⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-07 更新
Deblur-Avatar: Animatable Avatars from Motion-Blurred Monocular Videos
Authors:Xianrui Luo, Juewen Peng, Zhongang Cai, Lei Yang, Fan Yang, Zhiguo Cao, Guosheng Lin
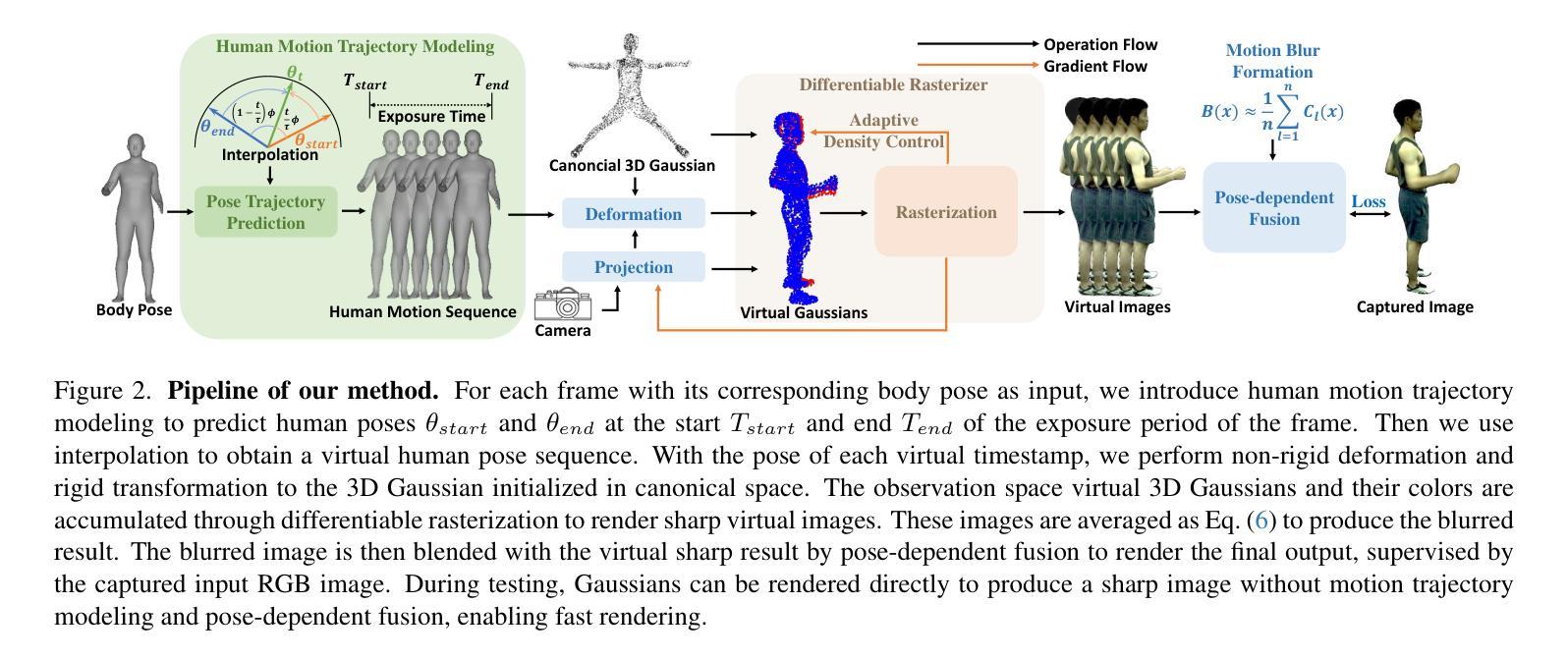
We introduce a novel framework for modeling high-fidelity, animatable 3D human avatars from motion-blurred monocular video inputs. Motion blur is prevalent in real-world dynamic video capture, especially due to human movements in 3D human avatar modeling. Existing methods either (1) assume sharp image inputs, failing to address the detail loss introduced by motion blur, or (2) mainly consider blur by camera movements, neglecting the human motion blur which is more common in animatable avatars. Our proposed approach integrates a human movement-based motion blur model into 3D Gaussian Splatting (3DGS). By explicitly modeling human motion trajectories during exposure time, we jointly optimize the trajectories and 3D Gaussians to reconstruct sharp, high-quality human avatars. We employ a pose-dependent fusion mechanism to distinguish moving body regions, optimizing both blurred and sharp areas effectively. Extensive experiments on synthetic and real-world datasets demonstrate that our method significantly outperforms existing methods in rendering quality and quantitative metrics, producing sharp avatar reconstructions and enabling real-time rendering under challenging motion blur conditions.
我们引入了一种新型框架,用于从运动模糊的单目视频输入中建立高保真、可动画的3D人类化身。运动模糊在现实世界中的动态视频捕捉中普遍存在,特别是在3D人类化身建模中。现有方法要么(1)假设图像输入是清晰的,无法处理运动模糊引入的细节损失,要么(2)主要考虑由相机运动引起的模糊,而忽略了在可动画化身中更常见的运动模糊。我们提出的方法将基于人类运动的运动模糊模型集成到3D高斯喷绘(3DGS)中。通过显式建模曝光时间期间的人类运动轨迹,我们联合优化轨迹和3D高斯分布,以重建清晰、高质量的人类化身。我们采用姿态相关融合机制来区分移动的身体区域,有效地优化模糊和清晰区域。在合成和真实世界数据集上的大量实验表明,我们的方法在渲染质量和定量指标方面显著优于现有方法,能够产生清晰的化身重建,并在具有挑战性的运动模糊条件下实现实时渲染。
论文及项目相关链接
Summary
基于运动模糊的单目视频输入,提出了一种新型框架来建模高保真、可动画的3D人类化身。该方法通过整合基于人类运动的运动模糊模型与三维高斯拼贴技术,优化轨迹和三维高斯分布,重建出清晰、高质量的人类化身。采用姿态相关融合机制区分移动区域,有效优化模糊和清晰区域。实验证明,该方法在渲染质量和定量指标上显著优于现有方法,可在具有挑战性的运动模糊条件下实现清晰的化身重建和实时渲染。
Key Takeaways
- 引入了一种新型框架,能够从运动模糊的单目视频输入中建模高保真、可动画的3D人类化身。
- 整合了基于人类运动的运动模糊模型与三维高斯拼贴技术。
- 通过优化轨迹和三维高斯分布来重建清晰、高质量的人类化身。
- 采用姿态相关融合机制来区分移动区域,同时优化模糊和清晰区域。
- 该方法能够处理真实世界中的动态视频捕捉,尤其是由于人类运动引起的运动模糊。
- 与现有方法相比,该方法在渲染质量和定量指标上表现出显著优势。
点此查看论文截图