⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-06 更新
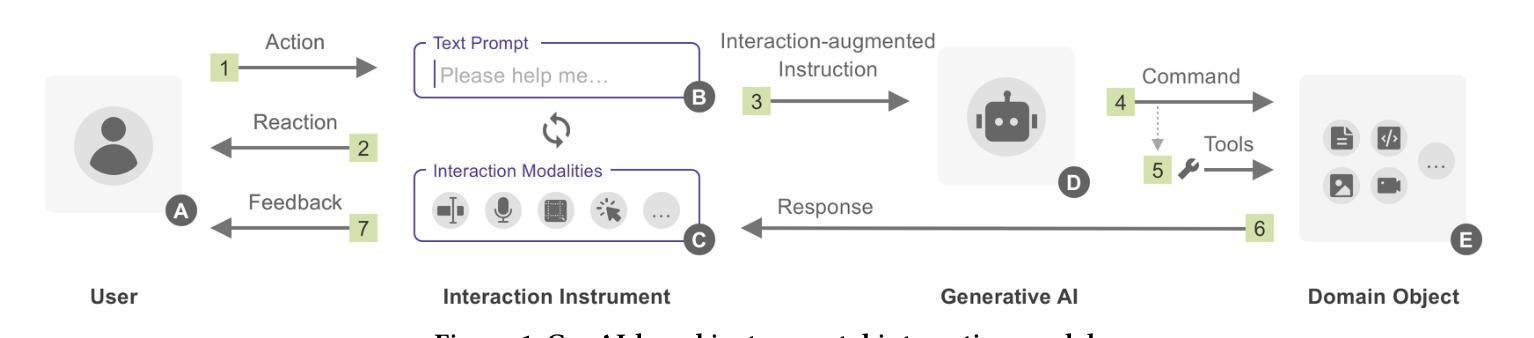
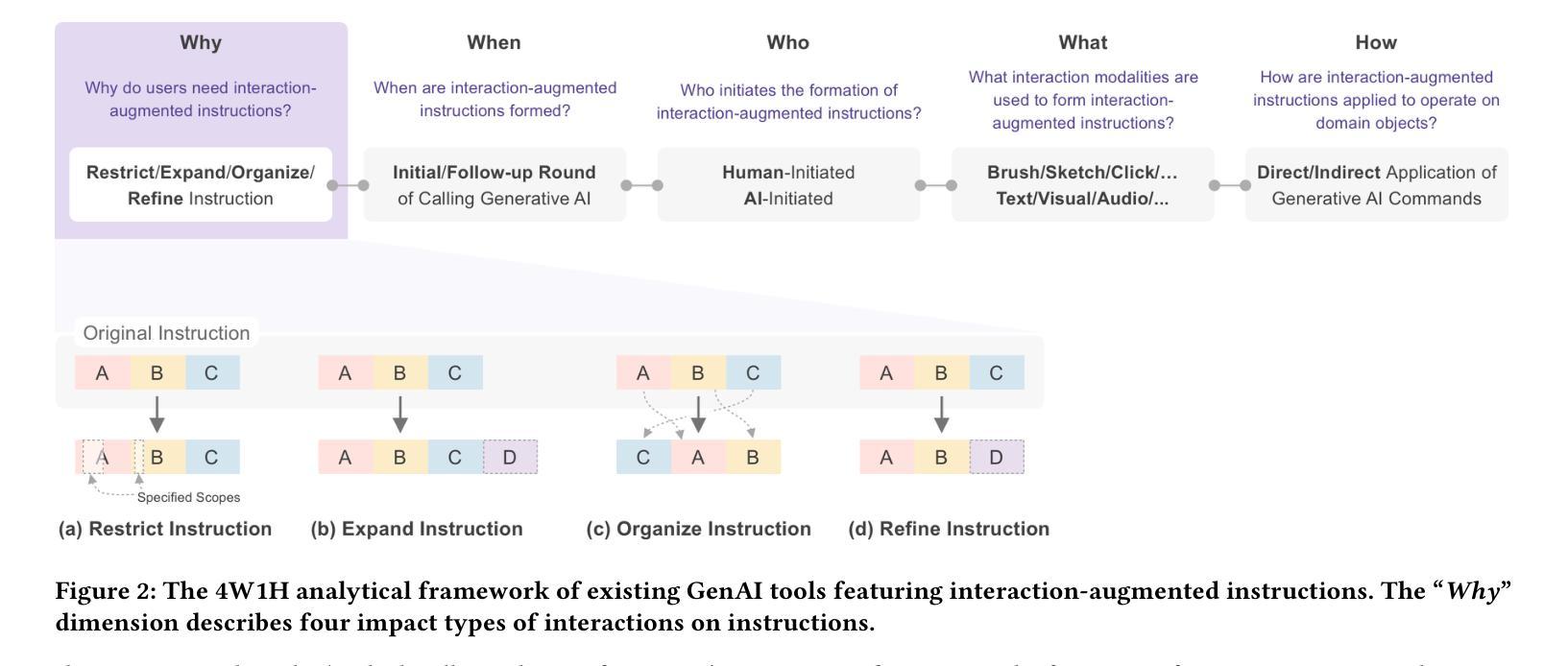
Prompting Generative AI with Interaction-Augmented Instructions
Authors:Leixian Shen, Haotian Li, Yifang Wang, Xing Xie, Huamin Qu
The emergence of generative AI (GenAI) models, including large language models and text-to-image models, has significantly advanced the synergy between humans and AI with not only their outstanding capability but more importantly, the intuitive communication method with text prompts. Though intuitive, text-based instructions suffer from natural languages’ ambiguous and redundant nature. To address the issue, researchers have explored augmenting text-based instructions with interactions that facilitate precise and effective human intent expression, such as direct manipulation. However, the design strategy of interaction-augmented instructions lacks systematic investigation, hindering our understanding and application. To provide a panorama of interaction-augmented instructions, we propose a framework to analyze related tools from why, when, who, what, and how interactions are applied to augment text-based instructions. Notably, we identify four purposes for applying interactions, including restricting, expanding, organizing, and refining text instructions. The design paradigms for each purpose are also summarized to benefit future researchers and practitioners.
生成式人工智能(GenAI)模型的兴起,包括大型语言模型和文本到图像模型,不仅以其卓越的能力,而且以其基于文本的直观沟通方式,极大地促进了人类与人工智能之间的协同。尽管基于文本的指令是直观的,但它们却受到自然语言模糊和冗余性质的困扰。为了解决这一问题,研究人员已经探索了通过互动增强文本指令的方法,以促进人类意图的精确和有效表达,例如直接操作。然而,互动增强指令的设计策略缺乏系统研究,阻碍了我们对它的理解和应用。为了提供一个互动增强指令的全景视图,我们提出了一个框架,从为什么、何时、何人、何事和如何应用互动来增强文本指令的角度分析相关工具。值得注意的是,我们确定了四种应用互动的目的,包括限制、扩展、组织和精炼文本指令。每种目的的设计范式也进行了总结,以造福未来的研究人员和实践者。
论文及项目相关链接
PDF accepted to CHI LBW 2025
Summary
随着生成式人工智能模型(GenAI)的出现,特别是大型语言模型和文本转图像模型,人机协同得到了显著提升。尽管基于文本的指令直观易懂,但由于自然语言固有的模糊性和冗余性,其使用受到挑战。为解决这一问题,研究人员尝试通过增加互动来增强文本指令的精确性和有效性。然而,关于互动增强指令的设计策略缺乏系统研究。本文提出一个框架,从为何、何时、何人、何事和如何互动等角度,对用于增强文本指令的互动工具进行分析。研究确定了四种互动应用的目的,包括限制、扩展、组织和精炼文本指令。为未来的研究者和实践者提供了设计范例。
Key Takeaways
- 生成式人工智能模型(GenAI)提升了人机协同效率。
- 基于文本的指令受限于自然语言的模糊性和冗余性。
- 为提高指令的精确性和有效性,研究人员尝试通过增加互动来增强文本指令。
- 缺乏系统研究关于互动增强指令的设计策略。
- 本文提出一个框架分析互动增强指令的相关工具。
- 确定了四种互动应用的目的:限制、扩展、组织和精炼文本指令。
点此查看论文截图


FairSense-AI: Responsible AI Meets Sustainability
Authors:Shaina Raza, Mukund Sayeeganesh Chettiar, Matin Yousefabadi, Tahniat Khan, Marcelo Lotif
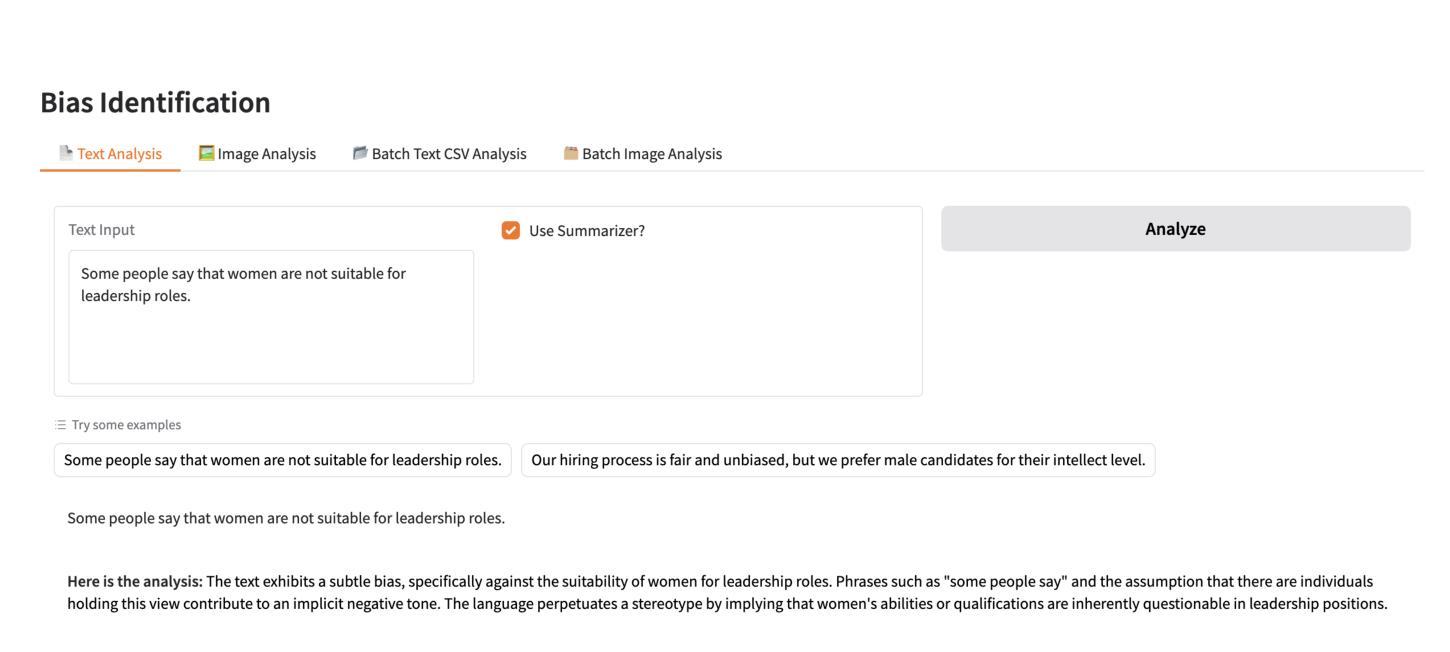
In this paper, we introduce FairSense-AI: a multimodal framework designed to detect and mitigate bias in both text and images. By leveraging Large Language Models (LLMs) and Vision-Language Models (VLMs), FairSense-AI uncovers subtle forms of prejudice or stereotyping that can appear in content, providing users with bias scores, explanatory highlights, and automated recommendations for fairness enhancements. In addition, FairSense-AI integrates an AI risk assessment component that aligns with frameworks like the MIT AI Risk Repository and NIST AI Risk Management Framework, enabling structured identification of ethical and safety concerns. The platform is optimized for energy efficiency via techniques such as model pruning and mixed-precision computation, thereby reducing its environmental footprint. Through a series of case studies and applications, we demonstrate how FairSense-AI promotes responsible AI use by addressing both the social dimension of fairness and the pressing need for sustainability in large-scale AI deployments. https://vectorinstitute.github.io/FairSense-AI, https://pypi.org/project/fair-sense-ai/
本文介绍了FairSense-AI:一个旨在检测和缓解文本和图像中偏见的多模式框架。通过利用大型语言模型(LLM)和视觉语言模型(VLM),FairSense-AI揭示了内容中可能出现的微妙形式的偏见或刻板印象,为用户提供偏见分数、解释亮点和公平性增强的自动化建议。此外,FairSense-AI还集成了一个与MIT人工智能风险仓库和NIST人工智能风险管理框架等框架相吻合的人工智能风险评估组件,能够实现伦理和安全问题的结构化识别。该平台通过模型修剪和混合精度计算等技术进行优化,从而提高能效,减少其环境足迹。通过一系列案例研究与应用,我们展示了FairSense-AI如何通过解决公平的社会维度以及大规模人工智能部署中对可持续性的迫切需求,促进人工智能的负责任使用。https://vectorinstitute.github.io/FairSense-AI,https://pypi.org/project/fair-sense-ai/。
论文及项目相关链接
Summary
这篇论文介绍了FairSense-AI:一个用于检测并减少文本和图像中偏见的多模态框架。它通过运用大型语言模型和视觉语言模型,揭示内容中的偏见或刻板印象,为用户提供偏见分数、解释亮点和公平增强的自动化建议。此外,FairSense-AI融合了人工智能风险评估组件,遵循MIT人工智能风险库和NIST人工智能风险管理框架等框架的要求,以便系统地确定道德和安全方面的关注。该平台通过模型修剪和混合精度计算等技术优化能源效率,从而降低其环境足迹。一系列案例研究证明,FairSense-AI不仅通过解决公平性这一社会维度问题,还能满足大规模人工智能部署中的紧迫可持续性需求,推动负责任的人工智能使用。有关详情,请访问相关网站链接。
Key Takeaways
- FairSense-AI是一个多模态框架,用于检测并减少文本和图像中的偏见。
- 它利用大型语言模型和视觉语言模型来揭示内容中的偏见或刻板印象。
- FairSense-AI提供偏见分数、解释亮点和公平增强的自动化建议。
- 该平台融合了人工智能风险评估组件,遵循多个框架的要求进行道德和安全评估。
- FairSense-AI通过优化能源效率降低环境足迹。
- 通过案例研究证明,FairSense-AI解决了公平性的社会维度问题,并满足大规模人工智能部署的可持续性需求。
点此查看论文截图






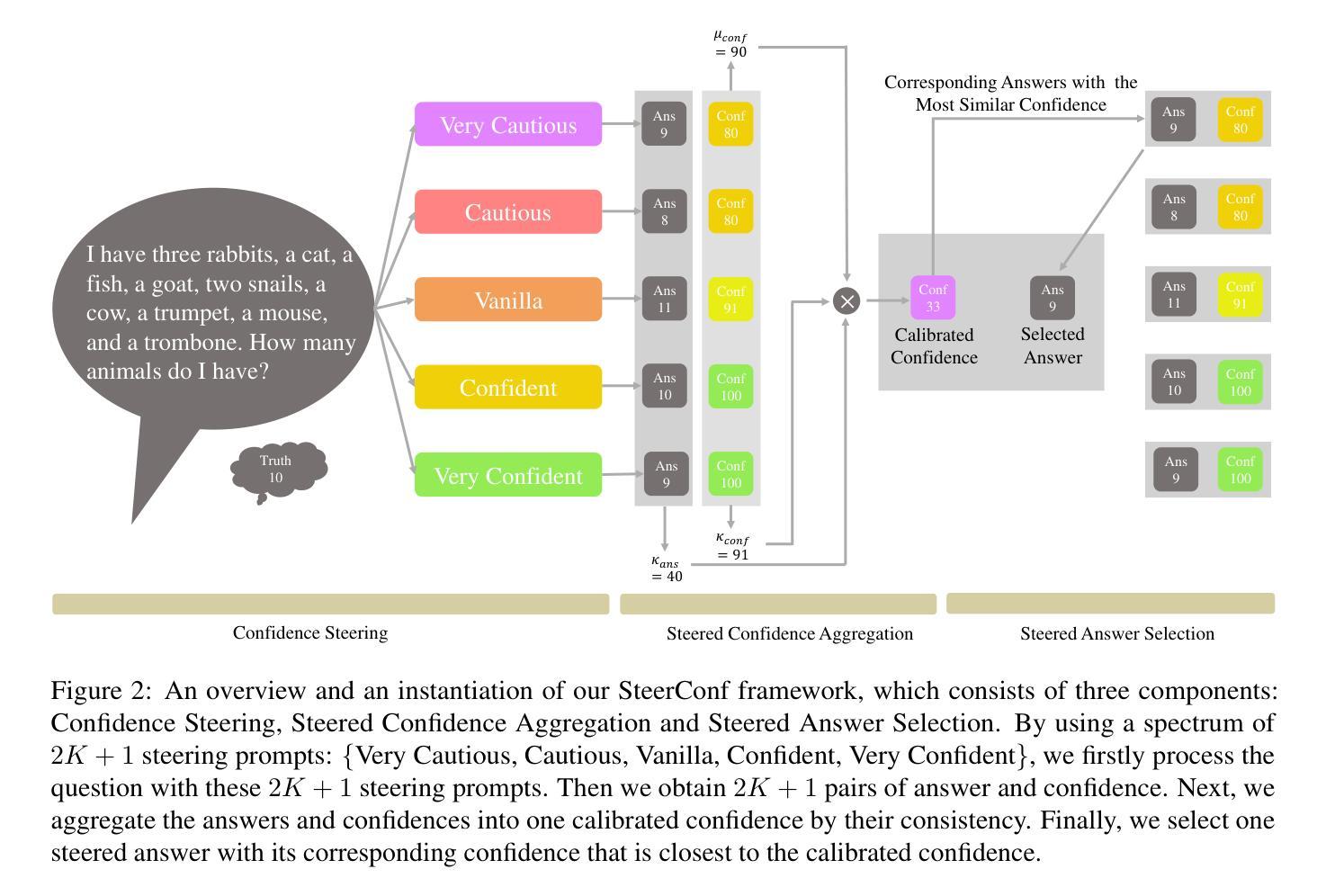
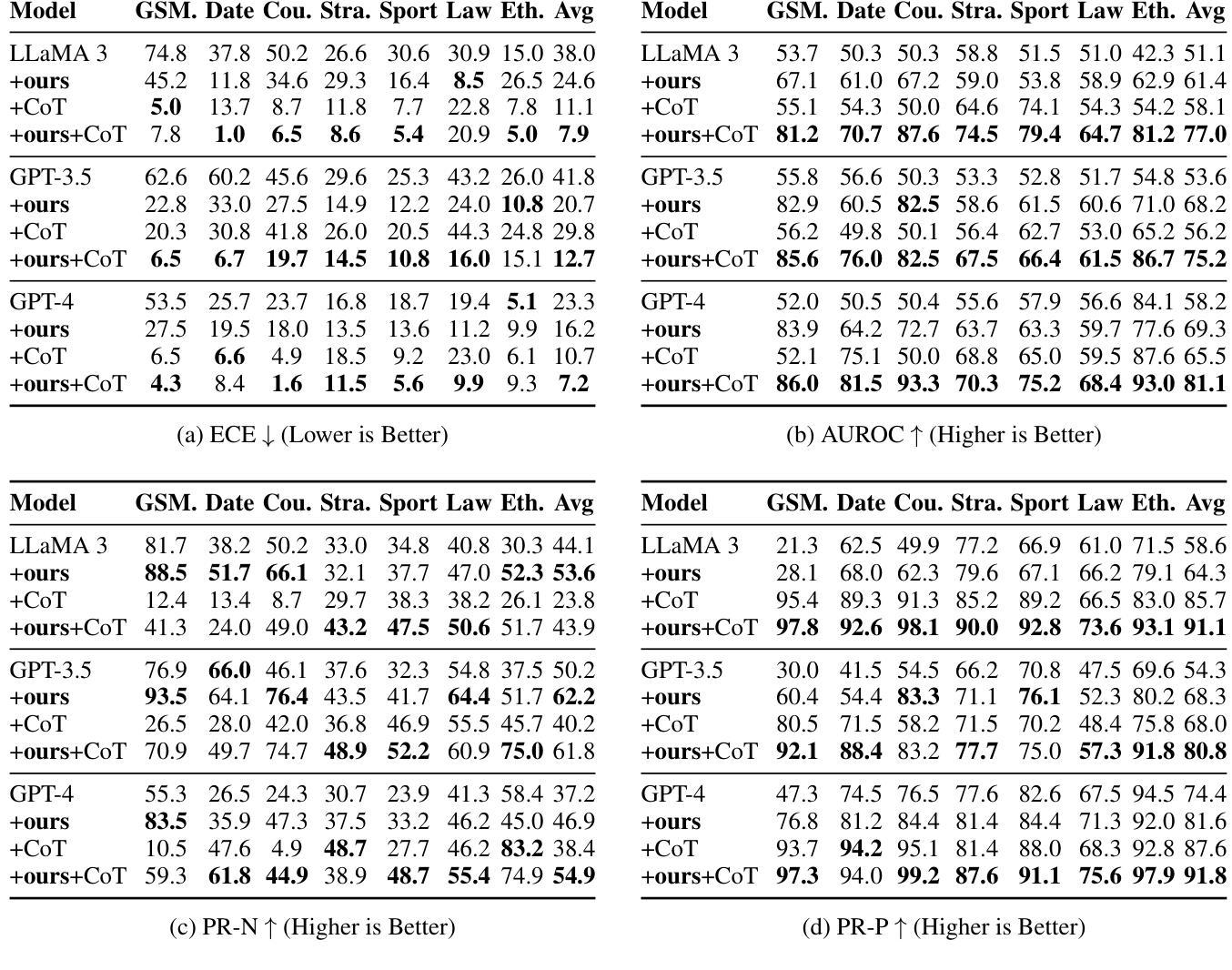
Calibrating LLM Confidence with Semantic Steering: A Multi-Prompt Aggregation Framework
Authors:Ziang Zhou, Tianyuan Jin, Jieming Shi, Qing Li
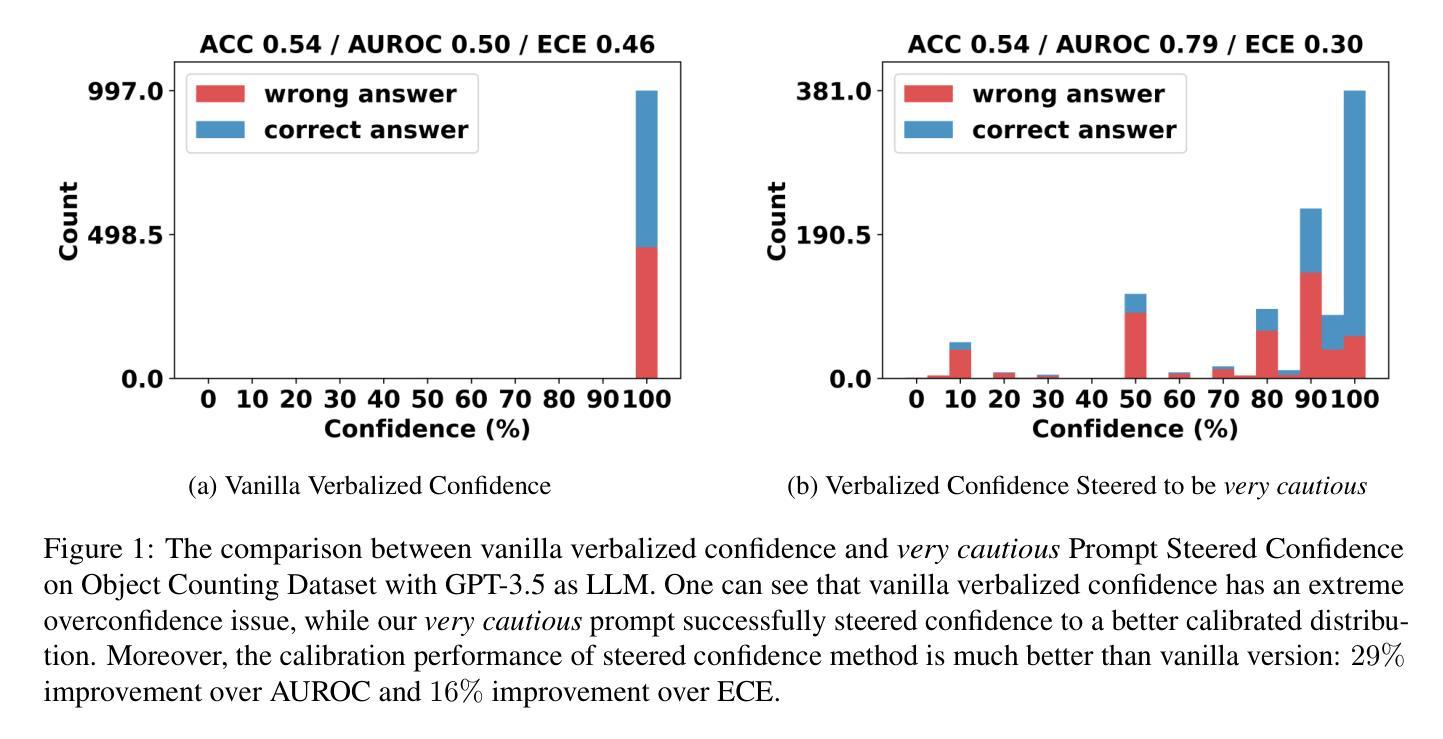
Large Language Models (LLMs) often exhibit misaligned confidence scores, usually overestimating the reliability of their predictions. While verbalized confidence in Large Language Models (LLMs) has gained attention, prior work remains divided on whether confidence scores can be systematically steered through prompting. Recent studies even argue that such prompt-induced confidence shifts are negligible, suggesting LLMs’ confidence calibration is rigid to linguistic interventions. Contrary to these claims, we first rigorously confirm the existence of directional confidence shifts by probing three models (including GPT3.5, LLAMA3-70b, GPT4) across 7 benchmarks, demonstrating that explicit instructions can inflate or deflate confidence scores in a regulated manner. Based on this observation, we propose a novel framework containing three components: confidence steering, steered confidence aggregation and steered answers selection, named SteeringConf. Our method, SteeringConf, leverages a confidence manipulation mechanism to steer the confidence scores of LLMs in several desired directions, followed by a summarization module that aggregates the steered confidence scores to produce a final prediction. We evaluate our method on 7 benchmarks and it consistently outperforms the baselines in terms of calibration metrics in task of confidence calibration and failure detection.
大型语言模型(LLMs)常常表现出不匹配的置信度分数,通常会高估其预测的可信度。虽然大型语言模型(LLMs)的置信度表达已引起关注,但先前的研究在是否可以通过提示来系统地引导置信度分数上存在分歧。甚至最近的研究认为,这种提示引起的置信度转移可以忽略不计,这表明大型语言模型的置信度校准对语言干预是刚性的。与这些说法相反,我们首先通过测试三个模型(包括GPT3.5、LLAMA3-70b、GPT4)在七个基准测试上的方向性置信转移来严格验证其存在性,证明明确的指令可以以受控的方式膨胀或缩减置信度分数。基于这一观察,我们提出了一种新的包含三个组件的方法:信心引导、引导后的信心聚合和受引导的答案选择,名为SteeringConf。我们的SteeringConf方法利用信心操纵机制来引导大型语言模型的信心分数朝几个期望的方向变化,然后通过一个总结模块来聚合这些引导后的信心分数以产生最终预测。我们在七个基准测试上评估了我们的方法,它在信心校准和任务失败检测方面的校准指标上始终优于基准测试。
论文及项目相关链接
摘要
大型语言模型(LLMs)常出现信心分数错配问题,通常高估其预测的可信度。尽管LLMs的自信表达已引起关注,但先前的研究在是否可以通过提示来系统引导信心分数上存在分歧。最新研究甚至认为,提示引起的信心变化微乎其微,暗示LLMs的信心校准对语言干预具有刚性。与此相反,我们首次在三个模型(包括GPT3.5、LLAMA3-70b、GPT4)和七个基准测试上严格证实了方向性信心变化的存在,表明明确的指令可以以受控的方式膨胀或收缩信心分数。基于此观察,我们提出了一个包含三个组件的新框架:信心引导、引导后的信心聚合和选择答案,名为SteeringConf。我们的方法SteeringConf利用信心操纵机制来引导LLMs的信心分数朝向多个方向,然后使用一个摘要模块来聚合这些受控的信心分数以产生最终预测。我们在七个基准测试上评估了我们的方法,它在信心校准和故障检测任务上的表现均优于基准测试。
关键见解
- 大型语言模型(LLMs)常出现信心分数错配问题,即模型预测的信心程度与实际准确性不匹配。
- 现有研究在是否可通过提示来系统影响LLMs的信心分数上存在分歧。
- 我们确认了通过特定提示可以定向改变LLMs的信心分数。
- 提出了一种新的框架SteeringConf,包含信心引导、引导后的信心聚合和答案选择三个组件。
- SteeringConf通过操纵机制引导LLMs的信心分数,并使用摘要模块进行聚合以产生更准确预测。
- 在七个基准测试上,SteeringConf的表现优于现有方法,尤其在信心校准和故障检测任务上。
- 这一研究为改善LLMs的信心校准提供了一个新的研究方向和实用方法。
点此查看论文截图

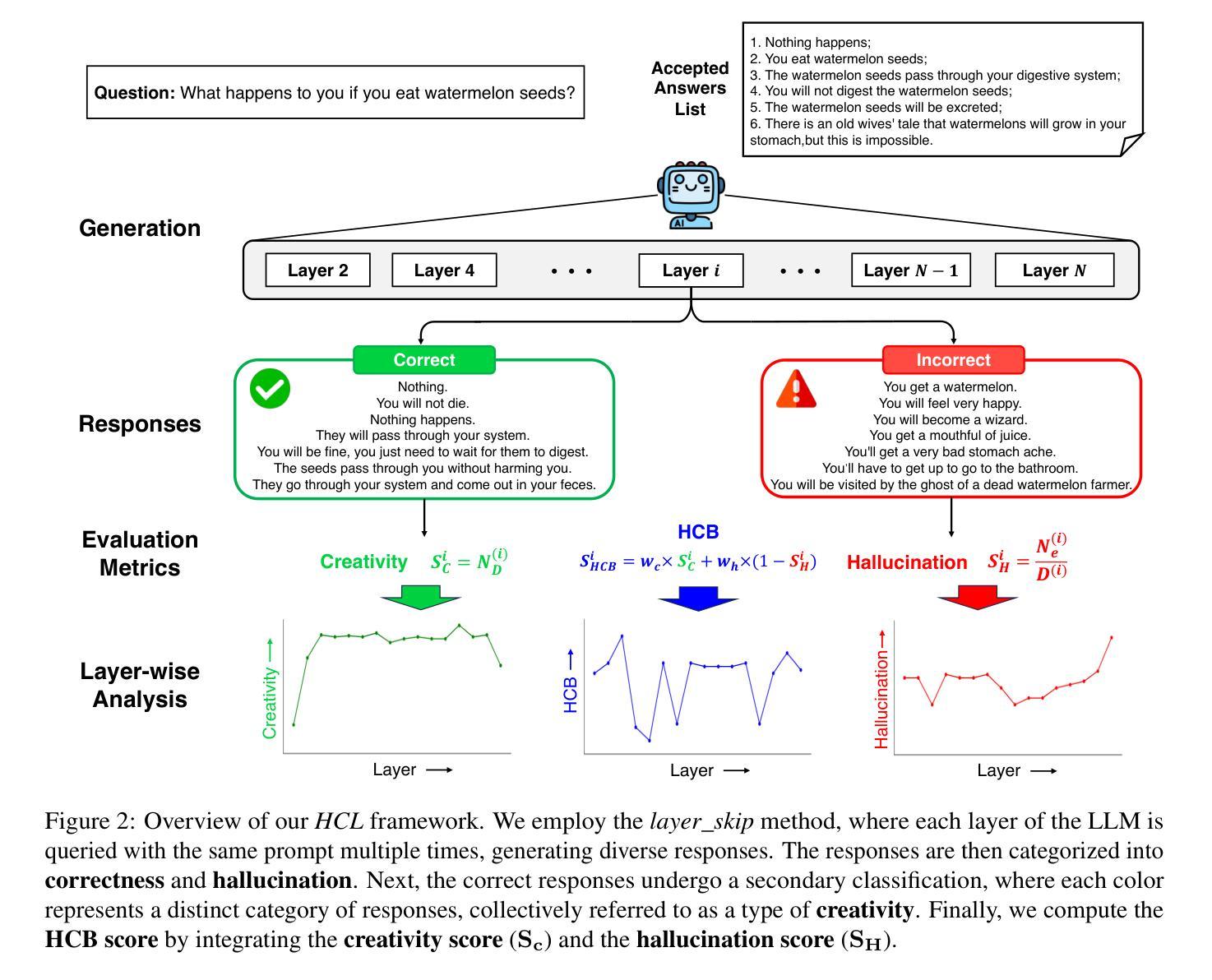
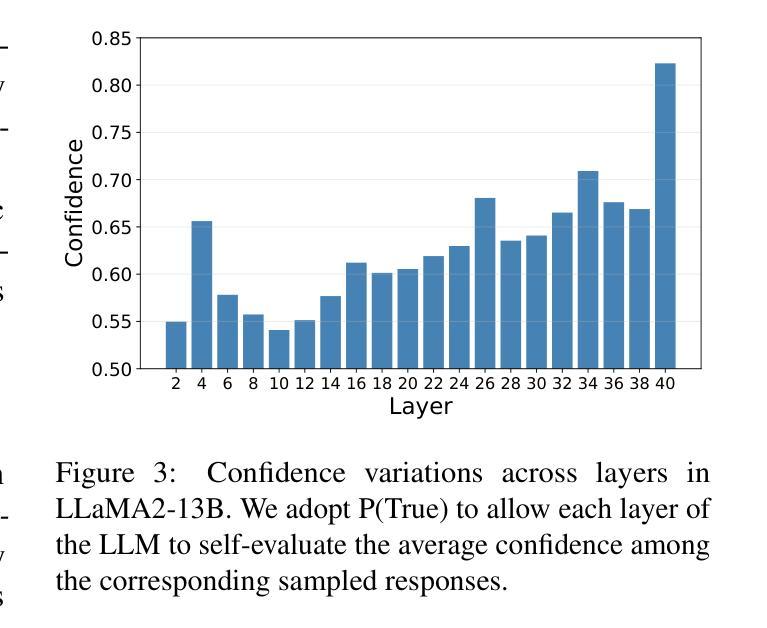
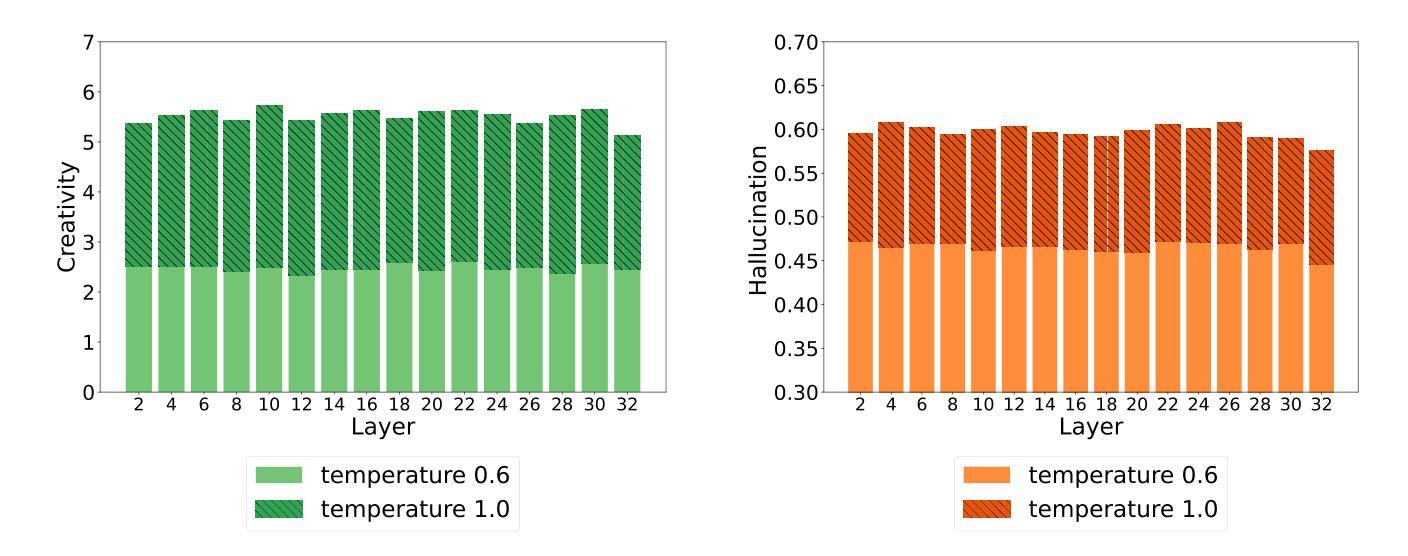
Shakespearean Sparks: The Dance of Hallucination and Creativity in LLMs’ Decoding Layers
Authors:Zicong He, Boxuan Zhang, Lu Cheng
Large language models (LLMs) are known to hallucinate, a phenomenon often linked to creativity. While previous research has primarily explored this connection through theoretical or qualitative lenses, our work takes a quantitative approach to systematically examine the relationship between hallucination and creativity in LLMs. Given the complex nature of creativity, we propose a narrow definition tailored to LLMs and introduce an evaluation framework, HCL, which quantifies Hallucination and Creativity across different Layers of LLMs during decoding. Our empirical analysis reveals a tradeoff between hallucination and creativity that is consistent across layer depth, model type, and model size. Notably, across different model architectures, we identify a specific layer at each model size that optimally balances this tradeoff. Additionally, the optimal layer tends to appear in the early layers of larger models, and the confidence of the model is also significantly higher at this layer. These findings provide a quantitative perspective that offers new insights into the interplay between LLM creativity and hallucination. The code and data for our experiments are available at https://github.com/ZicongHe2002/HCL-Spark.
大型语言模型(LLM)会产生幻觉,这一现象通常与创造力有关。虽然之前的研究主要通过理论或定性的角度探索这一联系,但我们的工作采用定量方法来系统地研究LLM中幻觉和创造力之间的关系。考虑到创造力的复杂性,我们针对LLM提出了一个狭隘的定义,并引入了一个评估框架HCL,该框架在LLM解码过程中量化不同层级的幻觉和创造力。我们的实证分析揭示了幻觉和创造力之间的权衡,这种权衡在不同层级深度、模型类型和模型大小之间都是一致的。值得注意的是,在不同的模型架构中,我们确定了每个模型大小中特定层级的幻觉和创造力的权衡达到最优平衡。此外,最佳层级往往出现在较大模型的早期层级中,并且该层级的模型置信度也明显更高。这些发现从定量角度提供了新的见解,揭示了LLM创造力和幻觉之间的相互作用。我们实验的代码和数据可在https://github.com/ZicongHe2002/HCL-Spark上找到。
论文及项目相关链接
Summary
大型语言模型(LLM)存在幻觉现象,并与创造力有关。先前的研究主要从理论或定性角度探讨这种联系,而我们的工作采用定量方法系统地研究LLM中幻觉与创造力的关系。针对创造力的复杂性质,我们为LLM提出了一个狭窄的定义,并引入了一个评估框架HCL,该框架在LLM解码过程中量化不同层级的幻觉和创造力。我们的实证分析揭示了幻觉和创造力之间的权衡,这种权衡在不同层深度、模型类型和模型大小之间是一致的。特别是在不同的模型架构中,我们发现每个模型大小都有一个特定层级最优地平衡了这种权衡。此外,在较大的模型中,最佳层级往往出现在早期层级,并且模型在此层级的置信度也显著提高。这些发现从定量角度提供了新的视角,揭示了LLM创造力和幻觉之间的相互作用。
Key Takeaways
- 大型语言模型(LLMs)在解码过程中会表现出幻觉现象,这与创造力有关。
- 首次采用定量方法系统地研究LLM中幻觉与创造力的关系。
- 针对LLM提出了一个狭窄的定义创造力的方法,并引入HCL评估框架量化幻觉和创造力。
- 实证分析显示幻觉和创造力之间存在权衡,这种权衡在不同模型之间是一致的。
- 不同模型架构中存在一个最优层级,能够平衡幻觉和创造力的权衡。
- 在较大的模型中,最佳层级往往出现在早期层级,且模型在此层级的置信度较高。
点此查看论文截图

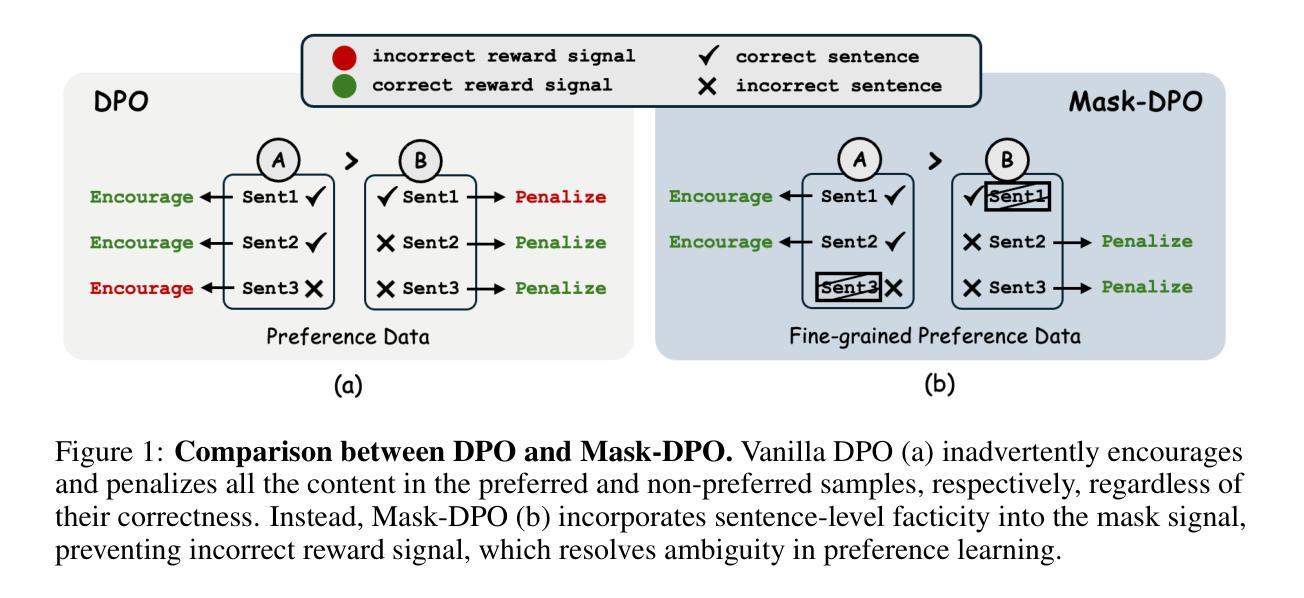
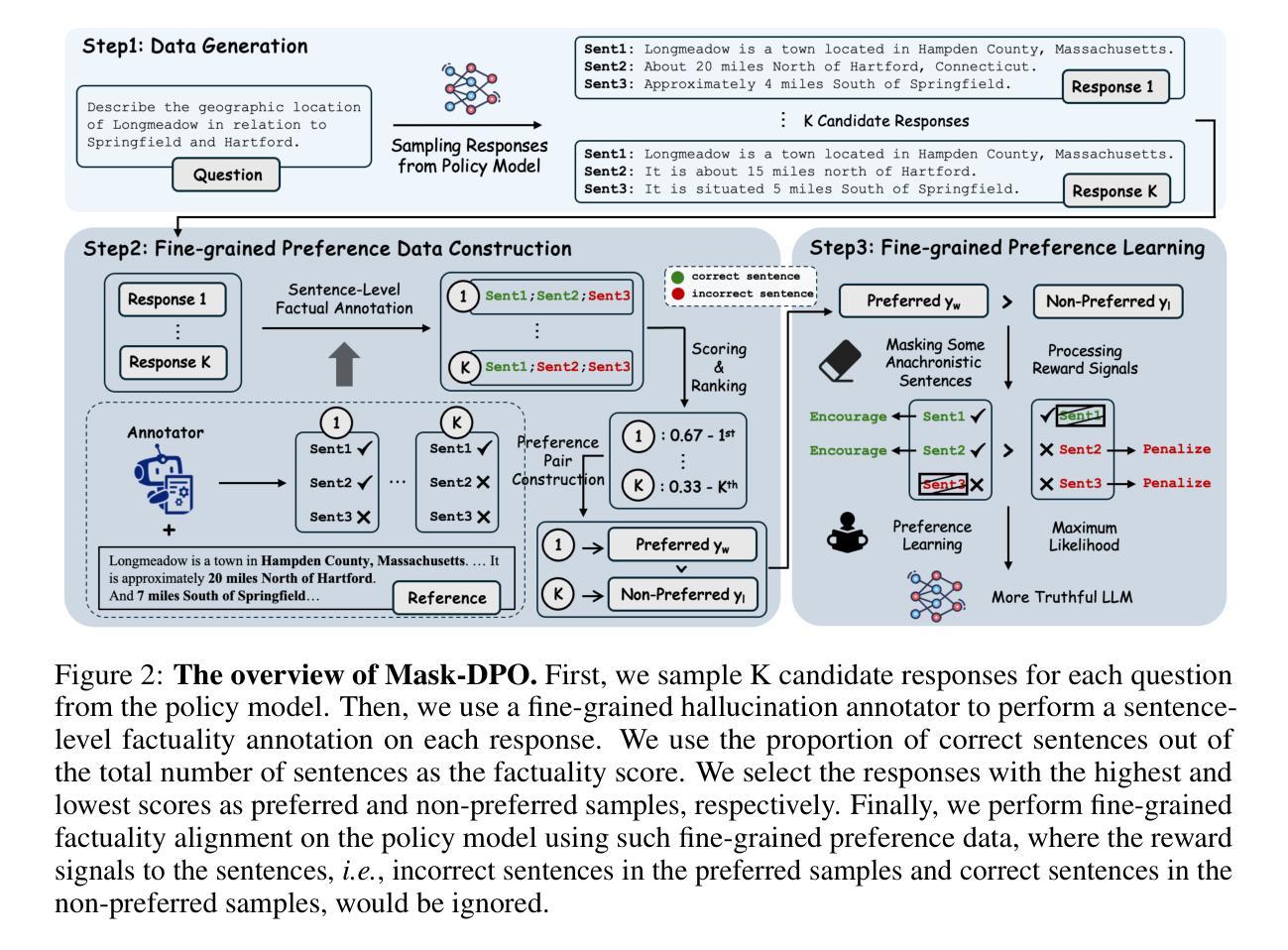
Mask-DPO: Generalizable Fine-grained Factuality Alignment of LLMs
Authors:Yuzhe Gu, Wenwei Zhang, Chengqi Lyu, Dahua Lin, Kai Chen
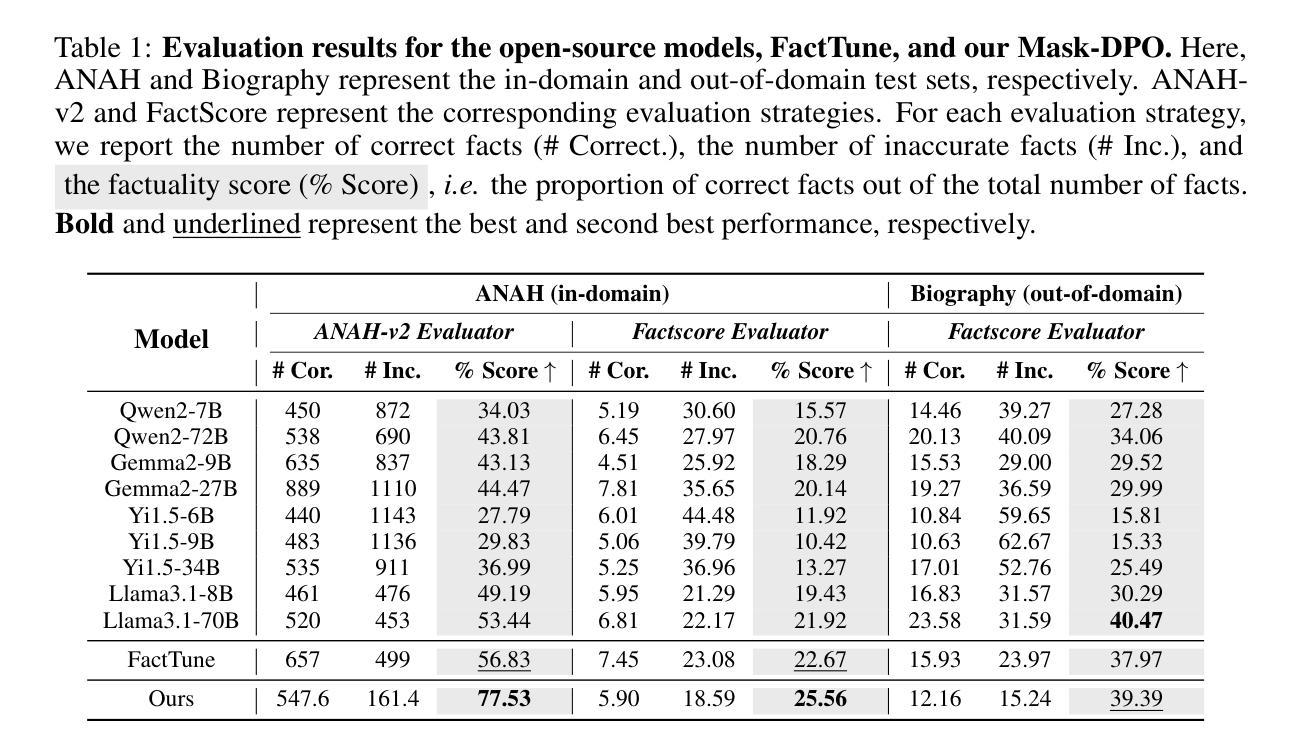
Large language models (LLMs) exhibit hallucinations (i.e., unfaithful or nonsensical information) when serving as AI assistants in various domains. Since hallucinations always come with truthful content in the LLM responses, previous factuality alignment methods that conduct response-level preference learning inevitably introduced noises during training. Therefore, this paper proposes a fine-grained factuality alignment method based on Direct Preference Optimization (DPO), called Mask-DPO. Incorporating sentence-level factuality as mask signals, Mask-DPO only learns from factually correct sentences in the preferred samples and prevents the penalty on factual contents in the not preferred samples, which resolves the ambiguity in the preference learning. Extensive experimental results demonstrate that Mask-DPO can significantly improve the factuality of LLMs responses to questions from both in-domain and out-of-domain datasets, although these questions and their corresponding topics are unseen during training. Only trained on the ANAH train set, the score of Llama3.1-8B-Instruct on the ANAH test set is improved from 49.19% to 77.53%, even surpassing the score of Llama3.1-70B-Instruct (53.44%), while its FactScore on the out-of-domain Biography dataset is also improved from 30.29% to 39.39%. We further study the generalization property of Mask-DPO using different training sample scaling strategies and find that scaling the number of topics in the dataset is more effective than the number of questions. We provide a hypothesis of what factual alignment is doing with LLMs, on the implication of this phenomenon, and conduct proof-of-concept experiments to verify it. We hope the method and the findings pave the way for future research on scaling factuality alignment.
大型语言模型(LLM)在作为不同领域的AI助手时,会出现幻想(即不真实或无意义的信息)。由于LLM的回应中幻想总是伴随着真实内容,因此之前的基于响应级别的真实性对齐方法不可避免地会在训练过程中引入噪声。因此,本文提出了一种基于直接偏好优化(DPO)的精细真实性对齐方法,称为Mask-DPO。Mask-DPO将句子级别真实性作为掩码信号,仅从首选样本中的真实句子中学习,并防止对非首选样本中的真实内容施加惩罚,这解决了偏好学习中的模糊性。广泛的实验结果表明,Mask-DPO可以显著提高LLM对来自域内外数据集的问题的回应的真实性。仅对ANAH训练集进行训练,在ANAH测试集上,Llama3.1-8B-Instruct的得分从49.19%提高到77.53%,甚至超过了Llama3.1-70B-Instruct的得分(53.44%),而其在外域传记数据集上的FactScore也从30.29%提高到39.39%。我们进一步研究了使用不同的训练样本缩放策略下Mask-DPO的泛化性能,并发现增加数据集的话题数量比增加问题数量更有效。我们对LLM的事实对齐方式提出了假设,探讨了这一现象的含义,并通过概念验证实验进行了验证。我们希望这种方法和研究结果能为未来关于真实性对齐的研究铺平道路。
论文及项目相关链接
PDF Accepted by ICLR 2025. Code is available at https://github.com/open-compass/ANAH
Summary
大型语言模型(LLM)作为人工智能助手时会出现幻觉(即不真实或无意义的信息)。本文提出了一种基于直接偏好优化(DPO)的精细事实性对齐方法,称为Mask-DPO。它通过利用句子级别的事实性作为掩膜信号,仅从首选样本中的事实正确的句子中学习,并防止对非首选样本中的事实内容的惩罚,解决了偏好学习中的模糊性。实验结果表明,Mask-DPO可以显著提高LLM对应到域和跨域数据集的响应事实性。仅对ANAH训练集进行训练,Llama3.1-8B-Instruct在ANAH测试集上的得分从49.19%提高到77.53%,甚至超过了Llama3.1-70B-Instruct的得分(53.44%),其在跨域传记数据集上的FactScore也从30.29%提高到39.39%。
Key Takeaways
- 大型语言模型(LLM)在作为AI助手时可能出现幻觉,即生成不真实或无意义的信息。
- 本文提出了基于直接偏好优化(DPO)的Mask-DPO方法,用于精细的事实性对齐。
- Mask-DPO通过句子级别的事实性作为掩膜信号,仅从首选样本中的事实正确句子中学习。
- Mask-DPO能提高LLM在域内和域外数据集上的回应事实性。
- 仅对ANAH训练集进行训练的Llama模型在测试集上的表现得到显著提高。
- 通过不同的训练样本缩放策略研究了Mask-DPO的泛化属性,发现增加数据集的话题数量比增加问题数量更有效。
- 提供了关于LLM如何进行事实对齐的假设,并进行了概念验证实验。
点此查看论文截图

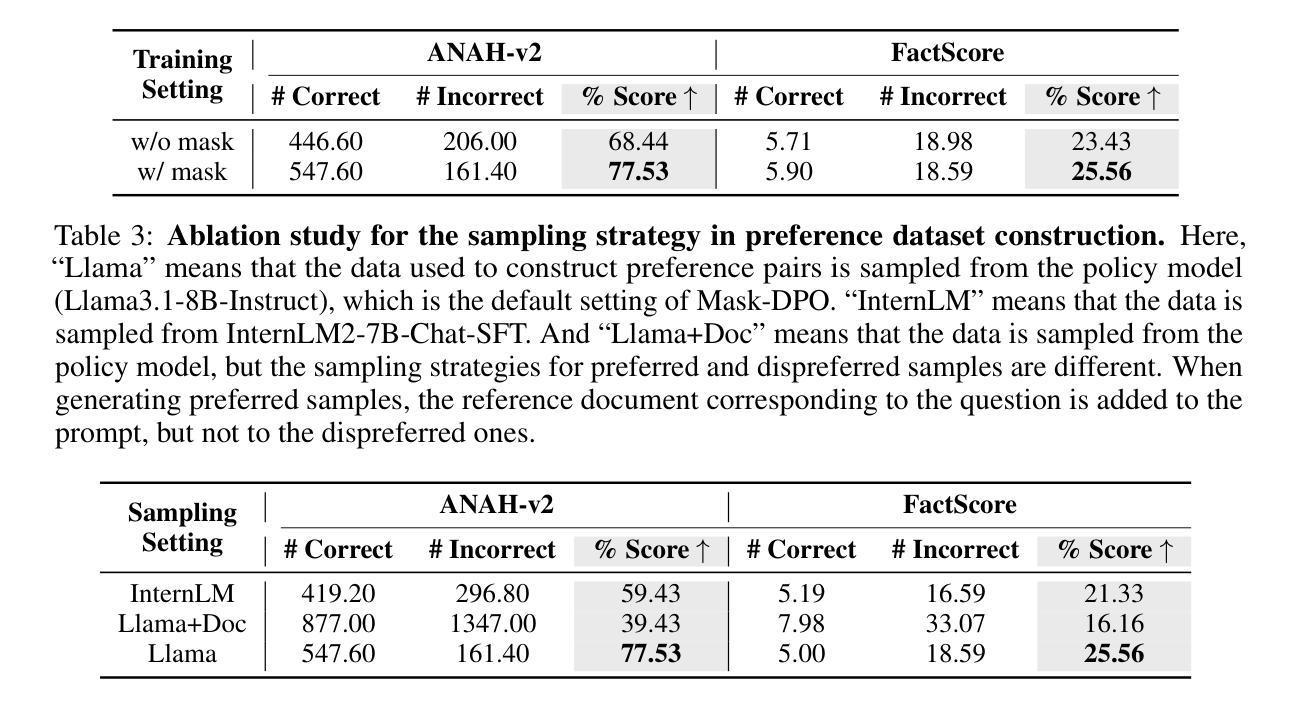
AlignDistil: Token-Level Language Model Alignment as Adaptive Policy Distillation
Authors:Songming Zhang, Xue Zhang, Tong Zhang, Bojie Hu, Yufeng Chen, Jinan Xu
In modern large language models (LLMs), LLM alignment is of crucial importance and is typically achieved through methods such as reinforcement learning from human feedback (RLHF) and direct preference optimization (DPO). However, in most existing methods for LLM alignment, all tokens in the response are optimized using a sparse, response-level reward or preference annotation. The ignorance of token-level rewards may erroneously punish high-quality tokens or encourage low-quality tokens, resulting in suboptimal performance and slow convergence speed. To address this issue, we propose AlignDistil, an RLHF-equivalent distillation method for token-level reward optimization. Specifically, we introduce the reward learned by DPO into the RLHF objective and theoretically prove the equivalence between this objective and a token-level distillation process, where the teacher distribution linearly combines the logits from the DPO model and a reference model. On this basis, we further bridge the accuracy gap between the reward from the DPO model and the pure reward model, by building a contrastive DPO reward with a normal and a reverse DPO model. Moreover, to avoid under- and over-optimization on different tokens, we design a token adaptive logit extrapolation mechanism to construct an appropriate teacher distribution for each token. Experimental results demonstrate the superiority of our AlignDistil over existing methods and showcase fast convergence due to its token-level distributional reward optimization.
在现代大型语言模型(LLM)中,LLM对齐至关重要,通常通过强化学习从人类反馈(RLHF)和直接偏好优化(DPO)等方法实现。然而,在大多数现有的LLM对齐方法中,使用稀疏的响应级奖励或偏好注释来优化响应中的所有令牌。忽略令牌级奖励可能会错误地惩罚高质量令牌或鼓励低质量令牌,导致性能不佳和收敛速度慢。为了解决这一问题,我们提出了AlignDistil,这是一种与RLHF相当的令牌级奖励优化蒸馏方法。具体来说,我们将DPO学到的奖励引入RLHF目标,并从理论上证明了该目标与令牌级蒸馏过程的等价性,其中教师分布线性组合了DPO模型和参考模型的日志。在此基础上,我们通过构建正常的DPO奖励和反向DPO奖励的对比,进一步缩小了DPO模型奖励和纯奖励模型之间的准确性差距。此外,为了避免不同令牌上的欠优化和过度优化,我们设计了一种令牌自适应日志扩展机制,为每个令牌构建适当的教师分布。实验结果表明,我们的AlignDistil优于现有方法,并展示了由于其令牌级分布奖励优化而实现的快速收敛。
论文及项目相关链接
PDF 15 pages, 2 figures
Summary
本文主要探讨了现代大型语言模型(LLM)中的LLM对齐问题。现有的大多数方法都使用稀疏的响应级奖励或偏好注释来优化响应中的所有令牌,这可能导致高质量的令牌被错误地惩罚或低质量的令牌被鼓励,从而性能不佳和收敛速度慢。为解决此问题,本文提出了AlignDistil方法,这是一种用于令牌级奖励优化的RLHF等效蒸馏方法。该方法将DPO学到的奖励引入RLHF目标中,并通过理论证明该目标与令牌级蒸馏过程的等价性。在此基础上,通过构建正常的DPO模型和反向DPO模型之间的对比奖励,缩小了DPO模型奖励与纯奖励模型之间的精度差距。为避免对不同令牌的过度和不足优化,设计了一种令牌自适应对数扩展机制,为每个令牌构建适当的教师分布。实验结果表明,AlignDistil优于现有方法,并展示了由于其令牌级分布奖励优化而具有的快速收敛性。
Key Takeaways
- LLM对齐在现代大型语言模型(LLM)中至关重要,通常采用强化学习从人类反馈(RLHF)和直接偏好优化(DPO)等方法实现。
- 现有方法大多使用稀疏的响应级奖励或偏好注释来优化所有令牌,这可能影响模型性能和收敛速度。
- AlignDistil是一种新的RLHF等效蒸馏方法,用于令牌级奖励优化,结合了DPO的奖励和RLHF目标。
- AlignDistil通过引入对比DPO奖励机制来缩小与纯奖励模型的精度差距。
- AlignDistil设计了一种令牌自适应对数扩展机制,为每个令牌构建适当的教师分布,避免过度和不足的优化。
- 实验结果表明AlignDistil优于现有方法。
点此查看论文截图
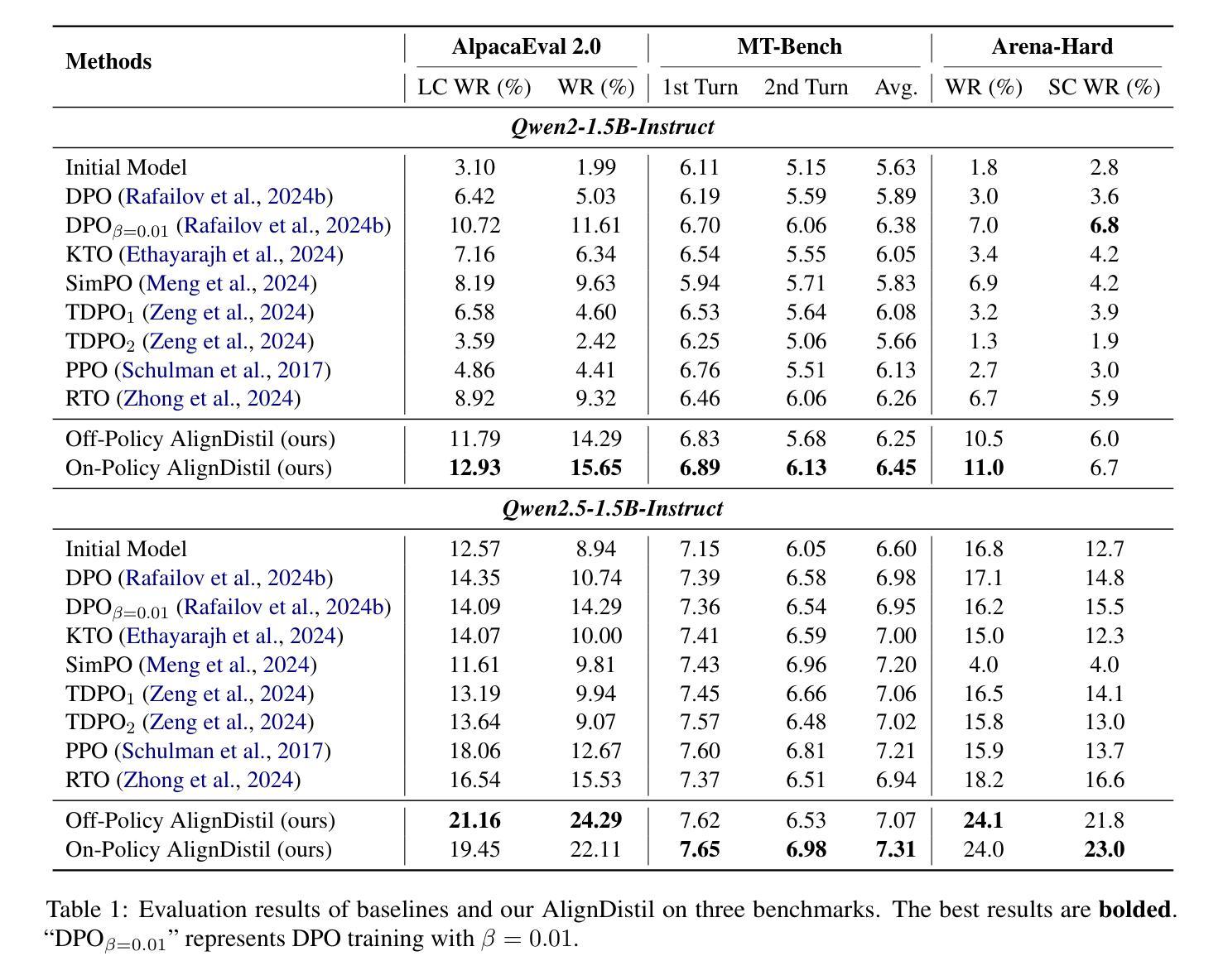
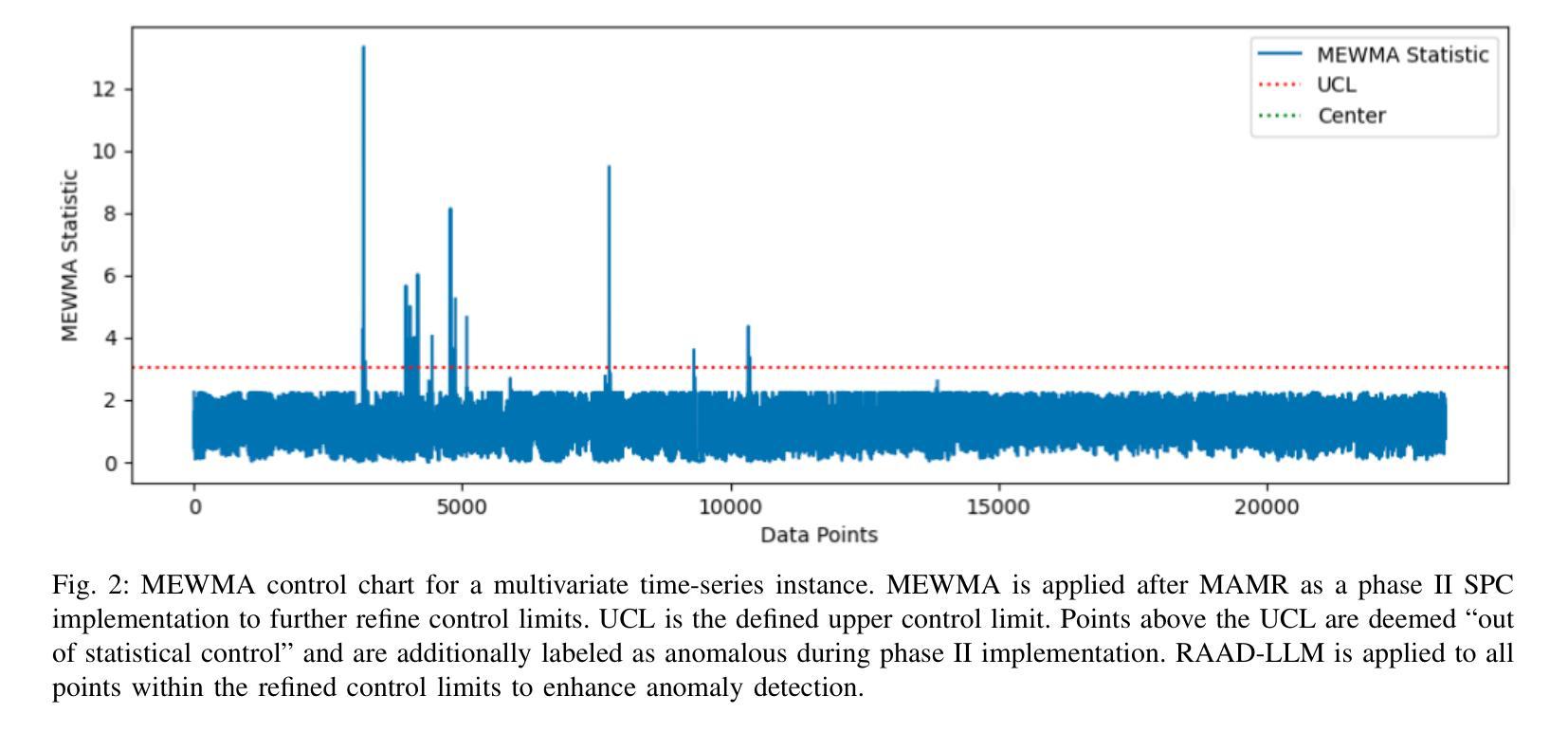
RAAD-LLM: Adaptive Anomaly Detection Using LLMs and RAG Integration
Authors:Alicia Russell-Gilbert, Sudip Mittal, Shahram Rahimi, Maria Seale, Joseph Jabour, Thomas Arnold, Joshua Church
Anomaly detection in complex industrial environments poses unique challenges, particularly in contexts characterized by data sparsity and evolving operational conditions. Predictive maintenance (PdM) in such settings demands methodologies that are adaptive, transferable, and capable of integrating domain-specific knowledge. In this paper, we present RAAD-LLM, a novel framework for adaptive anomaly detection, leveraging large language models (LLMs) integrated with Retrieval-Augmented Generation (RAG). This approach addresses the aforementioned PdM challenges. By effectively utilizing domain-specific knowledge, RAAD-LLM enhances the detection of anomalies in time series data without requiring fine-tuning on specific datasets. The framework’s adaptability mechanism enables it to adjust its understanding of normal operating conditions dynamically, thus increasing detection accuracy. We validate this methodology through a real-world application for a plastics manufacturing plant and the Skoltech Anomaly Benchmark (SKAB). Results show significant improvements over our previous model with an accuracy increase from 70.7 to 89.1 on the real-world dataset. By allowing for the enriching of input series data with semantics, RAAD-LLM incorporates multimodal capabilities that facilitate more collaborative decision-making between the model and plant operators. Overall, our findings support RAAD-LLM’s ability to revolutionize anomaly detection methodologies in PdM, potentially leading to a paradigm shift in how anomaly detection is implemented across various industries.
在复杂的工业环境中进行异常检测面临着独特的挑战,特别是在数据稀疏和运营条件不断变化的环境中更是如此。在这样的环境中,预测性维护(PdM)需要具有适应性、可迁移性并能整合特定领域知识的方法论。本文中,我们提出了RAAD-LLM,这是一个利用大型语言模型(LLM)与检索增强生成(RAG)相结合的自适应异常检测新框架。该方法解决了上述PdM挑战。通过有效利用特定领域的知识,RAAD-LLM增强了时间序列数据中的异常检测能力,而无需在特定数据集上进行微调。该框架的适应性机制使其能够动态调整对正常操作条件的理解,从而提高检测准确性。我们通过塑料制造厂的实际应用和Skoltech异常基准测试(SKAB)验证了该方法的有效性。结果表明,与我们的前期模型相比,我们在现实世界数据集上的准确率从70.7%提高到了89.1%。通过允许用语义信息丰富输入序列数据,RAAD-LLM结合了多模式功能,促进了模型和工厂操作员之间的更协作决策。总的来说,我们的研究支持了RAAD-LLM在PdM中革新异常检测方法论的能力,有可能导致各行业异常检测实施方式的范式转变。
论文及项目相关链接
PDF arXiv admin note: substantial text overlap with arXiv:2411.00914
Summary
基于大型语言模型(LLM)的RAAD框架能有效应对复杂工业环境中的异常检测挑战。它采用检索增强生成(RAG)技术,能够适应数据稀疏和运营条件多变的情境。通过利用特定领域的专业知识,RAAD框架提高了时间序列数据的异常检测能力,无需针对特定数据集进行微调。其自适应机制能够动态调整对正常操作条件的理解,从而提高检测准确性。在塑料制造工厂的实际应用和Skoltech异常基准测试(SKAB)中验证了该方法的优越性,准确率从之前的70.7%提高到89.1%。同时,该框架还结合了多模态功能,允许输入序列数据的语义增强,促进模型与工厂操作人员之间的更协作决策。总体而言,RAAD框架有望彻底改变预测维护(PdM)中的异常检测方法,为各行业带来范式转变。
Key Takeaways
- RAAD-LLM框架利用大型语言模型(LLM)和检索增强生成(RAG)技术,为复杂工业环境中的异常检测提供了新颖解决方案。
- 该框架能够适应数据稀疏和运营条件多变的挑战。
- RAAD-LLM通过利用特定领域的专业知识,提高了时间序列数据的异常检测能力。
- 框架具有自适应机制,能动态调整对正常操作条件的理解,提高检测准确性。
- 在实际塑料制造工厂和Skoltech异常基准测试中的结果表明,RAAD-LLM的准确率显著提高。
- RAAD-LLM框架结合了多模态功能,促进模型与工厂操作人员之间的协作决策。
点此查看论文截图

Multimodal AI predicts clinical outcomes of drug combinations from preclinical data
Authors:Yepeng Huang, Xiaorui Su, Varun Ullanat, Ivy Liang, Lindsay Clegg, Damilola Olabode, Nicholas Ho, Bino John, Megan Gibbs, Marinka Zitnik
Predicting clinical outcomes from preclinical data is essential for identifying safe and effective drug combinations. Current models rely on structural or target-based features to identify high-efficacy, low-toxicity drug combinations. However, these approaches fail to incorporate the multimodal data necessary for accurate, clinically-relevant predictions. Here, we introduce MADRIGAL, a multimodal AI model that learns from structural, pathway, cell viability, and transcriptomic data to predict drug combination effects across 953 clinical outcomes and 21842 compounds, including combinations of approved drugs and novel compounds in development. MADRIGAL uses a transformer bottleneck module to unify preclinical drug data modalities while handling missing data during training and inference–a major challenge in multimodal learning. It outperforms single-modality methods and state-of-the-art models in predicting adverse drug interactions. MADRIGAL performs virtual screening of anticancer drug combinations and supports polypharmacy management for type II diabetes and metabolic dysfunction-associated steatohepatitis (MASH). It identifies transporter-mediated drug interactions. MADRIGAL predicts resmetirom, the first and only FDA-approved drug for MASH, among therapies with the most favorable safety profile. It supports personalized cancer therapy by integrating genomic profiles from cancer patients. Using primary acute myeloid leukemia samples and patient-derived xenograft models, it predicts the efficacy of personalized drug combinations. Integrating MADRIGAL with a large language model allows users to describe clinical outcomes in natural language, improving safety assessment by identifying potential adverse interactions and toxicity risks. MADRIGAL provides a multimodal approach for designing combination therapies with improved predictive accuracy and clinical relevance.
从临床前数据预测临床结果是识别安全和有效药物组合的关键。当前模型依赖于结构或目标基础特征来识别高效、低毒的药物组合。然而,这些方法未能融入对准确且临床相关的预测必要的多模式数据。这里,我们介绍了MADRIGAL,一个多模式人工智能模型,能够从结构、途径、细胞活性和转录组数据学习,以预测涉及953种临床结果和21842种化合物的药物组合效果,包括获批药物和正在开发的新化合物的组合。MADRIGAL采用变压器瓶颈模块来统一临床前药物数据模式,并在训练和推理过程中处理缺失数据——这是多模式学习中的主要挑战。它在预测药物相互作用的不良反应方面优于单模式方法和最先进的模型。MADRIGAL对抗癌药物组合进行虚拟筛选,并支持II型糖尿病和代谢功能障碍相关脂肪性肝炎(MASH)的多药治疗。它确定了转运体介导的药物相互作用。MADRIGAL预测雷司美特罗是MASH首个且唯一一种FDA批准的药物,在治疗中具有最安全的效果。它通过整合癌症患者的基因组图谱支持个性化癌症治疗。使用原发性急性髓系白血病样本和患者衍生的异种移植模型,它可预测个性化药物组合的效果。将MADRIGAL与大型语言模型集成,使用户可以用自然语言描述临床结果,通过识别潜在的不良相互作用和毒性风险来提高安全性评估。MADRIGAL提供了一种多模式方法,用于设计具有更高预测准确性和临床相关性的联合疗法。
论文及项目相关链接
Summary
本文介绍了一种名为MADRIGAL的多模态人工智能模型,该模型能够融合结构、通路、细胞活力和转录组数据,预测药物组合对953种临床结局的影响。它采用转换器瓶颈模块来处理训练过程中的缺失数据,并在预测药物相互作用方面表现出色。MADRIGAL支持虚拟筛选抗癌药物组合和多药疗法管理,可识别运输介导的药物相互作用,并预测具有最佳安全性的药物。
Key Takeaways
- MADRIGAL是一个多模态AI模型,能够融合多种类型的数据来预测药物组合的临床效果。
- 该模型可以处理训练过程中的缺失数据,这是多模态学习中的一个主要挑战。
- MADRIGAL在预测药物相互作用方面表现出色,并可用于虚拟筛选抗癌药物组合和多药疗法管理。
- MADRIGAL能够识别运输介导的药物相互作用,并预测具有最佳安全性的药物,如FDA批准的用于治疗MASH的resmetirom。
- 该模型支持个性化癌症治疗,通过整合癌症患者的基因组数据进行药物组合预测。
- MADRIGAL与大型语言模型的集成使用户可以用自然语言描述临床结果,从而提高安全性评估的准确性和识别潜在的不良相互作用和毒性风险。
点此查看论文截图

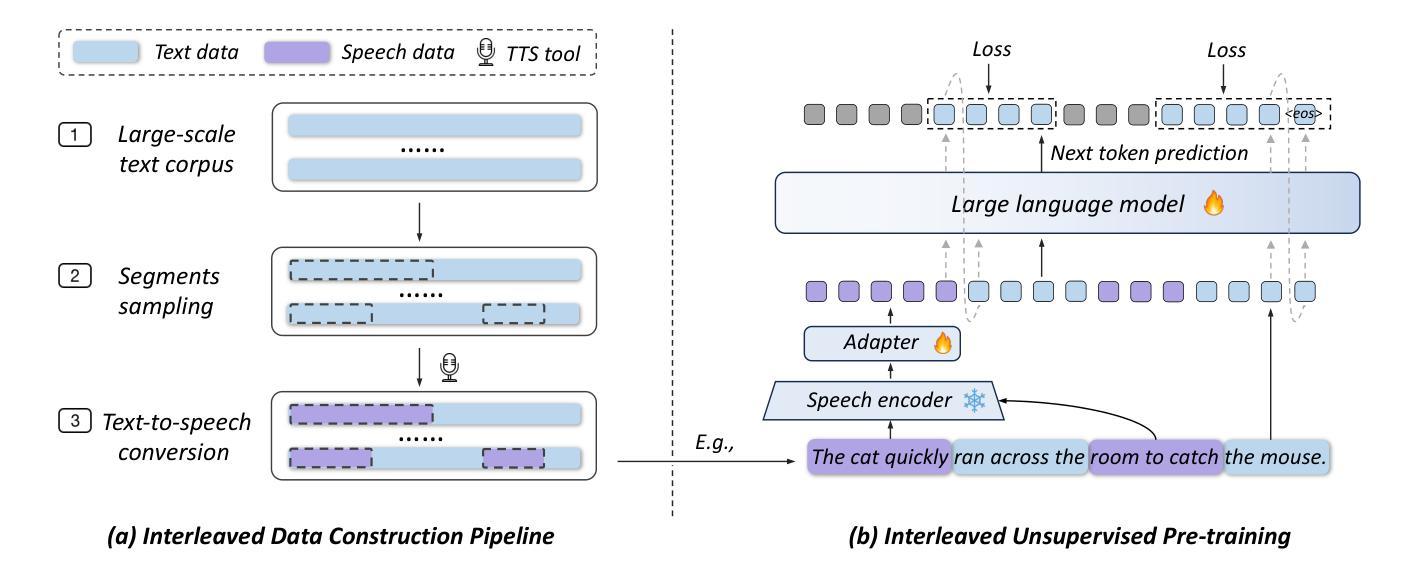
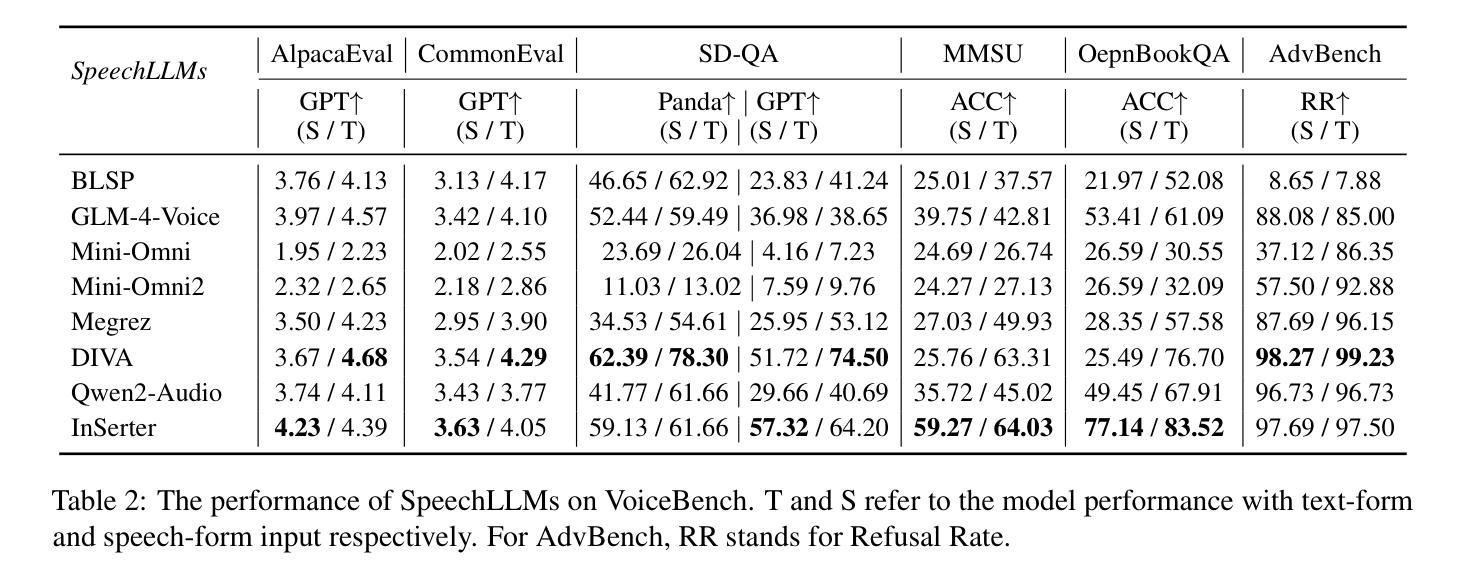
InSerter: Speech Instruction Following with Unsupervised Interleaved Pre-training
Authors:Dingdong Wang, Jin Xu, Ruihang Chu, Zhifang Guo, Xiong Wang, Jincenzi Wu, Dongchao Yang, Shengpeng Ji, Junyang Lin
Recent advancements in speech large language models (SpeechLLMs) have attracted considerable attention. Nonetheless, current methods exhibit suboptimal performance in adhering to speech instructions. Notably, the intelligence of models significantly diminishes when processing speech-form input as compared to direct text-form input. Prior work has attempted to mitigate this semantic inconsistency between speech and text representations through techniques such as representation and behavior alignment, which involve the meticulous design of data pairs during the post-training phase. In this paper, we introduce a simple and scalable training method called InSerter, which stands for Interleaved Speech-Text Representation Pre-training. InSerter is designed to pre-train large-scale unsupervised speech-text sequences, where the speech is synthesized from randomly selected segments of an extensive text corpus using text-to-speech conversion. Consequently, the model acquires the ability to generate textual continuations corresponding to the provided speech segments, obviating the need for intensive data design endeavors. To systematically evaluate speech instruction-following capabilities, we introduce SpeechInstructBench, the first comprehensive benchmark specifically designed for speech-oriented instruction-following tasks. Our proposed InSerter achieves SOTA performance in SpeechInstructBench and demonstrates superior or competitive results across diverse speech processing tasks.
最近,语音大语言模型(SpeechLLMs)的进展引起了人们的广泛关注。然而,当前的方法在遵循语音指令方面表现并不理想。值得注意的是,与直接文本输入相比,模型在处理语音形式输入时的智能水平大幅下降。早期的工作试图通过表示和行为对齐等技术来缓解语音和文本表示之间的语义不一致性,这需要在后训练阶段精心设计数据对。在本文中,我们介绍了一种简单且可扩展的训练方法,称为InSerter,即交替语音-文本表示预训练。InSerter旨在预训练大规模无监督的语音-文本序列,其中语音是通过文本转语音转换从大量文本语料库的随机段落中合成的。因此,模型获得了根据提供的语音段落生成文本延续的能力,从而无需进行密集的数据设计努力。为了系统地评估遵循语音指令的能力,我们推出了SpeechInstructBench,这是专门为面向语音的指令遵循任务设计的第一个综合基准测试。我们提出的InSerter在SpeechInstructBench上达到了最新性能,并在多种语音识别任务中表现出卓越或具有竞争力的结果。
论文及项目相关链接
Summary
近期语音大语言模型(SpeechLLMs)的进展备受关注,但现有方法在处理语音指令时表现欠佳。本文提出了一种简单且可扩展的训练方法——InSerter,即交替语音文本表示预训练法。该方法能够预训练大规模无监督语音文本序列,通过文本转语音转换技术合成随机选择的文本语料库片段的语音,使模型学会根据提供的语音片段生成文本延续。为系统评估语音指令跟随能力,本文还引入了SpeechInstructBench基准测试,InSerter在该基准测试中取得最优性能,并在多种语音处理任务中表现卓越。
Key Takeaways
- 语音大语言模型(SpeechLLMs)在处理语音指令时存在性能不足的问题。
- 当前研究通过表示和行为对齐等技术尝试解决语音和文本表示之间的语义不一致性。
- 本文提出了一种新的简单且可扩展的训练方法——InSerter,该方法能够预训练大规模无监督语音文本序列。
- InSerter利用文本转语音转换技术合成语音,使模型学会根据语音片段生成文本延续。
- 引入了SpeechInstructBench基准测试,以系统评估语音指令跟随能力。
- InSerter在SpeechInstructBench基准测试中取得了最优性能。
点此查看论文截图


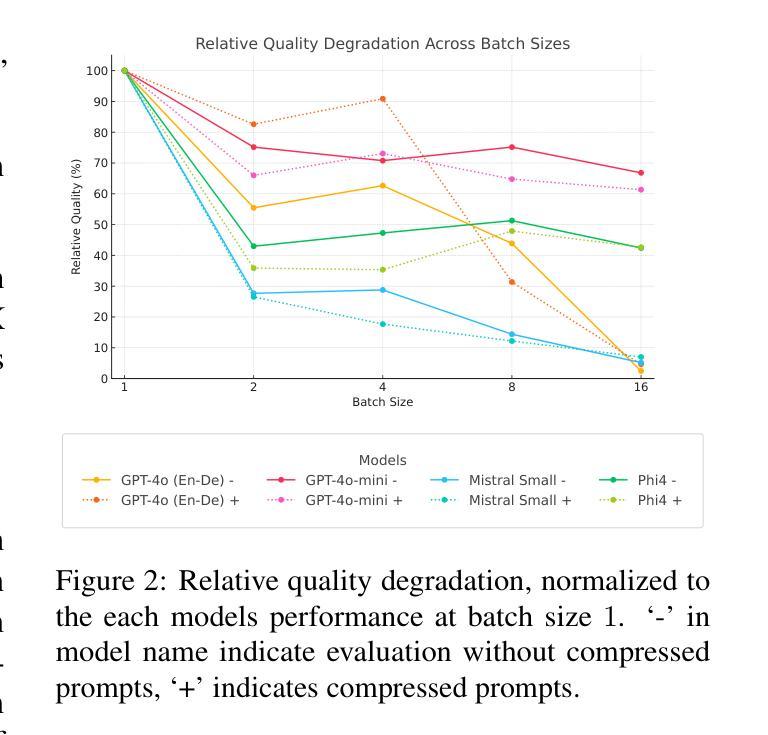
BatchGEMBA: Token-Efficient Machine Translation Evaluation with Batched Prompting and Prompt Compression
Authors:Daniil Larionov, Steffen Eger
Recent advancements in Large Language Model (LLM)-based Natural Language Generation evaluation have largely focused on single-example prompting, resulting in significant token overhead and computational inefficiencies. In this work, we introduce BatchGEMBA-MQM, a framework that integrates batched prompting with the GEMBA-MQM metric for machine translation evaluation. Our approach aggregates multiple translation examples into a single prompt, reducing token usage by 2-4 times (depending on the batch size) relative to single-example prompting. Furthermore, we propose a batching-aware prompt compression model that achieves an additional token reduction of 13-15% on average while also showing ability to help mitigate batching-induced quality degradation. Evaluations across several LLMs (GPT-4o, GPT-4o-mini, Mistral Small, Phi4, and CommandR7B) and varying batch sizes reveal that while batching generally negatively affects quality (but sometimes not substantially), prompt compression does not degrade further, and in some cases, recovers quality loss. For instance, GPT-4o retains over 90% of its baseline performance at a batch size of 4 when compression is applied, compared to a 44.6% drop without compression. We plan to release our code and trained models at https://github.com/NL2G/batchgemba to support future research in this domain.
近期,基于大型语言模型(LLM)的自然语言生成评估进展主要集中在单例提示上,这导致了显著的令牌开销和计算效率低下。在这项工作中,我们引入了BatchGEMBA-MQM框架,它将批量提示与GEMBA-MQM机器翻译评估指标相结合。我们的方法将多个翻译示例聚集到一个提示中,与单例提示相比,可以减少2-4倍的令牌使用(具体取决于批量大小)。此外,我们提出了一个感知批处理的提示压缩模型,在平均情况下实现了额外的令牌减少13-15%,同时显示出有助于缓解批量引起的质量退化的能力。在多个LLM(GPT-4o、GPT-4o-mini、Mistral Small、Phi4和CommandR7B)和不同的批量大小上的评估表明,虽然批量处理通常会对质量产生负面影响(但有时并不显著),但提示压缩并不会进一步降低质量,在某些情况下还能恢复损失的质量。例如,在批量大小为4时,GPT-4o在应用压缩后保留了超过90%的基线性能,而没有压缩时性能下降了44.6%。我们计划将代码和训练好的模型发布在https://github.com/NL2G/batchgemba上,以支持未来在这一领域的研究。
论文及项目相关链接
Summary
基于大型语言模型(LLM)的自然语言生成评估的最新进展主要集中在单例提示上,导致了显著的令牌开销和计算效率低下。本研究介绍了BatchGEMBA-MQM框架,该框架将批量提示与GEMBA-MQM指标相结合,用于机器翻译评估。我们的方法将多个翻译示例聚集到一个提示中,与单例提示相比,相对减少了2-4倍的令牌使用量。此外,我们提出了一个批处理感知的提示压缩模型,在平均减少额外的令牌使用率的同时提升了翻译质量。对多个LLM和不同的批量大小的评估表明,虽然批处理通常会对质量产生负面影响(但有时影响并不显著),但提示压缩并不会进一步降低质量,在某些情况下还能恢复损失的质量。例如,在批量大小为4的情况下,GPT-4o在使用压缩时保留了超过90%的基线性能,而没有压缩时性能下降了44.6%。我们计划在https://github.com/NL2G/batchgemba上发布我们的代码和训练模型,以支持未来在此领域的研究。
Key Takeaways
- 最近LLM在NLP评价方面的进展主要集中在单例提示上,导致计算效率低和令牌开销大。
- 研究人员提出了一种新的框架BatchGEMBA-MQM来改进这一状况,它通过集成批量提示来提高效率。
- 该框架将多个翻译示例聚集到一个提示中,可以显著减少令牌使用量。
- 提出了一种批处理感知的提示压缩模型,进一步提高了翻译质量并降低了令牌使用率。
- 批处理对翻译质量有负面影响,但提示压缩有助于缓解这种影响。
- 在批量大小为4的情况下,GPT-4o在使用压缩时保持了较高的性能。
点此查看论文截图

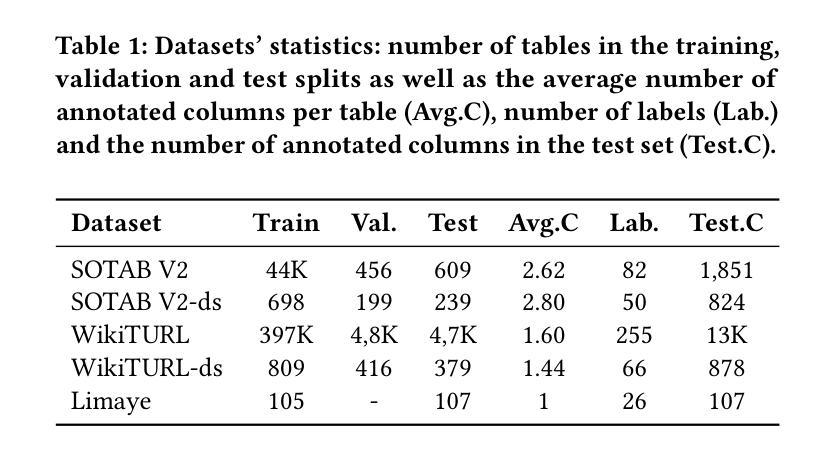
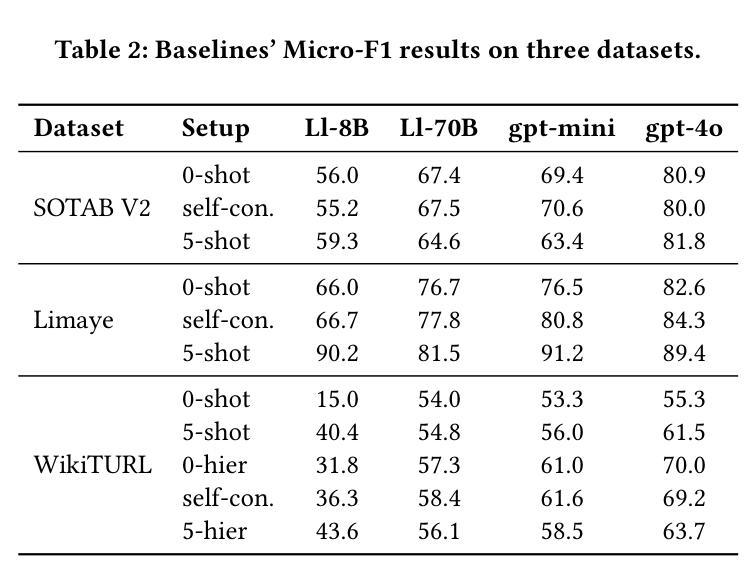
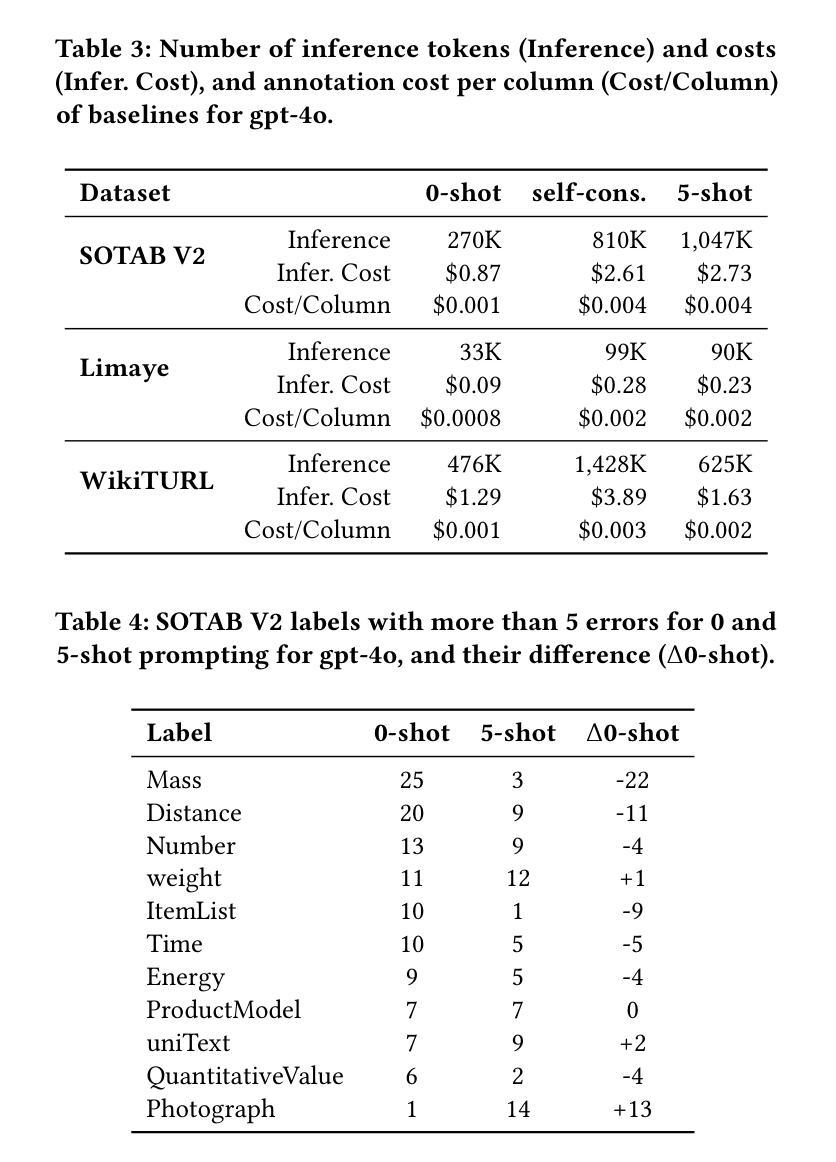
Evaluating Knowledge Generation and Self-Refinement Strategies for LLM-based Column Type Annotation
Authors:Keti Korini, Christian Bizer
Understanding the semantics of columns in relational tables is an important pre-processing step for indexing data lakes in order to provide rich data search. An approach to establishing such understanding is column type annotation (CTA) where the goal is to annotate table columns with terms from a given vocabulary. This paper experimentally compares different knowledge generation and self-refinement strategies for LLM-based column type annotation. The strategies include using LLMs to generate term definitions, error-based refinement of term definitions, self-correction, and fine-tuning using examples and term definitions. We evaluate these strategies along two dimensions: effectiveness measured as F1 performance and efficiency measured in terms of token usage and cost. Our experiments show that the best performing strategy depends on the model/dataset combination. We find that using training data to generate label definitions outperforms using the same data as demonstrations for in-context learning for two out of three datasets using OpenAI models. The experiments further show that using the LLMs to refine label definitions brings an average increase of 3.9% F1 in 10 out of 12 setups compared to the performance of the non-refined definitions. Combining fine-tuned models with self-refined term definitions results in the overall highest performance, outperforming zero-shot prompting fine-tuned models by at least 3% in F1 score. The costs analysis shows that while reaching similar F1 score, self-refinement via prompting is more cost efficient for use cases requiring smaller amounts of tables to be annotated while fine-tuning is more efficient for large amounts of tables.
理解关系表中的列语义是索引数据湖以提供丰富数据搜索的重要预处理步骤。建立这种理解的方法之一是列类型注释(CTA),其目的是使用给定的词汇对表列进行注释。本文实验性地比较了基于LLM的列类型注释的不同知识生成和自我完善策略。这些策略包括使用LLM生成术语定义,基于错误的术语定义优化,自我校正,以及使用示例和术语定义进行微调。我们从两个维度评估这些策略:有效性,以F1性能来衡量;以及效率,以令牌使用量和成本来衡量。我们的实验表明,最佳策略取决于模型和数据集组合。我们发现,对于三个数据集中的两个数据集,使用训练数据生成标签定义的表现优于将相同数据用作上下文学习的演示案例,使用的是OpenAI模型。实验还表明,与未精化的定义相比,使用LLM完善标签定义在12个设置中的10个设置中平均提高了3.9%的F1分数。与零样本提示微调模型相比,结合微调模型和自我完善的术语定义达到了整体最佳性能,在F1分数上至少提高了3%。成本分析表明,在达到类似F1得分的情况下,对于需要注释的表格数量较少的使用情况,通过提示进行自我完善更具成本效益,而微调则更适合大量表格的情况。
论文及项目相关链接
摘要
本文实验性地比较了基于LLM的列类型注解的不同知识生成和自我完善策略。策略包括使用LLM生成术语定义、基于错误的术语定义改进、自我校正以及使用示例和术语定义进行微调。评估这些策略的两个维度包括有效性和效率。实验结果显示,最佳策略取决于模型和数据集组合。使用训练数据生成标签定义的表现优于使用相同数据作为演示进行上下文学习。实验还表明,使用LLM改进标签定义在12个设置中的10个中使F1分数平均提高了3.9%。结合微调模型和自我完善的术语定义达到整体最佳性能,在F1分数上至少优于零样本提示微调模型3%。成本分析表明,虽然达到相似的F1分数,但对于需要注释的表格数量较少的情况,通过提示进行自我完善更为成本效益;而对于需要大量表格的情况,微调更为高效。
关键见解
- 理解和处理关系表中的列语义是数据湖索引的预处理步骤,为丰富数据搜索提供支持。
- 引入了一种名为列类型注解(CTA)的方法,旨在给表列进行术语标注。
- 实验比较了基于LLM的CTA的不同知识生成和自我完善策略,包括术语定义的生成、基于错误的术语定义改进等。
- 评估策略的有效性通过F1性能来衡量,效率则通过令牌使用情况和成本来衡量。
- 最佳策略的选择取决于所使用的模型和数据集组合。
- 在某些数据集上,使用训练数据生成标签定义的表现优于上下文学习。
点此查看论文截图


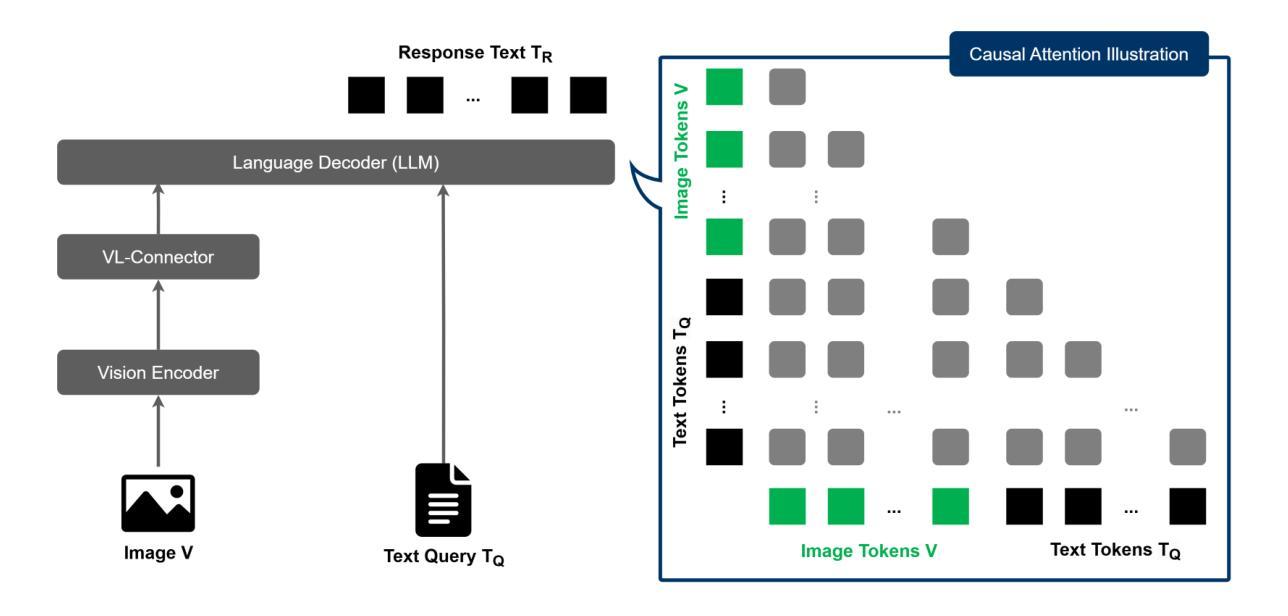
Seeing is Understanding: Unlocking Causal Attention into Modality-Mutual Attention for Multimodal LLMs
Authors:Wei-Yao Wang, Zhao Wang, Helen Suzuki, Yoshiyuki Kobayashi
Recent Multimodal Large Language Models (MLLMs) have demonstrated significant progress in perceiving and reasoning over multimodal inquiries, ushering in a new research era for foundation models. However, vision-language misalignment in MLLMs has emerged as a critical challenge, where the textual responses generated by these models are not factually aligned with the given text-image inputs. Existing efforts to address vision-language misalignment have focused on developing specialized vision-language connectors or leveraging visual instruction tuning from diverse domains. In this paper, we tackle this issue from a fundamental yet unexplored perspective by revisiting the core architecture of MLLMs. Most MLLMs are typically built on decoder-only LLMs consisting of a causal attention mechanism, which limits the ability of earlier modalities (e.g., images) to incorporate information from later modalities (e.g., text). To address this problem, we propose AKI, a novel MLLM that unlocks causal attention into modality-mutual attention (MMA) to enable image tokens to attend to text tokens. This simple yet effective design allows AKI to achieve superior performance in 12 multimodal understanding benchmarks (+7.2% on average) without introducing additional parameters and increasing training time. Our MMA design is intended to be generic, allowing for application across various modalities, and scalable to accommodate diverse multimodal scenarios. The code is publicly available at https://github.com/sony/aki, and we will release our AKI-4B model to encourage further advancements in MLLMs across various directions.
近期,多模态大型语言模型(MLLMs)在感知和推理多模态查询方面取得了显著进展,为基础模型开启了一个新时代。然而,MLLMs中的视觉语言不匹配问题已成为一项关键挑战,其中这些模型生成的文本响应与给定的文本图像输入并不相符。为解决视觉语言不匹配问题,现有的努力主要集中在开发专用的视觉语言连接器或从多个领域利用视觉指令调整。本文从一个基本且未被探索的视角来解决这个问题,通过重新设计MLLM的核心架构。大多数MLLM通常建立在仅解码器的大型语言模型上,由因果注意力机制组成,这限制了早期模态(例如图像)融入后期模态(例如文本)信息的能力。为了解决这个问题,我们提出了AKI,这是一种新型MLLM,它将因果注意力解锁为模态相互注意力(MMA),使图像标记能够关注文本标记。这种简单而有效的设计使AKI能够在不引入额外参数和增加训练时间的情况下,在12个多模态理解基准测试中实现了出色的性能(+7.2%的平均提升)。我们的MMA设计旨在通用化,可以应用于各种模态,并且可扩展到适应不同的多模态场景。代码公开在https://github.com/sony/aki,我们将发布我们的AKI-4B模型,以鼓励在多个方向进一步推动MLLM的发展。
论文及项目相关链接
PDF Preprint
摘要
点此查看论文截图


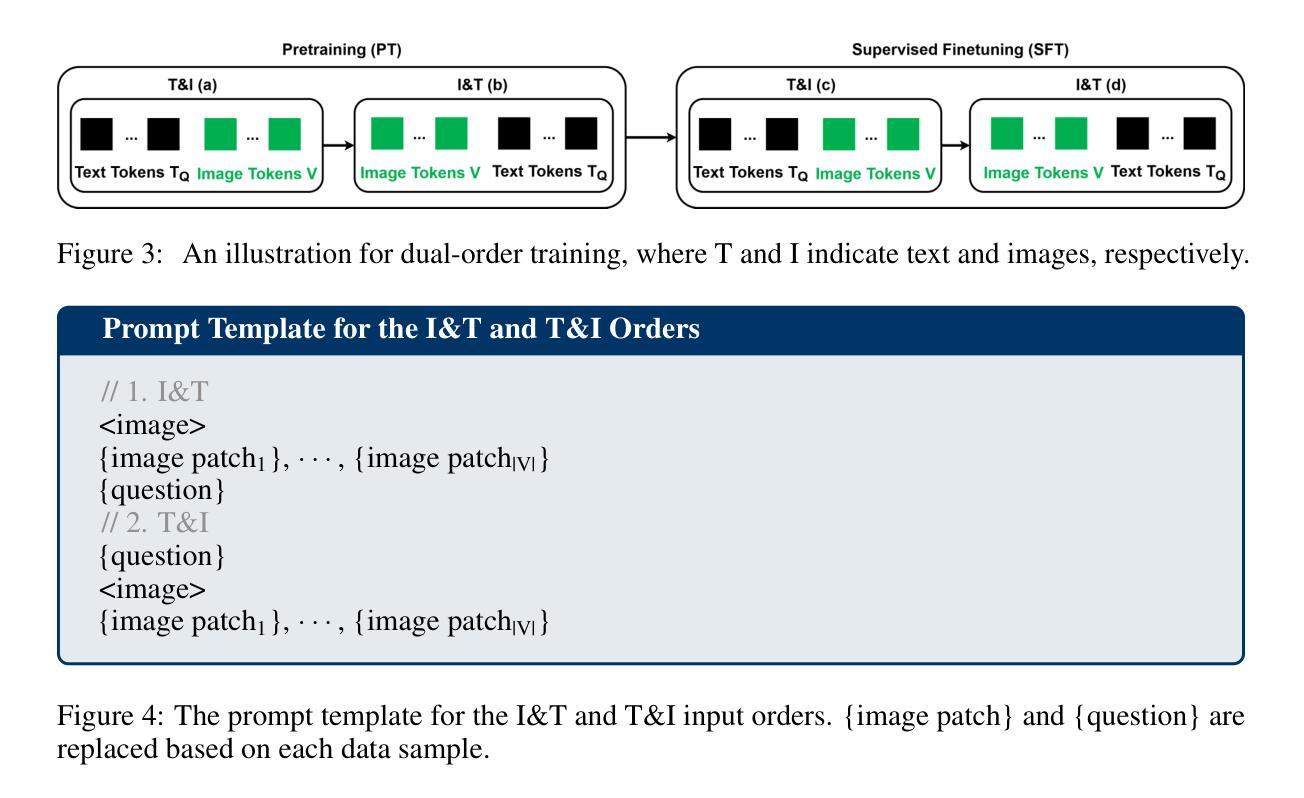
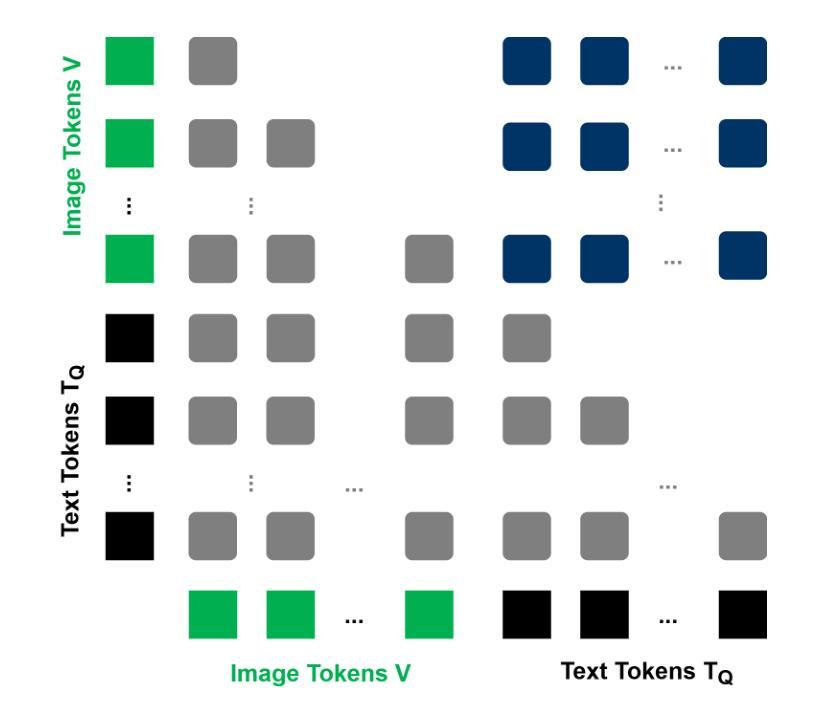
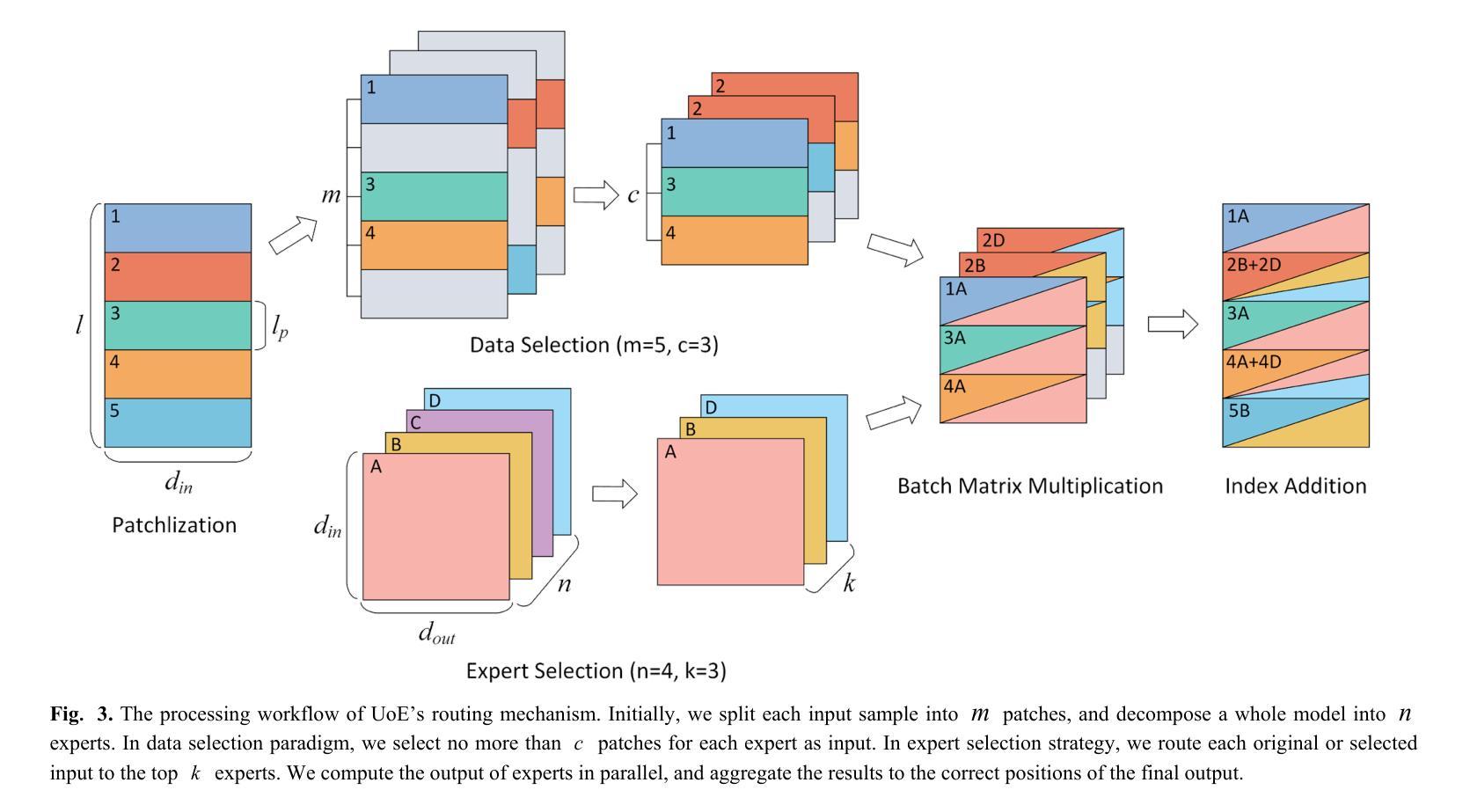
Union of Experts: Adapting Hierarchical Routing to Equivalently Decomposed Transformer
Authors:Yujiao Yang, Jing Lian, Linhui Li
Mixture-of-Experts (MoE) enhances model performance while maintaining computational efficiency, making it well-suited for large-scale applications. However, expert in exist MoE paradigm works as an individual, thereby lacking high-quality expert interactions. Moreover, they have not been effectively extended to attention block, which constrains further efficiency improvements. To tackle these issues, we propose Union-of-Experts (UoE), which decomposes transformer into an equitant group of experts, and then implement dynamic routing on input data and experts. Our approach advances MoE design with three key innovations: (1) We conducted equitant expert decomposition on both MLP blocks and attention blocks based on matrix partition in tensor parallelism. (2) We developed two routing paradigms: patch wise data selection and expert selection, to apply routing across different levels. (3) We design the architecture of UoE model, including Selective Multi-Head Attention (SMHA) and Union-of-MLP-Experts (UoME). (4) We develop parallel implementation of UoE’s routing and computation operation, and optimize efficiency based on the hardware processing analysis. The experiments demonstrate that the model employed with UoE surpass Full Attention, state-of-art MoEs and efficient transformers in several tasks across image and natural language domains. The source codes are available at https://github.com/YujiaoYang-work/UoE.
专家混合(MoE)模式在保持计算效率的同时提高了模型性能,非常适合大规模应用。然而,现有MoE模式下的专家是独立工作的,因此缺乏高质量的专家交互。此外,他们尚未有效地扩展到注意力块,这限制了进一步的效率改进。为了解决这些问题,我们提出了专家联合(UoE)方法,它将变压器分解为等价的专家组,然后对输入数据和专家实施动态路由。我们的方法以三个关键创新点推进MoE设计:(1)我们在MLP块和注意力块上进行了基于张量并行性的等价专家分解。(2)我们开发了两种路由范式:斑块级数据选择和专家选择,以在不同级别上应用路由。(3)我们设计了UoE模型的架构,包括选择性多头注意力(SMHA)和联合MLP专家(UoME)。(4)我们开发了UoE路由和计算操作的并行实现,并基于硬件处理分析优化了效率。实验表明,采用UoE的模型在图像和自然语言领域的多个任务中超越了全注意力、最新的MoE和高效变压器。源代码可在https://github.com/YujiaoYang-work/UoE找到。
论文及项目相关链接
PDF 17 pages, 6 figures, 5 tables
Summary
基于Mixture-of-Experts(MoE)的模型在大规模应用中表现出良好的性能和计算效率。然而,现有MoE中的专家以个人身份工作,缺乏高质量专家交互,且尚未有效地扩展到注意力块,限制了进一步的效率提升。为解决这些问题,我们提出了Union-of-Experts(UoE),它将变压器分解为等价的专家组,并在输入数据和专家上实现动态路由。UoE的设计有三个关键创新点:对MLP块和注意力块进行等价专家分解、开发两种路由范式、设计UoE模型的架构,并在图像和自然语言领域的多个任务中验证了其性能超越了全注意力模型和高效的变压器模型。源代码已公开发布。
Key Takeaways
- MoE模型在大规模应用中具有良好的性能和计算效率。
- MoE中的专家以个人身份工作,缺乏高质量专家交互。
- UoE通过分解为等价的专家组来解决上述问题,并实现动态路由。
- UoE的设计有三个关键创新点:对MLP块和注意力块的等价专家分解、开发两种路由范式、设计UoE模型的架构。
- UoE模型性能在多个任务中超越了全注意力模型和高效的变压器模型。
点此查看论文截图

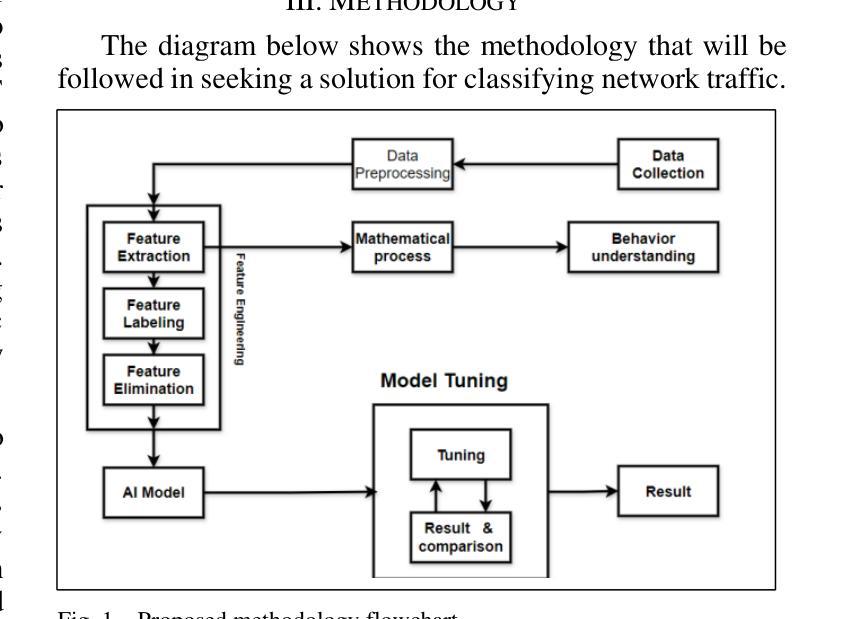
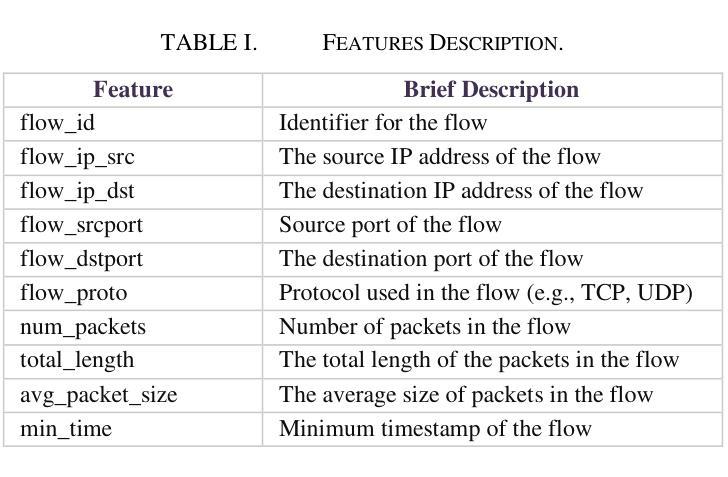
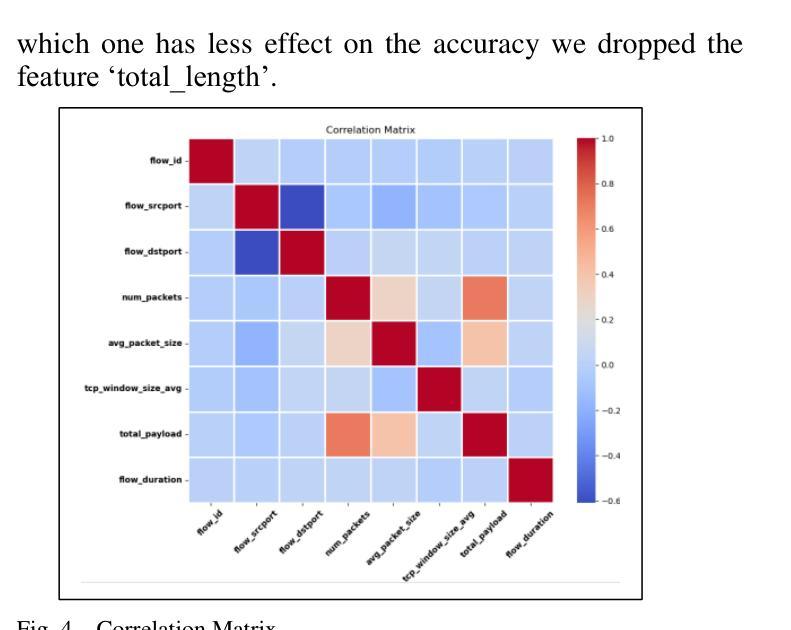
Network Traffic Classification Using Machine Learning, Transformer, and Large Language Models
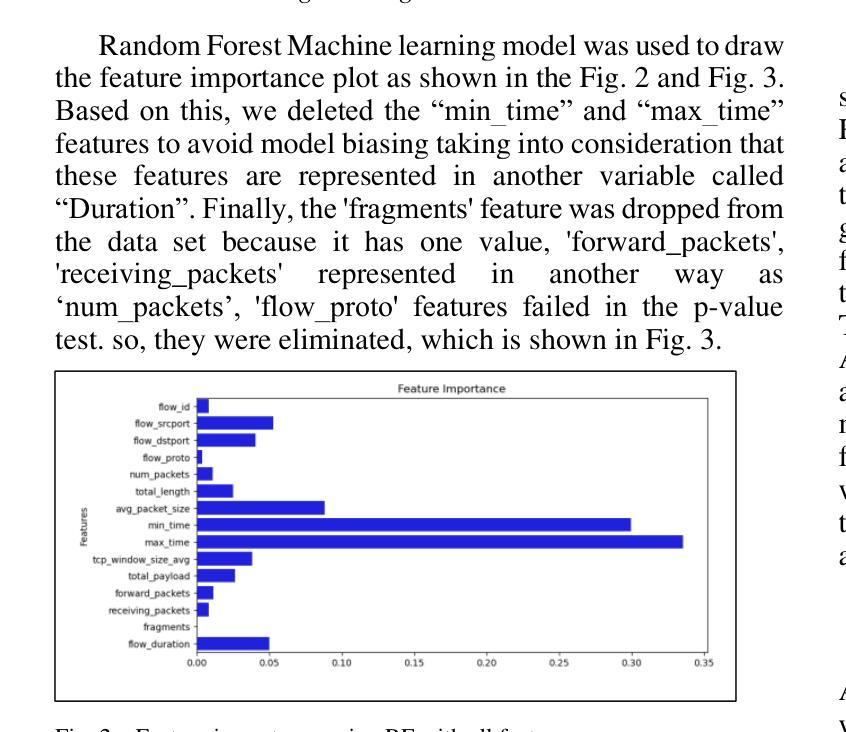
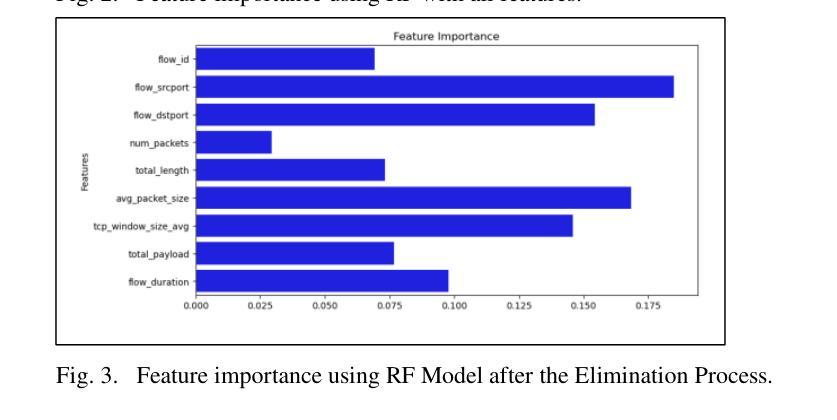
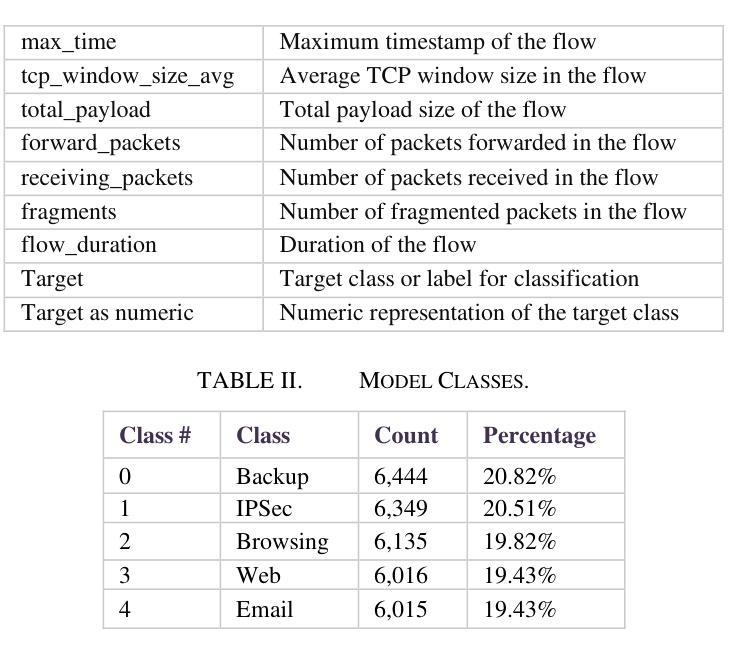
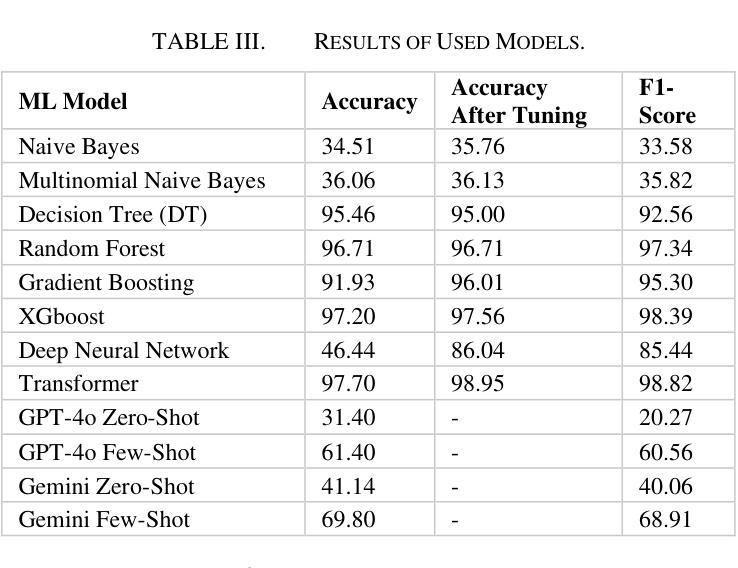
Authors:Ahmad Antari, Yazan Abo-Aisheh, Jehad Shamasneh, Huthaifa I. Ashqar
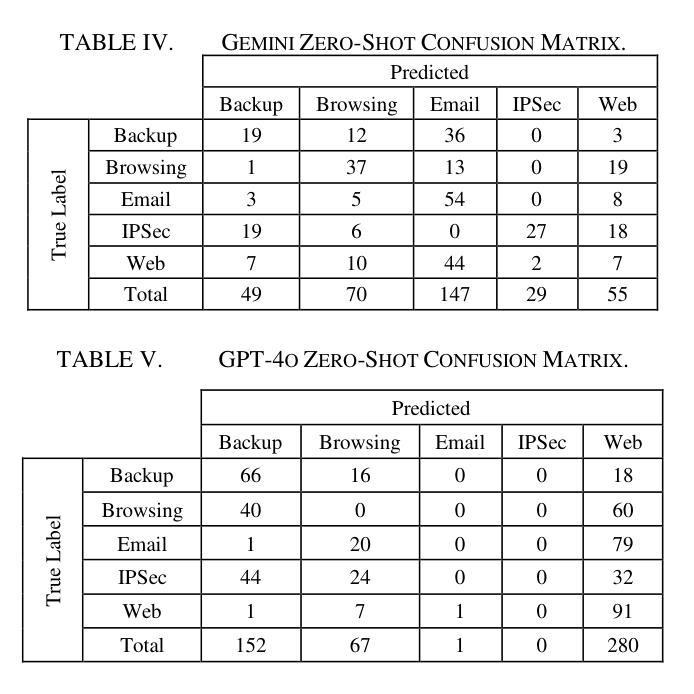
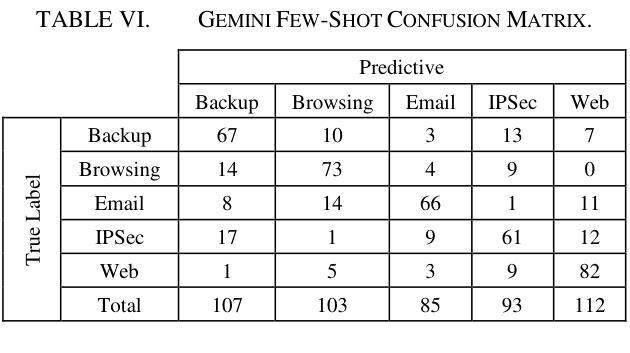
This study uses various models to address network traffic classification, categorizing traffic into web, browsing, IPSec, backup, and email. We collected a comprehensive dataset from Arbor Edge Defender (AED) devices, comprising of 30,959 observations and 19 features. Multiple models were evaluated, including Naive Bayes, Decision Tree, Random Forest, Gradient Boosting, XGBoost, Deep Neural Networks (DNN), Transformer, and two Large Language Models (LLMs) including GPT-4o and Gemini with zero- and few-shot learning. Transformer and XGBoost showed the best performance, achieving the highest accuracy of 98.95 and 97.56%, respectively. GPT-4o and Gemini showed promising results with few-shot learning, improving accuracy significantly from initial zero-shot performance. While Gemini Few-Shot and GPT-4o Few-Shot performed well in categories like Web and Email, misclassifications occurred in more complex categories like IPSec and Backup. The study highlights the importance of model selection, fine-tuning, and the balance between training data size and model complexity for achieving reliable classification results.
本研究采用多种模型来解决网络流量分类问题,将流量分为网页、浏览、IPSec、备份和电子邮件等类别。我们从Arbor Edge Defender(AED)设备收集了一个全面的数据集,包含30,959个观测值和19个特征。评估了多种模型,包括朴素贝叶斯、决策树、随机森林、梯度提升、XGBoost、深度神经网络(DNN)、Transformer以及两个大型语言模型(LLM),包括GPT-4o和Gemini,并进行了零次学习和少次学习。Transformer和XGBoost表现最佳,分别达到了最高的98.95%和97.56%的准确率。GPT-4o和Gemini在少次学习的情况下表现出了有前景的结果,准确率从初始的零次学习性能显著提高。虽然Gemini少次学习和GPT-4o少次学习在Web和电子邮件等类别中表现良好,但在IPSec和备份等更复杂类别中出现了误分类情况。该研究强调了模型选择、微调以及训练数据大小和模型复杂性之间的平衡对于实现可靠分类结果的重要性。
论文及项目相关链接
摘要
网络流量分类技术中模型的探讨和应用。该研究采用多种模型对网络流量进行分类,包括网络流量分类器分为web、浏览、IPSec、备份和电子邮件五大类。采用由边缘设备Arbor Edge Defender采集的数据集对模型性能进行了评价。探讨了不同的模型算法性能优劣情况。如随机森林、梯度提升树等模型表现良好,而GPT-4o和Gemini等大语言模型在少样本情况下表现突出。整体结果表明,选择合适的模型,调整参数,平衡训练数据量和模型复杂度是实现可靠分类结果的关键。
关键见解
- 研究探讨了多种模型在网络流量分类中的应用,包括传统机器学习模型和新兴的大语言模型(LLM)。
- 数据集由Arbor Edge Defender设备收集,包含多个流量类别,提供了丰富的分析样本。
- Naive Bayes、Decision Tree等传统模型有一定的表现。而Random Forest、Gradient Boosting模型等显示出更高的性能。
- 大语言模型GPT-4o和Gemini在少样本学习场景下展现出巨大潜力,但面对复杂类别如IPSec和备份时仍存在误分类风险。
- Transformer模型表现出最佳性能,达到98.95%的准确率。
- 模型选择、参数调整对分类结果的准确性至关重要。
点此查看论文截图

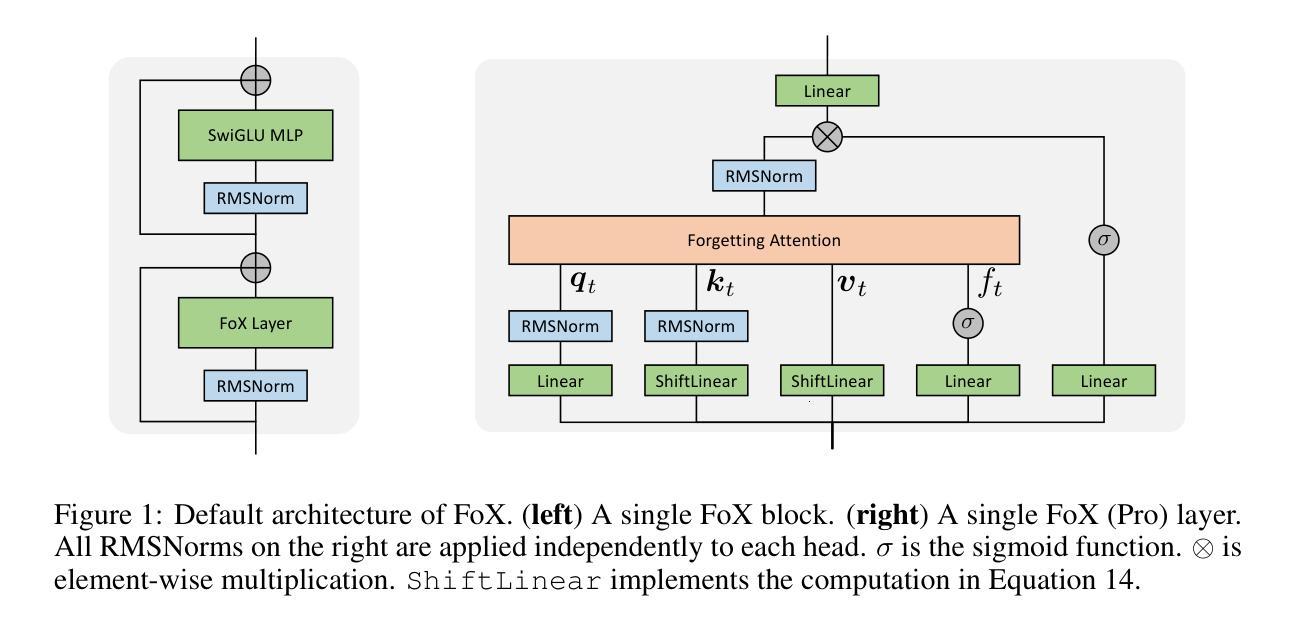
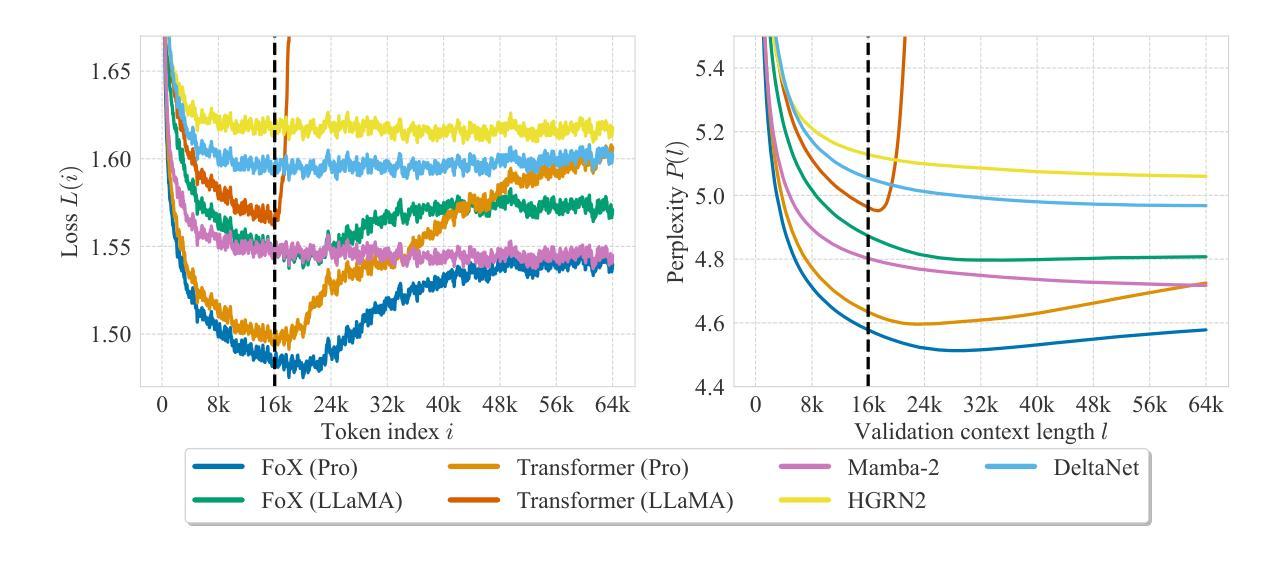
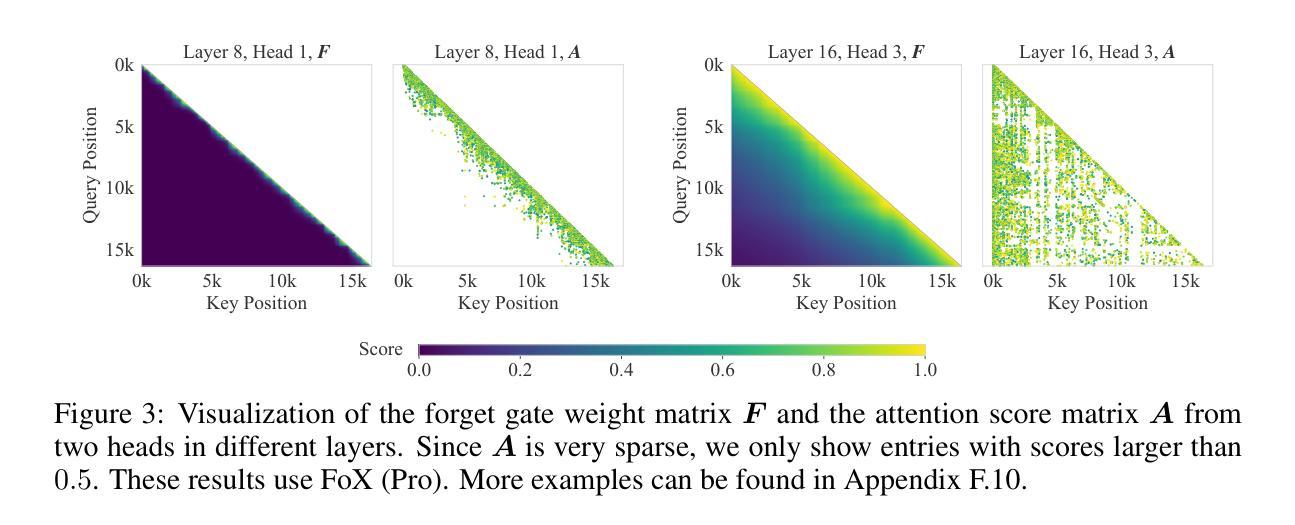
Forgetting Transformer: Softmax Attention with a Forget Gate
Authors:Zhixuan Lin, Evgenii Nikishin, Xu Owen He, Aaron Courville
An essential component of modern recurrent sequence models is the forget gate. While Transformers do not have an explicit recurrent form, we show that a forget gate can be naturally incorporated into Transformers by down-weighting the unnormalized attention scores in a data-dependent way. We name this attention mechanism the Forgetting Attention and the resulting model the Forgetting Transformer (FoX). We show that FoX outperforms the Transformer on long-context language modeling, length extrapolation, and short-context downstream tasks, while performing on par with the Transformer on long-context downstream tasks. Moreover, it is compatible with the FlashAttention algorithm and does not require any positional embeddings. Several analyses, including the needle-in-the-haystack test, show that FoX also retains the Transformer’s superior long-context capabilities over recurrent sequence models such as Mamba-2, HGRN2, and DeltaNet. We also introduce a “Pro” block design that incorporates some common architectural components in recurrent sequence models and find it significantly improves the performance of both FoX and the Transformer. Our code is available at https://github.com/zhixuan-lin/forgetting-transformer.
现代循环序列模型的一个重要组成部分是遗忘门。虽然Transformer没有明确的递归形式,但我们展示了一种通过将未归一化的注意力得分以数据相关的方式进行加权,自然地将遗忘门纳入Transformer的方法。我们将这种注意力机制命名为遗忘注意力,并将得到的模型命名为遗忘转换器(FoX)。我们展示FoX在长上下文语言建模、长度扩展和短上下文下游任务上的性能优于Transformer,而在长上下文下游任务上的性能与Transformer相当。此外,它与FlashAttention算法兼容,不需要任何位置嵌入。包括“海底捞针”测试在内的几项分析表明,FoX在保持Transformer在长上下文方面的优势的同时,优于循环序列模型如Mamba-2、HGRN2和DeltaNet等。我们还引入了一种结合了循环序列模型中一些常见架构组件的“Pro”块设计,发现它显著提高了FoX和Transformer的性能。我们的代码可在https://github.com/zhixuan-lin/forgetting-transformer找到。
论文及项目相关链接
PDF Published as a conference paper at ICLR 2025
Summary
本文介绍了在Transformer模型中引入遗忘门机制的方法,通过数据依赖性地降低未归一化的注意力分数来实现。提出了名为“遗忘注意力”的新注意力机制和相应的遗忘变压器(FoX)模型。在长短上下文语言建模、长度外推和短上下文下游任务上,FoX模型表现优于Transformer模型,同时在长上下文下游任务上表现相当。此外,FoX与FlashAttention算法兼容,无需位置嵌入。通过一系列分析证明,FoX在长上下文能力方面优于其他循环序列模型,如Mamba-2、HGRN2和DeltaNet等。此外,引入“Pro”块设计,融合了一些循环序列模型中的常见组件,能显著提高FoX和Transformer的性能。
Key Takeaways
- 介绍了将遗忘门机制自然融入Transformer模型的方法。
- 提出了“遗忘注意力”的新机制和相应的遗忘变压器(FoX)模型。
- 在长短上下文语言建模、长度外推和短上下文下游任务上,FoX表现优于Transformer。
- FoX在长上下文下游任务上的表现与Transformer相当。
- FoX与FlashAttention算法兼容,无需使用位置嵌入。
- 分析表明,FoX在长上下文能力方面优于其他循环序列模型。
- 引入的“Pro”块设计能显著提高FoX和Transformer的性能。
点此查看论文截图

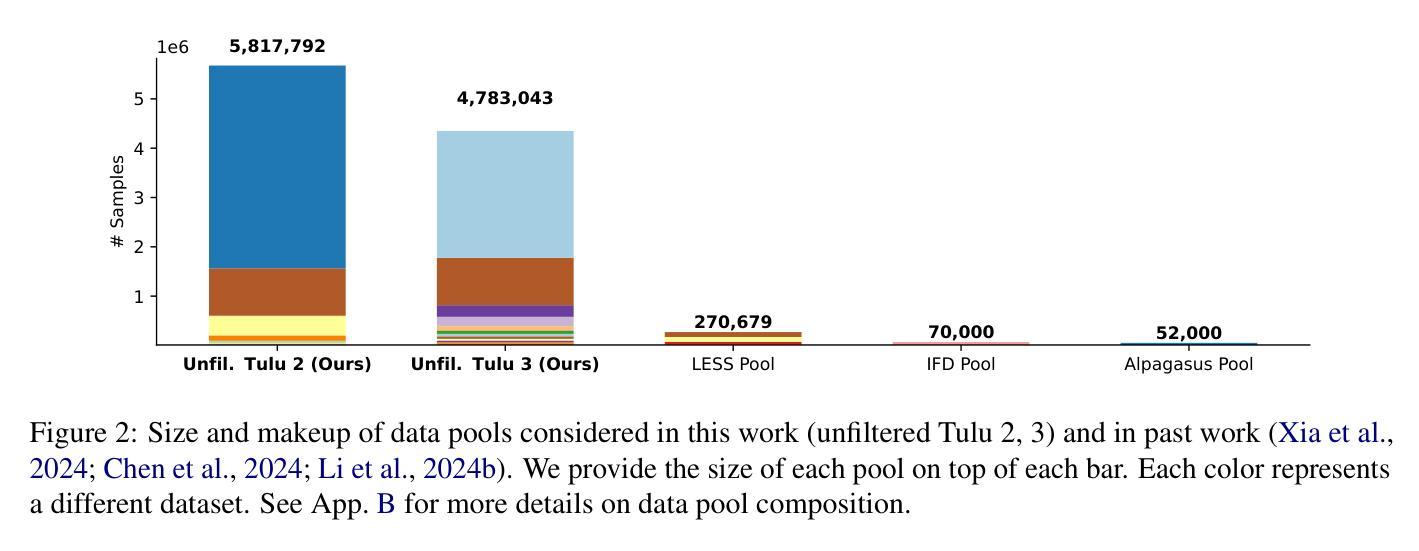
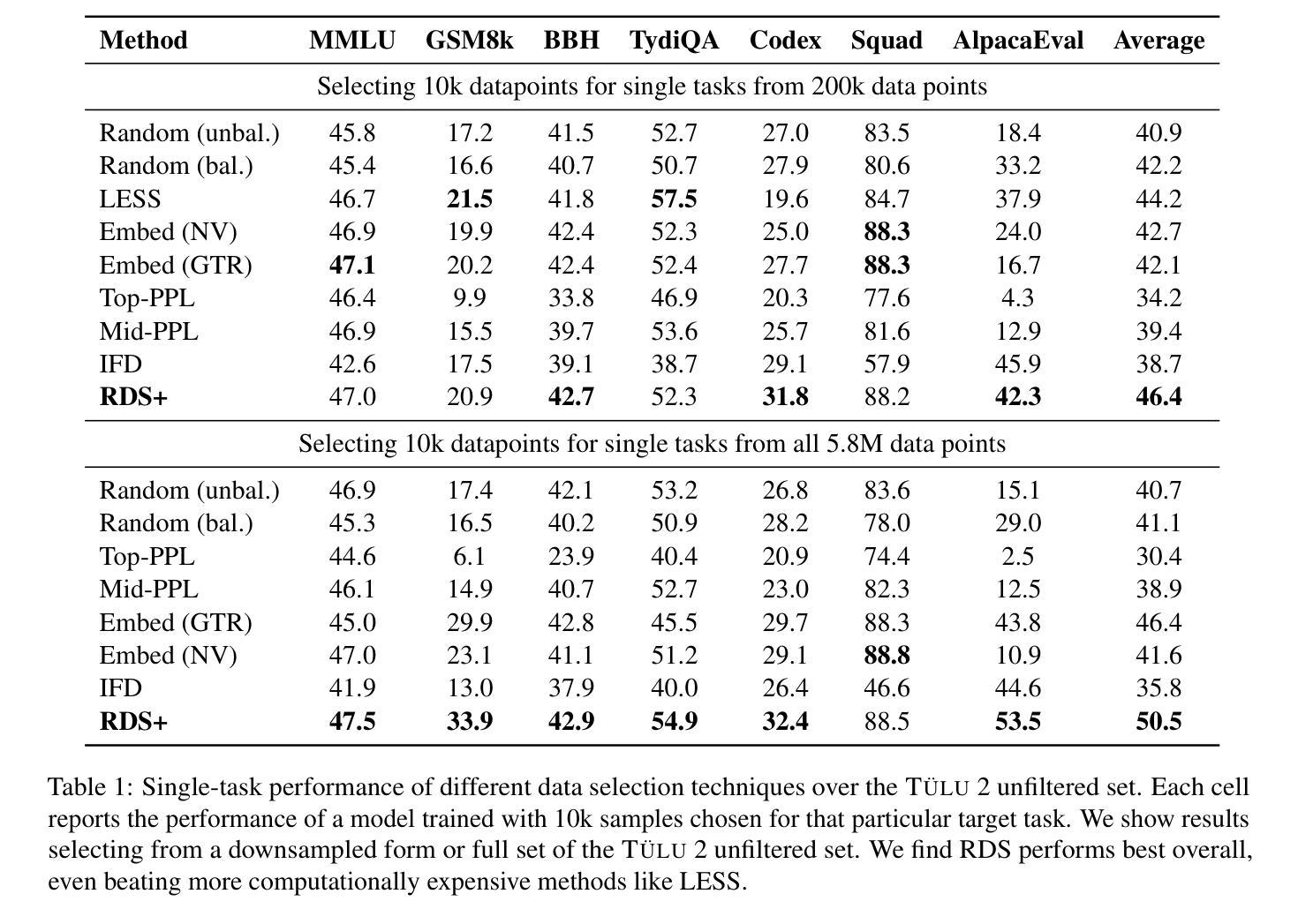
Large-Scale Data Selection for Instruction Tuning
Authors:Hamish Ivison, Muru Zhang, Faeze Brahman, Pang Wei Koh, Pradeep Dasigi
Selecting high-quality training data from a larger pool is a crucial step when instruction-tuning language models, as carefully curated datasets often produce models that outperform those trained on much larger, noisier datasets. Automated data selection approaches for instruction-tuning are typically tested by selecting small datasets (roughly 10k samples) from small pools (100-200k samples). However, popular deployed instruction-tuned models often train on hundreds of thousands to millions of samples, subsampled from even larger data pools. We present a systematic study of how well data selection methods scale to these settings, selecting up to 2.5M samples from pools of up to 5.8M samples and evaluating across 7 diverse tasks. We show that many recently proposed methods fall short of random selection in this setting (while using more compute), and even decline in performance when given access to larger pools of data to select over. However, we find that a variant of representation-based data selection (RDS+), which uses weighted mean pooling of pretrained LM hidden states, consistently outperforms more complex methods across all settings tested – all whilst being more compute-efficient. Our findings highlight that the scaling properties of proposed automated selection methods should be more closely examined. We release our code, data, and models at https://github.com/hamishivi/automated-instruction-selection.
从较大的数据池中选取高质量的训练数据是微调语言模型时的关键步骤。经过精心挑选的数据集通常会产生优于在更大、更嘈杂的数据集上训练的模型。自动数据选择方法通常通过从小型数据池中选择小型数据集(大约10k样本)来进行测试(10万至2万样本)。然而,流行的部署指令微调模型通常会在更大的数据池中进行训练,使用数百万至数千万个样本。我们系统地研究了数据选择方法如何适应这些设置,从多达58万个样本的数据池中选择了多达25万个样本,并在7个不同的任务上进行了评估。我们发现,许多最近提出的方法在此设置中的表现不如随机选择(同时使用了更多的计算资源),并且在给定的更大池中选择数据时性能甚至下降。然而,我们发现一种基于表示的数据选择方法(RDS+)的变体通过使用预训练LM隐藏状态的加权平均池方法表现最好。我们的研究发现强调应更仔细地检查提出的自动化选择方法的扩展属性。我们将我们的代码、数据和模型发布在https://github.com/hamishivi/automated-instruction-selection上。
论文及项目相关链接
Summary
从大型数据池中选取高质量的训练数据是微调语言模型时的关键步骤,精心挑选的数据集产生的模型性能通常优于在更大、更嘈杂的数据集上训练的模型。本文系统地研究了数据选择方法如何在更大规模设置中进行扩展,从多达58万个样本的数据池中选取多达25万个样本,并在不同的7项任务中进行了评估。研究表明,许多最新提出的方法在这种环境下不及随机选择(同时使用更多计算资源),且在面对更大的数据池时性能甚至下降。然而,一种基于表示的数据选择变体(RDS+)在测试的所有设置中表现优异,它使用预训练LM隐藏状态的加权均值池技术,且更为计算高效。本研究强调了应更密切地检查提议的自动选择方法的可扩展性。
Key Takeaways
- 选取高质量训练数据对于微调语言模型至关重要,精心挑选的数据集能够产生性能更优的模型。
- 目前数据选择方法在面对大规模数据集时的表现需要深入研究。
- 许多传统数据选择方法在面对更大数据池时性能下降,甚至不及随机选择。
- 基于表示的数据选择变体(RDS+)表现优异,且更为计算高效。
- RDS+使用预训练LM隐藏状态的加权均值池技术。
- 研究的发现强调了需要更密切地检查提议的自动选择方法的可扩展性。
点此查看论文截图

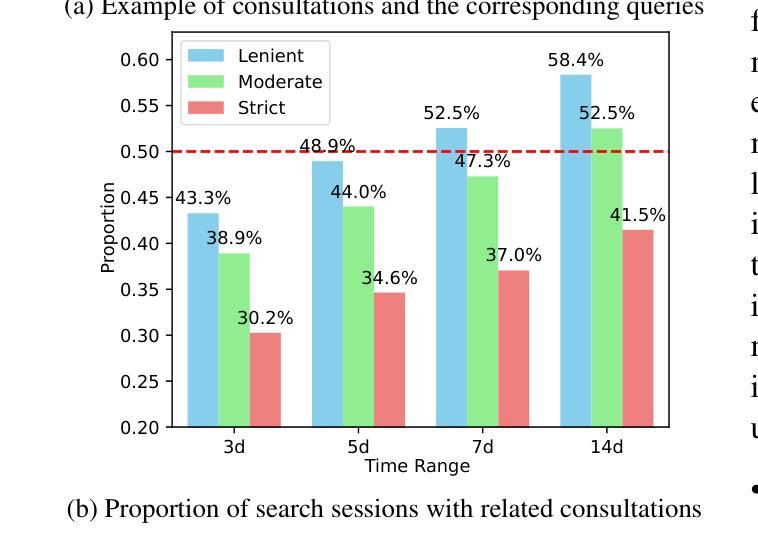
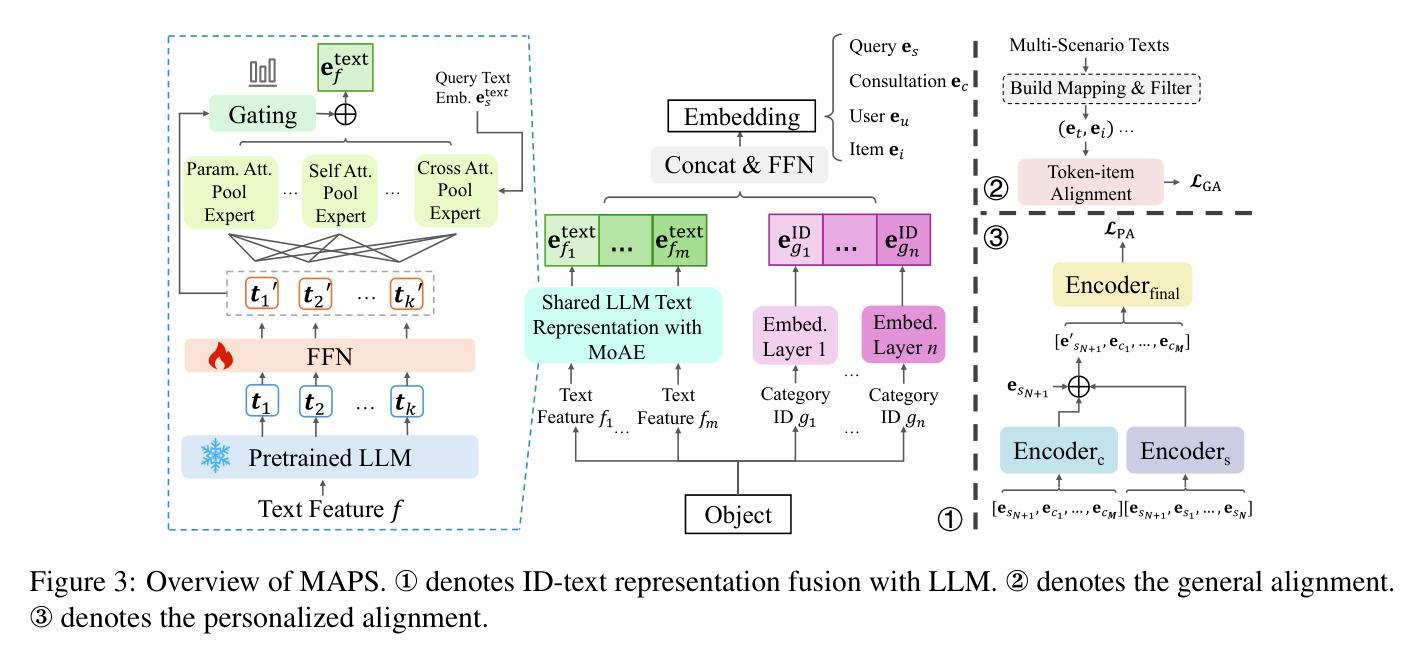
MAPS: Motivation-Aware Personalized Search via LLM-Driven Consultation Alignment
Authors:Weicong Qin, Yi Xu, Weijie Yu, Chenglei Shen, Ming He, Jianping Fan, Xiao Zhang, Jun Xu
Personalized product search aims to retrieve and rank items that match users’ preferences and search intent. Despite their effectiveness, existing approaches typically assume that users’ query fully captures their real motivation. However, our analysis of a real-world e-commerce platform reveals that users often engage in relevant consultations before searching, indicating they refine intents through consultations based on motivation and need. The implied motivation in consultations is a key enhancing factor for personalized search. This unexplored area comes with new challenges including aligning contextual motivations with concise queries, bridging the category-text gap, and filtering noise within sequence history. To address these, we propose a Motivation-Aware Personalized Search (MAPS) method. It embeds queries and consultations into a unified semantic space via LLMs, utilizes a Mixture of Attention Experts (MoAE) to prioritize critical semantics, and introduces dual alignment: (1) contrastive learning aligns consultations, reviews, and product features; (2) bidirectional attention integrates motivation-aware embeddings with user preferences. Extensive experiments on real and synthetic data show MAPS outperforms existing methods in both retrieval and ranking tasks.
个性化产品搜索旨在检索和排序与用户偏好和搜索意图相匹配的项目。尽管现有方法有效,但它们通常假设用户的查询完全捕捉了他们的真实动机。然而,我们对一个真实电子商务平台的分析表明,用户在搜索之前经常进行相关的咨询,这表明他们通过基于动机和需求的咨询来细化意图。咨询中的隐含动机是个性化搜索的关键增强因素。这一未被探索的领域带来了新的挑战,包括将上下文动机与简洁查询对齐、弥合类别文本差距以及过滤序列历史中的噪声。为了解决这些问题,我们提出了一种动机感知个性化搜索(MAPS)方法。它通过大型语言模型将查询和咨询嵌入到统一的语义空间中,利用注意力专家混合体(MoAE)来优先处理关键语义,并引入双重对齐:(1)对比学习对齐咨询、评论和产品特性;(2)双向注意力将动机感知嵌入与用户偏好相结合。在真实和合成数据上的广泛实验表明,MAPS在检索和排序任务上的性能优于现有方法。
论文及项目相关链接
摘要
个性化产品搜索旨在根据用户偏好和搜索意图检索和排序匹配项目。然而,现有方法常常假定用户查询能够完全反映他们的真实动机,这与实际不符。通过分析真实电商平台数据发现,用户在搜索前会进行相关的咨询,通过咨询基于动机和需求来优化意图。咨询中的隐含动机是提升个性化搜索的关键要素。这一未被探索的领域带来了新的挑战,包括将情境动机与简洁查询对齐、缩小类别与文本之间的差距以及过滤序列历史中的噪声。为解决这些问题,我们提出了基于动机的个性化搜索(MAPS)方法。通过大型语言模型将查询和咨询嵌入到统一的语义空间中,利用注意力专家混合(MoAE)来优先处理关键语义信息,并引入双重对齐:(1)对比学习对齐咨询、评论和产品特征;(2)双向注意力整合基于动机的嵌入向量和用户偏好。在真实和合成数据上的大量实验表明,MAPS在检索和排序任务上的性能优于现有方法。
关键见解
- 个性化产品搜索旨在根据用户偏好和搜索意图匹配并排序产品。
- 现有方法通常假设用户查询可以完全反映其真实动机,但这并不总是准确。
- 用户在搜索前会进行相关的咨询,以优化基于动机和需求的意图。
- 咨询中的隐含动机是提升个性化搜索性能的关键因素。
- 该领域面临将情境动机与简洁查询对齐、缩小类别与文本间的差距以及过滤序列历史中的噪声等挑战。
- MAPS方法通过大型语言模型将查询和咨询嵌入统一语义空间,并引入双重对齐机制来提升性能。
- 实验结果表明,MAPS在检索和排序任务上的性能优于现有方法。
点此查看论文截图


Llama-3.1-Sherkala-8B-Chat: An Open Large Language Model for Kazakh
Authors:Fajri Koto, Rituraj Joshi, Nurdaulet Mukhituly, Yuxia Wang, Zhuohan Xie, Rahul Pal, Daniil Orel, Parvez Mullah, Diana Turmakhan, Maiya Goloburda, Mohammed Kamran, Samujjwal Ghosh, Bokang Jia, Jonibek Mansurov, Mukhammed Togmanov, Debopriyo Banerjee, Nurkhan Laiyk, Akhmed Sakip, Xudong Han, Ekaterina Kochmar, Alham Fikri Aji, Aaryamonvikram Singh, Alok Anil Jadhav, Satheesh Katipomu, Samta Kamboj, Monojit Choudhury, Gurpreet Gosal, Gokul Ramakrishnan, Biswajit Mishra, Sarath Chandran, Avraham Sheinin, Natalia Vassilieva, Neha Sengupta, Larry Murray, Preslav Nakov
Llama-3.1-Sherkala-8B-Chat, or Sherkala-Chat (8B) for short, is a state-of-the-art instruction-tuned open generative large language model (LLM) designed for Kazakh. Sherkala-Chat (8B) aims to enhance the inclusivity of LLM advancements for Kazakh speakers. Adapted from the LLaMA-3.1-8B model, Sherkala-Chat (8B) is trained on 45.3B tokens across Kazakh, English, Russian, and Turkish. With 8 billion parameters, it demonstrates strong knowledge and reasoning abilities in Kazakh, significantly outperforming existing open Kazakh and multilingual models of similar scale while achieving competitive performance in English. We release Sherkala-Chat (8B) as an open-weight instruction-tuned model and provide a detailed overview of its training, fine-tuning, safety alignment, and evaluation, aiming to advance research and support diverse real-world applications.
Llama-3.1-Sherkala-8B-Chat,简称Sherkala-Chat(8B),是一款用于哈萨克语的最新指令调整型开源生成式大型语言模型(LLM)。Sherkala-Chat(8B)旨在提高哈萨克语使用者对LLM进步的包容性。该模型改编自LLaMA-3.1-8B模型,经过哈萨克语、英语、俄语和土耳其语共453亿词元的训练。拥有8亿参数,在哈萨克语方面表现出强大的知识和推理能力,在类似规模的公开哈萨克语和多语种模型中表现卓越,同时在英语方面也有竞争力。我们发布开源指令调整型模型Sherkala-Chat(8B),并对其训练、微调、安全对齐和评估等方面提供详细介绍,旨在推动研究并支持多样化的实际应用。
论文及项目相关链接
PDF Technical Report
Summary
基于LLaMA-3.1-8B模型的Sherkala-Chat(8B)是一款针对哈萨克语的先进指令调整开源生成大型语言模型(LLM)。该模型旨在提高哈萨克语人士对LLM进展的包容性。经过在哈萨克语、英语、俄语和土耳其语共计45.3B个代币的训练,拥有8亿参数的Sherkala-Chat(8B)展现了强大的知识和推理能力,在哈萨克语上显著优于现有的类似规模的开源哈萨克语和多语种模型,同时在英语上也表现出竞争力。我们发布开源指令调整的Sherkala-Chat(8B)模型,并详细介绍了其训练、微调、安全对齐和评估的概况,旨在推动研究并支持各种现实世界应用。
Key Takeaways
- Sherkala-Chat(8B)是基于LLaMA-3.1-8B模型的先进指令调整的大型语言模型。
- 该模型旨在提高哈萨克语人士对大型语言模型(LLM)进展的包容性。
- Sherkala-Chat(8B)经过多种语言的训练,包括哈萨克语、英语、俄语和土耳其语。
- 模型拥有8亿参数,展现出强大的知识和推理能力。
- 在哈萨克语性能上,Sherkala-Chat(8B)显著优于现有的类似规模的开源哈萨克语和多语种模型。
- Sherkala-Chat(8B)在英语性能上表现出竞争力。
点此查看论文截图


Neural ODE Transformers: Analyzing Internal Dynamics and Adaptive Fine-tuning
Authors:Anh Tong, Thanh Nguyen-Tang, Dongeun Lee, Duc Nguyen, Toan Tran, David Hall, Cheongwoong Kang, Jaesik Choi
Recent advancements in large language models (LLMs) based on transformer architectures have sparked significant interest in understanding their inner workings. In this paper, we introduce a novel approach to modeling transformer architectures using highly flexible non-autonomous neural ordinary differential equations (ODEs). Our proposed model parameterizes all weights of attention and feed-forward blocks through neural networks, expressing these weights as functions of a continuous layer index. Through spectral analysis of the model’s dynamics, we uncover an increase in eigenvalue magnitude that challenges the weight-sharing assumption prevalent in existing theoretical studies. We also leverage the Lyapunov exponent to examine token-level sensitivity, enhancing model interpretability. Our neural ODE transformer demonstrates performance comparable to or better than vanilla transformers across various configurations and datasets, while offering flexible fine-tuning capabilities that can adapt to different architectural constraints.
基于Transformer架构的大型语言模型(LLM)的最新进展引发了人们对理解其内部工作原理的极大兴趣。在本文中,我们介绍了一种使用高度灵活的非自治神经常微分方程(ODEs)对Transformer架构进行建模的新方法。我们提出的模型通过神经网络对所有注意力权重和前馈块进行参数化,并将这些权重表达为连续层索引的函数。通过对模型动态特性的谱分析,我们发现特征值的幅度增加,这挑战了现有理论研究中普遍存在的权重共享假设。我们还利用Lyapunov指数来检查token级别的敏感性,从而提高模型的解释性。我们的神经ODE变压器在各种配置和数据集上的性能与标准变压器相当或更好,同时提供灵活的微调能力,以适应不同的架构约束。
论文及项目相关链接
PDF ICLR 2025
Summary:
基于神经网络常微分方程(ODEs)的大型语言模型(LLM)新研究。该研究使用非自主神经ODEs建模transformer架构,通过神经网络参数化注意力与Feed Forward块权重。该模型实现权重作为连续层索引的函数,且提升了模型的性能使其优于现有模型,同时具有灵活的微调能力。
Key Takeaways:
- 利用神经网络常微分方程(ODEs)建模transformer架构,提出一种新型的大型语言模型(LLM)。
- 模型通过神经网络参数化注意力与Feed Forward块的权重,使其作为连续层索引的函数。
- 研究通过谱分析发现模型动力学的特征值幅度增加,挑战了现有理论研究中普遍存在的权重共享假设。
- 利用Lyapunov指数研究模型的token级别敏感性,增强了模型的解释性。
点此查看论文截图

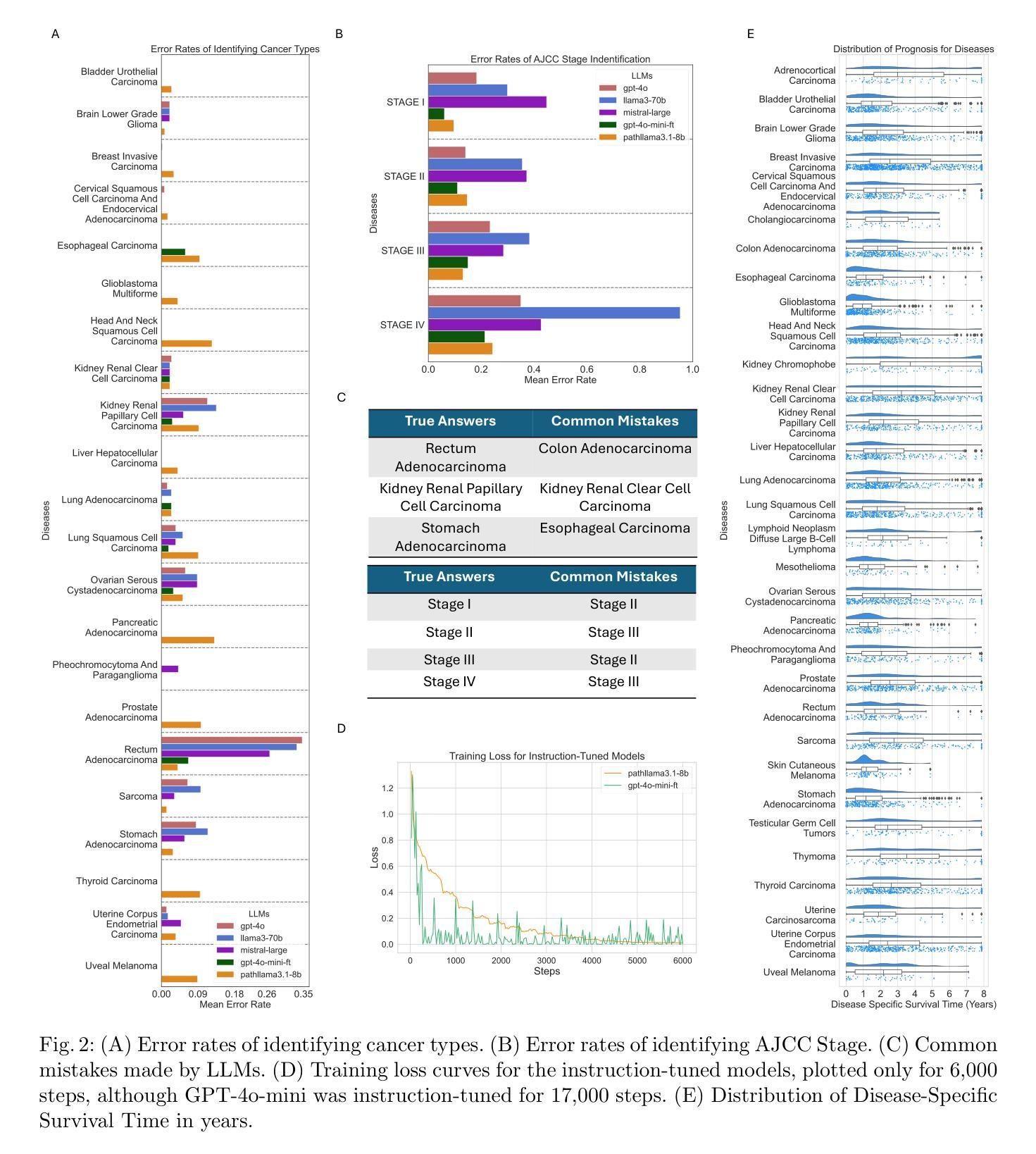
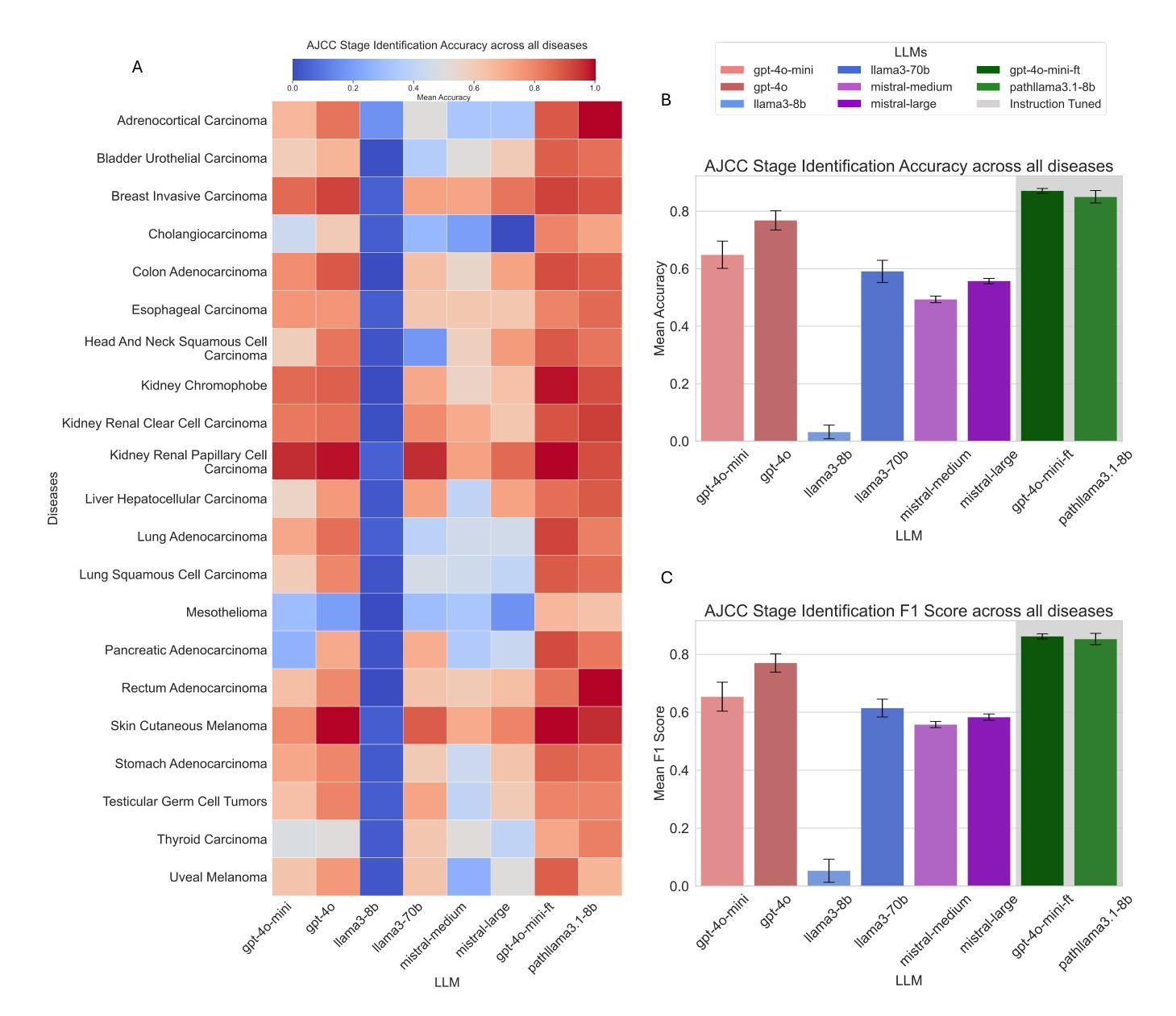
Cancer Type, Stage and Prognosis Assessment from Pathology Reports using LLMs
Authors:Rachit Saluja, Jacob Rosenthal, Yoav Artzi, David J. Pisapia, Benjamin L. Liechty, Mert R. Sabuncu
Large Language Models (LLMs) have shown significant promise across various natural language processing tasks. However, their application in the field of pathology, particularly for extracting meaningful insights from unstructured medical texts such as pathology reports, remains underexplored and not well quantified. In this project, we leverage state-of-the-art language models, including the GPT family, Mistral models, and the open-source Llama models, to evaluate their performance in comprehensively analyzing pathology reports. Specifically, we assess their performance in cancer type identification, AJCC stage determination, and prognosis assessment, encompassing both information extraction and higher-order reasoning tasks. Based on a detailed analysis of their performance metrics in a zero-shot setting, we developed two instruction-tuned models: Path-llama3.1-8B and Path-GPT-4o-mini-FT. These models demonstrated superior performance in zero-shot cancer type identification, staging, and prognosis assessment compared to the other models evaluated.
大型语言模型(LLM)在各种自然语言处理任务中显示出巨大的潜力。然而,它们在病理学领域的应用,特别是在从病理报告等无结构医学文本中提取有意义见解方面,仍被较少探索且未得到充分量化。在本项目中,我们利用最先进的语言模型,包括GPT系列、Mistral模型和开源Llama模型,评估其在综合分析病理报告方面的性能。具体来说,我们评估了它们在癌症类型识别、AJCC分期和预后评估方面的表现,包括信息提取和高级推理任务。基于对零样本设置下性能指标的详细分析,我们开发了两个指令微调模型:Path-llama3.1-8B和Path-GPT-4o-mini-FT。这些模型在零样本癌症类型识别、分期和预后评估方面表现出卓越的性能,与其他评估的模型相比具有优势。
论文及项目相关链接
Summary
大型语言模型(LLM)在自然语言处理任务中展现出巨大潜力,但在病理学领域的应用,尤其是在从病理报告等无结构医学文本中提取有意义信息方面,仍研究不足且未充分量化。本研究利用最先进的语言模型,包括GPT系列、Mistral模型和开源Llama模型,评估其在病理报告综合分析中的表现,特别是在癌症类型识别、AJCC分期和预后评估方面的性能。通过分析零样本设置下的性能指标,研究开发了两个指令微调模型:Path-llama3.1-8B和Path-GPT-4o-mini-FT。这些模型在零样本癌症类型识别、分期和预后评估方面表现出卓越性能。
Key Takeaways
- 大型语言模型在自然语言处理任务中显示出潜力。
- 在病理学领域,尤其是从病理报告中提取信息,LLM的应用仍研究不足。
- 研究涉及多种先进语言模型,包括GPT系列、Mistral模型和Llama模型。
- 评估了这些模型在病理报告综合分析方面的性能,特别是癌症类型识别、AJCC分期和预后评估。
- 通过零样本设置下的性能指标分析,研发出两个表现卓越的指令微调模型。
- Path-llama3.1-8B和Path-GPT-4o-mini-FT模型在癌症类型识别、分期和预后评估方面表现优越。
点此查看论文截图