⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-07 更新
A self-supervised cyclic neural-analytic approach for novel view synthesis and 3D reconstruction
Authors:Dragos Costea, Alina Marcu, Marius Leordeanu
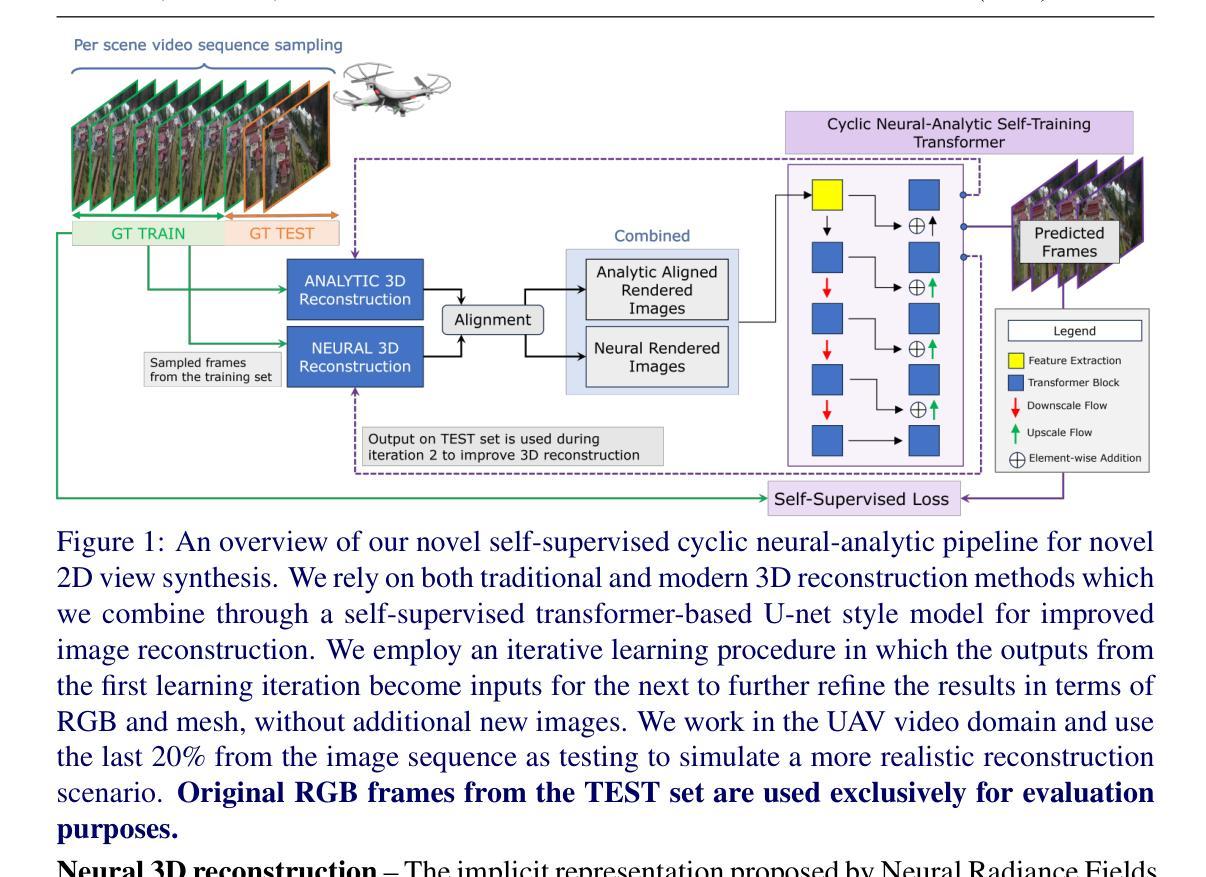
Generating novel views from recorded videos is crucial for enabling autonomous UAV navigation. Recent advancements in neural rendering have facilitated the rapid development of methods capable of rendering new trajectories. However, these methods often fail to generalize well to regions far from the training data without an optimized flight path, leading to suboptimal reconstructions. We propose a self-supervised cyclic neural-analytic pipeline that combines high-quality neural rendering outputs with precise geometric insights from analytical methods. Our solution improves RGB and mesh reconstructions for novel view synthesis, especially in undersampled areas and regions that are completely different from the training dataset. We use an effective transformer-based architecture for image reconstruction to refine and adapt the synthesis process, enabling effective handling of novel, unseen poses without relying on extensive labeled datasets. Our findings demonstrate substantial improvements in rendering views of novel and also 3D reconstruction, which to the best of our knowledge is a first, setting a new standard for autonomous navigation in complex outdoor environments.
从录制的视频中生成新型视角对于实现自主无人机导航至关重要。神经网络渲染的近期进展促进了能够呈现新轨迹的方法的快速发展。然而,这些方法在没有优化飞行路径的情况下,往往不能很好地推广到远离训练数据的区域,从而导致重建效果不理想。我们提出了一种自监督循环神经分析管道,该管道结合了高质量神经渲染输出和来自分析方法的精确几何洞察力。我们的解决方案改进了用于合成新型视角的RGB和网格重建,特别是在欠采样区域和与训练数据集完全不同的区域。我们采用有效的基于转换器的架构进行图像重建,以优化和适应合成过程,能够有效处理新型、未见姿态,而无需依赖大量标记数据集。我们的研究发现在新型视角渲染和3D重建方面取得了显著改进,据我们所知,这是第一次实现,为复杂室外环境中的自主导航设定了新的标准。
论文及项目相关链接
PDF Published in BMVC 2024, 10 pages, 4 figures
Summary
视频生成新技术能提升无人机自主导航能力。新方法结合了高质量神经渲染输出和精确几何分析,改善未知视角的合成和三维重建,尤其适用于采样不足和与训练集差异大的区域。采用有效的转换器架构进行图像重建,可精细调整并适应合成过程,有效处理新颖、未见姿态,无需依赖大量标注数据集。此技术革新了复杂户外环境的自主导航标准。
Key Takeaways
- 自主无人机导航中,从录制视频生成新颖视角至关重要。
- 神经渲染技术的最新进展促进了新型渲染方法的发展。
- 这些方法在没有优化飞行路径的情况下,难以很好地推广到远离训练数据的区域,导致重建效果不理想。
- 提出了一种自我监督的循环神经分析管道,结合了高质量神经渲染和精确几何分析。
- 该解决方案改进了RGB和网格重建用于新颖视角的合成,特别是在采样不足和与训练集完全不同的区域。
- 采用有效的转换器架构进行图像重建,提高合成过程的精细度和适应性。
点此查看论文截图

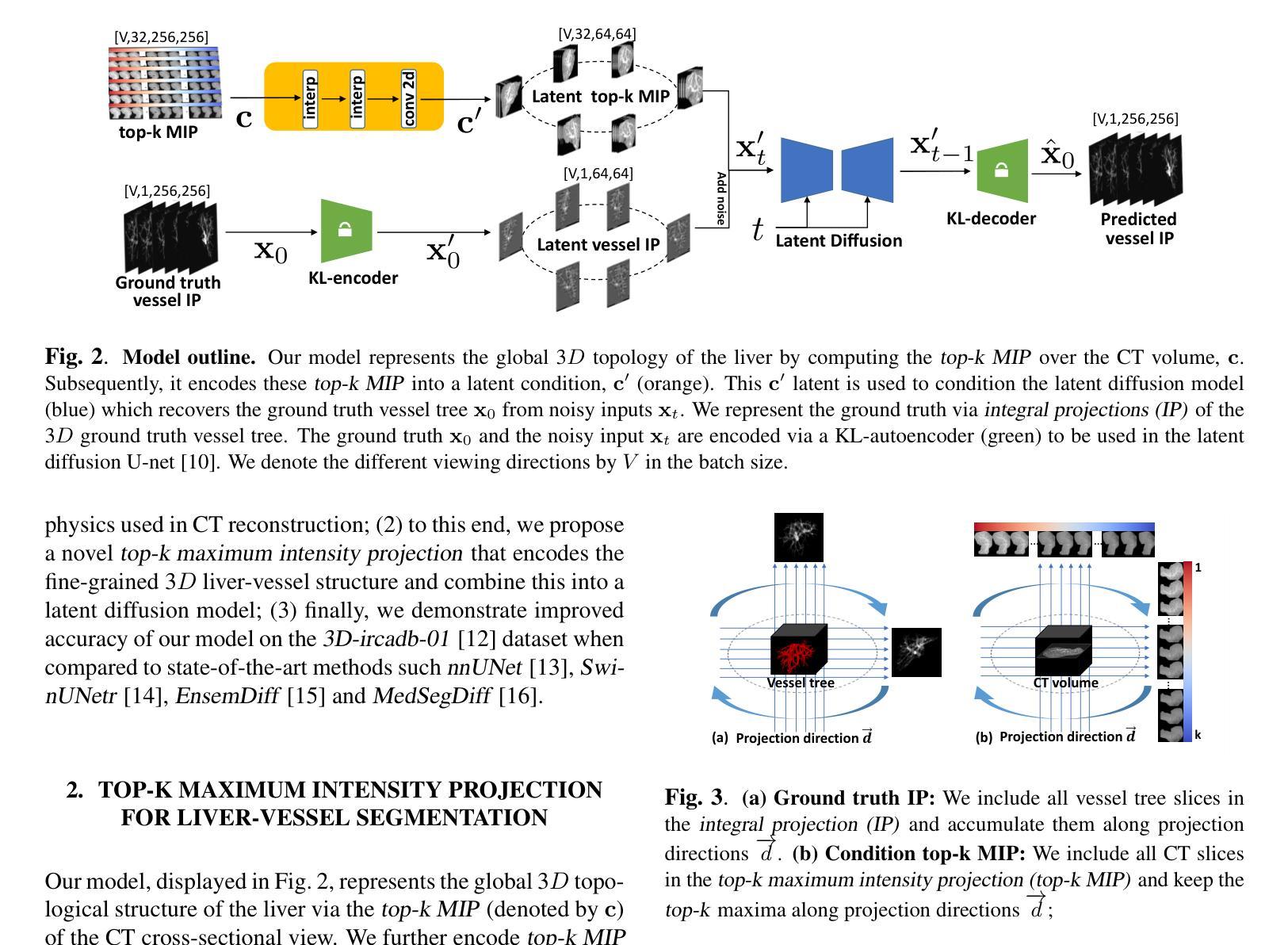
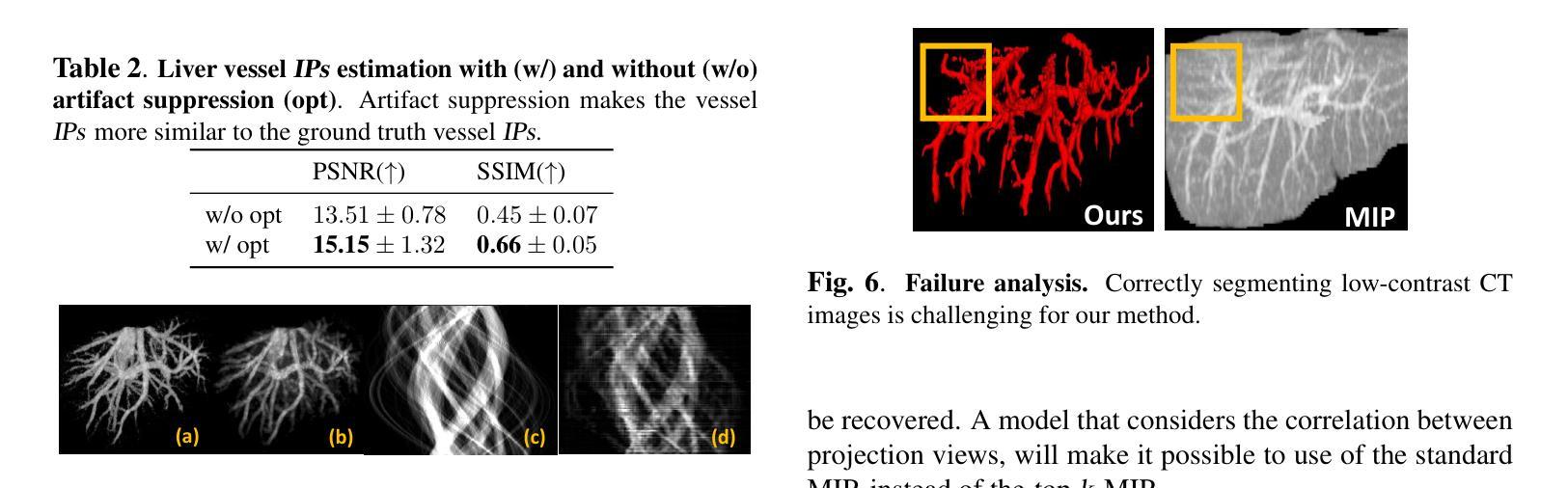
Top-K Maximum Intensity Projection Priors for 3D Liver Vessel Segmentation
Authors:Xiaotong Zhang, Alexander Broersen, Gonnie CM van Erp, Silvia L. Pintea, Jouke Dijkstra
Liver-vessel segmentation is an essential task in the pre-operative planning of liver resection. State-of-the-art 2D or 3D convolution-based methods focusing on liver vessel segmentation on 2D CT cross-sectional views, which do not take into account the global liver-vessel topology. To maintain this global vessel topology, we rely on the underlying physics used in the CT reconstruction process, and apply this to liver-vessel segmentation. Concretely, we introduce the concept of top-k maximum intensity projections, which mimics the CT reconstruction by replacing the integral along each projection direction, with keeping the top-k maxima along each projection direction. We use these top-k maximum projections to condition a diffusion model and generate 3D liver-vessel trees. We evaluate our 3D liver-vessel segmentation on the 3D-ircadb-01 dataset, and achieve the highest Dice coefficient, intersection-over-union (IoU), and Sensitivity scores compared to prior work.
肝脏血管分割是肝脏切除术前规划中的一项重要任务。目前最先进的2D或3D卷积方法主要关注于在2D CT横截面视图上的肝脏血管分割,这些方法并没有考虑到全局肝脏血管拓扑结构。为了保持这种全局血管拓扑结构,我们依赖于CT重建过程中使用的底层物理原理,并将其应用于肝脏血管分割。具体来说,我们引入了前k最大强度投影的概念,通过保留每个投影方向上的前k个最大值来模拟CT重建过程。我们使用这些前k最大投影来设定扩散模型并生成三维肝脏血管树。我们在三维肝脏数据集上进行评估3D-ircadb-01,与先前的工作相比,我们取得了最高的Dice系数、交并比(IoU)和敏感性得分。
论文及项目相关链接
PDF Accepted in 2025 IEEE International Symposium on Biomedical Imaging (ISBI 2025)
Summary
肝脏血管分割是肝脏切除术前规划的重要任务。当前方法主要关注二维CT横截面上的肝脏血管分割,忽略了全局血管拓扑结构。本研究利用CT重建过程中的物理原理,引入top-k最大强度投影的概念,生成三维肝脏血管树。在3D-ircadb-01数据集上评估该三维肝脏血管分割方法,较前期工作有更高的Dice系数、交并比(IoU)和敏感性得分。
Key Takeaways
- 肝脏血管分割是肝脏切除术前规划的重要部分。
- 当前方法主要关注二维CT横截面上的肝脏血管分割,忽略了全局血管拓扑结构的影响。
- 研究利用CT重建的物理原理来维护全局血管拓扑结构。
- 引入top-k最大强度投影的概念,模仿CT重建过程。
- 通过top-k最大强度投影来调控扩散模型,生成三维肝脏血管树。
- 在3D-ircadb-01数据集上评估该三维肝脏血管分割方法。
点此查看论文截图


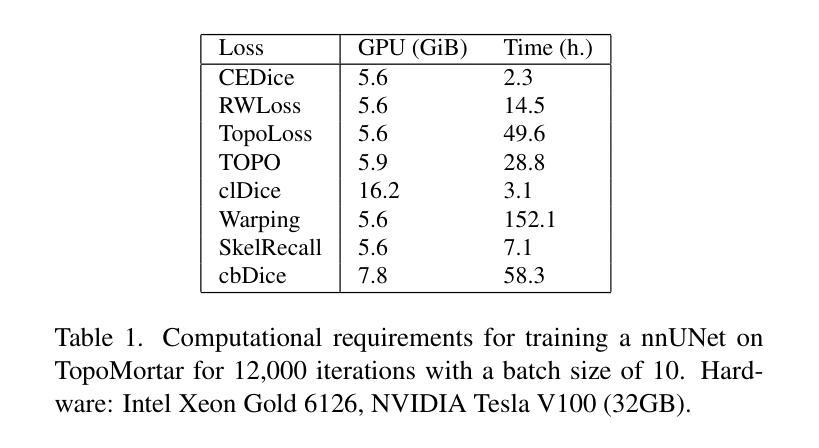
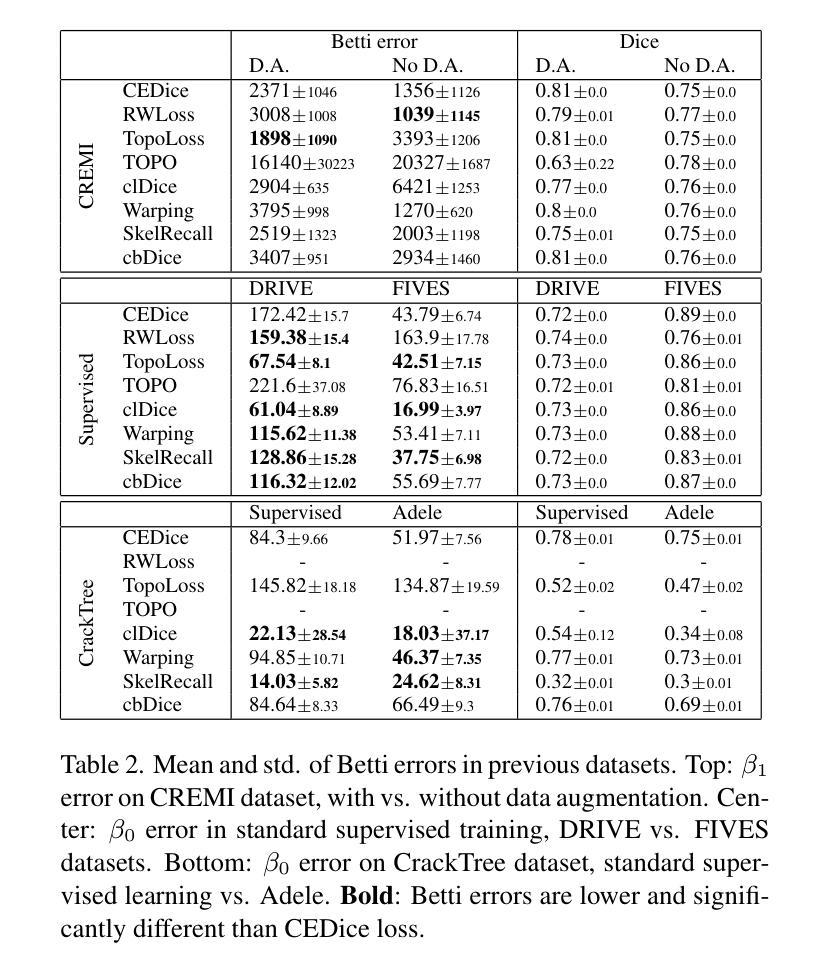
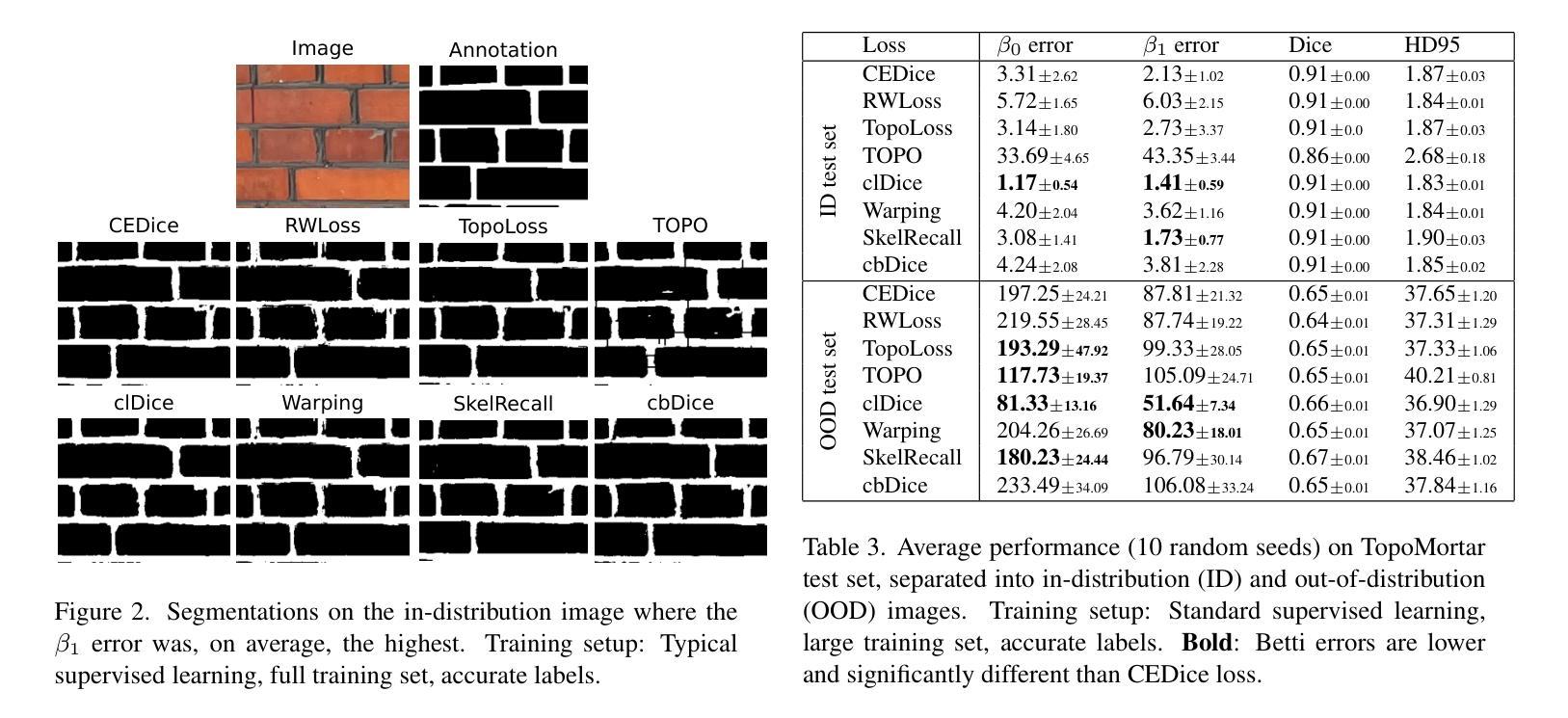
TopoMortar: A dataset to evaluate image segmentation methods focused on topology accuracy
Authors:Juan Miguel Valverde, Motoya Koga, Nijihiko Otsuka, Anders Bjorholm Dahl
We present TopoMortar, a brick wall dataset that is the first dataset specifically designed to evaluate topology-focused image segmentation methods, such as topology loss functions. TopoMortar enables to investigate in two ways whether methods incorporate prior topological knowledge. First, by eliminating challenges seen in real-world data, such as small training set, noisy labels, and out-of-distribution test-set images, that, as we show, impact the effectiveness of topology losses. Second, by allowing to assess in the same dataset topology accuracy across dataset challenges, isolating dataset-related effects from the effect of incorporating prior topological knowledge. In these two experiments, it is deliberately difficult to improve topology accuracy without actually using topology information, thus, permitting to attribute an improvement in topology accuracy to the incorporation of prior topological knowledge. To this end, TopoMortar includes three types of labels (accurate, noisy, pseudo-labels), two fixed training sets (large and small), and in-distribution and out-of-distribution test-set images. We compared eight loss functions on TopoMortar, and we found that clDice achieved the most topologically accurate segmentations, Skeleton Recall loss performed best particularly with noisy labels, and the relative advantageousness of the other loss functions depended on the experimental setting. Additionally, we show that simple methods, such as data augmentation and self-distillation, can elevate Cross entropy Dice loss to surpass most topology loss functions, and that those simple methods can enhance topology loss functions as well. clDice and Skeleton Recall loss, both skeletonization-based loss functions, were also the fastest to train, making this type of loss function a promising research direction. TopoMortar and our code can be found at https://github.com/jmlipman/TopoMortar
我们推出了TopoMortar,这是一款专门用于评估以拓扑为重点的图像分割方法(如拓扑损失函数)的砖墙数据集。TopoMortar能够通过两种方式研究方法是否融入了先验拓扑知识。首先,通过消除真实数据中的挑战,例如小训练集、标签噪声和超出分布范围的测试集图像,这些挑战如我们所展示的,会影响拓扑损失的有效性。其次,它允许在同一数据集中评估不同数据集挑战下的拓扑精度,从而区分数据集相关的影响与融入先验拓扑知识的影响。在这两项实验中,如果不实际使用拓扑信息,很难提高拓扑精度,因此,可以将拓扑精度的提高归因于融入的先验拓扑知识。为此,TopoMortar包括三种标签(准确、噪声、伪标签)、两个固定训练集(大型和小型)以及符合分布和超出分布的测试集图像。我们在TopoMortar上比较了八种损失函数,发现clDice获得了最准确的拓扑分割,特别是在带有噪声标签的情况下Skeleton Recall损失表现最佳,其他损失函数的相对优势取决于实验设置。此外,我们还证明了一些简单的方法(如数据增强和自我蒸馏)可以将Cross entropy Dice损失提升到超越大多数拓扑损失函数,并且这些简单的方法还可以增强拓扑损失函数的效果。clDice和Skeleton Recall损失都是基于骨架化的损失函数,也是训练速度最快的,这使得这种类型的损失函数成为一个有前景的研究方向。TopoMortar和我们的代码可以在https://github.com/jmlipman/TopoMortar找到。
论文及项目相关链接
摘要
TopoMortar数据集专为评估以拓扑为中心的图像分割方法而设计,如拓扑损失函数。该数据集通过消除真实数据中的挑战,如小训练集、标签噪声和超出分布范围的测试集图像,来探究方法是否融入了先验拓扑知识。同时,它允许在同一数据集中评估拓扑精度,以隔离数据集相关效应与融入先验拓扑知识的影响。为此,TopoMortar包含三种标签、两个固定训练集以及符合和超出分布的测试集图像。在TopoMortar上比较了八种损失函数,发现clDice实现最拓扑准确的分割,特别是带有噪声标签时Skeleton Recall损失表现最佳,其他损失函数的优势取决于实验设置。此外,简单的方法如数据增强和自我蒸馏可使Cross entropy Dice损失超越大多数拓扑损失函数,这些方法也能增强拓扑损失函数的效果。clDice和Skeleton Recall损失是基于骨架化的损失函数,训练速度最快,成为有前景的研究方向。
关键见解
- TopoMortar数据集专为评估拓扑聚焦的图像分割方法而设计,例如拓扑损失函数。
- 该数据集消除了真实数据中的挑战,如小训练集、标签噪声和超出分布范围的测试集图像。
- TopoMortar允许在同一数据集中评估拓扑精度,区分数据集相关效应与融入先验拓扑知识的影响。
- 在此数据集中比较了八种损失函数,发现clDice实现最拓扑准确的分割。
- 在处理带有噪声的标签时,Skeleton Recall损失表现最佳。
- 简单的方法(如数据增强和自我蒸馏)能显著提高损失函数的表现,尤其是基于骨架化的损失函数训练速度非常快。
点此查看论文截图

Deep Learning-Based Diffusion MRI Tractography: Integrating Spatial and Anatomical Information
Authors:Yiqiong Yang, Yitian Yuan, Baoxing Ren, Ye Wu, Yanqiu Feng, Xinyuan Zhang
Diffusion MRI tractography technique enables non-invasive visualization of the white matter pathways in the brain. It plays a crucial role in neuroscience and clinical fields by facilitating the study of brain connectivity and neurological disorders. However, the accuracy of reconstructed tractograms has been a longstanding challenge. Recently, deep learning methods have been applied to improve tractograms for better white matter coverage, but often comes at the expense of generating excessive false-positive connections. This is largely due to their reliance on local information to predict long range streamlines. To improve the accuracy of streamline propagation predictions, we introduce a novel deep learning framework that integrates image-domain spatial information and anatomical information along tracts, with the former extracted through convolutional layers and the later modeled via a Transformer-decoder. Additionally, we employ a weighted loss function to address fiber class imbalance encountered during training. We evaluate the proposed method on the simulated ISMRM 2015 Tractography Challenge dataset, achieving a valid streamline rate of 66.2%, white matter coverage of 63.8%, and successfully reconstructing 24 out of 25 bundles. Furthermore, on the multi-site Tractoinferno dataset, the proposed method demonstrates its ability to handle various diffusion MRI acquisition schemes, achieving a 5.7% increase in white matter coverage and a 4.1% decrease in overreach compared to RNN-based methods.
扩散磁共振成像(MRI)纤维追踪技术能够实现大脑白质通路无创可视化。该技术对于神经科学和临床领域至关重要,能够促进脑连接和神经障碍的研究。然而,重建纤维追踪图的准确性一直是一个挑战。最近,深度学习方法被应用于提高纤维追踪图的覆盖范围,但往往会产生过多的假阳性连接。这主要是因为它们依赖局部信息来预测长距离流线。为了提高流线传播预测的准确度,我们引入了一种新型的深度学习框架,该框架结合了图像域的空间信息和沿纤维束的解剖信息。其中,前者通过卷积层提取,后者通过Transformer解码器建模。此外,我们还采用加权损失函数来解决训练过程中遇到的纤维类别不平衡问题。我们在模拟的ISMRM 2015年纤维追踪挑战赛数据集上评估了所提出的方法,实现了有效的流线率为66.2%,白质覆盖率为63.8%,成功重建了24个纤维束中的25个。在多站点Tractoinferno数据集上,该方法展示了其处理各种扩散MRI采集方案的能力,与基于RNN的方法相比,白质覆盖率提高了5.7%,超出率降低了4.1%。
论文及项目相关链接
Summary
本文介绍了一种结合图像域空间信息和解剖信息的新型深度学习框架,用于改善扩散MRI追踪图的准确性。该框架通过卷积层和Transformer解码器进行建模,使用加权损失函数解决训练过程中的纤维类别不平衡问题。在模拟的ISMRM 2015追踪图挑战赛数据集上,该方法实现了有效流线率为66.2%,白质覆盖率为63.8%,成功重建了24个束中的25个。在多站点Tractoinferno数据集上,该方法可处理各种扩散MRI采集方案,与RNN方法相比,白质覆盖率提高了5.7%,过度到达率降低了4.1%。
Key Takeaways
- 扩散MRI追踪技术可实现脑内白质通路的无创可视化。
- 在神经科学和临床领域,该技术对于研究脑连接和神经疾病至关重要。
- 深度学习已应用于改进追踪图以提高白质覆盖率,但存在生成过多假阳性连接的问题。
- 提出的新型深度学习框架结合了图像域空间信息和解剖信息,以提高流线传播预测的准确性。
- 该框架使用卷积层和Transformer解码器进行建模,并采用了加权损失函数来解决纤维类别不平衡问题。
- 在模拟数据集上,该方法的流线率和白质覆盖率表现良好。
点此查看论文截图

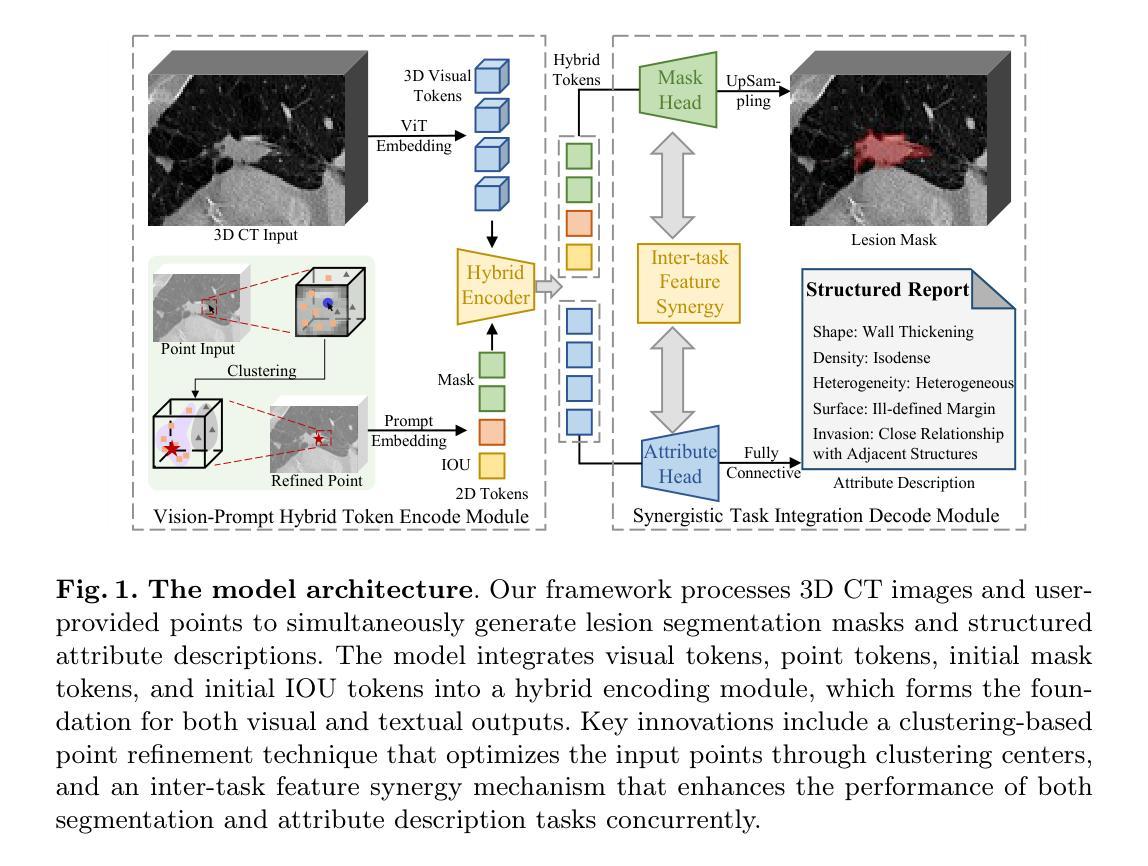
Interactive Segmentation and Report Generation for CT Images
Authors:Yannian Gu, Wenhui Lei, Hanyu Chen, Xiaofan Zhang, Shaoting Zhang
Automated CT report generation plays a crucial role in improving diagnostic accuracy and clinical workflow efficiency. However, existing methods lack interpretability and impede patient-clinician understanding, while their static nature restricts radiologists from dynamically adjusting assessments during image review. Inspired by interactive segmentation techniques, we propose a novel interactive framework for 3D lesion morphology reporting that seamlessly generates segmentation masks with comprehensive attribute descriptions, enabling clinicians to generate detailed lesion profiles for enhanced diagnostic assessment. To our best knowledge, we are the first to integrate the interactive segmentation and structured reports in 3D CT medical images. Experimental results across 15 lesion types demonstrate the effectiveness of our approach in providing a more comprehensive and reliable reporting system for lesion segmentation and capturing. The source code will be made publicly available following paper acceptance.
自动化CT报告生成在提高诊断准确性和临床工作流程效率方面起着至关重要的作用。然而,现有方法缺乏解释性,阻碍医患之间的理解,而其静态性质限制了放射科医生在图像审查过程中动态调整评估的能力。受交互式分割技术的启发,我们提出了一种用于3D病变形态报告的新型交互式框架,该框架可以无缝生成带有综合属性描述的分割掩模,使临床医生能够生成详细的病变特征,从而提高诊断评估水平。据我们所知,我们是首次将交互式分割和结构化报告整合到3D CT医学图像中。跨越15种病变类型的实验结果表明,我们的方法在提供病变分割和捕获的更全面、可靠的报告系统方面非常有效。论文被接受后,源代码将公开发布。
论文及项目相关链接
Summary
在CT影像诊断中,自动化报告生成在提高诊断准确性和临床工作效率方面发挥着重要作用。然而,现有方法缺乏可解释性,阻碍医患沟通,同时静态的特性限制了放射科医生在查看图像时的动态评估能力。受交互式分割技术的启发,我们提出了一种新颖的交互式框架,用于生成包含综合属性描述的分割掩膜,使临床医生能够生成详细的病灶图谱,提高诊断评估的准确性。据我们所知,我们是首次将交互式分割和结构化报告整合到三维CT医学图像中。跨越十五种病灶类型的实验结果表明,我们的方法提供了更全面可靠的病灶分割报告系统。
Key Takeaways
- 自动化CT报告生成在影像诊断中能提高诊断准确性和临床工作效率。
- 当前的方法缺乏可解释性,阻碍了医患沟通。
- 交互式分割技术为改进现有方法提供了新的思路。
- 提出了一种新颖的交互式框架,用于生成包含综合属性描述的分割掩膜。
- 该框架使临床医生能够生成详细的病灶图谱,提高诊断评估的准确性。
- 首次将交互式分割和结构化报告整合到三维CT医学图像中。
点此查看论文截图

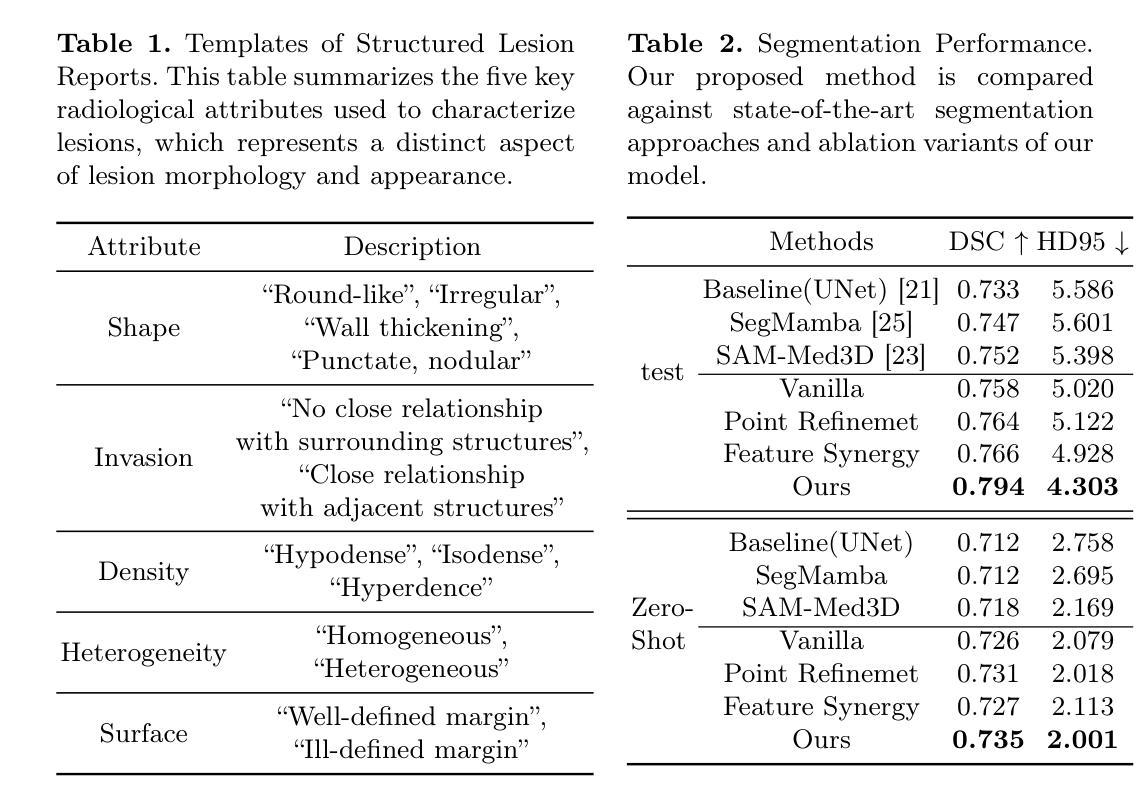
UnPuzzle: A Unified Framework for Pathology Image Analysis
Authors:Dankai Liao, Sicheng Chen, Nuwa Xi, Qiaochu Xue, Jieyu Li, Lingxuan Hou, Zeyu Liu, Chang Han Low, Yufeng Wu, Yiling Liu, Yanqin Jiang, Dandan Li, Yueming Jin, Shangqing Lyu
Pathology image analysis plays a pivotal role in medical diagnosis, with deep learning techniques significantly advancing diagnostic accuracy and research. While numerous studies have been conducted to address specific pathological tasks, the lack of standardization in pre-processing methods and model/database architectures complicates fair comparisons across different approaches. This highlights the need for a unified pipeline and comprehensive benchmarks to enable consistent evaluation and accelerate research progress. In this paper, we present UnPuzzle, a novel and unified framework for pathological AI research that covers a broad range of pathology tasks with benchmark results. From high-level to low-level, upstream to downstream tasks, UnPuzzle offers a modular pipeline that encompasses data pre-processing, model composition,taskconfiguration,andexperimentconduction.Specifically, it facilitates efficient benchmarking for both Whole Slide Images (WSIs) and Region of Interest (ROI) tasks. Moreover, the framework supports variouslearningparadigms,includingself-supervisedlearning,multi-task learning,andmulti-modallearning,enablingcomprehensivedevelopment of pathology AI models. Through extensive benchmarking across multiple datasets, we demonstrate the effectiveness of UnPuzzle in streamlining pathology AI research and promoting reproducibility. We envision UnPuzzle as a cornerstone for future advancements in pathology AI, providing a more accessible, transparent, and standardized approach to model evaluation. The UnPuzzle repository is publicly available at https://github.com/Puzzle-AI/UnPuzzle.
病理学图像分析在医学诊断中扮演着至关重要的角色,深度学习技术显著提高了诊断准确性和研究水平。虽然已进行了大量研究来解决特定的病理任务,但在预处理方法和模型/数据库架构方面缺乏标准化,这使得不同的方法之间难以进行公平的比较。这强调了需要一个统一的流程和综合基准测试,以实现一致的评价并加速研究进展。在本文中,我们提出了UnPuzzle,这是一个用于病理人工智能研究的新型统一框架,涵盖广泛的病理任务并提供基准测试结果。从高级到低级,从上游到下游任务,UnPuzzle提供了一个模块化流程,包括数据预处理、模型组合、任务配置和实验执行。具体来说,它便于对整个幻灯片图像(WSIs)和感兴趣区域(ROI)任务进行高效基准测试。此外,该框架支持多种学习范式,包括自我监督学习、多任务学习和多模式学习,从而实现病理人工智能模型的全面发展。通过多个数据集的大量基准测试,我们证明了UnPuzzle在简化病理人工智能研究并促进可重复性方面的有效性。我们期望UnPuzzle能成为未来病理人工智能发展的基石,提供一种更可访问、透明和标准化的模型评估方法。UnPuzzle仓库可在https://github.com/Puzzle-AI/UnPuzzle公开访问。
论文及项目相关链接
PDF 11 pages,2 figures
Summary
病理学图像分析在医学诊断中扮演重要角色,深度学习技术显著提高了诊断准确性和研究水平。当前缺乏标准化预处理方法和模型/数据库架构,导致不同方法之间的公平比较变得复杂。本文提出了UnPuzzle,一个用于病理学人工智能研究的新型统一框架,涵盖广泛的任务,并提供模块化管道,包括数据处理、模型构建、任务配置和实验执行。它支持多种学习范式,并通过跨多个数据集的大量基准测试证明了其在简化病理学人工智能研究和促进可重复性的有效性。
Key Takeaways
- 病理学图像分析在医学诊断中起关键作用,深度学习技术提高了诊断准确性和研究水平。
- 当前缺乏统一的预处理方法和模型/数据库架构,需要更标准化的研究评估流程。
- UnPuzzle是一个用于病理学人工智能研究的统一框架,涵盖多种任务并提供模块化管道。
- UnPuzzle支持多种学习范式,包括自监督学习、多任务学习和多模态学习。
- UnPuzzle通过跨多个数据集的基准测试证明了其有效性。
- UnPuzzle旨在成为病理学人工智能未来进步的基石,提供更易于访问、透明和标准化的模型评估方法。
点此查看论文截图

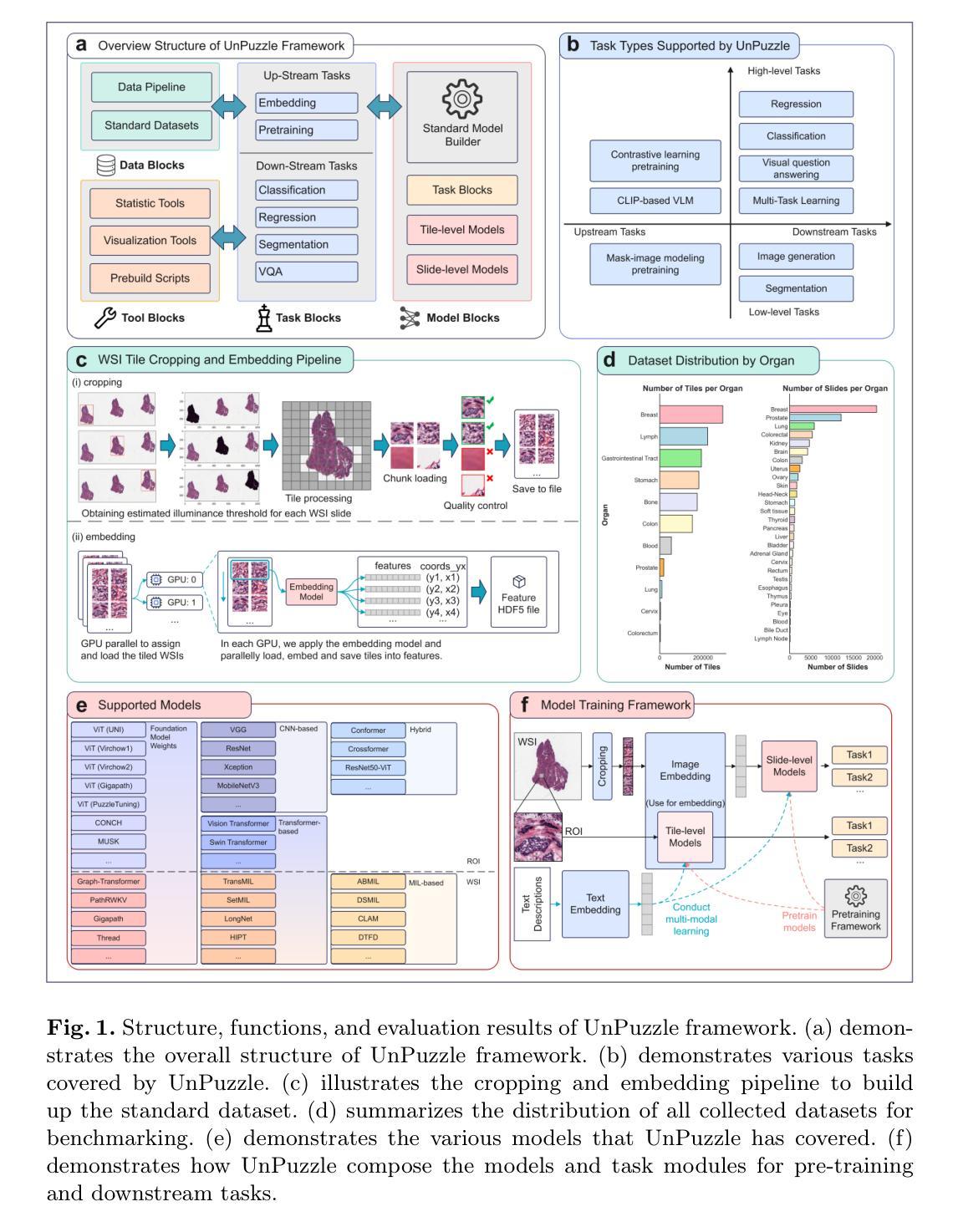
Implicit U-KAN2.0: Dynamic, Efficient and Interpretable Medical Image Segmentation
Authors:Chun-Wun Cheng, Yining Zhao, Yanqi Cheng, Javier Montoya, Carola-Bibiane Schönlieb, Angelica I Aviles-Rivero
Image segmentation is a fundamental task in both image analysis and medical applications. State-of-the-art methods predominantly rely on encoder-decoder architectures with a U-shaped design, commonly referred to as U-Net. Recent advancements integrating transformers and MLPs improve performance but still face key limitations, such as poor interpretability, difficulty handling intrinsic noise, and constrained expressiveness due to discrete layer structures, often lacking a solid theoretical foundation.In this work, we introduce Implicit U-KAN 2.0, a novel U-Net variant that adopts a two-phase encoder-decoder structure. In the SONO phase, we use a second-order neural ordinary differential equation (NODEs), called the SONO block, for a more efficient, expressive, and theoretically grounded modeling approach. In the SONO-MultiKAN phase, we integrate the second-order NODEs and MultiKAN layer as the core computational block to enhance interpretability and representation power. Our contributions are threefold. First, U-KAN 2.0 is an implicit deep neural network incorporating MultiKAN and second order NODEs, improving interpretability and performance while reducing computational costs. Second, we provide a theoretical analysis demonstrating that the approximation ability of the MultiKAN block is independent of the input dimension. Third, we conduct extensive experiments on a variety of 2D and a single 3D dataset, demonstrating that our model consistently outperforms existing segmentation networks.
图像分割是图像分析和医学应用中的基本任务。最先进的方法主要依赖于编码器-解码器架构,并且具有U形设计,通常称为U-Net。最近融合了变压器和多层感知机的进展提高了性能,但仍然面临关键局限,如解释性差、处理内在噪声困难、由于离散层结构导致的表达能力受限,并且通常缺乏坚实理论基础。
在这项工作中,我们引入了Implicit U-KAN 2.0,这是一种采用两阶段编码器-解码器结构的新型U-Net变体。在SONO阶段,我们使用称为SONO块的二阶神经常微分方程(NODEs),以更有效、更具表现力和理论基础的建模方法。在SONO-MultiKAN阶段,我们将二阶NODEs和MultiKAN层作为核心计算块进行集成,以提高可解释性和表示能力。我们的贡献有三点。首先,U-KAN 2.0是一个隐式深度神经网络,结合了MultiKAN和二阶NODEs,在提高可解释性和性能的同时降低了计算成本。其次,我们提供了理论分析,证明MultiKAN块的逼近能力与输入维度无关。最后,我们在多种二维和单个三维数据集上进行了广泛实验,结果表明我们的模型始终优于现有分割网络。
论文及项目相关链接
Summary
本工作提出了Implicit U-KAN 2.0,一种新型U-Net变体,采用两阶段编码器-解码器结构。引入SONO块和SONO-MultiKAN阶段,提高模型效率、表达力、可解释性和理论支撑。在多种数据集上的实验表明,该模型在图像分割任务上优于现有网络。
Key Takeaways
- Implicit U-KAN 2.0是一种新型的U-Net变体,采用两阶段编码器-解码器结构。
- 该模型引入SONO块和SONO-MultiKAN阶段,以提高模型效率和表达力。
- SONO块采用二阶神经常微分方程(NODEs),提高模型的理论支撑。
- MultiKAN块具有独立输入维度的近似能力,增强模型的可解释性。
- 在多种二维和单一三维数据集上进行的实验表明,该模型的性能优于现有分割网络。
- 该模型具有较低的计算成本。
点此查看论文截图

Linking quantum mechanical features to structural phase-transformation in inorganic solids
Authors:Prashant Singh, Anis Biswas, Alexander Thayer, Yaroslav Mudryk
We present a new descriptor, i.e., local lattice distortion, to predict structural phase transformation in inorganic compounds containing lanthanides and transition metals. The descriptor utilizes local lattice and angular distortions obtained from structural optimization of experimentally known crystalline phases within state-of-the-art density-functional theory method. The predictive power of the descriptor was tested on lanthanide based RE2In (RE=rare-earth) compounds known for a variety of phase transformations. We show that the inclusion of quantum-mechanical effects through local-charge, bonding, symmetry, and electronic-structure enhances the robustness of the descriptor in predicting structural phase transformation. To gain further insights, we analyzed phononic and electronic behavior of Y2In, and show that experimentally observed phase transformation can only be predicted when atomic strains are included. The descriptor was used to predict structural phase change in couple of new compounds, i.e., (Yb1-xErx)2In and Gd2(In1-xAlx), which was validated by X-ray powder diffraction measurements. Finally, we demonstrated the generality of the proposed descriptor by predicting phase transformation behavior in different classes of compounds indicating the usefulness of our approach in mapping desired phase changes in novel functional materials.
我们提出了一种新的描述符,即局部晶格畸变,用于预测含稀土元素和过渡金属的无机化合物的结构相变。该描述符利用局部晶格和角度畸变,这些畸变是通过最新发展的密度泛函理论方法对已知晶体结构进行优化而获得的。该描述符的预测能力在基于稀土元素的RE2In(RE=稀土元素)化合物上得到了测试,这些化合物具有多种相变。我们表明,通过局部电荷、键合、对称性和电子结构融入量子力学效应,增强了该描述符在预测结构相变方面的稳健性。为了深入了解,我们分析了Y2In的声学和电子行为,并表明只有当包含原子应变时,才能预测实验观察到的相变。该描述符被用于预测几种新化合物的结构相变,如(Yb1-xErx)2In和Gd2(In1-xAlx),并通过X射线粉末衍射测量验证了其预测结果。最后,我们通过预测不同类别化合物的相变行为来展示所提出描述符的普遍性,这证明了我们方法在新型功能材料中映射所需相变的实用性。
论文及项目相关链接
PDF 25 page, 8 figures, 78 references
Summary
一种新型描述符——局部晶格畸变被提出来预测含稀土元素和过渡金属的无机化合物的结构相变。该描述符利用局部晶格和角度畸变,通过先进的密度泛函理论方法对已知晶体结构进行优化得到。通过测试在稀土元素RE₂In(RE=稀土元素)化合物中的预测能力,显示出该描述符在预测结构相变方面具有良好的鲁棒性,并且量子机械效应包括局部电荷、键合、对称和电子结构的加入增强了预测的准确性。对新化合物(Yb¹ₓEr)₂In和Gd₂(In¹ₓAl)进行了预测,并通过X射线粉末衍射测量验证了预测的相变行为。最终证明了该描述符的通用性,在预测不同化合物的相变行为方面表现出良好的潜力。
Key Takeaways
- 引入了一种新型描述符——局部晶格畸变,用于预测无机化合物的结构相变。
- 描述符结合了先进的密度泛函理论方法来优化已知晶体结构,并利用局部晶格和角度畸变进行预测。
- 描述符在稀土元素RE₂In化合物中的预测能力得到了测试验证。
- 描述符在考虑量子机械效应(如局部电荷、键合、对称和电子结构)的情况下,更能准确预测结构相变。
- 对新化合物(Yb¹ₓEr)₂In和Gd₂(In¹ₓAl)的相变行为进行了预测,并通过实验验证了其准确性。
- 描述符具有良好的通用性,能够预测不同化合物的相变行为。
点此查看论文截图

Can Diffusion Models Provide Rigorous Uncertainty Quantification for Bayesian Inverse Problems?
Authors:Evan Scope Crafts, Umberto Villa
In recent years, the ascendance of diffusion modeling as a state-of-the-art generative modeling approach has spurred significant interest in their use as priors in Bayesian inverse problems. However, it is unclear how to optimally integrate a diffusion model trained on the prior distribution with a given likelihood function to obtain posterior samples. While algorithms that have been developed for this purpose can produce high-quality, diverse point estimates of the unknown parameters of interest, they are often tested on problems where the prior distribution is analytically unknown, making it difficult to assess their performance in providing rigorous uncertainty quantification. In this work, we introduce a new framework, Bayesian Inverse Problem Solvers through Diffusion Annealing (BIPSDA), for diffusion model based posterior sampling. The framework unifies several recently proposed diffusion model based posterior sampling algorithms and contains novel algorithms that can be realized through flexible combinations of design choices. Algorithms within our framework were tested on model problems with a Gaussian mixture prior and likelihood functions inspired by problems in image inpainting, x-ray tomography, and phase retrieval. In this setting, approximate ground-truth posterior samples can be obtained, enabling principled evaluation of the performance of the algorithms. The results demonstrate that BIPSDA algorithms can provide strong performance on the image inpainting and x-ray tomography based problems, while the challenging phase retrieval problem, which is difficult to sample from even when the posterior density is known, remains outside the reach of the diffusion model based samplers.
近年来,扩散模型作为一种最先进的生成建模方法逐渐兴起,这激发了对其在贝叶斯反问题中作为先验使用的极大兴趣。然而,对于如何将训练的扩散模型与给定的似然函数相结合以获得后验样本的最优方法尚不清楚。尽管为此目的而开发的算法可以产生高质量的未知参数估计值,但这些估计值往往是多样化的。但这些算法经常在先验分布分析未知的问题上接受测试,这使得它们在提供严格的不确定性量化方面的性能难以评估。在这项工作中,我们引入了基于扩散退火的贝叶斯反问题求解器(BIPSDA)的新框架,用于基于扩散模型的采样。该框架统一了最近提出的几种基于扩散模型的采样算法,并包含了可以通过灵活组合设计选择来实现的新算法。在我们的框架内的算法是在具有高斯混合先验和受图像修复、X射线断层扫描和相位检索问题启发的似然函数模型问题上进行的测试。在此设置中,可以获得近似真实的后验样本,这能够按照原则评估算法的性能。结果表明,BIPSDA算法在图像修复和基于X射线断层扫描的问题上表现出强大的性能,而对于即使已知后验密度也很难采样的具有挑战性的相位检索问题,基于扩散模型的采样器仍无法解决。
论文及项目相关链接
Summary
本文介绍了通过扩散退火解决贝叶斯反问题的新框架BIPSDA,该框架整合了多种扩散模型后采样算法,包括新颖算法,可通过灵活的设计选择实现。在具有高斯混合先验和受图像补全、X射线断层扫描和相位检索问题启发的似然函数的模型问题上测试了该框架的算法,可以获得近似真实的后验样本,从而可以原则性地评估算法性能。结果表明,BIPSDA算法在图像补全和基于X射线断层扫描的问题上表现强劲,而在采样困难的相位检索问题上则有待进一步突破。
Key Takeaways
- 扩散模型作为最先进的生成建模方法,在贝叶斯反问题中被广泛用作先验。
- 现有算法在将扩散模型与给定的似然函数结合以获取后验样本方面存在不确定性。
- 引入了一个新框架BIPSDA,用于基于扩散模型的后验采样。
- BIPSDA框架整合了多种扩散模型后采样算法,包括新颖算法。
- 在具有高斯混合先验和特定似然函数的模型问题上测试了BIPSDA框架的算法。
- BIPSDA算法在图像补全和基于X射线断层扫描的问题上表现良好。
点此查看论文截图

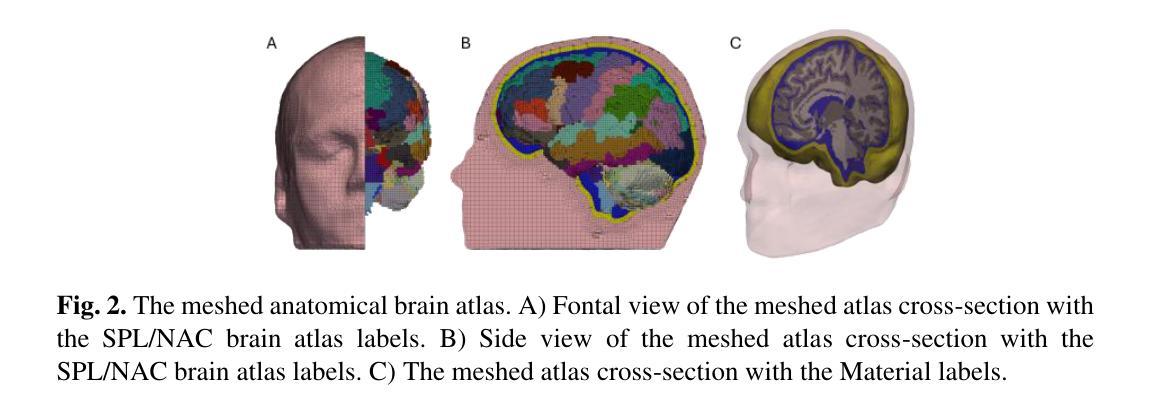
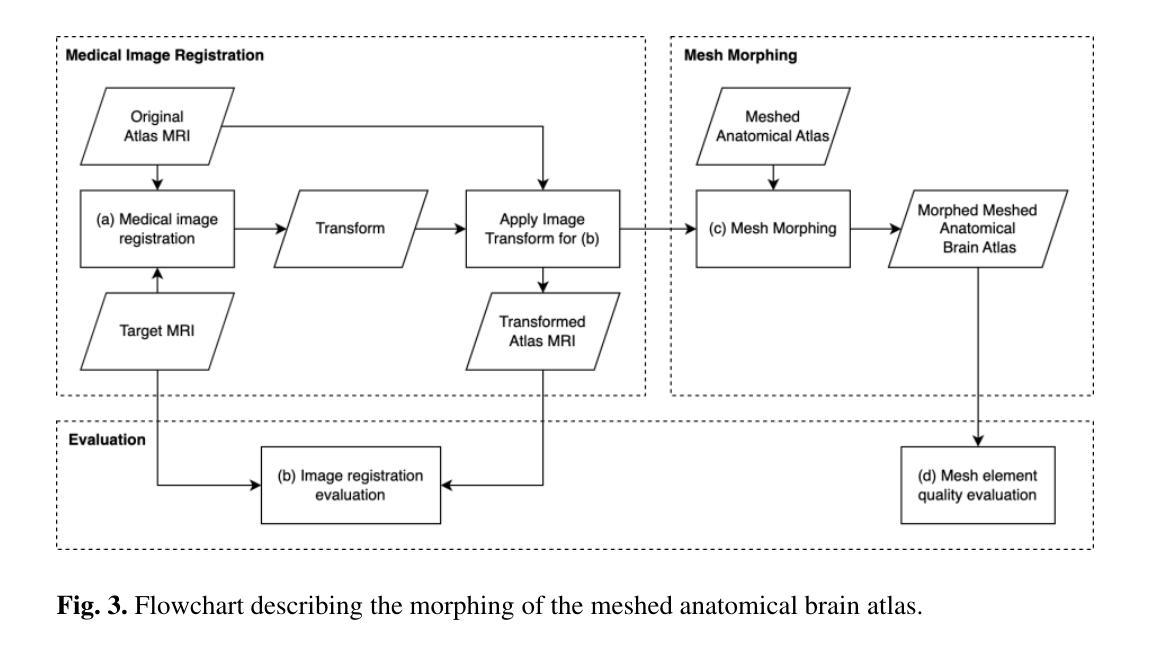
Personalizing the meshed SPL/NAC Brain Atlas for patient-specific scientific computing using SynthMorph
Authors:Andy Huynh, Benjamin Zwick, Michael Halle, Adam Wittek, Karol Miller
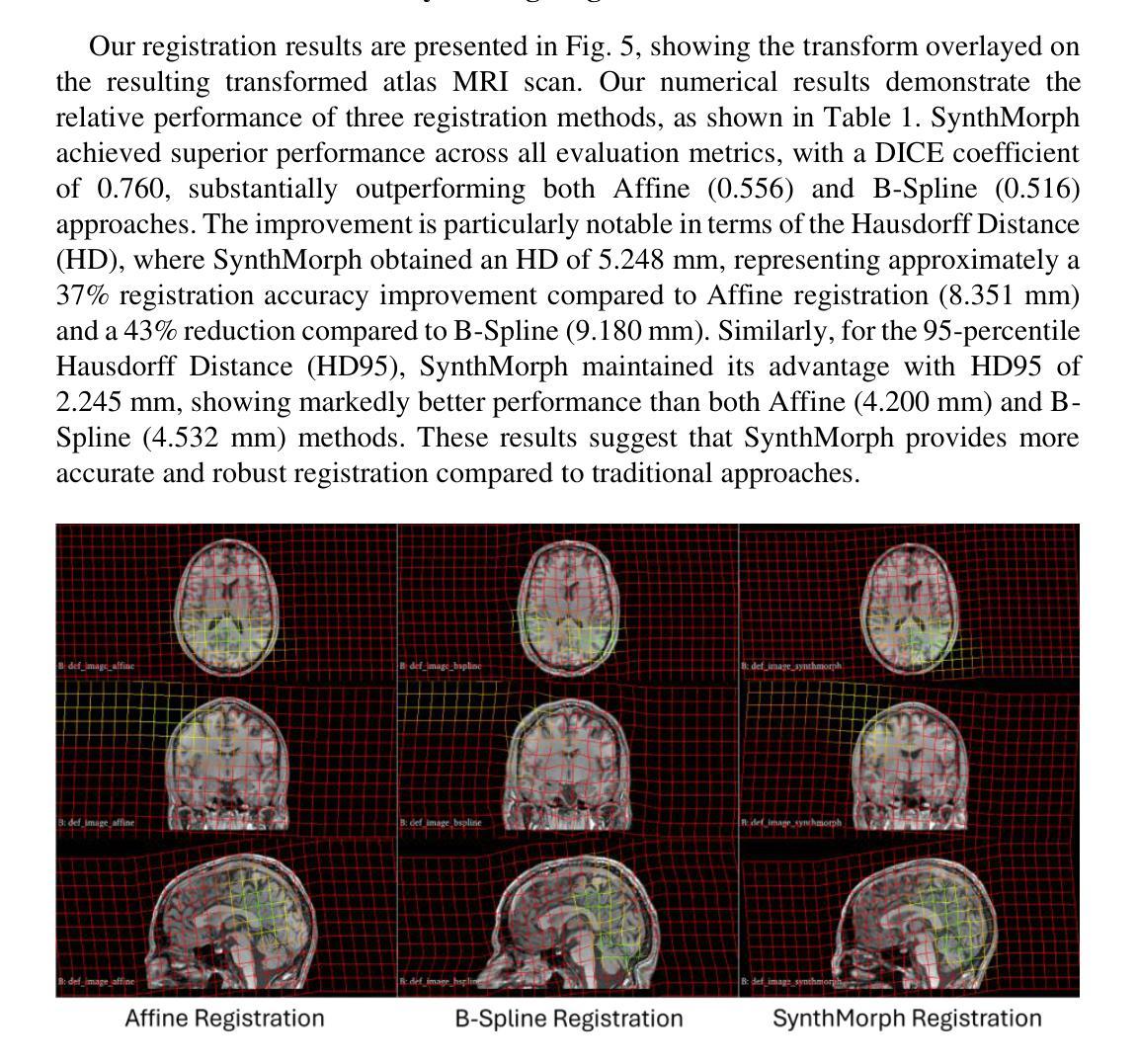
Developing personalized computational models of the human brain remains a challenge for patient-specific clinical applications and neuroscience research. Efficient and accurate biophysical simulations rely on high-quality personalized computational meshes derived from patient’s segmented anatomical MRI scans. However, both automatic and manual segmentation are particularly challenging for tissues with limited visibility or low contrast. In this work, we present a new method to create personalized computational meshes of the brain, streamlining the development of computational brain models for clinical applications and neuroscience research. Our method uses SynthMorph, a state-of-the-art anatomy-aware, learning-based medical image registration approach, to morph a comprehensive hexahedral mesh of the open-source SPL/NAC Brain Atlas to patient-specific MRI scans. Each patient-specific mesh includes over 300 labeled anatomical structures, more than any existing manual or automatic methods. Our registration-based method takes approximately 20 minutes, significantly faster than current state-of-the-art mesh generation pipelines, which can take up to two hours. We evaluated several state-of-the-art medical image registration methods, including SynthMorph, to determine the most optimal registration method to morph our meshed anatomical brain atlas to patient MRI scans. Our results demonstrate that SynthMorph achieved high DICE similarity coefficients and low Hausdorff Distance metrics between anatomical structures, while maintaining high mesh element quality. These findings demonstrate that our registration-based method efficiently and accurately produces high-quality, comprehensive personalized brain meshes, representing an important step toward clinical translation.
构建个性化的计算化人类大脑模型仍然是针对患者特定临床应用和神经科学研究的挑战。高效且准确的生物物理模拟依赖于由患者分割的MRI扫描图像生成的高质量个性化计算网格。然而,对于可见度有限或对比度较低的组织,自动和手动分割都具有特别的挑战性。在这项工作中,我们提出了一种创建个性化计算大脑网格的新方法,以简化计算大脑模型的临床应用和神经科学研究开发。我们的方法使用SynthMorph(一种基于学习的、先进的解剖学意识医学图像配准方法),将开源SPL/NAC脑图谱的全面六面体网格变形为针对患者的MRI扫描图像。每个患者特定的网格包括超过300个标记的解剖结构,比现有的任何手动或自动方法都要多。我们的基于配准的方法大约需要20分钟的时间,这大大快于当前的先进网格生成管道(可能需要长达两个小时的时间)。我们评估了几种先进的医学图像配准方法,包括SynthMorph,以确定将我们网格化的解剖脑图谱变形为患者MRI扫描图像的最优配准方法。我们的结果表明,SynthMorph在解剖结构之间实现了高的DICE相似性系数和低的Hausdorff距离指标,同时保持了高的网格元素质量。这些发现表明,我们的基于配准的方法能够高效且准确地产生高质量、全面的个性化大脑网格,这是向临床应用翻译的重要一步。
论文及项目相关链接
Summary
本文介绍了一种基于注册的新方法,用于创建个性化的脑计算网格模型。该方法利用最新的解剖学意识图像注册技术,将开源SPL/NAC Brain Atlas的综合六面体网格形态化至患者特定的MRI扫描。新方法能高效、准确地生成个性化的脑网格模型,有望促进其在临床应用和神经科学研究中的发展。
Key Takeaways
- 利用SynthMorph注册技术创建个性化脑计算网格模型。
- 将开源SPL/NAC Brain Atlas的网格形态化至患者特定MRI扫描。
- 每个个性化网格包含超过300个标记的解剖结构,超越现有手动或自动方法。
- 注册方法耗时约20分钟,显著快于当前最先进的网格生成流程。
- 对比评估了多种先进的医学图像注册方法,确定SynthMorph为最佳选择。
- SynthMorph在解剖结构间实现了高DICE相似系数和低Hausdorff距离指标。
点此查看论文截图


Multimodal Distillation-Driven Ensemble Learning for Long-Tailed Histopathology Whole Slide Images Analysis
Authors:Xitong Ling, Yifeng Ping, Jiawen Li, Jing Peng, Yuxuan Chen, Minxi Ouyang, Yizhi Wang, Yonghong He, Tian Guan, Xiaoping Liu, Lianghui Zhu
Multiple Instance Learning (MIL) plays a significant role in computational pathology, enabling weakly supervised analysis of Whole Slide Image (WSI) datasets. The field of WSI analysis is confronted with a severe long-tailed distribution problem, which significantly impacts the performance of classifiers. Long-tailed distributions lead to class imbalance, where some classes have sparse samples while others are abundant, making it difficult for classifiers to accurately identify minority class samples. To address this issue, we propose an ensemble learning method based on MIL, which employs expert decoders with shared aggregators and consistency constraints to learn diverse distributions and reduce the impact of class imbalance on classifier performance. Moreover, we introduce a multimodal distillation framework that leverages text encoders pre-trained on pathology-text pairs to distill knowledge and guide the MIL aggregator in capturing stronger semantic features relevant to class information. To ensure flexibility, we use learnable prompts to guide the distillation process of the pre-trained text encoder, avoiding limitations imposed by specific prompts. Our method, MDE-MIL, integrates multiple expert branches focusing on specific data distributions to address long-tailed issues. Consistency control ensures generalization across classes. Multimodal distillation enhances feature extraction. Experiments on Camelyon+-LT and PANDA-LT datasets show it outperforms state-of-the-art methods.
多实例学习(MIL)在计算病理学中扮演着重要角色,它能够对全切片图像(WSI)数据集进行弱监督分析。WSI分析领域面临着一个严重的长尾分布问题,这严重影响了分类器的性能。长尾分布导致类别不平衡,其中一些类别的样本稀少,而其他类别则很丰富,这使得分类器难以准确识别出少数类别的样本。为了解决这个问题,我们提出了一种基于MIL的集成学习方法,该方法使用带有共享聚合器和一致性约束的专家解码器来学习各种分布,并减少类别不平衡对分类器性能的影响。此外,我们引入了一个多模态蒸馏框架,该框架利用在病理学文本对上预训练的文本编码器进行知识蒸馏,并指导MIL聚合器捕获与类别信息相关的更强语义特征。为了确保灵活性,我们使用可学习的提示来引导预训练文本编码器的蒸馏过程,避免特定提示所带来的限制。我们的方法MDE-MIL集成了多个专注于特定数据分布的专家分支,以解决长尾问题。一致性控制确保跨类别的泛化。多模态蒸馏增强了特征提取。在Camelyon+-LT和PANDA-LT数据集上的实验表明,该方法优于最先进的方法。
论文及项目相关链接
Summary
本文介绍了在计算病理学领域中,多实例学习(MIL)在处理全幻灯片图像(WSI)数据集时的应用。针对WSI分析面临的严重长尾分布问题,提出了一种基于MIL的集成学习方法。该方法采用具有共享聚合器和一致性约束的专家解码器,以学习各种分布并减少类别不平衡对分类器性能的影响。此外,引入了一种多模态蒸馏框架,利用在病理学文本对上预训练的文本编码器进行知识蒸馏,引导MIL聚合器捕获与类别信息相关的更强语义特征。实验结果表明,该方法在Camelyon+-LT和PANDA-LT数据集上的性能优于现有技术。
Key Takeaways
- 多实例学习(MIL)在计算病理学中的重要作用,特别是在全幻灯片图像(WSI)数据集上的弱监督分析。
- WSI分析面临的长尾分布问题及其对分类器性能的影响。
- 基于MIL的集成学习方法,通过采用专家解码器和共享聚合器来解决类别不平衡问题。
- 引入多模态蒸馏框架,利用预训练的文本编码器进行知识蒸馏,提高MIL的性能。
- 使用一致性控制确保跨类别的泛化能力。
- MDE-MIL方法通过集成多个专注于特定数据分布的专家分支来解决长尾问题。
点此查看论文截图

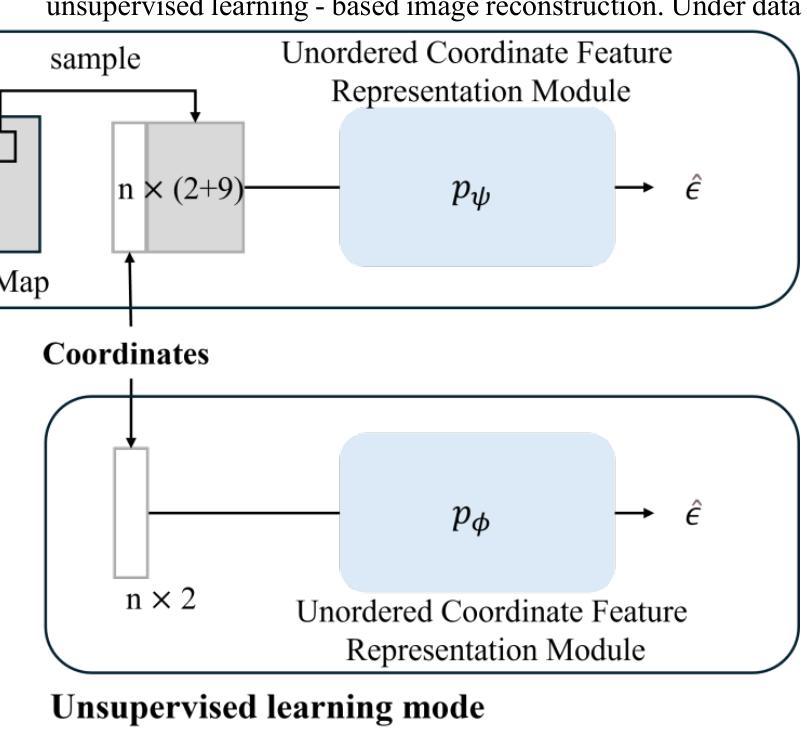
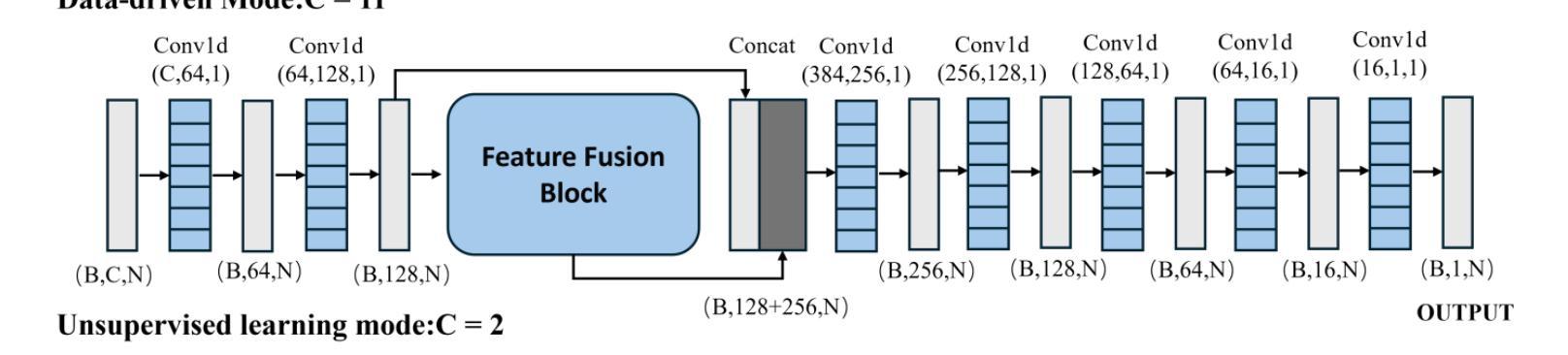
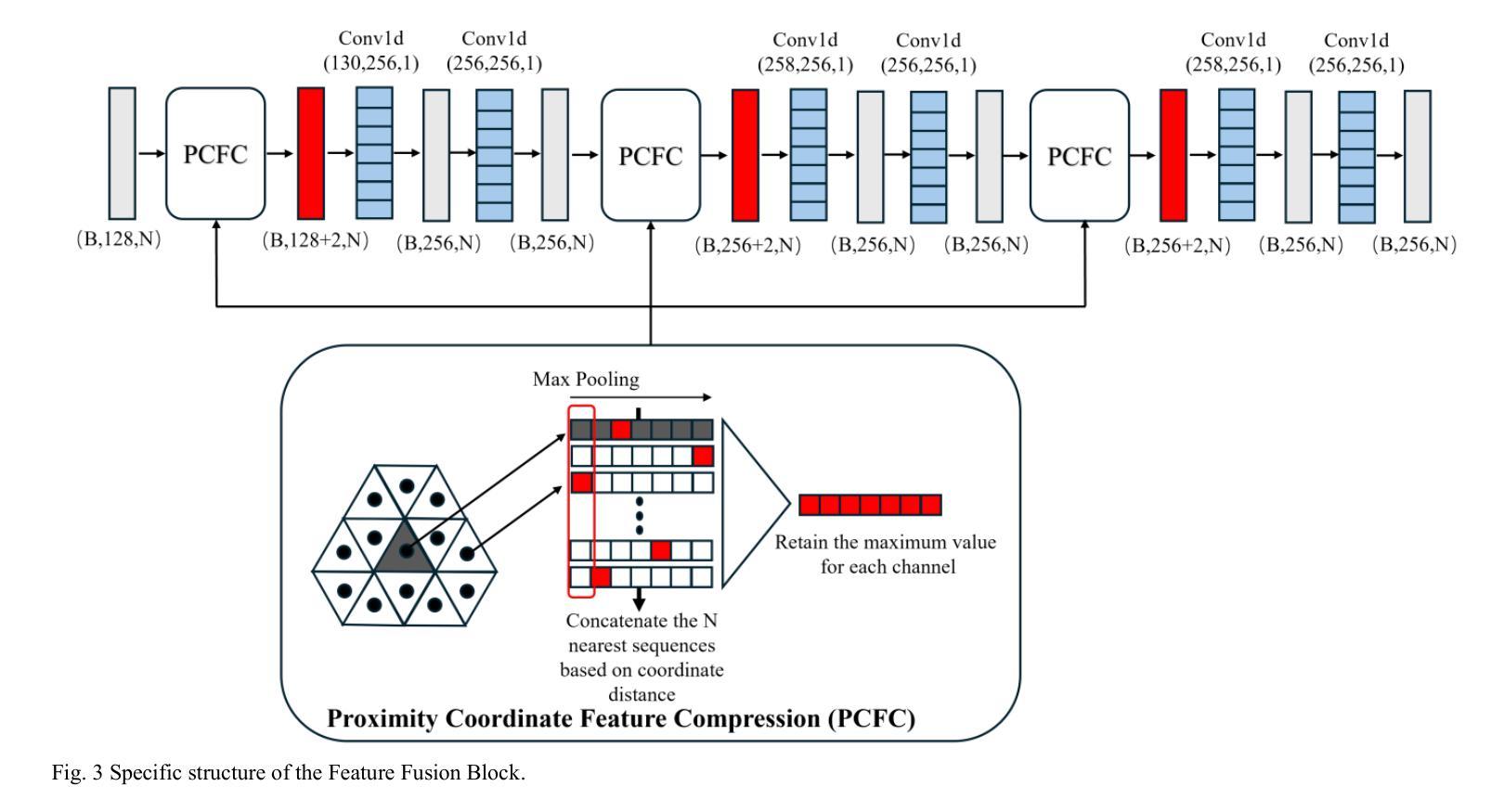
MR-EIT: Multi-Resolution Reconstruction for Electrical Impedance Tomography via Data-Driven and Unsupervised Dual-Mode Neural Networks
Authors:Fangming Shi, Jinzhen Liu, Xiangqian Meng, Yapeng Zhou, Hui Xiong
This paper presents a multi-resolution reconstruction method for Electrical Impedance Tomography (EIT), referred to as MR-EIT, which is capable of operating in both supervised and unsupervised learning modes. MR-EIT integrates an ordered feature extraction module and an unordered coordinate feature expression module. The former achieves the mapping from voltage to two-dimensional conductivity features through pre-training, while the latter realizes multi-resolution reconstruction independent of the order and size of the input sequence by utilizing symmetric functions and local feature extraction mechanisms. In the data-driven mode, MR-EIT reconstructs high-resolution images from low-resolution data of finite element meshes through two stages of pre-training and joint training, and demonstrates excellent performance in simulation experiments. In the unsupervised learning mode, MR-EIT does not require pre-training data and performs iterative optimization solely based on measured voltages to rapidly achieve image reconstruction from low to high resolution. It shows robustness to noise and efficient super-resolution reconstruction capabilities in both simulation and real water tank experiments. Experimental results indicate that MR-EIT outperforms the comparison methods in terms of Structural Similarity (SSIM) and Relative Image Error (RIE), especially in the unsupervised learning mode, where it can significantly reduce the number of iterations and improve image reconstruction quality.
本文提出了一种用于电阻抗断层扫描(EIT)的多分辨率重建方法,简称为MR-EIT。该方法既可在有监督学习模式,也可在无监督学习模式下运行。MR-EIT结合了有序特征提取模块和无序坐标特征表达式模块。前者通过预训练实现电压到二维导电率特征的映射,后者则利用对称函数和局部特征提取机制,实现了独立于输入序列顺序和大小的多分辨率重建。在数据驱动模式下,MR-EIT通过两个阶段(预训练和联合训练)从有限元网格的低分辨率数据中重建高分辨率图像,并在模拟实验中表现出卓越的性能。在无监督学习模式下,MR-EIT无需预训练数据,仅基于测量的电压进行迭代优化,从而迅速实现从低分辨率到高分辨率的图像重建。该方法对噪声具有鲁棒性,并且在模拟和实际水箱实验中均表现出高效的超分辨率重建能力。实验结果表明,MR-EIT在结构相似性(SSIM)和相对图像误差(RIE)方面优于比较方法,特别是在无监督学习模式下,可以显著减少迭代次数并提高图像重建质量。
论文及项目相关链接
Summary
本文介绍了一种多分辨率重建方法,用于电气阻抗层析成像(EIT),称为MR-EIT。该方法可在有监督和无监督学习模式下运行,集成了有序特征提取模块和无序坐标特征表达模块。通过预训练实现电压到二维导电特征的映射,利用对称函数和局部特征提取机制实现独立于输入序列顺序和大小的多分辨率重建。在数据驱动模式下,MR-EIT通过两个阶段进行高分辨率图像重建,模拟实验表现优异。无监督模式下,MR-EIT无需预训练数据,基于测量电压进行迭代优化,实现快速低分辨率至高分辨率的图像重建,对噪声具有鲁棒性,仿真和真实水箱实验中的超分辨率重建能力出色。
Key Takeaways
- MR-EIT是一种多分辨率重建方法,用于电气阻抗层析成像(EIT)。
- MR-EIT可在有监督和无监督学习模式下运行。
- MR-EIT集成了有序特征提取模块与无序坐标特征表达模块。
- 通过预训练实现电压到二维导电特征的映射。
- MR-EIT利用对称函数和局部特征提取机制进行多分辨率重建,该机制独立于输入序列的顺序和大小。
- 在数据驱动模式下,MR-EIT通过两个阶段进行高分辨率图像重建,表现优异。
点此查看论文截图


Geodesic Diffusion Models for Medical Image-to-Image Generation
Authors:Teng Zhang, Hongxu Jiang, Kuang Gong, Wei Shao
Diffusion models transform an unknown data distribution into a Gaussian prior by progressively adding noise until the data become indistinguishable from pure noise. This stochastic process traces a path in probability space, evolving from the original data distribution (considered as a Gaussian with near-zero variance) to an isotropic Gaussian. The denoiser then learns to reverse this process, generating high-quality samples from random Gaussian noise. However, standard diffusion models, such as the Denoising Diffusion Probabilistic Model (DDPM), do not ensure a geodesic (i.e., shortest) path in probability space. This inefficiency necessitates the use of many intermediate time steps, leading to high computational costs in training and sampling. To address this limitation, we propose the Geodesic Diffusion Model (GDM), which defines a geodesic path under the Fisher-Rao metric with a variance-exploding noise scheduler. This formulation transforms the data distribution into a Gaussian prior with minimal energy, significantly improving the efficiency of diffusion models. We trained GDM by continuously sampling time steps from 0 to 1 and using as few as 15 evenly spaced time steps for model sampling. We evaluated GDM on two medical image-to-image generation tasks: CT image denoising and MRI image super-resolution. Experimental results show that GDM achieved state-of-the-art performance while reducing training time by a 50-fold compared to DDPM and 10-fold compared to Fast-DDPM, with 66 times faster sampling than DDPM and a similar sampling speed to Fast-DDPM. These efficiency gains enable rapid model exploration and real-time clinical applications. Our code is publicly available at: https://github.com/mirthAI/GDM-VE.
扩散模型通过逐步添加噪声将未知数据分布转变为高斯先验,直到数据无法与纯噪声区分开。这一随机过程在概率空间中追踪一条路径,从原始数据分布(被视为方差接近零的高斯分布)演变到各向同性高斯。然后,去噪器学习反转这一过程,从随机高斯噪声中生成高质量样本。然而,标准扩散模型,如降噪扩散概率模型(DDPM),并不能确保概率空间中的测地线(即最短)路径。这种低效性需要使用许多中间时间步,导致训练和采样中的计算成本高昂。为了解决这一局限性,我们提出了测地扩散模型(GDM),它在Fisher-Rao度量下定义了一个测地线路径,并配备了一个方差爆炸噪声调度器。这种表述将数据分布转变为高斯先验,以最小的能量消耗,显著提高了扩散模型的效率。我们通过从0到1持续采样时间步,并使用最多15个均匀间隔的时间步来训练GDM模型进行采样。我们在两项医学图像到图像生成任务上评估了GDM:CT图像去噪和MRI图像超分辨率。实验结果表明,GDM达到了最先进的性能,与DDPM相比,训练时间减少了50倍,与Fast-DDPM相比减少了10倍。与DDPM相比,GDM的采样速度快66倍,与Fast-DDPM的采样速度相似。这些效率提升使得模型能够快速探索并应用于实时临床。我们的代码公开在:https://github.com/mirthAI/GDM-VE。
论文及项目相关链接
摘要
扩散模型通过逐步添加噪声将未知数据分布转化为高斯先验,直到数据变得与纯噪声无法区分。在概率空间中,它从原始数据分布(被视为具有近零方差的高斯分布)演化到一个等距高斯。去噪器学习逆转这一过程,从随机高斯噪声中生成高质量样本。然而,标准扩散模型(如去噪扩散概率模型DDPM)并不确保概率空间中的最短路径(即测地线)。这种低效需要大量中间时间步骤,导致训练和采样中的高计算成本。为解决这一问题,我们提出了Geodesic Diffusion Model(GDM),在Fisher-Rao度量下定义了测地线路径,并采用方差爆炸噪声调度器。这种表述将数据分布转换为高斯先验,以最小的能量,显著提高了扩散模型的效率。我们在两个医学图像到图像生成任务上评估了GDM:CT图像去噪和MRI图像超分辨率。实验结果表明,GDM在减少训练时间的同时实现了最先进的性能,相较于DDPM减少50倍,相较于Fast-DDPM减少10倍;相较于DDPM采样速度提高66倍,与Fast-DDPM采样速度相似。这些效率提升使模型快速探索及实时临床应用成为可能。我们的代码公开在:https://github.com/mirthAI/GDM-VE。
关键见解
- 扩散模型通过逐步添加噪声将数据分布转化为高斯先验。
- 标准扩散模型在概率空间中并不总是采取最短的测地线路径,导致训练和采样的高计算成本。
- 提出的Geodesic Diffusion Model(GDM)在Fisher-Rao度量下定义测地线路径,提高扩散模型的效率。
- GDM在医学图像生成任务上表现卓越,如CT图像去噪和MRI图像超分辨率。
- GDM相较于其他模型大幅减少了训练时间和采样时间。
- GDM的实现代码已公开,便于研究者和开发者使用。
点此查看论文截图


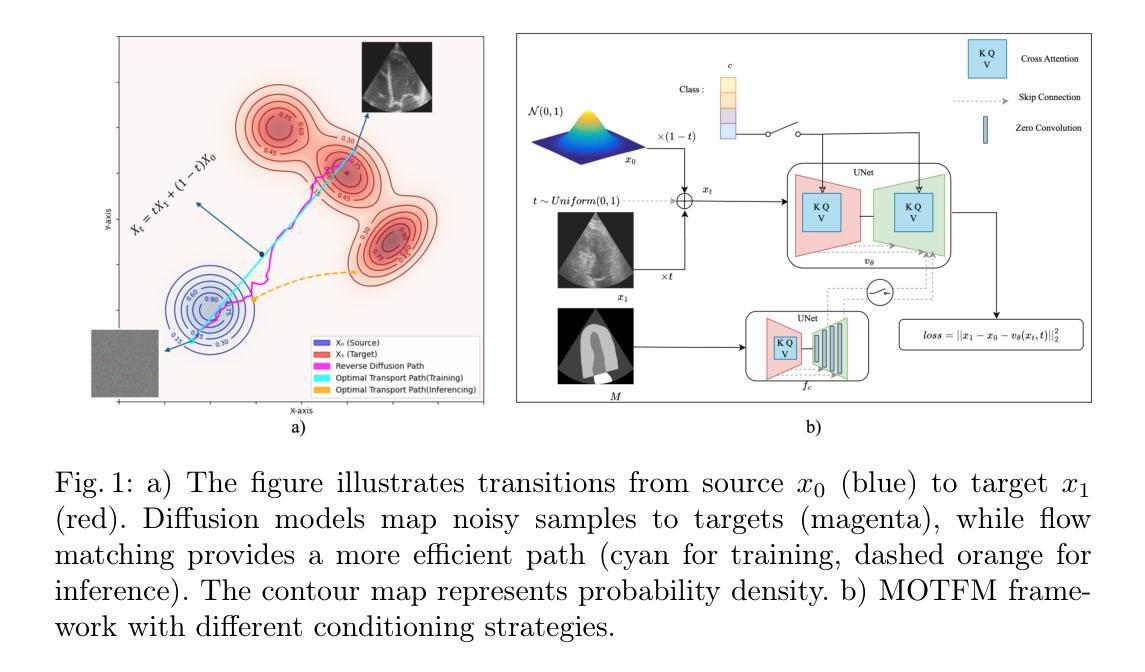
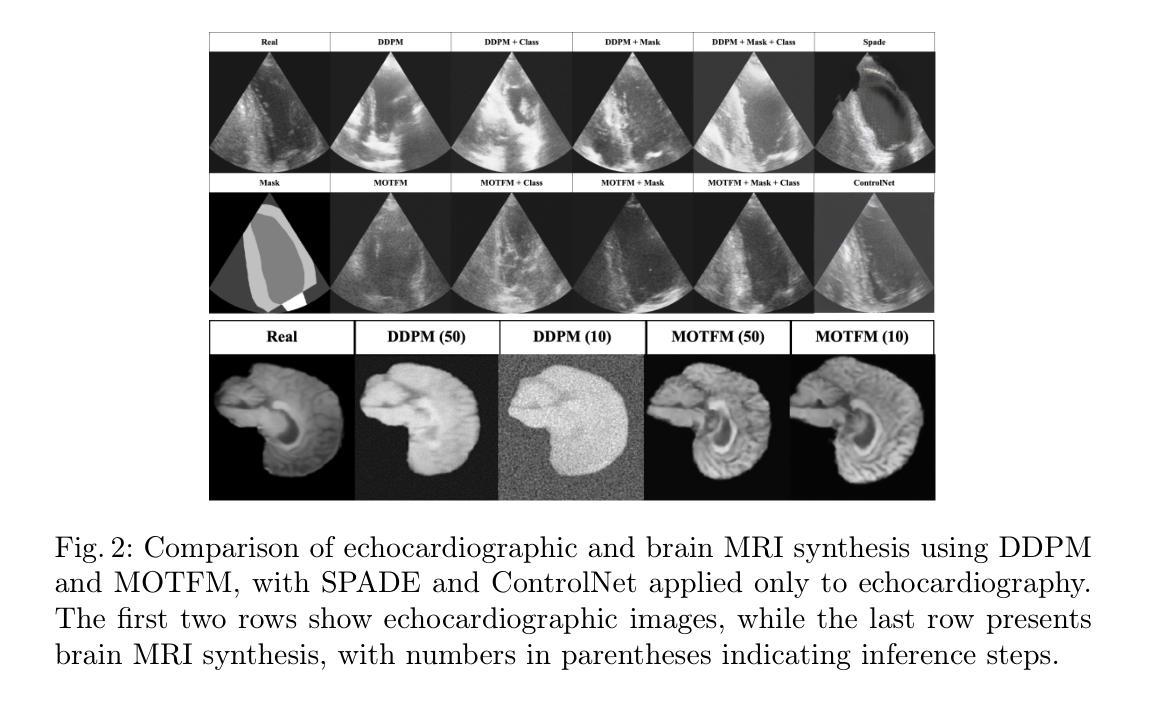
Flow Matching for Medical Image Synthesis: Bridging the Gap Between Speed and Quality
Authors:Milad Yazdani, Yasamin Medghalchi, Pooria Ashrafian, Ilker Hacihaliloglu, Dena Shahriari
Deep learning models have emerged as a powerful tool for various medical applications. However, their success depends on large, high-quality datasets that are challenging to obtain due to privacy concerns and costly annotation. Generative models, such as diffusion models, offer a potential solution by synthesizing medical images, but their practical adoption is hindered by long inference times. In this paper, we propose the use of an optimal transport flow matching approach to accelerate image generation. By introducing a straighter mapping between the source and target distribution, our method significantly reduces inference time while preserving and further enhancing the quality of the outputs. Furthermore, this approach is highly adaptable, supporting various medical imaging modalities, conditioning mechanisms (such as class labels and masks), and different spatial dimensions, including 2D and 3D. Beyond image generation, it can also be applied to related tasks such as image enhancement. Our results demonstrate the efficiency and versatility of this framework, making it a promising advancement for medical imaging applications. Code with checkpoints and a synthetic dataset (beneficial for classification and segmentation) is now available on: https://github.com/milad1378yz/MOTFM.
深度学习模型在各种医疗应用中已崭露头角。然而,它们的成功依赖于难以获得的大规模高质量数据集,这主要是由于隐私担忧和昂贵的标注成本所致。生成模型,如扩散模型,通过合成医疗图像提供了一个潜在的解决方案,但它们由于漫长的推理时间而阻碍了实际应用。在本文中,我们提出了一种使用最优传输流匹配方法来加速图像生成的方法。通过引入源和目标分布之间的更直接映射,我们的方法在保持和进一步提高输出质量的同时,显著减少了推理时间。此外,这种方法具有高度适应性,支持各种医学成像模式、调节机制(如类别标签和掩码),以及不同的空间维度,包括二维和三维。除了图像生成,它还可以应用于图像增强等相关任务。我们的结果证明了该框架的高效率和多功能性,使其成为医疗成像应用中的一项有前途的进步。关于检查点和合成数据集的代码现在可以在以下链接找到:https://github.com/milad1378yz/MOTFM(这个合成数据集对分类和分割任务有益)。
论文及项目相关链接
Summary
医学图像生成领域,提出一种基于最优传输流匹配(OTFM)的加速图像生成方法。该方法通过源与目标分布之间的更直接映射,显著减少推理时间,同时保证输出质量。方法高度灵活,适用于多种医学成像模式、条件机制和空间维度。代码及数据集已在GitHub上公开。
Key Takeaways
- 最优传输流匹配(OTFM)方法被应用于医学图像生成,旨在加速推理过程。
- OTFM方法通过创建源和目标分布之间的直接映射,提高了图像生成的效率。
- 该方法在保证图像质量的同时,显著减少了推理时间。
- OTFM方法高度灵活,能够适应不同的医学成像模式、条件机制和空间维度(如2D和3D)。
- 该方法不仅适用于图像生成,还可以应用于相关任务,如图像增强。
- 公开的代码和合成数据集可用于分类和分割任务。
点此查看论文截图

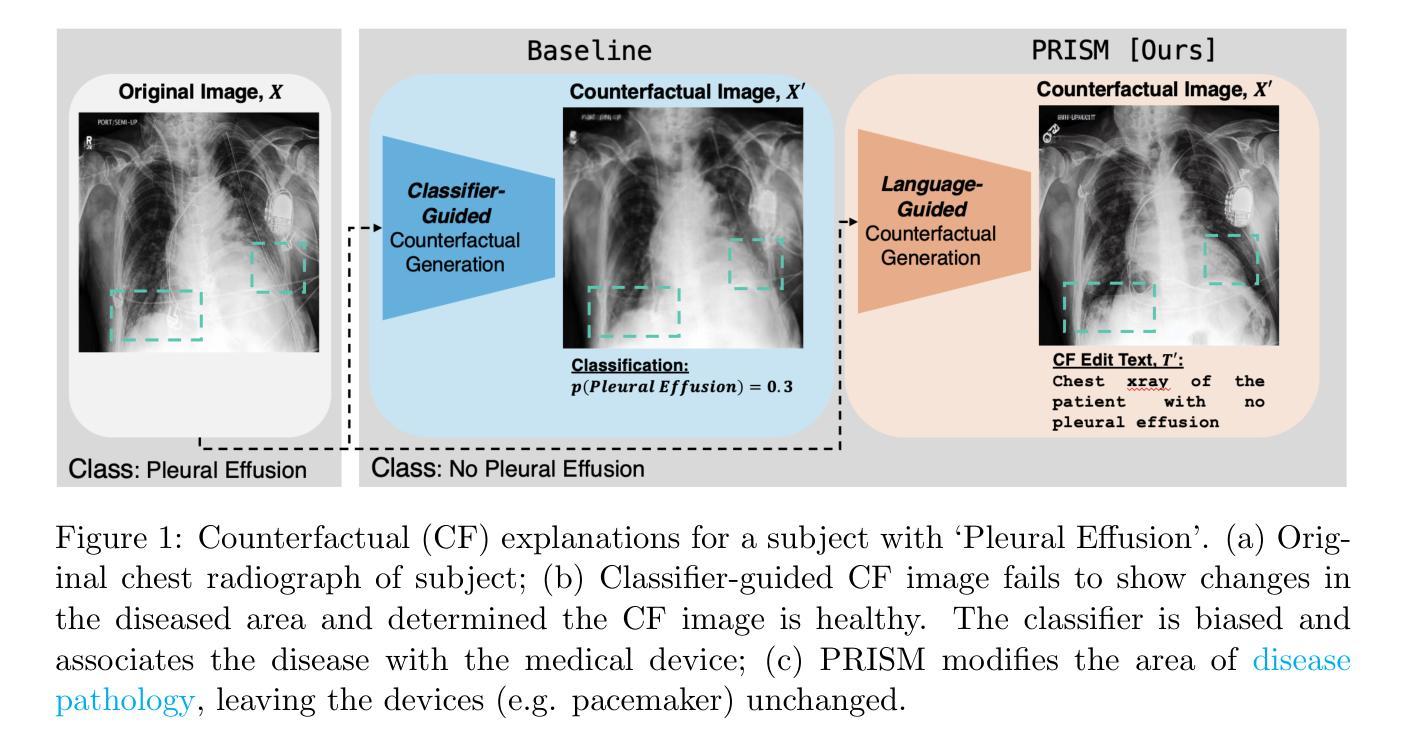
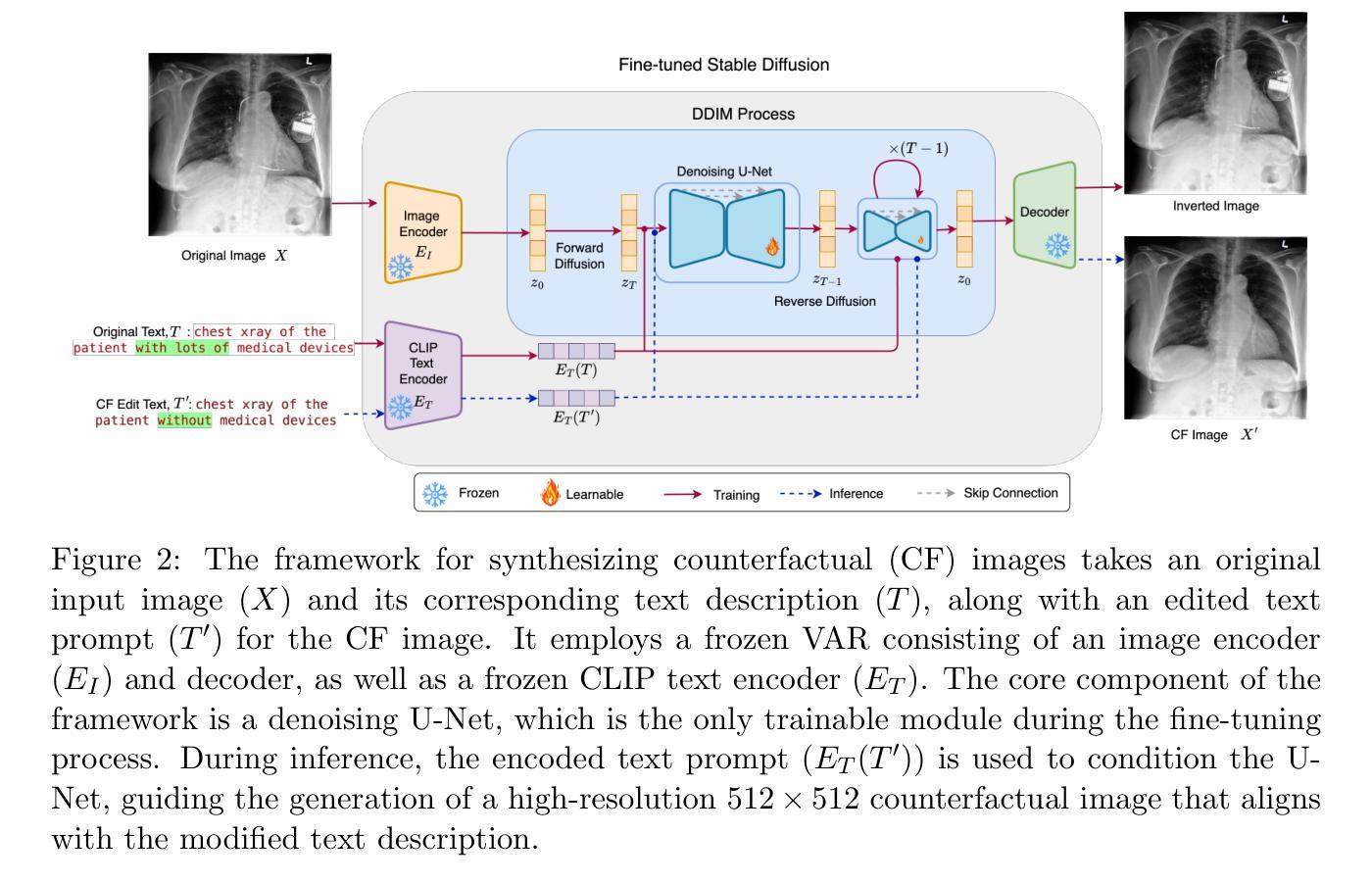
PRISM: High-Resolution & Precise Counterfactual Medical Image Generation using Language-guided Stable Diffusion
Authors:Amar Kumar, Anita Kriz, Mohammad Havaei, Tal Arbel
Developing reliable and generalizable deep learning systems for medical imaging faces significant obstacles due to spurious correlations, data imbalances, and limited text annotations in datasets. Addressing these challenges requires architectures robust to the unique complexities posed by medical imaging data. The rapid advancements in vision-language foundation models within the natural image domain prompt the question of how they can be adapted for medical imaging tasks. In this work, we present PRISM, a framework that leverages foundation models to generate high-resolution, language-guided medical image counterfactuals using Stable Diffusion. Our approach demonstrates unprecedented precision in selectively modifying spurious correlations (the medical devices) and disease features, enabling the removal and addition of specific attributes while preserving other image characteristics. Through extensive evaluation, we show how PRISM advances counterfactual generation and enables the development of more robust downstream classifiers for clinically deployable solutions. To facilitate broader adoption and research, we make our code publicly available at https://github.com/Amarkr1/PRISM.
在医学图像领域,开发可靠且可推广的深度学习系统面临着重大挑战,这主要是由于数据中的虚假关联、数据不平衡以及文本注释有限。要解决这些挑战,需要构建能够应对医学成像数据独特复杂性的架构。自然图像领域的视觉语言基础模型的快速发展引发了一个问题,即如何将这些模型适应于医学成像任务。在这项工作中,我们提出了PRISM框架,该框架利用基础模型,使用Stable Diffusion生成高分辨率的、受语言引导的医疗图像反事实。我们的方法以前所未有的精度选择性地修改虚假关联(医疗器材)和疾病特征,能够在保留其他图像特征的同时删除和添加特定属性。通过广泛的评估,我们展示了PRISM在反事实生成方面的进展,并证明其能够开发更稳健的下游分类器,用于临床部署解决方案。为了促进更广泛的采用和研究,我们在https://github.com/Amarkr1/PRISM上公开了我们的代码。
论文及项目相关链接
PDF Under Review for MIDL 2025
Summary
针对医学成像领域的深度学习系统面临诸多挑战,如虚假关联、数据不平衡和标注文本有限等。为解决这些问题,需要适应医学成像数据独特复杂性的稳健架构。本研究提出PRISM框架,利用基础模型生成高分辨率、语言引导的医疗图像反事实,利用Stable Diffusion进行选择性地修改虚假关联和疾病特征,实现特定属性的添加和移除,同时保留其他图像特征。PRISM推动反事实生成技术的发展,并有助于开发更稳健的下游分类器,为临床部署解决方案提供可能。
Key Takeaways
- 医学成像领域的深度学习系统面临诸多挑战,包括虚假关联、数据不平衡和标注文本有限等。
- PRISM框架利用基础模型生成语言引导的高分辨率医疗图像反事实。
- PRISM能够选择性地修改医学图像中的虚假关联和疾病特征。
- PRISM通过添加和移除特定属性,同时保留其他图像特征,实现精准修改。
- PRISM框架推动了反事实生成技术的发展。
- PRISM有助于开发更稳健的下游分类器,为临床部署解决方案提供支持。
点此查看论文截图


Tool or Tutor? Experimental evidence from AI deployment in cancer diagnosis
Authors:Vivianna Fang He, Sihan Li, Phanish Puranam
Professionals increasingly use Artificial Intelligence (AI) to enhance their capabilities and assist with task execution. While prior research has examined these uses separately, their potential interaction remains underexplored. We propose that AI-driven training (“tutor” effect) and AI-assisted task completion (“tool” effect) can be complementary and test this hypothesis in the context of lung cancer diagnosis. In a field experiment with 336 medical students, we manipulated AI deployment in training, in practice, and in both. Our findings reveal that while AI-integrated training and AI assistance independently improved diagnostic performance, their combination yielded the highest accuracy. These results underscore AI’s dual role in enhancing human performance through both learning and real-time support, offering insights into AI deployment in professional settings where human expertise remains essential.
专业人员越来越多地使用人工智能(AI)来增强自身能力并辅助执行任务。虽然之前的研究已经分别研究了这些用途,但它们之间的潜在相互作用仍未得到充分探索。我们提出AI驱动的培训(“导师”效应)和AI辅助任务完成(“工具”效应)可以互补,并在肺癌诊断的情境中检验这一假设。在一项有336名医学学生参与的实验中,我们操作了培训、实践和两者都涉及的AI部署情况。我们的研究发现,虽然AI集成培训和AI辅助独立改善了诊断性能,但它们的结合却获得了最高的准确率。这些结果强调了人工智能通过学习和实时支持增强人类性能的双面角色,为在专业环境中部署人工智能提供了见解,在这些环境中,人类专业知识仍然至关重要。
论文及项目相关链接
Summary
人工智能(AI)在医学图像诊断领域正被越来越多的专业人士用来提升能力和辅助任务执行。本研究探讨了AI在训练(“导师效应”)和完成医学任务(“工具效应”)方面的潜力互补性,并在肺癌诊断的情境下进行了测试。实验发现,结合AI训练和AI辅助的独立提高诊断性能的同时,两者的结合能产生最高的准确度。这表明AI通过学习和实时支持两方面增强人类表现,对于在专业人士仍需发挥重要作用的专业环境中部署AI具有启示意义。
Key Takeaways
- AI在医学图像诊断领域得到广泛应用,能够提升专业人士的能力和辅助任务执行。
- AI在训练和任务完成方面的潜力可以互补。
- 在肺癌诊断的情境下,AI训练和AI辅助的结合产生了最高的诊断准确度。
- AI通过学习和实时支持两方面增强人类表现。
- AI部署对于在专业人士仍需发挥重要作用的专业环境中具有启示意义。
- 实验结果表明,AI的“导师效应”和“工具效应”共同作用可最大化提高诊断准确性。
点此查看论文截图

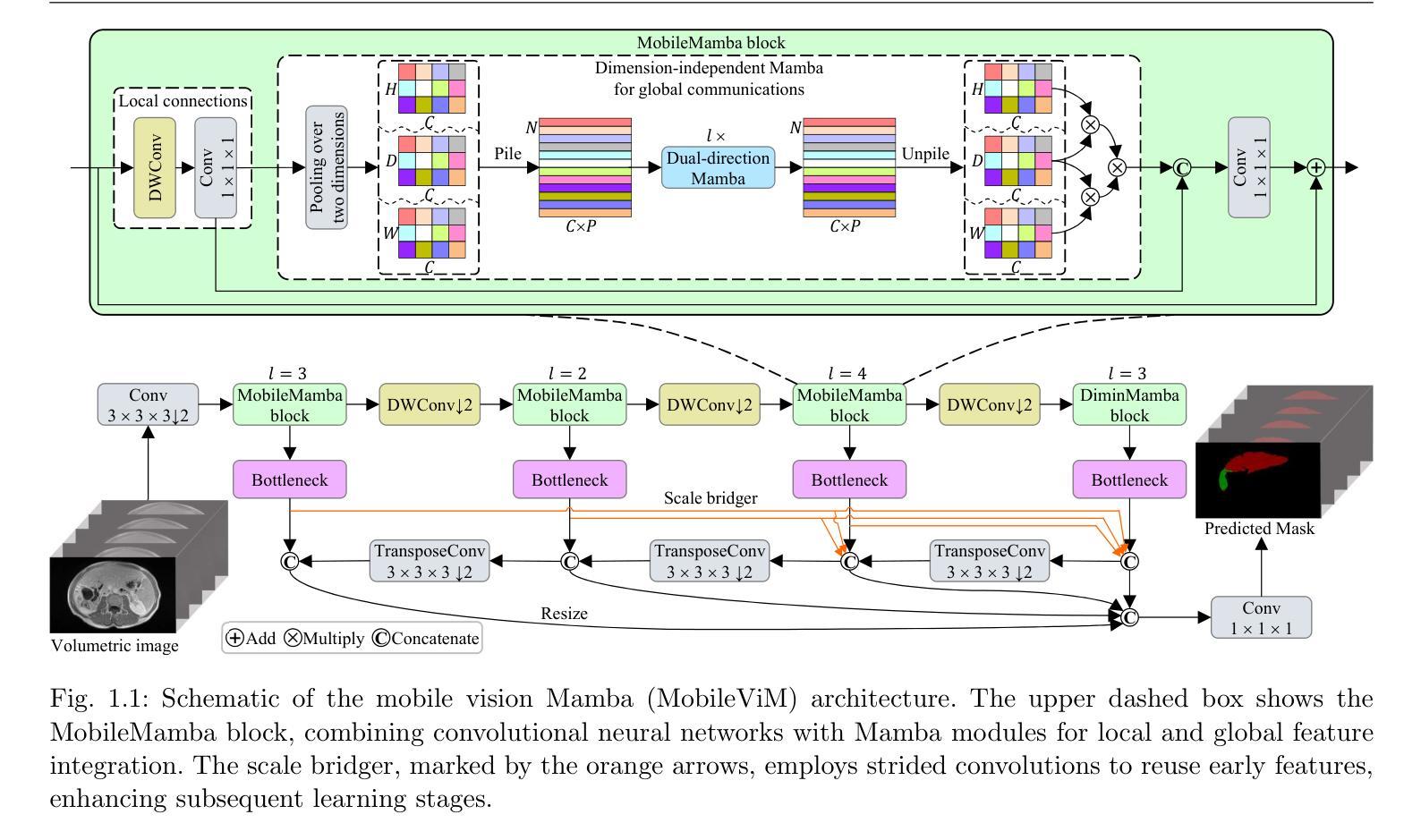
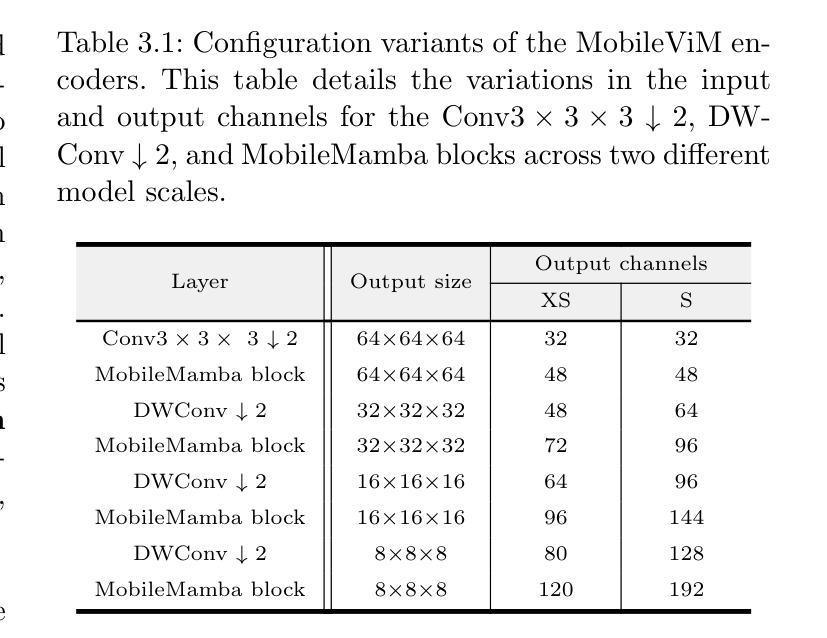
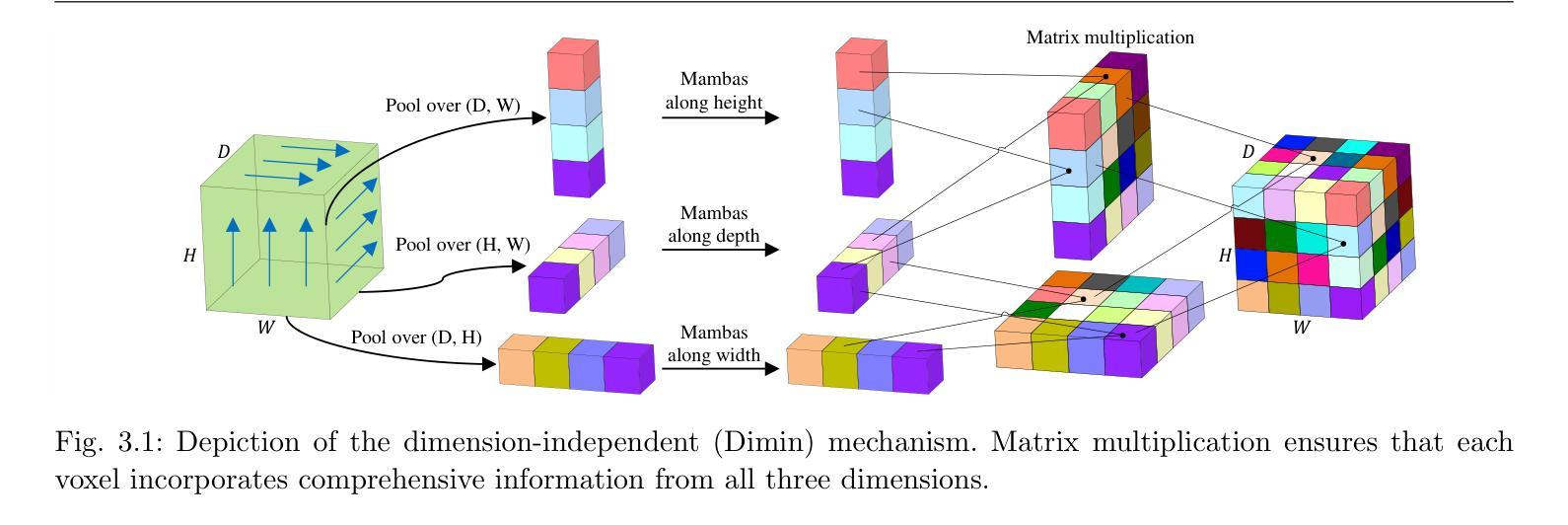
MobileViM: A Light-weight and Dimension-independent Vision Mamba for 3D Medical Image Analysis
Authors:Wei Dai, Jun Liu
Efficient evaluation of three-dimensional (3D) medical images is crucial for diagnostic and therapeutic practices in healthcare. Recent years have seen a substantial uptake in applying deep learning and computer vision to analyse and interpret medical images. Traditional approaches, such as convolutional neural networks (CNNs) and vision transformers (ViTs), face significant computational challenges, prompting the need for architectural advancements. Recent efforts have led to the introduction of novel architectures like the ``Mamba’’ model as alternative solutions to traditional CNNs or ViTs. The Mamba model excels in the linear processing of one-dimensional data with low computational demands. However, Mamba’s potential for 3D medical image analysis remains underexplored and could face significant computational challenges as the dimension increases. This manuscript presents MobileViM, a streamlined architecture for efficient segmentation of 3D medical images. In the MobileViM network, we invent a new dimension-independent mechanism and a dual-direction traversing approach to incorporate with a vision-Mamba-based framework. MobileViM also features a cross-scale bridging technique to improve efficiency and accuracy across various medical imaging modalities. With these enhancements, MobileViM achieves segmentation speeds exceeding 90 frames per second (FPS) on a single graphics processing unit (i.e., NVIDIA RTX 4090). This performance is over 24 FPS faster than the state-of-the-art deep learning models for processing 3D images with the same computational resources. In addition, experimental evaluations demonstrate that MobileViM delivers superior performance, with Dice similarity scores reaching 92.72%, 86.69%, 80.46%, and 77.43% for PENGWIN, BraTS2024, ATLAS, and Toothfairy2 datasets, respectively, which significantly surpasses existing models.
高效评估三维(3D)医学图像对医疗诊断和治疗实践至关重要。近年来,深度学习和计算机视觉在医学图像分析和解释方面的应用有所增长。传统方法,如卷积神经网络(CNNs)和视觉转换器(ViTs),面临重大的计算挑战,促使架构发展的需求。最近的努力导致了新型架构的出现,如作为替代传统CNN或ViT的解决方案的“Mamba”模型。Mamba模型在处理一维数据的线性处理方面表现出色且计算需求较低。然而,Mamba在3D医学图像分析方面的潜力尚未得到充分探索,随着维度的增加可能会面临重大的计算挑战。本文提出了MobileViM,这是一个用于高效分割3D医学图像的流线化架构。在MobileViM网络中,我们发明了一种新的维度独立机制和一种双向遍历方法与基于视觉Mamba的框架相结合。MobileViM还采用跨尺度桥接技术,以提高不同医学成像模式的效率和准确性。通过这些增强功能,MobileViM在单个图形处理单元(即NVIDIA RTX 4090)上实现了超过每秒90帧(FPS)的分割速度。此性能比使用相同计算资源的最新深度学习模型处理3D图像的速度快24 FPS以上。此外,实验评估表明,MobileViM的性能卓越,在PENGWIN、BraTS2024、ATLAS和Toothfairy2数据集上的Dice相似度得分分别达到92.72%、86.69%、80.46%和77.43%,显著超越了现有模型。
论文及项目相关链接
Summary
提出一种高效的三维医学图像分割架构MobileViM,采用维度独立机制、双向遍历方法和跨尺度桥接技术,实现快速而精确的医学图像分析,速度超过现有模型,并在多个数据集上取得优异性能。
Key Takeaways
- MobileViM是一个针对三维医学图像分割的流线型架构。
- 该架构采用新的维度独立机制和双向遍历方法,结合视觉Mamba基础框架。
- MobileViM的跨尺度桥接技术提高了在各种医学成像模式中的效率和准确性。
- MobileViM实现了在单个图形处理单元上的每秒超过90帧的分割速度,比现有模型快24帧以上。
- MobileViM在多个数据集上的性能表现优于现有模型,Dice相似度得分分别为92.72%、86.69%、80.46%和77.43%。
- 该架构解决了传统卷积神经网络和视觉变压器在三维医学图像分析中的计算挑战。
点此查看论文截图

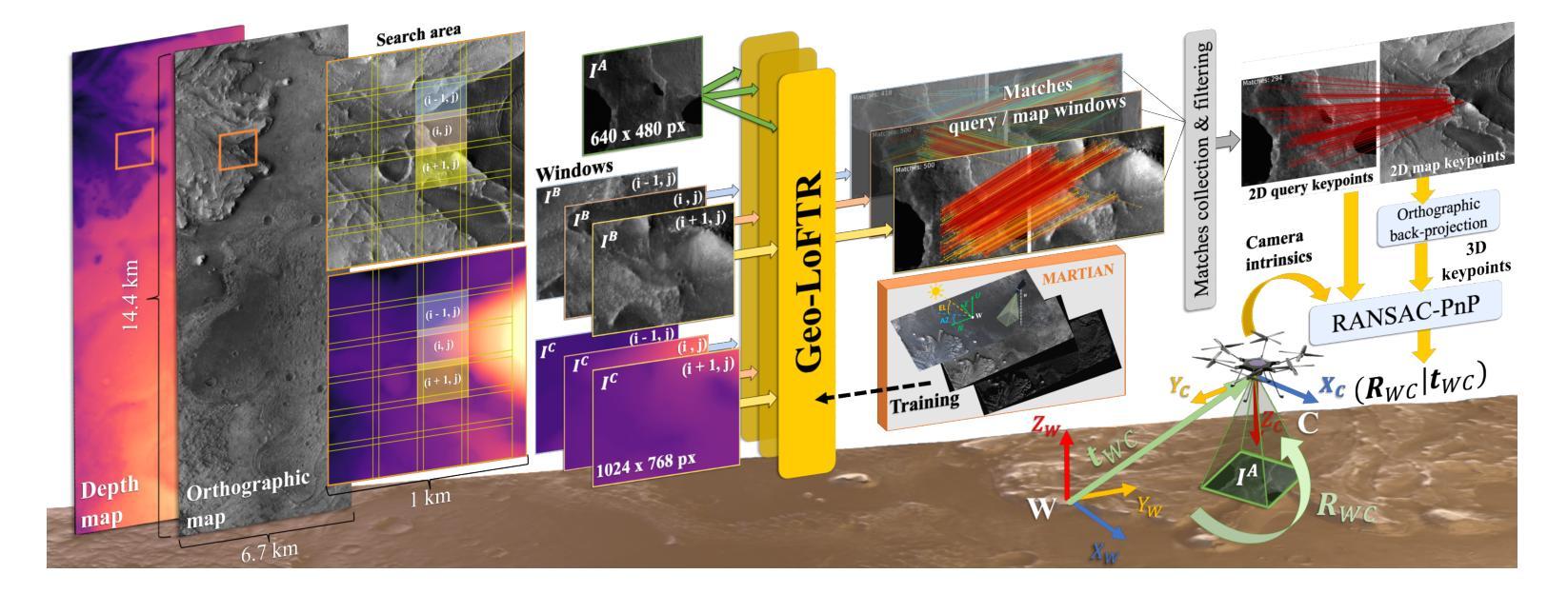
Vision-based Geo-Localization of Future Mars Rotorcraft in Challenging Illumination Conditions
Authors:Dario Pisanti, Robert Hewitt, Roland Brockers, Georgios Georgakis
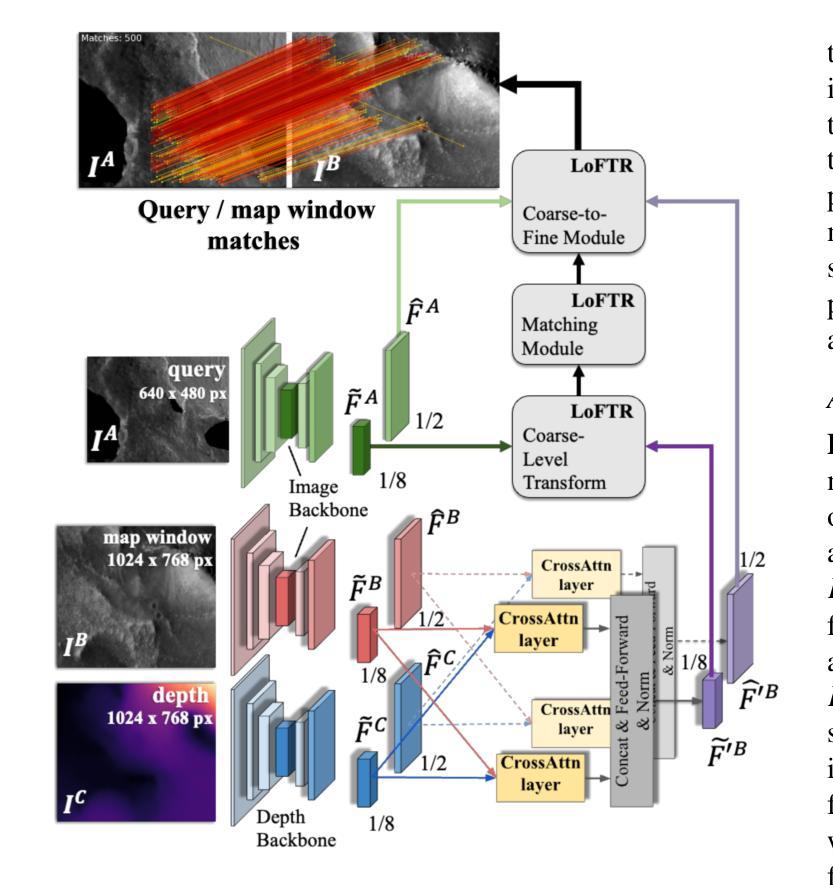
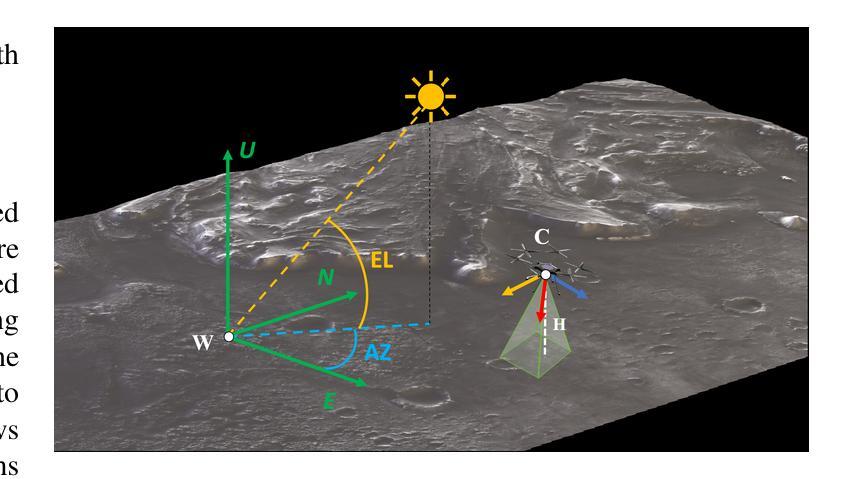
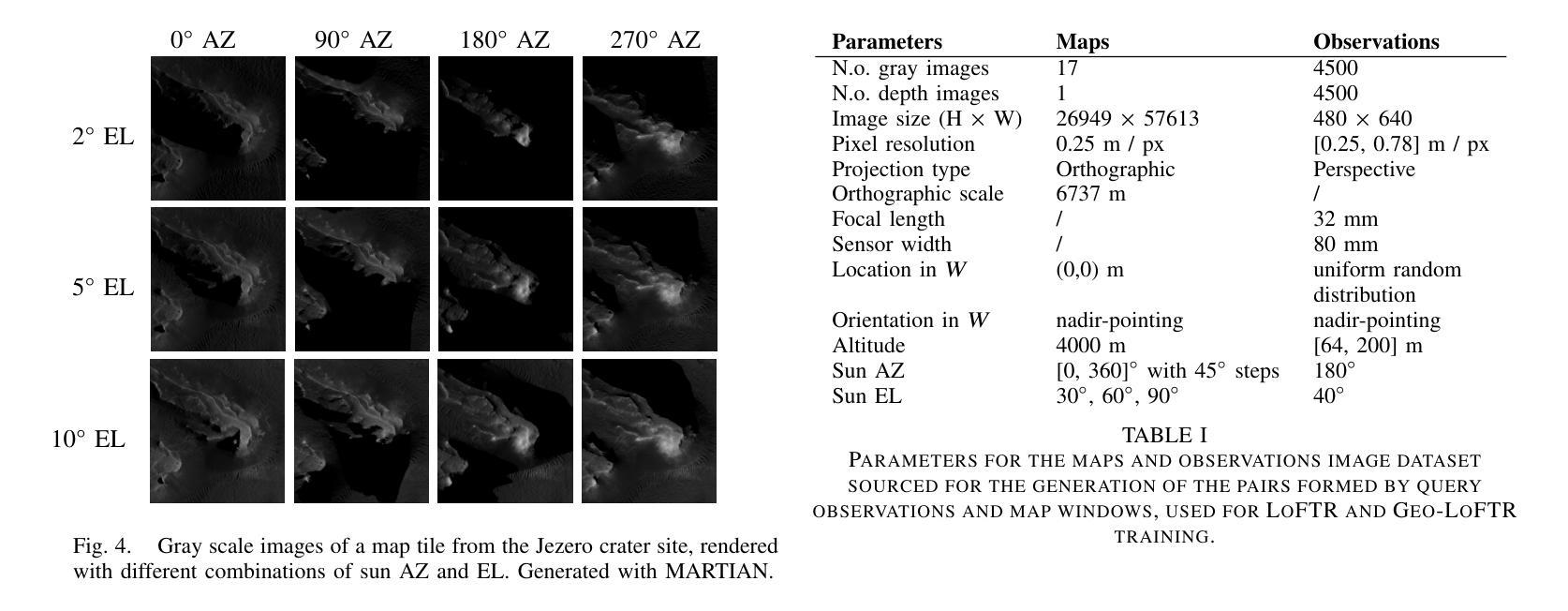
Planetary exploration using aerial assets has the potential for unprecedented scientific discoveries on Mars. While NASA’s Mars helicopter Ingenuity proved flight in Martian atmosphere is possible, future Mars rotocrafts will require advanced navigation capabilities for long-range flights. One such critical capability is Map-based Localization (MbL) which registers an onboard image to a reference map during flight in order to mitigate cumulative drift from visual odometry. However, significant illumination differences between rotocraft observations and a reference map prove challenging for traditional MbL systems, restricting the operational window of the vehicle. In this work, we investigate a new MbL system and propose Geo-LoFTR, a geometry-aided deep learning model for image registration that is more robust under large illumination differences than prior models. The system is supported by a custom simulation framework that uses real orbital maps to produce large amounts of realistic images of the Martian terrain. Comprehensive evaluations show that our proposed system outperforms prior MbL efforts in terms of localization accuracy under significant lighting and scale variations. Furthermore, we demonstrate the validity of our approach across a simulated Martian day.
利用空中资源进行行星探索具有在火星上获得前所未有的科学发现的潜力。虽然美国宇航局的火星直升机“机智号”证明了在火星大气中飞行是可能的,但未来的火星旋翼机将需要先进的导航能力以进行远程飞行。其中一项关键能力是地图定位(MbL),它在飞行过程中将机载图像注册到参考地图上,以减少视觉里程计的累积漂移。然而,旋翼机观测与参考地图之间的显著照明差异给传统MbL系统带来了挑战,限制了车辆的作业窗口。在这项工作中,我们调查了一种新的MbL系统,并提出Geo-LoFTR,这是一种辅助几何的深度学习图像注册模型,与先前模型相比,它在较大的照明差异下更为稳健。该系统由一个自定义仿真框架支持,该框架使用真实的轨道地图生成大量真实的火星地形图像。综合评估表明,我们提出的系统在照明和比例尺变化较大的情况下,在定位精度方面优于先前的MbL工作。此外,我们在模拟的火星日周期中验证了我们的方法的有效性。
论文及项目相关链接
Summary
在火星上,利用空中资源进行行星探索具有巨大的科学发现潜力。NASA的火星直升机“机智号”证明了在火星大气中飞行的可行性,但未来的火星旋翼飞行器需要先进的导航能力以实现远程飞行。其中一项关键能力是基于地图的定位(MbL),它在飞行过程中将机上图像注册到参考地图上,以减轻由视觉里程计引起的累积漂移问题。然而,旋翼飞行器观测和参考地图之间的显著照明差异对传统的MbL系统构成挑战,限制了车辆的操作窗口。本研究调查了一种新型的MbL系统,并提出Geo-LoFTR,这是一种辅助几何的深度学习模型,用于图像注册,能够在较大的照明差异下比先前模型表现出更强的稳健性。该系统得到了一个自定义仿真框架的支持,该框架使用真实的轨道地图生成大量逼真的火星地形图像。综合评估表明,我们的系统在照明和比例变化较大的情况下,定位精度优于先前的MbL努力。此外,我们在模拟的火星日周期内验证了我们的方法的有效性。
Key Takeaways
- 行星探索利用空中资源具有巨大的科学发现潜力,特别是在火星上。
- NASA的火星直升机“机智号”证明了在火星大气中飞行的可行性。
- 未来的火星旋翼飞行器需要先进的导航能力,其中关键之一是基于地图的定位(MbL)。
- 旋翼飞行器观测和参考地图之间的照明差异对传统的MbL系统构成挑战。
- Geo-LoFTR是一种新型的MbL系统,通过辅助几何的深度学习模型进行图像注册,表现更强的稳健性。
- 自定义仿真框架支持Geo-LoFTR系统,使用真实的轨道地图生成大量逼真的火星地形图像。
点此查看论文截图


Rethinking High-speed Image Reconstruction Framework with Spike Camera
Authors:Kang Chen, Yajing Zheng, Tiejun Huang, Zhaofei Yu
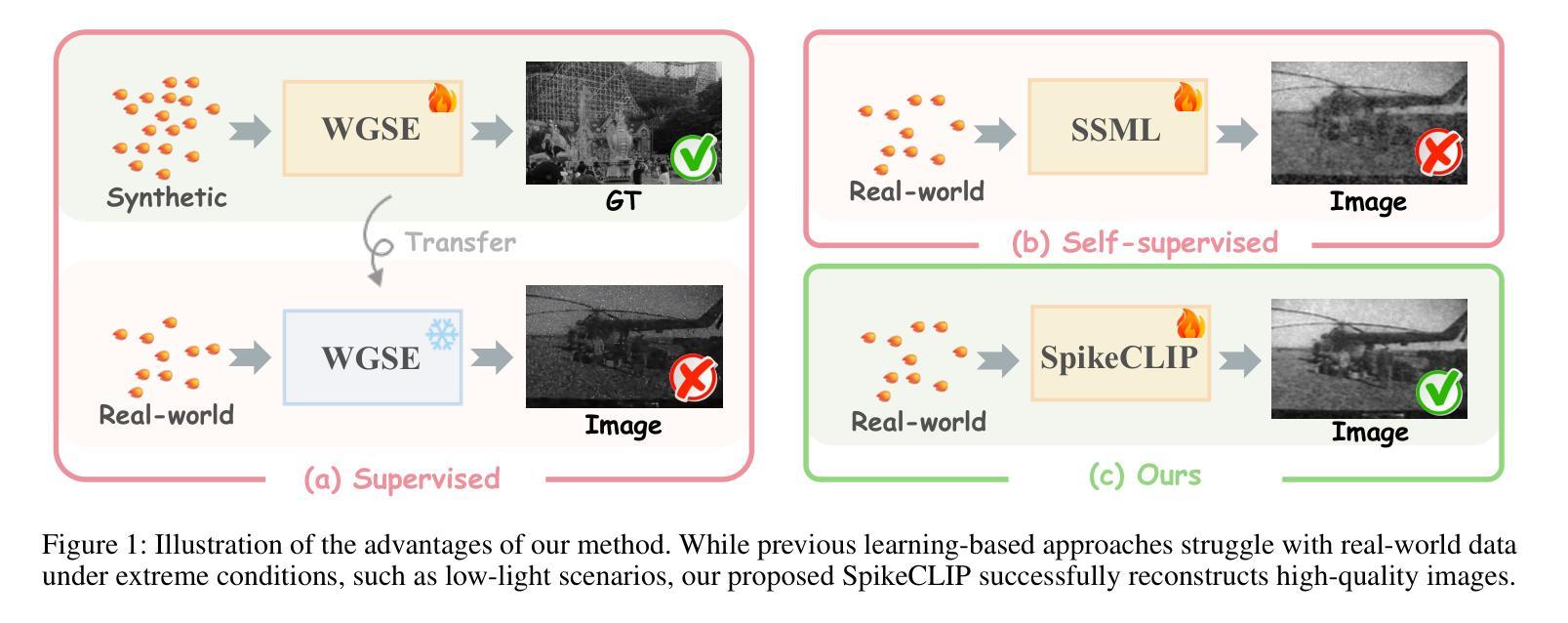
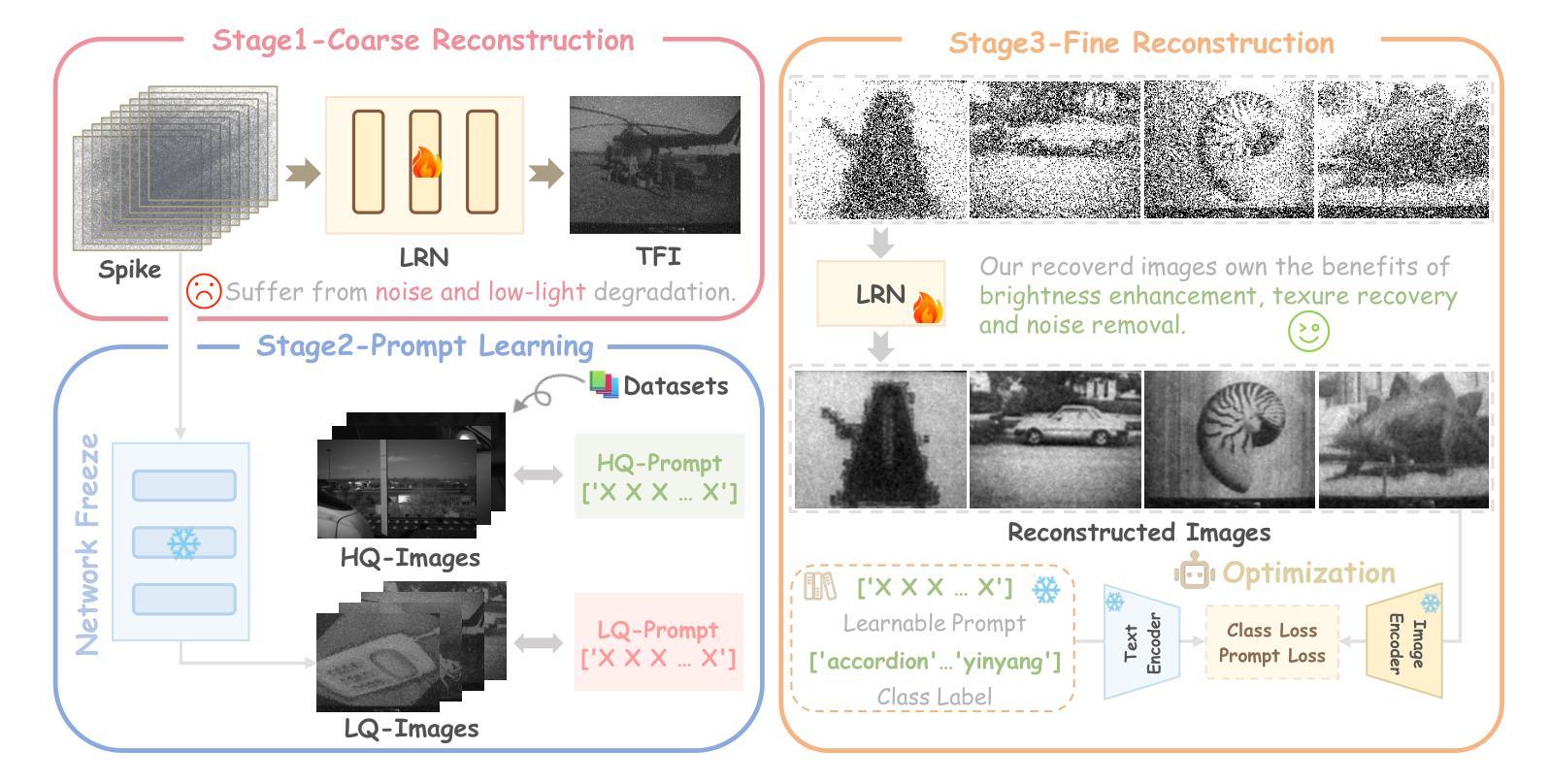
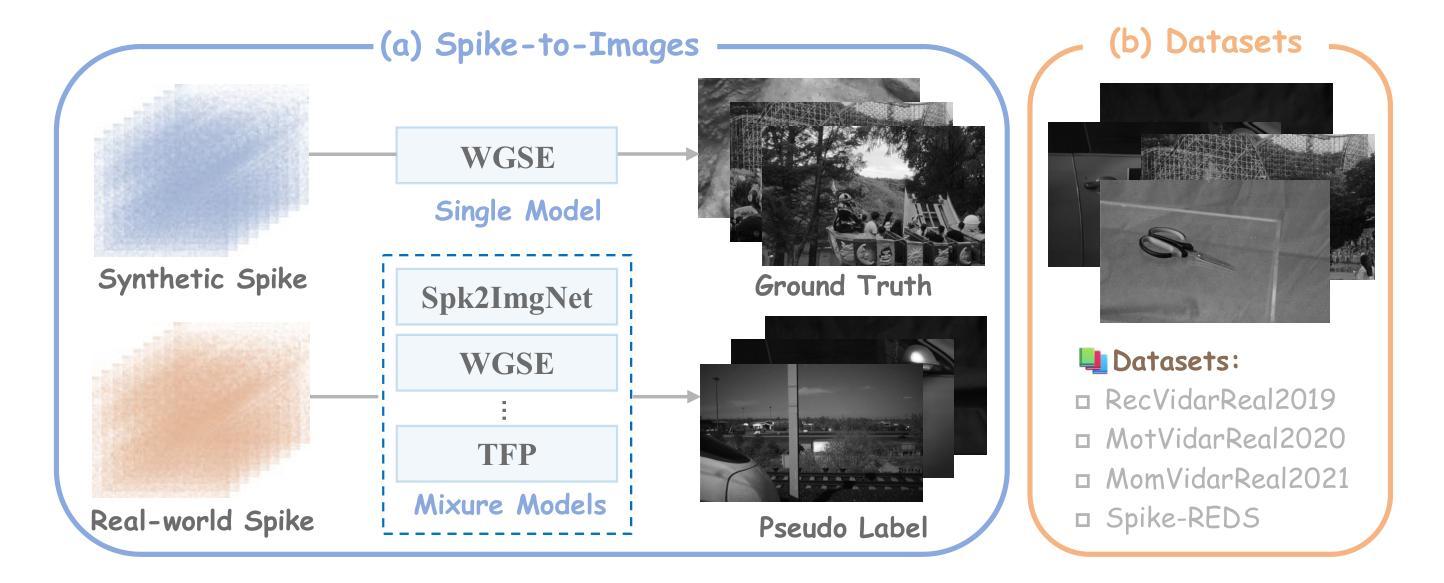
Spike cameras, as innovative neuromorphic devices, generate continuous spike streams to capture high-speed scenes with lower bandwidth and higher dynamic range than traditional RGB cameras. However, reconstructing high-quality images from the spike input under low-light conditions remains challenging. Conventional learning-based methods often rely on the synthetic dataset as the supervision for training. Still, these approaches falter when dealing with noisy spikes fired under the low-light environment, leading to further performance degradation in the real-world dataset. This phenomenon is primarily due to inadequate noise modelling and the domain gap between synthetic and real datasets, resulting in recovered images with unclear textures, excessive noise, and diminished brightness. To address these challenges, we introduce a novel spike-to-image reconstruction framework SpikeCLIP that goes beyond traditional training paradigms. Leveraging the CLIP model’s powerful capability to align text and images, we incorporate the textual description of the captured scene and unpaired high-quality datasets as the supervision. Our experiments on real-world low-light datasets U-CALTECH and U-CIFAR demonstrate that SpikeCLIP significantly enhances texture details and the luminance balance of recovered images. Furthermore, the reconstructed images are well-aligned with the broader visual features needed for downstream tasks, ensuring more robust and versatile performance in challenging environments.
脉冲相机作为一种创新的神经形态设备,能够产生连续的脉冲流,以低于传统RGB相机的带宽和更高的动态范围来捕捉高速场景。然而,在低光照条件下从脉冲输入重建高质量图像仍然具有挑战性。传统的基于学习的方法通常依赖于合成数据集作为训练过程的监督。然而,这些方法在处理低光环境下产生的噪声脉冲时常常表现不佳,导致在实际数据集上的性能进一步下降。这种现象的主要原因是噪声建模不足以及合成数据集和真实数据集之间的域差距,导致恢复后的图像纹理不清晰、噪声过多以及亮度降低。为了解决这些挑战,我们引入了一种新型的脉冲到图像重建框架SpikeCLIP,它超越了传统的训练模式。我们借助CLIP模型的强大文本和图像对齐能力,将捕获场景的文本描述和未配对的高质量数据集作为监督信息。我们在实际低光数据集U-CALTECH和U-CIFAR上的实验表明,SpikeCLIP显著提高了恢复图像的纹理细节和亮度平衡。此外,重建的图像与下游任务所需的更广泛的视觉特征对齐,确保在具有挑战性的环境中表现出更稳健和多功能性。
论文及项目相关链接
PDF Accepted by AAAI2025
Summary
这是一篇关于脉冲相机在低光照环境下图像重建的研究。该研究引入了SpikeCLIP框架,利用CLIP模型的文本与图像对齐能力,结合场景文本描述和高质量数据集进行监督,解决了传统学习方法在面对噪声脉冲时的性能下降问题。实验证明,SpikeCLIP能够显著提高低光照环境下重建图像的纹理细节和亮度平衡。
Key Takeaways
- 脉冲相机通过连续脉冲流捕捉高速场景,相比传统RGB相机具有更低的带宽和更高的动态范围。
- 低光照环境下从脉冲输入重建高质量图像具有挑战性。
- 常规的学习型方法依赖于合成数据集进行训练,但在面对低光照环境下噪声脉冲时表现不佳。
- SpikeCLIP框架超越了传统训练模式,利用CLIP模型的文本与图像对齐能力。
- SpikeCLIP结合场景文本描述和未配对的高质量数据集进行监督。
- 在真实世界的低光照数据集U-CALTECH和U-CIFAR上的实验证明,SpikeCLIP能显著提高重建图像的纹理细节和亮度平衡。
点此查看论文截图


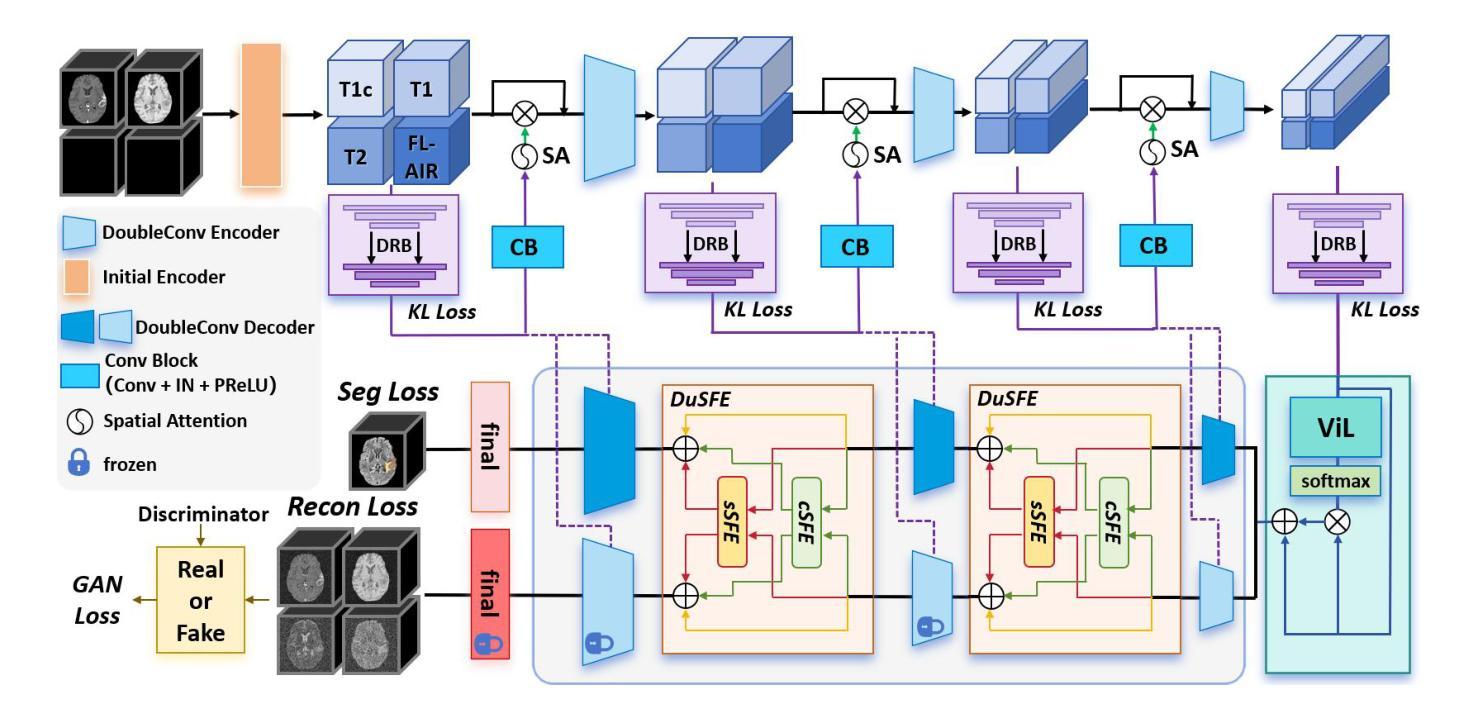
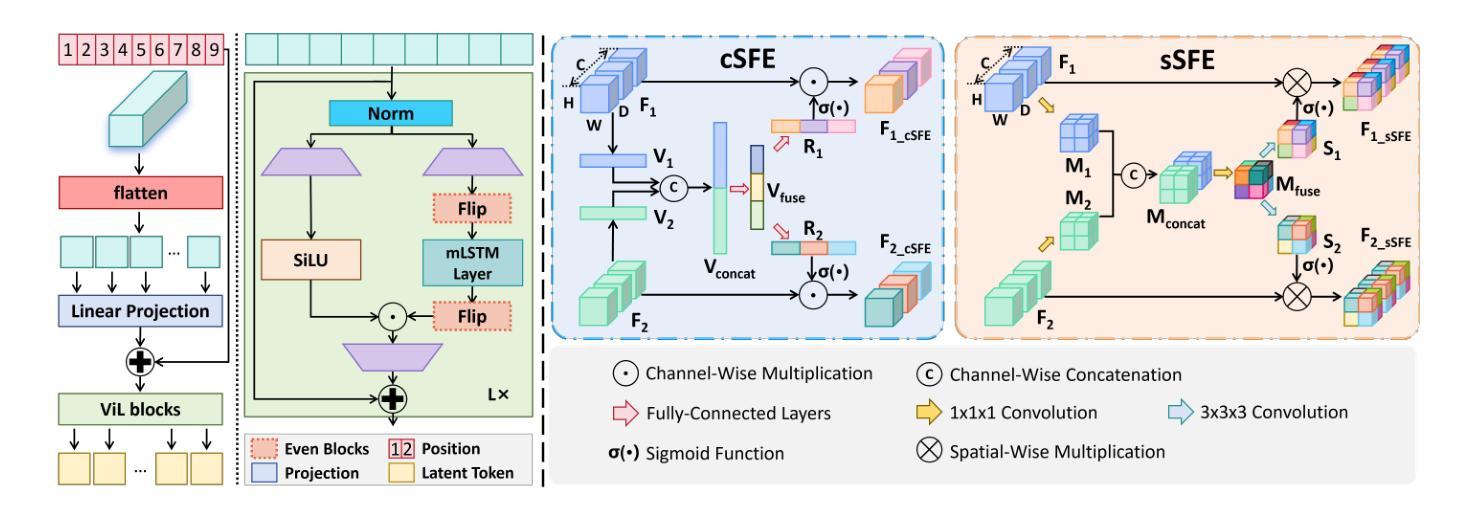
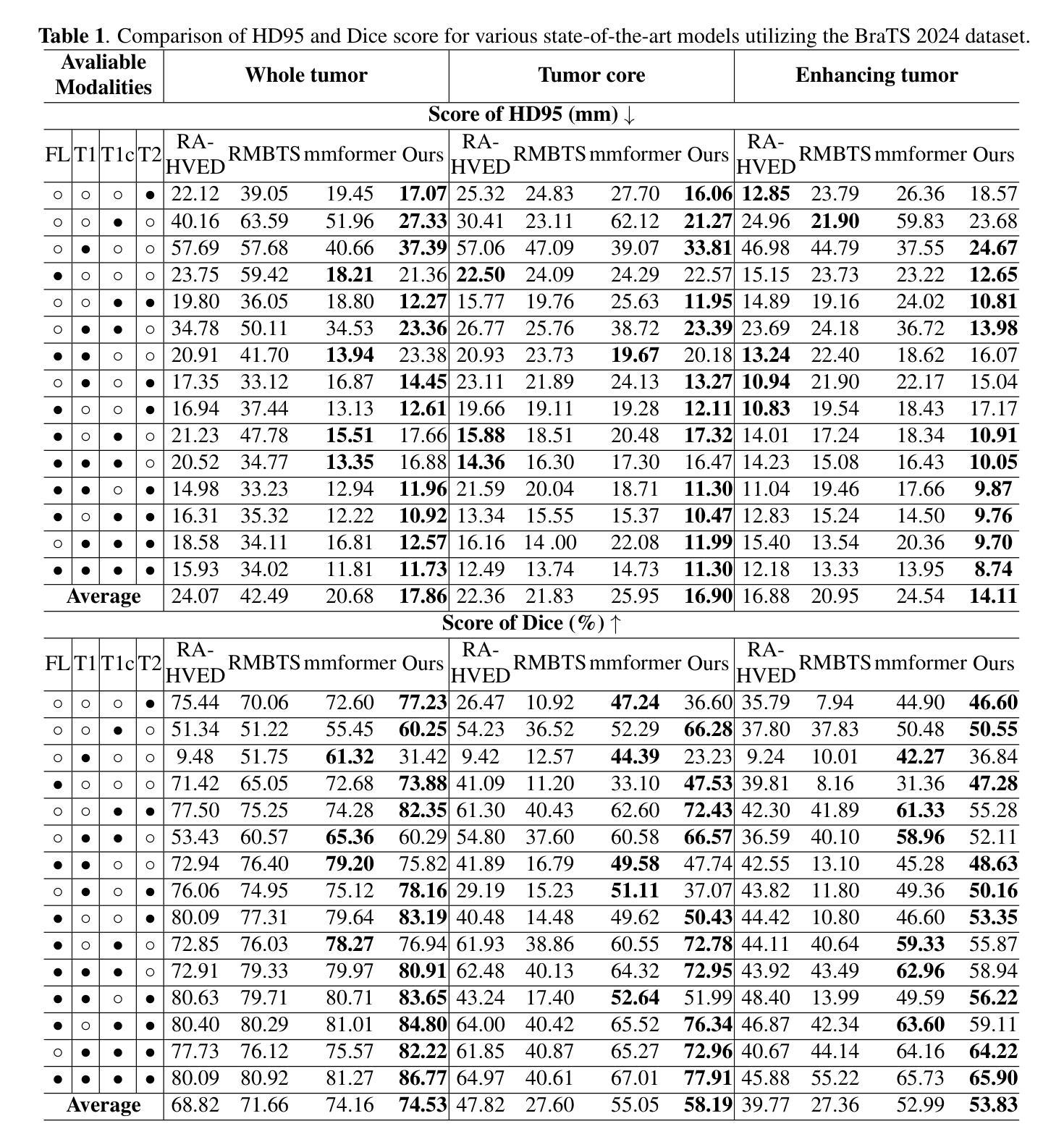
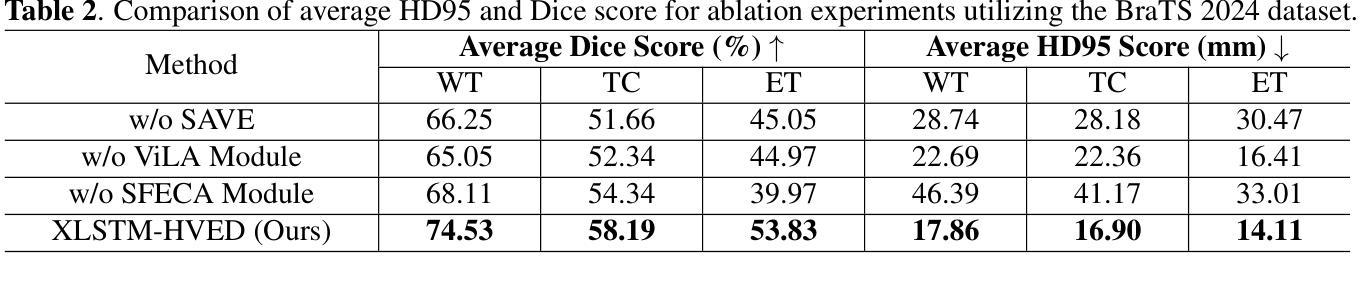
XLSTM-HVED: Cross-Modal Brain Tumor Segmentation and MRI Reconstruction Method Using Vision XLSTM and Heteromodal Variational Encoder-Decoder
Authors:Shenghao Zhu, Yifei Chen, Shuo Jiang, Weihong Chen, Chang Liu, Yuanhan Wang, Xu Chen, Yifan Ke, Feiwei Qin, Changmiao Wang, Zhu Zhu
Neurogliomas are among the most aggressive forms of cancer, presenting considerable challenges in both treatment and monitoring due to their unpredictable biological behavior. Magnetic resonance imaging (MRI) is currently the preferred method for diagnosing and monitoring gliomas. However, the lack of specific imaging techniques often compromises the accuracy of tumor segmentation during the imaging process. To address this issue, we introduce the XLSTM-HVED model. This model integrates a hetero-modal encoder-decoder framework with the Vision XLSTM module to reconstruct missing MRI modalities. By deeply fusing spatial and temporal features, it enhances tumor segmentation performance. The key innovation of our approach is the Self-Attention Variational Encoder (SAVE) module, which improves the integration of modal features. Additionally, it optimizes the interaction of features between segmentation and reconstruction tasks through the Squeeze-Fusion-Excitation Cross Awareness (SFECA) module. Our experiments using the BraTS 2024 dataset demonstrate that our model significantly outperforms existing advanced methods in handling cases where modalities are missing. Our source code is available at https://github.com/Quanato607/XLSTM-HVED.
神经胶质瘤是最具侵袭性的癌症之一,由于其不可预测的生物行为,为治疗和监测带来了相当大的挑战。目前,磁共振成像(MRI)是诊断和治疗胶质瘤的首选方法。然而,缺乏特定的成像技术往往会影响成像过程中肿瘤分割的准确性。为了解决这一问题,我们引入了XLSTM-HVED模型。该模型结合了异模式编码器-解码器框架和Vision XLSTM模块,以重建缺失的MRI模式。通过深度融合空间和时间特征,提高了肿瘤分割的性能。我们方法的关键创新点是自注意力变分编码器(SAVE)模块,它改进了模式特征的融合。此外,它通过Squeeze-Fusion-Excitation Cross Awareness(SFECA)模块优化了分割和重建任务之间的特征交互。我们使用BraTS 2024数据集进行的实验表明,我们的模型在处理缺失模式的情况时显著优于现有的高级方法。我们的源代码可在[https://github.com/Quanato607/XLSTM-HVED找到。]
论文及项目相关链接
PDF 5 pages, 2 figures
Summary
本文介绍了神经胶质瘤的治疗和监测挑战,以及磁共振成像(MRI)在诊断与监测中的作用。为解决MRI成像过程中因缺乏特定成像技术而影响肿瘤分割准确性的问题,提出了XLSTM-HVED模型。该模型结合了异模态编码器-解码器框架与Vision XLSTM模块,可重建缺失的MRI模态,通过深度融合时空特征提高肿瘤分割性能。其关键创新在于自注意力变分编码器(SAVE)模块,可改进模态特征的整合。同时,通过Squeeze-Fusion-Excitation Cross Awareness(SFECA)模块优化分割与重建任务之间的特征交互。使用BraTS 2024数据集的实验表明,该模型在处理缺失模态的情况时显著优于现有先进方法。
Key Takeaways
- 神经胶质瘤治疗与监测存在挑战,MRI是目前首选的诊断与监测方法。
- 缺乏特定成像技术会影响MRI成像过程中的肿瘤分割准确性。
- XLSTM-HVED模型通过结合异模态编码器-解码器框架与Vision XLSTM模块,旨在解决这一问题。
- 该模型可重建缺失的MRI模态,并通过深度融合时空特征提高肿瘤分割性能。
- 自注意力变分编码器(SAVE)模块是模型的关键创新,可改进模态特征的整合。
- SFECA模块优化分割与重建任务之间的特征交互。
点此查看论文截图