⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-06 更新
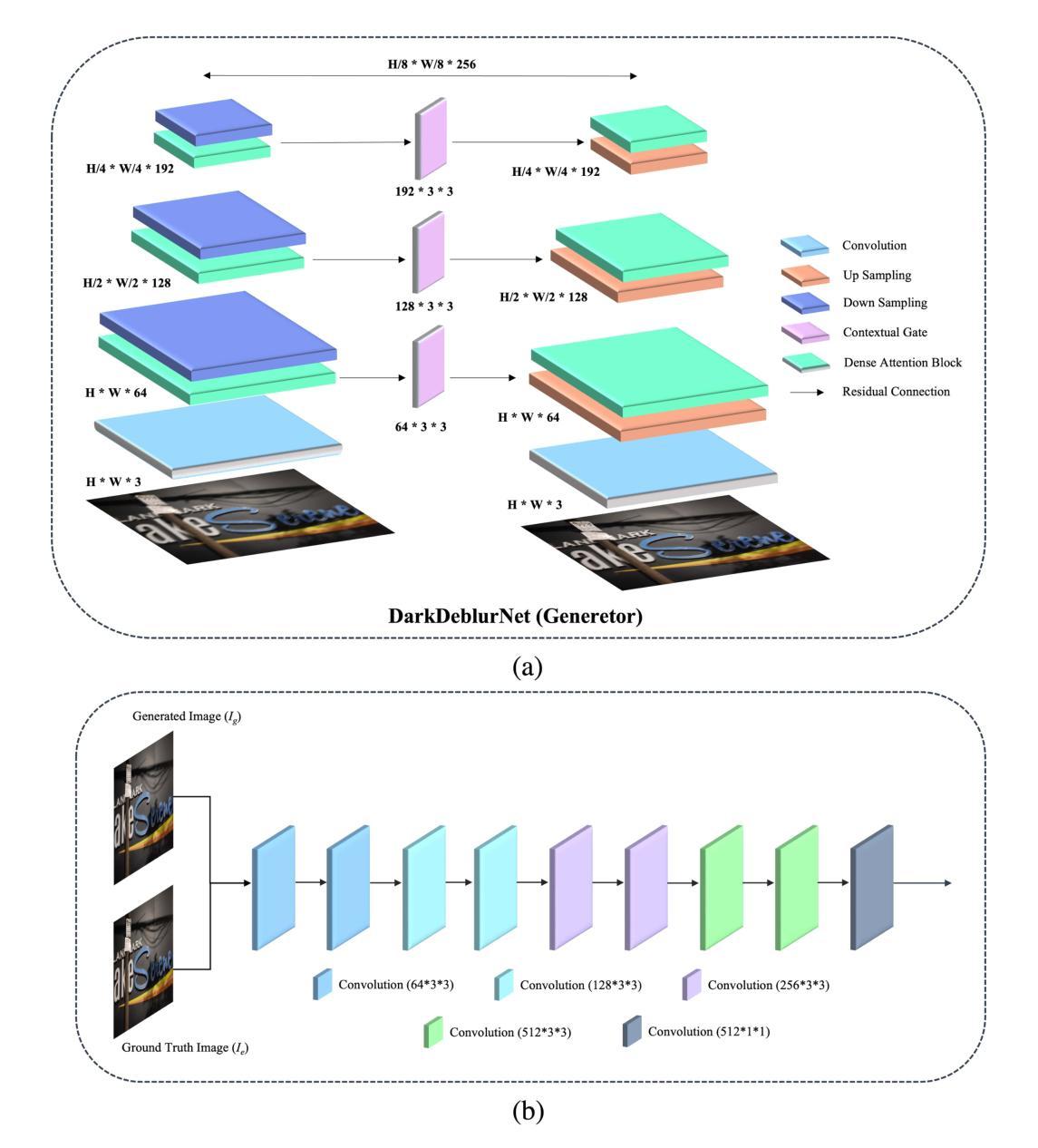
DarkDeblur: Learning single-shot image deblurring in low-light condition
Authors:S M A Sharif, Rizwan Ali Naqvi, Farman Alic, Mithun Biswas
Single-shot image deblurring in a low-light condition is known to be a profoundly challenging image translation task. This study tackles the limitations of the low-light image deblurring with a learning-based approach and proposes a novel deep network named as DarkDeblurNet. The proposed DarkDeblur- Net comprises a dense-attention block and a contextual gating mechanism in a feature pyramid structure to leverage content awareness. The model additionally incorporates a multi-term objective function to perceive a plausible perceptual image quality while performing image deblurring in the low-light settings. The practicability of the proposed model has been verified by fusing it in numerous computer vision applications. Apart from that, this study introduces a benchmark dataset collected with actual hardware to assess the low-light image deblurring methods in a real-world setup. The experimental results illustrate that the proposed method can outperform the state-of-the-art methods in both synthesized and real-world data for single-shot image deblurring, even in challenging lighting environment.
在低光照条件下进行单幅图像去模糊是一项具有挑战性的图像翻译任务。本研究采用基于学习的方法解决低光图像去模糊的局限性,并提出了一种名为DarkDeblurNet的新型深度网络。所提出的DarkDeblurNet包含一个密集注意力块和特征金字塔结构中的上下文门控机制,以利用内容感知能力。该模型还结合了一个多目标目标函数,在暗光环境下进行图像去模糊操作时感知合理的感知图像质量。通过将其融合到许多计算机视觉应用中,已经验证了所提出模型的实用性。除此之外,本研究还引入了使用实际硬件收集的基准数据集,以在真实环境中评估低光图像去模糊方法。实验结果证明,所提出的方法在合成数据和真实世界数据的单幅图像去模糊方面都能超越最新技术,即使在具有挑战性的光照环境中也是如此。
论文及项目相关链接
Summary
本研究的目的是解决在低光照条件下单幅图像去模糊这一具有挑战性的图像翻译任务。该研究采用学习的方法解决了低光照图像去模糊的局限性,提出了一种名为DarkDeblurNet的新型深度网络。该网络在特征金字塔结构中结合了密集注意块和上下文门控机制,以提高内容感知能力。该模型还采用了一种多目标函数,以在去模糊低光照图像时感知合理的图像质量。该模型在各种计算机视觉应用中的实用性已经得到了验证。此外,本研究还引入了一个使用实际硬件收集的基准数据集,以在真实环境中评估低光照图像去模糊方法的效果。实验结果表明,所提出的方法在合成和真实数据中均优于当前最先进的单幅图像去模糊方法,即使在具有挑战性的光照环境中也是如此。
Key Takeaways
- 低光照条件下单幅图像去模糊是一项重大挑战。
- 研究采用学习的方法解决低光照图像去模糊的局限性。
- 提出了一种名为DarkDeblurNet的新型深度网络用于低光照图像去模糊。
- DarkDeblurNet结合了密集注意块和上下文门控机制以提高内容感知能力。
- 该模型采用多目标函数以在去模糊低光照图像时感知合理的图像质量。
- DarkDeblurNet模型已在多个计算机视觉应用中验证了其实用性。
点此查看论文截图


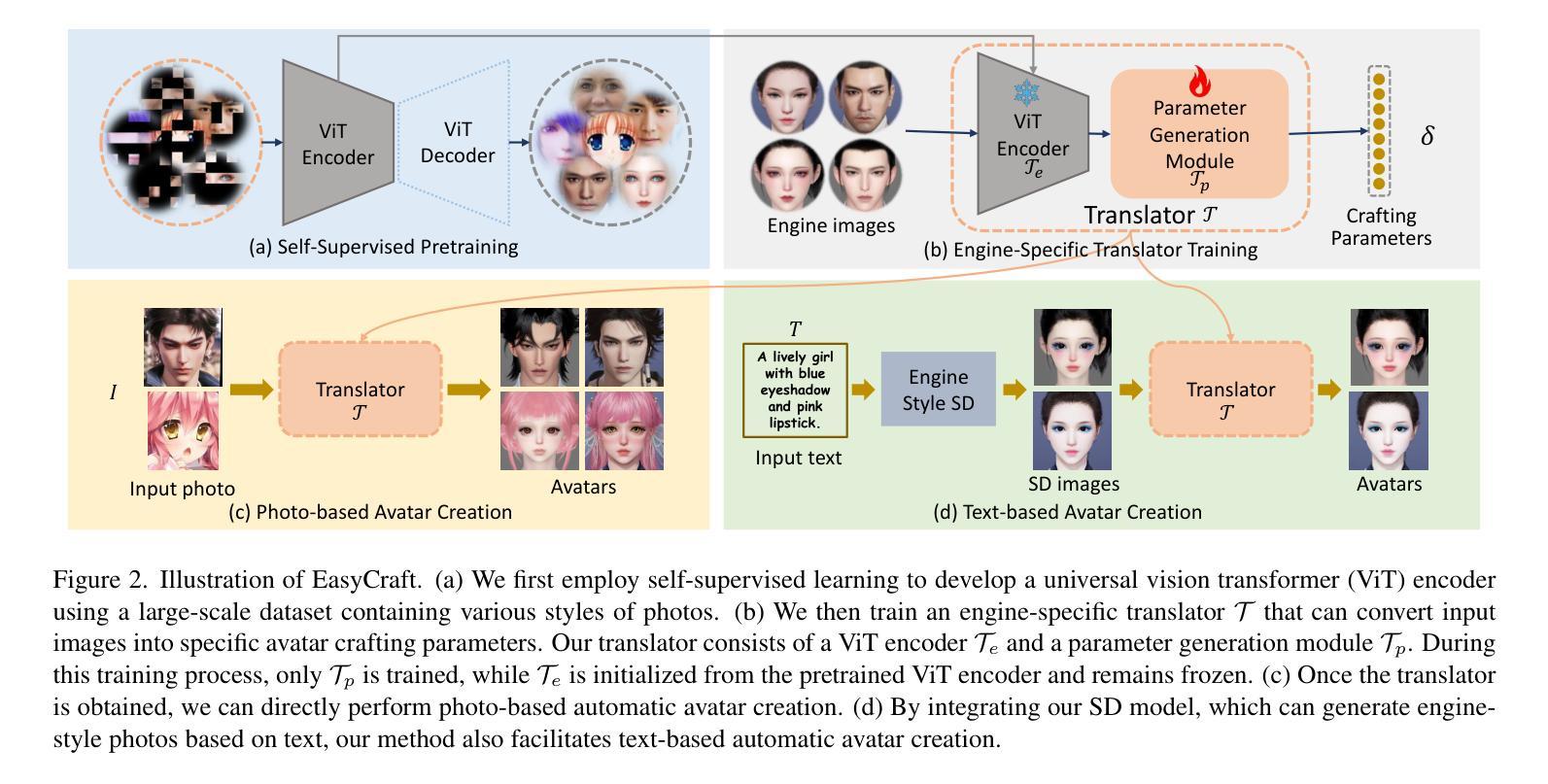
EasyCraft: A Robust and Efficient Framework for Automatic Avatar Crafting
Authors:Suzhen Wang, Weijie Chen, Wei Zhang, Minda Zhao, Lincheng Li, Rongsheng Zhang, Zhipeng Hu, Xin Yu
Character customization, or ‘face crafting,’ is a vital feature in role-playing games (RPGs), enhancing player engagement by enabling the creation of personalized avatars. Existing automated methods often struggle with generalizability across diverse game engines due to their reliance on the intermediate constraints of specific image domain and typically support only one type of input, either text or image. To overcome these challenges, we introduce EasyCraft, an innovative end-to-end feedforward framework that automates character crafting by uniquely supporting both text and image inputs. Our approach employs a translator capable of converting facial images of any style into crafting parameters. We first establish a unified feature distribution in the translator’s image encoder through self-supervised learning on a large-scale dataset, enabling photos of any style to be embedded into a unified feature representation. Subsequently, we map this unified feature distribution to crafting parameters specific to a game engine, a process that can be easily adapted to most game engines and thus enhances EasyCraft’s generalizability. By integrating text-to-image techniques with our translator, EasyCraft also facilitates precise, text-based character crafting. EasyCraft’s ability to integrate diverse inputs significantly enhances the versatility and accuracy of avatar creation. Extensive experiments on two RPG games demonstrate the effectiveness of our method, achieving state-of-the-art results and facilitating adaptability across various avatar engines.
角色定制,又称“角色塑造”,是角色扮演游戏(RPG)中的重要功能之一,它通过让玩家创建个性化的角色来增强玩家参与度。现有的自动化方法通常受到特定图像域的中间约束的限制,并且仅支持文本或图像等单一类型的输入,因此在跨越不同游戏引擎时的通用性方面存在困难。为了克服这些挑战,我们引入了EasyCraft,这是一个创新的端到端前馈框架,它通过独特的方式支持文本和图像输入来自动进行角色塑造。我们的方法采用了一种能够将任何风格的面部图像转换为制作参数的转换器。我们首先在转换器的图像编码器上建立统一特征分布,通过大规模数据集上的自我监督学习,使得任何风格的照片都可以嵌入到统一特征表示中。随后,我们将这一统一特征分布映射到特定游戏引擎的制作参数上,这一过程可以轻松适应大多数游戏引擎,从而提高了EasyCraft的通用性。通过将文本到图像技术与我们的转换器相结合,EasyCraft还可以实现基于文本的精确角色塑造。EasyCraft能够整合各种输入,从而极大地提高了角色创建的多样性和准确性。在两款RPG游戏上的广泛实验证明了我们的方法的有效性,达到了最先进的成果,并在各种角色引擎之间实现了适应性。
论文及项目相关链接
Summary:
角色游戏中的个性化角色定制(即“面部制作”)是一个重要功能,能够提升玩家的参与度。现有自动化方法常常局限于特定的游戏引擎和图像领域,并且只能支持文本或图像单一输入类型。本研究提出了一种创新的端到端前馈框架EasyCraft,它能够支持文本和图像两种输入方式,实现角色自动化定制。该框架通过一种能够将面部图像转换为制作参数的翻译器来达成目标。通过建立统一的特征分布和提升翻译器图像编码器的自我学习能力,使得任何风格的照片都能嵌入到统一的特征表示中。随后,将这一统一特征分布映射到特定游戏引擎的制作参数,这一流程可以轻易地适应大多数游戏引擎,从而增强了EasyCraft的通用性。此外,本研究还通过整合文本到图像的技术来提升精准文本制作角色的能力。实验表明,该方法的成果具有显著效果,实现了跨多种角色引擎的适应性。
Key Takeaways:
- 角色游戏中的个性化角色定制对于提升玩家参与度至关重要。
- 当前自动化方法在游戏引擎通用性方面存在挑战,通常受限于特定图像领域和单一输入类型。
- EasyCraft是一种创新的端到端前馈框架,支持文本和图像两种输入方式,实现角色自动化定制。
- EasyCraft通过自我监督学习建立统一特征分布,使得任何风格的照片都能嵌入到统一的特征表示中。
- EasyCraft通过将统一特征分布映射到游戏引擎的制作参数,适应多种游戏引擎。
- EasyCraft集成了文本到图像的技术,提高了基于文本的角色制作的精准度。
点此查看论文截图



Personalizing the meshed SPL/NAC Brain Atlas for patient-specific scientific computing using SynthMorph
Authors:Andy Huynh, Benjamin Zwick, Michael Halle, Adam Wittek, Karol Miller
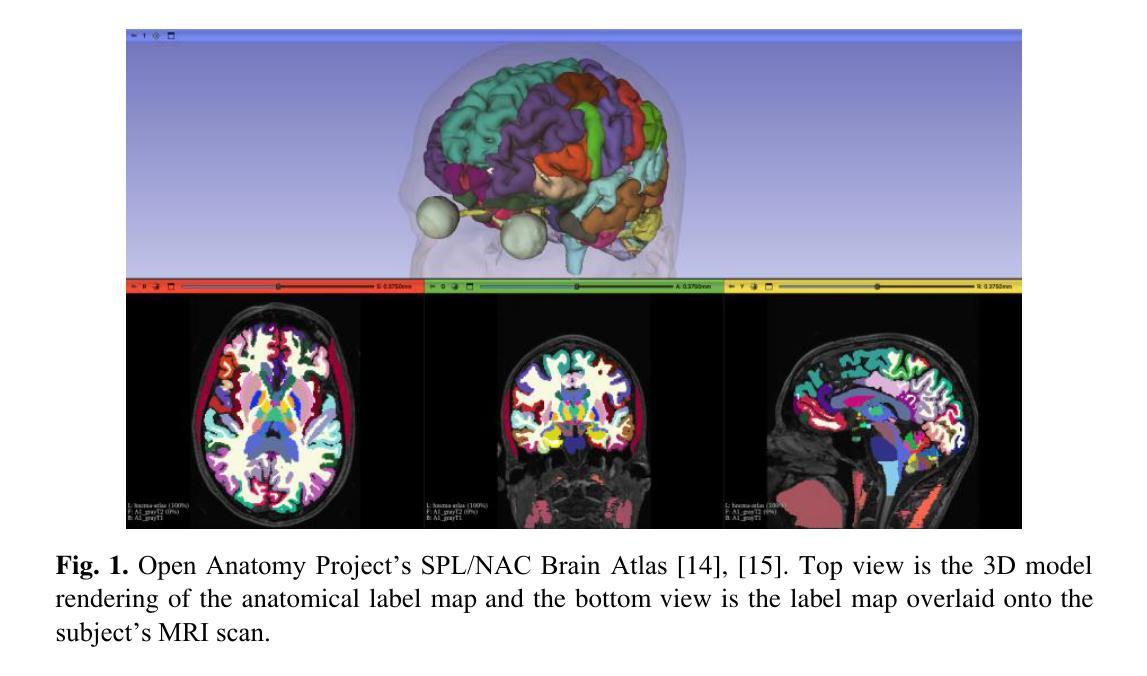
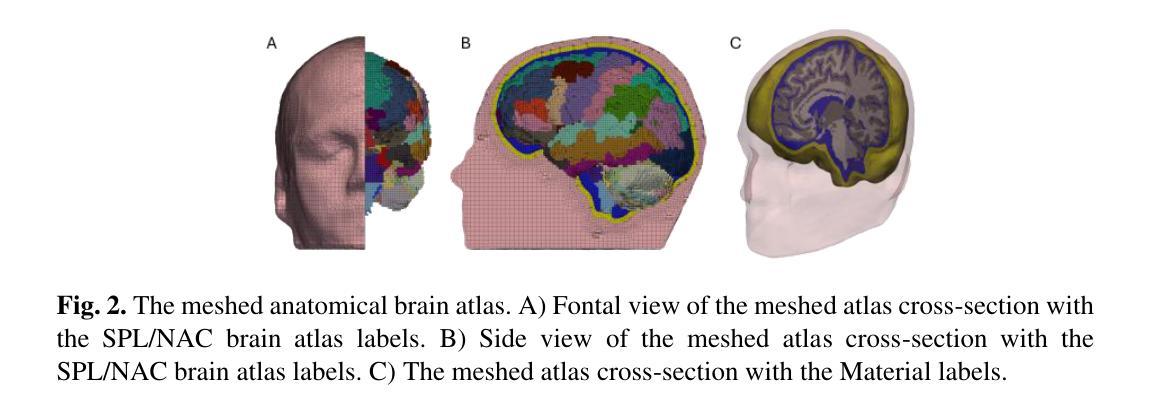
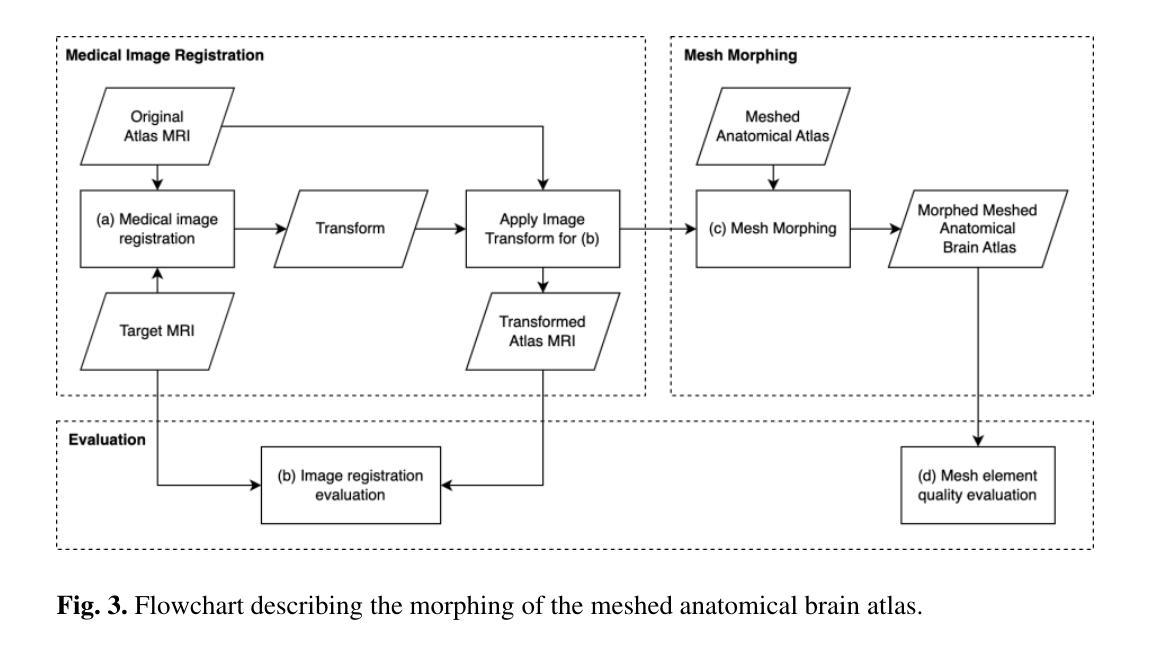
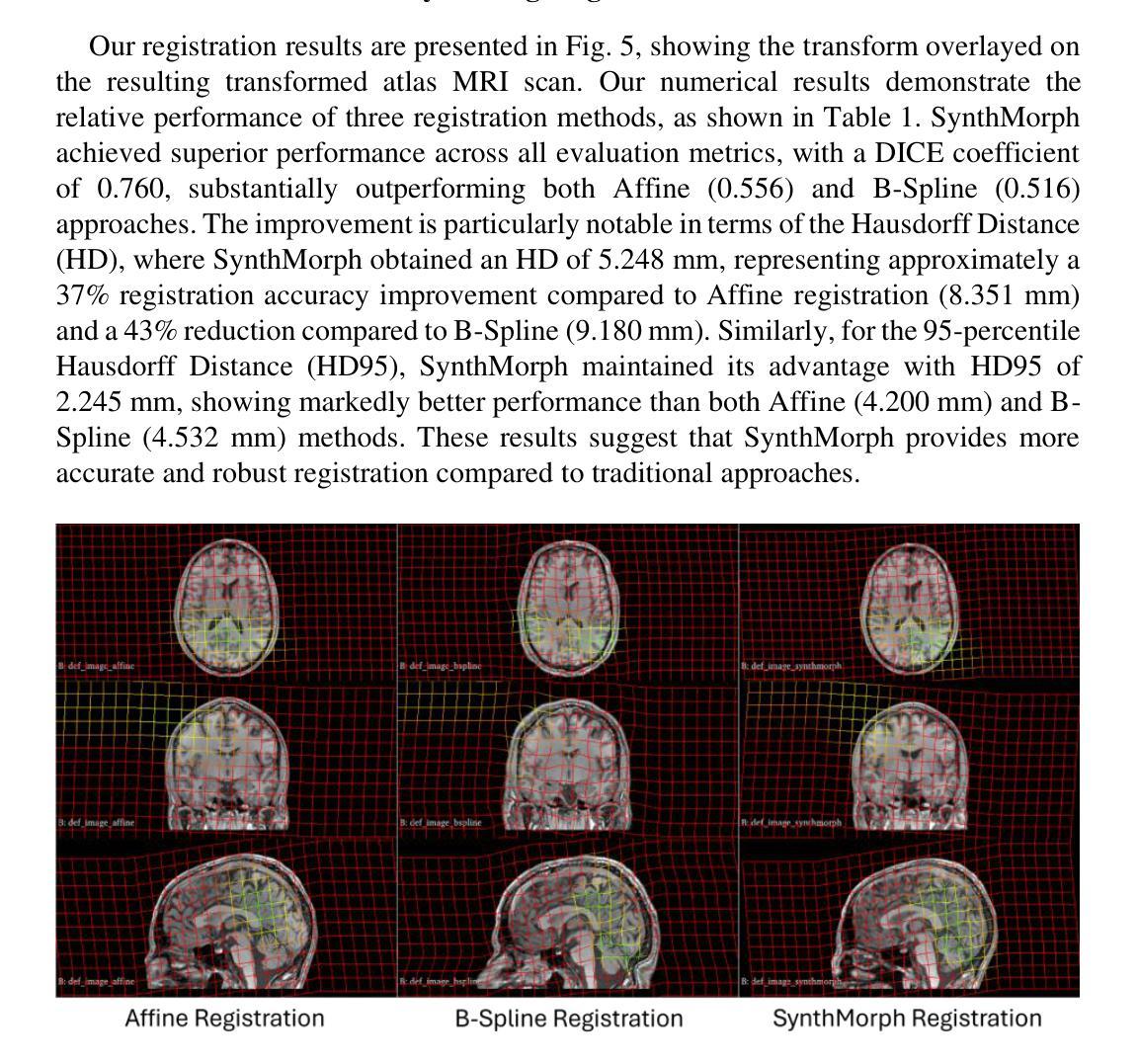
Developing personalized computational models of the human brain remains a challenge for patient-specific clinical applications and neuroscience research. Efficient and accurate biophysical simulations rely on high-quality personalized computational meshes derived from patient’s segmented anatomical MRI scans. However, both automatic and manual segmentation are particularly challenging for tissues with limited visibility or low contrast. In this work, we present a new method to create personalized computational meshes of the brain, streamlining the development of computational brain models for clinical applications and neuroscience research. Our method uses SynthMorph, a state-of-the-art anatomy-aware, learning-based medical image registration approach, to morph a comprehensive hexahedral mesh of the open-source SPL/NAC Brain Atlas to patient-specific MRI scans. Each patient-specific mesh includes over 300 labeled anatomical structures, more than any existing manual or automatic methods. Our registration-based method takes approximately 20 minutes, significantly faster than current state-of-the-art mesh generation pipelines, which can take up to two hours. We evaluated several state-of-the-art medical image registration methods, including SynthMorph, to determine the most optimal registration method to morph our meshed anatomical brain atlas to patient MRI scans. Our results demonstrate that SynthMorph achieved high DICE similarity coefficients and low Hausdorff Distance metrics between anatomical structures, while maintaining high mesh element quality. These findings demonstrate that our registration-based method efficiently and accurately produces high-quality, comprehensive personalized brain meshes, representing an important step toward clinical translation.
构建个性化的人类大脑计算模型仍然是针对特定患者的临床应用和神经科学研究的一大挑战。高效且准确的生物物理模拟依赖于从患者分割的MRI扫描结果中得出的高质量个性化计算网格。然而,对于可见度有限或对比度较低的组织,自动和手动分割都具有特殊挑战性。在这项工作中,我们提出了一种创建个性化大脑计算网格的新方法,为临床应用和神经科学研究中计算大脑模型的发展提供了便利。我们的方法使用SynthMorph——一种基于最新解剖结构感知的学习型医学图像配准方法,将开源SPL/NAC脑图谱的综合六面体网格转变为针对特定患者的MRI扫描。每个患者特定的网格包括超过300个标记的解剖结构,比现有的任何手动或自动方法都要多。我们的基于配准的方法大约需要20分钟,显著快于当前最先进的网格生成管道(可能长达两个小时)。我们评估了几种最先进的医学图像配准方法,包括SynthMorph,以确定将我们网格化的解剖结构脑图谱转变为患者MRI扫描的最优配准方法。我们的结果表明,SynthMorph在解剖结构之间实现了高的DICE相似系数和低的Hausdorff距离指标,同时保持了高的网格元素质量。这些发现表明,我们的基于配准的方法能够高效且准确地产生高质量、全面的个性化大脑网格,是向临床应用翻译的重要一步。
论文及项目相关链接
Summary
大脑的计算模型发展具有个性化是一个对临床诊断和治疗和神经科学研究极具挑战的任务。本文提出了一种新的创建个性化大脑计算网格的方法,该方法使用SynthMorph技术将开源SPL/NAC Brain Atlas的综合六面体网格映射到患者特定的MRI扫描上。此方法快速高效,能够在大约20分钟内生成包含超过300个标记解剖结构的个性化网格,比现有的最先进的网格生成管道更快速。评估和对比实验证明,该方法能够高效且准确地生成高质量、全面的个性化大脑网格。
Key Takeaways
- 个性化的计算模型对于临床和神经科学研究具有挑战。
- 提出一种基于SynthMorph的新方法创建个性化大脑计算网格。
- 该方法能够映射开源大脑图谱到患者特定的MRI扫描上。
- 方法快速高效,仅需要大约20分钟生成包含超过300个标记解剖结构的个性化网格。
- 对比实验显示,该方法在生成高质量网格方面表现优秀。
- SynthMorph技术在解剖结构映射方面表现出高DICE相似系数和低Hausdorff距离指标。
点此查看论文截图


MFM-DA: Instance-Aware Adaptor and Hierarchical Alignment for Efficient Domain Adaptation in Medical Foundation Models
Authors:Jia-Xuan Jiang, Wenhui Lei, Yifeng Wu, Hongtao Wu, Furong Li, Yining Xie, Xiaofan Zhang, Zhong Wang
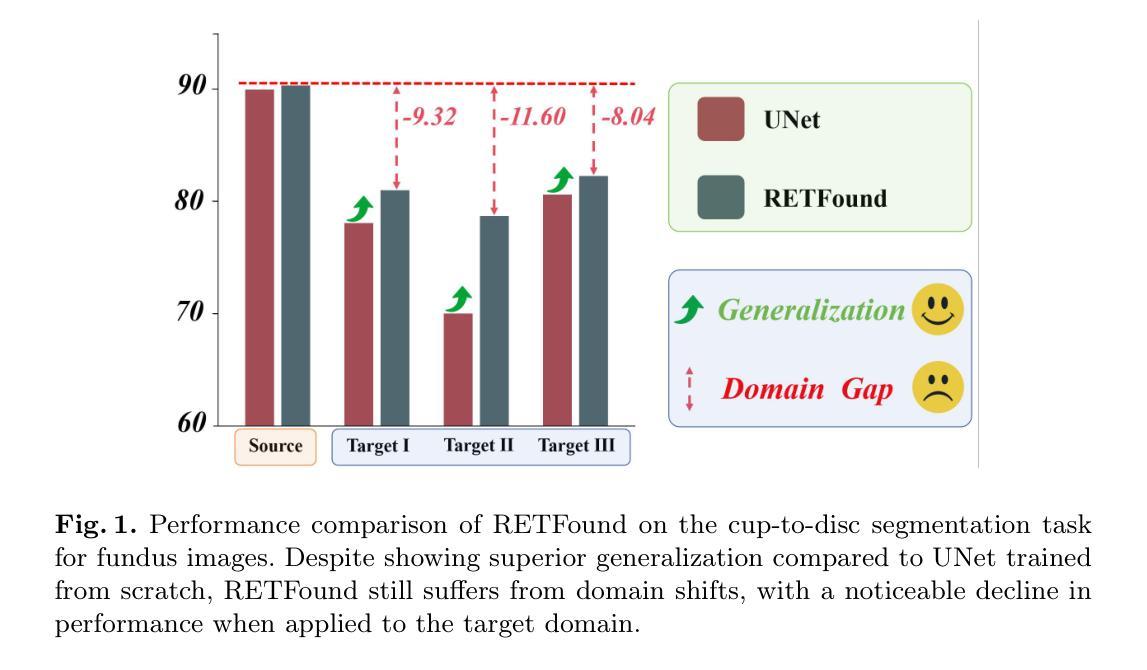
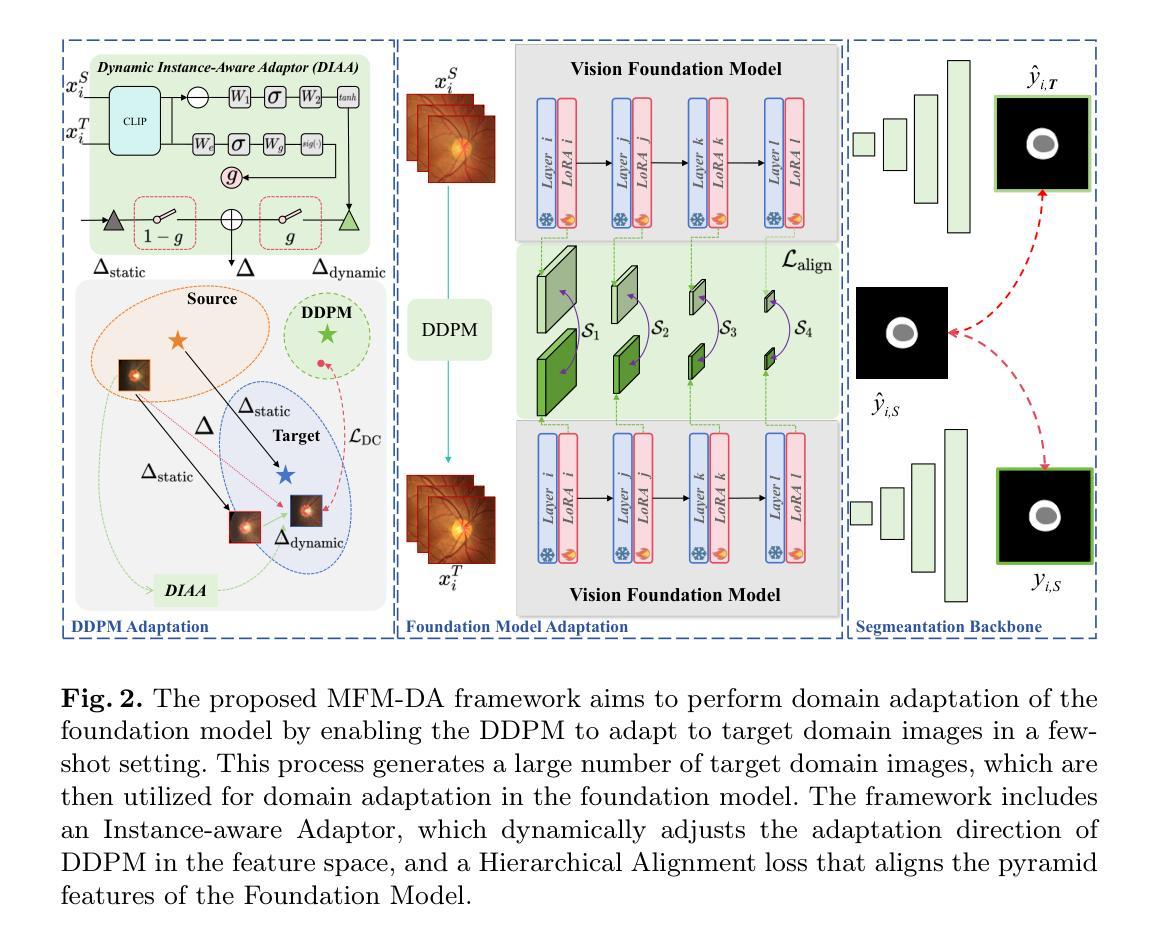
Medical Foundation Models (MFMs), trained on large-scale datasets, have demonstrated superior performance across various tasks. However, these models still struggle with domain gaps in practical applications. Specifically, even after fine-tuning on source-domain data, task-adapted foundation models often perform poorly in the target domain. To address this challenge, we propose a few-shot unsupervised domain adaptation (UDA) framework for MFMs, named MFM-DA, which only leverages a limited number of unlabeled target-domain images. Our approach begins by training a Denoising Diffusion Probabilistic Model (DDPM), which is then adapted to the target domain using a proposed dynamic instance-aware adaptor and a distribution direction loss, enabling the DDPM to translate source-domain images into the target domain style. The adapted images are subsequently processed through the MFM, where we introduce a designed channel-spatial alignment Low-Rank Adaptation (LoRA) to ensure effective feature alignment. Extensive experiments on optic cup and disc segmentation tasks demonstrate that MFM-DA outperforms state-of-the-art methods. Our work provides a practical solution to the domain gap issue in real-world MFM deployment. Code will be available at here.
基于大规模数据集训练的医学基础模型(MFMs)在各种任务中表现出卓越的性能。然而,这些模型在实际应用中的领域差异上仍然存在问题。具体来说,即使在源域数据上进行微调后,任务适应的基础模型在目标域中的表现往往很差。为了解决这一挑战,我们提出了一种针对MFMs的少量无监督领域自适应(UDA)框架,名为MFM-DA,它仅利用少量无标签的目标域图像。我们的方法首先训练一个去噪扩散概率模型(DDPM),然后使用该模型通过提出的动态实例感知适配器和分布方向损失来适应目标域,使DDPM能够将源域图像转换为目标域风格。适应后的图像随后通过MFM进行处理,我们在这里引入了一种设计的通道空间对齐低秩适配(LoRA)以确保有效的特征对齐。在视神经杯和视盘分割任务上的大量实验表明,MFM-DA优于最新方法。我们的工作为解决现实世界MFM部署中的领域差异问题提供了实际解决方案。代码将在此处提供。
论文及项目相关链接
Summary
大型医疗基础模型(MFMs)在各种任务中表现出卓越性能,但在实际应用中存在领域差距问题。为解决这一问题,我们提出一种面向MFM的少数样本无监督领域自适应(UDA)框架,名为MFM-DA,仅需利用有限数量的无标签目标领域图像。通过训练去噪扩散概率模型(DDPM),并结合动态实例感知适配器和分布方向损失,使DDPM能够翻译源领域图像为目标领域风格。经过处理的图像再通过MFM,引入通道空间对齐低秩适配(LoRA)技术,确保特征的有效对齐。在光学杯和光盘分割任务上的广泛实验表明,MFM-DA优于最新方法。我们的研究为解决现实世界中MFM部署的领域差距问题提供了实用解决方案。
Key Takeaways
- MFMs在各种任务中表现出卓越性能,但在实际应用中存在领域差距问题。
- 提出一种面向MFM的少数样本无监督领域自适应框架MFM-DA。
- MFM-DA利用DDPM翻译源领域图像为目标领域风格。
- 通过动态实例感知适配器和分布方向损失实现DDPM的适配。
- 引入通道空间对齐低秩适配(LoRA)技术,确保特征有效对齐。
- 在光学杯和光盘分割任务上,MFM-DA表现优于现有方法。
点此查看论文截图

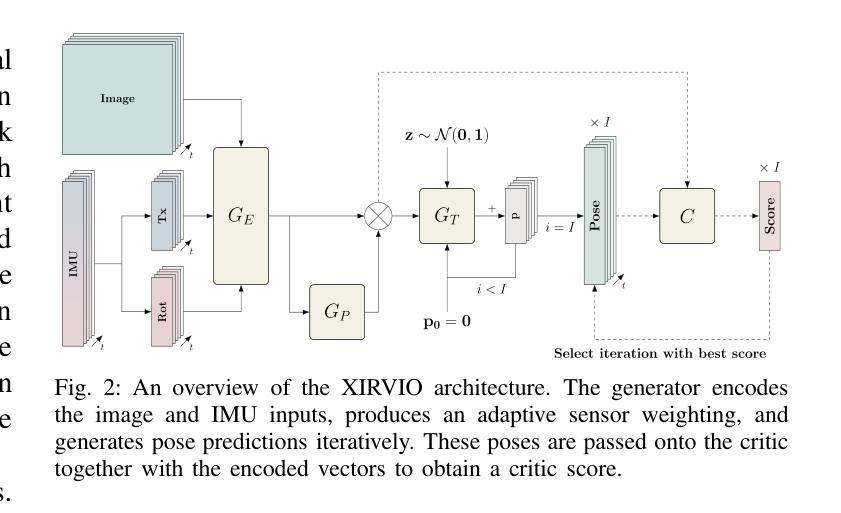
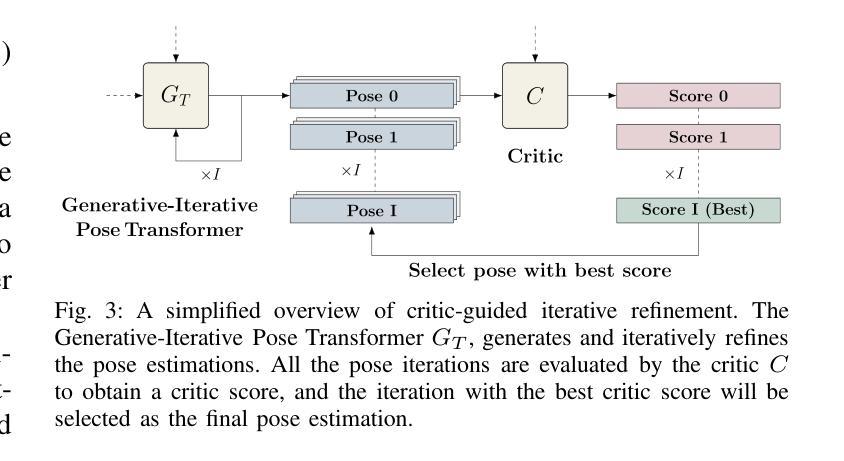
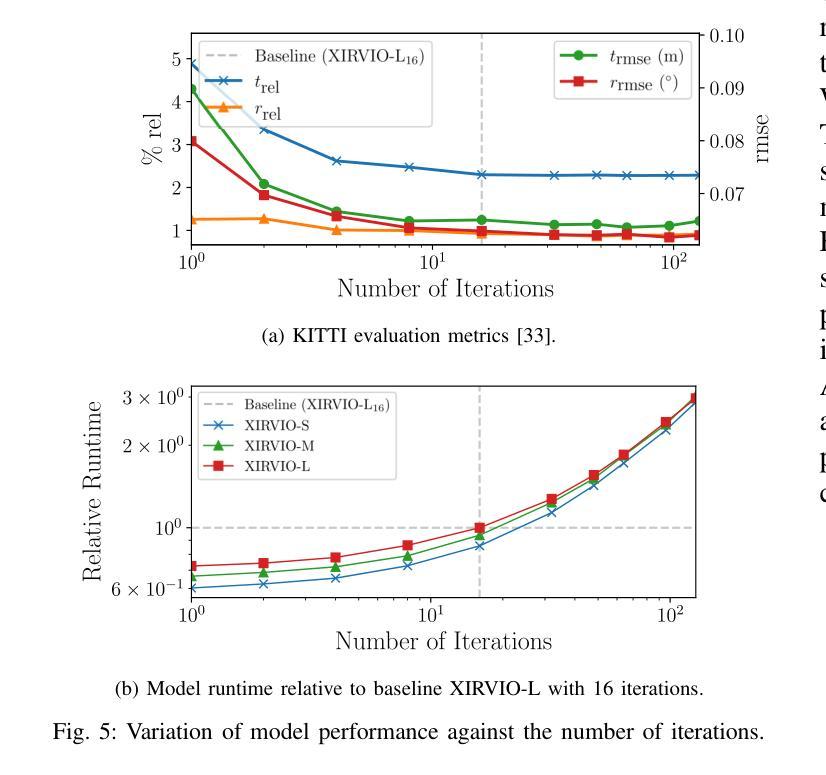
XIRVIO: Critic-guided Iterative Refinement for Visual-Inertial Odometry with Explainable Adaptive Weighting
Authors:Chit Yuen Lam, Ronald Clark, Basaran Bahadir Kocer
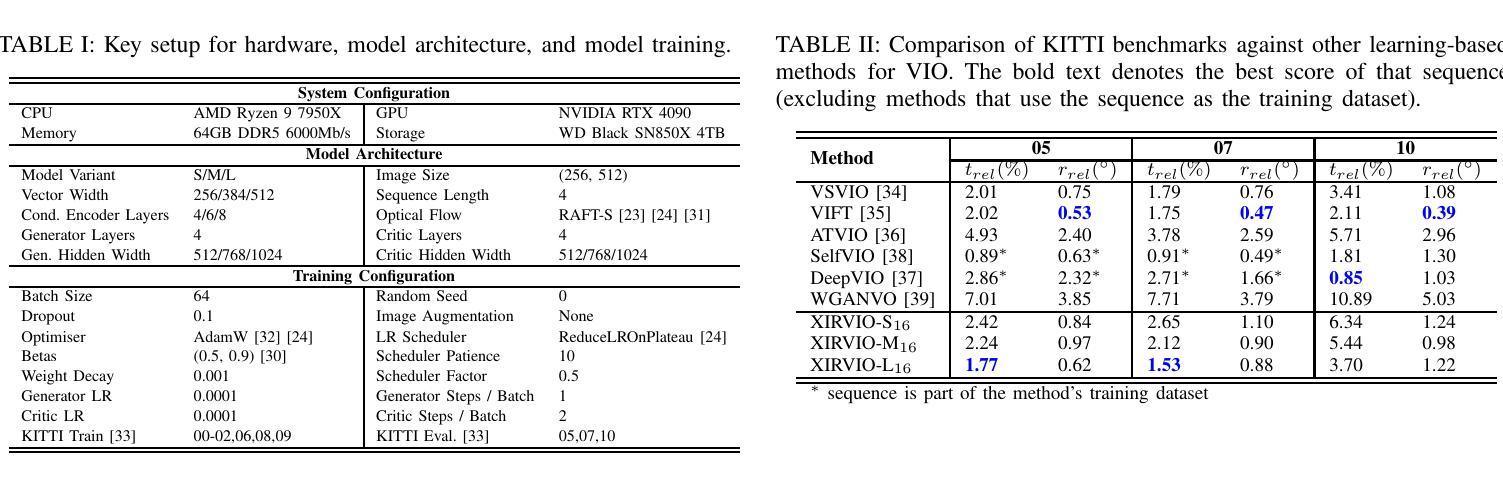
We introduce XIRVIO, a transformer-based Generative Adversarial Network (GAN) framework for monocular visual inertial odometry (VIO). By taking sequences of images and 6-DoF inertial measurements as inputs, XIRVIO’s generator predicts pose trajectories through an iterative refinement process which are then evaluated by the critic to select the iteration with the optimised prediction. Additionally, the self-emergent adaptive sensor weighting reveals how XIRVIO attends to each sensory input based on contextual cues in the data, making it a promising approach for achieving explainability in safety-critical VIO applications. Evaluations on the KITTI dataset demonstrate that XIRVIO matches well-known state-of-the-art learning-based methods in terms of both translation and rotation errors.
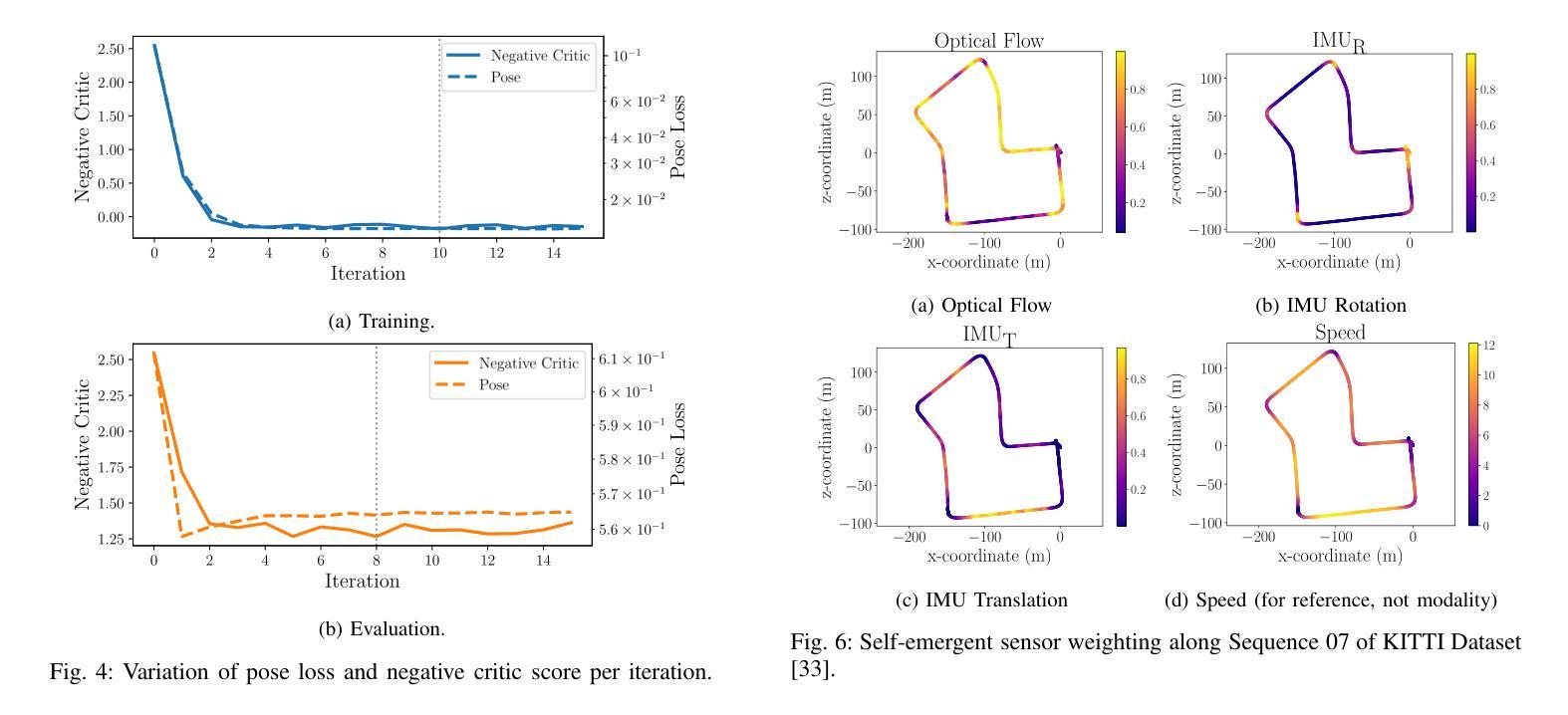
我们介绍了XIRVIO,这是一个基于Transformer的生成对抗网络(GAN)框架,用于单目视觉惯性里程计(VIO)。XIRVIO的生成器以图像序列和6DoF惯性测量为输入,通过迭代优化过程预测姿态轨迹,然后由评判器评估并选择具有优化预测结果的迭代。此外,自适应传感器权重的自我涌现揭示了XIRVIO如何根据数据中的上下文线索关注每个感官输入,使其成为在安全关键的VIO应用中实现可解释性的有前途的方法。在KITTI数据集上的评估表明,XIRVIO在平移和旋转误差方面与知名最先进的基于学习的方法相匹配。
论文及项目相关链接
PDF 7 pages, 6 figures
Summary
XIRVIO是一种基于Transformer的生成对抗网络(GAN)框架,用于单目视觉惯性里程计(VIO)。它通过接收图像序列和6自由度(6-DoF)惯性测量作为输入,生成器通过迭代优化过程预测姿态轨迹,然后由批判家评估并选择最佳迭代预测。此外,自适应传感器权重的自我涌现显示了XIRVIO如何根据数据中的上下文线索关注每个感官输入,使其在安全性至关重要的VIO应用中实现可解释性的有前途的方法。在KITTI数据集上的评估表明,XIRVIO在翻译和旋转误差方面与基于学习的先进方法相匹配。
Key Takeaways
- XIRVIO是一个基于Transformer的GAN框架,用于单目视觉惯性里程计(VIO)。
- 它通过图像序列和6-DoF惯性测量作为输入来预测姿态轨迹。
- 生成器通过迭代优化过程进行预测,然后由批判家选择最佳迭代预测。
- 自适应传感器权重的自我涌现揭示了XIRVIO如何根据上下文线索关注每个感官输入。
- XIRVIO在VIO应用中具有实现可解释性的潜力,尤其在安全性至关重要的场景中。
- 在KITTI数据集上的评估显示,XIRVIO在翻译和旋转误差方面与最先进的基于学习的方法相匹配。
- XIRVIO框架有助于解释视觉惯性数据并优化姿态轨迹预测。
点此查看论文截图