⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-06 更新
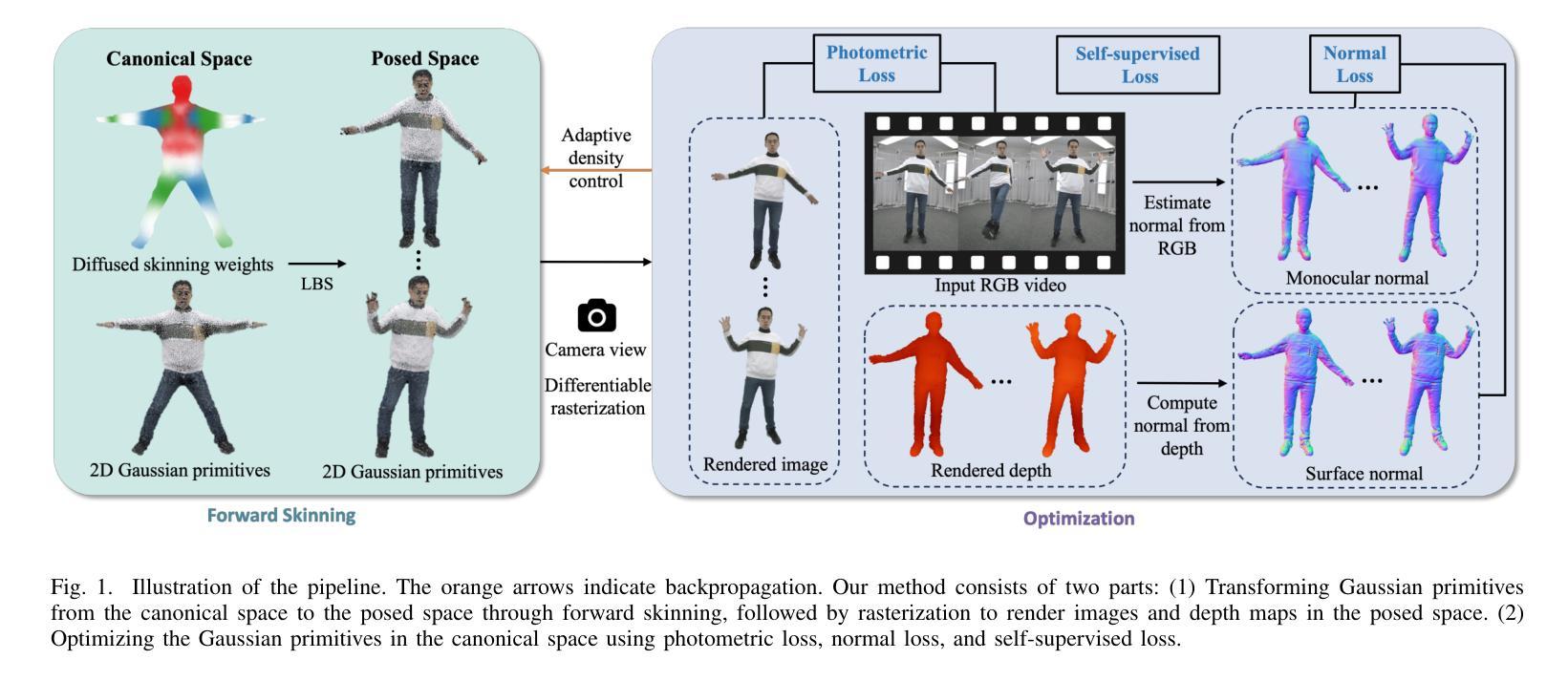
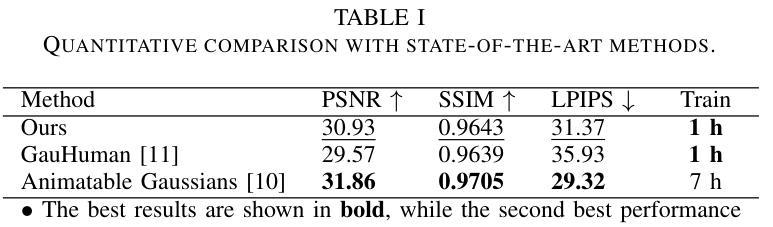
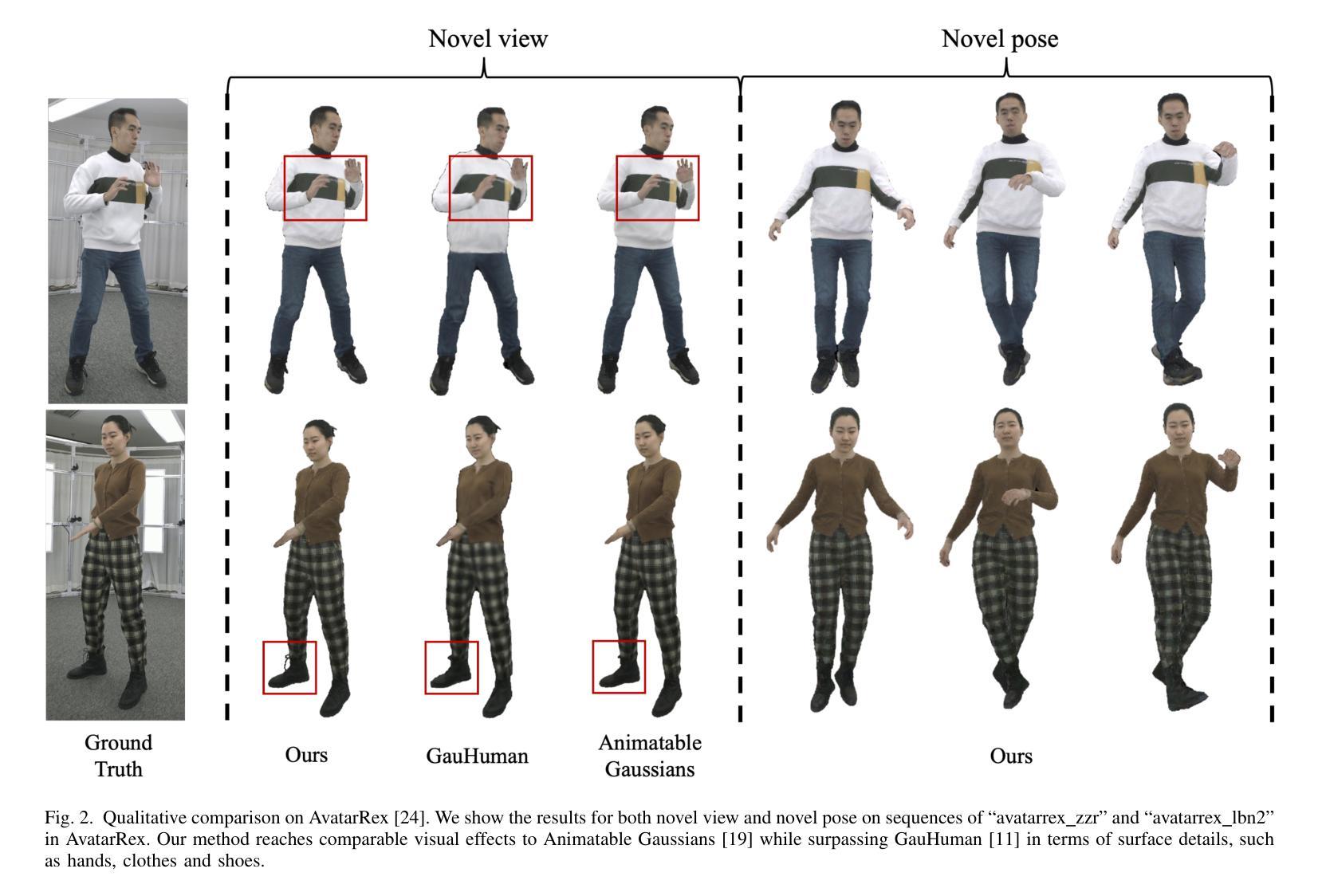
2DGS-Avatar: Animatable High-fidelity Clothed Avatar via 2D Gaussian Splatting
Authors:Qipeng Yan, Mingyang Sun, Lihua Zhang
Real-time rendering of high-fidelity and animatable avatars from monocular videos remains a challenging problem in computer vision and graphics. Over the past few years, the Neural Radiance Field (NeRF) has made significant progress in rendering quality but behaves poorly in run-time performance due to the low efficiency of volumetric rendering. Recently, methods based on 3D Gaussian Splatting (3DGS) have shown great potential in fast training and real-time rendering. However, they still suffer from artifacts caused by inaccurate geometry. To address these problems, we propose 2DGS-Avatar, a novel approach based on 2D Gaussian Splatting (2DGS) for modeling animatable clothed avatars with high-fidelity and fast training performance. Given monocular RGB videos as input, our method generates an avatar that can be driven by poses and rendered in real-time. Compared to 3DGS-based methods, our 2DGS-Avatar retains the advantages of fast training and rendering while also capturing detailed, dynamic, and photo-realistic appearances. We conduct abundant experiments on popular datasets such as AvatarRex and THuman4.0, demonstrating impressive performance in both qualitative and quantitative metrics.
从单目视频中实时渲染高保真和可动画的化身仍是计算机视觉和图形学中的一个具有挑战性的问题。过去几年里,神经辐射场(NeRF)在渲染质量方面取得了重大进展,但由于体积渲染的低效率,其在运行时性能上表现不佳。最近,基于三维高斯贴片技术(3DGS)的方法在快速训练和实时渲染方面显示出巨大潜力。然而,它们仍然受到由不准确几何形状引起的人工效应的影响。为了解决这些问题,我们提出了基于二维高斯贴片技术(2DGS)的2DGS化身方法,用于建模高保真和快速训练性能的可动画服装化身。我们的方法以单目RGB视频为输入,生成可以通过姿态驱动并在实时中呈现的化身。与基于三维高斯贴片技术的方法相比,我们的二维高斯贴片技术化身保留了快速训练和渲染的优点,同时捕捉到了详细、动态和逼真的外观。我们在流行的数据集如AvatarRex和THuman4.0上进行了大量实验,在定性和定量指标上都取得了令人印象深刻的表现。
论文及项目相关链接
PDF ICVRV 2024
Summary
基于单目视频实时渲染高质量动画人物仍是计算机视觉和图形学领域的一个挑战性问题。过去几年,神经辐射场(NeRF)在提高渲染质量方面取得了显著进展,但由于体积渲染的低效率,在运行时性能上表现不佳。最近,基于3D高斯描画(3DGS)的方法在快速训练和实时渲染方面显示出巨大潜力,但仍存在由几何不准确导致的伪影问题。为解决这些问题,本文提出一种基于二维高斯描画(2DGS)的新型方法——2DGS-Avatar,用于建模高质量、可动画的服装人物,具有快速训练性能。以单目RGB视频为输入,我们的方法生成的人物可以通过姿态驱动,实现实时渲染。相较于基于3DGS的方法,2DGS-Avatar既保留了快速训练和渲染的优势,又能捕捉详细、动态、逼真的外观。在流行的数据集如AvatarRex和THuman4.0上的实验表现出色。
Key Takeaways
- Real-time rendering of high-fidelity and animatable avatars from monocular videos remains a challenging problem.
- Neural Radiance Field (NeRF)虽能提高渲染质量,但运行时性能不佳。
- 基于3D Gaussian Splatting (3DGS)的方法虽可实现快速训练和实时渲染,但存在由几何不准确导致的伪影问题。
- 2DGS-Avatar方法基于二维高斯描画(2DGS),可建模高质量、可动画的服装人物,兼具快速训练性能。
- 2DGS-Avatar能捕捉详细、动态、逼真的外观。
- 2DGS-Avatar在多个数据集上的实验表现出色。
点此查看论文截图


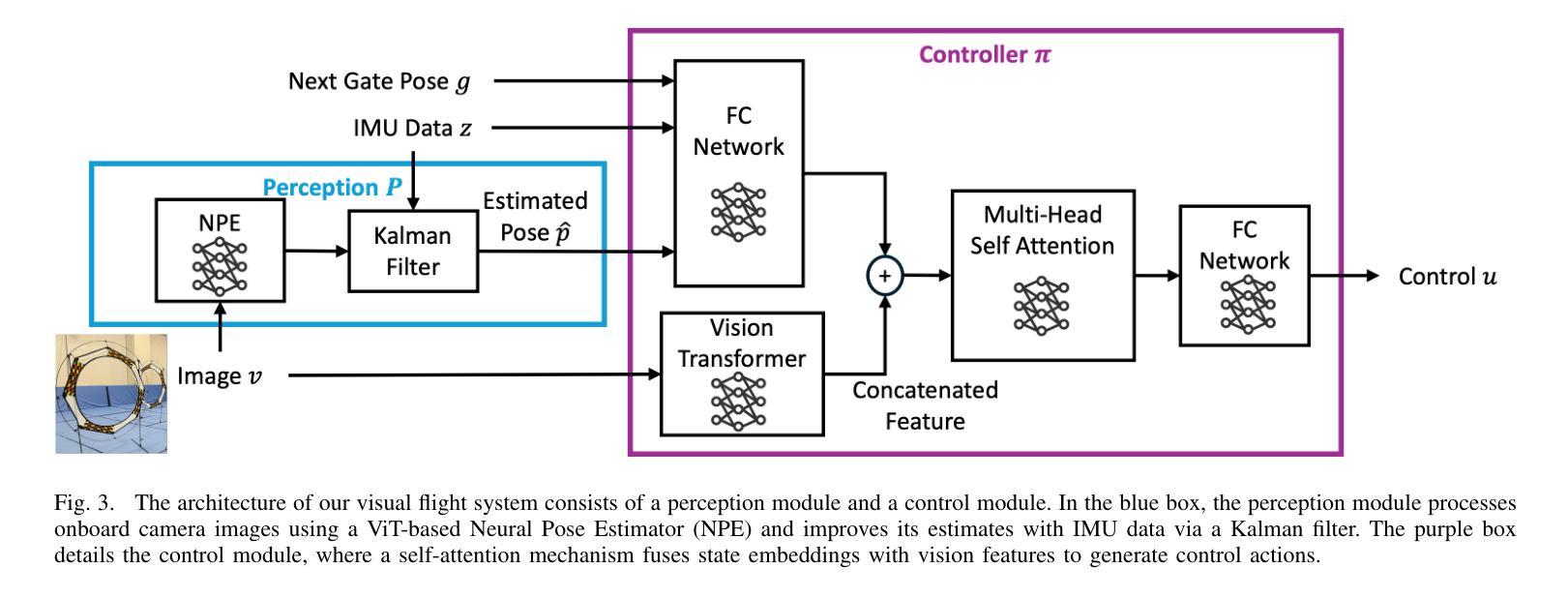
Zero-Shot Sim-to-Real Visual Quadrotor Control with Hard Constraints
Authors:Yan Miao, Will Shen, Sayan Mitra
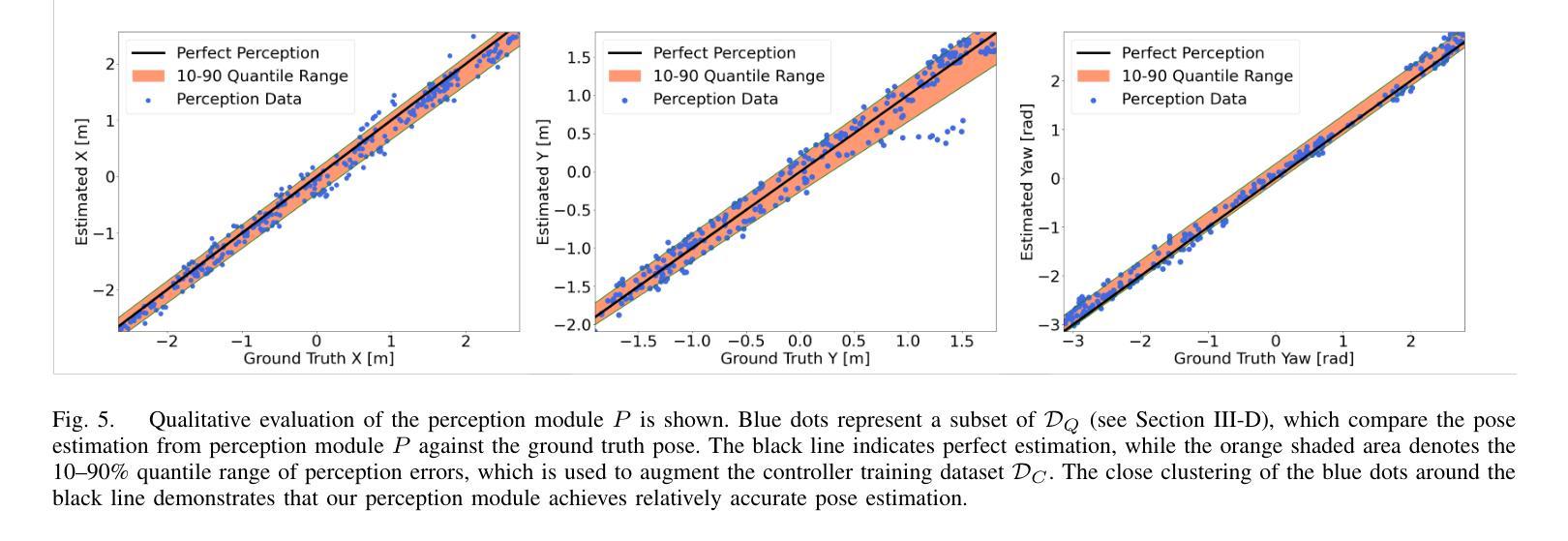
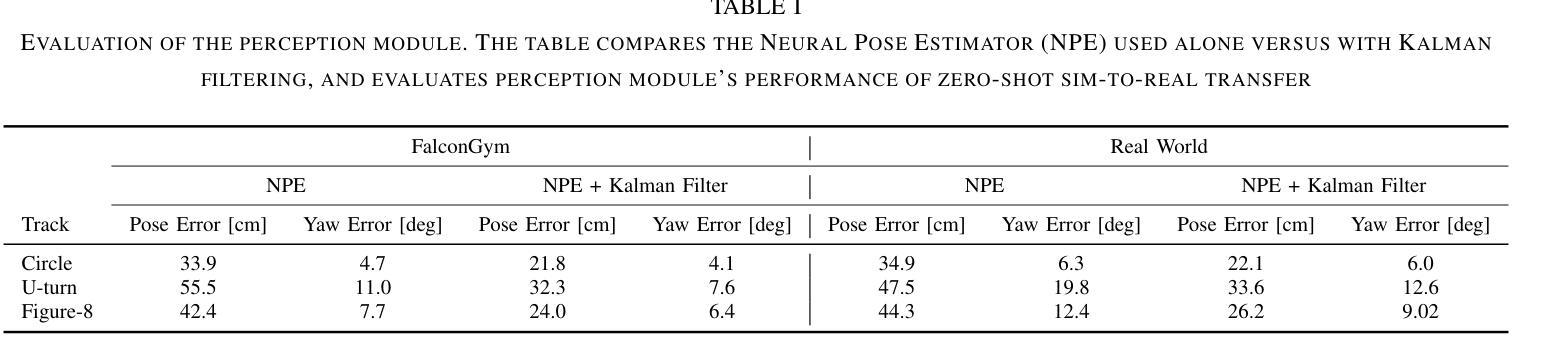
We present the first framework demonstrating zero-shot sim-to-real transfer of visual control policies learned in a Neural Radiance Field (NeRF) environment for quadrotors to fly through racing gates. Robust transfer from simulation to real flight poses a major challenge, as standard simulators often lack sufficient visual fidelity. To address this, we construct a photorealistic simulation environment of quadrotor racing tracks, called FalconGym, which provides effectively unlimited synthetic images for training. Within FalconGym, we develop a pipelined approach for crossing gates that combines (i) a Neural Pose Estimator (NPE) coupled with a Kalman filter to reliably infer quadrotor poses from single-frame RGB images and IMU data, and (ii) a self-attention-based multi-modal controller that adaptively integrates visual features and pose estimation. This multi-modal design compensates for perception noise and intermittent gate visibility. We train this controller purely in FalconGym with imitation learning and deploy the resulting policy to real hardware with no additional fine-tuning. Simulation experiments on three distinct tracks (circle, U-turn and figure-8) demonstrate that our controller outperforms a vision-only state-of-the-art baseline in both success rate and gate-crossing accuracy. In 30 live hardware flights spanning three tracks and 120 gates, our controller achieves a 95.8% success rate and an average error of just 10 cm when flying through 38 cm-radius gates.
我们首次提出了一种框架,该框架展示了在神经网络辐射场(NeRF)环境中学习的视觉控制策略,用于无射击模拟到真实飞行的四旋翼无人机穿越竞速门时的零射击模拟到现实转移。从模拟到真实飞行的稳健转移是一个巨大的挑战,因为标准模拟器通常缺乏足够的视觉逼真度。为了解决这个问题,我们构建了名为FalconGym的四旋翼竞速轨道的逼真模拟环境,它提供了用于训练的有效无限合成图像。在FalconGym中,我们开发了一种穿越大门的管道方法,它结合了(i)与卡尔曼滤波器耦合的神经网络姿态估计器(NPE),可以从单帧RGB图像和IMU数据中可靠地推断出四旋翼的姿态;(ii)基于自注意力的多模态控制器,自适应地融合了视觉特征和姿态估计。这种多模态设计可以补偿感知噪声和间歇性大门可见性。我们仅使用模仿学习在FalconGym中训练此控制器,并将结果策略部署到实际硬件上,无需进行任何额外的微调。在三个不同轨道(圆形、U形转弯和图形数字-信道人投为青睐被下注者们也为接受的代位用语统计俱乐部反馈拟把八大域的共同体语义做近似处本位专题搜索曲线、花环轨迹等)上的模拟实验表明,我们的控制器在成功率和穿越大门准确性方面都优于仅使用视觉的最新技术基线。在跨越三个轨道和穿过涵盖竞赛排门的实战硬件飞行测试中(总共穿过高达三次合计人数),我们的控制器成功率达到了高达95.8%,并且在穿越直径仅为约三十八厘米的赛道门时平均误差仅为十厘米。这是一个巨大的成功!
论文及项目相关链接
摘要
本研究首次展示了在Neural Radiance Field(NeRF)环境中学习的视觉控制策略实现零样本模拟到真实场景的迁移,应用于四旋翼飞行器穿越竞速门。针对从模拟到真实飞行的稳健迁移所面临的视觉逼真度不足的问题,研究构建了名为FalconGym的高保真模拟环境,用于四旋翼竞速赛道的训练,并提供无限合成图像。在FalconGym中,研究开发出一种穿越门框的流水线方法,包括(i)结合卡尔曼滤波器的神经网络姿态估计器(NPE),可从单帧RGB图像和IMU数据中可靠推断四旋翼的姿态;(ii)基于自注意力机制的多模态控制器,能自适应地融合视觉特征和姿态估计。这种多模态设计弥补了感知噪声和间歇性门框可见性的问题。研究仅使用FalconGym模拟环境进行模仿学习训练该控制器,并直接应用于真实硬件,无需额外微调。在三个不同赛道(圆圈、U型转弯和八字形)的模拟实验表明,该控制器在成功率和穿越门框的准确性方面均优于仅使用视觉的最新技术基线。在跨越三个赛道、穿越120个门框的30次实际硬件飞行测试中,该控制器的成功率达到95.8%,平均误差仅为10厘米。
关键见解
- 研究实现了首个在NeRF环境中学习视觉控制策略的零样本模拟到真实迁移应用,针对四旋翼飞行器穿越竞速门。
- 构建名为FalconGym的高保真模拟环境,以应对从模拟到真实飞行中的视觉逼真度挑战。
- 开发出结合神经网络姿态估计器和卡尔曼滤波器的管线方法,能从单帧图像和IMU数据中推断四旋翼的姿态。
- 采用基于自注意力机制的多模态控制器设计,融合视觉特征和姿态估计,以应对感知噪声和间歇性门框可见性问题。
- 在模拟环境中进行广泛实验,证明所提出控制器在成功率和穿越门框准确性方面优于现有视觉基线技术。
- 在实际硬件飞行测试中,控制器表现出高成功率和低误差,平均误差仅为10厘米。
点此查看论文截图



Data Augmentation for NeRFs in the Low Data Limit
Authors:Ayush Gaggar, Todd D. Murphey
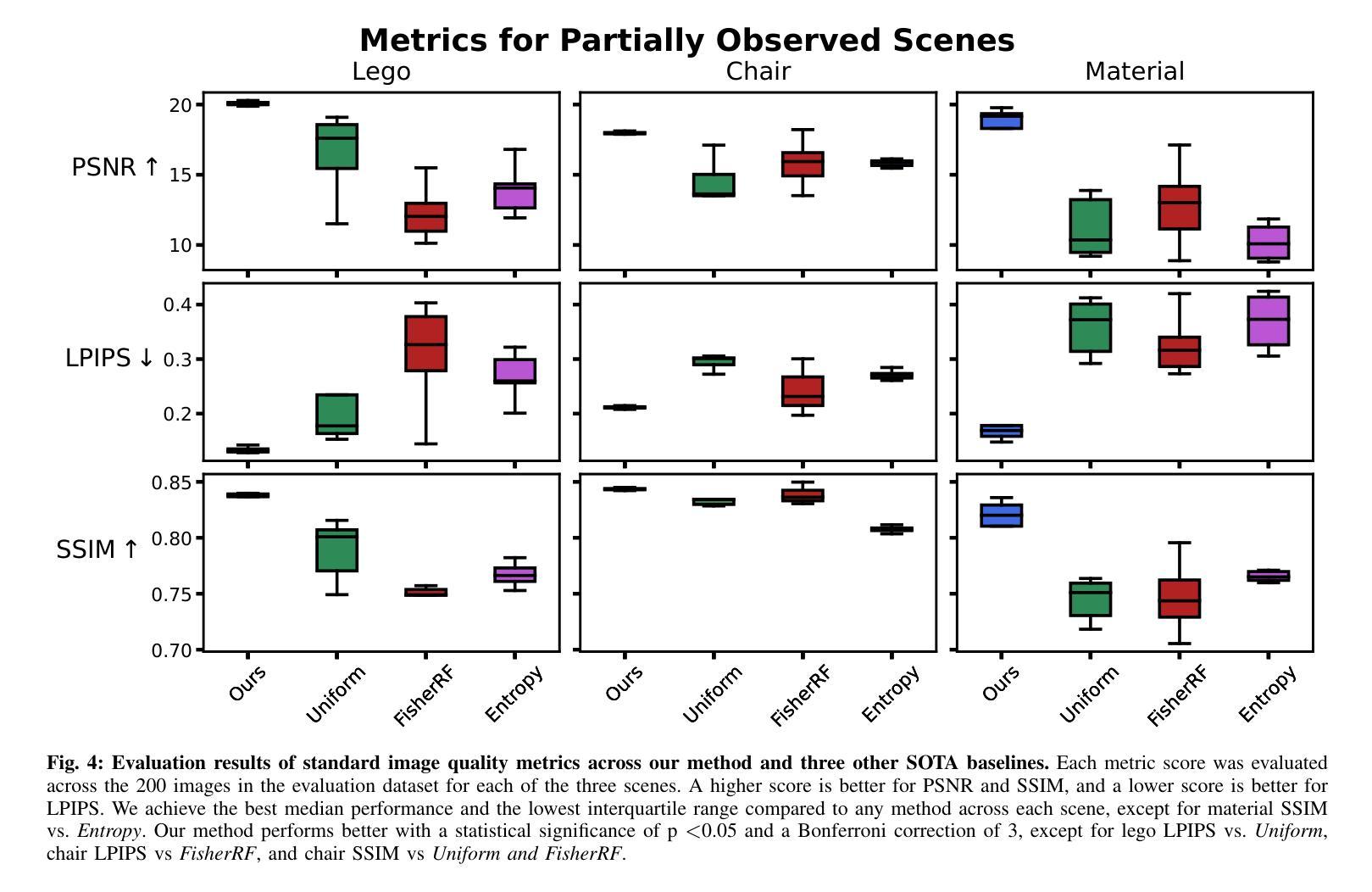
Current methods based on Neural Radiance Fields fail in the low data limit, particularly when training on incomplete scene data. Prior works augment training data only in next-best-view applications, which lead to hallucinations and model collapse with sparse data. In contrast, we propose adding a set of views during training by rejection sampling from a posterior uncertainty distribution, generated by combining a volumetric uncertainty estimator with spatial coverage. We validate our results on partially observed scenes; on average, our method performs 39.9% better with 87.5% less variability across established scene reconstruction benchmarks, as compared to state of the art baselines. We further demonstrate that augmenting the training set by sampling from any distribution leads to better, more consistent scene reconstruction in sparse environments. This work is foundational for robotic tasks where augmenting a dataset with informative data is critical in resource-constrained, a priori unknown environments. Videos and source code are available at https://murpheylab.github.io/low-data-nerf/.
当前基于神经辐射场的方法在数据稀缺的情况下表现不佳,特别是在对不完整场景数据进行训练时。早期的工作仅在最佳后续视图应用程序中扩充训练数据,这导致在稀疏数据情况下出现幻觉和模型崩溃。相比之下,我们提出通过从后验不确定性分布中进行拒绝采样来在训练过程中增加一组视图,该分布是通过结合体积不确定性估计器和空间覆盖率生成的。我们在部分观测场景上验证了我们的结果;平均而言,我们的方法在建立的场景重建基准测试上比最新技术基准高出39.9%,并且具有较低的87.5%变异性。我们进一步证明,通过从任何分布中采样来扩充训练集,可以在稀疏环境中实现更好、更一致的场景重建。这项工作在机器人任务中是基础性的,因为在资源受限、事先未知的环境中,用信息丰富的数据扩充数据集是至关重要的。相关视频和源代码可在https://murpheylab.github.io/low-data-nerf/找到。
论文及项目相关链接
PDF To be published in 2025 IEEE International Conference on Robotics and Automation (ICRA 2025)
Summary
基于神经辐射场(NeRF)的当前方法在数据有限时表现不佳,特别是在训练不完整场景数据时。以往的工作仅在最佳视角应用中进行数据增强,导致在稀疏数据时产生幻象和模型崩溃。相反,我们提出通过从后验不确定性分布中进行拒绝采样来添加一组视图,该分布是通过结合体积不确定性估计器和空间覆盖率生成的。我们在部分观测场景上验证了我们的方法,平均而言,与最新技术基准相比,我们的方法在建立的场景重建基准测试上表现更好,平均高出39.9%,且变异度降低了87.5%。我们还证明,从任何分布中对训练集进行增强,可以在稀疏环境中实现更好、更一致的场景重建。这项工作对于机器人任务至关重要,在资源受限、先验未知的的环境中,数据增强具有重要意义。
Key Takeaways
- 当前基于NeRF的方法在数据有限、尤其是场景数据不完整时表现不佳。
- 以往的数据增强方法仅在最佳视角应用中使用,这可能导致幻象和模型崩溃在稀疏数据时。
- 提出了一种新的数据增强方法,通过从后验不确定性分布进行拒绝采样来添加更多的视图。
- 方法在部分观测场景上的表现优于现有技术基准,平均性能提升39.9%,且变异度降低了87.5%。
- 从任何分布中对训练集进行增强可以在稀疏环境中实现更好的场景重建。
- 该研究对于机器人任务具有重要意义,特别是在资源受限、先验未知的的环境中。
点此查看论文截图



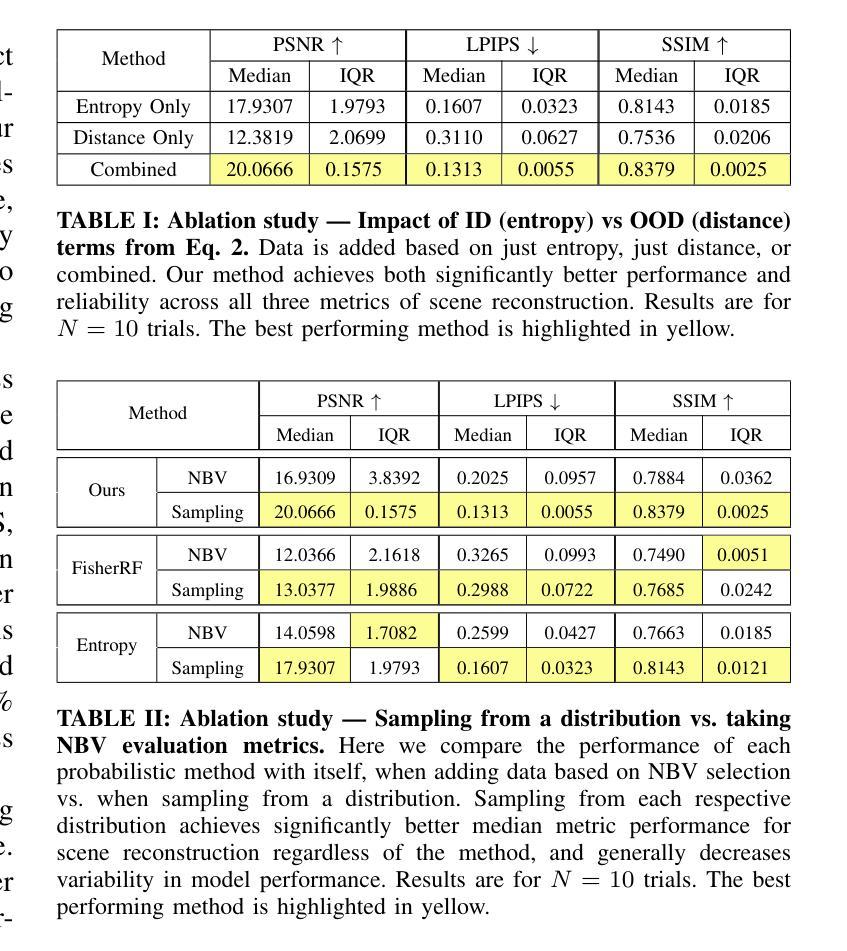
Difix3D+: Improving 3D Reconstructions with Single-Step Diffusion Models
Authors:Jay Zhangjie Wu, Yuxuan Zhang, Haithem Turki, Xuanchi Ren, Jun Gao, Mike Zheng Shou, Sanja Fidler, Zan Gojcic, Huan Ling
Neural Radiance Fields and 3D Gaussian Splatting have revolutionized 3D reconstruction and novel-view synthesis task. However, achieving photorealistic rendering from extreme novel viewpoints remains challenging, as artifacts persist across representations. In this work, we introduce Difix3D+, a novel pipeline designed to enhance 3D reconstruction and novel-view synthesis through single-step diffusion models. At the core of our approach is Difix, a single-step image diffusion model trained to enhance and remove artifacts in rendered novel views caused by underconstrained regions of the 3D representation. Difix serves two critical roles in our pipeline. First, it is used during the reconstruction phase to clean up pseudo-training views that are rendered from the reconstruction and then distilled back into 3D. This greatly enhances underconstrained regions and improves the overall 3D representation quality. More importantly, Difix also acts as a neural enhancer during inference, effectively removing residual artifacts arising from imperfect 3D supervision and the limited capacity of current reconstruction models. Difix3D+ is a general solution, a single model compatible with both NeRF and 3DGS representations, and it achieves an average 2$\times$ improvement in FID score over baselines while maintaining 3D consistency.
神经辐射场和三维高斯描绘技术已经彻底改变了三维重建和新型视图合成任务。然而,从极端新视角实现逼真渲染仍然是一个挑战,因为不同表示形式之间存在持久性的伪影。在这项工作中,我们引入了Difix3D+,这是一种新型管道设计,旨在通过单步扩散模型增强三维重建和新型视图合成。我们方法的核心是Difix,这是一种单步图像扩散模型,经过训练可增强并消除由于三维表示中的约束不足而在渲染新视图中产生的伪影。Difix在我们的管道中扮演两个关键角色。首先,它用于重建阶段,清理从重建生成的伪训练视图,然后将其蒸馏回三维空间。这极大地增强了约束不足的区域并提高了整体的三维表示质量。更重要的是,在推理过程中,Difix还充当神经增强器,有效地消除了由于不完美的三维监督和当前重建模型的有限容量而产生的残余伪影。Difix3D+是一种通用解决方案,一个兼容NeRF和3DGS表示的单一模型,在基线基础上实现了FID得分的平均两倍提升,同时保持了三维一致性。
论文及项目相关链接
PDF CVPR 2025
Summary:神经辐射场和三维高斯绘制在三维重建和视角合成任务中起到了革命性的作用。然而,从极端全新视角实现逼真的渲染仍然存在挑战,因为表示中的伪影仍然存在。在这项工作中,我们引入了Difix3D+,这是一种通过单步扩散模型设计的增强三维重建和视角合成的新管道。我们的方法的核心是Difix,这是一种单步图像扩散模型,经过训练,旨在增强并消除由于三维表示的欠约束区域导致的渲染新视图中的伪影。Difix在我们的管道中扮演了两个关键角色。首先,它在重建阶段用于清理从重建生成的伪训练视图,然后将其蒸馏回三维。这极大地增强了欠约束区域并提高了整体的三维表示质量。更重要的是,在推理过程中,Difix还充当神经增强器,有效地消除了由不完美的三维监督和当前重建模型的有限容量引起的残余伪影。Difix3D+是一种通用解决方案,一个与NeRF和3DGS表示兼容的单一模型,在基线的基础上实现了FID分数的平均两倍改进,同时保持了三维一致性。
Key Takeaways:
- 神经辐射场和三维高斯绘制已对三维重建和视角合成产生重大影响。
- 从极端全新视角进行逼真渲染仍存在挑战,主要因为表示中的伪影问题。
- 引入的Difix3D+管道通过使用单步扩散模型增强三维重建和视角合成。
- 核心模型Difix经过训练,能增强并消除由于三维表示欠约束区域导致的渲染新视图中的伪影。
- Difix在管道中扮演了关键角色,既在重建阶段清理伪训练视图,也在推理过程中充当神经增强器。
- Difix3D+对基线进行了改进,实现了FID分数的平均两倍提升,同时保持了三维一致性。
点此查看论文截图

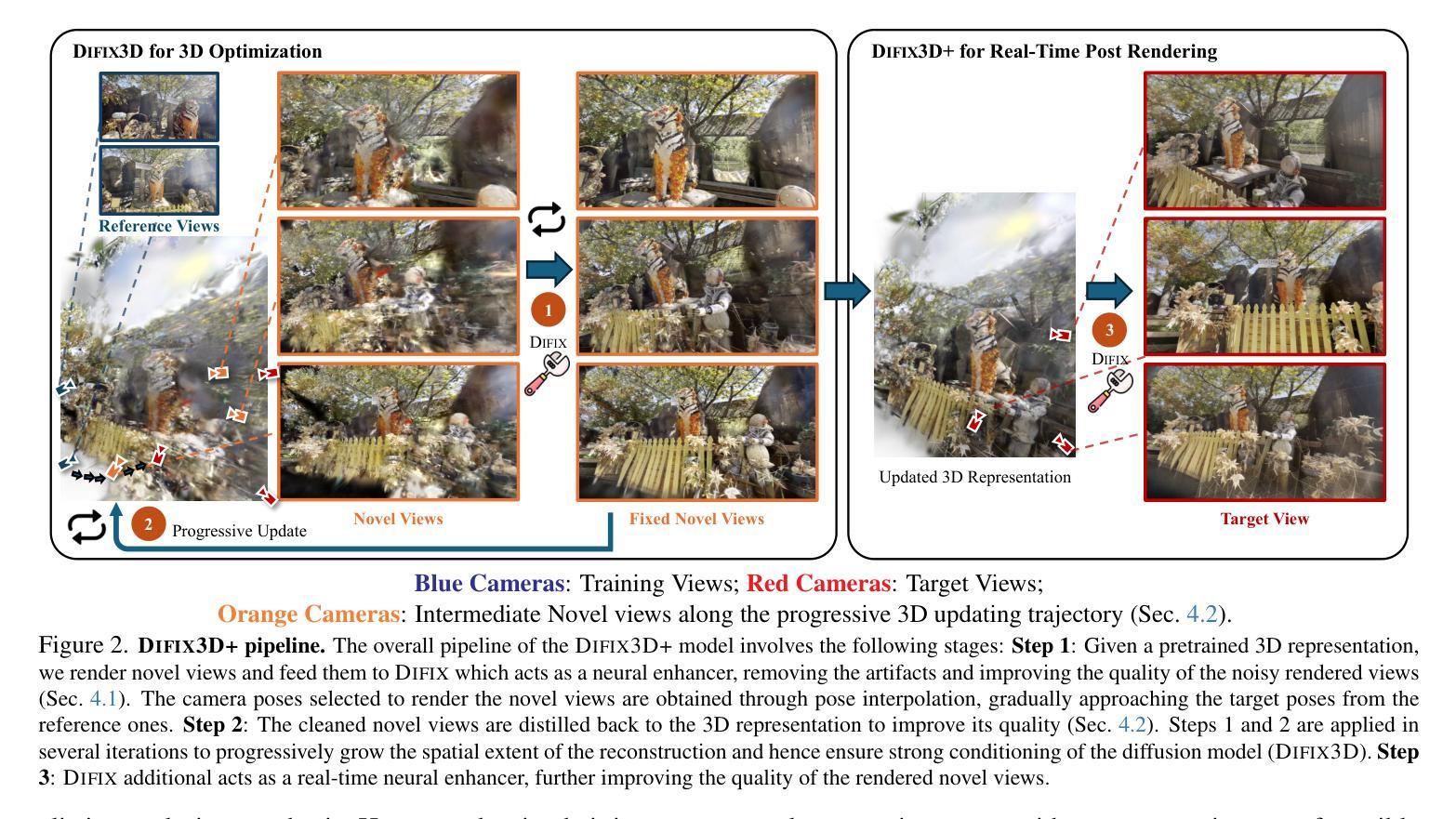


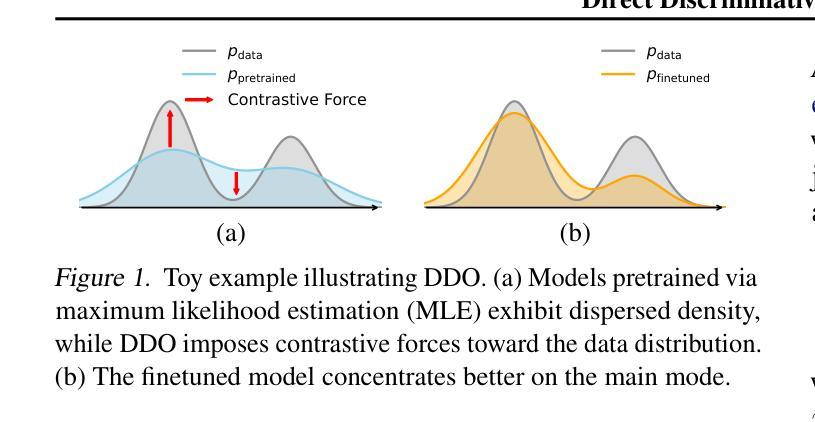
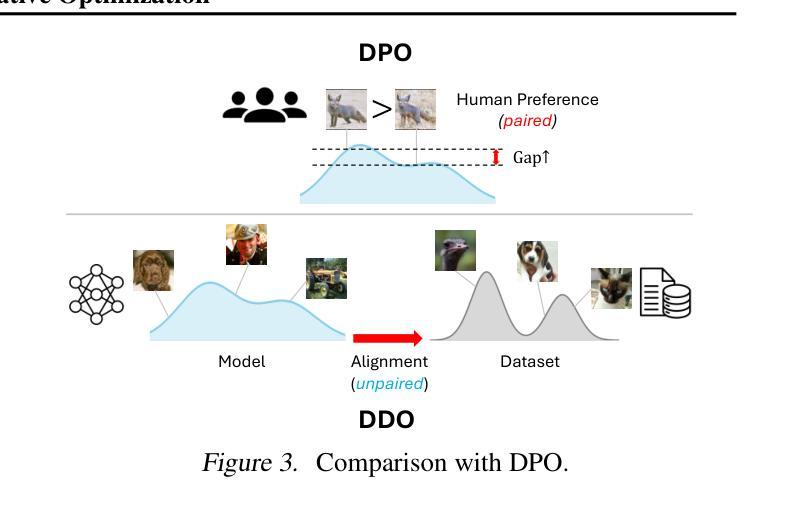
Direct Discriminative Optimization: Your Likelihood-Based Visual Generative Model is Secretly a GAN Discriminator
Authors:Kaiwen Zheng, Yongxin Chen, Huayu Chen, Guande He, Ming-Yu Liu, Jun Zhu, Qinsheng Zhang
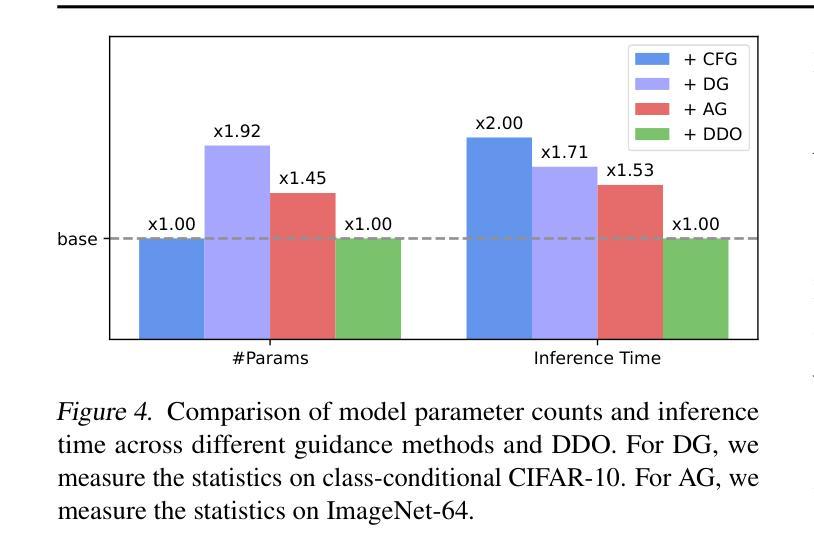
While likelihood-based generative models, particularly diffusion and autoregressive models, have achieved remarkable fidelity in visual generation, the maximum likelihood estimation (MLE) objective inherently suffers from a mode-covering tendency that limits the generation quality under limited model capacity. In this work, we propose Direct Discriminative Optimization (DDO) as a unified framework that bridges likelihood-based generative training and the GAN objective to bypass this fundamental constraint. Our key insight is to parameterize a discriminator implicitly using the likelihood ratio between a learnable target model and a fixed reference model, drawing parallels with the philosophy of Direct Preference Optimization (DPO). Unlike GANs, this parameterization eliminates the need for joint training of generator and discriminator networks, allowing for direct, efficient, and effective finetuning of a well-trained model to its full potential beyond the limits of MLE. DDO can be performed iteratively in a self-play manner for progressive model refinement, with each round requiring less than 1% of pretraining epochs. Our experiments demonstrate the effectiveness of DDO by significantly advancing the previous SOTA diffusion model EDM, reducing FID scores from 1.79/1.58 to new records of 1.30/0.97 on CIFAR-10/ImageNet-64 datasets, and by consistently improving both guidance-free and CFG-enhanced FIDs of visual autoregressive models on ImageNet 256$\times$256.
基于概率的生成模型,特别是扩散和自回归模型,在视觉生成方面取得了显著的保真度。然而,最大似然估计(MLE)目标本质上存在模式覆盖的倾向,这在有限的模型容量下限制了生成质量。在这项工作中,我们提出了直接判别优化(DDO)作为一个统一的框架,它结合了基于概率的生成训练和GAN目标,以规避这一基本约束。我们的关键见解是,使用一个判别器来隐含地参数化可学习目标模型与固定参考模型之间的概率比率,这与直接偏好优化(DPO)的理念相类似。不同于GAN,这种参数化方式消除了对生成器和判别器网络联合训练的需要,允许对预训练良好的模型进行直接、高效和有效的微调,充分发挥其潜力,超越MLE的限制。DDO可以自我迭代的方式进行自我完善模型优化,每一轮所需的训练时间不到预训练周期的百分之一。我们的实验通过显著改进先前的最佳扩散模型EDM,在CIFAR-10和ImageNet-64数据集上将FID分数从原来的1.79/1.58降低到新的记录水平1.30/0.97,并且持续改进无指导和CFG增强的ImageNet 256×256的视觉自回归模型的FID分数。
论文及项目相关链接
PDF Project Page: https://research.nvidia.com/labs/dir/ddo/
Summary
本文提出了Direct Discriminative Optimization(DDO)框架,旨在解决基于可能性的生成模型在面对有限模型容量时的模式覆盖倾向问题。通过结合可能性的生成训练和GAN目标,DDO能够绕过这一基本限制。实验结果显示,DDO能有效提升现有扩散模型和自回归模型的性能。
Key Takeaways
- Direct Discriminative Optimization(DDO)框架解决了基于可能性的生成模型在有限模型容量下的模式覆盖问题。
- DDO结合了可能性的生成训练和GAN目标。
- DDO通过参数化判别器,利用目标模型与固定参考模型之间的可能性比率,与Direct Preference Optimization(DPO)理念相似。
- DDO不需要联合训练生成器和判别器网络,可直接、高效、有效地对预训练模型进行微调,充分发挥其潜力。
- DDO可以通过自我对抗的方式进行迭代,实现模型的渐进改进,每次迭代所需的预训练周期不到1%。
- 实验结果显示,DDO在CIFAR-10和ImageNet-64数据集上显著提升了之前的最佳扩散模型EDM的性能,FID分数降至新低。
点此查看论文截图

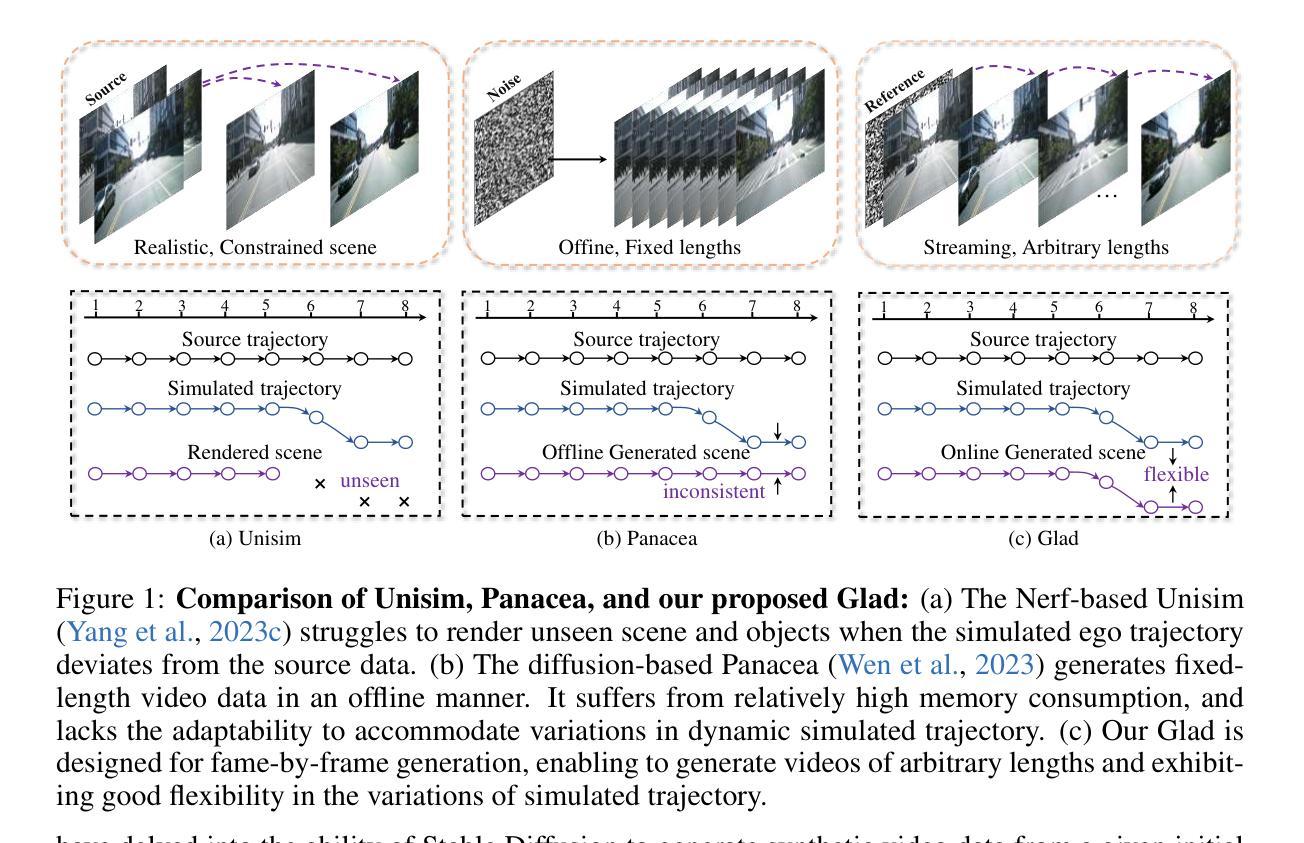
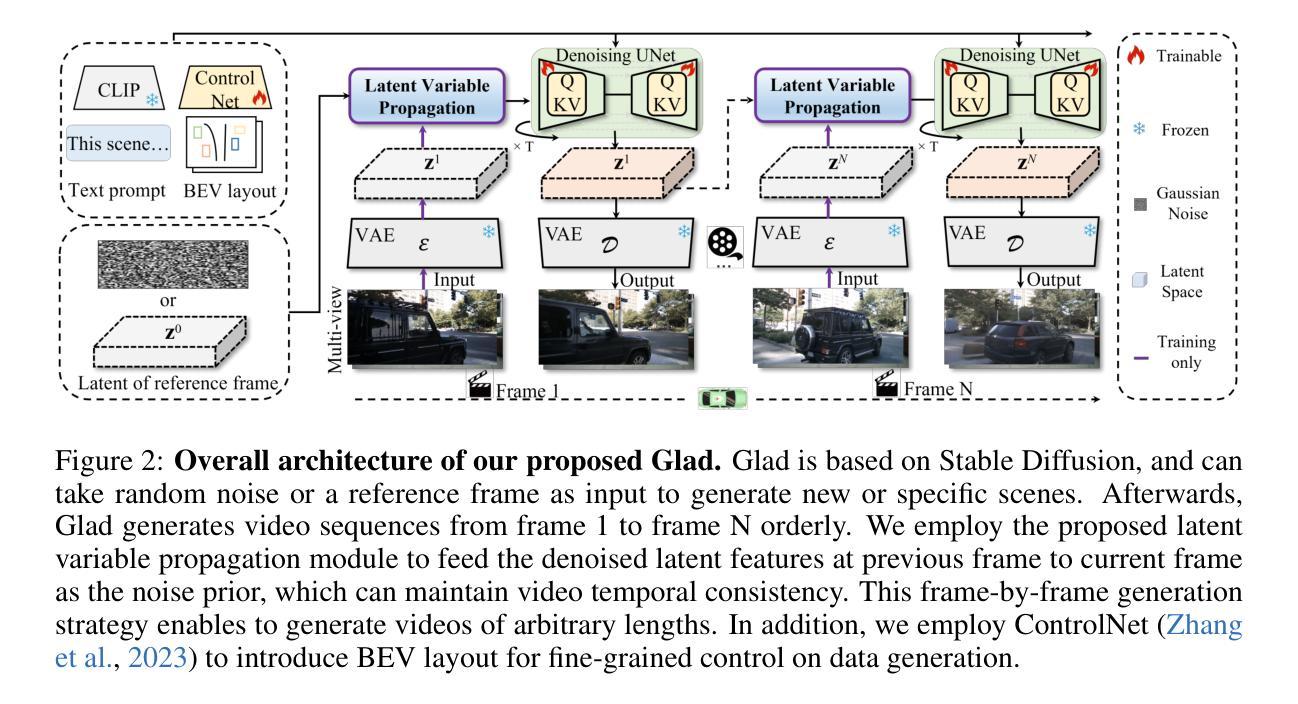
Glad: A Streaming Scene Generator for Autonomous Driving
Authors:Bin Xie, Yingfei Liu, Tiancai Wang, Jiale Cao, Xiangyu Zhang
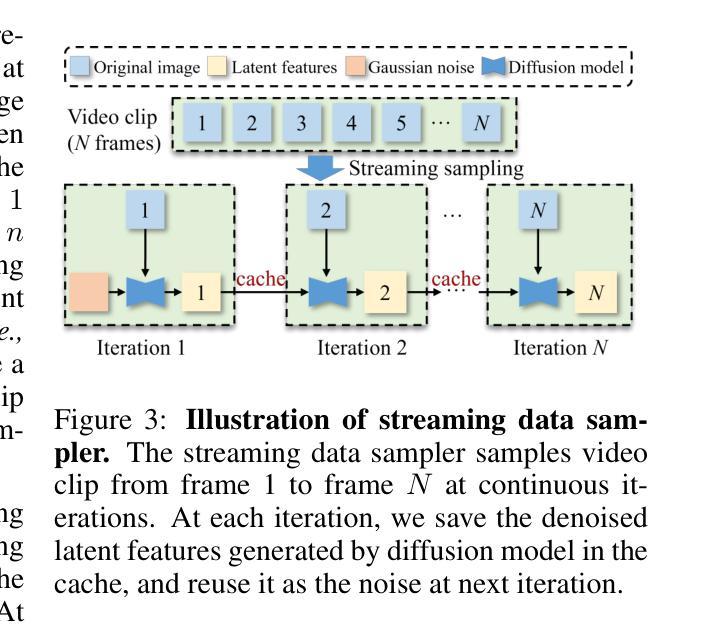
The generation and simulation of diverse real-world scenes have significant application value in the field of autonomous driving, especially for the corner cases. Recently, researchers have explored employing neural radiance fields or diffusion models to generate novel views or synthetic data under driving scenes. However, these approaches suffer from unseen scenes or restricted video length, thus lacking sufficient adaptability for data generation and simulation. To address these issues, we propose a simple yet effective framework, named Glad, to generate video data in a frame-by-frame style. To ensure the temporal consistency of synthetic video, we introduce a latent variable propagation module, which views the latent features of previous frame as noise prior and injects it into the latent features of current frame. In addition, we design a streaming data sampler to orderly sample the original image in a video clip at continuous iterations. Given the reference frame, our Glad can be viewed as a streaming simulator by generating the videos for specific scenes. Extensive experiments are performed on the widely-used nuScenes dataset. Experimental results demonstrate that our proposed Glad achieves promising performance, serving as a strong baseline for online video generation. We will release the source code and models publicly.
现实世界场景的生成与模拟在自动驾驶领域具有重要的应用价值,尤其对于一些特殊场景。近期,研究者尝试采用神经辐射场或扩散模型来生成驾驶场景下的新型视角或合成数据。然而,这些方法在面临未知场景或视频长度受限时,其在数据生成和模拟方面的适应性不足。为了解决这些问题,我们提出了一种简单有效的框架,名为Glad,以逐帧的方式生成视频数据。为了保证合成视频的时空一致性,我们引入了潜在变量传播模块,将前一帧的潜在特征视为噪声先验,并将其注入当前帧的潜在特征。此外,我们设计了一种流式数据采样器,以有序的方式在连续迭代中对视频片段中的原始图像进行采样。给定参考帧,我们的Glad可被视为一种流式模拟器,为特定场景生成视频。我们在广泛使用的nuScenes数据集上进行了大量实验。实验结果表明,我们提出的Glad取得了有前景的性能,成为在线视频生成的一个强有力的基准模型。我们将公开源代码和模型。
论文及项目相关链接
PDF Accepted by ICLR2025
Summary
该文本介绍了一种名为Glad的框架,用于以逐帧的方式生成视频数据,用于自主驾驶领域的场景生成和模拟。该框架解决了现有方法在面对未见场景或视频长度受限时的适应能力不足的问题。通过引入潜在变量传播模块和流式数据采样器,确保合成视频的时空一致性。在广泛使用的nuScenes数据集上进行的实验表明,Glad框架取得了良好的性能,成为在线视频生成的强大基线。
Key Takeaways
- Glad框架被用于生成和模拟自主驾驶中的多样现实世界场景,特别是针对角落情况的场景。
- 现有方法在面对未见场景或视频长度受限时存在适应能力不足的问题。
- Glad框架采用逐帧的方式生成视频数据。
- 潜在变量传播模块确保合成视频的时空一致性,将前一帧的潜在特征视为噪声先验,并注入当前帧的潜在特征中。
- 流式数据采样器能够有序地采样视频片段中的原始图像。
- Glad框架在nuScenes数据集上取得了良好的性能。
点此查看论文截图

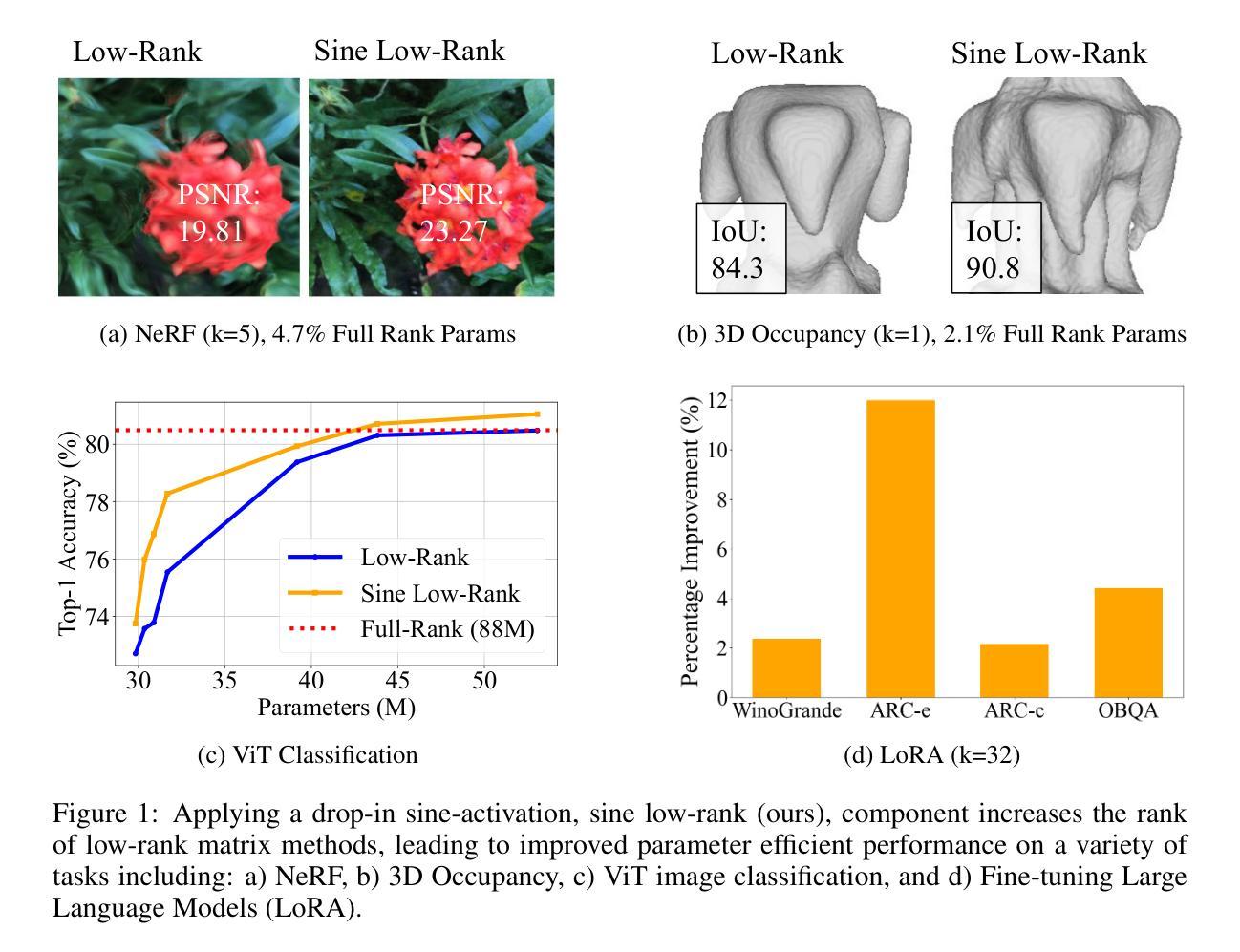
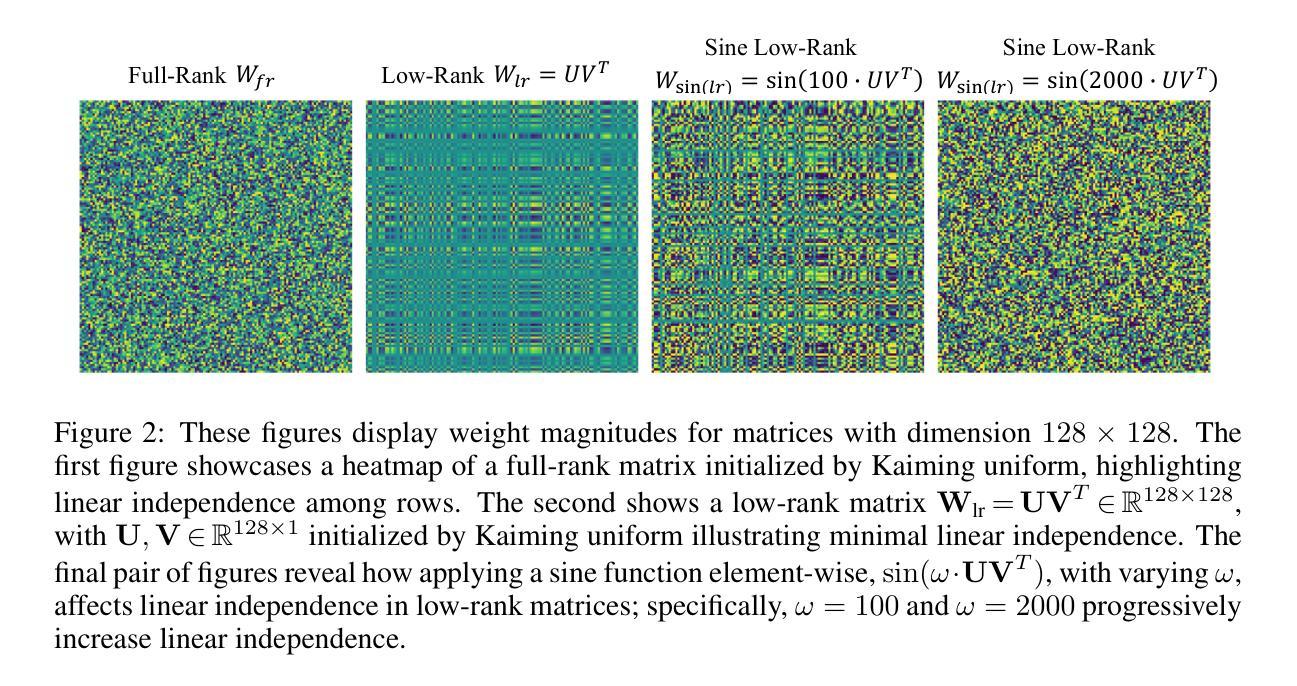
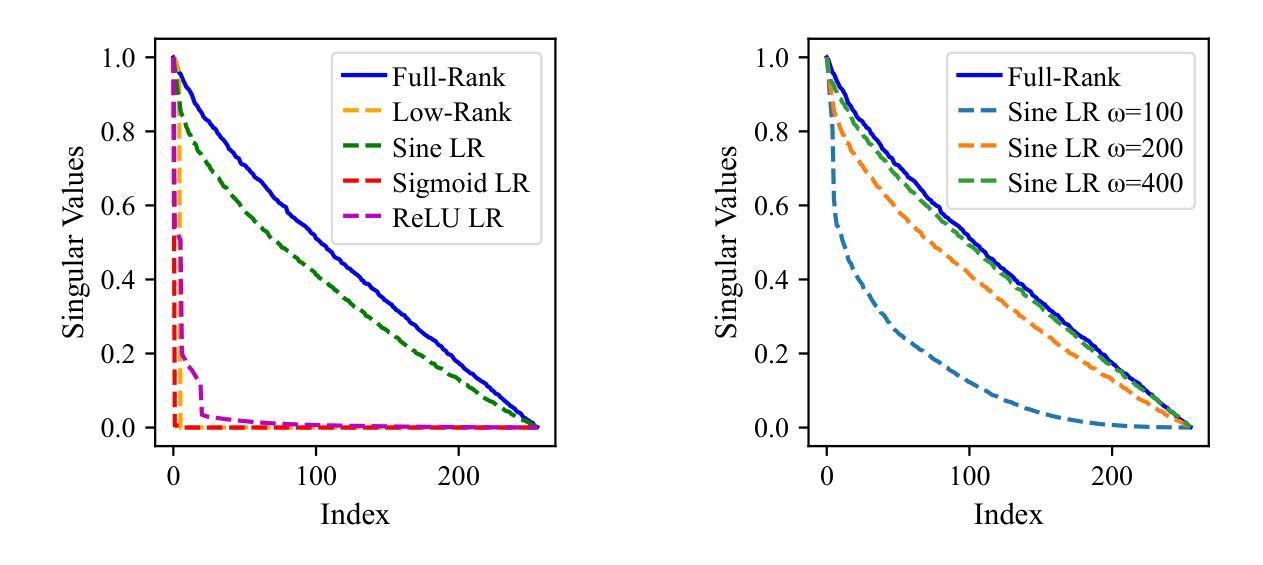
Efficient Learning With Sine-Activated Low-rank Matrices
Authors:Yiping Ji, Hemanth Saratchandran, Cameron Gordon, Zeyu Zhang, Simon Lucey
Low-rank decomposition has emerged as a vital tool for enhancing parameter efficiency in neural network architectures, gaining traction across diverse applications in machine learning. These techniques significantly lower the number of parameters, striking a balance between compactness and performance. However, a common challenge has been the compromise between parameter efficiency and the accuracy of the model, where reduced parameters often lead to diminished accuracy compared to their full-rank counterparts. In this work, we propose a novel theoretical framework that integrates a sinusoidal function within the low-rank decomposition process. This approach not only preserves the benefits of the parameter efficiency characteristic of low-rank methods but also increases the decomposition’s rank, thereby enhancing model performance. Our method proves to be a plug in enhancement for existing low-rank models, as evidenced by its successful application in Vision Transformers (ViT), Large Language Models (LLMs), Neural Radiance Fields (NeRF) and 3D shape modelling.
低秩分解已成为提高神经网络架构参数效率的重要工具,在机器学习的各种应用中受到广泛关注。这些技术显著减少了参数数量,在紧凑性和性能之间取得了平衡。然而,一个常见的挑战是参数效率与模型准确性之间的权衡,减少的参数往往会导致与全秩模型相比准确性降低。在这项工作中,我们提出了一种新的理论框架,该框架将正弦函数整合到低秩分解过程中。这种方法不仅保留了低秩方法参数效率的优点,还提高了分解的秩,从而增强了模型性能。我们的方法被证明是对现有低秩模型的增强插件,其在视觉转换器(ViT)、大型语言模型(LLM)、神经辐射场(NeRF)和3D形状建模中的应用成功证实了这一点。
论文及项目相关链接
PDF The first two authors contributed equally. Paper accepted at ICLR 2025
Summary
低秩分解在提升神经网络架构的参数效率方面发挥了重要作用,广泛应用于机器学习中的不同应用。然而,参数效率的降低往往会导致模型准确性的下降。本研究提出了一种新的理论框架,该框架在低秩分解过程中融入了正弦函数,旨在保留低秩方法的参数效率优势的同时提高模型性能。此方法成功应用于Vision Transformers(ViT)、大型语言模型(LLMs)、神经辐射场(NeRF)和三维建模等领域。
Key Takeaways
- 低秩分解是提高神经网络参数效率的重要工具,广泛应用于机器学习各个领域。
- 现有低秩方法常在参数效率和模型准确性之间做出妥协。
- 本研究提出了一种新的理论框架,结合正弦函数在低秩分解中,旨在提高模型性能。
- 该方法旨在保留低秩方法的参数效率优势。
- 此方法成功应用于Vision Transformers(ViT)、大型语言模型(LLMs)、神经辐射场(NeRF)和三维建模等领域。
- 该方法可作为现有低秩模型的增强插件。
点此查看论文截图