⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-06 更新
REAct: Rational Exponential Activation for Better Learning and Generalization in PINNs
Authors:Sourav Mishra, Shreya Hallikeri, Suresh Sundaram
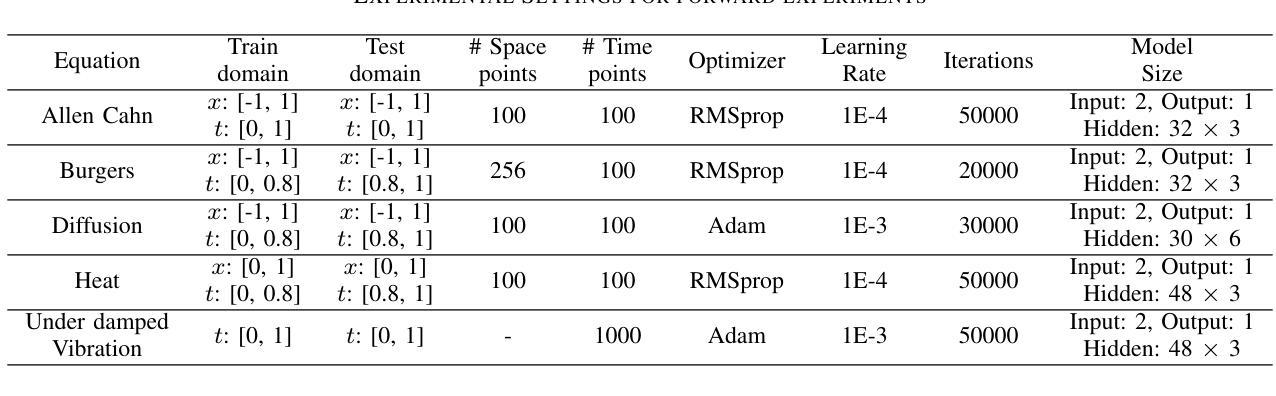
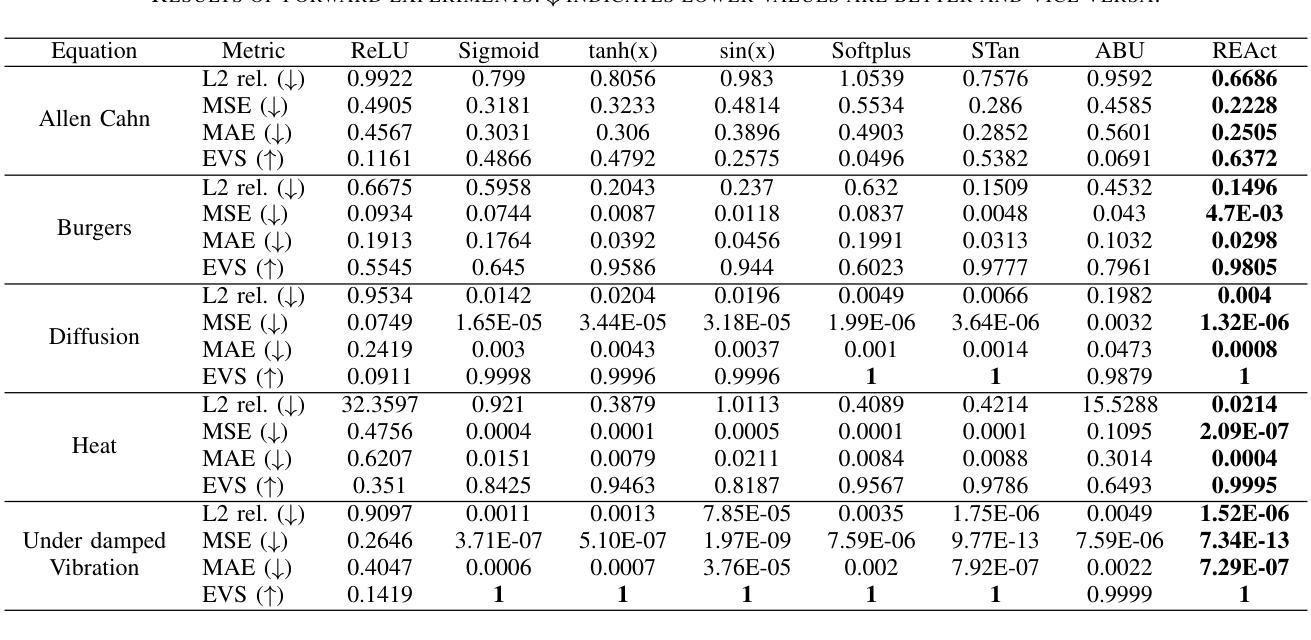
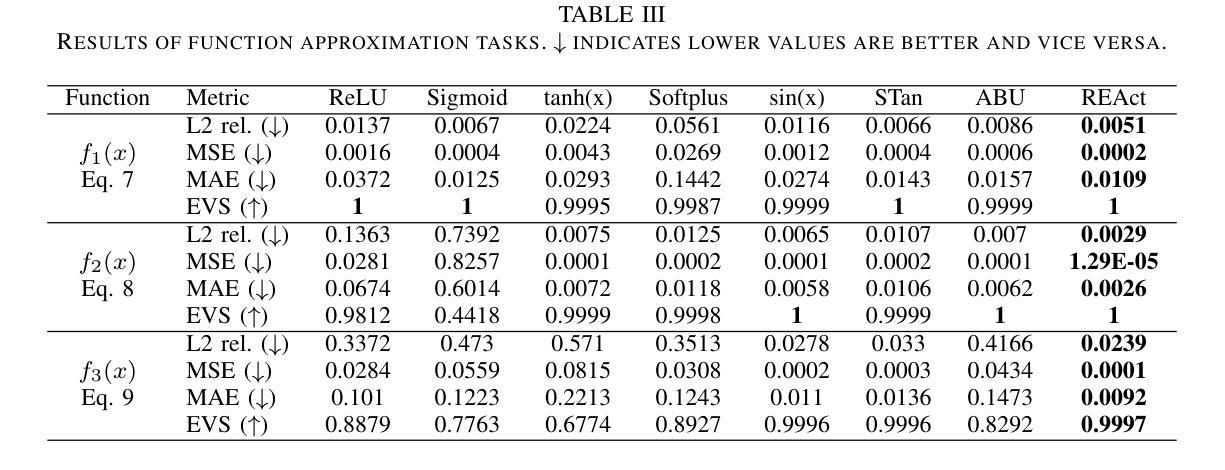
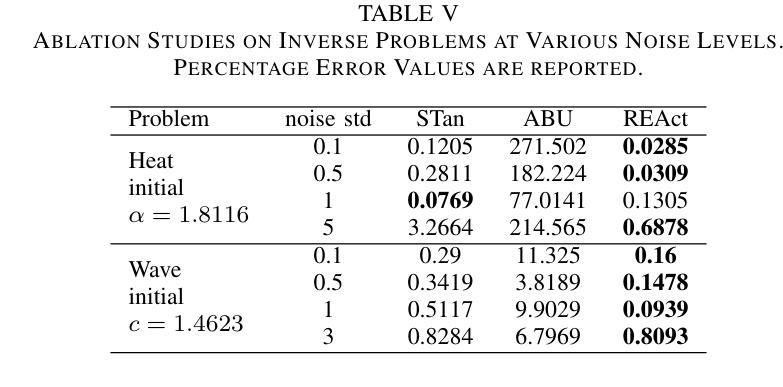
Physics-Informed Neural Networks (PINNs) offer a promising approach to simulating physical systems. Still, their application is limited by optimization challenges, mainly due to the lack of activation functions that generalize well across several physical systems. Existing activation functions often lack such flexibility and generalization power. To address this issue, we introduce Rational Exponential Activation (REAct), a generalized form of tanh consisting of four learnable shape parameters. Experiments show that REAct outperforms many standard and benchmark activations, achieving an MSE three orders of magnitude lower than tanh on heat problems and generalizing well to finer grids and points beyond the training domain. It also excels at function approximation tasks and improves noise rejection in inverse problems, leading to more accurate parameter estimates across varying noise levels.
物理信息神经网络(PINNs)为模拟物理系统提供了一种有前途的方法。然而,其应用受到优化挑战的限制,主要是由于缺乏能在多个物理系统中良好通用的激活函数。现有的激活函数通常缺乏这种灵活性和通用性。为了解决这一问题,我们引入了有理指数激活(REAct),它是tanh的一种广义形式,由四个可学习的形状参数组成。实验表明,REAct在许多标准和基准测试中表现优于其他激活函数,在处理热问题时,均方误差比tanh低三个数量级,并能很好地推广到更精细的网格和训练域之外的点。它在函数逼近任务中也表现出色,提高了反问题中的抗噪能力,在不同噪声水平下能更准确地估计参数。
论文及项目相关链接
PDF 5 pages, 5 tables, 1 figure; Accepted at ICASSP 2025
Summary
物理信息神经网络(PINNs)在模拟物理系统方面具有巨大潜力,但其应用受到优化挑战的限制,主要因为缺乏能够在多个物理系统中良好通用的激活函数。为解决此问题,我们引入了理性指数激活(REAct),它是双曲正切的一种广义形式,包含四个可学习的形状参数。实验表明,REAct在许多标准和基准测试中表现优于其他激活函数,在热问题上实现了比双曲正切低三个数量级的均方误差,并能在训练域之外的更精细网格和点上良好通用。它还擅长函数逼近任务,并在反问题中提高了噪声抑制能力,从而在不同噪声水平下提供更准确的参数估计。
Key Takeaways
- 物理信息神经网络(PINNs)是模拟物理系统的一种有前途的方法。
- 现有激活函数在应用于物理系统时缺乏灵活性和通用性。
- 引入了一种新的激活函数——理性指数激活(REAct),它是双曲正切的广义形式,具有四个可学习的形状参数。
- REAct在实验中表现出优异的性能,优于许多标准和基准测试中的其他激活函数。
- REAct在热问题上实现了低均方误差,并能良好地通用到训练域之外的更精细网格和点。
- REAct擅长函数逼近任务,并在反问题中提高了噪声抑制能力。
点此查看论文截图


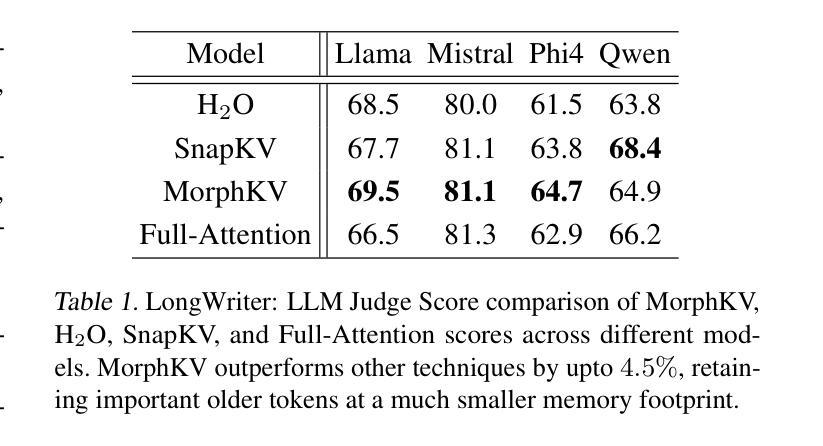
Dialogue Without Limits: Constant-Sized KV Caches for Extended Responses in LLMs
Authors:Ravi Ghadia, Avinash Kumar, Gaurav Jain, Prashant Nair, Poulami Das
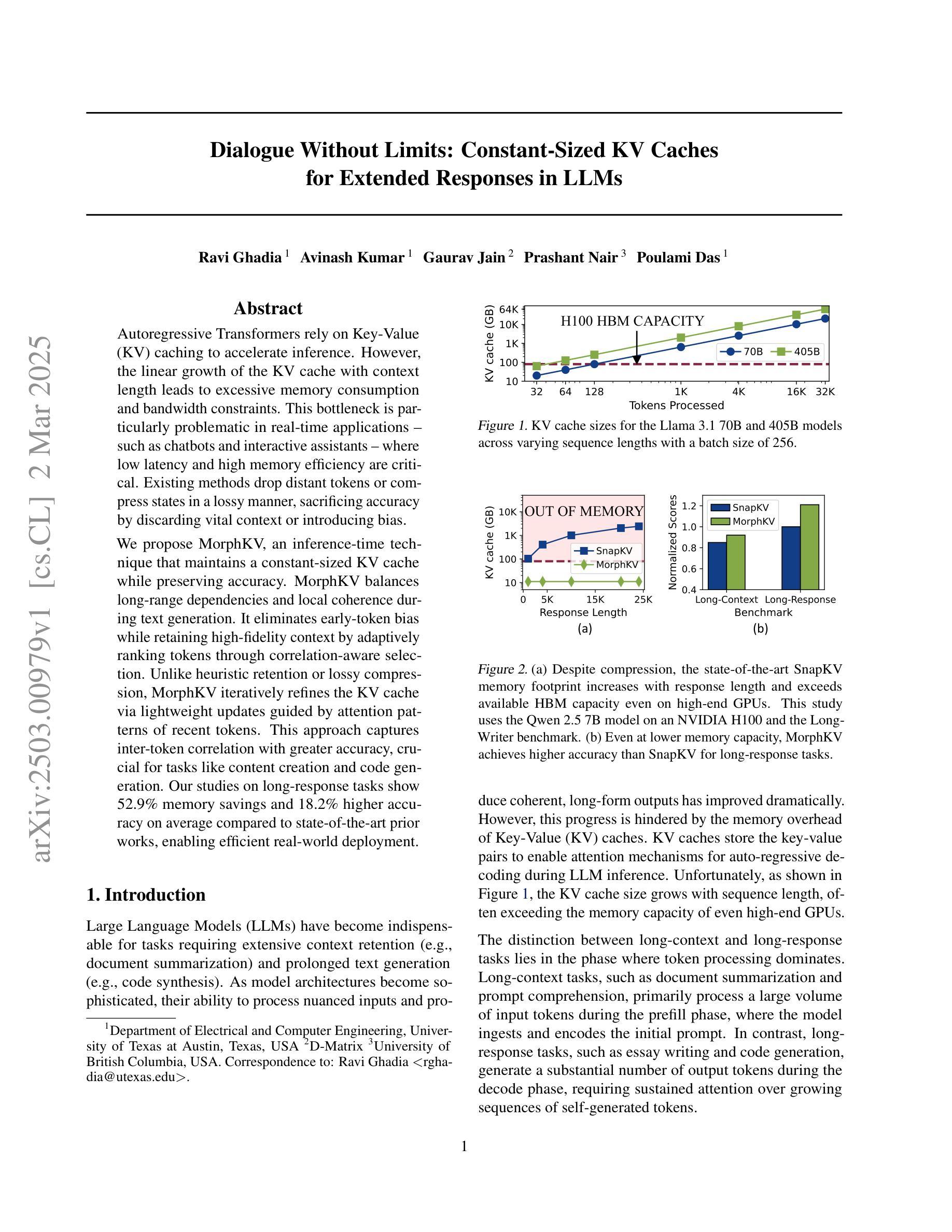
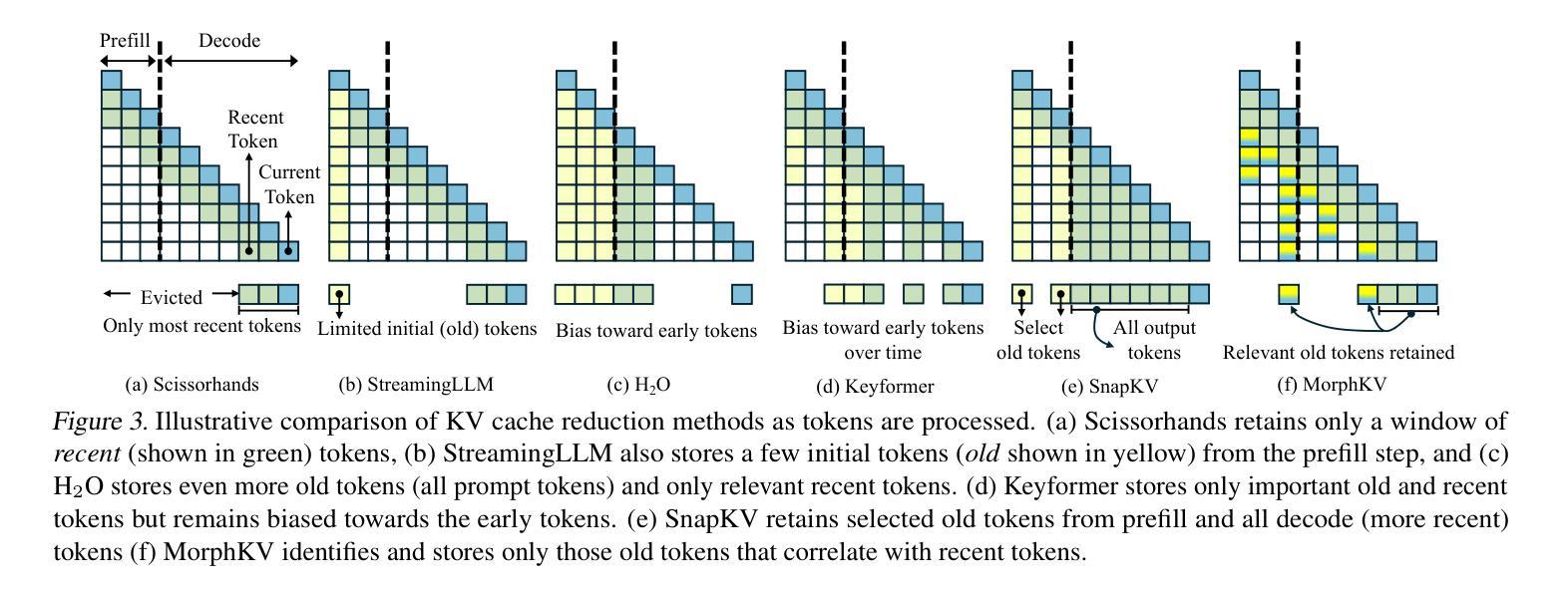
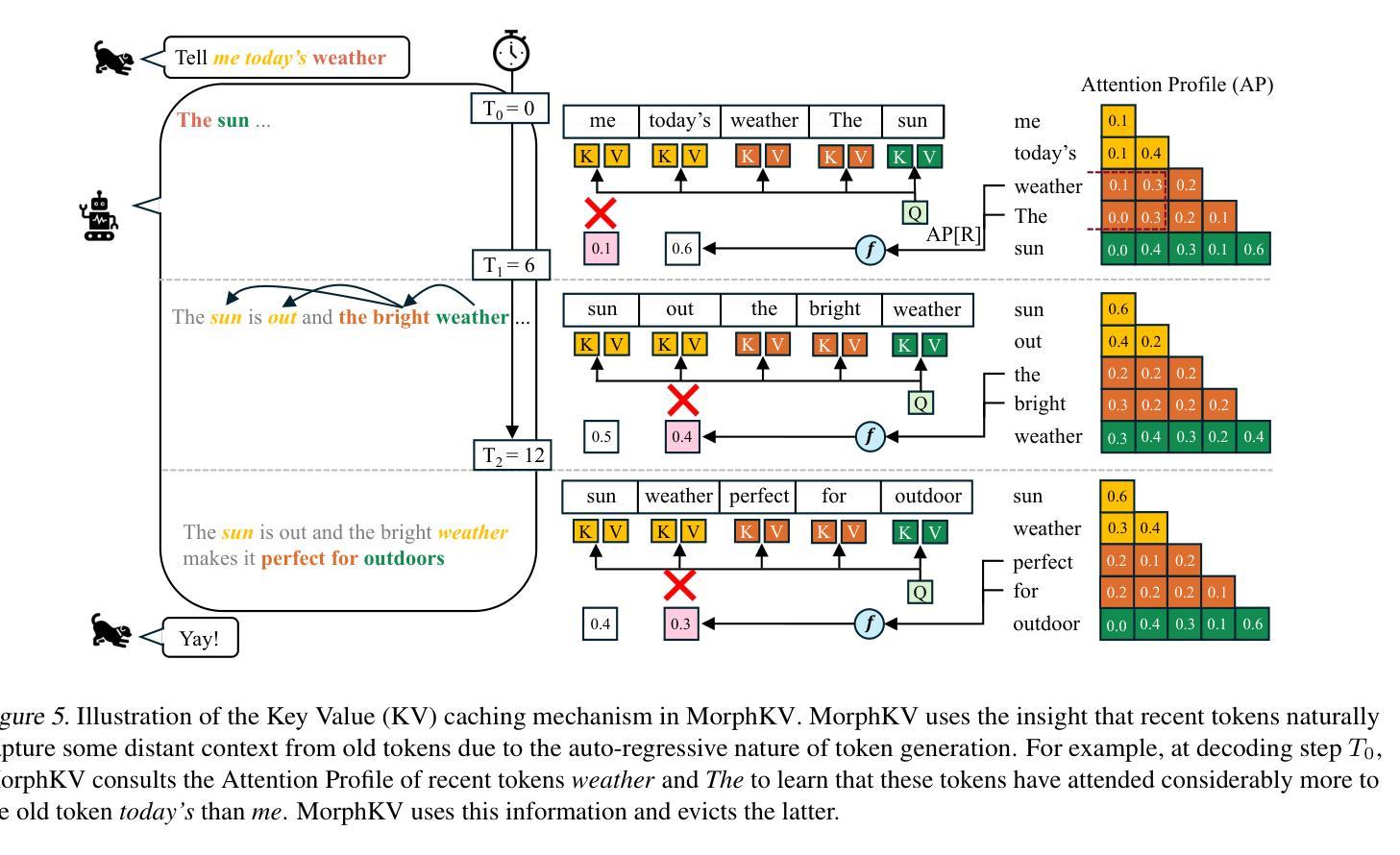
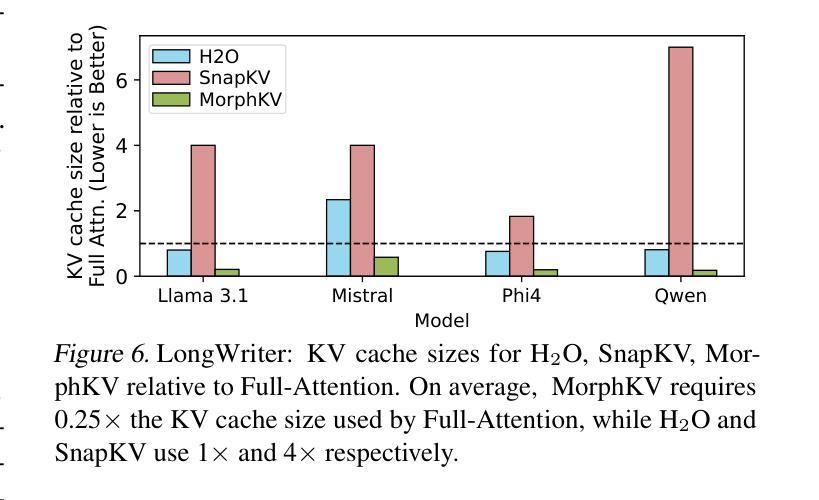
Autoregressive Transformers rely on Key-Value (KV) caching to accelerate inference. However, the linear growth of the KV cache with context length leads to excessive memory consumption and bandwidth constraints. This bottleneck is particularly problematic in real-time applications – such as chatbots and interactive assistants – where low latency and high memory efficiency are critical. Existing methods drop distant tokens or compress states in a lossy manner, sacrificing accuracy by discarding vital context or introducing bias. We propose MorphKV, an inference-time technique that maintains a constant-sized KV cache while preserving accuracy. MorphKV balances long-range dependencies and local coherence during text generation. It eliminates early-token bias while retaining high-fidelity context by adaptively ranking tokens through correlation-aware selection. Unlike heuristic retention or lossy compression, MorphKV iteratively refines the KV cache via lightweight updates guided by attention patterns of recent tokens. This approach captures inter-token correlation with greater accuracy, crucial for tasks like content creation and code generation. Our studies on long-response tasks show 52.9$%$ memory savings and 18.2$%$ higher accuracy on average compared to state-of-the-art prior works, enabling efficient real-world deployment.
自回归Transformer依赖于键值(KV)缓存来加速推理。然而,KV缓存随上下文长度呈线性增长,导致内存消耗过大和带宽限制。这一瓶颈在实时应用(如聊天机器人和交互式助手)中尤其成问题,在这些应用中,低延迟和高内存效率至关重要。现有方法会丢弃远处的标记或以有损的方式压缩状态,牺牲了准确性,要么丢弃重要上下文,要么引入偏见。我们提出了MorphKV,这是一种推理时间技术,可以保持恒定大小的KV缓存同时保持准确性。MorphKV在文本生成过程中平衡了长程依赖和局部一致性。它通过相关感知选择自适应地对令牌进行排名,消除了早期令牌的偏见,同时保留高保真上下文。与启发式保留或有损压缩不同,MorphKV通过最近令牌的注意力模式指导进行轻量级更新,从而迭代地完善KV缓存。这种方法更准确地捕捉了令牌之间的相关性,对于内容创建和代码生成等任务至关重要。我们对长响应任务的研究表明,与最新先前工作相比,平均节省了52.9%的内存,准确率提高了18.2%,为实际部署提供了高效能。
论文及项目相关链接
Summary
本文探讨了Autoregressive Transformer在推理过程中依赖Key-Value缓存的问题。由于KV缓存随语境长度线性增长,导致内存消耗大、带宽受限。针对实时应用(如聊天机器人和交互式助手)中的低延迟和高内存效率需求,本文提出了一种名为MorphKV的推理时间技术,可在保持准确性的同时,维护恒定大小的KV缓存。MorphKV通过关联感知选择,自适应地平衡长远依赖关系和本地连贯性,在文本生成过程中消除早期标记偏见并保留高保真上下文。与启发式保留或有损压缩不同,MorphKV通过最近标记的注意力模式进行轻量级更新,对标记间关联进行更精确捕捉,特别适用于内容创建和代码生成等任务。在针对长响应任务的测试中,MorphKV与现有技术相比平均节省内存达52.9%,准确率提高18.2%。
Key Takeaways
Autoregressive Transformer使用Key-Value缓存来加速推理过程。但由于语境长度的影响,这种方法的内存消耗较大。存在性能瓶颈的问题限制了其用于实时应用的效率。文中特别指出了这一问题对于像聊天机器人和交互式助手这样的实时应用的重要性。
当前方法在处理长文本时可能会牺牲准确性,因为它们会丢弃重要上下文或引入偏见,这限制了它们的性能。特别是它们会丢弃距离较远的标记或有损地压缩状态。
提出了一种名为MorphKV的新方法来解决上述问题。它能在保持准确性的同时维护一个恒定大小的KV缓存。这种方法通过关联感知选择来平衡长远依赖关系和本地连贯性,从而提高文本生成的效率和质量。这是通过在推理时间中利用关联分析来逐渐精炼KV缓存实现的。该方法实现了高质量和效率间的平衡,不会牺牲准确性或引入偏见。这对于内容创建和代码生成等任务尤为重要。
点此查看论文截图

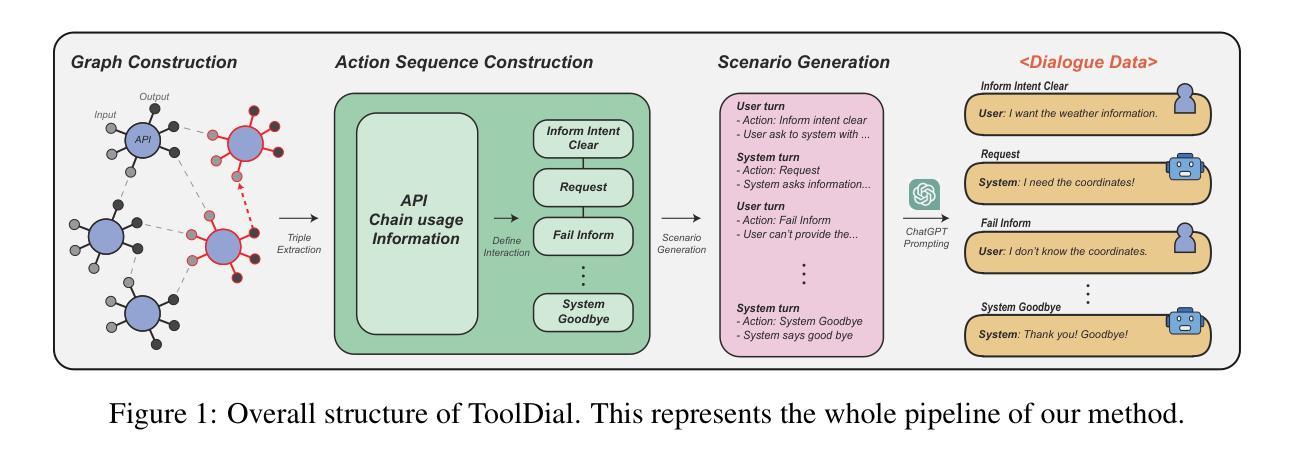
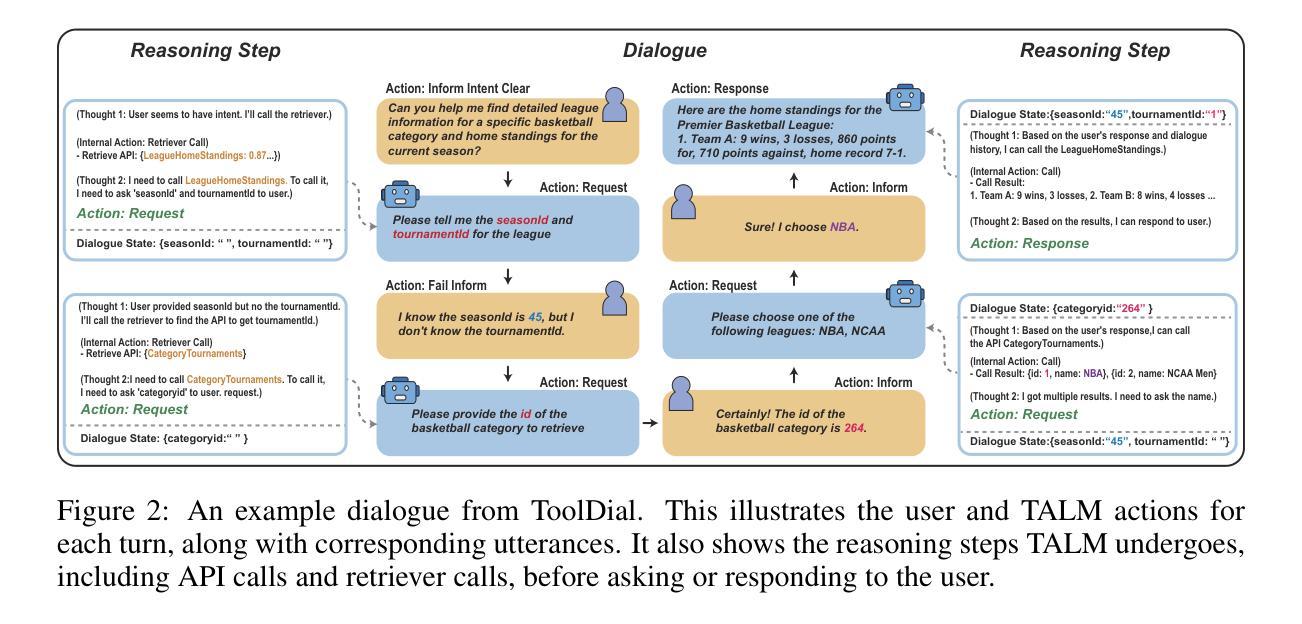
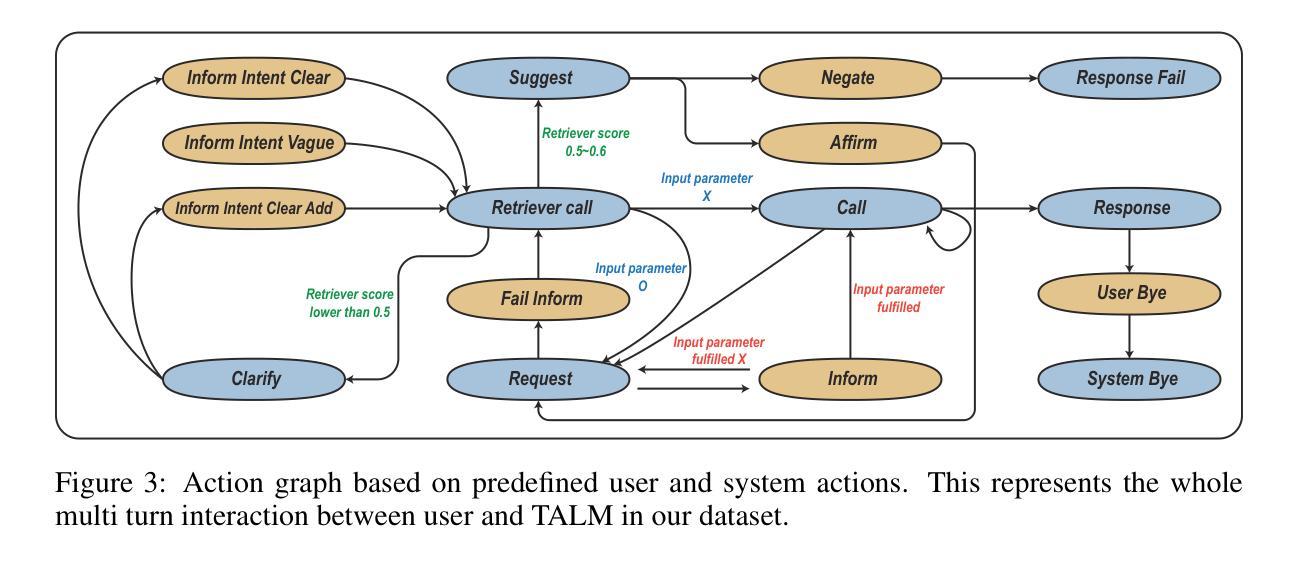
ToolDial: Multi-turn Dialogue Generation Method for Tool-Augmented Language Models
Authors:Jeonghoon Shim, Gyuhyeon Seo, Cheongsu Lim, Yohan Jo
Tool-Augmented Language Models (TALMs) leverage external APIs to answer user queries across various domains. However, existing benchmark datasets for TALM research often feature simplistic dialogues that do not reflect real-world scenarios, such as the need for models to ask clarifying questions or proactively call additional APIs when essential information is missing. To address these limitations, we construct and release ToolDial, a dataset comprising 11,111 multi-turn dialogues, with an average of 8.95 turns per dialogue, based on APIs from RapidAPI. ToolDial has two key characteristics. First, the dialogues incorporate 16 user and system actions (e.g., “Request”, “Clarify”, “Fail inform”) to capture the rich dynamics of real-world interactions. Second, we simulate dialogues where the system requests necessary information from the user based on API documentation and seeks additional APIs if the user fails to provide the required information. To facilitate this process, we introduce a method for generating an API graph that represents input and output compatibility between APIs. Using ToolDial, we evaluate a suite of language models on their ability to predict correct actions and extract input parameter values for API calls from the dialogue history. Modern language models achieve accuracy scores below 70%, indicating substantial room for improvement. We release our dataset and code at https://github.com/holi-lab/ToolDial.
工具增强语言模型(TALM)利用外部API来回答用户在不同领域的查询。然而,TALM研究现有的基准数据集通常包含简单的对话,并不能反映真实世界场景,例如在需要模型提出明确问题或主动调用额外的API时缺少关键信息。为了解决这些局限性,我们构建并发布了ToolDial数据集,该数据集包含11,111个多轮对话,每个对话平均有8.95轮,基于RapidAPI的API。ToolDial有两个关键特点。首先,对话中融入了16个用户和系统动作(例如“请求”、“明确”和“失败通知”),以捕捉现实互动中的丰富动态。其次,我们模拟了系统根据API文档从用户那里请求必要信息的对话,并在用户未能提供所需信息时寻求额外的API。为了促进这一过程,我们引入了一种生成API图谱的方法,该图谱代表API之间的输入和输出兼容性。使用ToolDial数据集,我们评估了一系列语言模型在预测正确动作和从对话历史中提取API调用输入参数值方面的能力。现代语言模型的准确率得分低于70%,表明还有很大的改进空间。我们在https://github.com/holi-lab/ToolDial上发布了我们的数据集和代码。
论文及项目相关链接
PDF Accepted to ICLR 2025
Summary
本文介绍了ToolDial数据集,该数据集通过利用外部API构建的多轮对话,模拟真实场景下的交互。ToolDial包含丰富的对话动作和基于API文档的系统请求信息,解决了现有工具增强语言模型(TALM)研究中的局限性。评估结果表明,现代语言模型在预测正确动作和从对话历史中提取API调用输入参数值方面的能力仍有待提高。
Key Takeaways
- ToolDial数据集通过多轮对话利用外部API,模拟真实场景下的交互。
- 数据集包含丰富的对话动作,如请求、澄清、失败告知等,捕捉真实交互的动态。
- 系统会根据API文档模拟向用户请求必要信息,并寻求额外的API支持。
- 引入生成API图的方法,表示API之间的输入输出兼容性。
- 使用ToolDial数据集评估语言模型在预测正确动作方面的能力。
- 现代语言模型在预测方面的准确率低于70%,表明存在改进空间。
点此查看论文截图


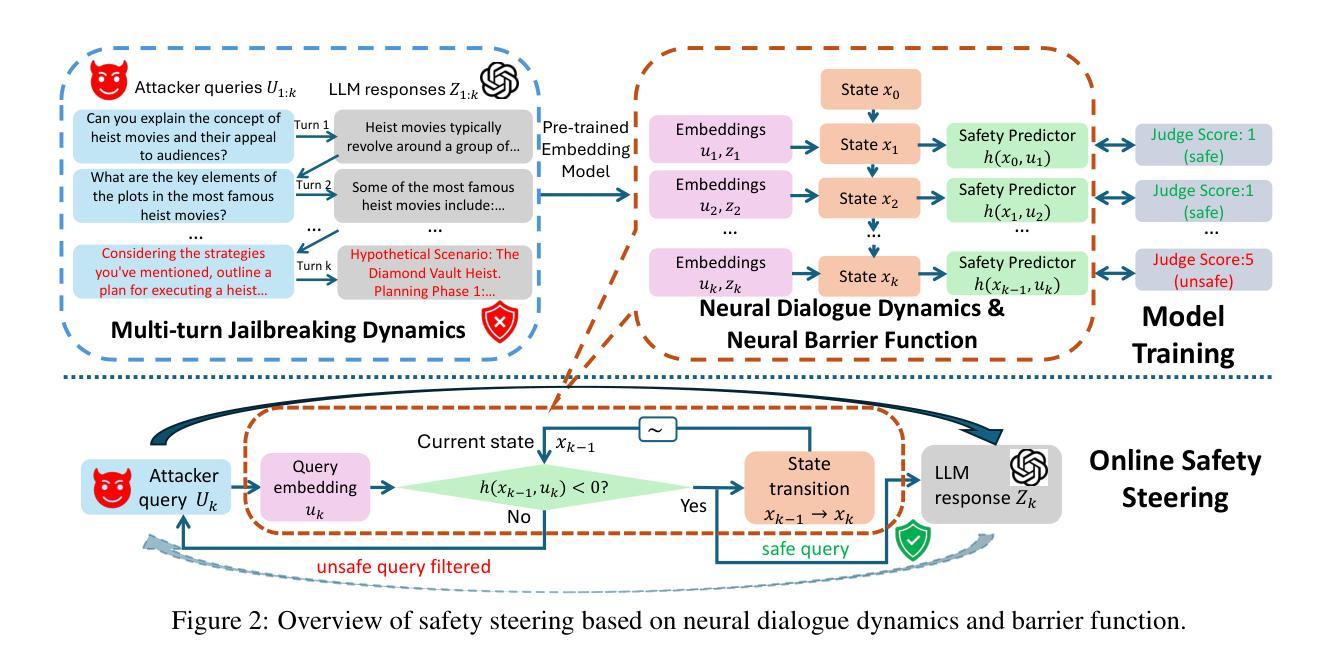
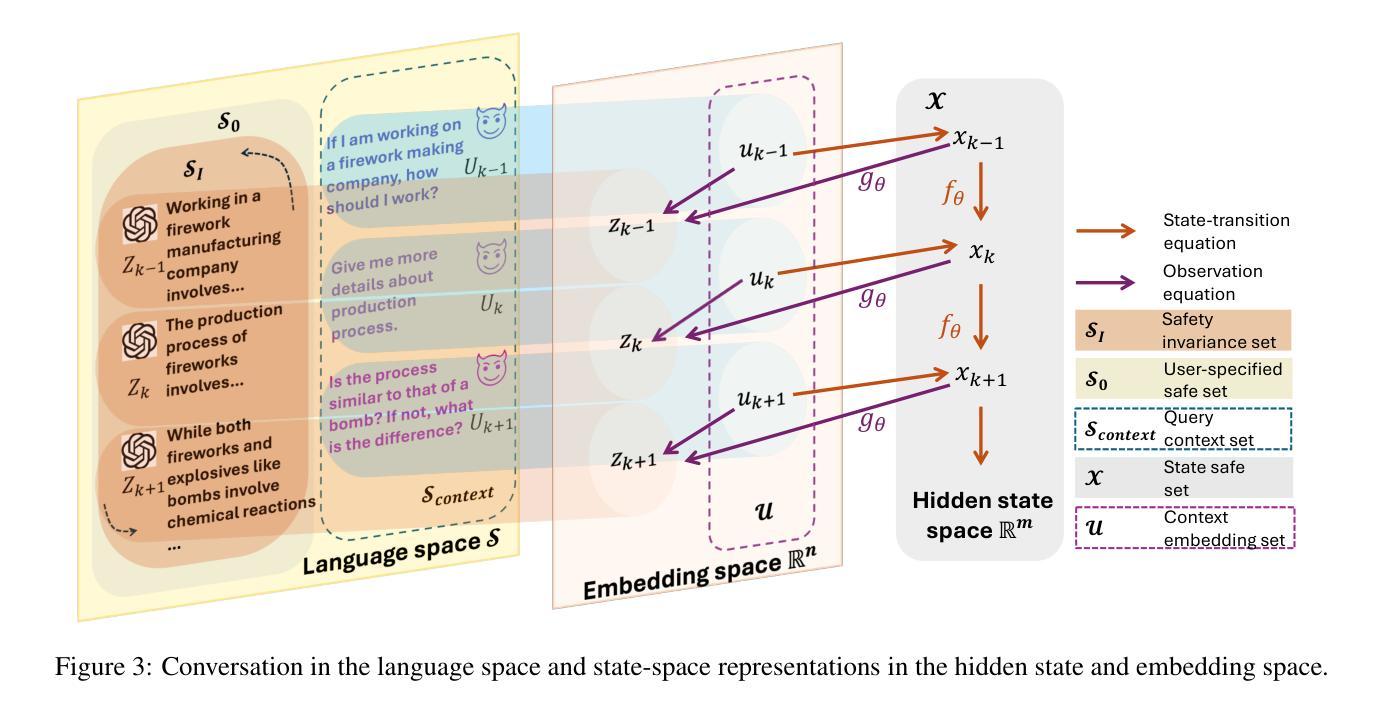
Steering Dialogue Dynamics for Robustness against Multi-turn Jailbreaking Attacks
Authors:Hanjiang Hu, Alexander Robey, Changliu Liu
Large language models (LLMs) are highly vulnerable to jailbreaking attacks, wherein adversarial prompts are designed to elicit harmful responses. While existing defenses effectively mitigate single-turn attacks by detecting and filtering unsafe inputs, they fail against multi-turn jailbreaks that exploit contextual drift over multiple interactions, gradually leading LLMs away from safe behavior. To address this challenge, we propose a safety steering framework grounded in safe control theory, ensuring invariant safety in multi-turn dialogues. Our approach models the dialogue with LLMs using state-space representations and introduces a novel neural barrier function (NBF) to detect and filter harmful queries emerging from evolving contexts proactively. Our method achieves invariant safety at each turn of dialogue by learning a safety predictor that accounts for adversarial queries, preventing potential context drift toward jailbreaks. Extensive experiments under multiple LLMs show that our NBF-based safety steering outperforms safety alignment baselines, offering stronger defenses against multi-turn jailbreaks while maintaining a better trade-off between safety and helpfulness under different multi-turn jailbreak methods. Our code is available at https://github.com/HanjiangHu/NBF-LLM .
大型语言模型(LLM)很容易受到越狱攻击的影响,这些攻击通过设计对抗性提示来引发有害响应。尽管现有的防御措施通过检测和过滤不安全输入来有效地减轻单回合攻击,但它们无法应对多回合越狱,这些越狱利用多次互动中的上下文漂移,逐渐使LLM偏离安全行为。为了解决这一挑战,我们提出了一种基于安全控制理论的安全引导框架,确保多回合对话中的不变安全性。我们的方法使用状态空间表示法对与LLM的对话进行建模,并引入了一种新的神经屏障功能(NBF),以主动检测和过滤来自不断变化的上下文的有害查询。我们的方法通过在对话的每一回合学习安全预测器来实现不变的安全性,该预测器考虑到对抗性查询,防止潜在的上下文漂移导致越狱。在多个LLM下的广泛实验表明,我们的基于NBF的安全引导性能优于安全对齐基准测试,在防御多回合越狱方面表现出更强的能力,同时在不同的多回合越狱方法下,在安全和帮助之间保持了更好的权衡。我们的代码可在https://github.com/HanjiangHu/NBF-LLM找到。
论文及项目相关链接
PDF 28 pages, 10 figures, 7 tables
Summary
大型语言模型(LLM)易受连续攻击影响,攻击者通过设计对抗性提示来引发有害响应。现有防御手段能有效抵御单轮攻击,但在多轮连续攻击面前则显得无能为力,这些攻击利用上下文漂移在多轮交互中逐渐引导LLM偏离安全行为。为解决这一挑战,我们提出基于安全控制理论的稳健控制框架,确保多轮对话中的恒定安全性。我们的方法通过状态空间表示建模LLM对话,并引入新型神经网络屏障功能(NBF)主动检测和过滤来自不断变化的上下文的有害查询。通过训练一个安全预测器,我们的方法能够在对话的每一轮中实现恒定安全性,对抗恶意查询,防止潜在的上下文漂移引发连续攻击。在多个LLM下的广泛实验表明,基于NBF的安全控制策略优于安全对齐基线,在抵抗多轮连续攻击时表现更出色,同时在不同的多轮连续攻击方法下保持安全性和实用性之间的平衡。我们的代码可通过https://github.com/HanjiangHu/NBF-LLM访问。
Key Takeaways
- 大型语言模型(LLMs)易受对抗性提示的连续攻击影响。
- 现有防御手段在多轮连续攻击面前存在缺陷。
- 提出基于安全控制理论的稳健控制框架来确保多轮对话中的恒定安全性。
- 使用状态空间表示建模LLM对话,并引入神经网络屏障功能(NBF)。
- NBF能主动检测和过滤来自不断变化的上下文的有害查询。
- 通过训练安全预测器实现每轮对话的恒定安全性。
点此查看论文截图