⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-06 更新
A Hypernetwork-Based Approach to KAN Representation of Audio Signals
Authors:Patryk Marszałek, Maciej Rut, Piotr Kawa, Piotr Syga
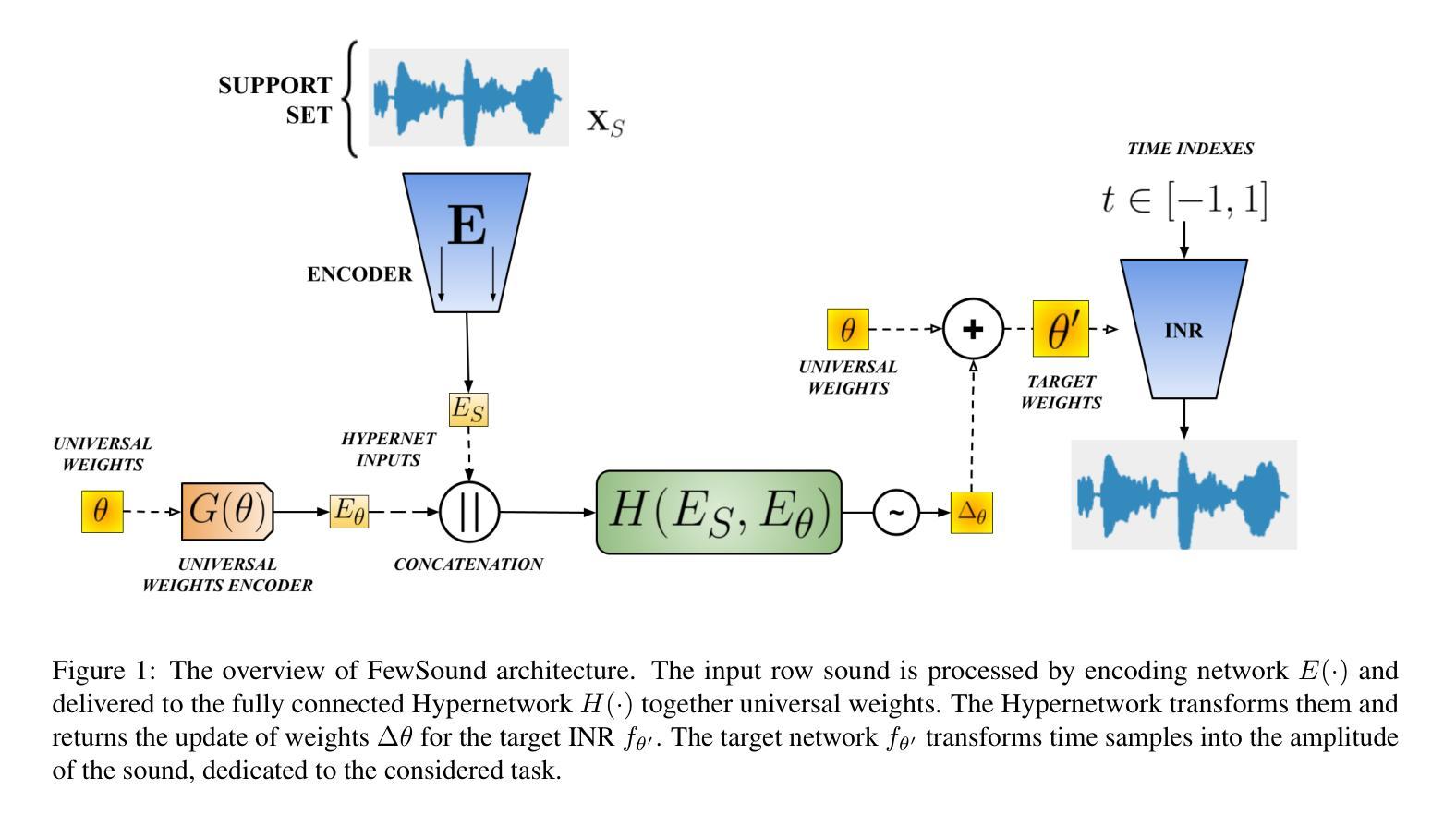
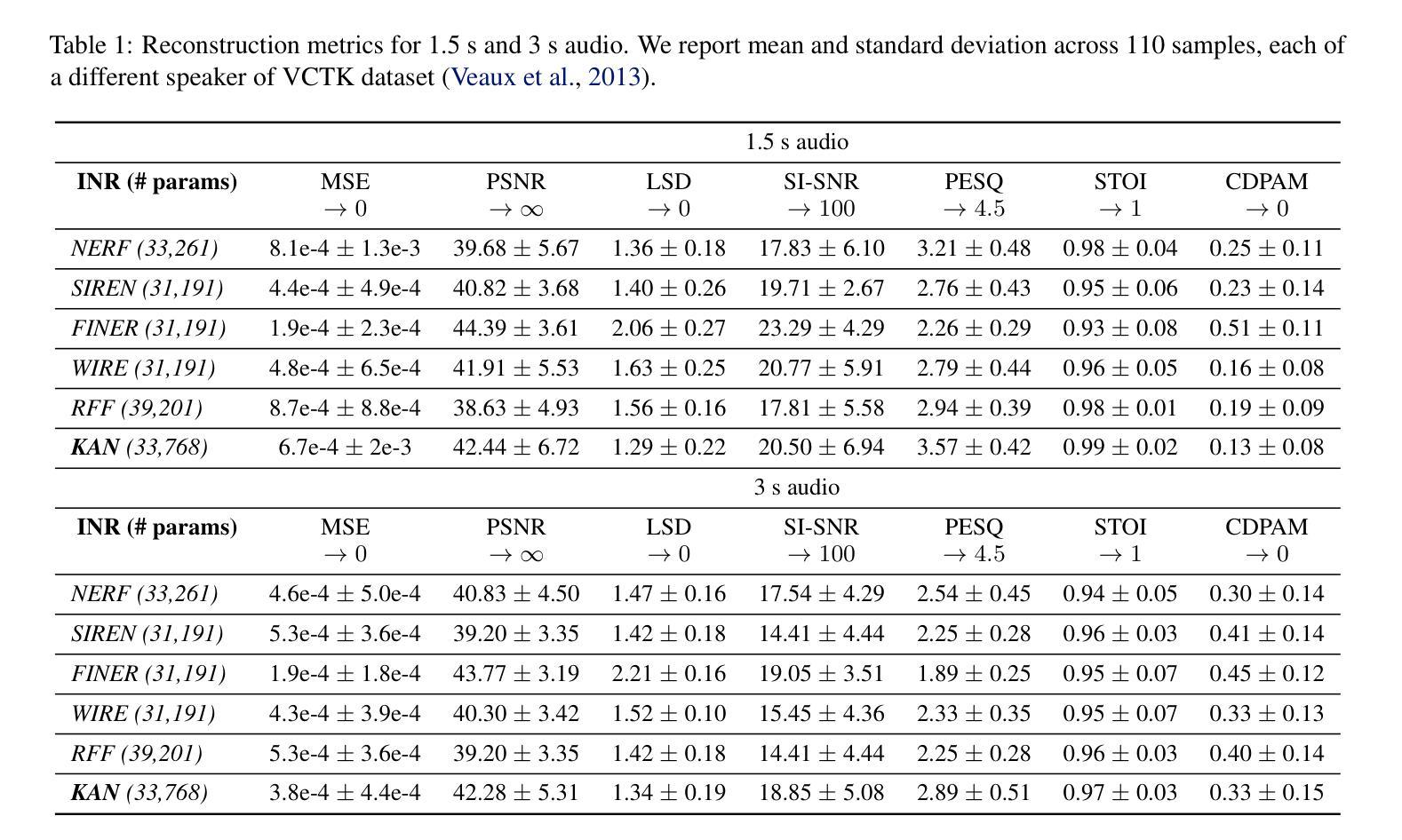
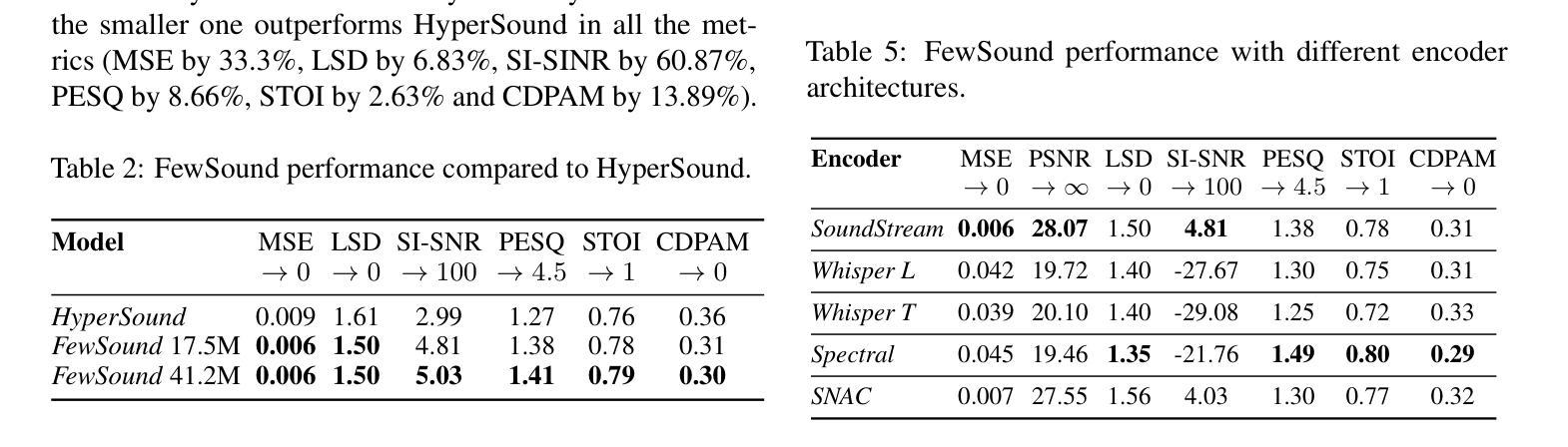
Implicit neural representations (INR) have gained prominence for efficiently encoding multimedia data, yet their applications in audio signals remain limited. This study introduces the Kolmogorov-Arnold Network (KAN), a novel architecture using learnable activation functions, as an effective INR model for audio representation. KAN demonstrates superior perceptual performance over previous INRs, achieving the lowest Log-SpectralDistance of 1.29 and the highest Perceptual Evaluation of Speech Quality of 3.57 for 1.5 s audio. To extend KAN’s utility, we propose FewSound, a hypernetwork-based architecture that enhances INR parameter updates. FewSound outperforms the state-of-the-art HyperSound, with a 33.3% improvement in MSE and 60.87% in SI-SNR. These results show KAN as a robust and adaptable audio representation with the potential for scalability and integration into various hypernetwork frameworks. The source code can be accessed at https://github.com/gmum/fewsound.git.
隐式神经表示(INR)在多媒体数据编码方面表现出色,但在音频信号方面的应用仍然有限。本研究引入了Kolmogorov-Arnold网络(KAN),这是一种使用可学习激活函数的新型架构,作为音频表示的有效INR模型。KAN在感知性能上优于先前的INR,在1.5秒音频上实现了最低的Log-SpectralDistance为1.29和最高的语音质量感知评价为3.57。为了拓展KAN的实用性,我们提出了基于超网络的FewSound架构,用于增强INR参数更新。FewSound的表现优于当前最先进的HyperSound,在MSE上提高了33.3%,在SI-SNR上提高了60.87%。这些结果表明,KAN是一种稳健且可适应的音频表示方法,具有可扩展性和集成到各种超网络框架的潜力。源代码可在https://github.com/gmum/fewsound.git访问。
论文及项目相关链接
Summary
本文介绍了一种名为Kolmogorov-Arnold网络(KAN)的新型神经网络架构,该架构采用可学习的激活函数,作为音频表示的有效隐式神经表示(INR)模型。KAN在音频信号上的表现优于先前的INR模型,并在短短的1.5秒音频上实现了最低的逻辑谱距离和最高的语音质量感知评价。此外,本研究还提出了基于超网络的FewSound架构,可增强INR参数更新,其性能优于现有的HyperSound,在MSE和SI-SNR方面取得了显著改进。这些结果表明,KAN作为一种稳健且可适应的音频表示方法,具有可扩展性和集成到各种超网络框架的潜力。
Key Takeaways
- Kolmogorv-Arnold网络(KAN)是一种新型的隐式神经表示(INR)模型,使用可学习的激活函数,能有效编码音频数据。
- KAN在音频表现上超越了先前的INR模型,实现了更低的逻辑谱距离和更高的语音质量感知评价。
- FewSound架构是基于超网络的设计,能增强INR模型的参数更新。
- FewSound在性能上超越了现有的HyperSound,在均方误差(MSE)和信号干扰源到噪声比率(SI-SNR)方面取得了显著改进。
- KAN模型具有可扩展性和适应性,可应用于各种超网络框架。
- 该研究的源代码已公开,可方便后续研究和使用。
点此查看论文截图

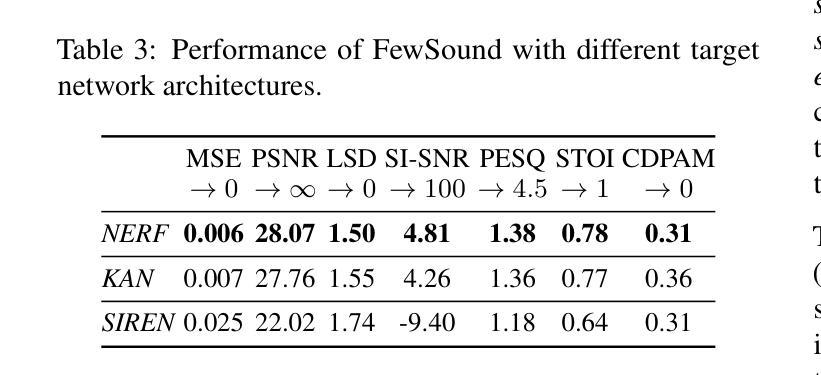
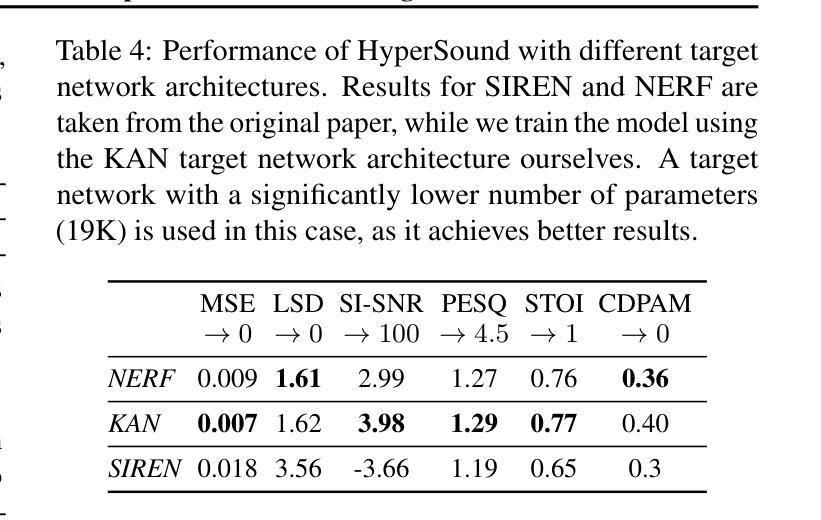
MM-OR: A Large Multimodal Operating Room Dataset for Semantic Understanding of High-Intensity Surgical Environments
Authors:Ege Özsoy, Chantal Pellegrini, Tobias Czempiel, Felix Tristram, Kun Yuan, David Bani-Harouni, Ulrich Eck, Benjamin Busam, Matthias Keicher, Nassir Navab
Operating rooms (ORs) are complex, high-stakes environments requiring precise understanding of interactions among medical staff, tools, and equipment for enhancing surgical assistance, situational awareness, and patient safety. Current datasets fall short in scale, realism and do not capture the multimodal nature of OR scenes, limiting progress in OR modeling. To this end, we introduce MM-OR, a realistic and large-scale multimodal spatiotemporal OR dataset, and the first dataset to enable multimodal scene graph generation. MM-OR captures comprehensive OR scenes containing RGB-D data, detail views, audio, speech transcripts, robotic logs, and tracking data and is annotated with panoptic segmentations, semantic scene graphs, and downstream task labels. Further, we propose MM2SG, the first multimodal large vision-language model for scene graph generation, and through extensive experiments, demonstrate its ability to effectively leverage multimodal inputs. Together, MM-OR and MM2SG establish a new benchmark for holistic OR understanding, and open the path towards multimodal scene analysis in complex, high-stakes environments. Our code, and data is available at https://github.com/egeozsoy/MM-OR.
手术室(ORs)是一个复杂且高风险的环境,需要精确理解医疗人员、工具和设备之间的交互,以提高手术辅助、情境意识和病人安全。当前的数据集在规模、真实感方面存在不足,并且未能捕捉到手术室场景的多模式性质,从而限制了手术室建模的进展。为此,我们引入了MM-OR,这是一个真实且大规模的多模式时空手术室数据集,也是第一个能够实现多模式场景图生成的数据集。MM-OR捕捉了包含RGB-D数据、细节视图、音频、语音记录、机器人日志和跟踪数据的全面手术室场景,并带有全景分割、语义场景图和下游任务标签的注释。此外,我们提出了MM2SG,这是第一个用于场景图生成的大型多模式视觉语言模型,并通过大量实验证明了其有效利用多模式输入的能力。总之,MM-OR和MM2SG为全面的手术室理解建立了新的基准,并为复杂高风险环境中的多模式场景分析开辟了道路。我们的代码和数据可在 https://github.com/egeozsoy/MM-OR 中获取。
论文及项目相关链接
Summary
手术环境复杂且风险高,需要深入理解手术室内的交互情况以提升手术辅助、态势感知和患者安全。当前数据集在规模、现实性和多模态捕捉方面存在不足,限制了手术室建模的进展。为此,我们推出MM-OR数据集,这是一个大规模、现实的多模态时空手术室数据集,也是首个能够实现多模态场景图生成的数据集。MM-OR捕捉了全面的手术室场景,包括RGB-D数据、细节视图、音频、语音记录、机器人日志和跟踪数据,并带有全景分割、语义场景图和下游任务标签的注释。此外,我们还提出了MM2SG,这是首个用于场景图生成的大型多模态视觉语言模型,并通过大量实验证明其有效利用多模态输入的能力。总之,MM-OR和MM2SG为全面的手术室理解建立了新的基准,并为复杂高风险环境中的多模态场景分析开辟了道路。
Key Takeaways
- 手术室是复杂的医疗环境,需要增强对医疗人员、工具和设备的交互理解以提升手术效率和安全性。
- 当前数据集在规模、现实性和多模态捕捉方面存在局限性,限制了手术室环境的建模研究。
- MM-OR数据集是首个大规模、现实的多模态时空手术室数据集,能够全面捕捉手术室的多种信息。
- MM-OR数据集包含RGB-D数据、细节视图、音频、语音记录等多模态信息,并带有全面的注释。
- MM2SG是首个用于场景图生成的大型多模态视觉语言模型,能有效利用多模态输入。
- MM-OR和MM2SG共同为手术室的全面理解设立了新标准。
点此查看论文截图


Pruning Deep Neural Networks via a Combination of the Marchenko-Pastur Distribution and Regularization
Authors:Leonid Berlyand, Theo Bourdais, Houman Owhadi, Yitzchak Shmalo
Deep neural networks (DNNs) have brought significant advancements in various applications in recent years, such as image recognition, speech recognition, and natural language processing. In particular, Vision Transformers (ViTs) have emerged as a powerful class of models in the field of deep learning for image classification. In this work, we propose a novel Random Matrix Theory (RMT)-based method for pruning pre-trained DNNs, based on the sparsification of weights and singular vectors, and apply it to ViTs. RMT provides a robust framework to analyze the statistical properties of large matrices, which has been shown to be crucial for understanding and optimizing the performance of DNNs. We demonstrate that our RMT-based pruning can be used to reduce the number of parameters of ViT models (trained on ImageNet) by 30-50% with less than 1% loss in accuracy. To our knowledge, this represents the state-of-the-art in pruning for these ViT models. Furthermore, we provide a rigorous mathematical underpinning of the above numerical studies, namely we proved a theorem for fully connected DNNs, and other more general DNN structures, describing how the randomness in the weight matrices of a DNN decreases as the weights approach a local or global minimum (during training). We verify this theorem through numerical experiments on fully connected DNNs, providing empirical support for our theoretical findings. Moreover, we prove a theorem that describes how DNN loss decreases as we remove randomness in the weight layers, and show a monotone dependence of the decrease in loss with the amount of randomness that we remove. Our results also provide significant RMT-based insights into the role of regularization during training and pruning.
近年来,深度神经网络(DNNs)在各种应用中取得了显著进展,如图像识别、语音识别和自然语言处理。特别是,视觉Transformer(ViTs)作为深度学习领域的一种强大模型,在图像分类中崭露头角。在这项工作中,我们提出了一种基于随机矩阵理论(RMT)的预训练DNN压缩方法,该方法基于权重和奇异向量的稀疏化,并应用于ViTs。RMT提供了一个强大的框架来分析大型矩阵的统计特性,这已被证明对于理解和优化DNN的性能至关重要。我们证明,我们的基于RMT的压缩技术可用于将经过ImageNet训练的ViT模型的参数数量减少30-50%,同时精度损失不到1%。据我们所知,这是针对这些ViT模型的最新压缩技术。此外,我们对上述数值研究进行了严格的数学支撑,即我们为全连接DNN和其他更一般的DNN结构证明了一个定理,描述了DNN权重矩阵中的随机性如何随着权重接近局部或全局最小值(在训练过程中)而减少。我们通过全连接DNN的数值实验验证了这一定理,为我们的理论发现提供了实证支持。此外,我们证明了另一个定理,描述了随着我们在权重层中消除随机性,DNN损失如何减少,以及损失减少与我们消除的随机性量之间的单调依赖性。我们的结果还提供了基于RMT的关于训练和压缩过程中正则化作用的深刻见解。
论文及项目相关链接
Summary
本文介绍了基于随机矩阵理论(RMT)的深度学习神经网络(DNN)剪枝方法,并将其应用于图像分类领域的Vision Transformers(ViTs)。研究团队提出了利用权重稀疏化和奇异向量进行剪枝的新方法,对在ImageNet上训练的ViT模型参数减少了30%~50%,而精度损失不到1%,达到业界领先水平。同时,本文提供了严谨的数学理论基础,通过理论推导和数值实验证明了对全连接神经网络结构中的随机性减少与损失降低的关系。此外,本文还探讨了训练过程中的正则化作用。
Key Takeaways
- 提出基于随机矩阵理论(RMT)的剪枝新方法用于预训练深度神经网络(DNN)。
- 方法应用于Vision Transformers(ViTs)在图像分类领域表现优秀,可大幅减少模型参数而精度损失极小。
- 研究提供了严谨的数学理论支撑,包括证明全连接神经网络结构中的随机性减少与损失降低的关系。
点此查看论文截图


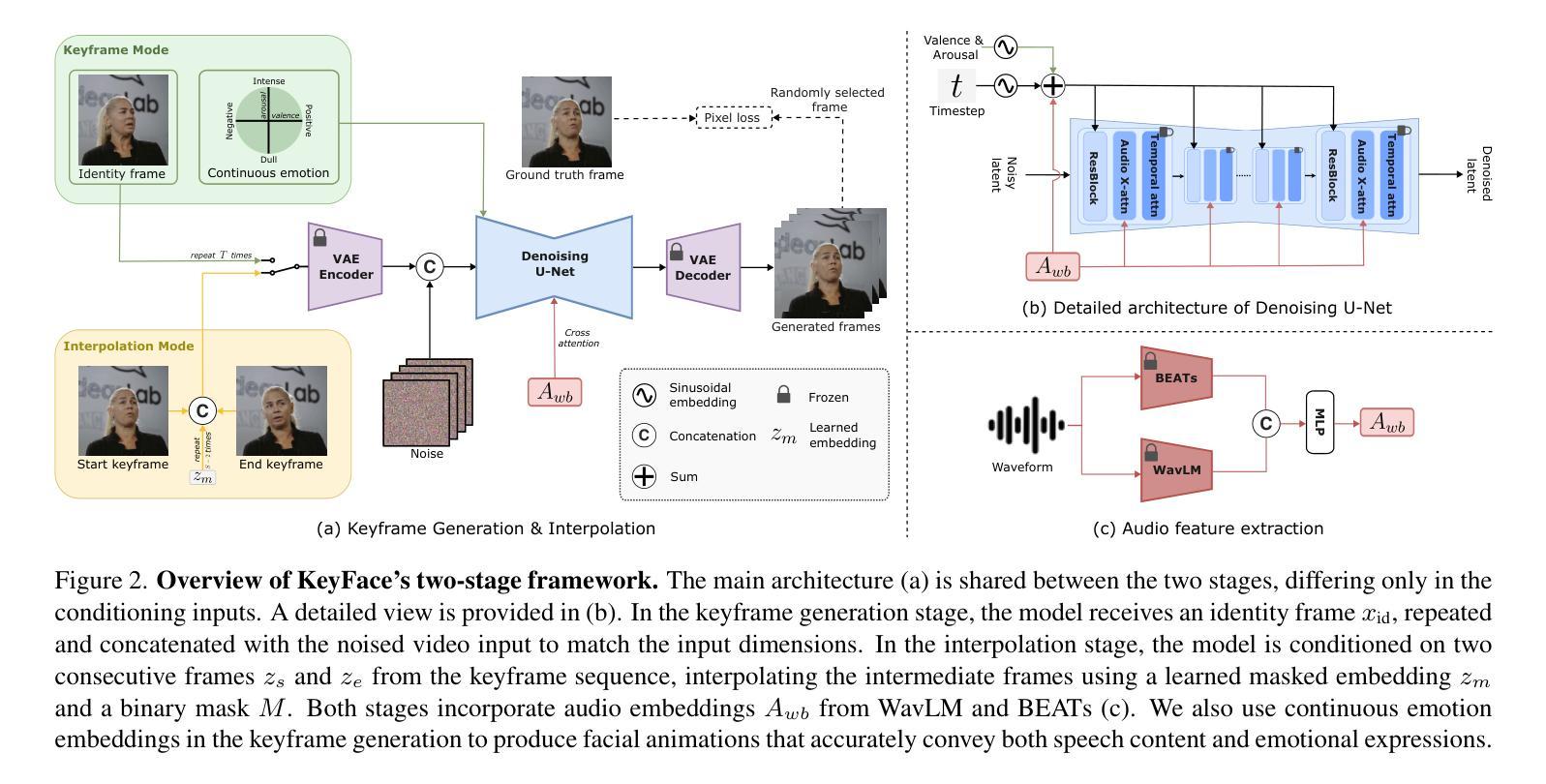
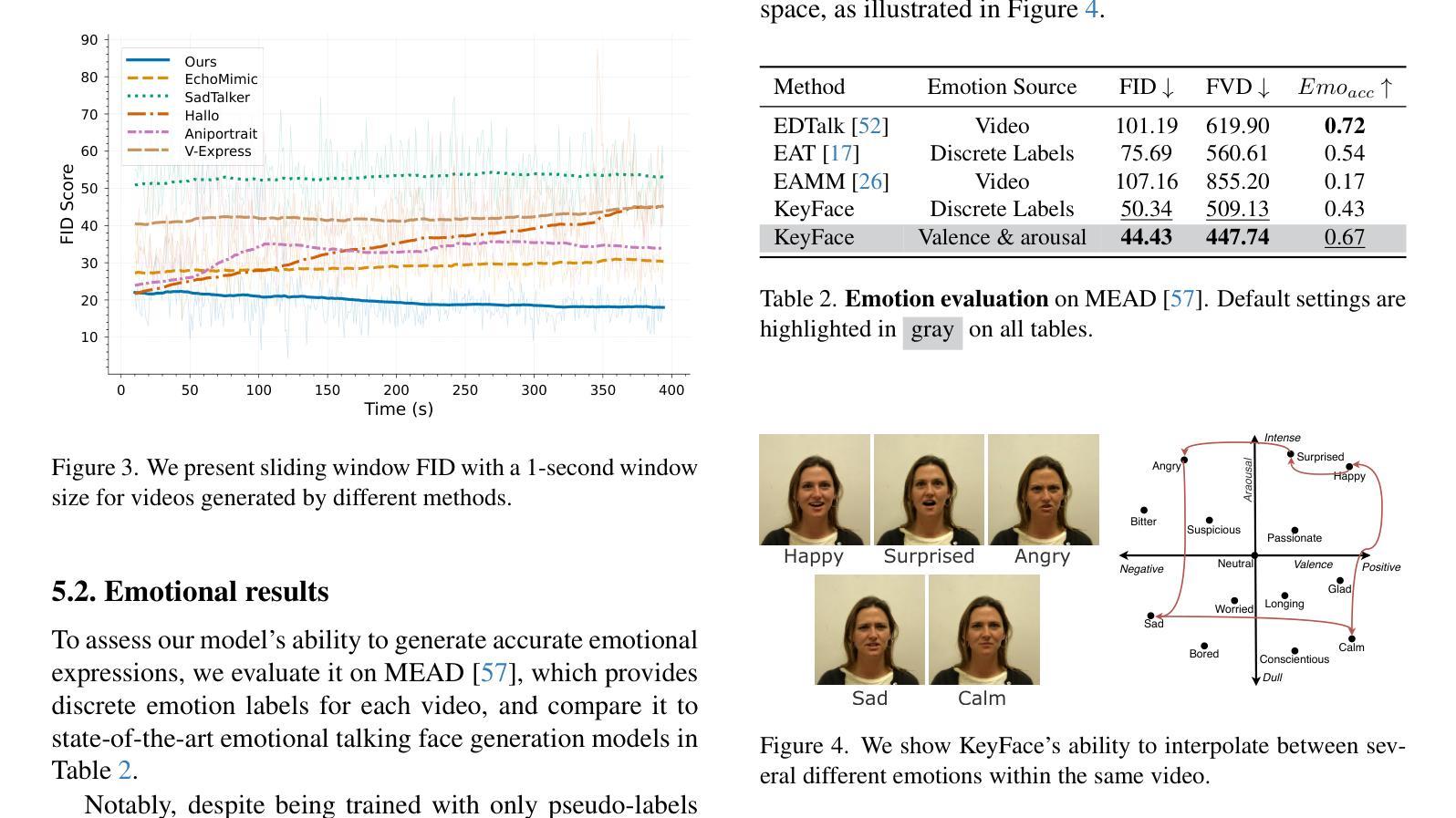
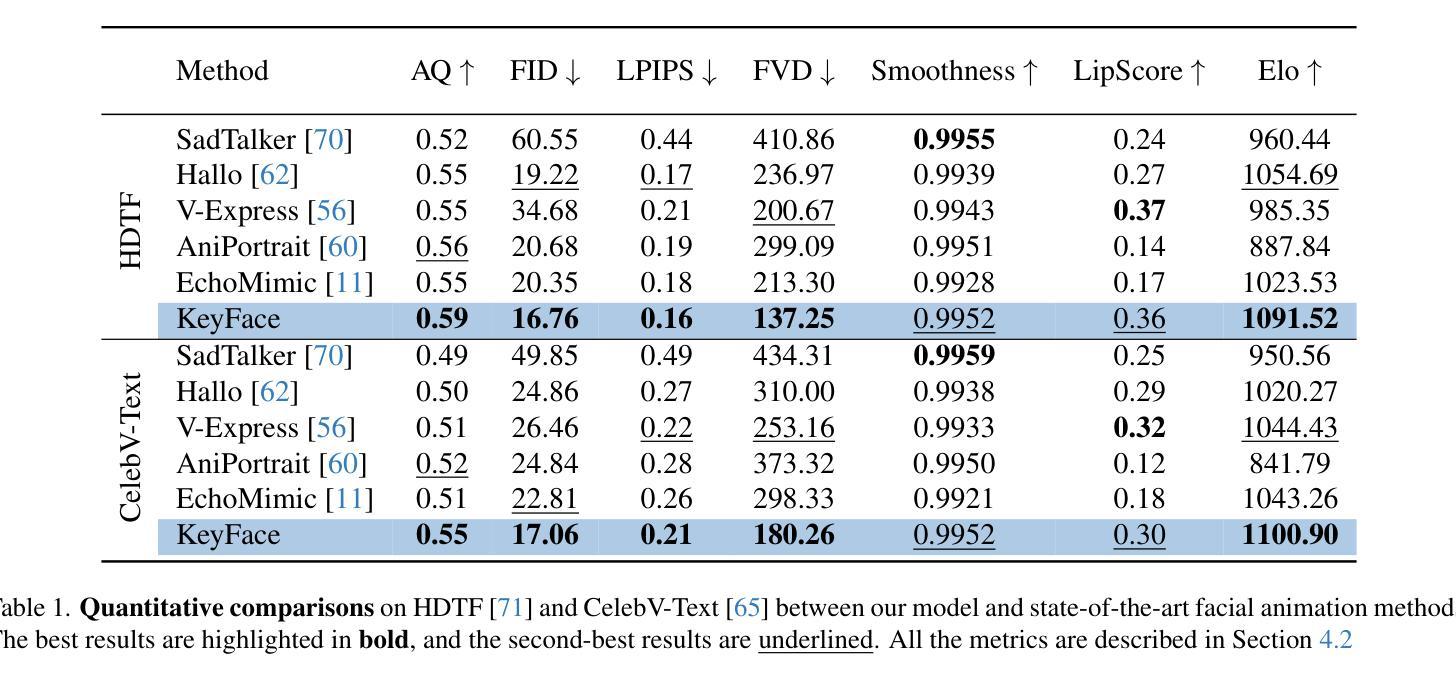
KeyFace: Expressive Audio-Driven Facial Animation for Long Sequences via KeyFrame Interpolation
Authors:Antoni Bigata, Michał Stypułkowski, Rodrigo Mira, Stella Bounareli, Konstantinos Vougioukas, Zoe Landgraf, Nikita Drobyshev, Maciej Zieba, Stavros Petridis, Maja Pantic
Current audio-driven facial animation methods achieve impressive results for short videos but suffer from error accumulation and identity drift when extended to longer durations. Existing methods attempt to mitigate this through external spatial control, increasing long-term consistency but compromising the naturalness of motion. We propose KeyFace, a novel two-stage diffusion-based framework, to address these issues. In the first stage, keyframes are generated at a low frame rate, conditioned on audio input and an identity frame, to capture essential facial expressions and movements over extended periods of time. In the second stage, an interpolation model fills in the gaps between keyframes, ensuring smooth transitions and temporal coherence. To further enhance realism, we incorporate continuous emotion representations and handle a wide range of non-speech vocalizations (NSVs), such as laughter and sighs. We also introduce two new evaluation metrics for assessing lip synchronization and NSV generation. Experimental results show that KeyFace outperforms state-of-the-art methods in generating natural, coherent facial animations over extended durations, successfully encompassing NSVs and continuous emotions.
当前基于音频驱动的面部动画方法在短视频上取得了令人印象深刻的效果,但当扩展到更长时间时,会出现误差累积和身份漂移的问题。现有方法试图通过外部空间控制来减轻这一问题,虽然增加了长期一致性,但牺牲了动作的自然性。我们提出了KeyFace,这是一种基于新型两阶段扩散的框架来解决这些问题。在第一阶段,以音频输入和身份帧为条件,在低帧率下生成关键帧,以捕捉长时间段内的重要面部表情和动作。在第二阶段,插值模型填补了关键帧之间的空白,确保了平滑过渡和时间连贯性。为了进一步提高逼真度,我们融入了连续的情绪表示,并处理了各种非语音声音(NSVs),如笑声和叹息声。我们还引入了两个新的评估指标,用于评估唇同步和非语音生成。实验结果表明,KeyFace在生成长时间的自然、连贯的面部动画方面优于最先进的方法,成功涵盖了非语音声音和连续情绪。
论文及项目相关链接
PDF CVPR 2025
Summary
本文提出一种名为KeyFace的新型两阶段扩散框架,旨在解决音频驱动面部动画在长时间序列中面临的误差累积和身份漂移问题。第一阶段根据音频输入和身份帧在低帧率下生成关键帧,捕捉长时间的面部表情和动作。第二阶段采用插值模型填充关键帧之间的间隙,确保平滑过渡和时间连贯性。为增强真实感,KeyFace还融入了连续情感表示,并处理各种非语音发声(NSVs)。实验结果表明,KeyFace在生成自然、连贯的长时间面部动画方面优于现有技术,成功涵盖NSVs和连续情感。
Key Takeaways
- 当前音频驱动的面部动画方法在短时间视频上表现令人印象深刻,但在长时间序列上遭遇误差累积和身份漂移的挑战。
- KeyFace是一个新型的两阶段扩散框架,旨在解决这些问题。
- 第一阶段根据音频输入和身份帧生成低帧率的关键帧,捕捉长时间内的面部表情和动作。
- 第二阶段采用插值模型确保关键帧之间的平滑过渡和时间连贯性。
- KeyFace融入连续情感表示,增强动画的真实感。
- KeyFace能够处理各种非语音发声(NSVs),如笑声和叹息。
点此查看论文截图

Enhancing Social Media Rumor Detection: A Semantic and Graph Neural Network Approach for the 2024 Global Election
Authors:Liu Yan, Liu Yunpeng, Zhao Liang
The development of social media platforms has revolutionized the speed and manner in which information is disseminated, leading to both beneficial and detrimental effects on society. While these platforms facilitate rapid communication, they also accelerate the spread of rumors and extremist speech, impacting public perception and behavior significantly. This issue is particularly pronounced during election periods, where the influence of social media on election outcomes has become a matter of global concern. With the unprecedented number of elections in 2024, against this backdrop, the election ecosystem has encountered unprecedented challenges. This study addresses the urgent need for effective rumor detection on social media by proposing a novel method that combines semantic analysis with graph neural networks. We have meticulously collected a dataset from PolitiFact and Twitter, focusing on politically relevant rumors. Our approach involves semantic analysis using a fine-tuned BERT model to vectorize text content and construct a directed graph where tweets and comments are nodes, and interactions are edges. The core of our method is a graph neural network, SAGEWithEdgeAttention, which extends the GraphSAGE model by incorporating first-order differences as edge attributes and applying an attention mechanism to enhance feature aggregation. This innovative approach allows for the fine-grained analysis of the complex social network structure, improving rumor detection accuracy. The study concludes that our method significantly outperforms traditional content analysis and time-based models, offering a theoretically sound and practically efficient solution.
社交媒体平台的发展在信息传播的速度和方式上带来了革命性的变革,对社会产生了有益和有害的影响。这些平台虽然促进了快速通信,但也加速了谣言和极端言论的传播,对公众认知和行为产生了重大影响。在选举期间,这个问题尤为突出,社交媒体对选举结果的影响已成为全球关注的问题。在即将到来的2024年众多选举的背景下,选举生态系统面临着前所未有的挑战。本研究针对社交媒体上迫切需要的有效谣言检测,提出了一种结合语义分析和图神经网络的新方法。我们从PolitiFact和Twitter精心收集了一个数据集,重点关注与政治相关的谣言。我们的方法使用微调后的BERT模型进行语义分析,将文本内容向量化,并构建一个由推文和评论作为节点、互动作为边的有向图。我们的方法的核心是图神经网络SAGEWithEdgeAttention,它通过引入一阶差分作为边属性并在特征聚合过程中应用注意力机制来扩展GraphSAGE模型。这种创新的方法允许对复杂的社交网络结构进行精细分析,提高了谣言检测的准确性。研究表明,我们的方法显著优于传统的基于内容和基于时间模型,提供了一个理论上有依据、实践上有效的解决方案。
论文及项目相关链接
摘要
社交媒体平台的发展为信息传播的速度和方式带来了革命性的变化,既产生了积极的影响,也带来了消极的影响。这些平台促进了快速沟通,但也加速了谣言和极端言论的传播,对公众认知和行为产生了重大影响。特别是在选举期间,社交媒体对选举结果的影响已成为全球关注的问题。随着2024年选举数量的空前增加,选举生态系统面临着前所未有的挑战。本研究提出了一种新的谣言检测法应对这一紧迫需求,该方法结合了语义分析与图神经网络。我们从PolitiFact和Twitter收集了政治相关的谣言数据集。我们的方法使用微调后的BERT模型进行语义分析,将文本内容向量化,并构建一个以推文和评论为节点、互动为边的有向图。该方法的核心是图神经网络SAGEWithEdgeAttention,它扩展了GraphSAGE模型,将一阶差分作为边属性并应用注意力机制以增强特征聚合。这种创新的方法允许对复杂的社会网络结构进行精细分析,提高了谣言检测的准确性。研究表明,我们的方法显著优于传统的基于内容和基于时间的模型,提供了一个理论扎实、实践高效的解决方案。
关键见解
- 社交媒体平台的发展在信息传播方面产生了革命性的影响,既有正面也有负面效果。
- 社交媒体在选举期间对公众认知和行为的冲击尤为显著,已成为全球关注的议题。
- 面对2024年选举增多的背景,选举生态系统面临前所未有的挑战。
- 研究提出了一种结合语义分析与图神经网络的全新谣言检测法。
- 数据集来自PolitiFact和Twitter,集中于政治相关的谣言。
- 方法的核心是SAGEWithEdgeAttention图神经网络,它扩展了GraphSAGE模型并应用了注意力机制。
点此查看论文截图


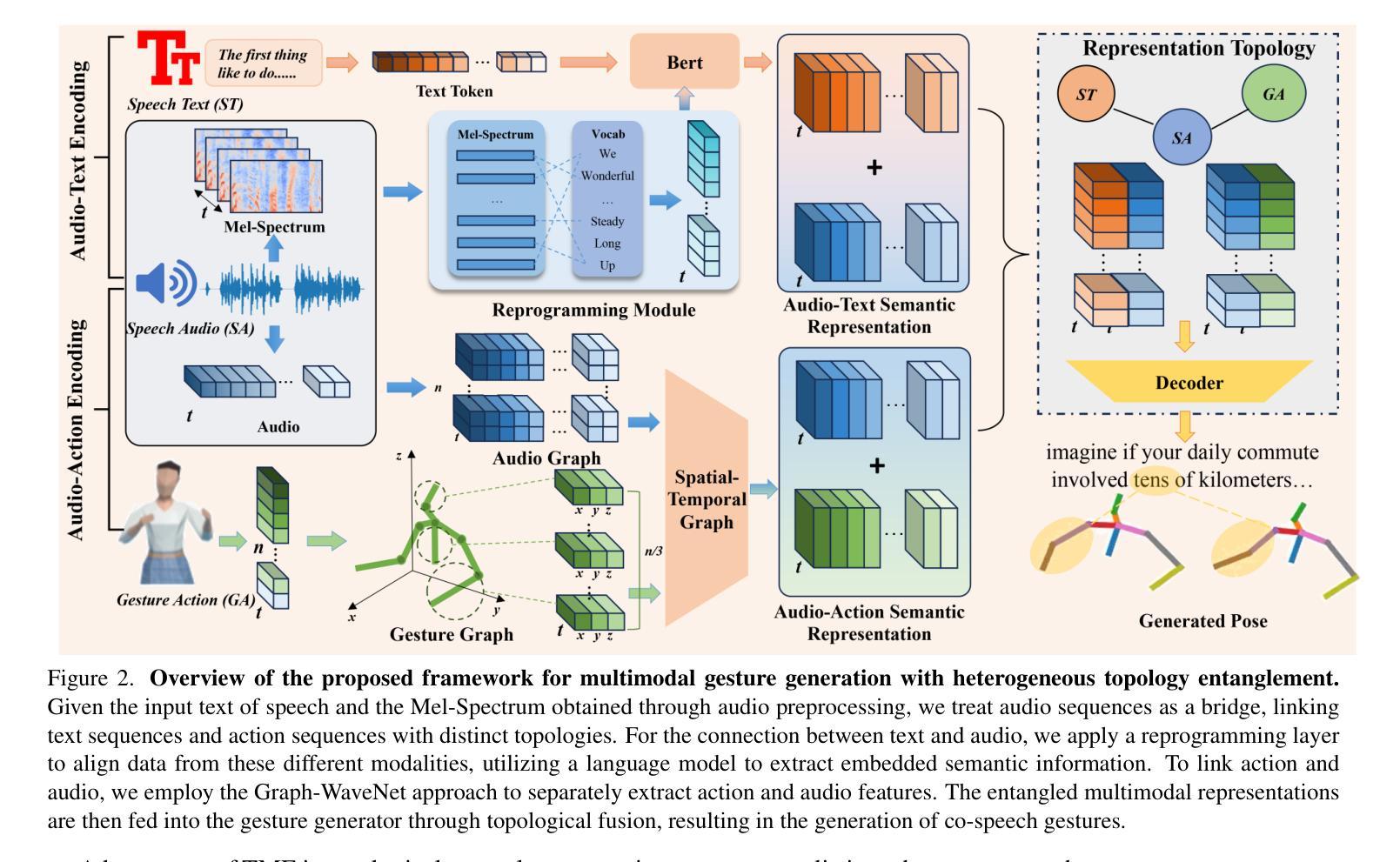
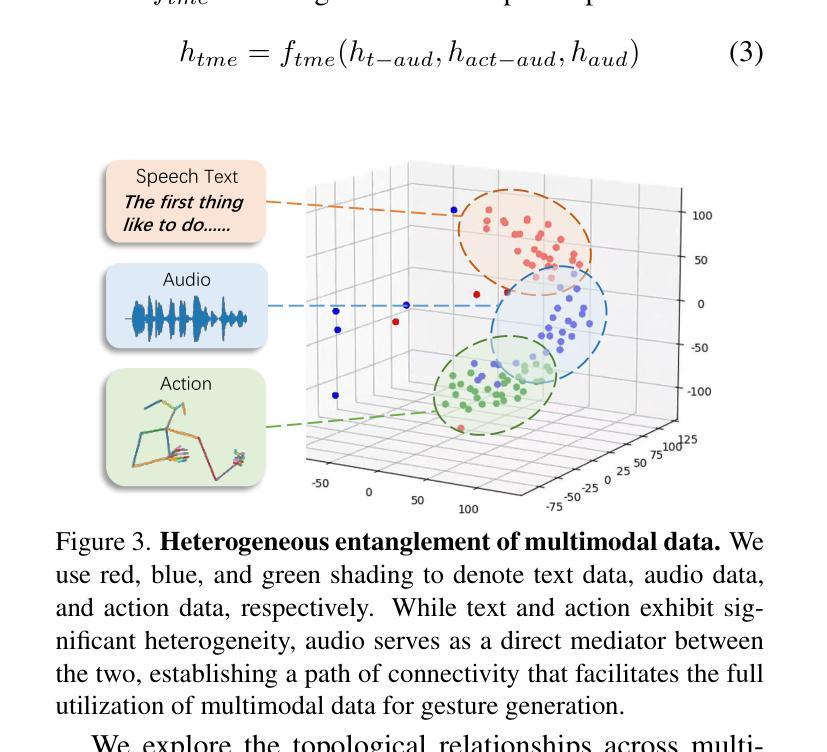
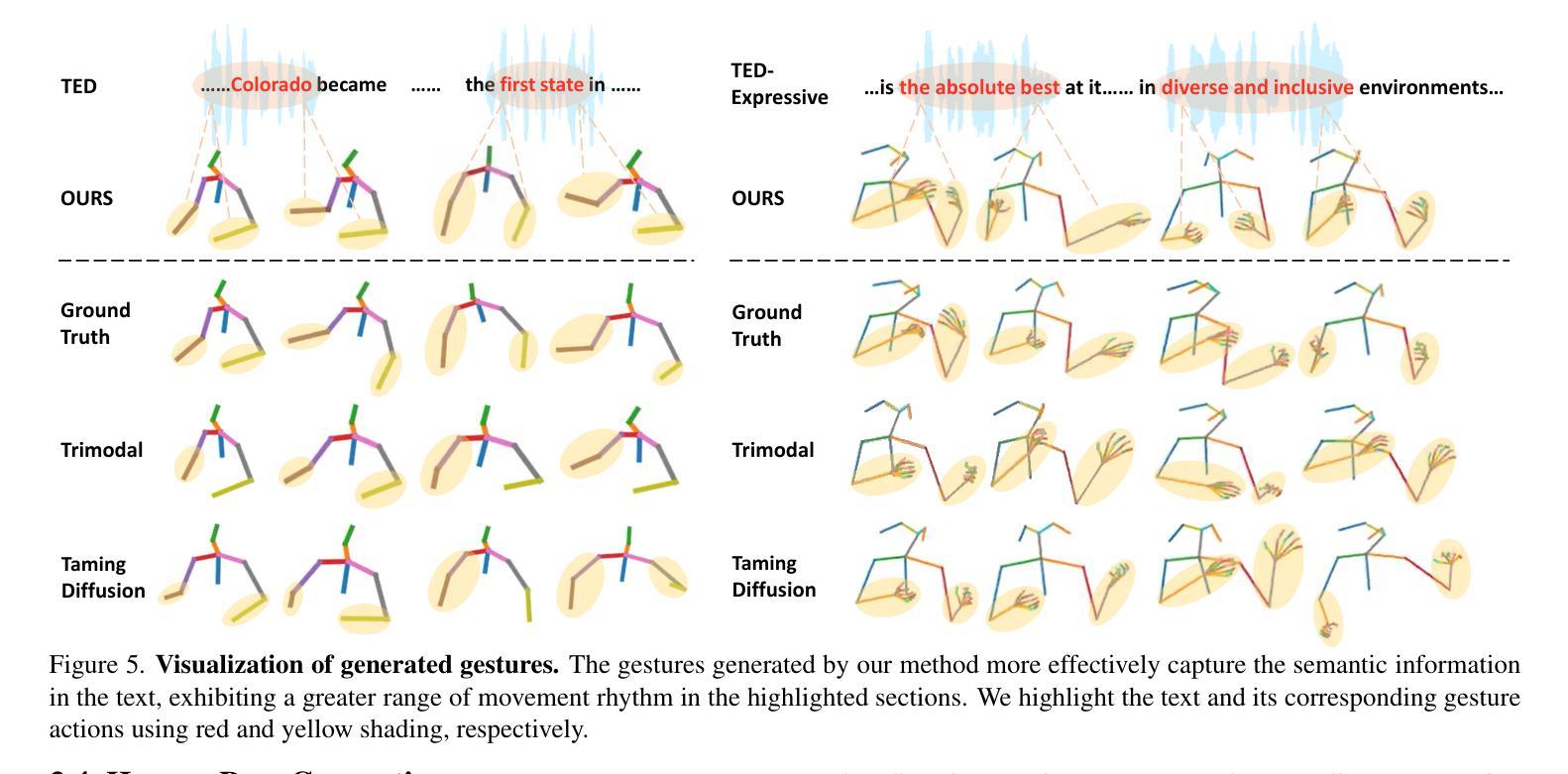
HOP: Heterogeneous Topology-based Multimodal Entanglement for Co-Speech Gesture Generation
Authors:Hongye Cheng, Tianyu Wang, Guangsi Shi, Zexing Zhao, Yanwei Fu
Co-speech gestures are crucial non-verbal cues that enhance speech clarity and expressiveness in human communication, which have attracted increasing attention in multimodal research. While the existing methods have made strides in gesture accuracy, challenges remain in generating diverse and coherent gestures, as most approaches assume independence among multimodal inputs and lack explicit modeling of their interactions. In this work, we propose a novel multimodal learning method named HOP for co-speech gesture generation that captures the heterogeneous entanglement between gesture motion, audio rhythm, and text semantics, enabling the generation of coordinated gestures. By leveraging spatiotemporal graph modeling, we achieve the alignment of audio and action. Moreover, to enhance modality coherence, we build the audio-text semantic representation based on a reprogramming module, which is beneficial for cross-modality adaptation. Our approach enables the trimodal system to learn each other’s features and represent them in the form of topological entanglement. Extensive experiments demonstrate that HOP achieves state-of-the-art performance, offering more natural and expressive co-speech gesture generation. More information, codes, and demos are available here: https://star-uu-wang.github.io/HOP/
对话中的协同语音手势是非语言线索中至关重要的部分,能增强人类交流中的语音清晰度和表达力,在多模态研究中引起了越来越多的关注。虽然现有方法在手势准确性方面取得了进展,但在生成多样和连贯的手势方面仍存在挑战。大多数方法假设多模态输入是独立的,缺乏对其交互的显式建模。在这项工作中,我们提出了一种名为HOP的协同语音手势生成的多模态学习方法,该方法能够捕捉手势运动、音频节奏和文本语义之间的异质纠缠,从而实现协调手势的生成。通过利用时空图建模,我们实现了音频和动作的对齐。此外,为了增强模态连贯性,我们基于重构模块构建了音频-文本语义表示,这有利于跨模态适应。我们的方法使三模态系统能够相互学习特征并以拓扑纠缠的形式表示它们。大量实验表明,HOP达到了最先进的性能,实现了更自然、更富有表现力的协同语音手势生成。更多信息、代码和演示可在以下网址找到:https://star-uu-wang.github.io/HOP/。
论文及项目相关链接
PDF Accepted by CVPR 2025. See https://star-uu-wang.github.io/HOP/
Summary
本文提出一种名为HOP的多模态学习方法,用于生成协同语音手势。该方法通过时空图建模实现音频和动作的同步,并通过编程模块构建音频文本语义表示,增强模态一致性。该方法能够生成多样且连贯的手势,实现语音、手势和文本之间的协调。实验证明,该方法在协同语音手势生成方面取得了最佳性能。
Key Takeaways
- 协同语音手势是人类沟通中重要的非语言线索,能提高语音的清晰度和表达力。
- 当前的手势生成方法主要面临生成多样性和连贯性挑战,且大多假设多模态输入独立,缺乏对其交互的显式建模。
- HOP方法通过时空图建模实现音频和动作的同步,提高手势的协调性。
- HOP方法利用编程模块构建音频文本语义表示,增强模态一致性,有利于跨模态适应。
- HOP方法实现了语音、手势和文本之间的协调,生成更自然和表达性更强的协同语音手势。
- 实验证明,HOP方法在协同语音手势生成方面取得了最佳性能。
点此查看论文截图


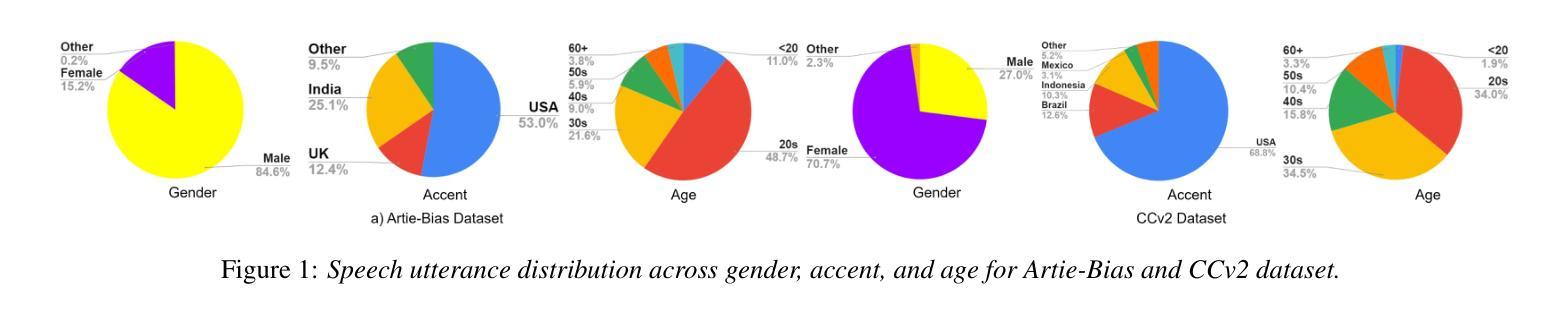
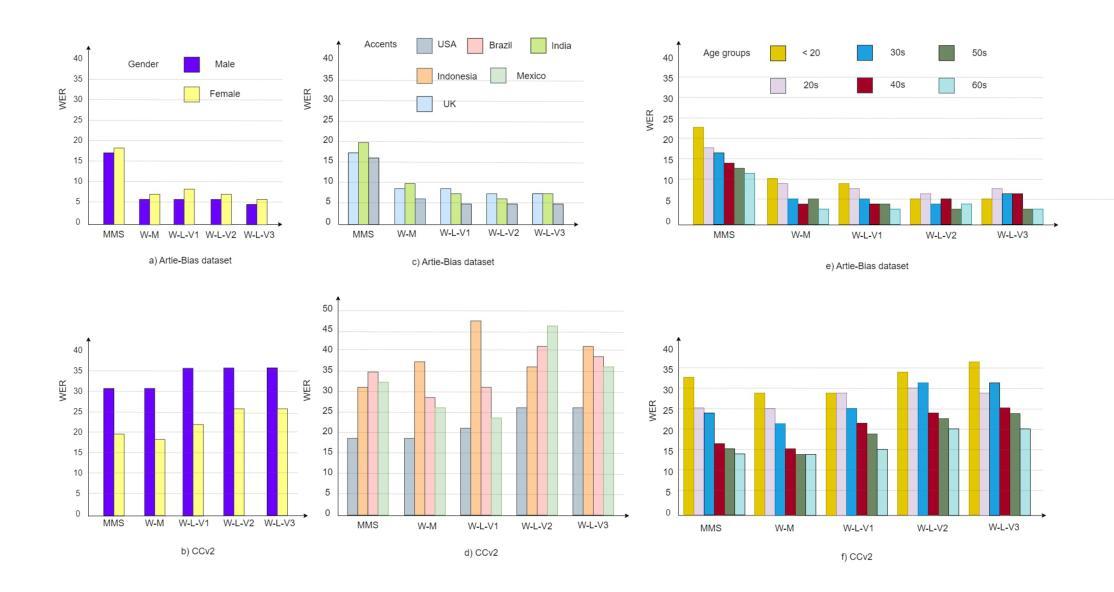
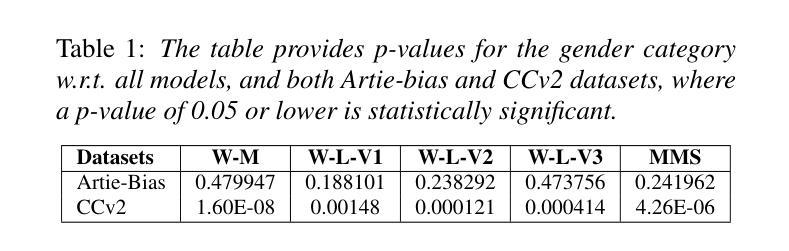
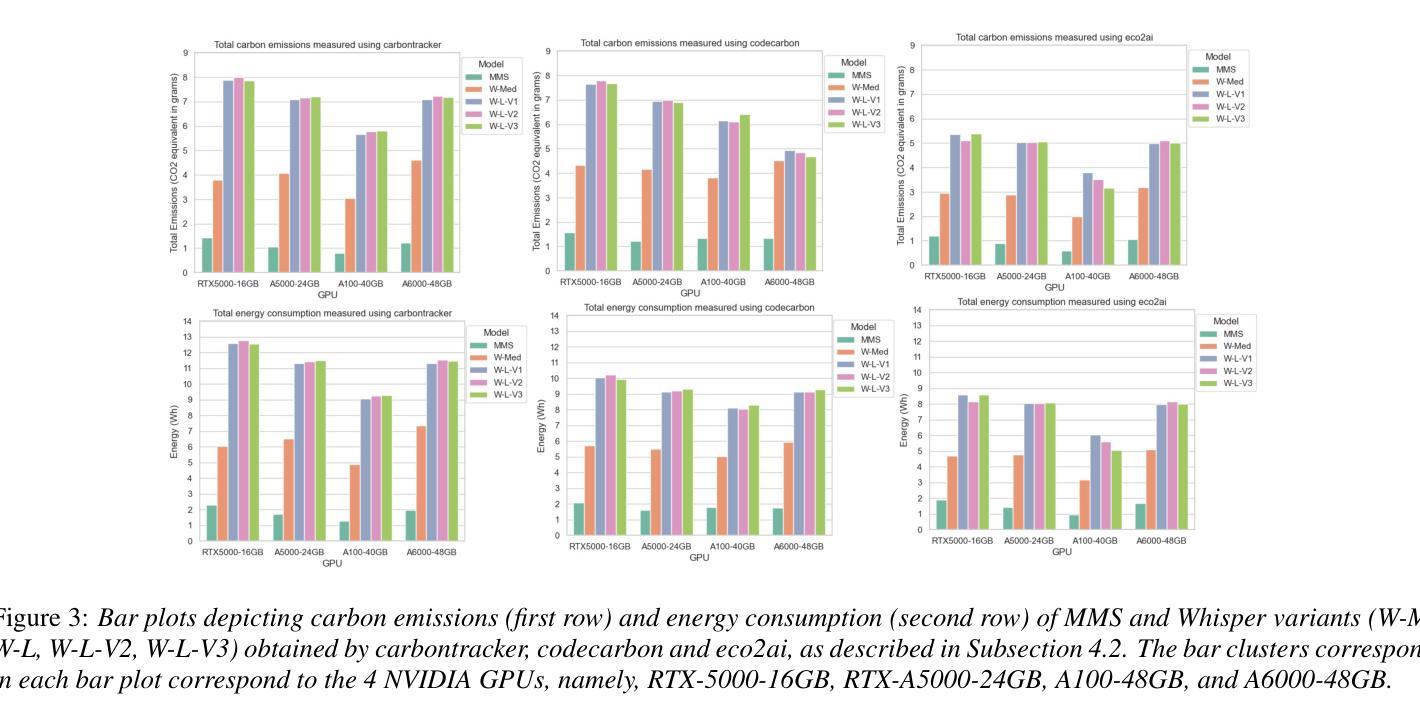
Unveiling Biases while Embracing Sustainability: Assessing the Dual Challenges of Automatic Speech Recognition Systems
Authors:Ajinkya Kulkarni, Atharva Kulkarni, Miguel Couceiro, Isabel Trancoso
In this paper, we present a bias and sustainability focused investigation of Automatic Speech Recognition (ASR) systems, namely Whisper and Massively Multilingual Speech (MMS), which have achieved state-of-the-art (SOTA) performances. Despite their improved performance in controlled settings, there remains a critical gap in understanding their efficacy and equity in real-world scenarios. We analyze ASR biases w.r.t. gender, accent, and age group, as well as their effect on downstream tasks. In addition, we examine the environmental impact of ASR systems, scrutinizing the use of large acoustic models on carbon emission and energy consumption. We also provide insights into our empirical analyses, offering a valuable contribution to the claims surrounding bias and sustainability in ASR systems.
本文重点关注自动语音识别(ASR)系统的偏见和可持续性调查,特别是已经达到最新技术水平(SOTA)的Whisper和大规模多语种语音(MMS)。尽管它们在受控环境中的性能得到了提高,但在真实场景中的效率和公平仍存在关键差距。我们分析了ASR与性别、口音和年龄组之间的偏见及其对下游任务的影响。此外,我们还考察了ASR系统的环境影响,详细分析了大型声学模型对碳排放和能源消耗的影响。我们还提供了实证分析的见解,为ASR系统中有关偏见和可持续性的主张做出了宝贵贡献。
论文及项目相关链接
PDF Interspeech 2024
Summary
本文研究了自动语音识别(ASR)系统的偏见和可持续性,特别是表现最佳的Whisper和Massively Multilingual Speech(MMS)。文章探讨了ASR系统在实际场景中的效率和公平性问题,重点分析了其在性别、口音和年龄组方面的偏见及其对下游任务的影响。此外,本文还探讨了ASR系统的环境影响,特别是大型声学模型对碳排放和能源消耗的影响。
Key Takeaways
- 自动语音识别(ASR)系统存在偏见问题,特别是在性别、口音和年龄组方面。
- ASR系统的性能在实际场景中可能存在公平性问题。
- ASR系统的偏见对下游任务产生影响。
- 大型声学模型在碳排放和能源消耗方面存在环境影响。
- ASR系统的可持续性是研究的重点之一。
- 文章提供了关于ASR系统中偏见和可持续性的实证分析和见解。
点此查看论文截图

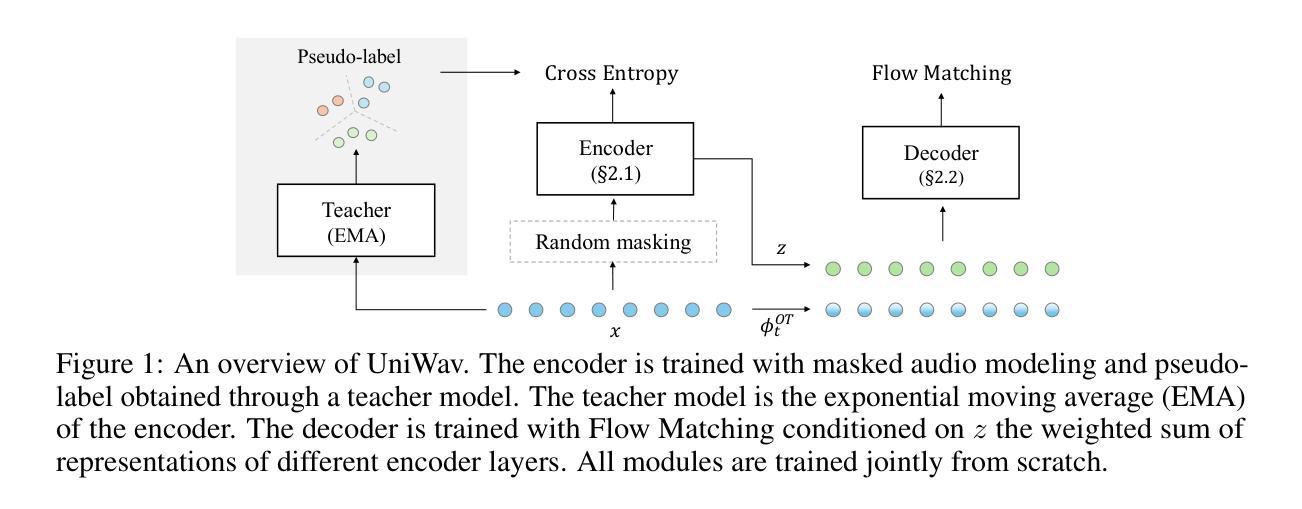
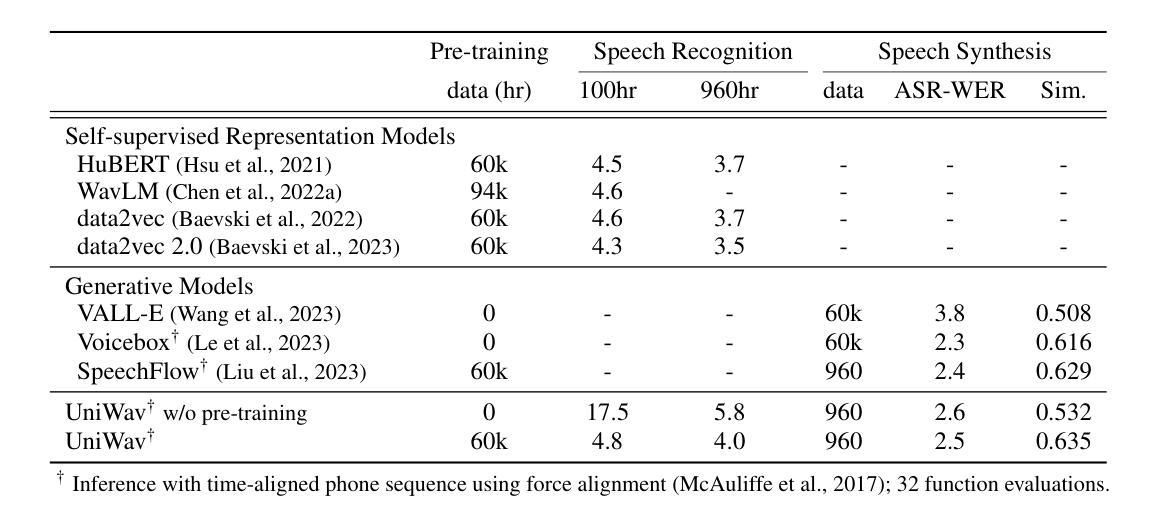
UniWav: Towards Unified Pre-training for Speech Representation Learning and Generation
Authors:Alexander H. Liu, Sang-gil Lee, Chao-Han Huck Yang, Yuan Gong, Yu-Chiang Frank Wang, James R. Glass, Rafael Valle, Bryan Catanzaro
Pre-training and representation learning have been playing an increasingly important role in modern speech processing. Nevertheless, different applications have been relying on different foundation models, since predominant pre-training techniques are either designed for discriminative tasks or generative tasks. In this work, we make the first attempt at building a unified pre-training framework for both types of tasks in speech. We show that with the appropriate design choices for pre-training, one can jointly learn a representation encoder and generative audio decoder that can be applied to both types of tasks. We propose UniWav, an encoder-decoder framework designed to unify pre-training representation learning and generative tasks. On speech recognition, text-to-speech, and speech tokenization, UniWav achieves comparable performance to different existing foundation models, each trained on a specific task. Our findings suggest that a single general-purpose foundation model for speech can be built to replace different foundation models, reducing the overhead and cost of pre-training.
预训练和表示学习在现代语音识别中扮演着越来越重要的角色。然而,不同的应用依赖于不同的基础模型,因为主流的预训练技术要么是为判别任务设计的,要么是为生成任务设计的。在这项工作中,我们首次尝试为这两种类型的任务构建统一的预训练框架。我们表明,通过适当的预训练设计选择,可以联合学习一个表示编码器和一个生成音频解码器,这两种类型的应用都可以使用。我们提出了UniWav,这是一种为统一预训练表示学习和生成任务而设计的编码器-解码器框架。在语音识别、文本到语音和语音标记化方面,UniWav实现了与针对不同任务训练的现有基础模型相当的性能。我们的研究结果表明,可以构建一个通用的单一基础模型来进行语音训练,以替代不同的基础模型,从而降低预训练的开销和成本。
论文及项目相关链接
PDF ICLR 2025; demo page at https://alexander-h-liu.github.io/uniwav-demo.github.io/
Summary
本文介绍了在语音处理中预训练和表示学习的重要性,并指出目前不同的应用依赖于不同的基础模型,主流的预训练技术主要是为判别任务或生成任务设计的。本研究首次尝试为这两种任务构建统一的预训练框架,并证明通过适当的预训练设计选择,可以联合学习适用于这两种任务的表示编码器和生成音频解码器。本研究提出了UniWav这一编码解码框架,旨在统一预训练表示学习和生成任务。在语音识别、文本到语音和语音标记化方面,UniWav的性能与针对特定任务训练的现有基础模型相当。研究结果表明,可以构建单一通用的语音基础模型来替代不同的基础模型,从而降低预训练的开销和成本。
Key Takeaways
- 预训练和表示学习在现代语音处理中扮演着越来越重要的角色。
- 目前不同的语音应用依赖于不同的基础模型,而主流预训练技术主要面向判别任务或生成任务。
- 研究首次尝试为判别任务和生成任务构建统一的预训练框架。
- 通过适当的预训练设计选择,可以联合学习表示编码器和生成音频解码器,适用于两种任务。
- 提出的UniWav框架旨在统一预训练表示学习和生成任务。
- UniWav在语音识别、文本到语音和语音标记化方面的性能与特定任务的基础模型相当。
点此查看论文截图

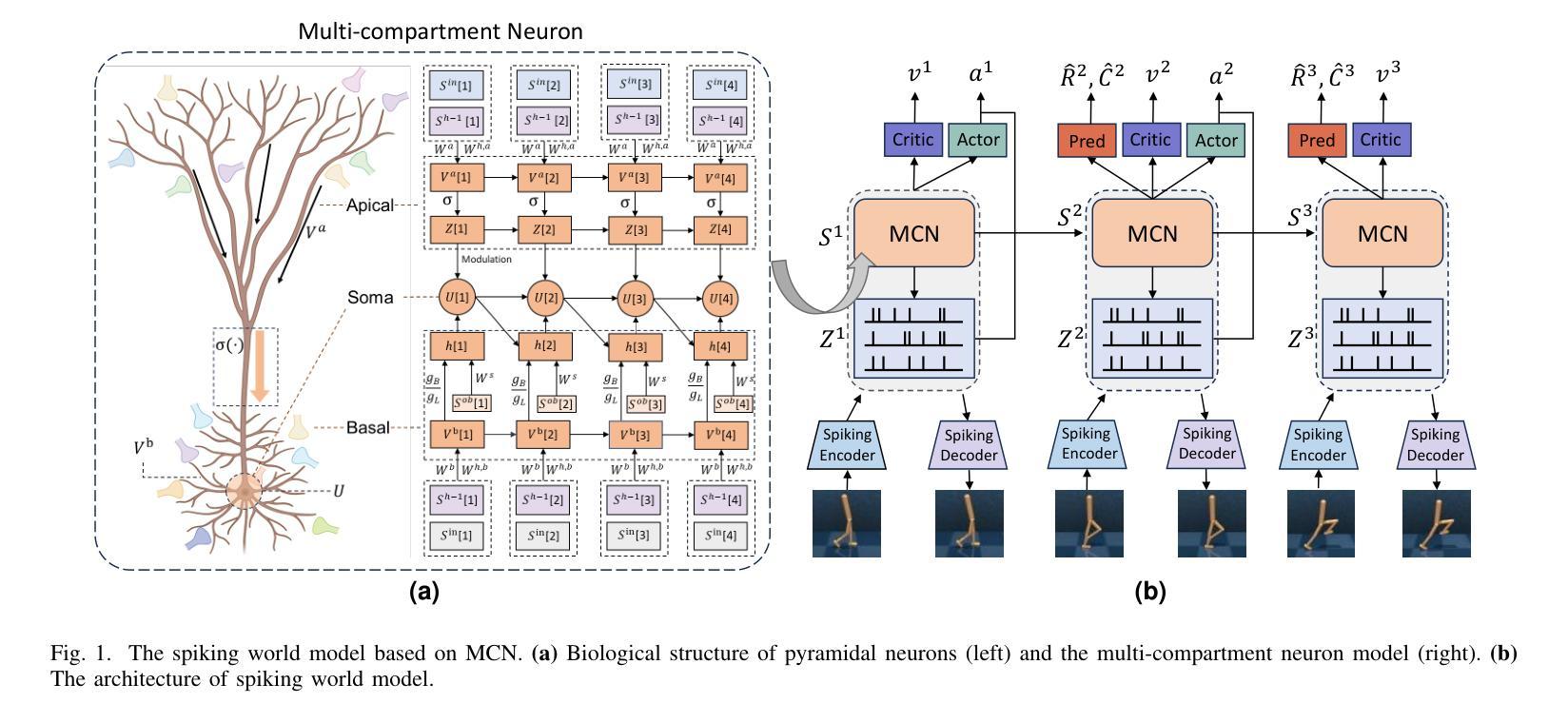
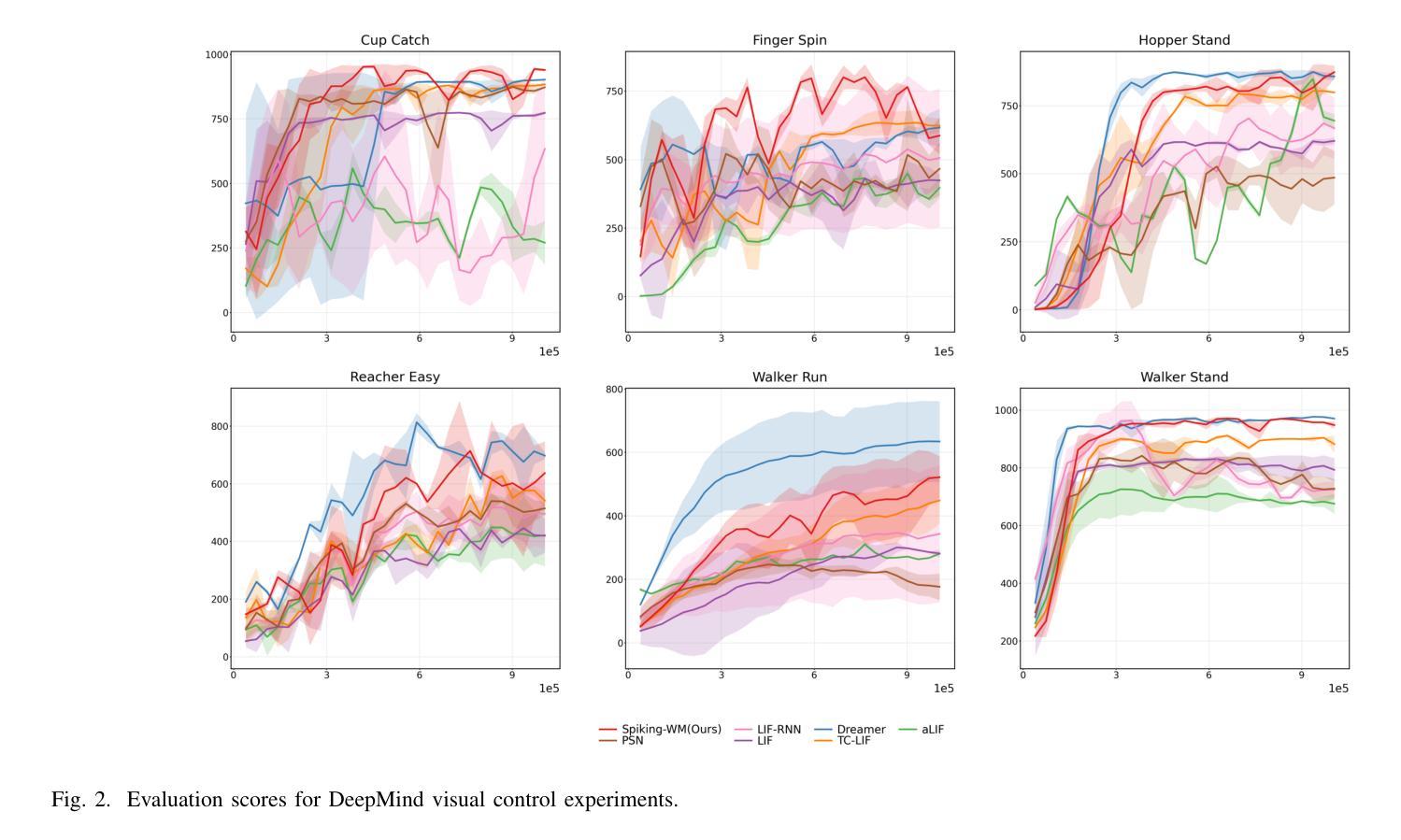
Implementing Spiking World Model with Multi-Compartment Neurons for Model-based Reinforcement Learning
Authors:Yinqian Sun, Feifei Zhao, Mingyang Lv, Yi Zeng
Brain-inspired spiking neural networks (SNNs) have garnered significant research attention in algorithm design and perception applications. However, their potential in the decision-making domain, particularly in model-based reinforcement learning, remains underexplored. The difficulty lies in the need for spiking neurons with long-term temporal memory capabilities, as well as network optimization that can integrate and learn information for accurate predictions. The dynamic dendritic information integration mechanism of biological neurons brings us valuable insights for addressing these challenges. In this study, we propose a multi-compartment neuron model capable of nonlinearly integrating information from multiple dendritic sources to dynamically process long sequential inputs. Based on this model, we construct a Spiking World Model (Spiking-WM), to enable model-based deep reinforcement learning (DRL) with SNNs. We evaluated our model using the DeepMind Control Suite, demonstrating that Spiking-WM outperforms existing SNN-based models and achieves performance comparable to artificial neural network (ANN)-based world models employing Gated Recurrent Units (GRUs). Furthermore, we assess the long-term memory capabilities of the proposed model in speech datasets, including SHD, TIMIT, and LibriSpeech 100h, showing that our multi-compartment neuron model surpasses other SNN-based architectures in processing long sequences. Our findings underscore the critical role of dendritic information integration in shaping neuronal function, emphasizing the importance of cooperative dendritic processing in enhancing neural computation.
受大脑启发的脉冲神经网络(SNNs)在算法设计和感知应用方面引起了研究人员的广泛关注。然而,它们在决策领域,特别是在基于模型的强化学习中的潜力,尚未得到充分探索。难点在于需要具有长期时间记忆能力的脉冲神经元,以及能够整合和学习信息进行准确预测的网络优化。生物神经元的动态树突信息整合机制为我们解决这些挑战提供了宝贵的见解。
论文及项目相关链接
Summary
本文探索了基于脑启发脉冲神经网络(SNNs)的决策制定领域,特别是模型基础上的强化学习。研究提出了一种多室神经元模型,能够动态处理长序列输入,并基于此构建了Spiking World Model(Spiking-WM)。在DeepMind Control Suite上的评估显示,Spiking-WM的表现在现有SNN模型之上,且与采用GRU的基于人工神经网络的世界模型表现相当。此外,在语音数据集上的长期记忆能力评估也证明了该模型的优势。
Key Takeaways
- 脉冲神经网络(SNNs)在决策制定领域的潜力尚未得到充分探索。
- 多室神经元模型能够非线性地整合来自多个树突来源的信息,以动态处理长序列输入。
- Spiking World Model(Spiking-WM)结合了多室神经元模型,实现了基于模型的深度强化学习(DRL)。
- Spiking-WM在DeepMind Control Suite上的表现优于现有SNN模型,并与基于GRU的ANN模型表现相当。
- 在语音数据集上,多室神经元模型在处理长序列方面超越了其他SNN架构。
- 神经元中的树突信息整合对神经元功能至关重要,合作树突处理有助于增强神经计算。
点此查看论文截图


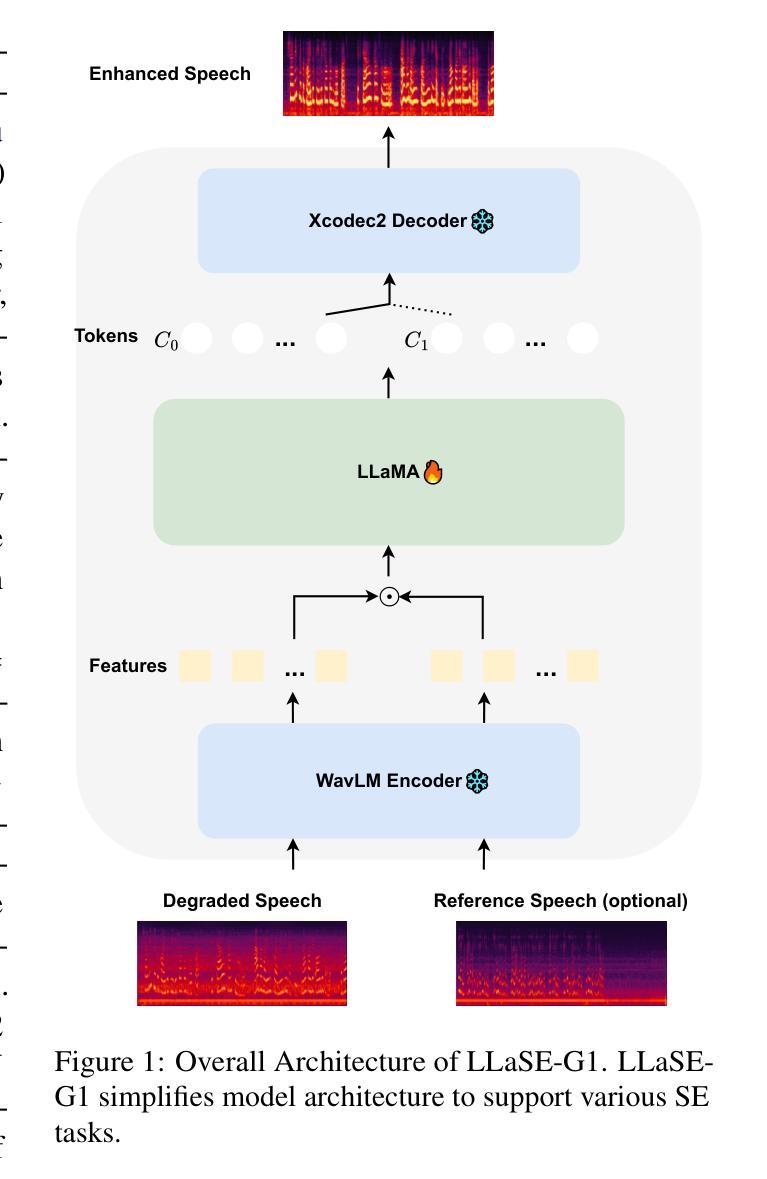
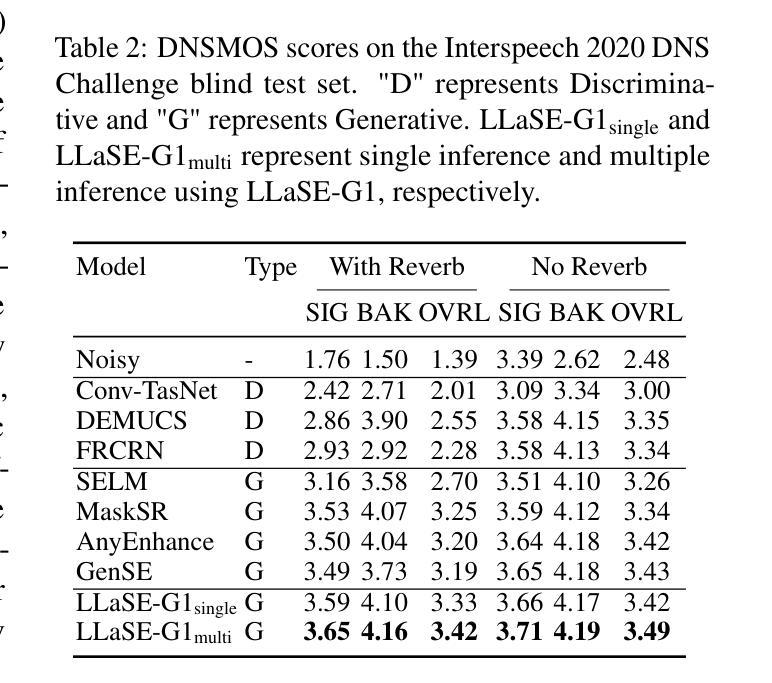
LLaSE-G1: Incentivizing Generalization Capability for LLaMA-based Speech Enhancement
Authors:Boyi Kang, Xinfa Zhu, Zihan Zhang, Zhen Ye, Mingshuai Liu, Ziqian Wang, Yike Zhu, Guobin Ma, Jun Chen, Longshuai Xiao, Chao Weng, Wei Xue, Lei Xie
Recent advancements in language models (LMs) have demonstrated strong capabilities in semantic understanding and contextual modeling, which have flourished in generative speech enhancement (SE). However, many LM-based SE approaches primarily focus on semantic information, often neglecting the critical role of acoustic information, which leads to acoustic inconsistency after enhancement and limited generalization across diverse SE tasks. In this paper, we introduce LLaSE-G1, a LLaMA-based language model that incentivizes generalization capabilities for speech enhancement. LLaSE-G1 offers the following key contributions: First, to mitigate acoustic inconsistency, LLaSE-G1 employs continuous representations from WavLM as input and predicts speech tokens from X-Codec2, maximizing acoustic preservation. Second, to promote generalization capability, LLaSE-G1 introduces dual-channel inputs and outputs, unifying multiple SE tasks without requiring task-specific IDs. Third, LLaSE-G1 outperforms prior task-specific discriminative and generative SE models, demonstrating scaling effects at test time and emerging capabilities for unseen SE tasks. Additionally, we release our code and models to support further research in this area.
最近的语言模型(LM)进展表明,它们在语义理解和上下文建模方面表现出强大的能力,尤其在生成性语音增强(SE)领域蓬勃发展。然而,许多基于LM的SE方法主要关注语义信息,往往忽视了声音信息的关键作用,这导致增强后的语音出现声音不一致,以及在多种SE任务中的泛化能力受限。在本文中,我们介绍了LLaSE-G1,这是一个基于LLaMA的语言模型,旨在激励其在语音增强方面的泛化能力。LLaSE-G1有以下主要贡献:首先,为了缓解声音不一致的问题,LLaSE-G1采用WavLM的连续表示作为输入,并预测X-Codec2的语音令牌,最大限度地保留声音。其次,为了提升泛化能力,LLaSE-G1引入了双通道输入和输出,统一了多个SE任务,无需特定任务标识。最后,LLaSE-G1超越了先前的特定任务的判别性和生成性SE模型,显示了测试时的扩展效果以及在未见过的SE任务中的新兴能力。此外,我们发布了相关代码和模型,以支持该领域的进一步研究。
论文及项目相关链接
PDF 13 pages, 2 figures, 8 tables
摘要
LM近期的进展为语音增强带来了强大的语义理解和上下文建模能力。然而,许多基于LM的SE方法主要关注语义信息,忽略了声学信息的重要性。本文介绍LLaSE-G1模型,旨在解决这一问题并提升语音增强的泛化能力。LLaSE-G1使用WavLM的连续表示作为输入,预测X-Codec2的语音令牌,最大化声学保留,缓解声学不一致问题。通过引入双通道输入输出促进泛化能力,统一多种SE任务无需特定任务标识。相较于之前的任务特定判别和生成式SE模型,LLaSE-G1展现出卓越性能,支持未见过的SE任务。我们公开了代码和模型以支持该领域进一步研究。
关键见解
- LLaSE-G1模型解决了声学信息在基于LM的语音增强中被忽视的问题,从而实现了声学一致性。
- LLaSE-G1采用WavLM的连续表示作为输入,预测语音令牌以增强声学保留效果。
- 通过引入双通道输入输出设计,LLaSE-G1提升了模型的泛化能力,能够统一处理多种语音增强任务。
- LLaSE-G1相较于任务特定的判别和生成式模型展现出卓越性能。
- LLaSE-G1具备出色的测试时扩展性,并展现出处理未见过的语音增强任务的能力。
- LLaSE-G1代码和模型的公开将促进该领域的进一步研究。
点此查看论文截图

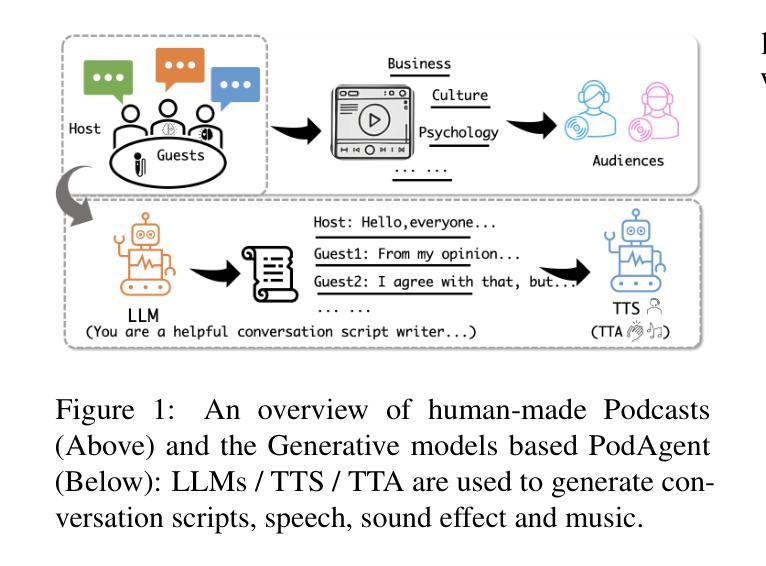
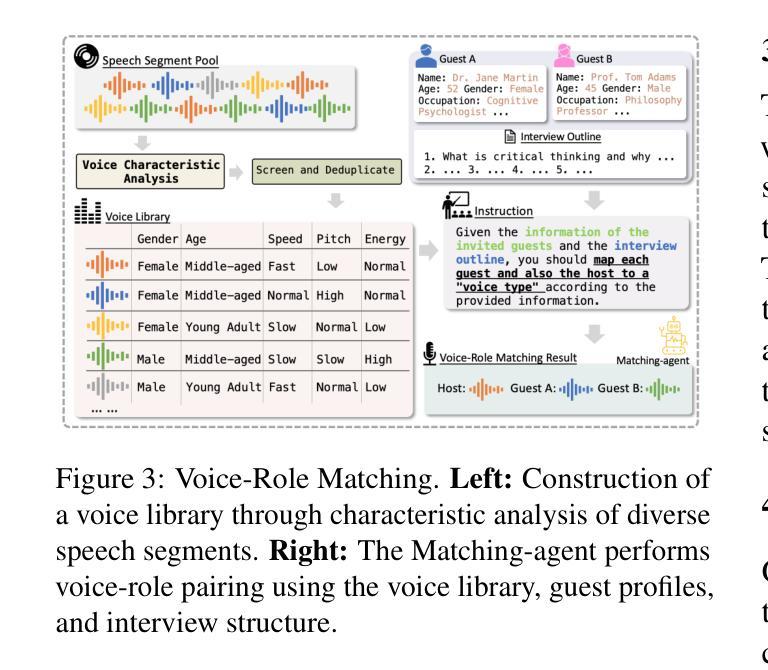
PodAgent: A Comprehensive Framework for Podcast Generation
Authors:Yujia Xiao, Lei He, Haohan Guo, Fenglong Xie, Tan Lee
Existing Existing automatic audio generation methods struggle to generate podcast-like audio programs effectively. The key challenges lie in in-depth content generation, appropriate and expressive voice production. This paper proposed PodAgent, a comprehensive framework for creating audio programs. PodAgent 1) generates informative topic-discussion content by designing a Host-Guest-Writer multi-agent collaboration system, 2) builds a voice pool for suitable voice-role matching and 3) utilizes LLM-enhanced speech synthesis method to generate expressive conversational speech. Given the absence of standardized evaluation criteria for podcast-like audio generation, we developed comprehensive assessment guidelines to effectively evaluate the model’s performance. Experimental results demonstrate PodAgent’s effectiveness, significantly surpassing direct GPT-4 generation in topic-discussion dialogue content, achieving an 87.4% voice-matching accuracy, and producing more expressive speech through LLM-guided synthesis. Demo page: https://podcast-agent.github.io/demo/. Source code: https://github.com/yujxx/PodAgent.
当前存在的自动音频生成方法在生成类似播客的节目时面临诸多挑战。主要困难在于深度内容生成和合适且富有表现力的声音生成。本文提出了PodAgent,一个用于创建音频节目的综合框架。PodAgent 1)通过设计主持人-嘉宾-编剧多智能体协作系统生成信息丰富的主题讨论内容,2)构建声音库,进行合适的语音角色匹配,以及3)利用增强的大型语言模型(LLM)语音合成方法生成富有表现力的对话语音。由于缺乏针对类似播客音频生成的标准化评估标准,我们制定了全面的评估准则以有效评估模型性能。实验结果表明PodAgent的有效性,其在主题讨论对话内容方面显著超越了直接的GPT-4生成,达到87.4%的语音匹配准确率,并通过LLM引导的合成产生了更具表现力的语音。演示页面:https://podcast-agent.github.io/demo/。源代码:https://github.com/yujxx/PodAgent。
论文及项目相关链接
Summary
本文介绍了PodAgent框架,一个用于生成音频节目的综合系统。它通过设计主持人-嘉宾-作者多智能体协作系统生成内容,建立语音库进行合适的语音角色匹配,并利用LLM增强的语音合成方法生成表达性对话语音。尽管缺乏针对类似播客音频生成的标准化评估标准,但实验结果表明PodAgent的有效性,其在主题讨论对话内容方面显著超越了GPT-4直接生成,实现了87.4%的语音匹配准确率,并通过LLM引导的合成产生了更具表现力的语音。
Key Takeaways
- PodAgent是一个全面的框架,用于生成音频节目,涵盖了内容生成、语音匹配和语音合成等方面。
- 该框架通过设计多智能体协作系统(主持人-嘉宾-作者)来生成内容丰富的主题讨论。
- PodAgent建立了语音库,用于合适的语音角色匹配,使生成的音频节目更具真实感。
- 利用LLM增强的语音合成方法,PodAgent能够生成表达性对话语音,提高音频节目的质量。
- PodAgent在主题讨论对话内容方面显著超越了GPT-4直接生成。
- PodAgent实现了87.4%的语音匹配准确率,表明其在语音匹配方面的准确性较高。
点此查看论文截图




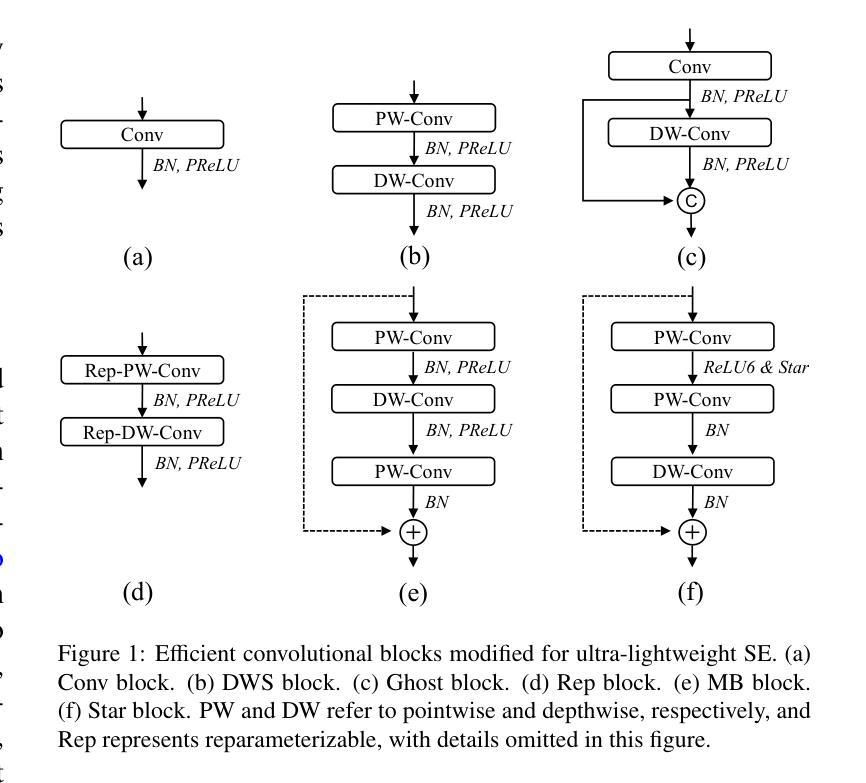
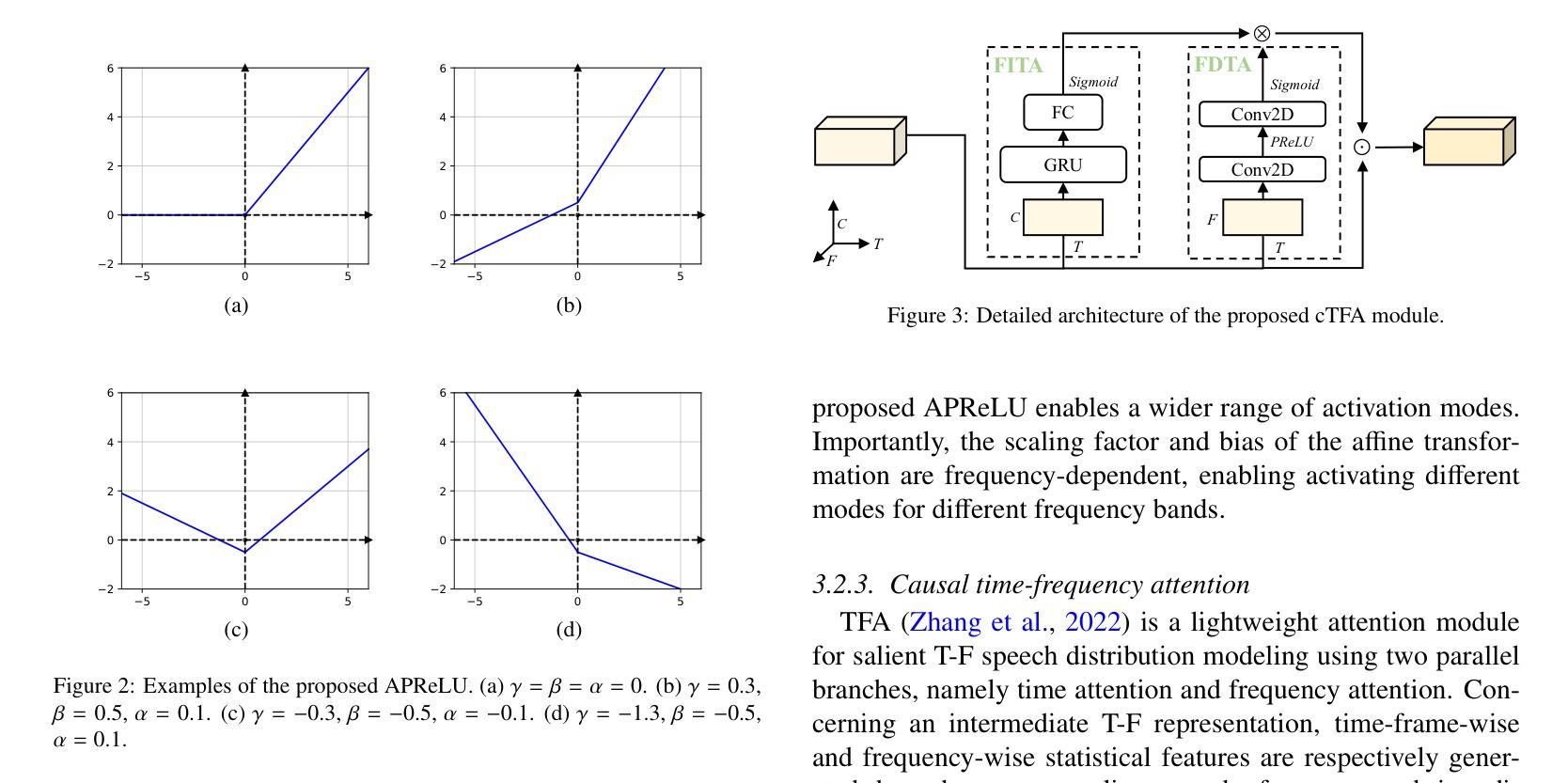
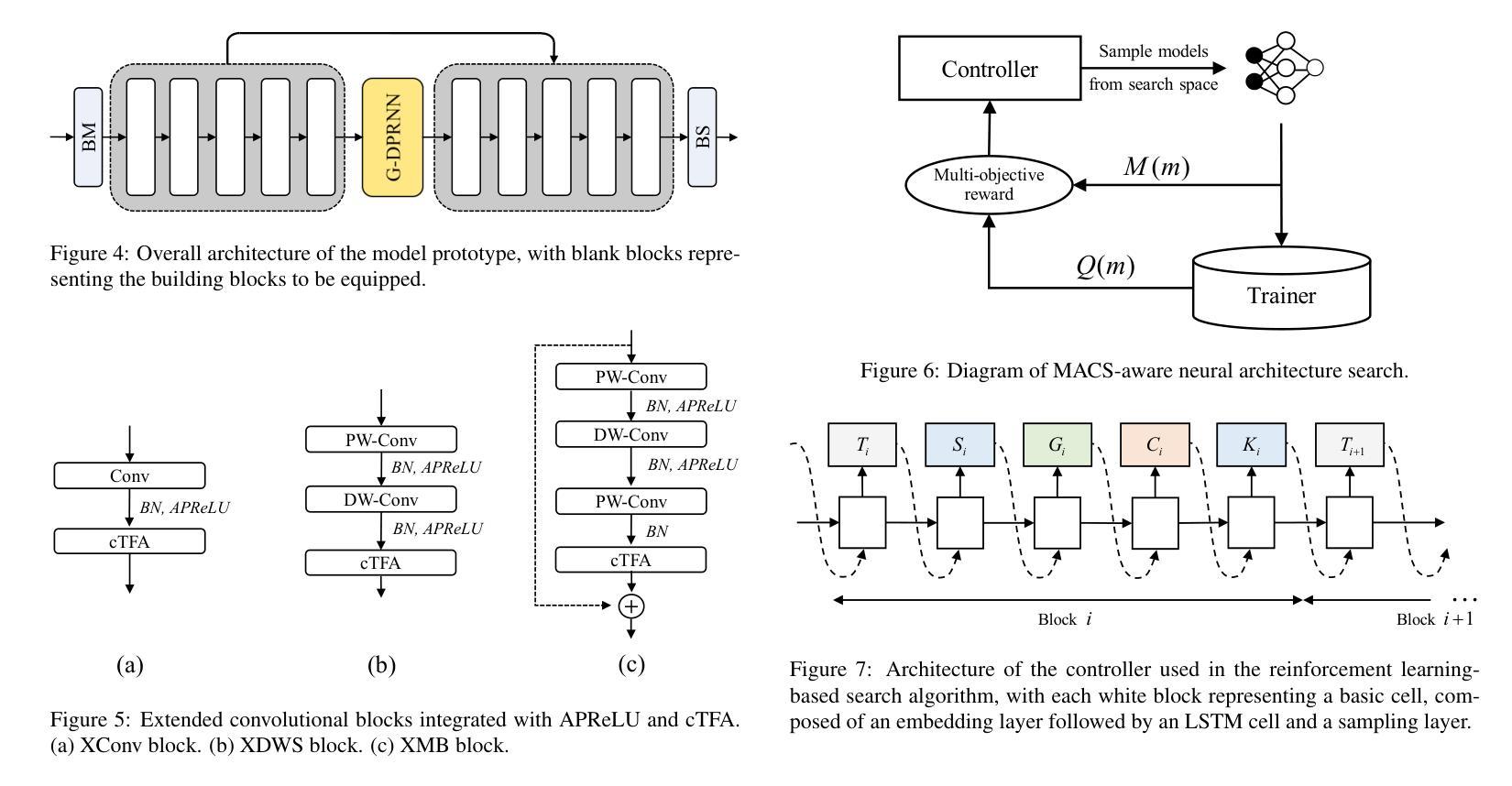
UL-UNAS: Ultra-Lightweight U-Nets for Real-Time Speech Enhancement via Network Architecture Search
Authors:Xiaobin Rong, Dahan Wang, Yuxiang Hu, Changbao Zhu, Kai Chen, Jing Lu
Lightweight models are essential for real-time speech enhancement applications. In recent years, there has been a growing trend toward developing increasingly compact models for speech enhancement. In this paper, we propose an Ultra-Lightweight U-net optimized by Network Architecture Search (UL-UNAS), which is suitable for implementation in low-footprint devices. Firstly, we explore the application of various efficient convolutional blocks within the U-Net framework to identify the most promising candidates. Secondly, we introduce two boosting components to enhance the capacity of these convolutional blocks: a novel activation function named affine PReLU and a causal time-frequency attention module. Furthermore, we leverage neural architecture search to discover an optimal architecture within our carefully designed search space. By integrating the above strategies, UL-UNAS not only significantly outperforms the latest ultra-lightweight models with the same or lower computational complexity, but also delivers competitive performance compared to recent baseline models that require substantially higher computational resources.
轻量级模型对于实时语音增强应用至关重要。近年来,开发用于语音增强的越来越紧凑的模型成为了一个增长的趋势。在本文中,我们提出了一种通过神经网络架构搜索(UL-UNAS)优化的超轻量级U-net,适用于在低足迹设备中实现。首先,我们在U-Net框架内探索了各种高效卷积块的应用,以识别最有前途的候选者。其次,我们引入了两个增强组件来提高这些卷积块的能力:一种名为仿射PReLU的新型激活函数和一个因果时频注意模块。此外,我们利用神经网络架构搜索,在精心设计的搜索空间中发现最优架构。通过整合上述策略,UL-UNAS不仅显著优于具有相同或更低计算复杂度的最新超轻量级模型,而且与需要更高计算资源的最近基线模型相比也表现出竞争力。
论文及项目相关链接
PDF 13 pages, 8 figures, submitted to Neural Networks
Summary:
本文提出了一种基于网络架构搜索的超轻量级U形网络(UL-UNAS),适用于低占用空间设备的实时语音增强应用。通过探索高效的卷积块、引入新型激活函数和时间频率注意力模块,以及利用神经网络架构搜索优化结构,UL-UNAS在保持较低计算复杂度的同时,实现了出色的性能,超越了其他最新超轻量级模型,并与需要更高计算资源的基础模型相比具有竞争力。
Key Takeaways:
- 超轻量级模型在实时语音增强应用中至关重要。
- 论文提出了基于网络架构搜索的超轻量级U形网络(UL-UNAS)。
- 通过探索高效的卷积块来优化U形网络框架。
- 引入了新型激活函数(affine PReLU)和因果时间-频率注意力模块,增强了卷积块的能力。
- 利用神经网络架构搜索在精心设计搜索空间内发现最优架构。
- UL-UNAS在保持较低计算复杂度的同时实现了出色的性能。
点此查看论文截图