similar quality as diffusion models with high-quality dataset. This allows VILA-U to perform comparably to more complex models using a fully token-based autoregressive framework.
VILA-U是一个统一的基础模型,融合了视频、图像、语言理解和生成。传统的视觉语言模型(VLMs)使用单独的模块来理解和生成视觉内容,这可能会导致对齐问题和增加复杂性。相比之下,VILA-U采用单个的自回归下一个令牌预测框架来完成这两个任务,无需使用如扩散模型等额外组件。这种方法不仅简化了模型,而且在视觉语言的理解和生成方面达到了接近最新技术的性能。VILA-U的成功归因于两个主要因素:在预训练期间,离散视觉令牌与文本输入的统一视觉塔对齐,这增强了视觉感知能力;自回归图像生成可以使用高质量数据集达到与扩散模型相当的质量。这使得VILA-U能够在完全基于令牌的自回归框架下与更复杂的模型进行相当的性能表现。
论文及项目相关链接
PDF Code: https://github.com/mit-han-lab/vila-u. The first two authors contributed equally to this work
Summary
VILA-U是一种统一基础模型,融合了视频、图像、语言理解和生成能力。相比传统视觉语言模型使用分离模块进行视觉内容理解和生成导致的错位和复杂性增加问题,VILA-U采用单一的自回归下一代标记预测框架,同时支持两项任务,无需使用如扩散模型等额外组件。此方法简化了模型结构,同时实现了近乎最先进水平的视觉语言理解和生成性能。其成功归功于两大因素:在预训练阶段将离散视觉标记与文本输入对齐的统一视觉塔,增强了视觉感知能力;以及使用高质量数据集可实现与扩散模型相当质量的自回归图像生成。这使得VILA-U在完全基于标记的自回归框架下,表现与更复杂模型相当。
Key Takeaways
- VILA-U是一个统一基础模型,集成了视频、图像、语言的理解和生成能力。
- 传统视觉语言模型使用分离模块,可能导致错位和复杂性增加。
- VILA-U采用单一自回归下一代标记预测框架,简化模型结构。
- VILA-U不需要额外的组件,如扩散模型。
- VILA-U实现了近乎最先进水平的视觉语言理解和生成性能。
- VILA-U的成功归功于统一视觉塔和自回归图像生成技术。
点此查看论文截图