⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-06 更新
MX-Font++: Mixture of Heterogeneous Aggregation Experts for Few-shot Font Generation
Authors:Weihang Wang, Duolin Sun, Jielei Zhang, Longwen Gao
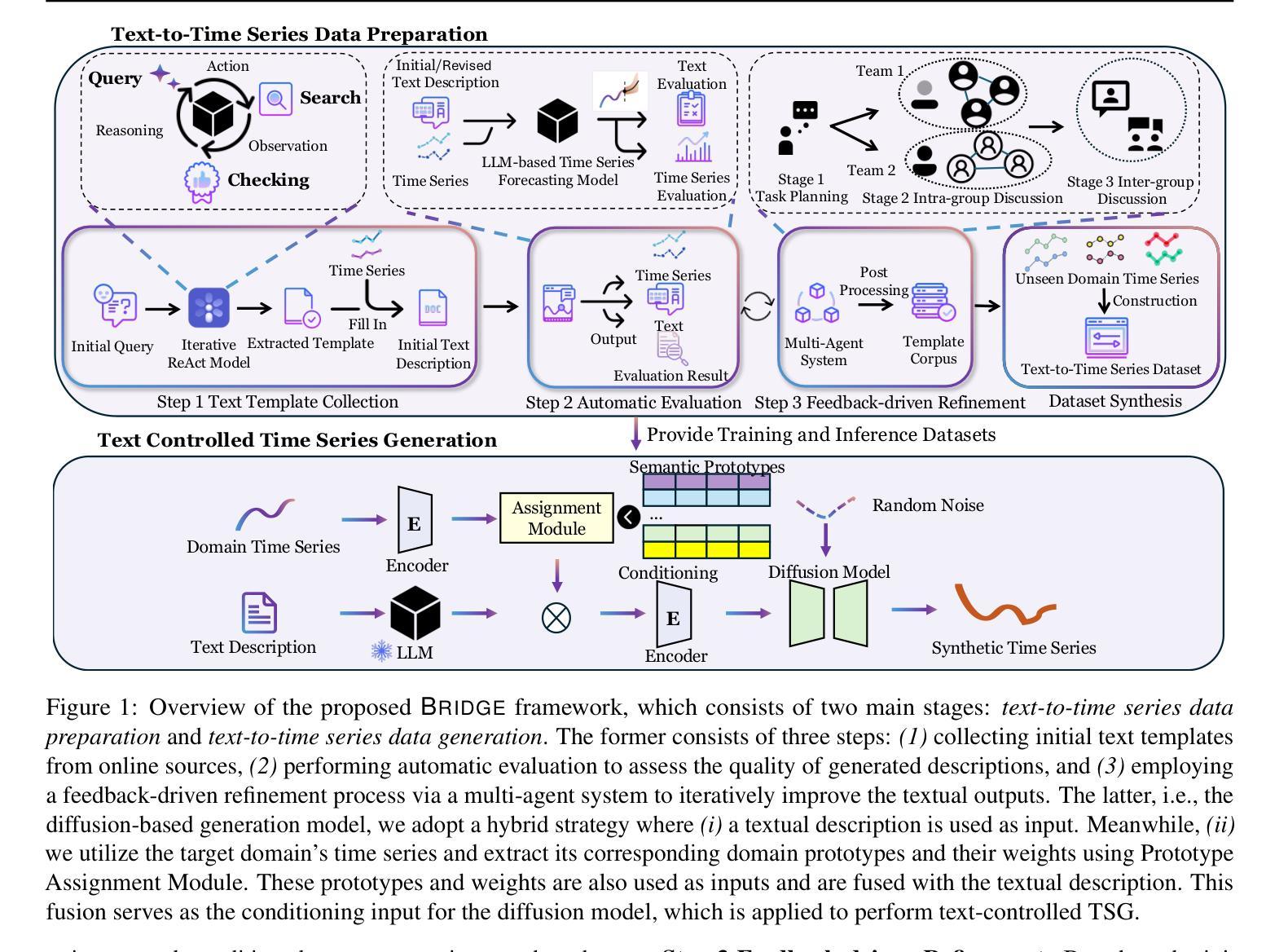
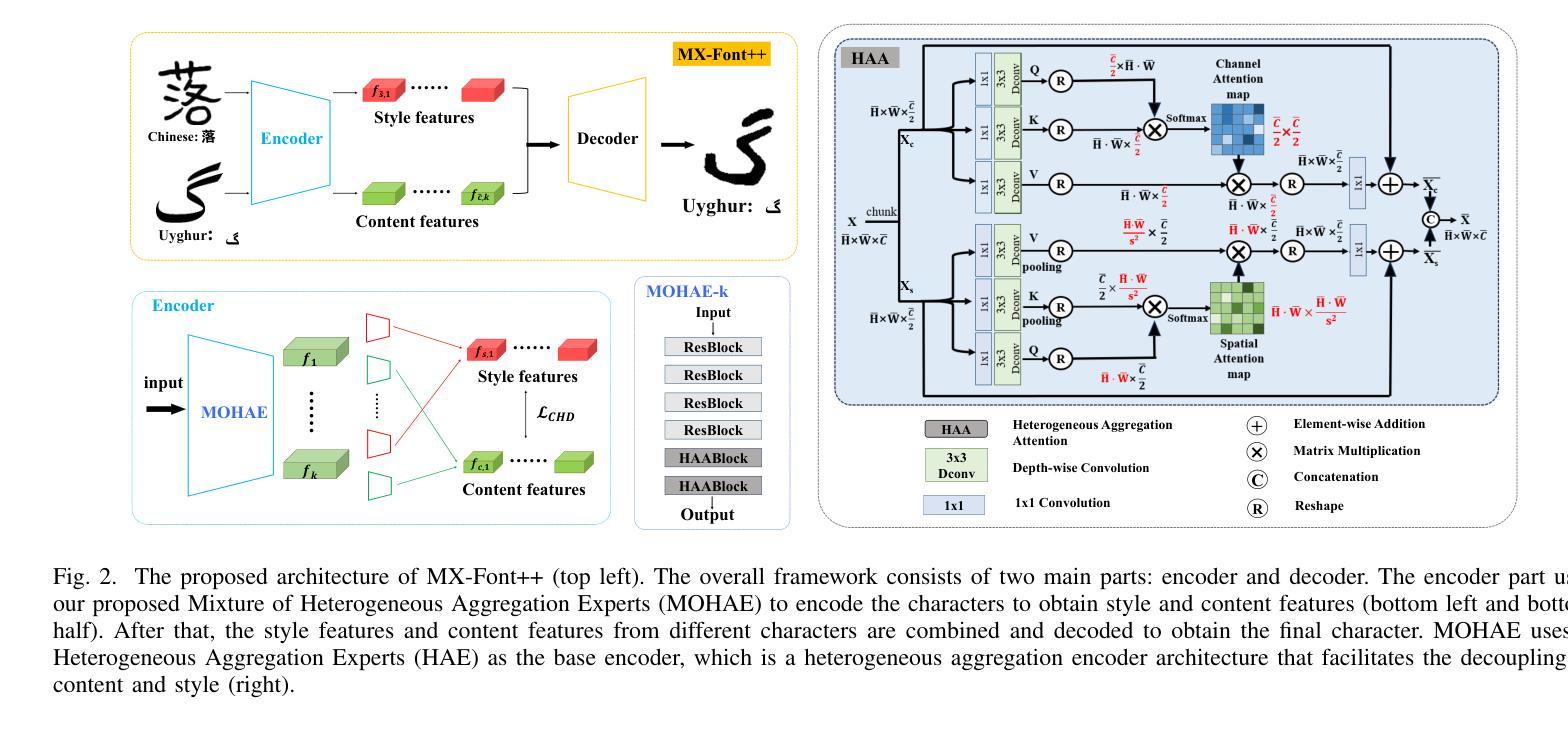
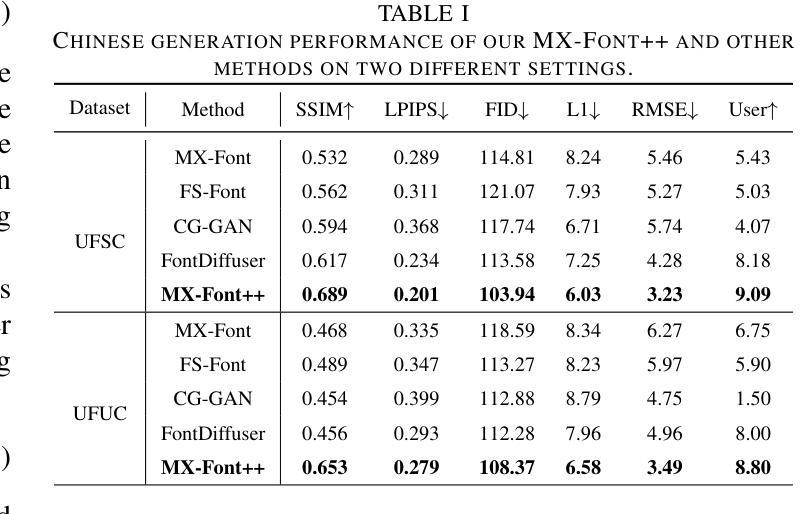
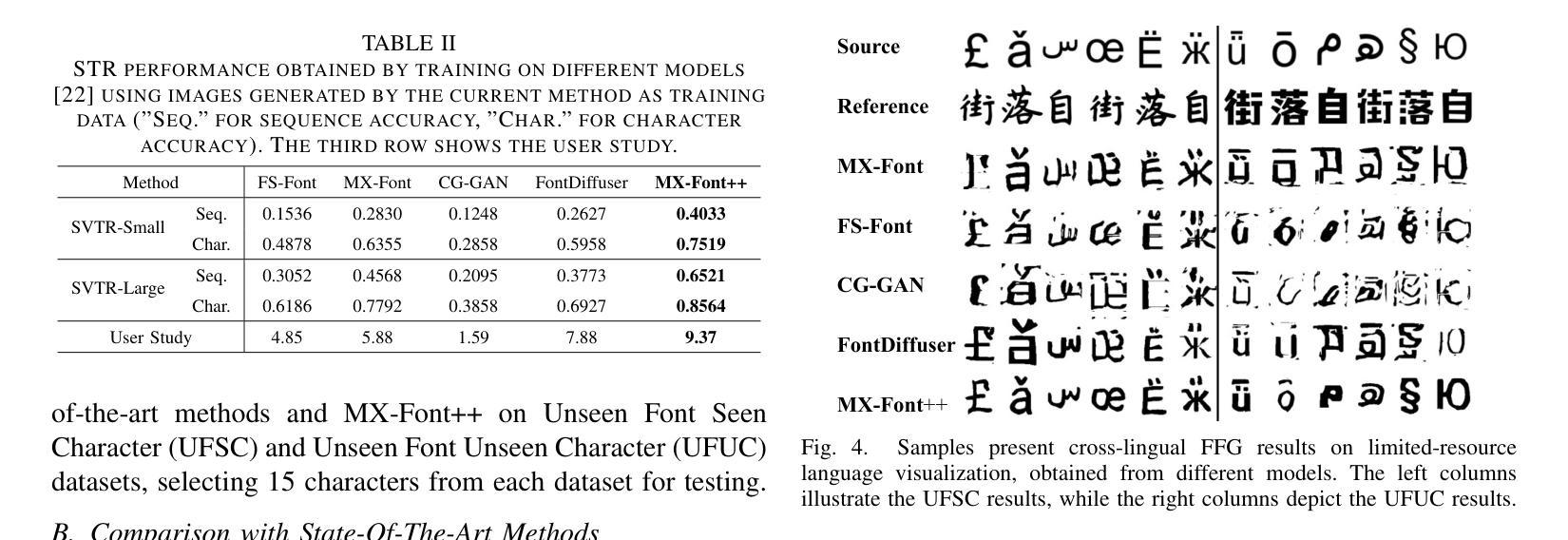
Few-shot Font Generation (FFG) aims to create new font libraries using limited reference glyphs, with crucial applications in digital accessibility and equity for low-resource languages, especially in multilingual artificial intelligence systems. Although existing methods have shown promising performance, transitioning to unseen characters in low-resource languages remains a significant challenge, especially when font glyphs vary considerably across training sets. MX-Font considers the content of a character from the perspective of a local component, employing a Mixture of Experts (MoE) approach to adaptively extract the component for better transition. However, the lack of a robust feature extractor prevents them from adequately decoupling content and style, leading to sub-optimal generation results. To alleviate these problems, we propose Heterogeneous Aggregation Experts (HAE), a powerful feature extraction expert that helps decouple content and style downstream from being able to aggregate information in channel and spatial dimensions. Additionally, we propose a novel content-style homogeneity loss to enhance the untangling. Extensive experiments on several datasets demonstrate that our MX-Font++ yields superior visual results in FFG and effectively outperforms state-of-the-art methods. Code and data are available at https://github.com/stephensun11/MXFontpp.
少量样本字体生成(FFG)旨在利用有限的参考字形创建新的字体库,这在低资源语言的多语言人工智能系统中对数字无障碍和公平性有着至关重要的应用。尽管现有方法已经显示出有前景的性能,但在低资源语言中过渡到未见字符仍然是一个重大挑战,尤其是在训练集中的字体字形变化很大时。MX-Font从字符内容的角度考虑局部组件,采用专家混合(MoE)方法自适应提取组件,以便更好地过渡。然而,缺乏稳健的特征提取器阻碍了它们充分地解耦内容和风格,从而导致生成结果不理想。为了缓解这些问题,我们提出了Heterogeneous Aggregation Experts(HAE),这是一种强大的特征提取专家,有助于从下游解耦内容和风格,能够在通道和空间维度上聚合信息。此外,我们还提出了一种新型的内容风格同质性损失,以增强解开效果。在多个数据集上的广泛实验表明,我们的MX-Font++在FFG中产生了卓越的视觉结果,并有效地超越了最新方法。代码和数据集可在https://github.com/stephensun11/MXFontpp获得。
论文及项目相关链接
PDF 4 pages, 4 figures, accepted by ICASSP 2025
Summary
FFG面临在低资源语言中对未见字符进行字体生成的挑战。为解决现有方法中的缺陷,例如缺乏稳健的特征提取器,研究者提出了Heterogeneous Aggregation Experts(HAE)与新的内容风格同质性损失机制,强化了特征提取能力并优化了字体生成效果。其代码和数据集已公开于github。MX-Font++展现出卓越的视觉生成效果,有效超越了现有技术。
Key Takeaways
- Few-shot Font Generation(FFG)旨在利用有限的参考字符创建新的字体库,这在多语言人工智能系统中为低资源语言的数字无障碍访问和公平性应用提供了重要的应用价值。然而,处理低资源语言中的未见字符仍是主要挑战之一。
点此查看论文截图


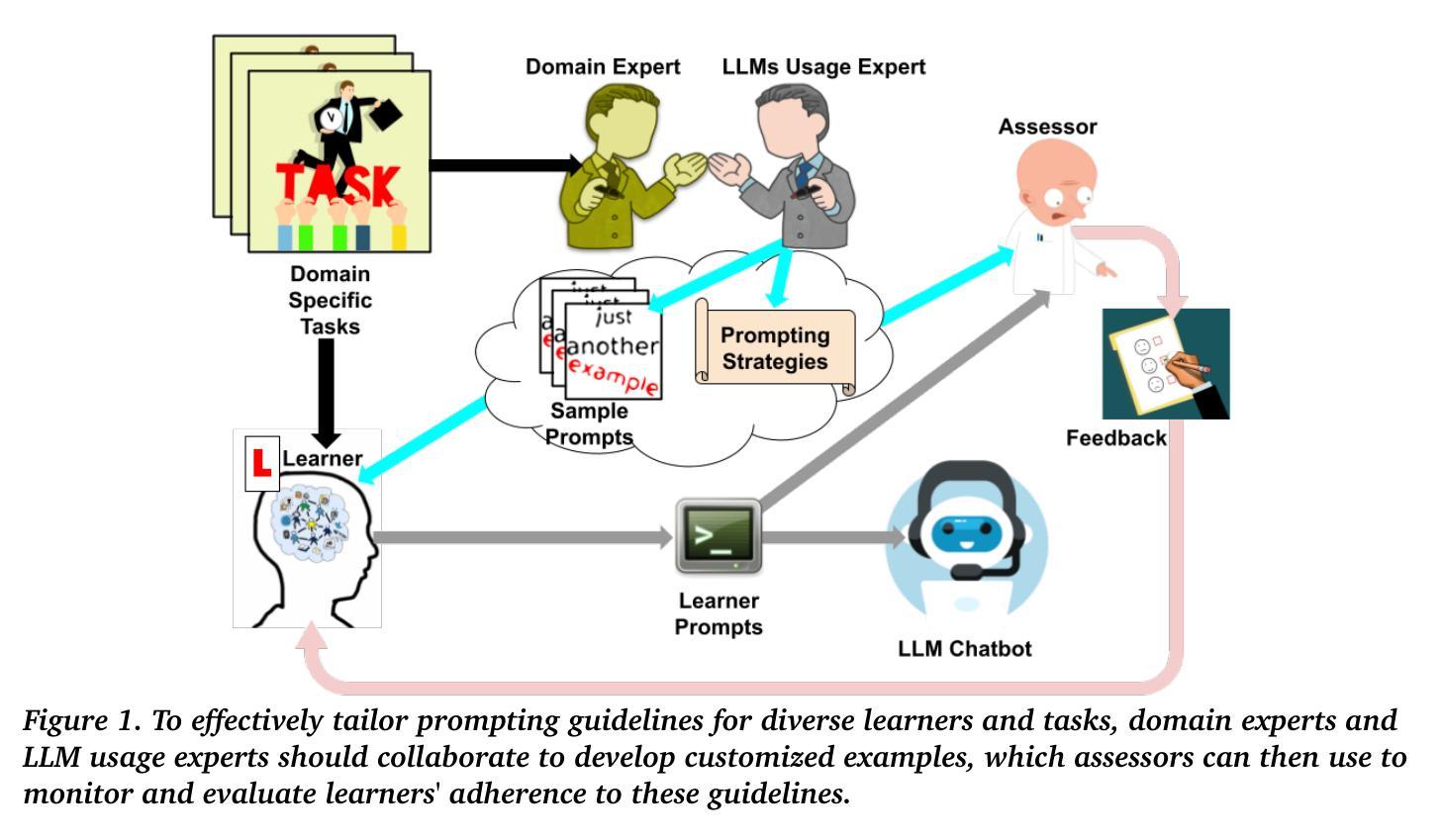
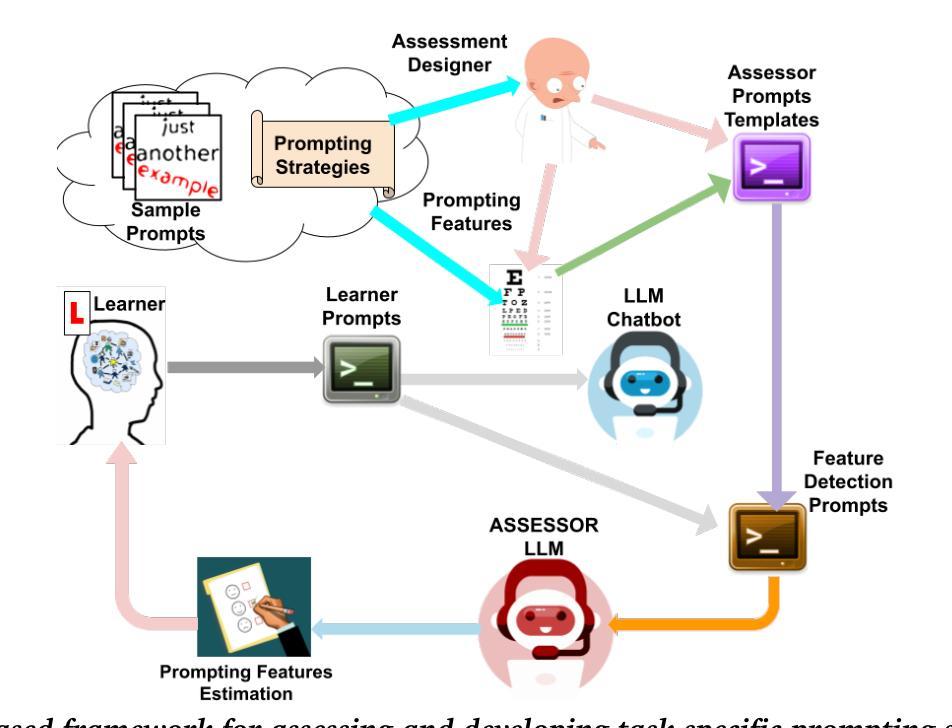
Use Me Wisely: AI-Driven Assessment for LLM Prompting Skills Development
Authors:Dimitri Ognibene, Gregor Donabauer, Emily Theophilou, Cansu Koyuturk, Mona Yavari, Sathya Bursic, Alessia Telari, Alessia Testa, Raffaele Boiano, Davide Taibi, Davinia Hernandez-Leo, Udo Kruschwitz, Martin Ruskov
The use of large language model (LLM)-powered chatbots, such as ChatGPT, has become popular across various domains, supporting a range of tasks and processes. However, due to the intrinsic complexity of LLMs, effective prompting is more challenging than it may seem. This highlights the need for innovative educational and support strategies that are both widely accessible and seamlessly integrated into task workflows. Yet, LLM prompting is highly task- and domain-dependent, limiting the effectiveness of generic approaches. In this study, we explore whether LLM-based methods can facilitate learning assessments by using ad-hoc guidelines and a minimal number of annotated prompt samples. Our framework transforms these guidelines into features that can be identified within learners’ prompts. Using these feature descriptions and annotated examples, we create few-shot learning detectors. We then evaluate different configurations of these detectors, testing three state-of-the-art LLMs and ensembles. We run experiments with cross-validation on a sample of original prompts, as well as tests on prompts collected from task-naive learners. Our results show how LLMs perform on feature detection. Notably, GPT- 4 demonstrates strong performance on most features, while closely related models, such as GPT-3 and GPT-3.5 Turbo (Instruct), show inconsistent behaviors in feature classification. These differences highlight the need for further research into how design choices impact feature selection and prompt detection. Our findings contribute to the fields of generative AI literacy and computer-supported learning assessment, offering valuable insights for both researchers and practitioners.
使用大型语言模型(LLM)驱动的聊天机器人,如ChatGPT,已逐渐成为各个领域的热门趋势,支持各种任务和流程。然而,由于LLM的内在复杂性,有效的提示比看起来更具挑战性。这突出表明需要创新和广泛的支持策略,并且能够无缝集成到任务工作流程中。然而,LLM的提示高度依赖于任务和领域,限制了通用方法的有效性。在本研究中,我们探索了基于LLM的方法是否可以通过使用专门的指南和少量注释的提示样本来促进学习评估。我们的框架将这些指南转化为可以在学习者提示中识别的特征。使用这些特征描述和注释示例,我们创建了少数学习检测器。然后,我们评估了这些检测器的不同配置,测试了三种最先进的LLM和集成方法。我们在原始提示的样本上进行了交叉验证实验,并对从任务无关学习者收集的提示进行了测试。我们的结果展示了LLM在特征检测方面的表现。值得注意的是,GPT-4在大多数特征上表现出强大的性能,而与之密切相关的模型,如GPT-3和GPT-3.5 Turbo(Instruct),在特征分类方面表现出不一致的行为。这些差异进一步突出了设计选择对特征选择和提示检测的影响,需要进行更多的研究。我们的研究为生成性人工智能素养和计算机支持的学习评估领域提供了有价值的见解,对研究者和实践者都有所贡献。
论文及项目相关链接
PDF Preprint accepted for Publication in Educational Technology & Society (ET&S)
Summary
大型语言模型(LLM)驱动的聊天机器人,如ChatGPT,已广泛应用于各个领域,支持各种任务与流程。但LLM的复杂性使得有效提示更具挑战性,需要创新与广泛接入的教育和支持策略。本研究探索了基于LLM的方法是否可以通过即席指南和少量标注提示样本来促进学习评估。我们创建了一种少样本学习检测器来检测学习者的提示特征,并对三种尖端LLM和集成配置进行了评估。结果显示GPT-4在特征检测上表现优异,而GPT-3及其更新版本在特征分类上表现不一。这些差异强调了设计选择对特征选择和提示检测的影响,为生成式人工智能素养和计算机支持的学习评估领域提供了宝贵见解。
Key Takeaways
- LLM驱动的聊天机器人广泛应用于各领域。
- LLM的复杂性导致有效提示面临挑战。
- 需要创新与广泛接入的教育和支持策略以应对这一挑战。
- 研究通过即席指南和少量标注提示样本探索了基于LLM的方法对学习评估的促进。
- 创建了少样本学习检测器以检测学习者的提示特征。
- GPT-4在特征检测上表现优异。
点此查看论文截图

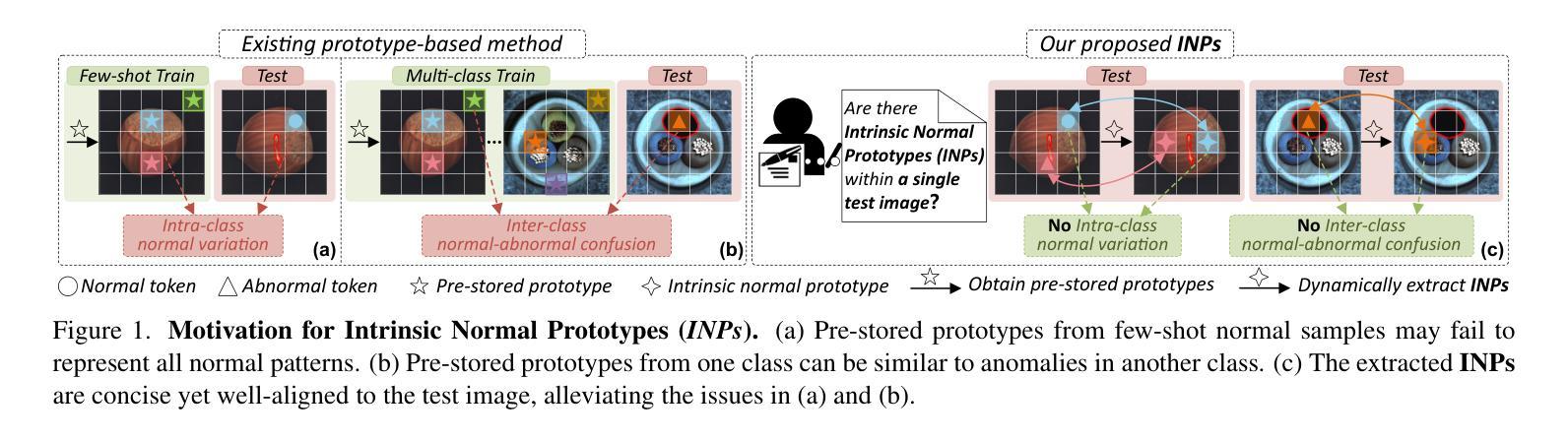
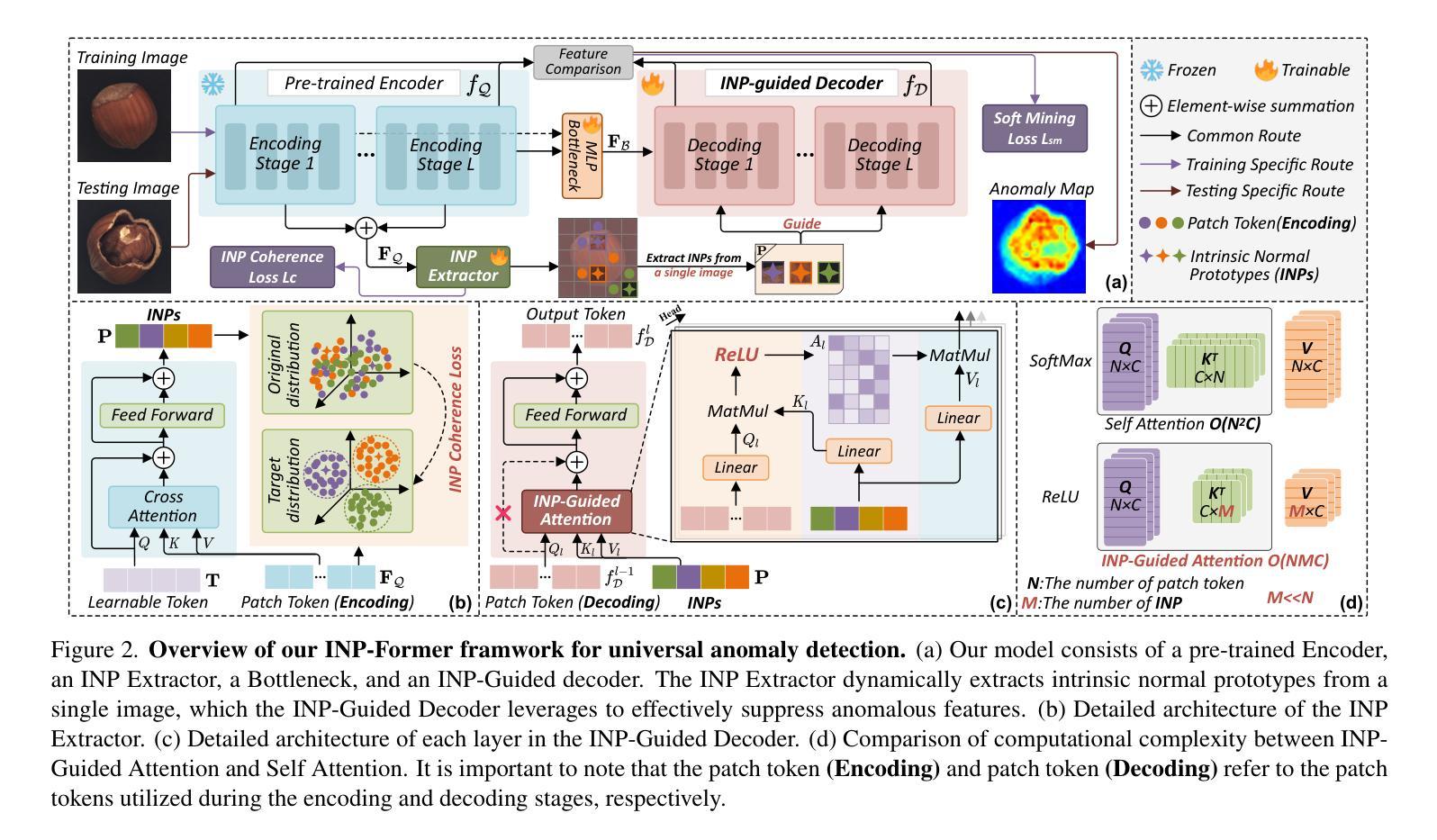
Exploring Intrinsic Normal Prototypes within a Single Image for Universal Anomaly Detection
Authors:Wei Luo, Yunkang Cao, Haiming Yao, Xiaotian Zhang, Jianan Lou, Yuqi Cheng, Weiming Shen, Wenyong Yu
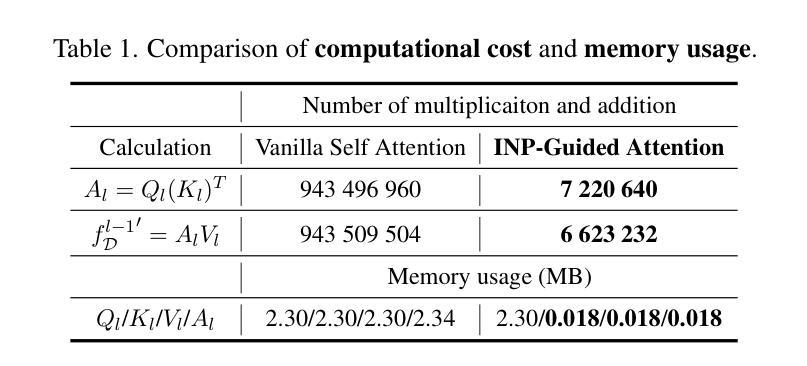
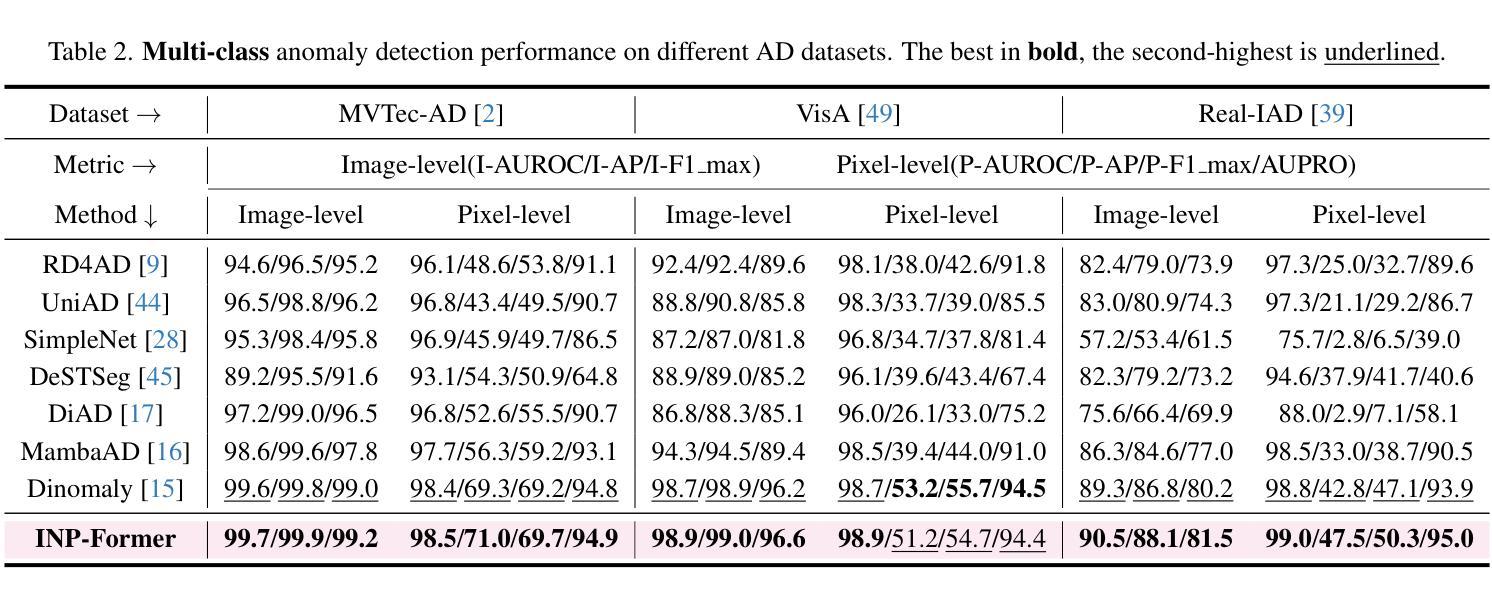
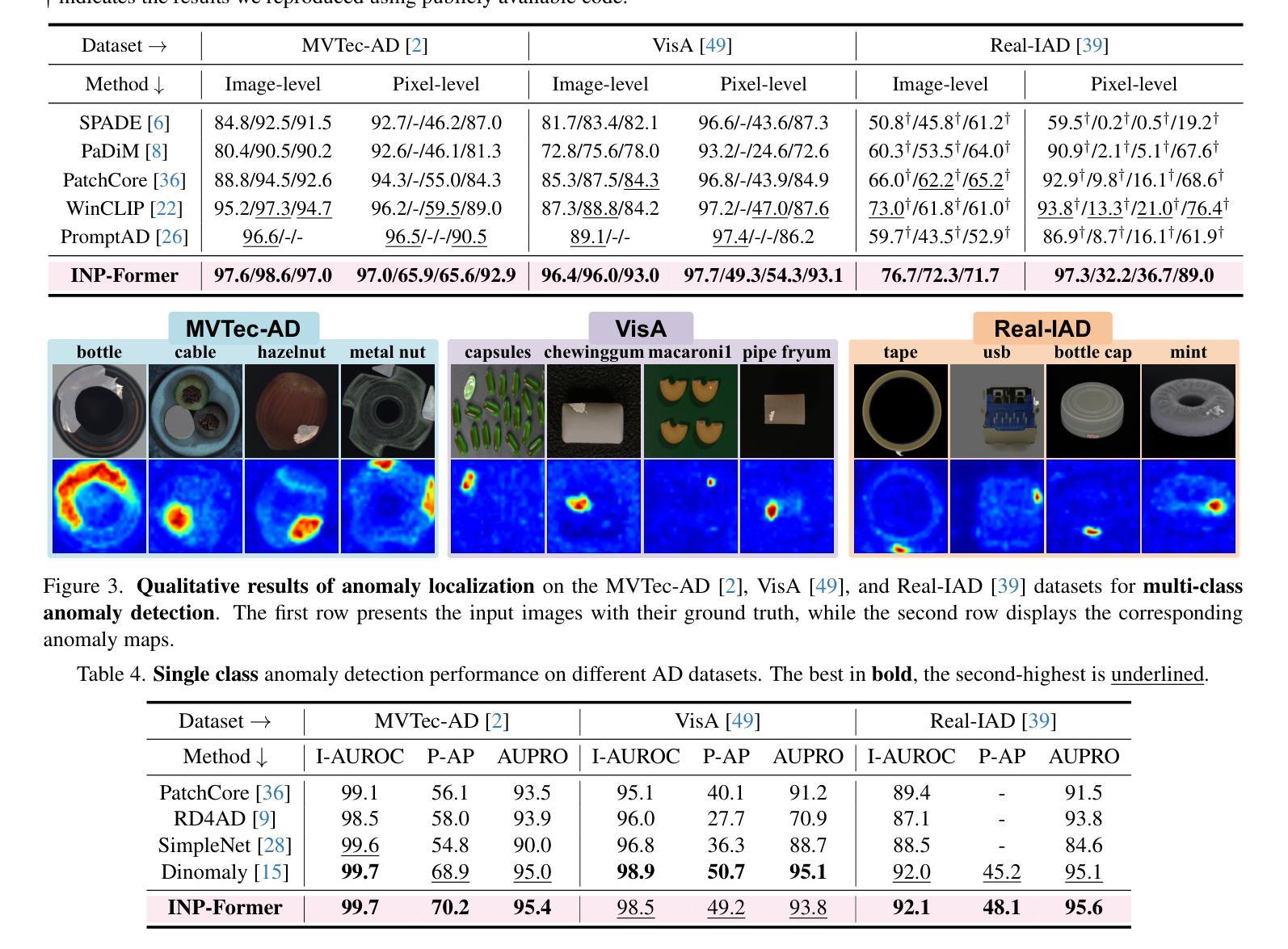
Anomaly detection (AD) is essential for industrial inspection, yet existing methods typically rely on ``comparing’’ test images to normal references from a training set. However, variations in appearance and positioning often complicate the alignment of these references with the test image, limiting detection accuracy. We observe that most anomalies manifest as local variations, meaning that even within anomalous images, valuable normal information remains. We argue that this information is useful and may be more aligned with the anomalies since both the anomalies and the normal information originate from the same image. Therefore, rather than relying on external normality from the training set, we propose INP-Former, a novel method that extracts Intrinsic Normal Prototypes (INPs) directly from the test image. Specifically, we introduce the INP Extractor, which linearly combines normal tokens to represent INPs. We further propose an INP Coherence Loss to ensure INPs can faithfully represent normality for the testing image. These INPs then guide the INP-Guided Decoder to reconstruct only normal tokens, with reconstruction errors serving as anomaly scores. Additionally, we propose a Soft Mining Loss to prioritize hard-to-optimize samples during training. INP-Former achieves state-of-the-art performance in single-class, multi-class, and few-shot AD tasks across MVTec-AD, VisA, and Real-IAD, positioning it as a versatile and universal solution for AD. Remarkably, INP-Former also demonstrates some zero-shot AD capability. Code is available at:https://github.com/luow23/INP-Former.
异常检测(AD)在工业检测中至关重要,但现有方法通常依赖于将测试图像与训练集中的正常参考图像进行“比较”。然而,外观和位置的变化经常使这些参考图像与测试图像的对齐变得复杂,从而限制了检测精度。我们观察到,大多数异常表现为局部变化,这意味着即使在异常图像内部,仍然有宝贵的正常信息。我们认为这些信息是有用的,并且可能与异常更对齐,因为异常和正常信息都来自同一图像。因此,我们提出了一种新方法INP-Former,它直接从测试图像中提取内在正常原型(INPs)。具体来说,我们引入了INP提取器,它线性组合正常令牌来表示INPs。我们还提出了一种INP一致性损失,以确保INPs能够忠实地代表测试图像的正常性。这些INPs然后引导INP引导解码器仅重建正常令牌,重建误差作为异常分数。此外,我们还提出了一种软挖掘损失,以在训练过程中优先处理难以优化的样本。INP-Former在MVTec-AD、VisA和Real-IAD的单类、多类和少数异常检测任务上实现了卓越的性能,成为了一种通用且万能的异常检测解决方案。值得注意的是,INP-Former还表现出一些零样本异常检测能力。代码可访问于:https://github.com/luow23/INP-Former。
论文及项目相关链接
PDF Accepted by CVPR2025
Summary
本文提出一种名为INP-Former的新型工业检测异常检测算法。它无需依赖训练集中的正常图像参照,而是直接从测试图像中提取内部正常原型(INPs)。通过引入INP提取器和INP一致性损失,确保INPs能准确代表测试图像的正常性。利用这些INPs引导解码器重建正常令牌,重建误差作为异常分数。此外,还提出了软挖掘损失以在训练过程中优先处理难以优化的样本。该算法在MVTec-AD、VisA和Real-IAD等多个单类、多类和少例异常检测任务上表现卓越,具备零样本异常检测的潜力。
Key Takeaways
- 现有工业检测异常检测方法常依赖训练集中的正常图像参照,但图像外观和位置的差异会影响检测精度。
- INP-Former算法直接从测试图像中提取内部正常原型(INPs),无需依赖外部正常图像。
- 引入的INP提取器通过线性组合正常令牌来代表INPs。
- INP一致性损失确保INPs能准确代表测试图像的正常性。
- 利用INPs引导解码器重建正常令牌,重建误差作为异常分数。
- 软挖掘损失优先处理训练过程中的难以优化样本。
点此查看论文截图

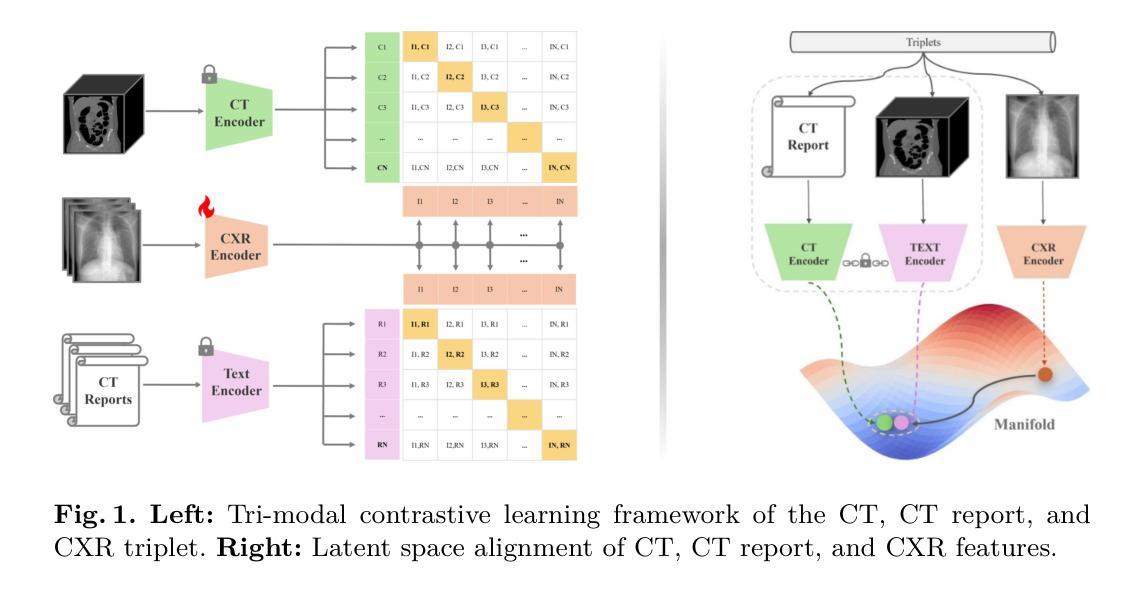
X2CT-CLIP: Enable Multi-Abnormality Detection in Computed Tomography from Chest Radiography via Tri-Modal Contrastive Learning
Authors:Jianzhong You, Yuan Gao, Sangwook Kim, Chris Mcintosh
Computed tomography (CT) is a key imaging modality for diagnosis, yet its clinical utility is marred by high radiation exposure and long turnaround times, restricting its use for larger-scale screening. Although chest radiography (CXR) is more accessible and safer, existing CXR foundation models focus primarily on detecting diseases that are readily visible on the CXR. Recently, works have explored training disease classification models on simulated CXRs, but they remain limited to recognizing a single disease type from CT. CT foundation models have also emerged with significantly improved detection of pathologies in CT. However, the generalized application of CT-derived labels on CXR has remained illusive. In this study, we propose X2CT-CLIP, a tri-modal knowledge transfer learning framework that bridges the modality gap between CT and CXR while reducing the computational burden of model training. Our approach is the first work to enable multi-abnormality classification in CT, using CXR, by transferring knowledge from 3D CT volumes and associated radiology reports to a CXR encoder via a carefully designed tri-modal alignment mechanism in latent space. Extensive evaluations on three multi-label CT datasets demonstrate that our method outperforms state-of-the-art baselines in cross-modal retrieval, few-shot adaptation, and external validation. These results highlight the potential of CXR, enriched with knowledge derived from CT, as a viable efficient alternative for disease detection in resource-limited settings.
计算机断层扫描(CT)是诊断的关键成像方式,但其临床应用受到高辐射暴露和长时间等待结果的限制,阻碍了其在大规模筛查中的使用。虽然胸部放射摄影(CXR)更容易获取且更安全,但现有的CXR基础模型主要关注于检测在CXR上容易看到的疾病。近期,一些研究开始探索在模拟的CXR上进行疾病分类模型训练,但它们仅限于从CT中识别单一疾病类型。同时,CT基础模型也已经出现,显著提高了在CT中的病理检测能力。然而,将CT衍生的标签泛化到CXR上仍然具有挑战性。在本研究中,我们提出了X2CT-CLIP,这是一个三模态知识迁移学习框架,它缩小了CT和CXR之间的模态差距,同时降低了模型训练的计算负担。我们的方法是通过从3D CT体积和相关放射学报告转移到CXR编码器,使用精心设计的潜在空间三模态对齐机制,实现了使用CXR在CT中进行多异常分类。在三个多标签CT数据集上的广泛评估表明,我们的方法在跨模态检索、小样本适应和外部验证方面均优于最新基线。这些结果凸显了丰富知识的CXR的潜力,即将其作为资源受限环境中疾病检测的可行高效替代方案。
论文及项目相关链接
PDF 11 pages, 1 figure, 5 tables
Summary:本研究提出了一个名为X2CT-CLIP的三模态知识迁移学习框架,旨在缩小CT和CXR之间的模态差距,同时降低模型训练的计算负担。该框架通过精心设计三模态对齐机制,在潜在空间中实现了从三维CT体积和关联的放射学报告向CXR编码器的知识迁移,能够利用CXR进行多异常性CT分类。在三个多标签CT数据集上的评估显示,该方法在跨模态检索、少样本适应和外部验证方面均优于现有技术基线。这证明了利用CT知识增强的CXR在资源受限环境中进行疾病检测的可行性。
Key Takeaways:
- X2CT-CLIP框架实现了CT和CXR之间的知识迁移,缩小了模态差距。
- 该框架通过三模态对齐机制,在潜在空间中整合了CT、CXR和放射学报告的信息。
- X2CT-CLIP能够在CXR上进行多异常性CT分类,这是以往研究未曾实现的。
- 在多个多标签CT数据集上的评估表明,X2CT-CLIP在跨模态检索、少样本适应和外部验证方面均表现出优异性能。
- 该研究证明了利用CT知识增强的CXR在资源受限环境中进行疾病检测的潜力。
- CT的高辐射暴露和长时间处理限制了其在大规模筛查中的应用,而X2CT-CLIP提供了一种利用CXR进行疾病检测的有效替代方案。
点此查看论文截图


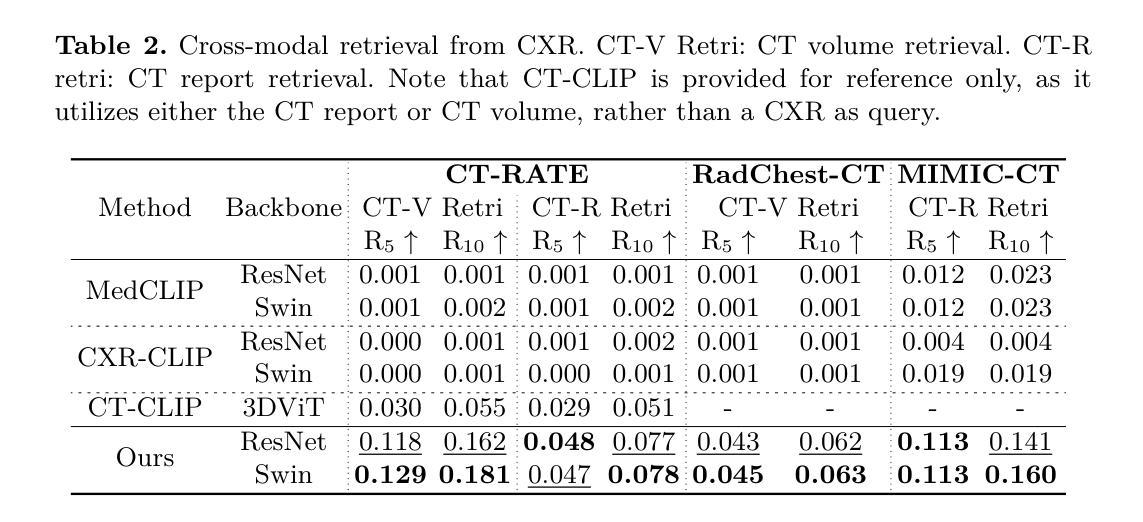
Malware Classification from Memory Dumps Using Machine Learning, Transformers, and Large Language Models
Authors:Areej Dweib, Montaser Tanina, Shehab Alawi, Mohammad Dyab, Huthaifa I. Ashqar
This study investigates the performance of various classification models for a malware classification task using different feature sets and data configurations. Six models-Logistic Regression, K-Nearest Neighbors (KNN), Support Vector Machines (SVM), Decision Trees, Random Forest (RF), and Extreme Gradient Boosting (XGB)-were evaluated alongside two deep learning models, Recurrent Neural Networks (RNN) and Transformers, as well as the Gemini zero-shot and few-shot learning methods. Four feature sets were tested including All Features, Literature Review Features, the Top 45 Features from RF, and Down-Sampled with Top 45 Features. XGB achieved the highest accuracy of 87.42% using the Top 45 Features, outperforming all other models. RF followed closely with 87.23% accuracy on the same feature set. In contrast, deep learning models underperformed, with RNN achieving 66.71% accuracy and Transformers reaching 71.59%. Down-sampling reduced performance across all models, with XGB dropping to 81.31%. Gemini zero-shot and few-shot learning approaches showed the lowest performance, with accuracies of 40.65% and 48.65%, respectively. The results highlight the importance of feature selection in improving model performance while reducing computational complexity. Traditional models like XGB and RF demonstrated superior performance, while deep learning and few-shot methods struggled to match their accuracy. This study underscores the effectiveness of traditional machine learning models for structured datasets and provides a foundation for future research into hybrid approaches and larger datasets.
本研究旨在探究不同分类模型在恶意软件分类任务中的性能表现,采用多种特征集和数据配置。共评估了六种模型,包括逻辑回归、K近邻(KNN)、支持向量机(SVM)、决策树、随机森林(RF)和极端梯度提升(XGB),以及两种深度学习模型——循环神经网络(RNN)和Transformer,以及Gemini零样本学习和小样本学习方法。测试了四个特征集,包括所有特征、文献综述特征、来自随机森林的前45个特征和降维后保留的前45个特征。使用前45个特征时,极端梯度提升达到了最高精度87.42%,超过了其他所有模型。随机森林在同一特征集上的准确率为87.23%。相比之下,深度学习模型表现不佳,循环神经网络的准确率为66.71%,Transformer的准确率为71.59%。降维导致所有模型的性能下降,极端梯度提升的准确率降至81.31%。Gemini零样本学习和小样本学习方法的表现最低,准确率分别为40.65%和48.65%。结果强调了特征选择在提高模型性能的同时降低计算复杂度的重要性。传统的机器学习模型如极端梯度提升和随机森林表现出了卓越的性能,而深度学习和小样本方法则在准确性方面遇到了挑战。本研究突显了传统机器学习模型在处理结构化数据集方面的有效性,并为未来的混合方法和大型数据集研究提供了基础。
论文及项目相关链接
Summary
本研究探讨了不同分类模型在特定恶意软件分类任务上的性能表现。通过对比多种特征集和数据配置方式,包括逻辑回归、K近邻、支持向量机、决策树、随机森林和极端梯度提升等传统模型与深度学习模型(循环神经网络和Transformer)以及Gemini零射和少射学习方法。实验结果显示,使用前45个特征的极端梯度提升模型性能最佳,准确率为87.42%,随机森林模型紧随其后,准确率为87.23%。深度学习模型表现较差,循环神经网络的准确率为66.71%,Transformer的准确率为71.59%。此外,特征选择对模型性能有重要影响。本研究强调了传统机器学习模型在处理结构化数据集方面的有效性,为未来的混合方法和大数据集研究提供了基础。
Key Takeaways
- 研究对比了多种分类模型在恶意软件分类任务上的性能。
- 极端梯度提升模型使用特定特征集表现出最佳性能。
- 随机森林模型在相同特征集上准确率接近极端梯度提升模型。
- 深度学习模型表现较差,尤其是循环神经网络。
- 特征选择对模型性能有重要影响。
- Gemini零射和少射学习方法表现最低。
点此查看论文截图

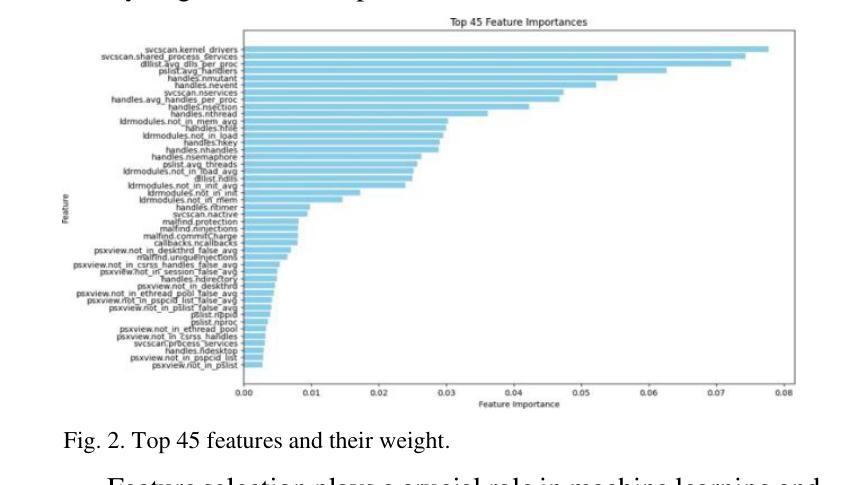
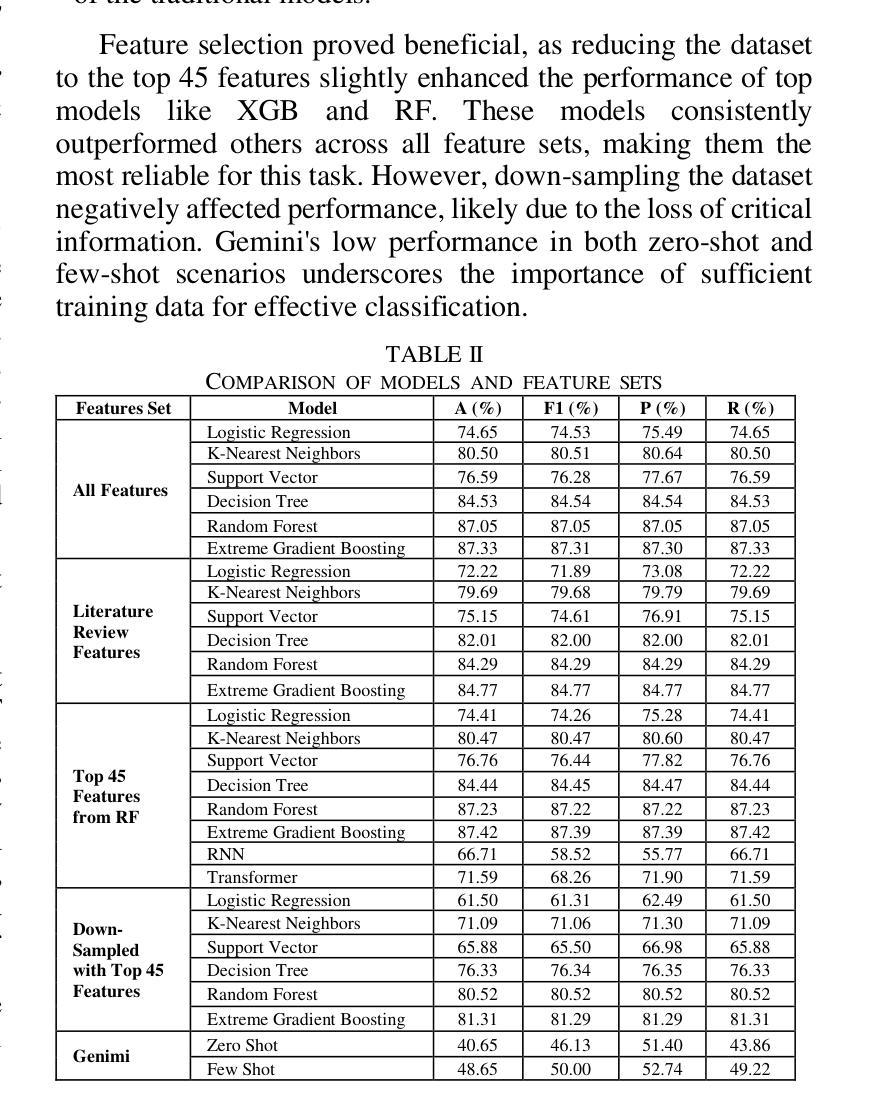
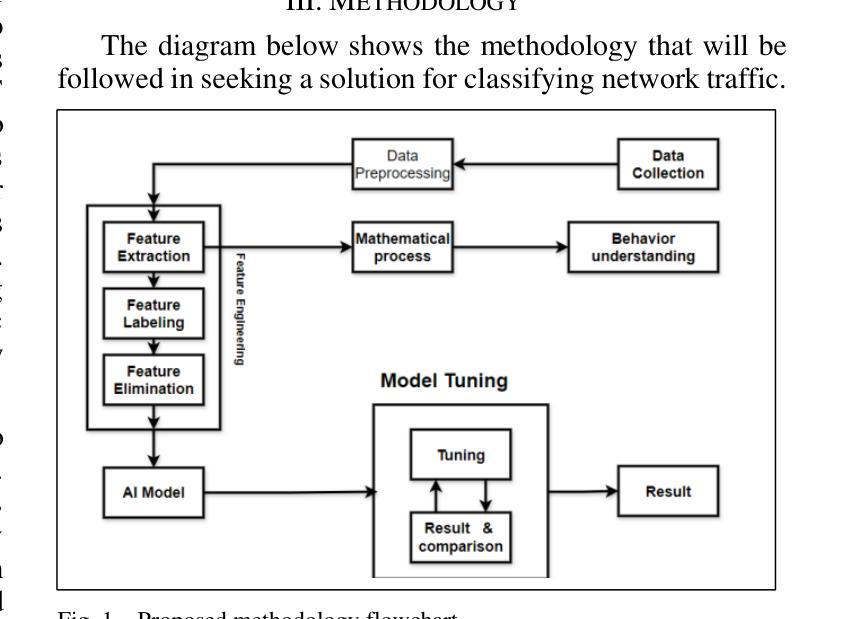
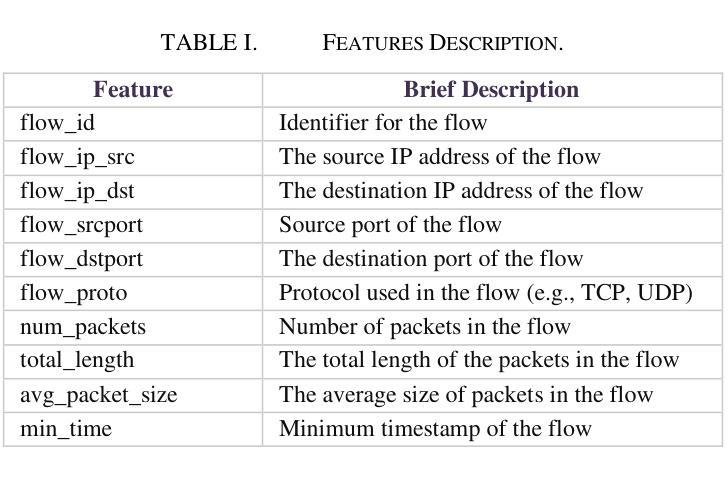
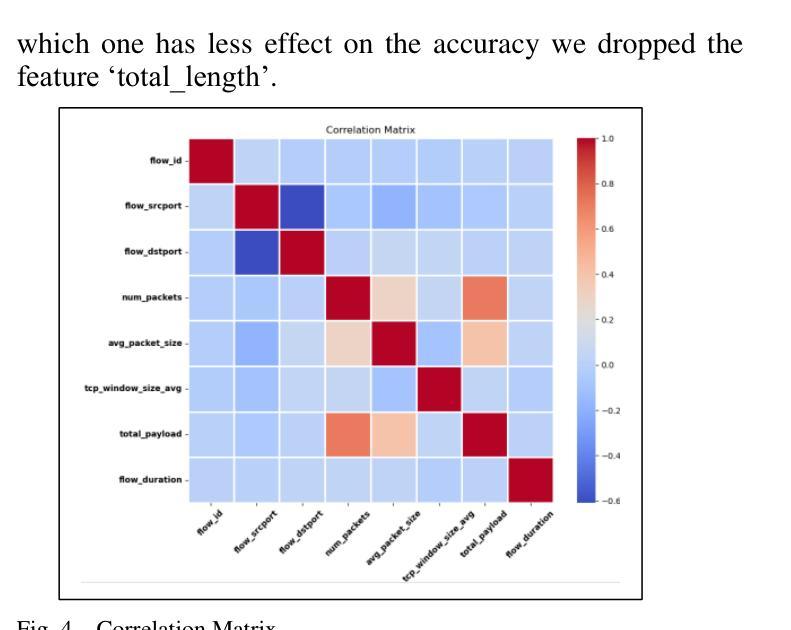
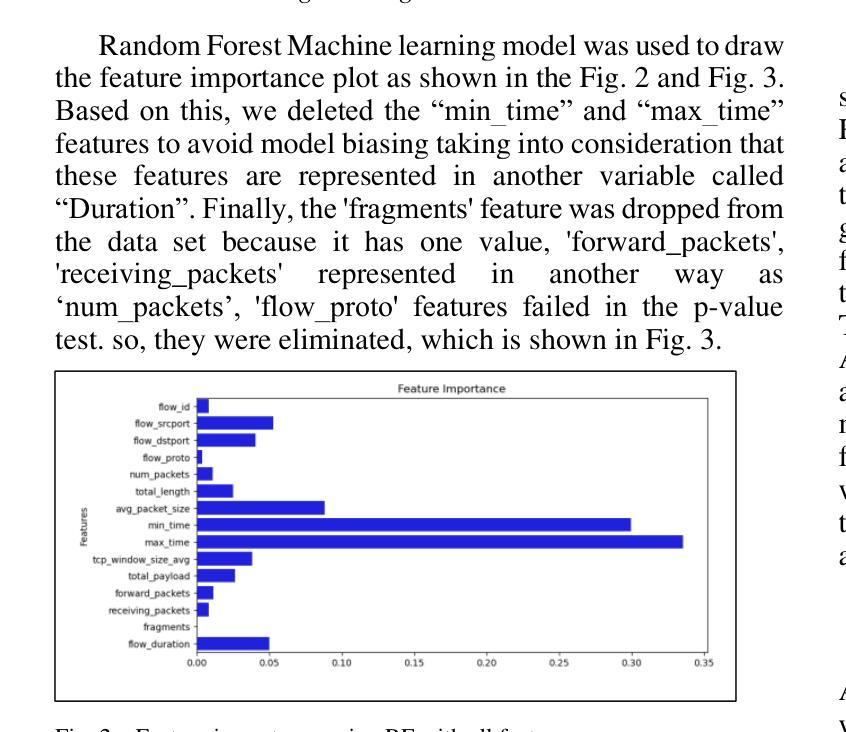
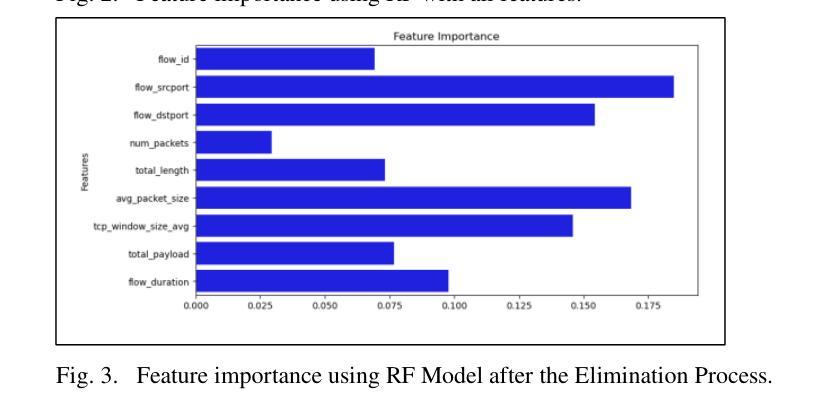
Network Traffic Classification Using Machine Learning, Transformer, and Large Language Models
Authors:Ahmad Antari, Yazan Abo-Aisheh, Jehad Shamasneh, Huthaifa I. Ashqar
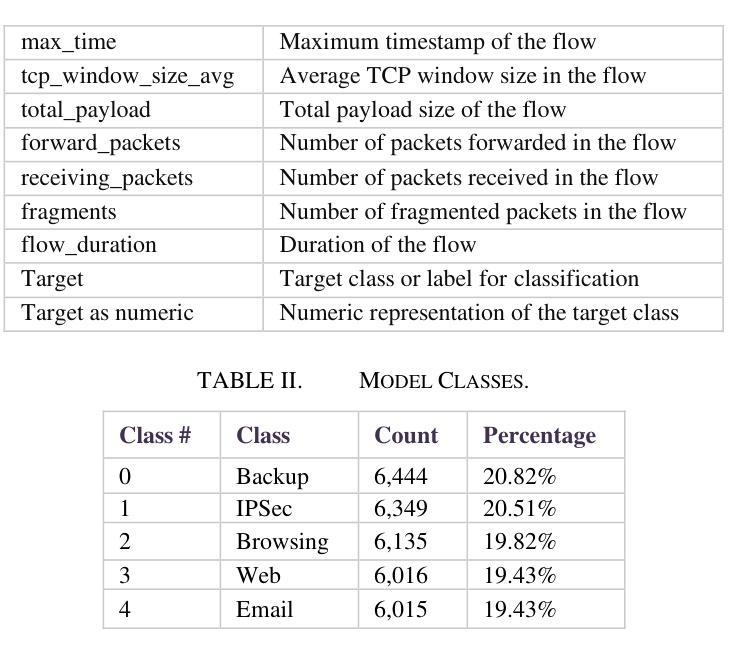
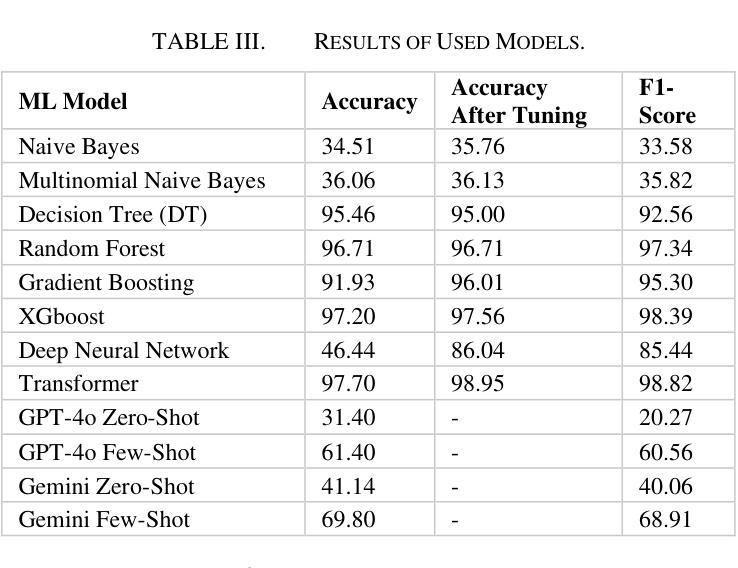
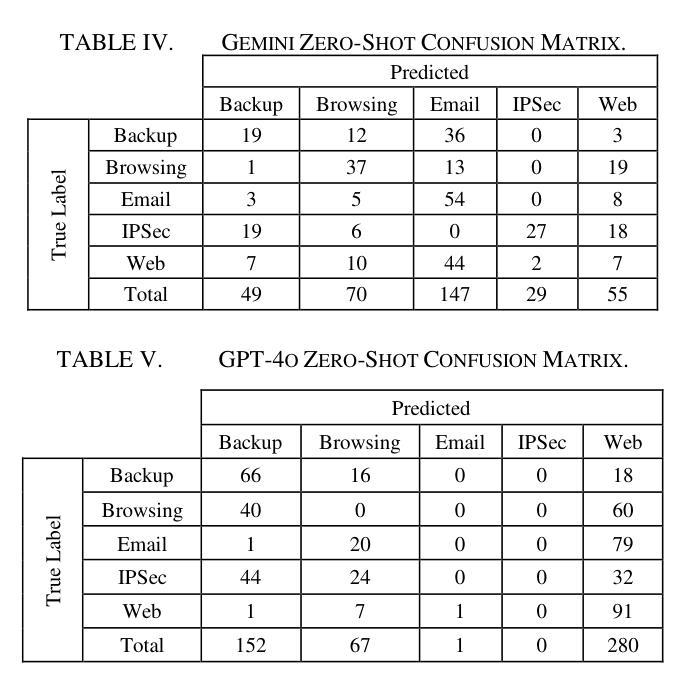
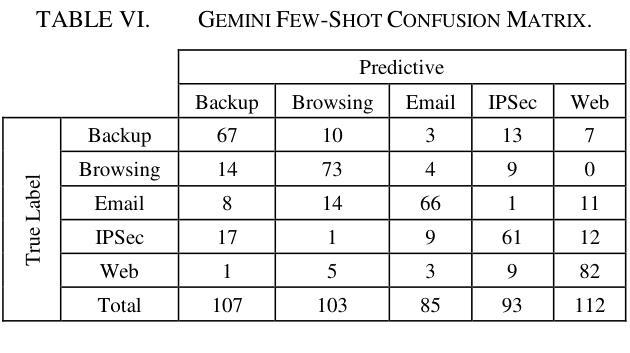
This study uses various models to address network traffic classification, categorizing traffic into web, browsing, IPSec, backup, and email. We collected a comprehensive dataset from Arbor Edge Defender (AED) devices, comprising of 30,959 observations and 19 features. Multiple models were evaluated, including Naive Bayes, Decision Tree, Random Forest, Gradient Boosting, XGBoost, Deep Neural Networks (DNN), Transformer, and two Large Language Models (LLMs) including GPT-4o and Gemini with zero- and few-shot learning. Transformer and XGBoost showed the best performance, achieving the highest accuracy of 98.95 and 97.56%, respectively. GPT-4o and Gemini showed promising results with few-shot learning, improving accuracy significantly from initial zero-shot performance. While Gemini Few-Shot and GPT-4o Few-Shot performed well in categories like Web and Email, misclassifications occurred in more complex categories like IPSec and Backup. The study highlights the importance of model selection, fine-tuning, and the balance between training data size and model complexity for achieving reliable classification results.
本研究使用多种模型来解决网络流量分类问题,将流量分为网页、浏览、IPSec、备份和电子邮件。我们从Arbor Edge Defender (AED)设备收集了一个综合数据集,包含30,959个观测值和19个特征。我们评估了多种模型,包括朴素贝叶斯、决策树、随机森林、梯度提升、XGBoost、深度神经网络(DNN)、Transformer以及两个大型语言模型(LLMs),包括GPT-4o和Gemini,实现零次和少次学习。Transformer和XGBoost表现最佳,准确率分别高达98.95%和97.56%。GPT-4o和Gemini在少次学习上展现出有前景的结果,准确率较初始的零次学习显著提高。虽然Gemini少次学习和GPT-4o少次学习在Web和电子邮件等类别中表现良好,但在更复杂的类别如IPSec和备份中出现了误分类。该研究强调了模型选择、微调以及训练数据大小与模型复杂性之间的平衡对于实现可靠分类结果的重要性。
论文及项目相关链接
Summary
本文研究了网络流量分类问题,采用多种模型对流量进行分类,包括Naive Bayes、Decision Tree等机器学习模型和GPT-4o等语言模型。实验结果显示,Transformer和XGBoost表现最佳,准确率分别高达98.95%和97.56%。GPT-4o和Gemini在少样本学习场景下也表现出潜力,虽在复杂类别如IPSec和备份中出现误分类情况,但相比零样本情况下有明显提升。该研究强调了模型选择、精细调整和训练数据量与模型复杂性之间的平衡对可靠分类结果的重要性。
Key Takeaways
- 研究采用多种模型进行网络流量分类,包括机器学习模型和语言模型。
- Transformer和XGBoost表现最佳,准确率超过其他模型。
- GPT-4o和Gemini在少样本学习场景下展现出潜力,准确率有所提升。
- 在复杂类别如IPSec和备份中,会出现一定的误分类情况。
- 模型选择对分类结果具有重要影响。
- 精细调整是取得可靠分类结果的关键因素之一。
点此查看论文截图

HoT: Highlighted Chain of Thought for Referencing Supportive Facts from Inputs
Authors:Tin Nguyen, Logan Bolton, Mohammad Reza Taesiri, Anh Totti Nguyen
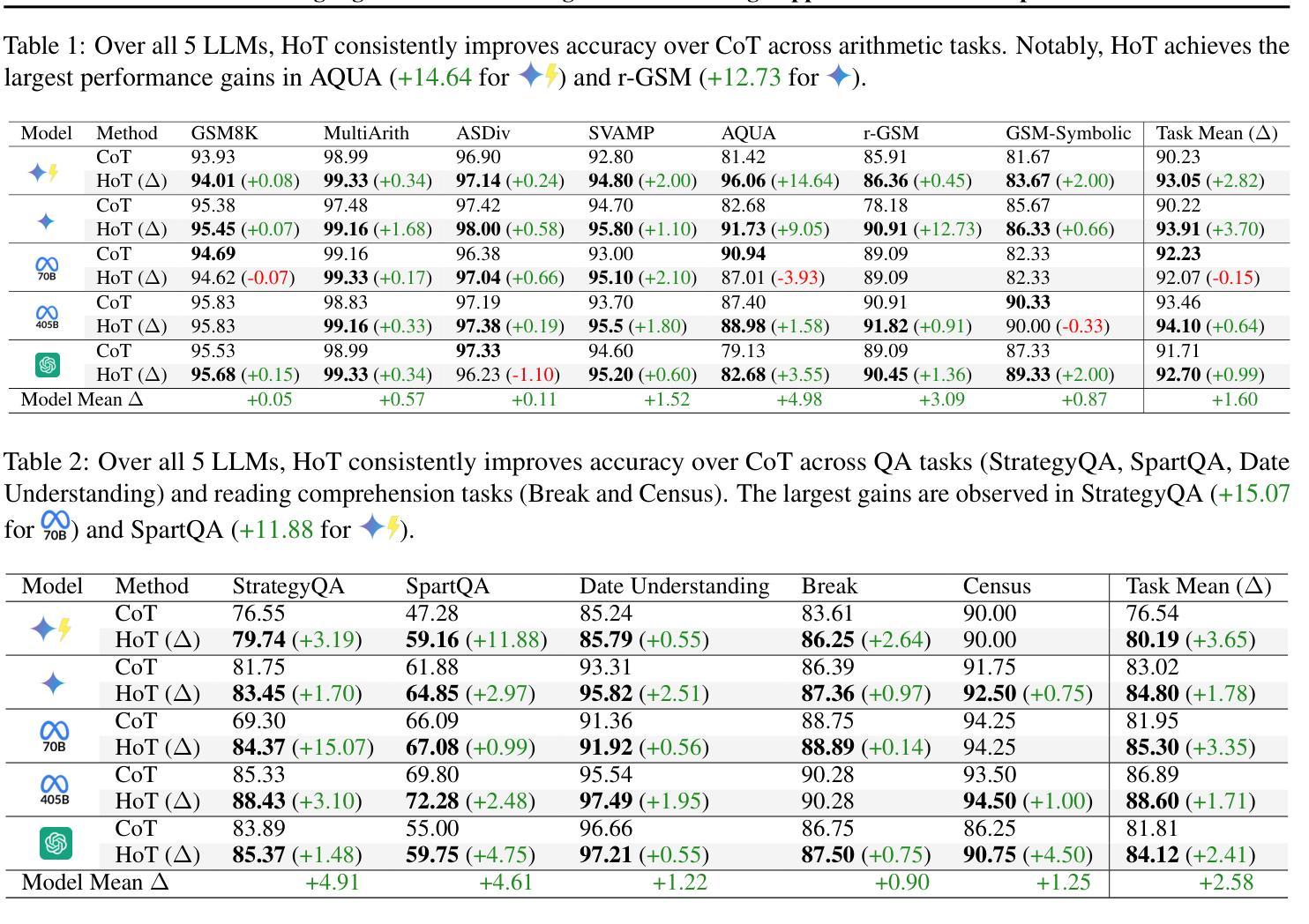
An Achilles heel of Large Language Models (LLMs) is their tendency to hallucinate non-factual statements. A response mixed of factual and non-factual statements poses a challenge for humans to verify and accurately base their decisions on. To combat this problem, we propose Highlighted Chain-of-Thought Prompting (HoT), a technique for prompting LLMs to generate responses with XML tags that ground facts to those provided in the query. That is, given an input question, LLMs would first re-format the question to add XML tags highlighting key facts, and then, generate a response with highlights over the facts referenced from the input. Interestingly, in few-shot settings, HoT outperforms vanilla chain of thought prompting (CoT) on a wide range of 17 tasks from arithmetic, reading comprehension to logical reasoning. When asking humans to verify LLM responses, highlights help time-limited participants to more accurately and efficiently recognize when LLMs are correct. Yet, surprisingly, when LLMs are wrong, HoTs tend to make users believe that an answer is correct.
大型语言模型(LLM)的一个弱点是它们倾向于产生非事实性的陈述。由事实和虚构陈述组成的回答对人类验证并准确做出决策构成了挑战。为了解决这个问题,我们提出了“突出重点思维链提示”(HoT)技术,这是一种提示LLM生成带有XML标签的响应的方法,这些标签将事实依据与查询中提供的事实相联系。也就是说,给定一个输入问题,LLM会首先重新格式化问题,添加突出关键事实的XML标签,然后生成包含从输入中引用的重点事实的响应。有趣的是,在少量样本的情况下,HoT在算术、阅读理解到逻辑推理等17项任务上的表现优于普通思维链提示(CoT)。当要求人类验证LLM的响应时,重点有助于时间有限的参与者更准确、高效地识别LLM的正确性。然而,令人惊讶的是,当LLM错误时,HoT往往使用户认为答案是正确的。
论文及项目相关链接
Summary
大型语言模型的弱点之一是它们容易生成非事实性的陈述。针对这一问题,本文提出了一种名为“Highlighted Chain-of-Thought Prompting”(HoT)的技术,该技术通过在生成响应时添加XML标签来将事实与查询中的事实相关联。在少数场景下,HoT在多种任务上的表现优于传统的思维链提示(CoT)。对于人类验证者而言,这种高亮显示有助于更快速准确地判断LLM的正确性,但有趣的是,当LLM出错时,HoT技术可能会让用户误认为答案是正确的。
Key Takeaways
- 大型语言模型(LLMs)存在生成非事实性陈述的问题。
- Highlighted Chain-of-Thought Prompting(HoT)技术通过添加XML标签来关联事实与查询。
- 在少数场景下,HoT在多种任务上的表现优于传统的思维链提示(CoT)。
- 高亮显示有助于人类验证者更快速准确地判断LLM的正确性。
- HoT技术能提高LLM在各方面的性能表现。
- HoT对于时间限制的环境特别有帮助,能显著提高判断准确性。
点此查看论文截图



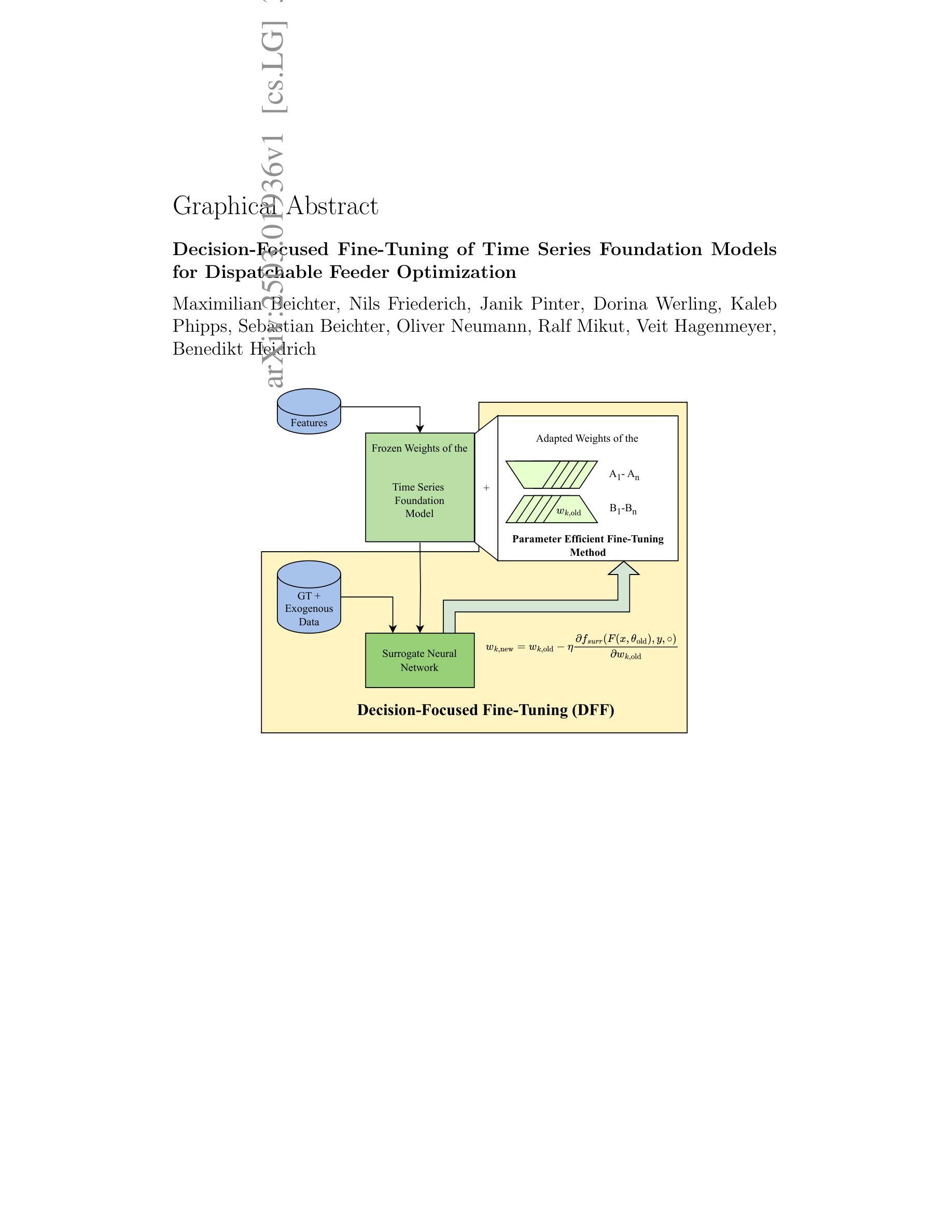
Decision-Focused Fine-Tuning of Time Series Foundation Models for Dispatchable Feeder Optimization
Authors:Maximilian Beichter, Nils Friederich, Janik Pinter, Dorina Werling, Kaleb Phipps, Sebastian Beichter, Oliver Neumann, Ralf Mikut, Veit Hagenmeyer, Benedikt Heidrich
Time series foundation models provide a universal solution for generating forecasts to support optimization problems in energy systems. Those foundation models are typically trained in a prediction-focused manner to maximize forecast quality. In contrast, decision-focused learning directly improves the resulting value of the forecast in downstream optimization rather than merely maximizing forecasting quality. The practical integration of forecast values into forecasting models is challenging, particularly when addressing complex applications with diverse instances, such as buildings. This becomes even more complicated when instances possess specific characteristics that require instance-specific, tailored predictions to increase the forecast value. To tackle this challenge, we use decision-focused fine-tuning within time series foundation models to offer a scalable and efficient solution for decision-focused learning applied to the dispatchable feeder optimization problem. To obtain more robust predictions for scarce building data, we use Moirai as a state-of-the-art foundation model, which offers robust and generalized results with few-shot parameter-efficient fine-tuning. Comparing the decision-focused fine-tuned Moirai with a state-of-the-art classical prediction-focused fine-tuning Morai, we observe an improvement of 9.45% in average total daily costs.
时间序列基础模型为生成预测提供了通用解决方案,以支持能源系统中的优化问题。这些基础模型通常采用以预测为重点的训练方式,以最大化预测质量。相比之下,以决策为重点的学习直接提高了下游优化中预测结果的价值,而不仅仅是最大化预测质量。将预测值实际集成到预测模型中是有挑战性的,特别是在处理具有多种实例的复杂应用程序时,如建筑物。当实例具有特定特征,需要针对实例进行特定预测以提高预测价值时,情况变得更加复杂。为了应对这一挑战,我们在时间序列基础模型中使用以决策为重点的微调,为应用于可调度馈线优化问题的以决策为重点的学习提供可伸缩和高效的解决方案。为了获得稀缺建筑数据的更稳健预测,我们使用Moirai作为最先进的基础模型,它提供了稳健和通用的结果,并具备少量的参数高效微调。通过将重点决策的微调Moirai与以预测为重点的常规微调Moirai进行对比,我们观察到平均总日常成本提高了9.45%。
论文及项目相关链接
Summary
时间序列表模型为能源系统的优化问题提供了通用的预测解决方案。通常,这些基础模型以预测为重点进行训练,以最大化预测质量。然而,决策重点学习直接提高预测在下游优化中的价值,而非仅追求最大化预测质量。将预测值实际融入预测模型面临挑战,特别是在处理具有不同实例的复杂应用时,如建筑物。针对具有特定特性的实例,需要定制预测以提高预测价值。为应对这一挑战,我们采用决策重点微调时间序列表模型的方法,为调度馈线优化问题提供可伸缩和高效的解决方案。为获取稀缺建筑数据的稳健预测结果,我们采用Moirai这一前沿基础模型,它凭借少参数高效微调展现出稳健和泛化的结果。相较于采用传统预测重点调教的Moirai模型,决策重点调教的Moirai模型平均总日常成本降低了9.45%。
Key Takeaways
- 时间序列表模型为能源系统的优化问题提供通用预测解决方案。
- 传统的时间序列模型以预测质量为重点进行训练。
- 决策重点学习旨在提高预测在下游优化中的价值。
- 将预测值融入预测模型面临挑战,特别是在处理复杂应用时。
- 为应对具有特定特性的实例挑战,需进行定制预测。
- 采用决策重点微调时间序列表模型的方法解决调度馈线优化问题。
点此查看论文截图
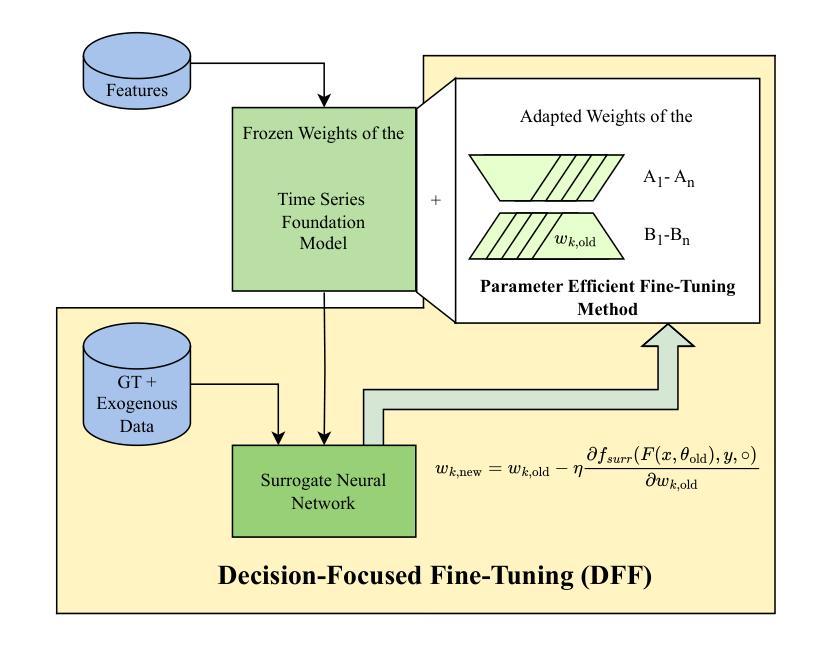
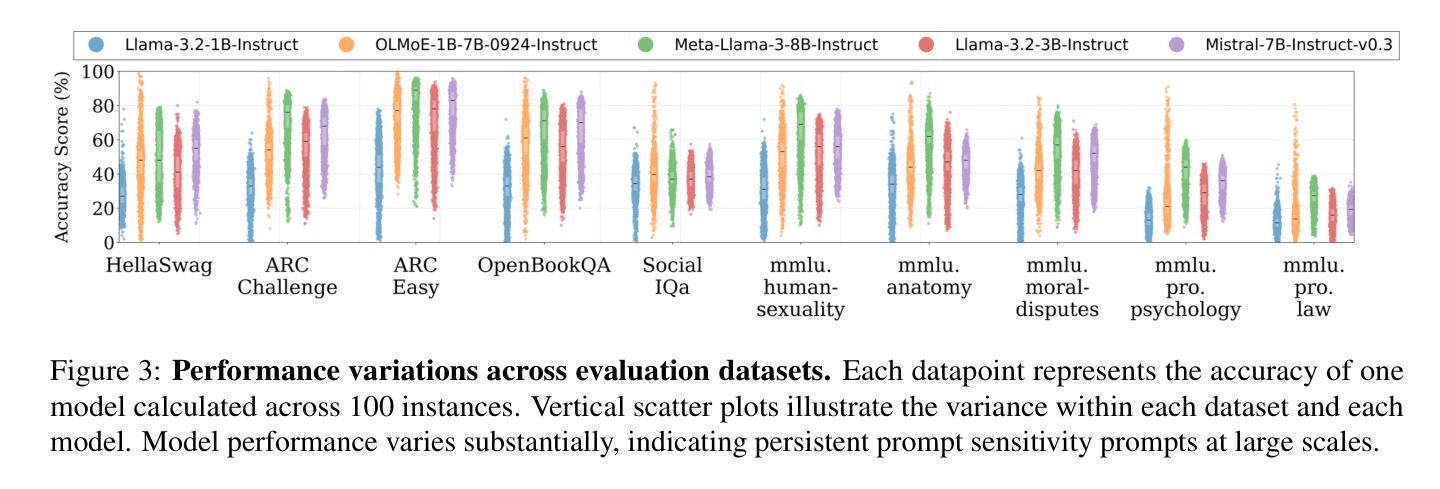
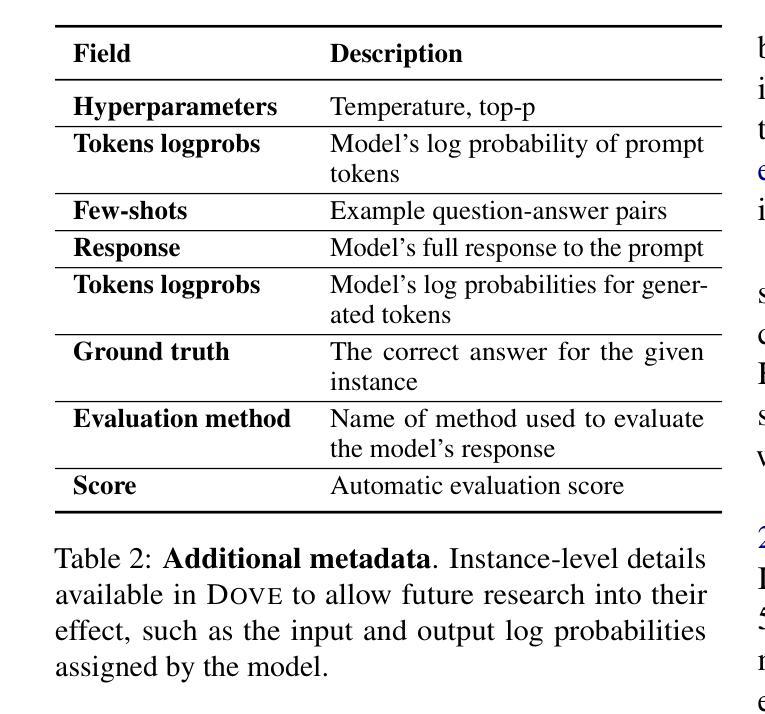
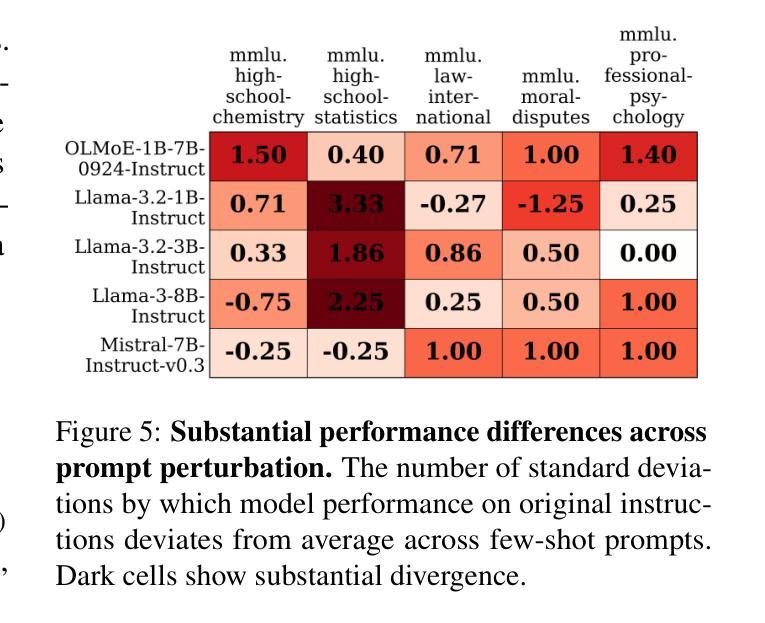
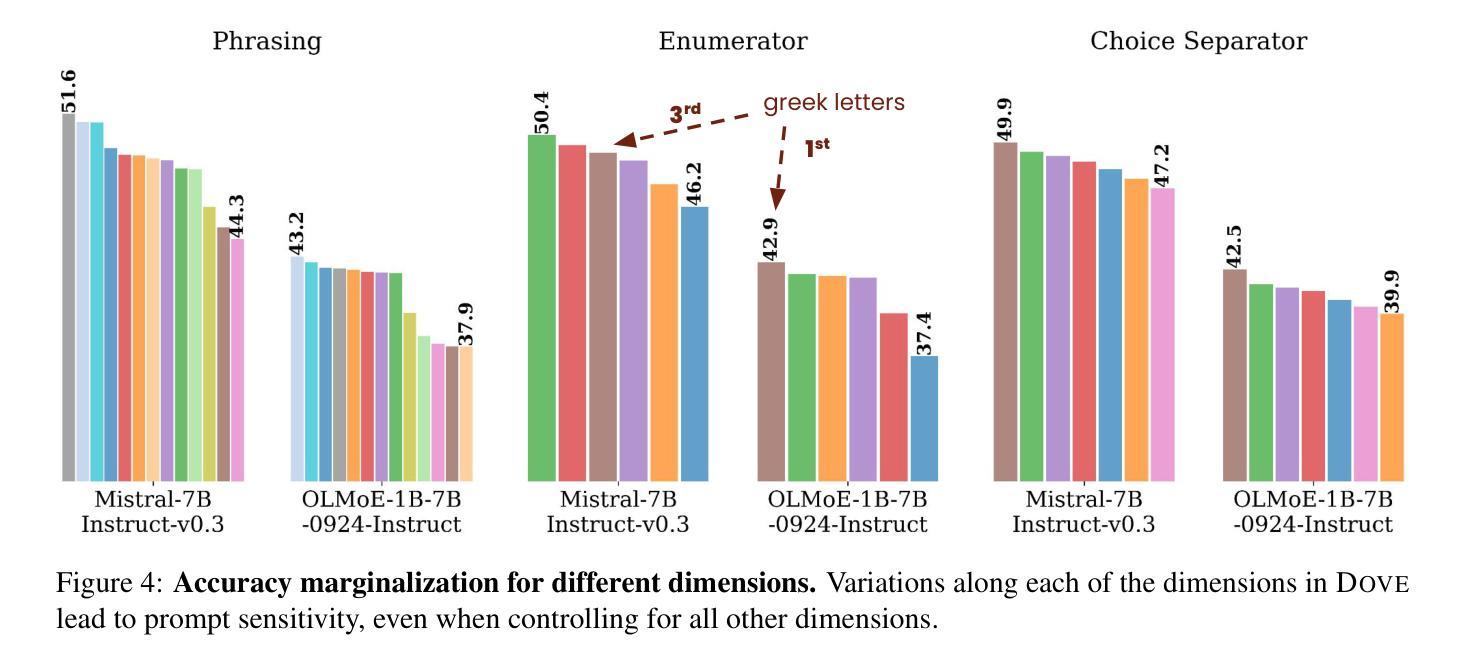
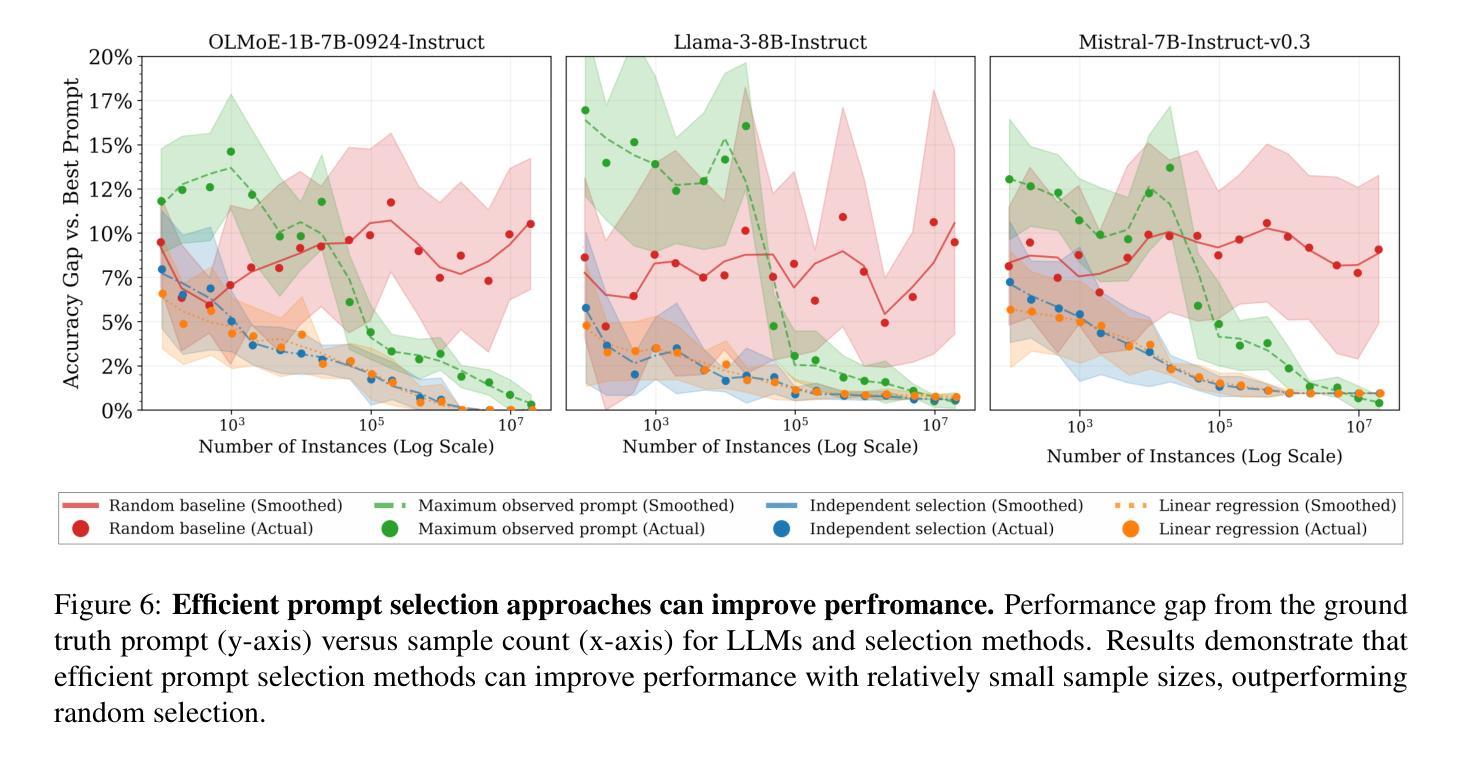
DOVE: A Large-Scale Multi-Dimensional Predictions Dataset Towards Meaningful LLM Evaluation
Authors:Eliya Habba, Ofir Arviv, Itay Itzhak, Yotam Perlitz, Elron Bandel, Leshem Choshen, Michal Shmueli-Scheuer, Gabriel Stanovsky
Recent work found that LLMs are sensitive to a wide range of arbitrary prompt dimensions, including the type of delimiters, answer enumerators, instruction wording, and more. This throws into question popular single-prompt evaluation practices. We present DOVE (Dataset Of Variation Evaluation) a large-scale dataset containing prompt perturbations of various evaluation benchmarks. In contrast to previous work, we examine LLM sensitivity from an holistic perspective, and assess the joint effects of perturbations along various dimensions, resulting in thousands of perturbations per instance. We evaluate several model families against DOVE, leading to several findings, including efficient methods for choosing well-performing prompts, observing that few-shot examples reduce sensitivity, and identifying instances which are inherently hard across all perturbations. DOVE consists of more than 250M prompt perturbations and model outputs, which we make publicly available to spur a community-wide effort toward meaningful, robust, and efficient evaluation. Browse the data, contribute, and more: https://slab-nlp.github.io/DOVE/
最近的研究发现,大型语言模型对多种任意的提示维度都非常敏感,包括分隔符的类型、答案枚举器、指令措辞等等。这质疑了流行的单一提示评估方法。我们推出了DOVE(变异评估数据集),这是一个大规模的数据集,包含了各种评估基准测试的提示扰动。与以前的工作相比,我们从整体的角度来审视大型语言模型的敏感性,并评估了不同维度扰动所产生的联合效应,导致每个实例都有成千上万的扰动。我们对多个模型家族进行了DOVE评估,得到了几项发现,包括选择表现良好的提示的有效方法、观察到少量示例可以减少敏感性以及识别出所有扰动都固有的难以应对的实例。DOVE包含了超过2.5亿个提示扰动和模型输出,我们将其公开提供,以激发社区进行有意义、稳健和高效的评估的努力。请浏览数据、做出贡献等:https://slab-nlp.github.io/DOVE/
论文及项目相关链接
Summary
大型语言模型(LLM)对提示维度的敏感性研究近日受到关注,包括分隔符、答案枚举器、指令表述等。这质疑了流行的单一提示评估方法。本文提出DOVE(变异数据集评估)大型数据集,包含各种评估基准测试的提示扰动。我们全面考察LLM敏感性,并评估各维度扰动的联合效应,每个实例产生数千种扰动。我们对多个模型家族进行DOVE评估,发现有效选择表现良好的提示方法,发现少量示例可以减少敏感性,并识别出所有扰动都固有的难以实例化的实例。DOVE包含超过2.5亿个提示扰动和模型输出,我们将其公开供公众使用,以激发有意义的、稳健的和高效的评估的社区努力。
Key Takeaways
- 大型语言模型(LLMs)对提示维度敏感,包括分隔符和指令表述等。
- 单一提示评估方法受到质疑,需要更全面和多元的评估方法。
- 介绍了DOVE数据集,包含多种评估基准测试的提示扰动,可以全面评估LLM的敏感性。
- DOVE数据集包含超过250M的提示扰动和模型输出,供公众使用和贡献。
- 通过DOVE评估,发现了一些有效的选择表现良好的提示方法。
- 少量示例可以减少LLM的敏感性。
点此查看论文截图

MFM-DA: Instance-Aware Adaptor and Hierarchical Alignment for Efficient Domain Adaptation in Medical Foundation Models
Authors:Jia-Xuan Jiang, Wenhui Lei, Yifeng Wu, Hongtao Wu, Furong Li, Yining Xie, Xiaofan Zhang, Zhong Wang
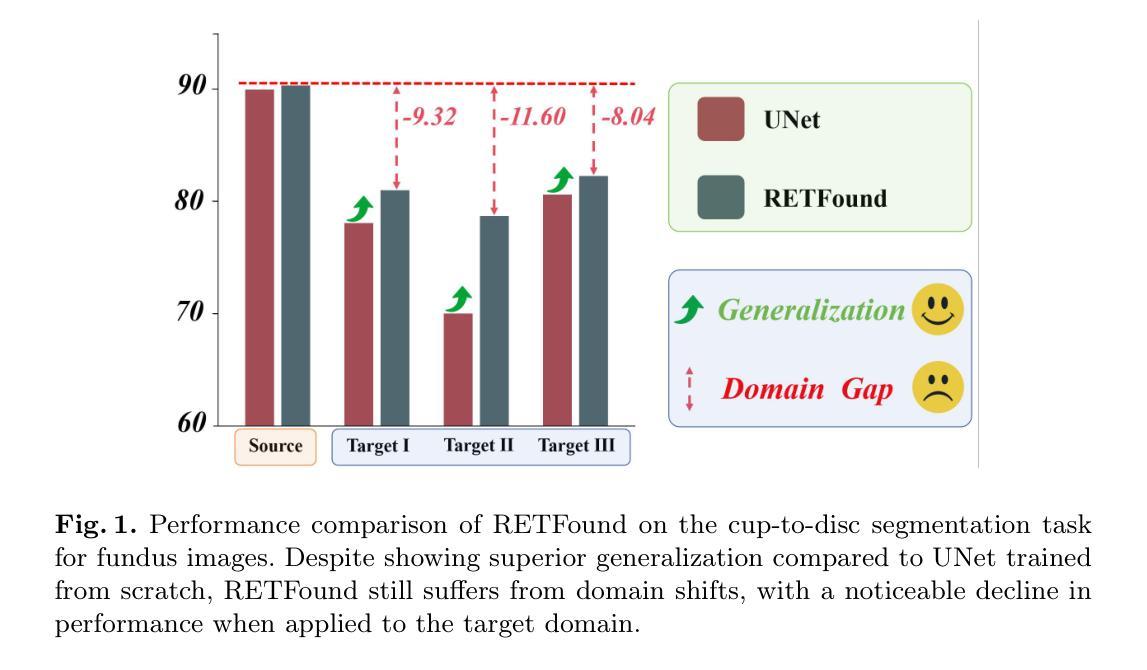
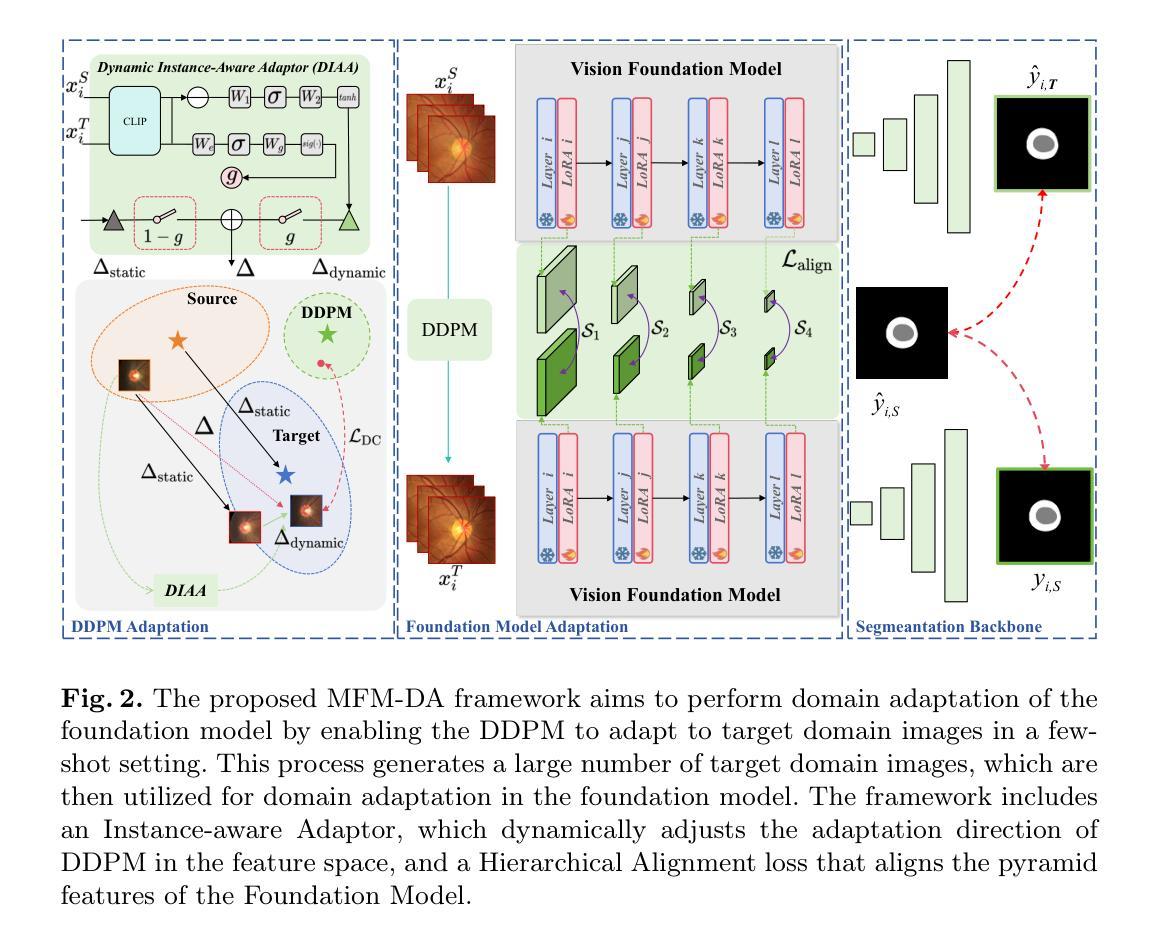
Medical Foundation Models (MFMs), trained on large-scale datasets, have demonstrated superior performance across various tasks. However, these models still struggle with domain gaps in practical applications. Specifically, even after fine-tuning on source-domain data, task-adapted foundation models often perform poorly in the target domain. To address this challenge, we propose a few-shot unsupervised domain adaptation (UDA) framework for MFMs, named MFM-DA, which only leverages a limited number of unlabeled target-domain images. Our approach begins by training a Denoising Diffusion Probabilistic Model (DDPM), which is then adapted to the target domain using a proposed dynamic instance-aware adaptor and a distribution direction loss, enabling the DDPM to translate source-domain images into the target domain style. The adapted images are subsequently processed through the MFM, where we introduce a designed channel-spatial alignment Low-Rank Adaptation (LoRA) to ensure effective feature alignment. Extensive experiments on optic cup and disc segmentation tasks demonstrate that MFM-DA outperforms state-of-the-art methods. Our work provides a practical solution to the domain gap issue in real-world MFM deployment. Code will be available at here.
医疗基础模型(MFMs)经过大规模数据集训练,在各种任务中表现出卓越的性能。然而,这些模型在实际应用中仍然面临领域差距的挑战。具体来说,即使在源域数据上进行微调后,任务适应的基础模型在目标域中的表现往往很差。为了解决这一挑战,我们为MFMs提出了一种小样本的无监督域自适应(UDA)框架,名为MFM-DA,它仅利用少量无标签的目标域图像。我们的方法首先训练一个去噪扩散概率模型(DDPM),然后使用一个提出的动态实例感知适配器和分布方向损失来适应目标域,使DDPM能够将源域图像翻译成目标域风格。适应后的图像随后通过MFM进行处理,我们在这里引入了一种设计的通道空间对齐低秩适配(LoRA)以确保有效的特征对齐。在视神经杯和视盘分割任务上的大量实验表明,MFM-DA优于最新方法。我们的工作为解决现实世界MFM部署中的领域差距问题提供了实际解决方案。代码将在此处提供。
论文及项目相关链接
Summary
基于大规模数据集训练的医学基础模型(MFMs)在各种任务中表现出卓越的性能,但在实际应用中仍面临领域差距的挑战。为解决这一问题,我们提出了一种用于MFM的少样本无监督域自适应(UDA)框架,名为MFM-DA,仅利用少量无标签的目标域图像。通过训练去噪扩散概率模型(DDPM),并结合动态实例感知适配器和分布方向损失,使DDPM能够将源域图像转化为目标域风格。适应后的图像再通过MFM处理,我们引入通道空间对齐的低秩适配(LoRA)技术,确保有效特征对齐。在视杯和视盘分割任务上的大量实验表明,MFM-DA优于现有方法。我们的工作为解决现实世界中MFM部署的域差距问题提供了实用解决方案。
Key Takeaways
- MFMs在多种任务上表现出卓越性能,但在实际应用中存在领域差距问题。
- 提出了一种名为MFM-DA的少样本无监督域自适应框架,用于解决MFM在目标域性能不佳的问题。
- 利用无标签的目标域图像进行训练,通过DDPM将源域图像转化为目标域风格。
- 使用动态实例感知适配器和分布方向损失来增强DDPM的适应性。
- 引入通道空间对齐的低秩适配技术(LoRA)来确保在MFM中的有效特征对齐。
- 在视杯和视盘分割任务上的实验表明,MFM-DA的性能优于现有方法。
点此查看论文截图

Dynamic Gradient Sparsification Training for Few-Shot Fine-tuning of CT Lymph Node Segmentation Foundation Model
Authors:Zihao Luo, Zijun Gao, Wenjun Liao, Shichuan Zhang, Guotai Wang, Xiangde Luo
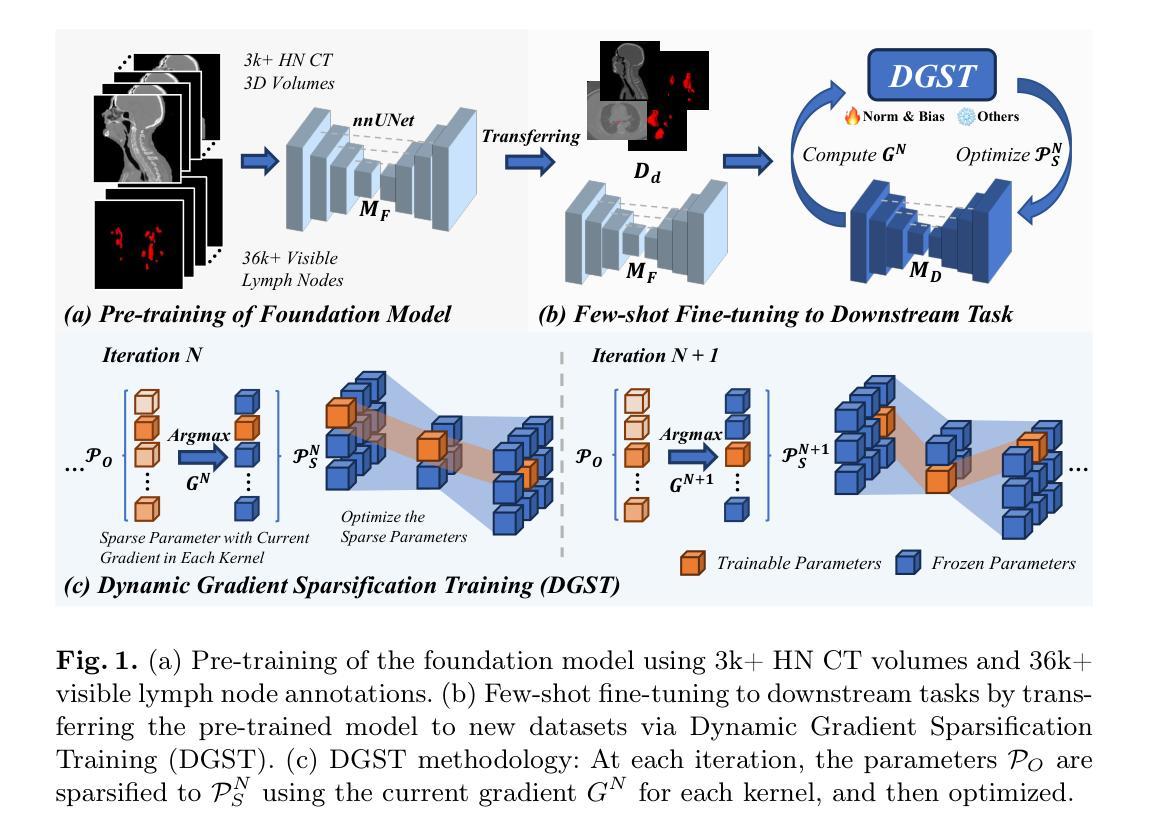
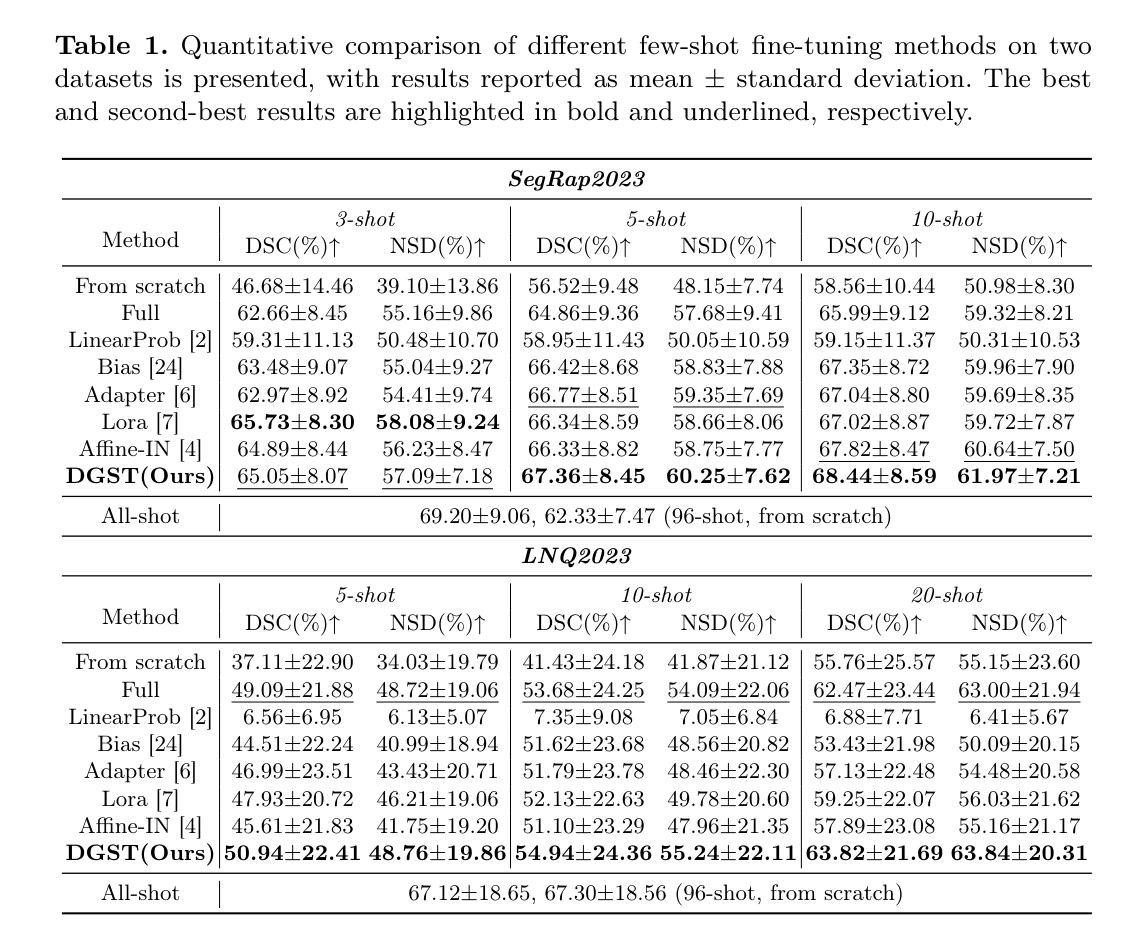
Accurate lymph node (LN) segmentation is critical in radiotherapy treatment and prognosis analysis, but is limited by the need for large annotated datasets. While deep learning-based segmentation foundation models show potential in developing high-performing models with fewer samples, their medical adaptation faces LN domain-specific prior deficiencies and inefficient few-shot fine-tuning for complex clinical practices, highlighting the necessity of an LN segmentation foundation model. In this work, we annotated 36,106 visible LNs from 3,346 publicly available head-and-neck CT scans to establish a robust LN segmentation model (nnUNetv2). Building on this, we propose Dynamic Gradient Sparsification Training (DGST), a few-shot fine-tuning approach that preserves foundational knowledge while dynamically updating the most critical parameters of the LN segmentation model with few annotations. We validate it on two publicly available LN segmentation datasets: SegRap2023 and LNQ2023. The results show that DGST outperforms existing few-shot fine-tuning methods, achieving satisfactory performance with limited labeled data. We release the dataset, models and all implementations to facilitate relevant research: https://github.com/Zihaoluoh/LN-Seg-FM.
准确的淋巴结(LN)分割对于放射治疗治疗和预后分析至关重要,但受限于需要大量标注数据集。虽然基于深度学习的分割基础模型在利用较少样本开发高性能模型方面显示出潜力,但它们在医学适应方面面临淋巴结领域特定先验知识不足和复杂临床实践中的低效小样本微调问题,这突出了需要一种淋巴结分割基础模型。在这项工作中,我们从3,346个公开可用的头部和颈部CT扫描中标注了36,106个可见淋巴结,以建立一个稳健的淋巴结分割模型(nnUNetv2)。在此基础上,我们提出了动态梯度稀疏训练(DGST),这是一种小样本的微调方法,既保留了基础知识,又能用少量注释动态更新淋巴结分割模型中最关键的参数。我们在两个公开的淋巴结分割数据集SegRap2023和LNQ2023上对其进行了验证。结果表明,DGST在有限的标注数据上取得了令人满意的性能,超越了现有的小样例微调方法。我们公开了数据集、模型和所有实现,以促进相关研究:https://github.com/Zihaoluoh/LN-Seg-FM。
论文及项目相关链接
PDF 10 pages, 3 figures, 2 tables, and the lymph node segmentation foundation model code and pretrained model are available
Summary
文本主要介绍了淋巴节点(LN)分割在放射治疗与预后分析中的重要性,但由于需要大量标注数据集而受到限制。基于深度学习的方法具有在少量样本下开发高性能模型的潜力,但在医学适应方面面临淋巴节点特定先验知识不足和复杂临床实践中的低效少样本微调问题。为此,本研究标注了36,106个可见的淋巴节点,建立了稳健的分割模型nnUNetv2,并提出动态梯度稀疏化训练(DGST)方法,这是一种少样本微调方法,能够保留基础知识并动态更新淋巴节点分割模型的关键参数。在公开数据集SegRap2023和LNQ2023上的验证结果表明,DGST优于现有的少样本微调方法,在有限标注数据下实现了令人满意的性能。
Key Takeaways
- 淋巴节点(LN)分割在放射治疗与预后分析中至关重要,但受限于缺乏大量标注数据集。
- 深度学习模型在少量样本下具有开发高性能模型的潜力,但医学适应面临特定领域知识的不足和复杂临床实践中的低效微调问题。
- 研究建立了稳健的淋巴节点分割模型nnUNetv2,通过标注大量淋巴节点数据。
- 提出了动态梯度稀疏化训练(DGST)方法,这是一种少样本微调策略,能够保留基础知识并动态更新模型关键参数。
- DGST方法在公开数据集SegRap2023和LNQ2023上的验证结果优于现有方法。
- 研究成果包括数据集、模型和所有实现,已公开发布以促进相关研究。
点此查看论文截图

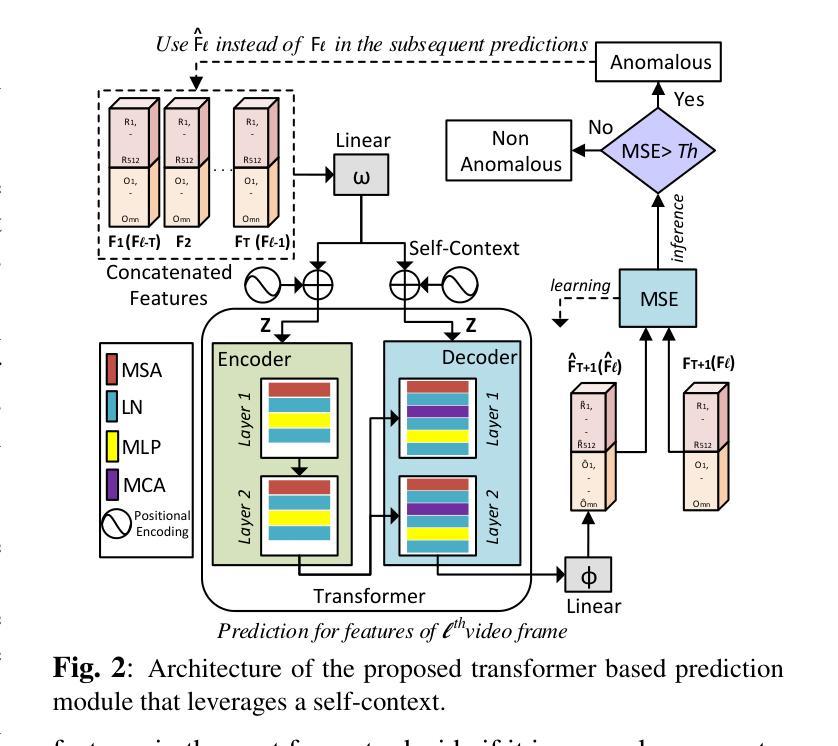
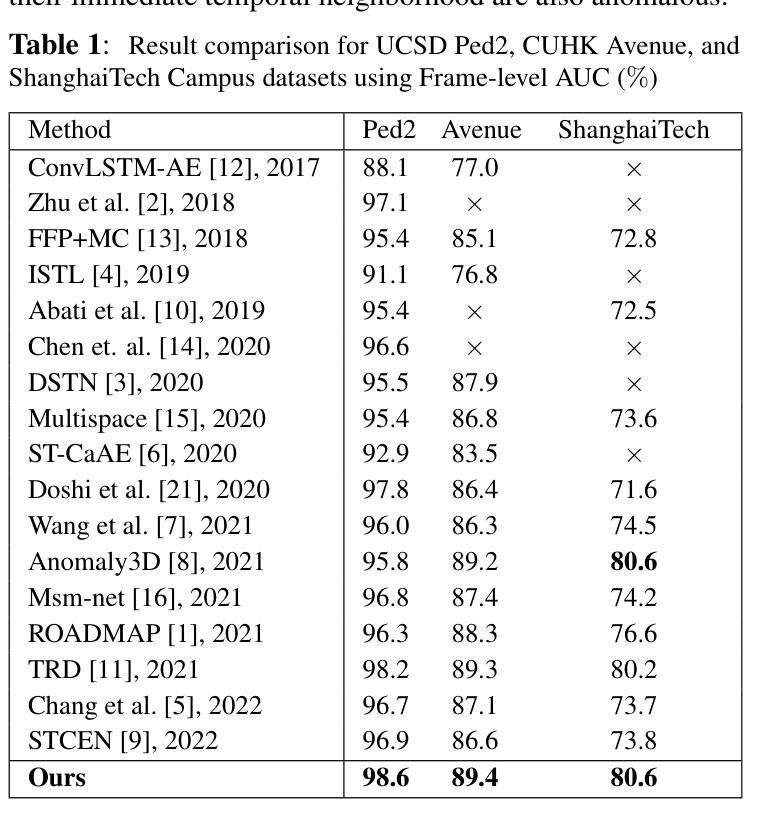
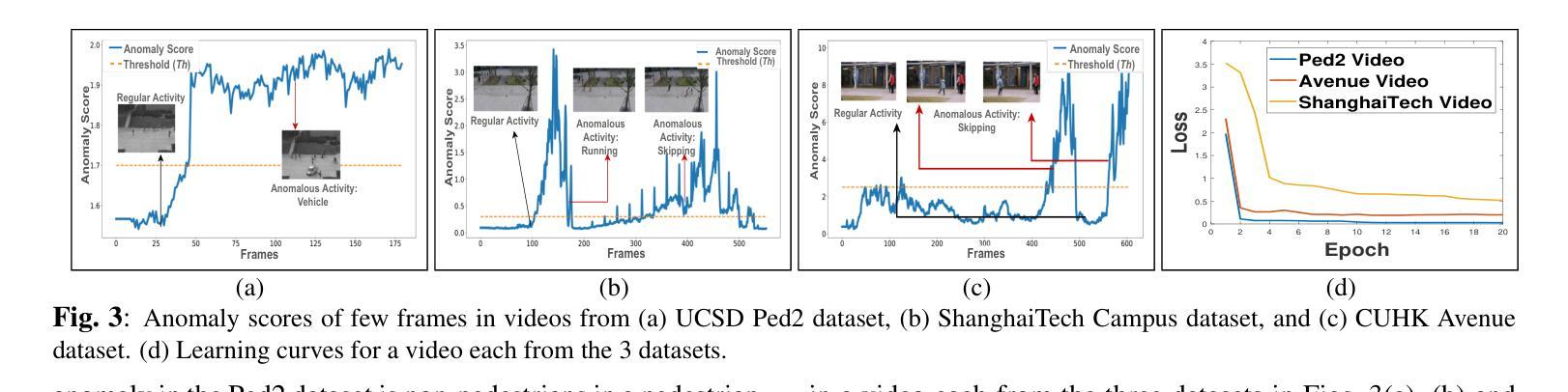
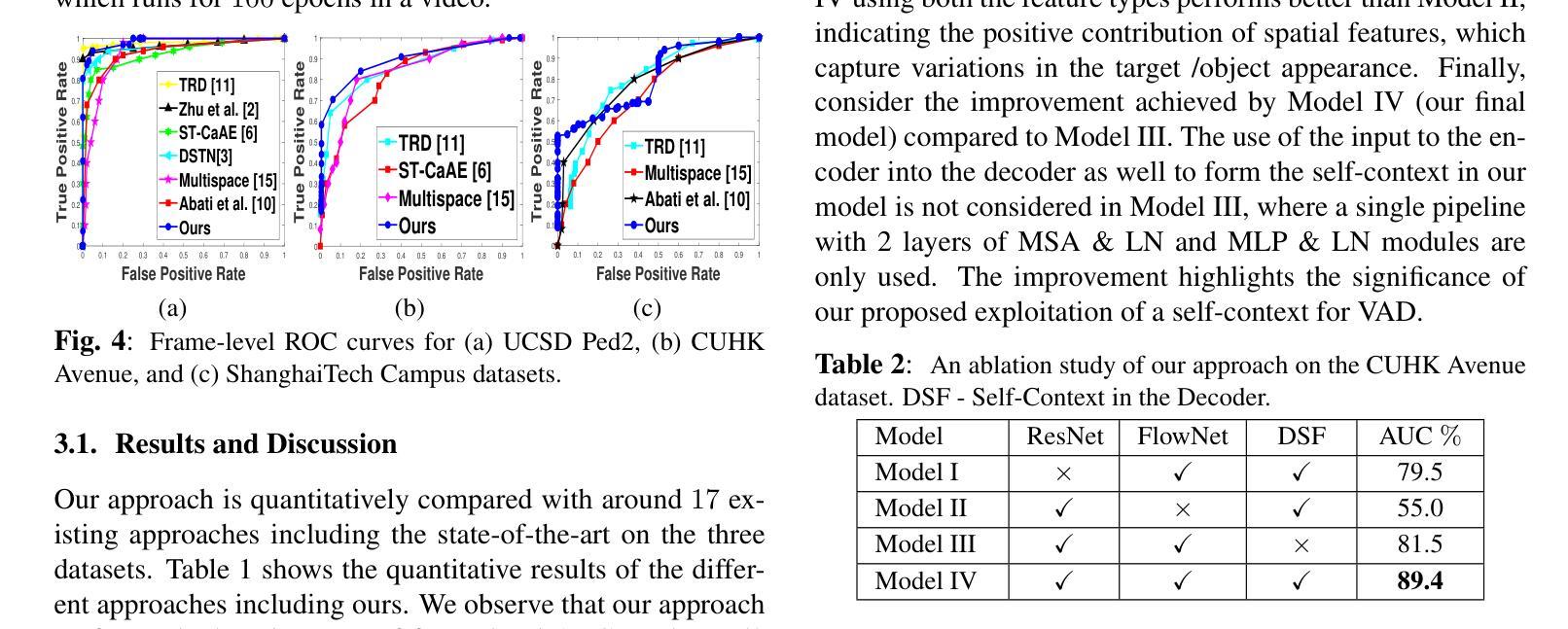
Transformer Based Self-Context Aware Prediction for Few-Shot Anomaly Detection in Videos
Authors:Gargi V. Pillai, Ashish Verma, Debashis Sen
Anomaly detection in videos is a challenging task as anomalies in different videos are of different kinds. Therefore, a promising way to approach video anomaly detection is by learning the non-anomalous nature of the video at hand. To this end, we propose a one-class few-shot learning driven transformer based approach for anomaly detection in videos that is self-context aware. Features from the first few consecutive non-anomalous frames in a video are used to train the transformer in predicting the non-anomalous feature of the subsequent frame. This takes place under the attention of a self-context learned from the input features themselves. After the learning, given a few previous frames, the video-specific transformer is used to infer if a frame is anomalous or not by comparing the feature predicted by it with the actual. The effectiveness of the proposed method with respect to the state-of-the-art is demonstrated through qualitative and quantitative results on different standard datasets. We also study the positive effect of the self-context used in our approach.
视频中的异常检测是一项具有挑战性的任务,因为不同视频中的异常是不同的。因此,一种有前景的视频异常检测方法是通过学习现有视频的非异常性质来识别异常。为此,我们提出了一种基于一类少样本学习的自我上下文感知的转换器方法来进行视频异常检测。利用视频片段中的前几帧连续的非异常特征来训练转换器预测后续帧的非异常特征。这是在输入特征本身的自我上下文关注下进行的。学习完成后,通过比较由视频特定转换器预测的特征与实际特征,利用前几帧即可推断某一帧是否为异常帧。通过在不同标准数据集上的定性和定量结果,验证了该方法相对于最新技术前沿的有效性。我们还研究了所用自我上下文在方法中的积极影响。
论文及项目相关链接
PDF Copyright 2022 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Summary
视频异常检测是一项具有挑战性的任务,因为不同视频中的异常事件类型各异。一种可行的方法是学习视频的非异常特性。为此,我们提出了一种基于一类小样本学习的自上下文感知的视频异常检测Transformer方法。该方法使用视频中的前几帧非异常特征来训练Transformer预测后续帧的非异常特征。经过训练后,使用针对视频的Transformer通过比较其预测的特征与实际特征来推断某一帧是否为异常帧。本文所提方法在不同标准数据集上的定性和定量结果均验证了其相对于最新技术前沿的有效性,并对自上下文在方法中的积极作用进行了研究。
Key Takeaways
- 视频异常检测具有挑战性,因为不同视频中的异常事件多样。
- 学习视频的非异常特性是检测异常事件的一种有效方法。
- 提出了一种基于一类小样本学习的自上下文感知的视频异常检测Transformer方法。
- 该方法使用视频中的前几帧非异常特征来训练Transformer预测后续帧的非异常特征。
- 通过比较预测特征和实际特征来推断某一帧是否为异常帧。
- 所提方法在多个标准数据集上的结果验证了其有效性。
点此查看论文截图

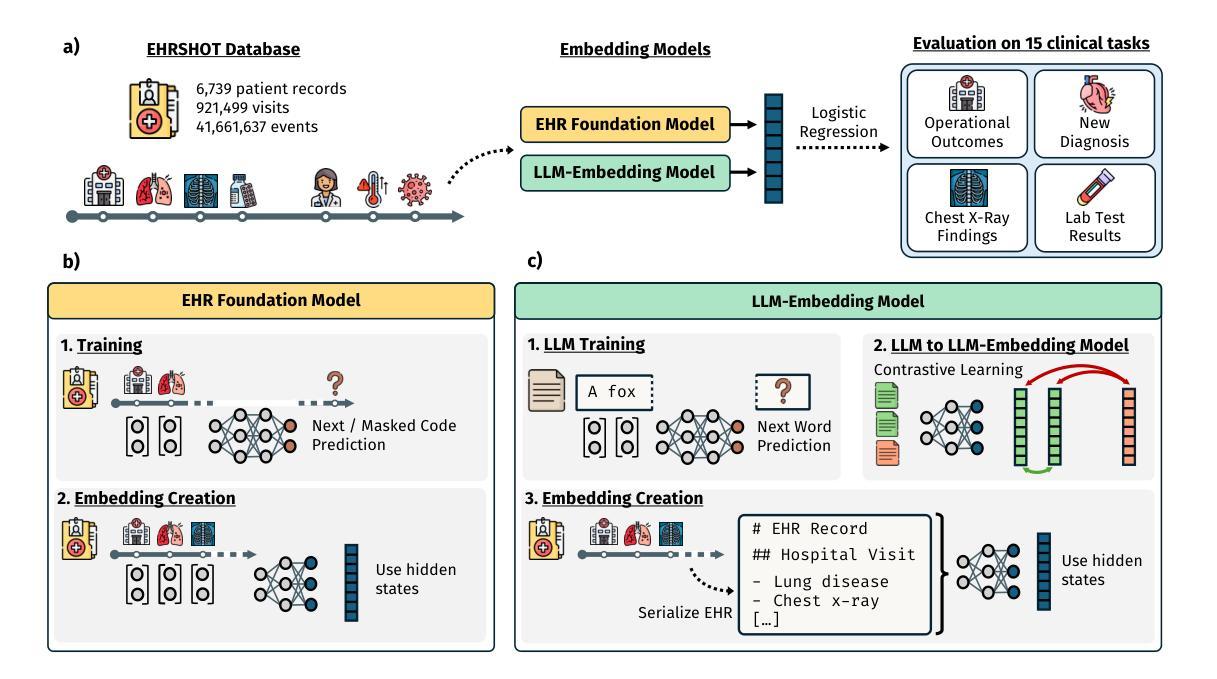
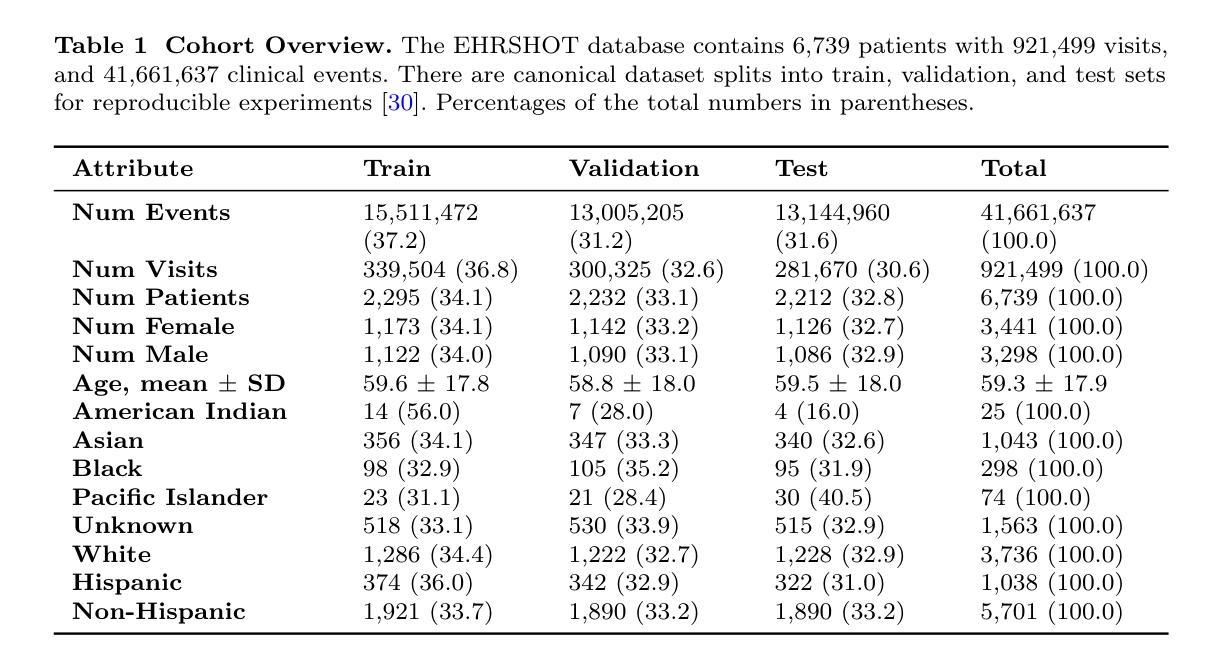
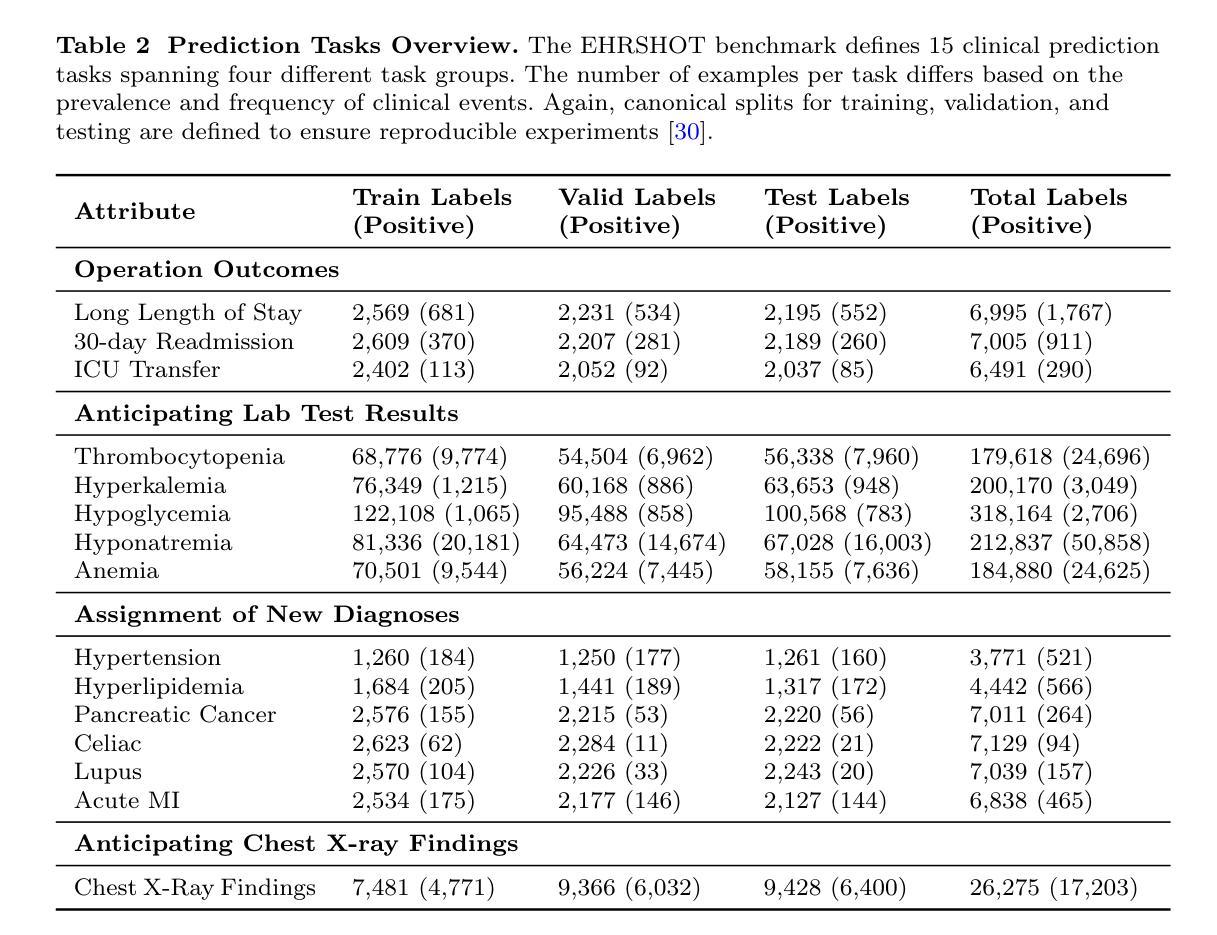
Large Language Models are Powerful EHR Encoders
Authors:Stefan Hegselmann, Georg von Arnim, Tillmann Rheude, Noel Kronenberg, David Sontag, Gerhard Hindricks, Roland Eils, Benjamin Wild
Electronic Health Records (EHRs) offer rich potential for clinical prediction, yet their inherent complexity and heterogeneity pose significant challenges for traditional machine learning approaches. Domain-specific EHR foundation models trained on large collections of unlabeled EHR data have demonstrated promising improvements in predictive accuracy and generalization; however, their training is constrained by limited access to diverse, high-quality datasets and inconsistencies in coding standards and healthcare practices. In this study, we explore the possibility of using general-purpose Large Language Models (LLMs) based embedding methods as EHR encoders. By serializing patient records into structured Markdown text, transforming codes into human-readable descriptors, we leverage the extensive generalization capabilities of LLMs pretrained on vast public corpora, thereby bypassing the need for proprietary medical datasets. We systematically evaluate two state-of-the-art LLM-embedding models, GTE-Qwen2-7B-Instruct and LLM2Vec-Llama3.1-8B-Instruct, across 15 diverse clinical prediction tasks from the EHRSHOT benchmark, comparing their performance to an EHRspecific foundation model, CLIMBR-T-Base, and traditional machine learning baselines. Our results demonstrate that LLM-based embeddings frequently match or exceed the performance of specialized models, even in few-shot settings, and that their effectiveness scales with the size of the underlying LLM and the available context window. Overall, our findings demonstrate that repurposing LLMs for EHR encoding offers a scalable and effective approach for clinical prediction, capable of overcoming the limitations of traditional EHR modeling and facilitating more interoperable and generalizable healthcare applications.
电子健康记录(EHRs)为临床预测提供了巨大的潜力,但它们固有的复杂性和异质性给传统的机器学习方法带来了巨大的挑战。基于大量未标记的EHR数据训练的特定领域的EHR基础模型在预测精度和通用性方面显示出有希望的改进;然而,它们的训练受到多样、高质量数据集访问受限以及编码标准和医疗保健实践不一致的制约。在这项研究中,我们探讨了使用基于通用大型语言模型(LLMs)的嵌入方法作为EHR编码器的可能性。通过将患者记录序列化为结构化Markdown文本,将代码转换为人类可读的描述符,我们充分利用了LLMs在大量公共语料库上的预训练产生的广泛泛化能力,从而绕过了对专有医疗数据集的需求。我们系统地评估了两种最先进的LLM嵌入模型,GTE-Qwen2-7B-Instruct和LLM2Vec-Llama3.1-8B-Instruct,在EHRSHOT基准测试的15个不同临床预测任务上,与EHR特定的基础模型CLIMBR-T-Base和传统机器学习基准进行了性能比较。结果表明,基于LLM的嵌入在少样本情况下经常与专用模型的表现相匹配甚至超过它们,其有效性随着底层LLM的大小和可用上下文窗口的大小而提高。总的来说,我们的研究结果表明,将LLMs重新用于EHR编码提供了一种可扩展和有效的临床预测方法,能够克服传统EHR建模的限制,促进更互联和更通用的医疗保健应用程序的开发。
论文及项目相关链接
Summary
本文探讨了电子健康记录(EHRs)在临床预测中的丰富潜力,以及传统机器学习方法面临的挑战。研究使用基于大型语言模型(LLMs)的嵌入方法作为EHR编码器,通过序列化患者记录为结构化Markdown文本,将代码转换为人类可读描述符,利用LLMs在大量公共语料库上的预训练能力,从而绕过对专有医疗数据集的需求。研究评估了两种先进的LLM嵌入模型,并证明其性能与EHR特定基础模型和传统机器学习基准相当或更优,尤其是在少样本情况下。这些结果表明,使用LLMs进行EHR编码提供了一种可扩展和有效的临床预测方法,能够克服传统EHR建模的限制,促进更互通和通用的医疗保健应用。
Key Takeaways
- 电子健康记录(EHRs)在临床预测中具有巨大潜力,但传统机器学习方法面临复杂性和异质性的挑战。
- 特定领域的EHR基础模型在预测准确性和泛化能力方面已显示出改进,但存在数据集访问有限和编码标准不一致的问题。
- 研究使用大型语言模型(LLMs)作为EHR编码器,通过序列化患者记录并利用LLMs的广泛泛化能力绕过专有医疗数据集的需求。
- LLM嵌入模型在多样化的临床预测任务上的性能评估显示,它们与EHR特定基础模型和传统机器学习基准相比具有竞争力。
- LLM模型在少样本设置下表现良好,且其有效性随着模型大小和可用上下文窗口的大小而增加。
- 使用LLMs进行EHR编码提供了一种可扩展的方法,能够克服传统EHR建模的限制。
点此查看论文截图


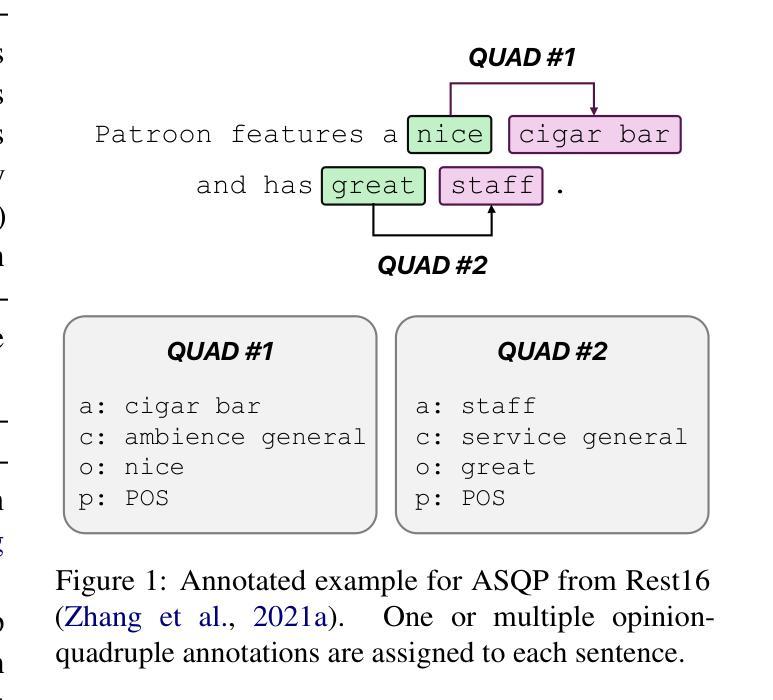
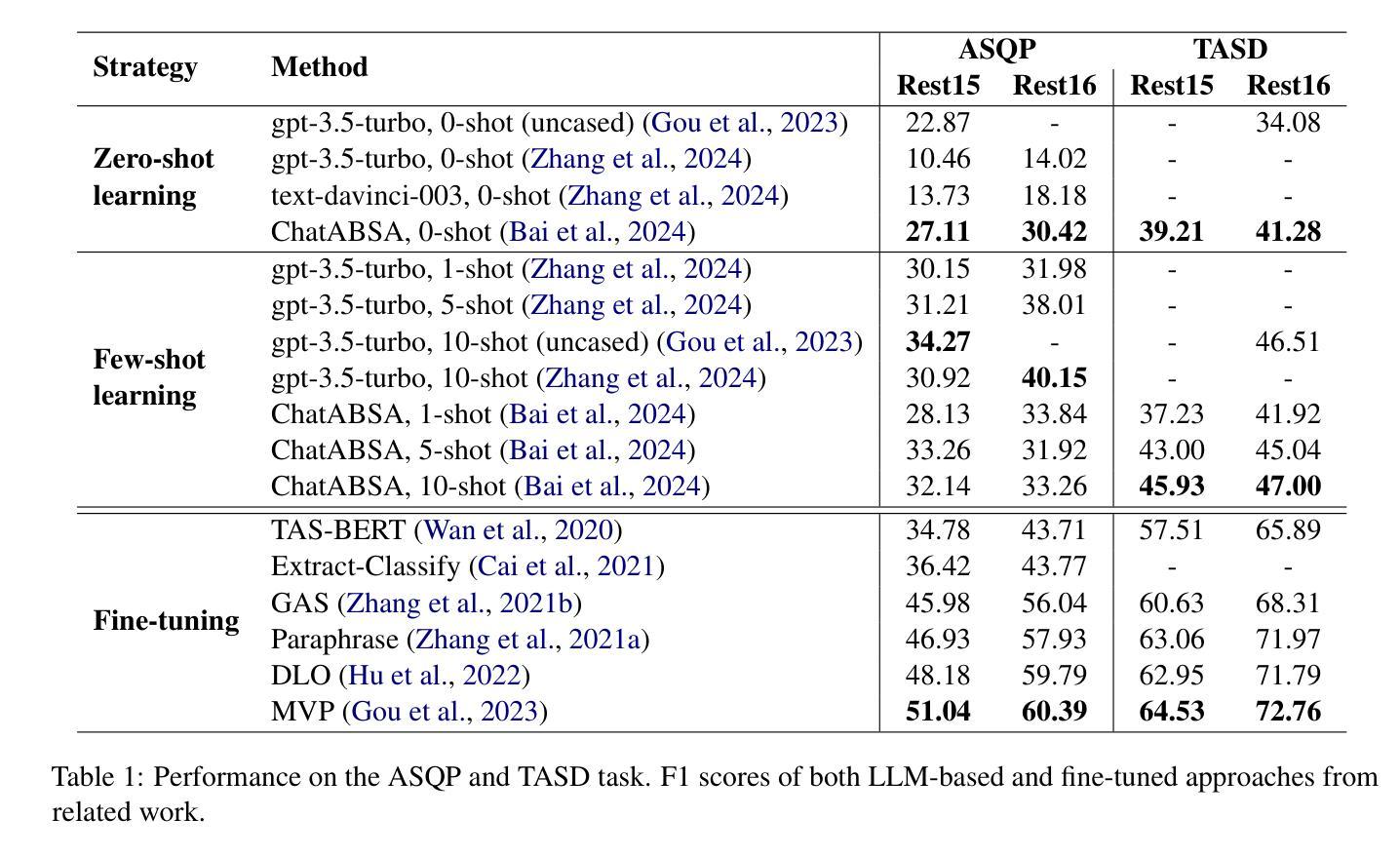
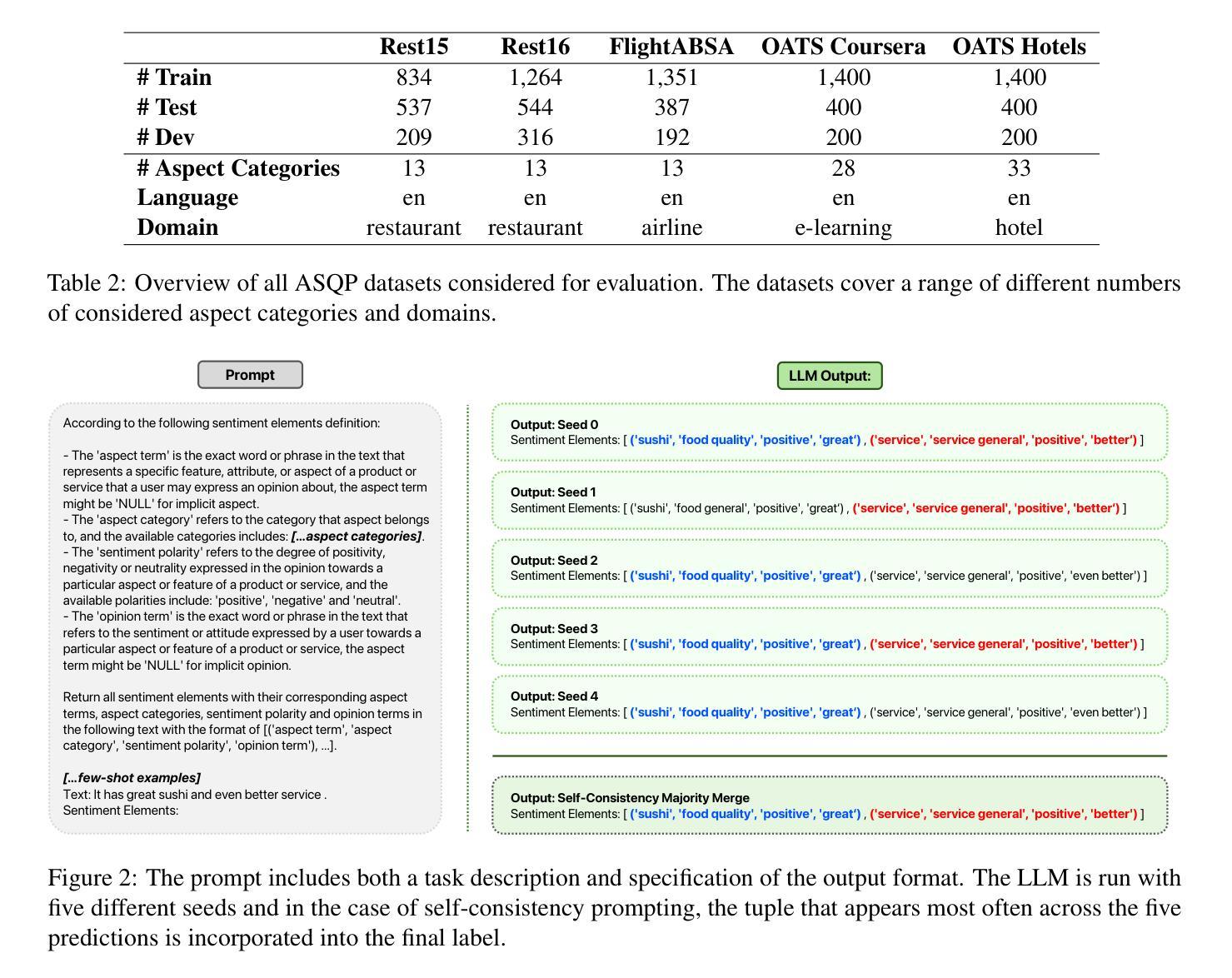
Do we still need Human Annotators? Prompting Large Language Models for Aspect Sentiment Quad Prediction
Authors:Nils Constantin Hellwig, Jakob Fehle, Udo Kruschwitz, Christian Wolff
Aspect sentiment quadruple prediction (ASQP) facilitates a detailed understanding of opinions expressed in a text by identifying the opinion term, aspect term, aspect category and sentiment polarity for each opinion. However, annotating a full set of training examples to fine-tune models for ASQP is a resource-intensive process. In this study, we explore the capabilities of large language models (LLMs) for zero- and few-shot learning on the ASQP task across five diverse datasets. We report F1 scores slightly below those obtained with state-of-the-art fine-tuned models but exceeding previously reported zero- and few-shot performance. In the 40-shot setting on the Rest16 restaurant domain dataset, LLMs achieved an F1 score of 52.46, compared to 60.39 by the best-performing fine-tuned method MVP. Additionally, we report the performance of LLMs in target aspect sentiment detection (TASD), where the F1 scores were also close to fine-tuned models, achieving 66.03 on Rest16 in the 40-shot setting, compared to 72.76 with MVP. While human annotators remain essential for achieving optimal performance, LLMs can reduce the need for extensive manual annotation in ASQP tasks.
面向方面的情感四重预测(ASQP)能够通过识别每个意见的观点词、方面词、方面类别和情感极性,从而促进对文本中所表达意见的深入理解。然而,对全套训练示例进行标注以微调ASQP模型是一个资源密集型的流程。在本研究中,我们探讨了大型语言模型(LLM)在五个不同数据集上的零样本和少样本学习在ASQP任务上的能力。我们报告的F1分数略低于使用最新微调模型所获得的分数,但超过了之前报告的零样本和少样本性能。在Rest16餐厅领域数据集的40个样本设置中,与表现最佳的MVP微调方法相比,LLMs取得了F1分数为52.46的业绩。此外,我们报告了LLM在目标方面情感检测(TASD)方面的表现,其F1分数也接近经过微调的模型。在Rest16的40个样本设置中,与MVP的72.76相比,LLMs取得了66.03的F1分数。虽然人类注释者对于实现最佳性能仍然至关重要,但LLM可以减少ASQP任务中对大量手动标注的需求。
论文及项目相关链接
Summary
本文探讨了大型语言模型(LLMs)在面向方面的情感四重预测(ASQP)任务中的零样本和少样本学习能力。研究发现在五个不同的数据集上,LLMs的性能表现良好,虽然略低于经过精细调整的模型,但在零样本和少样本场景下的性能表现优于先前报告。在Rest16餐厅领域数据集的40个样本中,LLMs的F1分数达到52.46%,而最佳精细调整方法MVP的F1分数为60.39。此外,LLMs在目标方面情感检测(TASD)方面的性能也接近精细调整模型。虽然人类注释者对于实现最佳性能至关重要,但LLMs可以减少对ASQP任务中大量手动注释的需求。
Key Takeaways
- 大型语言模型(LLMs)在面向方面的情感四重预测(ASQP)任务中展现出零样本和少样本学习能力。
- 在五个不同的数据集上,LLMs的性能表现良好,其F1分数略低于经过精细调整的模型。
- 在Rest16餐厅领域数据集的40个样本中,LLMs的F1分数达到52.46%,与最佳精细调整方法MVP相比具有一定竞争力。
- LLMs在目标方面情感检测(TASD)方面的性能接近精细调整模型,其F1分数在Rest16数据集上达到66.03%。
- 虽然人类注释者对于优化ASQP任务性能至关重要,但LLMs的应用可以减少对大量手动注释的需求。
- LLMs在ASQP任务中的表现表明它们具有潜在的实用价值,特别是在资源有限的情况下。
点此查看论文截图

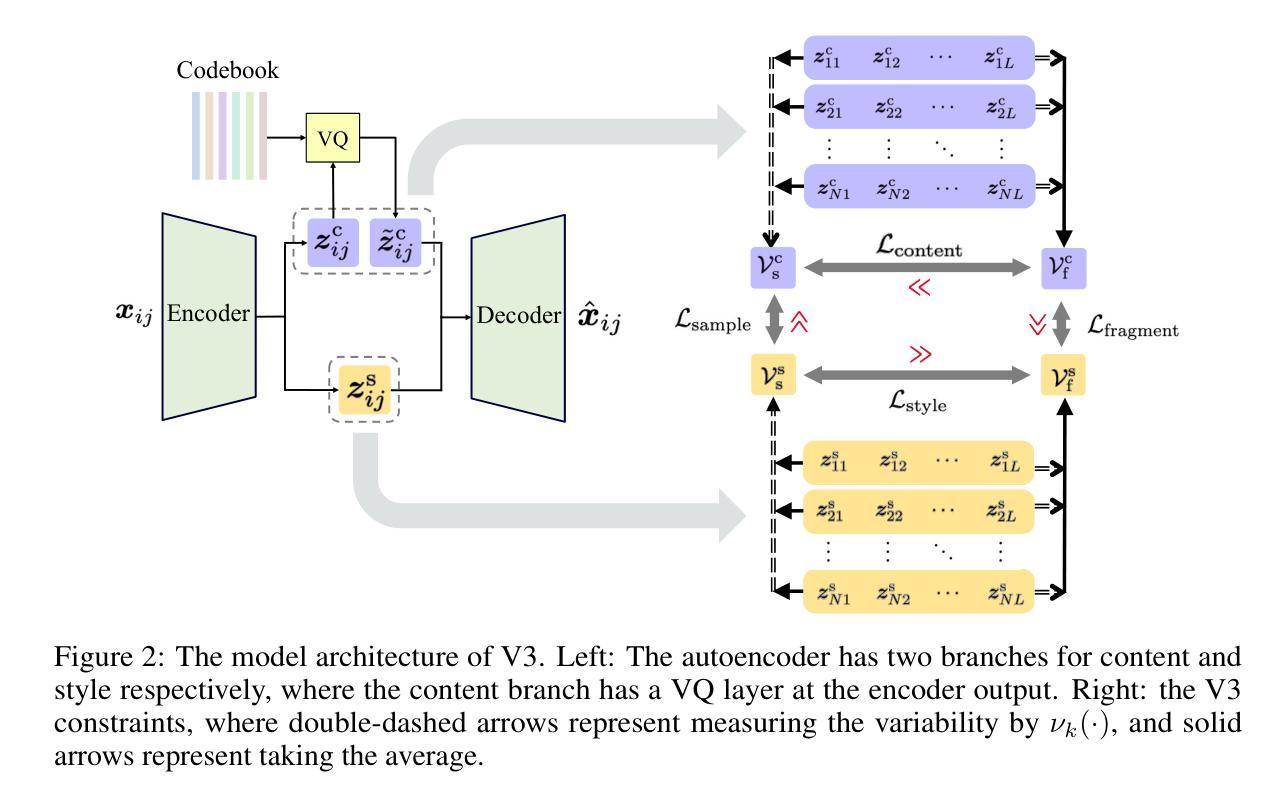
Unsupervised Disentanglement of Content and Style via Variance-Invariance Constraints
Authors:Yuxuan Wu, Ziyu Wang, Bhiksha Raj, Gus Xia
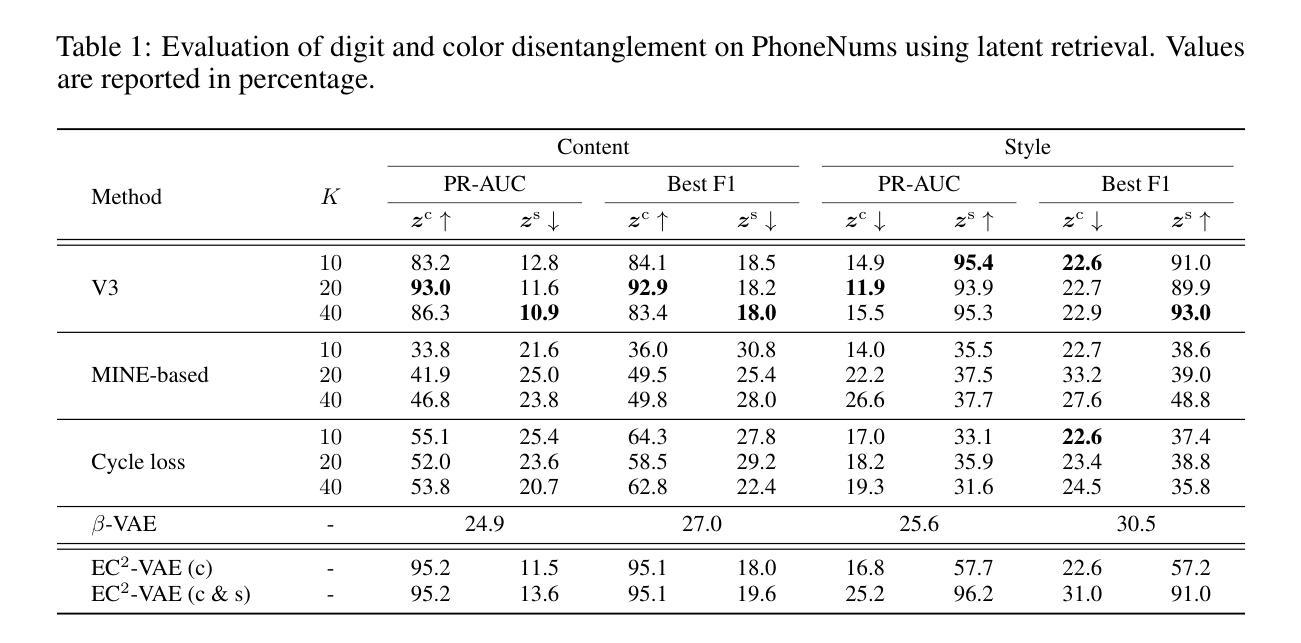
We contribute an unsupervised method that effectively learns disentangled content and style representations from sequences of observations. Unlike most disentanglement algorithms that rely on domain-specific labels or knowledge, our method is based on the insight of domain-general statistical differences between content and style – content varies more among different fragments within a sample but maintains an invariant vocabulary across data samples, whereas style remains relatively invariant within a sample but exhibits more significant variation across different samples. We integrate such inductive bias into an encoder-decoder architecture and name our method after V3 (variance-versus-invariance). Experimental results show that V3 generalizes across multiple domains and modalities, successfully learning disentangled content and style representations, such as pitch and timbre from music audio, digit and color from images of hand-written digits, and action and character appearance from simple animations. V3 demonstrates strong disentanglement performance compared to existing unsupervised methods, along with superior out-of-distribution generalization under few-shot adaptation compared to supervised counterparts. Lastly, symbolic-level interpretability emerges in the learned content codebook, forging a near one-to-one alignment between machine representation and human knowledge.
我们提出了一种无监督的方法,该方法可以有效地从观察序列中学习分离的内容和风格表示。与大多数依赖于特定领域标签或知识的解纠缠算法不同,我们的方法基于内容和风格之间的一般统计差异:内容在同一样本的不同片段之间变化较大,但在不同的数据样本之间保持不变的词汇表,而风格在同一样本内相对保持不变,但在不同的样本之间表现出更大的变化。我们将这种归纳偏见整合到编码器-解码器架构中,并将我们的方法命名为V3(方差与不变性)。实验结果表明,V3可以跨多个领域和模式进行推广,成功学习解纠缠的内容和风格表示,例如音乐音频中的音高和音色,手写数字图像中的数字和颜色,以及简单动画中的动作和角色外观。与现有的无监督方法相比,V3表现出强大的解纠缠性能,并且在少量适应的情况下具有出色的分布外泛化能力,优于有监督的同类方法。最后,在学习的内容代码库中出现了符号级的可解释性,为机器表示和人类知识之间建立了一对一的对应关系。
论文及项目相关链接
Summary
本摘要介绍了一种能够从序列观察中学习分离内容和风格表示的无监督方法。该方法基于内容和风格在统计上的差异,通过引入方差与不变性的观点,成功地在多个领域和模态中学习到分离的内容和风格表示。实验结果表明,该方法在音频、图像和简单动画等领域具有良好的表现,与其他无监督方法相比,具有较强的解耦性能,并在少数适应情况下展现出出色的泛化能力。此外,学到的内容代码本具有符号级的可解释性,实现了机器表示和人类知识之间近乎一对一的对应关系。
Key Takeaways
- 介绍了一种无监督学习方法,能够从序列观察中学习分离内容和风格表示。
- 基于内容和风格在统计上的差异来区分两者。
- 通过方差与不变性的观点整合这种归纳偏见。
- 在多个领域和模态中成功应用,如音乐音频、手写数字图像和简单动画。
- 与现有无监督方法相比,具有较强的解耦性能。
- 在少数适应情况下展现出出色的泛化能力。
点此查看论文截图


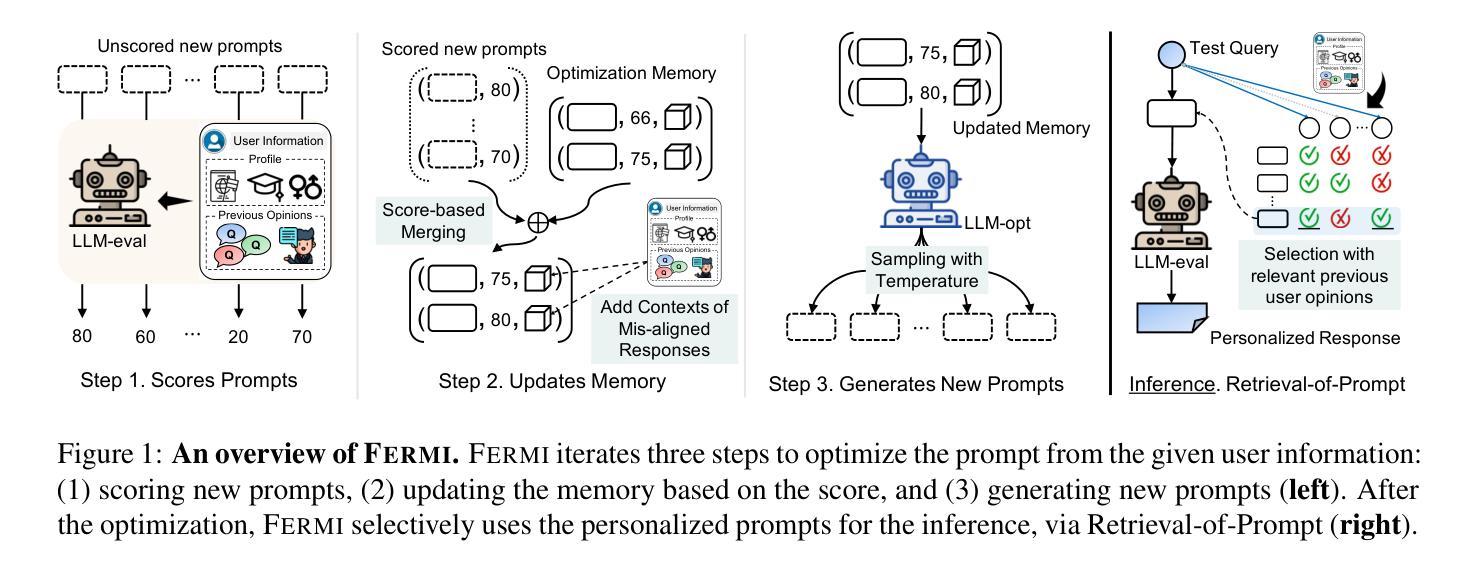
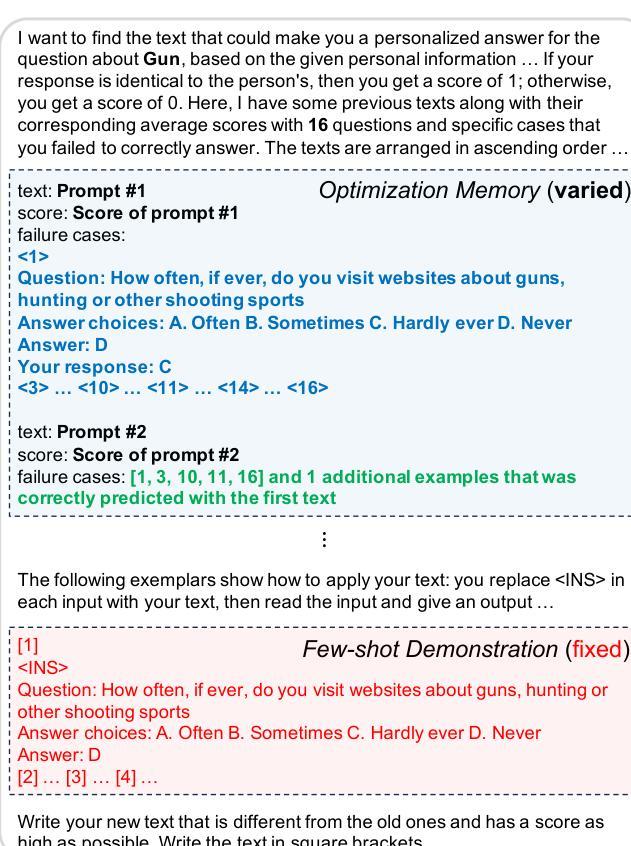
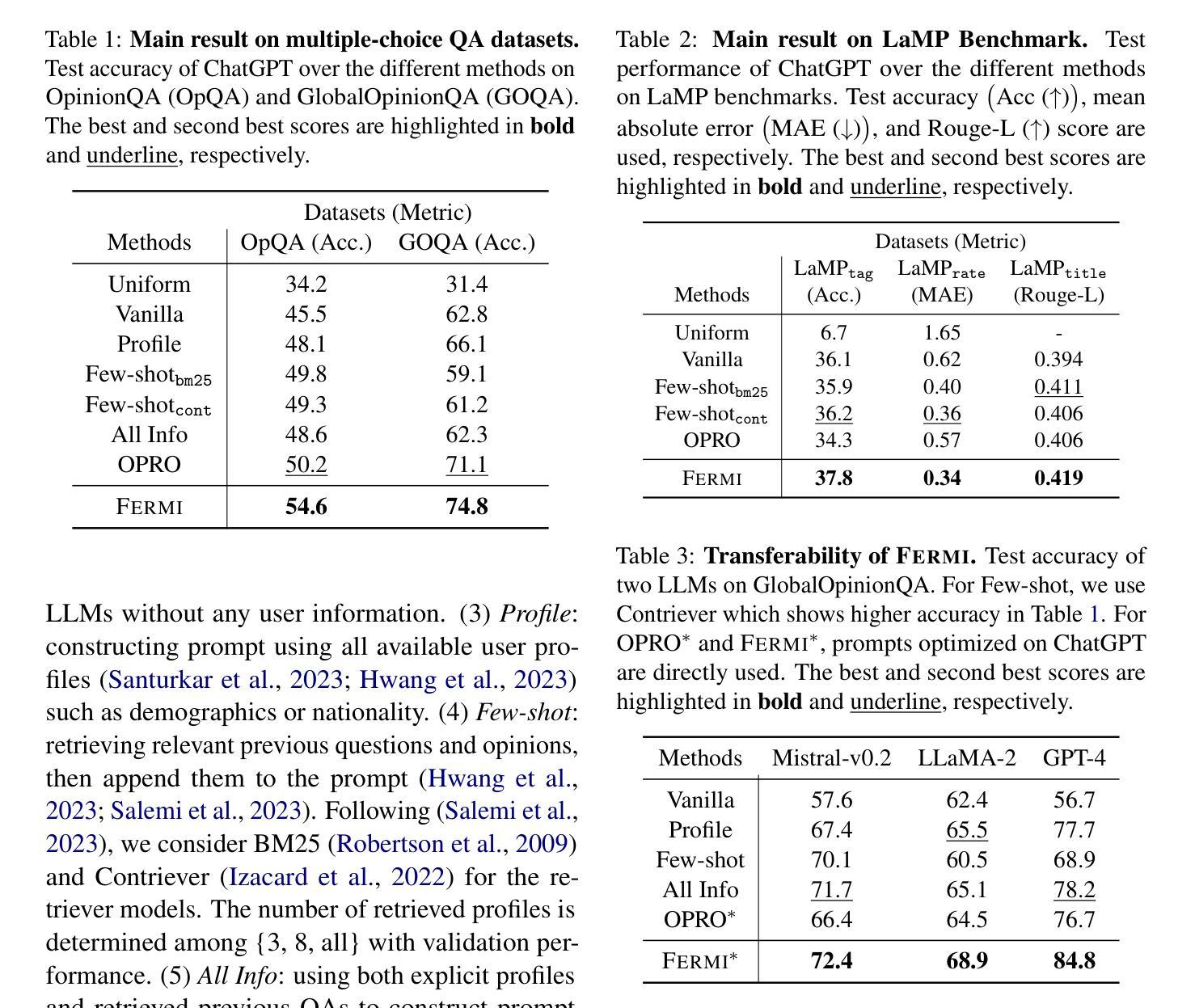
Few-shot Personalization of LLMs with Mis-aligned Responses
Authors:Jaehyung Kim, Yiming Yang
As the diversity of users increases, the capability of providing personalized responses by large language models (LLMs) has become increasingly important. Existing approaches have only limited successes in LLM personalization, due to the absence of personalized learning or the reliance on shared personal data. This paper proposes a new approach for a few-shot personalization of LLMs with their mis-aligned responses (Fermi). Our key idea is to learn a set of personalized prompts for each user by progressively improving the prompts using LLMs, based on user profile (e.g., demographic information) and a few examples of previous opinions. During an iterative process of prompt improvement, we incorporate the contexts of mis-aligned responses by LLMs, which are especially crucial for the effective personalization of LLMs. In addition, we develop an effective inference method to further leverage the context of the test query and the personalized prompts. Our experimental results demonstrate that Fermi significantly improves performance across various benchmarks, compared to best-performing baselines.
随着用户多样性的增加,大型语言模型(LLM)提供个性化响应的能力变得越来越重要。由于缺少个性化学习或依赖共享个人数据,现有方法在LLM个性化方面的成果有限。本文针对LLM的误对齐响应(费米)提出了一种新的少样本个性化方法。我们的主要思想是基于用户配置文件(例如人口统计信息)和先前的几个观点的示例,通过逐步改进提示来学习每个用户的个性化提示集。在逐步改进提示的过程中,我们融入了LLM产生的误对齐响应的上下文,这对于实现LLM的有效个性化尤为重要。此外,我们开发了一种有效的推理方法,以进一步利用测试查询的上下文和个性化提示。我们的实验结果表明,费米在各种基准测试上的表现与最佳基线相比有显著提高。
论文及项目相关链接
PDF NAACL 25 (main, long), 32 pages
Summary
随着用户多样性的增加,大型语言模型(LLM)提供个性化响应的能力变得至关重要。本文提出了一种新的基于用户配置文件和之前意见的几个示例来逐步改进提示的方法,以实现LLM的少量个性化响应。在迭代改进提示的过程中,我们结合了LLM的误对齐响应的上下文,这对于LLM的有效个性化至关重要。实验结果表明,与最佳基线相比,我们的方法在各种基准测试中性能显著提高。
Key Takeaways
- 用户多样性的增加使得大型语言模型(LLM)的个性化响应能力变得重要。
- 现有LLM个性化方法的局限性在于缺乏个性化学习或依赖共享个人数据。
- 本文提出了一种基于用户配置文件和之前意见的几个示例来逐步改进提示的新方法。
- 结合LLM误对齐响应的上下文对于有效个性化至关重要。
- 开发了一种有效的推理方法,进一步利用测试查询的上下文和个性化的提示。
- 实验结果表明,该方法在各种基准测试中性能显著提高。
点此查看论文截图