⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-07 更新
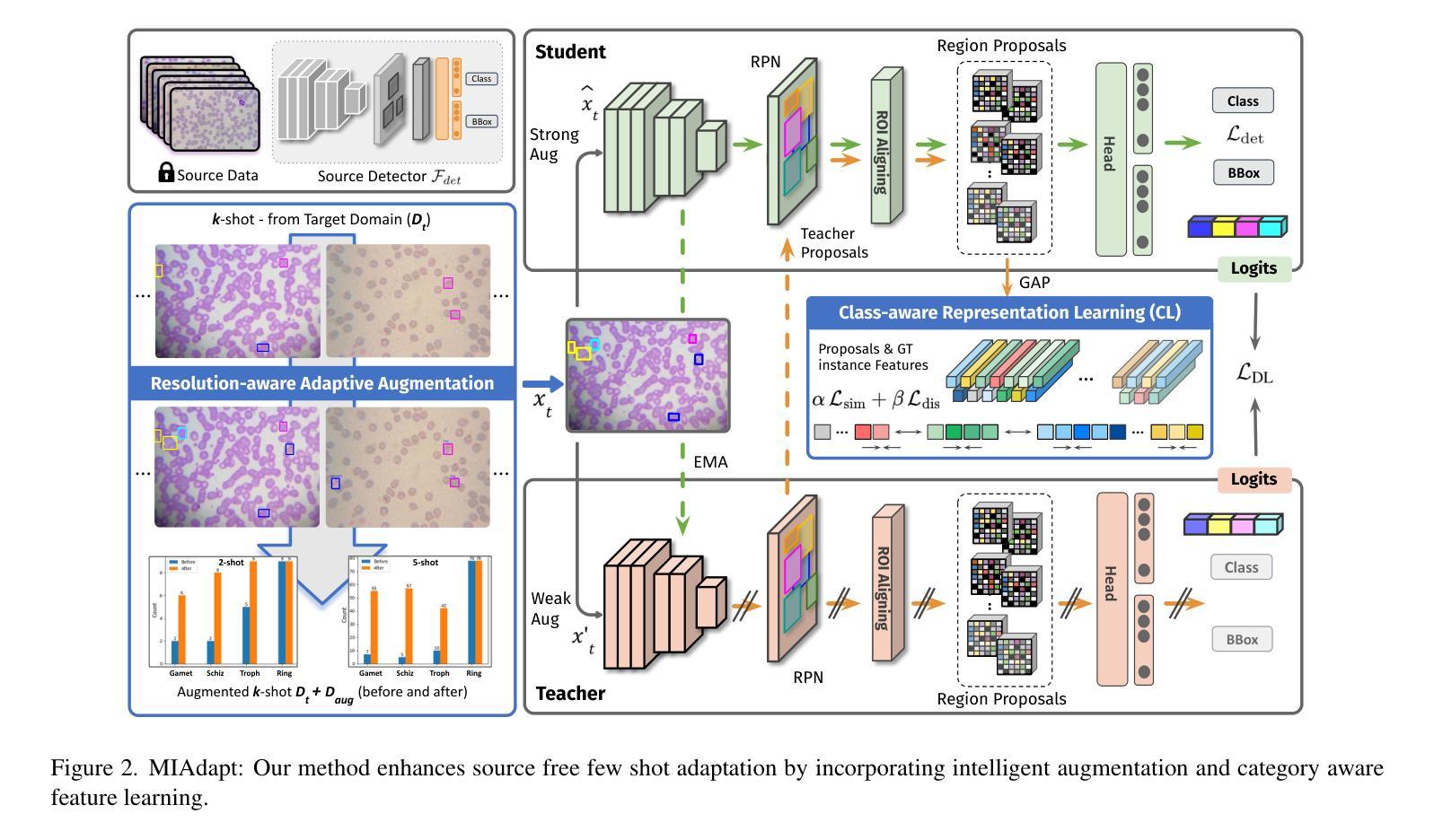
MIAdapt: Source-free Few-shot Domain Adaptive Object Detection for Microscopic Images
Authors:Nimra Dilawar, Sara Nadeem, Javed Iqbal, Waqas Sultani, Mohsen Ali
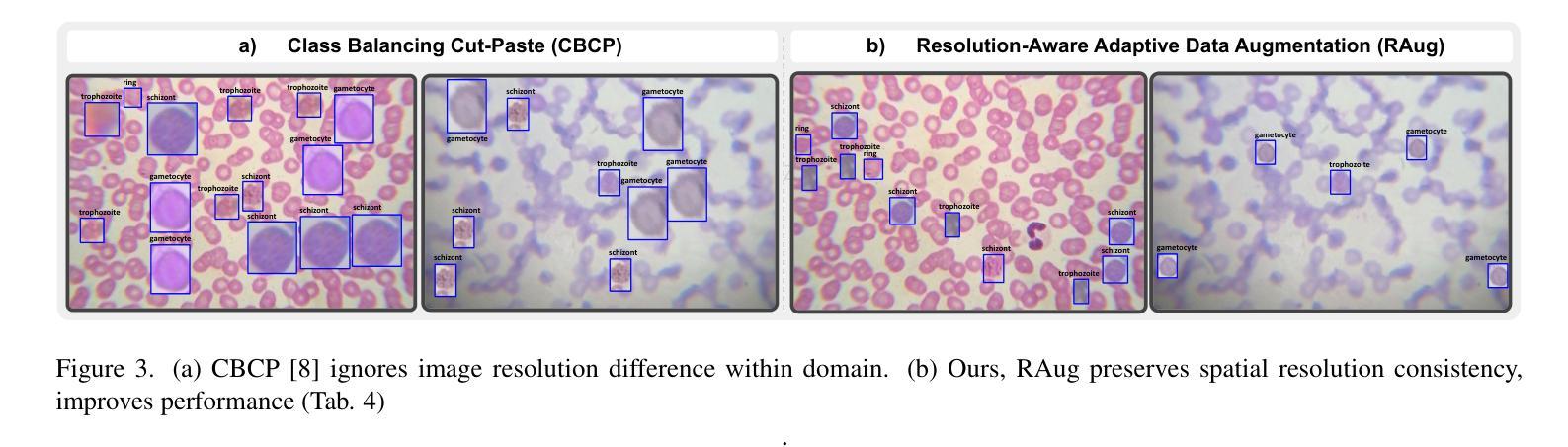
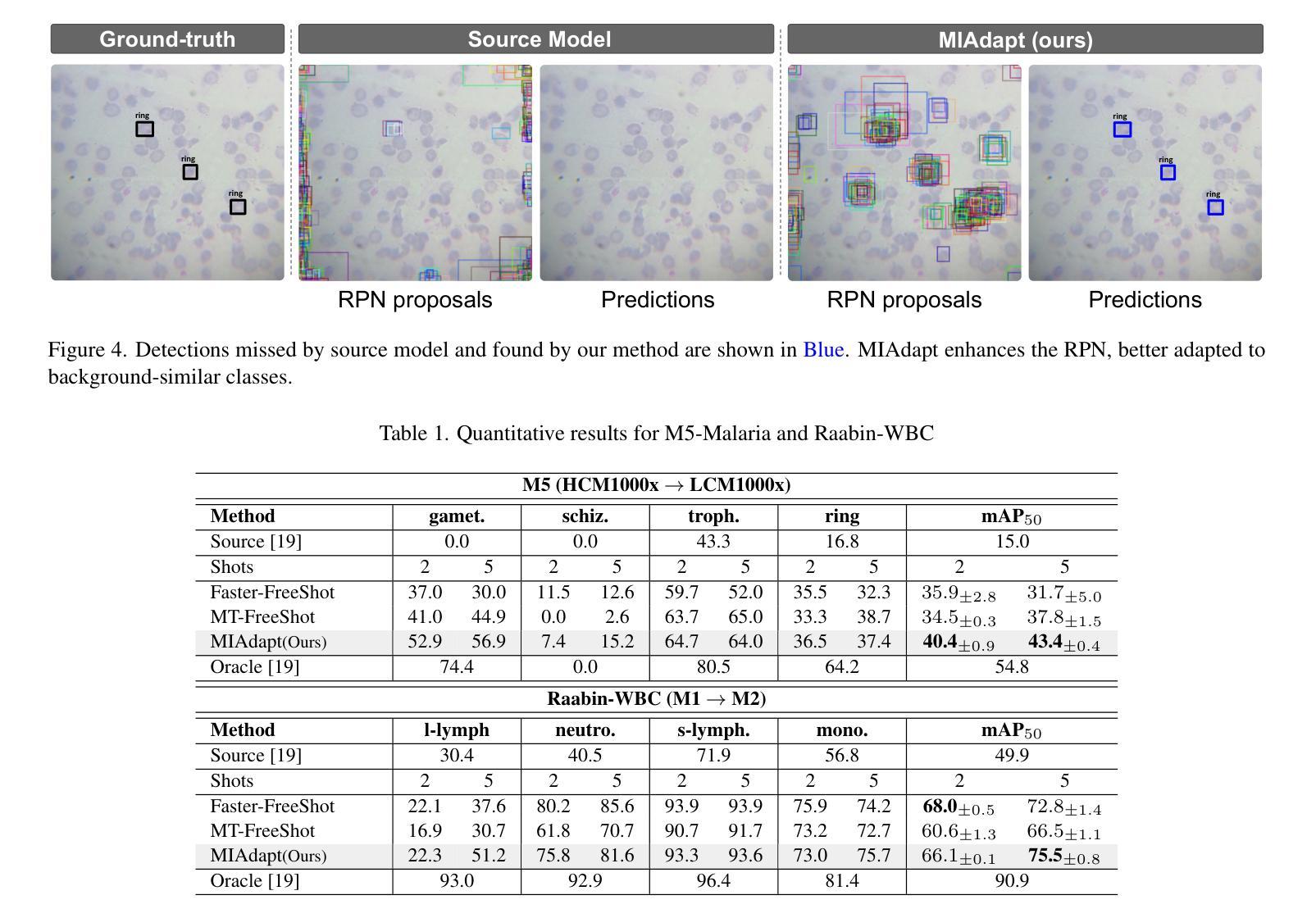
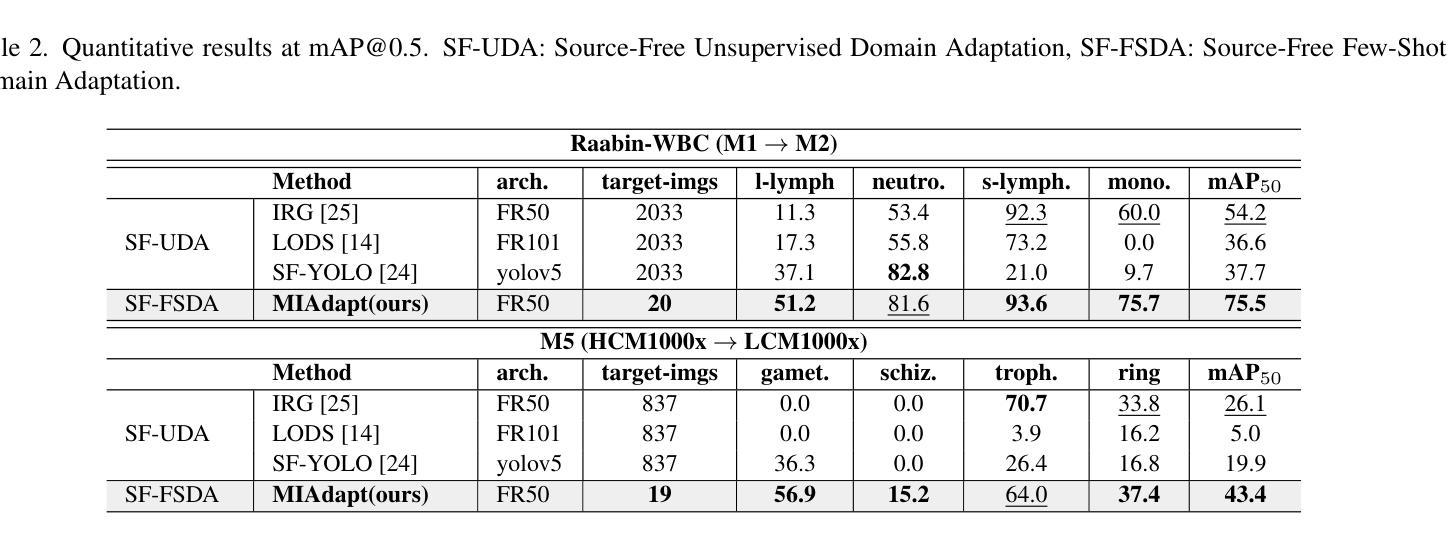
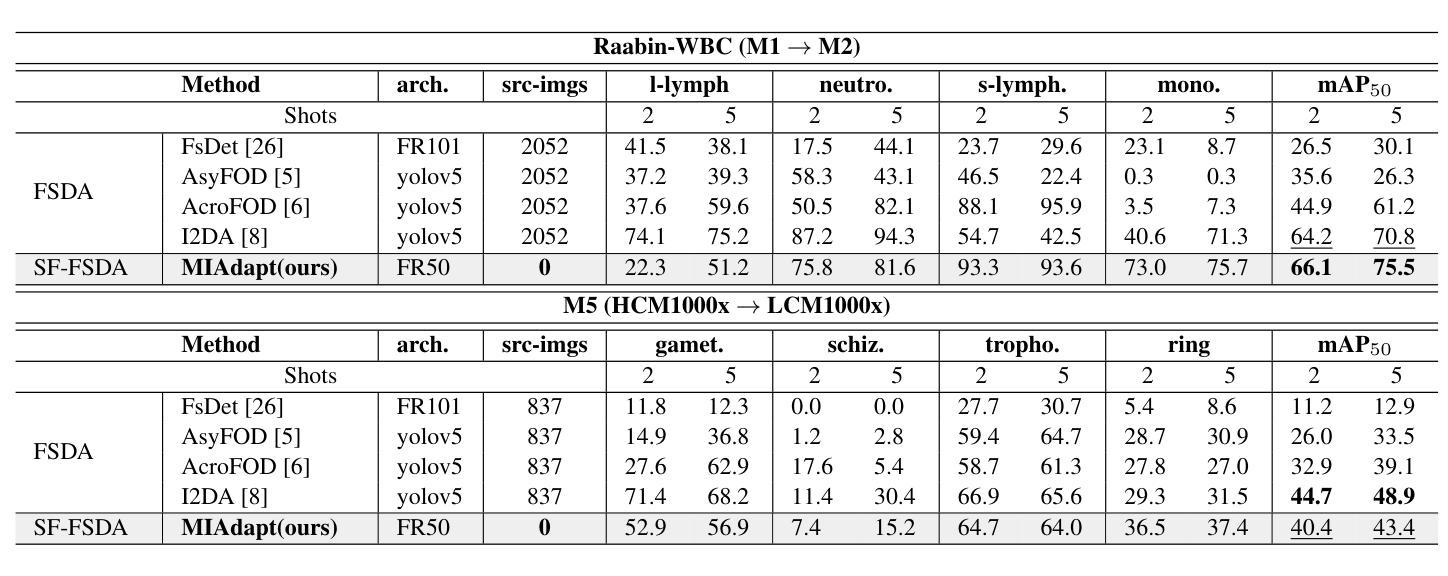
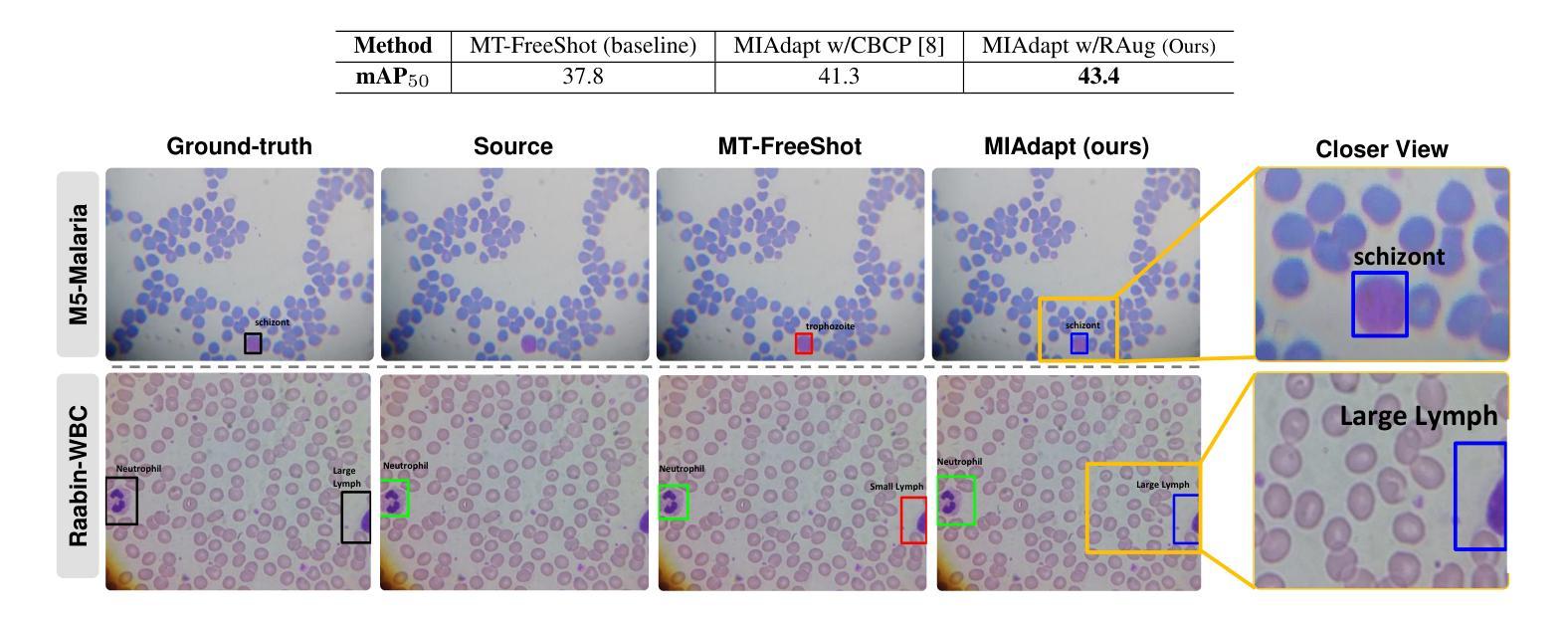
Existing generic unsupervised domain adaptation approaches require access to both a large labeled source dataset and a sufficient unlabeled target dataset during adaptation. However, collecting a large dataset, even if unlabeled, is a challenging and expensive endeavor, especially in medical imaging. In addition, constraints such as privacy issues can result in cases where source data is unavailable. Taking in consideration these challenges, we propose MIAdapt, an adaptive approach for Microscopic Imagery Adaptation as a solution for Source-free Few-shot Domain Adaptive Object detection (SF-FSDA). We also define two competitive baselines (1) Faster-FreeShot and (2) MT-FreeShot. Extensive experiments on the challenging M5-Malaria and Raabin-WBC datasets validate the effectiveness of MIAdapt. Without using any image from the source domain MIAdapt surpasses state-of-the-art source-free UDA (SF-UDA) methods by +21.3% mAP and few-shot domain adaptation (FSDA) approaches by +4.7% mAP on Raabin-WBC. Our code and models will be publicly available.
现有的通用无监督域自适应方法要求在适应过程中访问大量标记源数据集和足够的无标记目标数据集。然而,收集大数据集,即使是无标签的,也是一项具有挑战性和昂贵的工作,特别是在医学影像领域。此外,隐私问题等约束可能导致源数据不可用。考虑到这些挑战,我们提出了MIAdapt,这是一种用于显微镜图像自适应的适应性方法,作为无源域数据低样本域自适应对象检测(SF-FSDA)的解决方案。我们还定义了两个有竞争力的基线模型:(1)Faster-FreeShot和(2)MT-FreeShot。在具有挑战性的M5-Malaria和Raabin-WBC数据集上的大量实验验证了MIAdapt的有效性。MIAdapt在不使用任何源域图像的情况下,在Raabin-WBC数据集上超过了最新的无源域自适应(SF-UDA)方法,提高了+21.3%的平均准确率(mAP),并且超过了低样本域自适应(FSDA)方法提高了+4.7%的mAP。我们的代码和模型将公开可用。
论文及项目相关链接
PDF Under Review
Summary
数据源受限的情况下进行域自适应物体检测是新的挑战。研究团队提出MIAdapt方法用于显微镜图像域自适应,解决无源少样本域自适应物体检测(SF-FSDA)问题。通过M5疟疾和Raabin-WBC数据集的实验验证,MIAdapt较现有的源自由UDA(SF-UDA)方法和少样本域自适应(FSDA)方法有显著提升,提高了平均精度(mAP)。
Key Takeaways
- 现有通用无监督域自适应方法需要大量标注源数据集和足够的未标注目标数据集进行适应,但在医疗影像等领域数据收集困难且昂贵。
- 研究提出了MIAdapt方法用于显微镜图像域自适应,解决无源少样本域自适应物体检测的挑战。
- 定义了两个竞争基准线方法:Faster-FreeShot和MT-FreeShot。
- 在具有挑战性的M5疟疾和Raabin-WBC数据集上进行的广泛实验验证了MIAdapt的有效性。
- MIAdapt较现有源自由UDA方法和少样本域自适应方法有显著提升,提高了平均精度(mAP)。
- MIAdapt在不对源域图像进行使用的情况下实现性能提升。
点此查看论文截图

Label-Efficient LiDAR Semantic Segmentation with 2D-3D Vision Transformer Adapters
Authors:Julia Hindel, Rohit Mohan, Jelena Bratulic, Daniele Cattaneo, Thomas Brox, Abhinav Valada
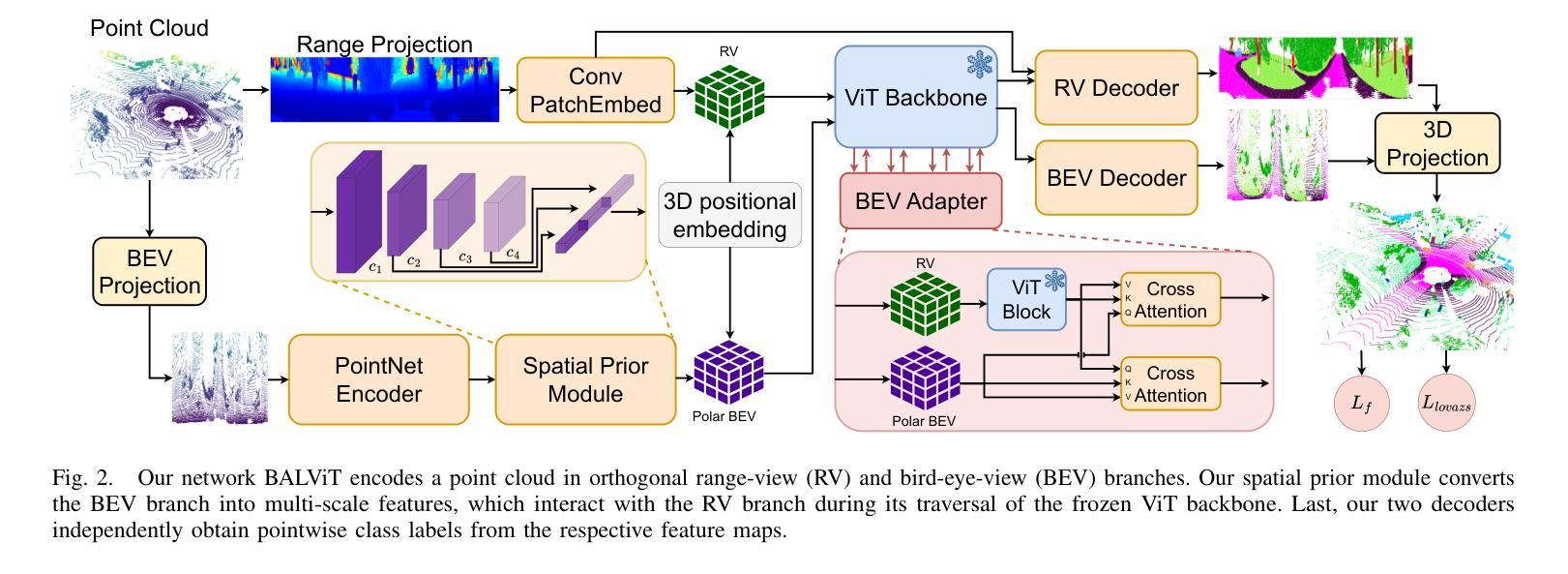
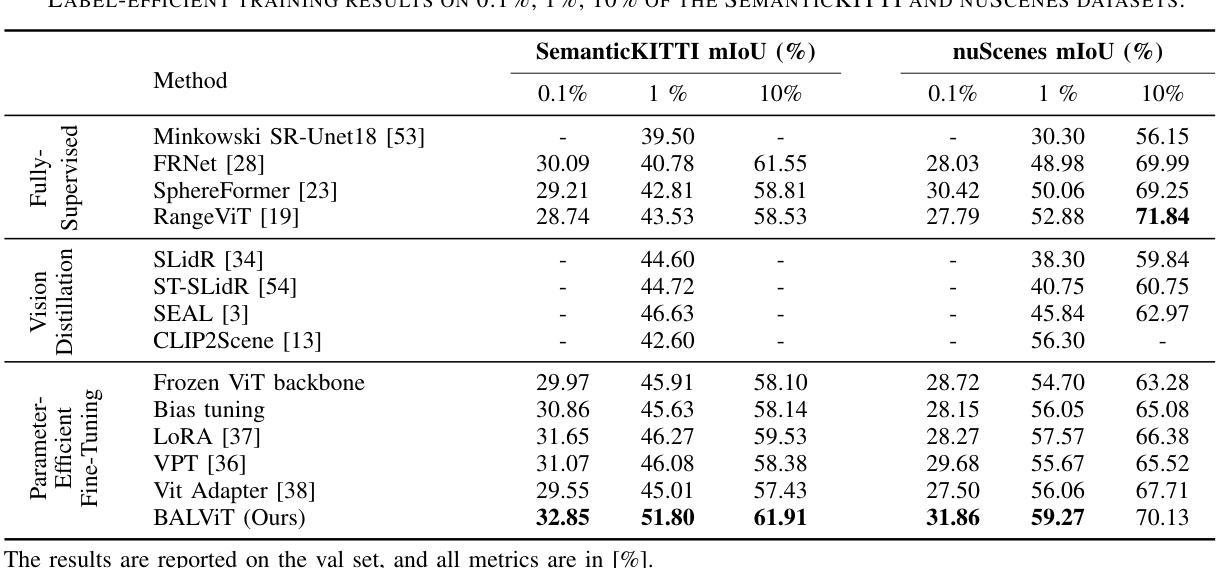
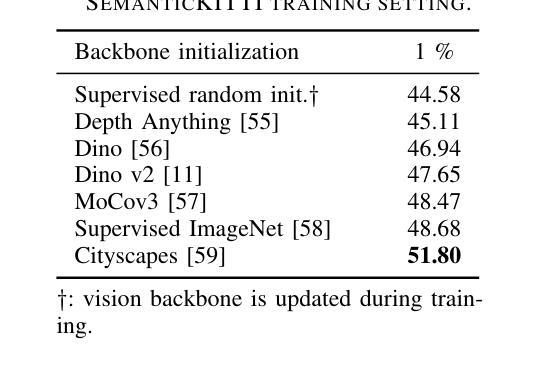
LiDAR semantic segmentation models are typically trained from random initialization as universal pre-training is hindered by the lack of large, diverse datasets. Moreover, most point cloud segmentation architectures incorporate custom network layers, limiting the transferability of advances from vision-based architectures. Inspired by recent advances in universal foundation models, we propose BALViT, a novel approach that leverages frozen vision models as amodal feature encoders for learning strong LiDAR encoders. Specifically, BALViT incorporates both range-view and bird’s-eye-view LiDAR encoding mechanisms, which we combine through a novel 2D-3D adapter. While the range-view features are processed through a frozen image backbone, our bird’s-eye-view branch enhances them through multiple cross-attention interactions. Thereby, we continuously improve the vision network with domain-dependent knowledge, resulting in a strong label-efficient LiDAR encoding mechanism. Extensive evaluations of BALViT on the SemanticKITTI and nuScenes benchmarks demonstrate that it outperforms state-of-the-art methods on small data regimes. We make the code and models publicly available at: http://balvit.cs.uni-freiburg.de.
激光雷达语义分割模型通常从随机初始化开始训练,因为缺乏大规模、多样化的数据集,通用预训练受到阻碍。此外,大多数点云分割架构都融入了自定义网络层,限制了基于视觉架构的进展的迁移性。受通用基础模型的最新进展的启发,我们提出了BALViT,这是一种新型方法,它利用冻结的视觉模型作为模态特征编码器,用于学习强大的激光雷达编码器。具体来说,BALViT结合了范围视图和鸟瞰视图激光雷达编码机制,我们通过新型2D-3D适配器将它们结合起来。范围视图特征通过冻结的图像主干进行处理,而我们的鸟瞰视图分支则通过多次交叉注意力交互来增强它们。因此,我们利用领域相关知识不断改善视觉网络,从而形成了强大的标签有效激光雷达编码机制。BALViT在SemanticKITTI和nuScenes基准测试上的广泛评估表明,它在小数据环境下优于最新方法。我们在http://balvit.cs.uni-freiburg.de公开了代码和模型。
论文及项目相关链接
Summary
LiDAR语义分割模型通常从随机初始化开始训练,因为通用预训练受限于缺乏大规模、多样化的数据集。本文提出BALViT方法,利用冻结的视觉模型作为模态特征编码器,用于学习强大的LiDAR编码器。BALViT结合了范围视图和鸟瞰视图两种LiDAR编码机制,并通过新型2D-3D适配器进行融合。范围视图特征通过冻结的图像主干进行处理,而鸟瞰视图分支则通过多次交叉注意力交互增强特征。因此,BALViT不断以领域相关知识优化视觉网络,形成强大的标签效率LiDAR编码机制。在SemanticKITTI和nuScenes基准测试上的评估显示,它在小数据情况下表现优于最新方法。代码和模型可在公开网站下载。
Key Takeaways
- LiDAR语义分割模型通常从随机初始化训练,因为预训练受限于数据集规模和多样性。
- BALViT方法利用冻结的视觉模型作为模态特征编码器进行LiDAR学习。
- BALViT结合范围视图和鸟瞰视图两种LiDAR编码机制。
- 范围视图特征通过图像主干处理,鸟瞰视图分支通过多次交叉注意力交互增强。
- BALViT提高了领域相关知识的使用效率,优化了标签效率LiDAR编码机制。
- 在SemanticKITTI和nuScenes基准测试中,BALViT在小数据情况下表现优于其他方法。
点此查看论文截图


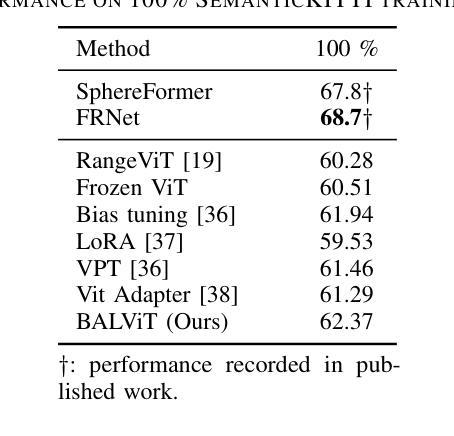
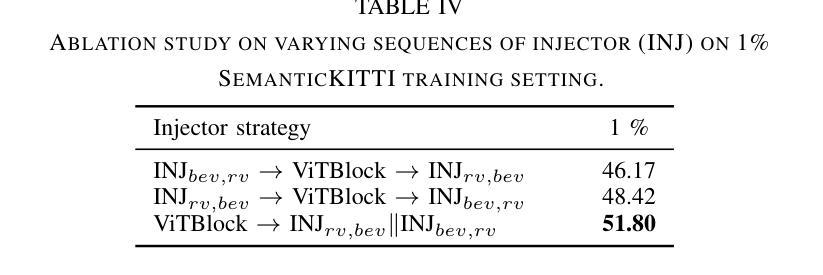
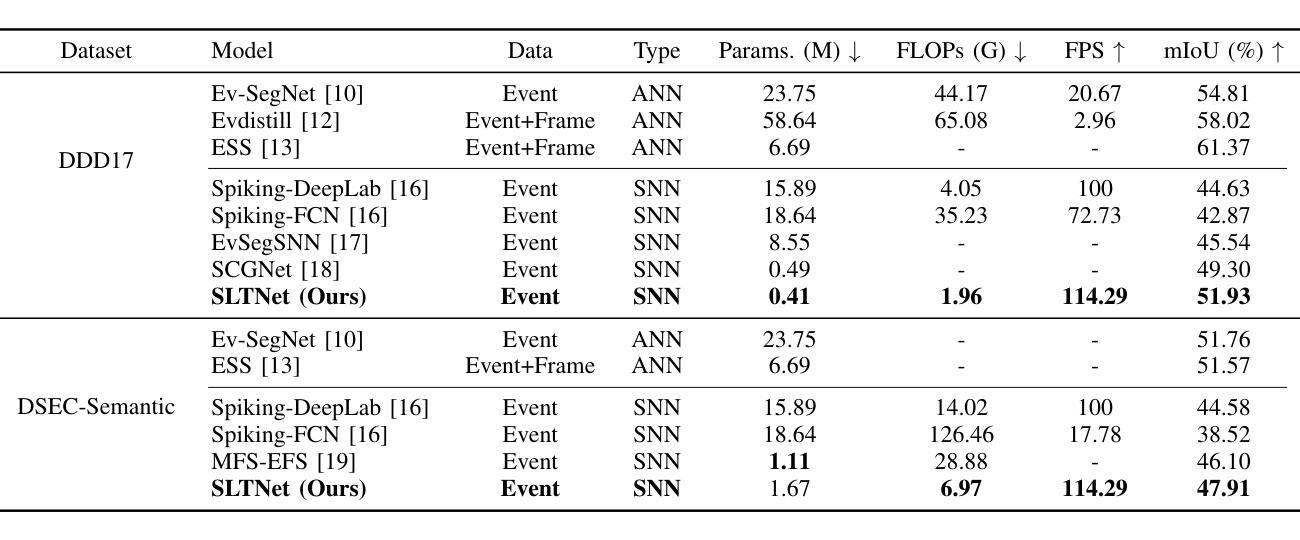
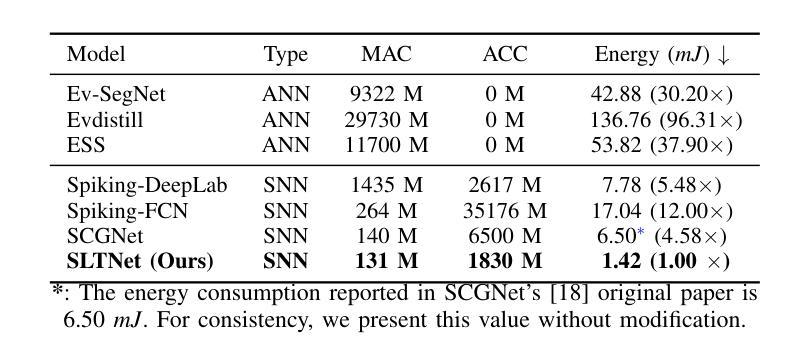
SLTNet: Efficient Event-based Semantic Segmentation with Spike-driven Lightweight Transformer-based Networks
Authors:Xiaxin Zhu, Fangming Guo, Xianlei Long, Qingyi Gu, Chao Chen, Fuqiang Gu
Event-based semantic segmentation has great potential in autonomous driving and robotics due to the advantages of event cameras, such as high dynamic range, low latency, and low power cost. Unfortunately, current artificial neural network (ANN)-based segmentation methods suffer from high computational demands, the requirements for image frames, and massive energy consumption, limiting their efficiency and application on resource-constrained edge/mobile platforms. To address these problems, we introduce SLTNet, a spike-driven lightweight transformer-based network designed for event-based semantic segmentation. Specifically, SLTNet is built on efficient spike-driven convolution blocks (SCBs) to extract rich semantic features while reducing the model’s parameters. Then, to enhance the long-range contextural feature interaction, we propose novel spike-driven transformer blocks (STBs) with binary mask operations. Based on these basic blocks, SLTNet employs a high-efficiency single-branch architecture while maintaining the low energy consumption of the Spiking Neural Network (SNN). Finally, extensive experiments on DDD17 and DSEC-Semantic datasets demonstrate that SLTNet outperforms state-of-the-art (SOTA) SNN-based methods by at most 9.06% and 9.39% mIoU, respectively, with extremely 4.58x lower energy consumption and 114 FPS inference speed. Our code is open-sourced and available at https://github.com/longxianlei/SLTNet-v1.0.
基于事件的语义分割在自动驾驶和机器人技术方面有着巨大的潜力,这是因为事件相机具有诸如高动态范围、低延迟和低功耗等优势。然而,当前基于人工神经网络(ANN)的分割方法存在计算量大、对图像帧的要求高以及能耗巨大的问题,这限制了它们在资源受限的边缘/移动平台上的效率和应用。为了解决这些问题,我们引入了SLTNet,这是一个用于基于事件的语义分割的脉冲驱动轻量化变压器网络。具体而言,SLTNet建立在高效的脉冲驱动卷积块(SCB)上,以提取丰富的语义特征,同时减少模型的参数。然后,为了增强长距离上下文特征的交互,我们提出了新型的脉冲驱动变压器块(STB)与二进制掩码操作。基于这些基本块,SLTNet采用高效的单分支架构,同时保持脉冲神经网络(SNN)的低能耗。最后,在DDD17和DSEC-Semantic数据集上的大量实验表明,SLTNet相较于最先进(SOTA)的基于SNN的方法最多高出9.06%和9.39%的mIoU,同时能耗降低了4.58倍,推理速度达到每秒114帧。我们的代码已开源,可在https://github.com/longxianlei/SLTNet-v1.0获取。
论文及项目相关链接
PDF Submitted to 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2025)
摘要
事件驱动的语义分割在自动驾驶和机器人领域具有巨大潜力,得益于事件相机的高动态范围、低延迟和低功耗优势。然而,当前基于人工神经网络(ANN)的分割方法存在计算量大、对图像帧的要求高、能耗巨大等问题,限制了其在资源受限的边缘/移动平台上的效率和应用。为解决这些问题,我们提出了SLTNet,这是一个用于事件驱动的语义分割的脉冲驱动轻量级Transformer网络。SLTNet采用高效的脉冲驱动卷积块(SCB)提取丰富的语义特征,同时减少模型参数。为增强长距离上下文特征的交互,我们提出了新型的脉冲驱动Transformer块(STB)与二进制掩码操作。基于这些基本块,SLTNet采用高效的单分支架构,同时保持脉冲神经网络(SNN)的低能耗。在DDD17和DSEC-Semantic数据集上的实验表明,SLTNet较先进的SNN方法最多可提高9.06%和9.39%的mIoU,同时能耗降低4.58倍,推理速度达到每秒114帧。我们的代码已开源,可在https://github.com/longxianlei/SLTNet-v1.0访问。
关键见解
- 事件驱动的语义分割在自动驾驶和机器人领域具有潜力,因事件相机的独特优势。
- 当前基于ANN的方法在计算效率、资源需求和能耗方面存在局限。
- SLTNet采用脉冲驱动技术,结合卷积和Transformer块,以提高语义分割效率。
- SLTNet设计旨在提取丰富语义特征,同时减少模型参数和能耗。
- 通过新颖的脉冲驱动Transformer块,实现长距离上下文特征交互。
- SLTNet采用单分支高效架构,结合SNN的低能耗特点。
点此查看论文截图



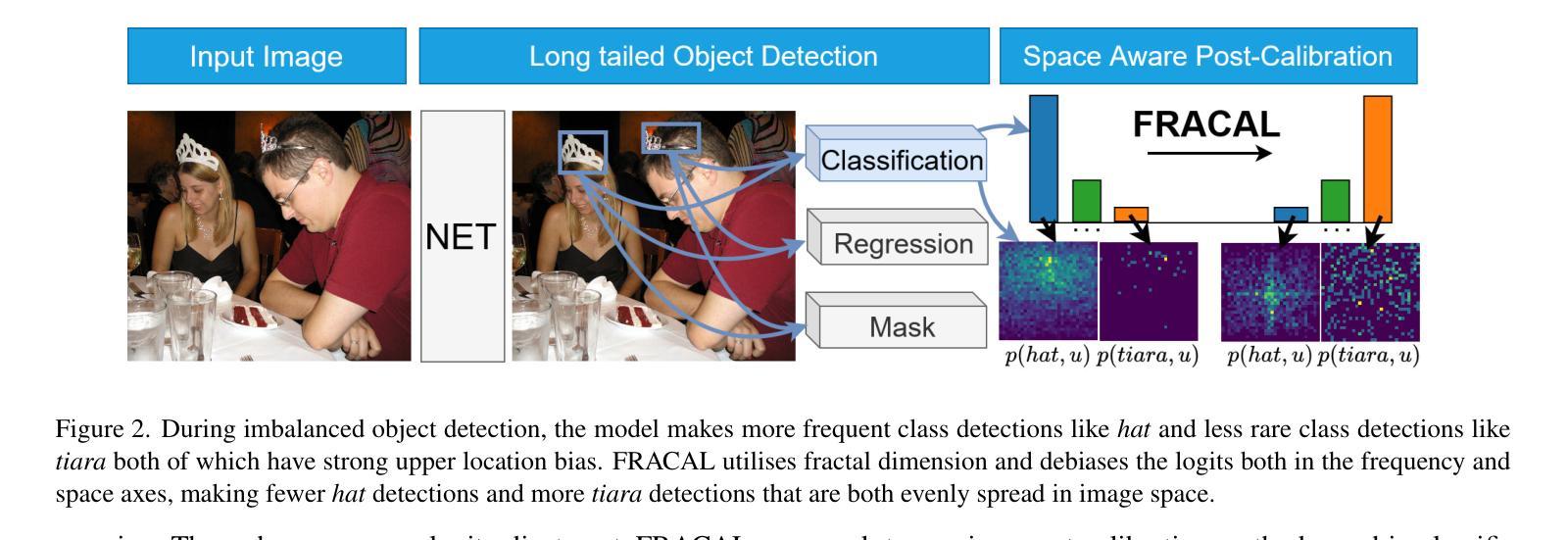
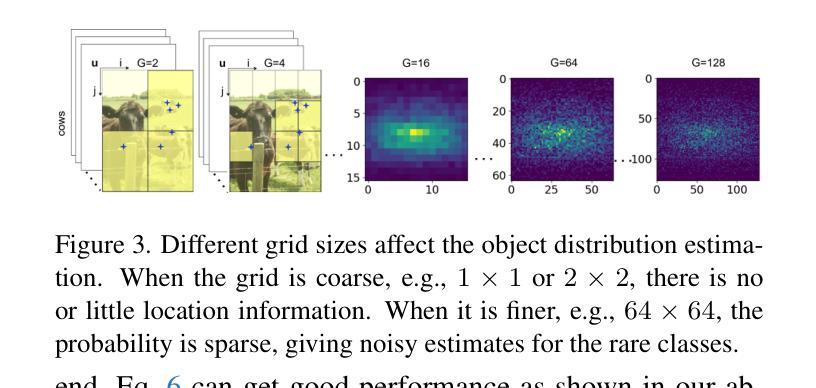
Fractal Calibration for long-tailed object detection
Authors:Konstantinos Panagiotis Alexandridis, Ismail Elezi, Jiankang Deng, Anh Nguyen, Shan Luo
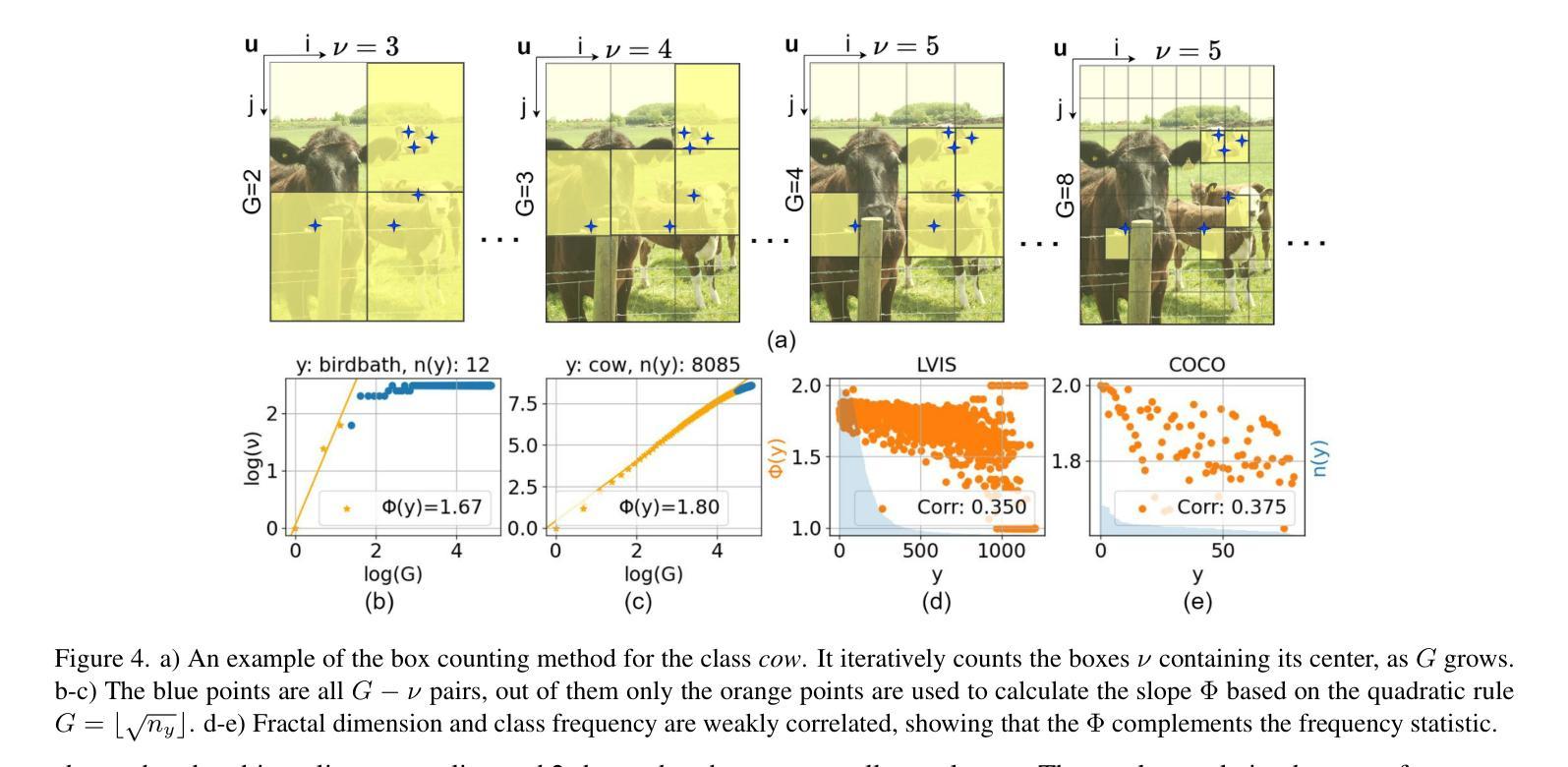
Real-world datasets follow an imbalanced distribution, which poses significant challenges in rare-category object detection. Recent studies tackle this problem by developing re-weighting and re-sampling methods, that utilise the class frequencies of the dataset. However, these techniques focus solely on the frequency statistics and ignore the distribution of the classes in image space, missing important information. In contrast to them, we propose FRActal CALibration (FRACAL): a novel post-calibration method for long-tailed object detection. FRACAL devises a logit adjustment method that utilises the fractal dimension to estimate how uniformly classes are distributed in image space. During inference, it uses the fractal dimension to inversely downweight the probabilities of uniformly spaced class predictions achieving balance in two axes: between frequent and rare categories, and between uniformly spaced and sparsely spaced classes. FRACAL is a post-processing method and it does not require any training, also it can be combined with many off-the-shelf models such as one-stage sigmoid detectors and two-stage instance segmentation models. FRACAL boosts the rare class performance by up to 8.6% and surpasses all previous methods on LVIS dataset, while showing good generalisation to other datasets such as COCO, V3Det and OpenImages. We provide the code at https://github.com/kostas1515/FRACAL.
现实世界的数据集呈现出不均衡的分布,这给罕见类别对象检测带来了巨大的挑战。最近的研究通过开发重新加权和重新采样方法来解决此问题,这些方法利用数据集的类别频率。然而,这些技术只关注频率统计,而忽略了类别在图像空间中的分布,从而丢失了重要信息。与之相反,我们提出了FRACtal CALibration(FRACAL):一种用于长尾对象检测的新型后校准方法。FRACAL设计了一种逻辑调整方法,利用分形维度来估计类别在图像空间中的分布有多均匀。在推理过程中,它使用分形维度来逆向下调整均匀间隔的类别预测概率,从而在两个轴之间实现平衡:常见类别与罕见类别之间,以及均匀间隔的类别与稀疏间隔的类别之间。FRACAL是一种后处理方法,无需任何训练,它可以与许多现成的模型(如单阶段Sigmoid检测器和两阶段实例分割模型)相结合。FRACAL提高了罕见类别的性能,提高了高达8.6%,并在LVIS数据集上超越了所有之前的方法,同时在其他数据集如COCO、V3Det和OpenImages上也表现出良好的泛化能力。我们的代码位于https://github.com/kostas1515/FRACAL。
论文及项目相关链接
PDF CVPR2025
Summary
基于现实世界的复杂数据集不平衡分布的问题,文章提出了一种名为FRACAL的新型后校准方法,用于长尾目标检测。该方法利用分形维度来估计类别在图像空间中的分布均匀性,并在推理过程中通过反向下调概率实现平衡。此方法无需额外训练,可以与其他现成模型相结合,显著提升稀有类别的性能。
Key Takeaways
- 现实世界的目标检测数据集存在类别不平衡问题,对稀有类别检测构成挑战。
- 当前研究主要通过重加权和重采样方法解决此问题,但仅关注频率统计而忽略了类别在图像空间中的分布。
- FRACAL是一种新型后校准方法,利用分形维度来估计类别分布的均匀性。
- FRACAL在推理过程中通过反向下调概率实现平衡,兼顾常见和稀有类别,以及均匀和稀疏分布的类别。
- FRACAL是一种后处理方法,无需额外训练,可与其他现成模型(如单阶段Sigmoid检测器和两阶段实例分割模型)结合使用。
- FRACAL在LVIS数据集上的性能超越了所有之前的方法,并提高了稀有类别的性能高达8.6%。
点此查看论文截图


Scale-Invariant Object Detection by Adaptive Convolution with Unified Global-Local Context
Authors:Amrita Singh, Snehasis Mukherjee
Dense features are important for detecting minute objects in images. Unfortunately, despite the remarkable efficacy of the CNN models in multi-scale object detection, CNN models often fail to detect smaller objects in images due to the loss of dense features during the pooling process. Atrous convolution addresses this issue by applying sparse kernels. However, sparse kernels often can lose the multi-scale detection efficacy of the CNN model. In this paper, we propose an object detection model using a Switchable (adaptive) Atrous Convolutional Network (SAC-Net) based on the efficientDet model. A fixed atrous rate limits the performance of the CNN models in the convolutional layers. To overcome this limitation, we introduce a switchable mechanism that allows for dynamically adjusting the atrous rate during the forward pass. The proposed SAC-Net encapsulates the benefits of both low-level and high-level features to achieve improved performance on multi-scale object detection tasks, without losing the dense features. Further, we apply a depth-wise switchable atrous rate to the proposed network, to improve the scale-invariant features. Finally, we apply global context on the proposed model. Our extensive experiments on benchmark datasets demonstrate that the proposed SAC-Net outperforms the state-of-the-art models by a significant margin in terms of accuracy.
密集特征对于检测图像中的微小物体非常重要。然而,尽管CNN模型在多尺度目标检测中效果显著,但由于池化过程中密集特征的损失,CNN模型往往无法检测图像中的较小物体。空洞卷积通过应用稀疏核来解决这个问题。然而,稀疏核往往会损失CNN模型的多尺度检测效果。在本文中,我们提出了一种基于efficientDet模型的可切换(自适应)空洞卷积网络(SAC-Net)的目标检测模型。固定的空洞率限制了CNN模型在卷积层中的性能。为了克服这一限制,我们引入了一种可切换机制,允许在前向传递过程中动态调整空洞率。所提出的SAC-Net结合了低层次和高层次特征的优势,能够在多尺度目标检测任务上实现改进的性能,同时不损失密集特征。此外,我们对所提出的网络应用了深度可切换空洞率,以改进尺度不变特征。最后,我们在所提模型上应用了全局上下文。我们在基准数据集上进行的广泛实验表明,所提出的SAC-Net在准确性方面显著优于最新模型。
论文及项目相关链接
Summary
基于EfficientDet模型的Switchable(自适应)膨胀卷积网络(SAC-Net)能有效解决CNN模型在多尺度目标检测中因池化过程损失密集特征而导致无法检测较小目标的问题。SAC-Net通过引入可切换机制,动态调整膨胀率,结合高低层次特征的优点,实现了多尺度目标检测任务的性能提升,同时保留了密集特征。
Key Takeaways
- CNN模型在检测较小图像目标时可能因池化过程中损失密集特征而失效。
- 膨胀卷积有助于解决此问题,但固定膨胀率限制了CNN模型的性能。
- SAC-Net引入可切换机制,允许在向前传递过程中动态调整膨胀率。
- SAC-Net结合高低层次特征的优点,实现多尺度目标检测性能的提升。
- 提出了一种深度可切换的膨胀率,以改善尺度不变特征。
点此查看论文截图

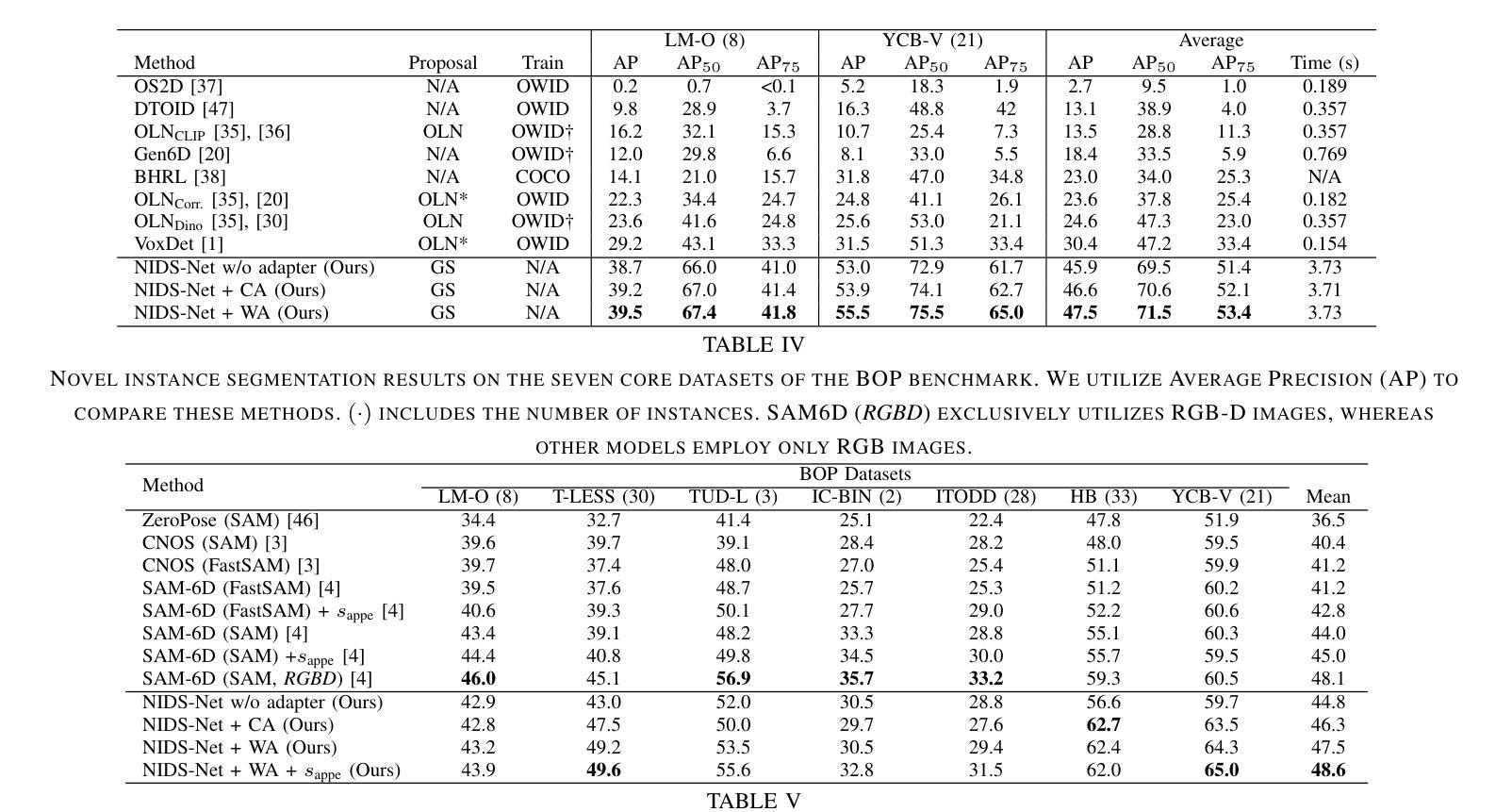
Adapting Pre-Trained Vision Models for Novel Instance Detection and Segmentation
Authors:Yangxiao Lu, Jishnu Jaykumar P, Yunhui Guo, Nicholas Ruozzi, Yu Xiang
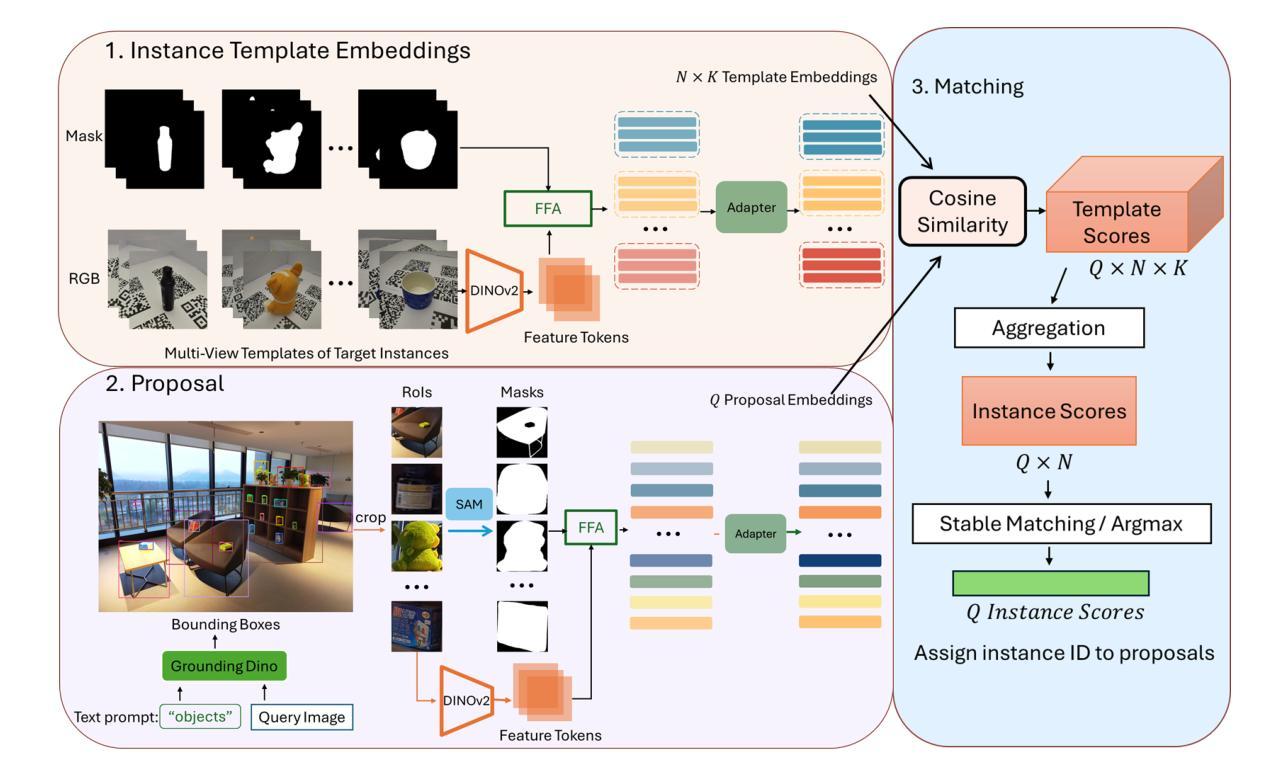
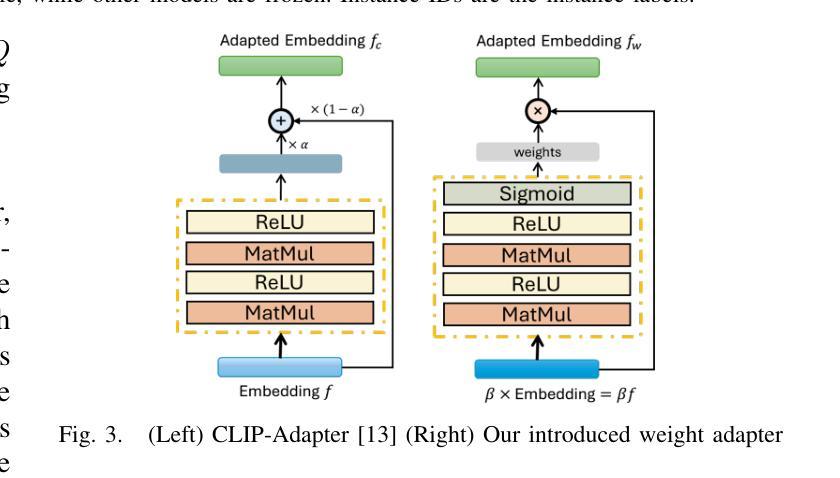
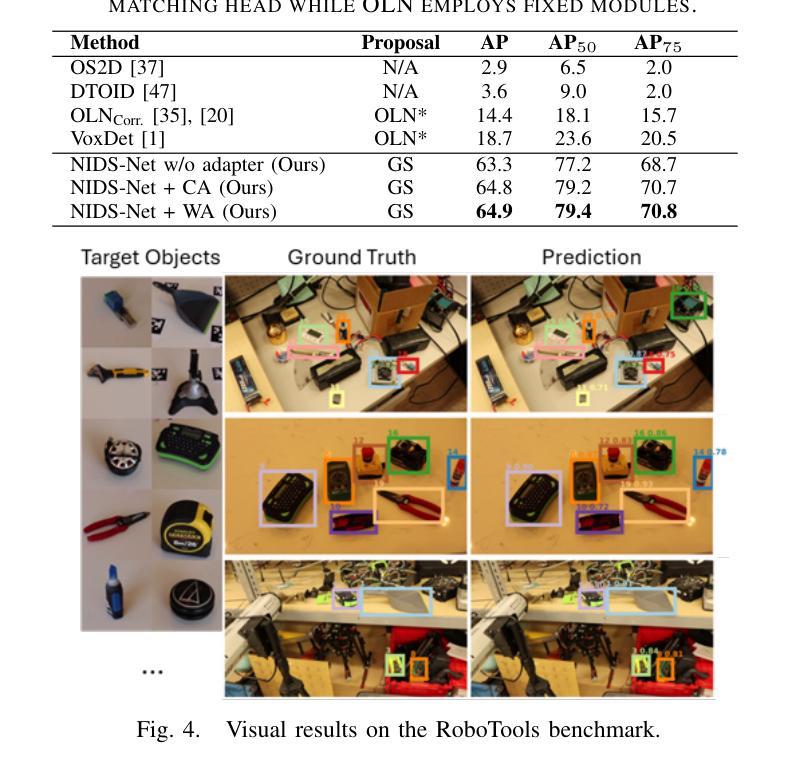
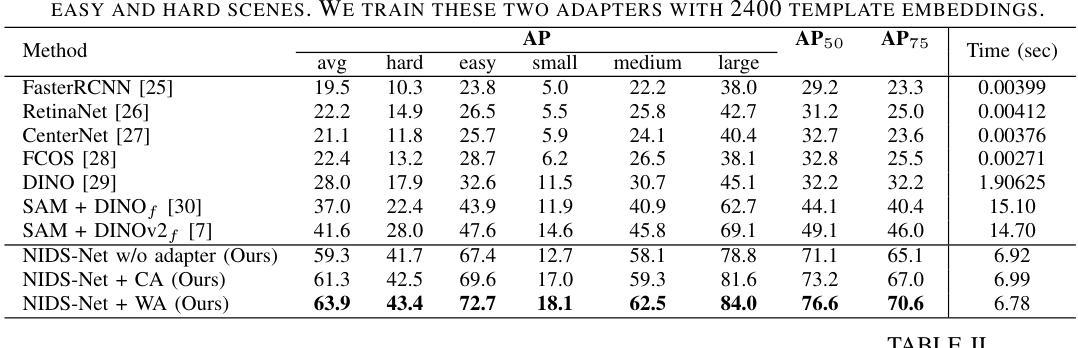
Novel Instance Detection and Segmentation (NIDS) aims at detecting and segmenting novel object instances given a few examples of each instance. We propose a unified, simple, yet effective framework (NIDS-Net) comprising object proposal generation, embedding creation for both instance templates and proposal regions, and embedding matching for instance label assignment. Leveraging recent advancements in large vision methods, we utilize Grounding DINO and Segment Anything Model (SAM) to obtain object proposals with accurate bounding boxes and masks. Central to our approach is the generation of high-quality instance embeddings. We utilized foreground feature averages of patch embeddings from the DINOv2 ViT backbone, followed by refinement through a weight adapter mechanism that we introduce. We show experimentally that our weight adapter can adjust the embeddings locally within their feature space and effectively limit overfitting in the few-shot setting. Furthermore, the weight adapter optimizes weights to enhance the distinctiveness of instance embeddings during similarity computation. This methodology enables a straightforward matching strategy that results in significant performance gains. Our framework surpasses current state-of-the-art methods, demonstrating notable improvements in four detection datasets. In the segmentation tasks on seven core datasets of the BOP challenge, our method outperforms the leading published RGB methods and remains competitive with the best RGB-D method. We have also verified our method using real-world images from a Fetch robot and a RealSense camera. Project Page: https://irvlutd.github.io/NIDSNet/
新型实例检测与分割(NIDS)旨在通过每个实例的几个示例来检测和分割新型对象实例。我们提出了一个统一、简单、有效的框架(NIDS-Net),它包括生成对象提案、为实例模板和提案区域创建嵌入,以及用于实例标签分配的嵌入匹配。我们利用大型视觉方法的最新进展,使用接地DINO和分段任何模型(SAM)获得带有精确边界框和蒙版的对象提案。我们的方法的核心是生成高质量实例嵌入。我们使用DINOv2 ViT骨干网中补丁嵌入的前景特征平均值,然后通过我们引入的权重适配器机制进行微调。实验表明,我们的权重适配器可以在其特征空间内局部调整嵌入,并在小样本设置中有效限制过拟合。此外,权重适配器优化权重,在相似度计算过程中增强实例嵌入的区分度。这种方法使得简单的匹配策略能够带来显著的性能提升。我们的框架超越了当前的最先进方法,在四个检测数据集上取得了显著的改进。在BOP挑战中的七个核心数据集上的分割任务中,我们的方法优于领先的已发布RGB方法,并且与最佳的RGB-D方法保持竞争力。我们还使用Fetch机器人和RealSense相机拍摄的真实世界图像验证了我们的方法。项目页面:https://irvlutd.github.io/NIDSnet/
论文及项目相关链接
PDF Project Page: https://irvlutd.github.io/NIDSNet/
Summary
本文介绍了针对新型实例检测和分割任务的新方法(NIDS-Net)。它整合了实例提案生成、实例模板与提案区域的嵌入创建,以及嵌入匹配来分配实例标签。该方法借鉴了最新的大规模视觉方法,并结合了Grounding DINO和SAM模型来获取准确边界框和掩模的实例提案。核心在于生成高质量的实例嵌入,利用前景特征平均方法获得补丁嵌入,再通过新引入的权重适配器机制进行精炼。实验表明,权重适配器能够在特征空间内局部调整嵌入,有效限制小样本过拟合问题,同时优化权重提高实例嵌入的区分度。此方法在四个检测数据集和七个分割数据集上表现优于当前最佳方法。同时,通过实际应用验证了方法的可行性。更多详情参见项目页面:https://irvlutd.github.io/NIDSnet/。
Key Takeaways
- NIDS-Net是一种用于新型实例检测和分割的统一框架,涵盖了对象提案生成、嵌入创建和嵌入匹配等关键环节。
- 利用先进的视觉方法如Grounding DINO和SAM获取精确边界框和掩模的实例提案。
- 提出了利用前景特征平均和权重适配器机制来生成高质量实例嵌入的方法。权重适配器能够在特征空间内局部调整嵌入,优化权重以提高实例嵌入的区分度。
点此查看论文截图