⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-06 更新
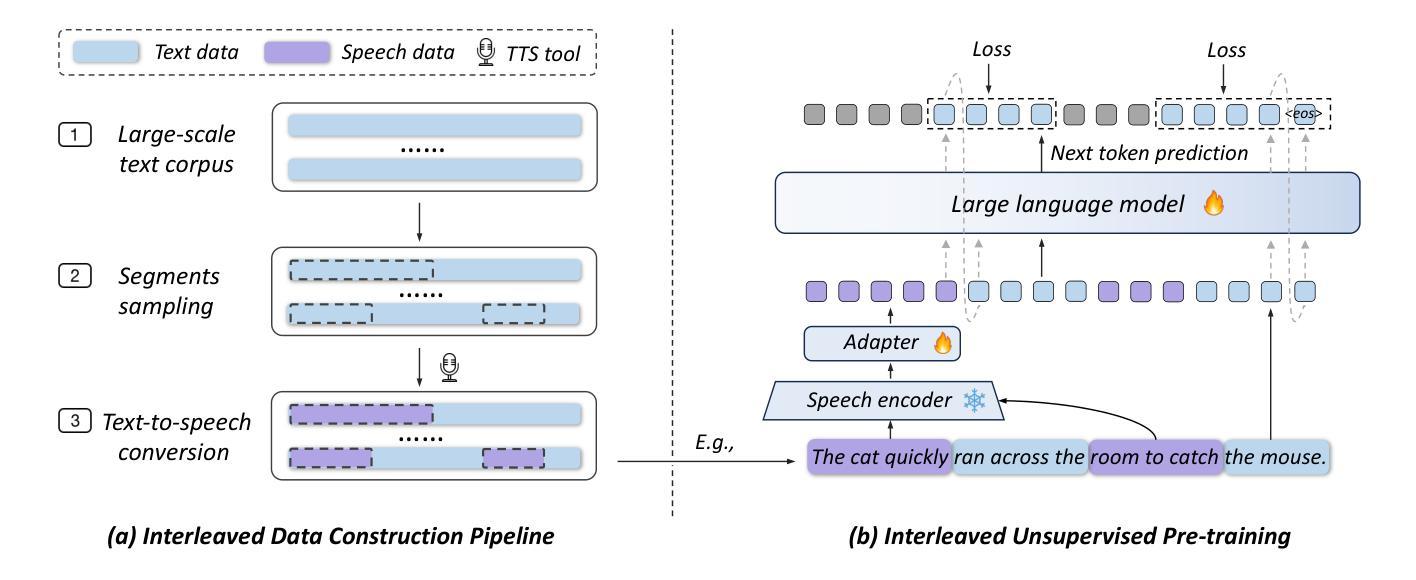
InSerter: Speech Instruction Following with Unsupervised Interleaved Pre-training
Authors:Dingdong Wang, Jin Xu, Ruihang Chu, Zhifang Guo, Xiong Wang, Jincenzi Wu, Dongchao Yang, Shengpeng Ji, Junyang Lin
Recent advancements in speech large language models (SpeechLLMs) have attracted considerable attention. Nonetheless, current methods exhibit suboptimal performance in adhering to speech instructions. Notably, the intelligence of models significantly diminishes when processing speech-form input as compared to direct text-form input. Prior work has attempted to mitigate this semantic inconsistency between speech and text representations through techniques such as representation and behavior alignment, which involve the meticulous design of data pairs during the post-training phase. In this paper, we introduce a simple and scalable training method called InSerter, which stands for Interleaved Speech-Text Representation Pre-training. InSerter is designed to pre-train large-scale unsupervised speech-text sequences, where the speech is synthesized from randomly selected segments of an extensive text corpus using text-to-speech conversion. Consequently, the model acquires the ability to generate textual continuations corresponding to the provided speech segments, obviating the need for intensive data design endeavors. To systematically evaluate speech instruction-following capabilities, we introduce SpeechInstructBench, the first comprehensive benchmark specifically designed for speech-oriented instruction-following tasks. Our proposed InSerter achieves SOTA performance in SpeechInstructBench and demonstrates superior or competitive results across diverse speech processing tasks.
近期,语音大语言模型(SpeechLLMs)的进展引起了广泛的关注。然而,当前的方法在遵循语音指令方面表现并不理想。值得注意的是,与直接文本输入相比,模型在处理语音形式的输入时,智能性会显著降低。之前的研究试图通过表示和行为对齐等技术来缓解语音和文本表示之间的语义不一致问题,这需要在后训练阶段精心设计数据对。在本文中,我们介绍了一种简单且可扩展的训练方法,称为InSerter(交替语音-文本表示预训练方法)。InSerter旨在预训练大规模无监督的语音-文本序列,其中语音是通过从大量文本语料库中随机选择的片段使用文本到语音的转换技术合成的。因此,模型能够生成与提供的语音片段相对应的文本延续,无需进行密集的数据设计工作。为了系统地评估遵循语音指令的能力,我们推出了SpeechInstructBench——首个专为面向语音的指令遵循任务设计的综合基准测试。我们提出的InSerter在SpeechInstructBench上达到了最先进的性能,并在多种语音处理任务中表现出卓越或具有竞争力的结果。
论文及项目相关链接
Summary
本文介绍了针对语音大型语言模型(SpeechLLMs)的新训练方法和评估基准。现有模型在处理语音指令时表现不佳,尤其在将语音转化为文本时智力显著下降。为解决语义不一致问题,本文提出了一种简单且可扩展的预训练方法——InSerter,该方法利用文本转语音转换技术,从大规模文本语料库中随机选择片段进行语音合成,使模型学会根据语音生成相应文本延续。同时,引入了SpeechInstructBench基准,以评估模型遵循语音指令的能力。InSerter在SpeechInstructBench上达到SOTA性能,并在多种语音处理任务中表现优异。
Key Takeaways
- 现有语音大型语言模型(SpeechLLMs)在处理语音指令时存在语义不一致问题。
- InSerter是一种简单且可扩展的预训练方法,旨在提高模型处理语音和文本的能力。
- InSerter利用文本转语音转换技术,合成语音并训练模型生成相应文本延续。
- SpeechInstructBench是首个针对语音指令遵循任务的全面基准。
- InSerter在SpeechInstructBench上实现SOTA性能。
- InSerter在多种语音处理任务中表现优异,具有广泛的应用潜力。
- 该方法有助于改善语音与文本之间的语义一致性,提高模型的智能性。
点此查看论文截图


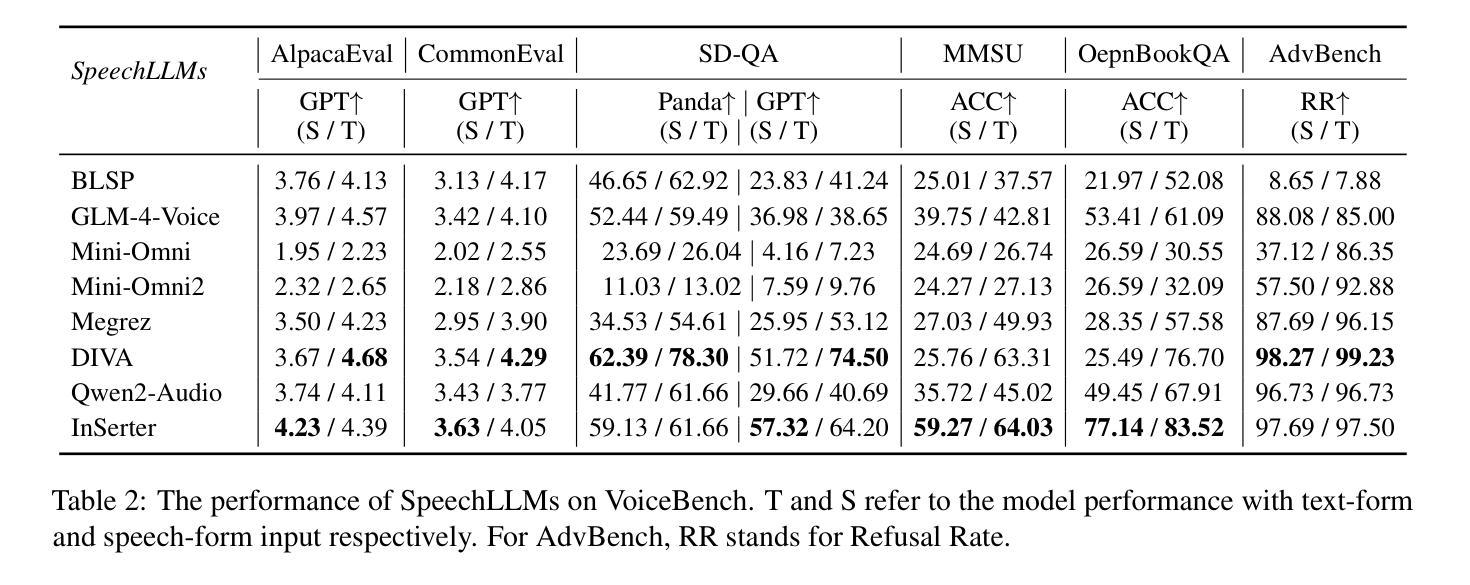
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Authors:Xinsheng Wang, Mingqi Jiang, Ziyang Ma, Ziyu Zhang, Songxiang Liu, Linqin Li, Zheng Liang, Qixi Zheng, Rui Wang, Xiaoqin Feng, Weizhen Bian, Zhen Ye, Sitong Cheng, Ruibin Yuan, Zhixian Zhao, Xinfa Zhu, Jiahao Pan, Liumeng Xue, Pengcheng Zhu, Yunlin Chen, Zhifei Li, Xie Chen, Lei Xie, Yike Guo, Wei Xue
Recent advancements in large language models (LLMs) have driven significant progress in zero-shot text-to-speech (TTS) synthesis. However, existing foundation models rely on multi-stage processing or complex architectures for predicting multiple codebooks, limiting efficiency and integration flexibility. To overcome these challenges, we introduce Spark-TTS, a novel system powered by BiCodec, a single-stream speech codec that decomposes speech into two complementary token types: low-bitrate semantic tokens for linguistic content and fixed-length global tokens for speaker attributes. This disentangled representation, combined with the Qwen2.5 LLM and a chain-of-thought (CoT) generation approach, enables both coarse-grained control (e.g., gender, speaking style) and fine-grained adjustments (e.g., precise pitch values, speaking rate). To facilitate research in controllable TTS, we introduce VoxBox, a meticulously curated 100,000-hour dataset with comprehensive attribute annotations. Extensive experiments demonstrate that Spark-TTS not only achieves state-of-the-art zero-shot voice cloning but also generates highly customizable voices that surpass the limitations of reference-based synthesis. Source code, pre-trained models, and audio samples are available at https://github.com/SparkAudio/Spark-TTS.
近期大型语言模型(LLM)的进展为零样本文本到语音(TTS)合成领域带来了显著进步。然而,现有的基础模型依赖于多阶段处理或复杂的架构来预测多个编码簿,这限制了效率和集成灵活性。为了克服这些挑战,我们推出了Spark-TTS,一个由BiCodec驱动的新型系统。BiCodec是一种单流语音编解码器,它将语音分解成两种互补的令牌类型:用于语言内容的低比特率语义令牌和用于说话人属性的固定长度全局令牌。这种解耦的表示形式,结合Qwen2.5 LLM和思维链(CoT)生成方法,既可实现粗粒度控制(例如性别、讲话风格),也可进行细粒度调整(例如精确音调值、讲话速度)。为了促进可控TTS的研究,我们推出了VoxBox,这是一个精心挑选的10万小时数据集,具有全面的属性注释。大量实验表明,Spark-TTS不仅实现了最先进的零样本声音克隆,而且生成了高度可定制的声音,超越了基于参考合成的局限性。相关源代码、预训练模型和音频样本可在https://github.com/SparkAudio/Spark-TTS找到。
论文及项目相关链接
PDF Submitted to ACL 2025
Summary
Spark-TTS系统通过BiCodec和Qwen2.5 LLM等技术,实现了零样本文本到语音合成的新突破。系统采用单一流语音编码方式,将语音分解为语义令牌和全局令牌,支持粗粒度控制(如性别、说话风格)和细粒度调整(如精确音调值、语速)。同时,引入VoxBox数据集促进可控TTS研究,达到领先水平,并生成高度可定制的语音。
Key Takeaways
- Spark-TTS通过BiCodec实现单一流语音编码,提高效率和集成灵活性。
- 系统分解语音为语义令牌和全局令牌,分别负责语言内容和说话人属性。
- 结合Qwen2.5 LLM和链思维(CoT)生成方法,实现粗粒度和细粒度控制。
- 引入VoxBox数据集,促进可控TTS研究。
- Spark-TTS达到零样本语音克隆的领先水平。
- 系统生成高度可定制的语音,突破参考基础合成的限制。
点此查看论文截图

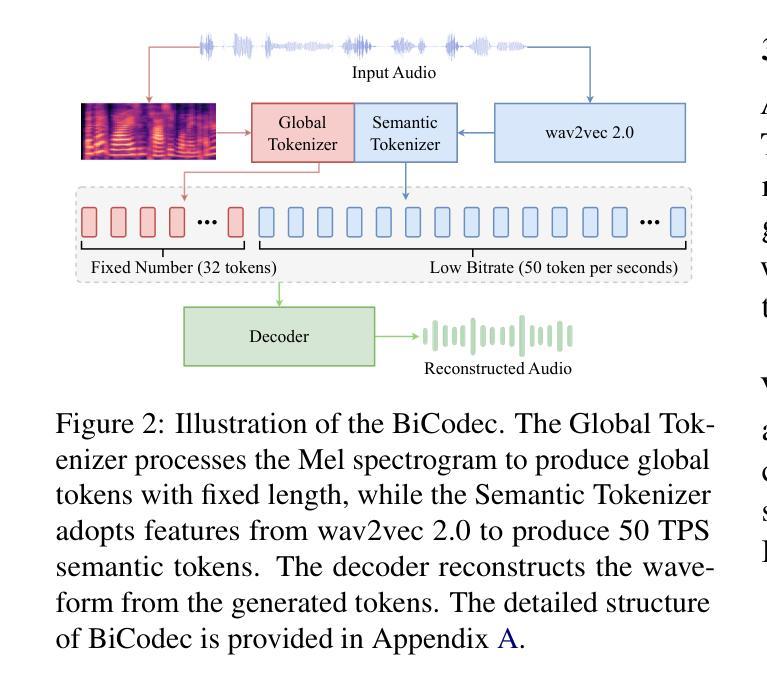
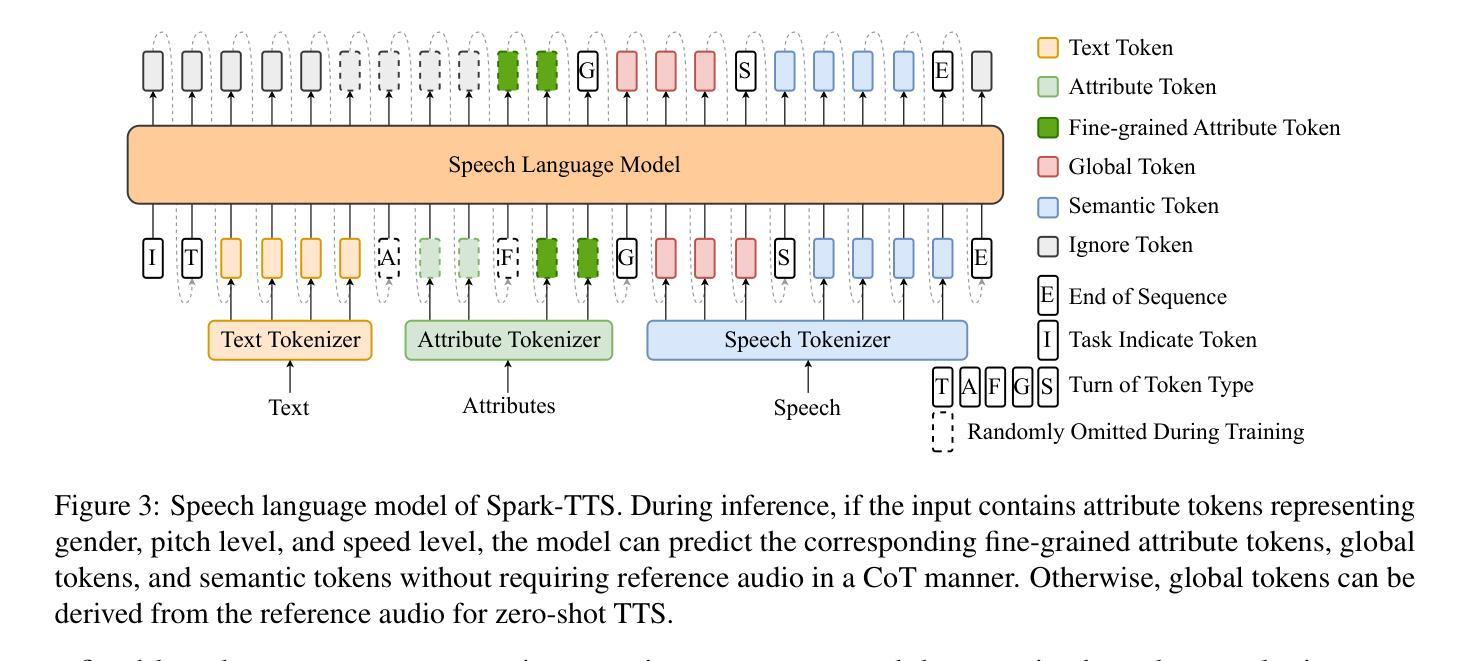
UniWav: Towards Unified Pre-training for Speech Representation Learning and Generation
Authors:Alexander H. Liu, Sang-gil Lee, Chao-Han Huck Yang, Yuan Gong, Yu-Chiang Frank Wang, James R. Glass, Rafael Valle, Bryan Catanzaro
Pre-training and representation learning have been playing an increasingly important role in modern speech processing. Nevertheless, different applications have been relying on different foundation models, since predominant pre-training techniques are either designed for discriminative tasks or generative tasks. In this work, we make the first attempt at building a unified pre-training framework for both types of tasks in speech. We show that with the appropriate design choices for pre-training, one can jointly learn a representation encoder and generative audio decoder that can be applied to both types of tasks. We propose UniWav, an encoder-decoder framework designed to unify pre-training representation learning and generative tasks. On speech recognition, text-to-speech, and speech tokenization, UniWav achieves comparable performance to different existing foundation models, each trained on a specific task. Our findings suggest that a single general-purpose foundation model for speech can be built to replace different foundation models, reducing the overhead and cost of pre-training.
预训练和表示学习在现代语音识别中扮演着越来越重要的角色。然而,不同的应用依赖于不同的基础模型,因为主流的预训练技术要么是为判别任务设计的,要么是为生成任务设计的。在这项工作中,我们首次尝试为这两种类型的任务构建统一的预训练框架。我们表明,通过适当的预训练设计选择,可以联合学习一个表示编码器和生成音频解码器,该解码器可应用于这两种类型的任务。我们提出了UniWav,这是一个为统一预训练表示学习和生成任务而设计的编码器-解码器框架。在语音识别、文本到语音和语音标记化方面,UniWav的性能与针对不同任务训练的现有基础模型相当。我们的研究结果表明,可以构建一个通用的单一基础模型来进行语音处理,以替代不同的基础模型,从而降低预训练的开销和成本。
论文及项目相关链接
PDF ICLR 2025; demo page at https://alexander-h-liu.github.io/uniwav-demo.github.io/
Summary
本文探讨了现代语音处理中预训练和表示学习的重要性,并提出了一种新的统一预训练框架UniWav,可同时应用于判别任务和生成任务的语音处理。通过适当的设计选择,联合学习表示编码器和生成音频解码器可应用于这两种任务。在语音识别、文本到语音和语音标记化方面,UniWav实现了与针对特定任务训练的现有基础模型相当的性能。研究结果表明,可以构建一种通用的语音基础模型来替代不同的基础模型,降低预训练的开销和成本。
Key Takeaways
- 预训练和表示学习在现代语音处理中扮演越来越重要的角色。
- 现有的预训练技术主要针对判别任务或生成任务,导致不同应用依赖不同的基础模型。
- 本文首次尝试为两种任务类型构建统一的预训练框架。
- 通过适当的设计,可以联合学习表示编码器和生成音频解码器,使其适用于两种任务。
- 提出的UniWav框架旨在统一预训练表示学习和生成任务。
- UniWav在语音识别、文本到语音和语音标记化方面的性能与现有基础模型相当。
点此查看论文截图

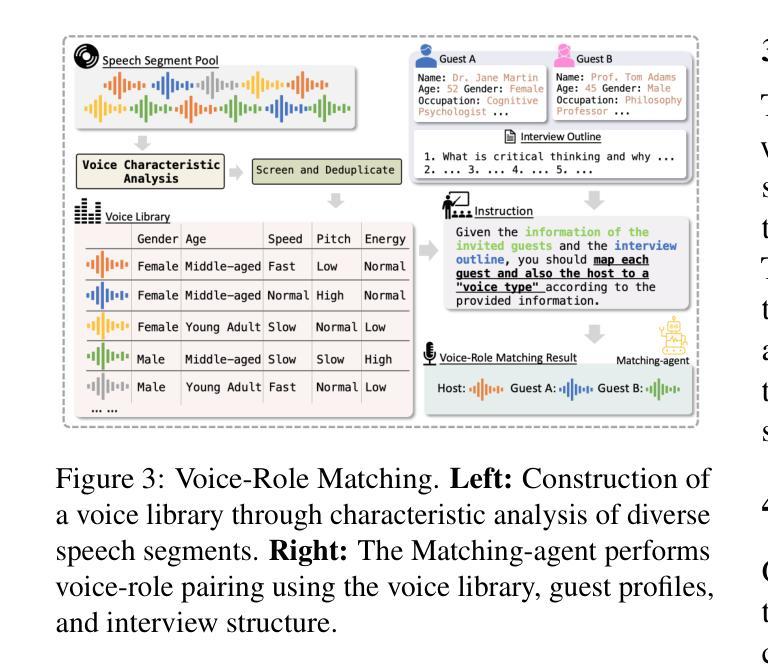
PodAgent: A Comprehensive Framework for Podcast Generation
Authors:Yujia Xiao, Lei He, Haohan Guo, Fenglong Xie, Tan Lee
Existing Existing automatic audio generation methods struggle to generate podcast-like audio programs effectively. The key challenges lie in in-depth content generation, appropriate and expressive voice production. This paper proposed PodAgent, a comprehensive framework for creating audio programs. PodAgent 1) generates informative topic-discussion content by designing a Host-Guest-Writer multi-agent collaboration system, 2) builds a voice pool for suitable voice-role matching and 3) utilizes LLM-enhanced speech synthesis method to generate expressive conversational speech. Given the absence of standardized evaluation criteria for podcast-like audio generation, we developed comprehensive assessment guidelines to effectively evaluate the model’s performance. Experimental results demonstrate PodAgent’s effectiveness, significantly surpassing direct GPT-4 generation in topic-discussion dialogue content, achieving an 87.4% voice-matching accuracy, and producing more expressive speech through LLM-guided synthesis. Demo page: https://podcast-agent.github.io/demo/. Source code: https://github.com/yujxx/PodAgent.
现有的自动音频生成方法在生成类似播客节目的音频节目时面临挑战。主要挑战在于深入的内容生成、适当且富有表现力的声音生成。本文提出了PodAgent,一个用于创建音频节目的综合框架。PodAgent 1)通过设计主持人-嘉宾-编剧多智能体协作系统,生成信息丰富的主题讨论内容;2)建立声音库,实现适合的声音角色匹配;3)利用增强的大型语言模型(LLM)语音合成方法,生成富有表现力的对话语音。由于缺乏类似播客音频生成的标准化评估标准,我们制定了全面的评估指南,以有效评估模型性能。实验结果表明,PodAgent的有效性在主题讨论对话内容方面显著超越了直接的GPT-4生成,实现了87.4%的声音匹配准确率,并通过LLM引导的合成产生了更具表现力的语音。演示页面:https://podcast-agent.github.io/demo/。源代码:https://github.com/yujxx/PodAgent。
论文及项目相关链接
Summary
自动音频生成技术在生成类似播客节目的音频时面临挑战,包括内容深度和语音表达等方面。本文提出PodAgent框架,通过设计主持人-嘉宾-作者多智能体协作系统生成信息丰富的主题讨论内容,建立语音库进行合适的语音角色匹配,并利用大型语言模型增强的语音合成方法生成富有表现力的对话语音。由于没有针对类似播客音频生成的标准化评估标准,我们制定了全面的评估准则以有效评估模型性能。实验结果显示,PodAgent显著超越GPT-4的直接生成方式,达到话题讨论内容生成的优良水平,实现87.4%的语音匹配准确度,并通过大型语言模型指导的合成技术生成更具表现力的语音。Demo页面与源代码已公开分享。
Key Takeaways
- PodAgent是一个用于创建音频节目的综合框架,解决了现有自动音频生成方法在生成类似播客节目的音频时面临的挑战。
- PodAgent通过多智能体协作系统生成信息丰富的主题讨论内容。
- 该框架建立了语音库以实现合适的语音角色匹配。
- 利用大型语言模型增强的语音合成方法,PodAgent能够生成富有表现力的对话语音。
- 没有针对类似播客音频生成的标准化评估标准,因此该论文制定了全面的评估准则。
- 实验结果显示,PodAgent在话题讨论内容生成、语音匹配准确度和语音表现力方面表现出色。
点此查看论文截图




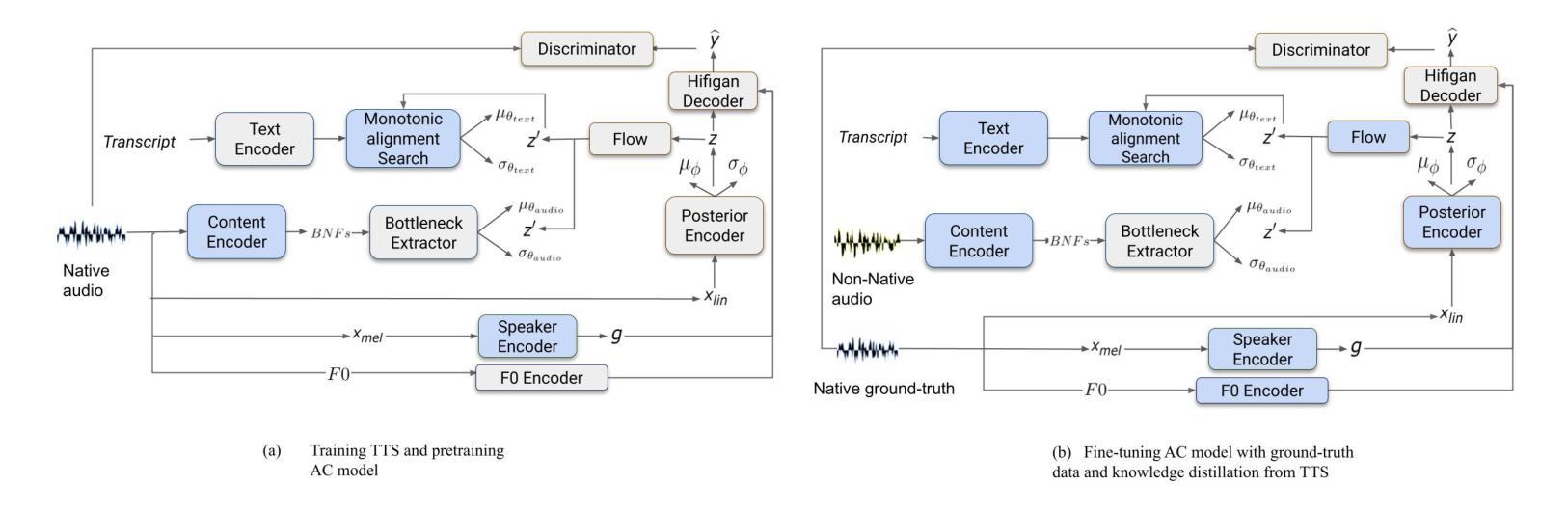
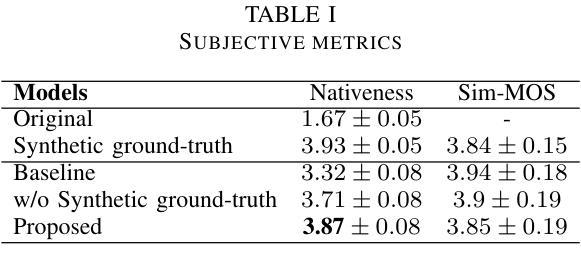
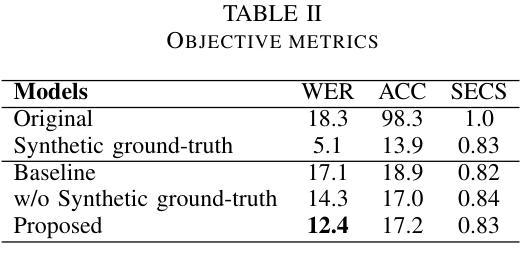
Improving Pronunciation and Accent Conversion through Knowledge Distillation And Synthetic Ground-Truth from Native TTS
Authors:Tuan Nam Nguyen, Seymanur Akti, Ngoc Quan Pham, Alexander Waibel
Previous approaches on accent conversion (AC) mainly aimed at making non-native speech sound more native while maintaining the original content and speaker identity. However, non-native speakers sometimes have pronunciation issues, which can make it difficult for listeners to understand them. Hence, we developed a new AC approach that not only focuses on accent conversion but also improves pronunciation of non-native accented speaker. By providing the non-native audio and the corresponding transcript, we generate the ideal ground-truth audio with native-like pronunciation with original duration and prosody. This ground-truth data aids the model in learning a direct mapping between accented and native speech. We utilize the end-to-end VITS framework to achieve high-quality waveform reconstruction for the AC task. As a result, our system not only produces audio that closely resembles native accents and while retaining the original speaker’s identity but also improve pronunciation, as demonstrated by evaluation results.
之前的口音转换(AC)方法主要致力于使非母语者的发音听起来更自然,同时保持原始内容和说话者的身份。然而,非母语者有时会有发音问题,这使得听众难以理解他们。因此,我们开发了一种新的口音转换方法,不仅专注于口音转换,还能提高非母语者的发音。通过提供非母语音频和相应的文字转录,我们生成具有原生发音的理想地面真实音频,并保留原始的持续时间和韵律。这些地面真实数据有助于模型学习带有口音和原生语音之间的直接映射。我们利用端到端的VITS框架实现高质量的波形重建来完成口音转换任务。因此,我们的系统不仅能够生成模仿原生口音的音频,同时保留原始说话者的身份,还能提高发音水平,评价结果已经证明了这一点。
论文及项目相关链接
PDF accepted at ICASSP 2025
摘要
传统口音转换(AC)方法主要致力于使非母语发音听起来更自然,同时保持原始内容和说话人身份。然而,非母语者有时存在发音问题,这使得听众难以理解他们。因此,我们开发了一种新的AC方法,不仅关注口音转换,还能提高非母语者的发音。通过提供非母语音频和相应的文字转录,我们生成具有与母语者相似的发音的理想地面真实音频,保持原始的持续时间和韵律。这种地面真实数据有助于模型学习带有口音和母语之间的直接映射。我们利用端到端的VITS框架来实现高质量波形重建来完成AC任务。因此,我们的系统不仅能够生成类似于母语口音的音频并保持原始说话人的身份,还能提高发音质量,评估结果可以证明这一点。
关键见解
- 传统口音转换方法主要关注使非母语语音听起来更自然,同时保持内容和说话人身份不变。
- 非母语者在发音方面有时会遇到问题,影响听众的理解。
- 新开发的AC方法不仅转换口音,还提高了非母语者的发音质量。
- 通过提供非母语音频和相应的文字转录,生成具有与母语者相似发音的理想地面真实音频。
- 地面真实数据有助于模型学习带有口音和母语之间的直接映射关系。
- 利用端到端的VITS框架实现了高质量波形重建,这对于AC任务至关重要。
点此查看论文截图