⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-06 更新
KeyFace: Expressive Audio-Driven Facial Animation for Long Sequences via KeyFrame Interpolation
Authors:Antoni Bigata, Michał Stypułkowski, Rodrigo Mira, Stella Bounareli, Konstantinos Vougioukas, Zoe Landgraf, Nikita Drobyshev, Maciej Zieba, Stavros Petridis, Maja Pantic
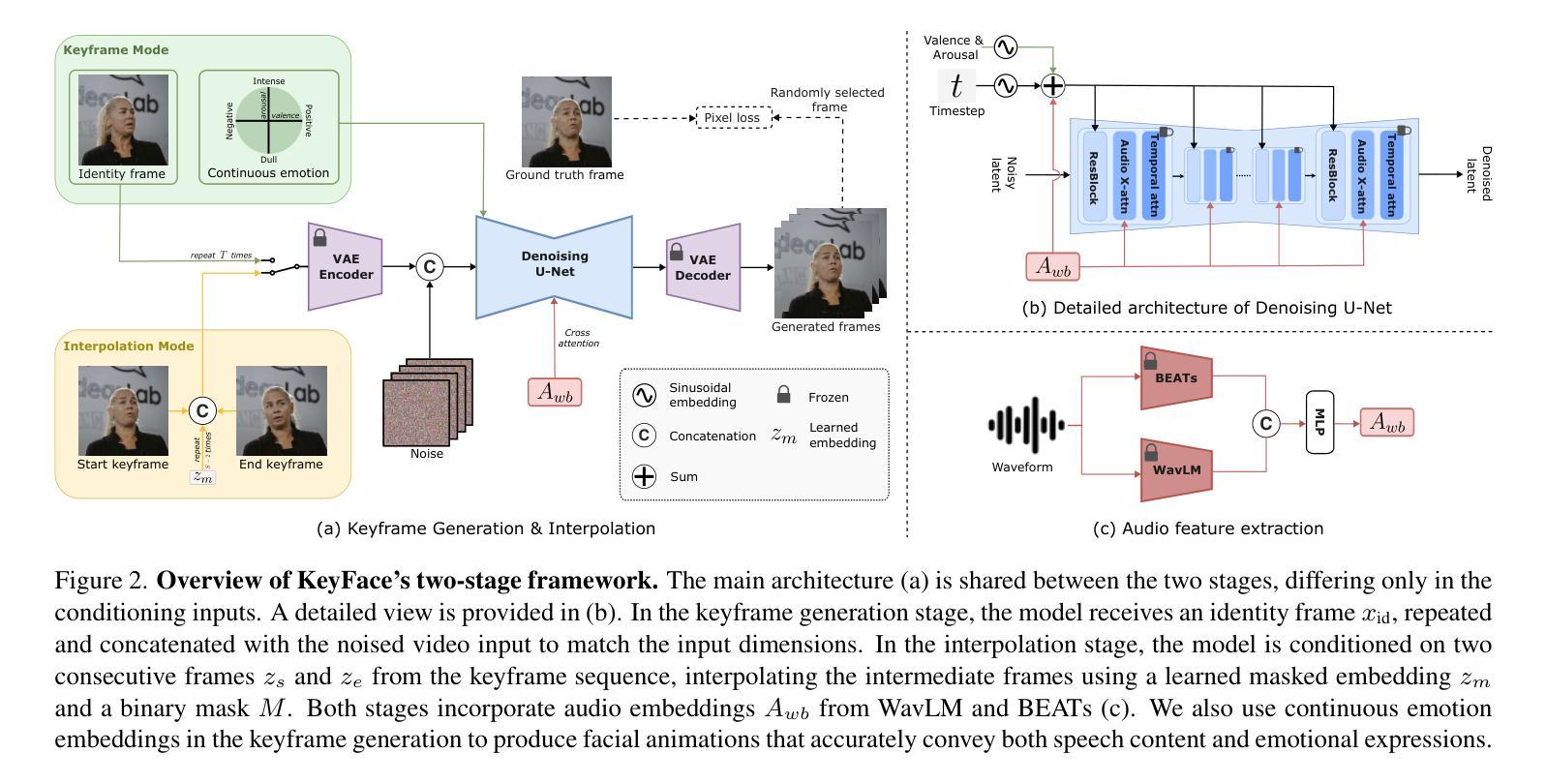
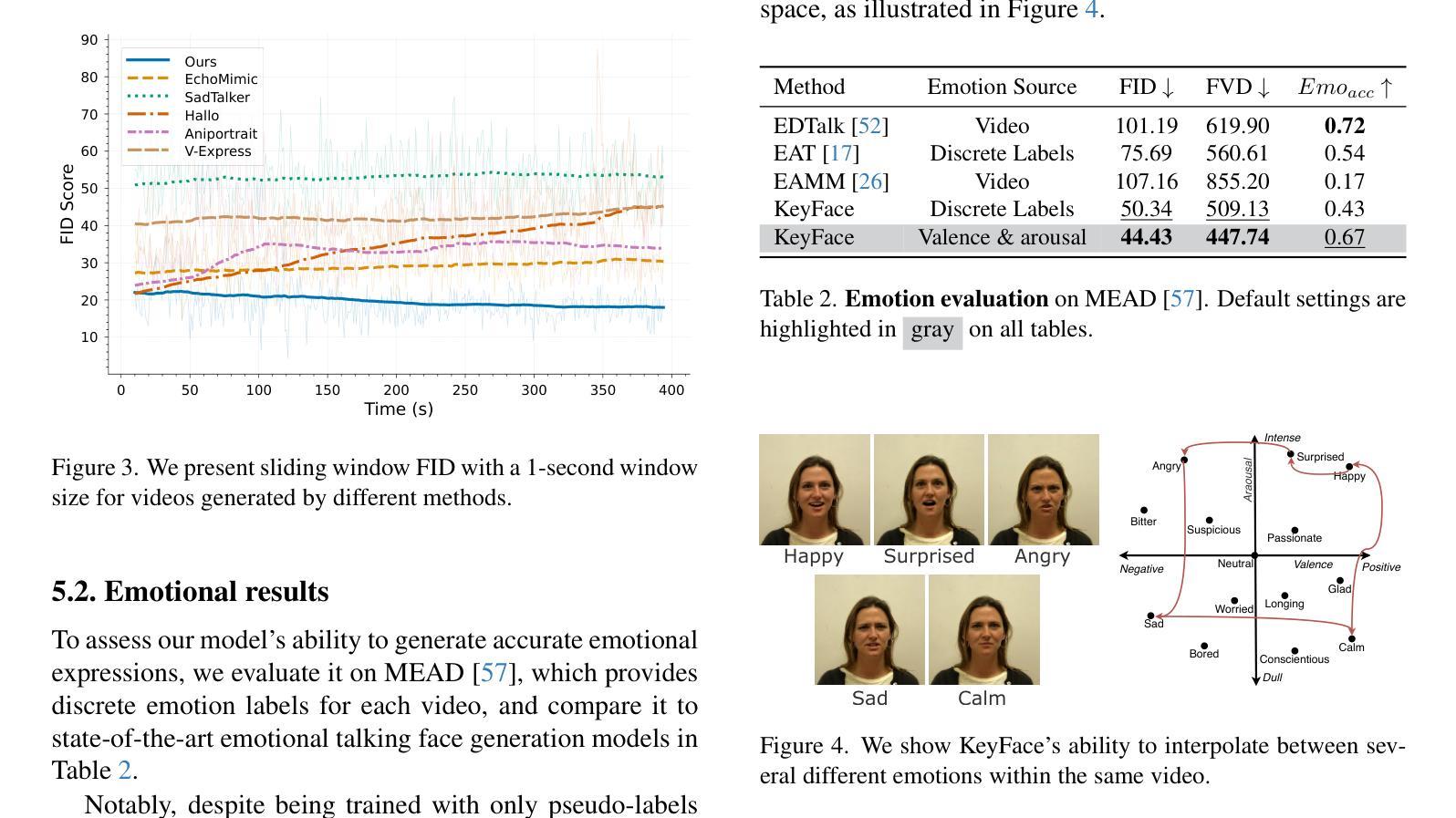
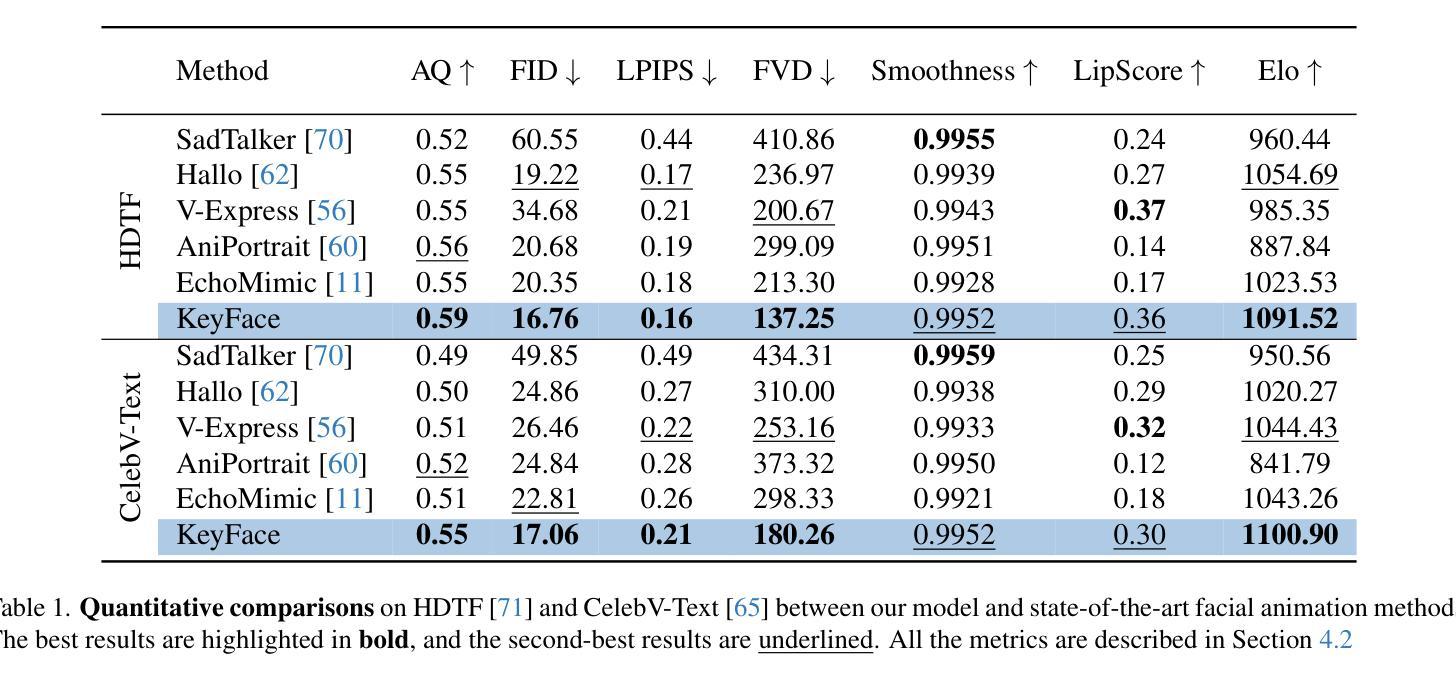
Current audio-driven facial animation methods achieve impressive results for short videos but suffer from error accumulation and identity drift when extended to longer durations. Existing methods attempt to mitigate this through external spatial control, increasing long-term consistency but compromising the naturalness of motion. We propose KeyFace, a novel two-stage diffusion-based framework, to address these issues. In the first stage, keyframes are generated at a low frame rate, conditioned on audio input and an identity frame, to capture essential facial expressions and movements over extended periods of time. In the second stage, an interpolation model fills in the gaps between keyframes, ensuring smooth transitions and temporal coherence. To further enhance realism, we incorporate continuous emotion representations and handle a wide range of non-speech vocalizations (NSVs), such as laughter and sighs. We also introduce two new evaluation metrics for assessing lip synchronization and NSV generation. Experimental results show that KeyFace outperforms state-of-the-art methods in generating natural, coherent facial animations over extended durations, successfully encompassing NSVs and continuous emotions.
当前基于音频驱动的面部动画方法在短视频上取得了令人印象深刻的效果,但当扩展到更长时间时,会出现误差累积和身份漂移的问题。现有方法试图通过外部空间控制来减轻这一问题,虽然增强了长期一致性,但牺牲了动作的自然性。我们提出了KeyFace,这是一种基于新型两阶段扩散的方法框架,来解决这些问题。在第一阶段,根据音频输入和身份帧,以低帧率生成关键帧,以捕捉长时间内的关键面部表情和动作。在第二阶段,插值模型填补了关键帧之间的空白,确保了平滑过渡和时间连贯性。为了进一步提高逼真度,我们融入了连续情感表示,并处理了各种非语音声化(NSVs),如笑声和叹息声。我们还引入了两个新的评估指标,用于评估唇同步和非语音声化生成。实验结果表明,KeyFace在生成自然、连贯的面部动画方面优于最先进的方法,成功涵盖了非语音声化和连续情感,特别是在长时间段内。
论文及项目相关链接
PDF CVPR 2025
Summary
本文提出一种名为KeyFace的新型两阶段扩散框架,用于解决音频驱动面部动画在长时间序列中面临的误差累积和身份漂移问题。该框架分为两个阶段:第一阶段根据音频输入和身份帧生成低帧率的关键帧,捕捉长时间的面部表情和动作;第二阶段采用插值模型填补关键帧之间的空白,确保平滑过渡和时间连贯性。KeyFace还增强了现实感,融入了连续情感表示,并处理各种非语音声音(NSVs),如笑声和叹息声。
Key Takeaways
- 当前音频驱动的面部动画方法在长时间序列中存在误差累积和身份漂移问题。
- KeyFace是一种新型两阶段扩散框架,旨在解决这些问题。
- 第一阶段根据音频输入和身份帧生成低帧率关键帧,捕捉长时间面部表情和动作。
- 第二阶段使用插值模型填补关键帧间的空白,确保平滑过渡和时间连贯性。
- KeyFace融入连续情感表示,增强现实感。
- 该方法能够处理各种非语音声音(NSVs),如笑声和叹息声。
- 引入新的评估指标来评估唇同步和非语音生成的效果。
点此查看论文截图

Talking Turns: Benchmarking Audio Foundation Models on Turn-Taking Dynamics
Authors:Siddhant Arora, Zhiyun Lu, Chung-Cheng Chiu, Ruoming Pang, Shinji Watanabe
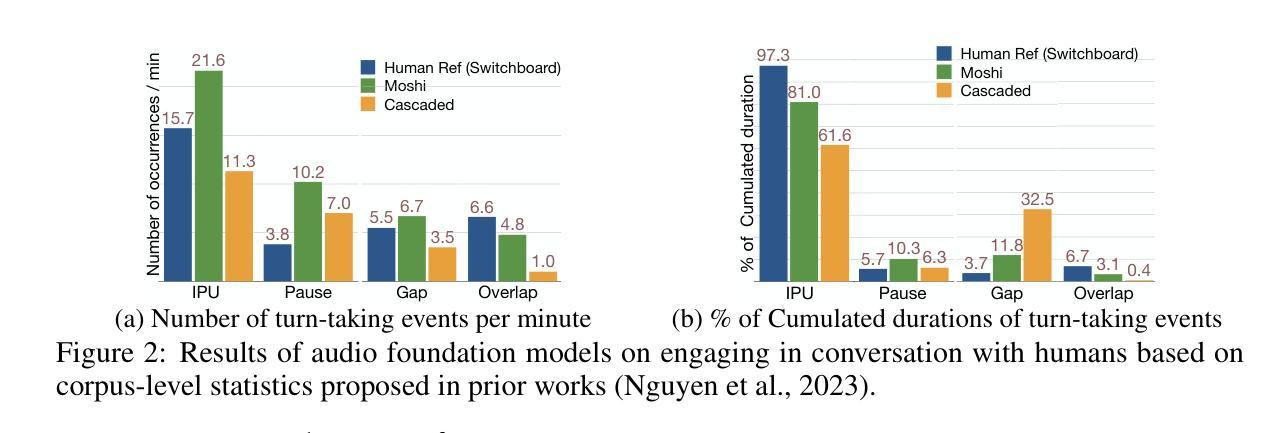
The recent wave of audio foundation models (FMs) could provide new capabilities for conversational modeling. However, there have been limited efforts to evaluate these audio FMs comprehensively on their ability to have natural and interactive conversations. To engage in meaningful conversation with the end user, we would want the FMs to additionally perform a fluent succession of turns without too much overlapping speech or long stretches of silence. Inspired by this, we ask whether the recently proposed audio FMs can understand, predict, and perform turn-taking events? To answer this, we propose a novel evaluation protocol that can assess spoken dialog system’s turn-taking capabilities using a supervised model as a judge that has been trained to predict turn-taking events in human-human conversations. Using this protocol, we present the first comprehensive user study that evaluates existing spoken dialogue systems on their ability to perform turn-taking events and reveal many interesting insights, such as they sometimes do not understand when to speak up, can interrupt too aggressively and rarely backchannel. We further evaluate multiple open-source and proprietary audio FMs accessible through APIs on carefully curated test benchmarks from Switchboard to measure their ability to understand and predict turn-taking events and identify significant room for improvement. We will open source our evaluation platform to promote the development of advanced conversational AI systems.
最近的音频基础模型(FMs)浪潮为对话建模提供了新的能力。然而,关于这些音频FM在具有自然和交互性对话的能力方面的全面评估工作还非常有限。为了与最终用户进行有意义的对话,我们希望FM能够执行流畅的连续对话,而不会存在过多的重叠语音或长时间的沉默。受此启发,我们想知道最近提出的音频FM是否能够理解、预测并执行对话中的轮流发言事件?为了回答这个问题,我们提出了一种新的评估协议,该协议可以利用训练好的监督模型作为裁判来评估对话系统的轮流发言能力,该模型经过训练可以预测人类对话中的轮流发言事件。使用此协议,我们首次进行了全面的用户研究,评估现有对话系统在执行轮流发言事件方面的能力,并揭示了许多有趣的见解,例如它们有时不明白何时应该发言、可能会过于中断对话且很少进行后向渠道交流等。我们还对可通过API访问的多个开源和专有音频FM进行了评估,以衡量其在理解和预测轮流发言事件方面的能力,并发现了巨大的改进空间。我们将开源我们的评估平台,以促进先进的对话AI系统的发展。
论文及项目相关链接
PDF Accepted at ICLR 2025
Summary
本文探讨了音频基础模型(FMs)在对话建模方面的新能力,并提出了一个评估对话系统轮流发言能力的评价协议。通过用户研究和测试,发现现有对话系统在轮流发言方面存在不足,如不理解何时发言、过于频繁打断对方以及缺乏回应等。同时,对通过API访问的开源和专有音频FMs进行了评估,发现其在理解和预测轮流发言事件方面存在改进空间。本文将公开评价平台,以促进先进对话AI系统的发展。
Key Takeaways
- 音频基础模型(FMs)在对话建模方面具有新能力,但对其自然和互动性对话能力的评估仍有限。
- 提出了一个评估对话系统轮流发言能力的评价协议,使用监督模型作为判官,该模型经过训练可预测人类对话中的轮流发言事件。
- 用户研究表明,现有对话系统在理解并执行轮流发言事件方面存在缺陷,如不懂何时发言、过于打断对方及缺乏回应。
- 对多种开源和专有音频FMs进行了评估,发现它们在理解和预测轮流发言事件方面有待提高。
- 这些FMs在测试平台上的表现不佳,尤其是在处理重叠语音和长时间沉默时。
- 为改进对话系统的性能,需要更多地关注其轮流发言能力,并对其进行更深入的研究。
点此查看论文截图

Towards High-fidelity 3D Talking Avatar with Personalized Dynamic Texture
Authors:Xuanchen Li, Jianyu Wang, Yuhao Cheng, Yikun Zeng, Xingyu Ren, Wenhan Zhu, Weiming Zhao, Yichao Yan
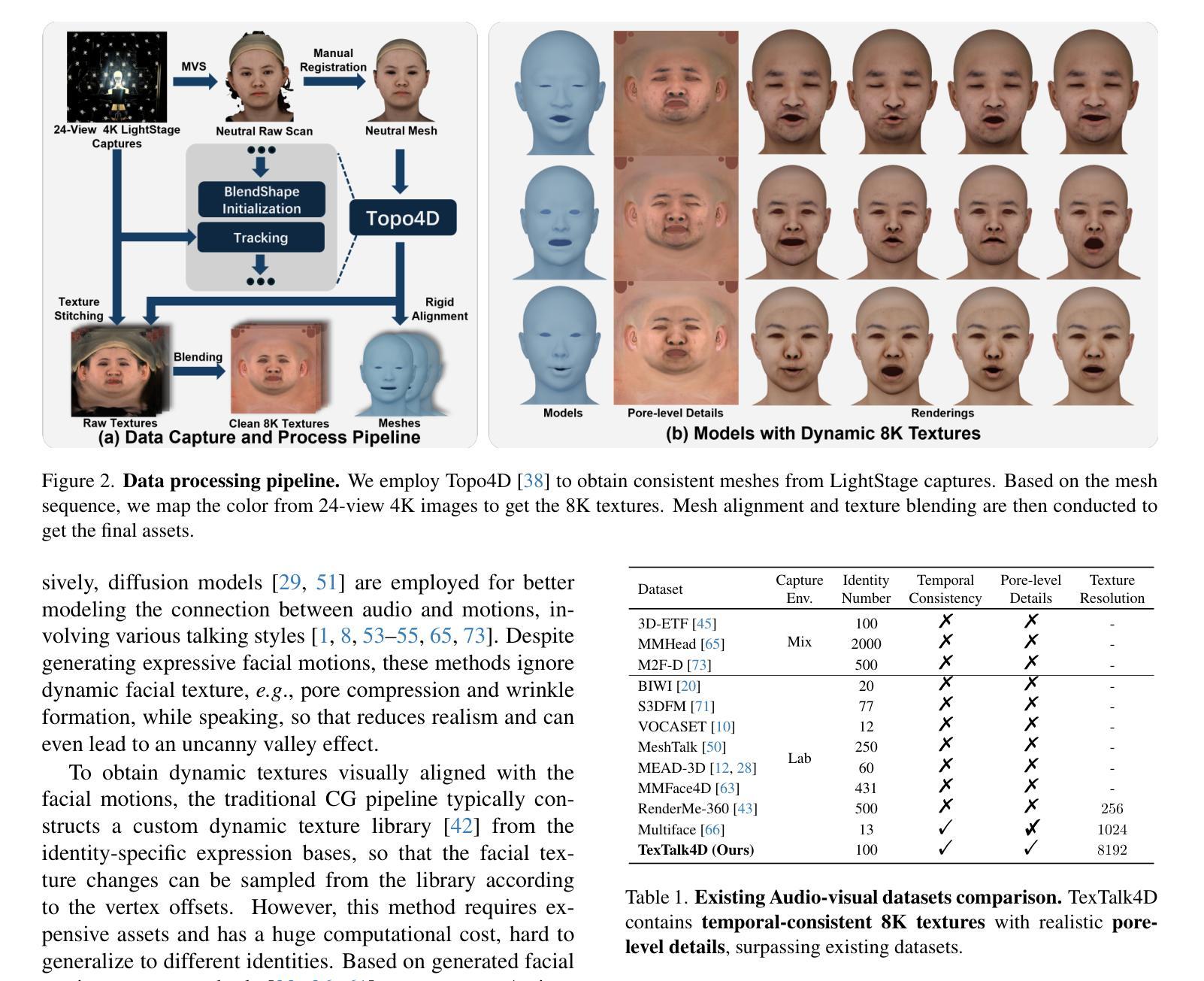
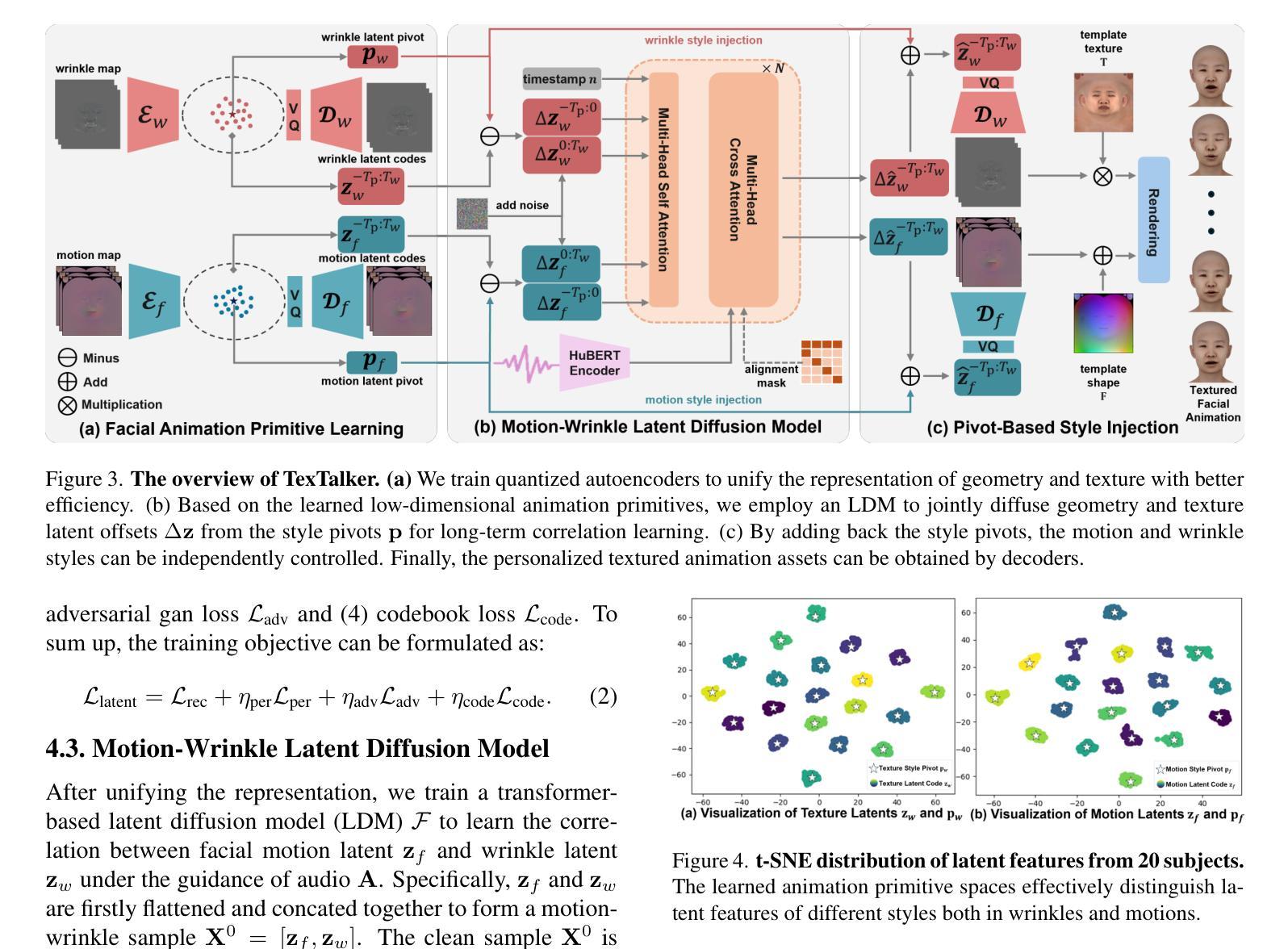
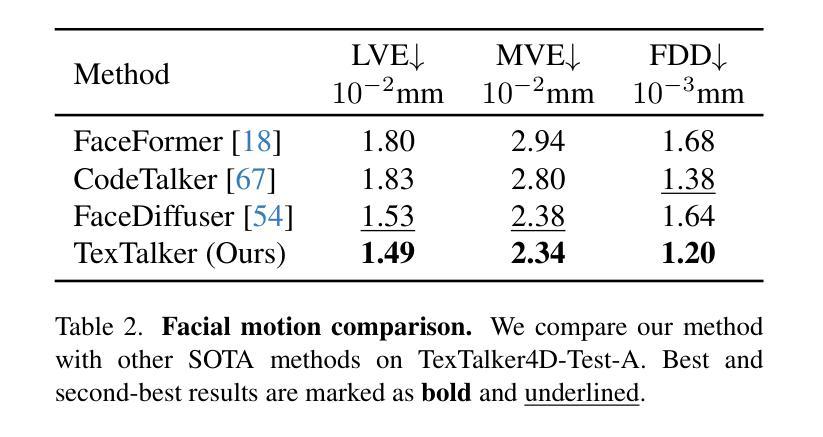
Significant progress has been made for speech-driven 3D face animation, but most works focus on learning the motion of mesh/geometry, ignoring the impact of dynamic texture. In this work, we reveal that dynamic texture plays a key role in rendering high-fidelity talking avatars, and introduce a high-resolution 4D dataset \textbf{TexTalk4D}, consisting of 100 minutes of audio-synced scan-level meshes with detailed 8K dynamic textures from 100 subjects. Based on the dataset, we explore the inherent correlation between motion and texture, and propose a diffusion-based framework \textbf{TexTalker} to simultaneously generate facial motions and dynamic textures from speech. Furthermore, we propose a novel pivot-based style injection strategy to capture the complicity of different texture and motion styles, which allows disentangled control. TexTalker, as the first method to generate audio-synced facial motion with dynamic texture, not only outperforms the prior arts in synthesising facial motions, but also produces realistic textures that are consistent with the underlying facial movements. Project page: https://xuanchenli.github.io/TexTalk/.
在语音驱动的三维面部动画方面已经取得了重大进展,但大多数工作主要集中在学习网格/几何的运动,而忽略了动态纹理的影响。在这项工作中,我们揭示了动态纹理在高保真语音交流角色渲染中的关键作用,并引入了一个高分辨率的4D数据集TexTalk4D,该数据集包含来自100个主题的100分钟音频同步扫描级别的网格,具有详细的8K动态纹理。基于该数据集,我们探索了运动和纹理之间的内在关联,并提出了一种基于扩散的框架TexTalker,可以从语音中同时生成面部运动和动态纹理。此外,我们提出了一种基于枢轴的风格注入策略,以捕捉不同纹理和运动风格的复杂性,从而实现了解耦控制。TexTalker作为第一种生成带有动态纹理的音频同步面部运动的方法,不仅在合成面部运动方面优于现有技术,而且生成的纹理与底层面部运动保持一致。项目页面:https://xuanchenli.github.io/TexTalk/。
论文及项目相关链接
摘要
本文揭示了动态纹理在高保真度语音动画中的重要性,并构建了一个高分辨率的4D数据集TexTalk4D,包含来自一百位对象的共一百万分钟音频同步扫描级别网格和详细的8K动态纹理。基于该数据集,本文探讨了运动和纹理之间的内在关联,并提出了一个基于扩散的TexTalker框架,可从语音中同时生成面部运动和动态纹理。此外,还提出了一种基于轴心的风格注入策略,以捕捉不同纹理和运动风格的复杂性,从而实现了解耦控制。TexTalker作为首个生成带有动态纹理的音频同步面部运动的方法,不仅在合成面部运动方面优于现有技术,而且生成的纹理与底层面部运动保持一致。
要点
- 动态纹理在高保真语音动画中的重要性。
- 构建了高分辨率的TexTalk4D数据集,包含音频同步的面部网格和动态纹理。
- 探讨了运动和纹理之间的内在关联。
- 提出了TexTalker框架,能从语音中生成面部运动和动态纹理。
- 采用基于轴心的风格注入策略,实现纹理和运动风格的解耦控制。
- TexTalker在合成面部运动和生成纹理方面优于现有技术。
点此查看论文截图

AdaMesh: Personalized Facial Expressions and Head Poses for Adaptive Speech-Driven 3D Facial Animation
Authors:Liyang Chen, Weihong Bao, Shun Lei, Boshi Tang, Zhiyong Wu, Shiyin Kang, Haozhi Huang, Helen Meng
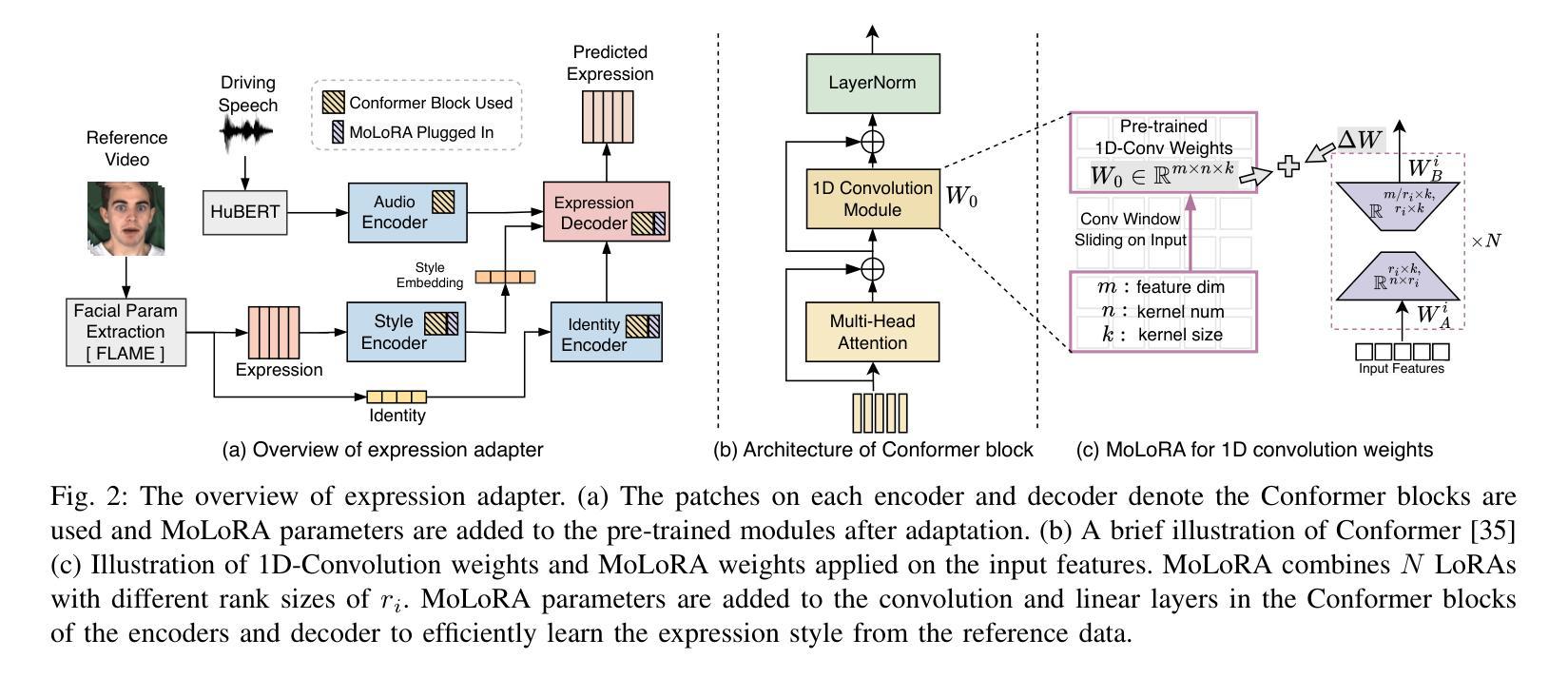
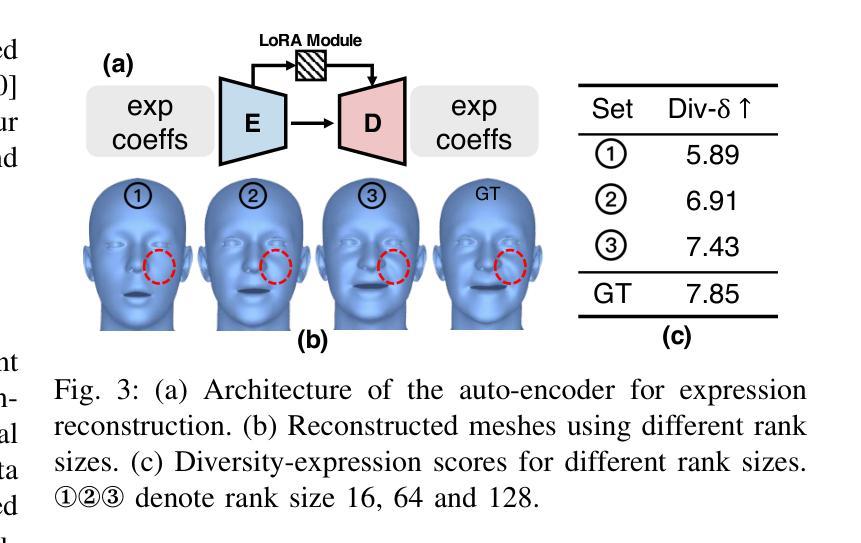
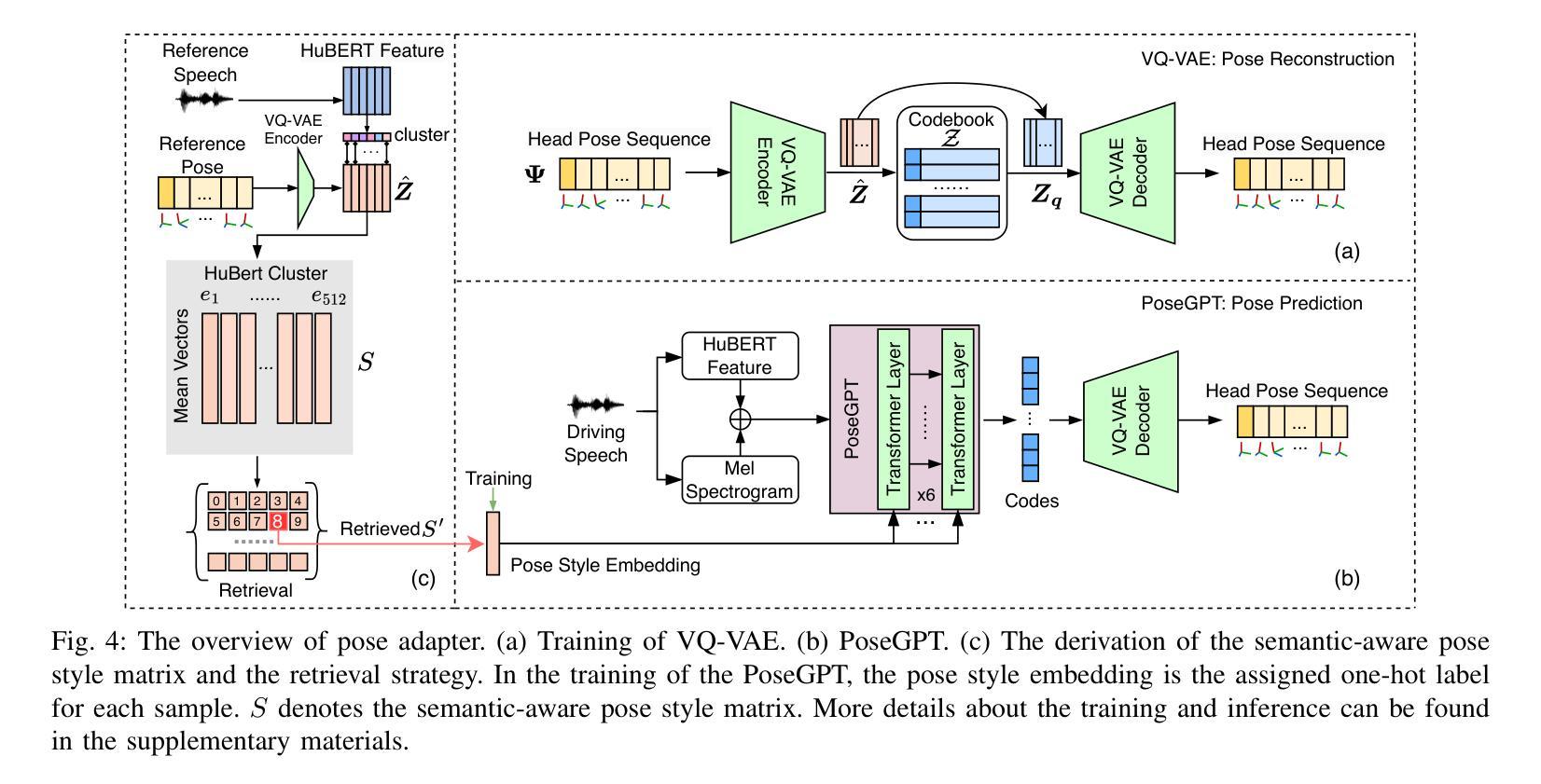
Speech-driven 3D facial animation aims at generating facial movements that are synchronized with the driving speech, which has been widely explored recently. Existing works mostly neglect the person-specific talking style in generation, including facial expression and head pose styles. Several works intend to capture the personalities by fine-tuning modules. However, limited training data leads to the lack of vividness. In this work, we propose AdaMesh, a novel adaptive speech-driven facial animation approach, which learns the personalized talking style from a reference video of about 10 seconds and generates vivid facial expressions and head poses. Specifically, we propose mixture-of-low-rank adaptation (MoLoRA) to fine-tune the expression adapter, which efficiently captures the facial expression style. For the personalized pose style, we propose a pose adapter by building a discrete pose prior and retrieving the appropriate style embedding with a semantic-aware pose style matrix without fine-tuning. Extensive experimental results show that our approach outperforms state-of-the-art methods, preserves the talking style in the reference video, and generates vivid facial animation. The supplementary video and code will be available at https://adamesh.github.io.
语音驱动的三维面部动画旨在生成与驱动语音同步的面部动作,这最近已经得到了广泛的研究。现有工作大多忽视了生成中的个人说话风格,包括面部表情和头部姿势风格。一些作品意图通过微调模块来捕捉个性。然而,有限的训练数据导致生动性不足。在这项工作中,我们提出了AdaMesh,这是一种新型自适应语音驱动面部动画方法,它从约10秒的参考视频中学习个性化的说话风格,并生成逼真的面部表情和头部姿势。具体来说,我们提出低阶适应混合(MoLoRA)来微调表情适配器,这有效地捕捉了面部表情风格。对于个性化的姿势风格,我们通过建立离散姿势先验和通过语义感知姿势风格矩阵检索适当的风格嵌入,而无需微调,从而提出了姿态适配器。大量的实验结果表明,我们的方法优于最新方法,保留了参考视频中的说话风格,并生成了生动的面部动画。补充视频和代码将在https://adamesh.github.io上提供。
论文及项目相关链接
PDF Accepted by IEEE Transactions on Multimedia
Summary
本文提出了一种名为AdaMesh的新型自适应语音驱动面部动画方法,可从约10秒的参考视频中学习个性化说话风格,并生成生动的面部表情和头部姿态。通过混合低阶适应(MoLoRA)技术精细调整表情适配器,有效捕捉面部表情风格。对于个性化的姿态风格,通过构建离散姿态先验和语义感知姿态风格矩阵,提出姿态适配器,无需精细调整即可检索适当的风格嵌入。实验结果表明,该方法优于现有技术,能保留参考视频中的说话风格,生成生动的面部动画。
Key Takeaways
- AdaMesh是一种自适应语音驱动的面部动画方法,能从参考视频中学习个性化说话风格。
- 方法包括表情和头部姿态的个性化风格捕捉。
- 通过混合低阶适应(MoLoRA)技术精细调整表情适配器,有效捕捉面部表情风格。
- 提出姿态适配器,通过构建离散姿态先验和语义感知姿态风格矩阵,实现姿态风格的捕捉。
- 方法在实验中表现出优异的性能,优于现有技术。
- AdaMesh能保留参考视频中的说话风格,并生成生动的面部动画。
点此查看论文截图