⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-06 更新
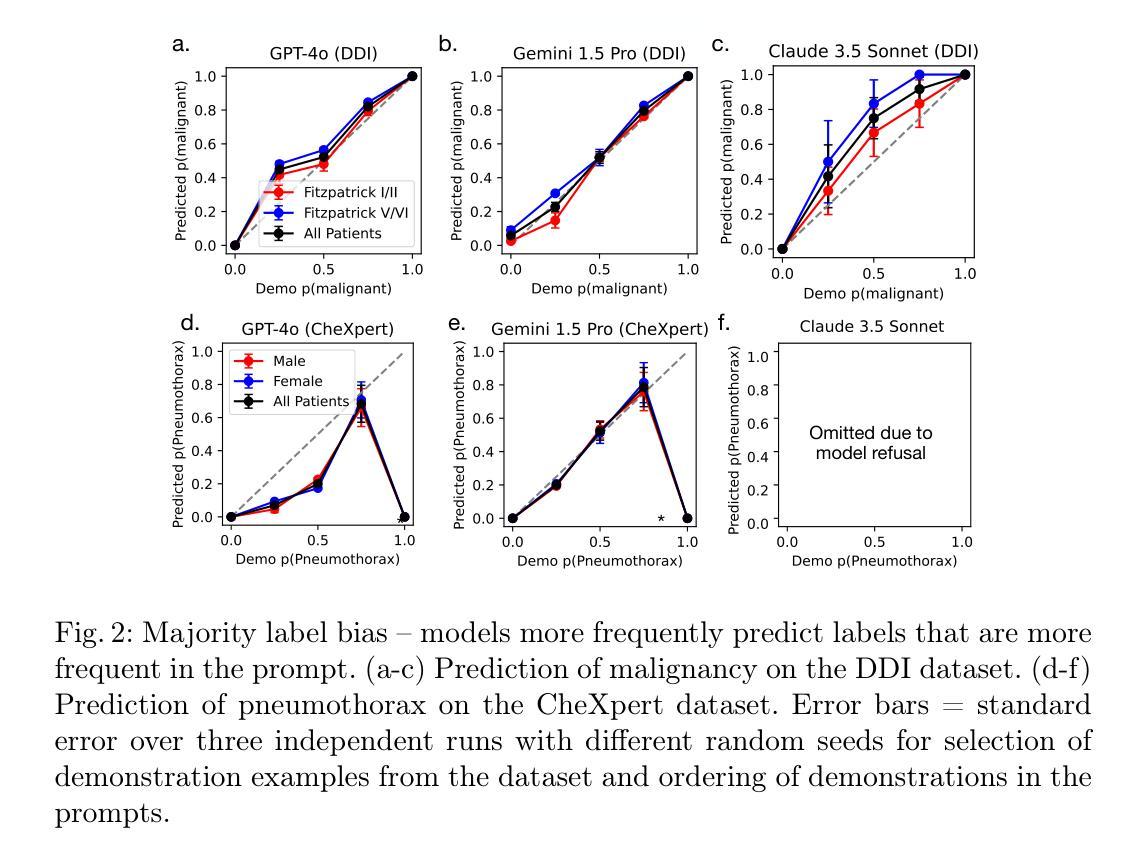
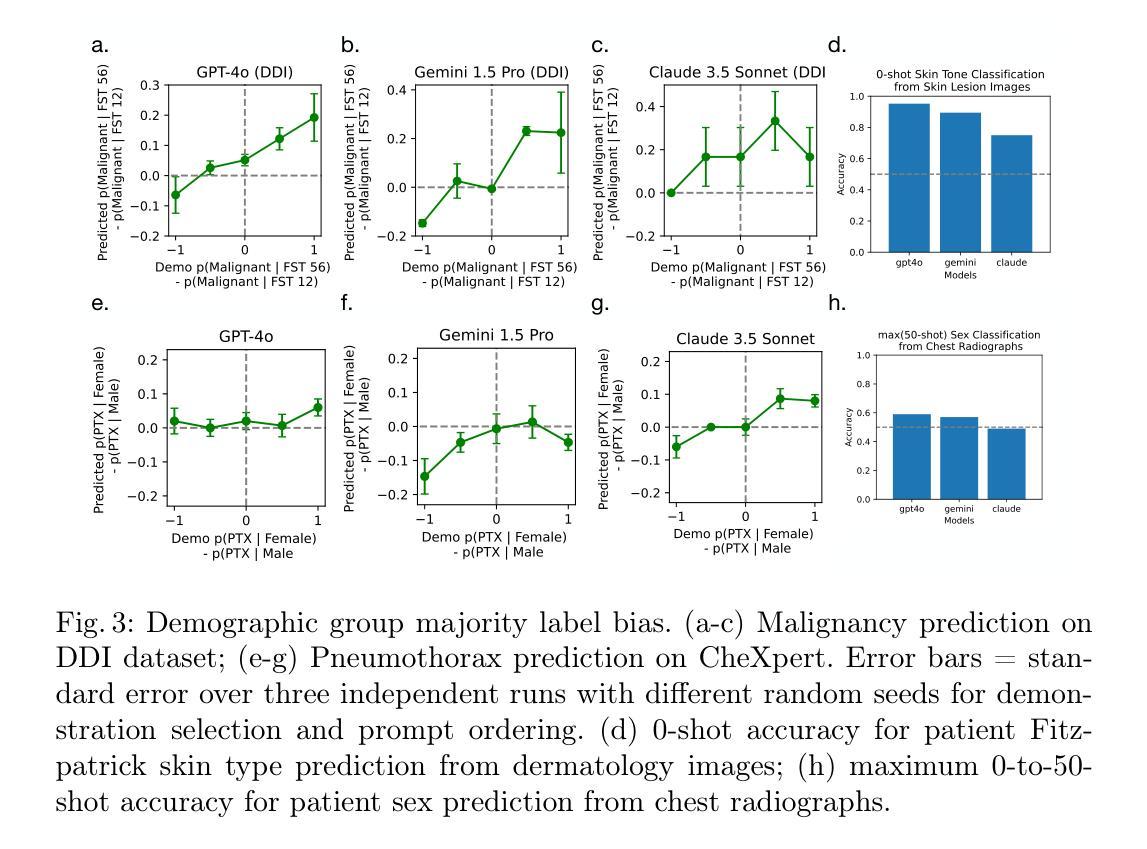
BiasICL: In-Context Learning and Demographic Biases of Vision Language Models
Authors:Sonnet Xu, Joseph Janizek, Yixing Jiang, Roxana Daneshjou
Vision language models (VLMs) show promise in medical diagnosis, but their performance across demographic subgroups when using in-context learning (ICL) remains poorly understood. We examine how the demographic composition of demonstration examples affects VLM performance in two medical imaging tasks: skin lesion malignancy prediction and pneumothorax detection from chest radiographs. Our analysis reveals that ICL influences model predictions through multiple mechanisms: (1) ICL allows VLMs to learn subgroup-specific disease base rates from prompts and (2) ICL leads VLMs to make predictions that perform differently across demographic groups, even after controlling for subgroup-specific disease base rates. Our empirical results inform best-practices for prompting current VLMs (specifically examining demographic subgroup performance, and matching base rates of labels to target distribution at a bulk level and within subgroups), while also suggesting next steps for improving our theoretical understanding of these models.
视觉语言模型(VLMs)在医学诊断方面显示出潜力,但在使用上下文学习(ICL)时,它们在人口统计学分组中的表现仍然知之甚少。我们研究了演示示例的人口统计学构成如何影响视觉语言模型在两项医学成像任务中的表现:皮肤病变恶性预测和从胸部放射片中检测气胸。我们的分析表明,上下文学习通过多种机制影响模型预测:(1)上下文学习允许视觉语言模型从提示中学习特定人群的疾病基础率;(2)即使在控制了特定人群的疾病基础率后,上下文学习仍会导致视觉语言模型在不同人群群体中的预测表现不同。我们的经验结果为当前视觉语言模型的提示使用提供了最佳实践(特别是检查人口统计学分组的表现,以及在大规模和子组内匹配标签的基础率与目标的分布),同时也为我们改进对这些模型的理论理解提出了下一步的建议。
论文及项目相关链接
Summary
在医疗诊断领域,视觉语言模型(VLMs)具有巨大的潜力。本文探究了在皮肤病变恶性和胸腔气胸检测两个医学图像任务中,上下文学习如何影响模型对种族亚组的预测表现。分析发现上下文学习对模型预测有多个影响机制,包括学习种族亚组特定的疾病基本概率以及预测表现的差异。本文提供了关于当前VLMs的提示最佳实践,包括检查种族亚组的表现,以及匹配标签的基础概率和目标分布的建议,同时也提出了改进模型理论理解的方向。
Key Takeaways
- VLMs在医学图像诊断中展现潜力。
- 上下文学习(ICL)影响模型对种族亚组的预测表现。
- ICL允许模型从提示中学习种族亚组特定的疾病基础概率。
- ICL导致模型在不同种族亚组间的预测表现存在差异。
- 最佳实践包括检查种族亚组的表现,匹配标签的基础概率和目标分布。
- 需要改进对VLMs的理论理解。
点此查看论文截图

Pruning Deep Neural Networks via a Combination of the Marchenko-Pastur Distribution and Regularization
Authors:Leonid Berlyand, Theo Bourdais, Houman Owhadi, Yitzchak Shmalo
Deep neural networks (DNNs) have brought significant advancements in various applications in recent years, such as image recognition, speech recognition, and natural language processing. In particular, Vision Transformers (ViTs) have emerged as a powerful class of models in the field of deep learning for image classification. In this work, we propose a novel Random Matrix Theory (RMT)-based method for pruning pre-trained DNNs, based on the sparsification of weights and singular vectors, and apply it to ViTs. RMT provides a robust framework to analyze the statistical properties of large matrices, which has been shown to be crucial for understanding and optimizing the performance of DNNs. We demonstrate that our RMT-based pruning can be used to reduce the number of parameters of ViT models (trained on ImageNet) by 30-50% with less than 1% loss in accuracy. To our knowledge, this represents the state-of-the-art in pruning for these ViT models. Furthermore, we provide a rigorous mathematical underpinning of the above numerical studies, namely we proved a theorem for fully connected DNNs, and other more general DNN structures, describing how the randomness in the weight matrices of a DNN decreases as the weights approach a local or global minimum (during training). We verify this theorem through numerical experiments on fully connected DNNs, providing empirical support for our theoretical findings. Moreover, we prove a theorem that describes how DNN loss decreases as we remove randomness in the weight layers, and show a monotone dependence of the decrease in loss with the amount of randomness that we remove. Our results also provide significant RMT-based insights into the role of regularization during training and pruning.
近年来,深度神经网络(DNNs)在各种应用中取得了重大进展,如图像识别、语音识别和自然语言处理。特别是,Vision Transformers(ViTs)作为深度学习领域图像分类的强大模型已经崭露头角。在这项工作中,我们提出了一种基于随机矩阵理论(RMT)的方法来修剪预训练的DNNs,该方法基于权重和奇异向量的稀疏化,并适用于ViTs。RMT提供了一个分析大型矩阵统计特性的稳健框架,已被证明对于理解和优化DNN的性能至关重要。我们证明,基于RMT的修剪方法可用于将ImageNet训练的ViT模型的参数数量减少30%~50%,同时精度损失不到1%。据我们所知,这是针对这些ViT模型的最先进的修剪技术。此外,我们对上述数值研究进行了严格的数学证明,即我们为全连接DNNs和其他更一般的DNN结构证明了一个定理,描述了DNN权重矩阵中的随机性如何随着权重接近局部或全局最小值(在训练过程中)而减少。我们通过全连接DNN上的数值实验验证了这一定理,为我们的理论发现提供了实证支持。此外,我们证明了另一个定理,描述了当我们消除权重层中的随机性时,DNN损失如何减少,并展示了我们所消除的随机性与损失减少之间的单调依赖性。我们的结果还提供了基于RMT的关于训练和修剪过程中正则化作用的深刻见解。
论文及项目相关链接
Summary
在深度学习中,Vision Transformers(ViTs)已成为图像分类中的强大模型。本研究提出一种基于随机矩阵理论(RMT)的预训练深度神经网络(DNNs)修剪方法,通过权重和奇异向量的稀疏化应用于ViTs。该方法可减少在ImageNet上训练的ViT模型的参数数量达30%~50%,同时保证精度损失小于1%。我们还为上述数值研究提供了严格的数学支撑,包括描述DNN权重矩阵随机性在训练过程中如何减少的理论,以及描述如何随着随机性的移除,DNN损失如何减少的理论。我们的结果还为训练过程中的正则化作用提供了重要的RMT见解。
Key Takeaways
- 提出了基于随机矩阵理论(RMT)的预训练深度神经网络(DNNs)修剪方法,并应用于Vision Transformers(ViTs)。
- 通过此方法,可以减少ViT模型的参数数量达30%~50%,同时保证精度损失小于1%,达到当前最优水平。
- 提供了严格的数学理论支撑,包括描述DNN权重矩阵随机性在训练过程中的变化和DNN损失随随机性移除而减少的理论。
- 通过数值实验验证了理论的有效性。
- 研究结果对训练过程中的正则化作用提供了重要的见解。
- 此方法基于RMT,为理解大型矩阵的统计属性提供了新的视角,有助于理解和优化DNN的性能。
- 该研究为未来的DNN和ViT模型的发展提供了新的思路和方法。
点此查看论文截图


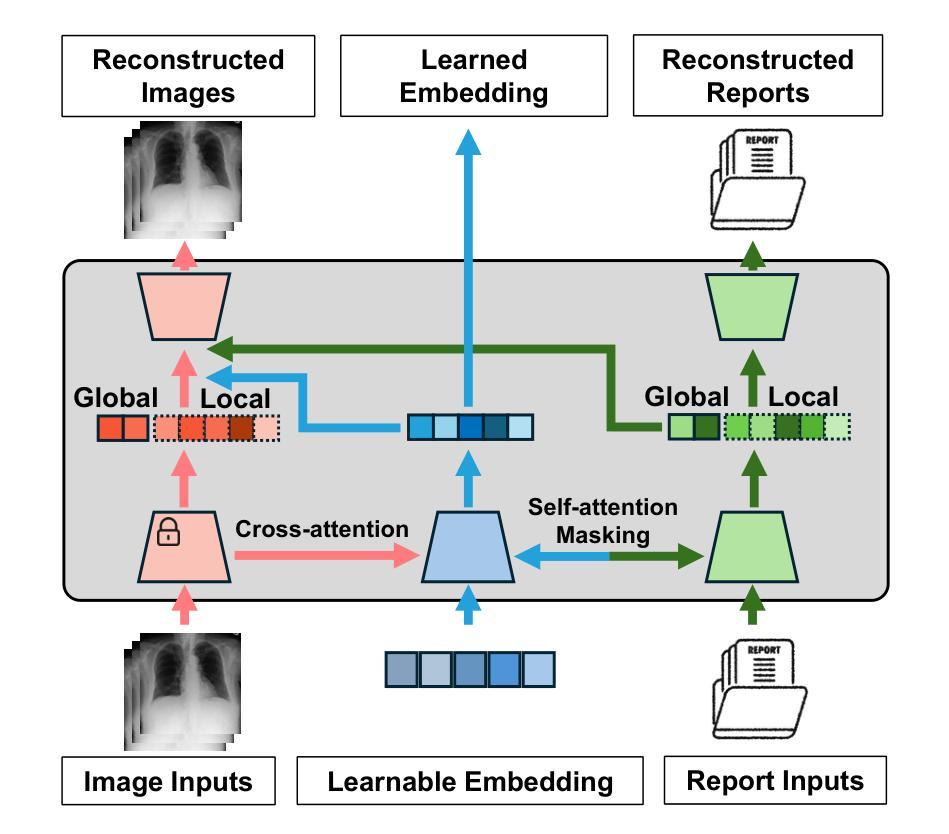
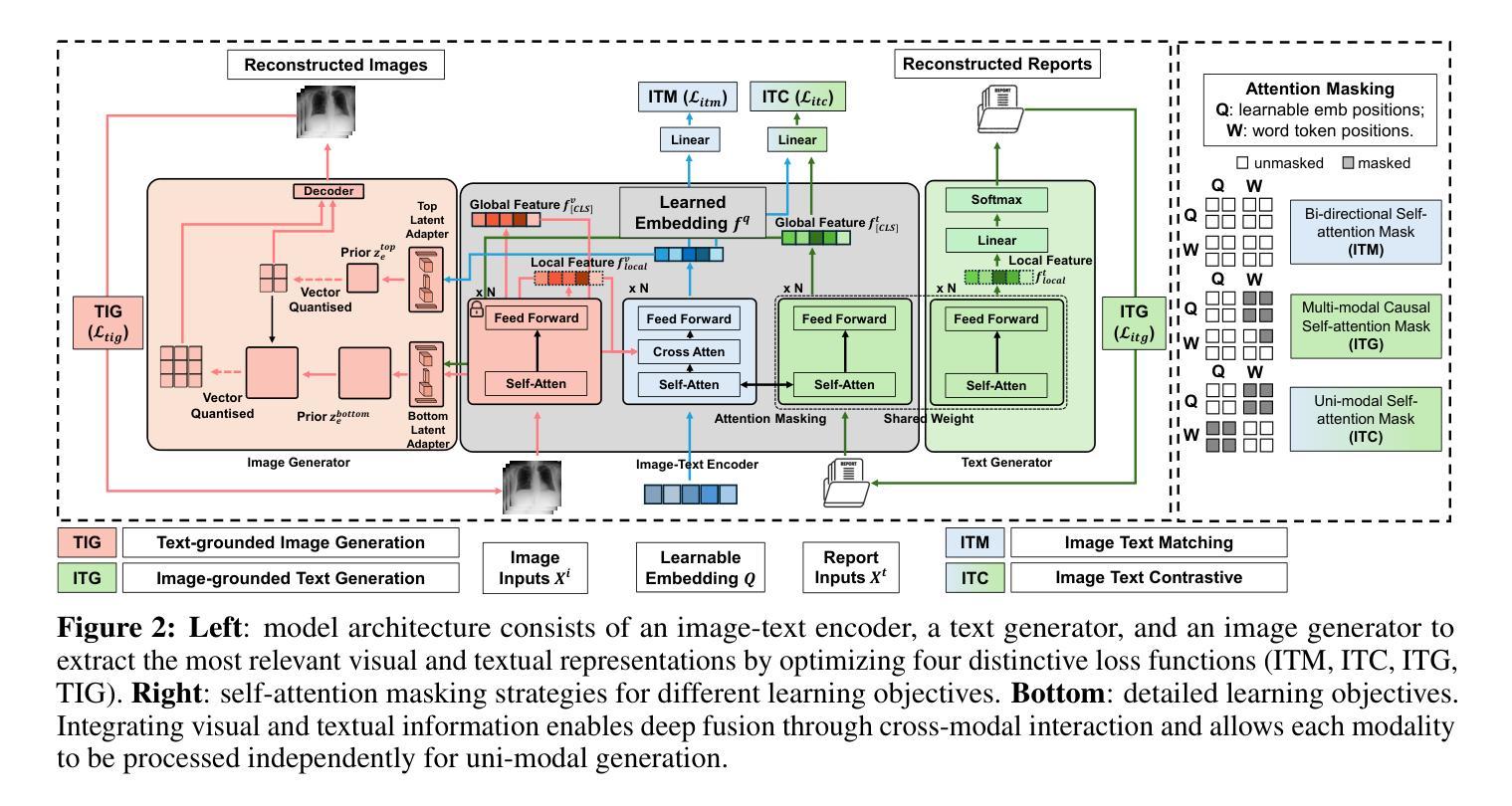
MedUnifier: Unifying Vision-and-Language Pre-training on Medical Data with Vision Generation Task using Discrete Visual Representations
Authors:Ziyang Zhang, Yang Yu, Yucheng Chen, Xulei Yang, Si Yong Yeo
Despite significant progress in Vision-Language Pre-training (VLP), current approaches predominantly emphasize feature extraction and cross-modal comprehension, with limited attention to generating or transforming visual content. This gap hinders the model’s ability to synthesize coherent and novel visual representations from textual prompts, thereby reducing the effectiveness of multi-modal learning. In this work, we propose MedUnifier, a unified VLP framework tailored for medical data. MedUnifier seamlessly integrates text-grounded image generation capabilities with multi-modal learning strategies, including image-text contrastive alignment, image-text matching and image-grounded text generation. Unlike traditional methods that reply on continuous visual representations, our approach employs visual vector quantization, which not only facilitates a more cohesive learning strategy for cross-modal understanding but also enhances multi-modal generation quality by effectively leveraging discrete representations. Our framework’s effectiveness is evidenced by the experiments on established benchmarks, including uni-modal tasks (supervised fine-tuning), cross-modal tasks (image-text retrieval and zero-shot image classification), and multi-modal tasks (medical report generation, image synthesis), where it achieves state-of-the-art performance across various tasks. MedUnifier also offers a highly adaptable tool for a wide range of language and vision tasks in healthcare, marking advancement toward the development of a generalizable AI model for medical applications.
尽管视觉语言预训练(VLP)领域取得了显著进展,但当前的方法主要侧重于特征提取和跨模态理解,对生成或转换视觉内容的关注有限。这一差距阻碍了模型从文本提示中合成连贯且新颖的视觉表示的能力,从而降低了多模态学习的有效性。在此工作中,我们提出了针对医疗数据的统一VLP框架MedUnifier。MedUnifier无缝集成了基于文本的图像生成能力与多模态学习策略,包括图像文本对比对齐、图像文本匹配和基于图像的文本生成。不同于传统方法依赖连续视觉表示,我们的方法采用视觉向量量化,这不仅有助于更连贯的跨模态理解学习策略,而且通过有效利用离散表示提高了多模态生成质量。我们的框架在公认基准测试上的实验证明了其有效性,包括单模态任务(监督微调)、跨模态任务(图像文本检索和零样本图像分类)和多模态任务(医学报告生成、图像合成)。它在各种任务上实现了最先进的性能。MedUnifier还为医疗保健领域的各种语言和视觉任务提供了高度灵活的工具,标志着在开发用于医疗应用的可推广人工智能模型方面取得了进展。
论文及项目相关链接
PDF To be pubilshed in CVPR 2025
Summary:提出了一种针对医疗数据的统一视觉语言预训练框架MedUnifier。该框架融合了文本驱动图像生成能力与多模态学习策略,包括图像文本对比对齐、图像文本匹配和图像驱动文本生成。通过离散表示而非连续视觉表示的方式,提高了多模态生成的连贯性和质量,并在多个任务上取得了优异性能。
Key Takeaways:
- 当前视觉语言预训练(VLP)主要关注特征提取和跨模态理解,忽视了对视觉内容的生成或转换。
- MedUnifier框架旨在解决这一问题,通过整合文本驱动的图像生成和多模态学习策略,提高模型合成连贯和新颖的视觉表示的能力。
- MedUnifier采用视觉向量量化,有效利用离散表示,提高多模态生成的连贯性和质量。
- 框架在多种任务上表现出卓越性能,包括单模态任务、跨模态任务和多模态任务。
- MedUnifier框架高度适应于各种语言和视觉任务,特别适用于医疗健康领域。
- 框架的发展为医疗应用的通用人工智能模型的发展带来了进步。
点此查看论文截图

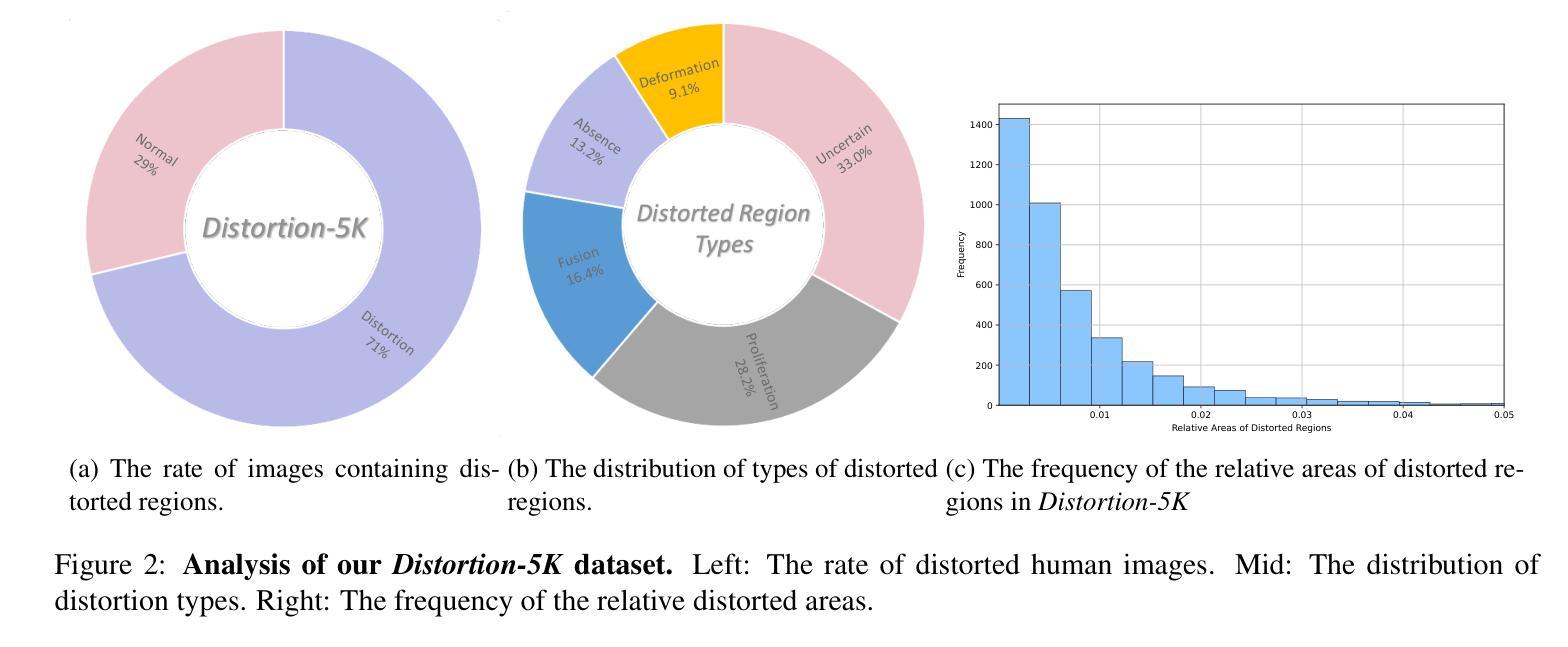
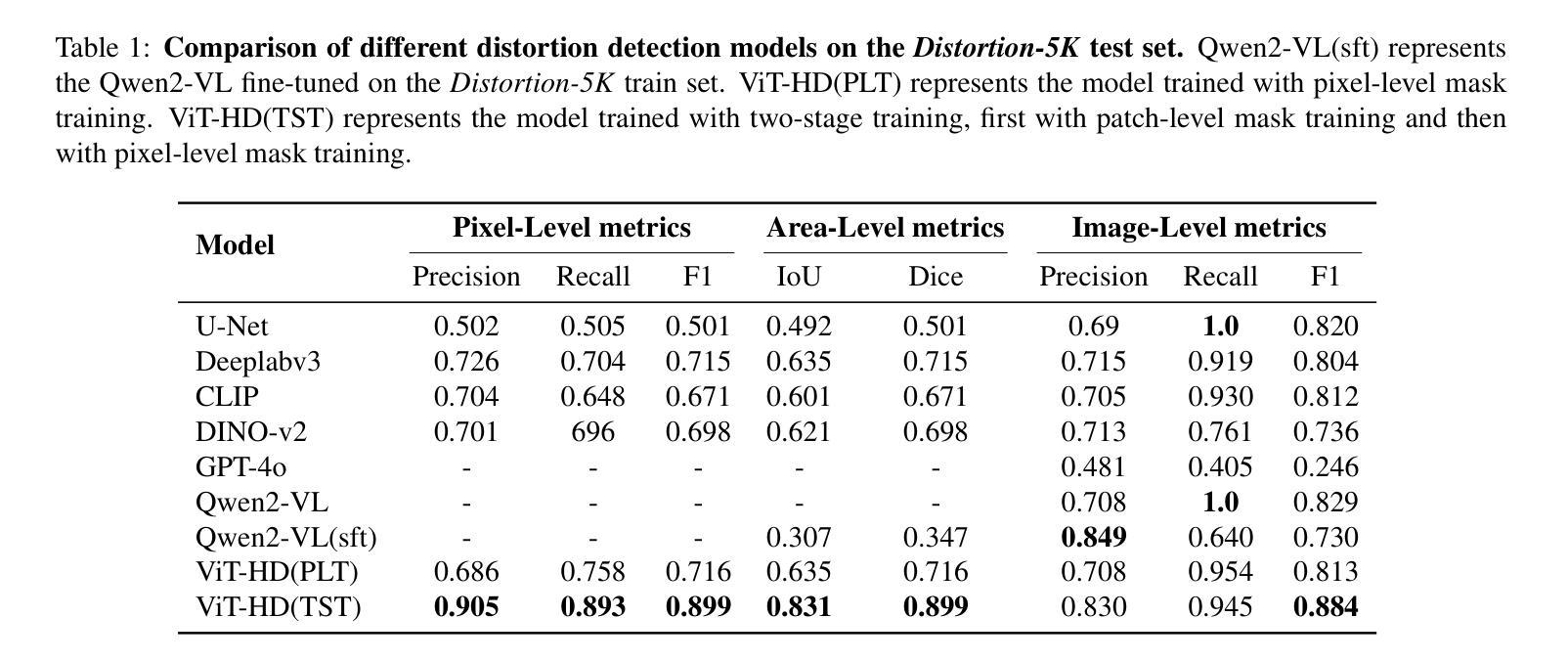
Evaluating and Predicting Distorted Human Body Parts for Generated Images
Authors:Lu Ma, Kaibo Cao, Hao Liang, Jiaxin Lin, Zhuang Li, Yuhong Liu, Jihong Zhang, Wentao Zhang, Bin Cui
Recent advancements in text-to-image (T2I) models enable high-quality image synthesis, yet generating anatomically accurate human figures remains challenging. AI-generated images frequently exhibit distortions such as proliferated limbs, missing fingers, deformed extremities, or fused body parts. Existing evaluation metrics like Inception Score (IS) and Fr'echet Inception Distance (FID) lack the granularity to detect these distortions, while human preference-based metrics focus on abstract quality assessments rather than anatomical fidelity. To address this gap, we establish the first standards for identifying human body distortions in AI-generated images and introduce Distortion-5K, a comprehensive dataset comprising 4,700 annotated images of normal and malformed human figures across diverse styles and distortion types. Based on this dataset, we propose ViT-HD, a Vision Transformer-based model tailored for detecting human body distortions in AI-generated images, which outperforms state-of-the-art segmentation models and visual language models, achieving an F1 score of 0.899 and IoU of 0.831 on distortion localization. Additionally, we construct the Human Distortion Benchmark with 500 human-centric prompts to evaluate four popular T2I models using trained ViT-HD, revealing that nearly 50% of generated images contain distortions. This work pioneers a systematic approach to evaluating anatomical accuracy in AI-generated humans, offering tools to advance the fidelity of T2I models and their real-world applicability. The Distortion-5K dataset, trained ViT-HD will soon be released in our GitHub repository: \href{https://github.com/TheRoadQaQ/Predicting-Distortion}{https://github.com/TheRoadQaQ/Predicting-Distortion}.
近期文本到图像(T2I)模型的进展使得高质量图像合成成为可能,但生成解剖上准确的人体图像仍然具有挑战性。AI生成的图像经常出现肢体增生、手指缺失、极端部位变形或身体部位融合等失真现象。现有的评估指标,如Inception Score(IS)和Fréchet Inception Distance(FID),缺乏检测这些失真的粒度,而基于人类偏好的度量标准则更注重抽象质量评估,而非解剖准确性。为了解决这一差距,我们制定了识别AI生成图像中人体失真的第一项标准,并推出了Distortion-5K,这是一组包含4700张正常和畸形人体图像的综合数据集,图像跨越多种风格和失真类型并已进行标注。基于该数据集,我们提出了基于Vision Transformer的ViT-HD模型,该模型专为检测AI生成图像中的人体失真而设计。在失真定位方面,它超越了最新的分割模型和视觉语言模型,取得了F1分数为0.899和IoU为0.831的成绩。此外,我们还构建了以500个人类为中心的提示语为基础的人类失真基准测试集,使用训练好的ViT-HD评估了四种流行的T2I模型,发现近50%的生成图像存在失真。这项工作开创了一种系统评估AI生成人体解剖准确性的方法,为改进T2I模型的保真度和其在实际应用中的适用性提供了工具。Distortion-5K数据集和训练好的ViT-HD模型将很快在我们的GitHub仓库中发布:[https://github.com/TheRoadQaQ/Predicting-Distortion]。
论文及项目相关链接
PDF 8 pages, 6 figures
Summary
本文关注于人工智能生成图像中的人体失真问题。针对现有评估指标无法有效检测人体结构失真的问题,建立了首个针对AI生成图像中人体失真的标准,并引入了Distortion-5K数据集。基于该数据集,提出了针对AI生成图像中人体失真的检测模型ViT-HD,该模型在失真定位方面表现出卓越性能。此外,构建了人类失真基准测试,揭示了当前T2I模型中人体失真的普遍存在。本文为评估AI生成人类的解剖学准确性提供了系统方法,有助于提高T2I模型的逼真度和实际应用价值。
Key Takeaways
- AI生成图像中人体失真是一个挑战,包括肢体增生、手指缺失、极端部位变形、身体部位融合等问题。
- 现有评估指标如Inception Score和Fréchet Inception Distance无法细致检测这些失真。
- 建立了首个针对AI生成图像中人体失真的标准。
- 引入了Distortion-5K数据集,包含4700张正常和畸形人类图像的标注。
- 提出了基于Vision Transformer的ViT-HD模型,用于检测AI生成图像中的人体失真,性能卓越。
- 构建了人类失真基准测试,发现近50%的生成图像存在失真。
- 该工作为评估AI生成人类的解剖学准确性提供了系统方法,有助于提升T2I模型的逼真度和实际应用。
点此查看论文截图



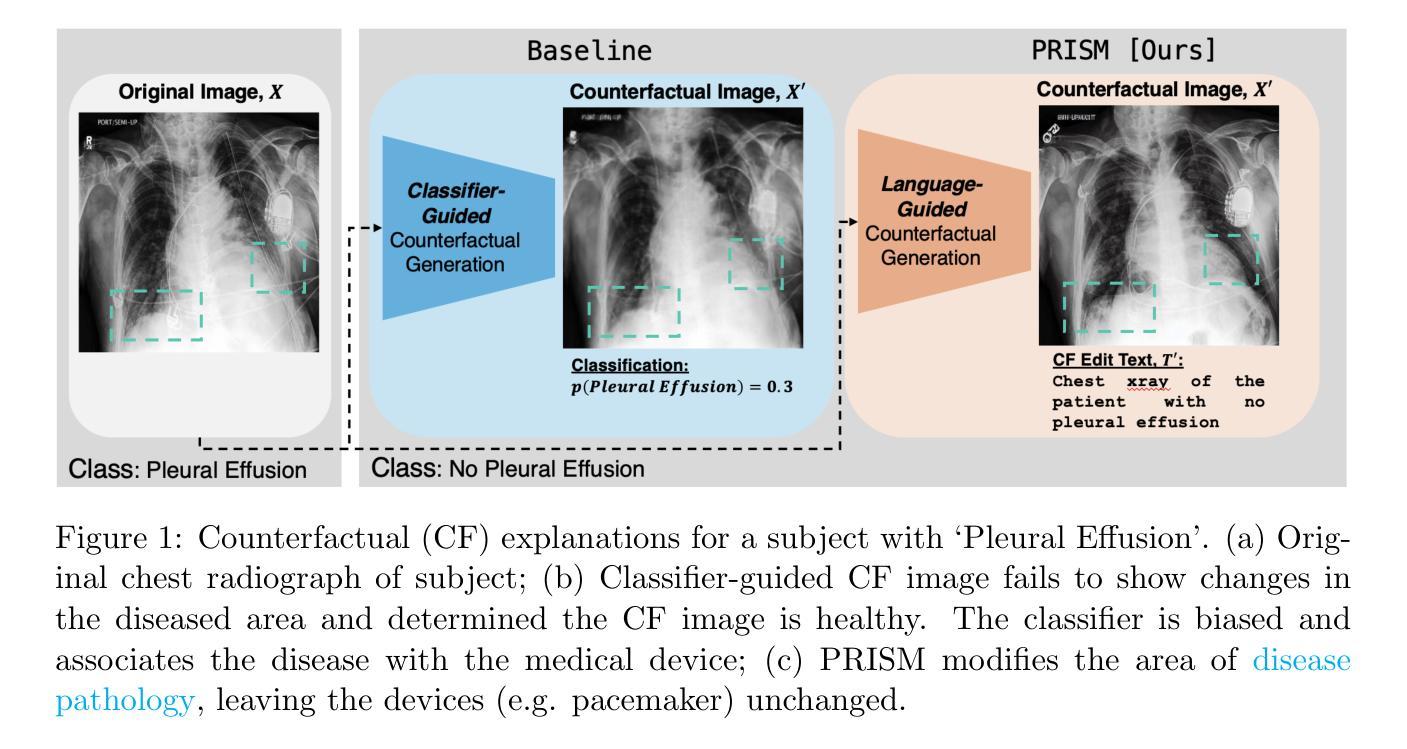
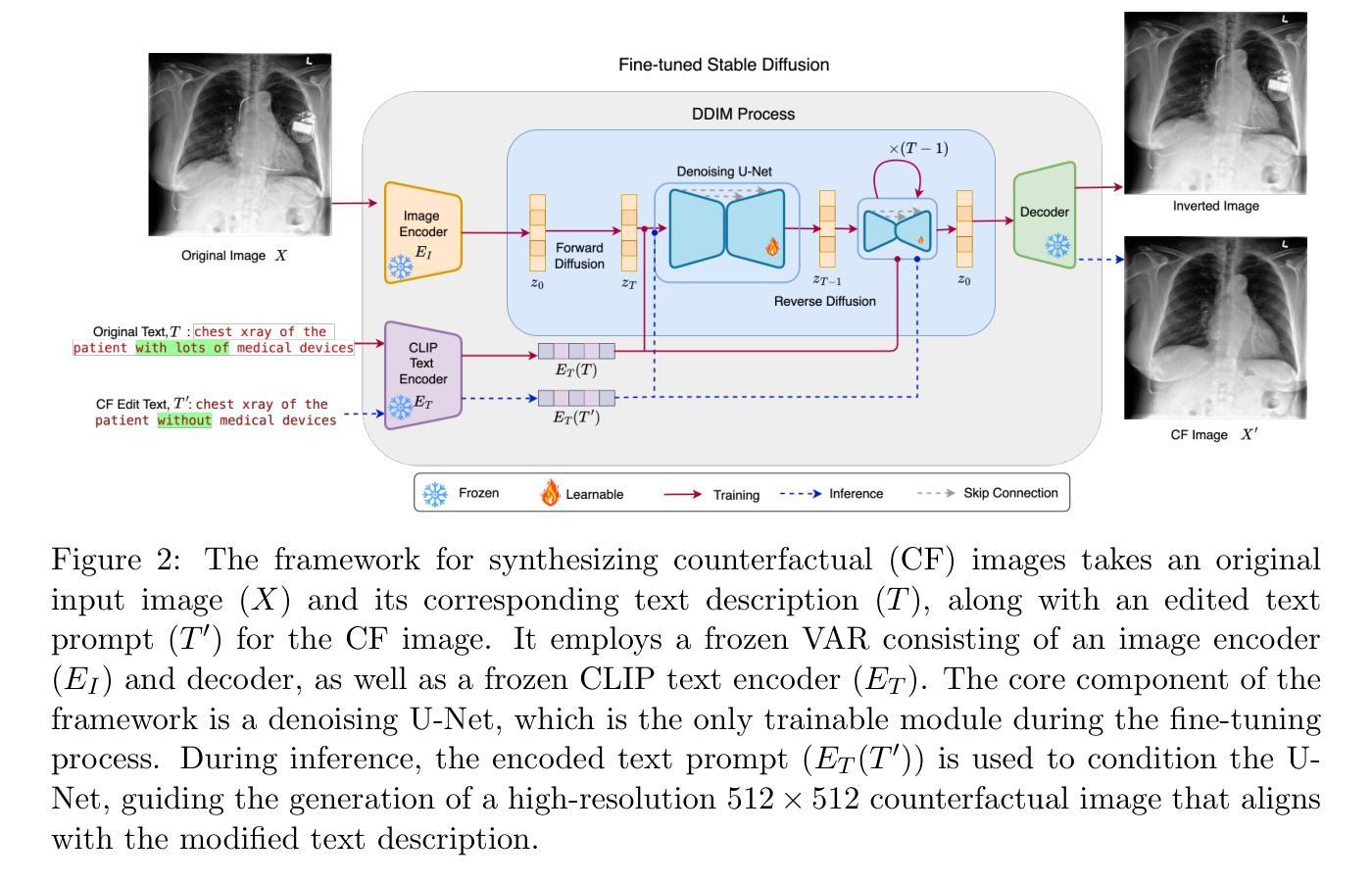
PRISM: High-Resolution & Precise Counterfactual Medical Image Generation using Language-guided Stable Diffusion
Authors:Amar Kumar, Anita Kriz, Mohammad Havaei, Tal Arbel
Developing reliable and generalizable deep learning systems for medical imaging faces significant obstacles due to spurious correlations, data imbalances, and limited text annotations in datasets. Addressing these challenges requires architectures robust to the unique complexities posed by medical imaging data. The rapid advancements in vision-language foundation models within the natural image domain prompt the question of how they can be adapted for medical imaging tasks. In this work, we present PRISM, a framework that leverages foundation models to generate high-resolution, language-guided medical image counterfactuals using Stable Diffusion. Our approach demonstrates unprecedented precision in selectively modifying spurious correlations (the medical devices) and disease features, enabling the removal and addition of specific attributes while preserving other image characteristics. Through extensive evaluation, we show how PRISM advances counterfactual generation and enables the development of more robust downstream classifiers for clinically deployable solutions. To facilitate broader adoption and research, we make our code publicly available at https://github.com/Amarkr1/PRISM.
针对医学影像开发可靠且通用的深度学习系统面临着重大挑战,这主要是由于数据集中的虚假关联、数据不平衡和文本注释有限等问题。要解决这些挑战,需要针对医学影像数据带来的独特复杂性构建稳健的架构。自然图像领域中的视觉语言基础模型的快速发展引发了一个问题:如何将其适应医学影像任务。在这项工作中,我们提出了PRISM框架,该框架利用基础模型,使用Stable Diffusion生成高分辨率的语言引导医学影像反事实。我们的方法展示了在选择性修改虚假关联(医疗设备)和疾病特征方面具有前所未有的精度,能够在保留其他图像特征的同时删除和添加特定属性。通过广泛评估,我们展示了PRISM如何推动反事实生成的发展,并使得开发更稳健的下游分类器用于临床部署解决方案成为可能。为了便于更广泛的采用和研究,我们在https://github.com/Amarkr1/PRISM上公开了我们的代码。
论文及项目相关链接
PDF Under Review for MIDL 2025
Summary
该文本介绍了一个名为PRISM的框架,该框架利用基础模型生成高分辨率的语言引导医学图像反事实,使用Stable Diffusion解决医学成像数据中的复杂问题。PRISM能够精准地选择性修改医学图像中的无关特征和疾病特征,使得特定属性可以被移除和添加而其他图像特征保持不变。它有助于开发更稳健的下游分类器以实现临床部署的解决方案。
Key Takeaways
- PRISM框架利用基础模型解决医学成像数据中的复杂问题,包括无关特征和疾病特征的去除和添加。
- PRISM通过使用Stable Diffusion生成高分辨率的语言引导医学图像反事实。
- PRISM在反事实生成方面取得了进展,有助于开发更稳健的下游分类器以实现临床部署的解决方案。
点此查看论文截图

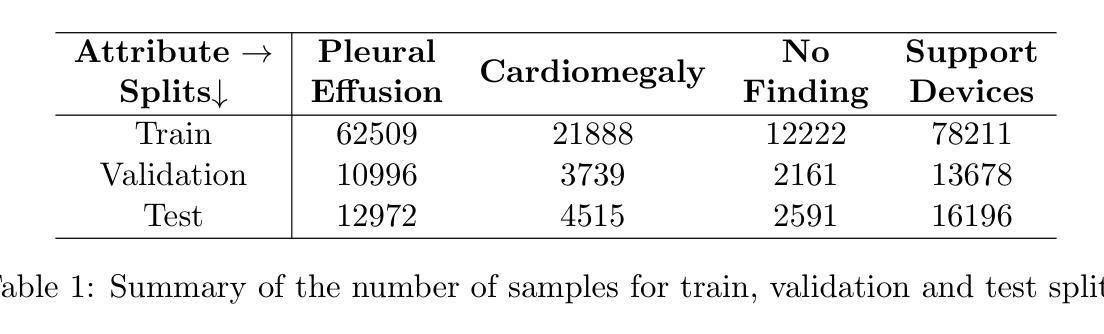

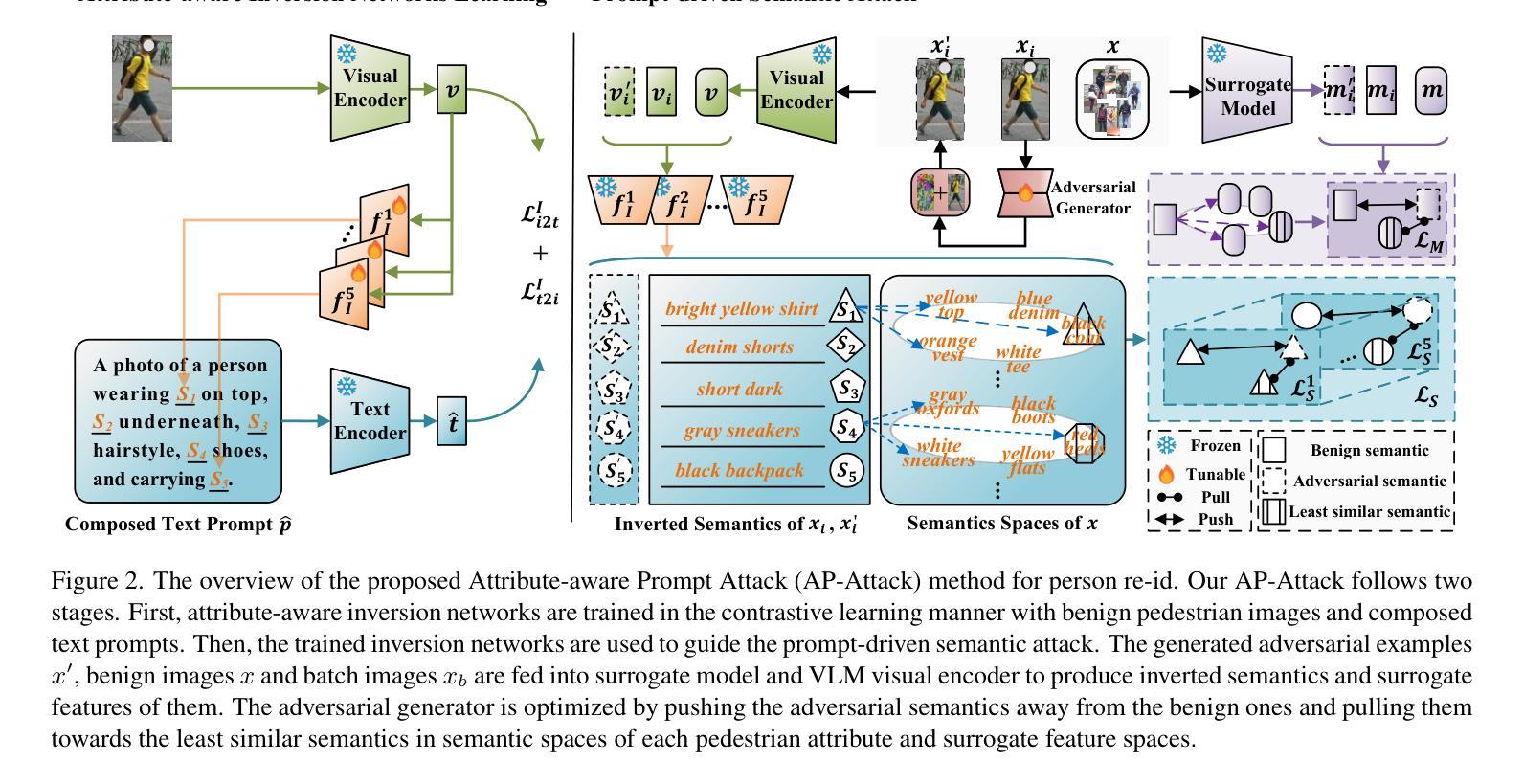
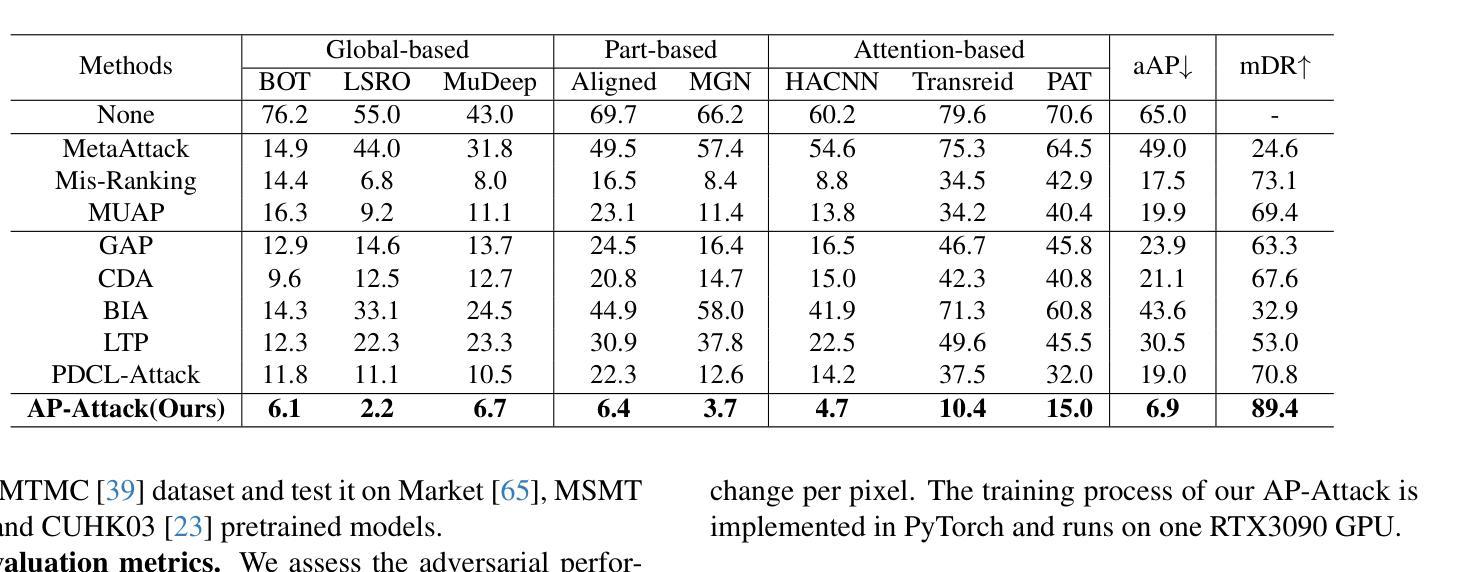
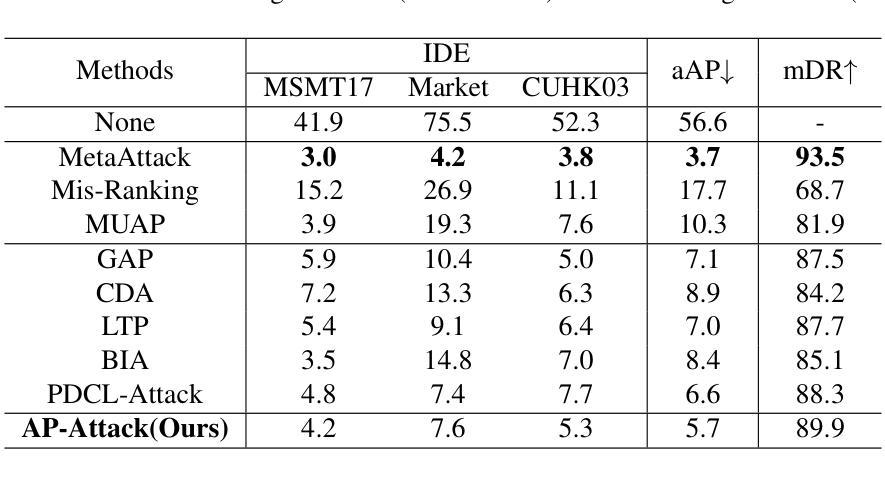
Prompt-driven Transferable Adversarial Attack on Person Re-Identification with Attribute-aware Textual Inversion
Authors:Yuan Bian, Min Liu, Yunqi Yi, Xueping Wang, Yaonan Wang
Person re-identification (re-id) models are vital in security surveillance systems, requiring transferable adversarial attacks to explore the vulnerabilities of them. Recently, vision-language models (VLM) based attacks have shown superior transferability by attacking generalized image and textual features of VLM, but they lack comprehensive feature disruption due to the overemphasis on discriminative semantics in integral representation. In this paper, we introduce the Attribute-aware Prompt Attack (AP-Attack), a novel method that leverages VLM’s image-text alignment capability to explicitly disrupt fine-grained semantic features of pedestrian images by destroying attribute-specific textual embeddings. To obtain personalized textual descriptions for individual attributes, textual inversion networks are designed to map pedestrian images to pseudo tokens that represent semantic embeddings, trained in the contrastive learning manner with images and a predefined prompt template that explicitly describes the pedestrian attributes. Inverted benign and adversarial fine-grained textual semantics facilitate attacker in effectively conducting thorough disruptions, enhancing the transferability of adversarial examples. Extensive experiments show that AP-Attack achieves state-of-the-art transferability, significantly outperforming previous methods by 22.9% on mean Drop Rate in cross-model&dataset attack scenarios.
行人再识别(Re-ID)模型在安全监控系统中的作用至关重要,需要可迁移的对抗性攻击来探索其漏洞。最近,基于视觉语言模型(VLM)的攻击表现出通过攻击VLM的通用图像和文本特征而具有的出色可迁移性,但由于过分强调整体表示中的判别语义,它们缺乏全面的特征破坏。在本文中,我们介绍了属性感知提示攻击(AP-Attack),这是一种利用VLM的图像文本对齐能力来明确破坏行人图像的细粒度语义特征的新方法,通过破坏特定属性的文本嵌入来实现。为了获得针对各个属性的个性化文本描述,设计文本反转网络将行人图像映射到代表语义嵌入的伪令牌,利用对比学习方式与图像和预先定义的明确描述行人属性的提示模板进行训练。反转的良性和对抗性的细粒度文本语义有助于攻击者进行有效的全面破坏,提高对抗样本的可迁移性。大量实验表明,AP-Attack在可迁移性方面达到了最新水平,在跨模型和数据集攻击场景中,平均下降率提高了22.9%,显著优于以前的方法。
论文及项目相关链接
Summary
本文提出一种名为属性感知提示攻击(AP-Attack)的新方法,利用视觉语言模型(VLM)的图像文本对齐能力,通过破坏行人图像的细粒度语义特征来进行攻击。该方法设计文本反演网络,将行人图像映射到代表语义嵌入的伪令牌上,通过与图像和预定义提示模板进行对比学习训练,明确描述行人属性。这种攻击方法能有效全面破坏细粒度文本语义,提高对抗样本的迁移性,实现跨模型和数据集攻击场景下的最佳迁移性。
Key Takeaways
- 属性感知提示攻击(AP-Attack)利用视觉语言模型(VLM)的图像文本对齐能力,针对行人图像的细粒度语义特征进行攻击。
- 通过设计文本反演网络,将行人图像映射到语义嵌入的伪令牌上。
- 使用对比学习方式训练文本反演网络,结合图像和预定义的提示模板描述行人属性。
- AP-Attack能有效全面破坏细粒度文本语义,增强对抗样本的迁移性。
- 该方法在跨模型和跨数据集攻击场景下表现出最佳迁移性,较之前的方法平均下降率提高了22.9%。
- AP-Attack针对的是人重新识别(re-id)模型的脆弱性,对安全监控系统具有重要意义。
点此查看论文截图

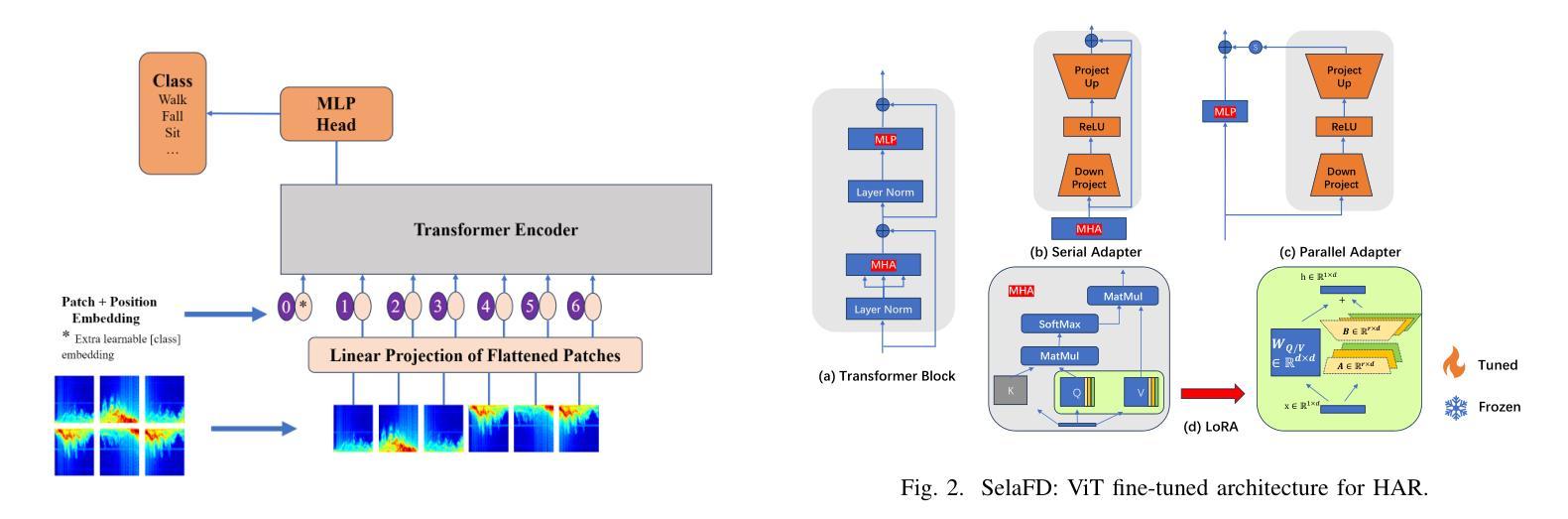
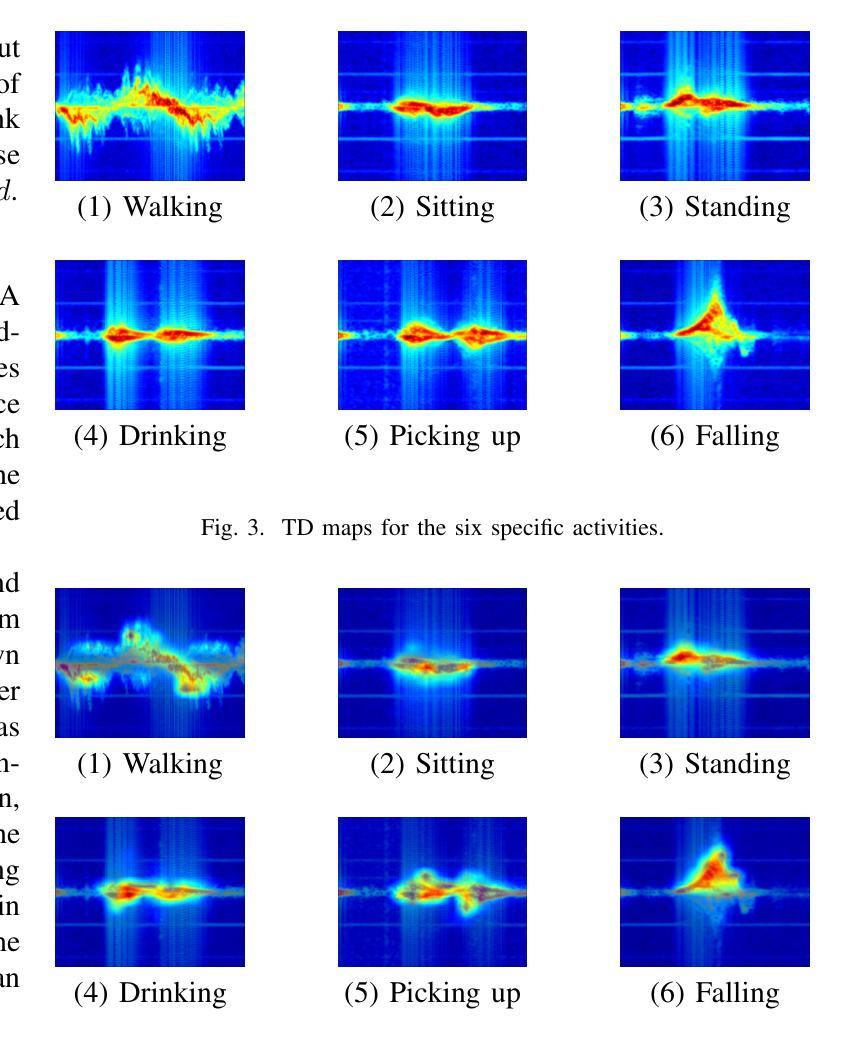
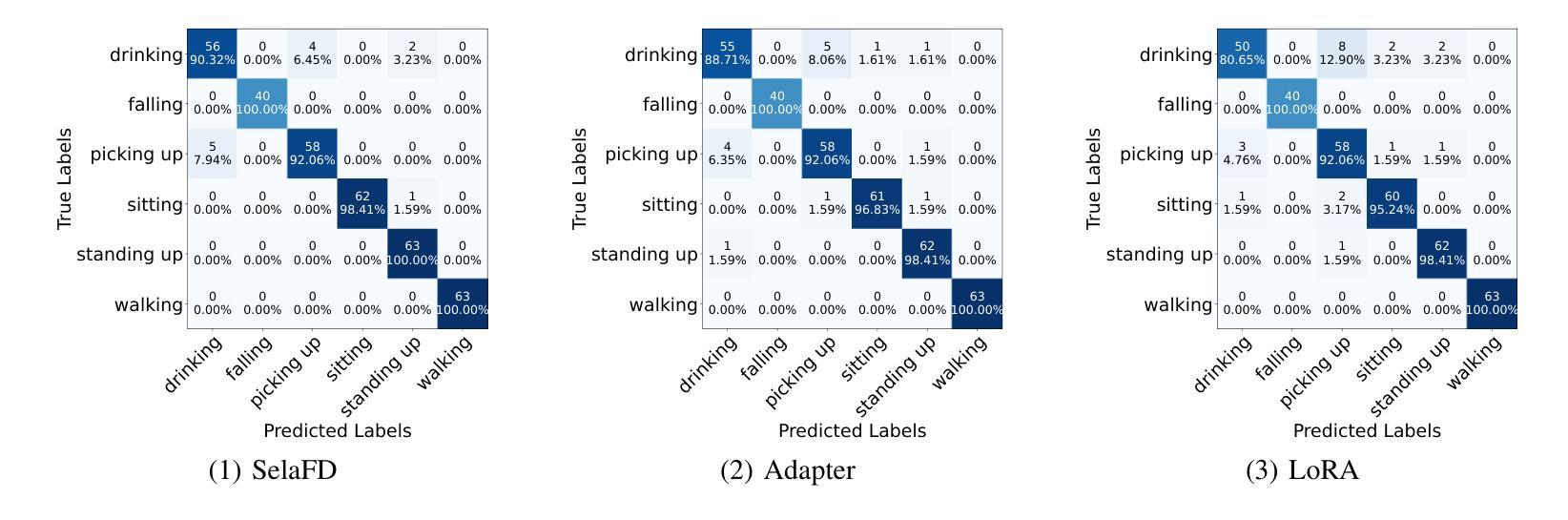
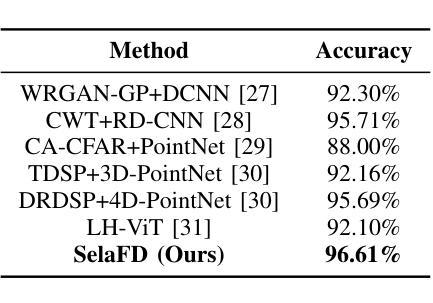
SelaFD:Seamless Adaptation of Vision Transformer Fine-tuning for Radar-based Human Activity Recognition
Authors:Yijun Wang, Yong Wang, Chendong xu, Shuai Yao, Qisong Wu
Human Activity Recognition (HAR) such as fall detection has become increasingly critical due to the aging population, necessitating effective monitoring systems to prevent serious injuries and fatalities associated with falls. This study focuses on fine-tuning the Vision Transformer (ViT) model specifically for HAR using radar-based Time-Doppler signatures. Unlike traditional image datasets, these signals present unique challenges due to their non-visual nature and the high degree of similarity among various activities. Directly fine-tuning the ViT with all parameters proves suboptimal for this application. To address this challenge, we propose a novel approach that employs Low-Rank Adaptation (LoRA) fine-tuning in the weight space to facilitate knowledge transfer from pre-trained ViT models. Additionally, to extract fine-grained features, we enhance feature representation through the integration of a serial-parallel adapter in the feature space. Our innovative joint fine-tuning method, tailored for radar-based Time-Doppler signatures, significantly improves HAR accuracy, surpassing existing state-of-the-art methodologies in this domain. Our code is released at https://github.com/wangyijunlyy/SelaFD.
人类活动识别(HAR)如跌倒检测,由于人口老龄化而变得越来越重要,需要有效的监控系统来防止与跌倒相关的严重伤害和死亡。本研究专注于使用基于雷达的Time-Doppler特征对Vision Transformer(ViT)模型进行微调,以应用于HAR。与传统的图像数据集不同,这些信号由于其非视觉性质和各种活动之间的高度相似性而具有独特的挑战。直接使用所有参数对ViT进行微调对于此应用而言证明是次优的。为了应对这一挑战,我们提出了一种采用权重空间中的低秩适配(LoRA)微调的新方法,以促进从预训练的ViT模型的知识转移。此外,为了提取细粒度特征,我们通过特征空间中串行并行适配器的集成增强了特征表示。我们针对基于雷达的Time-Doppler特征量身定制的创新联合微调方法,显著提高了HAR的准确性,超越了该领域的现有最新方法。我们的代码已发布在https://github.com/wangyijunlyy/SelaFD。
论文及项目相关链接
Summary
雷达基于时间的Doppler签名对于人体活动识别至关重要,该研究使用低秩适配(LoRA)技术对预训练的Vision Transformer(ViT)模型进行微调,通过串行并行适配器强化特征表示来提升人体活动识别的精确度。研究成果有效提升了基于雷达Time-Doppler信号的HAR准确度,超越当前领域最先进的方法。代码已发布在GitHub上。
Key Takeaways
- 研究关注雷达基于时间的Doppler签名在人体活动识别(HAR)中的应用。
- 直接使用所有参数微调ViT模型对于此应用是次优的。
- 提出使用低秩适配(LoRA)技术进行微调,在权重空间促进知识从预训练ViT模型中迁移。
- 通过集成串行并行适配器强化特征表示,以提取精细特征。
- 针对雷达基于时间的Doppler签名定制的创新联合微调方法显著提高了HAR的准确性。
- 该方法超越了当前领域最先进的方法。
点此查看论文截图


Locality Alignment Improves Vision-Language Models
Authors:Ian Covert, Tony Sun, James Zou, Tatsunori Hashimoto
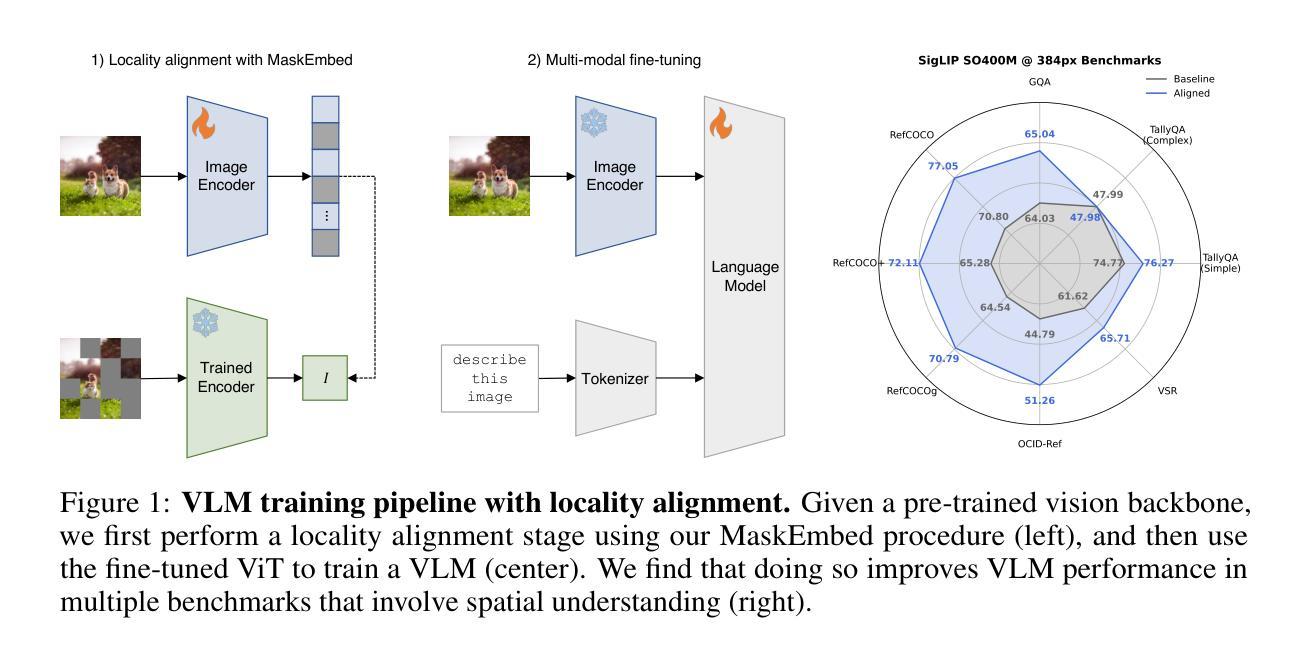
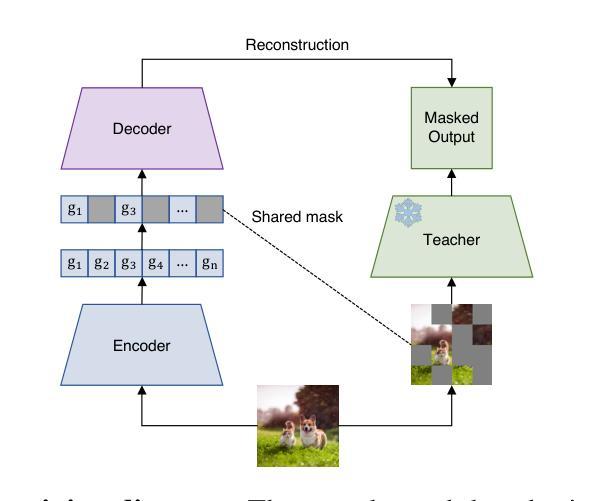
Vision language models (VLMs) have seen growing adoption in recent years, but many still struggle with basic spatial reasoning errors. We hypothesize that this is due to VLMs adopting pre-trained vision backbones, specifically vision transformers (ViTs) trained with image-level supervision and minimal inductive biases. Such models may fail to encode the class contents at each position in the image, and our goal is to resolve this with a vision backbone that effectively captures both local and global image semantics. Our main insight is that we do not require new supervision to learn this capability - pre-trained models contain significant knowledge of local semantics that we can extract and use for scalable self-supervision. We propose a new efficient post-training stage for ViTs called locality alignment and a novel fine-tuning procedure called MaskEmbed that uses a masked reconstruction loss to learn semantic contributions for each image patch. We first evaluate locality alignment with a vision-only benchmark, finding that it improves a model’s performance at patch-level semantic segmentation, especially for strong backbones trained with image-caption pairs (e.g., CLIP and SigLIP). We then train a series of VLMs with and without locality alignment, and show that locality-aligned backbones improve performance across a range of benchmarks, particularly ones that involve spatial understanding (e.g., RefCOCO, OCID-Ref, TallyQA, VSR, AI2D). Overall, we demonstrate that we can efficiently learn local semantic extraction via a locality alignment stage, and that this procedure benefits VLM training recipes that use off-the-shelf vision backbones.
视觉语言模型(VLMs)近年来得到了越来越多的应用,但许多模型仍面临基本的空间推理错误问题。我们假设这是由于VLMs采用了预训练的视觉主干网,特别是使用图像级监督和少量归纳偏置训练的视觉变压器(ViTs)。这种模型可能无法编码图像中每个位置的类别内容,我们的目标是通过有效地捕捉局部和全局图像语义的视觉主干网来解决这个问题。我们的主要见解是,我们不需要新的监督来学习这种能力——预训练模型包含大量的局部语义知识,我们可以提取并用于可扩展的自我监督。我们为ViTs提出了一种新的高效后训练阶段,称为局部对齐,以及一种使用遮罩重建损失来学习每个图像补丁语义贡献的新微调程序,称为MaskEmbed。我们首先使用仅视觉的基准测试评估局部对齐,发现它在补丁级语义分割方面提高了模型的性能,特别是对于使用图像标题对训练的强主干网(例如CLIP和SigLIP)。然后,我们训练了一系列带有和不带有局部对齐的VLMs,并显示局部对齐的主干网在多个基准测试中提高了性能,特别是涉及空间理解的任务(例如RefCOCO、OCID-Ref、TallyQA、VSR、AI2D)。总的来说,我们证明了我们可以通过局部对齐阶段有效地学习局部语义提取,并且该程序有利于使用现成的视觉主干网的VLM训练配方。
论文及项目相关链接
PDF ICLR 2025 Camera-Ready
Summary
近期视觉语言模型(VLM)的应用逐渐增多,但许多模型在基本空间推理方面仍存在错误。研究认为这是因为VLM采用了预训练的视觉主干,特别是以图像级监督训练的视觉转换器(ViT),缺乏归纳偏见。为解决这一问题,研究提出了一种新的高效后训练阶段——局部对齐,以及一种使用掩码重建损失学习图像补丁语义贡献的新微调程序——MaskEmbed。实验表明,局部对齐能提高模型在仅视觉基准测试中的性能,特别是在使用图像-字幕对训练的强主干上表现显著。此外,局部对齐的VLM在涉及空间理解的基准测试中表现优异。总之,研究证明可通过局部对齐阶段有效地学习局部语义提取,并有益于使用现成视觉主干的VLM训练配方。
Key Takeaways
- VLM在基本空间推理方面存在错误,这可能是由于采用了预训练的视觉主干(如ViT),缺乏归纳偏见。
- 研究提出了一种新的高效后训练阶段——局部对齐,旨在解决上述问题。
- 局部对齐能提高模型在仅视觉基准测试中的性能,特别是在使用图像-字幕对训练的强主干上表现显著。
- MaskEmbed是一种新的微调程序,使用掩码重建损失来学习图像补丁的语义贡献。
- 局部对齐的VLM在涉及空间理解的基准测试中表现优越。
- 研究证明了通过局部对齐阶段可以有效地学习局部语义提取。
点此查看论文截图